# StarCoder2
StarCoder2模型是一系列3B、7B和15B模型,使用来自Stack-v2数据集的3.3 至4.3万亿个代码标记进行训练,包含600多种编程语言。
## 论文
`StarCoder 2 and The Stack v2: The Next Generation`
[StarCoder2](https://arxiv.org/pdf/2402.19173)
## 模型结构
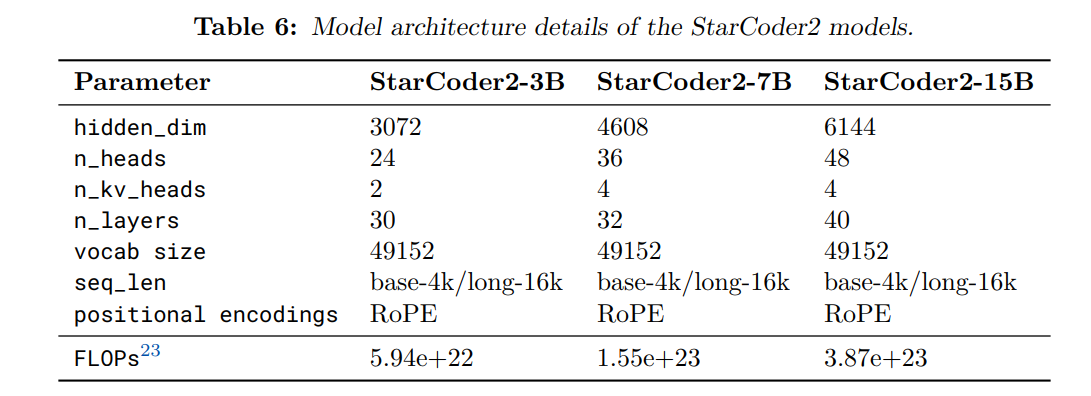
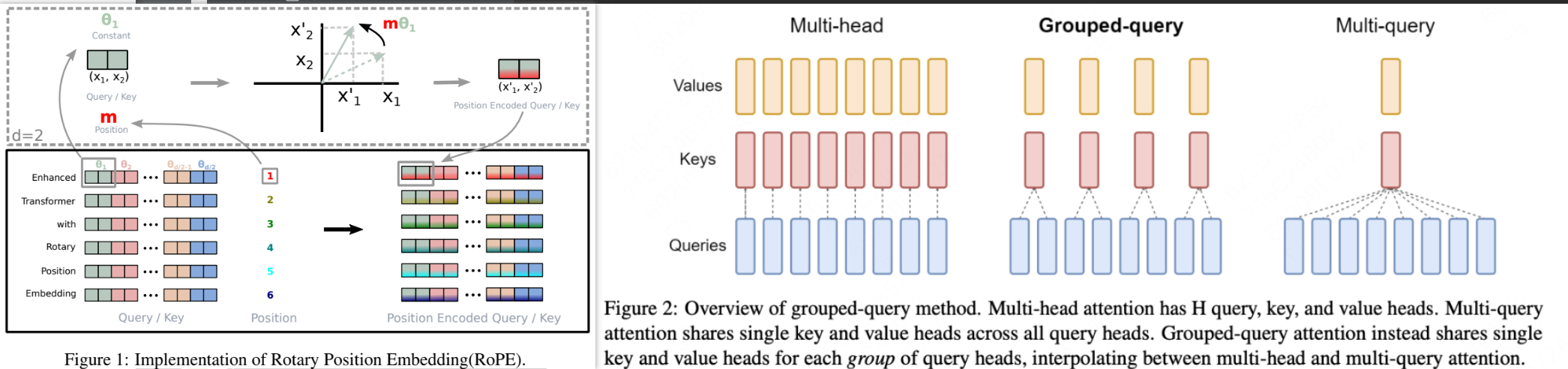
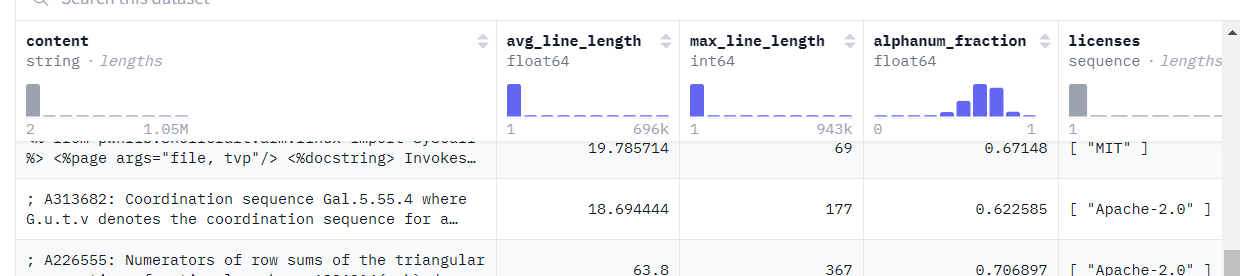
StarCoder2的模型结构主要基于StarCoderBase模型架构进行了微小的改动,首先使用RoPE旋转位置编码。其次使用了GQA模块替换了MQA模块。
## 算法原理
使用GQA模块能够带来更好的速度,使用GQA的head数量不同则会带来速度和性能平衡转换
使用了RoPE位置旋转编码来替代Embedding编码,使得模型获得更好的外推性。
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/starcoder2_pytorch
pip install -r requirements.txt -i http://mirrors.huaweicloud.com/repository/pypi/simple
export HF_ENDPOINT=https://hf-mirror.com
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t starcoder2:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/starcoder2_pytorch
pip install -r requirements.txt -i http://mirrors.huaweicloud.com/repository/pypi/simple
export HF_ENDPOINT=https://hf-mirror.com
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动: dtk24.04
python: python3.10
torch: 2.1.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install -r requirements.txt -i http://mirrors.huaweicloud.com/repository/pypi/simple
export HF_ENDPOINT=https://hf-mirror.com
```
## 数据集
finetune训练样例数据采用bigcode/the-stack-smol 下的子集/data/rust
- 数据集快速下载中心:
- [SCNet AIDatasets](http://113.200.138.88:18080/aidatasets)
- 数据集快速通道下载地址:
- [数据集快速下载地址](http://113.200.138.88:18080/aidatasets/project-dependency/the-stack-smol/-/tree/main)
- 官方下载地址
- [下载地址](https://hf-mirror.com/datasets/bigcode/the-stack-smol)
```angular2html
├── data
│ ├── assembly
│ │ └── data.json
│ ├── rust
│ │ └── data.json
......
```
## 训练
### 单机两卡
具体参数更改请在train.sh文件中进行,以下为必要参数
dataset_name="{数据集地址}"
model_name="{预训练模型加载地址}"
```bash
bash ./train.sh
```
## 推理
基于Huggingface's Transformers进行推理.
- 模型权重快速下载中心
- [SCNet AIModels](http://113.200.138.88:18080/aimodels)
- 模型权重快速通道下载地址
- [模型权重快速下载地址](http://113.200.138.88:18080/aimodels/starcoder2-7b)
- 官方下载地址:
- [官方权重下载地址](https://huggingface.co/bigcode/starcoder2-7b)
默认需存放至weights文件夹中
也可自行更改 inference.py文件中的 model_name 参数
```bash
HIP_VISIBLE_DEVICES=0 python inference.py
```
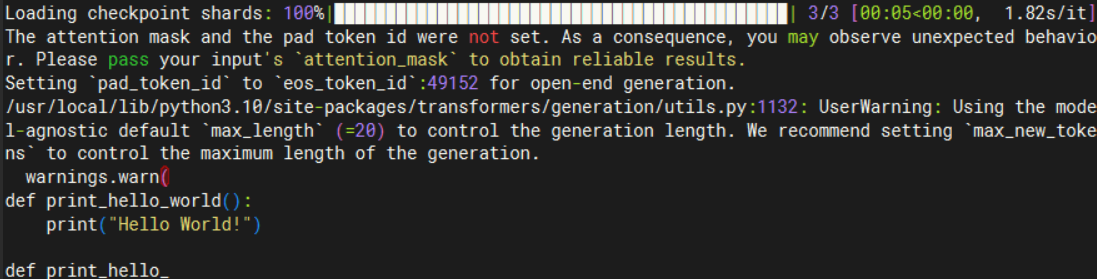
## Result
prompt:def print_hello_world():",
result:
### 精度
训练集bigcode/the-stack-smol/data/rust
| device | train_loss | steps |
|:--------:|:----------:|:-----:|
| A800*2 | 1.2758 | 100 |
| K100*2 | 1.2772 | 100 |
## 应用场景
### 算法类别
代码生成
### 热点应用行业
制造,能源,教育
## 预训练权重
模型目录结构如下:
```
# starcoder2-7b/
├── config.json
├── generation_config.json
├── merges.txt
├── model-00001-of-00003.safetensors
├── model-00002-of-00003.safetensors
├── model-00003-of-00003.safetensors
├── model.safetensors.index.json
├── README.md
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
└── vocab.json
```
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/starcoder2_pytorch
## 参考资料
- https://github.com/bigcode-project/starcoder2
- https://huggingface.co/bigcode/starcoder2-7b
- https://huggingface.co/datasets/bigcode/the-stack-smol