
update codes
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
README_ori.md
0 → 100644
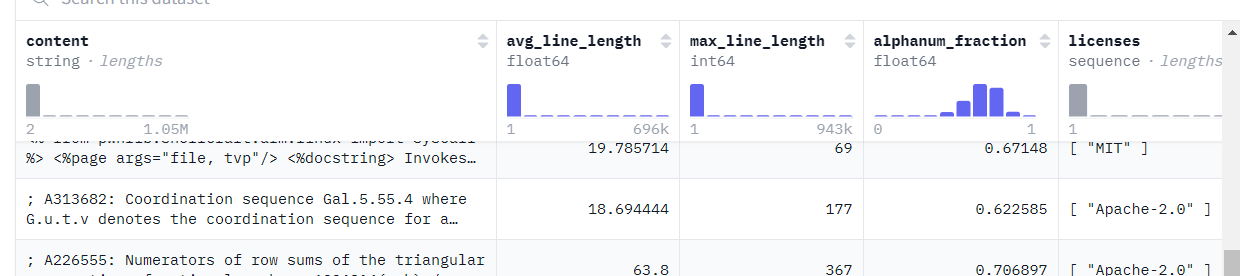
asserts/dataset.png
0 → 100644
{kind=link}
23.6 KB
{kind=link}
52 KB
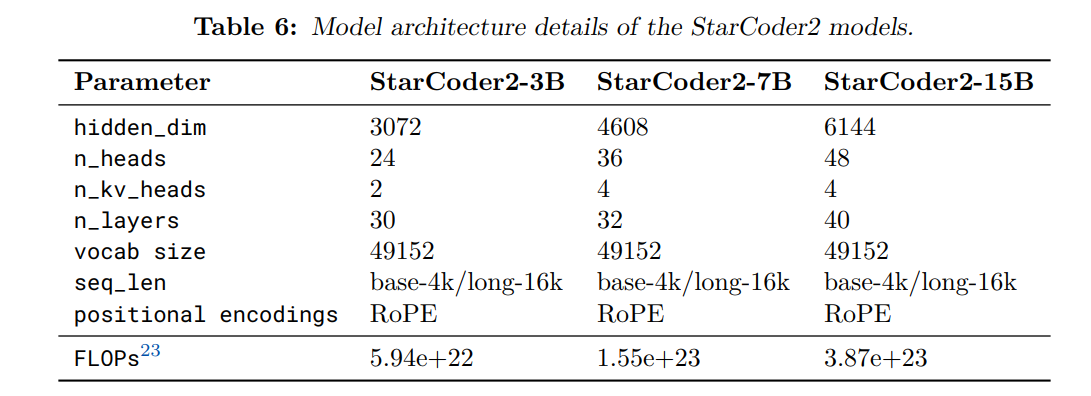
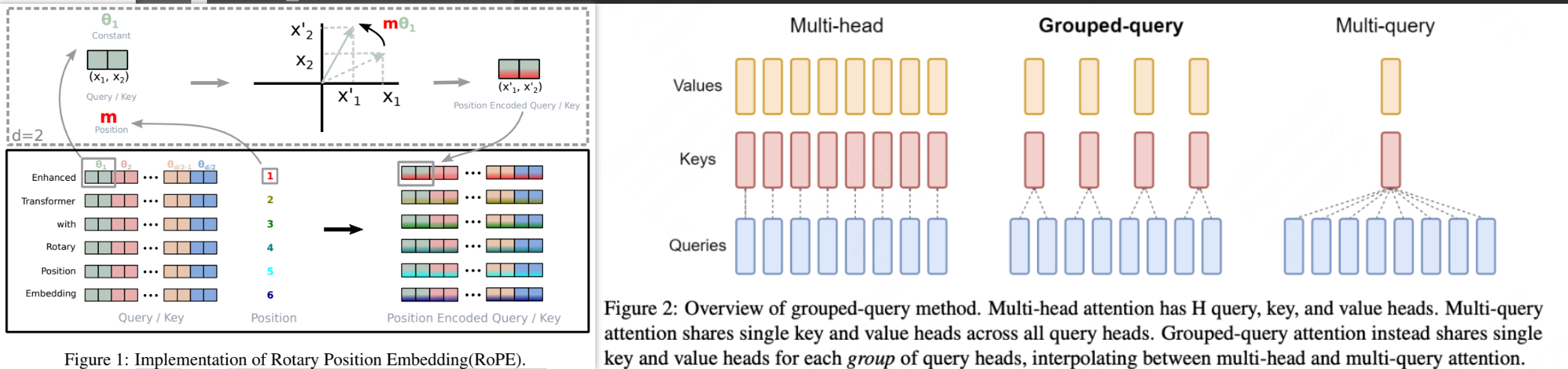
asserts/model_blocks.png
0 → 100644
{kind=link}
270 KB
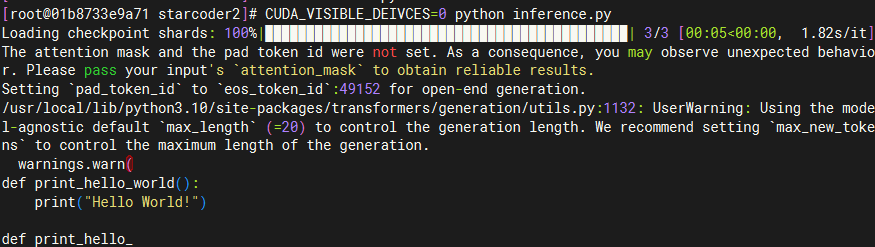
asserts/result.png
0 → 100644
{kind=link}
24.4 KB
finetune.py
0 → 100644
inference.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| transformers==4.39.3 | |||
| trl==0.9.4 | |||
| accelerate==0.27.1 | |||
| datasets>=2.16.1 | |||
| peft==0.8.2 | |||
| wandb==0.16.3 | |||
| huggingface_hub==0.20.3 | |||
| \ No newline at end of file |
train.sh
0 → 100644