[Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset](https://openaccess.thecvf.com/content_cvpr_2017/html/Carreira_Quo_Vadis_Action_CVPR_2017_paper.html)
The paucity of videos in current action classification datasets (UCF-101 and HMDB-51) has made it difficult to identify good video architectures, as most methods obtain similar performance on existing small-scale benchmarks. This paper re-evaluates state-of-the-art architectures in light of the new Kinetics Human Action Video dataset. Kinetics has two orders of magnitude more data, with 400 human action classes and over 400 clips per class, and is collected from realistic, challenging YouTube videos. We provide an analysis on how current architectures fare on the task of action classification on this dataset and how much performance improves on the smaller benchmark datasets after pre-training on Kinetics. We also introduce a new Two-Stream Inflated 3D ConvNet (I3D) that is based on 2D ConvNet inflation: filters and pooling kernels of very deep image classification ConvNets are expanded into 3D, making it possible to learn seamless spatio-temporal feature extractors from video while leveraging successful ImageNet architecture designs and even their parameters. We show that, after pre-training on Kinetics, I3D models considerably improve upon the state-of-the-art in action classification, reaching 80.9% on HMDB-51 and 98.0% on UCF-101.
1. The **gpus** indicates the number of gpu we used to get the checkpoint. It is noteworthy that the configs we provide are used for 8 gpus as default.
According to the [Linear Scaling Rule](https://arxiv.org/abs/1706.02677), you may set the learning rate proportional to the batch size if you use different GPUs or videos per GPU,
e.g., lr=0.01 for 4 GPUs x 2 video/gpu and lr=0.08 for 16 GPUs x 4 video/gpu.
2. The **inference_time** is got by this [benchmark script](/tools/analysis/benchmark.py), where we use the sampling frames strategy of the test setting and only care about the model inference time, not including the IO time and pre-processing time. For each setting, we use 1 gpu and set batch size (videos per gpu) to 1 to calculate the inference time.
3. The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at [Kinetics400-Validation](https://mycuhk-my.sharepoint.com/:u:/g/personal/1155136485_link_cuhk_edu_hk/EbXw2WX94J1Hunyt3MWNDJUBz-nHvQYhO9pvKqm6g39PMA?e=a9QldB). The corresponding [data list](https://download.openmmlab.com/mmaction/dataset/k400_val/kinetics_val_list.txt)(each line is of the format 'video_id, num_frames, label_index') and the [label map](https://download.openmmlab.com/mmaction/dataset/k400_val/kinetics_class2ind.txt) are also available.
:::
For more details on data preparation, you can refer to Kinetics400 in [Data Preparation](/docs/data_preparation.md).
## Train
You can use the following command to train a model.
Training Json Log:https://download.openmmlab.com/mmaction/recognition/i3d/i3d_nl_embedded_gaussian_r50_32x2x1_100e_kinetics400_rgb/20200813_034054.log.json
Training Log:https://download.openmmlab.com/mmaction/recognition/i3d/i3d_nl_embedded_gaussian_r50_32x2x1_100e_kinetics400_rgb/20200813_034054.log
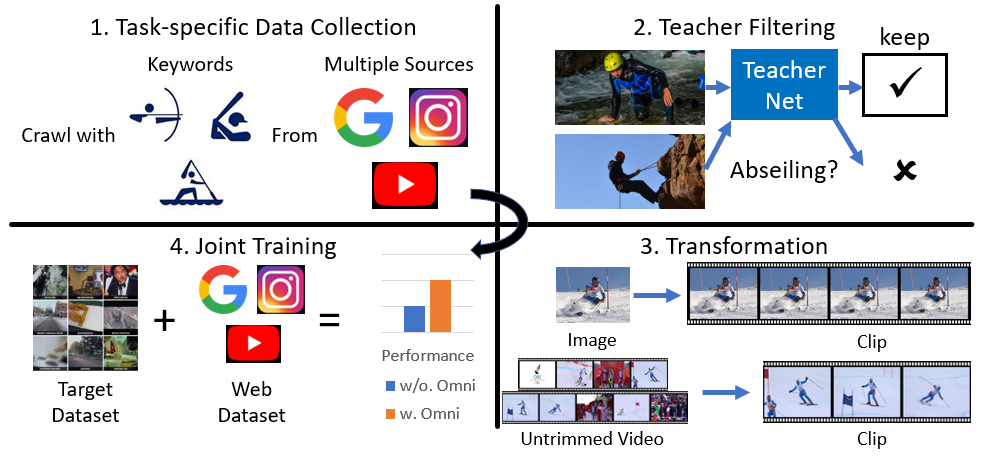
We introduce OmniSource, a novel framework for leveraging web data to train video recognition models. OmniSource overcomes the barriers between data formats, such as images, short videos, and long untrimmed videos for webly-supervised learning. First, data samples with multiple formats, curated by task-specific data collection and automatically filtered by a teacher model, are transformed into a unified form. Then a joint-training strategy is proposed to deal with the domain gaps between multiple data sources and formats in webly-supervised learning. Several good practices, including data balancing, resampling, and cross-dataset mixup are adopted in joint training. Experiments show that by utilizing data from multiple sources and formats, OmniSource is more data-efficient in training. With only 3.5M images and 800K minutes videos crawled from the internet without human labeling (less than 2% of prior works), our models learned with OmniSource improve Top-1 accuracy of 2D- and 3D-ConvNet baseline models by 3.0% and 3.9%, respectively, on the Kinetics-400 benchmark. With OmniSource, we establish new records with different pretraining strategies for video recognition. Our best models achieve 80.4%, 80.5%, and 83.6 Top-1 accuracies on the Kinetics-400 benchmark respectively for training-from-scratch, ImageNet pre-training and IG-65M pre-training.
We currently released 4 models trained with OmniSource framework, including both 2D and 3D architectures. We compare the performance of models trained with or without OmniSource in the following table.
1. The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at [Kinetics400-Validation](https://mycuhk-my.sharepoint.com/:u:/g/personal/1155136485_link_cuhk_edu_hk/EbXw2WX94J1Hunyt3MWNDJUBz-nHvQYhO9pvKqm6g39PMA?e=a9QldB). The corresponding [data list](https://download.openmmlab.com/mmaction/dataset/k400_val/kinetics_val_list.txt)(each line is of the format 'video_id, num_frames, label_index') and the [label map](https://download.openmmlab.com/mmaction/dataset/k400_val/kinetics_class2ind.txt) are also available.
## Benchmark on Mini-Kinetics
We release a subset of web dataset used in the OmniSource paper. Specifically, we release the web data in the 200 classes of [Mini-Kinetics](https://arxiv.org/pdf/1712.04851.pdf). The statistics of those datasets is detailed in [preparing_omnisource](/tools/data/omnisource/README.md). To obtain those data, you need to fill in a [data request form](https://docs.google.com/forms/d/e/1FAIpQLSd8_GlmHzG8FcDbW-OEu__G7qLgOSYZpH-i5vYVJcu7wcb_TQ/viewform?usp=sf_link). After we received your request, the download link of these data will be send to you. For more details on the released OmniSource web dataset, please refer to [preparing_omnisource](/tools/data/omnisource/README.md).
We benchmark the OmniSource framework on the released subset, results are listed in the following table (we report the Top-1 and Top-5 accuracy on Mini-Kinetics validation). The benchmark can be used as a baseline for video recognition with web data.
In ECCV, 2020. [Paper](https://arxiv.org/abs/2003.13042), [Dataset](https://docs.google.com/forms/d/e/1FAIpQLSd8_GlmHzG8FcDbW-OEu__G7qLgOSYZpH-i5vYVJcu7wcb_TQ/viewform?usp=sf_link)
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/baseline/tsn_r50_1x1x8_100e_minikinetics_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/baseline/tsn_r50_1x1x8_100e_minikinetics_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/googleimage/tsn_r50_1x1x8_100e_minikinetics_googleimage_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/googleimage/tsn_r50_1x1x8_100e_minikinetics_googleimage_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/webimage/tsn_r50_1x1x8_100e_minikinetics_webimage_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/webimage/tsn_r50_1x1x8_100e_minikinetics_webimage_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/insvideo/tsn_r50_1x1x8_100e_minikinetics_insvideo_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/insvideo/tsn_r50_1x1x8_100e_minikinetics_insvideo_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/kineticsraw/tsn_r50_1x1x8_100e_minikinetics_kineticsraw_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/kineticsraw/tsn_r50_1x1x8_100e_minikinetics_kineticsraw_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/omnisource/tsn_r50_1x1x8_100e_minikinetics_omnisource_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/tsn_r50_1x1x8_100e_minikinetics_rgb/omnisource/tsn_r50_1x1x8_100e_minikinetics_omnisource_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/baseline/slowonly_r50_8x8x1_256e_minikinetics_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/baseline/slowonly_r50_8x8x1_256e_minikinetics_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/googleimage/slowonly_r50_8x8x1_256e_minikinetics_googleimage_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/googleimage/slowonly_r50_8x8x1_256e_minikinetics_googleimage_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/webimage/slowonly_r50_8x8x1_256e_minikinetics_webimage_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/webimage/slowonly_r50_8x8x1_256e_minikinetics_webimage_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/insvideo/slowonly_r50_8x8x1_256e_minikinetics_insvideo_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/insvideo/slowonly_r50_8x8x1_256e_minikinetics_insvideo_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/kineticsraw/slowonly_r50_8x8x1_256e_minikinetics_kineticsraw_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/kineticsraw/slowonly_r50_8x8x1_256e_minikinetics_kineticsraw_rgb_20201030.log
Training Json Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/omnisource/slowonly_r50_8x8x1_256e_minikinetics_omnisource_rgb_20201030.json
Training Log:https://download.openmmlab.com/mmaction/recognition/omnisource/slowonly_r50_8x8x1_256e_minikinetics_rgb/omnisource/slowonly_r50_8x8x1_256e_minikinetics_omnisource_rgb_20201030.log

{kind=link}