"vscode:/vscode.git/clone" did not exist on "11e42d1094e9c99ed45d6167e823ab93423d18be"

readme
parents
Showing
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
Makefile
0 → 100644
QuickStart.gif
0 → 100644
{kind=link}
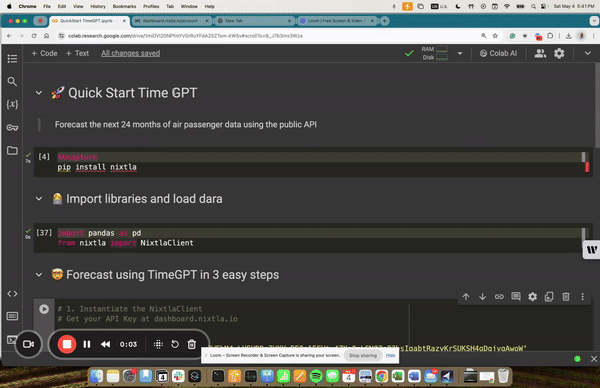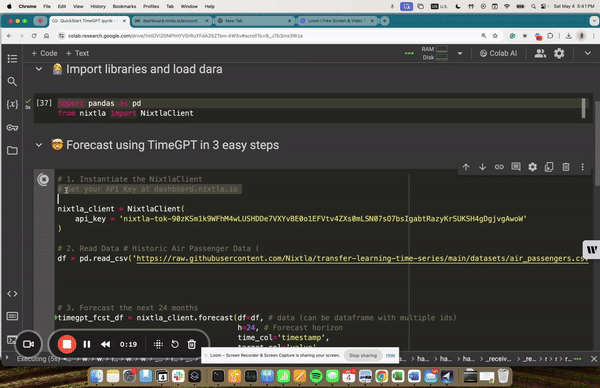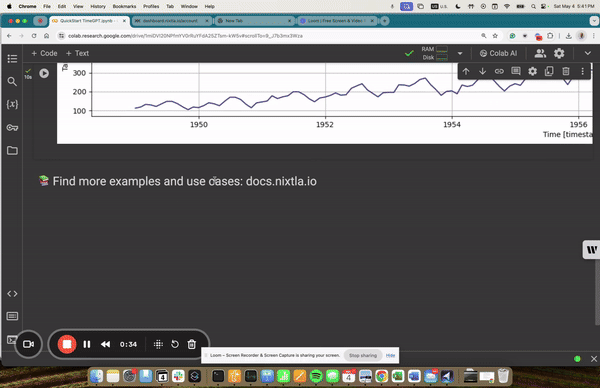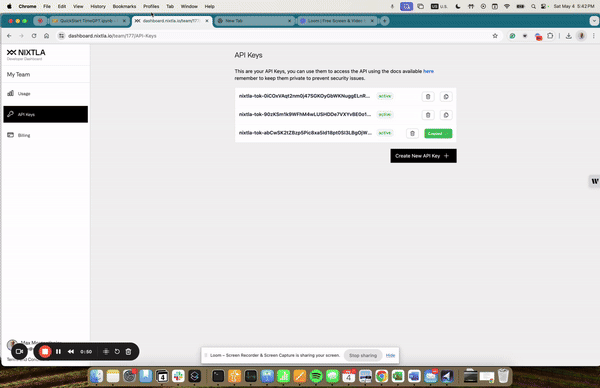
1.93 MB
QuickstartTGPT.mp4
0 → 100644
File added
README.md
0 → 100644
README_origin.md
0 → 100644
THIRD_PARTY_LICENSES.md
0 → 100644
action_files/__init__.py
0 → 100644
action_files/comment_file.py
0 → 100644
docs/mintlify/dark.png
0 → 100644
{kind=link}

2.82 KB
docs/mintlify/favicon.svg
0 → 100644
{kind=link}
docs/mintlify/light.png
0 → 100644
{kind=link}
2.78 KB