
readme
parents
Showing
{kind=link}

60.5 KB
{kind=link}

58.9 KB
{kind=link}

71 KB
{kind=link}

1.49 MB
{kind=link}

177 KB
{kind=link}

89.6 KB
{kind=link}

285 KB
{kind=link}
188 KB
{kind=link}
94.3 KB
{kind=link}

230 KB
{kind=link}
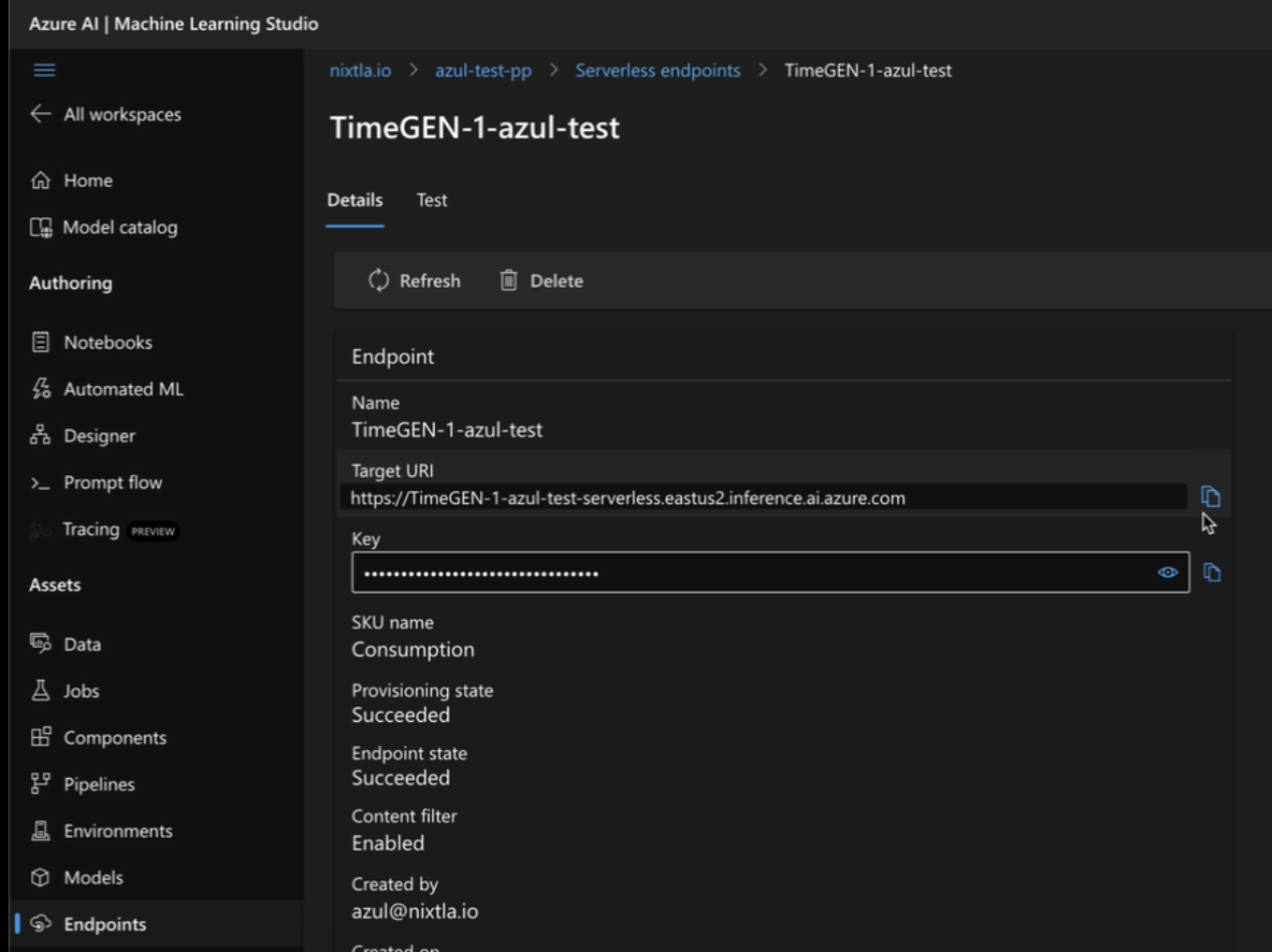
282 KB
{kind=link}
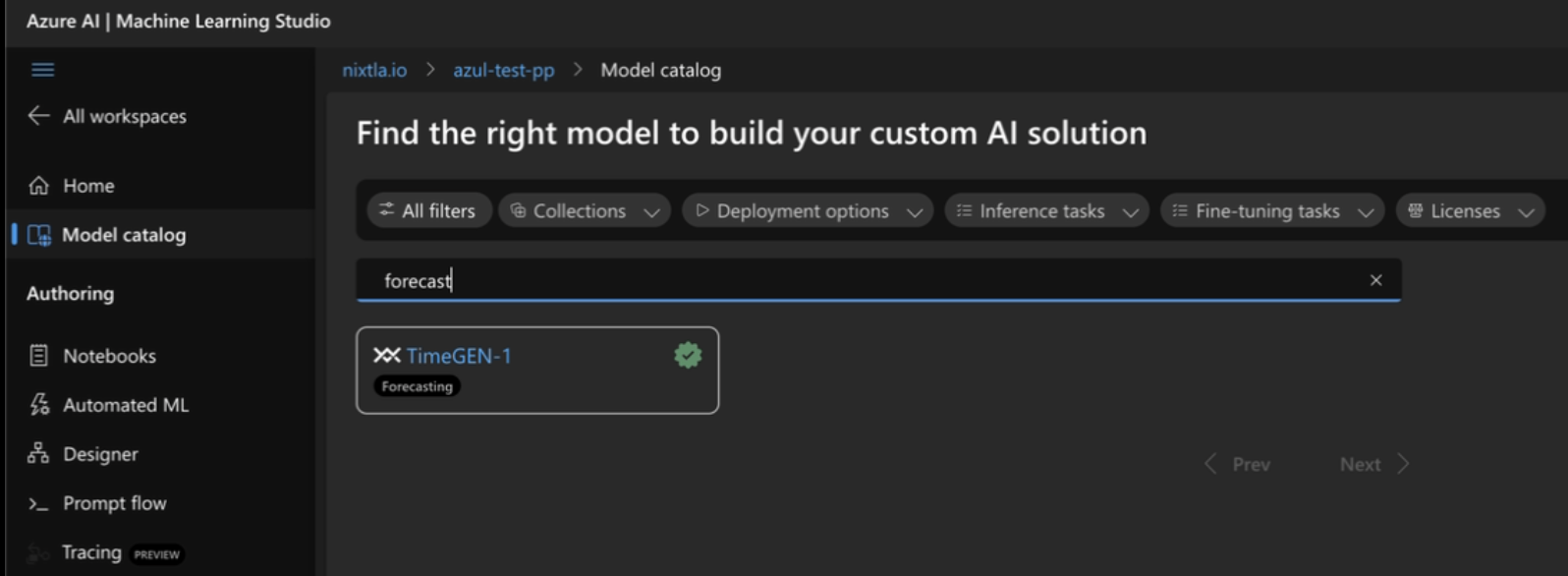
190 KB
{kind=link}

37.5 KB
60.5 KB
58.9 KB
71 KB
1.49 MB
177 KB
89.6 KB
285 KB
188 KB
94.3 KB
230 KB
282 KB
190 KB
37.5 KB