中文 | English
![]()
论文 | 对话演示 | 详细描述 | 模型权重 | 始智AI
----- **Monkey** 引入了一种高效的训练方法,可以有效地将输入分辨率提高到 896 x 1344 ,同时不需要从开始进行预训练。为了弥合简单的文本描述和高输入分辨率之间的差距,Monkey 还提出了一种多级描述生成方法,该方法自动提供丰富的信息,可以指导模型学习场景和对象之间的关联。通过这两种设计的协同作用,Monkey 在多个基准测试中取得了优异的结果。与各种多模态大模型(包括 GPT4V)相比,Monkey 通过关注文本信息并捕获图像中的精细细节,在图像字幕方面表现出了良好的性能;高输入分辨率还可以使模型在具有密集文本的文档图像中展现出出色的性能。 ## 新闻 * ```2023.12.21``` 🚀🚀🚀 Monkey 训练使用的 JSON 文件发布。 * ```2023.12.16``` 🚀🚀🚀 Monkey 可以使用 8 NVIDIA 3090 GPUs 进行训练。详见[训练](#训练)。 * ```2023.11.25``` 🚀🚀🚀 Monkey [对话演示](http://vlrlab-monkey.xyz:7681/)发布。 * ```2023.11.06``` 🚀🚀🚀 Monkey [论文](https://arxiv.org/abs/2311.06607)发布。 ## 贡献 - **上下文关联。** Monkey在回答问题时展现了更有效地推断目标之间关系的卓越能力,从而能够提供更全面和更有洞察力的结果。 - **支持高达 1344 x 896 的分辨率。** Monkey支持的分辨率的显着超越了 LMM 通常采用的标准 448 x 448 分辨率,增强了辨别和理解不明显或紧密聚集的对象和密集文本的能力。 - **性能提高** 在 16 个不同的数据集上进行了测试,结果表明 Monkey 在图像字幕、一般视觉问答、以文本为中心的视觉问答和面向文档的视觉问答等任务中表现出色。 ## 环境 ```python conda create -n monkey python=3.9 conda activate monkey git clone https://github.com/Yuliang-Liu/Monkey.git cd ./Monkey pip install -r requirements.txt ``` ## 演示 演示快速且易于使用。只需从桌面或手机上传图像,或直接拍照即可。 为了提供更好的交互体验,我们还推出了原始演示的升级版本[对话演示](http://27.18.93.119:7681/)。 我们观察到对于一些随机图片Monkey可以取得比GPT4V更准确的结果。
我们还提供原始演示的源代码和模型权重,允许您自定义某些参数以获得更独特的体验。具体操作如下:
1. 确保您配置好了[环境](#环境).
2. 您可以选择在线或离线方法运行demo.py:
- **离线:**
- 下载[模型权重](http://huggingface.co/echo840/Monkey).
- 修改`demo.py`文件里的`DEFAULT_CKPT_PATH="pathto/Monkey"`为您下载的模型权重的路径。
- 用下面的命令运行演示:
```
python demo.py
```
- **在线:**
- 使用下面的命令加载模型并运行演示:
```
python demo.py -c echo840/Monkey
```
## 数据集
Monkey训练使用的json文件可以在[链接](https://drive.google.com/file/d/18z_uQTe8Jq61V5rgHtxOt85uKBodbvw1/view?usp=sharing)获取。
我们开源了多级描述生成方法生成的数据。您可以在这里下载:[详细描述数据](https://huggingface.co/datasets/echo840/Detailed_Caption).
## 评估
我们在`evaluate_vqa.py`文件中提供了 14 个视觉问答(VQA)数据集的评估代码,以便于快速验证结果。具体操作如下:
1. 确保您配置好了[环境](#环境).
2. 修改`sys.path.append("pathto/Monkey")`为该项目的地址。
3. 准备需要评估的数据集。
4. 运行评估代码。
以ESTVQA数据集的评测为例:
- 按照下面的格式准备数据集:
```
├── data
| ├── estvqa
| ├── test_image
| ├── {image_path0}
| ├── {image_path1}
| ·
| ·
| ├── estvqa.jsonl
```
- 注释文件`.jsonl`每行的格式示例:
```
{"image": "data/estvqa/test_image/011364.jpg", "question": "What is this store?", "answer": "pizzeria", "question_id": 0}
```
- 修改这个字典`ds_collections`:
```
ds_collections = {
'estvqa_test': {
'test': 'data/estvqa/estvqa.jsonl',
'metric': 'anls',
'max_new_tokens': 100,
},
...
}
```
- 运行下面的命令:
```
bash eval/eval.sh 'EVAL_PTH' 'SAVE_NAME'
```
## 训练
我们还提供 Monkey 的模型定义和训练代码,您可以在上面进行探索。 通过执行`finetune_ds_debug.sh`来进行训练。
Monkey训练使用的json文件可以在[链接](https://drive.google.com/file/d/18z_uQTe8Jq61V5rgHtxOt85uKBodbvw1/view?usp=sharing)获取。
**注意:** 需要指定训练数据的路径,该路径应该是包含对话列表的 json 文件。
受 Qwen-VL 的启发,我们冻结了大型语言模型(LLM),并将 LoRA 引入四个线性层```"c_attn"、"attn.c_proj"、"w1"、"w2"```进行训练。 这使得使用 8 个 NVIDIA 3090 GPU 训练 Monkey 成为可能。
- 添加LoRA:需要将```modeling_qwen.py```的内容替换为```modeling_qwen_nvdia3090.py```的内容
- 冻结LLM:需要在```finetune_multitask.py```中冻结除LoRA和Resampler模块的其他模块
## 推理
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "echo840/Monkey"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
tokenizer.padding_side = 'left'
tokenizer.pad_token_id = tokenizer.eod_id
img_path = ""
question = ""
query = f'{img_path} {question} Answer: ' #VQA
# query = f'
{img_path} Generate the detailed caption in English: ' #detailed caption
input_ids = tokenizer(query, return_tensors='pt', padding='longest')
attention_mask = input_ids.attention_mask
input_ids = input_ids.input_ids
pred = model.generate(
input_ids=input_ids.cuda(),
attention_mask=attention_mask.cuda(),
do_sample=False,
num_beams=1,
max_new_tokens=512,
min_new_tokens=1,
length_penalty=1,
num_return_sequences=1,
output_hidden_states=True,
use_cache=True,
pad_token_id=tokenizer.eod_id,
eos_token_id=tokenizer.eod_id,
)
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip()
print(response)
```
## 性能
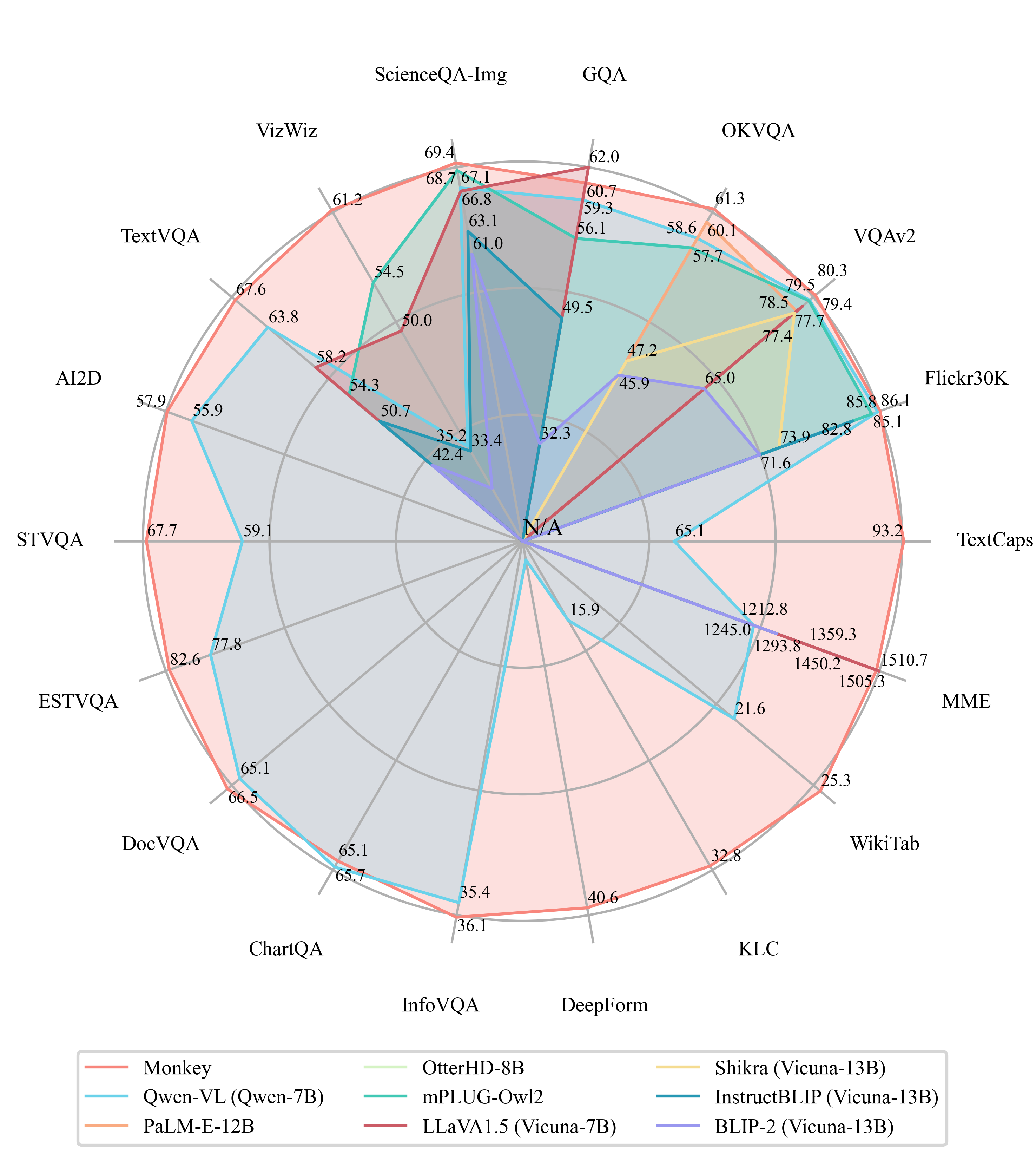
## 展示
Monkey 可以准确地描述图像中的细节。

Monkey 在密集文本问答任务中表现特别好。 例如,在商品标签的密集文本中,Monkey 可以准确回答有关该商品的各种信息,与包括 GPT4V 在内的其他 LMMs 相比,Monkey的性能非常突出。


Monkey 在日常生活场景中也表现同样出色。 它可以完成各种问答和字幕任务,详细描述图像中的各种细节,甚至是不显眼的水印。

与现有的 LMMs(包括 GPT4V、Qwen-vl 等)进行定性比较,Moneky 显示出令人鼓舞的结果。 您可以尝试使用我们提供的演示。

## Citing Monkey
如果您觉得我们的论文和代码对研究有帮助,请考虑star和引用:
```BibTeX
@article{li2023monkey,
title={Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models},
author={Li, Zhang and Yang, Biao and Liu, Qiang and Ma, Zhiyin and Zhang, Shuo and Yang, Jingxu and Sun, Yabo and Liu, Yuliang and Bai, Xiang},
journal={arXiv preprint arXiv:2311.06607},
year={2023}
}
```
## Acknowledgement
我们在 [Qwen-VL](https://github.com/QwenLM/Qwen-VL.git) 的基础上构建代码。感谢 Qwen 的作者提供的框架。
## Copyright
我们欢迎提出建议来帮助我们改进 Monkey。如有任何疑问,请联系刘禹良博士:ylliu@hust.edu.cn。如果您发现有趣的事,也请随时通过电子邮件与我们分享或提出问题。谢谢!