
sd3.5
Showing
.gitignore
0 → 100755
Dockerfile
0 → 100644
LICENSE
0 → 100755
README.md
0 → 100644
README_official.md
0 → 100755
icon.png
0 → 100644
{kind=link}
68.4 KB
mmditx.py
0 → 100755
This diff is collapsed.
model.properties
0 → 100644
other_impls.py
0 → 100755
This diff is collapsed.
readme_imgs/alg.png
0 → 100644
{kind=link}
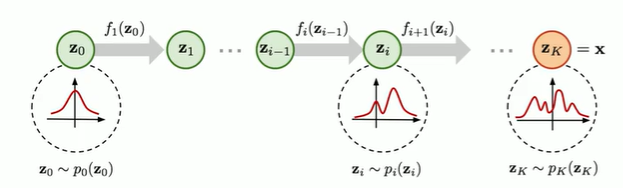
74 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
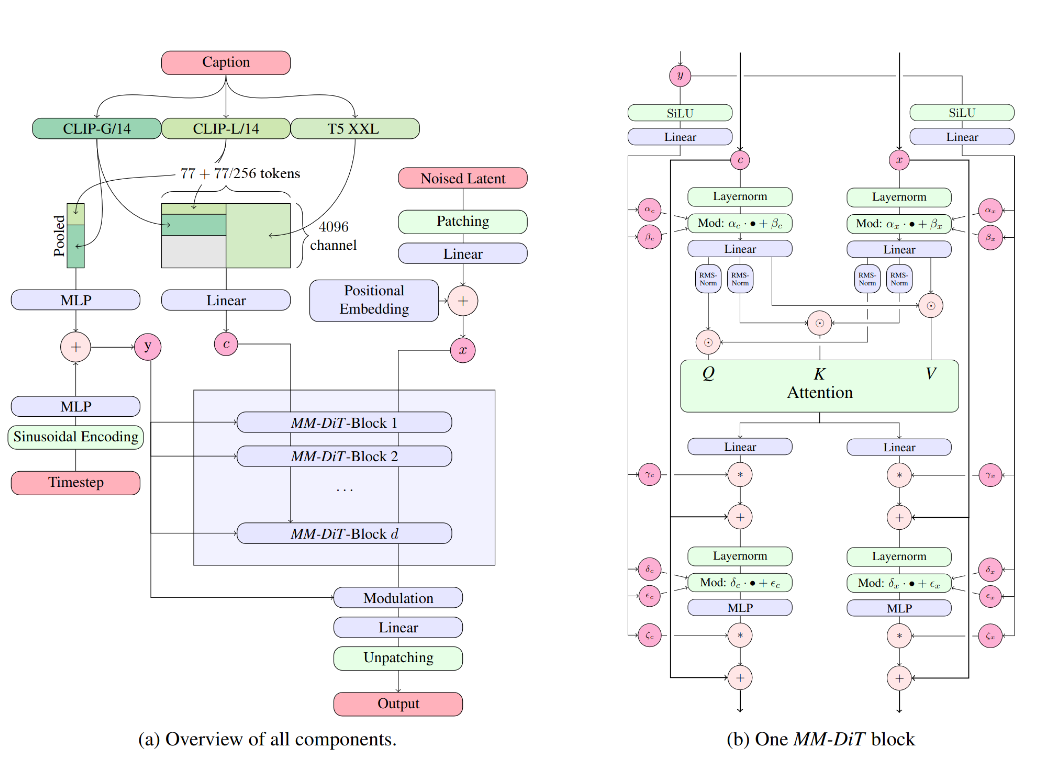
146 KB
readme_imgs/result1.png
0 → 100644
{kind=link}

1.22 MB
readme_imgs/result2.png
0 → 100644
{kind=link}

2.53 MB
requirements.txt
0 → 100755
| # --extra-index-url https://download.pytorch.org/whl/cu118 | ||
| transformers | ||
| # torch | ||
| # torchvision | ||
| numpy | ||
| fire | ||
| pillow | ||
| numpy | ||
| einops | ||
| sentencepiece | ||
| protobuf |
sd3_impls.py
0 → 100755
This diff is collapsed.
sd3_infer.py
0 → 100755