# SadTalker
## 论文
`SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation`
- https://arxiv.org/abs/2211.12194
## 模型结构
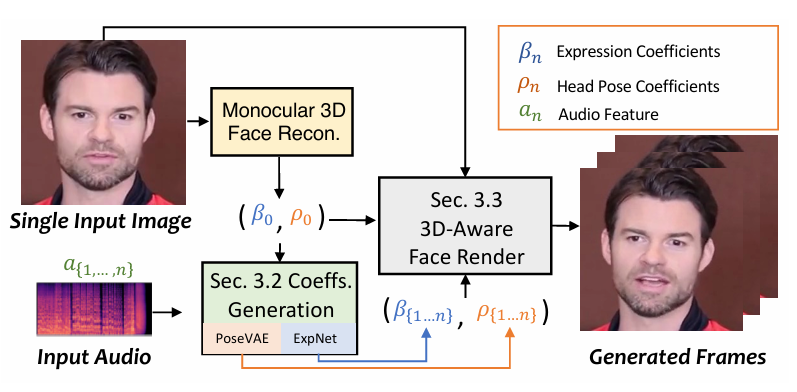
SadTalker利用 3DMM 系数作为中间表示。首先从原始图像中提取出系数,然后使用 ExpNet 和 PoseVAE 从音频中提取出真实的 3DMM 的系数(面部表情系数 β , 头部姿势 ρ),最后通过 3D-aware face render 生成得到最后的视频。
## 算法原理
将 3DMM(3D Morphable Models)的运动系数看做中间表达,将整个任务划分成两部分。训练的时候会分模型训练,在推理的时候是 end-to-end 的模式:
1、从语音中生成更加真实的运动系数(如 head pose、lip motion、eye blink),并且每个系数是单独学习的,这样会解耦来降低不确定性:
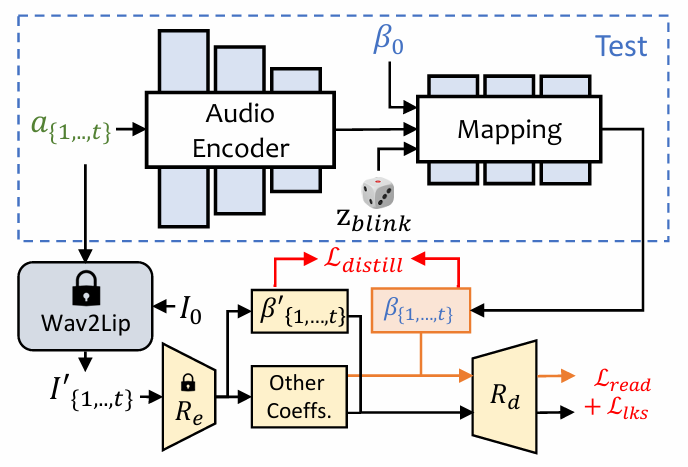
ExpNet:通过第一帧的 expression coefficient β 来将 expression motion 和 specific person 进行关联,为了降低在说话过程中其他面部部位的影响只使用 lip motion coefficient 作为 target coefficient 。其他不是很重要的面部动作(如眨眼)会使用额外的 landmark loss 来训练。
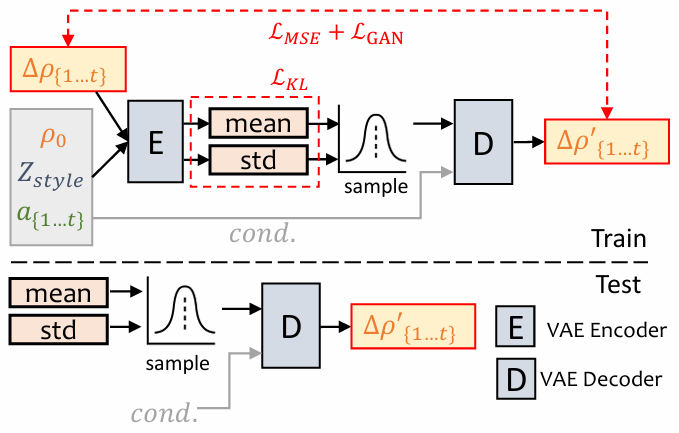
PoseVAE:训练时,pose VAE 在固定 n 帧上使用 encoder-decoder 的结构进行训练,encoder 和 decoder 输入包含连续的 t 帧 head pose ,且假设其服从高斯分布。decoder 中,网络学习的目标是从分布中通过采样来生成 t 帧 pose ,但不是直接生成 pose,而是学习和第一帧 pose ρ0 的残差,这样能保证生成的 pose 更连续、稳定、一致,所以也叫 conditional VAE,这里的 conditional 就是第一帧的 head pose。此外,还将每个声音的特征和 style identity 作为条件来作为 identity style。KL 散度用于衡量生成的 motion。MSE 和 GAN loss 用于保证生成的质量。
2、生成了 3DMM 系数后,会从原本的图片建立 3D 人脸,然后再生成最后的视频:
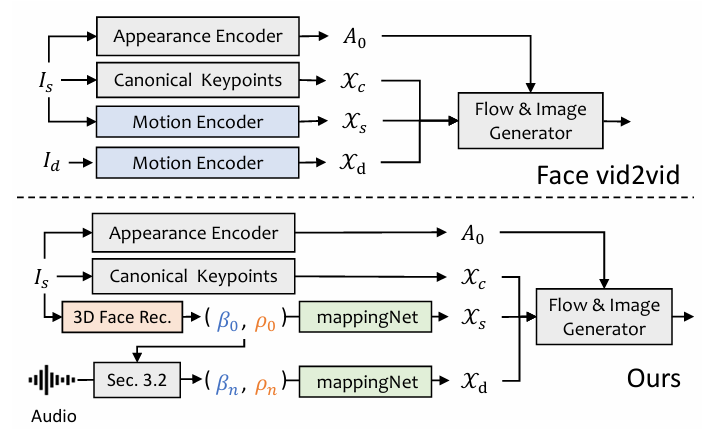
3D-aware Face Render:类似于 face-vid2vid 的结构能够实现从单张图中学习隐含的 3D 信息,但 face-vid2vid 需要真实视频作为驱动信号,而 3D-aware Face Render 利用 mappingNet 学习 3DMM 运动系数与无监督 3D 关键点之间关系。
## 环境配置
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/jupyterlab-pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.8
docker run -it --name=SadTalker --network=host --privileged=true --device=/dev/kfd --device=/dev/dri --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data:/path/SadTalker -v /opt/hyhal/:/opt/hyhal/:ro bash # 为以上拉取的docker的镜像ID替换
cd SadTalker
# 安装ffmpeg:格式转换相关
apt update
apt install ffmpeg
# 安装依赖
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
docker build --no-cache -t sadtalker:latest .
docker run -it --name=SadTalker --network=host --privileged=true --device=/dev/kfd --device=/dev/dri --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v /path/your_code_data:/path/SadTalker -v /opt/hyhal/:/opt/hyhal/:ro sadtalker /bin/bash
cd SadTalker
# 安装ffmpeg:格式转换相关
apt update
apt install ffmpeg
# 安装依赖
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install -r requirements.txt
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.sourcefind.cn/tool/
```
DTK软件栈:dtk24.04.2
python:python3.8
pytorch:2.1.0
torchvision:0.16.0
torchaudio:2.1.2
```
`Tips:以上dtk软件栈、python、pytorch等DCU相关工具版本需要严格一一对应`
2、其他非特殊库直接按照下面步骤进行安装
```
cd SadTalker
# 安装ffmpeg:格式转换相关
apt update
apt install ffmpeg
# 安装依赖
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install -r requirements.txt
```
## 数据集
推理测试所用数据已保存在SadTalker/dataset/下,目录结构如下:
```
SadTalker:
── dataset
│ ├── bus_chinese.wav
│ └── image.png
```
## 训练
官方暂未开放
## 推理
1、分别下载预训练模型和gfpgan模型
1-1 预训练模型
* [Google Drive](https://drive.google.com/file/d/1gwWh45pF7aelNP_P78uDJL8Sycep-K7j/view?usp=sharing)
* [GitHub Releases](https://github.com/OpenTalker/SadTalker/releases)
* [Baidu (百度云盘)](https://pan.baidu.com/s/1kb1BCPaLOWX1JJb9Czbn6w?pwd=sadt) (Password: `sadt`)
1-2 gfpgan模型
* [Google Drive](https://drive.google.com/file/d/19AIBsmfcHW6BRJmeqSFlG5fL445Xmsyi?usp=sharing)
* [GitHub Releases](https://github.com/OpenTalker/SadTalker/releases)
* [Baidu (百度云盘)](https://pan.baidu.com/s/1P4fRgk9gaSutZnn8YW034Q?pwd=sadt) (Password: `sadt`)
2、运行自动下载(GitHub Releases):
```
cd SadTalker
sh scripts/download_models.sh
```
模型目录结构如下,checkpoints是预训练模型,gfpgan是人脸检测和增强模型:
```
SadTalker:
── checkpoints
│ └── ...
── gfpgan
│ └── weights
│ └── ...
```
推理运行代码:
```
HIP_VISIBLE_DEVICES=0 python inference.py \
--driven_audio dataset/bus_chinese.wav \
--source_image dataset/image.png \
--still \
--preprocess full \
--enhancer gfpgan \
--result_dir result/
# --driven_audio 音频数据的路径
# --source_image 图片数据的路径
# --still 使用与原始图像相同的姿势参数,头部运动较少
# --preprocess full 对图像进行['crop', 'extcrop', 'resize', 'full', 'extfull']预处理
# --enhancer 使用或通过人脸修复网络[gfpgan, RestoreFormer]增强生成的人脸
# --result_dir 输出路径
# 更多参数设置可参考inference.py的parser注释和docs/best_practice.md
```
## result
默认推理结果为:

### 精度
无
## 应用场景
### 算法类别
`视频生成`
### 热点应用行业
`家具,电商,医疗,广媒,教育`
## 预训练权重
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/sadtalker_pytorch
## 参考资料
- https://github.com/OpenTalker/SadTalker