![]()
Paper | Demo | Model&Code update soon
----- **Monkey** brings a training-efficient approach to effectively improve the input resolution capacity up to 896 x 1344 pixels without pretraining from the start. To bridge the gap between simple text labels and high input resolution, we propose a multi-level description generation method, which automatically provides rich information that can guide the model to learn the contextual association between scenes and objects. With the synergy of these two designs, our model achieved excellent results on multiple benchmarks. By comparing our model with various LMMs, including GPT4V, our model demonstrates promising performance in image captioning by paying attention to textual information and capturing fine details within the images; its improved input resolution also enables remarkable performance in document images with dense text. ## Spotlights - **Contextual associations.** Our method demonstrates a superior ability to infer the relationships between targets more effectively when answering questions, which results in delivering more comprehensive and insightful results. - **Support resolution up to 1344 x 896.** Surpassing the standard 448 x 448 resolution typically employed for LMMs, this significant increase in resolution augments the ability to discern and understand unnoticeable or tightly clustered objects and dense text. - **Enhanced general performance.** We carried out testing across 16 diverse datasets, leading to impressive performance by our Monkey model in tasks such as Image Captioning, General Visual Question Answering, Text-centric Visual Question Answering, and Document-oriented Visual Question Answering. ## Demo [Demo](http://121.60.58.184:7680/) is fast and easy to use. Simply uploading an image from your desktop or phone, or capture one directly. Before 14/11/2023, we have observed that for some random pictures Monkey can achieve more accurate results than GPT4V.
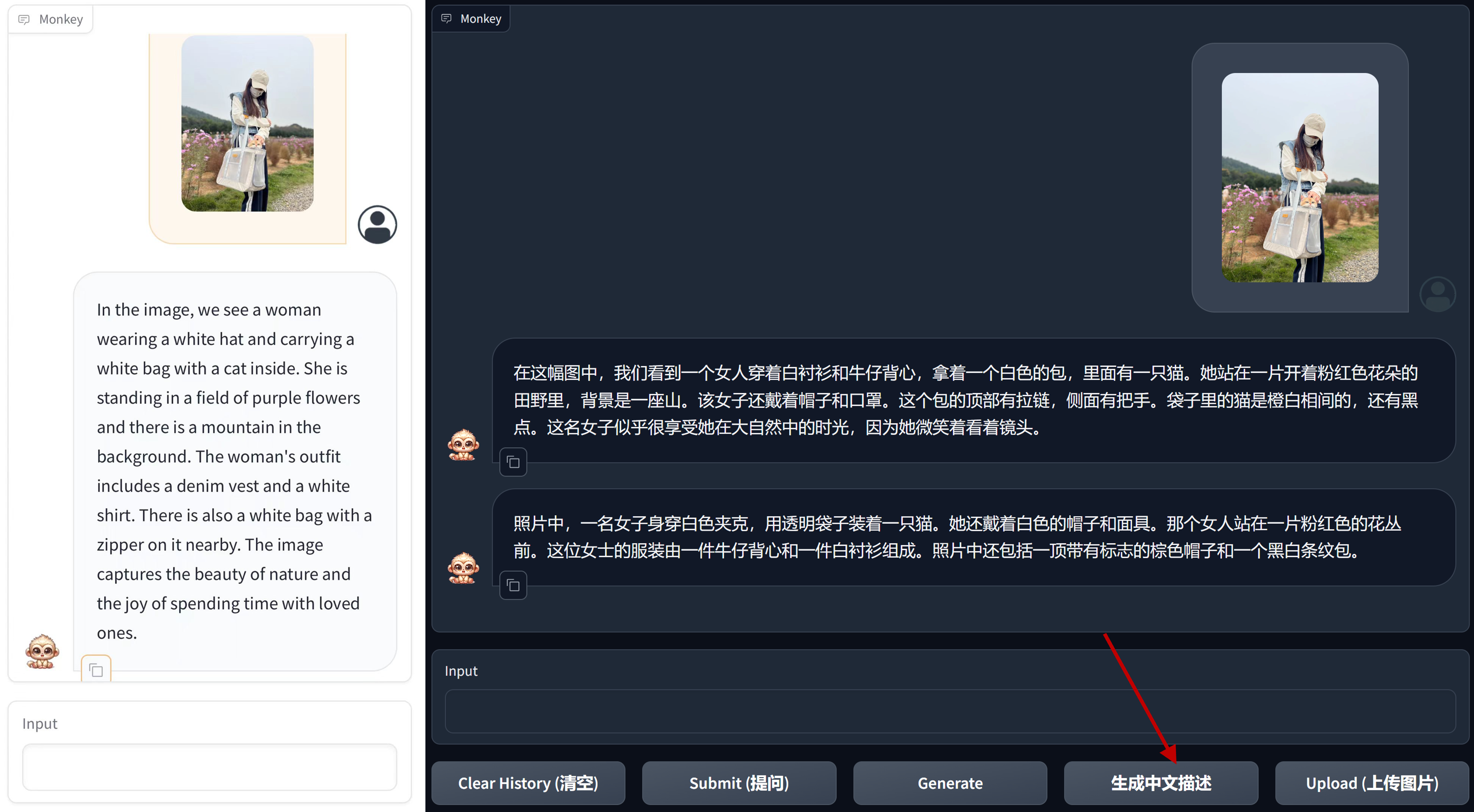
For those who prefer responses in Chinese, use the '生成中文描述' button to get descriptions in Chinese.
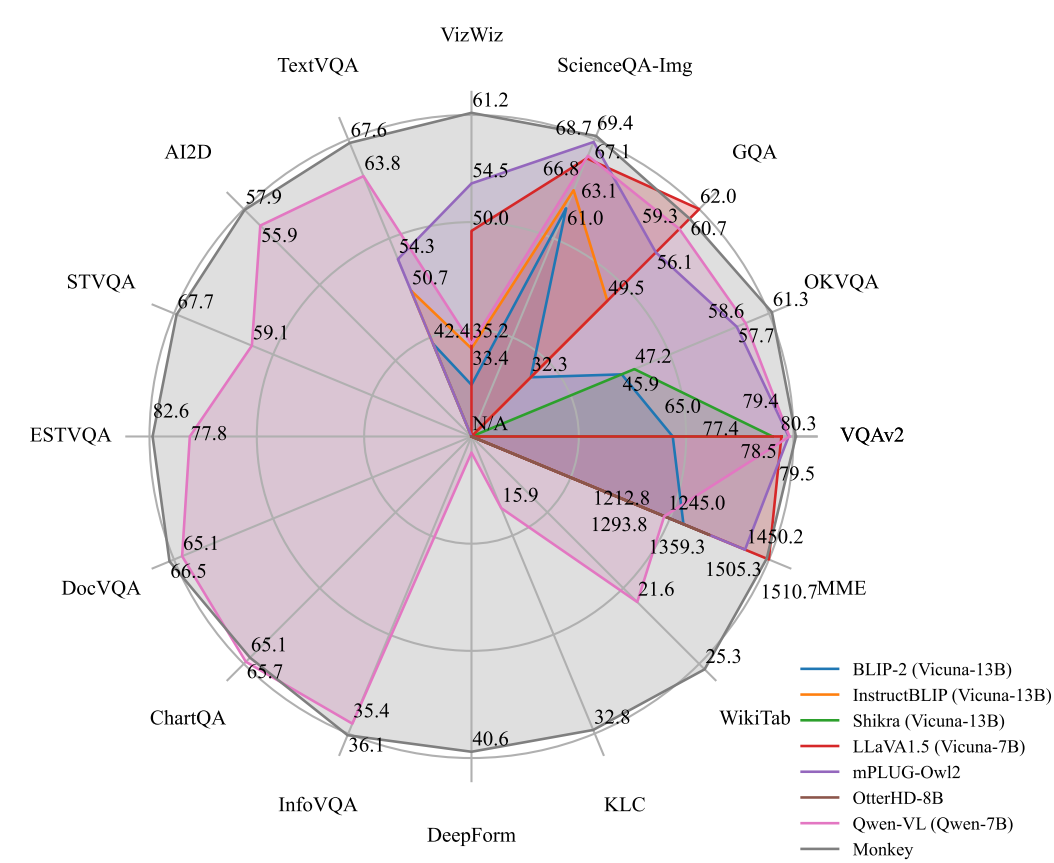
## performance
## Cases
Our model can accurately describe the details in the image.

Besides, our model has also demonstrated some capabilities in fine-grained question answering.
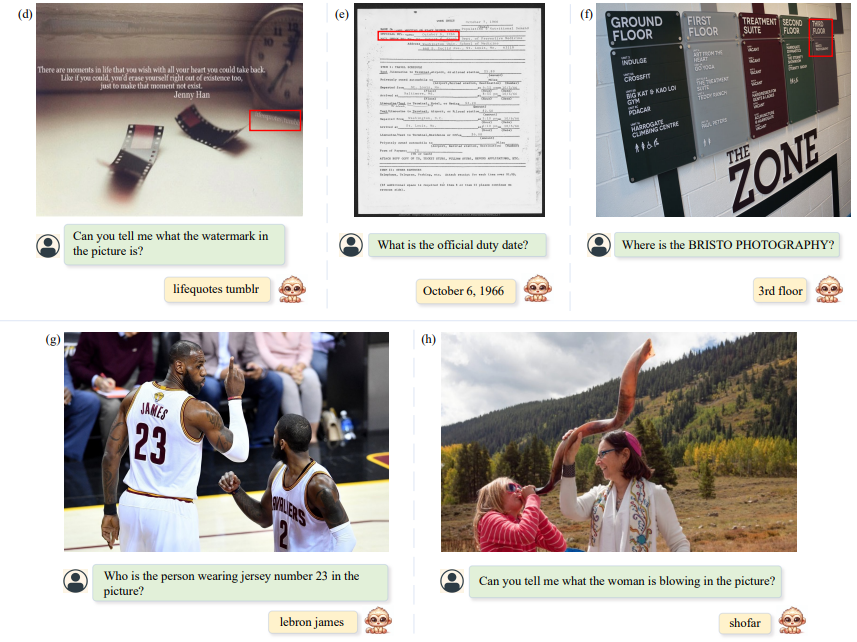
We have also achieved impressive performance on document-based tasks.

We qualitatively compare with existing LMMs including GPT4V, Qwen-vl, etc, which shows inspiring results. One can have a try using the provided demo.

## Citing Monkey
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
```BibTeX
@article{zhang2023Monkey,
title={Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models},
author={Zhang, Li and Biao, Yang and Qiang, Liu and Zhiyin, Ma and Shuo, Zhang and Jingxu, Yang and Yuliang, Liu and Xiang, Bai},
journal={arXiv preprint arXiv:2311.06607},
year={2023}
}
```
If you find the Monkey cute, please star. It would be a great encouragement for us.
## Acknowledgement
[Qwen-VL](https://github.com/QwenLM/Qwen-VL.git): the codebase we built upon. Thanks for the authors of Qwen for providing the framework.
## Copyright
We welcome suggestions to help us improve the Monkey. For any query, please contact Dr. Yuliang Liu: ylliu@hust.edu.cn. If you find something interesting, please also feel free to share with me through email or open an issue. Thanks!