# Step3
## 论文
`
Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding
`
- https://arxiv.org/abs/2507.19427
## 模型结构
Step3 是一个先进的多模态推理模型,基于混合专家架构构建,拥有 321B 总参数,单token激活38B参数。
它采用端到端设计,旨在最大限度地降低解码成本,同时在视觉语言推理领域提供顶级性能。
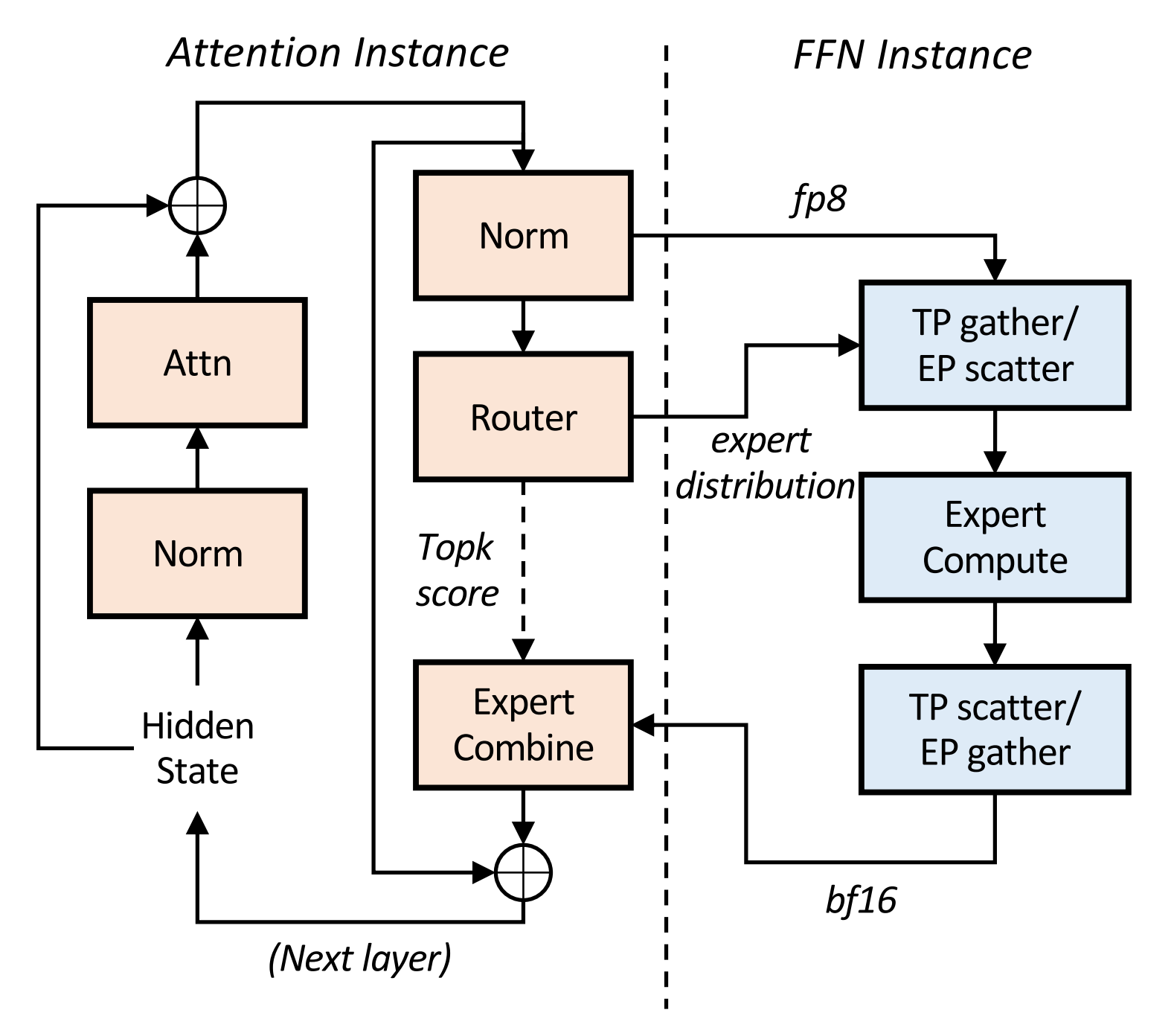
通过 Multi-Matrix Factorization Attention(MFA)和Attention-FFN Disaggregation (AFD)的协同设计,Step3 高端和低端加速器上均保持卓越的效率。
AFD的架构实现如图所示。
## 算法原理
Step-3引入了两大优化设计:
- 在模型算法方面,引入了MFA(Multi-matrix Factorization Attention)算法,其计算密度设计更加均衡,相较于MHA, GQA, MLA实现更低的decode成本。
- 在系统设计方面,引入了Attention FFN分离架构(Attention-FFN Disaggregation, AFD), 并根据具体硬件配置相应并行策略。
## 环境配置
### 硬件需求
DCU型号:BW1000,节点数量:2 台,卡数:2*8 张。
### 通信配置
一、节点间基础通信
`在本地机器上配置以下内容:`
1、关闭防火墙:
```
systemctl stop firewalld # 若为centos
ufw disable # 若为Ubuntu
```
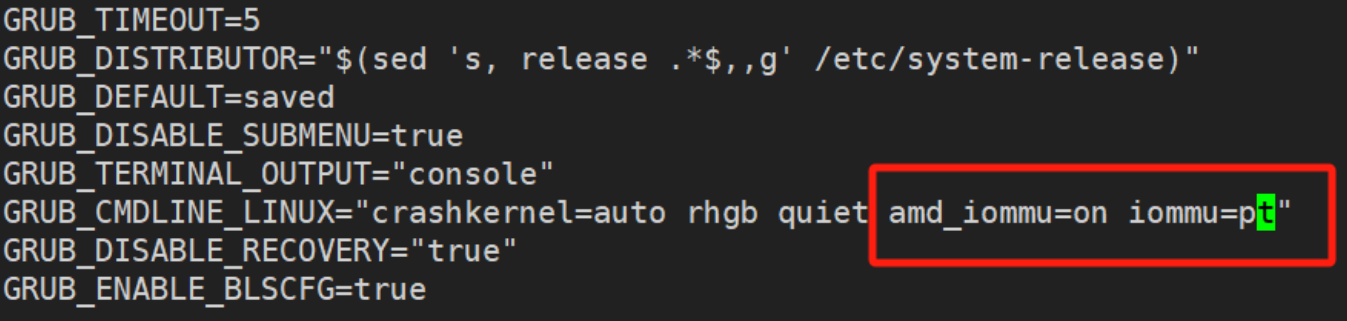
2、设置amd_iommu=on:
```
vim /etc/default/grub
```
更新下配置:
```
grub2-mkconfig -o /boot/efi/EFI/rocky/grub.cfg
```
重启机器后校验是否生效(检查是否存在imxxx=pt):
```
BOOT_IMAGE=(hd0,gpt3)/vmlinuz-4.18.0-372.9.1.el8.x86_64 root=UUID=80974f58-7d23-49bb-bd8b-8e299eb0d188 ro crashkernel=auto rhgb quiet systemd.unified_cgroup_hierachy=1 systemd.unified_cgroup_hierarchy=1 amd_iommu=on iommu=pt
```
`在后面步骤启动的容器里面配置以下内容:`
```
apt update
apt install openssh-server -y
```
vim /etc/ssh/sshd_config # 修改下面PermitRootLogin为yes
```
# 取消以下4句命令的注释
RSAAuthentication yes #启用 RSA 认证
PubkeyAuthentication yes #启用公钥私钥配对认证方式
AuthorizedKeysFile ~/.ssh/authorized_keys #公钥文件路径(和下面生成的文件同)
PermitRootLogin yes #root能使用ssh登录
```
重启ssh服务,并设置开机启动:
```
service sshd restart
chkconfig sshd on
查看sshd状态:service ssh status
开启sshd服务:/etc/init.d/ssh restart
```
下面开始设置节点间免密通信的秘钥:
1、ssh-keygen生成秘钥
```
ssh-keygen -t ed25519 # 此处以ed25519为例,读者可自己设置为其它名字,遇到提问全部回车键确认
```
2、将需要使用的各个节点`~/.ssh/authorized_keys`里的秘钥收集复制到`~/.ssh/id_rsa.pub`,每个节点`~/.ssh/id_rsa.pub`里的所有秘钥最终一致。格式类似如下:
3、设置节点间的通信端口号
```
/usr/sbin/sshd -p 10085 # 不同节点可以设置不同的端口号,打通秘钥和端口号之后可以用ssh -p之类的命令验证节点间是否通信已经通畅,否则需检查前面步骤是否设置成功。
```
以上设置非标准步骤,不同服务器或集群存在明显差异,无法完全复制此过程,请读者根据自己机器的实际情况灵活采用,总体目标是开启amd_iommu、打通节点间的容器内可以直接免密登录。
二、ray相关通信
`在后面步骤启动的容器里面配置以下内容:`
```
vim ~/.bashrc
```
在脚本`.bashrc`最后面添加以下命令(以BW千卡集群为例):
```
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export VLLM_HOST_IP=x.x.x.x
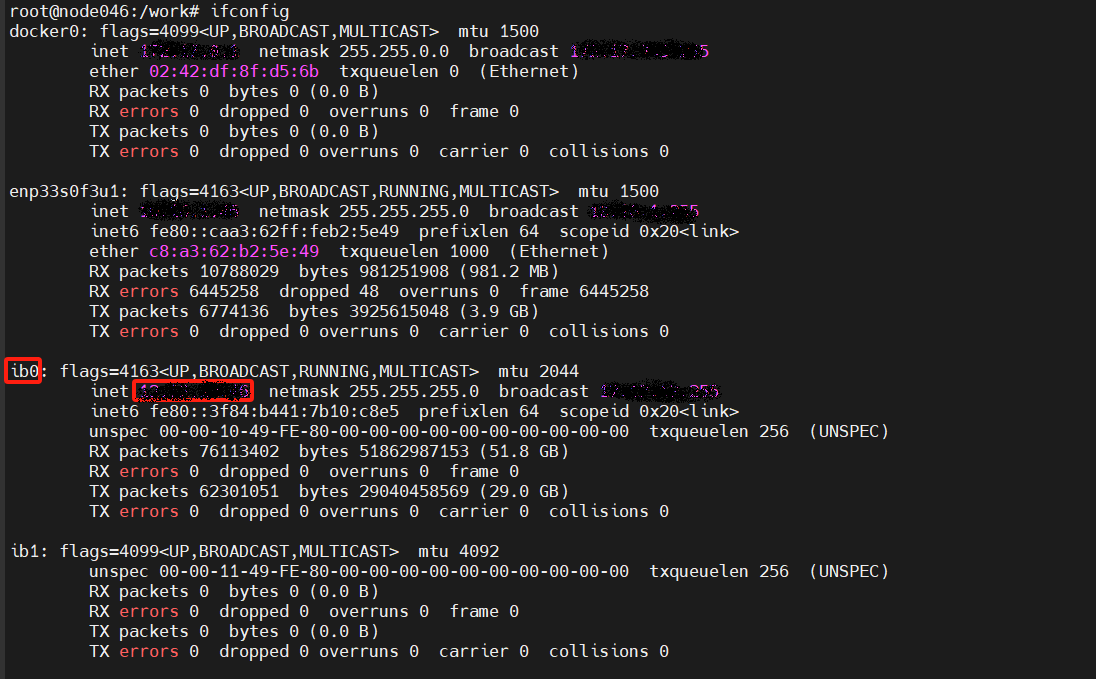
export NCCL_SOCKET_IFNAME=ib0
export GLOO_SOCKET_IFNAME=ib0
unset NCCL_ALGO
export NCCL_MIN_NCHANNELS=16
export NCCL_MAX_NCHANNELS=16
export NCCL_NET_GDR_READ=1
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export LMSLIM_USE_LIGHTOP=0
#针对hycpu环境建议设置绑核操作:
export VLLM_NUMA_BIND=1
export VLLM_RANK0_NUMA=0
export VLLM_RANK1_NUMA=1
export VLLM_RANK2_NUMA=2
export VLLM_RANK3_NUMA=3
export VLLM_RANK4_NUMA=4
export VLLM_RANK5_NUMA=5
export VLLM_RANK6_NUMA=6
export VLLM_RANK7_NUMA=7
#BW集群需要额外设置的环境变量:
export NCCL_NET_GDR_LEVEL=7
export NCCL_SDMA_COPY_ENABLE=0
export NCCL_IB_HCA=mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1,mlx5_8:1,mlx5_9:1
export NCCL_TOPO_FILE="topo-input.xml"
# 若为K100_AI卡,则添加以下信息(本步骤以BW卡为示例,故注释了以下信息。):
# export VLLM_ENFORCE_EAGER_BS_THRESHOLD=44
```
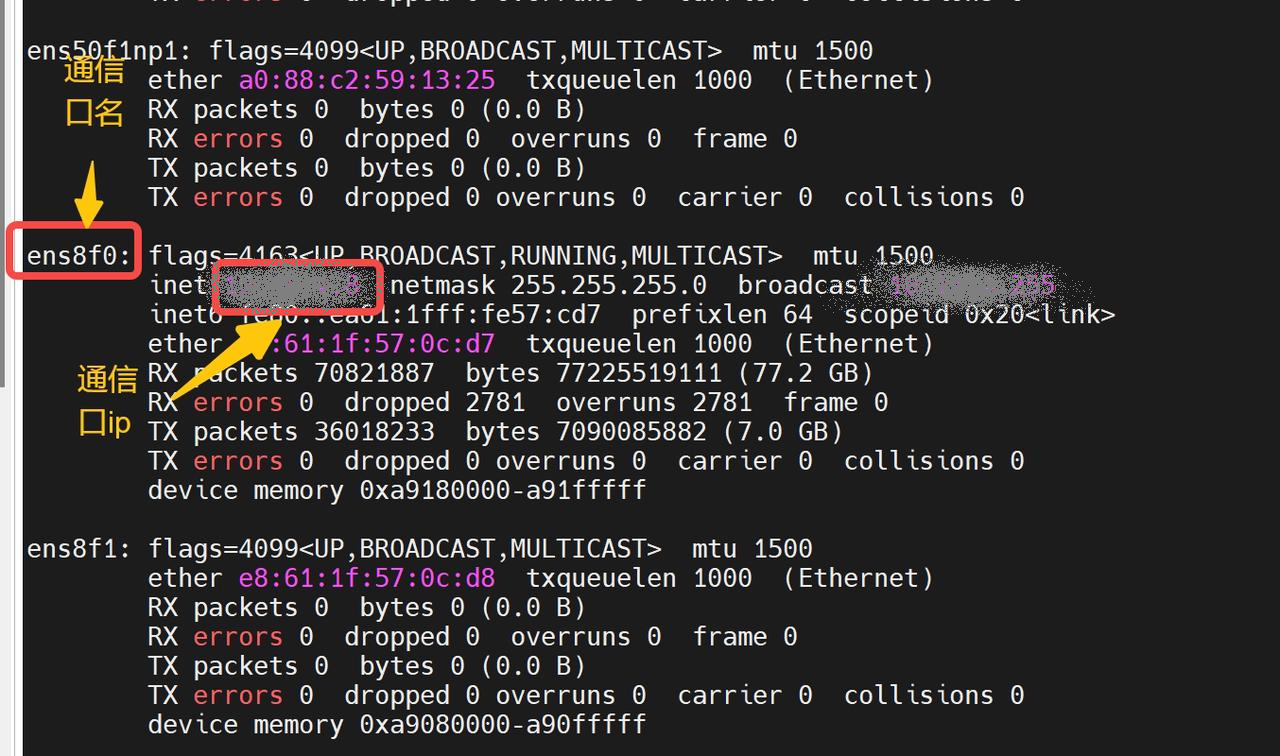
其中`VLLM_HOST_IP`和`NCCL_SOCKET_IFNAME`需要替换成每个自己机器上查到的信息,每个节点的ip不同,查询方式如下:
```
通信口和ip查询方法:ifconfig
VLLM_HOST_IP: 节点本地通信口ip
NCCL_SOCKET_IFNAME和GLOO_SOCKET_IFNAME: 节点本地通信网口名
```
`示例:`
带BW卡的集群VLLM_HOST_IP需要设置为ib网卡对应的IP,避免出现rccl超时问题:
注意:添加完以上信息后需要激活环境变量
```
source ~/.bashrc
```
`Tips:由于通信配置方面属于运维人员的专业内容,以上关于通信的配置建议读者联系运维人员进行配置。`
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:vllm-ubuntu22.04-dtk25.04.1-rc5-das1.6-py3.10-20250802-step3
docker run -it --name step_vllm --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/Step3_pytorch:/home/Step3_pytorch f0e4191089de /bin/bash
wget --content-disposition 'https://download.sourcefind.cn:65024/file/4/triton/DAS1.6/triton-3.0.0+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl'
pip install triton-3.0.0+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl
```
### Dockerfile(方法二)
```
cd $PWD/Step3_pytorch/docker
docker build --no-cache -t step3:latest .
docker run -it --name step_vllm --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/Step3_pytorch:/home/Step3_pytorch f0e4191089de /bin/bash
wget --content-disposition 'https://download.sourcefind.cn:65024/file/4/triton/DAS1.6/triton-3.0.0+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl'
pip install triton-3.0.0+das.opt1.dtk25041-cp310-cp310-manylinux_2_28_x86_64.whl
```
## 数据集
`无`
## 训练
`无`
## 推理
预训练权重目录结构,将后续模型地址切换成实际模型权重地址:
```
/home/Step3_pytorch/
└── stepfun-ai/step3
```
### 多机多卡
启动ray集群
```
# 启动ray
# 启动主节点的ray, x.x.x.x 为前面步骤中ifconfig查到的主节点ip(VLLM_HOST_IP),--port为端口号,可以随意设置,保持主节点和其余节点端口号一致。
ray start --head --node-ip-address=x.x.x.x --port=6379 --num-gpus=8 --num-cpus=32
# 启动其它节点的ray,注意 x.x.x.x 为前面步骤中ifconfig查到的主节点ip(VLLM_HOST_IP)。
ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
# 可用ray status 查看ray的集群启动状态。
```
vLLM Deployment(vllm官方暂不支持AFD,只支持非分离模式部署):
```
#head节点执行
VLLM_USE_NN=0 VLLM_USE_FLASH_ATTN_PA=0 vllm serve /path/to/step3 \
--reasoning-parser step3 \
--enable-auto-tool-choice \
--tool-call-parser step3 \
--trust-remote-code \
--max-num-batched-tokens 4096 \
--distributed-executor-backend ray \
--dtype float16 \
-tp 16 \
--port $PORT_SERVING
```
- Client Request Examples
```
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/path/to/step3",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://xxxxx.png"
},
},
{"type": "text", "text": "Please describe the image."},
],
},
],
)
print("Chat response:", chat_response)
```
- You can also upload base64-encoded local images:
```
import base64
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
image_path = "/path/to/local/image.png"
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read())
encoded_image_text = encoded_image.decode("utf-8")
base64_step = f"data:image;base64,{encoded_image_text}"
chat_response = client.chat.completions.create(
model="step3",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": base64_step
},
},
{"type": "text", "text": "Please describe the image."},
],
},
],
)
print("Chat response:", chat_response)
```
- text only:
```
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/path/to/step3", # 模型路径
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "The capital of France is"},
],
)
print("Chat response:", chat_response.choices[0].message.content)
```
更多资料可参考源项目中的[`README_ori`](./README_ori.md)。
## result
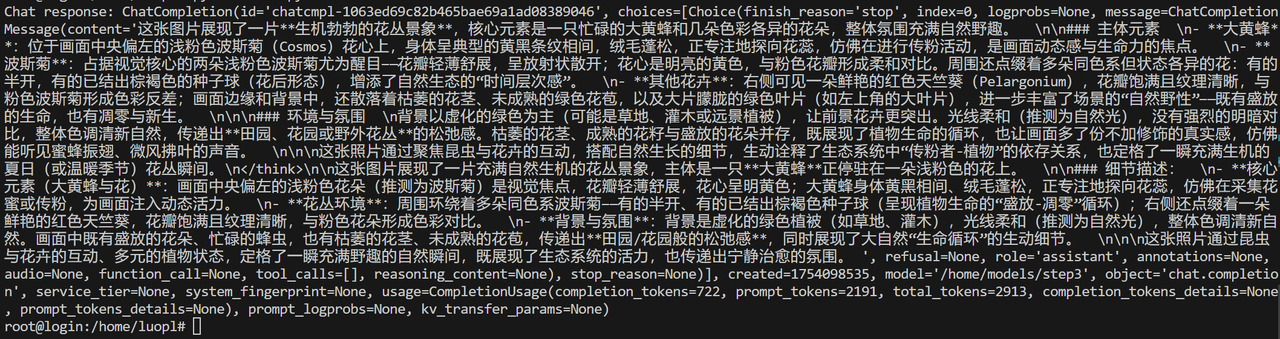
example1:
- text:Please describe the image.
- image:
- 输出结果:
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`电商,教育,广媒`
## 预训练权重
huggingface权重下载地址为:
- [stepfun-ai/step3](https://huggingface.co/stepfun-ai/step3)
`注:建议加镜像源下载:export HF_ENDPOINT=https://hf-mirror.com`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/step3_pytorch
## 参考资料
- https://github.com/stepfun-ai/Step3/tree/main