# Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Zhang Li*, Biao Yang*, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu†, Xiang Bai
Huazhong University of Science and Technology, Kingsoft
*Equal Contribution; † Corresponding Author
---
**Monkey** introduces a resource-efficient method to enhance input resolution within the LMM paradigm. Using the wealth of excellent open-source efforts, we eschew the laborious pre-training phase by using existing LMMs(Qwen-VL). We propose a simple but effective module that segments high-resolution images into smaller, local segments via a sliding window technique. Each segment is encoded independently using a static visual encoder, enriched with various LoRA adjustments, and a trainable visual resampler. These segmented encodings are subsequently amalgamated and presented to the language decoder, complemented by a resized global image feature to maintain overall structural integrity. In parallel, we’ve developed a hierarchical pipeline for enhancing caption data quality, good at generating detailed image descriptions that encapsulate local elements, textual content, and the broader structural context.
## Spotlights
- **Contextual associations. **. Our method demonstrates a superior ability to infer the relationships between targets more effectively when answering questions, which results in delivering more comprehensive and insightful results.
- **Support resolution up to 1344 x 896. ** Surpassing the standard 448 x 448 resolution typically employed for LMMs, this significant increase in resolution augments the ability to discern and understand unnoticeable or tightly clustered objects and dense text.
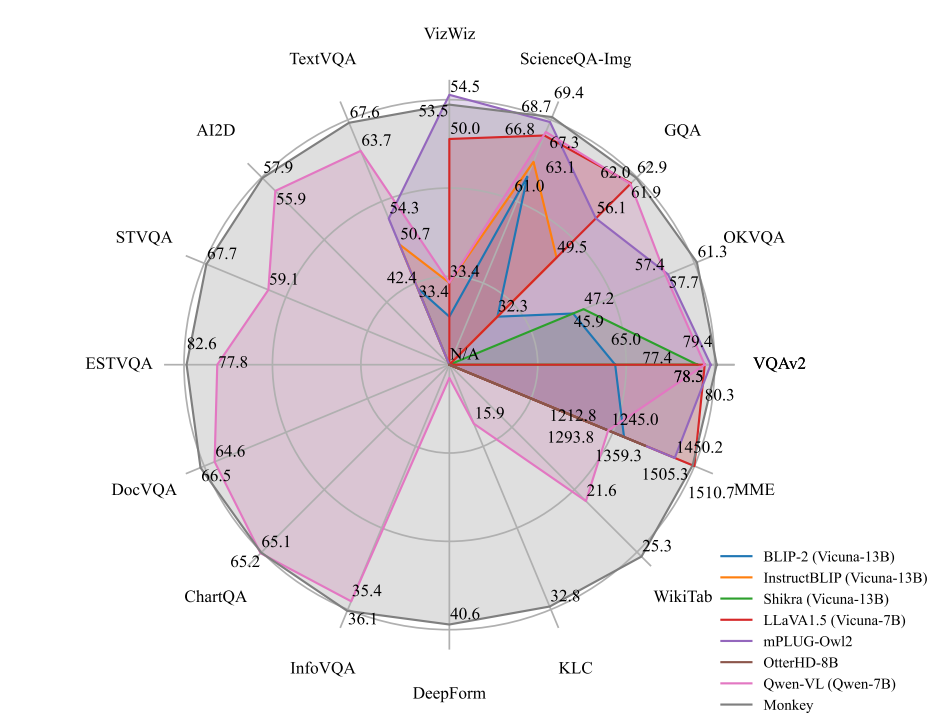
- **Enhanced general performance. ** We carried out testing across 16 diverse datasets, leading to impressive performance by our Monkey model in tasks such as Image Captioning, General Visual Question Answering, Text-centric Visual Question Answering, and Document-oriented Visual Question Answering.
## performance
## Demo
We have a demo open for everyone to play.[Demo](https://74a00f7621c2ecf691.gradio.live/ )
## Cases
Our model can accurately describe almost all the details in the image.

Besides, our model has also demonstrated some capabilities in fine-grained question answering and even answering questions involving world knowledge.
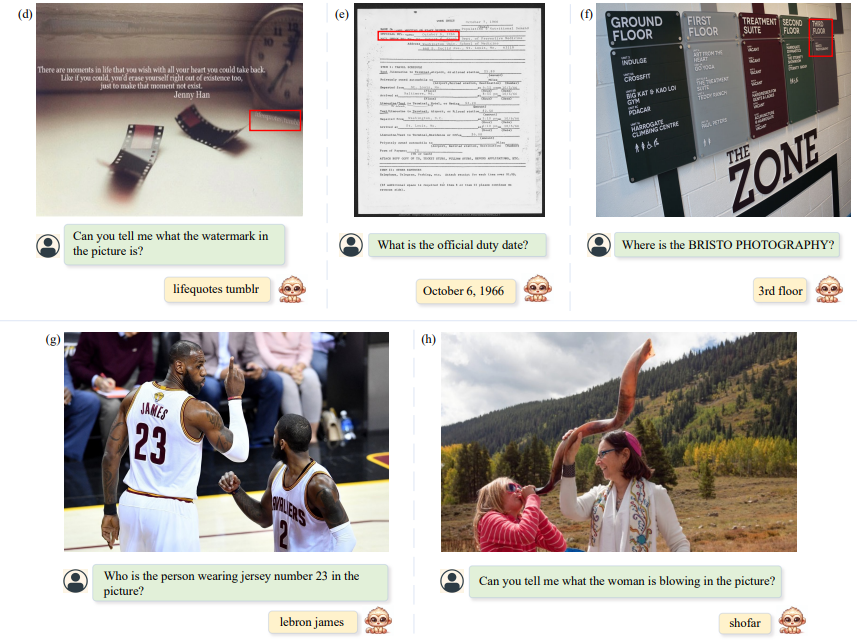
With the power of large-scale architecture, we have also achieved impressive performance on document-based tasks.

## Acknowledgement
[Qwen-VL]https://github.com/QwenLM/Qwen-VL.git): the codebase we built upon. Thanks for the authors of Qwen for providing the framework.