# SadTalker
## 论文
`SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation`
- https://arxiv.org/abs/2211.12194
## 模型结构
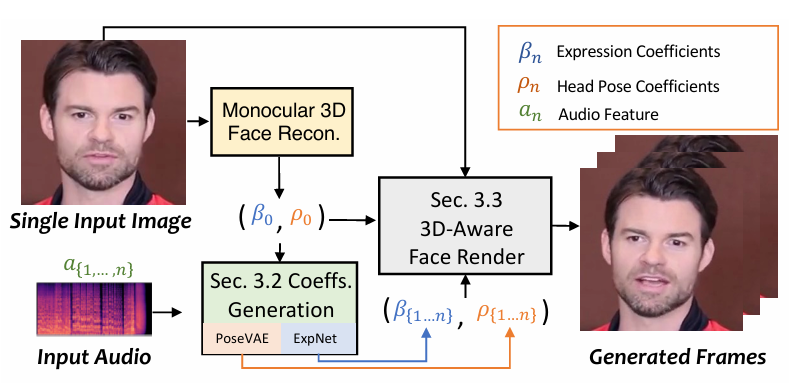
SadTalker利用 3DMM 系数作为中间表示。首先从原始图像中提取出系数,然后使用 ExpNet 和 PoseVAE 从音频中提取出真实的 3DMM 的系数(面部表情系数 β , 头部姿势 ρ),最后通过 3D-aware face render 生成得到最后的视频。
## 算法原理
将 3DMM(3D Morphable Models)的运动系数看做中间表达,将整个任务划分成两部分。训练的时候会分模型训练,在推理的时候是 end-to-end 的模式:
1、从语音中生成更加真实的运动系数(如 head pose、lip motion、eye blink),并且每个系数是单独学习的,这样会解耦来降低不确定性:
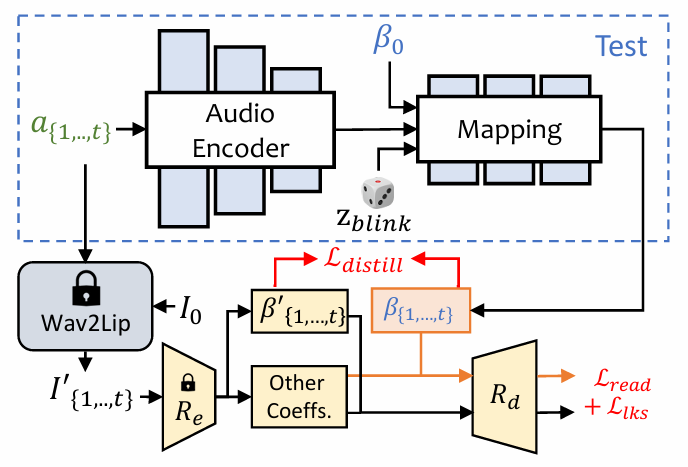
ExpNet:通过第一帧的 expression coefficient β 来将 expression motion 和 specific person 进行关联,为了降低在说话过程中其他面部部位的影响只使用 lip motion coefficient 作为 target coefficient 。其他不是很重要的面部动作(如眨眼)会使用额外的 landmark loss 来训练。
PoseVAE:训练时,pose VAE 在固定 n 帧上使用 encoder-decoder 的结构进行训练,encoder 和 decoder 输入包含连续的 t 帧 head pose ,且假设其服从高斯分布。decoder 中,网络学习的目标是从分布中通过采样来生成 t 帧 pose ,但不是直接生成 pose,而是学习和第一帧 pose ρ0 的残差,这样能保证生成的 pose 更连续、稳定、一致,所以也叫 conditional VAE,这里的 conditional 就是第一帧的 head pose。此外,还将每个声音的特征和 style identity 作为条件来作为 identity style。KL 散度用于衡量生成的 motion。MSE 和 GAN loss 用于保证生成的质量。
2、生成了 3DMM 系数后,会从原本的图片建立 3D 人脸,然后再生成最后的视频:
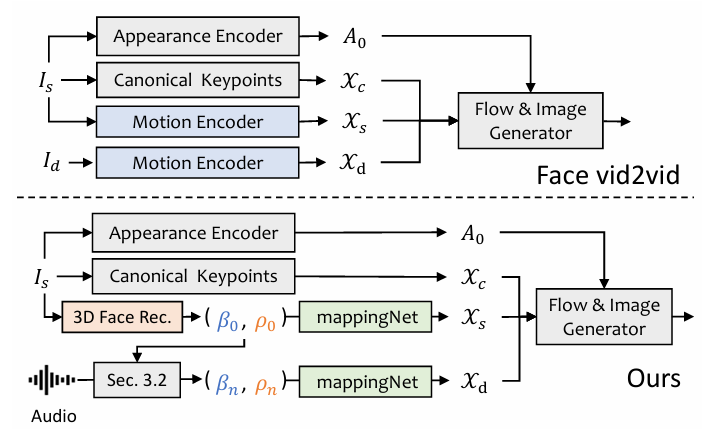
3D-aware Face Render:类似于 face-vid2vid 的结构能够实现从单张图中学习隐含的 3D 信息,但 face-vid2vid 需要真实视频作为驱动信号,而 3D-aware Face Render 利用 mappingNet 学习 3DMM 运动系数与无监督 3D 关键点之间关系。