# TextMonkey
TextMonkey是这是一种专为以文本为中心的任务而定制的大型多模态模型 (LMM),包括文档问答 (DocVQA) 和场景文本分析。
## 论文
- [TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document](https://arxiv.org/abs/2403.04473)
## 模型结构
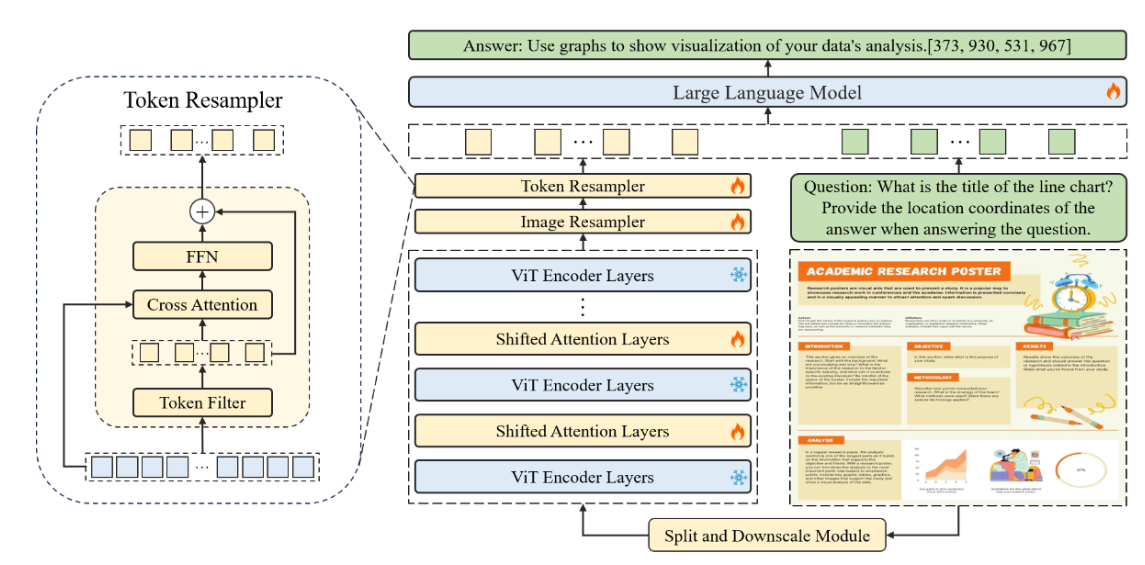
首先使用滑动窗口模块将输入图像划分为不重叠的 patch,每个 patch 的大小为 448x448 像素。这些 patch 进一步细分为 14x14 像素的更小的patch ,每个 patch 都被视为一个 token。利用预训练的 CLIP 模型,然后分别在每个窗口 patch 上处理这些 token。为了建立各个窗口 patch 之间的连接,在 Transformer 块之间以一定间隔集成移位窗口注意力(Shifted Window Attention)。为了生成分层表示,输入图像的大小被调整为 448x448,并输入CLIP提取全局特征。这个全局特征以及来自子图像的特征,然后由共享图像重采样器处理以与语言域对齐。然后,通过压缩标记的长度,使用 Token Resampler 进一步最小化语言空间中的冗余。
## 算法原理
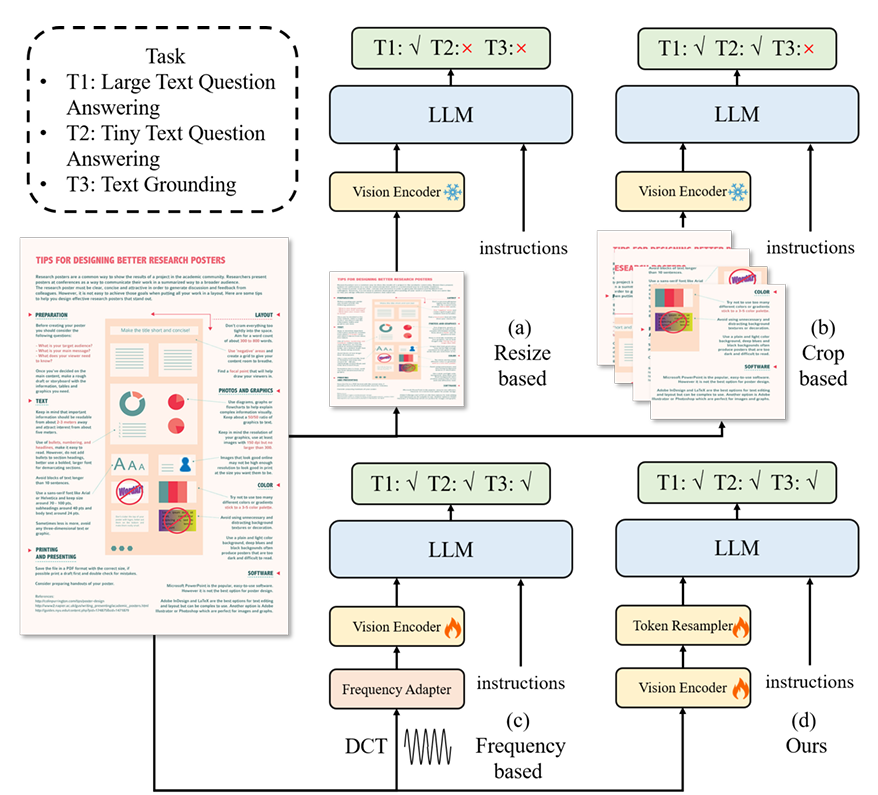
为了进行统一的文档结构学习,该工作基于开源数据集构建了一个全面的结构化解析数据集DocStruct4M。对于文档图片或者网页截图,主要采用空格和换行表示文字布局;对于表格,其改进的Markdown语法既能表示跨行跨列,又相比html缩减了大量标签;对于图表,同样采用markdown来表示其数学特征,并且限定数值的有效位以保证其在图片中视觉可见;对于自然图,采用描述加上ocr文本的形式。
## 环境配置
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name textmonkey bash
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t textmonkey:latest .
docker run --shm-size=64G --name mplug-doclocal -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it textmonkey bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04
python:python3.10
torch:2.1
torchvision: 0.16.0
deepspped: 0.12.3
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
conda create -n textmonkey python=3.10
conda activate textmonkey
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
```
## 数据集
迷你数据集 [mm_tutorial](./assets/mm_tutorial)
完整数据集[MelosY/TextMonkey_Data](https://huggingface.co/datasets/MelosY/TextMonkey_Data)
预训练需要准备你的训练数据,需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含以下信息,示例如下所示:用于正常训练的完整数据集请按此目录结构进行制备:
```
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是TextMonkey,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: ![]() /home/wanglch/projects/TextMonkey/Monkey/assets/mm_tutorial/Chongqing.jpeg\nPicture 2:
/home/wanglch/projects/TextMonkey/Monkey/assets/mm_tutorial/Chongqing.jpeg\nPicture 2: ![]() /home/wanglch/projects/TextMonkey/Monkey/assets/mm_tutorial/Beijing.jpeg\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
```
## 训练
根据实际情况在脚本中修相关路径
--deepspeed
--model_name_or_path
--data_path
--image_folder
--output_dir
### 单机多卡
训练需要8卡 A800 80G
```
sh finetune_textmonkey_dcu.sh
```
## 推理
### 单机单卡
### 网页问答
修改模型路径为本地模型路径
```
sh textmonkey_inference_web.sh
```
### 指令问答
```
python demo_textmonkey.py
```
## result
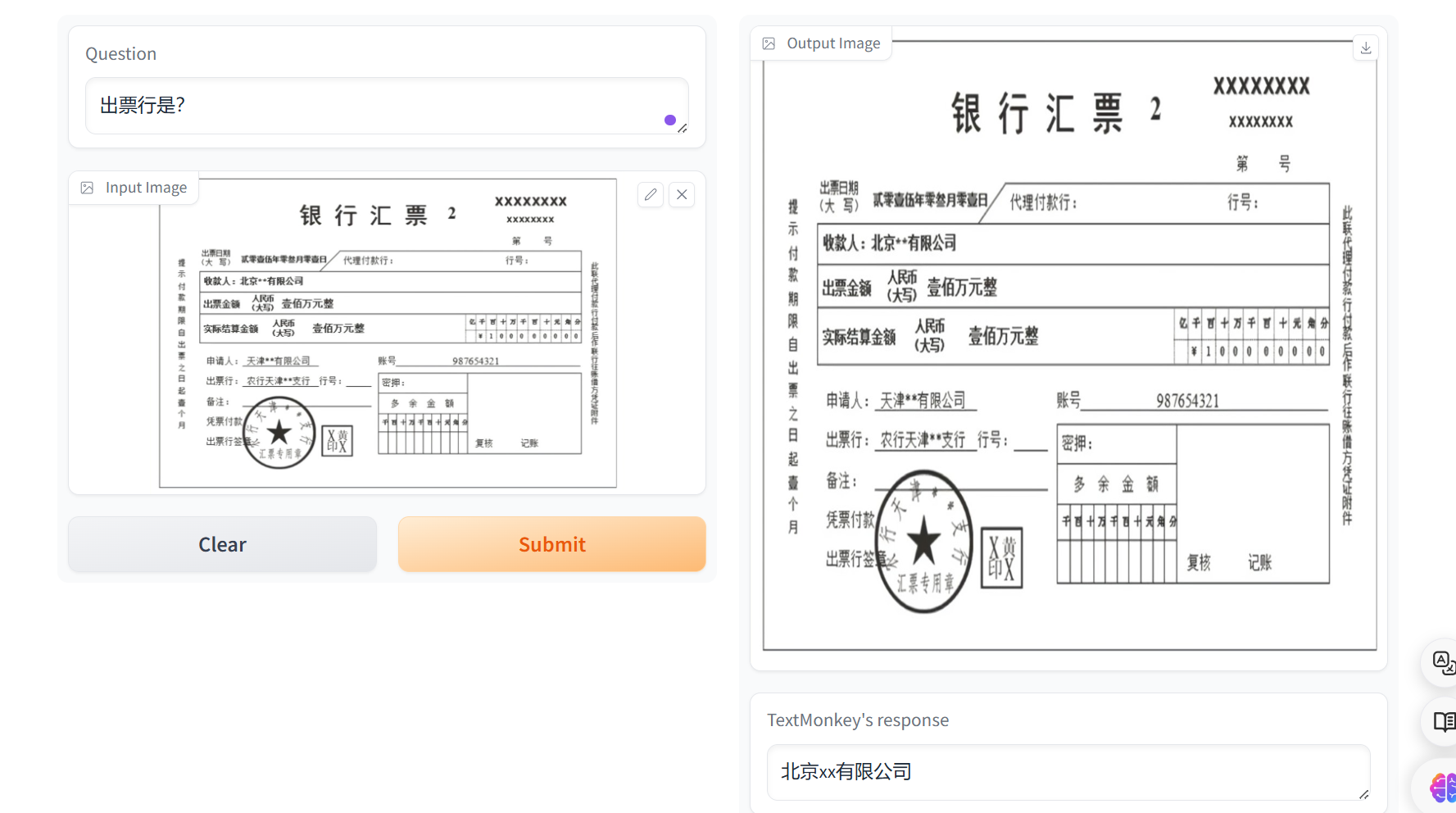
### 网页问答
### 指令问答
### 精度
迷你数据集 [mm_tutorial](./assets/mm_tutorial) ,使用的加速卡:K100/A800。
| device | train_loss |
| :------: | :------: |
| K100 | |
| A800 | |
## 应用场景
### 算法类别
`OCR,对话问答`
### 热点应用行业
`金融,教育,政府,交通`
## 预训练权重
- [lvskiller/TextMonkey](https://www.modelscope.cn/models/lvskiller/TextMonkey)
预训练权重快速下载中心:[SCNet AIModels](http://113.200.138.88:18080/aimodels)
项目中的预训练权重可从快速下载通道下载: [TextMonkey](http://113.200.138.88:18080/aimodels/TextMonkey_pytorch)
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/textmonkey_pytorch.git
## 参考资料
- [TextMonkey github](https://github.com/Yuliang-Liu/Monkey/blob/main/monkey_model/text_monkey/README.md)
/home/wanglch/projects/TextMonkey/Monkey/assets/mm_tutorial/Beijing.jpeg\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
```
## 训练
根据实际情况在脚本中修相关路径
--deepspeed
--model_name_or_path
--data_path
--image_folder
--output_dir
### 单机多卡
训练需要8卡 A800 80G
```
sh finetune_textmonkey_dcu.sh
```
## 推理
### 单机单卡
### 网页问答
修改模型路径为本地模型路径
```
sh textmonkey_inference_web.sh
```
### 指令问答
```
python demo_textmonkey.py
```
## result
### 网页问答
### 指令问答
### 精度
迷你数据集 [mm_tutorial](./assets/mm_tutorial) ,使用的加速卡:K100/A800。
| device | train_loss |
| :------: | :------: |
| K100 | |
| A800 | |
## 应用场景
### 算法类别
`OCR,对话问答`
### 热点应用行业
`金融,教育,政府,交通`
## 预训练权重
- [lvskiller/TextMonkey](https://www.modelscope.cn/models/lvskiller/TextMonkey)
预训练权重快速下载中心:[SCNet AIModels](http://113.200.138.88:18080/aimodels)
项目中的预训练权重可从快速下载通道下载: [TextMonkey](http://113.200.138.88:18080/aimodels/TextMonkey_pytorch)
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/textmonkey_pytorch.git
## 参考资料
- [TextMonkey github](https://github.com/Yuliang-Liu/Monkey/blob/main/monkey_model/text_monkey/README.md)