# TimesFM
## 论文
`A decoder-only foundation model for time-series forecasting`
- https://arxiv.org/abs/2310.10688
## 模型结构
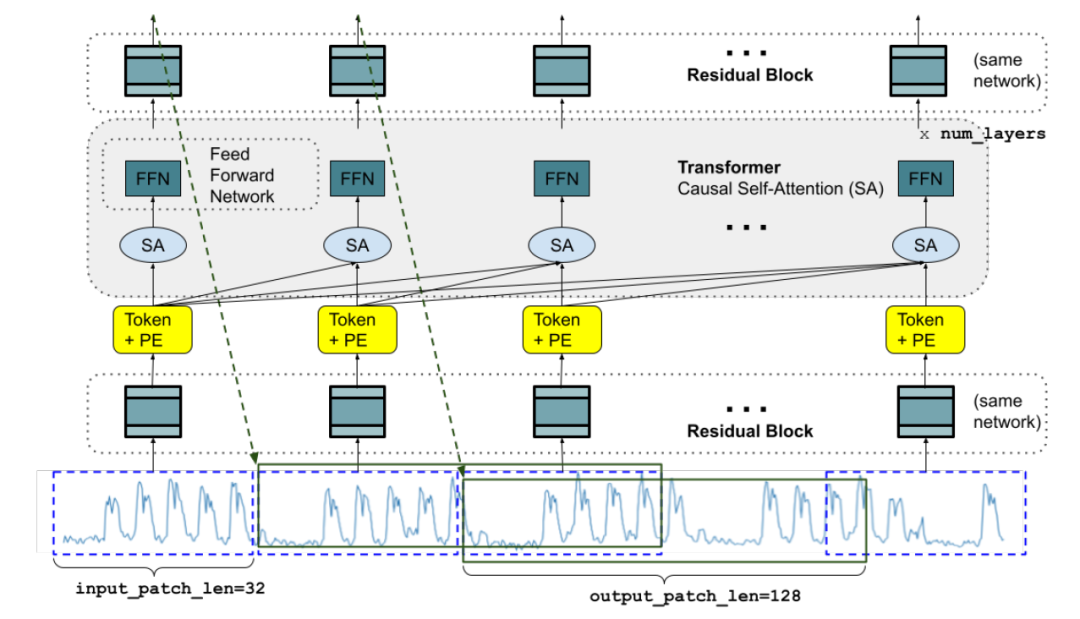
TimesFM是一种基于区块的decoder-only的模型,基于自注意力机制和传统的位置编码,主要由三个主要组件组成:输入层、Transformer层和输出层
## 算法原理
输入层:将时间序列数据分割成相等长度的时序数据块(patch),然后通过残差块对每个时序数据块进行线性变化,进而得到Token。
Transformer层:应用了位置编码和自注意力机制。位置编码将时间信息注入Token(令牌)序列;自注意力允许模型学习序列中不同标记之间的依赖关系和关系:位置编码介入自注意力的构造意味着模型可以适应数据中不同的时间粒度和频率。
输出层:使用层归一化和残差连接,将输出Token映射到最终预测。
TimesFM在真实世界的大型时间序列语料库上进行了预训练,可以为未见过的数据集生成可变长度的预测。
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/jax:0.4.23-ubuntu20.04-dtk24.04-py310
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data/:/path/your_code_data/ imageID /bin/bash
cd /your_code_path/timesfm
pip install -r requirements.txt
pip install tensorflow-2.13.1+das1.0+git429d21b.abi1.dtk2404-cp310-cp310-manylinux2014_x86_64.whl
```
### Dockerfile(方法二)
```
cd ./docker
docker build --no-cache -t timesfm:latest .
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data/:/path/your_code_data/ imageID /bin/bash
cd /your_code_path/timesfm
pip install -r requirements.txt
pip install tensorflow-2.13.1+das1.0+git429d21b.abi1.dtk2404-cp310-cp310-manylinux2014_x86_64.whl
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24.04
python:python3.10
jax:0.4.23
tensorflow:2.13.1
```
`Tips:以上dtk软件栈、python、jax等DCU相关工具版本需要严格一一对应`
2、其他非特殊库直接按照下面步骤进行安装
```
cd /your_code_path/timesfm
pip install -r requirements.txt
```
## 数据集
基准测试数据集运行时会gluonts自动下载,长期基准测试数据集需从Google Drive手动下载(需要魔法):
- https://drive.google.com/file/d/1alE33S1GmP5wACMXaLu50rDIoVzBM4ik/view?usp=share_link
下载完成后,将数据解压到datasets目录下,若有自订目录需求,可修改timesfm/experiments/long_horizon_benchmarks/run_eval.py:
```
DATA_DICT = {
"ettm2": {
"boundaries": [34560, 46080, 57600],
"data_path": "./datasets/ETT-small/ETTm2.csv", # 修改数据集存放路径
"freq": "15min",
},
...
}
```
长期基准测试数据集目录结构如下:
```
── datasets
│ ├── electricity
│ ├── electricity.csv
│ ├── ETT-small
│ ├── ETTh1.csv
│ ├── ETTh2.csv
│ ├── ETTh1.csv
│ └── ETTm1.csv
│ ├── exchange_rate
│ └── exchange_rate.csv
│ ├── illness
│ └── national illness.csv
│ ├── traffic
│ └── traffic.csv
│ └── weather
│ └── weather.csv
```
## 训练
官方暂未开放
## 推理
检查点可通过以下方式进行下载:
-https://hf-mirror.com/google/timesfm-1.0-200m
```
# "model"是自定义目录,可自订
1、通过git
cd timesfm
git clone https://hf-mirror.com/google/timesfm-1.0-200m model
2、通过huggingface-cli
cd timesfm
export HF_DATASETS_CACHE="/home/suily/timesfm/model"
export HF_ENDPOINT=https://hf-mirror.com # 设置下载地址
huggingface-cli download --resume-download google/timesfm-1.0-200m --local-dir model
```
```
sh train.sh
# 由于基准测试未直接提供调用数据集的接口,须在代码内部手动进行更改:
# 修改timesfm/experiments/extended_benchmarks/run_timesfm.py:dataset_names内填入所需数据集name
```
## result
此处填算法效果测试图(包括输入、输出)
### 精度
k100和A800精度相差不到0.01%
测试数据:
```
1、基准测试:
"ett_small_15min",
"traffic",
"m3_quarterly",
"m3_yearly",
"tourism_yearly"
2、长期基准测试:
"etth1",
"ettm1"
```
根据测试结果情况填写表格:
| xxx | xxx | xxx | xxx | xxx |
| :------: | :------: | :------: | :------: |:------: |
| xxx | xxx | xxx | xxx | xxx |
| xxx | xx | xxx | xxx | xxx |
## 应用场景
### 算法类别
`时序预测`
### 热点应用行业
`交通,零售,金融,气象`
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/timesfm_jax
## 参考资料
- https://github.com/google-research/timesfm