# Vary
**开源多模态OCR大模型**
## 论文
- [Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models](https://arxiv.org/abs/2312.06109)
## 模型结构
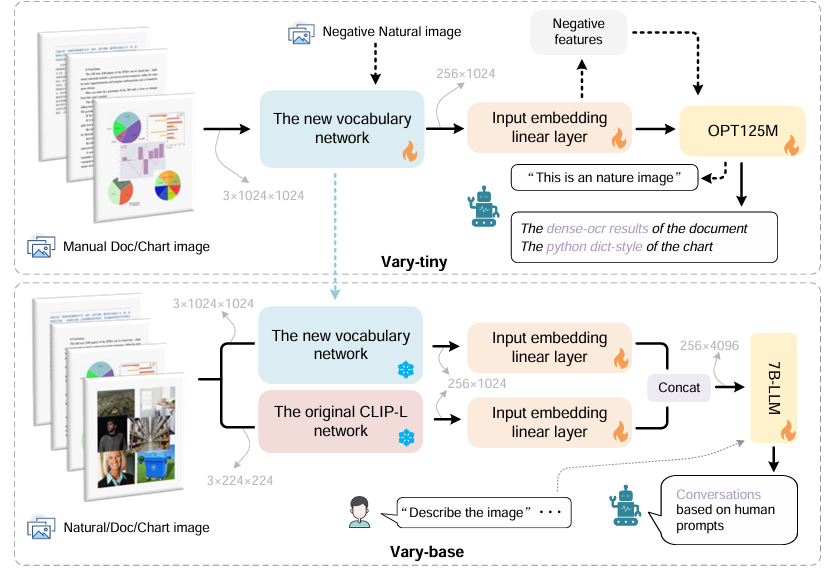
Vary的整体思想很简单,主要分为两个阶段,Vary-tiny和Vary-base:
Vary-tiny:设计了一个词汇表网络和一个小型的仅解码器的转换器,通过自回归生成所需的新视觉词汇表。这个词汇表会和OPT-125M模型一起训练。
Vary-base:将新的视觉词汇表与原始词汇表(CLIP)合并,扩展了vanilla(原始的)视觉词汇表。联合LLM-7B模型进行训练。
## 算法原理
Vary享有两种构象:Vary-tiny 和 Vary-base。我们设计 Vary-tiny 来 “编写”新的视觉词汇,而 Vary-base 则利用新的词汇。具体来说,Vary-tiny 主要由词汇网络和微型 OPT-125M组成。在这两个模块之间,我们添加了一个线性层来对齐通道尺寸。由于 Vary-tiny 主要关注细粒度感知,因此它没有文本输入分支。我们希望新的视觉词汇网络能在处理人工图像(即文档和图表)方面表现出色,以弥补 CLIP 的不足。同时,我们也希望在对自然图像进行标记时,它不会成为 CLIP 的噪音。因此,在生成过程中,我们将人工文档和图表数据作为正样本,将自然图像作为负样本来训练 Vary-tiny。完成上述过程后,我们提取词汇网络并将其添加到一个大型模型中,从而建立 Vary-base。新旧词汇网络享有独立的输入嵌入层,并在 LLM 之前进行整合。在这一阶段,我们冻结新旧视觉词汇网络的权重,并解冻其他模块的权重。
## 环境配置
`注:在部署环境前需修改本仓库vary/demo/run_qwen_vary.py和vary/model/vary_qwen_vary.py中的模型路径改为本地模型路径,同时将模型中的config.json文件中的模型路径改为本地路径,完成以上操作后再执行pip install e .指令。`
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu22.04-dtk23.10.1-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name vary bash
cd /path/your_code_data/
pip install e .
pip install ninja
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t vary:latest .
docker run --shm-size=64G --name vary -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it vary:latest bash
cd /path/your_code_data/
pip intall e .
pip install ninja
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk23.10
python:python3.10
torch:2.1
torchvision: 0.16.0
deepspped: 0.12.3
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
```
conda create -n vary python=3.10
conda activate vary
cd /path/your_code_data/
pip install e .
pip install ninja
```
## 数据集
本项目暂未开放数据集,需自己构建数据集
可参考本项目github论文
- [Ucas-HaoranWei/Vary](https://github.com/Ucas-HaoranWei/Vary)
## 训练
无
## 推理
**需严格按照本仓库代码目录进行排列**
备注:在run.sh修改 --image-file 替换ocr文件
```
python /home/wanglch/projects/Vary_pytorch/vary/demo/run_qwen_vary.py --model-name /home/wanglch/projects/Vary_pytorch/cache/models--HaoranWei--vary-llava80k --image-file /home/wanglch/projects/Vary_pytorch/image/pic.jpg
```
备注:修改 vary/demo/run_qwen_vary.py 替换57行代码执行不同任务操作
```
qs = 'Provide the ocr results of this image.' # 执行ocr任务
qs = 'Detevate the ** in this image.' # 检测任务
qs = 'Convert the document to markdown format.' # 公式转markdown
qs = 'Describe this image in within 100 words.' # 多模态描述
```
### 推理代码
```
bash run.sh
```
## result
### 英语文档ocr结果
### 中文文档ocr结果
### 车牌识别结果
### 内容识别结果
## 应用场景
### 算法类别
`OCR`
### 热点应用行业
`金融,教育,政府,科研,交通,广媒`
## 预训练权重
-[Vary weights huggingface 预训练模型下载地址] 可联系作者获取模型权重!
`weihaoran18@mails.ucas.ac.cn`
- 本项目提供权重地址为[Here](https://pan.baidu.com/s/1CjlRmq0_q-NSJez2BKrghg),
验证码可在本仓库留言索取。
-[Download the CLIP-VIT-L]
## 源码仓库及问题反馈
- http://developer.hpccube.com/codes/modelzoo/vary_pytorch.git
## 参考资料
- [Ucas-HaoranWei/Vary](https://github.com/Ucas-HaoranWei/Vary)







