
Make data pre-processing pipeline customizable (#935)
* define data pipelines * update two config files * minor fix for config files * allow img_scale to be optional and update config * add some docstrings * add extra aug to transform * bug fix for mask resizing * fix cropping * add faster rcnn example * fix imports * fix robustness testing * add img_norm_cfg to img_meta * fix the inference api with the new data pipeline * fix proposal loading * delete args of DefaultFormatBundle * add more configs * update configs * bug fix * add a brief doc * update gt_labels in RandomCrop * fix key error for new apis * bug fix for masks of crowd bboxes * add argument data_root * minor fix * update new hrnet configs * update docs * rename MultiscaleFlipAug to MultiScaleFlipAug * add __repr__ for all transforms * move DATA_PIPELINE.md to docs/ * fix image url
Showing
demo/data_pipeline.png
0 → 100644
{kind=link}
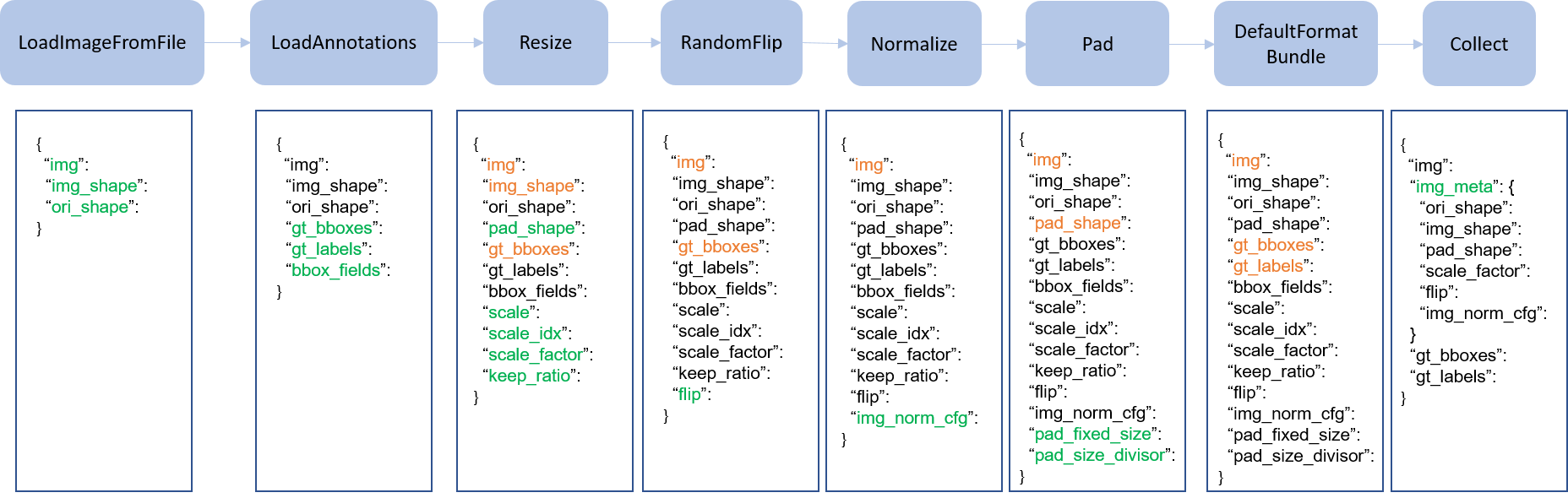
82.1 KB
docs/DATA_PIPELINE.md
0 → 100644