"openmmapi/src/MonteCarloFlexibleBarostatImpl.cpp" did not exist on "b7a24d6cf0304b32a7625ca665f49af71c6088ce"

first
Showing
SenseNova-SI-main/uv.lock
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
doc/1.png
0 → 100644
{kind=link}
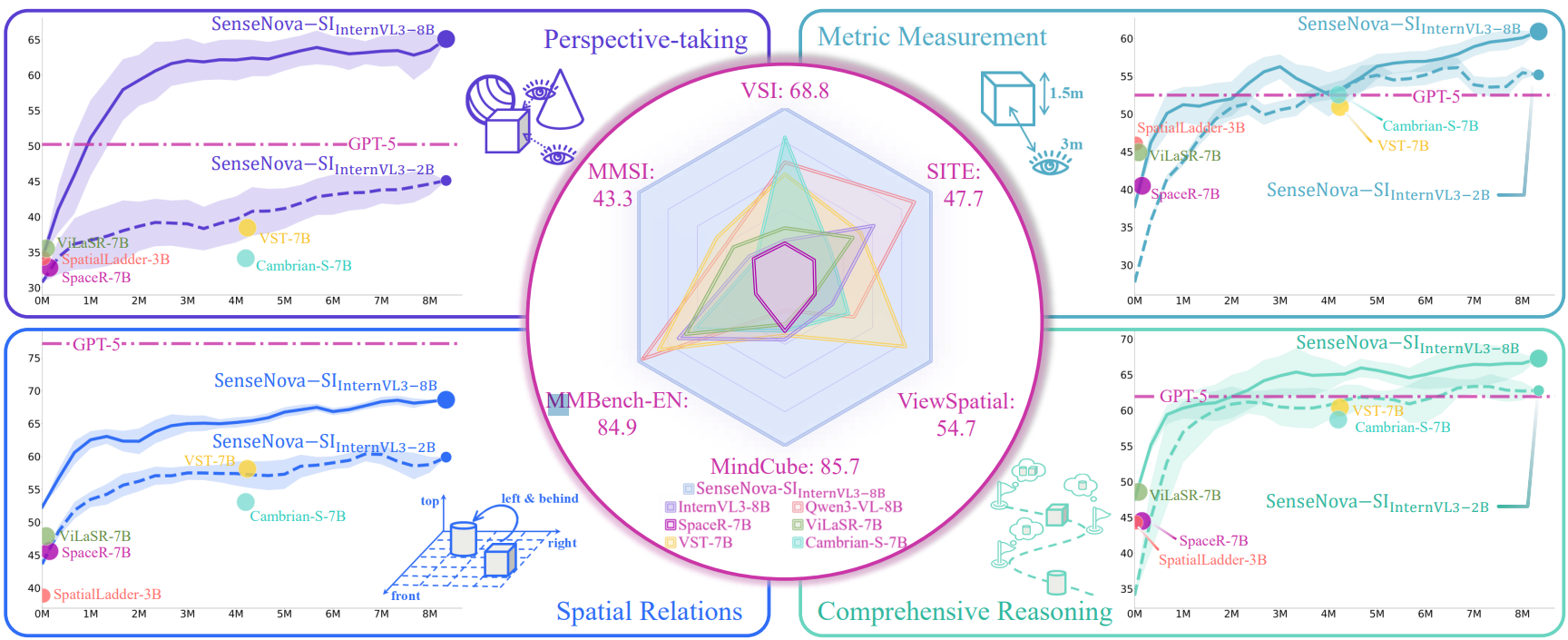
439 KB
doc/2.jpg
0 → 100644
{kind=link}

85.6 KB
doc/3.png
0 → 100644
{kind=link}
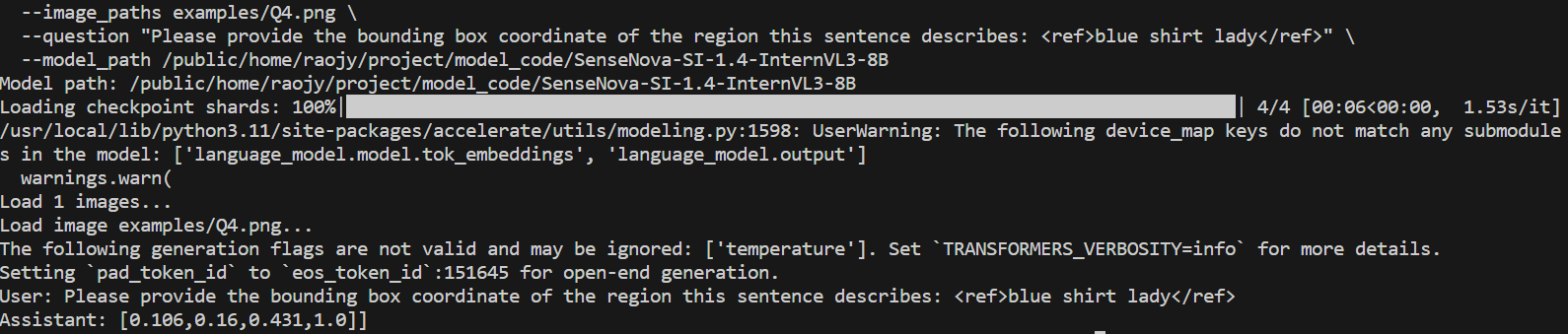
59.1 KB
doc/4.png
0 → 100644
{kind=link}

54.2 KB
doc/5.png
0 → 100644
{kind=link}

65.2 KB
icon.png
0 → 100644
{kind=link}
50.3 KB
model.properties
0 → 100644