
Initial commit
Showing
docs/main_arch.png
0 → 100644
{kind=link}

685 KB
docs/trade-off.png
0 → 100644
{kind=link}
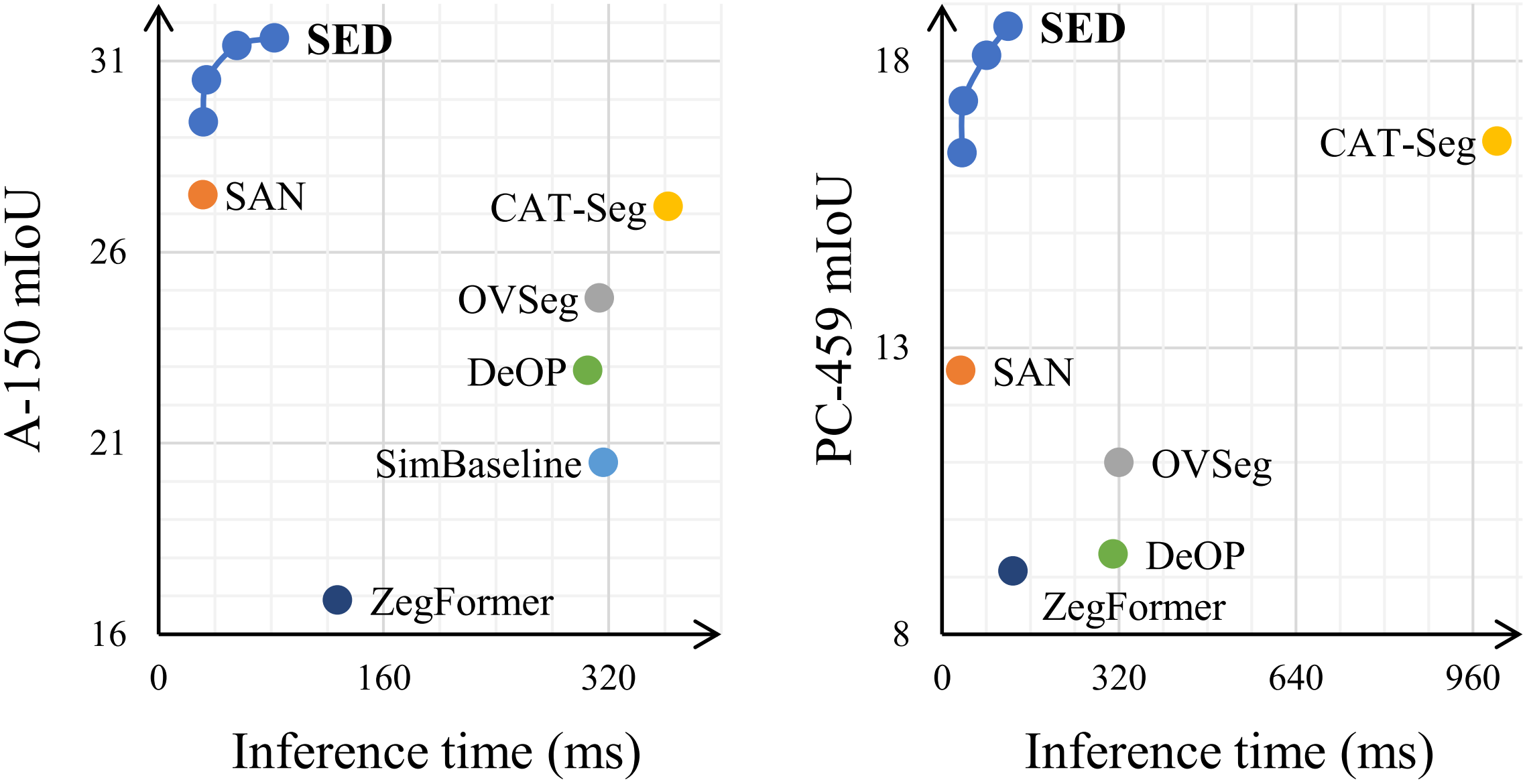
207 KB
eval.sh
0 → 100644
model.properties
0 → 100644
open_clip/.gitignore
0 → 100644
open_clip/CITATION.cff
0 → 100644
open_clip/HISTORY.md
0 → 100644
open_clip/LICENSE
0 → 100644
open_clip/MANIFEST.in
0 → 100644
open_clip/Makefile
0 → 100644
open_clip/README.md
0 → 100644
This diff is collapsed.
open_clip/pytest.ini
0 → 100644
open_clip/requirements.txt
0 → 100644
open_clip/setup.py
0 → 100644
File added