
v1.0
Showing
doc/transformer.png
0 → 100644
{kind=link}
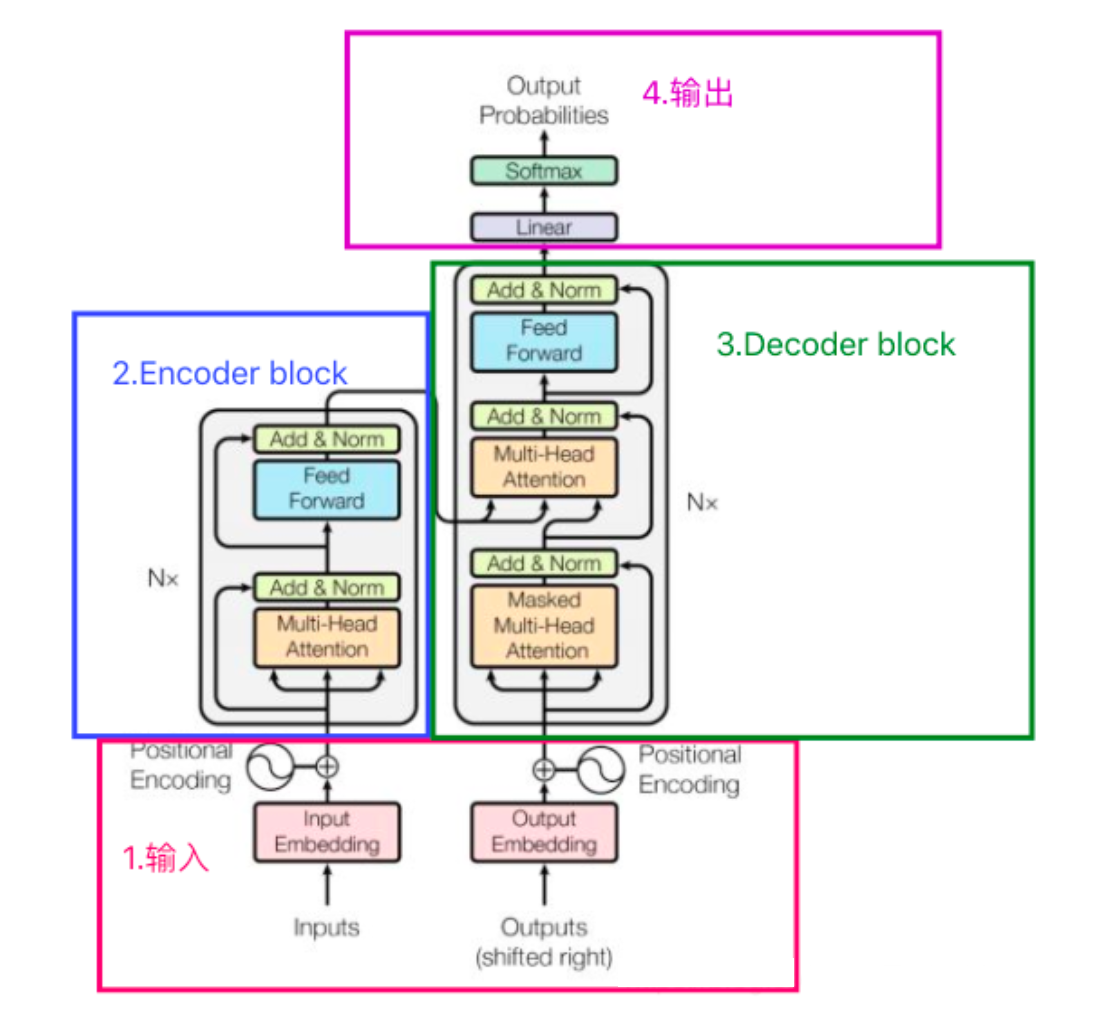
396 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
lit_gpt/__init__.py
0 → 100644
lit_gpt/adapter.py
0 → 100644
lit_gpt/adapter_v2.py
0 → 100644
lit_gpt/config.py
0 → 100644
lit_gpt/lora.py
0 → 100644
lit_gpt/model.py
0 → 100644
lit_gpt/packed_dataset.py
0 → 100644
lit_gpt/rmsnorm.py
0 → 100644
lit_gpt/speed_monitor.py
0 → 100644
lit_gpt/tokenizer.py
0 → 100644
lit_gpt/utils.py
0 → 100644
model.properties
0 → 100644
pretrain/tinyllama.py
0 → 100644
pretrain/tinyllama_code.py
0 → 100644
requirements.txt
0 → 100644
| torch>=2.1.0dev | |||
| lightning==2.1.2 | |||
| lightning[app] | |||
| jsonargparse[signatures] # CLI | |||
| pandas | |||
| pyarrow | |||
| tokenizers | |||
| sentencepiece | |||
| wandb | |||
| zstd | |||
| # for finetuning | |||
| bitsandbytes==0.40.0 | |||
| transformers==4.31.0 | |||
| peft==0.4.0 | |||
| accelerate==0.21.0 | |||
| einops==0.6.1 | |||
| evaluate==0.4.0 | |||
| scikit-learn==1.2.2 | |||
| sentencepiece==0.1.99 | |||
| wandb==0.15.3 | |||
| # other optional dependencies are | |||
| # sentencepiece # pythia, falcon, redpajama | |||
| # tokenizers # llama-based models | |||
| # bitsandbytes>=0.41.1 # quantize/bnb.py | |||
| # scipy # TODO: remove when https://github.com/TimDettmers/bitsandbytes/pull/525 is released | |||
| # datasets # quantize/gptq.py | |||
| # zstandard # scripts/prepare_redpajama.py | |||
| # git+https://github.com/EleutherAI/lm-evaluation-harness.git@master # eval |