# Mobile Video Networks (MoViNets)
[](https://colab.research.google.com/github/tensorflow/models/blob/master/official/vision/beta/projects/movinet/movinet_tutorial.ipynb)
[](https://tfhub.dev/google/collections/movinet)
[](https://arxiv.org/abs/2103.11511)
This repository is the official implementation of
[MoViNets: Mobile Video Networks for Efficient Video
Recognition](https://arxiv.org/abs/2103.11511).
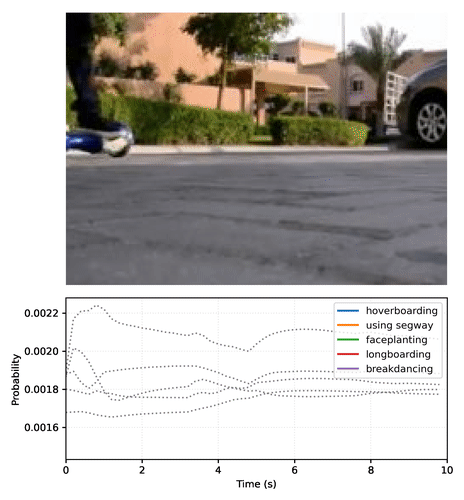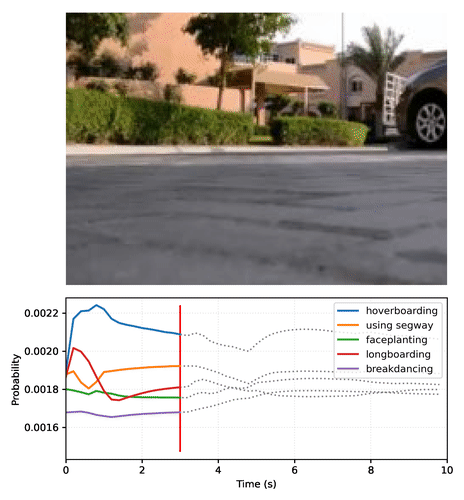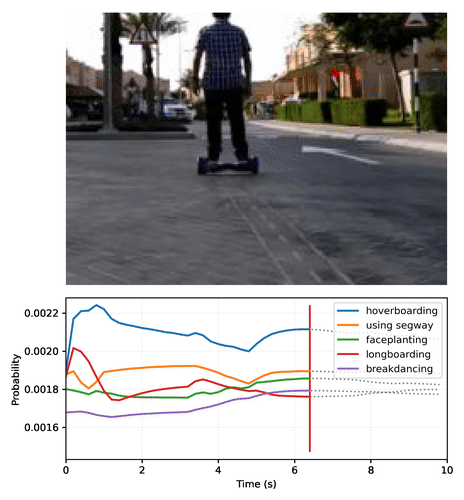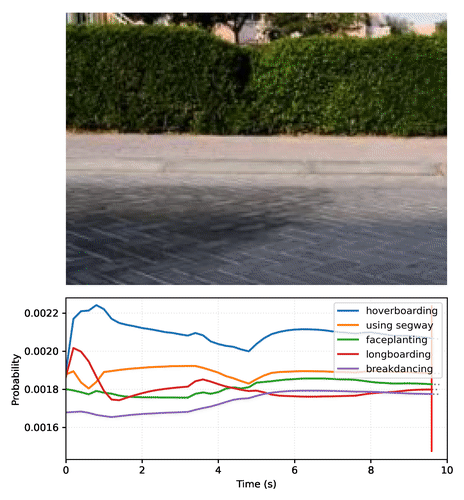
## Description
Mobile Video Networks (MoViNets) are efficient video classification models
runnable on mobile devices. MoViNets demonstrate state-of-the-art accuracy and
efficiency on several large-scale video action recognition datasets.
On [Kinetics 600](https://deepmind.com/research/open-source/kinetics),
MoViNet-A6 achieves 84.8% top-1 accuracy, outperforming recent
Vision Transformer models like [ViViT](https://arxiv.org/abs/2103.15691) (83.0%)
and [VATT](https://arxiv.org/abs/2104.11178) (83.6%) without any additional
training data, while using 10x fewer FLOPs. And streaming MoViNet-A0 achieves
72% accuracy while using 3x fewer FLOPs than MobileNetV3-large (68%).
There is a large gap between video model performance of accurate models and
efficient models for video action recognition. On the one hand, 2D MobileNet
CNNs are fast and can operate on streaming video in real time, but are prone to
be noisy and inaccurate. On the other hand, 3D CNNs are accurate, but are
memory and computation intensive and cannot operate on streaming video.
MoViNets bridge this gap, producing:
- State-of-the art efficiency and accuracy across the model family (MoViNet-A0
to A6).
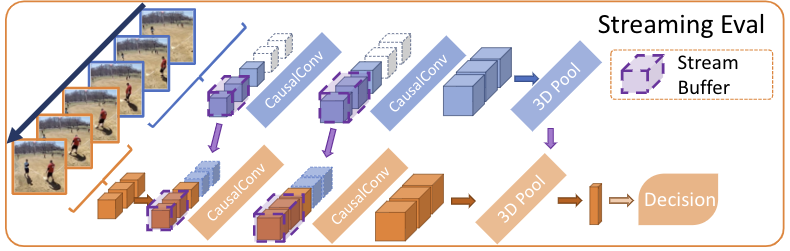
- Streaming models with 3D causal convolutions substantially reducing memory
usage.
- Temporal ensembles of models to boost efficiency even higher.
MoViNets also improve computational efficiency by outputting high-quality
predictions frame by frame, as opposed to the traditional multi-clip evaluation
approach that performs redundant computation and limits temporal scope.

## History
- **2021-05-30** Add streaming MoViNet checkpoints and examples.
- **2021-05-11** Initial Commit.
## Authors and Maintainers
* Dan Kondratyuk ([@hyperparticle](https://github.com/hyperparticle))
* Liangzhe Yuan ([@yuanliangzhe](https://github.com/yuanliangzhe))
* Yeqing Li ([@yeqingli](https://github.com/yeqingli))
## Table of Contents
- [Requirements](#requirements)
- [Results and Pretrained Weights](#results-and-pretrained-weights)
- [Kinetics 600](#kinetics-600)
- [Prediction Examples](#prediction-examples)
- [Training and Evaluation](#training-and-evaluation)
- [References](#references)
- [License](#license)
- [Citation](#citation)
## Requirements
[](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0)
[](https://www.python.org/downloads/release/python-360/)
To install requirements:
```shell
pip install -r requirements.txt
```
## Results and Pretrained Weights
[](https://tfhub.dev/google/collections/movinet)
[](https://tensorboard.dev/experiment/Q07RQUlVRWOY4yDw3SnSkA/)
### Kinetics 600

[tensorboard.dev summary](https://tensorboard.dev/experiment/Q07RQUlVRWOY4yDw3SnSkA/)
of training runs across all models.
The table below summarizes the performance of each model on
[Kinetics 600](https://deepmind.com/research/open-source/kinetics)
and provides links to download pretrained models. All models are evaluated on
single clips with the same resolution as training.
Note: MoViNet-A6 can be constructed as an ensemble of MoViNet-A4 and
MoViNet-A5.
#### Base Models
Base models implement standard 3D convolutions without stream buffers.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | Input Shape | GFLOPs\* | Chekpoint | TF Hub SavedModel |
|------------|----------------|----------------|-------------|----------|-----------|-------------------|
| MoViNet-A0-Base | 72.28 | 90.92 | 50 x 172 x 172 | 2.7 | [checkpoint (12 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a0/base/kinetics-600/classification/) |
| MoViNet-A1-Base | 76.69 | 93.40 | 50 x 172 x 172 | 6.0 | [checkpoint (18 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a1/base/kinetics-600/classification/) |
| MoViNet-A2-Base | 78.62 | 94.17 | 50 x 224 x 224 | 10 | [checkpoint (20 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a2/base/kinetics-600/classification/) |
| MoViNet-A3-Base | 81.79 | 95.67 | 120 x 256 x 256 | 57 | [checkpoint (29 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a3/base/kinetics-600/classification/) |
| MoViNet-A4-Base | 83.48 | 96.16 | 80 x 290 x 290 | 110 | [checkpoint (44 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a4/base/kinetics-600/classification/) |
| MoViNet-A5-Base | 84.27 | 96.39 | 120 x 320 x 320 | 280 | [checkpoint (72 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_base.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a5/base/kinetics-600/classification/) |
\*GFLOPs per video on Kinetics 600.
#### Streaming Models
Streaming models implement causal 3D convolutions with stream buffers.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | Input Shape\* | GFLOPs\*\* | Chekpoint | TF Hub SavedModel |
|------------|----------------|----------------|---------------|------------|-----------|-------------------|
| MoViNet-A0-Stream | 72.05 | 90.63 | 50 x 172 x 172 | 2.7 | [checkpoint (12 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a0/stream/kinetics-600/classification/) |
| MoViNet-A1-Stream | 76.45 | 93.25 | 50 x 172 x 172 | 6.0 | [checkpoint (18 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a1/stream/kinetics-600/classification/) |
| MoViNet-A2-Stream | 78.40 | 94.05 | 50 x 224 x 224 | 10 | [checkpoint (20 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a2/stream/kinetics-600/classification/) |
| MoViNet-A3-Stream | 80.09 | 94.84 | 120 x 256 x 256 | 57 | [checkpoint (29 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a3/stream/kinetics-600/classification/) |
| MoViNet-A4-Stream | 81.49 | 95.66 | 80 x 290 x 290 | 110 | [checkpoint (44 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a4/stream/kinetics-600/classification/) |
| MoViNet-A5-Stream | 82.37 | 95.79 | 120 x 320 x 320 | 280 | [checkpoint (72 MB)](https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_stream.tar.gz) | [tfhub](https://tfhub.dev/tensorflow/movinet/a5/stream/kinetics-600/classification/) |
\*In streaming mode, the number of frames correspond to the total accumulated
duration of the 10-second clip.
\*\*GFLOPs per video on Kinetics 600.
## Prediction Examples
Please check out our [Colab Notebook](https://colab.research.google.com/github/tensorflow/models/tree/master/official/vision/beta/projects/movinet/movinet_tutorial.ipynb)
to get started with MoViNets.
This section provides examples on how to run prediction.
For base models, run the following:
```python
import tensorflow as tf
from official.vision.beta.projects.movinet.modeling import movinet
from official.vision.beta.projects.movinet.modeling import movinet_model
# Create backbone and model.
backbone = movinet.Movinet(
model_id='a0',
causal=True,
use_external_states=True,
)
model = movinet_model.MovinetClassifier(
backbone, num_classes=600, output_states=True)
# Create your example input here.
# Refer to the paper for recommended input shapes.
inputs = tf.ones([1, 8, 172, 172, 3])
# [Optional] Build the model and load a pretrained checkpoint
model.build(inputs.shape)
checkpoint_dir = '/path/to/checkpoint'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
# Run the model prediction.
output = model(inputs)
prediction = tf.argmax(output, -1)
```
For streaming models, run the following:
```python
import tensorflow as tf
from official.vision.beta.projects.movinet.modeling import movinet
from official.vision.beta.projects.movinet.modeling import movinet_model
# Create backbone and model.
backbone = movinet.Movinet(
model_id='a0',
causal=True,
use_external_states=True,
)
model = movinet_model.MovinetClassifier(
backbone, num_classes=600, output_states=True)
# Create your example input here.
# Refer to the paper for recommended input shapes.
inputs = tf.ones([1, 8, 172, 172, 3])
# [Optional] Build the model and load a pretrained checkpoint
model.build(inputs.shape)
checkpoint_dir = '/path/to/checkpoint'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
# Split the video into individual frames.
# Note: we can also split into larger clips as well (e.g., 8-frame clips).
# Running on larger clips will slightly reduce latency overhead, but
# will consume more memory.
frames = tf.split(inputs, inputs.shape[1], axis=1)
# Initialize the dict of states. All state tensors are initially zeros.
init_states = model.init_states(tf.shape(inputs))
# Run the model prediction by looping over each frame.
states = init_states
predictions = []
for frame in frames:
output, states = model({**states, 'image': frame})
predictions.append(output)
# The video classification will simply be the last output of the model.
final_prediction = tf.argmax(predictions[-1], -1)
# Alternatively, we can run the network on the entire input video.
# The output should be effectively the same
# (but it may differ a small amount due to floating point errors).
non_streaming_output, _ = model({**init_states, 'image': inputs})
non_streaming_prediction = tf.argmax(non_streaming_output, -1)
```
## Training and Evaluation
Run this command line for continuous training and evaluation.
```shell
MODE=train_and_eval # Can also be 'train'
CONFIG_FILE=official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
python3 official/vision/beta/projects/movinet/train.py \
--experiment=movinet_kinetics600 \
--mode=${MODE} \
--model_dir=/tmp/movinet/ \
--config_file=${CONFIG_FILE} \
--params_override="" \
--gin_file="" \
--gin_params="" \
--tpu="" \
--tf_data_service=""
```
Run this command line for evaluation.
```shell
MODE=eval # Can also be 'eval_continuous' for use during training
CONFIG_FILE=official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
python3 official/vision/beta/projects/movinet/train.py \
--experiment=movinet_kinetics600 \
--mode=${MODE} \
--model_dir=/tmp/movinet/ \
--config_file=${CONFIG_FILE} \
--params_override="" \
--gin_file="" \
--gin_params="" \
--tpu="" \
--tf_data_service=""
```
## License
[](https://opensource.org/licenses/Apache-2.0)
This project is licensed under the terms of the **Apache License 2.0**.
## Citation
If you want to cite this code in your research paper, please use the following
information.
```
@article{kondratyuk2021movinets,
title={MoViNets: Mobile Video Networks for Efficient Video Recognition},
author={Dan Kondratyuk, Liangzhe Yuan, Yandong Li, Li Zhang, Matthew Brown, and Boqing Gong},
journal={arXiv preprint arXiv:2103.11511},
year={2021}
}
```