# SD2.1 MIGraphX Pipeline
使用 MIGraphX 后端,执行 SD2.1 文生图任务。
## 论文
High-Resolution Image Synthesis with Latent Diffusion Models
+ [https://arxiv.org/abs/2112.10752](https://arxiv.org/abs/2112.10752)
## 模型结构
通过串联或更通用的交叉注意机制来调节LDM
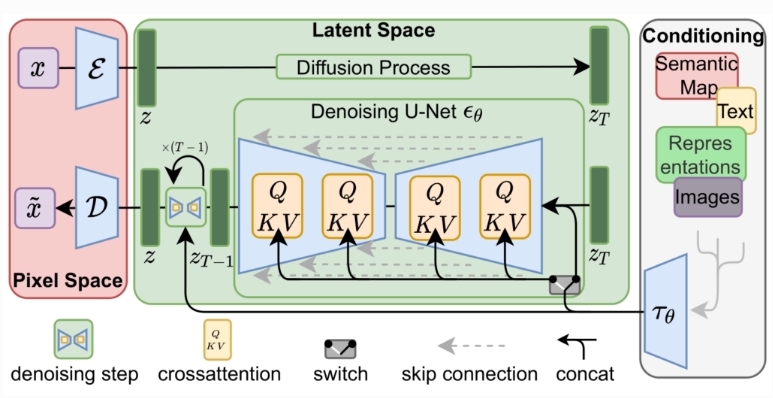
## 算法原理
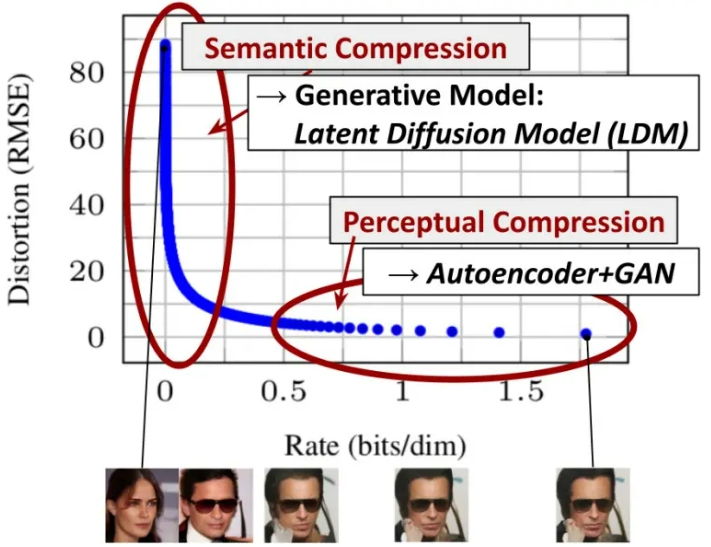
通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型(DM)在图像数据和其他数据上实现了最先进的合成结果。为了在有限的计算资源上进行DM训练,同时保持其质量和灵活性,我们将其应用于强大的预训练自动编码器的潜在空间。在这种表示上训练扩散模型首次能够在降低复杂性和空间下采样之间达到接近最佳的点,提高了视觉逼真度。通过在模型架构中引入跨注意力层,将扩散模型变成了强大而灵活的生成器,用于文本或边界框等一般条件输入,高分辨率合成以卷积方式成为可能。我们的潜在扩散模型(LDM)在各种任务上实现了极具竞争力的性能,包括无条件图像生成、修复和超分辨率,同时与基于像素的DM相比,显著降低了计算要求。
## 环境配置
执行以下命令:
```bash
source /opt/dtk/env.sh
export PYTHONPATH=/opt/dtk/lib:$PYTHONPATH
python -c "import migraphx"
```
若回显 `ModuleNotFoundError: No module named 'migraphx'`,则说明没有安装 MIGraphX,请移步 [DAS资源下载目录](https://das.sourcefind.cn:55011/portal/#/installation?id=f0c8268b-756c-11ef-95cc-005056904552&type=frame) 下载安装包并安装 MIGraphX。
然后安装第三方依赖:
```bash
pip install -r requirements.txt
```
> :memo: **注意:** 这里会默认安装 PyPI 官方提供的 PyTorch,在 DCU 上,需要安装经过适配的 PyTorch 版本,请前往 [DAS资源下载目录](https://das.sourcefind.cn:55011/portal/#/installation?id=04749079-6b33-11ef-b472-005056904552&type=frame) 手动下载安装 PyTorch。
接下来,安装migraphx_diffusers:
```bash
pip install dist/migraphx_diffusers-${version}-py3-none-any.whl
```
最后,设置环境变量:
```bash
source set_env.sh /path/to/your/rocblas_lib
```
## 数据集
无
## 推理
### 模型准备
下载官方模型:
```bash
huggingface-cli download stabilityai/stable-diffusion-2-1-base --local-dir ./stable-diffusion-2-1-base --local-dir-use-symlinks False
```
导出 ONNX 模型:
```bash
# pip install optimum[exporters]
# optimum-cli export onnx --model ./stable-diffusion-2-1-base ./stable-diffusion-2-1-base-onnx --task text-to-image
python tools/export_onnxs.py --pipeline-dir stable-diffusion-2-1-base
```
模型优化:
```bash
bash tools/onnx_optimize.sh ./stable-diffusion-2-1-base ./stable-diffusion-2-1-base-opt
```
### 快速开始
```python
from diffusers import DiffusionPipeline
import migraphx_diffusers
pipe = DiffusionPipeline.from_pretrained(
"./stable-diffusion-2-1-base-opt",
migraphx_config=migraphx_diffusers.DEFAULT_ARGS['sd2.1']
)
pipe.to("cuda")
image = pipe("sunflower").images[0]
image.save("sd2.1_output_512.png")
```
> :memo: **注意:** 在执行 `from_pretrained` 函数前必须执行 `import migraphx_diffusers`,使 MIGraphX 模型的加载逻辑生效。
生成结果:

也可直接使用 `tools/run_pipe.py` 脚本进行快速的推理:
```bash
python tools/run_pipe.py -m ./stable-diffusion-2-1-base-opt -p "sunflower"
```
脚本参数说明:
| 参数 | 说明 | 类型 | 默认值 |
| --- | --- | --- | --- |
| `-m` / `--model-dir` | **必选**,pipeline 模型路径 | str | None |
| `--force-compile` | 可选,是否强制重新编译模型 | bool | False |
| `--num-images-per-prompt` | 可选,一条提示词一次生成图片的数量 | int | 1 |
| `--img-size` | 可选,生成图像尺寸,如果不设置,则跟随各 pipeline 默认的图像尺寸参数 | int | None |
| `-p` / `--prompt` | **必选**,提示词,描述图片内容、风格、生成要求等 | str | None |
| `-n` / `--negative-prompt` | 可选,反向提示词,例如 "ugly" | str | None |
| `-t` / `--num-inference-steps` | 可选,生成图片时迭代多少步 | int | 50 |
| `--seed` | 可选,随机数种子 | int | 42 |
| `--save-prefix` | 可选,保存图片的前缀 | str | None |
### 参数配置
此项目使用 MIGraphX 静态 shape 推理,在加载各个子模型时,需要 `batch`、`img_size` 两个参数来固定模型的 shape;此外还需要 `model_dtype` 与 `force_compile` 两个参数,前者用来固定模型推理时采用的数据精度,后者用来控制当 .mxr 模型已经存在的情况下,是否强制重新编译。
+ `batch`: 模型输入的 batch 大小,默认为 1
+ `img_size`: 模型输入的图片尺寸,sdxl 默认为 1024,sd2.1 默认为 512
+ `model_dtype`: 模型推理时使用的数据精度,默认为 `fp16`
+ `force_compile`: 是否强制重新编译模型,默认为 `false`
加载 pipeline 时,这些参数通过 `migraphx_config` 传递给 `DiffusionPipeline.from_pretrained` 函数,在此函数内部,程序会解析出以上四个参数,并在调用各个子模型的 `from_pretrained` 函数时传入这四个参数。
各 pipeline 默认的参数配置存放于文件 [migraphx_diffusers/default_args.json](migraphx_diffusers/default_args.json) 中,可通过 `migraphx_diffusers.DEFAULT_ARGS['sd2.1']` 获取 SD2.1 的默认参数配置,其内容如下:
```json
{
"sd2.1":{
"use_migraphx_models": [
"text_encoder",
"unet",
"vae_decoder"
],
"common_args": {
"batch": 1,
"img_size": 512,
"model_dtype": "fp16",
"force_compile": false
},
"model_args": {
"text_encoder": {
"batch": 1
}
}
}
}
```
其中:
+ `use_migraphx_models`: 指定在推理时,哪些子模型使用 MIGraphX 后端进行推理,此列表以外的子模型,使用 PyTorch 进行推理。
+ `common_args`: MIGraphX 加载各子模型的通用参数;
+ `model_args`: 若某个子模型不想按照通用参数加载模型,可在此字段中单独进行配置,例如:
```json
"model_args": {
"vae_decoder":{
"model_dtype": "fp32",
"force_compile": true
}
}
```
> :memo: **注意:** pipeline 的 batch 含义为 **1** 条 prompt 生成 batch 张图片。 prompt 数量决定文本编码器的 batch,也就是说,不管 pipeline 是单 batch 推理还是多 batch 推理,文本编码器的 batch 均为 1,所以在默认配置文件中,将 `text_encoder` 的 batch 固定为 1。
### 模型加载与缓存
各子模型加载流程如下:
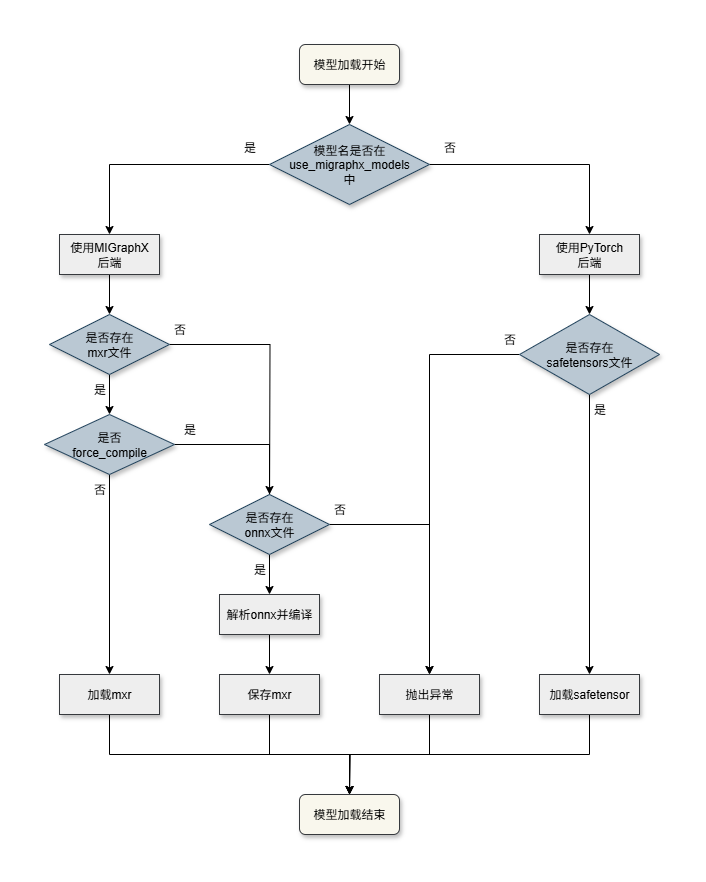 加载与缓存逻辑:
+ 若模型名在 `use_migraphx_models` 列表中,则使用 MIGraphX 后端:
+ 若存在 .mxr 缓存且 `force_compile` 为 false,则直接从 .mxr 缓存文件中加载模型;
+ 否则判断是否存在 .onnx 文件,若存在则解析 .onnx 文件并编译,且对编译后的模型保存为 .mxr 文件,不存在则抛出异常。
+ 否则使用 PyTorch 后端:
+ 若存在 .safetensors 文件,则从中加载权重,否则抛出异常。
### 目录结构与命名规则
整体的目录结构遵循 [huggingface](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main) 的格式,以 sd2.1 为例,其目录结构如下:
```
├── ./stable-diffusion-2-1-base-opt/
├── model_index.json
├── feature_extractor
│ └── preprocessor_config.json
├── scheduler/
│ └── scheduler_config.json
├── text_encoder/
│ ├── config.json
│ └── model.onnx
├── tokenizer/
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet/
│ ├── config.json
│ ├── model.onnx
│ └── model.onnx.data
└── vae_decoder/
├── config.json
└── model.onnx
```
每个子模型的 ONNX 文件均需命名为 model.onnx,若模型较大,可以只将模型结构存放于 model.onnx 内,而将权重数据外存为 model.onnx.data 文件。
若想使用编译好的 mxr 文件,则需要将 mxr 文件重命名为 `model_{model_dtype}_b{batch}_{img_size}_gpu.mxr`,然后将其放置于对应的子模型目录下。最后加载模型时,还应且将 `force_compile` 设置为 False。
如果某个子模型想使用 PyTorch 推理,则需要在 `use_migraphx_models` 列表中移除该子模型的名称,并在对应的子目录下放置 safetensors 文件,名称与 [huggingface](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main) 保持一致即可。
### 多 batch 推理
当前仅支持一个提示词同时生成一张图片,即 batch=1 推理,多 batch 推理功能适配中。
### 不同的图像尺寸
在默认配置中,sdxl生成图像尺寸为 1024x1024, 如果想要生成其他尺寸的图像,只需修改 `img_size` 字段即可。
示例:
```python
from diffusers import DiffusionPipeline
import migraphx_diffusers
migraphx_config = migraphx_diffusers.DEFAULT_ARGS['sd2.1']
migraphx_config['common_args']['img_size'] = 1024 # 修改图像尺寸
pipe = DiffusionPipeline.from_pretrained(
"./stable-diffusion-2-1-base-opt/",
migraphx_config=migraphx_config
)
pipe.to("cuda")
image = pipe("sunflower").images[0]
image.save("sd2.1_output_1024.png")
```
生成结果:
加载与缓存逻辑:
+ 若模型名在 `use_migraphx_models` 列表中,则使用 MIGraphX 后端:
+ 若存在 .mxr 缓存且 `force_compile` 为 false,则直接从 .mxr 缓存文件中加载模型;
+ 否则判断是否存在 .onnx 文件,若存在则解析 .onnx 文件并编译,且对编译后的模型保存为 .mxr 文件,不存在则抛出异常。
+ 否则使用 PyTorch 后端:
+ 若存在 .safetensors 文件,则从中加载权重,否则抛出异常。
### 目录结构与命名规则
整体的目录结构遵循 [huggingface](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main) 的格式,以 sd2.1 为例,其目录结构如下:
```
├── ./stable-diffusion-2-1-base-opt/
├── model_index.json
├── feature_extractor
│ └── preprocessor_config.json
├── scheduler/
│ └── scheduler_config.json
├── text_encoder/
│ ├── config.json
│ └── model.onnx
├── tokenizer/
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet/
│ ├── config.json
│ ├── model.onnx
│ └── model.onnx.data
└── vae_decoder/
├── config.json
└── model.onnx
```
每个子模型的 ONNX 文件均需命名为 model.onnx,若模型较大,可以只将模型结构存放于 model.onnx 内,而将权重数据外存为 model.onnx.data 文件。
若想使用编译好的 mxr 文件,则需要将 mxr 文件重命名为 `model_{model_dtype}_b{batch}_{img_size}_gpu.mxr`,然后将其放置于对应的子模型目录下。最后加载模型时,还应且将 `force_compile` 设置为 False。
如果某个子模型想使用 PyTorch 推理,则需要在 `use_migraphx_models` 列表中移除该子模型的名称,并在对应的子目录下放置 safetensors 文件,名称与 [huggingface](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main) 保持一致即可。
### 多 batch 推理
当前仅支持一个提示词同时生成一张图片,即 batch=1 推理,多 batch 推理功能适配中。
### 不同的图像尺寸
在默认配置中,sdxl生成图像尺寸为 1024x1024, 如果想要生成其他尺寸的图像,只需修改 `img_size` 字段即可。
示例:
```python
from diffusers import DiffusionPipeline
import migraphx_diffusers
migraphx_config = migraphx_diffusers.DEFAULT_ARGS['sd2.1']
migraphx_config['common_args']['img_size'] = 1024 # 修改图像尺寸
pipe = DiffusionPipeline.from_pretrained(
"./stable-diffusion-2-1-base-opt/",
migraphx_config=migraphx_config
)
pipe.to("cuda")
image = pipe("sunflower").images[0]
image.save("sd2.1_output_1024.png")
```
生成结果:
 ### Tools
1. [以通用方式加载并运行pipeline](tools/README.md#以通用方式加载并运行pipeline)
2. [批量生成图片](tools/README.md#批量生成图片)
3. [统计各模块耗时](tools/README.md#统计各模块耗时)
4. [端到端性能测试](tools/README.md#SD2.1端到端性能测试)
5. [模型精度评估](tools/README.md#模型精度评估)
### result
SD2.1 生成样例:
### Tools
1. [以通用方式加载并运行pipeline](tools/README.md#以通用方式加载并运行pipeline)
2. [批量生成图片](tools/README.md#批量生成图片)
3. [统计各模块耗时](tools/README.md#统计各模块耗时)
4. [端到端性能测试](tools/README.md#SD2.1端到端性能测试)
5. [模型精度评估](tools/README.md#模型精度评估)
### result
SD2.1 生成样例:
| 自然风景 |
人物肖像 |
 |
 |
| 科幻与奇幻 |
生物 |
 |
 |
| 建筑与空间 |
抽象与艺术 |
 |
 |
| 日常生活 |
历史与复古 |
 |
 |
| 暗黑与怪诞 |
科技与数码 |
 |
 |
更多生成示例: [examples](examples)
### 精度
在 PartiPrompts 数据集上的精度指标如下:
| Category | NumPrompts | NumImages | MeanCLIPScore (BW) |
| ---------------- | ----------- | ---------- | ------------------ |
| All | 1632 | 6528 | 33.1719 |
| Animals | 314 | 1256 | 34.2835 |
| Food & Beverage | 74 | 296 | 30.6977 |
| Abstract | 51 | 204 | 27.0132 |
| Arts | 66 | 264 | 36.591 |
| People | 177 | 708 | 32.911 |
| Vehicles | 104 | 416 | 32.57 |
| Outdoor Scenes | 131 | 524 | 32.4758 |
| World Knowledge | 214 | 856 | 34.5407 |
| Artifacts | 287 | 1148 | 32.847 |
| Indoor Scenes | 40 | 160 | 33.5314 |
| Produce & Plants | 50 | 200 | 32.069 |
| Illustrations | 124 | 496 | 32.8778 |
## 应用场景
### 算法类别
`以文生图`
### 热点应用行业
`绘画`,`动漫`,`媒体`
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/sd2.1-migraphx
## 参考资料
1. [stablediffusion_v2.1_migraphx](https://sourcefind.cn/#/model-zoo/1862330225368723457)
2. [stablediffusion_v2.1_pytorch](https://sourcefind.cn/#/model-zoo/1793173002231443458)
3. [https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-2-1)