
Initial commit
parents
Showing
LICENSE
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
Step3-Sys-Tech-Report.pdf
0 → 100644
File added
docker/Dockerfile
0 → 100644
docs/deploy_guidance.md
0 → 100644
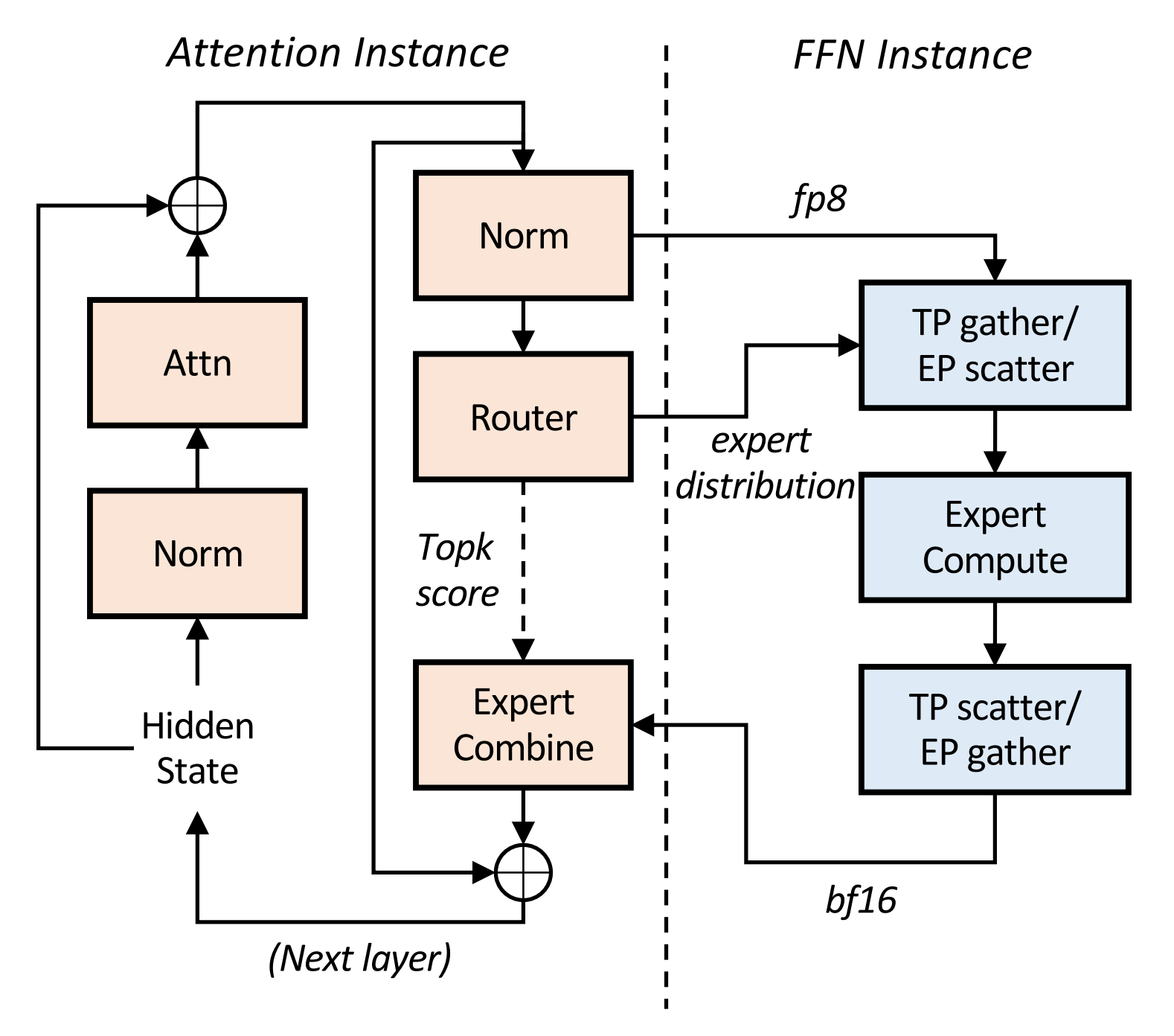
figures/AFD_architecture.png
0 → 100644
{kind=link}
134 KB
figures/bee.jpg
0 → 100644
{kind=link}

5.12 MB
figures/result.png
0 → 100644
{kind=link}
893 KB
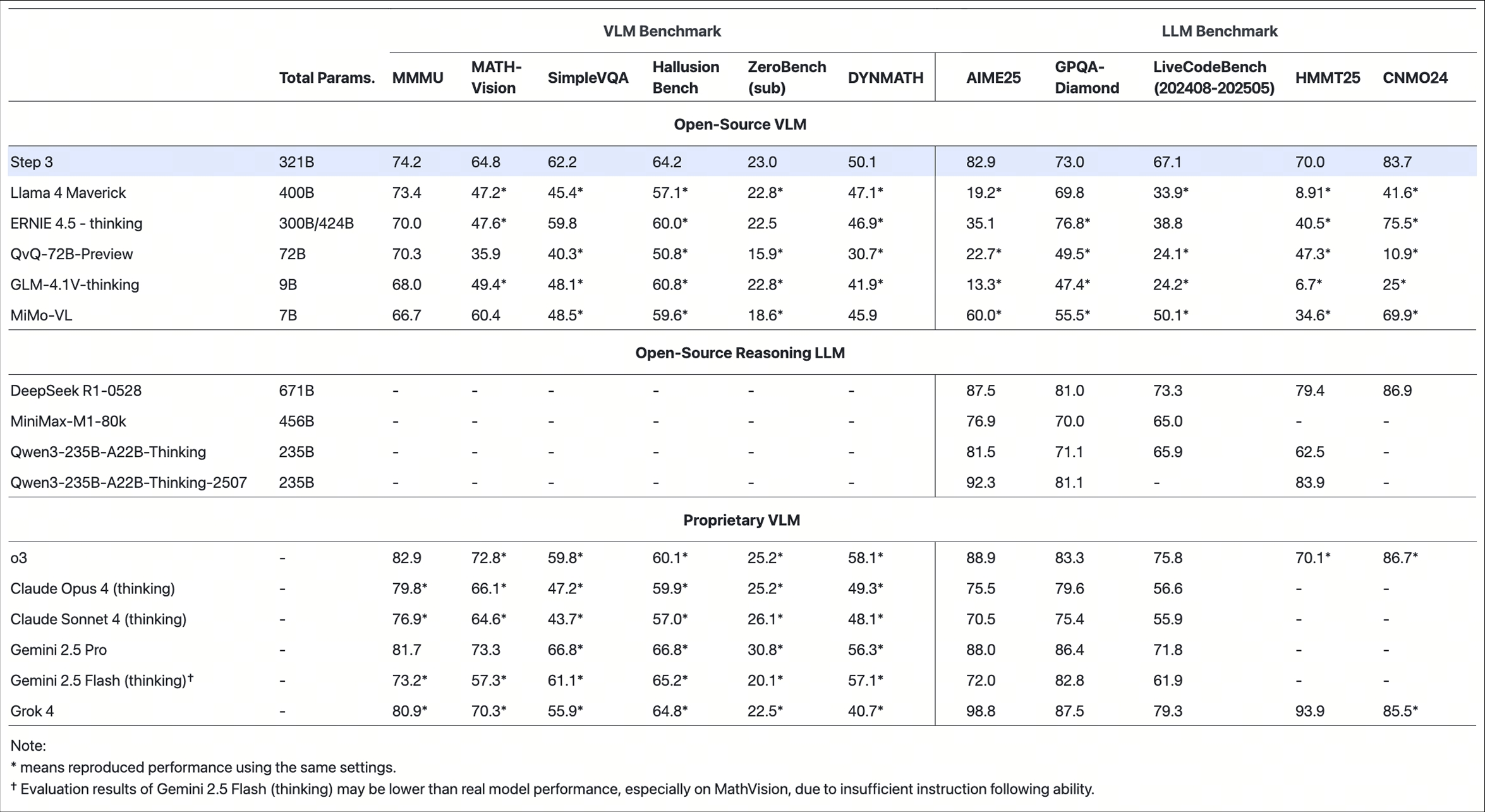
figures/step3_bmk.jpeg
0 → 100644
{kind=link}
604 KB
figures/stepfun-logo.png
0 → 100644
{kind=link}
7.12 KB
icon.png
0 → 100644
{kind=link}
64.3 KB
model.properties
0 → 100644