# SpeechT5
## 论文
- https://arxiv.org/abs/2110.07205
## 开源代码
- https://github.com/microsoft/SpeechT5
## 模型结构
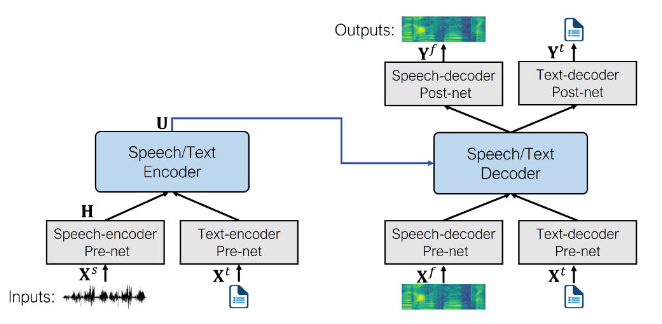
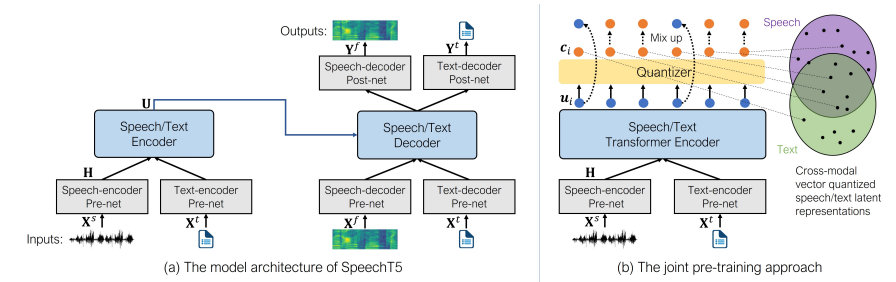
speechT5的核心是一个常规的**Transformer编码器-解码器**,为了使得同一个Transformer可以同时处理文本和语音数据,添加了**pre-nets**和**post-nets**,**pre-net**将输入的文本或语音转换为Transformer使用的隐藏表示;**post-net**从Transformer中获取输出并转换为文本或语音。
## 算法原理
在预训练期间,同时使用所有的 per-nets 和 post-nets 。预训练后,整个编码器 - 解码器主干在单个任务上进行微调。这种经过微调的模型仅使用特定于给定任务的 per-nets 和 post-nets 。*例如:要将 SpeechT5 用于文本到语音转换,您需要将文本编码器 per-nets 交换为文本输入,将语音解码器 per-nets 和 post-nets 交换为语音输出。*
**注意: 即使微调模型一开始使用共享预训练模型的同一组权重,但最终版本最终还是完全不同。例如,您不能采用经过微调的 ASR 模型并换掉 per-nets 和 post-nets 来获得有效的 TTS 模型。SpeechT5 很灵活,但不是那么灵活。**
## 环境配置
### Docker (方法一)
**注意修改路径参数**
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --network=host --ipc=host --name=your_container_name --shm-size=32G --device=/dev/kfd --device=/dev/mkfd --device=/dev/dri -v /opt/hyhal:/opt/hyhal:ro -v /path/your_code_data/:/path/your_code_data/ --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310 /bin/bash
# 独立安装项目依赖包fairseq
git clone -b 1.0.0a0 http://developer.hpccube.com/codes/OpenDAS/fairseq.git
cd fairseq
pip3 install --editable ./
# 安装项目依赖包
cd speechT5_pytorch
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
```
### Dockerfile (方法二)
```
cd ./docker
docker build --no-cache -t speecht5 .
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
git clone -b 1.0.0a0 http://developer.hpccube.com/codes/OpenDAS/fairseq.git
cd fairseq
pip3 install --editable ./
cd speechT5_pytorch
pip3 install -r requirements.txt
```
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24.04
python:python3.10
torch:2.1.0
torchvision:0.16.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、fairseq库需要单独安装,可参考如下命令:
```
git clone -b 1.0.0a0 http://developer.hpccube.com/codes/OpenDAS/fairseq.git
cd fairseq
pip3 install --editable ./
```
3、其他非特殊库直接按照requirements.txt安装
```
cd speechT5_pytorch
pip3 install -r requirements.txt
```
## 数据集
**内网可从此地址拷贝:/public/home/changhl/dataset/LibriSpeech**
- SCnet快速下载链接:
- [librispeech_asr数据集下载](http://113.200.138.88:18080/aidatasets/librispeech_asr_dummy)
- 官方下载链接:
- [librispeech_asr数据集下载](http://www.openslr.org/12)
`librispeech_asr`:语音识别数据集,数据集中包括音频文件以及文本转录文件。其中音频文件以flac格式存储,文本转录文件以txt格式存储。
```
LibriSpeech
├── train-clean-100
│ ├── 1272
│ │ ├── 1272-128104
│ │ │ ├── 1272-128104-0000.flac
│ │ │ ├── 1272-128104-0001.flac
│ │ │ ├── 1272-128104-0002.flac
│ │ │ ├── 1272-128104-0003.flac
│ │ │ ├── ...
│ │ │ ├── 1272-128104.trans.txt
│ │ └── ...
│ └── ...
├── train-clean-360
├── train-other-500
├── dev-clean
├── dev-other
├── test-clean
└── test-othe
```
- `train-clean-100`:包含大约 100 小时的清晰语音。
- `1272`:说话人ID(1272)。
- `1272-128104`:说话人ID(1272)-文本章节ID(128204)。
- `1272-128104-0000.flac`:说话人ID(1272)-文本章节ID(128204)-文本片段ID(0)的音频文件。
- `1272-128104.trans.txt`:说话人ID(1272)-文本章节ID(128204)的转录文本文件。
## 预训练模型
**ASR任务训练前先下载预训练好的权重文件、SPM_TOKENIZER、字典等文件**
- 官方下载地址:
- [speecht5初始权重](https://huggingface.co/ajyy/SpeechT5/resolve/main/speecht5_base.pt)
- [SPM_TOKENIZER下载地址](https://drive.google.com/uc?export=download&id=1wClgQjXXoU2lmpbaEa1v2SqMbg7cAutq)
- [字典](https://huggingface.co/ajyy/SpeechT5/resolve/main/speecht5_base.pt)
## 训练
### ASR训练
**step1:生成训练集的train.tsv文件和valid.tsv文件**
```
cd speecht5_pytorch/SpeechT5/fairseq
python examples/wav2vec/wav2vec_manifest.py dataset/LibriSpeech/dev-clean --dest /public/home/changhl/py_project/train_0910 --ext flac --valid-percent 0.1
# python wav2vec_manifest.py 数据集目录 --dest tsv文件的存储目录 --ext 语音文件类型(flac) --valid-percent 0.1
# 数据集目录为dataset/LibriSpeech/dev-clean,因为选取整个数据集,训练耗时过长,可以选择所有的librispeech数据集。
```
**step2:生成step1生成的tsv文件的标签文件:train.txt和valid.txt**
```
cd speecht5_pytorch/SpeechT5/fairseq
python examples/wav2vec/libri_labels.py /public/home/changhl/py_project/train_0910/train.tsv --output-dir /public/home/changhl/py_project/train_0910 --output-name train
python examples/wav2vec/libri_labels.py /public/home/changhl/py_project/train_0910/valid.tsv --output-dir /public/home/changhl/py_project/train_0910 --output-name valid
# python libri_labels.py tsv文件目录 \
# --output-dir txt文件保存目录 \
# --output-name txt文件名模型(和tsv的文件名相同)
```
**step3:字典文件迁移**
将下载的dict.txt字典文件迁移至train.tsv的同一目录下
**step4:训练**
```
cd speecht5_pytorch
export HIP_VISIBLE_DEVICES=0 # 自行指定可见卡
bash asr_train.sh \
--dcu 1 \
--log /public/home/changhl/py_project/SpeechT5/log \
--td /public/home/changhl/py_project/train_0910 \
--res /public/home/changhl/py_project/SpeechT5/res \
--lab /public/home/changhl/py_project/train_0910 \
--token /public/home/changhl/dataset/spm_char.model \
--speecht5 /public/home/changhl/py_project/SpeechT5/SpeechT5/speecht5 \
--checkpoint /public/home/changhl/dataset/speecht5_base.pt \
--epoch 3
# 具体参数解析-h查看
```
- `dcu`:训练所用的卡数
- `log`:训练日志文件保存目录
- `td`:train.tsv文件和valid.tsv文件的所在目录
- `res`:训练结果.pt文件保存目录
- `lab`:train.txt和valid.txt文件的所在目录
- `token`:下载的spm_char.model文件路径——SPM_TOKENIZER文件
- `speecht5`:/speecht5_pytorch/SpeechT5/speecht5该目录的绝对路径
- `checkpoint`:预训练的初始权重路径
- `epoch`:训练次数
## 应用场景
### 算法分类
```
语音识别
```
### 热点应用行业
```
金融,通信,广媒
```
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/SpeechT5_pytorch
## 参考
[GitHub - microsoft/SpeechT5](https://github.com/microsoft/SpeechT5/tree/main/SpeechT5)