description: "Learn how to forecast multiple time series at once with TimeGPT."
icon: "chart-line-up"
---
# Multiple Series Forecasting with TimeGPT
TimeGPT can concurrently forecast multiple series at once. To do this, you must provide a DataFrame with multiple unique values defined under the `unique_id` column.
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/capabilities/forecast/06_multiple_series.ipynb)
<Info>
TimeGPT is a powerful forecasting solution that supports simultaneous predictions for multiple time series. This guide will walk you through setting up your Nixtla Client, loading data, and generating forecasts.
</Info>
## How It Works
<CardGroup>
<Card title="Key Concept" icon="lightbulb">
Forecasting multiple series requires each observation to have a unique identifier under the `unique_id` column. TimeGPT automatically handles each series individually and returns forecasts for every unique series in your dataset.
</Card>
</CardGroup>
<Steps>
<Step title="1. Import Required Libraries">
<CodeGroup>
```python Import Libraries
import pandas as pd
from nixtla import NixtlaClient
```
</CodeGroup>
</Step>
<Step title="2. Initialize the Nixtla Client">
Choose between the default Nixtla endpoint or an Azure AI endpoint.
If using an Azure AI endpoint, set the `model` parameter explicitly to `"azureai"`:
</Info>
<CodeGroup>
```python Azure AI Model Setting
nixtla_client.forecast(
...,
model="azureai"
)
```
</CodeGroup>
<CardGroup>
<Card title="Choosing the Right Model" icon="gear">
If you're using the public API, two models are supported: `timegpt-1` and `timegpt-1-long-horizon`.
The default is `timegpt-1`. Check out the [long horizon tutorial](https://docs.nixtla.io/docs/tutorials-long_horizon_forecasting) to learn when and how to apply `timegpt-1-long-horizon`.
</Card>
</CardGroup>
For further details, visit the detailed tutorial:
[Multiple series forecasting](https://docs.nixtla.io/docs/tutorials-multiple_series_forecasting).
description: "Learn how to use the level parameter to generate prediction intervals that quantify forecast uncertainty."
icon: "chart-candlestick"
---
<CardGroup>
<Card title="What are Prediction Intervals?" icon="circle-info">
Prediction intervals measure the uncertainty around forecasted values. By specifying a confidence level, you can visualize the range in which future observations are expected to fall.
</Card>
<Card title="Key Parameter: level" icon="gear">
The **level** parameter accepts values between 0 and 100 (including decimals). For example, `[80]` represents an 80% confidence interval.
</Card>
</CardGroup>
## Overview
Use the `forecast` method's **level** parameter to generate prediction intervals. This helps quantify the uncertainty around your forecasts.
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/capabilities/forecast/10_prediction_intervals.ipynb)
<Steps>
<Step title="Step 1: Import Dependencies">
```python Import Dependencies
import pandas as pd
from nixtla import NixtlaClient
```
</Step>
<Step title="Step 2: Initialize NixtlaClient">
```python Initialize NixtlaClient
nixtla_client = NixtlaClient(
# defaults to os.environ.get("NIXTLA_API_KEY")
api_key='my_api_key_provided_by_nixtla'
)
```
</Step>
<Step title="(Optional) Use an Azure AI Endpoint">
<AccordionGroup>
<Accordion title="Configuring an Azure AI Endpoint">
<Check>
**Use an Azure AI endpoint**
To use an Azure AI endpoint, set the `base_url` argument as follows:
If you are using an Azure AI endpoint, set the `model` parameter to `"azureai"`:
</Info>
```python Azure AI Models
nixtla_client.forecast(..., model="azureai")
```
The public API supports two models:
- `timegpt-1` (default)
- `timegpt-1-long-horizon`
See [this tutorial](https://docs.nixtla.io/docs/tutorials-long_horizon_forecasting) for guidance on using **timegpt-1-long-horizon**.
</Accordion>
</AccordionGroup>
<Info>
For more information on uncertainty estimation, refer to the tutorials about [quantile forecasts](https://docs.nixtla.io/docs/tutorials-quantile_forecasts) and [prediction intervals](https://docs.nixtla.io/docs/tutorials-prediction_intervals).
description: "Get started quickly with TimeGPT forecasting using the Nixtla API."
icon: "rocket"
---
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/capabilities/forecast/01_quickstart.ipynb)
# Quickstart
TimeGPT makes forecasting straightforward with the `forecast` method in the Nixtla API. Pass in your DataFrame, specify the time and target columns, and call `forecast`. You can also visualize results with the `plot` method.
<Info>
Detailed guidance on data requirements is available [here](https://docs.nixtla.io/docs/getting-started-data_requirements).
</Info>
<Steps>
<Step title="1. Install & Import Dependencies">
Make sure you have the latest Nixtla Client installed, then import the required libraries:
```bash Nixtla Client Installation
pip install nixtla
```
```python Import Libraries
import pandas as pd
from nixtla import NixtlaClient
```
</Step>
<Step title="2. Initialize the Nixtla Client">
<Tabs>
<Tab title="Standard Usage">
<Check>
Provide your API key from Nixtla to authenticate:
</Check>
```python Nixtla Client Standard Initialization
nixtla_client = NixtlaClient(
# defaults to os.environ.get("NIXTLA_API_KEY")
api_key='my_api_key_provided_by_nixtla'
)
```
</Tab>
<Tab title="Using Azure AI Endpoint">
<Check>
Use an Azure AI endpoint<br/>
If you'd like to use Azure AI, set the `base_url` to your Azure endpoint:
description: "Preview changes locally to update your docs"
---
<Info>
**Prerequisite**: Please install Node.js (version 19 or higher) before proceeding.
Please upgrade to `docs.json` before proceeding and delete the legacy `mint.json` file.
</Info>
Follow these steps to install and run Mintlify on your operating system:
**Step 1**: Install Mintlify:
<CodeGroup>
```bash npm
npm i -g mintlify
```
```bash yarn
yarn global add mintlify
```
</CodeGroup>
**Step 2**: Navigate to the docs directory (where the `docs.json` file is located) and execute the following command:
```bash
mintlify dev
```
A local preview of your documentation will be available at `http://localhost:3000`.
### Custom Ports
By default, Mintlify uses port 3000. You can customize the port Mintlify runs on by using the `--port` flag. To run Mintlify on port 3333, for instance, use this command:
```bash
mintlify dev --port 3333
```
If you attempt to run Mintlify on a port that's already in use, it will use the next available port:
```md
Port 3000 is already in use. Trying 3001 instead.
```
## Mintlify Versions
Please note that each CLI release is associated with a specific version of Mintlify. If your local website doesn't align with the production version, please update the CLI:
<CodeGroup>
```bash npm
npm i -g mintlify@latest
```
```bash yarn
yarn global upgrade mintlify
```
</CodeGroup>
## Validating Links
The CLI can assist with validating reference links made in your documentation. To identify any broken links, use the following command:
```bash
mintlify broken-links
```
## Deployment
<Tip>
Unlimited editors available under the [Pro Plan](https://mintlify.com/pricing)
and above.
</Tip>
If the deployment is successful, you should see Checks passed
## Code Formatting
We suggest using extensions on your IDE to recognize and format MDX. If you're a VSCode user, consider the [MDX VSCode extension](https://marketplace.visualstudio.com/items?itemName=unifiedjs.vscode-mdx) for syntax highlighting, and [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) for code formatting.
## Troubleshooting
<AccordionGroup>
<Accordion title='Error: Could not load the "sharp" module using the darwin-arm64 runtime'>
This may be due to an outdated version of node. Try the following:
1. Remove the currently-installed version of mintlify: `npm remove -g mintlify`
2. Upgrade to Node v19 or higher.
3. Reinstall mintlify: `npm install -g mintlify`
</Accordion>
<Accordion title="Issue: Encountering an unknown error">
Solution: Go to the root of your device and delete the ~/.mintlify folder. Afterwards, run `mintlify dev` again.
</Accordion>
</AccordionGroup>
Curious about what changed in the CLI version? [Check out the CLI changelog.](https://www.npmjs.com/package/mintlify?activeTab=versions)
description: "Complete list of changes for each version of the Nixtla client."
icon: "clipboard"
---
## Changelog Overview
Below you’ll find the complete list of changes for each version of the Nixtla client. Expand any version to see details about new features, improvements, changes, or deprecations, along with links to full release notes.
<AccordionGroup>
<Accordion title="Version 0.6.6">
### Feature Enhancements
<Info>
**Online anomaly detection**
We introduce the `online_anomaly_detection` method, which allows you to define a `detection_size` on which to look for anomalies.
</Info>
[See full changelog here](https://github.com/Nixtla/nixtla/releases/v0.6.6)
</Accordion>
<Accordion title="Version 0.6.5">
### Feature Enhancements
<CardGroup>
<Card title="Persisting fine-tuned models">
You can now run an isolated fine-tuning process, save the model, and use it afterward in all of our methods:
<br />
<Steps>
<Steps title="Fine-tune the model" />
<Steps title="Save the model" />
<Steps title="Use it in forecast, cross_validation, or detect_anomalies" />
</Steps>
</Card>
<Card title="zstd compression">
All requests above 1MB are automatically compressed using
[zstd](https://github.com/facebook/zstd), which helps when sending large data volumes or with slower connections.
</Card>
<Card title="Refit argument in `cross_validation`">
Set `refit=False` to fine-tune the model only on the first window in
`cross_validation`. This significantly decreases computation time.
</Card>
</CardGroup>
[See full changelog here](https://github.com/Nixtla/nixtla/releases/v0.6.5)
</Accordion>
<Accordion title="Version 0.6.4">
### Feature Enhancements
<CardGroup>
<Card title="Integer and custom pandas frequencies">
The client now supports integer timestamps and frequencies, and custom pandas timestamps
Historicalforecasts(alsocalledin-sampleforecasts)arepredictionsmadeonpreviouslyobserveddatatoevaluateamodel's accuracy. By comparing these predictions to the actual values, you can assess how well your model performs on known data.
<Info>
**Learn more:**[Making historical forecasts with TimeGPT](https://docs.nixtla.io/docs/tutorials-historical_forecast)
</Info>
</Accordion>
<Accordion title="Anomaly Detection">
Anomaly detection identifies points in a time series that differ significantly from typical behavior. These anomalies may stem from data collection errors, abrupt changes in underlying patterns, or external events. They can distort forecasts by obscuring trends or seasonal patterns.
Common uses include:
- Fraud detection in finance
- Performance monitoring for digital services
- Spotting unexpected trends in energy consumption
<Info>
**Learn more:**[Detect anomalies with TimeGPT](https://docs.nixtla.io/docs/capabilities-anomaly-detection-anomaly_detection)
</Info>
</Accordion>
<Accordion title="Time Series Cross Validation">
Time series cross-validation assesses how well a forecasting model performs by repeatedly training on historical data and testing on the next time segment. Unlike standard cross-validation, it respects the time order and avoids data leakage.
<Steps>
<Step>Partition your time-based dataset into multiple segments.</Step>
<Step>Train the model on an earlier segment.</Step>
<Step>Forecast the subsequent segment.</Step>
<Step>Compare predictions to actual values.</Step>
<Step>Slide the window forward and repeat.</Step>
</Steps>
<Info>
**Learn more:**[Performing cross-validation with TimeGPT](https://docs.nixtla.io/docs/tutorials-cross_validation)
</Info>
</Accordion>
<Accordion title="Exogenous Variables">
Exogenous variables are external factors that influence a target time series but are not driven by the series itself (e.g., holidays or weather conditions). Including these variables in a forecast can improve accuracy by capturing additional context.
<Info>
**Learn more:**[Including exogenous variables in TimeGPT](https://docs.nixtla.io/docs/tutorials-exogenous_variables)
description: "Get started with TimeGPT using Polars for efficient data processing."
icon: "bolt-lightning"
---
<Info>
TimeGPT is a production-ready, generative pretrained transformer for time series. It can make accurate predictions in just a few lines of code across domains like retail, electricity, finance, and IoT.
</Info>
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/getting-started/21_polars_quickstart.ipynb)
<Steps>
<Step title="Create a TimeGPT Account and Generate an API Key">
3. Select **API Keys** in the menu, then click **Create New API Key**
4. Copy your generated API key using the provided button
<Frame caption="TimeGPT dashboard with API key management">

</Frame>
</Step>
<Step title="Install Nixtla">
```bash install-nixtla
pip install nixtla
```
</Step>
<Step title="Import and Validate Your Nixtla Client">
```python client-setup
from nixtla import NixtlaClient
# Instantiate the NixtlaClient
nixtla_client = NixtlaClient(
api_key='my_api_key_provided_by_nixtla'
)
# Validate the API key
nixtla_client.validate_api_key()
```
<Warning>
For enhanced security, check [Setting Up your API Key](https://docs.nixtla.io/docs/getting-started-setting_up_your_api_key).
</Warning>
</Step>
<Step title="Make Forecasts with Polars">
<AccordionGroup>
<Accordion title="1. Load and Preview the Dataset">
<Info>
We use the **AirPassengers** dataset, containing monthly airline passenger totals from 1949 to 1960. This dataset is a classic example for time series forecasting.
<Frame caption="Monthly airline passengers from 1949–1960">

</Frame>
</Accordion>
<Accordion title="2. Data Requirements">
<Info>
- The target variable column should not contain missing or non-numeric values.
- Ensure there are no gaps in the timestamps.
- The time column must be of type [Date](https://docs.pola.rs/api/python/stable/reference/api/polars.datatypes.Date.html) or [Datetime](https://docs.pola.rs/api/python/stable/reference/api/polars.datatypes.Datetime.html).
For comprehensive details, visit [Data Requirements](https://docs.nixtla.io/docs/getting-started-data_requirements).
</Info>
</Accordion>
<Accordion title="3. Generate a 12-Month Forecast">
```python forecast-timegpt-12-months
timegpt_fcst_df = nixtla_client.forecast(
df=df,
h=12,
freq='1mo',
time_col='timestamp',
target_col='value'
)
timegpt_fcst_df.head()
```
<Info>
Forecast values for the next 12 months:
</Info>
| timestamp | TimeGPT |
| ------------ | ------------ |
| 1961-01-01 | 437.837921 |
| 1961-02-01 | 426.062714 |
| 1961-03-01 | 463.116547 |
| 1961-04-01 | 478.244507 |
| 1961-05-01 | 505.646484 |
<Info>
Plot the 12-month forecast alongside the actual data:
<Frame caption="Comparison of forecast and actual data (12 months)">
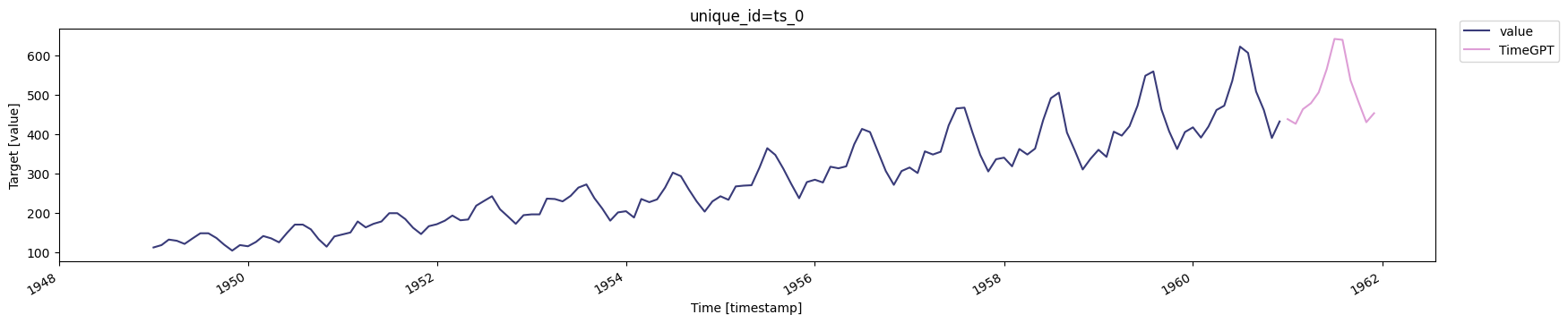
description: "Learn how to configure confidence levels to control anomaly detection sensitivity."
icon: "percent"
---
## Confidence Level in Anomaly Detection
The confidence level is used to determine the threshold for anomaly detection. By default, any values that lie outside the 99% confidence interval are labeled as anomalies.
Use the `level` parameter (0-100) to control how many anomalies are detected.
- Increasing the `level`(closer to 100) decreases the number of anomalies.
- Decreasing the `level`(closer to 0) increases the number of anomalies.
## How to Add Confidence Levels
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/capabilities/historical-anomaly-detection/04_confidence_levels.ipynb)
### Step 1: Set Up Data and Client
Follow the steps in the historical anomaly detection tutorial to set up the data and client.
### Step 2: Detect Anomalies with a Confidence Level
To detect anomalies with a confidence level, use the `level` parameter. In this example, we'll use a 70% confidence level.
```python
# Anomaly detection using a 70% confidence interval
anomalies_df = nixtla_client.detect_anomalies(
df,
freq='D',
level=70
)
```
### Step 3: Visualize Results
To visualize the results, use the `plot` method:
```python
nixtla_client.plot(df, anomalies_df)
```
<Frame caption="Anomalies detected with a 70% confidence interval">

</Frame>
This plot highlights points that fall outside the 70% confidence interval, indicating they are considered anomalies. Points within the interval are considered normal behavior.
description: "Learn how to enrich datasets with date features for historical anomaly detection."
icon: "calendar"
---
## Why Add Date Features?
Date features help the model recognize seasonal patterns, holiday effects, or recurring fluctuations. Examples include `day_of_week`, `month`, `year`, and more.
Adding date features is a powerful way to enrich your dataset when no exogenous variables are available. These features help guide the historical anomaly detection model in recognizing seasonal and temporal patterns.
## How to Add Date Features
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/tutorials/20_anomaly_detection.ipynb)
### Step 1: Set Up Data and Client
Follow the steps in the historical anomaly detection tutorial to set up the data and client.
### Step 2: Add Date Features for Anomaly Detection
To add date features, use the `date_features` parameter. You can enable all possible features by setting `date_features=True`, or specify certain features to focus on:
```python
# Add date features at the month and year levels
anomalies_df_x = nixtla_client.detect_anomalies(
df,
freq='D',
date_features=['month', 'year'],
date_features_to_one_hot=True,
level=99.99,
)
```
This code extracts monthly and yearly patterns, then converts them to one-hot-encoded features, creating multiple exogenous variables for the anomaly detection model.
### Step 3: Review Output Logs
When you run the detection, logs inform you about which exogenous features were used:
description: "Explore special topics in TimeGPT including irregular timestamps, bounded forecasts, hierarchical forecasts, missing values, and improving forecast accuracy."
icon: "gear"
---
# Special Topics in TimeGPT
<Info>
**TimeGPT** is a robust foundation model for time series forecasting. It provides advanced capabilities, including hierarchical and bounded forecasts. Certain special situations require specific considerations, such as handling irregular timestamps or datasets containing missing values, to leverage the full potential of **TimeGPT**.
</Info>
In this section, we cover these special topics to help you get the most out of TimeGPT:
Discover techniques to enhance forecasting accuracy when working with TimeGPT.
</Card>
</CardGroup>
## Getting Started with Special Topics
Sometimes, the best way to integrate special features in TimeGPT is by following a series of clear, sequential steps. Below is a simplified workflow to guide you:
<Steps>
<Step title="Step 1: Identify the Special Topic">
Determine the challenge you are addressing (e.g., irregular timestamps, bounded forecasts, hierarchical forecasts, handling missing values, or improving accuracy).
</Step>
<Step title="Step 2: Prepare Your Data">
Align your time series data with the requirements of the specific topic.
<Info>
For instance, if timestamps are irregular, you might need to resample or align data before passing it to TimeGPT.
</Info>
</Step>
<Step title="Step 3: Configure TimeGPT">
Modify your forecasts to accommodate the special topic. For example, set upper and lower bounds for bounded forecasts.
<CodeGroup>
```python Configuring TimeGPT for Bounded Forecasting
# Example: Configuring TimeGPT for bounded forecasting
from timegpt import TimeGPT
timegpt_model = TimeGPT(
lower_bound=0,
upper_bound=100 # Example bounds
)
# Fit the model (pseudo-code)
timegpt_model.fit(training_data)
# Make a forecast with the specified bounds
forecast = timegpt_model.predict(future_data)
print(forecast)
```
</CodeGroup>
</Step>
<Step title="Step 4: Monitor and Evaluate Forecasts">
Use appropriate evaluation metrics to ensure the forecasts meet your accuracy requirements. Adjust parameters or data preprocessing steps as needed.
</Step>
<Step title="Step 5: Iterate and Improve">
Incorporate feedback from real-world usage to refine your approach. Revisit the documentation for each specific topic and apply best practices.
</Step>
</Steps>
<AccordionGroup>
<Accordion title="Need More Guidance?">
Refer to the linked tutorials in the **Overview of Special Topics** section for deeper insights on each specialized area.
</Accordion>
</AccordionGroup>
<Check>
With a careful approach to preparing data and configuring **TimeGPT** for these special scenarios, you can unlock superior forecasting performance for a wide range of real-world applications.
description: "Learn how to generate forecasts for multiple time series simultaneously."
icon: "layer-group"
---
# Multiple Series Forecasting
<Info>
TimeGPT provides straightforward multi-series forecasting. This approach enables you to forecast several time series concurrently rather than focusing on just one.
</Info>
<Check>
• Forecasts are univariate: TimeGPT does not directly account for interactions between target variables in different series.
• Exogenous Features: You can still include additional explanatory (exogenous) variables like categories, numeric columns, holidays, or special events to enrich the model.
</Check>
Given these capabilities, TimeGPT can be fine-tuned to your own datasets for precise and efficient forecasting. Below, let's see how to use multiple series forecasting in practice:
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/tutorials/05_multiple_series.ipynb)
<CardGroup cols={2}>
<Card title="Key Concept" icon="lightbulb">
Global models like TimeGPT can handle multiple series in a single training session and produce a separate forecast for each.
</Card>
<Card title="Benefit" icon="check">
Multi-series learning improves efficiency, leveraging shared patterns across series that often lead to better forecasts.
</Card>
</CardGroup>
<Steps>
<Steps title="1. Install and import packages">
Install and import the required libraries, then initialize the Nixtla client.
```python Nixtla Client Initialization
import pandas as pd
from nixtla import NixtlaClient
nixtla_client = NixtlaClient(
api_key='my_api_key_provided_by_nixtla'
)
```
<AccordionGroup>
<Accordion title="Using an Azure AI Endpoint">
To use Azure AI endpoints, specify the `base_url` parameter:
```python Azure AI Endpoint Setup
nixtla_client = NixtlaClient(
base_url="your azure ai endpoint",
api_key="your api_key"
)
```
</Accordion>
</AccordionGroup>
</Steps>
<Steps title="2. Load the data">
You can now load the electricity prices dataset from various European markets. TimeGPT automatically treats it as multiple series based on the `unique_id` column.
Now, let's visualize the data using the `NixtlaClient.plot()` method.
```python Plot Electricity Series
nixtla_client.plot(df)
```
<Frame caption="Electricity Markets Series Plot">
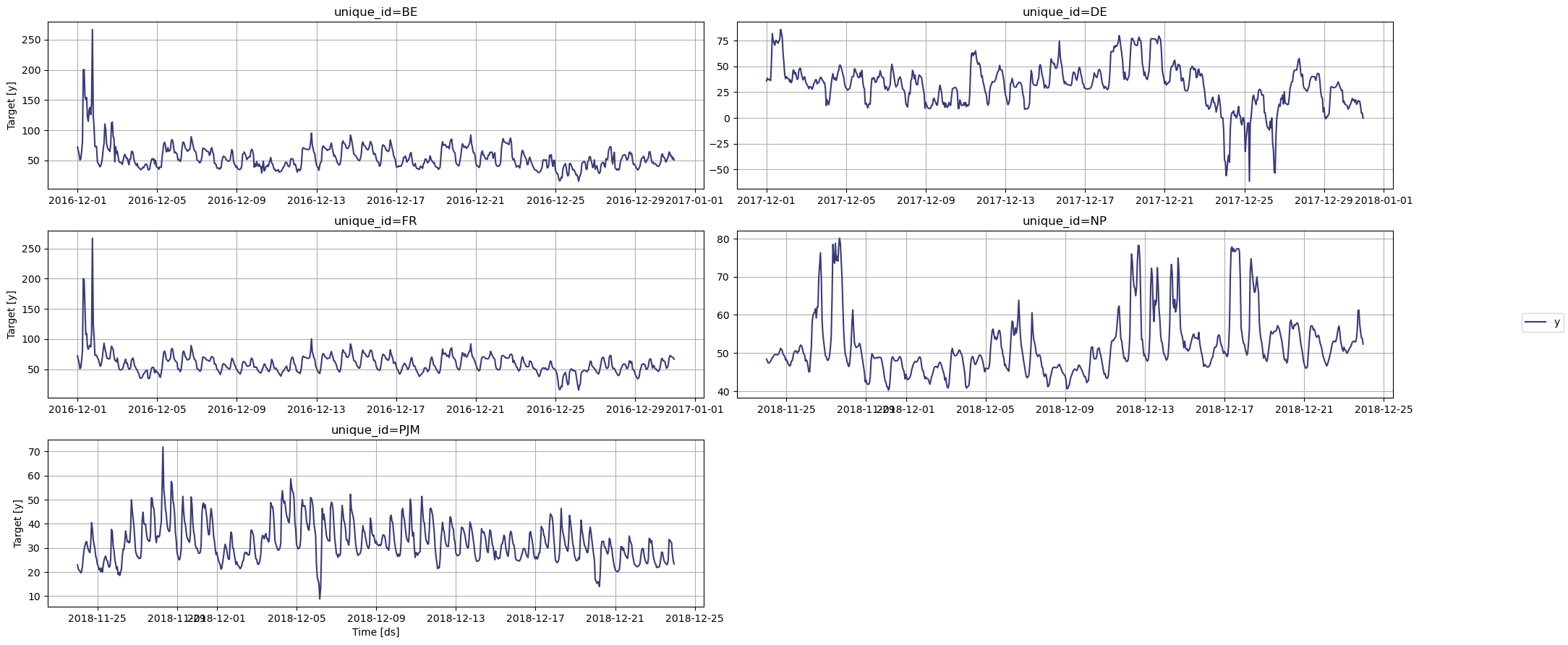
</Frame>
</Steps>
<Steps title="3. Forecast multiple series">
Pass the DataFrame to the `forecast()` method. TimeGPT automatically handles each unique series based on `unique_id`.
You can also produce historical forecasts (including prediction intervals) by setting `add_history=True`. This allows you to compare previously observed values with model predictions.
```python Historical Forecasts with Prediction Intervals
historical_fcst_df = nixtla_client.forecast(
df=df,
h=24,
level=[80, 90],
add_history=True
)
historical_fcst_df.head()
```
</Steps>
</Steps>
<Check>
Congratulations! You have successfully performed multi-series forecasting with TimeGPT, taking advantage of its global modeling approach.
Congratulations\! You now have an overview of how to set up and train TimeGPT for both single and multiple series forecasting as well as for long-horizon use cases.
description: "Learn how to create prediction intervals with TimeGPT"
icon: "chart-area"
---
## What Are Prediction Intervals?
A prediction interval provides a range where a future observation of a time series is expected to fall, with a specific level of probability.
For example, a 95% prediction interval means that the true future value is expected to lie within this range 95 times out of 100.
Wider intervals reflect greater uncertainty, while narrower intervals indicate higher confidence in the forecast.
With TimeGPT, you can easily generate prediction intervals for any confidence level between 0% and 100%.
These intervals are constructed using **[conformal prediction](https://en.wikipedia.org/wiki/Conformal_prediction)**, a distribution-free framework for uncertainty quantification.
Prediction intervals differ from confidence intervals:
- **Prediction Intervals**: Capture the uncertainty in future observations.
- **Confidence Intervals**: Quantify the uncertainty in the estimated model parameters (e.g., the mean).
As a result, prediction intervals are typically wider, as they account for both model and data variability.
## How to Generate Prediction Intervals
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/capabilities/forecast/10_prediction_intervals.ipynb)
### Step 1: Import Packages
Import the required packages and initialize the Nixtla client.
```python
import pandas as pd
from nixtla import NixtlaClient
nixtla_client = NixtlaClient(
api_key='my_api_key_provided_by_nixtla' # defaults to os.environ.get("NIXTLA_API_KEY")
)
```
### Step 2: Load Data
In this tutorial, we will use the Air Passengers dataset.
description: "Learn how to generate quantile forecasts with TimeGPT"
icon: "ruler-vertical"
---
## What Are Quantile Forecasts?
Quantile forecasts correspond to specific percentiles of the forecast distribution and provide a more complete representation of the range of possible outcomes.
- The 0.5 quantile (or 50th percentile) is the median forecast, meaning there is a 50% chance that the actual value will fall below or above this point.
- The 0.1 quantile (or 10th percentile) forecast represents a value that the actual observation is expected to fall below 10% of the time.
- The 0.9 quantile (or 90th percentile) forecast represents a value that the actual observation is expected to fall below 90% of the time.
TimeGPT supports quantile forecasts. In this tutorial, we will show you how to generate them.
## Why Use Quantile Forecasts
- Quantile forecasts can provide information about best and worst-case scenarios, allowing you to make better decisions under uncertainty.
- In many real-world scenarios, being wrong in one direction is more costly than being wrong in the other. Quantile forecasts allow you to focus on the specific percentiles that matter most for your particular use case.
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/tutorials/10_uncertainty_quantification_with_quantile_forecasts.ipynb)
## How to Generate Quantile Forecasts
### Step 1: Import Packages
Import the required packages and initialize a Nixtla client to connect with TimeGPT.
```python
import pandas as pd
from nixtla import NixtlaClient
from IPython.display import display
nixtla_client = NixtlaClient(
api_key='my_api_key_provided_by_nixtla' # Defaults to os.environ.get("NIXTLA_API_KEY")
)
```
### Step 2: Load Data
In this tutorial, we will use the Air Passengers dataset.
To specify the desired quantiles, you need to pass a list of quantiles to the `quantiles` parameter. Choose quantiles between 0 and 1 based on your uncertainty analysis needs.
The plot now includes quantile forecasts for the historical data. This allows you to evaluate how well the quantile forecasts capture the true variability and identify any systematic bias.
### Step 6: Cross-Validation
To evaluate the performance of the quantile forecasts across multiple time windows, you can use the `cross_validation` method.
```python
cv_df = nixtla_client.cross_validation(
df=df,
h=12,
n_windows=4,
quantiles=quantiles,
time_col='timestamp',
target_col='value'
)
```
After computing the forecasts, you can visualize the results for each cross-validation cutoff to better understand model performance over time.
Each plot shows a different cross-validation window (or cutoff) for the time series. This allows you to evaluate how well the predicted intervals capture the true values across multiple, independent forecast windows.
<Check>
Congratulations! You have successfully generated quantile forecasts using TimeGPT. You also visualized historical quantile predictions and evaluated their performance through cross-validation.
description: "Learn how to generate quantile forecasts and prediction intervals to capture uncertainty in your forecasts."
icon: "question"
---
In time series forecasting, it is important to consider the full probability distribution of the predictions rather than a single point estimate. This provides a more accurate representation of the uncertainty around the forecasts and allows better decision-making.
**TimeGPT** supports uncertainty quantification through quantile forecasts and prediction intervals.
## Why Consider the Full Probability Distribution?
When you focus on a single point prediction, you lose valuable information about the range of possible outcomes. By quantifying uncertainty, you can:
- Identify best-case and worst-case scenarios
- Improve risk management and contingency planning
- Gain confidence in decisions that rely on forecast accuracy
description: "Learn how to validate TimeGPT models by comparing historical forecasts against actual data."
icon: "clock-rotate-left"
---
Our time series model offers a powerful feature that allows you to retrieve historical forecasts alongside prospective predictions. You can access this functionality by using the forecast method and setting `add_history=True`.
[](https://colab.research.google.com/github/Nixtla/nixtla/blob/main/nbs/docs/tutorials/09_historical_forecast.ipynb)
<Info>
Historical forecasts can help you understand how well the model has performed in the past. This view provides insight into the model's predictive accuracy and any patterns in its performance.
</Info>
<Tabs>
<Tab title="Overview">
<CardGroup>
<Card>
<Card title="Key Benefit">
Adding historical forecasts (`add_history=True`) lets you compare model predictions against actual data, helping to identify trends.
</Card>
</Card>
<Card>
<Card title="When to Use Historical Forecasts">
Useful for performance evaluation, model reliability checks, and building trust in the predictions.
</Card>
</Card>
</CardGroup>
</Tab>
</Tabs>
<Steps>
<Step title="1. Import Required Packages">
First, install and import the required packages. Then, initialize the Nixtla client. Replace `my_api_key_provided_by_nixtla` with your actual API key.
```python Import Packages and Initialize NixtlaClient
import pandas as pd
from nixtla import NixtlaClient
```
```python Initialize NixtlaClient with API Key
nixtla_client = NixtlaClient(
# Defaults to os.environ.get("NIXTLA_API_KEY")
api_key='my_api_key_provided_by_nixtla'
)
```
<Check>
**Use an Azure AI endpoint**<br/>
If you want to use an Azure AI endpoint, set the `base_url` argument:
```python Initialize NixtlaClient with Azure AI Endpoint
This dataset contains monthly passenger counts for an airline, starting in January 1949. The `timestamp` column is the time dimension, and `value` is the passenger count.
</Info>
</Accordion>
</AccordionGroup>
You can visualize the dataset using Nixtla's built-in plotting function:

</Frame>
</Step>
<Step title="3. Generate Historical Forecast">
<AccordionGroup>
<Accordion title="Using add_history=True">
Set `add_history=True` to generate historical fitted values. The returned DataFrame includes future forecasts (`h` steps ahead) and historical predictions.
<Warning>
Historical forecasts are unaffected by `h` and rely on the data frequency. They are generated in a rolling-window manner, building a full series of predictions sequentially.
</Warning>
```python Generate Historical Forecast with add_history
<Frame caption="Historical and Future Predictions Plot">

</Frame>
</Card>
</Card>
</CardGroup>
<Info>
Note that initial values of the dataset are not included in the historical forecasts. The model needs a certain number of observations before it can begin generating historical predictions. These early points serve as input data and cannot themselves be forecasted.
description: "Learn how to validate time series models with cross-validation and historical forecasts"
icon: "check"
---
<Info>
Time series data can be highly variable. Validating your model's accuracy and reliability is crucial for confident forecasting.
</Info>
One of the primary challenges in time series forecasting is the inherent uncertainty and variability over time. It is therefore critical to validate the accuracy and reliability of the models you use.
`TimeGPT` provides capabilities for cross-validation and historical forecasts to assist in validating your predictions.
Before you begin, clarify what you want to achieve with your validation process. For example:
- Measure performance over different time windows.
- Evaluate historical forecasts for accuracy insight.
</Step>
<Step title="Step 2: Choose Your Validation Method">
Decide whether cross-validation, historical forecasting, or both suit your scenario. Consult the resources below to learn how to implement each approach.
</Step>
<Step title="Step 3: Implement & Assess">
Implement your validation method in a controlled environment. Review performance metrics such as Root Mean Squared Error (RMSE) or Mean Absolute Error (MAE) to determine success.
Learn how to generate historical forecasts within sample data to validate how `TimeGPT` would have performed historically, offering deeper insights into your model's accuracy.
</Card>
</CardGroup>
<AccordionGroup>
<Accordion title="Why Cross-Validation Is Crucial">
Cross-validation helps you evaluate your model's ability to generalize by testing it on multiple consecutive time windows.
By doing so, you gain confidence that the model isn't overfitting to a single period of data.
Historical forecasts provide insight into how your model would have performed in real-world conditions.
These forecasts simulate past scenarios and compare predictions to actual outcomes, helping refine your approach and understanding of model performance.
</Accordion>
</AccordionGroup>
<Check>
By combining cross-validation and historical forecasts, you can get a comprehensive view of how reliable your time series predictions are.
</Check>
## Example Usage
Below is a simple example of how you might set up a validation workflow in code:
# Compare model insights from both cross-validation and historical forecasts
```
<Warning>
Always ensure your validation data is representative of real-world conditions. Avoid data leakage by not including future data when training.
</Warning>
<Info>
For more in-depth usage and parameter configurations, refer to the official [Cross-Validation](https://docs.nixtla.io/docs/tutorials-cross_validation) and [Historical Forecasting](https://docs.nixtla.io/docs/tutorials-historical_forecast) documentation.
