
update README
Showing
figures/amd_iommu.png
0 → 100644
{kind=link}
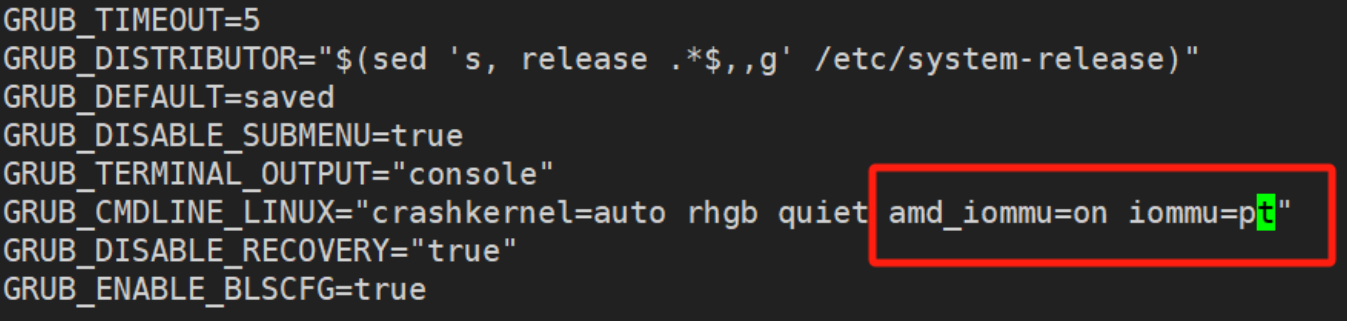
127 KB
figures/id_rsa.png
0 → 100644
{kind=link}

82.7 KB
figures/ip.png
0 → 100644
{kind=link}
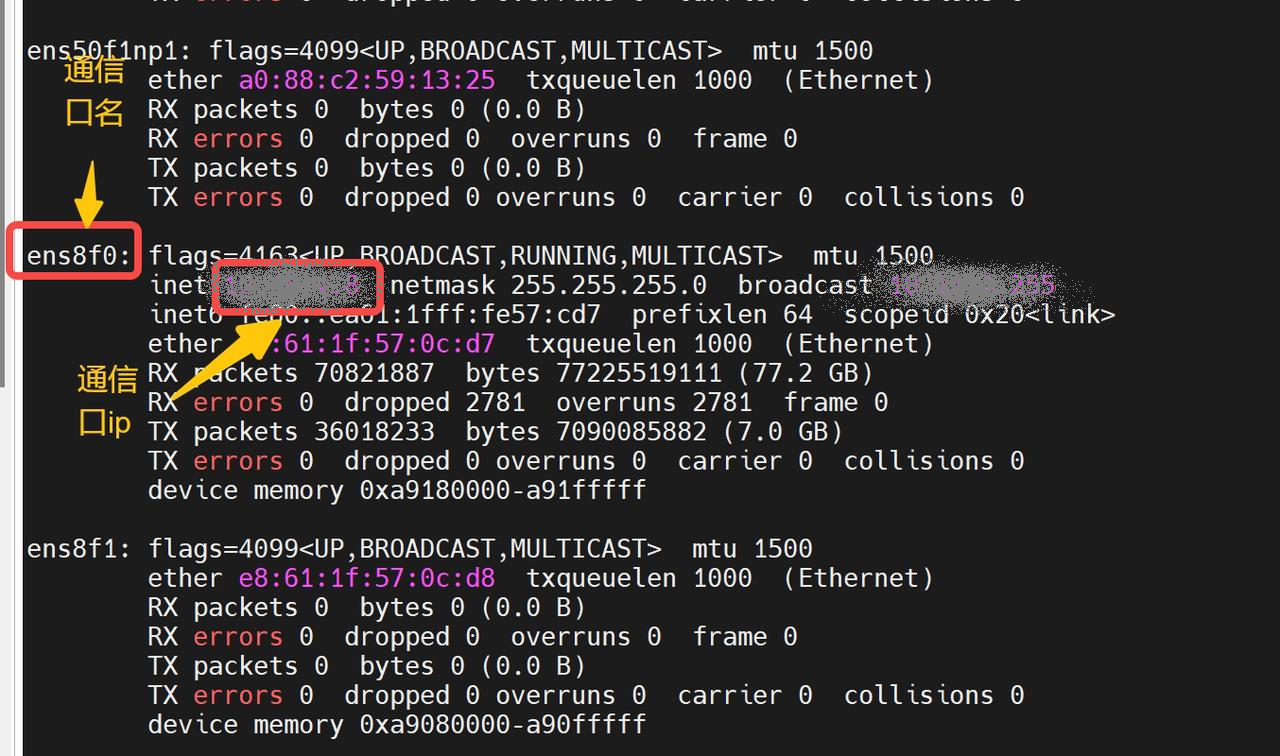
1.06 MB
figures/ip_bw.png
0 → 100644
{kind=link}
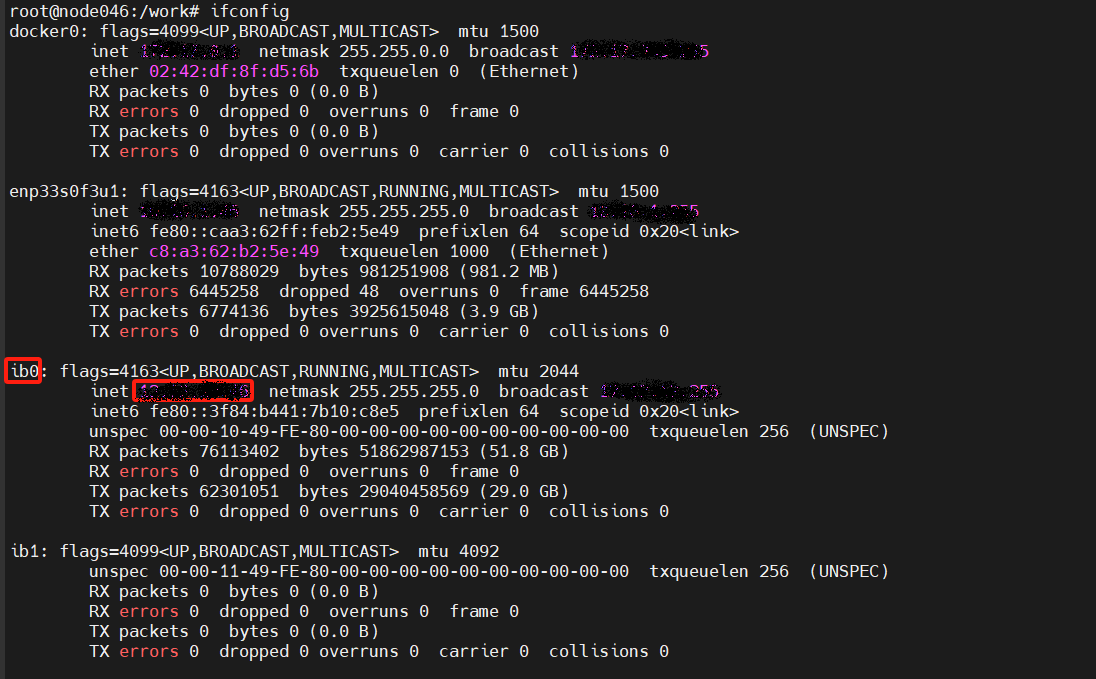
97.1 KB