`timesfm-1.0-200m` is the first open model checkpoint:
<divalign=center>
- It performs univariate time series forecasting for context lengths up to 512 time points and any horizon lengths, with an optional frequency indicator.
<imgsrc="./doc/timesfm.png"/>
- It focuses on point forecasts and does not support probabilistic forecasts. We experimentally offer quantile heads but they have not been calibrated after pretraining.
</div>
- It requires the context to be contiguous (i.e. no "holes"), and the context and the horizon to be of the same frequency.
## 环境配置
## Benchmarks
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
Please refer to our result tables on the [extended benchmarks](https://github.com/google-research/timesfm/blob/master/experiments/extended_benchmarks/tfm_results.png) and the [long horizon benchmarks](https://github.com/google-research/timesfm/blob/master/experiments/long_horizon_benchmarks/tfm_long_horizon.png).
Please look into the README files in the respective benchmark directories within `experiments/` for instructions for running TimesFM on the respective benchmarks.
## Installation
This HuggingFace repo hosts TimesFm checkpoints. Please visit our [GitHub repo](https://github.com/google-research/timesfm) and follow the instructions there to install the `timesfm` library for model inference.
In particular, the dependency `lingvo` does not support ARM architectures and the inference code is not working for machines with Apple silicon. We are aware of this issue and are working on a solution. Stay tuned.
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --group-add video --shm-size=32G --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data/:/path/your_code_data/ imageID /bin/bash
1. The context_len here can be set as the max context length **of the model**. You can provide a shorter series to the `tfm.forecast()` function and the model will handle it. Currently, the model handles a max context length of 512, which can be increased in later releases. The input time series can have **any context length**. Padding / truncation will be handled by the inference code if needed.
cd /your_code_path/timesfm
pip install -r requirements.txt
2. The horizon length can be set to anything. We recommend setting it to the largest horizon length you would need in the forecasting tasks for your application. We generally recommend horizon length <= context length but it is not a requirement in the function call.
We provide APIs to forecast from either array inputs or `pandas` dataframe. Both forecast methods expect (1) the input time series contexts, (2) along with their frequencies. Please look at the documentation of the functions `tfm.forecast()` and `tfm.forecast_on_df()` for detailed instructions.
```
DTK软件栈:dtk24.04
In particular, regarding the frequency, TimesFM expects a categorical indicator valued in {0, 1, 2}:
python:python3.10
jax:0.4.23
-**0** (default): high frequency, long horizon time series. We recommend using this for time series up to daily granularity.
tensorflow:2.13.1
-**1**: medium frequency time series. We recommend using this for weekly and monthly data.
-**2**: low frequency, short horizon time series. We recommend using this for anything beyond monthly, e.g. quarterly or yearly.
This categorical value should be directly provided with the array inputs. For dataframe inputs, we convert the conventional letter coding of frequencies to our expected categories, that
-**0**: T, MIN, H, D, B, U
-**1**: W, M
-**2**: Q, Y
Notice you do **NOT** have to strictly follow our recommendation here. Although this is our setup during model training and we expect it to offer the best forecast result, you can also view the frequency input as a free parameter and modify it per your specific use case.
Examples:
Array inputs, with the frequencies set to low, medium, and high respectively.
This is not an officially supported Google product.
## Checkpoint timesfm-1.0-200m
`timesfm-1.0-200m` is the first open model checkpoint:
- It performs univariate time series forecasting for context lengths up to 512 time points and any horizon lengths, with an optional frequency indicator.
- It focuses on point forecasts and does not support probabilistic forecasts. We experimentally offer quantile heads but they have not been calibrated after pretraining.
- It requires the context to be contiguous (i.e. no "holes"), and the context and the horizon to be of the same frequency.
## Benchmarks
Please refer to our result tables on the [extended benchmarks](https://github.com/google-research/timesfm/blob/master/experiments/extended_benchmarks/tfm_results.png) and the [long horizon benchmarks](https://github.com/google-research/timesfm/blob/master/experiments/long_horizon_benchmarks/tfm_long_horizon.png).
Please look into the README files in the respective benchmark directories within `experiments/` for instructions for running TimesFM on the respective benchmarks.
## Installation
This HuggingFace repo hosts TimesFm checkpoints. Please visit our [GitHub repo](https://github.com/google-research/timesfm) and follow the instructions there to install the `timesfm` library for model inference.
In particular, the dependency `lingvo` does not support ARM architectures and the inference code is not working for machines with Apple silicon. We are aware of this issue and are working on a solution. Stay tuned.
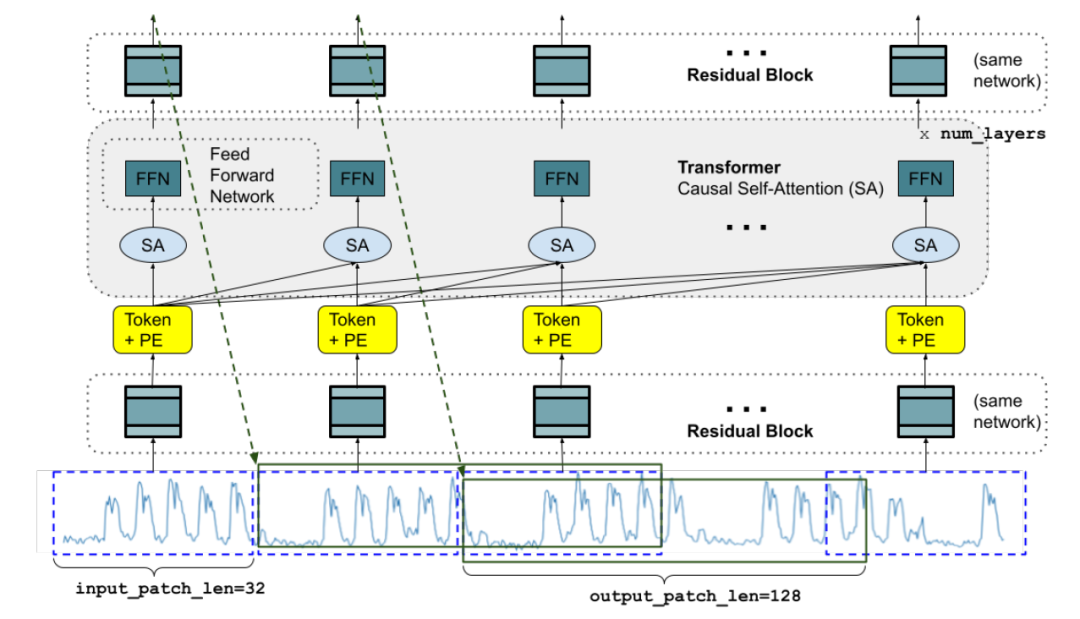
Note that the four parameters are fixed to load the 200m model
```python
input_patch_len=32,
output_patch_len=128,
num_layers=20,
model_dims=1280,
```
1. The context_len here can be set as the max context length **of the model**. You can provide a shorter series to the `tfm.forecast()` function and the model will handle it. Currently, the model handles a max context length of 512, which can be increased in later releases. The input time series can have **any context length**. Padding / truncation will be handled by the inference code if needed.
2. The horizon length can be set to anything. We recommend setting it to the largest horizon length you would need in the forecasting tasks for your application. We generally recommend horizon length <= context length but it is not a requirement in the function call.
### Perform inference
We provide APIs to forecast from either array inputs or `pandas` dataframe. Both forecast methods expect (1) the input time series contexts, (2) along with their frequencies. Please look at the documentation of the functions `tfm.forecast()` and `tfm.forecast_on_df()` for detailed instructions.
In particular, regarding the frequency, TimesFM expects a categorical indicator valued in {0, 1, 2}:
-**0** (default): high frequency, long horizon time series. We recommend using this for time series up to daily granularity.
-**1**: medium frequency time series. We recommend using this for weekly and monthly data.
-**2**: low frequency, short horizon time series. We recommend using this for anything beyond monthly, e.g. quarterly or yearly.
This categorical value should be directly provided with the array inputs. For dataframe inputs, we convert the conventional letter coding of frequencies to our expected categories, that
-**0**: T, MIN, H, D, B, U
-**1**: W, M
-**2**: Q, Y
Notice you do **NOT** have to strictly follow our recommendation here. Although this is our setup during model training and we expect it to offer the best forecast result, you can also view the frequency input as a free parameter and modify it per your specific use case.
Examples:
Array inputs, with the frequencies set to low, medium, and high respectively.

{kind=link}