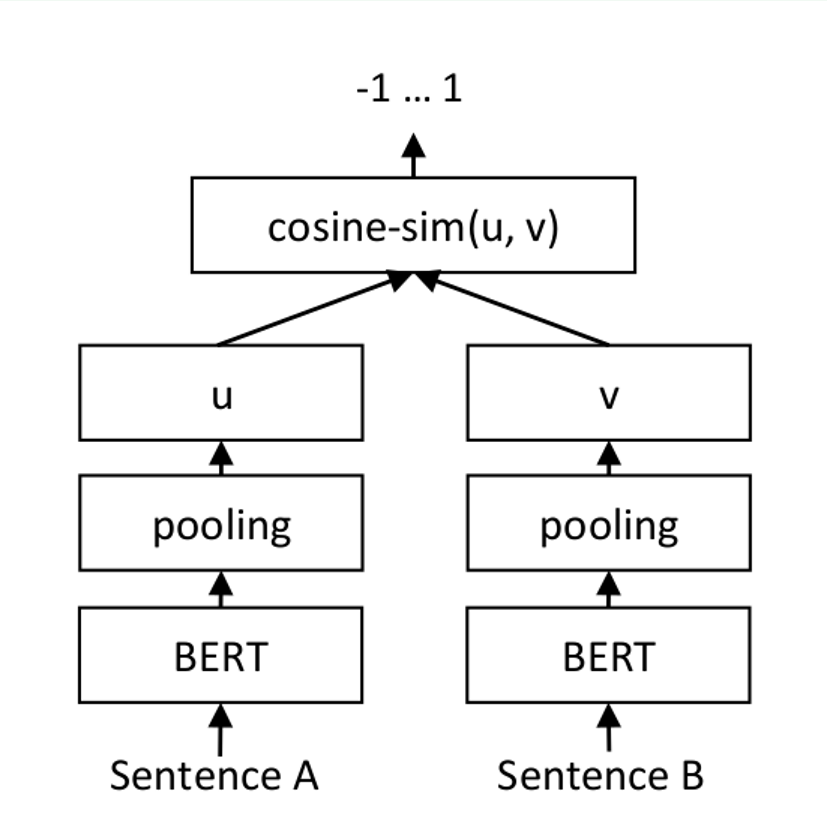
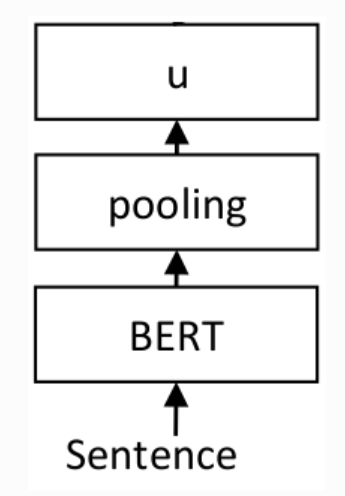
因数据较多,这里仅用[Simple Wikipedia Version 1.0](https://cs.pomona.edu/~dkauchak/simplification/)数据集进行展示,数据集已在 datasets/simple_wikipedia_v1 中提供
因数据较多,这里仅用[Simple Wikipedia Version 1.0](https://cs.pomona.edu/~dkauchak/simplification/)数据集进行展示,数据集已在 datasets/simple_wikipedia_v1 中提供,详细数据请参考[all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)模型中的Model card。
@@ -102,7 +102,7 @@ for sentence, embedding in zip(sentences, sentence_embeddings):
...
@@ -102,7 +102,7 @@ for sentence, embedding in zip(sentences, sentence_embeddings):
print("Embedding:",embedding)
print("Embedding:",embedding)
print("")
print("")
````
````
bbnnm,,,nmm
## Pre-Trained Models
## Pre-Trained Models
We provide a large list of [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html) for more than 100 languages. Some models are general purpose models, while others produce embeddings for specific use cases. Pre-trained models can be loaded by just passing the model name: `SentenceTransformer('model_name')`.
We provide a large list of [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html) for more than 100 languages. Some models are general purpose models, while others produce embeddings for specific use cases. Pre-trained models can be loaded by just passing the model name: `SentenceTransformer('model_name')`.

{kind=link}
{kind=link}