
v1.0
parents
Showing
Seg_UKAN/dataset.py
0 → 100644
Seg_UKAN/doc/algorithm.png
0 → 100644
{kind=link}
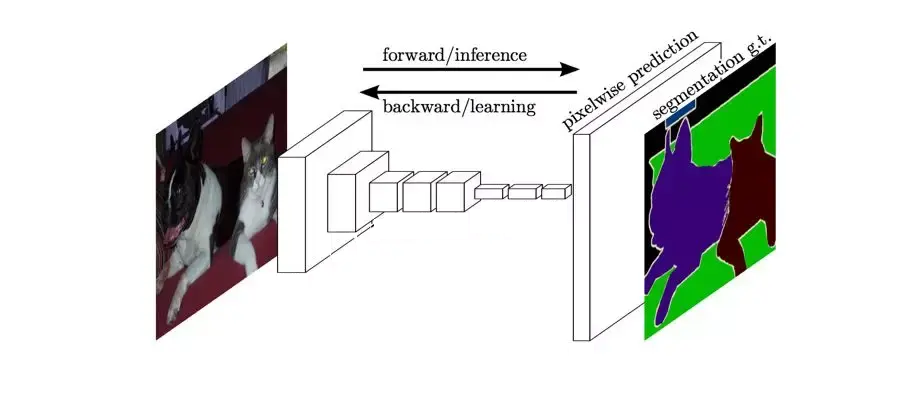
145 KB
Seg_UKAN/doc/seg.png
0 → 100644
{kind=link}
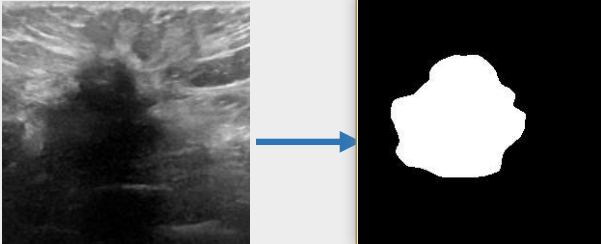
54.9 KB
Seg_UKAN/doc/structure.png
0 → 100644
{kind=link}
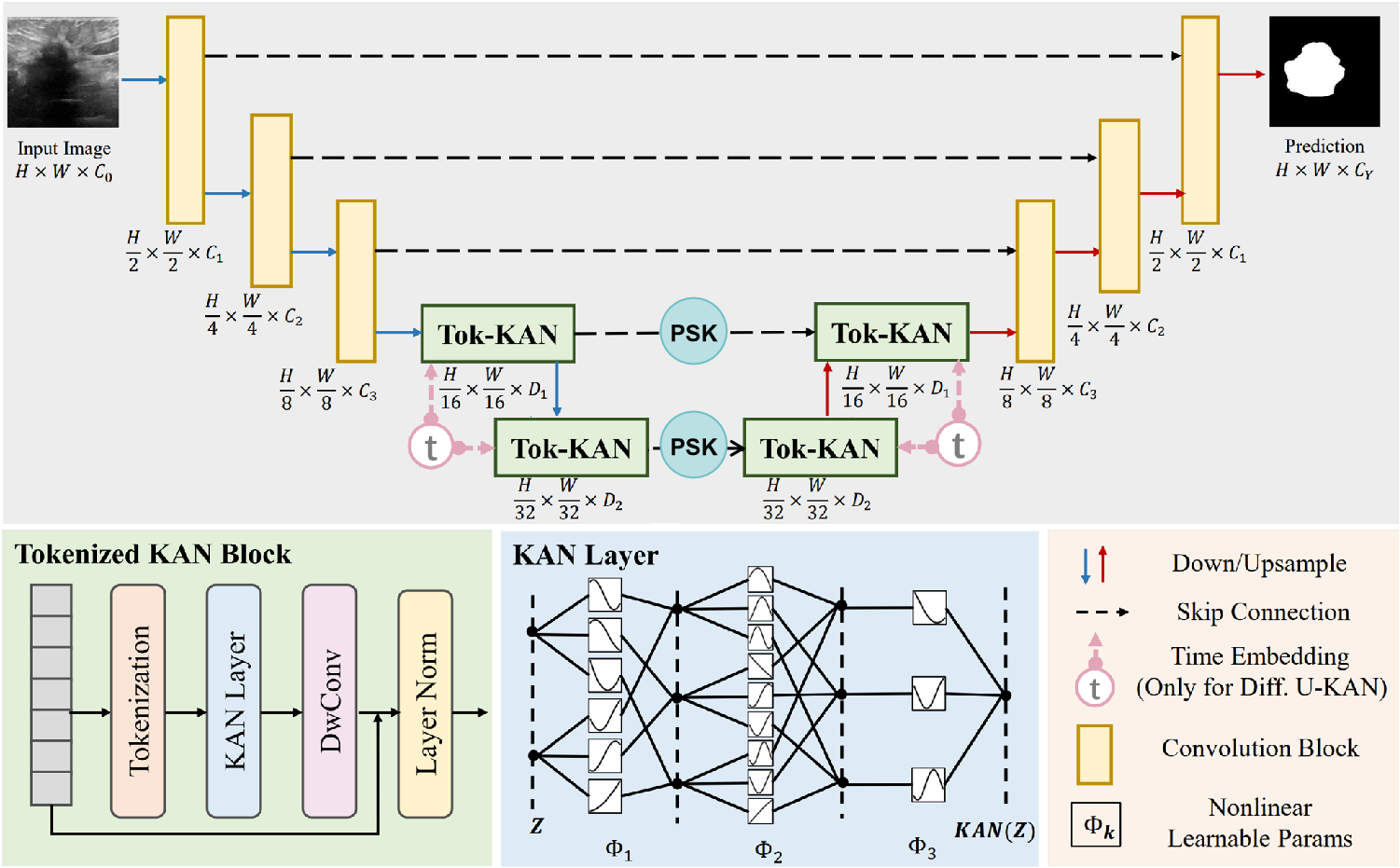
320 KB
Seg_UKAN/environment.yml
0 → 100644
Seg_UKAN/inputs/busi.zip
0 → 100644
File added
Seg_UKAN/kan.py
0 → 100644
Seg_UKAN/losses.py
0 → 100644
Seg_UKAN/metrics.py
0 → 100644
Seg_UKAN/model.properties
0 → 100644
Seg_UKAN/requirements.txt
0 → 100644
Seg_UKAN/scripts.sh
0 → 100644
Seg_UKAN/train.py
0 → 100644
Seg_UKAN/train.sh
0 → 100644
Seg_UKAN/utils.py
0 → 100644
Seg_UKAN/val.py
0 → 100644
Seg_UKAN/val.sh
0 → 100644
assets/framework-1.jpg
0 → 100644
{kind=link}

1.35 MB
assets/logo_1.png
0 → 100644
{kind=link}
230 KB
docker/Dockerfile
0 → 100644