# Sa2VA
Sa2VA:将SAM2与LLaVA结合,从而实现对静态和动态视觉内容的扎实、多模态理解。
## 论文
`Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos`
- https://arxiv.org/abs/2501.04001
## 模型结构
Sa2VA 是将基础视频分割模型 SAM-2 与高级视觉语言模型 LLaVA 相结合。基础模型结构都是Transformer结构。
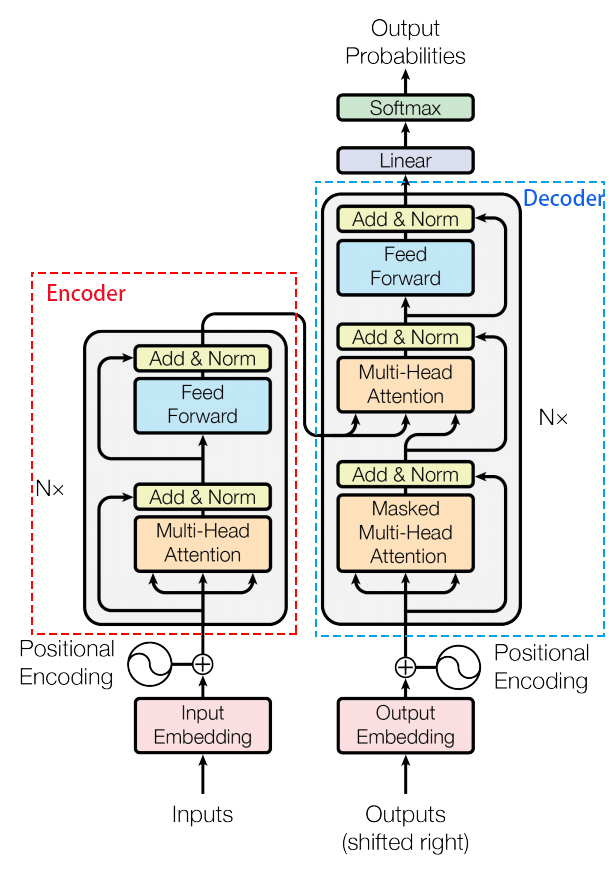
Transformer
## 算法原理
Sa2VA是第一个对图像和视频进行密集理解的统一模型。与通常仅限于特定模态和任务的现有多模态大型语言模型不同,Sa2VA支持广泛的图像和视频任务,包括引用分割和对话,只需进行最小的一次指令调整。Sa2VA将基础视频分割模型SAM-2与高级视觉语言模型LLaVA相结合,将文本、图像和视频统一到一个共享的LLM令牌空间中。
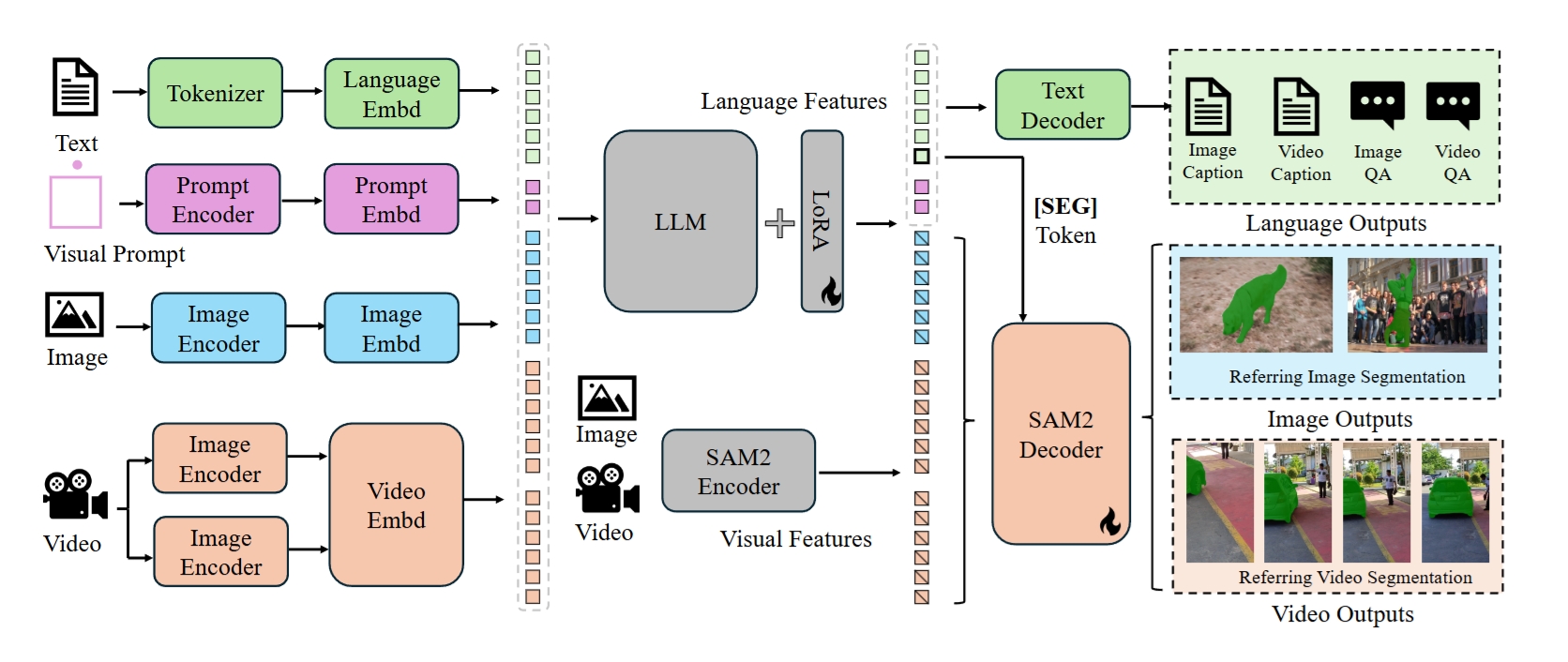
Sa2VA
## 环境配置
```
mv sa2va_pytorch sa2va # 去框架名后缀
# docker的-v 路径、docker_name和imageID根据实际情况修改
# pip安装时如果出现下载慢可以尝试别的镜像源
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.3-py3.10 # 本镜像imageID为:0291c26699b0
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=16G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --network=host --name docker_name imageID bash
cd /your_code_path/sa2va
cd deme
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd /your_code_path/sa2va/docker
docker build --no-cache -t codestral:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=16G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --network=host --name docker_name imageID bash
cd /your_code_path/sa2va
cd demo
pip install -r requirements.txt
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动: dtk24.04.3
python: python3.10
pytorch: 2.3.0
```
`Tips:以上DTK驱动、python、pytorch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirements.txt安装:
```
cd /your_code_path/sa2va
cd demo
pip install -r requirements.txt
```
## 数据集
该项目所需数据集较大,如下所示:
```
data/
├── video_datas
| ├── revos
| ├── mevis
| └── davis17
| └── chat_univi # video-chat data
| └── sam_v_full # please download this from sam-2 offical repp.
| └── sam_v_final_v3.json
├── ref_seg
| ├── refclef
| ├── refcoco
| ├── refcoco+
| ├── refcocog
| ├──
├── glamm_data
| ├── images
| ├── annotations
├── osprey-724k
| ├── Osprey-724K
| ├── coco
├── llava_data
| ├── llava_images
| ├── LLaVA-Instruct-150K
| ├── LLaVA-Pretrain
```
下载链接https://huggingface.co/datasets/Dense-World/Sa2VA-Training \
也可从[SCNet](http://113.200.138.88:18080/aidatasets/Sa2VA-Training)上高速下载。
## 训练
本项目训练所需计算资源较大,建议至少8卡。
```
bash tools/dist.sh train projects/llava_sam2/configs/sa2va_4b.py 8
```
## 推理
方式一
通过gradio启用webui界面推理:
```
# 如果访问不了huggingface请设置镜像,下同
# export HF_ENDPOINT=https://hf-mirror.com
HIP_VISIBLE_DEVICES=0 PYTHONPATH=. python projects/llava_sam2/gradio/app.py ByteDance/Sa2VA-4B
```
ps:注意gradio版本,这里测试了4.44.0是没问题的。
方式二
通过脚本,输入为视频图片序列和文本指令:
```
# 图片序列
HIP_VISIBLE_DEVICES=5 python demo/demo.py data/GOT-10k_Test_000001/ --model_path ByteDance/Sa2VA-4B --work-dir OUTPUT_DIR --text "Please describe the video content."
```
## result
方式一
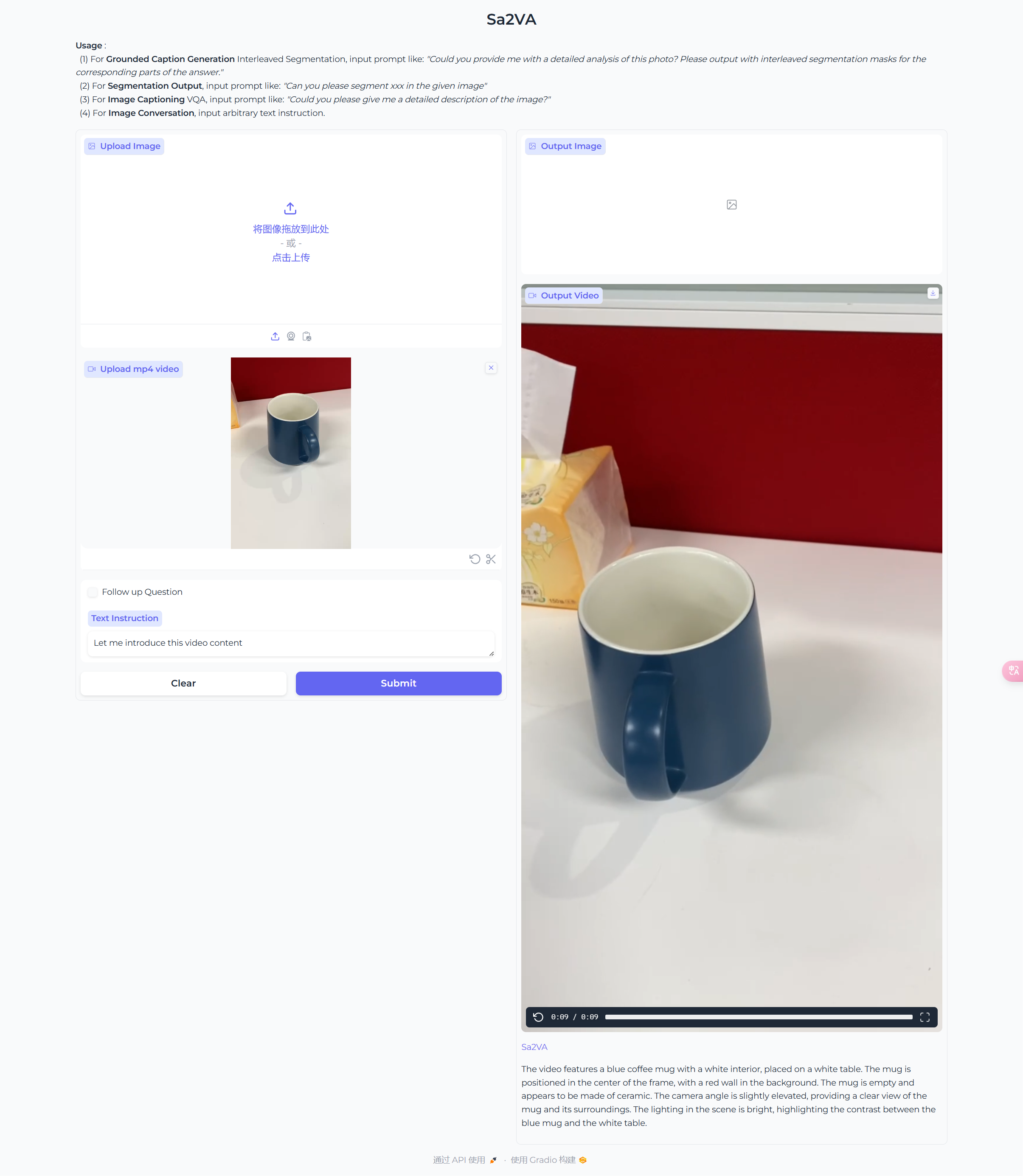
推理结果
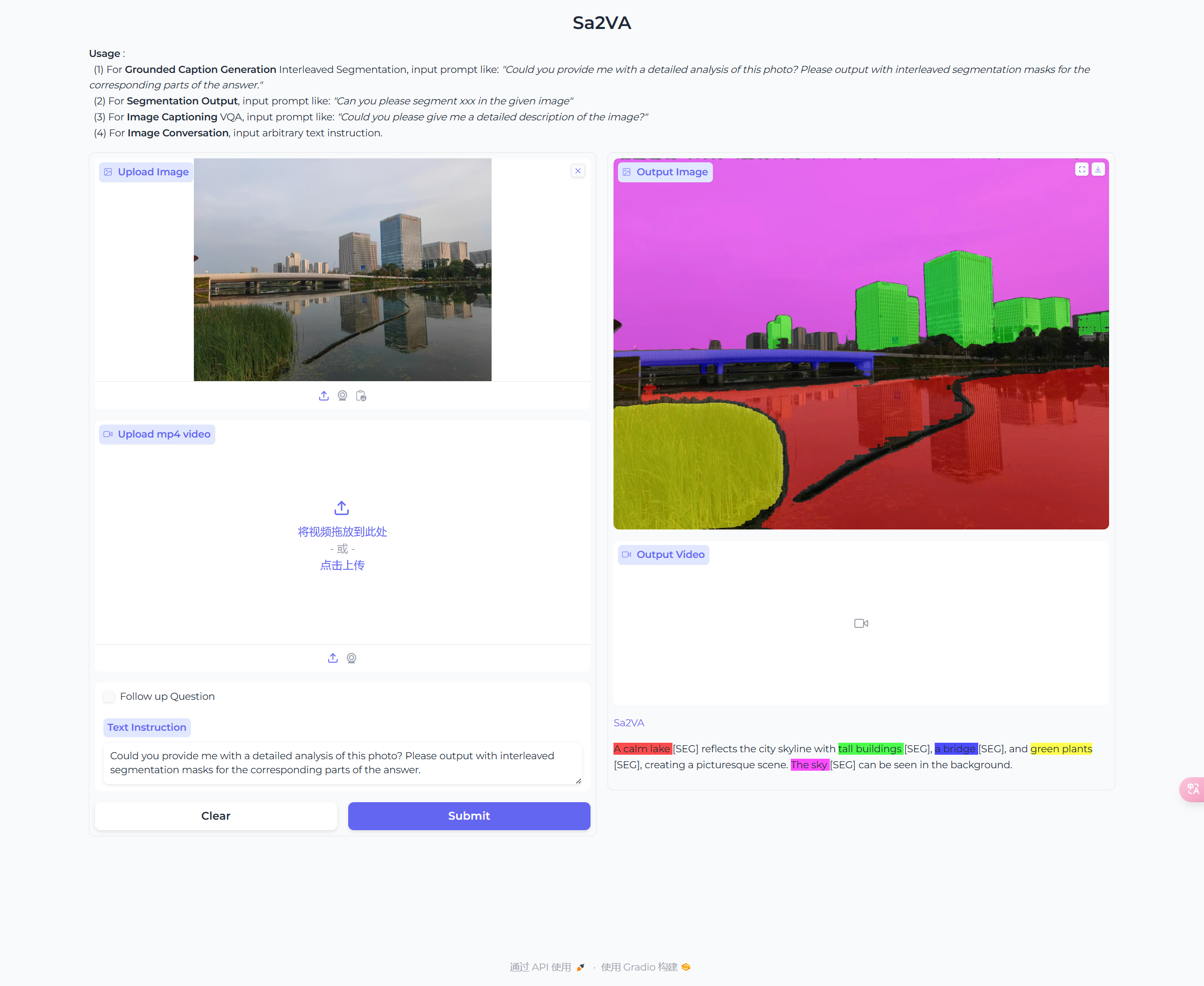
推理结果
方式二
输入视频序列为:data/GOT-10k_Test_000001;输入的指令提示为:"Please describe the video content."

GOT-10k_Test_000001
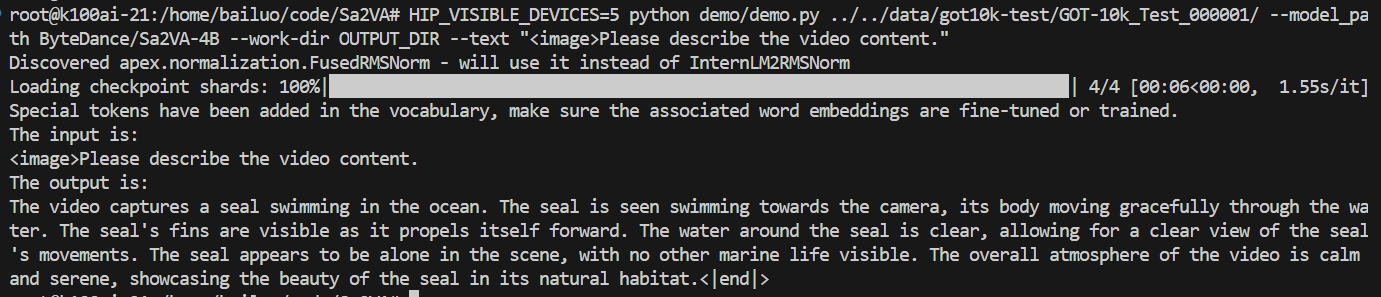
推理结果
### 精度
无。
## 应用场景
### 算法类别
`图像理解`
### 热点应用行业
`零售,制造,电商,医疗,教育`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/sa2va_pytorch
## 参考资料
- https://github.com/magic-research/Sa2VA