# Stable Diffusion
## 论文
`DENOISING DIFFUSION IMPLICIT MODELS`
- https://arxiv.org/pdf/2010.02502
## 模型结构
通过串联或更通用的交叉注意机制来调节LDM
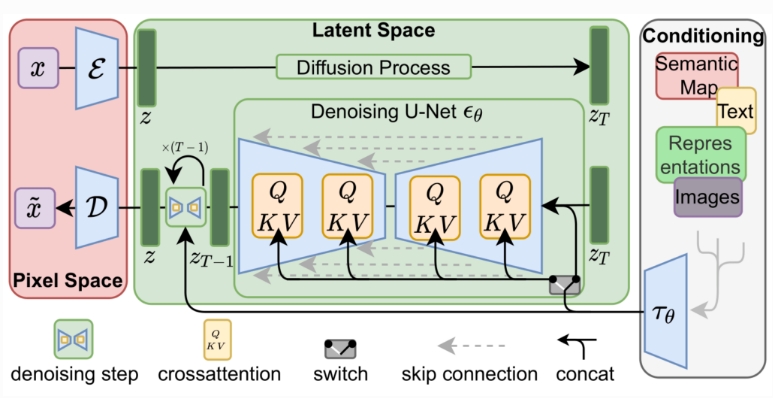
## 算法原理
通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型(DM)在图像数据和其他数据上实现了最先进的合成结果。为了在有限的计算资源上进行DM训练,同时保持其质量和灵活性,我们将其应用于强大的预训练自动编码器的潜在空间。在这种表示上训练扩散模型首次能够在降低复杂性和空间下采样之间达到接近最佳的点,提高了视觉逼真度。通过在模型架构中引入跨注意力层,将扩散模型变成了强大而灵活的生成器,用于文本或边界框等一般条件输入,高分辨率合成以卷积方式成为可能。我们的潜在扩散模型(LDM)在各种任务上实现了极具竞争力的性能,包括无条件图像生成、修复和超分辨率,同时与基于像素的DM相比,显著降低了计算要求。
## 环境配置
### Docker(方法一):
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-py3.8-dtk24.04.3-ubuntu20.04
docker run --shm-size 10g --network=host --name=stablediffusion_v2-1 --privileged --device=/dev/kfd --device=/dev/mkfd --device=/dev/dri -v /opt/hyhal:/opt/hyhal --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -it image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-py3.8-dtk24.04.3-ubuntu20.04 bash
cd diffusers-0.27.0
python setup.py install
cd examples/text_to_image
pip install -r requirements.txt
```
### Anaconda(方法三):
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合开发者社区](https://developer.sourcefind.cn/)下载安装
```
DTK:dtk24.04.3
python:3.10
torch:2.1.0
diffusers和其他深度学习库(requirements)可以参考方法一进行安装。
```
tips:以上dtk驱动、python、torch等DCU相关工具需要严格一一对应。
## 数据集
pokemon-blip-captions
可以从以下网址下载:
- http://113.200.138.88:18080/aidatasets/pokemon-blip-captions
## 训练
### 下载Stable Diffusion v2.1模型
```
模型文件可以从modelscope下载:
- https://www.modelscope.cn/models/AI-ModelScope/stable-diffusion-2-1-base
```
### 单机单卡运行:
```
cd examples/text_to_image
```
运行diffusers示例:
```
bash run.sh
```
### 单机多卡运行:
```
cd examples/text_to_image
```
运行diffusers示例(以四卡为例):
```
bash run-4.sh
```
## result
### 精度
无
## 应用场景
### 算法类别
`以文生图`
### 热点应用行业
`绘画,动漫,媒体`
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/stable_diffusion_diffusers/-/tree/main
## 参考资料
https://github.com/Stability-AI/stablediffusion