# ViT
## 论文
`An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale`
- https://arxiv.org/abs/2010.11929
## 模型结构
ViT主要包括patch embeding、transformer encoder、MLP head三部分:以图像块的线性嵌入为输入、添加位置嵌入和可学习的cls_token(patch embeding),并直接应用无decoder的Transformer进行学习。由于没有归纳偏置,ViT在中小型数据集上性能不如CNN,但当模型和数据量提升时性能会持续提升。
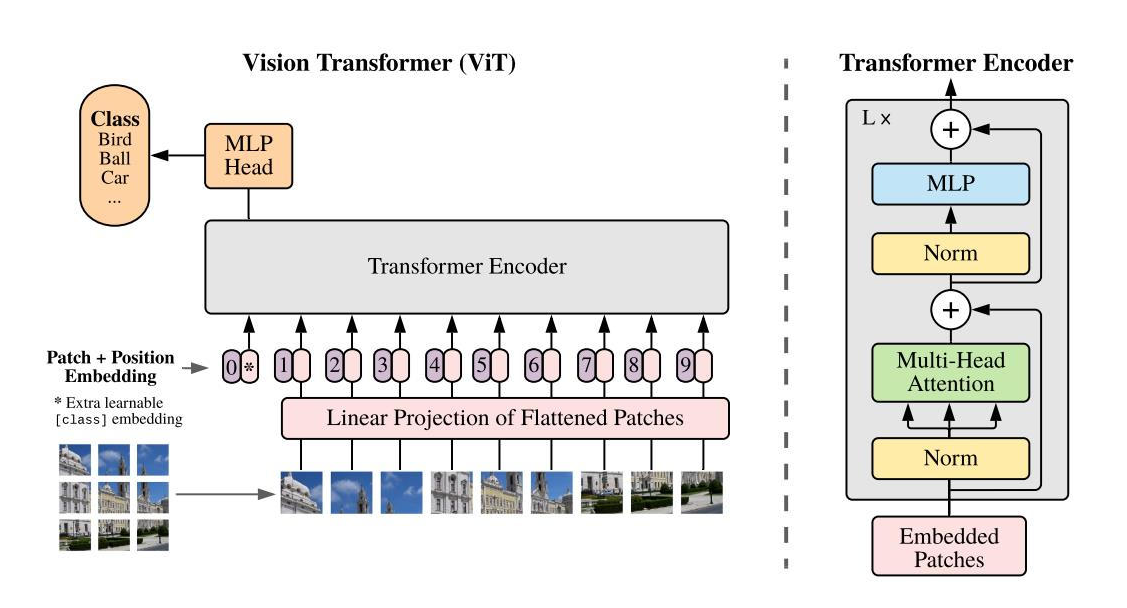
## 算法原理
整个模型结构可以分为五个步骤进行:
1、将图片切分成多个patch。
2、将得到的patches经过一个线性映射层后得到多个token embedding。
3、将得到的多个token embedding concat一个额外的cls_token,然后和位置编码相加,构成完整的encoder模块的输入。
4、 将相加后的结果传入Transformer Encoder模块。
5、Transformer Encoder 模块的输出经过MLP Head 模块做分类输出。
## 环境配置
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/jax:0.4.23-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --network=host --privileged=true --name=vit --device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro /bin/bash # 为以上拉取的docker的镜像ID替换
cd /your_code_path/vision_transformer
pip install flax==0.6.9 # flax会强制安装某版本ai包
pip install -r requirements.txt
pip uninstall tensorflow
pip uninstall jax
pip uninstall jaxlib
pip install tensorflow-cpu==2.14.0
wget https://cancon.hpccube.com:65024/directlink/4/jax/DAS1.1/jax-0.4.23+das1.1.git387bd43.abi1.dtk2404-py3-none-any.whl
wget https://cancon.hpccube.com:65024/directlink/4/jax/DAS1.0/jaxlib-0.4.23+das1.0+git97306ab.abi1.dtk2404-cp310-cp310-manylinux2014_x86_64.whl
pip install jax-0.4.23+das1.1.git387bd43.abi1.dtk2404-py3-none-any.whl
pip install jaxlib-0.4.23+das1.1.git387bd43.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl
```
### Dockerfile(方法二)
```
docker build --no-cache -t vit:latest .
docker run -it --network=host --privileged=true --name=vit --device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro vit /bin/bash
cd /your_code_path/vision_transformer
pip install flax==0.6.9 # flax会强制安装某版本ai包
pip install -r requirements.txt
pip uninstall tensorflow
pip uninstall jax
pip uninstall jaxlib
pip install tensorflow-cpu==2.14.0
wget https://cancon.hpccube.com:65024/directlink/4/jax/DAS1.1/jax-0.4.23+das1.1.git387bd43.abi1.dtk2404-py3-none-any.whl
wget https://cancon.hpccube.com:65024/directlink/4/jax/DAS1.0/jaxlib-0.4.23+das1.0+git97306ab.abi1.dtk2404-cp310-cp310-manylinux2014_x86_64.whl
pip install jax-0.4.23+das1.1.git387bd43.abi1.dtk2404-py3-none-any.whl
pip install jaxlib-0.4.23+das1.1.git387bd43.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24.04.1
python:python3.10
jax:0.4.23
```
`Tips:以上dtk软件栈、python、jax等DCU相关工具版本需要严格一一对应`
2、其他非特殊库直接按照下面步骤进行安装
```
cd /your_code_path/vision_transformer
pip install flax==0.6.9 # flax会强制安装某版本ai包
pip install -r requirements.txt
pip install tensorflow-cpu==2.14.0
```
## 数据集
### 训练数据集
`cifar10 cifar100`
数据集根据训练命令由tensorflow_datasets自动下载和处理,相关代码见vision_transformer/vit_jax/input_pipeline.py
注:若发生错误All attempts to get a Google authentication bearer token failed..,按以下代码更改
```
vim /usr/local/lib/python3.10/site-packages/tensorflow_datasets/core/utils/gcs_utils.py
搜索_is_gcs_disabled,修改为_is_gcs_disabled = True
```
数据集下载地址及处理设置见./configs/common.py,默认存储地址为/root/tensorflow_datasets/,数据集目录结构如下:
```
── cifar10
│ ├── 3.0.2
│ ├── cifar10-test.tfrecord-00000-of-00001
│ ├── cifar10-train.tfrecord-00000-of-00001
│ ├── dataset_info.json
│ ├── features.json
│ └── label.labels.txt
── cifar100
│ └── 3.0.2
│ ├── cifar100-test.tfrecord-00000-of-00001
│ ├── cifar100-train.tfrecord-00000-of-00001
│ ├── coarse_label.labels.txt
│ ├── dataset_info.json
│ ├── features.json
│ └── label.labels.txt
```
### 推理数据集
推理所用图片和文件可根据[scnet](http://113.200.138.88:18080/aidatasets/project-dependency/vision_transformer_jax)或以下代码进行下载:
```
# ./dataset是存储地址,可自订
wget https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt -P ./dataset
wget https://picsum.photos/384 -O ./dataset/picsum.jpg # 将图片调整为384分辨率
```
数据集目录结构如下:
```
── dataset
│ ├── ilsvrc2012_wordnet_lemmas.txt
│ └── picsum.jpg
```
## 训练
检查点可通过[scnet](http://113.200.138.88:18080/aimodels/findsource-dependency/vision_transformer_jax/-/tree/master/imagenet21k?ref_type=heads)或以下方式进行下载:
```
cd /your_code_path/vision_transformer/test_result # test_result为检查点下载地址,可自订
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-L_16.npz
```
### 单机单卡
```
cd /your_code_path/vision_transformer
sh test.sh
# workdir=$(pwd)/test_result/dcu/vit-$(date +%s) # 指定存储日志和模型数据的目录
# config=$(pwd)/vit_jax/configs/vit.py:$model_datasets # 指定用于微调的模型/数据集
# config.pretrained_dir=$(pwd)/test_result # 检查点所在目录
# config.accum_steps=64 # 累加梯度的轮次(tpu=8,cpu=64)
# config.total_steps=500 # 微调轮次
# config.warmup_steps=50 # 学习率衰减轮次
# config.batch=512 # 训练批次
# config.pp.crop=384 # 图像块的分辨率
# config.optim_dtype='bfloat16' # 精度
```
## 推理
检查点可通过[scnet](http://113.200.138.88:18080/aimodels/findsource-dependency/vision_transformer_jax/-/tree/master/imagenet21k+imagenet2012?ref_type=heads)或以下方式进行下载:
```
cd /your_code_path/vision_transformer/test_result # test_result为检查点下载地址,可自订
wget https://storage.googleapis.com/vit_models/imagenet21k+imagenet2012/ViT-B_16.npz -O ViT-B_16_imagenet2012.npz
wget https://storage.googleapis.com/vit_models/imagenet21k+imagenet2012/ViT-L_16.npz -O ViT-L_16_imagenet2012.npz
```
```
cd /your_code_path/vision_transformer
python test.py # 文件内可修改模型目录和数据集目录
```
## result
测试图为:
```
----ViT-B_16:
dcu推理结果:
0.73861 : alp
0.24576 : valley, vale
0.00416 : lakeside, lakeshore
0.00404 : cliff, drop, drop-off
0.00094 : promontory, headland, head, foreland
0.00060 : mountain_tent
0.00055 : dam, dike, dyke
0.00033 : volcano
0.00031 : ski
0.00012 : solar_dish, solar_collector, solar_furnace
gpu推理结果:
0.73976 : alp
0.24465 : valley, vale
0.00414 : lakeside, lakeshore
0.00404 : cliff, drop, drop-off
0.00094 : promontory, headland, head, foreland
0.00060 : mountain_tent
0.00054 : dam, dike, dyke
0.00033 : volcano
0.00031 : ski
0.00012 : solar_dish, solar_collector, solar_furnace
----ViT-L_16:
dcu推理结果:
0.87382 : alp
0.11846 : valley, vale
0.00550 : cliff, drop, drop-off
0.00023 : mountain_tent
0.00017 : promontory, headland, head, foreland
0.00015 : lakeside, lakeshore
0.00013 : dam, dike, dyke
0.00006 : volcano
0.00006 : ski
0.00004 : sandbar, sand_bar
gpu推理结果:
0.87399 : alp
0.11828 : valley, vale
0.00550 : cliff, drop, drop-off
0.00023 : mountain_tent
0.00017 : promontory, headland, head, foreland
0.00015 : lakeside, lakeshore
0.00013 : dam, dike, dyke
0.00006 : volcano
0.00006 : ski
0.00004 : sandbar, sand_bar
```
### 精度
k800*1(1410Mhz,80G,cuda11.8):
| 参数 | acc | loss |
| -------------------------------- | ------- | -------- |
| model_datasets='b16,cifar10'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.98047 | 0.428023 |
| model_datasets='b16,cifar100'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.89206 | 1.25078 |
| model_datasets='l16,cifar10'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.98890 | 0.348941 |
| model_datasets='l16,cifar100'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.91375 | 1.05141 |
k100*1(1270Mhz,64G,dtk24.04.1):
| 参数 | acc | loss |
| ------------------------------------------------------------ | ------- | -------- |
| model_datasets='b16,cifar10'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.98037 | 0.43239 |
| model_datasets='b16,cifar100'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.89001 | 1.2273 |
| model_datasets='l16,cifar10'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.98921 | 0.306221 |
| model_datasets='l16,cifar100'
config.batch=512
config.total_steps=500
config.optim_dtype = 'bfloat16' | 0.91447 | 0.976117 |
## 应用场景
### 算法类别
`图像分类`
### 热点应用行业
`制造,电商,医疗,广媒,教育`
## 预训练权重
- http://113.200.138.88:18080/aimodels/findsource-dependency/vision_transformer_jax
- https://console.cloud.google.com/storage/browser/vit_models/imagenet21k/ (微调用)
https://console.cloud.google.com/storage/browser/vit_models/imagenet21k+imagenet2012/ (推理用)
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/vision_transformer_jax
## 参考资料
- https://github.com/google-research/vision_transformer
