# Sentence-BERT
## 论文
`Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks`
- https://arxiv.org/pdf/1908.10084.pdf
## 模型结构
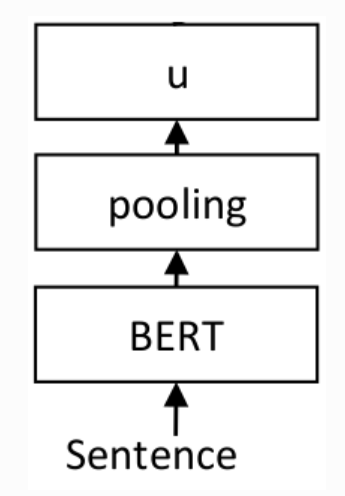
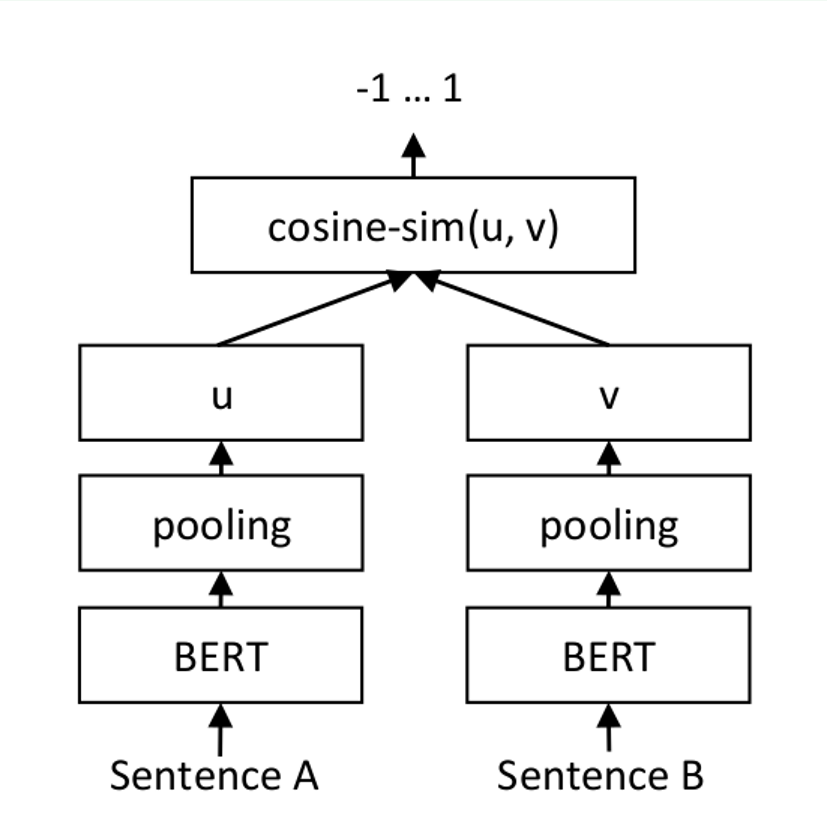
一种对预训练BERT网络的改进,它使用连体和三重网络结构来获得语义上有意义的句子嵌入,可以使用余弦相似度进行比较。
## 算法原理
对于每个句子对,通过网络传递句子A和句子B,从而得到embeddings u 和 v。使用余弦相似度计算embedding的相似度,并将结果与 gold similarity score进行比较。这允许网络进行微调,并识别句子的相似性.
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
### Dockerfile(方法二)
```bash
cd ./docker
docker build --no-cache -t sbert:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
### Anaconda(方法三)
1. 关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```bash
DTK软件栈:dtk24.04
python:python3.10
torch:2.1.0
torchvision: 0.16.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2. 其他非特殊库直接按照requirements.txt安装
```bash
cd /your_code_path/sentence-bert_pytorch
pip install -r requirements.txt
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
## 数据集
**训练数据**: [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb),训练代码自动下载。
**推理数据**: 需要转换成txt格式,参考[gen_simple_wikipedia_v1.py](./gen_simple_wikipedia_v1.py)文件,生成`simple_wiki_pair.txt`。
数据集的目录结构如下:
```
├── dataset
│ ├──simple_wikipedia_v1
│ ├──simple_wiki_pair.txt # 生成的
│ ├──wiki.simple
│ └──wiki.unsimplified
```
## 训练
- **训练**默认模型[bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased)
- **微调**默认模型[all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)
### 单机多卡
- 训练
```bash
bash train.sh
```
- 微调
```bash
bash finetune.sh
```
### 单机单卡
- 训练
```bash
python training_stsbenchmark.py --train_batch_size 64 --num_epochs 5
```
- 微调
```bash
python training_stsbenchmark_continue_training.py --train_batch_size 64 --num_epochs 5
```
## 推理
1. 预训练模型下载[pretrained models](https://www.sbert.net/docs/pretrained_models.html), 当前默认为[all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)模型;
2. 执行以下命令,测试数据默认为`./datasets/simple_wikipedia_v1/simple_wiki_pair.txt`,可修改`--data_path`参数为其他待测文件地址,文件内容格式请参考[simple_wiki_pair.txt](./datasets/simple_wikipedia_v1/simple_wiki_pair.txt)。
```bash
python infer.py --data_path ./dataset/simple_wikipedia_v1/simple_wiki_pair.txt --model_name_or_path all-MiniLM-L6-v2
```
## result
### 精度
在sts-test数据集上评估模型,Cosine-Similarity得分对比
| device | backbone | epoch | Pearson | Spearman |
| :------: | :------: | :------: | :------: | :------: |
| K100 | bert-base-uncased | 5 | 0.8500 | 0.8460 |
| A800 | bert-base-uncased | 5 | 0.8449 | 0.8385 |
## 应用场景
### 算法类别
语义文本相似度
### 热点应用行业
教育,网安,政府
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/sentence-bert_pytorch
## 参考资料
- https://github.com/UKPLab/sentence-transformers