
stylegan3
Showing
pngs/loss.png
0 → 100644
{kind=link}
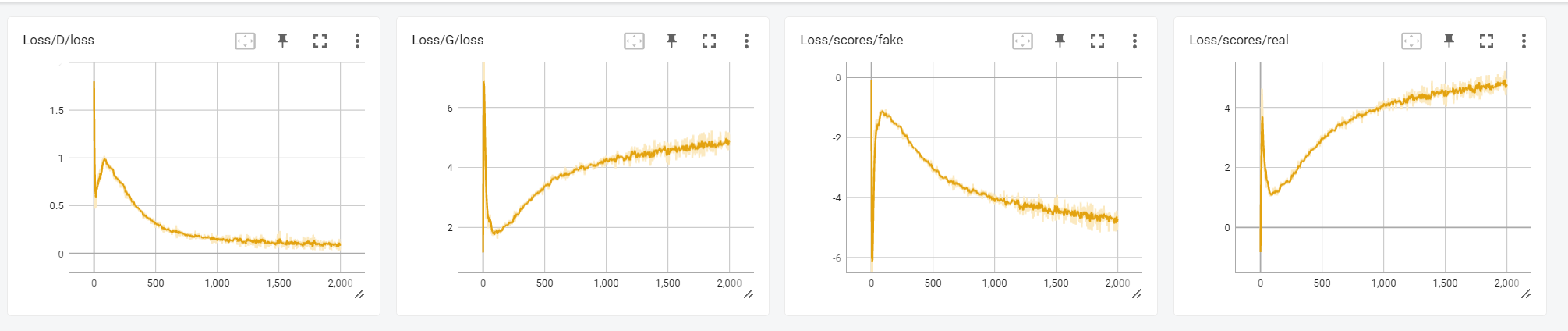
64.9 KB
pngs/show.gif
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
pngs/stru.png
0 → 100644
{kind=link}
236 KB
readme_imgs/image-1.png
0 → 100644
{kind=link}
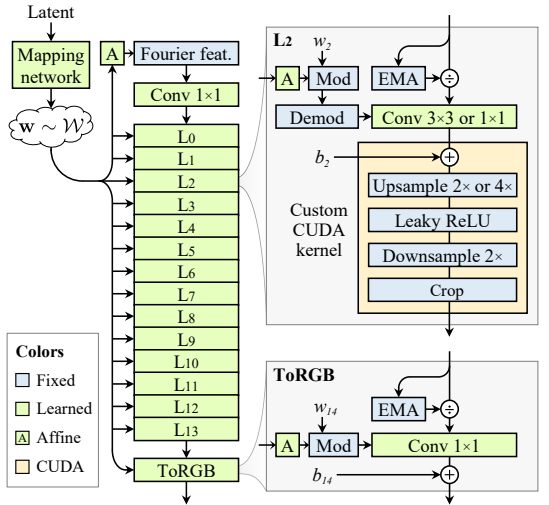
71.7 KB
readme_imgs/image-2.png
0 → 100644
{kind=link}
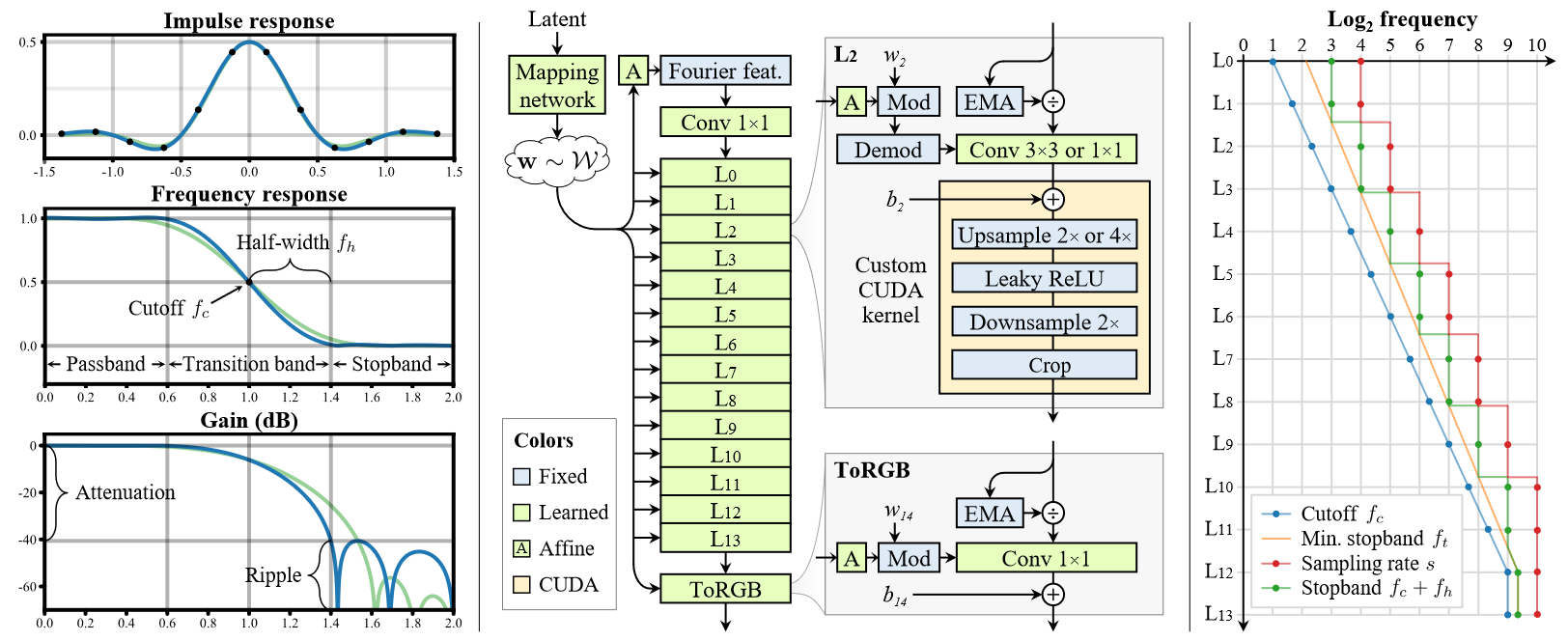
184 KB
requirements.txt
0 → 100644
torch_utils/__init__.py
0 → 100644
torch_utils/custom_ops.py
0 → 100644
torch_utils/misc.py
0 → 100644
File added
torch_utils/ops/__init__.py
0 → 100644
torch_utils/ops/bias_act.cpp
0 → 100644
torch_utils/ops/bias_act.cu
0 → 100644
torch_utils/ops/bias_act.h
0 → 100644
torch_utils/ops/bias_act.py
0 → 100644