# Step-Video-TI2V
## 论文
`
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
`
- https://arxiv.org/abs/2503.11251
## 模型结构
Step-Video-TI2V 是基于 Step-Video-T2V 进行训练的。引入了两个关键改进:图像条件和运动条件。这些增强功能支持从给定图像生成视频,同时允许用户调整输出视频的动态程度。
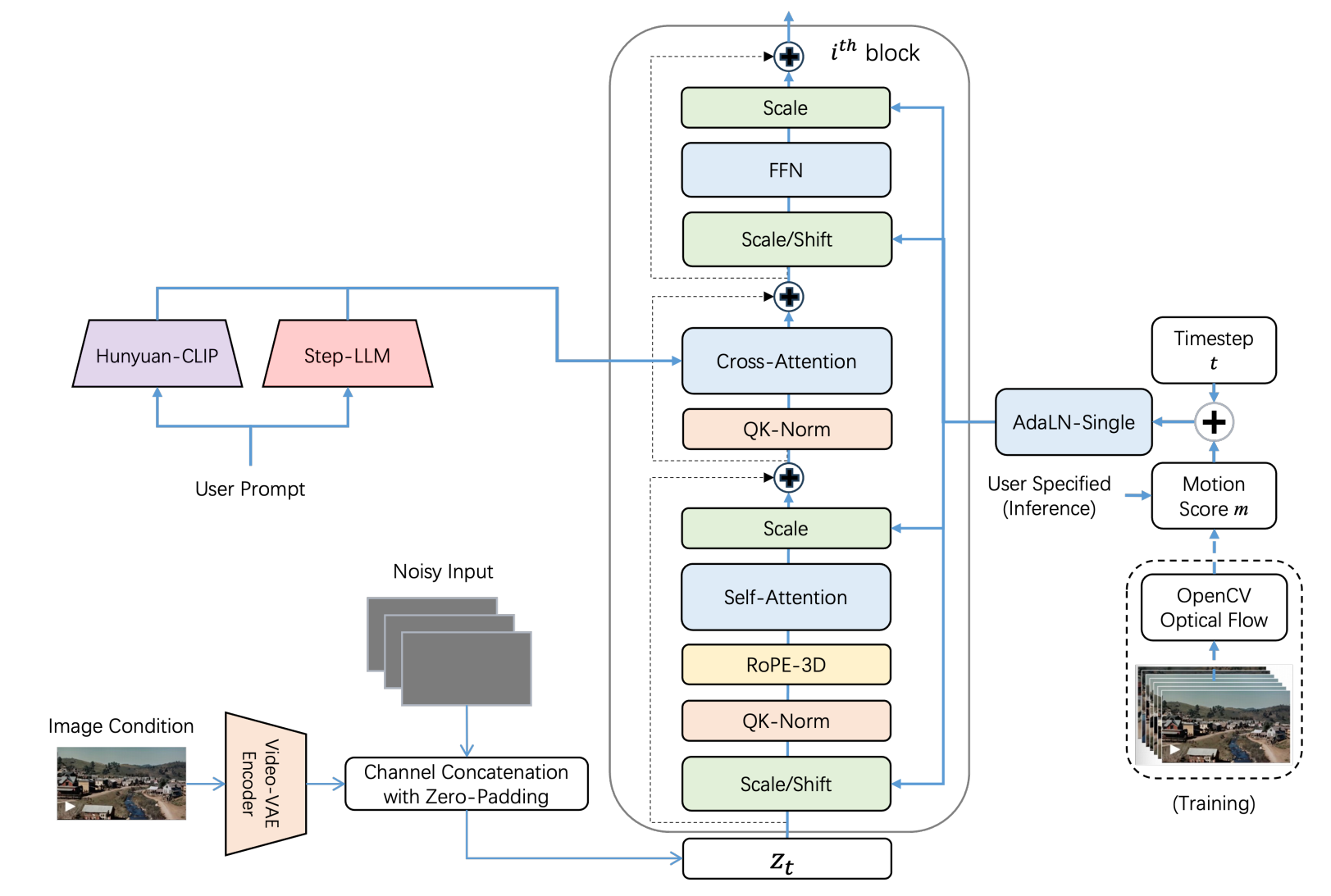
## 算法原理
为了将图像条件作为生成视频的第一帧,Step-Video-TI2V
使用 Step-Video-T2V 的 Video-VAE 将其编码为潜在表示, 并在视频潜在表示的通道维度上进行拼接。
此外,引入了一个运动分数条件,允许用户控制从图像条件下生成的视频的动态程度。
## 环境配置
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04-py3.10-fixpy
# 为以上拉取的docker的镜像ID替换
docker run -it --name TI2V_test --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/Step-Video-TI2V_pytorch:/home/Step-Video-TI2V_pytorch /bin/bash
cd /home/Step-Video-TI2V_pytorch
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/
#注意fix.sh里面的xfuser包的位置根据自己安装包的位置自行调整
sh fix.sh
```
### Dockerfile(方法二)
```
cd /home/Step-Video-T2V_pytorch/docker
docker build --no-cache -t Step-Video-TI2V:latest .
docker run -it --name TI2V_test --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v $PWD/Step-Video-TI2V_pytorch:/home/Step-Video-TI2V_pytorch Step-Video-TI2V /bin/bash
cd /home/Step-Video-TI2V_pytorch
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/
#注意fix.sh里面的xfuser包的位置根据自己安装包的位置自行调整
sh fix.sh
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk25.04
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
flash-attn:2.6.1
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/Step-Video-TI2V_pytorch
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
注意fix.sh里面的xfuser包的位置根据自己安装包的位置自行调整
sh fix.sh
```
## 数据集
`无`
## 训练
`无`
## 推理
预训练权重目录结构:
```
/home/Step-Video-TI2V_pytorch
└── stepfun-ai/stepvideo-ti2v
```
### 单机多卡
```
#根据自己的DCU架构调整TORCH_CUDA_ARCH_LIST值
export TORCH_CUDA_ARCH_LIST="8.0"
#注意修改where_you_download_dir为自己的模型地址
HIP_VISIBLE_DEVICES=0 python api/call_remote_server.py --model_dir where_you_download_dir &
#注意为了避免超显存服务端和客户端尽量选择不同的卡号,run.sh里的其他参数也可根据自己的硬件资源自行调整
export HIP_VISIBLE_DEVICES=1
sh run.sh
```
更多资料可参考源项目中的[`README_orgin`](./README_orgin.md)。
## result
视频生成效果示例:

### 精度
`DCU与GPU精度一致,推理框架pytorch。`
## 应用场景
### 算法类别
`视频生成`
### 热点应用行业
`影视,电商,教育,广媒`
## 预训练权重
huggingface权重下载地址为:
- [stepfun-ai/stepvideo-ti2v](https://huggingface.co/stepfun-ai/stepvideo-ti2v)
`注:建议加镜像源下载:export HF_ENDPOINT=https://hf-mirror.com`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/step-video-ti2v_pytorch
## 参考资料
- https://github.com/stepfun-ai/Step-Video-TI2V