# Deploying the SE-ResNeXt101-32x4d model using Triton Inference Server
The [NVIDIA Triton Inference Server](https://github.com/NVIDIA/triton-inference-server) provides a datacenter and cloud inferencing solution optimized for NVIDIA GPUs. The server provides an inference service via an HTTP or gRPC endpoint, allowing remote clients to request inferencing for any number of GPU or CPU models being managed by the server.
This folder contains instructions on how to deploy and run inference on
Triton Inference Server as well as gather detailed performance analysis.
## Table Of Contents
*[Model overview](#model-overview)
*[Setup](#setup)
*[Inference container](#inference-container)
*[Deploying the model](#deploying-the-model)
*[Running the Triton Inference Server](#running-the-triton-inference-server)
The SE-ResNeXt101-32x4d is a [ResNeXt101-32x4d](https://arxiv.org/pdf/1611.05431.pdf)
model with added Squeeze-and-Excitation module introduced
in [Squeeze-and-Excitation Networks](https://arxiv.org/pdf/1709.01507.pdf) paper.
The SE-ResNeXt101-32x4d model can be deployed for inference on the [NVIDIA Triton Inference Server](https://github.com/NVIDIA/triton-inference-server) using
TorchScript, ONNX Runtime or TensorRT as an execution backend.
## Setup
This script requires trained SE-ResNeXt101-32x4d model checkpoint that can be used for deployment.
### Inference container
For easy-to-use deployment, a build script for special inference container was prepared. To build that container, go to the main repository folder and run:
Here `device=0,1,2,3` selects the GPUs indexed by ordinals `0,1,2` and `3`, respectively. The server will see only these GPUs. If you write `device=all`, then the server will see all the available GPUs. `PATH_TO_MODEL_REPOSITORY` indicates location to where the
deployed models were stored.
### Deploying the model
To deploy the SE-ResNext101-32x4d model into the Triton Inference Server, you must run the `deployer.py` script from inside the deployment Docker container to achieve a compatible format.
Here `device=0,1,2,3` selects GPUs indexed by ordinals `0,1,2` and `3`, respectively. The server will see only these GPUs. If you write `device=all`, then the server will see all the available GPUs. `PATH_TO_MODEL_REPOSITORY` indicates the location where the
deployed models were stored. An additional `--model-controle-mode` option allows to reload the model when it changes in the filesystem. It is a required option for benchmark scripts that works with multiple model versions on a single Triton Inference Server instance.
## Quick Start Guide
### Running the client
The client `client.py` checks the model accuracy against synthetic or real validation
data. The client connects to Triton Inference Server and performs inference.
Performance data can be gathered using the `perf_client` tool. To use this tool to measure performance for batch_size=32, the following command can be used:
For more information about `perf_client`, refer to the [documentation](https://docs.nvidia.com/deeplearning/sdk/triton-inference-server-master-branch-guide/docs/optimization.html#perf-client).
## Advanced
### Automated benchmark script
To automate benchmarks of different model configurations, a special benchmark script is located in `triton/scripts/benchmark.sh`. To use this script,
run Triton Inference Server and then execute the script as follows:
The benchmark script tests all supported backends with different batch sizes and server configuration. Logs from execution will be stored in `<LOG DIRECTORY>`.
To process static configuration logs, `triton/scripts/process_output.sh` script can be used.
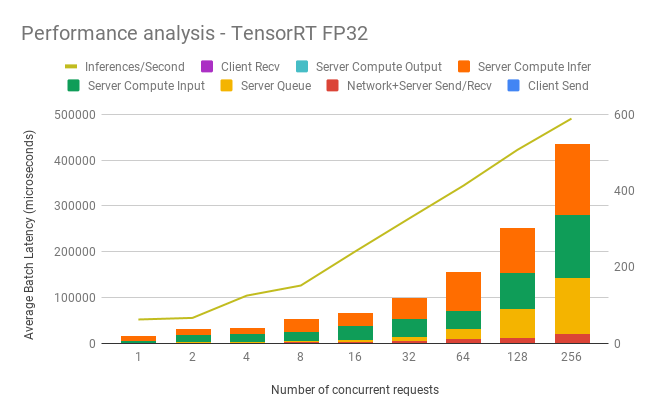
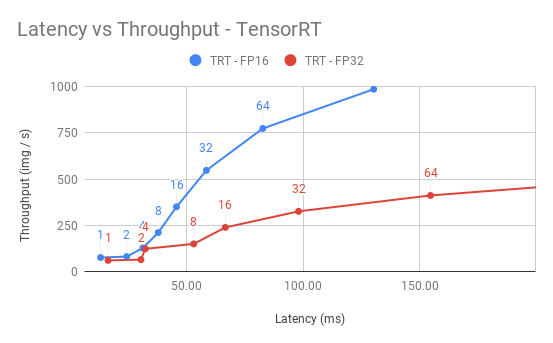
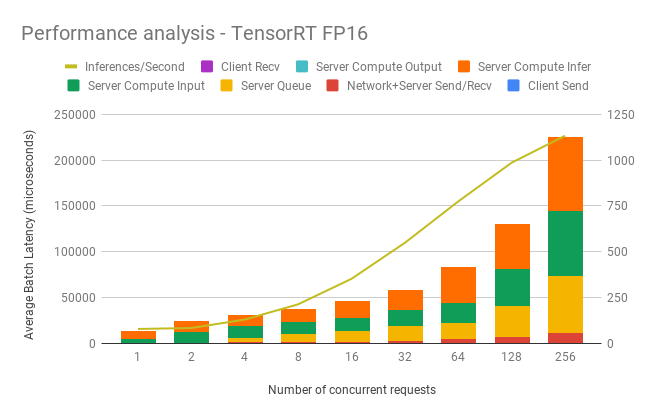
## Performance
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference).
### Dynamic batching performance
The Triton Inference Server has a dynamic batching mechanism built-in that can be enabled. When it is enabled, the server creates inference batches from multiple received requests. This allows us to achieve better performance than doing inference on each single request. The single request is assumed to be a single image that needs to be inferenced. With dynamic batching enabled, the server will concatenate single image requests into an inference batch. The upper bound of the size of the inference batch is set to 64. All these parameters are configurable.
Our results were obtained by running automated benchmark script.
Throughput is measured in images/second, and latency in milliseconds.

{kind=link}
{kind=link}
{kind=link}