# SpeechT5
## 论文
- https://arxiv.org/abs/2110.07205
## 开源代码
- https://github.com/microsoft/SpeechT5
## 模型结构
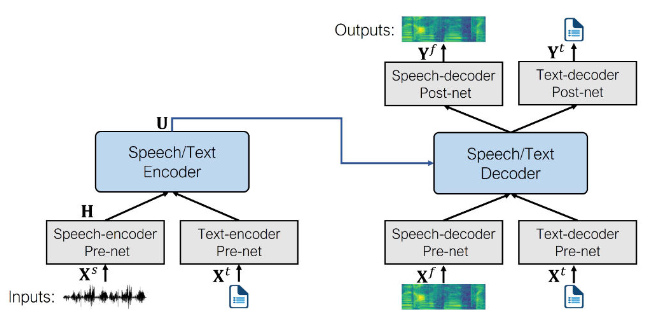
speechT5的核心是一个常规的**Transformer编码器-解码器**,为了使得同一个Transformer可以同时处理文本和语音数据,添加了**pre-nets**和**post-nets**,**pre-net**将输入的文本或语音转换为Transformer使用的隐藏表示;**post-net**从Transformer中获取输出并转换为文本或语音。
## 算法原理
在预训练期间,同时使用所有的 per-nets 和 post-nets 。预训练后,整个编码器 - 解码器主干在单个任务上进行微调。这种经过微调的模型仅使用特定于给定任务的 per-nets 和 post-nets 。*例如:要将 SpeechT5 用于文本到语音转换,您需要将文本编码器 per-nets 交换为文本输入,将语音解码器 per-nets 和 post-nets 交换为语音输出。*
**注意: 即使微调模型一开始使用共享预训练模型的同一组权重,但最终版本最终还是完全不同。例如,您不能采用经过微调的 ASR 模型并换掉 per-nets 和 post-nets 来获得有效的 TTS 模型。SpeechT5 很灵活,但不是那么灵活。**
## 环境配置
### Docker (方法一)
**注意修改路径参数**
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run -it --network=host --ipc=host --name=your_container_name --shm-size=32G --device=/dev/kfd --device=/dev/mkfd --device=/dev/dri -v /opt/hyhal:/opt/hyhal:ro -v /path/your_code_data/:/path/your_code_data/ --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310 /bin/bash
cd /path/your_code_data/
pip3 install -r requirements.txt
```
### Dockerfile (方法二)
```
cd ./docker
docker build --no-cache -t speecht5 .
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
pip3 install -r requirements.txt
```
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.sourcefind.cn/tool/
```
DTK软件栈:dtk24.04
python:python3.10
torch:2.1.0
torchvision:0.16.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
```
pip3 install -r requirements.txt
```
## 数据集
**在本案例中已经构建了案例测试数据,无需手动下载数据集。若需要完整数据集,请按照下载链接进行下载**
- 官方下载链接:
- [CMU_ARCTIC数据集下载](https://hf-mirror.com/datasets/Matthijs/cmu-arctic-xvectors)
- [librispeech_asr数据集下载](http://www.openslr.org/12)
`CMU_ARCTIC`:说话人识别的数据集,其将每个说话人的声音特征描述为(1,512)的张量,音频特征文件以npy格式存储。
```
├── CMU_ARCTIC
│ ├── cmu_us_awb_arctic-wav-arctic_a0001.npy
│ ├── cmu_us_awb_arctic-wav-arctic_a0002.npy
│ ├── cmu_us_awb_arctic-wav-arctic_a0003.npy
│ ├── ...
```
- `cmu_us_awb_arctic-wav-arctic_a0001.npy`:说话人的声音特征文件。
`librispeech_asr`:语音识别数据集,数据集中包括音频文件以及文本转录文件。其中音频文件以flac格式存储,文本转录文件以txt格式存储。
```
LibriSpeech
├── train-clean-100
│ ├── 1272
│ │ ├── 1272-128104
│ │ │ ├── 1272-128104-0000.flac
│ │ │ ├── 1272-128104-0001.flac
│ │ │ ├── 1272-128104-0002.flac
│ │ │ ├── 1272-128104-0003.flac
│ │ │ ├── ...
│ │ │ ├── 1272-128104.trans.txt
│ │ └── ...
│ └── ...
├── train-clean-360
├── train-other-500
├── dev-clean
├── dev-other
├── test-clean
└── test-othe
```
- `train-clean-100`:包含大约 100 小时的清晰语音。
- `1272`:说话人ID(1272)。
- `1272-128104`:说话人ID(1272)-文本章节ID(128204)。
- `1272-128104-0000.flac`:说话人ID(1272)-文本章节ID(128204)-文本片段ID(0)的音频文件。
- `1272-128104.trans.txt`:说话人ID(1272)-文本章节ID(128204)的转录文本文件。
## 预训练模型
**推理前先下载预训练好的权重文件**
- 官方下载地址:
- [tts模型权重下载地址](https://hf-mirror.com/microsoft/speecht5_tts)
- [vc模型权重下载地址](https://hf-mirror.com/microsoft/speecht5_vc)
- [asr模型权重下载地址](https://hf-mirror.com/microsoft/speecht5_asr)
- [hifigan模型权重下载地址](https://hf-mirror.com/microsoft/speecht5_hifigan)
## 推理
### TTS推理
```
cd inference
python speech_tts.py -hip 7 -m model/tts -v model/hifigan -t "hi, nice to meet you." -s ../data/CMU_ARCTIC/cmu_us_awb_arctic-wav-arctic_a0001.npy
```
- -hip: 显卡序号,默认为0。
- 当export HIP_VISIBLE_DEVICES指定可见卡后,**无需该参数**,默认使用‘0’卡
- 当没有指定可见卡时,需要使用该参数规定运算的显卡
- -m: tts模型路径
- -v: 声码器hifigan的模型路径
- -t: 文本输入,因为输入文本中包含空格,需要用" "将输入文本包含在内。
- -s: CMU_ARCTIC数据集下的发声人特征文件
- -res: 结果输出文件tts.wav的存储路径
### VC推理
```
cd inference
python speech_vc.py -hip 7 -m model/speecht5_vc -v model/speecht5_hifigan -is ../data/librispeech/dev-clean/1272/128104/1272-128104-0000.flac -s data/CMU_ARCTIC/cmu_us_awb_arctic-wav-arctic_a0001.npy
```
- -hip: 显卡序号,默认为0。
- 当export HIP_VISIBLE_DEVICES指定可见卡后,**无需该参数**,默认使用‘0’卡
- 当没有指定可见卡时,需要使用该参数规定运算的显卡
- -m: vc模型路径
- -v: 声码器hifigan的模型路径
- -is:语音输入
- -s: CMU_ARCTIC数据集下的发声人特征文件
- -res: 结果输出文件tts.wav的存储路径
### ASR推理
```
cd inference
python speech_asr.py -hip 7 -m model/speecht5_asr -is ../data/librispeech/dev-clean/1272/128104/1272-128104-0000.flac
```
- -hip: 显卡序号,默认为0。
- 当export HIP_VISIBLE_DEVICES指定可见卡后,**无需该参数**,默认使用‘0’卡
- 当没有指定可见卡时,需要使用该参数规定运算的显卡
- -m: asr模型路径
- -is:语音输入
- -res: 结果输出文件tts.wav的存储路径
## result
### TTS
- 输入:“hi,nice to meet you”
- 输出:./res/tts.wav
### VC
- 输入:./data/librispeech/dev-clean/1272/128104/1272-128104-0000.flac
- 输出:./res/vc.wav
### ASR
- 输入:./data/librispeech/dev-clean/1272/128104/1272-128104-0000.flac
- 输出:./res/asr.txt
#### benchmark 计算
```
cd speecht5_pytorch
python benchmark.py -m model/speecht5_asr -ds librispeech_asr_test.py -b 32
```
- -m: asr模型路径
- -ds: 测试数据的处理脚本,默认为同级目录下的librispeech_asr_test.py
- -dr: 数据集路径,默认为speech_pytorch
- -b: 测试batch_size,默认为32(最大为128)
## 应用场景
### 算法分类
```
语音识别
```
### 热点应用行业
```
金融,通信,广媒
```
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/SpeechT5_pytorch
## 参考
[GitHub - microsoft/SpeechT5](https://github.com/microsoft/SpeechT5/tree/main/SpeechT5)