# Vary-toy
**开源多模态OCR大模型**
## 论文
- [Small Language Model Meets with Reinforced Vision Vocabulary](https://arxiv.org/abs/2401.12503)
## 模型结构
最近Vary的团队开发了一个更小版本的Vary模型——1.8B Vary-toy,与Vary相比,Vary-toy除了小之外,还优化了新视觉词表。解决了原Vary只用新视觉词表做pdf ocr的网络容量浪费,以及吃不到SAM预训练优势的问题。与Vary-toy同时发布的还有更强的视觉词表网络,其不仅能做pdf-level ocr,还能做通用视觉目标检测。Vary-toy在消费级显卡可训练、8G显存的老显卡可运行,依旧支持中英文。
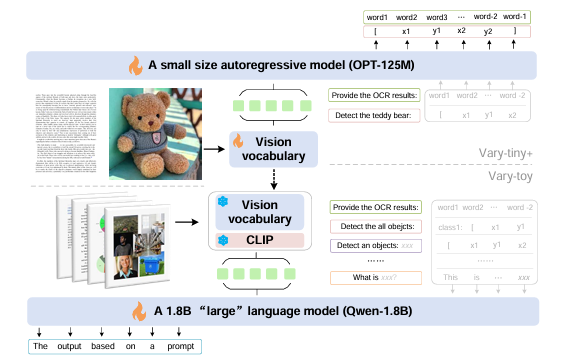
## 算法原理
Vary-toy 利用 Vary-tiny+ 管道来生成新的愿景 Vary-toy的词汇。这样的视觉词汇可以有效地编码密集的文本和自然物体位置信息转换为令牌。基于改进的词汇量,Vary-toy 不仅拥有所有以前的功能(文档OCR),但也很好地处理了对象检测任务。
## 环境配置
**注意:** 🚨
|在部署环境前需将[vary/demo/run_qwen_vary.py](https://developer.sourcefind.cn/codes/modelzoo/vary-toy_pytorch/-/blob/main/vary/demo/run_qwen_vary.py)、[vary/model/vary_qwen_vary.py](https://developer.sourcefind.cn/codes/modelzoo/vary-toy_pytorch/-/blob/main/vary/model/vary_qwen_vary.py)、[vary/model/vary_toy_qwen1_8.py](https://developer.sourcefind.cn/codes/modelzoo/vary-toy_pytorch/-/blob/main/vary/model/vary_toy_**qwen1_8.py)中的模型路径改为本地模型路径,同时将Vary-toy模型中的config.json文件中的模型路径改为本地路径,完成以上操作后再执行pip install e .指令。 |
| -------- |
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name vary-toy bash
cd /path/your_code_data/
pip install e .
pip install numpy==1.24.3
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t vary-toy:latest .
docker run --shm-size=64G --name vary-toy -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it vary-toy:latest bash
cd /path/your_code_data/
pip intall e .
pip install numpy==1.24.3
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:python3.10
torch:2.1
torchvision: 0.16.0
deepspped: 0.12.3
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
```
conda create -n vary-toy python=3.10
conda activate vary-toy
cd /path/your_code_data/
pip install e .
pip install numpy==1.24.3
```
## 数据集
无, 本项目暂未开放数据集
## 训练
无
## 推理
**需严格按照本仓库代码目录进行排列**
备注:在run.sh修改 --image-file 替换ocr文件
```
python /home/wanglch/projects/Vary-toy_pytorch/vary/demo/run_qwen_vary.py --model-name /home/wanglch/projects/Vary-toy_pytorch/cache/models--HaoranWei--Vary-toy --image-file /home/wanglch/projects/Vary-toy_pytorch/image/pic.jpg
```
备注:修改 vary/demo/run_qwen_vary.py 替换57行代码执行不同任务操作
```
qs = 'Provide the ocr results of this image.' # 执行ocr任务
qs = 'Detevate the ** in this image.' # 检测任务
qs = 'Convert the document to markdown format.' # 公式转markdown
qs = 'Describe this image in within 100 words.' # 多模态描述
```
### 推理代码
```
bash run.sh
```
## result
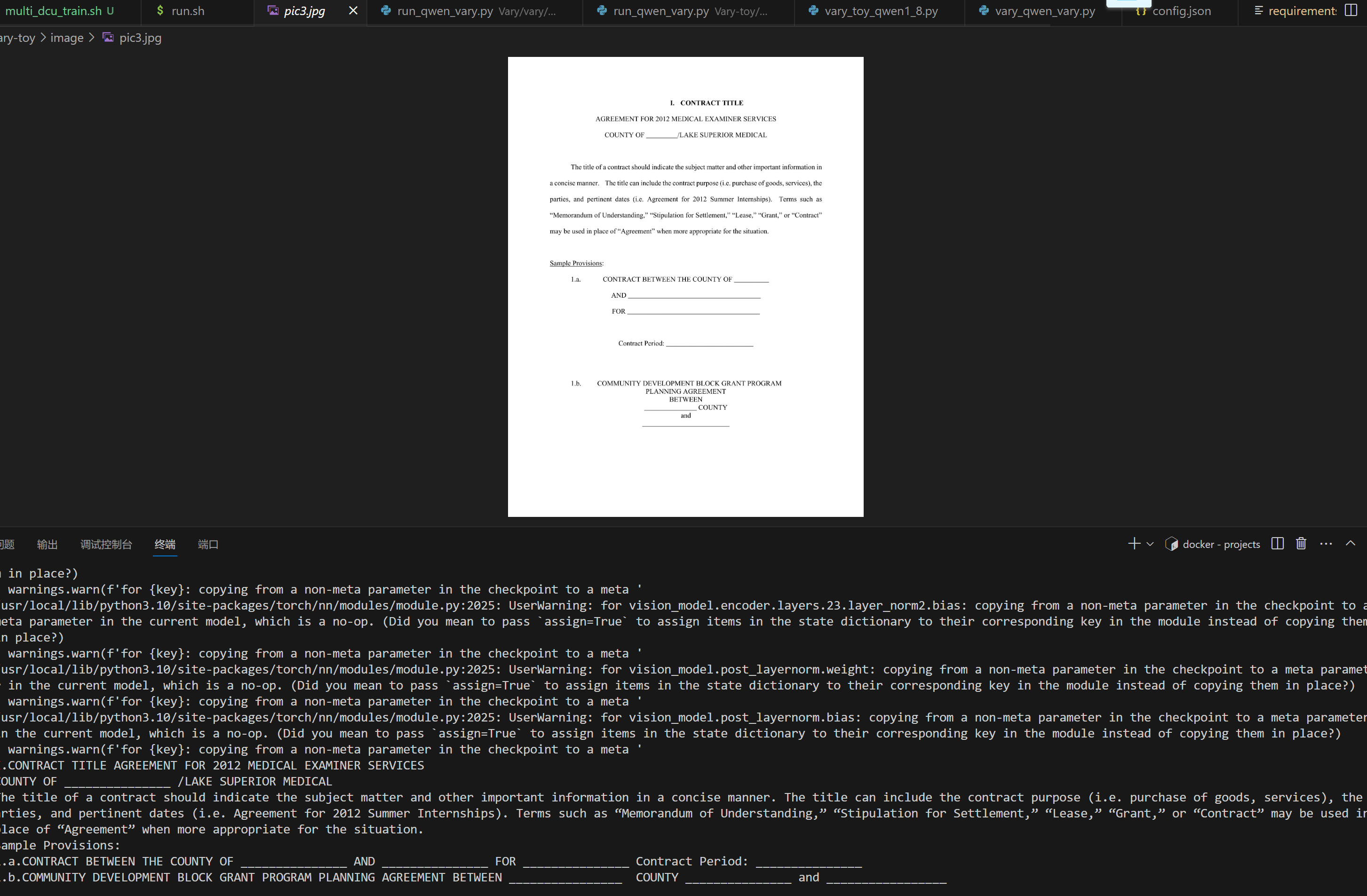
**英语文档ocr结果**
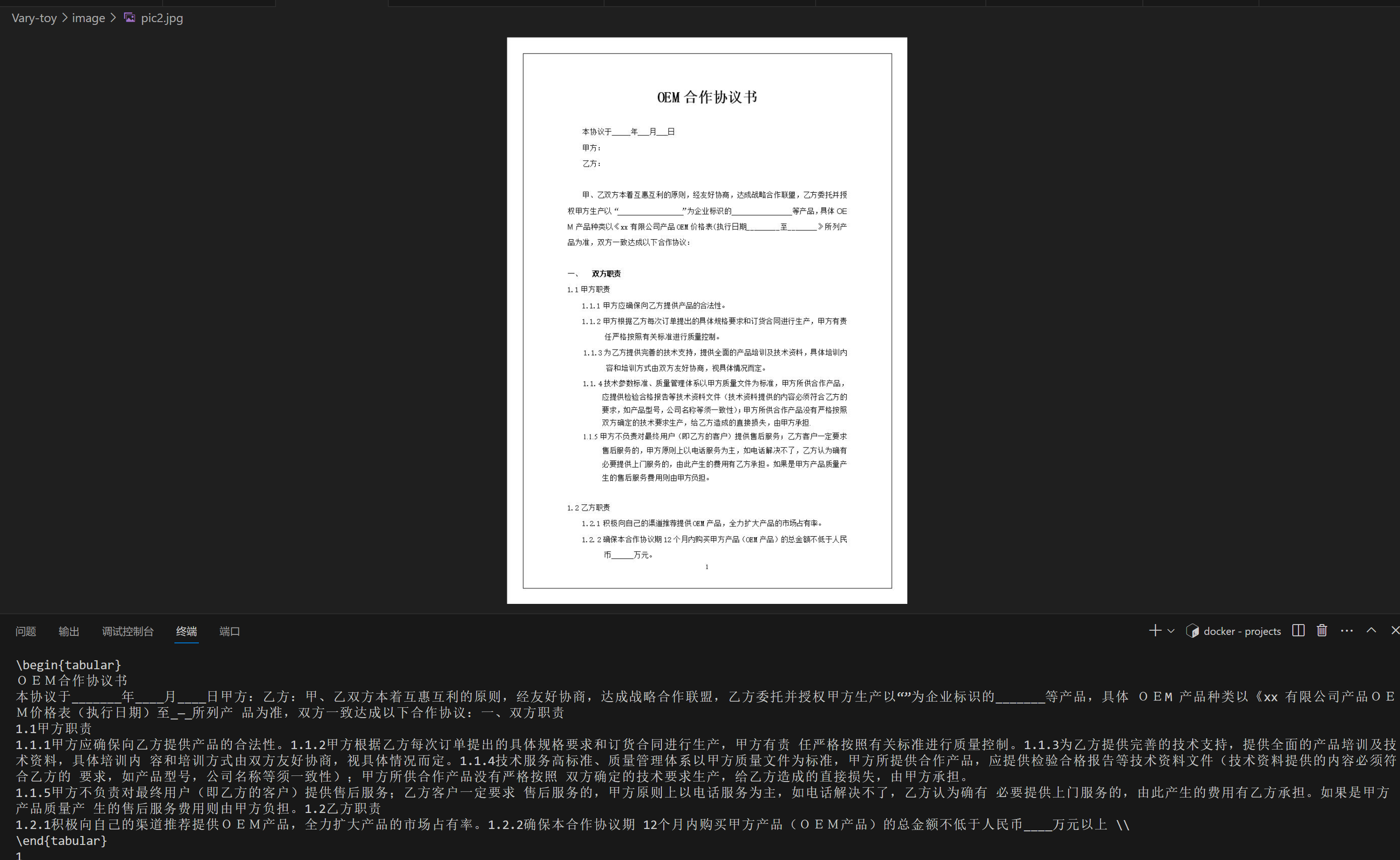
**中文文档ocr结果**
### 精度
无
## 应用场景
### 算法类别
`OCR`
### 热点应用行业
`金融,教育,政府,科研`
## 预训练权重
[Vary-toy](https://huggingface.co/Haoran-megvii/Vary-toy).
[clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/vary-toy_pytorch.git
## 参考资料
- 本项目gitlab地址[Ucas-HaoranWei/Vary-toy](https://github.com/Ucas-HaoranWei/Vary-toy/tree/main)