
sdxl
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
README.md
0 → 100644
icon.png
0 → 100644
{kind=link}
68.4 KB
inference_diffusers.py
0 → 100644
model.properties
0 → 100644
readme_imgs/alg.png
0 → 100644
{kind=link}
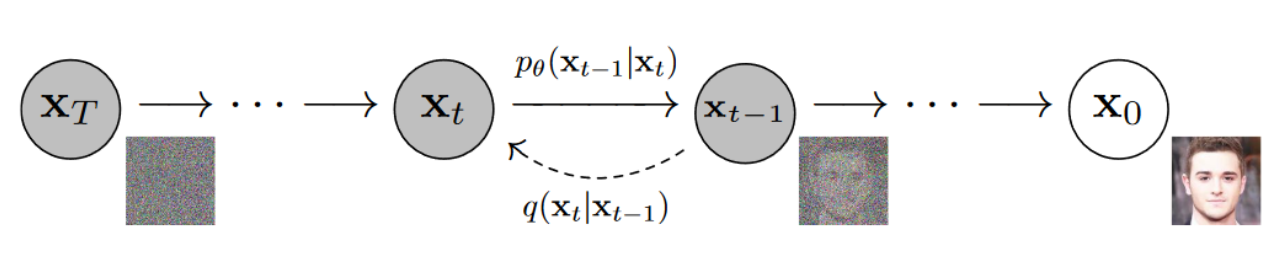
122 KB
readme_imgs/i2i.png
0 → 100644
{kind=link}

1.35 MB
readme_imgs/i2i_input.png
0 → 100644
{kind=link}

1.58 MB
readme_imgs/inpainting.png
0 → 100644
{kind=link}

1.25 MB
{kind=link}

395 KB
{kind=link}

11.8 KB
readme_imgs/mr.png
0 → 100644
{kind=link}
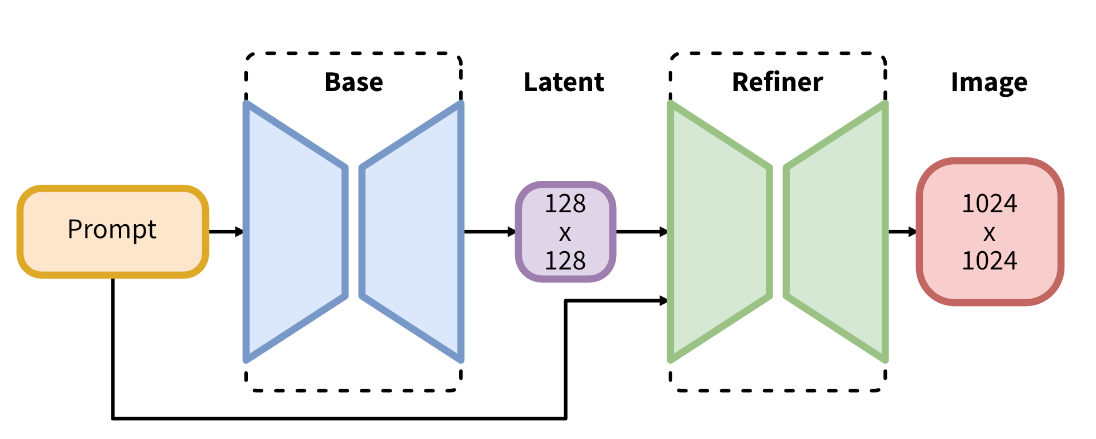
49.9 KB
readme_imgs/t2i.png
0 → 100644
{kind=link}

1.38 MB
requirements.txt
0 → 100644
{kind=link}

395 KB
{kind=link}

11.8 KB
test_imgs/sdxl-text2img.png
0 → 100644
{kind=link}

1.58 MB