
Initial commit
Showing
.github/workflows/build.yml
0 → 100644
.style.yapf
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
README_origin.md
0 → 100644
lit.ipynb
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
mixer_figure.png
0 → 100644
{kind=link}
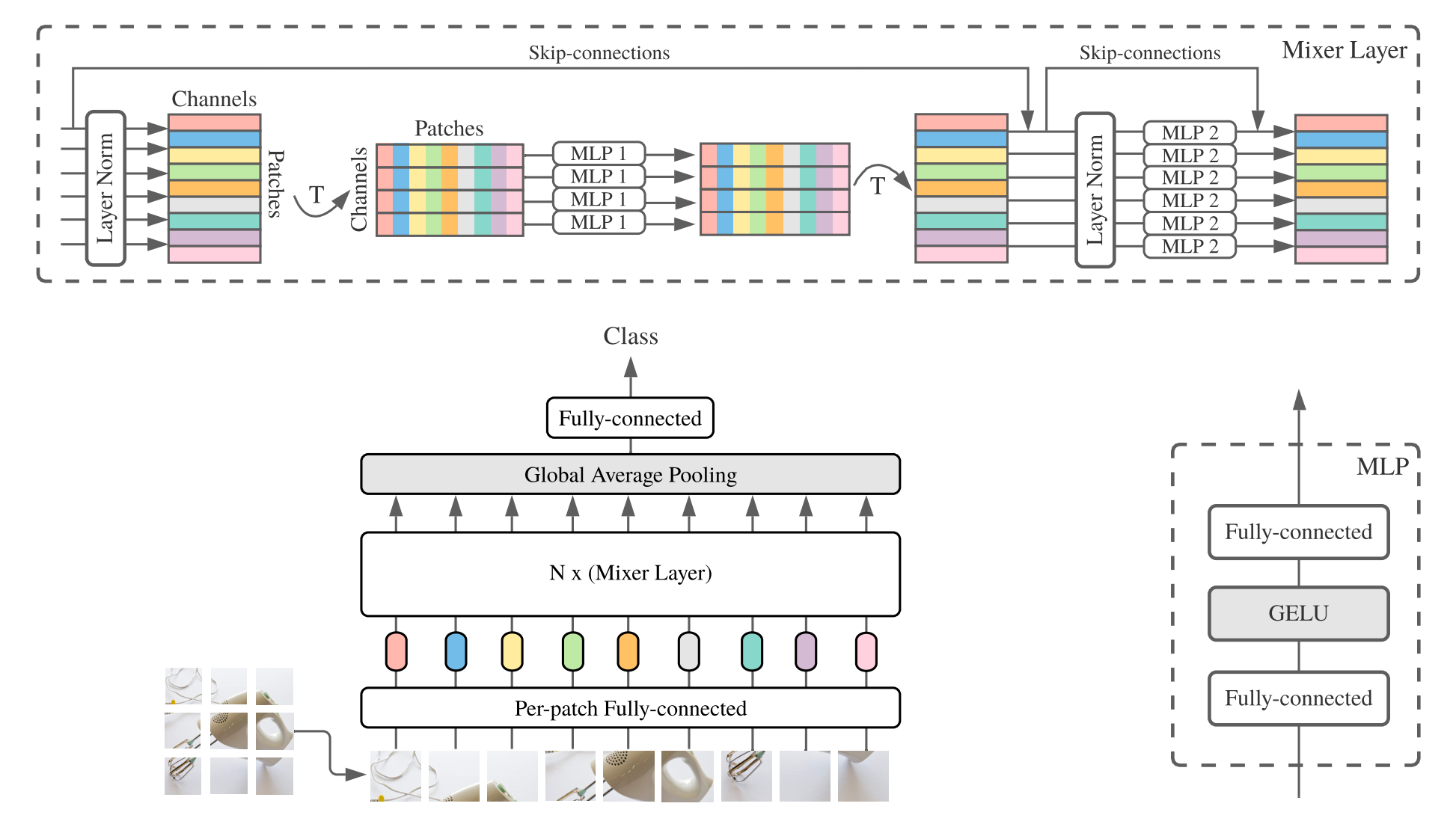
298 KB
model_cards/lit.md
0 → 100644
requirements.txt
0 → 100644
| absl-py>=0.12.0 | ||
| # aqtp!=0.1.1 # https://github.com/google/aqt/issues/196 | ||
| chex>=0.0.7 | ||
| clu>=0.0.3 | ||
| einops>=0.3.0 | ||
| flax>=0.6.4 | ||
| git+https://github.com/google/flaxformer | ||
| # jax[cuda11_cudnn86]>=0.4.2 | ||
| #--find-links https://storage.googleapis.com/jax-releases/jax_cuda_releases.html | ||
| ml-collections>=0.1.0 | ||
| numpy>=1.19.5 | ||
| pandas>=1.1.0 | ||
| tensorflow-cpu>=2.13.0 # tensorflow-cpu>=2.4.0 # Using tensorflow-cpu to have all GPU memory for JAX. | ||
| tensorflow-datasets>=4.0.1 | ||
| tensorflow-probability>=0.11.1 | ||
| # tensorflow-text>=2.9.0 | ||
| # 适配 | ||
| aqtp==0.1.0 | ||
| tensorflow-text==2.13.0 | ||
| scipy==1.12.0 | ||
| orbax-checkpoint==0.4.1 | ||
| gsutil | ||
| # tensorflow-2.13.1+das1.1.git56b06c8.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl | ||
| # jax-0.4.23+das1.1.git387bd43.abi1.dtk2404-py3-none-any.whl | ||
| # jaxlib-0.4.23+das1.1.git387bd43.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64.whl |
setup.py
0 → 100644
test.py
0 → 100644
test.sh
0 → 100644
version.py
0 → 100644
vit_figure.png
0 → 100644
{kind=link}
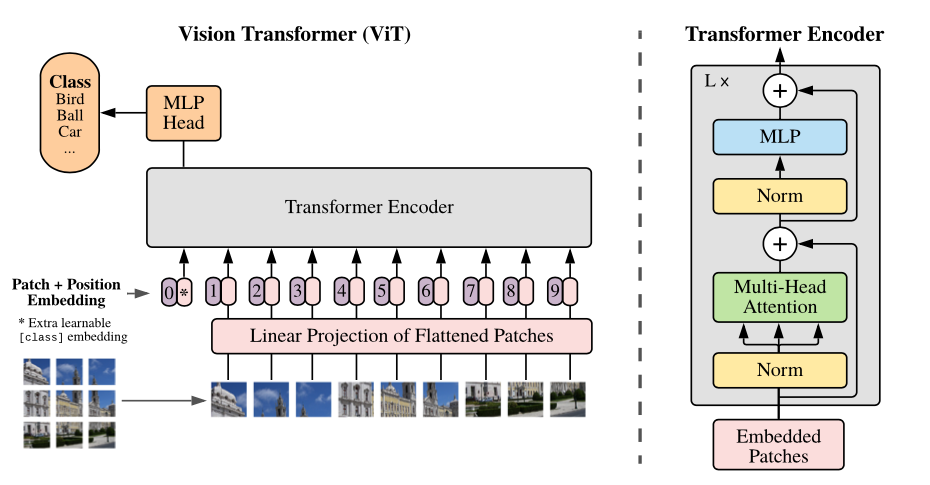
127 KB
vit_jax.ipynb
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
vit_jax/__init__.py
0 → 100644
vit_jax/checkpoint.py
0 → 100644
vit_jax/checkpoint_test.py
0 → 100644
vit_jax/configs/README.md
0 → 100644
vit_jax/configs/__init__.py
0 → 100644