Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
video_migraphx
Commits
efe19856
Commit
efe19856
authored
Oct 24, 2023
by
lijian6
Browse files
Update
Signed-off-by:
lijian
<
lijian6@sugon.com
>
parent
58b13eb2
Changes
44
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
69 additions
and
50 deletions
+69
-50
Doc/YoloV7_suanfa.png
Doc/YoloV7_suanfa.png
+0
-0
README.md
README.md
+62
-46
docker/Dockerfile
docker/Dockerfile
+1
-0
model.properties
model.properties
+6
-4
No files found.
Doc/YoloV7_suanfa.png
0 → 100644
View file @
efe19856
90.6 KB
README.md
View file @
efe19856
#
Video_MIGraphX
#
YoloV7
## 目录
-
[
目录结构
](
#目录结构
)
-
[
项目介绍
](
#项目介绍
)
-
[
环境配置
](
#环境配置
)
-
[
编译运行
](
#编译运行
)
-
[
参考文档
](
#参考文档
)
-
[
历史版本
](
#历史版本
)
## 论文
## 目录结构
```
├── CMakeLists.txt
├── Doc
├── include
├── lib
│ ├── libdecode0.so
│ ├── libdecode1.so
│ └── libQueue.so
├── README.md
├── Resource
│ ├── Configuration.xml
│ ├── Images
│ └── Models
└── src
├── Inference
├── main.cpp
├── RetinaFace.cpp
├── SSD.cpp
├── Utility
├── YOLOV3.cpp
├── YOLOV5.cpp
└── YOLOV7.cpp
```
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
-
https://arxiv.org/pdf/2207.02696.pdf
## 模型结构
YOLOV7是2022年最新出现的一种YOLO系列目标检测模型,该模型的网络结构包括三个部分:input、backbone和head。
<img
src=
"./Doc/YoloV7_model.png"
alt=
"YOLOV7_02"
style=
"zoom:67%;"
/>
## 算法原理
## 项目介绍
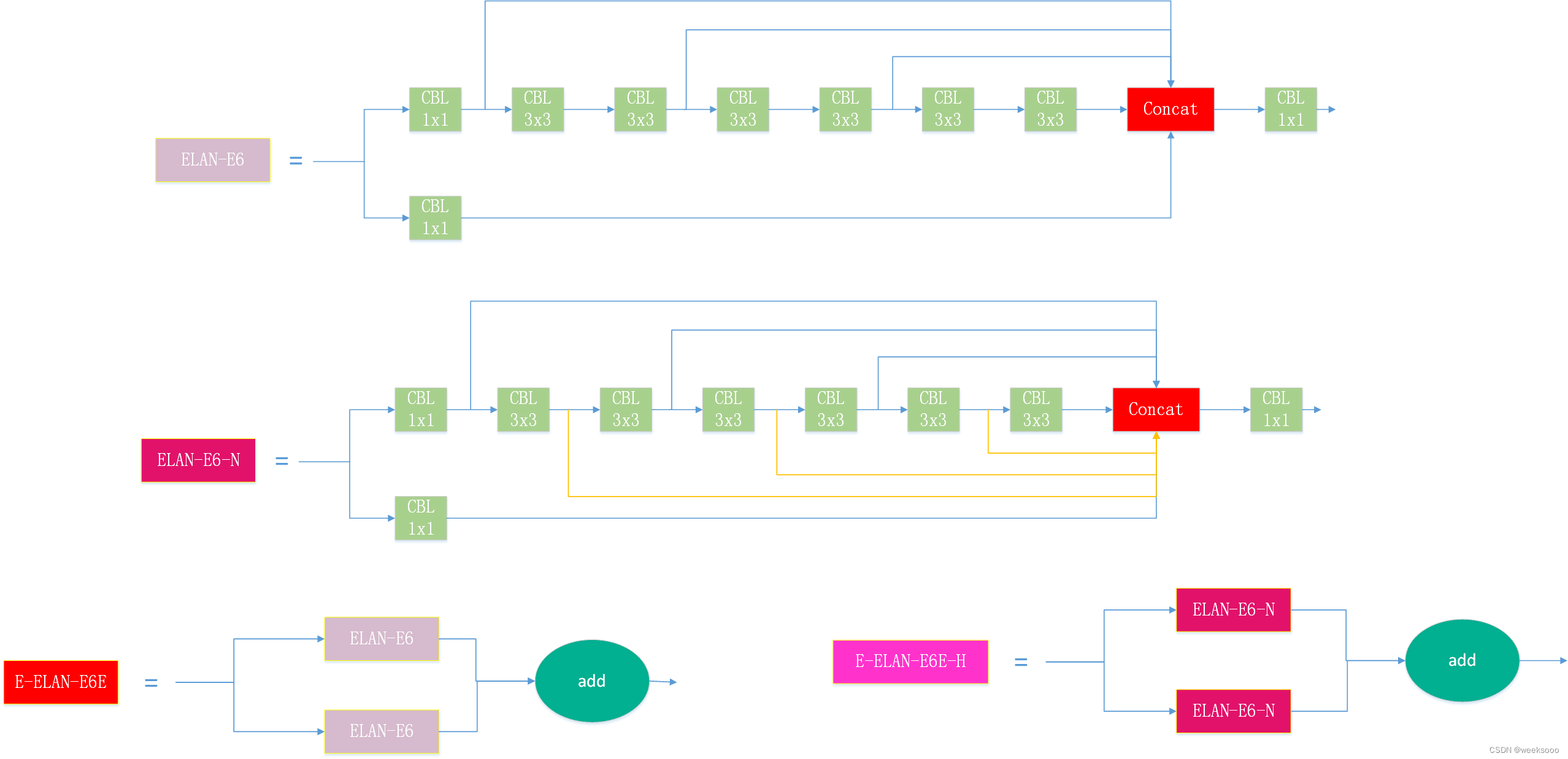
YOLOv7的作者提出了 Extended-ELAN (E-ELAN)结构。E-ELAN采用了ELAN类似的特征聚合和特征转移流程,仅在计算模块中采用了类似ShuffleNet的分组卷积、扩张模块和混洗模块,最终通过聚合模块融合特征。通过采
用这种方法可以获得更加多样的特征,同时提高参数的计算和利用效率。
基于CPU和解码卡解码的视频推理范例
<img
src=
"./Doc/YoloV7_suanfa.png"
alt=
"YOLOV7_suanfa"
style=
"zoom:67%;"
/>
## 环境配置
### Docker(方法一)
推荐使用docker方式运行,提供
[
光源
](
https://www.sourcefind.cn/#/service-list
)
拉取的docker
镜像
拉取
镜像
:
```
```
plaintext
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:decode-ffmpeg-dtk23.04
```
## 编译运行
创建并启动容器:
```
plaintext
docker run --shm-size 16g --network=host --name=video_migraphx --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/video_migraphx:/home/video_migraphx -it <Your Image ID> /bin/bash
```
### Dockerfile(方法二)
```
cd ./docker
docker build --no-cache -t video_migraphx:test .
docker run --shm-size 16g --network=host --name=video_migraphx --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/video_migraphx:/home/video_migraphx -it <Your Image ID> /bin/bash
```
## 数据集
根据提供的视频文件,进行目标检测。
## 推理
### 编译
### 编译
工程
```
git clone https://developer.hpccube.com/codes/modelzoo/video_migraphx
git clone https://developer.hpccube.com/codes/modelzoo/video_migraphx
.git
cd video_migraphx
mkdir build
cd build
...
...
@@ -60,22 +61,37 @@ cmake ../ -DUSE_P2P=1
make
```
### 运行
### 运行
示例
```
./Video_MIGraphX
```
根据提示选择要运行的示例程序,运行解码卡示例需要提前安装并初始化解码卡。比如执行:
```
如在CPU端解码,运行yolov3-tiny示例:
./Video_MIGraphX --cpu --net=0
```
运行CPU解码并运行YOLOV3推理示例程序
注意:如果需要运行解码卡硬件帧示例,需要提前安装dma-buffer驱动
## result
无
## 参考文档
### 精度
无
文档参考Doc目录下说明文档.
## 应用场景
### 算法类别
`目标检测`
### 热点应用行业
`监控`
,
`交通`
,
`教育`
,
`化工`
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/video_migraphx
https://developer.hpccube.com/codes/modelzoo/video_migraphx.git
## 参考资料
https://github.com/WongKinYiu/yolov7
docker/Dockerfile
0 → 100644
View file @
efe19856
FROM
image.sourcefind.cn:5000/dcu/admin/base/custom:decode-ffmpeg-dtk23.04
model.properties
View file @
efe19856
# 模型唯一标识
modelCode
=
225
# 模型名称
modelName
=
V
ideo_
MIG
raph
X
modelName
=
v
ideo_
mig
raph
x
# 模型描述
modelDescription
=
Video MIGraphX是用于视频类的推理,使用ffmpeg解码,含有yolo系列,retinaface
,ssd模型
modelDescription
=
Video MIGraphX是用于视频类的
目标检测
推理,使用ffmpeg解码,含有yolo系列,retinaface
# 应用场景
appScenario
=
推理,
inference,MIGraphX,目标检测,视频解码,video
appScenario
=
推理,
目标检测,视频解码,监控,交通,教育,化工
# 框架类型
frameType
=
MIG
raph
X
frameType
=
mig
raph
x
Prev
1
2
3
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

 lijian <lijian6@sugon.com>
lijian <lijian6@sugon.com>{kind=link}
 lijian <lijian6@sugon.com>
lijian <lijian6@sugon.com>