# VisualGLM-6B
## 论文
无
## 模型结构
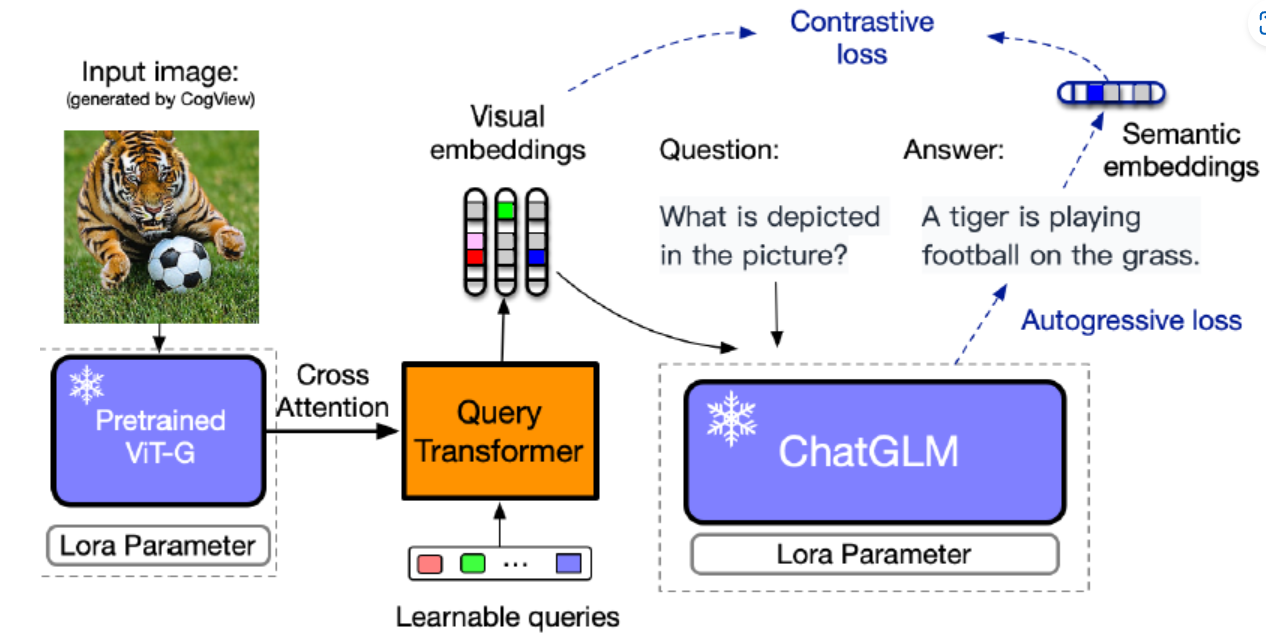
VisualGLM 模型架构是 ViT + QFormer + ChatGLM,在预训练阶段对 QFormer 和 ViT LoRA 进行训练,在微调阶段对 QFormer 和 ChatGLM LoRA 进行训练,训练目标是自回归损失(根据图像生成正确的文本)和对比损失(输入 ChatGLM 的视觉特征与对应文本的语义特征对齐)
## 算法原理
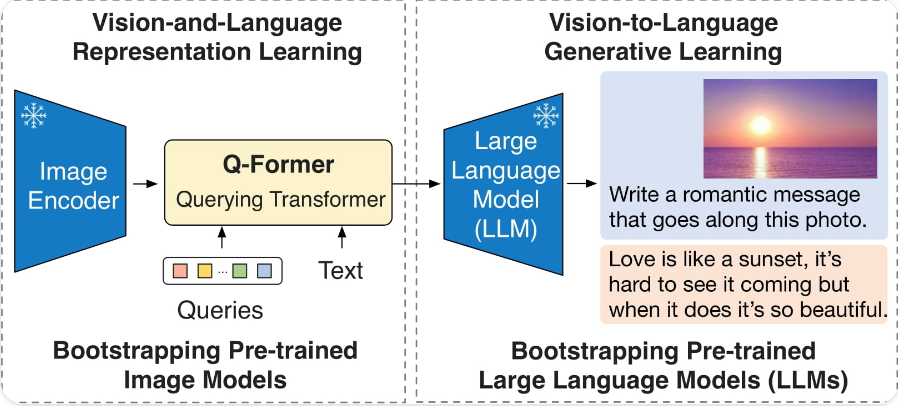
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁。BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。
在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。Q-Former 是一个 transformer 模型,它由两个子模块组成,这两个子模块共享相同的自注意力层:与冻结的图像编码器交互的图像 transformer,用于视觉特征提取文本 transformer,用作文本编码器和解码器。
VisualGLM-6B 由 SwissArmyTransformer(简称sat) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
## 环境配置
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /opt/hyhal:/opt/hyhal:ro --network=host --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
安装环境
```
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法, dockerfile在docker文件夹中
```
cd docker
docker build --no-cache -t visualglm:latest .
docker run -dit --shm-size 80g --network=host --name=visualglm --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /opt/hyhal/:/opt/hyhal/:ro visualglm:latest /bin/bash
docker exec -it visualglm /bin/bash
```
### Conda(方式三)
1.创建conda虚拟环境:
```
conda create -n visualglm python=3.10
conda activate visualglm
```
2.关于本项目DCU显卡所需的工具包、深度学习库等均可从光合开发者社区下载安装。
- [DTK 24.04.1](https://cancon.hpccube.com:65024/directlink/1/DTK-24.04.1/Ubuntu20.04.1/DTK-24.04.1-Ubuntu20.04.1-x86_64.tar.gz)
- [Pytorch 2.1](https://download.sourcefind.cn:65024/directlink/4/pytorch/DAS1.1/torch-2.1.0+das1.1.git3ac1bdd.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl)
- [deepspeed](https://download.sourcefind.cn:65024/directlink/4/deepspeed/DAS1.1/deepspeed-0.12.3+gita724046.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl)
- [torchvision](https://download.sourcefind.cn:65024/directlink/4/vision/DAS1.1/torchvision-0.16.0+das1.1.git7d45932.abi1.dtk2404.torch2.1-cp310-cp310-manylinux_2_31_x86_64.whl)
Tips:以上dtk驱动、torch等工具版本需要严格一一对应。
3. 其它依赖库参照requirements.txt安装:
```
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
## 数据集
无
## 推理
### 代码推理
进入容器后, 进行克隆
```
git clone https://developer.sourcefind.cn/codes/modelzoo/visualglm6b_pytorch
cd visualglm6b_pytorch
```
执行推理命令
```
python test.py #修改相关图像路径image_path和模型路径THUDM/visulglm-6b
```
### 交互式命令行推理
修改cli_demo_hf.py 中模型路径THUDM/visualglm-6b为本地模型路径
```
python cli_demo_hf.py
```
如果不修改模型路径,程序会自动下载sat模型(由于涉及到访问外网,可能无法下载)。执行上面命令,则可以通过命令行中进行交互式的对话,输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
### API部署推理
首先需要安装额外的依赖,然后运行仓库中的 api.py:
```
pip install fastapi uvicorn
python api.py
```
程序会自动下载 sat 模型,默认部署在本地的 8080 端口,通过 POST 方法进行调用。下面是用curl请求的例子(修改path/to/example.jpg为本地路径),一般而言可以也可以使用代码方法进行POST。
```
echo "{\"image\":\"$(base64 path/to/example.jpg)\",\"text\":\"描述这张图片\",\"history\":[]}" > temp.json
curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:8080
```
得到的返回值为
```
{"result":"这张照片中,一个年轻女子坐在沙发上,手里拿着笔记本电脑。她可能正在工作或学习,或者只是放松和享受时间。","history":[["描述这张图片","这张照片中,一个年轻女子坐在沙发上,手里拿着笔记本电脑。她可能正在工作或学习,或者只是放松和享受时间。"]],"status":200,"time":"2024-01-22 11:16:35"}
```
## result
以目录中examples/1.jpeg图片进行推理为例
推理后的结果为:
"泰坦尼克号,男女主角在船头拥抱。海水翻涌,他们的爱情如海浪般澎湃。 夕阳余晖下,两人的身影渐渐消失。"
### 精度
无
## 应用场景
### 算法类别
图像理解
### 热点应用行业
零售,广媒,科研
## 预训练权重
[huggingface](https://huggingface.co/THUDM/visualglm-6b/tree/main)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/visualglm6b_pytorch.git
## 参考资料
- https://github.com/THUDM/VisualGLM-6B?tab=readme-ov-file