
Initial commit
parents
Showing
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
File added
docker/Dockerfile
0 → 100644
image/car.png
0 → 100644
{kind=link}

42.9 KB
image/model.png
0 → 100644
{kind=link}
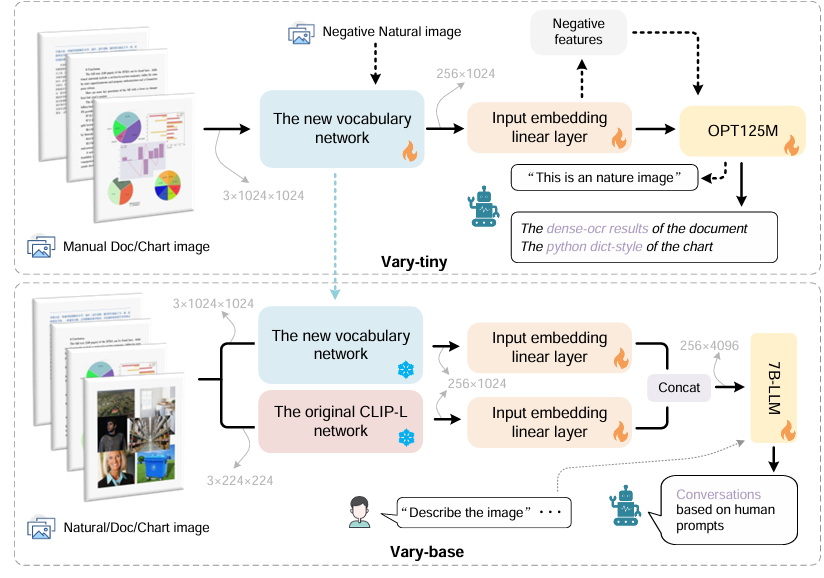
155 KB
image/pic.jpg
0 → 100644
{kind=link}

113 KB
image/pic2.jpg
0 → 100644
{kind=link}

119 KB
image/pic3.jpg
0 → 100644
{kind=link}

204 KB
model.properties
0 → 100644
pyproject.toml
0 → 100644
pyvenv.cfg
0 → 100644
run.sh
0 → 100644
vary/__init__.py
0 → 100644
vary/data/__init__.py
0 → 100644