# Swin-Transformer
## 论文
[Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
## 模型结构
Swin Transformer体系结构的概述如下图所示,其中说明了 tiny version ( Swin-T )。它首先通过 patch 分割模块(如ViT )将输入的RGB图像分割成不重叠的 patch 。每个 patch 被当作一个 "token" ( 相当于NLP中的词源 )处理,它的特征被设置为原始像素RGB值的 concatenation。在我们的实现中,我们使用了 4 × 4 的 patch 大小,因此每个 patch 的特征维度为 4 × 4 × 3 = 48。在这个原始值特征上应用一个线性嵌入层,将其投影到任意维度( 记为C )。
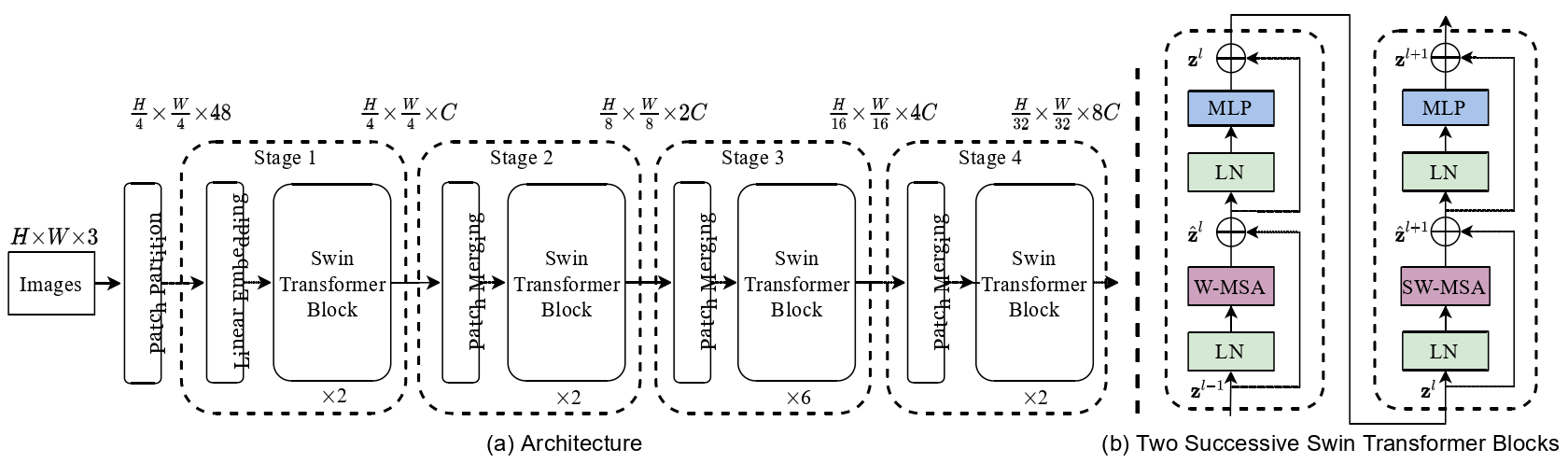
- ( a )Swin Transformer ( Swin-T )的结构;
- ( b )连续 2 个Swin Transformer 块。
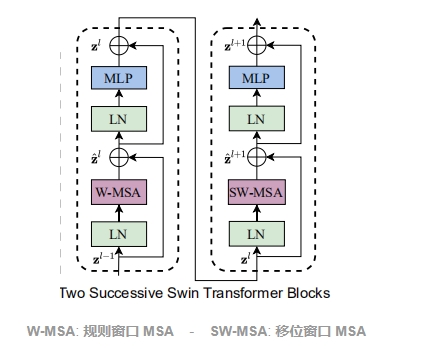
## 算法原理
Swin Transformer 相比于 Transformer block (例如 ViT),将 标准多头自注意力模块 (MSA) 替换为 基于移位窗口的多头自注意力模块 (W-MSA / SW-MSA) 且保持其他部分不变。如图所示,一个 Swin Transformer block 由一个 基于移位窗口的 MSA 模块 构成,且后接一个夹有 GeLU 非线性在中间的 2 层 MLP。LayerNorm (LN) 层被应用于每个 MSA 模块和每个 MLP 前,且一个 残差连接 被应用于每个模块后。
## 环境配置
### Docker(方法一)
提供[光源](https://sourcefind.cn/#/service-list)拉取的docker镜像:
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/
pip install -r requirements.txt
```
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
```bash
docker build -t swin_transformer:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/
pip install -r requirements.txt
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动: dtk24.04.2
python: 3.10
torch: 2.1.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install -r requirements.txt
```
## 数据集
在本测试中可以使用tiny-imagenet-200数据集。
[tiny-imagenet-200](http://cs231n.stanford.edu/tiny-imagenet-200.zip)
## 训练
### 单机单卡
```bash
HIP_VISIBLE_DEVICES=0 python3 -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path /code/Datasets/tiny-imagenet-200/ --batch-size 128 --disable_amp
```
### 单机多卡
```bash
HIP_VISIBLE_DEVICES=0,1,2,3 python3 -m torch.distributed.launch --nproc_per_node 4 --master_port 12345 main.py --cfg configs/swin/swin_tiny_patch4_window7_224.yaml --data-path /code/Datasets/tiny-imagenet-200/ --batch-size 128 --disable_amp
```
具体参数设置可参考main.py和config.py
## 推理
无
## result
### 精度
测试数据使用的是tiny-imagenet-200,使用的加速卡是DCU Z100L。
| 卡数 | 精度 |
| :------: | :------: |
| 1 | Acc@1:63.416 Acc:@5 85.666 |
## 应用场景
### 算法类别
`图像分类`
### 热点应用行业
`科研,教育,政府,金融`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/swin-transformer-pytorch
### 参考资料
- https://github.com/microsoft/Swin-Transformer