"
- ]
- },
- "metadata": {
- "needs_background": "light"
- },
- "output_type": "display_data"
- }
- ],
- "source": [
- "# Visualize the results.\n",
- "plt.figure(figsize=(10, 8))\n",
- "\n",
- "# Plot the waveform.\n",
- "plt.subplot(3, 1, 1)\n",
- "plt.plot(waveform)\n",
- "plt.xlim([0, len(waveform)])\n",
- "# Plot the log-mel spectrogram (returned by the model).\n",
- "plt.subplot(3, 1, 2)\n",
- "plt.imshow(spectrogram.T, aspect='auto', interpolation='nearest', origin='bottom')\n",
- "\n",
- "# Plot and label the model output scores for the top-scoring classes.\n",
- "mean_scores = np.mean(scores, axis=0)\n",
- "top_N = 10\n",
- "top_class_indices = np.argsort(mean_scores)[::-1][:top_N]\n",
- "plt.subplot(3, 1, 3)\n",
- "plt.imshow(scores[:, top_class_indices].T, aspect='auto', interpolation='nearest', cmap='gray_r')\n",
- "# Compensate for the PATCH_WINDOW_SECONDS (0.96 s) context window to align with spectrogram.\n",
- "patch_padding = (params.PATCH_WINDOW_SECONDS / 2) / params.PATCH_HOP_SECONDS\n",
- "plt.xlim([-patch_padding, scores.shape[0] + patch_padding])\n",
- "# Label the top_N classes.\n",
- "yticks = range(0, top_N, 1)\n",
- "plt.yticks(yticks, [class_names[top_class_indices[x]] for x in yticks])\n",
- "_ = plt.ylim(-0.5 + np.array([top_N, 0]))\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.7.6"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 2
-}
diff --git a/research/autoaugment/README.md b/research/autoaugment/README.md
deleted file mode 100644
index a26f4872cc3d30adb6d951fbd7dae53e7530a77f..0000000000000000000000000000000000000000
--- a/research/autoaugment/README.md
+++ /dev/null
@@ -1,70 +0,0 @@
-
-
-
-Train Wide-ResNet, Shake-Shake and ShakeDrop models on CIFAR-10
-and CIFAR-100 dataset with AutoAugment.
-
-The CIFAR-10/CIFAR-100 data can be downloaded from:
-https://www.cs.toronto.edu/~kriz/cifar.html. Use the Python version instead of the binary version.
-
-The code replicates the results from Tables 1 and 2 on CIFAR-10/100 with the
-following models: Wide-ResNet-28-10, Shake-Shake (26 2x32d), Shake-Shake (26
-2x96d) and PyramidNet+ShakeDrop.
-
-Related papers:
-
-AutoAugment: Learning Augmentation Policies from Data
-
-https://arxiv.org/abs/1805.09501
-
-Wide Residual Networks
-
-https://arxiv.org/abs/1605.07146
-
-Shake-Shake regularization
-
-https://arxiv.org/abs/1705.07485
-
-ShakeDrop regularization
-
-https://arxiv.org/abs/1802.02375
-
-Settings:
-
-CIFAR-10 Model | Learning Rate | Weight Decay | Num. Epochs | Batch Size
----------------------- | ------------- | ------------ | ----------- | ----------
-Wide-ResNet-28-10 | 0.1 | 5e-4 | 200 | 128
-Shake-Shake (26 2x32d) | 0.01 | 1e-3 | 1800 | 128
-Shake-Shake (26 2x96d) | 0.01 | 1e-3 | 1800 | 128
-PyramidNet + ShakeDrop | 0.05 | 5e-5 | 1800 | 64
-
-Prerequisite:
-
-1. Install TensorFlow. Be sure to run the code using python2 and not python3.
-
-2. Download CIFAR-10/CIFAR-100 dataset.
-
-```shell
-curl -o cifar-10-binary.tar.gz https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
-curl -o cifar-100-binary.tar.gz https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
-```
-
-How to run:
-
-```shell
-# cd to the your workspace.
-# Specify the directory where dataset is located using the data_path flag.
-# Note: User can split samples from training set into the eval set by changing train_size and validation_size.
-
-# For example, to train the Wide-ResNet-28-10 model on a GPU.
-python train_cifar.py --model_name=wrn \
- --checkpoint_dir=/tmp/training \
- --data_path=/tmp/data \
- --dataset='cifar10' \
- --use_cpu=0
-```
-
-## Contact for Issues
-
-* Barret Zoph, @barretzoph
-* Ekin Dogus Cubuk,
diff --git a/research/autoaugment/augmentation_transforms.py b/research/autoaugment/augmentation_transforms.py
deleted file mode 100644
index 584cce45eb57d4796653d2dc8264cdb6a6953fbe..0000000000000000000000000000000000000000
--- a/research/autoaugment/augmentation_transforms.py
+++ /dev/null
@@ -1,451 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Transforms used in the Augmentation Policies."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import random
-import numpy as np
-# pylint:disable=g-multiple-import
-from PIL import ImageOps, ImageEnhance, ImageFilter, Image
-# pylint:enable=g-multiple-import
-
-
-IMAGE_SIZE = 32
-# What is the dataset mean and std of the images on the training set
-MEANS = [0.49139968, 0.48215841, 0.44653091]
-STDS = [0.24703223, 0.24348513, 0.26158784]
-PARAMETER_MAX = 10 # What is the max 'level' a transform could be predicted
-
-
-def random_flip(x):
- """Flip the input x horizontally with 50% probability."""
- if np.random.rand(1)[0] > 0.5:
- return np.fliplr(x)
- return x
-
-
-def zero_pad_and_crop(img, amount=4):
- """Zero pad by `amount` zero pixels on each side then take a random crop.
-
- Args:
- img: numpy image that will be zero padded and cropped.
- amount: amount of zeros to pad `img` with horizontally and verically.
-
- Returns:
- The cropped zero padded img. The returned numpy array will be of the same
- shape as `img`.
- """
- padded_img = np.zeros((img.shape[0] + amount * 2, img.shape[1] + amount * 2,
- img.shape[2]))
- padded_img[amount:img.shape[0] + amount, amount:
- img.shape[1] + amount, :] = img
- top = np.random.randint(low=0, high=2 * amount)
- left = np.random.randint(low=0, high=2 * amount)
- new_img = padded_img[top:top + img.shape[0], left:left + img.shape[1], :]
- return new_img
-
-
-def create_cutout_mask(img_height, img_width, num_channels, size):
- """Creates a zero mask used for cutout of shape `img_height` x `img_width`.
-
- Args:
- img_height: Height of image cutout mask will be applied to.
- img_width: Width of image cutout mask will be applied to.
- num_channels: Number of channels in the image.
- size: Size of the zeros mask.
-
- Returns:
- A mask of shape `img_height` x `img_width` with all ones except for a
- square of zeros of shape `size` x `size`. This mask is meant to be
- elementwise multiplied with the original image. Additionally returns
- the `upper_coord` and `lower_coord` which specify where the cutout mask
- will be applied.
- """
- assert img_height == img_width
-
- # Sample center where cutout mask will be applied
- height_loc = np.random.randint(low=0, high=img_height)
- width_loc = np.random.randint(low=0, high=img_width)
-
- # Determine upper right and lower left corners of patch
- upper_coord = (max(0, height_loc - size // 2), max(0, width_loc - size // 2))
- lower_coord = (min(img_height, height_loc + size // 2),
- min(img_width, width_loc + size // 2))
- mask_height = lower_coord[0] - upper_coord[0]
- mask_width = lower_coord[1] - upper_coord[1]
- assert mask_height > 0
- assert mask_width > 0
-
- mask = np.ones((img_height, img_width, num_channels))
- zeros = np.zeros((mask_height, mask_width, num_channels))
- mask[upper_coord[0]:lower_coord[0], upper_coord[1]:lower_coord[1], :] = (
- zeros)
- return mask, upper_coord, lower_coord
-
-
-def cutout_numpy(img, size=16):
- """Apply cutout with mask of shape `size` x `size` to `img`.
-
- The cutout operation is from the paper https://arxiv.org/abs/1708.04552.
- This operation applies a `size`x`size` mask of zeros to a random location
- within `img`.
-
- Args:
- img: Numpy image that cutout will be applied to.
- size: Height/width of the cutout mask that will be
-
- Returns:
- A numpy tensor that is the result of applying the cutout mask to `img`.
- """
- img_height, img_width, num_channels = (img.shape[0], img.shape[1],
- img.shape[2])
- assert len(img.shape) == 3
- mask, _, _ = create_cutout_mask(img_height, img_width, num_channels, size)
- return img * mask
-
-
-def float_parameter(level, maxval):
- """Helper function to scale `val` between 0 and maxval .
-
- Args:
- level: Level of the operation that will be between [0, `PARAMETER_MAX`].
- maxval: Maximum value that the operation can have. This will be scaled
- to level/PARAMETER_MAX.
-
- Returns:
- A float that results from scaling `maxval` according to `level`.
- """
- return float(level) * maxval / PARAMETER_MAX
-
-
-def int_parameter(level, maxval):
- """Helper function to scale `val` between 0 and maxval .
-
- Args:
- level: Level of the operation that will be between [0, `PARAMETER_MAX`].
- maxval: Maximum value that the operation can have. This will be scaled
- to level/PARAMETER_MAX.
-
- Returns:
- An int that results from scaling `maxval` according to `level`.
- """
- return int(level * maxval / PARAMETER_MAX)
-
-
-def pil_wrap(img):
- """Convert the `img` numpy tensor to a PIL Image."""
- return Image.fromarray(
- np.uint8((img * STDS + MEANS) * 255.0)).convert('RGBA')
-
-
-def pil_unwrap(pil_img):
- """Converts the PIL img to a numpy array."""
- pic_array = (np.array(pil_img.getdata()).reshape((32, 32, 4)) / 255.0)
- i1, i2 = np.where(pic_array[:, :, 3] == 0)
- pic_array = (pic_array[:, :, :3] - MEANS) / STDS
- pic_array[i1, i2] = [0, 0, 0]
- return pic_array
-
-
-def apply_policy(policy, img):
- """Apply the `policy` to the numpy `img`.
-
- Args:
- policy: A list of tuples with the form (name, probability, level) where
- `name` is the name of the augmentation operation to apply, `probability`
- is the probability of applying the operation and `level` is what strength
- the operation to apply.
- img: Numpy image that will have `policy` applied to it.
-
- Returns:
- The result of applying `policy` to `img`.
- """
- pil_img = pil_wrap(img)
- for xform in policy:
- assert len(xform) == 3
- name, probability, level = xform
- xform_fn = NAME_TO_TRANSFORM[name].pil_transformer(probability, level)
- pil_img = xform_fn(pil_img)
- return pil_unwrap(pil_img)
-
-
-class TransformFunction(object):
- """Wraps the Transform function for pretty printing options."""
-
- def __init__(self, func, name):
- self.f = func
- self.name = name
-
- def __repr__(self):
- return '<' + self.name + '>'
-
- def __call__(self, pil_img):
- return self.f(pil_img)
-
-
-class TransformT(object):
- """Each instance of this class represents a specific transform."""
-
- def __init__(self, name, xform_fn):
- self.name = name
- self.xform = xform_fn
-
- def pil_transformer(self, probability, level):
-
- def return_function(im):
- if random.random() < probability:
- im = self.xform(im, level)
- return im
-
- name = self.name + '({:.1f},{})'.format(probability, level)
- return TransformFunction(return_function, name)
-
- def do_transform(self, image, level):
- f = self.pil_transformer(PARAMETER_MAX, level)
- return pil_unwrap(f(pil_wrap(image)))
-
-
-################## Transform Functions ##################
-identity = TransformT('identity', lambda pil_img, level: pil_img)
-flip_lr = TransformT(
- 'FlipLR',
- lambda pil_img, level: pil_img.transpose(Image.FLIP_LEFT_RIGHT))
-flip_ud = TransformT(
- 'FlipUD',
- lambda pil_img, level: pil_img.transpose(Image.FLIP_TOP_BOTTOM))
-# pylint:disable=g-long-lambda
-auto_contrast = TransformT(
- 'AutoContrast',
- lambda pil_img, level: ImageOps.autocontrast(
- pil_img.convert('RGB')).convert('RGBA'))
-equalize = TransformT(
- 'Equalize',
- lambda pil_img, level: ImageOps.equalize(
- pil_img.convert('RGB')).convert('RGBA'))
-invert = TransformT(
- 'Invert',
- lambda pil_img, level: ImageOps.invert(
- pil_img.convert('RGB')).convert('RGBA'))
-# pylint:enable=g-long-lambda
-blur = TransformT(
- 'Blur', lambda pil_img, level: pil_img.filter(ImageFilter.BLUR))
-smooth = TransformT(
- 'Smooth',
- lambda pil_img, level: pil_img.filter(ImageFilter.SMOOTH))
-
-
-def _rotate_impl(pil_img, level):
- """Rotates `pil_img` from -30 to 30 degrees depending on `level`."""
- degrees = int_parameter(level, 30)
- if random.random() > 0.5:
- degrees = -degrees
- return pil_img.rotate(degrees)
-
-
-rotate = TransformT('Rotate', _rotate_impl)
-
-
-def _posterize_impl(pil_img, level):
- """Applies PIL Posterize to `pil_img`."""
- level = int_parameter(level, 4)
- return ImageOps.posterize(pil_img.convert('RGB'), 4 - level).convert('RGBA')
-
-
-posterize = TransformT('Posterize', _posterize_impl)
-
-
-def _shear_x_impl(pil_img, level):
- """Applies PIL ShearX to `pil_img`.
-
- The ShearX operation shears the image along the horizontal axis with `level`
- magnitude.
-
- Args:
- pil_img: Image in PIL object.
- level: Strength of the operation specified as an Integer from
- [0, `PARAMETER_MAX`].
-
- Returns:
- A PIL Image that has had ShearX applied to it.
- """
- level = float_parameter(level, 0.3)
- if random.random() > 0.5:
- level = -level
- return pil_img.transform((32, 32), Image.AFFINE, (1, level, 0, 0, 1, 0))
-
-
-shear_x = TransformT('ShearX', _shear_x_impl)
-
-
-def _shear_y_impl(pil_img, level):
- """Applies PIL ShearY to `pil_img`.
-
- The ShearY operation shears the image along the vertical axis with `level`
- magnitude.
-
- Args:
- pil_img: Image in PIL object.
- level: Strength of the operation specified as an Integer from
- [0, `PARAMETER_MAX`].
-
- Returns:
- A PIL Image that has had ShearX applied to it.
- """
- level = float_parameter(level, 0.3)
- if random.random() > 0.5:
- level = -level
- return pil_img.transform((32, 32), Image.AFFINE, (1, 0, 0, level, 1, 0))
-
-
-shear_y = TransformT('ShearY', _shear_y_impl)
-
-
-def _translate_x_impl(pil_img, level):
- """Applies PIL TranslateX to `pil_img`.
-
- Translate the image in the horizontal direction by `level`
- number of pixels.
-
- Args:
- pil_img: Image in PIL object.
- level: Strength of the operation specified as an Integer from
- [0, `PARAMETER_MAX`].
-
- Returns:
- A PIL Image that has had TranslateX applied to it.
- """
- level = int_parameter(level, 10)
- if random.random() > 0.5:
- level = -level
- return pil_img.transform((32, 32), Image.AFFINE, (1, 0, level, 0, 1, 0))
-
-
-translate_x = TransformT('TranslateX', _translate_x_impl)
-
-
-def _translate_y_impl(pil_img, level):
- """Applies PIL TranslateY to `pil_img`.
-
- Translate the image in the vertical direction by `level`
- number of pixels.
-
- Args:
- pil_img: Image in PIL object.
- level: Strength of the operation specified as an Integer from
- [0, `PARAMETER_MAX`].
-
- Returns:
- A PIL Image that has had TranslateY applied to it.
- """
- level = int_parameter(level, 10)
- if random.random() > 0.5:
- level = -level
- return pil_img.transform((32, 32), Image.AFFINE, (1, 0, 0, 0, 1, level))
-
-
-translate_y = TransformT('TranslateY', _translate_y_impl)
-
-
-def _crop_impl(pil_img, level, interpolation=Image.BILINEAR):
- """Applies a crop to `pil_img` with the size depending on the `level`."""
- cropped = pil_img.crop((level, level, IMAGE_SIZE - level, IMAGE_SIZE - level))
- resized = cropped.resize((IMAGE_SIZE, IMAGE_SIZE), interpolation)
- return resized
-
-
-crop_bilinear = TransformT('CropBilinear', _crop_impl)
-
-
-def _solarize_impl(pil_img, level):
- """Applies PIL Solarize to `pil_img`.
-
- Translate the image in the vertical direction by `level`
- number of pixels.
-
- Args:
- pil_img: Image in PIL object.
- level: Strength of the operation specified as an Integer from
- [0, `PARAMETER_MAX`].
-
- Returns:
- A PIL Image that has had Solarize applied to it.
- """
- level = int_parameter(level, 256)
- return ImageOps.solarize(pil_img.convert('RGB'), 256 - level).convert('RGBA')
-
-
-solarize = TransformT('Solarize', _solarize_impl)
-
-
-def _cutout_pil_impl(pil_img, level):
- """Apply cutout to pil_img at the specified level."""
- size = int_parameter(level, 20)
- if size <= 0:
- return pil_img
- img_height, img_width, num_channels = (32, 32, 3)
- _, upper_coord, lower_coord = (
- create_cutout_mask(img_height, img_width, num_channels, size))
- pixels = pil_img.load() # create the pixel map
- for i in range(upper_coord[0], lower_coord[0]): # for every col:
- for j in range(upper_coord[1], lower_coord[1]): # For every row
- pixels[i, j] = (125, 122, 113, 0) # set the colour accordingly
- return pil_img
-
-cutout = TransformT('Cutout', _cutout_pil_impl)
-
-
-def _enhancer_impl(enhancer):
- """Sets level to be between 0.1 and 1.8 for ImageEnhance transforms of PIL."""
- def impl(pil_img, level):
- v = float_parameter(level, 1.8) + .1 # going to 0 just destroys it
- return enhancer(pil_img).enhance(v)
- return impl
-
-
-color = TransformT('Color', _enhancer_impl(ImageEnhance.Color))
-contrast = TransformT('Contrast', _enhancer_impl(ImageEnhance.Contrast))
-brightness = TransformT('Brightness', _enhancer_impl(
- ImageEnhance.Brightness))
-sharpness = TransformT('Sharpness', _enhancer_impl(ImageEnhance.Sharpness))
-
-ALL_TRANSFORMS = [
- flip_lr,
- flip_ud,
- auto_contrast,
- equalize,
- invert,
- rotate,
- posterize,
- crop_bilinear,
- solarize,
- color,
- contrast,
- brightness,
- sharpness,
- shear_x,
- shear_y,
- translate_x,
- translate_y,
- cutout,
- blur,
- smooth
-]
-
-NAME_TO_TRANSFORM = {t.name: t for t in ALL_TRANSFORMS}
-TRANSFORM_NAMES = NAME_TO_TRANSFORM.keys()
diff --git a/research/autoaugment/custom_ops.py b/research/autoaugment/custom_ops.py
deleted file mode 100644
index d2a690738608cd4b1a7f03e69af8be02648f86f5..0000000000000000000000000000000000000000
--- a/research/autoaugment/custom_ops.py
+++ /dev/null
@@ -1,197 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contains convenience wrappers for typical Neural Network TensorFlow layers.
-
- Ops that have different behavior during training or eval have an is_training
- parameter.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import numpy as np
-import tensorflow as tf
-
-
-arg_scope = tf.contrib.framework.arg_scope
-
-
-def variable(name, shape, dtype, initializer, trainable):
- """Returns a TF variable with the passed in specifications."""
- var = tf.get_variable(
- name,
- shape=shape,
- dtype=dtype,
- initializer=initializer,
- trainable=trainable)
- return var
-
-
-def global_avg_pool(x, scope=None):
- """Average pools away spatial height and width dimension of 4D tensor."""
- assert x.get_shape().ndims == 4
- with tf.name_scope(scope, 'global_avg_pool', [x]):
- kernel_size = (1, int(x.shape[1]), int(x.shape[2]), 1)
- squeeze_dims = (1, 2)
- result = tf.nn.avg_pool(
- x,
- ksize=kernel_size,
- strides=(1, 1, 1, 1),
- padding='VALID',
- data_format='NHWC')
- return tf.squeeze(result, squeeze_dims)
-
-
-def zero_pad(inputs, in_filter, out_filter):
- """Zero pads `input` tensor to have `out_filter` number of filters."""
- outputs = tf.pad(inputs, [[0, 0], [0, 0], [0, 0],
- [(out_filter - in_filter) // 2,
- (out_filter - in_filter) // 2]])
- return outputs
-
-
-@tf.contrib.framework.add_arg_scope
-def batch_norm(inputs,
- decay=0.999,
- center=True,
- scale=False,
- epsilon=0.001,
- is_training=True,
- reuse=None,
- scope=None):
- """Small wrapper around tf.contrib.layers.batch_norm."""
- return tf.contrib.layers.batch_norm(
- inputs,
- decay=decay,
- center=center,
- scale=scale,
- epsilon=epsilon,
- activation_fn=None,
- param_initializers=None,
- updates_collections=tf.GraphKeys.UPDATE_OPS,
- is_training=is_training,
- reuse=reuse,
- trainable=True,
- fused=True,
- data_format='NHWC',
- zero_debias_moving_mean=False,
- scope=scope)
-
-
-def stride_arr(stride_h, stride_w):
- return [1, stride_h, stride_w, 1]
-
-
-@tf.contrib.framework.add_arg_scope
-def conv2d(inputs,
- num_filters_out,
- kernel_size,
- stride=1,
- scope=None,
- reuse=None):
- """Adds a 2D convolution.
-
- conv2d creates a variable called 'weights', representing the convolutional
- kernel, that is convolved with the input.
-
- Args:
- inputs: a 4D tensor in NHWC format.
- num_filters_out: the number of output filters.
- kernel_size: an int specifying the kernel height and width size.
- stride: an int specifying the height and width stride.
- scope: Optional scope for variable_scope.
- reuse: whether or not the layer and its variables should be reused.
- Returns:
- a tensor that is the result of a convolution being applied to `inputs`.
- """
- with tf.variable_scope(scope, 'Conv', [inputs], reuse=reuse):
- num_filters_in = int(inputs.shape[3])
- weights_shape = [kernel_size, kernel_size, num_filters_in, num_filters_out]
-
- # Initialization
- n = int(weights_shape[0] * weights_shape[1] * weights_shape[3])
- weights_initializer = tf.random_normal_initializer(
- stddev=np.sqrt(2.0 / n))
-
- weights = variable(
- name='weights',
- shape=weights_shape,
- dtype=tf.float32,
- initializer=weights_initializer,
- trainable=True)
- strides = stride_arr(stride, stride)
- outputs = tf.nn.conv2d(
- inputs, weights, strides, padding='SAME', data_format='NHWC')
- return outputs
-
-
-@tf.contrib.framework.add_arg_scope
-def fc(inputs,
- num_units_out,
- scope=None,
- reuse=None):
- """Creates a fully connected layer applied to `inputs`.
-
- Args:
- inputs: a tensor that the fully connected layer will be applied to. It
- will be reshaped if it is not 2D.
- num_units_out: the number of output units in the layer.
- scope: Optional scope for variable_scope.
- reuse: whether or not the layer and its variables should be reused.
-
- Returns:
- a tensor that is the result of applying a linear matrix to `inputs`.
- """
- if len(inputs.shape) > 2:
- inputs = tf.reshape(inputs, [int(inputs.shape[0]), -1])
-
- with tf.variable_scope(scope, 'FC', [inputs], reuse=reuse):
- num_units_in = inputs.shape[1]
- weights_shape = [num_units_in, num_units_out]
- unif_init_range = 1.0 / (num_units_out)**(0.5)
- weights_initializer = tf.random_uniform_initializer(
- -unif_init_range, unif_init_range)
- weights = variable(
- name='weights',
- shape=weights_shape,
- dtype=tf.float32,
- initializer=weights_initializer,
- trainable=True)
- bias_initializer = tf.constant_initializer(0.0)
- biases = variable(
- name='biases',
- shape=[num_units_out,],
- dtype=tf.float32,
- initializer=bias_initializer,
- trainable=True)
- outputs = tf.nn.xw_plus_b(inputs, weights, biases)
- return outputs
-
-
-@tf.contrib.framework.add_arg_scope
-def avg_pool(inputs, kernel_size, stride=2, padding='VALID', scope=None):
- """Wrapper around tf.nn.avg_pool."""
- with tf.name_scope(scope, 'AvgPool', [inputs]):
- kernel = stride_arr(kernel_size, kernel_size)
- strides = stride_arr(stride, stride)
- return tf.nn.avg_pool(
- inputs,
- ksize=kernel,
- strides=strides,
- padding=padding,
- data_format='NHWC')
-
diff --git a/research/autoaugment/data_utils.py b/research/autoaugment/data_utils.py
deleted file mode 100644
index 9bf911560d10065a7b2acebb417828d47c176ea5..0000000000000000000000000000000000000000
--- a/research/autoaugment/data_utils.py
+++ /dev/null
@@ -1,184 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Data utils for CIFAR-10 and CIFAR-100."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import copy
-import cPickle
-import os
-import augmentation_transforms
-import numpy as np
-import policies as found_policies
-import tensorflow as tf
-
-
-# pylint:disable=logging-format-interpolation
-
-
-class DataSet(object):
- """Dataset object that produces augmented training and eval data."""
-
- def __init__(self, hparams):
- self.hparams = hparams
- self.epochs = 0
- self.curr_train_index = 0
-
- all_labels = []
-
- self.good_policies = found_policies.good_policies()
-
- # Determine how many databatched to load
- num_data_batches_to_load = 5
- total_batches_to_load = num_data_batches_to_load
- train_batches_to_load = total_batches_to_load
- assert hparams.train_size + hparams.validation_size <= 50000
- if hparams.eval_test:
- total_batches_to_load += 1
- # Determine how many images we have loaded
- total_dataset_size = 10000 * num_data_batches_to_load
- train_dataset_size = total_dataset_size
- if hparams.eval_test:
- total_dataset_size += 10000
-
- if hparams.dataset == 'cifar10':
- all_data = np.empty((total_batches_to_load, 10000, 3072), dtype=np.uint8)
- elif hparams.dataset == 'cifar100':
- assert num_data_batches_to_load == 5
- all_data = np.empty((1, 50000, 3072), dtype=np.uint8)
- if hparams.eval_test:
- test_data = np.empty((1, 10000, 3072), dtype=np.uint8)
- if hparams.dataset == 'cifar10':
- tf.logging.info('Cifar10')
- datafiles = [
- 'data_batch_1', 'data_batch_2', 'data_batch_3', 'data_batch_4',
- 'data_batch_5']
-
- datafiles = datafiles[:train_batches_to_load]
- if hparams.eval_test:
- datafiles.append('test_batch')
- num_classes = 10
- elif hparams.dataset == 'cifar100':
- datafiles = ['train']
- if hparams.eval_test:
- datafiles.append('test')
- num_classes = 100
- else:
- raise NotImplementedError('Unimplemented dataset: ', hparams.dataset)
- if hparams.dataset != 'test':
- for file_num, f in enumerate(datafiles):
- d = unpickle(os.path.join(hparams.data_path, f))
- if f == 'test':
- test_data[0] = copy.deepcopy(d['data'])
- all_data = np.concatenate([all_data, test_data], axis=1)
- else:
- all_data[file_num] = copy.deepcopy(d['data'])
- if hparams.dataset == 'cifar10':
- labels = np.array(d['labels'])
- else:
- labels = np.array(d['fine_labels'])
- nsamples = len(labels)
- for idx in range(nsamples):
- all_labels.append(labels[idx])
-
- all_data = all_data.reshape(total_dataset_size, 3072)
- all_data = all_data.reshape(-1, 3, 32, 32)
- all_data = all_data.transpose(0, 2, 3, 1).copy()
- all_data = all_data / 255.0
- mean = augmentation_transforms.MEANS
- std = augmentation_transforms.STDS
- tf.logging.info('mean:{} std: {}'.format(mean, std))
-
- all_data = (all_data - mean) / std
- all_labels = np.eye(num_classes)[np.array(all_labels, dtype=np.int32)]
- assert len(all_data) == len(all_labels)
- tf.logging.info(
- 'In CIFAR10 loader, number of images: {}'.format(len(all_data)))
-
- # Break off test data
- if hparams.eval_test:
- self.test_images = all_data[train_dataset_size:]
- self.test_labels = all_labels[train_dataset_size:]
-
- # Shuffle the rest of the data
- all_data = all_data[:train_dataset_size]
- all_labels = all_labels[:train_dataset_size]
- np.random.seed(0)
- perm = np.arange(len(all_data))
- np.random.shuffle(perm)
- all_data = all_data[perm]
- all_labels = all_labels[perm]
-
- # Break into train and val
- train_size, val_size = hparams.train_size, hparams.validation_size
- assert 50000 >= train_size + val_size
- self.train_images = all_data[:train_size]
- self.train_labels = all_labels[:train_size]
- self.val_images = all_data[train_size:train_size + val_size]
- self.val_labels = all_labels[train_size:train_size + val_size]
- self.num_train = self.train_images.shape[0]
-
- def next_batch(self):
- """Return the next minibatch of augmented data."""
- next_train_index = self.curr_train_index + self.hparams.batch_size
- if next_train_index > self.num_train:
- # Increase epoch number
- epoch = self.epochs + 1
- self.reset()
- self.epochs = epoch
- batched_data = (
- self.train_images[self.curr_train_index:
- self.curr_train_index + self.hparams.batch_size],
- self.train_labels[self.curr_train_index:
- self.curr_train_index + self.hparams.batch_size])
- final_imgs = []
-
- images, labels = batched_data
- for data in images:
- epoch_policy = self.good_policies[np.random.choice(
- len(self.good_policies))]
- final_img = augmentation_transforms.apply_policy(
- epoch_policy, data)
- final_img = augmentation_transforms.random_flip(
- augmentation_transforms.zero_pad_and_crop(final_img, 4))
- # Apply cutout
- final_img = augmentation_transforms.cutout_numpy(final_img)
- final_imgs.append(final_img)
- batched_data = (np.array(final_imgs, np.float32), labels)
- self.curr_train_index += self.hparams.batch_size
- return batched_data
-
- def reset(self):
- """Reset training data and index into the training data."""
- self.epochs = 0
- # Shuffle the training data
- perm = np.arange(self.num_train)
- np.random.shuffle(perm)
- assert self.num_train == self.train_images.shape[
- 0], 'Error incorrect shuffling mask'
- self.train_images = self.train_images[perm]
- self.train_labels = self.train_labels[perm]
- self.curr_train_index = 0
-
-
-def unpickle(f):
- tf.logging.info('loading file: {}'.format(f))
- fo = tf.gfile.Open(f, 'r')
- d = cPickle.load(fo)
- fo.close()
- return d
diff --git a/research/autoaugment/helper_utils.py b/research/autoaugment/helper_utils.py
deleted file mode 100644
index e896874383fb1abc3e9f6f0f452964b681a9c6c0..0000000000000000000000000000000000000000
--- a/research/autoaugment/helper_utils.py
+++ /dev/null
@@ -1,149 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Helper functions used for training AutoAugment models."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-
-def setup_loss(logits, labels):
- """Returns the cross entropy for the given `logits` and `labels`."""
- predictions = tf.nn.softmax(logits)
- cost = tf.losses.softmax_cross_entropy(onehot_labels=labels,
- logits=logits)
- return predictions, cost
-
-
-def decay_weights(cost, weight_decay_rate):
- """Calculates the loss for l2 weight decay and adds it to `cost`."""
- costs = []
- for var in tf.trainable_variables():
- costs.append(tf.nn.l2_loss(var))
- cost += tf.multiply(weight_decay_rate, tf.add_n(costs))
- return cost
-
-
-def eval_child_model(session, model, data_loader, mode):
- """Evaluates `model` on held out data depending on `mode`.
-
- Args:
- session: TensorFlow session the model will be run with.
- model: TensorFlow model that will be evaluated.
- data_loader: DataSet object that contains data that `model` will
- evaluate.
- mode: Will `model` either evaluate validation or test data.
-
- Returns:
- Accuracy of `model` when evaluated on the specified dataset.
-
- Raises:
- ValueError: if invalid dataset `mode` is specified.
- """
- if mode == 'val':
- images = data_loader.val_images
- labels = data_loader.val_labels
- elif mode == 'test':
- images = data_loader.test_images
- labels = data_loader.test_labels
- else:
- raise ValueError('Not valid eval mode')
- assert len(images) == len(labels)
- tf.logging.info('model.batch_size is {}'.format(model.batch_size))
- assert len(images) % model.batch_size == 0
- eval_batches = int(len(images) / model.batch_size)
- for i in range(eval_batches):
- eval_images = images[i * model.batch_size:(i + 1) * model.batch_size]
- eval_labels = labels[i * model.batch_size:(i + 1) * model.batch_size]
- _ = session.run(
- model.eval_op,
- feed_dict={
- model.images: eval_images,
- model.labels: eval_labels,
- })
- return session.run(model.accuracy)
-
-
-def cosine_lr(learning_rate, epoch, iteration, batches_per_epoch, total_epochs):
- """Cosine Learning rate.
-
- Args:
- learning_rate: Initial learning rate.
- epoch: Current epoch we are one. This is one based.
- iteration: Current batch in this epoch.
- batches_per_epoch: Batches per epoch.
- total_epochs: Total epochs you are training for.
-
- Returns:
- The learning rate to be used for this current batch.
- """
- t_total = total_epochs * batches_per_epoch
- t_cur = float(epoch * batches_per_epoch + iteration)
- return 0.5 * learning_rate * (1 + np.cos(np.pi * t_cur / t_total))
-
-
-def get_lr(curr_epoch, hparams, iteration=None):
- """Returns the learning rate during training based on the current epoch."""
- assert iteration is not None
- batches_per_epoch = int(hparams.train_size / hparams.batch_size)
- lr = cosine_lr(hparams.lr, curr_epoch, iteration, batches_per_epoch,
- hparams.num_epochs)
- return lr
-
-
-def run_epoch_training(session, model, data_loader, curr_epoch):
- """Runs one epoch of training for the model passed in.
-
- Args:
- session: TensorFlow session the model will be run with.
- model: TensorFlow model that will be evaluated.
- data_loader: DataSet object that contains data that `model` will
- evaluate.
- curr_epoch: How many of epochs of training have been done so far.
-
- Returns:
- The accuracy of 'model' on the training set
- """
- steps_per_epoch = int(model.hparams.train_size / model.hparams.batch_size)
- tf.logging.info('steps per epoch: {}'.format(steps_per_epoch))
- curr_step = session.run(model.global_step)
- assert curr_step % steps_per_epoch == 0
-
- # Get the current learning rate for the model based on the current epoch
- curr_lr = get_lr(curr_epoch, model.hparams, iteration=0)
- tf.logging.info('lr of {} for epoch {}'.format(curr_lr, curr_epoch))
-
- for step in xrange(steps_per_epoch):
- curr_lr = get_lr(curr_epoch, model.hparams, iteration=(step + 1))
- # Update the lr rate variable to the current LR.
- model.lr_rate_ph.load(curr_lr, session=session)
- if step % 20 == 0:
- tf.logging.info('Training {}/{}'.format(step, steps_per_epoch))
-
- train_images, train_labels = data_loader.next_batch()
- _, step, _ = session.run(
- [model.train_op, model.global_step, model.eval_op],
- feed_dict={
- model.images: train_images,
- model.labels: train_labels,
- })
-
- train_accuracy = session.run(model.accuracy)
- tf.logging.info('Train accuracy: {}'.format(train_accuracy))
- return train_accuracy
diff --git a/research/autoaugment/policies.py b/research/autoaugment/policies.py
deleted file mode 100644
index 36b10b0ee4c0a1b65d6cc0181bce8924322f1390..0000000000000000000000000000000000000000
--- a/research/autoaugment/policies.py
+++ /dev/null
@@ -1,140 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-def good_policies():
- """AutoAugment policies found on Cifar."""
- exp0_0 = [
- [('Invert', 0.1, 7), ('Contrast', 0.2, 6)],
- [('Rotate', 0.7, 2), ('TranslateX', 0.3, 9)],
- [('Sharpness', 0.8, 1), ('Sharpness', 0.9, 3)],
- [('ShearY', 0.5, 8), ('TranslateY', 0.7, 9)],
- [('AutoContrast', 0.5, 8), ('Equalize', 0.9, 2)]]
- exp0_1 = [
- [('Solarize', 0.4, 5), ('AutoContrast', 0.9, 3)],
- [('TranslateY', 0.9, 9), ('TranslateY', 0.7, 9)],
- [('AutoContrast', 0.9, 2), ('Solarize', 0.8, 3)],
- [('Equalize', 0.8, 8), ('Invert', 0.1, 3)],
- [('TranslateY', 0.7, 9), ('AutoContrast', 0.9, 1)]]
- exp0_2 = [
- [('Solarize', 0.4, 5), ('AutoContrast', 0.0, 2)],
- [('TranslateY', 0.7, 9), ('TranslateY', 0.7, 9)],
- [('AutoContrast', 0.9, 0), ('Solarize', 0.4, 3)],
- [('Equalize', 0.7, 5), ('Invert', 0.1, 3)],
- [('TranslateY', 0.7, 9), ('TranslateY', 0.7, 9)]]
- exp0_3 = [
- [('Solarize', 0.4, 5), ('AutoContrast', 0.9, 1)],
- [('TranslateY', 0.8, 9), ('TranslateY', 0.9, 9)],
- [('AutoContrast', 0.8, 0), ('TranslateY', 0.7, 9)],
- [('TranslateY', 0.2, 7), ('Color', 0.9, 6)],
- [('Equalize', 0.7, 6), ('Color', 0.4, 9)]]
- exp1_0 = [
- [('ShearY', 0.2, 7), ('Posterize', 0.3, 7)],
- [('Color', 0.4, 3), ('Brightness', 0.6, 7)],
- [('Sharpness', 0.3, 9), ('Brightness', 0.7, 9)],
- [('Equalize', 0.6, 5), ('Equalize', 0.5, 1)],
- [('Contrast', 0.6, 7), ('Sharpness', 0.6, 5)]]
- exp1_1 = [
- [('Brightness', 0.3, 7), ('AutoContrast', 0.5, 8)],
- [('AutoContrast', 0.9, 4), ('AutoContrast', 0.5, 6)],
- [('Solarize', 0.3, 5), ('Equalize', 0.6, 5)],
- [('TranslateY', 0.2, 4), ('Sharpness', 0.3, 3)],
- [('Brightness', 0.0, 8), ('Color', 0.8, 8)]]
- exp1_2 = [
- [('Solarize', 0.2, 6), ('Color', 0.8, 6)],
- [('Solarize', 0.2, 6), ('AutoContrast', 0.8, 1)],
- [('Solarize', 0.4, 1), ('Equalize', 0.6, 5)],
- [('Brightness', 0.0, 0), ('Solarize', 0.5, 2)],
- [('AutoContrast', 0.9, 5), ('Brightness', 0.5, 3)]]
- exp1_3 = [
- [('Contrast', 0.7, 5), ('Brightness', 0.0, 2)],
- [('Solarize', 0.2, 8), ('Solarize', 0.1, 5)],
- [('Contrast', 0.5, 1), ('TranslateY', 0.2, 9)],
- [('AutoContrast', 0.6, 5), ('TranslateY', 0.0, 9)],
- [('AutoContrast', 0.9, 4), ('Equalize', 0.8, 4)]]
- exp1_4 = [
- [('Brightness', 0.0, 7), ('Equalize', 0.4, 7)],
- [('Solarize', 0.2, 5), ('Equalize', 0.7, 5)],
- [('Equalize', 0.6, 8), ('Color', 0.6, 2)],
- [('Color', 0.3, 7), ('Color', 0.2, 4)],
- [('AutoContrast', 0.5, 2), ('Solarize', 0.7, 2)]]
- exp1_5 = [
- [('AutoContrast', 0.2, 0), ('Equalize', 0.1, 0)],
- [('ShearY', 0.6, 5), ('Equalize', 0.6, 5)],
- [('Brightness', 0.9, 3), ('AutoContrast', 0.4, 1)],
- [('Equalize', 0.8, 8), ('Equalize', 0.7, 7)],
- [('Equalize', 0.7, 7), ('Solarize', 0.5, 0)]]
- exp1_6 = [
- [('Equalize', 0.8, 4), ('TranslateY', 0.8, 9)],
- [('TranslateY', 0.8, 9), ('TranslateY', 0.6, 9)],
- [('TranslateY', 0.9, 0), ('TranslateY', 0.5, 9)],
- [('AutoContrast', 0.5, 3), ('Solarize', 0.3, 4)],
- [('Solarize', 0.5, 3), ('Equalize', 0.4, 4)]]
- exp2_0 = [
- [('Color', 0.7, 7), ('TranslateX', 0.5, 8)],
- [('Equalize', 0.3, 7), ('AutoContrast', 0.4, 8)],
- [('TranslateY', 0.4, 3), ('Sharpness', 0.2, 6)],
- [('Brightness', 0.9, 6), ('Color', 0.2, 8)],
- [('Solarize', 0.5, 2), ('Invert', 0.0, 3)]]
- exp2_1 = [
- [('AutoContrast', 0.1, 5), ('Brightness', 0.0, 0)],
- [('Cutout', 0.2, 4), ('Equalize', 0.1, 1)],
- [('Equalize', 0.7, 7), ('AutoContrast', 0.6, 4)],
- [('Color', 0.1, 8), ('ShearY', 0.2, 3)],
- [('ShearY', 0.4, 2), ('Rotate', 0.7, 0)]]
- exp2_2 = [
- [('ShearY', 0.1, 3), ('AutoContrast', 0.9, 5)],
- [('TranslateY', 0.3, 6), ('Cutout', 0.3, 3)],
- [('Equalize', 0.5, 0), ('Solarize', 0.6, 6)],
- [('AutoContrast', 0.3, 5), ('Rotate', 0.2, 7)],
- [('Equalize', 0.8, 2), ('Invert', 0.4, 0)]]
- exp2_3 = [
- [('Equalize', 0.9, 5), ('Color', 0.7, 0)],
- [('Equalize', 0.1, 1), ('ShearY', 0.1, 3)],
- [('AutoContrast', 0.7, 3), ('Equalize', 0.7, 0)],
- [('Brightness', 0.5, 1), ('Contrast', 0.1, 7)],
- [('Contrast', 0.1, 4), ('Solarize', 0.6, 5)]]
- exp2_4 = [
- [('Solarize', 0.2, 3), ('ShearX', 0.0, 0)],
- [('TranslateX', 0.3, 0), ('TranslateX', 0.6, 0)],
- [('Equalize', 0.5, 9), ('TranslateY', 0.6, 7)],
- [('ShearX', 0.1, 0), ('Sharpness', 0.5, 1)],
- [('Equalize', 0.8, 6), ('Invert', 0.3, 6)]]
- exp2_5 = [
- [('AutoContrast', 0.3, 9), ('Cutout', 0.5, 3)],
- [('ShearX', 0.4, 4), ('AutoContrast', 0.9, 2)],
- [('ShearX', 0.0, 3), ('Posterize', 0.0, 3)],
- [('Solarize', 0.4, 3), ('Color', 0.2, 4)],
- [('Equalize', 0.1, 4), ('Equalize', 0.7, 6)]]
- exp2_6 = [
- [('Equalize', 0.3, 8), ('AutoContrast', 0.4, 3)],
- [('Solarize', 0.6, 4), ('AutoContrast', 0.7, 6)],
- [('AutoContrast', 0.2, 9), ('Brightness', 0.4, 8)],
- [('Equalize', 0.1, 0), ('Equalize', 0.0, 6)],
- [('Equalize', 0.8, 4), ('Equalize', 0.0, 4)]]
- exp2_7 = [
- [('Equalize', 0.5, 5), ('AutoContrast', 0.1, 2)],
- [('Solarize', 0.5, 5), ('AutoContrast', 0.9, 5)],
- [('AutoContrast', 0.6, 1), ('AutoContrast', 0.7, 8)],
- [('Equalize', 0.2, 0), ('AutoContrast', 0.1, 2)],
- [('Equalize', 0.6, 9), ('Equalize', 0.4, 4)]]
- exp0s = exp0_0 + exp0_1 + exp0_2 + exp0_3
- exp1s = exp1_0 + exp1_1 + exp1_2 + exp1_3 + exp1_4 + exp1_5 + exp1_6
- exp2s = exp2_0 + exp2_1 + exp2_2 + exp2_3 + exp2_4 + exp2_5 + exp2_6 + exp2_7
- return exp0s + exp1s + exp2s
diff --git a/research/autoaugment/shake_drop.py b/research/autoaugment/shake_drop.py
deleted file mode 100644
index b6d3bcdb6c7fe38c64cfadd728bba8d71b72a518..0000000000000000000000000000000000000000
--- a/research/autoaugment/shake_drop.py
+++ /dev/null
@@ -1,178 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Builds the Shake-Shake Model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-import custom_ops as ops
-import tensorflow as tf
-
-
-def round_int(x):
- """Rounds `x` and then converts to an int."""
- return int(math.floor(x + 0.5))
-
-
-def shortcut(x, output_filters, stride):
- """Applies strided avg pool or zero padding to make output_filters match x."""
- num_filters = int(x.shape[3])
- if stride == 2:
- x = ops.avg_pool(x, 2, stride=stride, padding='SAME')
- if num_filters != output_filters:
- diff = output_filters - num_filters
- assert diff > 0
- # Zero padd diff zeros
- padding = [[0, 0], [0, 0], [0, 0], [0, diff]]
- x = tf.pad(x, padding)
- return x
-
-
-def calc_prob(curr_layer, total_layers, p_l):
- """Calculates drop prob depending on the current layer."""
- return 1 - (float(curr_layer) / total_layers) * p_l
-
-
-def bottleneck_layer(x, n, stride, prob, is_training, alpha, beta):
- """Bottleneck layer for shake drop model."""
- assert alpha[1] > alpha[0]
- assert beta[1] > beta[0]
- with tf.variable_scope('bottleneck_{}'.format(prob)):
- input_layer = x
- x = ops.batch_norm(x, scope='bn_1_pre')
- x = ops.conv2d(x, n, 1, scope='1x1_conv_contract')
- x = ops.batch_norm(x, scope='bn_1_post')
- x = tf.nn.relu(x)
- x = ops.conv2d(x, n, 3, stride=stride, scope='3x3')
- x = ops.batch_norm(x, scope='bn_2')
- x = tf.nn.relu(x)
- x = ops.conv2d(x, n * 4, 1, scope='1x1_conv_expand')
- x = ops.batch_norm(x, scope='bn_3')
-
- # Apply regularization here
- # Sample bernoulli with prob
- if is_training:
- batch_size = tf.shape(x)[0]
- bern_shape = [batch_size, 1, 1, 1]
- random_tensor = prob
- random_tensor += tf.random_uniform(bern_shape, dtype=tf.float32)
- binary_tensor = tf.floor(random_tensor)
-
- alpha_values = tf.random_uniform(
- [batch_size, 1, 1, 1], minval=alpha[0], maxval=alpha[1],
- dtype=tf.float32)
- beta_values = tf.random_uniform(
- [batch_size, 1, 1, 1], minval=beta[0], maxval=beta[1],
- dtype=tf.float32)
- rand_forward = (
- binary_tensor + alpha_values - binary_tensor * alpha_values)
- rand_backward = (
- binary_tensor + beta_values - binary_tensor * beta_values)
- x = x * rand_backward + tf.stop_gradient(x * rand_forward -
- x * rand_backward)
- else:
- expected_alpha = (alpha[1] + alpha[0])/2
- # prob is the expectation of the bernoulli variable
- x = (prob + expected_alpha - prob * expected_alpha) * x
-
- res = shortcut(input_layer, n * 4, stride)
- return x + res
-
-
-def build_shake_drop_model(images, num_classes, is_training):
- """Builds the PyramidNet Shake-Drop model.
-
- Build the PyramidNet Shake-Drop model from https://arxiv.org/abs/1802.02375.
-
- Args:
- images: Tensor of images that will be fed into the Wide ResNet Model.
- num_classes: Number of classed that the model needs to predict.
- is_training: Is the model training or not.
-
- Returns:
- The logits of the PyramidNet Shake-Drop model.
- """
- # ShakeDrop Hparams
- p_l = 0.5
- alpha_shake = [-1, 1]
- beta_shake = [0, 1]
-
- # PyramidNet Hparams
- alpha = 200
- depth = 272
- # This is for the bottleneck architecture specifically
- n = int((depth - 2) / 9)
- start_channel = 16
- add_channel = alpha / (3 * n)
-
- # Building the models
- x = images
- x = ops.conv2d(x, 16, 3, scope='init_conv')
- x = ops.batch_norm(x, scope='init_bn')
-
- layer_num = 1
- total_layers = n * 3
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 1, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
- for _ in range(1, n):
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 1, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
-
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 2, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
- for _ in range(1, n):
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 1, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
-
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 2, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
- for _ in range(1, n):
- start_channel += add_channel
- prob = calc_prob(layer_num, total_layers, p_l)
- x = bottleneck_layer(
- x, round_int(start_channel), 1, prob, is_training, alpha_shake,
- beta_shake)
- layer_num += 1
-
- assert layer_num - 1 == total_layers
- x = ops.batch_norm(x, scope='final_bn')
- x = tf.nn.relu(x)
- x = ops.global_avg_pool(x)
- # Fully connected
- logits = ops.fc(x, num_classes)
- return logits
diff --git a/research/autoaugment/shake_shake.py b/research/autoaugment/shake_shake.py
deleted file mode 100644
index b937372c5e52fc269baa53e4b59e52864acd2e69..0000000000000000000000000000000000000000
--- a/research/autoaugment/shake_shake.py
+++ /dev/null
@@ -1,147 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Builds the Shake-Shake Model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import custom_ops as ops
-import tensorflow as tf
-
-
-def _shake_shake_skip_connection(x, output_filters, stride):
- """Adds a residual connection to the filter x for the shake-shake model."""
- curr_filters = int(x.shape[3])
- if curr_filters == output_filters:
- return x
- stride_spec = ops.stride_arr(stride, stride)
- # Skip path 1
- path1 = tf.nn.avg_pool(
- x, [1, 1, 1, 1], stride_spec, 'VALID', data_format='NHWC')
- path1 = ops.conv2d(path1, int(output_filters / 2), 1, scope='path1_conv')
-
- # Skip path 2
- # First pad with 0's then crop
- pad_arr = [[0, 0], [0, 1], [0, 1], [0, 0]]
- path2 = tf.pad(x, pad_arr)[:, 1:, 1:, :]
- concat_axis = 3
-
- path2 = tf.nn.avg_pool(
- path2, [1, 1, 1, 1], stride_spec, 'VALID', data_format='NHWC')
- path2 = ops.conv2d(path2, int(output_filters / 2), 1, scope='path2_conv')
-
- # Concat and apply BN
- final_path = tf.concat(values=[path1, path2], axis=concat_axis)
- final_path = ops.batch_norm(final_path, scope='final_path_bn')
- return final_path
-
-
-def _shake_shake_branch(x, output_filters, stride, rand_forward, rand_backward,
- is_training):
- """Building a 2 branching convnet."""
- x = tf.nn.relu(x)
- x = ops.conv2d(x, output_filters, 3, stride=stride, scope='conv1')
- x = ops.batch_norm(x, scope='bn1')
- x = tf.nn.relu(x)
- x = ops.conv2d(x, output_filters, 3, scope='conv2')
- x = ops.batch_norm(x, scope='bn2')
- if is_training:
- x = x * rand_backward + tf.stop_gradient(x * rand_forward -
- x * rand_backward)
- else:
- x *= 1.0 / 2
- return x
-
-
-def _shake_shake_block(x, output_filters, stride, is_training):
- """Builds a full shake-shake sub layer."""
- batch_size = tf.shape(x)[0]
-
- # Generate random numbers for scaling the branches
- rand_forward = [
- tf.random_uniform(
- [batch_size, 1, 1, 1], minval=0, maxval=1, dtype=tf.float32)
- for _ in range(2)
- ]
- rand_backward = [
- tf.random_uniform(
- [batch_size, 1, 1, 1], minval=0, maxval=1, dtype=tf.float32)
- for _ in range(2)
- ]
- # Normalize so that all sum to 1
- total_forward = tf.add_n(rand_forward)
- total_backward = tf.add_n(rand_backward)
- rand_forward = [samp / total_forward for samp in rand_forward]
- rand_backward = [samp / total_backward for samp in rand_backward]
- zipped_rand = zip(rand_forward, rand_backward)
-
- branches = []
- for branch, (r_forward, r_backward) in enumerate(zipped_rand):
- with tf.variable_scope('branch_{}'.format(branch)):
- b = _shake_shake_branch(x, output_filters, stride, r_forward, r_backward,
- is_training)
- branches.append(b)
- res = _shake_shake_skip_connection(x, output_filters, stride)
- return res + tf.add_n(branches)
-
-
-def _shake_shake_layer(x, output_filters, num_blocks, stride,
- is_training):
- """Builds many sub layers into one full layer."""
- for block_num in range(num_blocks):
- curr_stride = stride if (block_num == 0) else 1
- with tf.variable_scope('layer_{}'.format(block_num)):
- x = _shake_shake_block(x, output_filters, curr_stride,
- is_training)
- return x
-
-
-def build_shake_shake_model(images, num_classes, hparams, is_training):
- """Builds the Shake-Shake model.
-
- Build the Shake-Shake model from https://arxiv.org/abs/1705.07485.
-
- Args:
- images: Tensor of images that will be fed into the Wide ResNet Model.
- num_classes: Number of classed that the model needs to predict.
- hparams: tf.HParams object that contains additional hparams needed to
- construct the model. In this case it is the `shake_shake_widen_factor`
- that is used to determine how many filters the model has.
- is_training: Is the model training or not.
-
- Returns:
- The logits of the Shake-Shake model.
- """
- depth = 26
- k = hparams.shake_shake_widen_factor # The widen factor
- n = int((depth - 2) / 6)
- x = images
-
- x = ops.conv2d(x, 16, 3, scope='init_conv')
- x = ops.batch_norm(x, scope='init_bn')
- with tf.variable_scope('L1'):
- x = _shake_shake_layer(x, 16 * k, n, 1, is_training)
- with tf.variable_scope('L2'):
- x = _shake_shake_layer(x, 32 * k, n, 2, is_training)
- with tf.variable_scope('L3'):
- x = _shake_shake_layer(x, 64 * k, n, 2, is_training)
- x = tf.nn.relu(x)
- x = ops.global_avg_pool(x)
-
- # Fully connected
- logits = ops.fc(x, num_classes)
- return logits
diff --git a/research/autoaugment/train_cifar.py b/research/autoaugment/train_cifar.py
deleted file mode 100644
index 9e3942ee26b1bd68234d34b17a818e058d9c881a..0000000000000000000000000000000000000000
--- a/research/autoaugment/train_cifar.py
+++ /dev/null
@@ -1,452 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""AutoAugment Train/Eval module.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import contextlib
-import os
-import time
-
-import custom_ops as ops
-import data_utils
-import helper_utils
-import numpy as np
-from shake_drop import build_shake_drop_model
-from shake_shake import build_shake_shake_model
-import tensorflow as tf
-from wrn import build_wrn_model
-
-tf.flags.DEFINE_string('model_name', 'wrn',
- 'wrn, shake_shake_32, shake_shake_96, shake_shake_112, '
- 'pyramid_net')
-tf.flags.DEFINE_string('checkpoint_dir', '/tmp/training', 'Training Directory.')
-tf.flags.DEFINE_string('data_path', '/tmp/data',
- 'Directory where dataset is located.')
-tf.flags.DEFINE_string('dataset', 'cifar10',
- 'Dataset to train with. Either cifar10 or cifar100')
-tf.flags.DEFINE_integer('use_cpu', 1, '1 if use CPU, else GPU.')
-
-FLAGS = tf.flags.FLAGS
-
-arg_scope = tf.contrib.framework.arg_scope
-
-
-def setup_arg_scopes(is_training):
- """Sets up the argscopes that will be used when building an image model.
-
- Args:
- is_training: Is the model training or not.
-
- Returns:
- Arg scopes to be put around the model being constructed.
- """
-
- batch_norm_decay = 0.9
- batch_norm_epsilon = 1e-5
- batch_norm_params = {
- # Decay for the moving averages.
- 'decay': batch_norm_decay,
- # epsilon to prevent 0s in variance.
- 'epsilon': batch_norm_epsilon,
- 'scale': True,
- # collection containing the moving mean and moving variance.
- 'is_training': is_training,
- }
-
- scopes = []
-
- scopes.append(arg_scope([ops.batch_norm], **batch_norm_params))
- return scopes
-
-
-def build_model(inputs, num_classes, is_training, hparams):
- """Constructs the vision model being trained/evaled.
-
- Args:
- inputs: input features/images being fed to the image model build built.
- num_classes: number of output classes being predicted.
- is_training: is the model training or not.
- hparams: additional hyperparameters associated with the image model.
-
- Returns:
- The logits of the image model.
- """
- scopes = setup_arg_scopes(is_training)
- with contextlib.nested(*scopes):
- if hparams.model_name == 'pyramid_net':
- logits = build_shake_drop_model(
- inputs, num_classes, is_training)
- elif hparams.model_name == 'wrn':
- logits = build_wrn_model(
- inputs, num_classes, hparams.wrn_size)
- elif hparams.model_name == 'shake_shake':
- logits = build_shake_shake_model(
- inputs, num_classes, hparams, is_training)
- return logits
-
-
-class CifarModel(object):
- """Builds an image model for Cifar10/Cifar100."""
-
- def __init__(self, hparams):
- self.hparams = hparams
-
- def build(self, mode):
- """Construct the cifar model."""
- assert mode in ['train', 'eval']
- self.mode = mode
- self._setup_misc(mode)
- self._setup_images_and_labels()
- self._build_graph(self.images, self.labels, mode)
-
- self.init = tf.group(tf.global_variables_initializer(),
- tf.local_variables_initializer())
-
- def _setup_misc(self, mode):
- """Sets up miscellaneous in the cifar model constructor."""
- self.lr_rate_ph = tf.Variable(0.0, name='lrn_rate', trainable=False)
- self.reuse = None if (mode == 'train') else True
- self.batch_size = self.hparams.batch_size
- if mode == 'eval':
- self.batch_size = 25
-
- def _setup_images_and_labels(self):
- """Sets up image and label placeholders for the cifar model."""
- if FLAGS.dataset == 'cifar10':
- self.num_classes = 10
- else:
- self.num_classes = 100
- self.images = tf.placeholder(tf.float32, [self.batch_size, 32, 32, 3])
- self.labels = tf.placeholder(tf.float32,
- [self.batch_size, self.num_classes])
-
- def assign_epoch(self, session, epoch_value):
- session.run(self._epoch_update, feed_dict={self._new_epoch: epoch_value})
-
- def _build_graph(self, images, labels, mode):
- """Constructs the TF graph for the cifar model.
-
- Args:
- images: A 4-D image Tensor
- labels: A 2-D labels Tensor.
- mode: string indicating training mode ( e.g., 'train', 'valid', 'test').
- """
- is_training = 'train' in mode
- if is_training:
- self.global_step = tf.train.get_or_create_global_step()
-
- logits = build_model(
- images,
- self.num_classes,
- is_training,
- self.hparams)
- self.predictions, self.cost = helper_utils.setup_loss(
- logits, labels)
- self.accuracy, self.eval_op = tf.metrics.accuracy(
- tf.argmax(labels, 1), tf.argmax(self.predictions, 1))
- self._calc_num_trainable_params()
-
- # Adds L2 weight decay to the cost
- self.cost = helper_utils.decay_weights(self.cost,
- self.hparams.weight_decay_rate)
-
- if is_training:
- self._build_train_op()
-
- # Setup checkpointing for this child model
- # Keep 2 or more checkpoints around during training.
- with tf.device('/cpu:0'):
- self.saver = tf.train.Saver(max_to_keep=2)
-
- self.init = tf.group(tf.global_variables_initializer(),
- tf.local_variables_initializer())
-
- def _calc_num_trainable_params(self):
- self.num_trainable_params = np.sum([
- np.prod(var.get_shape().as_list()) for var in tf.trainable_variables()
- ])
- tf.logging.info('number of trainable params: {}'.format(
- self.num_trainable_params))
-
- def _build_train_op(self):
- """Builds the train op for the cifar model."""
- hparams = self.hparams
- tvars = tf.trainable_variables()
- grads = tf.gradients(self.cost, tvars)
- if hparams.gradient_clipping_by_global_norm > 0.0:
- grads, norm = tf.clip_by_global_norm(
- grads, hparams.gradient_clipping_by_global_norm)
- tf.summary.scalar('grad_norm', norm)
-
- # Setup the initial learning rate
- initial_lr = self.lr_rate_ph
- optimizer = tf.train.MomentumOptimizer(
- initial_lr,
- 0.9,
- use_nesterov=True)
-
- self.optimizer = optimizer
- apply_op = optimizer.apply_gradients(
- zip(grads, tvars), global_step=self.global_step, name='train_step')
- train_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
- with tf.control_dependencies([apply_op]):
- self.train_op = tf.group(*train_ops)
-
-
-class CifarModelTrainer(object):
- """Trains an instance of the CifarModel class."""
-
- def __init__(self, hparams):
- self._session = None
- self.hparams = hparams
-
- self.model_dir = os.path.join(FLAGS.checkpoint_dir, 'model')
- self.log_dir = os.path.join(FLAGS.checkpoint_dir, 'log')
- # Set the random seed to be sure the same validation set
- # is used for each model
- np.random.seed(0)
- self.data_loader = data_utils.DataSet(hparams)
- np.random.seed() # Put the random seed back to random
- self.data_loader.reset()
-
- def save_model(self, step=None):
- """Dumps model into the backup_dir.
-
- Args:
- step: If provided, creates a checkpoint with the given step
- number, instead of overwriting the existing checkpoints.
- """
- model_save_name = os.path.join(self.model_dir, 'model.ckpt')
- if not tf.gfile.IsDirectory(self.model_dir):
- tf.gfile.MakeDirs(self.model_dir)
- self.saver.save(self.session, model_save_name, global_step=step)
- tf.logging.info('Saved child model')
-
- def extract_model_spec(self):
- """Loads a checkpoint with the architecture structure stored in the name."""
- checkpoint_path = tf.train.latest_checkpoint(self.model_dir)
- if checkpoint_path is not None:
- self.saver.restore(self.session, checkpoint_path)
- tf.logging.info('Loaded child model checkpoint from %s',
- checkpoint_path)
- else:
- self.save_model(step=0)
-
- def eval_child_model(self, model, data_loader, mode):
- """Evaluate the child model.
-
- Args:
- model: image model that will be evaluated.
- data_loader: dataset object to extract eval data from.
- mode: will the model be evalled on train, val or test.
-
- Returns:
- Accuracy of the model on the specified dataset.
- """
- tf.logging.info('Evaluating child model in mode %s', mode)
- while True:
- try:
- with self._new_session(model):
- accuracy = helper_utils.eval_child_model(
- self.session,
- model,
- data_loader,
- mode)
- tf.logging.info('Eval child model accuracy: {}'.format(accuracy))
- # If epoch trained without raising the below errors, break
- # from loop.
- break
- except (tf.errors.AbortedError, tf.errors.UnavailableError) as e:
- tf.logging.info('Retryable error caught: %s. Retrying.', e)
-
- return accuracy
-
- @contextlib.contextmanager
- def _new_session(self, m):
- """Creates a new session for model m."""
- # Create a new session for this model, initialize
- # variables, and save / restore from
- # checkpoint.
- self._session = tf.Session(
- '',
- config=tf.ConfigProto(
- allow_soft_placement=True, log_device_placement=False))
- self.session.run(m.init)
-
- # Load in a previous checkpoint, or save this one
- self.extract_model_spec()
- try:
- yield
- finally:
- tf.Session.reset('')
- self._session = None
-
- def _build_models(self):
- """Builds the image models for train and eval."""
- # Determine if we should build the train and eval model. When using
- # distributed training we only want to build one or the other and not both.
- with tf.variable_scope('model', use_resource=False):
- m = CifarModel(self.hparams)
- m.build('train')
- self._num_trainable_params = m.num_trainable_params
- self._saver = m.saver
- with tf.variable_scope('model', reuse=True, use_resource=False):
- meval = CifarModel(self.hparams)
- meval.build('eval')
- return m, meval
-
- def _calc_starting_epoch(self, m):
- """Calculates the starting epoch for model m based on global step."""
- hparams = self.hparams
- batch_size = hparams.batch_size
- steps_per_epoch = int(hparams.train_size / batch_size)
- with self._new_session(m):
- curr_step = self.session.run(m.global_step)
- total_steps = steps_per_epoch * hparams.num_epochs
- epochs_left = (total_steps - curr_step) // steps_per_epoch
- starting_epoch = hparams.num_epochs - epochs_left
- return starting_epoch
-
- def _run_training_loop(self, m, curr_epoch):
- """Trains the cifar model `m` for one epoch."""
- start_time = time.time()
- while True:
- try:
- with self._new_session(m):
- train_accuracy = helper_utils.run_epoch_training(
- self.session, m, self.data_loader, curr_epoch)
- tf.logging.info('Saving model after epoch')
- self.save_model(step=curr_epoch)
- break
- except (tf.errors.AbortedError, tf.errors.UnavailableError) as e:
- tf.logging.info('Retryable error caught: %s. Retrying.', e)
- tf.logging.info('Finished epoch: {}'.format(curr_epoch))
- tf.logging.info('Epoch time(min): {}'.format(
- (time.time() - start_time) / 60.0))
- return train_accuracy
-
- def _compute_final_accuracies(self, meval):
- """Run once training is finished to compute final val/test accuracies."""
- valid_accuracy = self.eval_child_model(meval, self.data_loader, 'val')
- if self.hparams.eval_test:
- test_accuracy = self.eval_child_model(meval, self.data_loader, 'test')
- else:
- test_accuracy = 0
- tf.logging.info('Test Accuracy: {}'.format(test_accuracy))
- return valid_accuracy, test_accuracy
-
- def run_model(self):
- """Trains and evalutes the image model."""
- hparams = self.hparams
-
- # Build the child graph
- with tf.Graph().as_default(), tf.device(
- '/cpu:0' if FLAGS.use_cpu else '/gpu:0'):
- m, meval = self._build_models()
-
- # Figure out what epoch we are on
- starting_epoch = self._calc_starting_epoch(m)
-
- # Run the validation error right at the beginning
- valid_accuracy = self.eval_child_model(
- meval, self.data_loader, 'val')
- tf.logging.info('Before Training Epoch: {} Val Acc: {}'.format(
- starting_epoch, valid_accuracy))
- training_accuracy = None
-
- for curr_epoch in xrange(starting_epoch, hparams.num_epochs):
-
- # Run one training epoch
- training_accuracy = self._run_training_loop(m, curr_epoch)
-
- valid_accuracy = self.eval_child_model(
- meval, self.data_loader, 'val')
- tf.logging.info('Epoch: {} Valid Acc: {}'.format(
- curr_epoch, valid_accuracy))
-
- valid_accuracy, test_accuracy = self._compute_final_accuracies(
- meval)
-
- tf.logging.info(
- 'Train Acc: {} Valid Acc: {} Test Acc: {}'.format(
- training_accuracy, valid_accuracy, test_accuracy))
-
- @property
- def saver(self):
- return self._saver
-
- @property
- def session(self):
- return self._session
-
- @property
- def num_trainable_params(self):
- return self._num_trainable_params
-
-
-def main(_):
- if FLAGS.dataset not in ['cifar10', 'cifar100']:
- raise ValueError('Invalid dataset: %s' % FLAGS.dataset)
- hparams = tf.contrib.training.HParams(
- train_size=50000,
- validation_size=0,
- eval_test=1,
- dataset=FLAGS.dataset,
- data_path=FLAGS.data_path,
- batch_size=128,
- gradient_clipping_by_global_norm=5.0)
- if FLAGS.model_name == 'wrn':
- hparams.add_hparam('model_name', 'wrn')
- hparams.add_hparam('num_epochs', 200)
- hparams.add_hparam('wrn_size', 160)
- hparams.add_hparam('lr', 0.1)
- hparams.add_hparam('weight_decay_rate', 5e-4)
- elif FLAGS.model_name == 'shake_shake_32':
- hparams.add_hparam('model_name', 'shake_shake')
- hparams.add_hparam('num_epochs', 1800)
- hparams.add_hparam('shake_shake_widen_factor', 2)
- hparams.add_hparam('lr', 0.01)
- hparams.add_hparam('weight_decay_rate', 0.001)
- elif FLAGS.model_name == 'shake_shake_96':
- hparams.add_hparam('model_name', 'shake_shake')
- hparams.add_hparam('num_epochs', 1800)
- hparams.add_hparam('shake_shake_widen_factor', 6)
- hparams.add_hparam('lr', 0.01)
- hparams.add_hparam('weight_decay_rate', 0.001)
- elif FLAGS.model_name == 'shake_shake_112':
- hparams.add_hparam('model_name', 'shake_shake')
- hparams.add_hparam('num_epochs', 1800)
- hparams.add_hparam('shake_shake_widen_factor', 7)
- hparams.add_hparam('lr', 0.01)
- hparams.add_hparam('weight_decay_rate', 0.001)
- elif FLAGS.model_name == 'pyramid_net':
- hparams.add_hparam('model_name', 'pyramid_net')
- hparams.add_hparam('num_epochs', 1800)
- hparams.add_hparam('lr', 0.05)
- hparams.add_hparam('weight_decay_rate', 5e-5)
- hparams.batch_size = 64
- else:
- raise ValueError('Not Valid Model Name: %s' % FLAGS.model_name)
- cifar_trainer = CifarModelTrainer(hparams)
- cifar_trainer.run_model()
-
-if __name__ == '__main__':
- tf.logging.set_verbosity(tf.logging.INFO)
- tf.app.run()
diff --git a/research/autoaugment/wrn.py b/research/autoaugment/wrn.py
deleted file mode 100644
index ea04e19cfc30f52fe49c475b6ed35610e7c87aa4..0000000000000000000000000000000000000000
--- a/research/autoaugment/wrn.py
+++ /dev/null
@@ -1,158 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Builds the Wide-ResNet Model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import custom_ops as ops
-import numpy as np
-import tensorflow as tf
-
-
-
-def residual_block(
- x, in_filter, out_filter, stride, activate_before_residual=False):
- """Adds residual connection to `x` in addition to applying BN->ReLU->3x3 Conv.
-
- Args:
- x: Tensor that is the output of the previous layer in the model.
- in_filter: Number of filters `x` has.
- out_filter: Number of filters that the output of this layer will have.
- stride: Integer that specified what stride should be applied to `x`.
- activate_before_residual: Boolean on whether a BN->ReLU should be applied
- to x before the convolution is applied.
-
- Returns:
- A Tensor that is the result of applying two sequences of BN->ReLU->3x3 Conv
- and then adding that Tensor to `x`.
- """
-
- if activate_before_residual: # Pass up RELU and BN activation for resnet
- with tf.variable_scope('shared_activation'):
- x = ops.batch_norm(x, scope='init_bn')
- x = tf.nn.relu(x)
- orig_x = x
- else:
- orig_x = x
-
- block_x = x
- if not activate_before_residual:
- with tf.variable_scope('residual_only_activation'):
- block_x = ops.batch_norm(block_x, scope='init_bn')
- block_x = tf.nn.relu(block_x)
-
- with tf.variable_scope('sub1'):
- block_x = ops.conv2d(
- block_x, out_filter, 3, stride=stride, scope='conv1')
-
- with tf.variable_scope('sub2'):
- block_x = ops.batch_norm(block_x, scope='bn2')
- block_x = tf.nn.relu(block_x)
- block_x = ops.conv2d(
- block_x, out_filter, 3, stride=1, scope='conv2')
-
- with tf.variable_scope(
- 'sub_add'): # If number of filters do not agree then zero pad them
- if in_filter != out_filter:
- orig_x = ops.avg_pool(orig_x, stride, stride)
- orig_x = ops.zero_pad(orig_x, in_filter, out_filter)
- x = orig_x + block_x
- return x
-
-
-def _res_add(in_filter, out_filter, stride, x, orig_x):
- """Adds `x` with `orig_x`, both of which are layers in the model.
-
- Args:
- in_filter: Number of filters in `orig_x`.
- out_filter: Number of filters in `x`.
- stride: Integer specifying the stide that should be applied `orig_x`.
- x: Tensor that is the output of the previous layer.
- orig_x: Tensor that is the output of an earlier layer in the network.
-
- Returns:
- A Tensor that is the result of `x` and `orig_x` being added after
- zero padding and striding are applied to `orig_x` to get the shapes
- to match.
- """
- if in_filter != out_filter:
- orig_x = ops.avg_pool(orig_x, stride, stride)
- orig_x = ops.zero_pad(orig_x, in_filter, out_filter)
- x = x + orig_x
- orig_x = x
- return x, orig_x
-
-
-def build_wrn_model(images, num_classes, wrn_size):
- """Builds the WRN model.
-
- Build the Wide ResNet model from https://arxiv.org/abs/1605.07146.
-
- Args:
- images: Tensor of images that will be fed into the Wide ResNet Model.
- num_classes: Number of classed that the model needs to predict.
- wrn_size: Parameter that scales the number of filters in the Wide ResNet
- model.
-
- Returns:
- The logits of the Wide ResNet model.
- """
- kernel_size = wrn_size
- filter_size = 3
- num_blocks_per_resnet = 4
- filters = [
- min(kernel_size, 16), kernel_size, kernel_size * 2, kernel_size * 4
- ]
- strides = [1, 2, 2] # stride for each resblock
-
- # Run the first conv
- with tf.variable_scope('init'):
- x = images
- output_filters = filters[0]
- x = ops.conv2d(x, output_filters, filter_size, scope='init_conv')
-
- first_x = x # Res from the beginning
- orig_x = x # Res from previous block
-
- for block_num in range(1, 4):
- with tf.variable_scope('unit_{}_0'.format(block_num)):
- activate_before_residual = True if block_num == 1 else False
- x = residual_block(
- x,
- filters[block_num - 1],
- filters[block_num],
- strides[block_num - 1],
- activate_before_residual=activate_before_residual)
- for i in range(1, num_blocks_per_resnet):
- with tf.variable_scope('unit_{}_{}'.format(block_num, i)):
- x = residual_block(
- x,
- filters[block_num],
- filters[block_num],
- 1,
- activate_before_residual=False)
- x, orig_x = _res_add(filters[block_num - 1], filters[block_num],
- strides[block_num - 1], x, orig_x)
- final_stride_val = np.prod(strides)
- x, _ = _res_add(filters[0], filters[3], final_stride_val, x, first_x)
- with tf.variable_scope('unit_last'):
- x = ops.batch_norm(x, scope='final_bn')
- x = tf.nn.relu(x)
- x = ops.global_avg_pool(x)
- logits = ops.fc(x, num_classes)
- return logits
diff --git a/research/autoencoder/AdditiveGaussianNoiseAutoencoderRunner.py b/research/autoencoder/AdditiveGaussianNoiseAutoencoderRunner.py
deleted file mode 100644
index 8d8ee08654985250ac61415df96889b4a4cf5f1b..0000000000000000000000000000000000000000
--- a/research/autoencoder/AdditiveGaussianNoiseAutoencoderRunner.py
+++ /dev/null
@@ -1,58 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import sklearn.preprocessing as prep
-import tensorflow as tf
-from tensorflow.examples.tutorials.mnist import input_data
-
-from autoencoder_models.DenoisingAutoencoder import AdditiveGaussianNoiseAutoencoder
-
-mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
-
-
-def standard_scale(X_train, X_test):
- preprocessor = prep.StandardScaler().fit(X_train)
- X_train = preprocessor.transform(X_train)
- X_test = preprocessor.transform(X_test)
- return X_train, X_test
-
-
-def get_random_block_from_data(data, batch_size):
- start_index = np.random.randint(0, len(data) - batch_size)
- return data[start_index:(start_index + batch_size)]
-
-
-X_train, X_test = standard_scale(mnist.train.images, mnist.test.images)
-
-n_samples = int(mnist.train.num_examples)
-training_epochs = 20
-batch_size = 128
-display_step = 1
-
-autoencoder = AdditiveGaussianNoiseAutoencoder(
- n_input=784,
- n_hidden=200,
- transfer_function=tf.nn.softplus,
- optimizer=tf.train.AdamOptimizer(learning_rate = 0.001),
- scale=0.01)
-
-for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(n_samples / batch_size)
- # Loop over all batches
- for i in range(total_batch):
- batch_xs = get_random_block_from_data(X_train, batch_size)
-
- # Fit training using batch data
- cost = autoencoder.partial_fit(batch_xs)
- # Compute average loss
- avg_cost += cost / n_samples * batch_size
-
- # Display logs per epoch step
- if epoch % display_step == 0:
- print("Epoch:", '%d,' % (epoch + 1),
- "Cost:", "{:.9f}".format(avg_cost))
-
-print("Total cost: " + str(autoencoder.calc_total_cost(X_test)))
diff --git a/research/autoencoder/AutoencoderRunner.py b/research/autoencoder/AutoencoderRunner.py
deleted file mode 100644
index 7f1ab2ecd5a91c12960714ea79a864631e634f8c..0000000000000000000000000000000000000000
--- a/research/autoencoder/AutoencoderRunner.py
+++ /dev/null
@@ -1,55 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import sklearn.preprocessing as prep
-import tensorflow as tf
-from tensorflow.examples.tutorials.mnist import input_data
-
-from autoencoder_models.Autoencoder import Autoencoder
-
-mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
-
-
-def standard_scale(X_train, X_test):
- preprocessor = prep.StandardScaler().fit(X_train)
- X_train = preprocessor.transform(X_train)
- X_test = preprocessor.transform(X_test)
- return X_train, X_test
-
-
-def get_random_block_from_data(data, batch_size):
- start_index = np.random.randint(0, len(data) - batch_size)
- return data[start_index:(start_index + batch_size)]
-
-
-X_train, X_test = standard_scale(mnist.train.images, mnist.test.images)
-
-n_samples = int(mnist.train.num_examples)
-training_epochs = 20
-batch_size = 128
-display_step = 1
-
-autoencoder = Autoencoder(n_layers=[784, 200],
- transfer_function = tf.nn.softplus,
- optimizer = tf.train.AdamOptimizer(learning_rate = 0.001))
-
-for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(n_samples / batch_size)
- # Loop over all batches
- for i in range(total_batch):
- batch_xs = get_random_block_from_data(X_train, batch_size)
-
- # Fit training using batch data
- cost = autoencoder.partial_fit(batch_xs)
- # Compute average loss
- avg_cost += cost / n_samples * batch_size
-
- # Display logs per epoch step
- if epoch % display_step == 0:
- print("Epoch:", '%d,' % (epoch + 1),
- "Cost:", "{:.9f}".format(avg_cost))
-
-print("Total cost: " + str(autoencoder.calc_total_cost(X_test)))
diff --git a/research/autoencoder/MaskingNoiseAutoencoderRunner.py b/research/autoencoder/MaskingNoiseAutoencoderRunner.py
deleted file mode 100644
index b776302e286ff740ba7b8e6f679a54b23944df12..0000000000000000000000000000000000000000
--- a/research/autoencoder/MaskingNoiseAutoencoderRunner.py
+++ /dev/null
@@ -1,55 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import sklearn.preprocessing as prep
-import tensorflow as tf
-from tensorflow.examples.tutorials.mnist import input_data
-
-from autoencoder_models.DenoisingAutoencoder import MaskingNoiseAutoencoder
-
-mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
-
-
-def standard_scale(X_train, X_test):
- preprocessor = prep.StandardScaler().fit(X_train)
- X_train = preprocessor.transform(X_train)
- X_test = preprocessor.transform(X_test)
- return X_train, X_test
-
-
-def get_random_block_from_data(data, batch_size):
- start_index = np.random.randint(0, len(data) - batch_size)
- return data[start_index:(start_index + batch_size)]
-
-
-X_train, X_test = standard_scale(mnist.train.images, mnist.test.images)
-
-n_samples = int(mnist.train.num_examples)
-training_epochs = 100
-batch_size = 128
-display_step = 1
-
-autoencoder = MaskingNoiseAutoencoder(
- n_input=784,
- n_hidden=200,
- transfer_function=tf.nn.softplus,
- optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
- dropout_probability=0.95)
-
-for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(n_samples / batch_size)
- for i in range(total_batch):
- batch_xs = get_random_block_from_data(X_train, batch_size)
-
- cost = autoencoder.partial_fit(batch_xs)
-
- avg_cost += cost / n_samples * batch_size
-
- if epoch % display_step == 0:
- print("Epoch:", '%d,' % (epoch + 1),
- "Cost:", "{:.9f}".format(avg_cost))
-
-print("Total cost: " + str(autoencoder.calc_total_cost(X_test)))
diff --git a/research/autoencoder/README.md b/research/autoencoder/README.md
deleted file mode 100644
index cba7b3b66f59ac9e3810ee1b98d67133296aea25..0000000000000000000000000000000000000000
--- a/research/autoencoder/README.md
+++ /dev/null
@@ -1,3 +0,0 @@
-
-
-
diff --git a/research/autoencoder/VariationalAutoencoderRunner.py b/research/autoencoder/VariationalAutoencoderRunner.py
deleted file mode 100644
index f5ce0045f3c6dfdd357cd874f8ee24df0d8cb3d9..0000000000000000000000000000000000000000
--- a/research/autoencoder/VariationalAutoencoderRunner.py
+++ /dev/null
@@ -1,56 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import sklearn.preprocessing as prep
-import tensorflow as tf
-from tensorflow.examples.tutorials.mnist import input_data
-
-from autoencoder_models.VariationalAutoencoder import VariationalAutoencoder
-
-mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
-
-
-def min_max_scale(X_train, X_test):
- preprocessor = prep.MinMaxScaler().fit(X_train)
- X_train = preprocessor.transform(X_train)
- X_test = preprocessor.transform(X_test)
- return X_train, X_test
-
-
-def get_random_block_from_data(data, batch_size):
- start_index = np.random.randint(0, len(data) - batch_size)
- return data[start_index:(start_index + batch_size)]
-
-
-X_train, X_test = min_max_scale(mnist.train.images, mnist.test.images)
-
-n_samples = int(mnist.train.num_examples)
-training_epochs = 20
-batch_size = 128
-display_step = 1
-
-autoencoder = VariationalAutoencoder(
- n_input=784,
- n_hidden=200,
- optimizer=tf.train.AdamOptimizer(learning_rate = 0.001))
-
-for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(n_samples / batch_size)
- # Loop over all batches
- for i in range(total_batch):
- batch_xs = get_random_block_from_data(X_train, batch_size)
-
- # Fit training using batch data
- cost = autoencoder.partial_fit(batch_xs)
- # Compute average loss
- avg_cost += cost / n_samples * batch_size
-
- # Display logs per epoch step
- if epoch % display_step == 0:
- print("Epoch:", '%d,' % (epoch + 1),
- "Cost:", "{:.9f}".format(avg_cost))
-
-print("Total cost: " + str(autoencoder.calc_total_cost(X_test)))
diff --git a/research/autoencoder/__init__.py b/research/autoencoder/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/autoencoder/autoencoder_models/Autoencoder.py b/research/autoencoder/autoencoder_models/Autoencoder.py
deleted file mode 100644
index 788a14642306ece056fc53a85ba8c60d87d31826..0000000000000000000000000000000000000000
--- a/research/autoencoder/autoencoder_models/Autoencoder.py
+++ /dev/null
@@ -1,91 +0,0 @@
-import numpy as np
-import tensorflow as tf
-
-
-class Autoencoder(object):
-
- def __init__(self, n_layers, transfer_function=tf.nn.softplus, optimizer=tf.train.AdamOptimizer()):
- self.n_layers = n_layers
- self.transfer = transfer_function
-
- network_weights = self._initialize_weights()
- self.weights = network_weights
-
- # model
- self.x = tf.placeholder(tf.float32, [None, self.n_layers[0]])
- self.hidden_encode = []
- h = self.x
- for layer in range(len(self.n_layers)-1):
- h = self.transfer(
- tf.add(tf.matmul(h, self.weights['encode'][layer]['w']),
- self.weights['encode'][layer]['b']))
- self.hidden_encode.append(h)
-
- self.hidden_recon = []
- for layer in range(len(self.n_layers)-1):
- h = self.transfer(
- tf.add(tf.matmul(h, self.weights['recon'][layer]['w']),
- self.weights['recon'][layer]['b']))
- self.hidden_recon.append(h)
- self.reconstruction = self.hidden_recon[-1]
-
- # cost
- self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2.0))
- self.optimizer = optimizer.minimize(self.cost)
-
- init = tf.global_variables_initializer()
- self.sess = tf.Session()
- self.sess.run(init)
-
-
- def _initialize_weights(self):
- all_weights = dict()
- initializer = tf.contrib.layers.xavier_initializer()
- # Encoding network weights
- encoder_weights = []
- for layer in range(len(self.n_layers)-1):
- w = tf.Variable(
- initializer((self.n_layers[layer], self.n_layers[layer + 1]),
- dtype=tf.float32))
- b = tf.Variable(
- tf.zeros([self.n_layers[layer + 1]], dtype=tf.float32))
- encoder_weights.append({'w': w, 'b': b})
- # Recon network weights
- recon_weights = []
- for layer in range(len(self.n_layers)-1, 0, -1):
- w = tf.Variable(
- initializer((self.n_layers[layer], self.n_layers[layer - 1]),
- dtype=tf.float32))
- b = tf.Variable(
- tf.zeros([self.n_layers[layer - 1]], dtype=tf.float32))
- recon_weights.append({'w': w, 'b': b})
- all_weights['encode'] = encoder_weights
- all_weights['recon'] = recon_weights
- return all_weights
-
- def partial_fit(self, X):
- cost, opt = self.sess.run((self.cost, self.optimizer), feed_dict={self.x: X})
- return cost
-
- def calc_total_cost(self, X):
- return self.sess.run(self.cost, feed_dict={self.x: X})
-
- def transform(self, X):
- return self.sess.run(self.hidden_encode[-1], feed_dict={self.x: X})
-
- def generate(self, hidden=None):
- if hidden is None:
- hidden = np.random.normal(size=self.weights['encode'][-1]['b'])
- return self.sess.run(self.reconstruction, feed_dict={self.hidden_encode[-1]: hidden})
-
- def reconstruct(self, X):
- return self.sess.run(self.reconstruction, feed_dict={self.x: X})
-
- def getWeights(self):
- raise NotImplementedError
- return self.sess.run(self.weights)
-
- def getBiases(self):
- raise NotImplementedError
- return self.sess.run(self.weights)
-
diff --git a/research/autoencoder/autoencoder_models/DenoisingAutoencoder.py b/research/autoencoder/autoencoder_models/DenoisingAutoencoder.py
deleted file mode 100644
index 22b5dcb44a4079b80bfcfc16e3dcda5b21ca8c1b..0000000000000000000000000000000000000000
--- a/research/autoencoder/autoencoder_models/DenoisingAutoencoder.py
+++ /dev/null
@@ -1,129 +0,0 @@
-import tensorflow as tf
-
-class AdditiveGaussianNoiseAutoencoder(object):
- def __init__(self, n_input, n_hidden, transfer_function = tf.nn.softplus, optimizer = tf.train.AdamOptimizer(),
- scale = 0.1):
- self.n_input = n_input
- self.n_hidden = n_hidden
- self.transfer = transfer_function
- self.scale = tf.placeholder(tf.float32)
- self.training_scale = scale
- network_weights = self._initialize_weights()
- self.weights = network_weights
-
- # model
- self.x = tf.placeholder(tf.float32, [None, self.n_input])
- self.hidden = self.transfer(tf.add(tf.matmul(self.x + scale * tf.random_normal((n_input,)),
- self.weights['w1']),
- self.weights['b1']))
- self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']), self.weights['b2'])
-
- # cost
- self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2.0))
- self.optimizer = optimizer.minimize(self.cost)
-
- init = tf.global_variables_initializer()
- self.sess = tf.Session()
- self.sess.run(init)
-
- def _initialize_weights(self):
- all_weights = dict()
- all_weights['w1'] = tf.get_variable("w1", shape=[self.n_input, self.n_hidden],
- initializer=tf.contrib.layers.xavier_initializer())
- all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype = tf.float32))
- all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32))
- all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype = tf.float32))
- return all_weights
-
- def partial_fit(self, X):
- cost, opt = self.sess.run((self.cost, self.optimizer), feed_dict = {self.x: X,
- self.scale: self.training_scale
- })
- return cost
-
- def calc_total_cost(self, X):
- return self.sess.run(self.cost, feed_dict = {self.x: X,
- self.scale: self.training_scale
- })
-
- def transform(self, X):
- return self.sess.run(self.hidden, feed_dict = {self.x: X,
- self.scale: self.training_scale
- })
-
- def generate(self, hidden=None):
- if hidden is None:
- hidden = self.sess.run(tf.random_normal([1, self.n_hidden]))
- return self.sess.run(self.reconstruction, feed_dict = {self.hidden: hidden})
-
- def reconstruct(self, X):
- return self.sess.run(self.reconstruction, feed_dict = {self.x: X,
- self.scale: self.training_scale
- })
-
- def getWeights(self):
- return self.sess.run(self.weights['w1'])
-
- def getBiases(self):
- return self.sess.run(self.weights['b1'])
-
-
-class MaskingNoiseAutoencoder(object):
- def __init__(self, n_input, n_hidden, transfer_function = tf.nn.softplus, optimizer = tf.train.AdamOptimizer(),
- dropout_probability = 0.95):
- self.n_input = n_input
- self.n_hidden = n_hidden
- self.transfer = transfer_function
- self.dropout_probability = dropout_probability
- self.keep_prob = tf.placeholder(tf.float32)
-
- network_weights = self._initialize_weights()
- self.weights = network_weights
-
- # model
- self.x = tf.placeholder(tf.float32, [None, self.n_input])
- self.hidden = self.transfer(tf.add(tf.matmul(tf.nn.dropout(self.x, self.keep_prob), self.weights['w1']),
- self.weights['b1']))
- self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']), self.weights['b2'])
-
- # cost
- self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2.0))
- self.optimizer = optimizer.minimize(self.cost)
-
- init = tf.global_variables_initializer()
- self.sess = tf.Session()
- self.sess.run(init)
-
- def _initialize_weights(self):
- all_weights = dict()
- all_weights['w1'] = tf.get_variable("w1", shape=[self.n_input, self.n_hidden],
- initializer=tf.contrib.layers.xavier_initializer())
- all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype = tf.float32))
- all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32))
- all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype = tf.float32))
- return all_weights
-
- def partial_fit(self, X):
- cost, opt = self.sess.run((self.cost, self.optimizer),
- feed_dict = {self.x: X, self.keep_prob: self.dropout_probability})
- return cost
-
- def calc_total_cost(self, X):
- return self.sess.run(self.cost, feed_dict = {self.x: X, self.keep_prob: 1.0})
-
- def transform(self, X):
- return self.sess.run(self.hidden, feed_dict = {self.x: X, self.keep_prob: 1.0})
-
- def generate(self, hidden=None):
- if hidden is None:
- hidden = self.sess.run(tf.random_normal([1, self.n_hidden]))
- return self.sess.run(self.reconstruction, feed_dict = {self.hidden: hidden})
-
- def reconstruct(self, X):
- return self.sess.run(self.reconstruction, feed_dict = {self.x: X, self.keep_prob: 1.0})
-
- def getWeights(self):
- return self.sess.run(self.weights['w1'])
-
- def getBiases(self):
- return self.sess.run(self.weights['b1'])
diff --git a/research/autoencoder/autoencoder_models/VariationalAutoencoder.py b/research/autoencoder/autoencoder_models/VariationalAutoencoder.py
deleted file mode 100644
index 3c2556ab89c2d32be0af5e61099aa12f91c1f176..0000000000000000000000000000000000000000
--- a/research/autoencoder/autoencoder_models/VariationalAutoencoder.py
+++ /dev/null
@@ -1,70 +0,0 @@
-import tensorflow as tf
-
-class VariationalAutoencoder(object):
-
- def __init__(self, n_input, n_hidden, optimizer = tf.train.AdamOptimizer()):
- self.n_input = n_input
- self.n_hidden = n_hidden
-
- network_weights = self._initialize_weights()
- self.weights = network_weights
-
- # model
- self.x = tf.placeholder(tf.float32, [None, self.n_input])
- self.z_mean = tf.add(tf.matmul(self.x, self.weights['w1']), self.weights['b1'])
- self.z_log_sigma_sq = tf.add(tf.matmul(self.x, self.weights['log_sigma_w1']), self.weights['log_sigma_b1'])
-
- # sample from gaussian distribution
- eps = tf.random_normal(tf.stack([tf.shape(self.x)[0], self.n_hidden]), 0, 1, dtype = tf.float32)
- self.z = tf.add(self.z_mean, tf.multiply(tf.sqrt(tf.exp(self.z_log_sigma_sq)), eps))
-
- self.reconstruction = tf.add(tf.matmul(self.z, self.weights['w2']), self.weights['b2'])
-
- # cost
- reconstr_loss = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction, self.x), 2.0), 1)
- latent_loss = -0.5 * tf.reduce_sum(1 + self.z_log_sigma_sq
- - tf.square(self.z_mean)
- - tf.exp(self.z_log_sigma_sq), 1)
- self.cost = tf.reduce_mean(reconstr_loss + latent_loss)
- self.optimizer = optimizer.minimize(self.cost)
-
- init = tf.global_variables_initializer()
- self.sess = tf.Session()
- self.sess.run(init)
-
- def _initialize_weights(self):
- all_weights = dict()
- all_weights['w1'] = tf.get_variable("w1", shape=[self.n_input, self.n_hidden],
- initializer=tf.contrib.layers.xavier_initializer())
- all_weights['log_sigma_w1'] = tf.get_variable("log_sigma_w1", shape=[self.n_input, self.n_hidden],
- initializer=tf.contrib.layers.xavier_initializer())
- all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
- all_weights['log_sigma_b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
- all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype=tf.float32))
- all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32))
- return all_weights
-
- def partial_fit(self, X):
- cost, opt = self.sess.run((self.cost, self.optimizer), feed_dict={self.x: X})
- return cost
-
- def calc_total_cost(self, X):
- return self.sess.run(self.cost, feed_dict = {self.x: X})
-
- def transform(self, X):
- return self.sess.run(self.z_mean, feed_dict={self.x: X})
-
- def generate(self, hidden = None):
- if hidden is None:
- hidden = self.sess.run(tf.random_normal([1, self.n_hidden]))
- return self.sess.run(self.reconstruction, feed_dict={self.z: hidden})
-
- def reconstruct(self, X):
- return self.sess.run(self.reconstruction, feed_dict={self.x: X})
-
- def getWeights(self):
- return self.sess.run(self.weights['w1'])
-
- def getBiases(self):
- return self.sess.run(self.weights['b1'])
-
diff --git a/research/autoencoder/autoencoder_models/__init__.py b/research/autoencoder/autoencoder_models/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/brain_coder/README.md b/research/brain_coder/README.md
deleted file mode 100644
index 3e2a1656d8f145569266c19c64b41779ccbf308c..0000000000000000000000000000000000000000
--- a/research/brain_coder/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-
-
-
-
-# Brain Coder
-
-*Authors: Daniel Abolafia, Mohammad Norouzi, Quoc Le*
-
-Brain coder is a code synthesis experimental environment. We provide code that reproduces the results from our recent paper [Neural Program Synthesis with Priority Queue Training](https://arxiv.org/abs/1801.03526). See single_task/README.md for details on how to build and reproduce those experiments.
-
-## Installation
-
-First install dependencies seperately:
-
-* [bazel](https://docs.bazel.build/versions/master/install.html)
-* [TensorFlow](https://www.tensorflow.org/install/)
-* [scipy](https://www.scipy.org/install.html)
-* [absl-py](https://github.com/abseil/abseil-py)
-
-Note: even if you already have these dependencies installed, make sure they are
-up-to-date to avoid unnecessary debugging.
-
-
-## Building
-
-Use bazel from the top-level repo directory.
-
-For example:
-
-```bash
-bazel build single_task:run
-```
-
-View README.md files in subdirectories for more details.
diff --git a/research/brain_coder/WORKSPACE b/research/brain_coder/WORKSPACE
deleted file mode 100644
index 7c07b5325e71a1684fb38089adeaaa9f4f00a775..0000000000000000000000000000000000000000
--- a/research/brain_coder/WORKSPACE
+++ /dev/null
@@ -1,5 +0,0 @@
-git_repository(
- name = "subpar",
- remote = "https://github.com/google/subpar",
- tag = "1.0.0",
-)
diff --git a/research/brain_coder/common/BUILD b/research/brain_coder/common/BUILD
deleted file mode 100644
index b5f79c25096ca574d4a133f871343eedd985b25e..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/BUILD
+++ /dev/null
@@ -1,106 +0,0 @@
-licenses(["notice"])
-
-package(default_visibility = [
- "//:__subpackages__",
-])
-
-py_library(
- name = "bf",
- srcs = ["bf.py"],
-)
-
-py_test(
- name = "bf_test",
- srcs = ["bf_test.py"],
- deps = [
- ":bf",
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "config_lib",
- srcs = ["config_lib.py"],
-)
-
-py_test(
- name = "config_lib_test",
- srcs = ["config_lib_test.py"],
- deps = [
- ":config_lib",
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "reward",
- srcs = ["reward.py"],
-)
-
-py_test(
- name = "reward_test",
- srcs = ["reward_test.py"],
- deps = [
- ":reward",
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "rollout",
- srcs = ["rollout.py"],
- deps = [
- ":utils",
- # numpy dep
- # scipy dep
- ],
-)
-
-py_test(
- name = "rollout_test",
- srcs = ["rollout_test.py"],
- deps = [
- ":rollout",
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "schedules",
- srcs = ["schedules.py"],
- deps = [":config_lib"],
-)
-
-py_test(
- name = "schedules_test",
- srcs = ["schedules_test.py"],
- deps = [
- ":config_lib",
- ":schedules",
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "utils",
- srcs = ["utils.py"],
- deps = [
- # file dep
- # absl dep /logging
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_test(
- name = "utils_test",
- srcs = ["utils_test.py"],
- deps = [
- ":utils",
- # numpy dep
- # tensorflow dep
- ],
-)
diff --git a/research/brain_coder/common/bf.py b/research/brain_coder/common/bf.py
deleted file mode 100644
index f049c45258f7b78a25b5492108b2f8b37c8a55cd..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/bf.py
+++ /dev/null
@@ -1,234 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""BrainF**k interpreter.
-
-Language info: https://en.wikipedia.org/wiki/Brainfuck
-
-Based on public implementation:
-https://github.com/pocmo/Python-Brainfuck/blob/master/brainfuck.py
-"""
-
-from collections import namedtuple
-import time
-
-
-EvalResult = namedtuple(
- 'EvalResult', ['output', 'success', 'failure_reason', 'steps', 'time',
- 'memory', 'program_trace'])
-
-
-ExecutionSnapshot = namedtuple(
- 'ExecutionSnapshot',
- ['codeptr', 'codechar', 'memptr', 'memval', 'memory', 'next_input',
- 'output_buffer'])
-
-
-class Status(object):
- SUCCESS = 'success'
- TIMEOUT = 'timeout'
- STEP_LIMIT = 'step-limit'
- SYNTAX_ERROR = 'syntax-error'
-
-
-CHARS = INT_TO_CHAR = ['>', '<', '+', '-', '[', ']', '.', ',']
-CHAR_TO_INT = dict([(c, i) for i, c in enumerate(INT_TO_CHAR)])
-
-
-class LookAheadIterator(object):
- """Same API as Python iterator, with additional peek method."""
-
- def __init__(self, iterable):
- self._it = iter(iterable)
- self._current_element = None
- self._done = False
- self._preload_next()
-
- def _preload_next(self):
- try:
- self._current_element = self._it.next()
- except StopIteration:
- self._done = True
-
- def next(self):
- if self._done:
- raise StopIteration
- element = self._current_element
- self._preload_next()
- return element
-
- def peek(self, default_value=None):
- if self._done:
- if default_value is None:
- raise StopIteration
- return default_value
- return self._current_element
-
-
-def buildbracemap(code):
- """Build jump map.
-
- Args:
- code: List or string or BF chars.
-
- Returns:
- bracemap: dict mapping open and close brace positions in the code to their
- destination jumps. Specifically, positions of matching open/close braces
- if they exist.
- correct_syntax: True if all braces match. False if there are unmatched
- braces in the code. Even if there are unmatched braces, a bracemap will
- be built, and unmatched braces will map to themselves.
- """
- bracestack, bracemap = [], {}
-
- correct_syntax = True
- for position, command in enumerate(code):
- if command == '[':
- bracestack.append(position)
- if command == ']':
- if not bracestack: # Unmatched closing brace.
- bracemap[position] = position # Don't jump to any position.
- correct_syntax = False
- continue
- start = bracestack.pop()
- bracemap[start] = position
- bracemap[position] = start
- if bracestack: # Unmatched opening braces.
- for pos in bracestack:
- bracemap[pos] = pos # Don't jump to any position.
- correct_syntax = False
- return bracemap, correct_syntax
-
-
-def evaluate(code, input_buffer=None, init_memory=None, base=256, timeout=1.0,
- max_steps=None, require_correct_syntax=True, output_memory=False,
- debug=False):
- """Execute BF code.
-
- Args:
- code: String or list of BF characters. Any character not in CHARS will be
- ignored.
- input_buffer: A list of ints which will be used as the program's input
- stream. Each read op "," will read an int from this list. 0's will be
- read once the end of the list is reached, or if no input buffer is
- given.
- init_memory: A list of ints. Memory for first k positions will be
- initialized to this list (where k = len(init_memory)). Memory positions
- are initialized to 0 by default.
- base: Integer base for the memory. When a memory value is incremented to
- `base` it will overflow to 0. When a memory value is decremented to -1
- it will underflow to `base` - 1.
- timeout: Time limit for program execution in seconds. Set to None to
- disable.
- max_steps: Execution step limit. An execution step is the execution of one
- operation (code character), even if that op has been executed before.
- Execution exits when this many steps are reached. Set to None to
- disable. Disabled by default.
- require_correct_syntax: If True, unmatched braces will cause `evaluate` to
- return without executing the code. The failure reason will be
- `Status.SYNTAX_ERROR`. If False, unmatched braces are ignored
- and execution will continue.
- output_memory: If True, the state of the memory at the end of execution is
- returned.
- debug: If True, then a full program trace will be returned.
-
- Returns:
- EvalResult namedtuple containing
- output: List of ints which were written out by the program with the "."
- operation.
- success: Boolean. Whether execution completed successfully.
- failure_reason: One of the attributes of `Status`. Gives extra info
- about why execution was not successful.
- steps: Number of execution steps the program ran for.
- time: Amount of time in seconds the program ran for.
- memory: If `output_memory` is True, a list of memory cells up to the last
- one written to. otherwise, None.
- """
- input_iter = (
- LookAheadIterator(input_buffer) if input_buffer is not None
- else LookAheadIterator([]))
-
- # Null memory value. This is the value of an empty memory. Also the value
- # returned by the read operation when the input buffer is empty, or the
- # end of the buffer is reached.
- null_value = 0
-
- code = list(code)
- bracemap, correct_syntax = buildbracemap(code) # will modify code list
- if require_correct_syntax and not correct_syntax:
- return EvalResult([], False, Status.SYNTAX_ERROR, 0, 0.0,
- [] if output_memory else None, [] if debug else None)
-
- output_buffer = []
-
- codeptr, cellptr = 0, 0
-
- cells = list(init_memory) if init_memory else [0]
-
- program_trace = [] if debug else None
- success = True
- reason = Status.SUCCESS
- start_time = time.time()
- steps = 0
- while codeptr < len(code):
- command = code[codeptr]
-
- if debug:
- # Add step to program trace.
- program_trace.append(ExecutionSnapshot(
- codeptr=codeptr, codechar=command, memptr=cellptr,
- memval=cells[cellptr], memory=list(cells),
- next_input=input_iter.peek(null_value),
- output_buffer=list(output_buffer)))
-
- if command == '>':
- cellptr += 1
- if cellptr == len(cells): cells.append(null_value)
-
- if command == '<':
- cellptr = 0 if cellptr <= 0 else cellptr - 1
-
- if command == '+':
- cells[cellptr] = cells[cellptr] + 1 if cells[cellptr] < (base - 1) else 0
-
- if command == '-':
- cells[cellptr] = cells[cellptr] - 1 if cells[cellptr] > 0 else (base - 1)
-
- if command == '[' and cells[cellptr] == 0: codeptr = bracemap[codeptr]
- if command == ']' and cells[cellptr] != 0: codeptr = bracemap[codeptr]
-
- if command == '.': output_buffer.append(cells[cellptr])
- if command == ',': cells[cellptr] = next(input_iter, null_value)
-
- codeptr += 1
- steps += 1
-
- if timeout is not None and time.time() - start_time > timeout:
- success = False
- reason = Status.TIMEOUT
- break
- if max_steps is not None and steps >= max_steps:
- success = False
- reason = Status.STEP_LIMIT
- break
-
- if debug:
- # Add step to program trace.
- command = code[codeptr] if codeptr < len(code) else ''
- program_trace.append(ExecutionSnapshot(
- codeptr=codeptr, codechar=command, memptr=cellptr,
- memval=cells[cellptr], memory=list(cells),
- next_input=input_iter.peek(null_value),
- output_buffer=list(output_buffer)))
-
- return EvalResult(
- output=output_buffer,
- success=success,
- failure_reason=reason,
- steps=steps,
- time=time.time() - start_time,
- memory=cells if output_memory else None,
- program_trace=program_trace)
-
-
diff --git a/research/brain_coder/common/bf_test.py b/research/brain_coder/common/bf_test.py
deleted file mode 100644
index 2cbf505601a96ec1fc819f1d01fe551f2fae4a5d..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/bf_test.py
+++ /dev/null
@@ -1,137 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.bf."""
-
-import tensorflow as tf
-
-from common import bf # brain coder
-
-
-class BfTest(tf.test.TestCase):
-
- def assertCorrectOutput(self, target_output, eval_result):
- self.assertEqual(target_output, eval_result.output)
- self.assertTrue(eval_result.success)
- self.assertEqual(bf.Status.SUCCESS, eval_result.failure_reason)
-
- def testBasicOps(self):
- self.assertCorrectOutput(
- [3, 1, 2],
- bf.evaluate('+++.--.+.'))
- self.assertCorrectOutput(
- [1, 1, 2],
- bf.evaluate('+.<.>++.'))
- self.assertCorrectOutput(
- [0],
- bf.evaluate('+,.'))
- self.assertCorrectOutput(
- [ord(char) for char in 'Hello World!\n'],
- bf.evaluate(
- '>++++++++[-<+++++++++>]<.>>+>-[+]++>++>+++[>[->+++<<+++>]<<]>-----'
- '.>->+++..+++.>-.<<+[>[+>+]>>]<--------------.>>.+++.------.-------'
- '-.>+.>+.'))
-
- def testBase(self):
- self.assertCorrectOutput(
- [1, 4],
- bf.evaluate('+.--.', base=5, input_buffer=[]))
-
- def testInputBuffer(self):
- self.assertCorrectOutput(
- [2, 3, 4],
- bf.evaluate('>,[>,]<[.<]', input_buffer=[4, 3, 2]))
-
- def testBadChars(self):
- self.assertCorrectOutput(
- [2, 3, 4],
- bf.evaluate('>,[>,]hello----.[[[[[>+.',
- input_buffer=[],
- base=10,
- require_correct_syntax=False))
-
- eval_result = bf.evaluate(
- '+++.]]]]>----.[[[[[>+.',
- input_buffer=[],
- base=10,
- require_correct_syntax=True)
- self.assertEqual([], eval_result.output)
- self.assertFalse(eval_result.success)
- self.assertEqual(bf.Status.SYNTAX_ERROR,
- eval_result.failure_reason)
-
- def testTimeout(self):
- er = bf.evaluate('+.[].', base=5, input_buffer=[], timeout=0.1)
- self.assertEqual(
- ([1], False, bf.Status.TIMEOUT),
- (er.output, er.success, er.failure_reason))
- self.assertTrue(0.07 < er.time < 0.21)
-
- er = bf.evaluate('+.[-].', base=5, input_buffer=[], timeout=0.1)
- self.assertEqual(
- ([1, 0], True, bf.Status.SUCCESS),
- (er.output, er.success, er.failure_reason))
- self.assertTrue(er.time < 0.15)
-
- def testMaxSteps(self):
- er = bf.evaluate('+.[].', base=5, input_buffer=[], timeout=None,
- max_steps=100)
- self.assertEqual(
- ([1], False, bf.Status.STEP_LIMIT, 100),
- (er.output, er.success, er.failure_reason, er.steps))
-
- er = bf.evaluate('+.[-].', base=5, input_buffer=[], timeout=None,
- max_steps=100)
- self.assertEqual(
- ([1, 0], True, bf.Status.SUCCESS),
- (er.output, er.success, er.failure_reason))
- self.assertTrue(er.steps < 100)
-
- def testOutputMemory(self):
- er = bf.evaluate('+>++>+++>++++.', base=256, input_buffer=[],
- output_memory=True)
- self.assertEqual(
- ([4], True, bf.Status.SUCCESS),
- (er.output, er.success, er.failure_reason))
- self.assertEqual([1, 2, 3, 4], er.memory)
-
- def testProgramTrace(self):
- es = bf.ExecutionSnapshot
- er = bf.evaluate(',[.>,].', base=256, input_buffer=[2, 1], debug=True)
- self.assertEqual(
- [es(codeptr=0, codechar=',', memptr=0, memval=0, memory=[0],
- next_input=2, output_buffer=[]),
- es(codeptr=1, codechar='[', memptr=0, memval=2, memory=[2],
- next_input=1, output_buffer=[]),
- es(codeptr=2, codechar='.', memptr=0, memval=2, memory=[2],
- next_input=1, output_buffer=[]),
- es(codeptr=3, codechar='>', memptr=0, memval=2, memory=[2],
- next_input=1, output_buffer=[2]),
- es(codeptr=4, codechar=',', memptr=1, memval=0, memory=[2, 0],
- next_input=1, output_buffer=[2]),
- es(codeptr=5, codechar=']', memptr=1, memval=1, memory=[2, 1],
- next_input=0, output_buffer=[2]),
- es(codeptr=2, codechar='.', memptr=1, memval=1, memory=[2, 1],
- next_input=0, output_buffer=[2]),
- es(codeptr=3, codechar='>', memptr=1, memval=1, memory=[2, 1],
- next_input=0, output_buffer=[2, 1]),
- es(codeptr=4, codechar=',', memptr=2, memval=0, memory=[2, 1, 0],
- next_input=0, output_buffer=[2, 1]),
- es(codeptr=5, codechar=']', memptr=2, memval=0, memory=[2, 1, 0],
- next_input=0, output_buffer=[2, 1]),
- es(codeptr=6, codechar='.', memptr=2, memval=0, memory=[2, 1, 0],
- next_input=0, output_buffer=[2, 1]),
- es(codeptr=7, codechar='', memptr=2, memval=0, memory=[2, 1, 0],
- next_input=0, output_buffer=[2, 1, 0])],
- er.program_trace)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/common/config_lib.py b/research/brain_coder/common/config_lib.py
deleted file mode 100644
index 733fa202f2e500f964beff2111cb7445fa66a9e1..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/config_lib.py
+++ /dev/null
@@ -1,337 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Objects for storing configuration and passing config into binaries.
-
-Config class stores settings and hyperparameters for models, data, and anything
-else that may be specific to a particular run.
-"""
-
-import ast
-import itertools
-from six.moves import xrange
-
-
-class Config(dict):
- """Stores model configuration, hyperparameters, or dataset parameters."""
-
- def __getattr__(self, attr):
- return self[attr]
-
- def __setattr__(self, attr, value):
- self[attr] = value
-
- def pretty_str(self, new_lines=True, indent=2, final_indent=0):
- prefix = (' ' * indent) if new_lines else ''
- final_prefix = (' ' * final_indent) if new_lines else ''
- kv = ['%s%s=%s' % (prefix, k,
- (repr(v) if not isinstance(v, Config)
- else v.pretty_str(new_lines=new_lines,
- indent=indent+2,
- final_indent=indent)))
- for k, v in self.items()]
- if new_lines:
- return 'Config(\n%s\n%s)' % (',\n'.join(kv), final_prefix)
- else:
- return 'Config(%s)' % ', '.join(kv)
-
- def _update_iterator(self, *args, **kwargs):
- """Convert mixed input into an iterator over (key, value) tuples.
-
- Follows the dict.update call signature.
-
- Args:
- *args: (Optional) Pass a dict or iterable of (key, value) 2-tuples as
- an unnamed argument. Only one unnamed argument allowed.
- **kwargs: (Optional) Pass (key, value) pairs as named arguments, where the
- argument name is the key and the argument value is the value.
-
- Returns:
- An iterator over (key, value) tuples given in the input.
-
- Raises:
- TypeError: If more than one unnamed argument is given.
- """
- if len(args) > 1:
- raise TypeError('Expected at most 1 unnamed arguments, got %d'
- % len(args))
- obj = args[0] if args else dict()
- if isinstance(obj, dict):
- return itertools.chain(obj.items(), kwargs.items())
- # Assume obj is an iterable of 2-tuples.
- return itertools.chain(obj, kwargs.items())
-
- def make_default(self, keys=None):
- """Convert OneOf objects into their default configs.
-
- Recursively calls into Config objects.
-
- Args:
- keys: Iterable of key names to check. If None, all keys in self will be
- used.
- """
- if keys is None:
- keys = self.keys()
- for k in keys:
- # Replace OneOf with its default value.
- if isinstance(self[k], OneOf):
- self[k] = self[k].default()
- # Recursively call into all Config objects, even those that came from
- # OneOf objects in the previous code line (for nested OneOf objects).
- if isinstance(self[k], Config):
- self[k].make_default()
-
- def update(self, *args, **kwargs):
- """Same as dict.update except nested Config objects are updated.
-
- Args:
- *args: (Optional) Pass a dict or list of (key, value) 2-tuples as unnamed
- argument.
- **kwargs: (Optional) Pass (key, value) pairs as named arguments, where the
- argument name is the key and the argument value is the value.
- """
- key_set = set(self.keys())
- for k, v in self._update_iterator(*args, **kwargs):
- if k in key_set:
- key_set.remove(k) # This key is updated so exclude from make_default.
- if k in self and isinstance(self[k], Config) and isinstance(v, dict):
- self[k].update(v)
- elif k in self and isinstance(self[k], OneOf) and isinstance(v, dict):
- # Replace OneOf with the chosen config.
- self[k] = self[k].update(v)
- else:
- self[k] = v
- self.make_default(key_set)
-
- def strict_update(self, *args, **kwargs):
- """Same as Config.update except keys and types are not allowed to change.
-
- If a given key is not already in this instance, an exception is raised. If a
- given value does not have the same type as the existing value for the same
- key, an exception is raised. Use this method to catch config mistakes.
-
- Args:
- *args: (Optional) Pass a dict or list of (key, value) 2-tuples as unnamed
- argument.
- **kwargs: (Optional) Pass (key, value) pairs as named arguments, where the
- argument name is the key and the argument value is the value.
-
- Raises:
- TypeError: If more than one unnamed argument is given.
- TypeError: If new value type does not match existing type.
- KeyError: If a given key is not already defined in this instance.
- """
- key_set = set(self.keys())
- for k, v in self._update_iterator(*args, **kwargs):
- if k in self:
- key_set.remove(k) # This key is updated so exclude from make_default.
- if isinstance(self[k], Config):
- if not isinstance(v, dict):
- raise TypeError('dict required for Config value, got %s' % type(v))
- self[k].strict_update(v)
- elif isinstance(self[k], OneOf):
- if not isinstance(v, dict):
- raise TypeError('dict required for OneOf value, got %s' % type(v))
- # Replace OneOf with the chosen config.
- self[k] = self[k].strict_update(v)
- else:
- if not isinstance(v, type(self[k])):
- raise TypeError('Expecting type %s for key %s, got type %s'
- % (type(self[k]), k, type(v)))
- self[k] = v
- else:
- raise KeyError(
- 'Key %s does not exist. New key creation not allowed in '
- 'strict_update.' % k)
- self.make_default(key_set)
-
- @staticmethod
- def from_str(config_str):
- """Inverse of Config.__str__."""
- parsed = ast.literal_eval(config_str)
- assert isinstance(parsed, dict)
-
- def _make_config(dictionary):
- for k, v in dictionary.items():
- if isinstance(v, dict):
- dictionary[k] = _make_config(v)
- return Config(**dictionary)
- return _make_config(parsed)
-
- @staticmethod
- def parse(key_val_string):
- """Parse hyperparameter string into Config object.
-
- Format is 'key=val,key=val,...'
- Values can be any python literal, or another Config object encoded as
- 'c(key=val,key=val,...)'.
- c(...) expressions can be arbitrarily nested.
-
- Example:
- 'a=1,b=3e-5,c=[1,2,3],d="hello world",e={"a":1,"b":2},f=c(x=1,y=[10,20])'
-
- Args:
- key_val_string: The hyperparameter string.
-
- Returns:
- Config object parsed from the input string.
- """
- if not key_val_string.strip():
- return Config()
- def _pair_to_kv(pair):
- split_index = pair.find('=')
- key, val = pair[:split_index].strip(), pair[split_index+1:].strip()
- if val.startswith('c(') and val.endswith(')'):
- val = Config.parse(val[2:-1])
- else:
- val = ast.literal_eval(val)
- return key, val
- return Config(**dict([_pair_to_kv(pair)
- for pair in _comma_iterator(key_val_string)]))
-
-
-class OneOf(object):
- """Stores branching config.
-
- In some cases there may be options which each have their own set of config
- params. For example, if specifying config for an environment, each environment
- can have custom config options. OneOf is a way to organize branching config.
-
- Usage example:
- one_of = OneOf(
- [Config(a=1, b=2),
- Config(a=2, c='hello'),
- Config(a=3, d=10, e=-10)],
- a=1)
- config = one_of.strict_update(Config(a=3, d=20))
- config == {'a': 3, 'd': 20, 'e': -10}
- """
-
- def __init__(self, choices, **kwargs):
- """Constructor.
-
- Usage: OneOf([Config(...), Config(...), ...], attribute=default_value)
-
- Args:
- choices: An iterable of Config objects. When update/strict_update is
- called on this OneOf, one of these Config will be selected.
- **kwargs: Give exactly one config attribute to branch on. The value of
- this attribute during update/strict_update will determine which
- Config is used.
-
- Raises:
- ValueError: If kwargs does not contain exactly one entry. Should give one
- named argument which is used as the attribute to condition on.
- """
- if len(kwargs) != 1:
- raise ValueError(
- 'Incorrect usage. Must give exactly one named argument. The argument '
- 'name is the config attribute to condition on, and the argument '
- 'value is the default choice. Got %d named arguments.' % len(kwargs))
- key, default_value = kwargs.items()[0]
- self.key = key
- self.default_value = default_value
-
- # Make sure each choice is a Config object.
- for config in choices:
- if not isinstance(config, Config):
- raise TypeError('choices must be a list of Config objects. Got %s.'
- % type(config))
-
- # Map value for key to the config with that value.
- self.value_map = {config[key]: config for config in choices}
- self.default_config = self.value_map[self.default_value]
-
- # Make sure there are no duplicate values.
- if len(self.value_map) != len(choices):
- raise ValueError('Multiple choices given for the same value of %s.' % key)
-
- # Check that the default value is valid.
- if self.default_value not in self.value_map:
- raise ValueError(
- 'Default value is not an available choice. Got %s=%s. Choices are %s.'
- % (key, self.default_value, self.value_map.keys()))
-
- def default(self):
- return self.default_config
-
- def update(self, other):
- """Choose a config and update it.
-
- If `other` is a Config, one of the config choices is selected and updated.
- Otherwise `other` is returned.
-
- Args:
- other: Will update chosen config with this value by calling `update` on
- the config.
-
- Returns:
- The chosen config after updating it, or `other` if no config could be
- selected.
- """
- if not isinstance(other, Config):
- return other
- if self.key not in other or other[self.key] not in self.value_map:
- return other
- target = self.value_map[other[self.key]]
- target.update(other)
- return target
-
- def strict_update(self, config):
- """Choose a config and update it.
-
- `config` must be a Config object. `config` must have the key used to select
- among the config choices, and that key must have a value which one of the
- config choices has.
-
- Args:
- config: A Config object. the chosen config will be update by calling
- `strict_update`.
-
- Returns:
- The chosen config after updating it.
-
- Raises:
- TypeError: If `config` is not a Config instance.
- ValueError: If `config` does not have the branching key in its key set.
- ValueError: If the value of the config's branching key is not one of the
- valid choices.
- """
- if not isinstance(config, Config):
- raise TypeError('Expecting Config instance, got %s.' % type(config))
- if self.key not in config:
- raise ValueError(
- 'Branching key %s required but not found in %s' % (self.key, config))
- if config[self.key] not in self.value_map:
- raise ValueError(
- 'Value %s for key %s is not a possible choice. Choices are %s.'
- % (config[self.key], self.key, self.value_map.keys()))
- target = self.value_map[config[self.key]]
- target.strict_update(config)
- return target
-
-
-def _next_comma(string, start_index):
- """Finds the position of the next comma not used in a literal collection."""
- paren_count = 0
- for i in xrange(start_index, len(string)):
- c = string[i]
- if c == '(' or c == '[' or c == '{':
- paren_count += 1
- elif c == ')' or c == ']' or c == '}':
- paren_count -= 1
- if paren_count == 0 and c == ',':
- return i
- return -1
-
-
-def _comma_iterator(string):
- index = 0
- while 1:
- next_index = _next_comma(string, index)
- if next_index == -1:
- yield string[index:]
- return
- yield string[index:next_index]
- index = next_index + 1
diff --git a/research/brain_coder/common/config_lib_test.py b/research/brain_coder/common/config_lib_test.py
deleted file mode 100644
index cdc96f92d2428f06e780930979662fdfda92e3f5..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/config_lib_test.py
+++ /dev/null
@@ -1,425 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.config_lib."""
-
-import tensorflow as tf
-
-from common import config_lib # brain coder
-
-
-class ConfigLibTest(tf.test.TestCase):
-
- def testConfig(self):
- config = config_lib.Config(hello='world', foo='bar', num=123, f=56.7)
- self.assertEqual('world', config.hello)
- self.assertEqual('bar', config['foo'])
- config.hello = 'everyone'
- config['bar'] = 9000
- self.assertEqual('everyone', config['hello'])
- self.assertEqual(9000, config.bar)
- self.assertEqual(5, len(config))
-
- def testConfigUpdate(self):
- config = config_lib.Config(a=1, b=2, c=3)
- config.update({'b': 10, 'd': 4})
- self.assertEqual({'a': 1, 'b': 10, 'c': 3, 'd': 4}, config)
-
- config = config_lib.Config(a=1, b=2, c=3)
- config.update(b=10, d=4)
- self.assertEqual({'a': 1, 'b': 10, 'c': 3, 'd': 4}, config)
-
- config = config_lib.Config(a=1, b=2, c=3)
- config.update({'e': 5}, b=10, d=4)
- self.assertEqual({'a': 1, 'b': 10, 'c': 3, 'd': 4, 'e': 5}, config)
-
- config = config_lib.Config(
- a=1,
- b=2,
- x=config_lib.Config(
- l='a',
- y=config_lib.Config(m=1, n=2),
- z=config_lib.Config(
- q=config_lib.Config(a=10, b=20),
- r=config_lib.Config(s=1, t=2))))
- config.update(x={'y': {'m': 10}, 'z': {'r': {'s': 5}}})
- self.assertEqual(
- config_lib.Config(
- a=1, b=2,
- x=config_lib.Config(
- l='a',
- y=config_lib.Config(m=10, n=2),
- z=config_lib.Config(
- q=config_lib.Config(a=10, b=20),
- r=config_lib.Config(s=5, t=2)))),
- config)
-
- config = config_lib.Config(
- foo='bar',
- num=100,
- x=config_lib.Config(a=1, b=2, c=config_lib.Config(h=10, i=20, j=30)),
- y=config_lib.Config(qrs=5, tuv=10),
- d={'a': 1, 'b': 2},
- l=[1, 2, 3])
- config.update(
- config_lib.Config(
- foo='hat',
- num=50.5,
- x={'a': 5, 'z': -10},
- y=config_lib.Config(wxyz=-1)),
- d={'a': 10, 'c': 20},
- l=[3, 4, 5, 6])
- self.assertEqual(
- config_lib.Config(
- foo='hat',
- num=50.5,
- x=config_lib.Config(a=5, b=2, z=-10,
- c=config_lib.Config(h=10, i=20, j=30)),
- y=config_lib.Config(qrs=5, tuv=10, wxyz=-1),
- d={'a': 10, 'c': 20},
- l=[3, 4, 5, 6]),
- config)
- self.assertTrue(isinstance(config.x, config_lib.Config))
- self.assertTrue(isinstance(config.x.c, config_lib.Config))
- self.assertTrue(isinstance(config.y, config_lib.Config))
-
- config = config_lib.Config(
- foo='bar',
- num=100,
- x=config_lib.Config(a=1, b=2, c=config_lib.Config(h=10, i=20, j=30)),
- y=config_lib.Config(qrs=5, tuv=10),
- d={'a': 1, 'b': 2},
- l=[1, 2, 3])
- config.update(
- config_lib.Config(
- foo=1234,
- num='hello',
- x={'a': 5, 'z': -10, 'c': {'h': -5, 'k': 40}},
- y=[1, 2, 3, 4],
- d='stuff',
- l={'a': 1, 'b': 2}))
- self.assertEqual(
- config_lib.Config(
- foo=1234,
- num='hello',
- x=config_lib.Config(a=5, b=2, z=-10,
- c=config_lib.Config(h=-5, i=20, j=30, k=40)),
- y=[1, 2, 3, 4],
- d='stuff',
- l={'a': 1, 'b': 2}),
- config)
- self.assertTrue(isinstance(config.x, config_lib.Config))
- self.assertTrue(isinstance(config.x.c, config_lib.Config))
- self.assertTrue(isinstance(config.y, list))
-
- def testConfigStrictUpdate(self):
- config = config_lib.Config(a=1, b=2, c=3)
- config.strict_update({'b': 10, 'c': 20})
- self.assertEqual({'a': 1, 'b': 10, 'c': 20}, config)
-
- config = config_lib.Config(a=1, b=2, c=3)
- config.strict_update(b=10, c=20)
- self.assertEqual({'a': 1, 'b': 10, 'c': 20}, config)
-
- config = config_lib.Config(a=1, b=2, c=3, d=4)
- config.strict_update({'d': 100}, b=10, a=20)
- self.assertEqual({'a': 20, 'b': 10, 'c': 3, 'd': 100}, config)
-
- config = config_lib.Config(
- a=1,
- b=2,
- x=config_lib.Config(
- l='a',
- y=config_lib.Config(m=1, n=2),
- z=config_lib.Config(
- q=config_lib.Config(a=10, b=20),
- r=config_lib.Config(s=1, t=2))))
- config.strict_update(x={'y': {'m': 10}, 'z': {'r': {'s': 5}}})
- self.assertEqual(
- config_lib.Config(
- a=1, b=2,
- x=config_lib.Config(
- l='a',
- y=config_lib.Config(m=10, n=2),
- z=config_lib.Config(
- q=config_lib.Config(a=10, b=20),
- r=config_lib.Config(s=5, t=2)))),
- config)
-
- config = config_lib.Config(
- foo='bar',
- num=100,
- x=config_lib.Config(a=1, b=2, c=config_lib.Config(h=10, i=20, j=30)),
- y=config_lib.Config(qrs=5, tuv=10),
- d={'a': 1, 'b': 2},
- l=[1, 2, 3])
- config.strict_update(
- config_lib.Config(
- foo='hat',
- num=50,
- x={'a': 5, 'c': {'h': 100}},
- y=config_lib.Config(tuv=-1)),
- d={'a': 10, 'c': 20},
- l=[3, 4, 5, 6])
- self.assertEqual(
- config_lib.Config(
- foo='hat',
- num=50,
- x=config_lib.Config(a=5, b=2,
- c=config_lib.Config(h=100, i=20, j=30)),
- y=config_lib.Config(qrs=5, tuv=-1),
- d={'a': 10, 'c': 20},
- l=[3, 4, 5, 6]),
- config)
-
- def testConfigStrictUpdateFail(self):
- config = config_lib.Config(a=1, b=2, c=3, x=config_lib.Config(a=1, b=2))
- with self.assertRaises(KeyError):
- config.strict_update({'b': 10, 'c': 20, 'd': 50})
- with self.assertRaises(KeyError):
- config.strict_update(b=10, d=50)
- with self.assertRaises(KeyError):
- config.strict_update(x={'c': 3})
- with self.assertRaises(TypeError):
- config.strict_update(a='string')
- with self.assertRaises(TypeError):
- config.strict_update(x={'a': 'string'})
- with self.assertRaises(TypeError):
- config.strict_update(x=[1, 2, 3])
-
- def testConfigFromStr(self):
- config = config_lib.Config.from_str("{'c': {'d': 5}, 'b': 2, 'a': 1}")
- self.assertEqual(
- {'c': {'d': 5}, 'b': 2, 'a': 1}, config)
- self.assertTrue(isinstance(config, config_lib.Config))
- self.assertTrue(isinstance(config.c, config_lib.Config))
-
- def testConfigParse(self):
- config = config_lib.Config.parse(
- 'hello="world",num=1234.5,lst=[10,20.5,True,"hi",("a","b","c")],'
- 'dct={9:10,"stuff":"qwerty","subdict":{1:True,2:False}},'
- 'subconfig=c(a=1,b=[1,2,[3,4]],c=c(f="f",g="g"))')
- self.assertEqual(
- {'hello': 'world', 'num': 1234.5,
- 'lst': [10, 20.5, True, 'hi', ('a', 'b', 'c')],
- 'dct': {9: 10, 'stuff': 'qwerty', 'subdict': {1: True, 2: False}},
- 'subconfig': {'a': 1, 'b': [1, 2, [3, 4]], 'c': {'f': 'f', 'g': 'g'}}},
- config)
- self.assertTrue(isinstance(config, config_lib.Config))
- self.assertTrue(isinstance(config.subconfig, config_lib.Config))
- self.assertTrue(isinstance(config.subconfig.c, config_lib.Config))
- self.assertFalse(isinstance(config.dct, config_lib.Config))
- self.assertFalse(isinstance(config.dct['subdict'], config_lib.Config))
- self.assertTrue(isinstance(config.lst[4], tuple))
-
- def testConfigParseErrors(self):
- with self.assertRaises(SyntaxError):
- config_lib.Config.parse('a=[1,2,b="hello"')
- with self.assertRaises(SyntaxError):
- config_lib.Config.parse('a=1,b=c(x="a",y="b"')
- with self.assertRaises(SyntaxError):
- config_lib.Config.parse('a=1,b=c(x="a")y="b"')
- with self.assertRaises(SyntaxError):
- config_lib.Config.parse('a=1,b=c(x="a"),y="b",')
-
- def testOneOf(self):
- def make_config():
- return config_lib.Config(
- data=config_lib.OneOf(
- [config_lib.Config(task=1, a='hello'),
- config_lib.Config(task=2, a='world', b='stuff'),
- config_lib.Config(task=3, c=1234)],
- task=2),
- model=config_lib.Config(stuff=1))
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=1,a="hi")'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=1, a='hi'),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=2,a="hi")'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=2, a='hi', b='stuff'),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=3)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=3, c=1234),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=2, a='world', b='stuff'),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=4,d=9999)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=4, d=9999),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=5'))
- self.assertEqual(
- config_lib.Config(
- data=5,
- model=config_lib.Config(stuff=2)),
- config)
-
- def testOneOfStrict(self):
- def make_config():
- return config_lib.Config(
- data=config_lib.OneOf(
- [config_lib.Config(task=1, a='hello'),
- config_lib.Config(task=2, a='world', b='stuff'),
- config_lib.Config(task=3, c=1234)],
- task=2),
- model=config_lib.Config(stuff=1))
-
- config = make_config()
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=1,a="hi")'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=1, a='hi'),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=2,a="hi")'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=2, a='hi', b='stuff'),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=3)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=3, c=1234),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(task=2, a='world', b='stuff'),
- model=config_lib.Config(stuff=2)),
- config)
-
- def testNestedOneOf(self):
- def make_config():
- return config_lib.Config(
- data=config_lib.OneOf(
- [config_lib.Config(task=1, a='hello'),
- config_lib.Config(
- task=2,
- a=config_lib.OneOf(
- [config_lib.Config(x=1, y=2),
- config_lib.Config(x=-1, y=1000, z=4)],
- x=1)),
- config_lib.Config(task=3, c=1234)],
- task=2),
- model=config_lib.Config(stuff=1))
-
- config = make_config()
- config.update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=2,a=c(x=-1,z=8))'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(
- task=2,
- a=config_lib.Config(x=-1, y=1000, z=8)),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=2,a=c(x=-1,z=8))'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(
- task=2,
- a=config_lib.Config(x=-1, y=1000, z=8)),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.update(config_lib.Config.parse('model=c(stuff=2)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(
- task=2,
- a=config_lib.Config(x=1, y=2)),
- model=config_lib.Config(stuff=2)),
- config)
-
- config = make_config()
- config.strict_update(config_lib.Config.parse('model=c(stuff=2)'))
- self.assertEqual(
- config_lib.Config(
- data=config_lib.Config(
- task=2,
- a=config_lib.Config(x=1, y=2)),
- model=config_lib.Config(stuff=2)),
- config)
-
- def testOneOfStrictErrors(self):
- def make_config():
- return config_lib.Config(
- data=config_lib.OneOf(
- [config_lib.Config(task=1, a='hello'),
- config_lib.Config(task=2, a='world', b='stuff'),
- config_lib.Config(task=3, c=1234)],
- task=2),
- model=config_lib.Config(stuff=1))
-
- config = make_config()
- with self.assertRaises(TypeError):
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=[1,2,3]'))
-
- config = make_config()
- with self.assertRaises(KeyError):
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=3,c=5678,d=9999)'))
-
- config = make_config()
- with self.assertRaises(ValueError):
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=c(task=4,d=9999)'))
-
- config = make_config()
- with self.assertRaises(TypeError):
- config.strict_update(config_lib.Config.parse(
- 'model=c(stuff=2),data=5'))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/common/reward.py b/research/brain_coder/common/reward.py
deleted file mode 100644
index 87e01c9c52e1ee22f2745dce12bc5e2726711ff7..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/reward.py
+++ /dev/null
@@ -1,390 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Reward functions, distance functions, and reward managers."""
-
-from abc import ABCMeta
-from abc import abstractmethod
-from math import log
-
-
-# All sequences here are assumed to be lists of ints bounded
-# between 0 and `base`-1 (inclusive).
-
-
-#################################
-### Scalar Distance Functions ###
-#################################
-
-
-def abs_diff(a, b, base=0):
- """Absolute value of difference between scalars.
-
- abs_diff is symmetric, i.e. `a` and `b` are interchangeable.
-
- Args:
- a: First argument. An int.
- b: Seconds argument. An int.
- base: Dummy argument so that the argument signature matches other scalar
- diff functions. abs_diff is the same in all bases.
-
- Returns:
- abs(a - b).
- """
- del base # Unused.
- return abs(a - b)
-
-
-def mod_abs_diff(a, b, base):
- """Shortest distance between `a` and `b` in the modular integers base `base`.
-
- The smallest distance between a and b is returned.
- Example: mod_abs_diff(1, 99, 100) ==> 2. It is not 98.
-
- mod_abs_diff is symmetric, i.e. `a` and `b` are interchangeable.
-
- Args:
- a: First argument. An int.
- b: Seconds argument. An int.
- base: The modulo base. A positive int.
-
- Returns:
- Shortest distance.
- """
- diff = abs(a - b)
- if diff >= base:
- diff %= base
- return min(diff, (-diff) + base)
-
-
-###############################
-### List Distance Functions ###
-###############################
-
-
-def absolute_distance(pred, target, base, scalar_diff_fn=abs_diff):
- """Asymmetric list distance function.
-
- List distance is the sum of element-wise distances, like Hamming distance, but
- where `pred` can be longer or shorter than `target`. For each position in both
- `pred` and `target`, distance between those elements is computed with
- `scalar_diff_fn`. For missing or extra elements in `pred`, the maximum
- distance is assigned, which is equal to `base`.
-
- Distance is 0 when `pred` and `target` are identical, and will be a positive
- integer when they are not.
-
- Args:
- pred: Prediction list. Distance from this list is computed.
- target: Target list. Distance to this list is computed.
- base: The integer base to use. For example, a list of chars would use base
- 256.
- scalar_diff_fn: Element-wise distance function.
-
- Returns:
- List distance between `pred` and `target`.
- """
- d = 0
- for i, target_t in enumerate(target):
- if i >= len(pred):
- d += base # A missing slot is worth the max distance.
- else:
- # Add element-wise distance for this slot.
- d += scalar_diff_fn(pred[i], target_t, base)
- if len(pred) > len(target):
- # Each extra slot is worth the max distance.
- d += (len(pred) - len(target)) * base
- return d
-
-
-def log_absolute_distance(pred, target, base):
- """Asymmetric list distance function that uses log distance.
-
- A list distance which computes sum of element-wise distances, similar to
- `absolute_distance`. Unlike `absolute_distance`, this scales the resulting
- distance to be a float.
-
- Element-wise distance are log-scale. Distance between two list changes
- relatively less for elements that are far apart, but changes a lot (goes to 0
- faster) when values get close together.
-
- Args:
- pred: List of ints. Computes distance from this list to the target.
- target: List of ints. This is the "correct" list which the prediction list
- is trying to match.
- base: Integer base.
-
- Returns:
- Float distance normalized so that when `pred` is at most as long as `target`
- the distance is between 0.0 and 1.0. Distance grows unboundedly large
- as `pred` grows past `target` in length.
- """
- if not target:
- length_normalizer = 1.0
- if not pred:
- # Distance between [] and [] is 0.0 since they are equal.
- return 0.0
- else:
- length_normalizer = float(len(target))
- # max_dist is the maximum element-wise distance, before taking log and
- # scaling. Since we use `mod_abs_diff`, it would be (base // 2), but we add
- # 1 to it so that missing or extra positions get the maximum penalty.
- max_dist = base // 2 + 1
-
- # The log-distance will be scaled by a factor.
- # Note: +1 is added to the numerator and denominator to avoid log(0). This
- # only has a translational effect, i.e. log(dist + 1) / log(max_dist + 1).
- factor = log(max_dist + 1)
-
- d = 0.0 # Total distance to be computed.
- for i, target_t in enumerate(target):
- if i >= len(pred):
- # Assign the max element-wise distance for missing positions. This is 1.0
- # after scaling.
- d += 1.0
- else:
- # Add the log-dist divided by a scaling factor.
- d += log(mod_abs_diff(pred[i], target_t, base) + 1) / factor
- if len(pred) > len(target):
- # Add the max element-wise distance for each extra position.
- # Since max dist after scaling is 1, this is just the difference in list
- # lengths.
- d += (len(pred) - len(target))
- return d / length_normalizer # Normalize again by the target length.
-
-
-########################
-### Reward Functions ###
-########################
-
-# Reward functions assign reward based on program output.
-# Warning: only use these functions as the terminal rewards in episodes, i.e.
-# for the "final" programs.
-
-
-def absolute_distance_reward(pred, target, base, scalar_diff_fn=abs_diff):
- """Reward function based on absolute_distance function.
-
- Maximum reward, 1.0, is given when the lists are equal. Reward is scaled
- so that 0.0 reward is given when `pred` is the empty list (assuming `target`
- is not empty). Reward can go negative when `pred` is longer than `target`.
-
- This is an asymmetric reward function, so which list is the prediction and
- which is the target matters.
-
- Args:
- pred: Prediction sequence. This should be the sequence outputted by the
- generated code. List of ints n, where 0 <= n < base.
- target: Target sequence. The correct sequence that the generated code needs
- to output. List of ints n, where 0 <= n < base.
- base: Base of the computation.
- scalar_diff_fn: Element-wise distance function.
-
- Returns:
- Reward computed based on `pred` and `target`. A float.
- """
- unit_dist = float(base * len(target))
- if unit_dist == 0:
- unit_dist = base
- dist = absolute_distance(pred, target, base, scalar_diff_fn=scalar_diff_fn)
- return (unit_dist - dist) / unit_dist
-
-
-def absolute_mod_distance_reward(pred, target, base):
- """Same as `absolute_distance_reward` but `mod_abs_diff` scalar diff is used.
-
- Args:
- pred: Prediction sequence. This should be the sequence outputted by the
- generated code. List of ints n, where 0 <= n < base.
- target: Target sequence. The correct sequence that the generated code needs
- to output. List of ints n, where 0 <= n < base.
- base: Base of the computation.
-
- Returns:
- Reward computed based on `pred` and `target`. A float.
- """
- return absolute_distance_reward(pred, target, base, mod_abs_diff)
-
-
-def absolute_log_distance_reward(pred, target, base):
- """Compute reward using `log_absolute_distance`.
-
- Maximum reward, 1.0, is given when the lists are equal. Reward is scaled
- so that 0.0 reward is given when `pred` is the empty list (assuming `target`
- is not empty). Reward can go negative when `pred` is longer than `target`.
-
- This is an asymmetric reward function, so which list is the prediction and
- which is the target matters.
-
- This reward function has the nice property that much more reward is given
- for getting the correct value (at each position) than for there being any
- value at all. For example, in base 100, lets say pred = [1] * 1000
- and target = [10] * 1000. A lot of reward would be given for being 80%
- accurate (worst element-wise distance is 50, distances here are 9) using
- `absolute_distance`. `log_absolute_distance` on the other hand will give
- greater and greater reward increments the closer each predicted value gets to
- the target. That makes the reward given for accuracy somewhat independant of
- the base.
-
- Args:
- pred: Prediction sequence. This should be the sequence outputted by the
- generated code. List of ints n, where 0 <= n < base.
- target: Target sequence. The correct sequence that the generated code needs
- to output. List of ints n, where 0 <= n < base.
- base: Base of the computation.
-
- Returns:
- Reward computed based on `pred` and `target`. A float.
- """
- return 1.0 - log_absolute_distance(pred, target, base)
-
-
-#######################
-### Reward Managers ###
-#######################
-
-# Reward managers assign reward to many code attempts throughout an episode.
-
-
-class RewardManager(object):
- """Reward managers administer reward across an episode.
-
- Reward managers are used for "editor" environments. These are environments
- where the agent has some way to edit its code over time, and run its code
- many time in the same episode, so that it can make incremental improvements.
-
- Reward managers are instantiated with a target sequence, which is the known
- correct program output. The manager is called on the output from a proposed
- code, and returns reward. If many proposal outputs are tried, reward may be
- some stateful function that takes previous tries into account. This is done,
- in part, so that an agent cannot accumulate unbounded reward just by trying
- junk programs as often as possible. So reward managers should not give the
- same reward twice if the next proposal is not better than the last.
- """
- __metaclass__ = ABCMeta
-
- def __init__(self, target, base, distance_fn=absolute_distance):
- self._target = list(target)
- self._base = base
- self._distance_fn = distance_fn
-
- @abstractmethod
- def __call__(self, sequence):
- """Call this reward manager like a function to get reward.
-
- Calls to reward manager are stateful, and will take previous sequences
- into account. Repeated calls with the same sequence may produce different
- rewards.
-
- Args:
- sequence: List of integers (each between 0 and base - 1). This is the
- proposal sequence. Reward will be computed based on the distance
- from this sequence to the target (distance function and target are
- given in the constructor), as well as previous sequences tried during
- the lifetime of this object.
-
- Returns:
- Float value. The reward received from this call.
- """
- return 0.0
-
-
-class DeltaRewardManager(RewardManager):
- """Simple reward manager that assigns reward for the net change in distance.
-
- Given some (possibly asymmetric) list distance function, gives reward for
- relative changes in prediction distance to the target.
-
- For example, if on the first call the distance is 3.0, the change in distance
- is -3 (from starting distance of 0). That relative change will be scaled to
- produce a negative reward for this step. On the next call, the distance is 2.0
- which is a +1 change, and that will be scaled to give a positive reward.
- If the final call has distance 0 (the target is achieved), that is another
- positive change of +2. The total reward across all 3 calls is then 0, which is
- the highest posible episode total.
-
- Reward is scaled so that the maximum element-wise distance is worth 1.0.
- Maximum total episode reward attainable is 0.
- """
-
- def __init__(self, target, base, distance_fn=absolute_distance):
- super(DeltaRewardManager, self).__init__(target, base, distance_fn)
- self._last_diff = 0
-
- def _diff(self, seq):
- return self._distance_fn(seq, self._target, self._base)
-
- def _delta_reward(self, seq):
- # Reward is relative to previous sequence diff.
- # Reward is scaled so that maximum token difference is worth 1.0.
- # Reward = (last_diff - this_diff) / self.base.
- # Reward is positive if this sequence is closer to the target than the
- # previous sequence, and negative if this sequence is further away.
- diff = self._diff(seq)
- reward = (self._last_diff - diff) / float(self._base)
- self._last_diff = diff
- return reward
-
- def __call__(self, seq):
- return self._delta_reward(seq)
-
-
-class FloorRewardManager(RewardManager):
- """Assigns positive reward for each step taken closer to the target.
-
- Given some (possibly asymmetric) list distance function, gives reward for
- whenever a new episode minimum distance is reached. No reward is given if
- the distance regresses to a higher value, so that the sum of rewards
- for the episode is positive.
-
- Reward is scaled so that the maximum element-wise distance is worth 1.0.
- Maximum total episode reward attainable is len(target).
-
- If the prediction sequence is longer than the target, a reward of -1 is given.
- Subsequence predictions which are also longer get 0 reward. The -1 penalty
- will be canceled out with a +1 reward when a prediction is given which is at
- most the length of the target.
- """
-
- def __init__(self, target, base, distance_fn=absolute_distance):
- super(FloorRewardManager, self).__init__(target, base, distance_fn)
- self._last_diff = 0
- self._min_diff = self._max_diff()
- self._too_long_penality_given = False
-
- def _max_diff(self):
- return self._distance_fn([], self._target, self._base)
-
- def _diff(self, seq):
- return self._distance_fn(seq, self._target, self._base)
-
- def _delta_reward(self, seq):
- # Reward is only given if this sequence is closer to the target than any
- # previous sequence.
- # Reward is scaled so that maximum token difference is worth 1.0
- # Reward = (min_diff - this_diff) / self.base
- # Reward is always positive.
- diff = self._diff(seq)
- if diff < self._min_diff:
- reward = (self._min_diff - diff) / float(self._base)
- self._min_diff = diff
- else:
- reward = 0.0
- return reward
-
- def __call__(self, seq):
- if len(seq) > len(self._target): # Output is too long.
- if not self._too_long_penality_given:
- self._too_long_penality_given = True
- reward = -1.0
- else:
- reward = 0.0 # Don't give this penalty more than once.
- return reward
-
- reward = self._delta_reward(seq)
- if self._too_long_penality_given:
- reward += 1.0 # Return the subtracted reward.
- self._too_long_penality_given = False
- return reward
-
diff --git a/research/brain_coder/common/reward_test.py b/research/brain_coder/common/reward_test.py
deleted file mode 100644
index 38a1d4ace38cbc945362e52adb90cc9dd62f1be7..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/reward_test.py
+++ /dev/null
@@ -1,311 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.reward."""
-
-from math import log
-import numpy as np
-import tensorflow as tf
-
-from common import reward # brain coder
-
-
-class RewardTest(tf.test.TestCase):
-
- def testAbsDiff(self):
- self.assertEqual(5, reward.abs_diff(15, 20))
- self.assertEqual(5, reward.abs_diff(20, 15))
-
- def testModAbsDiff(self):
- self.assertEqual(5, reward.mod_abs_diff(15, 20, 25))
- self.assertEqual(5, reward.mod_abs_diff(20, 15, 25))
- self.assertEqual(2, reward.mod_abs_diff(1, 24, 25))
- self.assertEqual(2, reward.mod_abs_diff(24, 1, 25))
-
- self.assertEqual(0, reward.mod_abs_diff(0, 0, 5))
- self.assertEqual(1, reward.mod_abs_diff(0, 1, 5))
- self.assertEqual(2, reward.mod_abs_diff(0, 2, 5))
- self.assertEqual(2, reward.mod_abs_diff(0, 3, 5))
- self.assertEqual(1, reward.mod_abs_diff(0, 4, 5))
-
- self.assertEqual(0, reward.mod_abs_diff(-1, 4, 5))
- self.assertEqual(1, reward.mod_abs_diff(-5, 4, 5))
- self.assertEqual(1, reward.mod_abs_diff(-7, 4, 5))
- self.assertEqual(1, reward.mod_abs_diff(13, 4, 5))
- self.assertEqual(1, reward.mod_abs_diff(15, 4, 5))
-
- def testAbsoluteDistance_AbsDiffMethod(self):
- self.assertEqual(
- 4,
- reward.absolute_distance([0], [4], 5, scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([4], [4], 5, scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([], [], 5, scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1], [], 5, scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([], [1], 5, scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([1, 2, 3], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 1,
- reward.absolute_distance([1, 2, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 1,
- reward.absolute_distance([1, 2, 2], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1, 2], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1, 2, 3, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
- self.assertEqual(
- 6,
- reward.absolute_distance([4, 4, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.abs_diff))
-
- def testAbsoluteDistance_ModDiffMethod(self):
- self.assertEqual(
- 1,
- reward.absolute_distance([0], [4], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([4], [4], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([], [], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1], [], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([], [1], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 0,
- reward.absolute_distance([1, 2, 3], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 1,
- reward.absolute_distance([1, 2, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 1,
- reward.absolute_distance([1, 2, 2], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1, 2], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([1, 2, 3, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
- self.assertEqual(
- 5,
- reward.absolute_distance([4, 4, 4], [1, 2, 3], 5,
- scalar_diff_fn=reward.mod_abs_diff))
-
- def testLogAbsoluteDistance(self):
- def log_diff(diff, base):
- return log(diff + 1) / log(base // 2 + 2)
-
- self.assertEqual(
- log_diff(1, 5),
- reward.log_absolute_distance([0], [4], 5))
- self.assertEqual(
- log_diff(2, 5),
- reward.log_absolute_distance([1], [4], 5))
- self.assertEqual(
- log_diff(2, 5),
- reward.log_absolute_distance([2], [4], 5))
- self.assertEqual(
- log_diff(1, 5),
- reward.log_absolute_distance([3], [4], 5))
- self.assertEqual(
- log_diff(3, 5), # max_dist = base // 2 + 1 = 3
- reward.log_absolute_distance([], [4], 5))
- self.assertEqual(
- 0 + log_diff(3, 5), # max_dist = base // 2 + 1 = 3
- reward.log_absolute_distance([4, 4], [4], 5))
- self.assertEqual(
- 0,
- reward.log_absolute_distance([4], [4], 5))
- self.assertEqual(
- 0,
- reward.log_absolute_distance([], [], 5))
- self.assertEqual(
- 1,
- reward.log_absolute_distance([1], [], 5))
- self.assertEqual(
- 1,
- reward.log_absolute_distance([], [1], 5))
-
- self.assertEqual(
- 0,
- reward.log_absolute_distance([1, 2, 3], [1, 2, 3], 5))
- self.assertEqual(
- log_diff(1, 5) / 3, # divided by target length.
- reward.log_absolute_distance([1, 2, 4], [1, 2, 3], 5))
- self.assertEqual(
- log_diff(1, 5) / 3,
- reward.log_absolute_distance([1, 2, 2], [1, 2, 3], 5))
- self.assertEqual(
- log_diff(3, 5) / 3, # max_dist
- reward.log_absolute_distance([1, 2], [1, 2, 3], 5))
- self.assertEqual(
- log_diff(3, 5) / 3, # max_dist
- reward.log_absolute_distance([1, 2, 3, 4], [1, 2, 3], 5))
- # Add log differences for each position.
- self.assertEqual(
- (log_diff(2, 5) + log_diff(2, 5) + log_diff(1, 5)) / 3,
- reward.log_absolute_distance([4, 4, 4], [1, 2, 3], 5))
-
- def testAbsoluteDistanceReward(self):
- self.assertEqual(
- 1,
- reward.absolute_distance_reward([1, 2, 3], [1, 2, 3], 5))
- self.assertEqual(
- 1 - 1 / (5 * 3.), # 1 - distance / (base * target_len)
- reward.absolute_distance_reward([1, 2, 4], [1, 2, 3], 5))
- self.assertEqual(
- 1 - 1 / (5 * 3.),
- reward.absolute_distance_reward([1, 2, 2], [1, 2, 3], 5))
- self.assertTrue(np.isclose(
- 1 - 5 / (5 * 3.),
- reward.absolute_distance_reward([1, 2], [1, 2, 3], 5)))
- self.assertTrue(np.isclose(
- 1 - 5 / (5 * 3.),
- reward.absolute_distance_reward([1, 2, 3, 4], [1, 2, 3], 5)))
- # Add log differences for each position.
- self.assertEqual(
- 1 - (3 + 2 + 1) / (5 * 3.),
- reward.absolute_distance_reward([4, 4, 4], [1, 2, 3], 5))
- self.assertEqual(
- 1,
- reward.absolute_distance_reward([], [], 5))
-
- def testAbsoluteModDistanceReward(self):
- self.assertEqual(
- 1,
- reward.absolute_mod_distance_reward([1, 2, 3], [1, 2, 3], 5))
- self.assertEqual(
- 1 - 1 / (5 * 3.), # 1 - distance / (base * target_len)
- reward.absolute_mod_distance_reward([1, 2, 4], [1, 2, 3], 5))
- self.assertEqual(
- 1 - 1 / (5 * 3.),
- reward.absolute_mod_distance_reward([1, 2, 2], [1, 2, 3], 5))
- self.assertTrue(np.isclose(
- 1 - 5 / (5 * 3.),
- reward.absolute_mod_distance_reward([1, 2], [1, 2, 3], 5)))
- self.assertTrue(np.isclose(
- 1 - 5 / (5 * 3.),
- reward.absolute_mod_distance_reward([1, 2, 3, 4], [1, 2, 3], 5)))
- # Add log differences for each position.
- self.assertTrue(np.isclose(
- 1 - (2 + 2 + 1) / (5 * 3.),
- reward.absolute_mod_distance_reward([4, 4, 4], [1, 2, 3], 5)))
- self.assertTrue(np.isclose(
- 1 - (1 + 2 + 2) / (5 * 3.),
- reward.absolute_mod_distance_reward([0, 1, 2], [4, 4, 4], 5)))
- self.assertEqual(
- 1,
- reward.absolute_mod_distance_reward([], [], 5))
-
- def testAbsoluteLogDistanceReward(self):
- def log_diff(diff, base):
- return log(diff + 1) / log(base // 2 + 2)
-
- self.assertEqual(
- 1,
- reward.absolute_log_distance_reward([1, 2, 3], [1, 2, 3], 5))
- self.assertEqual(
- 1 - log_diff(1, 5) / 3, # divided by target length.
- reward.absolute_log_distance_reward([1, 2, 4], [1, 2, 3], 5))
- self.assertEqual(
- 1 - log_diff(1, 5) / 3,
- reward.absolute_log_distance_reward([1, 2, 2], [1, 2, 3], 5))
- self.assertEqual(
- 1 - log_diff(3, 5) / 3, # max_dist
- reward.absolute_log_distance_reward([1, 2], [1, 2, 3], 5))
- self.assertEqual(
- 1 - log_diff(3, 5) / 3, # max_dist
- reward.absolute_log_distance_reward([1, 2, 3, 4], [1, 2, 3], 5))
- # Add log differences for each position.
- self.assertEqual(
- 1 - (log_diff(2, 5) + log_diff(2, 5) + log_diff(1, 5)) / 3,
- reward.absolute_log_distance_reward([4, 4, 4], [1, 2, 3], 5))
- self.assertEqual(
- 1 - (log_diff(1, 5) + log_diff(2, 5) + log_diff(2, 5)) / 3,
- reward.absolute_log_distance_reward([0, 1, 2], [4, 4, 4], 5))
- self.assertEqual(
- 1,
- reward.absolute_log_distance_reward([], [], 5))
-
- def testDeltaRewardManager(self):
- reward_manager = reward.DeltaRewardManager(
- [1, 2, 3, 4], base=5, distance_fn=reward.absolute_distance)
- self.assertEqual(-3, reward_manager([1]))
- self.assertEqual(0, reward_manager([1]))
- self.assertEqual(4 / 5., reward_manager([1, 3]))
- self.assertEqual(-4 / 5, reward_manager([1]))
- self.assertEqual(3, reward_manager([1, 2, 3, 4]))
- self.assertEqual(-1, reward_manager([1, 2, 3]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4, 3]))
- self.assertEqual(-1, reward_manager([1, 2, 3, 4, 3, 2]))
- self.assertEqual(2, reward_manager([1, 2, 3, 4]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4]))
-
- def testFloorRewardMananger(self):
- reward_manager = reward.FloorRewardManager(
- [1, 2, 3, 4], base=5, distance_fn=reward.absolute_distance)
- self.assertEqual(1, reward_manager([1]))
- self.assertEqual(0, reward_manager([1]))
- self.assertEqual(4 / 5., reward_manager([1, 3]))
- self.assertEqual(0, reward_manager([1]))
- self.assertEqual(1 / 5., reward_manager([1, 2]))
- self.assertEqual(0, reward_manager([0, 1]))
- self.assertEqual(0, reward_manager([]))
- self.assertEqual(0, reward_manager([1, 2]))
- self.assertEqual(2, reward_manager([1, 2, 3, 4]))
- self.assertEqual(0, reward_manager([1, 2, 3]))
- self.assertEqual(-1, reward_manager([1, 2, 3, 4, 3]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4, 3, 2]))
- self.assertEqual(1, reward_manager([1, 2, 3, 4]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4]))
-
- reward_manager = reward.FloorRewardManager(
- [1, 2, 3, 4], base=5, distance_fn=reward.absolute_distance)
- self.assertEqual(1, reward_manager([1]))
- self.assertEqual(-1, reward_manager([1, 0, 0, 0, 0, 0]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4, 0, 0]))
- self.assertEqual(0, reward_manager([1, 2, 3, 4, 0]))
- self.assertEqual(1, reward_manager([]))
- self.assertEqual(0, reward_manager([]))
- self.assertEqual(0, reward_manager([1]))
- self.assertEqual(1, reward_manager([1, 2]))
- self.assertEqual(-1, reward_manager([1, 2, 3, 4, 0, 0]))
- self.assertEqual(0, reward_manager([1, 1, 1, 1, 1]))
- self.assertEqual(1 + 2, reward_manager([1, 2, 3, 4]))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/common/rollout.py b/research/brain_coder/common/rollout.py
deleted file mode 100644
index e377aa662db640dfa907de83d32875cc096c4295..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/rollout.py
+++ /dev/null
@@ -1,306 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Utilities related to computing training batches from episode rollouts.
-
-Implementations here are based on code from Open AI:
-https://github.com/openai/universe-starter-agent/blob/master/a3c.py.
-"""
-
-from collections import namedtuple
-import numpy as np
-import scipy.signal
-
-from common import utils # brain coder
-
-
-class Rollout(object):
- """Holds a rollout for an episode.
-
- A rollout is a record of the states observed in some environment and actions
- taken by the agent to arrive at those states. Other information includes
- rewards received after each action, values estimated for each state, whether
- the rollout concluded the episide, and total reward received. Everything
- should be given in time order.
-
- At each time t, the agent sees state s_t, takes action a_t, and then receives
- reward r_t. The agent may optionally estimate a state value V(s_t) for each
- state.
-
- For an episode of length T:
- states = [s_0, ..., s_(T-1)]
- actions = [a_0, ..., a_(T-1)]
- rewards = [r_0, ..., r_(T-1)]
- values = [V(s_0), ..., V(s_(T-1))]
-
- Note that there is an extra state s_T observed after taking action a_(T-1),
- but this is not included in the rollout.
-
- Rollouts have an `terminated` attribute which is True when the rollout is
- "finalized", i.e. it holds a full episode. terminated will be False when
- time steps are still being added to it.
- """
-
- def __init__(self):
- self.states = []
- self.actions = []
- self.rewards = []
- self.values = []
- self.total_reward = 0.0
- self.terminated = False
-
- def add(self, state, action, reward, value=0.0, terminated=False):
- """Add the next timestep to this rollout.
-
- Args:
- state: The state observed at the start of this timestep.
- action: The action taken after observing the given state.
- reward: The reward received for taking the given action.
- value: The value estimated for the given state.
- terminated: Whether this timestep ends the episode.
-
- Raises:
- ValueError: If this.terminated is already True, meaning that the episode
- has already ended.
- """
- if self.terminated:
- raise ValueError(
- 'Trying to add timestep to an already terminal rollout.')
- self.states += [state]
- self.actions += [action]
- self.rewards += [reward]
- self.values += [value]
- self.terminated = terminated
- self.total_reward += reward
-
- def add_many(self, states, actions, rewards, values=None, terminated=False):
- """Add many timesteps to this rollout.
-
- Arguments are the same as `add`, but are lists of equal size.
-
- Args:
- states: The states observed.
- actions: The actions taken.
- rewards: The rewards received.
- values: The values estimated for the given states.
- terminated: Whether this sequence ends the episode.
-
- Raises:
- ValueError: If the lengths of all the input lists are not equal.
- ValueError: If this.terminated is already True, meaning that the episode
- has already ended.
- """
- if len(states) != len(actions):
- raise ValueError(
- 'Number of states and actions must be the same. Got %d states and '
- '%d actions' % (len(states), len(actions)))
- if len(states) != len(rewards):
- raise ValueError(
- 'Number of states and rewards must be the same. Got %d states and '
- '%d rewards' % (len(states), len(rewards)))
- if values is not None and len(states) != len(values):
- raise ValueError(
- 'Number of states and values must be the same. Got %d states and '
- '%d values' % (len(states), len(values)))
- if self.terminated:
- raise ValueError(
- 'Trying to add timesteps to an already terminal rollout.')
- self.states += states
- self.actions += actions
- self.rewards += rewards
- self.values += values if values is not None else [0.0] * len(states)
- self.terminated = terminated
- self.total_reward += sum(rewards)
-
- def extend(self, other):
- """Append another rollout to this rollout."""
- assert not self.terminated
- self.states.extend(other.states)
- self.actions.extend(other.actions)
- self.rewards.extend(other.rewards)
- self.values.extend(other.values)
- self.terminated = other.terminated
- self.total_reward += other.total_reward
-
-
-def discount(x, gamma):
- """Returns discounted sums for each value in x, with discount factor gamma.
-
- This can be used to compute the return (discounted sum of rewards) at each
- timestep given a sequence of rewards. See the definitions for return and
- REINFORCE in section 3 of https://arxiv.org/pdf/1602.01783.pdf.
-
- Let g^k mean gamma ** k.
- For list [x_0, ..., x_N], the following list of discounted sums is computed:
- [x_0 + g^1 * x_1 + g^2 * x_2 + ... g^N * x_N,
- x_1 + g^1 * x_2 + g^2 * x_3 + ... g^(N-1) * x_N,
- x_2 + g^1 * x_3 + g^2 * x_4 + ... g^(N-2) * x_N,
- ...,
- x_(N-1) + g^1 * x_N,
- x_N]
-
- Args:
- x: List of numbers [x_0, ..., x_N].
- gamma: Float between 0 and 1 (inclusive). This is the discount factor.
-
- Returns:
- List of discounted sums.
- """
- return scipy.signal.lfilter([1], [1, -gamma], x[::-1], axis=0)[::-1]
-
-
-def discounted_advantage_and_rewards(rewards, values, gamma, lambda_=1.0):
- """Compute advantages and returns (discounted sum of rewards).
-
- For an episode of length T, rewards = [r_0, ..., r_(T-1)].
- Each reward r_t is observed after taking action a_t at state s_t. A final
- state s_T is observed but no reward is given at this state since no action
- a_T is taken (otherwise there would be a new state s_(T+1)).
-
- `rewards` and `values` are for a single episode. Return R_t is the discounted
- sum of future rewards starting at time t, where `gamma` is the discount
- factor.
- R_t = r_t + gamma * r_(t+1) + gamma**2 * r_(t+2) + ...
- + gamma**(T-1-t) * r_(T-1)
-
- Advantage A(a_t, s_t) is approximated by computing A(a_t, s_t) = R_t - V(s_t)
- where V(s_t) is an approximation of the value at that state, given in the
- `values` list. Returns R_t are needed for all REINFORCE algorithms. Advantage
- is used for the advantage actor critic variant of REINFORCE.
- See algorithm S3 in https://arxiv.org/pdf/1602.01783.pdf.
-
- Additionally another parameter `lambda_` controls the bias-variance tradeoff.
- See "Generalized Advantage Estimation": https://arxiv.org/abs/1506.02438.
- lambda_ = 1 reduces to regular advantage.
- 0 <= lambda_ < 1 trades off variance for bias, with lambda_ = 0 being the
- most biased.
-
- Bootstrapping is also supported. If an episode does not end in a terminal
- state (either because the episode was ended early, or the environment does not
- have end states), the true return cannot be computed from the rewards alone.
- However, it can be estimated by computing the value (an approximation of
- return) of the last state s_T. Thus the `values` list will have an extra item:
- values = [V(s_0), ..., V(s_(T-1)), V(s_T)].
-
- Args:
- rewards: List of observed rewards [r_0, ..., r_(T-1)].
- values: List of estimated values [V(s_0), ..., V(s_(T-1))] with an optional
- extra V(s_T) item.
- gamma: Discount factor. Number between 0 and 1. 1 means no discount.
- If not 1, gamma is typically near 1, like 0.99.
- lambda_: Bias-variance tradeoff factor. Between 0 and 1.
-
- Returns:
- empirical_values: Returns at each timestep.
- generalized_advantage: Avantages at each timestep.
-
- Raises:
- ValueError: If shapes of `rewards` and `values` are not rank 1.
- ValueError: If len(values) not in (len(rewards), len(rewards) + 1).
- """
- rewards = np.asarray(rewards, dtype=np.float32)
- values = np.asarray(values, dtype=np.float32)
- if rewards.ndim != 1:
- raise ValueError('Single episode only. rewards must be rank 1.')
- if values.ndim != 1:
- raise ValueError('Single episode only. values must be rank 1.')
- if len(values) == len(rewards):
- # No bootstrapping.
- values = np.append(values, 0)
- empirical_values = discount(rewards, gamma)
- elif len(values) == len(rewards) + 1:
- # With bootstrapping.
- # Last value is for the terminal state (final state after last action was
- # taken).
- empirical_values = discount(np.append(rewards, values[-1]), gamma)[:-1]
- else:
- raise ValueError('values should contain the same number of items or one '
- 'more item than rewards')
- delta = rewards + gamma * values[1:] - values[:-1]
- generalized_advantage = discount(delta, gamma * lambda_)
-
- # empirical_values is the discounted sum of rewards into the future.
- # generalized_advantage is the target for each policy update.
- return empirical_values, generalized_advantage
-
-
-"""Batch holds a minibatch of episodes.
-
-Let bi = batch_index, i.e. the index of each episode in the minibatch.
-Let t = time.
-
-Attributes:
- states: States for each timestep in each episode. Indexed by states[bi, t].
- actions: Actions for each timestep in each episode. Indexed by actions[bi, t].
- discounted_adv: Advantages (computed by discounted_advantage_and_rewards)
- for each timestep in each episode. Indexed by discounted_adv[bi, t].
- discounted_r: Returns (discounted sum of rewards computed by
- discounted_advantage_and_rewards) for each timestep in each episode.
- Indexed by discounted_r[bi, t].
- total_rewards: Total reward for each episode, i.e. sum of rewards across all
- timesteps (not discounted). Indexed by total_rewards[bi].
- episode_lengths: Number of timesteps in each episode. If an episode has
- N actions, N rewards, and N states, then its length is N. Indexed by
- episode_lengths[bi].
- batch_size: Number of episodes in this minibatch. An integer.
- max_time: Maximum episode length in the batch. An integer.
-""" # pylint: disable=pointless-string-statement
-Batch = namedtuple(
- 'Batch',
- ['states', 'actions', 'discounted_adv', 'discounted_r', 'total_rewards',
- 'episode_lengths', 'batch_size', 'max_time'])
-
-
-def process_rollouts(rollouts, gamma, lambda_=1.0):
- """Convert a batch of rollouts into tensors ready to be fed into a model.
-
- Lists from each episode are stacked into 2D tensors and padded with 0s up to
- the maximum timestep in the batch.
-
- Args:
- rollouts: A list of Rollout instances.
- gamma: The discount factor. A number between 0 and 1 (inclusive). See gamma
- argument in discounted_advantage_and_rewards.
- lambda_: See lambda_ argument in discounted_advantage_and_rewards.
-
- Returns:
- Batch instance. states, actions, discounted_adv, and discounted_r are
- numpy arrays with shape (batch_size, max_episode_length). episode_lengths
- is a list of ints. total_rewards is a list of floats (total reward in each
- episode). batch_size and max_time are ints.
-
- Raises:
- ValueError: If any of the rollouts are not terminal.
- """
- for ro in rollouts:
- if not ro.terminated:
- raise ValueError('Can only process terminal rollouts.')
-
- episode_lengths = [len(ro.states) for ro in rollouts]
- batch_size = len(rollouts)
- max_time = max(episode_lengths)
-
- states = utils.stack_pad([ro.states for ro in rollouts], 0, max_time)
- actions = utils.stack_pad([ro.actions for ro in rollouts], 0, max_time)
-
- discounted_rewards = [None] * batch_size
- discounted_adv = [None] * batch_size
- for i, ro in enumerate(rollouts):
- disc_r, disc_adv = discounted_advantage_and_rewards(
- ro.rewards, ro.values, gamma, lambda_)
- discounted_rewards[i] = disc_r
- discounted_adv[i] = disc_adv
- discounted_rewards = utils.stack_pad(discounted_rewards, 0, max_time)
- discounted_adv = utils.stack_pad(discounted_adv, 0, max_time)
-
- total_rewards = [sum(ro.rewards) for ro in rollouts]
-
- return Batch(states=states,
- actions=actions,
- discounted_adv=discounted_adv,
- discounted_r=discounted_rewards,
- total_rewards=total_rewards,
- episode_lengths=episode_lengths,
- batch_size=batch_size,
- max_time=max_time)
diff --git a/research/brain_coder/common/rollout_test.py b/research/brain_coder/common/rollout_test.py
deleted file mode 100644
index 5be4cb0fafd8a2e94004c17b41e189d989a3a851..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/rollout_test.py
+++ /dev/null
@@ -1,129 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.rollout."""
-
-import numpy as np
-import tensorflow as tf
-
-from common import rollout as rollout_lib # brain coder
-
-
-class RolloutTest(tf.test.TestCase):
-
- def MakeRollout(self, states, actions, rewards, values=None, terminated=True):
- rollout = rollout_lib.Rollout()
- rollout.add_many(
- states=states, actions=actions, rewards=rewards, values=values,
- terminated=terminated)
- return rollout
-
- def testDiscount(self):
- discounted = np.array([1.0 / 2 ** n for n in range(4, -1, -1)])
- discounted[:2] += [1.0 / 2 ** n for n in range(1, -1, -1)]
-
- self.assertTrue(np.array_equal(
- rollout_lib.discount([0.0, 1.0, 0.0, 0.0, 1.0], 0.50),
- discounted))
- self.assertTrue(np.array_equal(
- rollout_lib.discount(np.array([0.0, 1.0, 0.0, 0.0, 1.0]), 0.50),
- discounted))
-
- def testDiscountedAdvantageAndRewards(self):
- # lambda=1, No bootstrapping.
- values = [0.1, 0.5, 0.5, 0.25]
- (empirical_values,
- generalized_advantage) = rollout_lib.discounted_advantage_and_rewards(
- [0.0, 0.0, 0.0, 1.0],
- values,
- gamma=0.75,
- lambda_=1.0)
- expected_discounted_r = (
- np.array([1.0 * 0.75 ** n for n in range(3, -1, -1)]))
- expected_adv = expected_discounted_r - values
- self.assertTrue(np.array_equal(empirical_values, expected_discounted_r))
- self.assertTrue(np.allclose(generalized_advantage, expected_adv))
-
- # lambda=1, With bootstrapping.
- values = [0.1, 0.5, 0.5, 0.25, 0.75]
- (empirical_values,
- generalized_advantage) = rollout_lib.discounted_advantage_and_rewards(
- [0.0, 0.0, 0.0, 1.0],
- values,
- gamma=0.75,
- lambda_=1.0)
- expected_discounted_r = (
- np.array([0.75 * 0.75 ** n for n in range(4, 0, -1)])
- + np.array([1.0 * 0.75 ** n for n in range(3, -1, -1)]))
- expected_adv = expected_discounted_r - values[:-1]
- self.assertTrue(np.array_equal(empirical_values, expected_discounted_r))
- self.assertTrue(np.allclose(generalized_advantage, expected_adv))
-
- # lambda=0.5, With bootstrapping.
- values = [0.1, 0.5, 0.5, 0.25, 0.75]
- rewards = [0.0, 0.0, 0.0, 1.0]
- l = 0.5 # lambda
- g = 0.75 # gamma
- (empirical_values,
- generalized_advantage) = rollout_lib.discounted_advantage_and_rewards(
- rewards,
- values,
- gamma=g,
- lambda_=l)
- expected_discounted_r = (
- np.array([0.75 * g ** n for n in range(4, 0, -1)])
- + np.array([1.0 * g ** n for n in range(3, -1, -1)]))
- expected_adv = [0.0] * len(values)
- for t in range(3, -1, -1):
- delta_t = rewards[t] + g * values[t + 1] - values[t]
- expected_adv[t] = delta_t + g * l * expected_adv[t + 1]
- expected_adv = expected_adv[:-1]
- self.assertTrue(np.array_equal(empirical_values, expected_discounted_r))
- self.assertTrue(np.allclose(generalized_advantage, expected_adv))
-
- def testProcessRollouts(self):
- g = 0.95
- rollouts = [
- self.MakeRollout(
- states=[3, 6, 9],
- actions=[1, 2, 3],
- rewards=[1.0, -1.0, 0.5],
- values=[0.5, 0.5, 0.1]),
- self.MakeRollout(
- states=[10],
- actions=[5],
- rewards=[1.0],
- values=[0.5])]
- batch = rollout_lib.process_rollouts(rollouts, gamma=g)
-
- self.assertEqual(2, batch.batch_size)
- self.assertEqual(3, batch.max_time)
- self.assertEqual([3, 1], batch.episode_lengths)
- self.assertEqual([0.5, 1.0], batch.total_rewards)
- self.assertEqual(
- [[3, 6, 9], [10, 0, 0]],
- batch.states.tolist())
- self.assertEqual(
- [[1, 2, 3], [5, 0, 0]],
- batch.actions.tolist())
-
- rew1, rew2 = rollouts[0].rewards, rollouts[1].rewards
- expected_discounted_rewards = [
- [rew1[0] + g * rew1[1] + g * g * rew1[2],
- rew1[1] + g * rew1[2],
- rew1[2]],
- [rew2[0], 0.0, 0.0]]
- expected_advantages = [
- [dr - v
- for dr, v
- in zip(expected_discounted_rewards[0], rollouts[0].values)],
- [expected_discounted_rewards[1][0] - rollouts[1].values[0], 0.0, 0.0]]
- self.assertTrue(
- np.allclose(expected_discounted_rewards, batch.discounted_r))
- self.assertTrue(
- np.allclose(expected_advantages, batch.discounted_adv))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/common/schedules.py b/research/brain_coder/common/schedules.py
deleted file mode 100644
index fff2481e536d65f154ad2d9dc3972657d860abf8..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/schedules.py
+++ /dev/null
@@ -1,301 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Schedule functions for controlling hparams over time."""
-
-from abc import ABCMeta
-from abc import abstractmethod
-import math
-
-from common import config_lib # brain coder
-
-
-class Schedule(object):
- """Schedule is a function which sets a hyperparameter's value over time.
-
- For example, a schedule can be used to decay an hparams, or oscillate it over
- time.
-
- This object is constructed with an instance of config_lib.Config (will be
- specific to each class implementation). For example if this is a decay
- schedule, the config may specify the rate of decay and decay start time. Then
- the object instance is called like a function, mapping global step (an integer
- counting how many calls to the train op have been made) to the hparam value.
-
- Properties of a schedule function f(t):
- 0) Domain of t is the non-negative integers (t may be 0).
- 1) Range of f is the reals.
- 2) Schedule functions can assume that they will be called in time order. This
- allows schedules to be stateful.
- 3) Schedule functions should be deterministic. Two schedule instances with the
- same config must always give the same value for each t, and regardless of
- what t's it was previously called on. Users may call f(t) on arbitrary
- (positive) time jumps. Essentially, multiple schedule instances used in
- replica training will behave the same.
- 4) Duplicate successive calls on the same time are allowed.
- """
- __metaclass__ = ABCMeta
-
- @abstractmethod
- def __init__(self, config):
- """Construct this schedule with a config specific to each class impl.
-
- Args:
- config: An instance of config_lib.Config.
- """
- pass
-
- @abstractmethod
- def __call__(self, global_step):
- """Map `global_step` to a value.
-
- `global_step` is an integer counting how many calls to the train op have
- been made across all replicas (hence why it is global). Implementations
- may assume calls to be made in time order, i.e. `global_step` now >=
- previous `global_step` values.
-
- Args:
- global_step: Non-negative integer.
-
- Returns:
- Hparam value at this step. A number.
- """
- pass
-
-
-class ConstSchedule(Schedule):
- """Constant function.
-
- config:
- const: Constant value at every step.
-
- f(t) = const.
- """
-
- def __init__(self, config):
- super(ConstSchedule, self).__init__(config)
- self.const = config.const
-
- def __call__(self, global_step):
- return self.const
-
-
-class LinearDecaySchedule(Schedule):
- """Linear decay function.
-
- config:
- initial: Decay starts from this value.
- final: Decay ends at this value.
- start_time: Step when decay starts. Constant before it.
- end_time: When decay ends. Constant after it.
-
- f(t) is a linear function when start_time <= t <= end_time, with slope of
- (final - initial) / (end_time - start_time). f(t) = initial
- when t <= start_time. f(t) = final when t >= end_time.
-
- If start_time == end_time, this becomes a step function.
- """
-
- def __init__(self, config):
- super(LinearDecaySchedule, self).__init__(config)
- self.initial = config.initial
- self.final = config.final
- self.start_time = config.start_time
- self.end_time = config.end_time
-
- if self.end_time < self.start_time:
- raise ValueError('start_time must be before end_time.')
-
- # Linear interpolation.
- self._time_diff = float(self.end_time - self.start_time)
- self._diff = float(self.final - self.initial)
- self._slope = (
- self._diff / self._time_diff if self._time_diff > 0 else float('inf'))
-
- def __call__(self, global_step):
- if global_step <= self.start_time:
- return self.initial
- if global_step > self.end_time:
- return self.final
- return self.initial + (global_step - self.start_time) * self._slope
-
-
-class ExponentialDecaySchedule(Schedule):
- """Exponential decay function.
-
- See https://en.wikipedia.org/wiki/Exponential_decay.
-
- Use this decay function to decay over orders of magnitude. For example, to
- decay learning rate from 1e-2 to 1e-6. Exponential decay will decay the
- exponent linearly.
-
- config:
- initial: Decay starts from this value.
- final: Decay ends at this value.
- start_time: Step when decay starts. Constant before it.
- end_time: When decay ends. Constant after it.
-
- f(t) is an exponential decay function when start_time <= t <= end_time. The
- decay rate and amplitude are chosen so that f(t) = initial when
- t = start_time, and f(t) = final when t = end_time. f(t) is constant for
- t < start_time or t > end_time. initial and final must be positive values.
-
- If start_time == end_time, this becomes a step function.
- """
-
- def __init__(self, config):
- super(ExponentialDecaySchedule, self).__init__(config)
- self.initial = config.initial
- self.final = config.final
- self.start_time = config.start_time
- self.end_time = config.end_time
-
- if self.initial <= 0 or self.final <= 0:
- raise ValueError('initial and final must be positive numbers.')
-
- # Linear interpolation in log space.
- self._linear_fn = LinearDecaySchedule(
- config_lib.Config(
- initial=math.log(self.initial),
- final=math.log(self.final),
- start_time=self.start_time,
- end_time=self.end_time))
-
- def __call__(self, global_step):
- return math.exp(self._linear_fn(global_step))
-
-
-class SmootherstepDecaySchedule(Schedule):
- """Smootherstep decay function.
-
- A sigmoidal like transition from initial to final values. A smoother
- transition than linear and exponential decays, hence the name.
- See https://en.wikipedia.org/wiki/Smoothstep.
-
- config:
- initial: Decay starts from this value.
- final: Decay ends at this value.
- start_time: Step when decay starts. Constant before it.
- end_time: When decay ends. Constant after it.
-
- f(t) is fully defined here:
- https://en.wikipedia.org/wiki/Smoothstep#Variations.
-
- f(t) is smooth, as in its first-derivative exists everywhere.
- """
-
- def __init__(self, config):
- super(SmootherstepDecaySchedule, self).__init__(config)
- self.initial = config.initial
- self.final = config.final
- self.start_time = config.start_time
- self.end_time = config.end_time
-
- if self.end_time < self.start_time:
- raise ValueError('start_time must be before end_time.')
-
- self._time_diff = float(self.end_time - self.start_time)
- self._diff = float(self.final - self.initial)
-
- def __call__(self, global_step):
- if global_step <= self.start_time:
- return self.initial
- if global_step > self.end_time:
- return self.final
- x = (global_step - self.start_time) / self._time_diff
-
- # Smootherstep
- return self.initial + x * x * x * (x * (x * 6 - 15) + 10) * self._diff
-
-
-class HardOscillatorSchedule(Schedule):
- """Hard oscillator function.
-
- config:
- high: Max value of the oscillator. Value at constant plateaus.
- low: Min value of the oscillator. Value at constant valleys.
- start_time: Global step when oscillation starts. Constant before this.
- period: Width of one oscillation, i.e. number of steps over which the
- oscillation takes place.
- transition_fraction: Fraction of the period spent transitioning between high
- and low values. 50% of this time is spent rising, and 50% of this time
- is spent falling. 50% of the remaining time is spent constant at the
- high value, and 50% of the remaining time is spent constant at the low
- value. transition_fraction = 1.0 means the entire period is spent
- rising and falling. transition_fraction = 0.0 means no time is spent
- rising and falling, i.e. the function jumps instantaneously between
- high and low.
-
- f(t) = high when t < start_time.
- f(t) is periodic when t >= start_time, with f(t + period) = f(t).
- f(t) is linear with positive slope when rising, and negative slope when
- falling. At the start of the period t0, f(t0) = high and begins to descend.
- At the middle of the period f is low and is constant until the ascension
- begins. f then rises from low to high and is constant again until the period
- repeats.
-
- Note: when transition_fraction is 0, f starts the period low and ends high.
- """
-
- def __init__(self, config):
- super(HardOscillatorSchedule, self).__init__(config)
- self.high = config.high
- self.low = config.low
- self.start_time = config.start_time
- self.period = float(config.period)
- self.transition_fraction = config.transition_fraction
- self.half_transition_fraction = config.transition_fraction / 2.0
-
- if self.transition_fraction < 0 or self.transition_fraction > 1.0:
- raise ValueError('transition_fraction must be between 0 and 1.0')
- if self.period <= 0:
- raise ValueError('period must be positive')
-
- self._slope = (
- float(self.high - self.low) / self.half_transition_fraction
- if self.half_transition_fraction > 0 else float('inf'))
-
- def __call__(self, global_step):
- if global_step < self.start_time:
- return self.high
- period_pos = ((global_step - self.start_time) / self.period) % 1.0
- if period_pos >= 0.5:
- # ascending
- period_pos -= 0.5
- if period_pos < self.half_transition_fraction:
- return self.low + period_pos * self._slope
- else:
- return self.high
- else:
- # descending
- if period_pos < self.half_transition_fraction:
- return self.high - period_pos * self._slope
- else:
- return self.low
-
-
-_NAME_TO_CONFIG = {
- 'const': ConstSchedule,
- 'linear_decay': LinearDecaySchedule,
- 'exp_decay': ExponentialDecaySchedule,
- 'smooth_decay': SmootherstepDecaySchedule,
- 'hard_osc': HardOscillatorSchedule,
-}
-
-
-def make_schedule(config):
- """Schedule factory.
-
- Given `config` containing a `fn` property, a Schedule implementation is
- instantiated with `config`. See `_NAME_TO_CONFIG` for `fn` options.
-
- Args:
- config: Config with a `fn` option that specifies which Schedule
- implementation to use. `config` is passed into the constructor.
-
- Returns:
- A Schedule impl instance.
- """
- schedule_class = _NAME_TO_CONFIG[config.fn]
- return schedule_class(config)
diff --git a/research/brain_coder/common/schedules_test.py b/research/brain_coder/common/schedules_test.py
deleted file mode 100644
index b17022f45a833fb3aa219fd06225f77fbd1b1055..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/schedules_test.py
+++ /dev/null
@@ -1,139 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.schedules."""
-
-from math import exp
-from math import sqrt
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from common import config_lib # brain coder
-from common import schedules # brain coder
-
-
-class SchedulesTest(tf.test.TestCase):
-
- def ScheduleTestHelper(self, config, schedule_subtype, io_values):
- """Run common checks for schedules.
-
- Args:
- config: Config object which is passed into schedules.make_schedule.
- schedule_subtype: The expected schedule type to be instantiated.
- io_values: List of (input, output) pairs. Must be in ascending input
- order. No duplicate inputs.
- """
-
- # Check that make_schedule makes the correct type.
- f = schedules.make_schedule(config)
- self.assertTrue(isinstance(f, schedule_subtype))
-
- # Check that multiple instances returned from make_schedule behave the same.
- fns = [schedules.make_schedule(config) for _ in xrange(3)]
-
- # Check that all the inputs map to the right outputs.
- for i, o in io_values:
- for f in fns:
- f_out = f(i)
- self.assertTrue(
- np.isclose(o, f_out),
- 'Wrong value at input %d. Expected %s, got %s' % (i, o, f_out))
-
- # Check that a subset of the io_values are still correct.
- f = schedules.make_schedule(config)
- subseq = [io_values[i**2] for i in xrange(int(sqrt(len(io_values))))]
- if subseq[-1] != io_values[-1]:
- subseq.append(io_values[-1])
- for i, o in subseq:
- f_out = f(i)
- self.assertTrue(
- np.isclose(o, f_out),
- 'Wrong value at input %d. Expected %s, got %s' % (i, o, f_out))
-
- # Check duplicate calls.
- f = schedules.make_schedule(config)
- for i, o in io_values:
- for _ in xrange(3):
- f_out = f(i)
- self.assertTrue(
- np.isclose(o, f_out),
- 'Duplicate calls at input %d are not equal. Expected %s, got %s'
- % (i, o, f_out))
-
- def testConstSchedule(self):
- self.ScheduleTestHelper(
- config_lib.Config(fn='const', const=5),
- schedules.ConstSchedule,
- [(0, 5), (1, 5), (10, 5), (20, 5), (100, 5), (1000000, 5)])
-
- def testLinearDecaySchedule(self):
- self.ScheduleTestHelper(
- config_lib.Config(fn='linear_decay', initial=2, final=0, start_time=10,
- end_time=20),
- schedules.LinearDecaySchedule,
- [(0, 2), (1, 2), (10, 2), (11, 1.8), (15, 1), (19, 0.2), (20, 0),
- (100000, 0)])
-
- # Test step function.
- self.ScheduleTestHelper(
- config_lib.Config(fn='linear_decay', initial=2, final=0, start_time=10,
- end_time=10),
- schedules.LinearDecaySchedule,
- [(0, 2), (1, 2), (10, 2), (11, 0), (15, 0)])
-
- def testExponentialDecaySchedule(self):
- self.ScheduleTestHelper(
- config_lib.Config(fn='exp_decay', initial=exp(-1), final=exp(-6),
- start_time=10, end_time=20),
- schedules.ExponentialDecaySchedule,
- [(0, exp(-1)), (1, exp(-1)), (10, exp(-1)), (11, exp(-1/2. - 1)),
- (15, exp(-5/2. - 1)), (19, exp(-9/2. - 1)), (20, exp(-6)),
- (100000, exp(-6))])
-
- # Test step function.
- self.ScheduleTestHelper(
- config_lib.Config(fn='exp_decay', initial=exp(-1), final=exp(-6),
- start_time=10, end_time=10),
- schedules.ExponentialDecaySchedule,
- [(0, exp(-1)), (1, exp(-1)), (10, exp(-1)), (11, exp(-6)),
- (15, exp(-6))])
-
- def testSmootherstepDecaySchedule(self):
- self.ScheduleTestHelper(
- config_lib.Config(fn='smooth_decay', initial=2, final=0, start_time=10,
- end_time=20),
- schedules.SmootherstepDecaySchedule,
- [(0, 2), (1, 2), (10, 2), (11, 1.98288), (15, 1), (19, 0.01712),
- (20, 0), (100000, 0)])
-
- # Test step function.
- self.ScheduleTestHelper(
- config_lib.Config(fn='smooth_decay', initial=2, final=0, start_time=10,
- end_time=10),
- schedules.SmootherstepDecaySchedule,
- [(0, 2), (1, 2), (10, 2), (11, 0), (15, 0)])
-
- def testHardOscillatorSchedule(self):
- self.ScheduleTestHelper(
- config_lib.Config(fn='hard_osc', high=2, low=0, start_time=100,
- period=10, transition_fraction=0.5),
- schedules.HardOscillatorSchedule,
- [(0, 2), (1, 2), (10, 2), (100, 2), (101, 1.2), (102, 0.4), (103, 0),
- (104, 0), (105, 0), (106, 0.8), (107, 1.6), (108, 2), (109, 2),
- (110, 2), (111, 1.2), (112, 0.4), (115, 0), (116, 0.8), (119, 2),
- (120, 2), (100001, 1.2), (100002, 0.4), (100005, 0), (100006, 0.8),
- (100010, 2)])
-
- # Test instantaneous step.
- self.ScheduleTestHelper(
- config_lib.Config(fn='hard_osc', high=2, low=0, start_time=100,
- period=10, transition_fraction=0),
- schedules.HardOscillatorSchedule,
- [(0, 2), (1, 2), (10, 2), (99, 2), (100, 0), (104, 0), (105, 2),
- (106, 2), (109, 2), (110, 0)])
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/common/utils.py b/research/brain_coder/common/utils.py
deleted file mode 100644
index fa5f1c50768986ee10eee6120a0bca392b1d9d0e..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/utils.py
+++ /dev/null
@@ -1,558 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Configuration class."""
-
-import bisect
-from collections import deque
-import cPickle
-import heapq
-import random
-
-from absl import logging
-import numpy as np
-import six
-from six.moves import xrange
-import tensorflow as tf
-
-
-def tuple_to_record(tuple_, record_type):
- return record_type(**dict(zip(record_type.__slots__, tuple_)))
-
-
-def make_record(type_name, attributes, defaults=None):
- """Factory for mutable record classes.
-
- A record acts just like a collections.namedtuple except slots are writable.
- One exception is that record classes are not equivalent to tuples or other
- record classes of the same length.
-
- Note, each call to `make_record` produces a unique type. Two calls will make
- different types even if `type_name` is the same each time.
-
- Args:
- type_name: Name of the record type to create.
- attributes: List of names of each record attribute. The order of the list
- is preserved.
- defaults: (optional) default values for attributes. A dict mapping attribute
- names to values.
-
- Returns:
- A new record type.
-
- Raises:
- ValueError: If,
- `defaults` is not a dict,
- `attributes` contains duplicate names,
- `defaults` keys are not contained in `attributes`.
- """
- if defaults is None:
- defaults = {}
- if not isinstance(defaults, dict):
- raise ValueError('defaults must be a dict.')
- attr_set = set(attributes)
- if len(attr_set) < len(attributes):
- raise ValueError('No duplicate attributes allowed.')
- if not set(defaults.keys()).issubset(attr_set):
- raise ValueError('Default attributes must be given in the attributes list.')
-
- class RecordClass(object):
- """A record type.
-
- Acts like mutable tuple with named slots.
- """
- __slots__ = list(attributes)
- _defaults = dict(defaults)
-
- def __init__(self, *args, **kwargs):
- if len(args) > len(self.__slots__):
- raise ValueError('Too many arguments. %s has length %d.'
- % (type(self).__name__, len(self.__slots__)))
- for attr, val in self._defaults.items():
- setattr(self, attr, val)
- for i, arg in enumerate(args):
- setattr(self, self.__slots__[i], arg)
- for attr, val in kwargs.items():
- setattr(self, attr, val)
- for attr in self.__slots__:
- if not hasattr(self, attr):
- raise ValueError('Required attr "%s" is not set.' % attr)
-
- def __len__(self):
- return len(self.__slots__)
-
- def __iter__(self):
- for attr in self.__slots__:
- yield getattr(self, attr)
-
- def __getitem__(self, index):
- return getattr(self, self.__slots__[index])
-
- def __setitem__(self, index, value):
- return setattr(self, self.__slots__[index], value)
-
- def __eq__(self, other):
- # Types must be equal as well as values.
- return (isinstance(other, type(self))
- and all(a == b for a, b in zip(self, other)))
-
- def __str__(self):
- return '%s(%s)' % (
- type(self).__name__,
- ', '.join(attr + '=' + str(getattr(self, attr))
- for attr in self.__slots__))
-
- def __repr__(self):
- return str(self)
-
- RecordClass.__name__ = type_name
- return RecordClass
-
-
-# Making minibatches.
-def stack_pad(tensors, pad_axes=None, pad_to_lengths=None, dtype=np.float32,
- pad_value=0):
- """Stack tensors along 0-th dim and pad them to be the same shape.
-
- Args:
- tensors: Any list of iterables (python list, numpy array, etc). Can be 1D
- or multi-D iterables.
- pad_axes: An int or list of ints. Axes to pad along.
- pad_to_lengths: Length in each dimension. If pad_axes was an int, this is an
- int or None. If pad_axes was a list of ints, this is a list of mixed int
- and None types with the same length, or None. A None length means the
- maximum length among the given tensors is used.
- dtype: Type of output numpy array. Defaults to np.float32.
- pad_value: Value to use for padding. Defaults to 0.
-
- Returns:
- Numpy array containing the tensors stacked along the 0-th dimension and
- padded along the specified dimensions.
-
- Raises:
- ValueError: If the tensors do not have equal shapes along non-padded
- dimensions.
- """
- tensors = [np.asarray(t) for t in tensors]
- max_lengths = [max(l) for l in zip(*[t.shape for t in tensors])]
- same_axes = dict(enumerate(max_lengths))
- if pad_axes is None:
- pad_axes = []
- if isinstance(pad_axes, six.integer_types):
- if pad_to_lengths is not None:
- max_lengths[pad_axes] = pad_to_lengths
- del same_axes[pad_axes]
- else:
- if pad_to_lengths is None:
- pad_to_lengths = [None] * len(pad_axes)
- for i, l in zip(pad_axes, pad_to_lengths):
- if l is not None:
- max_lengths[i] = l
- del same_axes[i]
- same_axes_items = same_axes.items()
- dest = np.full([len(tensors)] + max_lengths, pad_value, dtype=dtype)
- for i, t in enumerate(tensors):
- for j, l in same_axes_items:
- if t.shape[j] != l:
- raise ValueError(
- 'Tensor at index %d does not have size %d along axis %d'
- % (i, l, j))
- dest[[i] + [slice(0, d) for d in t.shape]] = t
- return dest
-
-
-class RandomQueue(deque):
-
- def __init__(self, capacity):
- super(RandomQueue, self).__init__([], capacity)
- self.capacity = capacity
-
- def random_sample(self, sample_size):
- idx = np.random.choice(len(self), sample_size)
- return [self[i] for i in idx]
-
- def push(self, item):
- # Append to right. Oldest element will be popped from left.
- self.append(item)
-
-
-class MPQItemContainer(object):
- """Class for holding an item with its score.
-
- Defines a comparison function for use in the heap-queue.
- """
-
- def __init__(self, score, item, extra_data):
- self.item = item
- self.score = score
- self.extra_data = extra_data
-
- def __cmp__(self, other):
- assert isinstance(other, type(self))
- return cmp(self.score, other.score)
-
- def __iter__(self):
- """Allows unpacking like a tuple."""
- yield self.score
- yield self.item
- yield self.extra_data
-
- def __repr__(self):
- """String representation of this item.
-
- `extra_data` is not included in the representation. We are assuming that
- `extra_data` is not easily interpreted by a human (if it was, it should be
- hashable, like a string or tuple).
-
- Returns:
- String representation of `self`.
- """
- return str((self.score, self.item))
-
- def __str__(self):
- return repr(self)
-
-
-class MaxUniquePriorityQueue(object):
- """A maximum priority queue where duplicates are not added.
-
- The top items by score remain in the queue. When the capacity is reached,
- the lowest scored item in the queue will be dropped.
-
- This implementation differs from a typical priority queue, in that the minimum
- score is popped, instead of the maximum. Largest scores remain stuck in the
- queue. This is useful for accumulating the best known items from a population.
-
- The items used to determine uniqueness must be hashable, but additional
- non-hashable data may be stored with each item.
- """
-
- def __init__(self, capacity):
- self.capacity = capacity
- self.heap = []
- self.unique_items = set()
-
- def push(self, score, item, extra_data=None):
- """Push an item onto the queue.
-
- If the queue is at capacity, the item with the smallest score will be
- dropped. Note that it is assumed each item has exactly one score. The same
- item with a different score will still be dropped.
-
- Args:
- score: Number used to prioritize items in the queue. Largest scores are
- kept in the queue.
- item: A hashable item to be stored. Duplicates of this item will not be
- added to the queue.
- extra_data: An extra (possible not hashable) data to store with the item.
- """
- if item in self.unique_items:
- return
- if len(self.heap) >= self.capacity:
- _, popped_item, _ = heapq.heappushpop(
- self.heap, MPQItemContainer(score, item, extra_data))
- self.unique_items.add(item)
- self.unique_items.remove(popped_item)
- else:
- heapq.heappush(self.heap, MPQItemContainer(score, item, extra_data))
- self.unique_items.add(item)
-
- def pop(self):
- """Pop the item with the lowest score.
-
- Returns:
- score: Item's score.
- item: The item that was popped.
- extra_data: Any extra data stored with the item.
- """
- if not self.heap:
- return ()
- score, item, extra_data = heapq.heappop(self.heap)
- self.unique_items.remove(item)
- return score, item, extra_data
-
- def get_max(self):
- """Peek at the item with the highest score.
-
- Returns:
- Same as `pop`.
- """
- if not self.heap:
- return ()
- score, item, extra_data = heapq.nlargest(1, self.heap)[0]
- return score, item, extra_data
-
- def get_min(self):
- """Peek at the item with the lowest score.
-
- Returns:
- Same as `pop`.
- """
- if not self.heap:
- return ()
- score, item, extra_data = heapq.nsmallest(1, self.heap)[0]
- return score, item, extra_data
-
- def random_sample(self, sample_size):
- """Randomly select items from the queue.
-
- This does not modify the queue.
-
- Items are drawn from a uniform distribution, and not weighted by score.
-
- Args:
- sample_size: Number of random samples to draw. The same item can be
- sampled multiple times.
-
- Returns:
- List of sampled items (of length `sample_size`). Each element in the list
- is a tuple: (item, extra_data).
- """
- idx = np.random.choice(len(self.heap), sample_size)
- return [(self.heap[i].item, self.heap[i].extra_data) for i in idx]
-
- def iter_in_order(self):
- """Iterate over items in the queue from largest score to smallest.
-
- Yields:
- item: Hashable item.
- extra_data: Extra data stored with the item.
- """
- for _, item, extra_data in heapq.nlargest(len(self.heap), self.heap):
- yield item, extra_data
-
- def __len__(self):
- return len(self.heap)
-
- def __iter__(self):
- for _, item, _ in self.heap:
- yield item
-
- def __repr__(self):
- return '[' + ', '.join(repr(c) for c in self.heap) + ']'
-
- def __str__(self):
- return repr(self)
-
-
-class RouletteWheel(object):
- """Randomly samples stored objects proportionally to their given weights.
-
- Stores objects and weights. Acts like a roulette wheel where each object is
- given a slice of the roulette disk proportional to its weight.
-
- This can be used as a replay buffer where past experiences are sampled
- proportionally to their weights. A good choice of "weight" for reinforcement
- learning is exp(reward / temperature) where temperature -> inf makes the
- distribution more uniform and temperature -> 0 makes the distribution more
- peaky.
-
- To prevent experiences from being overweighted by appearing in the replay
- buffer multiple times, a "unique mode" is supported where duplicate
- experiences are ignored. In unique mode, weights can be quickly retrieved from
- keys.
- """
-
- def __init__(self, unique_mode=False, save_file=None):
- """Construct empty RouletteWheel.
-
- If `save_file` is not None, and the file already exists on disk, whatever
- is in the file will be loaded into this instance. This allows jobs using
- RouletteWheel to resume after preemption.
-
- Args:
- unique_mode: If True, puts this RouletteWheel into unique mode, where
- objects are added with hashable keys, so that duplicates are ignored.
- save_file: Optional file path to save to. Must be a string containing
- an absolute path to a file, or None. File will be Python pickle
- format.
- """
- self.unique_mode = unique_mode
- self.objects = []
- self.weights = []
- self.partial_sums = []
- if self.unique_mode:
- self.keys_to_weights = {}
- self.save_file = save_file
- self.save_to_disk_buffer = []
-
- if save_file is not None and tf.gfile.Exists(save_file):
- # Load from disk.
- with tf.gfile.OpenFast(save_file, 'r') as f:
- count = 0
- while 1:
- try:
- obj, weight, key = cPickle.load(f)
- except EOFError:
- break
- else:
- self.add(obj, weight, key)
- count += 1
- logging.info('Loaded %d samples from disk.', count)
- # Clear buffer since these items are already on disk.
- self.save_to_disk_buffer = []
-
- def __iter__(self):
- return iter(zip(self.objects, self.weights))
-
- def __len__(self):
- return len(self.objects)
-
- def is_empty(self):
- """Returns whether there is anything in the roulette wheel."""
- return not self.partial_sums
-
- @property
- def total_weight(self):
- """Total cumulative weight across all objects."""
- if self.partial_sums:
- return self.partial_sums[-1]
- return 0.0
-
- def has_key(self, key):
- if self.unique_mode:
- RuntimeError('has_key method can only be called in unique mode.')
- return key in self.keys_to_weights
-
- def get_weight(self, key):
- if self.unique_mode:
- RuntimeError('get_weight method can only be called in unique mode.')
- return self.keys_to_weights[key]
-
- def add(self, obj, weight, key=None):
- """Add one object and its weight to the roulette wheel.
-
- Args:
- obj: Any object to be stored.
- weight: A non-negative float. The given object will be drawn with
- probability proportional to this weight when sampling.
- key: This argument is only used when in unique mode. To allow `obj` to
- be an unhashable type, like list, a separate hashable key is given.
- Each `key` should be unique to each `obj`. `key` is used to check if
- `obj` has been added to the roulette wheel before.
-
- Returns:
- True if the object was added, False if it was not added due to it being
- a duplicate (this only happens in unique mode).
-
- Raises:
- ValueError: If `weight` is negative.
- ValueError: If `key` is not given when in unique mode, or if `key` is
- given when not in unique mode.
- """
- if weight < 0:
- raise ValueError('Weight must be non-negative')
- if self.unique_mode:
- if key is None:
- raise ValueError(
- 'Hashable key required for objects when unique mode is enabled.')
- if key in self.keys_to_weights:
- # Weight updates are not allowed. Ignore the given value of `weight`.
- return False
- self.keys_to_weights[key] = weight
- elif key is not None:
- raise ValueError(
- 'key argument should not be used when unique mode is disabled.')
- self.objects.append(obj)
- self.weights.append(weight)
- self.partial_sums.append(self.total_weight + weight)
- if self.save_file is not None:
- # Record new item in buffer.
- self.save_to_disk_buffer.append((obj, weight, key))
- return True
-
- def add_many(self, objs, weights, keys=None):
- """Add many object and their weights to the roulette wheel.
-
- Arguments are the same as the `add` method, except each is a list. Lists
- must all be the same length.
-
- Args:
- objs: List of objects to be stored.
- weights: List of non-negative floats. See `add` method.
- keys: List of hashable keys. This argument is only used when in unique
- mode. See `add` method.
-
- Returns:
- Number of objects added. This number will be less than the number of
- objects provided if we are in unique mode and some keys are already
- in the roulette wheel.
-
- Raises:
- ValueError: If `keys` argument is provided when unique_mode == False, or
- is not provided when unique_mode == True.
- ValueError: If any of the lists are not the same length.
- ValueError: If any of the weights are negative.
- """
- if keys is not None and not self.unique_mode:
- raise ValueError('Not in unique mode. Do not provide keys.')
- elif keys is None and self.unique_mode:
- raise ValueError('In unique mode. You must provide hashable keys.')
- if keys and len(objs) != len(keys):
- raise ValueError('Number of objects does not equal number of keys.')
- if len(objs) != len(weights):
- raise ValueError('Number of objects does not equal number of weights.')
- return sum([self.add(obj, weights[i], key=keys[i] if keys else None)
- for i, obj in enumerate(objs)])
-
- def sample(self):
- """Spin the roulette wheel.
-
- Randomly select an object with probability proportional to its weight.
-
- Returns:
- object: The selected object.
- weight: The weight of the selected object.
-
- Raises:
- RuntimeError: If the roulette wheel is empty.
- """
- if self.is_empty():
- raise RuntimeError('Trying to sample from empty roulette wheel.')
- spin = random.random() * self.total_weight
-
- # Binary search.
- i = bisect.bisect_right(self.partial_sums, spin)
- if i == len(self.partial_sums):
- # This should not happen since random.random() will always be strictly
- # less than 1.0, and the last partial sum equals self.total_weight().
- # However it may happen due to rounding error. In that case it is easy to
- # handle this, just select the last object.
- i -= 1
-
- return self.objects[i], self.weights[i]
-
- def sample_many(self, count):
- """Spin the roulette wheel `count` times and return the results."""
- if self.is_empty():
- raise RuntimeError('Trying to sample from empty roulette wheel.')
- return [self.sample() for _ in xrange(count)]
-
- def incremental_save(self, log_info=False):
- """Write new entries to disk.
-
- This performs an append operation on the `save_file` given in the
- constructor. Any entries added since the last call to `incremental_save`
- will be appended to the file.
-
- If a new RouletteWheel is constructed with the same `save_file`, all the
- entries written there will be automatically loaded into the instance.
- This is useful when a job resumes after preemption.
-
- Args:
- log_info: If True, info about this operation will be logged.
-
- Raises:
- RuntimeError: If `save_file` given in the constructor is None.
- """
- if self.save_file is None:
- raise RuntimeError('Cannot call incremental_save. `save_file` is None.')
- if log_info:
- logging.info('Saving %d new samples to disk.',
- len(self.save_to_disk_buffer))
- with tf.gfile.OpenFast(self.save_file, 'a') as f:
- for entry in self.save_to_disk_buffer:
- cPickle.dump(entry, f)
- # Clear the buffer.
- self.save_to_disk_buffer = []
diff --git a/research/brain_coder/common/utils_test.py b/research/brain_coder/common/utils_test.py
deleted file mode 100644
index 569c2877d17bf7707616029cdd2a5eac55df7f60..0000000000000000000000000000000000000000
--- a/research/brain_coder/common/utils_test.py
+++ /dev/null
@@ -1,382 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for common.utils.
-"""
-
-from collections import Counter
-import random
-import tempfile
-import numpy as np
-import tensorflow as tf
-
-from common import utils # brain coder
-
-
-class UtilsTest(tf.test.TestCase):
-
- def testStackPad(self):
- # 1D.
- tensors = [[1, 2, 3], [4, 5, 6, 7, 8], [9]]
- result = utils.stack_pad(tensors, pad_axes=0, pad_to_lengths=6)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[1, 2, 3, 0, 0, 0],
- [4, 5, 6, 7, 8, 0],
- [9, 0, 0, 0, 0, 0]], dtype=np.float32)))
-
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[2, 2])
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6]],
- [[0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2]],
- [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0]]]], dtype=np.float32)))
-
- def testStackPadNoAxes(self):
- # 2D.
- tensors = [[[1, 2, 3], [4, 5, 6]],
- [[7, 8, 9], [1, 2, 3]],
- [[4, 5, 6], [7, 8, 9]]]
- result = utils.stack_pad(tensors)
- self.assertTrue(np.array_equal(
- result,
- np.asarray(tensors)))
-
- def testStackPadNoneLength(self):
- # 1D.
- tensors = [[1, 2, 3], [4, 5, 6, 7, 8], [9]]
- result = utils.stack_pad(tensors, pad_axes=0, pad_to_lengths=None)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[1, 2, 3, 0, 0],
- [4, 5, 6, 7, 8],
- [9, 0, 0, 0, 0]], dtype=np.float32)))
-
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=None)
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6]],
- [[0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2]],
- [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0]]]], dtype=np.float32)))
-
- # 3D with partial pad_to_lengths.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]]]
- result = utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[None, 3])
- self.assertTrue(np.array_equal(
- result,
- np.asarray([[[[1, 2, 3], [4, 5, 6], [0, 0, 0]],
- [[0, 0, 0], [0, 0, 0], [0, 0, 0]]],
- [[[7, 8, 9], [0, 1, 2], [0, 0, 0]],
- [[3, 4, 5], [6, 7, 8], [0, 0, 0]]],
- [[[0, 1, 2], [0, 0, 0], [0, 0, 0]],
- [[3, 4, 5], [0, 0, 0], [0, 0, 0]]]], dtype=np.float32)))
-
- def testStackPadValueError(self):
- # 3D.
- tensors = [[[[1, 2, 3], [4, 5, 6]]],
- [[[7, 8, 9], [0, 1, 2]], [[3, 4, 5], [6, 7, 8]]],
- [[[0, 1, 2]], [[3, 4, 5]]],
- [[[1, 2, 3, 4]]]]
-
- # Not all tensors have the same shape along axis 2.
- with self.assertRaises(ValueError):
- utils.stack_pad(tensors, pad_axes=[0, 1], pad_to_lengths=[2, 2])
-
- def testRecord(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'], {'b': 55})
- inst = my_record(a=1, b=2, c=3)
- self.assertEqual(1, inst.a)
- self.assertEqual(2, inst.b)
- self.assertEqual(3, inst.c)
- self.assertEqual(1, inst[0])
- self.assertEqual(2, inst[1])
- self.assertEqual(3, inst[2])
- self.assertEqual([1, 2, 3], list(iter(inst)))
- self.assertEqual(3, len(inst))
-
- inst.b = 999
- self.assertEqual(999, inst.b)
- self.assertEqual(999, inst[1])
-
- inst2 = my_record(1, 999, 3)
- self.assertTrue(inst == inst2)
- inst2[1] = 3
- self.assertFalse(inst == inst2)
-
- inst3 = my_record(a=1, c=3)
- inst.b = 55
- self.assertEqual(inst, inst3)
-
- def testRecordUnique(self):
- record1 = utils.make_record('record1', ['a', 'b', 'c'])
- record2 = utils.make_record('record2', ['a', 'b', 'c'])
- self.assertNotEqual(record1(1, 2, 3), record2(1, 2, 3))
- self.assertEqual(record1(1, 2, 3), record1(1, 2, 3))
-
- def testTupleToRecord(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'])
- inst = utils.tuple_to_record((5, 6, 7), my_record)
- self.assertEqual(my_record(5, 6, 7), inst)
-
- def testRecordErrors(self):
- my_record = utils.make_record('my_record', ['a', 'b', 'c'], {'b': 10})
-
- with self.assertRaises(ValueError):
- my_record(c=5) # Did not provide required argument 'a'.
- with self.assertRaises(ValueError):
- my_record(1, 2, 3, 4) # Too many arguments.
-
- def testRandomQueue(self):
- np.random.seed(567890)
- queue = utils.RandomQueue(5)
- queue.push(5)
- queue.push(6)
- queue.push(7)
- queue.push(8)
- queue.push(9)
- queue.push(10)
- self.assertTrue(5 not in queue)
- sample = queue.random_sample(1000)
- self.assertEqual(1000, len(sample))
- self.assertEqual([6, 7, 8, 9, 10], sorted(np.unique(sample).tolist()))
-
- def testMaxUniquePriorityQueue(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(1.0, 'string 1')
- queue.push(-0.5, 'string 2')
- queue.push(0.5, 'string 3')
- self.assertEqual((-0.5, 'string 2', None), queue.pop())
- queue.push(0.1, 'string 4')
- queue.push(1.5, 'string 5')
- queue.push(0.0, 'string 6')
- queue.push(0.2, 'string 7')
- self.assertEqual((1.5, 'string 5', None), queue.get_max())
- self.assertEqual((0.1, 'string 4', None), queue.get_min())
- self.assertEqual(
- [('string 5', None), ('string 1', None), ('string 3', None),
- ('string 7', None), ('string 4', None)],
- list(queue.iter_in_order()))
-
- def testMaxUniquePriorityQueue_Duplicates(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(0.0, 'string 1')
- queue.push(0.0, 'string 2')
- queue.push(0.0, 'string 3')
- self.assertEqual((0.0, 'string 1', None), queue.pop())
- self.assertEqual((0.0, 'string 2', None), queue.pop())
- self.assertEqual((0.0, 'string 3', None), queue.pop())
- self.assertEqual(0, len(queue))
- queue.push(0.1, 'string 4')
- queue.push(1.5, 'string 5')
- queue.push(0.3, 'string 6')
- queue.push(0.2, 'string 7')
- queue.push(0.0, 'string 8')
- queue.push(1.5, 'string 5')
- queue.push(1.5, 'string 5')
- self.assertEqual((1.5, 'string 5', None), queue.get_max())
- self.assertEqual((0.0, 'string 8', None), queue.get_min())
- self.assertEqual(
- [('string 5', None), ('string 6', None), ('string 7', None),
- ('string 4', None), ('string 8', None)],
- list(queue.iter_in_order()))
-
- def testMaxUniquePriorityQueue_ExtraData(self):
- queue = utils.MaxUniquePriorityQueue(5)
- queue.push(1.0, 'string 1', [1, 2, 3])
- queue.push(0.5, 'string 2', [4, 5, 6])
- queue.push(0.5, 'string 3', [7, 8, 9])
- queue.push(0.5, 'string 2', [10, 11, 12])
- self.assertEqual((0.5, 'string 2', [4, 5, 6]), queue.pop())
- self.assertEqual((0.5, 'string 3', [7, 8, 9]), queue.pop())
- self.assertEqual((1.0, 'string 1', [1, 2, 3]), queue.pop())
- self.assertEqual(0, len(queue))
- queue.push(0.5, 'string 2', [10, 11, 12])
- self.assertEqual((0.5, 'string 2', [10, 11, 12]), queue.pop())
-
- def testRouletteWheel(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel()
- self.assertTrue(r.is_empty())
- with self.assertRaises(RuntimeError):
- r.sample() # Cannot sample when empty.
- self.assertEqual(0, r.total_weight)
- self.assertEqual(True, r.add('a', 0.1))
- self.assertFalse(r.is_empty())
- self.assertEqual(0.1, r.total_weight)
- self.assertEqual(True, r.add('b', 0.01))
- self.assertEqual(0.11, r.total_weight)
- self.assertEqual(True, r.add('c', 0.5))
- self.assertEqual(True, r.add('d', 0.1))
- self.assertEqual(True, r.add('e', 0.05))
- self.assertEqual(True, r.add('f', 0.03))
- self.assertEqual(True, r.add('g', 0.001))
- self.assertEqual(0.791, r.total_weight)
- self.assertFalse(r.is_empty())
-
- # Check that sampling is correct.
- obj, weight = r.sample()
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
- for obj, weight in r.sample_many(100):
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
-
- # Check that sampling distribution is correct.
- n = 1000000
- c = Counter(r.sample_many(n))
- for obj, w in r:
- estimated_w = c[(obj, w)] / float(n) * r.total_weight
- self.assertTrue(
- np.isclose(w, estimated_w, atol=1e-3),
- 'Expected %s, got %s, for object %s' % (w, estimated_w, obj))
-
- def testRouletteWheel_AddMany(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel()
- self.assertTrue(r.is_empty())
- with self.assertRaises(RuntimeError):
- r.sample() # Cannot sample when empty.
- self.assertEqual(0, r.total_weight)
- count = r.add_many(
- ['a', 'b', 'c', 'd', 'e', 'f', 'g'],
- [0.1, 0.01, 0.5, 0.1, 0.05, 0.03, 0.001])
- self.assertEqual(7, count)
- self.assertFalse(r.is_empty())
- self.assertEqual(0.791, r.total_weight)
-
- # Adding no items is allowed.
- count = r.add_many([], [])
- self.assertEqual(0, count)
- self.assertFalse(r.is_empty())
- self.assertEqual(0.791, r.total_weight)
-
- # Check that sampling is correct.
- obj, weight = r.sample()
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
- for obj, weight in r.sample_many(100):
- self.assertTrue(isinstance(weight, float), 'Type: %s' % type(weight))
- self.assertTrue((obj, weight) in r)
-
- # Check that sampling distribution is correct.
- n = 1000000
- c = Counter(r.sample_many(n))
- for obj, w in r:
- estimated_w = c[(obj, w)] / float(n) * r.total_weight
- self.assertTrue(
- np.isclose(w, estimated_w, atol=1e-3),
- 'Expected %s, got %s, for object %s' % (w, estimated_w, obj))
-
- def testRouletteWheel_AddZeroWeights(self):
- r = utils.RouletteWheel()
- self.assertEqual(True, r.add('a', 0))
- self.assertFalse(r.is_empty())
- self.assertEqual(4, r.add_many(['b', 'c', 'd', 'e'], [0, 0.1, 0, 0]))
- self.assertEqual(
- [('a', 0.0), ('b', 0.0), ('c', 0.1), ('d', 0.0), ('e', 0.0)],
- list(r))
-
- def testRouletteWheel_UniqueMode(self):
- random.seed(12345678987654321)
- r = utils.RouletteWheel(unique_mode=True)
- self.assertEqual(True, r.add([1, 2, 3], 1, 'a'))
- self.assertEqual(True, r.add([4, 5], 0.5, 'b'))
- self.assertEqual(False, r.add([1, 2, 3], 1.5, 'a'))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5)],
- list(r))
- self.assertEqual(1.5, r.total_weight)
- self.assertEqual(
- 2,
- r.add_many(
- [[5, 6, 2, 3], [1, 2, 3], [8], [1, 2, 3]],
- [0.1, 0.2, 0.1, 2.0],
- ['c', 'a', 'd', 'a']))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([5, 6, 2, 3], 0.1), ([8], 0.1)],
- list(r))
- self.assertTrue(np.isclose(1.7, r.total_weight))
- self.assertEqual(0, r.add_many([], [], [])) # Adding no items is allowed.
- with self.assertRaises(ValueError):
- # Key not given.
- r.add([7, 8, 9], 2.0)
- with self.assertRaises(ValueError):
- # Keys not given.
- r.add_many([[7, 8, 9], [10]], [2.0, 2.0])
- self.assertEqual(True, r.has_key('a'))
- self.assertEqual(True, r.has_key('b'))
- self.assertEqual(False, r.has_key('z'))
- self.assertEqual(1.0, r.get_weight('a'))
- self.assertEqual(0.5, r.get_weight('b'))
-
- r = utils.RouletteWheel(unique_mode=False)
- self.assertEqual(True, r.add([1, 2, 3], 1))
- self.assertEqual(True, r.add([4, 5], 0.5))
- self.assertEqual(True, r.add([1, 2, 3], 1.5))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([1, 2, 3], 1.5)],
- list(r))
- self.assertEqual(3, r.total_weight)
- self.assertEqual(
- 4,
- r.add_many(
- [[5, 6, 2, 3], [1, 2, 3], [8], [1, 2, 3]],
- [0.1, 0.2, 0.1, 0.2]))
- self.assertEqual(
- [([1, 2, 3], 1.0), ([4, 5], 0.5), ([1, 2, 3], 1.5),
- ([5, 6, 2, 3], 0.1), ([1, 2, 3], 0.2), ([8], 0.1), ([1, 2, 3], 0.2)],
- list(r))
- self.assertTrue(np.isclose(3.6, r.total_weight))
- with self.assertRaises(ValueError):
- # Key is given.
- r.add([7, 8, 9], 2.0, 'a')
- with self.assertRaises(ValueError):
- # Keys are given.
- r.add_many([[7, 8, 9], [10]], [2.0, 2.0], ['a', 'b'])
-
- def testRouletteWheel_IncrementalSave(self):
- f = tempfile.NamedTemporaryFile()
- r = utils.RouletteWheel(unique_mode=True, save_file=f.name)
- entries = [
- ([1, 2, 3], 0.1, 'a'),
- ([4, 5], 0.2, 'b'),
- ([6], 0.3, 'c'),
- ([7, 8, 9, 10], 0.25, 'd'),
- ([-1, -2], 0.15, 'e'),
- ([-3, -4, -5], 0.5, 'f')]
-
- self.assertTrue(r.is_empty())
- for i in range(0, len(entries), 2):
- r.add(*entries[i])
- r.add(*entries[i + 1])
- r.incremental_save()
-
- r2 = utils.RouletteWheel(unique_mode=True, save_file=f.name)
- self.assertEqual(i + 2, len(r2))
- count = 0
- for j, (obj, weight) in enumerate(r2):
- self.assertEqual(entries[j][0], obj)
- self.assertEqual(entries[j][1], weight)
- self.assertEqual(weight, r2.get_weight(entries[j][2]))
- count += 1
- self.assertEqual(i + 2, count)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/BUILD b/research/brain_coder/single_task/BUILD
deleted file mode 100644
index 47e91b12b8ba40a2a9916a89375fbb773758d7cf..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/BUILD
+++ /dev/null
@@ -1,244 +0,0 @@
-licenses(["notice"])
-
-package(default_visibility = [
- "//learning/brain/research/neural_coder:__subpackages__",
-])
-
-load("@subpar//:subpar.bzl", "par_binary")
-
-par_binary(
- name = "run",
- srcs = ["run.py"],
- deps = [
- ":defaults",
- ":ga_train",
- ":pg_train",
- # absl dep :app
- # absl dep /flags
- # absl dep /logging
- ],
-)
-
-par_binary(
- name = "tune",
- srcs = ["tune.py"],
- deps = [
- ":defaults",
- ":run",
- # file dep
- # absl dep :app
- # absl dep /flags
- # absl dep /logging
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "ga_train",
- srcs = ["ga_train.py"],
- deps = [
- ":data",
- ":defaults",
- ":ga_lib",
- ":results_lib",
- # file dep
- # absl dep /flags
- # absl dep /logging
- # numpy dep
- # tensorflow dep
- "//common:utils", # project
- ],
-)
-
-py_library(
- name = "ga_lib",
- srcs = ["ga_lib.py"],
- deps = [
- ":misc",
- # absl dep /flags
- # absl dep /logging
- # numpy dep
- "//common:bf", # project
- "//common:utils", # project
- ],
-)
-
-py_test(
- name = "ga_train_test",
- srcs = ["ga_train_test.py"],
- deps = [
- ":defaults",
- ":run",
- # absl dep /flags
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "pg_train",
- srcs = ["pg_train.py"],
- deps = [
- ":data",
- ":defaults",
- ":pg_agent",
- ":results_lib",
- # file dep
- # absl dep /flags
- # absl dep /logging
- # tensorflow dep
- # tensorflow internal dep # build_cleaner: keep
- ],
-)
-
-py_library(
- name = "pg_agent",
- srcs = ["pg_agent.py"],
- deps = [
- ":misc",
- # file dep
- # absl dep /logging
- # numpy dep
- # tensorflow dep
- "//common:rollout", # project
- "//common:utils", # project
- ],
-)
-
-py_test(
- name = "pg_agent_test",
- srcs = ["pg_agent_test.py"],
- deps = [
- ":data",
- ":defaults",
- ":misc",
- ":pg_agent",
- ":pg_train",
- # absl dep /logging
- # numpy dep
- # tensorflow dep
- "//common:utils", # project
- ],
-)
-
-py_library(
- name = "defaults",
- srcs = ["defaults.py"],
- deps = [
- # absl dep /logging
- "//common:config_lib", # project
- ],
-)
-
-py_library(
- name = "misc",
- srcs = ["misc.py"],
-)
-
-py_library(
- name = "data",
- srcs = ["data.py"],
- deps = [
- ":code_tasks",
- # absl dep /logging
- ],
-)
-
-py_library(
- name = "code_tasks",
- srcs = ["code_tasks.py"],
- deps = [
- ":misc",
- ":test_tasks",
- # absl dep /logging
- # numpy dep
- "//common:bf", # project
- "//common:reward", # project
- ],
-)
-
-py_test(
- name = "code_tasks_test",
- srcs = ["code_tasks_test.py"],
- deps = [
- ":code_tasks",
- ":defaults",
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "test_tasks",
- srcs = ["test_tasks.py"],
- deps = [
- ":misc",
- "//common:reward", # project
- ],
-)
-
-py_test(
- name = "test_tasks_test",
- srcs = ["test_tasks_test.py"],
- deps = [
- ":misc",
- ":test_tasks",
- # numpy dep
- # tensorflow dep
- ],
-)
-
-py_test(
- name = "pg_train_test",
- size = "large",
- srcs = ["pg_train_test.py"],
- deps = [
- ":defaults",
- ":run",
- # absl dep /logging
- # tensorflow dep
- ],
-)
-
-py_library(
- name = "results_lib",
- srcs = ["results_lib.py"],
- deps = [
- # file dep
- # tensorflow dep
- ],
-)
-
-py_test(
- name = "results_lib_test",
- srcs = ["results_lib_test.py"],
- deps = [
- ":results_lib",
- # tensorflow dep
- ],
-)
-
-par_binary(
- name = "aggregate_experiment_results",
- srcs = ["aggregate_experiment_results.py"],
- deps = [
- ":misc",
- ":results_lib",
- # file dep
- # absl dep :app
- # absl dep /flags
- # numpy dep
- # tensorflow dep
- ],
-)
-
-par_binary(
- name = "aggregate_tuning_results",
- srcs = ["aggregate_tuning_results.py"],
- deps = [
- # file dep
- # absl dep :app
- # absl dep /flags
- # tensorflow dep
- ],
-)
diff --git a/research/brain_coder/single_task/README.md b/research/brain_coder/single_task/README.md
deleted file mode 100644
index 69eaabcc6ccabada838a0a2a3f12fd7eed69744c..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/README.md
+++ /dev/null
@@ -1,192 +0,0 @@
-# Experiments for ICLR 2018 paper.
-
-[Neural Program Synthesis with Priority Queue Training](https://arxiv.org/abs/1801.03526).
-
-Runs policy gradient (REINFORCE), priority queue training, genetic algorithm,
-and uniform random search.
-
-Run all examples below out of your top-level repo directory, i.e. where your git
-clone resides.
-
-
-## Just tell me how to run something and see results
-```bash
-# These tasks are the fastest to learn. 'echo' and 'count-down' are very
-# easy. run_eval_tasks.py will do most of the work to run all the jobs.
-# Should take between 10 and 30 minutes.
-
-# How many repetitions each experiment will run. In the paper, we use 25. Less
-# reps means faster experiments, but noisier results.
-REPS=25
-
-# Extra description in the job names for these experiments. Use this description
-# to distinguish between multiple runs of the same experiment.
-DESC="demo"
-
-# The tasks to run.
-TASKS="reverse echo-second-seq"
-
-# The model types and max NPE.
-EXPS=( pg-20M topk-20M ga-20M rand-20M )
-
-# Where training data is saved. This is chosen by launch_training.sh. Custom
-# implementations of launch_training.sh may use different locations.
-MODELS_DIR="/tmp/models"
-
-# Run run_eval_tasks.py for each experiment name in EXPS.
-for exp in "${EXPS[@]}"
-do
- ./single_task/run_eval_tasks.py \
- --exp "$exp" --tasks $TASKS --desc "$DESC" --reps $REPS
-done
-
-# During training or after completion, run this to aggregate results into a
-# table. This is also useful for seeing how much progress has been made.
-# Make sure the arguments here match the settings used above.
-# Note: This can take a few minutes because it reads from every experiment
-# directory.
-bazel run single_task:aggregate_experiment_results -- \
- --models_dir="$MODELS_DIR" \
- --max_npe="20M" \
- --task_list="$TASKS" \
- --model_types="[('pg', '$DESC'), ('topk', '$DESC'), ('ga', '$DESC'),
- ('rand', '$DESC')]" \
- --csv_file="/tmp/results_table.csv"
-```
-
-
-## Reproduce tuning results in paper
-```bash
-bazel build -c opt single_task:tune.par
-
-# PG and TopK Tuning.
-MAX_NPE=5000000
-CONFIG="
-env=c(task_cycle=['reverse-tune','remove-tune']),
-agent=c(
- algorithm='pg',
- grad_clip_threshold=50.0,param_init_factor=0.5,entropy_beta=0.05,lr=1e-5,
- optimizer='rmsprop',ema_baseline_decay=0.99,topk_loss_hparam=0.0,topk=0,
- replay_temperature=1.0,alpha=0.0,eos_token=False),
-timestep_limit=50,batch_size=64"
-
-./single_task/launch_tuning.sh \
- --job_name="iclr_pg_gridsearch.reverse-remove" \
- --config="$CONFIG" \
- --max_npe="$MAX_NPE" \
- --num_workers_per_tuner=1 \
- --num_ps_per_tuner=0 \
- --num_tuners=1 \
- --num_repetitions=50 \
- --hparam_space_type="pg" \
- --stop_on_success=true
-./single_task/launch_tuning.sh \
- --job_name="iclr_pg_topk_gridsearch.reverse-remove" \
- --config="$CONFIG" \
- --max_npe="$MAX_NPE" \
- --num_workers_per_tuner=1 \
- --num_ps_per_tuner=0 \
- --num_tuners=1 \
- --num_repetitions=50 \
- --hparam_space_type="pg-topk" \
- --fixed_hparams="topk=10" \
- --stop_on_success=true
-./single_task/launch_tuning.sh \
- --job_name="iclr_topk_gridsearch.reverse-remove" \
- --config="$CONFIG" \
- --max_npe="$MAX_NPE" \
- --num_workers_per_tuner=1 \
- --num_ps_per_tuner=0 \
- --num_tuners=1 \
- --num_repetitions=50 \
- --hparam_space_type="topk" \
- --fixed_hparams="topk=10" \
- --stop_on_success=true
-
-# GA Tuning.
-CONFIG="
-env=c(task_cycle=['reverse-tune','remove-char-tune']),
-agent=c(algorithm='ga'),
-timestep_limit=50"
-./single_task/launch_tuning.sh \
- --job_name="iclr_ga_gridsearch.reverse-remove" \
- --config="$CONFIG" \
- --max_npe="$MAX_NPE" \
- --num_workers_per_tuner=25 \
- --num_ps_per_tuner=0 \
- --num_tuners=1 \
- --num_repetitions=50 \
- --hparam_space_type="ga" \
- --stop_on_success=true
-
-# Aggregate tuning results. Run after tuning jobs complete.
-bazel run -c opt single_task:aggregate_tuning_results -- \
- --tuning_dir="$MODELS_DIR/iclr_pg_gridsearch.reverse-remove"
-bazel run -c opt single_task:aggregate_tuning_results -- \
- --tuning_dir="$MODELS_DIR/iclr_pg_topk_gridsearch.reverse-remove"
-bazel run -c opt single_task:aggregate_tuning_results -- \
- --tuning_dir="$MODELS_DIR/iclr_topk_gridsearch.reverse-remove"
-bazel run -c opt single_task:aggregate_tuning_results -- \
- --tuning_dir="$MODELS_DIR/iclr_ga_gridsearch.reverse-remove"
-```
-
-## Reproduce eval results in paper
-```bash
-DESC="v0" # Description for each experiment. "Version 0" is a good default.
-EXPS=( pg-5M topk-5M ga-5M rand-5M pg-20M topk-20M ga-20M rand-20M )
-for exp in "${EXPS[@]}"
-do
- ./single_task/run_eval_tasks.py \
- --exp "$exp" --iclr_tasks --desc "$DESC"
-done
-```
-
-## Run single experiment
-```bash
-EXP="topk-20M" # Learning algorithm + max-NPE
-TASK="reverse" # Coding task
-DESC="v0" # Description for each experiment. "Version 0" is a good default.
-./single_task/run_eval_tasks.py \
- --exp "$EXP" --task "$TASK" --desc "$DESC"
-```
-
-## Fetch eval results into a table
-```bash
-# These arguments should match the settings you used to run the experiments.
-MODELS_DIR="/tmp/models"
-MAX_NPE="20M"
-DESC="v0" # Same description used in the experiments.
-# MODEL_TYPES specifies each model type and the description used in their
-# experiments.
-MODEL_TYPES="[('pg', '$DESC'), ('topk', '$DESC'),
- ('ga', '$DESC'), ('rand', '$DESC')]"
-TASKS="" # Empty string will default to all ICLR tasks.
-# To specify custom task list, give task names separated by spaces. Example:
-# TASKS="reverse remove-char"
-bazel run single_task:aggregate_experiment_results -- \
- --models_dir="$MODELS_DIR" \
- --max_npe="$MAX_NPE" \
- --task_list="$TASKS" \
- --model_types="$MODEL_TYPES" \
- --csv_file="/tmp/results_table.csv"
-```
-
-## Reproduce shortest code examples in paper
-```bash
-# Maximum NPE is higher here. We only do 1 repetition, and the algorithm needs
-# time to simplify its solution.
-MODELS_DIR="/tmp/models"
-NPE="500M"
-DESC="short-code"
-./single_task/run_eval_tasks.py \
- --exp "simpl-$NPE" --desc "$DESC" --iclr_tasks --reps 1
-
-# Aggregate best code strings. Run after training completes.
-TASKS="" # Empty string. Will default to all ICLR tasks.
-bazel run single_task:aggregate_experiment_results -- \
- --models_dir="$MODELS_DIR" \
- --max_npe="$NPE" \
- --task_list="$TASKS" \
- --model_types="[('topk', '$DESC')]" \
- --data=code
-```
diff --git a/research/brain_coder/single_task/aggregate_experiment_results.py b/research/brain_coder/single_task/aggregate_experiment_results.py
deleted file mode 100644
index f106253004b3bbe1ff32443c41b8999b1c9e96f6..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/aggregate_experiment_results.py
+++ /dev/null
@@ -1,380 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-r"""This script crawls experiment directories for results and aggregates them.
-
-Usage example:
-
-MODELS_DIR="/tmp/models"
-bazel run single_task:aggregate_experiment_results -- \
- --models_dir="$MODELS_DIR" \
- --max_npe="20M" \
- --task_list="add echo" \
- --model_types="[('topk', 'v0'), ('ga', 'v0')]" \
- --csv_file=/tmp/results_table.csv
-"""
-
-import ast
-from collections import namedtuple
-import csv
-import os
-import re
-import StringIO
-import sys
-
-from absl import app
-from absl import flags
-import numpy as np
-import tensorflow as tf
-
-from single_task import misc # brain coder
-from single_task import results_lib # brain coder
-
-DEFAULT_MODELS = [('pg', 'v0'), ('topk', 'v0'), ('ga', 'v0'), ('rand', 'v0')]
-DEFAULT_TASKS = [
- 'reverse', 'remove-char', 'count-char', 'add', 'bool-logic', 'print-hello',
- 'echo-twice', 'echo-thrice', 'copy-reverse', 'zero-cascade', 'cascade',
- 'shift-left', 'shift-right', 'riffle', 'unriffle', 'middle-char',
- 'remove-last', 'remove-last-two', 'echo-alternating', 'echo-half', 'length',
- 'echo-second-seq', 'echo-nth-seq', 'substring', 'divide-2', 'dedup']
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string(
- 'models_dir', '',
- 'Absolute path where results folders are found.')
-flags.DEFINE_string(
- 'exp_prefix', 'bf_rl_iclr',
- 'Prefix for all experiment folders.')
-flags.DEFINE_string(
- 'max_npe', '5M',
- 'String representation of max NPE of the experiments.')
-flags.DEFINE_spaceseplist(
- 'task_list', DEFAULT_TASKS,
- 'List of task names separated by spaces. If empty string, defaults to '
- '`DEFAULT_TASKS`. These are the rows of the results table.')
-flags.DEFINE_string(
- 'model_types', str(DEFAULT_MODELS),
- 'String representation of a python list of 2-tuples, each a model_type + '
- 'job description pair. Descriptions allow you to choose among different '
- 'runs of the same experiment. These are the columns of the results table.')
-flags.DEFINE_string(
- 'csv_file', '/tmp/results_table.csv',
- 'Where to write results table. Format is CSV.')
-flags.DEFINE_enum(
- 'data', 'success_rates', ['success_rates', 'code'],
- 'What type of data to aggregate.')
-
-
-def make_csv_string(table):
- """Convert 2D list to CSV string."""
- s = StringIO.StringIO()
- writer = csv.writer(s)
- writer.writerows(table)
- value = s.getvalue()
- s.close()
- return value
-
-
-def process_results(metrics):
- """Extract useful information from given metrics.
-
- Args:
- metrics: List of results dicts. These should have been written to disk by
- training jobs.
-
- Returns:
- Dict mapping stats names to values.
-
- Raises:
- ValueError: If max_npe or max_global_repetitions values are inconsistant
- across dicts in the `metrics` list.
- """
- count = len(metrics)
- success_count = 0
- total_npe = 0 # Counting NPE across all runs.
- success_npe = 0 # Counting NPE in successful runs only.
- max_npe = 0
- max_repetitions = 0
- for metric_dict in metrics:
- if not max_npe:
- max_npe = metric_dict['max_npe']
- elif max_npe != metric_dict['max_npe']:
- raise ValueError(
- 'Invalid experiment. Different reps have different max-NPE settings.')
- if not max_repetitions:
- max_repetitions = metric_dict['max_global_repetitions']
- elif max_repetitions != metric_dict['max_global_repetitions']:
- raise ValueError(
- 'Invalid experiment. Different reps have different num-repetition '
- 'settings.')
- if metric_dict['found_solution']:
- success_count += 1
- success_npe += metric_dict['npe']
- total_npe += metric_dict['npe']
- stats = {}
- stats['max_npe'] = max_npe
- stats['max_repetitions'] = max_repetitions
- stats['repetitions'] = count
- stats['successes'] = success_count # successful reps
- stats['failures'] = count - success_count # failed reps
- stats['success_npe'] = success_npe
- stats['total_npe'] = total_npe
- if success_count:
- # Only successful runs counted.
- stats['avg_success_npe'] = stats['success_npe'] / float(success_count)
- else:
- stats['avg_success_npe'] = 0.0
- if count:
- stats['success_rate'] = success_count / float(count)
- stats['avg_total_npe'] = stats['total_npe'] / float(count)
- else:
- stats['success_rate'] = 0.0
- stats['avg_total_npe'] = 0.0
-
- return stats
-
-
-ProcessedResults = namedtuple('ProcessedResults', ['metrics', 'processed'])
-
-
-def get_results_for_experiment(
- models_dir, task_name, model_type='pg', max_npe='5M', desc='v0',
- name_prefix='bf_rl_paper', extra_desc=''):
- """Get and process results for a given experiment.
-
- An experiment is a set of runs with the same hyperparameters and environment.
- It is uniquely specified by a (task_name, model_type, max_npe) triple, as
- well as an optional description.
-
- We assume that each experiment has a folder with the same name as the job that
- ran the experiment. The name is computed by
- "%name_prefix%.%desc%-%max_npe%_%task_name%".
-
- Args:
- models_dir: Parent directory containing experiment folders.
- task_name: String name of task (the coding env). See code_tasks.py or
- run_eval_tasks.py
- model_type: Name of the algorithm, such as 'pg', 'topk', 'ga', 'rand'.
- max_npe: String SI unit representation of the maximum NPE threshold for the
- experiment. For example, "5M" means 5 million.
- desc: Description.
- name_prefix: Prefix of job names. Normally leave this as default.
- extra_desc: Optional extra description at the end of the job name.
-
- Returns:
- ProcessedResults namedtuple instance, containing
- metrics: Raw dicts read from disk.
- processed: Stats computed by `process_results`.
-
- Raises:
- ValueError: If max_npe in the metrics does not match NPE in the experiment
- folder name.
- """
- folder = name_prefix + '.{0}.{1}-{2}_{3}'.format(desc, model_type, max_npe,
- task_name)
- if extra_desc:
- folder += '.' + extra_desc
-
- results = results_lib.Results(os.path.join(models_dir, folder))
- metrics, _ = results.read_all()
- processed = process_results(metrics)
- if (not np.isclose(processed['max_npe'], misc.si_to_int(max_npe))
- and processed['repetitions']):
- raise ValueError(
- 'Invalid experiment. Max-NPE setting does not match expected max-NPE '
- 'in experiment name.')
- return ProcessedResults(metrics=metrics, processed=processed)
-
-
-BestCodeResults = namedtuple(
- 'BestCodeResults',
- ['code', 'reward', 'npe', 'folder', 'finished', 'error'])
-
-
-class BestCodeResultError(object):
- success = 0
- no_solution_found = 1
- experiment_does_not_exist = 2
-
-
-def get_best_code_for_experiment(
- models_dir, task_name, model_type='pg', max_npe='5M', desc=0,
- name_prefix='bf_rl_paper', extra_desc=''):
- """Like `get_results_for_experiment`, but fetches the code solutions."""
- folder = name_prefix + '.{0}.{1}-{2}_{3}'.format(desc, model_type, max_npe,
- task_name)
- if extra_desc:
- folder += '.' + extra_desc
-
- log_dir = os.path.join(models_dir, folder, 'logs')
- search_regex = r'^solutions_([0-9])+\.txt$'
- try:
- all_children = tf.gfile.ListDirectory(log_dir)
- except tf.errors.NotFoundError:
- return BestCodeResults(
- code=None, reward=0.0, npe=0, folder=folder, finished=False,
- error=BestCodeResultError.experiment_does_not_exist)
- solution_files = [
- fname for fname in all_children if re.search(search_regex, fname)]
- max_reward = 0.0
- npe = 0
- best_code = None
- for fname in solution_files:
- with tf.gfile.FastGFile(os.path.join(log_dir, fname), 'r') as reader:
- results = [ast.literal_eval(entry) for entry in reader]
- for res in results:
- if res['reward'] > max_reward:
- best_code = res['code']
- max_reward = res['reward']
- npe = res['npe']
- error = (
- BestCodeResultError.success if best_code
- else BestCodeResultError.no_solution_found)
- try:
- # If there is a status.txt file, check if it contains the status of the job.
- with tf.gfile.FastGFile(os.path.join(log_dir, 'status.txt'), 'r') as f:
- # Job is done, so mark this experiment as finished.
- finished = f.read().lower().strip() == 'done'
- except tf.errors.NotFoundError:
- # No status file has been written, so the experiment is not done. No need to
- # report an error here, because we do not require that experiment jobs write
- # out a status.txt file until they have finished.
- finished = False
- return BestCodeResults(
- code=best_code, reward=max_reward, npe=npe, folder=folder,
- finished=finished, error=error)
-
-
-def make_results_table(
- models=None,
- tasks=None,
- max_npe='5M',
- name_prefix='bf_rl_paper',
- extra_desc='',
- models_dir='/tmp'):
- """Creates a table of results: algorithm + version by tasks.
-
- Args:
- models: The table columns. A list of (algorithm, desc) tuples.
- tasks: The table rows. List of task names.
- max_npe: String SI unit representation of the maximum NPE threshold for the
- experiment. For example, "5M" means 5 million. All entries in the table
- share the same max-NPE.
- name_prefix: Name prefix used in logging directory for the experiment.
- extra_desc: Extra description added to name of logging directory for the
- experiment.
- models_dir: Parent directory containing all experiment folders.
-
- Returns:
- A 2D list holding the table cells.
- """
- if models is None:
- models = DEFAULT_MODELS
- if tasks is None:
- tasks = DEFAULT_TASKS
- model_results = {}
- for model_type, desc in models:
- model_results[model_type] = {
- tname: get_results_for_experiment(
- models_dir, tname, model_type, max_npe, desc,
- name_prefix=name_prefix, extra_desc=extra_desc
- ).processed
- for tname in tasks}
-
- def info(stats):
- return [str(stats['repetitions']),
- '%.2f' % stats['success_rate'],
- str(int(stats['avg_total_npe']))]
-
- rows = [['max NPE: ' + max_npe]
- + misc.flatten([['{0} ({1})'.format(m, d), '', '']
- for m, d in models])]
- rows.append(
- [''] + misc.flatten([['reps', 'success rate', 'avg NPE']
- for _ in models]))
- for tname in tasks:
- rows.append(
- [tname]
- + misc.flatten([info(model_results[model][tname])
- for model, _ in models]))
-
- return rows
-
-
-def print_results_table(results_table):
- """Print human readable results table to stdout."""
- print('')
- print('=== Results Table ===')
- print('Format: # reps [success rate, avg total NPE]')
-
- def info_str(info_row):
- # num_runs (success_rate, avg_total_npe)
- if not info_row[0]:
- return '0'
- return '%s [%s, %s]' % (str(info_row[0]).ljust(2), info_row[1], info_row[2])
-
- nc = len(results_table[0]) # num cols
- out_table = [
- [results_table[0][0]] + [results_table[0][i] for i in range(1, nc, 3)]]
- for row in results_table[2:]:
- out_table.append([row[0]] + [info_str(row[i:i+3]) for i in range(1, nc, 3)])
-
- nc = len(out_table[0]) # num cols
- col_widths = [max(len(row[col]) for row in out_table) for col in range(nc)]
-
- table_string = ''
- for row in out_table:
- table_string += ''.join(
- [row[c].ljust(col_widths[c] + 2) for c in range(nc)]) + '\n'
-
- print(table_string)
-
-
-def main(argv):
- del argv # Unused.
-
- name_prefix = FLAGS.exp_prefix
- print('Experiments prefix: %s' % name_prefix)
-
- model_types = ast.literal_eval(FLAGS.model_types)
-
- if FLAGS.data == 'success_rates':
- results_table = make_results_table(
- models=model_types, tasks=FLAGS.task_list, max_npe=FLAGS.max_npe,
- models_dir=FLAGS.models_dir,
- name_prefix=name_prefix, extra_desc='')
- with tf.gfile.FastGFile(FLAGS.csv_file, 'w') as f:
- f.write(make_csv_string(results_table))
-
- print_results_table(results_table)
- else:
- # Best code
- print('* = experiment is still running')
- print('')
- print('=== Best Synthesized Code ===')
- for model_type, desc in model_types:
- print('%s (%s)' % (model_type, desc))
- sys.stdout.flush()
- for tname in FLAGS.task_list:
- res = get_best_code_for_experiment(
- FLAGS.models_dir, tname, model_type, FLAGS.max_npe, desc,
- name_prefix=name_prefix, extra_desc='')
- unfinished_mark = '' if res.finished else ' *'
- tname += unfinished_mark
- if res.error == BestCodeResultError.success:
- print(' %s' % tname)
- print(' %s' % res.code)
- print(' R=%.6f, NPE=%s' % (res.reward, misc.int_to_si(res.npe)))
- elif res.error == BestCodeResultError.experiment_does_not_exist:
- print(' Experiment does not exist. Check arguments.')
- print(' Experiment folder: %s' % res.folder)
- break
- else:
- print(' %s' % tname)
- print(' (none)')
- sys.stdout.flush()
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/brain_coder/single_task/aggregate_tuning_results.py b/research/brain_coder/single_task/aggregate_tuning_results.py
deleted file mode 100644
index bb2e008ce583afbea8acabfe1ed8ccf264698f5e..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/aggregate_tuning_results.py
+++ /dev/null
@@ -1,71 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-r"""After running tuning, use this script to aggregate the results.
-
-Usage:
-
-OUT_DIR=""
-bazel run -c opt single_task:aggregate_tuning_results -- \
- --alsologtostderr \
- --tuning_dir="$OUT_DIR"
-"""
-
-import ast
-import os
-
-from absl import app
-from absl import flags
-import tensorflow as tf
-
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string(
- 'tuning_dir', '',
- 'Absolute path where results tuning trial folders are found.')
-
-
-def main(argv):
- del argv # Unused.
-
- try:
- trial_dirs = tf.gfile.ListDirectory(FLAGS.tuning_dir)
- except tf.errors.NotFoundError:
- print('Tuning directory %s does not exist.' % (FLAGS.tuning_dir,))
- return
-
- metrics = []
- for trial_dir in trial_dirs:
- tuning_results_file = os.path.join(
- FLAGS.tuning_dir, trial_dir, 'tuning_results.txt')
- if tf.gfile.Exists(tuning_results_file):
- with tf.gfile.FastGFile(tuning_results_file, 'r') as reader:
- for line in reader:
- metrics.append(ast.literal_eval(line.replace(': nan,', ': 0.0,')))
-
- if not metrics:
- print('No trials found.')
- return
-
- num_trials = [m['num_trials'] for m in metrics]
- assert all(n == num_trials[0] for n in num_trials)
- num_trials = num_trials[0]
- print('Found %d completed trials out of %d' % (len(metrics), num_trials))
-
- # Sort by objective descending.
- sorted_trials = sorted(metrics, key=lambda m: -m['objective'])
-
- for i, metrics in enumerate(sorted_trials):
- hparams = metrics['hparams']
- keys = sorted(hparams.keys())
- print(
- str(i).ljust(4) + ': '
- + '{0:.2f}'.format(metrics['objective']).ljust(10)
- + '['
- + ','.join(['{}={}'.format(k, hparams[k]).ljust(24) for k in keys])
- + ']')
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/brain_coder/single_task/code_tasks.py b/research/brain_coder/single_task/code_tasks.py
deleted file mode 100644
index 27cc7ecd1c76f2d765692ce0a94acd1df04ff681..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/code_tasks.py
+++ /dev/null
@@ -1,1381 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tasks for RL."""
-
-import abc
-import copy
-import itertools
-import random
-
-from absl import logging
-import numpy as np
-from six.moves import xrange
-
-from common import bf # brain coder
-from common import reward as r # brain coder
-from single_task import misc # brain coder
-from single_task import test_tasks # brain coder
-
-
-MAX_EXECUTION_STEPS = 5000
-
-
-def make_task(task_name, override_kwargs=None, max_code_length=100,
- require_correct_syntax=False,
- do_code_simplification=False,
- correct_bonus=2.0, code_length_bonus=1.0):
- """Make tasks with setting from paper."""
- logging.info('Making paper-config task.')
- n = 16 # Number of test cases.
- task_mapping = {
- 'print-hello': (
- PrintTask, dict(base=27, fixed_string=[8, 5, 12, 12, 15])),
- 'print': (PrintIntTask, dict(base=256, fixed_string=[1, 2, 3, 4, 5])),
- 'echo': (EchoTask, dict(base=27, min_length=1, max_length=6)),
- 'remove-char': (
- RemoveCharTask, dict(base=256, n=n, min_len=1, max_len=6)),
- 'reverse': (
- ReverseTask, dict(base=256, n=n, min_len=1, max_len=6)),
- 'reverse-tune': (
- ReverseTaskV2, dict(base=256, reward_type='static-bylen')),
- 'remove-char-tune': (RemoveCharTaskV2, dict(base=27)),
- 'prefix': (CommonPrefixTask, dict(base=27)),
- 'find': (FindSubStrTask, dict(base=27)),
- 'sort3': (SortFixedTaskV2, dict(base=27, n=150, length=3)),
- 'count-char': (CountCharTaskV2, dict(n=n, max_len=6)),
- 'bool-logic': (BooleanLogicTask, dict()),
- 'add': (AddTask, dict(n=9)),
- 'echo-twice': (EchoTwiceTask, dict(n=n)),
- 'echo-thrice': (EchoThriceTask, dict(n=n)),
- 'copy-reverse': (CopyReverseTask, dict(n=n)),
- 'zero-cascade': (EchoZeroCascadeTask, dict(n=n)),
- 'cascade': (EchoCascadeTask, dict(n=n)),
- 'shift-left': (ShiftLeftTask, dict(n=n)),
- 'shift-right': (ShiftRightTask, dict(n=n)),
- 'riffle': (RiffleTask, dict(n=n)),
- 'unriffle': (UnriffleTask, dict(n=n)),
- 'middle-char': (MiddleCharTask, dict(n=n)),
- 'remove-last': (RemoveLastTask, dict(n=n)),
- 'remove-last-two': (RemoveLastTwoTask, dict(n=n)),
- 'echo-alternating': (EchoAlternatingTask, dict(n=n)),
- 'echo-half': (EchoHalfTask, dict(n=n)),
- 'length': (LengthTask, dict(n=n)),
- 'echo-second-seq': (EchoSecondSequenceTask, dict(n=n)),
- 'echo-nth-seq': (EchoNthSequenceTask, dict(n=n)),
- 'substring': (SubstringTask, dict(n=n)),
- 'divide-2': (Divide2Task, dict(n=n)),
- 'dedup': (DedupTask, dict(n=n)),
- 'remove-target-char': (RemoveTargetCharTask, dict(n=n)),
- 'list-index': (ListIndexTask, dict(n=n)),
- 'fib': (FibonacciTask, dict()),
- 'count-down': (BottlesOfBeerTask, dict()),
- 'split': (SplitTask, dict()),
- 'trim-left': (TrimLeftTask, dict()),
- 'circle-route': (
- JudgeRouteCircleTask, dict(n=100, max_len=32)),
- 'multiply': (MultiplyTask, dict(n=100)),
- 'divmod': (DivModTask, dict(n=100)),
- }
-
- if task_name not in task_mapping:
- # Test tasks.
- if task_name == 'test-hill-climb':
- return test_tasks.BasicTaskManager(test_tasks.HillClimbingTask())
- raise ValueError('Unknown task type "%s"' % task_name)
- task_cls, kwargs = task_mapping[task_name]
-
- if override_kwargs:
- if not isinstance(override_kwargs, dict):
- raise ValueError(
- 'override_kwargs must be a dict, got: %s', override_kwargs)
- kwargs.update(override_kwargs)
-
- task = task_cls(**kwargs)
-
- reward_fn = r.absolute_distance_reward
- # reward_fn = r.absolute_mod_distance_reward
- # reward_fn = r.absolute_log_distance_reward
- logging.info('Using reward function: %s', reward_fn.__name__)
-
- # We want reward with and without code simplification to be scaled the same
- # way. Without code simplification, give the maximum code length bonus
- # every time.
- min_code_length = 0.0 if do_code_simplification else max_code_length
-
- return MultiIOTaskManager(
- task=task, correct_bonus=correct_bonus,
- code_length_bonus=code_length_bonus,
- max_code_length=max_code_length, min_code_length=min_code_length,
- reward_fn=reward_fn, require_correct_syntax=require_correct_syntax)
-
-
-def concat(lists):
- if not lists:
- return []
- l = lists[0]
- for k in lists[1:]:
- l += k
- return l
-
-
-def concat_join(lists, sep):
- if not lists:
- return []
- l = lists[0]
- for k in lists[1:]:
- l += [sep] + k
- return l
-
-
-def clipped_linear(x, x0, y0, slope, y_range):
- min_y, max_y = y_range
- return min(max(slope * (x - x0) + y0, min_y), max_y)
-
-
-class MultiIOTaskManager(object):
- """Supports tasks which test the code with multiple I/O examples."""
-
- def __init__(self, task, max_code_length=32, min_code_length=0,
- max_execution_steps=MAX_EXECUTION_STEPS, correct_bonus=1.0,
- code_length_bonus=1.0, failure_reward=-2.0, reward_fn=None,
- require_correct_syntax=False):
- assert isinstance(task, BaseTask)
- self.task = task
- self.max_code_length = max_code_length
- self.min_code_length = min_code_length
- self.max_execution_steps = max_execution_steps
- self.require_correct_syntax = require_correct_syntax
- self.correct_bonus = correct_bonus
- self.code_length_bonus = code_length_bonus
- self.failure_reward = failure_reward
- self.time_penalty = (
- 1.0 / (max_code_length - min_code_length)
- if max_code_length > min_code_length else 0.0)
- if reward_fn is None:
- self.reward_fn = r.absolute_distance_reward
- else:
- self.reward_fn = reward_fn
- self.input_type = (
- task.input_type if hasattr(task, 'input_type') else misc.IOType.integer)
- self.output_type = (
- task.output_type if hasattr(task, 'output_type')
- else misc.IOType.integer)
- self._compute_best_reward()
-
- def _compute_best_reward(self):
- io_seqs = self.task.make_io_set()
- reward = 0.0
- for _, output_seq in io_seqs:
- reward += self.reward_fn(output_seq, output_seq, self.task.base)
- reward += self.correct_bonus
- reward += self.code_length_bonus # Bonus for shortest code.
- self.best_reward = reward
- self.good_reward = 0.75 * reward
- logging.info('Known best reward: %.4f', self.best_reward)
-
- def _score_batch(self, code_strings):
- return [self._score_code(code) for code in code_strings]
-
- def _score_code(self, code):
- """Run test cases on code and compute reward.
-
- Args:
- code: A single BF code string.
-
- Returns:
- misc.RewardInfo namedtuple instance containing reward and code execution
- information, including inputs, expected outputs, code outputs, input
- and output types, and reason for the reward obtained.
- """
- # Get list of 2-tuples, each containing an input sequence and an output
- # sequence.
- io_seqs = self.task.make_io_set()
- terminal_reward = 0.0
- results = []
- reason = 'correct'
- for input_seq, output_seq in io_seqs:
- eval_result = bf.evaluate(
- code, input_buffer=input_seq, timeout=0.1,
- max_steps=self.max_execution_steps,
- base=self.task.base,
- require_correct_syntax=self.require_correct_syntax)
- result, success = eval_result.output, eval_result.success
- if not success:
- # Code execution timed out.
- terminal_reward = self.failure_reward
- results = []
- reason = eval_result.failure_reason
- break
- else:
- terminal_reward += self.reward_fn(result, output_seq, self.task.base)
- if result == output_seq:
- terminal_reward += self.correct_bonus # Bonus for correct answer.
-
- # Only add additional reward for shorter code. Subtracting reward
- # interferes with the main objective. Only optimize for length once
- # any solution is found.
- if self.min_code_length == self.max_code_length:
- terminal_reward += self.code_length_bonus
- else:
- terminal_reward += self.code_length_bonus * clipped_linear(
- x=len(code), x0=self.min_code_length, y0=1.0,
- slope=-self.time_penalty, y_range=(0.0, 1.0))
-
- # reason remains 'correct' if it is already
- elif reason == 'correct':
- reason = 'wrong'
- results.append(result)
-
- # Return list of rewards, one for each char in the code. All are 0 except
- # for the terminal reward.
- terminal_reward /= self.best_reward
- return misc.RewardInfo(
- episode_rewards=[0.0] * (len(code) - 1) + [terminal_reward],
- input_case=misc.IOTuple(i for i, o in io_seqs),
- correct_output=misc.IOTuple(o for i, o in io_seqs),
- code_output=misc.IOTuple(results),
- input_type=self.input_type,
- output_type=self.output_type,
- reason=reason)
-
- def rl_batch(self, batch_size):
- """Produces list of reward functions. One for each program in the batch."""
- return [self._score_code] * batch_size
-
-
-def conditional_overwrite(current_value, new_value, allowed_overwrite_values):
- if current_value in allowed_overwrite_values:
- return new_value
- return current_value
-
-
-class BaseTask(object):
- """A coding task.
-
- All coding tasks should inherit this class.
- """
- __metaclass__ = abc.ABCMeta
-
- def __init__(self, base=256):
- self.base = base # All tasks must set the integer base that the expect.
-
- @abc.abstractmethod
- def make_io_set(self):
- """Generate a set of test cases for the task.
-
- Returns:
- List of tuples, where each tuple is (input_case, output_case).
- input_case and output_case are lists of integers.
- """
- pass
-
-
-# ==============================================================================
-# ICLR tasks.
-# ==============================================================================
-
-
-class PrintTask(BaseTask):
- """Print string coding task.
-
- Code needs to output a fixed string (given as a hyperparameter to the
- task constructor). Program input is ignored.
- """
-
- def __init__(self, base, fixed_string=None):
- super(type(self), self).__init__()
- self.base = base # base includes EOS
- self.eos = 0
- if fixed_string:
- self.fixed_string = fixed_string
- else:
- self.fixed_string = [1, 2, 3, 0] # ABC
- self.min_length = self.max_length = len(self.fixed_string)
-
- def make_io_set(self):
- return [(list(), list(self.fixed_string))]
-
-
-class RemoveCharTaskV2(BaseTask):
- """Remove character coding task (version 2).
-
- Code needs to pipe input to output, but with all the 'A' (value 1) chars
- removed. 'A' appears exactly once in each input.
-
- Test cases are hard-coded.
- """
-
- def __init__(self, base):
- super(type(self), self).__init__()
- self.base = base
- self.eos = 0
- self.remove_char = 1
- assert base >= 27
-
- def make_io_set(self):
- rm = self.remove_char
- return [
- ([rm, 0], [0]),
- ([20, rm, 0], [20, 0]),
- ([rm, 13, 0], [13, 0]),
- ([6, rm, 17, 0], [6, 17, 0]),
- ([rm, 11, 24, 0], [11, 24, 0]),
- ([2, 16, 21, rm, 0], [2, 16, 21, 0]),
- ([18, rm, 12, 26, 7, 0], [18, 12, 26, 7, 0]),
- ([9, 10, 22, rm, 4, 0], [9, 10, 22, 4, 0])]
-
-
-class RemoveCharTask(BaseTask):
- """Remove character coding task.
-
- Code needs to pipe input to output, but with all the 'A' (value 1) chars
- removed. 'A' appears at least once in each input.
-
- Test cases are dynamically generated, allowing for the number of test cases
- to be a hyperparameter.
- """
-
- def __init__(self, base, n, min_len, max_len):
- super(type(self), self).__init__()
- self.base = base
- self.eos = 0
- self.remove_char = 1
- assert base >= 27
- self._io_pairs = self._make_io_examples(n, min_len, max_len)
-
- def _make_io_examples(self, n, min_len, max_len):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- for _ in xrange(n):
- length = rand.randrange(min_len, max_len + 1)
- rm_char_pos = rand.randrange(0, length)
- input_seq = [rand.randrange(1, self.base) for _ in xrange(length)]
- input_seq[rm_char_pos] = self.remove_char
- output_seq = list(input_seq)
- del output_seq[rm_char_pos]
- output_seq.append(0)
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class ReverseTaskV2(BaseTask):
- """Reverse string coding task (version 2).
-
- Code needs to pipe input to output, but in reverse order.
-
- Stochastic test case = new test case randomly generated for every run of
- `make_io_set`, i.e. different test cases every time code is scored.
-
- Task supports different types of test cases:
- rand-one: Code is scored on one stochastic test case.
- rand-many: Code is scored on 5 stochastic test cases.
- static-bylen: Code is scored on 5 static test cases. There is one test
- case for string lengths 1 through 5.
- rand-bylen: Code is scored on 5 stochastic test cases, where there is one
- test case for string lengths 1 through 5.
- """
-
- def __init__(self, base, reward_type):
- super(type(self), self).__init__()
- self.base = base # base includes EOS
- assert base >= 27
- self.eos = 0
- self.io_pair_fn = {
- # One random example at a time.
- 'rand-one': lambda: self._io_rand(1),
- # K randomy examples at a time (any lengths).
- 'rand-many': lambda: self._io_rand(5),
- # Static examples, one for each length.
- 'static-bylen': self._io_static_by_len,
- # Random examples, one for each length.
- 'rand-bylen': self._io_rand_by_len}[reward_type]
-
- def _make_io_examples(self, sequences):
- outputs = [list(i) for i in sequences]
- for o in outputs:
- o.reverse()
- o.append(0)
- inputs = [i + [0] for i in sequences]
- return zip(inputs, outputs)
-
- def _io_rand(self, k):
- inputs = [(np.random.choice(26, random.randrange(1, 6)) + 1).tolist()
- for _ in xrange(k)]
- return self._make_io_examples(inputs)
-
- def _io_rand_by_len(self, k=5):
- inputs = [(np.random.choice(26, length) + 1).tolist()
- for length in xrange(1, k + 1)]
- return self._make_io_examples(inputs)
-
- def _io_static_by_len(self):
- return [
- ([7, 0], [7, 0]),
- ([6, 2, 0], [2, 6, 0]),
- ([5, 1, 10, 0], [10, 1, 5, 0]),
- ([8, 6, 5, 15, 0], [15, 5, 6, 8, 0]),
- ([10, 12, 5, 2, 7, 0], [7, 2, 5, 12, 10, 0])]
-
- def make_io_set(self):
- return self.io_pair_fn()
-
-
-class ReverseTask(BaseTask):
- """Reverse string coding task.
-
- Code needs to pipe input to output, but in reverse order.
-
- Test cases are dynamically generated, allowing for the number of test cases
- to be a hyperparameter.
- """
-
- def __init__(self, base, n, min_len, max_len):
- super(type(self), self).__init__()
- self.base = base # base includes EOS
- assert base >= 27
- self.eos = 0
- self._io_pairs = self._make_io_examples(n, min_len, max_len)
-
- def _make_io_examples(self, n, min_len, max_len):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- for _ in xrange(n):
- length = rand.randrange(min_len, max_len + 1)
- input_seq = [rand.randrange(1, self.base) for _ in xrange(length)]
- output_seq = list(input_seq)
- output_seq.reverse()
- output_seq.append(0)
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class CommonPrefixTask(BaseTask):
- """Common prefix coding task.
-
- Code needs to output the common prefix between two input lists. Input lists
- are variable length, where each list ends with a 0. A common prefix is a
- sequence which both lists start with.
- """
-
- def __init__(self, base):
- super(type(self), self).__init__()
- assert base >= 27
- self.base = base
- self.eos = 0
-
- def make_io_set(self):
- return [
- ([12, 24, 18, 0, 12, 5, 0], [12, 0]),
- ([1, 2, 3, 0, 1, 2, 17, 14, 0], [1, 2, 0]),
- ([15, 2, 1, 9, 2, 0, 15, 2, 1, 25, 8, 14, 0], [15, 2, 1, 0]),
- ([14, 9, 7, 8, 6, 16, 0, 14, 9, 7, 8, 8, 6, 8, 26, 0],
- [14, 9, 7, 8, 0]),
- ([12, 4, 16, 22, 1, 17, 0, 12, 4, 16, 22, 1, 8, 10, 0],
- [12, 4, 16, 22, 1, 0])]
-
-
-class CountCharTask(BaseTask):
-
- def __init__(self):
- super(type(self), self).__init__()
- self.base = 27
- self.eos = 0
- self.char = 1
- self.input_type = misc.IOType.string
- self.output_type = misc.IOType.integer
-
- def make_io_set(self):
- return [
- ([10, 0], [0]),
- ([1, 0], [1]),
- ([1, 1, 0], [2]),
- ([11, 1, 0], [1]),
- ([1, 24, 0], [1]),
- ([13, 6, 0], [0]),
- ([9, 2, 7, 0], [0]),
- ([1, 24, 11, 0], [1]),
- ([19, 1, 1, 0], [2]),
- ([1, 6, 1, 0], [2]),
- ([22, 16, 17, 9, 0], [0]),
- ([1, 1, 1, 19, 0], [3]),
- ([1, 1, 1, 1, 0], [4]),
- ([9, 4, 19, 11, 5, 0], [0]),
- ([24, 11, 26, 1, 15, 0], [1]),
- ([1, 1, 20, 1, 1, 0], [4]),
- ([1, 1, 1, 1, 1, 0], [5])]
-
-
-class CountCharTaskV2(BaseTask):
- """Count char coding task (version 2).
-
- Code must output the number of occurances of character 'A' (value 1) in an
- input string.
-
- Test cases are dynamically generated, allowing for the number of test cases
- to be a hyperparameter.
- """
-
- def __init__(self, n, max_len):
- super(type(self), self).__init__()
- self.base = 27
- self.eos = 0
- self.char = 1
- self.other_chars = [c for c in xrange(self.base)
- if c not in (self.eos, self.char)]
- self.input_type = misc.IOType.string
- self.output_type = misc.IOType.integer
- self._io_pairs = self._make_io_examples(n, max_len)
-
- def _make_io_examples(self, n, max_len):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- io_examples.append(([10, 0], [0]))
- io_examples.append(([1, 0], [1]))
- io_examples.append(([1, 1, 0], [2]))
- io_examples.append(([9, 4, 19, 11, 5, 0], [0]))
- io_examples.append(([24, 11, 26, 1, 15, 0], [1]))
- for _ in xrange(n - 5):
- length = rand.randrange(2, max_len + 1)
- num_chars = rand.randrange(0, max_len + 1)
- input_seq = [self.char] * num_chars + [0] * (length - num_chars)
- rand.shuffle(input_seq)
- for i in xrange(len(input_seq)):
- if not input_seq[i]:
- input_seq[i] = self.other_chars[rand.randrange(len(self.other_chars))]
- output_seq = [num_chars]
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class AddTask(BaseTask):
- """Addition coding task.
-
- Code needs to read in two integers and output their sum mod the BF base,
- followed by a terminating 0.
- """
-
- def __init__(self, n=16):
- super(type(self), self).__init__()
- self.base = 256
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
- self._io_pairs = self._make_io_examples(n)
-
- def _make_io_examples(self, n):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = [
- ([4, 0], [4, 0]),
- ([0, 5], [5, 0]),
- ([1, 2], [3, 0]),
- ([67, 21], [88, 0]),
- ([55, 56], [111, 0]),
- ([128, 33], [161, 0]),
- ([221, 251], [216, 0]),
- ([130, 127], [1, 0]),
- ([255, 1], [0, 0])]
- extra_examples = max(n - len(io_examples), 0)
- for _ in xrange(extra_examples):
- a = rand.randrange(256)
- b = rand.randrange(256)
- input_seq = [a, b]
- output_seq = [(a + b) % 256, 0]
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class BooleanLogicTask(BaseTask):
- """Boolean logic (truth table) coding task.
-
- Code needs to memorize a boolean truth table. Specifically, it must encode a
- mapping from triple of bools to a single bool.
- """
-
- def __init__(self):
- super(type(self), self).__init__()
- self.base = 2
- self.input_type = misc.IOType.boolean
- self.output_type = misc.IOType.boolean
- # X(~Z) + (~Y)(~Z) + (~X)YZ
- self._truth_fn = (
- lambda x, y, z: # pylint: disable=g-long-lambda
- (x and not z) or (not y and not z) or (not x and y and z))
- self._test_cases = [
- ([x, y, z], [int(self._truth_fn(x, y, z))])
- for x, y, z in itertools.product(range(2), range(2), range(2))]
-
- def make_io_set(self):
- return copy.deepcopy(self._test_cases)
-
-
-# ------------------------------------------------------------------------------
-# The following tasks are generated from known BF solutions. This guarantees
-# that each task can be solved within the maximum code length, and maximum
-# execution steps.
-# ------------------------------------------------------------------------------
-
-
-def default_input_fn_factory(min_length=1, max_length=6, base=256):
- def _input_gen(rand):
- l = rand.randrange(min_length, max_length + 1)
- return [rand.randrange(base) for _ in xrange(l)]
- return _input_gen
-
-
-class KnownCodeBaseTask(BaseTask):
- """These tasks generate their test cases from a known BF solution.
-
- This ensures that each task has a solution which is under the max character
- length, and that it solves the test cases under the max number of execution
- steps.
- """
-
- def __init__(self, code_solution, make_input_fn, n=100, base=256,
- max_steps=5000, seed=6849275409234):
- super(KnownCodeBaseTask, self).__init__()
- # Make sure known solution is less than the code length used in experiments.
- assert len(code_solution) < 100
- self.code_solution = code_solution
- self.make_input_fn = make_input_fn
- self.n = n
- self.base = base
- self.max_steps = max_steps
- self.seed = seed
- self._test_cases = list(self._test_case_generator(code_solution))
-
- def _test_case_generator(self, code_solution):
- rand = random.Random(self.seed)
- for _ in xrange(self.n):
- input_case = self.make_input_fn(rand)
- result = bf.evaluate(
- code_solution, input_buffer=input_case, max_steps=self.max_steps,
- base=self.base, require_correct_syntax=False)
- if not result.success:
- raise RuntimeError(
- 'Program must succeed. Failed on input: %s' % input_case)
- yield input_case, result.output
-
- def make_io_set(self):
- return copy.deepcopy(self._test_cases)
-
-
-class EchoTwiceTask(KnownCodeBaseTask):
- """Echo twice."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,.[>,.]<[<]>[.>].',
- default_input_fn_factory(),
- **kwargs)
-
-
-class EchoThriceTask(KnownCodeBaseTask):
- """Echo three times."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,.[>,.]<[<]>[.>].<[<]>[.>].',
- default_input_fn_factory(),
- **kwargs)
-
-
-class CopyReverseTask(KnownCodeBaseTask):
- """Echo forwards, backwards, and then forwards again."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,.[>,.]<[.<].>[.>].',
- default_input_fn_factory(),
- **kwargs)
-
-
-class EchoZeroCascadeTask(KnownCodeBaseTask):
- """Print k-th char with k zeros inbetween (1-indexed)."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- ',[.>[->+>.<<]>+[-<+>]<<,]',
- default_input_fn_factory(),
- **kwargs)
-
-
-class EchoCascadeTask(KnownCodeBaseTask):
- """Print k-th char k times (1-indexed)."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- ',>>+<<[>>[-<+>]<[->+<<.>]>+<<,].',
- default_input_fn_factory(base=20),
- **kwargs)
-
-
-class ShiftLeftTask(KnownCodeBaseTask):
- """Circulate shift input left."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- ',>,[.,]<.,.',
- default_input_fn_factory(),
- **kwargs)
-
-
-class ShiftRightTask(KnownCodeBaseTask):
- """Circular shift input right."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,[>,]<.[-]<[<]>[.>].',
- default_input_fn_factory(),
- **kwargs)
-
-
-class RiffleTask(KnownCodeBaseTask):
- """Shuffle like a deck of cards.
-
- For input of length N, output values in the following index order:
- N-1, 0, N-2, 1, N-3, 2, ...
- """
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,[>,]<[.[-]<[<]>.[-]>[>]<]',
- default_input_fn_factory(base=20, max_length=8),
- **kwargs)
-
-
-class UnriffleTask(KnownCodeBaseTask):
- """Inverse of riffle."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,[>,[.[-]],]<[.<].',
- default_input_fn_factory(base=20, max_length=8),
- **kwargs)
-
-
-class MiddleCharTask(KnownCodeBaseTask):
- """Print middle char if length is odd, or 0 if even."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,[>,]<<[[>]<[,<[<]>,>[>]][>]<<]>.',
- default_input_fn_factory(max_length=10),
- **kwargs)
-
-
-class RemoveLastTask(KnownCodeBaseTask):
- """Remove last character."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- ',>,[[<.[-]>[-<+>]],].',
- default_input_fn_factory(base=20),
- **kwargs)
-
-
-class RemoveLastTwoTask(KnownCodeBaseTask):
- """Remove last two characters."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- ',>,>,[[<<.[-]>[-<+>]>[-<+>]],].',
- default_input_fn_factory(base=10),
- **kwargs)
-
-
-class EchoAlternatingTask(KnownCodeBaseTask):
- # Print even numbered chars first (0-indexed), then odd numbered chars
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>,[.,>,]<<[<]>[.>].',
- default_input_fn_factory(base=20, max_length=8),
- **kwargs)
-
-
-class EchoHalfTask(KnownCodeBaseTask):
- """Echo only first half of the input (round down when odd lengthed)."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>>+>,[[<]>+[>],]<[<]>-[-[-<<+>]<[>]>]<<[->+<]>[[>]>.,<+[<]>-].',
- default_input_fn_factory(base=20, max_length=9),
- **kwargs)
-
-
-class LengthTask(KnownCodeBaseTask):
- """Print length of the input sequence."""
-
- def __init__(self, **kwargs):
- super(type(self), self).__init__(
- '>+>,[[<]>+[>],]<[<]>-.',
- default_input_fn_factory(max_length=14),
- **kwargs)
-
-
-class EchoSecondSequenceTask(KnownCodeBaseTask):
- """Echo second sequence. Sequences are separated by 0."""
-
- def __init__(self, **kwargs):
- def echo_second_gen(rand):
- l = rand.randrange(1, 6)
- x = [rand.randrange(256) for _ in xrange(l)]
- l = rand.randrange(1, 6)
- y = [rand.randrange(256) for _ in xrange(l)]
- return x + [0] + y + [0]
- super(type(self), self).__init__(
- ',[,],[.,].',
- echo_second_gen,
- **kwargs)
-
-
-class EchoNthSequenceTask(KnownCodeBaseTask):
- """Echo n-th sequence (1-indexed). Sequences are separated by 0."""
-
- def __init__(self, **kwargs):
- def echo_nth_gen(rand):
- k = rand.randrange(1, 7)
- n = rand.randrange(1, k + 1)
- x = []
- for _ in xrange(k):
- l = rand.randrange(0, 4)
- x += [rand.randrange(256) for _ in xrange(l)] + [0]
- return [n] + x
- super(type(self), self).__init__(
- ',-[->,[,]<],[.,].',
- echo_nth_gen,
- **kwargs)
-
-
-class SubstringTask(KnownCodeBaseTask):
- """Echo substring.
-
- First two inputs are i and l, where i is the starting index (0-indexed)
- and l is the length of the substring.
- """
-
- def __init__(self, **kwargs):
- def substring_gen(rand):
- l = rand.randrange(2, 16)
- i, j = sorted([rand.randrange(l), rand.randrange(l)])
- n = j - i
- x = [rand.randrange(256) for _ in xrange(l)] + [0]
- return [i, n] + x
- super(type(self), self).__init__(
- '>,<,>[->,<]>,<<[->>.,<<]',
- substring_gen,
- **kwargs)
-
-
-class Divide2Task(KnownCodeBaseTask):
- """Divide by 2 (integer floor division)."""
-
- def __init__(self, **kwargs):
- def int_input_gen(rand):
- return [rand.randrange(256)]
- super(type(self), self).__init__(
- ',[-[->>+<]>[<]<]>>.',
- int_input_gen,
- **kwargs)
-
-
-class DedupTask(KnownCodeBaseTask):
- """Deduplicate adjacent duplicate chars."""
-
- def __init__(self, **kwargs):
- def dedup_input_gen(rand):
- np_random = np.random.RandomState(rand.randrange(2147483647))
- num_unique = rand.randrange(1, 5)
- unique = np_random.choice(6, num_unique, replace=False) + 1
- return [v for v in unique for _ in xrange(rand.randrange(1, 5))] + [0]
- super(type(self), self).__init__(
- '>>,.[[-<+<+>>],[-<->]<[[-<->]<.>]<[->>+<<]>>]',
- dedup_input_gen,
- **kwargs)
-
-
-# ==============================================================================
-# Extra tasks.
-# ==============================================================================
-
-
-class PrintIntTask(BaseTask):
- """Print integer coding task.
-
- Code needs to output a fixed single value (given as a hyperparameter to the
- task constructor). Program input is ignored.
- """
-
- def __init__(self, base, fixed_string):
- super(type(self), self).__init__()
- self.base = base
- self.eos = 0
- self.fixed_string = fixed_string
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def make_io_set(self):
- return [(list(), list(self.fixed_string))]
-
-
-class EchoTask(BaseTask):
- """Echo string coding task.
-
- Code needs to pipe input to putput (without any modifications).
- """
-
- def __init__(self, base, min_length=1, max_length=5):
- super(type(self), self).__init__()
- self.base = base # base includes EOS
- self.eos = 0
- self.min_length = min_length
- self.max_length = max_length
- self._io_pairs = self._make_io_examples(25)
-
- def _make_io_examples(self, n):
- # Test cases are fixed, but varied.
- np_random = np.random.RandomState(1234567890)
- io_pairs = []
- for _ in xrange(n):
- length = np_random.randint(self.min_length, self.max_length + 1)
- input_seq = np_random.randint(1, self.base, length).tolist() + [self.eos]
- output_seq = list(input_seq)
- io_pairs.append((input_seq, output_seq))
- return io_pairs
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class JudgeRouteCircleTask(BaseTask):
- """Judge route circle coding task.
-
- Code needs to determine if the given route makes a closed loop.
- Encoding: U = 1, R = 2, D = 3, L = 4.
-
- Based on
- https://leetcode.com/problems/judge-route-circle/description/
- """
- base = 256
- input_type = misc.IOType.integer
- output_type = misc.IOType.integer
-
- def __init__(self, n, max_len=12):
- super(type(self), self).__init__()
- self.eos = 0
- self._io_pairs = self._make_io_examples(n, max_len)
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def _solve(self, input_seq):
- assert input_seq[-1] == 0
- pos = [0, 0] # (x, y)
- for move in input_seq[:-1]:
- assert 0 < move <= 4
- if move & 1 == 0: # Left or Right.
- pos[0] += 3 - move # Add or subtract 1.
- else:
- pos[1] += 2 - move # Add or subtract 1.
- return [int(not pos[0] and not pos[1])]
-
- def _make_io_examples(self, n, max_len):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- io_examples.append(([0], [1]))
- io_examples.append(([4, 2, 0], [1]))
- io_examples.append(([2, 4, 0], [1]))
- io_examples.append(([3, 1, 0], [1]))
- io_examples.append(([1, 3, 0], [1]))
- io_examples.append(([1, 0], [0]))
- io_examples.append(([2, 0], [0]))
- io_examples.append(([3, 0], [0]))
- io_examples.append(([4, 0], [0]))
- for _ in xrange(n):
- is_true = rand.randrange(2)
- length = rand.randrange(1, max_len + 1)
- if is_true:
- # Make a true case.
- length = (length >> 1) << 1 # Make even.
- partition = (rand.randrange(length + 1) >> 1) << 1
- a = partition >> 1
- b = (length - partition) >> 1
- counts = {1: a, 2: b, 3: a, 4: b}
- else:
- # Make a false case.
- partitions = (
- [0]
- + sorted([rand.randrange(length + 1) for _ in range(3)])
- + [length])
- counts = {n: partitions[n] - partitions[n - 1] for n in range(1, 5)}
- if counts[1] == counts[3] and counts[2] == counts[4]:
- # By chance we sampled a true case. Make it false by exchanging
- # one count between even and odd pairs.
- base = 1 + 2 * rand.randrange(2)
- a, b = (base, base + 1) if rand.randrange(2) else (base + 1, base)
- if counts[a] == length or counts[b] == 0:
- # If counts are at their extreme values, then swap who gets
- # incremented and decremented.
- a, b = b, a
- counts[a] += 1
- counts[b] -= 1
- assert counts[a] <= length and counts[b] >= 0
- assert sum(counts.values()) == length
- input_seq = [n for n in xrange(1, 5) for _ in xrange(counts[n])]
- rand.shuffle(input_seq)
- input_seq += [0]
- output_seq = self._solve(input_seq)
- assert output_seq[0] == is_true
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class MultiplyTask(BaseTask):
- """Multiply coding task.
-
- Code needs to multiple two ints.
-
- Solution:
- http://robl.co/brief-look-at-brainfuck/
- ,>,><<[->[->+>+<<]>>[-<<+>>]<<<]>>.
- """
- base = 512
- input_type = misc.IOType.integer
- output_type = misc.IOType.integer
-
- def __init__(self, n):
- super(type(self), self).__init__()
- self.eos = 0
- self._io_pairs = self._make_io_examples(n)
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def _factors(self, n):
- return set(i for i in range(1, int(n**0.5) + 1) if n % i == 0)
-
- def _make_io_examples(self, n):
- """Generate test cases for the task."""
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- for _ in xrange(n):
- n = rand.randrange(self.base)
- if n == 0:
- a, b = 0, rand.randrange(self.base)
- else:
- f = list(self._factors(n))
- a = f[rand.randrange(len(f))]
- b = n // a
- if rand.randrange(2):
- a, b = b, a
- io_examples.append(([a, b], [n]))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class DivModTask(BaseTask):
- """Divmod coding task.
-
- Code needs to take the quotient and remainder of two ints.
-
- Solution:
- http://robl.co/brief-look-at-brainfuck/
- ,>,><<[>[->+>+<<]>[-<<-[>]>>>[<[-<->]<[>]>>[[-]>>+<]>-<]<<]>>>+<<[-<<+>>]<<<]>
- >>>>[-<<<<<+>>>>>]<<<<<.>.>
- """
- base = 512
- input_type = misc.IOType.integer
- output_type = misc.IOType.integer
-
- def __init__(self, n):
- super(type(self), self).__init__()
- self.eos = 0
- self._io_pairs = self._make_io_examples(n)
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def _make_io_examples(self, n):
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- for _ in xrange(n):
- n = rand.randrange(0, self.base)
- k = rand.randrange(1, self.base) # Divisor cannot be 0.
- io_examples.append(([n, k], list(divmod(n, k))))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class FibonacciTask(BaseTask):
-
- def __init__(self):
- super(type(self), self).__init__()
- self.base = 256
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def make_io_set(self):
- return [
- ([0], [0, 1]),
- ([1], [1, 1]),
- ([2], [1, 2]),
- ([3], [2, 3]),
- ([4], [3, 5]),
- ([5], [5, 8]),
- ([6], [8, 13]),
- ([7], [13, 21]),
- ([8], [21, 34]),
- ([9], [34, 55]),
- ([10], [55, 89]),
- ([11], [89, 144]),
- ([12], [144, 233]),
- ([13], [233, 121])]
-
-
-class FindSubStrTask(BaseTask):
- """Find sub-string coding task.
-
- Code needs to output a bool: True if the input string contains a hard-coded
- substring, 'AB' (values [1, 2]).
- """
-
- def __init__(self, base):
- super(type(self), self).__init__()
- assert base >= 27
- self.base = base
- self.eos = 0
- self.find_str = [1, 2]
- self.input_type = misc.IOType.string
- self.output_type = misc.IOType.boolean
-
- def make_io_set(self):
- return [
- ([1, 1, 23, 0], [0]),
- ([21, 3, 2, 0], [0]),
- ([2, 1, 19, 0], [0]),
- ([2, 24, 15, 3, 0], [0]),
- ([24, 6, 10, 16, 4, 0], [0]),
- ([1, 2, 12, 0], [1]),
- ([7, 1, 2, 0], [1]),
- ([1, 2, 11, 3, 0], [1]),
- ([1, 1, 2, 18, 0], [1]),
- ([7, 25, 1, 2, 0], [1]),
- ([3, 1, 2, 11, 8, 0], [1]),
- ([15, 16, 20, 1, 2, 0], [1])]
-
-
-class SortFixedTask(BaseTask):
- """Sort list coding task.
-
- Code needs to output a sorted input list. The task consists of lists of the
- same length L, where L is provided to this task's constructor as a
- hyperparameter.
- """
-
- def __init__(self, base, length=3):
- super(type(self), self).__init__()
- assert base >= 27
- self.base = base
- self.eos = 0
- self.length = length
- assert length == 3 # More lengths will be supported.
-
- def make_io_set(self):
- if self.length == 3:
- return [
- ([1, 20, 6], [1, 6, 20]),
- ([13, 6, 7], [6, 7, 13]),
- ([24, 2, 23], [2, 23, 24]),
- ([16, 12, 3], [3, 12, 16]),
- ([11, 24, 4], [4, 11, 24]),
- ([10, 1, 19], [1, 10, 19])]
-
-
-class SortFixedTaskV2(BaseTask):
- """Sort list coding task (version 2).
-
- Code needs to output a sorted input list. The task consists of lists of the
- same length L, where L is provided to this task's constructor as a
- hyperparameter.
-
- Test cases are dynamically generated, allowing for the number of test cases
- to be a hyperparameter.
- """
-
- def __init__(self, base, n, length=3):
- super(type(self), self).__init__()
- assert base >= 27
- self.base = base
- self.eos = 0
- self._io_pairs = self._make_io_examples(n, length)
- self.input_type = misc.IOType.integer
- self.output_type = misc.IOType.integer
-
- def _make_io_examples(self, n, length):
- rand = random.Random(6849275409234) # Test cases are fixed, but varied.
- io_examples = []
- for _ in xrange(n):
- input_seq = [rand.randrange(1, self.base) for _ in xrange(length)]
- output_seq = sorted(input_seq)
- io_examples.append((input_seq, output_seq))
- return io_examples
-
- def make_io_set(self):
- return copy.deepcopy(self._io_pairs)
-
-
-class RemoveTargetCharTask(KnownCodeBaseTask):
- """Remove target character from string, where first input is the target.
-
- Target can appear multiple times.
- """
-
- def __init__(self, **kwargs):
- def randrange_hole(rand, a, hole, b):
- x = rand.randrange(a, b - 1)
- if x >= hole:
- return x + 1
- return x
- def remove_target_char_gen(rand):
- char = rand.randrange(1, 6)
- l = rand.randrange(1, 8)
- input_seq = [randrange_hole(rand, 1, char, 256) for _ in xrange(l)]
- idx = range(l)
- rand.shuffle(idx)
- num_targets = rand.randrange(0, l)
- for pos in idx[:num_targets]:
- input_seq[pos] = char
- return [char] + input_seq + [0]
- super(type(self), self).__init__(
- ',>>>,[<<<[->+>+<<]>>[->->+<<]>[>[-<+>]<.[-]]>[-]<<<[-<+>]>>,].',
- remove_target_char_gen,
- **kwargs)
-
-
-class ListIndexTask(KnownCodeBaseTask):
- """Echo i-th value in the given list."""
-
- def __init__(self, **kwargs):
- def array_index_gen(rand):
- l = rand.randrange(1, 16)
- i = rand.randrange(l)
- return [i] + [rand.randrange(256) for _ in xrange(l)] + [0]
- super(type(self), self).__init__(
- ',[->,<]>,.',
- array_index_gen,
- **kwargs)
-
-
-# ==============================================================================
-# Tasks based on primaryobjects paper.
-# ==============================================================================
-
-
-def string2tokens(string):
- return [ord(c) for c in string]
-
-
-def stringlist2tokens(strings):
- return [string2tokens(string) for string in strings]
-
-
-def string2tokens_b27(string):
- return [ord(c.lower()) - ord('a') + 1 for c in string]
-
-
-def stringlist2tokens_b27(strings):
- return [string2tokens_b27(string) for string in strings]
-
-
-class BottlesOfBeerTask(BaseTask):
- """Bottles of beer coding task.
-
- This is a counting task. Code needs to read in an int N and then output
- every int from N to 0, each separated by a 0.
- """
- base = 256
- input_type = misc.IOType.integer
- output_type = misc.IOType.integer
-
- def make_io_set(self):
- return [
- ([1], [1, 0]),
- ([2], [2, 0, 1, 0]),
- ([3], [3, 0, 2, 0, 1, 0]),
- ([4], [4, 0, 3, 0, 2, 0, 1, 0]),
- ([5], [5, 0, 4, 0, 3, 0, 2, 0, 1, 0]),
- ([6], [6, 0, 5, 0, 4, 0, 3, 0, 2, 0, 1, 0])]
-
-
-class SplitTask(BaseTask):
- """Split coding task.
-
- Code needs to pipe input strings to output, but insert a 0 after every 3
- characters. This is in essence splitting the string into intervals of length
- 3.
- """
- base = 28
- input_type = misc.IOType.string
- output_type = misc.IOType.integer
-
- def _splicer(self, lst, insert, interval=3):
- for i, item in enumerate(lst):
- yield item
- if (i + 1) % interval == 0 and i < len(lst) - 1:
- yield insert
-
- def __init__(self):
- super(type(self), self).__init__()
- inputs = stringlist2tokens_b27(
- ['hello', 'orange', 'spaghetti', 'wins', 'one'])
- targets = [list(self._splicer(i, 27)) for i in inputs]
- self._test_cases = list(zip(inputs, targets))
-
- def make_io_set(self):
- return copy.deepcopy(self._test_cases)
-
-
-class TrimLeftTask(BaseTask):
- """Trim left coding task.
-
- Code needs to pipe input strings to output, but remove everything before the
- first quotation char (").
- """
- base = 256
- input_type = misc.IOType.integer
- output_type = misc.IOType.integer
-
- def __init__(self):
- super(type(self), self).__init__()
- inputs = stringlist2tokens(
- ['a "inside" over', 'xy "test" rights', 'ca6 "foresting" service',
- 'abc"def"yz.', 'A"B"'])
- targets = stringlist2tokens(
- ['"inside" over', '"test" rights', '"foresting" service', '"def"yz.',
- '"B"'])
- self._test_cases = list(zip(inputs, targets))
-
- def make_io_set(self):
- return copy.deepcopy(self._test_cases)
diff --git a/research/brain_coder/single_task/code_tasks_test.py b/research/brain_coder/single_task/code_tasks_test.py
deleted file mode 100644
index d3260a1a56ec0f7c36363d558122f7f7e49198e6..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/code_tasks_test.py
+++ /dev/null
@@ -1,108 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for code_tasks."""
-
-import numpy as np
-import tensorflow as tf
-
-from single_task import code_tasks # brain coder
-from single_task import defaults # brain coder
-
-
-def pad(string, pad_length, pad_char):
- return string + pad_char * (pad_length - len(string))
-
-
-class CodeTasksTest(tf.test.TestCase):
-
- def assertClose(self, a, b):
- self.assertTrue(
- np.isclose(a, b, atol=1e-4),
- 'Expecting approximately equal values. Got: %s, %s' % (a, b))
-
- def testMultiIOTaskManager(self):
- maxlen = 100
- padchr = '['
- task = code_tasks.make_paper_task(
- 'print', timestep_limit=maxlen, do_code_simplification=False)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(
- r(pad('++++++++.---.+++++++...', maxlen, padchr)).episode_rewards[-1],
- 0.2444)
- self.assertClose(
- r(pad('++++++++.---.+++++++..+++.',
- maxlen, padchr)).episode_rewards[-1],
- 1.0)
-
- task = code_tasks.make_paper_task(
- 'print', timestep_limit=maxlen, do_code_simplification=True)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(
- r('++++++++.---.+++++++...').episode_rewards[-1],
- 0.2444)
- self.assertClose(
- r('++++++++.---.+++++++..+++.').episode_rewards[-1],
- 0.935)
- self.assertClose(
- r(pad('++++++++.---.+++++++..+++.',
- maxlen, padchr)).episode_rewards[-1],
- 0.75)
-
- task = code_tasks.make_paper_task(
- 'reverse', timestep_limit=maxlen, do_code_simplification=False)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(
- r(pad('>,>,>,.<.<.<.', maxlen, padchr)).episode_rewards[-1],
- 0.1345)
- self.assertClose(
- r(pad(',[>,]+[,<.]', maxlen, padchr)).episode_rewards[-1],
- 1.0)
-
- task = code_tasks.make_paper_task(
- 'reverse', timestep_limit=maxlen, do_code_simplification=True)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(r('>,>,>,.<.<.<.').episode_rewards[-1], 0.1324)
- self.assertClose(r(',[>,]+[,<.]').episode_rewards[-1], 0.9725)
- self.assertClose(
- r(pad(',[>,]+[,<.]', maxlen, padchr)).episode_rewards[-1],
- 0.75)
-
- def testMakeTask(self):
- maxlen = 100
- padchr = '['
- config = defaults.default_config_with_updates(
- 'env=c(config_for_iclr=False,fixed_string=[8,5,12,12,15])')
- task = code_tasks.make_task(config.env, 'print', timestep_limit=maxlen)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(
- r('++++++++.---.+++++++...').episode_rewards[-1],
- 0.2444)
- self.assertClose(
- r('++++++++.---.+++++++..+++.').episode_rewards[-1],
- 0.935)
- self.assertClose(
- r(pad('++++++++.---.+++++++..+++.',
- maxlen, padchr)).episode_rewards[-1],
- 0.75)
-
- def testKnownCodeBaseTask(self):
- maxlen = 100
- padchr = '['
- task = code_tasks.make_paper_task(
- 'shift-left', timestep_limit=maxlen, do_code_simplification=False)
- reward_fns = task.rl_batch(1)
- r = reward_fns[0]
- self.assertClose(
- r(pad(',>,[.,]<.,.', maxlen, padchr)).episode_rewards[-1],
- 1.0)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/data.py b/research/brain_coder/single_task/data.py
deleted file mode 100644
index 8f34464f5a3e1c403b0f253f1520920c303b0819..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/data.py
+++ /dev/null
@@ -1,89 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Manage data for pretraining and RL tasks."""
-
-import ast
-from collections import namedtuple
-
-from absl import logging
-
-from single_task import code_tasks # brain coder
-
-
-RLBatch = namedtuple('RLBatch', ['reward_fns', 'batch_size', 'good_reward'])
-
-
-class DataManager(object):
- """Interface between environment and model."""
-
- def __init__(self, global_config, run_number=None,
- do_code_simplification=False):
- """Constructs a DataManager.
-
- Args:
- global_config: A config_lib.Config instance containing all config. See
- config in defaults.py.
- run_number: Which run this is (of the same experiment). This should be set
- when a task cycle is defined in the config. A task cycle is a list of
- tasks to cycle through repeatedly, and the selected task is a function
- of the run number, i.e. 0-th run, 1-st run, 2-nd run, etc...
- This can be None if only a single task is set in the config.
- do_code_simplification: When global_config.env.config_for_iclr is True,
- use this option to create code simplification (code golf) tasks, vs
- fixed length coding tasks. If True, a task with code simplification
- reward will be constructed.
-
- Raises:
- ValueError: If global_config.env.task and global_config.env.task_cycle
- are both set, or both not set. Only one should be given.
- ValueError: If global_config.env.task_cycle is set but run_number is None.
- """
- env_config = global_config.env
- self.batch_size = global_config.batch_size
-
- if env_config.task_cycle:
- if env_config.task:
- raise ValueError('Do not set both `task` and `task_cycle`.')
- if run_number is None:
- raise ValueError('Do not use task_cycle for single-run experiment.')
- index = run_number % len(env_config.task_cycle)
- self.task_name = env_config.task_cycle[index]
- logging.info('run_number: %d, task_cycle index: %d', run_number, index)
- logging.info('task_cycle: %s', env_config.task_cycle)
- elif env_config.task:
- self.task_name = env_config.task
- else:
- raise ValueError('Either `task` or `task_cycle` must be set.')
- logging.info('Task for this run: "%s"', self.task_name)
-
- logging.info('config_for_iclr=True; do_code_simplification=%s',
- do_code_simplification)
- self.rl_task = code_tasks.make_task(
- task_name=self.task_name,
- override_kwargs=ast.literal_eval(env_config.task_kwargs),
- max_code_length=global_config.timestep_limit,
- require_correct_syntax=env_config.correct_syntax,
- do_code_simplification=do_code_simplification,
- correct_bonus=env_config.task_manager_config.correct_bonus,
- code_length_bonus=env_config.task_manager_config.code_length_bonus)
-
- def sample_rl_batch(self):
- """Create reward functions from the current task.
-
- Returns:
- RLBatch namedtuple instance, which holds functions and information for
- a minibatch of episodes.
- * reward_fns: A reward function for each episode. Maps code string to
- reward.
- * batch_size: Number of episodes in this minibatch.
- * good_reward: Estimated threshold of rewards which indicate the algorithm
- is starting to solve the task. This is a heuristic that tries to
- reduce the amount of stuff written to disk.
- """
- reward_fns = self.rl_task.rl_batch(self.batch_size)
- return RLBatch(
- reward_fns=reward_fns,
- batch_size=self.batch_size,
- good_reward=self.rl_task.good_reward)
diff --git a/research/brain_coder/single_task/defaults.py b/research/brain_coder/single_task/defaults.py
deleted file mode 100644
index d9bd8b942532dfffcf06d90d331e58725c4d82a9..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/defaults.py
+++ /dev/null
@@ -1,82 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Default configuration for agent and environment."""
-
-from absl import logging
-
-from common import config_lib # brain coder
-
-
-def default_config():
- return config_lib.Config(
- agent=config_lib.OneOf(
- [config_lib.Config(
- algorithm='pg',
- policy_lstm_sizes=[35,35],
- # Set value_lstm_sizes to None to share weights with policy.
- value_lstm_sizes=[35,35],
- obs_embedding_size=10,
- grad_clip_threshold=10.0,
- param_init_factor=1.0,
- lr=5e-5,
- pi_loss_hparam=1.0,
- vf_loss_hparam=0.5,
- entropy_beta=1e-2,
- regularizer=0.0,
- softmax_tr=1.0, # Reciprocal temperature.
- optimizer='rmsprop', # 'adam', 'sgd', 'rmsprop'
- topk=0, # Top-k unique codes will be stored.
- topk_loss_hparam=0.0, # off policy loss multiplier.
- # Uniformly sample this many episodes from topk buffer per batch.
- # If topk is 0, this has no effect.
- topk_batch_size=1,
- # Exponential moving average baseline for REINFORCE.
- # If zero, A2C is used.
- # If non-zero, should be close to 1, like .99, .999, etc.
- ema_baseline_decay=0.99,
- # Whether agent can emit EOS token. If true, agent can emit EOS
- # token which ends the episode early (ends the sequence).
- # If false, agent must emit tokens until the timestep limit is
- # reached. e.g. True means variable length code, False means fixed
- # length code.
- # WARNING: Making this false slows things down.
- eos_token=False,
- replay_temperature=1.0,
- # Replay probability. 1 = always replay, 0 = always on policy.
- alpha=0.0,
- # Whether to normalize importance weights in each minibatch.
- iw_normalize=True),
- config_lib.Config(
- algorithm='ga',
- crossover_rate=0.99,
- mutation_rate=0.086),
- config_lib.Config(
- algorithm='rand')],
- algorithm='pg',
- ),
- env=config_lib.Config(
- # If True, task-specific settings are not needed.
- task='', # 'print', 'echo', 'reverse', 'remove', ...
- task_cycle=[], # If non-empty, reptitions will cycle through tasks.
- task_kwargs='{}', # Python dict literal.
- task_manager_config=config_lib.Config(
- # Reward recieved per test case. These bonuses will be scaled
- # based on how many test cases there are.
- correct_bonus=2.0, # Bonus for code getting correct answer.
- code_length_bonus=1.0), # Maximum bonus for short code.
- correct_syntax=False,
- ),
- batch_size=64,
- timestep_limit=32)
-
-
-def default_config_with_updates(config_string, do_logging=True):
- if do_logging:
- logging.info('Config string: "%s"', config_string)
- config = default_config()
- config.strict_update(config_lib.Config.parse(config_string))
- if do_logging:
- logging.info('Config:\n%s', config.pretty_str())
- return config
diff --git a/research/brain_coder/single_task/ga_lib.py b/research/brain_coder/single_task/ga_lib.py
deleted file mode 100644
index fadb96482b21a5c65c0d6d6cf4a3aec3b5708235..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/ga_lib.py
+++ /dev/null
@@ -1,472 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Genetic algorithm for BF tasks.
-
-Inspired by https://github.com/primaryobjects/AI-Programmer.
-GA function code borrowed from https://github.com/DEAP/deap.
-"""
-
-from collections import namedtuple
-import random
-
-from absl import flags
-from absl import logging
-import numpy as np
-from six.moves import xrange
-
-from common import bf # brain coder
-from common import utils # brain coder
-from single_task import misc # brain coder
-
-FLAGS = flags.FLAGS
-
-# Saving reward of previous programs saves computation if a program appears
-# again.
-USE_REWARD_CACHE = True # Disable this if GA is using up too much memory.
-GENES = bf.CHARS
-MAX_PROGRAM_STEPS = 500
-STEP_BONUS = True
-
-ALPHANUM_CHARS = (
- ['_'] +
- [chr(ord('a') + i_) for i_ in range(26)] +
- [chr(ord('A') + i_) for i_ in range(26)] +
- [chr(ord('0') + i_) for i_ in range(10)])
-
-Result = namedtuple(
- 'Result',
- ['reward', 'inputs', 'code_outputs', 'target_outputs', 'type_in',
- 'type_out', 'base', 'correct'])
-
-
-class IOType(object):
- string = 'string'
- integer = 'integer'
-
-
-class CustomType(object):
-
- def __init__(self, to_str_fn):
- self.to_str_fn = to_str_fn
-
- def __call__(self, obj):
- return self.to_str_fn(obj)
-
-
-def tokens_list_repr(tokens, repr_type, base):
- """Make human readable representation of program IO."""
- if isinstance(repr_type, CustomType):
- return repr_type(tokens)
- elif repr_type == IOType.string:
- chars = (
- [ALPHANUM_CHARS[t] for t in tokens] if base < len(ALPHANUM_CHARS)
- else [chr(t) for t in tokens])
- return ''.join(chars)
- elif repr_type == IOType.integer:
- return str(tokens)
- raise ValueError('No such representation type "%s"', repr_type)
-
-
-def io_repr(result):
- """Make human readable representation of test cases."""
- inputs = ','.join(
- tokens_list_repr(tokens, result.type_in, result.base)
- for tokens in result.inputs)
- code_outputs = ','.join(
- tokens_list_repr(tokens, result.type_out, result.base)
- for tokens in result.code_outputs)
- target_outputs = ','.join(
- tokens_list_repr(tokens, result.type_out, result.base)
- for tokens in result.target_outputs)
- return inputs, target_outputs, code_outputs
-
-
-def make_task_eval_fn(task_manager):
- """Returns a wrapper that converts an RL task into a GA task.
-
- Args:
- task_manager: Is a task manager object from code_tasks.py
-
- Returns:
- A function that takes as input a single list of a code chars, and outputs
- a Result namedtuple instance containing the reward and information about
- code execution.
- """
- def to_data_list(single_or_tuple):
- if isinstance(single_or_tuple, misc.IOTuple):
- return list(single_or_tuple)
- return [single_or_tuple]
-
- def to_ga_type(rl_type):
- if rl_type == misc.IOType.string:
- return IOType.string
- return IOType.integer
-
- # Wrapper function.
- def evalbf(bf_chars):
- result = task_manager._score_code(''.join(bf_chars))
- reward = sum(result.episode_rewards)
- correct = result.reason == 'correct'
- return Result(
- reward=reward,
- inputs=to_data_list(result.input_case),
- code_outputs=to_data_list(result.code_output),
- target_outputs=to_data_list(result.correct_output),
- type_in=to_ga_type(result.input_type),
- type_out=to_ga_type(result.output_type),
- correct=correct,
- base=task_manager.task.base)
-
- return evalbf
-
-
-def debug_str(individual, task_eval_fn):
- res = task_eval_fn(individual)
- input_str, target_output_str, code_output_str = io_repr(res)
- return (
- ''.join(individual) +
- ' | ' + input_str +
- ' | ' + target_output_str +
- ' | ' + code_output_str +
- ' | ' + str(res.reward) +
- ' | ' + str(res.correct))
-
-
-def mutate_single(code_tokens, mutation_rate):
- """Mutate a single code string.
-
- Args:
- code_tokens: A string/list/Individual of BF code chars. Must end with EOS
- symbol '_'.
- mutation_rate: Float between 0 and 1 which sets the probability of each char
- being mutated.
-
- Returns:
- An Individual instance containing the mutated code string.
-
- Raises:
- ValueError: If `code_tokens` does not end with EOS symbol.
- """
- if len(code_tokens) <= 1:
- return code_tokens
- if code_tokens[-1] == '_':
- # Do this check to ensure that the code strings have not been corrupted.
- raise ValueError('`code_tokens` must end with EOS symbol.')
- else:
- cs = Individual(code_tokens)
- eos = []
- mutated = False
- for pos in range(len(cs)):
- if random.random() < mutation_rate:
- mutated = True
- new_char = GENES[random.randrange(len(GENES))]
- x = random.random()
- if x < 0.25 and pos != 0 and pos != len(cs) - 1:
- # Insertion mutation.
- if random.random() < 0.50:
- # Shift up.
- cs = cs[:pos] + [new_char] + cs[pos:-1]
- else:
- # Shift down.
- cs = cs[1:pos] + [new_char] + cs[pos:]
- elif x < 0.50:
- # Deletion mutation.
- if random.random() < 0.50:
- # Shift down.
- cs = cs[:pos] + cs[pos + 1:] + [new_char]
- else:
- # Shift up.
- cs = [new_char] + cs[:pos] + cs[pos + 1:]
- elif x < 0.75:
- # Shift rotate mutation (position invariant).
- if random.random() < 0.50:
- # Shift down.
- cs = cs[1:] + [cs[0]]
- else:
- # Shift up.
- cs = [cs[-1]] + cs[:-1]
- else:
- # Replacement mutation.
- cs = cs[:pos] + [new_char] + cs[pos + 1:]
- assert len(cs) + len(eos) == len(code_tokens)
- if mutated:
- return Individual(cs + eos)
- else:
- return Individual(code_tokens)
-
-
-def crossover(parent1, parent2):
- """Performs crossover mating between two code strings.
-
- Crossover mating is where a random position is selected, and the chars
- after that point are swapped. The resulting new code strings are returned.
-
- Args:
- parent1: First code string.
- parent2: Second code string.
-
- Returns:
- A 2-tuple of children, i.e. the resulting code strings after swapping.
- """
- max_parent, min_parent = (
- (parent1, parent2) if len(parent1) > len(parent2)
- else (parent2, parent1))
- pos = random.randrange(len(max_parent))
- if pos >= len(min_parent):
- child1 = max_parent[:pos]
- child2 = min_parent + max_parent[pos:]
- else:
- child1 = max_parent[:pos] + min_parent[pos:]
- child2 = min_parent[:pos] + max_parent[pos:]
- return Individual(child1), Individual(child2)
-
-
-def _make_even(n):
- """Return largest even integer less than or equal to `n`."""
- return (n >> 1) << 1
-
-
-def mutate_and_crossover(population, mutation_rate, crossover_rate):
- """Take a generational step over a population.
-
- Transforms population of parents into population of children (of the same
- size) via crossover mating and then mutation on the resulting children.
-
- Args:
- population: Parent population. A list of Individual objects.
- mutation_rate: Probability of mutation. See `mutate_single`.
- crossover_rate: Probability that two parents will mate.
-
- Returns:
- Child population. A list of Individual objects.
- """
- children = [None] * len(population)
- for i in xrange(0, _make_even(len(population)), 2):
- p1 = population[i]
- p2 = population[i + 1]
- if random.random() < crossover_rate:
- p1, p2 = crossover(p1, p2)
- c1 = mutate_single(p1, mutation_rate)
- c2 = mutate_single(p2, mutation_rate)
- children[i] = c1
- children[i + 1] = c2
- if children[-1] is None:
- children[-1] = population[-1]
- return children
-
-
-def ga_loop(population, cxpb, mutpb, ngen, task_eval_fn, halloffame=None,
- checkpoint_writer=None):
- """A bare bones genetic algorithm.
-
- Similar to chapter 7 of Back, Fogel and Michalewicz, "Evolutionary
- Computation 1 : Basic Algorithms and Operators", 2000.
-
- Args:
- population: A list of individuals.
- cxpb: The probability of mating two individuals.
- mutpb: The probability of mutating a gene.
- ngen: The number of generation. Unlimited if zero.
- task_eval_fn: A python function which maps an Individual to a Result
- namedtuple.
- halloffame: (optional) a utils.MaxUniquePriorityQueue object that will be
- used to aggregate the best individuals found during search.
- checkpoint_writer: (optional) an object that can save and load populations.
- Needs to have `write`, `load`, and `has_checkpoint` methods. Used to
- periodically save progress. In event of a restart, the population will
- be loaded from disk.
-
- Returns:
- GaResult namedtuple instance. This contains information about the GA run,
- including the resulting population, best reward (fitness) obtained, and
- the best code string found.
- """
-
- has_checkpoint = False
- if checkpoint_writer and checkpoint_writer.has_checkpoint():
- try:
- gen, population, halloffame = checkpoint_writer.load()
- except EOFError: # Data was corrupted. Start over.
- pass
- else:
- has_checkpoint = True
- logging.info(
- 'Loaded population from checkpoint. Starting at generation %d', gen)
-
- # Evaluate the individuals with an invalid fitness
- invalid_ind = [ind for ind in population if not ind.fitness.valid]
- for ind in invalid_ind:
- ind.fitness.values = task_eval_fn(ind).reward,
- for _, ind in halloffame.iter_in_order():
- ind.fitness.values = task_eval_fn(ind).reward,
-
- if not has_checkpoint:
- # Evaluate the individuals with an invalid fitness
- invalid_ind = [ind for ind in population if not ind.fitness.valid]
- for ind in invalid_ind:
- ind.fitness.values = task_eval_fn(ind).reward,
-
- if halloffame is not None:
- for ind in population:
- halloffame.push(ind.fitness.values, tuple(ind), ind)
-
- logging.info('Initialized new population.')
-
- gen = 1
-
- pop_size = len(population)
- program_reward_cache = {} if USE_REWARD_CACHE else None
-
- # Begin the generational process
- while ngen == 0 or gen <= ngen:
- # Select the next generation individuals
- offspring = roulette_selection(population, pop_size - len(halloffame))
-
- # Vary the pool of individuals
- # offspring = varAnd(offspring, toolbox, cxpb, mutpb)
- offspring = mutate_and_crossover(
- offspring, mutation_rate=mutpb, crossover_rate=cxpb)
-
- # Evaluate the individuals with an invalid fitness
- invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
- for ind in invalid_ind:
- str_repr = ''.join(ind)
- if program_reward_cache is not None and str_repr in program_reward_cache:
- ind.fitness.values = (program_reward_cache[str_repr],)
- else:
- eval_result = task_eval_fn(ind)
- ind.fitness.values = (eval_result.reward,)
- if program_reward_cache is not None:
- program_reward_cache[str_repr] = eval_result.reward
-
- # Replace the current population by the offspring
- population = list(offspring)
-
- # Update the hall of fame with the generated individuals
- if halloffame is not None:
- for ind in population:
- halloffame.push(ind.fitness.values, tuple(ind), ind)
-
- # elitism
- population.extend([ind for _, ind in halloffame.iter_in_order()])
-
- if gen % 100 == 0:
- top_code = '\n'.join([debug_str(ind, task_eval_fn)
- for ind in topk(population, k=4)])
- logging.info('gen: %d\nNPE: %d\n%s\n\n', gen, gen * pop_size, top_code)
-
- best_code = ''.join(halloffame.get_max()[1])
- res = task_eval_fn(best_code)
-
- # Write population and hall-of-fame to disk.
- if checkpoint_writer:
- checkpoint_writer.write(gen, population, halloffame)
-
- if res.correct:
- logging.info('Solution found:\n%s\nreward = %s\n',
- best_code, res.reward)
- break
-
- gen += 1
-
- best_code = ''.join(halloffame.get_max()[1])
- res = task_eval_fn(best_code)
-
- return GaResult(
- population=population, best_code=best_code, reward=res.reward,
- solution_found=res.correct, generations=gen,
- num_programs=gen * len(population),
- max_generations=ngen, max_num_programs=ngen * len(population))
-
-
-GaResult = namedtuple(
- 'GaResult',
- ['population', 'best_code', 'reward', 'generations', 'num_programs',
- 'solution_found', 'max_generations', 'max_num_programs'])
-
-
-def reward_conversion(reward):
- """Convert real value into positive value."""
- if reward <= 0:
- return 0.05
- return reward + 0.05
-
-
-def roulette_selection(population, k):
- """Select `k` individuals with prob proportional to fitness.
-
- Each of the `k` selections is independent.
-
- Warning:
- The roulette selection by definition cannot be used for minimization
- or when the fitness can be smaller or equal to 0.
-
- Args:
- population: A list of Individual objects to select from.
- k: The number of individuals to select.
-
- Returns:
- A list of selected individuals.
- """
- fitnesses = np.asarray(
- [reward_conversion(ind.fitness.values[0])
- for ind in population])
- assert np.all(fitnesses > 0)
-
- sum_fits = fitnesses.sum()
- chosen = [None] * k
- for i in xrange(k):
- u = random.random() * sum_fits
- sum_ = 0
- for ind, fitness in zip(population, fitnesses):
- sum_ += fitness
- if sum_ > u:
- chosen[i] = Individual(ind)
- break
- if not chosen[i]:
- chosen[i] = Individual(population[-1])
-
- return chosen
-
-
-def make_population(make_individual_fn, n):
- return [make_individual_fn() for _ in xrange(n)]
-
-
-def best(population):
- best_ind = None
- for ind in population:
- if best_ind is None or best_ind.fitness.values < ind.fitness.values:
- best_ind = ind
- return best_ind
-
-
-def topk(population, k):
- q = utils.MaxUniquePriorityQueue(k)
- for ind in population:
- q.push(ind.fitness.values, tuple(ind), ind)
- return [ind for _, ind in q.iter_in_order()]
-
-
-class Fitness(object):
-
- def __init__(self):
- self.values = ()
-
- @property
- def valid(self):
- """Assess if a fitness is valid or not."""
- return bool(self.values)
-
-
-class Individual(list):
-
- def __init__(self, *args):
- super(Individual, self).__init__(*args)
- self.fitness = Fitness()
-
-
-def random_individual(genome_size):
- return lambda: Individual(np.random.choice(GENES, genome_size).tolist())
diff --git a/research/brain_coder/single_task/ga_train.py b/research/brain_coder/single_task/ga_train.py
deleted file mode 100644
index 630eca427e478dbadad58bd94b56e89a5a747526..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/ga_train.py
+++ /dev/null
@@ -1,324 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Genetic algorithm for BF tasks.
-
-Also contains the uniform random search algorithm.
-
-Inspired by https://github.com/primaryobjects/AI-Programmer.
-GA function code borrowed from https://github.com/DEAP/deap.
-"""
-
-import cPickle
-import os
-import sys
-from time import sleep
-
-from absl import flags
-from absl import logging
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from common import utils # brain coder
-from single_task import data # brain coder
-from single_task import defaults # brain coder
-from single_task import ga_lib # brain coder
-from single_task import results_lib # brain coder
-
-FLAGS = flags.FLAGS
-
-
-def define_tuner_hparam_space(hparam_space_type):
- """Define tunable hparams for grid search."""
- if hparam_space_type != 'ga':
- raise ValueError('Hparam space is not valid: "%s"' % hparam_space_type)
- return {
- 'population_size': [10, 25, 50, 100, 500],
- 'crossover_rate': [0.2, 0.5, 0.7, 0.9, 0.95],
- 'mutation_rate': [0.01, 0.03, 0.05, 0.1, 0.15]}
-
-
-def write_hparams_to_config(config, hparams, hparam_space_type):
- """Write hparams given by the tuner into the Config object."""
- if hparam_space_type != 'ga':
- raise ValueError('Hparam space is not valid: "%s"' % hparam_space_type)
- config.batch_size = hparams.population_size
- config.agent.crossover_rate = hparams.crossover_rate
- config.agent.mutation_rate = hparams.mutation_rate
-
-
-class CheckpointWriter(object):
- """Manages loading and saving GA populations to disk.
-
- This object is used by the genetic algorithm to save progress periodically
- so that a recent population can be loaded from disk in the event of a restart.
- """
-
- def __init__(self, checkpoint_dir, population_size):
- self.checkpoint_file = os.path.join(checkpoint_dir, 'checkpoint.pickle')
- self.population_size = population_size
-
- def write(self, gen, population, halloffame):
- """Write GA state to disk.
-
- Overwrites previous saved state.
-
- Args:
- gen: Generation number.
- population: List of Individual objects.
- halloffame: Hall-of-fame buffer. Typically a priority queue.
- """
- raw = cPickle.dumps((gen, population, halloffame))
- with tf.gfile.FastGFile(self.checkpoint_file, 'w') as f:
- f.write(raw)
-
- def load(self):
- """Loads GA state from disk.
-
- Loads whatever is on disk, which will be whatever the most recent call
- to `write` wrote.
-
- Returns:
- gen: Generation number.
- population: List of Individual objects.
- halloffame: Hall-of-fame buffer. Typically a priority queue.
- """
- with tf.gfile.FastGFile(self.checkpoint_file, 'r') as f:
- raw = f.read()
- objs = cPickle.loads(raw)
- # Validate data.
- assert isinstance(objs, tuple) and len(objs) == 3, (
- 'Expecting a 3-tuple, but got %s instead.' % (objs,))
- gen, population, halloffame = objs
- assert isinstance(gen, int), (
- 'Expecting `gen` to be an integer, got %s' % (gen,))
- assert (
- isinstance(population, list)
- and len(population) == self.population_size
- ), (
- 'Expecting `population` to be a list with size %d, got %s'
- % (self.population_size, population))
- assert halloffame is None or len(halloffame) == 2, (
- 'Expecting hall-of-fame object to have length two, got length %d'
- % len(halloffame))
- logging.info('Loaded pop from checkpoint file: "%s".',
- self.checkpoint_file)
- return gen, population, halloffame
-
- def has_checkpoint(self):
- """Checks if a checkpoint exists on disk, and if so returns True."""
- return tf.gfile.Exists(self.checkpoint_file)
-
-
-def run_training(config=None, tuner=None, logdir=None, trial_name=None, # pylint: disable=unused-argument
- is_chief=True):
- """Do all training runs.
-
- This is the top level training function for policy gradient based models.
- Run this from the main function.
-
- Args:
- config: config_lib.Config instance containing global config (agent and
- environment hparams). If None, config will be parsed from FLAGS.config.
- tuner: (unused) A tuner instance. Leave as None if not tuning.
- logdir: Parent directory where all data from all runs will be written. If
- None, FLAGS.logdir will be used.
- trial_name: (unused) If tuning, set this to a unique string that identifies
- this trial. If `tuner` is not None, this also must be set.
- is_chief: True if this worker is the chief.
-
- Returns:
- List of results dicts which were written to disk. Each training run gets a
- results dict. Results dict contains metrics, i.e. (name, value) pairs which
- give information about the training run.
-
- Raises:
- ValueError: If FLAGS.num_workers does not divide FLAGS.num_repetitions.
- ValueError: If results dicts read from disk contain invalid data.
- """
- if not config:
- # If custom config is not given, get it from flags.
- config = defaults.default_config_with_updates(FLAGS.config)
- if not logdir:
- logdir = FLAGS.logdir
-
- if FLAGS.num_repetitions % FLAGS.num_workers != 0:
- raise ValueError('Number of workers must divide number of repetitions')
- num_local_reps = FLAGS.num_repetitions // FLAGS.num_workers
- logging.info('Running %d reps globally.', FLAGS.num_repetitions)
- logging.info('This worker will run %d local reps.', num_local_reps)
- if FLAGS.max_npe:
- max_generations = FLAGS.max_npe // config.batch_size
- logging.info('Max samples per rep: %d', FLAGS.max_npe)
- logging.info('Max generations per rep: %d', max_generations)
- else:
- max_generations = sys.maxint
- logging.info('Running unlimited generations.')
-
- assert FLAGS.num_workers > 0
- logging.info('Starting experiment. Directory: "%s"', logdir)
- results = results_lib.Results(logdir, FLAGS.task_id)
- local_results_list = results.read_this_shard()
- if local_results_list:
- if local_results_list[0]['max_npe'] != FLAGS.max_npe:
- raise ValueError(
- 'Cannot resume training. Max-NPE changed. Was %s, now %s',
- local_results_list[0]['max_npe'], FLAGS.max_npe)
- if local_results_list[0]['max_global_repetitions'] != FLAGS.num_repetitions:
- raise ValueError(
- 'Cannot resume training. Number of repetitions changed. Was %s, '
- 'now %s',
- local_results_list[0]['max_global_repetitions'],
- FLAGS.num_repetitions)
- start_rep = len(local_results_list)
-
- for rep in xrange(start_rep, num_local_reps):
- global_rep = num_local_reps * FLAGS.task_id + rep
- logging.info(
- 'Starting repetition: Rep = %d. (global rep = %d)',
- rep, global_rep)
-
- # Save data for each rep, like checkpoints, goes into separate folders.
- run_dir = os.path.join(logdir, 'run_%d' % global_rep)
-
- if not tf.gfile.IsDirectory(run_dir):
- tf.gfile.MakeDirs(run_dir)
- checkpoint_writer = CheckpointWriter(run_dir,
- population_size=config.batch_size)
-
- data_manager = data.DataManager(config, run_number=global_rep)
- task_eval_fn = ga_lib.make_task_eval_fn(data_manager.rl_task)
-
- if config.agent.algorithm == 'rand':
- logging.info('Running random search.')
- assert FLAGS.max_npe
- result = run_random_search(
- FLAGS.max_npe, run_dir, task_eval_fn, config.timestep_limit)
- else:
- assert config.agent.algorithm == 'ga'
- logging.info('Running genetic algorithm.')
- pop = ga_lib.make_population(
- ga_lib.random_individual(config.timestep_limit),
- n=config.batch_size)
- hof = utils.MaxUniquePriorityQueue(2) # Hall of fame.
- result = ga_lib.ga_loop(
- pop,
- cxpb=config.agent.crossover_rate, mutpb=config.agent.mutation_rate,
- task_eval_fn=task_eval_fn,
- ngen=max_generations, halloffame=hof,
- checkpoint_writer=checkpoint_writer)
-
- logging.info('Finished rep. Num gens: %d', result.generations)
-
- results_dict = {
- 'max_npe': FLAGS.max_npe,
- 'batch_size': config.batch_size,
- 'max_batches': FLAGS.max_npe // config.batch_size,
- 'npe': result.num_programs,
- 'max_global_repetitions': FLAGS.num_repetitions,
- 'max_local_repetitions': num_local_reps,
- 'code_solution': result.best_code if result.solution_found else '',
- 'best_reward': result.reward,
- 'num_batches': result.generations,
- 'found_solution': result.solution_found,
- 'task': data_manager.task_name,
- 'global_rep': global_rep}
- logging.info('results_dict: %s', results_dict)
- results.append(results_dict)
-
- if is_chief:
- logging.info(
- 'Worker is chief. Waiting for all workers to finish so that results '
- 'can be reported to the tuner.')
-
- global_results_list, shard_stats = results.read_all(
- num_shards=FLAGS.num_workers)
- while not all(s.finished for s in shard_stats):
- logging.info(
- 'Still waiting on these workers: %s',
- ', '.join(
- ['%d (%d reps left)'
- % (i, s.max_local_reps - s.num_local_reps_completed)
- for i, s in enumerate(shard_stats)
- if not s.finished]))
- sleep(60)
- global_results_list, shard_stats = results.read_all(
- num_shards=FLAGS.num_workers)
-
- logging.info(
- '%d results obtained. Chief worker is exiting the experiment.',
- len(global_results_list))
-
- return global_results_list
-
-
-def run_random_search(max_num_programs, checkpoint_dir, task_eval_fn,
- timestep_limit):
- """Run uniform random search routine.
-
- Randomly samples programs from a uniform distribution until either a valid
- program is found, or the maximum NPE is reached. Results are written to disk
- and returned.
-
- Args:
- max_num_programs: Maximum NPE (number of programs executed). If no solution
- is found after this many programs are tried, the run is stopped and
- considered a failure.
- checkpoint_dir: Where to save state during the run.
- task_eval_fn: Function that maps code string to result containing total
- reward and info about success.
- timestep_limit: Maximum length of code strings.
-
- Returns:
- ga_lib.GaResult namedtuple instance. This contains the best code and highest
- reward found.
- """
- checkpoint_file = os.path.join(checkpoint_dir, 'random_search.txt')
- num_programs_seen = 0
- found_solution = False
- best_code = ''
- best_reward = 0.0
- if tf.gfile.Exists(checkpoint_file):
- try:
- with tf.gfile.FastGFile(checkpoint_file, 'r') as f:
- lines = list(f)
- num_programs_seen = int(lines[0])
- found_solution = bool(int(lines[1]))
- if found_solution:
- best_code = lines[2]
- best_reward = float(lines[3])
- except: # pylint: disable=bare-except
- pass
-
- while not found_solution and num_programs_seen < max_num_programs:
- if num_programs_seen % 1000 == 0:
- logging.info('num_programs_seen = %d', num_programs_seen)
- with tf.gfile.FastGFile(checkpoint_file, 'w') as f:
- f.write(str(num_programs_seen) + '\n')
- f.write(str(int(found_solution)) + '\n')
-
- code = np.random.choice(ga_lib.GENES, timestep_limit).tolist()
- res = task_eval_fn(code)
- found_solution = res.correct
- num_programs_seen += 1
-
- if found_solution:
- best_code = ''.join(code)
- best_reward = res.reward
-
- logging.info('num_programs_seen = %d', num_programs_seen)
- logging.info('found solution: %s', found_solution)
- with tf.gfile.FastGFile(checkpoint_file, 'w') as f:
- f.write(str(num_programs_seen) + '\n')
- f.write(str(int(found_solution)) + '\n')
- if found_solution:
- f.write(best_code + '\n')
- f.write(str(best_reward) + '\n')
-
- return ga_lib.GaResult(
- population=[], best_code=best_code, reward=best_reward,
- solution_found=found_solution, generations=num_programs_seen,
- num_programs=num_programs_seen, max_generations=max_num_programs,
- max_num_programs=max_num_programs)
diff --git a/research/brain_coder/single_task/ga_train_test.py b/research/brain_coder/single_task/ga_train_test.py
deleted file mode 100644
index ff69ad84952a3fb90cad28b3cf8e67ff55c96e95..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/ga_train_test.py
+++ /dev/null
@@ -1,51 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for ga_train.
-
-Tests that ga runs for a few generations without crashing.
-"""
-
-from absl import flags
-import tensorflow as tf
-
-from single_task import defaults # brain coder
-from single_task import run # brain coder
-
-FLAGS = flags.FLAGS
-
-
-class GaTest(tf.test.TestCase):
-
- def RunTrainingSteps(self, config_string, num_steps=10):
- """Run a few training steps with the given config.
-
- Just check that nothing crashes.
-
- Args:
- config_string: Config encoded in a string. See
- $REPO_PATH/common/config_lib.py
- num_steps: Number of training steps to run. Defaults to 10.
- """
- config = defaults.default_config_with_updates(config_string)
- FLAGS.max_npe = num_steps * config.batch_size
- FLAGS.logdir = tf.test.get_temp_dir()
- FLAGS.config = config_string
- run.main(None)
-
- def testGeneticAlgorithm(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="ga"),'
- 'timestep_limit=40,batch_size=64')
-
- def testUniformRandomSearch(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="rand"),'
- 'timestep_limit=40,batch_size=64')
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/launch_training.sh b/research/brain_coder/single_task/launch_training.sh
deleted file mode 100755
index a4a4688ed2912792185aa8f3134b1680fed6f006..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/launch_training.sh
+++ /dev/null
@@ -1,72 +0,0 @@
-#!/bin/bash
-# Launches training jobs.
-# Modify this file to launch workers with your prefered cloud API.
-# The following implementation runs each worker as a subprocess on the local
-# machine.
-
-MODELS_DIR="/tmp/models"
-
-# Get command line options.
-OPTS=$(getopt -n "$0" -o "" --long "job_name:,config:,num_workers:,num_ps:,max_npe:,num_repetitions:,stop_on_success:" -- "$@")
-if [ $? != 0 ] ; then echo "Failed parsing options." >&2 ; exit 1 ; fi
-
-eval set -- "$OPTS"
-
-JOB_NAME="" # Name of the process and the logs directory.
-CONFIG="" # Model and environment hparams.
-# NUM_WORKERS: Number of workers to launch for this training job. If using
-# neural networks, each worker will be 1 replica.
-NUM_WORKERS=1
-# NUM_PS: Number of parameter servers to launch for this training job. Only set
-# this if using neural networks. For 1 worker, no parameter servers are needed.
-# For more than 1 worker, at least 1 parameter server is needed to store the
-# global model.
-NUM_PS=0
-# MAX_NPE: Maximum number of programs executed. Training will quit once this
-# threshold is reached. If 0, the threshold is infinite.
-MAX_NPE=0
-NUM_REPETITIONS=1 # How many times to run this experiment.
-STOP_ON_SUCCESS=true # Whether to halt training when a solution is found.
-
-# Parse options into variables.
-while true; do
- case "$1" in
- --job_name ) JOB_NAME="$2"; shift; shift ;;
- --config ) CONFIG="$2"; shift; shift ;;
- --num_workers ) NUM_WORKERS="$2"; shift; shift ;;
- --num_ps ) NUM_PS="$2"; shift; shift ;;
- --max_npe ) MAX_NPE="$2"; shift; shift ;;
- --num_repetitions ) NUM_REPETITIONS="$2"; shift; shift ;;
- --stop_on_success ) STOP_ON_SUCCESS="$2"; shift; shift ;;
- -- ) shift; break ;;
- * ) break ;;
- esac
-done
-
-# Launch jobs.
-# TODO: multi-worker RL training
-
-LOGDIR="$MODELS_DIR/$JOB_NAME"
-mkdir -p $LOGDIR
-
-BIN_DIR="bazel-bin/single_task"
-for (( i=0; i "$LOGDIR/task_$i.log" & # Run as subprocess
- echo "Launched task $i. Logs: $LOGDIR/task_$i.log"
-done
-
-
-# Use "pidof run.par" to find jobs.
-# Kill with "pkill run.par"
diff --git a/research/brain_coder/single_task/launch_tuning.sh b/research/brain_coder/single_task/launch_tuning.sh
deleted file mode 100755
index 97ce51b543e13d4b1c412656a93197b5b47373bb..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/launch_tuning.sh
+++ /dev/null
@@ -1,87 +0,0 @@
-#!/bin/bash
-# Launches tuning jobs.
-# Modify this file to launch workers with your prefered cloud API.
-# The following implementation runs each worker as a subprocess on the local
-# machine.
-
-MODELS_DIR="/tmp/models"
-
-# Get command line options.
-OPTS=$(getopt -n "$0" -o "" --long "job_name:,config:,num_tuners:,num_workers_per_tuner:,num_ps_per_tuner:,max_npe:,num_repetitions:,stop_on_success:,fixed_hparams:,hparam_space_type:" -- "$@")
-if [ $? != 0 ] ; then echo "Failed parsing options." >&2 ; exit 1 ; fi
-
-eval set -- "$OPTS"
-
-JOB_NAME="" # Name of the process and the logs directory.
-CONFIG="" # Model and environment hparams.
-# NUM_TUNERS: Number of tuning jobs to launch. Each tuning job can train a
-# hparam combination. So more tuners means more hparams tried in parallel.
-NUM_TUNERS=1
-# NUM_WORKERS_PER_TUNER: Number of workers to launch for each tuning job. If
-# using neural networks, each worker will be 1 replica.
-NUM_WORKERS_PER_TUNER=1
-# NUM_PS_PER_TUNER: Number of parameter servers to launch for this tuning job.
-# Only set this if using neural networks. For 1 worker per tuner, no parameter
-# servers are needed. For more than 1 worker per tuner, at least 1 parameter
-# server per tuner is needed to store the global model for each tuner.
-NUM_PS_PER_TUNER=0
-# MAX_NPE: Maximum number of programs executed. Training will quit once this
-# threshold is reached. If 0, the threshold is infinite.
-MAX_NPE=0
-NUM_REPETITIONS=25 # How many times to run this experiment.
-STOP_ON_SUCCESS=true # Whether to halt training when a solution is found.
-# FIXED_HPARAMS: Hold hparams fixed in the grid search. This reduces the search
-# space.
-FIXED_HPARAMS=""
-# HPARAM_SPACE_TYPE: Specifies the hparam search space. See
-# `define_tuner_hparam_space` functions defined in pg_train.py and ga_train.py.
-HPARAM_SPACE_TYPE="pg"
-
-# Parse options into variables.
-while true; do
- case "$1" in
- --job_name ) JOB_NAME="$2"; shift; shift ;;
- --config ) CONFIG="$2"; shift; shift ;;
- --num_tuners ) NUM_TUNERS="$2"; shift; shift ;;
- --num_workers_per_tuner ) NUM_WORKERS_PER_TUNER="$2"; shift; shift ;;
- --num_ps_per_tuner ) NUM_PS_PER_TUNER="$2"; shift; shift ;;
- --max_npe ) MAX_NPE="$2"; shift; shift ;;
- --num_repetitions ) NUM_REPETITIONS="$2"; shift; shift ;;
- --stop_on_success ) STOP_ON_SUCCESS="$2"; shift; shift ;;
- --fixed_hparams ) FIXED_HPARAMS="$2"; shift; shift ;;
- --hparam_space_type ) HPARAM_SPACE_TYPE="$2"; shift; shift ;;
- -- ) shift; break ;;
- * ) break ;;
- esac
-done
-
-# Launch jobs.
-# TODO: multi-worker RL training
-
-LOGDIR="$MODELS_DIR/$JOB_NAME"
-mkdir -p $LOGDIR
-
-BIN_DIR="bazel-bin/single_task"
-for ((tuner=0;tuner "$LOGDIR/tuner_$tuner.task_$i.log" & # Run as subprocess
- echo "Launched tuner $tuner, task $i. Logs: $LOGDIR/tuner_$tuner.task_$i.log"
- done
-done
-
-# Use "pidof tune.par" to find jobs.
-# Kill with "pkill tune.par"
diff --git a/research/brain_coder/single_task/misc.py b/research/brain_coder/single_task/misc.py
deleted file mode 100644
index 07061d81c8aaafd4d97efc11ecca451528c6e9dd..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/misc.py
+++ /dev/null
@@ -1,149 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Utilities specific to this project."""
-
-from collections import namedtuple
-from six import string_types
-
-
-#####################
-# BF-lang utilities #
-#####################
-
-
-BF_EOS_INT = 0 # Also used as SOS (start of sequence).
-BF_EOS_CHAR = TEXT_EOS_CHAR = '_'
-BF_LANG_INTS = range(1, 9)
-BF_INT_TO_CHAR = [BF_EOS_CHAR, '>', '<', '+', '-', '[', ']', '.', ',']
-BF_CHAR_TO_INT = dict([(c, i) for i, c in enumerate(BF_INT_TO_CHAR)])
-
-
-RewardInfo = namedtuple('RewardInfo', ['episode_rewards', 'input_case',
- 'correct_output',
- 'code_output', 'reason', 'input_type',
- 'output_type'])
-
-
-class IOType(object):
- string = 'string'
- integer = 'integer'
- boolean = 'boolean'
-
-
-class IOTuple(tuple):
- pass
-
-
-def flatten(lst):
- return [item for row in lst for item in row]
-
-
-def bf_num_tokens():
- # BF tokens plus EOS.
- return len(BF_INT_TO_CHAR)
-
-
-def bf_char2int(bf_char):
- """Convert BF code char to int token."""
- return BF_CHAR_TO_INT[bf_char]
-
-
-def bf_int2char(bf_int):
- """Convert BF int token to code char."""
- return BF_INT_TO_CHAR[bf_int]
-
-
-def bf_tokens_to_string(bf_tokens, truncate=True):
- """Convert token list to code string. Will truncate at EOS token.
-
- Args:
- bf_tokens: Python list of ints representing the code string.
- truncate: If true, the output string will end at the first EOS token.
- If false, the entire token list is converted to string.
-
- Returns:
- String representation of the tokens.
-
- Raises:
- ValueError: If bf_tokens is not a python list.
- """
- if not isinstance(bf_tokens, list):
- raise ValueError('Only python list supported here.')
- if truncate:
- try:
- eos_index = bf_tokens.index(BF_EOS_INT)
- except ValueError:
- eos_index = len(bf_tokens)
- else:
- eos_index = len(bf_tokens)
- return ''.join([BF_INT_TO_CHAR[t] for t in bf_tokens[:eos_index]])
-
-
-def bf_string_to_tokens(bf_string):
- """Convert string to token list. Will strip and append EOS token."""
- tokens = [BF_CHAR_TO_INT[char] for char in bf_string.strip()]
- tokens.append(BF_EOS_INT)
- return tokens
-
-
-def tokens_to_text(tokens):
- """Convert token list to human readable text."""
- return ''.join(
- [TEXT_EOS_CHAR if t == 0 else chr(t - 1 + ord('A')) for t in tokens])
-
-
-###################################
-# Number representation utilities #
-###################################
-
-
-# https://en.wikipedia.org/wiki/Metric_prefix
-si_magnitudes = {
- 'k': 1e3,
- 'm': 1e6,
- 'g': 1e9}
-
-
-def si_to_int(s):
- """Convert string ending with SI magnitude to int.
-
- Examples: 5K ==> 5000, 12M ==> 12000000.
-
- Args:
- s: String in the form 'xx..xP' where x is a digit and P is an SI prefix.
-
- Returns:
- Integer equivalent to the string.
- """
- if isinstance(s, string_types) and s[-1].lower() in si_magnitudes.keys():
- return int(int(s[:-1]) * si_magnitudes[s[-1].lower()])
- return int(s)
-
-
-def int_to_si(n):
- """Convert integer to string with SI magnitude.
-
- `n` will be truncated.
-
- Examples: 5432 ==> 5k, 12345678 ==> 12M
-
- Args:
- n: Integer to represent as a string.
-
- Returns:
- String representation of `n` containing SI magnitude.
- """
- m = abs(n)
- sign = -1 if n < 0 else 1
- if m < 1e3:
- return str(n)
- if m < 1e6:
- return '{0}K'.format(sign*int(m / 1e3))
- if m < 1e9:
- return '{0}M'.format(sign*int(m / 1e6))
- if m < 1e12:
- return '{0}G'.format(sign*int(m / 1e9))
- return str(m)
-
diff --git a/research/brain_coder/single_task/pg_agent.py b/research/brain_coder/single_task/pg_agent.py
deleted file mode 100644
index 13fc7da2dc89a1fbcc7fa5efbbce87008580aa92..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/pg_agent.py
+++ /dev/null
@@ -1,1297 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Language model agent.
-
-Agent outputs code in a sequence just like a language model. Can be trained
-as a language model or using RL, or a combination of the two.
-"""
-
-from collections import namedtuple
-from math import exp
-from math import log
-import time
-
-from absl import logging
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from common import rollout as rollout_lib # brain coder
-from common import utils # brain coder
-from single_task import misc # brain coder
-
-
-# Experiments in the ICLR 2018 paper used reduce_sum instead of reduce_mean for
-# some losses. We make all loses be batch_size independent, and multiply the
-# changed losses by 64, which was the fixed batch_size when the experiments
-# where run. The loss hyperparameters still match what is reported in the paper.
-MAGIC_LOSS_MULTIPLIER = 64
-
-
-def rshift_time(tensor_2d, fill=misc.BF_EOS_INT):
- """Right shifts a 2D tensor along the time dimension (axis-1)."""
- dim_0 = tf.shape(tensor_2d)[0]
- fill_tensor = tf.fill([dim_0, 1], fill)
- return tf.concat([fill_tensor, tensor_2d[:, :-1]], axis=1)
-
-
-def join(a, b):
- # Concat a and b along 0-th dim.
- if a is None or len(a) == 0: # pylint: disable=g-explicit-length-test
- return b
- if b is None or len(b) == 0: # pylint: disable=g-explicit-length-test
- return a
- return np.concatenate((a, b))
-
-
-def make_optimizer(kind, lr):
- if kind == 'sgd':
- return tf.train.GradientDescentOptimizer(lr)
- elif kind == 'adam':
- return tf.train.AdamOptimizer(lr)
- elif kind == 'rmsprop':
- return tf.train.RMSPropOptimizer(learning_rate=lr, decay=0.99)
- else:
- raise ValueError('Optimizer type "%s" not recognized.' % kind)
-
-
-class LinearWrapper(tf.contrib.rnn.RNNCell):
- """RNNCell wrapper that adds a linear layer to the output."""
-
- def __init__(self, cell, output_size, dtype=tf.float32, suppress_index=None):
- self.cell = cell
- self._output_size = output_size
- self._dtype = dtype
- self._suppress_index = suppress_index
- self.smallest_float = -2.4e38
-
- def __call__(self, inputs, state, scope=None):
- with tf.variable_scope(type(self).__name__):
- outputs, state = self.cell(inputs, state, scope=scope)
- logits = tf.matmul(
- outputs,
- tf.get_variable('w_output',
- [self.cell.output_size, self.output_size],
- dtype=self._dtype))
- if self._suppress_index is not None:
- # Replace the target index with -inf, so that it never gets selected.
- batch_size = tf.shape(logits)[0]
- logits = tf.concat(
- [logits[:, :self._suppress_index],
- tf.fill([batch_size, 1], self.smallest_float),
- logits[:, self._suppress_index + 1:]],
- axis=1)
-
- return logits, state
-
- @property
- def output_size(self):
- return self._output_size
-
- @property
- def state_size(self):
- return self.cell.state_size
-
- def zero_state(self, batch_size, dtype):
- return self.cell.zero_state(batch_size, dtype)
-
-
-UpdateStepResult = namedtuple(
- 'UpdateStepResult',
- ['global_step', 'global_npe', 'summaries_list', 'gradients_dict'])
-
-
-class AttrDict(dict):
- """Dict with attributes as keys.
-
- https://stackoverflow.com/a/14620633
- """
-
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-class LMAgent(object):
- """Language model agent."""
- action_space = misc.bf_num_tokens()
- observation_space = misc.bf_num_tokens()
-
- def __init__(self, global_config, task_id=0,
- logging_file=None,
- experience_replay_file=None,
- global_best_reward_fn=None,
- found_solution_op=None,
- assign_code_solution_fn=None,
- program_count=None,
- do_iw_summaries=False,
- stop_on_success=True,
- dtype=tf.float32,
- verbose_level=0,
- is_local=True):
- self.config = config = global_config.agent
- self.logging_file = logging_file
- self.experience_replay_file = experience_replay_file
- self.task_id = task_id
- self.verbose_level = verbose_level
- self.global_best_reward_fn = global_best_reward_fn
- self.found_solution_op = found_solution_op
- self.assign_code_solution_fn = assign_code_solution_fn
- self.parent_scope_name = tf.get_variable_scope().name
- self.dtype = dtype
- self.allow_eos_token = config.eos_token
- self.stop_on_success = stop_on_success
- self.pi_loss_hparam = config.pi_loss_hparam
- self.vf_loss_hparam = config.vf_loss_hparam
- self.is_local = is_local
-
- self.top_reward = 0.0
- self.embeddings_trainable = True
-
- self.no_op = tf.no_op()
-
- self.learning_rate = tf.constant(
- config.lr, dtype=dtype, name='learning_rate')
- self.initializer = tf.contrib.layers.variance_scaling_initializer(
- factor=config.param_init_factor,
- mode='FAN_AVG',
- uniform=True,
- dtype=dtype) # TF's default initializer.
- tf.get_variable_scope().set_initializer(self.initializer)
-
- self.a2c = config.ema_baseline_decay == 0
- if not self.a2c:
- logging.info('Using exponential moving average REINFORCE baselines.')
- self.ema_baseline_decay = config.ema_baseline_decay
- self.ema_by_len = [0.0] * global_config.timestep_limit
- else:
- logging.info('Using advantage (a2c) with learned value function.')
- self.ema_baseline_decay = 0.0
- self.ema_by_len = None
-
- # Top-k
- if config.topk and config.topk_loss_hparam:
- self.topk_loss_hparam = config.topk_loss_hparam
- self.topk_batch_size = config.topk_batch_size
- if self.topk_batch_size <= 0:
- raise ValueError('topk_batch_size must be a positive integer. Got %s',
- self.topk_batch_size)
- self.top_episodes = utils.MaxUniquePriorityQueue(config.topk)
- logging.info('Made max-priorty-queue with capacity %d',
- self.top_episodes.capacity)
- else:
- self.top_episodes = None
- self.topk_loss_hparam = 0.0
- logging.info('No max-priorty-queue')
-
- # Experience replay.
- self.replay_temperature = config.replay_temperature
- self.num_replay_per_batch = int(global_config.batch_size * config.alpha)
- self.num_on_policy_per_batch = (
- global_config.batch_size - self.num_replay_per_batch)
- self.replay_alpha = (
- self.num_replay_per_batch / float(global_config.batch_size))
- logging.info('num_replay_per_batch: %d', self.num_replay_per_batch)
- logging.info('num_on_policy_per_batch: %d', self.num_on_policy_per_batch)
- logging.info('replay_alpha: %s', self.replay_alpha)
- if self.num_replay_per_batch > 0:
- # Train with off-policy episodes from replay buffer.
- start_time = time.time()
- self.experience_replay = utils.RouletteWheel(
- unique_mode=True, save_file=experience_replay_file)
- logging.info('Took %s sec to load replay buffer from disk.',
- int(time.time() - start_time))
- logging.info('Replay buffer file location: "%s"',
- self.experience_replay.save_file)
- else:
- # Only train on-policy.
- self.experience_replay = None
-
- if program_count is not None:
- self.program_count = program_count
- self.program_count_add_ph = tf.placeholder(
- tf.int64, [], 'program_count_add_ph')
- self.program_count_add_op = self.program_count.assign_add(
- self.program_count_add_ph)
-
- ################################
- # RL policy and value networks #
- ################################
- batch_size = global_config.batch_size
- logging.info('batch_size: %d', batch_size)
-
- self.policy_cell = LinearWrapper(
- tf.contrib.rnn.MultiRNNCell(
- [tf.contrib.rnn.BasicLSTMCell(cell_size)
- for cell_size in config.policy_lstm_sizes]),
- self.action_space,
- dtype=dtype,
- suppress_index=None if self.allow_eos_token else misc.BF_EOS_INT)
- self.value_cell = LinearWrapper(
- tf.contrib.rnn.MultiRNNCell(
- [tf.contrib.rnn.BasicLSTMCell(cell_size)
- for cell_size in config.value_lstm_sizes]),
- 1,
- dtype=dtype)
-
- obs_embedding_scope = 'obs_embed'
- with tf.variable_scope(
- obs_embedding_scope,
- initializer=tf.random_uniform_initializer(minval=-1.0, maxval=1.0)):
- obs_embeddings = tf.get_variable(
- 'embeddings',
- [self.observation_space, config.obs_embedding_size],
- dtype=dtype, trainable=self.embeddings_trainable)
- self.obs_embeddings = obs_embeddings
-
- ################################
- # RL policy and value networks #
- ################################
-
- initial_state = tf.fill([batch_size], misc.BF_EOS_INT)
- def loop_fn(loop_time, cell_output, cell_state, loop_state):
- """Function called by tf.nn.raw_rnn to instantiate body of the while_loop.
-
- See https://www.tensorflow.org/api_docs/python/tf/nn/raw_rnn for more
- information.
-
- When time is 0, and cell_output, cell_state, loop_state are all None,
- `loop_fn` will create the initial input, internal cell state, and loop
- state. When time > 0, `loop_fn` will operate on previous cell output,
- state, and loop state.
-
- Args:
- loop_time: A scalar tensor holding the current timestep (zero based
- counting).
- cell_output: Output of the raw_rnn cell at the current timestep.
- cell_state: Cell internal state at the current timestep.
- loop_state: Additional loop state. These tensors were returned by the
- previous call to `loop_fn`.
-
- Returns:
- elements_finished: Bool tensor of shape [batch_size] which marks each
- sequence in the batch as being finished or not finished.
- next_input: A tensor containing input to be fed into the cell at the
- next timestep.
- next_cell_state: Cell internal state to be fed into the cell at the
- next timestep.
- emit_output: Tensor to be added to the TensorArray returned by raw_rnn
- as output from the while_loop.
- next_loop_state: Additional loop state. These tensors will be fed back
- into the next call to `loop_fn` as `loop_state`.
- """
- if cell_output is None: # 0th time step.
- next_cell_state = self.policy_cell.zero_state(batch_size, dtype)
- elements_finished = tf.zeros([batch_size], tf.bool)
- output_lengths = tf.ones([batch_size], dtype=tf.int32)
- next_input = tf.gather(obs_embeddings, initial_state)
- emit_output = None
- next_loop_state = (
- tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True),
- output_lengths,
- elements_finished
- )
- else:
- scaled_logits = cell_output * config.softmax_tr # Scale temperature.
- prev_chosen, prev_output_lengths, prev_elements_finished = loop_state
- next_cell_state = cell_state
- chosen_outputs = tf.to_int32(tf.where(
- tf.logical_not(prev_elements_finished),
- tf.multinomial(logits=scaled_logits, num_samples=1)[:, 0],
- tf.zeros([batch_size], dtype=tf.int64)))
- elements_finished = tf.logical_or(
- tf.equal(chosen_outputs, misc.BF_EOS_INT),
- loop_time >= global_config.timestep_limit)
- output_lengths = tf.where(
- elements_finished,
- prev_output_lengths,
- # length includes EOS token. empty seq has len 1.
- tf.tile(tf.expand_dims(loop_time + 1, 0), [batch_size])
- )
- next_input = tf.gather(obs_embeddings, chosen_outputs)
- emit_output = scaled_logits
- next_loop_state = (prev_chosen.write(loop_time - 1, chosen_outputs),
- output_lengths,
- tf.logical_or(prev_elements_finished,
- elements_finished))
- return (elements_finished, next_input, next_cell_state, emit_output,
- next_loop_state)
-
- with tf.variable_scope('policy'):
- (decoder_outputs_ta,
- _, # decoder_state
- (sampled_output_ta, output_lengths, _)) = tf.nn.raw_rnn(
- cell=self.policy_cell,
- loop_fn=loop_fn)
- policy_logits = tf.transpose(decoder_outputs_ta.stack(), (1, 0, 2),
- name='policy_logits')
- sampled_tokens = tf.transpose(sampled_output_ta.stack(), (1, 0),
- name='sampled_tokens')
- # Add SOS to beginning of the sequence.
- rshift_sampled_tokens = rshift_time(sampled_tokens, fill=misc.BF_EOS_INT)
-
- # Initial state is 0, 2nd state is first token.
- # Note: If value of last state is computed, this will be used as bootstrap.
- if self.a2c:
- with tf.variable_scope('value'):
- value_output, _ = tf.nn.dynamic_rnn(
- self.value_cell,
- tf.gather(obs_embeddings, rshift_sampled_tokens),
- sequence_length=output_lengths,
- dtype=dtype)
- value = tf.squeeze(value_output, axis=[2])
- else:
- value = tf.zeros([], dtype=dtype)
-
- # for sampling actions from the agent, and which told tensors for doing
- # gradient updates on the agent.
- self.sampled_batch = AttrDict(
- logits=policy_logits,
- value=value,
- tokens=sampled_tokens,
- episode_lengths=output_lengths,
- probs=tf.nn.softmax(policy_logits),
- log_probs=tf.nn.log_softmax(policy_logits))
-
- # adjusted_lengths can be less than the full length of each episode.
- # Use this to train on only part of an episode (starting from t=0).
- self.adjusted_lengths = tf.placeholder(
- tf.int32, [None], name='adjusted_lengths')
- self.policy_multipliers = tf.placeholder(
- dtype,
- [None, None],
- name='policy_multipliers')
- # Empirical value, i.e. discounted sum of observed future rewards from each
- # time step in the episode.
- self.empirical_values = tf.placeholder(
- dtype,
- [None, None],
- name='empirical_values')
-
- # Off-policy training. Just add supervised loss to the RL loss.
- self.off_policy_targets = tf.placeholder(
- tf.int32,
- [None, None],
- name='off_policy_targets')
- self.off_policy_target_lengths = tf.placeholder(
- tf.int32, [None], name='off_policy_target_lengths')
-
- self.actions = tf.placeholder(tf.int32, [None, None], name='actions')
- # Add SOS to beginning of the sequence.
- inputs = rshift_time(self.actions, fill=misc.BF_EOS_INT)
- with tf.variable_scope('policy', reuse=True):
- logits, _ = tf.nn.dynamic_rnn(
- self.policy_cell, tf.gather(obs_embeddings, inputs),
- sequence_length=self.adjusted_lengths,
- dtype=dtype)
-
- if self.a2c:
- with tf.variable_scope('value', reuse=True):
- value_output, _ = tf.nn.dynamic_rnn(
- self.value_cell,
- tf.gather(obs_embeddings, inputs),
- sequence_length=self.adjusted_lengths,
- dtype=dtype)
- value2 = tf.squeeze(value_output, axis=[2])
- else:
- value2 = tf.zeros([], dtype=dtype)
-
- self.given_batch = AttrDict(
- logits=logits,
- value=value2,
- tokens=sampled_tokens,
- episode_lengths=self.adjusted_lengths,
- probs=tf.nn.softmax(logits),
- log_probs=tf.nn.log_softmax(logits))
-
- # Episode masks.
- max_episode_length = tf.shape(self.actions)[1]
- # range_row shape: [1, max_episode_length]
- range_row = tf.expand_dims(tf.range(max_episode_length), 0)
- episode_masks = tf.cast(
- tf.less(range_row, tf.expand_dims(self.given_batch.episode_lengths, 1)),
- dtype=dtype)
- episode_masks_3d = tf.expand_dims(episode_masks, 2)
-
- # Length adjusted episodes.
- self.a_probs = a_probs = self.given_batch.probs * episode_masks_3d
- self.a_log_probs = a_log_probs = (
- self.given_batch.log_probs * episode_masks_3d)
- self.a_value = a_value = self.given_batch.value * episode_masks
- self.a_policy_multipliers = a_policy_multipliers = (
- self.policy_multipliers * episode_masks)
- if self.a2c:
- self.a_empirical_values = a_empirical_values = (
- self.empirical_values * episode_masks)
-
- # pi_loss is scalar
- acs_onehot = tf.one_hot(self.actions, self.action_space, dtype=dtype)
- self.acs_onehot = acs_onehot
- chosen_masked_log_probs = acs_onehot * a_log_probs
- pi_target = tf.expand_dims(a_policy_multipliers, -1)
- pi_loss_per_step = chosen_masked_log_probs * pi_target # Maximize.
- self.pi_loss = pi_loss = (
- -tf.reduce_mean(tf.reduce_sum(pi_loss_per_step, axis=[1, 2]), axis=0)
- * MAGIC_LOSS_MULTIPLIER) # Minimize.
- assert len(self.pi_loss.shape) == 0 # pylint: disable=g-explicit-length-test
-
- # shape: [batch_size, time]
- self.chosen_log_probs = tf.reduce_sum(chosen_masked_log_probs, axis=2)
- self.chosen_probs = tf.reduce_sum(acs_onehot * a_probs, axis=2)
-
- # loss of value function
- if self.a2c:
- vf_loss_per_step = tf.square(a_value - a_empirical_values)
- self.vf_loss = vf_loss = (
- tf.reduce_mean(tf.reduce_sum(vf_loss_per_step, axis=1), axis=0)
- * MAGIC_LOSS_MULTIPLIER) # Minimize.
- assert len(self.vf_loss.shape) == 0 # pylint: disable=g-explicit-length-test
- else:
- self.vf_loss = vf_loss = 0.0
-
- # Maximize entropy regularizer
- self.entropy = entropy = (
- -tf.reduce_mean(
- tf.reduce_sum(a_probs * a_log_probs, axis=[1, 2]), axis=0)
- * MAGIC_LOSS_MULTIPLIER) # Maximize
- self.negentropy = -entropy # Minimize negentropy.
- assert len(self.negentropy.shape) == 0 # pylint: disable=g-explicit-length-test
-
- # off-policy loss
- self.offp_switch = tf.placeholder(dtype, [], name='offp_switch')
- if self.top_episodes is not None:
- # Add SOS to beginning of the sequence.
- offp_inputs = tf.gather(obs_embeddings,
- rshift_time(self.off_policy_targets,
- fill=misc.BF_EOS_INT))
- with tf.variable_scope('policy', reuse=True):
- offp_logits, _ = tf.nn.dynamic_rnn(
- self.policy_cell, offp_inputs, self.off_policy_target_lengths,
- dtype=dtype) # shape: [batch_size, time, action_space]
- topk_loss_per_step = tf.nn.sparse_softmax_cross_entropy_with_logits(
- labels=self.off_policy_targets,
- logits=offp_logits,
- name='topk_loss_per_logit')
- # Take mean over batch dimension so that the loss multiplier strength is
- # independent of batch size. Sum over time dimension.
- topk_loss = tf.reduce_mean(
- tf.reduce_sum(topk_loss_per_step, axis=1), axis=0)
- assert len(topk_loss.shape) == 0 # pylint: disable=g-explicit-length-test
- self.topk_loss = topk_loss * self.offp_switch
- logging.info('Including off policy loss.')
- else:
- self.topk_loss = topk_loss = 0.0
-
- self.entropy_hparam = tf.constant(
- config.entropy_beta, dtype=dtype, name='entropy_beta')
-
- self.pi_loss_term = pi_loss * self.pi_loss_hparam
- self.vf_loss_term = vf_loss * self.vf_loss_hparam
- self.entropy_loss_term = self.negentropy * self.entropy_hparam
- self.topk_loss_term = self.topk_loss_hparam * topk_loss
- self.loss = (
- self.pi_loss_term
- + self.vf_loss_term
- + self.entropy_loss_term
- + self.topk_loss_term)
-
- params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
- tf.get_variable_scope().name)
- self.trainable_variables = params
- self.sync_variables = self.trainable_variables
- non_embedding_params = [p for p in params
- if obs_embedding_scope not in p.name]
- self.non_embedding_params = non_embedding_params
- self.params = params
-
- if config.regularizer:
- logging.info('Adding L2 regularizer with scale %.2f.',
- config.regularizer)
- self.regularizer = config.regularizer * sum(
- tf.nn.l2_loss(w) for w in non_embedding_params)
- self.loss += self.regularizer
- else:
- logging.info('Skipping regularizer.')
- self.regularizer = 0.0
-
- # Only build gradients graph for local model.
- if self.is_local:
- unclipped_grads = tf.gradients(self.loss, params)
- self.dense_unclipped_grads = [
- tf.convert_to_tensor(g) for g in unclipped_grads]
- self.grads, self.global_grad_norm = tf.clip_by_global_norm(
- unclipped_grads, config.grad_clip_threshold)
- self.gradients_dict = dict(zip(params, self.grads))
- self.optimizer = make_optimizer(config.optimizer, self.learning_rate)
- self.all_variables = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
- tf.get_variable_scope().name)
-
- self.do_iw_summaries = do_iw_summaries
- if self.do_iw_summaries:
- b = None
- self.log_iw_replay_ph = tf.placeholder(tf.float32, [b],
- 'log_iw_replay_ph')
- self.log_iw_policy_ph = tf.placeholder(tf.float32, [b],
- 'log_iw_policy_ph')
- self.log_prob_replay_ph = tf.placeholder(tf.float32, [b],
- 'log_prob_replay_ph')
- self.log_prob_policy_ph = tf.placeholder(tf.float32, [b],
- 'log_prob_policy_ph')
- self.log_norm_replay_weights_ph = tf.placeholder(
- tf.float32, [b], 'log_norm_replay_weights_ph')
- self.iw_summary_op = tf.summary.merge([
- tf.summary.histogram('is/log_iw_replay', self.log_iw_replay_ph),
- tf.summary.histogram('is/log_iw_policy', self.log_iw_policy_ph),
- tf.summary.histogram('is/log_prob_replay', self.log_prob_replay_ph),
- tf.summary.histogram('is/log_prob_policy', self.log_prob_policy_ph),
- tf.summary.histogram(
- 'is/log_norm_replay_weights', self.log_norm_replay_weights_ph),
- ])
-
- def make_summary_ops(self):
- """Construct summary ops for the model."""
- # size = number of timesteps across entire batch. Number normalized by size
- # will not be affected by the amount of padding at the ends of sequences
- # in the batch.
- size = tf.cast(
- tf.reduce_sum(self.given_batch.episode_lengths), dtype=self.dtype)
- offp_size = tf.cast(tf.reduce_sum(self.off_policy_target_lengths),
- dtype=self.dtype)
- scope_prefix = self.parent_scope_name
-
- def _remove_prefix(prefix, name):
- assert name.startswith(prefix)
- return name[len(prefix):]
-
- # RL summaries.
- self.rl_summary_op = tf.summary.merge(
- [tf.summary.scalar('model/policy_loss', self.pi_loss / size),
- tf.summary.scalar('model/value_loss', self.vf_loss / size),
- tf.summary.scalar('model/topk_loss', self.topk_loss / offp_size),
- tf.summary.scalar('model/entropy', self.entropy / size),
- tf.summary.scalar('model/loss', self.loss / size),
- tf.summary.scalar('model/grad_norm',
- tf.global_norm(self.grads)),
- tf.summary.scalar('model/unclipped_grad_norm', self.global_grad_norm),
- tf.summary.scalar('model/non_embedding_var_norm',
- tf.global_norm(self.non_embedding_params)),
- tf.summary.scalar('hparams/entropy_beta', self.entropy_hparam),
- tf.summary.scalar('hparams/topk_loss_hparam', self.topk_loss_hparam),
- tf.summary.scalar('hparams/learning_rate', self.learning_rate),
- tf.summary.scalar('model/trainable_var_norm',
- tf.global_norm(self.trainable_variables)),
- tf.summary.scalar('loss/loss', self.loss),
- tf.summary.scalar('loss/entropy', self.entropy_loss_term),
- tf.summary.scalar('loss/vf', self.vf_loss_term),
- tf.summary.scalar('loss/policy', self.pi_loss_term),
- tf.summary.scalar('loss/offp', self.topk_loss_term)] +
- [tf.summary.scalar(
- 'param_norms/' + _remove_prefix(scope_prefix + '/', p.name),
- tf.norm(p))
- for p in self.params] +
- [tf.summary.scalar(
- 'grad_norms/' + _remove_prefix(scope_prefix + '/', p.name),
- tf.norm(g))
- for p, g in zip(self.params, self.grads)] +
- [tf.summary.scalar(
- 'unclipped_grad_norms/' + _remove_prefix(scope_prefix + '/',
- p.name),
- tf.norm(g))
- for p, g in zip(self.params, self.dense_unclipped_grads)])
-
- self.text_summary_placeholder = tf.placeholder(tf.string, shape=[])
- self.rl_text_summary_op = tf.summary.text('rl',
- self.text_summary_placeholder)
-
- def _rl_text_summary(self, session, step, npe, tot_r, num_steps,
- input_case, code_output, code, reason):
- """Logs summary about a single episode and creates a text_summary for TB.
-
- Args:
- session: tf.Session instance.
- step: Global training step.
- npe: Number of programs executed so far.
- tot_r: Total reward.
- num_steps: Number of timesteps in the episode (i.e. code length).
- input_case: Inputs for test cases.
- code_output: Outputs produced by running the code on the inputs.
- code: String representation of the code.
- reason: Reason for the reward assigned by the task.
-
- Returns:
- Serialized text summary data for tensorboard.
- """
- if not input_case:
- input_case = ' '
- if not code_output:
- code_output = ' '
- if not code:
- code = ' '
- text = (
- 'Tot R: **%.2f**; Len: **%d**; Reason: **%s**\n\n'
- 'Input: **`%s`**; Output: **`%s`**\n\nCode: **`%s`**'
- % (tot_r, num_steps, reason, input_case, code_output, code))
- text_summary = session.run(self.rl_text_summary_op,
- {self.text_summary_placeholder: text})
- logging.info(
- 'Step %d.\t NPE: %d\t Reason: %s.\t Tot R: %.2f.\t Length: %d. '
- '\tInput: %s \tOutput: %s \tProgram: %s',
- step, npe, reason, tot_r, num_steps, input_case,
- code_output, code)
- return text_summary
-
- def _rl_reward_summary(self, total_rewards):
- """Create summary ops that report on episode rewards.
-
- Creates summaries for average, median, max, and min rewards in the batch.
-
- Args:
- total_rewards: Tensor of shape [batch_size] containing the total reward
- from each episode in the batch.
-
- Returns:
- tf.Summary op.
- """
- tr = np.asarray(total_rewards)
- reward_summary = tf.Summary(value=[
- tf.Summary.Value(
- tag='reward/avg',
- simple_value=np.mean(tr)),
- tf.Summary.Value(
- tag='reward/med',
- simple_value=np.median(tr)),
- tf.Summary.Value(
- tag='reward/max',
- simple_value=np.max(tr)),
- tf.Summary.Value(
- tag='reward/min',
- simple_value=np.min(tr))])
- return reward_summary
-
- def _iw_summary(self, session, replay_iw, replay_log_probs,
- norm_replay_weights, on_policy_iw,
- on_policy_log_probs):
- """Compute summaries for importance weights at a given batch.
-
- Args:
- session: tf.Session instance.
- replay_iw: Importance weights for episodes from replay buffer.
- replay_log_probs: Total log probabilities of the replay episodes under the
- current policy.
- norm_replay_weights: Normalized replay weights, i.e. values in `replay_iw`
- divided by the total weight in the entire replay buffer. Note, this is
- also the probability of selecting each episode from the replay buffer
- (in a roulette wheel replay buffer).
- on_policy_iw: Importance weights for episodes sampled from the current
- policy.
- on_policy_log_probs: Total log probabilities of the on-policy episodes
- under the current policy.
-
- Returns:
- Serialized TF summaries. Use a summary writer to write these summaries to
- disk.
- """
- return session.run(
- self.iw_summary_op,
- {self.log_iw_replay_ph: np.log(replay_iw),
- self.log_iw_policy_ph: np.log(on_policy_iw),
- self.log_norm_replay_weights_ph: np.log(norm_replay_weights),
- self.log_prob_replay_ph: replay_log_probs,
- self.log_prob_policy_ph: on_policy_log_probs})
-
- def _compute_iw(self, policy_log_probs, replay_weights):
- """Compute importance weights for a batch of episodes.
-
- Arguments are iterables of length batch_size.
-
- Args:
- policy_log_probs: Log probability of each episode under the current
- policy.
- replay_weights: Weight of each episode in the replay buffer. 0 for
- episodes not sampled from the replay buffer (i.e. sampled from the
- policy).
-
- Returns:
- Numpy array of shape [batch_size] containing the importance weight for
- each episode in the batch.
- """
- log_total_replay_weight = log(self.experience_replay.total_weight)
-
- # importance weight
- # = 1 / [(1 - a) + a * exp(log(replay_weight / total_weight / p))]
- # = 1 / ((1-a) + a*q/p)
- a = float(self.replay_alpha)
- a_com = 1.0 - a # compliment of a
- importance_weights = np.asarray(
- [1.0 / (a_com
- + a * exp((log(replay_weight) - log_total_replay_weight)
- - log_p))
- if replay_weight > 0 else 1.0 / a_com
- for log_p, replay_weight
- in zip(policy_log_probs, replay_weights)])
- return importance_weights
-
- def update_step(self, session, rl_batch, train_op, global_step_op,
- return_gradients=False):
- """Perform gradient update on the model.
-
- Args:
- session: tf.Session instance.
- rl_batch: RLBatch instance from data.py. Use DataManager to create a
- RLBatch for each call to update_step. RLBatch contains a batch of
- tasks.
- train_op: A TF op which will perform the gradient update. LMAgent does not
- own its training op, so that trainers can do distributed training
- and construct a specialized training op.
- global_step_op: A TF op which will return the current global step when
- run (should not increment it).
- return_gradients: If True, the gradients will be saved and returned from
- this method call. This is useful for testing.
-
- Returns:
- Results from the update step in a UpdateStepResult namedtuple, including
- global step, global NPE, serialized summaries, and optionally gradients.
- """
- assert self.is_local
-
- # Do update for REINFORCE or REINFORCE + replay buffer.
- if self.experience_replay is None:
- # Train with on-policy REINFORCE.
-
- # Sample new programs from the policy.
- num_programs_from_policy = rl_batch.batch_size
- (batch_actions,
- batch_values,
- episode_lengths) = session.run(
- [self.sampled_batch.tokens, self.sampled_batch.value,
- self.sampled_batch.episode_lengths])
- if episode_lengths.size == 0:
- # This should not happen.
- logging.warn(
- 'Shapes:\n'
- 'batch_actions.shape: %s\n'
- 'batch_values.shape: %s\n'
- 'episode_lengths.shape: %s\n',
- batch_actions.shape, batch_values.shape, episode_lengths.shape)
-
- # Compute rewards.
- code_scores = compute_rewards(
- rl_batch, batch_actions, episode_lengths)
- code_strings = code_scores.code_strings
- batch_tot_r = code_scores.total_rewards
- test_cases = code_scores.test_cases
- code_outputs = code_scores.code_outputs
- reasons = code_scores.reasons
-
- # Process on-policy samples.
- batch_targets, batch_returns = process_episodes(
- code_scores.batch_rewards, episode_lengths, a2c=self.a2c,
- baselines=self.ema_by_len,
- batch_values=batch_values)
- batch_policy_multipliers = batch_targets
- batch_emp_values = batch_returns if self.a2c else [[]]
- adjusted_lengths = episode_lengths
-
- if self.top_episodes:
- assert len(self.top_episodes) > 0 # pylint: disable=g-explicit-length-test
- off_policy_targets = [
- item for item, _
- in self.top_episodes.random_sample(self.topk_batch_size)]
- off_policy_target_lengths = [len(t) for t in off_policy_targets]
- off_policy_targets = utils.stack_pad(off_policy_targets, pad_axes=0,
- dtype=np.int32)
- offp_switch = 1
- else:
- off_policy_targets = [[0]]
- off_policy_target_lengths = [1]
- offp_switch = 0
-
- fetches = {
- 'global_step': global_step_op,
- 'program_count': self.program_count,
- 'summaries': self.rl_summary_op,
- 'train_op': train_op,
- 'gradients': self.gradients_dict if return_gradients else self.no_op}
- fetched = session.run(
- fetches,
- {self.actions: batch_actions,
- self.empirical_values: batch_emp_values,
- self.policy_multipliers: batch_policy_multipliers,
- self.adjusted_lengths: adjusted_lengths,
- self.off_policy_targets: off_policy_targets,
- self.off_policy_target_lengths: off_policy_target_lengths,
- self.offp_switch: offp_switch})
-
- combined_adjusted_lengths = adjusted_lengths
- combined_returns = batch_returns
- else:
- # Train with REINFORCE + off-policy replay buffer by using importance
- # sampling.
-
- # Sample new programs from the policy.
- # Note: batch size is constant. A full batch will be sampled, but not all
- # programs will be executed and added to the replay buffer. Those which
- # are not executed will be discarded and not counted.
- batch_actions, batch_values, episode_lengths, log_probs = session.run(
- [self.sampled_batch.tokens, self.sampled_batch.value,
- self.sampled_batch.episode_lengths, self.sampled_batch.log_probs])
- if episode_lengths.size == 0:
- # This should not happen.
- logging.warn(
- 'Shapes:\n'
- 'batch_actions.shape: %s\n'
- 'batch_values.shape: %s\n'
- 'episode_lengths.shape: %s\n',
- batch_actions.shape, batch_values.shape, episode_lengths.shape)
-
- # Sample from experince replay buffer
- empty_replay_buffer = (
- self.experience_replay.is_empty()
- if self.experience_replay is not None else True)
- num_programs_from_replay_buff = (
- self.num_replay_per_batch if not empty_replay_buffer else 0)
- num_programs_from_policy = (
- rl_batch.batch_size - num_programs_from_replay_buff)
- if (not empty_replay_buffer) and num_programs_from_replay_buff:
- result = self.experience_replay.sample_many(
- num_programs_from_replay_buff)
- experience_samples, replay_weights = zip(*result)
- (replay_actions,
- replay_rewards,
- _, # log probs
- replay_adjusted_lengths) = zip(*experience_samples)
-
- replay_batch_actions = utils.stack_pad(replay_actions, pad_axes=0,
- dtype=np.int32)
-
- # compute log probs for replay samples under current policy
- all_replay_log_probs, = session.run(
- [self.given_batch.log_probs],
- {self.actions: replay_batch_actions,
- self.adjusted_lengths: replay_adjusted_lengths})
- replay_log_probs = [
- np.choose(replay_actions[i], all_replay_log_probs[i, :l].T).sum()
- for i, l in enumerate(replay_adjusted_lengths)]
- else:
- # Replay buffer is empty. Do not sample from it.
- replay_actions = None
- replay_policy_multipliers = None
- replay_adjusted_lengths = None
- replay_log_probs = None
- replay_weights = None
- replay_returns = None
- on_policy_weights = [0] * num_programs_from_replay_buff
-
- assert not self.a2c # TODO(danabo): Support A2C with importance sampling.
-
- # Compute rewards.
- code_scores = compute_rewards(
- rl_batch, batch_actions, episode_lengths,
- batch_size=num_programs_from_policy)
- code_strings = code_scores.code_strings
- batch_tot_r = code_scores.total_rewards
- test_cases = code_scores.test_cases
- code_outputs = code_scores.code_outputs
- reasons = code_scores.reasons
-
- # Process on-policy samples.
- p = num_programs_from_policy
- batch_targets, batch_returns = process_episodes(
- code_scores.batch_rewards, episode_lengths[:p], a2c=False,
- baselines=self.ema_by_len)
- batch_policy_multipliers = batch_targets
- batch_emp_values = [[]]
- on_policy_returns = batch_returns
-
- # Process off-policy samples.
- if (not empty_replay_buffer) and num_programs_from_replay_buff:
- offp_batch_rewards = [
- [0.0] * (l - 1) + [r]
- for l, r in zip(replay_adjusted_lengths, replay_rewards)]
- assert len(offp_batch_rewards) == num_programs_from_replay_buff
- assert len(replay_adjusted_lengths) == num_programs_from_replay_buff
- replay_batch_targets, replay_returns = process_episodes(
- offp_batch_rewards, replay_adjusted_lengths, a2c=False,
- baselines=self.ema_by_len)
- # Convert 2D array back into ragged 2D list.
- replay_policy_multipliers = [
- replay_batch_targets[i, :l]
- for i, l
- in enumerate(
- replay_adjusted_lengths[:num_programs_from_replay_buff])]
-
- adjusted_lengths = episode_lengths[:num_programs_from_policy]
-
- if self.top_episodes:
- assert len(self.top_episodes) > 0 # pylint: disable=g-explicit-length-test
- off_policy_targets = [
- item for item, _
- in self.top_episodes.random_sample(self.topk_batch_size)]
- off_policy_target_lengths = [len(t) for t in off_policy_targets]
- off_policy_targets = utils.stack_pad(off_policy_targets, pad_axes=0,
- dtype=np.int32)
- offp_switch = 1
- else:
- off_policy_targets = [[0]]
- off_policy_target_lengths = [1]
- offp_switch = 0
-
- # On-policy episodes.
- if num_programs_from_policy:
- separate_actions = [
- batch_actions[i, :l]
- for i, l in enumerate(adjusted_lengths)]
- chosen_log_probs = [
- np.choose(separate_actions[i], log_probs[i, :l].T)
- for i, l in enumerate(adjusted_lengths)]
- new_experiences = [
- (separate_actions[i],
- batch_tot_r[i],
- chosen_log_probs[i].sum(), l)
- for i, l in enumerate(adjusted_lengths)]
- on_policy_policy_multipliers = [
- batch_policy_multipliers[i, :l]
- for i, l in enumerate(adjusted_lengths)]
- (on_policy_actions,
- _, # rewards
- on_policy_log_probs,
- on_policy_adjusted_lengths) = zip(*new_experiences)
- else:
- new_experiences = []
- on_policy_policy_multipliers = []
- on_policy_actions = []
- on_policy_log_probs = []
- on_policy_adjusted_lengths = []
-
- if (not empty_replay_buffer) and num_programs_from_replay_buff:
- # Look for new experiences in replay buffer. Assign weight if an episode
- # is in the buffer.
- on_policy_weights = [0] * num_programs_from_policy
- for i, cs in enumerate(code_strings):
- if self.experience_replay.has_key(cs):
- on_policy_weights[i] = self.experience_replay.get_weight(cs)
-
- # Randomly select on-policy or off policy episodes to train on.
- combined_actions = join(replay_actions, on_policy_actions)
- combined_policy_multipliers = join(
- replay_policy_multipliers, on_policy_policy_multipliers)
- combined_adjusted_lengths = join(
- replay_adjusted_lengths, on_policy_adjusted_lengths)
- combined_returns = join(replay_returns, on_policy_returns)
- combined_actions = utils.stack_pad(combined_actions, pad_axes=0)
- combined_policy_multipliers = utils.stack_pad(combined_policy_multipliers,
- pad_axes=0)
- # P
- combined_on_policy_log_probs = join(replay_log_probs, on_policy_log_probs)
- # Q
- # Assume weight is zero for all sequences sampled from the policy.
- combined_q_weights = join(replay_weights, on_policy_weights)
-
- # Importance adjustment. Naive formulation:
- # E_{x~p}[f(x)] ~= 1/N sum_{x~p}(f(x)) ~= 1/N sum_{x~q}(f(x) * p(x)/q(x)).
- # p(x) is the policy, and q(x) is the off-policy distribution, i.e. replay
- # buffer distribution. Importance weight w(x) = p(x) / q(x).
-
- # Instead of sampling from the replay buffer only, we sample from a
- # mixture distribution of the policy and replay buffer.
- # We are sampling from the mixture a*q(x) + (1-a)*p(x), where 0 <= a <= 1.
- # Thus the importance weight w(x) = p(x) / (a*q(x) + (1-a)*p(x))
- # = 1 / ((1-a) + a*q(x)/p(x)) where q(x) is 0 for x sampled from the
- # policy.
- # Note: a = self.replay_alpha
- if empty_replay_buffer:
- # The replay buffer is empty.
- # Do no gradient update this step. The replay buffer will have stuff in
- # it next time.
- combined_policy_multipliers *= 0
- elif not num_programs_from_replay_buff:
- combined_policy_multipliers = np.ones([len(combined_actions), 1],
- dtype=np.float32)
- else:
- # If a < 1 compute importance weights
- # importance weight
- # = 1 / [(1 - a) + a * exp(log(replay_weight / total_weight / p))]
- # = 1 / ((1-a) + a*q/p)
- importance_weights = self._compute_iw(combined_on_policy_log_probs,
- combined_q_weights)
- if self.config.iw_normalize:
- importance_weights *= (
- float(rl_batch.batch_size) / importance_weights.sum())
- combined_policy_multipliers *= importance_weights.reshape(-1, 1)
-
- # Train on replay batch, top-k MLE.
- assert self.program_count is not None
- fetches = {
- 'global_step': global_step_op,
- 'program_count': self.program_count,
- 'summaries': self.rl_summary_op,
- 'train_op': train_op,
- 'gradients': self.gradients_dict if return_gradients else self.no_op}
- fetched = session.run(
- fetches,
- {self.actions: combined_actions,
- self.empirical_values: [[]], # replay_emp_values,
- self.policy_multipliers: combined_policy_multipliers,
- self.adjusted_lengths: combined_adjusted_lengths,
- self.off_policy_targets: off_policy_targets,
- self.off_policy_target_lengths: off_policy_target_lengths,
- self.offp_switch: offp_switch})
-
- # Add to experience replay buffer.
- self.experience_replay.add_many(
- objs=new_experiences,
- weights=[exp(r / self.replay_temperature) for r in batch_tot_r],
- keys=code_strings)
-
- # Update program count.
- session.run(
- [self.program_count_add_op],
- {self.program_count_add_ph: num_programs_from_policy})
-
- # Update EMA baselines on the mini-batch which we just did traning on.
- if not self.a2c:
- for i in xrange(rl_batch.batch_size):
- episode_length = combined_adjusted_lengths[i]
- empirical_returns = combined_returns[i, :episode_length]
- for j in xrange(episode_length):
- # Update ema_baselines in place.
- self.ema_by_len[j] = (
- self.ema_baseline_decay * self.ema_by_len[j]
- + (1 - self.ema_baseline_decay) * empirical_returns[j])
-
- global_step = fetched['global_step']
- global_npe = fetched['program_count']
- core_summaries = fetched['summaries']
- summaries_list = [core_summaries]
-
- if num_programs_from_policy:
- s_i = 0
- text_summary = self._rl_text_summary(
- session,
- global_step,
- global_npe,
- batch_tot_r[s_i],
- episode_lengths[s_i], test_cases[s_i],
- code_outputs[s_i], code_strings[s_i], reasons[s_i])
- reward_summary = self._rl_reward_summary(batch_tot_r)
-
- is_best = False
- if self.global_best_reward_fn:
- # Save best reward.
- best_reward = np.max(batch_tot_r)
- is_best = self.global_best_reward_fn(session, best_reward)
-
- if self.found_solution_op is not None and 'correct' in reasons:
- session.run(self.found_solution_op)
-
- # Save program to disk for record keeping.
- if self.stop_on_success:
- solutions = [
- {'code': code_strings[i], 'reward': batch_tot_r[i],
- 'npe': global_npe}
- for i in xrange(len(reasons)) if reasons[i] == 'correct']
- elif is_best:
- solutions = [
- {'code': code_strings[np.argmax(batch_tot_r)],
- 'reward': np.max(batch_tot_r),
- 'npe': global_npe}]
- else:
- solutions = []
- if solutions:
- if self.assign_code_solution_fn:
- self.assign_code_solution_fn(session, solutions[0]['code'])
- with tf.gfile.FastGFile(self.logging_file, 'a') as writer:
- for solution_dict in solutions:
- writer.write(str(solution_dict) + '\n')
-
- max_i = np.argmax(batch_tot_r)
- max_tot_r = batch_tot_r[max_i]
- if max_tot_r >= self.top_reward:
- if max_tot_r >= self.top_reward:
- self.top_reward = max_tot_r
- logging.info('Top code: r=%.2f, \t%s', max_tot_r, code_strings[max_i])
- if self.top_episodes is not None:
- self.top_episodes.push(
- max_tot_r, tuple(batch_actions[max_i, :episode_lengths[max_i]]))
-
- summaries_list += [text_summary, reward_summary]
-
- if self.do_iw_summaries and not empty_replay_buffer:
- # prob of replay samples under replay buffer sampling.
- norm_replay_weights = [
- w / self.experience_replay.total_weight
- for w in replay_weights]
- replay_iw = self._compute_iw(replay_log_probs, replay_weights)
- on_policy_iw = self._compute_iw(on_policy_log_probs, on_policy_weights)
- summaries_list.append(
- self._iw_summary(
- session, replay_iw, replay_log_probs, norm_replay_weights,
- on_policy_iw, on_policy_log_probs))
-
- return UpdateStepResult(
- global_step=global_step,
- global_npe=global_npe,
- summaries_list=summaries_list,
- gradients_dict=fetched['gradients'])
-
-
-def io_to_text(io_case, io_type):
- if isinstance(io_case, misc.IOTuple):
- # If there are many strings, join them with ','.
- return ','.join([io_to_text(e, io_type) for e in io_case])
- if io_type == misc.IOType.string:
- # There is one string. Return it.
- return misc.tokens_to_text(io_case)
- if (io_type == misc.IOType.integer
- or io_type == misc.IOType.boolean):
- if len(io_case) == 1:
- return str(io_case[0])
- return str(io_case)
-
-
-CodeScoreInfo = namedtuple(
- 'CodeScoreInfo',
- ['code_strings', 'batch_rewards', 'total_rewards', 'test_cases',
- 'code_outputs', 'reasons'])
-
-
-def compute_rewards(rl_batch, batch_actions, episode_lengths, batch_size=None):
- """Compute rewards for each episode in the batch.
-
- Args:
- rl_batch: A data.RLBatch instance. This holds information about the task
- each episode is solving, and a reward function for each episode.
- batch_actions: Contains batch of episodes. Each sequence of actions will be
- converted into a BF program and then scored. A numpy array of shape
- [batch_size, max_sequence_length].
- episode_lengths: The sequence length of each episode in the batch. Iterable
- of length batch_size.
- batch_size: (optional) number of programs to score. Use this to limit the
- number of programs executed from this batch. For example, when doing
- importance sampling some of the on-policy episodes will be discarded
- and they should not be executed. `batch_size` can be less than or equal
- to the size of the input batch.
-
- Returns:
- CodeScoreInfo namedtuple instance. This holds not just the computed rewards,
- but additional information computed during code execution which can be used
- for debugging and monitoring. this includes: BF code strings, test cases
- the code was executed on, code outputs from those test cases, and reasons
- for success or failure.
- """
- code_strings = [
- ''.join([misc.bf_int2char(a) for a in action_sequence[:l]])
- for action_sequence, l in zip(batch_actions, episode_lengths)]
- if batch_size is None:
- batch_size = len(code_strings)
- else:
- assert batch_size <= len(code_strings)
- code_strings = code_strings[:batch_size]
-
- if isinstance(rl_batch.reward_fns, (list, tuple)):
- # reward_fns is a list of functions, same length as code_strings.
- assert len(rl_batch.reward_fns) >= batch_size
- r_fn_results = [
- rl_batch.reward_fns[i](code_strings[i]) for i in xrange(batch_size)]
- else:
- # reward_fns is allowed to be one function which processes a batch of code
- # strings. This is useful for efficiency and batch level computation.
- r_fn_results = rl_batch.reward_fns(code_strings)
-
- # Expecting that r_fn returns a list of rewards. Length of list equals
- # length of the code string (including EOS char).
-
- batch_rewards = [r.episode_rewards for r in r_fn_results]
- total_rewards = [sum(b) for b in batch_rewards]
- test_cases = [io_to_text(r.input_case, r.input_type) for r in r_fn_results]
- code_outputs = [io_to_text(r.code_output, r.output_type)
- for r in r_fn_results]
- reasons = [r.reason for r in r_fn_results]
- return CodeScoreInfo(
- code_strings=code_strings,
- batch_rewards=batch_rewards,
- total_rewards=total_rewards,
- test_cases=test_cases,
- code_outputs=code_outputs,
- reasons=reasons)
-
-
-def process_episodes(
- batch_rewards, episode_lengths, a2c=False, baselines=None,
- batch_values=None):
- """Compute REINFORCE targets.
-
- REINFORCE here takes the form:
- grad_t = grad[log(pi(a_t|c_t))*target_t]
- where c_t is context: i.e. RNN state or environment state (or both).
-
- Two types of targets are supported:
- 1) Advantage actor critic (a2c).
- 2) Vanilla REINFORCE with baseline.
-
- Args:
- batch_rewards: Rewards received in each episode in the batch. A numpy array
- of shape [batch_size, max_sequence_length]. Note, these are per-timestep
- rewards, not total reward.
- episode_lengths: Length of each episode. An iterable of length batch_size.
- a2c: A bool. Whether to compute a2c targets (True) or vanilla targets
- (False).
- baselines: If a2c is False, provide baselines for each timestep. This is a
- list (or indexable container) of length max_time. Note: baselines are
- shared across all episodes, which is why there is no batch dimension.
- It is up to the caller to update baselines accordingly.
- batch_values: If a2c is True, provide values computed by a value estimator.
- A numpy array of shape [batch_size, max_sequence_length].
-
- Returns:
- batch_targets: REINFORCE targets for each episode and timestep. A numpy
- array of shape [batch_size, max_sequence_length].
- batch_returns: Returns computed for each episode and timestep. This is for
- reference, and is not used in the REINFORCE gradient update (but was
- used to compute the targets). A numpy array of shape
- [batch_size, max_sequence_length].
- """
- num_programs = len(batch_rewards)
- assert num_programs <= len(episode_lengths)
- batch_returns = [None] * num_programs
- batch_targets = [None] * num_programs
- for i in xrange(num_programs):
- episode_length = episode_lengths[i]
- assert len(batch_rewards[i]) == episode_length
- # Compute target for each timestep.
- # If we are computing A2C:
- # target_t = advantage_t = R_t - V(c_t)
- # where V(c_t) is a learned value function (provided as `values`).
- # Otherwise:
- # target_t = R_t - baselines[t]
- # where `baselines` are provided.
- # In practice we use a more generalized formulation of advantage. See docs
- # for `discounted_advantage_and_rewards`.
- if a2c:
- # Compute advantage.
- assert batch_values is not None
- episode_values = batch_values[i, :episode_length]
- episode_rewards = batch_rewards[i]
- emp_val, gen_adv = rollout_lib.discounted_advantage_and_rewards(
- episode_rewards, episode_values, gamma=1.0, lambda_=1.0)
- batch_returns[i] = emp_val
- batch_targets[i] = gen_adv
- else:
- # Compute return for each timestep. See section 3 of
- # https://arxiv.org/pdf/1602.01783.pdf
- assert baselines is not None
- empirical_returns = rollout_lib.discount(batch_rewards[i], gamma=1.0)
- targets = [None] * episode_length
- for j in xrange(episode_length):
- targets[j] = empirical_returns[j] - baselines[j]
- batch_returns[i] = empirical_returns
- batch_targets[i] = targets
- batch_returns = utils.stack_pad(batch_returns, 0)
- if num_programs:
- batch_targets = utils.stack_pad(batch_targets, 0)
- else:
- batch_targets = np.array([], dtype=np.float32)
-
- return (batch_targets, batch_returns)
diff --git a/research/brain_coder/single_task/pg_agent_test.py b/research/brain_coder/single_task/pg_agent_test.py
deleted file mode 100644
index 503d37ecacbf968b0786b3553e6a97667569bf7d..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/pg_agent_test.py
+++ /dev/null
@@ -1,395 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for pg_agent."""
-
-from collections import Counter
-
-from absl import logging
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from common import utils # brain coder
-from single_task import data # brain coder
-from single_task import defaults # brain coder
-from single_task import misc # brain coder
-from single_task import pg_agent as agent_lib # brain coder
-from single_task import pg_train # brain coder
-
-
-# Symmetric mean absolute percentage error (SMAPE).
-# https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error
-def smape(a, b):
- return 2.0 * abs(a - b) / float(a + b)
-
-
-def onehot(dim, num_dims):
- value = np.zeros(num_dims, dtype=np.float32)
- value[dim] = 1
- return value
-
-
-def random_sequence(max_length, num_tokens, eos=0):
- length = np.random.randint(1, max_length - 1)
- return np.append(np.random.randint(1, num_tokens, length), eos)
-
-
-def repeat_and_pad(v, rep, total_len):
- return [v] * rep + [0.0] * (total_len - rep)
-
-
-class AgentTest(tf.test.TestCase):
-
- def testProcessEpisodes(self):
- batch_size = 3
-
- def reward_fn(code_string):
- return misc.RewardInfo(
- episode_rewards=[float(ord(c)) for c in code_string],
- input_case=[],
- correct_output=[],
- code_output=[],
- input_type=misc.IOType.integer,
- output_type=misc.IOType.integer,
- reason='none')
-
- rl_batch = data.RLBatch(
- reward_fns=[reward_fn for _ in range(batch_size)],
- batch_size=batch_size,
- good_reward=10.0)
- batch_actions = np.asarray([
- [4, 5, 3, 6, 8, 1, 0, 0],
- [1, 2, 3, 4, 0, 0, 0, 0],
- [8, 7, 6, 5, 4, 3, 2, 1]], dtype=np.int32)
- batch_values = np.asarray([
- [0, 1, 2, 1, 0, 1, 1, 0],
- [0, 2, 1, 2, 1, 0, 0, 0],
- [0, 1, 1, 0, 0, 0, 1, 1]], dtype=np.float32)
- episode_lengths = np.asarray([7, 5, 8], dtype=np.int32)
-
- scores = agent_lib.compute_rewards(
- rl_batch, batch_actions, episode_lengths)
- batch_targets, batch_returns = agent_lib.process_episodes(
- scores.batch_rewards, episode_lengths, a2c=True,
- batch_values=batch_values)
- self.assertEqual(
- [[473.0, 428.0, 337.0, 294.0, 201.0, 157.0, 95.0, 0.0],
- [305.0, 243.0, 183.0, 140.0, 95.0, 0.0, 0.0, 0.0],
- [484.0, 440.0, 394.0, 301.0, 210.0, 165.0, 122.0, 62.0]],
- batch_returns.tolist())
- self.assertEqual(
- [[473.0, 427.0, 335.0, 293.0, 201.0, 156.0, 94.0, 0.0],
- [305.0, 241.0, 182.0, 138.0, 94.0, 0.0, 0.0, 0.0],
- [484.0, 439.0, 393.0, 301.0, 210.0, 165.0, 121.0, 61.0]],
- batch_targets.tolist())
-
- def testVarUpdates(self):
- """Tests that variables get updated as expected.
-
- For the RL update, check that gradients are non-zero and that the global
- model gets updated.
- """
- config = defaults.default_config_with_updates(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",eos_token=True,optimizer="sgd",lr=1.0)')
- lr = config.agent.lr
-
- tf.reset_default_graph()
- trainer = pg_train.AsyncTrainer(
- config, task_id=0, ps_tasks=0, num_workers=1)
- global_init_op = tf.variables_initializer(
- tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, 'global'))
- with tf.Session() as sess:
- sess.run(global_init_op) # Initialize global copy.
- trainer.initialize(sess)
- model = trainer.model
- global_vars = sess.run(trainer.global_model.trainable_variables)
- local_vars = sess.run(model.trainable_variables)
-
- # Make sure names match.
- g_prefix = 'global/'
- l_prefix = 'local/'
- for g, l in zip(trainer.global_model.trainable_variables,
- model.trainable_variables):
- self.assertEqual(g.name[len(g_prefix):], l.name[len(l_prefix):])
-
- # Assert that shapes and values are the same between global and local
- # models.
- for g, l in zip(global_vars, local_vars):
- self.assertEqual(g.shape, l.shape)
- self.assertTrue(np.array_equal(g, l))
-
- # Make all gradients dense tensors.
- for param, grad in model.gradients_dict.items():
- if isinstance(grad, tf.IndexedSlices):
- # Converts to dense tensor.
- model.gradients_dict[param] = tf.multiply(grad, 1.0)
-
- # Perform update.
- results = model.update_step(
- sess, trainer.data_manager.sample_rl_batch(), trainer.train_op,
- trainer.global_step, return_gradients=True)
- grads_dict = results.gradients_dict
- for grad in grads_dict.values():
- self.assertIsNotNone(grad)
- self.assertTrue(np.count_nonzero(grad) > 0)
- global_update = sess.run(trainer.global_model.trainable_variables)
- for tf_var, var_before, var_after in zip(
- model.trainable_variables, local_vars, global_update):
- # Check that the params were updated.
- self.assertTrue(np.allclose(
- var_after,
- var_before - grads_dict[tf_var] * lr))
-
- # Test that global to local sync works.
- sess.run(trainer.sync_op)
- global_vars = sess.run(trainer.global_model.trainable_variables)
- local_vars = sess.run(model.trainable_variables)
- for l, g in zip(local_vars, global_vars):
- self.assertTrue(np.allclose(l, g))
-
- def testMonteCarloGradients(self):
- """Test Monte Carlo estimate of REINFORCE gradient.
-
- Test that the Monte Carlo estimate of the REINFORCE gradient is
- approximately equal to the true gradient. We compute the true gradient for a
- toy environment with a very small action space.
-
- Similar to section 5 of https://arxiv.org/pdf/1505.00521.pdf.
- """
- # Test may have different outcome on different machines due to different
- # rounding behavior of float arithmetic.
- tf.reset_default_graph()
- tf.set_random_seed(12345678987654321)
- np.random.seed(1294024302)
- max_length = 2
- num_tokens = misc.bf_num_tokens()
- eos = misc.BF_EOS_INT
- assert eos == 0
- def sequence_iterator(max_length):
- """Iterates through all sequences up to the given length."""
- yield [eos]
- for a in xrange(1, num_tokens):
- if max_length > 1:
- for sub_seq in sequence_iterator(max_length - 1):
- yield [a] + sub_seq
- else:
- yield [a]
- actions = list(sequence_iterator(max_length))
-
- # This batch contains all possible episodes up to max_length.
- actions_batch = utils.stack_pad(actions, 0)
- lengths_batch = [len(s) for s in actions]
-
- reward_map = {tuple(a): np.random.randint(-1, 7) for a in actions_batch}
- # reward_map = {tuple(a): np.random.normal(3, 1)
- # for a in actions_batch} # normal distribution
- # reward_map = {tuple(a): 1.0
- # for a in actions_batch} # expected reward is 1
-
- n = 100000 # MC sample size.
- config = defaults.default_config_with_updates(
- 'env=c(task="print"),'
- 'agent=c(algorithm="pg",optimizer="sgd",lr=1.0,ema_baseline_decay=0.99,'
- 'entropy_beta=0.0,topk_loss_hparam=0.0,regularizer=0.0,'
- 'policy_lstm_sizes=[10],eos_token=True),'
- 'batch_size='+str(n)+',timestep_limit='+str(max_length))
-
- dtype = tf.float64
- trainer = pg_train.AsyncTrainer(
- config, task_id=0, ps_tasks=0, num_workers=1, dtype=dtype)
- model = trainer.model
- actions_ph = model.actions
- lengths_ph = model.adjusted_lengths
- multipliers_ph = model.policy_multipliers
-
- global_init_op = tf.variables_initializer(
- tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, 'global'))
- with tf.Session() as sess, sess.graph.as_default():
- sess.run(global_init_op) # Initialize global copy.
- trainer.initialize(sess)
-
- # Compute exact gradients.
- # exact_grads = sum(P(a) * grad(log P(a)) * R(a) for a in actions_batch)
- true_loss_unnormalized = 0.0
- exact_grads = [np.zeros(v.shape) for v in model.trainable_variables]
- episode_probs_map = {}
- grads_map = {}
- for a_idx in xrange(len(actions_batch)):
- a = actions_batch[a_idx]
- grads_result, probs_result, loss = sess.run(
- [model.dense_unclipped_grads, model.chosen_probs, model.loss],
- {actions_ph: [a],
- lengths_ph: [lengths_batch[a_idx]],
- multipliers_ph: [
- repeat_and_pad(reward_map[tuple(a)],
- lengths_batch[a_idx],
- max_length)]})
- # Take product over time axis.
- episode_probs_result = np.prod(probs_result[0, :lengths_batch[a_idx]])
- for i in range(0, len(exact_grads)):
- exact_grads[i] += grads_result[i] * episode_probs_result
- episode_probs_map[tuple(a)] = episode_probs_result
- reward_map[tuple(a)] = reward_map[tuple(a)]
- grads_map[tuple(a)] = grads_result
- true_loss_unnormalized += loss
- # Normalize loss. Since each episode is feed into the model one at a time,
- # normalization needs to be done manually.
- true_loss = true_loss_unnormalized / float(len(actions_batch))
-
- # Compute Monte Carlo gradients.
- # E_a~P[grad(log P(a)) R(a)] is aprox. eq. to
- # sum(grad(log P(a)) R(a) for a in actions_sampled_from_P) / n
- # where len(actions_sampled_from_P) == n.
- #
- # In other words, sample from the policy and compute the gradients of the
- # log probs weighted by the returns. This will excersize the code in
- # agent.py
- sampled_actions, sampled_lengths = sess.run(
- [model.sampled_tokens, model.episode_lengths])
- pi_multipliers = [
- repeat_and_pad(reward_map[tuple(a)], l, max_length)
- for a, l in zip(sampled_actions, sampled_lengths)]
- mc_grads_unnormalized, sampled_probs, mc_loss_unnormalized = sess.run(
- [model.dense_unclipped_grads, model.chosen_probs, model.loss],
- {actions_ph: sampled_actions,
- multipliers_ph: pi_multipliers,
- lengths_ph: sampled_lengths})
- # Loss is already normalized across the minibatch, so no normalization
- # is needed.
- mc_grads = mc_grads_unnormalized
- mc_loss = mc_loss_unnormalized
-
- # Make sure true loss and MC loss are similar.
- loss_error = smape(true_loss, mc_loss)
- self.assertTrue(loss_error < 0.15, msg='actual: %s' % loss_error)
-
- # Check that probs computed for episodes sampled from the model are the same
- # as the recorded true probs.
- for i in range(100):
- acs = tuple(sampled_actions[i].tolist())
- sampled_prob = np.prod(sampled_probs[i, :sampled_lengths[i]])
- self.assertTrue(np.isclose(episode_probs_map[acs], sampled_prob))
-
- # Make sure MC estimates of true probs are close.
- counter = Counter(tuple(e) for e in sampled_actions)
- for acs, count in counter.iteritems():
- mc_prob = count / float(len(sampled_actions))
- true_prob = episode_probs_map[acs]
- error = smape(mc_prob, true_prob)
- self.assertTrue(
- error < 0.15,
- msg='actual: %s; count: %s; mc_prob: %s; true_prob: %s'
- % (error, count, mc_prob, true_prob))
-
- # Manually recompute MC gradients and make sure they match MC gradients
- # computed in TF.
- mc_grads_recompute = [np.zeros(v.shape) for v in model.trainable_variables]
- for i in range(n):
- acs = tuple(sampled_actions[i].tolist())
- for i in range(0, len(mc_grads_recompute)):
- mc_grads_recompute[i] += grads_map[acs][i]
- for i in range(0, len(mc_grads_recompute)):
- self.assertTrue(np.allclose(mc_grads[i], mc_grads_recompute[i] / n))
-
- # Check angle between gradients as fraction of pi.
- for index in range(len(mc_grads)):
- v1 = mc_grads[index].reshape(-1)
- v2 = exact_grads[index].reshape(-1)
- # angle = arccos(v1 . v2 / (|v1|*|v2|))
- angle_rad = np.arccos(
- np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)))
- logging.info('angle / pi: %s', angle_rad / np.pi)
- angle_frac = angle_rad / np.pi
- self.assertTrue(angle_frac < 0.02, msg='actual: %s' % angle_frac)
- # Check norms.
- for index in range(len(mc_grads)):
- v1_norm = np.linalg.norm(mc_grads[index].reshape(-1))
- v2_norm = np.linalg.norm(exact_grads[index].reshape(-1))
- error = smape(v1_norm, v2_norm)
- self.assertTrue(error < 0.02, msg='actual: %s' % error)
-
- # Check expected rewards.
- # E_a~P[R(a)] approx eq sum(P(a) * R(a) for a in actions)
- mc_expected_reward = np.mean(
- [reward_map[tuple(a)] for a in sampled_actions])
- exact_expected_reward = np.sum(
- [episode_probs_map[k] * reward_map[k] for k in reward_map])
- error = smape(mc_expected_reward, exact_expected_reward)
- self.assertTrue(error < 0.005, msg='actual: %s' % angle_frac)
-
- def testNumericalGradChecking(self):
- # Similar to
- # http://ufldl.stanford.edu/wiki/index.php/Gradient_checking_and_advanced_optimization.
- epsilon = 1e-4
- eos = misc.BF_EOS_INT
- self.assertEqual(0, eos)
- config = defaults.default_config_with_updates(
- 'env=c(task="print"),'
- 'agent=c(algorithm="pg",optimizer="sgd",lr=1.0,ema_baseline_decay=0.99,'
- 'entropy_beta=0.0,topk_loss_hparam=0.0,policy_lstm_sizes=[10],'
- 'eos_token=True),'
- 'batch_size=64')
- dtype = tf.float64
- tf.reset_default_graph()
- tf.set_random_seed(12345678987654321)
- np.random.seed(1294024302)
- trainer = pg_train.AsyncTrainer(
- config, task_id=0, ps_tasks=0, num_workers=1, dtype=dtype)
- model = trainer.model
- actions_ph = model.actions
- lengths_ph = model.adjusted_lengths
- multipliers_ph = model.policy_multipliers
- loss = model.pi_loss
- global_init_op = tf.variables_initializer(
- tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, 'global'))
-
- assign_add_placeholders = [None] * len(model.trainable_variables)
- assign_add_ops = [None] * len(model.trainable_variables)
- param_shapes = [None] * len(model.trainable_variables)
- for i, param in enumerate(model.trainable_variables):
- param_shapes[i] = param.get_shape().as_list()
- assign_add_placeholders[i] = tf.placeholder(dtype,
- np.prod(param_shapes[i]))
- assign_add_ops[i] = param.assign_add(
- tf.reshape(assign_add_placeholders[i], param_shapes[i]))
-
- with tf.Session() as sess:
- sess.run(global_init_op) # Initialize global copy.
- trainer.initialize(sess)
-
- actions_raw = [random_sequence(10, 9) for _ in xrange(16)]
- actions_batch = utils.stack_pad(actions_raw, 0)
- lengths_batch = [len(l) for l in actions_raw]
- feed = {actions_ph: actions_batch,
- multipliers_ph: np.ones_like(actions_batch),
- lengths_ph: lengths_batch}
-
- estimated_grads = [None] * len(model.trainable_variables)
- for i, param in enumerate(model.trainable_variables):
- param_size = np.prod(param_shapes[i])
- estimated_grads[i] = np.zeros(param_size, dtype=np.float64)
- for index in xrange(param_size):
- e = onehot(index, param_size) * epsilon
- sess.run(assign_add_ops[i],
- {assign_add_placeholders[i]: e})
- j_plus = sess.run(loss, feed)
- sess.run(assign_add_ops[i],
- {assign_add_placeholders[i]: -2 * e})
- j_minus = sess.run(loss, feed)
- sess.run(assign_add_ops[i],
- {assign_add_placeholders[i]: e})
- estimated_grads[i][index] = (j_plus - j_minus) / (2 * epsilon)
- estimated_grads[i] = estimated_grads[i].reshape(param_shapes[i])
-
- analytic_grads = sess.run(model.dense_unclipped_grads, feed)
-
- for g1, g2 in zip(estimated_grads[1:], analytic_grads[1:]):
- logging.info('norm (g1-g2): %s', np.abs(g1 - g2).mean())
- self.assertTrue(np.allclose(g1, g2))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/pg_train.py b/research/brain_coder/single_task/pg_train.py
deleted file mode 100644
index fde7cc84729a56002e8688d268a2085432ee124e..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/pg_train.py
+++ /dev/null
@@ -1,782 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-r"""Train RL agent on coding tasks."""
-
-import contextlib
-import cPickle
-import cProfile
-import marshal
-import os
-import time
-
-from absl import flags
-from absl import logging
-import tensorflow as tf
-
-# internal session lib import
-
-from single_task import data # brain coder
-from single_task import defaults # brain coder
-from single_task import pg_agent as agent_lib # brain coder
-from single_task import results_lib # brain coder
-
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string(
- 'master', '',
- 'URL of the TensorFlow master to use.')
-flags.DEFINE_integer(
- 'ps_tasks', 0,
- 'Number of parameter server tasks. Only set to 0 for '
- 'single worker training.')
-flags.DEFINE_integer(
- 'summary_interval', 10,
- 'How often to write summaries.')
-flags.DEFINE_integer(
- 'summary_tasks', 16,
- 'If greater than 0 only tasks 0 through summary_tasks - 1 '
- 'will write summaries. If 0, all tasks will write '
- 'summaries.')
-flags.DEFINE_bool(
- 'stop_on_success', True,
- 'If True, training will stop as soon as a solution is found. '
- 'If False, training will continue indefinitely until another '
- 'stopping condition is reached.')
-flags.DEFINE_bool(
- 'do_profiling', False,
- 'If True, cProfile profiler will run and results will be '
- 'written to logdir. WARNING: Results will not be written if '
- 'the code crashes. Make sure it exists successfully.')
-flags.DEFINE_integer('model_v', 0, 'Model verbosity level.')
-flags.DEFINE_bool(
- 'delayed_graph_cleanup', True,
- 'If true, container for n-th run will not be reset until the (n+1)-th run '
- 'is complete. This greatly reduces the chance that a worker is still '
- 'using the n-th container when it is cleared.')
-
-
-def define_tuner_hparam_space(hparam_space_type):
- """Define tunable hparams for grid search."""
- if hparam_space_type not in ('pg', 'pg-topk', 'topk', 'is'):
- raise ValueError('Hparam space is not valid: "%s"' % hparam_space_type)
-
- # Discrete hparam space is stored as a dict from hparam name to discrete
- # values.
- hparam_space = {}
-
- if hparam_space_type in ('pg', 'pg-topk', 'is'):
- # Add a floating point parameter named learning rate.
- hparam_space['lr'] = [1e-5, 1e-4, 1e-3]
- hparam_space['entropy_beta'] = [0.005, 0.01, 0.05, 0.10]
- else: # 'topk'
- # Add a floating point parameter named learning rate.
- hparam_space['lr'] = [1e-5, 1e-4, 1e-3]
- hparam_space['entropy_beta'] = [0.0, 0.005, 0.01, 0.05, 0.10]
-
- if hparam_space_type in ('topk', 'pg-topk'):
- # topk tuning will be enabled.
- hparam_space['topk'] = [10]
- hparam_space['topk_loss_hparam'] = [1.0, 10.0, 50.0, 200.0]
-
- elif hparam_space_type == 'is':
- # importance sampling tuning will be enabled.
- hparam_space['replay_temperature'] = [0.25, 0.5, 1.0, 2.0]
- hparam_space['alpha'] = [0.5, 0.75, 63/64.]
-
- return hparam_space
-
-
-def write_hparams_to_config(config, hparams, hparam_space_type):
- """Write hparams given by the tuner into the Config object."""
- if hparam_space_type not in ('pg', 'pg-topk', 'topk', 'is'):
- raise ValueError('Hparam space is not valid: "%s"' % hparam_space_type)
-
- config.agent.lr = hparams.lr
- config.agent.entropy_beta = hparams.entropy_beta
-
- if hparam_space_type in ('topk', 'pg-topk'):
- # topk tuning will be enabled.
- config.agent.topk = hparams.topk
- config.agent.topk_loss_hparam = hparams.topk_loss_hparam
- elif hparam_space_type == 'is':
- # importance sampling tuning will be enabled.
- config.agent.replay_temperature = hparams.replay_temperature
- config.agent.alpha = hparams.alpha
-
-
-def make_initialized_variable(value, name, shape=None, dtype=tf.float32):
- """Create a tf.Variable with a constant initializer.
-
- Args:
- value: Constant value to initialize the variable with. This is the value
- that the variable starts with.
- name: Name of the variable in the TF graph.
- shape: Shape of the variable. If None, variable will be a scalar.
- dtype: Data type of the variable. Should be a TF dtype. Defaults to
- tf.float32.
-
- Returns:
- tf.Variable instance.
- """
- if shape is None:
- shape = []
- return tf.get_variable(
- name=name, shape=shape, initializer=tf.constant_initializer(value),
- dtype=dtype, trainable=False)
-
-
-class AsyncTrainer(object):
- """Manages graph creation and training.
-
- This async trainer creates a global model on the parameter server, and a local
- model (for this worker). Gradient updates are sent to the global model, and
- the updated weights are synced to the local copy.
- """
-
- def __init__(self, config, task_id, ps_tasks, num_workers, is_chief=True,
- summary_writer=None,
- dtype=tf.float32,
- summary_interval=1,
- run_number=0,
- logging_dir='/tmp', model_v=0):
- self.config = config
- self.data_manager = data.DataManager(
- config, run_number=run_number,
- do_code_simplification=not FLAGS.stop_on_success)
- self.task_id = task_id
- self.ps_tasks = ps_tasks
- self.is_chief = is_chief
- if ps_tasks == 0:
- assert task_id == 0, 'No parameter servers specified. Expecting 1 task.'
- assert num_workers == 1, (
- 'No parameter servers specified. Expecting 1 task.')
- worker_device = '/job:localhost/replica:%d/task:0/cpu:0' % task_id
- # worker_device = '/cpu:0'
- # ps_device = '/cpu:0'
- else:
- assert num_workers > 0, 'There must be at least 1 training worker.'
- worker_device = '/job:worker/replica:%d/task:0/cpu:0' % task_id
- # ps_device = '/job:ps/replica:0/task:0/cpu:0'
- logging.info('worker_device: %s', worker_device)
-
- logging_file = os.path.join(
- logging_dir, 'solutions_%d.txt' % task_id)
- experience_replay_file = os.path.join(
- logging_dir, 'replay_buffer_%d.pickle' % task_id)
- self.topk_file = os.path.join(
- logging_dir, 'topk_buffer_%d.pickle' % task_id)
-
- tf.get_variable_scope().set_use_resource(True)
-
- # global model
- with tf.device(tf.train.replica_device_setter(ps_tasks,
- ps_device='/job:ps/replica:0',
- worker_device=worker_device)):
- with tf.variable_scope('global'):
- global_model = agent_lib.LMAgent(config, dtype=dtype, is_local=False)
- global_params_dict = {p.name: p
- for p in global_model.sync_variables}
- self.global_model = global_model
- self.global_step = make_initialized_variable(
- 0, 'global_step', dtype=tf.int64)
-
- self.global_best_reward = make_initialized_variable(
- -10.0, 'global_best_reward', dtype=tf.float64)
- self.is_best_model = make_initialized_variable(
- False, 'is_best_model', dtype=tf.bool)
- self.reset_is_best_model = self.is_best_model.assign(False)
- self.global_best_reward_placeholder = tf.placeholder(
- tf.float64, [], name='global_best_reward_placeholder')
- self.assign_global_best_reward_op = tf.group(
- self.global_best_reward.assign(
- self.global_best_reward_placeholder),
- self.is_best_model.assign(True))
- def assign_global_best_reward_fn(session, reward):
- reward = round(reward, 10)
- best_reward = round(session.run(self.global_best_reward), 10)
- is_best = reward > best_reward
- if is_best:
- session.run(self.assign_global_best_reward_op,
- {self.global_best_reward_placeholder: reward})
- return is_best
- self.assign_global_best_reward_fn = assign_global_best_reward_fn
-
- # Any worker will set to true when it finds a solution.
- self.found_solution_flag = make_initialized_variable(
- False, 'found_solution_flag', dtype=tf.bool)
- self.found_solution_op = self.found_solution_flag.assign(True)
-
- self.run_number = make_initialized_variable(
- run_number, 'run_number', dtype=tf.int32)
-
- # Store a solution when found.
- self.code_solution_variable = tf.get_variable(
- 'code_solution', [], tf.string,
- initializer=tf.constant_initializer(''))
- self.code_solution_ph = tf.placeholder(
- tf.string, [], name='code_solution_ph')
- self.code_solution_assign_op = self.code_solution_variable.assign(
- self.code_solution_ph)
- def assign_code_solution_fn(session, code_solution_string):
- session.run(self.code_solution_assign_op,
- {self.code_solution_ph: code_solution_string})
- self.assign_code_solution_fn = assign_code_solution_fn
-
- # Count all programs sampled from policy. This does not include
- # programs sampled from replay buffer.
- # This equals NPE (number of programs executed). Only programs sampled
- # from the policy need to be executed.
- self.program_count = make_initialized_variable(
- 0, 'program_count', dtype=tf.int64)
-
- # local model
- with tf.device(worker_device):
- with tf.variable_scope('local'):
- self.model = model = agent_lib.LMAgent(
- config,
- task_id=task_id,
- logging_file=logging_file,
- experience_replay_file=experience_replay_file,
- dtype=dtype,
- global_best_reward_fn=self.assign_global_best_reward_fn,
- found_solution_op=self.found_solution_op,
- assign_code_solution_fn=self.assign_code_solution_fn,
- program_count=self.program_count,
- stop_on_success=FLAGS.stop_on_success,
- verbose_level=model_v)
- local_params = model.trainable_variables
- local_params_dict = {p.name: p for p in local_params}
-
- # Pull global params to local model.
- def _global_to_local_scope(name):
- assert name.startswith('global/')
- return 'local' + name[6:]
- sync_dict = {
- local_params_dict[_global_to_local_scope(p_name)]: p
- for p_name, p in global_params_dict.items()}
- self.sync_op = tf.group(*[v_local.assign(v_global)
- for v_local, v_global
- in sync_dict.items()])
-
- # Pair local gradients with global params.
- grad_var_dict = {
- gradient: sync_dict[local_var]
- for local_var, gradient in model.gradients_dict.items()}
-
- # local model
- model.make_summary_ops() # Don't put summaries under 'local' scope.
- with tf.variable_scope('local'):
- self.train_op = model.optimizer.apply_gradients(
- grad_var_dict.items(), global_step=self.global_step)
- self.local_init_op = tf.variables_initializer(
- tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
- tf.get_variable_scope().name))
-
- self.local_step = 0
- self.last_summary_time = time.time()
- self.summary_interval = summary_interval
- self.summary_writer = summary_writer
- self.cached_global_step = -1
- self.cached_global_npe = -1
-
- logging.info('summary_interval: %d', self.summary_interval)
-
- # Load top-k buffer.
- if self.model.top_episodes is not None and tf.gfile.Exists(self.topk_file):
- try:
- with tf.gfile.FastGFile(self.topk_file, 'r') as f:
- self.model.top_episodes = cPickle.loads(f.read())
- logging.info(
- 'Loaded top-k buffer from disk with %d items. Location: "%s"',
- len(self.model.top_episodes), self.topk_file)
- except (cPickle.UnpicklingError, EOFError) as e:
- logging.warn(
- 'Failed to load existing top-k buffer from disk. Removing bad file.'
- '\nLocation: "%s"\nException: %s', self.topk_file, str(e))
- tf.gfile.Remove(self.topk_file)
-
- def initialize(self, session):
- """Run initialization ops."""
- session.run(self.local_init_op)
- session.run(self.sync_op)
- self.cached_global_step, self.cached_global_npe = session.run(
- [self.global_step, self.program_count])
-
- def update_global_model(self, session):
- """Run an update step.
-
- 1) Asynchronously copy global weights to local model.
- 2) Call into local model's update_step method, which does the following:
- a) Sample batch of programs from policy.
- b) Compute rewards.
- c) Compute gradients and update the global model asynchronously.
- 3) Write tensorboard summaries to disk.
-
- Args:
- session: tf.Session instance.
- """
- session.run(self.sync_op) # Copy weights from global to local.
-
- with session.as_default():
- result = self.model.update_step(
- session, self.data_manager.sample_rl_batch(), self.train_op,
- self.global_step)
- global_step = result.global_step
- global_npe = result.global_npe
- summaries = result.summaries_list
- self.cached_global_step = global_step
- self.cached_global_npe = global_npe
- self.local_step += 1
-
- if self.summary_writer and self.local_step % self.summary_interval == 0:
- if not isinstance(summaries, (tuple, list)):
- summaries = [summaries]
- summaries.append(self._local_step_summary())
- if self.is_chief:
- (global_best_reward,
- found_solution_flag,
- program_count) = session.run(
- [self.global_best_reward,
- self.found_solution_flag,
- self.program_count])
- summaries.append(
- tf.Summary(
- value=[tf.Summary.Value(
- tag='model/best_reward',
- simple_value=global_best_reward)]))
- summaries.append(
- tf.Summary(
- value=[tf.Summary.Value(
- tag='model/solution_found',
- simple_value=int(found_solution_flag))]))
- summaries.append(
- tf.Summary(
- value=[tf.Summary.Value(
- tag='model/program_count',
- simple_value=program_count)]))
- for s in summaries:
- self.summary_writer.add_summary(s, global_step)
- self.last_summary_time = time.time()
-
- def _local_step_summary(self):
- """Compute number of local steps per time increment."""
- dt = time.time() - self.last_summary_time
- steps_per_time = self.summary_interval / float(dt)
- return tf.Summary(value=[
- tf.Summary.Value(
- tag='local_step/per_sec',
- simple_value=steps_per_time),
- tf.Summary.Value(
- tag='local_step/step',
- simple_value=self.local_step)])
-
- def maybe_save_best_model(self, session, saver, checkpoint_file):
- """Check if this model got the highest reward and save to disk if so."""
- if self.is_chief and session.run(self.is_best_model):
- logging.info('Saving best model to "%s"', checkpoint_file)
- saver.save(session, checkpoint_file)
- session.run(self.reset_is_best_model)
-
- def save_replay_buffer(self):
- """Save replay buffer to disk.
-
- Call this periodically so that training can recover if jobs go down.
- """
- if self.model.experience_replay is not None:
- logging.info('Saving experience replay buffer to "%s".',
- self.model.experience_replay.save_file)
- self.model.experience_replay.incremental_save(True)
-
- def delete_replay_buffer(self):
- """Delete replay buffer from disk.
-
- Call this at the end of training to clean up. Replay buffer can get very
- large.
- """
- if self.model.experience_replay is not None:
- logging.info('Deleting experience replay buffer at "%s".',
- self.model.experience_replay.save_file)
- tf.gfile.Remove(self.model.experience_replay.save_file)
-
- def save_topk_buffer(self):
- """Save top-k buffer to disk.
-
- Call this periodically so that training can recover if jobs go down.
- """
- if self.model.top_episodes is not None:
- logging.info('Saving top-k buffer to "%s".', self.topk_file)
- # Overwrite previous data each time.
- with tf.gfile.FastGFile(self.topk_file, 'w') as f:
- f.write(cPickle.dumps(self.model.top_episodes))
-
-
-@contextlib.contextmanager
-def managed_session(sv, master='', config=None,
- start_standard_services=True,
- close_summary_writer=True,
- max_wait_secs=7200):
- # Same as Supervisor.managed_session, but with configurable timeout.
- try:
- sess = sv.prepare_or_wait_for_session(
- master=master, config=config,
- start_standard_services=start_standard_services,
- max_wait_secs=max_wait_secs)
- yield sess
- except tf.errors.DeadlineExceededError:
- raise
- except Exception as e: # pylint: disable=broad-except
- sv.request_stop(e)
- finally:
- try:
- # Request all the threads to stop and wait for them to do so. Any
- # exception raised by the threads is raised again from stop().
- # Passing stop_grace_period_secs is for blocked enqueue/dequeue
- # threads which are not checking for `should_stop()`. They
- # will be stopped when we close the session further down.
- sv.stop(close_summary_writer=close_summary_writer)
- finally:
- # Close the session to finish up all pending calls. We do not care
- # about exceptions raised when closing. This takes care of
- # blocked enqueue/dequeue calls.
- try:
- sess.close()
- except Exception: # pylint: disable=broad-except
- # Silently ignore exceptions raised by close().
- pass
-
-
-def train(config, is_chief, tuner=None, run_dir=None, run_number=0,
- results_writer=None):
- """Run training loop.
-
- Args:
- config: config_lib.Config instance containing global config (agent and env).
- is_chief: True if this worker is chief. Chief worker manages writing some
- data to disk and initialization of the global model.
- tuner: A tuner instance. If not tuning, leave as None.
- run_dir: Directory where all data for this run will be written. If None,
- run_dir = FLAGS.logdir. Set this argument when doing multiple runs.
- run_number: Which run is this.
- results_writer: Managest writing training results to disk. Results are a
- dict of metric names and values.
-
- Returns:
- The trainer object used to run training updates.
- """
- logging.info('Will run asynchronous training.')
-
- if run_dir is None:
- run_dir = FLAGS.logdir
- train_dir = os.path.join(run_dir, 'train')
- best_model_checkpoint = os.path.join(train_dir, 'best.ckpt')
- events_dir = '%s/events_%d' % (run_dir, FLAGS.task_id)
- logging.info('Events directory: %s', events_dir)
-
- logging_dir = os.path.join(run_dir, 'logs')
- if not tf.gfile.Exists(logging_dir):
- tf.gfile.MakeDirs(logging_dir)
- status_file = os.path.join(logging_dir, 'status.txt')
-
- if FLAGS.summary_tasks and FLAGS.task_id < FLAGS.summary_tasks:
- summary_writer = tf.summary.FileWriter(events_dir)
- else:
- summary_writer = None
-
- # Only profile task 0.
- if FLAGS.do_profiling:
- logging.info('Profiling enabled')
- profiler = cProfile.Profile()
- profiler.enable()
- else:
- profiler = None
-
- trainer = AsyncTrainer(
- config, FLAGS.task_id, FLAGS.ps_tasks, FLAGS.num_workers,
- is_chief=is_chief,
- summary_interval=FLAGS.summary_interval,
- summary_writer=summary_writer,
- logging_dir=logging_dir,
- run_number=run_number,
- model_v=FLAGS.model_v)
-
- variables_to_save = [v for v in tf.global_variables()
- if v.name.startswith('global')]
- global_init_op = tf.variables_initializer(variables_to_save)
- saver = tf.train.Saver(variables_to_save)
-
- var_list = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
- tf.get_variable_scope().name)
- logging.info('Trainable vars:')
- for v in var_list:
- logging.info(' %s, %s, %s', v.name, v.device, v.get_shape())
-
- logging.info('All vars:')
- for v in tf.global_variables():
- logging.info(' %s, %s, %s', v.name, v.device, v.get_shape())
-
- def init_fn(unused_sess):
- logging.info('No checkpoint found. Initialized global params.')
-
- sv = tf.train.Supervisor(is_chief=is_chief,
- logdir=train_dir,
- saver=saver,
- summary_op=None,
- init_op=global_init_op,
- init_fn=init_fn,
- summary_writer=summary_writer,
- ready_op=tf.report_uninitialized_variables(
- variables_to_save),
- ready_for_local_init_op=None,
- global_step=trainer.global_step,
- save_model_secs=30,
- save_summaries_secs=30)
-
- # Add a thread that periodically checks if this Trial should stop
- # based on an early stopping policy.
- if tuner:
- sv.Loop(60, tuner.check_for_stop, (sv.coord,))
-
- last_replay_save_time = time.time()
-
- global_step = -1
- logging.info(
- 'Starting session. '
- 'If this hangs, we\'re mostly likely waiting to connect '
- 'to the parameter server. One common cause is that the parameter '
- 'server DNS name isn\'t resolving yet, or is misspecified.')
- should_retry = True
- supervisor_deadline_exceeded = False
- while should_retry:
- try:
- with managed_session(
- sv, FLAGS.master, max_wait_secs=60) as session, session.as_default():
- should_retry = False
- do_training = True
-
- try:
- trainer.initialize(session)
- if session.run(trainer.run_number) != run_number:
- # If we loaded existing model from disk, and the saved run number is
- # different, throw an exception.
- raise RuntimeError(
- 'Expecting to be on run %d, but is actually on run %d. '
- 'run_dir: "%s"'
- % (run_number, session.run(trainer.run_number), run_dir))
- global_step = trainer.cached_global_step
- logging.info('Starting training at step=%d', global_step)
- while do_training:
- trainer.update_global_model(session)
-
- if is_chief:
- trainer.maybe_save_best_model(
- session, saver, best_model_checkpoint)
- global_step = trainer.cached_global_step
- global_npe = trainer.cached_global_npe
-
- if time.time() - last_replay_save_time >= 30:
- trainer.save_replay_buffer()
- trainer.save_topk_buffer()
- last_replay_save_time = time.time()
-
- # Stopping conditions.
- if tuner and tuner.should_trial_stop():
- logging.info('Tuner requested early stopping. Finishing.')
- do_training = False
- if is_chief and FLAGS.stop_on_success:
- found_solution = session.run(trainer.found_solution_flag)
- if found_solution:
- do_training = False
- logging.info('Solution found. Finishing.')
- if FLAGS.max_npe and global_npe >= FLAGS.max_npe:
- # Max NPE (number of programs executed) reached.
- logging.info('Max NPE reached. Finishing.')
- do_training = False
- if sv.should_stop():
- logging.info('Supervisor issued stop. Finishing.')
- do_training = False
-
- except tf.errors.NotFoundError:
- # Catch "Error while reading resource variable".
- # The chief worker likely destroyed the container, so do not retry.
- logging.info('Caught NotFoundError. Quitting.')
- do_training = False
- should_retry = False
- break
- except tf.errors.InternalError as e:
- # Catch "Invalid variable reference."
- if str(e).startswith('Invalid variable reference.'):
- # The chief worker likely destroyed the container, so do not
- # retry.
- logging.info(
- 'Caught "InternalError: Invalid variable reference.". '
- 'Quitting.')
- do_training = False
- should_retry = False
- break
- else:
- # Pass exception through.
- raise
-
- # Exited training loop. Write results to disk.
- if is_chief and results_writer:
- assert not should_retry
- with tf.gfile.FastGFile(status_file, 'w') as f:
- f.write('done')
- (program_count,
- found_solution,
- code_solution,
- best_reward,
- global_step) = session.run(
- [trainer.program_count,
- trainer.found_solution_flag,
- trainer.code_solution_variable,
- trainer.global_best_reward,
- trainer.global_step])
- results_dict = {
- 'max_npe': FLAGS.max_npe,
- 'batch_size': config.batch_size,
- 'max_batches': FLAGS.max_npe // config.batch_size,
- 'npe': program_count,
- 'max_global_repetitions': FLAGS.num_repetitions,
- 'max_local_repetitions': FLAGS.num_repetitions,
- 'code_solution': code_solution,
- 'best_reward': best_reward,
- 'num_batches': global_step,
- 'found_solution': found_solution,
- 'task': trainer.data_manager.task_name,
- 'global_rep': run_number}
- logging.info('results_dict: %s', results_dict)
- results_writer.append(results_dict)
-
- except tf.errors.AbortedError:
- # Catch "Graph handle is not found" error due to preempted jobs.
- logging.info('Caught AbortedError. Retying.')
- should_retry = True
- except tf.errors.DeadlineExceededError:
- supervisor_deadline_exceeded = True
- should_retry = False
-
- if is_chief:
- logging.info('This is chief worker. Stopping all workers.')
- sv.stop()
-
- if supervisor_deadline_exceeded:
- logging.info('Supervisor timed out. Quitting.')
- else:
- logging.info('Reached %s steps. Worker stopped.', global_step)
-
- # Dump profiling.
- """
- How to use profiling data.
-
- Download the profiler dump to your local machine, say to PROF_FILE_PATH.
- In a separate script, run something like the following:
-
- import pstats
- p = pstats.Stats(PROF_FILE_PATH)
- p.strip_dirs().sort_stats('cumtime').print_stats()
-
- This will sort by 'cumtime', which "is the cumulative time spent in this and
- all subfunctions (from invocation till exit)."
- https://docs.python.org/2/library/profile.html#instant-user-s-manual
- """ # pylint: disable=pointless-string-statement
- if profiler:
- prof_file = os.path.join(run_dir, 'task_%d.prof' % FLAGS.task_id)
- logging.info('Done profiling.\nDumping to "%s".', prof_file)
- profiler.create_stats()
- with tf.gfile.Open(prof_file, 'w') as f:
- f.write(marshal.dumps(profiler.stats))
-
- return trainer
-
-
-def run_training(config=None, tuner=None, logdir=None, trial_name=None,
- is_chief=True):
- """Do all training runs.
-
- This is the top level training function for policy gradient based models.
- Run this from the main function.
-
- Args:
- config: config_lib.Config instance containing global config (agent and
- environment hparams). If None, config will be parsed from FLAGS.config.
- tuner: A tuner instance. Leave as None if not tuning.
- logdir: Parent directory where all data from all runs will be written. If
- None, FLAGS.logdir will be used.
- trial_name: If tuning, set this to a unique string that identifies this
- trial. If `tuner` is not None, this also must be set.
- is_chief: True if this worker is the chief.
-
- Returns:
- List of results dicts which were written to disk. Each training run gets a
- results dict. Results dict contains metrics, i.e. (name, value) pairs which
- give information about the training run.
-
- Raises:
- ValueError: If results dicts read from disk contain invalid data.
- """
- if not config:
- # If custom config is not given, get it from flags.
- config = defaults.default_config_with_updates(FLAGS.config)
- if not logdir:
- logdir = FLAGS.logdir
- if not tf.gfile.Exists(logdir):
- tf.gfile.MakeDirs(logdir)
- assert FLAGS.num_repetitions > 0
- results = results_lib.Results(logdir)
- results_list, _ = results.read_all()
-
- logging.info('Starting experiment. Directory: "%s"', logdir)
-
- if results_list:
- if results_list[0]['max_npe'] != FLAGS.max_npe:
- raise ValueError(
- 'Cannot resume training. Max-NPE changed. Was %s, now %s',
- results_list[0]['max_npe'], FLAGS.max_npe)
- if results_list[0]['max_global_repetitions'] != FLAGS.num_repetitions:
- raise ValueError(
- 'Cannot resume training. Number of repetitions changed. Was %s, '
- 'now %s',
- results_list[0]['max_global_repetitions'],
- FLAGS.num_repetitions)
-
- while len(results_list) < FLAGS.num_repetitions:
- run_number = len(results_list)
- rep_container_name = trial_name if trial_name else 'container'
- if FLAGS.num_repetitions > 1:
- rep_dir = os.path.join(logdir, 'run_%d' % run_number)
- rep_container_name = rep_container_name + '_run_' + str(run_number)
- else:
- rep_dir = logdir
-
- logging.info(
- 'Starting repetition %d (%d out of %d)', run_number, run_number + 1,
- FLAGS.num_repetitions)
-
- # Train will write result to disk.
- with tf.container(rep_container_name):
- trainer = train(config, is_chief, tuner, rep_dir, run_number, results)
- logging.info('Done training.')
-
- if is_chief:
- # Destroy current container immediately (clears current graph).
- logging.info('Clearing shared variables.')
- tf.Session.reset(FLAGS.master, containers=[rep_container_name])
- logging.info('Shared variables cleared.')
-
- # Delete replay buffer on disk.
- assert trainer
- trainer.delete_replay_buffer()
- else:
- # Give chief worker time to clean up.
- sleep_sec = 30.0
- logging.info('Sleeping for %s sec.', sleep_sec)
- time.sleep(sleep_sec)
- tf.reset_default_graph()
- logging.info('Default graph reset.')
-
- # Expecting that train wrote new result to disk before returning.
- results_list, _ = results.read_all()
- return results_list
diff --git a/research/brain_coder/single_task/pg_train_test.py b/research/brain_coder/single_task/pg_train_test.py
deleted file mode 100644
index 0a562e5331e638cab82bc8033bfa2c1fc355e960..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/pg_train_test.py
+++ /dev/null
@@ -1,87 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for pg_train.
-
-These tests excersize code paths available through configuration options.
-Training will be run for just a few steps with the goal being to check that
-nothing crashes.
-"""
-
-from absl import flags
-import tensorflow as tf
-
-from single_task import defaults # brain coder
-from single_task import run # brain coder
-
-FLAGS = flags.FLAGS
-
-
-class TrainTest(tf.test.TestCase):
-
- def RunTrainingSteps(self, config_string, num_steps=10):
- """Run a few training steps with the given config.
-
- Just check that nothing crashes.
-
- Args:
- config_string: Config encoded in a string. See
- $REPO_PATH/common/config_lib.py
- num_steps: Number of training steps to run. Defaults to 10.
- """
- config = defaults.default_config_with_updates(config_string)
- FLAGS.master = ''
- FLAGS.max_npe = num_steps * config.batch_size
- FLAGS.summary_interval = 1
- FLAGS.logdir = tf.test.get_temp_dir()
- FLAGS.config = config_string
- tf.reset_default_graph()
- run.main(None)
-
- def testVanillaPolicyGradient(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg"),'
- 'timestep_limit=90,batch_size=64')
-
- def testVanillaPolicyGradient_VariableLengthSequences(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",eos_token=False),'
- 'timestep_limit=90,batch_size=64')
-
- def testVanillaActorCritic(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",ema_baseline_decay=0.0),'
- 'timestep_limit=90,batch_size=64')
-
- def testPolicyGradientWithTopK(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",topk_loss_hparam=1.0,topk=10),'
- 'timestep_limit=90,batch_size=64')
-
- def testVanillaActorCriticWithTopK(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",ema_baseline_decay=0.0,topk_loss_hparam=1.0,'
- 'topk=10),'
- 'timestep_limit=90,batch_size=64')
-
- def testPolicyGradientWithTopK_VariableLengthSequences(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",topk_loss_hparam=1.0,topk=10,eos_token=False),'
- 'timestep_limit=90,batch_size=64')
-
- def testPolicyGradientWithImportanceSampling(self):
- self.RunTrainingSteps(
- 'env=c(task="reverse"),'
- 'agent=c(algorithm="pg",alpha=0.5),'
- 'timestep_limit=90,batch_size=64')
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/results_lib.py b/research/brain_coder/single_task/results_lib.py
deleted file mode 100644
index fd28fdd49ba3200dc9faa18d1722235ee4bf2ac2..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/results_lib.py
+++ /dev/null
@@ -1,155 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Results object manages distributed reading and writing of results to disk."""
-
-import ast
-from collections import namedtuple
-import os
-import re
-from six.moves import xrange
-import tensorflow as tf
-
-
-ShardStats = namedtuple(
- 'ShardStats',
- ['num_local_reps_completed', 'max_local_reps', 'finished'])
-
-
-def ge_non_zero(a, b):
- return a >= b and b > 0
-
-
-def get_shard_id(file_name):
- assert file_name[-4:].lower() == '.txt'
- return int(file_name[file_name.rfind('_') + 1: -4])
-
-
-class Results(object):
- """Manages reading and writing training results to disk asynchronously.
-
- Each worker writes to its own file, so that there are no race conditions when
- writing happens. However any worker may read any file, as is the case for
- `read_all`. Writes are expected to be atomic so that workers will never
- read incomplete data, and this is likely to be the case on Unix systems.
- Reading out of date data is fine, as workers calling `read_all` will wait
- until data from every worker has been written before proceeding.
- """
- file_template = 'experiment_results_{0}.txt'
- search_regex = r'^experiment_results_([0-9])+\.txt$'
-
- def __init__(self, log_dir, shard_id=0):
- """Construct `Results` instance.
-
- Args:
- log_dir: Where to write results files.
- shard_id: Unique id for this file (i.e. shard). Each worker that will
- be writing results should use a different shard id. If there are
- N shards, each shard should be numbered 0 through N-1.
- """
- # Use different files for workers so that they can write to disk async.
- assert 0 <= shard_id
- self.file_name = self.file_template.format(shard_id)
- self.log_dir = log_dir
- self.results_file = os.path.join(self.log_dir, self.file_name)
-
- def append(self, metrics):
- """Append results to results list on disk."""
- with tf.gfile.FastGFile(self.results_file, 'a') as writer:
- writer.write(str(metrics) + '\n')
-
- def read_this_shard(self):
- """Read only from this shard."""
- return self._read_shard(self.results_file)
-
- def _read_shard(self, results_file):
- """Read only from the given shard file."""
- try:
- with tf.gfile.FastGFile(results_file, 'r') as reader:
- results = [ast.literal_eval(entry) for entry in reader]
- except tf.errors.NotFoundError:
- # No results written to disk yet. Return empty list.
- return []
- return results
-
- def _get_max_local_reps(self, shard_results):
- """Get maximum number of repetitions the given shard needs to complete.
-
- Worker working on each shard needs to complete a certain number of runs
- before it finishes. This method will return that number so that we can
- determine which shards are still not done.
-
- We assume that workers are including a 'max_local_repetitions' value in
- their results, which should be the total number of repetitions it needs to
- run.
-
- Args:
- shard_results: Dict mapping metric names to values. This should be read
- from a shard on disk.
-
- Returns:
- Maximum number of repetitions the given shard needs to complete.
- """
- mlrs = [r['max_local_repetitions'] for r in shard_results]
- if not mlrs:
- return 0
- for n in mlrs[1:]:
- assert n == mlrs[0], 'Some reps have different max rep.'
- return mlrs[0]
-
- def read_all(self, num_shards=None):
- """Read results across all shards, i.e. get global results list.
-
- Args:
- num_shards: (optional) specifies total number of shards. If the caller
- wants information about which shards are incomplete, provide this
- argument (so that shards which have yet to be created are still
- counted as incomplete shards). Otherwise, no information about
- incomplete shards will be returned.
-
- Returns:
- aggregate: Global list of results (across all shards).
- shard_stats: List of ShardStats instances, one for each shard. Or None if
- `num_shards` is None.
- """
- try:
- all_children = tf.gfile.ListDirectory(self.log_dir)
- except tf.errors.NotFoundError:
- if num_shards is None:
- return [], None
- return [], [[] for _ in xrange(num_shards)]
- shard_ids = {
- get_shard_id(fname): fname
- for fname in all_children if re.search(self.search_regex, fname)}
-
- if num_shards is None:
- aggregate = []
- shard_stats = None
- for results_file in shard_ids.values():
- aggregate.extend(self._read_shard(
- os.path.join(self.log_dir, results_file)))
- else:
- results_per_shard = [None] * num_shards
- for shard_id in xrange(num_shards):
- if shard_id in shard_ids:
- results_file = shard_ids[shard_id]
- results_per_shard[shard_id] = self._read_shard(
- os.path.join(self.log_dir, results_file))
- else:
- results_per_shard[shard_id] = []
-
- # Compute shard stats.
- shard_stats = []
- for shard_results in results_per_shard:
- max_local_reps = self._get_max_local_reps(shard_results)
- shard_stats.append(ShardStats(
- num_local_reps_completed=len(shard_results),
- max_local_reps=max_local_reps,
- finished=ge_non_zero(len(shard_results), max_local_reps)))
-
- # Compute aggregate.
- aggregate = [
- r for shard_results in results_per_shard for r in shard_results]
-
- return aggregate, shard_stats
diff --git a/research/brain_coder/single_task/results_lib_test.py b/research/brain_coder/single_task/results_lib_test.py
deleted file mode 100644
index 6fe838d74d6a3bdea4c3b219a4d3ceea4385a97e..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/results_lib_test.py
+++ /dev/null
@@ -1,84 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for results_lib."""
-
-import contextlib
-import os
-import shutil
-import tempfile
-from six.moves import xrange
-import tensorflow as tf
-
-from single_task import results_lib # brain coder
-
-
-@contextlib.contextmanager
-def temporary_directory(suffix='', prefix='tmp', base_path=None):
- """A context manager to create a temporary directory and clean up on exit.
-
- The parameters are the same ones expected by tempfile.mkdtemp.
- The directory will be securely and atomically created.
- Everything under it will be removed when exiting the context.
-
- Args:
- suffix: optional suffix.
- prefix: options prefix.
- base_path: the base path under which to create the temporary directory.
- Yields:
- The absolute path of the new temporary directory.
- """
- temp_dir_path = tempfile.mkdtemp(suffix, prefix, base_path)
- try:
- yield temp_dir_path
- finally:
- try:
- shutil.rmtree(temp_dir_path)
- except OSError as e:
- if e.message == 'Cannot call rmtree on a symbolic link':
- # Interesting synthetic exception made up by shutil.rmtree.
- # Means we received a symlink from mkdtemp.
- # Also means must clean up the symlink instead.
- os.unlink(temp_dir_path)
- else:
- raise
-
-
-def freeze(dictionary):
- """Convert dict to hashable frozenset."""
- return frozenset(dictionary.iteritems())
-
-
-class ResultsLibTest(tf.test.TestCase):
-
- def testResults(self):
- with temporary_directory() as logdir:
- results_obj = results_lib.Results(logdir)
- self.assertEqual(results_obj.read_this_shard(), [])
- results_obj.append(
- {'foo': 1.5, 'bar': 2.5, 'baz': 0})
- results_obj.append(
- {'foo': 5.5, 'bar': -1, 'baz': 2})
- self.assertEqual(
- results_obj.read_this_shard(),
- [{'foo': 1.5, 'bar': 2.5, 'baz': 0},
- {'foo': 5.5, 'bar': -1, 'baz': 2}])
-
- def testShardedResults(self):
- with temporary_directory() as logdir:
- n = 4 # Number of shards.
- results_objs = [
- results_lib.Results(logdir, shard_id=i) for i in xrange(n)]
- for i, robj in enumerate(results_objs):
- robj.append({'foo': i, 'bar': 1 + i * 2})
- results_list, _ = results_objs[0].read_all()
-
- # Check results. Order does not matter here.
- self.assertEqual(
- set(freeze(r) for r in results_list),
- set(freeze({'foo': i, 'bar': 1 + i * 2}) for i in xrange(n)))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/run.py b/research/brain_coder/single_task/run.py
deleted file mode 100644
index 9d8f37c973dcca3bbf8e25bce3d181e5405c6167..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/run.py
+++ /dev/null
@@ -1,142 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-r"""Run training.
-
-Choose training algorithm and task(s) and follow these examples.
-
-Run synchronous policy gradient training locally:
-
-CONFIG="agent=c(algorithm='pg'),env=c(task='reverse')"
-OUT_DIR="/tmp/bf_pg_local"
-rm -rf $OUT_DIR
-bazel run -c opt single_task:run -- \
- --alsologtostderr \
- --config="$CONFIG" \
- --max_npe=0 \
- --logdir="$OUT_DIR" \
- --summary_interval=1 \
- --model_v=0
-learning/brain/tensorboard/tensorboard.sh --port 12345 --logdir "$OUT_DIR"
-
-
-Run genetic algorithm locally:
-
-CONFIG="agent=c(algorithm='ga'),env=c(task='reverse')"
-OUT_DIR="/tmp/bf_ga_local"
-rm -rf $OUT_DIR
-bazel run -c opt single_task:run -- \
- --alsologtostderr \
- --config="$CONFIG" \
- --max_npe=0 \
- --logdir="$OUT_DIR"
-
-
-Run uniform random search locally:
-
-CONFIG="agent=c(algorithm='rand'),env=c(task='reverse')"
-OUT_DIR="/tmp/bf_rand_local"
-rm -rf $OUT_DIR
-bazel run -c opt single_task:run -- \
- --alsologtostderr \
- --config="$CONFIG" \
- --max_npe=0 \
- --logdir="$OUT_DIR"
-"""
-
-from absl import app
-from absl import flags
-from absl import logging
-
-from single_task import defaults # brain coder
-from single_task import ga_train # brain coder
-from single_task import pg_train # brain coder
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string('config', '', 'Configuration.')
-flags.DEFINE_string(
- 'logdir', None, 'Absolute path where to write results.')
-flags.DEFINE_integer('task_id', 0, 'ID for this worker.')
-flags.DEFINE_integer('num_workers', 1, 'How many workers there are.')
-flags.DEFINE_integer(
- 'max_npe', 0,
- 'NPE = number of programs executed. Maximum number of programs to execute '
- 'in each run. Training will complete when this threshold is reached. Set '
- 'to 0 for unlimited training.')
-flags.DEFINE_integer(
- 'num_repetitions', 1,
- 'Number of times the same experiment will be run (globally across all '
- 'workers). Each run is independent.')
-flags.DEFINE_string(
- 'log_level', 'INFO',
- 'The threshold for what messages will be logged. One of DEBUG, INFO, WARN, '
- 'ERROR, or FATAL.')
-
-
-# To register an algorithm:
-# 1) Add dependency in the BUILD file to this build rule.
-# 2) Import the algorithm's module at the top of this file.
-# 3) Add a new entry in the following dict. The key is the algorithm name
-# (used to select the algorithm in the config). The value is the module
-# defining the expected functions for training and tuning. See the docstring
-# for `get_namespace` for further details.
-ALGORITHM_REGISTRATION = {
- 'pg': pg_train,
- 'ga': ga_train,
- 'rand': ga_train,
-}
-
-
-def get_namespace(config_string):
- """Get namespace for the selected algorithm.
-
- Users who want to add additional algorithm types should modify this function.
- The algorithm's namespace should contain the following functions:
- run_training: Run the main training loop.
- define_tuner_hparam_space: Return the hparam tuning space for the algo.
- write_hparams_to_config: Helper for tuning. Write hparams chosen for tuning
- to the Config object.
- Look at pg_train.py and ga_train.py for function signatures and
- implementations.
-
- Args:
- config_string: String representation of a Config object. This will get
- parsed into a Config in order to determine what algorithm to use.
-
- Returns:
- algorithm_namespace: The module corresponding to the algorithm given in the
- config.
- config: The Config object resulting from parsing `config_string`.
-
- Raises:
- ValueError: If config.agent.algorithm is not one of the registered
- algorithms.
- """
- config = defaults.default_config_with_updates(config_string)
- if config.agent.algorithm not in ALGORITHM_REGISTRATION:
- raise ValueError('Unknown algorithm type "%s"' % (config.agent.algorithm,))
- else:
- return ALGORITHM_REGISTRATION[config.agent.algorithm], config
-
-
-def main(argv):
- del argv # Unused.
-
- logging.set_verbosity(FLAGS.log_level)
-
- flags.mark_flag_as_required('logdir')
- if FLAGS.num_workers <= 0:
- raise ValueError('num_workers flag must be greater than 0.')
- if FLAGS.task_id < 0:
- raise ValueError('task_id flag must be greater than or equal to 0.')
- if FLAGS.task_id >= FLAGS.num_workers:
- raise ValueError(
- 'task_id flag must be strictly less than num_workers flag.')
-
- ns, _ = get_namespace(FLAGS.config)
- ns.run_training(is_chief=FLAGS.task_id == 0)
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/brain_coder/single_task/run_eval_tasks.py b/research/brain_coder/single_task/run_eval_tasks.py
deleted file mode 100755
index eb684c344381462cd3626404b5d7fd7cf5d72b22..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/run_eval_tasks.py
+++ /dev/null
@@ -1,296 +0,0 @@
-#!/usr/bin/env python
-from __future__ import print_function
-
-r"""This script can launch any eval experiments from the paper.
-
-This is a script. Run with python, not bazel.
-
-Usage:
-./single_task/run_eval_tasks.py \
- --exp EXP --desc DESC [--tuning_tasks] [--iclr_tasks] [--task TASK] \
- [--tasks TASK1 TASK2 ...]
-
-where EXP is one of the keys in `experiments`,
-and DESC is a string description of the set of experiments (such as "v0")
-
-Set only one of these flags:
---tuning_tasks flag only runs tuning tasks.
---iclr_tasks flag only runs the tasks included in the paper.
---regression_tests flag runs tasks which function as regression tests.
---task flag manually selects a single task to run.
---tasks flag takes a custom list of tasks.
-
-Other flags:
---reps N specifies N repetitions per experiment, Default is 25.
---training_replicas R specifies that R workers will be launched to train one
- task (for neural network algorithms). These workers will update a global
- model stored on a parameter server. Defaults to 1. If R > 1, a parameter
- server will also be launched.
-
-
-Run everything:
-exps=( pg-20M pg-topk-20M topk-20M ga-20M rand-20M )
-BIN_DIR="single_task"
-for exp in "${exps[@]}"
-do
- ./$BIN_DIR/run_eval_tasks.py \
- --exp "$exp" --iclr_tasks
-done
-"""
-
-import argparse
-from collections import namedtuple
-import subprocess
-
-
-S = namedtuple('S', ['length'])
-default_length = 100
-
-
-iclr_tasks = [
- 'reverse', 'remove-char', 'count-char', 'add', 'bool-logic', 'print-hello',
- 'echo-twice', 'echo-thrice', 'copy-reverse', 'zero-cascade', 'cascade',
- 'shift-left', 'shift-right', 'riffle', 'unriffle', 'middle-char',
- 'remove-last', 'remove-last-two', 'echo-alternating', 'echo-half', 'length',
- 'echo-second-seq', 'echo-nth-seq', 'substring', 'divide-2', 'dedup']
-
-
-regression_test_tasks = ['reverse', 'test-hill-climb']
-
-
-E = namedtuple(
- 'E',
- ['name', 'method_type', 'config', 'simplify', 'batch_size', 'max_npe'])
-
-
-def make_experiment_settings(name, **kwargs):
- # Unpack experiment info from name.
- def split_last(string, char):
- i = string.rindex(char)
- return string[:i], string[i+1:]
- def si_to_int(si_string):
- return int(
- si_string.upper().replace('K', '0'*3).replace('M', '0'*6)
- .replace('G', '0'*9))
- method_type, max_npe = split_last(name, '-')
- assert method_type
- assert max_npe
- return E(
- name=name, method_type=method_type, max_npe=si_to_int(max_npe), **kwargs)
-
-
-experiments_set = {
- make_experiment_settings(
- 'pg-20M',
- config='entropy_beta=0.05,lr=0.0001,topk_loss_hparam=0.0,topk=0,'
- 'pi_loss_hparam=1.0,alpha=0.0',
- simplify=False,
- batch_size=64),
- make_experiment_settings(
- 'pg-topk-20M',
- config='entropy_beta=0.01,lr=0.0001,topk_loss_hparam=50.0,topk=10,'
- 'pi_loss_hparam=1.0,alpha=0.0',
- simplify=False,
- batch_size=64),
- make_experiment_settings(
- 'topk-20M',
- config='entropy_beta=0.01,lr=0.0001,topk_loss_hparam=200.0,topk=10,'
- 'pi_loss_hparam=0.0,alpha=0.0',
- simplify=False,
- batch_size=64),
- make_experiment_settings(
- 'topk-0ent-20M',
- config='entropy_beta=0.000,lr=0.0001,topk_loss_hparam=200.0,topk=10,'
- 'pi_loss_hparam=0.0,alpha=0.0',
- simplify=False,
- batch_size=64),
- make_experiment_settings(
- 'ga-20M',
- config='crossover_rate=0.95,mutation_rate=0.15',
- simplify=False,
- batch_size=100), # Population size.
- make_experiment_settings(
- 'rand-20M',
- config='',
- simplify=False,
- batch_size=1),
- make_experiment_settings(
- 'simpl-500M',
- config='entropy_beta=0.05,lr=0.0001,topk_loss_hparam=0.5,topk=10,'
- 'pi_loss_hparam=1.0,alpha=0.0',
- simplify=True,
- batch_size=64),
-}
-
-experiments = {e.name: e for e in experiments_set}
-
-
-# pylint: disable=redefined-outer-name
-def parse_args(extra_args=()):
- """Parse arguments and extract task and experiment info."""
- parser = argparse.ArgumentParser(description='Run all eval tasks.')
- parser.add_argument('--exp', required=True)
- parser.add_argument('--tuning_tasks', action='store_true')
- parser.add_argument('--iclr_tasks', action='store_true')
- parser.add_argument('--regression_tests', action='store_true')
- parser.add_argument('--desc', default='v0')
- parser.add_argument('--reps', default=25)
- parser.add_argument('--task')
- parser.add_argument('--tasks', nargs='+')
- for arg_string, default in extra_args:
- parser.add_argument(arg_string, default=default)
- args = parser.parse_args()
-
- print('Running experiment: %s' % (args.exp,))
- if args.desc:
- print('Extra description: "%s"' % (args.desc,))
- if args.exp not in experiments:
- raise ValueError('Experiment name is not valid')
- experiment_name = args.exp
- experiment_settings = experiments[experiment_name]
- assert experiment_settings.name == experiment_name
-
- if args.tasks:
- print('Launching tasks from args: %s' % (args.tasks,))
- tasks = {t: S(length=default_length) for t in args.tasks}
- elif args.task:
- print('Launching single task "%s"' % args.task)
- tasks = {args.task: S(length=default_length)}
- elif args.tuning_tasks:
- print('Only running tuning tasks')
- tasks = {name: S(length=default_length)
- for name in ['reverse-tune', 'remove-char-tune']}
- elif args.iclr_tasks:
- print('Running eval tasks from ICLR paper.')
- tasks = {name: S(length=default_length) for name in iclr_tasks}
- elif args.regression_tests:
- tasks = {name: S(length=default_length) for name in regression_test_tasks}
- print('Tasks: %s' % tasks.keys())
-
- print('reps = %d' % (int(args.reps),))
-
- return args, tasks, experiment_settings
-
-
-def run(command_string):
- subprocess.call(command_string, shell=True)
-
-
-if __name__ == '__main__':
- LAUNCH_TRAINING_COMMAND = 'single_task/launch_training.sh'
- COMPILE_COMMAND = 'bazel build -c opt single_task:run.par'
-
- args, tasks, experiment_settings = parse_args(
- extra_args=(('--training_replicas', 1),))
-
- if experiment_settings.method_type in (
- 'pg', 'pg-topk', 'topk', 'topk-0ent', 'simpl'):
- # Runs PG and TopK.
-
- def make_run_cmd(job_name, task, max_npe, num_reps, code_length,
- batch_size, do_simplify, custom_config_str):
- """Constructs terminal command for launching NN based algorithms.
-
- The arguments to this function will be used to create config for the
- experiment.
-
- Args:
- job_name: Name of the job to launch. Should uniquely identify this
- experiment run.
- task: Name of the coding task to solve.
- max_npe: Maximum number of programs executed. An integer.
- num_reps: Number of times to run the experiment. An integer.
- code_length: Maximum allowed length of synthesized code.
- batch_size: Minibatch size for gradient descent.
- do_simplify: Whether to run the experiment in code simplification mode.
- A bool.
- custom_config_str: Additional config for the model config string.
-
- Returns:
- The terminal command that launches the specified experiment.
- """
- config = """
- env=c(task='{0}',correct_syntax=False),
- agent=c(
- algorithm='pg',
- policy_lstm_sizes=[35,35],value_lstm_sizes=[35,35],
- grad_clip_threshold=50.0,param_init_factor=0.5,regularizer=0.0,
- softmax_tr=1.0,optimizer='rmsprop',ema_baseline_decay=0.99,
- eos_token={3},{4}),
- timestep_limit={1},batch_size={2}
- """.replace(' ', '').replace('\n', '').format(
- task, code_length, batch_size, do_simplify, custom_config_str)
- num_ps = 0 if args.training_replicas == 1 else 1
- return (
- r'{0} --job_name={1} --config="{2}" --max_npe={3} '
- '--num_repetitions={4} --num_workers={5} --num_ps={6} '
- '--stop_on_success={7}'
- .format(LAUNCH_TRAINING_COMMAND, job_name, config, max_npe, num_reps,
- args.training_replicas, num_ps, str(not do_simplify).lower()))
-
- else:
- # Runs GA and Rand.
- assert experiment_settings.method_type in ('ga', 'rand')
-
- def make_run_cmd(job_name, task, max_npe, num_reps, code_length,
- batch_size, do_simplify, custom_config_str):
- """Constructs terminal command for launching GA or uniform random search.
-
- The arguments to this function will be used to create config for the
- experiment.
-
- Args:
- job_name: Name of the job to launch. Should uniquely identify this
- experiment run.
- task: Name of the coding task to solve.
- max_npe: Maximum number of programs executed. An integer.
- num_reps: Number of times to run the experiment. An integer.
- code_length: Maximum allowed length of synthesized code.
- batch_size: Minibatch size for gradient descent.
- do_simplify: Whether to run the experiment in code simplification mode.
- A bool.
- custom_config_str: Additional config for the model config string.
-
- Returns:
- The terminal command that launches the specified experiment.
- """
- assert not do_simplify
- if custom_config_str:
- custom_config_str = ',' + custom_config_str
- config = """
- env=c(task='{0}',correct_syntax=False),
- agent=c(
- algorithm='{4}'
- {3}),
- timestep_limit={1},batch_size={2}
- """.replace(' ', '').replace('\n', '').format(
- task, code_length, batch_size, custom_config_str,
- experiment_settings.method_type)
- num_workers = num_reps # Do each rep in parallel.
- return (
- r'{0} --job_name={1} --config="{2}" --max_npe={3} '
- '--num_repetitions={4} --num_workers={5} --num_ps={6} '
- '--stop_on_success={7}'
- .format(LAUNCH_TRAINING_COMMAND, job_name, config, max_npe, num_reps,
- num_workers, 0, str(not do_simplify).lower()))
-
- print('Compiling...')
- run(COMPILE_COMMAND)
-
- print('Launching %d coding tasks...' % len(tasks))
- for task, task_settings in tasks.iteritems():
- name = 'bf_rl_iclr'
- desc = '{0}.{1}_{2}'.format(args.desc, experiment_settings.name, task)
- job_name = '{}.{}'.format(name, desc)
- print('Job name: %s' % job_name)
- reps = int(args.reps) if not experiment_settings.simplify else 1
- run_cmd = make_run_cmd(
- job_name, task, experiment_settings.max_npe, reps,
- task_settings.length, experiment_settings.batch_size,
- experiment_settings.simplify,
- experiment_settings.config)
- print('Running command:\n' + run_cmd)
- run(run_cmd)
-
- print('Done.')
-# pylint: enable=redefined-outer-name
diff --git a/research/brain_coder/single_task/test_tasks.py b/research/brain_coder/single_task/test_tasks.py
deleted file mode 100644
index fb07a12653ebad6b38dc3786e749d3e8bf2b2072..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/test_tasks.py
+++ /dev/null
@@ -1,127 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tasks that test correctness of algorithms."""
-
-from six.moves import xrange
-from common import reward as reward_lib # brain coder
-from single_task import misc # brain coder
-
-
-class BasicTaskManager(object):
- """Wraps a generic reward function."""
-
- def __init__(self, reward_fn):
- self.reward_fn = reward_fn
- self.good_reward = 1.0
-
- def _score_string(self, string):
- actions = misc.bf_string_to_tokens(string)
- reward, correct = self.reward_fn(actions)
- return misc.RewardInfo(
- episode_rewards=[0.0] * (len(string) - 1) + [reward],
- input_case=None,
- correct_output=None,
- code_output=actions,
- input_type=None,
- output_type=misc.IOType.integer,
- reason='correct' if correct else 'wrong')
-
- def rl_batch(self, batch_size):
- reward_fns = [self._score_string] * batch_size
- return reward_fns
-
-
-class Trie(object):
- """Trie for sequences."""
- EOS = ()
-
- def __init__(self):
- self.trie = {}
-
- def insert(self, sequence):
- d = self.trie
- for e in sequence:
- if e not in d:
- d[e] = {}
- d = d[e]
- d[self.EOS] = True # Terminate sequence.
-
- def prefix_match(self, sequence):
- """Return prefix of `sequence` which exists in the trie."""
- d = self.trie
- index = 0
- for i, e in enumerate(sequence + [self.EOS]):
- index = i
- if e in d:
- d = d[e]
- if e == self.EOS:
- return sequence, True
- else:
- break
- return sequence[:index], False
-
- def next_choices(self, sequence):
- d = self.trie
- for e in sequence:
- if e in d:
- d = d[e]
- else:
- raise ValueError('Sequence not a prefix: %s' % (sequence,))
- return d.keys()
-
-
-class HillClimbingTask(object):
- """Simple task that tests reward hill climbing ability.
-
- There are a set of paths (sequences of tokens) which are rewarded. The total
- reward for a path is proportional to its length, so the longest path is the
- target. Shorter paths can be dead ends.
- """
-
- def __init__(self):
- # Paths are sequences of sub-sequences. Here we form unique sub-sequences
- # out of 3 arbitrary ints. We use sub-sequences instead of single entities
- # to make the task harder by making the episodes last longer, i.e. more
- # for the agent to remember.
- a = (1, 2, 3)
- b = (4, 5, 6)
- c = (7, 8, 7)
- d = (6, 5, 4)
- e = (3, 2, 1)
- f = (8, 5, 1)
- g = (6, 4, 2)
- h = (1, 8, 3)
- self.paths = Trie()
- self.paths.insert([a, b, h])
- self.paths.insert([a, b, c, d, e, f, g, h])
- self.paths.insert([a, b, c, d, e, b, a])
- self.paths.insert([a, b, g, h])
- self.paths.insert([a, e, f, g])
- self.correct_sequence = misc.flatten([a, b, c, d, e, f, g, h])
-
- def distance_fn(a, b):
- len_diff = abs(len(a) - len(b))
- return sum(reward_lib.mod_abs_diff(ai - 1, bi - 1, 8)
- for ai, bi in zip(a, b)) + len_diff * 4 # 8 / 2 = 4
- self.distance_fn = distance_fn
-
- def __call__(self, actions):
- # Compute reward for action sequence.
- actions = [a for a in actions if a > 0]
- sequence = [tuple(actions[i: i + 3]) for i in xrange(0, len(actions), 3)]
- prefix, complete = self.paths.prefix_match(sequence)
- if complete:
- return float(len(prefix)), actions == self.correct_sequence
- if len(prefix) == len(sequence):
- return float(len(prefix)), False
- next_pred = sequence[len(prefix)]
- choices = self.paths.next_choices(prefix)
- if choices == [()]:
- return (len(prefix) - len(next_pred) / 3.0), False
- min_dist = min(self.distance_fn(c, next_pred) for c in choices)
- # +1 reward for each element in the sequence correct, plus fraction torwards
- # closest next element.
- # Maximum distance possible is num_actions * base / 2 = 3 * 8 / 2 = 12
- return (len(prefix) + (1 - min_dist / 12.0)), False
diff --git a/research/brain_coder/single_task/test_tasks_test.py b/research/brain_coder/single_task/test_tasks_test.py
deleted file mode 100644
index bc905c6936de4c686e6cac1203c65c36bd7a0b16..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/test_tasks_test.py
+++ /dev/null
@@ -1,63 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-"""Tests for test_tasks."""
-
-import numpy as np
-import tensorflow as tf
-
-from single_task import misc # brain coder
-from single_task import test_tasks # brain coder
-
-
-def get_reward(reward_fn, candidate):
- return sum(reward_fn(misc.bf_tokens_to_string(candidate)).episode_rewards)
-
-
-class TestTasksTest(tf.test.TestCase):
-
- def testHillClimbingTask(self):
- task = test_tasks.BasicTaskManager(test_tasks.HillClimbingTask())
- reward_fns = task.rl_batch(1)
- reward_fn = reward_fns[0]
- self.assertTrue(np.isclose(get_reward(reward_fn, [1, 2, 0]), 8 / 12.))
- self.assertTrue(np.isclose(get_reward(reward_fn, [1, 2, 2, 0]), 11 / 12.))
- self.assertTrue(np.isclose(get_reward(reward_fn, [1, 2, 3, 0]), 1.0))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 2, 0]), 1. + 8 / 12.))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 0]), 2.0))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 1, 8, 3, 0]), 3.0))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 7, 8, 7, 0]), 3.0))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 1, 8, 3, 1, 0]),
- 3.0 - 4 / 12.))
- self.assertTrue(
- np.isclose(
- get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 1, 8, 3, 1, 1, 1, 1, 0]),
- 2.0))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 7, 8, 7, 3, 0]),
- 3.0 + 1 / 12.))
- self.assertTrue(
- np.isclose(
- get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 7, 8, 7, 6, 5, 4, 3, 2, 1,
- 8, 5, 1, 6, 4, 2, 1, 8, 3, 0]),
- 8.0))
- self.assertTrue(
- np.isclose(
- get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 7, 8, 7, 6, 5, 4, 3, 2, 1,
- 8, 5, 1, 6, 4, 2, 1, 8, 3, 1, 1, 0]),
- 8.0 - 8 / 12.))
- self.assertTrue(
- np.isclose(get_reward(reward_fn, [1, 2, 3, 4, 5, 6, 7, 8, 7, 6, 5, 4, 3,
- 2, 1, 8, 5, 1, 6, 4, 2, 1, 8, 3, 1, 1,
- 1, 1, 1, 1, 1, 0]),
- 7.0))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/brain_coder/single_task/tune.py b/research/brain_coder/single_task/tune.py
deleted file mode 100644
index 3473b5e94bd3c1f737a18f0187790d5df2d7a2aa..0000000000000000000000000000000000000000
--- a/research/brain_coder/single_task/tune.py
+++ /dev/null
@@ -1,262 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-r"""Run grid search.
-
-Look at launch_tuning.sh for details on how to tune at scale.
-
-Usage example:
-Tune with one worker on the local machine.
-
-CONFIG="agent=c(algorithm='pg'),"
-CONFIG+="env=c(task_cycle=['reverse-tune', 'remove-tune'])"
-HPARAM_SPACE_TYPE="pg"
-OUT_DIR="/tmp/bf_pg_tune"
-MAX_NPE=5000000
-NUM_REPETITIONS=50
-rm -rf $OUT_DIR
-mkdir $OUT_DIR
-bazel run -c opt single_task:tune -- \
- --alsologtostderr \
- --config="$CONFIG" \
- --max_npe="$MAX_NPE" \
- --num_repetitions="$NUM_REPETITIONS" \
- --logdir="$OUT_DIR" \
- --summary_interval=1 \
- --model_v=0 \
- --hparam_space="$HPARAM_SPACE_TYPE" \
- --tuner_id=0 \
- --num_tuners=1 \
- 2>&1 >"$OUT_DIR/tuner_0.log"
-learning/brain/tensorboard/tensorboard.sh --port 12345 --logdir "$OUT_DIR"
-"""
-
-import ast
-import os
-
-from absl import app
-from absl import flags
-from absl import logging
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from single_task import defaults # brain coder
-from single_task import run as run_lib # brain coder
-
-FLAGS = flags.FLAGS
-flags.DEFINE_integer(
- 'tuner_id', 0,
- 'The unique ID for this tuning worker.')
-flags.DEFINE_integer(
- 'num_tuners', 1,
- 'How many tuners are there.')
-flags.DEFINE_string(
- 'hparam_space', 'default',
- 'String name which denotes the hparam space to tune over. This is '
- 'algorithm dependent.')
-flags.DEFINE_string(
- 'fixed_hparams', '',
- 'HParams string. Used to fix hparams during tuning.')
-flags.DEFINE_float(
- 'success_rate_objective_weight', 1.0,
- 'How much to weight success rate vs num programs seen. By default, only '
- 'success rate is optimized (this is the setting used in the paper).')
-
-
-def parse_hparams_string(hparams_str):
- hparams = {}
- for term in hparams_str.split(','):
- if not term:
- continue
- name, value = term.split('=')
- hparams[name.strip()] = ast.literal_eval(value)
- return hparams
-
-
-def int_to_multibase(n, bases):
- digits = [0] * len(bases)
- for i, b in enumerate(bases):
- n, d = divmod(n, b)
- digits[i] = d
- return digits
-
-
-def hparams_for_index(index, tuning_space):
- keys = sorted(tuning_space.keys())
- indices = int_to_multibase(index, [len(tuning_space[k]) for k in keys])
- return tf.contrib.training.HParams(
- **{k: tuning_space[k][i] for k, i in zip(keys, indices)})
-
-
-def run_tuner_loop(ns):
- """Run tuning loop for this worker."""
- is_chief = FLAGS.task_id == 0
- tuning_space = ns.define_tuner_hparam_space(
- hparam_space_type=FLAGS.hparam_space)
- fixed_hparams = parse_hparams_string(FLAGS.fixed_hparams)
- for name, value in fixed_hparams.iteritems():
- tuning_space[name] = [value]
- tuning_space_size = np.prod([len(values) for values in tuning_space.values()])
-
- num_local_trials, remainder = divmod(tuning_space_size, FLAGS.num_tuners)
- if FLAGS.tuner_id < remainder:
- num_local_trials += 1
- starting_trial_id = (
- num_local_trials * FLAGS.tuner_id + min(remainder, FLAGS.tuner_id))
-
- logging.info('tuning_space_size: %d', tuning_space_size)
- logging.info('num_local_trials: %d', num_local_trials)
- logging.info('starting_trial_id: %d', starting_trial_id)
-
- for local_trial_index in xrange(num_local_trials):
- trial_config = defaults.default_config_with_updates(FLAGS.config)
- global_trial_index = local_trial_index + starting_trial_id
- trial_name = 'trial_' + str(global_trial_index)
- trial_dir = os.path.join(FLAGS.logdir, trial_name)
- hparams = hparams_for_index(global_trial_index, tuning_space)
- ns.write_hparams_to_config(
- trial_config, hparams, hparam_space_type=FLAGS.hparam_space)
-
- results_list = ns.run_training(
- config=trial_config, tuner=None, logdir=trial_dir, is_chief=is_chief,
- trial_name=trial_name)
-
- if not is_chief:
- # Only chief worker needs to write tuning results to disk.
- continue
-
- objective, metrics = compute_tuning_objective(
- results_list, hparams, trial_name, num_trials=tuning_space_size)
- logging.info('metrics:\n%s', metrics)
- logging.info('objective: %s', objective)
- logging.info('programs_seen_fraction: %s',
- metrics['programs_seen_fraction'])
- logging.info('success_rate: %s', metrics['success_rate'])
- logging.info('success_rate_objective_weight: %s',
- FLAGS.success_rate_objective_weight)
-
- tuning_results_file = os.path.join(trial_dir, 'tuning_results.txt')
- with tf.gfile.FastGFile(tuning_results_file, 'a') as writer:
- writer.write(str(metrics) + '\n')
-
- logging.info('Trial %s complete.', trial_name)
-
-
-def compute_tuning_objective(results_list, hparams, trial_name, num_trials):
- """Compute tuning objective and metrics given results and trial information.
-
- Args:
- results_list: List of results dicts read from disk. These are written by
- workers.
- hparams: tf.contrib.training.HParams instance containing the hparams used
- in this trial (only the hparams which are being tuned).
- trial_name: Name of this trial. Used to create a trial directory.
- num_trials: Total number of trials that need to be run. This is saved in the
- metrics dict for future reference.
-
- Returns:
- objective: The objective computed for this trial. Choose the hparams for the
- trial with the largest objective value.
- metrics: Information about this trial. A dict.
- """
- found_solution = [r['found_solution'] for r in results_list]
- successful_program_counts = [
- r['npe'] for r in results_list if r['found_solution']]
-
- success_rate = sum(found_solution) / float(len(results_list))
-
- max_programs = FLAGS.max_npe # Per run.
- all_program_counts = [
- r['npe'] if r['found_solution'] else max_programs
- for r in results_list]
- programs_seen_fraction = (
- float(sum(all_program_counts))
- / (max_programs * len(all_program_counts)))
-
- # min/max/avg stats are over successful runs.
- metrics = {
- 'num_runs': len(results_list),
- 'num_succeeded': sum(found_solution),
- 'success_rate': success_rate,
- 'programs_seen_fraction': programs_seen_fraction,
- 'avg_programs': np.mean(successful_program_counts),
- 'max_possible_programs_per_run': max_programs,
- 'global_step': sum([r['num_batches'] for r in results_list]),
- 'hparams': hparams.values(),
- 'trial_name': trial_name,
- 'num_trials': num_trials}
-
- # Report stats per tasks.
- tasks = [r['task'] for r in results_list]
- for task in set(tasks):
- task_list = [r for r in results_list if r['task'] == task]
- found_solution = [r['found_solution'] for r in task_list]
- successful_rewards = [
- r['best_reward'] for r in task_list
- if r['found_solution']]
- successful_num_batches = [
- r['num_batches']
- for r in task_list if r['found_solution']]
- successful_program_counts = [
- r['npe'] for r in task_list if r['found_solution']]
- metrics_append = {
- task + '__num_runs': len(task_list),
- task + '__num_succeeded': sum(found_solution),
- task + '__success_rate': (
- sum(found_solution) / float(len(task_list)))}
- metrics.update(metrics_append)
- if any(found_solution):
- metrics_append = {
- task + '__min_reward': min(successful_rewards),
- task + '__max_reward': max(successful_rewards),
- task + '__avg_reward': np.median(successful_rewards),
- task + '__min_programs': min(successful_program_counts),
- task + '__max_programs': max(successful_program_counts),
- task + '__avg_programs': np.mean(successful_program_counts),
- task + '__min_batches': min(successful_num_batches),
- task + '__max_batches': max(successful_num_batches),
- task + '__avg_batches': np.mean(successful_num_batches)}
- metrics.update(metrics_append)
-
- # Objective will be maximized.
- # Maximize success rate, minimize num programs seen.
- # Max objective is always 1.
- weight = FLAGS.success_rate_objective_weight
- objective = (
- weight * success_rate
- + (1 - weight) * (1 - programs_seen_fraction))
- metrics['objective'] = objective
-
- return objective, metrics
-
-
-def main(argv):
- del argv
-
- logging.set_verbosity(FLAGS.log_level)
-
- if not FLAGS.logdir:
- raise ValueError('logdir flag must be provided.')
- if FLAGS.num_workers <= 0:
- raise ValueError('num_workers flag must be greater than 0.')
- if FLAGS.task_id < 0:
- raise ValueError('task_id flag must be greater than or equal to 0.')
- if FLAGS.task_id >= FLAGS.num_workers:
- raise ValueError(
- 'task_id flag must be strictly less than num_workers flag.')
- if FLAGS.num_tuners <= 0:
- raise ValueError('num_tuners flag must be greater than 0.')
- if FLAGS.tuner_id < 0:
- raise ValueError('tuner_id flag must be greater than or equal to 0.')
- if FLAGS.tuner_id >= FLAGS.num_tuners:
- raise ValueError(
- 'tuner_id flag must be strictly less than num_tuners flag.')
-
- ns, _ = run_lib.get_namespace(FLAGS.config)
- run_tuner_loop(ns)
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/cognitive_mapping_and_planning/.gitignore b/research/cognitive_mapping_and_planning/.gitignore
deleted file mode 100644
index cbc6a8f0271075171ffdf3c2bc5fb9c528b08fc6..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/.gitignore
+++ /dev/null
@@ -1,4 +0,0 @@
-deps
-*.pyc
-lib*.so
-lib*.so*
diff --git a/research/cognitive_mapping_and_planning/README.md b/research/cognitive_mapping_and_planning/README.md
deleted file mode 100644
index 4457bafbb4d229998a01dadc46efe41f4ba1a3e0..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/README.md
+++ /dev/null
@@ -1,127 +0,0 @@
-
-
-
-
-# Cognitive Mapping and Planning for Visual Navigation
-**Saurabh Gupta, James Davidson, Sergey Levine, Rahul Sukthankar, Jitendra Malik**
-
-**Computer Vision and Pattern Recognition (CVPR) 2017.**
-
-**[ArXiv](https://arxiv.org/abs/1702.03920),
-[Project Website](https://sites.google.com/corp/view/cognitive-mapping-and-planning/)**
-
-### Citing
-If you find this code base and models useful in your research, please consider
-citing the following paper:
- ```
- @inproceedings{gupta2017cognitive,
- title={Cognitive Mapping and Planning for Visual Navigation},
- author={Gupta, Saurabh and Davidson, James and Levine, Sergey and
- Sukthankar, Rahul and Malik, Jitendra},
- booktitle={CVPR},
- year={2017}
- }
- ```
-
-### Contents
-1. [Requirements: software](#requirements-software)
-2. [Requirements: data](#requirements-data)
-3. [Test Pre-trained Models](#test-pre-trained-models)
-4. [Train your Own Models](#train-your-own-models)
-
-### Requirements: software
-1. Python Virtual Env Setup: All code is implemented in Python but depends on a
- small number of python packages and a couple of C libraries. We recommend
- using virtual environment for installing these python packages and python
- bindings for these C libraries.
- ```Shell
- VENV_DIR=venv
- pip install virtualenv
- virtualenv $VENV_DIR
- source $VENV_DIR/bin/activate
-
- # You may need to upgrade pip for installing openv-python.
- pip install --upgrade pip
- # Install simple dependencies.
- pip install -r requirements.txt
-
- # Patch bugs in dependencies.
- sh patches/apply_patches.sh
- ```
-
-2. Install [Tensorflow](https://www.tensorflow.org/) inside this virtual
- environment. You will need to use one of the latest nightly builds
- (see instructions [here](https://github.com/tensorflow/tensorflow#installation)).
-
-3. Swiftshader: We use
- [Swiftshader](https://github.com/google/swiftshader.git), a CPU based
- renderer to render the meshes. It is possible to use other renderers,
- replace `SwiftshaderRenderer` in `render/swiftshader_renderer.py` with
- bindings to your renderer.
- ```Shell
- mkdir -p deps
- git clone --recursive https://github.com/google/swiftshader.git deps/swiftshader-src
- cd deps/swiftshader-src && git checkout 91da6b00584afd7dcaed66da88e2b617429b3950
- git submodule update
- mkdir build && cd build && cmake .. && make -j 16 libEGL libGLESv2
- cd ../../../
- cp deps/swiftshader-src/build/libEGL* libEGL.so.1
- cp deps/swiftshader-src/build/libGLESv2* libGLESv2.so.2
- ```
-
-4. PyAssimp: We use [PyAssimp](https://github.com/assimp/assimp.git) to load
- meshes. It is possible to use other libraries to load meshes, replace
- `Shape` `render/swiftshader_renderer.py` with bindings to your library for
- loading meshes.
- ```Shell
- mkdir -p deps
- git clone https://github.com/assimp/assimp.git deps/assimp-src
- cd deps/assimp-src
- git checkout 2afeddd5cb63d14bc77b53740b38a54a97d94ee8
- cmake CMakeLists.txt -G 'Unix Makefiles' && make -j 16
- cd port/PyAssimp && python setup.py install
- cd ../../../..
- cp deps/assimp-src/lib/libassimp* .
- ```
-
-5. graph-tool: We use [graph-tool](https://git.skewed.de/count0/graph-tool)
- library for graph processing.
- ```Shell
- mkdir -p deps
- # If the following git clone command fails, you can also download the source
- # from https://downloads.skewed.de/graph-tool/graph-tool-2.2.44.tar.bz2
- git clone https://git.skewed.de/count0/graph-tool deps/graph-tool-src
- cd deps/graph-tool-src && git checkout 178add3a571feb6666f4f119027705d95d2951ab
- bash autogen.sh
- ./configure --disable-cairo --disable-sparsehash --prefix=$HOME/.local
- make -j 16
- make install
- cd ../../
- ```
-
-### Requirements: data
-1. Download the Stanford 3D Indoor Spaces Dataset (S3DIS Dataset) and ImageNet
- Pre-trained models for initializing different models. Follow instructions in
- `data/README.md`
-
-### Test Pre-trained Models
-1. Download pre-trained models. See `output/README.md`.
-
-2. Test models using `scripts/script_test_pretrained_models.sh`.
-
-### Train Your Own Models
-All models were trained asynchronously with 16 workers each worker using data
-from a single floor. The default hyper-parameters correspond to this setting.
-See [distributed training with
-Tensorflow](https://www.tensorflow.org/deploy/distributed) for setting up
-distributed training. Training with a single worker is possible with the current
-code base but will require some minor changes to allow each worker to load all
-training environments.
-
-### Contact
-For questions or issues open an issue on the tensorflow/models [issues
-tracker](https://github.com/tensorflow/models/issues). Please assign issues to
-@s-gupta.
-
-### Credits
-This code was written by Saurabh Gupta (@s-gupta).
diff --git a/research/cognitive_mapping_and_planning/__init__.py b/research/cognitive_mapping_and_planning/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/cfgs/__init__.py b/research/cognitive_mapping_and_planning/cfgs/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/cfgs/config_cmp.py b/research/cognitive_mapping_and_planning/cfgs/config_cmp.py
deleted file mode 100644
index 715eee2b973cb66f816ecdb65bbcc3abdd8a9483..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/cfgs/config_cmp.py
+++ /dev/null
@@ -1,283 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import os, sys
-import numpy as np
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-import logging
-import src.utils as utils
-import cfgs.config_common as cc
-
-
-import tensorflow as tf
-
-
-rgb_resnet_v2_50_path = 'data/init_models/resnet_v2_50/model.ckpt-5136169'
-d_resnet_v2_50_path = 'data/init_models/distill_rgb_to_d_resnet_v2_50/model.ckpt-120002'
-
-def get_default_args():
- summary_args = utils.Foo(display_interval=1, test_iters=26,
- arop_full_summary_iters=14)
-
- control_args = utils.Foo(train=False, test=False,
- force_batchnorm_is_training_at_test=False,
- reset_rng_seed=False, only_eval_when_done=False,
- test_mode=None)
- return summary_args, control_args
-
-def get_default_cmp_args():
- batch_norm_param = {'center': True, 'scale': True,
- 'activation_fn':tf.nn.relu}
-
- mapper_arch_args = utils.Foo(
- dim_reduce_neurons=64,
- fc_neurons=[1024, 1024],
- fc_out_size=8,
- fc_out_neurons=64,
- encoder='resnet_v2_50',
- deconv_neurons=[64, 32, 16, 8, 4, 2],
- deconv_strides=[2, 2, 2, 2, 2, 2],
- deconv_layers_per_block=2,
- deconv_kernel_size=4,
- fc_dropout=0.5,
- combine_type='wt_avg_logits',
- batch_norm_param=batch_norm_param)
-
- readout_maps_arch_args = utils.Foo(
- num_neurons=[],
- strides=[],
- kernel_size=None,
- layers_per_block=None)
-
- arch_args = utils.Foo(
- vin_val_neurons=8, vin_action_neurons=8, vin_ks=3, vin_share_wts=False,
- pred_neurons=[64, 64], pred_batch_norm_param=batch_norm_param,
- conv_on_value_map=0, fr_neurons=16, fr_ver='v2', fr_inside_neurons=64,
- fr_stride=1, crop_remove_each=30, value_crop_size=4,
- action_sample_type='sample', action_sample_combine_type='one_or_other',
- sample_gt_prob_type='inverse_sigmoid_decay', dagger_sample_bn_false=True,
- vin_num_iters=36, isd_k=750., use_agent_loc=False, multi_scale=True,
- readout_maps=False, rom_arch=readout_maps_arch_args)
-
- return arch_args, mapper_arch_args
-
-def get_arch_vars(arch_str):
- if arch_str == '': vals = []
- else: vals = arch_str.split('_')
- ks = ['var1', 'var2', 'var3']
- ks = ks[:len(vals)]
-
- # Exp Ver.
- if len(vals) == 0: ks.append('var1'); vals.append('v0')
- # custom arch.
- if len(vals) == 1: ks.append('var2'); vals.append('')
- # map scape for projection baseline.
- if len(vals) == 2: ks.append('var3'); vals.append('fr2')
-
- assert(len(vals) == 3)
-
- vars = utils.Foo()
- for k, v in zip(ks, vals):
- setattr(vars, k, v)
-
- logging.error('arch_vars: %s', vars)
- return vars
-
-def process_arch_str(args, arch_str):
- # This function modifies args.
- args.arch, args.mapper_arch = get_default_cmp_args()
-
- arch_vars = get_arch_vars(arch_str)
-
- args.navtask.task_params.outputs.ego_maps = True
- args.navtask.task_params.outputs.ego_goal_imgs = True
- args.navtask.task_params.outputs.egomotion = True
- args.navtask.task_params.toy_problem = False
-
- if arch_vars.var1 == 'lmap':
- args = process_arch_learned_map(args, arch_vars)
-
- elif arch_vars.var1 == 'pmap':
- args = process_arch_projected_map(args, arch_vars)
-
- else:
- logging.fatal('arch_vars.var1 should be lmap or pmap, but is %s', arch_vars.var1)
- assert(False)
-
- return args
-
-def process_arch_learned_map(args, arch_vars):
- # Multiscale vision based system.
- args.navtask.task_params.input_type = 'vision'
- args.navtask.task_params.outputs.images = True
-
- if args.navtask.camera_param.modalities[0] == 'rgb':
- args.solver.pretrained_path = rgb_resnet_v2_50_path
- elif args.navtask.camera_param.modalities[0] == 'depth':
- args.solver.pretrained_path = d_resnet_v2_50_path
-
- if arch_vars.var2 == 'Ssc':
- sc = 1./args.navtask.task_params.step_size
- args.arch.vin_num_iters = 40
- args.navtask.task_params.map_scales = [sc]
- max_dist = args.navtask.task_params.max_dist * \
- args.navtask.task_params.num_goals
- args.navtask.task_params.map_crop_sizes = [2*max_dist]
-
- args.arch.fr_stride = 1
- args.arch.vin_action_neurons = 8
- args.arch.vin_val_neurons = 3
- args.arch.fr_inside_neurons = 32
-
- args.mapper_arch.pad_map_with_zeros_each = [24]
- args.mapper_arch.deconv_neurons = [64, 32, 16]
- args.mapper_arch.deconv_strides = [1, 2, 1]
-
- elif (arch_vars.var2 == 'Msc' or arch_vars.var2 == 'MscROMms' or
- arch_vars.var2 == 'MscROMss' or arch_vars.var2 == 'MscNoVin'):
- # Code for multi-scale planner.
- args.arch.vin_num_iters = 8
- args.arch.crop_remove_each = 4
- args.arch.value_crop_size = 8
-
- sc = 1./args.navtask.task_params.step_size
- max_dist = args.navtask.task_params.max_dist * \
- args.navtask.task_params.num_goals
- n_scales = np.log2(float(max_dist) / float(args.arch.vin_num_iters))
- n_scales = int(np.ceil(n_scales)+1)
-
- args.navtask.task_params.map_scales = \
- list(sc*(0.5**(np.arange(n_scales))[::-1]))
- args.navtask.task_params.map_crop_sizes = [16 for x in range(n_scales)]
-
- args.arch.fr_stride = 1
- args.arch.vin_action_neurons = 8
- args.arch.vin_val_neurons = 3
- args.arch.fr_inside_neurons = 32
-
- args.mapper_arch.pad_map_with_zeros_each = [0 for _ in range(n_scales)]
- args.mapper_arch.deconv_neurons = [64*n_scales, 32*n_scales, 16*n_scales]
- args.mapper_arch.deconv_strides = [1, 2, 1]
-
- if arch_vars.var2 == 'MscNoVin':
- # No planning version.
- args.arch.fr_stride = [1, 2, 1, 2]
- args.arch.vin_action_neurons = None
- args.arch.vin_val_neurons = 16
- args.arch.fr_inside_neurons = 32
-
- args.arch.crop_remove_each = 0
- args.arch.value_crop_size = 4
- args.arch.vin_num_iters = 0
-
- elif arch_vars.var2 == 'MscROMms' or arch_vars.var2 == 'MscROMss':
- # Code with read outs, MscROMms flattens and reads out,
- # MscROMss does not flatten and produces output at multiple scales.
- args.navtask.task_params.outputs.readout_maps = True
- args.navtask.task_params.map_resize_method = 'antialiasing'
- args.arch.readout_maps = True
-
- if arch_vars.var2 == 'MscROMms':
- args.arch.rom_arch.num_neurons = [64, 1]
- args.arch.rom_arch.kernel_size = 4
- args.arch.rom_arch.strides = [2,2]
- args.arch.rom_arch.layers_per_block = 2
-
- args.navtask.task_params.readout_maps_crop_sizes = [64]
- args.navtask.task_params.readout_maps_scales = [sc]
-
- elif arch_vars.var2 == 'MscROMss':
- args.arch.rom_arch.num_neurons = \
- [64, len(args.navtask.task_params.map_scales)]
- args.arch.rom_arch.kernel_size = 4
- args.arch.rom_arch.strides = [1,1]
- args.arch.rom_arch.layers_per_block = 1
-
- args.navtask.task_params.readout_maps_crop_sizes = \
- args.navtask.task_params.map_crop_sizes
- args.navtask.task_params.readout_maps_scales = \
- args.navtask.task_params.map_scales
-
- else:
- logging.fatal('arch_vars.var2 not one of Msc, MscROMms, MscROMss, MscNoVin.')
- assert(False)
-
- map_channels = args.mapper_arch.deconv_neurons[-1] / \
- (2*len(args.navtask.task_params.map_scales))
- args.navtask.task_params.map_channels = map_channels
-
- return args
-
-def process_arch_projected_map(args, arch_vars):
- # Single scale vision based system which does not use a mapper but instead
- # uses an analytically estimated map.
- ds = int(arch_vars.var3[2])
- args.navtask.task_params.input_type = 'analytical_counts'
- args.navtask.task_params.outputs.analytical_counts = True
-
- assert(args.navtask.task_params.modalities[0] == 'depth')
- args.navtask.camera_param.img_channels = None
-
- analytical_counts = utils.Foo(map_sizes=[512/ds],
- xy_resolution=[5.*ds],
- z_bins=[[-10, 10, 150, 200]],
- non_linearity=[arch_vars.var2])
- args.navtask.task_params.analytical_counts = analytical_counts
-
- sc = 1./ds
- args.arch.vin_num_iters = 36
- args.navtask.task_params.map_scales = [sc]
- args.navtask.task_params.map_crop_sizes = [512/ds]
-
- args.arch.fr_stride = [1,2]
- args.arch.vin_action_neurons = 8
- args.arch.vin_val_neurons = 3
- args.arch.fr_inside_neurons = 32
-
- map_channels = len(analytical_counts.z_bins[0]) + 1
- args.navtask.task_params.map_channels = map_channels
- args.solver.freeze_conv = False
-
- return args
-
-def get_args_for_config(config_name):
- args = utils.Foo()
-
- args.summary, args.control = get_default_args()
-
- exp_name, mode_str = config_name.split('+')
- arch_str, solver_str, navtask_str = exp_name.split('.')
- logging.error('config_name: %s', config_name)
- logging.error('arch_str: %s', arch_str)
- logging.error('navtask_str: %s', navtask_str)
- logging.error('solver_str: %s', solver_str)
- logging.error('mode_str: %s', mode_str)
-
- args.solver = cc.process_solver_str(solver_str)
- args.navtask = cc.process_navtask_str(navtask_str)
-
- args = process_arch_str(args, arch_str)
- args.arch.isd_k = args.solver.isd_k
-
- # Train, test, etc.
- mode, imset = mode_str.split('_')
- args = cc.adjust_args_for_mode(args, mode)
- args.navtask.building_names = args.navtask.dataset.get_split(imset)
- args.control.test_name = '{:s}_on_{:s}'.format(mode, imset)
-
- # Log the arguments
- logging.error('%s', args)
- return args
diff --git a/research/cognitive_mapping_and_planning/cfgs/config_common.py b/research/cognitive_mapping_and_planning/cfgs/config_common.py
deleted file mode 100644
index 440bf5b72f87a1eeca38e22f33b22e82de7345c0..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/cfgs/config_common.py
+++ /dev/null
@@ -1,261 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import os
-import numpy as np
-import logging
-import src.utils as utils
-import datasets.nav_env_config as nec
-from datasets import factory
-
-def adjust_args_for_mode(args, mode):
- if mode == 'train':
- args.control.train = True
-
- elif mode == 'val1':
- # Same settings as for training, to make sure nothing wonky is happening
- # there.
- args.control.test = True
- args.control.test_mode = 'val'
- args.navtask.task_params.batch_size = 32
-
- elif mode == 'val2':
- # No data augmentation, not sampling but taking the argmax action, not
- # sampling from the ground truth at all.
- args.control.test = True
- args.arch.action_sample_type = 'argmax'
- args.arch.sample_gt_prob_type = 'zero'
- args.navtask.task_params.data_augment = \
- utils.Foo(lr_flip=0, delta_angle=0, delta_xy=0, relight=False,
- relight_fast=False, structured=False)
- args.control.test_mode = 'val'
- args.navtask.task_params.batch_size = 32
-
- elif mode == 'bench':
- # Actually testing the agent in settings that are kept same between
- # different runs.
- args.navtask.task_params.batch_size = 16
- args.control.test = True
- args.arch.action_sample_type = 'argmax'
- args.arch.sample_gt_prob_type = 'zero'
- args.navtask.task_params.data_augment = \
- utils.Foo(lr_flip=0, delta_angle=0, delta_xy=0, relight=False,
- relight_fast=False, structured=False)
- args.summary.test_iters = 250
- args.control.only_eval_when_done = True
- args.control.reset_rng_seed = True
- args.control.test_mode = 'test'
- else:
- logging.fatal('Unknown mode: %s.', mode)
- assert(False)
- return args
-
-def get_solver_vars(solver_str):
- if solver_str == '': vals = [];
- else: vals = solver_str.split('_')
- ks = ['clip', 'dlw', 'long', 'typ', 'isdk', 'adam_eps', 'init_lr'];
- ks = ks[:len(vals)]
-
- # Gradient clipping or not.
- if len(vals) == 0: ks.append('clip'); vals.append('noclip');
- # data loss weight.
- if len(vals) == 1: ks.append('dlw'); vals.append('dlw20')
- # how long to train for.
- if len(vals) == 2: ks.append('long'); vals.append('nolong')
- # Adam
- if len(vals) == 3: ks.append('typ'); vals.append('adam2')
- # reg loss wt
- if len(vals) == 4: ks.append('rlw'); vals.append('rlw1')
- # isd_k
- if len(vals) == 5: ks.append('isdk'); vals.append('isdk415') # 415, inflexion at 2.5k.
- # adam eps
- if len(vals) == 6: ks.append('adam_eps'); vals.append('aeps1en8')
- # init lr
- if len(vals) == 7: ks.append('init_lr'); vals.append('lr1en3')
-
- assert(len(vals) == 8)
-
- vars = utils.Foo()
- for k, v in zip(ks, vals):
- setattr(vars, k, v)
- logging.error('solver_vars: %s', vars)
- return vars
-
-def process_solver_str(solver_str):
- solver = utils.Foo(
- seed=0, learning_rate_decay=None, clip_gradient_norm=None, max_steps=None,
- initial_learning_rate=None, momentum=None, steps_per_decay=None,
- logdir=None, sync=False, adjust_lr_sync=True, wt_decay=0.0001,
- data_loss_wt=None, reg_loss_wt=None, freeze_conv=True, num_workers=1,
- task=0, ps_tasks=0, master='local', typ=None, momentum2=None,
- adam_eps=None)
-
- # Clobber with overrides from solver str.
- solver_vars = get_solver_vars(solver_str)
-
- solver.data_loss_wt = float(solver_vars.dlw[3:].replace('x', '.'))
- solver.adam_eps = float(solver_vars.adam_eps[4:].replace('x', '.').replace('n', '-'))
- solver.initial_learning_rate = float(solver_vars.init_lr[2:].replace('x', '.').replace('n', '-'))
- solver.reg_loss_wt = float(solver_vars.rlw[3:].replace('x', '.'))
- solver.isd_k = float(solver_vars.isdk[4:].replace('x', '.'))
-
- long = solver_vars.long
- if long == 'long':
- solver.steps_per_decay = 40000
- solver.max_steps = 120000
- elif long == 'long2':
- solver.steps_per_decay = 80000
- solver.max_steps = 120000
- elif long == 'nolong' or long == 'nol':
- solver.steps_per_decay = 20000
- solver.max_steps = 60000
- else:
- logging.fatal('solver_vars.long should be long, long2, nolong or nol.')
- assert(False)
-
- clip = solver_vars.clip
- if clip == 'noclip' or clip == 'nocl':
- solver.clip_gradient_norm = 0
- elif clip[:4] == 'clip':
- solver.clip_gradient_norm = float(clip[4:].replace('x', '.'))
- else:
- logging.fatal('Unknown solver_vars.clip: %s', clip)
- assert(False)
-
- typ = solver_vars.typ
- if typ == 'adam':
- solver.typ = 'adam'
- solver.momentum = 0.9
- solver.momentum2 = 0.999
- solver.learning_rate_decay = 1.0
- elif typ == 'adam2':
- solver.typ = 'adam'
- solver.momentum = 0.9
- solver.momentum2 = 0.999
- solver.learning_rate_decay = 0.1
- elif typ == 'sgd':
- solver.typ = 'sgd'
- solver.momentum = 0.99
- solver.momentum2 = None
- solver.learning_rate_decay = 0.1
- else:
- logging.fatal('Unknown solver_vars.typ: %s', typ)
- assert(False)
-
- logging.error('solver: %s', solver)
- return solver
-
-def get_navtask_vars(navtask_str):
- if navtask_str == '': vals = []
- else: vals = navtask_str.split('_')
-
- ks_all = ['dataset_name', 'modality', 'task', 'history', 'max_dist',
- 'num_steps', 'step_size', 'n_ori', 'aux_views', 'data_aug']
- ks = ks_all[:len(vals)]
-
- # All data or not.
- if len(vals) == 0: ks.append('dataset_name'); vals.append('sbpd')
- # modality
- if len(vals) == 1: ks.append('modality'); vals.append('rgb')
- # semantic task?
- if len(vals) == 2: ks.append('task'); vals.append('r2r')
- # number of history frames.
- if len(vals) == 3: ks.append('history'); vals.append('h0')
- # max steps
- if len(vals) == 4: ks.append('max_dist'); vals.append('32')
- # num steps
- if len(vals) == 5: ks.append('num_steps'); vals.append('40')
- # step size
- if len(vals) == 6: ks.append('step_size'); vals.append('8')
- # n_ori
- if len(vals) == 7: ks.append('n_ori'); vals.append('4')
- # Auxiliary views.
- if len(vals) == 8: ks.append('aux_views'); vals.append('nv0')
- # Normal data augmentation as opposed to structured data augmentation (if set
- # to straug.
- if len(vals) == 9: ks.append('data_aug'); vals.append('straug')
-
- assert(len(vals) == 10)
- for i in range(len(ks)):
- assert(ks[i] == ks_all[i])
-
- vars = utils.Foo()
- for k, v in zip(ks, vals):
- setattr(vars, k, v)
- logging.error('navtask_vars: %s', vals)
- return vars
-
-def process_navtask_str(navtask_str):
- navtask = nec.nav_env_base_config()
-
- # Clobber with overrides from strings.
- navtask_vars = get_navtask_vars(navtask_str)
-
- navtask.task_params.n_ori = int(navtask_vars.n_ori)
- navtask.task_params.max_dist = int(navtask_vars.max_dist)
- navtask.task_params.num_steps = int(navtask_vars.num_steps)
- navtask.task_params.step_size = int(navtask_vars.step_size)
- navtask.task_params.data_augment.delta_xy = int(navtask_vars.step_size)/2.
- n_aux_views_each = int(navtask_vars.aux_views[2])
- aux_delta_thetas = np.concatenate((np.arange(n_aux_views_each) + 1,
- -1 -np.arange(n_aux_views_each)))
- aux_delta_thetas = aux_delta_thetas*np.deg2rad(navtask.camera_param.fov)
- navtask.task_params.aux_delta_thetas = aux_delta_thetas
-
- if navtask_vars.data_aug == 'aug':
- navtask.task_params.data_augment.structured = False
- elif navtask_vars.data_aug == 'straug':
- navtask.task_params.data_augment.structured = True
- else:
- logging.fatal('Unknown navtask_vars.data_aug %s.', navtask_vars.data_aug)
- assert(False)
-
- navtask.task_params.num_history_frames = int(navtask_vars.history[1:])
- navtask.task_params.n_views = 1+navtask.task_params.num_history_frames
-
- navtask.task_params.goal_channels = int(navtask_vars.n_ori)
-
- if navtask_vars.task == 'hard':
- navtask.task_params.type = 'rng_rejection_sampling_many'
- navtask.task_params.rejection_sampling_M = 2000
- navtask.task_params.min_dist = 10
- elif navtask_vars.task == 'r2r':
- navtask.task_params.type = 'room_to_room_many'
- elif navtask_vars.task == 'ST':
- # Semantic task at hand.
- navtask.task_params.goal_channels = \
- len(navtask.task_params.semantic_task.class_map_names)
- navtask.task_params.rel_goal_loc_dim = \
- len(navtask.task_params.semantic_task.class_map_names)
- navtask.task_params.type = 'to_nearest_obj_acc'
- else:
- logging.fatal('navtask_vars.task: should be hard or r2r, ST')
- assert(False)
-
- if navtask_vars.modality == 'rgb':
- navtask.camera_param.modalities = ['rgb']
- navtask.camera_param.img_channels = 3
- elif navtask_vars.modality == 'd':
- navtask.camera_param.modalities = ['depth']
- navtask.camera_param.img_channels = 2
-
- navtask.task_params.img_height = navtask.camera_param.height
- navtask.task_params.img_width = navtask.camera_param.width
- navtask.task_params.modalities = navtask.camera_param.modalities
- navtask.task_params.img_channels = navtask.camera_param.img_channels
- navtask.task_params.img_fov = navtask.camera_param.fov
-
- navtask.dataset = factory.get_dataset(navtask_vars.dataset_name)
- return navtask
diff --git a/research/cognitive_mapping_and_planning/cfgs/config_distill.py b/research/cognitive_mapping_and_planning/cfgs/config_distill.py
deleted file mode 100644
index 53be2f8a5f12ee701a53c1c354079659da6958d4..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/cfgs/config_distill.py
+++ /dev/null
@@ -1,114 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import pprint
-import copy
-import os
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-import logging
-import src.utils as utils
-import cfgs.config_common as cc
-
-
-import tensorflow as tf
-
-rgb_resnet_v2_50_path = 'cache/resnet_v2_50_inception_preprocessed/model.ckpt-5136169'
-
-def get_default_args():
- robot = utils.Foo(radius=15, base=10, height=140, sensor_height=120,
- camera_elevation_degree=-15)
-
- camera_param = utils.Foo(width=225, height=225, z_near=0.05, z_far=20.0,
- fov=60., modalities=['rgb', 'depth'])
-
- env = utils.Foo(padding=10, resolution=5, num_point_threshold=2,
- valid_min=-10, valid_max=200, n_samples_per_face=200)
-
- data_augment = utils.Foo(lr_flip=0, delta_angle=1, delta_xy=4, relight=False,
- relight_fast=False, structured=False)
-
- task_params = utils.Foo(num_actions=4, step_size=4, num_steps=0,
- batch_size=32, room_seed=0, base_class='Building',
- task='mapping', n_ori=6, data_augment=data_augment,
- output_transform_to_global_map=False,
- output_canonical_map=False,
- output_incremental_transform=False,
- output_free_space=False, move_type='shortest_path',
- toy_problem=0)
-
- buildinger_args = utils.Foo(building_names=['area1_gates_wingA_floor1_westpart'],
- env_class=None, robot=robot,
- task_params=task_params, env=env,
- camera_param=camera_param)
-
- solver_args = utils.Foo(seed=0, learning_rate_decay=0.1,
- clip_gradient_norm=0, max_steps=120000,
- initial_learning_rate=0.001, momentum=0.99,
- steps_per_decay=40000, logdir=None, sync=False,
- adjust_lr_sync=True, wt_decay=0.0001,
- data_loss_wt=1.0, reg_loss_wt=1.0,
- num_workers=1, task=0, ps_tasks=0, master='local')
-
- summary_args = utils.Foo(display_interval=1, test_iters=100)
-
- control_args = utils.Foo(train=False, test=False,
- force_batchnorm_is_training_at_test=False)
-
- arch_args = utils.Foo(rgb_encoder='resnet_v2_50', d_encoder='resnet_v2_50')
-
- return utils.Foo(solver=solver_args,
- summary=summary_args, control=control_args, arch=arch_args,
- buildinger=buildinger_args)
-
-def get_vars(config_name):
- vars = config_name.split('_')
- if len(vars) == 1: # All data or not.
- vars.append('noall')
- if len(vars) == 2: # n_ori
- vars.append('4')
- logging.error('vars: %s', vars)
- return vars
-
-def get_args_for_config(config_name):
- args = get_default_args()
- config_name, mode = config_name.split('+')
- vars = get_vars(config_name)
-
- logging.info('config_name: %s, mode: %s', config_name, mode)
-
- args.buildinger.task_params.n_ori = int(vars[2])
- args.solver.freeze_conv = True
- args.solver.pretrained_path = rgb_resnet_v2_50_path
- args.buildinger.task_params.img_channels = 5
- args.solver.data_loss_wt = 0.00001
-
- if vars[0] == 'v0':
- None
- else:
- logging.error('config_name: %s undefined', config_name)
-
- args.buildinger.task_params.height = args.buildinger.camera_param.height
- args.buildinger.task_params.width = args.buildinger.camera_param.width
- args.buildinger.task_params.modalities = args.buildinger.camera_param.modalities
-
- if vars[1] == 'all':
- args = cc.get_args_for_mode_building_all(args, mode)
- elif vars[1] == 'noall':
- args = cc.get_args_for_mode_building(args, mode)
-
- # Log the arguments
- logging.error('%s', args)
- return args
diff --git a/research/cognitive_mapping_and_planning/cfgs/config_vision_baseline.py b/research/cognitive_mapping_and_planning/cfgs/config_vision_baseline.py
deleted file mode 100644
index 3cc64fe594ab025fbcfb41543302fa42c7fc0074..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/cfgs/config_vision_baseline.py
+++ /dev/null
@@ -1,173 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import pprint
-import os
-import numpy as np
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-import logging
-import src.utils as utils
-import cfgs.config_common as cc
-import datasets.nav_env_config as nec
-
-
-import tensorflow as tf
-
-FLAGS = flags.FLAGS
-
-get_solver_vars = cc.get_solver_vars
-get_navtask_vars = cc.get_navtask_vars
-
-
-rgb_resnet_v2_50_path = 'data/init_models/resnet_v2_50/model.ckpt-5136169'
-d_resnet_v2_50_path = 'data/init_models/distill_rgb_to_d_resnet_v2_50/model.ckpt-120002'
-
-def get_default_args():
- summary_args = utils.Foo(display_interval=1, test_iters=26,
- arop_full_summary_iters=14)
-
- control_args = utils.Foo(train=False, test=False,
- force_batchnorm_is_training_at_test=False,
- reset_rng_seed=False, only_eval_when_done=False,
- test_mode=None)
- return summary_args, control_args
-
-def get_default_baseline_args():
- batch_norm_param = {'center': True, 'scale': True,
- 'activation_fn':tf.nn.relu}
- arch_args = utils.Foo(
- pred_neurons=[], goal_embed_neurons=[], img_embed_neurons=[],
- batch_norm_param=batch_norm_param, dim_reduce_neurons=64, combine_type='',
- encoder='resnet_v2_50', action_sample_type='sample',
- action_sample_combine_type='one_or_other',
- sample_gt_prob_type='inverse_sigmoid_decay', dagger_sample_bn_false=True,
- isd_k=750., use_visit_count=False, lstm_output=False, lstm_ego=False,
- lstm_img=False, fc_dropout=0.0, embed_goal_for_state=False,
- lstm_output_init_state_from_goal=False)
- return arch_args
-
-def get_arch_vars(arch_str):
- if arch_str == '': vals = []
- else: vals = arch_str.split('_')
-
- ks = ['ver', 'lstm_dim', 'dropout']
-
- # Exp Ver
- if len(vals) == 0: vals.append('v0')
- # LSTM dimentsions
- if len(vals) == 1: vals.append('lstm2048')
- # Dropout
- if len(vals) == 2: vals.append('noDO')
-
- assert(len(vals) == 3)
-
- vars = utils.Foo()
- for k, v in zip(ks, vals):
- setattr(vars, k, v)
-
- logging.error('arch_vars: %s', vars)
- return vars
-
-def process_arch_str(args, arch_str):
- # This function modifies args.
- args.arch = get_default_baseline_args()
- arch_vars = get_arch_vars(arch_str)
-
- args.navtask.task_params.outputs.rel_goal_loc = True
- args.navtask.task_params.input_type = 'vision'
- args.navtask.task_params.outputs.images = True
-
- if args.navtask.camera_param.modalities[0] == 'rgb':
- args.solver.pretrained_path = rgb_resnet_v2_50_path
- elif args.navtask.camera_param.modalities[0] == 'depth':
- args.solver.pretrained_path = d_resnet_v2_50_path
- else:
- logging.fatal('Neither of rgb or d')
-
- if arch_vars.dropout == 'DO':
- args.arch.fc_dropout = 0.5
-
- args.tfcode = 'B'
-
- exp_ver = arch_vars.ver
- if exp_ver == 'v0':
- # Multiplicative interaction between goal loc and image features.
- args.arch.combine_type = 'multiply'
- args.arch.pred_neurons = [256, 256]
- args.arch.goal_embed_neurons = [64, 8]
- args.arch.img_embed_neurons = [1024, 512, 256*8]
-
- elif exp_ver == 'v1':
- # Additive interaction between goal and image features.
- args.arch.combine_type = 'add'
- args.arch.pred_neurons = [256, 256]
- args.arch.goal_embed_neurons = [64, 256]
- args.arch.img_embed_neurons = [1024, 512, 256]
-
- elif exp_ver == 'v2':
- # LSTM at the output on top of multiple interactions.
- args.arch.combine_type = 'multiply'
- args.arch.goal_embed_neurons = [64, 8]
- args.arch.img_embed_neurons = [1024, 512, 256*8]
- args.arch.lstm_output = True
- args.arch.lstm_output_dim = int(arch_vars.lstm_dim[4:])
- args.arch.pred_neurons = [256] # The other is inside the LSTM.
-
- elif exp_ver == 'v0blind':
- # LSTM only on the goal location.
- args.arch.combine_type = 'goalonly'
- args.arch.goal_embed_neurons = [64, 256]
- args.arch.img_embed_neurons = [2] # I dont know what it will do otherwise.
- args.arch.lstm_output = True
- args.arch.lstm_output_dim = 256
- args.arch.pred_neurons = [256] # The other is inside the LSTM.
-
- else:
- logging.fatal('exp_ver: %s undefined', exp_ver)
- assert(False)
-
- # Log the arguments
- logging.error('%s', args)
- return args
-
-def get_args_for_config(config_name):
- args = utils.Foo()
-
- args.summary, args.control = get_default_args()
-
- exp_name, mode_str = config_name.split('+')
- arch_str, solver_str, navtask_str = exp_name.split('.')
- logging.error('config_name: %s', config_name)
- logging.error('arch_str: %s', arch_str)
- logging.error('navtask_str: %s', navtask_str)
- logging.error('solver_str: %s', solver_str)
- logging.error('mode_str: %s', mode_str)
-
- args.solver = cc.process_solver_str(solver_str)
- args.navtask = cc.process_navtask_str(navtask_str)
-
- args = process_arch_str(args, arch_str)
- args.arch.isd_k = args.solver.isd_k
-
- # Train, test, etc.
- mode, imset = mode_str.split('_')
- args = cc.adjust_args_for_mode(args, mode)
- args.navtask.building_names = args.navtask.dataset.get_split(imset)
- args.control.test_name = '{:s}_on_{:s}'.format(mode, imset)
-
- # Log the arguments
- logging.error('%s', args)
- return args
diff --git a/research/cognitive_mapping_and_planning/data/.gitignore b/research/cognitive_mapping_and_planning/data/.gitignore
deleted file mode 100644
index 2b6d5e46652d14a9c0a8025dbcccfc2dd4376e4a..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/data/.gitignore
+++ /dev/null
@@ -1,3 +0,0 @@
-stanford_building_parser_dataset_raw
-stanford_building_parser_dataset
-init_models
diff --git a/research/cognitive_mapping_and_planning/data/README.md b/research/cognitive_mapping_and_planning/data/README.md
deleted file mode 100644
index a8928345351dac19c0e12fd33f99dd2aa600e23b..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/data/README.md
+++ /dev/null
@@ -1,33 +0,0 @@
-This directory contains the data needed for training and benchmarking various
-navigation models.
-
-1. Download the data from the [dataset website]
- (http://buildingparser.stanford.edu/dataset.html).
- 1. [Raw meshes](https://goo.gl/forms/2YSPaO2UKmn5Td5m2). We need the meshes
- which are in the noXYZ folder. Download the tar files and place them in
- the `stanford_building_parser_dataset_raw` folder. You need to download
- `area_1_noXYZ.tar`, `area_3_noXYZ.tar`, `area_5a_noXYZ.tar`,
- `area_5b_noXYZ.tar`, `area_6_noXYZ.tar` for training and
- `area_4_noXYZ.tar` for evaluation.
- 2. [Annotations](https://goo.gl/forms/4SoGp4KtH1jfRqEj2) for setting up
- tasks. We will need the file called `Stanford3dDataset_v1.2.zip`. Place
- the file in the directory `stanford_building_parser_dataset_raw`.
-
-2. Preprocess the data.
- 1. Extract meshes using `scripts/script_preprocess_meshes_S3DIS.sh`. After
- this `ls data/stanford_building_parser_dataset/mesh` should have 6
- folders `area1`, `area3`, `area4`, `area5a`, `area5b`, `area6`, with
- textures and obj files within each directory.
- 2. Extract out room information and semantics from zip file using
- `scripts/script_preprocess_annoations_S3DIS.sh`. After this there should
- be `room-dimension` and `class-maps` folder in
- `data/stanford_building_parser_dataset`. (If you find this script to
- crash because of an exception in np.loadtxt while processing
- `Area_5/office_19/Annotations/ceiling_1.txt`, there is a special
- character on line 323474, that should be removed manually.)
-
-3. Download ImageNet Pre-trained models. We used ResNet-v2-50 for representing
- images. For RGB images this is pre-trained on ImageNet. For Depth images we
- [distill](https://arxiv.org/abs/1507.00448) the RGB model to depth images
- using paired RGB-D images. Both there models are available through
- `scripts/script_download_init_models.sh`
diff --git a/research/cognitive_mapping_and_planning/datasets/__init__.py b/research/cognitive_mapping_and_planning/datasets/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/datasets/factory.py b/research/cognitive_mapping_and_planning/datasets/factory.py
deleted file mode 100644
index 3f7b5c0a602dbacf9619dc1c2ec98e94200428b6..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/datasets/factory.py
+++ /dev/null
@@ -1,113 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Wrapper for selecting the navigation environment that we want to train and
-test on.
-"""
-import numpy as np
-import os, glob
-import platform
-
-import logging
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-
-import render.swiftshader_renderer as renderer
-import src.file_utils as fu
-import src.utils as utils
-
-def get_dataset(dataset_name):
- if dataset_name == 'sbpd':
- dataset = StanfordBuildingParserDataset(dataset_name)
- else:
- logging.fatal('Not one of sbpd')
- return dataset
-
-class Loader():
- def get_data_dir():
- pass
-
- def get_meta_data(self, file_name, data_dir=None):
- if data_dir is None:
- data_dir = self.get_data_dir()
- full_file_name = os.path.join(data_dir, 'meta', file_name)
- assert(fu.exists(full_file_name)), \
- '{:s} does not exist'.format(full_file_name)
- ext = os.path.splitext(full_file_name)[1]
- if ext == '.txt':
- ls = []
- with fu.fopen(full_file_name, 'r') as f:
- for l in f:
- ls.append(l.rstrip())
- elif ext == '.pkl':
- ls = utils.load_variables(full_file_name)
- return ls
-
- def load_building(self, name, data_dir=None):
- if data_dir is None:
- data_dir = self.get_data_dir()
- out = {}
- out['name'] = name
- out['data_dir'] = data_dir
- out['room_dimension_file'] = os.path.join(data_dir, 'room-dimension',
- name+'.pkl')
- out['class_map_folder'] = os.path.join(data_dir, 'class-maps')
- return out
-
- def load_building_meshes(self, building):
- dir_name = os.path.join(building['data_dir'], 'mesh', building['name'])
- mesh_file_name = glob.glob1(dir_name, '*.obj')[0]
- mesh_file_name_full = os.path.join(dir_name, mesh_file_name)
- logging.error('Loading building from obj file: %s', mesh_file_name_full)
- shape = renderer.Shape(mesh_file_name_full, load_materials=True,
- name_prefix=building['name']+'_')
- return [shape]
-
-class StanfordBuildingParserDataset(Loader):
- def __init__(self, ver):
- self.ver = ver
- self.data_dir = None
-
- def get_data_dir(self):
- if self.data_dir is None:
- self.data_dir = 'data/stanford_building_parser_dataset/'
- return self.data_dir
-
- def get_benchmark_sets(self):
- return self._get_benchmark_sets()
-
- def get_split(self, split_name):
- if self.ver == 'sbpd':
- return self._get_split(split_name)
- else:
- logging.fatal('Unknown version.')
-
- def _get_benchmark_sets(self):
- sets = ['train1', 'val', 'test']
- return sets
-
- def _get_split(self, split_name):
- train = ['area1', 'area5a', 'area5b', 'area6']
- train1 = ['area1']
- val = ['area3']
- test = ['area4']
-
- sets = {}
- sets['train'] = train
- sets['train1'] = train1
- sets['val'] = val
- sets['test'] = test
- sets['all'] = sorted(list(set(train + val + test)))
- return sets[split_name]
diff --git a/research/cognitive_mapping_and_planning/datasets/nav_env.py b/research/cognitive_mapping_and_planning/datasets/nav_env.py
deleted file mode 100644
index 5710e26dcb113121d99400cb060104224dd91749..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/datasets/nav_env.py
+++ /dev/null
@@ -1,1465 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Navidation Environment. Includes the following classes along with some
-helper functions.
- Building: Loads buildings, computes traversibility, exposes functionality for
- rendering images.
-
- GridWorld: Base class which implements functionality for moving an agent on a
- grid world.
-
- NavigationEnv: Base class which generates navigation problems on a grid world.
-
- VisualNavigationEnv: Builds upon NavigationEnv and Building to provide
- interface that is used externally to train the agent.
-
- MeshMapper: Class used for distilling the model, testing the mapper.
-
- BuildingMultiplexer: Wrapper class that instantiates a VisualNavigationEnv for
- each building and multiplexes between them as needed.
-"""
-
-import numpy as np
-import os
-import re
-import matplotlib.pyplot as plt
-
-import graph_tool as gt
-import graph_tool.topology
-
-from tensorflow.python.platform import gfile
-import logging
-import src.file_utils as fu
-import src.utils as utils
-import src.graph_utils as gu
-import src.map_utils as mu
-import src.depth_utils as du
-import render.swiftshader_renderer as sru
-from render.swiftshader_renderer import SwiftshaderRenderer
-import cv2
-
-label_nodes_with_class = gu.label_nodes_with_class
-label_nodes_with_class_geodesic = gu.label_nodes_with_class_geodesic
-get_distance_node_list = gu.get_distance_node_list
-convert_to_graph_tool = gu.convert_to_graph_tool
-generate_graph = gu.generate_graph
-get_hardness_distribution = gu.get_hardness_distribution
-rng_next_goal_rejection_sampling = gu.rng_next_goal_rejection_sampling
-rng_next_goal = gu.rng_next_goal
-rng_room_to_room = gu.rng_room_to_room
-rng_target_dist_field = gu.rng_target_dist_field
-
-compute_traversibility = mu.compute_traversibility
-make_map = mu.make_map
-resize_maps = mu.resize_maps
-pick_largest_cc = mu.pick_largest_cc
-get_graph_origin_loc = mu.get_graph_origin_loc
-generate_egocentric_maps = mu.generate_egocentric_maps
-generate_goal_images = mu.generate_goal_images
-get_map_to_predict = mu.get_map_to_predict
-
-bin_points = du.bin_points
-make_geocentric = du.make_geocentric
-get_point_cloud_from_z = du.get_point_cloud_from_z
-get_camera_matrix = du.get_camera_matrix
-
-def _get_semantic_maps(folder_name, building_name, map, flip):
- # Load file from the cache.
- file_name = '{:s}_{:d}_{:d}_{:d}_{:d}_{:d}_{:d}.pkl'
- file_name = file_name.format(building_name, map.size[0], map.size[1],
- map.origin[0], map.origin[1], map.resolution,
- flip)
- file_name = os.path.join(folder_name, file_name)
- logging.info('Loading semantic maps from %s.', file_name)
-
- if fu.exists(file_name):
- a = utils.load_variables(file_name)
- maps = a['maps'] #HxWx#C
- cats = a['cats']
- else:
- logging.error('file_name: %s not found.', file_name)
- maps = None
- cats = None
- return maps, cats
-
-def _select_classes(all_maps, all_cats, cats_to_use):
- inds = []
- for c in cats_to_use:
- ind = all_cats.index(c)
- inds.append(ind)
- out_maps = all_maps[:,:,inds]
- return out_maps
-
-def _get_room_dimensions(file_name, resolution, origin, flip=False):
- if fu.exists(file_name):
- a = utils.load_variables(file_name)['room_dimension']
- names = a.keys()
- dims = np.concatenate(a.values(), axis=0).reshape((-1,6))
- ind = np.argsort(names)
- dims = dims[ind,:]
- names = [names[x] for x in ind]
- if flip:
- dims_new = dims*1
- dims_new[:,1] = -dims[:,4]
- dims_new[:,4] = -dims[:,1]
- dims = dims_new*1
-
- dims = dims*100.
- dims[:,0] = dims[:,0] - origin[0]
- dims[:,1] = dims[:,1] - origin[1]
- dims[:,3] = dims[:,3] - origin[0]
- dims[:,4] = dims[:,4] - origin[1]
- dims = dims / resolution
- out = {'names': names, 'dims': dims}
- else:
- out = None
- return out
-
-def _filter_rooms(room_dims, room_regex):
- pattern = re.compile(room_regex)
- ind = []
- for i, name in enumerate(room_dims['names']):
- if pattern.match(name):
- ind.append(i)
- new_room_dims = {}
- new_room_dims['names'] = [room_dims['names'][i] for i in ind]
- new_room_dims['dims'] = room_dims['dims'][ind,:]*1
- return new_room_dims
-
-def _label_nodes_with_room_id(xyt, room_dims):
- # Label the room with the ID into things.
- node_room_id = -1*np.ones((xyt.shape[0], 1))
- dims = room_dims['dims']
- for x, name in enumerate(room_dims['names']):
- all_ = np.concatenate((xyt[:,[0]] >= dims[x,0],
- xyt[:,[0]] <= dims[x,3],
- xyt[:,[1]] >= dims[x,1],
- xyt[:,[1]] <= dims[x,4]), axis=1)
- node_room_id[np.all(all_, axis=1), 0] = x
- return node_room_id
-
-def get_path_ids(start_node_id, end_node_id, pred_map):
- id = start_node_id
- path = [id]
- while id != end_node_id:
- id = pred_map[id]
- path.append(id)
- return path
-
-def image_pre(images, modalities):
- # Assumes images are ...xHxWxC.
- # We always assume images are RGB followed by Depth.
- if 'depth' in modalities:
- d = images[...,-1][...,np.newaxis]*1.
- d[d < 0.01] = np.NaN; isnan = np.isnan(d);
- d = 100./d; d[isnan] = 0.;
- images = np.concatenate((images[...,:-1], d, isnan), axis=images.ndim-1)
- if 'rgb' in modalities:
- images[...,:3] = images[...,:3]*1. - 128
- return images
-
-def _get_relative_goal_loc(goal_loc, loc, theta):
- r = np.sqrt(np.sum(np.square(goal_loc - loc), axis=1))
- t = np.arctan2(goal_loc[:,1] - loc[:,1], goal_loc[:,0] - loc[:,0])
- t = t-theta[:,0] + np.pi/2
- return np.expand_dims(r,axis=1), np.expand_dims(t, axis=1)
-
-def _gen_perturbs(rng, batch_size, num_steps, lr_flip, delta_angle, delta_xy,
- structured):
- perturbs = []
- for i in range(batch_size):
- # Doing things one by one for each episode in this batch. This way this
- # remains replicatable even when we change the batch size.
- p = np.zeros((num_steps+1, 4))
- if lr_flip:
- # Flip the whole trajectory.
- p[:,3] = rng.rand(1)-0.5
- if delta_angle > 0:
- if structured:
- p[:,2] = (rng.rand(1)-0.5)* delta_angle
- else:
- p[:,2] = (rng.rand(p.shape[0])-0.5)* delta_angle
- if delta_xy > 0:
- if structured:
- p[:,:2] = (rng.rand(1, 2)-0.5)*delta_xy
- else:
- p[:,:2] = (rng.rand(p.shape[0], 2)-0.5)*delta_xy
- perturbs.append(p)
- return perturbs
-
-def get_multiplexer_class(args, task_number):
- assert(args.task_params.base_class == 'Building')
- logging.info('Returning BuildingMultiplexer')
- R = BuildingMultiplexer(args, task_number)
- return R
-
-class GridWorld():
- def __init__(self):
- """Class members that will be assigned by any class that actually uses this
- class."""
- self.restrict_to_largest_cc = None
- self.robot = None
- self.env = None
- self.category_list = None
- self.traversible = None
-
- def get_loc_axis(self, node, delta_theta, perturb=None):
- """Based on the node orientation returns X, and Y axis. Used to sample the
- map in egocentric coordinate frame.
- """
- if type(node) == tuple:
- node = np.array([node])
- if perturb is None:
- perturb = np.zeros((node.shape[0], 4))
- xyt = self.to_actual_xyt_vec(node)
- x = xyt[:,[0]] + perturb[:,[0]]
- y = xyt[:,[1]] + perturb[:,[1]]
- t = xyt[:,[2]] + perturb[:,[2]]
- theta = t*delta_theta
- loc = np.concatenate((x,y), axis=1)
- x_axis = np.concatenate((np.cos(theta), np.sin(theta)), axis=1)
- y_axis = np.concatenate((np.cos(theta+np.pi/2.), np.sin(theta+np.pi/2.)),
- axis=1)
- # Flip the sampled map where need be.
- y_axis[np.where(perturb[:,3] > 0)[0], :] *= -1.
- return loc, x_axis, y_axis, theta
-
- def to_actual_xyt(self, pqr):
- """Converts from node to location on the map."""
- (p, q, r) = pqr
- if self.task.n_ori == 6:
- out = (p - q * 0.5 + self.task.origin_loc[0],
- q * np.sqrt(3.) / 2. + self.task.origin_loc[1], r)
- elif self.task.n_ori == 4:
- out = (p + self.task.origin_loc[0],
- q + self.task.origin_loc[1], r)
- return out
-
- def to_actual_xyt_vec(self, pqr):
- """Converts from node array to location array on the map."""
- p = pqr[:,0][:, np.newaxis]
- q = pqr[:,1][:, np.newaxis]
- r = pqr[:,2][:, np.newaxis]
- if self.task.n_ori == 6:
- out = np.concatenate((p - q * 0.5 + self.task.origin_loc[0],
- q * np.sqrt(3.) / 2. + self.task.origin_loc[1],
- r), axis=1)
- elif self.task.n_ori == 4:
- out = np.concatenate((p + self.task.origin_loc[0],
- q + self.task.origin_loc[1],
- r), axis=1)
- return out
-
- def raw_valid_fn_vec(self, xyt):
- """Returns if the given set of nodes is valid or not."""
- height = self.traversible.shape[0]
- width = self.traversible.shape[1]
- x = np.round(xyt[:,[0]]).astype(np.int32)
- y = np.round(xyt[:,[1]]).astype(np.int32)
- is_inside = np.all(np.concatenate((x >= 0, y >= 0,
- x < width, y < height), axis=1), axis=1)
- x = np.minimum(np.maximum(x, 0), width-1)
- y = np.minimum(np.maximum(y, 0), height-1)
- ind = np.ravel_multi_index((y,x), self.traversible.shape)
- is_traversible = self.traversible.ravel()[ind]
-
- is_valid = np.all(np.concatenate((is_inside[:,np.newaxis], is_traversible),
- axis=1), axis=1)
- return is_valid
-
-
- def valid_fn_vec(self, pqr):
- """Returns if the given set of nodes is valid or not."""
- xyt = self.to_actual_xyt_vec(np.array(pqr))
- height = self.traversible.shape[0]
- width = self.traversible.shape[1]
- x = np.round(xyt[:,[0]]).astype(np.int32)
- y = np.round(xyt[:,[1]]).astype(np.int32)
- is_inside = np.all(np.concatenate((x >= 0, y >= 0,
- x < width, y < height), axis=1), axis=1)
- x = np.minimum(np.maximum(x, 0), width-1)
- y = np.minimum(np.maximum(y, 0), height-1)
- ind = np.ravel_multi_index((y,x), self.traversible.shape)
- is_traversible = self.traversible.ravel()[ind]
-
- is_valid = np.all(np.concatenate((is_inside[:,np.newaxis], is_traversible),
- axis=1), axis=1)
- return is_valid
-
- def get_feasible_actions(self, node_ids):
- """Returns the feasible set of actions from the current node."""
- a = np.zeros((len(node_ids), self.task_params.num_actions), dtype=np.int32)
- gtG = self.task.gtG
- next_node = []
- for i, c in enumerate(node_ids):
- neigh = gtG.vertex(c).out_neighbours()
- neigh_edge = gtG.vertex(c).out_edges()
- nn = {}
- for n, e in zip(neigh, neigh_edge):
- _ = gtG.ep['action'][e]
- a[i,_] = 1
- nn[_] = int(n)
- next_node.append(nn)
- return a, next_node
-
- def take_action(self, current_node_ids, action):
- """Returns the new node after taking the action action. Stays at the current
- node if the action is invalid."""
- actions, next_node_ids = self.get_feasible_actions(current_node_ids)
- new_node_ids = []
- for i, (c,a) in enumerate(zip(current_node_ids, action)):
- if actions[i,a] == 1:
- new_node_ids.append(next_node_ids[i][a])
- else:
- new_node_ids.append(c)
- return new_node_ids
-
- def set_r_obj(self, r_obj):
- """Sets the SwiftshaderRenderer object used for rendering."""
- self.r_obj = r_obj
-
-class Building(GridWorld):
- def __init__(self, building_name, robot, env,
- category_list=None, small=False, flip=False, logdir=None,
- building_loader=None):
-
- self.restrict_to_largest_cc = True
- self.robot = robot
- self.env = env
- self.logdir = logdir
-
- # Load the building meta data.
- building = building_loader.load_building(building_name)
- if small:
- building['mesh_names'] = building['mesh_names'][:5]
-
- # New code.
- shapess = building_loader.load_building_meshes(building)
- if flip:
- for shapes in shapess:
- shapes.flip_shape()
-
- vs = []
- for shapes in shapess:
- vs.append(shapes.get_vertices()[0])
- vs = np.concatenate(vs, axis=0)
- map = make_map(env.padding, env.resolution, vertex=vs, sc=100.)
- map = compute_traversibility(
- map, robot.base, robot.height, robot.radius, env.valid_min,
- env.valid_max, env.num_point_threshold, shapess=shapess, sc=100.,
- n_samples_per_face=env.n_samples_per_face)
-
- room_dims = _get_room_dimensions(building['room_dimension_file'],
- env.resolution, map.origin, flip=flip)
- class_maps, class_map_names = _get_semantic_maps(
- building['class_map_folder'], building_name, map, flip)
-
- self.class_maps = class_maps
- self.class_map_names = class_map_names
- self.building = building
- self.shapess = shapess
- self.map = map
- self.traversible = map.traversible*1
- self.building_name = building_name
- self.room_dims = room_dims
- self.flipped = flip
- self.renderer_entitiy_ids = []
-
- if self.restrict_to_largest_cc:
- self.traversible = pick_largest_cc(self.traversible)
-
- def load_building_into_scene(self):
- # Loads the scene.
- self.renderer_entitiy_ids += self.r_obj.load_shapes(self.shapess)
- # Free up memory, we dont need the mesh or the materials anymore.
- self.shapess = None
-
- def add_entity_at_nodes(self, nodes, height, shape):
- xyt = self.to_actual_xyt_vec(nodes)
- nxy = xyt[:,:2]*1.
- nxy = nxy * self.map.resolution
- nxy = nxy + self.map.origin
- Ts = np.concatenate((nxy, nxy[:,:1]), axis=1)
- Ts[:,2] = height; Ts = Ts / 100.;
-
- # Merge all the shapes into a single shape and add that shape.
- shape.replicate_shape(Ts)
- entity_ids = self.r_obj.load_shapes([shape])
- self.renderer_entitiy_ids += entity_ids
- return entity_ids
-
- def add_shapes(self, shapes):
- scene = self.r_obj.viz.scene()
- for shape in shapes:
- scene.AddShape(shape)
-
- def add_materials(self, materials):
- scene = self.r_obj.viz.scene()
- for material in materials:
- scene.AddOrUpdateMaterial(material)
-
- def set_building_visibility(self, visibility):
- self.r_obj.set_entity_visible(self.renderer_entitiy_ids, visibility)
-
- def render_nodes(self, nodes, perturb=None, aux_delta_theta=0.):
- self.set_building_visibility(True)
- if perturb is None:
- perturb = np.zeros((len(nodes), 4))
-
- imgs = []
- r = 2
- elevation_z = r * np.tan(np.deg2rad(self.robot.camera_elevation_degree))
-
- for i in range(len(nodes)):
- xyt = self.to_actual_xyt(nodes[i])
- lookat_theta = 3.0 * np.pi / 2.0 - (xyt[2]+perturb[i,2]+aux_delta_theta) * (self.task.delta_theta)
- nxy = np.array([xyt[0]+perturb[i,0], xyt[1]+perturb[i,1]]).reshape(1, -1)
- nxy = nxy * self.map.resolution
- nxy = nxy + self.map.origin
- camera_xyz = np.zeros((1, 3))
- camera_xyz[...] = [nxy[0, 0], nxy[0, 1], self.robot.sensor_height]
- camera_xyz = camera_xyz / 100.
- lookat_xyz = np.array([-r * np.sin(lookat_theta),
- -r * np.cos(lookat_theta), elevation_z])
- lookat_xyz = lookat_xyz + camera_xyz[0, :]
- self.r_obj.position_camera(camera_xyz[0, :].tolist(),
- lookat_xyz.tolist(), [0.0, 0.0, 1.0])
- img = self.r_obj.render(take_screenshot=True, output_type=0)
- img = [x for x in img if x is not None]
- img = np.concatenate(img, axis=2).astype(np.float32)
- if perturb[i,3]>0:
- img = img[:,::-1,:]
- imgs.append(img)
-
- self.set_building_visibility(False)
- return imgs
-
-
-class MeshMapper(Building):
- def __init__(self, robot, env, task_params, building_name, category_list,
- flip, logdir=None, building_loader=None):
- Building.__init__(self, building_name, robot, env, category_list,
- small=task_params.toy_problem, flip=flip, logdir=logdir,
- building_loader=building_loader)
- self.task_params = task_params
- self.task = None
- self._preprocess_for_task(self.task_params.building_seed)
-
- def _preprocess_for_task(self, seed):
- if self.task is None or self.task.seed != seed:
- rng = np.random.RandomState(seed)
- origin_loc = get_graph_origin_loc(rng, self.traversible)
- self.task = utils.Foo(seed=seed, origin_loc=origin_loc,
- n_ori=self.task_params.n_ori)
- G = generate_graph(self.valid_fn_vec,
- self.task_params.step_size, self.task.n_ori,
- (0, 0, 0))
- gtG, nodes, nodes_to_id = convert_to_graph_tool(G)
- self.task.gtG = gtG
- self.task.nodes = nodes
- self.task.delta_theta = 2.0*np.pi/(self.task.n_ori*1.)
- self.task.nodes_to_id = nodes_to_id
- logging.info('Building %s, #V=%d, #E=%d', self.building_name,
- self.task.nodes.shape[0], self.task.gtG.num_edges())
-
- if self.logdir is not None:
- write_traversible = cv2.applyColorMap(self.traversible.astype(np.uint8)*255, cv2.COLORMAP_JET)
- img_path = os.path.join(self.logdir,
- '{:s}_{:d}_graph.png'.format(self.building_name,
- seed))
- node_xyt = self.to_actual_xyt_vec(self.task.nodes)
- plt.set_cmap('jet');
- fig, ax = utils.subplot(plt, (1,1), (12,12))
- ax.plot(node_xyt[:,0], node_xyt[:,1], 'm.')
- ax.imshow(self.traversible, origin='lower');
- ax.set_axis_off(); ax.axis('equal');
- ax.set_title('{:s}, {:d}, {:d}'.format(self.building_name,
- self.task.nodes.shape[0],
- self.task.gtG.num_edges()))
- if self.room_dims is not None:
- for i, r in enumerate(self.room_dims['dims']*1):
- min_ = r[:3]*1
- max_ = r[3:]*1
- xmin, ymin, zmin = min_
- xmax, ymax, zmax = max_
-
- ax.plot([xmin, xmax, xmax, xmin, xmin],
- [ymin, ymin, ymax, ymax, ymin], 'g')
- with fu.fopen(img_path, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- plt.close(fig)
-
-
- def _gen_rng(self, rng):
- # instances is a list of list of node_ids.
- if self.task_params.move_type == 'circle':
- _, _, _, _, paths = rng_target_dist_field(self.task_params.batch_size,
- self.task.gtG, rng, 0, 1,
- compute_path=True)
- instances_ = paths
-
- instances = []
- for instance_ in instances_:
- instance = instance_
- for i in range(self.task_params.num_steps):
- instance.append(self.take_action([instance[-1]], [1])[0])
- instances.append(instance)
-
- elif self.task_params.move_type == 'shortest_path':
- _, _, _, _, paths = rng_target_dist_field(self.task_params.batch_size,
- self.task.gtG, rng,
- self.task_params.num_steps,
- self.task_params.num_steps+1,
- compute_path=True)
- instances = paths
-
- elif self.task_params.move_type == 'circle+forward':
- _, _, _, _, paths = rng_target_dist_field(self.task_params.batch_size,
- self.task.gtG, rng, 0, 1,
- compute_path=True)
- instances_ = paths
- instances = []
- for instance_ in instances_:
- instance = instance_
- for i in range(self.task_params.n_ori-1):
- instance.append(self.take_action([instance[-1]], [1])[0])
- while len(instance) <= self.task_params.num_steps:
- while self.take_action([instance[-1]], [3])[0] == instance[-1] and len(instance) <= self.task_params.num_steps:
- instance.append(self.take_action([instance[-1]], [2])[0])
- if len(instance) <= self.task_params.num_steps:
- instance.append(self.take_action([instance[-1]], [3])[0])
- instances.append(instance)
-
- # Do random perturbation if needed.
- perturbs = _gen_perturbs(rng, self.task_params.batch_size,
- self.task_params.num_steps,
- self.task_params.data_augment.lr_flip,
- self.task_params.data_augment.delta_angle,
- self.task_params.data_augment.delta_xy,
- self.task_params.data_augment.structured)
- return instances, perturbs
-
- def worker(self, instances, perturbs):
- # Output the images and the free space.
-
- # Make the instances be all the same length.
- for i in range(len(instances)):
- for j in range(self.task_params.num_steps - len(instances[i]) + 1):
- instances[i].append(instances[i][-1])
- if perturbs[i].shape[0] < self.task_params.num_steps+1:
- p = np.zeros((self.task_params.num_steps+1, 4))
- p[:perturbs[i].shape[0], :] = perturbs[i]
- p[perturbs[i].shape[0]:, :] = perturbs[i][-1,:]
- perturbs[i] = p
-
- instances_ = []
- for instance in instances:
- instances_ = instances_ + instance
- perturbs_ = np.concatenate(perturbs, axis=0)
-
- instances_nodes = self.task.nodes[instances_,:]
- instances_nodes = [tuple(x) for x in instances_nodes]
-
- imgs_ = self.render_nodes(instances_nodes, perturbs_)
- imgs = []; next = 0;
- for instance in instances:
- img_i = []
- for _ in instance:
- img_i.append(imgs_[next])
- next = next+1
- imgs.append(img_i)
- imgs = np.array(imgs)
-
- # Render out the maps in the egocentric view for all nodes and not just the
- # last node.
- all_nodes = []
- for x in instances:
- all_nodes = all_nodes + x
- all_perturbs = np.concatenate(perturbs, axis=0)
- loc, x_axis, y_axis, theta = self.get_loc_axis(
- self.task.nodes[all_nodes, :]*1, delta_theta=self.task.delta_theta,
- perturb=all_perturbs)
- fss = None
- valids = None
- loc_on_map = None
- theta_on_map = None
- cum_fs = None
- cum_valid = None
- incremental_locs = None
- incremental_thetas = None
-
- if self.task_params.output_free_space:
- fss, valids = get_map_to_predict(loc, x_axis, y_axis,
- map=self.traversible*1.,
- map_size=self.task_params.map_size)
- fss = np.array(fss) > 0.5
- fss = np.reshape(fss, [self.task_params.batch_size,
- self.task_params.num_steps+1,
- self.task_params.map_size,
- self.task_params.map_size])
- valids = np.reshape(np.array(valids), fss.shape)
-
- if self.task_params.output_transform_to_global_map:
- # Output the transform to the global map.
- loc_on_map = np.reshape(loc*1, [self.task_params.batch_size,
- self.task_params.num_steps+1, -1])
- # Converting to location wrt to first location so that warping happens
- # properly.
- theta_on_map = np.reshape(theta*1, [self.task_params.batch_size,
- self.task_params.num_steps+1, -1])
-
- if self.task_params.output_incremental_transform:
- # Output the transform to the global map.
- incremental_locs_ = np.reshape(loc*1, [self.task_params.batch_size,
- self.task_params.num_steps+1, -1])
- incremental_locs_[:,1:,:] -= incremental_locs_[:,:-1,:]
- t0 = -np.pi/2+np.reshape(theta*1, [self.task_params.batch_size,
- self.task_params.num_steps+1, -1])
- t = t0*1
- incremental_locs = incremental_locs_*1
- incremental_locs[:,:,0] = np.sum(incremental_locs_ * np.concatenate((np.cos(t), np.sin(t)), axis=-1), axis=-1)
- incremental_locs[:,:,1] = np.sum(incremental_locs_ * np.concatenate((np.cos(t+np.pi/2), np.sin(t+np.pi/2)), axis=-1), axis=-1)
- incremental_locs[:,0,:] = incremental_locs_[:,0,:]
- # print incremental_locs_[0,:,:], incremental_locs[0,:,:], t0[0,:,:]
-
- incremental_thetas = np.reshape(theta*1, [self.task_params.batch_size,
- self.task_params.num_steps+1,
- -1])
- incremental_thetas[:,1:,:] += -incremental_thetas[:,:-1,:]
-
- if self.task_params.output_canonical_map:
- loc_ = loc[0::(self.task_params.num_steps+1), :]
- x_axis = np.zeros_like(loc_); x_axis[:,1] = 1
- y_axis = np.zeros_like(loc_); y_axis[:,0] = -1
- cum_fs, cum_valid = get_map_to_predict(loc_, x_axis, y_axis,
- map=self.traversible*1.,
- map_size=self.task_params.map_size)
- cum_fs = np.array(cum_fs) > 0.5
- cum_fs = np.reshape(cum_fs, [self.task_params.batch_size, 1,
- self.task_params.map_size,
- self.task_params.map_size])
- cum_valid = np.reshape(np.array(cum_valid), cum_fs.shape)
-
-
- inputs = {'fs_maps': fss,
- 'valid_maps': valids,
- 'imgs': imgs,
- 'loc_on_map': loc_on_map,
- 'theta_on_map': theta_on_map,
- 'cum_fs_maps': cum_fs,
- 'cum_valid_maps': cum_valid,
- 'incremental_thetas': incremental_thetas,
- 'incremental_locs': incremental_locs}
- return inputs
-
- def pre(self, inputs):
- inputs['imgs'] = image_pre(inputs['imgs'], self.task_params.modalities)
- if inputs['loc_on_map'] is not None:
- inputs['loc_on_map'] = inputs['loc_on_map'] - inputs['loc_on_map'][:,[0],:]
- if inputs['theta_on_map'] is not None:
- inputs['theta_on_map'] = np.pi/2. - inputs['theta_on_map']
- return inputs
-
-def _nav_env_reset_helper(type, rng, nodes, batch_size, gtG, max_dist,
- num_steps, num_goals, data_augment, **kwargs):
- """Generates and returns a new episode."""
- max_compute = max_dist + 4*num_steps
- if type == 'general':
- start_node_ids, end_node_ids, dist, pred_map, paths = \
- rng_target_dist_field(batch_size, gtG, rng, max_dist, max_compute,
- nodes=nodes, compute_path=False)
- target_class = None
-
- elif type == 'room_to_room_many':
- goal_node_ids = []; dists = [];
- node_room_ids = kwargs['node_room_ids']
- # Sample the first one
- start_node_ids_, end_node_ids_, dist_, _, _ = rng_room_to_room(
- batch_size, gtG, rng, max_dist, max_compute,
- node_room_ids=node_room_ids, nodes=nodes)
- start_node_ids = start_node_ids_
- goal_node_ids.append(end_node_ids_)
- dists.append(dist_)
- for n in range(num_goals-1):
- start_node_ids_, end_node_ids_, dist_, _, _ = rng_next_goal(
- goal_node_ids[n], batch_size, gtG, rng, max_dist,
- max_compute, node_room_ids=node_room_ids, nodes=nodes,
- dists_from_start_node=dists[n])
- goal_node_ids.append(end_node_ids_)
- dists.append(dist_)
- target_class = None
-
- elif type == 'rng_rejection_sampling_many':
- num_goals = num_goals
- goal_node_ids = []; dists = [];
-
- n_ori = kwargs['n_ori']
- step_size = kwargs['step_size']
- min_dist = kwargs['min_dist']
- sampling_distribution = kwargs['sampling_distribution']
- target_distribution = kwargs['target_distribution']
- rejection_sampling_M = kwargs['rejection_sampling_M']
- distribution_bins = kwargs['distribution_bins']
-
- for n in range(num_goals):
- if n == 0: input_nodes = None
- else: input_nodes = goal_node_ids[n-1]
- start_node_ids_, end_node_ids_, dist_, _, _, _, _ = rng_next_goal_rejection_sampling(
- input_nodes, batch_size, gtG, rng, max_dist, min_dist,
- max_compute, sampling_distribution, target_distribution, nodes,
- n_ori, step_size, distribution_bins, rejection_sampling_M)
- if n == 0: start_node_ids = start_node_ids_
- goal_node_ids.append(end_node_ids_)
- dists.append(dist_)
- target_class = None
-
- elif type == 'room_to_room_back':
- num_goals = num_goals
- assert(num_goals == 2), 'num_goals must be 2.'
- goal_node_ids = []; dists = [];
- node_room_ids = kwargs['node_room_ids']
- # Sample the first one.
- start_node_ids_, end_node_ids_, dist_, _, _ = rng_room_to_room(
- batch_size, gtG, rng, max_dist, max_compute,
- node_room_ids=node_room_ids, nodes=nodes)
- start_node_ids = start_node_ids_
- goal_node_ids.append(end_node_ids_)
- dists.append(dist_)
-
- # Set second goal to be starting position, and compute distance to the start node.
- goal_node_ids.append(start_node_ids)
- dist = []
- for i in range(batch_size):
- dist_ = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=True),
- source=gtG.vertex(start_node_ids[i]), target=None)
- dist_ = np.array(dist_.get_array())
- dist.append(dist_)
- dists.append(dist)
- target_class = None
-
- elif type[:14] == 'to_nearest_obj':
- # Generate an episode by sampling one of the target classes (with
- # probability proportional to the number of nodes in the world).
- # With the sampled class sample a node that is within some distance from
- # the sampled class.
- class_nodes = kwargs['class_nodes']
- sampling = kwargs['sampling']
- dist_to_class = kwargs['dist_to_class']
-
- assert(num_goals == 1), 'Only supports a single goal.'
- ind = rng.choice(class_nodes.shape[0], size=batch_size)
- target_class = class_nodes[ind,1]
- start_node_ids = []; dists = []; goal_node_ids = [];
-
- for t in target_class:
- if sampling == 'uniform':
- max_dist = max_dist
- cnts = np.bincount(dist_to_class[t], minlength=max_dist+1)*1.
- cnts[max_dist+1:] = 0
- p_each = 1./ cnts / (max_dist+1.)
- p_each[cnts == 0] = 0
- p = p_each[dist_to_class[t]]*1.; p = p/np.sum(p)
- start_node_id = rng.choice(p.shape[0], size=1, p=p)[0]
- else:
- logging.fatal('Sampling not one of uniform.')
- start_node_ids.append(start_node_id)
- dists.append(dist_to_class[t])
- # Dummy goal node, same as the start node, so that vis is better.
- goal_node_ids.append(start_node_id)
- dists = [dists]
- goal_node_ids = [goal_node_ids]
-
- return start_node_ids, goal_node_ids, dists, target_class
-
-
-class NavigationEnv(GridWorld, Building):
- """Wrapper around GridWorld which sets up navigation tasks.
- """
- def _debug_save_hardness(self, seed):
- out_path = os.path.join(self.logdir, '{:s}_{:d}_hardness.png'.format(self.building_name, seed))
- batch_size = 4000
- rng = np.random.RandomState(0)
- start_node_ids, end_node_ids, dists, pred_maps, paths, hardnesss, gt_dists = \
- rng_next_goal_rejection_sampling(
- None, batch_size, self.task.gtG, rng, self.task_params.max_dist,
- self.task_params.min_dist, self.task_params.max_dist,
- self.task.sampling_distribution, self.task.target_distribution,
- self.task.nodes, self.task_params.n_ori, self.task_params.step_size,
- self.task.distribution_bins, self.task.rejection_sampling_M)
- bins = self.task.distribution_bins
- n_bins = self.task.n_bins
- with plt.style.context('ggplot'):
- fig, axes = utils.subplot(plt, (1,2), (10,10))
- ax = axes[0]
- _ = ax.hist(hardnesss, bins=bins, weights=np.ones_like(hardnesss)/len(hardnesss))
- ax.plot(bins[:-1]+0.5/n_bins, self.task.target_distribution, 'g')
- ax.plot(bins[:-1]+0.5/n_bins, self.task.sampling_distribution, 'b')
- ax.grid('on')
-
- ax = axes[1]
- _ = ax.hist(gt_dists, bins=np.arange(self.task_params.max_dist+1))
- ax.grid('on')
- ax.set_title('Mean: {:0.2f}, Median: {:0.2f}'.format(np.mean(gt_dists),
- np.median(gt_dists)))
- with fu.fopen(out_path, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
-
- def _debug_save_map_nodes(self, seed):
- """Saves traversible space along with nodes generated on the graph. Takes
- the seed as input."""
- img_path = os.path.join(self.logdir, '{:s}_{:d}_graph.png'.format(self.building_name, seed))
- node_xyt = self.to_actual_xyt_vec(self.task.nodes)
- plt.set_cmap('jet');
- fig, ax = utils.subplot(plt, (1,1), (12,12))
- ax.plot(node_xyt[:,0], node_xyt[:,1], 'm.')
- ax.set_axis_off(); ax.axis('equal');
-
- if self.room_dims is not None:
- for i, r in enumerate(self.room_dims['dims']*1):
- min_ = r[:3]*1
- max_ = r[3:]*1
- xmin, ymin, zmin = min_
- xmax, ymax, zmax = max_
-
- ax.plot([xmin, xmax, xmax, xmin, xmin],
- [ymin, ymin, ymax, ymax, ymin], 'g')
- ax.imshow(self.traversible, origin='lower');
- with fu.fopen(img_path, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
-
- def _debug_semantic_maps(self, seed):
- """Saves traversible space along with nodes generated on the graph. Takes
- the seed as input."""
- for i, cls in enumerate(self.task_params.semantic_task.class_map_names):
- img_path = os.path.join(self.logdir, '{:s}_flip{:d}_{:s}_graph.png'.format(self.building_name, seed, cls))
- maps = self.traversible*1.
- maps += 0.5*(self.task.class_maps_dilated[:,:,i])
- write_traversible = (maps*1.+1.)/3.0
- write_traversible = (write_traversible*255.).astype(np.uint8)[:,:,np.newaxis]
- write_traversible = write_traversible + np.zeros((1,1,3), dtype=np.uint8)
- fu.write_image(img_path, write_traversible[::-1,:,:])
-
- def _preprocess_for_task(self, seed):
- """Sets up the task field for doing navigation on the grid world."""
- if self.task is None or self.task.seed != seed:
- rng = np.random.RandomState(seed)
- origin_loc = get_graph_origin_loc(rng, self.traversible)
- self.task = utils.Foo(seed=seed, origin_loc=origin_loc,
- n_ori=self.task_params.n_ori)
- G = generate_graph(self.valid_fn_vec, self.task_params.step_size,
- self.task.n_ori, (0, 0, 0))
- gtG, nodes, nodes_to_id = convert_to_graph_tool(G)
- self.task.gtG = gtG
- self.task.nodes = nodes
- self.task.delta_theta = 2.0*np.pi/(self.task.n_ori*1.)
- self.task.nodes_to_id = nodes_to_id
-
- logging.info('Building %s, #V=%d, #E=%d', self.building_name,
- self.task.nodes.shape[0], self.task.gtG.num_edges())
- type = self.task_params.type
- if type == 'general':
- # Do nothing
- _ = None
-
- elif type == 'room_to_room_many' or type == 'room_to_room_back':
- if type == 'room_to_room_back':
- assert(self.task_params.num_goals == 2), 'num_goals must be 2.'
-
- self.room_dims = _filter_rooms(self.room_dims, self.task_params.room_regex)
- xyt = self.to_actual_xyt_vec(self.task.nodes)
- self.task.node_room_ids = _label_nodes_with_room_id(xyt, self.room_dims)
- self.task.reset_kwargs = {'node_room_ids': self.task.node_room_ids}
-
- elif type == 'rng_rejection_sampling_many':
- n_bins = 20
- rejection_sampling_M = self.task_params.rejection_sampling_M
- min_dist = self.task_params.min_dist
- bins = np.arange(n_bins+1)/(n_bins*1.)
- target_d = np.zeros(n_bins); target_d[...] = 1./n_bins;
-
- sampling_d = get_hardness_distribution(
- self.task.gtG, self.task_params.max_dist, self.task_params.min_dist,
- np.random.RandomState(0), 4000, bins, self.task.nodes,
- self.task_params.n_ori, self.task_params.step_size)
-
- self.task.reset_kwargs = {'distribution_bins': bins,
- 'target_distribution': target_d,
- 'sampling_distribution': sampling_d,
- 'rejection_sampling_M': rejection_sampling_M,
- 'n_bins': n_bins,
- 'n_ori': self.task_params.n_ori,
- 'step_size': self.task_params.step_size,
- 'min_dist': self.task_params.min_dist}
- self.task.n_bins = n_bins
- self.task.distribution_bins = bins
- self.task.target_distribution = target_d
- self.task.sampling_distribution = sampling_d
- self.task.rejection_sampling_M = rejection_sampling_M
-
- if self.logdir is not None:
- self._debug_save_hardness(seed)
-
- elif type[:14] == 'to_nearest_obj':
- self.room_dims = _filter_rooms(self.room_dims, self.task_params.room_regex)
- xyt = self.to_actual_xyt_vec(self.task.nodes)
-
- self.class_maps = _select_classes(self.class_maps,
- self.class_map_names,
- self.task_params.semantic_task.class_map_names)*1
- self.class_map_names = self.task_params.semantic_task.class_map_names
- nodes_xyt = self.to_actual_xyt_vec(np.array(self.task.nodes))
-
- tt = utils.Timer(); tt.tic();
- if self.task_params.type == 'to_nearest_obj_acc':
- self.task.class_maps_dilated, self.task.node_class_label = label_nodes_with_class_geodesic(
- nodes_xyt, self.class_maps,
- self.task_params.semantic_task.pix_distance+8, self.map.traversible,
- ff_cost=1., fo_cost=1., oo_cost=4., connectivity=8.)
-
- dists = []
- for i in range(len(self.class_map_names)):
- class_nodes_ = np.where(self.task.node_class_label[:,i])[0]
- dists.append(get_distance_node_list(gtG, source_nodes=class_nodes_, direction='to'))
- self.task.dist_to_class = dists
- a_, b_ = np.where(self.task.node_class_label)
- self.task.class_nodes = np.concatenate((a_[:,np.newaxis], b_[:,np.newaxis]), axis=1)
-
- if self.logdir is not None:
- self._debug_semantic_maps(seed)
-
- self.task.reset_kwargs = {'sampling': self.task_params.semantic_task.sampling,
- 'class_nodes': self.task.class_nodes,
- 'dist_to_class': self.task.dist_to_class}
-
- if self.logdir is not None:
- self._debug_save_map_nodes(seed)
-
- def reset(self, rngs):
- rng = rngs[0]; rng_perturb = rngs[1];
- nodes = self.task.nodes
- tp = self.task_params
-
- start_node_ids, goal_node_ids, dists, target_class = \
- _nav_env_reset_helper(tp.type, rng, self.task.nodes, tp.batch_size,
- self.task.gtG, tp.max_dist, tp.num_steps,
- tp.num_goals, tp.data_augment,
- **(self.task.reset_kwargs))
-
- start_nodes = [tuple(nodes[_,:]) for _ in start_node_ids]
- goal_nodes = [[tuple(nodes[_,:]) for _ in __] for __ in goal_node_ids]
- data_augment = tp.data_augment
- perturbs = _gen_perturbs(rng_perturb, tp.batch_size,
- (tp.num_steps+1)*tp.num_goals,
- data_augment.lr_flip, data_augment.delta_angle,
- data_augment.delta_xy, data_augment.structured)
- perturbs = np.array(perturbs) # batch x steps x 4
- end_perturbs = perturbs[:,-(tp.num_goals):,:]*1 # fixed perturb for the goal.
- perturbs = perturbs[:,:-(tp.num_goals),:]*1
-
- history = -np.ones((tp.batch_size, tp.num_steps*tp.num_goals), dtype=np.int32)
- self.episode = utils.Foo(
- start_nodes=start_nodes, start_node_ids=start_node_ids,
- goal_nodes=goal_nodes, goal_node_ids=goal_node_ids, dist_to_goal=dists,
- perturbs=perturbs, goal_perturbs=end_perturbs, history=history,
- target_class=target_class, history_frames=[])
- return start_node_ids
-
- def take_action(self, current_node_ids, action, step_number):
- """In addition to returning the action, also returns the reward that the
- agent receives."""
- goal_number = step_number / self.task_params.num_steps
- new_node_ids = GridWorld.take_action(self, current_node_ids, action)
- rewards = []
- for i, n in enumerate(new_node_ids):
- reward = 0
- if n == self.episode.goal_node_ids[goal_number][i]:
- reward = self.task_params.reward_at_goal
- reward = reward - self.task_params.reward_time_penalty
- rewards.append(reward)
- return new_node_ids, rewards
-
-
- def get_optimal_action(self, current_node_ids, step_number):
- """Returns the optimal action from the current node."""
- goal_number = step_number / self.task_params.num_steps
- gtG = self.task.gtG
- a = np.zeros((len(current_node_ids), self.task_params.num_actions), dtype=np.int32)
- d_dict = self.episode.dist_to_goal[goal_number]
- for i, c in enumerate(current_node_ids):
- neigh = gtG.vertex(c).out_neighbours()
- neigh_edge = gtG.vertex(c).out_edges()
- ds = np.array([d_dict[i][int(x)] for x in neigh])
- ds_min = np.min(ds)
- for i_, e in enumerate(neigh_edge):
- if ds[i_] == ds_min:
- _ = gtG.ep['action'][e]
- a[i, _] = 1
- return a
-
- def get_targets(self, current_node_ids, step_number):
- """Returns the target actions from the current node."""
- action = self.get_optimal_action(current_node_ids, step_number)
- action = np.expand_dims(action, axis=1)
- return vars(utils.Foo(action=action))
-
- def get_targets_name(self):
- """Returns the list of names of the targets."""
- return ['action']
-
- def cleanup(self):
- self.episode = None
-
-class VisualNavigationEnv(NavigationEnv):
- """Class for doing visual navigation in environments. Functions for computing
- features on states, etc.
- """
- def __init__(self, robot, env, task_params, category_list=None,
- building_name=None, flip=False, logdir=None,
- building_loader=None, r_obj=None):
- tt = utils.Timer()
- tt.tic()
- Building.__init__(self, building_name, robot, env, category_list,
- small=task_params.toy_problem, flip=flip, logdir=logdir,
- building_loader=building_loader)
-
- self.set_r_obj(r_obj)
- self.task_params = task_params
- self.task = None
- self.episode = None
- self._preprocess_for_task(self.task_params.building_seed)
- if hasattr(self.task_params, 'map_scales'):
- self.task.scaled_maps = resize_maps(
- self.traversible.astype(np.float32)*1, self.task_params.map_scales,
- self.task_params.map_resize_method)
- else:
- logging.fatal('VisualNavigationEnv does not support scale_f anymore.')
- self.task.readout_maps_scaled = resize_maps(
- self.traversible.astype(np.float32)*1,
- self.task_params.readout_maps_scales,
- self.task_params.map_resize_method)
- tt.toc(log_at=1, log_str='VisualNavigationEnv __init__: ')
-
- def get_weight(self):
- return self.task.nodes.shape[0]
-
- def get_common_data(self):
- goal_nodes = self.episode.goal_nodes
- start_nodes = self.episode.start_nodes
- perturbs = self.episode.perturbs
- goal_perturbs = self.episode.goal_perturbs
- target_class = self.episode.target_class
-
- goal_locs = []; rel_goal_locs = [];
- for i in range(len(goal_nodes)):
- end_nodes = goal_nodes[i]
- goal_loc, _, _, goal_theta = self.get_loc_axis(
- np.array(end_nodes), delta_theta=self.task.delta_theta,
- perturb=goal_perturbs[:,i,:])
-
- # Compute the relative location to all goals from the starting location.
- loc, _, _, theta = self.get_loc_axis(np.array(start_nodes),
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,0,:])
- r_goal, t_goal = _get_relative_goal_loc(goal_loc*1., loc, theta)
- rel_goal_loc = np.concatenate((r_goal*np.cos(t_goal), r_goal*np.sin(t_goal),
- np.cos(goal_theta-theta),
- np.sin(goal_theta-theta)), axis=1)
- rel_goal_locs.append(np.expand_dims(rel_goal_loc, axis=1))
- goal_locs.append(np.expand_dims(goal_loc, axis=1))
-
- map = self.traversible*1.
- maps = np.repeat(np.expand_dims(np.expand_dims(map, axis=0), axis=0),
- self.task_params.batch_size, axis=0)*1
- if self.task_params.type[:14] == 'to_nearest_obj':
- for i in range(self.task_params.batch_size):
- maps[i,0,:,:] += 0.5*(self.task.class_maps_dilated[:,:,target_class[i]])
-
- rel_goal_locs = np.concatenate(rel_goal_locs, axis=1)
- goal_locs = np.concatenate(goal_locs, axis=1)
- maps = np.expand_dims(maps, axis=-1)
-
- if self.task_params.type[:14] == 'to_nearest_obj':
- rel_goal_locs = np.zeros((self.task_params.batch_size, 1,
- len(self.task_params.semantic_task.class_map_names)),
- dtype=np.float32)
- goal_locs = np.zeros((self.task_params.batch_size, 1, 2),
- dtype=np.float32)
- for i in range(self.task_params.batch_size):
- t = target_class[i]
- rel_goal_locs[i,0,t] = 1.
- goal_locs[i,0,0] = t
- goal_locs[i,0,1] = np.NaN
-
- return vars(utils.Foo(orig_maps=maps, goal_loc=goal_locs,
- rel_goal_loc_at_start=rel_goal_locs))
-
- def pre_common_data(self, inputs):
- return inputs
-
-
- def get_features(self, current_node_ids, step_number):
- task_params = self.task_params
- goal_number = step_number / self.task_params.num_steps
- end_nodes = self.task.nodes[self.episode.goal_node_ids[goal_number],:]*1
- current_nodes = self.task.nodes[current_node_ids,:]*1
- end_perturbs = self.episode.goal_perturbs[:,goal_number,:][:,np.newaxis,:]
- perturbs = self.episode.perturbs
- target_class = self.episode.target_class
-
- # Append to history.
- self.episode.history[:,step_number] = np.array(current_node_ids)
-
- # Render out the images from current node.
- outs = {}
-
- if self.task_params.outputs.images:
- imgs_all = []
- imgs = self.render_nodes([tuple(x) for x in current_nodes],
- perturb=perturbs[:,step_number,:])
- imgs_all.append(imgs)
- aux_delta_thetas = self.task_params.aux_delta_thetas
- for i in range(len(aux_delta_thetas)):
- imgs = self.render_nodes([tuple(x) for x in current_nodes],
- perturb=perturbs[:,step_number,:],
- aux_delta_theta=aux_delta_thetas[i])
- imgs_all.append(imgs)
- imgs_all = np.array(imgs_all) # A x B x H x W x C
- imgs_all = np.transpose(imgs_all, axes=[1,0,2,3,4])
- imgs_all = np.expand_dims(imgs_all, axis=1) # B x N x A x H x W x C
- if task_params.num_history_frames > 0:
- if step_number == 0:
- # Append the same frame 4 times
- for i in range(task_params.num_history_frames+1):
- self.episode.history_frames.insert(0, imgs_all*1.)
- self.episode.history_frames.insert(0, imgs_all)
- self.episode.history_frames.pop()
- imgs_all_with_history = np.concatenate(self.episode.history_frames, axis=2)
- else:
- imgs_all_with_history = imgs_all
- outs['imgs'] = imgs_all_with_history # B x N x A x H x W x C
-
- if self.task_params.outputs.node_ids:
- outs['node_ids'] = np.array(current_node_ids).reshape((-1,1,1))
- outs['perturbs'] = np.expand_dims(perturbs[:,step_number, :]*1., axis=1)
-
- if self.task_params.outputs.analytical_counts:
- assert(self.task_params.modalities == ['depth'])
- d = image_pre(outs['imgs']*1., self.task_params.modalities)
- cm = get_camera_matrix(self.task_params.img_width,
- self.task_params.img_height,
- self.task_params.img_fov)
- XYZ = get_point_cloud_from_z(100./d[...,0], cm)
- XYZ = make_geocentric(XYZ*100., self.robot.sensor_height,
- self.robot.camera_elevation_degree)
- for i in range(len(self.task_params.analytical_counts.map_sizes)):
- non_linearity = self.task_params.analytical_counts.non_linearity[i]
- count, isvalid = bin_points(XYZ*1.,
- map_size=self.task_params.analytical_counts.map_sizes[i],
- xy_resolution=self.task_params.analytical_counts.xy_resolution[i],
- z_bins=self.task_params.analytical_counts.z_bins[i])
- assert(count.shape[2] == 1), 'only works for n_views equal to 1.'
- count = count[:,:,0,:,:,:]
- isvalid = isvalid[:,:,0,:,:,:]
- if non_linearity == 'none':
- None
- elif non_linearity == 'min10':
- count = np.minimum(count, 10.)
- elif non_linearity == 'sqrt':
- count = np.sqrt(count)
- else:
- logging.fatal('Undefined non_linearity.')
- outs['analytical_counts_{:d}'.format(i)] = count
-
- # Compute the goal location in the cordinate frame of the robot.
- if self.task_params.outputs.rel_goal_loc:
- if self.task_params.type[:14] != 'to_nearest_obj':
- loc, _, _, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- goal_loc, _, _, goal_theta = self.get_loc_axis(end_nodes,
- delta_theta=self.task.delta_theta,
- perturb=end_perturbs[:,0,:])
- r_goal, t_goal = _get_relative_goal_loc(goal_loc, loc, theta)
-
- rel_goal_loc = np.concatenate((r_goal*np.cos(t_goal), r_goal*np.sin(t_goal),
- np.cos(goal_theta-theta),
- np.sin(goal_theta-theta)), axis=1)
- outs['rel_goal_loc'] = np.expand_dims(rel_goal_loc, axis=1)
- elif self.task_params.type[:14] == 'to_nearest_obj':
- rel_goal_loc = np.zeros((self.task_params.batch_size, 1,
- len(self.task_params.semantic_task.class_map_names)),
- dtype=np.float32)
- for i in range(self.task_params.batch_size):
- t = target_class[i]
- rel_goal_loc[i,0,t] = 1.
- outs['rel_goal_loc'] = rel_goal_loc
-
- # Location on map to plot the trajectory during validation.
- if self.task_params.outputs.loc_on_map:
- loc, x_axis, y_axis, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- outs['loc_on_map'] = np.expand_dims(loc, axis=1)
-
- # Compute gt_dist to goal
- if self.task_params.outputs.gt_dist_to_goal:
- gt_dist_to_goal = np.zeros((len(current_node_ids), 1), dtype=np.float32)
- for i, n in enumerate(current_node_ids):
- gt_dist_to_goal[i,0] = self.episode.dist_to_goal[goal_number][i][n]
- outs['gt_dist_to_goal'] = np.expand_dims(gt_dist_to_goal, axis=1)
-
- # Free space in front of you, map and goal as images.
- if self.task_params.outputs.ego_maps:
- loc, x_axis, y_axis, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- maps = generate_egocentric_maps(self.task.scaled_maps,
- self.task_params.map_scales,
- self.task_params.map_crop_sizes, loc,
- x_axis, y_axis, theta)
-
- for i in range(len(self.task_params.map_scales)):
- outs['ego_maps_{:d}'.format(i)] = \
- np.expand_dims(np.expand_dims(maps[i], axis=1), axis=-1)
-
- if self.task_params.outputs.readout_maps:
- loc, x_axis, y_axis, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- maps = generate_egocentric_maps(self.task.readout_maps_scaled,
- self.task_params.readout_maps_scales,
- self.task_params.readout_maps_crop_sizes,
- loc, x_axis, y_axis, theta)
- for i in range(len(self.task_params.readout_maps_scales)):
- outs['readout_maps_{:d}'.format(i)] = \
- np.expand_dims(np.expand_dims(maps[i], axis=1), axis=-1)
-
- # Images for the goal.
- if self.task_params.outputs.ego_goal_imgs:
- if self.task_params.type[:14] != 'to_nearest_obj':
- loc, x_axis, y_axis, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- goal_loc, _, _, _ = self.get_loc_axis(end_nodes,
- delta_theta=self.task.delta_theta,
- perturb=end_perturbs[:,0,:])
- rel_goal_orientation = np.mod(
- np.int32(current_nodes[:,2:] - end_nodes[:,2:]), self.task_params.n_ori)
- goal_dist, goal_theta = _get_relative_goal_loc(goal_loc, loc, theta)
- goals = generate_goal_images(self.task_params.map_scales,
- self.task_params.map_crop_sizes,
- self.task_params.n_ori, goal_dist,
- goal_theta, rel_goal_orientation)
- for i in range(len(self.task_params.map_scales)):
- outs['ego_goal_imgs_{:d}'.format(i)] = np.expand_dims(goals[i], axis=1)
-
- elif self.task_params.type[:14] == 'to_nearest_obj':
- for i in range(len(self.task_params.map_scales)):
- num_classes = len(self.task_params.semantic_task.class_map_names)
- outs['ego_goal_imgs_{:d}'.format(i)] = np.zeros((self.task_params.batch_size, 1,
- self.task_params.map_crop_sizes[i],
- self.task_params.map_crop_sizes[i],
- self.task_params.goal_channels))
- for i in range(self.task_params.batch_size):
- t = target_class[i]
- for j in range(len(self.task_params.map_scales)):
- outs['ego_goal_imgs_{:d}'.format(j)][i,:,:,:,t] = 1.
-
- # Incremental locs and theta (for map warping), always in the original scale
- # of the map, the subequent steps in the tf code scale appropriately.
- # Scaling is done by just multiplying incremental_locs appropriately.
- if self.task_params.outputs.egomotion:
- if step_number == 0:
- # Zero Ego Motion
- incremental_locs = np.zeros((self.task_params.batch_size, 1, 2), dtype=np.float32)
- incremental_thetas = np.zeros((self.task_params.batch_size, 1, 1), dtype=np.float32)
- else:
- previous_nodes = self.task.nodes[self.episode.history[:,step_number-1], :]*1
- loc, _, _, theta = self.get_loc_axis(current_nodes,
- delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number,:])
- previous_loc, _, _, previous_theta = self.get_loc_axis(
- previous_nodes, delta_theta=self.task.delta_theta,
- perturb=perturbs[:,step_number-1,:])
-
- incremental_locs_ = np.reshape(loc-previous_loc, [self.task_params.batch_size, 1, -1])
-
- t = -np.pi/2+np.reshape(theta*1, [self.task_params.batch_size, 1, -1])
- incremental_locs = incremental_locs_*1
- incremental_locs[:,:,0] = np.sum(incremental_locs_ *
- np.concatenate((np.cos(t), np.sin(t)),
- axis=-1), axis=-1)
- incremental_locs[:,:,1] = np.sum(incremental_locs_ *
- np.concatenate((np.cos(t+np.pi/2),
- np.sin(t+np.pi/2)),
- axis=-1), axis=-1)
- incremental_thetas = np.reshape(theta-previous_theta,
- [self.task_params.batch_size, 1, -1])
- outs['incremental_locs'] = incremental_locs
- outs['incremental_thetas'] = incremental_thetas
-
- if self.task_params.outputs.visit_count:
- # Output the visit count for this state, how many times has the current
- # state been visited, and how far in the history was the last visit
- # (except this one)
- visit_count = np.zeros((self.task_params.batch_size, 1), dtype=np.int32)
- last_visit = -np.ones((self.task_params.batch_size, 1), dtype=np.int32)
- if step_number >= 1:
- h = self.episode.history[:,:(step_number)]
- visit_count[:,0] = np.sum(h == np.array(current_node_ids).reshape([-1,1]),
- axis=1)
- last_visit[:,0] = np.argmax(h[:,::-1] == np.array(current_node_ids).reshape([-1,1]),
- axis=1) + 1
- last_visit[visit_count == 0] = -1 # -1 if not visited.
- outs['visit_count'] = np.expand_dims(visit_count, axis=1)
- outs['last_visit'] = np.expand_dims(last_visit, axis=1)
- return outs
-
- def get_features_name(self):
- f = []
- if self.task_params.outputs.images:
- f.append('imgs')
- if self.task_params.outputs.rel_goal_loc:
- f.append('rel_goal_loc')
- if self.task_params.outputs.loc_on_map:
- f.append('loc_on_map')
- if self.task_params.outputs.gt_dist_to_goal:
- f.append('gt_dist_to_goal')
- if self.task_params.outputs.ego_maps:
- for i in range(len(self.task_params.map_scales)):
- f.append('ego_maps_{:d}'.format(i))
- if self.task_params.outputs.readout_maps:
- for i in range(len(self.task_params.readout_maps_scales)):
- f.append('readout_maps_{:d}'.format(i))
- if self.task_params.outputs.ego_goal_imgs:
- for i in range(len(self.task_params.map_scales)):
- f.append('ego_goal_imgs_{:d}'.format(i))
- if self.task_params.outputs.egomotion:
- f.append('incremental_locs')
- f.append('incremental_thetas')
- if self.task_params.outputs.visit_count:
- f.append('visit_count')
- f.append('last_visit')
- if self.task_params.outputs.analytical_counts:
- for i in range(len(self.task_params.analytical_counts.map_sizes)):
- f.append('analytical_counts_{:d}'.format(i))
- if self.task_params.outputs.node_ids:
- f.append('node_ids')
- f.append('perturbs')
- return f
-
- def pre_features(self, inputs):
- if self.task_params.outputs.images:
- inputs['imgs'] = image_pre(inputs['imgs'], self.task_params.modalities)
- return inputs
-
-class BuildingMultiplexer():
- def __init__(self, args, task_number):
- params = vars(args)
- for k in params.keys():
- setattr(self, k, params[k])
- self.task_number = task_number
- self._pick_data(task_number)
- logging.info('Env Class: %s.', self.env_class)
- if self.task_params.task == 'planning':
- self._setup_planner()
- elif self.task_params.task == 'mapping':
- self._setup_mapper()
- elif self.task_params.task == 'map+plan':
- self._setup_mapper()
- else:
- logging.error('Undefined task: %s'.format(self.task_params.task))
-
- def _pick_data(self, task_number):
- logging.error('Input Building Names: %s', self.building_names)
- self.flip = [np.mod(task_number / len(self.building_names), 2) == 1]
- id = np.mod(task_number, len(self.building_names))
- self.building_names = [self.building_names[id]]
- self.task_params.building_seed = task_number
- logging.error('BuildingMultiplexer: Picked Building Name: %s', self.building_names)
- self.building_names = self.building_names[0].split('+')
- self.flip = [self.flip[0] for _ in self.building_names]
- logging.error('BuildingMultiplexer: Picked Building Name: %s', self.building_names)
- logging.error('BuildingMultiplexer: Flipping Buildings: %s', self.flip)
- logging.error('BuildingMultiplexer: Set building_seed: %d', self.task_params.building_seed)
- self.num_buildings = len(self.building_names)
- logging.error('BuildingMultiplexer: Num buildings: %d', self.num_buildings)
-
- def _setup_planner(self):
- # Load building env class.
- self.buildings = []
- for i, building_name in enumerate(self.building_names):
- b = self.env_class(robot=self.robot, env=self.env,
- task_params=self.task_params,
- building_name=building_name, flip=self.flip[i],
- logdir=self.logdir, building_loader=self.dataset)
- self.buildings.append(b)
-
- def _setup_mapper(self):
- # Set up the renderer.
- cp = self.camera_param
- rgb_shader, d_shader = sru.get_shaders(cp.modalities)
- r_obj = SwiftshaderRenderer()
- r_obj.init_display(width=cp.width, height=cp.height, fov=cp.fov,
- z_near=cp.z_near, z_far=cp.z_far, rgb_shader=rgb_shader,
- d_shader=d_shader)
- self.r_obj = r_obj
- r_obj.clear_scene()
-
- # Load building env class.
- self.buildings = []
- wt = []
- for i, building_name in enumerate(self.building_names):
- b = self.env_class(robot=self.robot, env=self.env,
- task_params=self.task_params,
- building_name=building_name, flip=self.flip[i],
- logdir=self.logdir, building_loader=self.dataset,
- r_obj=r_obj)
- wt.append(b.get_weight())
- b.load_building_into_scene()
- b.set_building_visibility(False)
- self.buildings.append(b)
- wt = np.array(wt).astype(np.float32)
- wt = wt / np.sum(wt+0.0001)
- self.building_sampling_weights = wt
-
- def sample_building(self, rng):
- if self.num_buildings == 1:
- building_id = rng.choice(range(len(self.building_names)))
- else:
- building_id = rng.choice(self.num_buildings,
- p=self.building_sampling_weights)
- b = self.buildings[building_id]
- instances = b._gen_rng(rng)
- self._building_id = building_id
- return self.buildings[building_id], instances
-
- def sample_env(self, rngs):
- rng = rngs[0];
- if self.num_buildings == 1:
- building_id = rng.choice(range(len(self.building_names)))
- else:
- building_id = rng.choice(self.num_buildings,
- p=self.building_sampling_weights)
- return self.buildings[building_id]
-
- def pre(self, inputs):
- return self.buildings[self._building_id].pre(inputs)
-
- def __del__(self):
- self.r_obj.clear_scene()
- logging.error('Clearing scene.')
diff --git a/research/cognitive_mapping_and_planning/datasets/nav_env_config.py b/research/cognitive_mapping_and_planning/datasets/nav_env_config.py
deleted file mode 100644
index 3d71c5767c4dc0ed9f05cce5c1790f11ede3778a..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/datasets/nav_env_config.py
+++ /dev/null
@@ -1,127 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Configs for stanford navigation environment.
-
-Base config for stanford navigation enviornment.
-"""
-import numpy as np
-import src.utils as utils
-import datasets.nav_env as nav_env
-
-def nav_env_base_config():
- """Returns the base config for stanford navigation environment.
-
- Returns:
- Base config for stanford navigation environment.
- """
- robot = utils.Foo(radius=15,
- base=10,
- height=140,
- sensor_height=120,
- camera_elevation_degree=-15)
-
- env = utils.Foo(padding=10,
- resolution=5,
- num_point_threshold=2,
- valid_min=-10,
- valid_max=200,
- n_samples_per_face=200)
-
- camera_param = utils.Foo(width=225,
- height=225,
- z_near=0.05,
- z_far=20.0,
- fov=60.,
- modalities=['rgb'],
- img_channels=3)
-
- data_augment = utils.Foo(lr_flip=0,
- delta_angle=0.5,
- delta_xy=4,
- relight=True,
- relight_fast=False,
- structured=False) # if True, uses the same perturb for the whole episode.
-
- outputs = utils.Foo(images=True,
- rel_goal_loc=False,
- loc_on_map=True,
- gt_dist_to_goal=True,
- ego_maps=False,
- ego_goal_imgs=False,
- egomotion=False,
- visit_count=False,
- analytical_counts=False,
- node_ids=True,
- readout_maps=False)
-
- # class_map_names=['board', 'chair', 'door', 'sofa', 'table']
- class_map_names = ['chair', 'door', 'table']
- semantic_task = utils.Foo(class_map_names=class_map_names, pix_distance=16,
- sampling='uniform')
-
- # time per iteration for cmp is 0.82 seconds per episode with 3.4s overhead per batch.
- task_params = utils.Foo(max_dist=32,
- step_size=8,
- num_steps=40,
- num_actions=4,
- batch_size=4,
- building_seed=0,
- num_goals=1,
- img_height=None,
- img_width=None,
- img_channels=None,
- modalities=None,
- outputs=outputs,
- map_scales=[1.],
- map_crop_sizes=[64],
- rel_goal_loc_dim=4,
- base_class='Building',
- task='map+plan',
- n_ori=4,
- type='room_to_room_many',
- data_augment=data_augment,
- room_regex='^((?!hallway).)*$',
- toy_problem=False,
- map_channels=1,
- gt_coverage=False,
- input_type='maps',
- full_information=False,
- aux_delta_thetas=[],
- semantic_task=semantic_task,
- num_history_frames=0,
- node_ids_dim=1,
- perturbs_dim=4,
- map_resize_method='linear_noantialiasing',
- readout_maps_channels=1,
- readout_maps_scales=[],
- readout_maps_crop_sizes=[],
- n_views=1,
- reward_time_penalty=0.1,
- reward_at_goal=1.,
- discount_factor=0.99,
- rejection_sampling_M=100,
- min_dist=None)
-
- navtask_args = utils.Foo(
- building_names=['area1_gates_wingA_floor1_westpart'],
- env_class=nav_env.VisualNavigationEnv,
- robot=robot,
- task_params=task_params,
- env=env,
- camera_param=camera_param,
- cache_rooms=True)
- return navtask_args
-
diff --git a/research/cognitive_mapping_and_planning/matplotlibrc b/research/cognitive_mapping_and_planning/matplotlibrc
deleted file mode 100644
index ed5097572ae68680d0c9afdf510968e1c3d175d4..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/matplotlibrc
+++ /dev/null
@@ -1 +0,0 @@
-backend : agg
diff --git a/research/cognitive_mapping_and_planning/output/.gitignore b/research/cognitive_mapping_and_planning/output/.gitignore
deleted file mode 100644
index a767cafbbd864d0baf76530294598e4c2be60a24..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/output/.gitignore
+++ /dev/null
@@ -1 +0,0 @@
-*
diff --git a/research/cognitive_mapping_and_planning/output/README.md b/research/cognitive_mapping_and_planning/output/README.md
deleted file mode 100644
index 7518c3874390da7e2aa65a89ccdec035ca7610e8..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/output/README.md
+++ /dev/null
@@ -1,16 +0,0 @@
-### Pre-Trained Models
-
-We provide the following pre-trained models:
-
-Config Name | Checkpoint | Mean Dist. | 50%ile Dist. | 75%ile Dist. | Success %age |
-:-: | :-: | :-: | :-: | :-: | :-: |
-cmp.lmap_Msc.clip5.sbpd_d_r2r | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/cmp.lmap_Msc.clip5.sbpd_d_r2r.tar) | 4.79 | 0 | 1 | 78.9 |
-cmp.lmap_Msc.clip5.sbpd_rgb_r2r | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/cmp.lmap_Msc.clip5.sbpd_rgb_r2r.tar) | 7.74 | 0 | 14 | 62.4 |
-cmp.lmap_Msc.clip5.sbpd_d_ST | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/cmp.lmap_Msc.clip5.sbpd_d_ST.tar) | 10.67 | 9 | 19 | 39.7 |
-cmp.lmap_Msc.clip5.sbpd_rgb_ST | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/cmp.lmap_Msc.clip5.sbpd_rgb_ST.tar) | 11.27 | 10 | 19 | 35.6 |
-cmp.lmap_Msc.clip5.sbpd_d_r2r_h0_64_80 | [ckpt](http:////download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/cmp.lmap_Msc.clip5.sbpd_d_r2r_h0_64_80.tar) | 11.6 | 0 | 19 | 66.9 |
-bl.v2.noclip.sbpd_d_r2r | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/bl.v2.noclip.sbpd_d_r2r.tar) | 5.90 | 0 | 6 | 71.2 |
-bl.v2.noclip.sbpd_rgb_r2r | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/bl.v2.noclip.sbpd_rgb_r2r.tar) | 10.21 | 1 | 21 | 53.4 |
-bl.v2.noclip.sbpd_d_ST | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/bl.v2.noclip.sbpd_d_ST.tar) | 13.29 | 14 | 23 | 28.0 |
-bl.v2.noclip.sbpd_rgb_ST | [ckpt](http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/bl.v2.noclip.sbpd_rgb_ST.tar) | 13.37 | 13 | 20 | 24.2 |
-bl.v2.noclip.sbpd_d_r2r_h0_64_80 | [ckpt](http:////download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/bl.v2.noclip.sbpd_d_r2r_h0_64_80.tar) | 15.30 | 0 | 29 | 57.9 |
diff --git a/research/cognitive_mapping_and_planning/patches/GLES2_2_0.py.patch b/research/cognitive_mapping_and_planning/patches/GLES2_2_0.py.patch
deleted file mode 100644
index de1be442d5b9fff44862d37b9329e32face2b663..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/patches/GLES2_2_0.py.patch
+++ /dev/null
@@ -1,14 +0,0 @@
-10c10
-< from OpenGL import platform, constant, arrays
----
-> from OpenGL import platform, constant, arrays, contextdata
-249a250
-> from OpenGL._bytes import _NULL_8_BYTE
-399c400
-< array = ArrayDatatype.asArray( pointer, type )
----
-> array = arrays.ArrayDatatype.asArray( pointer, type )
-405c406
-< ArrayDatatype.voidDataPointer( array )
----
-> arrays.ArrayDatatype.voidDataPointer( array )
diff --git a/research/cognitive_mapping_and_planning/patches/apply_patches.sh b/research/cognitive_mapping_and_planning/patches/apply_patches.sh
deleted file mode 100644
index 4a786058258decdfb381eff25684183d92788ebe..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/patches/apply_patches.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-echo $VIRTUAL_ENV
-patch $VIRTUAL_ENV/local/lib/python2.7/site-packages/OpenGL/GLES2/VERSION/GLES2_2_0.py patches/GLES2_2_0.py.patch
-patch $VIRTUAL_ENV/local/lib/python2.7/site-packages/OpenGL/platform/ctypesloader.py patches/ctypesloader.py.patch
diff --git a/research/cognitive_mapping_and_planning/patches/ctypesloader.py.patch b/research/cognitive_mapping_and_planning/patches/ctypesloader.py.patch
deleted file mode 100644
index 27dd43b18010dc5fdcd605b9a5d470abaa19151f..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/patches/ctypesloader.py.patch
+++ /dev/null
@@ -1,15 +0,0 @@
-45c45,46
-< return dllType( name, mode )
----
-> print './' + name
-> return dllType( './' + name, mode )
-47,48c48,53
-< err.args += (name,fullName)
-< raise
----
-> try:
-> print name
-> return dllType( name, mode )
-> except:
-> err.args += (name,fullName)
-> raise
diff --git a/research/cognitive_mapping_and_planning/render/__init__.py b/research/cognitive_mapping_and_planning/render/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.fp b/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.fp
deleted file mode 100644
index 23e93d27f585e93896799f177888e9c50fa03eed..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.fp
+++ /dev/null
@@ -1,30 +0,0 @@
-// This shader computes per-pixel depth (-z coordinate in the camera space, or
-// orthogonal distance to the camera plane). The result is multiplied by the
-// `kFixedPointFraction` constant and is encoded to RGB channels as an integer
-// (R being the least significant byte).
-
-#ifdef GL_ES
-#ifdef GL_FRAGMENT_PRECISION_HIGH
-precision highp float;
-#else
-precision mediump float;
-#endif
-#endif
-
-const float kFixedPointFraction = 1000.0;
-
-varying float vDepth;
-
-void main(void) {
- float d = vDepth;
-
- // Encode the depth to RGB.
- d *= (kFixedPointFraction / 255.0);
- gl_FragColor.r = mod(d, 1.0);
- d = (d - gl_FragColor.r) / 255.0;
- gl_FragColor.g = mod(d, 1.0);
- d = (d - gl_FragColor.g) / 255.0;
- gl_FragColor.b = mod(d, 1.0);
-
- gl_FragColor.a = 1.0;
-}
diff --git a/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.vp b/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.vp
deleted file mode 100644
index 2db74f14aa7f253b8f544ec1ab519129f13426a0..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/render/depth_rgb_encoded.vp
+++ /dev/null
@@ -1,15 +0,0 @@
-uniform mat4 uViewMatrix;
-uniform mat4 uProjectionMatrix;
-
-attribute vec3 aPosition;
-
-varying float vDepth;
-
-void main(void) {
- vec4 worldPosition = vec4(aPosition, 1.0);
- vec4 viewPosition = uViewMatrix * worldPosition;
- gl_Position = uProjectionMatrix * viewPosition;
-
- // Orthogonal depth is simply -z in the camera space.
- vDepth = -viewPosition.z;
-}
diff --git a/research/cognitive_mapping_and_planning/render/rgb_flat_color.fp b/research/cognitive_mapping_and_planning/render/rgb_flat_color.fp
deleted file mode 100644
index c8c24d76103793d9cfa9166517177cb332d1a92c..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/render/rgb_flat_color.fp
+++ /dev/null
@@ -1,11 +0,0 @@
-precision highp float;
-varying vec4 vColor;
-varying vec2 vTextureCoord;
-
-uniform sampler2D uTexture;
-
-void main(void) {
- vec4 color = vColor;
- color = texture2D(uTexture, vTextureCoord);
- gl_FragColor = color;
-}
diff --git a/research/cognitive_mapping_and_planning/render/rgb_flat_color.vp b/research/cognitive_mapping_and_planning/render/rgb_flat_color.vp
deleted file mode 100644
index ebc79173405f7449921fd40f778fe3695aab5ea8..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/render/rgb_flat_color.vp
+++ /dev/null
@@ -1,18 +0,0 @@
-uniform mat4 uViewMatrix;
-uniform mat4 uProjectionMatrix;
-uniform vec4 uColor;
-
-attribute vec4 aColor;
-attribute vec3 aPosition;
-attribute vec2 aTextureCoord;
-
-varying vec4 vColor;
-varying vec2 vTextureCoord;
-
-void main(void) {
- vec4 worldPosition = vec4(aPosition, 1.0);
- gl_Position = uProjectionMatrix * (uViewMatrix * worldPosition);
-
- vColor = aColor * uColor;
- vTextureCoord = aTextureCoord;
-}
diff --git a/research/cognitive_mapping_and_planning/render/swiftshader_renderer.py b/research/cognitive_mapping_and_planning/render/swiftshader_renderer.py
deleted file mode 100644
index 74b1be72c11a2877231a66886d02babfd4793ce8..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/render/swiftshader_renderer.py
+++ /dev/null
@@ -1,427 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Implements loading and rendering of meshes. Contains 2 classes:
- Shape: Class that exposes high level functions for loading and manipulating
- shapes. This currently is bound to assimp
- (https://github.com/assimp/assimp). If you want to interface to a different
- library, reimplement this class with bindings to your mesh loading library.
-
- SwiftshaderRenderer: Class that renders Shapes. Currently this uses python
- bindings to OpenGL (EGL), bindings to an alternate renderer may be implemented
- here.
-"""
-
-import numpy as np, os
-import cv2, ctypes, logging, os, numpy as np
-import pyassimp as assimp
-from OpenGL.GLES2 import *
-from OpenGL.EGL import *
-import src.rotation_utils as ru
-
-__version__ = 'swiftshader_renderer'
-
-def get_shaders(modalities):
- rgb_shader = 'rgb_flat_color' if 'rgb' in modalities else None
- d_shader = 'depth_rgb_encoded' if 'depth' in modalities else None
- return rgb_shader, d_shader
-
-def sample_points_on_faces(vs, fs, rng, n_samples_per_face):
- idx = np.repeat(np.arange(fs.shape[0]), n_samples_per_face)
-
- r = rng.rand(idx.size, 2)
- r1 = r[:,:1]; r2 = r[:,1:]; sqrt_r1 = np.sqrt(r1);
-
- v1 = vs[fs[idx, 0], :]; v2 = vs[fs[idx, 1], :]; v3 = vs[fs[idx, 2], :];
- pts = (1-sqrt_r1)*v1 + sqrt_r1*(1-r2)*v2 + sqrt_r1*r2*v3
-
- v1 = vs[fs[:,0], :]; v2 = vs[fs[:, 1], :]; v3 = vs[fs[:, 2], :];
- ar = 0.5*np.sqrt(np.sum(np.cross(v1-v3, v2-v3)**2, 1))
-
- return pts, ar, idx
-
-class Shape():
- def get_pyassimp_load_options(self):
- load_flags = assimp.postprocess.aiProcess_Triangulate;
- load_flags = load_flags | assimp.postprocess.aiProcess_SortByPType;
- load_flags = load_flags | assimp.postprocess.aiProcess_OptimizeMeshes;
- load_flags = load_flags | assimp.postprocess.aiProcess_RemoveRedundantMaterials;
- load_flags = load_flags | assimp.postprocess.aiProcess_FindDegenerates;
- load_flags = load_flags | assimp.postprocess.aiProcess_GenSmoothNormals;
- load_flags = load_flags | assimp.postprocess.aiProcess_JoinIdenticalVertices;
- load_flags = load_flags | assimp.postprocess.aiProcess_ImproveCacheLocality;
- load_flags = load_flags | assimp.postprocess.aiProcess_GenUVCoords;
- load_flags = load_flags | assimp.postprocess.aiProcess_FindInvalidData;
- return load_flags
-
- def __init__(self, obj_file, material_file=None, load_materials=True,
- name_prefix='', name_suffix=''):
- if material_file is not None:
- logging.error('Ignoring material file input, reading them off obj file.')
- load_flags = self.get_pyassimp_load_options()
- scene = assimp.load(obj_file, processing=load_flags)
- filter_ind = self._filter_triangles(scene.meshes)
- self.meshes = [scene.meshes[i] for i in filter_ind]
- for m in self.meshes:
- m.name = name_prefix + m.name + name_suffix
-
- dir_name = os.path.dirname(obj_file)
- # Load materials
- materials = None
- if load_materials:
- materials = []
- for m in self.meshes:
- file_name = os.path.join(dir_name, m.material.properties[('file', 1)])
- assert(os.path.exists(file_name)), \
- 'Texture file {:s} foes not exist.'.format(file_name)
- img_rgb = cv2.imread(file_name)[::-1,:,::-1]
- if img_rgb.shape[0] != img_rgb.shape[1]:
- logging.warn('Texture image not square.')
- sz = np.maximum(img_rgb.shape[0], img_rgb.shape[1])
- sz = int(np.power(2., np.ceil(np.log2(sz))))
- img_rgb = cv2.resize(img_rgb, (sz,sz), interpolation=cv2.INTER_LINEAR)
- else:
- sz = img_rgb.shape[0]
- sz_ = int(np.power(2., np.ceil(np.log2(sz))))
- if sz != sz_:
- logging.warn('Texture image not square of power of 2 size. ' +
- 'Changing size from %d to %d.', sz, sz_)
- sz = sz_
- img_rgb = cv2.resize(img_rgb, (sz,sz), interpolation=cv2.INTER_LINEAR)
- materials.append(img_rgb)
- self.scene = scene
- self.materials = materials
-
- def _filter_triangles(self, meshes):
- select = []
- for i in range(len(meshes)):
- if meshes[i].primitivetypes == 4:
- select.append(i)
- return select
-
- def flip_shape(self):
- for m in self.meshes:
- m.vertices[:,1] = -m.vertices[:,1]
- bb = m.faces*1
- bb[:,1] = m.faces[:,2]
- bb[:,2] = m.faces[:,1]
- m.faces = bb
- # m.vertices[:,[0,1]] = m.vertices[:,[1,0]]
-
- def get_vertices(self):
- vs = []
- for m in self.meshes:
- vs.append(m.vertices)
- vss = np.concatenate(vs, axis=0)
- return vss, vs
-
- def get_faces(self):
- vs = []
- for m in self.meshes:
- v = m.faces
- vs.append(v)
- return vs
-
- def get_number_of_meshes(self):
- return len(self.meshes)
-
- def scale(self, sx=1., sy=1., sz=1.):
- pass
-
- def sample_points_on_face_of_shape(self, i, n_samples_per_face, sc):
- v = self.meshes[i].vertices*sc
- f = self.meshes[i].faces
- p, face_areas, face_idx = sample_points_on_faces(
- v, f, np.random.RandomState(0), n_samples_per_face)
- return p, face_areas, face_idx
-
- def __del__(self):
- scene = self.scene
- assimp.release(scene)
-
-class SwiftshaderRenderer():
- def __init__(self):
- self.entities = {}
-
- def init_display(self, width, height, fov, z_near, z_far, rgb_shader,
- d_shader):
- self.init_renderer_egl(width, height)
- dir_path = os.path.dirname(os.path.realpath(__file__))
- if d_shader is not None and rgb_shader is not None:
- logging.fatal('Does not support setting both rgb_shader and d_shader.')
-
- if d_shader is not None:
- assert rgb_shader is None
- shader = d_shader
- self.modality = 'depth'
-
- if rgb_shader is not None:
- assert d_shader is None
- shader = rgb_shader
- self.modality = 'rgb'
-
- self.create_shaders(os.path.join(dir_path, shader+'.vp'),
- os.path.join(dir_path, shader + '.fp'))
- aspect = width*1./(height*1.)
- self.set_camera(fov, z_near, z_far, aspect)
-
- def init_renderer_egl(self, width, height):
- major,minor = ctypes.c_long(),ctypes.c_long()
- logging.info('init_renderer_egl: EGL_DEFAULT_DISPLAY: %s', EGL_DEFAULT_DISPLAY)
-
- egl_display = eglGetDisplay(EGL_DEFAULT_DISPLAY)
- logging.info('init_renderer_egl: egl_display: %s', egl_display)
-
- eglInitialize(egl_display, major, minor)
- logging.info('init_renderer_egl: EGL_OPENGL_API, EGL_OPENGL_ES_API: %s, %s',
- EGL_OPENGL_API, EGL_OPENGL_ES_API)
- eglBindAPI(EGL_OPENGL_ES_API)
-
- num_configs = ctypes.c_long()
- configs = (EGLConfig*1)()
- local_attributes = [EGL_RED_SIZE, 8, EGL_GREEN_SIZE, 8, EGL_BLUE_SIZE, 8,
- EGL_DEPTH_SIZE, 16, EGL_SURFACE_TYPE, EGL_PBUFFER_BIT,
- EGL_RENDERABLE_TYPE, EGL_OPENGL_ES2_BIT, EGL_NONE,]
- logging.error('init_renderer_egl: local attributes: %s', local_attributes)
- local_attributes = arrays.GLintArray.asArray(local_attributes)
- success = eglChooseConfig(egl_display, local_attributes, configs, 1, num_configs)
- logging.error('init_renderer_egl: eglChooseConfig success, num_configs: %d, %d', success, num_configs.value)
- egl_config = configs[0]
-
-
- context_attributes = [EGL_CONTEXT_CLIENT_VERSION, 2, EGL_NONE]
- context_attributes = arrays.GLintArray.asArray(context_attributes)
- egl_context = eglCreateContext(egl_display, egl_config, EGL_NO_CONTEXT, context_attributes)
-
- buffer_attributes = [EGL_WIDTH, width, EGL_HEIGHT, height, EGL_NONE]
- buffer_attributes = arrays.GLintArray.asArray(buffer_attributes)
- egl_surface = eglCreatePbufferSurface(egl_display, egl_config, buffer_attributes)
-
-
- eglMakeCurrent(egl_display, egl_surface, egl_surface, egl_context)
- logging.error("init_renderer_egl: egl_display: %s egl_surface: %s, egl_config: %s", egl_display, egl_surface, egl_context)
-
- glViewport(0, 0, width, height);
-
- self.egl_display = egl_display
- self.egl_surface = egl_surface
- self.egl_config = egl_config
- self.egl_mapping = {}
- self.render_timer = None
- self.load_timer = None
- self.height = height
- self.width = width
-
- def create_shaders(self, v_shader_file, f_shader_file):
- v_shader = glCreateShader(GL_VERTEX_SHADER)
- with open(v_shader_file, 'r') as f:
- ls = ''
- for l in f:
- ls = ls + l
- glShaderSource(v_shader, ls)
- glCompileShader(v_shader);
- assert(glGetShaderiv(v_shader, GL_COMPILE_STATUS) == 1)
-
- f_shader = glCreateShader(GL_FRAGMENT_SHADER)
- with open(f_shader_file, 'r') as f:
- ls = ''
- for l in f:
- ls = ls + l
- glShaderSource(f_shader, ls)
- glCompileShader(f_shader);
- assert(glGetShaderiv(f_shader, GL_COMPILE_STATUS) == 1)
-
- egl_program = glCreateProgram();
- assert(egl_program)
- glAttachShader(egl_program, v_shader)
- glAttachShader(egl_program, f_shader)
- glLinkProgram(egl_program);
- assert(glGetProgramiv(egl_program, GL_LINK_STATUS) == 1)
- glUseProgram(egl_program)
-
- glBindAttribLocation(egl_program, 0, "aPosition")
- glBindAttribLocation(egl_program, 1, "aColor")
- glBindAttribLocation(egl_program, 2, "aTextureCoord")
-
- self.egl_program = egl_program
- self.egl_mapping['vertexs'] = 0
- self.egl_mapping['vertexs_color'] = 1
- self.egl_mapping['vertexs_tc'] = 2
-
- glClearColor(0.0, 0.0, 0.0, 1.0);
- # glEnable(GL_CULL_FACE); glCullFace(GL_BACK);
- glEnable(GL_DEPTH_TEST);
-
- glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
-
- def set_camera(self, fov_vertical, z_near, z_far, aspect):
- width = 2*np.tan(np.deg2rad(fov_vertical)/2.0)*z_near*aspect;
- height = 2*np.tan(np.deg2rad(fov_vertical)/2.0)*z_near;
- egl_program = self.egl_program
- c = np.eye(4, dtype=np.float32)
- c[3,3] = 0
- c[3,2] = -1
- c[2,2] = -(z_near+z_far)/(z_far-z_near)
- c[2,3] = -2.0*(z_near*z_far)/(z_far-z_near)
- c[0,0] = 2.0*z_near/width
- c[1,1] = 2.0*z_near/height
- c = c.T
-
- projection_matrix_o = glGetUniformLocation(egl_program, 'uProjectionMatrix')
- projection_matrix = np.eye(4, dtype=np.float32)
- projection_matrix[...] = c
- projection_matrix = np.reshape(projection_matrix, (-1))
- glUniformMatrix4fv(projection_matrix_o, 1, GL_FALSE, projection_matrix)
-
-
- def load_default_object(self):
- v = np.array([[0.0, 0.5, 0.0, 1.0, 1.0, 0.0, 1.0],
- [-0.5, -0.5, 0.0, 1.0, 0.0, 1.0, 1.0],
- [0.5, -0.5, 0.0, 1.0, 1.0, 1.0, 1.0]], dtype=np.float32)
- v = np.concatenate((v,v+0.1), axis=0)
- v = np.ascontiguousarray(v, dtype=np.float32)
-
- vbo = glGenBuffers(1)
- glBindBuffer (GL_ARRAY_BUFFER, vbo)
- glBufferData (GL_ARRAY_BUFFER, v.dtype.itemsize*v.size, v, GL_STATIC_DRAW)
- glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 28, ctypes.c_void_p(0))
- glVertexAttribPointer(1, 4, GL_FLOAT, GL_FALSE, 28, ctypes.c_void_p(12))
- glEnableVertexAttribArray(0);
- glEnableVertexAttribArray(1);
-
- self.num_to_render = 6;
-
- def _actual_render(self):
- for entity_id, entity in self.entities.iteritems():
- if entity['visible']:
- vbo = entity['vbo']
- tbo = entity['tbo']
- num = entity['num']
-
- glBindBuffer(GL_ARRAY_BUFFER, vbo)
- glVertexAttribPointer(self.egl_mapping['vertexs'], 3, GL_FLOAT, GL_FALSE,
- 20, ctypes.c_void_p(0))
- glVertexAttribPointer(self.egl_mapping['vertexs_tc'], 2, GL_FLOAT,
- GL_FALSE, 20, ctypes.c_void_p(12))
- glEnableVertexAttribArray(self.egl_mapping['vertexs']);
- glEnableVertexAttribArray(self.egl_mapping['vertexs_tc']);
-
- glBindTexture(GL_TEXTURE_2D, tbo)
- glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
- glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
- glDrawArrays(GL_TRIANGLES, 0, num)
-
- def render(self, take_screenshot=False, output_type=0):
- # self.render_timer.tic()
- self._actual_render()
- # self.render_timer.toc(log_at=1000, log_str='render timer', type='time')
-
- np_rgb_img = None
- np_d_img = None
- c = 1000.
- if take_screenshot:
- if self.modality == 'rgb':
- screenshot_rgba = np.zeros((self.height, self.width, 4), dtype=np.uint8)
- glReadPixels(0, 0, self.width, self.height, GL_RGBA, GL_UNSIGNED_BYTE, screenshot_rgba)
- np_rgb_img = screenshot_rgba[::-1,:,:3];
-
- if self.modality == 'depth':
- screenshot_d = np.zeros((self.height, self.width, 4), dtype=np.uint8)
- glReadPixels(0, 0, self.width, self.height, GL_RGBA, GL_UNSIGNED_BYTE, screenshot_d)
- np_d_img = screenshot_d[::-1,:,:3];
- np_d_img = np_d_img[:,:,2]*(255.*255./c) + np_d_img[:,:,1]*(255./c) + np_d_img[:,:,0]*(1./c)
- np_d_img = np_d_img.astype(np.float32)
- np_d_img[np_d_img == 0] = np.NaN
- np_d_img = np_d_img[:,:,np.newaxis]
-
- glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
- return np_rgb_img, np_d_img
-
- def _load_mesh_into_gl(self, mesh, material):
- vvt = np.concatenate((mesh.vertices, mesh.texturecoords[0,:,:2]), axis=1)
- vvt = np.ascontiguousarray(vvt[mesh.faces.reshape((-1)),:], dtype=np.float32)
- num = vvt.shape[0]
- vvt = np.reshape(vvt, (-1))
-
- vbo = glGenBuffers(1)
- glBindBuffer(GL_ARRAY_BUFFER, vbo)
- glBufferData(GL_ARRAY_BUFFER, vvt.dtype.itemsize*vvt.size, vvt, GL_STATIC_DRAW)
-
- tbo = glGenTextures(1)
- glBindTexture(GL_TEXTURE_2D, tbo)
- glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, material.shape[1],
- material.shape[0], 0, GL_RGB, GL_UNSIGNED_BYTE,
- np.reshape(material, (-1)))
- return num, vbo, tbo
-
- def load_shapes(self, shapes):
- entities = self.entities
- entity_ids = []
- for i, shape in enumerate(shapes):
- for j in range(len(shape.meshes)):
- name = shape.meshes[j].name
- assert name not in entities, '{:s} entity already exists.'.format(name)
- num, vbo, tbo = self._load_mesh_into_gl(shape.meshes[j], shape.materials[j])
- entities[name] = {'num': num, 'vbo': vbo, 'tbo': tbo, 'visible': False}
- entity_ids.append(name)
- return entity_ids
-
- def set_entity_visible(self, entity_ids, visibility):
- for entity_id in entity_ids:
- self.entities[entity_id]['visible'] = visibility
-
- def position_camera(self, camera_xyz, lookat_xyz, up):
- camera_xyz = np.array(camera_xyz)
- lookat_xyz = np.array(lookat_xyz)
- up = np.array(up)
- lookat_to = lookat_xyz - camera_xyz
- lookat_from = np.array([0, 1., 0.])
- up_from = np.array([0, 0., 1.])
- up_to = up * 1.
- # np.set_printoptions(precision=2, suppress=True)
- # print up_from, lookat_from, up_to, lookat_to
- r = ru.rotate_camera_to_point_at(up_from, lookat_from, up_to, lookat_to)
- R = np.eye(4, dtype=np.float32)
- R[:3,:3] = r
-
- t = np.eye(4, dtype=np.float32)
- t[:3,3] = -camera_xyz
-
- view_matrix = np.dot(R.T, t)
- flip_yz = np.eye(4, dtype=np.float32)
- flip_yz[1,1] = 0; flip_yz[2,2] = 0; flip_yz[1,2] = 1; flip_yz[2,1] = -1;
- view_matrix = np.dot(flip_yz, view_matrix)
- view_matrix = view_matrix.T
- # print np.concatenate((R, t, view_matrix), axis=1)
- view_matrix = np.reshape(view_matrix, (-1))
- view_matrix_o = glGetUniformLocation(self.egl_program, 'uViewMatrix')
- glUniformMatrix4fv(view_matrix_o, 1, GL_FALSE, view_matrix)
- return None, None #camera_xyz, q
-
- def clear_scene(self):
- keys = self.entities.keys()
- for entity_id in keys:
- entity = self.entities.pop(entity_id, None)
- vbo = entity['vbo']
- tbo = entity['tbo']
- num = entity['num']
- glDeleteBuffers(1, [vbo])
- glDeleteTextures(1, [tbo])
-
- def __del__(self):
- self.clear_scene()
- eglMakeCurrent(self.egl_display, EGL_NO_SURFACE, EGL_NO_SURFACE, EGL_NO_CONTEXT)
- eglDestroySurface(self.egl_display, self.egl_surface)
- eglTerminate(self.egl_display)
diff --git a/research/cognitive_mapping_and_planning/requirements.txt b/research/cognitive_mapping_and_planning/requirements.txt
deleted file mode 100644
index 306c807a6c9fd9404afa1c05108e5e835e84edc6..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/requirements.txt
+++ /dev/null
@@ -1,9 +0,0 @@
-numpy
-pillow
-PyOpenGL
-PyOpenGL-accelerate
-six
-networkx
-scikit-image
-scipy
-opencv-python
diff --git a/research/cognitive_mapping_and_planning/scripts/__init__.py b/research/cognitive_mapping_and_planning/scripts/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/scripts/script_distill.py b/research/cognitive_mapping_and_planning/scripts/script_distill.py
deleted file mode 100644
index 010c690412ed28011146ab44109dc099d02324e7..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_distill.py
+++ /dev/null
@@ -1,177 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r""" Script to setup the grid moving agent.
-
-blaze build --define=ION_GFX_OGLES20=1 -c opt --copt=-mavx --config=cuda_clang \
- learning/brain/public/tensorflow_std_server{,_gpu} \
- experimental/users/saurabhgupta/navigation/cmp/scripts/script_distill.par \
- experimental/users/saurabhgupta/navigation/cmp/scripts/script_distill
-
-
-./blaze-bin/experimental/users/saurabhgupta/navigation/cmp/scripts/script_distill \
- --logdir=/cns/iq-d/home/saurabhgupta/output/stanford-distill/local/v0/ \
- --config_name 'v0+train' --gfs_user robot-intelligence-gpu
-
-"""
-import sys, os, numpy as np
-import copy
-import argparse, pprint
-import time
-import cProfile
-
-
-import tensorflow as tf
-from tensorflow.contrib import slim
-from tensorflow.python.framework import ops
-from tensorflow.contrib.framework.python.ops import variables
-
-import logging
-from tensorflow.python.platform import gfile
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-from cfgs import config_distill
-from tfcode import tf_utils
-import src.utils as utils
-import src.file_utils as fu
-import tfcode.distillation as distill
-import datasets.nav_env as nav_env
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('master', 'local',
- 'The name of the TensorFlow master to use.')
-flags.DEFINE_integer('ps_tasks', 0, 'The number of parameter servers. If the '
- 'value is 0, then the parameters are handled locally by '
- 'the worker.')
-flags.DEFINE_integer('task', 0, 'The Task ID. This value is used when training '
- 'with multiple workers to identify each worker.')
-
-flags.DEFINE_integer('num_workers', 1, '')
-
-flags.DEFINE_string('config_name', '', '')
-
-flags.DEFINE_string('logdir', '', '')
-
-def main(_):
- args = config_distill.get_args_for_config(FLAGS.config_name)
- args.logdir = FLAGS.logdir
- args.solver.num_workers = FLAGS.num_workers
- args.solver.task = FLAGS.task
- args.solver.ps_tasks = FLAGS.ps_tasks
- args.solver.master = FLAGS.master
-
- args.buildinger.env_class = nav_env.MeshMapper
- fu.makedirs(args.logdir)
- args.buildinger.logdir = args.logdir
- R = nav_env.get_multiplexor_class(args.buildinger, args.solver.task)
-
- if False:
- pr = cProfile.Profile()
- pr.enable()
- rng = np.random.RandomState(0)
- for i in range(1):
- b, instances_perturbs = R.sample_building(rng)
- inputs = b.worker(*(instances_perturbs))
- for j in range(inputs['imgs'].shape[0]):
- p = os.path.join('tmp', '{:d}.png'.format(j))
- img = inputs['imgs'][j,0,:,:,:3]*1
- img = (img).astype(np.uint8)
- fu.write_image(p, img)
- print(inputs['imgs'].shape)
- inputs = R.pre(inputs)
- pr.disable()
- pr.print_stats(2)
-
- if args.control.train:
- if not gfile.Exists(args.logdir):
- gfile.MakeDirs(args.logdir)
-
- m = utils.Foo()
- m.tf_graph = tf.Graph()
-
- config = tf.ConfigProto()
- config.device_count['GPU'] = 1
- config.gpu_options.allow_growth = True
- config.gpu_options.per_process_gpu_memory_fraction = 0.8
-
- with m.tf_graph.as_default():
- with tf.device(tf.train.replica_device_setter(args.solver.ps_tasks)):
- m = distill.setup_to_run(m, args, is_training=True,
- batch_norm_is_training=True)
-
- train_step_kwargs = distill.setup_train_step_kwargs_mesh(
- m, R, os.path.join(args.logdir, 'train'),
- rng_seed=args.solver.task, is_chief=args.solver.task==0, iters=1,
- train_display_interval=args.summary.display_interval)
-
- final_loss = slim.learning.train(
- train_op=m.train_op,
- logdir=args.logdir,
- master=args.solver.master,
- is_chief=args.solver.task == 0,
- number_of_steps=args.solver.max_steps,
- train_step_fn=tf_utils.train_step_custom,
- train_step_kwargs=train_step_kwargs,
- global_step=m.global_step_op,
- init_op=m.init_op,
- init_fn=m.init_fn,
- sync_optimizer=m.sync_optimizer,
- saver=m.saver_op,
- summary_op=None, session_config=config)
-
- if args.control.test:
- m = utils.Foo()
- m.tf_graph = tf.Graph()
- checkpoint_dir = os.path.join(format(args.logdir))
- with m.tf_graph.as_default():
- m = distill.setup_to_run(m, args, is_training=False,
- batch_norm_is_training=args.control.force_batchnorm_is_training_at_test)
-
- train_step_kwargs = distill.setup_train_step_kwargs_mesh(
- m, R, os.path.join(args.logdir, args.control.test_name),
- rng_seed=args.solver.task+1, is_chief=args.solver.task==0,
- iters=args.summary.test_iters, train_display_interval=None)
-
- sv = slim.learning.supervisor.Supervisor(
- graph=ops.get_default_graph(), logdir=None, init_op=m.init_op,
- summary_op=None, summary_writer=None, global_step=None, saver=m.saver_op)
-
- last_checkpoint = None
- while True:
- last_checkpoint = slim.evaluation.wait_for_new_checkpoint(checkpoint_dir, last_checkpoint)
- checkpoint_iter = int(os.path.basename(last_checkpoint).split('-')[1])
- start = time.time()
- logging.info('Starting evaluation at %s using checkpoint %s.',
- time.strftime('%Y-%m-%d-%H:%M:%S', time.localtime()),
- last_checkpoint)
-
- config = tf.ConfigProto()
- config.device_count['GPU'] = 1
- config.gpu_options.allow_growth = True
- config.gpu_options.per_process_gpu_memory_fraction = 0.8
-
- with sv.managed_session(args.solver.master,config=config,
- start_standard_services=False) as sess:
- sess.run(m.init_op)
- sv.saver.restore(sess, last_checkpoint)
- sv.start_queue_runners(sess)
- vals, _ = tf_utils.train_step_custom(
- sess, None, m.global_step_op, train_step_kwargs, mode='val')
- if checkpoint_iter >= args.solver.max_steps:
- break
-
-if __name__ == '__main__':
- app.run()
diff --git a/research/cognitive_mapping_and_planning/scripts/script_download_init_models.sh b/research/cognitive_mapping_and_planning/scripts/script_download_init_models.sh
deleted file mode 100644
index 1900bd0b03566d29dac8a8de5f4fce623be98a92..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_download_init_models.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-# Script to download models to initialize the RGB and D models for training.We
-# use ResNet-v2-50 for both modalities.
-
-mkdir -p data/init_models
-cd data/init_models
-
-# RGB Models are initialized by pre-training on ImageNet.
-mkdir -p resnet_v2_50
-RGB_URL="http://download.tensorflow.org/models/resnet_v2_50_2017_04_14.tar.gz"
-wget $RGB_URL
-tar -xf resnet_v2_50_2017_04_14.tar.gz -C resnet_v2_50
-
-# Depth models are initialized by distilling the RGB model to D images using
-# Cross-Modal Distillation (https://arxiv.org/abs/1507.00448).
-mkdir -p distill_rgb_to_d_resnet_v2_50
-D_URL="http://download.tensorflow.org/models/cognitive_mapping_and_planning/2017_04_16/distill_rgb_to_d_resnet_v2_50.tar"
-wget $D_URL
-tar -xf distill_rgb_to_d_resnet_v2_50.tar -C distill_rgb_to_d_resnet_v2_50
diff --git a/research/cognitive_mapping_and_planning/scripts/script_env_vis.py b/research/cognitive_mapping_and_planning/scripts/script_env_vis.py
deleted file mode 100644
index 3690ff484fea9344db6fbe20ac54731200f0c84e..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_env_vis.py
+++ /dev/null
@@ -1,186 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A simple python function to walk in the enviornments that we have created.
-PYTHONPATH='.' PYOPENGL_PLATFORM=egl python scripts/script_env_vis.py \
- --dataset_name sbpd --building_name area3
-"""
-import sys
-import numpy as np
-import matplotlib
-matplotlib.use('TkAgg')
-from PIL import ImageTk, Image
-import Tkinter as tk
-import logging
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-
-import datasets.nav_env_config as nec
-import datasets.nav_env as nav_env
-import cv2
-from datasets import factory
-import render.swiftshader_renderer as renderer
-
-SwiftshaderRenderer = renderer.SwiftshaderRenderer
-VisualNavigationEnv = nav_env.VisualNavigationEnv
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string('dataset_name', 'sbpd', 'Name of the dataset.')
-flags.DEFINE_float('fov', 60., 'Field of view')
-flags.DEFINE_integer('image_size', 512, 'Size of the image.')
-flags.DEFINE_string('building_name', '', 'Name of the building.')
-
-def get_args():
- navtask = nec.nav_env_base_config()
- navtask.task_params.type = 'rng_rejection_sampling_many'
- navtask.task_params.rejection_sampling_M = 2000
- navtask.task_params.min_dist = 10
- sz = FLAGS.image_size
- navtask.camera_param.fov = FLAGS.fov
- navtask.camera_param.height = sz
- navtask.camera_param.width = sz
- navtask.task_params.img_height = sz
- navtask.task_params.img_width = sz
-
- # navtask.task_params.semantic_task.class_map_names = ['chair', 'door', 'table']
- # navtask.task_params.type = 'to_nearest_obj_acc'
-
- logging.info('navtask: %s', navtask)
- return navtask
-
-def load_building(dataset_name, building_name):
- dataset = factory.get_dataset(dataset_name)
-
- navtask = get_args()
- cp = navtask.camera_param
- rgb_shader, d_shader = renderer.get_shaders(cp.modalities)
- r_obj = SwiftshaderRenderer()
- r_obj.init_display(width=cp.width, height=cp.height,
- fov=cp.fov, z_near=cp.z_near, z_far=cp.z_far,
- rgb_shader=rgb_shader, d_shader=d_shader)
- r_obj.clear_scene()
- b = VisualNavigationEnv(robot=navtask.robot, env=navtask.env,
- task_params=navtask.task_params,
- building_name=building_name, flip=False,
- logdir=None, building_loader=dataset,
- r_obj=r_obj)
- b.load_building_into_scene()
- b.set_building_visibility(False)
- return b
-
-def walk_through(b):
- # init agent at a random location in the environment.
- init_env_state = b.reset([np.random.RandomState(0), np.random.RandomState(0)])
-
- global current_node
- rng = np.random.RandomState(0)
- current_node = rng.choice(b.task.nodes.shape[0])
-
- root = tk.Tk()
- image = b.render_nodes(b.task.nodes[[current_node],:])[0]
- print(image.shape)
- image = image.astype(np.uint8)
- im = Image.fromarray(image)
- im = ImageTk.PhotoImage(im)
- panel = tk.Label(root, image=im)
-
- map_size = b.traversible.shape
- sc = np.max(map_size)/256.
- loc = np.array([[map_size[1]/2., map_size[0]/2.]])
- x_axis = np.zeros_like(loc); x_axis[:,1] = sc
- y_axis = np.zeros_like(loc); y_axis[:,0] = -sc
- cum_fs, cum_valid = nav_env.get_map_to_predict(loc, x_axis, y_axis,
- map=b.traversible*1.,
- map_size=256)
- cum_fs = cum_fs[0]
- cum_fs = cv2.applyColorMap((cum_fs*255).astype(np.uint8), cv2.COLORMAP_JET)
- im = Image.fromarray(cum_fs)
- im = ImageTk.PhotoImage(im)
- panel_overhead = tk.Label(root, image=im)
-
- def refresh():
- global current_node
- image = b.render_nodes(b.task.nodes[[current_node],:])[0]
- image = image.astype(np.uint8)
- im = Image.fromarray(image)
- im = ImageTk.PhotoImage(im)
- panel.configure(image=im)
- panel.image = im
-
- def left_key(event):
- global current_node
- current_node = b.take_action([current_node], [2], 1)[0][0]
- refresh()
-
- def up_key(event):
- global current_node
- current_node = b.take_action([current_node], [3], 1)[0][0]
- refresh()
-
- def right_key(event):
- global current_node
- current_node = b.take_action([current_node], [1], 1)[0][0]
- refresh()
-
- def quit(event):
- root.destroy()
-
- panel_overhead.grid(row=4, column=5, rowspan=1, columnspan=1,
- sticky=tk.W+tk.E+tk.N+tk.S)
- panel.bind('', left_key)
- panel.bind('', up_key)
- panel.bind('', right_key)
- panel.bind('q', quit)
- panel.focus_set()
- panel.grid(row=0, column=0, rowspan=5, columnspan=5,
- sticky=tk.W+tk.E+tk.N+tk.S)
- root.mainloop()
-
-def simple_window():
- root = tk.Tk()
-
- image = np.zeros((128, 128, 3), dtype=np.uint8)
- image[32:96, 32:96, 0] = 255
- im = Image.fromarray(image)
- im = ImageTk.PhotoImage(im)
-
- image = np.zeros((128, 128, 3), dtype=np.uint8)
- image[32:96, 32:96, 1] = 255
- im2 = Image.fromarray(image)
- im2 = ImageTk.PhotoImage(im2)
-
- panel = tk.Label(root, image=im)
-
- def left_key(event):
- panel.configure(image=im2)
- panel.image = im2
-
- def quit(event):
- sys.exit()
-
- panel.bind('', left_key)
- panel.bind('', left_key)
- panel.bind('', left_key)
- panel.bind('q', quit)
- panel.focus_set()
- panel.pack(side = "bottom", fill = "both", expand = "yes")
- root.mainloop()
-
-def main(_):
- b = load_building(FLAGS.dataset_name, FLAGS.building_name)
- walk_through(b)
-
-if __name__ == '__main__':
- app.run()
diff --git a/research/cognitive_mapping_and_planning/scripts/script_nav_agent_release.py b/research/cognitive_mapping_and_planning/scripts/script_nav_agent_release.py
deleted file mode 100644
index dab2819a6fcf100cb2e385e45b7aa694c4c5f033..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_nav_agent_release.py
+++ /dev/null
@@ -1,253 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r""" Script to train and test the grid navigation agent.
-Usage:
- 1. Testing a model.
- CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 \
- PYTHONPATH='.' PYOPENGL_PLATFORM=egl python scripts/script_nav_agent_release.py \
- --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_r2r
-
- 2. Training a model (locally).
- CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 \
- PYTHONPATH='.' PYOPENGL_PLATFORM=egl python scripts/script_nav_agent_release.py \
- --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r+train_train \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_r2r_
-
- 3. Training a model (distributed).
- # See https://www.tensorflow.org/deploy/distributed on how to setup distributed
- # training.
- CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 \
- PYTHONPATH='.' PYOPENGL_PLATFORM=egl python scripts/script_nav_agent_release.py \
- --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r+train_train \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_r2r_ \
- --ps_tasks $num_ps --master $master_name --task $worker_id
-"""
-
-import sys, os, numpy as np
-import copy
-import argparse, pprint
-import time
-import cProfile
-import platform
-
-
-import tensorflow as tf
-from tensorflow.contrib import slim
-from tensorflow.python.framework import ops
-from tensorflow.contrib.framework.python.ops import variables
-
-import logging
-from tensorflow.python.platform import gfile
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-from cfgs import config_cmp
-from cfgs import config_vision_baseline
-import datasets.nav_env as nav_env
-import src.file_utils as fu
-import src.utils as utils
-import tfcode.cmp as cmp
-from tfcode import tf_utils
-from tfcode import vision_baseline_lstm
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('master', '',
- 'The address of the tensorflow master')
-flags.DEFINE_integer('ps_tasks', 0, 'The number of parameter servers. If the '
- 'value is 0, then the parameters are handled locally by '
- 'the worker.')
-flags.DEFINE_integer('task', 0, 'The Task ID. This value is used when training '
- 'with multiple workers to identify each worker.')
-
-flags.DEFINE_integer('num_workers', 1, '')
-
-flags.DEFINE_string('config_name', '', '')
-
-flags.DEFINE_string('logdir', '', '')
-
-flags.DEFINE_integer('solver_seed', 0, '')
-
-flags.DEFINE_integer('delay_start_iters', 20, '')
-
-logging.basicConfig(level=logging.INFO)
-
-def main(_):
- _launcher(FLAGS.config_name, FLAGS.logdir)
-
-def _launcher(config_name, logdir):
- args = _setup_args(config_name, logdir)
-
- fu.makedirs(args.logdir)
-
- if args.control.train:
- _train(args)
-
- if args.control.test:
- _test(args)
-
-def get_args_for_config(config_name):
- configs = config_name.split('.')
- type = configs[0]
- config_name = '.'.join(configs[1:])
- if type == 'cmp':
- args = config_cmp.get_args_for_config(config_name)
- args.setup_to_run = cmp.setup_to_run
- args.setup_train_step_kwargs = cmp.setup_train_step_kwargs
-
- elif type == 'bl':
- args = config_vision_baseline.get_args_for_config(config_name)
- args.setup_to_run = vision_baseline_lstm.setup_to_run
- args.setup_train_step_kwargs = vision_baseline_lstm.setup_train_step_kwargs
-
- else:
- logging.fatal('Unknown type: {:s}'.format(type))
- return args
-
-def _setup_args(config_name, logdir):
- args = get_args_for_config(config_name)
- args.solver.num_workers = FLAGS.num_workers
- args.solver.task = FLAGS.task
- args.solver.ps_tasks = FLAGS.ps_tasks
- args.solver.master = FLAGS.master
- args.solver.seed = FLAGS.solver_seed
- args.logdir = logdir
- args.navtask.logdir = None
- return args
-
-def _train(args):
- container_name = ""
-
- R = lambda: nav_env.get_multiplexer_class(args.navtask, args.solver.task)
- m = utils.Foo()
- m.tf_graph = tf.Graph()
-
- config = tf.ConfigProto()
- config.device_count['GPU'] = 1
-
- with m.tf_graph.as_default():
- with tf.device(tf.train.replica_device_setter(args.solver.ps_tasks,
- merge_devices=True)):
- with tf.container(container_name):
- m = args.setup_to_run(m, args, is_training=True,
- batch_norm_is_training=True, summary_mode='train')
-
- train_step_kwargs = args.setup_train_step_kwargs(
- m, R(), os.path.join(args.logdir, 'train'), rng_seed=args.solver.task,
- is_chief=args.solver.task==0,
- num_steps=args.navtask.task_params.num_steps*args.navtask.task_params.num_goals, iters=1,
- train_display_interval=args.summary.display_interval,
- dagger_sample_bn_false=args.arch.dagger_sample_bn_false)
-
- delay_start = (args.solver.task*(args.solver.task+1))/2 * FLAGS.delay_start_iters
- logging.error('delaying start for task %d by %d steps.',
- args.solver.task, delay_start)
-
- additional_args = {}
- final_loss = slim.learning.train(
- train_op=m.train_op,
- logdir=args.logdir,
- master=args.solver.master,
- is_chief=args.solver.task == 0,
- number_of_steps=args.solver.max_steps,
- train_step_fn=tf_utils.train_step_custom_online_sampling,
- train_step_kwargs=train_step_kwargs,
- global_step=m.global_step_op,
- init_op=m.init_op,
- init_fn=m.init_fn,
- sync_optimizer=m.sync_optimizer,
- saver=m.saver_op,
- startup_delay_steps=delay_start,
- summary_op=None, session_config=config, **additional_args)
-
-def _test(args):
- args.solver.master = ''
- container_name = ""
- checkpoint_dir = os.path.join(format(args.logdir))
- logging.error('Checkpoint_dir: %s', args.logdir)
-
- config = tf.ConfigProto();
- config.device_count['GPU'] = 1;
-
- m = utils.Foo()
- m.tf_graph = tf.Graph()
-
- rng_data_seed = 0; rng_action_seed = 0;
- R = lambda: nav_env.get_multiplexer_class(args.navtask, rng_data_seed)
- with m.tf_graph.as_default():
- with tf.container(container_name):
- m = args.setup_to_run(
- m, args, is_training=False,
- batch_norm_is_training=args.control.force_batchnorm_is_training_at_test,
- summary_mode=args.control.test_mode)
- train_step_kwargs = args.setup_train_step_kwargs(
- m, R(), os.path.join(args.logdir, args.control.test_name),
- rng_seed=rng_data_seed, is_chief=True,
- num_steps=args.navtask.task_params.num_steps*args.navtask.task_params.num_goals,
- iters=args.summary.test_iters, train_display_interval=None,
- dagger_sample_bn_false=args.arch.dagger_sample_bn_false)
-
- saver = slim.learning.tf_saver.Saver(variables.get_variables_to_restore())
-
- sv = slim.learning.supervisor.Supervisor(
- graph=ops.get_default_graph(), logdir=None, init_op=m.init_op,
- summary_op=None, summary_writer=None, global_step=None, saver=m.saver_op)
-
- last_checkpoint = None
- reported = False
- while True:
- last_checkpoint_ = None
- while last_checkpoint_ is None:
- last_checkpoint_ = slim.evaluation.wait_for_new_checkpoint(
- checkpoint_dir, last_checkpoint, seconds_to_sleep=10, timeout=60)
- if last_checkpoint_ is None: break
-
- last_checkpoint = last_checkpoint_
- checkpoint_iter = int(os.path.basename(last_checkpoint).split('-')[1])
-
- logging.info('Starting evaluation at %s using checkpoint %s.',
- time.strftime('%Y-%m-%d-%H:%M:%S', time.localtime()),
- last_checkpoint)
-
- if (args.control.only_eval_when_done == False or
- checkpoint_iter >= args.solver.max_steps):
- start = time.time()
- logging.info('Starting evaluation at %s using checkpoint %s.',
- time.strftime('%Y-%m-%d-%H:%M:%S', time.localtime()),
- last_checkpoint)
-
- with sv.managed_session(args.solver.master, config=config,
- start_standard_services=False) as sess:
- sess.run(m.init_op)
- sv.saver.restore(sess, last_checkpoint)
- sv.start_queue_runners(sess)
- if args.control.reset_rng_seed:
- train_step_kwargs['rng_data'] = [np.random.RandomState(rng_data_seed),
- np.random.RandomState(rng_data_seed)]
- train_step_kwargs['rng_action'] = np.random.RandomState(rng_action_seed)
- vals, _ = tf_utils.train_step_custom_online_sampling(
- sess, None, m.global_step_op, train_step_kwargs,
- mode=args.control.test_mode)
- should_stop = False
-
- if checkpoint_iter >= args.solver.max_steps:
- should_stop = True
-
- if should_stop:
- break
-
-if __name__ == '__main__':
- app.run()
diff --git a/research/cognitive_mapping_and_planning/scripts/script_plot_trajectory.py b/research/cognitive_mapping_and_planning/scripts/script_plot_trajectory.py
deleted file mode 100644
index 08273a83b512fa3100f7df6e20d41d666b037aad..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_plot_trajectory.py
+++ /dev/null
@@ -1,339 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""
-Code for plotting trajectories in the top view, and also plot first person views
-from saved trajectories. Does not run the network but only loads the mesh data
-to plot the view points.
- CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64
- PYTHONPATH='.' PYOPENGL_PLATFORM=egl python scripts/script_plot_trajectory.py \
- --first_person --num_steps 40 \
- --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r \
- --imset test --alsologtostderr --base_dir output --out_dir vis
-
-"""
-import os, sys, numpy as np, copy
-import matplotlib
-matplotlib.use("Agg")
-import matplotlib.pyplot as plt
-import matplotlib.animation as animation
-from matplotlib.gridspec import GridSpec
-
-import tensorflow as tf
-from tensorflow.contrib import slim
-import cv2
-import logging
-from tensorflow.python.platform import gfile
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-
-from datasets import nav_env
-import scripts.script_nav_agent_release as sna
-import src.file_utils as fu
-from src import graph_utils
-from src import utils
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('out_dir', 'vis', 'Directory where to store the output')
-flags.DEFINE_string('type', '', 'Optional type.')
-flags.DEFINE_bool('first_person', False, 'Visualize the first person view.')
-flags.DEFINE_bool('top_view', False, 'Visualize the trajectory in the top view.')
-flags.DEFINE_integer('num_steps', 40, 'Number of steps to run the model for.')
-flags.DEFINE_string('imset', 'test', '')
-flags.DEFINE_string('base_dir', 'output', 'Cache directory.')
-
-def _get_suffix_str():
- return ''
-
-
-def _load_trajectory():
- base_dir = FLAGS.base_dir
- config_name = FLAGS.config_name+_get_suffix_str()
-
- dir_name = os.path.join(base_dir, FLAGS.type, config_name)
- logging.info('Waiting for snapshot in directory %s.', dir_name)
- last_checkpoint = slim.evaluation.wait_for_new_checkpoint(dir_name, None)
- checkpoint_iter = int(os.path.basename(last_checkpoint).split('-')[1])
-
- # Load the distances.
- a = utils.load_variables(os.path.join(dir_name, 'bench_on_'+FLAGS.imset,
- 'all_locs_at_t_{:d}.pkl'.format(checkpoint_iter)))
- return a
-
-def _compute_hardness():
- # Load the stanford data to compute the hardness.
- if FLAGS.type == '':
- args = sna.get_args_for_config(FLAGS.config_name+'+bench_'+FLAGS.imset)
- else:
- args = sna.get_args_for_config(FLAGS.type+'.'+FLAGS.config_name+'+bench_'+FLAGS.imset)
-
- args.navtask.logdir = None
- R = lambda: nav_env.get_multiplexer_class(args.navtask, 0)
- R = R()
-
- rng_data = [np.random.RandomState(0), np.random.RandomState(0)]
-
- # Sample a room.
- h_dists = []
- gt_dists = []
- for i in range(250):
- e = R.sample_env(rng_data)
- nodes = e.task.nodes
-
- # Initialize the agent.
- init_env_state = e.reset(rng_data)
-
- gt_dist_to_goal = [e.episode.dist_to_goal[0][j][s]
- for j, s in enumerate(e.episode.start_node_ids)]
-
- for j in range(args.navtask.task_params.batch_size):
- start_node_id = e.episode.start_node_ids[j]
- end_node_id =e.episode.goal_node_ids[0][j]
- h_dist = graph_utils.heuristic_fn_vec(
- nodes[[start_node_id],:], nodes[[end_node_id], :],
- n_ori=args.navtask.task_params.n_ori,
- step_size=args.navtask.task_params.step_size)[0][0]
- gt_dist = e.episode.dist_to_goal[0][j][start_node_id]
- h_dists.append(h_dist)
- gt_dists.append(gt_dist)
-
- h_dists = np.array(h_dists)
- gt_dists = np.array(gt_dists)
- e = R.sample_env([np.random.RandomState(0), np.random.RandomState(0)])
- input = e.get_common_data()
- orig_maps = input['orig_maps'][0,0,:,:,0]
- return h_dists, gt_dists, orig_maps
-
-def plot_trajectory_first_person(dt, orig_maps, out_dir):
- out_dir = os.path.join(out_dir, FLAGS.config_name+_get_suffix_str(),
- FLAGS.imset)
- fu.makedirs(out_dir)
-
- # Load the model so that we can render.
- plt.set_cmap('gray')
- samples_per_action = 8; wait_at_action = 0;
-
- Writer = animation.writers['mencoder']
- writer = Writer(fps=3*(samples_per_action+wait_at_action),
- metadata=dict(artist='anonymous'), bitrate=1800)
-
- args = sna.get_args_for_config(FLAGS.config_name + '+bench_'+FLAGS.imset)
- args.navtask.logdir = None
- navtask_ = copy.deepcopy(args.navtask)
- navtask_.camera_param.modalities = ['rgb']
- navtask_.task_params.modalities = ['rgb']
- sz = 512
- navtask_.camera_param.height = sz
- navtask_.camera_param.width = sz
- navtask_.task_params.img_height = sz
- navtask_.task_params.img_width = sz
- R = lambda: nav_env.get_multiplexer_class(navtask_, 0)
- R = R()
- b = R.buildings[0]
-
- f = [0 for _ in range(wait_at_action)] + \
- [float(_)/samples_per_action for _ in range(samples_per_action)];
-
- # Generate things for it to render.
- inds_to_do = []
- inds_to_do += [1, 4, 10] #1291, 1268, 1273, 1289, 1302, 1426, 1413, 1449, 1399, 1390]
-
- for i in inds_to_do:
- fig = plt.figure(figsize=(10,8))
- gs = GridSpec(3,4)
- gs.update(wspace=0.05, hspace=0.05, left=0.0, top=0.97, right=1.0, bottom=0.)
- ax = fig.add_subplot(gs[:,:-1])
- ax1 = fig.add_subplot(gs[0,-1])
- ax2 = fig.add_subplot(gs[1,-1])
- ax3 = fig.add_subplot(gs[2,-1])
- axes = [ax, ax1, ax2, ax3]
- # ax = fig.add_subplot(gs[:,:])
- # axes = [ax]
- for ax in axes:
- ax.set_axis_off()
-
- node_ids = dt['all_node_ids'][i, :, 0]*1
- # Prune so that last node is not repeated more than 3 times?
- if np.all(node_ids[-4:] == node_ids[-1]):
- while node_ids[-4] == node_ids[-1]:
- node_ids = node_ids[:-1]
- num_steps = np.minimum(FLAGS.num_steps, len(node_ids))
-
- xyt = b.to_actual_xyt_vec(b.task.nodes[node_ids])
- xyt_diff = xyt[1:,:] - xyt[:-1:,:]
- xyt_diff[:,2] = np.mod(xyt_diff[:,2], 4)
- ind = np.where(xyt_diff[:,2] == 3)[0]
- xyt_diff[ind, 2] = -1
- xyt_diff = np.expand_dims(xyt_diff, axis=1)
- to_cat = [xyt_diff*_ for _ in f]
- perturbs_all = np.concatenate(to_cat, axis=1)
- perturbs_all = np.concatenate([perturbs_all, np.zeros_like(perturbs_all[:,:,:1])], axis=2)
- node_ids_all = np.expand_dims(node_ids, axis=1)*1
- node_ids_all = np.concatenate([node_ids_all for _ in f], axis=1)
- node_ids_all = np.reshape(node_ids_all[:-1,:], -1)
- perturbs_all = np.reshape(perturbs_all, [-1, 4])
- imgs = b.render_nodes(b.task.nodes[node_ids_all,:], perturb=perturbs_all)
-
- # Get action at each node.
- actions = []
- _, action_to_nodes = b.get_feasible_actions(node_ids)
- for j in range(num_steps-1):
- action_to_node = action_to_nodes[j]
- node_to_action = dict(zip(action_to_node.values(), action_to_node.keys()))
- actions.append(node_to_action[node_ids[j+1]])
-
- def init_fn():
- return fig,
- gt_dist_to_goal = []
-
- # Render trajectories.
- def worker(j):
- # Plot the image.
- step_number = j/(samples_per_action + wait_at_action)
- img = imgs[j]; ax = axes[0]; ax.clear(); ax.set_axis_off();
- img = img.astype(np.uint8); ax.imshow(img);
- tt = ax.set_title(
- "First Person View\n" +
- "Top corners show diagnostics (distance, agents' action) not input to agent.",
- fontsize=12)
- plt.setp(tt, color='white')
-
- # Distance to goal.
- t = 'Dist to Goal:\n{:2d} steps'.format(int(dt['all_d_at_t'][i, step_number]))
- t = ax.text(0.01, 0.99, t,
- horizontalalignment='left',
- verticalalignment='top',
- fontsize=20, color='red',
- transform=ax.transAxes, alpha=1.0)
- t.set_bbox(dict(color='white', alpha=0.85, pad=-0.1))
-
- # Action to take.
- action_latex = ['$\odot$ ', '$\curvearrowright$ ', '$\curvearrowleft$ ', r'$\Uparrow$ ']
- t = ax.text(0.99, 0.99, action_latex[actions[step_number]],
- horizontalalignment='right',
- verticalalignment='top',
- fontsize=40, color='green',
- transform=ax.transAxes, alpha=1.0)
- t.set_bbox(dict(color='white', alpha=0.85, pad=-0.1))
-
-
- # Plot the map top view.
- ax = axes[-1]
- if j == 0:
- # Plot the map
- locs = dt['all_locs'][i,:num_steps,:]
- goal_loc = dt['all_goal_locs'][i,:,:]
- xymin = np.minimum(np.min(goal_loc, axis=0), np.min(locs, axis=0))
- xymax = np.maximum(np.max(goal_loc, axis=0), np.max(locs, axis=0))
- xy1 = (xymax+xymin)/2. - 0.7*np.maximum(np.max(xymax-xymin), 24)
- xy2 = (xymax+xymin)/2. + 0.7*np.maximum(np.max(xymax-xymin), 24)
-
- ax.set_axis_on()
- ax.patch.set_facecolor((0.333, 0.333, 0.333))
- ax.set_xticks([]); ax.set_yticks([]);
- ax.imshow(orig_maps, origin='lower', vmin=-1.0, vmax=2.0)
- ax.plot(goal_loc[:,0], goal_loc[:,1], 'g*', markersize=12)
-
- locs = dt['all_locs'][i,:1,:]
- ax.plot(locs[:,0], locs[:,1], 'b.', markersize=12)
-
- ax.set_xlim([xy1[0], xy2[0]])
- ax.set_ylim([xy1[1], xy2[1]])
-
- locs = dt['all_locs'][i,step_number,:]
- locs = np.expand_dims(locs, axis=0)
- ax.plot(locs[:,0], locs[:,1], 'r.', alpha=1.0, linewidth=0, markersize=4)
- tt = ax.set_title('Trajectory in topview', fontsize=14)
- plt.setp(tt, color='white')
- return fig,
-
- line_ani = animation.FuncAnimation(fig, worker,
- (num_steps-1)*(wait_at_action+samples_per_action),
- interval=500, blit=True, init_func=init_fn)
- tmp_file_name = 'tmp.mp4'
- line_ani.save(tmp_file_name, writer=writer, savefig_kwargs={'facecolor':'black'})
- out_file_name = os.path.join(out_dir, 'vis_{:04d}.mp4'.format(i))
- print(out_file_name)
-
- if fu.exists(out_file_name):
- gfile.Remove(out_file_name)
- gfile.Copy(tmp_file_name, out_file_name)
- gfile.Remove(tmp_file_name)
- plt.close(fig)
-
-def plot_trajectory(dt, hardness, orig_maps, out_dir):
- out_dir = os.path.join(out_dir, FLAGS.config_name+_get_suffix_str(),
- FLAGS.imset)
- fu.makedirs(out_dir)
- out_file = os.path.join(out_dir, 'all_locs_at_t.pkl')
- dt['hardness'] = hardness
- utils.save_variables(out_file, dt.values(), dt.keys(), overwrite=True)
-
- #Plot trajectories onto the maps
- plt.set_cmap('gray')
- for i in range(4000):
- goal_loc = dt['all_goal_locs'][i, :, :]
- locs = np.concatenate((dt['all_locs'][i,:,:],
- dt['all_locs'][i,:,:]), axis=0)
- xymin = np.minimum(np.min(goal_loc, axis=0), np.min(locs, axis=0))
- xymax = np.maximum(np.max(goal_loc, axis=0), np.max(locs, axis=0))
- xy1 = (xymax+xymin)/2. - 1.*np.maximum(np.max(xymax-xymin), 24)
- xy2 = (xymax+xymin)/2. + 1.*np.maximum(np.max(xymax-xymin), 24)
-
- fig, ax = utils.tight_imshow_figure(plt, figsize=(6,6))
- ax.set_axis_on()
- ax.patch.set_facecolor((0.333, 0.333, 0.333))
- ax.set_xticks([])
- ax.set_yticks([])
-
- all_locs = dt['all_locs'][i,:,:]*1
- uniq = np.where(np.any(all_locs[1:,:] != all_locs[:-1,:], axis=1))[0]+1
- uniq = np.sort(uniq).tolist()
- uniq.insert(0,0)
- uniq = np.array(uniq)
- all_locs = all_locs[uniq, :]
-
- ax.plot(dt['all_locs'][i, 0, 0],
- dt['all_locs'][i, 0, 1], 'b.', markersize=24)
- ax.plot(dt['all_goal_locs'][i, 0, 0],
- dt['all_goal_locs'][i, 0, 1], 'g*', markersize=19)
- ax.plot(all_locs[:,0], all_locs[:,1], 'r', alpha=0.4, linewidth=2)
- ax.scatter(all_locs[:,0], all_locs[:,1],
- c=5+np.arange(all_locs.shape[0])*1./all_locs.shape[0],
- cmap='Reds', s=30, linewidth=0)
- ax.imshow(orig_maps, origin='lower', vmin=-1.0, vmax=2.0, aspect='equal')
- ax.set_xlim([xy1[0], xy2[0]])
- ax.set_ylim([xy1[1], xy2[1]])
-
- file_name = os.path.join(out_dir, 'trajectory_{:04d}.png'.format(i))
- print(file_name)
- with fu.fopen(file_name, 'w') as f:
- plt.savefig(f)
- plt.close(fig)
-
-
-def main(_):
- a = _load_trajectory()
- h_dists, gt_dists, orig_maps = _compute_hardness()
- hardness = 1.-h_dists*1./ gt_dists
-
- if FLAGS.top_view:
- plot_trajectory(a, hardness, orig_maps, out_dir=FLAGS.out_dir)
-
- if FLAGS.first_person:
- plot_trajectory_first_person(a, orig_maps, out_dir=FLAGS.out_dir)
-
-if __name__ == '__main__':
- app.run()
diff --git a/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.py b/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.py
deleted file mode 100644
index 58f32d121acf4c638625079907b02161e808af68..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.py
+++ /dev/null
@@ -1,197 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import os
-import glob
-import numpy as np
-import logging
-import cPickle
-from datasets import nav_env
-from datasets import factory
-from src import utils
-from src import map_utils as mu
-
-logging.basicConfig(level=logging.INFO)
-DATA_DIR = 'data/stanford_building_parser_dataset_raw/'
-
-mkdir_if_missing = utils.mkdir_if_missing
-save_variables = utils.save_variables
-
-def _get_semantic_maps(building_name, transform, map_, flip, cats):
- rooms = get_room_in_building(building_name)
- maps = []
- for cat in cats:
- maps.append(np.zeros((map_.size[1], map_.size[0])))
-
- for r in rooms:
- room = load_room(building_name, r, category_list=cats)
- classes = room['class_id']
- for i, cat in enumerate(cats):
- c_ind = cats.index(cat)
- ind = [_ for _, c in enumerate(classes) if c == c_ind]
- if len(ind) > 0:
- vs = [room['vertexs'][x]*1 for x in ind]
- vs = np.concatenate(vs, axis=0)
- if transform:
- vs = np.array([vs[:,1], vs[:,0], vs[:,2]]).T
- vs[:,0] = -vs[:,0]
- vs[:,1] += 4.20
- vs[:,0] += 6.20
- vs = vs*100.
- if flip:
- vs[:,1] = -vs[:,1]
- maps[i] = maps[i] + \
- mu._project_to_map(map_, vs, ignore_points_outside_map=True)
- return maps
-
-def _map_building_name(building_name):
- b = int(building_name.split('_')[0][4])
- out_name = 'Area_{:d}'.format(b)
- if b == 5:
- if int(building_name.split('_')[0][5]) == 1:
- transform = True
- else:
- transform = False
- else:
- transform = False
- return out_name, transform
-
-def get_categories():
- cats = ['beam', 'board', 'bookcase', 'ceiling', 'chair', 'clutter', 'column',
- 'door', 'floor', 'sofa', 'table', 'wall', 'window']
- return cats
-
-def _write_map_files(b_in, b_out, transform):
- cats = get_categories()
-
- env = utils.Foo(padding=10, resolution=5, num_point_threshold=2,
- valid_min=-10, valid_max=200, n_samples_per_face=200)
- robot = utils.Foo(radius=15, base=10, height=140, sensor_height=120,
- camera_elevation_degree=-15)
-
- building_loader = factory.get_dataset('sbpd')
- for flip in [False, True]:
- b = nav_env.Building(b_out, robot, env, flip=flip,
- building_loader=building_loader)
- logging.info("building_in: %s, building_out: %s, transform: %d", b_in,
- b_out, transform)
- maps = _get_semantic_maps(b_in, transform, b.map, flip, cats)
- maps = np.transpose(np.array(maps), axes=[1,2,0])
-
- # Load file from the cache.
- file_name = '{:s}_{:d}_{:d}_{:d}_{:d}_{:d}_{:d}.pkl'
- file_name = file_name.format(b.building_name, b.map.size[0], b.map.size[1],
- b.map.origin[0], b.map.origin[1],
- b.map.resolution, flip)
- out_file = os.path.join(DATA_DIR, 'processing', 'class-maps', file_name)
- logging.info('Writing semantic maps to %s.', out_file)
- save_variables(out_file, [maps, cats], ['maps', 'cats'], overwrite=True)
-
-def _transform_area5b(room_dimension):
- for a in room_dimension.keys():
- r = room_dimension[a]*1
- r[[0,1,3,4]] = r[[1,0,4,3]]
- r[[0,3]] = -r[[3,0]]
- r[[1,4]] += 4.20
- r[[0,3]] += 6.20
- room_dimension[a] = r
- return room_dimension
-
-def collect_room(building_name, room_name):
- room_dir = os.path.join(DATA_DIR, 'Stanford3dDataset_v1.2', building_name,
- room_name, 'Annotations')
- files = glob.glob1(room_dir, '*.txt')
- files = sorted(files, key=lambda s: s.lower())
- vertexs = []; colors = [];
- for f in files:
- file_name = os.path.join(room_dir, f)
- logging.info(' %s', file_name)
- a = np.loadtxt(file_name)
- vertex = a[:,:3]*1.
- color = a[:,3:]*1
- color = color.astype(np.uint8)
- vertexs.append(vertex)
- colors.append(color)
- files = [f.split('.')[0] for f in files]
- out = {'vertexs': vertexs, 'colors': colors, 'names': files}
- return out
-
-def load_room(building_name, room_name, category_list=None):
- room = collect_room(building_name, room_name)
- room['building_name'] = building_name
- room['room_name'] = room_name
- instance_id = range(len(room['names']))
- room['instance_id'] = instance_id
- if category_list is not None:
- name = [r.split('_')[0] for r in room['names']]
- class_id = []
- for n in name:
- if n in category_list:
- class_id.append(category_list.index(n))
- else:
- class_id.append(len(category_list))
- room['class_id'] = class_id
- room['category_list'] = category_list
- return room
-
-def get_room_in_building(building_name):
- building_dir = os.path.join(DATA_DIR, 'Stanford3dDataset_v1.2', building_name)
- rn = os.listdir(building_dir)
- rn = [x for x in rn if os.path.isdir(os.path.join(building_dir, x))]
- rn = sorted(rn, key=lambda s: s.lower())
- return rn
-
-def write_room_dimensions(b_in, b_out, transform):
- rooms = get_room_in_building(b_in)
- room_dimension = {}
- for r in rooms:
- room = load_room(b_in, r, category_list=None)
- vertex = np.concatenate(room['vertexs'], axis=0)
- room_dimension[r] = np.concatenate((np.min(vertex, axis=0), np.max(vertex, axis=0)), axis=0)
- if transform == 1:
- room_dimension = _transform_area5b(room_dimension)
-
- out_file = os.path.join(DATA_DIR, 'processing', 'room-dimension', b_out+'.pkl')
- save_variables(out_file, [room_dimension], ['room_dimension'], overwrite=True)
-
-def write_room_dimensions_all(I):
- mkdir_if_missing(os.path.join(DATA_DIR, 'processing', 'room-dimension'))
- bs_in = ['Area_1', 'Area_2', 'Area_3', 'Area_4', 'Area_5', 'Area_5', 'Area_6']
- bs_out = ['area1', 'area2', 'area3', 'area4', 'area5a', 'area5b', 'area6']
- transforms = [0, 0, 0, 0, 0, 1, 0]
-
- for i in I:
- b_in = bs_in[i]
- b_out = bs_out[i]
- t = transforms[i]
- write_room_dimensions(b_in, b_out, t)
-
-def write_class_maps_all(I):
- mkdir_if_missing(os.path.join(DATA_DIR, 'processing', 'class-maps'))
- bs_in = ['Area_1', 'Area_2', 'Area_3', 'Area_4', 'Area_5', 'Area_5', 'Area_6']
- bs_out = ['area1', 'area2', 'area3', 'area4', 'area5a', 'area5b', 'area6']
- transforms = [0, 0, 0, 0, 0, 1, 0]
-
- for i in I:
- b_in = bs_in[i]
- b_out = bs_out[i]
- t = transforms[i]
- _write_map_files(b_in, b_out, t)
-
-
-if __name__ == '__main__':
- write_room_dimensions_all([0, 2, 3, 4, 5, 6])
- write_class_maps_all([0, 2, 3, 4, 5, 6])
-
diff --git a/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.sh b/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.sh
deleted file mode 100644
index 1384fabe69259ccc514a14d62aee358d1909bffb..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_preprocess_annoations_S3DIS.sh
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-cd data/stanford_building_parser_dataset_raw
-unzip Stanford3dDataset_v1.2.zip
-cd ../../
-PYOPENGL_PLATFORM=egl PYTHONPATH='.' python scripts/script_preprocess_annoations_S3DIS.py
-
-mv data/stanford_building_parser_dataset_raw/processing/room-dimension data/stanford_building_parser_dataset/.
-mv data/stanford_building_parser_dataset_raw/processing/class-maps data/stanford_building_parser_dataset/.
-
-echo "You may now delete data/stanford_building_parser_dataset_raw if needed."
diff --git a/research/cognitive_mapping_and_planning/scripts/script_preprocess_meshes_S3DIS.sh b/research/cognitive_mapping_and_planning/scripts/script_preprocess_meshes_S3DIS.sh
deleted file mode 100644
index 557a4dde611d42e71d71dd1589abf96f55e6eec6..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_preprocess_meshes_S3DIS.sh
+++ /dev/null
@@ -1,37 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-mkdir -p data/stanford_building_parser_dataset
-mkdir -p data/stanford_building_parser_dataset/mesh
-cd data/stanford_building_parser_dataset_raw
-
-# Untar the files and extract the meshes.
-for t in "1" "3" "4" "5a" "5b" "6"; do
- tar -xf area_"$t"_noXYZ.tar area_$t/3d/rgb_textures
- mv area_$t/3d/rgb_textures ../stanford_building_parser_dataset/mesh/area$t
- rmdir area_$t/3d
- rmdir area_$t
-done
-
-cd ../../
-
-# Preprocess meshes to remove the group and chunk information.
-cd data/stanford_building_parser_dataset/
-for t in "1" "3" "4" "5a" "5b" "6"; do
- obj_name=`ls mesh/area$t/*.obj`
- cp $obj_name "$obj_name".bck
- cat $obj_name.bck | grep -v '^g' | grep -v '^o' > $obj_name
-done
-cd ../../
diff --git a/research/cognitive_mapping_and_planning/scripts/script_test_pretrained_models.sh b/research/cognitive_mapping_and_planning/scripts/script_test_pretrained_models.sh
deleted file mode 100644
index a4299fff5346afb53783a61de5c3e84f102a6304..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/scripts/script_test_pretrained_models.sh
+++ /dev/null
@@ -1,63 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Test CMP models.
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_r2r
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name cmp.lmap_Msc.clip5.sbpd_rgb_r2r+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_rgb_r2r
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name cmp.lmap_Msc.clip5.sbpd_d_ST+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_ST
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name cmp.lmap_Msc.clip5.sbpd_rgb_ST+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_rgb_ST
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r_h0_64_80+bench_test \
- --logdir output/cmp.lmap_Msc.clip5.sbpd_d_r2r_h0_64_80
-
-# Test LSTM baseline models.
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name bl.v2.noclip.sbpd_d_r2r+bench_test \
- --logdir output/bl.v2.noclip.sbpd_d_r2r
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name bl.v2.noclip.sbpd_rgb_r2r+bench_test \
- --logdir output/bl.v2.noclip.sbpd_rgb_r2r
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name bl.v2.noclip.sbpd_d_ST+bench_test \
- --logdir output/bl.v2.noclip.sbpd_d_ST
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name bl.v2.noclip.sbpd_rgb_ST+bench_test \
- --logdir output/bl.v2.noclip.sbpd_rgb_ST
-
-CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
- python scripts/script_nav_agent_release.py --config_name bl.v2.noclip.sbpd_d_r2r_h0_64_80+bench_test \
- --logdir output/bl.v2.noclip.sbpd_d_r2r_h0_64_80
-
-# Visualize test trajectories in top view.
-# CUDA_VISIBLE_DEVICES=0 LD_LIBRARY_PATH=/opt/cuda-8.0/lib64:/opt/cudnnv51/lib64 PYTHONPATH='.' PYOPENGL_PLATFORM=egl \
-# python scripts/script_plot_trajectory.py \
-# --first_person --num_steps 40 \
-# --config_name cmp.lmap_Msc.clip5.sbpd_d_r2r \
-# --imset test --alsologtostderr
diff --git a/research/cognitive_mapping_and_planning/src/__init__.py b/research/cognitive_mapping_and_planning/src/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/src/depth_utils.py b/research/cognitive_mapping_and_planning/src/depth_utils.py
deleted file mode 100644
index 35f14fc7c37fffb2a408decede11e378867a2834..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/depth_utils.py
+++ /dev/null
@@ -1,96 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for processing depth images.
-"""
-import numpy as np
-import src.rotation_utils as ru
-import src.utils as utils
-
-def get_camera_matrix(width, height, fov):
- """Returns a camera matrix from image size and fov."""
- xc = (width-1.) / 2.
- zc = (height-1.) / 2.
- f = (width / 2.) / np.tan(np.deg2rad(fov / 2.))
- camera_matrix = utils.Foo(xc=xc, zc=zc, f=f)
- return camera_matrix
-
-def get_point_cloud_from_z(Y, camera_matrix):
- """Projects the depth image Y into a 3D point cloud.
- Inputs:
- Y is ...xHxW
- camera_matrix
- Outputs:
- X is positive going right
- Y is positive into the image
- Z is positive up in the image
- XYZ is ...xHxWx3
- """
- x, z = np.meshgrid(np.arange(Y.shape[-1]),
- np.arange(Y.shape[-2]-1, -1, -1))
- for i in range(Y.ndim-2):
- x = np.expand_dims(x, axis=0)
- z = np.expand_dims(z, axis=0)
- X = (x-camera_matrix.xc) * Y / camera_matrix.f
- Z = (z-camera_matrix.zc) * Y / camera_matrix.f
- XYZ = np.concatenate((X[...,np.newaxis], Y[...,np.newaxis],
- Z[...,np.newaxis]), axis=X.ndim)
- return XYZ
-
-def make_geocentric(XYZ, sensor_height, camera_elevation_degree):
- """Transforms the point cloud into geocentric coordinate frame.
- Input:
- XYZ : ...x3
- sensor_height : height of the sensor
- camera_elevation_degree : camera elevation to rectify.
- Output:
- XYZ : ...x3
- """
- R = ru.get_r_matrix([1.,0.,0.], angle=np.deg2rad(camera_elevation_degree))
- XYZ = np.matmul(XYZ.reshape(-1,3), R.T).reshape(XYZ.shape)
- XYZ[...,2] = XYZ[...,2] + sensor_height
- return XYZ
-
-def bin_points(XYZ_cms, map_size, z_bins, xy_resolution):
- """Bins points into xy-z bins
- XYZ_cms is ... x H x W x3
- Outputs is ... x map_size x map_size x (len(z_bins)+1)
- """
- sh = XYZ_cms.shape
- XYZ_cms = XYZ_cms.reshape([-1, sh[-3], sh[-2], sh[-1]])
- n_z_bins = len(z_bins)+1
- map_center = (map_size-1.)/2.
- counts = []
- isvalids = []
- for XYZ_cm in XYZ_cms:
- isnotnan = np.logical_not(np.isnan(XYZ_cm[:,:,0]))
- X_bin = np.round(XYZ_cm[:,:,0] / xy_resolution + map_center).astype(np.int32)
- Y_bin = np.round(XYZ_cm[:,:,1] / xy_resolution + map_center).astype(np.int32)
- Z_bin = np.digitize(XYZ_cm[:,:,2], bins=z_bins).astype(np.int32)
-
- isvalid = np.array([X_bin >= 0, X_bin < map_size, Y_bin >= 0, Y_bin < map_size,
- Z_bin >= 0, Z_bin < n_z_bins, isnotnan])
- isvalid = np.all(isvalid, axis=0)
-
- ind = (Y_bin * map_size + X_bin) * n_z_bins + Z_bin
- ind[np.logical_not(isvalid)] = 0
- count = np.bincount(ind.ravel(), isvalid.ravel().astype(np.int32),
- minlength=map_size*map_size*n_z_bins)
- count = np.reshape(count, [map_size, map_size, n_z_bins])
- counts.append(count)
- isvalids.append(isvalid)
- counts = np.array(counts).reshape(list(sh[:-3]) + [map_size, map_size, n_z_bins])
- isvalids = np.array(isvalids).reshape(list(sh[:-3]) + [sh[-3], sh[-2], 1])
- return counts, isvalids
diff --git a/research/cognitive_mapping_and_planning/src/file_utils.py b/research/cognitive_mapping_and_planning/src/file_utils.py
deleted file mode 100644
index b386236ca6e04c9fa1e452b6ad3e70c6ab9bb88a..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/file_utils.py
+++ /dev/null
@@ -1,42 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for manipulating files.
-"""
-import os
-import numpy as np
-import PIL
-from tensorflow.python.platform import gfile
-import cv2
-
-exists = lambda path: gfile.Exists(path)
-fopen = lambda path, mode: gfile.Open(path, mode)
-makedirs = lambda path: gfile.MakeDirs(path)
-listdir = lambda path: gfile.ListDir(path)
-copyfile = lambda a, b, o: gfile.Copy(a,b,o)
-
-def write_image(image_path, rgb):
- ext = os.path.splitext(image_path)[1]
- with gfile.GFile(image_path, 'w') as f:
- img_str = cv2.imencode(ext, rgb[:,:,::-1])[1].tostring()
- f.write(img_str)
-
-def read_image(image_path, type='rgb'):
- with fopen(image_path, 'r') as f:
- I = PIL.Image.open(f)
- II = np.array(I)
- if type == 'rgb':
- II = II[:,:,:3]
- return II
diff --git a/research/cognitive_mapping_and_planning/src/graph_utils.py b/research/cognitive_mapping_and_planning/src/graph_utils.py
deleted file mode 100644
index cd99fd22a2f630438f31eecd7fbfece2c6008ead..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/graph_utils.py
+++ /dev/null
@@ -1,552 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Various function to manipulate graphs for computing distances.
-"""
-import skimage.morphology
-import numpy as np
-import networkx as nx
-import itertools
-import logging
-from datasets.nav_env import get_path_ids
-import graph_tool as gt
-import graph_tool.topology
-import graph_tool.generation
-import src.utils as utils
-
-# Compute shortest path from all nodes to or from all source nodes
-def get_distance_node_list(gtG, source_nodes, direction, weights=None):
- gtG_ = gt.Graph(gtG)
- v = gtG_.add_vertex()
-
- if weights is not None:
- weights = gtG_.edge_properties[weights]
-
- for s in source_nodes:
- e = gtG_.add_edge(s, int(v))
- if weights is not None:
- weights[e] = 0.
-
- if direction == 'to':
- dist = gt.topology.shortest_distance(
- gt.GraphView(gtG_, reversed=True), source=gtG_.vertex(int(v)),
- target=None, weights=weights)
- elif direction == 'from':
- dist = gt.topology.shortest_distance(
- gt.GraphView(gtG_, reversed=False), source=gtG_.vertex(int(v)),
- target=None, weights=weights)
- dist = np.array(dist.get_array())
- dist = dist[:-1]
- if weights is None:
- dist = dist-1
- return dist
-
-# Functions for semantically labelling nodes in the traversal graph.
-def generate_lattice(sz_x, sz_y):
- """Generates a lattice with sz_x vertices along x and sz_y vertices along y
- direction Each of these vertices is step_size distance apart. Origin is at
- (0,0). """
- g = gt.generation.lattice([sz_x, sz_y])
- x, y = np.meshgrid(np.arange(sz_x), np.arange(sz_y))
- x = np.reshape(x, [-1,1]); y = np.reshape(y, [-1,1]);
- nodes = np.concatenate((x,y), axis=1)
- return g, nodes
-
-def add_diagonal_edges(g, nodes, sz_x, sz_y, edge_len):
- offset = [sz_x+1, sz_x-1]
- for o in offset:
- s = np.arange(nodes.shape[0]-o-1)
- t = s + o
- ind = np.all(np.abs(nodes[s,:] - nodes[t,:]) == np.array([[1,1]]), axis=1)
- s = s[ind][:,np.newaxis]
- t = t[ind][:,np.newaxis]
- st = np.concatenate((s,t), axis=1)
- for i in range(st.shape[0]):
- e = g.add_edge(st[i,0], st[i,1], add_missing=False)
- g.ep['wts'][e] = edge_len
-
-def convert_traversible_to_graph(traversible, ff_cost=1., fo_cost=1.,
- oo_cost=1., connectivity=4):
- assert(connectivity == 4 or connectivity == 8)
-
- sz_x = traversible.shape[1]
- sz_y = traversible.shape[0]
- g, nodes = generate_lattice(sz_x, sz_y)
-
- # Assign costs.
- edge_wts = g.new_edge_property('float')
- g.edge_properties['wts'] = edge_wts
- wts = np.ones(g.num_edges(), dtype=np.float32)
- edge_wts.get_array()[:] = wts
-
- if connectivity == 8:
- add_diagonal_edges(g, nodes, sz_x, sz_y, np.sqrt(2.))
-
- se = np.array([[int(e.source()), int(e.target())] for e in g.edges()])
- s_xy = nodes[se[:,0]]
- t_xy = nodes[se[:,1]]
- s_t = np.ravel_multi_index((s_xy[:,1], s_xy[:,0]), traversible.shape)
- t_t = np.ravel_multi_index((t_xy[:,1], t_xy[:,0]), traversible.shape)
- s_t = traversible.ravel()[s_t]
- t_t = traversible.ravel()[t_t]
-
- wts = np.zeros(g.num_edges(), dtype=np.float32)
- wts[np.logical_and(s_t == True, t_t == True)] = ff_cost
- wts[np.logical_and(s_t == False, t_t == False)] = oo_cost
- wts[np.logical_xor(s_t, t_t)] = fo_cost
-
- edge_wts = g.edge_properties['wts']
- for i, e in enumerate(g.edges()):
- edge_wts[e] = edge_wts[e] * wts[i]
- # d = edge_wts.get_array()*1.
- # edge_wts.get_array()[:] = d*wts
- return g, nodes
-
-def label_nodes_with_class(nodes_xyt, class_maps, pix):
- """
- Returns:
- class_maps__: one-hot class_map for each class.
- node_class_label: one-hot class_map for each class, nodes_xyt.shape[0] x n_classes
- """
- # Assign each pixel to a node.
- selem = skimage.morphology.disk(pix)
- class_maps_ = class_maps*1.
- for i in range(class_maps.shape[2]):
- class_maps_[:,:,i] = skimage.morphology.dilation(class_maps[:,:,i]*1, selem)
- class_maps__ = np.argmax(class_maps_, axis=2)
- class_maps__[np.max(class_maps_, axis=2) == 0] = -1
-
- # For each node pick out the label from this class map.
- x = np.round(nodes_xyt[:,[0]]).astype(np.int32)
- y = np.round(nodes_xyt[:,[1]]).astype(np.int32)
- ind = np.ravel_multi_index((y,x), class_maps__.shape)
- node_class_label = class_maps__.ravel()[ind][:,0]
-
- # Convert to one hot versions.
- class_maps_one_hot = np.zeros(class_maps.shape, dtype=np.bool)
- node_class_label_one_hot = np.zeros((node_class_label.shape[0], class_maps.shape[2]), dtype=np.bool)
- for i in range(class_maps.shape[2]):
- class_maps_one_hot[:,:,i] = class_maps__ == i
- node_class_label_one_hot[:,i] = node_class_label == i
- return class_maps_one_hot, node_class_label_one_hot
-
-def label_nodes_with_class_geodesic(nodes_xyt, class_maps, pix, traversible,
- ff_cost=1., fo_cost=1., oo_cost=1.,
- connectivity=4):
- """Labels nodes in nodes_xyt with class labels using geodesic distance as
- defined by traversible from class_maps.
- Inputs:
- nodes_xyt
- class_maps: counts for each class.
- pix: distance threshold to consider close enough to target.
- traversible: binary map of whether traversible or not.
- Output:
- labels: For each node in nodes_xyt returns a label of the class or -1 is
- unlabelled.
- """
- g, nodes = convert_traversible_to_graph(traversible, ff_cost=ff_cost,
- fo_cost=fo_cost, oo_cost=oo_cost,
- connectivity=connectivity)
-
- class_dist = np.zeros_like(class_maps*1.)
- n_classes = class_maps.shape[2]
- if False:
- # Assign each pixel to a class based on number of points.
- selem = skimage.morphology.disk(pix)
- class_maps_ = class_maps*1.
- class_maps__ = np.argmax(class_maps_, axis=2)
- class_maps__[np.max(class_maps_, axis=2) == 0] = -1
-
- # Label nodes with classes.
- for i in range(n_classes):
- # class_node_ids = np.where(class_maps__.ravel() == i)[0]
- class_node_ids = np.where(class_maps[:,:,i].ravel() > 0)[0]
- dist_i = get_distance_node_list(g, class_node_ids, 'to', weights='wts')
- class_dist[:,:,i] = np.reshape(dist_i, class_dist[:,:,i].shape)
- class_map_geodesic = (class_dist <= pix)
- class_map_geodesic = np.reshape(class_map_geodesic, [-1, n_classes])
-
- # For each node pick out the label from this class map.
- x = np.round(nodes_xyt[:,[0]]).astype(np.int32)
- y = np.round(nodes_xyt[:,[1]]).astype(np.int32)
- ind = np.ravel_multi_index((y,x), class_dist[:,:,0].shape)
- node_class_label = class_map_geodesic[ind[:,0],:]
- class_map_geodesic = class_dist <= pix
- return class_map_geodesic, node_class_label
-
-def _get_next_nodes_undirected(n, sc, n_ori):
- nodes_to_add = []
- nodes_to_validate = []
- (p, q, r) = n
- nodes_to_add.append((n, (p, q, r), 0))
- if n_ori == 4:
- for _ in [1, 2, 3, 4]:
- if _ == 1:
- v = (p - sc, q, r)
- elif _ == 2:
- v = (p + sc, q, r)
- elif _ == 3:
- v = (p, q - sc, r)
- elif _ == 4:
- v = (p, q + sc, r)
- nodes_to_validate.append((n, v, _))
- return nodes_to_add, nodes_to_validate
-
-def _get_next_nodes(n, sc, n_ori):
- nodes_to_add = []
- nodes_to_validate = []
- (p, q, r) = n
- for r_, a_ in zip([-1, 0, 1], [1, 0, 2]):
- nodes_to_add.append((n, (p, q, np.mod(r+r_, n_ori)), a_))
-
- if n_ori == 6:
- if r == 0:
- v = (p + sc, q, r)
- elif r == 1:
- v = (p + sc, q + sc, r)
- elif r == 2:
- v = (p, q + sc, r)
- elif r == 3:
- v = (p - sc, q, r)
- elif r == 4:
- v = (p - sc, q - sc, r)
- elif r == 5:
- v = (p, q - sc, r)
- elif n_ori == 4:
- if r == 0:
- v = (p + sc, q, r)
- elif r == 1:
- v = (p, q + sc, r)
- elif r == 2:
- v = (p - sc, q, r)
- elif r == 3:
- v = (p, q - sc, r)
- nodes_to_validate.append((n,v,3))
-
- return nodes_to_add, nodes_to_validate
-
-def generate_graph(valid_fn_vec=None, sc=1., n_ori=6,
- starting_location=(0, 0, 0), vis=False, directed=True):
- timer = utils.Timer()
- timer.tic()
- if directed: G = nx.DiGraph(directed=True)
- else: G = nx.Graph()
- G.add_node(starting_location)
- new_nodes = G.nodes()
- while len(new_nodes) != 0:
- nodes_to_add = []
- nodes_to_validate = []
- for n in new_nodes:
- if directed:
- na, nv = _get_next_nodes(n, sc, n_ori)
- else:
- na, nv = _get_next_nodes_undirected(n, sc, n_ori)
- nodes_to_add = nodes_to_add + na
- if valid_fn_vec is not None:
- nodes_to_validate = nodes_to_validate + nv
- else:
- node_to_add = nodes_to_add + nv
-
- # Validate nodes.
- vs = [_[1] for _ in nodes_to_validate]
- valids = valid_fn_vec(vs)
-
- for nva, valid in zip(nodes_to_validate, valids):
- if valid:
- nodes_to_add.append(nva)
-
- new_nodes = []
- for n,v,a in nodes_to_add:
- if not G.has_node(v):
- new_nodes.append(v)
- G.add_edge(n, v, action=a)
-
- timer.toc(average=True, log_at=1, log_str='src.graph_utils.generate_graph')
- return (G)
-
-def vis_G(G, ax, vertex_color='r', edge_color='b', r=None):
- if edge_color is not None:
- for e in G.edges():
- XYT = zip(*e)
- x = XYT[-3]
- y = XYT[-2]
- t = XYT[-1]
- if r is None or t[0] == r:
- ax.plot(x, y, edge_color)
- if vertex_color is not None:
- XYT = zip(*G.nodes())
- x = XYT[-3]
- y = XYT[-2]
- t = XYT[-1]
- ax.plot(x, y, vertex_color + '.')
-
-def convert_to_graph_tool(G):
- timer = utils.Timer()
- timer.tic()
- gtG = gt.Graph(directed=G.is_directed())
- gtG.ep['action'] = gtG.new_edge_property('int')
-
- nodes_list = G.nodes()
- nodes_array = np.array(nodes_list)
-
- nodes_id = np.zeros((nodes_array.shape[0],), dtype=np.int64)
-
- for i in range(nodes_array.shape[0]):
- v = gtG.add_vertex()
- nodes_id[i] = int(v)
-
- # d = {key: value for (key, value) in zip(nodes_list, nodes_id)}
- d = dict(itertools.izip(nodes_list, nodes_id))
-
- for src, dst, data in G.edges_iter(data=True):
- e = gtG.add_edge(d[src], d[dst])
- gtG.ep['action'][e] = data['action']
- nodes_to_id = d
- timer.toc(average=True, log_at=1, log_str='src.graph_utils.convert_to_graph_tool')
- return gtG, nodes_array, nodes_to_id
-
-
-def _rejection_sampling(rng, sampling_d, target_d, bins, hardness, M):
- bin_ind = np.digitize(hardness, bins)-1
- i = 0
- ratio = target_d[bin_ind] / (M*sampling_d[bin_ind])
- while i < ratio.size and rng.rand() > ratio[i]:
- i = i+1
- return i
-
-def heuristic_fn_vec(n1, n2, n_ori, step_size):
- # n1 is a vector and n2 is a single point.
- dx = (n1[:,0] - n2[0,0])/step_size
- dy = (n1[:,1] - n2[0,1])/step_size
- dt = n1[:,2] - n2[0,2]
- dt = np.mod(dt, n_ori)
- dt = np.minimum(dt, n_ori-dt)
-
- if n_ori == 6:
- if dx*dy > 0:
- d = np.maximum(np.abs(dx), np.abs(dy))
- else:
- d = np.abs(dy-dx)
- elif n_ori == 4:
- d = np.abs(dx) + np.abs(dy)
-
- return (d + dt).reshape((-1,1))
-
-def get_hardness_distribution(gtG, max_dist, min_dist, rng, trials, bins, nodes,
- n_ori, step_size):
- heuristic_fn = lambda node_ids, node_id: \
- heuristic_fn_vec(nodes[node_ids, :], nodes[[node_id], :], n_ori, step_size)
- num_nodes = gtG.num_vertices()
- gt_dists = []; h_dists = [];
- for i in range(trials):
- end_node_id = rng.choice(num_nodes)
- gt_dist = gt.topology.shortest_distance(gt.GraphView(gtG, reversed=True),
- source=gtG.vertex(end_node_id),
- target=None, max_dist=max_dist)
- gt_dist = np.array(gt_dist.get_array())
- ind = np.where(np.logical_and(gt_dist <= max_dist, gt_dist >= min_dist))[0]
- gt_dist = gt_dist[ind]
- h_dist = heuristic_fn(ind, end_node_id)[:,0]
- gt_dists.append(gt_dist)
- h_dists.append(h_dist)
- gt_dists = np.concatenate(gt_dists)
- h_dists = np.concatenate(h_dists)
- hardness = 1. - h_dists*1./gt_dists
- hist, _ = np.histogram(hardness, bins)
- hist = hist.astype(np.float64)
- hist = hist / np.sum(hist)
- return hist
-
-def rng_next_goal_rejection_sampling(start_node_ids, batch_size, gtG, rng,
- max_dist, min_dist, max_dist_to_compute,
- sampling_d, target_d,
- nodes, n_ori, step_size, bins, M):
- sample_start_nodes = start_node_ids is None
- dists = []; pred_maps = []; end_node_ids = []; start_node_ids_ = [];
- hardnesss = []; gt_dists = [];
- num_nodes = gtG.num_vertices()
- for i in range(batch_size):
- done = False
- while not done:
- if sample_start_nodes:
- start_node_id = rng.choice(num_nodes)
- else:
- start_node_id = start_node_ids[i]
-
- gt_dist = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=False), source=start_node_id, target=None,
- max_dist=max_dist)
- gt_dist = np.array(gt_dist.get_array())
- ind = np.where(np.logical_and(gt_dist <= max_dist, gt_dist >= min_dist))[0]
- ind = rng.permutation(ind)
- gt_dist = gt_dist[ind]*1.
- h_dist = heuristic_fn_vec(nodes[ind, :], nodes[[start_node_id], :],
- n_ori, step_size)[:,0]
- hardness = 1. - h_dist / gt_dist
- sampled_ind = _rejection_sampling(rng, sampling_d, target_d, bins,
- hardness, M)
- if sampled_ind < ind.size:
- # print sampled_ind
- end_node_id = ind[sampled_ind]
- hardness = hardness[sampled_ind]
- gt_dist = gt_dist[sampled_ind]
- done = True
-
- # Compute distance from end node to all nodes, to return.
- dist, pred_map = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=True), source=end_node_id, target=None,
- max_dist=max_dist_to_compute, pred_map=True)
- dist = np.array(dist.get_array())
- pred_map = np.array(pred_map.get_array())
-
- hardnesss.append(hardness); dists.append(dist); pred_maps.append(pred_map);
- start_node_ids_.append(start_node_id); end_node_ids.append(end_node_id);
- gt_dists.append(gt_dist);
- paths = None
- return start_node_ids_, end_node_ids, dists, pred_maps, paths, hardnesss, gt_dists
-
-
-def rng_next_goal(start_node_ids, batch_size, gtG, rng, max_dist,
- max_dist_to_compute, node_room_ids, nodes=None,
- compute_path=False, dists_from_start_node=None):
- # Compute the distance field from the starting location, and then pick a
- # destination in another room if possible otherwise anywhere outside this
- # room.
- dists = []; pred_maps = []; paths = []; end_node_ids = [];
- for i in range(batch_size):
- room_id = node_room_ids[start_node_ids[i]]
- # Compute distances.
- if dists_from_start_node == None:
- dist, pred_map = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=False), source=gtG.vertex(start_node_ids[i]),
- target=None, max_dist=max_dist_to_compute, pred_map=True)
- dist = np.array(dist.get_array())
- else:
- dist = dists_from_start_node[i]
-
- # Randomly sample nodes which are within max_dist.
- near_ids = dist <= max_dist
- near_ids = near_ids[:, np.newaxis]
- # Check to see if there is a non-negative node which is close enough.
- non_same_room_ids = node_room_ids != room_id
- non_hallway_ids = node_room_ids != -1
- good1_ids = np.logical_and(near_ids, np.logical_and(non_same_room_ids, non_hallway_ids))
- good2_ids = np.logical_and(near_ids, non_hallway_ids)
- good3_ids = near_ids
- if np.any(good1_ids):
- end_node_id = rng.choice(np.where(good1_ids)[0])
- elif np.any(good2_ids):
- end_node_id = rng.choice(np.where(good2_ids)[0])
- elif np.any(good3_ids):
- end_node_id = rng.choice(np.where(good3_ids)[0])
- else:
- logging.error('Did not find any good nodes.')
-
- # Compute distance to this new goal for doing distance queries.
- dist, pred_map = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=True), source=gtG.vertex(end_node_id),
- target=None, max_dist=max_dist_to_compute, pred_map=True)
- dist = np.array(dist.get_array())
- pred_map = np.array(pred_map.get_array())
-
- dists.append(dist)
- pred_maps.append(pred_map)
- end_node_ids.append(end_node_id)
-
- path = None
- if compute_path:
- path = get_path_ids(start_node_ids[i], end_node_ids[i], pred_map)
- paths.append(path)
-
- return start_node_ids, end_node_ids, dists, pred_maps, paths
-
-
-def rng_room_to_room(batch_size, gtG, rng, max_dist, max_dist_to_compute,
- node_room_ids, nodes=None, compute_path=False):
- # Sample one of the rooms, compute the distance field. Pick a destination in
- # another room if possible otherwise anywhere outside this room.
- dists = []; pred_maps = []; paths = []; start_node_ids = []; end_node_ids = [];
- room_ids = np.unique(node_room_ids[node_room_ids[:,0] >= 0, 0])
- for i in range(batch_size):
- room_id = rng.choice(room_ids)
- end_node_id = rng.choice(np.where(node_room_ids[:,0] == room_id)[0])
- end_node_ids.append(end_node_id)
-
- # Compute distances.
- dist, pred_map = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=True), source=gtG.vertex(end_node_id),
- target=None, max_dist=max_dist_to_compute, pred_map=True)
- dist = np.array(dist.get_array())
- pred_map = np.array(pred_map.get_array())
- dists.append(dist)
- pred_maps.append(pred_map)
-
- # Randomly sample nodes which are within max_dist.
- near_ids = dist <= max_dist
- near_ids = near_ids[:, np.newaxis]
-
- # Check to see if there is a non-negative node which is close enough.
- non_same_room_ids = node_room_ids != room_id
- non_hallway_ids = node_room_ids != -1
- good1_ids = np.logical_and(near_ids, np.logical_and(non_same_room_ids, non_hallway_ids))
- good2_ids = np.logical_and(near_ids, non_hallway_ids)
- good3_ids = near_ids
- if np.any(good1_ids):
- start_node_id = rng.choice(np.where(good1_ids)[0])
- elif np.any(good2_ids):
- start_node_id = rng.choice(np.where(good2_ids)[0])
- elif np.any(good3_ids):
- start_node_id = rng.choice(np.where(good3_ids)[0])
- else:
- logging.error('Did not find any good nodes.')
-
- start_node_ids.append(start_node_id)
-
- path = None
- if compute_path:
- path = get_path_ids(start_node_ids[i], end_node_ids[i], pred_map)
- paths.append(path)
-
- return start_node_ids, end_node_ids, dists, pred_maps, paths
-
-
-def rng_target_dist_field(batch_size, gtG, rng, max_dist, max_dist_to_compute,
- nodes=None, compute_path=False):
- # Sample a single node, compute distance to all nodes less than max_dist,
- # sample nodes which are a particular distance away.
- dists = []; pred_maps = []; paths = []; start_node_ids = []
- end_node_ids = rng.choice(gtG.num_vertices(), size=(batch_size,),
- replace=False).tolist()
-
- for i in range(batch_size):
- dist, pred_map = gt.topology.shortest_distance(
- gt.GraphView(gtG, reversed=True), source=gtG.vertex(end_node_ids[i]),
- target=None, max_dist=max_dist_to_compute, pred_map=True)
- dist = np.array(dist.get_array())
- pred_map = np.array(pred_map.get_array())
- dists.append(dist)
- pred_maps.append(pred_map)
-
- # Randomly sample nodes which are withing max_dist
- near_ids = np.where(dist <= max_dist)[0]
- start_node_id = rng.choice(near_ids, size=(1,), replace=False)[0]
- start_node_ids.append(start_node_id)
-
- path = None
- if compute_path:
- path = get_path_ids(start_node_ids[i], end_node_ids[i], pred_map)
- paths.append(path)
-
- return start_node_ids, end_node_ids, dists, pred_maps, paths
diff --git a/research/cognitive_mapping_and_planning/src/map_utils.py b/research/cognitive_mapping_and_planning/src/map_utils.py
deleted file mode 100644
index 6756131a9eac161e7633ef089ed573e324f859e1..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/map_utils.py
+++ /dev/null
@@ -1,245 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Various function to compute the ground truth map for training etc.
-"""
-import copy
-import skimage.morphology
-import logging
-import numpy as np
-import scipy.ndimage
-import matplotlib.pyplot as plt
-import PIL
-
-import src.utils as utils
-import cv2
-
-def _get_xy_bounding_box(vertex, padding):
- """Returns the xy bounding box of the environment."""
- min_ = np.floor(np.min(vertex[:, :2], axis=0) - padding).astype(np.int)
- max_ = np.ceil(np.max(vertex[:, :2], axis=0) + padding).astype(np.int)
- return min_, max_
-
-def _project_to_map(map, vertex, wt=None, ignore_points_outside_map=False):
- """Projects points to map, returns how many points are present at each
- location."""
- num_points = np.zeros((map.size[1], map.size[0]))
- vertex_ = vertex[:, :2] - map.origin
- vertex_ = np.round(vertex_ / map.resolution).astype(np.int)
- if ignore_points_outside_map:
- good_ind = np.all(np.array([vertex_[:,1] >= 0, vertex_[:,1] < map.size[1],
- vertex_[:,0] >= 0, vertex_[:,0] < map.size[0]]),
- axis=0)
- vertex_ = vertex_[good_ind, :]
- if wt is not None:
- wt = wt[good_ind, :]
- if wt is None:
- np.add.at(num_points, (vertex_[:, 1], vertex_[:, 0]), 1)
- else:
- assert(wt.shape[0] == vertex.shape[0]), \
- 'number of weights should be same as vertices.'
- np.add.at(num_points, (vertex_[:, 1], vertex_[:, 0]), wt)
- return num_points
-
-def make_map(padding, resolution, vertex=None, sc=1.):
- """Returns a map structure."""
- min_, max_ = _get_xy_bounding_box(vertex*sc, padding=padding)
- sz = np.ceil((max_ - min_ + 1) / resolution).astype(np.int32)
- max_ = min_ + sz * resolution - 1
- map = utils.Foo(origin=min_, size=sz, max=max_, resolution=resolution,
- padding=padding)
- return map
-
-def _fill_holes(img, thresh):
- """Fills holes less than thresh area (assumes 4 connectivity when computing
- hole area."""
- l, n = scipy.ndimage.label(np.logical_not(img))
- img_ = img == True
- cnts = np.bincount(l.reshape(-1))
- for i, cnt in enumerate(cnts):
- if cnt < thresh:
- l[l == i] = -1
- img_[l == -1] = True
- return img_
-
-def compute_traversibility(map, robot_base, robot_height, robot_radius,
- valid_min, valid_max, num_point_threshold, shapess,
- sc=100., n_samples_per_face=200):
- """Returns a bit map with pixels that are traversible or not as long as the
- robot center is inside this volume we are good colisions can be detected by
- doing a line search on things, or walking from current location to final
- location in the bitmap, or doing bwlabel on the traversibility map."""
-
- tt = utils.Timer()
- tt.tic()
- num_obstcale_points = np.zeros((map.size[1], map.size[0]))
- num_points = np.zeros((map.size[1], map.size[0]))
-
- for i, shapes in enumerate(shapess):
- for j in range(shapes.get_number_of_meshes()):
- p, face_areas, face_idx = shapes.sample_points_on_face_of_shape(
- j, n_samples_per_face, sc)
- wt = face_areas[face_idx]/n_samples_per_face
-
- ind = np.all(np.concatenate(
- (p[:, [2]] > robot_base,
- p[:, [2]] < robot_base + robot_height), axis=1),axis=1)
- num_obstcale_points += _project_to_map(map, p[ind, :], wt[ind])
-
- ind = np.all(np.concatenate(
- (p[:, [2]] > valid_min,
- p[:, [2]] < valid_max), axis=1),axis=1)
- num_points += _project_to_map(map, p[ind, :], wt[ind])
-
- selem = skimage.morphology.disk(robot_radius / map.resolution)
- obstacle_free = skimage.morphology.binary_dilation(
- _fill_holes(num_obstcale_points > num_point_threshold, 20), selem) != True
- valid_space = _fill_holes(num_points > num_point_threshold, 20)
- traversible = np.all(np.concatenate((obstacle_free[...,np.newaxis],
- valid_space[...,np.newaxis]), axis=2),
- axis=2)
- # plt.imshow(np.concatenate((obstacle_free, valid_space, traversible), axis=1))
- # plt.show()
-
- map_out = copy.deepcopy(map)
- map_out.num_obstcale_points = num_obstcale_points
- map_out.num_points = num_points
- map_out.traversible = traversible
- map_out.obstacle_free = obstacle_free
- map_out.valid_space = valid_space
- tt.toc(log_at=1, log_str='src.map_utils.compute_traversibility: ')
- return map_out
-
-
-def resize_maps(map, map_scales, resize_method):
- scaled_maps = []
- for i, sc in enumerate(map_scales):
- if resize_method == 'antialiasing':
- # Resize using open cv so that we can compute the size.
- # Use PIL resize to use anti aliasing feature.
- map_ = cv2.resize(map*1, None, None, fx=sc, fy=sc, interpolation=cv2.INTER_LINEAR)
- w = map_.shape[1]; h = map_.shape[0]
-
- map_img = PIL.Image.fromarray((map*255).astype(np.uint8))
- map__img = map_img.resize((w,h), PIL.Image.ANTIALIAS)
- map_ = np.asarray(map__img).astype(np.float32)
- map_ = map_/255.
- map_ = np.minimum(map_, 1.0)
- map_ = np.maximum(map_, 0.0)
- elif resize_method == 'linear_noantialiasing':
- map_ = cv2.resize(map*1, None, None, fx=sc, fy=sc, interpolation=cv2.INTER_LINEAR)
- else:
- logging.error('Unknown resizing method')
- scaled_maps.append(map_)
- return scaled_maps
-
-
-def pick_largest_cc(traversible):
- out = scipy.ndimage.label(traversible)[0]
- cnt = np.bincount(out.reshape(-1))[1:]
- return out == np.argmax(cnt) + 1
-
-def get_graph_origin_loc(rng, traversible):
- """Erode the traversibility mask so that we get points in the bulk of the
- graph, and not end up with a situation where the graph is localized in the
- corner of a cramped room. Output Locs is in the coordinate frame of the
- map."""
-
- aa = pick_largest_cc(skimage.morphology.binary_erosion(traversible == True,
- selem=np.ones((15,15))))
- y, x = np.where(aa > 0)
- ind = rng.choice(y.size)
- locs = np.array([x[ind], y[ind]])
- locs = locs + rng.rand(*(locs.shape)) - 0.5
- return locs
-
-
-def generate_egocentric_maps(scaled_maps, map_scales, map_crop_sizes, loc,
- x_axis, y_axis, theta):
- maps = []
- for i, (map_, sc, map_crop_size) in enumerate(zip(scaled_maps, map_scales, map_crop_sizes)):
- maps_i = np.array(get_map_to_predict(loc*sc, x_axis, y_axis, map_,
- map_crop_size,
- interpolation=cv2.INTER_LINEAR)[0])
- maps_i[np.isnan(maps_i)] = 0
- maps.append(maps_i)
- return maps
-
-def generate_goal_images(map_scales, map_crop_sizes, n_ori, goal_dist,
- goal_theta, rel_goal_orientation):
- goal_dist = goal_dist[:,0]
- goal_theta = goal_theta[:,0]
- rel_goal_orientation = rel_goal_orientation[:,0]
-
- goals = [];
- # Generate the map images.
- for i, (sc, map_crop_size) in enumerate(zip(map_scales, map_crop_sizes)):
- goal_i = np.zeros((goal_dist.shape[0], map_crop_size, map_crop_size, n_ori),
- dtype=np.float32)
- x = goal_dist*np.cos(goal_theta)*sc + (map_crop_size-1.)/2.
- y = goal_dist*np.sin(goal_theta)*sc + (map_crop_size-1.)/2.
-
- for j in range(goal_dist.shape[0]):
- gc = rel_goal_orientation[j]
- x0 = np.floor(x[j]).astype(np.int32); x1 = x0 + 1;
- y0 = np.floor(y[j]).astype(np.int32); y1 = y0 + 1;
- if x0 >= 0 and x0 <= map_crop_size-1:
- if y0 >= 0 and y0 <= map_crop_size-1:
- goal_i[j, y0, x0, gc] = (x1-x[j])*(y1-y[j])
- if y1 >= 0 and y1 <= map_crop_size-1:
- goal_i[j, y1, x0, gc] = (x1-x[j])*(y[j]-y0)
-
- if x1 >= 0 and x1 <= map_crop_size-1:
- if y0 >= 0 and y0 <= map_crop_size-1:
- goal_i[j, y0, x1, gc] = (x[j]-x0)*(y1-y[j])
- if y1 >= 0 and y1 <= map_crop_size-1:
- goal_i[j, y1, x1, gc] = (x[j]-x0)*(y[j]-y0)
-
- goals.append(goal_i)
- return goals
-
-def get_map_to_predict(src_locs, src_x_axiss, src_y_axiss, map, map_size,
- interpolation=cv2.INTER_LINEAR):
- fss = []
- valids = []
-
- center = (map_size-1.0)/2.0
- dst_theta = np.pi/2.0
- dst_loc = np.array([center, center])
- dst_x_axis = np.array([np.cos(dst_theta), np.sin(dst_theta)])
- dst_y_axis = np.array([np.cos(dst_theta+np.pi/2), np.sin(dst_theta+np.pi/2)])
-
- def compute_points(center, x_axis, y_axis):
- points = np.zeros((3,2),dtype=np.float32)
- points[0,:] = center
- points[1,:] = center + x_axis
- points[2,:] = center + y_axis
- return points
-
- dst_points = compute_points(dst_loc, dst_x_axis, dst_y_axis)
- for i in range(src_locs.shape[0]):
- src_loc = src_locs[i,:]
- src_x_axis = src_x_axiss[i,:]
- src_y_axis = src_y_axiss[i,:]
- src_points = compute_points(src_loc, src_x_axis, src_y_axis)
- M = cv2.getAffineTransform(src_points, dst_points)
-
- fs = cv2.warpAffine(map, M, (map_size, map_size), None, flags=interpolation,
- borderValue=np.NaN)
- valid = np.invert(np.isnan(fs))
- valids.append(valid)
- fss.append(fs)
- return fss, valids
-
diff --git a/research/cognitive_mapping_and_planning/src/rotation_utils.py b/research/cognitive_mapping_and_planning/src/rotation_utils.py
deleted file mode 100644
index 8d6d4f3cbdb1f808d210dce8b22fa3ba831d45a9..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/rotation_utils.py
+++ /dev/null
@@ -1,73 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for generating and applying rotation matrices.
-"""
-import numpy as np
-
-ANGLE_EPS = 0.001
-
-
-def normalize(v):
- return v / np.linalg.norm(v)
-
-
-def get_r_matrix(ax_, angle):
- ax = normalize(ax_)
- if np.abs(angle) > ANGLE_EPS:
- S_hat = np.array(
- [[0.0, -ax[2], ax[1]], [ax[2], 0.0, -ax[0]], [-ax[1], ax[0], 0.0]],
- dtype=np.float32)
- R = np.eye(3) + np.sin(angle)*S_hat + \
- (1-np.cos(angle))*(np.linalg.matrix_power(S_hat, 2))
- else:
- R = np.eye(3)
- return R
-
-
-def r_between(v_from_, v_to_):
- v_from = normalize(v_from_)
- v_to = normalize(v_to_)
- ax = normalize(np.cross(v_from, v_to))
- angle = np.arccos(np.dot(v_from, v_to))
- return get_r_matrix(ax, angle)
-
-
-def rotate_camera_to_point_at(up_from, lookat_from, up_to, lookat_to):
- inputs = [up_from, lookat_from, up_to, lookat_to]
- for i in range(4):
- inputs[i] = normalize(np.array(inputs[i]).reshape((-1,)))
- up_from, lookat_from, up_to, lookat_to = inputs
- r1 = r_between(lookat_from, lookat_to)
-
- new_x = np.dot(r1, np.array([1, 0, 0]).reshape((-1, 1))).reshape((-1))
- to_x = normalize(np.cross(lookat_to, up_to))
- angle = np.arccos(np.dot(new_x, to_x))
- if angle > ANGLE_EPS:
- if angle < np.pi - ANGLE_EPS:
- ax = normalize(np.cross(new_x, to_x))
- flip = np.dot(lookat_to, ax)
- if flip > 0:
- r2 = get_r_matrix(lookat_to, angle)
- elif flip < 0:
- r2 = get_r_matrix(lookat_to, -1. * angle)
- else:
- # Angle of rotation is too close to 180 degrees, direction of rotation
- # does not matter.
- r2 = get_r_matrix(lookat_to, angle)
- else:
- r2 = np.eye(3)
- return np.dot(r2, r1)
-
diff --git a/research/cognitive_mapping_and_planning/src/utils.py b/research/cognitive_mapping_and_planning/src/utils.py
deleted file mode 100644
index a1b9e44260b7c7884855761f56ac60d6f508c2fb..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/src/utils.py
+++ /dev/null
@@ -1,168 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Generaly Utilities.
-"""
-
-import numpy as np, cPickle, os, time
-from six.moves import xrange
-import src.file_utils as fu
-import logging
-
-class Timer():
- def __init__(self):
- self.calls = 0.
- self.start_time = 0.
- self.time_per_call = 0.
- self.total_time = 0.
- self.last_log_time = 0.
-
- def tic(self):
- self.start_time = time.time()
-
- def toc(self, average=True, log_at=-1, log_str='', type='calls'):
- if self.start_time == 0:
- logging.error('Timer not started by calling tic().')
- t = time.time()
- diff = time.time() - self.start_time
- self.total_time += diff
- self.calls += 1.
- self.time_per_call = self.total_time/self.calls
-
- if type == 'calls' and log_at > 0 and np.mod(self.calls, log_at) == 0:
- _ = []
- logging.info('%s: %f seconds.', log_str, self.time_per_call)
- elif type == 'time' and log_at > 0 and t - self.last_log_time >= log_at:
- _ = []
- logging.info('%s: %f seconds.', log_str, self.time_per_call)
- self.last_log_time = t
-
- if average:
- return self.time_per_call
- else:
- return diff
-
-class Foo(object):
- def __init__(self, **kwargs):
- self.__dict__.update(kwargs)
- def __str__(self):
- str_ = ''
- for v in vars(self).keys():
- a = getattr(self, v)
- if True: #isinstance(v, object):
- str__ = str(a)
- str__ = str__.replace('\n', '\n ')
- else:
- str__ = str(a)
- str_ += '{:s}: {:s}'.format(v, str__)
- str_ += '\n'
- return str_
-
-
-def dict_equal(dict1, dict2):
- assert(set(dict1.keys()) == set(dict2.keys())), "Sets of keys between 2 dictionaries are different."
- for k in dict1.keys():
- assert(type(dict1[k]) == type(dict2[k])), "Type of key '{:s}' if different.".format(k)
- if type(dict1[k]) == np.ndarray:
- assert(dict1[k].dtype == dict2[k].dtype), "Numpy Type of key '{:s}' if different.".format(k)
- assert(np.allclose(dict1[k], dict2[k])), "Value for key '{:s}' do not match.".format(k)
- else:
- assert(dict1[k] == dict2[k]), "Value for key '{:s}' do not match.".format(k)
- return True
-
-def subplot(plt, Y_X, sz_y_sz_x = (10, 10)):
- Y,X = Y_X
- sz_y, sz_x = sz_y_sz_x
- plt.rcParams['figure.figsize'] = (X*sz_x, Y*sz_y)
- fig, axes = plt.subplots(Y, X)
- plt.subplots_adjust(wspace=0.1, hspace=0.1)
- return fig, axes
-
-def tic_toc_print(interval, string):
- global tic_toc_print_time_old
- if 'tic_toc_print_time_old' not in globals():
- tic_toc_print_time_old = time.time()
- print(string)
- else:
- new_time = time.time()
- if new_time - tic_toc_print_time_old > interval:
- tic_toc_print_time_old = new_time;
- print(string)
-
-def mkdir_if_missing(output_dir):
- if not fu.exists(output_dir):
- fu.makedirs(output_dir)
-
-def save_variables(pickle_file_name, var, info, overwrite = False):
- if fu.exists(pickle_file_name) and overwrite == False:
- raise Exception('{:s} exists and over write is false.'.format(pickle_file_name))
- # Construct the dictionary
- assert(type(var) == list); assert(type(info) == list);
- d = {}
- for i in xrange(len(var)):
- d[info[i]] = var[i]
- with fu.fopen(pickle_file_name, 'w') as f:
- cPickle.dump(d, f, cPickle.HIGHEST_PROTOCOL)
-
-def load_variables(pickle_file_name):
- if fu.exists(pickle_file_name):
- with fu.fopen(pickle_file_name, 'r') as f:
- d = cPickle.load(f)
- return d
- else:
- raise Exception('{:s} does not exists.'.format(pickle_file_name))
-
-def voc_ap(rec, prec):
- rec = rec.reshape((-1,1))
- prec = prec.reshape((-1,1))
- z = np.zeros((1,1))
- o = np.ones((1,1))
- mrec = np.vstack((z, rec, o))
- mpre = np.vstack((z, prec, z))
- for i in range(len(mpre)-2, -1, -1):
- mpre[i] = max(mpre[i], mpre[i+1])
-
- I = np.where(mrec[1:] != mrec[0:-1])[0]+1;
- ap = 0;
- for i in I:
- ap = ap + (mrec[i] - mrec[i-1])*mpre[i];
- return ap
-
-def tight_imshow_figure(plt, figsize=None):
- fig = plt.figure(figsize=figsize)
- ax = plt.Axes(fig, [0,0,1,1])
- ax.set_axis_off()
- fig.add_axes(ax)
- return fig, ax
-
-def calc_pr(gt, out, wt=None):
- if wt is None:
- wt = np.ones((gt.size,1))
-
- gt = gt.astype(np.float64).reshape((-1,1))
- wt = wt.astype(np.float64).reshape((-1,1))
- out = out.astype(np.float64).reshape((-1,1))
-
- gt = gt*wt
- tog = np.concatenate([gt, wt, out], axis=1)*1.
- ind = np.argsort(tog[:,2], axis=0)[::-1]
- tog = tog[ind,:]
- cumsumsortgt = np.cumsum(tog[:,0])
- cumsumsortwt = np.cumsum(tog[:,1])
- prec = cumsumsortgt / cumsumsortwt
- rec = cumsumsortgt / np.sum(tog[:,0])
-
- ap = voc_ap(rec, prec)
- return ap, rec, prec
diff --git a/research/cognitive_mapping_and_planning/tfcode/__init__.py b/research/cognitive_mapping_and_planning/tfcode/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_mapping_and_planning/tfcode/cmp.py b/research/cognitive_mapping_and_planning/tfcode/cmp.py
deleted file mode 100644
index 228ef90fddcd9ff41b26795544d93a1f18466158..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/cmp.py
+++ /dev/null
@@ -1,553 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Code for setting up the network for CMP.
-
-Sets up the mapper and the planner.
-"""
-
-import sys, os, numpy as np
-import matplotlib.pyplot as plt
-import copy
-import argparse, pprint
-import time
-
-
-import tensorflow as tf
-
-from tensorflow.contrib import slim
-from tensorflow.contrib.slim import arg_scope
-
-import logging
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-from src import utils
-import src.file_utils as fu
-import tfcode.nav_utils as nu
-import tfcode.cmp_utils as cu
-import tfcode.cmp_summary as cmp_s
-from tfcode import tf_utils
-
-value_iteration_network = cu.value_iteration_network
-rotate_preds = cu.rotate_preds
-deconv = cu.deconv
-get_visual_frustum = cu.get_visual_frustum
-fr_v2 = cu.fr_v2
-
-setup_train_step_kwargs = nu.default_train_step_kwargs
-compute_losses_multi_or = nu.compute_losses_multi_or
-
-get_repr_from_image = nu.get_repr_from_image
-
-_save_d_at_t = nu.save_d_at_t
-_save_all = nu.save_all
-_eval_ap = nu.eval_ap
-_eval_dist = nu.eval_dist
-_plot_trajectories = nu.plot_trajectories
-
-_vis_readout_maps = cmp_s._vis_readout_maps
-_vis = cmp_s._vis
-_summary_vis = cmp_s._summary_vis
-_summary_readout_maps = cmp_s._summary_readout_maps
-_add_summaries = cmp_s._add_summaries
-
-def _inputs(problem):
- # Set up inputs.
- with tf.name_scope('inputs'):
- inputs = []
- inputs.append(('orig_maps', tf.float32,
- (problem.batch_size, 1, None, None, 1)))
- inputs.append(('goal_loc', tf.float32,
- (problem.batch_size, problem.num_goals, 2)))
- common_input_data, _ = tf_utils.setup_inputs(inputs)
-
- inputs = []
- if problem.input_type == 'vision':
- # Multiple images from an array of cameras.
- inputs.append(('imgs', tf.float32,
- (problem.batch_size, None, len(problem.aux_delta_thetas)+1,
- problem.img_height, problem.img_width,
- problem.img_channels)))
- elif problem.input_type == 'analytical_counts':
- for i in range(len(problem.map_crop_sizes)):
- inputs.append(('analytical_counts_{:d}'.format(i), tf.float32,
- (problem.batch_size, None, problem.map_crop_sizes[i],
- problem.map_crop_sizes[i], problem.map_channels)))
-
- if problem.outputs.readout_maps:
- for i in range(len(problem.readout_maps_crop_sizes)):
- inputs.append(('readout_maps_{:d}'.format(i), tf.float32,
- (problem.batch_size, None,
- problem.readout_maps_crop_sizes[i],
- problem.readout_maps_crop_sizes[i],
- problem.readout_maps_channels)))
-
- for i in range(len(problem.map_crop_sizes)):
- inputs.append(('ego_goal_imgs_{:d}'.format(i), tf.float32,
- (problem.batch_size, None, problem.map_crop_sizes[i],
- problem.map_crop_sizes[i], problem.goal_channels)))
- for s in ['sum_num', 'sum_denom', 'max_denom']:
- inputs.append(('running_'+s+'_{:d}'.format(i), tf.float32,
- (problem.batch_size, 1, problem.map_crop_sizes[i],
- problem.map_crop_sizes[i], problem.map_channels)))
-
- inputs.append(('incremental_locs', tf.float32,
- (problem.batch_size, None, 2)))
- inputs.append(('incremental_thetas', tf.float32,
- (problem.batch_size, None, 1)))
- inputs.append(('step_number', tf.int32, (1, None, 1)))
- inputs.append(('node_ids', tf.int32, (problem.batch_size, None,
- problem.node_ids_dim)))
- inputs.append(('perturbs', tf.float32, (problem.batch_size, None,
- problem.perturbs_dim)))
-
- # For plotting result plots
- inputs.append(('loc_on_map', tf.float32, (problem.batch_size, None, 2)))
- inputs.append(('gt_dist_to_goal', tf.float32, (problem.batch_size, None, 1)))
-
- step_input_data, _ = tf_utils.setup_inputs(inputs)
-
- inputs = []
- inputs.append(('action', tf.int32, (problem.batch_size, None, problem.num_actions)))
- train_data, _ = tf_utils.setup_inputs(inputs)
- train_data.update(step_input_data)
- train_data.update(common_input_data)
- return common_input_data, step_input_data, train_data
-
-def readout_general(multi_scale_belief, num_neurons, strides, layers_per_block,
- kernel_size, batch_norm_is_training_op, wt_decay):
- multi_scale_belief = tf.stop_gradient(multi_scale_belief)
- with tf.variable_scope('readout_maps_deconv'):
- x, outs = deconv(multi_scale_belief, batch_norm_is_training_op,
- wt_decay=wt_decay, neurons=num_neurons, strides=strides,
- layers_per_block=layers_per_block, kernel_size=kernel_size,
- conv_fn=slim.conv2d_transpose, offset=0,
- name='readout_maps_deconv')
- probs = tf.sigmoid(x)
- return x, probs
-
-
-def running_combine(fss_logits, confs_probs, incremental_locs,
- incremental_thetas, previous_sum_num, previous_sum_denom,
- previous_max_denom, map_size, num_steps):
- # fss_logits is B x N x H x W x C
- # confs_logits is B x N x H x W x C
- # incremental_locs is B x N x 2
- # incremental_thetas is B x N x 1
- # previous_sum_num etc is B x 1 x H x W x C
-
- with tf.name_scope('combine_{:d}'.format(num_steps)):
- running_sum_nums_ = []; running_sum_denoms_ = [];
- running_max_denoms_ = [];
-
- fss_logits_ = tf.unstack(fss_logits, axis=1, num=num_steps)
- confs_probs_ = tf.unstack(confs_probs, axis=1, num=num_steps)
- incremental_locs_ = tf.unstack(incremental_locs, axis=1, num=num_steps)
- incremental_thetas_ = tf.unstack(incremental_thetas, axis=1, num=num_steps)
- running_sum_num = tf.unstack(previous_sum_num, axis=1, num=1)[0]
- running_sum_denom = tf.unstack(previous_sum_denom, axis=1, num=1)[0]
- running_max_denom = tf.unstack(previous_max_denom, axis=1, num=1)[0]
-
- for i in range(num_steps):
- # Rotate the previous running_num and running_denom
- running_sum_num, running_sum_denom, running_max_denom = rotate_preds(
- incremental_locs_[i], incremental_thetas_[i], map_size,
- [running_sum_num, running_sum_denom, running_max_denom],
- output_valid_mask=False)[0]
- # print i, num_steps, running_sum_num.get_shape().as_list()
- running_sum_num = running_sum_num + fss_logits_[i] * confs_probs_[i]
- running_sum_denom = running_sum_denom + confs_probs_[i]
- running_max_denom = tf.maximum(running_max_denom, confs_probs_[i])
- running_sum_nums_.append(running_sum_num)
- running_sum_denoms_.append(running_sum_denom)
- running_max_denoms_.append(running_max_denom)
-
- running_sum_nums = tf.stack(running_sum_nums_, axis=1)
- running_sum_denoms = tf.stack(running_sum_denoms_, axis=1)
- running_max_denoms = tf.stack(running_max_denoms_, axis=1)
- return running_sum_nums, running_sum_denoms, running_max_denoms
-
-def get_map_from_images(imgs, mapper_arch, task_params, freeze_conv, wt_decay,
- is_training, batch_norm_is_training_op, num_maps,
- split_maps=True):
- # Hit image with a resnet.
- n_views = len(task_params.aux_delta_thetas) + 1
- out = utils.Foo()
-
- images_reshaped = tf.reshape(imgs,
- shape=[-1, task_params.img_height,
- task_params.img_width,
- task_params.img_channels], name='re_image')
-
- x, out.vars_to_restore = get_repr_from_image(
- images_reshaped, task_params.modalities, task_params.data_augment,
- mapper_arch.encoder, freeze_conv, wt_decay, is_training)
-
- # Reshape into nice things so that these can be accumulated over time steps
- # for faster backprop.
- sh_before = x.get_shape().as_list()
- out.encoder_output = tf.reshape(x, shape=[task_params.batch_size, -1, n_views] + sh_before[1:])
- x = tf.reshape(out.encoder_output, shape=[-1] + sh_before[1:])
-
- # Add a layer to reduce dimensions for a fc layer.
- if mapper_arch.dim_reduce_neurons > 0:
- ks = 1; neurons = mapper_arch.dim_reduce_neurons;
- init_var = np.sqrt(2.0/(ks**2)/neurons)
- batch_norm_param = mapper_arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- out.conv_feat = slim.conv2d(x, neurons, kernel_size=ks, stride=1,
- normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_param,
- padding='SAME', scope='dim_reduce',
- weights_regularizer=slim.l2_regularizer(wt_decay),
- weights_initializer=tf.random_normal_initializer(stddev=init_var))
- reshape_conv_feat = slim.flatten(out.conv_feat)
- sh = reshape_conv_feat.get_shape().as_list()
- out.reshape_conv_feat = tf.reshape(reshape_conv_feat, shape=[-1, sh[1]*n_views])
-
- with tf.variable_scope('fc'):
- # Fully connected layers to compute the representation in top-view space.
- fc_batch_norm_param = {'center': True, 'scale': True,
- 'activation_fn':tf.nn.relu,
- 'is_training': batch_norm_is_training_op}
- f = out.reshape_conv_feat
- out_neurons = (mapper_arch.fc_out_size**2)*mapper_arch.fc_out_neurons
- neurons = mapper_arch.fc_neurons + [out_neurons]
- f, _ = tf_utils.fc_network(f, neurons=neurons, wt_decay=wt_decay,
- name='fc', offset=0,
- batch_norm_param=fc_batch_norm_param,
- is_training=is_training,
- dropout_ratio=mapper_arch.fc_dropout)
- f = tf.reshape(f, shape=[-1, mapper_arch.fc_out_size,
- mapper_arch.fc_out_size,
- mapper_arch.fc_out_neurons], name='re_fc')
-
- # Use pool5 to predict the free space map via deconv layers.
- with tf.variable_scope('deconv'):
- x, outs = deconv(f, batch_norm_is_training_op, wt_decay=wt_decay,
- neurons=mapper_arch.deconv_neurons,
- strides=mapper_arch.deconv_strides,
- layers_per_block=mapper_arch.deconv_layers_per_block,
- kernel_size=mapper_arch.deconv_kernel_size,
- conv_fn=slim.conv2d_transpose, offset=0, name='deconv')
-
- # Reshape x the right way.
- sh = x.get_shape().as_list()
- x = tf.reshape(x, shape=[task_params.batch_size, -1] + sh[1:])
- out.deconv_output = x
-
- # Separate out the map and the confidence predictions, pass the confidence
- # through a sigmoid.
- if split_maps:
- with tf.name_scope('split'):
- out_all = tf.split(value=x, axis=4, num_or_size_splits=2*num_maps)
- out.fss_logits = out_all[:num_maps]
- out.confs_logits = out_all[num_maps:]
- with tf.name_scope('sigmoid'):
- out.confs_probs = [tf.nn.sigmoid(x) for x in out.confs_logits]
- return out
-
-def setup_to_run(m, args, is_training, batch_norm_is_training, summary_mode):
- assert(args.arch.multi_scale), 'removed support for old single scale code.'
- # Set up the model.
- tf.set_random_seed(args.solver.seed)
- task_params = args.navtask.task_params
-
- batch_norm_is_training_op = \
- tf.placeholder_with_default(batch_norm_is_training, shape=[],
- name='batch_norm_is_training_op')
-
- # Setup the inputs
- m.input_tensors = {}
- m.train_ops = {}
- m.input_tensors['common'], m.input_tensors['step'], m.input_tensors['train'] = \
- _inputs(task_params)
-
- m.init_fn = None
-
- if task_params.input_type == 'vision':
- m.vision_ops = get_map_from_images(
- m.input_tensors['step']['imgs'], args.mapper_arch,
- task_params, args.solver.freeze_conv,
- args.solver.wt_decay, is_training, batch_norm_is_training_op,
- num_maps=len(task_params.map_crop_sizes))
-
- # Load variables from snapshot if needed.
- if args.solver.pretrained_path is not None:
- m.init_fn = slim.assign_from_checkpoint_fn(args.solver.pretrained_path,
- m.vision_ops.vars_to_restore)
-
- # Set up caching of vision features if needed.
- if args.solver.freeze_conv:
- m.train_ops['step_data_cache'] = [m.vision_ops.encoder_output]
- else:
- m.train_ops['step_data_cache'] = []
-
- # Set up blobs that are needed for the computation in rest of the graph.
- m.ego_map_ops = m.vision_ops.fss_logits
- m.coverage_ops = m.vision_ops.confs_probs
-
- # Zero pad these to make them same size as what the planner expects.
- for i in range(len(m.ego_map_ops)):
- if args.mapper_arch.pad_map_with_zeros_each[i] > 0:
- paddings = np.zeros((5,2), dtype=np.int32)
- paddings[2:4,:] = args.mapper_arch.pad_map_with_zeros_each[i]
- paddings_op = tf.constant(paddings, dtype=tf.int32)
- m.ego_map_ops[i] = tf.pad(m.ego_map_ops[i], paddings=paddings_op)
- m.coverage_ops[i] = tf.pad(m.coverage_ops[i], paddings=paddings_op)
-
- elif task_params.input_type == 'analytical_counts':
- m.ego_map_ops = []; m.coverage_ops = []
- for i in range(len(task_params.map_crop_sizes)):
- ego_map_op = m.input_tensors['step']['analytical_counts_{:d}'.format(i)]
- coverage_op = tf.cast(tf.greater_equal(
- tf.reduce_max(ego_map_op, reduction_indices=[4],
- keep_dims=True), 1), tf.float32)
- coverage_op = tf.ones_like(ego_map_op) * coverage_op
- m.ego_map_ops.append(ego_map_op)
- m.coverage_ops.append(coverage_op)
- m.train_ops['step_data_cache'] = []
-
- num_steps = task_params.num_steps
- num_goals = task_params.num_goals
-
- map_crop_size_ops = []
- for map_crop_size in task_params.map_crop_sizes:
- map_crop_size_ops.append(tf.constant(map_crop_size, dtype=tf.int32, shape=(2,)))
-
- with tf.name_scope('check_size'):
- is_single_step = tf.equal(tf.unstack(tf.shape(m.ego_map_ops[0]), num=5)[1], 1)
-
- fr_ops = []; value_ops = [];
- fr_intermediate_ops = []; value_intermediate_ops = [];
- crop_value_ops = [];
- resize_crop_value_ops = [];
- confs = []; occupancys = [];
-
- previous_value_op = None
- updated_state = []; state_names = [];
-
- for i in range(len(task_params.map_crop_sizes)):
- map_crop_size = task_params.map_crop_sizes[i]
- with tf.variable_scope('scale_{:d}'.format(i)):
- # Accumulate the map.
- fn = lambda ns: running_combine(
- m.ego_map_ops[i],
- m.coverage_ops[i],
- m.input_tensors['step']['incremental_locs'] * task_params.map_scales[i],
- m.input_tensors['step']['incremental_thetas'],
- m.input_tensors['step']['running_sum_num_{:d}'.format(i)],
- m.input_tensors['step']['running_sum_denom_{:d}'.format(i)],
- m.input_tensors['step']['running_max_denom_{:d}'.format(i)],
- map_crop_size, ns)
-
- running_sum_num, running_sum_denom, running_max_denom = \
- tf.cond(is_single_step, lambda: fn(1), lambda: fn(num_steps*num_goals))
- updated_state += [running_sum_num, running_sum_denom, running_max_denom]
- state_names += ['running_sum_num_{:d}'.format(i),
- 'running_sum_denom_{:d}'.format(i),
- 'running_max_denom_{:d}'.format(i)]
-
- # Concat the accumulated map and goal
- occupancy = running_sum_num / tf.maximum(running_sum_denom, 0.001)
- conf = running_max_denom
- # print occupancy.get_shape().as_list()
-
- # Concat occupancy, how much occupied and goal.
- with tf.name_scope('concat'):
- sh = [-1, map_crop_size, map_crop_size, task_params.map_channels]
- occupancy = tf.reshape(occupancy, shape=sh)
- conf = tf.reshape(conf, shape=sh)
-
- sh = [-1, map_crop_size, map_crop_size, task_params.goal_channels]
- goal = tf.reshape(m.input_tensors['step']['ego_goal_imgs_{:d}'.format(i)], shape=sh)
- to_concat = [occupancy, conf, goal]
-
- if previous_value_op is not None:
- to_concat.append(previous_value_op)
-
- x = tf.concat(to_concat, 3)
-
- # Pass the map, previous rewards and the goal through a few convolutional
- # layers to get fR.
- fr_op, fr_intermediate_op = fr_v2(
- x, output_neurons=args.arch.fr_neurons,
- inside_neurons=args.arch.fr_inside_neurons,
- is_training=batch_norm_is_training_op, name='fr',
- wt_decay=args.solver.wt_decay, stride=args.arch.fr_stride)
-
- # Do Value Iteration on the fR
- if args.arch.vin_num_iters > 0:
- value_op, value_intermediate_op = value_iteration_network(
- fr_op, num_iters=args.arch.vin_num_iters,
- val_neurons=args.arch.vin_val_neurons,
- action_neurons=args.arch.vin_action_neurons,
- kernel_size=args.arch.vin_ks, share_wts=args.arch.vin_share_wts,
- name='vin', wt_decay=args.solver.wt_decay)
- else:
- value_op = fr_op
- value_intermediate_op = []
-
- # Crop out and upsample the previous value map.
- remove = args.arch.crop_remove_each
- if remove > 0:
- crop_value_op = value_op[:, remove:-remove, remove:-remove,:]
- else:
- crop_value_op = value_op
- crop_value_op = tf.reshape(crop_value_op, shape=[-1, args.arch.value_crop_size,
- args.arch.value_crop_size,
- args.arch.vin_val_neurons])
- if i < len(task_params.map_crop_sizes)-1:
- # Reshape it to shape of the next scale.
- previous_value_op = tf.image.resize_bilinear(crop_value_op,
- map_crop_size_ops[i+1],
- align_corners=True)
- resize_crop_value_ops.append(previous_value_op)
-
- occupancys.append(occupancy)
- confs.append(conf)
- value_ops.append(value_op)
- crop_value_ops.append(crop_value_op)
- fr_ops.append(fr_op)
- fr_intermediate_ops.append(fr_intermediate_op)
-
- m.value_ops = value_ops
- m.value_intermediate_ops = value_intermediate_ops
- m.fr_ops = fr_ops
- m.fr_intermediate_ops = fr_intermediate_ops
- m.final_value_op = crop_value_op
- m.crop_value_ops = crop_value_ops
- m.resize_crop_value_ops = resize_crop_value_ops
- m.confs = confs
- m.occupancys = occupancys
-
- sh = [-1, args.arch.vin_val_neurons*((args.arch.value_crop_size)**2)]
- m.value_features_op = tf.reshape(m.final_value_op, sh, name='reshape_value_op')
-
- # Determine what action to take.
- with tf.variable_scope('action_pred'):
- batch_norm_param = args.arch.pred_batch_norm_param
- if batch_norm_param is not None:
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.action_logits_op, _ = tf_utils.fc_network(
- m.value_features_op, neurons=args.arch.pred_neurons,
- wt_decay=args.solver.wt_decay, name='pred', offset=0,
- num_pred=task_params.num_actions,
- batch_norm_param=batch_norm_param)
- m.action_prob_op = tf.nn.softmax(m.action_logits_op)
-
- init_state = tf.constant(0., dtype=tf.float32, shape=[
- task_params.batch_size, 1, map_crop_size, map_crop_size,
- task_params.map_channels])
-
- m.train_ops['state_names'] = state_names
- m.train_ops['updated_state'] = updated_state
- m.train_ops['init_state'] = [init_state for _ in updated_state]
-
- m.train_ops['step'] = m.action_prob_op
- m.train_ops['common'] = [m.input_tensors['common']['orig_maps'],
- m.input_tensors['common']['goal_loc']]
- m.train_ops['batch_norm_is_training_op'] = batch_norm_is_training_op
- m.loss_ops = []; m.loss_ops_names = [];
-
- if args.arch.readout_maps:
- with tf.name_scope('readout_maps'):
- all_occupancys = tf.concat(m.occupancys + m.confs, 3)
- readout_maps, probs = readout_general(
- all_occupancys, num_neurons=args.arch.rom_arch.num_neurons,
- strides=args.arch.rom_arch.strides,
- layers_per_block=args.arch.rom_arch.layers_per_block,
- kernel_size=args.arch.rom_arch.kernel_size,
- batch_norm_is_training_op=batch_norm_is_training_op,
- wt_decay=args.solver.wt_decay)
-
- gt_ego_maps = [m.input_tensors['step']['readout_maps_{:d}'.format(i)]
- for i in range(len(task_params.readout_maps_crop_sizes))]
- m.readout_maps_gt = tf.concat(gt_ego_maps, 4)
- gt_shape = tf.shape(m.readout_maps_gt)
- m.readout_maps_logits = tf.reshape(readout_maps, gt_shape)
- m.readout_maps_probs = tf.reshape(probs, gt_shape)
-
- # Add a loss op
- m.readout_maps_loss_op = tf.losses.sigmoid_cross_entropy(
- tf.reshape(m.readout_maps_gt, [-1, len(task_params.readout_maps_crop_sizes)]),
- tf.reshape(readout_maps, [-1, len(task_params.readout_maps_crop_sizes)]),
- scope='loss')
- m.readout_maps_loss_op = 10.*m.readout_maps_loss_op
-
- ewma_decay = 0.99 if is_training else 0.0
- weight = tf.ones_like(m.input_tensors['train']['action'], dtype=tf.float32,
- name='weight')
- m.reg_loss_op, m.data_loss_op, m.total_loss_op, m.acc_ops = \
- compute_losses_multi_or(m.action_logits_op,
- m.input_tensors['train']['action'], weights=weight,
- num_actions=task_params.num_actions,
- data_loss_wt=args.solver.data_loss_wt,
- reg_loss_wt=args.solver.reg_loss_wt,
- ewma_decay=ewma_decay)
-
- if args.arch.readout_maps:
- m.total_loss_op = m.total_loss_op + m.readout_maps_loss_op
- m.loss_ops += [m.readout_maps_loss_op]
- m.loss_ops_names += ['readout_maps_loss']
-
- m.loss_ops += [m.reg_loss_op, m.data_loss_op, m.total_loss_op]
- m.loss_ops_names += ['reg_loss', 'data_loss', 'total_loss']
-
- if args.solver.freeze_conv:
- vars_to_optimize = list(set(tf.trainable_variables()) -
- set(m.vision_ops.vars_to_restore))
- else:
- vars_to_optimize = None
-
- m.lr_op, m.global_step_op, m.train_op, m.should_stop_op, m.optimizer, \
- m.sync_optimizer = tf_utils.setup_training(
- m.total_loss_op,
- args.solver.initial_learning_rate,
- args.solver.steps_per_decay,
- args.solver.learning_rate_decay,
- args.solver.momentum,
- args.solver.max_steps,
- args.solver.sync,
- args.solver.adjust_lr_sync,
- args.solver.num_workers,
- args.solver.task,
- vars_to_optimize=vars_to_optimize,
- clip_gradient_norm=args.solver.clip_gradient_norm,
- typ=args.solver.typ, momentum2=args.solver.momentum2,
- adam_eps=args.solver.adam_eps)
-
- if args.arch.sample_gt_prob_type == 'inverse_sigmoid_decay':
- m.sample_gt_prob_op = tf_utils.inverse_sigmoid_decay(args.arch.isd_k,
- m.global_step_op)
- elif args.arch.sample_gt_prob_type == 'zero':
- m.sample_gt_prob_op = tf.constant(-1.0, dtype=tf.float32)
-
- elif args.arch.sample_gt_prob_type.split('_')[0] == 'step':
- step = int(args.arch.sample_gt_prob_type.split('_')[1])
- m.sample_gt_prob_op = tf_utils.step_gt_prob(
- step, m.input_tensors['step']['step_number'][0,0,0])
-
- m.sample_action_type = args.arch.action_sample_type
- m.sample_action_combine_type = args.arch.action_sample_combine_type
-
- m.summary_ops = {
- summary_mode: _add_summaries(m, args, summary_mode,
- args.summary.arop_full_summary_iters)}
-
- m.init_op = tf.group(tf.global_variables_initializer(),
- tf.local_variables_initializer())
- m.saver_op = tf.train.Saver(keep_checkpoint_every_n_hours=4,
- write_version=tf.train.SaverDef.V2)
- return m
diff --git a/research/cognitive_mapping_and_planning/tfcode/cmp_summary.py b/research/cognitive_mapping_and_planning/tfcode/cmp_summary.py
deleted file mode 100644
index 55313bfbd52a9e079e1de5093ae1882a9bf1d858..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/cmp_summary.py
+++ /dev/null
@@ -1,213 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Code for setting up summaries for CMP.
-"""
-
-import sys, os, numpy as np
-import matplotlib.pyplot as plt
-
-
-import tensorflow as tf
-
-from tensorflow.contrib import slim
-from tensorflow.contrib.slim import arg_scope
-
-import logging
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-from src import utils
-import src.file_utils as fu
-import tfcode.nav_utils as nu
-
-def _vis_readout_maps(outputs, global_step, output_dir, metric_summary, N):
- # outputs is [gt_map, pred_map]:
- if N >= 0:
- outputs = outputs[:N]
- N = len(outputs)
-
- plt.set_cmap('jet')
- fig, axes = utils.subplot(plt, (N, outputs[0][0].shape[4]*2), (5,5))
- axes = axes.ravel()[::-1].tolist()
- for i in range(N):
- gt_map, pred_map = outputs[i]
- for j in [0]:
- for k in range(gt_map.shape[4]):
- # Display something like the midpoint of the trajectory.
- id = np.int(gt_map.shape[1]/2)
-
- ax = axes.pop();
- ax.imshow(gt_map[j,id,:,:,k], origin='lower', interpolation='none',
- vmin=0., vmax=1.)
- ax.set_axis_off();
- if i == 0: ax.set_title('gt_map')
-
- ax = axes.pop();
- ax.imshow(pred_map[j,id,:,:,k], origin='lower', interpolation='none',
- vmin=0., vmax=1.)
- ax.set_axis_off();
- if i == 0: ax.set_title('pred_map')
-
- file_name = os.path.join(output_dir, 'readout_map_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- plt.close(fig)
-
-def _vis(outputs, global_step, output_dir, metric_summary, N):
- # Plot the value map, goal for various maps to see what if the model is
- # learning anything useful.
- #
- # outputs is [values, goals, maps, occupancy, conf].
- #
- if N >= 0:
- outputs = outputs[:N]
- N = len(outputs)
-
- plt.set_cmap('jet')
- fig, axes = utils.subplot(plt, (N, outputs[0][0].shape[4]*5), (5,5))
- axes = axes.ravel()[::-1].tolist()
- for i in range(N):
- values, goals, maps, occupancy, conf = outputs[i]
- for j in [0]:
- for k in range(values.shape[4]):
- # Display something like the midpoint of the trajectory.
- id = np.int(values.shape[1]/2)
-
- ax = axes.pop();
- ax.imshow(goals[j,id,:,:,k], origin='lower', interpolation='none')
- ax.set_axis_off();
- if i == 0: ax.set_title('goal')
-
- ax = axes.pop();
- ax.imshow(occupancy[j,id,:,:,k], origin='lower', interpolation='none')
- ax.set_axis_off();
- if i == 0: ax.set_title('occupancy')
-
- ax = axes.pop();
- ax.imshow(conf[j,id,:,:,k], origin='lower', interpolation='none',
- vmin=0., vmax=1.)
- ax.set_axis_off();
- if i == 0: ax.set_title('conf')
-
- ax = axes.pop();
- ax.imshow(values[j,id,:,:,k], origin='lower', interpolation='none')
- ax.set_axis_off();
- if i == 0: ax.set_title('value')
-
- ax = axes.pop();
- ax.imshow(maps[j,id,:,:,k], origin='lower', interpolation='none')
- ax.set_axis_off();
- if i == 0: ax.set_title('incr map')
-
- file_name = os.path.join(output_dir, 'value_vis_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- plt.close(fig)
-
-def _summary_vis(m, batch_size, num_steps, arop_full_summary_iters):
- arop = []; arop_summary_iters = []; arop_eval_fns = [];
- vis_value_ops = []; vis_goal_ops = []; vis_map_ops = [];
- vis_occupancy_ops = []; vis_conf_ops = [];
- for i, val_op in enumerate(m.value_ops):
- vis_value_op = tf.reduce_mean(tf.abs(val_op), axis=3, keep_dims=True)
- vis_value_ops.append(vis_value_op)
-
- vis_occupancy_op = tf.reduce_mean(tf.abs(m.occupancys[i]), 3, True)
- vis_occupancy_ops.append(vis_occupancy_op)
-
- vis_conf_op = tf.reduce_max(tf.abs(m.confs[i]), axis=3, keep_dims=True)
- vis_conf_ops.append(vis_conf_op)
-
- ego_goal_imgs_i_op = m.input_tensors['step']['ego_goal_imgs_{:d}'.format(i)]
- vis_goal_op = tf.reduce_max(ego_goal_imgs_i_op, 4, True)
- vis_goal_ops.append(vis_goal_op)
-
- vis_map_op = tf.reduce_mean(tf.abs(m.ego_map_ops[i]), 4, True)
- vis_map_ops.append(vis_map_op)
-
- vis_goal_ops = tf.concat(vis_goal_ops, 4)
- vis_map_ops = tf.concat(vis_map_ops, 4)
- vis_value_ops = tf.concat(vis_value_ops, 3)
- vis_occupancy_ops = tf.concat(vis_occupancy_ops, 3)
- vis_conf_ops = tf.concat(vis_conf_ops, 3)
-
- sh = tf.unstack(tf.shape(vis_value_ops))[1:]
- vis_value_ops = tf.reshape(vis_value_ops, shape=[batch_size, -1] + sh)
-
- sh = tf.unstack(tf.shape(vis_conf_ops))[1:]
- vis_conf_ops = tf.reshape(vis_conf_ops, shape=[batch_size, -1] + sh)
-
- sh = tf.unstack(tf.shape(vis_occupancy_ops))[1:]
- vis_occupancy_ops = tf.reshape(vis_occupancy_ops, shape=[batch_size,-1] + sh)
-
- # Save memory, only return time steps that need to be visualized, factor of
- # 32 CPU memory saving.
- id = np.int(num_steps/2)
- vis_goal_ops = tf.expand_dims(vis_goal_ops[:,id,:,:,:], axis=1)
- vis_map_ops = tf.expand_dims(vis_map_ops[:,id,:,:,:], axis=1)
- vis_value_ops = tf.expand_dims(vis_value_ops[:,id,:,:,:], axis=1)
- vis_conf_ops = tf.expand_dims(vis_conf_ops[:,id,:,:,:], axis=1)
- vis_occupancy_ops = tf.expand_dims(vis_occupancy_ops[:,id,:,:,:], axis=1)
-
- arop += [[vis_value_ops, vis_goal_ops, vis_map_ops, vis_occupancy_ops,
- vis_conf_ops]]
- arop_summary_iters += [arop_full_summary_iters]
- arop_eval_fns += [_vis]
- return arop, arop_summary_iters, arop_eval_fns
-
-def _summary_readout_maps(m, num_steps, arop_full_summary_iters):
- arop = []; arop_summary_iters = []; arop_eval_fns = [];
- id = np.int(num_steps-1)
- vis_readout_maps_gt = m.readout_maps_gt
- vis_readout_maps_prob = tf.reshape(m.readout_maps_probs,
- shape=tf.shape(vis_readout_maps_gt))
- vis_readout_maps_gt = tf.expand_dims(vis_readout_maps_gt[:,id,:,:,:], 1)
- vis_readout_maps_prob = tf.expand_dims(vis_readout_maps_prob[:,id,:,:,:], 1)
- arop += [[vis_readout_maps_gt, vis_readout_maps_prob]]
- arop_summary_iters += [arop_full_summary_iters]
- arop_eval_fns += [_vis_readout_maps]
- return arop, arop_summary_iters, arop_eval_fns
-
-def _add_summaries(m, args, summary_mode, arop_full_summary_iters):
- task_params = args.navtask.task_params
-
- summarize_ops = [m.lr_op, m.global_step_op, m.sample_gt_prob_op] + \
- m.loss_ops + m.acc_ops
- summarize_names = ['lr', 'global_step', 'sample_gt_prob_op'] + \
- m.loss_ops_names + ['acc_{:d}'.format(i) for i in range(len(m.acc_ops))]
- to_aggregate = [0, 0, 0] + [1]*len(m.loss_ops_names) + [1]*len(m.acc_ops)
-
- scope_name = 'summary'
- with tf.name_scope(scope_name):
- s_ops = nu.add_default_summaries(summary_mode, arop_full_summary_iters,
- summarize_ops, summarize_names,
- to_aggregate, m.action_prob_op,
- m.input_tensors, scope_name=scope_name)
- if summary_mode == 'val':
- arop, arop_summary_iters, arop_eval_fns = _summary_vis(
- m, task_params.batch_size, task_params.num_steps,
- arop_full_summary_iters)
- s_ops.additional_return_ops += arop
- s_ops.arop_summary_iters += arop_summary_iters
- s_ops.arop_eval_fns += arop_eval_fns
-
- if args.arch.readout_maps:
- arop, arop_summary_iters, arop_eval_fns = _summary_readout_maps(
- m, task_params.num_steps, arop_full_summary_iters)
- s_ops.additional_return_ops += arop
- s_ops.arop_summary_iters += arop_summary_iters
- s_ops.arop_eval_fns += arop_eval_fns
-
- return s_ops
diff --git a/research/cognitive_mapping_and_planning/tfcode/cmp_utils.py b/research/cognitive_mapping_and_planning/tfcode/cmp_utils.py
deleted file mode 100644
index 6d87c697b4b29128c8b8a42caac27aeb4d657ec6..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/cmp_utils.py
+++ /dev/null
@@ -1,164 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utility functions for setting up the CMP graph.
-"""
-
-import os, numpy as np
-import matplotlib.pyplot as plt
-
-
-import tensorflow as tf
-
-from tensorflow.contrib import slim
-from tensorflow.contrib.slim import arg_scope
-import logging
-from src import utils
-import src.file_utils as fu
-from tfcode import tf_utils
-
-resnet_v2 = tf_utils.resnet_v2
-custom_residual_block = tf_utils.custom_residual_block
-
-def value_iteration_network(
- fr, num_iters, val_neurons, action_neurons, kernel_size, share_wts=False,
- name='vin', wt_decay=0.0001, activation_fn=None, shape_aware=False):
- """
- Constructs a Value Iteration Network, convolutions and max pooling across
- channels.
- Input:
- fr: NxWxHxC
- val_neurons: Number of channels for maintaining the value.
- action_neurons: Computes action_neurons * val_neurons at each iteration to
- max pool over.
- Output:
- value image: NxHxWx(val_neurons)
- """
- init_var = np.sqrt(2.0/(kernel_size**2)/(val_neurons*action_neurons))
- vals = []
- with tf.variable_scope(name) as varscope:
- if shape_aware == False:
- fr_shape = tf.unstack(tf.shape(fr))
- val_shape = tf.stack(fr_shape[:-1] + [val_neurons])
- val = tf.zeros(val_shape, name='val_init')
- else:
- val = tf.expand_dims(tf.zeros_like(fr[:,:,:,0]), dim=-1) * \
- tf.constant(0., dtype=tf.float32, shape=[1,1,1,val_neurons])
- val_shape = tf.shape(val)
- vals.append(val)
- for i in range(num_iters):
- if share_wts:
- # The first Value Iteration maybe special, so it can have its own
- # paramterss.
- scope = 'conv'
- if i == 0: scope = 'conv_0'
- if i > 1: varscope.reuse_variables()
- else:
- scope = 'conv_{:d}'.format(i)
- val = slim.conv2d(tf.concat([val, fr], 3, name='concat_{:d}'.format(i)),
- num_outputs=action_neurons*val_neurons,
- kernel_size=kernel_size, stride=1, activation_fn=activation_fn,
- scope=scope, normalizer_fn=None,
- weights_regularizer=slim.l2_regularizer(wt_decay),
- weights_initializer=tf.random_normal_initializer(stddev=init_var),
- biases_initializer=tf.zeros_initializer())
- val = tf.reshape(val, [-1, action_neurons*val_neurons, 1, 1],
- name='re_{:d}'.format(i))
- val = slim.max_pool2d(val, kernel_size=[action_neurons,1],
- stride=[action_neurons,1], padding='VALID',
- scope='val_{:d}'.format(i))
- val = tf.reshape(val, val_shape, name='unre_{:d}'.format(i))
- vals.append(val)
- return val, vals
-
-
-def rotate_preds(loc_on_map, relative_theta, map_size, preds,
- output_valid_mask):
- with tf.name_scope('rotate'):
- flow_op = tf_utils.get_flow(loc_on_map, relative_theta, map_size=map_size)
- if type(preds) != list:
- rotated_preds, valid_mask_warps = tf_utils.dense_resample(preds, flow_op,
- output_valid_mask)
- else:
- rotated_preds = [] ;valid_mask_warps = []
- for pred in preds:
- rotated_pred, valid_mask_warp = tf_utils.dense_resample(pred, flow_op,
- output_valid_mask)
- rotated_preds.append(rotated_pred)
- valid_mask_warps.append(valid_mask_warp)
- return rotated_preds, valid_mask_warps
-
-def get_visual_frustum(map_size, shape_like, expand_dims=[0,0]):
- with tf.name_scope('visual_frustum'):
- l = np.tril(np.ones(map_size)) ;l = l + l[:,::-1]
- l = (l == 2).astype(np.float32)
- for e in expand_dims:
- l = np.expand_dims(l, axis=e)
- confs_probs = tf.constant(l, dtype=tf.float32)
- confs_probs = tf.ones_like(shape_like, dtype=tf.float32) * confs_probs
- return confs_probs
-
-def deconv(x, is_training, wt_decay, neurons, strides, layers_per_block,
- kernel_size, conv_fn, name, offset=0):
- """Generates a up sampling network with residual connections.
- """
- batch_norm_param = {'center': True, 'scale': True,
- 'activation_fn': tf.nn.relu,
- 'is_training': is_training}
- outs = []
- for i, (neuron, stride) in enumerate(zip(neurons, strides)):
- for s in range(layers_per_block):
- scope = '{:s}_{:d}_{:d}'.format(name, i+1+offset,s+1)
- x = custom_residual_block(x, neuron, kernel_size, stride, scope,
- is_training, wt_decay, use_residual=True,
- residual_stride_conv=True, conv_fn=conv_fn,
- batch_norm_param=batch_norm_param)
- stride = 1
- outs.append((x,True))
- return x, outs
-
-def fr_v2(x, output_neurons, inside_neurons, is_training, name='fr',
- wt_decay=0.0001, stride=1, updates_collections=tf.GraphKeys.UPDATE_OPS):
- """Performs fusion of information between the map and the reward map.
- Inputs
- x: NxHxWxC1
-
- Outputs
- fr map: NxHxWx(output_neurons)
- """
- if type(stride) != list:
- stride = [stride]
- with slim.arg_scope(resnet_v2.resnet_utils.resnet_arg_scope(
- is_training=is_training, weight_decay=wt_decay)):
- with slim.arg_scope([slim.batch_norm], updates_collections=updates_collections) as arg_sc:
- # Change the updates_collections for the conv normalizer_params to None
- for i in range(len(arg_sc.keys())):
- if 'convolution' in arg_sc.keys()[i]:
- arg_sc.values()[i]['normalizer_params']['updates_collections'] = updates_collections
- with slim.arg_scope(arg_sc):
- bottleneck = resnet_v2.bottleneck
- blocks = []
- for i, s in enumerate(stride):
- b = resnet_v2.resnet_utils.Block(
- 'block{:d}'.format(i + 1), bottleneck, [{
- 'depth': output_neurons,
- 'depth_bottleneck': inside_neurons,
- 'stride': stride[i]
- }])
- blocks.append(b)
- x, outs = resnet_v2.resnet_v2(x, blocks, num_classes=None, global_pool=False,
- output_stride=None, include_root_block=False,
- reuse=False, scope=name)
- return x, outs
diff --git a/research/cognitive_mapping_and_planning/tfcode/nav_utils.py b/research/cognitive_mapping_and_planning/tfcode/nav_utils.py
deleted file mode 100644
index 2f764f33df91a80f6539dcbae1e0fa7093becd29..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/nav_utils.py
+++ /dev/null
@@ -1,435 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Various losses for training navigation agents.
-
-Defines various loss functions for navigation agents,
-compute_losses_multi_or.
-"""
-
-import os, numpy as np
-import matplotlib.pyplot as plt
-
-
-import tensorflow as tf
-
-from tensorflow.contrib import slim
-from tensorflow.contrib.slim import arg_scope
-from tensorflow.contrib.slim.nets import resnet_v2
-from tensorflow.python.training import moving_averages
-import logging
-from src import utils
-import src.file_utils as fu
-from tfcode import tf_utils
-
-
-def compute_losses_multi_or(logits, actions_one_hot, weights=None,
- num_actions=-1, data_loss_wt=1., reg_loss_wt=1.,
- ewma_decay=0.99, reg_loss_op=None):
- assert(num_actions > 0), 'num_actions must be specified and must be > 0.'
-
- with tf.name_scope('loss'):
- if weights is None:
- weight = tf.ones_like(actions_one_hot, dtype=tf.float32, name='weight')
-
- actions_one_hot = tf.cast(tf.reshape(actions_one_hot, [-1, num_actions],
- 're_actions_one_hot'), tf.float32)
- weights = tf.reduce_sum(tf.reshape(weights, [-1, num_actions], 're_weight'),
- reduction_indices=1)
- total = tf.reduce_sum(weights)
-
- action_prob = tf.nn.softmax(logits)
- action_prob = tf.reduce_sum(tf.multiply(action_prob, actions_one_hot),
- reduction_indices=1)
- example_loss = -tf.log(tf.maximum(tf.constant(1e-4), action_prob))
-
- data_loss_op = tf.reduce_sum(example_loss * weights) / total
- if reg_loss_op is None:
- if reg_loss_wt > 0:
- reg_loss_op = tf.add_n(tf.losses.get_regularization_losses())
- else:
- reg_loss_op = tf.constant(0.)
-
- if reg_loss_wt > 0:
- total_loss_op = data_loss_wt*data_loss_op + reg_loss_wt*reg_loss_op
- else:
- total_loss_op = data_loss_wt*data_loss_op
-
- is_correct = tf.cast(tf.greater(action_prob, 0.5, name='pred_class'), tf.float32)
- acc_op = tf.reduce_sum(is_correct*weights) / total
-
- ewma_acc_op = moving_averages.weighted_moving_average(
- acc_op, ewma_decay, weight=total, name='ewma_acc')
-
- acc_ops = [ewma_acc_op]
-
- return reg_loss_op, data_loss_op, total_loss_op, acc_ops
-
-
-def get_repr_from_image(images_reshaped, modalities, data_augment, encoder,
- freeze_conv, wt_decay, is_training):
- # Pass image through lots of convolutional layers, to obtain pool5
- if modalities == ['rgb']:
- with tf.name_scope('pre_rgb'):
- x = (images_reshaped + 128.) / 255. # Convert to brightness between 0 and 1.
- if data_augment.relight and is_training:
- x = tf_utils.distort_image(x, fast_mode=data_augment.relight_fast)
- x = (x-0.5)*2.0
- scope_name = encoder
- elif modalities == ['depth']:
- with tf.name_scope('pre_d'):
- d_image = images_reshaped
- x = 2*(d_image[...,0] - 80.0)/100.0
- y = d_image[...,1]
- d_image = tf.concat([tf.expand_dims(x, -1), tf.expand_dims(y, -1)], 3)
- x = d_image
- scope_name = 'd_'+encoder
-
- resnet_is_training = is_training and (not freeze_conv)
- with slim.arg_scope(resnet_v2.resnet_utils.resnet_arg_scope(resnet_is_training)):
- fn = getattr(tf_utils, encoder)
- x, end_points = fn(x, num_classes=None, global_pool=False,
- output_stride=None, reuse=None,
- scope=scope_name)
- vars_ = slim.get_variables_to_restore()
-
- conv_feat = x
- return conv_feat, vars_
-
-def default_train_step_kwargs(m, obj, logdir, rng_seed, is_chief, num_steps,
- iters, train_display_interval,
- dagger_sample_bn_false):
- train_step_kwargs = {}
- train_step_kwargs['obj'] = obj
- train_step_kwargs['m'] = m
-
- # rng_data has 2 independent rngs, one for sampling episodes and one for
- # sampling perturbs (so that we can make results reproducible.
- train_step_kwargs['rng_data'] = [np.random.RandomState(rng_seed),
- np.random.RandomState(rng_seed)]
- train_step_kwargs['rng_action'] = np.random.RandomState(rng_seed)
- if is_chief:
- train_step_kwargs['writer'] = tf.summary.FileWriter(logdir) #, m.tf_graph)
- else:
- train_step_kwargs['writer'] = None
- train_step_kwargs['iters'] = iters
- train_step_kwargs['train_display_interval'] = train_display_interval
- train_step_kwargs['num_steps'] = num_steps
- train_step_kwargs['logdir'] = logdir
- train_step_kwargs['dagger_sample_bn_false'] = dagger_sample_bn_false
- return train_step_kwargs
-
-# Utilities for visualizing and analysing validation output.
-def save_d_at_t(outputs, global_step, output_dir, metric_summary, N):
- """Save distance to goal at all time steps.
-
- Args:
- outputs : [gt_dist_to_goal].
- global_step : number of iterations.
- output_dir : output directory.
- metric_summary : to append scalars to summary.
- N : number of outputs to process.
-
- """
- d_at_t = np.concatenate(map(lambda x: x[0][:,:,0]*1, outputs), axis=0)
- fig, axes = utils.subplot(plt, (1,1), (5,5))
- axes.plot(np.arange(d_at_t.shape[1]), np.mean(d_at_t, axis=0), 'r.')
- axes.set_xlabel('time step')
- axes.set_ylabel('dist to next goal')
- axes.grid('on')
- file_name = os.path.join(output_dir, 'dist_at_t_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- file_name = os.path.join(output_dir, 'dist_at_t_{:d}.pkl'.format(global_step))
- utils.save_variables(file_name, [d_at_t], ['d_at_t'], overwrite=True)
- plt.close(fig)
- return None
-
-def save_all(outputs, global_step, output_dir, metric_summary, N):
- """Save numerous statistics.
-
- Args:
- outputs : [locs, goal_loc, gt_dist_to_goal, node_ids, perturbs]
- global_step : number of iterations.
- output_dir : output directory.
- metric_summary : to append scalars to summary.
- N : number of outputs to process.
- """
- all_locs = np.concatenate(map(lambda x: x[0], outputs), axis=0)
- all_goal_locs = np.concatenate(map(lambda x: x[1], outputs), axis=0)
- all_d_at_t = np.concatenate(map(lambda x: x[2][:,:,0]*1, outputs), axis=0)
- all_node_ids = np.concatenate(map(lambda x: x[3], outputs), axis=0)
- all_perturbs = np.concatenate(map(lambda x: x[4], outputs), axis=0)
-
- file_name = os.path.join(output_dir, 'all_locs_at_t_{:d}.pkl'.format(global_step))
- vars = [all_locs, all_goal_locs, all_d_at_t, all_node_ids, all_perturbs]
- var_names = ['all_locs', 'all_goal_locs', 'all_d_at_t', 'all_node_ids', 'all_perturbs']
- utils.save_variables(file_name, vars, var_names, overwrite=True)
- return None
-
-def eval_ap(outputs, global_step, output_dir, metric_summary, N, num_classes=4):
- """Processes the collected outputs to compute AP for action prediction.
-
- Args:
- outputs : [logits, labels]
- global_step : global_step.
- output_dir : where to store results.
- metric_summary : summary object to add summaries to.
- N : number of outputs to process.
- num_classes : number of classes to compute AP over, and to reshape tensors.
- """
- if N >= 0:
- outputs = outputs[:N]
- logits = np.concatenate(map(lambda x: x[0], outputs), axis=0).reshape((-1, num_classes))
- labels = np.concatenate(map(lambda x: x[1], outputs), axis=0).reshape((-1, num_classes))
- aps = []
- for i in range(logits.shape[1]):
- ap, rec, prec = utils.calc_pr(labels[:,i], logits[:,i])
- ap = ap[0]
- tf_utils.add_value_to_summary(metric_summary, 'aps/ap_{:d}: '.format(i), ap)
- aps.append(ap)
- return aps
-
-def eval_dist(outputs, global_step, output_dir, metric_summary, N):
- """Processes the collected outputs during validation to
- 1. Plot the distance over time curve.
- 2. Compute mean and median distances.
- 3. Plots histogram of end distances.
-
- Args:
- outputs : [locs, goal_loc, gt_dist_to_goal].
- global_step : global_step.
- output_dir : where to store results.
- metric_summary : summary object to add summaries to.
- N : number of outputs to process.
- """
- SUCCESS_THRESH = 3
- if N >= 0:
- outputs = outputs[:N]
-
- # Plot distance at time t.
- d_at_t = []
- for i in range(len(outputs)):
- locs, goal_loc, gt_dist_to_goal = outputs[i]
- d_at_t.append(gt_dist_to_goal[:,:,0]*1)
-
- # Plot the distance.
- fig, axes = utils.subplot(plt, (1,1), (5,5))
- d_at_t = np.concatenate(d_at_t, axis=0)
- axes.plot(np.arange(d_at_t.shape[1]), np.mean(d_at_t, axis=0), 'r.')
- axes.set_xlabel('time step')
- axes.set_ylabel('dist to next goal')
- axes.grid('on')
- file_name = os.path.join(output_dir, 'dist_at_t_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- file_name = os.path.join(output_dir, 'dist_at_t_{:d}.pkl'.format(global_step))
- utils.save_variables(file_name, [d_at_t], ['d_at_t'], overwrite=True)
- plt.close(fig)
-
- # Plot the trajectories and the init_distance and final distance.
- d_inits = []
- d_ends = []
- for i in range(len(outputs)):
- locs, goal_loc, gt_dist_to_goal = outputs[i]
- d_inits.append(gt_dist_to_goal[:,0,0]*1)
- d_ends.append(gt_dist_to_goal[:,-1,0]*1)
-
- # Plot the distance.
- fig, axes = utils.subplot(plt, (1,1), (5,5))
- d_inits = np.concatenate(d_inits, axis=0)
- d_ends = np.concatenate(d_ends, axis=0)
- axes.plot(d_inits+np.random.rand(*(d_inits.shape))-0.5,
- d_ends+np.random.rand(*(d_ends.shape))-0.5, '.', mec='red', mew=1.0)
- axes.set_xlabel('init dist'); axes.set_ylabel('final dist');
- axes.grid('on'); axes.axis('equal');
- title_str = 'mean: {:0.1f}, 50: {:0.1f}, 75: {:0.2f}, s: {:0.1f}'
- title_str = title_str.format(
- np.mean(d_ends), np.median(d_ends), np.percentile(d_ends, q=75),
- 100*(np.mean(d_ends <= SUCCESS_THRESH)))
- axes.set_title(title_str)
- file_name = os.path.join(output_dir, 'dist_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
-
- file_name = os.path.join(output_dir, 'dist_{:d}.pkl'.format(global_step))
- utils.save_variables(file_name, [d_inits, d_ends], ['d_inits', 'd_ends'],
- overwrite=True)
- plt.close(fig)
-
- # Plot the histogram of the end_distance.
- with plt.style.context('seaborn-white'):
- d_ends_ = np.sort(d_ends)
- d_inits_ = np.sort(d_inits)
- leg = [];
- fig, ax = utils.subplot(plt, (1,1), (5,5))
- ax.grid('on')
- ax.set_xlabel('Distance from goal'); ax.xaxis.label.set_fontsize(16);
- ax.set_ylabel('Fraction of data'); ax.yaxis.label.set_fontsize(16);
- ax.plot(d_ends_, np.arange(d_ends_.size)*1./d_ends_.size, 'r')
- ax.plot(d_inits_, np.arange(d_inits_.size)*1./d_inits_.size, 'k')
- leg.append('Final'); leg.append('Init');
- ax.legend(leg, fontsize='x-large');
- ax.set_axis_on()
- title_str = 'mean: {:0.1f}, 50: {:0.1f}, 75: {:0.2f}, s: {:0.1f}'
- title_str = title_str.format(
- np.mean(d_ends), np.median(d_ends), np.percentile(d_ends, q=75),
- 100*(np.mean(d_ends <= SUCCESS_THRESH)))
- ax.set_title(title_str)
- file_name = os.path.join(output_dir, 'dist_hist_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
-
- # Log distance metrics.
- tf_utils.add_value_to_summary(metric_summary, 'dists/success_init: ',
- 100*(np.mean(d_inits <= SUCCESS_THRESH)))
- tf_utils.add_value_to_summary(metric_summary, 'dists/success_end: ',
- 100*(np.mean(d_ends <= SUCCESS_THRESH)))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_init (75): ',
- np.percentile(d_inits, q=75))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_end (75): ',
- np.percentile(d_ends, q=75))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_init (median): ',
- np.median(d_inits))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_end (median): ',
- np.median(d_ends))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_init (mean): ',
- np.mean(d_inits))
- tf_utils.add_value_to_summary(metric_summary, 'dists/dist_end (mean): ',
- np.mean(d_ends))
- return np.median(d_inits), np.median(d_ends), np.mean(d_inits), np.mean(d_ends), \
- np.percentile(d_inits, q=75), np.percentile(d_ends, q=75), \
- 100*(np.mean(d_inits) <= SUCCESS_THRESH), 100*(np.mean(d_ends) <= SUCCESS_THRESH)
-
-def plot_trajectories(outputs, global_step, output_dir, metric_summary, N):
- """Processes the collected outputs during validation to plot the trajectories
- in the top view.
-
- Args:
- outputs : [locs, orig_maps, goal_loc].
- global_step : global_step.
- output_dir : where to store results.
- metric_summary : summary object to add summaries to.
- N : number of outputs to process.
- """
- if N >= 0:
- outputs = outputs[:N]
- N = len(outputs)
-
- plt.set_cmap('gray')
- fig, axes = utils.subplot(plt, (N, outputs[0][1].shape[0]), (5,5))
- axes = axes.ravel()[::-1].tolist()
- for i in range(N):
- locs, orig_maps, goal_loc = outputs[i]
- is_semantic = np.isnan(goal_loc[0,0,1])
- for j in range(orig_maps.shape[0]):
- ax = axes.pop();
- ax.plot(locs[j,0,0], locs[j,0,1], 'ys')
- # Plot one by one, so that they come in different colors.
- for k in range(goal_loc.shape[1]):
- if not is_semantic:
- ax.plot(goal_loc[j,k,0], goal_loc[j,k,1], 's')
- if False:
- ax.plot(locs[j,:,0], locs[j,:,1], 'r.', ms=3)
- ax.imshow(orig_maps[j,0,:,:,0], origin='lower')
- ax.set_axis_off();
- else:
- ax.scatter(locs[j,:,0], locs[j,:,1], c=np.arange(locs.shape[1]),
- cmap='jet', s=10, lw=0)
- ax.imshow(orig_maps[j,0,:,:,0], origin='lower', vmin=-1.0, vmax=2.0)
- if not is_semantic:
- xymin = np.minimum(np.min(goal_loc[j,:,:], axis=0), np.min(locs[j,:,:], axis=0))
- xymax = np.maximum(np.max(goal_loc[j,:,:], axis=0), np.max(locs[j,:,:], axis=0))
- else:
- xymin = np.min(locs[j,:,:], axis=0)
- xymax = np.max(locs[j,:,:], axis=0)
- xy1 = (xymax+xymin)/2. - np.maximum(np.max(xymax-xymin), 12)
- xy2 = (xymax+xymin)/2. + np.maximum(np.max(xymax-xymin), 12)
- ax.set_xlim([xy1[0], xy2[0]])
- ax.set_ylim([xy1[1], xy2[1]])
- ax.set_axis_off()
- file_name = os.path.join(output_dir, 'trajectory_{:d}.png'.format(global_step))
- with fu.fopen(file_name, 'w') as f:
- fig.savefig(f, bbox_inches='tight', transparent=True, pad_inches=0)
- plt.close(fig)
- return None
-
-def add_default_summaries(mode, arop_full_summary_iters, summarize_ops,
- summarize_names, to_aggregate, action_prob_op,
- input_tensors, scope_name):
- assert(mode == 'train' or mode == 'val' or mode == 'test'), \
- 'add_default_summaries mode is neither train or val or test.'
-
- s_ops = tf_utils.get_default_summary_ops()
-
- if mode == 'train':
- s_ops.summary_ops, s_ops.print_summary_ops, additional_return_ops, \
- arop_summary_iters, arop_eval_fns = tf_utils.simple_summaries(
- summarize_ops, summarize_names, mode, to_aggregate=False,
- scope_name=scope_name)
- s_ops.additional_return_ops += additional_return_ops
- s_ops.arop_summary_iters += arop_summary_iters
- s_ops.arop_eval_fns += arop_eval_fns
- elif mode == 'val':
- s_ops.summary_ops, s_ops.print_summary_ops, additional_return_ops, \
- arop_summary_iters, arop_eval_fns = tf_utils.simple_summaries(
- summarize_ops, summarize_names, mode, to_aggregate=to_aggregate,
- scope_name=scope_name)
- s_ops.additional_return_ops += additional_return_ops
- s_ops.arop_summary_iters += arop_summary_iters
- s_ops.arop_eval_fns += arop_eval_fns
-
- elif mode == 'test':
- s_ops.summary_ops, s_ops.print_summary_ops, additional_return_ops, \
- arop_summary_iters, arop_eval_fns = tf_utils.simple_summaries(
- [], [], mode, to_aggregate=[], scope_name=scope_name)
- s_ops.additional_return_ops += additional_return_ops
- s_ops.arop_summary_iters += arop_summary_iters
- s_ops.arop_eval_fns += arop_eval_fns
-
-
- if mode == 'val':
- arop = s_ops.additional_return_ops
- arop += [[action_prob_op, input_tensors['train']['action']]]
- arop += [[input_tensors['step']['loc_on_map'],
- input_tensors['common']['goal_loc'],
- input_tensors['step']['gt_dist_to_goal']]]
- arop += [[input_tensors['step']['loc_on_map'],
- input_tensors['common']['orig_maps'],
- input_tensors['common']['goal_loc']]]
- s_ops.arop_summary_iters += [-1, arop_full_summary_iters,
- arop_full_summary_iters]
- s_ops.arop_eval_fns += [eval_ap, eval_dist, plot_trajectories]
-
- elif mode == 'test':
- arop = s_ops.additional_return_ops
- arop += [[input_tensors['step']['loc_on_map'],
- input_tensors['common']['goal_loc'],
- input_tensors['step']['gt_dist_to_goal']]]
- arop += [[input_tensors['step']['gt_dist_to_goal']]]
- arop += [[input_tensors['step']['loc_on_map'],
- input_tensors['common']['goal_loc'],
- input_tensors['step']['gt_dist_to_goal'],
- input_tensors['step']['node_ids'],
- input_tensors['step']['perturbs']]]
- arop += [[input_tensors['step']['loc_on_map'],
- input_tensors['common']['orig_maps'],
- input_tensors['common']['goal_loc']]]
- s_ops.arop_summary_iters += [-1, -1, -1, arop_full_summary_iters]
- s_ops.arop_eval_fns += [eval_dist, save_d_at_t, save_all,
- plot_trajectories]
- return s_ops
-
-
diff --git a/research/cognitive_mapping_and_planning/tfcode/tf_utils.py b/research/cognitive_mapping_and_planning/tfcode/tf_utils.py
deleted file mode 100644
index 5f96d8ff5ce7473f0ec49096abcbac274e6c4fcc..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/tf_utils.py
+++ /dev/null
@@ -1,840 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import numpy as np
-import sys
-import tensorflow as tf
-import src.utils as utils
-import logging
-from tensorflow.contrib import slim
-from tensorflow.contrib.metrics.python.ops import confusion_matrix_ops
-from tensorflow.contrib.slim import arg_scope
-from tensorflow.contrib.slim.nets import resnet_v2
-from tensorflow.python.framework import dtypes
-from tensorflow.python.ops import array_ops
-from tensorflow.python.ops import check_ops
-from tensorflow.python.ops import math_ops
-from tensorflow.python.ops import variable_scope
-sys.path.insert(0, '../slim')
-from preprocessing import inception_preprocessing as ip
-
-resnet_v2_50 = resnet_v2.resnet_v2_50
-
-
-def custom_residual_block(x, neurons, kernel_size, stride, name, is_training,
- wt_decay=0.0001, use_residual=True,
- residual_stride_conv=True, conv_fn=slim.conv2d,
- batch_norm_param=None):
-
- # batch norm x and relu
- init_var = np.sqrt(2.0/(kernel_size**2)/neurons)
- with arg_scope([conv_fn],
- weights_regularizer=slim.l2_regularizer(wt_decay),
- weights_initializer=tf.random_normal_initializer(stddev=init_var),
- biases_initializer=tf.zeros_initializer()):
-
- if batch_norm_param is None:
- batch_norm_param = {'center': True, 'scale': False,
- 'activation_fn':tf.nn.relu,
- 'is_training': is_training}
-
- y = slim.batch_norm(x, scope=name+'_bn', **batch_norm_param)
-
- y = conv_fn(y, num_outputs=neurons, kernel_size=kernel_size, stride=stride,
- activation_fn=None, scope=name+'_1',
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_param)
-
- y = conv_fn(y, num_outputs=neurons, kernel_size=kernel_size,
- stride=1, activation_fn=None, scope=name+'_2')
-
- if use_residual:
- if stride != 1 or x.get_shape().as_list()[-1] != neurons:
- batch_norm_param_ = dict(batch_norm_param)
- batch_norm_param_['activation_fn'] = None
- x = conv_fn(x, num_outputs=neurons, kernel_size=1,
- stride=stride if residual_stride_conv else 1,
- activation_fn=None, scope=name+'_0_1x1',
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_param_)
- if not residual_stride_conv:
- x = slim.avg_pool2d(x, 1, stride=stride, scope=name+'_0_avg')
-
- y = tf.add(x, y, name=name+'_add')
-
- return y
-
-def step_gt_prob(step, step_number_op):
- # Change samping probability from 1 to -1 at step steps.
- with tf.name_scope('step_gt_prob'):
- out = tf.cond(tf.less(step_number_op, step),
- lambda: tf.constant(1.), lambda: tf.constant(-1.))
- return out
-
-def inverse_sigmoid_decay(k, global_step_op):
- with tf.name_scope('inverse_sigmoid_decay'):
- k = tf.constant(k, dtype=tf.float32)
- tmp = k*tf.exp(-tf.cast(global_step_op, tf.float32)/k)
- tmp = tmp / (1. + tmp)
- return tmp
-
-def dense_resample(im, flow_im, output_valid_mask, name='dense_resample'):
- """ Resample reward at particular locations.
- Args:
- im: ...xHxWxC matrix to sample from.
- flow_im: ...xHxWx2 matrix, samples the image using absolute offsets as given
- by the flow_im.
- """
- with tf.name_scope(name):
- valid_mask = None
-
- x, y = tf.unstack(flow_im, axis=-1)
- x = tf.cast(tf.reshape(x, [-1]), tf.float32)
- y = tf.cast(tf.reshape(y, [-1]), tf.float32)
-
- # constants
- shape = tf.unstack(tf.shape(im))
- channels = shape[-1]
- width = shape[-2]
- height = shape[-3]
- num_batch = tf.cast(tf.reduce_prod(tf.stack(shape[:-3])), 'int32')
- zero = tf.constant(0, dtype=tf.int32)
-
- # Round up and down.
- x0 = tf.cast(tf.floor(x), 'int32'); x1 = x0 + 1;
- y0 = tf.cast(tf.floor(y), 'int32'); y1 = y0 + 1;
-
- if output_valid_mask:
- valid_mask = tf.logical_and(
- tf.logical_and(tf.less_equal(x, tf.cast(width, tf.float32)-1.), tf.greater_equal(x, 0.)),
- tf.logical_and(tf.less_equal(y, tf.cast(height, tf.float32)-1.), tf.greater_equal(y, 0.)))
- valid_mask = tf.reshape(valid_mask, shape=shape[:-1] + [1])
-
- x0 = tf.clip_by_value(x0, zero, width-1)
- x1 = tf.clip_by_value(x1, zero, width-1)
- y0 = tf.clip_by_value(y0, zero, height-1)
- y1 = tf.clip_by_value(y1, zero, height-1)
-
- dim2 = width; dim1 = width * height;
-
- # Create base index
- base = tf.reshape(tf.range(num_batch) * dim1, shape=[-1,1])
- base = tf.reshape(tf.tile(base, [1, height*width]), shape=[-1])
-
- base_y0 = base + y0 * dim2
- base_y1 = base + y1 * dim2
- idx_a = base_y0 + x0
- idx_b = base_y1 + x0
- idx_c = base_y0 + x1
- idx_d = base_y1 + x1
-
- # use indices to lookup pixels in the flat image and restore channels dim
- sh = tf.stack([tf.constant(-1,dtype=tf.int32), channels])
- im_flat = tf.cast(tf.reshape(im, sh), dtype=tf.float32)
- pixel_a = tf.gather(im_flat, idx_a)
- pixel_b = tf.gather(im_flat, idx_b)
- pixel_c = tf.gather(im_flat, idx_c)
- pixel_d = tf.gather(im_flat, idx_d)
-
- # and finally calculate interpolated values
- x1_f = tf.to_float(x1)
- y1_f = tf.to_float(y1)
-
- wa = tf.expand_dims(((x1_f - x) * (y1_f - y)), 1)
- wb = tf.expand_dims((x1_f - x) * (1.0 - (y1_f - y)), 1)
- wc = tf.expand_dims(((1.0 - (x1_f - x)) * (y1_f - y)), 1)
- wd = tf.expand_dims(((1.0 - (x1_f - x)) * (1.0 - (y1_f - y))), 1)
-
- output = tf.add_n([wa * pixel_a, wb * pixel_b, wc * pixel_c, wd * pixel_d])
- output = tf.reshape(output, shape=tf.shape(im))
- return output, valid_mask
-
-def get_flow(t, theta, map_size, name_scope='gen_flow'):
- """
- Rotates the map by theta and translates the rotated map by t.
-
- Assume that the robot rotates by an angle theta and then moves forward by
- translation t. This function returns the flow field field. For every pixel in
- the new image it tells us which pixel in the original image it came from:
- NewI(x, y) = OldI(flow_x(x,y), flow_y(x,y)).
-
- Assume there is a point p in the original image. Robot rotates by R and moves
- forward by t. p1 = Rt*p; p2 = p1 - t; (the world moves in opposite direction.
- So, p2 = Rt*p - t, thus p2 came from R*(p2+t), which is what this function
- calculates.
-
- t: ... x 2 (translation for B batches of N motions each).
- theta: ... x 1 (rotation for B batches of N motions each).
-
- Output: ... x map_size x map_size x 2
- """
-
- with tf.name_scope(name_scope):
- tx, ty = tf.unstack(tf.reshape(t, shape=[-1, 1, 1, 1, 2]), axis=4)
- theta = tf.reshape(theta, shape=[-1, 1, 1, 1])
- c = tf.constant((map_size-1.)/2., dtype=tf.float32)
-
- x, y = np.meshgrid(np.arange(map_size), np.arange(map_size))
- x = tf.constant(x[np.newaxis, :, :, np.newaxis], dtype=tf.float32, name='x',
- shape=[1, map_size, map_size, 1])
- y = tf.constant(y[np.newaxis, :, :, np.newaxis], dtype=tf.float32, name='y',
- shape=[1,map_size, map_size, 1])
-
- x = x-(-tx+c)
- y = y-(-ty+c)
-
- sin_theta = tf.sin(theta)
- cos_theta = tf.cos(theta)
- xr = cos_theta*x - sin_theta*y
- yr = sin_theta*x + cos_theta*y
-
- xr = xr + c
- yr = yr + c
-
- flow = tf.stack([xr, yr], axis=-1)
- sh = tf.unstack(tf.shape(t), axis=0)
- sh = tf.stack(sh[:-1]+[tf.constant(_, dtype=tf.int32) for _ in [map_size, map_size, 2]])
- flow = tf.reshape(flow, shape=sh)
- return flow
-
-def distort_image(im, fast_mode=False):
- # All images in the same batch are transformed the same way, but over
- # iterations you see different distortions.
- # im should be float with values between 0 and 1.
- im_ = tf.reshape(im, shape=(-1,1,3))
- im_ = ip.apply_with_random_selector(
- im_, lambda x, ordering: ip.distort_color(x, ordering, fast_mode),
- num_cases=4)
- im_ = tf.reshape(im_, tf.shape(im))
- return im_
-
-def fc_network(x, neurons, wt_decay, name, num_pred=None, offset=0,
- batch_norm_param=None, dropout_ratio=0.0, is_training=None):
- if dropout_ratio > 0:
- assert(is_training is not None), \
- 'is_training needs to be defined when trainnig with dropout.'
-
- repr = []
- for i, neuron in enumerate(neurons):
- init_var = np.sqrt(2.0/neuron)
- if batch_norm_param is not None:
- x = slim.fully_connected(x, neuron, activation_fn=None,
- weights_initializer=tf.random_normal_initializer(stddev=init_var),
- weights_regularizer=slim.l2_regularizer(wt_decay),
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_param,
- biases_initializer=tf.zeros_initializer(),
- scope='{:s}_{:d}'.format(name, offset+i))
- else:
- x = slim.fully_connected(x, neuron, activation_fn=tf.nn.relu,
- weights_initializer=tf.random_normal_initializer(stddev=init_var),
- weights_regularizer=slim.l2_regularizer(wt_decay),
- biases_initializer=tf.zeros_initializer(),
- scope='{:s}_{:d}'.format(name, offset+i))
- if dropout_ratio > 0:
- x = slim.dropout(x, keep_prob=1-dropout_ratio, is_training=is_training,
- scope='{:s}_{:d}'.format('dropout_'+name, offset+i))
- repr.append(x)
-
- if num_pred is not None:
- init_var = np.sqrt(2.0/num_pred)
- x = slim.fully_connected(x, num_pred,
- weights_regularizer=slim.l2_regularizer(wt_decay),
- weights_initializer=tf.random_normal_initializer(stddev=init_var),
- biases_initializer=tf.zeros_initializer(),
- activation_fn=None,
- scope='{:s}_pred'.format(name))
- return x, repr
-
-def concat_state_x_list(f, names):
- af = {}
- for i, k in enumerate(names):
- af[k] = np.concatenate([x[i] for x in f], axis=1)
- return af
-
-def concat_state_x(f, names):
- af = {}
- for k in names:
- af[k] = np.concatenate([x[k] for x in f], axis=1)
- # af[k] = np.swapaxes(af[k], 0, 1)
- return af
-
-def sample_action(rng, action_probs, optimal_action, sample_gt_prob,
- type='sample', combine_type='one_or_other'):
- optimal_action_ = optimal_action/np.sum(optimal_action+0., 1, keepdims=True)
- action_probs_ = action_probs/np.sum(action_probs+0.001, 1, keepdims=True)
- batch_size = action_probs_.shape[0]
-
- action = np.zeros((batch_size), dtype=np.int32)
- action_sample_wt = np.zeros((batch_size), dtype=np.float32)
- if combine_type == 'add':
- sample_gt_prob_ = np.minimum(np.maximum(sample_gt_prob, 0.), 1.)
-
- for i in range(batch_size):
- if combine_type == 'one_or_other':
- sample_gt = rng.rand() < sample_gt_prob
- if sample_gt: distr_ = optimal_action_[i,:]*1.
- else: distr_ = action_probs_[i,:]*1.
- elif combine_type == 'add':
- distr_ = optimal_action_[i,:]*sample_gt_prob_ + \
- (1.-sample_gt_prob_)*action_probs_[i,:]
- distr_ = distr_ / np.sum(distr_)
-
- if type == 'sample':
- action[i] = np.argmax(rng.multinomial(1, distr_, size=1))
- elif type == 'argmax':
- action[i] = np.argmax(distr_)
- action_sample_wt[i] = action_probs_[i, action[i]] / distr_[action[i]]
- return action, action_sample_wt
-
-def train_step_custom_online_sampling(sess, train_op, global_step,
- train_step_kwargs, mode='train'):
- m = train_step_kwargs['m']
- obj = train_step_kwargs['obj']
- rng_data = train_step_kwargs['rng_data']
- rng_action = train_step_kwargs['rng_action']
- writer = train_step_kwargs['writer']
- iters = train_step_kwargs['iters']
- num_steps = train_step_kwargs['num_steps']
- logdir = train_step_kwargs['logdir']
- dagger_sample_bn_false = train_step_kwargs['dagger_sample_bn_false']
- train_display_interval = train_step_kwargs['train_display_interval']
- if 'outputs' not in m.train_ops:
- m.train_ops['outputs'] = []
-
- s_ops = m.summary_ops[mode]
- val_additional_ops = []
-
- # Print all variables here.
- if False:
- v = tf.get_collection(tf.GraphKeys.VARIABLES)
- v_op = [_.value() for _ in v]
- v_op_value = sess.run(v_op)
-
- filter = lambda x, y: 'Adam' in x.name
- # filter = lambda x, y: np.is_any_nan(y)
- ind = [i for i, (_, __) in enumerate(zip(v, v_op_value)) if filter(_, __)]
- v = [v[i] for i in ind]
- v_op_value = [v_op_value[i] for i in ind]
-
- for i in range(len(v)):
- logging.info('XXXX: variable: %30s, is_any_nan: %5s, norm: %f.',
- v[i].name, np.any(np.isnan(v_op_value[i])),
- np.linalg.norm(v_op_value[i]))
-
- tt = utils.Timer()
- for i in range(iters):
- tt.tic()
- # Sample a room.
- e = obj.sample_env(rng_data)
-
- # Initialize the agent.
- init_env_state = e.reset(rng_data)
-
- # Get and process the common data.
- input = e.get_common_data()
- input = e.pre_common_data(input)
- feed_dict = prepare_feed_dict(m.input_tensors['common'], input)
- if dagger_sample_bn_false:
- feed_dict[m.train_ops['batch_norm_is_training_op']] = False
- common_data = sess.run(m.train_ops['common'], feed_dict=feed_dict)
-
- states = []
- state_features = []
- state_targets = []
- net_state_to_input = []
- step_data_cache = []
- executed_actions = []
- rewards = []
- action_sample_wts = []
- states.append(init_env_state)
-
- net_state = sess.run(m.train_ops['init_state'], feed_dict=feed_dict)
- net_state = dict(zip(m.train_ops['state_names'], net_state))
- net_state_to_input.append(net_state)
- for j in range(num_steps):
- f = e.get_features(states[j], j)
- f = e.pre_features(f)
- f.update(net_state)
- f['step_number'] = np.ones((1,1,1), dtype=np.int32)*j
- state_features.append(f)
-
- feed_dict = prepare_feed_dict(m.input_tensors['step'], state_features[-1])
- optimal_action = e.get_optimal_action(states[j], j)
- for x, v in zip(m.train_ops['common'], common_data):
- feed_dict[x] = v
- if dagger_sample_bn_false:
- feed_dict[m.train_ops['batch_norm_is_training_op']] = False
- outs = sess.run([m.train_ops['step'], m.sample_gt_prob_op,
- m.train_ops['step_data_cache'],
- m.train_ops['updated_state'],
- m.train_ops['outputs']], feed_dict=feed_dict)
- action_probs = outs[0]
- sample_gt_prob = outs[1]
- step_data_cache.append(dict(zip(m.train_ops['step_data_cache'], outs[2])))
- net_state = outs[3]
- if hasattr(e, 'update_state'):
- outputs = outs[4]
- outputs = dict(zip(m.train_ops['output_names'], outputs))
- e.update_state(outputs, j)
- state_targets.append(e.get_targets(states[j], j))
-
- if j < num_steps-1:
- # Sample from action_probs and optimal action.
- action, action_sample_wt = sample_action(
- rng_action, action_probs, optimal_action, sample_gt_prob,
- m.sample_action_type, m.sample_action_combine_type)
- next_state, reward = e.take_action(states[j], action, j)
- executed_actions.append(action)
- states.append(next_state)
- rewards.append(reward)
- action_sample_wts.append(action_sample_wt)
- net_state = dict(zip(m.train_ops['state_names'], net_state))
- net_state_to_input.append(net_state)
-
- # Concatenate things together for training.
- rewards = np.array(rewards).T
- action_sample_wts = np.array(action_sample_wts).T
- executed_actions = np.array(executed_actions).T
- all_state_targets = concat_state_x(state_targets, e.get_targets_name())
- all_state_features = concat_state_x(state_features,
- e.get_features_name()+['step_number'])
- # all_state_net = concat_state_x(net_state_to_input,
- # m.train_ops['state_names'])
- all_step_data_cache = concat_state_x(step_data_cache,
- m.train_ops['step_data_cache'])
-
- dict_train = dict(input)
- dict_train.update(all_state_features)
- dict_train.update(all_state_targets)
- # dict_train.update(all_state_net)
- dict_train.update(net_state_to_input[0])
- dict_train.update(all_step_data_cache)
- dict_train.update({'rewards': rewards,
- 'action_sample_wts': action_sample_wts,
- 'executed_actions': executed_actions})
- feed_dict = prepare_feed_dict(m.input_tensors['train'], dict_train)
- for x in m.train_ops['step_data_cache']:
- feed_dict[x] = all_step_data_cache[x]
- if mode == 'train':
- n_step = sess.run(global_step)
-
- if np.mod(n_step, train_display_interval) == 0:
- total_loss, np_global_step, summary, print_summary = sess.run(
- [train_op, global_step, s_ops.summary_ops, s_ops.print_summary_ops],
- feed_dict=feed_dict)
- logging.error("")
- else:
- total_loss, np_global_step, summary = sess.run(
- [train_op, global_step, s_ops.summary_ops], feed_dict=feed_dict)
-
- if writer is not None and summary is not None:
- writer.add_summary(summary, np_global_step)
-
- should_stop = sess.run(m.should_stop_op)
-
- if mode != 'train':
- arop = [[] for j in range(len(s_ops.additional_return_ops))]
- for j in range(len(s_ops.additional_return_ops)):
- if s_ops.arop_summary_iters[j] < 0 or i < s_ops.arop_summary_iters[j]:
- arop[j] = s_ops.additional_return_ops[j]
- val = sess.run(arop, feed_dict=feed_dict)
- val_additional_ops.append(val)
- tt.toc(log_at=60, log_str='val timer {:d} / {:d}: '.format(i, iters),
- type='time')
-
- if mode != 'train':
- # Write the default val summaries.
- summary, print_summary, np_global_step = sess.run(
- [s_ops.summary_ops, s_ops.print_summary_ops, global_step])
- if writer is not None and summary is not None:
- writer.add_summary(summary, np_global_step)
-
- # write custom validation ops
- val_summarys = []
- val_additional_ops = zip(*val_additional_ops)
- if len(s_ops.arop_eval_fns) > 0:
- val_metric_summary = tf.summary.Summary()
- for i in range(len(s_ops.arop_eval_fns)):
- val_summary = None
- if s_ops.arop_eval_fns[i] is not None:
- val_summary = s_ops.arop_eval_fns[i](val_additional_ops[i],
- np_global_step, logdir,
- val_metric_summary,
- s_ops.arop_summary_iters[i])
- val_summarys.append(val_summary)
- if writer is not None:
- writer.add_summary(val_metric_summary, np_global_step)
-
- # Return the additional val_ops
- total_loss = (val_additional_ops, val_summarys)
- should_stop = None
-
- return total_loss, should_stop
-
-def train_step_custom_v2(sess, train_op, global_step, train_step_kwargs,
- mode='train'):
- m = train_step_kwargs['m']
- obj = train_step_kwargs['obj']
- rng = train_step_kwargs['rng']
- writer = train_step_kwargs['writer']
- iters = train_step_kwargs['iters']
- logdir = train_step_kwargs['logdir']
- train_display_interval = train_step_kwargs['train_display_interval']
-
- s_ops = m.summary_ops[mode]
- val_additional_ops = []
-
- # Print all variables here.
- if False:
- v = tf.get_collection(tf.GraphKeys.VARIABLES)
- v_op = [_.value() for _ in v]
- v_op_value = sess.run(v_op)
-
- filter = lambda x, y: 'Adam' in x.name
- # filter = lambda x, y: np.is_any_nan(y)
- ind = [i for i, (_, __) in enumerate(zip(v, v_op_value)) if filter(_, __)]
- v = [v[i] for i in ind]
- v_op_value = [v_op_value[i] for i in ind]
-
- for i in range(len(v)):
- logging.info('XXXX: variable: %30s, is_any_nan: %5s, norm: %f.',
- v[i].name, np.any(np.isnan(v_op_value[i])),
- np.linalg.norm(v_op_value[i]))
-
- tt = utils.Timer()
- for i in range(iters):
- tt.tic()
- e = obj.sample_env(rng)
- rngs = e.gen_rng(rng)
- input_data = e.gen_data(*rngs)
- input_data = e.pre_data(input_data)
- feed_dict = prepare_feed_dict(m.input_tensors, input_data)
-
- if mode == 'train':
- n_step = sess.run(global_step)
-
- if np.mod(n_step, train_display_interval) == 0:
- total_loss, np_global_step, summary, print_summary = sess.run(
- [train_op, global_step, s_ops.summary_ops, s_ops.print_summary_ops],
- feed_dict=feed_dict)
- else:
- total_loss, np_global_step, summary = sess.run(
- [train_op, global_step, s_ops.summary_ops],
- feed_dict=feed_dict)
-
- if writer is not None and summary is not None:
- writer.add_summary(summary, np_global_step)
-
- should_stop = sess.run(m.should_stop_op)
-
- if mode != 'train':
- arop = [[] for j in range(len(s_ops.additional_return_ops))]
- for j in range(len(s_ops.additional_return_ops)):
- if s_ops.arop_summary_iters[j] < 0 or i < s_ops.arop_summary_iters[j]:
- arop[j] = s_ops.additional_return_ops[j]
- val = sess.run(arop, feed_dict=feed_dict)
- val_additional_ops.append(val)
- tt.toc(log_at=60, log_str='val timer {:d} / {:d}: '.format(i, iters),
- type='time')
-
- if mode != 'train':
- # Write the default val summaries.
- summary, print_summary, np_global_step = sess.run(
- [s_ops.summary_ops, s_ops.print_summary_ops, global_step])
- if writer is not None and summary is not None:
- writer.add_summary(summary, np_global_step)
-
- # write custom validation ops
- val_summarys = []
- val_additional_ops = zip(*val_additional_ops)
- if len(s_ops.arop_eval_fns) > 0:
- val_metric_summary = tf.summary.Summary()
- for i in range(len(s_ops.arop_eval_fns)):
- val_summary = None
- if s_ops.arop_eval_fns[i] is not None:
- val_summary = s_ops.arop_eval_fns[i](val_additional_ops[i],
- np_global_step, logdir,
- val_metric_summary,
- s_ops.arop_summary_iters[i])
- val_summarys.append(val_summary)
- if writer is not None:
- writer.add_summary(val_metric_summary, np_global_step)
-
- # Return the additional val_ops
- total_loss = (val_additional_ops, val_summarys)
- should_stop = None
-
- return total_loss, should_stop
-
-def train_step_custom(sess, train_op, global_step, train_step_kwargs,
- mode='train'):
- m = train_step_kwargs['m']
- params = train_step_kwargs['params']
- rng = train_step_kwargs['rng']
- writer = train_step_kwargs['writer']
- iters = train_step_kwargs['iters']
- gen_rng = train_step_kwargs['gen_rng']
- logdir = train_step_kwargs['logdir']
- gen_data = train_step_kwargs['gen_data']
- pre_data = train_step_kwargs['pre_data']
- train_display_interval = train_step_kwargs['train_display_interval']
-
- val_additional_ops = []
- # Print all variables here.
- if False:
- v = tf.get_collection(tf.GraphKeys.VARIABLES)
- for _ in v:
- val = sess.run(_.value())
- logging.info('variable: %30s, is_any_nan: %5s, norm: %f.', _.name,
- np.any(np.isnan(val)), np.linalg.norm(val))
-
- for i in range(iters):
- rngs = gen_rng(params, rng)
- input_data = gen_data(params, *rngs)
- input_data = pre_data(params, input_data)
- feed_dict = prepare_feed_dict(m.input_tensors, input_data)
-
- if mode == 'train':
- n_step = sess.run(global_step)
-
- if np.mod(n_step, train_display_interval) == 0:
- total_loss, np_global_step, summary, print_summary = sess.run(
- [train_op, global_step, m.summary_op[mode], m.print_summary_op[mode]],
- feed_dict=feed_dict)
- else:
- total_loss, np_global_step, summary = sess.run(
- [train_op, global_step, m.summary_op[mode]],
- feed_dict=feed_dict)
-
- if writer is not None:
- writer.add_summary(summary, np_global_step)
-
- should_stop = sess.run(m.should_stop_op)
-
- if mode == 'val':
- val = sess.run(m.agg_update_op[mode] + m.additional_return_op[mode],
- feed_dict=feed_dict)
- val_additional_ops.append(val[len(m.agg_update_op[mode]):])
-
- if mode == 'val':
- summary, print_summary, np_global_step = sess.run(
- [m.summary_op[mode], m.print_summary_op[mode], global_step])
- if writer is not None:
- writer.add_summary(summary, np_global_step)
- sess.run([m.agg_reset_op[mode]])
-
- # write custom validation ops
- if m.eval_metrics_fn[mode] is not None:
- val_metric_summary = m.eval_metrics_fn[mode](val_additional_ops,
- np_global_step, logdir)
- if writer is not None:
- writer.add_summary(val_metric_summary, np_global_step)
-
- total_loss = val_additional_ops
- should_stop = None
-
- return total_loss, should_stop
-
-def setup_training(loss_op, initial_learning_rate, steps_per_decay,
- learning_rate_decay, momentum, max_steps,
- sync=False, adjust_lr_sync=True,
- num_workers=1, replica_id=0, vars_to_optimize=None,
- clip_gradient_norm=0, typ=None, momentum2=0.999,
- adam_eps=1e-8):
- if sync and adjust_lr_sync:
- initial_learning_rate = initial_learning_rate * num_workers
- max_steps = np.int(max_steps / num_workers)
- steps_per_decay = np.int(steps_per_decay / num_workers)
-
- global_step_op = slim.get_or_create_global_step()
- lr_op = tf.train.exponential_decay(initial_learning_rate,
- global_step_op, steps_per_decay, learning_rate_decay, staircase=True)
- if typ == 'sgd':
- optimizer = tf.train.MomentumOptimizer(lr_op, momentum)
- elif typ == 'adam':
- optimizer = tf.train.AdamOptimizer(learning_rate=lr_op, beta1=momentum,
- beta2=momentum2, epsilon=adam_eps)
-
- if sync:
-
- sync_optimizer = tf.train.SyncReplicasOptimizer(optimizer,
- replicas_to_aggregate=num_workers,
- replica_id=replica_id,
- total_num_replicas=num_workers)
- train_op = slim.learning.create_train_op(loss_op, sync_optimizer,
- variables_to_train=vars_to_optimize,
- clip_gradient_norm=clip_gradient_norm)
- else:
- sync_optimizer = None
- train_op = slim.learning.create_train_op(loss_op, optimizer,
- variables_to_train=vars_to_optimize,
- clip_gradient_norm=clip_gradient_norm)
- should_stop_op = tf.greater_equal(global_step_op, max_steps)
- return lr_op, global_step_op, train_op, should_stop_op, optimizer, sync_optimizer
-
-def add_value_to_summary(metric_summary, tag, val, log=True, tag_str=None):
- """Adds a scalar summary to the summary object. Optionally also logs to
- logging."""
- new_value = metric_summary.value.add();
- new_value.tag = tag
- new_value.simple_value = val
- if log:
- if tag_str is None:
- tag_str = tag + '%f'
- logging.info(tag_str, val)
-
-def add_scalar_summary_op(tensor, name=None,
- summary_key='summaries', print_summary_key='print_summaries', prefix=''):
- collections = []
- op = tf.summary.scalar(name, tensor, collections=collections)
- if summary_key != print_summary_key:
- tf.add_to_collection(summary_key, op)
-
- op = tf.Print(op, [tensor], ' {:-<25s}: '.format(name) + prefix)
- tf.add_to_collection(print_summary_key, op)
- return op
-
-def setup_inputs(inputs):
- input_tensors = {}
- input_shapes = {}
- for (name, typ, sz) in inputs:
- _ = tf.placeholder(typ, shape=sz, name=name)
- input_tensors[name] = _
- input_shapes[name] = sz
- return input_tensors, input_shapes
-
-def prepare_feed_dict(input_tensors, inputs):
- feed_dict = {}
- for n in input_tensors.keys():
- feed_dict[input_tensors[n]] = inputs[n].astype(input_tensors[n].dtype.as_numpy_dtype)
- return feed_dict
-
-def simple_add_summaries(summarize_ops, summarize_names,
- summary_key='summaries',
- print_summary_key='print_summaries', prefix=''):
- for op, name, in zip(summarize_ops, summarize_names):
- add_scalar_summary_op(op, name, summary_key, print_summary_key, prefix)
-
- summary_op = tf.summary.merge_all(summary_key)
- print_summary_op = tf.summary.merge_all(print_summary_key)
- return summary_op, print_summary_op
-
-def add_summary_ops(m, summarize_ops, summarize_names, to_aggregate=None,
- summary_key='summaries',
- print_summary_key='print_summaries', prefix=''):
- if type(to_aggregate) != list:
- to_aggregate = [to_aggregate for _ in summarize_ops]
-
- # set up aggregating metrics
- if np.any(to_aggregate):
- agg_ops = []
- for op, name, to_agg in zip(summarize_ops, summarize_names, to_aggregate):
- if to_agg:
- # agg_ops.append(slim.metrics.streaming_mean(op, return_reset_op=True))
- agg_ops.append(tf.contrib.metrics.streaming_mean(op))
- # agg_ops.append(tf.contrib.metrics.streaming_mean(op, return_reset_op=True))
- else:
- agg_ops.append([None, None, None])
-
- # agg_values_op, agg_update_op, agg_reset_op = zip(*agg_ops)
- # agg_update_op = [x for x in agg_update_op if x is not None]
- # agg_reset_op = [x for x in agg_reset_op if x is not None]
- agg_values_op, agg_update_op = zip(*agg_ops)
- agg_update_op = [x for x in agg_update_op if x is not None]
- agg_reset_op = [tf.no_op()]
- else:
- agg_values_op = [None for _ in to_aggregate]
- agg_update_op = [tf.no_op()]
- agg_reset_op = [tf.no_op()]
-
- for op, name, to_agg, agg_op in zip(summarize_ops, summarize_names, to_aggregate, agg_values_op):
- if to_agg:
- add_scalar_summary_op(agg_op, name, summary_key, print_summary_key, prefix)
- else:
- add_scalar_summary_op(op, name, summary_key, print_summary_key, prefix)
-
- summary_op = tf.summary.merge_all(summary_key)
- print_summary_op = tf.summary.merge_all(print_summary_key)
- return summary_op, print_summary_op, agg_update_op, agg_reset_op
-
-
-
-def accum_val_ops(outputs, names, global_step, output_dir, metric_summary, N):
- """Processes the collected outputs to compute AP for action prediction.
-
- Args:
- outputs : List of scalar ops to summarize.
- names : Name of the scalar ops.
- global_step : global_step.
- output_dir : where to store results.
- metric_summary : summary object to add summaries to.
- N : number of outputs to process.
- """
- outs = []
- if N >= 0:
- outputs = outputs[:N]
- for i in range(len(outputs[0])):
- scalar = np.array(map(lambda x: x[i], outputs))
- assert(scalar.ndim == 1)
- add_value_to_summary(metric_summary, names[i], np.mean(scalar),
- tag_str='{:>27s}: [{:s}]: %f'.format(names[i], ''))
- outs.append(np.mean(scalar))
- return outs
-
-def get_default_summary_ops():
- return utils.Foo(summary_ops=None, print_summary_ops=None,
- additional_return_ops=[], arop_summary_iters=[],
- arop_eval_fns=[])
-
-
-def simple_summaries(summarize_ops, summarize_names, mode, to_aggregate=False,
- scope_name='summary'):
-
- if type(to_aggregate) != list:
- to_aggregate = [to_aggregate for _ in summarize_ops]
-
- summary_key = '{:s}_summaries'.format(mode)
- print_summary_key = '{:s}_print_summaries'.format(mode)
- prefix=' [{:s}]: '.format(mode)
-
- # Default ops for things that dont need to be aggregated.
- if not np.all(to_aggregate):
- for op, name, to_agg in zip(summarize_ops, summarize_names, to_aggregate):
- if not to_agg:
- add_scalar_summary_op(op, name, summary_key, print_summary_key, prefix)
- summary_ops = tf.summary.merge_all(summary_key)
- print_summary_ops = tf.summary.merge_all(print_summary_key)
- else:
- summary_ops = tf.no_op()
- print_summary_ops = tf.no_op()
-
- # Default ops for things that dont need to be aggregated.
- if np.any(to_aggregate):
- additional_return_ops = [[summarize_ops[i]
- for i, x in enumerate(to_aggregate )if x]]
- arop_summary_iters = [-1]
- s_names = ['{:s}/{:s}'.format(scope_name, summarize_names[i])
- for i, x in enumerate(to_aggregate) if x]
- fn = lambda outputs, global_step, output_dir, metric_summary, N: \
- accum_val_ops(outputs, s_names, global_step, output_dir, metric_summary,
- N)
- arop_eval_fns = [fn]
- else:
- additional_return_ops = []
- arop_summary_iters = []
- arop_eval_fns = []
- return summary_ops, print_summary_ops, additional_return_ops, \
- arop_summary_iters, arop_eval_fns
diff --git a/research/cognitive_mapping_and_planning/tfcode/vision_baseline_lstm.py b/research/cognitive_mapping_and_planning/tfcode/vision_baseline_lstm.py
deleted file mode 100644
index ccf3ab23b06b71ed2a6d300b9a7d2a67a396c52e..0000000000000000000000000000000000000000
--- a/research/cognitive_mapping_and_planning/tfcode/vision_baseline_lstm.py
+++ /dev/null
@@ -1,533 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-import numpy as np
-
-
-import tensorflow as tf
-
-from tensorflow.contrib import slim
-
-import logging
-from tensorflow.python.platform import app
-from tensorflow.python.platform import flags
-from src import utils
-import src.file_utils as fu
-import tfcode.nav_utils as nu
-from tfcode import tf_utils
-
-setup_train_step_kwargs = nu.default_train_step_kwargs
-compute_losses_multi_or = nu.compute_losses_multi_or
-get_repr_from_image = nu.get_repr_from_image
-
-_save_d_at_t = nu.save_d_at_t
-_save_all = nu.save_all
-_eval_ap = nu.eval_ap
-_eval_dist = nu.eval_dist
-_plot_trajectories = nu.plot_trajectories
-
-def lstm_online(cell_fn, num_steps, inputs, state, varscope):
- # inputs is B x num_steps x C, C channels.
- # state is 2 tuple with B x 1 x C1, B x 1 x C2
- # Output state is always B x 1 x C
- inputs = tf.unstack(inputs, axis=1, num=num_steps)
- state = tf.unstack(state, axis=1, num=1)[0]
- outputs = []
-
- if num_steps > 1:
- varscope.reuse_variables()
-
- for s in range(num_steps):
- output, state = cell_fn(inputs[s], state)
- outputs.append(output)
- outputs = tf.stack(outputs, axis=1)
- state = tf.stack([state], axis=1)
- return outputs, state
-
-def _inputs(problem, lstm_states, lstm_state_dims):
- # Set up inputs.
- with tf.name_scope('inputs'):
- n_views = problem.n_views
-
- inputs = []
- inputs.append(('orig_maps', tf.float32,
- (problem.batch_size, 1, None, None, 1)))
- inputs.append(('goal_loc', tf.float32,
- (problem.batch_size, problem.num_goals, 2)))
-
- # For initing LSTM.
- inputs.append(('rel_goal_loc_at_start', tf.float32,
- (problem.batch_size, problem.num_goals,
- problem.rel_goal_loc_dim)))
- common_input_data, _ = tf_utils.setup_inputs(inputs)
-
- inputs = []
- inputs.append(('imgs', tf.float32, (problem.batch_size, None, n_views,
- problem.img_height, problem.img_width,
- problem.img_channels)))
- # Goal location as a tuple of delta location and delta theta.
- inputs.append(('rel_goal_loc', tf.float32, (problem.batch_size, None,
- problem.rel_goal_loc_dim)))
- if problem.outputs.visit_count:
- inputs.append(('visit_count', tf.int32, (problem.batch_size, None, 1)))
- inputs.append(('last_visit', tf.int32, (problem.batch_size, None, 1)))
-
- for i, (state, dim) in enumerate(zip(lstm_states, lstm_state_dims)):
- inputs.append((state, tf.float32, (problem.batch_size, 1, dim)))
-
- if problem.outputs.egomotion:
- inputs.append(('incremental_locs', tf.float32,
- (problem.batch_size, None, 2)))
- inputs.append(('incremental_thetas', tf.float32,
- (problem.batch_size, None, 1)))
-
- inputs.append(('step_number', tf.int32, (1, None, 1)))
- inputs.append(('node_ids', tf.int32, (problem.batch_size, None,
- problem.node_ids_dim)))
- inputs.append(('perturbs', tf.float32, (problem.batch_size, None,
- problem.perturbs_dim)))
-
- # For plotting result plots
- inputs.append(('loc_on_map', tf.float32, (problem.batch_size, None, 2)))
- inputs.append(('gt_dist_to_goal', tf.float32, (problem.batch_size, None, 1)))
- step_input_data, _ = tf_utils.setup_inputs(inputs)
-
- inputs = []
- inputs.append(('executed_actions', tf.int32, (problem.batch_size, None)))
- inputs.append(('rewards', tf.float32, (problem.batch_size, None)))
- inputs.append(('action_sample_wts', tf.float32, (problem.batch_size, None)))
- inputs.append(('action', tf.int32, (problem.batch_size, None,
- problem.num_actions)))
- train_data, _ = tf_utils.setup_inputs(inputs)
- train_data.update(step_input_data)
- train_data.update(common_input_data)
- return common_input_data, step_input_data, train_data
-
-
-def _add_summaries(m, summary_mode, arop_full_summary_iters):
- summarize_ops = [m.lr_op, m.global_step_op, m.sample_gt_prob_op,
- m.total_loss_op, m.data_loss_op, m.reg_loss_op] + m.acc_ops
- summarize_names = ['lr', 'global_step', 'sample_gt_prob_op', 'total_loss',
- 'data_loss', 'reg_loss'] + \
- ['acc_{:d}'.format(i) for i in range(len(m.acc_ops))]
- to_aggregate = [0, 0, 0, 1, 1, 1] + [1]*len(m.acc_ops)
-
- scope_name = 'summary'
- with tf.name_scope(scope_name):
- s_ops = nu.add_default_summaries(summary_mode, arop_full_summary_iters,
- summarize_ops, summarize_names,
- to_aggregate, m.action_prob_op,
- m.input_tensors, scope_name=scope_name)
- m.summary_ops = {summary_mode: s_ops}
-
-def visit_count_fc(visit_count, last_visit, embed_neurons, wt_decay, fc_dropout):
- with tf.variable_scope('embed_visit_count'):
- visit_count = tf.reshape(visit_count, shape=[-1])
- last_visit = tf.reshape(last_visit, shape=[-1])
-
- visit_count = tf.clip_by_value(visit_count, clip_value_min=-1,
- clip_value_max=15)
- last_visit = tf.clip_by_value(last_visit, clip_value_min=-1,
- clip_value_max=15)
- visit_count = tf.one_hot(visit_count, depth=16, axis=1, dtype=tf.float32,
- on_value=10., off_value=0.)
- last_visit = tf.one_hot(last_visit, depth=16, axis=1, dtype=tf.float32,
- on_value=10., off_value=0.)
- f = tf.concat([visit_count, last_visit], 1)
- x, _ = tf_utils.fc_network(
- f, neurons=embed_neurons, wt_decay=wt_decay, name='visit_count_embed',
- offset=0, batch_norm_param=None, dropout_ratio=fc_dropout,
- is_training=is_training)
- return x
-
-def lstm_setup(name, x, batch_size, is_single_step, lstm_dim, lstm_out,
- num_steps, state_input_op):
- # returns state_name, state_init_op, updated_state_op, out_op
- with tf.name_scope('reshape_'+name):
- sh = x.get_shape().as_list()
- x = tf.reshape(x, shape=[batch_size, -1, sh[-1]])
-
- with tf.variable_scope(name) as varscope:
- cell = tf.contrib.rnn.LSTMCell(
- num_units=lstm_dim, forget_bias=1.0, state_is_tuple=False,
- num_proj=lstm_out, use_peepholes=True,
- initializer=tf.random_uniform_initializer(-0.01, 0.01, seed=0),
- cell_clip=None, proj_clip=None)
-
- sh = [batch_size, 1, lstm_dim+lstm_out]
- state_init_op = tf.constant(0., dtype=tf.float32, shape=sh)
-
- fn = lambda ns: lstm_online(cell, ns, x, state_input_op, varscope)
- out_op, updated_state_op = tf.cond(is_single_step, lambda: fn(1), lambda:
- fn(num_steps))
-
- return name, state_init_op, updated_state_op, out_op
-
-def combine_setup(name, combine_type, embed_img, embed_goal, num_img_neuorons=None,
- num_goal_neurons=None):
- with tf.name_scope(name + '_' + combine_type):
- if combine_type == 'add':
- # Simple concat features from goal and image
- out = embed_img + embed_goal
-
- elif combine_type == 'multiply':
- # Multiply things together
- re_embed_img = tf.reshape(
- embed_img, shape=[-1, num_img_neuorons / num_goal_neurons,
- num_goal_neurons])
- re_embed_goal = tf.reshape(embed_goal, shape=[-1, num_goal_neurons, 1])
- x = tf.matmul(re_embed_img, re_embed_goal, transpose_a=False, transpose_b=False)
- out = slim.flatten(x)
- elif combine_type == 'none' or combine_type == 'imgonly':
- out = embed_img
- elif combine_type == 'goalonly':
- out = embed_goal
- else:
- logging.fatal('Undefined combine_type: %s', combine_type)
- return out
-
-
-def preprocess_egomotion(locs, thetas):
- with tf.name_scope('pre_ego'):
- pre_ego = tf.concat([locs, tf.sin(thetas), tf.cos(thetas)], 2)
- sh = pre_ego.get_shape().as_list()
- pre_ego = tf.reshape(pre_ego, [-1, sh[-1]])
- return pre_ego
-
-def setup_to_run(m, args, is_training, batch_norm_is_training, summary_mode):
- # Set up the model.
- tf.set_random_seed(args.solver.seed)
- task_params = args.navtask.task_params
- num_steps = task_params.num_steps
- num_goals = task_params.num_goals
- num_actions = task_params.num_actions
- num_actions_ = num_actions
-
- n_views = task_params.n_views
-
- batch_norm_is_training_op = \
- tf.placeholder_with_default(batch_norm_is_training, shape=[],
- name='batch_norm_is_training_op')
- # Setup the inputs
- m.input_tensors = {}
- lstm_states = []; lstm_state_dims = [];
- state_names = []; updated_state_ops = []; init_state_ops = [];
- if args.arch.lstm_output:
- lstm_states += ['lstm_output']
- lstm_state_dims += [args.arch.lstm_output_dim+task_params.num_actions]
- if args.arch.lstm_ego:
- lstm_states += ['lstm_ego']
- lstm_state_dims += [args.arch.lstm_ego_dim + args.arch.lstm_ego_out]
- lstm_states += ['lstm_img']
- lstm_state_dims += [args.arch.lstm_img_dim + args.arch.lstm_img_out]
- elif args.arch.lstm_img:
- # An LSTM only on the image
- lstm_states += ['lstm_img']
- lstm_state_dims += [args.arch.lstm_img_dim + args.arch.lstm_img_out]
- else:
- # No LSTMs involved here.
- None
-
- m.input_tensors['common'], m.input_tensors['step'], m.input_tensors['train'] = \
- _inputs(task_params, lstm_states, lstm_state_dims)
-
- with tf.name_scope('check_size'):
- is_single_step = tf.equal(tf.unstack(tf.shape(m.input_tensors['step']['imgs']),
- num=6)[1], 1)
-
- images_reshaped = tf.reshape(m.input_tensors['step']['imgs'],
- shape=[-1, task_params.img_height, task_params.img_width,
- task_params.img_channels], name='re_image')
-
- rel_goal_loc_reshaped = tf.reshape(m.input_tensors['step']['rel_goal_loc'],
- shape=[-1, task_params.rel_goal_loc_dim], name='re_rel_goal_loc')
-
- x, vars_ = get_repr_from_image(
- images_reshaped, task_params.modalities, task_params.data_augment,
- args.arch.encoder, args.solver.freeze_conv, args.solver.wt_decay,
- is_training)
-
- # Reshape into nice things so that these can be accumulated over time steps
- # for faster backprop.
- sh_before = x.get_shape().as_list()
- m.encoder_output = tf.reshape(
- x, shape=[task_params.batch_size, -1, n_views] + sh_before[1:])
- x = tf.reshape(m.encoder_output, shape=[-1] + sh_before[1:])
-
- # Add a layer to reduce dimensions for a fc layer.
- if args.arch.dim_reduce_neurons > 0:
- ks = 1; neurons = args.arch.dim_reduce_neurons;
- init_var = np.sqrt(2.0/(ks**2)/neurons)
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.conv_feat = slim.conv2d(
- x, neurons, kernel_size=ks, stride=1, normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_param, padding='SAME', scope='dim_reduce',
- weights_regularizer=slim.l2_regularizer(args.solver.wt_decay),
- weights_initializer=tf.random_normal_initializer(stddev=init_var))
- reshape_conv_feat = slim.flatten(m.conv_feat)
- sh = reshape_conv_feat.get_shape().as_list()
- m.reshape_conv_feat = tf.reshape(reshape_conv_feat,
- shape=[-1, sh[1]*n_views])
-
- # Restore these from a checkpoint.
- if args.solver.pretrained_path is not None:
- m.init_fn = slim.assign_from_checkpoint_fn(args.solver.pretrained_path,
- vars_)
- else:
- m.init_fn = None
-
- # Hit the goal_location with a bunch of fully connected layers, to embed it
- # into some space.
- with tf.variable_scope('embed_goal'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.embed_goal, _ = tf_utils.fc_network(
- rel_goal_loc_reshaped, neurons=args.arch.goal_embed_neurons,
- wt_decay=args.solver.wt_decay, name='goal_embed', offset=0,
- batch_norm_param=batch_norm_param, dropout_ratio=args.arch.fc_dropout,
- is_training=is_training)
-
- if args.arch.embed_goal_for_state:
- with tf.variable_scope('embed_goal_for_state'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.embed_goal_for_state, _ = tf_utils.fc_network(
- m.input_tensors['common']['rel_goal_loc_at_start'][:,0,:],
- neurons=args.arch.goal_embed_neurons, wt_decay=args.solver.wt_decay,
- name='goal_embed', offset=0, batch_norm_param=batch_norm_param,
- dropout_ratio=args.arch.fc_dropout, is_training=is_training)
-
- # Hit the goal_location with a bunch of fully connected layers, to embed it
- # into some space.
- with tf.variable_scope('embed_img'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.embed_img, _ = tf_utils.fc_network(
- m.reshape_conv_feat, neurons=args.arch.img_embed_neurons,
- wt_decay=args.solver.wt_decay, name='img_embed', offset=0,
- batch_norm_param=batch_norm_param, dropout_ratio=args.arch.fc_dropout,
- is_training=is_training)
-
- # For lstm_ego, and lstm_image, embed the ego motion, accumulate it into an
- # LSTM, combine with image features and accumulate those in an LSTM. Finally
- # combine what you get from the image LSTM with the goal to output an action.
- if args.arch.lstm_ego:
- ego_reshaped = preprocess_egomotion(m.input_tensors['step']['incremental_locs'],
- m.input_tensors['step']['incremental_thetas'])
- with tf.variable_scope('embed_ego'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- m.embed_ego, _ = tf_utils.fc_network(
- ego_reshaped, neurons=args.arch.ego_embed_neurons,
- wt_decay=args.solver.wt_decay, name='ego_embed', offset=0,
- batch_norm_param=batch_norm_param, dropout_ratio=args.arch.fc_dropout,
- is_training=is_training)
-
- state_name, state_init_op, updated_state_op, out_op = lstm_setup(
- 'lstm_ego', m.embed_ego, task_params.batch_size, is_single_step,
- args.arch.lstm_ego_dim, args.arch.lstm_ego_out, num_steps*num_goals,
- m.input_tensors['step']['lstm_ego'])
- state_names += [state_name]
- init_state_ops += [state_init_op]
- updated_state_ops += [updated_state_op]
-
- # Combine the output with the vision features.
- m.img_ego_op = combine_setup('img_ego', args.arch.combine_type_ego,
- m.embed_img, out_op,
- args.arch.img_embed_neurons[-1],
- args.arch.lstm_ego_out)
-
- # LSTM on these vision features.
- state_name, state_init_op, updated_state_op, out_op = lstm_setup(
- 'lstm_img', m.img_ego_op, task_params.batch_size, is_single_step,
- args.arch.lstm_img_dim, args.arch.lstm_img_out, num_steps*num_goals,
- m.input_tensors['step']['lstm_img'])
- state_names += [state_name]
- init_state_ops += [state_init_op]
- updated_state_ops += [updated_state_op]
-
- m.img_for_goal = out_op
- num_img_for_goal_neurons = args.arch.lstm_img_out
-
- elif args.arch.lstm_img:
- # LSTM on just the image features.
- state_name, state_init_op, updated_state_op, out_op = lstm_setup(
- 'lstm_img', m.embed_img, task_params.batch_size, is_single_step,
- args.arch.lstm_img_dim, args.arch.lstm_img_out, num_steps*num_goals,
- m.input_tensors['step']['lstm_img'])
- state_names += [state_name]
- init_state_ops += [state_init_op]
- updated_state_ops += [updated_state_op]
- m.img_for_goal = out_op
- num_img_for_goal_neurons = args.arch.lstm_img_out
-
- else:
- m.img_for_goal = m.embed_img
- num_img_for_goal_neurons = args.arch.img_embed_neurons[-1]
-
-
- if args.arch.use_visit_count:
- m.embed_visit_count = visit_count_fc(
- m.input_tensors['step']['visit_count'],
- m.input_tensors['step']['last_visit'], args.arch.goal_embed_neurons,
- args.solver.wt_decay, args.arch.fc_dropout, is_training=is_training)
- m.embed_goal = m.embed_goal + m.embed_visit_count
-
- m.combined_f = combine_setup('img_goal', args.arch.combine_type,
- m.img_for_goal, m.embed_goal,
- num_img_for_goal_neurons,
- args.arch.goal_embed_neurons[-1])
-
- # LSTM on the combined representation.
- if args.arch.lstm_output:
- name = 'lstm_output'
- # A few fully connected layers here.
- with tf.variable_scope('action_pred'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- x, _ = tf_utils.fc_network(
- m.combined_f, neurons=args.arch.pred_neurons,
- wt_decay=args.solver.wt_decay, name='pred', offset=0,
- batch_norm_param=batch_norm_param, dropout_ratio=args.arch.fc_dropout)
-
- if args.arch.lstm_output_init_state_from_goal:
- # Use the goal embedding to initialize the LSTM state.
- # UGLY CLUGGY HACK: if this is doing computation for a single time step
- # then this will not involve back prop, so we can use the state input from
- # the feed dict, otherwise we compute the state representation from the
- # goal and feed that in. Necessary for using goal location to generate the
- # state representation.
- m.embed_goal_for_state = tf.expand_dims(m.embed_goal_for_state, dim=1)
- state_op = tf.cond(is_single_step, lambda: m.input_tensors['step'][name],
- lambda: m.embed_goal_for_state)
- state_name, state_init_op, updated_state_op, out_op = lstm_setup(
- name, x, task_params.batch_size, is_single_step,
- args.arch.lstm_output_dim,
- num_actions_,
- num_steps*num_goals, state_op)
- init_state_ops += [m.embed_goal_for_state]
- else:
- state_op = m.input_tensors['step'][name]
- state_name, state_init_op, updated_state_op, out_op = lstm_setup(
- name, x, task_params.batch_size, is_single_step,
- args.arch.lstm_output_dim,
- num_actions_, num_steps*num_goals, state_op)
- init_state_ops += [state_init_op]
-
- state_names += [state_name]
- updated_state_ops += [updated_state_op]
-
- out_op = tf.reshape(out_op, shape=[-1, num_actions_])
- if num_actions_ > num_actions:
- m.action_logits_op = out_op[:,:num_actions]
- m.baseline_op = out_op[:,num_actions:]
- else:
- m.action_logits_op = out_op
- m.baseline_op = None
- m.action_prob_op = tf.nn.softmax(m.action_logits_op)
-
- else:
- # A few fully connected layers here.
- with tf.variable_scope('action_pred'):
- batch_norm_param = args.arch.batch_norm_param
- batch_norm_param['is_training'] = batch_norm_is_training_op
- out_op, _ = tf_utils.fc_network(
- m.combined_f, neurons=args.arch.pred_neurons,
- wt_decay=args.solver.wt_decay, name='pred', offset=0,
- num_pred=num_actions_,
- batch_norm_param=batch_norm_param,
- dropout_ratio=args.arch.fc_dropout, is_training=is_training)
- if num_actions_ > num_actions:
- m.action_logits_op = out_op[:,:num_actions]
- m.baseline_op = out_op[:,num_actions:]
- else:
- m.action_logits_op = out_op
- m.baseline_op = None
- m.action_prob_op = tf.nn.softmax(m.action_logits_op)
-
- m.train_ops = {}
- m.train_ops['step'] = m.action_prob_op
- m.train_ops['common'] = [m.input_tensors['common']['orig_maps'],
- m.input_tensors['common']['goal_loc'],
- m.input_tensors['common']['rel_goal_loc_at_start']]
- m.train_ops['state_names'] = state_names
- m.train_ops['init_state'] = init_state_ops
- m.train_ops['updated_state'] = updated_state_ops
- m.train_ops['batch_norm_is_training_op'] = batch_norm_is_training_op
-
- # Flat list of ops which cache the step data.
- m.train_ops['step_data_cache'] = [tf.no_op()]
-
- if args.solver.freeze_conv:
- m.train_ops['step_data_cache'] = [m.encoder_output]
- else:
- m.train_ops['step_data_cache'] = []
-
- ewma_decay = 0.99 if is_training else 0.0
- weight = tf.ones_like(m.input_tensors['train']['action'], dtype=tf.float32,
- name='weight')
-
- m.reg_loss_op, m.data_loss_op, m.total_loss_op, m.acc_ops = \
- compute_losses_multi_or(
- m.action_logits_op, m.input_tensors['train']['action'],
- weights=weight, num_actions=num_actions,
- data_loss_wt=args.solver.data_loss_wt,
- reg_loss_wt=args.solver.reg_loss_wt, ewma_decay=ewma_decay)
-
-
- if args.solver.freeze_conv:
- vars_to_optimize = list(set(tf.trainable_variables()) - set(vars_))
- else:
- vars_to_optimize = None
-
- m.lr_op, m.global_step_op, m.train_op, m.should_stop_op, m.optimizer, \
- m.sync_optimizer = tf_utils.setup_training(
- m.total_loss_op,
- args.solver.initial_learning_rate,
- args.solver.steps_per_decay,
- args.solver.learning_rate_decay,
- args.solver.momentum,
- args.solver.max_steps,
- args.solver.sync,
- args.solver.adjust_lr_sync,
- args.solver.num_workers,
- args.solver.task,
- vars_to_optimize=vars_to_optimize,
- clip_gradient_norm=args.solver.clip_gradient_norm,
- typ=args.solver.typ, momentum2=args.solver.momentum2,
- adam_eps=args.solver.adam_eps)
-
-
- if args.arch.sample_gt_prob_type == 'inverse_sigmoid_decay':
- m.sample_gt_prob_op = tf_utils.inverse_sigmoid_decay(args.arch.isd_k,
- m.global_step_op)
- elif args.arch.sample_gt_prob_type == 'zero':
- m.sample_gt_prob_op = tf.constant(-1.0, dtype=tf.float32)
- elif args.arch.sample_gt_prob_type.split('_')[0] == 'step':
- step = int(args.arch.sample_gt_prob_type.split('_')[1])
- m.sample_gt_prob_op = tf_utils.step_gt_prob(
- step, m.input_tensors['step']['step_number'][0,0,0])
-
- m.sample_action_type = args.arch.action_sample_type
- m.sample_action_combine_type = args.arch.action_sample_combine_type
- _add_summaries(m, summary_mode, args.summary.arop_full_summary_iters)
-
- m.init_op = tf.group(tf.global_variables_initializer(),
- tf.local_variables_initializer())
- m.saver_op = tf.train.Saver(keep_checkpoint_every_n_hours=4,
- write_version=tf.train.SaverDef.V2)
-
- return m
diff --git a/research/cognitive_planning/BUILD b/research/cognitive_planning/BUILD
deleted file mode 100644
index 3561987df8ae43df60c78690b6c3a52fcb887a3e..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/BUILD
+++ /dev/null
@@ -1,19 +0,0 @@
-package(default_visibility = [":internal"])
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-package_group(
- name = "internal",
- packages = [
- "//cognitive_planning/...",
- ],
-)
-
-py_binary(
- name = "train_supervised_active_vision",
- srcs = [
- "train_supervised_active_vision.py",
- ],
-)
diff --git a/research/cognitive_planning/README.md b/research/cognitive_planning/README.md
deleted file mode 100644
index 1c63ddc3f906a74141e7dccd4dee161eb095e546..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/README.md
+++ /dev/null
@@ -1,157 +0,0 @@
-# cognitive_planning
-
-**Visual Representation for Semantic Target Driven Navigation**
-
-Arsalan Mousavian, Alexander Toshev, Marek Fiser, Jana Kosecka, James Davidson
-
-This is the implementation of semantic target driven navigation training and evaluation on
-Active Vision dataset.
-
-ECCV Workshop on Visual Learning and Embodied Agents in Simulation Environments
-2018.
-
-/(train|dev|test).txt`. For sequence tagging data, each line should contain a word followed by a space followed by that word's tag. Sentences should be separated by empty lines. For dependency parsing, each tag should be of the form ``-`` (e.g., `0-root`).
-
-After all of the data has been downloaded, run `preprocessing.py`.
-
-## Training a Model
-Run `python cvt.py --mode=train --model_name=chunking_model`. By default this trains a model on the chunking data downloaded with `fetch_data.sh`. To change which task(s) are trained on or model hyperparameters, modify [base/configure.py](base/configure.py). Models are automatically checkpointed every 1000 steps; training will continue from the latest checkpoint if training is interrupted and restarted. Model checkpoints and other data such as dev set accuracy over time are stored in `data/models/`.
-
-## Evaluating a Model
-Run `python cvt.py --mode=eval --model_name=chunking_model`. A CVT model trained on the chunking data for 200k steps should get at least 97.1 F1 on the dev set and 96.6 F1 on the test set.
-
-## Citation
-If you use this code for your publication, please cite the original paper:
-```
-@inproceedings{clark2018semi,
- title = {Semi-Supervised Sequence Modeling with Cross-View Training},
- author = {Kevin Clark and Minh-Thang Luong and Christopher D. Manning and Quoc V. Le},
- booktitle = {EMNLP},
- year = {2018}
-}
-```
-
-## Contact
-* [Kevin Clark](https://cs.stanford.edu/~kevclark/) (@clarkkev).
-* [Thang Luong](https://nlp.stanford.edu/~lmthang/) (@lmthang).
-
diff --git a/research/cvt_text/__init__.py b/research/cvt_text/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/base/__init__.py b/research/cvt_text/base/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/base/configure.py b/research/cvt_text/base/configure.py
deleted file mode 100644
index 38a69859412ab8b23f8399df105ba5d403b7de5b..0000000000000000000000000000000000000000
--- a/research/cvt_text/base/configure.py
+++ /dev/null
@@ -1,139 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Classes for storing hyperparameters, data locations, etc."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import json
-from os.path import join
-import tensorflow as tf
-
-
-class Config(object):
- """Stores everything needed to train a model."""
-
- def __init__(self, **kwargs):
- # general
- self.data_dir = './data' # top directory for data (corpora, models, etc.)
- self.model_name = 'default_model' # name identifying the current model
-
- # mode
- self.mode = 'train' # either "train" or "eval"
- self.task_names = ['chunk'] # list of tasks this model will learn
- # more than one trains a multi-task model
- self.is_semisup = True # whether to use CVT or train purely supervised
- self.for_preprocessing = False # is this for the preprocessing script
-
- # embeddings
- self.pretrained_embeddings = 'glove.6B.300d.txt' # which pretrained
- # embeddings to use
- self.word_embedding_size = 300 # size of each word embedding
-
- # encoder
- self.use_chars = True # whether to include a character-level cnn
- self.char_embedding_size = 50 # size of character embeddings
- self.char_cnn_filter_widths = [2, 3, 4] # filter widths for the char cnn
- self.char_cnn_n_filters = 100 # number of filters for each filter width
- self.unidirectional_sizes = [1024] # size of first Bi-LSTM
- self.bidirectional_sizes = [512] # size of second Bi-LSTM
- self.projection_size = 512 # projections size for LSTMs and hidden layers
-
- # dependency parsing
- self.depparse_projection_size = 128 # size of the representations used in
- # the bilinear classifier for parsing
-
- # tagging
- self.label_encoding = 'BIOES' # label encoding scheme for entity-level
- # tagging tasks
- self.label_smoothing = 0.1 # label smoothing rate for tagging tasks
-
- # optimization
- self.lr = 0.5 # base learning rate
- self.momentum = 0.9 # momentum
- self.grad_clip = 1.0 # maximum gradient norm during optimization
- self.warm_up_steps = 5000.0 # linearly ramp up the lr for this many steps
- self.lr_decay = 0.005 # factor for gradually decaying the lr
-
- # EMA
- self.ema_decay = 0.998 # EMA coefficient for averaged model weights
- self.ema_test = True # whether to use EMA weights at test time
- self.ema_teacher = False # whether to use EMA weights for the teacher model
-
- # regularization
- self.labeled_keep_prob = 0.5 # 1 - dropout on labeled examples
- self.unlabeled_keep_prob = 0.8 # 1 - dropout on unlabeled examples
-
- # sizing
- self.max_sentence_length = 100 # maximum length of unlabeled sentences
- self.max_word_length = 20 # maximum length of words for char cnn
- self.train_batch_size = 64 # train batch size
- self.test_batch_size = 64 # test batch size
- self.buckets = [(0, 15), (15, 40), (40, 1000)] # buckets for binning
- # sentences by length
-
- # training
- self.print_every = 25 # how often to print out training progress
- self.eval_dev_every = 500 # how often to evaluate on the dev set
- self.eval_train_every = 2000 # how often to evaluate on the train set
- self.save_model_every = 1000 # how often to checkpoint the model
-
- # data set
- self.train_set_percent = 100 # how much of the train set to use
-
- for k, v in kwargs.iteritems():
- if k not in self.__dict__:
- raise ValueError("Unknown argument", k)
- self.__dict__[k] = v
-
- self.dev_set = self.mode == "train" # whether to evaluate on the dev or
- # test set
-
- # locations of various data files
- self.raw_data_topdir = join(self.data_dir, 'raw_data')
- self.unsupervised_data = join(
- self.raw_data_topdir,
- 'unlabeled_data',
- '1-billion-word-language-modeling-benchmark-r13output',
- 'training-monolingual.tokenized.shuffled')
- self.pretrained_embeddings_file = join(
- self.raw_data_topdir, 'pretrained_embeddings',
- self.pretrained_embeddings)
-
- self.preprocessed_data_topdir = join(self.data_dir, 'preprocessed_data')
- self.embeddings_dir = join(self.preprocessed_data_topdir,
- self.pretrained_embeddings.rsplit('.', 1)[0])
- self.word_vocabulary = join(self.embeddings_dir, 'word_vocabulary.pkl')
- self.word_embeddings = join(self.embeddings_dir, 'word_embeddings.pkl')
-
- self.model_dir = join(self.data_dir, "models", self.model_name)
- self.checkpoints_dir = join(self.model_dir, 'checkpoints')
- self.checkpoint = join(self.checkpoints_dir, 'checkpoint.ckpt')
- self.best_model_checkpoints_dir = join(
- self.model_dir, 'best_model_checkpoints')
- self.best_model_checkpoint = join(
- self.best_model_checkpoints_dir, 'checkpoint.ckpt')
- self.progress = join(self.checkpoints_dir, 'progress.pkl')
- self.summaries_dir = join(self.model_dir, 'summaries')
- self.history_file = join(self.model_dir, 'history.pkl')
-
- def write(self):
- tf.gfile.MakeDirs(self.model_dir)
- with open(join(self.model_dir, 'config.json'), 'w') as f:
- f.write(json.dumps(self.__dict__, sort_keys=True, indent=4,
- separators=(',', ': ')))
-
diff --git a/research/cvt_text/base/embeddings.py b/research/cvt_text/base/embeddings.py
deleted file mode 100644
index 8863f547efb560d627a01c150c451e5221b9df77..0000000000000000000000000000000000000000
--- a/research/cvt_text/base/embeddings.py
+++ /dev/null
@@ -1,167 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-
-"""Utilities for handling word embeddings."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import re
-import numpy as np
-import tensorflow as tf
-
-from base import utils
-
-
-_CHARS = [
- # punctuation
- '!', '\'', '#', '$', '%', '&', '"', '(', ')', '*', '+', ',', '-', '.',
- '/', '\\', '_', '`', '{', '}', '[', ']', '<', '>', ':', ';', '?', '@',
- # digits
- '0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
- # letters
- 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N',
- 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
- 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
- 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
- # special characters
- '£', '€', '®', '™', '�', '½', '»', '•', '—', '“', '”', '°', '‘', '’'
-]
-
-# words not in GloVe that still should have embeddings
-_EXTRA_WORDS = [
- # common digit patterns
- '0/0', '0/00', '00/00', '0/000',
- '00/00/00', '0/00/00', '00/00/0000', '0/00/0000',
- '00-00', '00-00-00', '0-00-00', '00-00-0000', '0-00-0000', '0000-00-00',
- '00-0-00-0', '00000000', '0:00.000', '00:00.000',
- '0%', '00%', '00.' '0000.', '0.0bn', '0.0m', '0-', '00-',
- # ontonotes uses **f to represent formulas and -amp- instead of amperstands
- '**f', '-amp-'
-]
-SPECIAL_TOKENS = ['', '', '', '', '']
-NUM_CHARS = len(_CHARS) + len(SPECIAL_TOKENS)
-PAD, UNK, START, END, MISSING = 0, 1, 2, 3, 4
-
-
-class Vocabulary(collections.OrderedDict):
- def __getitem__(self, w):
- return self.get(w, UNK)
-
-
-@utils.Memoize
-def get_char_vocab():
- characters = _CHARS
- for i, special in enumerate(SPECIAL_TOKENS):
- characters.insert(i, special)
- return Vocabulary({c: i for i, c in enumerate(characters)})
-
-
-@utils.Memoize
-def get_inv_char_vocab():
- return {i: c for c, i in get_char_vocab().items()}
-
-
-def get_word_vocab(config):
- return Vocabulary(utils.load_cpickle(config.word_vocabulary))
-
-
-def get_word_embeddings(config):
- return utils.load_cpickle(config.word_embeddings)
-
-
-@utils.Memoize
-def _punctuation_ids(vocab_path):
- vocab = Vocabulary(utils.load_cpickle(vocab_path))
- return set(i for w, i in vocab.iteritems() if w in [
- '!', '...', '``', '{', '}', '(', ')', '[', ']', '--', '-', ',', '.',
- "''", '`', ';', ':', '?'])
-
-
-def get_punctuation_ids(config):
- return _punctuation_ids(config.word_vocabulary)
-
-
-class PretrainedEmbeddingLoader(object):
- def __init__(self, config):
- self.config = config
- self.vocabulary = {}
- self.vectors = []
- self.vector_size = config.word_embedding_size
-
- def _add_vector(self, w):
- if w not in self.vocabulary:
- self.vocabulary[w] = len(self.vectors)
- self.vectors.append(np.zeros(self.vector_size, dtype='float32'))
-
- def build(self):
- utils.log('loading pretrained embeddings from',
- self.config.pretrained_embeddings_file)
- for special in SPECIAL_TOKENS:
- self._add_vector(special)
- for extra in _EXTRA_WORDS:
- self._add_vector(extra)
- with tf.gfile.GFile(
- self.config.pretrained_embeddings_file, 'r') as f:
- for i, line in enumerate(f):
- if i % 10000 == 0:
- utils.log('on line', i)
-
- split = line.decode('utf8').split()
- w = normalize_word(split[0])
-
- try:
- vec = np.array(map(float, split[1:]), dtype='float32')
- if vec.size != self.vector_size:
- utils.log('vector for line', i, 'has size', vec.size, 'so skipping')
- utils.log(line[:100] + '...')
- continue
- except:
- utils.log('can\'t parse line', i, 'so skipping')
- utils.log(line[:100] + '...')
- continue
- if w not in self.vocabulary:
- self.vocabulary[w] = len(self.vectors)
- self.vectors.append(vec)
- utils.log('writing vectors!')
- self._write()
-
- def _write(self):
- utils.write_cpickle(np.vstack(self.vectors), self.config.word_embeddings)
- utils.write_cpickle(self.vocabulary, self.config.word_vocabulary)
-
-
-def normalize_chars(w):
- if w == '-LRB-':
- return '('
- elif w == '-RRB-':
- return ')'
- elif w == '-LCB-':
- return '{'
- elif w == '-RCB-':
- return '}'
- elif w == '-LSB-':
- return '['
- elif w == '-RSB-':
- return ']'
- return w.replace(r'\/', '/').replace(r'\*', '*')
-
-
-def normalize_word(w):
- return re.sub(r'\d', '0', normalize_chars(w).lower())
diff --git a/research/cvt_text/base/utils.py b/research/cvt_text/base/utils.py
deleted file mode 100644
index 3a9ee40d5a50b98ec06a315b8c23e2fce3b9e6f5..0000000000000000000000000000000000000000
--- a/research/cvt_text/base/utils.py
+++ /dev/null
@@ -1,68 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Various utilities."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import cPickle
-import sys
-import tensorflow as tf
-
-
-class Memoize(object):
- def __init__(self, f):
- self.f = f
- self.cache = {}
-
- def __call__(self, *args):
- if args not in self.cache:
- self.cache[args] = self.f(*args)
- return self.cache[args]
-
-
-def load_cpickle(path, memoized=True):
- return _load_cpickle_memoize(path) if memoized else _load_cpickle(path)
-
-
-def _load_cpickle(path):
- with tf.gfile.GFile(path, 'r') as f:
- return cPickle.load(f)
-
-
-@Memoize
-def _load_cpickle_memoize(path):
- return _load_cpickle(path)
-
-
-def write_cpickle(o, path):
- tf.gfile.MakeDirs(path.rsplit('/', 1)[0])
- with tf.gfile.GFile(path, 'w') as f:
- cPickle.dump(o, f, -1)
-
-
-def log(*args):
- msg = ' '.join(map(str, args))
- sys.stdout.write(msg + '\n')
- sys.stdout.flush()
-
-
-def heading(*args):
- log()
- log(80 * '=')
- log(*args)
- log(80 * '=')
diff --git a/research/cvt_text/corpus_processing/__init__.py b/research/cvt_text/corpus_processing/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/corpus_processing/example.py b/research/cvt_text/corpus_processing/example.py
deleted file mode 100644
index 023d2fa07cf02f2b672901b0c378ae4a56ef8271..0000000000000000000000000000000000000000
--- a/research/cvt_text/corpus_processing/example.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Base class for training examples."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from base import embeddings
-
-
-CONTRACTION_WORDS = set(w + 'n' for w in
- ['do', 'does', 'did', 'is', 'are', 'was', 'were', 'has',
- 'have', 'had', 'could', 'would', 'should', 'ca', 'wo',
- 'ai', 'might'])
-
-
-class Example(object):
- def __init__(self, words, word_vocab, char_vocab):
- words = words[:]
- # Fix inconsistent tokenization between datasets
- for i in range(len(words)):
- if (words[i].lower() == '\'t' and i > 0 and
- words[i - 1].lower() in CONTRACTION_WORDS):
- words[i] = words[i - 1][-1] + words[i]
- words[i - 1] = words[i - 1][:-1]
-
- self.words = ([embeddings.START] +
- [word_vocab[embeddings.normalize_word(w)] for w in words] +
- [embeddings.END])
- self.chars = ([[embeddings.MISSING]] +
- [[char_vocab[c] for c in embeddings.normalize_chars(w)]
- for w in words] +
- [[embeddings.MISSING]])
-
- def __repr__(self,):
- inv_char_vocab = embeddings.get_inv_char_vocab()
- return ' '.join([''.join([inv_char_vocab[c] for c in w])
- for w in self.chars])
diff --git a/research/cvt_text/corpus_processing/minibatching.py b/research/cvt_text/corpus_processing/minibatching.py
deleted file mode 100644
index c0ebbf723db74b7214bdf0b98284b1222dddbc2c..0000000000000000000000000000000000000000
--- a/research/cvt_text/corpus_processing/minibatching.py
+++ /dev/null
@@ -1,143 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for constructing minibatches."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import random
-import numpy as np
-
-from base import embeddings
-
-
-def get_bucket(config, l):
- for i, (s, e) in enumerate(config.buckets):
- if s <= l < e:
- return config.buckets[i]
-
-
-def build_array(nested_lists, dtype='int32'):
- depth_to_sizes = collections.defaultdict(set)
- _get_sizes(nested_lists, depth_to_sizes)
- shape = [max(depth_to_sizes[depth]) for depth in range(len(depth_to_sizes))]
-
- copy_depth = len(depth_to_sizes) - 1
- while copy_depth > 0 and len(depth_to_sizes[copy_depth]) == 1:
- copy_depth -= 1
-
- arr = np.zeros(shape, dtype=dtype)
- _fill_array(nested_lists, arr, copy_depth)
-
- return arr
-
-
-def _get_sizes(nested_lists, depth_to_sizes, depth=0):
- depth_to_sizes[depth].add(len(nested_lists))
- first_elem = nested_lists[0]
- if (isinstance(first_elem, collections.Sequence) or
- isinstance(first_elem, np.ndarray)):
- for sublist in nested_lists:
- _get_sizes(sublist, depth_to_sizes, depth + 1)
-
-
-def _fill_array(nested_lists, arr, copy_depth, depth=0):
- if depth == copy_depth:
- for i in range(len(nested_lists)):
- if isinstance(nested_lists[i], np.ndarray):
- arr[i] = nested_lists[i]
- else:
- arr[i] = np.array(nested_lists[i])
- else:
- for i in range(len(nested_lists)):
- _fill_array(nested_lists[i], arr[i], copy_depth, depth + 1)
-
-
-class Dataset(object):
- def __init__(self, config, examples, task_name='unlabeled', is_training=False):
- self._config = config
- self.examples = examples
- self.size = len(examples)
- self.task_name = task_name
- self.is_training = is_training
-
- def get_minibatches(self, minibatch_size):
- by_bucket = collections.defaultdict(list)
- for i, e in enumerate(self.examples):
- by_bucket[get_bucket(self._config, len(e.words))].append(i)
-
- # save memory by weighting examples so longer sentences have
- # smaller minibatches.
- weight = lambda ind: np.sqrt(len(self.examples[ind].words))
- total_weight = float(sum(weight(i) for i in range(len(self.examples))))
- weight_per_batch = minibatch_size * total_weight / len(self.examples)
- cumulative_weight = 0.0
- id_batches = []
- for _, ids in by_bucket.iteritems():
- ids = np.array(ids)
- np.random.shuffle(ids)
- curr_batch, curr_weight = [], 0.0
- for i, curr_id in enumerate(ids):
- curr_batch.append(curr_id)
- curr_weight += weight(curr_id)
- if (i == len(ids) - 1 or cumulative_weight + curr_weight >=
- (len(id_batches) + 1) * weight_per_batch):
- cumulative_weight += curr_weight
- id_batches.append(np.array(curr_batch))
- curr_batch, curr_weight = [], 0.0
- random.shuffle(id_batches)
-
- for id_batch in id_batches:
- yield self._make_minibatch(id_batch)
-
- def endless_minibatches(self, minibatch_size):
- while True:
- for mb in self.get_minibatches(minibatch_size):
- yield mb
-
- def _make_minibatch(self, ids):
- examples = [self.examples[i] for i in ids]
- sentence_lengths = np.array([len(e.words) for e in examples])
- max_word_length = min(max(max(len(word) for word in e.chars)
- for e in examples),
- self._config.max_word_length)
- characters = [[[embeddings.PAD] + [embeddings.START] + w[:max_word_length] +
- [embeddings.END] + [embeddings.PAD] for w in e.chars]
- for e in examples]
- # the first and last words are masked because they are start/end tokens
- mask = build_array([[0] + [1] * (length - 2) + [0]
- for length in sentence_lengths])
- words = build_array([e.words for e in examples])
- chars = build_array(characters, dtype='int16')
- return Minibatch(
- task_name=self.task_name,
- size=ids.size,
- examples=examples,
- ids=ids,
- teacher_predictions={},
- words=words,
- chars=chars,
- lengths=sentence_lengths,
- mask=mask,
- )
-
-
-Minibatch = collections.namedtuple('Minibatch', [
- 'task_name', 'size', 'examples', 'ids', 'teacher_predictions',
- 'words', 'chars', 'lengths', 'mask'
-])
diff --git a/research/cvt_text/corpus_processing/scorer.py b/research/cvt_text/corpus_processing/scorer.py
deleted file mode 100644
index 8173dae36d83face5c2f01e804b3a46b043259a7..0000000000000000000000000000000000000000
--- a/research/cvt_text/corpus_processing/scorer.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Abstract base class for evaluation."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-
-
-class Scorer(object):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self):
- self._updated = False
- self._cached_results = {}
-
- @abc.abstractmethod
- def update(self, examples, predictions, loss):
- self._updated = True
-
- @abc.abstractmethod
- def get_loss(self):
- pass
-
- @abc.abstractmethod
- def _get_results(self):
- return []
-
- def get_results(self, prefix=""):
- results = self._get_results() if self._updated else self._cached_results
- self._cached_results = results
- self._updated = False
- return [(prefix + k, v) for k, v in results]
-
- def results_str(self):
- return " - ".join(["{:}: {:.2f}".format(k, v)
- for k, v in self.get_results()])
diff --git a/research/cvt_text/corpus_processing/unlabeled_data.py b/research/cvt_text/corpus_processing/unlabeled_data.py
deleted file mode 100644
index 0021c50618a453a0c319c511556412781268c6ed..0000000000000000000000000000000000000000
--- a/research/cvt_text/corpus_processing/unlabeled_data.py
+++ /dev/null
@@ -1,81 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Reads data from a large unlabeled corpus."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import tensorflow as tf
-
-from base import embeddings
-from corpus_processing import example
-from corpus_processing import minibatching
-
-
-class UnlabeledDataReader(object):
- def __init__(self, config, starting_file=0, starting_line=0, one_pass=False):
- self.config = config
- self.current_file = starting_file
- self.current_line = starting_line
- self._one_pass = one_pass
-
- def endless_minibatches(self):
- for examples in self.get_unlabeled_examples():
- d = minibatching.Dataset(self.config, examples, 'unlabeled')
- for mb in d.get_minibatches(self.config.train_batch_size):
- yield mb
-
- def _make_examples(self, sentences):
- word_vocab = embeddings.get_word_vocab(self.config)
- char_vocab = embeddings.get_char_vocab()
- return [
- example.Example(sentence, word_vocab, char_vocab)
- for sentence in sentences
- ]
-
- def get_unlabeled_examples(self):
- lines = []
- for words in self.get_unlabeled_sentences():
- lines.append(words)
- if len(lines) >= 10000:
- yield self._make_examples(lines)
- lines = []
-
- def get_unlabeled_sentences(self):
- while True:
- file_ids_and_names = sorted([
- (int(fname.split('-')[1].replace('.txt', '')), fname) for fname in
- tf.gfile.ListDirectory(self.config.unsupervised_data)])
- for fid, fname in file_ids_and_names:
- if fid < self.current_file:
- continue
- self.current_file = fid
- self.current_line = 0
- with tf.gfile.FastGFile(os.path.join(self.config.unsupervised_data,
- fname), 'r') as f:
- for i, line in enumerate(f):
- if i < self.current_line:
- continue
- self.current_line = i
- words = line.strip().split()
- if len(words) < self.config.max_sentence_length:
- yield words
- self.current_file = 0
- self.current_line = 0
- if self._one_pass:
- break
diff --git a/research/cvt_text/cvt.py b/research/cvt_text/cvt.py
deleted file mode 100644
index 593ce5bb62e197d3392fb0e602afc1db896edd7a..0000000000000000000000000000000000000000
--- a/research/cvt_text/cvt.py
+++ /dev/null
@@ -1,67 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Run training and evaluation for CVT text models."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from base import configure
-from base import utils
-from training import trainer
-from training import training_progress
-
-
-FLAGS = tf.app.flags.FLAGS
-tf.app.flags.DEFINE_string('mode', 'train', '"train" or "eval')
-tf.app.flags.DEFINE_string('model_name', 'default_model',
- 'A name identifying the model being '
- 'trained/evaluated')
-
-
-def main():
- utils.heading('SETUP')
- config = configure.Config(mode=FLAGS.mode, model_name=FLAGS.model_name)
- config.write()
- with tf.Graph().as_default() as graph:
- model_trainer = trainer.Trainer(config)
- summary_writer = tf.summary.FileWriter(config.summaries_dir)
- checkpoints_saver = tf.train.Saver(max_to_keep=1)
- best_model_saver = tf.train.Saver(max_to_keep=1)
- init_op = tf.global_variables_initializer()
- graph.finalize()
- with tf.Session() as sess:
- sess.run(init_op)
- progress = training_progress.TrainingProgress(
- config, sess, checkpoints_saver, best_model_saver,
- config.mode == 'train')
- utils.log()
- if config.mode == 'train':
- utils.heading('START TRAINING ({:})'.format(config.model_name))
- model_trainer.train(sess, progress, summary_writer)
- elif config.mode == 'eval':
- utils.heading('RUN EVALUATION ({:})'.format(config.model_name))
- progress.best_model_saver.restore(sess, tf.train.latest_checkpoint(
- config.checkpoints_dir))
- model_trainer.evaluate_all_tasks(sess, summary_writer, None)
- else:
- raise ValueError('Mode must be "train" or "eval"')
-
-
-if __name__ == '__main__':
- main()
diff --git a/research/cvt_text/fetch_data.sh b/research/cvt_text/fetch_data.sh
deleted file mode 100755
index dcdb54cf88387b6e2f9e01d493b8be1f9249e7f5..0000000000000000000000000000000000000000
--- a/research/cvt_text/fetch_data.sh
+++ /dev/null
@@ -1,51 +0,0 @@
-#!/bin/bash
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-TOPDIR='./data'
-RUNDIR=${PWD}
-
-mkdir -p ${TOPDIR}
-cd ${TOPDIR}
-mkdir -p raw_data
-mkdir -p raw_data/pretrained_embeddings
-mkdir -p raw_data/unlabeled_data
-mkdir -p raw_data/chunk
-cd ${RUNDIR}
-
-echo "Preparing GloVe embeddings"
-cd "${TOPDIR}/raw_data/pretrained_embeddings"
-curl -OL http://nlp.stanford.edu/data/glove.6B.zip
-unzip glove.6B.zip
-cd ${RUNDIR}
-echo
-
-echo "Preparing lm1b corpus"
-cd "${TOPDIR}/raw_data/unlabeled_data"
-curl -OL http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz
-tar xzf 1-billion-word-language-modeling-benchmark-r13output.tar.gz
-cd ${RUNDIR}
-echo
-
-echo "Preparing chunking corpus"
-cd "${TOPDIR}/raw_data/chunk"
-curl -OL https://www.clips.uantwerpen.be/conll2000/chunking/train.txt.gz
-curl -OL http://www.clips.uantwerpen.be/conll2000/chunking/test.txt.gz
-gunzip *
-cd ${RUNDIR}
-echo
-
-echo "Done with data fetching!"
-
diff --git a/research/cvt_text/model/__init__.py b/research/cvt_text/model/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/model/encoder.py b/research/cvt_text/model/encoder.py
deleted file mode 100644
index 4b6da1255f57545995c4c4ce7079fc132b21585c..0000000000000000000000000000000000000000
--- a/research/cvt_text/model/encoder.py
+++ /dev/null
@@ -1,110 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""CNN-BiLSTM sentence encoder."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-from base import embeddings
-from model import model_helpers
-
-
-class Encoder(object):
- def __init__(self, config, inputs, pretrained_embeddings):
- self._config = config
- self._inputs = inputs
-
- self.word_reprs = self._get_word_reprs(pretrained_embeddings)
- self.uni_fw, self.uni_bw = self._get_unidirectional_reprs(self.word_reprs)
- self.uni_reprs = tf.concat([self.uni_fw, self.uni_bw], axis=-1)
- self.bi_fw, self.bi_bw, self.bi_reprs = self._get_bidirectional_reprs(
- self.uni_reprs)
-
- def _get_word_reprs(self, pretrained_embeddings):
- with tf.variable_scope('word_embeddings'):
- word_embedding_matrix = tf.get_variable(
- 'word_embedding_matrix', initializer=pretrained_embeddings)
- word_embeddings = tf.nn.embedding_lookup(
- word_embedding_matrix, self._inputs.words)
- word_embeddings = tf.nn.dropout(word_embeddings, self._inputs.keep_prob)
- word_embeddings *= tf.get_variable('emb_scale', initializer=1.0)
-
- if not self._config.use_chars:
- return word_embeddings
-
- with tf.variable_scope('char_embeddings'):
- char_embedding_matrix = tf.get_variable(
- 'char_embeddings',
- shape=[embeddings.NUM_CHARS, self._config.char_embedding_size])
- char_embeddings = tf.nn.embedding_lookup(char_embedding_matrix,
- self._inputs.chars)
- shape = tf.shape(char_embeddings)
- char_embeddings = tf.reshape(
- char_embeddings,
- shape=[-1, shape[-2], self._config.char_embedding_size])
- char_reprs = []
- for filter_width in self._config.char_cnn_filter_widths:
- conv = tf.layers.conv1d(
- char_embeddings, self._config.char_cnn_n_filters, filter_width)
- conv = tf.nn.relu(conv)
- conv = tf.nn.dropout(tf.reduce_max(conv, axis=1),
- self._inputs.keep_prob)
- conv = tf.reshape(conv, shape=[-1, shape[1],
- self._config.char_cnn_n_filters])
- char_reprs.append(conv)
- return tf.concat([word_embeddings] + char_reprs, axis=-1)
-
- def _get_unidirectional_reprs(self, word_reprs):
- with tf.variable_scope('unidirectional_reprs'):
- word_lstm_input_size = (
- self._config.word_embedding_size if not self._config.use_chars else
- (self._config.word_embedding_size +
- len(self._config.char_cnn_filter_widths)
- * self._config.char_cnn_n_filters))
- word_reprs.set_shape([None, None, word_lstm_input_size])
- (outputs_fw, outputs_bw), _ = tf.nn.bidirectional_dynamic_rnn(
- model_helpers.multi_lstm_cell(self._config.unidirectional_sizes,
- self._inputs.keep_prob,
- self._config.projection_size),
- model_helpers.multi_lstm_cell(self._config.unidirectional_sizes,
- self._inputs.keep_prob,
- self._config.projection_size),
- word_reprs,
- dtype=tf.float32,
- sequence_length=self._inputs.lengths,
- scope='unilstm'
- )
- return outputs_fw, outputs_bw
-
- def _get_bidirectional_reprs(self, uni_reprs):
- with tf.variable_scope('bidirectional_reprs'):
- current_outputs = uni_reprs
- outputs_fw, outputs_bw = None, None
- for size in self._config.bidirectional_sizes:
- (outputs_fw, outputs_bw), _ = tf.nn.bidirectional_dynamic_rnn(
- model_helpers.lstm_cell(size, self._inputs.keep_prob,
- self._config.projection_size),
- model_helpers.lstm_cell(size, self._inputs.keep_prob,
- self._config.projection_size),
- current_outputs,
- dtype=tf.float32,
- sequence_length=self._inputs.lengths,
- scope='bilstm'
- )
- current_outputs = tf.concat([outputs_fw, outputs_bw], axis=-1)
- return outputs_fw, outputs_bw, current_outputs
diff --git a/research/cvt_text/model/model_helpers.py b/research/cvt_text/model/model_helpers.py
deleted file mode 100644
index 3c0cb670c455b8c4fcdcd6b05b5586cb979552b9..0000000000000000000000000000000000000000
--- a/research/cvt_text/model/model_helpers.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for building the model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-
-def project(input_layers, size, name='projection'):
- return tf.add_n([tf.layers.dense(layer, size, name=name + '_' + str(i))
- for i, layer in enumerate(input_layers)])
-
-
-def lstm_cell(cell_size, keep_prob, num_proj):
- return tf.contrib.rnn.DropoutWrapper(
- tf.contrib.rnn.LSTMCell(cell_size, num_proj=min(cell_size, num_proj)),
- output_keep_prob=keep_prob)
-
-
-def multi_lstm_cell(cell_sizes, keep_prob, num_proj):
- return tf.contrib.rnn.MultiRNNCell([lstm_cell(cell_size, keep_prob, num_proj)
- for cell_size in cell_sizes])
-
-
-def masked_ce_loss(logits, labels, mask, sparse=False, roll_direction=0):
- if roll_direction != 0:
- labels = _roll(labels, roll_direction, sparse)
- mask *= _roll(mask, roll_direction, True)
- ce = ((tf.nn.sparse_softmax_cross_entropy_with_logits if sparse
- else tf.nn.softmax_cross_entropy_with_logits_v2)
- (logits=logits, labels=labels))
- return tf.reduce_sum(mask * ce) / tf.to_float(tf.reduce_sum(mask))
-
-
-def _roll(arr, direction, sparse=False):
- if sparse:
- return tf.concat([arr[:, direction:], arr[:, :direction]], axis=1)
- return tf.concat([arr[:, direction:, :], arr[:, :direction, :]], axis=1)
diff --git a/research/cvt_text/model/multitask_model.py b/research/cvt_text/model/multitask_model.py
deleted file mode 100644
index 16dfdf7da6d9bb6c531f60d88224593155af19e7..0000000000000000000000000000000000000000
--- a/research/cvt_text/model/multitask_model.py
+++ /dev/null
@@ -1,132 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A multi-task and semi-supervised NLP model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from model import encoder
-from model import shared_inputs
-
-
-class Inference(object):
- def __init__(self, config, inputs, pretrained_embeddings, tasks):
- with tf.variable_scope('encoder'):
- self.encoder = encoder.Encoder(config, inputs, pretrained_embeddings)
- self.modules = {}
- for task in tasks:
- with tf.variable_scope(task.name):
- self.modules[task.name] = task.get_module(inputs, self.encoder)
-
-
-class Model(object):
- def __init__(self, config, pretrained_embeddings, tasks):
- self._config = config
- self._tasks = tasks
-
- self._global_step, self._optimizer = self._get_optimizer()
- self._inputs = shared_inputs.Inputs(config)
- with tf.variable_scope('model', reuse=tf.AUTO_REUSE) as scope:
- inference = Inference(config, self._inputs, pretrained_embeddings,
- tasks)
- self._trainer = inference
- self._tester = inference
- self._teacher = inference
- if config.ema_test or config.ema_teacher:
- ema = tf.train.ExponentialMovingAverage(config.ema_decay)
- model_vars = tf.get_collection("trainable_variables", "model")
- ema_op = ema.apply(model_vars)
- tf.add_to_collection(tf.GraphKeys.UPDATE_OPS, ema_op)
-
- def ema_getter(getter, name, *args, **kwargs):
- var = getter(name, *args, **kwargs)
- return ema.average(var)
-
- scope.set_custom_getter(ema_getter)
- inference_ema = Inference(
- config, self._inputs, pretrained_embeddings, tasks)
- if config.ema_teacher:
- self._teacher = inference_ema
- if config.ema_test:
- self._tester = inference_ema
-
- self._unlabeled_loss = self._get_consistency_loss(tasks)
- self._unlabeled_train_op = self._get_train_op(self._unlabeled_loss)
- self._labeled_train_ops = {}
- for task in self._tasks:
- task_loss = self._trainer.modules[task.name].supervised_loss
- self._labeled_train_ops[task.name] = self._get_train_op(task_loss)
-
- def _get_consistency_loss(self, tasks):
- return sum([self._trainer.modules[task.name].unsupervised_loss
- for task in tasks])
-
- def _get_optimizer(self):
- global_step = tf.get_variable('global_step', initializer=0, trainable=False)
- warm_up_multiplier = (tf.minimum(tf.to_float(global_step),
- self._config.warm_up_steps)
- / self._config.warm_up_steps)
- decay_multiplier = 1.0 / (1 + self._config.lr_decay *
- tf.sqrt(tf.to_float(global_step)))
- lr = self._config.lr * warm_up_multiplier * decay_multiplier
- optimizer = tf.train.MomentumOptimizer(lr, self._config.momentum)
- return global_step, optimizer
-
- def _get_train_op(self, loss):
- grads, vs = zip(*self._optimizer.compute_gradients(loss))
- grads, _ = tf.clip_by_global_norm(grads, self._config.grad_clip)
- update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
- with tf.control_dependencies(update_ops):
- return self._optimizer.apply_gradients(
- zip(grads, vs), global_step=self._global_step)
-
- def _create_feed_dict(self, mb, model, is_training=True):
- feed = self._inputs.create_feed_dict(mb, is_training)
- if mb.task_name in model.modules:
- model.modules[mb.task_name].update_feed_dict(feed, mb)
- else:
- for module in model.modules.values():
- module.update_feed_dict(feed, mb)
- return feed
-
- def train_unlabeled(self, sess, mb):
- return sess.run([self._unlabeled_train_op, self._unlabeled_loss],
- feed_dict=self._create_feed_dict(mb, self._trainer))[1]
-
- def train_labeled(self, sess, mb):
- return sess.run([self._labeled_train_ops[mb.task_name],
- self._trainer.modules[mb.task_name].supervised_loss,],
- feed_dict=self._create_feed_dict(mb, self._trainer))[1]
-
- def run_teacher(self, sess, mb):
- result = sess.run({task.name: self._teacher.modules[task.name].probs
- for task in self._tasks},
- feed_dict=self._create_feed_dict(mb, self._teacher,
- False))
- for task_name, probs in result.iteritems():
- mb.teacher_predictions[task_name] = probs.astype('float16')
-
- def test(self, sess, mb):
- return sess.run(
- [self._tester.modules[mb.task_name].supervised_loss,
- self._tester.modules[mb.task_name].preds],
- feed_dict=self._create_feed_dict(mb, self._tester, False))
-
- def get_global_step(self, sess):
- return sess.run(self._global_step)
diff --git a/research/cvt_text/model/shared_inputs.py b/research/cvt_text/model/shared_inputs.py
deleted file mode 100644
index 2a97004b3270eb01c3eb459eb892514b3584bf5a..0000000000000000000000000000000000000000
--- a/research/cvt_text/model/shared_inputs.py
+++ /dev/null
@@ -1,48 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Placeholders for non-task-specific model inputs."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-
-class Inputs(object):
- def __init__(self, config):
- self._config = config
- self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
- self.label_smoothing = tf.placeholder(tf.float32, name='label_smoothing')
- self.lengths = tf.placeholder(tf.int32, shape=[None], name='lengths')
- self.mask = tf.placeholder(tf.float32, [None, None], name='mask')
- self.words = tf.placeholder(tf.int32, shape=[None, None], name='words')
- self.chars = tf.placeholder(tf.int32, shape=[None, None, None],
- name='chars')
-
- def create_feed_dict(self, mb, is_training):
- cvt = mb.task_name == 'unlabeled'
- return {
- self.keep_prob: 1.0 if not is_training else
- (self._config.unlabeled_keep_prob if cvt else
- self._config.labeled_keep_prob),
- self.label_smoothing: self._config.label_smoothing
- if (is_training and not cvt) else 0.0,
- self.lengths: mb.lengths,
- self.words: mb.words,
- self.chars: mb.chars,
- self.mask: mb.mask.astype('float32')
- }
diff --git a/research/cvt_text/model/task_module.py b/research/cvt_text/model/task_module.py
deleted file mode 100644
index 92440b4d98ad8feaa7db6f9e6a642a42805c08a4..0000000000000000000000000000000000000000
--- a/research/cvt_text/model/task_module.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Base classes for task-specific modules."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-
-
-class SupervisedModule(object):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self):
- self.supervised_loss = NotImplemented
- self.probs = NotImplemented
- self.preds = NotImplemented
-
- @abc.abstractmethod
- def update_feed_dict(self, feed, mb):
- pass
-
-
-class SemiSupervisedModule(SupervisedModule):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self):
- super(SemiSupervisedModule, self).__init__()
- self.unsupervised_loss = NotImplemented
-
diff --git a/research/cvt_text/preprocessing.py b/research/cvt_text/preprocessing.py
deleted file mode 100644
index 3dbf106be571a0e2098baab030e831ca72ea73aa..0000000000000000000000000000000000000000
--- a/research/cvt_text/preprocessing.py
+++ /dev/null
@@ -1,87 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""
-Preprocesses pretrained word embeddings, creates dev sets for tasks without a
-provided one, and figures out the set of output classes for each task.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import random
-
-from base import configure
-from base import embeddings
-from base import utils
-from task_specific.word_level import word_level_data
-
-
-def main(data_dir='./data'):
- random.seed(0)
-
- utils.log("BUILDING WORD VOCABULARY/EMBEDDINGS")
- for pretrained in ['glove.6B.300d.txt']:
- config = configure.Config(data_dir=data_dir,
- for_preprocessing=True,
- pretrained_embeddings=pretrained,
- word_embedding_size=300)
- embeddings.PretrainedEmbeddingLoader(config).build()
-
- utils.log("CONSTRUCTING DEV SETS")
- for task_name in ["chunk"]:
- # chunking does not come with a provided dev split, so create one by
- # selecting a random subset of the data
- config = configure.Config(data_dir=data_dir,
- for_preprocessing=True)
- task_data_dir = os.path.join(config.raw_data_topdir, task_name) + '/'
- train_sentences = word_level_data.TaggedDataLoader(
- config, task_name, False).get_labeled_sentences("train")
- random.shuffle(train_sentences)
- write_sentences(task_data_dir + 'train_subset.txt', train_sentences[1500:])
- write_sentences(task_data_dir + 'dev.txt', train_sentences[:1500])
-
- utils.log("WRITING LABEL MAPPINGS")
- for task_name in ["chunk"]:
- for i, label_encoding in enumerate(["BIOES"]):
- config = configure.Config(data_dir=data_dir,
- for_preprocessing=True,
- label_encoding=label_encoding)
- token_level = task_name in ["ccg", "pos", "depparse"]
- loader = word_level_data.TaggedDataLoader(config, task_name, token_level)
- if token_level:
- if i != 0:
- continue
- utils.log("WRITING LABEL MAPPING FOR", task_name.upper())
- else:
- utils.log(" Writing label mapping for", task_name.upper(),
- label_encoding)
- utils.log(" ", len(loader.label_mapping), "classes")
- utils.write_cpickle(loader.label_mapping,
- loader.label_mapping_path)
-
-
-def write_sentences(fname, sentences):
- with open(fname, 'w') as f:
- for words, tags in sentences:
- for word, tag in zip(words, tags):
- f.write(word + " " + tag + "\n")
- f.write("\n")
-
-
-if __name__ == '__main__':
- main()
diff --git a/research/cvt_text/task_specific/__init__.py b/research/cvt_text/task_specific/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/task_specific/task_definitions.py b/research/cvt_text/task_specific/task_definitions.py
deleted file mode 100644
index f13fb559285fa7919c4af42ce60848fefeeeefdd..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/task_definitions.py
+++ /dev/null
@@ -1,91 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Defines all the tasks the model can learn."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-
-from base import embeddings
-from task_specific.word_level import depparse_module
-from task_specific.word_level import depparse_scorer
-from task_specific.word_level import tagging_module
-from task_specific.word_level import tagging_scorers
-from task_specific.word_level import word_level_data
-
-
-class Task(object):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self, config, name, loader):
- self.config = config
- self.name = name
- self.loader = loader
- self.train_set = self.loader.get_dataset("train")
- self.val_set = self.loader.get_dataset("dev" if config.dev_set else "test")
-
- @abc.abstractmethod
- def get_module(self, inputs, encoder):
- pass
-
- @abc.abstractmethod
- def get_scorer(self):
- pass
-
-
-class Tagging(Task):
- def __init__(self, config, name, is_token_level=True):
- super(Tagging, self).__init__(
- config, name, word_level_data.TaggedDataLoader(
- config, name, is_token_level))
- self.n_classes = len(set(self.loader.label_mapping.values()))
- self.is_token_level = is_token_level
-
- def get_module(self, inputs, encoder):
- return tagging_module.TaggingModule(
- self.config, self.name, self.n_classes, inputs, encoder)
-
- def get_scorer(self):
- if self.is_token_level:
- return tagging_scorers.AccuracyScorer()
- else:
- return tagging_scorers.EntityLevelF1Scorer(self.loader.label_mapping)
-
-
-class DependencyParsing(Tagging):
- def __init__(self, config, name):
- super(DependencyParsing, self).__init__(config, name, True)
-
- def get_module(self, inputs, encoder):
- return depparse_module.DepparseModule(
- self.config, self.name, self.n_classes, inputs, encoder)
-
- def get_scorer(self):
- return depparse_scorer.DepparseScorer(
- self.n_classes, (embeddings.get_punctuation_ids(self.config)))
-
-
-def get_task(config, name):
- if name in ["ccg", "pos"]:
- return Tagging(config, name, True)
- elif name in ["chunk", "ner", "er"]:
- return Tagging(config, name, False)
- elif name == "depparse":
- return DependencyParsing(config, name)
- else:
- raise ValueError("Unknown task", name)
diff --git a/research/cvt_text/task_specific/word_level/__init__.py b/research/cvt_text/task_specific/word_level/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/task_specific/word_level/depparse_module.py b/research/cvt_text/task_specific/word_level/depparse_module.py
deleted file mode 100644
index b1207a9815219ca3f53e2a958bf8df8656c009fa..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/depparse_module.py
+++ /dev/null
@@ -1,126 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Dependency parsing module."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from corpus_processing import minibatching
-from model import model_helpers
-from model import task_module
-
-
-class DepparseModule(task_module.SemiSupervisedModule):
- def __init__(self, config, task_name, n_classes, inputs, encoder):
- super(DepparseModule, self).__init__()
-
- self.task_name = task_name
- self.n_classes = n_classes
- self.labels = labels = tf.placeholder(tf.float32, [None, None, None],
- name=task_name + '_labels')
-
- class PredictionModule(object):
- def __init__(self, name, dep_reprs, head_reprs, roll_direction=0):
- self.name = name
- with tf.variable_scope(name + '/predictions'):
- # apply hidden layers to the input representations
- arc_dep_hidden = model_helpers.project(
- dep_reprs, config.projection_size, 'arc_dep_hidden')
- arc_head_hidden = model_helpers.project(
- head_reprs, config.projection_size, 'arc_head_hidden')
- arc_dep_hidden = tf.nn.relu(arc_dep_hidden)
- arc_head_hidden = tf.nn.relu(arc_head_hidden)
- arc_head_hidden = tf.nn.dropout(arc_head_hidden, inputs.keep_prob)
- arc_dep_hidden = tf.nn.dropout(arc_dep_hidden, inputs.keep_prob)
-
- # bilinear classifier excluding the final dot product
- arc_head = tf.layers.dense(
- arc_head_hidden, config.depparse_projection_size, name='arc_head')
- W = tf.get_variable('shared_W',
- shape=[config.projection_size, n_classes,
- config.depparse_projection_size])
- Wr = tf.get_variable('relation_specific_W',
- shape=[config.projection_size,
- config.depparse_projection_size])
- Wr_proj = tf.tile(tf.expand_dims(Wr, axis=-2), [1, n_classes, 1])
- W += Wr_proj
- arc_dep = tf.tensordot(arc_dep_hidden, W, axes=[[-1], [0]])
- shape = tf.shape(arc_dep)
- arc_dep = tf.reshape(arc_dep,
- [shape[0], -1, config.depparse_projection_size])
-
- # apply the transformer scaling trick to prevent dot products from
- # getting too large (possibly not necessary)
- scale = np.power(
- config.depparse_projection_size, 0.25).astype('float32')
- scale = tf.get_variable('scale', initializer=scale, dtype=tf.float32)
- arc_dep /= scale
- arc_head /= scale
-
- # compute the scores for each candidate arc
- word_scores = tf.matmul(arc_head, arc_dep, transpose_b=True)
- root_scores = tf.layers.dense(arc_head, n_classes, name='root_score')
- arc_scores = tf.concat([root_scores, word_scores], axis=-1)
-
- # disallow the model from making impossible predictions
- mask = inputs.mask
- mask_shape = tf.shape(mask)
- mask = tf.tile(tf.expand_dims(mask, -1), [1, 1, n_classes])
- mask = tf.reshape(mask, [-1, mask_shape[1] * n_classes])
- mask = tf.concat([tf.ones((mask_shape[0], 1)),
- tf.zeros((mask_shape[0], n_classes - 1)), mask],
- axis=1)
- mask = tf.tile(tf.expand_dims(mask, 1), [1, mask_shape[1], 1])
- arc_scores += (mask - 1) * 100.0
-
- self.logits = arc_scores
- self.loss = model_helpers.masked_ce_loss(
- self.logits, labels, inputs.mask,
- roll_direction=roll_direction)
-
- primary = PredictionModule(
- 'primary',
- [encoder.uni_reprs, encoder.bi_reprs],
- [encoder.uni_reprs, encoder.bi_reprs])
- ps = [
- PredictionModule(
- 'full',
- [encoder.uni_reprs, encoder.bi_reprs],
- [encoder.uni_reprs, encoder.bi_reprs]),
- PredictionModule('fw_fw', [encoder.uni_fw], [encoder.uni_fw]),
- PredictionModule('fw_bw', [encoder.uni_fw], [encoder.uni_bw]),
- PredictionModule('bw_fw', [encoder.uni_bw], [encoder.uni_fw]),
- PredictionModule('bw_bw', [encoder.uni_bw], [encoder.uni_bw]),
- ]
-
- self.unsupervised_loss = sum(p.loss for p in ps)
- self.supervised_loss = primary.loss
- self.probs = tf.nn.softmax(primary.logits)
- self.preds = tf.argmax(primary.logits, axis=-1)
-
- def update_feed_dict(self, feed, mb):
- if self.task_name in mb.teacher_predictions:
- feed[self.labels] = mb.teacher_predictions[self.task_name]
- elif mb.task_name != 'unlabeled':
- labels = minibatching.build_array(
- [[0] + e.labels + [0] for e in mb.examples])
- feed[self.labels] = np.eye(
- (1 + mb.words.shape[1]) * self.n_classes)[labels]
-
diff --git a/research/cvt_text/task_specific/word_level/depparse_scorer.py b/research/cvt_text/task_specific/word_level/depparse_scorer.py
deleted file mode 100644
index 142cf79f9b3c9a7c172c1ea642683fa69b46dd4c..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/depparse_scorer.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Dependency parsing evaluation (computes UAS/LAS)."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from task_specific.word_level import word_level_scorer
-
-
-class DepparseScorer(word_level_scorer.WordLevelScorer):
- def __init__(self, n_relations, punctuation):
- super(DepparseScorer, self).__init__()
- self._n_relations = n_relations
- self._punctuation = punctuation if punctuation else None
-
- def _get_results(self):
- correct_unlabeled, correct_labeled, count = 0, 0, 0
- for example, preds in zip(self._examples, self._preds):
- for w, y_true, y_pred in zip(example.words[1:-1], example.labels, preds):
- if w in self._punctuation:
- continue
- count += 1
- correct_labeled += (1 if y_pred == y_true else 0)
- correct_unlabeled += (1 if int(y_pred // self._n_relations) ==
- int(y_true // self._n_relations) else 0)
- return [
- ("las", 100.0 * correct_labeled / count),
- ("uas", 100.0 * correct_unlabeled / count),
- ("loss", self.get_loss()),
- ]
diff --git a/research/cvt_text/task_specific/word_level/tagging_module.py b/research/cvt_text/task_specific/word_level/tagging_module.py
deleted file mode 100644
index f1d85f333dbab5318f87cf39ec256e3f6c5832f6..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/tagging_module.py
+++ /dev/null
@@ -1,76 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Sequence tagging module."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from corpus_processing import minibatching
-from model import model_helpers
-from model import task_module
-
-
-class TaggingModule(task_module.SemiSupervisedModule):
- def __init__(self, config, task_name, n_classes, inputs,
- encoder):
- super(TaggingModule, self).__init__()
- self.task_name = task_name
- self.n_classes = n_classes
- self.labels = labels = tf.placeholder(tf.float32, [None, None, None],
- name=task_name + '_labels')
-
- class PredictionModule(object):
- def __init__(self, name, input_reprs, roll_direction=0, activate=True):
- self.name = name
- with tf.variable_scope(name + '/predictions'):
- projected = model_helpers.project(input_reprs, config.projection_size)
- if activate:
- projected = tf.nn.relu(projected)
- self.logits = tf.layers.dense(projected, n_classes, name='predict')
-
- targets = labels
- targets *= (1 - inputs.label_smoothing)
- targets += inputs.label_smoothing / n_classes
- self.loss = model_helpers.masked_ce_loss(
- self.logits, targets, inputs.mask, roll_direction=roll_direction)
-
- primary = PredictionModule('primary',
- ([encoder.uni_reprs, encoder.bi_reprs]))
- ps = [
- PredictionModule('full', ([encoder.uni_reprs, encoder.bi_reprs]),
- activate=False),
- PredictionModule('forwards', [encoder.uni_fw]),
- PredictionModule('backwards', [encoder.uni_bw]),
- PredictionModule('future', [encoder.uni_fw], roll_direction=1),
- PredictionModule('past', [encoder.uni_bw], roll_direction=-1),
- ]
-
- self.unsupervised_loss = sum(p.loss for p in ps)
- self.supervised_loss = primary.loss
- self.probs = tf.nn.softmax(primary.logits)
- self.preds = tf.argmax(primary.logits, axis=-1)
-
- def update_feed_dict(self, feed, mb):
- if self.task_name in mb.teacher_predictions:
- feed[self.labels] = mb.teacher_predictions[self.task_name]
- elif mb.task_name != 'unlabeled':
- labels = minibatching.build_array(
- [[0] + e.labels + [0] for e in mb.examples])
- feed[self.labels] = np.eye(self.n_classes)[labels]
diff --git a/research/cvt_text/task_specific/word_level/tagging_scorers.py b/research/cvt_text/task_specific/word_level/tagging_scorers.py
deleted file mode 100644
index ee8a7c74f8181618a9c81389d8b24bc12c70b32f..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/tagging_scorers.py
+++ /dev/null
@@ -1,83 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Sequence tagging evaluation."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-
-from task_specific.word_level import tagging_utils
-from task_specific.word_level import word_level_scorer
-
-
-class AccuracyScorer(word_level_scorer.WordLevelScorer):
- def __init__(self, auto_fail_label=None):
- super(AccuracyScorer, self).__init__()
- self._auto_fail_label = auto_fail_label
-
- def _get_results(self):
- correct, count = 0, 0
- for example, preds in zip(self._examples, self._preds):
- for y_true, y_pred in zip(example.labels, preds):
- count += 1
- correct += (1 if y_pred == y_true and y_true != self._auto_fail_label
- else 0)
- return [
- ("accuracy", 100.0 * correct / count),
- ("loss", self.get_loss())
- ]
-
-
-class F1Scorer(word_level_scorer.WordLevelScorer):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self):
- super(F1Scorer, self).__init__()
- self._n_correct, self._n_predicted, self._n_gold = 0, 0, 0
-
- def _get_results(self):
- if self._n_correct == 0:
- p, r, f1 = 0, 0, 0
- else:
- p = 100.0 * self._n_correct / self._n_predicted
- r = 100.0 * self._n_correct / self._n_gold
- f1 = 2 * p * r / (p + r)
- return [
- ("precision", p),
- ("recall", r),
- ("f1", f1),
- ("loss", self.get_loss()),
- ]
-
-
-class EntityLevelF1Scorer(F1Scorer):
- def __init__(self, label_mapping):
- super(EntityLevelF1Scorer, self).__init__()
- self._inv_label_mapping = {v: k for k, v in label_mapping.iteritems()}
-
- def _get_results(self):
- self._n_correct, self._n_predicted, self._n_gold = 0, 0, 0
- for example, preds in zip(self._examples, self._preds):
- sent_spans = set(tagging_utils.get_span_labels(
- example.labels, self._inv_label_mapping))
- span_preds = set(tagging_utils.get_span_labels(
- preds, self._inv_label_mapping))
- self._n_correct += len(sent_spans & span_preds)
- self._n_gold += len(sent_spans)
- self._n_predicted += len(span_preds)
- return super(EntityLevelF1Scorer, self)._get_results()
diff --git a/research/cvt_text/task_specific/word_level/tagging_utils.py b/research/cvt_text/task_specific/word_level/tagging_utils.py
deleted file mode 100644
index b300e492592f185c0ea169a4c7149e86669232f8..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/tagging_utils.py
+++ /dev/null
@@ -1,59 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for sequence tagging tasks for entity-level tasks (e.g., NER)."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-def get_span_labels(sentence_tags, inv_label_mapping=None):
- """Go from token-level labels to list of entities (start, end, class)."""
-
- if inv_label_mapping:
- sentence_tags = [inv_label_mapping[i] for i in sentence_tags]
- span_labels = []
- last = 'O'
- start = -1
- for i, tag in enumerate(sentence_tags):
- pos, _ = (None, 'O') if tag == 'O' else tag.split('-')
- if (pos == 'S' or pos == 'B' or tag == 'O') and last != 'O':
- span_labels.append((start, i - 1, last.split('-')[-1]))
- if pos == 'B' or pos == 'S' or last == 'O':
- start = i
- last = tag
- if sentence_tags[-1] != 'O':
- span_labels.append((start, len(sentence_tags) - 1,
- sentence_tags[-1].split('-')[-1]))
- return span_labels
-
-
-def get_tags(span_labels, length, encoding):
- """Converts a list of entities to token-label labels based on the provided
- encoding (e.g., BIOES).
- """
-
- tags = ['O' for _ in range(length)]
- for s, e, t in span_labels:
- for i in range(s, e + 1):
- tags[i] = 'I-' + t
- if 'E' in encoding:
- tags[e] = 'E-' + t
- if 'B' in encoding:
- tags[s] = 'B-' + t
- if 'S' in encoding and s == e:
- tags[s] = 'S-' + t
- return tags
diff --git a/research/cvt_text/task_specific/word_level/word_level_data.py b/research/cvt_text/task_specific/word_level/word_level_data.py
deleted file mode 100644
index 40fa27b188c26099dfed48da19a2925f0d13fd93..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/word_level_data.py
+++ /dev/null
@@ -1,161 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for processing word-level datasets."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import os
-import random
-import tensorflow as tf
-
-from base import embeddings
-from base import utils
-from corpus_processing import example
-from corpus_processing import minibatching
-from task_specific.word_level import tagging_utils
-
-
-class TaggedDataLoader(object):
- def __init__(self, config, name, is_token_level):
- self._config = config
- self._task_name = name
- self._raw_data_path = os.path.join(config.raw_data_topdir, name)
- self._is_token_level = is_token_level
- self.label_mapping_path = os.path.join(
- config.preprocessed_data_topdir,
- (name if is_token_level else
- name + '_' + config.label_encoding) + '_label_mapping.pkl')
-
- if self.label_mapping:
- self._n_classes = len(set(self.label_mapping.values()))
- else:
- self._n_classes = None
-
- def get_dataset(self, split):
- if (split == 'train' and not self._config.for_preprocessing and
- tf.gfile.Exists(os.path.join(self._raw_data_path, 'train_subset.txt'))):
- split = 'train_subset'
- return minibatching.Dataset(
- self._config, self._get_examples(split), self._task_name)
-
- def get_labeled_sentences(self, split):
- sentences = []
- path = os.path.join(self._raw_data_path, split + '.txt')
- if not tf.gfile.Exists(path):
- if self._config.for_preprocessing:
- return []
- else:
- raise ValueError('Unable to load data from', path)
-
- with tf.gfile.GFile(path, 'r') as f:
- sentence = []
- for line in f:
- line = line.strip().split()
- if not line:
- if sentence:
- words, tags = zip(*sentence)
- sentences.append((words, tags))
- sentence = []
- continue
- if line[0] == '-DOCSTART-':
- continue
- word, tag = line[0], line[-1]
- sentence.append((word, tag))
- return sentences
-
- @property
- def label_mapping(self):
- if not self._config.for_preprocessing:
- return utils.load_cpickle(self.label_mapping_path)
-
- tag_counts = collections.Counter()
- train_tags = set()
- for split in ['train', 'dev', 'test']:
- for words, tags in self.get_labeled_sentences(split):
- if not self._is_token_level:
- span_labels = tagging_utils.get_span_labels(tags)
- tags = tagging_utils.get_tags(
- span_labels, len(words), self._config.label_encoding)
- for tag in tags:
- if self._task_name == 'depparse':
- tag = tag.split('-')[1]
- tag_counts[tag] += 1
- if split == 'train':
- train_tags.add(tag)
- if self._task_name == 'ccg':
- # for CCG, there are tags in the test sets that aren't in the train set
- # all tags not in the train set get mapped to a special label
- # the model will never predict this label because it never sees it in the
- # training set
- not_in_train_tags = []
- for tag, count in tag_counts.items():
- if tag not in train_tags:
- not_in_train_tags.append(tag)
- label_mapping = {
- label: i for i, label in enumerate(sorted(filter(
- lambda t: t not in not_in_train_tags, tag_counts.keys())))
- }
- n = len(label_mapping)
- for tag in not_in_train_tags:
- label_mapping[tag] = n
- else:
- labels = sorted(tag_counts.keys())
- if self._task_name == 'depparse':
- labels.remove('root')
- labels.insert(0, 'root')
- label_mapping = {label: i for i, label in enumerate(labels)}
- return label_mapping
-
- def _get_examples(self, split):
- word_vocab = embeddings.get_word_vocab(self._config)
- char_vocab = embeddings.get_char_vocab()
- examples = [
- TaggingExample(
- self._config, self._is_token_level, words, tags,
- word_vocab, char_vocab, self.label_mapping, self._task_name)
- for words, tags in self.get_labeled_sentences(split)]
- if self._config.train_set_percent < 100:
- utils.log('using reduced train set ({:}%)'.format(
- self._config.train_set_percent))
- random.shuffle(examples)
- examples = examples[:int(len(examples) *
- self._config.train_set_percent / 100.0)]
- return examples
-
-
-class TaggingExample(example.Example):
- def __init__(self, config, is_token_level, words, original_tags,
- word_vocab, char_vocab, label_mapping, task_name):
- super(TaggingExample, self).__init__(words, word_vocab, char_vocab)
- if is_token_level:
- labels = original_tags
- else:
- span_labels = tagging_utils.get_span_labels(original_tags)
- labels = tagging_utils.get_tags(
- span_labels, len(words), config.label_encoding)
-
- if task_name == 'depparse':
- self.labels = []
- for l in labels:
- split = l.split('-')
- self.labels.append(
- len(label_mapping) * (0 if split[0] == '0' else 1 + int(split[0]))
- + label_mapping[split[1]])
- else:
- self.labels = [label_mapping[l] for l in labels]
diff --git a/research/cvt_text/task_specific/word_level/word_level_scorer.py b/research/cvt_text/task_specific/word_level/word_level_scorer.py
deleted file mode 100644
index e29848d9ca1043fbba86a5bdf98b83269ecdb528..0000000000000000000000000000000000000000
--- a/research/cvt_text/task_specific/word_level/word_level_scorer.py
+++ /dev/null
@@ -1,48 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Base class for word-level scorers."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-
-from corpus_processing import scorer
-
-
-class WordLevelScorer(scorer.Scorer):
- __metaclass__ = abc.ABCMeta
-
- def __init__(self):
- super(WordLevelScorer, self).__init__()
- self._total_loss = 0
- self._total_words = 0
- self._examples = []
- self._preds = []
-
- def update(self, examples, predictions, loss):
- super(WordLevelScorer, self).update(examples, predictions, loss)
- n_words = 0
- for example, preds in zip(examples, predictions):
- self._examples.append(example)
- self._preds.append(list(preds)[1:len(example.words) - 1])
- n_words += len(example.words) - 2
- self._total_loss += loss * n_words
- self._total_words += n_words
-
- def get_loss(self):
- return self._total_loss / max(1, self._total_words)
diff --git a/research/cvt_text/training/__init__.py b/research/cvt_text/training/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cvt_text/training/trainer.py b/research/cvt_text/training/trainer.py
deleted file mode 100644
index 23dc4dad2c1f577ca87f264a640562e092a3ec96..0000000000000000000000000000000000000000
--- a/research/cvt_text/training/trainer.py
+++ /dev/null
@@ -1,139 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Runs training for CVT text models."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import bisect
-import time
-import numpy as np
-import tensorflow as tf
-
-from base import utils
-from model import multitask_model
-from task_specific import task_definitions
-
-
-class Trainer(object):
- def __init__(self, config):
- self._config = config
- self.tasks = [task_definitions.get_task(self._config, task_name)
- for task_name in self._config.task_names]
-
- utils.log('Loading Pretrained Embeddings')
- pretrained_embeddings = utils.load_cpickle(self._config.word_embeddings)
-
- utils.log('Building Model')
- self._model = multitask_model.Model(
- self._config, pretrained_embeddings, self.tasks)
- utils.log()
-
- def train(self, sess, progress, summary_writer):
- heading = lambda s: utils.heading(s, '(' + self._config.model_name + ')')
- trained_on_sentences = 0
- start_time = time.time()
- unsupervised_loss_total, unsupervised_loss_count = 0, 0
- supervised_loss_total, supervised_loss_count = 0, 0
- for mb in self._get_training_mbs(progress.unlabeled_data_reader):
- if mb.task_name != 'unlabeled':
- loss = self._model.train_labeled(sess, mb)
- supervised_loss_total += loss
- supervised_loss_count += 1
-
- if mb.task_name == 'unlabeled':
- self._model.run_teacher(sess, mb)
- loss = self._model.train_unlabeled(sess, mb)
- unsupervised_loss_total += loss
- unsupervised_loss_count += 1
- mb.teacher_predictions.clear()
-
- trained_on_sentences += mb.size
- global_step = self._model.get_global_step(sess)
-
- if global_step % self._config.print_every == 0:
- utils.log('step {:} - '
- 'supervised loss: {:.2f} - '
- 'unsupervised loss: {:.2f} - '
- '{:.1f} sentences per second'.format(
- global_step,
- supervised_loss_total / max(1, supervised_loss_count),
- unsupervised_loss_total / max(1, unsupervised_loss_count),
- trained_on_sentences / (time.time() - start_time)))
- unsupervised_loss_total, unsupervised_loss_count = 0, 0
- supervised_loss_total, supervised_loss_count = 0, 0
-
- if global_step % self._config.eval_dev_every == 0:
- heading('EVAL ON DEV')
- self.evaluate_all_tasks(sess, summary_writer, progress.history)
- progress.save_if_best_dev_model(sess, global_step)
- utils.log()
-
- if global_step % self._config.eval_train_every == 0:
- heading('EVAL ON TRAIN')
- self.evaluate_all_tasks(sess, summary_writer, progress.history, True)
- utils.log()
-
- if global_step % self._config.save_model_every == 0:
- heading('CHECKPOINTING MODEL')
- progress.write(sess, global_step)
- utils.log()
-
- def evaluate_all_tasks(self, sess, summary_writer, history, train_set=False):
- for task in self.tasks:
- results = self._evaluate_task(sess, task, summary_writer, train_set)
- if history is not None:
- results.append(('step', self._model.get_global_step(sess)))
- history.append(results)
- if history is not None:
- utils.write_cpickle(history, self._config.history_file)
-
- def _evaluate_task(self, sess, task, summary_writer, train_set):
- scorer = task.get_scorer()
- data = task.train_set if train_set else task.val_set
- for i, mb in enumerate(data.get_minibatches(self._config.test_batch_size)):
- loss, batch_preds = self._model.test(sess, mb)
- scorer.update(mb.examples, batch_preds, loss)
-
- results = scorer.get_results(task.name +
- ('_train_' if train_set else '_dev_'))
- utils.log(task.name.upper() + ': ' + scorer.results_str())
- write_summary(summary_writer, results,
- global_step=self._model.get_global_step(sess))
- return results
-
- def _get_training_mbs(self, unlabeled_data_reader):
- datasets = [task.train_set for task in self.tasks]
- weights = [np.sqrt(dataset.size) for dataset in datasets]
- thresholds = np.cumsum([w / np.sum(weights) for w in weights])
-
- labeled_mbs = [dataset.endless_minibatches(self._config.train_batch_size)
- for dataset in datasets]
- unlabeled_mbs = unlabeled_data_reader.endless_minibatches()
- while True:
- dataset_ind = bisect.bisect(thresholds, np.random.random())
- yield next(labeled_mbs[dataset_ind])
- if self._config.is_semisup:
- yield next(unlabeled_mbs)
-
-
-def write_summary(writer, results, global_step):
- for k, v in results:
- if 'f1' in k or 'acc' in k or 'loss' in k:
- writer.add_summary(tf.Summary(
- value=[tf.Summary.Value(tag=k, simple_value=v)]), global_step)
- writer.flush()
diff --git a/research/cvt_text/training/training_progress.py b/research/cvt_text/training/training_progress.py
deleted file mode 100644
index a9ec96d5df8308e0d68302b529f348fa24ba0f22..0000000000000000000000000000000000000000
--- a/research/cvt_text/training/training_progress.py
+++ /dev/null
@@ -1,79 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""
-Tracks and saves training progress (models and other data such as the current
-location in the lm1b corpus) for later reloading.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from base import utils
-from corpus_processing import unlabeled_data
-
-
-class TrainingProgress(object):
- def __init__(self, config, sess, checkpoint_saver, best_model_saver,
- restore_if_possible=True):
- self.config = config
- self.checkpoint_saver = checkpoint_saver
- self.best_model_saver = best_model_saver
-
- tf.gfile.MakeDirs(config.checkpoints_dir)
- if restore_if_possible and tf.gfile.Exists(config.progress):
- history, current_file, current_line = utils.load_cpickle(
- config.progress, memoized=False)
- self.history = history
- self.unlabeled_data_reader = unlabeled_data.UnlabeledDataReader(
- config, current_file, current_line)
- utils.log("Continuing from global step", dict(self.history[-1])["step"],
- "(lm1b file {:}, line {:})".format(current_file, current_line))
- self.checkpoint_saver.restore(sess, tf.train.latest_checkpoint(
- self.config.checkpoints_dir))
- else:
- utils.log("No previous checkpoint found - starting from scratch")
- self.history = []
- self.unlabeled_data_reader = (
- unlabeled_data.UnlabeledDataReader(config))
-
- def write(self, sess, global_step):
- self.checkpoint_saver.save(sess, self.config.checkpoint,
- global_step=global_step)
- utils.write_cpickle(
- (self.history, self.unlabeled_data_reader.current_file,
- self.unlabeled_data_reader.current_line),
- self.config.progress)
-
- def save_if_best_dev_model(self, sess, global_step):
- best_avg_score = 0
- for i, results in enumerate(self.history):
- if any("train" in metric for metric, value in results):
- continue
- total, count = 0, 0
- for metric, value in results:
- if "f1" in metric or "las" in metric or "accuracy" in metric:
- total += value
- count += 1
- avg_score = total / count
- if avg_score >= best_avg_score:
- best_avg_score = avg_score
- if i == len(self.history) - 1:
- utils.log("New best model! Saving...")
- self.best_model_saver.save(sess, self.config.best_model_checkpoint,
- global_step=global_step)
diff --git a/research/deep_contextual_bandits/README.md b/research/deep_contextual_bandits/README.md
deleted file mode 100644
index b81309af5b08003eb727e079e70c3dd08eedb6f6..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/README.md
+++ /dev/null
@@ -1,444 +0,0 @@
-
-
-
-
-# Deep Bayesian Bandits Library
-
-This library corresponds to the *[Deep Bayesian Bandits Showdown: An Empirical
-Comparison of Bayesian Deep Networks for Thompson
-Sampling](https://arxiv.org/abs/1802.09127)* paper, published in
-[ICLR](https://iclr.cc/) 2018. We provide a benchmark to test decision-making
-algorithms for contextual-bandits. In particular, the current library implements
-a variety of algorithms (many of them based on approximate Bayesian Neural
-Networks and Thompson sampling), and a number of real and syntethic data
-problems exhibiting a diverse set of properties.
-
-It is a Python library that uses [TensorFlow](https://www.tensorflow.org/).
-
-We encourage contributors to add new approximate Bayesian Neural Networks or,
-more generally, contextual bandits algorithms to the library. Also, we would
-like to extend the data sources over time, so we warmly encourage contributions
-in this front too!
-
-Please, use the following when citing the code or the paper:
-
-```
-@article{riquelme2018deep, title={Deep Bayesian Bandits Showdown: An Empirical
-Comparison of Bayesian Deep Networks for Thompson Sampling},
-author={Riquelme, Carlos and Tucker, George and Snoek, Jasper},
-journal={International Conference on Learning Representations, ICLR.}, year={2018}}
-```
-
-**Contact**. This repository is maintained by [Carlos Riquelme](http://rikel.me) ([rikel](https://github.com/rikel)). Feel free to reach out directly at [rikel@google.com](mailto:rikel@google.com) with any questions or comments.
-
-
-We first briefly introduce contextual bandits, Thompson sampling, enumerate the
-implemented algorithms, and the available data sources. Then, we provide a
-simple complete example illustrating how to use the library.
-
-## Contextual Bandits
-
-Contextual bandits are a rich decision-making framework where an algorithm has
-to choose among a set of *k* actions at every time step *t*, after observing
-a context (or side-information) denoted by *Xt*. The general pseudocode for
-the process if we use algorithm **A** is as follows:
-
-```
-At time t = 1, ..., T:
- 1. Observe new context: X_t
- 2. Choose action: a_t = A.action(X_t)
- 3. Observe reward: r_t
- 4. Update internal state of the algorithm: A.update((X_t, a_t, r_t))
-```
-
-The goal is to maximize the total sum of rewards: ∑t rt
-
-For example, each *Xt* could encode the properties of a specific user (and
-the time or day), and we may have to choose an ad, discount coupon, treatment,
-hyper-parameters, or version of a website to show or provide to the user.
-Hopefully, over time, we will learn how to match each type of user to the most
-beneficial personalized action under some metric (the reward).
-
-## Thompson Sampling
-
-Thompson Sampling is a meta-algorithm that chooses an action for the contextual
-bandit in a statistically efficient manner, simultaneously finding the best arm
-while attempting to incur low cost. Informally speaking, we assume the expected
-reward is given by some function
-**E**[rt | Xt, at] = f(Xt, at).
-Unfortunately, function **f** is unknown, as otherwise we could just choose the
-action with highest expected value:
-at* = arg maxi f(Xt, at).
-
-The idea behind Thompson Sampling is based on keeping a posterior distribution
-πt over functions in some family f ∈ F after observing the first
-*t-1* datapoints. Then, at time *t*, we sample one potential explanation of
-the underlying process: ft ∼ πt, and act optimally (i.e., greedily)
-*according to ft*. In other words, we choose
-at = arg maxi ft(Xt, ai).
-Finally, we update our posterior distribution with the new collected
-datapoint (Xt, at, rt).
-
-The main issue is that keeping an updated posterior πt (or, even,
-sampling from it) is often intractable for highly parameterized models like deep
-neural networks. The algorithms we list in the next section provide tractable
-*approximations* that can be used in combination with Thompson Sampling to solve
-the contextual bandit problem.
-
-## Algorithms
-
-The Deep Bayesian Bandits library includes the following algorithms (see the
-[paper](https://arxiv.org/abs/1802.09127) for further details):
-
-1. **Linear Algorithms**. As a powerful baseline, we provide linear algorithms.
- In particular, we focus on the exact Bayesian linear regression
- implementation, while it is easy to derive the greedy OLS version (possibly,
- with epsilon-greedy exploration). The algorithm is implemented in
- *linear_full_posterior_sampling.py*, and it is instantiated as follows:
-
- ```
- linear_full = LinearFullPosteriorSampling('MyLinearTS', my_hparams)
- ```
-
-2. **Neural Linear**. We introduce an algorithm we call Neural Linear, which
- operates by learning a neural network to map contexts to rewards for each
- action, and ---simultaneously--- it updates a Bayesian linear regression in
- the last layer (i.e., the one that maps the final representation **z** to
- the rewards **r**). Thompson Sampling samples the linear parameters
- βi for each action *i*, but keeps the network that computes the
- representation. Then, both parts (network and Bayesian linear regression)
- are updated, possibly at different frequencies. The algorithm is implemented
- in *neural_linear_sampling.py*, and we create an algorithm instance like
- this:
-
- ```
- neural_linear = NeuralLinearPosteriorSampling('MyNLinear', my_hparams)
- ```
-
-3. **Neural Greedy**. Another standard benchmark is to train a neural network
- that maps contexts to rewards, and at each time *t* just acts greedily
- according to the current model. In particular, this approach does *not*
- explicitly use Thompson Sampling. However, due to stochastic gradient
- descent, there is still some randomness in its output. It is
- straight-forward to add epsilon-greedy exploration to choose random
- actions with probability ε ∈ (0, 1). The algorithm is
- implemented in *neural_bandit_model.py*, and it is used together with
- *PosteriorBNNSampling* (defined in *posterior_bnn_sampling.py*) by calling:
-
- ```
- neural_greedy = PosteriorBNNSampling('MyNGreedy', my_hparams, 'RMSProp')
- ```
-
-4. **Stochastic Variational Inference**, Bayes by Backpropagation. We implement
- a Bayesian neural network by modeling each individual weight posterior as a
- univariate Gaussian distribution: wij ∼ N(μij, σij2).
- Thompson sampling then samples a network at each time step
- by sampling each weight independently. The variational approach consists in
- maximizing a proxy for maximum likelihood of the observed data, the ELBO or
- variational lower bound, to fit the values of μij, σij2
- for every *i, j*.
-
- See [Weight Uncertainty in Neural
- Networks](https://arxiv.org/abs/1505.05424).
-
- The BNN algorithm is implemented in *variational_neural_bandit_model.py*,
- and it is used together with *PosteriorBNNSampling* (defined in
- *posterior_bnn_sampling.py*) by calling:
-
- ```
- bbb = PosteriorBNNSampling('myBBB', my_hparams, 'Variational')
- ```
-
-5. **Expectation-Propagation**, Black-box alpha-divergence minimization.
- The family of expectation-propagation algorithms is based on the message
- passing framework . They iteratively approximate the posterior by updating a
- single approximation factor (or site) at a time, which usually corresponds
- to the likelihood of one data point. We focus on methods that directly
- optimize the global EP objective via stochastic gradient descent, as, for
- instance, Power EP. For further details see original paper below.
-
- See [Black-box alpha-divergence
- Minimization](https://arxiv.org/abs/1511.03243).
-
- We create an instance of the algorithm like this:
-
- ```
- bb_adiv = PosteriorBNNSampling('MyEP', my_hparams, 'AlphaDiv')
- ```
-
-6. **Dropout**. Dropout is a training technique where the output of each neuron
- is independently zeroed out with probability *p* at each forward pass.
- Once the network has been trained, dropout can still be used to obtain a
- distribution of predictions for a specific input. Following the best action
- with respect to the random dropout prediction can be interpreted as an
- implicit form of Thompson sampling. The code for dropout is the same as for
- Neural Greedy (see above), but we need to set two hyper-parameters:
- *use_dropout=True* and *keep_prob=p* where *p* takes the desired value in
- (0, 1). Then:
-
- ```
- dropout = PosteriorBNNSampling('MyDropout', my_hparams, 'RMSProp')
- ```
-
-7. **Monte Carlo Methods**. To be added soon.
-
-8. **Bootstrapped Networks**. This algorithm trains simultaneously and in
- parallel **q** neural networks based on different datasets D1, ..., Dq. The way those datasets are collected is by adding each new collected
- datapoint (Xt, at, rt) to each dataset *Di* independently and with
- probability p ∈ (0, 1]. Therefore, the main hyperparameters of the
- algorithm are **(q, p)**. In order to choose an action for a new context,
- one of the **q** networks is first selected with uniform probability (i.e.,
- *1/q*). Then, the best action according to the *selected* network is
- played.
-
- See [Deep Exploration via Bootstrapped
- DQN](https://arxiv.org/abs/1602.04621).
-
- The algorithm is implemented in *bootstrapped_bnn_sampling.py*, and we
- instantiate it as (where *my_hparams* contains both **q** and **p**):
-
- ```
- bootstrap = BootstrappedBNNSampling('MyBoot', my_hparams)
- ```
-
-9. **Parameter-Noise**. Another approach to approximate a distribution over
- neural networks (or more generally, models) that map contexts to rewards,
- consists in randomly perturbing a point estimate trained by Stochastic
- Gradient Descent on the data. The Parameter-Noise algorithm uses a heuristic
- to control the amount of noise σt2 it adds independently to the
- parameters representing a neural network: θt' = θt + ε where
- ε ∼ N(0, σt2 Id).
- After using θt' for decision making, the following SGD
- training steps start again from θt. The key hyperparameters to set
- are those controlling the noise heuristic.
-
- See [Parameter Space Noise for
- Exploration](https://arxiv.org/abs/1706.01905).
-
- The algorithm is implemented in *parameter_noise_sampling.py*, and we create
- an instance by calling:
-
- ```
- parameter_noise = ParameterNoiseSampling('MyParamNoise', my_hparams)
- ```
-
-10. **Gaussian Processes**. Another standard benchmark are Gaussian Processes,
- see *Gaussian Processes for Machine Learning* by Rasmussen and Williams for
- an introduction. To model the expected reward of different actions, we fit a
- multitask GP.
-
- See [Multi-task Gaussian Process
- Prediction](http://papers.nips.cc/paper/3189-multi-task-gaussian-process-prediction.pdf).
-
- Our implementation is provided in *multitask_gp.py*, and it is instantiated
- as follows:
-
- ```
- gp = PosteriorBNNSampling('MyMultitaskGP', my_hparams, 'GP')
- ```
-
-In the code snippet at the bottom, we show how to instantiate some of these
-algorithms, and how to run the contextual bandit simulator, and display the
-high-level results.
-
-## Data
-
-In the paper we use two types of contextual datasets: synthetic and based on
-real-world data.
-
-We provide functions that sample problems from those datasets. In the case of
-real-world data, you first need to download the raw datasets, and pass the route
-to the functions. Links for the datasets are provided below.
-
-### Synthetic Datasets
-
-Synthetic datasets are contained in the *synthetic_data_sampler.py* file. In
-particular, it includes:
-
-1. **Linear data**. Provides a number of linear arms, and Gaussian contexts.
-
-2. **Sparse linear data**. Provides a number of sparse linear arms, and
- Gaussian contexts.
-
-3. **Wheel bandit data**. Provides sampled data from the wheel bandit data, see
- [Section 5.4](https://arxiv.org/abs/1802.09127) in the paper.
-
-### Real-World Datasets
-
-Real-world data generating functions are contained in the *data_sampler.py*
-file.
-
-In particular, it includes:
-
-1. **Mushroom data**. Each incoming context represents a different type of
- mushroom, and the actions are eat or no-eat. Eating an edible mushroom
- provides positive reward, while eating a poisonous one provides positive
- reward with probability *p*, and a large negative reward with probability
- *1-p*. All the rewards, and the value of *p* are customizable. The
- [dataset](https://archive.ics.uci.edu/ml/datasets/mushroom) is part of the
- UCI repository, and the bandit problem was proposed in Blundell et al.
- (2015). Data is available [here](https://storage.googleapis.com/bandits_datasets/mushroom.data)
- or alternatively [here](https://archive.ics.uci.edu/ml/machine-learning-databases/mushroom/),
- use the *agaricus-lepiota.data* file.
-
-2. **Stock data**. We created the Financial Dataset by pulling the stock prices
- of *d = 21* publicly traded companies in NYSE and Nasdaq, for the last 14
- years (*n = 3713*). For each day, the context was the price difference
- between the beginning and end of the session for each stock. We
- synthetically created the arms to be a linear combination of the contexts,
- representing *k = 8* different potential portfolios. Data is available
- [here](https://storage.googleapis.com/bandits_datasets/raw_stock_contexts).
-
-3. **Jester data**. We create a recommendation system bandit problem as
- follows. The Jester Dataset (Goldberg et al., 2001) provides continuous
- ratings in *[-10, 10]* for 100 jokes from a total of 73421 users. We find
- a *complete* subset of *n = 19181* users rating all 40 jokes. Following
- Riquelme et al. (2017), we take *d = 32* of the ratings as the context of
- the user, and *k = 8* as the arms. The agent recommends one joke, and
- obtains the reward corresponding to the rating of the user for the selected
- joke. Data is available [here](https://storage.googleapis.com/bandits_datasets/jester_data_40jokes_19181users.npy).
-
-4. **Statlog data**. The Shuttle Statlog Dataset (Asuncion & Newman, 2007)
- provides the value of *d = 9* indicators during a space shuttle flight,
- and the goal is to predict the state of the radiator subsystem of the
- shuttle. There are *k = 7* possible states, and if the agent selects the
- right state, then reward 1 is generated. Otherwise, the agent obtains no
- reward (*r = 0*). The most interesting aspect of the dataset is that one
- action is the optimal one in 80% of the cases, and some algorithms may
- commit to this action instead of further exploring. In this case, the number
- of contexts is *n = 43500*. Data is available [here](https://storage.googleapis.com/bandits_datasets/shuttle.trn) or alternatively
- [here](https://archive.ics.uci.edu/ml/datasets/Statlog+\(Shuttle\)), use
- *shuttle.trn* file.
-
-5. **Adult data**. The Adult Dataset (Kohavi, 1996; Asuncion & Newman, 2007)
- comprises personal information from the US Census Bureau database, and the
- standard prediction task is to determine if a person makes over 50K a year
- or not. However, we consider the *k = 14* different occupations as
- feasible actions, based on *d = 94* covariates (many of them binarized).
- As in previous datasets, the agent obtains a reward of 1 for making the
- right prediction, and 0 otherwise. The total number of contexts is *n =
- 45222*. Data is available [here](https://storage.googleapis.com/bandits_datasets/adult.full) or alternatively
- [here](https://archive.ics.uci.edu/ml/datasets/adult), use *adult.data*
- file.
-
-6. **Census data**. The US Census (1990) Dataset (Asuncion & Newman, 2007)
- contains a number of personal features (age, native language, education...)
- which we summarize in *d = 389* covariates, including binary dummy
- variables for categorical features. Our goal again is to predict the
- occupation of the individual among *k = 9* classes. The agent obtains
- reward 1 for making the right prediction, and 0 otherwise. Data is available
- [here](https://storage.googleapis.com/bandits_datasets/USCensus1990.data.txt) or alternatively [here](https://archive.ics.uci.edu/ml/datasets/US+Census+Data+\(1990\)), use
- *USCensus1990.data.txt* file.
-
-7. **Covertype data**. The Covertype Dataset (Asuncion & Newman, 2007)
- classifies the cover type of northern Colorado forest areas in *k = 7*
- classes, based on *d = 54* features, including elevation, slope, aspect,
- and soil type. Again, the agent obtains reward 1 if the correct class is
- selected, and 0 otherwise. Data is available [here](https://storage.googleapis.com/bandits_datasets/covtype.data) or alternatively
- [here](https://archive.ics.uci.edu/ml/datasets/covertype), use
- *covtype.data* file.
-
-In datasets 4-7, each feature of the dataset is normalized first.
-
-## Usage: Basic Example
-
-This library requires Tensorflow, Numpy, and Pandas.
-
-The file *example_main.py* provides a complete example on how to use the
-library. We run the code:
-
-```
- python example_main.py
-```
-
-**Do not forget to** configure the routes to the data files at the top of *example_main.py*.
-
-For example, we can run the Mushroom bandit for 2000 contexts on a few
-algorithms as follows:
-
-```
- # Problem parameters
- num_contexts = 2000
-
- # Choose data source among:
- # {linear, sparse_linear, mushroom, financial, jester,
- # statlog, adult, covertype, census, wheel}
- data_type = 'mushroom'
-
- # Create dataset
- sampled_vals = sample_data(data_type, num_contexts)
- dataset, opt_rewards, opt_actions, num_actions, context_dim = sampled_vals
-
- # Define hyperparameters and algorithms
- hparams_linear = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- a0=6,
- b0=6,
- lambda_prior=0.25,
- initial_pulls=2)
-
- hparams_dropout = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=50,
- training_epochs=100,
- keep_prob=0.80,
- use_dropout=True)
-
- ### Create hyper-parameter configurations for other algorithms
- [...]
-
- algos = [
- UniformSampling('Uniform Sampling', hparams),
- PosteriorBNNSampling('Dropout', hparams_dropout, 'RMSProp'),
- PosteriorBNNSampling('BBB', hparams_bbb, 'Variational'),
- NeuralLinearPosteriorSampling('NeuralLinear', hparams_nlinear),
- LinearFullPosteriorSampling('LinFullPost', hparams_linear),
- BootstrappedBNNSampling('BootRMS', hparams_boot),
- ParameterNoiseSampling('ParamNoise', hparams_pnoise),
- ]
-
- # Run contextual bandit problem
- t_init = time.time()
- results = run_contextual_bandit(context_dim, num_actions, dataset, algos)
- _, h_rewards = results
-
- # Display results
- display_results(algos, opt_rewards, opt_actions, h_rewards, t_init, data_type)
-
-```
-
-The previous code leads to final results that look like:
-
-```
----------------------------------------------------
----------------------------------------------------
-mushroom bandit completed after 69.8401839733 seconds.
----------------------------------------------------
- 0) LinFullPost | total reward = 4365.0.
- 1) NeuralLinear | total reward = 4110.0.
- 2) Dropout | total reward = 3430.0.
- 3) ParamNoise | total reward = 3270.0.
- 4) BootRMS | total reward = 3050.0.
- 5) BBB | total reward = 2505.0.
- 6) Uniform Sampling | total reward = -4930.0.
----------------------------------------------------
-Optimal total reward = 5235.
-Frequency of optimal actions (action, frequency):
-[[0, 953], [1, 1047]]
----------------------------------------------------
----------------------------------------------------
-```
diff --git a/research/deep_contextual_bandits/bandits/algorithms/bb_alpha_divergence_model.py b/research/deep_contextual_bandits/bandits/algorithms/bb_alpha_divergence_model.py
deleted file mode 100644
index 5b9c0ebd0988873eaf97d8d68d25dae5e5b9cd71..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/bb_alpha_divergence_model.py
+++ /dev/null
@@ -1,373 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Bayesian NN using expectation propagation (Black-Box Alpha-Divergence).
-
-See https://arxiv.org/abs/1511.03243 for details.
-All formulas used in this implementation are derived in:
-https://www.overleaf.com/12837696kwzjxkyhdytk#/49028744/.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import sys
-import numpy as np
-import tensorflow as tf
-from absl import flags
-
-from bandits.core.bayesian_nn import BayesianNN
-
-
-FLAGS = flags.FLAGS
-tfd = tf.contrib.distributions # update to: tensorflow_probability.distributions
-
-
-def log_gaussian(x, mu, sigma, reduce_sum=True):
- res = tfd.Normal(mu, sigma).log_prob(x)
- if reduce_sum:
- return tf.reduce_sum(res)
- else:
- return res
-
-
-class BBAlphaDivergence(BayesianNN):
- """Implements an approximate Bayesian NN via Black-Box Alpha-Divergence."""
-
- def __init__(self, hparams, name):
-
- self.name = name
- self.hparams = hparams
-
- self.alpha = getattr(self.hparams, 'alpha', 1.0)
- self.num_mc_nn_samples = getattr(self.hparams, 'num_mc_nn_samples', 10)
-
- self.n_in = self.hparams.context_dim
- self.n_out = self.hparams.num_actions
- self.layers = self.hparams.layer_sizes
- self.batch_size = self.hparams.batch_size
-
- self.show_training = self.hparams.show_training
- self.freq_summary = self.hparams.freq_summary
- self.verbose = getattr(self.hparams, 'verbose', True)
-
- self.cleared_times_trained = self.hparams.cleared_times_trained
- self.initial_training_steps = self.hparams.initial_training_steps
- self.training_schedule = np.linspace(self.initial_training_steps,
- self.hparams.training_epochs,
- self.cleared_times_trained)
-
- self.times_trained = 0
- self.initialize_model()
-
- def initialize_model(self):
- """Builds and initialize the model."""
-
- self.num_w = 0
- self.num_b = 0
-
- self.weights_m = {}
- self.weights_std = {}
- self.biases_m = {}
- self.biases_std = {}
-
- self.h_max_var = []
-
- if self.hparams.use_sigma_exp_transform:
- self.sigma_transform = tfd.bijectors.Exp()
- else:
- self.sigma_transform = tfd.bijectors.Softplus()
-
- # Build the graph corresponding to the Bayesian NN instance.
- self.graph = tf.Graph()
-
- with self.graph.as_default():
-
- self.sess = tf.Session()
- self.x = tf.placeholder(shape=[None, self.n_in],
- dtype=tf.float32, name='x')
- self.y = tf.placeholder(shape=[None, self.n_out],
- dtype=tf.float32, name='y')
- self.weights = tf.placeholder(shape=[None, self.n_out],
- dtype=tf.float32, name='w')
- self.data_size = tf.placeholder(tf.float32, shape=(), name='data_size')
-
- self.prior_variance = self.hparams.prior_variance
- if self.prior_variance < 0:
- # if not fixed, we learn the prior.
- self.prior_variance = self.sigma_transform.forward(
- self.build_mu_variable([1, 1]))
-
- self.build_model()
- self.sess.run(tf.global_variables_initializer())
-
- def build_mu_variable(self, shape):
- """Returns a mean variable initialized as N(0, 0.05)."""
- return tf.Variable(tf.random_normal(shape, 0.0, 0.05))
-
- def build_sigma_variable(self, shape, init=-5.):
- """Returns a sigma variable initialized as N(init, 0.05)."""
- # Initialize sigma to be very small initially to encourage MAP opt first
- return tf.Variable(tf.random_normal(shape, init, 0.05))
-
- def build_layer(self, input_x, shape, layer_id, activation_fn=tf.nn.relu):
- """Builds a layer with N(mean, std) for each weight, and samples from it."""
-
- w_mu = self.build_mu_variable(shape)
- w_sigma = self.sigma_transform.forward(self.build_sigma_variable(shape))
-
- w_noise = tf.random_normal(shape)
- w = w_mu + w_sigma * w_noise
-
- b_mu = self.build_mu_variable([1, shape[1]])
- b_sigma = self.sigma_transform.forward(
- self.build_sigma_variable([1, shape[1]]))
-
- b_noise = tf.random_normal([1, shape[1]])
- b = b_mu + b_sigma * b_noise
-
- # Create outputs
- output_h = activation_fn(tf.matmul(input_x, w) + b)
-
- # Store means and stds
- self.weights_m[layer_id] = w_mu
- self.weights_std[layer_id] = w_sigma
- self.biases_m[layer_id] = b_mu
- self.biases_std[layer_id] = b_sigma
-
- return output_h
-
- def sample_neural_network(self, activation_fn=tf.nn.relu):
- """Samples a nn from posterior, computes data log lk and log f factor."""
-
- with self.graph.as_default():
-
- log_f = 0
- n = self.data_size
- input_x = self.x
-
- for layer_id in range(self.total_layers):
-
- # load mean and std of each weight
- w_mu = self.weights_m[layer_id]
- w_sigma = self.weights_std[layer_id]
- b_mu = self.biases_m[layer_id]
- b_sigma = self.biases_std[layer_id]
-
- # sample weights from Gaussian distribution
- shape = w_mu.shape
- w_noise = tf.random_normal(shape)
- b_noise = tf.random_normal([1, int(shape[1])])
- w = w_mu + w_sigma * w_noise
- b = b_mu + b_sigma * b_noise
-
- # compute contribution to log_f
- t1 = w * w_mu / (n * w_sigma ** 2)
- t2 = (0.5 * w ** 2 / n) * (1 / self.prior_variance - 1 / w_sigma ** 2)
- log_f += tf.reduce_sum(t1 + t2)
-
- t1 = b * b_mu / (n * b_sigma ** 2)
- t2 = (0.5 * b ** 2 / n) * (1 / self.prior_variance - 1 / b_sigma ** 2)
- log_f += tf.reduce_sum(t1 + t2)
-
- if layer_id < self.total_layers - 1:
- output_h = activation_fn(tf.matmul(input_x, w) + b)
- else:
- output_h = tf.matmul(input_x, w) + b
-
- input_x = output_h
-
- # compute log likelihood of the observed reward under the sampled nn
- log_likelihood = log_gaussian(
- self.y, output_h, self.noise_sigma, reduce_sum=False)
- weighted_log_likelihood = tf.reduce_sum(log_likelihood * self.weights, -1)
-
- return log_f, weighted_log_likelihood
-
- def log_z_q(self):
- """Computes log-partition function of current posterior parameters."""
-
- with self.graph.as_default():
-
- log_z_q = 0
-
- for layer_id in range(self.total_layers):
-
- w_mu = self.weights_m[layer_id]
- w_sigma = self.weights_std[layer_id]
- b_mu = self.biases_m[layer_id]
- b_sigma = self.biases_std[layer_id]
-
- w_term = 0.5 * tf.reduce_sum(w_mu ** 2 / w_sigma ** 2)
- w_term += 0.5 * tf.reduce_sum(tf.log(2 * np.pi) + 2 * tf.log(w_sigma))
-
- b_term = 0.5 * tf.reduce_sum(b_mu ** 2 / b_sigma ** 2)
- b_term += 0.5 * tf.reduce_sum(tf.log(2 * np.pi) + 2 * tf.log(b_sigma))
-
- log_z_q += w_term + b_term
-
- return log_z_q
-
- def log_z_prior(self):
- """Computes log-partition function of the prior parameters."""
- num_params = self.num_w + self.num_b
- return num_params * 0.5 * tf.log(2 * np.pi * self.prior_variance)
-
- def log_alpha_likelihood_ratio(self, activation_fn=tf.nn.relu):
-
- # each nn sample returns (log f, log likelihoods)
- nn_samples = [
- self.sample_neural_network(activation_fn)
- for _ in range(self.num_mc_nn_samples)
- ]
- nn_log_f_samples = [elt[0] for elt in nn_samples]
- nn_log_lk_samples = [elt[1] for elt in nn_samples]
-
- # we stack the (log f, log likelihoods) from the k nn samples
- nn_log_f_stack = tf.stack(nn_log_f_samples) # k x 1
- nn_log_lk_stack = tf.stack(nn_log_lk_samples) # k x N
- nn_f_tile = tf.tile(nn_log_f_stack, [self.batch_size])
- nn_f_tile = tf.reshape(nn_f_tile,
- [self.num_mc_nn_samples, self.batch_size])
-
- # now both the log f and log likelihood terms have shape: k x N
- # apply formula in https://www.overleaf.com/12837696kwzjxkyhdytk#/49028744/
- nn_log_ratio = nn_log_lk_stack - nn_f_tile
- nn_log_ratio = self.alpha * tf.transpose(nn_log_ratio)
- logsumexp_value = tf.reduce_logsumexp(nn_log_ratio, -1)
- log_k_scalar = tf.log(tf.cast(self.num_mc_nn_samples, tf.float32))
- log_k = log_k_scalar * tf.ones([self.batch_size])
-
- return tf.reduce_sum(logsumexp_value - log_k, -1)
-
- def build_model(self, activation_fn=tf.nn.relu):
- """Defines the actual NN model with fully connected layers.
-
- Args:
- activation_fn: Activation function for the neural network.
-
- The loss is computed for partial feedback settings (bandits), so only
- the observed outcome is backpropagated (see weighted loss).
- Selects the optimizer and, finally, it also initializes the graph.
- """
-
- print('Initializing model {}.'.format(self.name))
-
- # Build terms for the noise sigma estimation for each action.
- noise_sigma_mu = (self.build_mu_variable([1, self.n_out])
- + self.sigma_transform.inverse(self.hparams.noise_sigma))
- noise_sigma_sigma = self.sigma_transform.forward(
- self.build_sigma_variable([1, self.n_out]))
-
- pre_noise_sigma = noise_sigma_mu + tf.random_normal(
- [1, self.n_out]) * noise_sigma_sigma
- self.noise_sigma = self.sigma_transform.forward(pre_noise_sigma)
-
- # Build network
- input_x = self.x
- n_in = self.n_in
- self.total_layers = len(self.layers) + 1
- if self.layers[0] == 0:
- self.total_layers = 1
-
- for l_number, n_nodes in enumerate(self.layers):
- if n_nodes > 0:
- h = self.build_layer(input_x, [n_in, n_nodes], l_number)
- input_x = h
- n_in = n_nodes
- self.num_w += n_in * n_nodes
- self.num_b += n_nodes
-
- self.y_pred = self.build_layer(input_x, [n_in, self.n_out],
- self.total_layers - 1,
- activation_fn=lambda x: x)
-
- # Compute energy function based on sampled nn's
- log_coeff = self.data_size / (self.batch_size * self.alpha)
- log_ratio = log_coeff * self.log_alpha_likelihood_ratio(activation_fn)
- logzprior = self.log_z_prior()
- logzq = self.log_z_q()
- energy = logzprior - logzq - log_ratio
-
- self.loss = energy
- self.global_step = tf.train.get_or_create_global_step()
- self.train_op = tf.train.AdamOptimizer(self.hparams.initial_lr).minimize(
- self.loss, global_step=self.global_step)
-
- # Useful for debugging
- sq_loss = tf.squared_difference(self.y_pred, self.y)
- weighted_sq_loss = self.weights * sq_loss
- self.cost = tf.reduce_sum(weighted_sq_loss) / self.batch_size
-
- # Create tensorboard metrics
- self.create_summaries()
- self.summary_writer = tf.summary.FileWriter('{}/graph_{}'.format(
- FLAGS.logdir, self.name), self.sess.graph)
-
- def create_summaries(self):
- tf.summary.scalar('loss', self.loss)
- tf.summary.scalar('cost', self.cost)
- self.summary_op = tf.summary.merge_all()
-
- def assign_lr(self):
- """Resets the learning rate in dynamic schedules for subsequent trainings.
-
- In bandits settings, we do expand our dataset over time. Then, we need to
- re-train the network with the new data. Those algorithms that do not keep
- the step constant, can reset it at the start of each training process.
- """
-
- decay_steps = 1
- if self.hparams.activate_decay:
- current_gs = self.sess.run(self.global_step)
- with self.graph.as_default():
- self.lr = tf.train.inverse_time_decay(self.hparams.initial_lr,
- self.global_step - current_gs,
- decay_steps,
- self.hparams.lr_decay_rate)
-
- def train(self, data, num_steps):
- """Trains the BNN for num_steps, using the data in 'data'.
-
- Args:
- data: ContextualDataset object that provides the data.
- num_steps: Number of minibatches to train the network for.
- """
-
- if self.times_trained < self.cleared_times_trained:
- num_steps = int(self.training_schedule[self.times_trained])
- self.times_trained += 1
-
- if self.verbose:
- print('Training {} for {} steps...'.format(self.name, num_steps))
-
- with self.graph.as_default():
-
- for step in range(num_steps):
- x, y, w = data.get_batch_with_weights(self.hparams.batch_size)
- _, summary, global_step, loss = self.sess.run(
- [self.train_op, self.summary_op, self.global_step, self.loss],
- feed_dict={self.x: x, self.y: y, self.weights: w,
- self.data_size: data.num_points()})
-
- weights_l = self.sess.run(self.weights_std[0])
- self.h_max_var.append(np.max(weights_l))
-
- if step % self.freq_summary == 0:
- if self.show_training:
- print('step: {}, loss: {}'.format(step, loss))
- sys.stdout.flush()
- self.summary_writer.add_summary(summary, global_step)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/bf_variational_neural_bandit_model.py b/research/deep_contextual_bandits/bandits/algorithms/bf_variational_neural_bandit_model.py
deleted file mode 100644
index cb87c23358f27bd93e30528b20f7a3bb3ba876dd..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/bf_variational_neural_bandit_model.py
+++ /dev/null
@@ -1,352 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Bayesian NN using factorized VI (Bayes By Backprop. Blundell et al. 2014).
-
-See https://arxiv.org/abs/1505.05424 for details.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-# import tensorflow_probability as tfp
-
-from absl import flags
-from bandits.core.bayesian_nn import BayesianNN
-
-
-FLAGS = flags.FLAGS
-# tfd = tfp.distributions
-tfd = tf.contrib.distributions
-tfl = tf.contrib.layers
-
-
-def log_gaussian(x, mu, sigma, reduce_sum=True):
- """Returns log Gaussian pdf."""
- res = tfd.Normal(mu, sigma).log_prob(x)
- if reduce_sum:
- return tf.reduce_sum(res)
- else:
- return res
-
-
-def analytic_kl(mu_1, sigma_1, mu_2, sigma_2):
- """KL for two Gaussian distributions with diagonal covariance matrix."""
- kl = tfd.kl_divergence(tfd.MVNDiag(mu_1, sigma_1), tfd.MVNDiag(mu_2, sigma_2))
- return kl
-
-
-class BfVariationalNeuralBanditModel(BayesianNN):
- """Implements an approximate Bayesian NN using Variational Inference."""
-
- def __init__(self, hparams, name="BBBNN"):
-
- self.name = name
- self.hparams = hparams
-
- self.n_in = self.hparams.context_dim
- self.n_out = self.hparams.num_actions
- self.layers = self.hparams.layer_sizes
- self.init_scale = self.hparams.init_scale
- self.f_num_points = None
- if "f_num_points" in hparams:
- self.f_num_points = self.hparams.f_num_points
-
- self.cleared_times_trained = self.hparams.cleared_times_trained
- self.initial_training_steps = self.hparams.initial_training_steps
- self.training_schedule = np.linspace(self.initial_training_steps,
- self.hparams.training_epochs,
- self.cleared_times_trained)
- self.verbose = getattr(self.hparams, "verbose", True)
-
- self.weights_m = {}
- self.weights_std = {}
- self.biases_m = {}
- self.biases_std = {}
-
- self.times_trained = 0
-
- if self.hparams.use_sigma_exp_transform:
- self.sigma_transform = tf.exp
- self.inverse_sigma_transform = np.log
- else:
- self.sigma_transform = tf.nn.softplus
- self.inverse_sigma_transform = lambda y: y + np.log(1. - np.exp(-y))
-
- # Whether to use the local reparameterization trick to compute the loss.
- # See details in https://arxiv.org/abs/1506.02557
- self.use_local_reparameterization = True
-
- self.build_graph()
-
- def build_mu_variable(self, shape):
- """Returns a mean variable initialized as N(0, 0.05)."""
- return tf.Variable(tf.random_normal(shape, 0.0, 0.05))
-
- def build_sigma_variable(self, shape, init=-5.):
- """Returns a sigma variable initialized as N(init, 0.05)."""
- # Initialize sigma to be very small initially to encourage MAP opt first
- return tf.Variable(tf.random_normal(shape, init, 0.05))
-
- def build_layer(self, input_x, input_x_local, shape,
- layer_id, activation_fn=tf.nn.relu):
- """Builds a variational layer, and computes KL term.
-
- Args:
- input_x: Input to the variational layer.
- input_x_local: Input when the local reparameterization trick was applied.
- shape: [number_inputs, number_outputs] for the layer.
- layer_id: Number of layer in the architecture.
- activation_fn: Activation function to apply.
-
- Returns:
- output_h: Output of the variational layer.
- output_h_local: Output when local reparameterization trick was applied.
- neg_kl: Negative KL term for the layer.
- """
-
- w_mu = self.build_mu_variable(shape)
- w_sigma = self.sigma_transform(self.build_sigma_variable(shape))
- w_noise = tf.random_normal(shape)
- w = w_mu + w_sigma * w_noise
-
- b_mu = self.build_mu_variable([1, shape[1]])
- b_sigma = self.sigma_transform(self.build_sigma_variable([1, shape[1]]))
- b = b_mu
-
- # Store means and stds
- self.weights_m[layer_id] = w_mu
- self.weights_std[layer_id] = w_sigma
- self.biases_m[layer_id] = b_mu
- self.biases_std[layer_id] = b_sigma
-
- # Create outputs
- output_h = activation_fn(tf.matmul(input_x, w) + b)
-
- if self.use_local_reparameterization:
- # Use analytic KL divergence wrt the prior
- neg_kl = -analytic_kl(w_mu, w_sigma,
- 0., tf.to_float(np.sqrt(2./shape[0])))
- else:
- # Create empirical KL loss terms
- log_p = log_gaussian(w, 0., tf.to_float(np.sqrt(2./shape[0])))
- log_q = log_gaussian(w, tf.stop_gradient(w_mu), tf.stop_gradient(w_sigma))
- neg_kl = log_p - log_q
-
- # Apply local reparameterization trick: sample activations pre nonlinearity
- m_h = tf.matmul(input_x_local, w_mu) + b
- v_h = tf.matmul(tf.square(input_x_local), tf.square(w_sigma))
- output_h_local = m_h + tf.sqrt(v_h + 1e-6) * tf.random_normal(tf.shape(v_h))
- output_h_local = activation_fn(output_h_local)
-
- return output_h, output_h_local, neg_kl
-
- def build_action_noise(self):
- """Defines a model for additive noise per action, and its KL term."""
-
- # Define mean and std variables (log-normal dist) for each action.
- noise_sigma_mu = (self.build_mu_variable([1, self.n_out])
- + self.inverse_sigma_transform(self.hparams.noise_sigma))
- noise_sigma_sigma = self.sigma_transform(
- self.build_sigma_variable([1, self.n_out]))
-
- pre_noise_sigma = (noise_sigma_mu
- + tf.random_normal([1, self.n_out]) * noise_sigma_sigma)
- self.noise_sigma = self.sigma_transform(pre_noise_sigma)
-
- # Compute KL for additive noise sigma terms.
- if getattr(self.hparams, "infer_noise_sigma", False):
- neg_kl_term = log_gaussian(
- pre_noise_sigma,
- self.inverse_sigma_transform(self.hparams.noise_sigma),
- self.hparams.prior_sigma
- )
- neg_kl_term -= log_gaussian(pre_noise_sigma,
- noise_sigma_mu,
- noise_sigma_sigma)
- else:
- neg_kl_term = 0.
-
- return neg_kl_term
-
- def build_model(self, activation_fn=tf.nn.relu):
- """Defines the actual NN model with fully connected layers.
-
- The loss is computed for partial feedback settings (bandits), so only
- the observed outcome is backpropagated (see weighted loss).
- Selects the optimizer and, finally, it also initializes the graph.
-
- Args:
- activation_fn: the activation function used in the nn layers.
- """
-
- def weight_prior(dtype, shape, c, d, e):
- del c, d, e
- return tfd.Independent(
- tfd.Normal(loc=tf.zeros(shape, dtype),
- scale=tf.to_float(np.sqrt(2) / shape[0])),
- reinterpreted_batch_ndims=tf.size(shape))
-
- if self.verbose:
- print("Initializing model {}.".format(self.name))
-
- # Compute model additive noise for each action with log-normal distribution
- neg_kl_term = self.build_action_noise()
-
- # Build variational network using self.x as input.
- input_x = self.x
-
- # Create Keras model using DenseLocalReparameterization (prior N(0, 1)).
- model_layers = [
- tfl.DenseLocalReparameterization(
- n_nodes,
- activation=tf.nn.relu,
- kernel_prior_fn=weight_prior
- )
- for n_nodes in self.layers if n_nodes > 0
- ]
-
- output_layer = tfl.DenseLocalReparameterization(
- self.n_out,
- activation=lambda x: x,
- kernel_prior_fn=weight_prior
- )
- model_layers.append(output_layer)
-
- model = tf.keras.Sequential(model_layers)
- self.y_pred = model(input_x)
-
- # Compute KL term
- neg_kl_term -= tf.add_n(model.losses)
-
- # Compute log likelihood (with learned or fixed noise level)
- if getattr(self.hparams, "infer_noise_sigma", False):
- log_likelihood = log_gaussian(
- self.y, self.y_pred, self.noise_sigma, reduce_sum=False)
- else:
- log_likelihood = log_gaussian(
- self.y, self.y_pred, self.hparams.noise_sigma, reduce_sum=False)
-
- # Only take into account observed outcomes (bandits setting)
- batch_size = tf.to_float(tf.shape(self.x)[0])
- weighted_log_likelihood = tf.reduce_sum(
- log_likelihood * self.weights) / batch_size
-
- # The objective is 1/n * (\sum_i log_like_i - KL); neg_kl_term estimates -KL
- elbo = weighted_log_likelihood + (neg_kl_term / self.n)
-
- self.loss = -elbo
- self.global_step = tf.train.get_or_create_global_step()
- self.train_op = tf.train.AdamOptimizer(self.hparams.initial_lr).minimize(
- self.loss, global_step=self.global_step)
-
- # Create tensorboard metrics
- self.create_summaries()
- self.summary_writer = tf.summary.FileWriter(
- "{}/graph_{}".format(FLAGS.logdir, self.name), self.sess.graph)
-
- def build_graph(self):
- """Defines graph, session, placeholders, and model.
-
- Placeholders are: n (size of the dataset), x and y (context and observed
- reward for each action), and weights (one-hot encoding of selected action
- for each context, i.e., only possibly non-zero element in each y).
- """
-
- self.graph = tf.Graph()
- with self.graph.as_default():
-
- self.sess = tf.Session()
-
- self.n = tf.placeholder(shape=[], dtype=tf.float32)
-
- self.x = tf.placeholder(shape=[None, self.n_in], dtype=tf.float32)
- self.y = tf.placeholder(shape=[None, self.n_out], dtype=tf.float32)
- self.weights = tf.placeholder(shape=[None, self.n_out], dtype=tf.float32)
-
- self.build_model()
- self.sess.run(tf.global_variables_initializer())
-
- def create_summaries(self):
- """Defines summaries including mean loss, and global step."""
-
- with self.graph.as_default():
- with tf.name_scope(self.name + "_summaries"):
- tf.summary.scalar("loss", self.loss)
- tf.summary.scalar("global_step", self.global_step)
- self.summary_op = tf.summary.merge_all()
-
- def assign_lr(self):
- """Resets the learning rate in dynamic schedules for subsequent trainings.
-
- In bandits settings, we do expand our dataset over time. Then, we need to
- re-train the network with the new data. The algorithms that do not keep
- the step constant, can reset it at the start of each *training* process.
- """
-
- decay_steps = 1
- if self.hparams.activate_decay:
- current_gs = self.sess.run(self.global_step)
- with self.graph.as_default():
- self.lr = tf.train.inverse_time_decay(self.hparams.initial_lr,
- self.global_step - current_gs,
- decay_steps,
- self.hparams.lr_decay_rate)
-
- def train(self, data, num_steps):
- """Trains the BNN for num_steps, using the data in 'data'.
-
- Args:
- data: ContextualDataset object that provides the data.
- num_steps: Number of minibatches to train the network for.
-
- Returns:
- losses: Loss history during training.
- """
-
- if self.times_trained < self.cleared_times_trained:
- num_steps = int(self.training_schedule[self.times_trained])
- self.times_trained += 1
-
- losses = []
-
- with self.graph.as_default():
-
- if self.verbose:
- print("Training {} for {} steps...".format(self.name, num_steps))
-
- for step in range(num_steps):
- x, y, weights = data.get_batch_with_weights(self.hparams.batch_size)
- _, summary, global_step, loss = self.sess.run(
- [self.train_op, self.summary_op, self.global_step, self.loss],
- feed_dict={
- self.x: x,
- self.y: y,
- self.weights: weights,
- self.n: data.num_points(self.f_num_points),
- })
-
- losses.append(loss)
-
- if step % self.hparams.freq_summary == 0:
- if self.hparams.show_training:
- print("{} | step: {}, loss: {}".format(
- self.name, global_step, loss))
- self.summary_writer.add_summary(summary, global_step)
-
- return losses
diff --git a/research/deep_contextual_bandits/bandits/algorithms/bootstrapped_bnn_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/bootstrapped_bnn_sampling.py
deleted file mode 100644
index 7c44b681c7bd1da113ec29c1bb6d370c88d7053f..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/bootstrapped_bnn_sampling.py
+++ /dev/null
@@ -1,98 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual algorithm based on boostrapping neural networks."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-from bandits.core.contextual_dataset import ContextualDataset
-from bandits.algorithms.neural_bandit_model import NeuralBanditModel
-
-
-class BootstrappedBNNSampling(BanditAlgorithm):
- """Thompson Sampling algorithm based on training several neural networks."""
-
- def __init__(self, name, hparams, optimizer='RMS'):
- """Creates a BootstrappedSGDSampling object based on a specific optimizer.
-
- hparams.q: Number of models that are independently trained.
- hparams.p: Prob of independently including each datapoint in each model.
-
- Args:
- name: Name given to the instance.
- hparams: Hyperparameters for each individual model.
- optimizer: Neural network optimization algorithm.
- """
-
- self.name = name
- self.hparams = hparams
- self.optimizer_n = optimizer
-
- self.training_freq = hparams.training_freq
- self.training_epochs = hparams.training_epochs
- self.t = 0
-
- self.q = hparams.q
- self.p = hparams.p
-
- self.datasets = [
- ContextualDataset(hparams.context_dim,
- hparams.num_actions,
- hparams.buffer_s)
- for _ in range(self.q)
- ]
-
- self.bnn_boot = [
- NeuralBanditModel(optimizer, hparams, '{}-{}-bnn'.format(name, i))
- for i in range(self.q)
- ]
-
- def action(self, context):
- """Selects action for context based on Thompson Sampling using one BNN."""
-
- if self.t < self.hparams.num_actions * self.hparams.initial_pulls:
- # round robin until each action has been taken "initial_pulls" times
- return self.t % self.hparams.num_actions
-
- # choose model uniformly at random
- model_index = np.random.randint(self.q)
-
- with self.bnn_boot[model_index].graph.as_default():
- c = context.reshape((1, self.hparams.context_dim))
- output = self.bnn_boot[model_index].sess.run(
- self.bnn_boot[model_index].y_pred,
- feed_dict={self.bnn_boot[model_index].x: c})
- return np.argmax(output)
-
- def update(self, context, action, reward):
- """Updates the data buffer, and re-trains the BNN every self.freq_update."""
-
- self.t += 1
- for i in range(self.q):
- # include the data point with probability p independently in each dataset
- if np.random.random() < self.p or self.t < 2:
- self.datasets[i].add(context, action, reward)
-
- if self.t % self.training_freq == 0:
- # update all the models:
- for i in range(self.q):
- if self.hparams.reset_lr:
- self.bnn_boot[i].assign_lr()
- self.bnn_boot[i].train(self.datasets[i], self.training_epochs)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/fixed_policy_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/fixed_policy_sampling.py
deleted file mode 100644
index d5ad6e3ed9ed9d1478e6ac132b41cfb5ae1bb47a..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/fixed_policy_sampling.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual bandit algorithm that selects an action at random."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-
-
-class FixedPolicySampling(BanditAlgorithm):
- """Defines a baseline; returns an action at random with probs given by p."""
-
- def __init__(self, name, p, hparams):
- """Creates a FixedPolicySampling object.
-
- Args:
- name: Name of the algorithm.
- p: Vector of normalized probabilities corresponding to sampling each arm.
- hparams: Hyper-parameters, including the number of arms (num_actions).
-
- Raises:
- ValueError: when p dimension does not match the number of actions.
- """
-
- self.name = name
- self.p = p
- self.hparams = hparams
-
- if len(p) != self.hparams.num_actions:
- raise ValueError('Policy needs k probabilities.')
-
- def action(self, context):
- """Selects an action at random according to distribution p."""
- return np.random.choice(range(self.hparams.num_actions), p=self.p)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/linear_full_posterior_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/linear_full_posterior_sampling.py
deleted file mode 100644
index 15ef8fa9b562101111042dc2ce7b17174018ab6e..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/linear_full_posterior_sampling.py
+++ /dev/null
@@ -1,164 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual algorithm that keeps a full linear posterior for each arm."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-from scipy.stats import invgamma
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-from bandits.core.contextual_dataset import ContextualDataset
-
-
-class LinearFullPosteriorSampling(BanditAlgorithm):
- """Thompson Sampling with independent linear models and unknown noise var."""
-
- def __init__(self, name, hparams):
- """Initialize posterior distributions and hyperparameters.
-
- Assume a linear model for each action i: reward = context^T beta_i + noise
- Each beta_i has a Gaussian prior (lambda parameter), each sigma2_i (noise
- level) has an inverse Gamma prior (a0, b0 parameters). Mean, covariance,
- and precision matrices are initialized, and the ContextualDataset created.
-
- Args:
- name: Name of the algorithm.
- hparams: Hyper-parameters of the algorithm.
- """
-
- self.name = name
- self.hparams = hparams
-
- # Gaussian prior for each beta_i
- self._lambda_prior = self.hparams.lambda_prior
-
- self.mu = [
- np.zeros(self.hparams.context_dim + 1)
- for _ in range(self.hparams.num_actions)
- ]
-
- self.cov = [(1.0 / self.lambda_prior) * np.eye(self.hparams.context_dim + 1)
- for _ in range(self.hparams.num_actions)]
-
- self.precision = [
- self.lambda_prior * np.eye(self.hparams.context_dim + 1)
- for _ in range(self.hparams.num_actions)
- ]
-
- # Inverse Gamma prior for each sigma2_i
- self._a0 = self.hparams.a0
- self._b0 = self.hparams.b0
-
- self.a = [self._a0 for _ in range(self.hparams.num_actions)]
- self.b = [self._b0 for _ in range(self.hparams.num_actions)]
-
- self.t = 0
- self.data_h = ContextualDataset(hparams.context_dim,
- hparams.num_actions,
- intercept=True)
-
- def action(self, context):
- """Samples beta's from posterior, and chooses best action accordingly.
-
- Args:
- context: Context for which the action need to be chosen.
-
- Returns:
- action: Selected action for the context.
- """
-
- # Round robin until each action has been selected "initial_pulls" times
- if self.t < self.hparams.num_actions * self.hparams.initial_pulls:
- return self.t % self.hparams.num_actions
-
- # Sample sigma2, and beta conditional on sigma2
- sigma2_s = [
- self.b[i] * invgamma.rvs(self.a[i])
- for i in range(self.hparams.num_actions)
- ]
-
- try:
- beta_s = [
- np.random.multivariate_normal(self.mu[i], sigma2_s[i] * self.cov[i])
- for i in range(self.hparams.num_actions)
- ]
- except np.linalg.LinAlgError as e:
- # Sampling could fail if covariance is not positive definite
- print('Exception when sampling from {}.'.format(self.name))
- print('Details: {} | {}.'.format(e.message, e.args))
- d = self.hparams.context_dim + 1
- beta_s = [
- np.random.multivariate_normal(np.zeros((d)), np.eye(d))
- for i in range(self.hparams.num_actions)
- ]
-
- # Compute sampled expected values, intercept is last component of beta
- vals = [
- np.dot(beta_s[i][:-1], context.T) + beta_s[i][-1]
- for i in range(self.hparams.num_actions)
- ]
-
- return np.argmax(vals)
-
- def update(self, context, action, reward):
- """Updates action posterior using the linear Bayesian regression formula.
-
- Args:
- context: Last observed context.
- action: Last observed action.
- reward: Last observed reward.
- """
-
- self.t += 1
- self.data_h.add(context, action, reward)
-
- # Update posterior of action with formulas: \beta | x,y ~ N(mu_q, cov_q)
- x, y = self.data_h.get_data(action)
-
- # The algorithm could be improved with sequential update formulas (cheaper)
- s = np.dot(x.T, x)
-
- # Some terms are removed as we assume prior mu_0 = 0.
- precision_a = s + self.lambda_prior * np.eye(self.hparams.context_dim + 1)
- cov_a = np.linalg.inv(precision_a)
- mu_a = np.dot(cov_a, np.dot(x.T, y))
-
- # Inverse Gamma posterior update
- a_post = self.a0 + x.shape[0] / 2.0
- b_upd = 0.5 * (np.dot(y.T, y) - np.dot(mu_a.T, np.dot(precision_a, mu_a)))
- b_post = self.b0 + b_upd
-
- # Store new posterior distributions
- self.mu[action] = mu_a
- self.cov[action] = cov_a
- self.precision[action] = precision_a
- self.a[action] = a_post
- self.b[action] = b_post
-
- @property
- def a0(self):
- return self._a0
-
- @property
- def b0(self):
- return self._b0
-
- @property
- def lambda_prior(self):
- return self._lambda_prior
diff --git a/research/deep_contextual_bandits/bandits/algorithms/multitask_gp.py b/research/deep_contextual_bandits/bandits/algorithms/multitask_gp.py
deleted file mode 100644
index 0c35dfaeaf9e30993d49d807f16dd64e15d3fc66..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/multitask_gp.py
+++ /dev/null
@@ -1,374 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A Multitask Gaussian process."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from absl import flags
-from absl import logging
-
-import numpy as np
-import tensorflow as tf
-from bandits.core.bayesian_nn import BayesianNN
-
-FLAGS = flags.FLAGS
-tfd = tf.contrib.distributions
-
-class MultitaskGP(BayesianNN):
- """Implements a Gaussian process with multi-task outputs.
-
- Optimizes the hyperparameters over the log marginal likelihood.
- Uses a Matern 3/2 + linear covariance and returns
- sampled predictions for test inputs. The outputs are optionally
- correlated where the correlation structure is learned through latent
- embeddings of the tasks.
- """
-
- def __init__(self, hparams):
- self.name = "MultiTaskGP"
- self.hparams = hparams
-
- self.n_in = self.hparams.context_dim
- self.n_out = self.hparams.num_outputs
- self.keep_fixed_after_max_obs = self.hparams.keep_fixed_after_max_obs
-
- self._show_training = self.hparams.show_training
- self._freq_summary = self.hparams.freq_summary
-
- # Dimensionality of the latent task vectors
- self.task_latent_dim = self.hparams.task_latent_dim
-
- # Maximum number of observations to include
- self.max_num_points = self.hparams.max_num_points
-
- if self.hparams.learn_embeddings:
- self.learn_embeddings = self.hparams.learn_embeddings
- else:
- self.learn_embeddings = False
-
- # create the graph corresponding to the BNN instance
- self.graph = tf.Graph()
- with self.graph.as_default():
- # store a new session for the graph
- self.sess = tf.Session()
-
- with tf.variable_scope(self.name, reuse=tf.AUTO_REUSE):
- self.n = tf.placeholder(shape=[], dtype=tf.float64)
- self.x = tf.placeholder(shape=[None, self.n_in], dtype=tf.float64)
- self.x_in = tf.placeholder(shape=[None, self.n_in], dtype=tf.float64)
- self.y = tf.placeholder(shape=[None, self.n_out], dtype=tf.float64)
- self.weights = tf.placeholder(shape=[None, self.n_out],
- dtype=tf.float64)
-
- self.build_model()
- self.sess.run(tf.global_variables_initializer())
-
- def atleast_2d(self, x, dims):
- return tf.reshape(tf.expand_dims(x, axis=0), (-1, dims))
-
- def sq_dist(self, x, x2):
- a2 = tf.reduce_sum(tf.square(x), 1)
- b2 = tf.reduce_sum(tf.square(x2), 1)
- sqdists = tf.expand_dims(a2, 1) + b2 - 2.0 * tf.matmul(x, tf.transpose(x2))
- return sqdists
-
- # Covariance between outputs
- def task_cov(self, x, x2):
- """Squared Exponential Covariance Kernel over latent task embeddings."""
- # Index into latent task vectors
- x_vecs = tf.gather(self.task_vectors, tf.argmax(x, axis=1), axis=0)
- x2_vecs = tf.gather(self.task_vectors, tf.argmax(x2, axis=1), axis=0)
- r = self.sq_dist(self.atleast_2d(x_vecs, self.task_latent_dim),
- self.atleast_2d(x2_vecs, self.task_latent_dim))
- return tf.exp(-r)
-
- def cov(self, x, x2):
- """Matern 3/2 + Linear Gaussian Process Covariance Function."""
- ls = tf.clip_by_value(self.length_scales, -5.0, 5.0)
- ls_lin = tf.clip_by_value(self.length_scales_lin, -5.0, 5.0)
- r = self.sq_dist(self.atleast_2d(x, self.n_in)/tf.nn.softplus(ls),
- self.atleast_2d(x2, self.n_in)/tf.nn.softplus(ls))
- r = tf.clip_by_value(r, 0, 1e8)
-
- # Matern 3/2 Covariance
- matern = (1.0 + tf.sqrt(3.0*r + 1e-16)) * tf.exp(-tf.sqrt(3.0*r + 1e-16))
- # Linear Covariance
- lin = tf.matmul(x / tf.nn.softplus(ls_lin),
- x2 / tf.nn.softplus(ls_lin), transpose_b=True)
- return (tf.nn.softplus(self.amplitude) * matern +
- tf.nn.softplus(self.amplitude_linear) * lin)
-
- def build_model(self):
- """Defines the GP model.
-
- The loss is computed for partial feedback settings (bandits), so only
- the observed outcome is backpropagated (see weighted loss).
- Selects the optimizer and, finally, it also initializes the graph.
- """
-
- logging.info("Initializing model %s.", self.name)
- self.global_step = tf.train.get_or_create_global_step()
-
- # Define state for the model (inputs, etc.)
- self.x_train = tf.get_variable(
- "training_data",
- initializer=tf.ones(
- [self.hparams.batch_size, self.n_in], dtype=tf.float64),
- validate_shape=False,
- trainable=False)
- self.y_train = tf.get_variable(
- "training_labels",
- initializer=tf.zeros([self.hparams.batch_size, 1], dtype=tf.float64),
- validate_shape=False,
- trainable=False)
- self.weights_train = tf.get_variable(
- "weights_train",
- initializer=tf.ones(
- [self.hparams.batch_size, self.n_out], dtype=tf.float64),
- validate_shape=False,
- trainable=False)
- self.input_op = tf.assign(self.x_train, self.x_in, validate_shape=False)
- self.input_w_op = tf.assign(
- self.weights_train, self.weights, validate_shape=False)
-
- self.input_std = tf.get_variable(
- "data_standard_deviation",
- initializer=tf.ones([1, self.n_out], dtype=tf.float64),
- dtype=tf.float64,
- trainable=False)
- self.input_mean = tf.get_variable(
- "data_mean",
- initializer=tf.zeros([1, self.n_out], dtype=tf.float64),
- dtype=tf.float64,
- trainable=True)
-
- # GP Hyperparameters
- self.noise = tf.get_variable(
- "noise", initializer=tf.cast(0.0, dtype=tf.float64))
- self.amplitude = tf.get_variable(
- "amplitude", initializer=tf.cast(1.0, dtype=tf.float64))
- self.amplitude_linear = tf.get_variable(
- "linear_amplitude", initializer=tf.cast(1.0, dtype=tf.float64))
- self.length_scales = tf.get_variable(
- "length_scales", initializer=tf.zeros([1, self.n_in], dtype=tf.float64))
- self.length_scales_lin = tf.get_variable(
- "length_scales_linear",
- initializer=tf.zeros([1, self.n_in], dtype=tf.float64))
-
- # Latent embeddings of the different outputs for task covariance
- self.task_vectors = tf.get_variable(
- "latent_task_vectors",
- initializer=tf.random_normal(
- [self.n_out, self.task_latent_dim], dtype=tf.float64))
-
- # Normalize outputs across each dimension
- # Since we have different numbers of observations across each task, we
- # normalize by their respective counts.
- index_counts = self.atleast_2d(tf.reduce_sum(self.weights, axis=0),
- self.n_out)
- index_counts = tf.where(index_counts > 0, index_counts,
- tf.ones(tf.shape(index_counts), dtype=tf.float64))
- self.mean_op = tf.assign(self.input_mean,
- tf.reduce_sum(self.y, axis=0) / index_counts)
- self.var_op = tf.assign(
- self.input_std, tf.sqrt(1e-4 + tf.reduce_sum(tf.square(
- self.y - tf.reduce_sum(self.y, axis=0) / index_counts), axis=0)
- / index_counts))
-
- with tf.control_dependencies([self.var_op]):
- y_normed = self.atleast_2d(
- (self.y - self.input_mean) / self.input_std, self.n_out)
- y_normed = self.atleast_2d(tf.boolean_mask(y_normed, self.weights > 0), 1)
- self.out_op = tf.assign(self.y_train, y_normed, validate_shape=False)
-
- # Observation noise
- alpha = tf.nn.softplus(self.noise) + 1e-6
-
- # Covariance
- with tf.control_dependencies([self.input_op, self.input_w_op, self.out_op]):
- self.self_cov = (self.cov(self.x_in, self.x_in) *
- self.task_cov(self.weights, self.weights) +
- tf.eye(tf.shape(self.x_in)[0], dtype=tf.float64) * alpha)
-
- self.chol = tf.cholesky(self.self_cov)
- self.kinv = tf.cholesky_solve(self.chol, tf.eye(tf.shape(self.x_in)[0],
- dtype=tf.float64))
-
- self.input_inv = tf.Variable(
- tf.eye(self.hparams.batch_size, dtype=tf.float64),
- validate_shape=False,
- trainable=False)
- self.input_cov_op = tf.assign(self.input_inv, self.kinv,
- validate_shape=False)
-
- # Log determinant by taking the singular values along the diagonal
- # of self.chol
- with tf.control_dependencies([self.input_cov_op]):
- logdet = 2.0 * tf.reduce_sum(tf.log(tf.diag_part(self.chol) + 1e-16))
-
- # Log Marginal likelihood
- self.marginal_ll = -tf.reduce_sum(-0.5 * tf.matmul(
- tf.transpose(y_normed), tf.matmul(self.kinv, y_normed)) - 0.5 * logdet -
- 0.5 * self.n * np.log(2 * np.pi))
-
- zero = tf.cast(0., dtype=tf.float64)
- one = tf.cast(1., dtype=tf.float64)
- standard_normal = tfd.Normal(loc=zero, scale=one)
-
- # Loss is marginal likelihood and priors
- self.loss = tf.reduce_sum(
- self.marginal_ll -
- (standard_normal.log_prob(self.amplitude) +
- standard_normal.log_prob(tf.exp(self.noise)) +
- standard_normal.log_prob(self.amplitude_linear) +
- tfd.Normal(loc=zero, scale=one * 10.).log_prob(
- self.task_vectors))
- )
-
- # Optimizer for hyperparameters
- optimizer = tf.train.AdamOptimizer(learning_rate=self.hparams.lr)
- vars_to_optimize = [
- self.amplitude, self.length_scales, self.length_scales_lin,
- self.amplitude_linear, self.noise, self.input_mean
- ]
-
- if self.learn_embeddings:
- vars_to_optimize.append(self.task_vectors)
- grads = optimizer.compute_gradients(self.loss, vars_to_optimize)
- self.train_op = optimizer.apply_gradients(grads,
- global_step=self.global_step)
-
- # Predictions for test data
- self.y_mean, self.y_pred = self.posterior_mean_and_sample(self.x)
-
- # create tensorboard metrics
- self.create_summaries()
- self.summary_writer = tf.summary.FileWriter("{}/graph_{}".format(
- FLAGS.logdir, self.name), self.sess.graph)
- self.check = tf.add_check_numerics_ops()
-
- def posterior_mean_and_sample(self, candidates):
- """Draw samples for test predictions.
-
- Given a Tensor of 'candidates' inputs, returns samples from the posterior
- and the posterior mean prediction for those inputs.
-
- Args:
- candidates: A (num-examples x num-dims) Tensor containing the inputs for
- which to return predictions.
- Returns:
- y_mean: The posterior mean prediction given these inputs
- y_sample: A sample from the posterior of the outputs given these inputs
- """
- # Cross-covariance for test predictions
- w = tf.identity(self.weights_train)
- inds = tf.squeeze(
- tf.reshape(
- tf.tile(
- tf.reshape(tf.range(self.n_out), (self.n_out, 1)),
- (1, tf.shape(candidates)[0])), (-1, 1)))
-
- cross_cov = self.cov(tf.tile(candidates, [self.n_out, 1]), self.x_train)
- cross_task_cov = self.task_cov(tf.one_hot(inds, self.n_out), w)
- cross_cov *= cross_task_cov
-
- # Test mean prediction
- y_mean = tf.matmul(cross_cov, tf.matmul(self.input_inv, self.y_train))
-
- # Test sample predictions
- # Note this can be done much more efficiently using Kronecker products
- # if all tasks are fully observed (which we won't assume)
- test_cov = (
- self.cov(tf.tile(candidates, [self.n_out, 1]),
- tf.tile(candidates, [self.n_out, 1])) *
- self.task_cov(tf.one_hot(inds, self.n_out),
- tf.one_hot(inds, self.n_out)) -
- tf.matmul(cross_cov,
- tf.matmul(self.input_inv,
- tf.transpose(cross_cov))))
-
- # Get the matrix square root through an SVD for drawing samples
- # This seems more numerically stable than the Cholesky
- s, _, v = tf.svd(test_cov, full_matrices=True)
- test_sqrt = tf.matmul(v, tf.matmul(tf.diag(s), tf.transpose(v)))
-
- y_sample = (
- tf.matmul(
- test_sqrt,
- tf.random_normal([tf.shape(test_sqrt)[0], 1], dtype=tf.float64)) +
- y_mean)
-
- y_sample = (
- tf.transpose(tf.reshape(y_sample,
- (self.n_out, -1))) * self.input_std +
- self.input_mean)
-
- return y_mean, y_sample
-
- def create_summaries(self):
- with self.graph.as_default():
- tf.summary.scalar("loss", self.loss)
- tf.summary.scalar("log_noise", self.noise)
- tf.summary.scalar("log_amp", self.amplitude)
- tf.summary.scalar("log_amp_lin", self.amplitude_linear)
- tf.summary.histogram("length_scales", self.length_scales)
- tf.summary.histogram("length_scales_lin", self.length_scales_lin)
- self.summary_op = tf.summary.merge_all()
-
- def train(self, data, num_steps):
- """Trains the GP for num_steps, using the data in 'data'.
-
- Args:
- data: ContextualDataset object that provides the data.
- num_steps: Number of minibatches to train the network for.
- """
-
- logging.info("Training %s for %d steps...", self.name, num_steps)
- for step in range(num_steps):
- numpts = min(data.num_points(None), self.max_num_points)
- if numpts >= self.max_num_points and self.keep_fixed_after_max_obs:
- x = data.contexts[:numpts, :]
- y = data.rewards[:numpts, :]
- weights = np.zeros((x.shape[0], self.n_out))
- for i, val in enumerate(data.actions[:numpts]):
- weights[i, val] = 1.0
- else:
- x, y, weights = data.get_batch_with_weights(numpts)
-
- ops = [
- self.global_step, self.summary_op, self.loss, self.noise,
- self.amplitude, self.amplitude_linear, self.length_scales,
- self.length_scales_lin, self.input_cov_op, self.input_op, self.var_op,
- self.input_w_op, self.out_op, self.train_op
- ]
-
- res = self.sess.run(ops,
- feed_dict={self.x: x,
- self.x_in: x,
- self.y: y,
- self.weights: weights,
- self.n: numpts,
- })
-
- if step % self._freq_summary == 0:
- if self._show_training:
- logging.info("step: %d, loss: %g noise: %f amp: %f amp_lin: %f",
- step, res[2], res[3], res[4], res[5])
- summary = res[1]
- global_step = res[0]
- self.summary_writer.add_summary(summary, global_step=global_step)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/neural_bandit_model.py b/research/deep_contextual_bandits/bandits/algorithms/neural_bandit_model.py
deleted file mode 100644
index 99d7cd4dc8e2c35571f82bbb79ea1564a148ff5d..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/neural_bandit_model.py
+++ /dev/null
@@ -1,220 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define a family of neural network architectures for bandits.
-
-The network accepts different type of optimizers that could lead to different
-approximations of the posterior distribution or simply to point estimates.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from absl import flags
-from bandits.core.bayesian_nn import BayesianNN
-
-FLAGS = flags.FLAGS
-
-
-class NeuralBanditModel(BayesianNN):
- """Implements a neural network for bandit problems."""
-
- def __init__(self, optimizer, hparams, name):
- """Saves hyper-params and builds the Tensorflow graph."""
-
- self.opt_name = optimizer
- self.name = name
- self.hparams = hparams
- self.verbose = getattr(self.hparams, "verbose", True)
- self.times_trained = 0
- self.build_model()
-
- def build_layer(self, x, num_units):
- """Builds a layer with input x; dropout and layer norm if specified."""
-
- init_s = self.hparams.init_scale
-
- layer_n = getattr(self.hparams, "layer_norm", False)
- dropout = getattr(self.hparams, "use_dropout", False)
-
- nn = tf.contrib.layers.fully_connected(
- x,
- num_units,
- activation_fn=self.hparams.activation,
- normalizer_fn=None if not layer_n else tf.contrib.layers.layer_norm,
- normalizer_params={},
- weights_initializer=tf.random_uniform_initializer(-init_s, init_s)
- )
-
- if dropout:
- nn = tf.nn.dropout(nn, self.hparams.keep_prob)
-
- return nn
-
- def forward_pass(self):
-
- init_s = self.hparams.init_scale
-
- scope_name = "prediction_{}".format(self.name)
- with tf.variable_scope(scope_name, reuse=tf.AUTO_REUSE):
- nn = self.x
- for num_units in self.hparams.layer_sizes:
- if num_units > 0:
- nn = self.build_layer(nn, num_units)
-
- y_pred = tf.layers.dense(
- nn,
- self.hparams.num_actions,
- kernel_initializer=tf.random_uniform_initializer(-init_s, init_s))
-
- return nn, y_pred
-
- def build_model(self):
- """Defines the actual NN model with fully connected layers.
-
- The loss is computed for partial feedback settings (bandits), so only
- the observed outcome is backpropagated (see weighted loss).
- Selects the optimizer and, finally, it also initializes the graph.
- """
-
- # create and store the graph corresponding to the BNN instance
- self.graph = tf.Graph()
-
- with self.graph.as_default():
-
- # create and store a new session for the graph
- self.sess = tf.Session()
-
- with tf.name_scope(self.name):
-
- self.global_step = tf.train.get_or_create_global_step()
-
- # context
- self.x = tf.placeholder(
- shape=[None, self.hparams.context_dim],
- dtype=tf.float32,
- name="{}_x".format(self.name))
-
- # reward vector
- self.y = tf.placeholder(
- shape=[None, self.hparams.num_actions],
- dtype=tf.float32,
- name="{}_y".format(self.name))
-
- # weights (1 for selected action, 0 otherwise)
- self.weights = tf.placeholder(
- shape=[None, self.hparams.num_actions],
- dtype=tf.float32,
- name="{}_w".format(self.name))
-
- # with tf.variable_scope("prediction_{}".format(self.name)):
- self.nn, self.y_pred = self.forward_pass()
- self.loss = tf.squared_difference(self.y_pred, self.y)
- self.weighted_loss = tf.multiply(self.weights, self.loss)
- self.cost = tf.reduce_sum(self.weighted_loss) / self.hparams.batch_size
-
- if self.hparams.activate_decay:
- self.lr = tf.train.inverse_time_decay(
- self.hparams.initial_lr, self.global_step,
- 1, self.hparams.lr_decay_rate)
- else:
- self.lr = tf.Variable(self.hparams.initial_lr, trainable=False)
-
- # create tensorboard metrics
- self.create_summaries()
- self.summary_writer = tf.summary.FileWriter(
- "{}/graph_{}".format(FLAGS.logdir, self.name), self.sess.graph)
-
- tvars = tf.trainable_variables()
- grads, _ = tf.clip_by_global_norm(
- tf.gradients(self.cost, tvars), self.hparams.max_grad_norm)
-
- self.optimizer = self.select_optimizer()
-
- self.train_op = self.optimizer.apply_gradients(
- zip(grads, tvars), global_step=self.global_step)
-
- self.init = tf.global_variables_initializer()
-
- self.initialize_graph()
-
- def initialize_graph(self):
- """Initializes all variables."""
-
- with self.graph.as_default():
- if self.verbose:
- print("Initializing model {}.".format(self.name))
- self.sess.run(self.init)
-
- def assign_lr(self):
- """Resets the learning rate in dynamic schedules for subsequent trainings.
-
- In bandits settings, we do expand our dataset over time. Then, we need to
- re-train the network with the new data. The algorithms that do not keep
- the step constant, can reset it at the start of each *training* process.
- """
-
- decay_steps = 1
- if self.hparams.activate_decay:
- current_gs = self.sess.run(self.global_step)
- with self.graph.as_default():
- self.lr = tf.train.inverse_time_decay(self.hparams.initial_lr,
- self.global_step - current_gs,
- decay_steps,
- self.hparams.lr_decay_rate)
-
- def select_optimizer(self):
- """Selects optimizer. To be extended (SGLD, KFAC, etc)."""
- return tf.train.RMSPropOptimizer(self.lr)
-
- def create_summaries(self):
- """Defines summaries including mean loss, learning rate, and global step."""
-
- with self.graph.as_default():
- with tf.name_scope(self.name + "_summaries"):
- tf.summary.scalar("cost", self.cost)
- tf.summary.scalar("lr", self.lr)
- tf.summary.scalar("global_step", self.global_step)
- self.summary_op = tf.summary.merge_all()
-
- def train(self, data, num_steps):
- """Trains the network for num_steps, using the provided data.
-
- Args:
- data: ContextualDataset object that provides the data.
- num_steps: Number of minibatches to train the network for.
- """
-
- if self.verbose:
- print("Training {} for {} steps...".format(self.name, num_steps))
-
- with self.graph.as_default():
-
- for step in range(num_steps):
- x, y, w = data.get_batch_with_weights(self.hparams.batch_size)
- _, cost, summary, lr = self.sess.run(
- [self.train_op, self.cost, self.summary_op, self.lr],
- feed_dict={self.x: x, self.y: y, self.weights: w})
-
- if step % self.hparams.freq_summary == 0:
- if self.hparams.show_training:
- print("{} | step: {}, lr: {}, loss: {}".format(
- self.name, step, lr, cost))
- self.summary_writer.add_summary(summary, step)
-
- self.times_trained += 1
diff --git a/research/deep_contextual_bandits/bandits/algorithms/neural_linear_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/neural_linear_sampling.py
deleted file mode 100644
index 43fc551614b49ad34538aa64090bcda5f823a60f..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/neural_linear_sampling.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Thompson Sampling with linear posterior over a learnt deep representation."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-from scipy.stats import invgamma
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-from bandits.core.contextual_dataset import ContextualDataset
-from bandits.algorithms.neural_bandit_model import NeuralBanditModel
-
-
-class NeuralLinearPosteriorSampling(BanditAlgorithm):
- """Full Bayesian linear regression on the last layer of a deep neural net."""
-
- def __init__(self, name, hparams, optimizer='RMS'):
-
- self.name = name
- self.hparams = hparams
- self.latent_dim = self.hparams.layer_sizes[-1]
-
- # Gaussian prior for each beta_i
- self._lambda_prior = self.hparams.lambda_prior
-
- self.mu = [
- np.zeros(self.latent_dim)
- for _ in range(self.hparams.num_actions)
- ]
-
- self.cov = [(1.0 / self.lambda_prior) * np.eye(self.latent_dim)
- for _ in range(self.hparams.num_actions)]
-
- self.precision = [
- self.lambda_prior * np.eye(self.latent_dim)
- for _ in range(self.hparams.num_actions)
- ]
-
- # Inverse Gamma prior for each sigma2_i
- self._a0 = self.hparams.a0
- self._b0 = self.hparams.b0
-
- self.a = [self._a0 for _ in range(self.hparams.num_actions)]
- self.b = [self._b0 for _ in range(self.hparams.num_actions)]
-
- # Regression and NN Update Frequency
- self.update_freq_lr = hparams.training_freq
- self.update_freq_nn = hparams.training_freq_network
-
- self.t = 0
- self.optimizer_n = optimizer
-
- self.num_epochs = hparams.training_epochs
- self.data_h = ContextualDataset(hparams.context_dim,
- hparams.num_actions,
- intercept=False)
- self.latent_h = ContextualDataset(self.latent_dim,
- hparams.num_actions,
- intercept=False)
- self.bnn = NeuralBanditModel(optimizer, hparams, '{}-bnn'.format(name))
-
- def action(self, context):
- """Samples beta's from posterior, and chooses best action accordingly."""
-
- # Round robin until each action has been selected "initial_pulls" times
- if self.t < self.hparams.num_actions * self.hparams.initial_pulls:
- return self.t % self.hparams.num_actions
-
- # Sample sigma2, and beta conditional on sigma2
- sigma2_s = [
- self.b[i] * invgamma.rvs(self.a[i])
- for i in range(self.hparams.num_actions)
- ]
-
- try:
- beta_s = [
- np.random.multivariate_normal(self.mu[i], sigma2_s[i] * self.cov[i])
- for i in range(self.hparams.num_actions)
- ]
- except np.linalg.LinAlgError as e:
- # Sampling could fail if covariance is not positive definite
- print('Exception when sampling for {}.'.format(self.name))
- print('Details: {} | {}.'.format(e.message, e.args))
- d = self.latent_dim
- beta_s = [
- np.random.multivariate_normal(np.zeros((d)), np.eye(d))
- for i in range(self.hparams.num_actions)
- ]
-
- # Compute last-layer representation for the current context
- with self.bnn.graph.as_default():
- c = context.reshape((1, self.hparams.context_dim))
- z_context = self.bnn.sess.run(self.bnn.nn, feed_dict={self.bnn.x: c})
-
- # Apply Thompson Sampling to last-layer representation
- vals = [
- np.dot(beta_s[i], z_context.T) for i in range(self.hparams.num_actions)
- ]
- return np.argmax(vals)
-
- def update(self, context, action, reward):
- """Updates the posterior using linear bayesian regression formula."""
-
- self.t += 1
- self.data_h.add(context, action, reward)
- c = context.reshape((1, self.hparams.context_dim))
- z_context = self.bnn.sess.run(self.bnn.nn, feed_dict={self.bnn.x: c})
- self.latent_h.add(z_context, action, reward)
-
- # Retrain the network on the original data (data_h)
- if self.t % self.update_freq_nn == 0:
-
- if self.hparams.reset_lr:
- self.bnn.assign_lr()
- self.bnn.train(self.data_h, self.num_epochs)
-
- # Update the latent representation of every datapoint collected so far
- new_z = self.bnn.sess.run(self.bnn.nn,
- feed_dict={self.bnn.x: self.data_h.contexts})
- self.latent_h.replace_data(contexts=new_z)
-
- # Update the Bayesian Linear Regression
- if self.t % self.update_freq_lr == 0:
-
- # Find all the actions to update
- actions_to_update = self.latent_h.actions[:-self.update_freq_lr]
-
- for action_v in np.unique(actions_to_update):
-
- # Update action posterior with formulas: \beta | z,y ~ N(mu_q, cov_q)
- z, y = self.latent_h.get_data(action_v)
-
- # The algorithm could be improved with sequential formulas (cheaper)
- s = np.dot(z.T, z)
-
- # Some terms are removed as we assume prior mu_0 = 0.
- precision_a = s + self.lambda_prior * np.eye(self.latent_dim)
- cov_a = np.linalg.inv(precision_a)
- mu_a = np.dot(cov_a, np.dot(z.T, y))
-
- # Inverse Gamma posterior update
- a_post = self.a0 + z.shape[0] / 2.0
- b_upd = 0.5 * np.dot(y.T, y)
- b_upd -= 0.5 * np.dot(mu_a.T, np.dot(precision_a, mu_a))
- b_post = self.b0 + b_upd
-
- # Store new posterior distributions
- self.mu[action_v] = mu_a
- self.cov[action_v] = cov_a
- self.precision[action_v] = precision_a
- self.a[action_v] = a_post
- self.b[action_v] = b_post
-
- @property
- def a0(self):
- return self._a0
-
- @property
- def b0(self):
- return self._b0
-
- @property
- def lambda_prior(self):
- return self._lambda_prior
diff --git a/research/deep_contextual_bandits/bandits/algorithms/parameter_noise_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/parameter_noise_sampling.py
deleted file mode 100644
index 19944ad577372b6971f03f1117fc33d5a2a276b1..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/parameter_noise_sampling.py
+++ /dev/null
@@ -1,187 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual algorithm based on Thompson Sampling + direct noise injection."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-from scipy.special import logsumexp
-import tensorflow as tf
-
-from absl import flags
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-from bandits.core.contextual_dataset import ContextualDataset
-from bandits.algorithms.neural_bandit_model import NeuralBanditModel
-
-FLAGS = flags.FLAGS
-
-
-class ParameterNoiseSampling(BanditAlgorithm):
- """Parameter Noise Sampling algorithm based on adding noise to net params.
-
- Described in https://arxiv.org/abs/1706.01905
- """
-
- def __init__(self, name, hparams):
- """Creates the algorithm, and sets up the adaptive Gaussian noise."""
-
- self.name = name
- self.hparams = hparams
- self.verbose = getattr(self.hparams, 'verbose', True)
- self.noise_std = getattr(self.hparams, 'noise_std', 0.005)
- self.eps = getattr(self.hparams, 'eps', 0.05)
- self.d_samples = getattr(self.hparams, 'd_samples', 300)
- self.optimizer = getattr(self.hparams, 'optimizer', 'RMS')
-
- # keep track of noise heuristic statistics
- self.std_h = [self.noise_std]
- self.eps_h = [self.eps]
- self.kl_h = []
- self.t = 0
-
- self.freq_update = hparams.training_freq
- self.num_epochs = hparams.training_epochs
-
- self.data_h = ContextualDataset(hparams.context_dim, hparams.num_actions,
- hparams.buffer_s)
- self.bnn = NeuralBanditModel(self.optimizer, hparams, '{}-bnn'.format(name))
-
- with self.bnn.graph.as_default():
-
- # noise-injection std placeholder
- self.bnn.noise_std_ph = tf.placeholder(tf.float32, shape=())
-
- # create noise corruption op; adds noise to all weights
- tvars = tf.trainable_variables()
- self.bnn.noisy_grads = [
- tf.random_normal(v.get_shape(), 0, self.bnn.noise_std_ph)
- for v in tvars
- ]
-
- # add noise to all params, then compute prediction, then subtract.
- with tf.control_dependencies(self.bnn.noisy_grads):
- self.bnn.noise_add_ops = [
- tvars[i].assign_add(n) for i, n in enumerate(self.bnn.noisy_grads)
- ]
- with tf.control_dependencies(self.bnn.noise_add_ops):
- # we force the prediction for 'y' to be recomputed after adding noise
- self.bnn.noisy_nn, self.bnn.noisy_pred_val = self.bnn.forward_pass()
-
- self.bnn.noisy_pred = tf.identity(self.bnn.noisy_pred_val)
- with tf.control_dependencies([tf.identity(self.bnn.noisy_pred)]):
- self.bnn.noise_sub_ops = [
- tvars[i].assign_add(-n)
- for i, n in enumerate(self.bnn.noisy_grads)
- ]
-
- def action(self, context):
- """Selects action based on Thompson Sampling *after* adding noise."""
-
- if self.t < self.hparams.num_actions * self.hparams.initial_pulls:
- # round robin until each action has been taken "initial_pulls" times
- return self.t % self.hparams.num_actions
-
- with self.bnn.graph.as_default():
- # run noise prediction op to choose action, and subtract noise op after.
- c = context.reshape((1, self.hparams.context_dim))
- output, _ = self.bnn.sess.run(
- [self.bnn.noisy_pred, self.bnn.noise_sub_ops],
- feed_dict={self.bnn.x: c,
- self.bnn.noise_std_ph: self.noise_std})
- return np.argmax(output)
-
- def update(self, context, action, reward):
- """Updates the data buffer, and re-trains the BNN and noise level."""
-
- self.t += 1
- self.data_h.add(context, action, reward)
-
- if self.t % self.freq_update == 0:
- self.bnn.train(self.data_h, self.num_epochs)
- self.update_noise()
-
- def update_noise(self):
- """Increase noise if distance btw original and corrupted distrib small."""
-
- kl = self.compute_distance()
- delta = -np.log1p(- self.eps + self.eps / self.hparams.num_actions)
-
- if kl < delta:
- self.noise_std *= 1.01
- else:
- self.noise_std /= 1.01
-
- self.eps *= 0.99
-
- if self.verbose:
- print('Update eps={} | kl={} | std={} | delta={} | increase={}.'.format(
- self.eps, kl, self.noise_std, delta, kl < delta))
-
- # store noise-injection statistics for inspection: std, KL, eps.
- self.std_h.append(self.noise_std)
- self.kl_h.append(kl)
- self.eps_h.append(self.eps)
-
- def compute_distance(self):
- """Computes empirical KL for original and corrupted output distributions."""
-
- random_inputs, _ = self.data_h.get_batch(self.d_samples)
- y_model = self.bnn.sess.run(
- self.bnn.y_pred,
- feed_dict={
- self.bnn.x: random_inputs,
- self.bnn.noise_std_ph: self.noise_std
- })
- y_noisy, _ = self.bnn.sess.run(
- [self.bnn.noisy_pred, self.bnn.noise_sub_ops],
- feed_dict={
- self.bnn.x: random_inputs,
- self.bnn.noise_std_ph: self.noise_std
- })
-
- if self.verbose:
- # display how often original & perturbed models propose different actions
- s = np.sum([np.argmax(y_model[i, :]) == np.argmax(y_noisy[i, :])
- for i in range(y_model.shape[0])])
- print('{} | % of agreement btw original / corrupted actions: {}.'.format(
- self.name, s / self.d_samples))
-
- kl = self.compute_kl_with_logits(y_model, y_noisy)
- return kl
-
- def compute_kl_with_logits(self, logits1, logits2):
- """Computes KL from logits samples from two distributions."""
-
- def exp_times_diff(a, b):
- return np.multiply(np.exp(a), a - b)
-
- logsumexp1 = logsumexp(logits1, axis=1)
- logsumexp2 = logsumexp(logits2, axis=1)
- logsumexp_diff = logsumexp2 - logsumexp1
-
- exp_diff = exp_times_diff(logits1, logits2)
- exp_diff = np.sum(exp_diff, axis=1)
-
- inv_exp_sum = np.sum(np.exp(logits1), axis=1)
- term1 = np.divide(exp_diff, inv_exp_sum)
-
- kl = term1 + logsumexp_diff
- kl = np.maximum(kl, 0.0)
- kl = np.nan_to_num(kl)
- return np.mean(kl)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/posterior_bnn_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/posterior_bnn_sampling.py
deleted file mode 100644
index 0f0c5d365a3a3e48006fe6b4e7e47ab73ea756cf..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/posterior_bnn_sampling.py
+++ /dev/null
@@ -1,92 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual bandit algorithm based on Thompson Sampling and a Bayesian NN."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-from bandits.algorithms.bb_alpha_divergence_model import BBAlphaDivergence
-from bandits.algorithms.bf_variational_neural_bandit_model import BfVariationalNeuralBanditModel
-from bandits.core.contextual_dataset import ContextualDataset
-from bandits.algorithms.multitask_gp import MultitaskGP
-from bandits.algorithms.neural_bandit_model import NeuralBanditModel
-from bandits.algorithms.variational_neural_bandit_model import VariationalNeuralBanditModel
-
-
-class PosteriorBNNSampling(BanditAlgorithm):
- """Posterior Sampling algorithm based on a Bayesian neural network."""
-
- def __init__(self, name, hparams, bnn_model='RMSProp'):
- """Creates a PosteriorBNNSampling object based on a specific optimizer.
-
- The algorithm has two basic tools: an Approx BNN and a Contextual Dataset.
- The Bayesian Network keeps the posterior based on the optimizer iterations.
-
- Args:
- name: Name of the algorithm.
- hparams: Hyper-parameters of the algorithm.
- bnn_model: Type of BNN. By default RMSProp (point estimate).
- """
-
- self.name = name
- self.hparams = hparams
- self.optimizer_n = hparams.optimizer
-
- self.training_freq = hparams.training_freq
- self.training_epochs = hparams.training_epochs
- self.t = 0
- self.data_h = ContextualDataset(hparams.context_dim, hparams.num_actions,
- hparams.buffer_s)
-
- # to be extended with more BNNs (BB alpha-div, GPs, SGFS, constSGD...)
- bnn_name = '{}-bnn'.format(name)
- if bnn_model == 'Variational':
- self.bnn = VariationalNeuralBanditModel(hparams, bnn_name)
- elif bnn_model == 'AlphaDiv':
- self.bnn = BBAlphaDivergence(hparams, bnn_name)
- elif bnn_model == 'Variational_BF':
- self.bnn = BfVariationalNeuralBanditModel(hparams, bnn_name)
- elif bnn_model == 'GP':
- self.bnn = MultitaskGP(hparams)
- else:
- self.bnn = NeuralBanditModel(self.optimizer_n, hparams, bnn_name)
-
- def action(self, context):
- """Selects action for context based on Thompson Sampling using the BNN."""
-
- if self.t < self.hparams.num_actions * self.hparams.initial_pulls:
- # round robin until each action has been taken "initial_pulls" times
- return self.t % self.hparams.num_actions
-
- with self.bnn.graph.as_default():
- c = context.reshape((1, self.hparams.context_dim))
- output = self.bnn.sess.run(self.bnn.y_pred, feed_dict={self.bnn.x: c})
- return np.argmax(output)
-
- def update(self, context, action, reward):
- """Updates data buffer, and re-trains the BNN every training_freq steps."""
-
- self.t += 1
- self.data_h.add(context, action, reward)
-
- if self.t % self.training_freq == 0:
- if self.hparams.reset_lr:
- self.bnn.assign_lr()
- self.bnn.train(self.data_h, self.training_epochs)
diff --git a/research/deep_contextual_bandits/bandits/algorithms/uniform_sampling.py b/research/deep_contextual_bandits/bandits/algorithms/uniform_sampling.py
deleted file mode 100644
index 15c073fbe89da4e9aef595c8772ceaa3667e1952..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/uniform_sampling.py
+++ /dev/null
@@ -1,43 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contextual bandit algorithm that selects an action uniformly at random."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-from bandits.core.bandit_algorithm import BanditAlgorithm
-
-
-class UniformSampling(BanditAlgorithm):
- """Defines a baseline; returns one action uniformly at random."""
-
- def __init__(self, name, hparams):
- """Creates a UniformSampling object.
-
- Args:
- name: Name of the algorithm.
- hparams: Hyper-parameters, including the number of arms (num_actions).
- """
-
- self.name = name
- self.hparams = hparams
-
- def action(self, context):
- """Selects an action uniformly at random."""
- return np.random.choice(range(self.hparams.num_actions))
diff --git a/research/deep_contextual_bandits/bandits/algorithms/variational_neural_bandit_model.py b/research/deep_contextual_bandits/bandits/algorithms/variational_neural_bandit_model.py
deleted file mode 100644
index 7700c08ba9f7861aac522ba6da9f7371b5e203af..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/algorithms/variational_neural_bandit_model.py
+++ /dev/null
@@ -1,346 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Bayesian NN using factorized VI (Bayes By Backprop. Blundell et al. 2014).
-
-See https://arxiv.org/abs/1505.05424 for details.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from absl import flags
-from bandits.core.bayesian_nn import BayesianNN
-
-FLAGS = flags.FLAGS
-
-
-def log_gaussian(x, mu, sigma, reduce_sum=True):
- """Returns log Gaussian pdf."""
- res = (-0.5 * np.log(2 * np.pi) - tf.log(sigma) - tf.square(x - mu) /
- (2 * tf.square(sigma)))
- if reduce_sum:
- return tf.reduce_sum(res)
- else:
- return res
-
-
-def analytic_kl(mu_1, sigma_1, mu_2, sigma_2):
- """KL for two Gaussian distributions with diagonal covariance matrix."""
- sigma_1_sq = tf.square(sigma_1)
- sigma_2_sq = tf.square(sigma_2)
-
- t1 = tf.square(mu_1 - mu_2) / (2. * sigma_2_sq)
- t2 = (sigma_1_sq/sigma_2_sq - 1. - tf.log(sigma_1_sq) + tf.log(sigma_2_sq))/2.
- return tf.reduce_sum(t1 + t2)
-
-
-class VariationalNeuralBanditModel(BayesianNN):
- """Implements an approximate Bayesian NN using Variational Inference."""
-
- def __init__(self, hparams, name="BBBNN"):
-
- self.name = name
- self.hparams = hparams
-
- self.n_in = self.hparams.context_dim
- self.n_out = self.hparams.num_actions
- self.layers = self.hparams.layer_sizes
- self.init_scale = self.hparams.init_scale
- self.f_num_points = None
- if "f_num_points" in hparams:
- self.f_num_points = self.hparams.f_num_points
-
- self.cleared_times_trained = self.hparams.cleared_times_trained
- self.initial_training_steps = self.hparams.initial_training_steps
- self.training_schedule = np.linspace(self.initial_training_steps,
- self.hparams.training_epochs,
- self.cleared_times_trained)
- self.verbose = getattr(self.hparams, "verbose", True)
-
- self.weights_m = {}
- self.weights_std = {}
- self.biases_m = {}
- self.biases_std = {}
-
- self.times_trained = 0
-
- if self.hparams.use_sigma_exp_transform:
- self.sigma_transform = tf.exp
- self.inverse_sigma_transform = np.log
- else:
- self.sigma_transform = tf.nn.softplus
- self.inverse_sigma_transform = lambda y: y + np.log(1. - np.exp(-y))
-
- # Whether to use the local reparameterization trick to compute the loss.
- # See details in https://arxiv.org/abs/1506.02557
- self.use_local_reparameterization = True
-
- self.build_graph()
-
- def build_mu_variable(self, shape):
- """Returns a mean variable initialized as N(0, 0.05)."""
- return tf.Variable(tf.random_normal(shape, 0.0, 0.05))
-
- def build_sigma_variable(self, shape, init=-5.):
- """Returns a sigma variable initialized as N(init, 0.05)."""
- # Initialize sigma to be very small initially to encourage MAP opt first
- return tf.Variable(tf.random_normal(shape, init, 0.05))
-
- def build_layer(self, input_x, input_x_local, shape,
- layer_id, activation_fn=tf.nn.relu):
- """Builds a variational layer, and computes KL term.
-
- Args:
- input_x: Input to the variational layer.
- input_x_local: Input when the local reparameterization trick was applied.
- shape: [number_inputs, number_outputs] for the layer.
- layer_id: Number of layer in the architecture.
- activation_fn: Activation function to apply.
-
- Returns:
- output_h: Output of the variational layer.
- output_h_local: Output when local reparameterization trick was applied.
- neg_kl: Negative KL term for the layer.
- """
-
- w_mu = self.build_mu_variable(shape)
- w_sigma = self.sigma_transform(self.build_sigma_variable(shape))
- w_noise = tf.random_normal(shape)
- w = w_mu + w_sigma * w_noise
-
- b_mu = self.build_mu_variable([1, shape[1]])
- b_sigma = self.sigma_transform(self.build_sigma_variable([1, shape[1]]))
- b = b_mu
-
- # Store means and stds
- self.weights_m[layer_id] = w_mu
- self.weights_std[layer_id] = w_sigma
- self.biases_m[layer_id] = b_mu
- self.biases_std[layer_id] = b_sigma
-
- # Create outputs
- output_h = activation_fn(tf.matmul(input_x, w) + b)
-
- if self.use_local_reparameterization:
- # Use analytic KL divergence wrt the prior
- neg_kl = -analytic_kl(w_mu, w_sigma,
- 0., tf.to_float(np.sqrt(2./shape[0])))
- else:
- # Create empirical KL loss terms
- log_p = log_gaussian(w, 0., tf.to_float(np.sqrt(2./shape[0])))
- log_q = log_gaussian(w, tf.stop_gradient(w_mu), tf.stop_gradient(w_sigma))
- neg_kl = log_p - log_q
-
- # Apply local reparameterization trick: sample activations pre nonlinearity
- m_h = tf.matmul(input_x_local, w_mu) + b
- v_h = tf.matmul(tf.square(input_x_local), tf.square(w_sigma))
- output_h_local = m_h + tf.sqrt(v_h + 1e-6) * tf.random_normal(tf.shape(v_h))
- output_h_local = activation_fn(output_h_local)
-
- return output_h, output_h_local, neg_kl
-
- def build_action_noise(self):
- """Defines a model for additive noise per action, and its KL term."""
-
- # Define mean and std variables (log-normal dist) for each action.
- noise_sigma_mu = (self.build_mu_variable([1, self.n_out])
- + self.inverse_sigma_transform(self.hparams.noise_sigma))
- noise_sigma_sigma = self.sigma_transform(
- self.build_sigma_variable([1, self.n_out]))
-
- pre_noise_sigma = (noise_sigma_mu
- + tf.random_normal([1, self.n_out]) * noise_sigma_sigma)
- self.noise_sigma = self.sigma_transform(pre_noise_sigma)
-
- # Compute KL for additive noise sigma terms.
- if getattr(self.hparams, "infer_noise_sigma", False):
- neg_kl_term = log_gaussian(
- pre_noise_sigma,
- self.inverse_sigma_transform(self.hparams.noise_sigma),
- self.hparams.prior_sigma
- )
- neg_kl_term -= log_gaussian(pre_noise_sigma,
- noise_sigma_mu,
- noise_sigma_sigma)
- else:
- neg_kl_term = 0.
-
- return neg_kl_term
-
- def build_model(self, activation_fn=tf.nn.relu):
- """Defines the actual NN model with fully connected layers.
-
- The loss is computed for partial feedback settings (bandits), so only
- the observed outcome is backpropagated (see weighted loss).
- Selects the optimizer and, finally, it also initializes the graph.
-
- Args:
- activation_fn: the activation function used in the nn layers.
- """
-
- if self.verbose:
- print("Initializing model {}.".format(self.name))
- neg_kl_term, l_number = 0, 0
- use_local_reparameterization = self.use_local_reparameterization
-
- # Compute model additive noise for each action with log-normal distribution
- neg_kl_term += self.build_action_noise()
-
- # Build network.
- input_x = self.x
- input_local = self.x
- n_in = self.n_in
-
- for l_number, n_nodes in enumerate(self.layers):
- if n_nodes > 0:
- h, h_local, neg_kl = self.build_layer(input_x, input_local,
- [n_in, n_nodes], l_number)
-
- neg_kl_term += neg_kl
- input_x, input_local = h, h_local
- n_in = n_nodes
-
- # Create last linear layer
- h, h_local, neg_kl = self.build_layer(input_x, input_local,
- [n_in, self.n_out],
- l_number + 1,
- activation_fn=lambda x: x)
- neg_kl_term += neg_kl
-
- self.y_pred = h
- self.y_pred_local = h_local
-
- # Compute log likelihood (with learned or fixed noise level)
- if getattr(self.hparams, "infer_noise_sigma", False):
- log_likelihood = log_gaussian(
- self.y, self.y_pred_local, self.noise_sigma, reduce_sum=False)
- else:
- y_hat = self.y_pred_local if use_local_reparameterization else self.y_pred
- log_likelihood = log_gaussian(
- self.y, y_hat, self.hparams.noise_sigma, reduce_sum=False)
-
- # Only take into account observed outcomes (bandits setting)
- batch_size = tf.to_float(tf.shape(self.x)[0])
- weighted_log_likelihood = tf.reduce_sum(
- log_likelihood * self.weights) / batch_size
-
- # The objective is 1/n * (\sum_i log_like_i - KL); neg_kl_term estimates -KL
- elbo = weighted_log_likelihood + (neg_kl_term / self.n)
-
- self.loss = -elbo
- self.global_step = tf.train.get_or_create_global_step()
- self.train_op = tf.train.AdamOptimizer(self.hparams.initial_lr).minimize(
- self.loss, global_step=self.global_step)
-
- # Create tensorboard metrics
- self.create_summaries()
- self.summary_writer = tf.summary.FileWriter(
- "{}/graph_{}".format(FLAGS.logdir, self.name), self.sess.graph)
-
- def build_graph(self):
- """Defines graph, session, placeholders, and model.
-
- Placeholders are: n (size of the dataset), x and y (context and observed
- reward for each action), and weights (one-hot encoding of selected action
- for each context, i.e., only possibly non-zero element in each y).
- """
-
- self.graph = tf.Graph()
- with self.graph.as_default():
-
- self.sess = tf.Session()
-
- self.n = tf.placeholder(shape=[], dtype=tf.float32)
-
- self.x = tf.placeholder(shape=[None, self.n_in], dtype=tf.float32)
- self.y = tf.placeholder(shape=[None, self.n_out], dtype=tf.float32)
- self.weights = tf.placeholder(shape=[None, self.n_out], dtype=tf.float32)
-
- self.build_model()
- self.sess.run(tf.global_variables_initializer())
-
- def create_summaries(self):
- """Defines summaries including mean loss, and global step."""
-
- with self.graph.as_default():
- with tf.name_scope(self.name + "_summaries"):
- tf.summary.scalar("loss", self.loss)
- tf.summary.scalar("global_step", self.global_step)
- self.summary_op = tf.summary.merge_all()
-
- def assign_lr(self):
- """Resets the learning rate in dynamic schedules for subsequent trainings.
-
- In bandits settings, we do expand our dataset over time. Then, we need to
- re-train the network with the new data. The algorithms that do not keep
- the step constant, can reset it at the start of each *training* process.
- """
-
- decay_steps = 1
- if self.hparams.activate_decay:
- current_gs = self.sess.run(self.global_step)
- with self.graph.as_default():
- self.lr = tf.train.inverse_time_decay(self.hparams.initial_lr,
- self.global_step - current_gs,
- decay_steps,
- self.hparams.lr_decay_rate)
-
- def train(self, data, num_steps):
- """Trains the BNN for num_steps, using the data in 'data'.
-
- Args:
- data: ContextualDataset object that provides the data.
- num_steps: Number of minibatches to train the network for.
-
- Returns:
- losses: Loss history during training.
- """
-
- if self.times_trained < self.cleared_times_trained:
- num_steps = int(self.training_schedule[self.times_trained])
- self.times_trained += 1
-
- losses = []
-
- with self.graph.as_default():
-
- if self.verbose:
- print("Training {} for {} steps...".format(self.name, num_steps))
-
- for step in range(num_steps):
- x, y, weights = data.get_batch_with_weights(self.hparams.batch_size)
- _, summary, global_step, loss = self.sess.run(
- [self.train_op, self.summary_op, self.global_step, self.loss],
- feed_dict={
- self.x: x,
- self.y: y,
- self.weights: weights,
- self.n: data.num_points(self.f_num_points),
- })
-
- losses.append(loss)
-
- if step % self.hparams.freq_summary == 0:
- if self.hparams.show_training:
- print("{} | step: {}, loss: {}".format(
- self.name, global_step, loss))
- self.summary_writer.add_summary(summary, global_step)
-
- return losses
diff --git a/research/deep_contextual_bandits/bandits/core/bandit_algorithm.py b/research/deep_contextual_bandits/bandits/core/bandit_algorithm.py
deleted file mode 100644
index cae4e1676a865d538fa41936feb9118283b92a2c..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/core/bandit_algorithm.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define the abstract class for contextual bandit algorithms."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-class BanditAlgorithm(object):
- """A bandit algorithm must be able to do two basic operations.
-
- 1. Choose an action given a context.
- 2. Update its internal model given a triple (context, played action, reward).
- """
-
- def action(self, context):
- pass
-
- def update(self, context, action, reward):
- pass
diff --git a/research/deep_contextual_bandits/bandits/core/bayesian_nn.py b/research/deep_contextual_bandits/bandits/core/bayesian_nn.py
deleted file mode 100644
index 310961591317f8c9ff958a5178e81e0422385baf..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/core/bayesian_nn.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define the abstract class for Bayesian Neural Networks."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-class BayesianNN(object):
- """A Bayesian neural network keeps a distribution over neural nets."""
-
- def __init__(self, optimizer):
- pass
-
- def build_model(self):
- pass
-
- def train(self, data):
- pass
-
- def sample(self, steps):
- pass
diff --git a/research/deep_contextual_bandits/bandits/core/contextual_bandit.py b/research/deep_contextual_bandits/bandits/core/contextual_bandit.py
deleted file mode 100644
index 98467378953b9f3e38057be8a0068fdbc7b59a84..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/core/contextual_bandit.py
+++ /dev/null
@@ -1,125 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define a contextual bandit from which we can sample and compute rewards.
-
-We can feed the data, sample a context, its reward for a specific action, and
-also the optimal action for a given context.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-
-def run_contextual_bandit(context_dim, num_actions, dataset, algos):
- """Run a contextual bandit problem on a set of algorithms.
-
- Args:
- context_dim: Dimension of the context.
- num_actions: Number of available actions.
- dataset: Matrix where every row is a context + num_actions rewards.
- algos: List of algorithms to use in the contextual bandit instance.
-
- Returns:
- h_actions: Matrix with actions: size (num_context, num_algorithms).
- h_rewards: Matrix with rewards: size (num_context, num_algorithms).
- """
-
- num_contexts = dataset.shape[0]
-
- # Create contextual bandit
- cmab = ContextualBandit(context_dim, num_actions)
- cmab.feed_data(dataset)
-
- h_actions = np.empty((0, len(algos)), float)
- h_rewards = np.empty((0, len(algos)), float)
-
- # Run the contextual bandit process
- for i in range(num_contexts):
- context = cmab.context(i)
- actions = [a.action(context) for a in algos]
- rewards = [cmab.reward(i, action) for action in actions]
-
- for j, a in enumerate(algos):
- a.update(context, actions[j], rewards[j])
-
- h_actions = np.vstack((h_actions, np.array(actions)))
- h_rewards = np.vstack((h_rewards, np.array(rewards)))
-
- return h_actions, h_rewards
-
-
-class ContextualBandit(object):
- """Implements a Contextual Bandit with d-dimensional contexts and k arms."""
-
- def __init__(self, context_dim, num_actions):
- """Creates a contextual bandit object.
-
- Args:
- context_dim: Dimension of the contexts.
- num_actions: Number of arms for the multi-armed bandit.
- """
-
- self._context_dim = context_dim
- self._num_actions = num_actions
-
- def feed_data(self, data):
- """Feeds the data (contexts + rewards) to the bandit object.
-
- Args:
- data: Numpy array with shape [n, d+k], where n is the number of contexts,
- d is the dimension of each context, and k the number of arms (rewards).
-
- Raises:
- ValueError: when data dimensions do not correspond to the object values.
- """
-
- if data.shape[1] != self.context_dim + self.num_actions:
- raise ValueError('Data dimensions do not match.')
-
- self._number_contexts = data.shape[0]
- self.data = data
- self.order = range(self.number_contexts)
-
- def reset(self):
- """Randomly shuffle the order of the contexts to deliver."""
- self.order = np.random.permutation(self.number_contexts)
-
- def context(self, number):
- """Returns the number-th context."""
- return self.data[self.order[number]][:self.context_dim]
-
- def reward(self, number, action):
- """Returns the reward for the number-th context and action."""
- return self.data[self.order[number]][self.context_dim + action]
-
- def optimal(self, number):
- """Returns the optimal action (in hindsight) for the number-th context."""
- return np.argmax(self.data[self.order[number]][self.context_dim:])
-
- @property
- def context_dim(self):
- return self._context_dim
-
- @property
- def num_actions(self):
- return self._num_actions
-
- @property
- def number_contexts(self):
- return self._number_contexts
diff --git a/research/deep_contextual_bandits/bandits/core/contextual_dataset.py b/research/deep_contextual_bandits/bandits/core/contextual_dataset.py
deleted file mode 100644
index 9fae7629c7c2ee39ab6b98ddac73876b5fca421a..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/core/contextual_dataset.py
+++ /dev/null
@@ -1,166 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define a data buffer for contextual bandit algorithms."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-
-class ContextualDataset(object):
- """The buffer is able to append new data, and sample random minibatches."""
-
- def __init__(self, context_dim, num_actions, buffer_s=-1, intercept=False):
- """Creates a ContextualDataset object.
-
- The data is stored in attributes: contexts and rewards.
- The sequence of taken actions are stored in attribute actions.
-
- Args:
- context_dim: Dimension of the contexts.
- num_actions: Number of arms for the multi-armed bandit.
- buffer_s: Size of buffer for training. Only last buffer_s will be
- returned as minibatch. If buffer_s = -1, all data will be used.
- intercept: If True, it adds a constant (1.0) dimension to each context X,
- at the end.
- """
-
- self._context_dim = context_dim
- self._num_actions = num_actions
- self._contexts = None
- self._rewards = None
- self.actions = []
- self.buffer_s = buffer_s
- self.intercept = intercept
-
- def add(self, context, action, reward):
- """Adds a new triplet (context, action, reward) to the dataset.
-
- The reward for the actions that weren't played is assumed to be zero.
-
- Args:
- context: A d-dimensional vector with the context.
- action: Integer between 0 and k-1 representing the chosen arm.
- reward: Real number representing the reward for the (context, action).
- """
-
- if self.intercept:
- c = np.array(context[:])
- c = np.append(c, 1.0).reshape((1, self.context_dim + 1))
- else:
- c = np.array(context[:]).reshape((1, self.context_dim))
-
- if self.contexts is None:
- self.contexts = c
- else:
- self.contexts = np.vstack((self.contexts, c))
-
- r = np.zeros((1, self.num_actions))
- r[0, action] = reward
- if self.rewards is None:
- self.rewards = r
- else:
- self.rewards = np.vstack((self.rewards, r))
-
- self.actions.append(action)
-
- def replace_data(self, contexts=None, actions=None, rewards=None):
- if contexts is not None:
- self.contexts = contexts
- if actions is not None:
- self.actions = actions
- if rewards is not None:
- self.rewards = rewards
-
- def get_batch(self, batch_size):
- """Returns a random minibatch of (contexts, rewards) with batch_size."""
- n, _ = self.contexts.shape
- if self.buffer_s == -1:
- # use all the data
- ind = np.random.choice(range(n), batch_size)
- else:
- # use only buffer (last buffer_s observations)
- ind = np.random.choice(range(max(0, n - self.buffer_s), n), batch_size)
- return self.contexts[ind, :], self.rewards[ind, :]
-
- def get_data(self, action):
- """Returns all (context, reward) where the action was played."""
- n, _ = self.contexts.shape
- ind = np.array([i for i in range(n) if self.actions[i] == action])
- return self.contexts[ind, :], self.rewards[ind, action]
-
- def get_data_with_weights(self):
- """Returns all observations with one-hot weights for actions."""
- weights = np.zeros((self.contexts.shape[0], self.num_actions))
- a_ind = np.array([(i, val) for i, val in enumerate(self.actions)])
- weights[a_ind[:, 0], a_ind[:, 1]] = 1.0
- return self.contexts, self.rewards, weights
-
- def get_batch_with_weights(self, batch_size):
- """Returns a random mini-batch with one-hot weights for actions."""
- n, _ = self.contexts.shape
- if self.buffer_s == -1:
- # use all the data
- ind = np.random.choice(range(n), batch_size)
- else:
- # use only buffer (last buffer_s obs)
- ind = np.random.choice(range(max(0, n - self.buffer_s), n), batch_size)
-
- weights = np.zeros((batch_size, self.num_actions))
- sampled_actions = np.array(self.actions)[ind]
- a_ind = np.array([(i, val) for i, val in enumerate(sampled_actions)])
- weights[a_ind[:, 0], a_ind[:, 1]] = 1.0
- return self.contexts[ind, :], self.rewards[ind, :], weights
-
- def num_points(self, f=None):
- """Returns number of points in the buffer (after applying function f)."""
- if f is not None:
- return f(self.contexts.shape[0])
- return self.contexts.shape[0]
-
- @property
- def context_dim(self):
- return self._context_dim
-
- @property
- def num_actions(self):
- return self._num_actions
-
- @property
- def contexts(self):
- return self._contexts
-
- @contexts.setter
- def contexts(self, value):
- self._contexts = value
-
- @property
- def actions(self):
- return self._actions
-
- @actions.setter
- def actions(self, value):
- self._actions = value
-
- @property
- def rewards(self):
- return self._rewards
-
- @rewards.setter
- def rewards(self, value):
- self._rewards = value
diff --git a/research/deep_contextual_bandits/bandits/data/data_sampler.py b/research/deep_contextual_bandits/bandits/data/data_sampler.py
deleted file mode 100644
index 55d1bae383637485182a9524ba8a3cb37b76bd0d..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/data/data_sampler.py
+++ /dev/null
@@ -1,374 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Functions to create bandit problems from datasets."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import pandas as pd
-import tensorflow as tf
-
-
-def one_hot(df, cols):
- """Returns one-hot encoding of DataFrame df including columns in cols."""
- for col in cols:
- dummies = pd.get_dummies(df[col], prefix=col, drop_first=False)
- df = pd.concat([df, dummies], axis=1)
- df = df.drop(col, axis=1)
- return df
-
-
-def sample_mushroom_data(file_name,
- num_contexts,
- r_noeat=0,
- r_eat_safe=5,
- r_eat_poison_bad=-35,
- r_eat_poison_good=5,
- prob_poison_bad=0.5):
- """Samples bandit game from Mushroom UCI Dataset.
-
- Args:
- file_name: Route of file containing the original Mushroom UCI dataset.
- num_contexts: Number of points to sample, i.e. (context, action rewards).
- r_noeat: Reward for not eating a mushroom.
- r_eat_safe: Reward for eating a non-poisonous mushroom.
- r_eat_poison_bad: Reward for eating a poisonous mushroom if harmed.
- r_eat_poison_good: Reward for eating a poisonous mushroom if not harmed.
- prob_poison_bad: Probability of being harmed by eating a poisonous mushroom.
-
- Returns:
- dataset: Sampled matrix with n rows: (context, eat_reward, no_eat_reward).
- opt_vals: Vector of expected optimal (reward, action) for each context.
-
- We assume r_eat_safe > r_noeat, and r_eat_poison_good > r_eat_poison_bad.
- """
-
- # first two cols of df encode whether mushroom is edible or poisonous
- df = pd.read_csv(file_name, header=None)
- df = one_hot(df, df.columns)
- ind = np.random.choice(range(df.shape[0]), num_contexts, replace=True)
-
- contexts = df.iloc[ind, 2:]
- no_eat_reward = r_noeat * np.ones((num_contexts, 1))
- random_poison = np.random.choice(
- [r_eat_poison_bad, r_eat_poison_good],
- p=[prob_poison_bad, 1 - prob_poison_bad],
- size=num_contexts)
- eat_reward = r_eat_safe * df.iloc[ind, 0]
- eat_reward += np.multiply(random_poison, df.iloc[ind, 1])
- eat_reward = eat_reward.values.reshape((num_contexts, 1))
-
- # compute optimal expected reward and optimal actions
- exp_eat_poison_reward = r_eat_poison_bad * prob_poison_bad
- exp_eat_poison_reward += r_eat_poison_good * (1 - prob_poison_bad)
- opt_exp_reward = r_eat_safe * df.iloc[ind, 0] + max(
- r_noeat, exp_eat_poison_reward) * df.iloc[ind, 1]
-
- if r_noeat > exp_eat_poison_reward:
- # actions: no eat = 0 ; eat = 1
- opt_actions = df.iloc[ind, 0] # indicator of edible
- else:
- # should always eat (higher expected reward)
- opt_actions = np.ones((num_contexts, 1))
-
- opt_vals = (opt_exp_reward.values, opt_actions.values)
-
- return np.hstack((contexts, no_eat_reward, eat_reward)), opt_vals
-
-
-def sample_stock_data(file_name, context_dim, num_actions, num_contexts,
- sigma, shuffle_rows=True):
- """Samples linear bandit game from stock prices dataset.
-
- Args:
- file_name: Route of file containing the stock prices dataset.
- context_dim: Context dimension (i.e. vector with the price of each stock).
- num_actions: Number of actions (different linear portfolio strategies).
- num_contexts: Number of contexts to sample.
- sigma: Vector with additive noise levels for each action.
- shuffle_rows: If True, rows from original dataset are shuffled.
-
- Returns:
- dataset: Sampled matrix with rows: (context, reward_1, ..., reward_k).
- opt_vals: Vector of expected optimal (reward, action) for each context.
- """
-
- with tf.gfile.Open(file_name, 'r') as f:
- contexts = np.loadtxt(f, skiprows=1)
-
- if shuffle_rows:
- np.random.shuffle(contexts)
- contexts = contexts[:num_contexts, :]
-
- betas = np.random.uniform(-1, 1, (context_dim, num_actions))
- betas /= np.linalg.norm(betas, axis=0)
-
- mean_rewards = np.dot(contexts, betas)
- noise = np.random.normal(scale=sigma, size=mean_rewards.shape)
- rewards = mean_rewards + noise
-
- opt_actions = np.argmax(mean_rewards, axis=1)
- opt_rewards = [mean_rewards[i, a] for i, a in enumerate(opt_actions)]
- return np.hstack((contexts, rewards)), (np.array(opt_rewards), opt_actions)
-
-
-def sample_jester_data(file_name, context_dim, num_actions, num_contexts,
- shuffle_rows=True, shuffle_cols=False):
- """Samples bandit game from (user, joke) dense subset of Jester dataset.
-
- Args:
- file_name: Route of file containing the modified Jester dataset.
- context_dim: Context dimension (i.e. vector with some ratings from a user).
- num_actions: Number of actions (number of joke ratings to predict).
- num_contexts: Number of contexts to sample.
- shuffle_rows: If True, rows from original dataset are shuffled.
- shuffle_cols: Whether or not context/action jokes are randomly shuffled.
-
- Returns:
- dataset: Sampled matrix with rows: (context, rating_1, ..., rating_k).
- opt_vals: Vector of deterministic optimal (reward, action) for each context.
- """
-
- with tf.gfile.Open(file_name, 'rb') as f:
- dataset = np.load(f)
-
- if shuffle_cols:
- dataset = dataset[:, np.random.permutation(dataset.shape[1])]
- if shuffle_rows:
- np.random.shuffle(dataset)
- dataset = dataset[:num_contexts, :]
-
- assert context_dim + num_actions == dataset.shape[1], 'Wrong data dimensions.'
-
- opt_actions = np.argmax(dataset[:, context_dim:], axis=1)
- opt_rewards = np.array([dataset[i, context_dim + a]
- for i, a in enumerate(opt_actions)])
-
- return dataset, (opt_rewards, opt_actions)
-
-
-def sample_statlog_data(file_name, num_contexts, shuffle_rows=True,
- remove_underrepresented=False):
- """Returns bandit problem dataset based on the UCI statlog data.
-
- Args:
- file_name: Route of file containing the Statlog dataset.
- num_contexts: Number of contexts to sample.
- shuffle_rows: If True, rows from original dataset are shuffled.
- remove_underrepresented: If True, removes arms with very few rewards.
-
- Returns:
- dataset: Sampled matrix with rows: (context, action rewards).
- opt_vals: Vector of deterministic optimal (reward, action) for each context.
-
- https://archive.ics.uci.edu/ml/datasets/Statlog+(Shuttle)
- """
-
- with tf.gfile.Open(file_name, 'r') as f:
- data = np.loadtxt(f)
-
- num_actions = 7 # some of the actions are very rarely optimal.
-
- # Shuffle data
- if shuffle_rows:
- np.random.shuffle(data)
- data = data[:num_contexts, :]
-
- # Last column is label, rest are features
- contexts = data[:, :-1]
- labels = data[:, -1].astype(int) - 1 # convert to 0 based index
-
- if remove_underrepresented:
- contexts, labels = remove_underrepresented_classes(contexts, labels)
-
- return classification_to_bandit_problem(contexts, labels, num_actions)
-
-
-def sample_adult_data(file_name, num_contexts, shuffle_rows=True,
- remove_underrepresented=False):
- """Returns bandit problem dataset based on the UCI adult data.
-
- Args:
- file_name: Route of file containing the Adult dataset.
- num_contexts: Number of contexts to sample.
- shuffle_rows: If True, rows from original dataset are shuffled.
- remove_underrepresented: If True, removes arms with very few rewards.
-
- Returns:
- dataset: Sampled matrix with rows: (context, action rewards).
- opt_vals: Vector of deterministic optimal (reward, action) for each context.
-
- Preprocessing:
- * drop rows with missing values
- * convert categorical variables to 1 hot encoding
-
- https://archive.ics.uci.edu/ml/datasets/census+income
- """
- with tf.gfile.Open(file_name, 'r') as f:
- df = pd.read_csv(f, header=None,
- na_values=[' ?']).dropna()
-
- num_actions = 14
-
- if shuffle_rows:
- df = df.sample(frac=1)
- df = df.iloc[:num_contexts, :]
-
- labels = df[6].astype('category').cat.codes.as_matrix()
- df = df.drop([6], axis=1)
-
- # Convert categorical variables to 1 hot encoding
- cols_to_transform = [1, 3, 5, 7, 8, 9, 13, 14]
- df = pd.get_dummies(df, columns=cols_to_transform)
-
- if remove_underrepresented:
- df, labels = remove_underrepresented_classes(df, labels)
- contexts = df.as_matrix()
-
- return classification_to_bandit_problem(contexts, labels, num_actions)
-
-
-def sample_census_data(file_name, num_contexts, shuffle_rows=True,
- remove_underrepresented=False):
- """Returns bandit problem dataset based on the UCI census data.
-
- Args:
- file_name: Route of file containing the Census dataset.
- num_contexts: Number of contexts to sample.
- shuffle_rows: If True, rows from original dataset are shuffled.
- remove_underrepresented: If True, removes arms with very few rewards.
-
- Returns:
- dataset: Sampled matrix with rows: (context, action rewards).
- opt_vals: Vector of deterministic optimal (reward, action) for each context.
-
- Preprocessing:
- * drop rows with missing labels
- * convert categorical variables to 1 hot encoding
-
- Note: this is the processed (not the 'raw') dataset. It contains a subset
- of the raw features and they've all been discretized.
-
- https://archive.ics.uci.edu/ml/datasets/US+Census+Data+%281990%29
- """
- # Note: this dataset is quite large. It will be slow to load and preprocess.
- with tf.gfile.Open(file_name, 'r') as f:
- df = (pd.read_csv(f, header=0, na_values=['?'])
- .dropna())
-
- num_actions = 9
-
- if shuffle_rows:
- df = df.sample(frac=1)
- df = df.iloc[:num_contexts, :]
-
- # Assuming what the paper calls response variable is the label?
- labels = df['dOccup'].astype('category').cat.codes.as_matrix()
- # In addition to label, also drop the (unique?) key.
- df = df.drop(['dOccup', 'caseid'], axis=1)
-
- # All columns are categorical. Convert to 1 hot encoding.
- df = pd.get_dummies(df, columns=df.columns)
-
- if remove_underrepresented:
- df, labels = remove_underrepresented_classes(df, labels)
- contexts = df.as_matrix()
-
- return classification_to_bandit_problem(contexts, labels, num_actions)
-
-
-def sample_covertype_data(file_name, num_contexts, shuffle_rows=True,
- remove_underrepresented=False):
- """Returns bandit problem dataset based on the UCI Cover_Type data.
-
- Args:
- file_name: Route of file containing the Covertype dataset.
- num_contexts: Number of contexts to sample.
- shuffle_rows: If True, rows from original dataset are shuffled.
- remove_underrepresented: If True, removes arms with very few rewards.
-
- Returns:
- dataset: Sampled matrix with rows: (context, action rewards).
- opt_vals: Vector of deterministic optimal (reward, action) for each context.
-
- Preprocessing:
- * drop rows with missing labels
- * convert categorical variables to 1 hot encoding
-
- https://archive.ics.uci.edu/ml/datasets/Covertype
- """
- with tf.gfile.Open(file_name, 'r') as f:
- df = (pd.read_csv(f, header=0, na_values=['?'])
- .dropna())
-
- num_actions = 7
-
- if shuffle_rows:
- df = df.sample(frac=1)
- df = df.iloc[:num_contexts, :]
-
- # Assuming what the paper calls response variable is the label?
- # Last column is label.
- labels = df[df.columns[-1]].astype('category').cat.codes.as_matrix()
- df = df.drop([df.columns[-1]], axis=1)
-
- # All columns are either quantitative or already converted to 1 hot.
- if remove_underrepresented:
- df, labels = remove_underrepresented_classes(df, labels)
- contexts = df.as_matrix()
-
- return classification_to_bandit_problem(contexts, labels, num_actions)
-
-
-def classification_to_bandit_problem(contexts, labels, num_actions=None):
- """Normalize contexts and encode deterministic rewards."""
-
- if num_actions is None:
- num_actions = np.max(labels) + 1
- num_contexts = contexts.shape[0]
-
- # Due to random subsampling in small problems, some features may be constant
- sstd = safe_std(np.std(contexts, axis=0, keepdims=True)[0, :])
-
- # Normalize features
- contexts = ((contexts - np.mean(contexts, axis=0, keepdims=True)) / sstd)
-
- # One hot encode labels as rewards
- rewards = np.zeros((num_contexts, num_actions))
- rewards[np.arange(num_contexts), labels] = 1.0
-
- return contexts, rewards, (np.ones(num_contexts), labels)
-
-
-def safe_std(values):
- """Remove zero std values for ones."""
- return np.array([val if val != 0.0 else 1.0 for val in values])
-
-
-def remove_underrepresented_classes(features, labels, thresh=0.0005):
- """Removes classes when number of datapoints fraction is below a threshold."""
-
- # Threshold doesn't seem to agree with https://arxiv.org/pdf/1706.04687.pdf
- # Example: for Covertype, they report 4 classes after filtering, we get 7?
- total_count = labels.shape[0]
- unique, counts = np.unique(labels, return_counts=True)
- ratios = counts.astype('float') / total_count
- vals_and_ratios = dict(zip(unique, ratios))
- print('Unique classes and their ratio of total: %s' % vals_and_ratios)
- keep = [vals_and_ratios[v] >= thresh for v in labels]
- return features[keep], labels[np.array(keep)]
diff --git a/research/deep_contextual_bandits/bandits/data/synthetic_data_sampler.py b/research/deep_contextual_bandits/bandits/data/synthetic_data_sampler.py
deleted file mode 100644
index c7de48aba4de109392aa8efad06071886cf67964..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/bandits/data/synthetic_data_sampler.py
+++ /dev/null
@@ -1,179 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Several functions to sample contextual data."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-
-def sample_contextual_data(num_contexts, dim_context, num_actions, sigma):
- """Samples independent Gaussian data.
-
- There is nothing to learn here as the rewards do not depend on the context.
-
- Args:
- num_contexts: Number of contexts to sample.
- dim_context: Dimension of the contexts.
- num_actions: Number of arms for the multi-armed bandit.
- sigma: Standard deviation of the independent Gaussian samples.
-
- Returns:
- data: A [num_contexts, dim_context + num_actions] numpy array with the data.
- """
- size_data = [num_contexts, dim_context + num_actions]
- return np.random.normal(scale=sigma, size=size_data)
-
-
-def sample_linear_data(num_contexts, dim_context, num_actions, sigma=0.0):
- """Samples data from linearly parameterized arms.
-
- The reward for context X and arm j is given by X^T beta_j, for some latent
- set of parameters {beta_j : j = 1, ..., k}. The beta's are sampled uniformly
- at random, the contexts are Gaussian, and sigma-noise is added to the rewards.
-
- Args:
- num_contexts: Number of contexts to sample.
- dim_context: Dimension of the contexts.
- num_actions: Number of arms for the multi-armed bandit.
- sigma: Standard deviation of the additive noise. Set to zero for no noise.
-
- Returns:
- data: A [n, d+k] numpy array with the data.
- betas: Latent parameters that determine expected reward for each arm.
- opt: (optimal_rewards, optimal_actions) for all contexts.
- """
-
- betas = np.random.uniform(-1, 1, (dim_context, num_actions))
- betas /= np.linalg.norm(betas, axis=0)
- contexts = np.random.normal(size=[num_contexts, dim_context])
- rewards = np.dot(contexts, betas)
- opt_actions = np.argmax(rewards, axis=1)
- rewards += np.random.normal(scale=sigma, size=rewards.shape)
- opt_rewards = np.array([rewards[i, act] for i, act in enumerate(opt_actions)])
- return np.hstack((contexts, rewards)), betas, (opt_rewards, opt_actions)
-
-
-def sample_sparse_linear_data(num_contexts, dim_context, num_actions,
- sparse_dim, sigma=0.0):
- """Samples data from sparse linearly parameterized arms.
-
- The reward for context X and arm j is given by X^T beta_j, for some latent
- set of parameters {beta_j : j = 1, ..., k}. The beta's are sampled uniformly
- at random, the contexts are Gaussian, and sigma-noise is added to the rewards.
- Only s components out of d are non-zero for each arm's beta.
-
- Args:
- num_contexts: Number of contexts to sample.
- dim_context: Dimension of the contexts.
- num_actions: Number of arms for the multi-armed bandit.
- sparse_dim: Dimension of the latent subspace (sparsity pattern dimension).
- sigma: Standard deviation of the additive noise. Set to zero for no noise.
-
- Returns:
- data: A [num_contexts, dim_context+num_actions] numpy array with the data.
- betas: Latent parameters that determine expected reward for each arm.
- opt: (optimal_rewards, optimal_actions) for all contexts.
- """
-
- flatten = lambda l: [item for sublist in l for item in sublist]
- sparse_pattern = flatten(
- [[(j, i) for j in np.random.choice(range(dim_context),
- sparse_dim,
- replace=False)]
- for i in range(num_actions)])
- betas = np.random.uniform(-1, 1, (dim_context, num_actions))
- mask = np.zeros((dim_context, num_actions))
- for elt in sparse_pattern:
- mask[elt] = 1
- betas = np.multiply(betas, mask)
- betas /= np.linalg.norm(betas, axis=0)
- contexts = np.random.normal(size=[num_contexts, dim_context])
- rewards = np.dot(contexts, betas)
- opt_actions = np.argmax(rewards, axis=1)
- rewards += np.random.normal(scale=sigma, size=rewards.shape)
- opt_rewards = np.array([rewards[i, act] for i, act in enumerate(opt_actions)])
- return np.hstack((contexts, rewards)), betas, (opt_rewards, opt_actions)
-
-
-def sample_wheel_bandit_data(num_contexts, delta, mean_v, std_v,
- mu_large, std_large):
- """Samples from Wheel bandit game (see https://arxiv.org/abs/1802.09127).
-
- Args:
- num_contexts: Number of points to sample, i.e. (context, action rewards).
- delta: Exploration parameter: high reward in one region if norm above delta.
- mean_v: Mean reward for each action if context norm is below delta.
- std_v: Gaussian reward std for each action if context norm is below delta.
- mu_large: Mean reward for optimal action if context norm is above delta.
- std_large: Reward std for optimal action if context norm is above delta.
-
- Returns:
- dataset: Sampled matrix with n rows: (context, action rewards).
- opt_vals: Vector of expected optimal (reward, action) for each context.
- """
-
- context_dim = 2
- num_actions = 5
-
- data = []
- rewards = []
- opt_actions = []
- opt_rewards = []
-
- # sample uniform contexts in unit ball
- while len(data) < num_contexts:
- raw_data = np.random.uniform(-1, 1, (int(num_contexts / 3), context_dim))
-
- for i in range(raw_data.shape[0]):
- if np.linalg.norm(raw_data[i, :]) <= 1:
- data.append(raw_data[i, :])
-
- contexts = np.stack(data)[:num_contexts, :]
-
- # sample rewards
- for i in range(num_contexts):
- r = [np.random.normal(mean_v[j], std_v[j]) for j in range(num_actions)]
- if np.linalg.norm(contexts[i, :]) >= delta:
- # large reward in the right region for the context
- r_big = np.random.normal(mu_large, std_large)
- if contexts[i, 0] > 0:
- if contexts[i, 1] > 0:
- r[0] = r_big
- opt_actions.append(0)
- else:
- r[1] = r_big
- opt_actions.append(1)
- else:
- if contexts[i, 1] > 0:
- r[2] = r_big
- opt_actions.append(2)
- else:
- r[3] = r_big
- opt_actions.append(3)
- else:
- opt_actions.append(np.argmax(mean_v))
-
- opt_rewards.append(r[opt_actions[-1]])
- rewards.append(r)
-
- rewards = np.stack(rewards)
- opt_rewards = np.array(opt_rewards)
- opt_actions = np.array(opt_actions)
-
- return np.hstack((contexts, rewards)), (opt_rewards, opt_actions)
diff --git a/research/deep_contextual_bandits/example_main.py b/research/deep_contextual_bandits/example_main.py
deleted file mode 100644
index c71a5aa26f94adbf5989d002fd5c768582c14e14..0000000000000000000000000000000000000000
--- a/research/deep_contextual_bandits/example_main.py
+++ /dev/null
@@ -1,454 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Simple example of contextual bandits simulation.
-
-Code corresponding to:
-Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks
-for Thompson Sampling, by Carlos Riquelme, George Tucker, and Jasper Snoek.
-https://arxiv.org/abs/1802.09127
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import time
-from absl import app
-from absl import flags
-import numpy as np
-import os
-import tensorflow as tf
-
-from bandits.algorithms.bootstrapped_bnn_sampling import BootstrappedBNNSampling
-from bandits.core.contextual_bandit import run_contextual_bandit
-from bandits.data.data_sampler import sample_adult_data
-from bandits.data.data_sampler import sample_census_data
-from bandits.data.data_sampler import sample_covertype_data
-from bandits.data.data_sampler import sample_jester_data
-from bandits.data.data_sampler import sample_mushroom_data
-from bandits.data.data_sampler import sample_statlog_data
-from bandits.data.data_sampler import sample_stock_data
-from bandits.algorithms.fixed_policy_sampling import FixedPolicySampling
-from bandits.algorithms.linear_full_posterior_sampling import LinearFullPosteriorSampling
-from bandits.algorithms.neural_linear_sampling import NeuralLinearPosteriorSampling
-from bandits.algorithms.parameter_noise_sampling import ParameterNoiseSampling
-from bandits.algorithms.posterior_bnn_sampling import PosteriorBNNSampling
-from bandits.data.synthetic_data_sampler import sample_linear_data
-from bandits.data.synthetic_data_sampler import sample_sparse_linear_data
-from bandits.data.synthetic_data_sampler import sample_wheel_bandit_data
-from bandits.algorithms.uniform_sampling import UniformSampling
-
-# Set up your file routes to the data files.
-base_route = os.getcwd()
-data_route = 'contextual_bandits/datasets'
-
-FLAGS = flags.FLAGS
-FLAGS.set_default('alsologtostderr', True)
-flags.DEFINE_string('logdir', '/tmp/bandits/', 'Base directory to save output')
-flags.DEFINE_string(
- 'mushroom_data',
- os.path.join(base_route, data_route, 'mushroom.data'),
- 'Directory where Mushroom data is stored.')
-flags.DEFINE_string(
- 'financial_data',
- os.path.join(base_route, data_route, 'raw_stock_contexts'),
- 'Directory where Financial data is stored.')
-flags.DEFINE_string(
- 'jester_data',
- os.path.join(base_route, data_route, 'jester_data_40jokes_19181users.npy'),
- 'Directory where Jester data is stored.')
-flags.DEFINE_string(
- 'statlog_data',
- os.path.join(base_route, data_route, 'shuttle.trn'),
- 'Directory where Statlog data is stored.')
-flags.DEFINE_string(
- 'adult_data',
- os.path.join(base_route, data_route, 'adult.full'),
- 'Directory where Adult data is stored.')
-flags.DEFINE_string(
- 'covertype_data',
- os.path.join(base_route, data_route, 'covtype.data'),
- 'Directory where Covertype data is stored.')
-flags.DEFINE_string(
- 'census_data',
- os.path.join(base_route, data_route, 'USCensus1990.data.txt'),
- 'Directory where Census data is stored.')
-
-
-def sample_data(data_type, num_contexts=None):
- """Sample data from given 'data_type'.
-
- Args:
- data_type: Dataset from which to sample.
- num_contexts: Number of contexts to sample.
-
- Returns:
- dataset: Sampled matrix with rows: (context, reward_1, ..., reward_num_act).
- opt_rewards: Vector of expected optimal reward for each context.
- opt_actions: Vector of optimal action for each context.
- num_actions: Number of available actions.
- context_dim: Dimension of each context.
- """
-
- if data_type == 'linear':
- # Create linear dataset
- num_actions = 8
- context_dim = 10
- noise_stds = [0.01 * (i + 1) for i in range(num_actions)]
- dataset, _, opt_linear = sample_linear_data(num_contexts, context_dim,
- num_actions, sigma=noise_stds)
- opt_rewards, opt_actions = opt_linear
- elif data_type == 'sparse_linear':
- # Create sparse linear dataset
- num_actions = 7
- context_dim = 10
- noise_stds = [0.01 * (i + 1) for i in range(num_actions)]
- num_nnz_dims = int(context_dim / 3.0)
- dataset, _, opt_sparse_linear = sample_sparse_linear_data(
- num_contexts, context_dim, num_actions, num_nnz_dims, sigma=noise_stds)
- opt_rewards, opt_actions = opt_sparse_linear
- elif data_type == 'mushroom':
- # Create mushroom dataset
- num_actions = 2
- context_dim = 117
- file_name = FLAGS.mushroom_data
- dataset, opt_mushroom = sample_mushroom_data(file_name, num_contexts)
- opt_rewards, opt_actions = opt_mushroom
- elif data_type == 'financial':
- num_actions = 8
- context_dim = 21
- num_contexts = min(3713, num_contexts)
- noise_stds = [0.01 * (i + 1) for i in range(num_actions)]
- file_name = FLAGS.financial_data
- dataset, opt_financial = sample_stock_data(file_name, context_dim,
- num_actions, num_contexts,
- noise_stds, shuffle_rows=True)
- opt_rewards, opt_actions = opt_financial
- elif data_type == 'jester':
- num_actions = 8
- context_dim = 32
- num_contexts = min(19181, num_contexts)
- file_name = FLAGS.jester_data
- dataset, opt_jester = sample_jester_data(file_name, context_dim,
- num_actions, num_contexts,
- shuffle_rows=True,
- shuffle_cols=True)
- opt_rewards, opt_actions = opt_jester
- elif data_type == 'statlog':
- file_name = FLAGS.statlog_data
- num_actions = 7
- num_contexts = min(43500, num_contexts)
- sampled_vals = sample_statlog_data(file_name, num_contexts,
- shuffle_rows=True)
- contexts, rewards, (opt_rewards, opt_actions) = sampled_vals
- dataset = np.hstack((contexts, rewards))
- context_dim = contexts.shape[1]
- elif data_type == 'adult':
- file_name = FLAGS.adult_data
- num_actions = 14
- num_contexts = min(45222, num_contexts)
- sampled_vals = sample_adult_data(file_name, num_contexts,
- shuffle_rows=True)
- contexts, rewards, (opt_rewards, opt_actions) = sampled_vals
- dataset = np.hstack((contexts, rewards))
- context_dim = contexts.shape[1]
- elif data_type == 'covertype':
- file_name = FLAGS.covertype_data
- num_actions = 7
- num_contexts = min(150000, num_contexts)
- sampled_vals = sample_covertype_data(file_name, num_contexts,
- shuffle_rows=True)
- contexts, rewards, (opt_rewards, opt_actions) = sampled_vals
- dataset = np.hstack((contexts, rewards))
- context_dim = contexts.shape[1]
- elif data_type == 'census':
- file_name = FLAGS.census_data
- num_actions = 9
- num_contexts = min(150000, num_contexts)
- sampled_vals = sample_census_data(file_name, num_contexts,
- shuffle_rows=True)
- contexts, rewards, (opt_rewards, opt_actions) = sampled_vals
- dataset = np.hstack((contexts, rewards))
- context_dim = contexts.shape[1]
- elif data_type == 'wheel':
- delta = 0.95
- num_actions = 5
- context_dim = 2
- mean_v = [1.0, 1.0, 1.0, 1.0, 1.2]
- std_v = [0.05, 0.05, 0.05, 0.05, 0.05]
- mu_large = 50
- std_large = 0.01
- dataset, opt_wheel = sample_wheel_bandit_data(num_contexts, delta,
- mean_v, std_v,
- mu_large, std_large)
- opt_rewards, opt_actions = opt_wheel
-
- return dataset, opt_rewards, opt_actions, num_actions, context_dim
-
-
-def display_results(algos, opt_rewards, opt_actions, h_rewards, t_init, name):
- """Displays summary statistics of the performance of each algorithm."""
-
- print('---------------------------------------------------')
- print('---------------------------------------------------')
- print('{} bandit completed after {} seconds.'.format(
- name, time.time() - t_init))
- print('---------------------------------------------------')
-
- performance_pairs = []
- for j, a in enumerate(algos):
- performance_pairs.append((a.name, np.sum(h_rewards[:, j])))
- performance_pairs = sorted(performance_pairs,
- key=lambda elt: elt[1],
- reverse=True)
- for i, (name, reward) in enumerate(performance_pairs):
- print('{:3}) {:20}| \t \t total reward = {:10}.'.format(i, name, reward))
-
- print('---------------------------------------------------')
- print('Optimal total reward = {}.'.format(np.sum(opt_rewards)))
- print('Frequency of optimal actions (action, frequency):')
- print([[elt, list(opt_actions).count(elt)] for elt in set(opt_actions)])
- print('---------------------------------------------------')
- print('---------------------------------------------------')
-
-
-def main(_):
-
- # Problem parameters
- num_contexts = 2000
-
- # Data type in {linear, sparse_linear, mushroom, financial, jester,
- # statlog, adult, covertype, census, wheel}
- data_type = 'mushroom'
-
- # Create dataset
- sampled_vals = sample_data(data_type, num_contexts)
- dataset, opt_rewards, opt_actions, num_actions, context_dim = sampled_vals
-
- # Define hyperparameters and algorithms
- hparams = tf.contrib.training.HParams(num_actions=num_actions)
-
- hparams_linear = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- a0=6,
- b0=6,
- lambda_prior=0.25,
- initial_pulls=2)
-
- hparams_rms = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=50,
- training_epochs=100,
- p=0.95,
- q=3)
-
- hparams_dropout = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=50,
- training_epochs=100,
- use_dropout=True,
- keep_prob=0.80)
-
- hparams_bbb = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- use_sigma_exp_transform=True,
- cleared_times_trained=10,
- initial_training_steps=100,
- noise_sigma=0.1,
- reset_lr=False,
- training_freq=50,
- training_epochs=100)
-
- hparams_nlinear = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=1,
- training_freq_network=50,
- training_epochs=100,
- a0=6,
- b0=6,
- lambda_prior=0.25)
-
- hparams_nlinear2 = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=10,
- training_freq_network=50,
- training_epochs=100,
- a0=6,
- b0=6,
- lambda_prior=0.25)
-
- hparams_pnoise = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- reset_lr=True,
- lr_decay_rate=0.5,
- training_freq=50,
- training_epochs=100,
- noise_std=0.05,
- eps=0.1,
- d_samples=300,
- )
-
- hparams_alpha_div = tf.contrib.training.HParams(num_actions=num_actions,
- context_dim=context_dim,
- init_scale=0.3,
- activation=tf.nn.relu,
- layer_sizes=[50],
- batch_size=512,
- activate_decay=True,
- initial_lr=0.1,
- max_grad_norm=5.0,
- show_training=False,
- freq_summary=1000,
- buffer_s=-1,
- initial_pulls=2,
- optimizer='RMS',
- use_sigma_exp_transform=True,
- cleared_times_trained=10,
- initial_training_steps=100,
- noise_sigma=0.1,
- reset_lr=False,
- training_freq=50,
- training_epochs=100,
- alpha=1.0,
- k=20,
- prior_variance=0.1)
-
- hparams_gp = tf.contrib.training.HParams(num_actions=num_actions,
- num_outputs=num_actions,
- context_dim=context_dim,
- reset_lr=False,
- learn_embeddings=True,
- max_num_points=1000,
- show_training=False,
- freq_summary=1000,
- batch_size=512,
- keep_fixed_after_max_obs=True,
- training_freq=50,
- initial_pulls=2,
- training_epochs=100,
- lr=0.01,
- buffer_s=-1,
- initial_lr=0.001,
- lr_decay_rate=0.0,
- optimizer='RMS',
- task_latent_dim=5,
- activate_decay=False)
-
- algos = [
- UniformSampling('Uniform Sampling', hparams),
- UniformSampling('Uniform Sampling 2', hparams),
- FixedPolicySampling('fixed1', [0.75, 0.25], hparams),
- FixedPolicySampling('fixed2', [0.25, 0.75], hparams),
- PosteriorBNNSampling('RMS', hparams_rms, 'RMSProp'),
- PosteriorBNNSampling('Dropout', hparams_dropout, 'RMSProp'),
- PosteriorBNNSampling('BBB', hparams_bbb, 'Variational'),
- NeuralLinearPosteriorSampling('NeuralLinear', hparams_nlinear),
- NeuralLinearPosteriorSampling('NeuralLinear2', hparams_nlinear2),
- LinearFullPosteriorSampling('LinFullPost', hparams_linear),
- BootstrappedBNNSampling('BootRMS', hparams_rms),
- ParameterNoiseSampling('ParamNoise', hparams_pnoise),
- PosteriorBNNSampling('BBAlphaDiv', hparams_alpha_div, 'AlphaDiv'),
- PosteriorBNNSampling('MultitaskGP', hparams_gp, 'GP'),
- ]
-
- # Run contextual bandit problem
- t_init = time.time()
- results = run_contextual_bandit(context_dim, num_actions, dataset, algos)
- _, h_rewards = results
-
- # Display results
- display_results(algos, opt_rewards, opt_actions, h_rewards, t_init, data_type)
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/deep_speech/README.md b/research/deep_speech/README.md
deleted file mode 100644
index 59a9dea7f81e3963372b23d8c4436e3e04d763ac..0000000000000000000000000000000000000000
--- a/research/deep_speech/README.md
+++ /dev/null
@@ -1,74 +0,0 @@
-
-
-
-
-# DeepSpeech2 Model
-
-## Overview
-This is an implementation of the [DeepSpeech2](https://arxiv.org/pdf/1512.02595.pdf) model. Current implementation is based on the code from the authors' [DeepSpeech code](https://github.com/PaddlePaddle/DeepSpeech) and the implementation in the [MLPerf Repo](https://github.com/mlperf/reference/tree/master/speech_recognition).
-
-DeepSpeech2 is an end-to-end deep neural network for automatic speech
-recognition (ASR). It consists of 2 convolutional layers, 5 bidirectional RNN
-layers and a fully connected layer. The feature in use is linear spectrogram
-extracted from audio input. The network uses Connectionist Temporal Classification [CTC](https://www.cs.toronto.edu/~graves/icml_2006.pdf) as the loss function.
-
-## Dataset
-The [OpenSLR LibriSpeech Corpus](http://www.openslr.org/12/) are used for model training and evaluation.
-
-The training data is a combination of train-clean-100 and train-clean-360 (~130k
-examples in total). The validation set is dev-clean which has 2.7K lines.
-The download script will preprocess the data into three columns: wav_filename,
-wav_filesize, transcript. data/dataset.py will parse the csv file and build a
-tf.data.Dataset object to feed data. Within each epoch (except for the
-first if sortagrad is enabled), the training data will be shuffled batch-wise.
-
-## Running Code
-
-### Configure Python path
-Add the top-level /models folder to the Python path with the command:
-```
-export PYTHONPATH="$PYTHONPATH:/path/to/models"
-```
-
-### Install dependencies
-
-First install shared dependencies before running the code. Issue the following command:
-```
-pip3 install -r requirements.txt
-```
-or
-```
-pip install -r requirements.txt
-```
-
-### Run each step individually
-
-#### Download and preprocess dataset
-To download the dataset, issue the following command:
-```
-python data/download.py
-```
-Arguments:
- * `--data_dir`: Directory where to download and save the preprocessed data. By default, it is `/tmp/librispeech_data`.
-
-Use the `--help` or `-h` flag to get a full list of possible arguments.
-
-#### Train and evaluate model
-To train and evaluate the model, issue the following command:
-```
-python deep_speech.py
-```
-Arguments:
- * `--model_dir`: Directory to save model training checkpoints. By default, it is `/tmp/deep_speech_model/`.
- * `--train_data_dir`: Directory of the training dataset.
- * `--eval_data_dir`: Directory of the evaluation dataset.
- * `--num_gpus`: Number of GPUs to use (specify -1 if you want to use all available GPUs).
-
-There are other arguments about DeepSpeech2 model and training/evaluation process. Use the `--help` or `-h` flag to get a full list of possible arguments with detailed descriptions.
-
-### Run the benchmark
-A shell script [run_deep_speech.sh](run_deep_speech.sh) is provided to run the whole pipeline with default parameters. Issue the following command to run the benchmark:
-```
-sh run_deep_speech.sh
-```
-Note by default, the training dataset in the benchmark include train-clean-100, train-clean-360 and train-other-500, and the evaluation dataset include dev-clean and dev-other.
diff --git a/research/deep_speech/__init__.py b/research/deep_speech/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/deep_speech/data/__init__.py b/research/deep_speech/data/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/deep_speech/data/dataset.py b/research/deep_speech/data/dataset.py
deleted file mode 100644
index 4a8cb59955c4608e20dcec6d9c5e38d705f24311..0000000000000000000000000000000000000000
--- a/research/deep_speech/data/dataset.py
+++ /dev/null
@@ -1,274 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Generate tf.data.Dataset object for deep speech training/evaluation."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-import random
-# pylint: disable=g-bad-import-order
-import numpy as np
-from six.moves import xrange # pylint: disable=redefined-builtin
-import soundfile
-import tensorflow as tf
-# pylint: enable=g-bad-import-order
-
-import data.featurizer as featurizer # pylint: disable=g-bad-import-order
-
-
-class AudioConfig(object):
- """Configs for spectrogram extraction from audio."""
-
- def __init__(self,
- sample_rate,
- window_ms,
- stride_ms,
- normalize=False):
- """Initialize the AudioConfig class.
-
- Args:
- sample_rate: an integer denoting the sample rate of the input waveform.
- window_ms: an integer for the length of a spectrogram frame, in ms.
- stride_ms: an integer for the frame stride, in ms.
- normalize: a boolean for whether apply normalization on the audio feature.
- """
-
- self.sample_rate = sample_rate
- self.window_ms = window_ms
- self.stride_ms = stride_ms
- self.normalize = normalize
-
-
-class DatasetConfig(object):
- """Config class for generating the DeepSpeechDataset."""
-
- def __init__(self, audio_config, data_path, vocab_file_path, sortagrad):
- """Initialize the configs for deep speech dataset.
-
- Args:
- audio_config: AudioConfig object specifying the audio-related configs.
- data_path: a string denoting the full path of a manifest file.
- vocab_file_path: a string specifying the vocabulary file path.
- sortagrad: a boolean, if set to true, audio sequences will be fed by
- increasing length in the first training epoch, which will
- expedite network convergence.
-
- Raises:
- RuntimeError: file path not exist.
- """
-
- self.audio_config = audio_config
- assert tf.gfile.Exists(data_path)
- assert tf.gfile.Exists(vocab_file_path)
- self.data_path = data_path
- self.vocab_file_path = vocab_file_path
- self.sortagrad = sortagrad
-
-
-def _normalize_audio_feature(audio_feature):
- """Perform mean and variance normalization on the spectrogram feature.
-
- Args:
- audio_feature: a numpy array for the spectrogram feature.
-
- Returns:
- a numpy array of the normalized spectrogram.
- """
- mean = np.mean(audio_feature, axis=0)
- var = np.var(audio_feature, axis=0)
- normalized = (audio_feature - mean) / (np.sqrt(var) + 1e-6)
-
- return normalized
-
-
-def _preprocess_audio(audio_file_path, audio_featurizer, normalize):
- """Load the audio file and compute spectrogram feature."""
- data, _ = soundfile.read(audio_file_path)
- feature = featurizer.compute_spectrogram_feature(
- data, audio_featurizer.sample_rate, audio_featurizer.stride_ms,
- audio_featurizer.window_ms)
- # Feature normalization
- if normalize:
- feature = _normalize_audio_feature(feature)
-
- # Adding Channel dimension for conv2D input.
- feature = np.expand_dims(feature, axis=2)
- return feature
-
-
-def _preprocess_data(file_path):
- """Generate a list of tuples (wav_filename, wav_filesize, transcript).
-
- Each dataset file contains three columns: "wav_filename", "wav_filesize",
- and "transcript". This function parses the csv file and stores each example
- by the increasing order of audio length (indicated by wav_filesize).
- AS the waveforms are ordered in increasing length, audio samples in a
- mini-batch have similar length.
-
- Args:
- file_path: a string specifying the csv file path for a dataset.
-
- Returns:
- A list of tuples (wav_filename, wav_filesize, transcript) sorted by
- file_size.
- """
- tf.logging.info("Loading data set {}".format(file_path))
- with tf.gfile.Open(file_path, "r") as f:
- lines = f.read().splitlines()
- # Skip the csv header in lines[0].
- lines = lines[1:]
- # The metadata file is tab separated.
- lines = [line.split("\t", 2) for line in lines]
- # Sort input data by the length of audio sequence.
- lines.sort(key=lambda item: int(item[1]))
-
- return [tuple(line) for line in lines]
-
-
-class DeepSpeechDataset(object):
- """Dataset class for training/evaluation of DeepSpeech model."""
-
- def __init__(self, dataset_config):
- """Initialize the DeepSpeechDataset class.
-
- Args:
- dataset_config: DatasetConfig object.
- """
- self.config = dataset_config
- # Instantiate audio feature extractor.
- self.audio_featurizer = featurizer.AudioFeaturizer(
- sample_rate=self.config.audio_config.sample_rate,
- window_ms=self.config.audio_config.window_ms,
- stride_ms=self.config.audio_config.stride_ms)
- # Instantiate text feature extractor.
- self.text_featurizer = featurizer.TextFeaturizer(
- vocab_file=self.config.vocab_file_path)
-
- self.speech_labels = self.text_featurizer.speech_labels
- self.entries = _preprocess_data(self.config.data_path)
- # The generated spectrogram will have 161 feature bins.
- self.num_feature_bins = 161
-
-
-def batch_wise_dataset_shuffle(entries, epoch_index, sortagrad, batch_size):
- """Batch-wise shuffling of the data entries.
-
- Each data entry is in the format of (audio_file, file_size, transcript).
- If epoch_index is 0 and sortagrad is true, we don't perform shuffling and
- return entries in sorted file_size order. Otherwise, do batch_wise shuffling.
-
- Args:
- entries: a list of data entries.
- epoch_index: an integer of epoch index
- sortagrad: a boolean to control whether sorting the audio in the first
- training epoch.
- batch_size: an integer for the batch size.
-
- Returns:
- The shuffled data entries.
- """
- shuffled_entries = []
- if epoch_index == 0 and sortagrad:
- # No need to shuffle.
- shuffled_entries = entries
- else:
- # Shuffle entries batch-wise.
- max_buckets = int(math.floor(len(entries) / batch_size))
- total_buckets = [i for i in xrange(max_buckets)]
- random.shuffle(total_buckets)
- shuffled_entries = []
- for i in total_buckets:
- shuffled_entries.extend(entries[i * batch_size : (i + 1) * batch_size])
- # If the last batch doesn't contain enough batch_size examples,
- # just append it to the shuffled_entries.
- shuffled_entries.extend(entries[max_buckets * batch_size:])
-
- return shuffled_entries
-
-
-def input_fn(batch_size, deep_speech_dataset, repeat=1):
- """Input function for model training and evaluation.
-
- Args:
- batch_size: an integer denoting the size of a batch.
- deep_speech_dataset: DeepSpeechDataset object.
- repeat: an integer for how many times to repeat the dataset.
-
- Returns:
- a tf.data.Dataset object for model to consume.
- """
- # Dataset properties
- data_entries = deep_speech_dataset.entries
- num_feature_bins = deep_speech_dataset.num_feature_bins
- audio_featurizer = deep_speech_dataset.audio_featurizer
- feature_normalize = deep_speech_dataset.config.audio_config.normalize
- text_featurizer = deep_speech_dataset.text_featurizer
-
- def _gen_data():
- """Dataset generator function."""
- for audio_file, _, transcript in data_entries:
- features = _preprocess_audio(
- audio_file, audio_featurizer, feature_normalize)
- labels = featurizer.compute_label_feature(
- transcript, text_featurizer.token_to_index)
- input_length = [features.shape[0]]
- label_length = [len(labels)]
- # Yield a tuple of (features, labels) where features is a dict containing
- # all info about the actual data features.
- yield (
- {
- "features": features,
- "input_length": input_length,
- "label_length": label_length
- },
- labels)
-
- dataset = tf.data.Dataset.from_generator(
- _gen_data,
- output_types=(
- {
- "features": tf.float32,
- "input_length": tf.int32,
- "label_length": tf.int32
- },
- tf.int32),
- output_shapes=(
- {
- "features": tf.TensorShape([None, num_feature_bins, 1]),
- "input_length": tf.TensorShape([1]),
- "label_length": tf.TensorShape([1])
- },
- tf.TensorShape([None]))
- )
-
- # Repeat and batch the dataset
- dataset = dataset.repeat(repeat)
-
- # Padding the features to its max length dimensions.
- dataset = dataset.padded_batch(
- batch_size=batch_size,
- padded_shapes=(
- {
- "features": tf.TensorShape([None, num_feature_bins, 1]),
- "input_length": tf.TensorShape([1]),
- "label_length": tf.TensorShape([1])
- },
- tf.TensorShape([None]))
- )
-
- # Prefetch to improve speed of input pipeline.
- dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
- return dataset
diff --git a/research/deep_speech/data/download.py b/research/deep_speech/data/download.py
deleted file mode 100644
index 5ded03762138a0006c36585e2e8da450baaccac7..0000000000000000000000000000000000000000
--- a/research/deep_speech/data/download.py
+++ /dev/null
@@ -1,208 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Download and preprocess LibriSpeech dataset for DeepSpeech model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import codecs
-import fnmatch
-import os
-import sys
-import tarfile
-import tempfile
-import unicodedata
-
-from absl import app as absl_app
-from absl import flags as absl_flags
-import pandas
-from six.moves import urllib
-from sox import Transformer
-import tensorflow as tf
-
-LIBRI_SPEECH_URLS = {
- "train-clean-100":
- "http://www.openslr.org/resources/12/train-clean-100.tar.gz",
- "train-clean-360":
- "http://www.openslr.org/resources/12/train-clean-360.tar.gz",
- "train-other-500":
- "http://www.openslr.org/resources/12/train-other-500.tar.gz",
- "dev-clean":
- "http://www.openslr.org/resources/12/dev-clean.tar.gz",
- "dev-other":
- "http://www.openslr.org/resources/12/dev-other.tar.gz",
- "test-clean":
- "http://www.openslr.org/resources/12/test-clean.tar.gz",
- "test-other":
- "http://www.openslr.org/resources/12/test-other.tar.gz"
-}
-
-
-def download_and_extract(directory, url):
- """Download and extract the given split of dataset.
-
- Args:
- directory: the directory where to extract the tarball.
- url: the url to download the data file.
- """
-
- if not tf.gfile.Exists(directory):
- tf.gfile.MakeDirs(directory)
-
- _, tar_filepath = tempfile.mkstemp(suffix=".tar.gz")
-
- try:
- tf.logging.info("Downloading %s to %s" % (url, tar_filepath))
-
- def _progress(count, block_size, total_size):
- sys.stdout.write("\r>> Downloading {} {:.1f}%".format(
- tar_filepath, 100.0 * count * block_size / total_size))
- sys.stdout.flush()
-
- urllib.request.urlretrieve(url, tar_filepath, _progress)
- print()
- statinfo = os.stat(tar_filepath)
- tf.logging.info(
- "Successfully downloaded %s, size(bytes): %d" % (url, statinfo.st_size))
- with tarfile.open(tar_filepath, "r") as tar:
- tar.extractall(directory)
- finally:
- tf.gfile.Remove(tar_filepath)
-
-
-def convert_audio_and_split_transcript(input_dir, source_name, target_name,
- output_dir, output_file):
- """Convert FLAC to WAV and split the transcript.
-
- For audio file, convert the format from FLAC to WAV using the sox.Transformer
- library.
- For transcripts, each line contains the sequence id and the corresponding
- transcript (separated by space):
- Input data format: seq-id transcript_of_seq-id
- For example:
- 1-2-0 transcript_of_1-2-0.flac
- 1-2-1 transcript_of_1-2-1.flac
- ...
-
- Each sequence id has a corresponding .flac file.
- Parse the transcript file and generate a new csv file which has three columns:
- "wav_filename": the absolute path to a wav file.
- "wav_filesize": the size of the corresponding wav file.
- "transcript": the transcript for this audio segement.
-
- Args:
- input_dir: the directory which holds the input dataset.
- source_name: the name of the specified dataset. e.g. test-clean
- target_name: the directory name for the newly generated audio files.
- e.g. test-clean-wav
- output_dir: the directory to place the newly generated csv files.
- output_file: the name of the newly generated csv file. e.g. test-clean.csv
- """
-
- tf.logging.info("Preprocessing audio and transcript for %s" % source_name)
- source_dir = os.path.join(input_dir, source_name)
- target_dir = os.path.join(input_dir, target_name)
-
- if not tf.gfile.Exists(target_dir):
- tf.gfile.MakeDirs(target_dir)
-
- files = []
- tfm = Transformer()
- # Convert all FLAC file into WAV format. At the same time, generate the csv
- # file.
- for root, _, filenames in tf.gfile.Walk(source_dir):
- for filename in fnmatch.filter(filenames, "*.trans.txt"):
- trans_file = os.path.join(root, filename)
- with codecs.open(trans_file, "r", "utf-8") as fin:
- for line in fin:
- seqid, transcript = line.split(" ", 1)
- # We do a encode-decode transformation here because the output type
- # of encode is a bytes object, we need convert it to string.
- transcript = unicodedata.normalize("NFKD", transcript).encode(
- "ascii", "ignore").decode("ascii", "ignore").strip().lower()
-
- # Convert FLAC to WAV.
- flac_file = os.path.join(root, seqid + ".flac")
- wav_file = os.path.join(target_dir, seqid + ".wav")
- if not tf.gfile.Exists(wav_file):
- tfm.build(flac_file, wav_file)
- wav_filesize = os.path.getsize(wav_file)
-
- files.append((os.path.abspath(wav_file), wav_filesize, transcript))
-
- # Write to CSV file which contains three columns:
- # "wav_filename", "wav_filesize", "transcript".
- csv_file_path = os.path.join(output_dir, output_file)
- df = pandas.DataFrame(
- data=files, columns=["wav_filename", "wav_filesize", "transcript"])
- df.to_csv(csv_file_path, index=False, sep="\t")
- tf.logging.info("Successfully generated csv file {}".format(csv_file_path))
-
-
-def download_and_process_datasets(directory, datasets):
- """Download and pre-process the specified list of LibriSpeech dataset.
-
- Args:
- directory: the directory to put all the downloaded and preprocessed data.
- datasets: list of dataset names that will be downloaded and processed.
- """
-
- tf.logging.info("Preparing LibriSpeech dataset: {}".format(
- ",".join(datasets)))
- for dataset in datasets:
- tf.logging.info("Preparing dataset %s", dataset)
- dataset_dir = os.path.join(directory, dataset)
- download_and_extract(dataset_dir, LIBRI_SPEECH_URLS[dataset])
- convert_audio_and_split_transcript(
- dataset_dir + "/LibriSpeech", dataset, dataset + "-wav",
- dataset_dir + "/LibriSpeech", dataset + ".csv")
-
-
-def define_data_download_flags():
- """Define flags for data downloading."""
- absl_flags.DEFINE_string(
- "data_dir", "/tmp/librispeech_data",
- "Directory to download data and extract the tarball")
- absl_flags.DEFINE_bool("train_only", False,
- "If true, only download the training set")
- absl_flags.DEFINE_bool("dev_only", False,
- "If true, only download the dev set")
- absl_flags.DEFINE_bool("test_only", False,
- "If true, only download the test set")
-
-
-def main(_):
- if not tf.gfile.Exists(FLAGS.data_dir):
- tf.gfile.MakeDirs(FLAGS.data_dir)
-
- if FLAGS.train_only:
- download_and_process_datasets(
- FLAGS.data_dir,
- ["train-clean-100", "train-clean-360", "train-other-500"])
- elif FLAGS.dev_only:
- download_and_process_datasets(FLAGS.data_dir, ["dev-clean", "dev-other"])
- elif FLAGS.test_only:
- download_and_process_datasets(FLAGS.data_dir, ["test-clean", "test-other"])
- else:
- # By default we download the entire dataset.
- download_and_process_datasets(FLAGS.data_dir, LIBRI_SPEECH_URLS.keys())
-
-
-if __name__ == "__main__":
- tf.logging.set_verbosity(tf.logging.INFO)
- define_data_download_flags()
- FLAGS = absl_flags.FLAGS
- absl_app.run(main)
diff --git a/research/deep_speech/data/featurizer.py b/research/deep_speech/data/featurizer.py
deleted file mode 100644
index 10b7069d3136d306075e9770685061749e634023..0000000000000000000000000000000000000000
--- a/research/deep_speech/data/featurizer.py
+++ /dev/null
@@ -1,118 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Utility class for extracting features from the text and audio input."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import codecs
-import numpy as np
-
-
-def compute_spectrogram_feature(samples, sample_rate, stride_ms=10.0,
- window_ms=20.0, max_freq=None, eps=1e-14):
- """Compute the spectrograms for the input samples(waveforms).
-
- More about spectrogram computation, please refer to:
- https://en.wikipedia.org/wiki/Short-time_Fourier_transform.
- """
- if max_freq is None:
- max_freq = sample_rate / 2
- if max_freq > sample_rate / 2:
- raise ValueError("max_freq must not be greater than half of sample rate.")
-
- if stride_ms > window_ms:
- raise ValueError("Stride size must not be greater than window size.")
-
- stride_size = int(0.001 * sample_rate * stride_ms)
- window_size = int(0.001 * sample_rate * window_ms)
-
- # Extract strided windows
- truncate_size = (len(samples) - window_size) % stride_size
- samples = samples[:len(samples) - truncate_size]
- nshape = (window_size, (len(samples) - window_size) // stride_size + 1)
- nstrides = (samples.strides[0], samples.strides[0] * stride_size)
- windows = np.lib.stride_tricks.as_strided(
- samples, shape=nshape, strides=nstrides)
- assert np.all(
- windows[:, 1] == samples[stride_size:(stride_size + window_size)])
-
- # Window weighting, squared Fast Fourier Transform (fft), scaling
- weighting = np.hanning(window_size)[:, None]
- fft = np.fft.rfft(windows * weighting, axis=0)
- fft = np.absolute(fft)
- fft = fft**2
- scale = np.sum(weighting**2) * sample_rate
- fft[1:-1, :] *= (2.0 / scale)
- fft[(0, -1), :] /= scale
- # Prepare fft frequency list
- freqs = float(sample_rate) / window_size * np.arange(fft.shape[0])
-
- # Compute spectrogram feature
- ind = np.where(freqs <= max_freq)[0][-1] + 1
- specgram = np.log(fft[:ind, :] + eps)
- return np.transpose(specgram, (1, 0))
-
-
-class AudioFeaturizer(object):
- """Class to extract spectrogram features from the audio input."""
-
- def __init__(self,
- sample_rate=16000,
- window_ms=20.0,
- stride_ms=10.0):
- """Initialize the audio featurizer class according to the configs.
-
- Args:
- sample_rate: an integer specifying the sample rate of the input waveform.
- window_ms: an integer for the length of a spectrogram frame, in ms.
- stride_ms: an integer for the frame stride, in ms.
- """
- self.sample_rate = sample_rate
- self.window_ms = window_ms
- self.stride_ms = stride_ms
-
-
-def compute_label_feature(text, token_to_idx):
- """Convert string to a list of integers."""
- tokens = list(text.strip().lower())
- feats = [token_to_idx[token] for token in tokens]
- return feats
-
-
-class TextFeaturizer(object):
- """Extract text feature based on char-level granularity.
-
- By looking up the vocabulary table, each input string (one line of transcript)
- will be converted to a sequence of integer indexes.
- """
-
- def __init__(self, vocab_file):
- lines = []
- with codecs.open(vocab_file, "r", "utf-8") as fin:
- lines.extend(fin.readlines())
- self.token_to_index = {}
- self.index_to_token = {}
- self.speech_labels = ""
- index = 0
- for line in lines:
- line = line[:-1] # Strip the '\n' char.
- if line.startswith("#"):
- # Skip from reading comment line.
- continue
- self.token_to_index[line] = index
- self.index_to_token[index] = line
- self.speech_labels += line
- index += 1
diff --git a/research/deep_speech/data/vocabulary.txt b/research/deep_speech/data/vocabulary.txt
deleted file mode 100644
index 51852b3a78b0b14e19b15782002cf8c401ac71c9..0000000000000000000000000000000000000000
--- a/research/deep_speech/data/vocabulary.txt
+++ /dev/null
@@ -1,33 +0,0 @@
-# List of alphabets (utf-8 encoded). Note that '#' starts a comment line, which
-# will be ignored by the parser.
-# begin of vocabulary
-
-a
-b
-c
-d
-e
-f
-g
-h
-i
-j
-k
-l
-m
-n
-o
-p
-q
-r
-s
-t
-u
-v
-w
-x
-y
-z
-'
--
-# end of vocabulary
diff --git a/research/deep_speech/decoder.py b/research/deep_speech/decoder.py
deleted file mode 100644
index f46983170f5885385942be1b24e262f30b4be8e0..0000000000000000000000000000000000000000
--- a/research/deep_speech/decoder.py
+++ /dev/null
@@ -1,95 +0,0 @@
-
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Deep speech decoder."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import itertools
-
-from nltk.metrics import distance
-import numpy as np
-
-
-class DeepSpeechDecoder(object):
- """Greedy decoder implementation for Deep Speech model."""
-
- def __init__(self, labels, blank_index=28):
- """Decoder initialization.
-
- Arguments:
- labels: a string specifying the speech labels for the decoder to use.
- blank_index: an integer specifying index for the blank character.
- Defaults to 28.
- """
- # e.g. labels = "[a-z]' _"
- self.labels = labels
- self.blank_index = blank_index
- self.int_to_char = dict([(i, c) for (i, c) in enumerate(labels)])
-
- def convert_to_string(self, sequence):
- """Convert a sequence of indexes into corresponding string."""
- return ''.join([self.int_to_char[i] for i in sequence])
-
- def wer(self, decode, target):
- """Computes the Word Error Rate (WER).
-
- WER is defined as the edit distance between the two provided sentences after
- tokenizing to words.
-
- Args:
- decode: string of the decoded output.
- target: a string for the ground truth label.
-
- Returns:
- A float number for the WER of the current decode-target pair.
- """
- # Map each word to a new char.
- words = set(decode.split() + target.split())
- word2char = dict(zip(words, range(len(words))))
-
- new_decode = [chr(word2char[w]) for w in decode.split()]
- new_target = [chr(word2char[w]) for w in target.split()]
-
- return distance.edit_distance(''.join(new_decode), ''.join(new_target))
-
- def cer(self, decode, target):
- """Computes the Character Error Rate (CER).
-
- CER is defined as the edit distance between the two given strings.
-
- Args:
- decode: a string of the decoded output.
- target: a string for the ground truth label.
-
- Returns:
- A float number denoting the CER for the current sentence pair.
- """
- return distance.edit_distance(decode, target)
-
- def decode(self, logits):
- """Decode the best guess from logits using greedy algorithm."""
- # Choose the class with maximimum probability.
- best = list(np.argmax(logits, axis=1))
- # Merge repeated chars.
- merge = [k for k, _ in itertools.groupby(best)]
- # Remove the blank index in the decoded sequence.
- merge_remove_blank = []
- for k in merge:
- if k != self.blank_index:
- merge_remove_blank.append(k)
-
- return self.convert_to_string(merge_remove_blank)
diff --git a/research/deep_speech/deep_speech.py b/research/deep_speech/deep_speech.py
deleted file mode 100644
index 3d809c3cbc245e20b752bf2d2e45823f33521d64..0000000000000000000000000000000000000000
--- a/research/deep_speech/deep_speech.py
+++ /dev/null
@@ -1,432 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Main entry to train and evaluate DeepSpeech model."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-# pylint: disable=g-bad-import-order
-from absl import app as absl_app
-from absl import flags
-import tensorflow as tf
-# pylint: enable=g-bad-import-order
-
-import data.dataset as dataset
-import decoder
-import deep_speech_model
-from official.utils.flags import core as flags_core
-from official.utils.misc import distribution_utils
-from official.utils.misc import model_helpers
-
-# Default vocabulary file
-_VOCABULARY_FILE = os.path.join(
- os.path.dirname(__file__), "data/vocabulary.txt")
-# Evaluation metrics
-_WER_KEY = "WER"
-_CER_KEY = "CER"
-
-
-def compute_length_after_conv(max_time_steps, ctc_time_steps, input_length):
- """Computes the time_steps/ctc_input_length after convolution.
-
- Suppose that the original feature contains two parts:
- 1) Real spectrogram signals, spanning input_length steps.
- 2) Padded part with all 0s.
- The total length of those two parts is denoted as max_time_steps, which is
- the padded length of the current batch. After convolution layers, the time
- steps of a spectrogram feature will be decreased. As we know the percentage
- of its original length within the entire length, we can compute the time steps
- for the signal after conv as follows (using ctc_input_length to denote):
- ctc_input_length = (input_length / max_time_steps) * output_length_of_conv.
- This length is then fed into ctc loss function to compute loss.
-
- Args:
- max_time_steps: max_time_steps for the batch, after padding.
- ctc_time_steps: number of timesteps after convolution.
- input_length: actual length of the original spectrogram, without padding.
-
- Returns:
- the ctc_input_length after convolution layer.
- """
- ctc_input_length = tf.to_float(tf.multiply(
- input_length, ctc_time_steps))
- return tf.to_int32(tf.floordiv(
- ctc_input_length, tf.to_float(max_time_steps)))
-
-
-def ctc_loss(label_length, ctc_input_length, labels, logits):
- """Computes the ctc loss for the current batch of predictions."""
- label_length = tf.to_int32(tf.squeeze(label_length))
- ctc_input_length = tf.to_int32(tf.squeeze(ctc_input_length))
- sparse_labels = tf.to_int32(
- tf.keras.backend.ctc_label_dense_to_sparse(labels, label_length))
- y_pred = tf.log(tf.transpose(
- logits, perm=[1, 0, 2]) + tf.keras.backend.epsilon())
-
- return tf.expand_dims(
- tf.nn.ctc_loss(labels=sparse_labels, inputs=y_pred,
- sequence_length=ctc_input_length),
- axis=1)
-
-
-def evaluate_model(estimator, speech_labels, entries, input_fn_eval):
- """Evaluate the model performance using WER anc CER as metrics.
-
- WER: Word Error Rate
- CER: Character Error Rate
-
- Args:
- estimator: estimator to evaluate.
- speech_labels: a string specifying all the character in the vocabulary.
- entries: a list of data entries (audio_file, file_size, transcript) for the
- given dataset.
- input_fn_eval: data input function for evaluation.
-
- Returns:
- Evaluation result containing 'wer' and 'cer' as two metrics.
- """
- # Get predictions
- predictions = estimator.predict(input_fn=input_fn_eval)
-
- # Get probabilities of each predicted class
- probs = [pred["probabilities"] for pred in predictions]
-
- num_of_examples = len(probs)
- targets = [entry[2] for entry in entries] # The ground truth transcript
-
- total_wer, total_cer = 0, 0
- greedy_decoder = decoder.DeepSpeechDecoder(speech_labels)
- for i in range(num_of_examples):
- # Decode string.
- decoded_str = greedy_decoder.decode(probs[i])
- # Compute CER.
- total_cer += greedy_decoder.cer(decoded_str, targets[i]) / float(
- len(targets[i]))
- # Compute WER.
- total_wer += greedy_decoder.wer(decoded_str, targets[i]) / float(
- len(targets[i].split()))
-
- # Get mean value
- total_cer /= num_of_examples
- total_wer /= num_of_examples
-
- global_step = estimator.get_variable_value(tf.GraphKeys.GLOBAL_STEP)
- eval_results = {
- _WER_KEY: total_wer,
- _CER_KEY: total_cer,
- tf.GraphKeys.GLOBAL_STEP: global_step,
- }
-
- return eval_results
-
-
-def model_fn(features, labels, mode, params):
- """Define model function for deep speech model.
-
- Args:
- features: a dictionary of input_data features. It includes the data
- input_length, label_length and the spectrogram features.
- labels: a list of labels for the input data.
- mode: current estimator mode; should be one of
- `tf.estimator.ModeKeys.TRAIN`, `EVALUATE`, `PREDICT`.
- params: a dict of hyper parameters to be passed to model_fn.
-
- Returns:
- EstimatorSpec parameterized according to the input params and the
- current mode.
- """
- num_classes = params["num_classes"]
- input_length = features["input_length"]
- label_length = features["label_length"]
- features = features["features"]
-
- # Create DeepSpeech2 model.
- model = deep_speech_model.DeepSpeech2(
- flags_obj.rnn_hidden_layers, flags_obj.rnn_type,
- flags_obj.is_bidirectional, flags_obj.rnn_hidden_size,
- num_classes, flags_obj.use_bias)
-
- if mode == tf.estimator.ModeKeys.PREDICT:
- logits = model(features, training=False)
- predictions = {
- "classes": tf.argmax(logits, axis=2),
- "probabilities": tf.nn.softmax(logits),
- "logits": logits
- }
- return tf.estimator.EstimatorSpec(
- mode=mode,
- predictions=predictions)
-
- # In training mode.
- logits = model(features, training=True)
- probs = tf.nn.softmax(logits)
- ctc_input_length = compute_length_after_conv(
- tf.shape(features)[1], tf.shape(probs)[1], input_length)
- # Compute CTC loss
- loss = tf.reduce_mean(ctc_loss(
- label_length, ctc_input_length, labels, probs))
-
- optimizer = tf.train.AdamOptimizer(learning_rate=flags_obj.learning_rate)
- global_step = tf.train.get_or_create_global_step()
- minimize_op = optimizer.minimize(loss, global_step=global_step)
- update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
- # Create the train_op that groups both minimize_ops and update_ops
- train_op = tf.group(minimize_op, update_ops)
-
- return tf.estimator.EstimatorSpec(
- mode=mode,
- loss=loss,
- train_op=train_op)
-
-
-def generate_dataset(data_dir):
- """Generate a speech dataset."""
- audio_conf = dataset.AudioConfig(sample_rate=flags_obj.sample_rate,
- window_ms=flags_obj.window_ms,
- stride_ms=flags_obj.stride_ms,
- normalize=True)
- train_data_conf = dataset.DatasetConfig(
- audio_conf,
- data_dir,
- flags_obj.vocabulary_file,
- flags_obj.sortagrad
- )
- speech_dataset = dataset.DeepSpeechDataset(train_data_conf)
- return speech_dataset
-
-def per_device_batch_size(batch_size, num_gpus):
- """For multi-gpu, batch-size must be a multiple of the number of GPUs.
-
-
- Note that distribution strategy handles this automatically when used with
- Keras. For using with Estimator, we need to get per GPU batch.
-
- Args:
- batch_size: Global batch size to be divided among devices. This should be
- equal to num_gpus times the single-GPU batch_size for multi-gpu training.
- num_gpus: How many GPUs are used with DistributionStrategies.
-
- Returns:
- Batch size per device.
-
- Raises:
- ValueError: if batch_size is not divisible by number of devices
- """
- if num_gpus <= 1:
- return batch_size
-
- remainder = batch_size % num_gpus
- if remainder:
- err = ('When running with multiple GPUs, batch size '
- 'must be a multiple of the number of available GPUs. Found {} '
- 'GPUs with a batch size of {}; try --batch_size={} instead.'
- ).format(num_gpus, batch_size, batch_size - remainder)
- raise ValueError(err)
- return int(batch_size / num_gpus)
-
-def run_deep_speech(_):
- """Run deep speech training and eval loop."""
- tf.set_random_seed(flags_obj.seed)
- # Data preprocessing
- tf.logging.info("Data preprocessing...")
- train_speech_dataset = generate_dataset(flags_obj.train_data_dir)
- eval_speech_dataset = generate_dataset(flags_obj.eval_data_dir)
-
- # Number of label classes. Label string is "[a-z]' -"
- num_classes = len(train_speech_dataset.speech_labels)
-
- # Use distribution strategy for multi-gpu training
- num_gpus = flags_core.get_num_gpus(flags_obj)
- distribution_strategy = distribution_utils.get_distribution_strategy(num_gpus=num_gpus)
- run_config = tf.estimator.RunConfig(
- train_distribute=distribution_strategy)
-
- estimator = tf.estimator.Estimator(
- model_fn=model_fn,
- model_dir=flags_obj.model_dir,
- config=run_config,
- params={
- "num_classes": num_classes,
- }
- )
-
- # Benchmark logging
- run_params = {
- "batch_size": flags_obj.batch_size,
- "train_epochs": flags_obj.train_epochs,
- "rnn_hidden_size": flags_obj.rnn_hidden_size,
- "rnn_hidden_layers": flags_obj.rnn_hidden_layers,
- "rnn_type": flags_obj.rnn_type,
- "is_bidirectional": flags_obj.is_bidirectional,
- "use_bias": flags_obj.use_bias
- }
-
- per_replica_batch_size = per_device_batch_size(flags_obj.batch_size, num_gpus)
-
- def input_fn_train():
- return dataset.input_fn(
- per_replica_batch_size, train_speech_dataset)
-
- def input_fn_eval():
- return dataset.input_fn(
- per_replica_batch_size, eval_speech_dataset)
-
- total_training_cycle = (flags_obj.train_epochs //
- flags_obj.epochs_between_evals)
- for cycle_index in range(total_training_cycle):
- tf.logging.info("Starting a training cycle: %d/%d",
- cycle_index + 1, total_training_cycle)
-
- # Perform batch_wise dataset shuffling
- train_speech_dataset.entries = dataset.batch_wise_dataset_shuffle(
- train_speech_dataset.entries, cycle_index, flags_obj.sortagrad,
- flags_obj.batch_size)
-
- estimator.train(input_fn=input_fn_train)
-
- # Evaluation
- tf.logging.info("Starting to evaluate...")
-
- eval_results = evaluate_model(
- estimator, eval_speech_dataset.speech_labels,
- eval_speech_dataset.entries, input_fn_eval)
-
- # Log the WER and CER results.
- benchmark_logger.log_evaluation_result(eval_results)
- tf.logging.info(
- "Iteration {}: WER = {:.2f}, CER = {:.2f}".format(
- cycle_index + 1, eval_results[_WER_KEY], eval_results[_CER_KEY]))
-
- # If some evaluation threshold is met
- if model_helpers.past_stop_threshold(
- flags_obj.wer_threshold, eval_results[_WER_KEY]):
- break
-
-
-def define_deep_speech_flags():
- """Add flags for run_deep_speech."""
- # Add common flags
- flags_core.define_base(
- data_dir=False, # we use train_data_dir and eval_data_dir instead
- export_dir=True,
- train_epochs=True,
- hooks=True,
- num_gpu=True,
- epochs_between_evals=True
- )
- flags_core.define_performance(
- num_parallel_calls=False,
- inter_op=False,
- intra_op=False,
- synthetic_data=False,
- max_train_steps=False,
- dtype=False
- )
- flags_core.define_benchmark()
- flags.adopt_module_key_flags(flags_core)
-
- flags_core.set_defaults(
- model_dir="/tmp/deep_speech_model/",
- export_dir="/tmp/deep_speech_saved_model/",
- train_epochs=10,
- batch_size=128,
- hooks="")
-
- # Deep speech flags
- flags.DEFINE_integer(
- name="seed", default=1,
- help=flags_core.help_wrap("The random seed."))
-
- flags.DEFINE_string(
- name="train_data_dir",
- default="/tmp/librispeech_data/test-clean/LibriSpeech/test-clean.csv",
- help=flags_core.help_wrap("The csv file path of train dataset."))
-
- flags.DEFINE_string(
- name="eval_data_dir",
- default="/tmp/librispeech_data/test-clean/LibriSpeech/test-clean.csv",
- help=flags_core.help_wrap("The csv file path of evaluation dataset."))
-
- flags.DEFINE_bool(
- name="sortagrad", default=True,
- help=flags_core.help_wrap(
- "If true, sort examples by audio length and perform no "
- "batch_wise shuffling for the first epoch."))
-
- flags.DEFINE_integer(
- name="sample_rate", default=16000,
- help=flags_core.help_wrap("The sample rate for audio."))
-
- flags.DEFINE_integer(
- name="window_ms", default=20,
- help=flags_core.help_wrap("The frame length for spectrogram."))
-
- flags.DEFINE_integer(
- name="stride_ms", default=10,
- help=flags_core.help_wrap("The frame step."))
-
- flags.DEFINE_string(
- name="vocabulary_file", default=_VOCABULARY_FILE,
- help=flags_core.help_wrap("The file path of vocabulary file."))
-
- # RNN related flags
- flags.DEFINE_integer(
- name="rnn_hidden_size", default=800,
- help=flags_core.help_wrap("The hidden size of RNNs."))
-
- flags.DEFINE_integer(
- name="rnn_hidden_layers", default=5,
- help=flags_core.help_wrap("The number of RNN layers."))
-
- flags.DEFINE_bool(
- name="use_bias", default=True,
- help=flags_core.help_wrap("Use bias in the last fully-connected layer"))
-
- flags.DEFINE_bool(
- name="is_bidirectional", default=True,
- help=flags_core.help_wrap("If rnn unit is bidirectional"))
-
- flags.DEFINE_enum(
- name="rnn_type", default="gru",
- enum_values=deep_speech_model.SUPPORTED_RNNS.keys(),
- case_sensitive=False,
- help=flags_core.help_wrap("Type of RNN cell."))
-
- # Training related flags
- flags.DEFINE_float(
- name="learning_rate", default=5e-4,
- help=flags_core.help_wrap("The initial learning rate."))
-
- # Evaluation metrics threshold
- flags.DEFINE_float(
- name="wer_threshold", default=None,
- help=flags_core.help_wrap(
- "If passed, training will stop when the evaluation metric WER is "
- "greater than or equal to wer_threshold. For libri speech dataset "
- "the desired wer_threshold is 0.23 which is the result achieved by "
- "MLPerf implementation."))
-
-
-def main(_):
- run_deep_speech(flags_obj)
-
-
-if __name__ == "__main__":
- tf.logging.set_verbosity(tf.logging.INFO)
- define_deep_speech_flags()
- flags_obj = flags.FLAGS
- absl_app.run(main)
-
diff --git a/research/deep_speech/deep_speech_model.py b/research/deep_speech/deep_speech_model.py
deleted file mode 100644
index dd768f825c792eb9f8f8ca7dbef6a25f5ce81091..0000000000000000000000000000000000000000
--- a/research/deep_speech/deep_speech_model.py
+++ /dev/null
@@ -1,185 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Network structure for DeepSpeech2 model."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from six.moves import xrange # pylint: disable=redefined-builtin
-import tensorflow as tf
-
-# Supported rnn cells.
-SUPPORTED_RNNS = {
- "lstm": tf.contrib.rnn.BasicLSTMCell,
- "rnn": tf.contrib.rnn.RNNCell,
- "gru": tf.contrib.rnn.GRUCell,
-}
-
-# Parameters for batch normalization.
-_BATCH_NORM_EPSILON = 1e-5
-_BATCH_NORM_DECAY = 0.997
-
-# Filters of convolution layer
-_CONV_FILTERS = 32
-
-
-def batch_norm(inputs, training):
- """Batch normalization layer.
-
- Note that the momentum to use will affect validation accuracy over time.
- Batch norm has different behaviors during training/evaluation. With a large
- momentum, the model takes longer to get a near-accurate estimation of the
- moving mean/variance over the entire training dataset, which means we need
- more iterations to see good evaluation results. If the training data is evenly
- distributed over the feature space, we can also try setting a smaller momentum
- (such as 0.1) to get good evaluation result sooner.
-
- Args:
- inputs: input data for batch norm layer.
- training: a boolean to indicate if it is in training stage.
-
- Returns:
- tensor output from batch norm layer.
- """
- return tf.layers.batch_normalization(
- inputs=inputs, momentum=_BATCH_NORM_DECAY, epsilon=_BATCH_NORM_EPSILON,
- fused=True, training=training)
-
-
-def _conv_bn_layer(inputs, padding, filters, kernel_size, strides, layer_id,
- training):
- """Defines 2D convolutional + batch normalization layer.
-
- Args:
- inputs: input data for convolution layer.
- padding: padding to be applied before convolution layer.
- filters: an integer, number of output filters in the convolution.
- kernel_size: a tuple specifying the height and width of the 2D convolution
- window.
- strides: a tuple specifying the stride length of the convolution.
- layer_id: an integer specifying the layer index.
- training: a boolean to indicate which stage we are in (training/eval).
-
- Returns:
- tensor output from the current layer.
- """
- # Perform symmetric padding on the feature dimension of time_step
- # This step is required to avoid issues when RNN output sequence is shorter
- # than the label length.
- inputs = tf.pad(
- inputs,
- [[0, 0], [padding[0], padding[0]], [padding[1], padding[1]], [0, 0]])
- inputs = tf.layers.conv2d(
- inputs=inputs, filters=filters, kernel_size=kernel_size, strides=strides,
- padding="valid", use_bias=False, activation=tf.nn.relu6,
- name="cnn_{}".format(layer_id))
- return batch_norm(inputs, training)
-
-
-def _rnn_layer(inputs, rnn_cell, rnn_hidden_size, layer_id, is_batch_norm,
- is_bidirectional, training):
- """Defines a batch normalization + rnn layer.
-
- Args:
- inputs: input tensors for the current layer.
- rnn_cell: RNN cell instance to use.
- rnn_hidden_size: an integer for the dimensionality of the rnn output space.
- layer_id: an integer for the index of current layer.
- is_batch_norm: a boolean specifying whether to perform batch normalization
- on input states.
- is_bidirectional: a boolean specifying whether the rnn layer is
- bi-directional.
- training: a boolean to indicate which stage we are in (training/eval).
-
- Returns:
- tensor output for the current layer.
- """
- if is_batch_norm:
- inputs = batch_norm(inputs, training)
-
- # Construct forward/backward RNN cells.
- fw_cell = rnn_cell(num_units=rnn_hidden_size,
- name="rnn_fw_{}".format(layer_id))
- bw_cell = rnn_cell(num_units=rnn_hidden_size,
- name="rnn_bw_{}".format(layer_id))
-
- if is_bidirectional:
- outputs, _ = tf.nn.bidirectional_dynamic_rnn(
- cell_fw=fw_cell, cell_bw=bw_cell, inputs=inputs, dtype=tf.float32,
- swap_memory=True)
- rnn_outputs = tf.concat(outputs, -1)
- else:
- rnn_outputs = tf.nn.dynamic_rnn(
- fw_cell, inputs, dtype=tf.float32, swap_memory=True)
-
- return rnn_outputs
-
-
-class DeepSpeech2(object):
- """Define DeepSpeech2 model."""
-
- def __init__(self, num_rnn_layers, rnn_type, is_bidirectional,
- rnn_hidden_size, num_classes, use_bias):
- """Initialize DeepSpeech2 model.
-
- Args:
- num_rnn_layers: an integer, the number of rnn layers. By default, it's 5.
- rnn_type: a string, one of the supported rnn cells: gru, rnn and lstm.
- is_bidirectional: a boolean to indicate if the rnn layer is bidirectional.
- rnn_hidden_size: an integer for the number of hidden states in each unit.
- num_classes: an integer, the number of output classes/labels.
- use_bias: a boolean specifying whether to use bias in the last fc layer.
- """
- self.num_rnn_layers = num_rnn_layers
- self.rnn_type = rnn_type
- self.is_bidirectional = is_bidirectional
- self.rnn_hidden_size = rnn_hidden_size
- self.num_classes = num_classes
- self.use_bias = use_bias
-
- def __call__(self, inputs, training):
- # Two cnn layers.
- inputs = _conv_bn_layer(
- inputs, padding=(20, 5), filters=_CONV_FILTERS, kernel_size=(41, 11),
- strides=(2, 2), layer_id=1, training=training)
-
- inputs = _conv_bn_layer(
- inputs, padding=(10, 5), filters=_CONV_FILTERS, kernel_size=(21, 11),
- strides=(2, 1), layer_id=2, training=training)
-
- # output of conv_layer2 with the shape of
- # [batch_size (N), times (T), features (F), channels (C)].
- # Convert the conv output to rnn input.
- batch_size = tf.shape(inputs)[0]
- feat_size = inputs.get_shape().as_list()[2]
- inputs = tf.reshape(
- inputs,
- [batch_size, -1, feat_size * _CONV_FILTERS])
-
- # RNN layers.
- rnn_cell = SUPPORTED_RNNS[self.rnn_type]
- for layer_counter in xrange(self.num_rnn_layers):
- # No batch normalization on the first layer.
- is_batch_norm = (layer_counter != 0)
- inputs = _rnn_layer(
- inputs, rnn_cell, self.rnn_hidden_size, layer_counter + 1,
- is_batch_norm, self.is_bidirectional, training)
-
- # FC layer with batch norm.
- inputs = batch_norm(inputs, training)
- logits = tf.layers.dense(inputs, self.num_classes, use_bias=self.use_bias)
-
- return logits
-
diff --git a/research/deep_speech/requirements.txt b/research/deep_speech/requirements.txt
deleted file mode 100644
index d951b6c439294c37eabb65e20f2a043eecf3bb5e..0000000000000000000000000000000000000000
--- a/research/deep_speech/requirements.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-nltk>=3.3
-pandas>=0.23.3
-soundfile>=0.10.2
-sox>=1.3.3
diff --git a/research/deep_speech/run_deep_speech.sh b/research/deep_speech/run_deep_speech.sh
deleted file mode 100755
index f1559aa614e084d17bcad93a739481cfda545bc6..0000000000000000000000000000000000000000
--- a/research/deep_speech/run_deep_speech.sh
+++ /dev/null
@@ -1,50 +0,0 @@
-#!/bin/bash
-# Script to run deep speech model to achieve the MLPerf target (WER = 0.23)
-# Step 1: download the LibriSpeech dataset.
-echo "Data downloading..."
-python data/download.py
-
-## After data downloading, the dataset directories are:
-train_clean_100="/tmp/librispeech_data/train-clean-100/LibriSpeech/train-clean-100.csv"
-train_clean_360="/tmp/librispeech_data/train-clean-360/LibriSpeech/train-clean-360.csv"
-train_other_500="/tmp/librispeech_data/train-other-500/LibriSpeech/train-other-500.csv"
-dev_clean="/tmp/librispeech_data/dev-clean/LibriSpeech/dev-clean.csv"
-dev_other="/tmp/librispeech_data/dev-other/LibriSpeech/dev-other.csv"
-test_clean="/tmp/librispeech_data/test-clean/LibriSpeech/test-clean.csv"
-test_other="/tmp/librispeech_data/test-other/LibriSpeech/test-other.csv"
-
-# Step 2: generate train dataset and evaluation dataset
-echo "Data preprocessing..."
-train_file="/tmp/librispeech_data/train_dataset.csv"
-eval_file="/tmp/librispeech_data/eval_dataset.csv"
-
-head -1 $train_clean_100 > $train_file
-for filename in $train_clean_100 $train_clean_360 $train_other_500
-do
- sed 1d $filename >> $train_file
-done
-
-head -1 $dev_clean > $eval_file
-for filename in $dev_clean $dev_other
-do
- sed 1d $filename >> $eval_file
-done
-
-# Step 3: filter out the audio files that exceed max time duration.
-final_train_file="/tmp/librispeech_data/final_train_dataset.csv"
-final_eval_file="/tmp/librispeech_data/final_eval_dataset.csv"
-
-MAX_AUDIO_LEN=27.0
-awk -v maxlen="$MAX_AUDIO_LEN" 'BEGIN{FS="\t";} NR==1{print $0} NR>1{cmd="soxi -D "$1""; cmd|getline x; if(x<=maxlen) {print $0}; close(cmd);}' $train_file > $final_train_file
-awk -v maxlen="$MAX_AUDIO_LEN" 'BEGIN{FS="\t";} NR==1{print $0} NR>1{cmd="soxi -D "$1""; cmd|getline x; if(x<=maxlen) {print $0}; close(cmd);}' $eval_file > $final_eval_file
-
-# Step 4: run the training and evaluation loop in background, and save the running info to a log file
-echo "Model training and evaluation..."
-start=`date +%s`
-
-log_file=log_`date +%Y-%m-%d`
-nohup python deep_speech.py --train_data_dir=$final_train_file --eval_data_dir=$final_eval_file --num_gpus=-1 --wer_threshold=0.23 --seed=1 >$log_file 2>&1&
-
-end=`date +%s`
-runtime=$((end-start))
-echo "Model training time is" $runtime "seconds."
diff --git a/research/deeplab/README.md b/research/deeplab/README.md
deleted file mode 100644
index 8609432b5bd78b56bf18a557dd5b813ed6a3fc77..0000000000000000000000000000000000000000
--- a/research/deeplab/README.md
+++ /dev/null
@@ -1,321 +0,0 @@
-# DeepLab: Deep Labelling for Semantic Image Segmentation
-
-DeepLab is a state-of-art deep learning model for semantic image segmentation,
-where the goal is to assign semantic labels (e.g., person, dog, cat and so on)
-to every pixel in the input image. Current implementation includes the following
-features:
-
-1. DeepLabv1 [1]: We use *atrous convolution* to explicitly control the
- resolution at which feature responses are computed within Deep Convolutional
- Neural Networks.
-
-2. DeepLabv2 [2]: We use *atrous spatial pyramid pooling* (ASPP) to robustly
- segment objects at multiple scales with filters at multiple sampling rates
- and effective fields-of-views.
-
-3. DeepLabv3 [3]: We augment the ASPP module with *image-level feature* [5, 6]
- to capture longer range information. We also include *batch normalization*
- [7] parameters to facilitate the training. In particular, we applying atrous
- convolution to extract output features at different output strides during
- training and evaluation, which efficiently enables training BN at output
- stride = 16 and attains a high performance at output stride = 8 during
- evaluation.
-
-4. DeepLabv3+ [4]: We extend DeepLabv3 to include a simple yet effective
- decoder module to refine the segmentation results especially along object
- boundaries. Furthermore, in this encoder-decoder structure one can
- arbitrarily control the resolution of extracted encoder features by atrous
- convolution to trade-off precision and runtime.
-
-If you find the code useful for your research, please consider citing our latest
-works:
-
-* DeepLabv3+:
-
-```
-@inproceedings{deeplabv3plus2018,
- title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
- author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
- booktitle={ECCV},
- year={2018}
-}
-```
-
-* MobileNetv2:
-
-```
-@inproceedings{mobilenetv22018,
- title={MobileNetV2: Inverted Residuals and Linear Bottlenecks},
- author={Mark Sandler and Andrew Howard and Menglong Zhu and Andrey Zhmoginov and Liang-Chieh Chen},
- booktitle={CVPR},
- year={2018}
-}
-```
-
-* MobileNetv3:
-
-```
-@inproceedings{mobilenetv32019,
- title={Searching for MobileNetV3},
- author={Andrew Howard and Mark Sandler and Grace Chu and Liang-Chieh Chen and Bo Chen and Mingxing Tan and Weijun Wang and Yukun Zhu and Ruoming Pang and Vijay Vasudevan and Quoc V. Le and Hartwig Adam},
- booktitle={ICCV},
- year={2019}
-}
-```
-
-* Architecture search for dense prediction cell:
-
-```
-@inproceedings{dpc2018,
- title={Searching for Efficient Multi-Scale Architectures for Dense Image Prediction},
- author={Liang-Chieh Chen and Maxwell D. Collins and Yukun Zhu and George Papandreou and Barret Zoph and Florian Schroff and Hartwig Adam and Jonathon Shlens},
- booktitle={NIPS},
- year={2018}
-}
-
-```
-
-* Auto-DeepLab (also called hnasnet in core/nas_network.py):
-
-```
-@inproceedings{autodeeplab2019,
- title={Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic
-Image Segmentation},
- author={Chenxi Liu and Liang-Chieh Chen and Florian Schroff and Hartwig Adam
- and Wei Hua and Alan Yuille and Li Fei-Fei},
- booktitle={CVPR},
- year={2019}
-}
-
-```
-
-
-In the current implementation, we support adopting the following network
-backbones:
-
-1. MobileNetv2 [8] and MobileNetv3 [16]: A fast network structure designed
- for mobile devices.
-
-2. Xception [9, 10]: A powerful network structure intended for server-side
- deployment.
-
-3. ResNet-v1-{50,101} [14]: We provide both the original ResNet-v1 and its
- 'beta' variant where the 'stem' is modified for semantic segmentation.
-
-4. PNASNet [15]: A Powerful network structure found by neural architecture
- search.
-
-5. Auto-DeepLab (called HNASNet in the code): A segmentation-specific network
- backbone found by neural architecture search.
-
-This directory contains our TensorFlow [11] implementation. We provide codes
-allowing users to train the model, evaluate results in terms of mIOU (mean
-intersection-over-union), and visualize segmentation results. We use PASCAL VOC
-2012 [12] and Cityscapes [13] semantic segmentation benchmarks as an example in
-the code.
-
-Some segmentation results on Flickr images:
-
- -Running: - -* Installation.
-* Running DeepLab on PASCAL VOC 2012 semantic segmentation dataset.
-* Running DeepLab on Cityscapes semantic segmentation dataset.
-* Running DeepLab on ADE20K semantic segmentation dataset.
- -Models: - -* Checkpoints and frozen inference graphs.
- -Misc: - -* Please check FAQ if you have some questions before reporting the issues.
- -## Getting Help - -To get help with issues you may encounter while using the DeepLab Tensorflow -implementation, create a new question on -[StackOverflow](https://stackoverflow.com/) with the tag "tensorflow". - -Please report bugs (i.e., broken code, not usage questions) to the -tensorflow/models GitHub [issue -tracker](https://github.com/tensorflow/models/issues), prefixing the issue name -with "deeplab". - -## License - -All the codes in deeplab folder is covered by the [LICENSE](https://github.com/tensorflow/models/blob/master/LICENSE) -under tensorflow/models. Please refer to the LICENSE for details. - -## Change Logs - -### March 26, 2020 -* Supported EdgeTPU-DeepLab and EdgeTPU-DeepLab-slim on Cityscapes. -**Contributor**: Yun Long. - -### November 20, 2019 -* Supported MobileNetV3 large and small model variants on Cityscapes. -**Contributor**: Yukun Zhu. - - -### March 27, 2019 - -* Supported using different loss weights on different classes during training. -**Contributor**: Yuwei Yang. - - -### March 26, 2019 - -* Supported ResNet-v1-18. **Contributor**: Michalis Raptis. - - -### March 6, 2019 - -* Released the evaluation code (under the `evaluation` folder) for image -parsing, a.k.a. panoptic segmentation. In particular, the released code supports -evaluating the parsing results in terms of both the parsing covering and -panoptic quality metrics. **Contributors**: Maxwell Collins and Ting Liu. - - -### February 6, 2019 - -* Updated decoder module to exploit multiple low-level features with different -output_strides. - -### December 3, 2018 - -* Released the MobileNet-v2 checkpoint on ADE20K. - - -### November 19, 2018 - -* Supported NAS architecture for feature extraction. **Contributor**: Chenxi Liu. - -* Supported hard pixel mining during training. - - -### October 1, 2018 - -* Released MobileNet-v2 depth-multiplier = 0.5 COCO-pretrained checkpoints on -PASCAL VOC 2012, and Xception-65 COCO pretrained checkpoint (i.e., no PASCAL -pretrained). - - -### September 5, 2018 - -* Released Cityscapes pretrained checkpoints with found best dense prediction cell. - - -### May 26, 2018 - -* Updated ADE20K pretrained checkpoint. - - -### May 18, 2018 -* Added builders for ResNet-v1 and Xception model variants. -* Added ADE20K support, including colormap and pretrained Xception_65 checkpoint. -* Fixed a bug on using non-default depth_multiplier for MobileNet-v2. - - -### March 22, 2018 - -* Released checkpoints using MobileNet-V2 as network backbone and pretrained on -PASCAL VOC 2012 and Cityscapes. - - -### March 5, 2018 - -* First release of DeepLab in TensorFlow including deeper Xception network -backbone. Included chekcpoints that have been pretrained on PASCAL VOC 2012 -and Cityscapes. - -## References - -1. **Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs**
- Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (+ equal - contribution).
- [[link]](https://arxiv.org/abs/1412.7062). In ICLR, 2015. - -2. **DeepLab: Semantic Image Segmentation with Deep Convolutional Nets,** - **Atrous Convolution, and Fully Connected CRFs**
- Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille (+ equal - contribution).
- [[link]](http://arxiv.org/abs/1606.00915). TPAMI 2017. - -3. **Rethinking Atrous Convolution for Semantic Image Segmentation**
- Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam.
- [[link]](http://arxiv.org/abs/1706.05587). arXiv: 1706.05587, 2017. - -4. **Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation**
- Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam.
- [[link]](https://arxiv.org/abs/1802.02611). In ECCV, 2018. - -5. **ParseNet: Looking Wider to See Better**
- Wei Liu, Andrew Rabinovich, Alexander C Berg
- [[link]](https://arxiv.org/abs/1506.04579). arXiv:1506.04579, 2015. - -6. **Pyramid Scene Parsing Network**
- Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
- [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. - -7. **Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate shift**
- Sergey Ioffe, Christian Szegedy
- [[link]](https://arxiv.org/abs/1502.03167). In ICML, 2015. - -8. **MobileNetV2: Inverted Residuals and Linear Bottlenecks**
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
- [[link]](https://arxiv.org/abs/1801.04381). In CVPR, 2018. - -9. **Xception: Deep Learning with Depthwise Separable Convolutions**
- François Chollet
- [[link]](https://arxiv.org/abs/1610.02357). In CVPR, 2017. - -10. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
- Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
- [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge - Workshop, 2017. - -11. **Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems**
- M. Abadi, A. Agarwal, et al.
- [[link]](https://arxiv.org/abs/1603.04467). arXiv:1603.04467, 2016. - -12. **The Pascal Visual Object Classes Challenge – A Retrospective,**
- Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John - Winn, and Andrew Zisserma.
- [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. - -13. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
- [[link]](https://www.cityscapes-dataset.com/). In CVPR, 2016. - -14. **Deep Residual Learning for Image Recognition**
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
- [[link]](https://arxiv.org/abs/1512.03385). In CVPR, 2016. - -15. **Progressive Neural Architecture Search**
- Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy.
- [[link]](https://arxiv.org/abs/1712.00559). In ECCV, 2018. - -16. **Searching for MobileNetV3**
- Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam.
- [[link]](https://arxiv.org/abs/1905.02244). In ICCV, 2019. diff --git a/research/deeplab/__init__.py b/research/deeplab/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/common.py b/research/deeplab/common.py deleted file mode 100644 index 928f7176c377e69aa2c5b8bc676f092cf97819c9..0000000000000000000000000000000000000000 --- a/research/deeplab/common.py +++ /dev/null @@ -1,295 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Provides flags that are common to scripts. - -Common flags from train/eval/vis/export_model.py are collected in this script. -""" -import collections -import copy -import json -import tensorflow as tf - -flags = tf.app.flags - -# Flags for input preprocessing. - -flags.DEFINE_integer('min_resize_value', None, - 'Desired size of the smaller image side.') - -flags.DEFINE_integer('max_resize_value', None, - 'Maximum allowed size of the larger image side.') - -flags.DEFINE_integer('resize_factor', None, - 'Resized dimensions are multiple of factor plus one.') - -flags.DEFINE_boolean('keep_aspect_ratio', True, - 'Keep aspect ratio after resizing or not.') - -# Model dependent flags. - -flags.DEFINE_integer('logits_kernel_size', 1, - 'The kernel size for the convolutional kernel that ' - 'generates logits.') - -# When using 'mobilent_v2', we set atrous_rates = decoder_output_stride = None. -# When using 'xception_65' or 'resnet_v1' model variants, we set -# atrous_rates = [6, 12, 18] (output stride 16) and decoder_output_stride = 4. -# See core/feature_extractor.py for supported model variants. -flags.DEFINE_string('model_variant', 'mobilenet_v2', 'DeepLab model variant.') - -flags.DEFINE_multi_float('image_pyramid', None, - 'Input scales for multi-scale feature extraction.') - -flags.DEFINE_boolean('add_image_level_feature', True, - 'Add image level feature.') - -flags.DEFINE_list( - 'image_pooling_crop_size', None, - 'Image pooling crop size [height, width] used in the ASPP module. When ' - 'value is None, the model performs image pooling with "crop_size". This' - 'flag is useful when one likes to use different image pooling sizes.') - -flags.DEFINE_list( - 'image_pooling_stride', '1,1', - 'Image pooling stride [height, width] used in the ASPP image pooling. ') - -flags.DEFINE_boolean('aspp_with_batch_norm', True, - 'Use batch norm parameters for ASPP or not.') - -flags.DEFINE_boolean('aspp_with_separable_conv', True, - 'Use separable convolution for ASPP or not.') - -# Defaults to None. Set multi_grid = [1, 2, 4] when using provided -# 'resnet_v1_{50,101}_beta' checkpoints. -flags.DEFINE_multi_integer('multi_grid', None, - 'Employ a hierarchy of atrous rates for ResNet.') - -flags.DEFINE_float('depth_multiplier', 1.0, - 'Multiplier for the depth (number of channels) for all ' - 'convolution ops used in MobileNet.') - -flags.DEFINE_integer('divisible_by', None, - 'An integer that ensures the layer # channels are ' - 'divisible by this value. Used in MobileNet.') - -# For `xception_65`, use decoder_output_stride = 4. For `mobilenet_v2`, use -# decoder_output_stride = None. -flags.DEFINE_list('decoder_output_stride', None, - 'Comma-separated list of strings with the number specifying ' - 'output stride of low-level features at each network level.' - 'Current semantic segmentation implementation assumes at ' - 'most one output stride (i.e., either None or a list with ' - 'only one element.') - -flags.DEFINE_boolean('decoder_use_separable_conv', True, - 'Employ separable convolution for decoder or not.') - -flags.DEFINE_enum('merge_method', 'max', ['max', 'avg'], - 'Scheme to merge multi scale features.') - -flags.DEFINE_boolean( - 'prediction_with_upsampled_logits', True, - 'When performing prediction, there are two options: (1) bilinear ' - 'upsampling the logits followed by softmax, or (2) softmax followed by ' - 'bilinear upsampling.') - -flags.DEFINE_string( - 'dense_prediction_cell_json', - '', - 'A JSON file that specifies the dense prediction cell.') - -flags.DEFINE_integer( - 'nas_stem_output_num_conv_filters', 20, - 'Number of filters of the stem output tensor in NAS models.') - -flags.DEFINE_bool('nas_use_classification_head', False, - 'Use image classification head for NAS model variants.') - -flags.DEFINE_bool('nas_remove_os32_stride', False, - 'Remove the stride in the output stride 32 branch.') - -flags.DEFINE_bool('use_bounded_activation', False, - 'Whether or not to use bounded activations. Bounded ' - 'activations better lend themselves to quantized inference.') - -flags.DEFINE_boolean('aspp_with_concat_projection', True, - 'ASPP with concat projection.') - -flags.DEFINE_boolean('aspp_with_squeeze_and_excitation', False, - 'ASPP with squeeze and excitation.') - -flags.DEFINE_integer('aspp_convs_filters', 256, 'ASPP convolution filters.') - -flags.DEFINE_boolean('decoder_use_sum_merge', False, - 'Decoder uses simply sum merge.') - -flags.DEFINE_integer('decoder_filters', 256, 'Decoder filters.') - -flags.DEFINE_boolean('decoder_output_is_logits', False, - 'Use decoder output as logits or not.') - -flags.DEFINE_boolean('image_se_uses_qsigmoid', False, 'Use q-sigmoid.') - -flags.DEFINE_multi_float( - 'label_weights', None, - 'A list of label weights, each element represents the weight for the label ' - 'of its index, for example, label_weights = [0.1, 0.5] means the weight ' - 'for label 0 is 0.1 and the weight for label 1 is 0.5. If set as None, all ' - 'the labels have the same weight 1.0.') - -flags.DEFINE_float('batch_norm_decay', 0.9997, 'Batchnorm decay.') - -FLAGS = flags.FLAGS - -# Constants - -# Perform semantic segmentation predictions. -OUTPUT_TYPE = 'semantic' - -# Semantic segmentation item names. -LABELS_CLASS = 'labels_class' -IMAGE = 'image' -HEIGHT = 'height' -WIDTH = 'width' -IMAGE_NAME = 'image_name' -LABEL = 'label' -ORIGINAL_IMAGE = 'original_image' - -# Test set name. -TEST_SET = 'test' - - -class ModelOptions( - collections.namedtuple('ModelOptions', [ - 'outputs_to_num_classes', - 'crop_size', - 'atrous_rates', - 'output_stride', - 'preprocessed_images_dtype', - 'merge_method', - 'add_image_level_feature', - 'image_pooling_crop_size', - 'image_pooling_stride', - 'aspp_with_batch_norm', - 'aspp_with_separable_conv', - 'multi_grid', - 'decoder_output_stride', - 'decoder_use_separable_conv', - 'logits_kernel_size', - 'model_variant', - 'depth_multiplier', - 'divisible_by', - 'prediction_with_upsampled_logits', - 'dense_prediction_cell_config', - 'nas_architecture_options', - 'use_bounded_activation', - 'aspp_with_concat_projection', - 'aspp_with_squeeze_and_excitation', - 'aspp_convs_filters', - 'decoder_use_sum_merge', - 'decoder_filters', - 'decoder_output_is_logits', - 'image_se_uses_qsigmoid', - 'label_weights', - 'sync_batch_norm_method', - 'batch_norm_decay', - ])): - """Immutable class to hold model options.""" - - __slots__ = () - - def __new__(cls, - outputs_to_num_classes, - crop_size=None, - atrous_rates=None, - output_stride=8, - preprocessed_images_dtype=tf.float32): - """Constructor to set default values. - - Args: - outputs_to_num_classes: A dictionary from output type to the number of - classes. For example, for the task of semantic segmentation with 21 - semantic classes, we would have outputs_to_num_classes['semantic'] = 21. - crop_size: A tuple [crop_height, crop_width]. - atrous_rates: A list of atrous convolution rates for ASPP. - output_stride: The ratio of input to output spatial resolution. - preprocessed_images_dtype: The type after the preprocessing function. - - Returns: - A new ModelOptions instance. - """ - dense_prediction_cell_config = None - if FLAGS.dense_prediction_cell_json: - with tf.gfile.Open(FLAGS.dense_prediction_cell_json, 'r') as f: - dense_prediction_cell_config = json.load(f) - decoder_output_stride = None - if FLAGS.decoder_output_stride: - decoder_output_stride = [ - int(x) for x in FLAGS.decoder_output_stride] - if sorted(decoder_output_stride, reverse=True) != decoder_output_stride: - raise ValueError('Decoder output stride need to be sorted in the ' - 'descending order.') - image_pooling_crop_size = None - if FLAGS.image_pooling_crop_size: - image_pooling_crop_size = [int(x) for x in FLAGS.image_pooling_crop_size] - image_pooling_stride = [1, 1] - if FLAGS.image_pooling_stride: - image_pooling_stride = [int(x) for x in FLAGS.image_pooling_stride] - label_weights = FLAGS.label_weights - if label_weights is None: - label_weights = 1.0 - nas_architecture_options = { - 'nas_stem_output_num_conv_filters': ( - FLAGS.nas_stem_output_num_conv_filters), - 'nas_use_classification_head': FLAGS.nas_use_classification_head, - 'nas_remove_os32_stride': FLAGS.nas_remove_os32_stride, - } - return super(ModelOptions, cls).__new__( - cls, outputs_to_num_classes, crop_size, atrous_rates, output_stride, - preprocessed_images_dtype, - FLAGS.merge_method, - FLAGS.add_image_level_feature, - image_pooling_crop_size, - image_pooling_stride, - FLAGS.aspp_with_batch_norm, - FLAGS.aspp_with_separable_conv, - FLAGS.multi_grid, - decoder_output_stride, - FLAGS.decoder_use_separable_conv, - FLAGS.logits_kernel_size, - FLAGS.model_variant, - FLAGS.depth_multiplier, - FLAGS.divisible_by, - FLAGS.prediction_with_upsampled_logits, - dense_prediction_cell_config, - nas_architecture_options, - FLAGS.use_bounded_activation, - FLAGS.aspp_with_concat_projection, - FLAGS.aspp_with_squeeze_and_excitation, - FLAGS.aspp_convs_filters, - FLAGS.decoder_use_sum_merge, - FLAGS.decoder_filters, - FLAGS.decoder_output_is_logits, - FLAGS.image_se_uses_qsigmoid, - label_weights, - 'None', - FLAGS.batch_norm_decay) - - def __deepcopy__(self, memo): - return ModelOptions(copy.deepcopy(self.outputs_to_num_classes), - self.crop_size, - self.atrous_rates, - self.output_stride, - self.preprocessed_images_dtype) diff --git a/research/deeplab/common_test.py b/research/deeplab/common_test.py deleted file mode 100644 index 45b64e50e3bb0a574c0ec230075e6fddff3ae996..0000000000000000000000000000000000000000 --- a/research/deeplab/common_test.py +++ /dev/null @@ -1,52 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for common.py.""" -import copy - -import tensorflow as tf - -from deeplab import common - - -class CommonTest(tf.test.TestCase): - - def testOutputsToNumClasses(self): - num_classes = 21 - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) - self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], - num_classes) - - def testDeepcopy(self): - num_classes = 21 - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) - model_options_new = copy.deepcopy(model_options) - self.assertEqual((model_options_new. - outputs_to_num_classes[common.OUTPUT_TYPE]), - num_classes) - - num_classes_new = 22 - model_options_new.outputs_to_num_classes[common.OUTPUT_TYPE] = ( - num_classes_new) - self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], - num_classes) - self.assertEqual((model_options_new. - outputs_to_num_classes[common.OUTPUT_TYPE]), - num_classes_new) - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/__init__.py b/research/deeplab/core/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/core/conv2d_ws.py b/research/deeplab/core/conv2d_ws.py deleted file mode 100644 index 9aaaf33dd3c2e098d7d5e815b4918c436ee1796c..0000000000000000000000000000000000000000 --- a/research/deeplab/core/conv2d_ws.py +++ /dev/null @@ -1,369 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Augment slim.conv2d with optional Weight Standardization (WS). - -WS is a normalization method to accelerate micro-batch training. When used with -Group Normalization and trained with 1 image/GPU, WS is able to match or -outperform the performances of BN trained with large batch sizes. -[1] Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, Alan Yuille - Weight Standardization. arXiv:1903.10520 -[2] Lei Huang, Xianglong Liu, Yang Liu, Bo Lang, Dacheng Tao - Centered Weight Normalization in Accelerating Training of Deep Neural - Networks. ICCV 2017 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers - -from tensorflow.contrib.layers.python.layers import layers -from tensorflow.contrib.layers.python.layers import utils - - -class Conv2D(tf.keras.layers.Conv2D, tf.layers.Layer): - """2D convolution layer (e.g. spatial convolution over images). - - This layer creates a convolution kernel that is convolved - (actually cross-correlated) with the layer input to produce a tensor of - outputs. If `use_bias` is True (and a `bias_initializer` is provided), - a bias vector is created and added to the outputs. Finally, if - `activation` is not `None`, it is applied to the outputs as well. - """ - - def __init__(self, - filters, - kernel_size, - strides=(1, 1), - padding='valid', - data_format='channels_last', - dilation_rate=(1, 1), - activation=None, - use_bias=True, - kernel_initializer=None, - bias_initializer=tf.zeros_initializer(), - kernel_regularizer=None, - bias_regularizer=None, - use_weight_standardization=False, - activity_regularizer=None, - kernel_constraint=None, - bias_constraint=None, - trainable=True, - name=None, - **kwargs): - """Constructs the 2D convolution layer. - - Args: - filters: Integer, the dimensionality of the output space (i.e. the number - of filters in the convolution). - kernel_size: An integer or tuple/list of 2 integers, specifying the height - and width of the 2D convolution window. Can be a single integer to - specify the same value for all spatial dimensions. - strides: An integer or tuple/list of 2 integers, specifying the strides of - the convolution along the height and width. Can be a single integer to - specify the same value for all spatial dimensions. Specifying any stride - value != 1 is incompatible with specifying any `dilation_rate` value != - 1. - padding: One of `"valid"` or `"same"` (case-insensitive). - data_format: A string, one of `channels_last` (default) or - `channels_first`. The ordering of the dimensions in the inputs. - `channels_last` corresponds to inputs with shape `(batch, height, width, - channels)` while `channels_first` corresponds to inputs with shape - `(batch, channels, height, width)`. - dilation_rate: An integer or tuple/list of 2 integers, specifying the - dilation rate to use for dilated convolution. Can be a single integer to - specify the same value for all spatial dimensions. Currently, specifying - any `dilation_rate` value != 1 is incompatible with specifying any - stride value != 1. - activation: Activation function. Set it to None to maintain a linear - activation. - use_bias: Boolean, whether the layer uses a bias. - kernel_initializer: An initializer for the convolution kernel. - bias_initializer: An initializer for the bias vector. If None, the default - initializer will be used. - kernel_regularizer: Optional regularizer for the convolution kernel. - bias_regularizer: Optional regularizer for the bias vector. - use_weight_standardization: Boolean, whether the layer uses weight - standardization. - activity_regularizer: Optional regularizer function for the output. - kernel_constraint: Optional projection function to be applied to the - kernel after being updated by an `Optimizer` (e.g. used to implement - norm constraints or value constraints for layer weights). The function - must take as input the unprojected variable and must return the - projected variable (which must have the same shape). Constraints are not - safe to use when doing asynchronous distributed training. - bias_constraint: Optional projection function to be applied to the bias - after being updated by an `Optimizer`. - trainable: Boolean, if `True` also add variables to the graph collection - `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). - name: A string, the name of the layer. - **kwargs: Arbitrary keyword arguments passed to tf.keras.layers.Conv2D - """ - - super(Conv2D, self).__init__( - filters=filters, - kernel_size=kernel_size, - strides=strides, - padding=padding, - data_format=data_format, - dilation_rate=dilation_rate, - activation=activation, - use_bias=use_bias, - kernel_initializer=kernel_initializer, - bias_initializer=bias_initializer, - kernel_regularizer=kernel_regularizer, - bias_regularizer=bias_regularizer, - activity_regularizer=activity_regularizer, - kernel_constraint=kernel_constraint, - bias_constraint=bias_constraint, - trainable=trainable, - name=name, - **kwargs) - self.use_weight_standardization = use_weight_standardization - - def call(self, inputs): - if self.use_weight_standardization: - mean, var = tf.nn.moments(self.kernel, [0, 1, 2], keep_dims=True) - kernel = (self.kernel - mean) / tf.sqrt(var + 1e-5) - outputs = self._convolution_op(inputs, kernel) - else: - outputs = self._convolution_op(inputs, self.kernel) - - if self.use_bias: - if self.data_format == 'channels_first': - if self.rank == 1: - # tf.nn.bias_add does not accept a 1D input tensor. - bias = tf.reshape(self.bias, (1, self.filters, 1)) - outputs += bias - else: - outputs = tf.nn.bias_add(outputs, self.bias, data_format='NCHW') - else: - outputs = tf.nn.bias_add(outputs, self.bias, data_format='NHWC') - - if self.activation is not None: - return self.activation(outputs) - return outputs - - -@contrib_framework.add_arg_scope -def conv2d(inputs, - num_outputs, - kernel_size, - stride=1, - padding='SAME', - data_format=None, - rate=1, - activation_fn=tf.nn.relu, - normalizer_fn=None, - normalizer_params=None, - weights_initializer=contrib_layers.xavier_initializer(), - weights_regularizer=None, - biases_initializer=tf.zeros_initializer(), - biases_regularizer=None, - use_weight_standardization=False, - reuse=None, - variables_collections=None, - outputs_collections=None, - trainable=True, - scope=None): - """Adds a 2D convolution followed by an optional batch_norm layer. - - `convolution` creates a variable called `weights`, representing the - convolutional kernel, that is convolved (actually cross-correlated) with the - `inputs` to produce a `Tensor` of activations. If a `normalizer_fn` is - provided (such as `batch_norm`), it is then applied. Otherwise, if - `normalizer_fn` is None and a `biases_initializer` is provided then a `biases` - variable would be created and added the activations. Finally, if - `activation_fn` is not `None`, it is applied to the activations as well. - - Performs atrous convolution with input stride/dilation rate equal to `rate` - if a value > 1 for any dimension of `rate` is specified. In this case - `stride` values != 1 are not supported. - - Args: - inputs: A Tensor of rank N+2 of shape `[batch_size] + input_spatial_shape + - [in_channels]` if data_format does not start with "NC" (default), or - `[batch_size, in_channels] + input_spatial_shape` if data_format starts - with "NC". - num_outputs: Integer, the number of output filters. - kernel_size: A sequence of N positive integers specifying the spatial - dimensions of the filters. Can be a single integer to specify the same - value for all spatial dimensions. - stride: A sequence of N positive integers specifying the stride at which to - compute output. Can be a single integer to specify the same value for all - spatial dimensions. Specifying any `stride` value != 1 is incompatible - with specifying any `rate` value != 1. - padding: One of `"VALID"` or `"SAME"`. - data_format: A string or None. Specifies whether the channel dimension of - the `input` and output is the last dimension (default, or if `data_format` - does not start with "NC"), or the second dimension (if `data_format` - starts with "NC"). For N=1, the valid values are "NWC" (default) and - "NCW". For N=2, the valid values are "NHWC" (default) and "NCHW". For - N=3, the valid values are "NDHWC" (default) and "NCDHW". - rate: A sequence of N positive integers specifying the dilation rate to use - for atrous convolution. Can be a single integer to specify the same value - for all spatial dimensions. Specifying any `rate` value != 1 is - incompatible with specifying any `stride` value != 1. - activation_fn: Activation function. The default value is a ReLU function. - Explicitly set it to None to skip it and maintain a linear activation. - normalizer_fn: Normalization function to use instead of `biases`. If - `normalizer_fn` is provided then `biases_initializer` and - `biases_regularizer` are ignored and `biases` are not created nor added. - default set to None for no normalizer function - normalizer_params: Normalization function parameters. - weights_initializer: An initializer for the weights. - weights_regularizer: Optional regularizer for the weights. - biases_initializer: An initializer for the biases. If None skip biases. - biases_regularizer: Optional regularizer for the biases. - use_weight_standardization: Boolean, whether the layer uses weight - standardization. - reuse: Whether or not the layer and its variables should be reused. To be - able to reuse the layer scope must be given. - variables_collections: Optional list of collections for all the variables or - a dictionary containing a different list of collection per variable. - outputs_collections: Collection to add the outputs. - trainable: If `True` also add variables to the graph collection - `GraphKeys.TRAINABLE_VARIABLES` (see tf.Variable). - scope: Optional scope for `variable_scope`. - - Returns: - A tensor representing the output of the operation. - - Raises: - ValueError: If `data_format` is invalid. - ValueError: Both 'rate' and `stride` are not uniformly 1. - """ - if data_format not in [None, 'NWC', 'NCW', 'NHWC', 'NCHW', 'NDHWC', 'NCDHW']: - raise ValueError('Invalid data_format: %r' % (data_format,)) - - # pylint: disable=protected-access - layer_variable_getter = layers._build_variable_getter({ - 'bias': 'biases', - 'kernel': 'weights' - }) - # pylint: enable=protected-access - with tf.variable_scope( - scope, 'Conv', [inputs], reuse=reuse, - custom_getter=layer_variable_getter) as sc: - inputs = tf.convert_to_tensor(inputs) - input_rank = inputs.get_shape().ndims - - if input_rank != 4: - raise ValueError('Convolution expects input with rank %d, got %d' % - (4, input_rank)) - - data_format = ('channels_first' if data_format and - data_format.startswith('NC') else 'channels_last') - layer = Conv2D( - filters=num_outputs, - kernel_size=kernel_size, - strides=stride, - padding=padding, - data_format=data_format, - dilation_rate=rate, - activation=None, - use_bias=not normalizer_fn and biases_initializer, - kernel_initializer=weights_initializer, - bias_initializer=biases_initializer, - kernel_regularizer=weights_regularizer, - bias_regularizer=biases_regularizer, - use_weight_standardization=use_weight_standardization, - activity_regularizer=None, - trainable=trainable, - name=sc.name, - dtype=inputs.dtype.base_dtype, - _scope=sc, - _reuse=reuse) - outputs = layer.apply(inputs) - - # Add variables to collections. - # pylint: disable=protected-access - layers._add_variable_to_collections(layer.kernel, variables_collections, - 'weights') - if layer.use_bias: - layers._add_variable_to_collections(layer.bias, variables_collections, - 'biases') - # pylint: enable=protected-access - if normalizer_fn is not None: - normalizer_params = normalizer_params or {} - outputs = normalizer_fn(outputs, **normalizer_params) - - if activation_fn is not None: - outputs = activation_fn(outputs) - return utils.collect_named_outputs(outputs_collections, sc.name, outputs) - - -def conv2d_same(inputs, num_outputs, kernel_size, stride, rate=1, scope=None): - """Strided 2-D convolution with 'SAME' padding. - - When stride > 1, then we do explicit zero-padding, followed by conv2d with - 'VALID' padding. - - Note that - - net = conv2d_same(inputs, num_outputs, 3, stride=stride) - - is equivalent to - - net = conv2d(inputs, num_outputs, 3, stride=1, padding='SAME') - net = subsample(net, factor=stride) - - whereas - - net = conv2d(inputs, num_outputs, 3, stride=stride, padding='SAME') - - is different when the input's height or width is even, which is why we add the - current function. For more details, see ResnetUtilsTest.testConv2DSameEven(). - - Args: - inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. - num_outputs: An integer, the number of output filters. - kernel_size: An int with the kernel_size of the filters. - stride: An integer, the output stride. - rate: An integer, rate for atrous convolution. - scope: Scope. - - Returns: - output: A 4-D tensor of size [batch, height_out, width_out, channels] with - the convolution output. - """ - if stride == 1: - return conv2d( - inputs, - num_outputs, - kernel_size, - stride=1, - rate=rate, - padding='SAME', - scope=scope) - else: - kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) - pad_total = kernel_size_effective - 1 - pad_beg = pad_total // 2 - pad_end = pad_total - pad_beg - inputs = tf.pad(inputs, - [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]]) - return conv2d( - inputs, - num_outputs, - kernel_size, - stride=stride, - rate=rate, - padding='VALID', - scope=scope) diff --git a/research/deeplab/core/conv2d_ws_test.py b/research/deeplab/core/conv2d_ws_test.py deleted file mode 100644 index b6bea85ee034779ff5bf87b88cd912aa8dc863f2..0000000000000000000000000000000000000000 --- a/research/deeplab/core/conv2d_ws_test.py +++ /dev/null @@ -1,420 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for conv2d_ws.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers -from deeplab.core import conv2d_ws - - -class ConvolutionTest(tf.test.TestCase): - - def testInvalidShape(self): - with self.cached_session(): - images_3d = tf.random_uniform((5, 6, 7, 9, 3), seed=1) - with self.assertRaisesRegexp( - ValueError, 'Convolution expects input with rank 4, got 5'): - conv2d_ws.conv2d(images_3d, 32, 3) - - def testInvalidDataFormat(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.assertRaisesRegexp(ValueError, 'data_format'): - conv2d_ws.conv2d(images, 32, 3, data_format='CHWN') - - def testCreateConv(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, height, width, 4)).astype(np.float32) - output = conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateConvWithWS(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, height, width, 4)).astype(np.float32) - output = conv2d_ws.conv2d( - images, 32, [3, 3], use_weight_standardization=True) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateConvNCHW(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, 4, height, width)).astype(np.float32) - output = conv2d_ws.conv2d(images, 32, [3, 3], data_format='NCHW') - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, 32, height, width]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateSquareConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, 3) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - - def testCreateConvWithTensorShape(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, images.get_shape()[1:3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - - def testCreateFullyConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - output = conv2d_ws.conv2d( - images, 64, images.get_shape()[1:3], padding='VALID') - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 64]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [64]) - - def testFullyConvWithCustomGetter(self): - height, width = 7, 9 - with self.cached_session(): - called = [0] - - def custom_getter(getter, *args, **kwargs): - called[0] += 1 - return getter(*args, **kwargs) - - with tf.variable_scope('test', custom_getter=custom_getter): - images = tf.random_uniform((5, height, width, 32), seed=1) - conv2d_ws.conv2d(images, 64, images.get_shape()[1:3]) - self.assertEqual(called[0], 2) # Custom getter called twice. - - def testCreateVerticalConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 4), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 1]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 1, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateHorizontalConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 4), seed=1) - output = conv2d_ws.conv2d(images, 32, [1, 3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [1, 3, 4, 32]) - - def testCreateConvWithStride(self): - height, width = 6, 8 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], stride=2) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), - [5, height / 2, width / 2, 32]) - - def testCreateConvCreatesWeightsAndBiasesVars(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.cached_session(): - self.assertFalse(contrib_framework.get_variables('conv1/weights')) - self.assertFalse(contrib_framework.get_variables('conv1/biases')) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertTrue(contrib_framework.get_variables('conv1/weights')) - self.assertTrue(contrib_framework.get_variables('conv1/biases')) - - def testCreateConvWithScope(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(output.op.name, 'conv1/Relu') - - def testCreateConvWithCollection(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with tf.name_scope('fe'): - conv = conv2d_ws.conv2d( - images, 32, [3, 3], outputs_collections='outputs', scope='Conv') - output_collected = tf.get_collection('outputs')[0] - self.assertEqual(output_collected.aliases, ['Conv']) - self.assertEqual(output_collected, conv) - - def testCreateConvWithoutActivation(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], activation_fn=None) - self.assertEqual(output.op.name, 'Conv/BiasAdd') - - def testCreateConvValid(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], padding='VALID') - self.assertListEqual(output.get_shape().as_list(), [5, 5, 7, 32]) - - def testCreateConvWithWD(self): - height, width = 7, 9 - weight_decay = 0.01 - with self.cached_session() as sess: - images = tf.random_uniform((5, height, width, 3), seed=1) - regularizer = contrib_layers.l2_regularizer(weight_decay) - conv2d_ws.conv2d(images, 32, [3, 3], weights_regularizer=regularizer) - l2_loss = tf.nn.l2_loss( - contrib_framework.get_variables_by_name('weights')[0]) - wd = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)[0] - self.assertEqual(wd.op.name, 'Conv/kernel/Regularizer/l2_regularizer') - sess.run(tf.global_variables_initializer()) - self.assertAlmostEqual(sess.run(wd), weight_decay * l2_loss.eval()) - - def testCreateConvNoRegularizers(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual( - tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES), []) - - def testReuseVars(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(len(contrib_framework.get_variables()), 2) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 2) - - def testNonReuseVars(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 2) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 4) - - def testReuseConvWithWD(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - weight_decay = contrib_layers.l2_regularizer(0.01) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - weights_regularizer=weight_decay): - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(len(contrib_framework.get_variables()), 2) - self.assertEqual( - len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 2) - self.assertEqual( - len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1) - - def testConvWithBatchNorm(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - normalizer_fn=contrib_layers.batch_norm, - normalizer_params={'decay': 0.9}): - net = conv2d_ws.conv2d(images, 32, [3, 3]) - net = conv2d_ws.conv2d(net, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 8) - self.assertEqual( - len(contrib_framework.get_variables('Conv/BatchNorm')), 3) - self.assertEqual( - len(contrib_framework.get_variables('Conv_1/BatchNorm')), 3) - - def testReuseConvWithBatchNorm(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - normalizer_fn=contrib_layers.batch_norm, - normalizer_params={'decay': 0.9}): - net = conv2d_ws.conv2d(images, 32, [3, 3], scope='Conv') - net = conv2d_ws.conv2d(net, 32, [3, 3], scope='Conv', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 4) - self.assertEqual( - len(contrib_framework.get_variables('Conv/BatchNorm')), 3) - self.assertEqual( - len(contrib_framework.get_variables('Conv_1/BatchNorm')), 0) - - def testCreateConvCreatesWeightsAndBiasesVarsWithRateTwo(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.cached_session(): - self.assertFalse(contrib_framework.get_variables('conv1/weights')) - self.assertFalse(contrib_framework.get_variables('conv1/biases')) - conv2d_ws.conv2d(images, 32, [3, 3], rate=2, scope='conv1') - self.assertTrue(contrib_framework.get_variables('conv1/weights')) - self.assertTrue(contrib_framework.get_variables('conv1/biases')) - - def testOutputSizeWithRateTwoSamePadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 10, 12, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='SAME') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testOutputSizeWithRateTwoValidPadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 6, 8, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testOutputSizeWithRateTwoThreeValidPadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 6, 6, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=[2, 3], padding='VALID') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testDynamicOutputSizeWithRateOneValidPadding(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [None, None, None, num_filters] - expected_size_dynamic = [5, 7, 9, num_filters] - - with self.cached_session(): - images = tf.placeholder(np.float32, [None, None, None, input_size[3]]) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=1, padding='VALID') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testDynamicOutputSizeWithRateOneValidPaddingNCHW(self): - if tf.test.is_gpu_available(cuda_only=True): - num_filters = 32 - input_size = [5, 3, 9, 11] - expected_size = [None, num_filters, None, None] - expected_size_dynamic = [5, num_filters, 7, 9] - - with self.session(use_gpu=True): - images = tf.placeholder(np.float32, [None, input_size[1], None, None]) - output = conv2d_ws.conv2d( - images, - num_filters, [3, 3], - rate=1, - padding='VALID', - data_format='NCHW') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testDynamicOutputSizeWithRateTwoValidPadding(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [None, None, None, num_filters] - expected_size_dynamic = [5, 5, 7, num_filters] - - with self.cached_session(): - images = tf.placeholder(np.float32, [None, None, None, input_size[3]]) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testWithScope(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [5, 5, 7, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID', scope='conv7') - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'conv7/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testWithScopeWithoutActivation(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [5, 5, 7, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, - num_filters, [3, 3], - rate=2, - padding='VALID', - activation_fn=None, - scope='conv7') - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'conv7/BiasAdd') - self.assertListEqual(list(output.eval().shape), expected_size) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/dense_prediction_cell.py b/research/deeplab/core/dense_prediction_cell.py deleted file mode 100644 index 8e32f8e227f0841d51df780618523a53c5eb4ae3..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell.py +++ /dev/null @@ -1,290 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Dense Prediction Cell class that can be evolved in semantic segmentation. - -DensePredictionCell is used as a `layer` in semantic segmentation whose -architecture is determined by the `config`, a dictionary specifying -the architecture. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import utils - -slim = contrib_slim - -# Local constants. -_META_ARCHITECTURE_SCOPE = 'meta_architecture' -_CONCAT_PROJECTION_SCOPE = 'concat_projection' -_OP = 'op' -_CONV = 'conv' -_PYRAMID_POOLING = 'pyramid_pooling' -_KERNEL = 'kernel' -_RATE = 'rate' -_GRID_SIZE = 'grid_size' -_TARGET_SIZE = 'target_size' -_INPUT = 'input' - - -def dense_prediction_cell_hparams(): - """DensePredictionCell HParams. - - Returns: - A dictionary of hyper-parameters used for dense prediction cell with keys: - - reduction_size: Integer, the number of output filters for each operation - inside the cell. - - dropout_on_concat_features: Boolean, apply dropout on the concatenated - features or not. - - dropout_on_projection_features: Boolean, apply dropout on the projection - features or not. - - dropout_keep_prob: Float, when `dropout_on_concat_features' or - `dropout_on_projection_features' is True, the `keep_prob` value used - in the dropout operation. - - concat_channels: Integer, the concatenated features will be - channel-reduced to `concat_channels` channels. - - conv_rate_multiplier: Integer, used to multiply the convolution rates. - This is useful in the case when the output_stride is changed from 16 - to 8, we need to double the convolution rates correspondingly. - """ - return { - 'reduction_size': 256, - 'dropout_on_concat_features': True, - 'dropout_on_projection_features': False, - 'dropout_keep_prob': 0.9, - 'concat_channels': 256, - 'conv_rate_multiplier': 1, - } - - -class DensePredictionCell(object): - """DensePredictionCell class used as a 'layer' in semantic segmentation.""" - - def __init__(self, config, hparams=None): - """Initializes the dense prediction cell. - - Args: - config: A dictionary storing the architecture of a dense prediction cell. - hparams: A dictionary of hyper-parameters, provided by users. This - dictionary will be used to update the default dictionary returned by - dense_prediction_cell_hparams(). - - Raises: - ValueError: If `conv_rate_multiplier` has value < 1. - """ - self.hparams = dense_prediction_cell_hparams() - if hparams is not None: - self.hparams.update(hparams) - self.config = config - - # Check values in hparams are valid or not. - if self.hparams['conv_rate_multiplier'] < 1: - raise ValueError('conv_rate_multiplier cannot have value < 1.') - - def _get_pyramid_pooling_arguments( - self, crop_size, output_stride, image_grid, image_pooling_crop_size=None): - """Gets arguments for pyramid pooling. - - Args: - crop_size: A list of two integers, [crop_height, crop_width] specifying - whole patch crop size. - output_stride: Integer, output stride value for extracted features. - image_grid: A list of two integers, [image_grid_height, image_grid_width], - specifying the grid size of how the pyramid pooling will be performed. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - - Returns: - A list of (resize_value, pooled_kernel) - """ - resize_height = utils.scale_dimension(crop_size[0], 1. / output_stride) - resize_width = utils.scale_dimension(crop_size[1], 1. / output_stride) - # If image_pooling_crop_size is not specified, use crop_size. - if image_pooling_crop_size is None: - image_pooling_crop_size = crop_size - pooled_height = utils.scale_dimension( - image_pooling_crop_size[0], 1. / (output_stride * image_grid[0])) - pooled_width = utils.scale_dimension( - image_pooling_crop_size[1], 1. / (output_stride * image_grid[1])) - return ([resize_height, resize_width], [pooled_height, pooled_width]) - - def _parse_operation(self, config, crop_size, output_stride, - image_pooling_crop_size=None): - """Parses one operation. - - When 'operation' is 'pyramid_pooling', we compute the required - hyper-parameters and save in config. - - Args: - config: A dictionary storing required hyper-parameters for one - operation. - crop_size: A list of two integers, [crop_height, crop_width] specifying - whole patch crop size. - output_stride: Integer, output stride value for extracted features. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - - Returns: - A dictionary stores the related information for the operation. - """ - if config[_OP] == _PYRAMID_POOLING: - (config[_TARGET_SIZE], - config[_KERNEL]) = self._get_pyramid_pooling_arguments( - crop_size=crop_size, - output_stride=output_stride, - image_grid=config[_GRID_SIZE], - image_pooling_crop_size=image_pooling_crop_size) - - return config - - def build_cell(self, - features, - output_stride=16, - crop_size=None, - image_pooling_crop_size=None, - weight_decay=0.00004, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - scope=None): - """Builds the dense prediction cell based on the config. - - Args: - features: Input feature map of size [batch, height, width, channels]. - output_stride: Int, output stride at which the features were extracted. - crop_size: A list [crop_height, crop_width], determining the input - features resolution. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - weight_decay: Float, the weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Boolean, is training or not. - fine_tune_batch_norm: Boolean, fine-tuning batch norm parameters or not. - scope: Optional string, specifying the variable scope. - - Returns: - Features after passing through the constructed dense prediction cell with - shape = [batch, height, width, channels] where channels are determined - by `reduction_size` returned by dense_prediction_cell_hparams(). - - Raises: - ValueError: Use Convolution with kernel size not equal to 1x1 or 3x3 or - the operation is not recognized. - """ - batch_norm_params = { - 'is_training': is_training and fine_tune_batch_norm, - 'decay': 0.9997, - 'epsilon': 1e-5, - 'scale': True, - } - hparams = self.hparams - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=tf.nn.relu, - normalizer_fn=slim.batch_norm, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([slim.batch_norm], **batch_norm_params): - with tf.variable_scope(scope, _META_ARCHITECTURE_SCOPE, [features]): - depth = hparams['reduction_size'] - branch_logits = [] - for i, current_config in enumerate(self.config): - scope = 'branch%d' % i - current_config = self._parse_operation( - config=current_config, - crop_size=crop_size, - output_stride=output_stride, - image_pooling_crop_size=image_pooling_crop_size) - tf.logging.info(current_config) - if current_config[_INPUT] < 0: - operation_input = features - else: - operation_input = branch_logits[current_config[_INPUT]] - if current_config[_OP] == _CONV: - if current_config[_KERNEL] == [1, 1] or current_config[ - _KERNEL] == 1: - branch_logits.append( - slim.conv2d(operation_input, depth, 1, scope=scope)) - else: - conv_rate = [r * hparams['conv_rate_multiplier'] - for r in current_config[_RATE]] - branch_logits.append( - utils.split_separable_conv2d( - operation_input, - filters=depth, - kernel_size=current_config[_KERNEL], - rate=conv_rate, - weight_decay=weight_decay, - scope=scope)) - elif current_config[_OP] == _PYRAMID_POOLING: - pooled_features = slim.avg_pool2d( - operation_input, - kernel_size=current_config[_KERNEL], - stride=[1, 1], - padding='VALID') - pooled_features = slim.conv2d( - pooled_features, - depth, - 1, - scope=scope) - pooled_features = tf.image.resize_bilinear( - pooled_features, - current_config[_TARGET_SIZE], - align_corners=True) - # Set shape for resize_height/resize_width if they are not Tensor. - resize_height = current_config[_TARGET_SIZE][0] - resize_width = current_config[_TARGET_SIZE][1] - if isinstance(resize_height, tf.Tensor): - resize_height = None - if isinstance(resize_width, tf.Tensor): - resize_width = None - pooled_features.set_shape( - [None, resize_height, resize_width, depth]) - branch_logits.append(pooled_features) - else: - raise ValueError('Unrecognized operation.') - # Merge branch logits. - concat_logits = tf.concat(branch_logits, 3) - if self.hparams['dropout_on_concat_features']: - concat_logits = slim.dropout( - concat_logits, - keep_prob=self.hparams['dropout_keep_prob'], - is_training=is_training, - scope=_CONCAT_PROJECTION_SCOPE + '_dropout') - concat_logits = slim.conv2d(concat_logits, - self.hparams['concat_channels'], - 1, - scope=_CONCAT_PROJECTION_SCOPE) - if self.hparams['dropout_on_projection_features']: - concat_logits = slim.dropout( - concat_logits, - keep_prob=self.hparams['dropout_keep_prob'], - is_training=is_training, - scope=_CONCAT_PROJECTION_SCOPE + '_dropout') - return concat_logits diff --git a/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json b/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json deleted file mode 100644 index 12b093d07d1a696258cae7eaf4d793978433a69f..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json +++ /dev/null @@ -1 +0,0 @@ -[{"kernel": 3, "rate": [1, 6], "op": "conv", "input": -1}, {"kernel": 3, "rate": [18, 15], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 3], "op": "conv", "input": 1}, {"kernel": 3, "rate": [1, 1], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 21], "op": "conv", "input": 0}] \ No newline at end of file diff --git a/research/deeplab/core/dense_prediction_cell_test.py b/research/deeplab/core/dense_prediction_cell_test.py deleted file mode 100644 index 1396a73626d90c5da1db3b187c5a927a0c9eeb11..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell_test.py +++ /dev/null @@ -1,136 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for dense_prediction_cell.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf - -from deeplab.core import dense_prediction_cell - - -class DensePredictionCellTest(tf.test.TestCase): - - def setUp(self): - self.segmentation_layer = dense_prediction_cell.DensePredictionCell( - config=[ - { - dense_prediction_cell._INPUT: -1, - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: 1, - }, - { - dense_prediction_cell._INPUT: 0, - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: 3, - dense_prediction_cell._RATE: [1, 3], - }, - { - dense_prediction_cell._INPUT: 1, - dense_prediction_cell._OP: ( - dense_prediction_cell._PYRAMID_POOLING), - dense_prediction_cell._GRID_SIZE: [1, 2], - }, - ], - hparams={'conv_rate_multiplier': 2}) - - def testPyramidPoolingArguments(self): - features_size, pooled_kernel = ( - self.segmentation_layer._get_pyramid_pooling_arguments( - crop_size=[513, 513], - output_stride=16, - image_grid=[4, 4])) - self.assertListEqual(features_size, [33, 33]) - self.assertListEqual(pooled_kernel, [9, 9]) - - def testPyramidPoolingArgumentsWithImageGrid1x1(self): - features_size, pooled_kernel = ( - self.segmentation_layer._get_pyramid_pooling_arguments( - crop_size=[257, 257], - output_stride=16, - image_grid=[1, 1])) - self.assertListEqual(features_size, [17, 17]) - self.assertListEqual(pooled_kernel, [17, 17]) - - def testParseOperationStringWithConv1x1(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: [1, 1], - }, - crop_size=[513, 513], output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._CONV) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [1, 1]) - - def testParseOperationStringWithConv3x3(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: [3, 3], - dense_prediction_cell._RATE: [9, 6], - }, - crop_size=[513, 513], output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._CONV) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [3, 3]) - self.assertEqual(operation[dense_prediction_cell._RATE], [9, 6]) - - def testParseOperationStringWithPyramidPooling2x2(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._PYRAMID_POOLING, - dense_prediction_cell._GRID_SIZE: [2, 2], - }, - crop_size=[513, 513], - output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._PYRAMID_POOLING) - # The feature maps of size [33, 33] should be covered by 2x2 kernels with - # size [17, 17]. - self.assertListEqual( - operation[dense_prediction_cell._TARGET_SIZE], [33, 33]) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [17, 17]) - - def testBuildCell(self): - with self.test_session(graph=tf.Graph()) as sess: - features = tf.random_normal([2, 33, 33, 5]) - concat_logits = self.segmentation_layer.build_cell( - features, - output_stride=8, - crop_size=[257, 257]) - sess.run(tf.global_variables_initializer()) - concat_logits = sess.run(concat_logits) - self.assertTrue(concat_logits.any()) - - def testBuildCellWithImagePoolingCropSize(self): - with self.test_session(graph=tf.Graph()) as sess: - features = tf.random_normal([2, 33, 33, 5]) - concat_logits = self.segmentation_layer.build_cell( - features, - output_stride=8, - crop_size=[257, 257], - image_pooling_crop_size=[129, 129]) - sess.run(tf.global_variables_initializer()) - concat_logits = sess.run(concat_logits) - self.assertTrue(concat_logits.any()) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/feature_extractor.py b/research/deeplab/core/feature_extractor.py deleted file mode 100644 index 553bd9b6a7393dd7f3e0ebce80302919215a9bfe..0000000000000000000000000000000000000000 --- a/research/deeplab/core/feature_extractor.py +++ /dev/null @@ -1,711 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Extracts features for different models.""" -import copy -import functools - -import tensorflow.compat.v1 as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import nas_network -from deeplab.core import resnet_v1_beta -from deeplab.core import xception -from nets.mobilenet import conv_blocks -from nets.mobilenet import mobilenet -from nets.mobilenet import mobilenet_v2 -from nets.mobilenet import mobilenet_v3 - -slim = contrib_slim - -# Default end point for MobileNetv2 (one-based indexing). -_MOBILENET_V2_FINAL_ENDPOINT = 'layer_18' -# Default end point for MobileNetv3. -_MOBILENET_V3_LARGE_FINAL_ENDPOINT = 'layer_17' -_MOBILENET_V3_SMALL_FINAL_ENDPOINT = 'layer_13' -# Default end point for EdgeTPU Mobilenet. -_MOBILENET_EDGETPU = 'layer_24' - - -def _mobilenet_v2(net, - depth_multiplier, - output_stride, - conv_defs=None, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Auxiliary function to add support for 'reuse' to mobilenet_v2. - - Args: - net: Input tensor of shape [batch_size, height, width, channels]. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops. The value must be greater than zero. Typical - usage will be to set this value in (0, 1) to reduce the number of - parameters or computation cost of the model. - output_stride: An integer that specifies the requested ratio of input to - output spatial resolution. If not None, then we invoke atrous convolution - if necessary to prevent the network from reducing the spatial resolution - of the activation maps. Allowed values are 8 (accurate fully convolutional - mode), 16 (fast fully convolutional mode), 32 (classification mode). - conv_defs: MobileNet con def. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - reuse: Reuse model variables. - scope: Optional variable scope. - final_endpoint: The endpoint to construct the network up to. - - Returns: - Features extracted by MobileNetv2. - """ - if divisible_by is None: - divisible_by = 8 if depth_multiplier == 1.0 else 1 - if conv_defs is None: - conv_defs = mobilenet_v2.V2_DEF - with tf.variable_scope( - scope, 'MobilenetV2', [net], reuse=reuse) as scope: - return mobilenet_v2.mobilenet_base( - net, - conv_defs=conv_defs, - depth_multiplier=depth_multiplier, - min_depth=8 if depth_multiplier == 1.0 else 1, - divisible_by=divisible_by, - final_endpoint=final_endpoint or _MOBILENET_V2_FINAL_ENDPOINT, - output_stride=output_stride, - scope=scope) - - -def _mobilenet_v3(net, - depth_multiplier, - output_stride, - conv_defs=None, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Auxiliary function to build mobilenet v3. - - Args: - net: Input tensor of shape [batch_size, height, width, channels]. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops. The value must be greater than zero. Typical - usage will be to set this value in (0, 1) to reduce the number of - parameters or computation cost of the model. - output_stride: An integer that specifies the requested ratio of input to - output spatial resolution. If not None, then we invoke atrous convolution - if necessary to prevent the network from reducing the spatial resolution - of the activation maps. Allowed values are 8 (accurate fully convolutional - mode), 16 (fast fully convolutional mode), 32 (classification mode). - conv_defs: A list of ConvDef namedtuples specifying the net architecture. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - reuse: Reuse model variables. - scope: Optional variable scope. - final_endpoint: The endpoint to construct the network up to. - - Returns: - net: The output tensor. - end_points: A set of activations for external use. - - Raises: - ValueError: If conv_defs or final_endpoint is not specified. - """ - del divisible_by - with tf.variable_scope( - scope, 'MobilenetV3', [net], reuse=reuse) as scope: - if conv_defs is None: - raise ValueError('conv_defs must be specified for mobilenet v3.') - if final_endpoint is None: - raise ValueError('Final endpoint must be specified for mobilenet v3.') - net, end_points = mobilenet_v3.mobilenet_base( - net, - depth_multiplier=depth_multiplier, - conv_defs=conv_defs, - output_stride=output_stride, - final_endpoint=final_endpoint, - scope=scope) - - return net, end_points - - -def mobilenet_v3_large_seg(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Final mobilenet v3 large model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_LARGE) - - # Reduce the filters by a factor of 2 in the last block. - for layer, expansion in [(13, 336), (14, 480), (15, 480), (16, None)]: - conv_defs['spec'][layer].params['num_outputs'] /= 2 - # Update expansion size - if expansion is not None: - factor = expansion / conv_defs['spec'][layer - 1].params['num_outputs'] - conv_defs['spec'][layer].params[ - 'expansion_size'] = mobilenet_v3.expand_input(factor) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, - final_endpoint=_MOBILENET_V3_LARGE_FINAL_ENDPOINT) - - -def mobilenet_edgetpu(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """EdgeTPU version of mobilenet model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_EDGETPU) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, # the scope is 'MobilenetEdgeTPU' - final_endpoint=_MOBILENET_EDGETPU) - - -def mobilenet_v3_small_seg(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Final mobilenet v3 small model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_SMALL) - - # Reduce the filters by a factor of 2 in the last block. - for layer, expansion in [(9, 144), (10, 288), (11, 288), (12, None)]: - conv_defs['spec'][layer].params['num_outputs'] /= 2 - # Update expansion size - if expansion is not None: - factor = expansion / conv_defs['spec'][layer - 1].params['num_outputs'] - conv_defs['spec'][layer].params[ - 'expansion_size'] = mobilenet_v3.expand_input(factor) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, - final_endpoint=_MOBILENET_V3_SMALL_FINAL_ENDPOINT) - - -# A map from network name to network function. -networks_map = { - 'mobilenet_v2': _mobilenet_v2, - 'mobilenet_edgetpu': mobilenet_edgetpu, - 'mobilenet_v3_large_seg': mobilenet_v3_large_seg, - 'mobilenet_v3_small_seg': mobilenet_v3_small_seg, - 'resnet_v1_18': resnet_v1_beta.resnet_v1_18, - 'resnet_v1_18_beta': resnet_v1_beta.resnet_v1_18_beta, - 'resnet_v1_50': resnet_v1_beta.resnet_v1_50, - 'resnet_v1_50_beta': resnet_v1_beta.resnet_v1_50_beta, - 'resnet_v1_101': resnet_v1_beta.resnet_v1_101, - 'resnet_v1_101_beta': resnet_v1_beta.resnet_v1_101_beta, - 'xception_41': xception.xception_41, - 'xception_65': xception.xception_65, - 'xception_71': xception.xception_71, - 'nas_pnasnet': nas_network.pnasnet, - 'nas_hnasnet': nas_network.hnasnet, -} - - -def mobilenet_v2_arg_scope(is_training=True, - weight_decay=0.00004, - stddev=0.09, - activation=tf.nn.relu6, - bn_decay=0.997, - bn_epsilon=None, - bn_renorm=None): - """Defines the default MobilenetV2 arg scope. - - Args: - is_training: Whether or not we're training the model. If this is set to None - is_training parameter in batch_norm is not set. Please note that this also - sets the is_training parameter in dropout to None. - weight_decay: The weight decay to use for regularizing the model. - stddev: Standard deviation for initialization, if negative uses xavier. - activation: If True, a modified activation is used (initialized ~ReLU6). - bn_decay: decay for the batch norm moving averages. - bn_epsilon: batch normalization epsilon. - bn_renorm: whether to use batchnorm renormalization - - Returns: - An `arg_scope` to use for the mobilenet v1 model. - """ - batch_norm_params = { - 'center': True, - 'scale': True, - 'decay': bn_decay, - } - if bn_epsilon is not None: - batch_norm_params['epsilon'] = bn_epsilon - if is_training is not None: - batch_norm_params['is_training'] = is_training - if bn_renorm is not None: - batch_norm_params['renorm'] = bn_renorm - dropout_params = {} - if is_training is not None: - dropout_params['is_training'] = is_training - - instance_norm_params = { - 'center': True, - 'scale': True, - 'epsilon': 0.001, - } - - if stddev < 0: - weight_intitializer = slim.initializers.xavier_initializer() - else: - weight_intitializer = tf.truncated_normal_initializer(stddev=stddev) - - # Set weight_decay for weights in Conv and FC layers. - with slim.arg_scope( - [slim.conv2d, slim.fully_connected, slim.separable_conv2d], - weights_initializer=weight_intitializer, - activation_fn=activation, - normalizer_fn=slim.batch_norm), \ - slim.arg_scope( - [conv_blocks.expanded_conv], normalizer_fn=slim.batch_norm), \ - slim.arg_scope([mobilenet.apply_activation], activation_fn=activation),\ - slim.arg_scope([slim.batch_norm], **batch_norm_params), \ - slim.arg_scope([mobilenet.mobilenet_base, mobilenet.mobilenet], - is_training=is_training),\ - slim.arg_scope([slim.dropout], **dropout_params), \ - slim.arg_scope([slim.instance_norm], **instance_norm_params), \ - slim.arg_scope([slim.conv2d], \ - weights_regularizer=slim.l2_regularizer(weight_decay)), \ - slim.arg_scope([slim.separable_conv2d], weights_regularizer=None), \ - slim.arg_scope([slim.conv2d, slim.separable_conv2d], padding='SAME') as s: - return s - - -# A map from network name to network arg scope. -arg_scopes_map = { - 'mobilenet_v2': mobilenet_v2.training_scope, - 'mobilenet_edgetpu': mobilenet_v2_arg_scope, - 'mobilenet_v3_large_seg': mobilenet_v2_arg_scope, - 'mobilenet_v3_small_seg': mobilenet_v2_arg_scope, - 'resnet_v1_18': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_18_beta': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_50': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_50_beta': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_101': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_101_beta': resnet_v1_beta.resnet_arg_scope, - 'xception_41': xception.xception_arg_scope, - 'xception_65': xception.xception_arg_scope, - 'xception_71': xception.xception_arg_scope, - 'nas_pnasnet': nas_network.nas_arg_scope, - 'nas_hnasnet': nas_network.nas_arg_scope, -} - -# Names for end point features. -DECODER_END_POINTS = 'decoder_end_points' - -# A dictionary from network name to a map of end point features. -networks_to_feature_maps = { - 'mobilenet_v2': { - DECODER_END_POINTS: { - 4: ['layer_4/depthwise_output'], - 8: ['layer_7/depthwise_output'], - 16: ['layer_14/depthwise_output'], - }, - }, - 'mobilenet_v3_large_seg': { - DECODER_END_POINTS: { - 4: ['layer_4/depthwise_output'], - 8: ['layer_7/depthwise_output'], - 16: ['layer_13/depthwise_output'], - }, - }, - 'mobilenet_v3_small_seg': { - DECODER_END_POINTS: { - 4: ['layer_2/depthwise_output'], - 8: ['layer_4/depthwise_output'], - 16: ['layer_9/depthwise_output'], - }, - }, - 'resnet_v1_18': { - DECODER_END_POINTS: { - 4: ['block1/unit_1/lite_bottleneck_v1/conv2'], - 8: ['block2/unit_1/lite_bottleneck_v1/conv2'], - 16: ['block3/unit_1/lite_bottleneck_v1/conv2'], - }, - }, - 'resnet_v1_18_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_1/lite_bottleneck_v1/conv2'], - 8: ['block2/unit_1/lite_bottleneck_v1/conv2'], - 16: ['block3/unit_1/lite_bottleneck_v1/conv2'], - }, - }, - 'resnet_v1_50': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_5/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_50_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_5/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_101': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_22/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_101_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_22/bottleneck_v1/conv3'], - }, - }, - 'xception_41': { - DECODER_END_POINTS: { - 4: ['entry_flow/block2/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'xception_65': { - DECODER_END_POINTS: { - 4: ['entry_flow/block2/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'xception_71': { - DECODER_END_POINTS: { - 4: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block5/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'nas_pnasnet': { - DECODER_END_POINTS: { - 4: ['Stem'], - 8: ['Cell_3'], - 16: ['Cell_7'], - }, - }, - 'nas_hnasnet': { - DECODER_END_POINTS: { - 4: ['Cell_2'], - 8: ['Cell_5'], - 16: ['Cell_7'], - }, - }, -} - -# A map from feature extractor name to the network name scope used in the -# ImageNet pretrained versions of these models. -name_scope = { - 'mobilenet_v2': 'MobilenetV2', - 'mobilenet_edgetpu': 'MobilenetEdgeTPU', - 'mobilenet_v3_large_seg': 'MobilenetV3', - 'mobilenet_v3_small_seg': 'MobilenetV3', - 'resnet_v1_18': 'resnet_v1_18', - 'resnet_v1_18_beta': 'resnet_v1_18', - 'resnet_v1_50': 'resnet_v1_50', - 'resnet_v1_50_beta': 'resnet_v1_50', - 'resnet_v1_101': 'resnet_v1_101', - 'resnet_v1_101_beta': 'resnet_v1_101', - 'xception_41': 'xception_41', - 'xception_65': 'xception_65', - 'xception_71': 'xception_71', - 'nas_pnasnet': 'pnasnet', - 'nas_hnasnet': 'hnasnet', -} - -# Mean pixel value. -_MEAN_RGB = [123.15, 115.90, 103.06] - - -def _preprocess_subtract_imagenet_mean(inputs, dtype=tf.float32): - """Subtract Imagenet mean RGB value.""" - mean_rgb = tf.reshape(_MEAN_RGB, [1, 1, 1, 3]) - num_channels = tf.shape(inputs)[-1] - # We set mean pixel as 0 for the non-RGB channels. - mean_rgb_extended = tf.concat( - [mean_rgb, tf.zeros([1, 1, 1, num_channels - 3])], axis=3) - return tf.cast(inputs - mean_rgb_extended, dtype=dtype) - - -def _preprocess_zero_mean_unit_range(inputs, dtype=tf.float32): - """Map image values from [0, 255] to [-1, 1].""" - preprocessed_inputs = (2.0 / 255.0) * tf.to_float(inputs) - 1.0 - return tf.cast(preprocessed_inputs, dtype=dtype) - - -_PREPROCESS_FN = { - 'mobilenet_v2': _preprocess_zero_mean_unit_range, - 'mobilenet_edgetpu': _preprocess_zero_mean_unit_range, - 'mobilenet_v3_large_seg': _preprocess_zero_mean_unit_range, - 'mobilenet_v3_small_seg': _preprocess_zero_mean_unit_range, - 'resnet_v1_18': _preprocess_subtract_imagenet_mean, - 'resnet_v1_18_beta': _preprocess_zero_mean_unit_range, - 'resnet_v1_50': _preprocess_subtract_imagenet_mean, - 'resnet_v1_50_beta': _preprocess_zero_mean_unit_range, - 'resnet_v1_101': _preprocess_subtract_imagenet_mean, - 'resnet_v1_101_beta': _preprocess_zero_mean_unit_range, - 'xception_41': _preprocess_zero_mean_unit_range, - 'xception_65': _preprocess_zero_mean_unit_range, - 'xception_71': _preprocess_zero_mean_unit_range, - 'nas_pnasnet': _preprocess_zero_mean_unit_range, - 'nas_hnasnet': _preprocess_zero_mean_unit_range, -} - - -def mean_pixel(model_variant=None): - """Gets mean pixel value. - - This function returns different mean pixel value, depending on the input - model_variant which adopts different preprocessing functions. We currently - handle the following preprocessing functions: - (1) _preprocess_subtract_imagenet_mean. We simply return mean pixel value. - (2) _preprocess_zero_mean_unit_range. We return [127.5, 127.5, 127.5]. - The return values are used in a way that the padded regions after - pre-processing will contain value 0. - - Args: - model_variant: Model variant (string) for feature extraction. For - backwards compatibility, model_variant=None returns _MEAN_RGB. - - Returns: - Mean pixel value. - """ - if model_variant in ['resnet_v1_50', - 'resnet_v1_101'] or model_variant is None: - return _MEAN_RGB - else: - return [127.5, 127.5, 127.5] - - -def extract_features(images, - output_stride=8, - multi_grid=None, - depth_multiplier=1.0, - divisible_by=None, - final_endpoint=None, - model_variant=None, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - regularize_depthwise=False, - preprocess_images=True, - preprocessed_images_dtype=tf.float32, - num_classes=None, - global_pool=False, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - use_bounded_activation=False): - """Extracts features by the particular model_variant. - - Args: - images: A tensor of size [batch, height, width, channels]. - output_stride: The ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops used in MobileNet. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - final_endpoint: The MobileNet endpoint to construct the network up to. - model_variant: Model variant for feature extraction. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - preprocess_images: Performs preprocessing on images or not. Defaults to - True. Set to False if preprocessing will be done by other functions. We - supprot two types of preprocessing: (1) Mean pixel substraction and (2) - Pixel values normalization to be [-1, 1]. - preprocessed_images_dtype: The type after the preprocessing function. - num_classes: Number of classes for image classification task. Defaults - to None for dense prediction tasks. - global_pool: Global pooling for image classification task. Defaults to - False, since dense prediction tasks do not use this. - nas_architecture_options: A dictionary storing NAS architecture options. - It is either None or its kerys are: - - `nas_stem_output_num_conv_filters`: Number of filters of the NAS stem - output tensor. - - `nas_use_classification_head`: Boolean, use image classification head. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. It is either None or its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. Currently, - bounded activation is only used in xception model. - - Returns: - features: A tensor of size [batch, feature_height, feature_width, - feature_channels], where feature_height/feature_width are determined - by the images height/width and output_stride. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: Unrecognized model variant. - """ - if 'resnet' in model_variant: - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.95, - batch_norm_epsilon=1e-5, - batch_norm_scale=True) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - multi_grid=multi_grid, - reuse=reuse, - scope=name_scope[model_variant]) - elif 'xception' in model_variant: - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.9997, - batch_norm_epsilon=1e-3, - batch_norm_scale=True, - regularize_depthwise=regularize_depthwise, - use_bounded_activation=use_bounded_activation) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=name_scope[model_variant]) - elif 'mobilenet' in model_variant or model_variant.startswith('mnas'): - arg_scope = arg_scopes_map[model_variant]( - is_training=(is_training and fine_tune_batch_norm), - weight_decay=weight_decay) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - depth_multiplier=depth_multiplier, - divisible_by=divisible_by, - output_stride=output_stride, - reuse=reuse, - scope=name_scope[model_variant], - final_endpoint=final_endpoint) - elif model_variant.startswith('nas'): - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.9997, - batch_norm_epsilon=1e-3) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - nas_architecture_options=nas_architecture_options, - nas_training_hyper_parameters=nas_training_hyper_parameters, - reuse=reuse, - scope=name_scope[model_variant]) - else: - raise ValueError('Unknown model variant %s.' % model_variant) - - return features, end_points - - -def get_network(network_name, preprocess_images, - preprocessed_images_dtype=tf.float32, arg_scope=None): - """Gets the network. - - Args: - network_name: Network name. - preprocess_images: Preprocesses the images or not. - preprocessed_images_dtype: The type after the preprocessing function. - arg_scope: Optional, arg_scope to build the network. If not provided the - default arg_scope of the network would be used. - - Returns: - A network function that is used to extract features. - - Raises: - ValueError: network is not supported. - """ - if network_name not in networks_map: - raise ValueError('Unsupported network %s.' % network_name) - arg_scope = arg_scope or arg_scopes_map[network_name]() - def _identity_function(inputs, dtype=preprocessed_images_dtype): - return tf.cast(inputs, dtype=dtype) - if preprocess_images: - preprocess_function = _PREPROCESS_FN[network_name] - else: - preprocess_function = _identity_function - func = networks_map[network_name] - @functools.wraps(func) - def network_fn(inputs, *args, **kwargs): - with slim.arg_scope(arg_scope): - return func(preprocess_function(inputs, preprocessed_images_dtype), - *args, **kwargs) - return network_fn diff --git a/research/deeplab/core/nas_cell.py b/research/deeplab/core/nas_cell.py deleted file mode 100644 index d179082dc72b6692e96289ef9ed6964165023c33..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_cell.py +++ /dev/null @@ -1,221 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Cell structure used by NAS.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools -from six.moves import range -from six.moves import zip -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import xception as xception_utils -from deeplab.core.utils import resize_bilinear -from deeplab.core.utils import scale_dimension -from tensorflow.contrib.slim.nets import resnet_utils - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim - -separable_conv2d_same = functools.partial(xception_utils.separable_conv2d_same, - regularize_depthwise=True) - - -class NASBaseCell(object): - """NASNet Cell class that is used as a 'layer' in image architectures.""" - - def __init__(self, num_conv_filters, operations, used_hiddenstates, - hiddenstate_indices, drop_path_keep_prob, total_num_cells, - total_training_steps, batch_norm_fn=slim.batch_norm): - """Init function. - - For more details about NAS cell, see - https://arxiv.org/abs/1707.07012 and https://arxiv.org/abs/1712.00559. - - Args: - num_conv_filters: The number of filters for each convolution operation. - operations: List of operations that are performed in the NASNet Cell in - order. - used_hiddenstates: Binary array that signals if the hiddenstate was used - within the cell. This is used to determine what outputs of the cell - should be concatenated together. - hiddenstate_indices: Determines what hiddenstates should be combined - together with the specified operations to create the NASNet cell. - drop_path_keep_prob: Float, drop path keep probability. - total_num_cells: Integer, total number of cells. - total_training_steps: Integer, total training steps. - batch_norm_fn: Function, batch norm function. Defaults to - slim.batch_norm. - """ - if len(hiddenstate_indices) != len(operations): - raise ValueError( - 'Number of hiddenstate_indices and operations should be the same.') - if len(operations) % 2: - raise ValueError('Number of operations should be even.') - self._num_conv_filters = num_conv_filters - self._operations = operations - self._used_hiddenstates = used_hiddenstates - self._hiddenstate_indices = hiddenstate_indices - self._drop_path_keep_prob = drop_path_keep_prob - self._total_num_cells = total_num_cells - self._total_training_steps = total_training_steps - self._batch_norm_fn = batch_norm_fn - - def __call__(self, net, scope, filter_scaling, stride, prev_layer, cell_num): - """Runs the conv cell.""" - self._cell_num = cell_num - self._filter_scaling = filter_scaling - self._filter_size = int(self._num_conv_filters * filter_scaling) - - with tf.variable_scope(scope): - net = self._cell_base(net, prev_layer) - for i in range(len(self._operations) // 2): - with tf.variable_scope('comb_iter_{}'.format(i)): - h1 = net[self._hiddenstate_indices[i * 2]] - h2 = net[self._hiddenstate_indices[i * 2 + 1]] - with tf.variable_scope('left'): - h1 = self._apply_conv_operation( - h1, self._operations[i * 2], stride, - self._hiddenstate_indices[i * 2] < 2) - with tf.variable_scope('right'): - h2 = self._apply_conv_operation( - h2, self._operations[i * 2 + 1], stride, - self._hiddenstate_indices[i * 2 + 1] < 2) - with tf.variable_scope('combine'): - h = h1 + h2 - net.append(h) - - with tf.variable_scope('cell_output'): - net = self._combine_unused_states(net) - - return net - - def _cell_base(self, net, prev_layer): - """Runs the beginning of the conv cell before the chosen ops are run.""" - filter_size = self._filter_size - - if prev_layer is None: - prev_layer = net - else: - if net.shape[2] != prev_layer.shape[2]: - prev_layer = resize_bilinear( - prev_layer, tf.shape(net)[1:3], prev_layer.dtype) - if filter_size != prev_layer.shape[3]: - prev_layer = tf.nn.relu(prev_layer) - prev_layer = slim.conv2d(prev_layer, filter_size, 1, scope='prev_1x1') - prev_layer = self._batch_norm_fn(prev_layer, scope='prev_bn') - - net = tf.nn.relu(net) - net = slim.conv2d(net, filter_size, 1, scope='1x1') - net = self._batch_norm_fn(net, scope='beginning_bn') - net = tf.split(axis=3, num_or_size_splits=1, value=net) - net.append(prev_layer) - return net - - def _apply_conv_operation(self, net, operation, stride, - is_from_original_input): - """Applies the predicted conv operation to net.""" - if stride > 1 and not is_from_original_input: - stride = 1 - input_filters = net.shape[3] - filter_size = self._filter_size - if 'separable' in operation: - num_layers = int(operation.split('_')[-1]) - kernel_size = int(operation.split('x')[0][-1]) - for layer_num in range(num_layers): - net = tf.nn.relu(net) - net = separable_conv2d_same( - net, - filter_size, - kernel_size, - depth_multiplier=1, - scope='separable_{0}x{0}_{1}'.format(kernel_size, layer_num + 1), - stride=stride) - net = self._batch_norm_fn( - net, scope='bn_sep_{0}x{0}_{1}'.format(kernel_size, layer_num + 1)) - stride = 1 - elif 'atrous' in operation: - kernel_size = int(operation.split('x')[0][-1]) - net = tf.nn.relu(net) - if stride == 2: - scaled_height = scale_dimension(tf.shape(net)[1], 0.5) - scaled_width = scale_dimension(tf.shape(net)[2], 0.5) - net = resize_bilinear(net, [scaled_height, scaled_width], net.dtype) - net = resnet_utils.conv2d_same( - net, filter_size, kernel_size, rate=1, stride=1, - scope='atrous_{0}x{0}'.format(kernel_size)) - else: - net = resnet_utils.conv2d_same( - net, filter_size, kernel_size, rate=2, stride=1, - scope='atrous_{0}x{0}'.format(kernel_size)) - net = self._batch_norm_fn(net, scope='bn_atr_{0}x{0}'.format(kernel_size)) - elif operation in ['none']: - if stride > 1 or (input_filters != filter_size): - net = tf.nn.relu(net) - net = slim.conv2d(net, filter_size, 1, stride=stride, scope='1x1') - net = self._batch_norm_fn(net, scope='bn_1') - elif 'pool' in operation: - pooling_type = operation.split('_')[0] - pooling_shape = int(operation.split('_')[-1].split('x')[0]) - if pooling_type == 'avg': - net = slim.avg_pool2d(net, pooling_shape, stride=stride, padding='SAME') - elif pooling_type == 'max': - net = slim.max_pool2d(net, pooling_shape, stride=stride, padding='SAME') - else: - raise ValueError('Unimplemented pooling type: ', pooling_type) - if input_filters != filter_size: - net = slim.conv2d(net, filter_size, 1, stride=1, scope='1x1') - net = self._batch_norm_fn(net, scope='bn_1') - else: - raise ValueError('Unimplemented operation', operation) - - if operation != 'none': - net = self._apply_drop_path(net) - return net - - def _combine_unused_states(self, net): - """Concatenates the unused hidden states of the cell.""" - used_hiddenstates = self._used_hiddenstates - states_to_combine = ([ - h for h, is_used in zip(net, used_hiddenstates) if not is_used]) - net = tf.concat(values=states_to_combine, axis=3) - return net - - @contrib_framework.add_arg_scope - def _apply_drop_path(self, net): - """Apply drop_path regularization.""" - drop_path_keep_prob = self._drop_path_keep_prob - if drop_path_keep_prob < 1.0: - # Scale keep prob by layer number. - assert self._cell_num != -1 - layer_ratio = (self._cell_num + 1) / float(self._total_num_cells) - drop_path_keep_prob = 1 - layer_ratio * (1 - drop_path_keep_prob) - # Decrease keep prob over time. - current_step = tf.cast(tf.train.get_or_create_global_step(), tf.float32) - current_ratio = tf.minimum(1.0, current_step / self._total_training_steps) - drop_path_keep_prob = (1 - current_ratio * (1 - drop_path_keep_prob)) - # Drop path. - noise_shape = [tf.shape(net)[0], 1, 1, 1] - random_tensor = drop_path_keep_prob - random_tensor += tf.random_uniform(noise_shape, dtype=tf.float32) - binary_tensor = tf.cast(tf.floor(random_tensor), net.dtype) - keep_prob_inv = tf.cast(1.0 / drop_path_keep_prob, net.dtype) - net = net * keep_prob_inv * binary_tensor - return net diff --git a/research/deeplab/core/nas_genotypes.py b/research/deeplab/core/nas_genotypes.py deleted file mode 100644 index a2e6dd55b450658e10acaa420a6cc31635817a8a..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_genotypes.py +++ /dev/null @@ -1,45 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Genotypes used by NAS.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import nas_cell - -slim = contrib_slim - - -class PNASCell(nas_cell.NASBaseCell): - """Configuration and construction of the PNASNet-5 Cell.""" - - def __init__(self, num_conv_filters, drop_path_keep_prob, total_num_cells, - total_training_steps, batch_norm_fn=slim.batch_norm): - # Name of operations: op_kernel-size_num-layers. - operations = [ - 'separable_5x5_2', 'max_pool_3x3', 'separable_7x7_2', 'max_pool_3x3', - 'separable_5x5_2', 'separable_3x3_2', 'separable_3x3_2', 'max_pool_3x3', - 'separable_3x3_2', 'none' - ] - used_hiddenstates = [1, 1, 0, 0, 0, 0, 0] - hiddenstate_indices = [1, 1, 0, 0, 0, 0, 4, 0, 1, 0] - - super(PNASCell, self).__init__( - num_conv_filters, operations, used_hiddenstates, hiddenstate_indices, - drop_path_keep_prob, total_num_cells, total_training_steps, - batch_norm_fn) diff --git a/research/deeplab/core/nas_network.py b/research/deeplab/core/nas_network.py deleted file mode 100644 index 1da2e04dbaa5cfcb7db6f21266daf846000481fd..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_network.py +++ /dev/null @@ -1,368 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Network structure used by NAS. - -Here we provide a few NAS backbones for semantic segmentation. -Currently, we have - -1. pnasnet -"Progressive Neural Architecture Search", Chenxi Liu, Barret Zoph, -Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, -Alan Yuille, Jonathan Huang, Kevin Murphy. In ECCV, 2018. - -2. hnasnet (also called Auto-DeepLab) -"Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic -Image Segmentation", Chenxi Liu, Liang-Chieh Chen, Florian Schroff, -Hartwig Adam, Wei Hua, Alan Yuille, Li Fei-Fei. In CVPR, 2019. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers -from tensorflow.contrib import slim as contrib_slim -from tensorflow.contrib import training as contrib_training - -from deeplab.core import nas_genotypes -from deeplab.core import utils -from deeplab.core.nas_cell import NASBaseCell -from tensorflow.contrib.slim.nets import resnet_utils - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim -resize_bilinear = utils.resize_bilinear -scale_dimension = utils.scale_dimension - - -def config(num_conv_filters=20, - total_training_steps=500000, - drop_path_keep_prob=1.0): - return contrib_training.HParams( - # Multiplier when spatial size is reduced by 2. - filter_scaling_rate=2.0, - # Number of filters of the stem output tensor. - num_conv_filters=num_conv_filters, - # Probability to keep each path in the cell when training. - drop_path_keep_prob=drop_path_keep_prob, - # Total training steps to help drop path probability calculation. - total_training_steps=total_training_steps, - ) - - -def nas_arg_scope(weight_decay=4e-5, - batch_norm_decay=0.9997, - batch_norm_epsilon=0.001, - sync_batch_norm_method='None'): - """Default arg scope for the NAS models.""" - batch_norm_params = { - # Decay for the moving averages. - 'decay': batch_norm_decay, - # epsilon to prevent 0s in variance. - 'epsilon': batch_norm_epsilon, - 'scale': True, - } - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - weights_regularizer = contrib_layers.l2_regularizer(weight_decay) - weights_initializer = contrib_layers.variance_scaling_initializer( - factor=1 / 3.0, mode='FAN_IN', uniform=True) - with arg_scope([slim.fully_connected, slim.conv2d, slim.separable_conv2d], - weights_regularizer=weights_regularizer, - weights_initializer=weights_initializer): - with arg_scope([slim.fully_connected], - activation_fn=None, scope='FC'): - with arg_scope([slim.conv2d, slim.separable_conv2d], - activation_fn=None, biases_initializer=None): - with arg_scope([batch_norm], **batch_norm_params) as sc: - return sc - - -def _nas_stem(inputs, - batch_norm_fn=slim.batch_norm): - """Stem used for NAS models.""" - net = resnet_utils.conv2d_same(inputs, 64, 3, stride=2, scope='conv0') - net = batch_norm_fn(net, scope='conv0_bn') - net = tf.nn.relu(net) - net = resnet_utils.conv2d_same(net, 64, 3, stride=1, scope='conv1') - net = batch_norm_fn(net, scope='conv1_bn') - cell_outputs = [net] - net = tf.nn.relu(net) - net = resnet_utils.conv2d_same(net, 128, 3, stride=2, scope='conv2') - net = batch_norm_fn(net, scope='conv2_bn') - cell_outputs.append(net) - return net, cell_outputs - - -def _build_nas_base(images, - cell, - backbone, - num_classes, - hparams, - global_pool=False, - output_stride=16, - nas_use_classification_head=False, - reuse=None, - scope=None, - final_endpoint=None, - batch_norm_fn=slim.batch_norm, - nas_remove_os32_stride=False): - """Constructs a NAS model. - - Args: - images: A tensor of size [batch, height, width, channels]. - cell: Cell structure used in the network. - backbone: Backbone structure used in the network. A list of integers in - which value 0 means "output_stride=4", value 1 means "output_stride=8", - value 2 means "output_stride=16", and value 3 means "output_stride=32". - num_classes: Number of classes to predict. - hparams: Hyperparameters needed to construct the network. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: Interger, the stride of output feature maps. - nas_use_classification_head: Boolean, use image classification head. - reuse: Whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - final_endpoint: The endpoint to construct the network up to. - batch_norm_fn: Batch norm function. - nas_remove_os32_stride: Boolean, remove stride in output_stride 32 branch. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If output_stride is not a multiple of backbone output stride. - """ - with tf.variable_scope(scope, 'nas', [images], reuse=reuse): - end_points = {} - def add_and_check_endpoint(endpoint_name, net): - end_points[endpoint_name] = net - return final_endpoint and (endpoint_name == final_endpoint) - - net, cell_outputs = _nas_stem(images, - batch_norm_fn=batch_norm_fn) - if add_and_check_endpoint('Stem', net): - return net, end_points - - # Run the cells - filter_scaling = 1.0 - for cell_num in range(len(backbone)): - stride = 1 - if cell_num == 0: - if backbone[0] == 1: - stride = 2 - filter_scaling *= hparams.filter_scaling_rate - else: - if backbone[cell_num] == backbone[cell_num - 1] + 1: - stride = 2 - if backbone[cell_num] == 3 and nas_remove_os32_stride: - stride = 1 - filter_scaling *= hparams.filter_scaling_rate - elif backbone[cell_num] == backbone[cell_num - 1] - 1: - if backbone[cell_num - 1] == 3 and nas_remove_os32_stride: - # No need to rescale features. - pass - else: - # Scale features by a factor of 2. - scaled_height = scale_dimension(net.shape[1].value, 2) - scaled_width = scale_dimension(net.shape[2].value, 2) - net = resize_bilinear(net, [scaled_height, scaled_width], net.dtype) - filter_scaling /= hparams.filter_scaling_rate - net = cell( - net, - scope='cell_{}'.format(cell_num), - filter_scaling=filter_scaling, - stride=stride, - prev_layer=cell_outputs[-2], - cell_num=cell_num) - if add_and_check_endpoint('Cell_{}'.format(cell_num), net): - return net, end_points - cell_outputs.append(net) - net = tf.nn.relu(net) - - if nas_use_classification_head: - # Add image classification head. - # We will expand the filters for different output_strides. - output_stride_to_expanded_filters = {8: 256, 16: 512, 32: 1024} - current_output_scale = 2 + backbone[-1] - current_output_stride = 2 ** current_output_scale - if output_stride % current_output_stride != 0: - raise ValueError( - 'output_stride must be a multiple of backbone output stride.') - output_stride //= current_output_stride - rate = 1 - if current_output_stride != 32: - num_downsampling = 5 - current_output_scale - for i in range(num_downsampling): - # Gradually donwsample feature maps to output stride = 32. - target_output_stride = 2 ** (current_output_scale + 1 + i) - target_filters = output_stride_to_expanded_filters[ - target_output_stride] - scope = 'downsample_os{}'.format(target_output_stride) - if output_stride != 1: - stride = 2 - output_stride //= 2 - else: - stride = 1 - rate *= 2 - net = resnet_utils.conv2d_same( - net, target_filters, 3, stride=stride, rate=rate, - scope=scope + '_conv') - net = batch_norm_fn(net, scope=scope + '_bn') - add_and_check_endpoint(scope, net) - net = tf.nn.relu(net) - # Apply 1x1 convolution to expand dimension to 2048. - scope = 'classification_head' - net = slim.conv2d(net, 2048, 1, scope=scope + '_conv') - net = batch_norm_fn(net, scope=scope + '_bn') - add_and_check_endpoint(scope, net) - net = tf.nn.relu(net) - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='global_pool', keepdims=True) - if num_classes is not None: - net = slim.conv2d(net, num_classes, 1, activation_fn=None, - normalizer_fn=None, scope='logits') - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def pnasnet(images, - num_classes, - is_training=True, - global_pool=False, - output_stride=16, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - reuse=None, - scope='pnasnet', - final_endpoint=None, - sync_batch_norm_method='None'): - """Builds PNASNet model.""" - if nas_architecture_options is None: - raise ValueError( - 'Using NAS model variants. nas_architecture_options cannot be None.') - hparams = config(num_conv_filters=nas_architecture_options[ - 'nas_stem_output_num_conv_filters']) - if nas_training_hyper_parameters: - hparams.set_hparam('drop_path_keep_prob', - nas_training_hyper_parameters['drop_path_keep_prob']) - hparams.set_hparam('total_training_steps', - nas_training_hyper_parameters['total_training_steps']) - if not is_training: - tf.logging.info('During inference, setting drop_path_keep_prob = 1.0.') - hparams.set_hparam('drop_path_keep_prob', 1.0) - tf.logging.info(hparams) - if output_stride == 8: - backbone = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] - elif output_stride == 16: - backbone = [1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2] - elif output_stride == 32: - backbone = [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] - else: - raise ValueError('Unsupported output_stride ', output_stride) - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - cell = nas_genotypes.PNASCell(hparams.num_conv_filters, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps, - batch_norm_fn=batch_norm) - with arg_scope([slim.dropout, batch_norm], is_training=is_training): - return _build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - global_pool=global_pool, - output_stride=output_stride, - nas_use_classification_head=nas_architecture_options[ - 'nas_use_classification_head'], - reuse=reuse, - scope=scope, - final_endpoint=final_endpoint, - batch_norm_fn=batch_norm, - nas_remove_os32_stride=nas_architecture_options[ - 'nas_remove_os32_stride']) - - -# pylint: disable=unused-argument -def hnasnet(images, - num_classes, - is_training=True, - global_pool=False, - output_stride=8, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - reuse=None, - scope='hnasnet', - final_endpoint=None, - sync_batch_norm_method='None'): - """Builds hierarchical model.""" - if nas_architecture_options is None: - raise ValueError( - 'Using NAS model variants. nas_architecture_options cannot be None.') - hparams = config(num_conv_filters=nas_architecture_options[ - 'nas_stem_output_num_conv_filters']) - if nas_training_hyper_parameters: - hparams.set_hparam('drop_path_keep_prob', - nas_training_hyper_parameters['drop_path_keep_prob']) - hparams.set_hparam('total_training_steps', - nas_training_hyper_parameters['total_training_steps']) - if not is_training: - tf.logging.info('During inference, setting drop_path_keep_prob = 1.0.') - hparams.set_hparam('drop_path_keep_prob', 1.0) - tf.logging.info(hparams) - operations = [ - 'atrous_5x5', 'separable_3x3_2', 'separable_3x3_2', 'atrous_3x3', - 'separable_3x3_2', 'separable_3x3_2', 'separable_5x5_2', - 'separable_5x5_2', 'separable_5x5_2', 'atrous_5x5' - ] - used_hiddenstates = [1, 1, 0, 0, 0, 0, 0] - hiddenstate_indices = [1, 0, 1, 0, 3, 1, 4, 2, 3, 5] - backbone = [0, 0, 0, 1, 2, 1, 2, 2, 3, 3, 2, 1] - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - cell = NASBaseCell(hparams.num_conv_filters, - operations, - used_hiddenstates, - hiddenstate_indices, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps, - batch_norm_fn=batch_norm) - with arg_scope([slim.dropout, batch_norm], is_training=is_training): - return _build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - global_pool=global_pool, - output_stride=output_stride, - nas_use_classification_head=nas_architecture_options[ - 'nas_use_classification_head'], - reuse=reuse, - scope=scope, - final_endpoint=final_endpoint, - batch_norm_fn=batch_norm, - nas_remove_os32_stride=nas_architecture_options[ - 'nas_remove_os32_stride']) diff --git a/research/deeplab/core/nas_network_test.py b/research/deeplab/core/nas_network_test.py deleted file mode 100644 index 18621b250ad7321f554b8d97449e19bde5ef4174..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_network_test.py +++ /dev/null @@ -1,111 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for resnet_v1_beta module.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim -from tensorflow.contrib import training as contrib_training - -from deeplab.core import nas_genotypes -from deeplab.core import nas_network - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Creates test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.to_float( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels])) - - -class NASNetworkTest(tf.test.TestCase): - """Tests with complete small NAS networks.""" - - def _pnasnet(self, - images, - backbone, - num_classes, - is_training=True, - output_stride=16, - final_endpoint=None): - """Build PNASNet model backbone.""" - hparams = contrib_training.HParams( - filter_scaling_rate=2.0, - num_conv_filters=10, - drop_path_keep_prob=1.0, - total_training_steps=200000, - ) - if not is_training: - hparams.set_hparam('drop_path_keep_prob', 1.0) - - cell = nas_genotypes.PNASCell(hparams.num_conv_filters, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps) - with arg_scope([slim.dropout, slim.batch_norm], is_training=is_training): - return nas_network._build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - reuse=tf.AUTO_REUSE, - scope='pnasnet_small', - final_endpoint=final_endpoint) - - def testFullyConvolutionalEndpointShapes(self): - num_classes = 10 - backbone = [0, 0, 0, 1, 2, 1, 2, 2, 3, 3, 2, 1] - inputs = create_test_input(None, 321, 321, 3) - with slim.arg_scope(nas_network.nas_arg_scope()): - _, end_points = self._pnasnet(inputs, backbone, num_classes) - endpoint_to_shape = { - 'Stem': [None, 81, 81, 128], - 'Cell_0': [None, 81, 81, 50], - 'Cell_1': [None, 81, 81, 50], - 'Cell_2': [None, 81, 81, 50], - 'Cell_3': [None, 41, 41, 100], - 'Cell_4': [None, 21, 21, 200], - 'Cell_5': [None, 41, 41, 100], - 'Cell_6': [None, 21, 21, 200], - 'Cell_7': [None, 21, 21, 200], - 'Cell_8': [None, 11, 11, 400], - 'Cell_9': [None, 11, 11, 400], - 'Cell_10': [None, 21, 21, 200], - 'Cell_11': [None, 41, 41, 100] - } - for endpoint, shape in endpoint_to_shape.items(): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/preprocess_utils.py b/research/deeplab/core/preprocess_utils.py deleted file mode 100644 index 440717e414d1a6f67b0947eb78830ff84baa812d..0000000000000000000000000000000000000000 --- a/research/deeplab/core/preprocess_utils.py +++ /dev/null @@ -1,533 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Utility functions related to preprocessing inputs.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -from six.moves import range -from six.moves import zip -import tensorflow as tf - - -def flip_dim(tensor_list, prob=0.5, dim=1): - """Randomly flips a dimension of the given tensor. - - The decision to randomly flip the `Tensors` is made together. In other words, - all or none of the images pass in are flipped. - - Note that tf.random_flip_left_right and tf.random_flip_up_down isn't used so - that we can control for the probability as well as ensure the same decision - is applied across the images. - - Args: - tensor_list: A list of `Tensors` with the same number of dimensions. - prob: The probability of a left-right flip. - dim: The dimension to flip, 0, 1, .. - - Returns: - outputs: A list of the possibly flipped `Tensors` as well as an indicator - `Tensor` at the end whose value is `True` if the inputs were flipped and - `False` otherwise. - - Raises: - ValueError: If dim is negative or greater than the dimension of a `Tensor`. - """ - random_value = tf.random_uniform([]) - - def flip(): - flipped = [] - for tensor in tensor_list: - if dim < 0 or dim >= len(tensor.get_shape().as_list()): - raise ValueError('dim must represent a valid dimension.') - flipped.append(tf.reverse_v2(tensor, [dim])) - return flipped - - is_flipped = tf.less_equal(random_value, prob) - outputs = tf.cond(is_flipped, flip, lambda: tensor_list) - if not isinstance(outputs, (list, tuple)): - outputs = [outputs] - outputs.append(is_flipped) - - return outputs - - -def _image_dimensions(image, rank): - """Returns the dimensions of an image tensor. - - Args: - image: A rank-D Tensor. For 3-D of shape: `[height, width, channels]`. - rank: The expected rank of the image - - Returns: - A list of corresponding to the dimensions of the input image. Dimensions - that are statically known are python integers, otherwise they are integer - scalar tensors. - """ - if image.get_shape().is_fully_defined(): - return image.get_shape().as_list() - else: - static_shape = image.get_shape().with_rank(rank).as_list() - dynamic_shape = tf.unstack(tf.shape(image), rank) - return [ - s if s is not None else d for s, d in zip(static_shape, dynamic_shape) - ] - - -def get_label_resize_method(label): - """Returns the resize method of labels depending on label dtype. - - Args: - label: Groundtruth label tensor. - - Returns: - tf.image.ResizeMethod.BILINEAR, if label dtype is floating. - tf.image.ResizeMethod.NEAREST_NEIGHBOR, if label dtype is integer. - - Raises: - ValueError: If label is neither floating nor integer. - """ - if label.dtype.is_floating: - return tf.image.ResizeMethod.BILINEAR - elif label.dtype.is_integer: - return tf.image.ResizeMethod.NEAREST_NEIGHBOR - else: - raise ValueError('Label type must be either floating or integer.') - - -def pad_to_bounding_box(image, offset_height, offset_width, target_height, - target_width, pad_value): - """Pads the given image with the given pad_value. - - Works like tf.image.pad_to_bounding_box, except it can pad the image - with any given arbitrary pad value and also handle images whose sizes are not - known during graph construction. - - Args: - image: 3-D tensor with shape [height, width, channels] - offset_height: Number of rows of zeros to add on top. - offset_width: Number of columns of zeros to add on the left. - target_height: Height of output image. - target_width: Width of output image. - pad_value: Value to pad the image tensor with. - - Returns: - 3-D tensor of shape [target_height, target_width, channels]. - - Raises: - ValueError: If the shape of image is incompatible with the offset_* or - target_* arguments. - """ - with tf.name_scope(None, 'pad_to_bounding_box', [image]): - image = tf.convert_to_tensor(image, name='image') - original_dtype = image.dtype - if original_dtype != tf.float32 and original_dtype != tf.float64: - # If image dtype is not float, we convert it to int32 to avoid overflow. - image = tf.cast(image, tf.int32) - image_rank_assert = tf.Assert( - tf.logical_or( - tf.equal(tf.rank(image), 3), - tf.equal(tf.rank(image), 4)), - ['Wrong image tensor rank.']) - with tf.control_dependencies([image_rank_assert]): - image -= pad_value - image_shape = image.get_shape() - is_batch = True - if image_shape.ndims == 3: - is_batch = False - image = tf.expand_dims(image, 0) - elif image_shape.ndims is None: - is_batch = False - image = tf.expand_dims(image, 0) - image.set_shape([None] * 4) - elif image.get_shape().ndims != 4: - raise ValueError('Input image must have either 3 or 4 dimensions.') - _, height, width, _ = _image_dimensions(image, rank=4) - target_width_assert = tf.Assert( - tf.greater_equal( - target_width, width), - ['target_width must be >= width']) - target_height_assert = tf.Assert( - tf.greater_equal(target_height, height), - ['target_height must be >= height']) - with tf.control_dependencies([target_width_assert]): - after_padding_width = target_width - offset_width - width - with tf.control_dependencies([target_height_assert]): - after_padding_height = target_height - offset_height - height - offset_assert = tf.Assert( - tf.logical_and( - tf.greater_equal(after_padding_width, 0), - tf.greater_equal(after_padding_height, 0)), - ['target size not possible with the given target offsets']) - batch_params = tf.stack([0, 0]) - height_params = tf.stack([offset_height, after_padding_height]) - width_params = tf.stack([offset_width, after_padding_width]) - channel_params = tf.stack([0, 0]) - with tf.control_dependencies([offset_assert]): - paddings = tf.stack([batch_params, height_params, width_params, - channel_params]) - padded = tf.pad(image, paddings) - if not is_batch: - padded = tf.squeeze(padded, axis=[0]) - outputs = padded + pad_value - if outputs.dtype != original_dtype: - outputs = tf.cast(outputs, original_dtype) - return outputs - - -def _crop(image, offset_height, offset_width, crop_height, crop_width): - """Crops the given image using the provided offsets and sizes. - - Note that the method doesn't assume we know the input image size but it does - assume we know the input image rank. - - Args: - image: an image of shape [height, width, channels]. - offset_height: a scalar tensor indicating the height offset. - offset_width: a scalar tensor indicating the width offset. - crop_height: the height of the cropped image. - crop_width: the width of the cropped image. - - Returns: - The cropped (and resized) image. - - Raises: - ValueError: if `image` doesn't have rank of 3. - InvalidArgumentError: if the rank is not 3 or if the image dimensions are - less than the crop size. - """ - original_shape = tf.shape(image) - - if len(image.get_shape().as_list()) != 3: - raise ValueError('input must have rank of 3') - original_channels = image.get_shape().as_list()[2] - - rank_assertion = tf.Assert( - tf.equal(tf.rank(image), 3), - ['Rank of image must be equal to 3.']) - with tf.control_dependencies([rank_assertion]): - cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]]) - - size_assertion = tf.Assert( - tf.logical_and( - tf.greater_equal(original_shape[0], crop_height), - tf.greater_equal(original_shape[1], crop_width)), - ['Crop size greater than the image size.']) - - offsets = tf.cast(tf.stack([offset_height, offset_width, 0]), tf.int32) - - # Use tf.slice instead of crop_to_bounding box as it accepts tensors to - # define the crop size. - with tf.control_dependencies([size_assertion]): - image = tf.slice(image, offsets, cropped_shape) - image = tf.reshape(image, cropped_shape) - image.set_shape([crop_height, crop_width, original_channels]) - return image - - -def random_crop(image_list, crop_height, crop_width): - """Crops the given list of images. - - The function applies the same crop to each image in the list. This can be - effectively applied when there are multiple image inputs of the same - dimension such as: - - image, depths, normals = random_crop([image, depths, normals], 120, 150) - - Args: - image_list: a list of image tensors of the same dimension but possibly - varying channel. - crop_height: the new height. - crop_width: the new width. - - Returns: - the image_list with cropped images. - - Raises: - ValueError: if there are multiple image inputs provided with different size - or the images are smaller than the crop dimensions. - """ - if not image_list: - raise ValueError('Empty image_list.') - - # Compute the rank assertions. - rank_assertions = [] - for i in range(len(image_list)): - image_rank = tf.rank(image_list[i]) - rank_assert = tf.Assert( - tf.equal(image_rank, 3), - ['Wrong rank for tensor %s [expected] [actual]', - image_list[i].name, 3, image_rank]) - rank_assertions.append(rank_assert) - - with tf.control_dependencies([rank_assertions[0]]): - image_shape = tf.shape(image_list[0]) - image_height = image_shape[0] - image_width = image_shape[1] - crop_size_assert = tf.Assert( - tf.logical_and( - tf.greater_equal(image_height, crop_height), - tf.greater_equal(image_width, crop_width)), - ['Crop size greater than the image size.']) - - asserts = [rank_assertions[0], crop_size_assert] - - for i in range(1, len(image_list)): - image = image_list[i] - asserts.append(rank_assertions[i]) - with tf.control_dependencies([rank_assertions[i]]): - shape = tf.shape(image) - height = shape[0] - width = shape[1] - - height_assert = tf.Assert( - tf.equal(height, image_height), - ['Wrong height for tensor %s [expected][actual]', - image.name, height, image_height]) - width_assert = tf.Assert( - tf.equal(width, image_width), - ['Wrong width for tensor %s [expected][actual]', - image.name, width, image_width]) - asserts.extend([height_assert, width_assert]) - - # Create a random bounding box. - # - # Use tf.random_uniform and not numpy.random.rand as doing the former would - # generate random numbers at graph eval time, unlike the latter which - # generates random numbers at graph definition time. - with tf.control_dependencies(asserts): - max_offset_height = tf.reshape(image_height - crop_height + 1, []) - max_offset_width = tf.reshape(image_width - crop_width + 1, []) - offset_height = tf.random_uniform( - [], maxval=max_offset_height, dtype=tf.int32) - offset_width = tf.random_uniform( - [], maxval=max_offset_width, dtype=tf.int32) - - return [_crop(image, offset_height, offset_width, - crop_height, crop_width) for image in image_list] - - -def get_random_scale(min_scale_factor, max_scale_factor, step_size): - """Gets a random scale value. - - Args: - min_scale_factor: Minimum scale value. - max_scale_factor: Maximum scale value. - step_size: The step size from minimum to maximum value. - - Returns: - A random scale value selected between minimum and maximum value. - - Raises: - ValueError: min_scale_factor has unexpected value. - """ - if min_scale_factor < 0 or min_scale_factor > max_scale_factor: - raise ValueError('Unexpected value of min_scale_factor.') - - if min_scale_factor == max_scale_factor: - return tf.cast(min_scale_factor, tf.float32) - - # When step_size = 0, we sample the value uniformly from [min, max). - if step_size == 0: - return tf.random_uniform([1], - minval=min_scale_factor, - maxval=max_scale_factor) - - # When step_size != 0, we randomly select one discrete value from [min, max]. - num_steps = int((max_scale_factor - min_scale_factor) / step_size + 1) - scale_factors = tf.lin_space(min_scale_factor, max_scale_factor, num_steps) - shuffled_scale_factors = tf.random_shuffle(scale_factors) - return shuffled_scale_factors[0] - - -def randomly_scale_image_and_label(image, label=None, scale=1.0): - """Randomly scales image and label. - - Args: - image: Image with shape [height, width, 3]. - label: Label with shape [height, width, 1]. - scale: The value to scale image and label. - - Returns: - Scaled image and label. - """ - # No random scaling if scale == 1. - if scale == 1.0: - return image, label - image_shape = tf.shape(image) - new_dim = tf.cast( - tf.cast([image_shape[0], image_shape[1]], tf.float32) * scale, - tf.int32) - - # Need squeeze and expand_dims because image interpolation takes - # 4D tensors as input. - image = tf.squeeze(tf.image.resize_bilinear( - tf.expand_dims(image, 0), - new_dim, - align_corners=True), [0]) - if label is not None: - label = tf.image.resize( - label, - new_dim, - method=get_label_resize_method(label), - align_corners=True) - - return image, label - - -def resolve_shape(tensor, rank=None, scope=None): - """Fully resolves the shape of a Tensor. - - Use as much as possible the shape components already known during graph - creation and resolve the remaining ones during runtime. - - Args: - tensor: Input tensor whose shape we query. - rank: The rank of the tensor, provided that we know it. - scope: Optional name scope. - - Returns: - shape: The full shape of the tensor. - """ - with tf.name_scope(scope, 'resolve_shape', [tensor]): - if rank is not None: - shape = tensor.get_shape().with_rank(rank).as_list() - else: - shape = tensor.get_shape().as_list() - - if None in shape: - shape_dynamic = tf.shape(tensor) - for i in range(len(shape)): - if shape[i] is None: - shape[i] = shape_dynamic[i] - - return shape - - -def resize_to_range(image, - label=None, - min_size=None, - max_size=None, - factor=None, - keep_aspect_ratio=True, - align_corners=True, - label_layout_is_chw=False, - scope=None, - method=tf.image.ResizeMethod.BILINEAR): - """Resizes image or label so their sides are within the provided range. - - The output size can be described by two cases: - 1. If the image can be rescaled so its minimum size is equal to min_size - without the other side exceeding max_size, then do so. - 2. Otherwise, resize so the largest side is equal to max_size. - - An integer in `range(factor)` is added to the computed sides so that the - final dimensions are multiples of `factor` plus one. - - Args: - image: A 3D tensor of shape [height, width, channels]. - label: (optional) A 3D tensor of shape [height, width, channels] (default) - or [channels, height, width] when label_layout_is_chw = True. - min_size: (scalar) desired size of the smaller image side. - max_size: (scalar) maximum allowed size of the larger image side. Note - that the output dimension is no larger than max_size and may be slightly - smaller than max_size when factor is not None. - factor: Make output size multiple of factor plus one. - keep_aspect_ratio: Boolean, keep aspect ratio or not. If True, the input - will be resized while keeping the original aspect ratio. If False, the - input will be resized to [max_resize_value, max_resize_value] without - keeping the original aspect ratio. - align_corners: If True, exactly align all 4 corners of input and output. - label_layout_is_chw: If true, the label has shape [channel, height, width]. - We support this case because for some instance segmentation dataset, the - instance segmentation is saved as [num_instances, height, width]. - scope: Optional name scope. - method: Image resize method. Defaults to tf.image.ResizeMethod.BILINEAR. - - Returns: - A 3-D tensor of shape [new_height, new_width, channels], where the image - has been resized (with the specified method) so that - min(new_height, new_width) == ceil(min_size) or - max(new_height, new_width) == ceil(max_size). - - Raises: - ValueError: If the image is not a 3D tensor. - """ - with tf.name_scope(scope, 'resize_to_range', [image]): - new_tensor_list = [] - min_size = tf.cast(min_size, tf.float32) - if max_size is not None: - max_size = tf.cast(max_size, tf.float32) - # Modify the max_size to be a multiple of factor plus 1 and make sure the - # max dimension after resizing is no larger than max_size. - if factor is not None: - max_size = (max_size - (max_size - 1) % factor) - - [orig_height, orig_width, _] = resolve_shape(image, rank=3) - orig_height = tf.cast(orig_height, tf.float32) - orig_width = tf.cast(orig_width, tf.float32) - orig_min_size = tf.minimum(orig_height, orig_width) - - # Calculate the larger of the possible sizes - large_scale_factor = min_size / orig_min_size - large_height = tf.cast(tf.floor(orig_height * large_scale_factor), tf.int32) - large_width = tf.cast(tf.floor(orig_width * large_scale_factor), tf.int32) - large_size = tf.stack([large_height, large_width]) - - new_size = large_size - if max_size is not None: - # Calculate the smaller of the possible sizes, use that if the larger - # is too big. - orig_max_size = tf.maximum(orig_height, orig_width) - small_scale_factor = max_size / orig_max_size - small_height = tf.cast( - tf.floor(orig_height * small_scale_factor), tf.int32) - small_width = tf.cast(tf.floor(orig_width * small_scale_factor), tf.int32) - small_size = tf.stack([small_height, small_width]) - new_size = tf.cond( - tf.cast(tf.reduce_max(large_size), tf.float32) > max_size, - lambda: small_size, - lambda: large_size) - # Ensure that both output sides are multiples of factor plus one. - if factor is not None: - new_size += (factor - (new_size - 1) % factor) % factor - if not keep_aspect_ratio: - # If not keep the aspect ratio, we resize everything to max_size, allowing - # us to do pre-processing without extra padding. - new_size = [tf.reduce_max(new_size), tf.reduce_max(new_size)] - new_tensor_list.append(tf.image.resize( - image, new_size, method=method, align_corners=align_corners)) - if label is not None: - if label_layout_is_chw: - # Input label has shape [channel, height, width]. - resized_label = tf.expand_dims(label, 3) - resized_label = tf.image.resize( - resized_label, - new_size, - method=get_label_resize_method(label), - align_corners=align_corners) - resized_label = tf.squeeze(resized_label, 3) - else: - # Input label has shape [height, width, channel]. - resized_label = tf.image.resize( - label, - new_size, - method=get_label_resize_method(label), - align_corners=align_corners) - new_tensor_list.append(resized_label) - else: - new_tensor_list.append(None) - return new_tensor_list diff --git a/research/deeplab/core/preprocess_utils_test.py b/research/deeplab/core/preprocess_utils_test.py deleted file mode 100644 index 606fe46dd62787cf1a8adfaa27121affc4a02498..0000000000000000000000000000000000000000 --- a/research/deeplab/core/preprocess_utils_test.py +++ /dev/null @@ -1,515 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for preprocess_utils.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -from six.moves import range -import tensorflow as tf - -from deeplab.core import preprocess_utils - - -class PreprocessUtilsTest(tf.test.TestCase): - - def testNoFlipWhenProbIsZero(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - image = tf.convert_to_tensor(numpy_image) - - with self.test_session(): - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=0) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=1) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=2) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - - def testFlipWhenProbIsOne(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - dim0_flipped = np.dstack([[[9., 0.], - [5., 6.]], - [[3., 5.], - [4., 3.]]]) - dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - dim2_flipped = np.dstack([[[4., 3.], - [3., 5.]], - [[5., 6.], - [9., 0.]]]) - image = tf.convert_to_tensor(numpy_image) - - with self.test_session(): - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=0) - self.assertAllEqual(dim0_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=1) - self.assertAllEqual(dim1_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=2) - self.assertAllEqual(dim2_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - - def testFlipMultipleImagesConsistentlyWhenProbIsOne(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - numpy_label = np.dstack([[[0., 1.], - [2., 3.]]]) - image_dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - label_dim1_flipped = np.dstack([[[1., 0.], - [3., 2.]]]) - image = tf.convert_to_tensor(numpy_image) - label = tf.convert_to_tensor(numpy_label) - - with self.test_session() as sess: - image, label, is_flipped = preprocess_utils.flip_dim( - [image, label], prob=1, dim=1) - actual_image, actual_label = sess.run([image, label]) - self.assertAllEqual(image_dim1_flipped, actual_image) - self.assertAllEqual(label_dim1_flipped, actual_label) - self.assertEqual(True, is_flipped.eval()) - - def testReturnRandomFlipsOnMultipleEvals(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - image = tf.convert_to_tensor(numpy_image) - tf.compat.v1.set_random_seed(53) - - with self.test_session() as sess: - actual, is_flipped = preprocess_utils.flip_dim( - [image], prob=0.5, dim=1) - actual_image, actual_is_flipped = sess.run([actual, is_flipped]) - self.assertAllEqual(numpy_image, actual_image) - self.assertEqual(False, actual_is_flipped) - actual_image, actual_is_flipped = sess.run([actual, is_flipped]) - self.assertAllEqual(dim1_flipped, actual_image) - self.assertEqual(True, actual_is_flipped) - - def testReturnCorrectCropOfSingleImage(self): - np.random.seed(0) - - height, width = 10, 20 - image = np.random.randint(0, 256, size=(height, width, 3)) - - crop_height, crop_width = 2, 4 - - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop([image_placeholder], - crop_height, - crop_width) - - with self.test_session(): - cropped_image = cropped.eval(feed_dict={image_placeholder: image}) - - # Ensure we can find the cropped image in the original: - is_found = False - for x in range(0, width - crop_width + 1): - for y in range(0, height - crop_height + 1): - if np.isclose(image[y:y+crop_height, x:x+crop_width, :], - cropped_image).all(): - is_found = True - break - - self.assertTrue(is_found) - - def testRandomCropMaintainsNumberOfChannels(self): - np.random.seed(0) - - crop_height, crop_width = 10, 20 - image = np.random.randint(0, 256, size=(100, 200, 3)) - - tf.compat.v1.set_random_seed(37) - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop( - [image_placeholder], crop_height, crop_width) - - with self.test_session(): - cropped_image = cropped.eval(feed_dict={image_placeholder: image}) - self.assertTupleEqual(cropped_image.shape, (crop_height, crop_width, 3)) - - def testReturnDifferentCropAreasOnTwoEvals(self): - tf.compat.v1.set_random_seed(0) - - crop_height, crop_width = 2, 3 - image = np.random.randint(0, 256, size=(100, 200, 3)) - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop( - [image_placeholder], crop_height, crop_width) - - with self.test_session(): - crop0 = cropped.eval(feed_dict={image_placeholder: image}) - crop1 = cropped.eval(feed_dict={image_placeholder: image}) - self.assertFalse(np.isclose(crop0, crop1).all()) - - def testReturnConsistenCropsOfImagesInTheList(self): - tf.compat.v1.set_random_seed(0) - - height, width = 10, 20 - crop_height, crop_width = 2, 3 - labels = np.linspace(0, height * width-1, height * width) - labels = labels.reshape((height, width, 1)) - image = np.tile(labels, (1, 1, 3)) - - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - label_placeholder = tf.placeholder(tf.int32, shape=(None, None, 1)) - [cropped_image, cropped_label] = preprocess_utils.random_crop( - [image_placeholder, label_placeholder], crop_height, crop_width) - - with self.test_session() as sess: - cropped_image, cropped_labels = sess.run([cropped_image, cropped_label], - feed_dict={ - image_placeholder: image, - label_placeholder: labels}) - for i in range(3): - self.assertAllEqual(cropped_image[:, :, i], cropped_labels.squeeze()) - - def testDieOnRandomCropWhenImagesWithDifferentWidth(self): - crop_height, crop_width = 2, 3 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaises(tf.errors.InvalidArgumentError): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(4, 6, 1)}) - - def testDieOnRandomCropWhenImagesWithDifferentHeight(self): - crop_height, crop_width = 2, 3 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Wrong height for tensor'): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(3, 5, 1)}) - - def testDieOnRandomCropWhenCropSizeIsGreaterThanImage(self): - crop_height, crop_width = 5, 9 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Crop size greater than the image size.'): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(4, 5, 1)}) - - def testReturnPaddedImageWithNonZeroPadValue(self): - for dtype in [np.int32, np.int64, np.float32, np.float64]: - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]).astype(dtype) - expected_image = np.dstack([[[255, 255, 255, 255, 255], - [255, 255, 255, 255, 255], - [255, 5, 6, 255, 255], - [255, 9, 0, 255, 255], - [255, 255, 255, 255, 255]], - [[255, 255, 255, 255, 255], - [255, 255, 255, 255, 255], - [255, 4, 3, 255, 255], - [255, 3, 5, 255, 255], - [255, 255, 255, 255, 255]]]).astype(dtype) - - with self.session() as sess: - padded_image = preprocess_utils.pad_to_bounding_box( - image, 2, 1, 5, 5, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, expected_image) - # Add batch size = 1 to image. - padded_image = preprocess_utils.pad_to_bounding_box( - np.expand_dims(image, 0), 2, 1, 5, 5, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, np.expand_dims(expected_image, 0)) - - def testReturnOriginalImageWhenTargetSizeIsEqualToImageSize(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.session() as sess: - padded_image = preprocess_utils.pad_to_bounding_box( - image, 0, 0, 2, 2, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, image) - - def testDieOnTargetSizeGreaterThanImageSize(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 2, 1, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target_width must be >= width'): - padded_image.eval(feed_dict={image_placeholder: image}) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 1, 2, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target_height must be >= height'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testDieIfTargetSizeNotPossibleWithGivenOffset(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 3, 0, 4, 4, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target size not possible with the given target offsets'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testDieIfImageTensorRankIsTwo(self): - image = np.vstack([[5, 6], - [9, 0]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 2, 2, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Wrong image tensor rank'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testResizeTensorsToRange(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 100 - factor = None - expected_shape_list = [(75, 50, 3), - (50, 100, 3), - (30, 100, 3)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=None, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - resized_image = session.run(new_tensor_list[0]) - self.assertEqual(resized_image.shape, expected_shape_list[i]) - - def testResizeTensorsToRangeWithFactor(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 98 - factor = 8 - expected_image_shape_list = [(81, 57, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(81, 57, 1), - (49, 97, 1), - (33, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithFactorAndLabelShapeCHW(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 98 - factor = 8 - expected_image_shape_list = [(81, 57, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(5, 81, 57), - (5, 49, 97), - (5, 33, 97)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([5, test_shape[0], test_shape[1]]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True, - label_layout_is_chw=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithSimilarMinMaxSizes(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - # Values set so that one of the side = 97. - min_size = 96 - max_size = 98 - factor = 8 - expected_image_shape_list = [(97, 65, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(97, 65, 1), - (49, 97, 1), - (33, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithEqualMaxSize(self): - test_shapes = [[97, 38], - [96, 97]] - # Make max_size equal to the larger value of test_shapes. - min_size = 97 - max_size = 97 - factor = 8 - expected_image_shape_list = [(97, 41, 3), - (97, 97, 3)] - expected_label_shape_list = [(97, 41, 1), - (97, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithPotentialErrorInTFCeil(self): - test_shape = [3936, 5248] - # Make max_size equal to the larger value of test_shapes. - min_size = 1441 - max_size = 1441 - factor = 16 - expected_image_shape = (1089, 1441, 3) - expected_label_shape = (1089, 1441, 1) - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape) - - def testResizeTensorsToRangeWithEqualMaxSizeWithoutAspectRatio(self): - test_shapes = [[97, 38], - [96, 97]] - # Make max_size equal to the larger value of test_shapes. - min_size = 97 - max_size = 97 - factor = 8 - keep_aspect_ratio = False - expected_image_shape_list = [(97, 97, 3), - (97, 97, 3)] - expected_label_shape_list = [(97, 97, 1), - (97, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - keep_aspect_ratio=keep_aspect_ratio, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/resnet_v1_beta.py b/research/deeplab/core/resnet_v1_beta.py deleted file mode 100644 index 0d5f1f19a234fb13cbac2d7397d0948b64d3011b..0000000000000000000000000000000000000000 --- a/research/deeplab/core/resnet_v1_beta.py +++ /dev/null @@ -1,827 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Resnet v1 model variants. - -Code branched out from slim/nets/resnet_v1.py, and please refer to it for -more details. - -The original version ResNets-v1 were proposed by: -[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition. arXiv:1512.03385 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import conv2d_ws -from deeplab.core import utils -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - -_DEFAULT_MULTI_GRID = [1, 1, 1] -_DEFAULT_MULTI_GRID_RESNET_18 = [1, 1] - - -@slim.add_arg_scope -def bottleneck(inputs, - depth, - depth_bottleneck, - stride, - unit_rate=1, - rate=1, - outputs_collections=None, - scope=None): - """Bottleneck residual unit variant with BN after convolutions. - - This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for - its definition. Note that we use here the bottleneck variant which has an - extra bottleneck layer. - - When putting together two consecutive ResNet blocks that use this unit, one - should use stride = 2 in the last unit of the first block. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth: The depth of the ResNet unit output. - depth_bottleneck: The depth of the bottleneck layers. - stride: The ResNet unit's stride. Determines the amount of downsampling of - the units output compared to its input. - unit_rate: An integer, unit rate for atrous convolution. - rate: An integer, rate for atrous convolution. - outputs_collections: Collection to add the ResNet unit output. - scope: Optional variable_scope. - - Returns: - The ResNet unit's output. - """ - with tf.variable_scope(scope, 'bottleneck_v1', [inputs]) as sc: - depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) - if depth == depth_in: - shortcut = resnet_utils.subsample(inputs, stride, 'shortcut') - else: - shortcut = conv2d_ws.conv2d( - inputs, - depth, - [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - - residual = conv2d_ws.conv2d(inputs, depth_bottleneck, [1, 1], stride=1, - scope='conv1') - residual = conv2d_ws.conv2d_same(residual, depth_bottleneck, 3, stride, - rate=rate*unit_rate, scope='conv2') - residual = conv2d_ws.conv2d(residual, depth, [1, 1], stride=1, - activation_fn=None, scope='conv3') - output = tf.nn.relu(shortcut + residual) - - return slim.utils.collect_named_outputs(outputs_collections, sc.name, - output) - - -@slim.add_arg_scope -def lite_bottleneck(inputs, - depth, - stride, - unit_rate=1, - rate=1, - outputs_collections=None, - scope=None): - """Bottleneck residual unit variant with BN after convolutions. - - This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for - its definition. Note that we use here the bottleneck variant which has an - extra bottleneck layer. - - When putting together two consecutive ResNet blocks that use this unit, one - should use stride = 2 in the last unit of the first block. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth: The depth of the ResNet unit output. - stride: The ResNet unit's stride. Determines the amount of downsampling of - the units output compared to its input. - unit_rate: An integer, unit rate for atrous convolution. - rate: An integer, rate for atrous convolution. - outputs_collections: Collection to add the ResNet unit output. - scope: Optional variable_scope. - - Returns: - The ResNet unit's output. - """ - with tf.variable_scope(scope, 'lite_bottleneck_v1', [inputs]) as sc: - depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) - if depth == depth_in: - shortcut = resnet_utils.subsample(inputs, stride, 'shortcut') - else: - shortcut = conv2d_ws.conv2d( - inputs, - depth, [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - - residual = conv2d_ws.conv2d_same( - inputs, depth, 3, 1, rate=rate * unit_rate, scope='conv1') - with slim.arg_scope([conv2d_ws.conv2d], activation_fn=None): - residual = conv2d_ws.conv2d_same( - residual, depth, 3, stride, rate=rate * unit_rate, scope='conv2') - output = tf.nn.relu(shortcut + residual) - - return slim.utils.collect_named_outputs(outputs_collections, sc.name, - output) - - -def root_block_fn_for_beta_variant(net, depth_multiplier=1.0): - """Gets root_block_fn for beta variant. - - ResNet-v1 beta variant modifies the first original 7x7 convolution to three - 3x3 convolutions. - - Args: - net: A tensor of size [batch, height, width, channels], input to the model. - depth_multiplier: Controls the number of convolution output channels for - each input channel. The total number of depthwise convolution output - channels will be equal to `num_filters_out * depth_multiplier`. - - Returns: - A tensor after three 3x3 convolutions. - """ - net = conv2d_ws.conv2d_same( - net, int(64 * depth_multiplier), 3, stride=2, scope='conv1_1') - net = conv2d_ws.conv2d_same( - net, int(64 * depth_multiplier), 3, stride=1, scope='conv1_2') - net = conv2d_ws.conv2d_same( - net, int(128 * depth_multiplier), 3, stride=1, scope='conv1_3') - - return net - - -def resnet_v1_beta(inputs, - blocks, - num_classes=None, - is_training=None, - global_pool=True, - output_stride=None, - root_block_fn=None, - reuse=None, - scope=None, - sync_batch_norm_method='None'): - """Generator for v1 ResNet models (beta variant). - - This function generates a family of modified ResNet v1 models. In particular, - the first original 7x7 convolution is replaced with three 3x3 convolutions. - See the resnet_v1_*() methods for specific model instantiations, obtained by - selecting different block instantiations that produce ResNets of various - depths. - - The code is modified from slim/nets/resnet_v1.py, and please refer to it for - more details. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - blocks: A list of length equal to the number of ResNet blocks. Each element - is a resnet_utils.Block object describing the units in the block. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - root_block_fn: The function consisting of convolution operations applied to - the root input. If root_block_fn is None, use the original setting of - RseNet-v1, which is simply one convolution with 7x7 kernel and stride=2. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If the target output_stride is not valid. - """ - if root_block_fn is None: - root_block_fn = functools.partial(conv2d_ws.conv2d_same, - num_outputs=64, - kernel_size=7, - stride=2, - scope='conv1') - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with tf.variable_scope(scope, 'resnet_v1', [inputs], reuse=reuse) as sc: - end_points_collection = sc.original_name_scope + '_end_points' - with slim.arg_scope([ - conv2d_ws.conv2d, bottleneck, lite_bottleneck, - resnet_utils.stack_blocks_dense - ], - outputs_collections=end_points_collection): - if is_training is not None: - arg_scope = slim.arg_scope([batch_norm], is_training=is_training) - else: - arg_scope = slim.arg_scope([]) - with arg_scope: - net = inputs - if output_stride is not None: - if output_stride % 4 != 0: - raise ValueError('The output_stride needs to be a multiple of 4.') - output_stride //= 4 - net = root_block_fn(net) - net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='pool1') - net = resnet_utils.stack_blocks_dense(net, blocks, output_stride) - - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='pool5', keepdims=True) - if num_classes is not None: - net = conv2d_ws.conv2d(net, num_classes, [1, 1], activation_fn=None, - normalizer_fn=None, scope='logits', - use_weight_standardization=False) - # Convert end_points_collection into a dictionary of end_points. - end_points = slim.utils.convert_collection_to_dict( - end_points_collection) - if num_classes is not None: - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def resnet_v1_beta_block(scope, base_depth, num_units, stride): - """Helper function for creating a resnet_v1 beta variant bottleneck block. - - Args: - scope: The scope of the block. - base_depth: The depth of the bottleneck layer for each unit. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - - Returns: - A resnet_v1 bottleneck block. - """ - return resnet_utils.Block(scope, bottleneck, [{ - 'depth': base_depth * 4, - 'depth_bottleneck': base_depth, - 'stride': 1, - 'unit_rate': 1 - }] * (num_units - 1) + [{ - 'depth': base_depth * 4, - 'depth_bottleneck': base_depth, - 'stride': stride, - 'unit_rate': 1 - }]) - - -def resnet_v1_small_beta_block(scope, base_depth, num_units, stride): - """Helper function for creating a resnet_18 beta variant bottleneck block. - - Args: - scope: The scope of the block. - base_depth: The depth of the bottleneck layer for each unit. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - - Returns: - A resnet_18 bottleneck block. - """ - block_args = [] - for _ in range(num_units - 1): - block_args.append({'depth': base_depth, 'stride': 1, 'unit_rate': 1}) - block_args.append({'depth': base_depth, 'stride': stride, 'unit_rate': 1}) - return resnet_utils.Block(scope, lite_bottleneck, block_args) - - -def resnet_v1_18(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_18', - sync_batch_norm_method='None'): - """Resnet v1 18. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID_RESNET_18 - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - - block4_args = [] - for rate in multi_grid: - block4_args.append({'depth': 512, 'stride': 1, 'unit_rate': rate}) - - blocks = [ - resnet_v1_small_beta_block( - 'block1', base_depth=64, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block2', base_depth=128, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block3', base_depth=256, num_units=2, stride=2), - resnet_utils.Block('block4', lite_bottleneck, block4_args), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_18_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - root_depth_multiplier=0.25, - reuse=None, - scope='resnet_v1_18', - sync_batch_norm_method='None'): - """Resnet v1 18 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-18. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - root_depth_multiplier: Float, depth multiplier used for the first three - convolution layers that replace the 7x7 convolution. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID_RESNET_18 - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - - block4_args = [] - for rate in multi_grid: - block4_args.append({'depth': 512, 'stride': 1, 'unit_rate': rate}) - - blocks = [ - resnet_v1_small_beta_block( - 'block1', base_depth=64, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block2', base_depth=128, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block3', base_depth=256, num_units=2, stride=2), - resnet_utils.Block('block4', lite_bottleneck, block4_args), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant, - depth_multiplier=root_depth_multiplier), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_50(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_50', - sync_batch_norm_method='None'): - """Resnet v1 50. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=6, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_50_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_50', - sync_batch_norm_method='None'): - """Resnet v1 50 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-50. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=6, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_101(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_101', - sync_batch_norm_method='None'): - """Resnet v1 101. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=23, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_101_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_101', - sync_batch_norm_method='None'): - """Resnet v1 101 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-101. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=23, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_arg_scope(weight_decay=0.0001, - batch_norm_decay=0.997, - batch_norm_epsilon=1e-5, - batch_norm_scale=True, - activation_fn=tf.nn.relu, - use_batch_norm=True, - sync_batch_norm_method='None', - normalization_method='unspecified', - use_weight_standardization=False): - """Defines the default ResNet arg scope. - - Args: - weight_decay: The weight decay to use for regularizing the model. - batch_norm_decay: The moving average decay when estimating layer activation - statistics in batch normalization. - batch_norm_epsilon: Small constant to prevent division by zero when - normalizing activations by their variance in batch normalization. - batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the - activations in the batch normalization layer. - activation_fn: The activation function which is used in ResNet. - use_batch_norm: Deprecated in favor of normalization_method. - sync_batch_norm_method: String, sync batchnorm method. - normalization_method: String, one of `batch`, `none`, or `group`, to use - batch normalization, no normalization, or group normalization. - use_weight_standardization: Boolean, whether to use weight standardization. - - Returns: - An `arg_scope` to use for the resnet models. - """ - batch_norm_params = { - 'decay': batch_norm_decay, - 'epsilon': batch_norm_epsilon, - 'scale': batch_norm_scale, - } - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - if normalization_method == 'batch': - normalizer_fn = batch_norm - elif normalization_method == 'none': - normalizer_fn = None - elif normalization_method == 'group': - normalizer_fn = slim.group_norm - elif normalization_method == 'unspecified': - normalizer_fn = batch_norm if use_batch_norm else None - else: - raise ValueError('Unrecognized normalization_method %s' % - normalization_method) - - with slim.arg_scope([conv2d_ws.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - weights_initializer=slim.variance_scaling_initializer(), - activation_fn=activation_fn, - normalizer_fn=normalizer_fn, - use_weight_standardization=use_weight_standardization): - with slim.arg_scope([batch_norm], **batch_norm_params): - # The following implies padding='SAME' for pool1, which makes feature - # alignment easier for dense prediction tasks. This is also used in - # https://github.com/facebook/fb.resnet.torch. However the accompanying - # code of 'Deep Residual Learning for Image Recognition' uses - # padding='VALID' for pool1. You can switch to that choice by setting - # slim.arg_scope([slim.max_pool2d], padding='VALID'). - with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc: - return arg_sc diff --git a/research/deeplab/core/resnet_v1_beta_test.py b/research/deeplab/core/resnet_v1_beta_test.py deleted file mode 100644 index 8b61edcce21803047ea047a0acb1bc9e7ae147da..0000000000000000000000000000000000000000 --- a/research/deeplab/core/resnet_v1_beta_test.py +++ /dev/null @@ -1,564 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for resnet_v1_beta module.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools - -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import resnet_v1_beta -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Create test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.to_float( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels])) - - -class ResnetCompleteNetworkTest(tf.test.TestCase): - """Tests with complete small ResNet v1 networks.""" - - def _resnet_small_lite_bottleneck(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_small'): - """A shallow and thin ResNet v1 with lite_bottleneck.""" - if multi_grid is None: - multi_grid = [1, 1] - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - block = resnet_v1_beta.resnet_v1_small_beta_block - blocks = [ - block('block1', base_depth=1, num_units=1, stride=2), - block('block2', base_depth=2, num_units=1, stride=2), - block('block3', base_depth=4, num_units=1, stride=2), - resnet_utils.Block('block4', resnet_v1_beta.lite_bottleneck, [ - {'depth': 8, - 'stride': 1, - 'unit_rate': rate} for rate in multi_grid])] - return resnet_v1_beta.resnet_v1_beta( - inputs, - blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial( - resnet_v1_beta.root_block_fn_for_beta_variant, - depth_multiplier=0.25), - reuse=reuse, - scope=scope) - - def _resnet_small(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_small'): - """A shallow and thin ResNet v1 for faster tests.""" - if multi_grid is None: - multi_grid = [1, 1, 1] - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - block = resnet_v1_beta.resnet_v1_beta_block - blocks = [ - block('block1', base_depth=1, num_units=1, stride=2), - block('block2', base_depth=2, num_units=1, stride=2), - block('block3', base_depth=4, num_units=1, stride=2), - resnet_utils.Block('block4', resnet_v1_beta.bottleneck, [ - {'depth': 32, 'depth_bottleneck': 8, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid])] - - return resnet_v1_beta.resnet_v1_beta( - inputs, - blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial( - resnet_v1_beta.root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope) - - def testClassificationEndPointsWithLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithMultigridAndLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - multi_grid = [1, 2] - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - multi_grid=multi_grid, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationShapesWithLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 112, 112, 16], - 'resnet/conv1_2': [2, 112, 112, 16], - 'resnet/conv1_3': [2, 112, 112, 32], - 'resnet/block1': [2, 28, 28, 1], - 'resnet/block2': [2, 14, 14, 2], - 'resnet/block3': [2, 7, 7, 4], - 'resnet/block4': [2, 7, 7, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapesWithLiteBottleneck(self): - global_pool = False - num_classes = 10 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 16], - 'resnet/conv1_2': [2, 161, 161, 16], - 'resnet/conv1_3': [2, 161, 161, 32], - 'resnet/block1': [2, 41, 41, 1], - 'resnet/block2': [2, 21, 21, 2], - 'resnet/block3': [2, 11, 11, 4], - 'resnet/block4': [2, 11, 11, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapesWithLiteBottleneck(self): - global_pool = False - num_classes = 10 - output_stride = 8 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 16], - 'resnet/conv1_2': [2, 161, 161, 16], - 'resnet/conv1_3': [2, 161, 161, 32], - 'resnet/block1': [2, 41, 41, 1], - 'resnet/block2': [2, 41, 41, 2], - 'resnet/block3': [2, 41, 41, 4], - 'resnet/block4': [2, 41, 41, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValuesWithLiteBottleneck(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 81, 81, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-4, rtol=1e-4) - - def testUnknownBatchSizeWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, _ = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidthWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 8]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 3, 3, 8)) - - def testAtrousFullyConvolutionalUnknownHeightWidthWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 8]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 9, 9, 8)) - - def testClassificationEndPoints(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithWS(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(use_weight_standardization=True)): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithGN(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(normalization_method='group')): - with slim.arg_scope([slim.group_norm], groups=1): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testInvalidGroupsWithGN(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with self.assertRaisesRegexp(ValueError, 'Invalid groups'): - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(normalization_method='group')): - with slim.arg_scope([slim.group_norm], groups=32): - _, _ = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - def testClassificationEndPointsWithGNWS(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope( - normalization_method='group', use_weight_standardization=True)): - with slim.arg_scope([slim.group_norm], groups=1): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithMultigrid(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - multi_grid = [1, 2, 4] - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - multi_grid=multi_grid, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationShapes(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 112, 112, 64], - 'resnet/conv1_2': [2, 112, 112, 64], - 'resnet/conv1_3': [2, 112, 112, 128], - 'resnet/block1': [2, 28, 28, 4], - 'resnet/block2': [2, 14, 14, 8], - 'resnet/block3': [2, 7, 7, 16], - 'resnet/block4': [2, 7, 7, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 10 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 64], - 'resnet/conv1_2': [2, 161, 161, 64], - 'resnet/conv1_3': [2, 161, 161, 128], - 'resnet/block1': [2, 41, 41, 4], - 'resnet/block2': [2, 21, 21, 8], - 'resnet/block3': [2, 11, 11, 16], - 'resnet/block4': [2, 11, 11, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 10 - output_stride = 8 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 64], - 'resnet/conv1_2': [2, 161, 161, 64], - 'resnet/conv1_3': [2, 161, 161, 128], - 'resnet/block1': [2, 41, 41, 4], - 'resnet/block2': [2, 41, 41, 8], - 'resnet/block3': [2, 41, 41, 16], - 'resnet/block4': [2, 41, 41, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValues(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 81, 81, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._resnet_small(inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._resnet_small(inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-4, rtol=1e-4) - - def testUnknownBatchSize(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, _ = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small(inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 32]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 3, 3, 32)) - - def testAtrousFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small(inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 32]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 9, 9, 32)) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/utils.py b/research/deeplab/core/utils.py deleted file mode 100644 index 4bf3d09ad4647c757da5f9ebb3c2f676e3ccc00c..0000000000000000000000000000000000000000 --- a/research/deeplab/core/utils.py +++ /dev/null @@ -1,214 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""This script contains utility functions.""" -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim - -slim = contrib_slim - - -# Quantized version of sigmoid function. -q_sigmoid = lambda x: tf.nn.relu6(x + 3) * 0.16667 - - -def resize_bilinear(images, size, output_dtype=tf.float32): - """Returns resized images as output_type. - - Args: - images: A tensor of size [batch, height_in, width_in, channels]. - size: A 1-D int32 Tensor of 2 elements: new_height, new_width. The new size - for the images. - output_dtype: The destination type. - Returns: - A tensor of size [batch, height_out, width_out, channels] as a dtype of - output_dtype. - """ - images = tf.image.resize_bilinear(images, size, align_corners=True) - return tf.cast(images, dtype=output_dtype) - - -def scale_dimension(dim, scale): - """Scales the input dimension. - - Args: - dim: Input dimension (a scalar or a scalar Tensor). - scale: The amount of scaling applied to the input. - - Returns: - Scaled dimension. - """ - if isinstance(dim, tf.Tensor): - return tf.cast((tf.to_float(dim) - 1.0) * scale + 1.0, dtype=tf.int32) - else: - return int((float(dim) - 1.0) * scale + 1.0) - - -def split_separable_conv2d(inputs, - filters, - kernel_size=3, - rate=1, - weight_decay=0.00004, - depthwise_weights_initializer_stddev=0.33, - pointwise_weights_initializer_stddev=0.06, - scope=None): - """Splits a separable conv2d into depthwise and pointwise conv2d. - - This operation differs from `tf.layers.separable_conv2d` as this operation - applies activation function between depthwise and pointwise conv2d. - - Args: - inputs: Input tensor with shape [batch, height, width, channels]. - filters: Number of filters in the 1x1 pointwise convolution. - kernel_size: A list of length 2: [kernel_height, kernel_width] of - of the filters. Can be an int if both values are the same. - rate: Atrous convolution rate for the depthwise convolution. - weight_decay: The weight decay to use for regularizing the model. - depthwise_weights_initializer_stddev: The standard deviation of the - truncated normal weight initializer for depthwise convolution. - pointwise_weights_initializer_stddev: The standard deviation of the - truncated normal weight initializer for pointwise convolution. - scope: Optional scope for the operation. - - Returns: - Computed features after split separable conv2d. - """ - outputs = slim.separable_conv2d( - inputs, - None, - kernel_size=kernel_size, - depth_multiplier=1, - rate=rate, - weights_initializer=tf.truncated_normal_initializer( - stddev=depthwise_weights_initializer_stddev), - weights_regularizer=None, - scope=scope + '_depthwise') - return slim.conv2d( - outputs, - filters, - 1, - weights_initializer=tf.truncated_normal_initializer( - stddev=pointwise_weights_initializer_stddev), - weights_regularizer=slim.l2_regularizer(weight_decay), - scope=scope + '_pointwise') - - -def get_label_weight_mask(labels, ignore_label, num_classes, label_weights=1.0): - """Gets the label weight mask. - - Args: - labels: A Tensor of labels with the shape of [-1]. - ignore_label: Integer, label to ignore. - num_classes: Integer, the number of semantic classes. - label_weights: A float or a list of weights. If it is a float, it means all - the labels have the same weight. If it is a list of weights, then each - element in the list represents the weight for the label of its index, for - example, label_weights = [0.1, 0.5] means the weight for label 0 is 0.1 - and the weight for label 1 is 0.5. - - Returns: - A Tensor of label weights with the same shape of labels, each element is the - weight for the label with the same index in labels and the element is 0.0 - if the label is to ignore. - - Raises: - ValueError: If label_weights is neither a float nor a list, or if - label_weights is a list and its length is not equal to num_classes. - """ - if not isinstance(label_weights, (float, list)): - raise ValueError( - 'The type of label_weights is invalid, it must be a float or a list.') - - if isinstance(label_weights, list) and len(label_weights) != num_classes: - raise ValueError( - 'Length of label_weights must be equal to num_classes if it is a list, ' - 'label_weights: %s, num_classes: %d.' % (label_weights, num_classes)) - - not_ignore_mask = tf.not_equal(labels, ignore_label) - not_ignore_mask = tf.cast(not_ignore_mask, tf.float32) - if isinstance(label_weights, float): - return not_ignore_mask * label_weights - - label_weights = tf.constant(label_weights, tf.float32) - weight_mask = tf.einsum('...y,y->...', - tf.one_hot(labels, num_classes, dtype=tf.float32), - label_weights) - return tf.multiply(not_ignore_mask, weight_mask) - - -def get_batch_norm_fn(sync_batch_norm_method): - """Gets batch norm function. - - Currently we only support the following methods: - - `None` (no sync batch norm). We use slim.batch_norm in this case. - - Args: - sync_batch_norm_method: String, method used to sync batch norm. - - Returns: - Batchnorm function. - - Raises: - ValueError: If sync_batch_norm_method is not supported. - """ - if sync_batch_norm_method == 'None': - return slim.batch_norm - else: - raise ValueError('Unsupported sync_batch_norm_method.') - - -def get_batch_norm_params(decay=0.9997, - epsilon=1e-5, - center=True, - scale=True, - is_training=True, - sync_batch_norm_method='None', - initialize_gamma_as_zeros=False): - """Gets batch norm parameters. - - Args: - decay: Float, decay for the moving average. - epsilon: Float, value added to variance to avoid dividing by zero. - center: Boolean. If True, add offset of `beta` to normalized tensor. If - False,`beta` is ignored. - scale: Boolean. If True, multiply by `gamma`. If False, `gamma` is not used. - is_training: Boolean, whether or not the layer is in training mode. - sync_batch_norm_method: String, method used to sync batch norm. - initialize_gamma_as_zeros: Boolean, initializing `gamma` as zeros or not. - - Returns: - A dictionary for batchnorm parameters. - - Raises: - ValueError: If sync_batch_norm_method is not supported. - """ - batch_norm_params = { - 'is_training': is_training, - 'decay': decay, - 'epsilon': epsilon, - 'scale': scale, - 'center': center, - } - if initialize_gamma_as_zeros: - if sync_batch_norm_method == 'None': - # Slim-type gamma_initialier. - batch_norm_params['param_initializers'] = { - 'gamma': tf.zeros_initializer(), - } - else: - raise ValueError('Unsupported sync_batch_norm_method.') - return batch_norm_params diff --git a/research/deeplab/core/utils_test.py b/research/deeplab/core/utils_test.py deleted file mode 100644 index cfdb63ef2d3faaa8090867a5382876972b0cff3d..0000000000000000000000000000000000000000 --- a/research/deeplab/core/utils_test.py +++ /dev/null @@ -1,90 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for utils.py.""" - -import numpy as np -import tensorflow as tf - -from deeplab.core import utils - - -class UtilsTest(tf.test.TestCase): - - def testScaleDimensionOutput(self): - self.assertEqual(161, utils.scale_dimension(321, 0.5)) - self.assertEqual(193, utils.scale_dimension(321, 0.6)) - self.assertEqual(241, utils.scale_dimension(321, 0.75)) - - def testGetLabelWeightMask_withFloatLabelWeights(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = 0.5 - expected_label_weight_mask = np.array([0.5, 0.0, 0.5, 0.5, 0.5], - dtype=np.float32) - - with self.test_session() as sess: - label_weight_mask = utils.get_label_weight_mask( - labels, ignore_label, num_classes, label_weights=label_weights) - label_weight_mask = sess.run(label_weight_mask) - self.assertAllEqual(label_weight_mask, expected_label_weight_mask) - - def testGetLabelWeightMask_withListLabelWeights(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = [0.0, 0.1, 0.2, 0.3, 0.4] - expected_label_weight_mask = np.array([0.0, 0.0, 0.1, 0.3, 0.2], - dtype=np.float32) - - with self.test_session() as sess: - label_weight_mask = utils.get_label_weight_mask( - labels, ignore_label, num_classes, label_weights=label_weights) - label_weight_mask = sess.run(label_weight_mask) - self.assertAllEqual(label_weight_mask, expected_label_weight_mask) - - def testGetLabelWeightMask_withInvalidLabelWeightsType(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - - self.assertRaisesWithRegexpMatch( - ValueError, - '^The type of label_weights is invalid, it must be a float or a list', - utils.get_label_weight_mask, - labels=labels, - ignore_label=ignore_label, - num_classes=num_classes, - label_weights=None) - - def testGetLabelWeightMask_withInvalidLabelWeightsLength(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = [0.0, 0.1, 0.2] - - self.assertRaisesWithRegexpMatch( - ValueError, - '^Length of label_weights must be equal to num_classes if it is a list', - utils.get_label_weight_mask, - labels=labels, - ignore_label=ignore_label, - num_classes=num_classes, - label_weights=label_weights) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/xception.py b/research/deeplab/core/xception.py deleted file mode 100644 index f9925714716ea0346dd8df75b956a876e52bde69..0000000000000000000000000000000000000000 --- a/research/deeplab/core/xception.py +++ /dev/null @@ -1,945 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -r"""Xception model. - -"Xception: Deep Learning with Depthwise Separable Convolutions" -Fran{\c{c}}ois Chollet -https://arxiv.org/abs/1610.02357 - -We implement the modified version by Jifeng Dai et al. for their COCO 2017 -detection challenge submission, where the model is made deeper and has aligned -features for dense prediction tasks. See their slides for details: - -"Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge -2017 Entry" -Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei and Jifeng Dai -ICCV 2017 COCO Challenge workshop -http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf - -We made a few more changes on top of MSRA's modifications: -1. Fully convolutional: All the max-pooling layers are replaced with separable - conv2d with stride = 2. This allows us to use atrous convolution to extract - feature maps at any resolution. - -2. We support adding ReLU and BatchNorm after depthwise convolution, motivated - by the design of MobileNetv1. - -"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision -Applications" -Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, -Tobias Weyand, Marco Andreetto, Hartwig Adam -https://arxiv.org/abs/1704.04861 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import collections -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import utils -from tensorflow.contrib.slim.nets import resnet_utils -from nets.mobilenet import conv_blocks as mobilenet_v3_ops - -slim = contrib_slim - - -_DEFAULT_MULTI_GRID = [1, 1, 1] -# The cap for tf.clip_by_value. -_CLIP_CAP = 6 - - -class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])): - """A named tuple describing an Xception block. - - Its parts are: - scope: The scope of the block. - unit_fn: The Xception unit function which takes as input a tensor and - returns another tensor with the output of the Xception unit. - args: A list of length equal to the number of units in the block. The list - contains one dictionary for each unit in the block to serve as argument to - unit_fn. - """ - - -def fixed_padding(inputs, kernel_size, rate=1): - """Pads the input along the spatial dimensions independently of input size. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - kernel_size: The kernel to be used in the conv2d or max_pool2d operation. - Should be a positive integer. - rate: An integer, rate for atrous convolution. - - Returns: - output: A tensor of size [batch, height_out, width_out, channels] with the - input, either intact (if kernel_size == 1) or padded (if kernel_size > 1). - """ - kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) - pad_total = kernel_size_effective - 1 - pad_beg = pad_total // 2 - pad_end = pad_total - pad_beg - padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], - [pad_beg, pad_end], [0, 0]]) - return padded_inputs - - -@slim.add_arg_scope -def separable_conv2d_same(inputs, - num_outputs, - kernel_size, - depth_multiplier, - stride, - rate=1, - use_explicit_padding=True, - regularize_depthwise=False, - scope=None, - **kwargs): - """Strided 2-D separable convolution with 'SAME' padding. - - If stride > 1 and use_explicit_padding is True, then we do explicit zero- - padding, followed by conv2d with 'VALID' padding. - - Note that - - net = separable_conv2d_same(inputs, num_outputs, 3, - depth_multiplier=1, stride=stride) - - is equivalent to - - net = slim.separable_conv2d(inputs, num_outputs, 3, - depth_multiplier=1, stride=1, padding='SAME') - net = resnet_utils.subsample(net, factor=stride) - - whereas - - net = slim.separable_conv2d(inputs, num_outputs, 3, stride=stride, - depth_multiplier=1, padding='SAME') - - is different when the input's height or width is even, which is why we add the - current function. - - Consequently, if the input feature map has even height or width, setting - `use_explicit_padding=False` will result in feature misalignment by one pixel - along the corresponding dimension. - - Args: - inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. - num_outputs: An integer, the number of output filters. - kernel_size: An int with the kernel_size of the filters. - depth_multiplier: The number of depthwise convolution output channels for - each input channel. The total number of depthwise convolution output - channels will be equal to `num_filters_in * depth_multiplier`. - stride: An integer, the output stride. - rate: An integer, rate for atrous convolution. - use_explicit_padding: If True, use explicit padding to make the model fully - compatible with the open source version, otherwise use the native - Tensorflow 'SAME' padding. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - scope: Scope. - **kwargs: additional keyword arguments to pass to slim.conv2d - - Returns: - output: A 4-D tensor of size [batch, height_out, width_out, channels] with - the convolution output. - """ - def _separable_conv2d(padding): - """Wrapper for separable conv2d.""" - return slim.separable_conv2d(inputs, - num_outputs, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - padding=padding, - scope=scope, - **kwargs) - def _split_separable_conv2d(padding): - """Splits separable conv2d into depthwise and pointwise conv2d.""" - outputs = slim.separable_conv2d(inputs, - None, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - padding=padding, - scope=scope + '_depthwise', - **kwargs) - return slim.conv2d(outputs, - num_outputs, - 1, - scope=scope + '_pointwise', - **kwargs) - if stride == 1 or not use_explicit_padding: - if regularize_depthwise: - outputs = _separable_conv2d(padding='SAME') - else: - outputs = _split_separable_conv2d(padding='SAME') - else: - inputs = fixed_padding(inputs, kernel_size, rate) - if regularize_depthwise: - outputs = _separable_conv2d(padding='VALID') - else: - outputs = _split_separable_conv2d(padding='VALID') - return outputs - - -@slim.add_arg_scope -def xception_module(inputs, - depth_list, - skip_connection_type, - stride, - kernel_size=3, - unit_rate_list=None, - rate=1, - activation_fn_in_separable_conv=False, - regularize_depthwise=False, - outputs_collections=None, - scope=None, - use_bounded_activation=False, - use_explicit_padding=True, - use_squeeze_excite=False, - se_pool_size=None): - """An Xception module. - - The output of one Xception module is equal to the sum of `residual` and - `shortcut`, where `residual` is the feature computed by three separable - convolution. The `shortcut` is the feature computed by 1x1 convolution with - or without striding. In some cases, the `shortcut` path could be a simple - identity function or none (i.e, no shortcut). - - Note that we replace the max pooling operations in the Xception module with - another separable convolution with striding, since atrous rate is not properly - supported in current TensorFlow max pooling implementation. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth_list: A list of three integers specifying the depth values of one - Xception module. - skip_connection_type: Skip connection type for the residual path. Only - supports 'conv', 'sum', or 'none'. - stride: The block unit's stride. Determines the amount of downsampling of - the units output compared to its input. - kernel_size: Integer, convolution kernel size. - unit_rate_list: A list of three integers, determining the unit rate for - each separable convolution in the xception module. - rate: An integer, rate for atrous convolution. - activation_fn_in_separable_conv: Includes activation function in the - separable convolution or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - outputs_collections: Collection to add the Xception unit output. - scope: Optional variable_scope. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - use_explicit_padding: If True, use explicit padding to make the model fully - compatible with the open source version, otherwise use the native - Tensorflow 'SAME' padding. - use_squeeze_excite: Boolean, use squeeze-and-excitation or not. - se_pool_size: None or integer specifying the pooling size used in SE module. - - Returns: - The Xception module's output. - - Raises: - ValueError: If depth_list and unit_rate_list do not contain three elements, - or if stride != 1 for the third separable convolution operation in the - residual path, or unsupported skip connection type. - """ - if len(depth_list) != 3: - raise ValueError('Expect three elements in depth_list.') - if unit_rate_list: - if len(unit_rate_list) != 3: - raise ValueError('Expect three elements in unit_rate_list.') - - with tf.variable_scope(scope, 'xception_module', [inputs]) as sc: - residual = inputs - - def _separable_conv(features, depth, kernel_size, depth_multiplier, - regularize_depthwise, rate, stride, scope): - """Separable conv block.""" - if activation_fn_in_separable_conv: - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - else: - if use_bounded_activation: - # When use_bounded_activation is True, we clip the feature values and - # apply relu6 for activation. - activation_fn = lambda x: tf.clip_by_value(x, -_CLIP_CAP, _CLIP_CAP) - features = tf.nn.relu6(features) - else: - # Original network design. - activation_fn = None - features = tf.nn.relu(features) - return separable_conv2d_same(features, - depth, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - activation_fn=activation_fn, - use_explicit_padding=use_explicit_padding, - regularize_depthwise=regularize_depthwise, - scope=scope) - for i in range(3): - residual = _separable_conv(residual, - depth_list[i], - kernel_size=kernel_size, - depth_multiplier=1, - regularize_depthwise=regularize_depthwise, - rate=rate*unit_rate_list[i], - stride=stride if i == 2 else 1, - scope='separable_conv' + str(i+1)) - if use_squeeze_excite: - residual = mobilenet_v3_ops.squeeze_excite( - input_tensor=residual, - squeeze_factor=16, - inner_activation_fn=tf.nn.relu, - gating_fn=lambda x: tf.nn.relu6(x+3)*0.16667, - pool=se_pool_size) - - if skip_connection_type == 'conv': - shortcut = slim.conv2d(inputs, - depth_list[-1], - [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - if use_bounded_activation: - residual = tf.clip_by_value(residual, -_CLIP_CAP, _CLIP_CAP) - shortcut = tf.clip_by_value(shortcut, -_CLIP_CAP, _CLIP_CAP) - outputs = residual + shortcut - if use_bounded_activation: - outputs = tf.nn.relu6(outputs) - elif skip_connection_type == 'sum': - if use_bounded_activation: - residual = tf.clip_by_value(residual, -_CLIP_CAP, _CLIP_CAP) - inputs = tf.clip_by_value(inputs, -_CLIP_CAP, _CLIP_CAP) - outputs = residual + inputs - if use_bounded_activation: - outputs = tf.nn.relu6(outputs) - elif skip_connection_type == 'none': - outputs = residual - else: - raise ValueError('Unsupported skip connection type.') - - return slim.utils.collect_named_outputs(outputs_collections, - sc.name, - outputs) - - -@slim.add_arg_scope -def stack_blocks_dense(net, - blocks, - output_stride=None, - outputs_collections=None): - """Stacks Xception blocks and controls output feature density. - - First, this function creates scopes for the Xception in the form of - 'block_name/unit_1', 'block_name/unit_2', etc. - - Second, this function allows the user to explicitly control the output - stride, which is the ratio of the input to output spatial resolution. This - is useful for dense prediction tasks such as semantic segmentation or - object detection. - - Control of the output feature density is implemented by atrous convolution. - - Args: - net: A tensor of size [batch, height, width, channels]. - blocks: A list of length equal to the number of Xception blocks. Each - element is an Xception Block object describing the units in the block. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution, which needs to be equal to - the product of unit strides from the start up to some level of Xception. - For example, if the Xception employs units with strides 1, 2, 1, 3, 4, 1, - then valid values for the output_stride are 1, 2, 6, 24 or None (which - is equivalent to output_stride=24). - outputs_collections: Collection to add the Xception block outputs. - - Returns: - net: Output tensor with stride equal to the specified output_stride. - - Raises: - ValueError: If the target output_stride is not valid. - """ - # The current_stride variable keeps track of the effective stride of the - # activations. This allows us to invoke atrous convolution whenever applying - # the next residual unit would result in the activations having stride larger - # than the target output_stride. - current_stride = 1 - - # The atrous convolution rate parameter. - rate = 1 - - for block in blocks: - with tf.variable_scope(block.scope, 'block', [net]) as sc: - for i, unit in enumerate(block.args): - if output_stride is not None and current_stride > output_stride: - raise ValueError('The target output_stride cannot be reached.') - with tf.variable_scope('unit_%d' % (i + 1), values=[net]): - # If we have reached the target output_stride, then we need to employ - # atrous convolution with stride=1 and multiply the atrous rate by the - # current unit's stride for use in subsequent layers. - if output_stride is not None and current_stride == output_stride: - net = block.unit_fn(net, rate=rate, **dict(unit, stride=1)) - rate *= unit.get('stride', 1) - else: - net = block.unit_fn(net, rate=1, **unit) - current_stride *= unit.get('stride', 1) - - # Collect activations at the block's end before performing subsampling. - net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net) - - if output_stride is not None and current_stride != output_stride: - raise ValueError('The target output_stride cannot be reached.') - - return net - - -def xception(inputs, - blocks, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - reuse=None, - scope=None, - sync_batch_norm_method='None'): - """Generator for Xception models. - - This function generates a family of Xception models. See the xception_*() - methods for specific model instantiations, obtained by selecting different - block instantiations that produce Xception of various depths. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. Must be - floating point. If a pretrained checkpoint is used, pixel values should be - the same as during training (see go/slim-classification-models for - specifics). - blocks: A list of length equal to the number of Xception blocks. Each - element is an Xception Block object describing the units in the block. - num_classes: Number of predicted classes for classification tasks. - If 0 or None, we return the features before the logit layer. - is_training: whether batch_norm layers are in training mode. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - keep_prob: Keep probability used in the pre-logits dropout layer. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. Currently only - support `None`. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is 0 or None, - then net is the output of the last Xception block, potentially after - global average pooling. If num_classes is a non-zero integer, net contains - the pre-softmax activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If the target output_stride is not valid. - """ - with tf.variable_scope( - scope, 'xception', [inputs], reuse=reuse) as sc: - end_points_collection = sc.original_name_scope + 'end_points' - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with slim.arg_scope([slim.conv2d, - slim.separable_conv2d, - xception_module, - stack_blocks_dense], - outputs_collections=end_points_collection): - with slim.arg_scope([batch_norm], is_training=is_training): - net = inputs - if output_stride is not None: - if output_stride % 2 != 0: - raise ValueError('The output_stride needs to be a multiple of 2.') - output_stride //= 2 - # Root block function operated on inputs. - net = resnet_utils.conv2d_same(net, 32, 3, stride=2, - scope='entry_flow/conv1_1') - net = resnet_utils.conv2d_same(net, 64, 3, stride=1, - scope='entry_flow/conv1_2') - - # Extract features for entry_flow, middle_flow, and exit_flow. - net = stack_blocks_dense(net, blocks, output_stride) - - # Convert end_points_collection into a dictionary of end_points. - end_points = slim.utils.convert_collection_to_dict( - end_points_collection, clear_collection=True) - - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='global_pool', keepdims=True) - end_points['global_pool'] = net - if num_classes: - net = slim.dropout(net, keep_prob=keep_prob, is_training=is_training, - scope='prelogits_dropout') - net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, - normalizer_fn=None, scope='logits') - end_points[sc.name + '/logits'] = net - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def xception_block(scope, - depth_list, - skip_connection_type, - activation_fn_in_separable_conv, - regularize_depthwise, - num_units, - stride, - kernel_size=3, - unit_rate_list=None, - use_squeeze_excite=False, - se_pool_size=None): - """Helper function for creating a Xception block. - - Args: - scope: The scope of the block. - depth_list: The depth of the bottleneck layer for each unit. - skip_connection_type: Skip connection type for the residual path. Only - supports 'conv', 'sum', or 'none'. - activation_fn_in_separable_conv: Includes activation function in the - separable convolution or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - kernel_size: Integer, convolution kernel size. - unit_rate_list: A list of three integers, determining the unit rate in the - corresponding xception block. - use_squeeze_excite: Boolean, use squeeze-and-excitation or not. - se_pool_size: None or integer specifying the pooling size used in SE module. - - Returns: - An Xception block. - """ - if unit_rate_list is None: - unit_rate_list = _DEFAULT_MULTI_GRID - return Block(scope, xception_module, [{ - 'depth_list': depth_list, - 'skip_connection_type': skip_connection_type, - 'activation_fn_in_separable_conv': activation_fn_in_separable_conv, - 'regularize_depthwise': regularize_depthwise, - 'stride': stride, - 'kernel_size': kernel_size, - 'unit_rate_list': unit_rate_list, - 'use_squeeze_excite': use_squeeze_excite, - 'se_pool_size': se_pool_size, - }] * num_units) - - -def xception_41(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_41', - sync_batch_norm_method='None'): - """Xception-41 model.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('entry_flow/block3', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=8, - stride=1), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - unit_rate_list=multi_grid), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_65_factory(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - kernel_size=3, - multi_grid=None, - reuse=None, - use_squeeze_excite=False, - se_pool_size=None, - scope='xception_65', - sync_batch_norm_method='None'): - """Xception-65 model factory.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block3', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=16, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - unit_rate_list=multi_grid, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_65(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_65', - sync_batch_norm_method='None'): - """Xception-65 model.""" - return xception_65_factory( - inputs=inputs, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=scope, - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_71_factory(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - kernel_size=3, - multi_grid=None, - reuse=None, - scope='xception_71', - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method='None'): - """Xception-71 model factory.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block3', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block4', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('entry_flow/block5', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=16, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - unit_rate_list=multi_grid, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_71(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_71', - sync_batch_norm_method='None'): - """Xception-71 model.""" - return xception_71_factory( - inputs=inputs, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=scope, - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_arg_scope(weight_decay=0.00004, - batch_norm_decay=0.9997, - batch_norm_epsilon=0.001, - batch_norm_scale=True, - weights_initializer_stddev=0.09, - regularize_depthwise=False, - use_batch_norm=True, - use_bounded_activation=False, - sync_batch_norm_method='None'): - """Defines the default Xception arg scope. - - Args: - weight_decay: The weight decay to use for regularizing the model. - batch_norm_decay: The moving average decay when estimating layer activation - statistics in batch normalization. - batch_norm_epsilon: Small constant to prevent division by zero when - normalizing activations by their variance in batch normalization. - batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the - activations in the batch normalization layer. - weights_initializer_stddev: The standard deviation of the trunctated normal - weight initializer. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - use_batch_norm: Whether or not to use batch normalization. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - sync_batch_norm_method: String, sync batchnorm method. Currently only - support `None`. Also, it is only effective for Xception. - - Returns: - An `arg_scope` to use for the Xception models. - """ - batch_norm_params = { - 'decay': batch_norm_decay, - 'epsilon': batch_norm_epsilon, - 'scale': batch_norm_scale, - } - if regularize_depthwise: - depthwise_regularizer = slim.l2_regularizer(weight_decay) - else: - depthwise_regularizer = None - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_initializer=tf.truncated_normal_initializer( - stddev=weights_initializer_stddev), - activation_fn=activation_fn, - normalizer_fn=batch_norm if use_batch_norm else None): - with slim.arg_scope([batch_norm], **batch_norm_params): - with slim.arg_scope( - [slim.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay)): - with slim.arg_scope( - [slim.separable_conv2d], - weights_regularizer=depthwise_regularizer): - with slim.arg_scope( - [xception_module], - use_bounded_activation=use_bounded_activation, - use_explicit_padding=not use_bounded_activation) as arg_sc: - return arg_sc diff --git a/research/deeplab/core/xception_test.py b/research/deeplab/core/xception_test.py deleted file mode 100644 index fc338daa6e56d1290f5a9330a6728c1f8512881e..0000000000000000000000000000000000000000 --- a/research/deeplab/core/xception_test.py +++ /dev/null @@ -1,488 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for xception.py.""" -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import xception -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Create test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.cast( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels]), - tf.float32) - - -class UtilityFunctionTest(tf.test.TestCase): - - def testSeparableConv2DSameWithInputEvenSize(self): - n, n2 = 4, 2 - - # Input image. - x = create_test_input(1, n, n, 1) - - # Convolution kernel. - dw = create_test_input(1, 3, 3, 1) - dw = tf.reshape(dw, [3, 3, 1, 1]) - - tf.get_variable('Conv/depthwise_weights', initializer=dw) - tf.get_variable('Conv/pointwise_weights', - initializer=tf.ones([1, 1, 1, 1])) - tf.get_variable('Conv/biases', initializer=tf.zeros([1])) - tf.get_variable_scope().reuse_variables() - - y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=1, scope='Conv') - y1_expected = tf.cast([[14, 28, 43, 26], - [28, 48, 66, 37], - [43, 66, 84, 46], - [26, 37, 46, 22]], tf.float32) - y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) - - y2 = resnet_utils.subsample(y1, 2) - y2_expected = tf.cast([[14, 43], - [43, 84]], tf.float32) - y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) - - y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, - regularize_depthwise=True, - stride=2, scope='Conv') - y3_expected = y2_expected - - y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=2, scope='Conv') - y4_expected = tf.cast([[48, 37], - [37, 22]], tf.float32) - y4_expected = tf.reshape(y4_expected, [1, n2, n2, 1]) - - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertAllClose(y1.eval(), y1_expected.eval()) - self.assertAllClose(y2.eval(), y2_expected.eval()) - self.assertAllClose(y3.eval(), y3_expected.eval()) - self.assertAllClose(y4.eval(), y4_expected.eval()) - - def testSeparableConv2DSameWithInputOddSize(self): - n, n2 = 5, 3 - - # Input image. - x = create_test_input(1, n, n, 1) - - # Convolution kernel. - dw = create_test_input(1, 3, 3, 1) - dw = tf.reshape(dw, [3, 3, 1, 1]) - - tf.get_variable('Conv/depthwise_weights', initializer=dw) - tf.get_variable('Conv/pointwise_weights', - initializer=tf.ones([1, 1, 1, 1])) - tf.get_variable('Conv/biases', initializer=tf.zeros([1])) - tf.get_variable_scope().reuse_variables() - - y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=1, scope='Conv') - y1_expected = tf.cast([[14, 28, 43, 58, 34], - [28, 48, 66, 84, 46], - [43, 66, 84, 102, 55], - [58, 84, 102, 120, 64], - [34, 46, 55, 64, 30]], tf.float32) - y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) - - y2 = resnet_utils.subsample(y1, 2) - y2_expected = tf.cast([[14, 43, 34], - [43, 84, 55], - [34, 55, 30]], tf.float32) - y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) - - y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, - regularize_depthwise=True, - stride=2, scope='Conv') - y3_expected = y2_expected - - y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=2, scope='Conv') - y4_expected = y2_expected - - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertAllClose(y1.eval(), y1_expected.eval()) - self.assertAllClose(y2.eval(), y2_expected.eval()) - self.assertAllClose(y3.eval(), y3_expected.eval()) - self.assertAllClose(y4.eval(), y4_expected.eval()) - - -class XceptionNetworkTest(tf.test.TestCase): - """Tests with small Xception network.""" - - def _xception_small(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - regularize_depthwise=True, - reuse=None, - scope='xception_small'): - """A shallow and thin Xception for faster tests.""" - block = xception.xception_block - blocks = [ - block('entry_flow/block1', - depth_list=[1, 1, 1], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('entry_flow/block2', - depth_list=[2, 2, 2], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('entry_flow/block3', - depth_list=[4, 4, 4], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1), - block('entry_flow/block4', - depth_list=[4, 4, 4], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('middle_flow/block1', - depth_list=[4, 4, 4], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=2, - stride=1), - block('exit_flow/block1', - depth_list=[8, 8, 8], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('exit_flow/block2', - depth_list=[16, 16, 16], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1), - ] - return xception.xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope) - - def testClassificationEndPoints(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - logits, end_points = self._xception_small( - inputs, - num_classes=num_classes, - global_pool=global_pool, - scope='xception') - self.assertTrue( - logits.op.name.startswith('xception/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertTrue('predictions' in end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - self.assertTrue('global_pool' in end_points) - self.assertListEqual(end_points['global_pool'].get_shape().as_list(), - [2, 1, 1, 16]) - - def testEndpointNames(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes=num_classes, - global_pool=global_pool, - scope='xception') - expected = [ - 'xception/entry_flow/conv1_1', - 'xception/entry_flow/conv1_2', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block1/unit_1/xception_module/shortcut', - 'xception/entry_flow/block1/unit_1/xception_module', - 'xception/entry_flow/block1', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block2/unit_1/xception_module/shortcut', - 'xception/entry_flow/block2/unit_1/xception_module', - 'xception/entry_flow/block2', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block3/unit_1/xception_module/shortcut', - 'xception/entry_flow/block3/unit_1/xception_module', - 'xception/entry_flow/block3', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block4/unit_1/xception_module/shortcut', - 'xception/entry_flow/block4/unit_1/xception_module', - 'xception/entry_flow/block4', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/middle_flow/block1/unit_1/xception_module', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv1', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv2', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv3', - 'xception/middle_flow/block1/unit_2/xception_module', - 'xception/middle_flow/block1', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/exit_flow/block1/unit_1/xception_module/shortcut', - 'xception/exit_flow/block1/unit_1/xception_module', - 'xception/exit_flow/block1', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv1', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv2', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv3', - 'xception/exit_flow/block2/unit_1/xception_module', - 'xception/exit_flow/block2', - 'global_pool', - 'xception/logits', - 'predictions', - ] - self.assertItemsEqual(list(end_points.keys()), expected) - - def testClassificationShapes(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 64, 64, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/conv1_1': [2, 32, 32, 32], - 'xception/entry_flow/block1': [2, 16, 16, 1], - 'xception/entry_flow/block2': [2, 8, 8, 2], - 'xception/entry_flow/block4': [2, 4, 4, 4], - 'xception/middle_flow/block1': [2, 4, 4, 4], - 'xception/exit_flow/block1': [2, 2, 2, 8], - 'xception/exit_flow/block2': [2, 2, 2, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 3 - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/conv1_1': [2, 33, 33, 32], - 'xception/entry_flow/block1': [2, 17, 17, 1], - 'xception/entry_flow/block2': [2, 9, 9, 2], - 'xception/entry_flow/block4': [2, 5, 5, 4], - 'xception/middle_flow/block1': [2, 5, 5, 4], - 'xception/exit_flow/block1': [2, 3, 3, 8], - 'xception/exit_flow/block2': [2, 3, 3, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 3 - output_stride = 8 - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/block1': [2, 17, 17, 1], - 'xception/entry_flow/block2': [2, 9, 9, 2], - 'xception/entry_flow/block4': [2, 9, 9, 4], - 'xception/middle_flow/block1': [2, 9, 9, 4], - 'xception/exit_flow/block1': [2, 9, 9, 8], - 'xception/exit_flow/block2': [2, 9, 9, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValues(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(xception.xception_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 96, 97, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._xception_small( - inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._xception_small( - inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-5, rtol=1e-5) - - def testUnknownBatchSize(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(xception.xception_arg_scope()): - logits, _ = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - self.assertTrue(logits.op.name.startswith('xception/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(xception.xception_arg_scope()): - output, _ = self._xception_small( - inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 16]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 3, 3, 16)) - - def testAtrousFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(xception.xception_arg_scope()): - output, _ = self._xception_small( - inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 16]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 9, 9, 16)) - - def testEndpointsReuse(self): - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points0 = xception.xception_65( - inputs, - num_classes=10, - reuse=False) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points1 = xception.xception_65( - inputs, - num_classes=10, - reuse=True) - self.assertItemsEqual(list(end_points0.keys()), list(end_points1.keys())) - - def testUseBoundedAcitvation(self): - global_pool = False - num_classes = 3 - output_stride = 16 - for use_bounded_activation in (True, False): - tf.reset_default_graph() - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope( - use_bounded_activation=use_bounded_activation)): - _, _ = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='xception') - for node in tf.get_default_graph().as_graph_def().node: - if node.op.startswith('Relu'): - self.assertEqual(node.op == 'Relu6', use_bounded_activation) - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/datasets/__init__.py b/research/deeplab/datasets/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/datasets/build_ade20k_data.py b/research/deeplab/datasets/build_ade20k_data.py deleted file mode 100644 index fc04ed0db04c83af6deaad8b59087624e8bd40e8..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_ade20k_data.py +++ /dev/null @@ -1,123 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts ADE20K data to TFRecord file format with Example protos.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import math -import os -import random -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string( - 'train_image_folder', - './ADE20K/ADEChallengeData2016/images/training', - 'Folder containing trainng images') -tf.app.flags.DEFINE_string( - 'train_image_label_folder', - './ADE20K/ADEChallengeData2016/annotations/training', - 'Folder containing annotations for trainng images') - -tf.app.flags.DEFINE_string( - 'val_image_folder', - './ADE20K/ADEChallengeData2016/images/validation', - 'Folder containing validation images') - -tf.app.flags.DEFINE_string( - 'val_image_label_folder', - './ADE20K/ADEChallengeData2016/annotations/validation', - 'Folder containing annotations for validation') - -tf.app.flags.DEFINE_string( - 'output_dir', './ADE20K/tfrecord', - 'Path to save converted tfrecord of Tensorflow example') - -_NUM_SHARDS = 4 - - -def _convert_dataset(dataset_split, dataset_dir, dataset_label_dir): - """Converts the ADE20k dataset into into tfrecord format. - - Args: - dataset_split: Dataset split (e.g., train, val). - dataset_dir: Dir in which the dataset locates. - dataset_label_dir: Dir in which the annotations locates. - - Raises: - RuntimeError: If loaded image and label have different shape. - """ - - img_names = tf.gfile.Glob(os.path.join(dataset_dir, '*.jpg')) - random.shuffle(img_names) - seg_names = [] - for f in img_names: - # get the filename without the extension - basename = os.path.basename(f).split('.')[0] - # cover its corresponding *_seg.png - seg = os.path.join(dataset_label_dir, basename+'.png') - seg_names.append(seg) - - num_images = len(img_names) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('jpeg', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - output_filename = os.path.join( - FLAGS.output_dir, - '%s-%05d-of-%05d.tfrecord' % (dataset_split, shard_id, _NUM_SHARDS)) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, num_images, shard_id)) - sys.stdout.flush() - # Read the image. - image_filename = img_names[i] - image_data = tf.gfile.FastGFile(image_filename, 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_filename = seg_names[i] - seg_data = tf.gfile.FastGFile(seg_filename, 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - example = build_data.image_seg_to_tfexample( - image_data, img_names[i], height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - tf.gfile.MakeDirs(FLAGS.output_dir) - _convert_dataset( - 'train', FLAGS.train_image_folder, FLAGS.train_image_label_folder) - _convert_dataset('val', FLAGS.val_image_folder, FLAGS.val_image_label_folder) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/build_cityscapes_data.py b/research/deeplab/datasets/build_cityscapes_data.py deleted file mode 100644 index ce81baef20a460abaa634d3f1dcb6760a0858dec..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_cityscapes_data.py +++ /dev/null @@ -1,188 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts Cityscapes data to TFRecord file format with Example protos. - -The Cityscapes dataset is expected to have the following directory structure: - - + cityscapes - - build_cityscapes_data.py (current working directiory). - - build_data.py - + cityscapesscripts - + annotation - + evaluation - + helpers - + preparation - + viewer - + gtFine - + train - + val - + test - + leftImg8bit - + train - + val - + test - + tfrecord - -This script converts data into sharded data files and save at tfrecord folder. - -Note that before running this script, the users should (1) register the -Cityscapes dataset website at https://www.cityscapes-dataset.com to -download the dataset, and (2) run the script provided by Cityscapes -`preparation/createTrainIdLabelImgs.py` to generate the training groundtruth. - -Also note that the tensorflow model will be trained with `TrainId' instead -of `EvalId' used on the evaluation server. Thus, the users need to convert -the predicted labels to `EvalId` for evaluation on the server. See the -vis.py for more details. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import glob -import math -import os.path -import re -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string('cityscapes_root', - './cityscapes', - 'Cityscapes dataset root folder.') - -tf.app.flags.DEFINE_string( - 'output_dir', - './tfrecord', - 'Path to save converted SSTable of TensorFlow examples.') - - -_NUM_SHARDS = 10 - -# A map from data type to folder name that saves the data. -_FOLDERS_MAP = { - 'image': 'leftImg8bit', - 'label': 'gtFine', -} - -# A map from data type to filename postfix. -_POSTFIX_MAP = { - 'image': '_leftImg8bit', - 'label': '_gtFine_labelTrainIds', -} - -# A map from data type to data format. -_DATA_FORMAT_MAP = { - 'image': 'png', - 'label': 'png', -} - -# Image file pattern. -_IMAGE_FILENAME_RE = re.compile('(.+)' + _POSTFIX_MAP['image']) - - -def _get_files(data, dataset_split): - """Gets files for the specified data type and dataset split. - - Args: - data: String, desired data ('image' or 'label'). - dataset_split: String, dataset split ('train', 'val', 'test') - - Returns: - A list of sorted file names or None when getting label for - test set. - """ - if data == 'label' and dataset_split == 'test': - return None - pattern = '*%s.%s' % (_POSTFIX_MAP[data], _DATA_FORMAT_MAP[data]) - search_files = os.path.join( - FLAGS.cityscapes_root, _FOLDERS_MAP[data], dataset_split, '*', pattern) - filenames = glob.glob(search_files) - return sorted(filenames) - - -def _convert_dataset(dataset_split): - """Converts the specified dataset split to TFRecord format. - - Args: - dataset_split: The dataset split (e.g., train, val). - - Raises: - RuntimeError: If loaded image and label have different shape, or if the - image file with specified postfix could not be found. - """ - image_files = _get_files('image', dataset_split) - label_files = _get_files('label', dataset_split) - - num_images = len(image_files) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('png', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - shard_filename = '%s-%05d-of-%05d.tfrecord' % ( - dataset_split, shard_id, _NUM_SHARDS) - output_filename = os.path.join(FLAGS.output_dir, shard_filename) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, num_images, shard_id)) - sys.stdout.flush() - # Read the image. - image_data = tf.gfile.FastGFile(image_files[i], 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_data = tf.gfile.FastGFile(label_files[i], 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - re_match = _IMAGE_FILENAME_RE.search(image_files[i]) - if re_match is None: - raise RuntimeError('Invalid image filename: ' + image_files[i]) - filename = os.path.basename(re_match.group(1)) - example = build_data.image_seg_to_tfexample( - image_data, filename, height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - # Only support converting 'train' and 'val' sets for now. - for dataset_split in ['train', 'val']: - _convert_dataset(dataset_split) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/build_data.py b/research/deeplab/datasets/build_data.py deleted file mode 100644 index 45628674dbf3653ca0ca20014a968794bb8cd861..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_data.py +++ /dev/null @@ -1,161 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Contains common utility functions and classes for building dataset. - -This script contains utility functions and classes to converts dataset to -TFRecord file format with Example protos. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -import collections -import six -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_enum('image_format', 'png', ['jpg', 'jpeg', 'png'], - 'Image format.') - -tf.app.flags.DEFINE_enum('label_format', 'png', ['png'], - 'Segmentation label format.') - -# A map from image format to expected data format. -_IMAGE_FORMAT_MAP = { - 'jpg': 'jpeg', - 'jpeg': 'jpeg', - 'png': 'png', -} - - -class ImageReader(object): - """Helper class that provides TensorFlow image coding utilities.""" - - def __init__(self, image_format='jpeg', channels=3): - """Class constructor. - - Args: - image_format: Image format. Only 'jpeg', 'jpg', or 'png' are supported. - channels: Image channels. - """ - with tf.Graph().as_default(): - self._decode_data = tf.placeholder(dtype=tf.string) - self._image_format = image_format - self._session = tf.Session() - if self._image_format in ('jpeg', 'jpg'): - self._decode = tf.image.decode_jpeg(self._decode_data, - channels=channels) - elif self._image_format == 'png': - self._decode = tf.image.decode_png(self._decode_data, - channels=channels) - - def read_image_dims(self, image_data): - """Reads the image dimensions. - - Args: - image_data: string of image data. - - Returns: - image_height and image_width. - """ - image = self.decode_image(image_data) - return image.shape[:2] - - def decode_image(self, image_data): - """Decodes the image data string. - - Args: - image_data: string of image data. - - Returns: - Decoded image data. - - Raises: - ValueError: Value of image channels not supported. - """ - image = self._session.run(self._decode, - feed_dict={self._decode_data: image_data}) - if len(image.shape) != 3 or image.shape[2] not in (1, 3): - raise ValueError('The image channels not supported.') - - return image - - -def _int64_list_feature(values): - """Returns a TF-Feature of int64_list. - - Args: - values: A scalar or list of values. - - Returns: - A TF-Feature. - """ - if not isinstance(values, collections.Iterable): - values = [values] - - return tf.train.Feature(int64_list=tf.train.Int64List(value=values)) - - -def _bytes_list_feature(values): - """Returns a TF-Feature of bytes. - - Args: - values: A string. - - Returns: - A TF-Feature. - """ - def norm2bytes(value): - return value.encode() if isinstance(value, str) and six.PY3 else value - - return tf.train.Feature( - bytes_list=tf.train.BytesList(value=[norm2bytes(values)])) - - -def image_seg_to_tfexample(image_data, filename, height, width, seg_data): - """Converts one image/segmentation pair to tf example. - - Args: - image_data: string of image data. - filename: image filename. - height: image height. - width: image width. - seg_data: string of semantic segmentation data. - - Returns: - tf example of one image/segmentation pair. - """ - return tf.train.Example(features=tf.train.Features(feature={ - 'image/encoded': _bytes_list_feature(image_data), - 'image/filename': _bytes_list_feature(filename), - 'image/format': _bytes_list_feature( - _IMAGE_FORMAT_MAP[FLAGS.image_format]), - 'image/height': _int64_list_feature(height), - 'image/width': _int64_list_feature(width), - 'image/channels': _int64_list_feature(3), - 'image/segmentation/class/encoded': ( - _bytes_list_feature(seg_data)), - 'image/segmentation/class/format': _bytes_list_feature( - FLAGS.label_format), - })) diff --git a/research/deeplab/datasets/build_voc2012_data.py b/research/deeplab/datasets/build_voc2012_data.py deleted file mode 100644 index f0bdecb6a0f954d90164ac64b55966d0fe754557..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_voc2012_data.py +++ /dev/null @@ -1,146 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts PASCAL VOC 2012 data to TFRecord file format with Example protos. - -PASCAL VOC 2012 dataset is expected to have the following directory structure: - - + pascal_voc_seg - - build_data.py - - build_voc2012_data.py (current working directory). - + VOCdevkit - + VOC2012 - + JPEGImages - + SegmentationClass - + ImageSets - + Segmentation - + tfrecord - -Image folder: - ./VOCdevkit/VOC2012/JPEGImages - -Semantic segmentation annotations: - ./VOCdevkit/VOC2012/SegmentationClass - -list folder: - ./VOCdevkit/VOC2012/ImageSets/Segmentation - -This script converts data into sharded data files and save at tfrecord folder. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import math -import os.path -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string('image_folder', - './VOCdevkit/VOC2012/JPEGImages', - 'Folder containing images.') - -tf.app.flags.DEFINE_string( - 'semantic_segmentation_folder', - './VOCdevkit/VOC2012/SegmentationClassRaw', - 'Folder containing semantic segmentation annotations.') - -tf.app.flags.DEFINE_string( - 'list_folder', - './VOCdevkit/VOC2012/ImageSets/Segmentation', - 'Folder containing lists for training and validation') - -tf.app.flags.DEFINE_string( - 'output_dir', - './tfrecord', - 'Path to save converted SSTable of TensorFlow examples.') - - -_NUM_SHARDS = 4 - - -def _convert_dataset(dataset_split): - """Converts the specified dataset split to TFRecord format. - - Args: - dataset_split: The dataset split (e.g., train, test). - - Raises: - RuntimeError: If loaded image and label have different shape. - """ - dataset = os.path.basename(dataset_split)[:-4] - sys.stdout.write('Processing ' + dataset) - filenames = [x.strip('\n') for x in open(dataset_split, 'r')] - num_images = len(filenames) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('jpeg', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - output_filename = os.path.join( - FLAGS.output_dir, - '%s-%05d-of-%05d.tfrecord' % (dataset, shard_id, _NUM_SHARDS)) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, len(filenames), shard_id)) - sys.stdout.flush() - # Read the image. - image_filename = os.path.join( - FLAGS.image_folder, filenames[i] + '.' + FLAGS.image_format) - image_data = tf.gfile.GFile(image_filename, 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_filename = os.path.join( - FLAGS.semantic_segmentation_folder, - filenames[i] + '.' + FLAGS.label_format) - seg_data = tf.gfile.GFile(seg_filename, 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - example = build_data.image_seg_to_tfexample( - image_data, filenames[i], height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - dataset_splits = tf.gfile.Glob(os.path.join(FLAGS.list_folder, '*.txt')) - for dataset_split in dataset_splits: - _convert_dataset(dataset_split) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/convert_cityscapes.sh b/research/deeplab/datasets/convert_cityscapes.sh deleted file mode 100644 index a95b5d66aad79ae7cbd6ad2d3ee60550ab7f6239..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/convert_cityscapes.sh +++ /dev/null @@ -1,58 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to preprocess the Cityscapes dataset. Note (1) the users should -# register the Cityscapes dataset website at -# https://www.cityscapes-dataset.com/downloads/ to download the dataset, -# and (2) the users should download the utility scripts provided by -# Cityscapes at https://github.com/mcordts/cityscapesScripts. -# -# Usage: -# bash ./convert_cityscapes.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_cityscapes_data.py -# - convert_cityscapes.sh -# + cityscapes -# + cityscapesscripts (downloaded scripts) -# + gtFine -# + leftImg8bit -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="." - -# Root path for Cityscapes dataset. -CITYSCAPES_ROOT="${WORK_DIR}/cityscapes" - -# Create training labels. -python "${CITYSCAPES_ROOT}/cityscapesscripts/preparation/createTrainIdLabelImgs.py" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${CITYSCAPES_ROOT}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -BUILD_SCRIPT="${CURRENT_DIR}/build_cityscapes_data.py" - -echo "Converting Cityscapes dataset..." -python "${BUILD_SCRIPT}" \ - --cityscapes_root="${CITYSCAPES_ROOT}" \ - --output_dir="${OUTPUT_DIR}" \ diff --git a/research/deeplab/datasets/data_generator.py b/research/deeplab/datasets/data_generator.py deleted file mode 100644 index d84e66f9c48181d579a027daa08206491d995b65..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/data_generator.py +++ /dev/null @@ -1,350 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Wrapper for providing semantic segmentaion data. - -The SegmentationDataset class provides both images and annotations (semantic -segmentation and/or instance segmentation) for TensorFlow. Currently, we -support the following datasets: - -1. PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). - -PASCAL VOC 2012 semantic segmentation dataset annotates 20 foreground objects -(e.g., bike, person, and so on) and leaves all the other semantic classes as -one background class. The dataset contains 1464, 1449, and 1456 annotated -images for the training, validation and test respectively. - -2. Cityscapes dataset (https://www.cityscapes-dataset.com) - -The Cityscapes dataset contains 19 semantic labels (such as road, person, car, -and so on) for urban street scenes. - -3. ADE20K dataset (http://groups.csail.mit.edu/vision/datasets/ADE20K) - -The ADE20K dataset contains 150 semantic labels both urban street scenes and -indoor scenes. - -References: - M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, - and A. Zisserman, The pascal visual object classes challenge a retrospective. - IJCV, 2014. - - M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, - U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban - scene understanding," In Proc. of CVPR, 2016. - - B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, "Scene Parsing - through ADE20K dataset", In Proc. of CVPR, 2017. -""" - -import collections -import os -import tensorflow as tf -from deeplab import common -from deeplab import input_preprocess - -# Named tuple to describe the dataset properties. -DatasetDescriptor = collections.namedtuple( - 'DatasetDescriptor', - [ - 'splits_to_sizes', # Splits of the dataset into training, val and test. - 'num_classes', # Number of semantic classes, including the - # background class (if exists). For example, there - # are 20 foreground classes + 1 background class in - # the PASCAL VOC 2012 dataset. Thus, we set - # num_classes=21. - 'ignore_label', # Ignore label value. - ]) - -_CITYSCAPES_INFORMATION = DatasetDescriptor( - splits_to_sizes={'train_fine': 2975, - 'train_coarse': 22973, - 'trainval_fine': 3475, - 'trainval_coarse': 23473, - 'val_fine': 500, - 'test_fine': 1525}, - num_classes=19, - ignore_label=255, -) - -_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 1464, - 'train_aug': 10582, - 'trainval': 2913, - 'val': 1449, - }, - num_classes=21, - ignore_label=255, -) - -_ADE20K_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 20210, # num of samples in images/training - 'val': 2000, # num of samples in images/validation - }, - num_classes=151, - ignore_label=0, -) - -_DATASETS_INFORMATION = { - 'cityscapes': _CITYSCAPES_INFORMATION, - 'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION, - 'ade20k': _ADE20K_INFORMATION, -} - -# Default file pattern of TFRecord of TensorFlow Example. -_FILE_PATTERN = '%s-*' - - -def get_cityscapes_dataset_name(): - return 'cityscapes' - - -class Dataset(object): - """Represents input dataset for deeplab model.""" - - def __init__(self, - dataset_name, - split_name, - dataset_dir, - batch_size, - crop_size, - min_resize_value=None, - max_resize_value=None, - resize_factor=None, - min_scale_factor=1., - max_scale_factor=1., - scale_factor_step_size=0, - model_variant=None, - num_readers=1, - is_training=False, - should_shuffle=False, - should_repeat=False): - """Initializes the dataset. - - Args: - dataset_name: Dataset name. - split_name: A train/val Split name. - dataset_dir: The directory of the dataset sources. - batch_size: Batch size. - crop_size: The size used to crop the image and label. - min_resize_value: Desired size of the smaller image side. - max_resize_value: Maximum allowed size of the larger image side. - resize_factor: Resized dimensions are multiple of factor plus one. - min_scale_factor: Minimum scale factor value. - max_scale_factor: Maximum scale factor value. - scale_factor_step_size: The step size from min scale factor to max scale - factor. The input is randomly scaled based on the value of - (min_scale_factor, max_scale_factor, scale_factor_step_size). - model_variant: Model variant (string) for choosing how to mean-subtract - the images. See feature_extractor.network_map for supported model - variants. - num_readers: Number of readers for data provider. - is_training: Boolean, if dataset is for training or not. - should_shuffle: Boolean, if should shuffle the input data. - should_repeat: Boolean, if should repeat the input data. - - Raises: - ValueError: Dataset name and split name are not supported. - """ - if dataset_name not in _DATASETS_INFORMATION: - raise ValueError('The specified dataset is not supported yet.') - self.dataset_name = dataset_name - - splits_to_sizes = _DATASETS_INFORMATION[dataset_name].splits_to_sizes - - if split_name not in splits_to_sizes: - raise ValueError('data split name %s not recognized' % split_name) - - if model_variant is None: - tf.logging.warning('Please specify a model_variant. See ' - 'feature_extractor.network_map for supported model ' - 'variants.') - - self.split_name = split_name - self.dataset_dir = dataset_dir - self.batch_size = batch_size - self.crop_size = crop_size - self.min_resize_value = min_resize_value - self.max_resize_value = max_resize_value - self.resize_factor = resize_factor - self.min_scale_factor = min_scale_factor - self.max_scale_factor = max_scale_factor - self.scale_factor_step_size = scale_factor_step_size - self.model_variant = model_variant - self.num_readers = num_readers - self.is_training = is_training - self.should_shuffle = should_shuffle - self.should_repeat = should_repeat - - self.num_of_classes = _DATASETS_INFORMATION[self.dataset_name].num_classes - self.ignore_label = _DATASETS_INFORMATION[self.dataset_name].ignore_label - - def _parse_function(self, example_proto): - """Function to parse the example proto. - - Args: - example_proto: Proto in the format of tf.Example. - - Returns: - A dictionary with parsed image, label, height, width and image name. - - Raises: - ValueError: Label is of wrong shape. - """ - - # Currently only supports jpeg and png. - # Need to use this logic because the shape is not known for - # tf.image.decode_image and we rely on this info to - # extend label if necessary. - def _decode_image(content, channels): - return tf.cond( - tf.image.is_jpeg(content), - lambda: tf.image.decode_jpeg(content, channels), - lambda: tf.image.decode_png(content, channels)) - - features = { - 'image/encoded': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/filename': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/format': - tf.FixedLenFeature((), tf.string, default_value='jpeg'), - 'image/height': - tf.FixedLenFeature((), tf.int64, default_value=0), - 'image/width': - tf.FixedLenFeature((), tf.int64, default_value=0), - 'image/segmentation/class/encoded': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/segmentation/class/format': - tf.FixedLenFeature((), tf.string, default_value='png'), - } - - parsed_features = tf.parse_single_example(example_proto, features) - - image = _decode_image(parsed_features['image/encoded'], channels=3) - - label = None - if self.split_name != common.TEST_SET: - label = _decode_image( - parsed_features['image/segmentation/class/encoded'], channels=1) - - image_name = parsed_features['image/filename'] - if image_name is None: - image_name = tf.constant('') - - sample = { - common.IMAGE: image, - common.IMAGE_NAME: image_name, - common.HEIGHT: parsed_features['image/height'], - common.WIDTH: parsed_features['image/width'], - } - - if label is not None: - if label.get_shape().ndims == 2: - label = tf.expand_dims(label, 2) - elif label.get_shape().ndims == 3 and label.shape.dims[2] == 1: - pass - else: - raise ValueError('Input label shape must be [height, width], or ' - '[height, width, 1].') - - label.set_shape([None, None, 1]) - - sample[common.LABELS_CLASS] = label - - return sample - - def _preprocess_image(self, sample): - """Preprocesses the image and label. - - Args: - sample: A sample containing image and label. - - Returns: - sample: Sample with preprocessed image and label. - - Raises: - ValueError: Ground truth label not provided during training. - """ - image = sample[common.IMAGE] - label = sample[common.LABELS_CLASS] - - original_image, image, label = input_preprocess.preprocess_image_and_label( - image=image, - label=label, - crop_height=self.crop_size[0], - crop_width=self.crop_size[1], - min_resize_value=self.min_resize_value, - max_resize_value=self.max_resize_value, - resize_factor=self.resize_factor, - min_scale_factor=self.min_scale_factor, - max_scale_factor=self.max_scale_factor, - scale_factor_step_size=self.scale_factor_step_size, - ignore_label=self.ignore_label, - is_training=self.is_training, - model_variant=self.model_variant) - - sample[common.IMAGE] = image - - if not self.is_training: - # Original image is only used during visualization. - sample[common.ORIGINAL_IMAGE] = original_image - - if label is not None: - sample[common.LABEL] = label - - # Remove common.LABEL_CLASS key in the sample since it is only used to - # derive label and not used in training and evaluation. - sample.pop(common.LABELS_CLASS, None) - - return sample - - def get_one_shot_iterator(self): - """Gets an iterator that iterates across the dataset once. - - Returns: - An iterator of type tf.data.Iterator. - """ - - files = self._get_all_files() - - dataset = ( - tf.data.TFRecordDataset(files, num_parallel_reads=self.num_readers) - .map(self._parse_function, num_parallel_calls=self.num_readers) - .map(self._preprocess_image, num_parallel_calls=self.num_readers)) - - if self.should_shuffle: - dataset = dataset.shuffle(buffer_size=100) - - if self.should_repeat: - dataset = dataset.repeat() # Repeat forever for training. - else: - dataset = dataset.repeat(1) - - dataset = dataset.batch(self.batch_size).prefetch(self.batch_size) - return dataset.make_one_shot_iterator() - - def _get_all_files(self): - """Gets all the files to read data from. - - Returns: - A list of input files. - """ - file_pattern = _FILE_PATTERN - file_pattern = os.path.join(self.dataset_dir, - file_pattern % self.split_name) - return tf.gfile.Glob(file_pattern) diff --git a/research/deeplab/datasets/data_generator_test.py b/research/deeplab/datasets/data_generator_test.py deleted file mode 100644 index f4425d01da0c6f3bafaaff7c038498349a5c3f98..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/data_generator_test.py +++ /dev/null @@ -1,115 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for deeplab.datasets.data_generator.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import collections - -from six.moves import range -import tensorflow as tf - -from deeplab import common -from deeplab.datasets import data_generator - -ImageAttributes = collections.namedtuple( - 'ImageAttributes', ['image', 'label', 'height', 'width', 'image_name']) - - -class DatasetTest(tf.test.TestCase): - - # Note: training dataset cannot be tested since there is shuffle operation. - # When disabling the shuffle, training dataset is operated same as validation - # dataset. Therefore it is not tested again. - def testPascalVocSegTestData(self): - dataset = data_generator.Dataset( - dataset_name='pascal_voc_seg', - split_name='val', - dataset_dir= - 'deeplab/testing/pascal_voc_seg', - batch_size=1, - crop_size=[3, 3], # Use small size for testing. - min_resize_value=3, - max_resize_value=3, - resize_factor=None, - min_scale_factor=0.01, - max_scale_factor=2.0, - scale_factor_step_size=0.25, - is_training=False, - model_variant='mobilenet_v2') - - self.assertAllEqual(dataset.num_of_classes, 21) - self.assertAllEqual(dataset.ignore_label, 255) - - num_of_images = 3 - with self.test_session() as sess: - iterator = dataset.get_one_shot_iterator() - - for i in range(num_of_images): - batch = iterator.get_next() - batch, = sess.run([batch]) - image_attributes = _get_attributes_of_image(i) - self.assertEqual(batch[common.HEIGHT][0], image_attributes.height) - self.assertEqual(batch[common.WIDTH][0], image_attributes.width) - self.assertEqual(batch[common.IMAGE_NAME][0], - image_attributes.image_name.encode()) - - # All data have been read. - with self.assertRaisesRegexp(tf.errors.OutOfRangeError, ''): - sess.run([iterator.get_next()]) - - -def _get_attributes_of_image(index): - """Gets the attributes of the image. - - Args: - index: Index of image in all images. - - Returns: - Attributes of the image in the format of ImageAttributes. - - Raises: - ValueError: If index is of wrong value. - """ - if index == 0: - return ImageAttributes( - image=None, - label=None, - height=366, - width=500, - image_name='2007_000033') - elif index == 1: - return ImageAttributes( - image=None, - label=None, - height=335, - width=500, - image_name='2007_000042') - elif index == 2: - return ImageAttributes( - image=None, - label=None, - height=333, - width=500, - image_name='2007_000061') - else: - raise ValueError('Index can only be 0, 1 or 2.') - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/datasets/download_and_convert_ade20k.sh b/research/deeplab/datasets/download_and_convert_ade20k.sh deleted file mode 100644 index 3614ae42c16e4f727a725066be8948b666995241..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/download_and_convert_ade20k.sh +++ /dev/null @@ -1,80 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to download and preprocess the ADE20K dataset. -# -# Usage: -# bash ./download_and_convert_ade20k.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_data.py -# - build_ade20k_data.py -# - download_and_convert_ade20k.sh -# + ADE20K -# + tfrecord -# + ADEChallengeData2016 -# + annotations -# + training -# + validation -# + images -# + training -# + validation - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="./ADE20K" -mkdir -p "${WORK_DIR}" -cd "${WORK_DIR}" - -# Helper function to download and unpack ADE20K dataset. -download_and_uncompress() { - local BASE_URL=${1} - local FILENAME=${2} - - if [ ! -f "${FILENAME}" ]; then - echo "Downloading ${FILENAME} to ${WORK_DIR}" - wget -nd -c "${BASE_URL}/${FILENAME}" - fi - echo "Uncompressing ${FILENAME}" - unzip "${FILENAME}" -} - -# Download the images. -BASE_URL="http://data.csail.mit.edu/places/ADEchallenge" -FILENAME="ADEChallengeData2016.zip" - -download_and_uncompress "${BASE_URL}" "${FILENAME}" - -cd "${CURRENT_DIR}" - -# Root path for ADE20K dataset. -ADE20K_ROOT="${WORK_DIR}/ADEChallengeData2016" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${WORK_DIR}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -echo "Converting ADE20K dataset..." -python ./build_ade20k_data.py \ - --train_image_folder="${ADE20K_ROOT}/images/training/" \ - --train_image_label_folder="${ADE20K_ROOT}/annotations/training/" \ - --val_image_folder="${ADE20K_ROOT}/images/validation/" \ - --val_image_label_folder="${ADE20K_ROOT}/annotations/validation/" \ - --output_dir="${OUTPUT_DIR}" diff --git a/research/deeplab/datasets/download_and_convert_voc2012.sh b/research/deeplab/datasets/download_and_convert_voc2012.sh deleted file mode 100644 index c02235182d427dfb1d63154a8266ad37b0a1d53f..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/download_and_convert_voc2012.sh +++ /dev/null @@ -1,91 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to download and preprocess the PASCAL VOC 2012 dataset. -# -# Usage: -# bash ./download_and_convert_voc2012.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_data.py -# - build_voc2012_data.py -# - download_and_convert_voc2012.sh -# - remove_gt_colormap.py -# + pascal_voc_seg -# + VOCdevkit -# + VOC2012 -# + JPEGImages -# + SegmentationClass -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="./pascal_voc_seg" -SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )" -mkdir -p "${WORK_DIR}" -cd "${WORK_DIR}" - -# Helper function to download and unpack VOC 2012 dataset. -download_and_uncompress() { - local BASE_URL=${1} - local FILENAME=${2} - - if [ ! -f "${FILENAME}" ]; then - echo "Downloading ${FILENAME} to ${WORK_DIR}" - wget -nd -c "${BASE_URL}/${FILENAME}" - fi - echo "Uncompressing ${FILENAME}" - tar -xf "${FILENAME}" -} - -# Download the images. -BASE_URL="http://host.robots.ox.ac.uk/pascal/VOC/voc2012/" -FILENAME="VOCtrainval_11-May-2012.tar" - -download_and_uncompress "${BASE_URL}" "${FILENAME}" - -cd "${CURRENT_DIR}" - -# Root path for PASCAL VOC 2012 dataset. -PASCAL_ROOT="${WORK_DIR}/VOCdevkit/VOC2012" - -# Remove the colormap in the ground truth annotations. -SEG_FOLDER="${PASCAL_ROOT}/SegmentationClass" -SEMANTIC_SEG_FOLDER="${PASCAL_ROOT}/SegmentationClassRaw" - -echo "Removing the color map in ground truth annotations..." -python3 "${SCRIPT_DIR}/remove_gt_colormap.py" \ - --original_gt_folder="${SEG_FOLDER}" \ - --output_dir="${SEMANTIC_SEG_FOLDER}" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${WORK_DIR}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -IMAGE_FOLDER="${PASCAL_ROOT}/JPEGImages" -LIST_FOLDER="${PASCAL_ROOT}/ImageSets/Segmentation" - -echo "Converting PASCAL VOC 2012 dataset..." -python3 "${SCRIPT_DIR}/build_voc2012_data.py" \ - --image_folder="${IMAGE_FOLDER}" \ - --semantic_segmentation_folder="${SEMANTIC_SEG_FOLDER}" \ - --list_folder="${LIST_FOLDER}" \ - --image_format="jpg" \ - --output_dir="${OUTPUT_DIR}" diff --git a/research/deeplab/datasets/remove_gt_colormap.py b/research/deeplab/datasets/remove_gt_colormap.py deleted file mode 100644 index 900570038ed0f1add9d670157494d4cab6bf5324..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/remove_gt_colormap.py +++ /dev/null @@ -1,83 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Removes the color map from segmentation annotations. - -Removes the color map from the ground truth segmentation annotations and save -the results to output_dir. -""" -import glob -import os.path -import numpy as np - -from PIL import Image - -import tensorflow as tf - -FLAGS = tf.compat.v1.flags.FLAGS - -tf.compat.v1.flags.DEFINE_string('original_gt_folder', - './VOCdevkit/VOC2012/SegmentationClass', - 'Original ground truth annotations.') - -tf.compat.v1.flags.DEFINE_string('segmentation_format', 'png', 'Segmentation format.') - -tf.compat.v1.flags.DEFINE_string('output_dir', - './VOCdevkit/VOC2012/SegmentationClassRaw', - 'folder to save modified ground truth annotations.') - - -def _remove_colormap(filename): - """Removes the color map from the annotation. - - Args: - filename: Ground truth annotation filename. - - Returns: - Annotation without color map. - """ - return np.array(Image.open(filename)) - - -def _save_annotation(annotation, filename): - """Saves the annotation as png file. - - Args: - annotation: Segmentation annotation. - filename: Output filename. - """ - pil_image = Image.fromarray(annotation.astype(dtype=np.uint8)) - with tf.io.gfile.GFile(filename, mode='w') as f: - pil_image.save(f, 'PNG') - - -def main(unused_argv): - # Create the output directory if not exists. - if not tf.io.gfile.isdir(FLAGS.output_dir): - tf.io.gfile.makedirs(FLAGS.output_dir) - - annotations = glob.glob(os.path.join(FLAGS.original_gt_folder, - '*.' + FLAGS.segmentation_format)) - for annotation in annotations: - raw_annotation = _remove_colormap(annotation) - filename = os.path.basename(annotation)[:-4] - _save_annotation(raw_annotation, - os.path.join( - FLAGS.output_dir, - filename + '.' + FLAGS.segmentation_format)) - - -if __name__ == '__main__': - tf.compat.v1.app.run() diff --git a/research/deeplab/deeplab_demo.ipynb b/research/deeplab/deeplab_demo.ipynb deleted file mode 100644 index 81ccfde1b6484625ad1e0662d9a4cf12941d262c..0000000000000000000000000000000000000000 --- a/research/deeplab/deeplab_demo.ipynb +++ /dev/null @@ -1,369 +0,0 @@ -{ - "cells": [ - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "KFPcBuVFw61h" - }, - "source": [ - "# Overview\n", - "\n", - "This colab demonstrates the steps to use the DeepLab model to perform semantic segmentation on a sample input image. Expected outputs are semantic labels overlayed on the sample image.\n", - "\n", - "### About DeepLab\n", - "The models used in this colab perform semantic segmentation. Semantic segmentation models focus on assigning semantic labels, such as sky, person, or car, to multiple objects and stuff in a single image." - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "t3ozFsEEP-u_" - }, - "source": [ - "# Instructions\n", - "\u003ch3\u003e\u003ca href=\"https://cloud.google.com/tpu/\"\u003e\u003cimg valign=\"middle\" src=\"https://raw.githubusercontent.com/GoogleCloudPlatform/tensorflow-without-a-phd/master/tensorflow-rl-pong/images/tpu-hexagon.png\" width=\"50\"\u003e\u003c/a\u003e \u0026nbsp;\u0026nbsp;Use a free TPU device\u003c/h3\u003e\n", - "\n", - " 1. On the main menu, click Runtime and select **Change runtime type**. Set \"TPU\" as the hardware accelerator.\n", - " 1. Click Runtime again and select **Runtime \u003e Run All**. You can also run the cells manually with Shift-ENTER." - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "7cRiapZ1P3wy" - }, - "source": [ - "## Import Libraries" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "code", - "colab": {}, - "colab_type": "code", - "id": "kAbdmRmvq0Je" - }, - "outputs": [], - "source": [ - "import os\n", - "from io import BytesIO\n", - "import tarfile\n", - "import tempfile\n", - "from six.moves import urllib\n", - "\n", - "from matplotlib import gridspec\n", - "from matplotlib import pyplot as plt\n", - "import numpy as np\n", - "from PIL import Image\n", - "\n", - "%tensorflow_version 1.x\n", - "import tensorflow as tf" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "p47cYGGOQE1W" - }, - "source": [ - "## Import helper methods\n", - "These methods help us perform the following tasks:\n", - "* Load the latest version of the pretrained DeepLab model\n", - "* Load the colormap from the PASCAL VOC dataset\n", - "* Adds colors to various labels, such as \"pink\" for people, \"green\" for bicycle and more\n", - "* Visualize an image, and add an overlay of colors on various regions" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "code", - "colab": {}, - "colab_type": "code", - "id": "vN0kU6NJ1Ye5" - }, - "outputs": [], - "source": [ - "class DeepLabModel(object):\n", - " \"\"\"Class to load deeplab model and run inference.\"\"\"\n", - "\n", - " INPUT_TENSOR_NAME = 'ImageTensor:0'\n", - " OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'\n", - " INPUT_SIZE = 513\n", - " FROZEN_GRAPH_NAME = 'frozen_inference_graph'\n", - "\n", - " def __init__(self, tarball_path):\n", - " \"\"\"Creates and loads pretrained deeplab model.\"\"\"\n", - " self.graph = tf.Graph()\n", - "\n", - " graph_def = None\n", - " # Extract frozen graph from tar archive.\n", - " tar_file = tarfile.open(tarball_path)\n", - " for tar_info in tar_file.getmembers():\n", - " if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):\n", - " file_handle = tar_file.extractfile(tar_info)\n", - " graph_def = tf.GraphDef.FromString(file_handle.read())\n", - " break\n", - "\n", - " tar_file.close()\n", - "\n", - " if graph_def is None:\n", - " raise RuntimeError('Cannot find inference graph in tar archive.')\n", - "\n", - " with self.graph.as_default():\n", - " tf.import_graph_def(graph_def, name='')\n", - "\n", - " self.sess = tf.Session(graph=self.graph)\n", - "\n", - " def run(self, image):\n", - " \"\"\"Runs inference on a single image.\n", - "\n", - " Args:\n", - " image: A PIL.Image object, raw input image.\n", - "\n", - " Returns:\n", - " resized_image: RGB image resized from original input image.\n", - " seg_map: Segmentation map of `resized_image`.\n", - " \"\"\"\n", - " width, height = image.size\n", - " resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)\n", - " target_size = (int(resize_ratio * width), int(resize_ratio * height))\n", - " resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS)\n", - " batch_seg_map = self.sess.run(\n", - " self.OUTPUT_TENSOR_NAME,\n", - " feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]})\n", - " seg_map = batch_seg_map[0]\n", - " return resized_image, seg_map\n", - "\n", - "\n", - "def create_pascal_label_colormap():\n", - " \"\"\"Creates a label colormap used in PASCAL VOC segmentation benchmark.\n", - "\n", - " Returns:\n", - " A Colormap for visualizing segmentation results.\n", - " \"\"\"\n", - " colormap = np.zeros((256, 3), dtype=int)\n", - " ind = np.arange(256, dtype=int)\n", - "\n", - " for shift in reversed(range(8)):\n", - " for channel in range(3):\n", - " colormap[:, channel] |= ((ind \u003e\u003e channel) \u0026 1) \u003c\u003c shift\n", - " ind \u003e\u003e= 3\n", - "\n", - " return colormap\n", - "\n", - "\n", - "def label_to_color_image(label):\n", - " \"\"\"Adds color defined by the dataset colormap to the label.\n", - "\n", - " Args:\n", - " label: A 2D array with integer type, storing the segmentation label.\n", - "\n", - " Returns:\n", - " result: A 2D array with floating type. The element of the array\n", - " is the color indexed by the corresponding element in the input label\n", - " to the PASCAL color map.\n", - "\n", - " Raises:\n", - " ValueError: If label is not of rank 2 or its value is larger than color\n", - " map maximum entry.\n", - " \"\"\"\n", - " if label.ndim != 2:\n", - " raise ValueError('Expect 2-D input label')\n", - "\n", - " colormap = create_pascal_label_colormap()\n", - "\n", - " if np.max(label) \u003e= len(colormap):\n", - " raise ValueError('label value too large.')\n", - "\n", - " return colormap[label]\n", - "\n", - "\n", - "def vis_segmentation(image, seg_map):\n", - " \"\"\"Visualizes input image, segmentation map and overlay view.\"\"\"\n", - " plt.figure(figsize=(15, 5))\n", - " grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1])\n", - "\n", - " plt.subplot(grid_spec[0])\n", - " plt.imshow(image)\n", - " plt.axis('off')\n", - " plt.title('input image')\n", - "\n", - " plt.subplot(grid_spec[1])\n", - " seg_image = label_to_color_image(seg_map).astype(np.uint8)\n", - " plt.imshow(seg_image)\n", - " plt.axis('off')\n", - " plt.title('segmentation map')\n", - "\n", - " plt.subplot(grid_spec[2])\n", - " plt.imshow(image)\n", - " plt.imshow(seg_image, alpha=0.7)\n", - " plt.axis('off')\n", - " plt.title('segmentation overlay')\n", - "\n", - " unique_labels = np.unique(seg_map)\n", - " ax = plt.subplot(grid_spec[3])\n", - " plt.imshow(\n", - " FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest')\n", - " ax.yaxis.tick_right()\n", - " plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels])\n", - " plt.xticks([], [])\n", - " ax.tick_params(width=0.0)\n", - " plt.grid('off')\n", - " plt.show()\n", - "\n", - "\n", - "LABEL_NAMES = np.asarray([\n", - " 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',\n", - " 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',\n", - " 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'\n", - "])\n", - "\n", - "FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1)\n", - "FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP)" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "nGcZzNkASG9A" - }, - "source": [ - "## Select a pretrained model\n", - "We have trained the DeepLab model using various backbone networks. Select one from the MODEL_NAME list." - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": {}, - "colab_type": "code", - "id": "c4oXKmnjw6i_" - }, - "outputs": [], - "source": [ - "MODEL_NAME = 'mobilenetv2_coco_voctrainaug' # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval']\n", - "\n", - "_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'\n", - "_MODEL_URLS = {\n", - " 'mobilenetv2_coco_voctrainaug':\n", - " 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',\n", - " 'mobilenetv2_coco_voctrainval':\n", - " 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz',\n", - " 'xception_coco_voctrainaug':\n", - " 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz',\n", - " 'xception_coco_voctrainval':\n", - " 'deeplabv3_pascal_trainval_2018_01_04.tar.gz',\n", - "}\n", - "_TARBALL_NAME = 'deeplab_model.tar.gz'\n", - "\n", - "model_dir = tempfile.mkdtemp()\n", - "tf.gfile.MakeDirs(model_dir)\n", - "\n", - "download_path = os.path.join(model_dir, _TARBALL_NAME)\n", - "print('downloading model, this might take a while...')\n", - "urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME],\n", - " download_path)\n", - "print('download completed! loading DeepLab model...')\n", - "\n", - "MODEL = DeepLabModel(download_path)\n", - "print('model loaded successfully!')" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "SZst78N-4OKO" - }, - "source": [ - "## Run on sample images\n", - "\n", - "Select one of sample images (leave `IMAGE_URL` empty) or feed any internet image\n", - "url for inference.\n", - "\n", - "Note that this colab uses single scale inference for fast computation,\n", - "so the results may slightly differ from the visualizations in the\n", - "[README](https://github.com/tensorflow/models/blob/master/research/deeplab/README.md) file,\n", - "which uses multi-scale and left-right flipped inputs." - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "form", - "colab": {}, - "colab_type": "code", - "id": "edGukUHXyymr" - }, - "outputs": [], - "source": [ - "\n", - "SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3']\n", - "IMAGE_URL = '' #@param {type:\"string\"}\n", - "\n", - "_SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/'\n", - " 'deeplab/g3doc/img/%s.jpg?raw=true')\n", - "\n", - "\n", - "def run_visualization(url):\n", - " \"\"\"Inferences DeepLab model and visualizes result.\"\"\"\n", - " try:\n", - " f = urllib.request.urlopen(url)\n", - " jpeg_str = f.read()\n", - " original_im = Image.open(BytesIO(jpeg_str))\n", - " except IOError:\n", - " print('Cannot retrieve image. Please check url: ' + url)\n", - " return\n", - "\n", - " print('running deeplab on image %s...' % url)\n", - " resized_im, seg_map = MODEL.run(original_im)\n", - "\n", - " vis_segmentation(resized_im, seg_map)\n", - "\n", - "\n", - "image_url = IMAGE_URL or _SAMPLE_URL % SAMPLE_IMAGE\n", - "run_visualization(image_url)" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "aUbVoHScTJYe" - }, - "source": [ - "## What's next\n", - "\n", - "* Learn about [Cloud TPUs](https://cloud.google.com/tpu/docs) that Google designed and optimized specifically to speed up and scale up ML workloads for training and inference and to enable ML engineers and researchers to iterate more quickly.\n", - "* Explore the range of [Cloud TPU tutorials and Colabs](https://cloud.google.com/tpu/docs/tutorials) to find other examples that can be used when implementing your ML project.\n", - "* For more information on running the DeepLab model on Cloud TPUs, see the [DeepLab tutorial](https://cloud.google.com/tpu/docs/tutorials/deeplab).\n" - ] - } - ], - "metadata": { - "colab": { - "collapsed_sections": [], - "name": "DeepLab Demo.ipynb", - "provenance": [], - "toc_visible": true, - "version": "0.3.2" - }, - "kernelspec": { - "display_name": "Python 3", - "name": "python3" - } - }, - "nbformat": 4, - "nbformat_minor": 0 -} diff --git a/research/deeplab/deprecated/__init__.py b/research/deeplab/deprecated/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/deprecated/segmentation_dataset.py b/research/deeplab/deprecated/segmentation_dataset.py deleted file mode 100644 index 2a5980b1d940878cd1aead4a5d301cca7b4a642b..0000000000000000000000000000000000000000 --- a/research/deeplab/deprecated/segmentation_dataset.py +++ /dev/null @@ -1,200 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Provides data from semantic segmentation datasets. - -The SegmentationDataset class provides both images and annotations (semantic -segmentation and/or instance segmentation) for TensorFlow. Currently, we -support the following datasets: - -1. PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). - -PASCAL VOC 2012 semantic segmentation dataset annotates 20 foreground objects -(e.g., bike, person, and so on) and leaves all the other semantic classes as -one background class. The dataset contains 1464, 1449, and 1456 annotated -images for the training, validation and test respectively. - -2. Cityscapes dataset (https://www.cityscapes-dataset.com) - -The Cityscapes dataset contains 19 semantic labels (such as road, person, car, -and so on) for urban street scenes. - -3. ADE20K dataset (http://groups.csail.mit.edu/vision/datasets/ADE20K) - -The ADE20K dataset contains 150 semantic labels both urban street scenes and -indoor scenes. - -References: - M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, - and A. Zisserman, The pascal visual object classes challenge a retrospective. - IJCV, 2014. - - M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, - U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban - scene understanding," In Proc. of CVPR, 2016. - - B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, "Scene Parsing - through ADE20K dataset", In Proc. of CVPR, 2017. -""" -import collections -import os.path -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -slim = contrib_slim - -dataset = slim.dataset - -tfexample_decoder = slim.tfexample_decoder - - -_ITEMS_TO_DESCRIPTIONS = { - 'image': 'A color image of varying height and width.', - 'labels_class': ('A semantic segmentation label whose size matches image.' - 'Its values range from 0 (background) to num_classes.'), -} - -# Named tuple to describe the dataset properties. -DatasetDescriptor = collections.namedtuple( - 'DatasetDescriptor', - ['splits_to_sizes', # Splits of the dataset into training, val, and test. - 'num_classes', # Number of semantic classes, including the background - # class (if exists). For example, there are 20 - # foreground classes + 1 background class in the PASCAL - # VOC 2012 dataset. Thus, we set num_classes=21. - 'ignore_label', # Ignore label value. - ] -) - -_CITYSCAPES_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 2975, - 'val': 500, - }, - num_classes=19, - ignore_label=255, -) - -_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 1464, - 'train_aug': 10582, - 'trainval': 2913, - 'val': 1449, - }, - num_classes=21, - ignore_label=255, -) - -# These number (i.e., 'train'/'test') seems to have to be hard coded -# You are required to figure it out for your training/testing example. -_ADE20K_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 20210, # num of samples in images/training - 'val': 2000, # num of samples in images/validation - }, - num_classes=151, - ignore_label=0, -) - - -_DATASETS_INFORMATION = { - 'cityscapes': _CITYSCAPES_INFORMATION, - 'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION, - 'ade20k': _ADE20K_INFORMATION, -} - -# Default file pattern of TFRecord of TensorFlow Example. -_FILE_PATTERN = '%s-*' - - -def get_cityscapes_dataset_name(): - return 'cityscapes' - - -def get_dataset(dataset_name, split_name, dataset_dir): - """Gets an instance of slim Dataset. - - Args: - dataset_name: Dataset name. - split_name: A train/val Split name. - dataset_dir: The directory of the dataset sources. - - Returns: - An instance of slim Dataset. - - Raises: - ValueError: if the dataset_name or split_name is not recognized. - """ - if dataset_name not in _DATASETS_INFORMATION: - raise ValueError('The specified dataset is not supported yet.') - - splits_to_sizes = _DATASETS_INFORMATION[dataset_name].splits_to_sizes - - if split_name not in splits_to_sizes: - raise ValueError('data split name %s not recognized' % split_name) - - # Prepare the variables for different datasets. - num_classes = _DATASETS_INFORMATION[dataset_name].num_classes - ignore_label = _DATASETS_INFORMATION[dataset_name].ignore_label - - file_pattern = _FILE_PATTERN - file_pattern = os.path.join(dataset_dir, file_pattern % split_name) - - # Specify how the TF-Examples are decoded. - keys_to_features = { - 'image/encoded': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/filename': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/format': tf.FixedLenFeature( - (), tf.string, default_value='jpeg'), - 'image/height': tf.FixedLenFeature( - (), tf.int64, default_value=0), - 'image/width': tf.FixedLenFeature( - (), tf.int64, default_value=0), - 'image/segmentation/class/encoded': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/segmentation/class/format': tf.FixedLenFeature( - (), tf.string, default_value='png'), - } - items_to_handlers = { - 'image': tfexample_decoder.Image( - image_key='image/encoded', - format_key='image/format', - channels=3), - 'image_name': tfexample_decoder.Tensor('image/filename'), - 'height': tfexample_decoder.Tensor('image/height'), - 'width': tfexample_decoder.Tensor('image/width'), - 'labels_class': tfexample_decoder.Image( - image_key='image/segmentation/class/encoded', - format_key='image/segmentation/class/format', - channels=1), - } - - decoder = tfexample_decoder.TFExampleDecoder( - keys_to_features, items_to_handlers) - - return dataset.Dataset( - data_sources=file_pattern, - reader=tf.TFRecordReader, - decoder=decoder, - num_samples=splits_to_sizes[split_name], - items_to_descriptions=_ITEMS_TO_DESCRIPTIONS, - ignore_label=ignore_label, - num_classes=num_classes, - name=dataset_name, - multi_label=True) diff --git a/research/deeplab/eval.py b/research/deeplab/eval.py deleted file mode 100644 index 4f5fb8ba9c7493e45e567e9cd5ba9fe567dd9690..0000000000000000000000000000000000000000 --- a/research/deeplab/eval.py +++ /dev/null @@ -1,227 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Evaluation script for the DeepLab model. - -See model.py for more details and usage. -""" - -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import metrics as contrib_metrics -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import tfprof as contrib_tfprof -from tensorflow.contrib import training as contrib_training -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator - -flags = tf.app.flags -FLAGS = flags.FLAGS - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -# Settings for log directories. - -flags.DEFINE_string('eval_logdir', None, 'Where to write the event logs.') - -flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') - -# Settings for evaluating the model. - -flags.DEFINE_integer('eval_batch_size', 1, - 'The number of images in each batch during evaluation.') - -flags.DEFINE_list('eval_crop_size', '513,513', - 'Image crop size [height, width] for evaluation.') - -flags.DEFINE_integer('eval_interval_secs', 60 * 5, - 'How often (in seconds) to run evaluation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. -flags.DEFINE_multi_float('eval_scales', [1.0], - 'The scales to resize images for evaluation.') - -# Change to True for adding flipped images during test. -flags.DEFINE_bool('add_flipped_images', False, - 'Add flipped images for evaluation or not.') - -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. - -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('eval_split', 'val', - 'Which split of the dataset used for evaluation') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - -flags.DEFINE_integer('max_number_of_evaluations', 0, - 'Maximum number of eval iterations. Will loop ' - 'indefinitely upon nonpositive values.') - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.eval_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=FLAGS.eval_batch_size, - crop_size=[int(sz) for sz in FLAGS.eval_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - model_variant=FLAGS.model_variant, - num_readers=2, - is_training=False, - should_shuffle=False, - should_repeat=False) - - tf.gfile.MakeDirs(FLAGS.eval_logdir) - tf.logging.info('Evaluating on %s set', FLAGS.eval_split) - - with tf.Graph().as_default(): - samples = dataset.get_one_shot_iterator().get_next() - - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_of_classes}, - crop_size=[int(sz) for sz in FLAGS.eval_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - # Set shape in order for tf.contrib.tfprof.model_analyzer to work properly. - samples[common.IMAGE].set_shape( - [FLAGS.eval_batch_size, - int(FLAGS.eval_crop_size[0]), - int(FLAGS.eval_crop_size[1]), - 3]) - if tuple(FLAGS.eval_scales) == (1.0,): - tf.logging.info('Performing single-scale test.') - predictions = model.predict_labels(samples[common.IMAGE], model_options, - image_pyramid=FLAGS.image_pyramid) - else: - tf.logging.info('Performing multi-scale test.') - if FLAGS.quantize_delay_step >= 0: - raise ValueError( - 'Quantize mode is not supported with multi-scale test.') - - predictions = model.predict_labels_multi_scale( - samples[common.IMAGE], - model_options=model_options, - eval_scales=FLAGS.eval_scales, - add_flipped_images=FLAGS.add_flipped_images) - predictions = predictions[common.OUTPUT_TYPE] - predictions = tf.reshape(predictions, shape=[-1]) - labels = tf.reshape(samples[common.LABEL], shape=[-1]) - weights = tf.to_float(tf.not_equal(labels, dataset.ignore_label)) - - # Set ignore_label regions to label 0, because metrics.mean_iou requires - # range of labels = [0, dataset.num_classes). Note the ignore_label regions - # are not evaluated since the corresponding regions contain weights = 0. - labels = tf.where( - tf.equal(labels, dataset.ignore_label), tf.zeros_like(labels), labels) - - predictions_tag = 'miou' - for eval_scale in FLAGS.eval_scales: - predictions_tag += '_' + str(eval_scale) - if FLAGS.add_flipped_images: - predictions_tag += '_flipped' - - # Define the evaluation metric. - metric_map = {} - num_classes = dataset.num_of_classes - metric_map['eval/%s_overall' % predictions_tag] = tf.metrics.mean_iou( - labels=labels, predictions=predictions, num_classes=num_classes, - weights=weights) - # IoU for each class. - one_hot_predictions = tf.one_hot(predictions, num_classes) - one_hot_predictions = tf.reshape(one_hot_predictions, [-1, num_classes]) - one_hot_labels = tf.one_hot(labels, num_classes) - one_hot_labels = tf.reshape(one_hot_labels, [-1, num_classes]) - for c in range(num_classes): - predictions_tag_c = '%s_class_%d' % (predictions_tag, c) - tp, tp_op = tf.metrics.true_positives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - fp, fp_op = tf.metrics.false_positives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - fn, fn_op = tf.metrics.false_negatives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - tp_fp_fn_op = tf.group(tp_op, fp_op, fn_op) - iou = tf.where(tf.greater(tp + fn, 0.0), - tp / (tp + fn + fp), - tf.constant(np.NaN)) - metric_map['eval/%s' % predictions_tag_c] = (iou, tp_fp_fn_op) - - (metrics_to_values, - metrics_to_updates) = contrib_metrics.aggregate_metric_map(metric_map) - - summary_ops = [] - for metric_name, metric_value in six.iteritems(metrics_to_values): - op = tf.summary.scalar(metric_name, metric_value) - op = tf.Print(op, [metric_value], metric_name) - summary_ops.append(op) - - summary_op = tf.summary.merge(summary_ops) - summary_hook = contrib_training.SummaryAtEndHook( - log_dir=FLAGS.eval_logdir, summary_op=summary_op) - hooks = [summary_hook] - - num_eval_iters = None - if FLAGS.max_number_of_evaluations > 0: - num_eval_iters = FLAGS.max_number_of_evaluations - - if FLAGS.quantize_delay_step >= 0: - contrib_quantize.create_eval_graph() - - contrib_tfprof.model_analyzer.print_model_analysis( - tf.get_default_graph(), - tfprof_options=contrib_tfprof.model_analyzer - .TRAINABLE_VARS_PARAMS_STAT_OPTIONS) - contrib_tfprof.model_analyzer.print_model_analysis( - tf.get_default_graph(), - tfprof_options=contrib_tfprof.model_analyzer.FLOAT_OPS_OPTIONS) - contrib_training.evaluate_repeatedly( - checkpoint_dir=FLAGS.checkpoint_dir, - master=FLAGS.master, - eval_ops=list(metrics_to_updates.values()), - max_number_of_evaluations=num_eval_iters, - hooks=hooks, - eval_interval_secs=FLAGS.eval_interval_secs) - - -if __name__ == '__main__': - flags.mark_flag_as_required('checkpoint_dir') - flags.mark_flag_as_required('eval_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/deeplab/evaluation/README.md b/research/deeplab/evaluation/README.md deleted file mode 100644 index 69255384e9a293e7acada74b40bd4288ba121edb..0000000000000000000000000000000000000000 --- a/research/deeplab/evaluation/README.md +++ /dev/null @@ -1,311 +0,0 @@ -# Evaluation Metrics for Whole Image Parsing - -Whole Image Parsing [1], also known as Panoptic Segmentation [2], generalizes -the tasks of semantic segmentation for "stuff" classes and instance -segmentation for "thing" classes, assigning both semantic and instance labels -to every pixel in an image. - -Previous works evaluate the parsing result with separate metrics (e.g., one for -semantic segmentation result and one for object detection result). Recently, -Kirillov et al. propose the unified instance-based Panoptic Quality (PQ) metric -[2] into several benchmarks [3, 4]. - -However, we notice that the instance-based PQ metric often places -disproportionate emphasis on small instance parsing, as well as on "thing" over -"stuff" classes. To remedy these effects, we propose an alternative -region-based Parsing Covering (PC) metric [5], which adapts the Covering -metric [6], previously used for class-agnostics segmentation quality -evaluation, to the task of image parsing. - -Here, we provide implementation of both PQ and PC for evaluating the parsing -results. We briefly explain both metrics below for reference. - -## Panoptic Quality (PQ) - -Given a groundtruth segmentation S and a predicted segmentation S', PQ is -defined as follows: - -
- Zhuowen Tu, Xiangrong Chen, Alan L. Yuille, and Song-Chun Zhu
- IJCV, 2005. - -2. **Panoptic Segmentation**
- Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother and Piotr - Dollár
- arXiv:1801.00868, 2018. - -3. **Microsoft COCO: Common Objects in Context**
- Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross - Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, - Piotr Dollar
- In the Proc. of ECCV, 2014. - -4. **The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes**
- Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulò, and Peter Kontschieder
- In the Proc. of ICCV, 2017. - -5. **DeeperLab: Single-Shot Image Parser**
- Tien-Ju Yang, Maxwell D. Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, - Xiao Zhang, Vivienne Sze, George Papandreou, Liang-Chieh Chen
- arXiv: 1902.05093, 2019. - -6. **Contour Detection and Hierarchical Image Segmentation**
- Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jitendra Malik
- PAMI, 2011 diff --git a/research/deeplab/evaluation/__init__.py b/research/deeplab/evaluation/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/evaluation/base_metric.py b/research/deeplab/evaluation/base_metric.py deleted file mode 100644 index ee7606ef44c1c2c027e593c494659f0dbcd455d3..0000000000000000000000000000000000000000 --- a/research/deeplab/evaluation/base_metric.py +++ /dev/null @@ -1,191 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Defines the top-level interface for evaluating segmentations.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc -import numpy as np -import six - - -_EPSILON = 1e-10 - - -def realdiv_maybe_zero(x, y): - """Element-wise x / y where y may contain zeros, for those returns 0 too.""" - return np.where( - np.less(np.abs(y), _EPSILON), np.zeros_like(x), np.divide(x, y)) - - -@six.add_metaclass(abc.ABCMeta) -class SegmentationMetric(object): - """Abstract base class for computers of segmentation metrics. - - Subclasses will implement both: - 1. Comparing the predicted segmentation for an image with the groundtruth. - 2. Computing the final metric over a set of images. - These are often done as separate steps, due to the need to accumulate - intermediate values other than the metric itself across images, computing the - actual metric value only on these accumulations after all the images have been - compared. - - A simple usage would be: - - metric = MetricImplementation(...) - for, in evaluation_set:
- = run_segmentation()
- metric.compare_and_accumulate(, )
- print(metric.result())
-
- """
-
- def __init__(self, num_categories, ignored_label, max_instances_per_category,
- offset):
- """Base initialization for SegmentationMetric.
-
- Args:
- num_categories: The number of segmentation categories (or "classes" in the
- dataset.
- ignored_label: A category id that is ignored in evaluation, e.g. the void
- label as defined in COCO panoptic segmentation dataset.
- max_instances_per_category: The maximum number of instances for each
- category. Used in ensuring unique instance labels.
- offset: The maximum number of unique labels. This is used, by multiplying
- the ground-truth labels, to generate unique ids for individual regions
- of overlap between groundtruth and predicted segments.
- """
- self.num_categories = num_categories
- self.ignored_label = ignored_label
- self.max_instances_per_category = max_instances_per_category
- self.offset = offset
- self.reset()
-
- def _naively_combine_labels(self, category_array, instance_array):
- """Naively creates a combined label array from categories and instances."""
- return (category_array.astype(np.uint32) * self.max_instances_per_category +
- instance_array.astype(np.uint32))
-
- @abc.abstractmethod
- def compare_and_accumulate(
- self, groundtruth_category_array, groundtruth_instance_array,
- predicted_category_array, predicted_instance_array):
- """Compares predicted segmentation with groundtruth, accumulates its metric.
-
- It is not assumed that instance ids are unique across different categories.
- See for example combine_semantic_and_instance_predictions.py in official
- PanopticAPI evaluation code for issues to consider when fusing category
- and instance labels.
-
- Instances ids of the ignored category have the meaning that id 0 is "void"
- and remaining ones are crowd instances.
-
- Args:
- groundtruth_category_array: A 2D numpy uint16 array of groundtruth
- per-pixel category labels.
- groundtruth_instance_array: A 2D numpy uint16 array of groundtruth
- instance labels.
- predicted_category_array: A 2D numpy uint16 array of predicted per-pixel
- category labels.
- predicted_instance_array: A 2D numpy uint16 array of predicted instance
- labels.
-
- Returns:
- The value of the metric over all comparisons done so far, including this
- one, as a float scalar.
- """
- raise NotImplementedError('Must be implemented in subclasses.')
-
- @abc.abstractmethod
- def result(self):
- """Computes the metric over all comparisons done so far."""
- raise NotImplementedError('Must be implemented in subclasses.')
-
- @abc.abstractmethod
- def detailed_results(self, is_thing=None):
- """Computes and returns the detailed final metric results.
-
- Args:
- is_thing: A boolean array of length `num_categories`. The entry
- `is_thing[category_id]` is True iff that category is a "thing" category
- instead of "stuff."
-
- Returns:
- A dictionary with a breakdown of metrics and/or metric factors by things,
- stuff, and all categories.
- """
- raise NotImplementedError('Not implemented in subclasses.')
-
- @abc.abstractmethod
- def result_per_category(self):
- """For supported metrics, return individual per-category metric values.
-
- Returns:
- A numpy array of shape `[self.num_categories]`, where index `i` is the
- metrics value over only that category.
- """
- raise NotImplementedError('Not implemented in subclass.')
-
- def print_detailed_results(self, is_thing=None, print_digits=3):
- """Prints out a detailed breakdown of metric results.
-
- Args:
- is_thing: A boolean array of length num_categories.
- `is_thing[category_id]` will say whether that category is a "thing"
- rather than "stuff."
- print_digits: Number of significant digits to print in computed metrics.
- """
- raise NotImplementedError('Not implemented in subclass.')
-
- @abc.abstractmethod
- def merge(self, other_instance):
- """Combines the accumulated results of another instance into self.
-
- The following two cases should put `metric_a` into an equivalent state.
-
- Case 1 (with merge):
-
- metric_a = MetricsSubclass(...)
- metric_a.compare_and_accumulate()
- metric_a.compare_and_accumulate()
-
- metric_b = MetricsSubclass(...)
- metric_b.compare_and_accumulate()
- metric_b.compare_and_accumulate()
-
- metric_a.merge(metric_b)
-
- Case 2 (without merge):
-
- metric_a = MetricsSubclass(...)
- metric_a.compare_and_accumulate()
- metric_a.compare_and_accumulate()
- metric_a.compare_and_accumulate()
- metric_a.compare_and_accumulate()
-
- Args:
- other_instance: Another compatible instance of the same metric subclass.
- """
- raise NotImplementedError('Not implemented in subclass.')
-
- @abc.abstractmethod
- def reset(self):
- """Resets the accumulation to the metric class's state at initialization.
-
- Note that this function will be called in SegmentationMetric.__init__.
- """
- raise NotImplementedError('Must be implemented in subclasses.')
diff --git a/research/deeplab/evaluation/eval_coco_format.py b/research/deeplab/evaluation/eval_coco_format.py
deleted file mode 100644
index 1a26446f16b9787f246034a58247eb36d0064f80..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/eval_coco_format.py
+++ /dev/null
@@ -1,338 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Computes evaluation metrics on groundtruth and predictions in COCO format.
-
-The Common Objects in Context (COCO) dataset defines a format for specifying
-combined semantic and instance segmentations as "panoptic" segmentations. This
-is done with the combination of JSON and image files as specified at:
-http://cocodataset.org/#format-results
-where the JSON file specifies the overall structure of the result,
-including the categories for each annotation, and the images specify the image
-region for each annotation in that image by its ID.
-
-This script computes additional metrics such as Parsing Covering on datasets and
-predictions in this format. An implementation of Panoptic Quality is also
-provided for convenience.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import json
-import multiprocessing
-import os
-
-from absl import app
-from absl import flags
-from absl import logging
-import numpy as np
-from PIL import Image
-import utils as panopticapi_utils
-import six
-
-from deeplab.evaluation import panoptic_quality
-from deeplab.evaluation import parsing_covering
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string(
- 'gt_json_file', None,
- ' Path to a JSON file giving ground-truth annotations in COCO format.')
-flags.DEFINE_string('pred_json_file', None,
- 'Path to a JSON file for the predictions to evaluate.')
-flags.DEFINE_string(
- 'gt_folder', None,
- 'Folder containing panoptic-format ID images to match ground-truth '
- 'annotations to image regions.')
-flags.DEFINE_string('pred_folder', None,
- 'Folder containing ID images for predictions.')
-flags.DEFINE_enum(
- 'metric', 'pq', ['pq', 'pc'], 'Shorthand name of a metric to compute. '
- 'Supported values are:\n'
- 'Panoptic Quality (pq)\n'
- 'Parsing Covering (pc)')
-flags.DEFINE_integer(
- 'num_categories', 201,
- 'The number of segmentation categories (or "classes") in the dataset.')
-flags.DEFINE_integer(
- 'ignored_label', 0,
- 'A category id that is ignored in evaluation, e.g. the void label as '
- 'defined in COCO panoptic segmentation dataset.')
-flags.DEFINE_integer(
- 'max_instances_per_category', 256,
- 'The maximum number of instances for each category. Used in ensuring '
- 'unique instance labels.')
-flags.DEFINE_integer('intersection_offset', None,
- 'The maximum number of unique labels.')
-flags.DEFINE_bool(
- 'normalize_by_image_size', True,
- 'Whether to normalize groundtruth instance region areas by image size. If '
- 'True, groundtruth instance areas and weighted IoUs will be divided by the '
- 'size of the corresponding image before accumulated across the dataset. '
- 'Only used for Parsing Covering (pc) evaluation.')
-flags.DEFINE_integer(
- 'num_workers', 0, 'If set to a positive number, will spawn child processes '
- 'to compute parts of the metric in parallel by splitting '
- 'the images between the workers. If set to -1, will use '
- 'the value of multiprocessing.cpu_count().')
-flags.DEFINE_integer('print_digits', 3,
- 'Number of significant digits to print in metrics.')
-
-
-def _build_metric(metric,
- num_categories,
- ignored_label,
- max_instances_per_category,
- intersection_offset=None,
- normalize_by_image_size=True):
- """Creates a metric aggregator objet of the given name."""
- if metric == 'pq':
- logging.warning('One should check Panoptic Quality results against the '
- 'official COCO API code. Small numerical differences '
- '(< 0.1%) can be magnified by rounding.')
- return panoptic_quality.PanopticQuality(num_categories, ignored_label,
- max_instances_per_category,
- intersection_offset)
- elif metric == 'pc':
- return parsing_covering.ParsingCovering(
- num_categories, ignored_label, max_instances_per_category,
- intersection_offset, normalize_by_image_size)
- else:
- raise ValueError('No implementation for metric "%s"' % metric)
-
-
-def _matched_annotations(gt_json, pred_json):
- """Yields a set of (groundtruth, prediction) image annotation pairs.."""
- image_id_to_pred_ann = {
- annotation['image_id']: annotation
- for annotation in pred_json['annotations']
- }
- for gt_ann in gt_json['annotations']:
- image_id = gt_ann['image_id']
- pred_ann = image_id_to_pred_ann[image_id]
- yield gt_ann, pred_ann
-
-
-def _open_panoptic_id_image(image_path):
- """Loads a COCO-format panoptic ID image from file."""
- return panopticapi_utils.rgb2id(
- np.array(Image.open(image_path), dtype=np.uint32))
-
-
-def _split_panoptic(ann_json, id_array, ignored_label, allow_crowds):
- """Given the COCO JSON and ID map, splits into categories and instances."""
- category = np.zeros(id_array.shape, np.uint16)
- instance = np.zeros(id_array.shape, np.uint16)
- next_instance_id = collections.defaultdict(int)
- # Skip instance label 0 for ignored label. That is reserved for void.
- next_instance_id[ignored_label] = 1
- for segment_info in ann_json['segments_info']:
- if allow_crowds and segment_info['iscrowd']:
- category_id = ignored_label
- else:
- category_id = segment_info['category_id']
- mask = np.equal(id_array, segment_info['id'])
- category[mask] = category_id
- instance[mask] = next_instance_id[category_id]
- next_instance_id[category_id] += 1
- return category, instance
-
-
-def _category_and_instance_from_annotation(ann_json, folder, ignored_label,
- allow_crowds):
- """Given the COCO JSON annotations, finds maps of categories and instances."""
- panoptic_id_image = _open_panoptic_id_image(
- os.path.join(folder, ann_json['file_name']))
- return _split_panoptic(ann_json, panoptic_id_image, ignored_label,
- allow_crowds)
-
-
-def _compute_metric(metric_aggregator, gt_folder, pred_folder,
- annotation_pairs):
- """Iterates over matched annotation pairs and computes a metric over them."""
- for gt_ann, pred_ann in annotation_pairs:
- # We only expect "iscrowd" to appear in the ground-truth, and not in model
- # output. In predicted JSON it is simply ignored, as done in official code.
- gt_category, gt_instance = _category_and_instance_from_annotation(
- gt_ann, gt_folder, metric_aggregator.ignored_label, True)
- pred_category, pred_instance = _category_and_instance_from_annotation(
- pred_ann, pred_folder, metric_aggregator.ignored_label, False)
-
- metric_aggregator.compare_and_accumulate(gt_category, gt_instance,
- pred_category, pred_instance)
- return metric_aggregator
-
-
-def _iterate_work_queue(work_queue):
- """Creates an iterable that retrieves items from a queue until one is None."""
- task = work_queue.get(block=True)
- while task is not None:
- yield task
- task = work_queue.get(block=True)
-
-
-def _run_metrics_worker(metric_aggregator, gt_folder, pred_folder, work_queue,
- result_queue):
- result = _compute_metric(metric_aggregator, gt_folder, pred_folder,
- _iterate_work_queue(work_queue))
- result_queue.put(result, block=True)
-
-
-def _is_thing_array(categories_json, ignored_label):
- """is_thing[category_id] is a bool on if category is "thing" or "stuff"."""
- is_thing_dict = {}
- for category_json in categories_json:
- is_thing_dict[category_json['id']] = bool(category_json['isthing'])
-
- # Check our assumption that the category ids are consecutive.
- # Usually metrics should be able to handle this case, but adding a warning
- # here.
- max_category_id = max(six.iterkeys(is_thing_dict))
- if len(is_thing_dict) != max_category_id + 1:
- seen_ids = six.viewkeys(is_thing_dict)
- all_ids = set(six.moves.range(max_category_id + 1))
- unseen_ids = all_ids.difference(seen_ids)
- if unseen_ids != {ignored_label}:
- logging.warning(
- 'Nonconsecutive category ids or no category JSON specified for ids: '
- '%s', unseen_ids)
-
- is_thing_array = np.zeros(max_category_id + 1)
- for category_id, is_thing in six.iteritems(is_thing_dict):
- is_thing_array[category_id] = is_thing
-
- return is_thing_array
-
-
-def eval_coco_format(gt_json_file,
- pred_json_file,
- gt_folder=None,
- pred_folder=None,
- metric='pq',
- num_categories=201,
- ignored_label=0,
- max_instances_per_category=256,
- intersection_offset=None,
- normalize_by_image_size=True,
- num_workers=0,
- print_digits=3):
- """Top-level code to compute metrics on a COCO-format result.
-
- Note that the default values are set for COCO panoptic segmentation dataset,
- and thus the users may want to change it for their own dataset evaluation.
-
- Args:
- gt_json_file: Path to a JSON file giving ground-truth annotations in COCO
- format.
- pred_json_file: Path to a JSON file for the predictions to evaluate.
- gt_folder: Folder containing panoptic-format ID images to match ground-truth
- annotations to image regions.
- pred_folder: Folder containing ID images for predictions.
- metric: Name of a metric to compute.
- num_categories: The number of segmentation categories (or "classes") in the
- dataset.
- ignored_label: A category id that is ignored in evaluation, e.g. the "void"
- label as defined in the COCO panoptic segmentation dataset.
- max_instances_per_category: The maximum number of instances for each
- category. Used in ensuring unique instance labels.
- intersection_offset: The maximum number of unique labels.
- normalize_by_image_size: Whether to normalize groundtruth instance region
- areas by image size. If True, groundtruth instance areas and weighted IoUs
- will be divided by the size of the corresponding image before accumulated
- across the dataset. Only used for Parsing Covering (pc) evaluation.
- num_workers: If set to a positive number, will spawn child processes to
- compute parts of the metric in parallel by splitting the images between
- the workers. If set to -1, will use the value of
- multiprocessing.cpu_count().
- print_digits: Number of significant digits to print in summary of computed
- metrics.
-
- Returns:
- The computed result of the metric as a float scalar.
- """
- with open(gt_json_file, 'r') as gt_json_fo:
- gt_json = json.load(gt_json_fo)
- with open(pred_json_file, 'r') as pred_json_fo:
- pred_json = json.load(pred_json_fo)
- if gt_folder is None:
- gt_folder = gt_json_file.replace('.json', '')
- if pred_folder is None:
- pred_folder = pred_json_file.replace('.json', '')
- if intersection_offset is None:
- intersection_offset = (num_categories + 1) * max_instances_per_category
-
- metric_aggregator = _build_metric(
- metric, num_categories, ignored_label, max_instances_per_category,
- intersection_offset, normalize_by_image_size)
-
- if num_workers == -1:
- logging.info('Attempting to get the CPU count to set # workers.')
- num_workers = multiprocessing.cpu_count()
-
- if num_workers > 0:
- logging.info('Computing metric in parallel with %d workers.', num_workers)
- work_queue = multiprocessing.Queue()
- result_queue = multiprocessing.Queue()
- workers = []
- worker_args = (metric_aggregator, gt_folder, pred_folder, work_queue,
- result_queue)
- for _ in six.moves.range(num_workers):
- workers.append(
- multiprocessing.Process(target=_run_metrics_worker, args=worker_args))
- for worker in workers:
- worker.start()
- for ann_pair in _matched_annotations(gt_json, pred_json):
- work_queue.put(ann_pair, block=True)
-
- # Will cause each worker to return a result and terminate upon recieving a
- # None task.
- for _ in six.moves.range(num_workers):
- work_queue.put(None, block=True)
-
- # Retrieve results.
- for _ in six.moves.range(num_workers):
- metric_aggregator.merge(result_queue.get(block=True))
-
- for worker in workers:
- worker.join()
- else:
- logging.info('Computing metric in a single process.')
- annotation_pairs = _matched_annotations(gt_json, pred_json)
- _compute_metric(metric_aggregator, gt_folder, pred_folder, annotation_pairs)
-
- is_thing = _is_thing_array(gt_json['categories'], ignored_label)
- metric_aggregator.print_detailed_results(
- is_thing=is_thing, print_digits=print_digits)
- return metric_aggregator.detailed_results(is_thing=is_thing)
-
-
-def main(argv):
- if len(argv) > 1:
- raise app.UsageError('Too many command-line arguments.')
-
- eval_coco_format(FLAGS.gt_json_file, FLAGS.pred_json_file, FLAGS.gt_folder,
- FLAGS.pred_folder, FLAGS.metric, FLAGS.num_categories,
- FLAGS.ignored_label, FLAGS.max_instances_per_category,
- FLAGS.intersection_offset, FLAGS.normalize_by_image_size,
- FLAGS.num_workers, FLAGS.print_digits)
-
-
-if __name__ == '__main__':
- flags.mark_flags_as_required(
- ['gt_json_file', 'gt_folder', 'pred_json_file', 'pred_folder'])
- app.run(main)
diff --git a/research/deeplab/evaluation/eval_coco_format_test.py b/research/deeplab/evaluation/eval_coco_format_test.py
deleted file mode 100644
index d9093ff127e5dce27775421b9d136fc7cbc27c77..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/eval_coco_format_test.py
+++ /dev/null
@@ -1,140 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for eval_coco_format script."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import flags
-from absl.testing import absltest
-import evaluation as panopticapi_eval
-
-from deeplab.evaluation import eval_coco_format
-
-_TEST_DIR = 'deeplab/evaluation/testdata'
-
-FLAGS = flags.FLAGS
-
-
-class EvalCocoFormatTest(absltest.TestCase):
-
- def test_compare_pq_with_reference_eval(self):
- sample_data_dir = os.path.join(_TEST_DIR)
- gt_json_file = os.path.join(sample_data_dir, 'coco_gt.json')
- gt_folder = os.path.join(sample_data_dir, 'coco_gt')
- pred_json_file = os.path.join(sample_data_dir, 'coco_pred.json')
- pred_folder = os.path.join(sample_data_dir, 'coco_pred')
-
- panopticapi_results = panopticapi_eval.pq_compute(
- gt_json_file, pred_json_file, gt_folder, pred_folder)
- deeplab_results = eval_coco_format.eval_coco_format(
- gt_json_file,
- pred_json_file,
- gt_folder,
- pred_folder,
- metric='pq',
- num_categories=7,
- ignored_label=0,
- max_instances_per_category=256,
- intersection_offset=(256 * 256))
- self.assertCountEqual(
- list(deeplab_results.keys()), ['All', 'Things', 'Stuff'])
- for cat_group in ['All', 'Things', 'Stuff']:
- self.assertCountEqual(deeplab_results[cat_group], ['pq', 'sq', 'rq', 'n'])
- for metric in ['pq', 'sq', 'rq', 'n']:
- self.assertAlmostEqual(deeplab_results[cat_group][metric],
- panopticapi_results[cat_group][metric])
-
- def test_compare_pc_with_golden_value(self):
- sample_data_dir = os.path.join(_TEST_DIR)
- gt_json_file = os.path.join(sample_data_dir, 'coco_gt.json')
- gt_folder = os.path.join(sample_data_dir, 'coco_gt')
- pred_json_file = os.path.join(sample_data_dir, 'coco_pred.json')
- pred_folder = os.path.join(sample_data_dir, 'coco_pred')
-
- deeplab_results = eval_coco_format.eval_coco_format(
- gt_json_file,
- pred_json_file,
- gt_folder,
- pred_folder,
- metric='pc',
- num_categories=7,
- ignored_label=0,
- max_instances_per_category=256,
- intersection_offset=(256 * 256),
- normalize_by_image_size=False)
- self.assertCountEqual(
- list(deeplab_results.keys()), ['All', 'Things', 'Stuff'])
- for cat_group in ['All', 'Things', 'Stuff']:
- self.assertCountEqual(deeplab_results[cat_group], ['pc', 'n'])
- self.assertAlmostEqual(deeplab_results['All']['pc'], 0.68210561)
- self.assertEqual(deeplab_results['All']['n'], 6)
- self.assertAlmostEqual(deeplab_results['Things']['pc'], 0.5890529)
- self.assertEqual(deeplab_results['Things']['n'], 4)
- self.assertAlmostEqual(deeplab_results['Stuff']['pc'], 0.86821097)
- self.assertEqual(deeplab_results['Stuff']['n'], 2)
-
- def test_compare_pc_with_golden_value_normalize_by_size(self):
- sample_data_dir = os.path.join(_TEST_DIR)
- gt_json_file = os.path.join(sample_data_dir, 'coco_gt.json')
- gt_folder = os.path.join(sample_data_dir, 'coco_gt')
- pred_json_file = os.path.join(sample_data_dir, 'coco_pred.json')
- pred_folder = os.path.join(sample_data_dir, 'coco_pred')
-
- deeplab_results = eval_coco_format.eval_coco_format(
- gt_json_file,
- pred_json_file,
- gt_folder,
- pred_folder,
- metric='pc',
- num_categories=7,
- ignored_label=0,
- max_instances_per_category=256,
- intersection_offset=(256 * 256),
- normalize_by_image_size=True)
- self.assertCountEqual(
- list(deeplab_results.keys()), ['All', 'Things', 'Stuff'])
- self.assertAlmostEqual(deeplab_results['All']['pc'], 0.68214908840)
-
- def test_pc_with_multiple_workers(self):
- sample_data_dir = os.path.join(_TEST_DIR)
- gt_json_file = os.path.join(sample_data_dir, 'coco_gt.json')
- gt_folder = os.path.join(sample_data_dir, 'coco_gt')
- pred_json_file = os.path.join(sample_data_dir, 'coco_pred.json')
- pred_folder = os.path.join(sample_data_dir, 'coco_pred')
-
- deeplab_results = eval_coco_format.eval_coco_format(
- gt_json_file,
- pred_json_file,
- gt_folder,
- pred_folder,
- metric='pc',
- num_categories=7,
- ignored_label=0,
- max_instances_per_category=256,
- intersection_offset=(256 * 256),
- num_workers=3,
- normalize_by_image_size=False)
- self.assertCountEqual(
- list(deeplab_results.keys()), ['All', 'Things', 'Stuff'])
- self.assertAlmostEqual(deeplab_results['All']['pc'], 0.68210561668)
-
-
-if __name__ == '__main__':
- absltest.main()
diff --git a/research/deeplab/evaluation/g3doc/img/equation_pc.png b/research/deeplab/evaluation/g3doc/img/equation_pc.png
deleted file mode 100644
index 90f15e7a461f929db9774f2c3c7e9dca549f433b..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/g3doc/img/equation_pc.png and /dev/null differ
diff --git a/research/deeplab/evaluation/g3doc/img/equation_pq.png b/research/deeplab/evaluation/g3doc/img/equation_pq.png
deleted file mode 100644
index 13a4393c181f27f5eb9be43f47e9cb132b28b924..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/g3doc/img/equation_pq.png and /dev/null differ
diff --git a/research/deeplab/evaluation/panoptic_quality.py b/research/deeplab/evaluation/panoptic_quality.py
deleted file mode 100644
index f7d0f3f98f09819feda52bc89069333665ff5d94..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/panoptic_quality.py
+++ /dev/null
@@ -1,259 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Implementation of the Panoptic Quality metric.
-
-Panoptic Quality is an instance-based metric for evaluating the task of
-image parsing, aka panoptic segmentation.
-
-Please see the paper for details:
-"Panoptic Segmentation", Alexander Kirillov, Kaiming He, Ross Girshick,
-Carsten Rother and Piotr Dollar. arXiv:1801.00868, 2018.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import numpy as np
-import prettytable
-import six
-
-from deeplab.evaluation import base_metric
-
-
-def _ids_to_counts(id_array):
- """Given a numpy array, a mapping from each unique entry to its count."""
- ids, counts = np.unique(id_array, return_counts=True)
- return dict(six.moves.zip(ids, counts))
-
-
-class PanopticQuality(base_metric.SegmentationMetric):
- """Metric class for Panoptic Quality.
-
- "Panoptic Segmentation" by Alexander Kirillov, Kaiming He, Ross Girshick,
- Carsten Rother, Piotr Dollar.
- https://arxiv.org/abs/1801.00868
- """
-
- def compare_and_accumulate(
- self, groundtruth_category_array, groundtruth_instance_array,
- predicted_category_array, predicted_instance_array):
- """See base class."""
- # First, combine the category and instance labels so that every unique
- # value for (category, instance) is assigned a unique integer label.
- pred_segment_id = self._naively_combine_labels(predicted_category_array,
- predicted_instance_array)
- gt_segment_id = self._naively_combine_labels(groundtruth_category_array,
- groundtruth_instance_array)
-
- # Pre-calculate areas for all groundtruth and predicted segments.
- gt_segment_areas = _ids_to_counts(gt_segment_id)
- pred_segment_areas = _ids_to_counts(pred_segment_id)
-
- # We assume there is only one void segment and it has instance id = 0.
- void_segment_id = self.ignored_label * self.max_instances_per_category
-
- # There may be other ignored groundtruth segments with instance id > 0, find
- # those ids using the unique segment ids extracted with the area computation
- # above.
- ignored_segment_ids = {
- gt_segment_id for gt_segment_id in six.iterkeys(gt_segment_areas)
- if (gt_segment_id //
- self.max_instances_per_category) == self.ignored_label
- }
-
- # Next, combine the groundtruth and predicted labels. Dividing up the pixels
- # based on which groundtruth segment and which predicted segment they belong
- # to, this will assign a different 32-bit integer label to each choice
- # of (groundtruth segment, predicted segment), encoded as
- # gt_segment_id * offset + pred_segment_id.
- intersection_id_array = (
- gt_segment_id.astype(np.uint32) * self.offset +
- pred_segment_id.astype(np.uint32))
-
- # For every combination of (groundtruth segment, predicted segment) with a
- # non-empty intersection, this counts the number of pixels in that
- # intersection.
- intersection_areas = _ids_to_counts(intersection_id_array)
-
- # Helper function that computes the area of the overlap between a predicted
- # segment and the ground-truth void/ignored segment.
- def prediction_void_overlap(pred_segment_id):
- void_intersection_id = void_segment_id * self.offset + pred_segment_id
- return intersection_areas.get(void_intersection_id, 0)
-
- # Compute overall ignored overlap.
- def prediction_ignored_overlap(pred_segment_id):
- total_ignored_overlap = 0
- for ignored_segment_id in ignored_segment_ids:
- intersection_id = ignored_segment_id * self.offset + pred_segment_id
- total_ignored_overlap += intersection_areas.get(intersection_id, 0)
- return total_ignored_overlap
-
- # Sets that are populated with which segments groundtruth/predicted segments
- # have been matched with overlapping predicted/groundtruth segments
- # respectively.
- gt_matched = set()
- pred_matched = set()
-
- # Calculate IoU per pair of intersecting segments of the same category.
- for intersection_id, intersection_area in six.iteritems(intersection_areas):
- gt_segment_id = intersection_id // self.offset
- pred_segment_id = intersection_id % self.offset
-
- gt_category = gt_segment_id // self.max_instances_per_category
- pred_category = pred_segment_id // self.max_instances_per_category
- if gt_category != pred_category:
- continue
-
- # Union between the groundtruth and predicted segments being compared does
- # not include the portion of the predicted segment that consists of
- # groundtruth "void" pixels.
- union = (
- gt_segment_areas[gt_segment_id] +
- pred_segment_areas[pred_segment_id] - intersection_area -
- prediction_void_overlap(pred_segment_id))
- iou = intersection_area / union
- if iou > 0.5:
- self.tp_per_class[gt_category] += 1
- self.iou_per_class[gt_category] += iou
- gt_matched.add(gt_segment_id)
- pred_matched.add(pred_segment_id)
-
- # Count false negatives for each category.
- for gt_segment_id in six.iterkeys(gt_segment_areas):
- if gt_segment_id in gt_matched:
- continue
- category = gt_segment_id // self.max_instances_per_category
- # Failing to detect a void segment is not a false negative.
- if category == self.ignored_label:
- continue
- self.fn_per_class[category] += 1
-
- # Count false positives for each category.
- for pred_segment_id in six.iterkeys(pred_segment_areas):
- if pred_segment_id in pred_matched:
- continue
- # A false positive is not penalized if is mostly ignored in the
- # groundtruth.
- if (prediction_ignored_overlap(pred_segment_id) /
- pred_segment_areas[pred_segment_id]) > 0.5:
- continue
- category = pred_segment_id // self.max_instances_per_category
- self.fp_per_class[category] += 1
-
- return self.result()
-
- def _valid_categories(self):
- """Categories with a "valid" value for the metric, have > 0 instances.
-
- We will ignore the `ignore_label` class and other classes which have
- `tp + fn + fp = 0`.
-
- Returns:
- Boolean array of shape `[num_categories]`.
- """
- valid_categories = np.not_equal(
- self.tp_per_class + self.fn_per_class + self.fp_per_class, 0)
- if self.ignored_label >= 0 and self.ignored_label < self.num_categories:
- valid_categories[self.ignored_label] = False
- return valid_categories
-
- def detailed_results(self, is_thing=None):
- """See base class."""
- valid_categories = self._valid_categories()
-
- # If known, break down which categories are valid _and_ things/stuff.
- category_sets = collections.OrderedDict()
- category_sets['All'] = valid_categories
- if is_thing is not None:
- category_sets['Things'] = np.logical_and(valid_categories, is_thing)
- category_sets['Stuff'] = np.logical_and(valid_categories,
- np.logical_not(is_thing))
-
- # Compute individual per-class metrics that constitute factors of PQ.
- sq = base_metric.realdiv_maybe_zero(self.iou_per_class, self.tp_per_class)
- rq = base_metric.realdiv_maybe_zero(
- self.tp_per_class,
- self.tp_per_class + 0.5 * self.fn_per_class + 0.5 * self.fp_per_class)
- pq = np.multiply(sq, rq)
-
- # Assemble detailed results dictionary.
- results = {}
- for category_set_name, in_category_set in six.iteritems(category_sets):
- if np.any(in_category_set):
- results[category_set_name] = {
- 'pq': np.mean(pq[in_category_set]),
- 'sq': np.mean(sq[in_category_set]),
- 'rq': np.mean(rq[in_category_set]),
- # The number of categories in this subset.
- 'n': np.sum(in_category_set.astype(np.int32)),
- }
- else:
- results[category_set_name] = {'pq': 0, 'sq': 0, 'rq': 0, 'n': 0}
-
- return results
-
- def result_per_category(self):
- """See base class."""
- sq = base_metric.realdiv_maybe_zero(self.iou_per_class, self.tp_per_class)
- rq = base_metric.realdiv_maybe_zero(
- self.tp_per_class,
- self.tp_per_class + 0.5 * self.fn_per_class + 0.5 * self.fp_per_class)
- return np.multiply(sq, rq)
-
- def print_detailed_results(self, is_thing=None, print_digits=3):
- """See base class."""
- results = self.detailed_results(is_thing=is_thing)
-
- tab = prettytable.PrettyTable()
-
- tab.add_column('', [], align='l')
- for fieldname in ['PQ', 'SQ', 'RQ', 'N']:
- tab.add_column(fieldname, [], align='r')
-
- for category_set, subset_results in six.iteritems(results):
- data_cols = [
- round(subset_results[col_key], print_digits) * 100
- for col_key in ['pq', 'sq', 'rq']
- ]
- data_cols += [subset_results['n']]
- tab.add_row([category_set] + data_cols)
-
- print(tab)
-
- def result(self):
- """See base class."""
- pq_per_class = self.result_per_category()
- valid_categories = self._valid_categories()
- if not np.any(valid_categories):
- return 0.
- return np.mean(pq_per_class[valid_categories])
-
- def merge(self, other_instance):
- """See base class."""
- self.iou_per_class += other_instance.iou_per_class
- self.tp_per_class += other_instance.tp_per_class
- self.fn_per_class += other_instance.fn_per_class
- self.fp_per_class += other_instance.fp_per_class
-
- def reset(self):
- """See base class."""
- self.iou_per_class = np.zeros(self.num_categories, dtype=np.float64)
- self.tp_per_class = np.zeros(self.num_categories, dtype=np.float64)
- self.fn_per_class = np.zeros(self.num_categories, dtype=np.float64)
- self.fp_per_class = np.zeros(self.num_categories, dtype=np.float64)
diff --git a/research/deeplab/evaluation/panoptic_quality_test.py b/research/deeplab/evaluation/panoptic_quality_test.py
deleted file mode 100644
index 00c88c293b8edc39b7ceb28b2fc7fea4da1c3cb0..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/panoptic_quality_test.py
+++ /dev/null
@@ -1,336 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for Panoptic Quality metric."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-from absl.testing import absltest
-import numpy as np
-import six
-
-from deeplab.evaluation import panoptic_quality
-from deeplab.evaluation import test_utils
-
-# See the definition of the color names at:
-# https://en.wikipedia.org/wiki/Web_colors.
-_CLASS_COLOR_MAP = {
- (0, 0, 0): 0,
- (0, 0, 255): 1, # Person (blue).
- (255, 0, 0): 2, # Bear (red).
- (0, 255, 0): 3, # Tree (lime).
- (255, 0, 255): 4, # Bird (fuchsia).
- (0, 255, 255): 5, # Sky (aqua).
- (255, 255, 0): 6, # Cat (yellow).
-}
-
-
-class PanopticQualityTest(absltest.TestCase):
-
- def test_perfect_match(self):
- categories = np.zeros([6, 6], np.uint16)
- instances = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 2, 2, 1, 1, 1],
- [1, 2, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=1,
- ignored_label=2,
- max_instances_per_category=16,
- offset=16)
- pq.compare_and_accumulate(categories, instances, categories, instances)
- np.testing.assert_array_equal(pq.iou_per_class, [2.0])
- np.testing.assert_array_equal(pq.tp_per_class, [2])
- np.testing.assert_array_equal(pq.fn_per_class, [0])
- np.testing.assert_array_equal(pq.fp_per_class, [0])
- np.testing.assert_array_equal(pq.result_per_category(), [1.0])
- self.assertEqual(pq.result(), 1.0)
-
- def test_totally_wrong(self):
- det_categories = np.array([
- [0, 0, 0, 0, 0, 0],
- [0, 1, 0, 0, 1, 0],
- [0, 1, 1, 1, 1, 0],
- [0, 1, 1, 1, 1, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- ],
- dtype=np.uint16)
- gt_categories = 1 - det_categories
- instances = np.zeros([6, 6], np.uint16)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=2,
- ignored_label=2,
- max_instances_per_category=1,
- offset=16)
- pq.compare_and_accumulate(gt_categories, instances, det_categories,
- instances)
- np.testing.assert_array_equal(pq.iou_per_class, [0.0, 0.0])
- np.testing.assert_array_equal(pq.tp_per_class, [0, 0])
- np.testing.assert_array_equal(pq.fn_per_class, [1, 1])
- np.testing.assert_array_equal(pq.fp_per_class, [1, 1])
- np.testing.assert_array_equal(pq.result_per_category(), [0.0, 0.0])
- self.assertEqual(pq.result(), 0.0)
-
- def test_matches_by_iou(self):
- good_det_labels = np.array(
- [
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 2, 2, 2, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
- gt_labels = np.array(
- [
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 2, 2, 2, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=1,
- ignored_label=2,
- max_instances_per_category=16,
- offset=16)
- pq.compare_and_accumulate(
- np.zeros_like(gt_labels), gt_labels, np.zeros_like(good_det_labels),
- good_det_labels)
-
- # iou(1, 1) = 28/30
- # iou(2, 2) = 6/8
- np.testing.assert_array_almost_equal(pq.iou_per_class, [28 / 30 + 6 / 8])
- np.testing.assert_array_equal(pq.tp_per_class, [2])
- np.testing.assert_array_equal(pq.fn_per_class, [0])
- np.testing.assert_array_equal(pq.fp_per_class, [0])
- self.assertAlmostEqual(pq.result(), (28 / 30 + 6 / 8) / 2)
-
- bad_det_labels = np.array(
- [
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
-
- pq.reset()
- pq.compare_and_accumulate(
- np.zeros_like(gt_labels), gt_labels, np.zeros_like(bad_det_labels),
- bad_det_labels)
-
- # iou(1, 1) = 27/32
- np.testing.assert_array_almost_equal(pq.iou_per_class, [27 / 32])
- np.testing.assert_array_equal(pq.tp_per_class, [1])
- np.testing.assert_array_equal(pq.fn_per_class, [1])
- np.testing.assert_array_equal(pq.fp_per_class, [1])
- self.assertAlmostEqual(pq.result(), (27 / 32) * (1 / 2))
-
- def test_wrong_instances(self):
- categories = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 2, 2, 1, 2, 2],
- [1, 2, 2, 1, 2, 2],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
- predicted_instances = np.array([
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 1, 1],
- [0, 0, 0, 0, 1, 1],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- ],
- dtype=np.uint16)
- groundtruth_instances = np.zeros([6, 6], dtype=np.uint16)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=3,
- ignored_label=0,
- max_instances_per_category=10,
- offset=100)
- pq.compare_and_accumulate(categories, groundtruth_instances, categories,
- predicted_instances)
-
- np.testing.assert_array_equal(pq.iou_per_class, [0.0, 1.0, 0.0])
- np.testing.assert_array_equal(pq.tp_per_class, [0, 1, 0])
- np.testing.assert_array_equal(pq.fn_per_class, [0, 0, 1])
- np.testing.assert_array_equal(pq.fp_per_class, [0, 0, 2])
- np.testing.assert_array_equal(pq.result_per_category(), [0, 1, 0])
- self.assertAlmostEqual(pq.result(), 0.5)
-
- def test_instance_order_is_arbitrary(self):
- categories = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 2, 2, 1, 2, 2],
- [1, 2, 2, 1, 2, 2],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
- predicted_instances = np.array([
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 1, 1],
- [0, 0, 0, 0, 1, 1],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- ],
- dtype=np.uint16)
- groundtruth_instances = np.array([
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 1, 1, 0, 0, 0],
- [0, 1, 1, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- ],
- dtype=np.uint16)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=3,
- ignored_label=0,
- max_instances_per_category=10,
- offset=100)
- pq.compare_and_accumulate(categories, groundtruth_instances, categories,
- predicted_instances)
-
- np.testing.assert_array_equal(pq.iou_per_class, [0.0, 1.0, 2.0])
- np.testing.assert_array_equal(pq.tp_per_class, [0, 1, 2])
- np.testing.assert_array_equal(pq.fn_per_class, [0, 0, 0])
- np.testing.assert_array_equal(pq.fp_per_class, [0, 0, 0])
- np.testing.assert_array_equal(pq.result_per_category(), [0, 1, 1])
- self.assertAlmostEqual(pq.result(), 1.0)
-
- def test_matches_expected(self):
- pred_classes = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', _CLASS_COLOR_MAP)
- pred_instances = test_utils.read_test_image(
- 'team_pred_instance.png', mode='L')
-
- instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- gt_instances, gt_classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_class_map)
-
- pq = panoptic_quality.PanopticQuality(
- num_categories=3,
- ignored_label=0,
- max_instances_per_category=256,
- offset=256 * 256)
- pq.compare_and_accumulate(gt_classes, gt_instances, pred_classes,
- pred_instances)
- np.testing.assert_array_almost_equal(
- pq.iou_per_class, [2.06104, 5.26827, 0.54069], decimal=4)
- np.testing.assert_array_equal(pq.tp_per_class, [1, 7, 1])
- np.testing.assert_array_equal(pq.fn_per_class, [0, 1, 0])
- np.testing.assert_array_equal(pq.fp_per_class, [0, 0, 0])
- np.testing.assert_array_almost_equal(pq.result_per_category(),
- [2.061038, 0.702436, 0.54069])
- self.assertAlmostEqual(pq.result(), 0.62156287)
-
- def test_merge_accumulates_all_across_instances(self):
- categories = np.zeros([6, 6], np.uint16)
- good_det_labels = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 2, 2, 2, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
- gt_labels = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 2, 2, 2, 1],
- [1, 2, 2, 2, 2, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
-
- good_pq = panoptic_quality.PanopticQuality(
- num_categories=1,
- ignored_label=2,
- max_instances_per_category=16,
- offset=16)
- for _ in six.moves.range(2):
- good_pq.compare_and_accumulate(categories, gt_labels, categories,
- good_det_labels)
-
- bad_det_labels = np.array([
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 2, 2, 1],
- [1, 1, 1, 1, 1, 1],
- ],
- dtype=np.uint16)
-
- bad_pq = panoptic_quality.PanopticQuality(
- num_categories=1,
- ignored_label=2,
- max_instances_per_category=16,
- offset=16)
- for _ in six.moves.range(2):
- bad_pq.compare_and_accumulate(categories, gt_labels, categories,
- bad_det_labels)
-
- good_pq.merge(bad_pq)
-
- np.testing.assert_array_almost_equal(
- good_pq.iou_per_class, [2 * (28 / 30 + 6 / 8) + 2 * (27 / 32)])
- np.testing.assert_array_equal(good_pq.tp_per_class, [2 * 2 + 2])
- np.testing.assert_array_equal(good_pq.fn_per_class, [2])
- np.testing.assert_array_equal(good_pq.fp_per_class, [2])
- self.assertAlmostEqual(good_pq.result(), 0.63177083)
-
-
-if __name__ == '__main__':
- absltest.main()
diff --git a/research/deeplab/evaluation/parsing_covering.py b/research/deeplab/evaluation/parsing_covering.py
deleted file mode 100644
index a40e55fc6be7a7563ceba75db17b188244dad832..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/parsing_covering.py
+++ /dev/null
@@ -1,246 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Implementation of the Parsing Covering metric.
-
-Parsing Covering is a region-based metric for evaluating the task of
-image parsing, aka panoptic segmentation.
-
-Please see the paper for details:
-"DeeperLab: Single-Shot Image Parser", Tien-Ju Yang, Maxwell D. Collins,
-Yukun Zhu, Jyh-Jing Hwang, Ting Liu, Xiao Zhang, Vivienne Sze,
-George Papandreou, Liang-Chieh Chen. arXiv: 1902.05093, 2019.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-
-import numpy as np
-import prettytable
-import six
-
-from deeplab.evaluation import base_metric
-
-
-class ParsingCovering(base_metric.SegmentationMetric):
- r"""Metric class for Parsing Covering.
-
- Computes segmentation covering metric introduced in (Arbelaez, et al., 2010)
- with extension to handle multi-class semantic labels (a.k.a. parsing
- covering). Specifically, segmentation covering (SC) is defined in Eq. (8) in
- (Arbelaez et al., 2010) as:
-
- SC(c) = \sum_{R\in S}(|R| * \max_{R'\in S'}O(R,R')) / \sum_{R\in S}|R|,
-
- where S are the groundtruth instance regions and S' are the predicted
- instance regions. The parsing covering is simply:
-
- PC = \sum_{c=1}^{C}SC(c) / C,
-
- where C is the number of classes.
- """
-
- def __init__(self,
- num_categories,
- ignored_label,
- max_instances_per_category,
- offset,
- normalize_by_image_size=True):
- """Initialization for ParsingCovering.
-
- Args:
- num_categories: The number of segmentation categories (or "classes" in the
- dataset.
- ignored_label: A category id that is ignored in evaluation, e.g. the void
- label as defined in COCO panoptic segmentation dataset.
- max_instances_per_category: The maximum number of instances for each
- category. Used in ensuring unique instance labels.
- offset: The maximum number of unique labels. This is used, by multiplying
- the ground-truth labels, to generate unique ids for individual regions
- of overlap between groundtruth and predicted segments.
- normalize_by_image_size: Whether to normalize groundtruth instance region
- areas by image size. If True, groundtruth instance areas and weighted
- IoUs will be divided by the size of the corresponding image before
- accumulated across the dataset.
- """
- super(ParsingCovering, self).__init__(num_categories, ignored_label,
- max_instances_per_category, offset)
- self.normalize_by_image_size = normalize_by_image_size
-
- def compare_and_accumulate(
- self, groundtruth_category_array, groundtruth_instance_array,
- predicted_category_array, predicted_instance_array):
- """See base class."""
- # Allocate intermediate data structures.
- max_ious = np.zeros([self.num_categories, self.max_instances_per_category],
- dtype=np.float64)
- gt_areas = np.zeros([self.num_categories, self.max_instances_per_category],
- dtype=np.float64)
- pred_areas = np.zeros(
- [self.num_categories, self.max_instances_per_category],
- dtype=np.float64)
- # This is a dictionary in the format:
- # {(category, gt_instance): [(pred_instance, intersection_area)]}.
- intersections = collections.defaultdict(list)
-
- # First, combine the category and instance labels so that every unique
- # value for (category, instance) is assigned a unique integer label.
- pred_segment_id = self._naively_combine_labels(predicted_category_array,
- predicted_instance_array)
- gt_segment_id = self._naively_combine_labels(groundtruth_category_array,
- groundtruth_instance_array)
-
- # Next, combine the groundtruth and predicted labels. Dividing up the pixels
- # based on which groundtruth segment and which predicted segment they belong
- # to, this will assign a different 32-bit integer label to each choice
- # of (groundtruth segment, predicted segment), encoded as
- # gt_segment_id * offset + pred_segment_id.
- intersection_id_array = (
- gt_segment_id.astype(np.uint32) * self.offset +
- pred_segment_id.astype(np.uint32))
-
- # For every combination of (groundtruth segment, predicted segment) with a
- # non-empty intersection, this counts the number of pixels in that
- # intersection.
- intersection_ids, intersection_areas = np.unique(
- intersection_id_array, return_counts=True)
-
- # Find areas of all groundtruth and predicted instances, as well as of their
- # intersections.
- for intersection_id, intersection_area in six.moves.zip(
- intersection_ids, intersection_areas):
- gt_segment_id = intersection_id // self.offset
- gt_category = gt_segment_id // self.max_instances_per_category
- if gt_category == self.ignored_label:
- continue
- gt_instance = gt_segment_id % self.max_instances_per_category
- gt_areas[gt_category, gt_instance] += intersection_area
-
- pred_segment_id = intersection_id % self.offset
- pred_category = pred_segment_id // self.max_instances_per_category
- pred_instance = pred_segment_id % self.max_instances_per_category
- pred_areas[pred_category, pred_instance] += intersection_area
- if pred_category != gt_category:
- continue
-
- intersections[gt_category, gt_instance].append((pred_instance,
- intersection_area))
-
- # Find maximum IoU for every groundtruth instance.
- for gt_label, instance_intersections in six.iteritems(intersections):
- category, gt_instance = gt_label
- gt_area = gt_areas[category, gt_instance]
- ious = []
- for pred_instance, intersection_area in instance_intersections:
- pred_area = pred_areas[category, pred_instance]
- union = gt_area + pred_area - intersection_area
- ious.append(intersection_area / union)
- max_ious[category, gt_instance] = max(ious)
-
- # Normalize groundtruth instance areas by image size if necessary.
- if self.normalize_by_image_size:
- gt_areas /= groundtruth_category_array.size
-
- # Compute per-class weighted IoUs and areas summed over all groundtruth
- # instances.
- self.weighted_iou_per_class += np.sum(max_ious * gt_areas, axis=-1)
- self.gt_area_per_class += np.sum(gt_areas, axis=-1)
-
- return self.result()
-
- def result_per_category(self):
- """See base class."""
- return base_metric.realdiv_maybe_zero(self.weighted_iou_per_class,
- self.gt_area_per_class)
-
- def _valid_categories(self):
- """Categories with a "valid" value for the metric, have > 0 instances.
-
- We will ignore the `ignore_label` class and other classes which have
- groundtruth area of 0.
-
- Returns:
- Boolean array of shape `[num_categories]`.
- """
- valid_categories = np.not_equal(self.gt_area_per_class, 0)
- if self.ignored_label >= 0 and self.ignored_label < self.num_categories:
- valid_categories[self.ignored_label] = False
- return valid_categories
-
- def detailed_results(self, is_thing=None):
- """See base class."""
- valid_categories = self._valid_categories()
-
- # If known, break down which categories are valid _and_ things/stuff.
- category_sets = collections.OrderedDict()
- category_sets['All'] = valid_categories
- if is_thing is not None:
- category_sets['Things'] = np.logical_and(valid_categories, is_thing)
- category_sets['Stuff'] = np.logical_and(valid_categories,
- np.logical_not(is_thing))
-
- covering_per_class = self.result_per_category()
- results = {}
- for category_set_name, in_category_set in six.iteritems(category_sets):
- if np.any(in_category_set):
- results[category_set_name] = {
- 'pc': np.mean(covering_per_class[in_category_set]),
- # The number of valid categories in this subset.
- 'n': np.sum(in_category_set.astype(np.int32)),
- }
- else:
- results[category_set_name] = {'pc': 0, 'n': 0}
-
- return results
-
- def print_detailed_results(self, is_thing=None, print_digits=3):
- """See base class."""
- results = self.detailed_results(is_thing=is_thing)
-
- tab = prettytable.PrettyTable()
-
- tab.add_column('', [], align='l')
- for fieldname in ['PC', 'N']:
- tab.add_column(fieldname, [], align='r')
-
- for category_set, subset_results in six.iteritems(results):
- data_cols = [
- round(subset_results['pc'], print_digits) * 100, subset_results['n']
- ]
- tab.add_row([category_set] + data_cols)
-
- print(tab)
-
- def result(self):
- """See base class."""
- covering_per_class = self.result_per_category()
- valid_categories = self._valid_categories()
- if not np.any(valid_categories):
- return 0.
- return np.mean(covering_per_class[valid_categories])
-
- def merge(self, other_instance):
- """See base class."""
- self.weighted_iou_per_class += other_instance.weighted_iou_per_class
- self.gt_area_per_class += other_instance.gt_area_per_class
-
- def reset(self):
- """See base class."""
- self.weighted_iou_per_class = np.zeros(
- self.num_categories, dtype=np.float64)
- self.gt_area_per_class = np.zeros(self.num_categories, dtype=np.float64)
diff --git a/research/deeplab/evaluation/parsing_covering_test.py b/research/deeplab/evaluation/parsing_covering_test.py
deleted file mode 100644
index 124d1b372559ef672ea1c9f821eac3fec52c97ea..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/parsing_covering_test.py
+++ /dev/null
@@ -1,173 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for Parsing Covering metric."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-from absl.testing import absltest
-import numpy as np
-
-from deeplab.evaluation import parsing_covering
-from deeplab.evaluation import test_utils
-
-# See the definition of the color names at:
-# https://en.wikipedia.org/wiki/Web_colors.
-_CLASS_COLOR_MAP = {
- (0, 0, 0): 0,
- (0, 0, 255): 1, # Person (blue).
- (255, 0, 0): 2, # Bear (red).
- (0, 255, 0): 3, # Tree (lime).
- (255, 0, 255): 4, # Bird (fuchsia).
- (0, 255, 255): 5, # Sky (aqua).
- (255, 255, 0): 6, # Cat (yellow).
-}
-
-
-class CoveringConveringTest(absltest.TestCase):
-
- def test_perfect_match(self):
- categories = np.zeros([6, 6], np.uint16)
- instances = np.array([
- [2, 2, 2, 2, 2, 2],
- [2, 4, 4, 4, 4, 2],
- [2, 4, 4, 4, 4, 2],
- [2, 4, 4, 4, 4, 2],
- [2, 4, 4, 2, 2, 2],
- [2, 4, 2, 2, 2, 2],
- ],
- dtype=np.uint16)
-
- pc = parsing_covering.ParsingCovering(
- num_categories=3,
- ignored_label=2,
- max_instances_per_category=2,
- offset=16,
- normalize_by_image_size=False)
- pc.compare_and_accumulate(categories, instances, categories, instances)
- np.testing.assert_array_equal(pc.weighted_iou_per_class, [0.0, 21.0, 0.0])
- np.testing.assert_array_equal(pc.gt_area_per_class, [0.0, 21.0, 0.0])
- np.testing.assert_array_equal(pc.result_per_category(), [0.0, 1.0, 0.0])
- self.assertEqual(pc.result(), 1.0)
-
- def test_totally_wrong(self):
- categories = np.zeros([6, 6], np.uint16)
- gt_instances = np.array([
- [0, 0, 0, 0, 0, 0],
- [0, 1, 0, 0, 1, 0],
- [0, 1, 1, 1, 1, 0],
- [0, 1, 1, 1, 1, 0],
- [0, 0, 0, 0, 0, 0],
- [0, 0, 0, 0, 0, 0],
- ],
- dtype=np.uint16)
- pred_instances = 1 - gt_instances
-
- pc = parsing_covering.ParsingCovering(
- num_categories=2,
- ignored_label=0,
- max_instances_per_category=1,
- offset=16,
- normalize_by_image_size=False)
- pc.compare_and_accumulate(categories, gt_instances, categories,
- pred_instances)
- np.testing.assert_array_equal(pc.weighted_iou_per_class, [0.0, 0.0])
- np.testing.assert_array_equal(pc.gt_area_per_class, [0.0, 10.0])
- np.testing.assert_array_equal(pc.result_per_category(), [0.0, 0.0])
- self.assertEqual(pc.result(), 0.0)
-
- def test_matches_expected(self):
- pred_classes = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', _CLASS_COLOR_MAP)
- pred_instances = test_utils.read_test_image(
- 'team_pred_instance.png', mode='L')
-
- instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- gt_instances, gt_classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_class_map)
-
- pc = parsing_covering.ParsingCovering(
- num_categories=3,
- ignored_label=0,
- max_instances_per_category=256,
- offset=256 * 256,
- normalize_by_image_size=False)
- pc.compare_and_accumulate(gt_classes, gt_instances, pred_classes,
- pred_instances)
- np.testing.assert_array_almost_equal(
- pc.weighted_iou_per_class, [0.0, 39864.14634, 3136], decimal=4)
- np.testing.assert_array_equal(pc.gt_area_per_class, [0.0, 56870, 5800])
- np.testing.assert_array_almost_equal(
- pc.result_per_category(), [0.0, 0.70097, 0.54069], decimal=4)
- self.assertAlmostEqual(pc.result(), 0.6208296732)
-
- def test_matches_expected_normalize_by_size(self):
- pred_classes = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', _CLASS_COLOR_MAP)
- pred_instances = test_utils.read_test_image(
- 'team_pred_instance.png', mode='L')
-
- instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- gt_instances, gt_classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_class_map)
-
- pc = parsing_covering.ParsingCovering(
- num_categories=3,
- ignored_label=0,
- max_instances_per_category=256,
- offset=256 * 256,
- normalize_by_image_size=True)
- pc.compare_and_accumulate(gt_classes, gt_instances, pred_classes,
- pred_instances)
- np.testing.assert_array_almost_equal(
- pc.weighted_iou_per_class, [0.0, 0.5002088756, 0.03935002196],
- decimal=4)
- np.testing.assert_array_almost_equal(
- pc.gt_area_per_class, [0.0, 0.7135955832, 0.07277746408], decimal=4)
- # Note that the per-category and overall PCs are identical to those without
- # normalization in the previous test, because we only have a single image.
- np.testing.assert_array_almost_equal(
- pc.result_per_category(), [0.0, 0.70097, 0.54069], decimal=4)
- self.assertAlmostEqual(pc.result(), 0.6208296732)
-
-
-if __name__ == '__main__':
- absltest.main()
diff --git a/research/deeplab/evaluation/streaming_metrics.py b/research/deeplab/evaluation/streaming_metrics.py
deleted file mode 100644
index 8313792676a62e58af70300a0cfa43528a904435..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/streaming_metrics.py
+++ /dev/null
@@ -1,240 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Code to compute segmentation in a "streaming" pattern in Tensorflow.
-
-These aggregate the metric over examples of the evaluation set. Each example is
-assumed to be fed in in a stream, and the metric implementation accumulates
-across them.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from deeplab.evaluation import panoptic_quality
-from deeplab.evaluation import parsing_covering
-
-_EPSILON = 1e-10
-
-
-def _realdiv_maybe_zero(x, y):
- """Support tf.realdiv(x, y) where y may contain zeros."""
- return tf.where(tf.less(y, _EPSILON), tf.zeros_like(x), tf.realdiv(x, y))
-
-
-def _running_total(value, shape, name=None):
- """Maintains a running total of tensor `value` between calls."""
- with tf.variable_scope(name, 'running_total', [value]):
- total_var = tf.get_variable(
- 'total',
- shape,
- value.dtype,
- initializer=tf.zeros_initializer(),
- trainable=False,
- collections=[
- tf.GraphKeys.LOCAL_VARIABLES, tf.GraphKeys.METRIC_VARIABLES
- ])
- updated_total = tf.assign_add(total_var, value, use_locking=True)
-
- return total_var, updated_total
-
-
-def _panoptic_quality_helper(
- groundtruth_category_array, groundtruth_instance_array,
- predicted_category_array, predicted_instance_array, num_classes,
- max_instances_per_category, ignored_label, offset):
- """Helper function to compute panoptic quality."""
- pq = panoptic_quality.PanopticQuality(num_classes, ignored_label,
- max_instances_per_category, offset)
- pq.compare_and_accumulate(groundtruth_category_array,
- groundtruth_instance_array,
- predicted_category_array, predicted_instance_array)
- return pq.iou_per_class, pq.tp_per_class, pq.fn_per_class, pq.fp_per_class
-
-
-def streaming_panoptic_quality(groundtruth_categories,
- groundtruth_instances,
- predicted_categories,
- predicted_instances,
- num_classes,
- max_instances_per_category,
- ignored_label,
- offset,
- name=None):
- """Aggregates the panoptic metric across calls with different input tensors.
-
- See tf.metrics.* functions for comparable functionality and usage.
-
- Args:
- groundtruth_categories: A 2D uint16 tensor of groundtruth category labels.
- groundtruth_instances: A 2D uint16 tensor of groundtruth instance labels.
- predicted_categories: A 2D uint16 tensor of predicted category labels.
- predicted_instances: A 2D uint16 tensor of predicted instance labels.
- num_classes: Number of classes in the dataset as an integer.
- max_instances_per_category: The maximum number of instances for each class
- as an integer or integer tensor.
- ignored_label: The class id to be ignored in evaluation as an integer or
- integer tensor.
- offset: The maximum number of unique labels as an integer or integer tensor.
- name: An optional variable_scope name.
-
- Returns:
- qualities: A tensor of shape `[6, num_classes]`, where (1) panoptic quality,
- (2) segmentation quality, (3) recognition quality, (4) total_tp,
- (5) total_fn and (6) total_fp are saved in the respective rows.
- update_ops: List of operations that update the running overall panoptic
- quality.
-
- Raises:
- RuntimeError: If eager execution is enabled.
- """
- if tf.executing_eagerly():
- raise RuntimeError('Cannot aggregate when eager execution is enabled.')
-
- input_args = [
- tf.convert_to_tensor(groundtruth_categories, tf.uint16),
- tf.convert_to_tensor(groundtruth_instances, tf.uint16),
- tf.convert_to_tensor(predicted_categories, tf.uint16),
- tf.convert_to_tensor(predicted_instances, tf.uint16),
- tf.convert_to_tensor(num_classes, tf.int32),
- tf.convert_to_tensor(max_instances_per_category, tf.int32),
- tf.convert_to_tensor(ignored_label, tf.int32),
- tf.convert_to_tensor(offset, tf.int32),
- ]
- return_types = [
- tf.float64,
- tf.float64,
- tf.float64,
- tf.float64,
- ]
- with tf.variable_scope(name, 'streaming_panoptic_quality', input_args):
- panoptic_results = tf.py_func(
- _panoptic_quality_helper, input_args, return_types, stateful=False)
- iou, tp, fn, fp = tuple(panoptic_results)
-
- total_iou, updated_iou = _running_total(
- iou, [num_classes], name='iou_total')
- total_tp, updated_tp = _running_total(tp, [num_classes], name='tp_total')
- total_fn, updated_fn = _running_total(fn, [num_classes], name='fn_total')
- total_fp, updated_fp = _running_total(fp, [num_classes], name='fp_total')
- update_ops = [updated_iou, updated_tp, updated_fn, updated_fp]
-
- sq = _realdiv_maybe_zero(total_iou, total_tp)
- rq = _realdiv_maybe_zero(total_tp,
- total_tp + 0.5 * total_fn + 0.5 * total_fp)
- pq = tf.multiply(sq, rq)
- qualities = tf.stack([pq, sq, rq, total_tp, total_fn, total_fp], axis=0)
- return qualities, update_ops
-
-
-def _parsing_covering_helper(
- groundtruth_category_array, groundtruth_instance_array,
- predicted_category_array, predicted_instance_array, num_classes,
- max_instances_per_category, ignored_label, offset, normalize_by_image_size):
- """Helper function to compute parsing covering."""
- pc = parsing_covering.ParsingCovering(num_classes, ignored_label,
- max_instances_per_category, offset,
- normalize_by_image_size)
- pc.compare_and_accumulate(groundtruth_category_array,
- groundtruth_instance_array,
- predicted_category_array, predicted_instance_array)
- return pc.weighted_iou_per_class, pc.gt_area_per_class
-
-
-def streaming_parsing_covering(groundtruth_categories,
- groundtruth_instances,
- predicted_categories,
- predicted_instances,
- num_classes,
- max_instances_per_category,
- ignored_label,
- offset,
- normalize_by_image_size=True,
- name=None):
- """Aggregates the covering across calls with different input tensors.
-
- See tf.metrics.* functions for comparable functionality and usage.
-
- Args:
- groundtruth_categories: A 2D uint16 tensor of groundtruth category labels.
- groundtruth_instances: A 2D uint16 tensor of groundtruth instance labels.
- predicted_categories: A 2D uint16 tensor of predicted category labels.
- predicted_instances: A 2D uint16 tensor of predicted instance labels.
- num_classes: Number of classes in the dataset as an integer.
- max_instances_per_category: The maximum number of instances for each class
- as an integer or integer tensor.
- ignored_label: The class id to be ignored in evaluation as an integer or
- integer tensor.
- offset: The maximum number of unique labels as an integer or integer tensor.
- normalize_by_image_size: Whether to normalize groundtruth region areas by
- image size. If True, groundtruth instance areas and weighted IoUs will be
- divided by the size of the corresponding image before accumulated across
- the dataset.
- name: An optional variable_scope name.
-
- Returns:
- coverings: A tensor of shape `[3, num_classes]`, where (1) per class
- coverings, (2) per class sum of weighted IoUs, and (3) per class sum of
- groundtruth region areas are saved in the perspective rows.
- update_ops: List of operations that update the running overall parsing
- covering.
-
- Raises:
- RuntimeError: If eager execution is enabled.
- """
- if tf.executing_eagerly():
- raise RuntimeError('Cannot aggregate when eager execution is enabled.')
-
- input_args = [
- tf.convert_to_tensor(groundtruth_categories, tf.uint16),
- tf.convert_to_tensor(groundtruth_instances, tf.uint16),
- tf.convert_to_tensor(predicted_categories, tf.uint16),
- tf.convert_to_tensor(predicted_instances, tf.uint16),
- tf.convert_to_tensor(num_classes, tf.int32),
- tf.convert_to_tensor(max_instances_per_category, tf.int32),
- tf.convert_to_tensor(ignored_label, tf.int32),
- tf.convert_to_tensor(offset, tf.int32),
- tf.convert_to_tensor(normalize_by_image_size, tf.bool),
- ]
- return_types = [
- tf.float64,
- tf.float64,
- ]
- with tf.variable_scope(name, 'streaming_parsing_covering', input_args):
- covering_results = tf.py_func(
- _parsing_covering_helper, input_args, return_types, stateful=False)
- weighted_iou_per_class, gt_area_per_class = tuple(covering_results)
-
- total_weighted_iou_per_class, updated_weighted_iou_per_class = (
- _running_total(
- weighted_iou_per_class, [num_classes],
- name='weighted_iou_per_class_total'))
- total_gt_area_per_class, updated_gt_area_per_class = _running_total(
- gt_area_per_class, [num_classes], name='gt_area_per_class_total')
-
- covering_per_class = _realdiv_maybe_zero(total_weighted_iou_per_class,
- total_gt_area_per_class)
- coverings = tf.stack([
- covering_per_class,
- total_weighted_iou_per_class,
- total_gt_area_per_class,
- ],
- axis=0)
- update_ops = [updated_weighted_iou_per_class, updated_gt_area_per_class]
-
- return coverings, update_ops
diff --git a/research/deeplab/evaluation/streaming_metrics_test.py b/research/deeplab/evaluation/streaming_metrics_test.py
deleted file mode 100644
index 656007e6238e5c106dd8eee08fe65e4ba7457801..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/streaming_metrics_test.py
+++ /dev/null
@@ -1,549 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for segmentation "streaming" metrics."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-
-
-
-import numpy as np
-import six
-import tensorflow as tf
-
-from deeplab.evaluation import streaming_metrics
-from deeplab.evaluation import test_utils
-
-# See the definition of the color names at:
-# https://en.wikipedia.org/wiki/Web_colors.
-_CLASS_COLOR_MAP = {
- (0, 0, 0): 0,
- (0, 0, 255): 1, # Person (blue).
- (255, 0, 0): 2, # Bear (red).
- (0, 255, 0): 3, # Tree (lime).
- (255, 0, 255): 4, # Bird (fuchsia).
- (0, 255, 255): 5, # Sky (aqua).
- (255, 255, 0): 6, # Cat (yellow).
-}
-
-
-class StreamingPanopticQualityTest(tf.test.TestCase):
-
- def test_streaming_metric_on_single_image(self):
- offset = 256 * 256
-
- instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- gt_instances, gt_classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_class_map)
-
- pred_classes = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', _CLASS_COLOR_MAP)
- pred_instances = test_utils.read_test_image(
- 'team_pred_instance.png', mode='L')
-
- gt_class_tensor = tf.placeholder(tf.uint16)
- gt_instance_tensor = tf.placeholder(tf.uint16)
- pred_class_tensor = tf.placeholder(tf.uint16)
- pred_instance_tensor = tf.placeholder(tf.uint16)
- qualities, update_pq = streaming_metrics.streaming_panoptic_quality(
- gt_class_tensor,
- gt_instance_tensor,
- pred_class_tensor,
- pred_instance_tensor,
- num_classes=3,
- max_instances_per_category=256,
- ignored_label=0,
- offset=offset)
- pq, sq, rq, total_tp, total_fn, total_fp = tf.unstack(qualities, 6, axis=0)
- feed_dict = {
- gt_class_tensor: gt_classes,
- gt_instance_tensor: gt_instances,
- pred_class_tensor: pred_classes,
- pred_instance_tensor: pred_instances
- }
-
- with self.session() as sess:
- sess.run(tf.local_variables_initializer())
- sess.run(update_pq, feed_dict=feed_dict)
- (result_pq, result_sq, result_rq, result_total_tp, result_total_fn,
- result_total_fp) = sess.run([pq, sq, rq, total_tp, total_fn, total_fp],
- feed_dict=feed_dict)
- np.testing.assert_array_almost_equal(
- result_pq, [2.06104, 0.7024, 0.54069], decimal=4)
- np.testing.assert_array_almost_equal(
- result_sq, [2.06104, 0.7526, 0.54069], decimal=4)
- np.testing.assert_array_almost_equal(result_rq, [1., 0.9333, 1.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_tp, [1., 7., 1.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_fn, [0., 1., 0.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_fp, [0., 0., 0.], decimal=4)
-
- def test_streaming_metric_on_multiple_images(self):
- num_classes = 7
- offset = 256 * 256
-
- bird_gt_instance_class_map = {
- 92: 5,
- 176: 3,
- 255: 4,
- }
- cat_gt_instance_class_map = {
- 0: 0,
- 255: 6,
- }
- team_gt_instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- test_image = collections.namedtuple(
- 'TestImage',
- ['gt_class_map', 'gt_path', 'pred_inst_path', 'pred_class_path'])
- test_images = [
- test_image(bird_gt_instance_class_map, 'bird_gt.png',
- 'bird_pred_instance.png', 'bird_pred_class.png'),
- test_image(cat_gt_instance_class_map, 'cat_gt.png',
- 'cat_pred_instance.png', 'cat_pred_class.png'),
- test_image(team_gt_instance_class_map, 'team_gt_instance.png',
- 'team_pred_instance.png', 'team_pred_class.png'),
- ]
-
- gt_classes = []
- gt_instances = []
- pred_classes = []
- pred_instances = []
- for test_image in test_images:
- (image_gt_instances,
- image_gt_classes) = test_utils.panoptic_segmentation_with_class_map(
- test_image.gt_path, test_image.gt_class_map)
- gt_classes.append(image_gt_classes)
- gt_instances.append(image_gt_instances)
-
- pred_classes.append(
- test_utils.read_segmentation_with_rgb_color_map(
- test_image.pred_class_path, _CLASS_COLOR_MAP))
- pred_instances.append(
- test_utils.read_test_image(test_image.pred_inst_path, mode='L'))
-
- gt_class_tensor = tf.placeholder(tf.uint16)
- gt_instance_tensor = tf.placeholder(tf.uint16)
- pred_class_tensor = tf.placeholder(tf.uint16)
- pred_instance_tensor = tf.placeholder(tf.uint16)
- qualities, update_pq = streaming_metrics.streaming_panoptic_quality(
- gt_class_tensor,
- gt_instance_tensor,
- pred_class_tensor,
- pred_instance_tensor,
- num_classes=num_classes,
- max_instances_per_category=256,
- ignored_label=0,
- offset=offset)
- pq, sq, rq, total_tp, total_fn, total_fp = tf.unstack(qualities, 6, axis=0)
- with self.session() as sess:
- sess.run(tf.local_variables_initializer())
- for pred_class, pred_instance, gt_class, gt_instance in six.moves.zip(
- pred_classes, pred_instances, gt_classes, gt_instances):
- sess.run(
- update_pq,
- feed_dict={
- gt_class_tensor: gt_class,
- gt_instance_tensor: gt_instance,
- pred_class_tensor: pred_class,
- pred_instance_tensor: pred_instance
- })
- (result_pq, result_sq, result_rq, result_total_tp, result_total_fn,
- result_total_fp) = sess.run(
- [pq, sq, rq, total_tp, total_fn, total_fp],
- feed_dict={
- gt_class_tensor: 0,
- gt_instance_tensor: 0,
- pred_class_tensor: 0,
- pred_instance_tensor: 0
- })
- np.testing.assert_array_almost_equal(
- result_pq,
- [4.3107, 0.7024, 0.54069, 0.745353, 0.85768, 0.99107, 0.77410],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_sq, [5.3883, 0.7526, 0.5407, 0.7454, 0.8577, 0.9911, 0.7741],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_rq, [0.8, 0.9333, 1., 1., 1., 1., 1.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_tp, [2., 7., 1., 1., 1., 1., 1.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_fn, [0., 1., 0., 0., 0., 0., 0.], decimal=4)
- np.testing.assert_array_almost_equal(
- result_total_fp, [1., 0., 0., 0., 0., 0., 0.], decimal=4)
-
-
-class StreamingParsingCoveringTest(tf.test.TestCase):
-
- def test_streaming_metric_on_single_image(self):
- offset = 256 * 256
-
- instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- gt_instances, gt_classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_class_map)
-
- pred_classes = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', _CLASS_COLOR_MAP)
- pred_instances = test_utils.read_test_image(
- 'team_pred_instance.png', mode='L')
-
- gt_class_tensor = tf.placeholder(tf.uint16)
- gt_instance_tensor = tf.placeholder(tf.uint16)
- pred_class_tensor = tf.placeholder(tf.uint16)
- pred_instance_tensor = tf.placeholder(tf.uint16)
- coverings, update_ops = streaming_metrics.streaming_parsing_covering(
- gt_class_tensor,
- gt_instance_tensor,
- pred_class_tensor,
- pred_instance_tensor,
- num_classes=3,
- max_instances_per_category=256,
- ignored_label=0,
- offset=offset,
- normalize_by_image_size=False)
- (per_class_coverings, per_class_weighted_ious, per_class_gt_areas) = (
- tf.unstack(coverings, num=3, axis=0))
- feed_dict = {
- gt_class_tensor: gt_classes,
- gt_instance_tensor: gt_instances,
- pred_class_tensor: pred_classes,
- pred_instance_tensor: pred_instances
- }
-
- with self.session() as sess:
- sess.run(tf.local_variables_initializer())
- sess.run(update_ops, feed_dict=feed_dict)
- (result_per_class_coverings, result_per_class_weighted_ious,
- result_per_class_gt_areas) = (
- sess.run([
- per_class_coverings,
- per_class_weighted_ious,
- per_class_gt_areas,
- ],
- feed_dict=feed_dict))
-
- np.testing.assert_array_almost_equal(
- result_per_class_coverings, [0.0, 0.7009696912, 0.5406896552],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_per_class_weighted_ious, [0.0, 39864.14634, 3136], decimal=4)
- np.testing.assert_array_equal(result_per_class_gt_areas, [0, 56870, 5800])
-
- def test_streaming_metric_on_multiple_images(self):
- """Tests streaming parsing covering metric."""
- num_classes = 7
- offset = 256 * 256
-
- bird_gt_instance_class_map = {
- 92: 5,
- 176: 3,
- 255: 4,
- }
- cat_gt_instance_class_map = {
- 0: 0,
- 255: 6,
- }
- team_gt_instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- test_image = collections.namedtuple(
- 'TestImage',
- ['gt_class_map', 'gt_path', 'pred_inst_path', 'pred_class_path'])
- test_images = [
- test_image(bird_gt_instance_class_map, 'bird_gt.png',
- 'bird_pred_instance.png', 'bird_pred_class.png'),
- test_image(cat_gt_instance_class_map, 'cat_gt.png',
- 'cat_pred_instance.png', 'cat_pred_class.png'),
- test_image(team_gt_instance_class_map, 'team_gt_instance.png',
- 'team_pred_instance.png', 'team_pred_class.png'),
- ]
-
- gt_classes = []
- gt_instances = []
- pred_classes = []
- pred_instances = []
- for test_image in test_images:
- (image_gt_instances,
- image_gt_classes) = test_utils.panoptic_segmentation_with_class_map(
- test_image.gt_path, test_image.gt_class_map)
- gt_classes.append(image_gt_classes)
- gt_instances.append(image_gt_instances)
-
- pred_instances.append(
- test_utils.read_test_image(test_image.pred_inst_path, mode='L'))
- pred_classes.append(
- test_utils.read_segmentation_with_rgb_color_map(
- test_image.pred_class_path, _CLASS_COLOR_MAP))
-
- gt_class_tensor = tf.placeholder(tf.uint16)
- gt_instance_tensor = tf.placeholder(tf.uint16)
- pred_class_tensor = tf.placeholder(tf.uint16)
- pred_instance_tensor = tf.placeholder(tf.uint16)
- coverings, update_ops = streaming_metrics.streaming_parsing_covering(
- gt_class_tensor,
- gt_instance_tensor,
- pred_class_tensor,
- pred_instance_tensor,
- num_classes=num_classes,
- max_instances_per_category=256,
- ignored_label=0,
- offset=offset,
- normalize_by_image_size=False)
- (per_class_coverings, per_class_weighted_ious, per_class_gt_areas) = (
- tf.unstack(coverings, num=3, axis=0))
-
- with self.session() as sess:
- sess.run(tf.local_variables_initializer())
- for pred_class, pred_instance, gt_class, gt_instance in six.moves.zip(
- pred_classes, pred_instances, gt_classes, gt_instances):
- sess.run(
- update_ops,
- feed_dict={
- gt_class_tensor: gt_class,
- gt_instance_tensor: gt_instance,
- pred_class_tensor: pred_class,
- pred_instance_tensor: pred_instance
- })
- (result_per_class_coverings, result_per_class_weighted_ious,
- result_per_class_gt_areas) = (
- sess.run(
- [
- per_class_coverings,
- per_class_weighted_ious,
- per_class_gt_areas,
- ],
- feed_dict={
- gt_class_tensor: 0,
- gt_instance_tensor: 0,
- pred_class_tensor: 0,
- pred_instance_tensor: 0
- }))
-
- np.testing.assert_array_almost_equal(
- result_per_class_coverings, [
- 0.0,
- 0.7009696912,
- 0.5406896552,
- 0.7453531599,
- 0.8576779026,
- 0.9910687881,
- 0.7741046032,
- ],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_per_class_weighted_ious, [
- 0.0,
- 39864.14634,
- 3136,
- 1177.657993,
- 2498.41573,
- 33366.31289,
- 26671,
- ],
- decimal=4)
- np.testing.assert_array_equal(result_per_class_gt_areas, [
- 0.0,
- 56870,
- 5800,
- 1580,
- 2913,
- 33667,
- 34454,
- ])
-
- def test_streaming_metric_on_multiple_images_normalize_by_size(self):
- """Tests streaming parsing covering metric with image size normalization."""
- num_classes = 7
- offset = 256 * 256
-
- bird_gt_instance_class_map = {
- 92: 5,
- 176: 3,
- 255: 4,
- }
- cat_gt_instance_class_map = {
- 0: 0,
- 255: 6,
- }
- team_gt_instance_class_map = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 2,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- test_image = collections.namedtuple(
- 'TestImage',
- ['gt_class_map', 'gt_path', 'pred_inst_path', 'pred_class_path'])
- test_images = [
- test_image(bird_gt_instance_class_map, 'bird_gt.png',
- 'bird_pred_instance.png', 'bird_pred_class.png'),
- test_image(cat_gt_instance_class_map, 'cat_gt.png',
- 'cat_pred_instance.png', 'cat_pred_class.png'),
- test_image(team_gt_instance_class_map, 'team_gt_instance.png',
- 'team_pred_instance.png', 'team_pred_class.png'),
- ]
-
- gt_classes = []
- gt_instances = []
- pred_classes = []
- pred_instances = []
- for test_image in test_images:
- (image_gt_instances,
- image_gt_classes) = test_utils.panoptic_segmentation_with_class_map(
- test_image.gt_path, test_image.gt_class_map)
- gt_classes.append(image_gt_classes)
- gt_instances.append(image_gt_instances)
-
- pred_instances.append(
- test_utils.read_test_image(test_image.pred_inst_path, mode='L'))
- pred_classes.append(
- test_utils.read_segmentation_with_rgb_color_map(
- test_image.pred_class_path, _CLASS_COLOR_MAP))
-
- gt_class_tensor = tf.placeholder(tf.uint16)
- gt_instance_tensor = tf.placeholder(tf.uint16)
- pred_class_tensor = tf.placeholder(tf.uint16)
- pred_instance_tensor = tf.placeholder(tf.uint16)
- coverings, update_ops = streaming_metrics.streaming_parsing_covering(
- gt_class_tensor,
- gt_instance_tensor,
- pred_class_tensor,
- pred_instance_tensor,
- num_classes=num_classes,
- max_instances_per_category=256,
- ignored_label=0,
- offset=offset,
- normalize_by_image_size=True)
- (per_class_coverings, per_class_weighted_ious, per_class_gt_areas) = (
- tf.unstack(coverings, num=3, axis=0))
-
- with self.session() as sess:
- sess.run(tf.local_variables_initializer())
- for pred_class, pred_instance, gt_class, gt_instance in six.moves.zip(
- pred_classes, pred_instances, gt_classes, gt_instances):
- sess.run(
- update_ops,
- feed_dict={
- gt_class_tensor: gt_class,
- gt_instance_tensor: gt_instance,
- pred_class_tensor: pred_class,
- pred_instance_tensor: pred_instance
- })
- (result_per_class_coverings, result_per_class_weighted_ious,
- result_per_class_gt_areas) = (
- sess.run(
- [
- per_class_coverings,
- per_class_weighted_ious,
- per_class_gt_areas,
- ],
- feed_dict={
- gt_class_tensor: 0,
- gt_instance_tensor: 0,
- pred_class_tensor: 0,
- pred_instance_tensor: 0
- }))
-
- np.testing.assert_array_almost_equal(
- result_per_class_coverings, [
- 0.0,
- 0.7009696912,
- 0.5406896552,
- 0.7453531599,
- 0.8576779026,
- 0.9910687881,
- 0.7741046032,
- ],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_per_class_weighted_ious, [
- 0.0,
- 0.5002088756,
- 0.03935002196,
- 0.03086105851,
- 0.06547211033,
- 0.8743792686,
- 0.2549565051,
- ],
- decimal=4)
- np.testing.assert_array_almost_equal(
- result_per_class_gt_areas, [
- 0.0,
- 0.7135955832,
- 0.07277746408,
- 0.04140461216,
- 0.07633647799,
- 0.8822589099,
- 0.3293566581,
- ],
- decimal=4)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/deeplab/evaluation/test_utils.py b/research/deeplab/evaluation/test_utils.py
deleted file mode 100644
index 9ad4f551271527ef1d1990398de5523b074d5779..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/test_utils.py
+++ /dev/null
@@ -1,119 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Utility functions to set up unit tests on Panoptic Segmentation code."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-
-
-from absl import flags
-import numpy as np
-import scipy.misc
-import six
-from six.moves import map
-
-FLAGS = flags.FLAGS
-
-_TEST_DIR = 'deeplab/evaluation/testdata'
-
-
-def read_test_image(testdata_path, *args, **kwargs):
- """Loads a test image.
-
- Args:
- testdata_path: Image path relative to panoptic_segmentation/testdata as a
- string.
- *args: Additional positional arguments passed to `imread`.
- **kwargs: Additional keyword arguments passed to `imread`.
-
- Returns:
- The image, as a numpy array.
- """
- image_path = os.path.join(_TEST_DIR, testdata_path)
- return scipy.misc.imread(image_path, *args, **kwargs)
-
-
-def read_segmentation_with_rgb_color_map(image_testdata_path,
- rgb_to_semantic_label,
- output_dtype=None):
- """Reads a test segmentation as an image and a map from colors to labels.
-
- Args:
- image_testdata_path: Image path relative to panoptic_segmentation/testdata
- as a string.
- rgb_to_semantic_label: Mapping from RGB colors to integer labels as a
- dictionary.
- output_dtype: Type of the output labels. If None, defaults to the type of
- the provided color map.
-
- Returns:
- A 2D numpy array of labels.
-
- Raises:
- ValueError: On an incomplete `rgb_to_semantic_label`.
- """
- rgb_image = read_test_image(image_testdata_path, mode='RGB')
- if len(rgb_image.shape) != 3 or rgb_image.shape[2] != 3:
- raise AssertionError(
- 'Expected RGB image, actual shape is %s' % rgb_image.sape)
-
- num_pixels = rgb_image.shape[0] * rgb_image.shape[1]
- unique_colors = np.unique(np.reshape(rgb_image, [num_pixels, 3]), axis=0)
- if not set(map(tuple, unique_colors)).issubset(
- six.viewkeys(rgb_to_semantic_label)):
- raise ValueError('RGB image has colors not in color map.')
-
- output_dtype = output_dtype or type(
- next(six.itervalues(rgb_to_semantic_label)))
- output_labels = np.empty(rgb_image.shape[:2], dtype=output_dtype)
- for rgb_color, int_label in six.iteritems(rgb_to_semantic_label):
- color_array = np.array(rgb_color, ndmin=3)
- output_labels[np.all(rgb_image == color_array, axis=2)] = int_label
- return output_labels
-
-
-def panoptic_segmentation_with_class_map(instance_testdata_path,
- instance_label_to_semantic_label):
- """Reads in a panoptic segmentation with an instance map and a map to classes.
-
- Args:
- instance_testdata_path: Path to a grayscale instance map, given as a string
- and relative to panoptic_segmentation/testdata.
- instance_label_to_semantic_label: A map from instance labels to class
- labels.
-
- Returns:
- A tuple `(instance_labels, class_labels)` of numpy arrays.
-
- Raises:
- ValueError: On a mismatched set of instances in
- the
- `instance_label_to_semantic_label`.
- """
- instance_labels = read_test_image(instance_testdata_path, mode='L')
- if set(np.unique(instance_labels)) != set(
- six.iterkeys(instance_label_to_semantic_label)):
- raise ValueError('Provided class map does not match present instance ids.')
-
- class_labels = np.empty_like(instance_labels)
- for instance_id, class_id in six.iteritems(instance_label_to_semantic_label):
- class_labels[instance_labels == instance_id] = class_id
-
- return instance_labels, class_labels
diff --git a/research/deeplab/evaluation/test_utils_test.py b/research/deeplab/evaluation/test_utils_test.py
deleted file mode 100644
index 9e9bed37e4bf721304e60d7fa12e6cfa9c4b7ef8..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/test_utils_test.py
+++ /dev/null
@@ -1,74 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for test_utils."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-from absl.testing import absltest
-import numpy as np
-
-from deeplab.evaluation import test_utils
-
-
-class TestUtilsTest(absltest.TestCase):
-
- def test_read_test_image(self):
- image_array = test_utils.read_test_image('team_pred_class.png')
- self.assertSequenceEqual(image_array.shape, (231, 345, 4))
-
- def test_reads_segmentation_with_color_map(self):
- rgb_to_semantic_label = {(0, 0, 0): 0, (0, 0, 255): 1, (255, 0, 0): 23}
- labels = test_utils.read_segmentation_with_rgb_color_map(
- 'team_pred_class.png', rgb_to_semantic_label)
-
- input_image = test_utils.read_test_image('team_pred_class.png')
- np.testing.assert_array_equal(
- labels == 0,
- np.logical_and(input_image[:, :, 0] == 0, input_image[:, :, 2] == 0))
- np.testing.assert_array_equal(labels == 1, input_image[:, :, 2] == 255)
- np.testing.assert_array_equal(labels == 23, input_image[:, :, 0] == 255)
-
- def test_reads_gt_segmentation(self):
- instance_label_to_semantic_label = {
- 0: 0,
- 47: 1,
- 97: 1,
- 133: 1,
- 150: 1,
- 174: 1,
- 198: 23,
- 215: 1,
- 244: 1,
- 255: 1,
- }
- instances, classes = test_utils.panoptic_segmentation_with_class_map(
- 'team_gt_instance.png', instance_label_to_semantic_label)
-
- expected_label_shape = (231, 345)
- self.assertSequenceEqual(instances.shape, expected_label_shape)
- self.assertSequenceEqual(classes.shape, expected_label_shape)
- np.testing.assert_array_equal(instances == 0, classes == 0)
- np.testing.assert_array_equal(instances == 198, classes == 23)
- np.testing.assert_array_equal(
- np.logical_and(instances != 0, instances != 198), classes == 1)
-
-
-if __name__ == '__main__':
- absltest.main()
diff --git a/research/deeplab/evaluation/testdata/README.md b/research/deeplab/evaluation/testdata/README.md
deleted file mode 100644
index 711b4767de830938b277d8d135175c2287d9c9db..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/testdata/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# Segmentation Evalaution Test Data
-
-## Source Images
-
-* [team_input.png](team_input.png) \
- Source:
- https://ai.googleblog.com/2018/03/semantic-image-segmentation-with.html
-* [cat_input.jpg](cat_input.jpg) \
- Source: https://www.flickr.com/photos/magdalena_b/4995858743
-* [bird_input.jpg](bird_input.jpg) \
- Source: https://www.flickr.com/photos/chivinskia/40619099560
-* [congress_input.jpg](congress_input.jpg) \
- Source:
- https://cao.house.gov/sites/cao.house.gov/files/documents/SAR-Jan-Jun-2016.pdf
diff --git a/research/deeplab/evaluation/testdata/bird_gt.png b/research/deeplab/evaluation/testdata/bird_gt.png
deleted file mode 100644
index 05d854915d1809abe3ba10f03c20e75706e0bb17..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/bird_gt.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/bird_pred_class.png b/research/deeplab/evaluation/testdata/bird_pred_class.png
deleted file mode 100644
index 07351bf061115d0990486cbb086b6b9ec53e691b..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/bird_pred_class.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/bird_pred_instance.png b/research/deeplab/evaluation/testdata/bird_pred_instance.png
deleted file mode 100644
index faa1371f52510fb6f15fecb0eecc3441b2c8eadb..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/bird_pred_instance.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/cat_gt.png b/research/deeplab/evaluation/testdata/cat_gt.png
deleted file mode 100644
index 41f60111f3de899a9e1ca3a646bea72d86b3009f..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/cat_gt.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/cat_pred_class.png b/research/deeplab/evaluation/testdata/cat_pred_class.png
deleted file mode 100644
index 3728c68ced20312567e70540b667b53269000318..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/cat_pred_class.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/cat_pred_instance.png b/research/deeplab/evaluation/testdata/cat_pred_instance.png
deleted file mode 100644
index ebd9ba4855f5c88a3b336d50e21d864a37175bbe..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/cat_pred_instance.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_gt.json b/research/deeplab/evaluation/testdata/coco_gt.json
deleted file mode 100644
index 5f79bf184338b8ec1ed540fd388f2de1f6a9451b..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/testdata/coco_gt.json
+++ /dev/null
@@ -1,214 +0,0 @@
-{
- "info": {
- "description": "Test COCO-format dataset",
- "url": "https://github.com/tensorflow/models/tree/master/research/deeplab",
- "version": "1.0",
- "year": 2019
- },
- "images": [
- {
- "id": 1,
- "file_name": "bird.jpg",
- "height": 159,
- "width": 240,
- "flickr_url": "https://www.flickr.com/photos/chivinskia/40619099560"
- },
- {
- "id": 2,
- "file_name": "cat.jpg",
- "height": 330,
- "width": 317,
- "flickr_url": "https://www.flickr.com/photos/magdalena_b/4995858743"
- },
- {
- "id": 3,
- "file_name": "team.jpg",
- "height": 231,
- "width": 345
- },
- {
- "id": 4,
- "file_name": "congress.jpg",
- "height": 267,
- "width": 525
- }
- ],
- "annotations": [
- {
- "image_id": 1,
- "file_name": "bird.png",
- "segments_info": [
- {
- "id": 255,
- "area": 2913,
- "category_id": 4,
- "iscrowd": 0
- },
- {
- "id": 2586368,
- "area": 1580,
- "category_id": 3,
- "iscrowd": 0
- },
- {
- "id": 16770360,
- "area": 33667,
- "category_id": 5,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 2,
- "file_name": "cat.png",
- "segments_info": [
- {
- "id": 16711691,
- "area": 34454,
- "category_id": 6,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 3,
- "file_name": "team.png",
- "segments_info": [
- {
- "id": 129,
- "area": 5443,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 255,
- "area": 3574,
- "category_id": 2,
- "iscrowd": 0
- },
- {
- "id": 47615,
- "area": 11483,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 65532,
- "area": 7080,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 8585107,
- "area": 11363,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 9011200,
- "area": 7158,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 12858027,
- "area": 6419,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16053492,
- "area": 4350,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16711680,
- "area": 5800,
- "category_id": 1,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 4,
- "file_name": "congress.png",
- "segments_info": [
- {
- "id": 255,
- "area": 243,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 65315,
- "area": 553,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 65516,
- "area": 652,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 9895680,
- "area": 82774,
- "category_id": 1,
- "iscrowd": 1
- },
- {
- "id": 16711739,
- "area": 137,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16711868,
- "area": 179,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16762624,
- "area": 2742,
- "category_id": 1,
- "iscrowd": 0
- }
- ]
- }
- ],
- "categories": [
- {
- "id": 1,
- "name": "person",
- "isthing": 1
- },
- {
- "id": 2,
- "name": "umbrella",
- "isthing": 1
- },
- {
- "id": 3,
- "name": "tree-merged",
- "isthing": 0
- },
- {
- "id": 4,
- "name": "bird",
- "isthing": 1
- },
- {
- "id": 5,
- "name": "sky",
- "isthing": 0
- },
- {
- "id": 6,
- "name": "cat",
- "isthing": 1
- }
- ]
-}
diff --git a/research/deeplab/evaluation/testdata/coco_gt/bird.png b/research/deeplab/evaluation/testdata/coco_gt/bird.png
deleted file mode 100644
index 9ef4ad9504126213bf2e3f1f49cdb65b189e6b95..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_gt/bird.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_gt/cat.png b/research/deeplab/evaluation/testdata/coco_gt/cat.png
deleted file mode 100644
index cb02530f2f912ef0d8252e327c6324211152c760..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_gt/cat.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_gt/congress.png b/research/deeplab/evaluation/testdata/coco_gt/congress.png
deleted file mode 100644
index a56b98d336172288b2c68284f5cc1373f515c342..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_gt/congress.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_gt/team.png b/research/deeplab/evaluation/testdata/coco_gt/team.png
deleted file mode 100644
index bde358d151a576049e993a0fd9ebb9661c7060a9..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_gt/team.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_pred.json b/research/deeplab/evaluation/testdata/coco_pred.json
deleted file mode 100644
index 4aead17a65d7d9203eabdb9f46c334d9e5aa402c..0000000000000000000000000000000000000000
--- a/research/deeplab/evaluation/testdata/coco_pred.json
+++ /dev/null
@@ -1,208 +0,0 @@
-{
- "info": {
- "description": "Test COCO-format dataset",
- "url": "https://github.com/tensorflow/models/tree/master/research/deeplab",
- "version": "1.0",
- "year": 2019
- },
- "images": [
- {
- "id": 1,
- "file_name": "bird.jpg",
- "height": 159,
- "width": 240,
- "flickr_url": "https://www.flickr.com/photos/chivinskia/40619099560"
- },
- {
- "id": 2,
- "file_name": "cat.jpg",
- "height": 330,
- "width": 317,
- "flickr_url": "https://www.flickr.com/photos/magdalena_b/4995858743"
- },
- {
- "id": 3,
- "file_name": "team.jpg",
- "height": 231,
- "width": 345
- },
- {
- "id": 4,
- "file_name": "congress.jpg",
- "height": 267,
- "width": 525
- }
- ],
- "annotations": [
- {
- "image_id": 1,
- "file_name": "bird.png",
- "segments_info": [
- {
- "id": 55551,
- "area": 3039,
- "category_id": 4,
- "iscrowd": 0
- },
- {
- "id": 16216831,
- "area": 33659,
- "category_id": 5,
- "iscrowd": 0
- },
- {
- "id": 16760832,
- "area": 1237,
- "category_id": 3,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 2,
- "file_name": "cat.png",
- "segments_info": [
- {
- "id": 36493,
- "area": 26910,
- "category_id": 6,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 3,
- "file_name": "team.png",
- "segments_info": [
- {
- "id": 0,
- "area": 22164,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 129,
- "area": 3418,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 255,
- "area": 12827,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 740608,
- "area": 8606,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 2555695,
- "area": 7636,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 2883541,
- "area": 6844,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 14408667,
- "area": 4766,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16711820,
- "area": 4767,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16768768,
- "area": 8667,
- "category_id": 1,
- "iscrowd": 0
- }
- ]
- },
- {
- "image_id": 4,
- "file_name": "congress.png",
- "segments_info": [
- {
- "id": 255,
- "area": 2599,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 37375,
- "area": 386,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 62207,
- "area": 384,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 5177088,
- "area": 260,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16711691,
- "area": 1011,
- "category_id": 1,
- "iscrowd": 0
- },
- {
- "id": 16774912,
- "area": 803,
- "category_id": 1,
- "iscrowd": 0
- }
- ]
- }
- ],
- "categories": [
- {
- "id": 1,
- "name": "person",
- "isthing": 1
- },
- {
- "id": 2,
- "name": "umbrella",
- "isthing": 1
- },
- {
- "id": 3,
- "name": "tree-merged",
- "isthing": 0
- },
- {
- "id": 4,
- "name": "bird",
- "isthing": 1
- },
- {
- "id": 5,
- "name": "sky",
- "isthing": 0
- },
- {
- "id": 6,
- "name": "cat",
- "isthing": 1
- }
- ]
-}
diff --git a/research/deeplab/evaluation/testdata/coco_pred/bird.png b/research/deeplab/evaluation/testdata/coco_pred/bird.png
deleted file mode 100644
index c9b4cbcbf444a890e26ad9091f8496e2596c04ad..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_pred/bird.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_pred/cat.png b/research/deeplab/evaluation/testdata/coco_pred/cat.png
deleted file mode 100644
index 324583271c4b11ef28e845e1cafb853383faf506..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_pred/cat.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_pred/congress.png b/research/deeplab/evaluation/testdata/coco_pred/congress.png
deleted file mode 100644
index fc7bb06050ed40f5c022f3cd7f0060c7fa84751a..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_pred/congress.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/coco_pred/team.png b/research/deeplab/evaluation/testdata/coco_pred/team.png
deleted file mode 100644
index 7300bf41f03a8ba08a1cb3f99821b69cddb318c2..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/coco_pred/team.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/team_gt_instance.png b/research/deeplab/evaluation/testdata/team_gt_instance.png
deleted file mode 100644
index 97abb55273ce409a5fbaa85cb999f0725d457dbf..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/team_gt_instance.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/team_pred_class.png b/research/deeplab/evaluation/testdata/team_pred_class.png
deleted file mode 100644
index 2ed78de2cbd923e6530f08fc2c47bf8377cfaf69..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/team_pred_class.png and /dev/null differ
diff --git a/research/deeplab/evaluation/testdata/team_pred_instance.png b/research/deeplab/evaluation/testdata/team_pred_instance.png
deleted file mode 100644
index 264606a4d8822108481132ff9e990d826c64a274..0000000000000000000000000000000000000000
Binary files a/research/deeplab/evaluation/testdata/team_pred_instance.png and /dev/null differ
diff --git a/research/deeplab/export_model.py b/research/deeplab/export_model.py
deleted file mode 100644
index b7307b5a212f4445f78b31a933443b2dcbd505e6..0000000000000000000000000000000000000000
--- a/research/deeplab/export_model.py
+++ /dev/null
@@ -1,201 +0,0 @@
-# Lint as: python2, python3
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Exports trained model to TensorFlow frozen graph."""
-
-import os
-import tensorflow as tf
-
-from tensorflow.contrib import quantize as contrib_quantize
-from tensorflow.python.tools import freeze_graph
-from deeplab import common
-from deeplab import input_preprocess
-from deeplab import model
-
-slim = tf.contrib.slim
-flags = tf.app.flags
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('checkpoint_path', None, 'Checkpoint path')
-
-flags.DEFINE_string('export_path', None,
- 'Path to output Tensorflow frozen graph.')
-
-flags.DEFINE_integer('num_classes', 21, 'Number of classes.')
-
-flags.DEFINE_multi_integer('crop_size', [513, 513],
- 'Crop size [height, width].')
-
-# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or
-# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note
-# one could use different atrous_rates/output_stride during training/evaluation.
-flags.DEFINE_multi_integer('atrous_rates', None,
- 'Atrous rates for atrous spatial pyramid pooling.')
-
-flags.DEFINE_integer('output_stride', 8,
- 'The ratio of input to output spatial resolution.')
-
-# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale inference.
-flags.DEFINE_multi_float('inference_scales', [1.0],
- 'The scales to resize images for inference.')
-
-flags.DEFINE_bool('add_flipped_images', False,
- 'Add flipped images during inference or not.')
-
-flags.DEFINE_integer(
- 'quantize_delay_step', -1,
- 'Steps to start quantized training. If < 0, will not quantize model.')
-
-flags.DEFINE_bool('save_inference_graph', False,
- 'Save inference graph in text proto.')
-
-# Input name of the exported model.
-_INPUT_NAME = 'ImageTensor'
-
-# Output name of the exported predictions.
-_OUTPUT_NAME = 'SemanticPredictions'
-_RAW_OUTPUT_NAME = 'RawSemanticPredictions'
-
-# Output name of the exported probabilities.
-_OUTPUT_PROB_NAME = 'SemanticProbabilities'
-_RAW_OUTPUT_PROB_NAME = 'RawSemanticProbabilities'
-
-
-def _create_input_tensors():
- """Creates and prepares input tensors for DeepLab model.
-
- This method creates a 4-D uint8 image tensor 'ImageTensor' with shape
- [1, None, None, 3]. The actual input tensor name to use during inference is
- 'ImageTensor:0'.
-
- Returns:
- image: Preprocessed 4-D float32 tensor with shape [1, crop_height,
- crop_width, 3].
- original_image_size: Original image shape tensor [height, width].
- resized_image_size: Resized image shape tensor [height, width].
- """
- # input_preprocess takes 4-D image tensor as input.
- input_image = tf.placeholder(tf.uint8, [1, None, None, 3], name=_INPUT_NAME)
- original_image_size = tf.shape(input_image)[1:3]
-
- # Squeeze the dimension in axis=0 since `preprocess_image_and_label` assumes
- # image to be 3-D.
- image = tf.squeeze(input_image, axis=0)
- resized_image, image, _ = input_preprocess.preprocess_image_and_label(
- image,
- label=None,
- crop_height=FLAGS.crop_size[0],
- crop_width=FLAGS.crop_size[1],
- min_resize_value=FLAGS.min_resize_value,
- max_resize_value=FLAGS.max_resize_value,
- resize_factor=FLAGS.resize_factor,
- is_training=False,
- model_variant=FLAGS.model_variant)
- resized_image_size = tf.shape(resized_image)[:2]
-
- # Expand the dimension in axis=0, since the following operations assume the
- # image to be 4-D.
- image = tf.expand_dims(image, 0)
-
- return image, original_image_size, resized_image_size
-
-
-def main(unused_argv):
- tf.logging.set_verbosity(tf.logging.INFO)
- tf.logging.info('Prepare to export model to: %s', FLAGS.export_path)
-
- with tf.Graph().as_default():
- image, image_size, resized_image_size = _create_input_tensors()
-
- model_options = common.ModelOptions(
- outputs_to_num_classes={common.OUTPUT_TYPE: FLAGS.num_classes},
- crop_size=FLAGS.crop_size,
- atrous_rates=FLAGS.atrous_rates,
- output_stride=FLAGS.output_stride)
-
- if tuple(FLAGS.inference_scales) == (1.0,):
- tf.logging.info('Exported model performs single-scale inference.')
- predictions = model.predict_labels(
- image,
- model_options=model_options,
- image_pyramid=FLAGS.image_pyramid)
- else:
- tf.logging.info('Exported model performs multi-scale inference.')
- if FLAGS.quantize_delay_step >= 0:
- raise ValueError(
- 'Quantize mode is not supported with multi-scale test.')
- predictions = model.predict_labels_multi_scale(
- image,
- model_options=model_options,
- eval_scales=FLAGS.inference_scales,
- add_flipped_images=FLAGS.add_flipped_images)
- raw_predictions = tf.identity(
- tf.cast(predictions[common.OUTPUT_TYPE], tf.float32),
- _RAW_OUTPUT_NAME)
- raw_probabilities = tf.identity(
- predictions[common.OUTPUT_TYPE + model.PROB_SUFFIX],
- _RAW_OUTPUT_PROB_NAME)
-
- # Crop the valid regions from the predictions.
- semantic_predictions = raw_predictions[
- :, :resized_image_size[0], :resized_image_size[1]]
- semantic_probabilities = raw_probabilities[
- :, :resized_image_size[0], :resized_image_size[1]]
-
- # Resize back the prediction to the original image size.
- def _resize_label(label, label_size):
- # Expand dimension of label to [1, height, width, 1] for resize operation.
- label = tf.expand_dims(label, 3)
- resized_label = tf.image.resize_images(
- label,
- label_size,
- method=tf.image.ResizeMethod.NEAREST_NEIGHBOR,
- align_corners=True)
- return tf.cast(tf.squeeze(resized_label, 3), tf.int32)
- semantic_predictions = _resize_label(semantic_predictions, image_size)
- semantic_predictions = tf.identity(semantic_predictions, name=_OUTPUT_NAME)
-
- semantic_probabilities = tf.image.resize_bilinear(
- semantic_probabilities, image_size, align_corners=True,
- name=_OUTPUT_PROB_NAME)
-
- if FLAGS.quantize_delay_step >= 0:
- contrib_quantize.create_eval_graph()
-
- saver = tf.train.Saver(tf.all_variables())
-
- dirname = os.path.dirname(FLAGS.export_path)
- tf.gfile.MakeDirs(dirname)
- graph_def = tf.get_default_graph().as_graph_def(add_shapes=True)
- freeze_graph.freeze_graph_with_def_protos(
- graph_def,
- saver.as_saver_def(),
- FLAGS.checkpoint_path,
- _OUTPUT_NAME + ',' + _OUTPUT_PROB_NAME,
- restore_op_name=None,
- filename_tensor_name=None,
- output_graph=FLAGS.export_path,
- clear_devices=True,
- initializer_nodes=None)
-
- if FLAGS.save_inference_graph:
- tf.train.write_graph(graph_def, dirname, 'inference_graph.pbtxt')
-
-
-if __name__ == '__main__':
- flags.mark_flag_as_required('checkpoint_path')
- flags.mark_flag_as_required('export_path')
- tf.app.run()
diff --git a/research/deeplab/g3doc/ade20k.md b/research/deeplab/g3doc/ade20k.md
deleted file mode 100644
index 9505ab2cd99ef1b9a7eb8a53a7f909aa4a32977b..0000000000000000000000000000000000000000
--- a/research/deeplab/g3doc/ade20k.md
+++ /dev/null
@@ -1,107 +0,0 @@
-# Running DeepLab on ADE20K Semantic Segmentation Dataset
-
-This page walks through the steps required to run DeepLab on ADE20K dataset on a
-local machine.
-
-## Download dataset and convert to TFRecord
-
-We have prepared the script (under the folder `datasets`) to download and
-convert ADE20K semantic segmentation dataset to TFRecord.
-
-```bash
-# From the tensorflow/models/research/deeplab/datasets directory.
-bash download_and_convert_ade20k.sh
-```
-
-The converted dataset will be saved at ./deeplab/datasets/ADE20K/tfrecord
-
-## Recommended Directory Structure for Training and Evaluation
-
-```
-+ datasets
- - build_data.py
- - build_ade20k_data.py
- - download_and_convert_ade20k.sh
- + ADE20K
- + tfrecord
- + exp
- + train_on_train_set
- + train
- + eval
- + vis
- + ADEChallengeData2016
- + annotations
- + training
- + validation
- + images
- + training
- + validation
-```
-
-where the folder `train_on_train_set` stores the train/eval/vis events and
-results (when training DeepLab on the ADE20K train set).
-
-## Running the train/eval/vis jobs
-
-A local training job using `xception_65` can be run with the following command:
-
-```bash
-# From tensorflow/models/research/
-python deeplab/train.py \
- --logtostderr \
- --training_number_of_steps=150000 \
- --train_split="train" \
- --model_variant="xception_65" \
- --atrous_rates=6 \
- --atrous_rates=12 \
- --atrous_rates=18 \
- --output_stride=16 \
- --decoder_output_stride=4 \
- --train_crop_size="513,513" \
- --train_batch_size=4 \
- --min_resize_value=513 \
- --max_resize_value=513 \
- --resize_factor=16 \
- --dataset="ade20k" \
- --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \
- --train_logdir=${PATH_TO_TRAIN_DIR}\
- --dataset_dir=${PATH_TO_DATASET}
-```
-
-where ${PATH\_TO\_INITIAL\_CHECKPOINT} is the path to the initial checkpoint.
-${PATH\_TO\_TRAIN\_DIR} is the directory in which training checkpoints and
-events will be written to (it is recommended to set it to the
-`train_on_train_set/train` above), and ${PATH\_TO\_DATASET} is the directory in
-which the ADE20K dataset resides (the `tfrecord` above)
-
-**Note that for train.py:**
-
-1. In order to fine tune the BN layers, one needs to use large batch size (>
- 12), and set fine_tune_batch_norm = True. Here, we simply use small batch
- size during training for the purpose of demonstration. If the users have
- limited GPU memory at hand, please fine-tune from our provided checkpoints
- whose batch norm parameters have been trained, and use smaller learning rate
- with fine_tune_batch_norm = False.
-
-2. User should fine tune the `min_resize_value` and `max_resize_value` to get
- better result. Note that `resize_factor` has to be equal to `output_stride`.
-
-3. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if
- setting output_stride=8.
-
-4. The users could skip the flag, `decoder_output_stride`, if you do not want
- to use the decoder structure.
-
-## Running Tensorboard
-
-Progress for training and evaluation jobs can be inspected using Tensorboard. If
-using the recommended directory structure, Tensorboard can be run using the
-following command:
-
-```bash
-tensorboard --logdir=${PATH_TO_LOG_DIRECTORY}
-```
-
-where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the train
-directorie (e.g., the folder `train_on_train_set` in the above example). Please
-note it may take Tensorboard a couple minutes to populate with data.
diff --git a/research/deeplab/g3doc/cityscapes.md b/research/deeplab/g3doc/cityscapes.md
deleted file mode 100644
index af703088e61b49aa81bf62b536469b410f0fb352..0000000000000000000000000000000000000000
--- a/research/deeplab/g3doc/cityscapes.md
+++ /dev/null
@@ -1,159 +0,0 @@
-# Running DeepLab on Cityscapes Semantic Segmentation Dataset
-
-This page walks through the steps required to run DeepLab on Cityscapes on a
-local machine.
-
-## Download dataset and convert to TFRecord
-
-We have prepared the script (under the folder `datasets`) to convert Cityscapes
-dataset to TFRecord. The users are required to download the dataset beforehand
-by registering the [website](https://www.cityscapes-dataset.com/).
-
-```bash
-# From the tensorflow/models/research/deeplab/datasets directory.
-sh convert_cityscapes.sh
-```
-
-The converted dataset will be saved at ./deeplab/datasets/cityscapes/tfrecord.
-
-## Recommended Directory Structure for Training and Evaluation
-
-```
-+ datasets
- + cityscapes
- + leftImg8bit
- + gtFine
- + tfrecord
- + exp
- + train_on_train_set
- + train
- + eval
- + vis
-```
-
-where the folder `train_on_train_set` stores the train/eval/vis events and
-results (when training DeepLab on the Cityscapes train set).
-
-## Running the train/eval/vis jobs
-
-A local training job using `xception_65` can be run with the following command:
-
-```bash
-# From tensorflow/models/research/
-python deeplab/train.py \
- --logtostderr \
- --training_number_of_steps=90000 \
- --train_split="train" \
- --model_variant="xception_65" \
- --atrous_rates=6 \
- --atrous_rates=12 \
- --atrous_rates=18 \
- --output_stride=16 \
- --decoder_output_stride=4 \
- --train_crop_size="769,769" \
- --train_batch_size=1 \
- --dataset="cityscapes" \
- --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \
- --train_logdir=${PATH_TO_TRAIN_DIR} \
- --dataset_dir=${PATH_TO_DATASET}
-```
-
-where ${PATH_TO_INITIAL_CHECKPOINT} is the path to the initial checkpoint
-(usually an ImageNet pretrained checkpoint), ${PATH_TO_TRAIN_DIR} is the
-directory in which training checkpoints and events will be written to, and
-${PATH_TO_DATASET} is the directory in which the Cityscapes dataset resides.
-
-**Note that for {train,eval,vis}.py**:
-
-1. In order to reproduce our results, one needs to use large batch size (> 8),
- and set fine_tune_batch_norm = True. Here, we simply use small batch size
- during training for the purpose of demonstration. If the users have limited
- GPU memory at hand, please fine-tune from our provided checkpoints whose
- batch norm parameters have been trained, and use smaller learning rate with
- fine_tune_batch_norm = False.
-
-2. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if
- setting output_stride=8.
-
-3. The users could skip the flag, `decoder_output_stride`, if you do not want
- to use the decoder structure.
-
-4. Change and add the following flags in order to use the provided dense
- prediction cell. Note we need to set decoder_output_stride if you want to
- use the provided checkpoints which include the decoder module.
-
-```bash
---model_variant="xception_71"
---dense_prediction_cell_json="deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json"
---decoder_output_stride=4
-```
-
-A local evaluation job using `xception_65` can be run with the following
-command:
-
-```bash
-# From tensorflow/models/research/
-python deeplab/eval.py \
- --logtostderr \
- --eval_split="val" \
- --model_variant="xception_65" \
- --atrous_rates=6 \
- --atrous_rates=12 \
- --atrous_rates=18 \
- --output_stride=16 \
- --decoder_output_stride=4 \
- --eval_crop_size="1025,2049" \
- --dataset="cityscapes" \
- --checkpoint_dir=${PATH_TO_CHECKPOINT} \
- --eval_logdir=${PATH_TO_EVAL_DIR} \
- --dataset_dir=${PATH_TO_DATASET}
-```
-
-where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the
-path to train_logdir), ${PATH_TO_EVAL_DIR} is the directory in which evaluation
-events will be written to, and ${PATH_TO_DATASET} is the directory in which the
-Cityscapes dataset resides.
-
-A local visualization job using `xception_65` can be run with the following
-command:
-
-```bash
-# From tensorflow/models/research/
-python deeplab/vis.py \
- --logtostderr \
- --vis_split="val" \
- --model_variant="xception_65" \
- --atrous_rates=6 \
- --atrous_rates=12 \
- --atrous_rates=18 \
- --output_stride=16 \
- --decoder_output_stride=4 \
- --vis_crop_size="1025,2049" \
- --dataset="cityscapes" \
- --colormap_type="cityscapes" \
- --checkpoint_dir=${PATH_TO_CHECKPOINT} \
- --vis_logdir=${PATH_TO_VIS_DIR} \
- --dataset_dir=${PATH_TO_DATASET}
-```
-
-where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the
-path to train_logdir), ${PATH_TO_VIS_DIR} is the directory in which evaluation
-events will be written to, and ${PATH_TO_DATASET} is the directory in which the
-Cityscapes dataset resides. Note that if the users would like to save the
-segmentation results for evaluation server, set also_save_raw_predictions =
-True.
-
-## Running Tensorboard
-
-Progress for training and evaluation jobs can be inspected using Tensorboard. If
-using the recommended directory structure, Tensorboard can be run using the
-following command:
-
-```bash
-tensorboard --logdir=${PATH_TO_LOG_DIRECTORY}
-```
-
-where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the
-train, eval, and vis directories (e.g., the folder `train_on_train_set` in the
-above example). Please note it may take Tensorboard a couple minutes to populate
-with data.
diff --git a/research/deeplab/g3doc/export_model.md b/research/deeplab/g3doc/export_model.md
deleted file mode 100644
index c41649e609a39ccb2e7c7622e1d4e25f86d20cb7..0000000000000000000000000000000000000000
--- a/research/deeplab/g3doc/export_model.md
+++ /dev/null
@@ -1,23 +0,0 @@
-# Export trained deeplab model to frozen inference graph
-
-After model training finishes, you could export it to a frozen TensorFlow
-inference graph proto. Your trained model checkpoint usually includes the
-following files:
-
-* model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001,
-* model.ckpt-${CHECKPOINT_NUMBER}.index
-* model.ckpt-${CHECKPOINT_NUMBER}.meta
-
-After you have identified a candidate checkpoint to export, you can run the
-following commandline to export to a frozen graph:
-
-```bash
-# From tensorflow/models/research/
-# Assume all checkpoint files share the same path prefix `${CHECKPOINT_PATH}`.
-python deeplab/export_model.py \
- --checkpoint_path=${CHECKPOINT_PATH} \
- --export_path=${OUTPUT_DIR}/frozen_inference_graph.pb
-```
-
-Please also add other model specific flags as you use for training, such as
-`model_variant`, `add_image_level_feature`, etc.
diff --git a/research/deeplab/g3doc/faq.md b/research/deeplab/g3doc/faq.md
deleted file mode 100644
index 26ff4b3281cd624cb25292d89ef3fad55b8851f2..0000000000000000000000000000000000000000
--- a/research/deeplab/g3doc/faq.md
+++ /dev/null
@@ -1,87 +0,0 @@
-# FAQ
-___
-Q1: What if I want to use other network backbones, such as ResNet [1], instead of only those provided ones (e.g., Xception)?
-
-A: The users could modify the provided core/feature_extractor.py to support more network backbones.
-___
-Q2: What if I want to train the model on other datasets?
-
-A: The users could modify the provided dataset/build_{cityscapes,voc2012}_data.py and dataset/segmentation_dataset.py to build their own dataset.
-___
-Q3: Where can I download the PASCAL VOC augmented training set?
-
-A: The PASCAL VOC augmented training set is provided by Bharath Hariharan et al. [2] Please refer to their [website](http://home.bharathh.info/pubs/codes/SBD/download.html) for details and consider citing their paper if using the dataset.
-___
-Q4: Why the implementation does not include DenseCRF [3]?
-
-A: We have not tried this. The interested users could take a look at Philipp Krähenbühl's [website](http://graphics.stanford.edu/projects/densecrf/) and [paper](https://arxiv.org/abs/1210.5644) for details.
-___
-Q5: What if I want to train the model and fine-tune the batch normalization parameters?
-
-A: If given the limited resource at hand, we would suggest you simply fine-tune
-from our provided checkpoint whose batch-norm parameters have been trained (i.e.,
-train with a smaller learning rate, set `fine_tune_batch_norm = false`, and
-employ longer training iterations since the learning rate is small). If
-you really would like to train by yourself, we would suggest
-
-1. Set `output_stride = 16` or maybe even `32` (remember to change the flag
-`atrous_rates` accordingly, e.g., `atrous_rates = [3, 6, 9]` for
-`output_stride = 32`).
-
-2. Use as many GPUs as possible (change the flag `num_clones` in train.py) and
-set `train_batch_size` as large as possible.
-
-3. Adjust the `train_crop_size` in train.py. Maybe set it to be smaller, e.g.,
-513x513 (or even 321x321), so that you could use a larger batch size.
-
-4. Use a smaller network backbone, such as MobileNet-v2.
-
-___
-Q6: How can I train the model asynchronously?
-
-A: In the train.py, the users could set `num_replicas` (number of machines for training) and `num_ps_tasks` (we usually set `num_ps_tasks` = `num_replicas` / 2). See slim.deployment.model_deploy for more details.
-___
-Q7: I could not reproduce the performance even with the provided checkpoints.
-
-A: Please try running
-
-```bash
-# Run the simple test with Xception_65 as network backbone.
-sh local_test.sh
-```
-
-or
-
-```bash
-# Run the simple test with MobileNet-v2 as network backbone.
-sh local_test_mobilenetv2.sh
-```
-
-First, make sure you could reproduce the results with our provided setting.
-After that, you could start to make a new change one at a time to help debug.
-___
-Q8: What value of `eval_crop_size` should I use?
-
-A: Our model uses whole-image inference, meaning that we need to set `eval_crop_size` equal to `output_stride` * k + 1, where k is an integer and set k so that the resulting `eval_crop_size` is slightly larger the largest
-image dimension in the dataset. For example, we have `eval_crop_size` = 513x513 for PASCAL dataset whose largest image dimension is 512. Similarly, we set `eval_crop_size` = 1025x2049 for Cityscapes images whose
-image dimension is all equal to 1024x2048.
-___
-Q9: Why multi-gpu training is slow?
-
-A: Please try to use more threads to pre-process the inputs. For, example change [num_readers = 4](https://github.com/tensorflow/models/blob/master/research/deeplab/train.py#L457).
-___
-
-
-## References
-
-1. **Deep Residual Learning for Image Recognition**
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- [[link]](https://arxiv.org/abs/1512.03385), In CVPR, 2016. - -2. **Semantic Contours from Inverse Detectors**
- Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
- [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html), In ICCV, 2011. - -3. **Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials**
- Philipp Krähenbühl, Vladlen Koltun
- [[link]](http://graphics.stanford.edu/projects/densecrf/), In NIPS, 2011. diff --git a/research/deeplab/g3doc/img/image1.jpg b/research/deeplab/g3doc/img/image1.jpg deleted file mode 100644 index 939b6f9cef3da337e1279246090f20bd78920bc8..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image1.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image2.jpg b/research/deeplab/g3doc/img/image2.jpg deleted file mode 100644 index 5ec1b8ac278906921bd3b6efec8fbe2e9d8c429e..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image2.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image3.jpg b/research/deeplab/g3doc/img/image3.jpg deleted file mode 100644 index d788e3dc68d684ca6e282bdff66a32abc767214a..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image3.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image_info.txt b/research/deeplab/g3doc/img/image_info.txt deleted file mode 100644 index 583d113e7ebb4d81ca1cdc51c3317243600809ee..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/img/image_info.txt +++ /dev/null @@ -1,13 +0,0 @@ -Image provenance: - -image1.jpg: Philippe Put, - https://www.flickr.com/photos/34547181@N00/14499172124 - -image2.jpg: Peretz Partensky - https://www.flickr.com/photos/ifl/3926001309 - -image3.jpg: Peter Harrison - https://www.flickr.com/photos/devcentre/392585679 - - -vis[1-3].png: Showing original image together with DeepLab segmentation map. diff --git a/research/deeplab/g3doc/img/vis1.png b/research/deeplab/g3doc/img/vis1.png deleted file mode 100644 index 41b8ecd89590dcf6b635e32c3af4d4b18fbafede..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis1.png and /dev/null differ diff --git a/research/deeplab/g3doc/img/vis2.png b/research/deeplab/g3doc/img/vis2.png deleted file mode 100644 index 7fa7a4cacc4807f2ab1a9c802757d76e932a41c1..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis2.png and /dev/null differ diff --git a/research/deeplab/g3doc/img/vis3.png b/research/deeplab/g3doc/img/vis3.png deleted file mode 100644 index 813b6340a61f63e3b838a91562bc0b914191ba47..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis3.png and /dev/null differ diff --git a/research/deeplab/g3doc/installation.md b/research/deeplab/g3doc/installation.md deleted file mode 100644 index 8629aba42207fc6e35c907024485c0e7f29f5e10..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/installation.md +++ /dev/null @@ -1,73 +0,0 @@ -# Installation - -## Dependencies - -DeepLab depends on the following libraries: - -* Numpy -* Pillow 1.0 -* tf Slim (which is included in the "tensorflow/models/research/" checkout) -* Jupyter notebook -* Matplotlib -* Tensorflow - -For detailed steps to install Tensorflow, follow the [Tensorflow installation -instructions](https://www.tensorflow.org/install/). A typical user can install -Tensorflow using one of the following commands: - -```bash -# For CPU -pip install tensorflow -# For GPU -pip install tensorflow-gpu -``` - -The remaining libraries can be installed on Ubuntu 14.04 using via apt-get: - -```bash -sudo apt-get install python-pil python-numpy -pip install --user jupyter -pip install --user matplotlib -pip install --user PrettyTable -``` - -## Add Libraries to PYTHONPATH - -When running locally, the tensorflow/models/research/ directory should be -appended to PYTHONPATH. This can be done by running the following from -tensorflow/models/research/: - -```bash -# From tensorflow/models/research/ -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# [Optional] for panoptic evaluation, you might need panopticapi: -# https://github.com/cocodataset/panopticapi -# Please clone it to a local directory ${PANOPTICAPI_DIR} -touch ${PANOPTICAPI_DIR}/panopticapi/__init__.py -export PYTHONPATH=$PYTHONPATH:${PANOPTICAPI_DIR}/panopticapi -``` - -Note: This command needs to run from every new terminal you start. If you wish -to avoid running this manually, you can add it as a new line to the end of your -~/.bashrc file. - -# Testing the Installation - -You can test if you have successfully installed the Tensorflow DeepLab by -running the following commands: - -Quick test by running model_test.py: - -```bash -# From tensorflow/models/research/ -python deeplab/model_test.py -``` - -Quick running the whole code on the PASCAL VOC 2012 dataset: - -```bash -# From tensorflow/models/research/deeplab -sh local_test.sh -``` - diff --git a/research/deeplab/g3doc/model_zoo.md b/research/deeplab/g3doc/model_zoo.md deleted file mode 100644 index 76972dc796e77838004a6f36bef73ca5bb66aff5..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/model_zoo.md +++ /dev/null @@ -1,254 +0,0 @@ -# TensorFlow DeepLab Model Zoo - -We provide deeplab models pretrained several datasets, including (1) PASCAL VOC -2012, (2) Cityscapes, and (3) ADE20K for reproducing our results, as well as -some checkpoints that are only pretrained on ImageNet for training your own -models. - -## DeepLab models trained on PASCAL VOC 2012 - -Un-tar'ed directory includes: - -* a frozen inference graph (`frozen_inference_graph.pb`). All frozen inference - graphs by default use output stride of 8, a single eval scale of 1.0 and - no left-right flips, unless otherwise specified. MobileNet-v2 based models - do not include the decoder module. - -* a checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`) - -### Model details - -We provide several checkpoints that have been pretrained on VOC 2012 train_aug -set or train_aug + trainval set. In the former case, one could train their model -with smaller batch size and freeze batch normalization when limited GPU memory -is available, since we have already fine-tuned the batch normalization for you. -In the latter case, one could directly evaluate the checkpoints on VOC 2012 test -set or use this checkpoint for demo. Note *MobileNet-v2* based models do not -employ ASPP and decoder modules for fast computation. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder ---------------------------- | :--------------: | :-----------------: | :---: | :-----: -mobilenetv2_dm05_coco_voc_trainaug | MobileNet-v2
Depth-Multiplier = 0.5 | ImageNet
MS-COCO
VOC 2012 train_aug set| N/A | N/A -mobilenetv2_dm05_coco_voc_trainval | MobileNet-v2
Depth-Multiplier = 0.5 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A -mobilenetv2_coco_voc_trainaug | MobileNet-v2 | ImageNet
MS-COCO
VOC 2012 train_aug set| N/A | N/A -mobilenetv2_coco_voc_trainval | MobileNet-v2 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A -xception65_coco_voc_trainaug | Xception_65 | ImageNet
MS-COCO
VOC 2012 train_aug set| [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 -xception65_coco_voc_trainval | Xception_65 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 - -In the table, **OS** denotes output stride. - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | PASCAL mIOU | File Size ------------------------------------------------------------------------------------------------------------------------- | :-------: | :------------------------: | :-------------: | :------------------: | :------------: | :----------------------------: | :-------: -[mobilenetv2_dm05_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz) | 16 | [1.0] | No | 0.88B | - | 70.19% (val) | 7.6MB -[mobilenetv2_dm05_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz) | 8 | [1.0] | No | 2.84B | - | 71.83% (test) | 7.6MB -[mobilenetv2_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 2.75B
152.59B | 0.1
26.9 | 75.32% (val)
77.33 (val) | 23MB -[mobilenetv2_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 152.59B | 26.9 | 80.25% (**test**) | 23MB -[xception65_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_pascal_train_aug_2018_01_04.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 54.17B
3055.35B | 0.7
223.2 | 82.20% (val)
83.58% (val) | 439MB -[xception65_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_pascal_trainval_2018_01_04.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 3055.35B | 223.2 | 87.80% (**test**) | 439MB - -In the table, we report both computation complexity (in terms of Multiply-Adds -and CPU Runtime) and segmentation performance (in terms of mIOU) on the PASCAL -VOC val or test set. The reported runtime is calculated by tfprof on a -workstation with CPU E5-1650 v3 @ 3.50GHz and 32GB memory. Note that applying -multi-scale inputs and left-right flips increases the segmentation performance -but also significantly increases the computation and thus may not be suitable -for real-time applications. - -## DeepLab models trained on Cityscapes - -### Model details - -We provide several checkpoints that have been pretrained on Cityscapes -train_fine set. Note *MobileNet-v2* based model has been pretrained on MS-COCO -dataset and does not employ ASPP and decoder modules for fast computation. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder -------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: -mobilenetv2_coco_cityscapes_trainfine | MobileNet-v2 | ImageNet
MS-COCO
Cityscapes train_fine set | N/A | N/A -mobilenetv3_large_cityscapes_trainfine | MobileNet-v3 Large | Cityscapes train_fine set
(No ImageNet) | N/A | OS = 8 -mobilenetv3_small_cityscapes_trainfine | MobileNet-v3 Small | Cityscapes train_fine set
(No ImageNet) | N/A | OS = 8 -xception65_cityscapes_trainfine | Xception_65 | ImageNet
Cityscapes train_fine set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 -xception71_dpc_cityscapes_trainfine | Xception_71 | ImageNet
MS-COCO
Cityscapes train_fine set | Dense Prediction Cell | OS = 4 -xception71_dpc_cityscapes_trainval | Xception_71 | ImageNet
MS-COCO
Cityscapes trainval_fine and coarse set | Dense Prediction Cell | OS = 4 - -In the table, **OS** denotes output stride. - -Note for mobilenet v3 models, we use additional commandline flags as follows: - -``` ---model_variant={ mobilenet_v3_large_seg | mobilenet_v3_small_seg } ---image_pooling_crop_size=769,769 ---image_pooling_stride=4,5 ---add_image_level_feature=1 ---aspp_convs_filters=128 ---aspp_with_concat_projection=0 ---aspp_with_squeeze_and_excitation=1 ---decoder_use_sum_merge=1 ---decoder_filters=19 ---decoder_output_is_logits=1 ---image_se_uses_qsigmoid=1 ---decoder_output_stride=8 ---output_stride=32 -``` - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | Cityscapes mIOU | File Size --------------------------------------------------------------------------------------------------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :------------: | :----------------------------: | :-------: -[mobilenetv2_coco_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_mnv2_cityscapes_train_2018_02_05.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 21.27B
433.24B | 0.8
51.12 | 70.71% (val)
73.57% (val) | 23MB -[mobilenetv3_large_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_mnv3_large_cityscapes_trainfine_2019_11_15.tar.gz) | 32 | [1.0] | No | 15.95B | 0.6 | 72.41% (val) | 17MB -[mobilenetv3_small_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_mnv3_small_cityscapes_trainfine_2019_11_15.tar.gz) | 32 | [1.0] | No | 4.63B | 0.4 | 68.99% (val) | 5MB -[xception65_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_cityscapes_train_2018_02_06.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 418.64B
8677.92B | 5.0
422.8 | 78.79% (val)
80.42% (val) | 439MB -[xception71_dpc_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainfine_2018_09_08.tar.gz) | 16 | [1.0] | No | 502.07B | - | 80.31% (val) | 445MB -[xception71_dpc_cityscapes_trainval](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainvalfine_2018_09_08.tar.gz) | 8 | [0.75:0.25:2] | Yes | - | - | 82.66% (**test**) | 446MB - -### EdgeTPU-DeepLab models on Cityscapes - -EdgeTPU is Google's machine learning accelerator architecture for edge devices -(exists in Coral devices and Pixel4's Neural Core). Leveraging nerual -architecture search (NAS, also named as Auto-ML) algorithms, -[EdgeTPU-Mobilenet](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) -has been released which yields higher hardware utilization, lower latency, as -well as better accuracy over Mobilenet-v2/v3. We use EdgeTPU-Mobilenet as the -backbone and provide checkpoints that have been pretrained on Cityscapes -train_fine set. We named them as EdgeTPU-DeepLab models. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder --------------------- | :----------------: | :----------------: | :--: | :-----: -EdgeTPU-DeepLab | EdgeMobilenet-1.0 | ImageNet | N/A | N/A -EdgeTPU-DeepLab-slim | EdgeMobilenet-0.75 | ImageNet | N/A | N/A - -For EdgeTPU-DeepLab-slim, the backbone feature extractor has depth multiplier = -0.75 and aspp_convs_filters = 128. We do not employ ASPP nor decoder modules to -further reduce the latency. We employ the same train/eval flags used for -MobileNet-v2 DeepLab model. Flags changed for EdgeTPU-DeepLab model are listed -here. - -``` ---decoder_output_stride='' ---aspp_convs_filters=256 ---model_variant=mobilenet_edgetpu -``` - -For EdgeTPU-DeepLab-slim, also include the following flags. - -``` ---depth_multiplier=0.75 ---aspp_convs_filters=128 -``` - -Checkpoint name | Eval OS | Eval scales | Cityscapes mIOU | Multiply-Adds | Simulator latency on Pixel 4 EdgeTPU ----------------------------------------------------------------------------------------------------- | :--------: | :---------: | :--------------------------: | :------------: | :----------------------------------: -[EdgeTPU-DeepLab](http://download.tensorflow.org/models/edgetpu-deeplab_2020_03_09.tar.gz) | 32
16 | [1.0] | 70.6% (val)
74.1% (val) | 5.6B
7.1B | 13.8 ms
17.5 ms -[EdgeTPU-DeepLab-slim](http://download.tensorflow.org/models/edgetpu-deeplab-slim_2020_03_09.tar.gz) | 32
16 | [1.0] | 70.0% (val)
73.2% (val) | 3.5B
4.3B | 9.9 ms
13.2 ms - -## DeepLab models trained on ADE20K - -### Model details - -We provide some checkpoints that have been pretrained on ADE20K training set. -Note that the model has only been pretrained on ImageNet, following the -dataset rule. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder | Input size -------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: | :-----: -mobilenetv2_ade20k_train | MobileNet-v2 | ImageNet
ADE20K training set | N/A | OS = 4 | 257x257 -xception65_ade20k_train | Xception_65 | ImageNet
ADE20K training set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 | 513x513 - -The input dimensions of ADE20K have a huge amount of variation. We resize inputs so that the longest size is 257 for MobileNet-v2 (faster inference) and 513 for Xception_65 (better performation). Note that we also include the decoder module in the MobileNet-v2 checkpoint. - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | mIOU | Pixel-wise Accuracy | File Size -------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :-------------------: | :-------: -[mobilenetv2_ade20k_train](http://download.tensorflow.org/models/deeplabv3_mnv2_ade20k_train_2018_12_03.tar.gz) | 16 | [1.0] | No | 32.04% (val) | 75.41% (val) | 24.8MB -[xception65_ade20k_train](http://download.tensorflow.org/models/deeplabv3_xception_ade20k_train_2018_05_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 45.65% (val) | 82.52% (val) | 439MB - - -## Checkpoints pretrained on ImageNet - -Un-tar'ed directory includes: - -* model checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`). - -### Model details - -We also provide some checkpoints that are pretrained on ImageNet and/or COCO (as -post-fixed in the model name) so that one could use this for training your own -models. - -* mobilenet_v2: We refer the interested users to the TensorFlow open source - [MobileNet-V2](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) - for details. - -* xception_{41,65,71}: We adapt the original Xception model to the task of - semantic segmentation with the following changes: (1) more layers, (2) all - max pooling operations are replaced by strided (atrous) separable - convolutions, and (3) extra batch-norm and ReLU after each 3x3 depthwise - convolution are added. We provide three Xception model variants with - different network depths. - -* resnet_v1_{50,101}_beta: We modify the original ResNet-101 [10], similar to - PSPNet [11] by replacing the first 7x7 convolution with three 3x3 - convolutions. See resnet_v1_beta.py for more details. - -Model name | File Size --------------------------------------------------------------------------------------- | :-------: -[xception_41_imagenet](http://download.tensorflow.org/models/xception_41_2018_05_09.tar.gz ) | 288MB -[xception_65_imagenet](http://download.tensorflow.org/models/deeplabv3_xception_2018_01_04.tar.gz) | 447MB -[xception_65_imagenet_coco](http://download.tensorflow.org/models/xception_65_coco_pretrained_2018_10_02.tar.gz) | 292MB -[xception_71_imagenet](http://download.tensorflow.org/models/xception_71_2018_05_09.tar.gz ) | 474MB -[resnet_v1_50_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_50_2018_05_04.tar.gz) | 274MB -[resnet_v1_101_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_101_2018_05_04.tar.gz) | 477MB - -## References - -1. **Mobilenets: Efficient convolutional neural networks for mobile vision applications**
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
- [[link]](https://arxiv.org/abs/1704.04861). arXiv:1704.04861, 2017. - -2. **Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation**
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
- [[link]](https://arxiv.org/abs/1801.04381). arXiv:1801.04381, 2018. - -3. **Xception: Deep Learning with Depthwise Separable Convolutions**
- François Chollet
- [[link]](https://arxiv.org/abs/1610.02357). In the Proc. of CVPR, 2017. - -4. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
- Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
- [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge - Workshop, 2017. - -5. **The Pascal Visual Object Classes Challenge: A Retrospective**
- Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John M. Winn, Andrew Zisserman
- [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. - -6. **Semantic Contours from Inverse Detectors**
- Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
- [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html). In the Proc. of ICCV, 2011. - -7. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
- [[link]](https://www.cityscapes-dataset.com/). In the Proc. of CVPR, 2016. - -8. **Microsoft COCO: Common Objects in Context**
- Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollar
- [[link]](http://cocodataset.org/). In the Proc. of ECCV, 2014. - -9. **ImageNet Large Scale Visual Recognition Challenge**
- Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, Li Fei-Fei
- [[link]](http://www.image-net.org/). IJCV, 2015. - -10. **Deep Residual Learning for Image Recognition**
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- [[link]](https://arxiv.org/abs/1512.03385). CVPR, 2016. - -11. **Pyramid Scene Parsing Network**
- Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
- [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. - -12. **Scene Parsing through ADE20K Dataset**
- Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba
- [[link]](http://groups.csail.mit.edu/vision/datasets/ADE20K/). In CVPR, - 2017. - -13. **Searching for MobileNetV3**
- Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
- [[link]](https://arxiv.org/abs/1905.02244). In ICCV, 2019. diff --git a/research/deeplab/g3doc/pascal.md b/research/deeplab/g3doc/pascal.md deleted file mode 100644 index f4bc84eabb83e90ff192077749784fb2560057dd..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/pascal.md +++ /dev/null @@ -1,161 +0,0 @@ -# Running DeepLab on PASCAL VOC 2012 Semantic Segmentation Dataset - -This page walks through the steps required to run DeepLab on PASCAL VOC 2012 on -a local machine. - -## Download dataset and convert to TFRecord - -We have prepared the script (under the folder `datasets`) to download and -convert PASCAL VOC 2012 semantic segmentation dataset to TFRecord. - -```bash -# From the tensorflow/models/research/deeplab/datasets directory. -sh download_and_convert_voc2012.sh -``` - -The converted dataset will be saved at -./deeplab/datasets/pascal_voc_seg/tfrecord - -## Recommended Directory Structure for Training and Evaluation - -``` -+ datasets - + pascal_voc_seg - + VOCdevkit - + VOC2012 - + JPEGImages - + SegmentationClass - + tfrecord - + exp - + train_on_train_set - + train - + eval - + vis -``` - -where the folder `train_on_train_set` stores the train/eval/vis events and -results (when training DeepLab on the PASCAL VOC 2012 train set). - -## Running the train/eval/vis jobs - -A local training job using `xception_65` can be run with the following command: - -```bash -# From tensorflow/models/research/ -python deeplab/train.py \ - --logtostderr \ - --training_number_of_steps=30000 \ - --train_split="train" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --train_crop_size="513,513" \ - --train_batch_size=1 \ - --dataset="pascal_voc_seg" \ - --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \ - --train_logdir=${PATH_TO_TRAIN_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_INITIAL_CHECKPOINT} is the path to the initial checkpoint -(usually an ImageNet pretrained checkpoint), ${PATH_TO_TRAIN_DIR} is the -directory in which training checkpoints and events will be written to, and -${PATH_TO_DATASET} is the directory in which the PASCAL VOC 2012 dataset -resides. - -**Note that for {train,eval,vis}.py:** - -1. In order to reproduce our results, one needs to use large batch size (> 12), - and set fine_tune_batch_norm = True. Here, we simply use small batch size - during training for the purpose of demonstration. If the users have limited - GPU memory at hand, please fine-tune from our provided checkpoints whose - batch norm parameters have been trained, and use smaller learning rate with - fine_tune_batch_norm = False. - -2. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if - setting output_stride=8. - -3. The users could skip the flag, `decoder_output_stride`, if you do not want - to use the decoder structure. - -A local evaluation job using `xception_65` can be run with the following -command: - -```bash -# From tensorflow/models/research/ -python deeplab/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --eval_crop_size="513,513" \ - --dataset="pascal_voc_seg" \ - --checkpoint_dir=${PATH_TO_CHECKPOINT} \ - --eval_logdir=${PATH_TO_EVAL_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the -path to train_logdir), ${PATH_TO_EVAL_DIR} is the directory in which evaluation -events will be written to, and ${PATH_TO_DATASET} is the directory in which the -PASCAL VOC 2012 dataset resides. - -A local visualization job using `xception_65` can be run with the following -command: - -```bash -# From tensorflow/models/research/ -python deeplab/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --vis_crop_size="513,513" \ - --dataset="pascal_voc_seg" \ - --checkpoint_dir=${PATH_TO_CHECKPOINT} \ - --vis_logdir=${PATH_TO_VIS_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the -path to train_logdir), ${PATH_TO_VIS_DIR} is the directory in which evaluation -events will be written to, and ${PATH_TO_DATASET} is the directory in which the -PASCAL VOC 2012 dataset resides. Note that if the users would like to save the -segmentation results for evaluation server, set also_save_raw_predictions = -True. - -## Running Tensorboard - -Progress for training and evaluation jobs can be inspected using Tensorboard. If -using the recommended directory structure, Tensorboard can be run using the -following command: - -```bash -tensorboard --logdir=${PATH_TO_LOG_DIRECTORY} -``` - -where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the -train, eval, and vis directories (e.g., the folder `train_on_train_set` in the -above example). Please note it may take Tensorboard a couple minutes to populate -with data. - -## Example - -We provide a script to run the {train,eval,vis,export_model}.py on the PASCAL VOC -2012 dataset as an example. See the code in local_test.sh for details. - -```bash -# From tensorflow/models/research/deeplab -sh local_test.sh -``` diff --git a/research/deeplab/g3doc/quantize.md b/research/deeplab/g3doc/quantize.md deleted file mode 100644 index d88a2e9a8acbac4a0de6e3ea2bed65cb44535665..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/quantize.md +++ /dev/null @@ -1,110 +0,0 @@ -# Quantize DeepLab model for faster on-device inference - -This page describes the steps required to quantize DeepLab model and convert it -to TFLite for on-device inference. The main steps include: - -1. Quantization-aware training -1. Exporting model -1. Converting to TFLite FlatBuffer - -We provide details for each step below. - -## Quantization-aware training - -DeepLab supports two approaches to quantize your model. - -1. **[Recommended]** Training a non-quantized model until convergence. Then - fine-tune the trained float model with quantization using a small learning - rate (on PASCAL we use the value of 3e-5) . This fine-tuning step usually - takes 2k to 5k steps to converge. - -1. Training a deeplab float model with delayed quantization. Usually we delay - quantization until the last a few thousand steps in training. - -In the current implementation, quantization is only supported with 1) -`num_clones=1` for training and 2) single scale inference for evaluation, -visualization and model export. To get the best performance for the quantized -model, we strongly recommend to train the float model with larger `num_clones` -and then fine-tune the model with a single clone. - -Here shows the commandline to quantize deeplab model trained on PASCAL VOC -dataset using fine-tuning: - -``` -# From tensorflow/models/research/ -python deeplab/train.py \ - --logtostderr \ - --training_number_of_steps=3000 \ - --train_split="train" \ - --model_variant="mobilenet_v2" \ - --output_stride=16 \ - --train_crop_size="513,513" \ - --train_batch_size=8 \ - --base_learning_rate=3e-5 \ - --dataset="pascal_voc_seg" \ - --initialize_last_layer \ - --quantize_delay_step=0 \ - --tf_initial_checkpoint=${PATH_TO_TRAINED_FLOAT_MODEL} \ - --train_logdir=${PATH_TO_TRAIN_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -## Converting to TFLite FlatBuffer - -First use the following commandline to export your trained model. - -``` -# From tensorflow/models/research/ -python deeplab/export_model.py \ - --checkpoint_path=${CHECKPOINT_PATH} \ - --quantize_delay_step=0 \ - --export_path=${OUTPUT_DIR}/frozen_inference_graph.pb - -``` - -Commandline below shows how to convert exported graphdef to TFlite model. - -``` -tflite_convert \ - --graph_def_file=${OUTPUT_DIR}/frozen_inference_graph.pb \ - --output_file=${OUTPUT_DIR}/frozen_inference_graph.tflite \ - --output_format=TFLITE \ - --input_shape=1,513,513,3 \ - --input_arrays="MobilenetV2/MobilenetV2/input" \ - --inference_type=QUANTIZED_UINT8 \ - --inference_input_type=QUANTIZED_UINT8 \ - --std_dev_values=128 \ - --mean_values=128 \ - --change_concat_input_ranges=true \ - --output_arrays="ArgMax" -``` - -**[Important]** Note that converted model expects 513x513 RGB input and doesn't -include preprocessing (resize and pad input image) and post processing (crop -padded region and resize to original input size). These steps can be implemented -outside of TFlite model. - -## Quantized model on PASCAL VOC - -We provide float and quantized checkpoints that have been pretrained on VOC 2012 -train_aug set, using MobileNet-v2 backbone with different depth multipliers. -Quantized model usually have 1% decay in mIoU. - -For quantized (8bit) model, un-tar'ed directory includes: - -* a frozen inference graph (frozen_inference_graph.pb) - -* a checkpoint (model.ckpt.data*, model.ckpt.index) - -* a converted TFlite FlatBuffer file (frozen_inference_graph.tflite) - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Quantize | PASCAL mIOU | Folder Size | TFLite File Size --------------------------------------------------------------------------------------------------------------------------------------------- | :-----: | :---------: | :-------------: | :-----------: | :------: | :----------: | :-------: | :-------: -[mobilenetv2_dm05_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz) | 16 | [1.0] | No | 0.88B | No | 70.19% (val) | 7.6MB | N/A -[mobilenetv2_dm05_coco_voc_trainaug_8bit](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_train_aug_8bit_2019_04_26.tar.gz) | 16 | [1.0] | No | 0.88B | Yes | 69.65% (val) | 8.2MB | 751.1KB -[mobilenetv2_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz) | 16 | [1.0] | No | 2.75B | No | 75.32% (val) | 23MB | N/A -[mobilenetv2_coco_voc_trainaug_8bit](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_8bit_2019_04_26.tar.gz) | 16 | [1.0] | No | 2.75B | Yes | 74.26% (val) | 24MB | 2.2MB - -Note that you might need the nightly build of TensorFlow (see -[here](https://www.tensorflow.org/install) for install instructions) to convert -above quantized model to TFLite. diff --git a/research/deeplab/input_preprocess.py b/research/deeplab/input_preprocess.py deleted file mode 100644 index 9ca8bce4eb9104b22469419c4e6af4beaba9406a..0000000000000000000000000000000000000000 --- a/research/deeplab/input_preprocess.py +++ /dev/null @@ -1,139 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Prepares the data used for DeepLab training/evaluation.""" -import tensorflow as tf -from deeplab.core import feature_extractor -from deeplab.core import preprocess_utils - - -# The probability of flipping the images and labels -# left-right during training -_PROB_OF_FLIP = 0.5 - - -def preprocess_image_and_label(image, - label, - crop_height, - crop_width, - min_resize_value=None, - max_resize_value=None, - resize_factor=None, - min_scale_factor=1., - max_scale_factor=1., - scale_factor_step_size=0, - ignore_label=255, - is_training=True, - model_variant=None): - """Preprocesses the image and label. - - Args: - image: Input image. - label: Ground truth annotation label. - crop_height: The height value used to crop the image and label. - crop_width: The width value used to crop the image and label. - min_resize_value: Desired size of the smaller image side. - max_resize_value: Maximum allowed size of the larger image side. - resize_factor: Resized dimensions are multiple of factor plus one. - min_scale_factor: Minimum scale factor value. - max_scale_factor: Maximum scale factor value. - scale_factor_step_size: The step size from min scale factor to max scale - factor. The input is randomly scaled based on the value of - (min_scale_factor, max_scale_factor, scale_factor_step_size). - ignore_label: The label value which will be ignored for training and - evaluation. - is_training: If the preprocessing is used for training or not. - model_variant: Model variant (string) for choosing how to mean-subtract the - images. See feature_extractor.network_map for supported model variants. - - Returns: - original_image: Original image (could be resized). - processed_image: Preprocessed image. - label: Preprocessed ground truth segmentation label. - - Raises: - ValueError: Ground truth label not provided during training. - """ - if is_training and label is None: - raise ValueError('During training, label must be provided.') - if model_variant is None: - tf.logging.warning('Default mean-subtraction is performed. Please specify ' - 'a model_variant. See feature_extractor.network_map for ' - 'supported model variants.') - - # Keep reference to original image. - original_image = image - - processed_image = tf.cast(image, tf.float32) - - if label is not None: - label = tf.cast(label, tf.int32) - - # Resize image and label to the desired range. - if min_resize_value or max_resize_value: - [processed_image, label] = ( - preprocess_utils.resize_to_range( - image=processed_image, - label=label, - min_size=min_resize_value, - max_size=max_resize_value, - factor=resize_factor, - align_corners=True)) - # The `original_image` becomes the resized image. - original_image = tf.identity(processed_image) - - # Data augmentation by randomly scaling the inputs. - if is_training: - scale = preprocess_utils.get_random_scale( - min_scale_factor, max_scale_factor, scale_factor_step_size) - processed_image, label = preprocess_utils.randomly_scale_image_and_label( - processed_image, label, scale) - processed_image.set_shape([None, None, 3]) - - # Pad image and label to have dimensions >= [crop_height, crop_width] - image_shape = tf.shape(processed_image) - image_height = image_shape[0] - image_width = image_shape[1] - - target_height = image_height + tf.maximum(crop_height - image_height, 0) - target_width = image_width + tf.maximum(crop_width - image_width, 0) - - # Pad image with mean pixel value. - mean_pixel = tf.reshape( - feature_extractor.mean_pixel(model_variant), [1, 1, 3]) - processed_image = preprocess_utils.pad_to_bounding_box( - processed_image, 0, 0, target_height, target_width, mean_pixel) - - if label is not None: - label = preprocess_utils.pad_to_bounding_box( - label, 0, 0, target_height, target_width, ignore_label) - - # Randomly crop the image and label. - if is_training and label is not None: - processed_image, label = preprocess_utils.random_crop( - [processed_image, label], crop_height, crop_width) - - processed_image.set_shape([crop_height, crop_width, 3]) - - if label is not None: - label.set_shape([crop_height, crop_width, 1]) - - if is_training: - # Randomly left-right flip the image and label. - processed_image, label, _ = preprocess_utils.flip_dim( - [processed_image, label], _PROB_OF_FLIP, dim=1) - - return original_image, processed_image, label diff --git a/research/deeplab/local_test.sh b/research/deeplab/local_test.sh deleted file mode 100644 index d5e4a5f42bb4241d4b6dd1b9d8a2619c4ca9dc8b..0000000000000000000000000000000000000000 --- a/research/deeplab/local_test.sh +++ /dev/null @@ -1,147 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# This script is used to run local test on PASCAL VOC 2012. Users could also -# modify from this script for their use case. -# -# Usage: -# # From the tensorflow/models/research/deeplab directory. -# sh ./local_test.sh -# -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -# Move one-level up to tensorflow/models/research directory. -cd .. - -# Update PYTHONPATH. -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# Set up the working environment. -CURRENT_DIR=$(pwd) -WORK_DIR="${CURRENT_DIR}/deeplab" - -# Run model_test first to make sure the PYTHONPATH is correctly set. -python "${WORK_DIR}"/model_test.py - -# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. -DATASET_DIR="datasets" -cd "${WORK_DIR}/${DATASET_DIR}" -sh download_and_convert_voc2012.sh - -# Go back to original directory. -cd "${CURRENT_DIR}" - -# Set up the working directories. -PASCAL_FOLDER="pascal_voc_seg" -EXP_FOLDER="exp/train_on_trainval_set" -INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" -TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" -EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" -VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" -EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" -mkdir -p "${INIT_FOLDER}" -mkdir -p "${TRAIN_LOGDIR}" -mkdir -p "${EVAL_LOGDIR}" -mkdir -p "${VIS_LOGDIR}" -mkdir -p "${EXPORT_DIR}" - -# Copy locally the trained checkpoint as the initial checkpoint. -TF_INIT_ROOT="http://download.tensorflow.org/models" -TF_INIT_CKPT="deeplabv3_pascal_train_aug_2018_01_04.tar.gz" -cd "${INIT_FOLDER}" -wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" -tar -xf "${TF_INIT_CKPT}" -cd "${CURRENT_DIR}" - -PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" - -# Train 10 iterations. -NUM_ITERATIONS=10 -python "${WORK_DIR}"/train.py \ - --logtostderr \ - --train_split="trainval" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --train_crop_size="513,513" \ - --train_batch_size=4 \ - --training_number_of_steps="${NUM_ITERATIONS}" \ - --fine_tune_batch_norm=true \ - --tf_initial_checkpoint="${INIT_FOLDER}/deeplabv3_pascal_train_aug/model.ckpt" \ - --train_logdir="${TRAIN_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" - -# Run evaluation. This performs eval over the full val split (1449 images) and -# will take a while. -# Using the provided checkpoint, one should expect mIOU=82.20%. -python "${WORK_DIR}"/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --eval_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --eval_logdir="${EVAL_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_evaluations=1 - -# Visualize the results. -python "${WORK_DIR}"/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --vis_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --vis_logdir="${VIS_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_iterations=1 - -# Export the trained checkpoint. -CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" -EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" - -python "${WORK_DIR}"/export_model.py \ - --logtostderr \ - --checkpoint_path="${CKPT_PATH}" \ - --export_path="${EXPORT_PATH}" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --num_classes=21 \ - --crop_size=513 \ - --crop_size=513 \ - --inference_scales=1.0 - -# Run inference with the exported checkpoint. -# Please refer to the provided deeplab_demo.ipynb for an example. diff --git a/research/deeplab/local_test_mobilenetv2.sh b/research/deeplab/local_test_mobilenetv2.sh deleted file mode 100644 index c38646fdf6caa3934b7c8db66e53ffbd4f9fd8c6..0000000000000000000000000000000000000000 --- a/research/deeplab/local_test_mobilenetv2.sh +++ /dev/null @@ -1,129 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# This script is used to run local test on PASCAL VOC 2012 using MobileNet-v2. -# Users could also modify from this script for their use case. -# -# Usage: -# # From the tensorflow/models/research/deeplab directory. -# sh ./local_test_mobilenetv2.sh -# -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -# Move one-level up to tensorflow/models/research directory. -cd .. - -# Update PYTHONPATH. -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# Set up the working environment. -CURRENT_DIR=$(pwd) -WORK_DIR="${CURRENT_DIR}/deeplab" - -# Run model_test first to make sure the PYTHONPATH is correctly set. -python "${WORK_DIR}"/model_test.py -v - -# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. -DATASET_DIR="datasets" -cd "${WORK_DIR}/${DATASET_DIR}" -sh download_and_convert_voc2012.sh - -# Go back to original directory. -cd "${CURRENT_DIR}" - -# Set up the working directories. -PASCAL_FOLDER="pascal_voc_seg" -EXP_FOLDER="exp/train_on_trainval_set_mobilenetv2" -INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" -TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" -EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" -VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" -EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" -mkdir -p "${INIT_FOLDER}" -mkdir -p "${TRAIN_LOGDIR}" -mkdir -p "${EVAL_LOGDIR}" -mkdir -p "${VIS_LOGDIR}" -mkdir -p "${EXPORT_DIR}" - -# Copy locally the trained checkpoint as the initial checkpoint. -TF_INIT_ROOT="http://download.tensorflow.org/models" -CKPT_NAME="deeplabv3_mnv2_pascal_train_aug" -TF_INIT_CKPT="${CKPT_NAME}_2018_01_29.tar.gz" -cd "${INIT_FOLDER}" -wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" -tar -xf "${TF_INIT_CKPT}" -cd "${CURRENT_DIR}" - -PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" - -# Train 10 iterations. -NUM_ITERATIONS=10 -python "${WORK_DIR}"/train.py \ - --logtostderr \ - --train_split="trainval" \ - --model_variant="mobilenet_v2" \ - --output_stride=16 \ - --train_crop_size="513,513" \ - --train_batch_size=4 \ - --training_number_of_steps="${NUM_ITERATIONS}" \ - --fine_tune_batch_norm=true \ - --tf_initial_checkpoint="${INIT_FOLDER}/${CKPT_NAME}/model.ckpt-30000" \ - --train_logdir="${TRAIN_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" - -# Run evaluation. This performs eval over the full val split (1449 images) and -# will take a while. -# Using the provided checkpoint, one should expect mIOU=75.34%. -python "${WORK_DIR}"/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="mobilenet_v2" \ - --eval_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --eval_logdir="${EVAL_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_evaluations=1 - -# Visualize the results. -python "${WORK_DIR}"/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="mobilenet_v2" \ - --vis_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --vis_logdir="${VIS_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_iterations=1 - -# Export the trained checkpoint. -CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" -EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" - -python "${WORK_DIR}"/export_model.py \ - --logtostderr \ - --checkpoint_path="${CKPT_PATH}" \ - --export_path="${EXPORT_PATH}" \ - --model_variant="mobilenet_v2" \ - --num_classes=21 \ - --crop_size=513 \ - --crop_size=513 \ - --inference_scales=1.0 - -# Run inference with the exported checkpoint. -# Please refer to the provided deeplab_demo.ipynb for an example. diff --git a/research/deeplab/model.py b/research/deeplab/model.py deleted file mode 100644 index 311aaa1acb13cb445053ac12fa09e354423e56df..0000000000000000000000000000000000000000 --- a/research/deeplab/model.py +++ /dev/null @@ -1,911 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Provides DeepLab model definition and helper functions. - -DeepLab is a deep learning system for semantic image segmentation with -the following features: - -(1) Atrous convolution to explicitly control the resolution at which -feature responses are computed within Deep Convolutional Neural Networks. - -(2) Atrous spatial pyramid pooling (ASPP) to robustly segment objects at -multiple scales with filters at multiple sampling rates and effective -fields-of-views. - -(3) ASPP module augmented with image-level feature and batch normalization. - -(4) A simple yet effective decoder module to recover the object boundaries. - -See the following papers for more details: - -"Encoder-Decoder with Atrous Separable Convolution for Semantic Image -Segmentation" -Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam. -(https://arxiv.org/abs/1802.02611) - -"Rethinking Atrous Convolution for Semantic Image Segmentation," -Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam -(https://arxiv.org/abs/1706.05587) - -"DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, -Atrous Convolution, and Fully Connected CRFs", -Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, -Alan L Yuille (* equal contribution) -(https://arxiv.org/abs/1606.00915) - -"Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected -CRFs" -Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, -Alan L. Yuille (* equal contribution) -(https://arxiv.org/abs/1412.7062) -""" -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import dense_prediction_cell -from deeplab.core import feature_extractor -from deeplab.core import utils - -slim = contrib_slim - -LOGITS_SCOPE_NAME = 'logits' -MERGED_LOGITS_SCOPE = 'merged_logits' -IMAGE_POOLING_SCOPE = 'image_pooling' -ASPP_SCOPE = 'aspp' -CONCAT_PROJECTION_SCOPE = 'concat_projection' -DECODER_SCOPE = 'decoder' -META_ARCHITECTURE_SCOPE = 'meta_architecture' - -PROB_SUFFIX = '_prob' - -_resize_bilinear = utils.resize_bilinear -scale_dimension = utils.scale_dimension -split_separable_conv2d = utils.split_separable_conv2d - - -def get_extra_layer_scopes(last_layers_contain_logits_only=False): - """Gets the scopes for extra layers. - - Args: - last_layers_contain_logits_only: Boolean, True if only consider logits as - the last layer (i.e., exclude ASPP module, decoder module and so on) - - Returns: - A list of scopes for extra layers. - """ - if last_layers_contain_logits_only: - return [LOGITS_SCOPE_NAME] - else: - return [ - LOGITS_SCOPE_NAME, - IMAGE_POOLING_SCOPE, - ASPP_SCOPE, - CONCAT_PROJECTION_SCOPE, - DECODER_SCOPE, - META_ARCHITECTURE_SCOPE, - ] - - -def predict_labels_multi_scale(images, - model_options, - eval_scales=(1.0,), - add_flipped_images=False): - """Predicts segmentation labels. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - eval_scales: The scales to resize images for evaluation. - add_flipped_images: Add flipped images for evaluation or not. - - Returns: - A dictionary with keys specifying the output_type (e.g., semantic - prediction) and values storing Tensors representing predictions (argmax - over channels). Each prediction has size [batch, height, width]. - """ - outputs_to_predictions = { - output: [] - for output in model_options.outputs_to_num_classes - } - - for i, image_scale in enumerate(eval_scales): - with tf.variable_scope(tf.get_variable_scope(), reuse=True if i else None): - outputs_to_scales_to_logits = multi_scale_logits( - images, - model_options=model_options, - image_pyramid=[image_scale], - is_training=False, - fine_tune_batch_norm=False) - - if add_flipped_images: - with tf.variable_scope(tf.get_variable_scope(), reuse=True): - outputs_to_scales_to_logits_reversed = multi_scale_logits( - tf.reverse_v2(images, [2]), - model_options=model_options, - image_pyramid=[image_scale], - is_training=False, - fine_tune_batch_norm=False) - - for output in sorted(outputs_to_scales_to_logits): - scales_to_logits = outputs_to_scales_to_logits[output] - logits = _resize_bilinear( - scales_to_logits[MERGED_LOGITS_SCOPE], - tf.shape(images)[1:3], - scales_to_logits[MERGED_LOGITS_SCOPE].dtype) - outputs_to_predictions[output].append( - tf.expand_dims(tf.nn.softmax(logits), 4)) - - if add_flipped_images: - scales_to_logits_reversed = ( - outputs_to_scales_to_logits_reversed[output]) - logits_reversed = _resize_bilinear( - tf.reverse_v2(scales_to_logits_reversed[MERGED_LOGITS_SCOPE], [2]), - tf.shape(images)[1:3], - scales_to_logits_reversed[MERGED_LOGITS_SCOPE].dtype) - outputs_to_predictions[output].append( - tf.expand_dims(tf.nn.softmax(logits_reversed), 4)) - - for output in sorted(outputs_to_predictions): - predictions = outputs_to_predictions[output] - # Compute average prediction across different scales and flipped images. - predictions = tf.reduce_mean(tf.concat(predictions, 4), axis=4) - outputs_to_predictions[output] = tf.argmax(predictions, 3) - outputs_to_predictions[output + PROB_SUFFIX] = tf.nn.softmax(predictions) - - return outputs_to_predictions - - -def predict_labels(images, model_options, image_pyramid=None): - """Predicts segmentation labels. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - image_pyramid: Input image scales for multi-scale feature extraction. - - Returns: - A dictionary with keys specifying the output_type (e.g., semantic - prediction) and values storing Tensors representing predictions (argmax - over channels). Each prediction has size [batch, height, width]. - """ - outputs_to_scales_to_logits = multi_scale_logits( - images, - model_options=model_options, - image_pyramid=image_pyramid, - is_training=False, - fine_tune_batch_norm=False) - - predictions = {} - for output in sorted(outputs_to_scales_to_logits): - scales_to_logits = outputs_to_scales_to_logits[output] - logits = scales_to_logits[MERGED_LOGITS_SCOPE] - # There are two ways to obtain the final prediction results: (1) bilinear - # upsampling the logits followed by argmax, or (2) argmax followed by - # nearest neighbor upsampling. The second option may introduce the "blocking - # effect" but is computationally efficient. - if model_options.prediction_with_upsampled_logits: - logits = _resize_bilinear(logits, - tf.shape(images)[1:3], - scales_to_logits[MERGED_LOGITS_SCOPE].dtype) - predictions[output] = tf.argmax(logits, 3) - predictions[output + PROB_SUFFIX] = tf.nn.softmax(logits) - else: - argmax_results = tf.argmax(logits, 3) - argmax_results = tf.image.resize_nearest_neighbor( - tf.expand_dims(argmax_results, 3), - tf.shape(images)[1:3], - align_corners=True, - name='resize_prediction') - predictions[output] = tf.squeeze(argmax_results, 3) - predictions[output + PROB_SUFFIX] = tf.image.resize_bilinear( - tf.nn.softmax(logits), - tf.shape(images)[1:3], - align_corners=True, - name='resize_prob') - return predictions - - -def multi_scale_logits(images, - model_options, - image_pyramid, - weight_decay=0.0001, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Gets the logits for multi-scale inputs. - - The returned logits are all downsampled (due to max-pooling layers) - for both training and evaluation. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - image_pyramid: Input image scales for multi-scale feature extraction. - weight_decay: The weight decay for model variables. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - outputs_to_scales_to_logits: A map of maps from output_type (e.g., - semantic prediction) to a dictionary of multi-scale logits names to - logits. For each output_type, the dictionary has keys which - correspond to the scales and values which correspond to the logits. - For example, if `scales` equals [1.0, 1.5], then the keys would - include 'merged_logits', 'logits_1.00' and 'logits_1.50'. - - Raises: - ValueError: If model_options doesn't specify crop_size and its - add_image_level_feature = True, since add_image_level_feature requires - crop_size information. - """ - # Setup default values. - if not image_pyramid: - image_pyramid = [1.0] - crop_height = ( - model_options.crop_size[0] - if model_options.crop_size else tf.shape(images)[1]) - crop_width = ( - model_options.crop_size[1] - if model_options.crop_size else tf.shape(images)[2]) - if model_options.image_pooling_crop_size: - image_pooling_crop_height = model_options.image_pooling_crop_size[0] - image_pooling_crop_width = model_options.image_pooling_crop_size[1] - - # Compute the height, width for the output logits. - if model_options.decoder_output_stride: - logits_output_stride = min(model_options.decoder_output_stride) - else: - logits_output_stride = model_options.output_stride - - logits_height = scale_dimension( - crop_height, - max(1.0, max(image_pyramid)) / logits_output_stride) - logits_width = scale_dimension( - crop_width, - max(1.0, max(image_pyramid)) / logits_output_stride) - - # Compute the logits for each scale in the image pyramid. - outputs_to_scales_to_logits = { - k: {} - for k in model_options.outputs_to_num_classes - } - - num_channels = images.get_shape().as_list()[-1] - - for image_scale in image_pyramid: - if image_scale != 1.0: - scaled_height = scale_dimension(crop_height, image_scale) - scaled_width = scale_dimension(crop_width, image_scale) - scaled_crop_size = [scaled_height, scaled_width] - scaled_images = _resize_bilinear(images, scaled_crop_size, images.dtype) - if model_options.crop_size: - scaled_images.set_shape( - [None, scaled_height, scaled_width, num_channels]) - # Adjust image_pooling_crop_size accordingly. - scaled_image_pooling_crop_size = None - if model_options.image_pooling_crop_size: - scaled_image_pooling_crop_size = [ - scale_dimension(image_pooling_crop_height, image_scale), - scale_dimension(image_pooling_crop_width, image_scale)] - else: - scaled_crop_size = model_options.crop_size - scaled_images = images - scaled_image_pooling_crop_size = model_options.image_pooling_crop_size - - updated_options = model_options._replace( - crop_size=scaled_crop_size, - image_pooling_crop_size=scaled_image_pooling_crop_size) - outputs_to_logits = _get_logits( - scaled_images, - updated_options, - weight_decay=weight_decay, - reuse=tf.AUTO_REUSE, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_training_hyper_parameters=nas_training_hyper_parameters) - - # Resize the logits to have the same dimension before merging. - for output in sorted(outputs_to_logits): - outputs_to_logits[output] = _resize_bilinear( - outputs_to_logits[output], [logits_height, logits_width], - outputs_to_logits[output].dtype) - - # Return when only one input scale. - if len(image_pyramid) == 1: - for output in sorted(model_options.outputs_to_num_classes): - outputs_to_scales_to_logits[output][ - MERGED_LOGITS_SCOPE] = outputs_to_logits[output] - return outputs_to_scales_to_logits - - # Save logits to the output map. - for output in sorted(model_options.outputs_to_num_classes): - outputs_to_scales_to_logits[output][ - 'logits_%.2f' % image_scale] = outputs_to_logits[output] - - # Merge the logits from all the multi-scale inputs. - for output in sorted(model_options.outputs_to_num_classes): - # Concatenate the multi-scale logits for each output type. - all_logits = [ - tf.expand_dims(logits, axis=4) - for logits in outputs_to_scales_to_logits[output].values() - ] - all_logits = tf.concat(all_logits, 4) - merge_fn = ( - tf.reduce_max - if model_options.merge_method == 'max' else tf.reduce_mean) - outputs_to_scales_to_logits[output][MERGED_LOGITS_SCOPE] = merge_fn( - all_logits, axis=4) - - return outputs_to_scales_to_logits - - -def extract_features(images, - model_options, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Extracts features by the particular model_variant. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - concat_logits: A tensor of size [batch, feature_height, feature_width, - feature_channels], where feature_height/feature_width are determined by - the images height/width and output_stride. - end_points: A dictionary from components of the network to the corresponding - activation. - """ - features, end_points = feature_extractor.extract_features( - images, - output_stride=model_options.output_stride, - multi_grid=model_options.multi_grid, - model_variant=model_options.model_variant, - depth_multiplier=model_options.depth_multiplier, - divisible_by=model_options.divisible_by, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - preprocessed_images_dtype=model_options.preprocessed_images_dtype, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_architecture_options=model_options.nas_architecture_options, - nas_training_hyper_parameters=nas_training_hyper_parameters, - use_bounded_activation=model_options.use_bounded_activation) - - if not model_options.aspp_with_batch_norm: - return features, end_points - else: - if model_options.dense_prediction_cell_config is not None: - tf.logging.info('Using dense prediction cell config.') - dense_prediction_layer = dense_prediction_cell.DensePredictionCell( - config=model_options.dense_prediction_cell_config, - hparams={ - 'conv_rate_multiplier': 16 // model_options.output_stride, - }) - concat_logits = dense_prediction_layer.build_cell( - features, - output_stride=model_options.output_stride, - crop_size=model_options.crop_size, - image_pooling_crop_size=model_options.image_pooling_crop_size, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm) - return concat_logits, end_points - else: - # The following codes employ the DeepLabv3 ASPP module. Note that we - # could express the ASPP module as one particular dense prediction - # cell architecture. We do not do so but leave the following codes - # for backward compatibility. - batch_norm_params = utils.get_batch_norm_params( - decay=0.9997, - epsilon=1e-5, - scale=True, - is_training=(is_training and fine_tune_batch_norm), - sync_batch_norm_method=model_options.sync_batch_norm_method) - batch_norm = utils.get_batch_norm_fn( - model_options.sync_batch_norm_method) - activation_fn = ( - tf.nn.relu6 if model_options.use_bounded_activation else tf.nn.relu) - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=activation_fn, - normalizer_fn=batch_norm, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([batch_norm], **batch_norm_params): - depth = model_options.aspp_convs_filters - branch_logits = [] - - if model_options.add_image_level_feature: - if model_options.crop_size is not None: - image_pooling_crop_size = model_options.image_pooling_crop_size - # If image_pooling_crop_size is not specified, use crop_size. - if image_pooling_crop_size is None: - image_pooling_crop_size = model_options.crop_size - pool_height = scale_dimension( - image_pooling_crop_size[0], - 1. / model_options.output_stride) - pool_width = scale_dimension( - image_pooling_crop_size[1], - 1. / model_options.output_stride) - image_feature = slim.avg_pool2d( - features, [pool_height, pool_width], - model_options.image_pooling_stride, padding='VALID') - resize_height = scale_dimension( - model_options.crop_size[0], - 1. / model_options.output_stride) - resize_width = scale_dimension( - model_options.crop_size[1], - 1. / model_options.output_stride) - else: - # If crop_size is None, we simply do global pooling. - pool_height = tf.shape(features)[1] - pool_width = tf.shape(features)[2] - image_feature = tf.reduce_mean( - features, axis=[1, 2], keepdims=True) - resize_height = pool_height - resize_width = pool_width - image_feature_activation_fn = tf.nn.relu - image_feature_normalizer_fn = batch_norm - if model_options.aspp_with_squeeze_and_excitation: - image_feature_activation_fn = tf.nn.sigmoid - if model_options.image_se_uses_qsigmoid: - image_feature_activation_fn = utils.q_sigmoid - image_feature_normalizer_fn = None - image_feature = slim.conv2d( - image_feature, depth, 1, - activation_fn=image_feature_activation_fn, - normalizer_fn=image_feature_normalizer_fn, - scope=IMAGE_POOLING_SCOPE) - image_feature = _resize_bilinear( - image_feature, - [resize_height, resize_width], - image_feature.dtype) - # Set shape for resize_height/resize_width if they are not Tensor. - if isinstance(resize_height, tf.Tensor): - resize_height = None - if isinstance(resize_width, tf.Tensor): - resize_width = None - image_feature.set_shape([None, resize_height, resize_width, depth]) - if not model_options.aspp_with_squeeze_and_excitation: - branch_logits.append(image_feature) - - # Employ a 1x1 convolution. - branch_logits.append(slim.conv2d(features, depth, 1, - scope=ASPP_SCOPE + str(0))) - - if model_options.atrous_rates: - # Employ 3x3 convolutions with different atrous rates. - for i, rate in enumerate(model_options.atrous_rates, 1): - scope = ASPP_SCOPE + str(i) - if model_options.aspp_with_separable_conv: - aspp_features = split_separable_conv2d( - features, - filters=depth, - rate=rate, - weight_decay=weight_decay, - scope=scope) - else: - aspp_features = slim.conv2d( - features, depth, 3, rate=rate, scope=scope) - branch_logits.append(aspp_features) - - # Merge branch logits. - concat_logits = tf.concat(branch_logits, 3) - if model_options.aspp_with_concat_projection: - concat_logits = slim.conv2d( - concat_logits, depth, 1, scope=CONCAT_PROJECTION_SCOPE) - concat_logits = slim.dropout( - concat_logits, - keep_prob=0.9, - is_training=is_training, - scope=CONCAT_PROJECTION_SCOPE + '_dropout') - if (model_options.add_image_level_feature and - model_options.aspp_with_squeeze_and_excitation): - concat_logits *= image_feature - - return concat_logits, end_points - - -def _get_logits(images, - model_options, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Gets the logits by atrous/image spatial pyramid pooling. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - outputs_to_logits: A map from output_type to logits. - """ - features, end_points = extract_features( - images, - model_options, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_training_hyper_parameters=nas_training_hyper_parameters) - - if model_options.decoder_output_stride: - crop_size = model_options.crop_size - if crop_size is None: - crop_size = [tf.shape(images)[1], tf.shape(images)[2]] - features = refine_by_decoder( - features, - end_points, - crop_size=crop_size, - decoder_output_stride=model_options.decoder_output_stride, - decoder_use_separable_conv=model_options.decoder_use_separable_conv, - decoder_use_sum_merge=model_options.decoder_use_sum_merge, - decoder_filters=model_options.decoder_filters, - decoder_output_is_logits=model_options.decoder_output_is_logits, - model_variant=model_options.model_variant, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - use_bounded_activation=model_options.use_bounded_activation) - - outputs_to_logits = {} - for output in sorted(model_options.outputs_to_num_classes): - if model_options.decoder_output_is_logits: - outputs_to_logits[output] = tf.identity(features, - name=output) - else: - outputs_to_logits[output] = get_branch_logits( - features, - model_options.outputs_to_num_classes[output], - model_options.atrous_rates, - aspp_with_batch_norm=model_options.aspp_with_batch_norm, - kernel_size=model_options.logits_kernel_size, - weight_decay=weight_decay, - reuse=reuse, - scope_suffix=output) - - return outputs_to_logits - - -def refine_by_decoder(features, - end_points, - crop_size=None, - decoder_output_stride=None, - decoder_use_separable_conv=False, - decoder_use_sum_merge=False, - decoder_filters=256, - decoder_output_is_logits=False, - model_variant=None, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - use_bounded_activation=False, - sync_batch_norm_method='None'): - """Adds the decoder to obtain sharper segmentation results. - - Args: - features: A tensor of size [batch, features_height, features_width, - features_channels]. - end_points: A dictionary from components of the network to the corresponding - activation. - crop_size: A tuple [crop_height, crop_width] specifying whole patch crop - size. - decoder_output_stride: A list of integers specifying the output stride of - low-level features used in the decoder module. - decoder_use_separable_conv: Employ separable convolution for decoder or not. - decoder_use_sum_merge: Boolean, decoder uses simple sum merge or not. - decoder_filters: Integer, decoder filter size. - decoder_output_is_logits: Boolean, using decoder output as logits or not. - model_variant: Model variant for feature extraction. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - sync_batch_norm_method: String, method used to sync batch norm. Currently - only support `None` (no sync batch norm) and `tpu` (use tpu code to - sync batch norm). - - Returns: - Decoder output with size [batch, decoder_height, decoder_width, - decoder_channels]. - - Raises: - ValueError: If crop_size is None. - """ - if crop_size is None: - raise ValueError('crop_size must be provided when using decoder.') - batch_norm_params = utils.get_batch_norm_params( - decay=0.9997, - epsilon=1e-5, - scale=True, - is_training=(is_training and fine_tune_batch_norm), - sync_batch_norm_method=sync_batch_norm_method) - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - decoder_depth = decoder_filters - projected_filters = 48 - if decoder_use_sum_merge: - # When using sum merge, the projected filters must be equal to decoder - # filters. - projected_filters = decoder_filters - if decoder_output_is_logits: - # Overwrite the setting when decoder output is logits. - activation_fn = None - normalizer_fn = None - conv2d_kernel = 1 - # Use original conv instead of separable conv. - decoder_use_separable_conv = False - else: - # Default setting when decoder output is not logits. - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - normalizer_fn = batch_norm - conv2d_kernel = 3 - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=activation_fn, - normalizer_fn=normalizer_fn, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([batch_norm], **batch_norm_params): - with tf.variable_scope(DECODER_SCOPE, DECODER_SCOPE, [features]): - decoder_features = features - decoder_stage = 0 - scope_suffix = '' - for output_stride in decoder_output_stride: - feature_list = feature_extractor.networks_to_feature_maps[ - model_variant][ - feature_extractor.DECODER_END_POINTS][output_stride] - # If only one decoder stage, we do not change the scope name in - # order for backward compactibility. - if decoder_stage: - scope_suffix = '_{}'.format(decoder_stage) - for i, name in enumerate(feature_list): - decoder_features_list = [decoder_features] - # MobileNet and NAS variants use different naming convention. - if ('mobilenet' in model_variant or - model_variant.startswith('mnas') or - model_variant.startswith('nas')): - feature_name = name - else: - feature_name = '{}/{}'.format( - feature_extractor.name_scope[model_variant], name) - decoder_features_list.append( - slim.conv2d( - end_points[feature_name], - projected_filters, - 1, - scope='feature_projection' + str(i) + scope_suffix)) - # Determine the output size. - decoder_height = scale_dimension(crop_size[0], 1.0 / output_stride) - decoder_width = scale_dimension(crop_size[1], 1.0 / output_stride) - # Resize to decoder_height/decoder_width. - for j, feature in enumerate(decoder_features_list): - decoder_features_list[j] = _resize_bilinear( - feature, [decoder_height, decoder_width], feature.dtype) - h = (None if isinstance(decoder_height, tf.Tensor) - else decoder_height) - w = (None if isinstance(decoder_width, tf.Tensor) - else decoder_width) - decoder_features_list[j].set_shape([None, h, w, None]) - if decoder_use_sum_merge: - decoder_features = _decoder_with_sum_merge( - decoder_features_list, - decoder_depth, - conv2d_kernel=conv2d_kernel, - decoder_use_separable_conv=decoder_use_separable_conv, - weight_decay=weight_decay, - scope_suffix=scope_suffix) - else: - if not decoder_use_separable_conv: - scope_suffix = str(i) + scope_suffix - decoder_features = _decoder_with_concat_merge( - decoder_features_list, - decoder_depth, - decoder_use_separable_conv=decoder_use_separable_conv, - weight_decay=weight_decay, - scope_suffix=scope_suffix) - decoder_stage += 1 - return decoder_features - - -def _decoder_with_sum_merge(decoder_features_list, - decoder_depth, - conv2d_kernel=3, - decoder_use_separable_conv=True, - weight_decay=0.0001, - scope_suffix=''): - """Decoder with sum to merge features. - - Args: - decoder_features_list: A list of decoder features. - decoder_depth: Integer, the filters used in the convolution. - conv2d_kernel: Integer, the convolution kernel size. - decoder_use_separable_conv: Boolean, use separable conv or not. - weight_decay: Weight decay for the model variables. - scope_suffix: String, used in the scope suffix. - - Returns: - decoder features merged with sum. - - Raises: - RuntimeError: If decoder_features_list have length not equal to 2. - """ - if len(decoder_features_list) != 2: - raise RuntimeError('Expect decoder_features has length 2.') - # Only apply one convolution when decoder use sum merge. - if decoder_use_separable_conv: - decoder_features = split_separable_conv2d( - decoder_features_list[0], - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_split_sep_conv0'+scope_suffix) + decoder_features_list[1] - else: - decoder_features = slim.conv2d( - decoder_features_list[0], - decoder_depth, - conv2d_kernel, - scope='decoder_conv0'+scope_suffix) + decoder_features_list[1] - return decoder_features - - -def _decoder_with_concat_merge(decoder_features_list, - decoder_depth, - decoder_use_separable_conv=True, - weight_decay=0.0001, - scope_suffix=''): - """Decoder with concatenation to merge features. - - This decoder method applies two convolutions to smooth the features obtained - by concatenating the input decoder_features_list. - - This decoder module is proposed in the DeepLabv3+ paper. - - Args: - decoder_features_list: A list of decoder features. - decoder_depth: Integer, the filters used in the convolution. - decoder_use_separable_conv: Boolean, use separable conv or not. - weight_decay: Weight decay for the model variables. - scope_suffix: String, used in the scope suffix. - - Returns: - decoder features merged with concatenation. - """ - if decoder_use_separable_conv: - decoder_features = split_separable_conv2d( - tf.concat(decoder_features_list, 3), - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_conv0'+scope_suffix) - decoder_features = split_separable_conv2d( - decoder_features, - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_conv1'+scope_suffix) - else: - num_convs = 2 - decoder_features = slim.repeat( - tf.concat(decoder_features_list, 3), - num_convs, - slim.conv2d, - decoder_depth, - 3, - scope='decoder_conv'+scope_suffix) - return decoder_features - - -def get_branch_logits(features, - num_classes, - atrous_rates=None, - aspp_with_batch_norm=False, - kernel_size=1, - weight_decay=0.0001, - reuse=None, - scope_suffix=''): - """Gets the logits from each model's branch. - - The underlying model is branched out in the last layer when atrous - spatial pyramid pooling is employed, and all branches are sum-merged - to form the final logits. - - Args: - features: A float tensor of shape [batch, height, width, channels]. - num_classes: Number of classes to predict. - atrous_rates: A list of atrous convolution rates for last layer. - aspp_with_batch_norm: Use batch normalization layers for ASPP. - kernel_size: Kernel size for convolution. - weight_decay: Weight decay for the model variables. - reuse: Reuse model variables or not. - scope_suffix: Scope suffix for the model variables. - - Returns: - Merged logits with shape [batch, height, width, num_classes]. - - Raises: - ValueError: Upon invalid input kernel_size value. - """ - # When using batch normalization with ASPP, ASPP has been applied before - # in extract_features, and thus we simply apply 1x1 convolution here. - if aspp_with_batch_norm or atrous_rates is None: - if kernel_size != 1: - raise ValueError('Kernel size must be 1 when atrous_rates is None or ' - 'using aspp_with_batch_norm. Gets %d.' % kernel_size) - atrous_rates = [1] - - with slim.arg_scope( - [slim.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - weights_initializer=tf.truncated_normal_initializer(stddev=0.01), - reuse=reuse): - with tf.variable_scope(LOGITS_SCOPE_NAME, LOGITS_SCOPE_NAME, [features]): - branch_logits = [] - for i, rate in enumerate(atrous_rates): - scope = scope_suffix - if i: - scope += '_%d' % i - - branch_logits.append( - slim.conv2d( - features, - num_classes, - kernel_size=kernel_size, - rate=rate, - activation_fn=None, - normalizer_fn=None, - scope=scope)) - - return tf.add_n(branch_logits) diff --git a/research/deeplab/model_test.py b/research/deeplab/model_test.py deleted file mode 100644 index d8413d7395d022adb4f43223eb06a4bdc1aa53db..0000000000000000000000000000000000000000 --- a/research/deeplab/model_test.py +++ /dev/null @@ -1,148 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for DeepLab model and some helper functions.""" - -import tensorflow as tf - -from deeplab import common -from deeplab import model - - -class DeeplabModelTest(tf.test.TestCase): - - def testWrongDeepLabVariant(self): - model_options = common.ModelOptions([])._replace( - model_variant='no_such_variant') - with self.assertRaises(ValueError): - model._get_logits(images=[], model_options=model_options) - - def testBuildDeepLabv2(self): - batch_size = 2 - crop_size = [41, 41] - - # Test with two image_pyramids. - image_pyramids = [[1], [0.5, 1]] - - # Test two model variants. - model_variants = ['xception_65', 'mobilenet_v2'] - - # Test with two output_types. - outputs_to_num_classes = {'semantic': 3, - 'direction': 2} - - expected_endpoints = [['merged_logits'], - ['merged_logits', - 'logits_0.50', - 'logits_1.00']] - expected_num_logits = [1, 3] - - for model_variant in model_variants: - model_options = common.ModelOptions(outputs_to_num_classes)._replace( - add_image_level_feature=False, - aspp_with_batch_norm=False, - aspp_with_separable_conv=False, - model_variant=model_variant) - - for i, image_pyramid in enumerate(image_pyramids): - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g): - inputs = tf.random_uniform( - (batch_size, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_logits = model.multi_scale_logits( - inputs, model_options, image_pyramid=image_pyramid) - - # Check computed results for each output type. - for output in outputs_to_num_classes: - scales_to_logits = outputs_to_scales_to_logits[output] - self.assertListEqual(sorted(scales_to_logits.keys()), - sorted(expected_endpoints[i])) - - # Expected number of logits = len(image_pyramid) + 1, since the - # last logits is merged from all the scales. - self.assertEqual(len(scales_to_logits), expected_num_logits[i]) - - def testForwardpassDeepLabv3plus(self): - crop_size = [33, 33] - outputs_to_num_classes = {'semantic': 3} - - model_options = common.ModelOptions( - outputs_to_num_classes, - crop_size, - output_stride=16 - )._replace( - add_image_level_feature=True, - aspp_with_batch_norm=True, - logits_kernel_size=1, - decoder_output_stride=[4], - model_variant='mobilenet_v2') # Employ MobileNetv2 for fast test. - - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g) as sess: - inputs = tf.random_uniform( - (1, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_logits = model.multi_scale_logits( - inputs, - model_options, - image_pyramid=[1.0]) - - sess.run(tf.global_variables_initializer()) - outputs_to_scales_to_logits = sess.run(outputs_to_scales_to_logits) - - # Check computed results for each output type. - for output in outputs_to_num_classes: - scales_to_logits = outputs_to_scales_to_logits[output] - # Expect only one output. - self.assertEqual(len(scales_to_logits), 1) - for logits in scales_to_logits.values(): - self.assertTrue(logits.any()) - - def testBuildDeepLabWithDensePredictionCell(self): - batch_size = 1 - crop_size = [33, 33] - outputs_to_num_classes = {'semantic': 2} - expected_endpoints = ['merged_logits'] - dense_prediction_cell_config = [ - {'kernel': 3, 'rate': [1, 6], 'op': 'conv', 'input': -1}, - {'kernel': 3, 'rate': [18, 15], 'op': 'conv', 'input': 0}, - ] - model_options = common.ModelOptions( - outputs_to_num_classes, - crop_size, - output_stride=16)._replace( - aspp_with_batch_norm=True, - model_variant='mobilenet_v2', - dense_prediction_cell_config=dense_prediction_cell_config) - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g): - inputs = tf.random_uniform( - (batch_size, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_model_results = model.multi_scale_logits( - inputs, - model_options, - image_pyramid=[1.0]) - for output in outputs_to_num_classes: - scales_to_model_results = outputs_to_scales_to_model_results[output] - self.assertListEqual( - list(scales_to_model_results), expected_endpoints) - self.assertEqual(len(scales_to_model_results), 1) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/testing/info.md b/research/deeplab/testing/info.md deleted file mode 100644 index b84d2adb1c5088ed2a6ec4799de7764d64f867b7..0000000000000000000000000000000000000000 --- a/research/deeplab/testing/info.md +++ /dev/null @@ -1,6 +0,0 @@ -This directory contains testing data. - -# pascal_voc_seg -This folder contains data specific to pascal_voc_seg dataset. val-00000-of-00001.tfrecord contains -three randomly generated images with format defined in -tensorflow/models/research/deeplab/datasets/build_voc2012_data.py. diff --git a/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord b/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord deleted file mode 100644 index e81455b2e1a1b5ac2f7c632512951a9ab26b7ef3..0000000000000000000000000000000000000000 Binary files a/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord and /dev/null differ diff --git a/research/deeplab/train.py b/research/deeplab/train.py deleted file mode 100644 index fbe060dccd41793e3e843f4fcbe155576e42eb14..0000000000000000000000000000000000000000 --- a/research/deeplab/train.py +++ /dev/null @@ -1,464 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Training script for the DeepLab model. - -See model.py for more details and usage. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import six -import tensorflow as tf -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import tfprof as contrib_tfprof -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator -from deeplab.utils import train_utils -from deployment import model_deploy - -slim = tf.contrib.slim -flags = tf.app.flags -FLAGS = flags.FLAGS - -# Settings for multi-GPUs/multi-replicas training. - -flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy.') - -flags.DEFINE_boolean('clone_on_cpu', False, 'Use CPUs to deploy clones.') - -flags.DEFINE_integer('num_replicas', 1, 'Number of worker replicas.') - -flags.DEFINE_integer('startup_delay_steps', 15, - 'Number of training steps between replicas startup.') - -flags.DEFINE_integer( - 'num_ps_tasks', 0, - 'The number of parameter servers. If the value is 0, then ' - 'the parameters are handled locally by the worker.') - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -flags.DEFINE_integer('task', 0, 'The task ID.') - -# Settings for logging. - -flags.DEFINE_string('train_logdir', None, - 'Where the checkpoint and logs are stored.') - -flags.DEFINE_integer('log_steps', 10, - 'Display logging information at every log_steps.') - -flags.DEFINE_integer('save_interval_secs', 1200, - 'How often, in seconds, we save the model to disk.') - -flags.DEFINE_integer('save_summaries_secs', 600, - 'How often, in seconds, we compute the summaries.') - -flags.DEFINE_boolean( - 'save_summaries_images', False, - 'Save sample inputs, labels, and semantic predictions as ' - 'images to summary.') - -# Settings for profiling. - -flags.DEFINE_string('profile_logdir', None, - 'Where the profile files are stored.') - -# Settings for training strategy. - -flags.DEFINE_enum('optimizer', 'momentum', ['momentum', 'adam'], - 'Which optimizer to use.') - - -# Momentum optimizer flags - -flags.DEFINE_enum('learning_policy', 'poly', ['poly', 'step'], - 'Learning rate policy for training.') - -# Use 0.007 when training on PASCAL augmented training set, train_aug. When -# fine-tuning on PASCAL trainval set, use learning rate=0.0001. -flags.DEFINE_float('base_learning_rate', .0001, - 'The base learning rate for model training.') - -flags.DEFINE_float('decay_steps', 0.0, - 'Decay steps for polynomial learning rate schedule.') - -flags.DEFINE_float('end_learning_rate', 0.0, - 'End learning rate for polynomial learning rate schedule.') - -flags.DEFINE_float('learning_rate_decay_factor', 0.1, - 'The rate to decay the base learning rate.') - -flags.DEFINE_integer('learning_rate_decay_step', 2000, - 'Decay the base learning rate at a fixed step.') - -flags.DEFINE_float('learning_power', 0.9, - 'The power value used in the poly learning policy.') - -flags.DEFINE_integer('training_number_of_steps', 30000, - 'The number of steps used for training') - -flags.DEFINE_float('momentum', 0.9, 'The momentum value to use') - -# Adam optimizer flags -flags.DEFINE_float('adam_learning_rate', 0.001, - 'Learning rate for the adam optimizer.') -flags.DEFINE_float('adam_epsilon', 1e-08, 'Adam optimizer epsilon.') - -# When fine_tune_batch_norm=True, use at least batch size larger than 12 -# (batch size more than 16 is better). Otherwise, one could use smaller batch -# size and set fine_tune_batch_norm=False. -flags.DEFINE_integer('train_batch_size', 8, - 'The number of images in each batch during training.') - -# For weight_decay, use 0.00004 for MobileNet-V2 or Xcpetion model variants. -# Use 0.0001 for ResNet model variants. -flags.DEFINE_float('weight_decay', 0.00004, - 'The value of the weight decay for training.') - -flags.DEFINE_list('train_crop_size', '513,513', - 'Image crop size [height, width] during training.') - -flags.DEFINE_float( - 'last_layer_gradient_multiplier', 1.0, - 'The gradient multiplier for last layers, which is used to ' - 'boost the gradient of last layers if the value > 1.') - -flags.DEFINE_boolean('upsample_logits', True, - 'Upsample logits during training.') - -# Hyper-parameters for NAS training strategy. - -flags.DEFINE_float( - 'drop_path_keep_prob', 1.0, - 'Probability to keep each path in the NAS cell when training.') - -# Settings for fine-tuning the network. - -flags.DEFINE_string('tf_initial_checkpoint', None, - 'The initial checkpoint in tensorflow format.') - -# Set to False if one does not want to re-use the trained classifier weights. -flags.DEFINE_boolean('initialize_last_layer', True, - 'Initialize the last layer.') - -flags.DEFINE_boolean('last_layers_contain_logits_only', False, - 'Only consider logits as last layers or not.') - -flags.DEFINE_integer('slow_start_step', 0, - 'Training model with small learning rate for few steps.') - -flags.DEFINE_float('slow_start_learning_rate', 1e-4, - 'Learning rate employed during slow start.') - -# Set to True if one wants to fine-tune the batch norm parameters in DeepLabv3. -# Set to False and use small batch size to save GPU memory. -flags.DEFINE_boolean('fine_tune_batch_norm', True, - 'Fine tune the batch norm parameters or not.') - -flags.DEFINE_float('min_scale_factor', 0.5, - 'Mininum scale factor for data augmentation.') - -flags.DEFINE_float('max_scale_factor', 2., - 'Maximum scale factor for data augmentation.') - -flags.DEFINE_float('scale_factor_step_size', 0.25, - 'Scale factor step size for data augmentation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Hard example mining related flags. -flags.DEFINE_integer( - 'hard_example_mining_step', 0, - 'The training step in which exact hard example mining kicks off. Note we ' - 'gradually reduce the mining percent to the specified ' - 'top_k_percent_pixels. For example, if hard_example_mining_step=100K and ' - 'top_k_percent_pixels=0.25, then mining percent will gradually reduce from ' - '100% to 25% until 100K steps after which we only mine top 25% pixels.') - -flags.DEFINE_float( - 'top_k_percent_pixels', 1.0, - 'The top k percent pixels (in terms of the loss values) used to compute ' - 'loss during training. This is useful for hard pixel mining.') - -# Quantization setting. -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('train_split', 'train', - 'Which split of the dataset to be used for training') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - - -def _build_deeplab(iterator, outputs_to_num_classes, ignore_label): - """Builds a clone of DeepLab. - - Args: - iterator: An iterator of type tf.data.Iterator for images and labels. - outputs_to_num_classes: A map from output type to the number of classes. For - example, for the task of semantic segmentation with 21 semantic classes, - we would have outputs_to_num_classes['semantic'] = 21. - ignore_label: Ignore label. - """ - samples = iterator.get_next() - - # Add name to input and label nodes so we can add to summary. - samples[common.IMAGE] = tf.identity(samples[common.IMAGE], name=common.IMAGE) - samples[common.LABEL] = tf.identity(samples[common.LABEL], name=common.LABEL) - - model_options = common.ModelOptions( - outputs_to_num_classes=outputs_to_num_classes, - crop_size=[int(sz) for sz in FLAGS.train_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - outputs_to_scales_to_logits = model.multi_scale_logits( - samples[common.IMAGE], - model_options=model_options, - image_pyramid=FLAGS.image_pyramid, - weight_decay=FLAGS.weight_decay, - is_training=True, - fine_tune_batch_norm=FLAGS.fine_tune_batch_norm, - nas_training_hyper_parameters={ - 'drop_path_keep_prob': FLAGS.drop_path_keep_prob, - 'total_training_steps': FLAGS.training_number_of_steps, - }) - - # Add name to graph node so we can add to summary. - output_type_dict = outputs_to_scales_to_logits[common.OUTPUT_TYPE] - output_type_dict[model.MERGED_LOGITS_SCOPE] = tf.identity( - output_type_dict[model.MERGED_LOGITS_SCOPE], name=common.OUTPUT_TYPE) - - for output, num_classes in six.iteritems(outputs_to_num_classes): - train_utils.add_softmax_cross_entropy_loss_for_each_scale( - outputs_to_scales_to_logits[output], - samples[common.LABEL], - num_classes, - ignore_label, - loss_weight=model_options.label_weights, - upsample_logits=FLAGS.upsample_logits, - hard_example_mining_step=FLAGS.hard_example_mining_step, - top_k_percent_pixels=FLAGS.top_k_percent_pixels, - scope=output) - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - # Set up deployment (i.e., multi-GPUs and/or multi-replicas). - config = model_deploy.DeploymentConfig( - num_clones=FLAGS.num_clones, - clone_on_cpu=FLAGS.clone_on_cpu, - replica_id=FLAGS.task, - num_replicas=FLAGS.num_replicas, - num_ps_tasks=FLAGS.num_ps_tasks) - - # Split the batch across GPUs. - assert FLAGS.train_batch_size % config.num_clones == 0, ( - 'Training batch size not divisble by number of clones (GPUs).') - - clone_batch_size = FLAGS.train_batch_size // config.num_clones - - tf.gfile.MakeDirs(FLAGS.train_logdir) - tf.logging.info('Training on %s set', FLAGS.train_split) - - with tf.Graph().as_default() as graph: - with tf.device(config.inputs_device()): - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.train_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=clone_batch_size, - crop_size=[int(sz) for sz in FLAGS.train_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - min_scale_factor=FLAGS.min_scale_factor, - max_scale_factor=FLAGS.max_scale_factor, - scale_factor_step_size=FLAGS.scale_factor_step_size, - model_variant=FLAGS.model_variant, - num_readers=4, - is_training=True, - should_shuffle=True, - should_repeat=True) - - # Create the global step on the device storing the variables. - with tf.device(config.variables_device()): - global_step = tf.train.get_or_create_global_step() - - # Define the model and create clones. - model_fn = _build_deeplab - model_args = (dataset.get_one_shot_iterator(), { - common.OUTPUT_TYPE: dataset.num_of_classes - }, dataset.ignore_label) - clones = model_deploy.create_clones(config, model_fn, args=model_args) - - # Gather update_ops from the first clone. These contain, for example, - # the updates for the batch_norm variables created by model_fn. - first_clone_scope = config.clone_scope(0) - update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, first_clone_scope) - - # Gather initial summaries. - summaries = set(tf.get_collection(tf.GraphKeys.SUMMARIES)) - - # Add summaries for model variables. - for model_var in tf.model_variables(): - summaries.add(tf.summary.histogram(model_var.op.name, model_var)) - - # Add summaries for images, labels, semantic predictions - if FLAGS.save_summaries_images: - summary_image = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.IMAGE)).strip('/')) - summaries.add( - tf.summary.image('samples/%s' % common.IMAGE, summary_image)) - - first_clone_label = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.LABEL)).strip('/')) - # Scale up summary image pixel values for better visualization. - pixel_scaling = max(1, 255 // dataset.num_of_classes) - summary_label = tf.cast(first_clone_label * pixel_scaling, tf.uint8) - summaries.add( - tf.summary.image('samples/%s' % common.LABEL, summary_label)) - - first_clone_output = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.OUTPUT_TYPE)).strip('/')) - predictions = tf.expand_dims(tf.argmax(first_clone_output, 3), -1) - - summary_predictions = tf.cast(predictions * pixel_scaling, tf.uint8) - summaries.add( - tf.summary.image( - 'samples/%s' % common.OUTPUT_TYPE, summary_predictions)) - - # Add summaries for losses. - for loss in tf.get_collection(tf.GraphKeys.LOSSES, first_clone_scope): - summaries.add(tf.summary.scalar('losses/%s' % loss.op.name, loss)) - - # Build the optimizer based on the device specification. - with tf.device(config.optimizer_device()): - learning_rate = train_utils.get_model_learning_rate( - FLAGS.learning_policy, - FLAGS.base_learning_rate, - FLAGS.learning_rate_decay_step, - FLAGS.learning_rate_decay_factor, - FLAGS.training_number_of_steps, - FLAGS.learning_power, - FLAGS.slow_start_step, - FLAGS.slow_start_learning_rate, - decay_steps=FLAGS.decay_steps, - end_learning_rate=FLAGS.end_learning_rate) - - summaries.add(tf.summary.scalar('learning_rate', learning_rate)) - - if FLAGS.optimizer == 'momentum': - optimizer = tf.train.MomentumOptimizer(learning_rate, FLAGS.momentum) - elif FLAGS.optimizer == 'adam': - optimizer = tf.train.AdamOptimizer( - learning_rate=FLAGS.adam_learning_rate, epsilon=FLAGS.adam_epsilon) - else: - raise ValueError('Unknown optimizer') - - if FLAGS.quantize_delay_step >= 0: - if FLAGS.num_clones > 1: - raise ValueError('Quantization doesn\'t support multi-clone yet.') - contrib_quantize.create_training_graph( - quant_delay=FLAGS.quantize_delay_step) - - startup_delay_steps = FLAGS.task * FLAGS.startup_delay_steps - - with tf.device(config.variables_device()): - total_loss, grads_and_vars = model_deploy.optimize_clones( - clones, optimizer) - total_loss = tf.check_numerics(total_loss, 'Loss is inf or nan.') - summaries.add(tf.summary.scalar('total_loss', total_loss)) - - # Modify the gradients for biases and last layer variables. - last_layers = model.get_extra_layer_scopes( - FLAGS.last_layers_contain_logits_only) - grad_mult = train_utils.get_model_gradient_multipliers( - last_layers, FLAGS.last_layer_gradient_multiplier) - if grad_mult: - grads_and_vars = slim.learning.multiply_gradients( - grads_and_vars, grad_mult) - - # Create gradient update op. - grad_updates = optimizer.apply_gradients( - grads_and_vars, global_step=global_step) - update_ops.append(grad_updates) - update_op = tf.group(*update_ops) - with tf.control_dependencies([update_op]): - train_tensor = tf.identity(total_loss, name='train_op') - - # Add the summaries from the first clone. These contain the summaries - # created by model_fn and either optimize_clones() or _gather_clone_loss(). - summaries |= set( - tf.get_collection(tf.GraphKeys.SUMMARIES, first_clone_scope)) - - # Merge all summaries together. - summary_op = tf.summary.merge(list(summaries)) - - # Soft placement allows placing on CPU ops without GPU implementation. - session_config = tf.ConfigProto( - allow_soft_placement=True, log_device_placement=False) - - # Start the training. - profile_dir = FLAGS.profile_logdir - if profile_dir is not None: - tf.gfile.MakeDirs(profile_dir) - - with contrib_tfprof.ProfileContext( - enabled=profile_dir is not None, profile_dir=profile_dir): - init_fn = None - if FLAGS.tf_initial_checkpoint: - init_fn = train_utils.get_model_init_fn( - FLAGS.train_logdir, - FLAGS.tf_initial_checkpoint, - FLAGS.initialize_last_layer, - last_layers, - ignore_missing_vars=True) - - slim.learning.train( - train_tensor, - logdir=FLAGS.train_logdir, - log_every_n_steps=FLAGS.log_steps, - master=FLAGS.master, - number_of_steps=FLAGS.training_number_of_steps, - is_chief=(FLAGS.task == 0), - session_config=session_config, - startup_delay_steps=startup_delay_steps, - init_fn=init_fn, - summary_op=summary_op, - save_summaries_secs=FLAGS.save_summaries_secs, - save_interval_secs=FLAGS.save_interval_secs) - - -if __name__ == '__main__': - flags.mark_flag_as_required('train_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/deeplab/utils/__init__.py b/research/deeplab/utils/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/utils/get_dataset_colormap.py b/research/deeplab/utils/get_dataset_colormap.py deleted file mode 100644 index c0502e3b3cdd4ee065701e5ee8d94d7f3701c576..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/get_dataset_colormap.py +++ /dev/null @@ -1,416 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Visualizes the segmentation results via specified color map. - -Visualizes the semantic segmentation results by the color map -defined by the different datasets. Supported colormaps are: - -* ADE20K (http://groups.csail.mit.edu/vision/datasets/ADE20K/). - -* Cityscapes dataset (https://www.cityscapes-dataset.com). - -* Mapillary Vistas (https://research.mapillary.com). - -* PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/). -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import numpy as np -from six.moves import range - -# Dataset names. -_ADE20K = 'ade20k' -_CITYSCAPES = 'cityscapes' -_MAPILLARY_VISTAS = 'mapillary_vistas' -_PASCAL = 'pascal' - -# Max number of entries in the colormap for each dataset. -_DATASET_MAX_ENTRIES = { - _ADE20K: 151, - _CITYSCAPES: 256, - _MAPILLARY_VISTAS: 66, - _PASCAL: 512, -} - - -def create_ade20k_label_colormap(): - """Creates a label colormap used in ADE20K segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - return np.asarray([ - [0, 0, 0], - [120, 120, 120], - [180, 120, 120], - [6, 230, 230], - [80, 50, 50], - [4, 200, 3], - [120, 120, 80], - [140, 140, 140], - [204, 5, 255], - [230, 230, 230], - [4, 250, 7], - [224, 5, 255], - [235, 255, 7], - [150, 5, 61], - [120, 120, 70], - [8, 255, 51], - [255, 6, 82], - [143, 255, 140], - [204, 255, 4], - [255, 51, 7], - [204, 70, 3], - [0, 102, 200], - [61, 230, 250], - [255, 6, 51], - [11, 102, 255], - [255, 7, 71], - [255, 9, 224], - [9, 7, 230], - [220, 220, 220], - [255, 9, 92], - [112, 9, 255], - [8, 255, 214], - [7, 255, 224], - [255, 184, 6], - [10, 255, 71], - [255, 41, 10], - [7, 255, 255], - [224, 255, 8], - [102, 8, 255], - [255, 61, 6], - [255, 194, 7], - [255, 122, 8], - [0, 255, 20], - [255, 8, 41], - [255, 5, 153], - [6, 51, 255], - [235, 12, 255], - [160, 150, 20], - [0, 163, 255], - [140, 140, 140], - [250, 10, 15], - [20, 255, 0], - [31, 255, 0], - [255, 31, 0], - [255, 224, 0], - [153, 255, 0], - [0, 0, 255], - [255, 71, 0], - [0, 235, 255], - [0, 173, 255], - [31, 0, 255], - [11, 200, 200], - [255, 82, 0], - [0, 255, 245], - [0, 61, 255], - [0, 255, 112], - [0, 255, 133], - [255, 0, 0], - [255, 163, 0], - [255, 102, 0], - [194, 255, 0], - [0, 143, 255], - [51, 255, 0], - [0, 82, 255], - [0, 255, 41], - [0, 255, 173], - [10, 0, 255], - [173, 255, 0], - [0, 255, 153], - [255, 92, 0], - [255, 0, 255], - [255, 0, 245], - [255, 0, 102], - [255, 173, 0], - [255, 0, 20], - [255, 184, 184], - [0, 31, 255], - [0, 255, 61], - [0, 71, 255], - [255, 0, 204], - [0, 255, 194], - [0, 255, 82], - [0, 10, 255], - [0, 112, 255], - [51, 0, 255], - [0, 194, 255], - [0, 122, 255], - [0, 255, 163], - [255, 153, 0], - [0, 255, 10], - [255, 112, 0], - [143, 255, 0], - [82, 0, 255], - [163, 255, 0], - [255, 235, 0], - [8, 184, 170], - [133, 0, 255], - [0, 255, 92], - [184, 0, 255], - [255, 0, 31], - [0, 184, 255], - [0, 214, 255], - [255, 0, 112], - [92, 255, 0], - [0, 224, 255], - [112, 224, 255], - [70, 184, 160], - [163, 0, 255], - [153, 0, 255], - [71, 255, 0], - [255, 0, 163], - [255, 204, 0], - [255, 0, 143], - [0, 255, 235], - [133, 255, 0], - [255, 0, 235], - [245, 0, 255], - [255, 0, 122], - [255, 245, 0], - [10, 190, 212], - [214, 255, 0], - [0, 204, 255], - [20, 0, 255], - [255, 255, 0], - [0, 153, 255], - [0, 41, 255], - [0, 255, 204], - [41, 0, 255], - [41, 255, 0], - [173, 0, 255], - [0, 245, 255], - [71, 0, 255], - [122, 0, 255], - [0, 255, 184], - [0, 92, 255], - [184, 255, 0], - [0, 133, 255], - [255, 214, 0], - [25, 194, 194], - [102, 255, 0], - [92, 0, 255], - ]) - - -def create_cityscapes_label_colormap(): - """Creates a label colormap used in CITYSCAPES segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - colormap = np.zeros((256, 3), dtype=np.uint8) - colormap[0] = [128, 64, 128] - colormap[1] = [244, 35, 232] - colormap[2] = [70, 70, 70] - colormap[3] = [102, 102, 156] - colormap[4] = [190, 153, 153] - colormap[5] = [153, 153, 153] - colormap[6] = [250, 170, 30] - colormap[7] = [220, 220, 0] - colormap[8] = [107, 142, 35] - colormap[9] = [152, 251, 152] - colormap[10] = [70, 130, 180] - colormap[11] = [220, 20, 60] - colormap[12] = [255, 0, 0] - colormap[13] = [0, 0, 142] - colormap[14] = [0, 0, 70] - colormap[15] = [0, 60, 100] - colormap[16] = [0, 80, 100] - colormap[17] = [0, 0, 230] - colormap[18] = [119, 11, 32] - return colormap - - -def create_mapillary_vistas_label_colormap(): - """Creates a label colormap used in Mapillary Vistas segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - return np.asarray([ - [165, 42, 42], - [0, 192, 0], - [196, 196, 196], - [190, 153, 153], - [180, 165, 180], - [102, 102, 156], - [102, 102, 156], - [128, 64, 255], - [140, 140, 200], - [170, 170, 170], - [250, 170, 160], - [96, 96, 96], - [230, 150, 140], - [128, 64, 128], - [110, 110, 110], - [244, 35, 232], - [150, 100, 100], - [70, 70, 70], - [150, 120, 90], - [220, 20, 60], - [255, 0, 0], - [255, 0, 0], - [255, 0, 0], - [200, 128, 128], - [255, 255, 255], - [64, 170, 64], - [128, 64, 64], - [70, 130, 180], - [255, 255, 255], - [152, 251, 152], - [107, 142, 35], - [0, 170, 30], - [255, 255, 128], - [250, 0, 30], - [0, 0, 0], - [220, 220, 220], - [170, 170, 170], - [222, 40, 40], - [100, 170, 30], - [40, 40, 40], - [33, 33, 33], - [170, 170, 170], - [0, 0, 142], - [170, 170, 170], - [210, 170, 100], - [153, 153, 153], - [128, 128, 128], - [0, 0, 142], - [250, 170, 30], - [192, 192, 192], - [220, 220, 0], - [180, 165, 180], - [119, 11, 32], - [0, 0, 142], - [0, 60, 100], - [0, 0, 142], - [0, 0, 90], - [0, 0, 230], - [0, 80, 100], - [128, 64, 64], - [0, 0, 110], - [0, 0, 70], - [0, 0, 192], - [32, 32, 32], - [0, 0, 0], - [0, 0, 0], - ]) - - -def create_pascal_label_colormap(): - """Creates a label colormap used in PASCAL VOC segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - colormap = np.zeros((_DATASET_MAX_ENTRIES[_PASCAL], 3), dtype=int) - ind = np.arange(_DATASET_MAX_ENTRIES[_PASCAL], dtype=int) - - for shift in reversed(list(range(8))): - for channel in range(3): - colormap[:, channel] |= bit_get(ind, channel) << shift - ind >>= 3 - - return colormap - - -def get_ade20k_name(): - return _ADE20K - - -def get_cityscapes_name(): - return _CITYSCAPES - - -def get_mapillary_vistas_name(): - return _MAPILLARY_VISTAS - - -def get_pascal_name(): - return _PASCAL - - -def bit_get(val, idx): - """Gets the bit value. - - Args: - val: Input value, int or numpy int array. - idx: Which bit of the input val. - - Returns: - The "idx"-th bit of input val. - """ - return (val >> idx) & 1 - - -def create_label_colormap(dataset=_PASCAL): - """Creates a label colormap for the specified dataset. - - Args: - dataset: The colormap used in the dataset. - - Returns: - A numpy array of the dataset colormap. - - Raises: - ValueError: If the dataset is not supported. - """ - if dataset == _ADE20K: - return create_ade20k_label_colormap() - elif dataset == _CITYSCAPES: - return create_cityscapes_label_colormap() - elif dataset == _MAPILLARY_VISTAS: - return create_mapillary_vistas_label_colormap() - elif dataset == _PASCAL: - return create_pascal_label_colormap() - else: - raise ValueError('Unsupported dataset.') - - -def label_to_color_image(label, dataset=_PASCAL): - """Adds color defined by the dataset colormap to the label. - - Args: - label: A 2D array with integer type, storing the segmentation label. - dataset: The colormap used in the dataset. - - Returns: - result: A 2D array with floating type. The element of the array - is the color indexed by the corresponding element in the input label - to the dataset color map. - - Raises: - ValueError: If label is not of rank 2 or its value is larger than color - map maximum entry. - """ - if label.ndim != 2: - raise ValueError('Expect 2-D input label. Got {}'.format(label.shape)) - - if np.max(label) >= _DATASET_MAX_ENTRIES[dataset]: - raise ValueError( - 'label value too large: {} >= {}.'.format( - np.max(label), _DATASET_MAX_ENTRIES[dataset])) - - colormap = create_label_colormap(dataset) - return colormap[label] - - -def get_dataset_colormap_max_entries(dataset): - return _DATASET_MAX_ENTRIES[dataset] diff --git a/research/deeplab/utils/get_dataset_colormap_test.py b/research/deeplab/utils/get_dataset_colormap_test.py deleted file mode 100644 index 89adb2c7391ce087100558fcf256acb1ca45638b..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/get_dataset_colormap_test.py +++ /dev/null @@ -1,97 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for get_dataset_colormap.py.""" - -import numpy as np -import tensorflow as tf - -from deeplab.utils import get_dataset_colormap - - -class VisualizationUtilTest(tf.test.TestCase): - - def testBitGet(self): - """Test that if the returned bit value is correct.""" - self.assertEqual(1, get_dataset_colormap.bit_get(9, 0)) - self.assertEqual(0, get_dataset_colormap.bit_get(9, 1)) - self.assertEqual(0, get_dataset_colormap.bit_get(9, 2)) - self.assertEqual(1, get_dataset_colormap.bit_get(9, 3)) - - def testPASCALLabelColorMapValue(self): - """Test the getd color map value.""" - colormap = get_dataset_colormap.create_pascal_label_colormap() - - # Only test a few sampled entries in the color map. - self.assertTrue(np.array_equal([128., 0., 128.], colormap[5, :])) - self.assertTrue(np.array_equal([128., 192., 128.], colormap[23, :])) - self.assertTrue(np.array_equal([128., 0., 192.], colormap[37, :])) - self.assertTrue(np.array_equal([224., 192., 192.], colormap[127, :])) - self.assertTrue(np.array_equal([192., 160., 192.], colormap[175, :])) - - def testLabelToPASCALColorImage(self): - """Test the value of the converted label value.""" - label = np.array([[0, 16, 16], [52, 7, 52]]) - expected_result = np.array([ - [[0, 0, 0], [0, 64, 0], [0, 64, 0]], - [[0, 64, 192], [128, 128, 128], [0, 64, 192]] - ]) - colored_label = get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - self.assertTrue(np.array_equal(expected_result, colored_label)) - - def testUnExpectedLabelValueForLabelToPASCALColorImage(self): - """Raise ValueError when input value exceeds range.""" - label = np.array([[120], [600]]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - - def testUnExpectedLabelDimensionForLabelToPASCALColorImage(self): - """Raise ValueError if input dimension is not correct.""" - label = np.array([120]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - - def testGetColormapForUnsupportedDataset(self): - with self.assertRaises(ValueError): - get_dataset_colormap.create_label_colormap('unsupported_dataset') - - def testUnExpectedLabelDimensionForLabelToADE20KColorImage(self): - label = np.array([250]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_ade20k_name()) - - def testFirstColorInADE20KColorMap(self): - label = np.array([[1, 3], [10, 20]]) - expected_result = np.array([ - [[120, 120, 120], [6, 230, 230]], - [[4, 250, 7], [204, 70, 3]] - ]) - colored_label = get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_ade20k_name()) - self.assertTrue(np.array_equal(colored_label, expected_result)) - - def testMapillaryVistasColorMapValue(self): - colormap = get_dataset_colormap.create_mapillary_vistas_label_colormap() - self.assertTrue(np.array_equal([190, 153, 153], colormap[3, :])) - self.assertTrue(np.array_equal([102, 102, 156], colormap[6, :])) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/utils/save_annotation.py b/research/deeplab/utils/save_annotation.py deleted file mode 100644 index 2444df79532d6ef999f470ab8eef5ab333491660..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/save_annotation.py +++ /dev/null @@ -1,66 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Saves an annotation as one png image. - -This script saves an annotation as one png image, and has the option to add -colormap to the png image for better visualization. -""" - -import numpy as np -import PIL.Image as img -import tensorflow as tf - -from deeplab.utils import get_dataset_colormap - - -def save_annotation(label, - save_dir, - filename, - add_colormap=True, - normalize_to_unit_values=False, - scale_values=False, - colormap_type=get_dataset_colormap.get_pascal_name()): - """Saves the given label to image on disk. - - Args: - label: The numpy array to be saved. The data will be converted - to uint8 and saved as png image. - save_dir: String, the directory to which the results will be saved. - filename: String, the image filename. - add_colormap: Boolean, add color map to the label or not. - normalize_to_unit_values: Boolean, normalize the input values to [0, 1]. - scale_values: Boolean, scale the input values to [0, 255] for visualization. - colormap_type: String, colormap type for visualization. - """ - # Add colormap for visualizing the prediction. - if add_colormap: - colored_label = get_dataset_colormap.label_to_color_image( - label, colormap_type) - else: - colored_label = label - if normalize_to_unit_values: - min_value = np.amin(colored_label) - max_value = np.amax(colored_label) - range_value = max_value - min_value - if range_value != 0: - colored_label = (colored_label - min_value) / range_value - - if scale_values: - colored_label = 255. * colored_label - - pil_image = img.fromarray(colored_label.astype(dtype=np.uint8)) - with tf.gfile.Open('%s/%s.png' % (save_dir, filename), mode='w') as f: - pil_image.save(f, 'PNG') diff --git a/research/deeplab/utils/train_utils.py b/research/deeplab/utils/train_utils.py deleted file mode 100644 index 14bbd6ee7e55533d94195fb4e7327e63e53a2800..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/train_utils.py +++ /dev/null @@ -1,372 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utility functions for training.""" - -import six -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework - -from deeplab.core import preprocess_utils -from deeplab.core import utils - - -def _div_maybe_zero(total_loss, num_present): - """Normalizes the total loss with the number of present pixels.""" - return tf.to_float(num_present > 0) * tf.math.divide( - total_loss, - tf.maximum(1e-5, num_present)) - - -def add_softmax_cross_entropy_loss_for_each_scale(scales_to_logits, - labels, - num_classes, - ignore_label, - loss_weight=1.0, - upsample_logits=True, - hard_example_mining_step=0, - top_k_percent_pixels=1.0, - gt_is_matting_map=False, - scope=None): - """Adds softmax cross entropy loss for logits of each scale. - - Args: - scales_to_logits: A map from logits names for different scales to logits. - The logits have shape [batch, logits_height, logits_width, num_classes]. - labels: Groundtruth labels with shape [batch, image_height, image_width, 1]. - num_classes: Integer, number of target classes. - ignore_label: Integer, label to ignore. - loss_weight: A float or a list of loss weights. If it is a float, it means - all the labels have the same weight. If it is a list of weights, then each - element in the list represents the weight for the label of its index, for - example, loss_weight = [0.1, 0.5] means the weight for label 0 is 0.1 and - the weight for label 1 is 0.5. - upsample_logits: Boolean, upsample logits or not. - hard_example_mining_step: An integer, the training step in which the hard - exampling mining kicks off. Note that we gradually reduce the mining - percent to the top_k_percent_pixels. For example, if - hard_example_mining_step = 100K and top_k_percent_pixels = 0.25, then - mining percent will gradually reduce from 100% to 25% until 100K steps - after which we only mine top 25% pixels. - top_k_percent_pixels: A float, the value lies in [0.0, 1.0]. When its value - < 1.0, only compute the loss for the top k percent pixels (e.g., the top - 20% pixels). This is useful for hard pixel mining. - gt_is_matting_map: If true, the groundtruth is a matting map of confidence - score. If false, the groundtruth is an integer valued class mask. - scope: String, the scope for the loss. - - Raises: - ValueError: Label or logits is None, or groundtruth is matting map while - label is not floating value. - """ - if labels is None: - raise ValueError('No label for softmax cross entropy loss.') - - # If input groundtruth is a matting map of confidence, check if the input - # labels are floating point values. - if gt_is_matting_map and not labels.dtype.is_floating: - raise ValueError('Labels must be floats if groundtruth is a matting map.') - - for scale, logits in six.iteritems(scales_to_logits): - loss_scope = None - if scope: - loss_scope = '%s_%s' % (scope, scale) - - if upsample_logits: - # Label is not downsampled, and instead we upsample logits. - logits = tf.image.resize_bilinear( - logits, - preprocess_utils.resolve_shape(labels, 4)[1:3], - align_corners=True) - scaled_labels = labels - else: - # Label is downsampled to the same size as logits. - # When gt_is_matting_map = true, label downsampling with nearest neighbor - # method may introduce artifacts. However, to avoid ignore_label from - # being interpolated with other labels, we still perform nearest neighbor - # interpolation. - # TODO(huizhongc): Change to bilinear interpolation by processing padded - # and non-padded label separately. - if gt_is_matting_map: - tf.logging.warning( - 'Label downsampling with nearest neighbor may introduce artifacts.') - - scaled_labels = tf.image.resize_nearest_neighbor( - labels, - preprocess_utils.resolve_shape(logits, 4)[1:3], - align_corners=True) - - scaled_labels = tf.reshape(scaled_labels, shape=[-1]) - weights = utils.get_label_weight_mask( - scaled_labels, ignore_label, num_classes, label_weights=loss_weight) - # Dimension of keep_mask is equal to the total number of pixels. - keep_mask = tf.cast( - tf.not_equal(scaled_labels, ignore_label), dtype=tf.float32) - - train_labels = None - logits = tf.reshape(logits, shape=[-1, num_classes]) - - if gt_is_matting_map: - # When the groundtruth is integer label mask, we can assign class - # dependent label weights to the loss. When the groundtruth is image - # matting confidence, we do not apply class-dependent label weight (i.e., - # label_weight = 1.0). - if loss_weight != 1.0: - raise ValueError( - 'loss_weight must equal to 1 if groundtruth is matting map.') - - # Assign label value 0 to ignore pixels. The exact label value of ignore - # pixel does not matter, because those ignore_value pixel losses will be - # multiplied to 0 weight. - train_labels = scaled_labels * keep_mask - - train_labels = tf.expand_dims(train_labels, 1) - train_labels = tf.concat([1 - train_labels, train_labels], axis=1) - else: - train_labels = tf.one_hot( - scaled_labels, num_classes, on_value=1.0, off_value=0.0) - - default_loss_scope = ('softmax_all_pixel_loss' - if top_k_percent_pixels == 1.0 else - 'softmax_hard_example_mining') - with tf.name_scope(loss_scope, default_loss_scope, - [logits, train_labels, weights]): - # Compute the loss for all pixels. - pixel_losses = tf.nn.softmax_cross_entropy_with_logits_v2( - labels=tf.stop_gradient( - train_labels, name='train_labels_stop_gradient'), - logits=logits, - name='pixel_losses') - weighted_pixel_losses = tf.multiply(pixel_losses, weights) - - if top_k_percent_pixels == 1.0: - total_loss = tf.reduce_sum(weighted_pixel_losses) - num_present = tf.reduce_sum(keep_mask) - loss = _div_maybe_zero(total_loss, num_present) - tf.losses.add_loss(loss) - else: - num_pixels = tf.to_float(tf.shape(logits)[0]) - # Compute the top_k_percent pixels based on current training step. - if hard_example_mining_step == 0: - # Directly focus on the top_k pixels. - top_k_pixels = tf.to_int32(top_k_percent_pixels * num_pixels) - else: - # Gradually reduce the mining percent to top_k_percent_pixels. - global_step = tf.to_float(tf.train.get_or_create_global_step()) - ratio = tf.minimum(1.0, global_step / hard_example_mining_step) - top_k_pixels = tf.to_int32( - (ratio * top_k_percent_pixels + (1.0 - ratio)) * num_pixels) - top_k_losses, _ = tf.nn.top_k(weighted_pixel_losses, - k=top_k_pixels, - sorted=True, - name='top_k_percent_pixels') - total_loss = tf.reduce_sum(top_k_losses) - num_present = tf.reduce_sum( - tf.to_float(tf.not_equal(top_k_losses, 0.0))) - loss = _div_maybe_zero(total_loss, num_present) - tf.losses.add_loss(loss) - - -def get_model_init_fn(train_logdir, - tf_initial_checkpoint, - initialize_last_layer, - last_layers, - ignore_missing_vars=False): - """Gets the function initializing model variables from a checkpoint. - - Args: - train_logdir: Log directory for training. - tf_initial_checkpoint: TensorFlow checkpoint for initialization. - initialize_last_layer: Initialize last layer or not. - last_layers: Last layers of the model. - ignore_missing_vars: Ignore missing variables in the checkpoint. - - Returns: - Initialization function. - """ - if tf_initial_checkpoint is None: - tf.logging.info('Not initializing the model from a checkpoint.') - return None - - if tf.train.latest_checkpoint(train_logdir): - tf.logging.info('Ignoring initialization; other checkpoint exists') - return None - - tf.logging.info('Initializing model from path: %s', tf_initial_checkpoint) - - # Variables that will not be restored. - exclude_list = ['global_step'] - if not initialize_last_layer: - exclude_list.extend(last_layers) - - variables_to_restore = contrib_framework.get_variables_to_restore( - exclude=exclude_list) - - if variables_to_restore: - init_op, init_feed_dict = contrib_framework.assign_from_checkpoint( - tf_initial_checkpoint, - variables_to_restore, - ignore_missing_vars=ignore_missing_vars) - global_step = tf.train.get_or_create_global_step() - - def restore_fn(sess): - sess.run(init_op, init_feed_dict) - sess.run([global_step]) - - return restore_fn - - return None - - -def get_model_gradient_multipliers(last_layers, last_layer_gradient_multiplier): - """Gets the gradient multipliers. - - The gradient multipliers will adjust the learning rates for model - variables. For the task of semantic segmentation, the models are - usually fine-tuned from the models trained on the task of image - classification. To fine-tune the models, we usually set larger (e.g., - 10 times larger) learning rate for the parameters of last layer. - - Args: - last_layers: Scopes of last layers. - last_layer_gradient_multiplier: The gradient multiplier for last layers. - - Returns: - The gradient multiplier map with variables as key, and multipliers as value. - """ - gradient_multipliers = {} - - for var in tf.model_variables(): - # Double the learning rate for biases. - if 'biases' in var.op.name: - gradient_multipliers[var.op.name] = 2. - - # Use larger learning rate for last layer variables. - for layer in last_layers: - if layer in var.op.name and 'biases' in var.op.name: - gradient_multipliers[var.op.name] = 2 * last_layer_gradient_multiplier - break - elif layer in var.op.name: - gradient_multipliers[var.op.name] = last_layer_gradient_multiplier - break - - return gradient_multipliers - - -def get_model_learning_rate(learning_policy, - base_learning_rate, - learning_rate_decay_step, - learning_rate_decay_factor, - training_number_of_steps, - learning_power, - slow_start_step, - slow_start_learning_rate, - slow_start_burnin_type='none', - decay_steps=0.0, - end_learning_rate=0.0, - boundaries=None, - boundary_learning_rates=None): - """Gets model's learning rate. - - Computes the model's learning rate for different learning policy. - Right now, only "step" and "poly" are supported. - (1) The learning policy for "step" is computed as follows: - current_learning_rate = base_learning_rate * - learning_rate_decay_factor ^ (global_step / learning_rate_decay_step) - See tf.train.exponential_decay for details. - (2) The learning policy for "poly" is computed as follows: - current_learning_rate = base_learning_rate * - (1 - global_step / training_number_of_steps) ^ learning_power - - Args: - learning_policy: Learning rate policy for training. - base_learning_rate: The base learning rate for model training. - learning_rate_decay_step: Decay the base learning rate at a fixed step. - learning_rate_decay_factor: The rate to decay the base learning rate. - training_number_of_steps: Number of steps for training. - learning_power: Power used for 'poly' learning policy. - slow_start_step: Training model with small learning rate for the first - few steps. - slow_start_learning_rate: The learning rate employed during slow start. - slow_start_burnin_type: The burnin type for the slow start stage. Can be - `none` which means no burnin or `linear` which means the learning rate - increases linearly from slow_start_learning_rate and reaches - base_learning_rate after slow_start_steps. - decay_steps: Float, `decay_steps` for polynomial learning rate. - end_learning_rate: Float, `end_learning_rate` for polynomial learning rate. - boundaries: A list of `Tensor`s or `int`s or `float`s with strictly - increasing entries. - boundary_learning_rates: A list of `Tensor`s or `float`s or `int`s that - specifies the values for the intervals defined by `boundaries`. It should - have one more element than `boundaries`, and all elements should have the - same type. - - Returns: - Learning rate for the specified learning policy. - - Raises: - ValueError: If learning policy or slow start burnin type is not recognized. - ValueError: If `boundaries` and `boundary_learning_rates` are not set for - multi_steps learning rate decay. - """ - global_step = tf.train.get_or_create_global_step() - adjusted_global_step = tf.maximum(global_step - slow_start_step, 0) - if decay_steps == 0.0: - tf.logging.info('Setting decay_steps to total training steps.') - decay_steps = training_number_of_steps - slow_start_step - if learning_policy == 'step': - learning_rate = tf.train.exponential_decay( - base_learning_rate, - adjusted_global_step, - learning_rate_decay_step, - learning_rate_decay_factor, - staircase=True) - elif learning_policy == 'poly': - learning_rate = tf.train.polynomial_decay( - base_learning_rate, - adjusted_global_step, - decay_steps=decay_steps, - end_learning_rate=end_learning_rate, - power=learning_power) - elif learning_policy == 'cosine': - learning_rate = tf.train.cosine_decay( - base_learning_rate, - adjusted_global_step, - training_number_of_steps - slow_start_step) - elif learning_policy == 'multi_steps': - if boundaries is None or boundary_learning_rates is None: - raise ValueError('Must set `boundaries` and `boundary_learning_rates` ' - 'for multi_steps learning rate decay.') - learning_rate = tf.train.piecewise_constant_decay( - adjusted_global_step, - boundaries, - boundary_learning_rates) - else: - raise ValueError('Unknown learning policy.') - - adjusted_slow_start_learning_rate = slow_start_learning_rate - if slow_start_burnin_type == 'linear': - # Do linear burnin. Increase linearly from slow_start_learning_rate and - # reach base_learning_rate after (global_step >= slow_start_steps). - adjusted_slow_start_learning_rate = ( - slow_start_learning_rate + - (base_learning_rate - slow_start_learning_rate) * - tf.to_float(global_step) / slow_start_step) - elif slow_start_burnin_type != 'none': - raise ValueError('Unknown burnin type.') - - # Employ small learning rate at the first few steps for warm start. - return tf.where(global_step < slow_start_step, - adjusted_slow_start_learning_rate, learning_rate) diff --git a/research/deeplab/vis.py b/research/deeplab/vis.py deleted file mode 100644 index 20808d37bf2f45f196a04391548c6745fcc6603b..0000000000000000000000000000000000000000 --- a/research/deeplab/vis.py +++ /dev/null @@ -1,327 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Segmentation results visualization on a given set of images. - -See model.py for more details and usage. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import os.path -import time -import numpy as np -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import training as contrib_training -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator -from deeplab.utils import save_annotation - -flags = tf.app.flags - -FLAGS = flags.FLAGS - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -# Settings for log directories. - -flags.DEFINE_string('vis_logdir', None, 'Where to write the event logs.') - -flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') - -# Settings for visualizing the model. - -flags.DEFINE_integer('vis_batch_size', 1, - 'The number of images in each batch during evaluation.') - -flags.DEFINE_list('vis_crop_size', '513,513', - 'Crop size [height, width] for visualization.') - -flags.DEFINE_integer('eval_interval_secs', 60 * 5, - 'How often (in seconds) to run evaluation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. -flags.DEFINE_multi_float('eval_scales', [1.0], - 'The scales to resize images for evaluation.') - -# Change to True for adding flipped images during test. -flags.DEFINE_bool('add_flipped_images', False, - 'Add flipped images for evaluation or not.') - -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. - -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('vis_split', 'val', - 'Which split of the dataset used for visualizing results') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - -flags.DEFINE_enum('colormap_type', 'pascal', ['pascal', 'cityscapes', 'ade20k'], - 'Visualization colormap type.') - -flags.DEFINE_boolean('also_save_raw_predictions', False, - 'Also save raw predictions.') - -flags.DEFINE_integer('max_number_of_iterations', 0, - 'Maximum number of visualization iterations. Will loop ' - 'indefinitely upon nonpositive values.') - -# The folder where semantic segmentation predictions are saved. -_SEMANTIC_PREDICTION_SAVE_FOLDER = 'segmentation_results' - -# The folder where raw semantic segmentation predictions are saved. -_RAW_SEMANTIC_PREDICTION_SAVE_FOLDER = 'raw_segmentation_results' - -# The format to save image. -_IMAGE_FORMAT = '%06d_image' - -# The format to save prediction -_PREDICTION_FORMAT = '%06d_prediction' - -# To evaluate Cityscapes results on the evaluation server, the labels used -# during training should be mapped to the labels for evaluation. -_CITYSCAPES_TRAIN_ID_TO_EVAL_ID = [7, 8, 11, 12, 13, 17, 19, 20, 21, 22, - 23, 24, 25, 26, 27, 28, 31, 32, 33] - - -def _convert_train_id_to_eval_id(prediction, train_id_to_eval_id): - """Converts the predicted label for evaluation. - - There are cases where the training labels are not equal to the evaluation - labels. This function is used to perform the conversion so that we could - evaluate the results on the evaluation server. - - Args: - prediction: Semantic segmentation prediction. - train_id_to_eval_id: A list mapping from train id to evaluation id. - - Returns: - Semantic segmentation prediction whose labels have been changed. - """ - converted_prediction = prediction.copy() - for train_id, eval_id in enumerate(train_id_to_eval_id): - converted_prediction[prediction == train_id] = eval_id - - return converted_prediction - - -def _process_batch(sess, original_images, semantic_predictions, image_names, - image_heights, image_widths, image_id_offset, save_dir, - raw_save_dir, train_id_to_eval_id=None): - """Evaluates one single batch qualitatively. - - Args: - sess: TensorFlow session. - original_images: One batch of original images. - semantic_predictions: One batch of semantic segmentation predictions. - image_names: Image names. - image_heights: Image heights. - image_widths: Image widths. - image_id_offset: Image id offset for indexing images. - save_dir: The directory where the predictions will be saved. - raw_save_dir: The directory where the raw predictions will be saved. - train_id_to_eval_id: A list mapping from train id to eval id. - """ - (original_images, - semantic_predictions, - image_names, - image_heights, - image_widths) = sess.run([original_images, semantic_predictions, - image_names, image_heights, image_widths]) - - num_image = semantic_predictions.shape[0] - for i in range(num_image): - image_height = np.squeeze(image_heights[i]) - image_width = np.squeeze(image_widths[i]) - original_image = np.squeeze(original_images[i]) - semantic_prediction = np.squeeze(semantic_predictions[i]) - crop_semantic_prediction = semantic_prediction[:image_height, :image_width] - - # Save image. - save_annotation.save_annotation( - original_image, save_dir, _IMAGE_FORMAT % (image_id_offset + i), - add_colormap=False) - - # Save prediction. - save_annotation.save_annotation( - crop_semantic_prediction, save_dir, - _PREDICTION_FORMAT % (image_id_offset + i), add_colormap=True, - colormap_type=FLAGS.colormap_type) - - if FLAGS.also_save_raw_predictions: - image_filename = os.path.basename(image_names[i]) - - if train_id_to_eval_id is not None: - crop_semantic_prediction = _convert_train_id_to_eval_id( - crop_semantic_prediction, - train_id_to_eval_id) - save_annotation.save_annotation( - crop_semantic_prediction, raw_save_dir, image_filename, - add_colormap=False) - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - - # Get dataset-dependent information. - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.vis_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=FLAGS.vis_batch_size, - crop_size=[int(sz) for sz in FLAGS.vis_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - model_variant=FLAGS.model_variant, - is_training=False, - should_shuffle=False, - should_repeat=False) - - train_id_to_eval_id = None - if dataset.dataset_name == data_generator.get_cityscapes_dataset_name(): - tf.logging.info('Cityscapes requires converting train_id to eval_id.') - train_id_to_eval_id = _CITYSCAPES_TRAIN_ID_TO_EVAL_ID - - # Prepare for visualization. - tf.gfile.MakeDirs(FLAGS.vis_logdir) - save_dir = os.path.join(FLAGS.vis_logdir, _SEMANTIC_PREDICTION_SAVE_FOLDER) - tf.gfile.MakeDirs(save_dir) - raw_save_dir = os.path.join( - FLAGS.vis_logdir, _RAW_SEMANTIC_PREDICTION_SAVE_FOLDER) - tf.gfile.MakeDirs(raw_save_dir) - - tf.logging.info('Visualizing on %s set', FLAGS.vis_split) - - with tf.Graph().as_default(): - samples = dataset.get_one_shot_iterator().get_next() - - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_of_classes}, - crop_size=[int(sz) for sz in FLAGS.vis_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - if tuple(FLAGS.eval_scales) == (1.0,): - tf.logging.info('Performing single-scale test.') - predictions = model.predict_labels( - samples[common.IMAGE], - model_options=model_options, - image_pyramid=FLAGS.image_pyramid) - else: - tf.logging.info('Performing multi-scale test.') - if FLAGS.quantize_delay_step >= 0: - raise ValueError( - 'Quantize mode is not supported with multi-scale test.') - predictions = model.predict_labels_multi_scale( - samples[common.IMAGE], - model_options=model_options, - eval_scales=FLAGS.eval_scales, - add_flipped_images=FLAGS.add_flipped_images) - predictions = predictions[common.OUTPUT_TYPE] - - if FLAGS.min_resize_value and FLAGS.max_resize_value: - # Only support batch_size = 1, since we assume the dimensions of original - # image after tf.squeeze is [height, width, 3]. - assert FLAGS.vis_batch_size == 1 - - # Reverse the resizing and padding operations performed in preprocessing. - # First, we slice the valid regions (i.e., remove padded region) and then - # we resize the predictions back. - original_image = tf.squeeze(samples[common.ORIGINAL_IMAGE]) - original_image_shape = tf.shape(original_image) - predictions = tf.slice( - predictions, - [0, 0, 0], - [1, original_image_shape[0], original_image_shape[1]]) - resized_shape = tf.to_int32([tf.squeeze(samples[common.HEIGHT]), - tf.squeeze(samples[common.WIDTH])]) - predictions = tf.squeeze( - tf.image.resize_images(tf.expand_dims(predictions, 3), - resized_shape, - method=tf.image.ResizeMethod.NEAREST_NEIGHBOR, - align_corners=True), 3) - - tf.train.get_or_create_global_step() - if FLAGS.quantize_delay_step >= 0: - contrib_quantize.create_eval_graph() - - num_iteration = 0 - max_num_iteration = FLAGS.max_number_of_iterations - - checkpoints_iterator = contrib_training.checkpoints_iterator( - FLAGS.checkpoint_dir, min_interval_secs=FLAGS.eval_interval_secs) - for checkpoint_path in checkpoints_iterator: - num_iteration += 1 - tf.logging.info( - 'Starting visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', - time.gmtime())) - tf.logging.info('Visualizing with model %s', checkpoint_path) - - scaffold = tf.train.Scaffold(init_op=tf.global_variables_initializer()) - session_creator = tf.train.ChiefSessionCreator( - scaffold=scaffold, - master=FLAGS.master, - checkpoint_filename_with_path=checkpoint_path) - with tf.train.MonitoredSession( - session_creator=session_creator, hooks=None) as sess: - batch = 0 - image_id_offset = 0 - - while not sess.should_stop(): - tf.logging.info('Visualizing batch %d', batch + 1) - _process_batch(sess=sess, - original_images=samples[common.ORIGINAL_IMAGE], - semantic_predictions=predictions, - image_names=samples[common.IMAGE_NAME], - image_heights=samples[common.HEIGHT], - image_widths=samples[common.WIDTH], - image_id_offset=image_id_offset, - save_dir=save_dir, - raw_save_dir=raw_save_dir, - train_id_to_eval_id=train_id_to_eval_id) - image_id_offset += FLAGS.vis_batch_size - batch += 1 - - tf.logging.info( - 'Finished visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', - time.gmtime())) - if max_num_iteration > 0 and num_iteration >= max_num_iteration: - break - -if __name__ == '__main__': - flags.mark_flag_as_required('checkpoint_dir') - flags.mark_flag_as_required('vis_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/delf/.gitignore b/research/delf/.gitignore deleted file mode 100644 index b61ddd100012ab30e0bf438f3a5ab01ea3f44281..0000000000000000000000000000000000000000 --- a/research/delf/.gitignore +++ /dev/null @@ -1,4 +0,0 @@ -*pyc -*~ -*pb2.py -*pb2.pyc diff --git a/research/delf/DETECTION.md b/research/delf/DETECTION.md deleted file mode 100644 index 7fa7570f74dc58622151bee37f9a2a5697b896de..0000000000000000000000000000000000000000 --- a/research/delf/DETECTION.md +++ /dev/null @@ -1,69 +0,0 @@ -## Quick start: landmark detection - -[](https://arxiv.org/abs/1812.01584) - -### Install DELF library - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -### Download Oxford buildings dataset - -To illustrate detector usage, please download the Oxford buildings dataset, by -following the instructions -[here](EXTRACTION_MATCHING.md#download-oxford-buildings-dataset). Then, create -the file `list_images_detector.txt` as follows: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -echo data/oxford5k_images/all_souls_000002.jpg >> list_images_detector.txt -echo data/oxford5k_images/all_souls_000035.jpg >> list_images_detector.txt -``` - -### Download detector model - -Also, you will need to download the pre-trained detector model: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir parameters && cd parameters -wget http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz -tar -xvzf d2r_frcnn_20190411.tar.gz -``` - -**Note**: this is the Faster-RCNN based model. We also release a MobileNet-SSD -model, see the [README](README.md#pre-trained-models) for download link. The -instructions should work seamlessly for both models. - -### Detecting landmarks - -Now that you have everything in place, running this command should detect boxes -for the images `all_souls_000002.jpg` and `all_souls_000035.jpg`, with a -threshold of 0.8, and produce visualizations. - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -python3 extract_boxes.py \ - --detector_path parameters/d2r_frcnn_20190411 \ - --detector_thresh 0.8 \ - --list_images_path list_images_detector.txt \ - --output_dir data/oxford5k_boxes \ - --output_viz_dir data/oxford5k_boxes_viz -``` - -Two images are generated in the `data/oxford5k_boxes_viz` directory, they should -look similar to these ones: - - - - -### Troubleshooting - -#### `matplotlib` - -`matplotlib` may complain with a message such as `no display name and no -$DISPLAY environment variable`. To fix this, one option is add the line -`backend : Agg` to the file `.config/matplotlib/matplotlibrc`. On this problem, -see the discussion -[here](https://stackoverflow.com/questions/37604289/tkinter-tclerror-no-display-name-and-no-display-environment-variable). diff --git a/research/delf/EXTRACTION_MATCHING.md b/research/delf/EXTRACTION_MATCHING.md deleted file mode 100644 index 53159638587282658129aa13ac165fbd7d3803ea..0000000000000000000000000000000000000000 --- a/research/delf/EXTRACTION_MATCHING.md +++ /dev/null @@ -1,87 +0,0 @@ -## Quick start: DELF extraction and matching - -[](https://arxiv.org/abs/1612.06321) - -### Install DELF library - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -### Download Oxford buildings dataset - -To illustrate DELF usage, please download the Oxford buildings dataset. To -follow these instructions closely, please download the dataset to the -`tensorflow/models/research/delf/delf/python/examples` directory, as in the -following commands: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir data && cd data -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images oxford5k_features -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ -cd ../ -echo data/oxford5k_images/hertford_000056.jpg >> list_images.txt -echo data/oxford5k_images/oxford_000317.jpg >> list_images.txt -``` - -### Download pre-trained DELF model - -Also, you will need to download the trained DELF model: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir parameters && cd parameters -wget http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz -tar -xvzf delf_gld_20190411.tar.gz -``` - -### DELF feature extraction - -Now that you have everything in place, running this command should extract DELF -features for the images `hertford_000056.jpg` and `oxford_000317.jpg`: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -python3 extract_features.py \ - --config_path delf_config_example.pbtxt \ - --list_images_path list_images.txt \ - --output_dir data/oxford5k_features -``` - -### Image matching using DELF features - -After feature extraction, run this command to perform feature matching between -the images `hertford_000056.jpg` and `oxford_000317.jpg`: - -```bash -python3 match_images.py \ - --image_1_path data/oxford5k_images/hertford_000056.jpg \ - --image_2_path data/oxford5k_images/oxford_000317.jpg \ - --features_1_path data/oxford5k_features/hertford_000056.delf \ - --features_2_path data/oxford5k_features/oxford_000317.delf \ - --output_image matched_images.png -``` - -The image `matched_images.png` is generated and should look similar to this one: - - - -### Troubleshooting - -#### `matplotlib` - -`matplotlib` may complain with a message such as `no display name and no -$DISPLAY environment variable`. To fix this, one option is add the line -`backend : Agg` to the file `.config/matplotlib/matplotlibrc`. On this problem, -see the discussion -[here](https://stackoverflow.com/questions/37604289/tkinter-tclerror-no-display-name-and-no-display-environment-variable). - -#### 'skimage' - -By default, skimage 0.13.XX or 0.14.1 is installed if you followed the -instructions. According to -[https://github.com/scikit-image/scikit-image/issues/3649#issuecomment-455273659] -If you have scikit-image related issues, upgrading to a version above 0.14.1 -with `pip3 install -U scikit-image` should fix the issue diff --git a/research/delf/INSTALL_INSTRUCTIONS.md b/research/delf/INSTALL_INSTRUCTIONS.md deleted file mode 100644 index 4f66e9389fdd126dd769a8282a69482b989c9c9e..0000000000000000000000000000000000000000 --- a/research/delf/INSTALL_INSTRUCTIONS.md +++ /dev/null @@ -1,122 +0,0 @@ -## DELF installation - -### Tensorflow - -[](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0) -[](https://www.python.org/downloads/release/python-360/) - -For detailed steps to install Tensorflow, follow the -[Tensorflow installation instructions](https://www.tensorflow.org/install/). A -typical user can install Tensorflow using one of the following commands: - -```bash -# For CPU: -pip3 install 'tensorflow' -# For GPU: -pip3 install 'tensorflow-gpu' -``` - -### TF-Slim - -Note: currently, we need to install the latest version from source, to avoid -using previous versions which relied on tf.contrib (which is now deprecated). - -```bash -git clone git@github.com:google-research/tf-slim.git -cd tf-slim -pip3 install . -``` - -Note that these commands assume you are cloning using SSH. If you are using -HTTPS instead, use `git clone https://github.com/google-research/tf-slim.git` -instead. See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. - -### Protobuf - -The DELF library uses [protobuf](https://github.com/google/protobuf) (the python -version) to configure feature extraction and its format. You will need the -`protoc` compiler, version >= 3.3. The easiest way to get it is to download -directly. For Linux, this can be done as (see -[here](https://github.com/google/protobuf/releases) for other platforms): - -```bash -wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip -unzip protoc-3.3.0-linux-x86_64.zip -PATH_TO_PROTOC=`pwd` -``` - -### Python dependencies - -Install python library dependencies: - -```bash -pip3 install matplotlib numpy scikit-image scipy -sudo apt-get install python3-tk -``` - -### `tensorflow/models` - -Now, clone `tensorflow/models`, and install required libraries: (note that the -`object_detection` library requires you to add `tensorflow/models/research/` to -your `PYTHONPATH`, as instructed -[here](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md)) - -```bash -git clone git@github.com:tensorflow/models.git - -# Setup the object_detection module by editing PYTHONPATH. -cd .. -# From tensorflow/models/research/ -export PYTHONPATH=$PYTHONPATH:`pwd` -``` - -Note that these commands assume you are cloning using SSH. If you are using -HTTPS instead, use `git clone https://github.com/tensorflow/models.git` instead. -See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. - -Then, compile DELF's protobufs. Use `PATH_TO_PROTOC` as the directory where you -downloaded the `protoc` compiler. - -```bash -# From tensorflow/models/research/delf/ -${PATH_TO_PROTOC?}/bin/protoc delf/protos/*.proto --python_out=. -``` - -Finally, install the DELF package. This may also install some other dependencies -under the hood. - -```bash -# From tensorflow/models/research/delf/ -pip3 install -e . # Install "delf" package. -``` - -At this point, running - -```bash -python3 -c 'import delf' -``` - -should just return without complaints. This indicates that the DELF package is -loaded successfully. - -### Troubleshooting - -#### `pip3 install` - -Issues might be observed if using `pip3 install` with `-e` option (editable -mode). You may try out to simply remove the `-e` from the commands above. Also, -depending on your machine setup, you might need to run the `sudo pip3 install` -command, that is with a `sudo` at the beginning. - -#### Cloning github repositories - -The default commands above assume you are cloning using SSH. If you are using -HTTPS instead, use for example `git clone -https://github.com/tensorflow/models.git` instead of `git clone -git@github.com:tensorflow/models.git`. See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. diff --git a/research/delf/README.md b/research/delf/README.md deleted file mode 100644 index f10852759c3455ae2990475ea917a4e45ee96264..0000000000000000000000000000000000000000 --- a/research/delf/README.md +++ /dev/null @@ -1,324 +0,0 @@ -# Deep Local and Global Image Features - -[](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0) -[](https://www.python.org/downloads/release/python-360/) - -This project presents code for deep local and global image feature methods, -which are particularly useful for the computer vision tasks of instance-level -recognition and retrieval. These were introduced in the -[DELF](https://arxiv.org/abs/1612.06321), -[Detect-to-Retrieve](https://arxiv.org/abs/1812.01584), -[DELG](https://arxiv.org/abs/2001.05027) and -[Google Landmarks Dataset v2](https://arxiv.org/abs/2004.01804) papers. - -We provide Tensorflow code for building and training models, and python code for -image retrieval and local feature matching. Pre-trained models for the landmark -recognition domain are also provided. - -If you make use of this codebase, please consider citing the following papers: - -DELF: -[](https://arxiv.org/abs/1612.06321) - -``` -"Large-Scale Image Retrieval with Attentive Deep Local Features", -H. Noh, A. Araujo, J. Sim, T. Weyand and B. Han, -Proc. ICCV'17 -``` - -Detect-to-Retrieve: -[](https://arxiv.org/abs/1812.01584) - -``` -"Detect-to-Retrieve: Efficient Regional Aggregation for Image Search", -M. Teichmann*, A. Araujo*, M. Zhu and J. Sim, -Proc. CVPR'19 -``` - -DELG: -[](https://arxiv.org/abs/2001.05027) - -``` -"Unifying Deep Local and Global Features for Image Search", -B. Cao*, A. Araujo* and J. Sim, -arxiv:2001.05027 -``` - -GLDv2: -[](https://arxiv.org/abs/2004.01804) - -``` -"Google Landmarks Dataset v2 - A Large-Scale Benchmark for Instance-Level Recognition and Retrieval", -T. Weyand*, A. Araujo*, B. Cao and J. Sim, -Proc. CVPR'20 -``` - -## News - -- [Apr'20] Check out our CVPR'20 paper: ["Google Landmarks Dataset v2 - A - Large-Scale Benchmark for Instance-Level Recognition and - Retrieval"](https://arxiv.org/abs/2004.01804) -- [Jan'20] Check out our new paper: - ["Unifying Deep Local and Global Features for Image Search"](https://arxiv.org/abs/2001.05027) -- [Jun'19] DELF achieved 2nd place in - [CVPR Visual Localization challenge (Local Features track)](https://sites.google.com/corp/view/ltvl2019). - See our slides - [here](https://docs.google.com/presentation/d/e/2PACX-1vTswzoXelqFqI_pCEIVl2uazeyGr7aKNklWHQCX-CbQ7MB17gaycqIaDTguuUCRm6_lXHwCdrkP7n1x/pub?start=false&loop=false&delayms=3000). -- [Apr'19] Check out our CVPR'19 paper: - ["Detect-to-Retrieve: Efficient Regional Aggregation for Image Search"](https://arxiv.org/abs/1812.01584) -- [Jun'18] DELF achieved state-of-the-art results in a CVPR'18 image retrieval - paper: [Radenovic et al., "Revisiting Oxford and Paris: Large-Scale Image - Retrieval Benchmarking"](https://arxiv.org/abs/1803.11285). -- [Apr'18] DELF was featured in - [ModelDepot](https://modeldepot.io/mikeshi/delf/overview) -- [Mar'18] DELF is now available in - [TF-Hub](https://www.tensorflow.org/hub/modules/google/delf/1) - -## Datasets - -We have two Google-Landmarks dataset versions: - -- Initial version (v1) can be found - [here](https://www.kaggle.com/google/google-landmarks-dataset). In includes - the Google Landmark Boxes which were described in the Detect-to-Retrieve - paper. -- Second version (v2) has been released as part of two Kaggle challenges: - [Landmark Recognition](https://www.kaggle.com/c/landmark-recognition-2019) - and [Landmark Retrieval](https://www.kaggle.com/c/landmark-retrieval-2019). - It can be downloaded from CVDF - [here](https://github.com/cvdfoundation/google-landmark). See also - [the CVPR'20 paper](https://arxiv.org/abs/2004.01804) on this new dataset - version. - -If you make use of these datasets in your research, please consider citing the -papers mentioned above. - -## Installation - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -## Quick start - -### Pre-trained models - -We release several pre-trained models. See instructions in the following -sections for examples on how to use the models. - -**DELF pre-trained on the Google-Landmarks dataset v1** -([link](http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz)). Presented -in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). Boosts -performance by ~4% mAP compared to ICCV'17 DELF model. - -**DELG pre-trained on the Google-Landmarks dataset v1** -([link](http://storage.googleapis.com/delf/delg_gld_20200520.tar.gz)). Presented -in the [DELG paper](https://arxiv.org/abs/2001.05027). - -**RN101-ArcFace pre-trained on the Google-Landmarks dataset v2 (train-clean)** -([link](https://storage.googleapis.com/delf/rn101_af_gldv2clean_20200521.tar.gz)). -Presented in the [GLDv2 paper](https://arxiv.org/abs/2004.01804). - -**DELF pre-trained on Landmarks-Clean/Landmarks-Full dataset** -([link](http://storage.googleapis.com/delf/delf_v1_20171026.tar.gz)). Presented -in the [DELF paper](https://arxiv.org/abs/1612.06321), model was trained on the -dataset released by the [DIR paper](https://arxiv.org/abs/1604.01325). - -**Faster-RCNN detector pre-trained on Google Landmark Boxes** -([link](http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz)). -Presented in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). - -**MobileNet-SSD detector pre-trained on Google Landmark Boxes** -([link](http://storage.googleapis.com/delf/d2r_mnetssd_20190411.tar.gz)). -Presented in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). - -Besides these, we also release pre-trained codebooks for local feature -aggregation. See the -[Detect-to-Retrieve instructions](delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md) -for details. - -### DELF extraction and matching - -Please follow [these instructions](EXTRACTION_MATCHING.md). At the end, you -should obtain a nice figure showing local feature matches, as: - - - -### DELF training - -Please follow [these instructions](delf/python/training/README.md). - -### DELG - -Please follow [these instructions](delf/python/delg/DELG_INSTRUCTIONS.md). At -the end, you should obtain image retrieval results on the Revisited Oxford/Paris -datasets. - -### GLDv2 baseline - -Please follow -[these instructions](delf/python/google_landmarks_dataset/README.md). At the -end, you should obtain image retrieval results on the Revisited Oxford/Paris -datasets. - -### Landmark detection - -Please follow [these instructions](DETECTION.md). At the end, you should obtain -a nice figure showing a detection, as: - - - -### Detect-to-Retrieve - -Please follow -[these instructions](delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md). -At the end, you should obtain image retrieval results on the Revisited -Oxford/Paris datasets. - -## Code overview - -DELF/D2R/DELG/GLD code is located under the `delf` directory. There are two -directories therein, `protos` and `python`. - -### `delf/protos` - -This directory contains protobufs: - -- `aggregation_config.proto`: protobuf for configuring local feature - aggregation. -- `box.proto`: protobuf for serializing detected boxes. -- `datum.proto`: general-purpose protobuf for serializing float tensors. -- `delf_config.proto`: protobuf for configuring DELF/DELG extraction. -- `feature.proto`: protobuf for serializing DELF features. - -### `delf/python` - -This directory contains files for several different purposes: - -- `box_io.py`, `datum_io.py`, `feature_io.py` are helper files for reading and - writing tensors and features. -- `delf_v1.py` contains code to create DELF models. -- `feature_aggregation_extractor.py` contains a module to perform local - feature aggregation. -- `feature_aggregation_similarity.py` contains a module to perform similarity - computation for aggregated local features. -- `feature_extractor.py` contains the code to extract features using DELF. - This is particularly useful for extracting features over multiple scales, - with keypoint selection based on attention scores, and PCA/whitening - post-processing. - -The subdirectory `delf/python/examples` contains sample scripts to run DELF -feature extraction/matching, and object detection: - -- `delf_config_example.pbtxt` shows an example instantiation of the DelfConfig - proto, used for DELF feature extraction. -- `detector.py` is a module to construct an object detector function. -- `extract_boxes.py` enables object detection from a list of images. -- `extract_features.py` enables DELF extraction from a list of images. -- `extractor.py` is a module to construct a DELF/DELG local feature extraction - function. -- `match_images.py` supports image matching using DELF features extracted - using `extract_features.py`. - -The subdirectory `delf/python/delg` contains sample scripts/configs related to -the DELG paper: - -- `delg_gld_config.pbtxt` gives the DelfConfig used in DELG paper. -- `extract_features.py` for local+global feature extraction on Revisited - datasets. -- `perform_retrieval.py` for performing retrieval/evaluating methods on - Revisited datasets. - -The subdirectory `delf/python/detect_to_retrieve` contains sample -scripts/configs related to the Detect-to-Retrieve paper: - -- `aggregation_extraction.py` is a library to extract/save feature - aggregation. -- `boxes_and_features_extraction.py` is a library to extract/save boxes and - DELF features. -- `cluster_delf_features.py` for local feature clustering. -- `dataset.py` for parsing/evaluating results on Revisited Oxford/Paris - datasets. -- `delf_gld_config.pbtxt` gives the DelfConfig used in Detect-to-Retrieve - paper. -- `extract_aggregation.py` for aggregated local feature extraction. -- `extract_index_boxes_and_features.py` for index image local feature - extraction / bounding box detection on Revisited datasets. -- `extract_query_features.py` for query image local feature extraction on - Revisited datasets. -- `image_reranking.py` is a module to re-rank images with geometric - verification. -- `perform_retrieval.py` for performing retrieval/evaluating methods using - aggregated local features on Revisited datasets. -- `index_aggregation_config.pbtxt`, `query_aggregation_config.pbtxt` give - AggregationConfig's for Detect-to-Retrieve experiments. - -The subdirectory `delf/python/google_landmarks_dataset` contains sample -scripts/modules for computing GLD metrics / reproducing results from the GLDv2 -paper: - -- `compute_recognition_metrics.py` performs recognition metric computation - given input predictions and solution files. -- `compute_retrieval_metrics.py` performs retrieval metric computation given - input predictions and solution files. -- `dataset_file_io.py` is a module for dataset-related file IO. -- `metrics.py` is a module for GLD metric computation. -- `rn101_af_gldv2clean_config.pbtxt` gives the DelfConfig used in the - ResNet101-ArcFace (trained on GLDv2-train-clean) baseline used in the GLDv2 - paper. - -The subdirectory `delf/python/training` contains sample scripts/modules for -performing DELF training: - -- `datasets/googlelandmarks.py` is the dataset module used for training. -- `model/delf_model.py` is the model module used for training. -- `model/export_model.py` is a script for exporting trained models in the - format used by the inference code. -- `model/export_model_utils.py` is a module with utilities for model - exporting. -- `model/resnet50.py` is a module with a backbone RN50 implementation. -- `build_image_dataset.py` converts downloaded dataset into TFRecords format - for training. -- `train.py` is the main training script. - -Besides these, other files in the different subdirectories contain tests for the -various modules. - -## Maintainers - -André Araujo (@andrefaraujo) - -## Release history - -### May, 2020 - -- Codebase is now Python3-first -- DELG model/code released -- GLDv2 baseline model released - -**Thanks to contributors**: Barbara Fusinska and André Araujo. - -### April, 2020 (version 2.0) - -- Initial DELF training code released. -- Codebase is now fully compatible with TF 2.1. - -**Thanks to contributors**: Arun Mukundan, Yuewei Na and André Araujo. - -### April, 2019 - -Detect-to-Retrieve code released. - -Includes pre-trained models to detect landmark boxes, and DELF model pre-trained -on Google Landmarks v1 dataset. - -**Thanks to contributors**: André Araujo, Marvin Teichmann, Menglong Zhu, -Jack Sim. - -### October, 2017 - -Initial release containing DELF-v1 code, including feature extraction and -matching examples. Pre-trained DELF model from ICCV'17 paper is released. - -**Thanks to contributors**: André Araujo, Hyeonwoo Noh, Youlong Cheng, -Jack Sim. diff --git a/research/delf/delf/__init__.py b/research/delf/delf/__init__.py deleted file mode 100644 index a52df3c4546414e61f479357d06b65d4c132c753..0000000000000000000000000000000000000000 --- a/research/delf/delf/__init__.py +++ /dev/null @@ -1,39 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Module to extract deep local features.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import -from delf.protos import aggregation_config_pb2 -from delf.protos import box_pb2 -from delf.protos import datum_pb2 -from delf.protos import delf_config_pb2 -from delf.protos import feature_pb2 -from delf.python import box_io -from delf.python import datum_io -from delf.python import feature_aggregation_extractor -from delf.python import feature_aggregation_similarity -from delf.python import feature_extractor -from delf.python import feature_io -from delf.python import utils -from delf.python.examples import detector -from delf.python.examples import extractor -from delf.python import detect_to_retrieve -from delf.python import training -from delf.python.training import model -from delf.python.training import datasets -# pylint: enable=unused-import diff --git a/research/delf/delf/protos/__init__.py b/research/delf/delf/protos/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/delf/delf/protos/aggregation_config.proto b/research/delf/delf/protos/aggregation_config.proto deleted file mode 100644 index b1d5953d43ffc84f435c57be7145c7c17ae01186..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/aggregation_config.proto +++ /dev/null @@ -1,63 +0,0 @@ -// Protocol buffer for feature aggregation configuration. -// -// Used for both extraction and comparison of aggregated representations. Note -// that some options are only relevant for the former or the latter. -// -// For more details, please refer to the paper: -// "Detect-to-Retrieve: Efficient Regional Aggregation for Image Search", -// Proc. CVPR'19 (https://arxiv.org/abs/1812.01584). - -syntax = "proto2"; - -package delf.protos; - -message AggregationConfig { - // Number of codewords (ie, visual words) in the codebook. - optional int32 codebook_size = 1 [default = 65536]; - - // Dimensionality of local features (eg, 128 for DELF used in - // Detect-to-Retrieve paper). - optional int32 feature_dimensionality = 2 [default = 128]; - - // Type of aggregation to use. - // For example, to use R-ASMK*, `aggregation_type` should be set to ASMK_STAR - // and `use_regional_aggregation` should be set to true. - enum AggregationType { - INVALID = 0; - VLAD = 1; - ASMK = 2; - ASMK_STAR = 3; - } - optional AggregationType aggregation_type = 3 [default = ASMK_STAR]; - - // L2 normalization option. - // - For vanilla aggregated kernels (eg, VLAD/ASMK/ASMK*), this should be - // set to true. - // - For regional aggregated kernels (ie, if `use_regional_aggregation` is - // true, leading to R-VLAD/R-ASMK/R-ASMK*), this should be set to false. - // Note that it is used differently depending on the `aggregation_type`: - // - For VLAD, this option is only used for extraction. - // - For ASMK/ASMK*, this option is only used for comparisons. - optional bool use_l2_normalization = 4 [default = true]; - - // Additional options used only for extraction. - // - Path to codebook checkpoint for aggregation. - optional string codebook_path = 5; - // - Number of visual words to assign each feature. - optional int32 num_assignments = 6 [default = 1]; - // - Whether to use regional aggregation. - optional bool use_regional_aggregation = 7 [default = false]; - // - Batch size to use for local features when computing aggregated - // representations. Particularly useful if `codebook_size` and - // `feature_dimensionality` are large, to avoid OOM. A value of zero or - // lower indicates that no batching is used. - optional int32 feature_batch_size = 10 [default = 100]; - - // Additional options used only for comparison. - // Only relevant if `aggregation_type` is ASMK or ASMK_STAR. - // - Power-law exponent for similarity of visual word descriptors. - optional float alpha = 8 [default = 3.0]; - // - Threshold above which similarity of visual word descriptors are - // considered; below this, similarity is set to zero. - optional float tau = 9 [default = 0.0]; -} diff --git a/research/delf/delf/protos/box.proto b/research/delf/delf/protos/box.proto deleted file mode 100644 index 28da7fb71410262f9be98e206e756c82ba3beb38..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/box.proto +++ /dev/null @@ -1,24 +0,0 @@ -// Protocol buffer for serializing detected bounding boxes. - -syntax = "proto2"; - -package delf.protos; - -message Box { - // Coordinates: [ymin, xmin, ymax, xmax] corresponds to - // [top, left, bottom, right]. - optional float ymin = 1; - optional float xmin = 2; - optional float ymax = 3; - optional float xmax = 4; - - // Detection score. Usually, the higher the more confident. - optional float score = 5; - - // Indicates which class the box corresponds to. - optional int32 class_index = 6; -} - -message Boxes { - repeated Box box = 1; -} diff --git a/research/delf/delf/protos/datum.proto b/research/delf/delf/protos/datum.proto deleted file mode 100644 index 6806e56b25e912bfb6a87280432c8566dba0c41a..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/datum.proto +++ /dev/null @@ -1,66 +0,0 @@ -// Protocol buffer for serializing arbitrary float tensors. -// Note: Currently only floating point feature is supported. - -syntax = "proto2"; - -package delf.protos; - -// A DatumProto is a data structure used to serialize tensor with arbitrary -// shape. DatumProto contains an array of floating point values and its shape -// is represented as a sequence of integer values. Values are contained in -// row major order. -// -// Example: -// 3 x 2 array -// -// [1.1, 2.2] -// [3.3, 4.4] -// [5.5, 6.6] -// -// can be represented with the following DatumProto: -// -// DatumProto { -// shape { -// dim: 3 -// dim: 2 -// } -// float_list { -// value: 1.1 -// value: 2.2 -// value: 3.3 -// value: 4.4 -// value: 5.5 -// value: 6.6 -// } -// } - -// DatumShape is array of dimension of the tensor. -message DatumShape { - repeated int64 dim = 1 [packed = true]; -} - -// FloatList is a container of tensor values, which are saved as a list of -// floating point values. -message FloatList { - repeated float value = 1 [packed = true]; -} - -// Uint32List is a container of tensor values, which are saved as a list of -// uint32 values. -message Uint32List { - repeated uint32 value = 1 [packed = true]; -} - -message DatumProto { - optional DatumShape shape = 1; - oneof kind_oneof { - FloatList float_list = 2; - Uint32List uint32_list = 3; - } -} - -// Groups two DatumProto's. -message DatumPairProto { - optional DatumProto first = 1; - optional DatumProto second = 2; -} diff --git a/research/delf/delf/protos/delf_config.proto b/research/delf/delf/protos/delf_config.proto deleted file mode 100644 index 10ae0a614cbdd483f08f1f9f806a9d3adbe6b46d..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/delf_config.proto +++ /dev/null @@ -1,121 +0,0 @@ -// Protocol buffer for configuring DELF feature extraction. - -syntax = "proto2"; - -package delf.protos; - -message DelfPcaParameters { - // Path to PCA mean file. - optional string mean_path = 1; // Required. - - // Path to PCA matrix file. - optional string projection_matrix_path = 2; // Required. - - // Dimensionality of feature after PCA. - optional int32 pca_dim = 3; // Required. - - // If whitening is to be used, this must be set to true. - optional bool use_whitening = 4 [default = false]; - - // Path to PCA variances file, used for whitening. This is used only if - // use_whitening is set to true. - optional string pca_variances_path = 5; -} - -message DelfLocalFeatureConfig { - // If PCA is to be used, this must be set to true. - optional bool use_pca = 1 [default = true]; - - // Target layer name for DELF model. This is used to obtain receptive field - // parameters used for localizing features with respect to the input image. - optional string layer_name = 2 [default = ""]; - - // Intersection over union threshold for the non-max suppression (NMS) - // operation. If two features overlap by at most this amount, both are kept. - // Otherwise, the one with largest attention score is kept. This should be a - // number between 0.0 (no region is selected) and 1.0 (all regions are - // selected and NMS is not performed). - optional float iou_threshold = 3 [default = 1.0]; - - // Maximum number of features that will be selected. The features with largest - // scores (eg, largest attention score if score_type is "Att") are the - // selected ones. - optional int32 max_feature_num = 4 [default = 1000]; - - // Threshold to be used for feature selection: no feature with score lower - // than this number will be selected). - optional float score_threshold = 5 [default = 100.0]; - - // PCA parameters for DELF local feature. This is used only if use_pca is - // true. - optional DelfPcaParameters pca_parameters = 6; -} - -message DelfGlobalFeatureConfig { - // If PCA is to be used, this must be set to true. - optional bool use_pca = 1 [default = true]; - - // PCA parameters for DELF global feature. This is used only if use_pca is - // true. - optional DelfPcaParameters pca_parameters = 2; - - // Denotes indices of DelfConfig's scales that will be used for global - // descriptor extraction. For example, if DelfConfig's image_scales are - // [0.25, 0.5, 1.0] and image_scales_ind is [0, 2], global descriptor - // extraction will use solely scales [0.25, 1.0]. Note that local feature - // extraction will still use [0.25, 0.5, 1.0] in this case. If empty (default) - // , all scales are used. - repeated int32 image_scales_ind = 3; -} - -message DelfConfig { - // Whether to extract local features when using the model. - // At least one of {use_local_features, use_global_features} must be true. - optional bool use_local_features = 7 [default = true]; - // Configuration used for local features. Note: this is used only if - // use_local_features is true. - optional DelfLocalFeatureConfig delf_local_config = 3; - - // Whether to extract global features when using the model. - // At least one of {use_local_features, use_global_features} must be true. - optional bool use_global_features = 8 [default = false]; - // Configuration used for global features. Note: this is used only if - // use_global_features is true. - optional DelfGlobalFeatureConfig delf_global_config = 9; - - // Path to DELF model. - optional string model_path = 1; // Required. - - // Image scales to be used. - repeated float image_scales = 2; - - // Image resizing options. - // - The maximum/minimum image size (in terms of height or width) to be used - // when extracting DELF features. If set to -1 (default), no upper/lower - // bound for image size. If use_square_images option is false (default): - // * If the height *OR* width is larger than max_image_size, it will be - // resized to max_image_size, and the other dimension will be resized by - // preserving the aspect ratio. - // * If both height *AND* width are smaller than min_image_size, the larger - // side is set to min_image_size. - // - If use_square_images option is true, it needs to be resized to square - // resolution. To be more specific: - // * If the height *OR* width is larger than max_image_size, it is resized - // to square resolution of max_image_size. - // * If both height *AND* width are smaller than min_image_size, it is - // resized to square resolution of min_image_size. - // * Else, if the input image's resolution is not square, it is resized to - // square resolution of the larger side. - // Image resizing is useful when we want to ensure that the input to the image - // pyramid has a reasonable number of pixels, which could have large impact in - // terms of image matching performance. - // When using local features, note that the feature locations and scales will - // be consistent with the original image input size. - // Note that when both max_image_size and min_image_size are specified - // (which is a valid and legit use case), as long as max_image_size >= - // min_image_size, there's no conflicting scenario (i.e. never triggers both - // enlarging / shrinking). Bilinear interpolation is used. - optional int32 max_image_size = 4 [default = -1]; - optional int32 min_image_size = 5 [default = -1]; - optional bool use_square_images = 6 [default = false]; -} diff --git a/research/delf/delf/protos/feature.proto b/research/delf/delf/protos/feature.proto deleted file mode 100644 index 64c342fe2c36b9170de10628b8ddc83ee3cfb2c6..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/feature.proto +++ /dev/null @@ -1,22 +0,0 @@ -// Protocol buffer for serializing the DELF feature information. - -syntax = "proto2"; - -package delf.protos; - -import "delf/protos/datum.proto"; - -// FloatList is the container of tensor values. The tensor values are saved as -// a list of floating point values. -message DelfFeature { - optional DatumProto descriptor = 1; - optional float x = 2; - optional float y = 3; - optional float scale = 4; - optional float orientation = 5; - optional float strength = 6; -} - -message DelfFeatures { - repeated DelfFeature feature = 1; -} diff --git a/research/delf/delf/python/__init__.py b/research/delf/delf/python/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/delf/delf/python/box_io.py b/research/delf/delf/python/box_io.py deleted file mode 100644 index 8b0f0d2c973d5b83f9110f651f5c5541fad049b7..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/box_io.py +++ /dev/null @@ -1,151 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Python interface for Boxes proto. - -Support read and write of Boxes from/to numpy arrays and file. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from delf import box_pb2 - - -def ArraysToBoxes(boxes, scores, class_indices): - """Converts `boxes` to Boxes proto. - - Args: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - - Returns: - boxes_proto: Boxes object. - """ - num_boxes = len(scores) - assert num_boxes == boxes.shape[0] - assert num_boxes == len(class_indices) - - boxes_proto = box_pb2.Boxes() - for i in range(num_boxes): - boxes_proto.box.add( - ymin=boxes[i, 0], - xmin=boxes[i, 1], - ymax=boxes[i, 2], - xmax=boxes[i, 3], - score=scores[i], - class_index=class_indices[i]) - - return boxes_proto - - -def BoxesToArrays(boxes_proto): - """Converts data saved in Boxes proto to numpy arrays. - - If there are no boxes, the function returns three empty arrays. - - Args: - boxes_proto: Boxes proto object. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - num_boxes = len(boxes_proto.box) - if num_boxes == 0: - return np.array([]), np.array([]), np.array([]) - - boxes = np.zeros([num_boxes, 4]) - scores = np.zeros([num_boxes]) - class_indices = np.zeros([num_boxes]) - - for i in range(num_boxes): - box_proto = boxes_proto.box[i] - boxes[i] = [box_proto.ymin, box_proto.xmin, box_proto.ymax, box_proto.xmax] - scores[i] = box_proto.score - class_indices[i] = box_proto.class_index - - return boxes, scores, class_indices - - -def SerializeToString(boxes, scores, class_indices): - """Converts numpy arrays to serialized Boxes. - - Args: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - - Returns: - Serialized Boxes string. - """ - boxes_proto = ArraysToBoxes(boxes, scores, class_indices) - return boxes_proto.SerializeToString() - - -def ParseFromString(string): - """Converts serialized Boxes proto string to numpy arrays. - - Args: - string: Serialized Boxes string. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - boxes_proto = box_pb2.Boxes() - boxes_proto.ParseFromString(string) - return BoxesToArrays(boxes_proto) - - -def ReadFromFile(file_path): - """Helper function to load data from a Boxes proto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParseFromString(f.read()) - - -def WriteToFile(file_path, boxes, scores, class_indices): - """Helper function to write data to a file in Boxes proto format. - - Args: - file_path: Path to file that will be written. - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - serialized_data = SerializeToString(boxes, scores, class_indices) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) diff --git a/research/delf/delf/python/box_io_test.py b/research/delf/delf/python/box_io_test.py deleted file mode 100644 index c659185daeec7efc9097ff72637d0d8f7c38664b..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/box_io_test.py +++ /dev/null @@ -1,82 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for box_io, the python interface of Boxes proto.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os - -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import box_io - -FLAGS = flags.FLAGS - - -class BoxesIoTest(tf.test.TestCase): - - def _create_data(self): - """Creates data to be used in tests. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format - [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - boxes = np.arange(24, dtype=np.float32).reshape(6, 4) - scores = np.arange(6, dtype=np.float32) - class_indices = np.arange(6, dtype=np.int32) - - return boxes, scores, class_indices - - def testConversionAndBack(self): - boxes, scores, class_indices = self._create_data() - - serialized = box_io.SerializeToString(boxes, scores, class_indices) - parsed_data = box_io.ParseFromString(serialized) - - self.assertAllEqual(boxes, parsed_data[0]) - self.assertAllEqual(scores, parsed_data[1]) - self.assertAllEqual(class_indices, parsed_data[2]) - - def testWriteAndReadToFile(self): - boxes, scores, class_indices = self._create_data() - - filename = os.path.join(FLAGS.test_tmpdir, 'test.boxes') - box_io.WriteToFile(filename, boxes, scores, class_indices) - data_read = box_io.ReadFromFile(filename) - - self.assertAllEqual(boxes, data_read[0]) - self.assertAllEqual(scores, data_read[1]) - self.assertAllEqual(class_indices, data_read[2]) - - def testWriteAndReadToFileEmptyFile(self): - filename = os.path.join(FLAGS.test_tmpdir, 'test.box') - box_io.WriteToFile(filename, np.array([]), np.array([]), np.array([])) - data_read = box_io.ReadFromFile(filename) - - self.assertAllEqual(np.array([]), data_read[0]) - self.assertAllEqual(np.array([]), data_read[1]) - self.assertAllEqual(np.array([]), data_read[2]) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/delf/delf/python/datum_io.py b/research/delf/delf/python/datum_io.py deleted file mode 100644 index f0d4cbfd11a140c6805c1fa017b7328cf3d04e38..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/datum_io.py +++ /dev/null @@ -1,221 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Python interface for DatumProto. - -DatumProto is protocol buffer used to serialize tensor with arbitrary shape. -Please refer to datum.proto for details. - -Support read and write of DatumProto from/to NumPy array and file. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from delf import datum_pb2 - - -def ArrayToDatum(arr): - """Converts NumPy array to DatumProto. - - Supports arrays of types: - - float16 (it is converted into a float32 in DatumProto) - - float32 - - float64 (it is converted into a float32 in DatumProto) - - uint8 (it is converted into a uint32 in DatumProto) - - uint16 (it is converted into a uint32 in DatumProto) - - uint32 - - uint64 (it is converted into a uint32 in DatumProto) - - Args: - arr: NumPy array of arbitrary shape. - - Returns: - datum: DatumProto object. - - Raises: - ValueError: If array type is unsupported. - """ - datum = datum_pb2.DatumProto() - if arr.dtype in ('float16', 'float32', 'float64'): - datum.float_list.value.extend(arr.astype('float32').flat) - elif arr.dtype in ('uint8', 'uint16', 'uint32', 'uint64'): - datum.uint32_list.value.extend(arr.astype('uint32').flat) - else: - raise ValueError('Unsupported array type: %s' % arr.dtype) - - datum.shape.dim.extend(arr.shape) - return datum - - -def ArraysToDatumPair(arr_1, arr_2): - """Converts numpy arrays to DatumPairProto. - - Supports same formats as `ArrayToDatum`, see documentation therein. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - - Returns: - datum_pair: DatumPairProto object. - """ - datum_pair = datum_pb2.DatumPairProto() - datum_pair.first.CopyFrom(ArrayToDatum(arr_1)) - datum_pair.second.CopyFrom(ArrayToDatum(arr_2)) - - return datum_pair - - -def DatumToArray(datum): - """Converts data saved in DatumProto to NumPy array. - - Args: - datum: DatumProto object. - - Returns: - NumPy array of arbitrary shape. - """ - if datum.HasField('float_list'): - return np.array(datum.float_list.value).astype('float32').reshape( - datum.shape.dim) - elif datum.HasField('uint32_list'): - return np.array(datum.uint32_list.value).astype('uint32').reshape( - datum.shape.dim) - else: - raise ValueError('Input DatumProto does not have float_list or uint32_list') - - -def DatumPairToArrays(datum_pair): - """Converts data saved in DatumPairProto to NumPy arrays. - - Args: - datum_pair: DatumPairProto object. - - Returns: - Two NumPy arrays of arbitrary shape. - """ - first_datum = DatumToArray(datum_pair.first) - second_datum = DatumToArray(datum_pair.second) - return first_datum, second_datum - - -def SerializeToString(arr): - """Converts NumPy array to serialized DatumProto. - - Args: - arr: NumPy array of arbitrary shape. - - Returns: - Serialized DatumProto string. - """ - datum = ArrayToDatum(arr) - return datum.SerializeToString() - - -def SerializePairToString(arr_1, arr_2): - """Converts pair of NumPy arrays to serialized DatumPairProto. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - - Returns: - Serialized DatumPairProto string. - """ - datum_pair = ArraysToDatumPair(arr_1, arr_2) - return datum_pair.SerializeToString() - - -def ParseFromString(string): - """Converts serialized DatumProto string to NumPy array. - - Args: - string: Serialized DatumProto string. - - Returns: - NumPy array. - """ - datum = datum_pb2.DatumProto() - datum.ParseFromString(string) - return DatumToArray(datum) - - -def ParsePairFromString(string): - """Converts serialized DatumPairProto string to NumPy arrays. - - Args: - string: Serialized DatumProto string. - - Returns: - Two NumPy arrays. - """ - datum_pair = datum_pb2.DatumPairProto() - datum_pair.ParseFromString(string) - return DatumPairToArrays(datum_pair) - - -def ReadFromFile(file_path): - """Helper function to load data from a DatumProto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - data: NumPy array. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParseFromString(f.read()) - - -def ReadPairFromFile(file_path): - """Helper function to load data from a DatumPairProto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - Two NumPy arrays. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParsePairFromString(f.read()) - - -def WriteToFile(data, file_path): - """Helper function to write data to a file in DatumProto format. - - Args: - data: NumPy array. - file_path: Path to file that will be written. - """ - serialized_data = SerializeToString(data) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) - - -def WritePairToFile(arr_1, arr_2, file_path): - """Helper function to write pair of arrays to a file in DatumPairProto format. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - file_path: Path to file that will be written. - """ - serialized_data = SerializePairToString(arr_1, arr_2) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) diff --git a/research/delf/delf/python/datum_io_test.py b/research/delf/delf/python/datum_io_test.py deleted file mode 100644 index f3587a10017f93af49715a9becc1ed72da8ebe69..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/datum_io_test.py +++ /dev/null @@ -1,97 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for datum_io, the python interface of DatumProto.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os - -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import datum_io - -FLAGS = flags.FLAGS - - -class DatumIoTest(tf.test.TestCase): - - def Conversion2dTestWithType(self, dtype): - original_data = np.arange(9).reshape(3, 3).astype(dtype) - serialized = datum_io.SerializeToString(original_data) - retrieved_data = datum_io.ParseFromString(serialized) - self.assertTrue(np.array_equal(original_data, retrieved_data)) - - def Conversion3dTestWithType(self, dtype): - original_data = np.arange(24).reshape(2, 3, 4).astype(dtype) - serialized = datum_io.SerializeToString(original_data) - retrieved_data = datum_io.ParseFromString(serialized) - self.assertTrue(np.array_equal(original_data, retrieved_data)) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # ParseFromString, DatumToArray. - def testConversion2dWithType(self): - self.Conversion2dTestWithType(np.uint16) - self.Conversion2dTestWithType(np.uint32) - self.Conversion2dTestWithType(np.uint64) - self.Conversion2dTestWithType(np.float16) - self.Conversion2dTestWithType(np.float32) - self.Conversion2dTestWithType(np.float64) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # ParseFromString, DatumToArray. - def testConversion3dWithType(self): - self.Conversion3dTestWithType(np.uint16) - self.Conversion3dTestWithType(np.uint32) - self.Conversion3dTestWithType(np.uint64) - self.Conversion3dTestWithType(np.float16) - self.Conversion3dTestWithType(np.float32) - self.Conversion3dTestWithType(np.float64) - - def testConversionWithUnsupportedType(self): - with self.assertRaisesRegex(ValueError, 'Unsupported array type'): - self.Conversion3dTestWithType(int) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # WriteToFile, ReadFromFile, ParseFromString, DatumToArray. - def testWriteAndReadToFile(self): - data = np.array([[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], - [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]) - filename = os.path.join(FLAGS.test_tmpdir, 'test.datum') - datum_io.WriteToFile(data, filename) - data_read = datum_io.ReadFromFile(filename) - self.assertAllEqual(data_read, data) - - # This test covers the following functions: ArraysToDatumPair, - # SerializePairToString, WritePairToFile, ReadPairFromFile, - # ParsePairFromString, DatumPairToArrays. - def testWriteAndReadPairToFile(self): - data_1 = np.array([[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], - [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]) - data_2 = np.array( - [[[255, 0, 5], [10, 300, 0]], [[20, 1, 100], [255, 360, 420]]], - dtype='uint32') - filename = os.path.join(FLAGS.test_tmpdir, 'test.datum_pair') - datum_io.WritePairToFile(data_1, data_2, filename) - data_read_1, data_read_2 = datum_io.ReadPairFromFile(filename) - self.assertAllEqual(data_read_1, data_1) - self.assertAllEqual(data_read_2, data_2) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md b/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md deleted file mode 100644 index 2b62ac29003e3d4b13a3ccc8fad5b43e236f96da..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md +++ /dev/null @@ -1,159 +0,0 @@ -## DELG instructions - -[](https://arxiv.org/abs/2001.05027) - -These instructions can be used to reproduce the results from the -[DELG paper](https://arxiv.org/abs/2001.05027) for the Revisited Oxford/Paris -datasets. - -### Install DELF library - -To be able to use this code, please follow -[these instructions](../../../INSTALL_INSTRUCTIONS.md) to properly install the -DELF library. - -### Download datasets - -```bash -mkdir -p ~/delg/data && cd ~/delg/data - -# Oxford dataset. -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ - -# Paris dataset. Download and move all images to same directory. -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_1.tgz -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_2.tgz -mkdir paris6k_images_tmp -tar -xvzf paris_1.tgz -C paris6k_images_tmp/ -tar -xvzf paris_2.tgz -C paris6k_images_tmp/ -mkdir paris6k_images -mv paris6k_images_tmp/paris/*/*.jpg paris6k_images/ - -# Revisited annotations. -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/roxford5k/gnd_roxford5k.mat -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/rparis6k/gnd_rparis6k.mat -``` - -### Download model - -This is necessary to reproduce the main paper results: - -```bash -# From models/research/delf/delf/python/delg -mkdir parameters && cd parameters - -# DELG-GLD model. -wget http://storage.googleapis.com/delf/delg_gld_20200520.tar.gz -tar -xvzf delg_gld_20200520.tar.gz -``` - -### Feature extraction - -We present here commands for extraction on `roxford5k`. To extract on `rparis6k` -instead, please edit the arguments accordingly (especially the -`dataset_file_path` argument). - -#### Query feature extraction - -For query feature extraction, the cropped query image should be used to extract -features, according to the Revisited Oxford/Paris experimental protocol. Note -that this is done in the `extract_features` script, when setting -`image_set=query`. - -Query feature extraction can be run as follows: - -```bash -# From models/research/delf/delf/python/delg -python3 extract_features.py \ - --delf_config_path delg_gld_config.pbtxt \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --images_dir ~/delg/data/oxford5k_images \ - --image_set query \ - --output_features_dir ~/delg/data/oxford5k_features/query -``` - -#### Index feature extraction - -Run index feature extraction as follows: - -```bash -# From models/research/delf/delf/python/delg -python3 extract_features.py \ - --delf_config_path delg_gld_config.pbtxt \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --images_dir ~/delg/data/oxford5k_images \ - --image_set index \ - --output_features_dir ~/delg/data/oxford5k_features/index -``` - -### Perform retrieval - -To run retrieval on `roxford5k`, the following command can be used: - -```bash -# From models/research/delf/delf/python/delg -python3 perform_retrieval.py \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --query_features_dir ~/delg/data/oxford5k_features/query \ - --index_features_dir ~/delg/data/oxford5k_features/index \ - --output_dir ~/delg/results/oxford5k -``` - -A file with named `metrics.txt` will be written to the path given in -`output_dir`, with retrieval metrics for an experiment where geometric -verification is not used. The contents should look approximately like: - -``` -hard - mAP=45.11 - mP@k[ 1 5 10] [85.71 72.29 60.14] - mR@k[ 1 5 10] [19.15 29.72 36.32] -medium - mAP=69.71 - mP@k[ 1 5 10] [95.71 92. 86.86] - mR@k[ 1 5 10] [10.17 25.94 33.83] -``` - -which are the results presented in Table 3 of the paper. - -If you want to run retrieval with geometric verification, set -`use_geometric_verification` to `True`. It's much slower since (1) in this code -example the re-ranking is loading DELF local features from disk, and (2) -re-ranking needs to be performed separately for each dataset protocol, since the -junk images from each protocol should be removed when re-ranking. Here is an -example command: - -```bash -# From models/research/delf/delf/python/delg -python3 perform_retrieval.py \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --query_features_dir ~/delg/data/oxford5k_features/query \ - --index_features_dir ~/delg/data/oxford5k_features/index \ - --use_geometric_verification \ - --output_dir ~/delg/results/oxford5k_with_gv -``` - -The `metrics.txt` should now show: - -``` -hard - mAP=45.11 - mP@k[ 1 5 10] [85.71 72.29 60.14] - mR@k[ 1 5 10] [19.15 29.72 36.32] -hard_after_gv - mAP=53.72 - mP@k[ 1 5 10] [91.43 83.81 74.38] - mR@k[ 1 5 10] [19.45 34.45 44.64] -medium - mAP=69.71 - mP@k[ 1 5 10] [95.71 92. 86.86] - mR@k[ 1 5 10] [10.17 25.94 33.83] -medium_after_gv - mAP=75.42 - mP@k[ 1 5 10] [97.14 95.24 93.81] - mR@k[ 1 5 10] [10.21 27.21 37.72] -``` - -which, again, are the results presented in Table 3 of the paper. diff --git a/research/delf/delf/python/delg/delg_gld_config.pbtxt b/research/delf/delf/python/delg/delg_gld_config.pbtxt deleted file mode 100644 index a659a0a3ee502c31f7d4b71fd634803f94d425b7..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/delg_gld_config.pbtxt +++ /dev/null @@ -1,22 +0,0 @@ -use_local_features: true -use_global_features: true -model_path: "parameters/delg_gld_20200520" -image_scales: 0.25 -image_scales: 0.35355338 -image_scales: 0.5 -image_scales: 0.70710677 -image_scales: 1.0 -image_scales: 1.4142135 -image_scales: 2.0 -delf_local_config { - use_pca: false - max_feature_num: 1000 - score_threshold: 175.0 -} -delf_global_config { - use_pca: false - image_scales_ind: 3 - image_scales_ind: 4 - image_scales_ind: 5 -} -max_image_size: 1024 diff --git a/research/delf/delf/python/delg/extract_features.py b/research/delf/delf/python/delg/extract_features.py deleted file mode 100644 index ad65d66e69ddaa032d1201b34a2f10a04fe61eb5..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/extract_features.py +++ /dev/null @@ -1,162 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Extracts DELG features for images from Revisited Oxford/Paris datasets. - -Note that query images are cropped before feature extraction, as required by the -evaluation protocols of these datasets. - -The types of extracted features (local and/or global) depend on the input -DelfConfig. - -The program checks if features already exist, and skips computation for those. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os -import time - -from absl import app -from absl import flags -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import datum_io -from delf import feature_io -from delf import utils -from delf.python.detect_to_retrieve import dataset -from delf import extractor - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'delf_config_path', '/tmp/delf_config_example.pbtxt', - 'Path to DelfConfig proto text file with configuration to be used for DELG ' - 'extraction. Local features are extracted if use_local_features is True; ' - 'global features are extracted if use_global_features is True.') -flags.DEFINE_string( - 'dataset_file_path', '/tmp/gnd_roxford5k.mat', - 'Dataset file for Revisited Oxford or Paris dataset, in .mat format.') -flags.DEFINE_string( - 'images_dir', '/tmp/images', - 'Directory where dataset images are located, all in .jpg format.') -flags.DEFINE_enum('image_set', 'query', ['query', 'index'], - 'Whether to extract features from query or index images.') -flags.DEFINE_string( - 'output_features_dir', '/tmp/features', - "Directory where DELG features will be written to. Each image's features " - 'will be written to files with same name but different extension: the ' - 'global feature is written to a file with extension .delg_global and the ' - 'local features are written to a file with extension .delg_local.') - -# Extensions. -_DELG_GLOBAL_EXTENSION = '.delg_global' -_DELG_LOCAL_EXTENSION = '.delg_local' -_IMAGE_EXTENSION = '.jpg' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 50 - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Read list of images from dataset file. - print('Reading list of images from dataset file...') - query_list, index_list, ground_truth = dataset.ReadDatasetFile( - FLAGS.dataset_file_path) - if FLAGS.image_set == 'query': - image_list = query_list - else: - image_list = index_list - num_images = len(image_list) - print('done! Found %d images' % num_images) - - # Parse DelfConfig proto. - config = delf_config_pb2.DelfConfig() - with tf.io.gfile.GFile(FLAGS.delf_config_path, 'r') as f: - text_format.Parse(f.read(), config) - - # Create output directory if necessary. - if not tf.io.gfile.exists(FLAGS.output_features_dir): - tf.io.gfile.makedirs(FLAGS.output_features_dir) - - extractor_fn = extractor.MakeExtractor(config) - - start = time.time() - for i in range(num_images): - if i == 0: - print('Starting to extract features...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Processing image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed)) - start = time.time() - - image_name = image_list[i] - input_image_filename = os.path.join(FLAGS.images_dir, - image_name + _IMAGE_EXTENSION) - - # Compose output file name and decide if image should be skipped. - should_skip_global = True - should_skip_local = True - if config.use_global_features: - output_global_feature_filename = os.path.join( - FLAGS.output_features_dir, image_name + _DELG_GLOBAL_EXTENSION) - if not tf.io.gfile.exists(output_global_feature_filename): - should_skip_global = False - if config.use_local_features: - output_local_feature_filename = os.path.join( - FLAGS.output_features_dir, image_name + _DELG_LOCAL_EXTENSION) - if not tf.io.gfile.exists(output_local_feature_filename): - should_skip_local = False - if should_skip_global and should_skip_local: - print('Skipping %s' % image_name) - continue - - pil_im = utils.RgbLoader(input_image_filename) - resize_factor = 1.0 - if FLAGS.image_set == 'query': - # Crop query image according to bounding box. - original_image_size = max(pil_im.size) - bbox = [int(round(b)) for b in ground_truth[i]['bbx']] - pil_im = pil_im.crop(bbox) - cropped_image_size = max(pil_im.size) - resize_factor = cropped_image_size / original_image_size - - im = np.array(pil_im) - - # Extract and save features. - extracted_features = extractor_fn(im, resize_factor) - if config.use_global_features: - global_descriptor = extracted_features['global_descriptor'] - datum_io.WriteToFile(global_descriptor, output_global_feature_filename) - if config.use_local_features: - locations = extracted_features['local_features']['locations'] - descriptors = extracted_features['local_features']['descriptors'] - feature_scales = extracted_features['local_features']['scales'] - attention = extracted_features['local_features']['attention'] - feature_io.WriteToFile(output_local_feature_filename, locations, - feature_scales, descriptors, attention) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/delg/measure_latency.py b/research/delf/delf/python/delg/measure_latency.py deleted file mode 100644 index 21ffbda4179a191139ae35244c8ae34693594fd9..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/measure_latency.py +++ /dev/null @@ -1,108 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Times DELF/G extraction.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import time - -from absl import app -from absl import flags -import numpy as np -from six.moves import range -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import utils -from delf import extractor - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'delf_config_path', '/tmp/delf_config_example.pbtxt', - 'Path to DelfConfig proto text file with configuration to be used for DELG ' - 'extraction. Local features are extracted if use_local_features is True; ' - 'global features are extracted if use_global_features is True.') -flags.DEFINE_string('list_images_path', '/tmp/list_images.txt', - 'Path to list of images whose features will be extracted.') -flags.DEFINE_integer('repeat_per_image', 10, - 'Number of times to repeat extraction per image.') - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 100 - - -def _ReadImageList(list_path): - """Helper function to read image paths. - - Args: - list_path: Path to list of images, one image path per line. - - Returns: - image_paths: List of image paths. - """ - with tf.io.gfile.GFile(list_path, 'r') as f: - image_paths = f.readlines() - image_paths = [entry.rstrip() for entry in image_paths] - return image_paths - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Read list of images. - print('Reading list of images...') - image_paths = _ReadImageList(FLAGS.list_images_path) - num_images = len(image_paths) - print(f'done! Found {num_images} images') - - # Load images in memory. - print('Loading images, %d times per image...' % FLAGS.repeat_per_image) - im_array = [] - for filename in image_paths: - im = np.array(utils.RgbLoader(filename)) - for _ in range(FLAGS.repeat_per_image): - im_array.append(im) - np.random.shuffle(im_array) - print('done!') - - # Parse DelfConfig proto. - config = delf_config_pb2.DelfConfig() - with tf.io.gfile.GFile(FLAGS.delf_config_path, 'r') as f: - text_format.Parse(f.read(), config) - - extractor_fn = extractor.MakeExtractor(config) - - start = time.time() - for i, im in enumerate(im_array): - if i == 0: - print('Starting to extract DELF features from images...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print(f'Processing image {i} out of {len(im_array)}, last ' - f'{_STATUS_CHECK_ITERATIONS} images took {elapsed} seconds,' - f'ie {elapsed/_STATUS_CHECK_ITERATIONS} secs/image.') - start = time.time() - - # Extract and save features. - extracted_features = extractor_fn(im) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/delg/perform_retrieval.py b/research/delf/delf/python/delg/perform_retrieval.py deleted file mode 100644 index fb53abb1a9e15a5d5a040be42213f325ab345163..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/perform_retrieval.py +++ /dev/null @@ -1,215 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Performs DELG-based image retrieval on Revisited Oxford/Paris datasets.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os -import time - -from absl import app -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import datum_io -from delf.python.detect_to_retrieve import dataset -from delf.python.detect_to_retrieve import image_reranking - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'dataset_file_path', '/tmp/gnd_roxford5k.mat', - 'Dataset file for Revisited Oxford or Paris dataset, in .mat format.') -flags.DEFINE_string('query_features_dir', '/tmp/features/query', - 'Directory where query DELG features are located.') -flags.DEFINE_string('index_features_dir', '/tmp/features/index', - 'Directory where index DELG features are located.') -flags.DEFINE_boolean( - 'use_geometric_verification', False, - 'If True, performs re-ranking using local feature-based geometric ' - 'verification.') -flags.DEFINE_float( - 'local_feature_distance_threshold', 1.0, - 'Optional, only used if `use_geometric_verification` is True. ' - 'Distance threshold below which a pair of local descriptors is considered ' - 'a potential match, and will be fed into RANSAC.') -flags.DEFINE_float( - 'ransac_residual_threshold', 20.0, - 'Optional, only used if `use_geometric_verification` is True. ' - 'Residual error threshold for considering matches as inliers, used in ' - 'RANSAC algorithm.') -flags.DEFINE_string( - 'output_dir', '/tmp/retrieval', - 'Directory where retrieval output will be written to. A file containing ' - "metrics for this run is saved therein, with file name 'metrics.txt'.") - -# Extensions. -_DELG_GLOBAL_EXTENSION = '.delg_global' -_DELG_LOCAL_EXTENSION = '.delg_local' - -# Precision-recall ranks to use in metric computation. -_PR_RANKS = (1, 5, 10) - -# Pace to log. -_STATUS_CHECK_LOAD_ITERATIONS = 50 - -# Output file names. -_METRICS_FILENAME = 'metrics.txt' - - -def _ReadDelgGlobalDescriptors(input_dir, image_list): - """Reads DELG global features. - - Args: - input_dir: Directory where features are located. - image_list: List of image names for which to load features. - - Returns: - global_descriptors: NumPy array of shape (len(image_list), D), where D - corresponds to the global descriptor dimensionality. - """ - num_images = len(image_list) - global_descriptors = [] - print('Starting to collect global descriptors for %d images...' % num_images) - start = time.time() - for i in range(num_images): - if i > 0 and i % _STATUS_CHECK_LOAD_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Reading global descriptors for image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_LOAD_ITERATIONS, elapsed)) - start = time.time() - - descriptor_filename = image_list[i] + _DELG_GLOBAL_EXTENSION - descriptor_fullpath = os.path.join(input_dir, descriptor_filename) - global_descriptors.append(datum_io.ReadFromFile(descriptor_fullpath)) - - return np.array(global_descriptors) - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Parse dataset to obtain query/index images, and ground-truth. - print('Parsing dataset...') - query_list, index_list, ground_truth = dataset.ReadDatasetFile( - FLAGS.dataset_file_path) - num_query_images = len(query_list) - num_index_images = len(index_list) - (_, medium_ground_truth, - hard_ground_truth) = dataset.ParseEasyMediumHardGroundTruth(ground_truth) - print('done! Found %d queries and %d index images' % - (num_query_images, num_index_images)) - - # Read global features. - query_global_features = _ReadDelgGlobalDescriptors(FLAGS.query_features_dir, - query_list) - index_global_features = _ReadDelgGlobalDescriptors(FLAGS.index_features_dir, - index_list) - - # Compute similarity between query and index images, potentially re-ranking - # with geometric verification. - ranks_before_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - if FLAGS.use_geometric_verification: - medium_ranks_after_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - hard_ranks_after_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - for i in range(num_query_images): - print('Performing retrieval with query %d (%s)...' % (i, query_list[i])) - start = time.time() - - # Compute similarity between global descriptors. - similarities = np.dot(index_global_features, query_global_features[i]) - ranks_before_gv[i] = np.argsort(-similarities) - - # Re-rank using geometric verification. - if FLAGS.use_geometric_verification: - medium_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification( - input_ranks=ranks_before_gv[i], - initial_scores=similarities, - query_name=query_list[i], - index_names=index_list, - query_features_dir=FLAGS.query_features_dir, - index_features_dir=FLAGS.index_features_dir, - junk_ids=set(medium_ground_truth[i]['junk']), - local_feature_extension=_DELG_LOCAL_EXTENSION, - ransac_seed=0, - feature_distance_threshold=FLAGS.local_feature_distance_threshold, - ransac_residual_threshold=FLAGS.ransac_residual_threshold) - hard_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification( - input_ranks=ranks_before_gv[i], - initial_scores=similarities, - query_name=query_list[i], - index_names=index_list, - query_features_dir=FLAGS.query_features_dir, - index_features_dir=FLAGS.index_features_dir, - junk_ids=set(hard_ground_truth[i]['junk']), - local_feature_extension=_DELG_LOCAL_EXTENSION, - ransac_seed=0, - feature_distance_threshold=FLAGS.local_feature_distance_threshold, - ransac_residual_threshold=FLAGS.ransac_residual_threshold) - - elapsed = (time.time() - start) - print('done! Retrieval for query %d took %f seconds' % (i, elapsed)) - - # Create output directory if necessary. - if not tf.io.gfile.exists(FLAGS.output_dir): - tf.io.gfile.makedirs(FLAGS.output_dir) - - # Compute metrics. - medium_metrics = dataset.ComputeMetrics(ranks_before_gv, medium_ground_truth, - _PR_RANKS) - hard_metrics = dataset.ComputeMetrics(ranks_before_gv, hard_ground_truth, - _PR_RANKS) - if FLAGS.use_geometric_verification: - medium_metrics_after_gv = dataset.ComputeMetrics(medium_ranks_after_gv, - medium_ground_truth, - _PR_RANKS) - hard_metrics_after_gv = dataset.ComputeMetrics(hard_ranks_after_gv, - hard_ground_truth, _PR_RANKS) - - # Write metrics to file. - mean_average_precision_dict = { - 'medium': medium_metrics[0], - 'hard': hard_metrics[0] - } - mean_precisions_dict = {'medium': medium_metrics[1], 'hard': hard_metrics[1]} - mean_recalls_dict = {'medium': medium_metrics[2], 'hard': hard_metrics[2]} - if FLAGS.use_geometric_verification: - mean_average_precision_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[0], - 'hard_after_gv': hard_metrics_after_gv[0] - }) - mean_precisions_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[1], - 'hard_after_gv': hard_metrics_after_gv[1] - }) - mean_recalls_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[2], - 'hard_after_gv': hard_metrics_after_gv[2] - }) - dataset.SaveMetricsFile(mean_average_precision_dict, mean_precisions_dict, - mean_recalls_dict, _PR_RANKS, - os.path.join(FLAGS.output_dir, _METRICS_FILENAME)) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md b/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md deleted file mode 100644 index 2d18a328997ace5ee01f60a4b2c95714a18eb7d9..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md +++ /dev/null @@ -1,231 +0,0 @@ -## Detect-to-Retrieve instructions - -[](https://arxiv.org/abs/1812.01584) - -These instructions can be used to reproduce the results from the -[Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584) for the Revisited -Oxford/Paris datasets. - -### Install DELF library - -To be able to use this code, please follow -[these instructions](../../../INSTALL_INSTRUCTIONS.md) to properly install the -DELF library. - -### Download datasets - -```bash -mkdir -p ~/detect_to_retrieve/data && cd ~/detect_to_retrieve/data - -# Oxford dataset. -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ - -# Paris dataset. Download and move all images to same directory. -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_1.tgz -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_2.tgz -mkdir paris6k_images_tmp -tar -xvzf paris_1.tgz -C paris6k_images_tmp/ -tar -xvzf paris_2.tgz -C paris6k_images_tmp/ -mkdir paris6k_images -mv paris6k_images_tmp/paris/*/*.jpg paris6k_images/ - -# Revisited annotations. -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/roxford5k/gnd_roxford5k.mat -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/rparis6k/gnd_rparis6k.mat -``` - -### Download models - -These are necessary to reproduce the main paper results: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -mkdir parameters && cd parameters - -# DELF-GLD model. -wget http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz -tar -xvzf delf_gld_20190411.tar.gz - -# Faster-RCNN detector model. -wget http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz -tar -xvzf d2r_frcnn_20190411.tar.gz - -# Codebooks. -# Note: you should use codebook trained on rparis6k for roxford5k retrieval -# experiments, and vice-versa. -wget http://storage.googleapis.com/delf/rparis6k_codebook_65536.tar.gz -mkdir rparis6k_codebook_65536 -tar -xvzf rparis6k_codebook_65536.tar.gz -C rparis6k_codebook_65536/ -wget http://storage.googleapis.com/delf/roxford5k_codebook_65536.tar.gz -mkdir roxford5k_codebook_65536 -tar -xvzf roxford5k_codebook_65536.tar.gz -C roxford5k_codebook_65536/ -``` - -We also make available other models/parameters that can be used to reproduce -more results from the paper: - -- [MobileNet-SSD trained detector](http://storage.googleapis.com/delf/d2r_mnetssd_20190411.tar.gz). -- Codebooks with 1024 centroids: - [rparis6k](http://storage.googleapis.com/delf/rparis6k_codebook_1024.tar.gz), - [roxford5k](http://storage.googleapis.com/delf/roxford5k_codebook_1024.tar.gz). - -### Feature extraction - -We present here commands for extraction on `roxford5k`. To extract on `rparis6k` -instead, please edit the arguments accordingly (especially the -`dataset_file_path` argument). - -#### Query feature extraction - -For query feature extraction, the cropped query image should be used to extract -features, according to the Revisited Oxford/Paris experimental protocol. Note -that this is done in the `extract_query_features` script. - -Query feature extraction can be run as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_query_features.py \ - --delf_config_path delf_gld_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --images_dir ~/detect_to_retrieve/data/oxford5k_images \ - --output_features_dir ~/detect_to_retrieve/data/oxford5k_features/query -``` - -#### Index feature extraction and box detection - -Index feature extraction / box detection can be run as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_index_boxes_and_features.py \ - --delf_config_path delf_gld_config.pbtxt \ - --detector_model_dir parameters/d2r_frcnn_20190411 \ - --detector_thresh 0.1 \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --images_dir ~/detect_to_retrieve/data/oxford5k_images \ - --output_boxes_dir ~/detect_to_retrieve/data/oxford5k_boxes/index \ - --output_features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --output_index_mapping ~/detect_to_retrieve/data/oxford5k_features/index_mapping_0.1.csv -``` - -### R-ASMK* aggregation extraction - -We present here commands for aggregation extraction on `roxford5k`. To extract -on `rparis6k` instead, please edit the arguments accordingly. In particular, -note that feature aggregation on `roxford5k` should use a codebook trained on -`rparis6k`, and vice-versa (this can be edited in the -`query_aggregation_config.pbtxt` and `index_aggregation_config.pbtxt` files. - -#### Query - -Run query feature aggregation as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_aggregation.py \ - --use_query_images True \ - --aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --features_dir ~/detect_to_retrieve/data/oxford5k_features/query \ - --output_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query -``` - -#### Index - -Run index feature aggregation as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_aggregation.py \ - --aggregation_config_path index_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --index_mapping_path ~/detect_to_retrieve/data/oxford5k_features/index_mapping_0.1.csv \ - --output_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 -``` - -### Perform retrieval - -Currently, we support retrieval via brute-force comparison of aggregated -features. - -To run retrieval on `roxford5k`, the following command can be used: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 perform_retrieval.py \ - --index_aggregation_config_path index_aggregation_config.pbtxt \ - --query_aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --index_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 \ - --query_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query \ - --output_dir ~/detect_to_retrieve/results/oxford5k -``` - -A file with named `metrics.txt` will be written to the path given in -`output_dir`, with retrieval metrics for an experiment where geometric -verification is not used. The contents should look approximately like: - -``` -hard -mAP=47.61 -mP@k[ 1 5 10] [84.29 73.71 64.43] -mR@k[ 1 5 10] [18.84 29.44 36.82] -medium -mAP=73.3 -mP@k[ 1 5 10] [97.14 94.57 90.14] -mR@k[ 1 5 10] [10.14 26.2 34.75] -``` - -which are the results presented in Table 2 of the paper (with small numerical -precision differences). - -If you want to run retrieval with geometric verification, set -`use_geometric_verification` to `True` and the arguments -`index_features_dir`/`query_features_dir`. It's much slower since (1) in this -code example the re-ranking is loading DELF local features from disk, and (2) -re-ranking needs to be performed separately for each dataset protocol, since the -junk images from each protocol should be removed when re-ranking. Here is an -example command: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 perform_retrieval.py \ - --index_aggregation_config_path index_aggregation_config.pbtxt \ - --query_aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --index_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 \ - --query_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query \ - --use_geometric_verification True \ - --index_features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --query_features_dir ~/detect_to_retrieve/data/oxford5k_features/query \ - --output_dir ~/detect_to_retrieve/results/oxford5k_with_gv -``` - -### Clustering - -In the code example above, we used a pre-trained DELF codebook. We also provide -code for re-training the codebook if desired. - -Note that for the time being this can only run on CPU, since the main ops in -K-means are not registered for GPU usage in Tensorflow. - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 cluster_delf_features.py \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_rparis6k.mat \ - --features_dir ~/detect_to_retrieve/data/paris6k_features/index_0.1 \ - --num_clusters 1024 \ - --num_iterations 50 \ - --output_cluster_dir ~/detect_to_retrieve/data/paris6k_clusters_1024 -``` - -### Next steps - -To make retrieval more scalable and handle larger datasets more smoothly, we are -considering to provide code for inverted index building and retrieval. Please -reach out if you would like to help doing that -- feel free submit a pull -request. diff --git a/research/delf/delf/python/detect_to_retrieve/__init__.py b/research/delf/delf/python/detect_to_retrieve/__init__.py deleted file mode 100644 index 06972a7d06738da1dc50e832c4e8443b0e6fb5b6..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/__init__.py +++ /dev/null @@ -1,24 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Module for Detect-to-Retrieve technique.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import -from delf.python.detect_to_retrieve import aggregation_extraction -from delf.python.detect_to_retrieve import boxes_and_features_extraction -from delf.python.detect_to_retrieve import dataset -# pylint: enable=unused-import diff --git a/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py b/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py deleted file mode 100644 index 4ddab944b8a3365209b8e92af38241d297974122..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py +++ /dev/null @@ -1,193 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Library to extract/save feature aggregation.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import csv -import os -import time - -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import aggregation_config_pb2 -from delf import datum_io -from delf import feature_aggregation_extractor -from delf import feature_io - -# Aliases for aggregation types. -_VLAD = aggregation_config_pb2.AggregationConfig.VLAD -_ASMK = aggregation_config_pb2.AggregationConfig.ASMK -_ASMK_STAR = aggregation_config_pb2.AggregationConfig.ASMK_STAR - -# Extensions. -_DELF_EXTENSION = '.delf' -_VLAD_EXTENSION_SUFFIX = 'vlad' -_ASMK_EXTENSION_SUFFIX = 'asmk' -_ASMK_STAR_EXTENSION_SUFFIX = 'asmk_star' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 50 - - -def _ReadMappingBasenameToBoxNames(input_path, index_image_names): - """Reads mapping from image name to DELF file names for each box. - - Args: - input_path: Path to CSV file containing mapping. - index_image_names: List containing index image names, in order, for the - dataset under consideration. - - Returns: - images_to_box_feature_files: Dict. key=string (image name); value=list of - strings (file names containing DELF features for boxes). - """ - images_to_box_feature_files = {} - with tf.io.gfile.GFile(input_path, 'r') as f: - reader = csv.DictReader(f) - for row in reader: - index_image_name = index_image_names[int(row['index_image_id'])] - if index_image_name not in images_to_box_feature_files: - images_to_box_feature_files[index_image_name] = [] - - images_to_box_feature_files[index_image_name].append(row['name']) - - return images_to_box_feature_files - - -def ExtractAggregatedRepresentationsToFiles(image_names, features_dir, - aggregation_config_path, - mapping_path, - output_aggregation_dir): - """Extracts aggregated feature representations, saving them to files. - - It checks if the aggregated representation for an image already exists, - and skips computation for those. - - Args: - image_names: List of image names. These are used to compose input file names - for the feature files, and the output file names for aggregated - representations. - features_dir: Directory where DELF features are located. - aggregation_config_path: Path to AggregationConfig proto text file with - configuration to be used for extraction. - mapping_path: Optional CSV file which maps each .delf file name to the index - image ID and detected box ID. If regional aggregation is performed, this - should be set. Otherwise, this is ignored. - output_aggregation_dir: Directory where aggregation output will be written - to. - - Raises: - ValueError: If AggregationConfig is malformed, or `mapping_path` is - missing. - """ - num_images = len(image_names) - - # Parse AggregationConfig proto, and select output extension. - config = aggregation_config_pb2.AggregationConfig() - with tf.io.gfile.GFile(aggregation_config_path, 'r') as f: - text_format.Merge(f.read(), config) - output_extension = '.' - if config.use_regional_aggregation: - output_extension += 'r' - if config.aggregation_type == _VLAD: - output_extension += _VLAD_EXTENSION_SUFFIX - elif config.aggregation_type == _ASMK: - output_extension += _ASMK_EXTENSION_SUFFIX - elif config.aggregation_type == _ASMK_STAR: - output_extension += _ASMK_STAR_EXTENSION_SUFFIX - else: - raise ValueError('Invalid aggregation type: %d' % config.aggregation_type) - - # Read index mapping path, if provided. - if mapping_path: - images_to_box_feature_files = _ReadMappingBasenameToBoxNames( - mapping_path, image_names) - - # Create output directory if necessary. - if not tf.io.gfile.exists(output_aggregation_dir): - tf.io.gfile.makedirs(output_aggregation_dir) - - extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation( - config) - - start = time.time() - for i in range(num_images): - if i == 0: - print('Starting to extract aggregation from images...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Processing image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed)) - start = time.time() - - image_name = image_names[i] - - # Compose output file name, skip extraction for this image if it already - # exists. - output_aggregation_filename = os.path.join(output_aggregation_dir, - image_name + output_extension) - if tf.io.gfile.exists(output_aggregation_filename): - print('Skipping %s' % image_name) - continue - - # Load DELF features. - if config.use_regional_aggregation: - if not mapping_path: - raise ValueError( - 'Requested regional aggregation, but mapping_path was not ' - 'provided') - descriptors_list = [] - num_features_per_box = [] - for box_feature_file in images_to_box_feature_files[image_name]: - delf_filename = os.path.join(features_dir, - box_feature_file + _DELF_EXTENSION) - _, _, box_descriptors, _, _ = feature_io.ReadFromFile(delf_filename) - # If `box_descriptors` is empty, reshape it such that it can be - # concatenated with other descriptors. - if not box_descriptors.shape[0]: - box_descriptors = np.reshape(box_descriptors, - [0, config.feature_dimensionality]) - descriptors_list.append(box_descriptors) - num_features_per_box.append(box_descriptors.shape[0]) - - descriptors = np.concatenate(descriptors_list) - else: - input_delf_filename = os.path.join(features_dir, - image_name + _DELF_EXTENSION) - _, _, descriptors, _, _ = feature_io.ReadFromFile(input_delf_filename) - # If `descriptors` is empty, reshape it to avoid extraction failure. - if not descriptors.shape[0]: - descriptors = np.reshape(descriptors, - [0, config.feature_dimensionality]) - num_features_per_box = None - - # Extract and save aggregation. If using VLAD, only - # `aggregated_descriptors` needs to be saved. - (aggregated_descriptors, - feature_visual_words) = extractor.Extract(descriptors, - num_features_per_box) - if config.aggregation_type == _VLAD: - datum_io.WriteToFile(aggregated_descriptors, - output_aggregation_filename) - else: - datum_io.WritePairToFile(aggregated_descriptors, - feature_visual_words.astype('uint32'), - output_aggregation_filename) diff --git a/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py b/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py deleted file mode 100644 index 1faef983b2e0413e2f2746c5d56b5e62045e5a39..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py +++ /dev/null @@ -1,202 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Library to extract/save boxes and DELF features.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import csv -import math -import os -import time - -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import box_io -from delf import feature_io -from delf import utils -from delf import detector -from delf import extractor - -# Extension of feature files. -_BOX_EXTENSION = '.boxes' -_DELF_EXTENSION = '.delf' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 100 - - -def _WriteMappingBasenameToIds(index_names_ids_and_boxes, output_path): - """Helper function to write CSV mapping from DELF file name to IDs. - - Args: - index_names_ids_and_boxes: List containing 3-element lists with name, image - ID and box ID. - output_path: Output CSV path. - """ - with tf.io.gfile.GFile(output_path, 'w') as f: - csv_writer = csv.DictWriter( - f, fieldnames=['name', 'index_image_id', 'box_id']) - csv_writer.writeheader() - for name_imid_boxid in index_names_ids_and_boxes: - csv_writer.writerow({ - 'name': name_imid_boxid[0], - 'index_image_id': name_imid_boxid[1], - 'box_id': name_imid_boxid[2], - }) - - -def ExtractBoxesAndFeaturesToFiles(image_names, image_paths, delf_config_path, - detector_model_dir, detector_thresh, - output_features_dir, output_boxes_dir, - output_mapping): - """Extracts boxes and features, saving them to files. - - Boxes are saved to.boxes files. DELF features are extracted for
- the entire image and saved into .delf files. In addition, DELF
- features are extracted for each high-confidence bounding box in the image, and
- saved into files named _0.delf, _1.delf, etc.
-
- It checks if descriptors/boxes already exist, and skips computation for those.
-
- Args:
- image_names: List of image names. These are used to compose output file
- names for boxes and features.
- image_paths: List of image paths. image_paths[i] is the path for the image
- named by image_names[i]. `image_names` and `image_paths` must have the
- same number of elements.
- delf_config_path: Path to DelfConfig proto text file.
- detector_model_dir: Directory where detector SavedModel is located.
- detector_thresh: Threshold used to decide if an image's detected box
- undergoes feature extraction.
- output_features_dir: Directory where DELF features will be written to.
- output_boxes_dir: Directory where detected boxes will be written to.
- output_mapping: CSV file which maps each .delf file name to the image ID and
- detected box ID.
-
- Raises:
- ValueError: If len(image_names) and len(image_paths) are different.
- """
- num_images = len(image_names)
- if len(image_paths) != num_images:
- raise ValueError(
- 'image_names and image_paths have different number of items')
-
- # Parse DelfConfig proto.
- config = delf_config_pb2.DelfConfig()
- with tf.io.gfile.GFile(delf_config_path, 'r') as f:
- text_format.Merge(f.read(), config)
-
- # Create output directories if necessary.
- if not tf.io.gfile.exists(output_features_dir):
- tf.io.gfile.makedirs(output_features_dir)
- if not tf.io.gfile.exists(output_boxes_dir):
- tf.io.gfile.makedirs(output_boxes_dir)
- if not tf.io.gfile.exists(os.path.dirname(output_mapping)):
- tf.io.gfile.makedirs(os.path.dirname(output_mapping))
-
- names_ids_and_boxes = []
- detector_fn = detector.MakeDetector(detector_model_dir)
- delf_extractor_fn = extractor.MakeExtractor(config)
-
- start = time.time()
- for i in range(num_images):
- if i == 0:
- print('Starting to extract features/boxes...')
- elif i % _STATUS_CHECK_ITERATIONS == 0:
- elapsed = (time.time() - start)
- print('Processing image %d out of %d, last %d '
- 'images took %f seconds' %
- (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed))
- start = time.time()
-
- image_name = image_names[i]
- output_feature_filename_whole_image = os.path.join(
- output_features_dir, image_name + _DELF_EXTENSION)
- output_box_filename = os.path.join(output_boxes_dir,
- image_name + _BOX_EXTENSION)
-
- pil_im = utils.RgbLoader(image_paths[i])
- width, height = pil_im.size
-
- # Extract and save boxes.
- if tf.io.gfile.exists(output_box_filename):
- print('Skipping box computation for %s' % image_name)
- (boxes_out, scores_out,
- class_indices_out) = box_io.ReadFromFile(output_box_filename)
- else:
- (boxes_out, scores_out,
- class_indices_out) = detector_fn(np.expand_dims(pil_im, 0))
- # Using only one image per batch.
- boxes_out = boxes_out[0]
- scores_out = scores_out[0]
- class_indices_out = class_indices_out[0]
- box_io.WriteToFile(output_box_filename, boxes_out, scores_out,
- class_indices_out)
-
- # Select boxes with scores greater than threshold. Those will be the
- # ones with extracted DELF features (besides the whole image, whose DELF
- # features are extracted in all cases).
- num_delf_files = 1
- selected_boxes = []
- for box_ind, box in enumerate(boxes_out):
- if scores_out[box_ind] >= detector_thresh:
- selected_boxes.append(box)
- num_delf_files += len(selected_boxes)
-
- # Extract and save DELF features.
- for delf_file_ind in range(num_delf_files):
- if delf_file_ind == 0:
- box_name = image_name
- output_feature_filename = output_feature_filename_whole_image
- else:
- box_name = image_name + '_' + str(delf_file_ind - 1)
- output_feature_filename = os.path.join(output_features_dir,
- box_name + _DELF_EXTENSION)
-
- names_ids_and_boxes.append([box_name, i, delf_file_ind - 1])
-
- if tf.io.gfile.exists(output_feature_filename):
- print('Skipping DELF computation for %s' % box_name)
- continue
-
- if delf_file_ind >= 1:
- bbox_for_cropping = selected_boxes[delf_file_ind - 1]
- bbox_for_cropping_pil_convention = [
- int(math.floor(bbox_for_cropping[1] * width)),
- int(math.floor(bbox_for_cropping[0] * height)),
- int(math.ceil(bbox_for_cropping[3] * width)),
- int(math.ceil(bbox_for_cropping[2] * height))
- ]
- pil_cropped_im = pil_im.crop(bbox_for_cropping_pil_convention)
- im = np.array(pil_cropped_im)
- else:
- im = np.array(pil_im)
-
- extracted_features = delf_extractor_fn(im)
- locations_out = extracted_features['local_features']['locations']
- descriptors_out = extracted_features['local_features']['descriptors']
- feature_scales_out = extracted_features['local_features']['scales']
- attention_out = extracted_features['local_features']['attention']
-
- feature_io.WriteToFile(output_feature_filename, locations_out,
- feature_scales_out, descriptors_out, attention_out)
-
- # Save mapping from output DELF name to image id and box id.
- _WriteMappingBasenameToIds(names_ids_and_boxes, output_mapping)
diff --git a/research/delf/delf/python/detect_to_retrieve/cluster_delf_features.py b/research/delf/delf/python/detect_to_retrieve/cluster_delf_features.py
deleted file mode 100644
index 9ddda8e4d0cae7950e76383950aab976249f3461..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/cluster_delf_features.py
+++ /dev/null
@@ -1,213 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Clusters DELF features using the K-means algorithm.
-
-All DELF local feature descriptors for a given dataset's index images are loaded
-as the input.
-
-Note that:
-- we only use features extracted from whole images (no features from boxes are
- used).
-- the codebook should be trained on Paris images for Oxford retrieval
- experiments, and vice-versa.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-import time
-
-import numpy as np
-import tensorflow as tf
-
-from tensorflow.python.platform import app
-from delf import feature_io
-from delf.python.detect_to_retrieve import dataset
-
-cmd_args = None
-
-# Extensions.
-_DELF_EXTENSION = '.delf'
-
-# Default DELF dimensionality.
-_DELF_DIM = 128
-
-# Pace to report log when collecting features.
-_STATUS_CHECK_ITERATIONS = 100
-
-
-class _IteratorInitHook(tf.estimator.SessionRunHook):
- """Hook to initialize data iterator after session is created."""
-
- def __init__(self):
- super(_IteratorInitHook, self).__init__()
- self.iterator_initializer_fn = None
-
- def after_create_session(self, session, coord):
- """Initialize the iterator after the session has been created."""
- del coord
- self.iterator_initializer_fn(session)
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Process output directory.
- if tf.io.gfile.exists(cmd_args.output_cluster_dir):
- raise RuntimeError(
- 'output_cluster_dir = %s already exists. This may indicate that a '
- 'previous run already wrote checkpoints in this directory, which would '
- 'lead to incorrect training. Please re-run this script by specifying an'
- ' inexisting directory.' % cmd_args.output_cluster_dir)
- else:
- tf.io.gfile.makedirs(cmd_args.output_cluster_dir)
-
- # Read list of index images from dataset file.
- print('Reading list of index images from dataset file...')
- _, index_list, _ = dataset.ReadDatasetFile(cmd_args.dataset_file_path)
- num_images = len(index_list)
- print('done! Found %d images' % num_images)
-
- # Loop over list of index images and collect DELF features.
- features_for_clustering = []
- start = time.clock()
- print('Starting to collect features from index images...')
- for i in range(num_images):
- if i > 0 and i % _STATUS_CHECK_ITERATIONS == 0:
- elapsed = (time.clock() - start)
- print('Processing index image %d out of %d, last %d '
- 'images took %f seconds' %
- (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed))
- start = time.clock()
-
- features_filename = index_list[i] + _DELF_EXTENSION
- features_fullpath = os.path.join(cmd_args.features_dir, features_filename)
- _, _, features, _, _ = feature_io.ReadFromFile(features_fullpath)
- if features.size != 0:
- assert features.shape[1] == _DELF_DIM
- for feature in features:
- features_for_clustering.append(feature)
-
- features_for_clustering = np.array(features_for_clustering, dtype=np.float32)
- print('All features were loaded! There are %d features, each with %d '
- 'dimensions' %
- (features_for_clustering.shape[0], features_for_clustering.shape[1]))
-
- # Run K-means clustering.
- def _get_input_fn():
- """Helper function to create input function and hook for training.
-
- Returns:
- input_fn: Input function for k-means Estimator training.
- init_hook: Hook used to load data during training.
- """
- init_hook = _IteratorInitHook()
-
- def _input_fn():
- """Produces tf.data.Dataset object for k-means training.
-
- Returns:
- Tensor with the data for training.
- """
- features_placeholder = tf.compat.v1.placeholder(
- tf.float32, features_for_clustering.shape)
- delf_dataset = tf.data.Dataset.from_tensor_slices((features_placeholder))
- delf_dataset = delf_dataset.shuffle(1000).batch(
- features_for_clustering.shape[0])
- iterator = delf_dataset.make_initializable_iterator()
-
- def _initializer_fn(sess):
- """Initialize dataset iterator, feed in the data."""
- sess.run(
- iterator.initializer,
- feed_dict={features_placeholder: features_for_clustering})
-
- init_hook.iterator_initializer_fn = _initializer_fn
- return iterator.get_next()
-
- return _input_fn, init_hook
-
- input_fn, init_hook = _get_input_fn()
-
- kmeans = tf.compat.v1.estimator.experimental.KMeans(
- num_clusters=cmd_args.num_clusters,
- model_dir=cmd_args.output_cluster_dir,
- use_mini_batch=False,
- )
-
- print('Starting K-means clustering...')
- start = time.clock()
- for i in range(cmd_args.num_iterations):
- kmeans.train(input_fn, hooks=[init_hook])
- average_sum_squared_error = kmeans.evaluate(
- input_fn, hooks=[init_hook])['score'] / features_for_clustering.shape[0]
- elapsed = (time.clock() - start)
- print('K-means iteration %d (out of %d) took %f seconds, '
- 'average-sum-of-squares: %f' %
- (i, cmd_args.num_iterations, elapsed, average_sum_squared_error))
- start = time.clock()
-
- print('K-means clustering finished!')
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--dataset_file_path',
- type=str,
- default='/tmp/gnd_roxford5k.mat',
- help="""
- Dataset file for Revisited Oxford or Paris dataset, in .mat format. The
- list of index images loaded from this file is used to collect local
- features, which are assumed to be in .delf file format.
- """)
- parser.add_argument(
- '--features_dir',
- type=str,
- default='/tmp/features',
- help="""
- Directory where DELF feature files are to be found.
- """)
- parser.add_argument(
- '--num_clusters',
- type=int,
- default=1024,
- help="""
- Number of clusters to use.
- """)
- parser.add_argument(
- '--num_iterations',
- type=int,
- default=50,
- help="""
- Number of iterations to use.
- """)
- parser.add_argument(
- '--output_cluster_dir',
- type=str,
- default='/tmp/cluster',
- help="""
- Directory where clustering outputs are written to. This directory should
- not exist before running this script; it will be created during
- clustering.
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/detect_to_retrieve/dataset.py b/research/delf/delf/python/detect_to_retrieve/dataset.py
deleted file mode 100644
index 9a1e6b247895aa7bd8022d3a2fb87b878bbb3b38..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/dataset.py
+++ /dev/null
@@ -1,469 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Python library to parse ground-truth/evaluate on Revisited datasets."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-from scipy.io import matlab
-import tensorflow as tf
-
-_GROUND_TRUTH_KEYS = ['easy', 'hard', 'junk']
-
-
-def ReadDatasetFile(dataset_file_path):
- """Reads dataset file in Revisited Oxford/Paris ".mat" format.
-
- Args:
- dataset_file_path: Path to dataset file, in .mat format.
-
- Returns:
- query_list: List of query image names.
- index_list: List of index image names.
- ground_truth: List containing ground-truth information for dataset. Each
- entry is a dict corresponding to the ground-truth information for a query.
- The dict may have keys 'easy', 'hard', or 'junk', mapping to a NumPy
- array of integers; additionally, it has a key 'bbx' mapping to a NumPy
- array of floats with bounding box coordinates.
- """
- with tf.io.gfile.GFile(dataset_file_path, 'rb') as f:
- cfg = matlab.loadmat(f)
-
- # Parse outputs according to the specificities of the dataset file.
- query_list = [str(im_array[0]) for im_array in np.squeeze(cfg['qimlist'])]
- index_list = [str(im_array[0]) for im_array in np.squeeze(cfg['imlist'])]
- ground_truth_raw = np.squeeze(cfg['gnd'])
- ground_truth = []
- for query_ground_truth_raw in ground_truth_raw:
- query_ground_truth = {}
- for ground_truth_key in _GROUND_TRUTH_KEYS:
- if ground_truth_key in query_ground_truth_raw.dtype.names:
- adjusted_labels = query_ground_truth_raw[ground_truth_key] - 1
- query_ground_truth[ground_truth_key] = adjusted_labels.flatten()
-
- query_ground_truth['bbx'] = np.squeeze(query_ground_truth_raw['bbx'])
- ground_truth.append(query_ground_truth)
-
- return query_list, index_list, ground_truth
-
-
-def _ParseGroundTruth(ok_list, junk_list):
- """Constructs dictionary of ok/junk indices for a data subset and query.
-
- Args:
- ok_list: List of NumPy arrays containing true positive indices for query.
- junk_list: List of NumPy arrays containing ignored indices for query.
-
- Returns:
- ok_junk_dict: Dict mapping 'ok' and 'junk' strings to NumPy array of
- indices.
- """
- ok_junk_dict = {}
- ok_junk_dict['ok'] = np.concatenate(ok_list)
- ok_junk_dict['junk'] = np.concatenate(junk_list)
- return ok_junk_dict
-
-
-def ParseEasyMediumHardGroundTruth(ground_truth):
- """Parses easy/medium/hard ground-truth from Revisited datasets.
-
- Args:
- ground_truth: Usually the output from ReadDatasetFile(). List containing
- ground-truth information for dataset. Each entry is a dict corresponding
- to the ground-truth information for a query. The dict must have keys
- 'easy', 'hard', and 'junk', mapping to a NumPy array of integers.
-
- Returns:
- easy_ground_truth: List containing ground-truth information for easy subset
- of dataset. Each entry is a dict corresponding to the ground-truth
- information for a query. The dict has keys 'ok' and 'junk', mapping to a
- NumPy array of integers.
- medium_ground_truth: Same as `easy_ground_truth`, but for the medium subset.
- hard_ground_truth: Same as `easy_ground_truth`, but for the hard subset.
- """
- num_queries = len(ground_truth)
-
- easy_ground_truth = []
- medium_ground_truth = []
- hard_ground_truth = []
- for i in range(num_queries):
- easy_ground_truth.append(
- _ParseGroundTruth([ground_truth[i]['easy']],
- [ground_truth[i]['junk'], ground_truth[i]['hard']]))
- medium_ground_truth.append(
- _ParseGroundTruth([ground_truth[i]['easy'], ground_truth[i]['hard']],
- [ground_truth[i]['junk']]))
- hard_ground_truth.append(
- _ParseGroundTruth([ground_truth[i]['hard']],
- [ground_truth[i]['junk'], ground_truth[i]['easy']]))
-
- return easy_ground_truth, medium_ground_truth, hard_ground_truth
-
-
-def AdjustPositiveRanks(positive_ranks, junk_ranks):
- """Adjusts positive ranks based on junk ranks.
-
- Args:
- positive_ranks: Sorted 1D NumPy integer array.
- junk_ranks: Sorted 1D NumPy integer array.
-
- Returns:
- adjusted_positive_ranks: Sorted 1D NumPy array.
- """
- if not junk_ranks.size:
- return positive_ranks
-
- adjusted_positive_ranks = positive_ranks
- j = 0
- for i, positive_index in enumerate(positive_ranks):
- while (j < len(junk_ranks) and positive_index > junk_ranks[j]):
- j += 1
-
- adjusted_positive_ranks[i] -= j
-
- return adjusted_positive_ranks
-
-
-def ComputeAveragePrecision(positive_ranks):
- """Computes average precision according to dataset convention.
-
- It assumes that `positive_ranks` contains the ranks for all expected positive
- index images to be retrieved. If `positive_ranks` is empty, returns
- `average_precision` = 0.
-
- Note that average precision computation here does NOT use the finite sum
- method (see
- https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Average_precision)
- which is common in information retrieval literature. Instead, the method
- implemented here integrates over the precision-recall curve by averaging two
- adjacent precision points, then multiplying by the recall step. This is the
- convention for the Revisited Oxford/Paris datasets.
-
- Args:
- positive_ranks: Sorted 1D NumPy integer array, zero-indexed.
-
- Returns:
- average_precision: Float.
- """
- average_precision = 0.0
-
- num_expected_positives = len(positive_ranks)
- if not num_expected_positives:
- return average_precision
-
- recall_step = 1.0 / num_expected_positives
- for i, rank in enumerate(positive_ranks):
- if not rank:
- left_precision = 1.0
- else:
- left_precision = i / rank
-
- right_precision = (i + 1) / (rank + 1)
- average_precision += (left_precision + right_precision) * recall_step / 2
-
- return average_precision
-
-
-def ComputePRAtRanks(positive_ranks, desired_pr_ranks):
- """Computes precision/recall at desired ranks.
-
- It assumes that `positive_ranks` contains the ranks for all expected positive
- index images to be retrieved. If `positive_ranks` is empty, return all-zeros
- `precisions`/`recalls`.
-
- If a desired rank is larger than the last positive rank, its precision is
- computed based on the last positive rank. For example, if `desired_pr_ranks`
- is [10] and `positive_ranks` = [0, 7] --> `precisions` = [0.25], `recalls` =
- [1.0].
-
- Args:
- positive_ranks: 1D NumPy integer array, zero-indexed.
- desired_pr_ranks: List of integers containing the desired precision/recall
- ranks to be reported. Eg, if precision@1/recall@1 and
- precision@10/recall@10 are desired, this should be set to [1, 10].
-
- Returns:
- precisions: Precision @ `desired_pr_ranks` (NumPy array of
- floats, with shape [len(desired_pr_ranks)]).
- recalls: Recall @ `desired_pr_ranks` (NumPy array of floats, with
- shape [len(desired_pr_ranks)]).
- """
- num_desired_pr_ranks = len(desired_pr_ranks)
- precisions = np.zeros([num_desired_pr_ranks])
- recalls = np.zeros([num_desired_pr_ranks])
-
- num_expected_positives = len(positive_ranks)
- if not num_expected_positives:
- return precisions, recalls
-
- positive_ranks_one_indexed = positive_ranks + 1
- for i, desired_pr_rank in enumerate(desired_pr_ranks):
- recalls[i] = np.sum(
- positive_ranks_one_indexed <= desired_pr_rank) / num_expected_positives
-
- # If `desired_pr_rank` is larger than last positive's rank, only compute
- # precision with respect to last positive's position.
- precision_rank = min(max(positive_ranks_one_indexed), desired_pr_rank)
- precisions[i] = np.sum(
- positive_ranks_one_indexed <= precision_rank) / precision_rank
-
- return precisions, recalls
-
-
-def ComputeMetrics(sorted_index_ids, ground_truth, desired_pr_ranks):
- """Computes metrics for retrieval results on the Revisited datasets.
-
- If there are no valid ground-truth index images for a given query, the metric
- results for the given query (`average_precisions`, `precisions` and `recalls`)
- are set to NaN, and they are not taken into account when computing the
- aggregated metrics (`mean_average_precision`, `mean_precisions` and
- `mean_recalls`) over all queries.
-
- Args:
- sorted_index_ids: Integer NumPy array of shape [#queries, #index_images].
- For each query, contains an array denoting the most relevant index images,
- sorted from most to least relevant.
- ground_truth: List containing ground-truth information for dataset. Each
- entry is a dict corresponding to the ground-truth information for a query.
- The dict has keys 'ok' and 'junk', mapping to a NumPy array of integers.
- desired_pr_ranks: List of integers containing the desired precision/recall
- ranks to be reported. Eg, if precision@1/recall@1 and
- precision@10/recall@10 are desired, this should be set to [1, 10]. The
- largest item should be <= #index_images.
-
- Returns:
- mean_average_precision: Mean average precision (float).
- mean_precisions: Mean precision @ `desired_pr_ranks` (NumPy array of
- floats, with shape [len(desired_pr_ranks)]).
- mean_recalls: Mean recall @ `desired_pr_ranks` (NumPy array of floats, with
- shape [len(desired_pr_ranks)]).
- average_precisions: Average precision for each query (NumPy array of floats,
- with shape [#queries]).
- precisions: Precision @ `desired_pr_ranks`, for each query (NumPy array of
- floats, with shape [#queries, len(desired_pr_ranks)]).
- recalls: Recall @ `desired_pr_ranks`, for each query (NumPy array of
- floats, with shape [#queries, len(desired_pr_ranks)]).
-
- Raises:
- ValueError: If largest desired PR rank in `desired_pr_ranks` >
- #index_images.
- """
- num_queries, num_index_images = sorted_index_ids.shape
- num_desired_pr_ranks = len(desired_pr_ranks)
-
- sorted_desired_pr_ranks = sorted(desired_pr_ranks)
-
- if sorted_desired_pr_ranks[-1] > num_index_images:
- raise ValueError(
- 'Requested PR ranks up to %d, however there are only %d images' %
- (sorted_desired_pr_ranks[-1], num_index_images))
-
- # Instantiate all outputs, then loop over each query and gather metrics.
- mean_average_precision = 0.0
- mean_precisions = np.zeros([num_desired_pr_ranks])
- mean_recalls = np.zeros([num_desired_pr_ranks])
- average_precisions = np.zeros([num_queries])
- precisions = np.zeros([num_queries, num_desired_pr_ranks])
- recalls = np.zeros([num_queries, num_desired_pr_ranks])
- num_empty_gt_queries = 0
- for i in range(num_queries):
- ok_index_images = ground_truth[i]['ok']
- junk_index_images = ground_truth[i]['junk']
-
- if not ok_index_images.size:
- average_precisions[i] = float('nan')
- precisions[i, :] = float('nan')
- recalls[i, :] = float('nan')
- num_empty_gt_queries += 1
- continue
-
- positive_ranks = np.arange(num_index_images)[np.in1d(
- sorted_index_ids[i], ok_index_images)]
- junk_ranks = np.arange(num_index_images)[np.in1d(sorted_index_ids[i],
- junk_index_images)]
-
- adjusted_positive_ranks = AdjustPositiveRanks(positive_ranks, junk_ranks)
-
- average_precisions[i] = ComputeAveragePrecision(adjusted_positive_ranks)
- precisions[i, :], recalls[i, :] = ComputePRAtRanks(adjusted_positive_ranks,
- desired_pr_ranks)
-
- mean_average_precision += average_precisions[i]
- mean_precisions += precisions[i, :]
- mean_recalls += recalls[i, :]
-
- # Normalize aggregated metrics by number of queries.
- num_valid_queries = num_queries - num_empty_gt_queries
- mean_average_precision /= num_valid_queries
- mean_precisions /= num_valid_queries
- mean_recalls /= num_valid_queries
-
- return (mean_average_precision, mean_precisions, mean_recalls,
- average_precisions, precisions, recalls)
-
-
-def SaveMetricsFile(mean_average_precision, mean_precisions, mean_recalls,
- pr_ranks, output_path):
- """Saves aggregated retrieval metrics to text file.
-
- Args:
- mean_average_precision: Dict mapping each dataset protocol to a float.
- mean_precisions: Dict mapping each dataset protocol to a NumPy array of
- floats with shape [len(pr_ranks)].
- mean_recalls: Dict mapping each dataset protocol to a NumPy array of floats
- with shape [len(pr_ranks)].
- pr_ranks: List of integers.
- output_path: Full file path.
- """
- with tf.io.gfile.GFile(output_path, 'w') as f:
- for k in sorted(mean_average_precision.keys()):
- f.write('{}\n mAP={}\n mP@k{} {}\n mR@k{} {}\n'.format(
- k, np.around(mean_average_precision[k] * 100, decimals=2),
- np.array(pr_ranks), np.around(mean_precisions[k] * 100, decimals=2),
- np.array(pr_ranks), np.around(mean_recalls[k] * 100, decimals=2)))
-
-
-def _ParseSpaceSeparatedStringsInBrackets(line, prefixes, ind):
- """Parses line containing space-separated strings in brackets.
-
- Args:
- line: String, containing line in metrics file with mP@k or mR@k figures.
- prefixes: Tuple/list of strings, containing valid prefixes.
- ind: Integer indicating which field within brackets is parsed.
-
- Yields:
- entry: String format entry.
-
- Raises:
- ValueError: If input line does not contain a valid prefix.
- """
- for prefix in prefixes:
- if line.startswith(prefix):
- line = line[len(prefix):]
- break
- else:
- raise ValueError('Line %s is malformed, cannot find valid prefixes' % line)
-
- for entry in line.split('[')[ind].split(']')[0].split():
- yield entry
-
-
-def _ParsePrRanks(line):
- """Parses PR ranks from mP@k line in metrics file.
-
- Args:
- line: String, containing line in metrics file with mP@k figures.
-
- Returns:
- pr_ranks: List of integers, containing used ranks.
-
- Raises:
- ValueError: If input line is malformed.
- """
- return [
- int(pr_rank) for pr_rank in _ParseSpaceSeparatedStringsInBrackets(
- line, [' mP@k['], 0) if pr_rank
- ]
-
-
-def _ParsePrScores(line, num_pr_ranks):
- """Parses PR scores from line in metrics file.
-
- Args:
- line: String, containing line in metrics file with mP@k or mR@k figures.
- num_pr_ranks: Integer, number of scores that should be in output list.
-
- Returns:
- pr_scores: List of floats, containing scores.
-
- Raises:
- ValueError: If input line is malformed.
- """
- pr_scores = [
- float(pr_score) for pr_score in _ParseSpaceSeparatedStringsInBrackets(
- line, (' mP@k[', ' mR@k['), 1) if pr_score
- ]
-
- if len(pr_scores) != num_pr_ranks:
- raise ValueError('Line %s is malformed, expected %d scores but found %d' %
- (line, num_pr_ranks, len(pr_scores)))
-
- return pr_scores
-
-
-def ReadMetricsFile(metrics_path):
- """Reads aggregated retrieval metrics from text file.
-
- Args:
- metrics_path: Full file path, containing aggregated retrieval metrics.
-
- Returns:
- mean_average_precision: Dict mapping each dataset protocol to a float.
- pr_ranks: List of integer ranks used in aggregated recall/precision metrics.
- mean_precisions: Dict mapping each dataset protocol to a NumPy array of
- floats with shape [len(`pr_ranks`)].
- mean_recalls: Dict mapping each dataset protocol to a NumPy array of floats
- with shape [len(`pr_ranks`)].
-
- Raises:
- ValueError: If input file is malformed.
- """
- with tf.io.gfile.GFile(metrics_path, 'r') as f:
- file_contents_stripped = [l.rstrip() for l in f]
-
- if len(file_contents_stripped) % 4:
- raise ValueError(
- 'Malformed input %s: number of lines must be a multiple of 4, '
- 'but it is %d' % (metrics_path, len(file_contents_stripped)))
-
- mean_average_precision = {}
- pr_ranks = []
- mean_precisions = {}
- mean_recalls = {}
- protocols = set()
- for i in range(0, len(file_contents_stripped), 4):
- protocol = file_contents_stripped[i]
- if protocol in protocols:
- raise ValueError(
- 'Malformed input %s: protocol %s is found a second time' %
- (metrics_path, protocol))
- protocols.add(protocol)
-
- # Parse mAP.
- mean_average_precision[protocol] = float(
- file_contents_stripped[i + 1].split('=')[1]) / 100.0
-
- # Parse (or check consistency of) pr_ranks.
- parsed_pr_ranks = _ParsePrRanks(file_contents_stripped[i + 2])
- if not pr_ranks:
- pr_ranks = parsed_pr_ranks
- else:
- if parsed_pr_ranks != pr_ranks:
- raise ValueError('Malformed input %s: inconsistent PR ranks' %
- metrics_path)
-
- # Parse mean precisions.
- mean_precisions[protocol] = np.array(
- _ParsePrScores(file_contents_stripped[i + 2], len(pr_ranks)),
- dtype=float) / 100.0
-
- # Parse mean recalls.
- mean_recalls[protocol] = np.array(
- _ParsePrScores(file_contents_stripped[i + 3], len(pr_ranks)),
- dtype=float) / 100.0
-
- return mean_average_precision, pr_ranks, mean_precisions, mean_recalls
diff --git a/research/delf/delf/python/detect_to_retrieve/dataset_test.py b/research/delf/delf/python/detect_to_retrieve/dataset_test.py
deleted file mode 100644
index 8e742703b04210787ede0bfc945a9f305d59efc7..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/dataset_test.py
+++ /dev/null
@@ -1,288 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for the python library parsing Revisited Oxford/Paris datasets."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import flags
-import numpy as np
-import tensorflow as tf
-
-from delf.python.detect_to_retrieve import dataset
-
-FLAGS = flags.FLAGS
-
-
-class DatasetTest(tf.test.TestCase):
-
- def testParseEasyMediumHardGroundTruth(self):
- # Define input.
- ground_truth = [{
- 'easy': np.array([10, 56, 100]),
- 'hard': np.array([0]),
- 'junk': np.array([6, 90])
- }, {
- 'easy': np.array([], dtype='int64'),
- 'hard': [5],
- 'junk': [99, 100]
- }, {
- 'easy': [33],
- 'hard': [66, 99],
- 'junk': np.array([], dtype='int64')
- }]
-
- # Run tested function.
- (easy_ground_truth, medium_ground_truth,
- hard_ground_truth) = dataset.ParseEasyMediumHardGroundTruth(ground_truth)
-
- # Define expected outputs.
- expected_easy_ground_truth = [{
- 'ok': np.array([10, 56, 100]),
- 'junk': np.array([6, 90, 0])
- }, {
- 'ok': np.array([], dtype='int64'),
- 'junk': np.array([99, 100, 5])
- }, {
- 'ok': np.array([33]),
- 'junk': np.array([66, 99])
- }]
- expected_medium_ground_truth = [{
- 'ok': np.array([10, 56, 100, 0]),
- 'junk': np.array([6, 90])
- }, {
- 'ok': np.array([5]),
- 'junk': np.array([99, 100])
- }, {
- 'ok': np.array([33, 66, 99]),
- 'junk': np.array([], dtype='int64')
- }]
- expected_hard_ground_truth = [{
- 'ok': np.array([0]),
- 'junk': np.array([6, 90, 10, 56, 100])
- }, {
- 'ok': np.array([5]),
- 'junk': np.array([99, 100])
- }, {
- 'ok': np.array([66, 99]),
- 'junk': np.array([33])
- }]
-
- # Compare actual versus expected.
- def _AssertListOfDictsOfArraysAreEqual(ground_truth, expected_ground_truth):
- """Helper function to compare ground-truth data.
-
- Args:
- ground_truth: List of dicts of arrays.
- expected_ground_truth: List of dicts of arrays.
- """
- self.assertEqual(len(ground_truth), len(expected_ground_truth))
-
- for i, ground_truth_entry in enumerate(ground_truth):
- self.assertEqual(sorted(ground_truth_entry.keys()), ['junk', 'ok'])
- self.assertAllEqual(ground_truth_entry['junk'],
- expected_ground_truth[i]['junk'])
- self.assertAllEqual(ground_truth_entry['ok'],
- expected_ground_truth[i]['ok'])
-
- _AssertListOfDictsOfArraysAreEqual(easy_ground_truth,
- expected_easy_ground_truth)
- _AssertListOfDictsOfArraysAreEqual(medium_ground_truth,
- expected_medium_ground_truth)
- _AssertListOfDictsOfArraysAreEqual(hard_ground_truth,
- expected_hard_ground_truth)
-
- def testAdjustPositiveRanksWorks(self):
- # Define inputs.
- positive_ranks = np.array([0, 2, 6, 10, 20])
- junk_ranks = np.array([1, 8, 9, 30])
-
- # Run tested function.
- adjusted_positive_ranks = dataset.AdjustPositiveRanks(
- positive_ranks, junk_ranks)
-
- # Define expected output.
- expected_adjusted_positive_ranks = [0, 1, 5, 7, 17]
-
- # Compare actual versus expected.
- self.assertAllEqual(adjusted_positive_ranks,
- expected_adjusted_positive_ranks)
-
- def testComputeAveragePrecisionWorks(self):
- # Define input.
- positive_ranks = [0, 2, 5]
-
- # Run tested function.
- average_precision = dataset.ComputeAveragePrecision(positive_ranks)
-
- # Define expected output.
- expected_average_precision = 0.677778
-
- # Compare actual versus expected.
- self.assertAllClose(average_precision, expected_average_precision)
-
- def testComputePRAtRanksWorks(self):
- # Define inputs.
- positive_ranks = np.array([0, 2, 5])
- desired_pr_ranks = np.array([1, 5, 10])
-
- # Run tested function.
- precisions, recalls = dataset.ComputePRAtRanks(positive_ranks,
- desired_pr_ranks)
-
- # Define expected outputs.
- expected_precisions = [1.0, 0.4, 0.5]
- expected_recalls = [0.333333, 0.666667, 1.0]
-
- # Compare actual versus expected.
- self.assertAllClose(precisions, expected_precisions)
- self.assertAllClose(recalls, expected_recalls)
-
- def testComputeMetricsWorks(self):
- # Define inputs: 3 queries. For the last one, there are no expected images
- # to be retrieved
- sorted_index_ids = np.array([[4, 2, 0, 1, 3], [0, 2, 4, 1, 3],
- [0, 1, 2, 3, 4]])
- ground_truth = [{
- 'ok': np.array([0, 1]),
- 'junk': np.array([2])
- }, {
- 'ok': np.array([0, 4]),
- 'junk': np.array([], dtype='int64')
- }, {
- 'ok': np.array([], dtype='int64'),
- 'junk': np.array([], dtype='int64')
- }]
- desired_pr_ranks = [1, 2, 5]
-
- # Run tested function.
- (mean_average_precision, mean_precisions, mean_recalls, average_precisions,
- precisions, recalls) = dataset.ComputeMetrics(sorted_index_ids,
- ground_truth,
- desired_pr_ranks)
-
- # Define expected outputs.
- expected_mean_average_precision = 0.604167
- expected_mean_precisions = [0.5, 0.5, 0.666667]
- expected_mean_recalls = [0.25, 0.5, 1.0]
- expected_average_precisions = [0.416667, 0.791667, float('nan')]
- expected_precisions = [[0.0, 0.5, 0.666667], [1.0, 0.5, 0.666667],
- [float('nan'),
- float('nan'),
- float('nan')]]
- expected_recalls = [[0.0, 0.5, 1.0], [0.5, 0.5, 1.0],
- [float('nan'), float('nan'),
- float('nan')]]
-
- # Compare actual versus expected.
- self.assertAllClose(mean_average_precision, expected_mean_average_precision)
- self.assertAllClose(mean_precisions, expected_mean_precisions)
- self.assertAllClose(mean_recalls, expected_mean_recalls)
- self.assertAllClose(average_precisions, expected_average_precisions)
- self.assertAllClose(precisions, expected_precisions)
- self.assertAllClose(recalls, expected_recalls)
-
- def testSaveMetricsFileWorks(self):
- # Define inputs.
- mean_average_precision = {'hard': 0.7, 'medium': 0.9}
- mean_precisions = {
- 'hard': np.array([1.0, 0.8]),
- 'medium': np.array([1.0, 1.0])
- }
- mean_recalls = {
- 'hard': np.array([0.5, 0.8]),
- 'medium': np.array([0.5, 1.0])
- }
- pr_ranks = [1, 5]
- output_path = os.path.join(FLAGS.test_tmpdir, 'metrics.txt')
-
- # Run tested function.
- dataset.SaveMetricsFile(mean_average_precision, mean_precisions,
- mean_recalls, pr_ranks, output_path)
-
- # Define expected results.
- expected_metrics = ('hard\n'
- ' mAP=70.0\n'
- ' mP@k[1 5] [100. 80.]\n'
- ' mR@k[1 5] [50. 80.]\n'
- 'medium\n'
- ' mAP=90.0\n'
- ' mP@k[1 5] [100. 100.]\n'
- ' mR@k[1 5] [ 50. 100.]\n')
-
- # Parse actual results, and compare to expected.
- with tf.io.gfile.GFile(output_path) as f:
- metrics = f.read()
-
- self.assertEqual(metrics, expected_metrics)
-
- def testSaveAndReadMetricsWorks(self):
- # Define inputs.
- mean_average_precision = {'hard': 0.7, 'medium': 0.9}
- mean_precisions = {
- 'hard': np.array([1.0, 0.8]),
- 'medium': np.array([1.0, 1.0])
- }
- mean_recalls = {
- 'hard': np.array([0.5, 0.8]),
- 'medium': np.array([0.5, 1.0])
- }
- pr_ranks = [1, 5]
- output_path = os.path.join(FLAGS.test_tmpdir, 'metrics.txt')
-
- # Run tested functions.
- dataset.SaveMetricsFile(mean_average_precision, mean_precisions,
- mean_recalls, pr_ranks, output_path)
- (read_mean_average_precision, read_pr_ranks, read_mean_precisions,
- read_mean_recalls) = dataset.ReadMetricsFile(output_path)
-
- # Compares actual and expected metrics.
- self.assertEqual(read_mean_average_precision, mean_average_precision)
- self.assertEqual(read_pr_ranks, pr_ranks)
- self.assertEqual(read_mean_precisions.keys(), mean_precisions.keys())
- self.assertAllEqual(read_mean_precisions['hard'], mean_precisions['hard'])
- self.assertAllEqual(read_mean_precisions['medium'],
- mean_precisions['medium'])
- self.assertEqual(read_mean_recalls.keys(), mean_recalls.keys())
- self.assertAllEqual(read_mean_recalls['hard'], mean_recalls['hard'])
- self.assertAllEqual(read_mean_recalls['medium'], mean_recalls['medium'])
-
- def testReadMetricsWithRepeatedProtocolFails(self):
- # Define inputs.
- input_path = os.path.join(FLAGS.test_tmpdir, 'metrics.txt')
- with tf.io.gfile.GFile(input_path, 'w') as f:
- f.write('hard\n'
- ' mAP=70.0\n'
- ' mP@k[1 5] [ 100. 80.]\n'
- ' mR@k[1 5] [ 50. 80.]\n'
- 'medium\n'
- ' mAP=90.0\n'
- ' mP@k[1 5] [ 100. 100.]\n'
- ' mR@k[1 5] [ 50. 100.]\n'
- 'medium\n'
- ' mAP=90.0\n'
- ' mP@k[1 5] [ 100. 100.]\n'
- ' mR@k[1 5] [ 50. 100.]\n')
-
- # Run tested functions.
- with self.assertRaisesRegex(ValueError, 'Malformed input'):
- dataset.ReadMetricsFile(input_path)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/detect_to_retrieve/delf_gld_config.pbtxt b/research/delf/delf/python/detect_to_retrieve/delf_gld_config.pbtxt
deleted file mode 100644
index 046aed766ce8cee4b6309c8385d451cf20ad633a..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/delf_gld_config.pbtxt
+++ /dev/null
@@ -1,25 +0,0 @@
-model_path: "parameters/delf_gld_20190411/model"
-image_scales: .25
-image_scales: .3536
-image_scales: .5
-image_scales: .7071
-image_scales: 1.0
-image_scales: 1.4142
-image_scales: 2.0
-delf_local_config {
- use_pca: true
- # Note that for the exported model provided as an example, layer_name and
- # iou_threshold are hard-coded in the checkpoint. So, the layer_name and
- # iou_threshold variables here have no effect on the provided
- # extract_features.py script.
- layer_name: "resnet_v1_50/block3"
- iou_threshold: 1.0
- max_feature_num: 1000
- score_threshold: 100.0
- pca_parameters {
- mean_path: "parameters/delf_gld_20190411/pca/mean.datum"
- projection_matrix_path: "parameters/delf_gld_20190411/pca/pca_proj_mat.datum"
- pca_dim: 128
- use_whitening: false
- }
-}
diff --git a/research/delf/delf/python/detect_to_retrieve/extract_aggregation.py b/research/delf/delf/python/detect_to_retrieve/extract_aggregation.py
deleted file mode 100644
index f9a0fb3e6c62c0adc583ad3b30b809f36742d586..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/extract_aggregation.py
+++ /dev/null
@@ -1,113 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Extracts aggregation for images from Revisited Oxford/Paris datasets.
-
-The program checks if the aggregated representation for an image already exists,
-and skips computation for those.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import sys
-
-from tensorflow.python.platform import app
-from delf.python.detect_to_retrieve import aggregation_extraction
-from delf.python.detect_to_retrieve import dataset
-
-cmd_args = None
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read list of images from dataset file.
- print('Reading list of images from dataset file...')
- query_list, index_list, _ = dataset.ReadDatasetFile(
- cmd_args.dataset_file_path)
- if cmd_args.use_query_images:
- image_list = query_list
- else:
- image_list = index_list
- num_images = len(image_list)
- print('done! Found %d images' % num_images)
-
- aggregation_extraction.ExtractAggregatedRepresentationsToFiles(
- image_names=image_list,
- features_dir=cmd_args.features_dir,
- aggregation_config_path=cmd_args.aggregation_config_path,
- mapping_path=cmd_args.index_mapping_path,
- output_aggregation_dir=cmd_args.output_aggregation_dir)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--aggregation_config_path',
- type=str,
- default='/tmp/aggregation_config.pbtxt',
- help="""
- Path to AggregationConfig proto text file with configuration to be used
- for extraction.
- """)
- parser.add_argument(
- '--dataset_file_path',
- type=str,
- default='/tmp/gnd_roxford5k.mat',
- help="""
- Dataset file for Revisited Oxford or Paris dataset, in .mat format.
- """)
- parser.add_argument(
- '--use_query_images',
- type=lambda x: (str(x).lower() == 'true'),
- default=False,
- help="""
- If True, processes the query images of the dataset. If False, processes
- the database (ie, index) images.
- """)
- parser.add_argument(
- '--features_dir',
- type=str,
- default='/tmp/features',
- help="""
- Directory where image features are located, all in .delf format.
- """)
- parser.add_argument(
- '--index_mapping_path',
- type=str,
- default='',
- help="""
- Optional CSV file which maps each .delf file name to the index image ID
- and detected box ID. If regional aggregation is performed, this should be
- set. Otherwise, this is ignored.
- Usually this file is obtained as an output from the
- `extract_index_boxes_and_features.py` script.
- """)
- parser.add_argument(
- '--output_aggregation_dir',
- type=str,
- default='/tmp/aggregation',
- help="""
- Directory where aggregation output will be written to. Each image's
- features will be written to a file with same name, and extension replaced
- by one of
- ['.vlad', '.asmk', '.asmk_star', '.rvlad', '.rasmk', '.rasmk_star'].
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/detect_to_retrieve/extract_index_boxes_and_features.py b/research/delf/delf/python/detect_to_retrieve/extract_index_boxes_and_features.py
deleted file mode 100644
index 2b891de4b0b093aa723c0dce547c2722ee475d7e..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/extract_index_boxes_and_features.py
+++ /dev/null
@@ -1,151 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Extracts DELF and boxes from the Revisited Oxford/Paris index datasets.
-
-Boxes are saved to .boxes files. DELF features are extracted for the
-entire image and saved into .delf files. In addition, DELF features
-are extracted for each high-confidence bounding box in the image, and saved into
-files named _0.delf, _1.delf, etc.
-
-The program checks if descriptors/boxes already exist, and skips computation for
-those.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-
-from tensorflow.python.platform import app
-from delf.python.detect_to_retrieve import boxes_and_features_extraction
-from delf.python.detect_to_retrieve import dataset
-
-cmd_args = None
-
-_IMAGE_EXTENSION = '.jpg'
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read list of index images from dataset file.
- print('Reading list of index images from dataset file...')
- _, index_list, _ = dataset.ReadDatasetFile(cmd_args.dataset_file_path)
- num_images = len(index_list)
- print('done! Found %d images' % num_images)
-
- # Compose list of image paths.
- image_paths = [
- os.path.join(cmd_args.images_dir, index_image_name + _IMAGE_EXTENSION)
- for index_image_name in index_list
- ]
-
- # Extract boxes/features and save them to files.
- boxes_and_features_extraction.ExtractBoxesAndFeaturesToFiles(
- image_names=index_list,
- image_paths=image_paths,
- delf_config_path=cmd_args.delf_config_path,
- detector_model_dir=cmd_args.detector_model_dir,
- detector_thresh=cmd_args.detector_thresh,
- output_features_dir=cmd_args.output_features_dir,
- output_boxes_dir=cmd_args.output_boxes_dir,
- output_mapping=cmd_args.output_index_mapping)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--delf_config_path',
- type=str,
- default='/tmp/delf_config_example.pbtxt',
- help="""
- Path to DelfConfig proto text file with configuration to be used for DELF
- extraction.
- """)
- parser.add_argument(
- '--detector_model_dir',
- type=str,
- default='/tmp/detector_model',
- help="""
- Directory where detector SavedModel is located.
- """)
- parser.add_argument(
- '--detector_thresh',
- type=float,
- default=0.1,
- help="""
- Threshold used to decide if an image's detected box undergoes feature
- extraction. For all detected boxes with detection score larger than this,
- a .delf file is saved containing the box features. Note that this
- threshold is used only to select which boxes are used in feature
- extraction; all detected boxes are actually saved in the .boxes file, even
- those with score lower than detector_thresh.
- """)
- parser.add_argument(
- '--dataset_file_path',
- type=str,
- default='/tmp/gnd_roxford5k.mat',
- help="""
- Dataset file for Revisited Oxford or Paris dataset, in .mat format.
- """)
- parser.add_argument(
- '--images_dir',
- type=str,
- default='/tmp/images',
- help="""
- Directory where dataset images are located, all in .jpg format.
- """)
- parser.add_argument(
- '--output_boxes_dir',
- type=str,
- default='/tmp/boxes',
- help="""
- Directory where detected boxes will be written to. Each image's boxes
- will be written to a file with same name, and extension replaced by
- .boxes.
- """)
- parser.add_argument(
- '--output_features_dir',
- type=str,
- default='/tmp/features',
- help="""
- Directory where DELF features will be written to. Each image's features
- will be written to a file with same name, and extension replaced by .delf,
- eg: .delf. In addition, DELF features are extracted for each
- high-confidence bounding box in the image, and saved into files named
- _0.delf, _1.delf, etc.
- """)
- parser.add_argument(
- '--output_index_mapping',
- type=str,
- default='/tmp/index_mapping.csv',
- help="""
- CSV file which maps each .delf file name to the index image ID and
- detected box ID. The format is 'name,index_image_id,box_id', including a
- header. The 'name' refers to the .delf file name without extension.
-
- For example, a few lines may be like:
- 'radcliffe_camera_000158,2,-1'
- 'radcliffe_camera_000158_0,2,0'
- 'radcliffe_camera_000158_1,2,1'
- 'radcliffe_camera_000158_2,2,2'
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/detect_to_retrieve/extract_query_features.py b/research/delf/delf/python/detect_to_retrieve/extract_query_features.py
deleted file mode 100644
index a0812b191265ec6e5350acf989432747d196a519..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/extract_query_features.py
+++ /dev/null
@@ -1,137 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Extracts DELF features for query images from Revisited Oxford/Paris datasets.
-
-Note that query images are cropped before feature extraction, as required by the
-evaluation protocols of these datasets.
-
-The program checks if descriptors already exist, and skips computation for
-those.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-import time
-
-import numpy as np
-import tensorflow as tf
-
-from google.protobuf import text_format
-from tensorflow.python.platform import app
-from delf import delf_config_pb2
-from delf import feature_io
-from delf import utils
-from delf.python.detect_to_retrieve import dataset
-from delf import extractor
-
-cmd_args = None
-
-# Extensions.
-_DELF_EXTENSION = '.delf'
-_IMAGE_EXTENSION = '.jpg'
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read list of query images from dataset file.
- print('Reading list of query images and boxes from dataset file...')
- query_list, _, ground_truth = dataset.ReadDatasetFile(
- cmd_args.dataset_file_path)
- num_images = len(query_list)
- print(f'done! Found {num_images} images')
-
- # Parse DelfConfig proto.
- config = delf_config_pb2.DelfConfig()
- with tf.io.gfile.GFile(cmd_args.delf_config_path, 'r') as f:
- text_format.Merge(f.read(), config)
-
- # Create output directory if necessary.
- if not tf.io.gfile.exists(cmd_args.output_features_dir):
- tf.io.gfile.makedirs(cmd_args.output_features_dir)
-
- extractor_fn = extractor.MakeExtractor(config)
-
- start = time.time()
- for i in range(num_images):
- query_image_name = query_list[i]
- input_image_filename = os.path.join(cmd_args.images_dir,
- query_image_name + _IMAGE_EXTENSION)
- output_feature_filename = os.path.join(
- cmd_args.output_features_dir, query_image_name + _DELF_EXTENSION)
- if tf.io.gfile.exists(output_feature_filename):
- print(f'Skipping {query_image_name}')
- continue
-
- # Crop query image according to bounding box.
- bbox = [int(round(b)) for b in ground_truth[i]['bbx']]
- im = np.array(utils.RgbLoader(input_image_filename).crop(bbox))
-
- # Extract and save features.
- extracted_features = extractor_fn(im)
- locations_out = extracted_features['local_features']['locations']
- descriptors_out = extracted_features['local_features']['descriptors']
- feature_scales_out = extracted_features['local_features']['scales']
- attention_out = extracted_features['local_features']['attention']
-
- feature_io.WriteToFile(output_feature_filename, locations_out,
- feature_scales_out, descriptors_out,
- attention_out)
-
- elapsed = (time.time() - start)
- print('Processed %d query images in %f seconds' % (num_images, elapsed))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--delf_config_path',
- type=str,
- default='/tmp/delf_config_example.pbtxt',
- help="""
- Path to DelfConfig proto text file with configuration to be used for DELF
- extraction.
- """)
- parser.add_argument(
- '--dataset_file_path',
- type=str,
- default='/tmp/gnd_roxford5k.mat',
- help="""
- Dataset file for Revisited Oxford or Paris dataset, in .mat format.
- """)
- parser.add_argument(
- '--images_dir',
- type=str,
- default='/tmp/images',
- help="""
- Directory where dataset images are located, all in .jpg format.
- """)
- parser.add_argument(
- '--output_features_dir',
- type=str,
- default='/tmp/features',
- help="""
- Directory where DELF features will be written to. Each image's features
- will be written to a file with same name, and extension replaced by .delf.
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/detect_to_retrieve/image_reranking.py b/research/delf/delf/python/detect_to_retrieve/image_reranking.py
deleted file mode 100644
index 60c29cc18a4436815c721855da0ca4577b06e6c4..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/image_reranking.py
+++ /dev/null
@@ -1,279 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Library to re-rank images based on geometric verification."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import io
-import os
-
-import matplotlib.pyplot as plt
-import numpy as np
-from scipy import spatial
-from skimage import feature
-from skimage import measure
-from skimage import transform
-
-from delf import feature_io
-
-# Extensions.
-_DELF_EXTENSION = '.delf'
-
-# Pace to log.
-_STATUS_CHECK_GV_ITERATIONS = 10
-
-# Re-ranking / geometric verification parameters.
-_NUM_TO_RERANK = 100
-_NUM_RANSAC_TRIALS = 1000
-_MIN_RANSAC_SAMPLES = 3
-
-
-def MatchFeatures(query_locations,
- query_descriptors,
- index_image_locations,
- index_image_descriptors,
- ransac_seed=None,
- feature_distance_threshold=0.9,
- ransac_residual_threshold=10.0,
- query_im_array=None,
- index_im_array=None,
- query_im_scale_factors=None,
- index_im_scale_factors=None):
- """Matches local features using geometric verification.
-
- First, finds putative local feature matches by matching `query_descriptors`
- against a KD-tree from the `index_image_descriptors`. Then, attempts to fit an
- affine transformation between the putative feature corresponces using their
- locations.
-
- Args:
- query_locations: Locations of local features for query image. NumPy array of
- shape [#query_features, 2].
- query_descriptors: Descriptors of local features for query image. NumPy
- array of shape [#query_features, depth].
- index_image_locations: Locations of local features for index image. NumPy
- array of shape [#index_image_features, 2].
- index_image_descriptors: Descriptors of local features for index image.
- NumPy array of shape [#index_image_features, depth].
- ransac_seed: Seed used by RANSAC. If None (default), no seed is provided.
- feature_distance_threshold: Distance threshold below which a pair of
- features is considered a potential match, and will be fed into RANSAC.
- ransac_residual_threshold: Residual error threshold for considering matches
- as inliers, used in RANSAC algorithm.
- query_im_array: Optional. If not None, contains a NumPy array with the query
- image, used to produce match visualization, if there is a match.
- index_im_array: Optional. Same as `query_im_array`, but for index image.
- query_im_scale_factors: Optional. If not None, contains a NumPy array with
- the query image scales, used to produce match visualization, if there is a
- match. If None and a visualization will be produced, [1.0, 1.0] is used
- (ie, feature locations are not scaled).
- index_im_scale_factors: Optional. Same as `query_im_scale_factors`, but for
- index image.
-
- Returns:
- score: Number of inliers of match. If no match is found, returns 0.
- match_viz_bytes: Encoded image bytes with visualization of the match, if
- there is one, and if `query_im_array` and `index_im_array` are properly
- set. Otherwise, it's an empty bytes string.
-
- Raises:
- ValueError: If local descriptors from query and index images have different
- dimensionalities.
- """
- num_features_query = query_locations.shape[0]
- num_features_index_image = index_image_locations.shape[0]
- if not num_features_query or not num_features_index_image:
- return 0, b''
-
- local_feature_dim = query_descriptors.shape[1]
- if index_image_descriptors.shape[1] != local_feature_dim:
- raise ValueError(
- 'Local feature dimensionality is not consistent for query and index '
- 'images.')
-
- # Find nearest-neighbor matches using a KD tree.
- index_image_tree = spatial.cKDTree(index_image_descriptors)
- _, indices = index_image_tree.query(
- query_descriptors, distance_upper_bound=feature_distance_threshold)
-
- # Select feature locations for putative matches.
- query_locations_to_use = np.array([
- query_locations[i,]
- for i in range(num_features_query)
- if indices[i] != num_features_index_image
- ])
- index_image_locations_to_use = np.array([
- index_image_locations[indices[i],]
- for i in range(num_features_query)
- if indices[i] != num_features_index_image
- ])
-
- # If there are not enough putative matches, early return 0.
- if query_locations_to_use.shape[0] <= _MIN_RANSAC_SAMPLES:
- return 0, b''
-
- # Perform geometric verification using RANSAC.
- _, inliers = measure.ransac(
- (index_image_locations_to_use, query_locations_to_use),
- transform.AffineTransform,
- min_samples=_MIN_RANSAC_SAMPLES,
- residual_threshold=ransac_residual_threshold,
- max_trials=_NUM_RANSAC_TRIALS,
- random_state=ransac_seed)
- match_viz_bytes = b''
-
- if inliers is None:
- inliers = []
- elif query_im_array is not None and index_im_array is not None:
- if query_im_scale_factors is None:
- query_im_scale_factors = [1.0, 1.0]
- if index_im_scale_factors is None:
- index_im_scale_factors = [1.0, 1.0]
- inlier_idxs = np.nonzero(inliers)[0]
- _, ax = plt.subplots()
- ax.axis('off')
- ax.xaxis.set_major_locator(plt.NullLocator())
- ax.yaxis.set_major_locator(plt.NullLocator())
- plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
- plt.margins(0, 0)
- feature.plot_matches(
- ax,
- query_im_array,
- index_im_array,
- query_locations_to_use * query_im_scale_factors,
- index_image_locations_to_use * index_im_scale_factors,
- np.column_stack((inlier_idxs, inlier_idxs)),
- only_matches=True)
-
- match_viz_io = io.BytesIO()
- plt.savefig(match_viz_io, format='jpeg', bbox_inches='tight', pad_inches=0)
- match_viz_bytes = match_viz_io.getvalue()
-
- return sum(inliers), match_viz_bytes
-
-
-def RerankByGeometricVerification(input_ranks,
- initial_scores,
- query_name,
- index_names,
- query_features_dir,
- index_features_dir,
- junk_ids,
- local_feature_extension=_DELF_EXTENSION,
- ransac_seed=None,
- feature_distance_threshold=0.9,
- ransac_residual_threshold=10.0):
- """Re-ranks retrieval results using geometric verification.
-
- Args:
- input_ranks: 1D NumPy array with indices of top-ranked index images, sorted
- from the most to the least similar.
- initial_scores: 1D NumPy array with initial similarity scores between query
- and index images. Entry i corresponds to score for image i.
- query_name: Name for query image (string).
- index_names: List of names for index images (strings).
- query_features_dir: Directory where query local feature file is located
- (string).
- index_features_dir: Directory where index local feature files are located
- (string).
- junk_ids: Set with indices of junk images which should not be considered
- during re-ranking.
- local_feature_extension: String, extension to use for loading local feature
- files.
- ransac_seed: Seed used by RANSAC. If None (default), no seed is provided.
- feature_distance_threshold: Distance threshold below which a pair of local
- features is considered a potential match, and will be fed into RANSAC.
- ransac_residual_threshold: Residual error threshold for considering matches
- as inliers, used in RANSAC algorithm.
-
- Returns:
- output_ranks: 1D NumPy array with index image indices, sorted from the most
- to the least similar according to the geometric verification and initial
- scores.
-
- Raises:
- ValueError: If `input_ranks`, `initial_scores` and `index_names` do not have
- the same number of entries.
- """
- num_index_images = len(index_names)
- if len(input_ranks) != num_index_images:
- raise ValueError('input_ranks and index_names have different number of '
- 'elements: %d vs %d' %
- (len(input_ranks), len(index_names)))
- if len(initial_scores) != num_index_images:
- raise ValueError('initial_scores and index_names have different number of '
- 'elements: %d vs %d' %
- (len(initial_scores), len(index_names)))
-
- # Filter out junk images from list that will be re-ranked.
- input_ranks_for_gv = []
- for ind in input_ranks:
- if ind not in junk_ids:
- input_ranks_for_gv.append(ind)
- num_to_rerank = min(_NUM_TO_RERANK, len(input_ranks_for_gv))
-
- # Load query image features.
- query_features_path = os.path.join(query_features_dir,
- query_name + local_feature_extension)
- query_locations, _, query_descriptors, _, _ = feature_io.ReadFromFile(
- query_features_path)
-
- # Initialize list containing number of inliers and initial similarity scores.
- inliers_and_initial_scores = []
- for i in range(num_index_images):
- inliers_and_initial_scores.append([0, initial_scores[i]])
-
- # Loop over top-ranked images and get results.
- print('Starting to re-rank')
- for i in range(num_to_rerank):
- if i > 0 and i % _STATUS_CHECK_GV_ITERATIONS == 0:
- print('Re-ranking: i = %d out of %d' % (i, num_to_rerank))
-
- index_image_id = input_ranks_for_gv[i]
-
- # Load index image features.
- index_image_features_path = os.path.join(
- index_features_dir,
- index_names[index_image_id] + local_feature_extension)
- (index_image_locations, _, index_image_descriptors, _,
- _) = feature_io.ReadFromFile(index_image_features_path)
-
- inliers_and_initial_scores[index_image_id][0], _ = MatchFeatures(
- query_locations,
- query_descriptors,
- index_image_locations,
- index_image_descriptors,
- ransac_seed=ransac_seed,
- feature_distance_threshold=feature_distance_threshold,
- ransac_residual_threshold=ransac_residual_threshold)
-
- # Sort based on (inliers_score, initial_score).
- def _InliersInitialScoresSorting(k):
- """Helper function to sort list based on two entries.
-
- Args:
- k: Index into `inliers_and_initial_scores`.
-
- Returns:
- Tuple containing inlier score and initial score.
- """
- return (inliers_and_initial_scores[k][0], inliers_and_initial_scores[k][1])
-
- output_ranks = sorted(
- range(num_index_images), key=_InliersInitialScoresSorting, reverse=True)
-
- return output_ranks
diff --git a/research/delf/delf/python/detect_to_retrieve/index_aggregation_config.pbtxt b/research/delf/delf/python/detect_to_retrieve/index_aggregation_config.pbtxt
deleted file mode 100644
index ba7ba4e4956637152d952aff1cccd66da42800f4..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/index_aggregation_config.pbtxt
+++ /dev/null
@@ -1,10 +0,0 @@
-codebook_size: 65536
-feature_dimensionality: 128
-aggregation_type: ASMK_STAR
-use_l2_normalization: false
-codebook_path: "parameters/rparis6k_codebook_65536/k65536_codebook_tfckpt/codebook"
-num_assignments: 1
-use_regional_aggregation: true
-feature_batch_size: 100
-alpha: 3.0
-tau: 0.0
diff --git a/research/delf/delf/python/detect_to_retrieve/perform_retrieval.py b/research/delf/delf/python/detect_to_retrieve/perform_retrieval.py
deleted file mode 100644
index c2034dfb285118f4ed8928f996e031365a3ffbbf..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/perform_retrieval.py
+++ /dev/null
@@ -1,301 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Performs image retrieval on Revisited Oxford/Paris datasets."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-import time
-
-import numpy as np
-import tensorflow as tf
-
-from google.protobuf import text_format
-from tensorflow.python.platform import app
-from delf import aggregation_config_pb2
-from delf import datum_io
-from delf import feature_aggregation_similarity
-from delf.python.detect_to_retrieve import dataset
-from delf.python.detect_to_retrieve import image_reranking
-
-cmd_args = None
-
-# Aliases for aggregation types.
-_VLAD = aggregation_config_pb2.AggregationConfig.VLAD
-_ASMK = aggregation_config_pb2.AggregationConfig.ASMK
-_ASMK_STAR = aggregation_config_pb2.AggregationConfig.ASMK_STAR
-
-# Extensions.
-_VLAD_EXTENSION_SUFFIX = 'vlad'
-_ASMK_EXTENSION_SUFFIX = 'asmk'
-_ASMK_STAR_EXTENSION_SUFFIX = 'asmk_star'
-
-# Precision-recall ranks to use in metric computation.
-_PR_RANKS = (1, 5, 10)
-
-# Pace to log.
-_STATUS_CHECK_LOAD_ITERATIONS = 50
-
-# Output file names.
-_METRICS_FILENAME = 'metrics.txt'
-
-
-def _ReadAggregatedDescriptors(input_dir, image_list, config):
- """Reads aggregated descriptors.
-
- Args:
- input_dir: Directory where aggregated descriptors are located.
- image_list: List of image names for which to load descriptors.
- config: AggregationConfig used for images.
-
- Returns:
- aggregated_descriptors: List containing #images items, each a 1D NumPy
- array.
- visual_words: If using VLAD aggregation, returns an empty list. Otherwise,
- returns a list containing #images items, each a 1D NumPy array.
- """
- # Compose extension of aggregated descriptors.
- extension = '.'
- if config.use_regional_aggregation:
- extension += 'r'
- if config.aggregation_type == _VLAD:
- extension += _VLAD_EXTENSION_SUFFIX
- elif config.aggregation_type == _ASMK:
- extension += _ASMK_EXTENSION_SUFFIX
- elif config.aggregation_type == _ASMK_STAR:
- extension += _ASMK_STAR_EXTENSION_SUFFIX
- else:
- raise ValueError('Invalid aggregation type: %d' % config.aggregation_type)
-
- num_images = len(image_list)
- aggregated_descriptors = []
- visual_words = []
- print('Starting to collect descriptors for %d images...' % num_images)
- start = time.clock()
- for i in range(num_images):
- if i > 0 and i % _STATUS_CHECK_LOAD_ITERATIONS == 0:
- elapsed = (time.clock() - start)
- print('Reading descriptors for image %d out of %d, last %d '
- 'images took %f seconds' %
- (i, num_images, _STATUS_CHECK_LOAD_ITERATIONS, elapsed))
- start = time.clock()
-
- descriptors_filename = image_list[i] + extension
- descriptors_fullpath = os.path.join(input_dir, descriptors_filename)
- if config.aggregation_type == _VLAD:
- aggregated_descriptors.append(datum_io.ReadFromFile(descriptors_fullpath))
- else:
- d, v = datum_io.ReadPairFromFile(descriptors_fullpath)
- if config.aggregation_type == _ASMK_STAR:
- d = d.astype('uint8')
-
- aggregated_descriptors.append(d)
- visual_words.append(v)
-
- return aggregated_descriptors, visual_words
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Parse dataset to obtain query/index images, and ground-truth.
- print('Parsing dataset...')
- query_list, index_list, ground_truth = dataset.ReadDatasetFile(
- cmd_args.dataset_file_path)
- num_query_images = len(query_list)
- num_index_images = len(index_list)
- (_, medium_ground_truth,
- hard_ground_truth) = dataset.ParseEasyMediumHardGroundTruth(ground_truth)
- print('done! Found %d queries and %d index images' %
- (num_query_images, num_index_images))
-
- # Parse AggregationConfig protos.
- query_config = aggregation_config_pb2.AggregationConfig()
- with tf.io.gfile.GFile(cmd_args.query_aggregation_config_path, 'r') as f:
- text_format.Merge(f.read(), query_config)
- index_config = aggregation_config_pb2.AggregationConfig()
- with tf.io.gfile.GFile(cmd_args.index_aggregation_config_path, 'r') as f:
- text_format.Merge(f.read(), index_config)
-
- # Read aggregated descriptors.
- query_aggregated_descriptors, query_visual_words = _ReadAggregatedDescriptors(
- cmd_args.query_aggregation_dir, query_list, query_config)
- index_aggregated_descriptors, index_visual_words = _ReadAggregatedDescriptors(
- cmd_args.index_aggregation_dir, index_list, index_config)
-
- # Create similarity computer.
- similarity_computer = (
- feature_aggregation_similarity.SimilarityAggregatedRepresentation(
- index_config))
-
- # Compute similarity between query and index images, potentially re-ranking
- # with geometric verification.
- ranks_before_gv = np.zeros([num_query_images, num_index_images],
- dtype='int32')
- if cmd_args.use_geometric_verification:
- medium_ranks_after_gv = np.zeros([num_query_images, num_index_images],
- dtype='int32')
- hard_ranks_after_gv = np.zeros([num_query_images, num_index_images],
- dtype='int32')
- for i in range(num_query_images):
- print('Performing retrieval with query %d (%s)...' % (i, query_list[i]))
- start = time.clock()
-
- # Compute similarity between aggregated descriptors.
- similarities = np.zeros([num_index_images])
- for j in range(num_index_images):
- similarities[j] = similarity_computer.ComputeSimilarity(
- query_aggregated_descriptors[i], index_aggregated_descriptors[j],
- query_visual_words[i], index_visual_words[j])
-
- ranks_before_gv[i] = np.argsort(-similarities)
-
- # Re-rank using geometric verification.
- if cmd_args.use_geometric_verification:
- medium_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification(
- ranks_before_gv[i], similarities, query_list[i], index_list,
- cmd_args.query_features_dir, cmd_args.index_features_dir,
- set(medium_ground_truth[i]['junk']))
- hard_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification(
- ranks_before_gv[i], similarities, query_list[i], index_list,
- cmd_args.query_features_dir, cmd_args.index_features_dir,
- set(hard_ground_truth[i]['junk']))
-
- elapsed = (time.clock() - start)
- print('done! Retrieval for query %d took %f seconds' % (i, elapsed))
-
- # Create output directory if necessary.
- if not tf.io.gfile.exists(cmd_args.output_dir):
- tf.io.gfile.makedirs(cmd_args.output_dir)
-
- # Compute metrics.
- medium_metrics = dataset.ComputeMetrics(ranks_before_gv, medium_ground_truth,
- _PR_RANKS)
- hard_metrics = dataset.ComputeMetrics(ranks_before_gv, hard_ground_truth,
- _PR_RANKS)
- if cmd_args.use_geometric_verification:
- medium_metrics_after_gv = dataset.ComputeMetrics(medium_ranks_after_gv,
- medium_ground_truth,
- _PR_RANKS)
- hard_metrics_after_gv = dataset.ComputeMetrics(hard_ranks_after_gv,
- hard_ground_truth, _PR_RANKS)
-
- # Write metrics to file.
- mean_average_precision_dict = {
- 'medium': medium_metrics[0],
- 'hard': hard_metrics[0]
- }
- mean_precisions_dict = {'medium': medium_metrics[1], 'hard': hard_metrics[1]}
- mean_recalls_dict = {'medium': medium_metrics[2], 'hard': hard_metrics[2]}
- if cmd_args.use_geometric_verification:
- mean_average_precision_dict.update({
- 'medium_after_gv': medium_metrics_after_gv[0],
- 'hard_after_gv': hard_metrics_after_gv[0]
- })
- mean_precisions_dict.update({
- 'medium_after_gv': medium_metrics_after_gv[1],
- 'hard_after_gv': hard_metrics_after_gv[1]
- })
- mean_recalls_dict.update({
- 'medium_after_gv': medium_metrics_after_gv[2],
- 'hard_after_gv': hard_metrics_after_gv[2]
- })
- dataset.SaveMetricsFile(mean_average_precision_dict, mean_precisions_dict,
- mean_recalls_dict, _PR_RANKS,
- os.path.join(cmd_args.output_dir, _METRICS_FILENAME))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--index_aggregation_config_path',
- type=str,
- default='/tmp/index_aggregation_config.pbtxt',
- help="""
- Path to index AggregationConfig proto text file. This is used to load the
- aggregated descriptors from the index, and to define the parameters used
- in computing similarity for aggregated descriptors.
- """)
- parser.add_argument(
- '--query_aggregation_config_path',
- type=str,
- default='/tmp/query_aggregation_config.pbtxt',
- help="""
- Path to query AggregationConfig proto text file. This is only used to load
- the aggregated descriptors for the queries.
- """)
- parser.add_argument(
- '--dataset_file_path',
- type=str,
- default='/tmp/gnd_roxford5k.mat',
- help="""
- Dataset file for Revisited Oxford or Paris dataset, in .mat format.
- """)
- parser.add_argument(
- '--index_aggregation_dir',
- type=str,
- default='/tmp/index_aggregation',
- help="""
- Directory where index aggregated descriptors are located.
- """)
- parser.add_argument(
- '--query_aggregation_dir',
- type=str,
- default='/tmp/query_aggregation',
- help="""
- Directory where query aggregated descriptors are located.
- """)
- parser.add_argument(
- '--use_geometric_verification',
- type=lambda x: (str(x).lower() == 'true'),
- default=False,
- help="""
- If True, performs re-ranking using local feature-based geometric
- verification.
- """)
- parser.add_argument(
- '--index_features_dir',
- type=str,
- default='/tmp/index_features',
- help="""
- Only used if `use_geometric_verification` is True.
- Directory where index local image features are located, all in .delf
- format.
- """)
- parser.add_argument(
- '--query_features_dir',
- type=str,
- default='/tmp/query_features',
- help="""
- Only used if `use_geometric_verification` is True.
- Directory where query local image features are located, all in .delf
- format.
- """)
- parser.add_argument(
- '--output_dir',
- type=str,
- default='/tmp/retrieval',
- help="""
- Directory where retrieval output will be written to. A file containing
- metrics for this run is saved therein, with file name "metrics.txt".
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/detect_to_retrieve/query_aggregation_config.pbtxt b/research/delf/delf/python/detect_to_retrieve/query_aggregation_config.pbtxt
deleted file mode 100644
index 39a917eef4389baa9a7f08722aed0a2e0cb6dd1f..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/detect_to_retrieve/query_aggregation_config.pbtxt
+++ /dev/null
@@ -1,7 +0,0 @@
-codebook_size: 65536
-feature_dimensionality: 128
-aggregation_type: ASMK_STAR
-codebook_path: "parameters/rparis6k_codebook_65536/k65536_codebook_tfckpt/codebook"
-num_assignments: 1
-use_regional_aggregation: false
-feature_batch_size: 100
diff --git a/research/delf/delf/python/examples/__init__.py b/research/delf/delf/python/examples/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/delf/delf/python/examples/delf_config_example.pbtxt b/research/delf/delf/python/examples/delf_config_example.pbtxt
deleted file mode 100644
index ff2d9c0023c41accd2cff51c0117d4ff01def2a0..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/delf_config_example.pbtxt
+++ /dev/null
@@ -1,25 +0,0 @@
-model_path: "parameters/delf_gld_20190411/model/"
-image_scales: .25
-image_scales: .3536
-image_scales: .5
-image_scales: .7071
-image_scales: 1.0
-image_scales: 1.4142
-image_scales: 2.0
-delf_local_config {
- use_pca: true
- # Note that for the exported model provided as an example, layer_name and
- # iou_threshold are hard-coded in the checkpoint. So, the layer_name and
- # iou_threshold variables here have no effect on the provided
- # extract_features.py script.
- layer_name: "resnet_v1_50/block3"
- iou_threshold: 1.0
- max_feature_num: 1000
- score_threshold: 100.0
- pca_parameters {
- mean_path: "parameters/delf_gld_20190411/pca/mean.datum"
- projection_matrix_path: "parameters/delf_gld_20190411/pca/pca_proj_mat.datum"
- pca_dim: 40
- use_whitening: false
- }
-}
diff --git a/research/delf/delf/python/examples/detection_example_1.jpg b/research/delf/delf/python/examples/detection_example_1.jpg
deleted file mode 100644
index afdb388f0dea74de9ac259cfd8a0f9b3b17779e8..0000000000000000000000000000000000000000
Binary files a/research/delf/delf/python/examples/detection_example_1.jpg and /dev/null differ
diff --git a/research/delf/delf/python/examples/detection_example_2.jpg b/research/delf/delf/python/examples/detection_example_2.jpg
deleted file mode 100644
index 5baf54a80888810f0a0daa279eb29936f15c8457..0000000000000000000000000000000000000000
Binary files a/research/delf/delf/python/examples/detection_example_2.jpg and /dev/null differ
diff --git a/research/delf/delf/python/examples/detector.py b/research/delf/delf/python/examples/detector.py
deleted file mode 100644
index fd8aef1cf7fef2aea7ae1e28e793f0ab172e915d..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/detector.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Module to construct object detector function."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-
-def MakeDetector(model_dir):
- """Creates a function to detect objects in an image.
-
- Args:
- model_dir: Directory where SavedModel is located.
-
- Returns:
- Function that receives an image and returns detection results.
- """
- model = tf.saved_model.load(model_dir)
-
- # Input and output tensors.
- feeds = ['input_images:0']
- fetches = ['detection_boxes:0', 'detection_scores:0', 'detection_classes:0']
-
- model = model.prune(feeds=feeds, fetches=fetches)
-
- def DetectorFn(images):
- """Receives an image and returns detected boxes.
-
- Args:
- images: Uint8 array with shape (batch, height, width 3) containing a batch
- of RGB images.
-
- Returns:
- Tuple (boxes, scores, class_indices).
- """
- boxes, scores, class_indices = model(tf.convert_to_tensor(images))
-
- return boxes.numpy(), scores.numpy(), class_indices.numpy()
-
- return DetectorFn
diff --git a/research/delf/delf/python/examples/extract_boxes.py b/research/delf/delf/python/examples/extract_boxes.py
deleted file mode 100644
index 8851c44fb9a051104adde50a4c869a28cfd513da..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/extract_boxes.py
+++ /dev/null
@@ -1,234 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Extracts bounding boxes from a list of images, saving them to files.
-
-The images must be in JPG format. The program checks if boxes already
-exist, and skips computation for those.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-import time
-
-import matplotlib.patches as patches
-import matplotlib.pyplot as plt
-import numpy as np
-import tensorflow as tf
-
-from tensorflow.python.platform import app
-from delf import box_io
-from delf import utils
-from delf import detector
-
-cmd_args = None
-
-# Extension/suffix of produced files.
-_BOX_EXT = '.boxes'
-_VIZ_SUFFIX = '_viz.jpg'
-
-# Used for plotting boxes.
-_BOX_EDGE_COLORS = ['r', 'y', 'b', 'm', 'k', 'g', 'c', 'w']
-
-# Pace to report extraction log.
-_STATUS_CHECK_ITERATIONS = 100
-
-
-def _ReadImageList(list_path):
- """Helper function to read image paths.
-
- Args:
- list_path: Path to list of images, one image path per line.
-
- Returns:
- image_paths: List of image paths.
- """
- with tf.io.gfile.GFile(list_path, 'r') as f:
- image_paths = f.readlines()
- image_paths = [entry.rstrip() for entry in image_paths]
- return image_paths
-
-
-def _FilterBoxesByScore(boxes, scores, class_indices, score_threshold):
- """Filter boxes based on detection scores.
-
- Boxes with detection score >= score_threshold are returned.
-
- Args:
- boxes: [N, 4] float array denoting bounding box coordinates, in format [top,
- left, bottom, right].
- scores: [N] float array with detection scores.
- class_indices: [N] int array with class indices.
- score_threshold: Float detection score threshold to use.
-
- Returns:
- selected_boxes: selected `boxes`.
- selected_scores: selected `scores`.
- selected_class_indices: selected `class_indices`.
- """
- selected_boxes = []
- selected_scores = []
- selected_class_indices = []
- for i, box in enumerate(boxes):
- if scores[i] >= score_threshold:
- selected_boxes.append(box)
- selected_scores.append(scores[i])
- selected_class_indices.append(class_indices[i])
-
- return np.array(selected_boxes), np.array(selected_scores), np.array(
- selected_class_indices)
-
-
-def _PlotBoxesAndSaveImage(image, boxes, output_path):
- """Plot boxes on image and save to output path.
-
- Args:
- image: Numpy array containing image.
- boxes: [N, 4] float array denoting bounding box coordinates, in format [top,
- left, bottom, right].
- output_path: String containing output path.
- """
- height = image.shape[0]
- width = image.shape[1]
-
- fig, ax = plt.subplots(1)
- ax.imshow(image)
- for i, box in enumerate(boxes):
- scaled_box = [
- box[0] * height, box[1] * width, box[2] * height, box[3] * width
- ]
- rect = patches.Rectangle([scaled_box[1], scaled_box[0]],
- scaled_box[3] - scaled_box[1],
- scaled_box[2] - scaled_box[0],
- linewidth=3,
- edgecolor=_BOX_EDGE_COLORS[i %
- len(_BOX_EDGE_COLORS)],
- facecolor='none')
- ax.add_patch(rect)
-
- ax.axis('off')
- plt.savefig(output_path, bbox_inches='tight')
- plt.close(fig)
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read list of images.
- print('Reading list of images...')
- image_paths = _ReadImageList(cmd_args.list_images_path)
- num_images = len(image_paths)
- print(f'done! Found {num_images} images')
-
- # Create output directories if necessary.
- if not tf.io.gfile.exists(cmd_args.output_dir):
- tf.io.gfile.makedirs(cmd_args.output_dir)
- if cmd_args.output_viz_dir and not tf.io.gfile.exists(
- cmd_args.output_viz_dir):
- tf.io.gfile.makedirs(cmd_args.output_viz_dir)
-
- detector_fn = detector.MakeDetector(cmd_args.detector_path)
-
- start = time.time()
- for i, image_path in enumerate(image_paths):
- # Report progress once in a while.
- if i == 0:
- print('Starting to detect objects in images...')
- elif i % _STATUS_CHECK_ITERATIONS == 0:
- elapsed = (time.time() - start)
- print(
- f'Processing image {i} out of {num_images}, last '
- f'{_STATUS_CHECK_ITERATIONS} images took {elapsed} seconds'
- )
- start = time.time()
-
- # If descriptor already exists, skip its computation.
- base_boxes_filename, _ = os.path.splitext(os.path.basename(image_path))
- out_boxes_filename = base_boxes_filename + _BOX_EXT
- out_boxes_fullpath = os.path.join(cmd_args.output_dir,
- out_boxes_filename)
- if tf.io.gfile.exists(out_boxes_fullpath):
- print(f'Skipping {image_path}')
- continue
-
- im = np.expand_dims(np.array(utils.RgbLoader(image_paths[i])), 0)
-
- # Extract and save boxes.
- (boxes_out, scores_out, class_indices_out) = detector_fn(im)
- (selected_boxes, selected_scores,
- selected_class_indices) = _FilterBoxesByScore(boxes_out[0],
- scores_out[0],
- class_indices_out[0],
- cmd_args.detector_thresh)
-
- box_io.WriteToFile(out_boxes_fullpath, selected_boxes, selected_scores,
- selected_class_indices)
- if cmd_args.output_viz_dir:
- out_viz_filename = base_boxes_filename + _VIZ_SUFFIX
- out_viz_fullpath = os.path.join(cmd_args.output_viz_dir,
- out_viz_filename)
- _PlotBoxesAndSaveImage(im[0], selected_boxes, out_viz_fullpath)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--detector_path',
- type=str,
- default='/tmp/d2r_frcnn_20190411/',
- help="""
- Path to exported detector model.
- """)
- parser.add_argument(
- '--detector_thresh',
- type=float,
- default=.0,
- help="""
- Detector threshold. Any box with confidence score lower than this is not
- returned.
- """)
- parser.add_argument(
- '--list_images_path',
- type=str,
- default='list_images.txt',
- help="""
- Path to list of images to undergo object detection.
- """)
- parser.add_argument(
- '--output_dir',
- type=str,
- default='test_boxes',
- help="""
- Directory where bounding boxes will be written to. Each image's boxes
- will be written to a file with same name, and extension replaced by
- .boxes.
- """)
- parser.add_argument(
- '--output_viz_dir',
- type=str,
- default='',
- help="""
- Optional. If set, a visualization of the detected boxes overlaid on the
- image is produced, and saved to this directory. Each image is saved with
- _viz.jpg suffix.
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/examples/extract_features.py b/research/delf/delf/python/examples/extract_features.py
deleted file mode 100644
index 05fd77316070d39722e133dbd544f5b53791f6d0..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/extract_features.py
+++ /dev/null
@@ -1,144 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Extracts DELF features from a list of images, saving them to file.
-
-The images must be in JPG format. The program checks if descriptors already
-exist, and skips computation for those.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import os
-import sys
-import time
-
-import numpy as np
-from six.moves import range
-import tensorflow as tf
-
-from google.protobuf import text_format
-from tensorflow.python.platform import app
-from delf import delf_config_pb2
-from delf import feature_io
-from delf import utils
-from delf import extractor
-
-cmd_args = None
-
-# Extension of feature files.
-_DELF_EXT = '.delf'
-
-# Pace to report extraction log.
-_STATUS_CHECK_ITERATIONS = 100
-
-
-def _ReadImageList(list_path):
- """Helper function to read image paths.
-
- Args:
- list_path: Path to list of images, one image path per line.
-
- Returns:
- image_paths: List of image paths.
- """
- with tf.io.gfile.GFile(list_path, 'r') as f:
- image_paths = f.readlines()
- image_paths = [entry.rstrip() for entry in image_paths]
- return image_paths
-
-
-def main(unused_argv):
- # Read list of images.
- print('Reading list of images...')
- image_paths = _ReadImageList(cmd_args.list_images_path)
- num_images = len(image_paths)
- print(f'done! Found {num_images} images')
-
- # Parse DelfConfig proto.
- config = delf_config_pb2.DelfConfig()
- with tf.io.gfile.GFile(cmd_args.config_path, 'r') as f:
- text_format.Merge(f.read(), config)
-
- # Create output directory if necessary.
- if not tf.io.gfile.exists(cmd_args.output_dir):
- tf.io.gfile.makedirs(cmd_args.output_dir)
-
- extractor_fn = extractor.MakeExtractor(config)
-
- start = time.time()
- for i in range(num_images):
- # Report progress once in a while.
- if i == 0:
- print('Starting to extract DELF features from images...')
- elif i % _STATUS_CHECK_ITERATIONS == 0:
- elapsed = (time.time() - start)
- print(
- f'Processing image {i} out of {num_images}, last '
- f'{_STATUS_CHECK_ITERATIONS} images took {elapsed} seconds'
- )
- start = time.time()
-
- # If descriptor already exists, skip its computation.
- out_desc_filename = os.path.splitext(os.path.basename(
- image_paths[i]))[0] + _DELF_EXT
- out_desc_fullpath = os.path.join(cmd_args.output_dir, out_desc_filename)
- if tf.io.gfile.exists(out_desc_fullpath):
- print(f'Skipping {image_paths[i]}')
- continue
-
- im = np.array(utils.RgbLoader(image_paths[i]))
-
- # Extract and save features.
- extracted_features = extractor_fn(im)
- locations_out = extracted_features['local_features']['locations']
- descriptors_out = extracted_features['local_features']['descriptors']
- feature_scales_out = extracted_features['local_features']['scales']
- attention_out = extracted_features['local_features']['attention']
-
- feature_io.WriteToFile(out_desc_fullpath, locations_out, feature_scales_out,
- descriptors_out, attention_out)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--config_path',
- type=str,
- default='delf_config_example.pbtxt',
- help="""
- Path to DelfConfig proto text file with configuration to be used for DELF
- extraction.
- """)
- parser.add_argument(
- '--list_images_path',
- type=str,
- default='list_images.txt',
- help="""
- Path to list of images whose DELF features will be extracted.
- """)
- parser.add_argument(
- '--output_dir',
- type=str,
- default='test_features',
- help="""
- Directory where DELF features will be written to. Each image's features
- will be written to a file with same name, and extension replaced by .delf.
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/examples/extractor.py b/research/delf/delf/python/examples/extractor.py
deleted file mode 100644
index bd63ab38362a9c6f9ccc5d3bfca1fd007045d261..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/extractor.py
+++ /dev/null
@@ -1,277 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Module to construct DELF feature extractor."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-from PIL import Image
-import tensorflow as tf
-
-from delf import datum_io
-from delf import feature_extractor
-
-# Minimum dimensions below which DELF features are not extracted (empty
-# features are returned). This applies after any resizing is performed.
-_MIN_HEIGHT = 10
-_MIN_WIDTH = 10
-
-
-def ResizeImage(image, config, resize_factor=1.0):
- """Resizes image according to config.
-
- Args:
- image: Uint8 array with shape (height, width, 3).
- config: DelfConfig proto containing the model configuration.
- resize_factor: Optional float resize factor for the input image. If given,
- the maximum and minimum allowed image sizes in `config` are scaled by this
- factor. Must be non-negative.
-
- Returns:
- resized_image: Uint8 array with resized image.
- scale_factors: 2D float array, with factors used for resizing along height
- and width (If upscaling, larger than 1; if downscaling, smaller than 1).
-
- Raises:
- ValueError: If `image` has incorrect number of dimensions/channels.
- """
- if resize_factor < 0.0:
- raise ValueError('negative resize_factor is not allowed: %f' %
- resize_factor)
- if image.ndim != 3:
- raise ValueError('image has incorrect number of dimensions: %d' %
- image.ndims)
- height, width, channels = image.shape
-
- # Take into account resize factor.
- max_image_size = resize_factor * config.max_image_size
- min_image_size = resize_factor * config.min_image_size
-
- if channels != 3:
- raise ValueError('image has incorrect number of channels: %d' % channels)
-
- largest_side = max(width, height)
-
- if max_image_size >= 0 and largest_side > max_image_size:
- scale_factor = max_image_size / largest_side
- elif min_image_size >= 0 and largest_side < min_image_size:
- scale_factor = min_image_size / largest_side
- elif config.use_square_images and (height != width):
- scale_factor = 1.0
- else:
- # No resizing needed, early return.
- return image, np.ones(2, dtype=float)
-
- # Note that new_shape is in (width, height) format (PIL convention), while
- # scale_factors are in (height, width) convention (NumPy convention).
- if config.use_square_images:
- new_shape = (int(round(largest_side * scale_factor)),
- int(round(largest_side * scale_factor)))
- else:
- new_shape = (int(round(width * scale_factor)),
- int(round(height * scale_factor)))
-
- scale_factors = np.array([new_shape[1] / height, new_shape[0] / width],
- dtype=float)
-
- pil_image = Image.fromarray(image)
- resized_image = np.array(pil_image.resize(new_shape, resample=Image.BILINEAR))
-
- return resized_image, scale_factors
-
-
-def MakeExtractor(config):
- """Creates a function to extract global and/or local features from an image.
-
- Args:
- config: DelfConfig proto containing the model configuration.
-
- Returns:
- Function that receives an image and returns features.
- """
- # Load model.
- model = tf.saved_model.load(config.model_path)
-
- # Input/output end-points/tensors.
- feeds = ['input_image:0', 'input_scales:0']
- fetches = []
- image_scales_tensor = tf.convert_to_tensor(list(config.image_scales))
-
- # Custom configuration needed when local features are used.
- if config.use_local_features:
- # Extra input/output end-points/tensors.
- feeds.append('input_abs_thres:0')
- feeds.append('input_max_feature_num:0')
- fetches.append('boxes:0')
- fetches.append('features:0')
- fetches.append('scales:0')
- fetches.append('scores:0')
- score_threshold_tensor = tf.constant(
- config.delf_local_config.score_threshold)
- max_feature_num_tensor = tf.constant(
- config.delf_local_config.max_feature_num)
-
- # If using PCA, pre-load required parameters.
- local_pca_parameters = {}
- if config.delf_local_config.use_pca:
- local_pca_parameters['mean'] = tf.constant(
- datum_io.ReadFromFile(
- config.delf_local_config.pca_parameters.mean_path),
- dtype=tf.float32)
- local_pca_parameters['matrix'] = tf.constant(
- datum_io.ReadFromFile(
- config.delf_local_config.pca_parameters.projection_matrix_path),
- dtype=tf.float32)
- local_pca_parameters[
- 'dim'] = config.delf_local_config.pca_parameters.pca_dim
- local_pca_parameters['use_whitening'] = (
- config.delf_local_config.pca_parameters.use_whitening)
- if config.delf_local_config.pca_parameters.use_whitening:
- local_pca_parameters['variances'] = tf.squeeze(
- tf.constant(
- datum_io.ReadFromFile(
- config.delf_local_config.pca_parameters.pca_variances_path),
- dtype=tf.float32))
- else:
- local_pca_parameters['variances'] = None
-
- # Custom configuration needed when global features are used.
- if config.use_global_features:
- # Extra output end-point.
- fetches.append('global_descriptors:0')
-
- # If using PCA, pre-load required parameters.
- global_pca_parameters = {}
- if config.delf_global_config.use_pca:
- global_pca_parameters['mean'] = tf.constant(
- datum_io.ReadFromFile(
- config.delf_global_config.pca_parameters.mean_path),
- dtype=tf.float32)
- global_pca_parameters['matrix'] = tf.constant(
- datum_io.ReadFromFile(
- config.delf_global_config.pca_parameters.projection_matrix_path),
- dtype=tf.float32)
- global_pca_parameters[
- 'dim'] = config.delf_global_config.pca_parameters.pca_dim
- global_pca_parameters['use_whitening'] = (
- config.delf_global_config.pca_parameters.use_whitening)
- if config.delf_global_config.pca_parameters.use_whitening:
- global_pca_parameters['variances'] = tf.squeeze(
- tf.constant(
- datum_io.ReadFromFile(config.delf_global_config.pca_parameters
- .pca_variances_path),
- dtype=tf.float32))
- else:
- global_pca_parameters['variances'] = None
-
- model = model.prune(feeds=feeds, fetches=fetches)
-
- def ExtractorFn(image, resize_factor=1.0):
- """Receives an image and returns DELF global and/or local features.
-
- If image is too small, returns empty features.
-
- Args:
- image: Uint8 array with shape (height, width, 3) containing the RGB image.
- resize_factor: Optional float resize factor for the input image. If given,
- the maximum and minimum allowed image sizes in the config are scaled by
- this factor.
-
- Returns:
- extracted_features: A dict containing the extracted global descriptors
- (key 'global_descriptor' mapping to a [D] float array), and/or local
- features (key 'local_features' mapping to a dict with keys 'locations',
- 'descriptors', 'scales', 'attention').
- """
-
- resized_image, scale_factors = ResizeImage(
- image, config, resize_factor=resize_factor)
-
- # If the image is too small, returns empty features.
- if resized_image.shape[0] < _MIN_HEIGHT or resized_image.shape[
- 1] < _MIN_WIDTH:
- extracted_features = {'global_descriptor': np.array([])}
- if config.use_local_features:
- extracted_features.update({
- 'local_features': {
- 'locations': np.array([]),
- 'descriptors': np.array([]),
- 'scales': np.array([]),
- 'attention': np.array([]),
- }
- })
- return extracted_features
-
- # Input tensors.
- image_tensor = tf.convert_to_tensor(resized_image)
-
- # Extracted features.
- extracted_features = {}
- output = None
-
- if config.use_local_features:
- output = model(image_tensor, image_scales_tensor, score_threshold_tensor,
- max_feature_num_tensor)
- else:
- output = model(image_tensor, image_scales_tensor)
-
- # Post-process extracted features: normalize, PCA (optional), pooling.
- if config.use_global_features:
- raw_global_descriptors = output[-1]
- if config.delf_global_config.image_scales_ind:
- raw_global_descriptors_selected_scales = tf.gather(
- raw_global_descriptors,
- list(config.delf_global_config.image_scales_ind))
- else:
- raw_global_descriptors_selected_scales = raw_global_descriptors
- global_descriptors_per_scale = feature_extractor.PostProcessDescriptors(
- raw_global_descriptors_selected_scales,
- config.delf_global_config.use_pca, global_pca_parameters)
- unnormalized_global_descriptor = tf.reduce_sum(
- global_descriptors_per_scale, axis=0, name='sum_pooling')
- global_descriptor = tf.nn.l2_normalize(
- unnormalized_global_descriptor, axis=0, name='final_l2_normalization')
- extracted_features.update({
- 'global_descriptor': global_descriptor.numpy(),
- })
-
- if config.use_local_features:
- boxes = output[0]
- raw_local_descriptors = output[1]
- feature_scales = output[2]
- attention_with_extra_dim = output[3]
-
- attention = tf.reshape(attention_with_extra_dim,
- [tf.shape(attention_with_extra_dim)[0]])
- locations, local_descriptors = (
- feature_extractor.DelfFeaturePostProcessing(
- boxes, raw_local_descriptors, config.delf_local_config.use_pca,
- local_pca_parameters))
- locations /= scale_factors
-
- extracted_features.update({
- 'local_features': {
- 'locations': locations.numpy(),
- 'descriptors': local_descriptors.numpy(),
- 'scales': feature_scales.numpy(),
- 'attention': attention.numpy(),
- }
- })
-
- return extracted_features
-
- return ExtractorFn
diff --git a/research/delf/delf/python/examples/extractor_test.py b/research/delf/delf/python/examples/extractor_test.py
deleted file mode 100644
index aa560c75a5ca7f8a48247eb7636643e2369c0e5e..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/extractor_test.py
+++ /dev/null
@@ -1,103 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DELF feature extractor."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from absl.testing import parameterized
-import numpy as np
-import tensorflow as tf
-
-from delf import delf_config_pb2
-from delf import extractor
-
-
-class ExtractorTest(tf.test.TestCase, parameterized.TestCase):
-
- @parameterized.named_parameters(
- ('Max-1Min-1', -1, -1, 1.0, False, [4, 2, 3], [1.0, 1.0]),
- ('Max-1Min-1Square', -1, -1, 1.0, True, [4, 4, 3], [1.0, 2.0]),
- ('Max2Min-1', 2, -1, 1.0, False, [2, 1, 3], [0.5, 0.5]),
- ('Max2Min-1Square', 2, -1, 1.0, True, [2, 2, 3], [0.5, 1.0]),
- ('Max8Min-1', 8, -1, 1.0, False, [4, 2, 3], [1.0, 1.0]),
- ('Max8Min-1Square', 8, -1, 1.0, True, [4, 4, 3], [1.0, 2.0]),
- ('Max-1Min1', -1, 1, 1.0, False, [4, 2, 3], [1.0, 1.0]),
- ('Max-1Min1Square', -1, 1, 1.0, True, [4, 4, 3], [1.0, 2.0]),
- ('Max-1Min8', -1, 8, 1.0, False, [8, 4, 3], [2.0, 2.0]),
- ('Max-1Min8Square', -1, 8, 1.0, True, [8, 8, 3], [2.0, 4.0]),
- ('Max16Min8', 16, 8, 1.0, False, [8, 4, 3], [2.0, 2.0]),
- ('Max16Min8Square', 16, 8, 1.0, True, [8, 8, 3], [2.0, 4.0]),
- ('Max2Min2', 2, 2, 1.0, False, [2, 1, 3], [0.5, 0.5]),
- ('Max2Min2Square', 2, 2, 1.0, True, [2, 2, 3], [0.5, 1.0]),
- ('Max-1Min-1Factor0.5', -1, -1, 0.5, False, [4, 2, 3], [1.0, 1.0]),
- ('Max-1Min-1Factor0.5Square', -1, -1, 0.5, True, [4, 4, 3], [1.0, 2.0]),
- ('Max2Min-1Factor2.0', 2, -1, 2.0, False, [4, 2, 3], [1.0, 1.0]),
- ('Max2Min-1Factor2.0Square', 2, -1, 2.0, True, [4, 4, 3], [1.0, 2.0]),
- ('Max-1Min8Factor0.5', -1, 8, 0.5, False, [4, 2, 3], [1.0, 1.0]),
- ('Max-1Min8Factor0.5Square', -1, 8, 0.5, True, [4, 4, 3], [1.0, 2.0]),
- ('Max-1Min8Factor0.25', -1, 8, 0.25, False, [4, 2, 3], [1.0, 1.0]),
- ('Max-1Min8Factor0.25Square', -1, 8, 0.25, True, [4, 4, 3], [1.0, 2.0]),
- ('Max2Min2Factor2.0', 2, 2, 2.0, False, [4, 2, 3], [1.0, 1.0]),
- ('Max2Min2Factor2.0Square', 2, 2, 2.0, True, [4, 4, 3], [1.0, 2.0]),
- ('Max16Min8Factor0.5', 16, 8, 0.5, False, [4, 2, 3], [1.0, 1.0]),
- ('Max16Min8Factor0.5Square', 16, 8, 0.5, True, [4, 4, 3], [1.0, 2.0]),
- )
- def testResizeImageWorks(self, max_image_size, min_image_size, resize_factor,
- square_output, expected_shape,
- expected_scale_factors):
- # Construct image of size 4x2x3.
- image = np.array([[[0, 0, 0], [1, 1, 1]], [[2, 2, 2], [3, 3, 3]],
- [[4, 4, 4], [5, 5, 5]], [[6, 6, 6], [7, 7, 7]]],
- dtype='uint8')
-
- # Set up config.
- config = delf_config_pb2.DelfConfig(
- max_image_size=max_image_size,
- min_image_size=min_image_size,
- use_square_images=square_output)
-
- resized_image, scale_factors = extractor.ResizeImage(
- image, config, resize_factor)
- self.assertAllEqual(resized_image.shape, expected_shape)
- self.assertAllClose(scale_factors, expected_scale_factors)
-
- @parameterized.named_parameters(
- ('Max2Min2', 2, 2, 1.0, False, [2, 1, 3], [0.666666, 0.5]),
- ('Max2Min2Square', 2, 2, 1.0, True, [2, 2, 3], [0.666666, 1.0]),
- )
- def testResizeImageRoundingWorks(self, max_image_size, min_image_size,
- resize_factor, square_output, expected_shape,
- expected_scale_factors):
- # Construct image of size 3x2x3.
- image = np.array([[[0, 0, 0], [1, 1, 1]], [[2, 2, 2], [3, 3, 3]],
- [[4, 4, 4], [5, 5, 5]]],
- dtype='uint8')
-
- # Set up config.
- config = delf_config_pb2.DelfConfig(
- max_image_size=max_image_size,
- min_image_size=min_image_size,
- use_square_images=square_output)
-
- resized_image, scale_factors = extractor.ResizeImage(
- image, config, resize_factor)
- self.assertAllEqual(resized_image.shape, expected_shape)
- self.assertAllClose(scale_factors, expected_scale_factors)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/examples/match_images.py b/research/delf/delf/python/examples/match_images.py
deleted file mode 100644
index bb030739cb9067bf3be50f999368af622f083b54..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/examples/match_images.py
+++ /dev/null
@@ -1,143 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Matches two images using their DELF features.
-
-The matching is done using feature-based nearest-neighbor search, followed by
-geometric verification using RANSAC.
-
-The DELF features can be extracted using the extract_features.py script.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import sys
-
-import matplotlib
-# Needed before pyplot import for matplotlib to work properly.
-matplotlib.use('Agg')
-import matplotlib.image as mpimg # pylint: disable=g-import-not-at-top
-import matplotlib.pyplot as plt
-import numpy as np
-from scipy import spatial
-from skimage import feature
-from skimage import measure
-from skimage import transform
-
-from tensorflow.python.platform import app
-from delf import feature_io
-
-cmd_args = None
-
-_DISTANCE_THRESHOLD = 0.8
-
-
-def main(unused_argv):
- # Read features.
- locations_1, _, descriptors_1, _, _ = feature_io.ReadFromFile(
- cmd_args.features_1_path)
- num_features_1 = locations_1.shape[0]
- print(f"Loaded image 1's {num_features_1} features")
- locations_2, _, descriptors_2, _, _ = feature_io.ReadFromFile(
- cmd_args.features_2_path)
- num_features_2 = locations_2.shape[0]
- print(f"Loaded image 2's {num_features_2} features")
-
- # Find nearest-neighbor matches using a KD tree.
- d1_tree = spatial.cKDTree(descriptors_1)
- _, indices = d1_tree.query(
- descriptors_2, distance_upper_bound=_DISTANCE_THRESHOLD)
-
- # Select feature locations for putative matches.
- locations_2_to_use = np.array([
- locations_2[i,]
- for i in range(num_features_2)
- if indices[i] != num_features_1
- ])
- locations_1_to_use = np.array([
- locations_1[indices[i],]
- for i in range(num_features_2)
- if indices[i] != num_features_1
- ])
-
- # Perform geometric verification using RANSAC.
- _, inliers = measure.ransac((locations_1_to_use, locations_2_to_use),
- transform.AffineTransform,
- min_samples=3,
- residual_threshold=20,
- max_trials=1000)
-
- print(f'Found {sum(inliers)} inliers')
-
- # Visualize correspondences, and save to file.
- _, ax = plt.subplots()
- img_1 = mpimg.imread(cmd_args.image_1_path)
- img_2 = mpimg.imread(cmd_args.image_2_path)
- inlier_idxs = np.nonzero(inliers)[0]
- feature.plot_matches(
- ax,
- img_1,
- img_2,
- locations_1_to_use,
- locations_2_to_use,
- np.column_stack((inlier_idxs, inlier_idxs)),
- matches_color='b')
- ax.axis('off')
- ax.set_title('DELF correspondences')
- plt.savefig(cmd_args.output_image)
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--image_1_path',
- type=str,
- default='test_images/image_1.jpg',
- help="""
- Path to test image 1.
- """)
- parser.add_argument(
- '--image_2_path',
- type=str,
- default='test_images/image_2.jpg',
- help="""
- Path to test image 2.
- """)
- parser.add_argument(
- '--features_1_path',
- type=str,
- default='test_features/image_1.delf',
- help="""
- Path to DELF features from image 1.
- """)
- parser.add_argument(
- '--features_2_path',
- type=str,
- default='test_features/image_2.delf',
- help="""
- Path to DELF features from image 2.
- """)
- parser.add_argument(
- '--output_image',
- type=str,
- default='test_match.png',
- help="""
- Path where an image showing the matches will be saved.
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/examples/matched_images_example.jpg b/research/delf/delf/python/examples/matched_images_example.jpg
deleted file mode 100644
index bbd0061ac02d460be3bc24a3f7f736d418b1da88..0000000000000000000000000000000000000000
Binary files a/research/delf/delf/python/examples/matched_images_example.jpg and /dev/null differ
diff --git a/research/delf/delf/python/feature_aggregation_extractor.py b/research/delf/delf/python/feature_aggregation_extractor.py
deleted file mode 100644
index f230642ea950d5393005583334836630328198c9..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_aggregation_extractor.py
+++ /dev/null
@@ -1,475 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Local feature aggregation extraction.
-
-For more details, please refer to the paper:
-"Detect-to-Retrieve: Efficient Regional Aggregation for Image Search",
-Proc. CVPR'19 (https://arxiv.org/abs/1812.01584).
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from delf import aggregation_config_pb2
-
-_CLUSTER_CENTERS_VAR_NAME = "clusters"
-_NORM_SQUARED_TOLERANCE = 1e-12
-
-# Aliases for aggregation types.
-_VLAD = aggregation_config_pb2.AggregationConfig.VLAD
-_ASMK = aggregation_config_pb2.AggregationConfig.ASMK
-_ASMK_STAR = aggregation_config_pb2.AggregationConfig.ASMK_STAR
-
-
-class ExtractAggregatedRepresentation(object):
- """Class for extraction of aggregated local feature representation.
-
- Args:
- aggregation_config: AggregationConfig object defining type of aggregation to
- use.
-
- Raises:
- ValueError: If aggregation type is invalid.
- """
-
- def __init__(self, aggregation_config):
- self._codebook_size = aggregation_config.codebook_size
- self._feature_dimensionality = aggregation_config.feature_dimensionality
- self._aggregation_type = aggregation_config.aggregation_type
- self._feature_batch_size = aggregation_config.feature_batch_size
- self._codebook_path = aggregation_config.codebook_path
- self._use_regional_aggregation = aggregation_config.use_regional_aggregation
- self._use_l2_normalization = aggregation_config.use_l2_normalization
- self._num_assignments = aggregation_config.num_assignments
-
- if self._aggregation_type not in [_VLAD, _ASMK, _ASMK_STAR]:
- raise ValueError("Invalid aggregation type: %d" % self._aggregation_type)
-
- # Load codebook
- codebook = tf.Variable(
- tf.zeros([self._codebook_size, self._feature_dimensionality],
- dtype=tf.float32),
- name=_CLUSTER_CENTERS_VAR_NAME)
- ckpt = tf.train.Checkpoint(codebook=codebook)
- ckpt.restore(self._codebook_path)
-
- self._codebook = codebook
-
- def Extract(self, features, num_features_per_region=None):
- """Extracts aggregated representation.
-
- Args:
- features: [N, D] float numpy array with N local feature descriptors.
- num_features_per_region: Required only if computing regional aggregated
- representations, otherwise optional. List of number of features per
- region, such that sum(num_features_per_region) = N. It indicates which
- features correspond to each region.
-
- Returns:
- aggregated_descriptors: 1-D numpy array.
- feature_visual_words: Used only for ASMK/ASMK* aggregation type. 1-D
- numpy array denoting visual words corresponding to the
- `aggregated_descriptors`.
-
- Raises:
- ValueError: If inputs are misconfigured.
- """
- features = tf.cast(features, dtype=tf.float32)
-
- if num_features_per_region is None:
- # Use dummy value since it is unused.
- num_features_per_region = []
- else:
- num_features_per_region = tf.cast(num_features_per_region, dtype=tf.int32)
- if len(num_features_per_region
- ) and sum(num_features_per_region) != features.shape[0]:
- raise ValueError(
- "Incorrect arguments: sum(num_features_per_region) and "
- "features.shape[0] are different: %d vs %d" %
- (sum(num_features_per_region), features.shape[0]))
-
- # Extract features based on desired options.
- if self._aggregation_type == _VLAD:
- # Feature visual words are unused in the case of VLAD, so just return
- # dummy constant.
- feature_visual_words = tf.constant(-1, dtype=tf.int32)
- if self._use_regional_aggregation:
- aggregated_descriptors = self._ComputeRvlad(
- features,
- num_features_per_region,
- self._codebook,
- use_l2_normalization=self._use_l2_normalization,
- num_assignments=self._num_assignments)
- else:
- aggregated_descriptors = self._ComputeVlad(
- features,
- self._codebook,
- use_l2_normalization=self._use_l2_normalization,
- num_assignments=self._num_assignments)
- elif (self._aggregation_type == _ASMK or
- self._aggregation_type == _ASMK_STAR):
- if self._use_regional_aggregation:
- (aggregated_descriptors,
- feature_visual_words) = self._ComputeRasmk(
- features,
- num_features_per_region,
- self._codebook,
- num_assignments=self._num_assignments)
- else:
- (aggregated_descriptors,
- feature_visual_words) = self._ComputeAsmk(
- features,
- self._codebook,
- num_assignments=self._num_assignments)
-
- feature_visual_words_output = feature_visual_words.numpy()
-
- # If using ASMK*/RASMK*, binarize the aggregated descriptors.
- if self._aggregation_type == _ASMK_STAR:
- reshaped_aggregated_descriptors = np.reshape(
- aggregated_descriptors, [-1, self._feature_dimensionality])
- packed_descriptors = np.packbits(
- reshaped_aggregated_descriptors > 0, axis=1)
- aggregated_descriptors_output = np.reshape(packed_descriptors, [-1])
- else:
- aggregated_descriptors_output = aggregated_descriptors.numpy()
-
- return aggregated_descriptors_output, feature_visual_words_output
-
- def _ComputeVlad(self,
- features,
- codebook,
- use_l2_normalization=True,
- num_assignments=1):
- """Compute VLAD representation.
-
- Args:
- features: [N, D] float tensor.
- codebook: [K, D] float tensor.
- use_l2_normalization: If False, does not L2-normalize after aggregation.
- num_assignments: Number of visual words to assign a feature to.
-
- Returns:
- vlad: [K*D] float tensor.
- """
-
- def _ComputeVladEmptyFeatures():
- """Computes VLAD if `features` is empty.
-
- Returns:
- [K*D] all-zeros tensor.
- """
- return tf.zeros([self._codebook_size * self._feature_dimensionality],
- dtype=tf.float32)
-
- def _ComputeVladNonEmptyFeatures():
- """Computes VLAD if `features` is not empty.
-
- Returns:
- [K*D] tensor with VLAD descriptor.
- """
- num_features = tf.shape(features)[0]
-
- # Find nearest visual words for each feature. Possibly batch the local
- # features to avoid OOM.
- if self._feature_batch_size <= 0:
- actual_batch_size = num_features
- else:
- actual_batch_size = self._feature_batch_size
-
- def _BatchNearestVisualWords(ind, selected_visual_words):
- """Compute nearest neighbor visual words for a batch of features.
-
- Args:
- ind: Integer index denoting feature.
- selected_visual_words: Partial set of visual words.
-
- Returns:
- output_ind: Next index.
- output_selected_visual_words: Updated set of visual words, including
- the visual words for the new batch.
- """
- # Handle case of last batch, where there may be fewer than
- # `actual_batch_size` features.
- batch_size_to_use = tf.cond(
- tf.greater(ind + actual_batch_size, num_features),
- true_fn=lambda: num_features - ind,
- false_fn=lambda: actual_batch_size)
-
- # Denote B = batch_size_to_use.
- # K*B x D.
- tiled_features = tf.reshape(
- tf.tile(
- tf.slice(features, [ind, 0],
- [batch_size_to_use, self._feature_dimensionality]),
- [1, self._codebook_size]), [-1, self._feature_dimensionality])
- # K*B x D.
- tiled_codebook = tf.reshape(
- tf.tile(tf.reshape(codebook, [1, -1]), [batch_size_to_use, 1]),
- [-1, self._feature_dimensionality])
- # B x K.
- squared_distances = tf.reshape(
- tf.reduce_sum(
- tf.math.squared_difference(tiled_features, tiled_codebook),
- axis=1), [batch_size_to_use, self._codebook_size])
- # B x K.
- nearest_visual_words = tf.argsort(squared_distances)
- # B x num_assignments.
- batch_selected_visual_words = tf.slice(
- nearest_visual_words, [0, 0], [batch_size_to_use, num_assignments])
- selected_visual_words = tf.concat(
- [selected_visual_words, batch_selected_visual_words], axis=0)
-
- return ind + batch_size_to_use, selected_visual_words
-
- ind_batch = tf.constant(0, dtype=tf.int32)
- keep_going = lambda j, selected_visual_words: tf.less(j, num_features)
- selected_visual_words = tf.zeros([0, num_assignments], dtype=tf.int32)
- _, selected_visual_words = tf.while_loop(
- cond=keep_going,
- body=_BatchNearestVisualWords,
- loop_vars=[ind_batch, selected_visual_words],
- shape_invariants=[
- ind_batch.get_shape(),
- tf.TensorShape([None, num_assignments])
- ],
- parallel_iterations=1,
- back_prop=False)
-
- # Helper function to collect residuals for relevant visual words.
- def _ConstructVladFromAssignments(ind, vlad):
- """Add contributions of a feature to a VLAD descriptor.
-
- Args:
- ind: Integer index denoting feature.
- vlad: Partial VLAD descriptor.
-
- Returns:
- output_ind: Next index (ie, ind+1).
- output_vlad: VLAD descriptor updated to take into account contribution
- from ind-th feature.
- """
- diff = tf.tile(
- tf.expand_dims(features[ind],
- axis=0), [num_assignments, 1]) - tf.gather(
- codebook, selected_visual_words[ind])
- return ind + 1, tf.tensor_scatter_nd_add(
- vlad, tf.expand_dims(selected_visual_words[ind], axis=1),
- tf.cast(diff, dtype=tf.float32))
-
- ind_vlad = tf.constant(0, dtype=tf.int32)
- keep_going = lambda j, vlad: tf.less(j, num_features)
- vlad = tf.zeros([self._codebook_size, self._feature_dimensionality],
- dtype=tf.float32)
- _, vlad = tf.while_loop(
- cond=keep_going,
- body=_ConstructVladFromAssignments,
- loop_vars=[ind_vlad, vlad],
- back_prop=False)
-
- vlad = tf.reshape(vlad,
- [self._codebook_size * self._feature_dimensionality])
- if use_l2_normalization:
- vlad = tf.math.l2_normalize(vlad, epsilon=_NORM_SQUARED_TOLERANCE)
-
- return vlad
-
- return tf.cond(
- tf.greater(tf.size(features), 0),
- true_fn=_ComputeVladNonEmptyFeatures,
- false_fn=_ComputeVladEmptyFeatures)
-
- def _ComputeRvlad(self,
- features,
- num_features_per_region,
- codebook,
- use_l2_normalization=False,
- num_assignments=1):
- """Compute R-VLAD representation.
-
- Args:
- features: [N, D] float tensor.
- num_features_per_region: [R] int tensor. Contains number of features per
- region, such that sum(num_features_per_region) = N. It indicates which
- features correspond to each region.
- codebook: [K, D] float tensor.
- use_l2_normalization: If True, performs L2-normalization after regional
- aggregation; if False (default), performs componentwise division by R
- after regional aggregation.
- num_assignments: Number of visual words to assign a feature to.
-
- Returns:
- rvlad: [K*D] float tensor.
- """
-
- def _ComputeRvladEmptyRegions():
- """Computes R-VLAD if `num_features_per_region` is empty.
-
- Returns:
- [K*D] all-zeros tensor.
- """
- return tf.zeros([self._codebook_size * self._feature_dimensionality],
- dtype=tf.float32)
-
- def _ComputeRvladNonEmptyRegions():
- """Computes R-VLAD if `num_features_per_region` is not empty.
-
- Returns:
- [K*D] tensor with R-VLAD descriptor.
- """
-
- # Helper function to compose initial R-VLAD from image regions.
- def _ConstructRvladFromVlad(ind, rvlad):
- """Add contributions from different regions into R-VLAD.
-
- Args:
- ind: Integer index denoting region.
- rvlad: Partial R-VLAD descriptor.
-
- Returns:
- output_ind: Next index (ie, ind+1).
- output_rvlad: R-VLAD descriptor updated to take into account
- contribution from ind-th region.
- """
- return ind + 1, rvlad + self._ComputeVlad(
- tf.slice(
- features, [tf.reduce_sum(num_features_per_region[:ind]), 0],
- [num_features_per_region[ind], self._feature_dimensionality]),
- codebook,
- num_assignments=num_assignments)
-
- i = tf.constant(0, dtype=tf.int32)
- num_regions = tf.shape(num_features_per_region)[0]
- keep_going = lambda j, rvlad: tf.less(j, num_regions)
- rvlad = tf.zeros([self._codebook_size * self._feature_dimensionality],
- dtype=tf.float32)
- _, rvlad = tf.while_loop(
- cond=keep_going,
- body=_ConstructRvladFromVlad,
- loop_vars=[i, rvlad],
- back_prop=False,
- parallel_iterations=1)
-
- if use_l2_normalization:
- rvlad = tf.math.l2_normalize(rvlad, epsilon=_NORM_SQUARED_TOLERANCE)
- else:
- rvlad /= tf.cast(num_regions, dtype=tf.float32)
-
- return rvlad
-
- return tf.cond(
- tf.greater(tf.size(num_features_per_region), 0),
- true_fn=_ComputeRvladNonEmptyRegions,
- false_fn=_ComputeRvladEmptyRegions)
-
- def _PerCentroidNormalization(self, unnormalized_vector):
- """Perform per-centroid normalization.
-
- Args:
- unnormalized_vector: [KxD] float tensor.
-
- Returns:
- per_centroid_normalized_vector: [KxD] float tensor, with normalized
- aggregated residuals. Some residuals may be all-zero.
- visual_words: Int tensor containing indices of visual words which are
- present for the set of features.
- """
- unnormalized_vector = tf.reshape(
- unnormalized_vector,
- [self._codebook_size, self._feature_dimensionality])
- per_centroid_norms = tf.norm(unnormalized_vector, axis=1)
-
- visual_words = tf.reshape(
- tf.where(
- tf.greater(
- per_centroid_norms,
- tf.cast(tf.sqrt(_NORM_SQUARED_TOLERANCE), dtype=tf.float32))),
- [-1])
-
- per_centroid_normalized_vector = tf.math.l2_normalize(
- unnormalized_vector, axis=1, epsilon=_NORM_SQUARED_TOLERANCE)
-
- return per_centroid_normalized_vector, visual_words
-
- def _ComputeAsmk(self, features, codebook, num_assignments=1):
- """Compute ASMK representation.
-
- Args:
- features: [N, D] float tensor.
- codebook: [K, D] float tensor.
- num_assignments: Number of visual words to assign a feature to.
-
- Returns:
- normalized_residuals: 1-dimensional float tensor with concatenated
- residuals which are non-zero. Note that the dimensionality is
- input-dependent.
- visual_words: 1-dimensional int tensor of sorted visual word ids.
- Dimensionality is shape(normalized_residuals)[0] / D.
- """
- unnormalized_vlad = self._ComputeVlad(
- features,
- codebook,
- use_l2_normalization=False,
- num_assignments=num_assignments)
-
- per_centroid_normalized_vlad, visual_words = self._PerCentroidNormalization(
- unnormalized_vlad)
-
- normalized_residuals = tf.reshape(
- tf.gather(per_centroid_normalized_vlad, visual_words),
- [tf.shape(visual_words)[0] * self._feature_dimensionality])
-
- return normalized_residuals, visual_words
-
- def _ComputeRasmk(self,
- features,
- num_features_per_region,
- codebook,
- num_assignments=1):
- """Compute R-ASMK representation.
-
- Args:
- features: [N, D] float tensor.
- num_features_per_region: [R] int tensor. Contains number of features per
- region, such that sum(num_features_per_region) = N. It indicates which
- features correspond to each region.
- codebook: [K, D] float tensor.
- num_assignments: Number of visual words to assign a feature to.
-
- Returns:
- normalized_residuals: 1-dimensional float tensor with concatenated
- residuals which are non-zero. Note that the dimensionality is
- input-dependent.
- visual_words: 1-dimensional int tensor of sorted visual word ids.
- Dimensionality is shape(normalized_residuals)[0] / D.
- """
- unnormalized_rvlad = self._ComputeRvlad(
- features,
- num_features_per_region,
- codebook,
- use_l2_normalization=False,
- num_assignments=num_assignments)
-
- (per_centroid_normalized_rvlad,
- visual_words) = self._PerCentroidNormalization(unnormalized_rvlad)
-
- normalized_residuals = tf.reshape(
- tf.gather(per_centroid_normalized_rvlad, visual_words),
- [tf.shape(visual_words)[0] * self._feature_dimensionality])
-
- return normalized_residuals, visual_words
diff --git a/research/delf/delf/python/feature_aggregation_extractor_test.py b/research/delf/delf/python/feature_aggregation_extractor_test.py
deleted file mode 100644
index dfba92a2b1b4847460fefbba5ef41fa8cce1ba42..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_aggregation_extractor_test.py
+++ /dev/null
@@ -1,494 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DELF feature aggregation."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import flags
-import numpy as np
-import tensorflow as tf
-
-from delf import aggregation_config_pb2
-from delf import feature_aggregation_extractor
-
-FLAGS = flags.FLAGS
-
-
-class FeatureAggregationTest(tf.test.TestCase):
-
- def _CreateCodebook(self, checkpoint_path):
- """Creates codebook used in tests.
-
- Args:
- checkpoint_path: Directory where codebook is saved to.
- """
- codebook = tf.Variable(
- [[0.5, 0.5], [0.0, 0.0], [1.0, 0.0], [-0.5, -0.5], [0.0, 1.0]],
- name='clusters',
- dtype=tf.float32)
- ckpt = tf.train.Checkpoint(codebook=codebook)
- ckpt.write(checkpoint_path)
-
- def setUp(self):
- self._codebook_path = os.path.join(FLAGS.test_tmpdir, 'test_codebook')
- self._CreateCodebook(self._codebook_path)
-
- def testComputeNormalizedVladWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = True
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- vlad, extra_output = extractor.Extract(features)
-
- # Define expected results.
- exp_vlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.316228, 0.316228, 0.632456, 0.632456
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(vlad, exp_vlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeNormalizedVladWithBatchingWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = True
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.feature_batch_size = 2
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- vlad, extra_output = extractor.Extract(features)
-
- # Define expected results.
- exp_vlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.316228, 0.316228, 0.632456, 0.632456
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(vlad, exp_vlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeUnnormalizedVladWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = False
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- vlad, extra_output = extractor.Extract(features)
-
- # Define expected results.
- exp_vlad = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.5, 0.5, 1.0, 1.0]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllEqual(vlad, exp_vlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeUnnormalizedVladMultipleAssignmentWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = False
- config.codebook_path = self._codebook_path
- config.num_assignments = 3
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- vlad, extra_output = extractor.Extract(features)
-
- # Define expected results.
- exp_vlad = [1.0, 1.0, 0.0, 0.0, 0.0, 2.0, -0.5, 0.5, 0.0, 0.0]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllEqual(vlad, exp_vlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeVladEmptyFeaturesWorks(self):
- # Construct inputs.
- # Empty feature array.
- features = np.array([[]])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.codebook_path = self._codebook_path
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- vlad, extra_output = extractor.Extract(features)
-
- # Define expected results.
- exp_vlad = np.zeros([10], dtype=float)
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllEqual(vlad, exp_vlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeUnnormalizedRvladWorks(self):
- # Construct inputs.
- # 4 2-D features: 3 in first region, 1 in second region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([3, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = False
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rvlad, extra_output = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rvlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.158114, 0.158114, 0.316228, 0.816228
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(rvlad, exp_rvlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeNormalizedRvladWorks(self):
- # Construct inputs.
- # 4 2-D features: 3 in first region, 1 in second region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([3, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = True
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rvlad, extra_output = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rvlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.175011, 0.175011, 0.350021, 0.903453
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(rvlad, exp_rvlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeRvladEmptyRegionsWorks(self):
- # Construct inputs.
- # Empty feature array.
- features = np.array([[]])
- num_features_per_region = np.array([])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.codebook_path = self._codebook_path
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rvlad, extra_output = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rvlad = np.zeros([10], dtype=float)
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllEqual(rvlad, exp_rvlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeUnnormalizedRvladSomeEmptyRegionsWorks(self):
- # Construct inputs.
- # 4 2-D features: 0 in first region, 3 in second region, 0 in third region,
- # 1 in fourth region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([0, 3, 0, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = False
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rvlad, extra_output = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rvlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.079057, 0.079057, 0.158114, 0.408114
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(rvlad, exp_rvlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeNormalizedRvladSomeEmptyRegionsWorks(self):
- # Construct inputs.
- # 4 2-D features: 0 in first region, 3 in second region, 0 in third region,
- # 1 in fourth region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([0, 3, 0, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.use_l2_normalization = True
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rvlad, extra_output = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rvlad = [
- 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -0.175011, 0.175011, 0.350021, 0.903453
- ]
- exp_extra_output = -1
-
- # Compare actual and expected results.
- self.assertAllClose(rvlad, exp_rvlad)
- self.assertAllEqual(extra_output, exp_extra_output)
-
- def testComputeRvladMisconfiguredFeatures(self):
- # Construct inputs.
- # 4 2-D features: 3 in first region, 1 in second region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- # Misconfigured number of features; there are only 4 features, but
- # sum(num_features_per_region) = 5.
- num_features_per_region = np.array([3, 2])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
- config.codebook_path = self._codebook_path
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- with self.assertRaisesRegex(
- ValueError,
- r'Incorrect arguments: sum\(num_features_per_region\) and '
- r'features.shape\[0\] are different'):
- extractor.Extract(features, num_features_per_region)
-
- def testComputeAsmkWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- asmk, visual_words = extractor.Extract(features)
-
- # Define expected results.
- exp_asmk = [-0.707107, 0.707107, 0.707107, 0.707107]
- exp_visual_words = [3, 4]
-
- # Compare actual and expected results.
- self.assertAllClose(asmk, exp_asmk)
- self.assertAllEqual(visual_words, exp_visual_words)
-
- def testComputeAsmkStarWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK_STAR
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- asmk_star, visual_words = extractor.Extract(features)
-
- # Define expected results.
- exp_asmk_star = [64, 192]
- exp_visual_words = [3, 4]
-
- # Compare actual and expected results.
- self.assertAllEqual(asmk_star, exp_asmk_star)
- self.assertAllEqual(visual_words, exp_visual_words)
-
- def testComputeAsmkMultipleAssignmentWorks(self):
- # Construct inputs.
- # 3 2-D features.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0]], dtype=float)
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK
- config.codebook_path = self._codebook_path
- config.num_assignments = 3
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- asmk, visual_words = extractor.Extract(features)
-
- # Define expected results.
- exp_asmk = [0.707107, 0.707107, 0.0, 1.0, -0.707107, 0.707107]
- exp_visual_words = [0, 2, 3]
-
- # Compare actual and expected results.
- self.assertAllClose(asmk, exp_asmk)
- self.assertAllEqual(visual_words, exp_visual_words)
-
- def testComputeRasmkWorks(self):
- # Construct inputs.
- # 4 2-D features: 3 in first region, 1 in second region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([3, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rasmk, visual_words = extractor.Extract(features, num_features_per_region)
-
- # Define expected results.
- exp_rasmk = [-0.707107, 0.707107, 0.361261, 0.932465]
- exp_visual_words = [3, 4]
-
- # Compare actual and expected results.
- self.assertAllClose(rasmk, exp_rasmk)
- self.assertAllEqual(visual_words, exp_visual_words)
-
- def testComputeRasmkStarWorks(self):
- # Construct inputs.
- # 4 2-D features: 3 in first region, 1 in second region.
- features = np.array([[1.0, 0.0], [-1.0, 0.0], [1.0, 2.0], [0.0, 2.0]],
- dtype=float)
- num_features_per_region = np.array([3, 1])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK_STAR
- config.codebook_path = self._codebook_path
- config.num_assignments = 1
- config.use_regional_aggregation = True
-
- # Run tested function.
- extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
- rasmk_star, visual_words = extractor.Extract(features,
- num_features_per_region)
-
- # Define expected results.
- exp_rasmk_star = [64, 192]
- exp_visual_words = [3, 4]
-
- # Compare actual and expected results.
- self.assertAllEqual(rasmk_star, exp_rasmk_star)
- self.assertAllEqual(visual_words, exp_visual_words)
-
- def testComputeUnknownAggregation(self):
- # Construct inputs.
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = 0
- config.codebook_path = self._codebook_path
- config.use_regional_aggregation = True
-
- # Run tested function.
- with self.assertRaisesRegex(ValueError, 'Invalid aggregation type'):
- feature_aggregation_extractor.ExtractAggregatedRepresentation(
- config)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/feature_aggregation_similarity.py b/research/delf/delf/python/feature_aggregation_similarity.py
deleted file mode 100644
index 991c95c767c6bed5d0db38226a0cf361eee18c2f..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_aggregation_similarity.py
+++ /dev/null
@@ -1,265 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Local feature aggregation similarity computation.
-
-For more details, please refer to the paper:
-"Detect-to-Retrieve: Efficient Regional Aggregation for Image Search",
-Proc. CVPR'19 (https://arxiv.org/abs/1812.01584).
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-from delf import aggregation_config_pb2
-
-# Aliases for aggregation types.
-_VLAD = aggregation_config_pb2.AggregationConfig.VLAD
-_ASMK = aggregation_config_pb2.AggregationConfig.ASMK
-_ASMK_STAR = aggregation_config_pb2.AggregationConfig.ASMK_STAR
-
-
-class SimilarityAggregatedRepresentation(object):
- """Class for computing similarity of aggregated local feature representations.
-
- Args:
- aggregation_config: AggregationConfig object defining type of aggregation to
- use.
-
- Raises:
- ValueError: If aggregation type is invalid.
- """
-
- def __init__(self, aggregation_config):
- self._feature_dimensionality = aggregation_config.feature_dimensionality
- self._aggregation_type = aggregation_config.aggregation_type
-
- # Only relevant if using ASMK/ASMK*. Otherwise, ignored.
- self._use_l2_normalization = aggregation_config.use_l2_normalization
- self._alpha = aggregation_config.alpha
- self._tau = aggregation_config.tau
-
- # Only relevant if using ASMK*. Otherwise, ignored.
- self._number_bits = np.array([bin(n).count('1') for n in range(256)])
-
- def ComputeSimilarity(self,
- aggregated_descriptors_1,
- aggregated_descriptors_2,
- feature_visual_words_1=None,
- feature_visual_words_2=None):
- """Computes similarity between aggregated descriptors.
-
- Args:
- aggregated_descriptors_1: 1-D NumPy array.
- aggregated_descriptors_2: 1-D NumPy array.
- feature_visual_words_1: Used only for ASMK/ASMK* aggregation type. 1-D
- sorted NumPy integer array denoting visual words corresponding to
- `aggregated_descriptors_1`.
- feature_visual_words_2: Used only for ASMK/ASMK* aggregation type. 1-D
- sorted NumPy integer array denoting visual words corresponding to
- `aggregated_descriptors_2`.
-
- Returns:
- similarity: Float. The larger, the more similar.
-
- Raises:
- ValueError: If aggregation type is invalid.
- """
- if self._aggregation_type == _VLAD:
- similarity = np.dot(aggregated_descriptors_1, aggregated_descriptors_2)
- elif self._aggregation_type == _ASMK:
- similarity = self._AsmkSimilarity(
- aggregated_descriptors_1,
- aggregated_descriptors_2,
- feature_visual_words_1,
- feature_visual_words_2,
- binarized=False)
- elif self._aggregation_type == _ASMK_STAR:
- similarity = self._AsmkSimilarity(
- aggregated_descriptors_1,
- aggregated_descriptors_2,
- feature_visual_words_1,
- feature_visual_words_2,
- binarized=True)
- else:
- raise ValueError('Invalid aggregation type: %d' % self._aggregation_type)
-
- return similarity
-
- def _CheckAsmkDimensionality(self, aggregated_descriptors, num_visual_words,
- descriptor_name):
- """Checks that ASMK dimensionality is as expected.
-
- Args:
- aggregated_descriptors: 1-D NumPy array.
- num_visual_words: Integer.
- descriptor_name: String.
-
- Raises:
- ValueError: If descriptor dimensionality is incorrect.
- """
- if len(aggregated_descriptors
- ) / num_visual_words != self._feature_dimensionality:
- raise ValueError(
- 'Feature dimensionality for aggregated descriptor %s is invalid: %d;'
- ' expected %d.' % (descriptor_name, len(aggregated_descriptors) /
- num_visual_words, self._feature_dimensionality))
-
- def _SigmaFn(self, x):
- """Selectivity ASMK/ASMK* similarity function.
-
- Args:
- x: Scalar or 1-D NumPy array.
-
- Returns:
- result: Same type as input, with output of selectivity function.
- """
- if np.isscalar(x):
- if x > self._tau:
- result = np.sign(x) * np.power(np.absolute(x), self._alpha)
- else:
- result = 0.0
- else:
- result = np.zeros_like(x)
- above_tau = np.nonzero(x > self._tau)
- result[above_tau] = np.sign(x[above_tau]) * np.power(
- np.absolute(x[above_tau]), self._alpha)
-
- return result
-
- def _BinaryNormalizedInnerProduct(self, descriptors_1, descriptors_2):
- """Computes normalized binary inner product.
-
- Args:
- descriptors_1: 1-D NumPy integer array.
- descriptors_2: 1-D NumPy integer array.
-
- Returns:
- inner_product: Float.
-
- Raises:
- ValueError: If the dimensionality of descriptors is different.
- """
- num_descriptors = len(descriptors_1)
- if num_descriptors != len(descriptors_2):
- raise ValueError(
- 'Descriptors have incompatible dimensionality: %d vs %d' %
- (len(descriptors_1), len(descriptors_2)))
-
- h = 0
- for i in range(num_descriptors):
- h += self._number_bits[np.bitwise_xor(descriptors_1[i], descriptors_2[i])]
-
- # If local feature dimensionality is lower than 8, then use that to compute
- # proper binarized inner product.
- bits_per_descriptor = min(self._feature_dimensionality, 8)
-
- total_num_bits = bits_per_descriptor * num_descriptors
-
- return 1.0 - 2.0 * h / total_num_bits
-
- def _AsmkSimilarity(self,
- aggregated_descriptors_1,
- aggregated_descriptors_2,
- visual_words_1,
- visual_words_2,
- binarized=False):
- """Compute ASMK-based similarity.
-
- If `aggregated_descriptors_1` or `aggregated_descriptors_2` is empty, we
- return a similarity of -1.0.
-
- If binarized is True, `aggregated_descriptors_1` and
- `aggregated_descriptors_2` must be of type uint8.
-
- Args:
- aggregated_descriptors_1: 1-D NumPy array.
- aggregated_descriptors_2: 1-D NumPy array.
- visual_words_1: 1-D sorted NumPy integer array denoting visual words
- corresponding to `aggregated_descriptors_1`.
- visual_words_2: 1-D sorted NumPy integer array denoting visual words
- corresponding to `aggregated_descriptors_2`.
- binarized: If True, compute ASMK* similarity.
-
- Returns:
- similarity: Float. The larger, the more similar.
-
- Raises:
- ValueError: If input descriptor dimensionality is inconsistent, or if
- descriptor type is unsupported.
- """
- num_visual_words_1 = len(visual_words_1)
- num_visual_words_2 = len(visual_words_2)
-
- if not num_visual_words_1 or not num_visual_words_2:
- return -1.0
-
- # Parse dimensionality used per visual word. They must be the same for both
- # aggregated descriptors. If using ASMK, they also must be equal to
- # self._feature_dimensionality.
- if binarized:
- if aggregated_descriptors_1.dtype != 'uint8':
- raise ValueError('Incorrect input descriptor type: %s' %
- aggregated_descriptors_1.dtype)
- if aggregated_descriptors_2.dtype != 'uint8':
- raise ValueError('Incorrect input descriptor type: %s' %
- aggregated_descriptors_2.dtype)
-
- per_visual_word_dimensionality = int(
- len(aggregated_descriptors_1) / num_visual_words_1)
- if len(aggregated_descriptors_2
- ) / num_visual_words_2 != per_visual_word_dimensionality:
- raise ValueError('ASMK* dimensionality is inconsistent.')
- else:
- per_visual_word_dimensionality = self._feature_dimensionality
- self._CheckAsmkDimensionality(aggregated_descriptors_1,
- num_visual_words_1, '1')
- self._CheckAsmkDimensionality(aggregated_descriptors_2,
- num_visual_words_2, '2')
-
- aggregated_descriptors_1_reshape = np.reshape(
- aggregated_descriptors_1,
- [num_visual_words_1, per_visual_word_dimensionality])
- aggregated_descriptors_2_reshape = np.reshape(
- aggregated_descriptors_2,
- [num_visual_words_2, per_visual_word_dimensionality])
-
- # Loop over visual words, compute similarity.
- unnormalized_similarity = 0.0
- ind_1 = 0
- ind_2 = 0
- while ind_1 < num_visual_words_1 and ind_2 < num_visual_words_2:
- if visual_words_1[ind_1] == visual_words_2[ind_2]:
- if binarized:
- inner_product = self._BinaryNormalizedInnerProduct(
- aggregated_descriptors_1_reshape[ind_1],
- aggregated_descriptors_2_reshape[ind_2])
- else:
- inner_product = np.dot(aggregated_descriptors_1_reshape[ind_1],
- aggregated_descriptors_2_reshape[ind_2])
- unnormalized_similarity += self._SigmaFn(inner_product)
- ind_1 += 1
- ind_2 += 1
- elif visual_words_1[ind_1] > visual_words_2[ind_2]:
- ind_2 += 1
- else:
- ind_1 += 1
-
- final_similarity = unnormalized_similarity
- if self._use_l2_normalization:
- final_similarity /= np.sqrt(num_visual_words_1 * num_visual_words_2)
-
- return final_similarity
diff --git a/research/delf/delf/python/feature_aggregation_similarity_test.py b/research/delf/delf/python/feature_aggregation_similarity_test.py
deleted file mode 100644
index e2f01b1d2a7b36b87773714f0cc027a98a36324f..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_aggregation_similarity_test.py
+++ /dev/null
@@ -1,137 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DELF feature aggregation similarity."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from delf import aggregation_config_pb2
-from delf import feature_aggregation_similarity
-
-
-class FeatureAggregationSimilarityTest(tf.test.TestCase):
-
- def testComputeVladSimilarityWorks(self):
- # Construct inputs.
- vlad_1 = np.array([0, 1, 2, 3, 4])
- vlad_2 = np.array([5, 6, 7, 8, 9])
- config = aggregation_config_pb2.AggregationConfig()
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.VLAD
-
- # Run tested function.
- similarity_computer = (
- feature_aggregation_similarity.SimilarityAggregatedRepresentation(
- config))
- similarity = similarity_computer.ComputeSimilarity(vlad_1, vlad_2)
-
- # Define expected results.
- exp_similarity = 80
-
- # Compare actual and expected results.
- self.assertAllEqual(similarity, exp_similarity)
-
- def testComputeAsmkSimilarityWorks(self):
- # Construct inputs.
- aggregated_descriptors_1 = np.array([
- 0.0, 0.0, -0.707107, -0.707107, 0.5, 0.866025, 0.816497, 0.577350, 1.0,
- 0.0
- ])
- visual_words_1 = np.array([0, 1, 2, 3, 4])
- aggregated_descriptors_2 = np.array(
- [0.0, 1.0, 1.0, 0.0, 0.707107, 0.707107])
- visual_words_2 = np.array([1, 2, 4])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK
- config.use_l2_normalization = True
-
- # Run tested function.
- similarity_computer = (
- feature_aggregation_similarity.SimilarityAggregatedRepresentation(
- config))
- similarity = similarity_computer.ComputeSimilarity(
- aggregated_descriptors_1, aggregated_descriptors_2, visual_words_1,
- visual_words_2)
-
- # Define expected results.
- exp_similarity = 0.123562
-
- # Compare actual and expected results.
- self.assertAllClose(similarity, exp_similarity)
-
- def testComputeAsmkSimilarityNoNormalizationWorks(self):
- # Construct inputs.
- aggregated_descriptors_1 = np.array([
- 0.0, 0.0, -0.707107, -0.707107, 0.5, 0.866025, 0.816497, 0.577350, 1.0,
- 0.0
- ])
- visual_words_1 = np.array([0, 1, 2, 3, 4])
- aggregated_descriptors_2 = np.array(
- [0.0, 1.0, 1.0, 0.0, 0.707107, 0.707107])
- visual_words_2 = np.array([1, 2, 4])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK
- config.use_l2_normalization = False
-
- # Run tested function.
- similarity_computer = (
- feature_aggregation_similarity.SimilarityAggregatedRepresentation(
- config))
- similarity = similarity_computer.ComputeSimilarity(
- aggregated_descriptors_1, aggregated_descriptors_2, visual_words_1,
- visual_words_2)
-
- # Define expected results.
- exp_similarity = 0.478554
-
- # Compare actual and expected results.
- self.assertAllClose(similarity, exp_similarity)
-
- def testComputeAsmkStarSimilarityWorks(self):
- # Construct inputs.
- aggregated_descriptors_1 = np.array([0, 0, 3, 3, 3], dtype='uint8')
- visual_words_1 = np.array([0, 1, 2, 3, 4])
- aggregated_descriptors_2 = np.array([1, 2, 3], dtype='uint8')
- visual_words_2 = np.array([1, 2, 4])
- config = aggregation_config_pb2.AggregationConfig()
- config.codebook_size = 5
- config.feature_dimensionality = 2
- config.aggregation_type = aggregation_config_pb2.AggregationConfig.ASMK_STAR
- config.use_l2_normalization = True
-
- # Run tested function.
- similarity_computer = (
- feature_aggregation_similarity.SimilarityAggregatedRepresentation(
- config))
- similarity = similarity_computer.ComputeSimilarity(
- aggregated_descriptors_1, aggregated_descriptors_2, visual_words_1,
- visual_words_2)
-
- # Define expected results.
- exp_similarity = 0.258199
-
- # Compare actual and expected results.
- self.assertAllClose(similarity, exp_similarity)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/feature_extractor.py b/research/delf/delf/python/feature_extractor.py
deleted file mode 100644
index 9545337f18724520e260af4e36ffa6ee35bce4c6..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_extractor.py
+++ /dev/null
@@ -1,175 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""DELF feature extractor."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-
-def NormalizePixelValues(image,
- pixel_value_offset=128.0,
- pixel_value_scale=128.0):
- """Normalize image pixel values.
-
- Args:
- image: a uint8 tensor.
- pixel_value_offset: a Python float, offset for normalizing pixel values.
- pixel_value_scale: a Python float, scale for normalizing pixel values.
-
- Returns:
- image: a float32 tensor of the same shape as the input image.
- """
- image = tf.cast(image, dtype=tf.float32)
- image = tf.truediv(tf.subtract(image, pixel_value_offset), pixel_value_scale)
- return image
-
-
-def CalculateReceptiveBoxes(height, width, rf, stride, padding):
- """Calculate receptive boxes for each feature point.
-
- Args:
- height: The height of feature map.
- width: The width of feature map.
- rf: The receptive field size.
- stride: The effective stride between two adjacent feature points.
- padding: The effective padding size.
-
- Returns:
- rf_boxes: [N, 4] receptive boxes tensor. Here N equals to height x width.
- Each box is represented by [ymin, xmin, ymax, xmax].
- """
- x, y = tf.meshgrid(tf.range(width), tf.range(height))
- coordinates = tf.reshape(tf.stack([y, x], axis=2), [-1, 2])
- # [y,x,y,x]
- point_boxes = tf.cast(
- tf.concat([coordinates, coordinates], 1), dtype=tf.float32)
- bias = [-padding, -padding, -padding + rf - 1, -padding + rf - 1]
- rf_boxes = stride * point_boxes + bias
- return rf_boxes
-
-
-def CalculateKeypointCenters(boxes):
- """Helper function to compute feature centers, from RF boxes.
-
- Args:
- boxes: [N, 4] float tensor.
-
- Returns:
- centers: [N, 2] float tensor.
- """
- return tf.divide(
- tf.add(
- tf.gather(boxes, [0, 1], axis=1), tf.gather(boxes, [2, 3], axis=1)),
- 2.0)
-
-
-def ApplyPcaAndWhitening(data,
- pca_matrix,
- pca_mean,
- output_dim,
- use_whitening=False,
- pca_variances=None):
- """Applies PCA/whitening to data.
-
- Args:
- data: [N, dim] float tensor containing data which undergoes PCA/whitening.
- pca_matrix: [dim, dim] float tensor PCA matrix, row-major.
- pca_mean: [dim] float tensor, mean to subtract before projection.
- output_dim: Number of dimensions to use in output data, of type int.
- use_whitening: Whether whitening is to be used.
- pca_variances: [dim] float tensor containing PCA variances. Only used if
- use_whitening is True.
-
- Returns:
- output: [N, output_dim] float tensor with output of PCA/whitening operation.
- """
- output = tf.matmul(
- tf.subtract(data, pca_mean),
- tf.slice(pca_matrix, [0, 0], [output_dim, -1]),
- transpose_b=True,
- name='pca_matmul')
-
- # Apply whitening if desired.
- if use_whitening:
- output = tf.divide(
- output,
- tf.sqrt(tf.slice(pca_variances, [0], [output_dim])),
- name='whitening')
-
- return output
-
-
-def PostProcessDescriptors(descriptors, use_pca, pca_parameters=None):
- """Post-process descriptors.
-
- Args:
- descriptors: [N, input_dim] float tensor.
- use_pca: Whether to use PCA.
- pca_parameters: Only used if `use_pca` is True. Dict containing PCA
- parameter tensors, with keys 'mean', 'matrix', 'dim', 'use_whitening',
- 'variances'.
-
- Returns:
- final_descriptors: [N, output_dim] float tensor with descriptors after
- normalization and (possibly) PCA/whitening.
- """
- # L2-normalize, and if desired apply PCA (followed by L2-normalization).
- final_descriptors = tf.nn.l2_normalize(
- descriptors, axis=1, name='l2_normalization')
-
- if use_pca:
- # Apply PCA, and whitening if desired.
- final_descriptors = ApplyPcaAndWhitening(final_descriptors,
- pca_parameters['matrix'],
- pca_parameters['mean'],
- pca_parameters['dim'],
- pca_parameters['use_whitening'],
- pca_parameters['variances'])
-
- # Re-normalize.
- final_descriptors = tf.nn.l2_normalize(
- final_descriptors, axis=1, name='pca_l2_normalization')
-
- return final_descriptors
-
-
-def DelfFeaturePostProcessing(boxes, descriptors, use_pca, pca_parameters=None):
- """Extract DELF features from input image.
-
- Args:
- boxes: [N, 4] float tensor which denotes the selected receptive box. N is
- the number of final feature points which pass through keypoint selection
- and NMS steps.
- descriptors: [N, input_dim] float tensor.
- use_pca: Whether to use PCA.
- pca_parameters: Only used if `use_pca` is True. Dict containing PCA
- parameter tensors, with keys 'mean', 'matrix', 'dim', 'use_whitening',
- 'variances'.
-
- Returns:
- locations: [N, 2] float tensor which denotes the selected keypoint
- locations.
- final_descriptors: [N, output_dim] float tensor with DELF descriptors after
- normalization and (possibly) PCA/whitening.
- """
-
- # Get center of descriptor boxes, corresponding to feature locations.
- locations = CalculateKeypointCenters(boxes)
- final_descriptors = PostProcessDescriptors(descriptors, use_pca,
- pca_parameters)
-
- return locations, final_descriptors
diff --git a/research/delf/delf/python/feature_extractor_test.py b/research/delf/delf/python/feature_extractor_test.py
deleted file mode 100644
index 0caa51c4321ae30866d2c1247626843a907c5a2d..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_extractor_test.py
+++ /dev/null
@@ -1,75 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DELF feature extractor."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from delf import feature_extractor
-
-
-class FeatureExtractorTest(tf.test.TestCase):
-
- def testNormalizePixelValues(self):
- image = tf.constant(
- [[[3, 255, 0], [34, 12, 5]], [[45, 5, 65], [56, 77, 89]]],
- dtype=tf.uint8)
- normalized_image = feature_extractor.NormalizePixelValues(
- image, pixel_value_offset=5.0, pixel_value_scale=2.0)
- exp_normalized_image = [[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]],
- [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]
-
- self.assertAllEqual(normalized_image, exp_normalized_image)
-
- def testCalculateReceptiveBoxes(self):
- boxes = feature_extractor.CalculateReceptiveBoxes(
- height=1, width=2, rf=291, stride=32, padding=145)
- exp_boxes = [[-145., -145., 145., 145.], [-145., -113., 145., 177.]]
-
- self.assertAllEqual(exp_boxes, boxes)
-
- def testCalculateKeypointCenters(self):
- boxes = [[-10.0, 0.0, 11.0, 21.0], [-2.5, 5.0, 18.5, 26.0],
- [45.0, -2.5, 66.0, 18.5]]
- centers = feature_extractor.CalculateKeypointCenters(boxes)
-
- exp_centers = [[0.5, 10.5], [8.0, 15.5], [55.5, 8.0]]
-
- self.assertAllEqual(exp_centers, centers)
-
- def testPcaWhitening(self):
- data = tf.constant([[1.0, 2.0, -2.0], [-5.0, 0.0, 3.0], [-1.0, 2.0, 0.0],
- [0.0, 4.0, -1.0]])
- pca_matrix = tf.constant([[2.0, 0.0, -1.0], [0.0, 1.0, 1.0],
- [-1.0, 1.0, 3.0]])
- pca_mean = tf.constant([1.0, 2.0, 3.0])
- output_dim = 2
- use_whitening = True
- pca_variances = tf.constant([4.0, 1.0])
-
- output = feature_extractor.ApplyPcaAndWhitening(data, pca_matrix, pca_mean,
- output_dim, use_whitening,
- pca_variances)
-
- exp_output = [[2.5, -5.0], [-6.0, -2.0], [-0.5, -3.0], [1.0, -2.0]]
-
- self.assertAllEqual(exp_output, output)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/feature_io.py b/research/delf/delf/python/feature_io.py
deleted file mode 100644
index 9b68586b8543b08bf16d345a65345be7cb6d8a67..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_io.py
+++ /dev/null
@@ -1,196 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Python interface for DelfFeatures proto.
-
-Support read and write of DelfFeatures from/to numpy arrays and file.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-from delf import feature_pb2
-from delf import datum_io
-
-
-def ArraysToDelfFeatures(locations,
- scales,
- descriptors,
- attention,
- orientations=None):
- """Converts DELF features to DelfFeatures proto.
-
- Args:
- locations: [N, 2] float array which denotes the selected keypoint locations.
- N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations. If None, all orientations
- are set to zero.
-
- Returns:
- delf_features: DelfFeatures object.
- """
- num_features = len(attention)
- assert num_features == locations.shape[0]
- assert num_features == len(scales)
- assert num_features == descriptors.shape[0]
-
- if orientations is None:
- orientations = np.zeros([num_features], dtype=np.float32)
- else:
- assert num_features == len(orientations)
-
- delf_features = feature_pb2.DelfFeatures()
- for i in range(num_features):
- delf_feature = delf_features.feature.add()
- delf_feature.y = locations[i, 0]
- delf_feature.x = locations[i, 1]
- delf_feature.scale = scales[i]
- delf_feature.orientation = orientations[i]
- delf_feature.strength = attention[i]
- delf_feature.descriptor.CopyFrom(datum_io.ArrayToDatum(descriptors[i,]))
-
- return delf_features
-
-
-def DelfFeaturesToArrays(delf_features):
- """Converts data saved in DelfFeatures to numpy arrays.
-
- If there are no features, the function returns four empty arrays.
-
- Args:
- delf_features: DelfFeatures object.
-
- Returns:
- locations: [N, 2] float array which denotes the selected keypoint
- locations. N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations.
- """
- num_features = len(delf_features.feature)
- if num_features == 0:
- return np.array([]), np.array([]), np.array([]), np.array([]), np.array([])
-
- # Figure out descriptor dimensionality by parsing first one.
- descriptor_dim = len(
- datum_io.DatumToArray(delf_features.feature[0].descriptor))
- locations = np.zeros([num_features, 2])
- scales = np.zeros([num_features])
- descriptors = np.zeros([num_features, descriptor_dim])
- attention = np.zeros([num_features])
- orientations = np.zeros([num_features])
-
- for i in range(num_features):
- delf_feature = delf_features.feature[i]
- locations[i, 0] = delf_feature.y
- locations[i, 1] = delf_feature.x
- scales[i] = delf_feature.scale
- descriptors[i,] = datum_io.DatumToArray(delf_feature.descriptor)
- attention[i] = delf_feature.strength
- orientations[i] = delf_feature.orientation
-
- return locations, scales, descriptors, attention, orientations
-
-
-def SerializeToString(locations,
- scales,
- descriptors,
- attention,
- orientations=None):
- """Converts numpy arrays to serialized DelfFeatures.
-
- Args:
- locations: [N, 2] float array which denotes the selected keypoint locations.
- N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations. If None, all orientations
- are set to zero.
-
- Returns:
- Serialized DelfFeatures string.
- """
- delf_features = ArraysToDelfFeatures(locations, scales, descriptors,
- attention, orientations)
- return delf_features.SerializeToString()
-
-
-def ParseFromString(string):
- """Converts serialized DelfFeatures string to numpy arrays.
-
- Args:
- string: Serialized DelfFeatures string.
-
- Returns:
- locations: [N, 2] float array which denotes the selected keypoint
- locations. N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations.
- """
- delf_features = feature_pb2.DelfFeatures()
- delf_features.ParseFromString(string)
- return DelfFeaturesToArrays(delf_features)
-
-
-def ReadFromFile(file_path):
- """Helper function to load data from a DelfFeatures format in a file.
-
- Args:
- file_path: Path to file containing data.
-
- Returns:
- locations: [N, 2] float array which denotes the selected keypoint
- locations. N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations.
- """
- with tf.io.gfile.GFile(file_path, 'rb') as f:
- return ParseFromString(f.read())
-
-
-def WriteToFile(file_path,
- locations,
- scales,
- descriptors,
- attention,
- orientations=None):
- """Helper function to write data to a file in DelfFeatures format.
-
- Args:
- file_path: Path to file that will be written.
- locations: [N, 2] float array which denotes the selected keypoint locations.
- N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations. If None, all orientations
- are set to zero.
- """
- serialized_data = SerializeToString(locations, scales, descriptors, attention,
- orientations)
- with tf.io.gfile.GFile(file_path, 'w') as f:
- f.write(serialized_data)
diff --git a/research/delf/delf/python/feature_io_test.py b/research/delf/delf/python/feature_io_test.py
deleted file mode 100644
index 8b68d3b241cf561de9362c84ec05e148d22ee0f2..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/feature_io_test.py
+++ /dev/null
@@ -1,112 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for feature_io, the python interface of DelfFeatures."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import flags
-import numpy as np
-import tensorflow as tf
-
-from delf import feature_io
-
-FLAGS = flags.FLAGS
-
-
-def create_data():
- """Creates data to be used in tests.
-
- Returns:
- locations: [N, 2] float array which denotes the selected keypoint
- locations. N is the number of features.
- scales: [N] float array with feature scales.
- descriptors: [N, depth] float array with DELF descriptors.
- attention: [N] float array with attention scores.
- orientations: [N] float array with orientations.
- """
- locations = np.arange(8, dtype=np.float32).reshape(4, 2)
- scales = np.arange(4, dtype=np.float32)
- attention = np.arange(4, dtype=np.float32)
- orientations = np.arange(4, dtype=np.float32)
- descriptors = np.zeros([4, 1024])
- descriptors[0,] = np.arange(1024)
- descriptors[1,] = np.zeros([1024])
- descriptors[2,] = np.ones([1024])
- descriptors[3,] = -np.ones([1024])
-
- return locations, scales, descriptors, attention, orientations
-
-
-class DelfFeaturesIoTest(tf.test.TestCase):
-
- def testConversionAndBack(self):
- locations, scales, descriptors, attention, orientations = create_data()
-
- serialized = feature_io.SerializeToString(locations, scales, descriptors,
- attention, orientations)
- parsed_data = feature_io.ParseFromString(serialized)
-
- self.assertAllEqual(locations, parsed_data[0])
- self.assertAllEqual(scales, parsed_data[1])
- self.assertAllEqual(descriptors, parsed_data[2])
- self.assertAllEqual(attention, parsed_data[3])
- self.assertAllEqual(orientations, parsed_data[4])
-
- def testConversionAndBackNoOrientations(self):
- locations, scales, descriptors, attention, _ = create_data()
-
- serialized = feature_io.SerializeToString(locations, scales, descriptors,
- attention)
- parsed_data = feature_io.ParseFromString(serialized)
-
- self.assertAllEqual(locations, parsed_data[0])
- self.assertAllEqual(scales, parsed_data[1])
- self.assertAllEqual(descriptors, parsed_data[2])
- self.assertAllEqual(attention, parsed_data[3])
- self.assertAllEqual(np.zeros([4]), parsed_data[4])
-
- def testWriteAndReadToFile(self):
- locations, scales, descriptors, attention, orientations = create_data()
-
- filename = os.path.join(FLAGS.test_tmpdir, 'test.delf')
- feature_io.WriteToFile(filename, locations, scales, descriptors, attention,
- orientations)
- data_read = feature_io.ReadFromFile(filename)
-
- self.assertAllEqual(locations, data_read[0])
- self.assertAllEqual(scales, data_read[1])
- self.assertAllEqual(descriptors, data_read[2])
- self.assertAllEqual(attention, data_read[3])
- self.assertAllEqual(orientations, data_read[4])
-
- def testWriteAndReadToFileEmptyFile(self):
- filename = os.path.join(FLAGS.test_tmpdir, 'test.delf')
- feature_io.WriteToFile(filename, np.array([]), np.array([]), np.array([]),
- np.array([]), np.array([]))
- data_read = feature_io.ReadFromFile(filename)
-
- self.assertAllEqual(np.array([]), data_read[0])
- self.assertAllEqual(np.array([]), data_read[1])
- self.assertAllEqual(np.array([]), data_read[2])
- self.assertAllEqual(np.array([]), data_read[3])
- self.assertAllEqual(np.array([]), data_read[4])
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/google_landmarks_dataset/README.md b/research/delf/delf/python/google_landmarks_dataset/README.md
deleted file mode 100644
index 485c1a946b5b21ddb369cc1bc8645534abbfad1e..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/README.md
+++ /dev/null
@@ -1,123 +0,0 @@
-## GLDv2 code/models
-
-[](https://arxiv.org/abs/2004.01804)
-
-These instructions can be used to reproduce results from the
-[GLDv2 paper](https://arxiv.org/abs/2004.01804). We present here results on the
-Revisited Oxford/Paris datasets since they are smaller and quicker to
-reproduce -- but note that a very similar procedure can be used to obtain
-results on the GLDv2 retrieval or recognition datasets.
-
-Note that this directory also contains code to compute GLDv2 metrics: see
-`compute_retrieval_metrics.py`, `compute_recognition_metrics.py` and associated
-file reading / metric computation modules.
-
-For more details on the dataset, please refer to its
-[website](https://github.com/cvdfoundation/google-landmark).
-
-### Install DELF library
-
-To be able to use this code, please follow
-[these instructions](../../../INSTALL_INSTRUCTIONS.md) to properly install the
-DELF library.
-
-### Download Revisited Oxford/Paris datasets
-
-```bash
-mkdir -p ~/revisitop/data && cd ~/revisitop/data
-
-# Oxford dataset.
-wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz
-mkdir oxford5k_images
-tar -xvzf oxbuild_images.tgz -C oxford5k_images/
-
-# Paris dataset. Download and move all images to same directory.
-wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_1.tgz
-wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_2.tgz
-mkdir paris6k_images_tmp
-tar -xvzf paris_1.tgz -C paris6k_images_tmp/
-tar -xvzf paris_2.tgz -C paris6k_images_tmp/
-mkdir paris6k_images
-mv paris6k_images_tmp/paris/*/*.jpg paris6k_images/
-
-# Revisited annotations.
-wget http://cmp.felk.cvut.cz/revisitop/data/datasets/roxford5k/gnd_roxford5k.mat
-wget http://cmp.felk.cvut.cz/revisitop/data/datasets/rparis6k/gnd_rparis6k.mat
-```
-
-### Download model
-
-```bash
-# From models/research/delf/delf/python/google_landmarks_dataset
-mkdir parameters && cd parameters
-
-# RN101-ArcFace model trained on GLDv2-clean.
-wget https://storage.googleapis.com/delf/rn101_af_gldv2clean_20200521.tar.gz
-tar -xvzf rn101_af_gldv2clean_20200521.tar.gz
-```
-
-### Feature extraction
-
-We present here commands for extraction on `roxford5k`. To extract on `rparis6k`
-instead, please edit the arguments accordingly (especially the
-`dataset_file_path` argument).
-
-#### Query feature extraction
-
-In the Revisited Oxford/Paris experimental protocol, query images must be the
-cropped before feature extraction (this is done in the `extract_features`
-script, when setting `image_set=query`). Note that this is specific to these
-datasets, and not required for the GLDv2 retrieval/recognition datasets.
-
-Run query feature extraction as follows:
-
-```bash
-# From models/research/delf/delf/python/google_landmarks_dataset
-python3 ../delg/extract_features.py \
- --delf_config_path rn101_af_gldv2clean_config.pbtxt \
- --dataset_file_path ~/revisitop/data/gnd_roxford5k.mat \
- --images_dir ~/revisitop/data/oxford5k_images \
- --image_set query \
- --output_features_dir ~/revisitop/data/oxford5k_features/query
-```
-
-#### Index feature extraction
-
-Run index feature extraction as follows:
-
-```bash
-# From models/research/delf/delf/python/google_landmarks_dataset
-python3 ../delg/extract_features.py \
- --delf_config_path rn101_af_gldv2clean_config.pbtxt \
- --dataset_file_path ~/revisitop/data/gnd_roxford5k.mat \
- --images_dir ~/revisitop/data/oxford5k_images \
- --image_set index \
- --output_features_dir ~/revisitop/data/oxford5k_features/index
-```
-
-### Perform retrieval
-
-To run retrieval on `roxford5k`, the following command can be used:
-
-```bash
-# From models/research/delf/delf/python/google_landmarks_dataset
-python3 ../delg/perform_retrieval.py \
- --dataset_file_path ~/revisitop/data/gnd_roxford5k.mat \
- --query_features_dir ~/revisitop/data/oxford5k_features/query \
- --index_features_dir ~/revisitop/data/oxford5k_features/index \
- --output_dir ~/revisitop/results/oxford5k
-```
-
-A file with named `metrics.txt` will be written to the path given in
-`output_dir`. The contents should look approximately like:
-
-```
-hard
- mAP=55.54
- mP@k[ 1 5 10] [88.57 80.86 70.14]
- mR@k[ 1 5 10] [19.46 33.65 42.44]
-medium
- mAP=76.23
- mP@k[ 1 5 10] [95.71 92.86 90.43]
- mR@k[ 1 5 10] [10.17 25.96 35.29]
-```
diff --git a/research/delf/delf/python/google_landmarks_dataset/compute_recognition_metrics.py b/research/delf/delf/python/google_landmarks_dataset/compute_recognition_metrics.py
deleted file mode 100644
index f80cf47de7487d4cd584c969d994f7d3f1135cae..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/compute_recognition_metrics.py
+++ /dev/null
@@ -1,99 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Computes metrics for Google Landmarks Recognition dataset predictions.
-
-Metrics are written to stdout.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import sys
-
-from tensorflow.python.platform import app
-from delf.python.google_landmarks_dataset import dataset_file_io
-from delf.python.google_landmarks_dataset import metrics
-
-cmd_args = None
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read solution.
- print('Reading solution...')
- public_solution, private_solution, ignored_ids = dataset_file_io.ReadSolution(
- cmd_args.solution_path, dataset_file_io.RECOGNITION_TASK_ID)
- print('done!')
-
- # Read predictions.
- print('Reading predictions...')
- public_predictions, private_predictions = dataset_file_io.ReadPredictions(
- cmd_args.predictions_path, set(public_solution.keys()),
- set(private_solution.keys()), set(ignored_ids),
- dataset_file_io.RECOGNITION_TASK_ID)
- print('done!')
-
- # Global Average Precision.
- print('**********************************************')
- print('(Public) Global Average Precision: %f' %
- metrics.GlobalAveragePrecision(public_predictions, public_solution))
- print('(Private) Global Average Precision: %f' %
- metrics.GlobalAveragePrecision(private_predictions, private_solution))
-
- # Global Average Precision ignoring non-landmark queries.
- print('**********************************************')
- print(
- '(Public) Global Average Precision ignoring non-landmark queries: %f' %
- metrics.GlobalAveragePrecision(
- public_predictions, public_solution, ignore_non_gt_test_images=True))
- print(
- '(Private) Global Average Precision ignoring non-landmark queries: %f' %
- metrics.GlobalAveragePrecision(
- private_predictions, private_solution,
- ignore_non_gt_test_images=True))
-
- # Top-1 accuracy.
- print('**********************************************')
- print('(Public) Top-1 accuracy: %.2f' %
- (100.0 * metrics.Top1Accuracy(public_predictions, public_solution)))
- print('(Private) Top-1 accuracy: %.2f' %
- (100.0 * metrics.Top1Accuracy(private_predictions, private_solution)))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--predictions_path',
- type=str,
- default='/tmp/predictions.csv',
- help="""
- Path to CSV predictions file, formatted with columns 'id,landmarks' (the
- file should include a header).
- """)
- parser.add_argument(
- '--solution_path',
- type=str,
- default='/tmp/solution.csv',
- help="""
- Path to CSV solution file, formatted with columns 'id,landmarks,Usage'
- (the file should include a header).
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/google_landmarks_dataset/compute_retrieval_metrics.py b/research/delf/delf/python/google_landmarks_dataset/compute_retrieval_metrics.py
deleted file mode 100644
index adcee356e5d64d094236cda9656c86164c24faf8..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/compute_retrieval_metrics.py
+++ /dev/null
@@ -1,106 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Computes metrics for Google Landmarks Retrieval dataset predictions.
-
-Metrics are written to stdout.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import argparse
-import sys
-
-from tensorflow.python.platform import app
-from delf.python.google_landmarks_dataset import dataset_file_io
-from delf.python.google_landmarks_dataset import metrics
-
-cmd_args = None
-
-
-def main(argv):
- if len(argv) > 1:
- raise RuntimeError('Too many command-line arguments.')
-
- # Read solution.
- print('Reading solution...')
- public_solution, private_solution, ignored_ids = dataset_file_io.ReadSolution(
- cmd_args.solution_path, dataset_file_io.RETRIEVAL_TASK_ID)
- print('done!')
-
- # Read predictions.
- print('Reading predictions...')
- public_predictions, private_predictions = dataset_file_io.ReadPredictions(
- cmd_args.predictions_path, set(public_solution.keys()),
- set(private_solution.keys()), set(ignored_ids),
- dataset_file_io.RETRIEVAL_TASK_ID)
- print('done!')
-
- # Mean average precision.
- print('**********************************************')
- print('(Public) Mean Average Precision: %f' %
- metrics.MeanAveragePrecision(public_predictions, public_solution))
- print('(Private) Mean Average Precision: %f' %
- metrics.MeanAveragePrecision(private_predictions, private_solution))
-
- # Mean precision@k.
- print('**********************************************')
- public_precisions = 100.0 * metrics.MeanPrecisions(public_predictions,
- public_solution)
- private_precisions = 100.0 * metrics.MeanPrecisions(private_predictions,
- private_solution)
- print('(Public) Mean precisions: P@1: %.2f, P@5: %.2f, P@10: %.2f, '
- 'P@50: %.2f, P@100: %.2f' %
- (public_precisions[0], public_precisions[4], public_precisions[9],
- public_precisions[49], public_precisions[99]))
- print('(Private) Mean precisions: P@1: %.2f, P@5: %.2f, P@10: %.2f, '
- 'P@50: %.2f, P@100: %.2f' %
- (private_precisions[0], private_precisions[4], private_precisions[9],
- private_precisions[49], private_precisions[99]))
-
- # Mean/median position of first correct.
- print('**********************************************')
- public_mean_position, public_median_position = metrics.MeanMedianPosition(
- public_predictions, public_solution)
- private_mean_position, private_median_position = metrics.MeanMedianPosition(
- private_predictions, private_solution)
- print('(Public) Mean position: %.2f, median position: %.2f' %
- (public_mean_position, public_median_position))
- print('(Private) Mean position: %.2f, median position: %.2f' %
- (private_mean_position, private_median_position))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.register('type', 'bool', lambda v: v.lower() == 'true')
- parser.add_argument(
- '--predictions_path',
- type=str,
- default='/tmp/predictions.csv',
- help="""
- Path to CSV predictions file, formatted with columns 'id,images' (the
- file should include a header).
- """)
- parser.add_argument(
- '--solution_path',
- type=str,
- default='/tmp/solution.csv',
- help="""
- Path to CSV solution file, formatted with columns 'id,images,Usage'
- (the file should include a header).
- """)
- cmd_args, unparsed = parser.parse_known_args()
- app.run(main=main, argv=[sys.argv[0]] + unparsed)
diff --git a/research/delf/delf/python/google_landmarks_dataset/dataset_file_io.py b/research/delf/delf/python/google_landmarks_dataset/dataset_file_io.py
deleted file mode 100644
index 93f2785d78f03b5b112bbba635b4778f2e9b9a08..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/dataset_file_io.py
+++ /dev/null
@@ -1,159 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""IO module for files from Landmark recognition/retrieval challenges."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import csv
-
-import tensorflow as tf
-
-RECOGNITION_TASK_ID = 'recognition'
-RETRIEVAL_TASK_ID = 'retrieval'
-
-
-def ReadSolution(file_path, task):
- """Reads solution from file, for a given task.
-
- Args:
- file_path: Path to CSV file with solution. File contains a header.
- task: Type of challenge task. Supported values: 'recognition', 'retrieval'.
-
- Returns:
- public_solution: Dict mapping test image ID to list of ground-truth IDs, for
- the Public subset of test images. If `task` == 'recognition', the IDs are
- integers corresponding to landmark IDs. If `task` == 'retrieval', the IDs
- are strings corresponding to index image IDs.
- private_solution: Same as `public_solution`, but for the private subset of
- test images.
- ignored_ids: List of test images that are ignored in scoring.
-
- Raises:
- ValueError: If Usage field is not Public, Private or Ignored; or if `task`
- is not supported.
- """
- public_solution = {}
- private_solution = {}
- ignored_ids = []
- with tf.io.gfile.GFile(file_path, 'r') as csv_file:
- reader = csv.reader(csv_file)
- next(reader, None) # Skip header.
- for row in reader:
- test_id = row[0]
- if row[2] == 'Ignored':
- ignored_ids.append(test_id)
- else:
- ground_truth_ids = []
- if task == RECOGNITION_TASK_ID:
- if row[1]:
- for landmark_id in row[1].split(' '):
- ground_truth_ids.append(int(landmark_id))
- elif task == RETRIEVAL_TASK_ID:
- for image_id in row[1].split(' '):
- ground_truth_ids.append(image_id)
- else:
- raise ValueError('Unrecognized task: %s' % task)
-
- if row[2] == 'Public':
- public_solution[test_id] = ground_truth_ids
- elif row[2] == 'Private':
- private_solution[test_id] = ground_truth_ids
- else:
- raise ValueError('Test image %s has unrecognized Usage tag %s' %
- (row[0], row[2]))
-
- return public_solution, private_solution, ignored_ids
-
-
-def ReadPredictions(file_path, public_ids, private_ids, ignored_ids, task):
- """Reads predictions from file, for a given task.
-
- Args:
- file_path: Path to CSV file with predictions. File contains a header.
- public_ids: Set (or list) of test image IDs in Public subset of test images.
- private_ids: Same as `public_ids`, but for the private subset of test
- images.
- ignored_ids: Set (or list) of test image IDs that are ignored in scoring and
- are associated to no ground-truth.
- task: Type of challenge task. Supported values: 'recognition', 'retrieval'.
-
- Returns:
- public_predictions: Dict mapping test image ID to prediction, for the Public
- subset of test images. If `task` == 'recognition', the prediction is a
- dict with keys 'class' (integer) and 'score' (float). If `task` ==
- 'retrieval', the prediction is a list of strings corresponding to index
- image IDs.
- private_predictions: Same as `public_predictions`, but for the private
- subset of test images.
-
- Raises:
- ValueError:
- - If test image ID is unrecognized/repeated;
- - If `task` is not supported;
- - If prediction is malformed.
- """
- public_predictions = {}
- private_predictions = {}
- with tf.io.gfile.GFile(file_path, 'r') as csv_file:
- reader = csv.reader(csv_file)
- next(reader, None) # Skip header.
- for row in reader:
- # Skip row if empty.
- if not row:
- continue
-
- test_id = row[0]
-
- # Makes sure this query has not yet been seen.
- if test_id in public_predictions:
- raise ValueError('Test image %s is repeated.' % test_id)
- if test_id in private_predictions:
- raise ValueError('Test image %s is repeated' % test_id)
-
- # If ignored, skip it.
- if test_id in ignored_ids:
- continue
-
- # Only parse result if there is a prediction.
- if row[1]:
- prediction_split = row[1].split(' ')
- # Remove empty spaces at end (if any).
- if not prediction_split[-1]:
- prediction_split = prediction_split[:-1]
-
- if task == RECOGNITION_TASK_ID:
- if len(prediction_split) != 2:
- raise ValueError('Prediction is malformed: there should only be 2 '
- 'elements in second column, but found %d for test '
- 'image %s' % (len(prediction_split), test_id))
-
- landmark_id = int(prediction_split[0])
- score = float(prediction_split[1])
- prediction_entry = {'class': landmark_id, 'score': score}
- elif task == RETRIEVAL_TASK_ID:
- prediction_entry = prediction_split
- else:
- raise ValueError('Unrecognized task: %s' % task)
-
- if test_id in public_ids:
- public_predictions[test_id] = prediction_entry
- elif test_id in private_ids:
- private_predictions[test_id] = prediction_entry
- else:
- raise ValueError('test_id %s is unrecognized' % test_id)
-
- return public_predictions, private_predictions
diff --git a/research/delf/delf/python/google_landmarks_dataset/dataset_file_io_test.py b/research/delf/delf/python/google_landmarks_dataset/dataset_file_io_test.py
deleted file mode 100644
index 0101d989fba85e487842e65b3b1aec4e728c101c..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/dataset_file_io_test.py
+++ /dev/null
@@ -1,170 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for dataset file IO module."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import flags
-import tensorflow as tf
-
-from delf.python.google_landmarks_dataset import dataset_file_io
-
-FLAGS = flags.FLAGS
-
-
-class DatasetFileIoTest(tf.test.TestCase):
-
- def testReadRecognitionSolutionWorks(self):
- # Define inputs.
- file_path = os.path.join(FLAGS.test_tmpdir,
- 'recognition_solution.csv')
- with tf.io.gfile.GFile(file_path, 'w') as f:
- f.write('id,landmarks,Usage\n')
- f.write('0123456789abcdef,0 12,Public\n')
- f.write('0223456789abcdef,,Public\n')
- f.write('0323456789abcdef,100,Ignored\n')
- f.write('0423456789abcdef,1,Private\n')
- f.write('0523456789abcdef,,Ignored\n')
-
- # Run tested function.
- (public_solution, private_solution,
- ignored_ids) = dataset_file_io.ReadSolution(
- file_path, dataset_file_io.RECOGNITION_TASK_ID)
-
- # Define expected results.
- expected_public_solution = {
- '0123456789abcdef': [0, 12],
- '0223456789abcdef': []
- }
- expected_private_solution = {
- '0423456789abcdef': [1],
- }
- expected_ignored_ids = ['0323456789abcdef', '0523456789abcdef']
-
- # Compare actual and expected results.
- self.assertEqual(public_solution, expected_public_solution)
- self.assertEqual(private_solution, expected_private_solution)
- self.assertEqual(ignored_ids, expected_ignored_ids)
-
- def testReadRetrievalSolutionWorks(self):
- # Define inputs.
- file_path = os.path.join(FLAGS.test_tmpdir,
- 'retrieval_solution.csv')
- with tf.io.gfile.GFile(file_path, 'w') as f:
- f.write('id,images,Usage\n')
- f.write('0123456789abcdef,None,Ignored\n')
- f.write('0223456789abcdef,fedcba9876543210 fedcba9876543200,Public\n')
- f.write('0323456789abcdef,fedcba9876543200,Private\n')
- f.write('0423456789abcdef,fedcba9876543220,Private\n')
- f.write('0523456789abcdef,None,Ignored\n')
-
- # Run tested function.
- (public_solution, private_solution,
- ignored_ids) = dataset_file_io.ReadSolution(
- file_path, dataset_file_io.RETRIEVAL_TASK_ID)
-
- # Define expected results.
- expected_public_solution = {
- '0223456789abcdef': ['fedcba9876543210', 'fedcba9876543200'],
- }
- expected_private_solution = {
- '0323456789abcdef': ['fedcba9876543200'],
- '0423456789abcdef': ['fedcba9876543220'],
- }
- expected_ignored_ids = ['0123456789abcdef', '0523456789abcdef']
-
- # Compare actual and expected results.
- self.assertEqual(public_solution, expected_public_solution)
- self.assertEqual(private_solution, expected_private_solution)
- self.assertEqual(ignored_ids, expected_ignored_ids)
-
- def testReadRecognitionPredictionsWorks(self):
- # Define inputs.
- file_path = os.path.join(FLAGS.test_tmpdir,
- 'recognition_predictions.csv')
- with tf.io.gfile.GFile(file_path, 'w') as f:
- f.write('id,landmarks\n')
- f.write('0123456789abcdef,12 0.1 \n')
- f.write('0423456789abcdef,0 19.0\n')
- f.write('0223456789abcdef,\n')
- f.write('\n')
- f.write('0523456789abcdef,14 0.01\n')
- public_ids = ['0123456789abcdef', '0223456789abcdef']
- private_ids = ['0423456789abcdef']
- ignored_ids = ['0323456789abcdef', '0523456789abcdef']
-
- # Run tested function.
- public_predictions, private_predictions = dataset_file_io.ReadPredictions(
- file_path, public_ids, private_ids, ignored_ids,
- dataset_file_io.RECOGNITION_TASK_ID)
-
- # Define expected results.
- expected_public_predictions = {
- '0123456789abcdef': {
- 'class': 12,
- 'score': 0.1
- }
- }
- expected_private_predictions = {
- '0423456789abcdef': {
- 'class': 0,
- 'score': 19.0
- }
- }
-
- # Compare actual and expected results.
- self.assertEqual(public_predictions, expected_public_predictions)
- self.assertEqual(private_predictions, expected_private_predictions)
-
- def testReadRetrievalPredictionsWorks(self):
- # Define inputs.
- file_path = os.path.join(FLAGS.test_tmpdir,
- 'retrieval_predictions.csv')
- with tf.io.gfile.GFile(file_path, 'w') as f:
- f.write('id,images\n')
- f.write('0123456789abcdef,fedcba9876543250 \n')
- f.write('0423456789abcdef,fedcba9876543260\n')
- f.write('0223456789abcdef,fedcba9876543210 fedcba9876543200 '
- 'fedcba9876543220\n')
- f.write('\n')
- f.write('0523456789abcdef,\n')
- public_ids = ['0223456789abcdef']
- private_ids = ['0323456789abcdef', '0423456789abcdef']
- ignored_ids = ['0123456789abcdef', '0523456789abcdef']
-
- # Run tested function.
- public_predictions, private_predictions = dataset_file_io.ReadPredictions(
- file_path, public_ids, private_ids, ignored_ids,
- dataset_file_io.RETRIEVAL_TASK_ID)
-
- # Define expected results.
- expected_public_predictions = {
- '0223456789abcdef': [
- 'fedcba9876543210', 'fedcba9876543200', 'fedcba9876543220'
- ]
- }
- expected_private_predictions = {'0423456789abcdef': ['fedcba9876543260']}
-
- # Compare actual and expected results.
- self.assertEqual(public_predictions, expected_public_predictions)
- self.assertEqual(private_predictions, expected_private_predictions)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/google_landmarks_dataset/metrics.py b/research/delf/delf/python/google_landmarks_dataset/metrics.py
deleted file mode 100644
index 1516be9d8569cecfe470d9ec98ce273a72cce84f..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/metrics.py
+++ /dev/null
@@ -1,254 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Python module to compute metrics for Google Landmarks dataset."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-
-def _CountPositives(solution):
- """Counts number of test images with non-empty ground-truth in `solution`.
-
- Args:
- solution: Dict mapping test image ID to list of ground-truth IDs.
-
- Returns:
- count: Number of test images with non-empty ground-truth.
- """
- count = 0
- for v in solution.values():
- if v:
- count += 1
-
- return count
-
-
-def GlobalAveragePrecision(predictions,
- recognition_solution,
- ignore_non_gt_test_images=False):
- """Computes global average precision for recognition prediction.
-
- Args:
- predictions: Dict mapping test image ID to a dict with keys 'class'
- (integer) and 'score' (float).
- recognition_solution: Dict mapping test image ID to list of ground-truth
- landmark IDs.
- ignore_non_gt_test_images: If True, ignore test images which do not have
- associated ground-truth landmark IDs. For the Google Landmark Recognition
- challenge, this should be set to False.
-
- Returns:
- gap: Global average precision score (float).
- """
- # Compute number of expected results.
- num_positives = _CountPositives(recognition_solution)
-
- gap = 0.0
- total_predictions = 0
- correct_predictions = 0
-
- # Sort predictions according to Kaggle's convention:
- # - first by score (descending);
- # - then by key (ascending);
- # - then by class (ascending).
- sorted_predictions_by_key_class = sorted(
- predictions.items(), key=lambda item: (item[0], item[1]['class']))
- sorted_predictions = sorted(
- sorted_predictions_by_key_class,
- key=lambda item: item[1]['score'],
- reverse=True)
-
- # Loop over sorted predictions (descending order) and compute GAPs.
- for key, prediction in sorted_predictions:
- if ignore_non_gt_test_images and not recognition_solution[key]:
- continue
-
- total_predictions += 1
- if prediction['class'] in recognition_solution[key]:
- correct_predictions += 1
- gap += correct_predictions / total_predictions
-
- gap /= num_positives
-
- return gap
-
-
-def Top1Accuracy(predictions, recognition_solution):
- """Computes top-1 accuracy for recognition prediction.
-
- Note that test images without ground-truth are ignored.
-
- Args:
- predictions: Dict mapping test image ID to a dict with keys 'class'
- (integer) and 'score' (float).
- recognition_solution: Dict mapping test image ID to list of ground-truth
- landmark IDs.
-
- Returns:
- accuracy: Top-1 accuracy (float).
- """
- # Loop over test images in solution. If it has at least one class label, we
- # check if the predicion is correct.
- num_correct_predictions = 0
- num_test_images_with_ground_truth = 0
- for key, ground_truth in recognition_solution.items():
- if ground_truth:
- num_test_images_with_ground_truth += 1
- if key in predictions:
- if predictions[key]['class'] in ground_truth:
- num_correct_predictions += 1
-
- return num_correct_predictions / num_test_images_with_ground_truth
-
-
-def MeanAveragePrecision(predictions, retrieval_solution, max_predictions=100):
- """Computes mean average precision for retrieval prediction.
-
- Args:
- predictions: Dict mapping test image ID to a list of strings corresponding
- to index image IDs.
- retrieval_solution: Dict mapping test image ID to list of ground-truth image
- IDs.
- max_predictions: Maximum number of predictions per query to take into
- account. For the Google Landmark Retrieval challenge, this should be set
- to 100.
-
- Returns:
- mean_ap: Mean average precision score (float).
-
- Raises:
- ValueError: If a test image in `predictions` is not included in
- `retrieval_solutions`.
- """
- # Compute number of test images.
- num_test_images = len(retrieval_solution.keys())
-
- # Loop over predictions for each query and compute mAP.
- mean_ap = 0.0
- for key, prediction in predictions.items():
- if key not in retrieval_solution:
- raise ValueError('Test image %s is not part of retrieval_solution' % key)
-
- # Loop over predicted images, keeping track of those which were already
- # used (duplicates are skipped).
- ap = 0.0
- already_predicted = set()
- num_expected_retrieved = min(len(retrieval_solution[key]), max_predictions)
- num_correct = 0
- for i in range(min(len(prediction), max_predictions)):
- if prediction[i] not in already_predicted:
- if prediction[i] in retrieval_solution[key]:
- num_correct += 1
- ap += num_correct / (i + 1)
- already_predicted.add(prediction[i])
-
- ap /= num_expected_retrieved
- mean_ap += ap
-
- mean_ap /= num_test_images
-
- return mean_ap
-
-
-def MeanPrecisions(predictions, retrieval_solution, max_predictions=100):
- """Computes mean precisions for retrieval prediction.
-
- Args:
- predictions: Dict mapping test image ID to a list of strings corresponding
- to index image IDs.
- retrieval_solution: Dict mapping test image ID to list of ground-truth image
- IDs.
- max_predictions: Maximum number of predictions per query to take into
- account.
-
- Returns:
- mean_precisions: NumPy array with mean precisions at ranks 1 through
- `max_predictions`.
-
- Raises:
- ValueError: If a test image in `predictions` is not included in
- `retrieval_solutions`.
- """
- # Compute number of test images.
- num_test_images = len(retrieval_solution.keys())
-
- # Loop over predictions for each query and compute precisions@k.
- precisions = np.zeros((num_test_images, max_predictions))
- count_test_images = 0
- for key, prediction in predictions.items():
- if key not in retrieval_solution:
- raise ValueError('Test image %s is not part of retrieval_solution' % key)
-
- # Loop over predicted images, keeping track of those which were already
- # used (duplicates are skipped).
- already_predicted = set()
- num_correct = 0
- for i in range(max_predictions):
- if i < len(prediction):
- if prediction[i] not in already_predicted:
- if prediction[i] in retrieval_solution[key]:
- num_correct += 1
- already_predicted.add(prediction[i])
- precisions[count_test_images, i] = num_correct / (i + 1)
- count_test_images += 1
-
- mean_precisions = np.mean(precisions, axis=0)
-
- return mean_precisions
-
-
-def MeanMedianPosition(predictions, retrieval_solution, max_predictions=100):
- """Computes mean and median positions of first correct image.
-
- Args:
- predictions: Dict mapping test image ID to a list of strings corresponding
- to index image IDs.
- retrieval_solution: Dict mapping test image ID to list of ground-truth image
- IDs.
- max_predictions: Maximum number of predictions per query to take into
- account.
-
- Returns:
- mean_position: Float.
- median_position: Float.
-
- Raises:
- ValueError: If a test image in `predictions` is not included in
- `retrieval_solutions`.
- """
- # Compute number of test images.
- num_test_images = len(retrieval_solution.keys())
-
- # Loop over predictions for each query to find first correct ranked image.
- positions = (max_predictions + 1) * np.ones((num_test_images))
- count_test_images = 0
- for key, prediction in predictions.items():
- if key not in retrieval_solution:
- raise ValueError('Test image %s is not part of retrieval_solution' % key)
-
- for i in range(min(len(prediction), max_predictions)):
- if prediction[i] in retrieval_solution[key]:
- positions[count_test_images] = i + 1
- break
-
- count_test_images += 1
-
- mean_position = np.mean(positions)
- median_position = np.median(positions)
-
- return mean_position, median_position
diff --git a/research/delf/delf/python/google_landmarks_dataset/metrics_test.py b/research/delf/delf/python/google_landmarks_dataset/metrics_test.py
deleted file mode 100644
index 50838cae2b5bfaa8f6f0c5cbfab2a07aa20b7c52..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/metrics_test.py
+++ /dev/null
@@ -1,219 +0,0 @@
-# Copyright 2019 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for Google Landmarks dataset metric computation."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from delf.python.google_landmarks_dataset import metrics
-
-
-def _CreateRecognitionSolution():
- """Creates recognition solution to be used in tests.
-
- Returns:
- solution: Dict mapping test image ID to list of ground-truth landmark IDs.
- """
- return {
- '0123456789abcdef': [0, 12],
- '0223456789abcdef': [100, 200, 300],
- '0323456789abcdef': [1],
- '0423456789abcdef': [],
- '0523456789abcdef': [],
- }
-
-
-def _CreateRecognitionPredictions():
- """Creates recognition predictions to be used in tests.
-
- Returns:
- predictions: Dict mapping test image ID to a dict with keys 'class'
- (integer) and 'score' (float).
- """
- return {
- '0223456789abcdef': {
- 'class': 0,
- 'score': 0.01
- },
- '0323456789abcdef': {
- 'class': 1,
- 'score': 10.0
- },
- '0423456789abcdef': {
- 'class': 150,
- 'score': 15.0
- },
- }
-
-
-def _CreateRetrievalSolution():
- """Creates retrieval solution to be used in tests.
-
- Returns:
- solution: Dict mapping test image ID to list of ground-truth image IDs.
- """
- return {
- '0123456789abcdef': ['fedcba9876543210', 'fedcba9876543220'],
- '0223456789abcdef': ['fedcba9876543210'],
- '0323456789abcdef': [
- 'fedcba9876543230', 'fedcba9876543240', 'fedcba9876543250'
- ],
- '0423456789abcdef': ['fedcba9876543230'],
- }
-
-
-def _CreateRetrievalPredictions():
- """Creates retrieval predictions to be used in tests.
-
- Returns:
- predictions: Dict mapping test image ID to a list with predicted index image
- ids.
- """
- return {
- '0223456789abcdef': ['fedcba9876543200', 'fedcba9876543210'],
- '0323456789abcdef': ['fedcba9876543240'],
- '0423456789abcdef': ['fedcba9876543230', 'fedcba9876543240'],
- }
-
-
-class MetricsTest(tf.test.TestCase):
-
- def testGlobalAveragePrecisionWorks(self):
- # Define input.
- predictions = _CreateRecognitionPredictions()
- solution = _CreateRecognitionSolution()
-
- # Run tested function.
- gap = metrics.GlobalAveragePrecision(predictions, solution)
-
- # Define expected results.
- expected_gap = 0.166667
-
- # Compare actual and expected results.
- self.assertAllClose(gap, expected_gap)
-
- def testGlobalAveragePrecisionIgnoreNonGroundTruthWorks(self):
- # Define input.
- predictions = _CreateRecognitionPredictions()
- solution = _CreateRecognitionSolution()
-
- # Run tested function.
- gap = metrics.GlobalAveragePrecision(
- predictions, solution, ignore_non_gt_test_images=True)
-
- # Define expected results.
- expected_gap = 0.333333
-
- # Compare actual and expected results.
- self.assertAllClose(gap, expected_gap)
-
- def testTop1AccuracyWorks(self):
- # Define input.
- predictions = _CreateRecognitionPredictions()
- solution = _CreateRecognitionSolution()
-
- # Run tested function.
- accuracy = metrics.Top1Accuracy(predictions, solution)
-
- # Define expected results.
- expected_accuracy = 0.333333
-
- # Compare actual and expected results.
- self.assertAllClose(accuracy, expected_accuracy)
-
- def testMeanAveragePrecisionWorks(self):
- # Define input.
- predictions = _CreateRetrievalPredictions()
- solution = _CreateRetrievalSolution()
-
- # Run tested function.
- mean_ap = metrics.MeanAveragePrecision(predictions, solution)
-
- # Define expected results.
- expected_mean_ap = 0.458333
-
- # Compare actual and expected results.
- self.assertAllClose(mean_ap, expected_mean_ap)
-
- def testMeanAveragePrecisionMaxPredictionsWorks(self):
- # Define input.
- predictions = _CreateRetrievalPredictions()
- solution = _CreateRetrievalSolution()
-
- # Run tested function.
- mean_ap = metrics.MeanAveragePrecision(
- predictions, solution, max_predictions=1)
-
- # Define expected results.
- expected_mean_ap = 0.5
-
- # Compare actual and expected results.
- self.assertAllClose(mean_ap, expected_mean_ap)
-
- def testMeanPrecisionsWorks(self):
- # Define input.
- predictions = _CreateRetrievalPredictions()
- solution = _CreateRetrievalSolution()
-
- # Run tested function.
- mean_precisions = metrics.MeanPrecisions(
- predictions, solution, max_predictions=2)
-
- # Define expected results.
- expected_mean_precisions = [0.5, 0.375]
-
- # Compare actual and expected results.
- self.assertAllClose(mean_precisions, expected_mean_precisions)
-
- def testMeanMedianPositionWorks(self):
- # Define input.
- predictions = _CreateRetrievalPredictions()
- solution = _CreateRetrievalSolution()
-
- # Run tested function.
- mean_position, median_position = metrics.MeanMedianPosition(
- predictions, solution)
-
- # Define expected results.
- expected_mean_position = 26.25
- expected_median_position = 1.5
-
- # Compare actual and expected results.
- self.assertAllClose(mean_position, expected_mean_position)
- self.assertAllClose(median_position, expected_median_position)
-
- def testMeanMedianPositionMaxPredictionsWorks(self):
- # Define input.
- predictions = _CreateRetrievalPredictions()
- solution = _CreateRetrievalSolution()
-
- # Run tested function.
- mean_position, median_position = metrics.MeanMedianPosition(
- predictions, solution, max_predictions=1)
-
- # Define expected results.
- expected_mean_position = 1.5
- expected_median_position = 1.5
-
- # Compare actual and expected results.
- self.assertAllClose(mean_position, expected_mean_position)
- self.assertAllClose(median_position, expected_median_position)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/google_landmarks_dataset/rn101_af_gldv2clean_config.pbtxt b/research/delf/delf/python/google_landmarks_dataset/rn101_af_gldv2clean_config.pbtxt
deleted file mode 100644
index 992cb0fd142ba8c6d89c763d5e323a0d33e7a3a5..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/google_landmarks_dataset/rn101_af_gldv2clean_config.pbtxt
+++ /dev/null
@@ -1,10 +0,0 @@
-use_local_features: false
-use_global_features: true
-model_path: "parameters/rn101_af_gldv2clean_20200521"
-image_scales: 0.70710677
-image_scales: 1.0
-image_scales: 1.4142135
-delf_global_config {
- use_pca: false
-}
-max_image_size: 1024
diff --git a/research/delf/delf/python/training/README.md b/research/delf/delf/python/training/README.md
deleted file mode 100644
index a836370fb7830392715c45298987c40e24859032..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/README.md
+++ /dev/null
@@ -1,128 +0,0 @@
-# DELF Training Instructions
-
-This README documents the end-to-end process for training a landmark detection and retrieval
-model using the DELF library on the [Google Landmarks Dataset v2](https://github.com/cvdfoundation/google-landmark) (GLDv2). This can be achieved following these steps:
-1. Install the DELF Python library.
-2. Download the raw images of the GLDv2 dataset.
-3. Prepare the training data.
-4. Run the training.
-
-The next sections will cove each of these steps in greater detail.
-
-## Prerequisites
-
-Clone the [TensorFlow Model Garden](https://github.com/tensorflow/models) repository and move
-into the `models/research/delf/delf/python/training`folder.
-```
-git clone https://github.com/tensorflow/models.git
-cd models/research/delf/delf/python/training
-```
-
-## Install the DELF Library
-
-The DELF Python library can be installed by running the [`install_delf.sh`](./install_delf.sh)
-script using the command:
-```
-bash install_delf.sh
-```
-The script installs both the DELF library and its dependencies in the following sequence:
-* Install TensorFlow 2.2 and TensorFlow 2.2 for GPU.
-* Install the [TF-Slim](https://github.com/google-research/tf-slim) library from source.
-* Download [protoc](https://github.com/protocolbuffers/protobuf) and compile the DELF Protocol
-Buffers.
-* Install the matplotlib, numpy, scikit-image, scipy and python3-tk Python libraries.
-* Install the [TensorFlow Object Detection API](https://github.com/tensorflow/models/tree/master/research/object_detection) from the cloned TensorFlow Model Garden repository.
-* Install the DELF package.
-
-*Please note that the current installation only works on 64 bits Linux architectures due to the
-`protoc` binary downloaded by the installation script. If you wish to install the DELF library on
-other architectures please update the [`install_delf.sh`](./install_delf.sh) script by referencing
-the desired `protoc` [binary release](https://github.com/protocolbuffers/protobuf/releases).*
-
-## Download the GLDv2 Training Data
-
-The [GLDv2](https://github.com/cvdfoundation/google-landmark) images are grouped in 3 datasets: TRAIN, INDEX, TEST. Images in each dataset are grouped into `*.tar` files and individually
-referenced in `*.csv`files containing training metadata and licensing information. The number of
-`*.tar` files per dataset is as follows:
-* TRAIN: 500 files.
-* INDEX: 100 files.
-* TEST: 20 files.
-
-To download the GLDv2 images, run the [`download_dataset.sh`](./download_dataset.sh) script like in
-the following example:
-```
-bash download_dataset.sh 500 100 20
-```
-The script takes the following parameters, in order:
-* The number of image files from the TRAIN dataset to download (maximum 500).
-* The number of image files from the INDEX dataset to download (maximum 100).
-* The number of image files from the TEST dataset to download (maximum 20).
-
-The script downloads the GLDv2 images under the following directory structure:
-* gldv2_dataset/
- * train/ - Contains raw images from the TRAIN dataset.
- * index/ - Contains raw images from the INDEX dataset.
- * test/ - Contains raw images from the TEST dataset.
-
-Each of the three folders `gldv2_dataset/train/`, `gldv2_dataset/index/` and `gldv2_dataset/test/`
-contains the following:
-* The downloaded `*.tar` files.
-* The corresponding MD5 checksum files, `*.txt`.
-* The unpacked content of the downloaded files. (*Images are organized in folders and subfolders
-based on the first, second and third character in their file name.*)
-* The CSV files containing training and licensing metadata of the downloaded images.
-
-*Please note that due to the large size of the GLDv2 dataset, the download can take up to 12
-hours and up to 1 TB of disk space. In order to save bandwidth and disk space, you may want to start by downloading only the TRAIN dataset, the only one required for the training, thus saving
-approximately ~95 GB, the equivalent of the INDEX and TEST datasets. To further save disk space,
-the `*.tar` files can be deleted after downloading and upacking them.*
-
-## Prepare the Data for Training
-
-Preparing the data for training consists of creating [TFRecord](https://www.tensorflow.org/tutorials/load_data/tfrecord)
-files from the raw GLDv2 images grouped into TRAIN and VALIDATION splits. The training set
-produced contains only the *clean* subset of the GLDv2 dataset. The [CVPR'20 paper](https://arxiv.org/abs/2004.01804)
-introducing the GLDv2 dataset contains a detailed description of the *clean* subset.
-
-Generating the TFRecord files containing the TRAIN and VALIDATION splits of the *clean* GLDv2
-subset can be achieved by running the [`build_image_dataset.py`](./build_image_dataset.py)
-script. Assuming that the GLDv2 images have been downloaded to the `gldv2_dataset` folder, the
-script can be run as follows:
-```
-python3 build_image_dataset.py \
- --train_csv_path=gldv2_dataset/train/train.csv \
- --train_clean_csv_path=gldv2_dataset/train/train_clean.csv \
- --train_directory=gldv2_dataset/train/*/*/*/ \
- --output_directory=gldv2_dataset/tfrecord/ \
- --num_shards=128 \
- --generate_train_validation_splits \
- --validation_split_size=0.2
-```
-*Please refer to the source code of the [`build_image_dataset.py`](./build_image_dataset.py) script for a detailed description of its parameters.*
-
-The TFRecord files written in the `OUTPUT_DIRECTORY` will be prefixed as follows:
-* TRAIN split: `train-*`
-* VALIDATION split: `validation-*`
-
-The same script can be used to generate TFRecord files for the TEST split for post-training
-evaluation purposes. This can be achieved by adding the parameters:
-```
- --test_csv_path=gldv2_dataset/train/test.csv \
- --test_directory=gldv2_dataset/test/*/*/*/ \
-```
-In this scenario, the TFRecord files of the TEST split written in the `OUTPUT_DIRECTORY` will be
-named according to the pattern `test-*`.
-
-*Please note that due to the large size of the GLDv2 dataset, the generation of the TFRecord
-files can take up to 12 hours and up to 500 GB of space disk.*
-
-## Running the Training
-
-Assuming the TFRecord files were generated in the `gldv2_dataset/tfrecord/` directory, running
-the following command should start training a model:
-
-```
-python3 train.py \
- --train_file_pattern=gldv2_dataset/tfrecord/train* \
- --validation_file_pattern=gldv2_dataset/tfrecord/validation*
-```
diff --git a/research/delf/delf/python/training/__init__.py b/research/delf/delf/python/training/__init__.py
deleted file mode 100644
index c87f3d895c72593403f71e2768b31307f3db5ea6..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/__init__.py
+++ /dev/null
@@ -1,22 +0,0 @@
-# Copyright 2020 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Module for DELF training."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# pylint: disable=unused-import
-from delf.python.training import build_image_dataset
-# pylint: enable=unused-import
diff --git a/research/delf/delf/python/training/build_image_dataset.py b/research/delf/delf/python/training/build_image_dataset.py
deleted file mode 100644
index 5df58df0b80d506330e3560b46b8835c283a2bf8..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/build_image_dataset.py
+++ /dev/null
@@ -1,473 +0,0 @@
-#!/usr/bin/python
-# Copyright 2020 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Converts landmark image data to TFRecords file format with Example protos.
-
-The image data set is expected to reside in JPEG files ends up with '.jpg'.
-
-This script converts the training and testing data into
-a sharded data set consisting of TFRecord files
- train_directory/train-00000-of-00128
- train_directory/train-00001-of-00128
- ...
- train_directory/train-00127-of-00128
-and
- test_directory/test-00000-of-00128
- test_directory/test-00001-of-00128
- ...
- test_directory/test-00127-of-00128
-where we have selected 128 shards for both data sets. Each record
-within the TFRecord file is a serialized Example proto. The Example proto
-contains the following fields:
- image/encoded: string containing JPEG encoded image in RGB colorspace
- image/height: integer, image height in pixels
- image/width: integer, image width in pixels
- image/colorspace: string, specifying the colorspace, always 'RGB'
- image/channels: integer, specifying the number of channels, always 3
- image/format: string, specifying the format, always 'JPEG'
- image/filename: string, the unique id of the image file
- e.g. '97c0a12e07ae8dd5' or '650c989dd3493748'
-Furthermore, if the data set type is training, it would contain one more field:
- image/class/label: integer, the landmark_id from the input training csv file.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import csv
-import os
-
-from absl import app
-from absl import flags
-
-import numpy as np
-import pandas as pd
-import tensorflow as tf
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('train_directory', '/tmp/', 'Training data directory.')
-flags.DEFINE_string('test_directory', None,
- '(Optional) Testing data directory. Required only if '
- 'test_csv_path is not None.')
-flags.DEFINE_string('output_directory', '/tmp/', 'Output data directory.')
-flags.DEFINE_string('train_csv_path', '/tmp/train.csv',
- 'Training data csv file path.')
-flags.DEFINE_string('train_clean_csv_path', None,
- ('(Optional) Clean training data csv file path. '
- 'If provided, filters images keeping the ones listed in '
- 'this file. In this case, also outputs a CSV file '
- 'relabeling.csv mapping new labels to old ones.'))
-flags.DEFINE_string('test_csv_path', None,
- '(Optional) Testing data csv file path. If None or absent,'
- 'TFRecords for the images in the test dataset are not'
- 'generated')
-flags.DEFINE_integer('num_shards', 128, 'Number of shards in output data.')
-flags.DEFINE_boolean('generate_train_validation_splits', False,
- '(Optional) Whether to split the train dataset into'
- 'TRAIN and VALIDATION splits.')
-flags.DEFINE_float('validation_split_size', 0.2,
- '(Optional) The size of the VALIDATION split as a fraction'
- 'of the train dataset.')
-flags.DEFINE_integer('seed', 0,
- '(Optional) The seed to be used while shuffling the train'
- 'dataset when generating the TRAIN and VALIDATION splits.'
- 'Recommended for splits reproducibility purposes.')
-
-_FILE_IDS_KEY = 'file_ids'
-_IMAGE_PATHS_KEY = 'image_paths'
-_LABELS_KEY = 'labels'
-_TEST_SPLIT = 'test'
-_TRAIN_SPLIT = 'train'
-_VALIDATION_SPLIT = 'validation'
-
-
-def _get_all_image_files_and_labels(name, csv_path, image_dir):
- """Process input and get the image file paths, image ids and the labels.
-
- Args:
- name: 'train' or 'test'.
- csv_path: path to the Google-landmark Dataset csv Data Sources files.
- image_dir: directory that stores downloaded images.
- Returns:
- image_paths: the paths to all images in the image_dir.
- file_ids: the unique ids of images.
- labels: the landmark id of all images. When name='test', the returned labels
- will be an empty list.
- Raises:
- ValueError: if input name is not supported.
- """
- image_paths = tf.io.gfile.glob(os.path.join(image_dir, '*.jpg'))
- file_ids = [os.path.basename(os.path.normpath(f))[:-4] for f in image_paths]
- if name == _TRAIN_SPLIT:
- with tf.io.gfile.GFile(csv_path, 'rb') as csv_file:
- df = pd.read_csv(csv_file)
- df = df.set_index('id')
- labels = [int(df.loc[fid]['landmark_id']) for fid in file_ids]
- elif name == _TEST_SPLIT:
- labels = []
- else:
- raise ValueError('Unsupported dataset split name: %s' % name)
- return image_paths, file_ids, labels
-
-
-def _get_clean_train_image_files_and_labels(csv_path, image_dir):
- """Get image file paths, image ids and labels for the clean training split.
-
- Args:
- csv_path: path to the Google-landmark Dataset v2 CSV Data Sources files
- of the clean train dataset. Assumes CSV header landmark_id;images.
- image_dir: directory that stores downloaded images.
-
- Returns:
- image_paths: the paths to all images in the image_dir.
- file_ids: the unique ids of images.
- labels: the landmark id of all images.
- relabeling: relabeling rules created to replace actual labels with
- a continuous set of labels.
- """
- # Load the content of the CSV file (landmark_id/label -> images).
- with tf.io.gfile.GFile(csv_path, 'rb') as csv_file:
- df = pd.read_csv(csv_file)
-
- # Create the dictionary (key = image_id, value = {label, file_id}).
- images = {}
- for _, row in df.iterrows():
- label = row['landmark_id']
- for file_id in row['images'].split(' '):
- images[file_id] = {}
- images[file_id]['label'] = label
- images[file_id]['file_id'] = file_id
-
- # Add the full image path to the dictionary of images.
- image_paths = tf.io.gfile.glob(os.path.join(image_dir, '*.jpg'))
- for image_path in image_paths:
- file_id = os.path.basename(os.path.normpath(image_path))[:-4]
- if file_id in images:
- images[file_id]['image_path'] = image_path
-
- # Explode the dictionary into lists (1 per image attribute).
- image_paths = []
- file_ids = []
- labels = []
- for _, value in images.items():
- image_paths.append(value['image_path'])
- file_ids.append(value['file_id'])
- labels.append(value['label'])
-
- # Relabel image labels to contiguous values.
- unique_labels = sorted(set(labels))
- relabeling = {label: index for index, label in enumerate(unique_labels)}
- new_labels = [relabeling[label] for label in labels]
- return image_paths, file_ids, new_labels, relabeling
-
-
-def _process_image(filename):
- """Process a single image file.
-
- Args:
- filename: string, path to an image file e.g., '/path/to/example.jpg'.
-
- Returns:
- image_buffer: string, JPEG encoding of RGB image.
- height: integer, image height in pixels.
- width: integer, image width in pixels.
- Raises:
- ValueError: if parsed image has wrong number of dimensions or channels.
- """
- # Read the image file.
- with tf.io.gfile.GFile(filename, 'rb') as f:
- image_data = f.read()
-
- # Decode the RGB JPEG.
- image = tf.io.decode_jpeg(image_data, channels=3)
-
- # Check that image converted to RGB
- if len(image.shape) != 3:
- raise ValueError('The parsed image number of dimensions is not 3 but %d' %
- (image.shape))
- height = image.shape[0]
- width = image.shape[1]
- if image.shape[2] != 3:
- raise ValueError('The parsed image channels is not 3 but %d' %
- (image.shape[2]))
-
- return image_data, height, width
-
-
-def _int64_feature(value):
- """Returns an int64_list from a bool / enum / int / uint."""
- return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
-
-
-def _bytes_feature(value):
- """Returns a bytes_list from a string / byte."""
- return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
-
-
-def _convert_to_example(file_id, image_buffer, height, width, label=None):
- """Build an Example proto for the given inputs.
-
- Args:
- file_id: string, unique id of an image file, e.g., '97c0a12e07ae8dd5'.
- image_buffer: string, JPEG encoding of RGB image.
- height: integer, image height in pixels.
- width: integer, image width in pixels.
- label: integer, the landmark id and prediction label.
-
- Returns:
- Example proto.
- """
- colorspace = 'RGB'
- channels = 3
- image_format = 'JPEG'
- features = {
- 'image/height': _int64_feature(height),
- 'image/width': _int64_feature(width),
- 'image/colorspace': _bytes_feature(colorspace.encode('utf-8')),
- 'image/channels': _int64_feature(channels),
- 'image/format': _bytes_feature(image_format.encode('utf-8')),
- 'image/id': _bytes_feature(file_id.encode('utf-8')),
- 'image/encoded': _bytes_feature(image_buffer)
- }
- if label is not None:
- features['image/class/label'] = _int64_feature(label)
- example = tf.train.Example(features=tf.train.Features(feature=features))
-
- return example
-
-
-def _write_tfrecord(output_prefix, image_paths, file_ids, labels):
- """Read image files and write image and label data into TFRecord files.
-
- Args:
- output_prefix: string, the prefix of output files, e.g. 'train'.
- image_paths: list of strings, the paths to images to be converted.
- file_ids: list of strings, the image unique ids.
- labels: list of integers, the landmark ids of images. It is an empty list
- when output_prefix='test'.
-
- Raises:
- ValueError: if the length of input images, ids and labels don't match
- """
- if output_prefix == _TEST_SPLIT:
- labels = [None] * len(image_paths)
- if not len(image_paths) == len(file_ids) == len(labels):
- raise ValueError('length of image_paths, file_ids, labels shoud be the' +
- ' same. But they are %d, %d, %d, respectively' %
- (len(image_paths), len(file_ids), len(labels)))
-
- spacing = np.linspace(0, len(image_paths), FLAGS.num_shards + 1, dtype=np.int)
-
- for shard in range(FLAGS.num_shards):
- output_file = os.path.join(
- FLAGS.output_directory,
- '%s-%.5d-of-%.5d' % (output_prefix, shard, FLAGS.num_shards))
- writer = tf.io.TFRecordWriter(output_file)
- print('Processing shard ', shard, ' and writing file ', output_file)
- for i in range(spacing[shard], spacing[shard + 1]):
- image_buffer, height, width = _process_image(image_paths[i])
- example = _convert_to_example(file_ids[i], image_buffer, height, width,
- labels[i])
- writer.write(example.SerializeToString())
- writer.close()
-
-
-def _write_relabeling_rules(relabeling_rules):
- """Write to a file the relabeling rules when the clean train dataset is used.
-
- Args:
- relabeling_rules: dictionary of relabeling rules applied when the clean
- train dataset is used (key = old_label, value = new_label).
- """
- relabeling_file_name = os.path.join(FLAGS.output_directory,
- 'relabeling.csv')
- with tf.io.gfile.GFile(relabeling_file_name, 'w') as relabeling_file:
- csv_writer = csv.writer(relabeling_file, delimiter=',')
- csv_writer.writerow(['new_label', 'old_label'])
- for old_label, new_label in relabeling_rules.items():
- csv_writer.writerow([new_label, old_label])
-
-
-def _build_train_and_validation_splits(image_paths, file_ids, labels,
- validation_split_size, seed):
- """Create TRAIN and VALIDATION splits containg all labels in equal proportion.
-
- Args:
- image_paths: list of paths to the image files in the train dataset.
- file_ids: list of image file ids in the train dataset.
- labels: list of image labels in the train dataset.
- validation_split_size: size of the VALIDATION split as a ratio of the train
- dataset.
- seed: seed to use for shuffling the dataset for reproducibility purposes.
-
- Returns:
- splits : tuple containing the TRAIN and VALIDATION splits.
- Raises:
- ValueError: if the image attributes arrays don't all have the same length,
- which makes the shuffling impossible.
- """
- # Ensure all image attribute arrays have the same length.
- total_images = len(file_ids)
- if not (len(image_paths) == total_images and len(labels) == total_images):
- raise ValueError('Inconsistencies between number of file_ids (%d), number '
- 'of image_paths (%d) and number of labels (%d). Cannot'
- 'shuffle the train dataset.'% (total_images,
- len(image_paths),
- len(labels)))
-
- # Stack all image attributes arrays in a single 2D array of dimensions
- # (3, number of images) and group by label the indices of datapoins in the
- # image attributes arrays. Explicitly convert label types from 'int' to 'str'
- # to avoid implicit conversion during stacking with image_paths and file_ids
- # which are 'str'.
- labels_str = [str(label) for label in labels]
- image_attrs = np.stack((image_paths, file_ids, labels_str))
- image_attrs_idx_by_label = {}
- for index, label in enumerate(labels):
- if label not in image_attrs_idx_by_label:
- image_attrs_idx_by_label[label] = []
- image_attrs_idx_by_label[label].append(index)
-
- # Create subsets of image attributes by label, shuffle them separately and
- # split each subset into TRAIN and VALIDATION splits based on the size of the
- # validation split.
- splits = {
- _VALIDATION_SPLIT: [],
- _TRAIN_SPLIT: []
- }
- rs = np.random.RandomState(np.random.MT19937(np.random.SeedSequence(seed)))
- for label, indexes in image_attrs_idx_by_label.items():
- # Create the subset for the current label.
- image_attrs_label = image_attrs[:, indexes]
- images_per_label = image_attrs_label.shape[1]
- # Shuffle the current label subset.
- columns_indices = np.arange(images_per_label)
- rs.shuffle(columns_indices)
- image_attrs_label = image_attrs_label[:, columns_indices]
- # Split the current label subset into TRAIN and VALIDATION splits and add
- # each split to the list of all splits.
- cutoff_idx = max(1, int(validation_split_size * images_per_label))
- splits[_VALIDATION_SPLIT].append(image_attrs_label[:, 0 : cutoff_idx])
- splits[_TRAIN_SPLIT].append(image_attrs_label[:, cutoff_idx : ])
-
- validation_split = np.concatenate(splits[_VALIDATION_SPLIT], axis=1)
- train_split = np.concatenate(splits[_TRAIN_SPLIT], axis=1)
-
- # Unstack the image attribute arrays in the TRAIN and VALIDATION splits and
- # convert them back to lists. Convert labels back to 'int' from 'str'
- # following the explicit type change from 'str' to 'int' for stacking.
- return (
- {
- _IMAGE_PATHS_KEY: validation_split[0, :].tolist(),
- _FILE_IDS_KEY: validation_split[1, :].tolist(),
- _LABELS_KEY: [int(label) for label in validation_split[2, :].tolist()]
- }, {
- _IMAGE_PATHS_KEY: train_split[0, :].tolist(),
- _FILE_IDS_KEY: train_split[1, :].tolist(),
- _LABELS_KEY: [int(label) for label in train_split[2, :].tolist()]
- })
-
-
-def _build_train_tfrecord_dataset(csv_path,
- clean_csv_path,
- image_dir,
- generate_train_validation_splits,
- validation_split_size,
- seed):
- """Build a TFRecord dataset for the train split.
-
- Args:
- csv_path: path to the train Google-landmark Dataset csv Data Sources files.
- clean_csv_path: path to the Google-landmark Dataset v2 CSV Data Sources
- files of the clean train dataset.
- image_dir: directory that stores downloaded images.
- generate_train_validation_splits: whether to split the test dataset into
- TRAIN and VALIDATION splits.
- validation_split_size: size of the VALIDATION split as a ratio of the train
- dataset. Only used if 'generate_train_validation_splits' is True.
- seed: seed to use for shuffling the dataset for reproducibility purposes.
- Only used if 'generate_train_validation_splits' is True.
-
- Returns:
- Nothing. After the function call, sharded TFRecord files are materialized.
- Raises:
- ValueError: if the size of the VALIDATION split is outside (0,1) when TRAIN
- and VALIDATION splits need to be generated.
- """
- # Make sure the size of the VALIDATION split is inside (0, 1) if we need to
- # generate the TRAIN and VALIDATION splits.
- if generate_train_validation_splits:
- if validation_split_size <= 0 or validation_split_size >= 1:
- raise ValueError('Invalid VALIDATION split size. Expected inside (0,1)'
- 'but received %f.' % validation_split_size)
-
- if clean_csv_path:
- # Load clean train images and labels and write the relabeling rules.
- (image_paths, file_ids, labels,
- relabeling_rules) = _get_clean_train_image_files_and_labels(clean_csv_path,
- image_dir)
- _write_relabeling_rules(relabeling_rules)
- else:
- # Load all train images.
- image_paths, file_ids, labels = _get_all_image_files_and_labels(
- _TRAIN_SPLIT, csv_path, image_dir)
-
- if generate_train_validation_splits:
- # Generate the TRAIN and VALIDATION splits and write them to TFRecord.
- validation_split, train_split = _build_train_and_validation_splits(
- image_paths, file_ids, labels, validation_split_size, seed)
- _write_tfrecord(_VALIDATION_SPLIT,
- validation_split[_IMAGE_PATHS_KEY],
- validation_split[_FILE_IDS_KEY],
- validation_split[_LABELS_KEY])
- _write_tfrecord(_TRAIN_SPLIT,
- train_split[_IMAGE_PATHS_KEY],
- train_split[_FILE_IDS_KEY],
- train_split[_LABELS_KEY])
- else:
- # Write to TFRecord a single split, TRAIN.
- _write_tfrecord(_TRAIN_SPLIT, image_paths, file_ids, labels)
-
-
-def _build_test_tfrecord_dataset(csv_path, image_dir):
- """Build a TFRecord dataset for the 'test' split.
-
- Args:
- csv_path: path to the 'test' Google-landmark Dataset csv Data Sources files.
- image_dir: directory that stores downloaded images.
-
- Returns:
- Nothing. After the function call, sharded TFRecord files are materialized.
- """
- image_paths, file_ids, labels = _get_all_image_files_and_labels(
- _TEST_SPLIT, csv_path, image_dir)
- _write_tfrecord(_TEST_SPLIT, image_paths, file_ids, labels)
-
-
-def main(unused_argv):
- _build_train_tfrecord_dataset(FLAGS.train_csv_path,
- FLAGS.train_clean_csv_path,
- FLAGS.train_directory,
- FLAGS.generate_train_validation_splits,
- FLAGS.validation_split_size,
- FLAGS.seed)
- if FLAGS.test_csv_path is not None:
- _build_test_tfrecord_dataset(FLAGS.test_csv_path, FLAGS.test_directory)
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/delf/delf/python/training/datasets/__init__.py b/research/delf/delf/python/training/datasets/__init__.py
deleted file mode 100644
index 7e0a672716945394cce4b2c69ee3d086192da87c..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/datasets/__init__.py
+++ /dev/null
@@ -1,22 +0,0 @@
-# Copyright 2020 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Module exposing datasets for training."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# pylint: disable=unused-import
-from delf.python.training.datasets import googlelandmarks
-# pylint: enable=unused-import
diff --git a/research/delf/delf/python/training/datasets/googlelandmarks.py b/research/delf/delf/python/training/datasets/googlelandmarks.py
deleted file mode 100644
index f289cc166460f3a2fd9f157bc672ea0a464a2995..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/datasets/googlelandmarks.py
+++ /dev/null
@@ -1,187 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Google Landmarks Dataset(GLD).
-
-Placeholder for Google Landmarks dataset.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import functools
-
-import tensorflow as tf
-
-
-class _GoogleLandmarksInfo(object):
- """Metadata about the Google Landmarks dataset."""
- num_classes = {
- 'gld_v1': 14951,
- 'gld_v2': 203094,
- 'gld_v2_clean': 81313
- }
-
-
-class _DataAugmentationParams(object):
- """Default parameters for augmentation."""
- # The following are used for training.
- min_object_covered = 0.1
- aspect_ratio_range_min = 3. / 4
- aspect_ratio_range_max = 4. / 3
- area_range_min = 0.08
- area_range_max = 1.0
- max_attempts = 100
- update_labels = False
- # 'central_fraction' is used for central crop in inference.
- central_fraction = 0.875
-
- random_reflection = False
- input_rows = 321
- input_cols = 321
-
-
-def NormalizeImages(images, pixel_value_scale=0.5, pixel_value_offset=0.5):
- """Normalize pixel values in image.
-
- Output is computed as
- normalized_images = (images - pixel_value_offset) / pixel_value_scale.
-
- Args:
- images: `Tensor`, images to normalize.
- pixel_value_scale: float, scale.
- pixel_value_offset: float, offset.
-
- Returns:
- normalized_images: `Tensor`, normalized images.
- """
- images = tf.cast(images, tf.float32)
- normalized_images = tf.math.divide(
- tf.subtract(images, pixel_value_offset), pixel_value_scale)
- return normalized_images
-
-
-def _ImageNetCrop(image):
- """Imagenet-style crop with random bbox and aspect ratio.
-
- Args:
- image: a `Tensor`, image to crop.
-
- Returns:
- cropped_image: `Tensor`, cropped image.
- """
-
- params = _DataAugmentationParams()
- bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
- (bbox_begin, bbox_size, _) = tf.image.sample_distorted_bounding_box(
- tf.shape(image),
- bounding_boxes=bbox,
- min_object_covered=params.min_object_covered,
- aspect_ratio_range=(params.aspect_ratio_range_min,
- params.aspect_ratio_range_max),
- area_range=(params.area_range_min, params.area_range_max),
- max_attempts=params.max_attempts,
- use_image_if_no_bounding_boxes=True)
- cropped_image = tf.slice(image, bbox_begin, bbox_size)
- cropped_image.set_shape([None, None, 3])
-
- cropped_image = tf.image.resize(
- cropped_image, [params.input_rows, params.input_cols], method='area')
- if params.random_reflection:
- cropped_image = tf.image.random_flip_left_right(cropped_image)
-
- return cropped_image
-
-
-def _ParseFunction(example, name_to_features, image_size, augmentation):
- """Parse a single TFExample to get the image and label and process the image.
-
- Args:
- example: a `TFExample`.
- name_to_features: a `dict`. The mapping from feature names to its type.
- image_size: an `int`. The image size for the decoded image, on each side.
- augmentation: a `boolean`. True if the image will be augmented.
-
- Returns:
- image: a `Tensor`. The processed image.
- label: a `Tensor`. The ground-truth label.
- """
- parsed_example = tf.io.parse_single_example(example, name_to_features)
- # Parse to get image.
- image = parsed_example['image/encoded']
- image = tf.io.decode_jpeg(image)
- if augmentation:
- image = _ImageNetCrop(image)
- else:
- image = tf.image.resize(image, [image_size, image_size])
- image.set_shape([image_size, image_size, 3])
- # Parse to get label.
- label = parsed_example['image/class/label']
- return image, label
-
-
-def CreateDataset(file_pattern,
- image_size=321,
- batch_size=32,
- augmentation=False,
- seed=0):
- """Creates a dataset.
-
- Args:
- file_pattern: str, file pattern of the dataset files.
- image_size: int, image size.
- batch_size: int, batch size.
- augmentation: bool, whether to apply augmentation.
- seed: int, seed for shuffling the dataset.
-
- Returns:
- tf.data.TFRecordDataset.
- """
-
- filenames = tf.io.gfile.glob(file_pattern)
-
- dataset = tf.data.TFRecordDataset(filenames)
- dataset = dataset.repeat().shuffle(buffer_size=100, seed=seed)
-
- # Create a description of the features.
- feature_description = {
- 'image/height': tf.io.FixedLenFeature([], tf.int64, default_value=0),
- 'image/width': tf.io.FixedLenFeature([], tf.int64, default_value=0),
- 'image/channels': tf.io.FixedLenFeature([], tf.int64, default_value=0),
- 'image/format': tf.io.FixedLenFeature([], tf.string, default_value=''),
- 'image/filename': tf.io.FixedLenFeature([], tf.string, default_value=''),
- 'image/encoded': tf.io.FixedLenFeature([], tf.string, default_value=''),
- 'image/class/label': tf.io.FixedLenFeature([], tf.int64, default_value=0),
- }
-
- customized_parse_func = functools.partial(
- _ParseFunction,
- name_to_features=feature_description,
- image_size=image_size,
- augmentation=augmentation)
- dataset = dataset.map(customized_parse_func)
- dataset = dataset.batch(batch_size)
-
- return dataset
-
-
-def GoogleLandmarksInfo():
- """Returns metadata information on the Google Landmarks dataset.
-
- Returns:
- object _GoogleLandmarksInfo containing metadata about the GLD dataset.
- """
- return _GoogleLandmarksInfo()
diff --git a/research/delf/delf/python/training/download_dataset.sh b/research/delf/delf/python/training/download_dataset.sh
deleted file mode 100755
index ecbd905eccde6b4056f4b3cc0a011695debb3390..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/download_dataset.sh
+++ /dev/null
@@ -1,161 +0,0 @@
-#!/bin/bash
-
-# Copyright 2020 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# This script downloads the Google Landmarks v2 dataset. To download the dataset
-# run the script like in the following example:
-# bash download_dataset.sh 500 100 20
-#
-# The script takes the following parameters, in order:
-# - number of image files from the TRAIN split to download (maximum 500)
-# - number of image files from the INDEX split to download (maximum 100)
-# - number of image files from the TEST split to download (maximum 20)
-
-image_files_train=$1 # Number of image files to download from the TRAIN split
-image_files_index=$2 # Number of image files to download from the INDEX split
-image_files_test=$3 # Number of image files to download from the TEST split
-
-splits=("train" "test" "index")
-dataset_root_folder=gldv2_dataset
-
-metadata_url="https://s3.amazonaws.com/google-landmark/metadata"
-ground_truth_url="https://s3.amazonaws.com/google-landmark/ground_truth"
-csv_train=(${metadata_url}/train.csv ${metadata_url}/train_clean.csv ${metadata_url}/train_attribution.csv ${metadata_url}/train_label_to_category.csv)
-csv_index=(${metadata_url}/index.csv ${metadata_url}/index_image_to_landmark.csv ${metadata_url}/index_label_to_category.csv)
-csv_test=(${metadata_url}/test.csv ${ground_truth_url}/recognition_solution_v2.1.csv ${ground_truth_url}/retrieval_solution_v2.1.csv)
-
-images_tar_file_base_url="https://s3.amazonaws.com/google-landmark"
-images_md5_file_base_url="https://s3.amazonaws.com/google-landmark/md5sum"
-num_processes=6
-
-make_folder() {
- # Creates a folder and checks if it exists. Exits if folder creation fails.
- local folder=$1
- if [ -d "${folder}" ]; then
- echo "Folder ${folder} already exists. Skipping folder creation."
- else
- echo "Creating folder ${folder}."
- if mkdir ${folder}; then
- echo "Successfully created folder ${folder}."
- else
- echo "Failed to create folder ${folder}. Exiting."
- exit 1
- fi
- fi
-}
-
-download_file() {
- # Downloads a file from an URL into a specified folder.
- local file_url=$1
- local folder=$2
- local file_path="${folder}/`basename ${file_url}`"
- echo "Downloading file ${file_url} to folder ${folder}."
- pushd . > /dev/null
- cd ${folder}
- curl -Os ${file_url}
- popd > /dev/null
-}
-
-validate_md5_checksum() {
- # Validate the MD5 checksum of a downloaded file.
- local content_file=$1
- local md5_file=$2
- echo "Checking MD5 checksum of file ${content_file} against ${md5_file}"
- if [[ "${OSTYPE}" == "linux-gnu" ]]; then
- content_md5=`md5sum ${content_file}`
- elif [[ "${OSTYPE}" == "darwin"* ]]; then
- content_md5=`md5 -r "${content_file}"`
- fi
- content_md5=`cut -d' ' -f1<<<"${content_md5}"`
- expected_md5=`cut -d' ' -f1<<${max_idx}?${max_idx}:${curr_max_idx}))
- for j in $(seq ${i} 1 ${last_idx}); do download_image_file "${split}" "${j}" "${split_folder}" & done
- wait
- done
-}
-
-download_csv_files() {
- # Downloads all medatada CSV files of a split.
- local split=$1
- local split_folder=$2
- local csv_list="csv_${split}[*]"
- for csv_file in ${!csv_list}; do
- download_file "${csv_file}" "${split_folder}"
- done
-}
-
-download_split() {
- # Downloads all artifacts, metadata CSV files and image files of a single split.
- local split=$1
- local split_folder=${dataset_root_folder}/${split}
- make_folder "${split_folder}"
- download_csv_files "${split}" "${split_folder}"
- download_image_files "${split}" "${split_folder}"
-}
-
-download_all_splits() {
- # Downloads all artifacts, metadata CSV files and image files of all splits.
- make_folder "${dataset_root_folder}"
- for split in "${splits[@]}"; do
- download_split "$split"
- done
-}
-
-download_all_splits
-
-exit 0
diff --git a/research/delf/delf/python/training/install_delf.sh b/research/delf/delf/python/training/install_delf.sh
deleted file mode 100755
index 4feb464aa7def067028e65281d906e006f4533a2..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/install_delf.sh
+++ /dev/null
@@ -1,153 +0,0 @@
-#!/bin/bash
-
-# Copyright 2020 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# This script installs the DELF package along with its dependencies. To install
-# the DELF package run the script like in the following example:
-# bash install_delf.sh
-
-protoc_folder="protoc"
-protoc_url="https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip"
-tf_slim_git_repo="https://github.com/google-research/tf-slim.git"
-
-handle_exit_code() {
- # Fail gracefully in case of an exit code different than 0.
- exit_code=$1
- error_message=$2
- if [ ${exit_code} -ne 0 ]; then
- echo "${error_message} Exiting."
- exit 1
- fi
-}
-
-install_tensorflow() {
- # Install TensorFlow 2.2.
- echo "Installing TensorFlow 2.2"
- pip3 install --upgrade tensorflow==2.2.0
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install Tensorflow 2.2."
- echo "Installing TensorFlow 2.2 for GPU"
- pip3 install --upgrade tensorflow-gpu==2.2.0
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install Tensorflow for GPU 2.2.0."
-}
-
-install_tf_slim() {
- # Install TF-Slim from source.
- echo "Installing TF-Slim from source: ${git_repo}"
- git clone ${tf_slim_git_repo}
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to clone TF-Slim repository ${tf_slim_git_repo}."
- pushd . > /dev/null
- cd tf-slim
- pip3 install .
- popd > /dev/null
- rm -rf tf-slim
-}
-
-download_protoc() {
- # Installs the Protobuf compiler protoc.
- echo "Downloading Protobuf compiler from ${protoc_url}"
- curl -L -Os ${protoc_url}
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to download Protobuf compiler from ${tf_slim_git_repo}."
-
- mkdir ${protoc_folder}
- local protoc_archive=`basename ${protoc_url}`
- unzip ${protoc_archive} -d ${protoc_folder}
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to unzip Protobuf compiler from ${protoc_archive}."
-
- rm ${protoc_archive}
-}
-
-compile_delf_protos() {
- # Compiles DELF protobufs from tensorflow/models/research/delf using the potoc compiler.
- echo "Compiling DELF Protobufs"
- PATH_TO_PROTOC="`pwd`/${protoc_folder}"
- pushd . > /dev/null
- cd ../../..
- ${PATH_TO_PROTOC}/bin/protoc delf/protos/*.proto --python_out=.
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to compile DELF Protobufs."
- popd > /dev/null
-}
-
-cleanup_protoc() {
- # Removes the downloaded Protobuf compiler protoc after the installation of the DELF package.
- echo "Cleaning up Protobuf compiler download"
- rm -rf ${protoc_folder}
-}
-
-install_python_libraries() {
- # Installs Python libraries upon which the DELF package has dependencies.
- echo "Installing matplotlib, numpy, scikit-image, scipy and python3-tk"
- pip3 install matplotlib numpy scikit-image scipy
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install at least one of: matplotlib numpy scikit-image scipy."
- sudo apt-get -y install python3-tk
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install python3-tk."
-}
-
-install_object_detection() {
- # Installs the object detection package from tensorflow/models/research.
- echo "Installing object detection"
- pushd . > /dev/null
- cd ../../../..
- export PYTHONPATH=$PYTHONPATH:`pwd`
- pip3 install .
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install the object_detection package."
- popd > /dev/null
-}
-
-install_delf_package() {
- # Installs the DELF package from tensorflow/models/research/delf/delf.
- echo "Installing DELF package"
- pushd . > /dev/null
- cd ../../..
- pip3 install -e .
- local exit_code=$?
- handle_exit_code ${exit_code} "Unable to install the DELF package."
- popd > /dev/null
-}
-
-post_install_check() {
- # Checks the DELF package has been successfully installed.
- echo "Checking DELF package installation"
- python3 -c 'import delf'
- local exit_code=$?
- handle_exit_code ${exit_code} "DELF package installation check failed."
- echo "Installation successful."
-}
-
-install_delf() {
- # Orchestrates DELF package installation.
- install_tensorflow
- install_tf_slim
- download_protoc
- compile_delf_protos
- cleanup_protoc
- install_python_libraries
- install_object_detection
- install_delf_package
- post_install_check
-}
-
-install_delf
-
-exit 0
diff --git a/research/delf/delf/python/training/model/__init__.py b/research/delf/delf/python/training/model/__init__.py
deleted file mode 100644
index dcc888bd8a65e9ba48f15e4082064e7285ac2591..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/__init__.py
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright 2020 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""DELF model module, used for training and exporting."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# pylint: disable=unused-import
-from delf.python.training.model import delf_model
-from delf.python.training.model import export_model_utils
-from delf.python.training.model import resnet50
-# pylint: enable=unused-import
diff --git a/research/delf/delf/python/training/model/delf_model.py b/research/delf/delf/python/training/model/delf_model.py
deleted file mode 100644
index 27409de99c52dcb0f0eb00ca9ae0602a2be0d30b..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/delf_model.py
+++ /dev/null
@@ -1,141 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""DELF model implementation based on the following paper.
-
- Large-Scale Image Retrieval with Attentive Deep Local Features
- https://arxiv.org/abs/1612.06321
-"""
-
-import tensorflow as tf
-
-from delf.python.training.model import resnet50 as resnet
-
-layers = tf.keras.layers
-reg = tf.keras.regularizers
-
-_DECAY = 0.0001
-
-
-class AttentionModel(tf.keras.Model):
- """Instantiates attention model.
-
- Uses two [kernel_size x kernel_size] convolutions and softplus as activation
- to compute an attention map with the same resolution as the featuremap.
- Features l2-normalized and aggregated using attention probabilites as weights.
- """
-
- def __init__(self, kernel_size=1, decay=_DECAY, name='attention'):
- """Initialization of attention model.
-
- Args:
- kernel_size: int, kernel size of convolutions.
- decay: float, decay for l2 regularization of kernel weights.
- name: str, name to identify model.
- """
- super(AttentionModel, self).__init__(name=name)
-
- # First convolutional layer (called with relu activation).
- self.conv1 = layers.Conv2D(
- 512,
- kernel_size,
- kernel_regularizer=reg.l2(decay),
- padding='same',
- name='attn_conv1')
- self.bn_conv1 = layers.BatchNormalization(axis=3, name='bn_conv1')
-
- # Second convolutional layer, with softplus activation.
- self.conv2 = layers.Conv2D(
- 1,
- kernel_size,
- kernel_regularizer=reg.l2(decay),
- padding='same',
- name='attn_conv2')
- self.activation_layer = layers.Activation('softplus')
-
- def call(self, inputs, training=True):
- x = self.conv1(inputs)
- x = self.bn_conv1(x, training=training)
- x = tf.nn.relu(x)
-
- score = self.conv2(x)
- prob = self.activation_layer(score)
-
- # L2-normalize the featuremap before pooling.
- inputs = tf.nn.l2_normalize(inputs, axis=-1)
- feat = tf.reduce_mean(tf.multiply(inputs, prob), [1, 2], keepdims=False)
-
- return feat, prob, score
-
-
-class Delf(tf.keras.Model):
- """Instantiates Keras DELF model using ResNet50 as backbone.
-
- This class implements the [DELF](https://arxiv.org/abs/1612.06321) model for
- extracting local features from images. The backbone is a ResNet50 network
- that extracts featuremaps from both conv_4 and conv_5 layers. Activations
- from conv_4 are used to compute an attention map of the same resolution.
- """
-
- def __init__(self, block3_strides=True, name='DELF'):
- """Initialization of DELF model.
-
- Args:
- block3_strides: bool, whether to add strides to the output of block3.
- name: str, name to identify model.
- """
- super(Delf, self).__init__(name=name)
-
- # Backbone using Keras ResNet50.
- self.backbone = resnet.ResNet50(
- 'channels_last',
- name='backbone',
- include_top=False,
- pooling='avg',
- block3_strides=block3_strides,
- average_pooling=False)
-
- # Attention model.
- self.attention = AttentionModel(name='attention')
-
- # Define classifiers for training backbone and attention models.
- def init_classifiers(self, num_classes):
- self.num_classes = num_classes
- self.desc_classification = layers.Dense(
- num_classes, activation=None, kernel_regularizer=None, name='desc_fc')
-
- self.attn_classification = layers.Dense(
- num_classes, activation=None, kernel_regularizer=None, name='att_fc')
-
- # Weights to optimize for descriptor fine tuning.
- @property
- def desc_trainable_weights(self):
- return (self.backbone.trainable_weights +
- self.desc_classification.trainable_weights)
-
- # Weights to optimize for attention model training.
- @property
- def attn_trainable_weights(self):
- return (self.attention.trainable_weights +
- self.attn_classification.trainable_weights)
-
- def call(self, input_image, training=True):
- blocks = {'block3': None}
- self.backbone(input_image, intermediates_dict=blocks, training=training)
-
- features = blocks['block3']
- _, probs, _ = self.attention(features, training=training)
-
- return probs, features
diff --git a/research/delf/delf/python/training/model/delf_model_test.py b/research/delf/delf/python/training/model/delf_model_test.py
deleted file mode 100644
index c4cbcef555db3cd6e6395aee69f1479863916bd4..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/delf_model_test.py
+++ /dev/null
@@ -1,115 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for the DELF model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from absl.testing import parameterized
-import tensorflow as tf
-
-from delf.python.training.model import delf_model
-
-
-class DelfTest(tf.test.TestCase, parameterized.TestCase):
-
- @parameterized.named_parameters(
- ('block3_stridesTrue', True),
- ('block3_stridesFalse', False),
- )
- def test_build_model(self, block3_strides):
- image_size = 321
- num_classes = 1000
- batch_size = 2
- input_shape = (batch_size, image_size, image_size, 3)
-
- model = delf_model.Delf(block3_strides=block3_strides, name='DELF')
- model.init_classifiers(num_classes)
-
- images = tf.random.uniform(input_shape, minval=-1.0, maxval=1.0, seed=0)
- blocks = {}
-
- # Get global feature by pooling block4 features.
- desc_prelogits = model.backbone(
- images, intermediates_dict=blocks, training=False)
- desc_logits = model.desc_classification(desc_prelogits)
- self.assertAllEqual(desc_prelogits.shape, (batch_size, 2048))
- self.assertAllEqual(desc_logits.shape, (batch_size, num_classes))
-
- features = blocks['block3']
- attn_prelogits, _, _ = model.attention(features)
- attn_logits = model.attn_classification(attn_prelogits)
- self.assertAllEqual(attn_prelogits.shape, (batch_size, 1024))
- self.assertAllEqual(attn_logits.shape, (batch_size, num_classes))
-
- @parameterized.named_parameters(
- ('block3_stridesTrue', True),
- ('block3_stridesFalse', False),
- )
- def test_train_step(self, block3_strides):
-
- image_size = 321
- num_classes = 1000
- batch_size = 2
- clip_val = 10.0
- input_shape = (batch_size, image_size, image_size, 3)
-
- model = delf_model.Delf(block3_strides=block3_strides, name='DELF')
- model.init_classifiers(num_classes)
-
- optimizer = tf.keras.optimizers.SGD(learning_rate=0.001, momentum=0.9)
-
- images = tf.random.uniform(input_shape, minval=0.0, maxval=1.0, seed=0)
- labels = tf.random.uniform((batch_size,),
- minval=0,
- maxval=model.num_classes - 1,
- dtype=tf.int64)
-
- loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
- from_logits=True, reduction=tf.keras.losses.Reduction.NONE)
-
- def compute_loss(labels, predictions):
- per_example_loss = loss_object(labels, predictions)
- return tf.nn.compute_average_loss(
- per_example_loss, global_batch_size=batch_size)
-
- with tf.GradientTape() as desc_tape:
- blocks = {}
- desc_prelogits = model.backbone(
- images, intermediates_dict=blocks, training=False)
- desc_logits = model.desc_classification(desc_prelogits)
- desc_logits = model.desc_classification(desc_prelogits)
- desc_loss = compute_loss(labels, desc_logits)
-
- gradients = desc_tape.gradient(desc_loss, model.desc_trainable_weights)
- clipped, _ = tf.clip_by_global_norm(gradients, clip_norm=clip_val)
- optimizer.apply_gradients(zip(clipped, model.desc_trainable_weights))
-
- with tf.GradientTape() as attn_tape:
- block3 = blocks['block3']
- block3 = tf.stop_gradient(block3)
- attn_prelogits, _, _ = model.attention(block3, training=True)
- attn_logits = model.attn_classification(attn_prelogits)
- attn_loss = compute_loss(labels, attn_logits)
-
- gradients = attn_tape.gradient(attn_loss, model.attn_trainable_weights)
- clipped, _ = tf.clip_by_global_norm(gradients, clip_norm=clip_val)
- optimizer.apply_gradients(zip(clipped, model.attn_trainable_weights))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/delf/delf/python/training/model/export_model.py b/research/delf/delf/python/training/model/export_model.py
deleted file mode 100644
index 4af69a231641ef2cc69a08fb9a5ba5c31655c26c..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/export_model.py
+++ /dev/null
@@ -1,137 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Export DELF tensorflow inference model.
-
-This model includes feature extraction, receptive field calculation and
-key-point selection and outputs the selected feature descriptors.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import app
-from absl import flags
-import tensorflow as tf
-
-from delf.python.training.model import delf_model
-from delf.python.training.model import export_model_utils
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('ckpt_path', '/tmp/delf-logdir/delf-weights',
- 'Path to saved checkpoint.')
-flags.DEFINE_string('export_path', None, 'Path where model will be exported.')
-flags.DEFINE_boolean('block3_strides', False,
- 'Whether to apply strides after block3.')
-flags.DEFINE_float('iou', 1.0, 'IOU for non-max suppression.')
-
-
-def _build_tensor_info(tensor_dict):
- """Replace the dict's value by the tensor info.
-
- Args:
- tensor_dict: A dictionary contains .
-
- Returns:
- dict: New dictionary contains .
- """
- return {
- k: tf.compat.v1.saved_model.utils.build_tensor_info(t)
- for k, t in tensor_dict.items()
- }
-
-
-def main(argv):
- if len(argv) > 1:
- raise app.UsageError('Too many command-line arguments.')
-
- export_path = FLAGS.export_path
- if os.path.exists(export_path):
- raise ValueError('Export_path already exists.')
-
- with tf.Graph().as_default() as g, tf.compat.v1.Session(graph=g) as sess:
-
- # Setup the DELF model for extraction.
- model = delf_model.Delf(block3_strides=FLAGS.block3_strides, name='DELF')
-
- # Initial forward pass to build model.
- images = tf.zeros((1, 321, 321, 3), dtype=tf.float32)
- model(images)
-
- stride_factor = 2.0 if FLAGS.block3_strides else 1.0
-
- # Setup the multiscale keypoint extraction.
- input_image = tf.compat.v1.placeholder(
- tf.uint8, shape=(None, None, 3), name='input_image')
- input_abs_thres = tf.compat.v1.placeholder(
- tf.float32, shape=(), name='input_abs_thres')
- input_scales = tf.compat.v1.placeholder(
- tf.float32, shape=[None], name='input_scales')
- input_max_feature_num = tf.compat.v1.placeholder(
- tf.int32, shape=(), name='input_max_feature_num')
-
- extracted_features = export_model_utils.ExtractLocalFeatures(
- input_image, input_scales, input_max_feature_num, input_abs_thres,
- FLAGS.iou, lambda x: model(x, training=False), stride_factor)
-
- # Load the weights.
- checkpoint_path = FLAGS.ckpt_path
- model.load_weights(checkpoint_path)
- print('Checkpoint loaded from ', checkpoint_path)
-
- named_input_tensors = {
- 'input_image': input_image,
- 'input_scales': input_scales,
- 'input_abs_thres': input_abs_thres,
- 'input_max_feature_num': input_max_feature_num,
- }
-
- # Outputs to the exported model.
- named_output_tensors = {}
- named_output_tensors['boxes'] = tf.identity(
- extracted_features[0], name='boxes')
- named_output_tensors['features'] = tf.identity(
- extracted_features[1], name='features')
- named_output_tensors['scales'] = tf.identity(
- extracted_features[2], name='scales')
- named_output_tensors['scores'] = tf.identity(
- extracted_features[3], name='scores')
-
- # Export the model.
- signature_def = tf.compat.v1.saved_model.signature_def_utils.build_signature_def(
- inputs=_build_tensor_info(named_input_tensors),
- outputs=_build_tensor_info(named_output_tensors))
-
- print('Exporting trained model to:', export_path)
- builder = tf.compat.v1.saved_model.builder.SavedModelBuilder(export_path)
-
- init_op = None
- builder.add_meta_graph_and_variables(
- sess, [tf.compat.v1.saved_model.tag_constants.SERVING],
- signature_def_map={
- tf.compat.v1.saved_model.signature_constants
- .DEFAULT_SERVING_SIGNATURE_DEF_KEY:
- signature_def
- },
- main_op=init_op)
- builder.save()
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/delf/delf/python/training/model/export_model_utils.py b/research/delf/delf/python/training/model/export_model_utils.py
deleted file mode 100644
index f4302aca139802e99d80bfd4e1fc27e353abdfbb..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/export_model_utils.py
+++ /dev/null
@@ -1,171 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Helper functions for DELF model exporting."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from delf import feature_extractor
-from delf.python.training.datasets import googlelandmarks as gld
-from object_detection.core import box_list
-from object_detection.core import box_list_ops
-
-
-def ExtractLocalFeatures(image, image_scales, max_feature_num, abs_thres, iou,
- attention_model_fn, stride_factor):
- """Extract local features for input image.
-
- Args:
- image: image tensor of type tf.uint8 with shape [h, w, channels].
- image_scales: 1D float tensor which contains float scales used for image
- pyramid construction.
- max_feature_num: int tensor denotes the maximum selected feature points.
- abs_thres: float tensor denotes the score threshold for feature selection.
- iou: float scalar denotes the iou threshold for NMS.
- attention_model_fn: model function. Follows the signature:
- * Args:
- * `images`: Image tensor which is re-scaled.
- * Returns:
- * `attention_prob`: attention map after the non-linearity.
- * `feature_map`: feature map after ResNet convolution.
- stride_factor: integer accounting for striding after block3.
-
- Returns:
- boxes: [N, 4] float tensor which denotes the selected receptive box. N is
- the number of final feature points which pass through keypoint selection
- and NMS steps.
- features: [N, depth] float tensor.
- feature_scales: [N] float tensor. It is the inverse of the input image
- scales such that larger image scales correspond to larger image regions,
- which is compatible with keypoints detected with other techniques, for
- example Congas.
- scores: [N, 1] float tensor denotes the attention score.
-
- """
- original_image_shape_float = tf.gather(
- tf.dtypes.cast(tf.shape(image), tf.float32), [0, 1])
-
- image_tensor = gld.NormalizeImages(
- image, pixel_value_offset=128.0, pixel_value_scale=128.0)
- image_tensor = tf.expand_dims(image_tensor, 0, name='image/expand_dims')
-
- # Hard code the feature depth and receptive field parameters for now.
- rf, stride, padding = [291.0, 16.0 * stride_factor, 145.0]
- feature_depth = 1024
-
- def _ProcessSingleScale(scale_index, boxes, features, scales, scores):
- """Resizes the image and run feature extraction and keypoint selection.
-
- This function will be passed into tf.while_loop() and be called
- repeatedly. The input boxes are collected from the previous iteration
- [0: scale_index -1]. We get the current scale by
- image_scales[scale_index], and run resize image, feature extraction and
- keypoint selection. Then we will get a new set of selected_boxes for
- current scale. In the end, we concat the previous boxes with current
- selected_boxes as the output.
- Args:
- scale_index: A valid index in the image_scales.
- boxes: Box tensor with the shape of [N, 4].
- features: Feature tensor with the shape of [N, depth].
- scales: Scale tensor with the shape of [N].
- scores: Attention score tensor with the shape of [N].
-
- Returns:
- scale_index: The next scale index for processing.
- boxes: Concatenated box tensor with the shape of [K, 4]. K >= N.
- features: Concatenated feature tensor with the shape of [K, depth].
- scales: Concatenated scale tensor with the shape of [K].
- scores: Concatenated score tensor with the shape of [K].
- """
- scale = tf.gather(image_scales, scale_index)
- new_image_size = tf.dtypes.cast(
- tf.round(original_image_shape_float * scale), tf.int32)
- resized_image = tf.image.resize(image_tensor, new_image_size)
-
- attention_prob, feature_map = attention_model_fn(resized_image)
- attention_prob = tf.squeeze(attention_prob, axis=[0])
- feature_map = tf.squeeze(feature_map, axis=[0])
-
- rf_boxes = feature_extractor.CalculateReceptiveBoxes(
- tf.shape(feature_map)[0],
- tf.shape(feature_map)[1], rf, stride, padding)
-
- # Re-project back to the original image space.
- rf_boxes = tf.divide(rf_boxes, scale)
- attention_prob = tf.reshape(attention_prob, [-1])
- feature_map = tf.reshape(feature_map, [-1, feature_depth])
-
- # Use attention score to select feature vectors.
- indices = tf.reshape(tf.where(attention_prob >= abs_thres), [-1])
- selected_boxes = tf.gather(rf_boxes, indices)
- selected_features = tf.gather(feature_map, indices)
- selected_scores = tf.gather(attention_prob, indices)
- selected_scales = tf.ones_like(selected_scores, tf.float32) / scale
-
- # Concat with the previous result from different scales.
- boxes = tf.concat([boxes, selected_boxes], 0)
- features = tf.concat([features, selected_features], 0)
- scales = tf.concat([scales, selected_scales], 0)
- scores = tf.concat([scores, selected_scores], 0)
-
- return scale_index + 1, boxes, features, scales, scores
-
- output_boxes = tf.zeros([0, 4], dtype=tf.float32)
- output_features = tf.zeros([0, feature_depth], dtype=tf.float32)
- output_scales = tf.zeros([0], dtype=tf.float32)
- output_scores = tf.zeros([0], dtype=tf.float32)
-
- # Process the first scale separately, the following scales will reuse the
- # graph variables.
- (_, output_boxes, output_features, output_scales,
- output_scores) = _ProcessSingleScale(0, output_boxes, output_features,
- output_scales, output_scores)
-
- i = tf.constant(1, dtype=tf.int32)
- num_scales = tf.shape(image_scales)[0]
- keep_going = lambda j, b, f, scales, scores: tf.less(j, num_scales)
-
- (_, output_boxes, output_features, output_scales,
- output_scores) = tf.while_loop(
- cond=keep_going,
- body=_ProcessSingleScale,
- loop_vars=[
- i, output_boxes, output_features, output_scales, output_scores
- ],
- shape_invariants=[
- i.get_shape(),
- tf.TensorShape([None, 4]),
- tf.TensorShape([None, feature_depth]),
- tf.TensorShape([None]),
- tf.TensorShape([None])
- ],
- back_prop=False)
-
- feature_boxes = box_list.BoxList(output_boxes)
- feature_boxes.add_field('features', output_features)
- feature_boxes.add_field('scales', output_scales)
- feature_boxes.add_field('scores', output_scores)
-
- nms_max_boxes = tf.minimum(max_feature_num, feature_boxes.num_boxes())
- final_boxes = box_list_ops.non_max_suppression(feature_boxes, iou,
- nms_max_boxes)
-
- return final_boxes.get(), final_boxes.get_field(
- 'features'), final_boxes.get_field('scales'), tf.expand_dims(
- final_boxes.get_field('scores'), 1)
diff --git a/research/delf/delf/python/training/model/resnet50.py b/research/delf/delf/python/training/model/resnet50.py
deleted file mode 100644
index 1c4d7c2f68dea12d74fcd32a8b52fd1285e92b59..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/model/resnet50.py
+++ /dev/null
@@ -1,358 +0,0 @@
-# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""ResNet50 backbone used in DELF model.
-
-Copied over from tensorflow/python/eager/benchmarks/resnet50/resnet50.py,
-because that code does not support dependencies.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import functools
-
-import tensorflow as tf
-
-layers = tf.keras.layers
-
-
-class _IdentityBlock(tf.keras.Model):
- """_IdentityBlock is the block that has no conv layer at shortcut.
-
- Args:
- kernel_size: the kernel size of middle conv layer at main path
- filters: list of integers, the filters of 3 conv layer at main path
- stage: integer, current stage label, used for generating layer names
- block: 'a','b'..., current block label, used for generating layer names
- data_format: data_format for the input ('channels_first' or
- 'channels_last').
- """
-
- def __init__(self, kernel_size, filters, stage, block, data_format):
- super(_IdentityBlock, self).__init__(name='')
- filters1, filters2, filters3 = filters
-
- conv_name_base = 'res' + str(stage) + block + '_branch'
- bn_name_base = 'bn' + str(stage) + block + '_branch'
- bn_axis = 1 if data_format == 'channels_first' else 3
-
- self.conv2a = layers.Conv2D(
- filters1, (1, 1), name=conv_name_base + '2a', data_format=data_format)
- self.bn2a = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2a')
-
- self.conv2b = layers.Conv2D(
- filters2,
- kernel_size,
- padding='same',
- data_format=data_format,
- name=conv_name_base + '2b')
- self.bn2b = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2b')
-
- self.conv2c = layers.Conv2D(
- filters3, (1, 1), name=conv_name_base + '2c', data_format=data_format)
- self.bn2c = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2c')
-
- def call(self, input_tensor, training=False):
- x = self.conv2a(input_tensor)
- x = self.bn2a(x, training=training)
- x = tf.nn.relu(x)
-
- x = self.conv2b(x)
- x = self.bn2b(x, training=training)
- x = tf.nn.relu(x)
-
- x = self.conv2c(x)
- x = self.bn2c(x, training=training)
-
- x += input_tensor
- return tf.nn.relu(x)
-
-
-class _ConvBlock(tf.keras.Model):
- """_ConvBlock is the block that has a conv layer at shortcut.
-
- Args:
- kernel_size: the kernel size of middle conv layer at main path
- filters: list of integers, the filters of 3 conv layer at main path
- stage: integer, current stage label, used for generating layer names
- block: 'a','b'..., current block label, used for generating layer names
- data_format: data_format for the input ('channels_first' or
- 'channels_last').
- strides: strides for the convolution. Note that from stage 3, the first
- conv layer at main path is with strides=(2,2), and the shortcut should
- have strides=(2,2) as well.
- """
-
- def __init__(self,
- kernel_size,
- filters,
- stage,
- block,
- data_format,
- strides=(2, 2)):
- super(_ConvBlock, self).__init__(name='')
- filters1, filters2, filters3 = filters
-
- conv_name_base = 'res' + str(stage) + block + '_branch'
- bn_name_base = 'bn' + str(stage) + block + '_branch'
- bn_axis = 1 if data_format == 'channels_first' else 3
-
- self.conv2a = layers.Conv2D(
- filters1, (1, 1),
- strides=strides,
- name=conv_name_base + '2a',
- data_format=data_format)
- self.bn2a = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2a')
-
- self.conv2b = layers.Conv2D(
- filters2,
- kernel_size,
- padding='same',
- name=conv_name_base + '2b',
- data_format=data_format)
- self.bn2b = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2b')
-
- self.conv2c = layers.Conv2D(
- filters3, (1, 1), name=conv_name_base + '2c', data_format=data_format)
- self.bn2c = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '2c')
-
- self.conv_shortcut = layers.Conv2D(
- filters3, (1, 1),
- strides=strides,
- name=conv_name_base + '1',
- data_format=data_format)
- self.bn_shortcut = layers.BatchNormalization(
- axis=bn_axis, name=bn_name_base + '1')
-
- def call(self, input_tensor, training=False):
- x = self.conv2a(input_tensor)
- x = self.bn2a(x, training=training)
- x = tf.nn.relu(x)
-
- x = self.conv2b(x)
- x = self.bn2b(x, training=training)
- x = tf.nn.relu(x)
-
- x = self.conv2c(x)
- x = self.bn2c(x, training=training)
-
- shortcut = self.conv_shortcut(input_tensor)
- shortcut = self.bn_shortcut(shortcut, training=training)
-
- x += shortcut
- return tf.nn.relu(x)
-
-
-# pylint: disable=not-callable
-class ResNet50(tf.keras.Model):
- """Instantiates the ResNet50 architecture.
-
- Args:
- data_format: format for the image. Either 'channels_first' or
- 'channels_last'. 'channels_first' is typically faster on GPUs while
- 'channels_last' is typically faster on CPUs. See
- https://www.tensorflow.org/performance/performance_guide#data_formats
- name: Prefix applied to names of variables created in the model.
- include_top: whether to include the fully-connected layer at the top of the
- network.
- pooling: Optional pooling mode for feature extraction when `include_top` is
- False. 'None' means that the output of the model will be the 4D tensor
- output of the last convolutional layer. 'avg' means that global average
- pooling will be applied to the output of the last convolutional layer, and
- thus the output of the model will be a 2D tensor. 'max' means that global
- max pooling will be applied.
- block3_strides: whether to add a stride of 2 to block3 to make it compatible
- with tf.slim ResNet implementation.
- average_pooling: whether to do average pooling of block4 features before
- global pooling.
- classes: optional number of classes to classify images into, only to be
- specified if `include_top` is True.
-
- Raises:
- ValueError: in case of invalid argument for data_format.
- """
-
- def __init__(self,
- data_format,
- name='',
- include_top=True,
- pooling=None,
- block3_strides=False,
- average_pooling=True,
- classes=1000):
- super(ResNet50, self).__init__(name=name)
-
- valid_channel_values = ('channels_first', 'channels_last')
- if data_format not in valid_channel_values:
- raise ValueError('Unknown data_format: %s. Valid values: %s' %
- (data_format, valid_channel_values))
- self.include_top = include_top
- self.block3_strides = block3_strides
- self.average_pooling = average_pooling
- self.pooling = pooling
-
- def conv_block(filters, stage, block, strides=(2, 2)):
- return _ConvBlock(
- 3,
- filters,
- stage=stage,
- block=block,
- data_format=data_format,
- strides=strides)
-
- def id_block(filters, stage, block):
- return _IdentityBlock(
- 3, filters, stage=stage, block=block, data_format=data_format)
-
- self.conv1 = layers.Conv2D(
- 64, (7, 7),
- strides=(2, 2),
- data_format=data_format,
- padding='same',
- name='conv1')
- bn_axis = 1 if data_format == 'channels_first' else 3
- self.bn_conv1 = layers.BatchNormalization(axis=bn_axis, name='bn_conv1')
- self.max_pool = layers.MaxPooling2D((3, 3),
- strides=(2, 2),
- data_format=data_format)
-
- self.l2a = conv_block([64, 64, 256], stage=2, block='a', strides=(1, 1))
- self.l2b = id_block([64, 64, 256], stage=2, block='b')
- self.l2c = id_block([64, 64, 256], stage=2, block='c')
-
- self.l3a = conv_block([128, 128, 512], stage=3, block='a')
- self.l3b = id_block([128, 128, 512], stage=3, block='b')
- self.l3c = id_block([128, 128, 512], stage=3, block='c')
- self.l3d = id_block([128, 128, 512], stage=3, block='d')
-
- self.l4a = conv_block([256, 256, 1024], stage=4, block='a')
- self.l4b = id_block([256, 256, 1024], stage=4, block='b')
- self.l4c = id_block([256, 256, 1024], stage=4, block='c')
- self.l4d = id_block([256, 256, 1024], stage=4, block='d')
- self.l4e = id_block([256, 256, 1024], stage=4, block='e')
- self.l4f = id_block([256, 256, 1024], stage=4, block='f')
-
- # Striding layer that can be used on top of block3 to produce feature maps
- # with the same resolution as the TF-Slim implementation.
- if self.block3_strides:
- self.subsampling_layer = layers.MaxPooling2D((1, 1),
- strides=(2, 2),
- data_format=data_format)
- self.l5a = conv_block([512, 512, 2048],
- stage=5,
- block='a',
- strides=(1, 1))
- else:
- self.l5a = conv_block([512, 512, 2048], stage=5, block='a')
- self.l5b = id_block([512, 512, 2048], stage=5, block='b')
- self.l5c = id_block([512, 512, 2048], stage=5, block='c')
-
- self.avg_pool = layers.AveragePooling2D((7, 7),
- strides=(7, 7),
- data_format=data_format)
-
- if self.include_top:
- self.flatten = layers.Flatten()
- self.fc1000 = layers.Dense(classes, name='fc1000')
- else:
- reduction_indices = [1, 2] if data_format == 'channels_last' else [2, 3]
- reduction_indices = tf.constant(reduction_indices)
- if pooling == 'avg':
- self.global_pooling = functools.partial(
- tf.reduce_mean, axis=reduction_indices, keepdims=False)
- elif pooling == 'max':
- self.global_pooling = functools.partial(
- tf.reduce_max, axis=reduction_indices, keepdims=False)
- else:
- self.global_pooling = None
-
- def call(self, inputs, training=True, intermediates_dict=None):
- """Call the ResNet50 model.
-
- Args:
- inputs: Images to compute features for.
- training: Whether model is in training phase.
- intermediates_dict: `None` or dictionary. If not None, accumulate feature
- maps from intermediate blocks into the dictionary. ""
-
- Returns:
- Tensor with featuremap.
- """
-
- x = self.conv1(inputs)
- x = self.bn_conv1(x, training=training)
- x = tf.nn.relu(x)
- if intermediates_dict is not None:
- intermediates_dict['block0'] = x
-
- x = self.max_pool(x)
- if intermediates_dict is not None:
- intermediates_dict['block0mp'] = x
-
- # Block 1 (equivalent to "conv2" in Resnet paper).
- x = self.l2a(x, training=training)
- x = self.l2b(x, training=training)
- x = self.l2c(x, training=training)
- if intermediates_dict is not None:
- intermediates_dict['block1'] = x
-
- # Block 2 (equivalent to "conv3" in Resnet paper).
- x = self.l3a(x, training=training)
- x = self.l3b(x, training=training)
- x = self.l3c(x, training=training)
- x = self.l3d(x, training=training)
- if intermediates_dict is not None:
- intermediates_dict['block2'] = x
-
- # Block 3 (equivalent to "conv4" in Resnet paper).
- x = self.l4a(x, training=training)
- x = self.l4b(x, training=training)
- x = self.l4c(x, training=training)
- x = self.l4d(x, training=training)
- x = self.l4e(x, training=training)
- x = self.l4f(x, training=training)
-
- if self.block3_strides:
- x = self.subsampling_layer(x)
- if intermediates_dict is not None:
- intermediates_dict['block3'] = x
- else:
- if intermediates_dict is not None:
- intermediates_dict['block3'] = x
-
- x = self.l5a(x, training=training)
- x = self.l5b(x, training=training)
- x = self.l5c(x, training=training)
-
- if self.average_pooling:
- x = self.avg_pool(x)
- if intermediates_dict is not None:
- intermediates_dict['block4'] = x
- else:
- if intermediates_dict is not None:
- intermediates_dict['block4'] = x
-
- if self.include_top:
- return self.fc1000(self.flatten(x))
- elif self.global_pooling:
- return self.global_pooling(x)
- else:
- return x
diff --git a/research/delf/delf/python/training/train.py b/research/delf/delf/python/training/train.py
deleted file mode 100644
index 9b0d0a6cdaea696398ae50fcdadbead91899539f..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/training/train.py
+++ /dev/null
@@ -1,442 +0,0 @@
-# Lint as: python3
-# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Training script for DELF on Google Landmarks Dataset.
-
-Script to train DELF using classification loss on Google Landmarks Dataset
-using MirroredStrategy to so it can run on multiple GPUs.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-from absl import app
-from absl import flags
-from absl import logging
-import tensorflow as tf
-import tensorflow_probability as tfp
-
-# Placeholder for internal import. Do not remove this line.
-from delf.python.training.datasets import googlelandmarks as gld
-from delf.python.training.model import delf_model
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_boolean('debug', False, 'Debug mode.')
-flags.DEFINE_string('logdir', '/tmp/delf', 'WithTensorBoard logdir.')
-flags.DEFINE_string('train_file_pattern', '/tmp/data/train*',
- 'File pattern of training dataset files.')
-flags.DEFINE_string('validation_file_pattern', '/tmp/data/validation*',
- 'File pattern of validation dataset files.')
-flags.DEFINE_enum('dataset_version', 'gld_v1',
- ['gld_v1', 'gld_v2', 'gld_v2_clean'],
- 'Google Landmarks dataset version, used to determine the'
- 'number of classes.')
-flags.DEFINE_integer('seed', 0, 'Seed to training dataset.')
-flags.DEFINE_float('initial_lr', 0.001, 'Initial learning rate.')
-flags.DEFINE_integer('batch_size', 32, 'Global batch size.')
-flags.DEFINE_integer('max_iters', 500000, 'Maximum iterations.')
-flags.DEFINE_boolean('block3_strides', False, 'Whether to use block3_strides.')
-flags.DEFINE_boolean('use_augmentation', True,
- 'Whether to use ImageNet style augmentation.')
-
-
-def _record_accuracy(metric, logits, labels):
- """Record accuracy given predicted logits and ground-truth labels."""
- softmax_probabilities = tf.keras.layers.Softmax()(logits)
- metric.update_state(labels, softmax_probabilities)
-
-
-def _attention_summaries(scores, global_step):
- """Record statistics of the attention score."""
- tf.summary.scalar('attention/max', tf.reduce_max(scores), step=global_step)
- tf.summary.scalar('attention/min', tf.reduce_min(scores), step=global_step)
- tf.summary.scalar('attention/mean', tf.reduce_mean(scores), step=global_step)
- tf.summary.scalar(
- 'attention/percent_25',
- tfp.stats.percentile(scores, 25.0),
- step=global_step)
- tf.summary.scalar(
- 'attention/percent_50',
- tfp.stats.percentile(scores, 50.0),
- step=global_step)
- tf.summary.scalar(
- 'attention/percent_75',
- tfp.stats.percentile(scores, 75.0),
- step=global_step)
-
-
-def create_model(num_classes):
- """Define DELF model, and initialize classifiers."""
- model = delf_model.Delf(block3_strides=FLAGS.block3_strides, name='DELF')
- model.init_classifiers(num_classes)
- return model
-
-
-def _learning_rate_schedule(global_step_value, max_iters, initial_lr):
- """Calculates learning_rate with linear decay.
-
- Args:
- global_step_value: int, global step.
- max_iters: int, maximum iterations.
- initial_lr: float, initial learning rate.
-
- Returns:
- lr: float, learning rate.
- """
- lr = initial_lr * (1.0 - global_step_value / max_iters)
- return lr
-
-
-def main(argv):
- if len(argv) > 1:
- raise app.UsageError('Too many command-line arguments.')
-
- #-------------------------------------------------------------
- # Log flags used.
- logging.info('Running training script with\n')
- logging.info('logdir= %s', FLAGS.logdir)
- logging.info('initial_lr= %f', FLAGS.initial_lr)
- logging.info('block3_strides= %s', str(FLAGS.block3_strides))
-
- # ------------------------------------------------------------
- # Create the strategy.
- strategy = tf.distribute.MirroredStrategy()
- logging.info('Number of devices: %d', strategy.num_replicas_in_sync)
- if FLAGS.debug:
- print('Number of devices:', strategy.num_replicas_in_sync)
-
- max_iters = FLAGS.max_iters
- global_batch_size = FLAGS.batch_size
- image_size = 321
- num_eval = 1000
- report_interval = 100
- eval_interval = 1000
- save_interval = 20000
-
- initial_lr = FLAGS.initial_lr
-
- clip_val = tf.constant(10.0)
-
- if FLAGS.debug:
- global_batch_size = 4
- max_iters = 4
- num_eval = 1
- save_interval = 1
- report_interval = 1
-
- # Determine the number of classes based on the version of the dataset.
- gld_info = gld.GoogleLandmarksInfo()
- num_classes = gld_info.num_classes[FLAGS.dataset_version]
-
- # ------------------------------------------------------------
- # Create the distributed train/validation sets.
- train_dataset = gld.CreateDataset(
- file_pattern=FLAGS.train_file_pattern,
- batch_size=global_batch_size,
- image_size=image_size,
- augmentation=FLAGS.use_augmentation,
- seed=FLAGS.seed)
- validation_dataset = gld.CreateDataset(
- file_pattern=FLAGS.validation_file_pattern,
- batch_size=global_batch_size,
- image_size=image_size,
- augmentation=False,
- seed=FLAGS.seed)
-
- train_iterator = strategy.make_dataset_iterator(train_dataset)
- validation_iterator = strategy.make_dataset_iterator(validation_dataset)
-
- train_iterator.initialize()
- validation_iterator.initialize()
-
- # Create a checkpoint directory to store the checkpoints.
- checkpoint_prefix = os.path.join(FLAGS.logdir, 'delf_tf2-ckpt')
-
- # ------------------------------------------------------------
- # Finally, we do everything in distributed scope.
- with strategy.scope():
- # Compute loss.
- # Set reduction to `none` so we can do the reduction afterwards and divide
- # by global batch size.
- loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
- from_logits=True, reduction=tf.keras.losses.Reduction.NONE)
-
- def compute_loss(labels, predictions):
- per_example_loss = loss_object(labels, predictions)
- return tf.nn.compute_average_loss(
- per_example_loss, global_batch_size=global_batch_size)
-
- # Set up metrics.
- desc_validation_loss = tf.keras.metrics.Mean(name='desc_validation_loss')
- attn_validation_loss = tf.keras.metrics.Mean(name='attn_validation_loss')
- desc_train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
- name='desc_train_accuracy')
- attn_train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
- name='attn_train_accuracy')
- desc_validation_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
- name='desc_validation_accuracy')
- attn_validation_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
- name='attn_validation_accuracy')
-
- # ------------------------------------------------------------
- # Setup DELF model and optimizer.
- model = create_model(num_classes)
- logging.info('Model, datasets loaded.\nnum_classes= %d', num_classes)
-
- optimizer = tf.keras.optimizers.SGD(learning_rate=initial_lr, momentum=0.9)
-
- # Setup summary writer.
- summary_writer = tf.summary.create_file_writer(
- os.path.join(FLAGS.logdir, 'train_logs'), flush_millis=10000)
-
- # Setup checkpoint directory.
- checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
- manager = tf.train.CheckpointManager(
- checkpoint, checkpoint_prefix, max_to_keep=3)
-
- # ------------------------------------------------------------
- # Train step to run on one GPU.
- def train_step(inputs):
- """Train one batch."""
- images, labels = inputs
- # Temporary workaround to avoid some corrupted labels.
- labels = tf.clip_by_value(labels, 0, model.num_classes)
-
- global_step = optimizer.iterations
- tf.summary.scalar(
- 'image_range/max', tf.reduce_max(images), step=global_step)
- tf.summary.scalar(
- 'image_range/min', tf.reduce_min(images), step=global_step)
-
- def _backprop_loss(tape, loss, weights):
- """Backpropogate losses using clipped gradients.
-
- Args:
- tape: gradient tape.
- loss: scalar Tensor, loss value.
- weights: keras model weights.
- """
- gradients = tape.gradient(loss, weights)
- clipped, _ = tf.clip_by_global_norm(gradients, clip_norm=clip_val)
- optimizer.apply_gradients(zip(clipped, weights))
-
- # Record gradients and loss through backbone.
- with tf.GradientTape() as desc_tape:
-
- blocks = {}
- prelogits = model.backbone(
- images, intermediates_dict=blocks, training=True)
-
- # Report sparsity.
- activations_zero_fractions = {
- 'sparsity/%s' % k: tf.nn.zero_fraction(v)
- for k, v in blocks.items()
- }
- for k, v in activations_zero_fractions.items():
- tf.summary.scalar(k, v, step=global_step)
-
- # Apply descriptor classifier.
- logits = model.desc_classification(prelogits)
-
- desc_loss = compute_loss(labels, logits)
-
- # Backprop only through backbone weights.
- _backprop_loss(desc_tape, desc_loss, model.desc_trainable_weights)
-
- # Record descriptor train accuracy.
- _record_accuracy(desc_train_accuracy, logits, labels)
-
- # Record gradients and loss through attention block.
- with tf.GradientTape() as attn_tape:
- block3 = blocks['block3'] # pytype: disable=key-error
-
- # Stopping gradients according to DELG paper:
- # (https://arxiv.org/abs/2001.05027).
- block3 = tf.stop_gradient(block3)
-
- prelogits, scores, _ = model.attention(block3, training=True)
- _attention_summaries(scores, global_step)
-
- # Apply attention block classifier.
- logits = model.attn_classification(prelogits)
-
- attn_loss = compute_loss(labels, logits)
-
- # Backprop only through attention weights.
- _backprop_loss(attn_tape, attn_loss, model.attn_trainable_weights)
-
- # Record attention train accuracy.
- _record_accuracy(attn_train_accuracy, logits, labels)
-
- return desc_loss, attn_loss
-
- # ------------------------------------------------------------
- def validation_step(inputs):
- """Validate one batch."""
- images, labels = inputs
- labels = tf.clip_by_value(labels, 0, model.num_classes)
-
- # Get descriptor predictions.
- blocks = {}
- prelogits = model.backbone(
- images, intermediates_dict=blocks, training=False)
- logits = model.desc_classification(prelogits, training=False)
- softmax_probabilities = tf.keras.layers.Softmax()(logits)
-
- validation_loss = loss_object(labels, logits)
- desc_validation_loss.update_state(validation_loss)
- desc_validation_accuracy.update_state(labels, softmax_probabilities)
-
- # Get attention predictions.
- block3 = blocks['block3'] # pytype: disable=key-error
- prelogits, _, _ = model.attention(block3, training=False)
-
- logits = model.attn_classification(prelogits, training=False)
- softmax_probabilities = tf.keras.layers.Softmax()(logits)
-
- validation_loss = loss_object(labels, logits)
- attn_validation_loss.update_state(validation_loss)
- attn_validation_accuracy.update_state(labels, softmax_probabilities)
-
- return desc_validation_accuracy.result(), attn_validation_accuracy.result(
- )
-
- # `run` replicates the provided computation and runs it
- # with the distributed input.
- @tf.function
- def distributed_train_step(dataset_inputs):
- """Get the actual losses."""
- # Each (desc, attn) is a list of 3 losses - crossentropy, reg, total.
- desc_per_replica_loss, attn_per_replica_loss = (
- strategy.run(train_step, args=(dataset_inputs,)))
-
- # Reduce over the replicas.
- desc_global_loss = strategy.reduce(
- tf.distribute.ReduceOp.SUM, desc_per_replica_loss, axis=None)
- attn_global_loss = strategy.reduce(
- tf.distribute.ReduceOp.SUM, attn_per_replica_loss, axis=None)
-
- return desc_global_loss, attn_global_loss
-
- @tf.function
- def distributed_validation_step(dataset_inputs):
- return strategy.run(validation_step, args=(dataset_inputs,))
-
- # ------------------------------------------------------------
- # *** TRAIN LOOP ***
- with summary_writer.as_default():
- with tf.summary.record_if(
- tf.math.equal(0, optimizer.iterations % report_interval)):
-
- global_step_value = optimizer.iterations.numpy()
- while global_step_value < max_iters:
-
- # input_batch : images(b, h, w, c), labels(b,).
- try:
- input_batch = train_iterator.get_next()
- except tf.errors.OutOfRangeError:
- # Break if we run out of data in the dataset.
- logging.info('Stopping training at global step %d, no more data',
- global_step_value)
- break
-
- # Set learning rate for optimizer to use.
- global_step = optimizer.iterations
- global_step_value = global_step.numpy()
-
- learning_rate = _learning_rate_schedule(global_step_value, max_iters,
- initial_lr)
- optimizer.learning_rate = learning_rate
- tf.summary.scalar(
- 'learning_rate', optimizer.learning_rate, step=global_step)
-
- # Run the training step over num_gpu gpus.
- desc_dist_loss, attn_dist_loss = distributed_train_step(input_batch)
-
- # Log losses and accuracies to tensorboard.
- tf.summary.scalar(
- 'loss/desc/crossentropy', desc_dist_loss, step=global_step)
- tf.summary.scalar(
- 'loss/attn/crossentropy', attn_dist_loss, step=global_step)
- tf.summary.scalar(
- 'train_accuracy/desc',
- desc_train_accuracy.result(),
- step=global_step)
- tf.summary.scalar(
- 'train_accuracy/attn',
- attn_train_accuracy.result(),
- step=global_step)
-
- # Print to console if running locally.
- if FLAGS.debug:
- if global_step_value % report_interval == 0:
- print(global_step.numpy())
- print('desc:', desc_dist_loss.numpy())
- print('attn:', attn_dist_loss.numpy())
-
- # Validate once in {eval_interval*n, n \in N} steps.
- if global_step_value % eval_interval == 0:
- for i in range(num_eval):
- try:
- validation_batch = validation_iterator.get_next()
- desc_validation_result, attn_validation_result = (
- distributed_validation_step(validation_batch))
- except tf.errors.OutOfRangeError:
- logging.info('Stopping eval at batch %d, no more data', i)
- break
-
- # Log validation results to tensorboard.
- tf.summary.scalar(
- 'validation/desc', desc_validation_result, step=global_step)
- tf.summary.scalar(
- 'validation/attn', attn_validation_result, step=global_step)
-
- logging.info('\nValidation(%f)\n', global_step_value)
- logging.info(': desc: %f\n', desc_validation_result.numpy())
- logging.info(': attn: %f\n', attn_validation_result.numpy())
- # Print to console.
- if FLAGS.debug:
- print('Validation: desc:', desc_validation_result.numpy())
- print(' : attn:', attn_validation_result.numpy())
-
- # Save checkpoint once (each save_interval*n, n \in N) steps.
- if global_step_value % save_interval == 0:
- save_path = manager.save()
- logging.info('Saved({global_step_value}) at %s', save_path)
-
- file_path = '%s/delf_weights' % FLAGS.logdir
- model.save_weights(file_path, save_format='tf')
- logging.info('Saved weights({global_step_value}) at %s', file_path)
-
- # Reset metrics for next step.
- desc_train_accuracy.reset_states()
- attn_train_accuracy.reset_states()
- desc_validation_loss.reset_states()
- attn_validation_loss.reset_states()
- desc_validation_accuracy.reset_states()
- attn_validation_accuracy.reset_states()
-
- if global_step.numpy() > max_iters:
- break
-
- logging.info('Finished training for %d steps.', max_iters)
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/delf/delf/python/utils.py b/research/delf/delf/python/utils.py
deleted file mode 100644
index dbab2d8c7f1f423991c98851ad509e4684b738b7..0000000000000000000000000000000000000000
--- a/research/delf/delf/python/utils.py
+++ /dev/null
@@ -1,41 +0,0 @@
-# Copyright 2020 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Helper functions for DELF."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from PIL import Image
-from PIL import ImageFile
-import tensorflow as tf
-
-# To avoid PIL crashing for truncated (corrupted) images.
-ImageFile.LOAD_TRUNCATED_IMAGES = True
-
-
-def RgbLoader(path):
- """Helper function to read image with PIL.
-
- Args:
- path: Path to image to be loaded.
-
- Returns:
- PIL image in RGB format.
- """
- with tf.io.gfile.GFile(path, 'rb') as f:
- img = Image.open(f)
- return img.convert('RGB')
-
diff --git a/research/delf/setup.py b/research/delf/setup.py
deleted file mode 100644
index 7aec6f0065a476dbc83b28145916f2981df4bd82..0000000000000000000000000000000000000000
--- a/research/delf/setup.py
+++ /dev/null
@@ -1,37 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Setup script for delf."""
-
-from setuptools import setup, find_packages
-
-install_requires = [
- 'absl-py >= 0.7.1',
- 'protobuf >= 3.8.0',
- 'pandas >= 0.24.2',
- 'numpy >= 1.16.1',
- 'scipy >= 1.2.2',
- 'tensorflow >= 2.0.0b1',
- 'tf_slim >= 1.1',
- 'tensorflow_probability >= 0.9.0',
-]
-
-setup(
- name='delf',
- version='2.0',
- include_package_data=True,
- packages=find_packages(),
- install_requires=install_requires,
- description='DELF (DEep Local Features)',
-)
diff --git a/research/domain_adaptation/README.md b/research/domain_adaptation/README.md
deleted file mode 100644
index e8a2b83794f11ed3711e6bc26254a90cb5469440..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/README.md
+++ /dev/null
@@ -1,124 +0,0 @@
-
-
-
-
-## Introduction
-This is the code used for two domain adaptation papers.
-
-The `domain_separation` directory contains code for the "Domain Separation
-Networks" paper by Bousmalis K., Trigeorgis G., et al. which was presented at
-NIPS 2016. The paper can be found here: https://arxiv.org/abs/1608.06019.
-
-The `pixel_domain_adaptation` directory contains the code used for the
-"Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial
-Networks" paper by Bousmalis K., et al. (presented at CVPR 2017). The paper can
-be found here: https://arxiv.org/abs/1612.05424. PixelDA aims to perform domain
-adaptation by transfering the visual style of the target domain (which has few
-or no labels) to a source domain (which has many labels). This is accomplished
-using a Generative Adversarial Network (GAN).
-
-### Other implementations
-* [Simplified-DSN](https://github.com/AmirHussein96/Simplified-DSN):
- An unofficial implementation of the [Domain Separation Networks paper](https://arxiv.org/abs/1608.06019).
-
-## Contact
-The domain separation code was open-sourced
-by [Konstantinos Bousmalis](https://github.com/bousmalis)
-(konstantinos@google.com), while the pixel level domain adaptation code was
-open-sourced by [David Dohan](https://github.com/dmrd) (ddohan@google.com).
-
-## Installation
-You will need to have the following installed on your machine before trying out the DSN code.
-
-* TensorFlow 1.x: https://www.tensorflow.org/install/
-* Bazel: https://bazel.build/
-
-## Initial setup
-In order to run the MNIST to MNIST-M experiments, you will need to set the
-data directory:
-
-```
-$ export DSN_DATA_DIR=/your/dir
-```
-
-Add models and models/slim to your `$PYTHONPATH` (assumes $PWD is /models):
-
-```
-$ export PYTHONPATH=$PYTHONPATH:$PWD:$PWD/slim
-```
-
-## Getting the datasets
-
-You can fetch the MNIST data by running
-
-```
- $ bazel run slim:download_and_convert_data -- --dataset_dir $DSN_DATA_DIR --dataset_name=mnist
-```
-
-The MNIST-M dataset is available online [here](http://bit.ly/2nrlUAJ). Once it is downloaded and extracted into your data directory, create TFRecord files by running:
-```
-$ bazel run domain_adaptation/datasets:download_and_convert_mnist_m -- --dataset_dir $DSN_DATA_DIR
-```
-
-# Running PixelDA from MNIST to MNIST-M
-You can run PixelDA as follows (using Tensorboard to examine the results):
-
-```
-$ bazel run domain_adaptation/pixel_domain_adaptation:pixelda_train -- --dataset_dir $DSN_DATA_DIR --source_dataset mnist --target_dataset mnist_m
-```
-
-And evaluation as:
-```
-$ bazel run domain_adaptation/pixel_domain_adaptation:pixelda_eval -- --dataset_dir $DSN_DATA_DIR --source_dataset mnist --target_dataset mnist_m --target_split_name test
-```
-
-The MNIST-M results in the paper were run with the following hparams flag:
-```
---hparams arch=resnet,domain_loss_weight=0.135603587834,num_training_examples=16000000,style_transfer_loss_weight=0.0113173311334,task_loss_in_g_weight=0.0100959947002,task_tower=mnist,task_tower_in_g_step=true
-```
-
-### A note on terminology/language of the code:
-
-The components of the network can be grouped into two parts
-which correspond to elements which are jointly optimized: The generator
-component and the discriminator component.
-
-The generator component takes either an image or noise vector and produces an
-output image.
-
-The discriminator component takes the generated images and the target images
-and attempts to discriminate between them.
-
-## Running DSN code for adapting MNIST to MNIST-M
-
-Then you need to build the binaries with Bazel:
-
-```
-$ bazel build -c opt domain_adaptation/domain_separation/...
-```
-
-You can then train with the following command:
-
-```
-$ ./bazel-bin/domain_adaptation/domain_separation/dsn_train \
- --similarity_loss=dann_loss \
- --basic_tower=dann_mnist \
- --source_dataset=mnist \
- --target_dataset=mnist_m \
- --learning_rate=0.0117249 \
- --gamma_weight=0.251175 \
- --weight_decay=1e-6 \
- --layers_to_regularize=fc3 \
- --nouse_separation \
- --master="" \
- --dataset_dir=${DSN_DATA_DIR} \
- -v --use_logging
-```
-
-Evaluation can be invoked with the following command:
-
-```
-$ ./bazel-bin/domain_adaptation/domain_separation/dsn_eval \
- -v --dataset mnist_m --split test --num_examples=9001 \
- --dataset_dir=${DSN_DATA_DIR}
-```
diff --git a/research/domain_adaptation/WORKSPACE b/research/domain_adaptation/WORKSPACE
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/domain_adaptation/__init__.py b/research/domain_adaptation/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/domain_adaptation/datasets/BUILD b/research/domain_adaptation/datasets/BUILD
deleted file mode 100644
index 067a79374fbcedaa6fcd90293e5365aaad4c18c6..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/datasets/BUILD
+++ /dev/null
@@ -1,45 +0,0 @@
-# Domain Adaptation Scenarios Datasets
-
-package(
- default_visibility = [
- ":internal",
- ],
-)
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-package_group(
- name = "internal",
- packages = [
- "//domain_adaptation/...",
- ],
-)
-
-py_library(
- name = "dataset_factory",
- srcs = ["dataset_factory.py"],
- deps = [
- ":mnist_m",
- "//slim:mnist",
- ],
-)
-
-py_binary(
- name = "download_and_convert_mnist_m",
- srcs = ["download_and_convert_mnist_m.py"],
- deps = [
-
- "//slim:dataset_utils",
- ],
-)
-
-py_binary(
- name = "mnist_m",
- srcs = ["mnist_m.py"],
- deps = [
-
- "//slim:dataset_utils",
- ],
-)
diff --git a/research/domain_adaptation/datasets/__init__.py b/research/domain_adaptation/datasets/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/domain_adaptation/datasets/dataset_factory.py b/research/domain_adaptation/datasets/dataset_factory.py
deleted file mode 100644
index 4ca1b41c412a78d25053fc786c8f81072fe90adb..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/datasets/dataset_factory.py
+++ /dev/null
@@ -1,107 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""A factory-pattern class which returns image/label pairs."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# Dependency imports
-import tensorflow as tf
-
-from slim.datasets import mnist
-from domain_adaptation.datasets import mnist_m
-
-slim = tf.contrib.slim
-
-
-def get_dataset(dataset_name,
- split_name,
- dataset_dir,
- file_pattern=None,
- reader=None):
- """Given a dataset name and a split_name returns a Dataset.
-
- Args:
- dataset_name: String, the name of the dataset.
- split_name: A train/test split name.
- dataset_dir: The directory where the dataset files are stored.
- file_pattern: The file pattern to use for matching the dataset source files.
- reader: The subclass of tf.ReaderBase. If left as `None`, then the default
- reader defined by each dataset is used.
-
- Returns:
- A tf-slim `Dataset` class.
-
- Raises:
- ValueError: if `dataset_name` isn't recognized.
- """
- dataset_name_to_module = {'mnist': mnist, 'mnist_m': mnist_m}
- if dataset_name not in dataset_name_to_module:
- raise ValueError('Name of dataset unknown %s.' % dataset_name)
-
- return dataset_name_to_module[dataset_name].get_split(split_name, dataset_dir,
- file_pattern, reader)
-
-
-def provide_batch(dataset_name, split_name, dataset_dir, num_readers,
- batch_size, num_preprocessing_threads):
- """Provides a batch of images and corresponding labels.
-
- Args:
- dataset_name: String, the name of the dataset.
- split_name: A train/test split name.
- dataset_dir: The directory where the dataset files are stored.
- num_readers: The number of readers used by DatasetDataProvider.
- batch_size: The size of the batch requested.
- num_preprocessing_threads: The number of preprocessing threads for
- tf.train.batch.
- file_pattern: The file pattern to use for matching the dataset source files.
- reader: The subclass of tf.ReaderBase. If left as `None`, then the default
- reader defined by each dataset is used.
-
- Returns:
- A batch of
- images: tensor of [batch_size, height, width, channels].
- labels: dictionary of labels.
- """
- dataset = get_dataset(dataset_name, split_name, dataset_dir)
- provider = slim.dataset_data_provider.DatasetDataProvider(
- dataset,
- num_readers=num_readers,
- common_queue_capacity=20 * batch_size,
- common_queue_min=10 * batch_size)
- [image, label] = provider.get(['image', 'label'])
-
- # Convert images to float32
- image = tf.image.convert_image_dtype(image, tf.float32)
- image -= 0.5
- image *= 2
-
- # Load the data.
- labels = {}
- images, labels['classes'] = tf.train.batch(
- [image, label],
- batch_size=batch_size,
- num_threads=num_preprocessing_threads,
- capacity=5 * batch_size)
- labels['classes'] = slim.one_hot_encoding(labels['classes'],
- dataset.num_classes)
-
- # Convert mnist to RGB and 32x32 so that it can match mnist_m.
- if dataset_name == 'mnist':
- images = tf.image.grayscale_to_rgb(images)
- images = tf.image.resize_images(images, [32, 32])
- return images, labels
diff --git a/research/domain_adaptation/datasets/download_and_convert_mnist_m.py b/research/domain_adaptation/datasets/download_and_convert_mnist_m.py
deleted file mode 100644
index 3b5004d3d8aaf54656389e517c50f38299714bc7..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/datasets/download_and_convert_mnist_m.py
+++ /dev/null
@@ -1,237 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-r"""Downloads and converts MNIST-M data to TFRecords of TF-Example protos.
-
-This module downloads the MNIST-M data, uncompresses it, reads the files
-that make up the MNIST-M data and creates two TFRecord datasets: one for train
-and one for test. Each TFRecord dataset is comprised of a set of TF-Example
-protocol buffers, each of which contain a single image and label.
-
-The script should take about a minute to run.
-
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import random
-import sys
-
-# Dependency imports
-import numpy as np
-from six.moves import urllib
-import tensorflow as tf
-
-from slim.datasets import dataset_utils
-
-tf.app.flags.DEFINE_string(
- 'dataset_dir', None,
- 'The directory where the output TFRecords and temporary files are saved.')
-
-FLAGS = tf.app.flags.FLAGS
-
-_IMAGE_SIZE = 32
-_NUM_CHANNELS = 3
-
-# The number of images in the training set.
-_NUM_TRAIN_SAMPLES = 59001
-
-# The number of images to be kept from the training set for the validation set.
-_NUM_VALIDATION = 1000
-
-# The number of images in the test set.
-_NUM_TEST_SAMPLES = 9001
-
-# Seed for repeatability.
-_RANDOM_SEED = 0
-
-# The names of the classes.
-_CLASS_NAMES = [
- 'zero',
- 'one',
- 'two',
- 'three',
- 'four',
- 'five',
- 'size',
- 'seven',
- 'eight',
- 'nine',
-]
-
-
-class ImageReader(object):
- """Helper class that provides TensorFlow image coding utilities."""
-
- def __init__(self):
- # Initializes function that decodes RGB PNG data.
- self._decode_png_data = tf.placeholder(dtype=tf.string)
- self._decode_png = tf.image.decode_png(self._decode_png_data, channels=3)
-
- def read_image_dims(self, sess, image_data):
- image = self.decode_png(sess, image_data)
- return image.shape[0], image.shape[1]
-
- def decode_png(self, sess, image_data):
- image = sess.run(
- self._decode_png, feed_dict={self._decode_png_data: image_data})
- assert len(image.shape) == 3
- assert image.shape[2] == 3
- return image
-
-
-def _convert_dataset(split_name, filenames, filename_to_class_id, dataset_dir):
- """Converts the given filenames to a TFRecord dataset.
-
- Args:
- split_name: The name of the dataset, either 'train' or 'valid'.
- filenames: A list of absolute paths to png images.
- filename_to_class_id: A dictionary from filenames (strings) to class ids
- (integers).
- dataset_dir: The directory where the converted datasets are stored.
- """
- print('Converting the {} split.'.format(split_name))
- # Train and validation splits are both in the train directory.
- if split_name in ['train', 'valid']:
- png_directory = os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train')
- elif split_name == 'test':
- png_directory = os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test')
-
- with tf.Graph().as_default():
- image_reader = ImageReader()
-
- with tf.Session('') as sess:
- output_filename = _get_output_filename(dataset_dir, split_name)
-
- with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
- for filename in filenames:
- # Read the filename:
- image_data = tf.gfile.FastGFile(
- os.path.join(png_directory, filename), 'r').read()
- height, width = image_reader.read_image_dims(sess, image_data)
-
- class_id = filename_to_class_id[filename]
- example = dataset_utils.image_to_tfexample(image_data, 'png', height,
- width, class_id)
- tfrecord_writer.write(example.SerializeToString())
-
- sys.stdout.write('\n')
- sys.stdout.flush()
-
-
-def _extract_labels(label_filename):
- """Extract the labels into a dict of filenames to int labels.
-
- Args:
- labels_filename: The filename of the MNIST-M labels.
-
- Returns:
- A dictionary of filenames to int labels.
- """
- print('Extracting labels from: ', label_filename)
- label_file = tf.gfile.FastGFile(label_filename, 'r').readlines()
- label_lines = [line.rstrip('\n').split() for line in label_file]
- labels = {}
- for line in label_lines:
- assert len(line) == 2
- labels[line[0]] = int(line[1])
- return labels
-
-
-def _get_output_filename(dataset_dir, split_name):
- """Creates the output filename.
-
- Args:
- dataset_dir: The directory where the temporary files are stored.
- split_name: The name of the train/test split.
-
- Returns:
- An absolute file path.
- """
- return '%s/mnist_m_%s.tfrecord' % (dataset_dir, split_name)
-
-
-def _get_filenames(dataset_dir):
- """Returns a list of filenames and inferred class names.
-
- Args:
- dataset_dir: A directory containing a set PNG encoded MNIST-M images.
-
- Returns:
- A list of image file paths, relative to `dataset_dir`.
- """
- photo_filenames = []
- for filename in os.listdir(dataset_dir):
- photo_filenames.append(filename)
- return photo_filenames
-
-
-def run(dataset_dir):
- """Runs the download and conversion operation.
-
- Args:
- dataset_dir: The dataset directory where the dataset is stored.
- """
- if not tf.gfile.Exists(dataset_dir):
- tf.gfile.MakeDirs(dataset_dir)
-
- train_filename = _get_output_filename(dataset_dir, 'train')
- testing_filename = _get_output_filename(dataset_dir, 'test')
-
- if tf.gfile.Exists(train_filename) and tf.gfile.Exists(testing_filename):
- print('Dataset files already exist. Exiting without re-creating them.')
- return
-
- # TODO(konstantinos): Add download and cleanup functionality
-
- train_validation_filenames = _get_filenames(
- os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train'))
- test_filenames = _get_filenames(
- os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test'))
-
- # Divide into train and validation:
- random.seed(_RANDOM_SEED)
- random.shuffle(train_validation_filenames)
- train_filenames = train_validation_filenames[_NUM_VALIDATION:]
- validation_filenames = train_validation_filenames[:_NUM_VALIDATION]
-
- train_validation_filenames_to_class_ids = _extract_labels(
- os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train_labels.txt'))
- test_filenames_to_class_ids = _extract_labels(
- os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test_labels.txt'))
-
- # Convert the train, validation, and test sets.
- _convert_dataset('train', train_filenames,
- train_validation_filenames_to_class_ids, dataset_dir)
- _convert_dataset('valid', validation_filenames,
- train_validation_filenames_to_class_ids, dataset_dir)
- _convert_dataset('test', test_filenames, test_filenames_to_class_ids,
- dataset_dir)
-
- # Finally, write the labels file:
- labels_to_class_names = dict(zip(range(len(_CLASS_NAMES)), _CLASS_NAMES))
- dataset_utils.write_label_file(labels_to_class_names, dataset_dir)
-
- print('\nFinished converting the MNIST-M dataset!')
-
-
-def main(_):
- assert FLAGS.dataset_dir
- run(FLAGS.dataset_dir)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/datasets/mnist_m.py b/research/domain_adaptation/datasets/mnist_m.py
deleted file mode 100644
index fab6c443cf3d2e9783d19bf52c81b7aa62d56a38..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/datasets/mnist_m.py
+++ /dev/null
@@ -1,98 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Provides data for the MNIST-M dataset.
-
-The dataset scripts used to create the dataset can be found at:
-tensorflow_models/domain_adaptation_/datasets/download_and_convert_mnist_m_dataset.py
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-# Dependency imports
-import tensorflow as tf
-
-from slim.datasets import dataset_utils
-
-slim = tf.contrib.slim
-
-_FILE_PATTERN = 'mnist_m_%s.tfrecord'
-
-_SPLITS_TO_SIZES = {'train': 58001, 'valid': 1000, 'test': 9001}
-
-_NUM_CLASSES = 10
-
-_ITEMS_TO_DESCRIPTIONS = {
- 'image': 'A [32 x 32 x 1] RGB image.',
- 'label': 'A single integer between 0 and 9',
-}
-
-
-def get_split(split_name, dataset_dir, file_pattern=None, reader=None):
- """Gets a dataset tuple with instructions for reading MNIST.
-
- Args:
- split_name: A train/test split name.
- dataset_dir: The base directory of the dataset sources.
-
- Returns:
- A `Dataset` namedtuple.
-
- Raises:
- ValueError: if `split_name` is not a valid train/test split.
- """
- if split_name not in _SPLITS_TO_SIZES:
- raise ValueError('split name %s was not recognized.' % split_name)
-
- if not file_pattern:
- file_pattern = _FILE_PATTERN
- file_pattern = os.path.join(dataset_dir, file_pattern % split_name)
-
- # Allowing None in the signature so that dataset_factory can use the default.
- if reader is None:
- reader = tf.TFRecordReader
-
- keys_to_features = {
- 'image/encoded':
- tf.FixedLenFeature((), tf.string, default_value=''),
- 'image/format':
- tf.FixedLenFeature((), tf.string, default_value='png'),
- 'image/class/label':
- tf.FixedLenFeature(
- [1], tf.int64, default_value=tf.zeros([1], dtype=tf.int64)),
- }
-
- items_to_handlers = {
- 'image': slim.tfexample_decoder.Image(shape=[32, 32, 3], channels=3),
- 'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[]),
- }
-
- decoder = slim.tfexample_decoder.TFExampleDecoder(
- keys_to_features, items_to_handlers)
-
- labels_to_names = None
- if dataset_utils.has_labels(dataset_dir):
- labels_to_names = dataset_utils.read_label_file(dataset_dir)
-
- return slim.dataset.Dataset(
- data_sources=file_pattern,
- reader=reader,
- decoder=decoder,
- num_samples=_SPLITS_TO_SIZES[split_name],
- num_classes=_NUM_CLASSES,
- items_to_descriptions=_ITEMS_TO_DESCRIPTIONS,
- labels_to_names=labels_to_names)
diff --git a/research/domain_adaptation/domain_separation/BUILD b/research/domain_adaptation/domain_separation/BUILD
deleted file mode 100644
index 14dceda27e49d74eaaaeae21676183b78c72b9c2..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/BUILD
+++ /dev/null
@@ -1,157 +0,0 @@
-# Domain Separation Networks
-
-package(
- default_visibility = [
- ":internal",
- ],
-)
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-package_group(
- name = "internal",
- packages = [
- "//domain_adaptation/...",
- ],
-)
-
-py_library(
- name = "models",
- srcs = [
- "models.py",
- ],
- deps = [
- ":utils",
- ],
-)
-
-py_library(
- name = "losses",
- srcs = [
- "losses.py",
- ],
- deps = [
- ":grl_op_grads_py",
- ":grl_op_shapes_py",
- ":grl_ops",
- ":utils",
- ],
-)
-
-py_test(
- name = "losses_test",
- srcs = [
- "losses_test.py",
- ],
- deps = [
- ":losses",
- ":utils",
- ],
-)
-
-py_library(
- name = "dsn",
- srcs = [
- "dsn.py",
- ],
- deps = [
- ":grl_op_grads_py",
- ":grl_op_shapes_py",
- ":grl_ops",
- ":losses",
- ":models",
- ":utils",
- ],
-)
-
-py_test(
- name = "dsn_test",
- srcs = [
- "dsn_test.py",
- ],
- deps = [
- ":dsn",
- ],
-)
-
-py_binary(
- name = "dsn_train",
- srcs = [
- "dsn_train.py",
- ],
- deps = [
- ":dsn",
- ":models",
- "//domain_adaptation/datasets:dataset_factory",
- ],
-)
-
-py_binary(
- name = "dsn_eval",
- srcs = [
- "dsn_eval.py",
- ],
- deps = [
- ":dsn",
- ":models",
- "//domain_adaptation/datasets:dataset_factory",
- ],
-)
-
-py_test(
- name = "models_test",
- srcs = [
- "models_test.py",
- ],
- deps = [
- ":models",
- "//domain_adaptation/datasets:dataset_factory",
- ],
-)
-
-py_library(
- name = "utils",
- srcs = [
- "utils.py",
- ],
- deps = [
- ],
-)
-
-py_library(
- name = "grl_op_grads_py",
- srcs = [
- "grl_op_grads.py",
- ],
- deps = [
- ":grl_ops",
- ],
-)
-
-py_library(
- name = "grl_op_shapes_py",
- srcs = [
- "grl_op_shapes.py",
- ],
- deps = [
- ],
-)
-
-py_library(
- name = "grl_ops",
- srcs = ["grl_ops.py"],
- data = ["_grl_ops.so"],
-)
-
-py_test(
- name = "grl_ops_test",
- size = "small",
- srcs = ["grl_ops_test.py"],
- deps = [
- ":grl_op_grads_py",
- ":grl_op_shapes_py",
- ":grl_ops",
- ],
-)
diff --git a/research/domain_adaptation/domain_separation/__init__.py b/research/domain_adaptation/domain_separation/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/domain_adaptation/domain_separation/_grl_ops.so b/research/domain_adaptation/domain_separation/_grl_ops.so
deleted file mode 100755
index 4c35473760a76dcb743d58f45eddccecb5f5161e..0000000000000000000000000000000000000000
Binary files a/research/domain_adaptation/domain_separation/_grl_ops.so and /dev/null differ
diff --git a/research/domain_adaptation/domain_separation/dsn.py b/research/domain_adaptation/domain_separation/dsn.py
deleted file mode 100644
index 3018e8a791840ae465bad493913235cc04c31cff..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/dsn.py
+++ /dev/null
@@ -1,355 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Functions to create a DSN model and add the different losses to it.
-
-Specifically, in this file we define the:
- - Shared Encoding Similarity Loss Module, with:
- - The MMD Similarity method
- - The Correlation Similarity method
- - The Gradient Reversal (Domain-Adversarial) method
- - Difference Loss Module
- - Reconstruction Loss Module
- - Task Loss Module
-"""
-from functools import partial
-
-import tensorflow as tf
-
-import losses
-import models
-import utils
-
-slim = tf.contrib.slim
-
-
-################################################################################
-# HELPER FUNCTIONS
-################################################################################
-def dsn_loss_coefficient(params):
- """The global_step-dependent weight that specifies when to kick in DSN losses.
-
- Args:
- params: A dictionary of parameters. Expecting 'domain_separation_startpoint'
-
- Returns:
- A weight to that effectively enables or disables the DSN-related losses,
- i.e. similarity, difference, and reconstruction losses.
- """
- return tf.where(
- tf.less(slim.get_or_create_global_step(),
- params['domain_separation_startpoint']), 1e-10, 1.0)
-
-
-################################################################################
-# MODEL CREATION
-################################################################################
-def create_model(source_images, source_labels, domain_selection_mask,
- target_images, target_labels, similarity_loss, params,
- basic_tower_name):
- """Creates a DSN model.
-
- Args:
- source_images: images from the source domain, a tensor of size
- [batch_size, height, width, channels]
- source_labels: a dictionary with the name, tensor pairs. 'classes' is one-
- hot for the number of classes.
- domain_selection_mask: a boolean tensor of size [batch_size, ] which denotes
- the labeled images that belong to the source domain.
- target_images: images from the target domain, a tensor of size
- [batch_size, height width, channels].
- target_labels: a dictionary with the name, tensor pairs.
- similarity_loss: The type of method to use for encouraging
- the codes from the shared encoder to be similar.
- params: A dictionary of parameters. Expecting 'weight_decay',
- 'layers_to_regularize', 'use_separation', 'domain_separation_startpoint',
- 'alpha_weight', 'beta_weight', 'gamma_weight', 'recon_loss_name',
- 'decoder_name', 'encoder_name'
- basic_tower_name: the name of the tower to use for the shared encoder.
-
- Raises:
- ValueError: if the arch is not one of the available architectures.
- """
- network = getattr(models, basic_tower_name)
- num_classes = source_labels['classes'].get_shape().as_list()[1]
-
- # Make sure we are using the appropriate number of classes.
- network = partial(network, num_classes=num_classes)
-
- # Add the classification/pose estimation loss to the source domain.
- source_endpoints = add_task_loss(source_images, source_labels, network,
- params)
-
- if similarity_loss == 'none':
- # No domain adaptation, we can stop here.
- return
-
- with tf.variable_scope('towers', reuse=True):
- target_logits, target_endpoints = network(
- target_images, weight_decay=params['weight_decay'], prefix='target')
-
- # Plot target accuracy of the train set.
- target_accuracy = utils.accuracy(
- tf.argmax(target_logits, 1), tf.argmax(target_labels['classes'], 1))
-
- if 'quaternions' in target_labels:
- target_quaternion_loss = losses.log_quaternion_loss(
- target_labels['quaternions'], target_endpoints['quaternion_pred'],
- params)
- tf.summary.scalar('eval/Target quaternions', target_quaternion_loss)
-
- tf.summary.scalar('eval/Target accuracy', target_accuracy)
-
- source_shared = source_endpoints[params['layers_to_regularize']]
- target_shared = target_endpoints[params['layers_to_regularize']]
-
- # When using the semisupervised model we include labeled target data in the
- # source classifier. We do not want to include these target domain when
- # we use the similarity loss.
- indices = tf.range(0, source_shared.get_shape().as_list()[0])
- indices = tf.boolean_mask(indices, domain_selection_mask)
- add_similarity_loss(similarity_loss,
- tf.gather(source_shared, indices),
- tf.gather(target_shared, indices), params)
-
- if params['use_separation']:
- add_autoencoders(
- source_images,
- source_shared,
- target_images,
- target_shared,
- params=params,)
-
-
-def add_similarity_loss(method_name,
- source_samples,
- target_samples,
- params,
- scope=None):
- """Adds a loss encouraging the shared encoding from each domain to be similar.
-
- Args:
- method_name: the name of the encoding similarity method to use. Valid
- options include `dann_loss', `mmd_loss' or `correlation_loss'.
- source_samples: a tensor of shape [num_samples, num_features].
- target_samples: a tensor of shape [num_samples, num_features].
- params: a dictionary of parameters. Expecting 'gamma_weight'.
- scope: optional name scope for summary tags.
- Raises:
- ValueError: if `method_name` is not recognized.
- """
- weight = dsn_loss_coefficient(params) * params['gamma_weight']
- method = getattr(losses, method_name)
- method(source_samples, target_samples, weight, scope)
-
-
-def add_reconstruction_loss(recon_loss_name, images, recons, weight, domain):
- """Adds a reconstruction loss.
-
- Args:
- recon_loss_name: The name of the reconstruction loss.
- images: A `Tensor` of size [batch_size, height, width, 3].
- recons: A `Tensor` whose size matches `images`.
- weight: A scalar coefficient for the loss.
- domain: The name of the domain being reconstructed.
-
- Raises:
- ValueError: If `recon_loss_name` is not recognized.
- """
- if recon_loss_name == 'sum_of_pairwise_squares':
- loss_fn = tf.contrib.losses.mean_pairwise_squared_error
- elif recon_loss_name == 'sum_of_squares':
- loss_fn = tf.contrib.losses.mean_squared_error
- else:
- raise ValueError('recon_loss_name value [%s] not recognized.' %
- recon_loss_name)
-
- loss = loss_fn(recons, images, weight)
- assert_op = tf.Assert(tf.is_finite(loss), [loss])
- with tf.control_dependencies([assert_op]):
- tf.summary.scalar('losses/%s Recon Loss' % domain, loss)
-
-
-def add_autoencoders(source_data, source_shared, target_data, target_shared,
- params):
- """Adds the encoders/decoders for our domain separation model w/ incoherence.
-
- Args:
- source_data: images from the source domain, a tensor of size
- [batch_size, height, width, channels]
- source_shared: a tensor with first dimension batch_size
- target_data: images from the target domain, a tensor of size
- [batch_size, height, width, channels]
- target_shared: a tensor with first dimension batch_size
- params: A dictionary of parameters. Expecting 'layers_to_regularize',
- 'beta_weight', 'alpha_weight', 'recon_loss_name', 'decoder_name',
- 'encoder_name', 'weight_decay'
- """
-
- def normalize_images(images):
- images -= tf.reduce_min(images)
- return images / tf.reduce_max(images)
-
- def concat_operation(shared_repr, private_repr):
- return shared_repr + private_repr
-
- mu = dsn_loss_coefficient(params)
-
- # The layer to concatenate the networks at.
- concat_layer = params['layers_to_regularize']
-
- # The coefficient for modulating the private/shared difference loss.
- difference_loss_weight = params['beta_weight'] * mu
-
- # The reconstruction weight.
- recon_loss_weight = params['alpha_weight'] * mu
-
- # The reconstruction loss to use.
- recon_loss_name = params['recon_loss_name']
-
- # The decoder/encoder to use.
- decoder_name = params['decoder_name']
- encoder_name = params['encoder_name']
-
- _, height, width, _ = source_data.get_shape().as_list()
- code_size = source_shared.get_shape().as_list()[-1]
- weight_decay = params['weight_decay']
-
- encoder_fn = getattr(models, encoder_name)
- # Target Auto-encoding.
- with tf.variable_scope('source_encoder'):
- source_endpoints = encoder_fn(
- source_data, code_size, weight_decay=weight_decay)
-
- with tf.variable_scope('target_encoder'):
- target_endpoints = encoder_fn(
- target_data, code_size, weight_decay=weight_decay)
-
- decoder_fn = getattr(models, decoder_name)
-
- decoder = partial(
- decoder_fn,
- height=height,
- width=width,
- channels=source_data.get_shape().as_list()[-1],
- weight_decay=weight_decay)
-
- # Source Auto-encoding.
- source_private = source_endpoints[concat_layer]
- target_private = target_endpoints[concat_layer]
- with tf.variable_scope('decoder'):
- source_recons = decoder(concat_operation(source_shared, source_private))
-
- with tf.variable_scope('decoder', reuse=True):
- source_private_recons = decoder(
- concat_operation(tf.zeros_like(source_private), source_private))
- source_shared_recons = decoder(
- concat_operation(source_shared, tf.zeros_like(source_shared)))
-
- with tf.variable_scope('decoder', reuse=True):
- target_recons = decoder(concat_operation(target_shared, target_private))
- target_shared_recons = decoder(
- concat_operation(target_shared, tf.zeros_like(target_shared)))
- target_private_recons = decoder(
- concat_operation(tf.zeros_like(target_private), target_private))
-
- losses.difference_loss(
- source_private,
- source_shared,
- weight=difference_loss_weight,
- name='Source')
- losses.difference_loss(
- target_private,
- target_shared,
- weight=difference_loss_weight,
- name='Target')
-
- add_reconstruction_loss(recon_loss_name, source_data, source_recons,
- recon_loss_weight, 'source')
- add_reconstruction_loss(recon_loss_name, target_data, target_recons,
- recon_loss_weight, 'target')
-
- # Add summaries
- source_reconstructions = tf.concat(
- axis=2,
- values=map(normalize_images, [
- source_data, source_recons, source_shared_recons,
- source_private_recons
- ]))
- target_reconstructions = tf.concat(
- axis=2,
- values=map(normalize_images, [
- target_data, target_recons, target_shared_recons,
- target_private_recons
- ]))
- tf.summary.image(
- 'Source Images:Recons:RGB',
- source_reconstructions[:, :, :, :3],
- max_outputs=10)
- tf.summary.image(
- 'Target Images:Recons:RGB',
- target_reconstructions[:, :, :, :3],
- max_outputs=10)
-
- if source_reconstructions.get_shape().as_list()[3] == 4:
- tf.summary.image(
- 'Source Images:Recons:Depth',
- source_reconstructions[:, :, :, 3:4],
- max_outputs=10)
- tf.summary.image(
- 'Target Images:Recons:Depth',
- target_reconstructions[:, :, :, 3:4],
- max_outputs=10)
-
-
-def add_task_loss(source_images, source_labels, basic_tower, params):
- """Adds a classification and/or pose estimation loss to the model.
-
- Args:
- source_images: images from the source domain, a tensor of size
- [batch_size, height, width, channels]
- source_labels: labels from the source domain, a tensor of size [batch_size].
- or a tuple of (quaternions, class_labels)
- basic_tower: a function that creates the single tower of the model.
- params: A dictionary of parameters. Expecting 'weight_decay', 'pose_weight'.
- Returns:
- The source endpoints.
-
- Raises:
- RuntimeError: if basic tower does not support pose estimation.
- """
- with tf.variable_scope('towers'):
- source_logits, source_endpoints = basic_tower(
- source_images, weight_decay=params['weight_decay'], prefix='Source')
-
- if 'quaternions' in source_labels: # We have pose estimation as well
- if 'quaternion_pred' not in source_endpoints:
- raise RuntimeError('Please use a model for estimation e.g. pose_mini')
-
- loss = losses.log_quaternion_loss(source_labels['quaternions'],
- source_endpoints['quaternion_pred'],
- params)
-
- assert_op = tf.Assert(tf.is_finite(loss), [loss])
- with tf.control_dependencies([assert_op]):
- quaternion_loss = loss
- tf.summary.histogram('log_quaternion_loss_hist', quaternion_loss)
- slim.losses.add_loss(quaternion_loss * params['pose_weight'])
- tf.summary.scalar('losses/quaternion_loss', quaternion_loss)
-
- classification_loss = tf.losses.softmax_cross_entropy(
- source_labels['classes'], source_logits)
-
- tf.summary.scalar('losses/classification_loss', classification_loss)
- return source_endpoints
diff --git a/research/domain_adaptation/domain_separation/dsn_eval.py b/research/domain_adaptation/domain_separation/dsn_eval.py
deleted file mode 100644
index b6cccdfcc17e8f18e8381530b5c8f41501bda29b..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/dsn_eval.py
+++ /dev/null
@@ -1,161 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# pylint: disable=line-too-long
-"""Evaluation for Domain Separation Networks (DSNs)."""
-# pylint: enable=line-too-long
-import math
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-from domain_adaptation.domain_separation import losses
-from domain_adaptation.domain_separation import models
-
-slim = tf.contrib.slim
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_integer('batch_size', 32,
- 'The number of images in each batch.')
-
-tf.app.flags.DEFINE_string('master', '',
- 'BNS name of the TensorFlow master to use.')
-
-tf.app.flags.DEFINE_string('checkpoint_dir', '/tmp/da/',
- 'Directory where the model was written to.')
-
-tf.app.flags.DEFINE_string(
- 'eval_dir', '/tmp/da/',
- 'Directory where we should write the tf summaries to.')
-
-tf.app.flags.DEFINE_string('dataset_dir', None,
- 'The directory where the dataset files are stored.')
-
-tf.app.flags.DEFINE_string('dataset', 'mnist_m',
- 'Which dataset to test on: "mnist", "mnist_m".')
-
-tf.app.flags.DEFINE_string('split', 'valid',
- 'Which portion to test on: "valid", "test".')
-
-tf.app.flags.DEFINE_integer('num_examples', 1000, 'Number of test examples.')
-
-tf.app.flags.DEFINE_string('basic_tower', 'dann_mnist',
- 'The basic tower building block.')
-
-tf.app.flags.DEFINE_bool('enable_precision_recall', False,
- 'If True, precision and recall for each class will '
- 'be added to the metrics.')
-
-tf.app.flags.DEFINE_bool('use_logging', False, 'Debugging messages.')
-
-
-def quaternion_metric(predictions, labels):
- params = {'batch_size': FLAGS.batch_size, 'use_logging': False}
- logcost = losses.log_quaternion_loss_batch(predictions, labels, params)
- return slim.metrics.streaming_mean(logcost)
-
-
-def angle_diff(true_q, pred_q):
- angles = 2 * (
- 180.0 /
- np.pi) * np.arccos(np.abs(np.sum(np.multiply(pred_q, true_q), axis=1)))
- return angles
-
-
-def provide_batch_fn():
- """ The provide_batch function to use. """
- return dataset_factory.provide_batch
-
-
-def main(_):
- g = tf.Graph()
- with g.as_default():
- # Load the data.
- images, labels = provide_batch_fn()(
- FLAGS.dataset, FLAGS.split, FLAGS.dataset_dir, 4, FLAGS.batch_size, 4)
-
- num_classes = labels['classes'].get_shape().as_list()[1]
-
- tf.summary.image('eval_images', images, max_outputs=3)
-
- # Define the model:
- with tf.variable_scope('towers'):
- basic_tower = getattr(models, FLAGS.basic_tower)
- predictions, endpoints = basic_tower(
- images,
- num_classes=num_classes,
- is_training=False,
- batch_norm_params=None)
- metric_names_to_values = {}
-
- # Define the metrics:
- if 'quaternions' in labels: # Also have to evaluate pose estimation!
- quaternion_loss = quaternion_metric(labels['quaternions'],
- endpoints['quaternion_pred'])
-
- angle_errors, = tf.py_func(
- angle_diff, [labels['quaternions'], endpoints['quaternion_pred']],
- [tf.float32])
-
- metric_names_to_values[
- 'Angular mean error'] = slim.metrics.streaming_mean(angle_errors)
- metric_names_to_values['Quaternion Loss'] = quaternion_loss
-
- accuracy = tf.contrib.metrics.streaming_accuracy(
- tf.argmax(predictions, 1), tf.argmax(labels['classes'], 1))
-
- predictions = tf.argmax(predictions, 1)
- labels = tf.argmax(labels['classes'], 1)
- metric_names_to_values['Accuracy'] = accuracy
-
- if FLAGS.enable_precision_recall:
- for i in xrange(num_classes):
- index_map = tf.one_hot(i, depth=num_classes)
- name = 'PR/Precision_{}'.format(i)
- metric_names_to_values[name] = slim.metrics.streaming_precision(
- tf.gather(index_map, predictions), tf.gather(index_map, labels))
- name = 'PR/Recall_{}'.format(i)
- metric_names_to_values[name] = slim.metrics.streaming_recall(
- tf.gather(index_map, predictions), tf.gather(index_map, labels))
-
- names_to_values, names_to_updates = slim.metrics.aggregate_metric_map(
- metric_names_to_values)
-
- # Create the summary ops such that they also print out to std output:
- summary_ops = []
- for metric_name, metric_value in names_to_values.iteritems():
- op = tf.summary.scalar(metric_name, metric_value)
- op = tf.Print(op, [metric_value], metric_name)
- summary_ops.append(op)
-
- # This ensures that we make a single pass over all of the data.
- num_batches = math.ceil(FLAGS.num_examples / float(FLAGS.batch_size))
-
- # Setup the global step.
- slim.get_or_create_global_step()
- slim.evaluation.evaluation_loop(
- FLAGS.master,
- checkpoint_dir=FLAGS.checkpoint_dir,
- logdir=FLAGS.eval_dir,
- num_evals=num_batches,
- eval_op=names_to_updates.values(),
- summary_op=tf.summary.merge(summary_ops))
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/domain_separation/dsn_test.py b/research/domain_adaptation/domain_separation/dsn_test.py
deleted file mode 100644
index 3d687398a9b9356455f739417bc96ddb2ca5ad40..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/dsn_test.py
+++ /dev/null
@@ -1,157 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DSN model assembly functions."""
-
-import numpy as np
-import tensorflow as tf
-
-import dsn
-
-
-class HelperFunctionsTest(tf.test.TestCase):
-
- def testBasicDomainSeparationStartPoint(self):
- with self.test_session() as sess:
- # Test for when global_step < domain_separation_startpoint
- step = tf.contrib.slim.get_or_create_global_step()
- sess.run(tf.global_variables_initializer()) # global_step = 0
- params = {'domain_separation_startpoint': 2}
- weight = dsn.dsn_loss_coefficient(params)
- weight_np = sess.run(weight)
- self.assertAlmostEqual(weight_np, 1e-10)
-
- step_op = tf.assign_add(step, 1)
- step_np = sess.run(step_op) # global_step = 1
- weight = dsn.dsn_loss_coefficient(params)
- weight_np = sess.run(weight)
- self.assertAlmostEqual(weight_np, 1e-10)
-
- # Test for when global_step >= domain_separation_startpoint
- step_np = sess.run(step_op) # global_step = 2
- tf.logging.info(step_np)
- weight = dsn.dsn_loss_coefficient(params)
- weight_np = sess.run(weight)
- self.assertAlmostEqual(weight_np, 1.0)
-
-
-class DsnModelAssemblyTest(tf.test.TestCase):
-
- def _testBuildDefaultModel(self):
- images = tf.to_float(np.random.rand(32, 28, 28, 1))
- labels = {}
- labels['classes'] = tf.one_hot(
- tf.to_int32(np.random.randint(0, 9, (32))), 10)
-
- params = {
- 'use_separation': True,
- 'layers_to_regularize': 'fc3',
- 'weight_decay': 0.0,
- 'ps_tasks': 1,
- 'domain_separation_startpoint': 1,
- 'alpha_weight': 1,
- 'beta_weight': 1,
- 'gamma_weight': 1,
- 'recon_loss_name': 'sum_of_squares',
- 'decoder_name': 'small_decoder',
- 'encoder_name': 'default_encoder',
- }
- return images, labels, params
-
- def testBuildModelDann(self):
- images, labels, params = self._testBuildDefaultModel()
-
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'dann_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 6)
-
- def testBuildModelDannSumOfPairwiseSquares(self):
- images, labels, params = self._testBuildDefaultModel()
-
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'dann_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 6)
-
- def testBuildModelDannMultiPSTasks(self):
- images, labels, params = self._testBuildDefaultModel()
- params['ps_tasks'] = 10
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'dann_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 6)
-
- def testBuildModelMmd(self):
- images, labels, params = self._testBuildDefaultModel()
-
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'mmd_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 6)
-
- def testBuildModelCorr(self):
- images, labels, params = self._testBuildDefaultModel()
-
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'correlation_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 6)
-
- def testBuildModelNoDomainAdaptation(self):
- images, labels, params = self._testBuildDefaultModel()
- params['use_separation'] = False
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels, 'none',
- params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 1)
- self.assertEqual(len(tf.contrib.losses.get_regularization_losses()), 0)
-
- def testBuildModelNoAdaptationWeightDecay(self):
- images, labels, params = self._testBuildDefaultModel()
- params['use_separation'] = False
- params['weight_decay'] = 1e-5
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels, 'none',
- params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 1)
- self.assertTrue(len(tf.contrib.losses.get_regularization_losses()) >= 1)
-
- def testBuildModelNoSeparation(self):
- images, labels, params = self._testBuildDefaultModel()
- params['use_separation'] = False
- with self.test_session():
- dsn.create_model(images, labels,
- tf.cast(tf.ones([32,]), tf.bool), images, labels,
- 'dann_loss', params, 'dann_mnist')
- loss_tensors = tf.contrib.losses.get_losses()
- self.assertEqual(len(loss_tensors), 2)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/domain_adaptation/domain_separation/dsn_train.py b/research/domain_adaptation/domain_separation/dsn_train.py
deleted file mode 100644
index 5e364ad3037b041125a3523370b3b040478f0d8e..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/dsn_train.py
+++ /dev/null
@@ -1,278 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Training for Domain Separation Networks (DSNs)."""
-from __future__ import division
-
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-import dsn
-
-slim = tf.contrib.slim
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_integer('batch_size', 32,
- 'The number of images in each batch.')
-
-tf.app.flags.DEFINE_string('source_dataset', 'pose_synthetic',
- 'Source dataset to train on.')
-
-tf.app.flags.DEFINE_string('target_dataset', 'pose_real',
- 'Target dataset to train on.')
-
-tf.app.flags.DEFINE_string('target_labeled_dataset', 'none',
- 'Target dataset to train on.')
-
-tf.app.flags.DEFINE_string('dataset_dir', None,
- 'The directory where the dataset files are stored.')
-
-tf.app.flags.DEFINE_string('master', '',
- 'BNS name of the TensorFlow master to use.')
-
-tf.app.flags.DEFINE_string('train_log_dir', '/tmp/da/',
- 'Directory where to write event logs.')
-
-tf.app.flags.DEFINE_string(
- 'layers_to_regularize', 'fc3',
- 'Comma-separated list of layer names to use MMD regularization on.')
-
-tf.app.flags.DEFINE_float('learning_rate', .01, 'The learning rate')
-
-tf.app.flags.DEFINE_float('alpha_weight', 1e-6,
- 'The coefficient for scaling the reconstruction '
- 'loss.')
-
-tf.app.flags.DEFINE_float(
- 'beta_weight', 1e-6,
- 'The coefficient for scaling the private/shared difference loss.')
-
-tf.app.flags.DEFINE_float(
- 'gamma_weight', 1e-6,
- 'The coefficient for scaling the shared encoding similarity loss.')
-
-tf.app.flags.DEFINE_float('pose_weight', 0.125,
- 'The coefficient for scaling the pose loss.')
-
-tf.app.flags.DEFINE_float(
- 'weight_decay', 1e-6,
- 'The coefficient for the L2 regularization applied for all weights.')
-
-tf.app.flags.DEFINE_integer(
- 'save_summaries_secs', 60,
- 'The frequency with which summaries are saved, in seconds.')
-
-tf.app.flags.DEFINE_integer(
- 'save_interval_secs', 60,
- 'The frequency with which the model is saved, in seconds.')
-
-tf.app.flags.DEFINE_integer(
- 'max_number_of_steps', None,
- 'The maximum number of gradient steps. Use None to train indefinitely.')
-
-tf.app.flags.DEFINE_integer(
- 'domain_separation_startpoint', 1,
- 'The global step to add the domain separation losses.')
-
-tf.app.flags.DEFINE_integer(
- 'bipartite_assignment_top_k', 3,
- 'The number of top-k matches to use in bipartite matching adaptation.')
-
-tf.app.flags.DEFINE_float('decay_rate', 0.95, 'Learning rate decay factor.')
-
-tf.app.flags.DEFINE_integer('decay_steps', 20000, 'Learning rate decay steps.')
-
-tf.app.flags.DEFINE_float('momentum', 0.9, 'The momentum value.')
-
-tf.app.flags.DEFINE_bool('use_separation', False,
- 'Use our domain separation model.')
-
-tf.app.flags.DEFINE_bool('use_logging', False, 'Debugging messages.')
-
-tf.app.flags.DEFINE_integer(
- 'ps_tasks', 0,
- 'The number of parameter servers. If the value is 0, then the parameters '
- 'are handled locally by the worker.')
-
-tf.app.flags.DEFINE_integer(
- 'num_readers', 4,
- 'The number of parallel readers that read data from the dataset.')
-
-tf.app.flags.DEFINE_integer('num_preprocessing_threads', 4,
- 'The number of threads used to create the batches.')
-
-tf.app.flags.DEFINE_integer(
- 'task', 0,
- 'The Task ID. This value is used when training with multiple workers to '
- 'identify each worker.')
-
-tf.app.flags.DEFINE_string('decoder_name', 'small_decoder',
- 'The decoder to use.')
-tf.app.flags.DEFINE_string('encoder_name', 'default_encoder',
- 'The encoder to use.')
-
-################################################################################
-# Flags that control the architecture and losses
-################################################################################
-tf.app.flags.DEFINE_string(
- 'similarity_loss', 'grl',
- 'The method to use for encouraging the common encoder codes to be '
- 'similar, one of "grl", "mmd", "corr".')
-
-tf.app.flags.DEFINE_string('recon_loss_name', 'sum_of_pairwise_squares',
- 'The name of the reconstruction loss.')
-
-tf.app.flags.DEFINE_string('basic_tower', 'pose_mini',
- 'The basic tower building block.')
-
-def provide_batch_fn():
- """ The provide_batch function to use. """
- return dataset_factory.provide_batch
-
-def main(_):
- model_params = {
- 'use_separation': FLAGS.use_separation,
- 'domain_separation_startpoint': FLAGS.domain_separation_startpoint,
- 'layers_to_regularize': FLAGS.layers_to_regularize,
- 'alpha_weight': FLAGS.alpha_weight,
- 'beta_weight': FLAGS.beta_weight,
- 'gamma_weight': FLAGS.gamma_weight,
- 'pose_weight': FLAGS.pose_weight,
- 'recon_loss_name': FLAGS.recon_loss_name,
- 'decoder_name': FLAGS.decoder_name,
- 'encoder_name': FLAGS.encoder_name,
- 'weight_decay': FLAGS.weight_decay,
- 'batch_size': FLAGS.batch_size,
- 'use_logging': FLAGS.use_logging,
- 'ps_tasks': FLAGS.ps_tasks,
- 'task': FLAGS.task,
- }
- g = tf.Graph()
- with g.as_default():
- with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
- # Load the data.
- source_images, source_labels = provide_batch_fn()(
- FLAGS.source_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers,
- FLAGS.batch_size, FLAGS.num_preprocessing_threads)
- target_images, target_labels = provide_batch_fn()(
- FLAGS.target_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers,
- FLAGS.batch_size, FLAGS.num_preprocessing_threads)
-
- # In the unsupervised case all the samples in the labeled
- # domain are from the source domain.
- domain_selection_mask = tf.fill((source_images.get_shape().as_list()[0],),
- True)
-
- # When using the semisupervised model we include labeled target data in
- # the source labelled data.
- if FLAGS.target_labeled_dataset != 'none':
- # 1000 is the maximum number of labelled target samples that exists in
- # the datasets.
- target_semi_images, target_semi_labels = provide_batch_fn()(
- FLAGS.target_labeled_dataset, 'train', FLAGS.batch_size)
-
- # Calculate the proportion of source domain samples in the semi-
- # supervised setting, so that the proportion is set accordingly in the
- # batches.
- proportion = float(source_labels['num_train_samples']) / (
- source_labels['num_train_samples'] +
- target_semi_labels['num_train_samples'])
-
- rnd_tensor = tf.random_uniform(
- (target_semi_images.get_shape().as_list()[0],))
-
- domain_selection_mask = rnd_tensor < proportion
- source_images = tf.where(domain_selection_mask, source_images,
- target_semi_images)
- source_class_labels = tf.where(domain_selection_mask,
- source_labels['classes'],
- target_semi_labels['classes'])
-
- if 'quaternions' in source_labels:
- source_pose_labels = tf.where(domain_selection_mask,
- source_labels['quaternions'],
- target_semi_labels['quaternions'])
- (source_images, source_class_labels, source_pose_labels,
- domain_selection_mask) = tf.train.shuffle_batch(
- [
- source_images, source_class_labels, source_pose_labels,
- domain_selection_mask
- ],
- FLAGS.batch_size,
- 50000,
- 5000,
- num_threads=1,
- enqueue_many=True)
-
- else:
- (source_images, source_class_labels,
- domain_selection_mask) = tf.train.shuffle_batch(
- [source_images, source_class_labels, domain_selection_mask],
- FLAGS.batch_size,
- 50000,
- 5000,
- num_threads=1,
- enqueue_many=True)
- source_labels = {}
- source_labels['classes'] = source_class_labels
- if 'quaternions' in source_labels:
- source_labels['quaternions'] = source_pose_labels
-
- slim.get_or_create_global_step()
- tf.summary.image('source_images', source_images, max_outputs=3)
- tf.summary.image('target_images', target_images, max_outputs=3)
-
- dsn.create_model(
- source_images,
- source_labels,
- domain_selection_mask,
- target_images,
- target_labels,
- FLAGS.similarity_loss,
- model_params,
- basic_tower_name=FLAGS.basic_tower)
-
- # Configure the optimization scheme:
- learning_rate = tf.train.exponential_decay(
- FLAGS.learning_rate,
- slim.get_or_create_global_step(),
- FLAGS.decay_steps,
- FLAGS.decay_rate,
- staircase=True,
- name='learning_rate')
-
- tf.summary.scalar('learning_rate', learning_rate)
- tf.summary.scalar('total_loss', tf.losses.get_total_loss())
-
- opt = tf.train.MomentumOptimizer(learning_rate, FLAGS.momentum)
- tf.logging.set_verbosity(tf.logging.INFO)
- # Run training.
- loss_tensor = slim.learning.create_train_op(
- slim.losses.get_total_loss(),
- opt,
- summarize_gradients=True,
- colocate_gradients_with_ops=True)
- slim.learning.train(
- train_op=loss_tensor,
- logdir=FLAGS.train_log_dir,
- master=FLAGS.master,
- is_chief=FLAGS.task == 0,
- number_of_steps=FLAGS.max_number_of_steps,
- save_summaries_secs=FLAGS.save_summaries_secs,
- save_interval_secs=FLAGS.save_interval_secs)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/domain_separation/grl_op_grads.py b/research/domain_adaptation/domain_separation/grl_op_grads.py
deleted file mode 100644
index fcd85ba2b5e7912bffe646a73558af8184812ea6..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_op_grads.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Gradients for operators defined in grl_ops.py."""
-import tensorflow as tf
-
-
-@tf.RegisterGradient("GradientReversal")
-def _GradientReversalGrad(_, grad):
- """The gradients for `gradient_reversal`.
-
- Args:
- _: The `gradient_reversal` `Operation` that we are differentiating,
- which we can use to find the inputs and outputs of the original op.
- grad: Gradient with respect to the output of the `gradient_reversal` op.
-
- Returns:
- Gradient with respect to the input of `gradient_reversal`, which is simply
- the negative of the input gradient.
-
- """
- return tf.negative(grad)
diff --git a/research/domain_adaptation/domain_separation/grl_op_kernels.cc b/research/domain_adaptation/domain_separation/grl_op_kernels.cc
deleted file mode 100644
index ba30128f11e9e88c702d3a80593d930519f346fe..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_op_kernels.cc
+++ /dev/null
@@ -1,47 +0,0 @@
-/* Copyright 2016 The TensorFlow Authors All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-// This file contains the implementations of the ops registered in
-// grl_ops.cc.
-
-#include "tensorflow/core/framework/op_kernel.h"
-#include "tensorflow/core/framework/types.pb.h"
-
-namespace tensorflow {
-
-// The gradient reversal op is used in domain adversarial training. It behaves
-// as the identity op during forward propagation, and multiplies its input by -1
-// during backward propagation.
-class GradientReversalOp : public OpKernel {
- public:
- explicit GradientReversalOp(OpKernelConstruction* context)
- : OpKernel(context) {}
-
- // Gradient reversal op behaves as the identity op during forward
- // propagation. Compute() function copied from the IdentityOp::Compute()
- // function here: third_party/tensorflow/core/kernels/identity_op.h.
- void Compute(OpKernelContext* context) override {
- if (IsRefType(context->input_dtype(0))) {
- context->forward_ref_input_to_ref_output(0, 0);
- } else {
- context->set_output(0, context->input(0));
- }
- }
-};
-
-REGISTER_KERNEL_BUILDER(Name("GradientReversal").Device(DEVICE_CPU),
- GradientReversalOp);
-
-} // namespace tensorflow
diff --git a/research/domain_adaptation/domain_separation/grl_op_shapes.py b/research/domain_adaptation/domain_separation/grl_op_shapes.py
deleted file mode 100644
index 52773c680af265beca9125e48bf68152b8a34e56..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_op_shapes.py
+++ /dev/null
@@ -1,16 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Shape inference for operators defined in grl_ops.cc."""
diff --git a/research/domain_adaptation/domain_separation/grl_ops.cc b/research/domain_adaptation/domain_separation/grl_ops.cc
deleted file mode 100644
index d441c2b484215605db65a043be6cfa0ab90da2c3..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_ops.cc
+++ /dev/null
@@ -1,36 +0,0 @@
-/* Copyright 2016 The TensorFlow Authors All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-// Contains custom ops.
-
-#include "tensorflow/core/framework/common_shape_fns.h"
-#include "tensorflow/core/framework/op.h"
-
-namespace tensorflow {
-
-// This custom op is used by adversarial training.
-REGISTER_OP("GradientReversal")
- .Input("input: float")
- .Output("output: float")
- .SetShapeFn(shape_inference::UnchangedShape)
- .Doc(R"doc(
-This op copies the input to the output during forward propagation, and
-negates the input during backward propagation.
-
-input: Tensor.
-output: Tensor, copied from input.
-)doc");
-
-} // namespace tensorflow
diff --git a/research/domain_adaptation/domain_separation/grl_ops.py b/research/domain_adaptation/domain_separation/grl_ops.py
deleted file mode 100644
index 50447247b10caf3e41f3c0fb1c6f943dd3d9de6e..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_ops.py
+++ /dev/null
@@ -1,28 +0,0 @@
-# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""GradientReversal op Python library."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os.path
-
-import tensorflow as tf
-
-tf.logging.info(tf.resource_loader.get_data_files_path())
-_grl_ops_module = tf.load_op_library(
- os.path.join(tf.resource_loader.get_data_files_path(),
- '_grl_ops.so'))
-gradient_reversal = _grl_ops_module.gradient_reversal
diff --git a/research/domain_adaptation/domain_separation/grl_ops_test.py b/research/domain_adaptation/domain_separation/grl_ops_test.py
deleted file mode 100644
index b431a6c02b60ade92a653d2ee8108c0586c70fbb..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/grl_ops_test.py
+++ /dev/null
@@ -1,73 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for grl_ops."""
-
-#from models.domain_adaptation.domain_separation import grl_op_grads # pylint: disable=unused-import
-#from models.domain_adaptation.domain_separation import grl_op_shapes # pylint: disable=unused-import
-import tensorflow as tf
-
-import grl_op_grads
-import grl_ops
-
-FLAGS = tf.app.flags.FLAGS
-
-
-class GRLOpsTest(tf.test.TestCase):
-
- def testGradientReversalOp(self):
- with tf.Graph().as_default():
- with self.test_session():
- # Test that in forward prop, gradient reversal op acts as the
- # identity operation.
- examples = tf.constant([5.0, 4.0, 3.0, 2.0, 1.0])
- output = grl_ops.gradient_reversal(examples)
- expected_output = examples
- self.assertAllEqual(output.eval(), expected_output.eval())
-
- # Test that shape inference works as expected.
- self.assertAllEqual(output.get_shape(), expected_output.get_shape())
-
- # Test that in backward prop, gradient reversal op multiplies
- # gradients by -1.
- examples = tf.constant([[1.0]])
- w = tf.get_variable(name='w', shape=[1, 1])
- b = tf.get_variable(name='b', shape=[1])
- init_op = tf.global_variables_initializer()
- init_op.run()
- features = tf.nn.xw_plus_b(examples, w, b)
- # Construct two outputs: features layer passes directly to output1, but
- # features layer passes through a gradient reversal layer before
- # reaching output2.
- output1 = features
- output2 = grl_ops.gradient_reversal(features)
- gold = tf.constant([1.0])
- loss1 = gold - output1
- loss2 = gold - output2
- opt = tf.train.GradientDescentOptimizer(learning_rate=0.01)
- grads_and_vars_1 = opt.compute_gradients(loss1,
- tf.trainable_variables())
- grads_and_vars_2 = opt.compute_gradients(loss2,
- tf.trainable_variables())
- self.assertAllEqual(len(grads_and_vars_1), len(grads_and_vars_2))
- for i in range(len(grads_and_vars_1)):
- g1 = grads_and_vars_1[i][0]
- g2 = grads_and_vars_2[i][0]
- # Verify that gradients of loss1 are the negative of gradients of
- # loss2.
- self.assertAllEqual(tf.negative(g1).eval(), g2.eval())
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/domain_adaptation/domain_separation/losses.py b/research/domain_adaptation/domain_separation/losses.py
deleted file mode 100644
index 0d882340de10e4dd64d44f9357e8bfc5b1dd4712..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/losses.py
+++ /dev/null
@@ -1,290 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Domain Adaptation Loss Functions.
-
-The following domain adaptation loss functions are defined:
-
-- Maximum Mean Discrepancy (MMD).
- Relevant paper:
- Gretton, Arthur, et al.,
- "A kernel two-sample test."
- The Journal of Machine Learning Research, 2012
-
-- Correlation Loss on a batch.
-"""
-from functools import partial
-import tensorflow as tf
-
-import grl_op_grads # pylint: disable=unused-import
-import grl_op_shapes # pylint: disable=unused-import
-import grl_ops
-import utils
-slim = tf.contrib.slim
-
-
-################################################################################
-# SIMILARITY LOSS
-################################################################################
-def maximum_mean_discrepancy(x, y, kernel=utils.gaussian_kernel_matrix):
- r"""Computes the Maximum Mean Discrepancy (MMD) of two samples: x and y.
-
- Maximum Mean Discrepancy (MMD) is a distance-measure between the samples of
- the distributions of x and y. Here we use the kernel two sample estimate
- using the empirical mean of the two distributions.
-
- MMD^2(P, Q) = || \E{\phi(x)} - \E{\phi(y)} ||^2
- = \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) },
-
- where K = <\phi(x), \phi(y)>,
- is the desired kernel function, in this case a radial basis kernel.
-
- Args:
- x: a tensor of shape [num_samples, num_features]
- y: a tensor of shape [num_samples, num_features]
- kernel: a function which computes the kernel in MMD. Defaults to the
- GaussianKernelMatrix.
-
- Returns:
- a scalar denoting the squared maximum mean discrepancy loss.
- """
- with tf.name_scope('MaximumMeanDiscrepancy'):
- # \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) }
- cost = tf.reduce_mean(kernel(x, x))
- cost += tf.reduce_mean(kernel(y, y))
- cost -= 2 * tf.reduce_mean(kernel(x, y))
-
- # We do not allow the loss to become negative.
- cost = tf.where(cost > 0, cost, 0, name='value')
- return cost
-
-
-def mmd_loss(source_samples, target_samples, weight, scope=None):
- """Adds a similarity loss term, the MMD between two representations.
-
- This Maximum Mean Discrepancy (MMD) loss is calculated with a number of
- different Gaussian kernels.
-
- Args:
- source_samples: a tensor of shape [num_samples, num_features].
- target_samples: a tensor of shape [num_samples, num_features].
- weight: the weight of the MMD loss.
- scope: optional name scope for summary tags.
-
- Returns:
- a scalar tensor representing the MMD loss value.
- """
- sigmas = [
- 1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 5, 10, 15, 20, 25, 30, 35, 100,
- 1e3, 1e4, 1e5, 1e6
- ]
- gaussian_kernel = partial(
- utils.gaussian_kernel_matrix, sigmas=tf.constant(sigmas))
-
- loss_value = maximum_mean_discrepancy(
- source_samples, target_samples, kernel=gaussian_kernel)
- loss_value = tf.maximum(1e-4, loss_value) * weight
- assert_op = tf.Assert(tf.is_finite(loss_value), [loss_value])
- with tf.control_dependencies([assert_op]):
- tag = 'MMD Loss'
- if scope:
- tag = scope + tag
- tf.summary.scalar(tag, loss_value)
- tf.losses.add_loss(loss_value)
-
- return loss_value
-
-
-def correlation_loss(source_samples, target_samples, weight, scope=None):
- """Adds a similarity loss term, the correlation between two representations.
-
- Args:
- source_samples: a tensor of shape [num_samples, num_features]
- target_samples: a tensor of shape [num_samples, num_features]
- weight: a scalar weight for the loss.
- scope: optional name scope for summary tags.
-
- Returns:
- a scalar tensor representing the correlation loss value.
- """
- with tf.name_scope('corr_loss'):
- source_samples -= tf.reduce_mean(source_samples, 0)
- target_samples -= tf.reduce_mean(target_samples, 0)
-
- source_samples = tf.nn.l2_normalize(source_samples, 1)
- target_samples = tf.nn.l2_normalize(target_samples, 1)
-
- source_cov = tf.matmul(tf.transpose(source_samples), source_samples)
- target_cov = tf.matmul(tf.transpose(target_samples), target_samples)
-
- corr_loss = tf.reduce_mean(tf.square(source_cov - target_cov)) * weight
-
- assert_op = tf.Assert(tf.is_finite(corr_loss), [corr_loss])
- with tf.control_dependencies([assert_op]):
- tag = 'Correlation Loss'
- if scope:
- tag = scope + tag
- tf.summary.scalar(tag, corr_loss)
- tf.losses.add_loss(corr_loss)
-
- return corr_loss
-
-
-def dann_loss(source_samples, target_samples, weight, scope=None):
- """Adds the domain adversarial (DANN) loss.
-
- Args:
- source_samples: a tensor of shape [num_samples, num_features].
- target_samples: a tensor of shape [num_samples, num_features].
- weight: the weight of the loss.
- scope: optional name scope for summary tags.
-
- Returns:
- a scalar tensor representing the correlation loss value.
- """
- with tf.variable_scope('dann'):
- batch_size = tf.shape(source_samples)[0]
- samples = tf.concat(axis=0, values=[source_samples, target_samples])
- samples = slim.flatten(samples)
-
- domain_selection_mask = tf.concat(
- axis=0, values=[tf.zeros((batch_size, 1)), tf.ones((batch_size, 1))])
-
- # Perform the gradient reversal and be careful with the shape.
- grl = grl_ops.gradient_reversal(samples)
- grl = tf.reshape(grl, (-1, samples.get_shape().as_list()[1]))
-
- grl = slim.fully_connected(grl, 100, scope='fc1')
- logits = slim.fully_connected(grl, 1, activation_fn=None, scope='fc2')
-
- domain_predictions = tf.sigmoid(logits)
-
- domain_loss = tf.losses.log_loss(
- domain_selection_mask, domain_predictions, weights=weight)
-
- domain_accuracy = utils.accuracy(
- tf.round(domain_predictions), domain_selection_mask)
-
- assert_op = tf.Assert(tf.is_finite(domain_loss), [domain_loss])
- with tf.control_dependencies([assert_op]):
- tag_loss = 'losses/domain_loss'
- tag_accuracy = 'losses/domain_accuracy'
- if scope:
- tag_loss = scope + tag_loss
- tag_accuracy = scope + tag_accuracy
-
- tf.summary.scalar(tag_loss, domain_loss)
- tf.summary.scalar(tag_accuracy, domain_accuracy)
-
- return domain_loss
-
-
-################################################################################
-# DIFFERENCE LOSS
-################################################################################
-def difference_loss(private_samples, shared_samples, weight=1.0, name=''):
- """Adds the difference loss between the private and shared representations.
-
- Args:
- private_samples: a tensor of shape [num_samples, num_features].
- shared_samples: a tensor of shape [num_samples, num_features].
- weight: the weight of the incoherence loss.
- name: the name of the tf summary.
- """
- private_samples -= tf.reduce_mean(private_samples, 0)
- shared_samples -= tf.reduce_mean(shared_samples, 0)
-
- private_samples = tf.nn.l2_normalize(private_samples, 1)
- shared_samples = tf.nn.l2_normalize(shared_samples, 1)
-
- correlation_matrix = tf.matmul(
- private_samples, shared_samples, transpose_a=True)
-
- cost = tf.reduce_mean(tf.square(correlation_matrix)) * weight
- cost = tf.where(cost > 0, cost, 0, name='value')
-
- tf.summary.scalar('losses/Difference Loss {}'.format(name),
- cost)
- assert_op = tf.Assert(tf.is_finite(cost), [cost])
- with tf.control_dependencies([assert_op]):
- tf.losses.add_loss(cost)
-
-
-################################################################################
-# TASK LOSS
-################################################################################
-def log_quaternion_loss_batch(predictions, labels, params):
- """A helper function to compute the error between quaternions.
-
- Args:
- predictions: A Tensor of size [batch_size, 4].
- labels: A Tensor of size [batch_size, 4].
- params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'.
-
- Returns:
- A Tensor of size [batch_size], denoting the error between the quaternions.
- """
- use_logging = params['use_logging']
- assertions = []
- if use_logging:
- assertions.append(
- tf.Assert(
- tf.reduce_all(
- tf.less(
- tf.abs(tf.reduce_sum(tf.square(predictions), [1]) - 1),
- 1e-4)),
- ['The l2 norm of each prediction quaternion vector should be 1.']))
- assertions.append(
- tf.Assert(
- tf.reduce_all(
- tf.less(
- tf.abs(tf.reduce_sum(tf.square(labels), [1]) - 1), 1e-4)),
- ['The l2 norm of each label quaternion vector should be 1.']))
-
- with tf.control_dependencies(assertions):
- product = tf.multiply(predictions, labels)
- internal_dot_products = tf.reduce_sum(product, [1])
-
- if use_logging:
- internal_dot_products = tf.Print(
- internal_dot_products,
- [internal_dot_products, tf.shape(internal_dot_products)],
- 'internal_dot_products:')
-
- logcost = tf.log(1e-4 + 1 - tf.abs(internal_dot_products))
- return logcost
-
-
-def log_quaternion_loss(predictions, labels, params):
- """A helper function to compute the mean error between batches of quaternions.
-
- The caller is expected to add the loss to the graph.
-
- Args:
- predictions: A Tensor of size [batch_size, 4].
- labels: A Tensor of size [batch_size, 4].
- params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'.
-
- Returns:
- A Tensor of size 1, denoting the mean error between batches of quaternions.
- """
- use_logging = params['use_logging']
- logcost = log_quaternion_loss_batch(predictions, labels, params)
- logcost = tf.reduce_sum(logcost, [0])
- batch_size = params['batch_size']
- logcost = tf.multiply(logcost, 1.0 / batch_size, name='log_quaternion_loss')
- if use_logging:
- logcost = tf.Print(
- logcost, [logcost], '[logcost]', name='log_quaternion_loss_print')
- return logcost
diff --git a/research/domain_adaptation/domain_separation/losses_test.py b/research/domain_adaptation/domain_separation/losses_test.py
deleted file mode 100644
index 46e50301be56f5977adcb3fb00587f076934b785..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/losses_test.py
+++ /dev/null
@@ -1,110 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DSN losses."""
-from functools import partial
-
-import numpy as np
-import tensorflow as tf
-
-import losses
-import utils
-
-
-def MaximumMeanDiscrepancySlow(x, y, sigmas):
- num_samples = x.get_shape().as_list()[0]
-
- def AverageGaussianKernel(x, y, sigmas):
- result = 0
- for sigma in sigmas:
- dist = tf.reduce_sum(tf.square(x - y))
- result += tf.exp((-1.0 / (2.0 * sigma)) * dist)
- return result / num_samples**2
-
- total = 0
-
- for i in range(num_samples):
- for j in range(num_samples):
- total += AverageGaussianKernel(x[i, :], x[j, :], sigmas)
- total += AverageGaussianKernel(y[i, :], y[j, :], sigmas)
- total += -2 * AverageGaussianKernel(x[i, :], y[j, :], sigmas)
-
- return total
-
-
-class LogQuaternionLossTest(tf.test.TestCase):
-
- def test_log_quaternion_loss_batch(self):
- with self.test_session():
- predictions = tf.random_uniform((10, 4), seed=1)
- predictions = tf.nn.l2_normalize(predictions, 1)
- labels = tf.random_uniform((10, 4), seed=1)
- labels = tf.nn.l2_normalize(labels, 1)
- params = {'batch_size': 10, 'use_logging': False}
- x = losses.log_quaternion_loss_batch(predictions, labels, params)
- self.assertTrue(((10,) == tf.shape(x).eval()).all())
-
-
-class MaximumMeanDiscrepancyTest(tf.test.TestCase):
-
- def test_mmd_name(self):
- with self.test_session():
- x = tf.random_uniform((2, 3), seed=1)
- kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.]))
- loss = losses.maximum_mean_discrepancy(x, x, kernel)
-
- self.assertEquals(loss.op.name, 'MaximumMeanDiscrepancy/value')
-
- def test_mmd_is_zero_when_inputs_are_same(self):
- with self.test_session():
- x = tf.random_uniform((2, 3), seed=1)
- kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.]))
- self.assertEquals(0, losses.maximum_mean_discrepancy(x, x, kernel).eval())
-
- def test_fast_mmd_is_similar_to_slow_mmd(self):
- with self.test_session():
- x = tf.constant(np.random.normal(size=(2, 3)), tf.float32)
- y = tf.constant(np.random.rand(2, 3), tf.float32)
-
- cost_old = MaximumMeanDiscrepancySlow(x, y, [1.]).eval()
- kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.]))
- cost_new = losses.maximum_mean_discrepancy(x, y, kernel).eval()
-
- self.assertAlmostEqual(cost_old, cost_new, delta=1e-5)
-
- def test_multiple_sigmas(self):
- with self.test_session():
- x = tf.constant(np.random.normal(size=(2, 3)), tf.float32)
- y = tf.constant(np.random.rand(2, 3), tf.float32)
-
- sigmas = tf.constant([2., 5., 10, 20, 30])
- kernel = partial(utils.gaussian_kernel_matrix, sigmas=sigmas)
- cost_old = MaximumMeanDiscrepancySlow(x, y, [2., 5., 10, 20, 30]).eval()
- cost_new = losses.maximum_mean_discrepancy(x, y, kernel=kernel).eval()
-
- self.assertAlmostEqual(cost_old, cost_new, delta=1e-5)
-
- def test_mmd_is_zero_when_distributions_are_same(self):
-
- with self.test_session():
- x = tf.random_uniform((1000, 10), seed=1)
- y = tf.random_uniform((1000, 10), seed=3)
-
- kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([100.]))
- loss = losses.maximum_mean_discrepancy(x, y, kernel=kernel).eval()
-
- self.assertAlmostEqual(0, loss, delta=1e-4)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/domain_adaptation/domain_separation/models.py b/research/domain_adaptation/domain_separation/models.py
deleted file mode 100644
index 04ccaf82eb9b31a6ea78871204c7df70eca3fbfd..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/models.py
+++ /dev/null
@@ -1,443 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains different architectures for the different DSN parts.
-
-We define here the modules that can be used in the different parts of the DSN
-model.
-- shared encoder (dsn_cropped_linemod, dann_xxxx)
-- private encoder (default_encoder)
-- decoder (large_decoder, gtsrb_decoder, small_decoder)
-"""
-import tensorflow as tf
-
-#from models.domain_adaptation.domain_separation
-import utils
-
-slim = tf.contrib.slim
-
-
-def default_batch_norm_params(is_training=False):
- """Returns default batch normalization parameters for DSNs.
-
- Args:
- is_training: whether or not the model is training.
-
- Returns:
- a dictionary that maps batch norm parameter names (strings) to values.
- """
- return {
- # Decay for the moving averages.
- 'decay': 0.5,
- # epsilon to prevent 0s in variance.
- 'epsilon': 0.001,
- 'is_training': is_training
- }
-
-
-################################################################################
-# PRIVATE ENCODERS
-################################################################################
-def default_encoder(images, code_size, batch_norm_params=None,
- weight_decay=0.0):
- """Encodes the given images to codes of the given size.
-
- Args:
- images: a tensor of size [batch_size, height, width, 1].
- code_size: the number of hidden units in the code layer of the classifier.
- batch_norm_params: a dictionary that maps batch norm parameter names to
- values.
- weight_decay: the value for the weight decay coefficient.
-
- Returns:
- end_points: the code of the input.
- """
- end_points = {}
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_params):
- with slim.arg_scope([slim.conv2d], kernel_size=[5, 5], padding='SAME'):
- net = slim.conv2d(images, 32, scope='conv1')
- net = slim.max_pool2d(net, [2, 2], 2, scope='pool1')
- net = slim.conv2d(net, 64, scope='conv2')
- net = slim.max_pool2d(net, [2, 2], 2, scope='pool2')
-
- net = slim.flatten(net)
- end_points['flatten'] = net
- net = slim.fully_connected(net, code_size, scope='fc1')
- end_points['fc3'] = net
- return end_points
-
-
-################################################################################
-# DECODERS
-################################################################################
-def large_decoder(codes,
- height,
- width,
- channels,
- batch_norm_params=None,
- weight_decay=0.0):
- """Decodes the codes to a fixed output size.
-
- Args:
- codes: a tensor of size [batch_size, code_size].
- height: the height of the output images.
- width: the width of the output images.
- channels: the number of the output channels.
- batch_norm_params: a dictionary that maps batch norm parameter names to
- values.
- weight_decay: the value for the weight decay coefficient.
-
- Returns:
- recons: the reconstruction tensor of shape [batch_size, height, width, 3].
- """
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_params):
- net = slim.fully_connected(codes, 600, scope='fc1')
- batch_size = net.get_shape().as_list()[0]
- net = tf.reshape(net, [batch_size, 10, 10, 6])
-
- net = slim.conv2d(net, 32, [5, 5], scope='conv1_1')
-
- net = tf.image.resize_nearest_neighbor(net, (16, 16))
-
- net = slim.conv2d(net, 32, [5, 5], scope='conv2_1')
-
- net = tf.image.resize_nearest_neighbor(net, (32, 32))
-
- net = slim.conv2d(net, 32, [5, 5], scope='conv3_2')
-
- output_size = [height, width]
- net = tf.image.resize_nearest_neighbor(net, output_size)
-
- with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]):
- net = slim.conv2d(net, channels, activation_fn=None, scope='conv4_1')
-
- return net
-
-
-def gtsrb_decoder(codes,
- height,
- width,
- channels,
- batch_norm_params=None,
- weight_decay=0.0):
- """Decodes the codes to a fixed output size. This decoder is specific to GTSRB
-
- Args:
- codes: a tensor of size [batch_size, 100].
- height: the height of the output images.
- width: the width of the output images.
- channels: the number of the output channels.
- batch_norm_params: a dictionary that maps batch norm parameter names to
- values.
- weight_decay: the value for the weight decay coefficient.
-
- Returns:
- recons: the reconstruction tensor of shape [batch_size, height, width, 3].
-
- Raises:
- ValueError: When the input code size is not 100.
- """
- batch_size, code_size = codes.get_shape().as_list()
- if code_size != 100:
- raise ValueError('The code size used as an input to the GTSRB decoder is '
- 'expected to be 100.')
-
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_params):
- net = codes
- net = tf.reshape(net, [batch_size, 10, 10, 1])
- net = slim.conv2d(net, 32, [3, 3], scope='conv1_1')
-
- # First upsampling 20x20
- net = tf.image.resize_nearest_neighbor(net, [20, 20])
-
- net = slim.conv2d(net, 32, [3, 3], scope='conv2_1')
-
- output_size = [height, width]
- # Final upsampling 40 x 40
- net = tf.image.resize_nearest_neighbor(net, output_size)
-
- with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]):
- net = slim.conv2d(net, 16, scope='conv3_1')
- net = slim.conv2d(net, channels, activation_fn=None, scope='conv3_2')
-
- return net
-
-
-def small_decoder(codes,
- height,
- width,
- channels,
- batch_norm_params=None,
- weight_decay=0.0):
- """Decodes the codes to a fixed output size.
-
- Args:
- codes: a tensor of size [batch_size, code_size].
- height: the height of the output images.
- width: the width of the output images.
- channels: the number of the output channels.
- batch_norm_params: a dictionary that maps batch norm parameter names to
- values.
- weight_decay: the value for the weight decay coefficient.
-
- Returns:
- recons: the reconstruction tensor of shape [batch_size, height, width, 3].
- """
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_params):
- net = slim.fully_connected(codes, 300, scope='fc1')
- batch_size = net.get_shape().as_list()[0]
- net = tf.reshape(net, [batch_size, 10, 10, 3])
-
- net = slim.conv2d(net, 16, [3, 3], scope='conv1_1')
- net = slim.conv2d(net, 16, [3, 3], scope='conv1_2')
-
- output_size = [height, width]
- net = tf.image.resize_nearest_neighbor(net, output_size)
-
- with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]):
- net = slim.conv2d(net, 16, scope='conv2_1')
- net = slim.conv2d(net, channels, activation_fn=None, scope='conv2_2')
-
- return net
-
-
-################################################################################
-# SHARED ENCODERS
-################################################################################
-def dann_mnist(images,
- weight_decay=0.0,
- prefix='model',
- num_classes=10,
- **kwargs):
- """Creates a convolution MNIST model.
-
- Note that this model implements the architecture for MNIST proposed in:
- Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN),
- JMLR 2015
-
- Args:
- images: the MNIST digits, a tensor of size [batch_size, 28, 28, 1].
- weight_decay: the value for the weight decay coefficient.
- prefix: name of the model to use when prefixing tags.
- num_classes: the number of output classes to use.
- **kwargs: Placeholder for keyword arguments used by other shared encoders.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
- end_points = {}
-
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
- end_points['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1')
- end_points['pool1'] = slim.max_pool2d(
- end_points['conv1'], [2, 2], 2, scope='pool1')
- end_points['conv2'] = slim.conv2d(
- end_points['pool1'], 48, [5, 5], scope='conv2')
- end_points['pool2'] = slim.max_pool2d(
- end_points['conv2'], [2, 2], 2, scope='pool2')
- end_points['fc3'] = slim.fully_connected(
- slim.flatten(end_points['pool2']), 100, scope='fc3')
- end_points['fc4'] = slim.fully_connected(
- slim.flatten(end_points['fc3']), 100, scope='fc4')
-
- logits = slim.fully_connected(
- end_points['fc4'], num_classes, activation_fn=None, scope='fc5')
-
- return logits, end_points
-
-
-def dann_svhn(images,
- weight_decay=0.0,
- prefix='model',
- num_classes=10,
- **kwargs):
- """Creates the convolutional SVHN model.
-
- Note that this model implements the architecture for MNIST proposed in:
- Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN),
- JMLR 2015
-
- Args:
- images: the SVHN digits, a tensor of size [batch_size, 32, 32, 3].
- weight_decay: the value for the weight decay coefficient.
- prefix: name of the model to use when prefixing tags.
- num_classes: the number of output classes to use.
- **kwargs: Placeholder for keyword arguments used by other shared encoders.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- end_points = {}
-
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
-
- end_points['conv1'] = slim.conv2d(images, 64, [5, 5], scope='conv1')
- end_points['pool1'] = slim.max_pool2d(
- end_points['conv1'], [3, 3], 2, scope='pool1')
- end_points['conv2'] = slim.conv2d(
- end_points['pool1'], 64, [5, 5], scope='conv2')
- end_points['pool2'] = slim.max_pool2d(
- end_points['conv2'], [3, 3], 2, scope='pool2')
- end_points['conv3'] = slim.conv2d(
- end_points['pool2'], 128, [5, 5], scope='conv3')
-
- end_points['fc3'] = slim.fully_connected(
- slim.flatten(end_points['conv3']), 3072, scope='fc3')
- end_points['fc4'] = slim.fully_connected(
- slim.flatten(end_points['fc3']), 2048, scope='fc4')
-
- logits = slim.fully_connected(
- end_points['fc4'], num_classes, activation_fn=None, scope='fc5')
-
- return logits, end_points
-
-
-def dann_gtsrb(images,
- weight_decay=0.0,
- prefix='model',
- num_classes=43,
- **kwargs):
- """Creates the convolutional GTSRB model.
-
- Note that this model implements the architecture for MNIST proposed in:
- Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN),
- JMLR 2015
-
- Args:
- images: the GTSRB images, a tensor of size [batch_size, 40, 40, 3].
- weight_decay: the value for the weight decay coefficient.
- prefix: name of the model to use when prefixing tags.
- num_classes: the number of output classes to use.
- **kwargs: Placeholder for keyword arguments used by other shared encoders.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- end_points = {}
-
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
-
- end_points['conv1'] = slim.conv2d(images, 96, [5, 5], scope='conv1')
- end_points['pool1'] = slim.max_pool2d(
- end_points['conv1'], [2, 2], 2, scope='pool1')
- end_points['conv2'] = slim.conv2d(
- end_points['pool1'], 144, [3, 3], scope='conv2')
- end_points['pool2'] = slim.max_pool2d(
- end_points['conv2'], [2, 2], 2, scope='pool2')
- end_points['conv3'] = slim.conv2d(
- end_points['pool2'], 256, [5, 5], scope='conv3')
- end_points['pool3'] = slim.max_pool2d(
- end_points['conv3'], [2, 2], 2, scope='pool3')
-
- end_points['fc3'] = slim.fully_connected(
- slim.flatten(end_points['pool3']), 512, scope='fc3')
-
- logits = slim.fully_connected(
- end_points['fc3'], num_classes, activation_fn=None, scope='fc4')
-
- return logits, end_points
-
-
-def dsn_cropped_linemod(images,
- weight_decay=0.0,
- prefix='model',
- num_classes=11,
- batch_norm_params=None,
- is_training=False):
- """Creates the convolutional pose estimation model for Cropped Linemod.
-
- Args:
- images: the Cropped Linemod samples, a tensor of size
- [batch_size, 64, 64, 4].
- weight_decay: the value for the weight decay coefficient.
- prefix: name of the model to use when prefixing tags.
- num_classes: the number of output classes to use.
- batch_norm_params: a dictionary that maps batch norm parameter names to
- values.
- is_training: specifies whether or not we're currently training the model.
- This variable will determine the behaviour of the dropout layer.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- end_points = {}
-
- tf.summary.image('{}/input_images'.format(prefix), images)
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm if batch_norm_params else None,
- normalizer_params=batch_norm_params):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
- end_points['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1')
- end_points['pool1'] = slim.max_pool2d(
- end_points['conv1'], [2, 2], 2, scope='pool1')
- end_points['conv2'] = slim.conv2d(
- end_points['pool1'], 64, [5, 5], scope='conv2')
- end_points['pool2'] = slim.max_pool2d(
- end_points['conv2'], [2, 2], 2, scope='pool2')
- net = slim.flatten(end_points['pool2'])
- end_points['fc3'] = slim.fully_connected(net, 128, scope='fc3')
- net = slim.dropout(
- end_points['fc3'], 0.5, is_training=is_training, scope='dropout')
-
- with tf.variable_scope('quaternion_prediction'):
- predicted_quaternion = slim.fully_connected(
- net, 4, activation_fn=tf.nn.tanh)
- predicted_quaternion = tf.nn.l2_normalize(predicted_quaternion, 1)
- logits = slim.fully_connected(
- net, num_classes, activation_fn=None, scope='fc4')
- end_points['quaternion_pred'] = predicted_quaternion
-
- return logits, end_points
diff --git a/research/domain_adaptation/domain_separation/models_test.py b/research/domain_adaptation/domain_separation/models_test.py
deleted file mode 100644
index 69d1a27259022569cc5865e49dd6bba5675d834f..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/models_test.py
+++ /dev/null
@@ -1,167 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for DSN components."""
-
-import numpy as np
-import tensorflow as tf
-
-#from models.domain_adaptation.domain_separation
-import models
-
-
-class SharedEncodersTest(tf.test.TestCase):
-
- def _testSharedEncoder(self,
- input_shape=[5, 28, 28, 1],
- model=models.dann_mnist,
- is_training=True):
- images = tf.to_float(np.random.rand(*input_shape))
-
- with self.test_session() as sess:
- logits, _ = model(images)
- sess.run(tf.global_variables_initializer())
- logits_np = sess.run(logits)
- return logits_np
-
- def testBuildGRLMnistModel(self):
- logits = self._testSharedEncoder(model=getattr(models,
- 'dann_mnist'))
- self.assertEqual(logits.shape, (5, 10))
- self.assertTrue(np.any(logits))
-
- def testBuildGRLSvhnModel(self):
- logits = self._testSharedEncoder(model=getattr(models,
- 'dann_svhn'))
- self.assertEqual(logits.shape, (5, 10))
- self.assertTrue(np.any(logits))
-
- def testBuildGRLGtsrbModel(self):
- logits = self._testSharedEncoder([5, 40, 40, 3],
- getattr(models, 'dann_gtsrb'))
- self.assertEqual(logits.shape, (5, 43))
- self.assertTrue(np.any(logits))
-
- def testBuildPoseModel(self):
- logits = self._testSharedEncoder([5, 64, 64, 4],
- getattr(models, 'dsn_cropped_linemod'))
- self.assertEqual(logits.shape, (5, 11))
- self.assertTrue(np.any(logits))
-
- def testBuildPoseModelWithBatchNorm(self):
- images = tf.to_float(np.random.rand(10, 64, 64, 4))
-
- with self.test_session() as sess:
- logits, _ = getattr(models, 'dsn_cropped_linemod')(
- images, batch_norm_params=models.default_batch_norm_params(True))
- sess.run(tf.global_variables_initializer())
- logits_np = sess.run(logits)
- self.assertEqual(logits_np.shape, (10, 11))
- self.assertTrue(np.any(logits_np))
-
-
-class EncoderTest(tf.test.TestCase):
-
- def _testEncoder(self, batch_norm_params=None, channels=1):
- images = tf.to_float(np.random.rand(10, 28, 28, channels))
-
- with self.test_session() as sess:
- end_points = models.default_encoder(
- images, 128, batch_norm_params=batch_norm_params)
- sess.run(tf.global_variables_initializer())
- private_code = sess.run(end_points['fc3'])
- self.assertEqual(private_code.shape, (10, 128))
- self.assertTrue(np.any(private_code))
- self.assertTrue(np.all(np.isfinite(private_code)))
-
- def testEncoder(self):
- self._testEncoder()
-
- def testEncoderMultiChannel(self):
- self._testEncoder(None, 4)
-
- def testEncoderIsTrainingBatchNorm(self):
- self._testEncoder(models.default_batch_norm_params(True))
-
- def testEncoderBatchNorm(self):
- self._testEncoder(models.default_batch_norm_params(False))
-
-
-class DecoderTest(tf.test.TestCase):
-
- def _testDecoder(self,
- height=64,
- width=64,
- channels=4,
- batch_norm_params=None,
- decoder=models.small_decoder):
- codes = tf.to_float(np.random.rand(32, 100))
-
- with self.test_session() as sess:
- output = decoder(
- codes,
- height=height,
- width=width,
- channels=channels,
- batch_norm_params=batch_norm_params)
- sess.run(tf.global_variables_initializer())
- output_np = sess.run(output)
- self.assertEqual(output_np.shape, (32, height, width, channels))
- self.assertTrue(np.any(output_np))
- self.assertTrue(np.all(np.isfinite(output_np)))
-
- def testSmallDecoder(self):
- self._testDecoder(28, 28, 4, None, getattr(models, 'small_decoder'))
-
- def testSmallDecoderThreeChannels(self):
- self._testDecoder(28, 28, 3)
-
- def testSmallDecoderBatchNorm(self):
- self._testDecoder(28, 28, 4, models.default_batch_norm_params(False))
-
- def testSmallDecoderIsTrainingBatchNorm(self):
- self._testDecoder(28, 28, 4, models.default_batch_norm_params(True))
-
- def testLargeDecoder(self):
- self._testDecoder(32, 32, 4, None, getattr(models, 'large_decoder'))
-
- def testLargeDecoderThreeChannels(self):
- self._testDecoder(32, 32, 3, None, getattr(models, 'large_decoder'))
-
- def testLargeDecoderBatchNorm(self):
- self._testDecoder(32, 32, 4,
- models.default_batch_norm_params(False),
- getattr(models, 'large_decoder'))
-
- def testLargeDecoderIsTrainingBatchNorm(self):
- self._testDecoder(32, 32, 4,
- models.default_batch_norm_params(True),
- getattr(models, 'large_decoder'))
-
- def testGtsrbDecoder(self):
- self._testDecoder(40, 40, 3, None, getattr(models, 'large_decoder'))
-
- def testGtsrbDecoderBatchNorm(self):
- self._testDecoder(40, 40, 4,
- models.default_batch_norm_params(False),
- getattr(models, 'gtsrb_decoder'))
-
- def testGtsrbDecoderIsTrainingBatchNorm(self):
- self._testDecoder(40, 40, 4,
- models.default_batch_norm_params(True),
- getattr(models, 'gtsrb_decoder'))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/domain_adaptation/domain_separation/utils.py b/research/domain_adaptation/domain_separation/utils.py
deleted file mode 100644
index e144ee86120bd58eb06b710fb35f3f58b5a05343..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/domain_separation/utils.py
+++ /dev/null
@@ -1,183 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Auxiliary functions for domain adaptation related losses.
-"""
-import math
-import tensorflow as tf
-
-
-def create_summaries(end_points, prefix='', max_images=3, use_op_name=False):
- """Creates a tf summary per endpoint.
-
- If the endpoint is a 4 dimensional tensor it displays it as an image
- otherwise if it is a two dimensional one it creates a histogram summary.
-
- Args:
- end_points: a dictionary of name, tf tensor pairs.
- prefix: an optional string to prefix the summary with.
- max_images: the maximum number of images to display per summary.
- use_op_name: Use the op name as opposed to the shorter end_points key.
- """
- for layer_name in end_points:
- if use_op_name:
- name = end_points[layer_name].op.name
- else:
- name = layer_name
- if len(end_points[layer_name].get_shape().as_list()) == 4:
- # if it's an actual image do not attempt to reshape it
- if end_points[layer_name].get_shape().as_list()[-1] == 1 or end_points[
- layer_name].get_shape().as_list()[-1] == 3:
- visualization_image = end_points[layer_name]
- else:
- visualization_image = reshape_feature_maps(end_points[layer_name])
- tf.summary.image(
- '{}/{}'.format(prefix, name),
- visualization_image,
- max_outputs=max_images)
- elif len(end_points[layer_name].get_shape().as_list()) == 3:
- images = tf.expand_dims(end_points[layer_name], 3)
- tf.summary.image(
- '{}/{}'.format(prefix, name),
- images,
- max_outputs=max_images)
- elif len(end_points[layer_name].get_shape().as_list()) == 2:
- tf.summary.histogram('{}/{}'.format(prefix, name), end_points[layer_name])
-
-
-def reshape_feature_maps(features_tensor):
- """Reshape activations for tf.summary.image visualization.
-
- Arguments:
- features_tensor: a tensor of activations with a square number of feature
- maps, eg 4, 9, 16, etc.
- Returns:
- A composite image with all the feature maps that can be passed as an
- argument to tf.summary.image.
- """
- assert len(features_tensor.get_shape().as_list()) == 4
- num_filters = features_tensor.get_shape().as_list()[-1]
- assert num_filters > 0
- num_filters_sqrt = math.sqrt(num_filters)
- assert num_filters_sqrt.is_integer(
- ), 'Number of filters should be a square number but got {}'.format(
- num_filters)
- num_filters_sqrt = int(num_filters_sqrt)
- conv_summary = tf.unstack(features_tensor, axis=3)
- conv_one_row = tf.concat(axis=2, values=conv_summary[0:num_filters_sqrt])
- ind = 1
- conv_final = conv_one_row
- for ind in range(1, num_filters_sqrt):
- conv_one_row = tf.concat(axis=2,
- values=conv_summary[
- ind * num_filters_sqrt + 0:ind * num_filters_sqrt + num_filters_sqrt])
- conv_final = tf.concat(
- axis=1, values=[tf.squeeze(conv_final), tf.squeeze(conv_one_row)])
- conv_final = tf.expand_dims(conv_final, -1)
- return conv_final
-
-
-def accuracy(predictions, labels):
- """Calculates the classificaton accuracy.
-
- Args:
- predictions: the predicted values, a tensor whose size matches 'labels'.
- labels: the ground truth values, a tensor of any size.
-
- Returns:
- a tensor whose value on evaluation returns the total accuracy.
- """
- return tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32))
-
-
-def compute_upsample_values(input_tensor, upsample_height, upsample_width):
- """Compute values for an upsampling op (ops.BatchCropAndResize).
-
- Args:
- input_tensor: image tensor with shape [batch, height, width, in_channels]
- upsample_height: integer
- upsample_width: integer
-
- Returns:
- grid_centers: tensor with shape [batch, 1]
- crop_sizes: tensor with shape [batch, 1]
- output_height: integer
- output_width: integer
- """
- batch, input_height, input_width, _ = input_tensor.shape
-
- height_half = input_height / 2.
- width_half = input_width / 2.
- grid_centers = tf.constant(batch * [[height_half, width_half]])
- crop_sizes = tf.constant(batch * [[input_height, input_width]])
- output_height = input_height * upsample_height
- output_width = input_width * upsample_width
-
- return grid_centers, tf.to_float(crop_sizes), output_height, output_width
-
-
-def compute_pairwise_distances(x, y):
- """Computes the squared pairwise Euclidean distances between x and y.
-
- Args:
- x: a tensor of shape [num_x_samples, num_features]
- y: a tensor of shape [num_y_samples, num_features]
-
- Returns:
- a distance matrix of dimensions [num_x_samples, num_y_samples].
-
- Raises:
- ValueError: if the inputs do no matched the specified dimensions.
- """
-
- if not len(x.get_shape()) == len(y.get_shape()) == 2:
- raise ValueError('Both inputs should be matrices.')
-
- if x.get_shape().as_list()[1] != y.get_shape().as_list()[1]:
- raise ValueError('The number of features should be the same.')
-
- norm = lambda x: tf.reduce_sum(tf.square(x), 1)
-
- # By making the `inner' dimensions of the two matrices equal to 1 using
- # broadcasting then we are essentially substracting every pair of rows
- # of x and y.
- # x will be num_samples x num_features x 1,
- # and y will be 1 x num_features x num_samples (after broadcasting).
- # After the substraction we will get a
- # num_x_samples x num_features x num_y_samples matrix.
- # The resulting dist will be of shape num_y_samples x num_x_samples.
- # and thus we need to transpose it again.
- return tf.transpose(norm(tf.expand_dims(x, 2) - tf.transpose(y)))
-
-
-def gaussian_kernel_matrix(x, y, sigmas):
- r"""Computes a Guassian Radial Basis Kernel between the samples of x and y.
-
- We create a sum of multiple gaussian kernels each having a width sigma_i.
-
- Args:
- x: a tensor of shape [num_samples, num_features]
- y: a tensor of shape [num_samples, num_features]
- sigmas: a tensor of floats which denote the widths of each of the
- gaussians in the kernel.
- Returns:
- A tensor of shape [num_samples{x}, num_samples{y}] with the RBF kernel.
- """
- beta = 1. / (2. * (tf.expand_dims(sigmas, 1)))
-
- dist = compute_pairwise_distances(x, y)
-
- s = tf.matmul(beta, tf.reshape(dist, (1, -1)))
-
- return tf.reshape(tf.reduce_sum(tf.exp(-s), 0), tf.shape(dist))
diff --git a/research/domain_adaptation/pixel_domain_adaptation/BUILD b/research/domain_adaptation/pixel_domain_adaptation/BUILD
deleted file mode 100644
index 2bc8d4a49a828f97b8f45166aa2bbc552d4a3b92..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/BUILD
+++ /dev/null
@@ -1,90 +0,0 @@
-# Description:
-# Contains code for domain-adaptation style transfer.
-
-package(
- default_visibility = [
- ":internal",
- ],
-)
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-package_group(
- name = "internal",
- packages = [
- "//domain_adaptation/...",
- ],
-)
-
-py_library(
- name = "pixelda_preprocess",
- srcs = ["pixelda_preprocess.py"],
- deps = [
-
- ],
-)
-
-py_test(
- name = "pixelda_preprocess_test",
- srcs = ["pixelda_preprocess_test.py"],
- deps = [
- ":pixelda_preprocess",
-
- ],
-)
-
-py_library(
- name = "pixelda_model",
- srcs = [
- "pixelda_model.py",
- "pixelda_task_towers.py",
- "hparams.py",
- ],
- deps = [
-
- ],
-)
-
-py_library(
- name = "pixelda_utils",
- srcs = ["pixelda_utils.py"],
- deps = [
-
- ],
-)
-
-py_library(
- name = "pixelda_losses",
- srcs = ["pixelda_losses.py"],
- deps = [
-
- ],
-)
-
-py_binary(
- name = "pixelda_train",
- srcs = ["pixelda_train.py"],
- deps = [
- ":pixelda_losses",
- ":pixelda_model",
- ":pixelda_preprocess",
- ":pixelda_utils",
-
- "//domain_adaptation/datasets:dataset_factory",
- ],
-)
-
-py_binary(
- name = "pixelda_eval",
- srcs = ["pixelda_eval.py"],
- deps = [
- ":pixelda_losses",
- ":pixelda_model",
- ":pixelda_preprocess",
- ":pixelda_utils",
-
- "//domain_adaptation/datasets:dataset_factory",
- ],
-)
diff --git a/research/domain_adaptation/pixel_domain_adaptation/README.md b/research/domain_adaptation/pixel_domain_adaptation/README.md
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD b/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD
deleted file mode 100644
index c41a4ffeee80114145c4c3fc32a2191879b1b08a..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD
+++ /dev/null
@@ -1,23 +0,0 @@
-licenses(["notice"]) # Apache 2.0
-
-py_binary(
- name = "baseline_train",
- srcs = ["baseline_train.py"],
- deps = [
-
- "//domain_adaptation/datasets:dataset_factory",
- "//domain_adaptation/pixel_domain_adaptation:pixelda_model",
- "//domain_adaptation/pixel_domain_adaptation:pixelda_preprocess",
- ],
-)
-
-py_binary(
- name = "baseline_eval",
- srcs = ["baseline_eval.py"],
- deps = [
-
- "//domain_adaptation/datasets:dataset_factory",
- "//domain_adaptation/pixel_domain_adaptation:pixelda_model",
- "//domain_adaptation/pixel_domain_adaptation:pixelda_preprocess",
- ],
-)
diff --git a/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md b/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md
deleted file mode 100644
index d61195ad2de6867801143aeda906cb5efe30a5e3..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md
+++ /dev/null
@@ -1,60 +0,0 @@
-The best baselines are obtainable via the following configuration:
-
-
-## MNIST => MNIST_M
-
-Accuracy:
-MNIST-Train: 99.9
-MNIST_M-Train: 63.9
-MNIST_M-Valid: 63.9
-MNIST_M-Test: 63.6
-
-Learning Rate = 0.0001
-Weight Decay = 0.0
-Number of Steps: 105,000
-
-## MNIST => USPS
-
-Accuracy:
-MNIST-Train: 100.0
-USPS-Train: 82.8
-USPS-Valid: 82.8
-USPS-Test: 78.9
-
-Learning Rate = 0.0001
-Weight Decay = 0.0
-Number of Steps: 22,000
-
-## MNIST_M => MNIST
-
-Accuracy:
-MNIST_M-Train: 100
-MNIST-Train: 98.5
-MNIST-Valid: 98.5
-MNIST-Test: 98.1
-
-Learning Rate = 0.001
-Weight Decay = 0.0
-Number of Steps: 604,400
-
-## MNIST_M => MNIST_M
-
-Accuracy:
-MNIST_M-Train: 100.0
-MNIST_M-Valid: 96.6
-MNIST_M-Test: 96.4
-
-Learning Rate = 0.001
-Weight Decay = 0.0
-Number of Steps: 139,400
-
-## USPS => USPS
-
-Accuracy:
-USPS-Train: 100.0
-USPS-Valid: 100.0
-USPS-Test: 96.5
-
-Learning Rate = 0.001
-Weight Decay = 0.0
-Number of Steps: 67,000
diff --git a/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py b/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py
deleted file mode 100644
index 6b7ef6452b4897b00dc8c977bf40526ad5052ede..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py
+++ /dev/null
@@ -1,141 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-r"""Evals the classification/pose baselines."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from functools import partial
-
-import math
-
-# Dependency imports
-
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess
-from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-slim = tf.contrib.slim
-
-flags.DEFINE_string('master', '', 'BNS name of the tensorflow server')
-
-flags.DEFINE_string(
- 'checkpoint_dir', None, 'The location of the checkpoint files.')
-
-flags.DEFINE_string(
- 'eval_dir', None, 'The directory where evaluation logs are written.')
-
-flags.DEFINE_integer('batch_size', 32, 'The number of samples per batch.')
-
-flags.DEFINE_string('dataset_name', None, 'The name of the dataset.')
-
-flags.DEFINE_string('dataset_dir', None,
- 'The directory where the data is stored.')
-
-flags.DEFINE_string('split_name', None, 'The name of the train/test split.')
-
-flags.DEFINE_integer('eval_interval_secs', 60 * 5,
- 'How often (in seconds) to run evaluation.')
-
-flags.DEFINE_integer(
- 'num_readers', 4,
- 'The number of parallel readers that read data from the dataset.')
-
-def main(unused_argv):
- tf.logging.set_verbosity(tf.logging.INFO)
- hparams = tf.contrib.training.HParams()
- hparams.weight_decay_task_classifier = 0.0
-
- if FLAGS.dataset_name in ['mnist', 'mnist_m', 'usps']:
- hparams.task_tower = 'mnist'
- else:
- raise ValueError('Unknown dataset %s' % FLAGS.dataset_name)
-
- if not tf.gfile.Exists(FLAGS.eval_dir):
- tf.gfile.MakeDirs(FLAGS.eval_dir)
-
- with tf.Graph().as_default():
- dataset = dataset_factory.get_dataset(FLAGS.dataset_name, FLAGS.split_name,
- FLAGS.dataset_dir)
- num_classes = dataset.num_classes
- num_samples = dataset.num_samples
-
- preprocess_fn = partial(pixelda_preprocess.preprocess_classification,
- is_training=False)
-
- images, labels = dataset_factory.provide_batch(
- FLAGS.dataset_name,
- FLAGS.split_name,
- dataset_dir=FLAGS.dataset_dir,
- num_readers=FLAGS.num_readers,
- batch_size=FLAGS.batch_size,
- num_preprocessing_threads=FLAGS.num_readers)
-
- # Define the model
- logits, _ = pixelda_task_towers.add_task_specific_model(
- images, hparams, num_classes=num_classes, is_training=True)
-
- #####################
- # Define the losses #
- #####################
- if 'classes' in labels:
- one_hot_labels = labels['classes']
- loss = tf.losses.softmax_cross_entropy(
- onehot_labels=one_hot_labels, logits=logits)
- tf.summary.scalar('losses/Classification_Loss', loss)
- else:
- raise ValueError('Only support classification for now.')
-
- total_loss = tf.losses.get_total_loss()
-
- predictions = tf.reshape(tf.argmax(logits, 1), shape=[-1])
- class_labels = tf.argmax(labels['classes'], 1)
-
- metrics_to_values, metrics_to_updates = slim.metrics.aggregate_metric_map({
- 'Mean_Loss':
- tf.contrib.metrics.streaming_mean(total_loss),
- 'Accuracy':
- tf.contrib.metrics.streaming_accuracy(predictions,
- tf.reshape(
- class_labels,
- shape=[-1])),
- 'Recall_at_5':
- tf.contrib.metrics.streaming_recall_at_k(logits, class_labels, 5),
- })
-
- tf.summary.histogram('outputs/Predictions', predictions)
- tf.summary.histogram('outputs/Ground_Truth', class_labels)
-
- for name, value in metrics_to_values.iteritems():
- tf.summary.scalar(name, value)
-
- num_batches = int(math.ceil(num_samples / float(FLAGS.batch_size)))
-
- slim.evaluation.evaluation_loop(
- master=FLAGS.master,
- checkpoint_dir=FLAGS.checkpoint_dir,
- logdir=FLAGS.eval_dir,
- num_evals=num_batches,
- eval_op=metrics_to_updates.values(),
- eval_interval_secs=FLAGS.eval_interval_secs)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py b/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py
deleted file mode 100644
index 8c92bd81a7b68879000dd793ba2fd013f395f408..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py
+++ /dev/null
@@ -1,161 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-r"""Trains the classification/pose baselines."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from functools import partial
-
-# Dependency imports
-
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess
-from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-slim = tf.contrib.slim
-
-flags.DEFINE_string('master', '', 'BNS name of the tensorflow server')
-
-flags.DEFINE_integer('task', 0, 'The task ID.')
-
-flags.DEFINE_integer('num_ps_tasks', 0,
- 'The number of parameter servers. If the value is 0, then '
- 'the parameters are handled locally by the worker.')
-
-flags.DEFINE_integer('batch_size', 32, 'The number of samples per batch.')
-
-flags.DEFINE_string('dataset_name', None, 'The name of the dataset.')
-
-flags.DEFINE_string('dataset_dir', None,
- 'The directory where the data is stored.')
-
-flags.DEFINE_string('split_name', None, 'The name of the train/test split.')
-
-flags.DEFINE_float('learning_rate', 0.001, 'The initial learning rate.')
-
-flags.DEFINE_integer(
- 'learning_rate_decay_steps', 20000,
- 'The frequency, in steps, at which the learning rate is decayed.')
-
-flags.DEFINE_float('learning_rate_decay_factor',
- 0.95,
- 'The factor with which the learning rate is decayed.')
-
-flags.DEFINE_float('adam_beta1', 0.5, 'The beta1 value for the AdamOptimizer')
-
-flags.DEFINE_float('weight_decay', 1e-5,
- 'The L2 coefficient on the model weights.')
-
-flags.DEFINE_string(
- 'logdir', None, 'The location of the logs and checkpoints.')
-
-flags.DEFINE_integer('save_interval_secs', 600,
- 'How often, in seconds, we save the model to disk.')
-
-flags.DEFINE_integer('save_summaries_secs', 600,
- 'How often, in seconds, we compute the summaries.')
-
-flags.DEFINE_integer(
- 'num_readers', 4,
- 'The number of parallel readers that read data from the dataset.')
-
-flags.DEFINE_float(
- 'moving_average_decay', 0.9999,
- 'The amount of decay to use for moving averages.')
-
-
-def main(unused_argv):
- tf.logging.set_verbosity(tf.logging.INFO)
- hparams = tf.contrib.training.HParams()
- hparams.weight_decay_task_classifier = FLAGS.weight_decay
-
- if FLAGS.dataset_name in ['mnist', 'mnist_m', 'usps']:
- hparams.task_tower = 'mnist'
- else:
- raise ValueError('Unknown dataset %s' % FLAGS.dataset_name)
-
- with tf.Graph().as_default():
- with tf.device(
- tf.train.replica_device_setter(FLAGS.num_ps_tasks, merge_devices=True)):
- dataset = dataset_factory.get_dataset(FLAGS.dataset_name,
- FLAGS.split_name, FLAGS.dataset_dir)
- num_classes = dataset.num_classes
-
- preprocess_fn = partial(pixelda_preprocess.preprocess_classification,
- is_training=True)
-
- images, labels = dataset_factory.provide_batch(
- FLAGS.dataset_name,
- FLAGS.split_name,
- dataset_dir=FLAGS.dataset_dir,
- num_readers=FLAGS.num_readers,
- batch_size=FLAGS.batch_size,
- num_preprocessing_threads=FLAGS.num_readers)
- # preprocess_fn=preprocess_fn)
-
- # Define the model
- logits, _ = pixelda_task_towers.add_task_specific_model(
- images, hparams, num_classes=num_classes, is_training=True)
-
- # Define the losses
- if 'classes' in labels:
- one_hot_labels = labels['classes']
- loss = tf.losses.softmax_cross_entropy(
- onehot_labels=one_hot_labels, logits=logits)
- tf.summary.scalar('losses/Classification_Loss', loss)
- else:
- raise ValueError('Only support classification for now.')
-
- total_loss = tf.losses.get_total_loss()
- tf.summary.scalar('losses/Total_Loss', total_loss)
-
- # Setup the moving averages
- moving_average_variables = slim.get_model_variables()
- variable_averages = tf.train.ExponentialMovingAverage(
- FLAGS.moving_average_decay, slim.get_or_create_global_step())
- tf.add_to_collection(
- tf.GraphKeys.UPDATE_OPS,
- variable_averages.apply(moving_average_variables))
-
- # Specify the optimization scheme:
- learning_rate = tf.train.exponential_decay(
- FLAGS.learning_rate,
- slim.get_or_create_global_step(),
- FLAGS.learning_rate_decay_steps,
- FLAGS.learning_rate_decay_factor,
- staircase=True)
-
- optimizer = tf.train.AdamOptimizer(learning_rate, beta1=FLAGS.adam_beta1)
-
- train_op = slim.learning.create_train_op(total_loss, optimizer)
-
- slim.learning.train(
- train_op,
- FLAGS.logdir,
- master=FLAGS.master,
- is_chief=(FLAGS.task == 0),
- save_summaries_secs=FLAGS.save_summaries_secs,
- save_interval_secs=FLAGS.save_interval_secs)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/pixel_domain_adaptation/hparams.py b/research/domain_adaptation/pixel_domain_adaptation/hparams.py
deleted file mode 100644
index ba9539f7d435c86f9fc92ed3406835bdaf2b50f3..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/hparams.py
+++ /dev/null
@@ -1,201 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Define model HParams."""
-import tensorflow as tf
-
-
-def create_hparams(hparam_string=None):
- """Create model hyperparameters. Parse nondefault from given string."""
- hparams = tf.contrib.training.HParams(
- # The name of the architecture to use.
- arch='resnet',
- lrelu_leakiness=0.2,
- batch_norm_decay=0.9,
- weight_decay=1e-5,
- normal_init_std=0.02,
- generator_kernel_size=3,
- discriminator_kernel_size=3,
-
- # Stop training after this many examples are processed
- # If none, train indefinitely
- num_training_examples=0,
-
- # Apply data augmentation to datasets
- # Applies only in training job
- augment_source_images=False,
- augment_target_images=False,
-
- # Discriminator
- # Number of filters in first layer of discriminator
- num_discriminator_filters=64,
- discriminator_conv_block_size=1, # How many convs to have at each size
- discriminator_filter_factor=2.0, # Multiply # filters by this each layer
- # Add gaussian noise with this stddev to every hidden layer of D
- discriminator_noise_stddev=0.2, # lmetz: Start seeing results at >= 0.1
- # If true, add this gaussian noise to input images to D as well
- discriminator_image_noise=False,
- discriminator_first_stride=1, # Stride in first conv of discriminator
- discriminator_do_pooling=False, # If true, replace stride 2 with avg pool
- discriminator_dropout_keep_prob=0.9, # keep probability for dropout
-
- # DCGAN Generator
- # Number of filters in generator decoder last layer (repeatedly halved
- # from 1st layer)
- num_decoder_filters=64,
- # Number of filters in generator encoder 1st layer (repeatedly doubled
- # after 1st layer)
- num_encoder_filters=64,
-
- # This is the shape to which the noise vector is projected (if we're
- # transferring from noise).
- # Write this way instead of [4, 4, 64] for hparam search flexibility
- projection_shape_size=4,
- projection_shape_channels=64,
-
- # Indicates the method by which we enlarge the spatial representation
- # of an image. Possible values include:
- # - resize_conv: Performs a nearest neighbor resize followed by a conv.
- # - conv2d_transpose: Performs a conv2d_transpose.
- upsample_method='resize_conv',
-
- # Visualization
- summary_steps=500, # Output image summary every N steps
-
- ###################################
- # Task Classifier Hyperparameters #
- ###################################
-
- # Which task-specific prediction tower to use. Possible choices are:
- # none: No task tower.
- # doubling_pose_estimator: classifier + quaternion regressor.
- # [conv + pool]* + FC
- # Classifiers used in DSN paper:
- # gtsrb: Classifier used for GTSRB
- # svhn: Classifier used for SVHN
- # mnist: Classifier used for MNIST
- # pose_mini: Classifier + regressor used for pose_mini
- task_tower='doubling_pose_estimator',
- weight_decay_task_classifier=1e-5,
- source_task_loss_weight=1.0,
- transferred_task_loss_weight=1.0,
-
- # Number of private layers in doubling_pose_estimator task tower
- num_private_layers=2,
-
- # The weight for the log quaternion loss we use for source and transferred
- # samples of the cropped_linemod dataset.
- # In the DSN work, 1/8 of the classifier weight worked well for our log
- # quaternion loss
- source_pose_weight=0.125 * 2.0,
- transferred_pose_weight=0.125 * 1.0,
-
- # If set to True, the style transfer network also attempts to change its
- # weights to maximize the performance of the task tower. If set to False,
- # then the style transfer network only attempts to change its weights to
- # make the transferred images more likely according to the domain
- # classifier.
- task_tower_in_g_step=True,
- task_loss_in_g_weight=1.0, # Weight of task loss in G
-
- #########################################
- # 'simple` generator arch model hparams #
- #########################################
- simple_num_conv_layers=1,
- simple_conv_filters=8,
-
- #########################
- # Resnet Hyperparameters#
- #########################
- resnet_blocks=6, # Number of resnet blocks
- resnet_filters=64, # Number of filters per conv in resnet blocks
- # If true, add original input back to result of convolutions inside the
- # resnet arch. If false, it turns into a simple stack of conv/relu/BN
- # layers.
- resnet_residuals=True,
-
- #######################################
- # The residual / interpretable model. #
- #######################################
- res_int_blocks=2, # The number of residual blocks.
- res_int_convs=2, # The number of conv calls inside each block.
- res_int_filters=64, # The number of filters used by each convolution.
-
- ####################
- # Latent variables #
- ####################
- # if true, then generate random noise and project to input for generator
- noise_channel=True,
- # The number of dimensions in the input noise vector.
- noise_dims=10,
-
- # If true, then one hot encode source image class and project as an
- # additional channel for the input to generator. This gives the generator
- # access to the class, which may help generation performance.
- condition_on_source_class=False,
-
- ########################
- # Loss Hyperparameters #
- ########################
- domain_loss_weight=1.0,
- style_transfer_loss_weight=1.0,
-
- ########################################################################
- # Encourages the transferred images to be similar to the source images #
- # using a configurable metric. #
- ########################################################################
-
- # The weight of the loss function encouraging the source and transferred
- # images to be similar. If set to 0, then the loss function is not used.
- transferred_similarity_loss_weight=0.0,
-
- # The type of loss used to encourage transferred and source image
- # similarity. Valid values include:
- # mpse: Mean Pairwise Squared Error
- # mse: Mean Squared Error
- # hinged_mse: Computes the mean squared error using squared differences
- # greater than hparams.transferred_similarity_max_diff
- # hinged_mae: Computes the mean absolute error using absolute
- # differences greater than hparams.transferred_similarity_max_diff.
- transferred_similarity_loss='mpse',
-
- # The maximum allowable difference between the source and target images.
- # This value is used, in effect, to produce a hinge loss. Note that the
- # range of values should be between 0 and 1.
- transferred_similarity_max_diff=0.4,
-
- ################################
- # Optimization Hyperparameters #
- ################################
- learning_rate=0.001,
- batch_size=32,
- lr_decay_steps=20000,
- lr_decay_rate=0.95,
-
- # Recomendation from the DCGAN paper:
- adam_beta1=0.5,
- clip_gradient_norm=5.0,
-
- # The number of times we run the discriminator train_op in a row.
- discriminator_steps=1,
-
- # The number of times we run the generator train_op in a row.
- generator_steps=1)
-
- if hparam_string:
- tf.logging.info('Parsing command line hparams: %s', hparam_string)
- hparams.parse(hparam_string)
-
- tf.logging.info('Final parsed hparams: %s', hparams.values())
- return hparams
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py
deleted file mode 100644
index 23824249a9e95586ed85e40cd89c5f6814977969..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py
+++ /dev/null
@@ -1,298 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-r"""Evaluates the PIXELDA model.
-
--- Compiles the model for CPU.
-$ bazel build -c opt third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation:pixelda_eval
-
--- Compile the model for GPU.
-$ bazel build -c opt --copt=-mavx --config=cuda \
- third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation:pixelda_eval
-
--- Runs the training.
-$ ./bazel-bin/third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation/pixelda_eval \
- --source_dataset=mnist \
- --target_dataset=mnist_m \
- --dataset_dir=/tmp/datasets/ \
- --alsologtostderr
-
--- Visualize the results.
-$ bash learning/brain/tensorboard/tensorboard.sh \
- --port 2222 --logdir=/tmp/pixelda/
-"""
-from functools import partial
-import math
-
-# Dependency imports
-
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-from domain_adaptation.pixel_domain_adaptation import pixelda_model
-from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess
-from domain_adaptation.pixel_domain_adaptation import pixelda_utils
-from domain_adaptation.pixel_domain_adaptation import pixelda_losses
-from domain_adaptation.pixel_domain_adaptation.hparams import create_hparams
-
-slim = tf.contrib.slim
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('master', '', 'BNS name of the TensorFlow master to use.')
-
-flags.DEFINE_string('checkpoint_dir', '/tmp/pixelda/',
- 'Directory where the model was written to.')
-
-flags.DEFINE_string('eval_dir', '/tmp/pixelda/',
- 'Directory where the results are saved to.')
-
-flags.DEFINE_integer('eval_interval_secs', 60,
- 'The frequency, in seconds, with which evaluation is run.')
-
-flags.DEFINE_string('target_split_name', 'test',
- 'The name of the train/test split.')
-flags.DEFINE_string('source_split_name', 'train', 'Split for source dataset.'
- ' Defaults to train.')
-
-flags.DEFINE_string('source_dataset', 'mnist',
- 'The name of the source dataset.')
-
-flags.DEFINE_string('target_dataset', 'mnist_m',
- 'The name of the target dataset.')
-
-flags.DEFINE_string(
- 'dataset_dir',
- '', # None,
- 'The directory where the datasets can be found.')
-
-flags.DEFINE_integer(
- 'num_readers', 4,
- 'The number of parallel readers that read data from the dataset.')
-
-flags.DEFINE_integer('num_preprocessing_threads', 4,
- 'The number of threads used to create the batches.')
-
-# HParams
-
-flags.DEFINE_string('hparams', '', 'Comma separated hyperparameter values')
-
-
-def run_eval(run_dir, checkpoint_dir, hparams):
- """Runs the eval loop.
-
- Args:
- run_dir: The directory where eval specific logs are placed
- checkpoint_dir: The directory where the checkpoints are stored
- hparams: The hyperparameters struct.
-
- Raises:
- ValueError: if hparams.arch is not recognized.
- """
- for checkpoint_path in slim.evaluation.checkpoints_iterator(
- checkpoint_dir, FLAGS.eval_interval_secs):
- with tf.Graph().as_default():
- #########################
- # Preprocess the inputs #
- #########################
- target_dataset = dataset_factory.get_dataset(
- FLAGS.target_dataset,
- split_name=FLAGS.target_split_name,
- dataset_dir=FLAGS.dataset_dir)
- target_images, target_labels = dataset_factory.provide_batch(
- FLAGS.target_dataset, FLAGS.target_split_name, FLAGS.dataset_dir,
- FLAGS.num_readers, hparams.batch_size,
- FLAGS.num_preprocessing_threads)
- num_target_classes = target_dataset.num_classes
- target_labels['class'] = tf.argmax(target_labels['classes'], 1)
- del target_labels['classes']
-
- if hparams.arch not in ['dcgan']:
- source_dataset = dataset_factory.get_dataset(
- FLAGS.source_dataset,
- split_name=FLAGS.source_split_name,
- dataset_dir=FLAGS.dataset_dir)
- num_source_classes = source_dataset.num_classes
- source_images, source_labels = dataset_factory.provide_batch(
- FLAGS.source_dataset, FLAGS.source_split_name, FLAGS.dataset_dir,
- FLAGS.num_readers, hparams.batch_size,
- FLAGS.num_preprocessing_threads)
- source_labels['class'] = tf.argmax(source_labels['classes'], 1)
- del source_labels['classes']
- if num_source_classes != num_target_classes:
- raise ValueError(
- 'Input and output datasets must have same number of classes')
- else:
- source_images = None
- source_labels = None
-
- ####################
- # Define the model #
- ####################
- end_points = pixelda_model.create_model(
- hparams,
- target_images,
- source_images=source_images,
- source_labels=source_labels,
- is_training=False,
- num_classes=num_target_classes)
-
- #######################
- # Metrics & Summaries #
- #######################
- names_to_values, names_to_updates = create_metrics(end_points,
- source_labels,
- target_labels, hparams)
- pixelda_utils.summarize_model(end_points)
- pixelda_utils.summarize_transferred_grid(
- end_points['transferred_images'], source_images, name='Transferred')
- if 'source_images_recon' in end_points:
- pixelda_utils.summarize_transferred_grid(
- end_points['source_images_recon'],
- source_images,
- name='Source Reconstruction')
- pixelda_utils.summarize_images(target_images, 'Target')
-
- for name, value in names_to_values.iteritems():
- tf.summary.scalar(name, value)
-
- # Use the entire split by default
- num_examples = target_dataset.num_samples
-
- num_batches = math.ceil(num_examples / float(hparams.batch_size))
- global_step = slim.get_or_create_global_step()
-
- result = slim.evaluation.evaluate_once(
- master=FLAGS.master,
- checkpoint_path=checkpoint_path,
- logdir=run_dir,
- num_evals=num_batches,
- eval_op=names_to_updates.values(),
- final_op=names_to_values)
-
-
-def to_degrees(log_quaternion_loss):
- """Converts a log quaternion distance to an angle.
-
- Args:
- log_quaternion_loss: The log quaternion distance between two
- unit quaternions (or a batch of pairs of quaternions).
-
- Returns:
- The angle in degrees of the implied angle-axis representation.
- """
- return tf.acos(-(tf.exp(log_quaternion_loss) - 1)) * 2 * 180 / math.pi
-
-
-def create_metrics(end_points, source_labels, target_labels, hparams):
- """Create metrics for the model.
-
- Args:
- end_points: A dictionary of end point name to tensor
- source_labels: Labels for source images. batch_size x 1
- target_labels: Labels for target images. batch_size x 1
- hparams: The hyperparameters struct.
-
- Returns:
- Tuple of (names_to_values, names_to_updates), dictionaries that map a metric
- name to its value and update op, respectively
-
- """
- ###########################################
- # Evaluate the Domain Prediction Accuracy #
- ###########################################
- batch_size = hparams.batch_size
- names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
- ('eval/Domain_Accuracy-Transferred'):
- tf.contrib.metrics.streaming_accuracy(
- tf.to_int32(
- tf.round(tf.sigmoid(end_points[
- 'transferred_domain_logits']))),
- tf.zeros(batch_size, dtype=tf.int32)),
- ('eval/Domain_Accuracy-Target'):
- tf.contrib.metrics.streaming_accuracy(
- tf.to_int32(
- tf.round(tf.sigmoid(end_points['target_domain_logits']))),
- tf.ones(batch_size, dtype=tf.int32))
- })
-
- ################################
- # Evaluate the task classifier #
- ################################
- if 'source_task_logits' in end_points:
- metric_name = 'eval/Task_Accuracy-Source'
- names_to_values[metric_name], names_to_updates[
- metric_name] = tf.contrib.metrics.streaming_accuracy(
- tf.argmax(end_points['source_task_logits'], 1),
- source_labels['class'])
-
- if 'transferred_task_logits' in end_points:
- metric_name = 'eval/Task_Accuracy-Transferred'
- names_to_values[metric_name], names_to_updates[
- metric_name] = tf.contrib.metrics.streaming_accuracy(
- tf.argmax(end_points['transferred_task_logits'], 1),
- source_labels['class'])
-
- if 'target_task_logits' in end_points:
- metric_name = 'eval/Task_Accuracy-Target'
- names_to_values[metric_name], names_to_updates[
- metric_name] = tf.contrib.metrics.streaming_accuracy(
- tf.argmax(end_points['target_task_logits'], 1),
- target_labels['class'])
-
- ##########################################################################
- # Pose data-specific losses.
- ##########################################################################
- if 'quaternion' in source_labels.keys():
- params = {}
- params['use_logging'] = False
- params['batch_size'] = batch_size
-
- angle_loss_source = to_degrees(
- pixelda_losses.log_quaternion_loss_batch(end_points[
- 'source_quaternion'], source_labels['quaternion'], params))
- angle_loss_transferred = to_degrees(
- pixelda_losses.log_quaternion_loss_batch(end_points[
- 'transferred_quaternion'], source_labels['quaternion'], params))
- angle_loss_target = to_degrees(
- pixelda_losses.log_quaternion_loss_batch(end_points[
- 'target_quaternion'], target_labels['quaternion'], params))
-
- metric_name = 'eval/Angle_Loss-Source'
- names_to_values[metric_name], names_to_updates[
- metric_name] = slim.metrics.mean(angle_loss_source)
-
- metric_name = 'eval/Angle_Loss-Transferred'
- names_to_values[metric_name], names_to_updates[
- metric_name] = slim.metrics.mean(angle_loss_transferred)
-
- metric_name = 'eval/Angle_Loss-Target'
- names_to_values[metric_name], names_to_updates[
- metric_name] = slim.metrics.mean(angle_loss_target)
-
- return names_to_values, names_to_updates
-
-
-def main(_):
- tf.logging.set_verbosity(tf.logging.INFO)
- hparams = create_hparams(FLAGS.hparams)
- run_eval(
- run_dir=FLAGS.eval_dir,
- checkpoint_dir=FLAGS.checkpoint_dir,
- hparams=hparams)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py
deleted file mode 100644
index cf39765d4d28c5a04cb8868cdc465cdd0129b0df..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py
+++ /dev/null
@@ -1,385 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Defines the various loss functions in use by the PIXELDA model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# Dependency imports
-
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-
-def add_domain_classifier_losses(end_points, hparams):
- """Adds losses related to the domain-classifier.
-
- Args:
- end_points: A map of network end point names to `Tensors`.
- hparams: The hyperparameters struct.
-
- Returns:
- loss: A `Tensor` representing the total task-classifier loss.
- """
- if hparams.domain_loss_weight == 0:
- tf.logging.info(
- 'Domain classifier loss weight is 0, so not creating losses.')
- return 0
-
- # The domain prediction loss is minimized with respect to the domain
- # classifier features only. Its aim is to predict the domain of the images.
- # Note: 1 = 'real image' label, 0 = 'fake image' label
- transferred_domain_loss = tf.losses.sigmoid_cross_entropy(
- multi_class_labels=tf.zeros_like(end_points['transferred_domain_logits']),
- logits=end_points['transferred_domain_logits'])
- tf.summary.scalar('Domain_loss_transferred', transferred_domain_loss)
-
- target_domain_loss = tf.losses.sigmoid_cross_entropy(
- multi_class_labels=tf.ones_like(end_points['target_domain_logits']),
- logits=end_points['target_domain_logits'])
- tf.summary.scalar('Domain_loss_target', target_domain_loss)
-
- # Compute the total domain loss:
- total_domain_loss = transferred_domain_loss + target_domain_loss
- total_domain_loss *= hparams.domain_loss_weight
- tf.summary.scalar('Domain_loss_total', total_domain_loss)
-
- return total_domain_loss
-
-def log_quaternion_loss_batch(predictions, labels, params):
- """A helper function to compute the error between quaternions.
-
- Args:
- predictions: A Tensor of size [batch_size, 4].
- labels: A Tensor of size [batch_size, 4].
- params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'.
-
- Returns:
- A Tensor of size [batch_size], denoting the error between the quaternions.
- """
- use_logging = params['use_logging']
- assertions = []
- if use_logging:
- assertions.append(
- tf.Assert(
- tf.reduce_all(
- tf.less(
- tf.abs(tf.reduce_sum(tf.square(predictions), [1]) - 1),
- 1e-4)),
- ['The l2 norm of each prediction quaternion vector should be 1.']))
- assertions.append(
- tf.Assert(
- tf.reduce_all(
- tf.less(
- tf.abs(tf.reduce_sum(tf.square(labels), [1]) - 1), 1e-4)),
- ['The l2 norm of each label quaternion vector should be 1.']))
-
- with tf.control_dependencies(assertions):
- product = tf.multiply(predictions, labels)
- internal_dot_products = tf.reduce_sum(product, [1])
-
- if use_logging:
- internal_dot_products = tf.Print(internal_dot_products, [
- internal_dot_products,
- tf.shape(internal_dot_products)
- ], 'internal_dot_products:')
-
- logcost = tf.log(1e-4 + 1 - tf.abs(internal_dot_products))
- return logcost
-
-
-def log_quaternion_loss(predictions, labels, params):
- """A helper function to compute the mean error between batches of quaternions.
-
- The caller is expected to add the loss to the graph.
-
- Args:
- predictions: A Tensor of size [batch_size, 4].
- labels: A Tensor of size [batch_size, 4].
- params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'.
-
- Returns:
- A Tensor of size 1, denoting the mean error between batches of quaternions.
- """
- use_logging = params['use_logging']
- logcost = log_quaternion_loss_batch(predictions, labels, params)
- logcost = tf.reduce_sum(logcost, [0])
- batch_size = params['batch_size']
- logcost = tf.multiply(logcost, 1.0 / batch_size, name='log_quaternion_loss')
- if use_logging:
- logcost = tf.Print(
- logcost, [logcost], '[logcost]', name='log_quaternion_loss_print')
- return logcost
-
-def _quaternion_loss(labels, predictions, weight, batch_size, domain,
- add_summaries):
- """Creates a Quaternion Loss.
-
- Args:
- labels: The true quaternions.
- predictions: The predicted quaternions.
- weight: A scalar weight.
- batch_size: The size of the batches.
- domain: The name of the domain from which the labels were taken.
- add_summaries: Whether or not to add summaries for the losses.
-
- Returns:
- A `Tensor` representing the loss.
- """
- assert domain in ['Source', 'Transferred']
-
- params = {'use_logging': False, 'batch_size': batch_size}
- loss = weight * log_quaternion_loss(labels, predictions, params)
-
- if add_summaries:
- assert_op = tf.Assert(tf.is_finite(loss), [loss])
- with tf.control_dependencies([assert_op]):
- tf.summary.histogram(
- 'Log_Quaternion_Loss_%s' % domain, loss, collections='losses')
- tf.summary.scalar(
- 'Task_Quaternion_Loss_%s' % domain, loss, collections='losses')
-
- return loss
-
-
-def _add_task_specific_losses(end_points, source_labels, num_classes, hparams,
- add_summaries=False):
- """Adds losses related to the task-classifier.
-
- Args:
- end_points: A map of network end point names to `Tensors`.
- source_labels: A dictionary of output labels to `Tensors`.
- num_classes: The number of classes used by the classifier.
- hparams: The hyperparameters struct.
- add_summaries: Whether or not to add the summaries.
-
- Returns:
- loss: A `Tensor` representing the total task-classifier loss.
- """
- # TODO(ddohan): Make sure the l2 regularization is added to the loss
-
- one_hot_labels = slim.one_hot_encoding(source_labels['class'], num_classes)
- total_loss = 0
-
- if 'source_task_logits' in end_points:
- loss = tf.losses.softmax_cross_entropy(
- onehot_labels=one_hot_labels,
- logits=end_points['source_task_logits'],
- weights=hparams.source_task_loss_weight)
- if add_summaries:
- tf.summary.scalar('Task_Classifier_Loss_Source', loss)
- total_loss += loss
-
- if 'transferred_task_logits' in end_points:
- loss = tf.losses.softmax_cross_entropy(
- onehot_labels=one_hot_labels,
- logits=end_points['transferred_task_logits'],
- weights=hparams.transferred_task_loss_weight)
- if add_summaries:
- tf.summary.scalar('Task_Classifier_Loss_Transferred', loss)
- total_loss += loss
-
- #########################
- # Pose specific losses. #
- #########################
- if 'quaternion' in source_labels:
- total_loss += _quaternion_loss(
- source_labels['quaternion'],
- end_points['source_quaternion'],
- hparams.source_pose_weight,
- hparams.batch_size,
- 'Source',
- add_summaries)
-
- total_loss += _quaternion_loss(
- source_labels['quaternion'],
- end_points['transferred_quaternion'],
- hparams.transferred_pose_weight,
- hparams.batch_size,
- 'Transferred',
- add_summaries)
-
- if add_summaries:
- tf.summary.scalar('Task_Loss_Total', total_loss)
-
- return total_loss
-
-
-def _transferred_similarity_loss(reconstructions,
- source_images,
- weight=1.0,
- method='mse',
- max_diff=0.4,
- name='similarity'):
- """Computes a loss encouraging similarity between source and transferred.
-
- Args:
- reconstructions: A `Tensor` of shape [batch_size, height, width, channels]
- source_images: A `Tensor` of shape [batch_size, height, width, channels].
- weight: Multiple similarity loss by this weight before returning
- method: One of:
- mpse = Mean Pairwise Squared Error
- mse = Mean Squared Error
- hinged_mse = Computes the mean squared error using squared differences
- greater than hparams.transferred_similarity_max_diff
- hinged_mae = Computes the mean absolute error using absolute
- differences greater than hparams.transferred_similarity_max_diff.
- max_diff: Maximum unpenalized difference for hinged losses
- name: Identifying name to use for creating summaries
-
-
- Returns:
- A `Tensor` representing the transferred similarity loss.
-
- Raises:
- ValueError: if `method` is not recognized.
- """
- if weight == 0:
- return 0
-
- source_channels = source_images.shape.as_list()[-1]
- reconstruction_channels = reconstructions.shape.as_list()[-1]
-
- # Convert grayscale source to RGB if target is RGB
- if source_channels == 1 and reconstruction_channels != 1:
- source_images = tf.tile(source_images, [1, 1, 1, reconstruction_channels])
- if reconstruction_channels == 1 and source_channels != 1:
- reconstructions = tf.tile(reconstructions, [1, 1, 1, source_channels])
-
- if method == 'mpse':
- reconstruction_similarity_loss_fn = (
- tf.contrib.losses.mean_pairwise_squared_error)
- elif method == 'masked_mpse':
-
- def masked_mpse(predictions, labels, weight):
- """Masked mpse assuming we have a depth to create a mask from."""
- assert labels.shape.as_list()[-1] == 4
- mask = tf.to_float(tf.less(labels[:, :, :, 3:4], 0.99))
- mask = tf.tile(mask, [1, 1, 1, 4])
- predictions *= mask
- labels *= mask
- tf.image_summary('masked_pred', predictions)
- tf.image_summary('masked_label', labels)
- return tf.contrib.losses.mean_pairwise_squared_error(
- predictions, labels, weight)
-
- reconstruction_similarity_loss_fn = masked_mpse
- elif method == 'mse':
- reconstruction_similarity_loss_fn = tf.contrib.losses.mean_squared_error
- elif method == 'hinged_mse':
-
- def hinged_mse(predictions, labels, weight):
- diffs = tf.square(predictions - labels)
- diffs = tf.maximum(0.0, diffs - max_diff)
- return tf.reduce_mean(diffs) * weight
-
- reconstruction_similarity_loss_fn = hinged_mse
- elif method == 'hinged_mae':
-
- def hinged_mae(predictions, labels, weight):
- diffs = tf.abs(predictions - labels)
- diffs = tf.maximum(0.0, diffs - max_diff)
- return tf.reduce_mean(diffs) * weight
-
- reconstruction_similarity_loss_fn = hinged_mae
- else:
- raise ValueError('Unknown reconstruction loss %s' % method)
-
- reconstruction_similarity_loss = reconstruction_similarity_loss_fn(
- reconstructions, source_images, weight)
-
- name = '%s_Similarity_(%s)' % (name, method)
- tf.summary.scalar(name, reconstruction_similarity_loss)
- return reconstruction_similarity_loss
-
-
-def g_step_loss(source_images, source_labels, end_points, hparams, num_classes):
- """Configures the loss function which runs during the g-step.
-
- Args:
- source_images: A `Tensor` of shape [batch_size, height, width, channels].
- source_labels: A dictionary of `Tensors` of shape [batch_size]. Valid keys
- are 'class' and 'quaternion'.
- end_points: A map of the network end points.
- hparams: The hyperparameters struct.
- num_classes: Number of classes for classifier loss
-
- Returns:
- A `Tensor` representing a loss function.
-
- Raises:
- ValueError: if hparams.transferred_similarity_loss_weight is non-zero but
- hparams.transferred_similarity_loss is invalid.
- """
- generator_loss = 0
-
- ################################################################
- # Adds a loss which encourages the discriminator probabilities #
- # to be high (near one).
- ################################################################
-
- # As per the GAN paper, maximize the log probs, instead of minimizing
- # log(1-probs). Since we're minimizing, we'll minimize -log(probs) which is
- # the same thing.
- style_transfer_loss = tf.losses.sigmoid_cross_entropy(
- logits=end_points['transferred_domain_logits'],
- multi_class_labels=tf.ones_like(end_points['transferred_domain_logits']),
- weights=hparams.style_transfer_loss_weight)
- tf.summary.scalar('Style_transfer_loss', style_transfer_loss)
- generator_loss += style_transfer_loss
-
- # Optimizes the style transfer network to produce transferred images similar
- # to the source images.
- generator_loss += _transferred_similarity_loss(
- end_points['transferred_images'],
- source_images,
- weight=hparams.transferred_similarity_loss_weight,
- method=hparams.transferred_similarity_loss,
- name='transferred_similarity')
-
- # Optimizes the style transfer network to maximize classification accuracy.
- if source_labels is not None and hparams.task_tower_in_g_step:
- generator_loss += _add_task_specific_losses(
- end_points, source_labels, num_classes,
- hparams) * hparams.task_loss_in_g_weight
-
- return generator_loss
-
-
-def d_step_loss(end_points, source_labels, num_classes, hparams):
- """Configures the losses during the D-Step.
-
- Note that during the D-step, the model optimizes both the domain (binary)
- classifier and the task classifier.
-
- Args:
- end_points: A map of the network end points.
- source_labels: A dictionary of output labels to `Tensors`.
- num_classes: The number of classes used by the classifier.
- hparams: The hyperparameters struct.
-
- Returns:
- A `Tensor` representing the value of the D-step loss.
- """
- domain_classifier_loss = add_domain_classifier_losses(end_points, hparams)
-
- task_classifier_loss = 0
- if source_labels is not None:
- task_classifier_loss = _add_task_specific_losses(
- end_points, source_labels, num_classes, hparams, add_summaries=True)
-
- return domain_classifier_loss + task_classifier_loss
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py
deleted file mode 100644
index 16b550a62d88ec2724c91f9dab9e3b34c736ec4f..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py
+++ /dev/null
@@ -1,713 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Contains the Domain Adaptation via Style Transfer (PixelDA) model components.
-
-A number of details in the implementation make reference to one of the following
-works:
-
-- "Unsupervised Representation Learning with Deep Convolutional
- Generative Adversarial Networks""
- https://arxiv.org/abs/1511.06434
-
-This paper makes several architecture recommendations:
-1. Use strided convs in discriminator, fractional-strided convs in generator
-2. batchnorm everywhere
-3. remove fully connected layers for deep models
-4. ReLu for all layers in generator, except tanh on output
-5. LeakyReLu for everything in discriminator
-"""
-import functools
-import math
-
-# Dependency imports
-import numpy as np
-
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers
-
-
-def create_model(hparams,
- target_images,
- source_images=None,
- source_labels=None,
- is_training=False,
- noise=None,
- num_classes=None):
- """Create a GAN model.
-
- Arguments:
- hparams: HParam object specifying model params
- target_images: A `Tensor` of size [batch_size, height, width, channels]. It
- is assumed that the images are [-1, 1] normalized.
- source_images: A `Tensor` of size [batch_size, height, width, channels]. It
- is assumed that the images are [-1, 1] normalized.
- source_labels: A `Tensor` of size [batch_size] of categorical labels between
- [0, num_classes]
- is_training: whether model is currently training
- noise: If None, model generates its own noise. Otherwise use provided.
- num_classes: Number of classes for classification
-
- Returns:
- end_points dict with model outputs
-
- Raises:
- ValueError: unknown hparams.arch setting
- """
- if num_classes is None and hparams.arch in ['resnet', 'simple']:
- raise ValueError('Num classes must be provided to create task classifier')
-
- if target_images.dtype != tf.float32:
- raise ValueError('target_images must be tf.float32 and [-1, 1] normalized.')
- if source_images is not None and source_images.dtype != tf.float32:
- raise ValueError('source_images must be tf.float32 and [-1, 1] normalized.')
-
- ###########################
- # Create latent variables #
- ###########################
- latent_vars = dict()
-
- if hparams.noise_channel:
- noise_shape = [hparams.batch_size, hparams.noise_dims]
- if noise is not None:
- assert noise.shape.as_list() == noise_shape
- tf.logging.info('Using provided noise')
- else:
- tf.logging.info('Using random noise')
- noise = tf.random_uniform(
- shape=noise_shape,
- minval=-1,
- maxval=1,
- dtype=tf.float32,
- name='random_noise')
- latent_vars['noise'] = noise
-
- ####################
- # Create generator #
- ####################
-
- with slim.arg_scope(
- [slim.conv2d, slim.conv2d_transpose, slim.fully_connected],
- normalizer_params=batch_norm_params(is_training,
- hparams.batch_norm_decay),
- weights_initializer=tf.random_normal_initializer(
- stddev=hparams.normal_init_std),
- weights_regularizer=tf.contrib.layers.l2_regularizer(
- hparams.weight_decay)):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
- if hparams.arch == 'dcgan':
- end_points = dcgan(
- target_images, latent_vars, hparams, scope='generator')
- elif hparams.arch == 'resnet':
- end_points = resnet_generator(
- source_images,
- target_images.shape.as_list()[1:4],
- hparams=hparams,
- latent_vars=latent_vars)
- elif hparams.arch == 'residual_interpretation':
- end_points = residual_interpretation_generator(
- source_images, is_training=is_training, hparams=hparams)
- elif hparams.arch == 'simple':
- end_points = simple_generator(
- source_images,
- target_images,
- is_training=is_training,
- hparams=hparams,
- latent_vars=latent_vars)
- elif hparams.arch == 'identity':
- # Pass through unmodified, besides changing # channels
- # Used to calculate baseline numbers
- # Also set `generator_steps=0` for baseline
- if hparams.generator_steps:
- raise ValueError('Must set generator_steps=0 for identity arch. Is %s'
- % hparams.generator_steps)
- transferred_images = source_images
- source_channels = source_images.shape.as_list()[-1]
- target_channels = target_images.shape.as_list()[-1]
- if source_channels == 1 and target_channels == 3:
- transferred_images = tf.tile(source_images, [1, 1, 1, 3])
- if source_channels == 3 and target_channels == 1:
- transferred_images = tf.image.rgb_to_grayscale(source_images)
- end_points = {'transferred_images': transferred_images}
- else:
- raise ValueError('Unknown architecture: %s' % hparams.arch)
-
- #####################
- # Domain Classifier #
- #####################
- if hparams.arch in [
- 'dcgan', 'resnet', 'residual_interpretation', 'simple', 'identity',
- ]:
-
- # Add a discriminator for these architectures
- end_points['transferred_domain_logits'] = predict_domain(
- end_points['transferred_images'],
- hparams,
- is_training=is_training,
- reuse=False)
- end_points['target_domain_logits'] = predict_domain(
- target_images,
- hparams,
- is_training=is_training,
- reuse=True)
-
- ###################
- # Task Classifier #
- ###################
- if hparams.task_tower != 'none' and hparams.arch in [
- 'resnet', 'residual_interpretation', 'simple', 'identity',
- ]:
- with tf.variable_scope('discriminator'):
- with tf.variable_scope('task_tower'):
- end_points['source_task_logits'], end_points[
- 'source_quaternion'] = pixelda_task_towers.add_task_specific_model(
- source_images,
- hparams,
- num_classes=num_classes,
- is_training=is_training,
- reuse_private=False,
- private_scope='source_task_classifier',
- reuse_shared=False)
- end_points['transferred_task_logits'], end_points[
- 'transferred_quaternion'] = (
- pixelda_task_towers.add_task_specific_model(
- end_points['transferred_images'],
- hparams,
- num_classes=num_classes,
- is_training=is_training,
- reuse_private=False,
- private_scope='transferred_task_classifier',
- reuse_shared=True))
- end_points['target_task_logits'], end_points[
- 'target_quaternion'] = pixelda_task_towers.add_task_specific_model(
- target_images,
- hparams,
- num_classes=num_classes,
- is_training=is_training,
- reuse_private=True,
- private_scope='transferred_task_classifier',
- reuse_shared=True)
- # Remove any endpoints with None values
- return dict((k, v) for k, v in end_points.iteritems() if v is not None)
-
-
-def batch_norm_params(is_training, batch_norm_decay):
- return {
- 'is_training': is_training,
- # Decay for the moving averages.
- 'decay': batch_norm_decay,
- # epsilon to prevent 0s in variance.
- 'epsilon': 0.001,
- }
-
-
-def lrelu(x, leakiness=0.2):
- """Relu, with optional leaky support."""
- return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
-
-
-def upsample(net, num_filters, scale=2, method='resize_conv', scope=None):
- """Performs spatial upsampling of the given features.
-
- Args:
- net: A `Tensor` of shape [batch_size, height, width, filters].
- num_filters: The number of output filters.
- scale: The scale of the upsampling. Must be a positive integer greater or
- equal to two.
- method: The method by which the features are upsampled. Valid options
- include 'resize_conv' and 'conv2d_transpose'.
- scope: An optional variable scope.
-
- Returns:
- A new set of features of shape
- [batch_size, height*scale, width*scale, num_filters].
-
- Raises:
- ValueError: if `method` is not valid or
- """
- if scale < 2:
- raise ValueError('scale must be greater or equal to two.')
-
- with tf.variable_scope(scope, 'upsample', [net]):
- if method == 'resize_conv':
- net = tf.image.resize_nearest_neighbor(
- net, [net.shape.as_list()[1] * scale,
- net.shape.as_list()[2] * scale],
- align_corners=True,
- name='resize')
- return slim.conv2d(net, num_filters, stride=1, scope='conv')
- elif method == 'conv2d_transpose':
- return slim.conv2d_transpose(net, num_filters, scope='deconv')
- else:
- raise ValueError('Upsample method [%s] was not recognized.' % method)
-
-
-def project_latent_vars(hparams, proj_shape, latent_vars, combine_method='sum'):
- """Generate noise and project to input volume size.
-
- Args:
- hparams: The hyperparameter HParams struct.
- proj_shape: Shape to project noise (not including batch size).
- latent_vars: dictionary of `'key': Tensor of shape [batch_size, N]`
- combine_method: How to combine the projected values.
- sum = project to volume then sum
- concat = concatenate along last dimension (i.e. channel)
-
- Returns:
- If combine_method=sum, a `Tensor` of size `hparams.projection_shape`
- If combine_method=concat and there are N latent vars, a `Tensor` of size
- `hparams.projection_shape`, with the last channel multiplied by N
-
-
- Raises:
- ValueError: combine_method is not one of sum/concat
- """
- values = []
- for var in latent_vars:
- with tf.variable_scope(var):
- # Project & reshape noise to a HxWxC input
- projected = slim.fully_connected(
- latent_vars[var],
- np.prod(proj_shape),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm)
- values.append(tf.reshape(projected, [hparams.batch_size] + proj_shape))
-
- if combine_method == 'sum':
- result = values[0]
- for value in values[1:]:
- result += value
- elif combine_method == 'concat':
- # Concatenate along last axis
- result = tf.concat(values, len(proj_shape))
- else:
- raise ValueError('Unknown combine_method %s' % combine_method)
-
- tf.logging.info('Latent variables projected to size %s volume', result.shape)
-
- return result
-
-
-def resnet_block(net, hparams):
- """Create a resnet block."""
- net_in = net
- net = slim.conv2d(
- net,
- hparams.resnet_filters,
- stride=1,
- normalizer_fn=slim.batch_norm,
- activation_fn=tf.nn.relu)
- net = slim.conv2d(
- net,
- hparams.resnet_filters,
- stride=1,
- normalizer_fn=slim.batch_norm,
- activation_fn=None)
- if hparams.resnet_residuals:
- net += net_in
- return net
-
-
-def resnet_stack(images, output_shape, hparams, scope=None):
- """Create a resnet style transfer block.
-
- Args:
- images: [batch-size, height, width, channels] image tensor to feed as input
- output_shape: output image shape in form [height, width, channels]
- hparams: hparams objects
- scope: Variable scope
-
- Returns:
- Images after processing with resnet blocks.
- """
- end_points = {}
- if hparams.noise_channel:
- # separate the noise for visualization
- end_points['noise'] = images[:, :, :, -1]
- assert images.shape.as_list()[1:3] == output_shape[0:2]
-
- with tf.variable_scope(scope, 'resnet_style_transfer', [images]):
- with slim.arg_scope(
- [slim.conv2d],
- normalizer_fn=slim.batch_norm,
- kernel_size=[hparams.generator_kernel_size] * 2,
- stride=1):
- net = slim.conv2d(
- images,
- hparams.resnet_filters,
- normalizer_fn=None,
- activation_fn=tf.nn.relu)
- for block in range(hparams.resnet_blocks):
- net = resnet_block(net, hparams)
- end_points['resnet_block_{}'.format(block)] = net
-
- net = slim.conv2d(
- net,
- output_shape[-1],
- kernel_size=[1, 1],
- normalizer_fn=None,
- activation_fn=tf.nn.tanh,
- scope='conv_out')
- end_points['transferred_images'] = net
- return net, end_points
-
-
-def predict_domain(images,
- hparams,
- is_training=False,
- reuse=False,
- scope='discriminator'):
- """Creates a discriminator for a GAN.
-
- Args:
- images: A `Tensor` of size [batch_size, height, width, channels]. It is
- assumed that the images are centered between -1 and 1.
- hparams: hparam object with params for discriminator
- is_training: Specifies whether or not we're training or testing.
- reuse: Whether to reuse variable scope
- scope: An optional variable_scope.
-
- Returns:
- [batch size, 1] - logit output of discriminator.
- """
- with tf.variable_scope(scope, 'discriminator', [images], reuse=reuse):
- lrelu_partial = functools.partial(lrelu, leakiness=hparams.lrelu_leakiness)
- with slim.arg_scope(
- [slim.conv2d],
- kernel_size=[hparams.discriminator_kernel_size] * 2,
- activation_fn=lrelu_partial,
- stride=2,
- normalizer_fn=slim.batch_norm):
-
- def add_noise(hidden, scope_num=None):
- if scope_num:
- hidden = slim.dropout(
- hidden,
- hparams.discriminator_dropout_keep_prob,
- is_training=is_training,
- scope='dropout_%s' % scope_num)
- if hparams.discriminator_noise_stddev == 0:
- return hidden
- return hidden + tf.random_normal(
- hidden.shape.as_list(),
- mean=0.0,
- stddev=hparams.discriminator_noise_stddev)
-
- # As per the recommendation of the DCGAN paper, we don't use batch norm
- # on the discriminator input (https://arxiv.org/pdf/1511.06434v2.pdf).
- if hparams.discriminator_image_noise:
- images = add_noise(images)
- net = slim.conv2d(
- images,
- hparams.num_discriminator_filters,
- normalizer_fn=None,
- stride=hparams.discriminator_first_stride,
- scope='conv1_stride%s' % hparams.discriminator_first_stride)
- net = add_noise(net, 1)
-
- block_id = 2
- # Repeatedly stack
- # discriminator_conv_block_size-1 conv layers with stride 1
- # followed by a stride 2 layer
- # Add (optional) noise at every point
- while net.shape.as_list()[1] > hparams.projection_shape_size:
- num_filters = int(hparams.num_discriminator_filters *
- (hparams.discriminator_filter_factor**(block_id - 1)))
- for conv_id in range(1, hparams.discriminator_conv_block_size):
- net = slim.conv2d(
- net,
- num_filters,
- stride=1,
- scope='conv_%s_%s' % (block_id, conv_id))
- if hparams.discriminator_do_pooling:
- net = slim.conv2d(
- net, num_filters, scope='conv_%s_prepool' % block_id)
- net = slim.avg_pool2d(
- net, kernel_size=[2, 2], stride=2, scope='pool_%s' % block_id)
- else:
- net = slim.conv2d(
- net, num_filters, scope='conv_%s_stride2' % block_id)
- net = add_noise(net, block_id)
- block_id += 1
- net = slim.flatten(net)
- net = slim.fully_connected(
- net,
- 1,
- # Models with BN here generally produce noise
- normalizer_fn=None,
- activation_fn=None,
- scope='fc_logit_out') # Returns logits!
- return net
-
-
-def dcgan_generator(images, output_shape, hparams, scope=None):
- """Transforms the visual style of the input images.
-
- Args:
- images: A `Tensor` of shape [batch_size, height, width, channels].
- output_shape: A list or tuple of 3 elements: the output height, width and
- number of channels.
- hparams: hparams object with generator parameters
- scope: Scope to place generator inside
-
- Returns:
- A `Tensor` of shape [batch_size, height, width, output_channels] which
- represents the result of style transfer.
-
- Raises:
- ValueError: If `output_shape` is not a list or tuple or if it doesn't have
- three elements or if `output_shape` or `images` arent square.
- """
- if not isinstance(output_shape, (tuple, list)):
- raise ValueError('output_shape must be a tuple or list.')
- elif len(output_shape) != 3:
- raise ValueError('output_shape must have three elements.')
-
- if output_shape[0] != output_shape[1]:
- raise ValueError('output_shape must be square')
- if images.shape.as_list()[1] != images.shape.as_list()[2]:
- raise ValueError('images height and width must match.')
-
- outdim = output_shape[0]
- indim = images.shape.as_list()[1]
- num_iterations = int(math.ceil(math.log(float(outdim) / float(indim), 2.0)))
-
- with slim.arg_scope(
- [slim.conv2d, slim.conv2d_transpose],
- kernel_size=[hparams.generator_kernel_size] * 2,
- stride=2):
- with tf.variable_scope(scope or 'generator'):
-
- net = images
-
- # Repeatedly halve # filters until = hparams.decode_filters in last layer
- for i in range(num_iterations):
- num_filters = hparams.num_decoder_filters * 2**(num_iterations - i - 1)
- net = slim.conv2d_transpose(net, num_filters, scope='deconv_%s' % i)
-
- # Crop down to desired size (e.g. 32x32 -> 28x28)
- dif = net.shape.as_list()[1] - outdim
- low = dif / 2
- high = net.shape.as_list()[1] - low
- net = net[:, low:high, low:high, :]
-
- # No batch norm on generator output
- net = slim.conv2d(
- net,
- output_shape[2],
- kernel_size=[1, 1],
- stride=1,
- normalizer_fn=None,
- activation_fn=tf.tanh,
- scope='conv_out')
- return net
-
-
-def dcgan(target_images, latent_vars, hparams, scope='dcgan'):
- """Creates the PixelDA model.
-
- Args:
- target_images: A `Tensor` of shape [batch_size, height, width, 3]
- sampled from the image domain to which we want to transfer.
- latent_vars: dictionary of 'key': Tensor of shape [batch_size, N]
- hparams: The hyperparameter map.
- scope: Surround generator component with this scope
-
- Returns:
- A dictionary of model outputs.
- """
- proj_shape = [
- hparams.projection_shape_size, hparams.projection_shape_size,
- hparams.projection_shape_channels
- ]
- source_volume = project_latent_vars(
- hparams, proj_shape, latent_vars, combine_method='concat')
-
- ###################################################
- # Transfer the source images to the target style. #
- ###################################################
- with tf.variable_scope(scope, 'generator', [target_images]):
- transferred_images = dcgan_generator(
- source_volume,
- output_shape=target_images.shape.as_list()[1:4],
- hparams=hparams)
- assert transferred_images.shape.as_list() == target_images.shape.as_list()
-
- return {'transferred_images': transferred_images}
-
-
-def resnet_generator(images, output_shape, hparams, latent_vars=None):
- """Creates a ResNet-based generator.
-
- Args:
- images: A `Tensor` of shape [batch_size, height, width, num_channels]
- sampled from the image domain from which we want to transfer
- output_shape: A length-3 array indicating the height, width and channels of
- the output.
- hparams: The hyperparameter map.
- latent_vars: dictionary of 'key': Tensor of shape [batch_size, N]
-
- Returns:
- A dictionary of model outputs.
- """
- with tf.variable_scope('generator'):
- if latent_vars:
- noise_channel = project_latent_vars(
- hparams,
- proj_shape=images.shape.as_list()[1:3] + [1],
- latent_vars=latent_vars,
- combine_method='concat')
- images = tf.concat([images, noise_channel], 3)
-
- transferred_images, end_points = resnet_stack(
- images,
- output_shape=output_shape,
- hparams=hparams,
- scope='resnet_stack')
- end_points['transferred_images'] = transferred_images
-
- return end_points
-
-
-def residual_interpretation_block(images, hparams, scope):
- """Learns a residual image which is added to the incoming image.
-
- Args:
- images: A `Tensor` of size [batch_size, height, width, 3]
- hparams: The hyperparameters struct.
- scope: The name of the variable op scope.
-
- Returns:
- The updated images.
- """
- with tf.variable_scope(scope):
- with slim.arg_scope(
- [slim.conv2d],
- normalizer_fn=None,
- kernel_size=[hparams.generator_kernel_size] * 2):
-
- net = images
- for _ in range(hparams.res_int_convs):
- net = slim.conv2d(
- net, hparams.res_int_filters, activation_fn=tf.nn.relu)
- net = slim.conv2d(net, 3, activation_fn=tf.nn.tanh)
-
- # Add the residual
- images += net
-
- # Clip the output
- images = tf.maximum(images, -1.0)
- images = tf.minimum(images, 1.0)
- return images
-
-
-def residual_interpretation_generator(images,
- is_training,
- hparams,
- latent_vars=None):
- """Creates a generator producing purely residual transformations.
-
- A residual generator differs from the resnet generator in that each 'block' of
- the residual generator produces a residual image. Consequently, the 'progress'
- of the model generation process can be directly observed at inference time,
- making it easier to diagnose and understand.
-
- Args:
- images: A `Tensor` of shape [batch_size, height, width, num_channels]
- sampled from the image domain from which we want to transfer. It is
- assumed that the images are centered between -1 and 1.
- is_training: whether or not the model is training.
- hparams: The hyperparameter map.
- latent_vars: dictionary of 'key': Tensor of shape [batch_size, N]
-
- Returns:
- A dictionary of model outputs.
- """
- end_points = {}
-
- with tf.variable_scope('generator'):
- if latent_vars:
- projected_latent = project_latent_vars(
- hparams,
- proj_shape=images.shape.as_list()[1:3] + [images.shape.as_list()[-1]],
- latent_vars=latent_vars,
- combine_method='sum')
- images += projected_latent
- with tf.variable_scope(None, 'residual_style_transfer', [images]):
- for i in range(hparams.res_int_blocks):
- images = residual_interpretation_block(images, hparams,
- 'residual_%d' % i)
- end_points['transferred_images_%d' % i] = images
-
- end_points['transferred_images'] = images
-
- return end_points
-
-
-def simple_generator(source_images, target_images, is_training, hparams,
- latent_vars):
- """Simple generator architecture (stack of convs) for trying small models."""
- end_points = {}
- with tf.variable_scope('generator'):
- feed_source_images = source_images
-
- if latent_vars:
- projected_latent = project_latent_vars(
- hparams,
- proj_shape=source_images.shape.as_list()[1:3] + [1],
- latent_vars=latent_vars,
- combine_method='concat')
- feed_source_images = tf.concat([source_images, projected_latent], 3)
-
- end_points = {}
-
- ###################################################
- # Transfer the source images to the target style. #
- ###################################################
- with slim.arg_scope(
- [slim.conv2d],
- normalizer_fn=slim.batch_norm,
- stride=1,
- kernel_size=[hparams.generator_kernel_size] * 2):
- net = feed_source_images
-
- # N convolutions
- for i in range(1, hparams.simple_num_conv_layers):
- normalizer_fn = None
- if i != 0:
- normalizer_fn = slim.batch_norm
- net = slim.conv2d(
- net,
- hparams.simple_conv_filters,
- normalizer_fn=normalizer_fn,
- activation_fn=tf.nn.relu)
-
- # Project back to right # image channels
- net = slim.conv2d(
- net,
- target_images.shape.as_list()[-1],
- kernel_size=[1, 1],
- stride=1,
- normalizer_fn=None,
- activation_fn=tf.tanh,
- scope='conv_out')
-
- transferred_images = net
- assert transferred_images.shape.as_list() == target_images.shape.as_list()
- end_points['transferred_images'] = transferred_images
-
- return end_points
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py
deleted file mode 100644
index 747c17b18bf007d85e606015da6687a343bf74d2..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py
+++ /dev/null
@@ -1,129 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Contains functions for preprocessing the inputs."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# Dependency imports
-
-import tensorflow as tf
-
-
-def preprocess_classification(image, labels, is_training=False):
- """Preprocesses the image and labels for classification purposes.
-
- Preprocessing includes shifting the images to be 0-centered between -1 and 1.
- This is not only a popular method of preprocessing (inception) but is also
- the mechanism used by DSNs.
-
- Args:
- image: A `Tensor` of size [height, width, 3].
- labels: A dictionary of labels.
- is_training: Whether or not we're training the model.
-
- Returns:
- The preprocessed image and labels.
- """
- # If the image is uint8, this will scale it to 0-1.
- image = tf.image.convert_image_dtype(image, tf.float32)
- image -= 0.5
- image *= 2
-
- return image, labels
-
-
-def preprocess_style_transfer(image,
- labels,
- augment=False,
- size=None,
- is_training=False):
- """Preprocesses the image and labels for style transfer purposes.
-
- Args:
- image: A `Tensor` of size [height, width, 3].
- labels: A dictionary of labels.
- augment: Whether to apply data augmentation to inputs
- size: The height and width to which images should be resized. If left as
- `None`, then no resizing is performed
- is_training: Whether or not we're training the model
-
- Returns:
- The preprocessed image and labels. Scaled to [-1, 1]
- """
- # If the image is uint8, this will scale it to 0-1.
- image = tf.image.convert_image_dtype(image, tf.float32)
- if augment and is_training:
- image = image_augmentation(image)
-
- if size:
- image = resize_image(image, size)
-
- image -= 0.5
- image *= 2
-
- return image, labels
-
-
-def image_augmentation(image):
- """Performs data augmentation by randomly permuting the inputs.
-
- Args:
- image: A float `Tensor` of size [height, width, channels] with values
- in range[0,1].
-
- Returns:
- The mutated batch of images
- """
- # Apply photometric data augmentation (contrast etc.)
- num_channels = image.shape_as_list()[-1]
- if num_channels == 4:
- # Only augment image part
- image, depth = image[:, :, 0:3], image[:, :, 3:4]
- elif num_channels == 1:
- image = tf.image.grayscale_to_rgb(image)
- image = tf.image.random_brightness(image, max_delta=0.1)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.032)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.clip_by_value(image, 0, 1.0)
- if num_channels == 4:
- image = tf.concat(2, [image, depth])
- elif num_channels == 1:
- image = tf.image.rgb_to_grayscale(image)
- return image
-
-
-def resize_image(image, size=None):
- """Resize image to target size.
-
- Args:
- image: A `Tensor` of size [height, width, 3].
- size: (height, width) to resize image to.
-
- Returns:
- resized image
- """
- if size is None:
- raise ValueError('Must specify size')
-
- if image.shape_as_list()[:2] == size:
- # Don't resize if not necessary
- return image
- image = tf.expand_dims(image, 0)
- image = tf.image.resize_images(image, size)
- image = tf.squeeze(image, 0)
- return image
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py
deleted file mode 100644
index 73f8c7ff05fc7d2614c419759a02f78ffbcdfec0..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py
+++ /dev/null
@@ -1,69 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Tests for domain_adaptation.pixel_domain_adaptation.pixelda_preprocess."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-# Dependency imports
-
-import tensorflow as tf
-
-from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess
-
-
-class PixelDAPreprocessTest(tf.test.TestCase):
-
- def assert_preprocess_classification_is_centered(self, dtype, is_training):
- tf.set_random_seed(0)
-
- if dtype == tf.uint8:
- image = tf.random_uniform((100, 200, 3), maxval=255, dtype=tf.int64)
- image = tf.cast(image, tf.uint8)
- else:
- image = tf.random_uniform((100, 200, 3), maxval=1.0, dtype=dtype)
-
- labels = {}
- image, labels = pixelda_preprocess.preprocess_classification(
- image, labels, is_training=is_training)
-
- with self.test_session() as sess:
- np_image = sess.run(image)
-
- self.assertTrue(np_image.min() <= -0.95)
- self.assertTrue(np_image.min() >= -1.0)
- self.assertTrue(np_image.max() >= 0.95)
- self.assertTrue(np_image.max() <= 1.0)
-
- def testPreprocessClassificationZeroCentersUint8DuringTrain(self):
- self.assert_preprocess_classification_is_centered(
- tf.uint8, is_training=True)
-
- def testPreprocessClassificationZeroCentersUint8DuringTest(self):
- self.assert_preprocess_classification_is_centered(
- tf.uint8, is_training=False)
-
- def testPreprocessClassificationZeroCentersFloatDuringTrain(self):
- self.assert_preprocess_classification_is_centered(
- tf.float32, is_training=True)
-
- def testPreprocessClassificationZeroCentersFloatDuringTest(self):
- self.assert_preprocess_classification_is_centered(
- tf.float32, is_training=False)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py
deleted file mode 100644
index 1cb42e2d890a7759318cf0981640c0dd1645461e..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py
+++ /dev/null
@@ -1,317 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Task towers for PixelDA model."""
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-
-def add_task_specific_model(images,
- hparams,
- num_classes=10,
- is_training=False,
- reuse_private=False,
- private_scope=None,
- reuse_shared=False,
- shared_scope=None):
- """Create a classifier for the given images.
-
- The classifier is composed of a few 'private' layers followed by a few
- 'shared' layers. This lets us account for different image 'style', while
- sharing the last few layers as 'content' layers.
-
- Args:
- images: A `Tensor` of size [batch_size, height, width, 3].
- hparams: model hparams
- num_classes: The number of output classes.
- is_training: whether model is training
- reuse_private: Whether or not to reuse the private weights, which are the
- first few layers in the classifier
- private_scope: The name of the variable_scope for the private (unshared)
- components of the classifier.
- reuse_shared: Whether or not to reuse the shared weights, which are the last
- few layers in the classifier
- shared_scope: The name of the variable_scope for the shared components of
- the classifier.
-
- Returns:
- The logits, a `Tensor` of shape [batch_size, num_classes].
-
- Raises:
- ValueError: If hparams.task_classifier is an unknown value
- """
-
- model = hparams.task_tower
- # Make sure the classifier name shows up in graph
- shared_scope = shared_scope or (model + '_shared')
- kwargs = {
- 'num_classes': num_classes,
- 'is_training': is_training,
- 'reuse_private': reuse_private,
- 'reuse_shared': reuse_shared,
- }
-
- if private_scope:
- kwargs['private_scope'] = private_scope
- if shared_scope:
- kwargs['shared_scope'] = shared_scope
-
- quaternion_pred = None
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_regularizer=tf.contrib.layers.l2_regularizer(
- hparams.weight_decay_task_classifier)):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
- if model == 'doubling_pose_estimator':
- logits, quaternion_pred = doubling_cnn_class_and_quaternion(
- images, num_private_layers=hparams.num_private_layers, **kwargs)
- elif model == 'mnist':
- logits, _ = mnist_classifier(images, **kwargs)
- elif model == 'svhn':
- logits, _ = svhn_classifier(images, **kwargs)
- elif model == 'gtsrb':
- logits, _ = gtsrb_classifier(images, **kwargs)
- elif model == 'pose_mini':
- logits, quaternion_pred = pose_mini_tower(images, **kwargs)
- else:
- raise ValueError('Unknown task classifier %s' % model)
-
- return logits, quaternion_pred
-
-
-#####################################
-# Classifiers used in the DSN paper #
-#####################################
-
-
-def mnist_classifier(images,
- is_training=False,
- num_classes=10,
- reuse_private=False,
- private_scope='mnist',
- reuse_shared=False,
- shared_scope='task_model'):
- """Creates the convolutional MNIST model from the gradient reversal paper.
-
- Note that since the output is a set of 'logits', the values fall in the
- interval of (-infinity, infinity). Consequently, to convert the outputs to a
- probability distribution over the characters, one will need to convert them
- using the softmax function:
- logits, endpoints = conv_mnist(images, is_training=False)
- predictions = tf.nn.softmax(logits)
-
- Args:
- images: the MNIST digits, a tensor of size [batch_size, 28, 28, 1].
- is_training: specifies whether or not we're currently training the model.
- This variable will determine the behaviour of the dropout layer.
- num_classes: the number of output classes to use.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- net = {}
-
- with tf.variable_scope(private_scope, reuse=reuse_private):
- net['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1')
- net['pool1'] = slim.max_pool2d(net['conv1'], [2, 2], 2, scope='pool1')
-
- with tf.variable_scope(shared_scope, reuse=reuse_shared):
- net['conv2'] = slim.conv2d(net['pool1'], 48, [5, 5], scope='conv2')
- net['pool2'] = slim.max_pool2d(net['conv2'], [2, 2], 2, scope='pool2')
- net['fc3'] = slim.fully_connected(
- slim.flatten(net['pool2']), 100, scope='fc3')
- net['fc4'] = slim.fully_connected(
- slim.flatten(net['fc3']), 100, scope='fc4')
- logits = slim.fully_connected(
- net['fc4'], num_classes, activation_fn=None, scope='fc5')
- return logits, net
-
-
-def svhn_classifier(images,
- is_training=False,
- num_classes=10,
- reuse_private=False,
- private_scope=None,
- reuse_shared=False,
- shared_scope='task_model'):
- """Creates the convolutional SVHN model from the gradient reversal paper.
-
- Note that since the output is a set of 'logits', the values fall in the
- interval of (-infinity, infinity). Consequently, to convert the outputs to a
- probability distribution over the characters, one will need to convert them
- using the softmax function:
- logits = mnist.Mnist(images, is_training=False)
- predictions = tf.nn.softmax(logits)
-
- Args:
- images: the SVHN digits, a tensor of size [batch_size, 40, 40, 3].
- is_training: specifies whether or not we're currently training the model.
- This variable will determine the behaviour of the dropout layer.
- num_classes: the number of output classes to use.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- net = {}
-
- with tf.variable_scope(private_scope, reuse=reuse_private):
- net['conv1'] = slim.conv2d(images, 64, [5, 5], scope='conv1')
- net['pool1'] = slim.max_pool2d(net['conv1'], [3, 3], 2, scope='pool1')
-
- with tf.variable_scope(shared_scope, reuse=reuse_shared):
- net['conv2'] = slim.conv2d(net['pool1'], 64, [5, 5], scope='conv2')
- net['pool2'] = slim.max_pool2d(net['conv2'], [3, 3], 2, scope='pool2')
- net['conv3'] = slim.conv2d(net['pool2'], 128, [5, 5], scope='conv3')
-
- net['fc3'] = slim.fully_connected(
- slim.flatten(net['conv3']), 3072, scope='fc3')
- net['fc4'] = slim.fully_connected(
- slim.flatten(net['fc3']), 2048, scope='fc4')
-
- logits = slim.fully_connected(
- net['fc4'], num_classes, activation_fn=None, scope='fc5')
-
- return logits, net
-
-
-def gtsrb_classifier(images,
- is_training=False,
- num_classes=43,
- reuse_private=False,
- private_scope='gtsrb',
- reuse_shared=False,
- shared_scope='task_model'):
- """Creates the convolutional GTSRB model from the gradient reversal paper.
-
- Note that since the output is a set of 'logits', the values fall in the
- interval of (-infinity, infinity). Consequently, to convert the outputs to a
- probability distribution over the characters, one will need to convert them
- using the softmax function:
- logits = mnist.Mnist(images, is_training=False)
- predictions = tf.nn.softmax(logits)
-
- Args:
- images: the SVHN digits, a tensor of size [batch_size, 40, 40, 3].
- is_training: specifies whether or not we're currently training the model.
- This variable will determine the behaviour of the dropout layer.
- num_classes: the number of output classes to use.
- reuse_private: Whether or not to reuse the private components of the model.
- private_scope: The name of the private scope.
- reuse_shared: Whether or not to reuse the shared components of the model.
- shared_scope: The name of the shared scope.
-
- Returns:
- the output logits, a tensor of size [batch_size, num_classes].
- a dictionary with key/values the layer names and tensors.
- """
-
- net = {}
-
- with tf.variable_scope(private_scope, reuse=reuse_private):
- net['conv1'] = slim.conv2d(images, 96, [5, 5], scope='conv1')
- net['pool1'] = slim.max_pool2d(net['conv1'], [2, 2], 2, scope='pool1')
- with tf.variable_scope(shared_scope, reuse=reuse_shared):
- net['conv2'] = slim.conv2d(net['pool1'], 144, [3, 3], scope='conv2')
- net['pool2'] = slim.max_pool2d(net['conv2'], [2, 2], 2, scope='pool2')
- net['conv3'] = slim.conv2d(net['pool2'], 256, [5, 5], scope='conv3')
- net['pool3'] = slim.max_pool2d(net['conv3'], [2, 2], 2, scope='pool3')
-
- net['fc3'] = slim.fully_connected(
- slim.flatten(net['pool3']), 512, scope='fc3')
- logits = slim.fully_connected(
- net['fc3'], num_classes, activation_fn=None, scope='fc4')
-
- return logits, net
-
-
-#########################
-# pose_mini task towers #
-#########################
-
-
-def pose_mini_tower(images,
- num_classes=11,
- is_training=False,
- reuse_private=False,
- private_scope='pose_mini',
- reuse_shared=False,
- shared_scope='task_model'):
- """Task tower for the pose_mini dataset."""
-
- with tf.variable_scope(private_scope, reuse=reuse_private):
- net = slim.conv2d(images, 32, [5, 5], scope='conv1')
- net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool1')
- with tf.variable_scope(shared_scope, reuse=reuse_shared):
- net = slim.conv2d(net, 64, [5, 5], scope='conv2')
- net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool2')
- net = slim.flatten(net)
-
- net = slim.fully_connected(net, 128, scope='fc3')
- net = slim.dropout(net, 0.5, is_training=is_training, scope='dropout')
- with tf.variable_scope('quaternion_prediction'):
- quaternion_pred = slim.fully_connected(
- net, 4, activation_fn=tf.tanh, scope='fc_q')
- quaternion_pred = tf.nn.l2_normalize(quaternion_pred, 1)
-
- logits = slim.fully_connected(
- net, num_classes, activation_fn=None, scope='fc4')
-
- return logits, quaternion_pred
-
-
-def doubling_cnn_class_and_quaternion(images,
- num_private_layers=1,
- num_classes=10,
- is_training=False,
- reuse_private=False,
- private_scope='doubling_cnn',
- reuse_shared=False,
- shared_scope='task_model'):
- """Alternate conv, pool while doubling filter count."""
- net = images
- depth = 32
- layer_id = 1
-
- with tf.variable_scope(private_scope, reuse=reuse_private):
- while num_private_layers > 0 and net.shape.as_list()[1] > 5:
- net = slim.conv2d(net, depth, [3, 3], scope='conv%s' % layer_id)
- net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool%s' % layer_id)
- depth *= 2
- layer_id += 1
- num_private_layers -= 1
-
- with tf.variable_scope(shared_scope, reuse=reuse_shared):
- while net.shape.as_list()[1] > 5:
- net = slim.conv2d(net, depth, [3, 3], scope='conv%s' % layer_id)
- net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool%s' % layer_id)
- depth *= 2
- layer_id += 1
-
- net = slim.flatten(net)
- net = slim.fully_connected(net, 100, scope='fc1')
- net = slim.dropout(net, 0.5, is_training=is_training, scope='dropout')
- quaternion_pred = slim.fully_connected(
- net, 4, activation_fn=tf.tanh, scope='fc_q')
- quaternion_pred = tf.nn.l2_normalize(quaternion_pred, 1)
-
- logits = slim.fully_connected(
- net, num_classes, activation_fn=None, scope='fc_logits')
-
- return logits, quaternion_pred
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py
deleted file mode 100644
index 4ca072cceafa48769623381b8e564fe650f2a514..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py
+++ /dev/null
@@ -1,409 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-r"""Trains the PixelDA model."""
-
-from functools import partial
-import os
-
-# Dependency imports
-
-import tensorflow as tf
-
-from domain_adaptation.datasets import dataset_factory
-from domain_adaptation.pixel_domain_adaptation import pixelda_losses
-from domain_adaptation.pixel_domain_adaptation import pixelda_model
-from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess
-from domain_adaptation.pixel_domain_adaptation import pixelda_utils
-from domain_adaptation.pixel_domain_adaptation.hparams import create_hparams
-
-slim = tf.contrib.slim
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('master', '', 'BNS name of the TensorFlow master to use.')
-
-flags.DEFINE_integer(
- 'ps_tasks', 0,
- 'The number of parameter servers. If the value is 0, then the parameters '
- 'are handled locally by the worker.')
-
-flags.DEFINE_integer(
- 'task', 0,
- 'The Task ID. This value is used when training with multiple workers to '
- 'identify each worker.')
-
-flags.DEFINE_string('train_log_dir', '/tmp/pixelda/',
- 'Directory where to write event logs.')
-
-flags.DEFINE_integer(
- 'save_summaries_steps', 500,
- 'The frequency with which summaries are saved, in seconds.')
-
-flags.DEFINE_integer('save_interval_secs', 300,
- 'The frequency with which the model is saved, in seconds.')
-
-flags.DEFINE_boolean('summarize_gradients', False,
- 'Whether to summarize model gradients')
-
-flags.DEFINE_integer(
- 'print_loss_steps', 100,
- 'The frequency with which the losses are printed, in steps.')
-
-flags.DEFINE_string('source_dataset', 'mnist', 'The name of the source dataset.'
- ' If hparams="arch=dcgan", this flag is ignored.')
-
-flags.DEFINE_string('target_dataset', 'mnist_m',
- 'The name of the target dataset.')
-
-flags.DEFINE_string('source_split_name', 'train',
- 'Name of the train split for the source.')
-
-flags.DEFINE_string('target_split_name', 'train',
- 'Name of the train split for the target.')
-
-flags.DEFINE_string('dataset_dir', '',
- 'The directory where the datasets can be found.')
-
-flags.DEFINE_integer(
- 'num_readers', 4,
- 'The number of parallel readers that read data from the dataset.')
-
-flags.DEFINE_integer('num_preprocessing_threads', 4,
- 'The number of threads used to create the batches.')
-
-# HParams
-
-flags.DEFINE_string('hparams', '', 'Comma separated hyperparameter values')
-
-
-def _get_vars_and_update_ops(hparams, scope):
- """Returns the variables and update ops for a particular variable scope.
-
- Args:
- hparams: The hyperparameters struct.
- scope: The variable scope.
-
- Returns:
- A tuple consisting of trainable variables and update ops.
- """
- is_trainable = lambda x: x in tf.trainable_variables()
- var_list = filter(is_trainable, slim.get_model_variables(scope))
- global_step = slim.get_or_create_global_step()
-
- update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope)
-
- tf.logging.info('All variables for scope: %s',
- slim.get_model_variables(scope))
- tf.logging.info('Trainable variables for scope: %s', var_list)
-
- return var_list, update_ops
-
-
-def _train(discriminator_train_op,
- generator_train_op,
- logdir,
- master='',
- is_chief=True,
- scaffold=None,
- hooks=None,
- chief_only_hooks=None,
- save_checkpoint_secs=600,
- save_summaries_steps=100,
- hparams=None):
- """Runs the training loop.
-
- Args:
- discriminator_train_op: A `Tensor` that, when executed, will apply the
- gradients and return the loss value for the discriminator.
- generator_train_op: A `Tensor` that, when executed, will apply the
- gradients and return the loss value for the generator.
- logdir: The directory where the graph and checkpoints are saved.
- master: The URL of the master.
- is_chief: Specifies whether or not the training is being run by the primary
- replica during replica training.
- scaffold: An tf.train.Scaffold instance.
- hooks: List of `tf.train.SessionRunHook` callbacks which are run inside the
- training loop.
- chief_only_hooks: List of `tf.train.SessionRunHook` instances which are run
- inside the training loop for the chief trainer only.
- save_checkpoint_secs: The frequency, in seconds, that a checkpoint is saved
- using a default checkpoint saver. If `save_checkpoint_secs` is set to
- `None`, then the default checkpoint saver isn't used.
- save_summaries_steps: The frequency, in number of global steps, that the
- summaries are written to disk using a default summary saver. If
- `save_summaries_steps` is set to `None`, then the default summary saver
- isn't used.
- hparams: The hparams struct.
-
- Returns:
- the value of the loss function after training.
-
- Raises:
- ValueError: if `logdir` is `None` and either `save_checkpoint_secs` or
- `save_summaries_steps` are `None.
- """
- global_step = slim.get_or_create_global_step()
-
- scaffold = scaffold or tf.train.Scaffold()
-
- hooks = hooks or []
-
- if is_chief:
- session_creator = tf.train.ChiefSessionCreator(
- scaffold=scaffold, checkpoint_dir=logdir, master=master)
-
- if chief_only_hooks:
- hooks.extend(chief_only_hooks)
- hooks.append(tf.train.StepCounterHook(output_dir=logdir))
-
- if save_summaries_steps:
- if logdir is None:
- raise ValueError(
- 'logdir cannot be None when save_summaries_steps is None')
- hooks.append(
- tf.train.SummarySaverHook(
- scaffold=scaffold,
- save_steps=save_summaries_steps,
- output_dir=logdir))
-
- if save_checkpoint_secs:
- if logdir is None:
- raise ValueError(
- 'logdir cannot be None when save_checkpoint_secs is None')
- hooks.append(
- tf.train.CheckpointSaverHook(
- logdir, save_secs=save_checkpoint_secs, scaffold=scaffold))
- else:
- session_creator = tf.train.WorkerSessionCreator(
- scaffold=scaffold, master=master)
-
- with tf.train.MonitoredSession(
- session_creator=session_creator, hooks=hooks) as session:
- loss = None
- while not session.should_stop():
- # Run the domain classifier op X times.
- for _ in range(hparams.discriminator_steps):
- if session.should_stop():
- return loss
- loss, np_global_step = session.run(
- [discriminator_train_op, global_step])
- if np_global_step % FLAGS.print_loss_steps == 0:
- tf.logging.info('Step %d: Discriminator Loss = %.2f', np_global_step,
- loss)
-
- # Run the generator op X times.
- for _ in range(hparams.generator_steps):
- if session.should_stop():
- return loss
- loss, np_global_step = session.run([generator_train_op, global_step])
- if np_global_step % FLAGS.print_loss_steps == 0:
- tf.logging.info('Step %d: Generator Loss = %.2f', np_global_step,
- loss)
- return loss
-
-
-def run_training(run_dir, checkpoint_dir, hparams):
- """Runs the training loop.
-
- Args:
- run_dir: The directory where training specific logs are placed
- checkpoint_dir: The directory where the checkpoints and log files are
- stored.
- hparams: The hyperparameters struct.
-
- Raises:
- ValueError: if hparams.arch is not recognized.
- """
- for path in [run_dir, checkpoint_dir]:
- if not tf.gfile.Exists(path):
- tf.gfile.MakeDirs(path)
-
- # Serialize hparams to log dir
- hparams_filename = os.path.join(checkpoint_dir, 'hparams.json')
- with tf.gfile.FastGFile(hparams_filename, 'w') as f:
- f.write(hparams.to_json())
-
- with tf.Graph().as_default():
- with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
- global_step = slim.get_or_create_global_step()
-
- #########################
- # Preprocess the inputs #
- #########################
- target_dataset = dataset_factory.get_dataset(
- FLAGS.target_dataset,
- split_name='train',
- dataset_dir=FLAGS.dataset_dir)
- target_images, _ = dataset_factory.provide_batch(
- FLAGS.target_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers,
- hparams.batch_size, FLAGS.num_preprocessing_threads)
- num_target_classes = target_dataset.num_classes
-
- if hparams.arch not in ['dcgan']:
- source_dataset = dataset_factory.get_dataset(
- FLAGS.source_dataset,
- split_name='train',
- dataset_dir=FLAGS.dataset_dir)
- num_source_classes = source_dataset.num_classes
- source_images, source_labels = dataset_factory.provide_batch(
- FLAGS.source_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers,
- hparams.batch_size, FLAGS.num_preprocessing_threads)
- # Data provider provides 1 hot labels, but we expect categorical.
- source_labels['class'] = tf.argmax(source_labels['classes'], 1)
- del source_labels['classes']
- if num_source_classes != num_target_classes:
- raise ValueError(
- 'Source and Target datasets must have same number of classes. '
- 'Are %d and %d' % (num_source_classes, num_target_classes))
- else:
- source_images = None
- source_labels = None
-
- ####################
- # Define the model #
- ####################
- end_points = pixelda_model.create_model(
- hparams,
- target_images,
- source_images=source_images,
- source_labels=source_labels,
- is_training=True,
- num_classes=num_target_classes)
-
- #################################
- # Get the variables to optimize #
- #################################
- generator_vars, generator_update_ops = _get_vars_and_update_ops(
- hparams, 'generator')
- discriminator_vars, discriminator_update_ops = _get_vars_and_update_ops(
- hparams, 'discriminator')
-
- ########################
- # Configure the losses #
- ########################
- generator_loss = pixelda_losses.g_step_loss(
- source_images,
- source_labels,
- end_points,
- hparams,
- num_classes=num_target_classes)
- discriminator_loss = pixelda_losses.d_step_loss(
- end_points, source_labels, num_target_classes, hparams)
-
- ###########################
- # Create the training ops #
- ###########################
- learning_rate = hparams.learning_rate
- if hparams.lr_decay_steps:
- learning_rate = tf.train.exponential_decay(
- learning_rate,
- slim.get_or_create_global_step(),
- decay_steps=hparams.lr_decay_steps,
- decay_rate=hparams.lr_decay_rate,
- staircase=True)
- tf.summary.scalar('Learning_rate', learning_rate)
-
-
- if hparams.discriminator_steps == 0:
- discriminator_train_op = tf.no_op()
- else:
- discriminator_optimizer = tf.train.AdamOptimizer(
- learning_rate, beta1=hparams.adam_beta1)
-
- discriminator_train_op = slim.learning.create_train_op(
- discriminator_loss,
- discriminator_optimizer,
- update_ops=discriminator_update_ops,
- variables_to_train=discriminator_vars,
- clip_gradient_norm=hparams.clip_gradient_norm,
- summarize_gradients=FLAGS.summarize_gradients)
-
- if hparams.generator_steps == 0:
- generator_train_op = tf.no_op()
- else:
- generator_optimizer = tf.train.AdamOptimizer(
- learning_rate, beta1=hparams.adam_beta1)
- generator_train_op = slim.learning.create_train_op(
- generator_loss,
- generator_optimizer,
- update_ops=generator_update_ops,
- variables_to_train=generator_vars,
- clip_gradient_norm=hparams.clip_gradient_norm,
- summarize_gradients=FLAGS.summarize_gradients)
-
- #############
- # Summaries #
- #############
- pixelda_utils.summarize_model(end_points)
- pixelda_utils.summarize_transferred_grid(
- end_points['transferred_images'], source_images, name='Transferred')
- if 'source_images_recon' in end_points:
- pixelda_utils.summarize_transferred_grid(
- end_points['source_images_recon'],
- source_images,
- name='Source Reconstruction')
- pixelda_utils.summaries_color_distributions(end_points['transferred_images'],
- 'Transferred')
- pixelda_utils.summaries_color_distributions(target_images, 'Target')
-
- if source_images is not None:
- pixelda_utils.summarize_transferred(source_images,
- end_points['transferred_images'])
- pixelda_utils.summaries_color_distributions(source_images, 'Source')
- pixelda_utils.summaries_color_distributions(
- tf.abs(source_images - end_points['transferred_images']),
- 'Abs(Source_minus_Transferred)')
-
- number_of_steps = None
- if hparams.num_training_examples:
- # Want to control by amount of data seen, not # steps
- number_of_steps = hparams.num_training_examples / hparams.batch_size
-
- hooks = [tf.train.StepCounterHook(),]
-
- chief_only_hooks = [
- tf.train.CheckpointSaverHook(
- saver=tf.train.Saver(),
- checkpoint_dir=run_dir,
- save_secs=FLAGS.save_interval_secs)
- ]
-
- if number_of_steps:
- hooks.append(tf.train.StopAtStepHook(last_step=number_of_steps))
-
- _train(
- discriminator_train_op,
- generator_train_op,
- logdir=run_dir,
- master=FLAGS.master,
- is_chief=FLAGS.task == 0,
- hooks=hooks,
- chief_only_hooks=chief_only_hooks,
- save_checkpoint_secs=None,
- save_summaries_steps=FLAGS.save_summaries_steps,
- hparams=hparams)
-
-def main(_):
- tf.logging.set_verbosity(tf.logging.INFO)
- hparams = create_hparams(FLAGS.hparams)
- run_training(
- run_dir=FLAGS.train_log_dir,
- checkpoint_dir=FLAGS.train_log_dir,
- hparams=hparams)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py b/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py
deleted file mode 100644
index 28e8006f267f9bf7f13c3dff78625cc4cbd00185..0000000000000000000000000000000000000000
--- a/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py
+++ /dev/null
@@ -1,195 +0,0 @@
-# Copyright 2017 Google Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Utilities for PixelDA model."""
-import math
-
-# Dependency imports
-
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-
-def remove_depth(images):
- """Takes a batch of images and remove depth channel if present."""
- if images.shape.as_list()[-1] == 4:
- return images[:, :, :, 0:3]
- return images
-
-
-def image_grid(images, max_grid_size=4):
- """Given images and N, return first N^2 images as an NxN image grid.
-
- Args:
- images: a `Tensor` of size [batch_size, height, width, channels]
- max_grid_size: Maximum image grid height/width
-
- Returns:
- Single image batch, of dim [1, h*n, w*n, c]
- """
- images = remove_depth(images)
- batch_size = images.shape.as_list()[0]
- grid_size = min(int(math.sqrt(batch_size)), max_grid_size)
- assert images.shape.as_list()[0] >= grid_size * grid_size
-
- # If we have a depth channel
- if images.shape.as_list()[-1] == 4:
- images = images[:grid_size * grid_size, :, :, 0:3]
- depth = tf.image.grayscale_to_rgb(images[:grid_size * grid_size, :, :, 3:4])
-
- images = tf.reshape(images, [-1, images.shape.as_list()[2], 3])
- split = tf.split(0, grid_size, images)
- depth = tf.reshape(depth, [-1, images.shape.as_list()[2], 3])
- depth_split = tf.split(0, grid_size, depth)
- grid = tf.concat(split + depth_split, 1)
- return tf.expand_dims(grid, 0)
- else:
- images = images[:grid_size * grid_size, :, :, :]
- images = tf.reshape(
- images, [-1, images.shape.as_list()[2],
- images.shape.as_list()[3]])
- split = tf.split(images, grid_size, 0)
- grid = tf.concat(split, 1)
- return tf.expand_dims(grid, 0)
-
-
-def source_and_output_image_grid(output_images,
- source_images=None,
- max_grid_size=4):
- """Create NxN image grid for output, concatenate source grid if given.
-
- Makes grid out of output_images and, if provided, source_images, and
- concatenates them.
-
- Args:
- output_images: [batch_size, h, w, c] tensor of images
- source_images: optional[batch_size, h, w, c] tensor of images
- max_grid_size: Image grid height/width
-
- Returns:
- Single image batch, of dim [1, h*n, w*n, c]
-
-
- """
- output_grid = image_grid(output_images, max_grid_size=max_grid_size)
- if source_images is not None:
- source_grid = image_grid(source_images, max_grid_size=max_grid_size)
- # Make sure they have the same # of channels before concat
- # Assumes either 1 or 3 channels
- if output_grid.shape.as_list()[-1] != source_grid.shape.as_list()[-1]:
- if output_grid.shape.as_list()[-1] == 1:
- output_grid = tf.tile(output_grid, [1, 1, 1, 3])
- if source_grid.shape.as_list()[-1] == 1:
- source_grid = tf.tile(source_grid, [1, 1, 1, 3])
- output_grid = tf.concat([output_grid, source_grid], 1)
- return output_grid
-
-
-def summarize_model(end_points):
- """Summarizes the given model via its end_points.
-
- Args:
- end_points: A dictionary of end_point names to `Tensor`.
- """
- tf.summary.histogram('domain_logits_transferred',
- tf.sigmoid(end_points['transferred_domain_logits']))
-
- tf.summary.histogram('domain_logits_target',
- tf.sigmoid(end_points['target_domain_logits']))
-
-
-def summarize_transferred_grid(transferred_images,
- source_images=None,
- name='Transferred'):
- """Produces a visual grid summarization of the image transferrence.
-
- Args:
- transferred_images: A `Tensor` of size [batch_size, height, width, c].
- source_images: A `Tensor` of size [batch_size, height, width, c].
- name: Name to use in summary name
- """
- if source_images is not None:
- grid = source_and_output_image_grid(transferred_images, source_images)
- else:
- grid = image_grid(transferred_images)
- tf.summary.image('%s_Images_Grid' % name, grid, max_outputs=1)
-
-
-def summarize_transferred(source_images,
- transferred_images,
- max_images=20,
- name='Transferred'):
- """Produces a visual summary of the image transferrence.
-
- This summary displays the source image, transferred image, and a grayscale
- difference image which highlights the differences between input and output.
-
- Args:
- source_images: A `Tensor` of size [batch_size, height, width, channels].
- transferred_images: A `Tensor` of size [batch_size, height, width, channels]
- max_images: The number of images to show.
- name: Name to use in summary name
-
- Raises:
- ValueError: If number of channels in source and target are incompatible
- """
- source_channels = source_images.shape.as_list()[-1]
- transferred_channels = transferred_images.shape.as_list()[-1]
- if source_channels < transferred_channels:
- if source_channels != 1:
- raise ValueError(
- 'Source must be 1 channel or same # of channels as target')
- source_images = tf.tile(source_images, [1, 1, 1, transferred_channels])
- if transferred_channels < source_channels:
- if transferred_channels != 1:
- raise ValueError(
- 'Target must be 1 channel or same # of channels as source')
- transferred_images = tf.tile(transferred_images, [1, 1, 1, source_channels])
- diffs = tf.abs(source_images - transferred_images)
- diffs = tf.reduce_max(diffs, reduction_indices=[3], keep_dims=True)
- diffs = tf.tile(diffs, [1, 1, 1, max(source_channels, transferred_channels)])
-
- transition_images = tf.concat([
- source_images,
- transferred_images,
- diffs,
- ], 2)
-
- tf.summary.image(
- '%s_difference' % name, transition_images, max_outputs=max_images)
-
-
-def summaries_color_distributions(images, name):
- """Produces a histogram of the color distributions of the images.
-
- Args:
- images: A `Tensor` of size [batch_size, height, width, 3].
- name: The name of the images being summarized.
- """
- tf.summary.histogram('color_values/%s' % name, images)
-
-
-def summarize_images(images, name):
- """Produces a visual summary of the given images.
-
- Args:
- images: A `Tensor` of size [batch_size, height, width, 3].
- name: The name of the images being summarized.
- """
- grid = image_grid(images)
- tf.summary.image('%s_Images' % name, grid, max_outputs=1)
diff --git a/research/efficient-hrl/README.md b/research/efficient-hrl/README.md
deleted file mode 100755
index 6c454c687a3b75e9cf68d1f3737d74b464167e14..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/README.md
+++ /dev/null
@@ -1,65 +0,0 @@
-
-
-
-Code for performing Hierarchical RL based on the following publications:
-
-"Data-Efficient Hierarchical Reinforcement Learning" by
-Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, and Sergey Levine
-(https://arxiv.org/abs/1805.08296).
-
-"Near-Optimal Representation Learning for Hierarchical Reinforcement Learning"
-by Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, and Sergey Levine
-(https://arxiv.org/abs/1810.01257).
-
-
-Requirements:
-* TensorFlow (see http://www.tensorflow.org for how to install/upgrade)
-* Gin Config (see https://github.com/google/gin-config)
-* Tensorflow Agents (see https://github.com/tensorflow/agents)
-* OpenAI Gym (see http://gym.openai.com/docs, be sure to install MuJoCo as well)
-* NumPy (see http://www.numpy.org/)
-
-
-Quick Start:
-
-Run a training job based on the original HIRO paper on Ant Maze:
-
-```
-python scripts/local_train.py test1 hiro_orig ant_maze base_uvf suite
-```
-
-Run a continuous evaluation job for that experiment:
-
-```
-python scripts/local_eval.py test1 hiro_orig ant_maze base_uvf suite
-```
-
-To run the same experiment with online representation learning (the
-"Near-Optimal" paper), change `hiro_orig` to `hiro_repr`.
-You can also run with `hiro_xy` to run the same experiment with HIRO on only the
-xy coordinates of the agent.
-
-To run on other environments, change `ant_maze` to something else; e.g.,
-`ant_push_multi`, `ant_fall_multi`, etc. See `context/configs/*` for other options.
-
-
-Basic Code Guide:
-
-The code for training resides in train.py. The code trains a lower-level policy
-(a UVF agent in the code) and a higher-level policy (a MetaAgent in the code)
-concurrently. The higher-level policy communicates goals to the lower-level
-policy. In the code, this is called a context. Not only does the lower-level
-policy act with respect to a context (a higher-level specified goal), but the
-higher-level policy also acts with respect to an environment-specified context
-(corresponding to the navigation target location associated with the task).
-Therefore, in `context/configs/*` you will find both specifications for task setup
-as well as goal configurations. Most remaining hyperparameters used for
-training/evaluation may be found in `configs/*`.
-
-NOTE: Not all the code corresponding to the "Near-Optimal" paper is included.
-Namely, changes to low-level policy training proposed in the paper (discounting
-and auxiliary rewards) are not implemented here. Performance should not change
-significantly.
-
-
-Maintained by Ofir Nachum (ofirnachum).
diff --git a/research/efficient-hrl/agent.py b/research/efficient-hrl/agent.py
deleted file mode 100644
index 0028ddffa0d37a0e80d2c990e6263a3d9b4ab948..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/agent.py
+++ /dev/null
@@ -1,774 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A UVF agent.
-"""
-
-import tensorflow as tf
-import gin.tf
-from agents import ddpg_agent
-# pylint: disable=unused-import
-import cond_fn
-from utils import utils as uvf_utils
-from context import gin_imports
-# pylint: enable=unused-import
-slim = tf.contrib.slim
-
-
-@gin.configurable
-class UvfAgentCore(object):
- """Defines basic functions for UVF agent. Must be inherited with an RL agent.
-
- Used as lower-level agent.
- """
-
- def __init__(self,
- observation_spec,
- action_spec,
- tf_env,
- tf_context,
- step_cond_fn=cond_fn.env_transition,
- reset_episode_cond_fn=cond_fn.env_restart,
- reset_env_cond_fn=cond_fn.false_fn,
- metrics=None,
- **base_agent_kwargs):
- """Constructs a UVF agent.
-
- Args:
- observation_spec: A TensorSpec defining the observations.
- action_spec: A BoundedTensorSpec defining the actions.
- tf_env: A Tensorflow environment object.
- tf_context: A Context class.
- step_cond_fn: A function indicating whether to increment the num of steps.
- reset_episode_cond_fn: A function indicating whether to restart the
- episode, resampling the context.
- reset_env_cond_fn: A function indicating whether to perform a manual reset
- of the environment.
- metrics: A list of functions that evaluate metrics of the agent.
- **base_agent_kwargs: A dictionary of parameters for base RL Agent.
- Raises:
- ValueError: If 'dqda_clipping' is < 0.
- """
- self._step_cond_fn = step_cond_fn
- self._reset_episode_cond_fn = reset_episode_cond_fn
- self._reset_env_cond_fn = reset_env_cond_fn
- self.metrics = metrics
-
- # expose tf_context methods
- self.tf_context = tf_context(tf_env=tf_env)
- self.set_replay = self.tf_context.set_replay
- self.sample_contexts = self.tf_context.sample_contexts
- self.compute_rewards = self.tf_context.compute_rewards
- self.gamma_index = self.tf_context.gamma_index
- self.context_specs = self.tf_context.context_specs
- self.context_as_action_specs = self.tf_context.context_as_action_specs
- self.init_context_vars = self.tf_context.create_vars
-
- self.env_observation_spec = observation_spec[0]
- merged_observation_spec = (uvf_utils.merge_specs(
- (self.env_observation_spec,) + self.context_specs),)
- self._context_vars = dict()
- self._action_vars = dict()
-
- self.BASE_AGENT_CLASS.__init__(
- self,
- observation_spec=merged_observation_spec,
- action_spec=action_spec,
- **base_agent_kwargs
- )
-
- def set_meta_agent(self, agent=None):
- self._meta_agent = agent
-
- @property
- def meta_agent(self):
- return self._meta_agent
-
- def actor_loss(self, states, actions, rewards, discounts,
- next_states):
- """Returns the next action for the state.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- context: A list of [num_context_dims] tensor representing a context.
- Returns:
- A [num_action_dims] tensor representing the action.
- """
- return self.BASE_AGENT_CLASS.actor_loss(self, states)
-
- def action(self, state, context=None):
- """Returns the next action for the state.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- context: A list of [num_context_dims] tensor representing a context.
- Returns:
- A [num_action_dims] tensor representing the action.
- """
- merged_state = self.merged_state(state, context)
- return self.BASE_AGENT_CLASS.action(self, merged_state)
-
- def actions(self, state, context=None):
- """Returns the next action for the state.
-
- Args:
- state: A [-1, num_state_dims] tensor representing a state.
- context: A list of [-1, num_context_dims] tensor representing a context.
- Returns:
- A [-1, num_action_dims] tensor representing the action.
- """
- merged_states = self.merged_states(state, context)
- return self.BASE_AGENT_CLASS.actor_net(self, merged_states)
-
- def log_probs(self, states, actions, state_reprs, contexts=None):
- assert contexts is not None
- batch_dims = [tf.shape(states)[0], tf.shape(states)[1]]
- contexts = self.tf_context.context_multi_transition_fn(
- contexts, states=tf.to_float(state_reprs))
-
- flat_states = tf.reshape(states,
- [batch_dims[0] * batch_dims[1], states.shape[-1]])
- flat_contexts = [tf.reshape(tf.cast(context, states.dtype),
- [batch_dims[0] * batch_dims[1], context.shape[-1]])
- for context in contexts]
- flat_pred_actions = self.actions(flat_states, flat_contexts)
- pred_actions = tf.reshape(flat_pred_actions,
- batch_dims + [flat_pred_actions.shape[-1]])
-
- error = tf.square(actions - pred_actions)
- spec_range = (self._action_spec.maximum - self._action_spec.minimum) / 2
- normalized_error = tf.cast(error, tf.float64) / tf.constant(spec_range) ** 2
- return -normalized_error
-
- @gin.configurable('uvf_add_noise_fn')
- def add_noise_fn(self, action_fn, stddev=1.0, debug=False,
- clip=True, global_step=None):
- """Returns the action_fn with additive Gaussian noise.
-
- Args:
- action_fn: A callable(`state`, `context`) which returns a
- [num_action_dims] tensor representing a action.
- stddev: stddev for the Ornstein-Uhlenbeck noise.
- debug: Print debug messages.
- Returns:
- A [num_action_dims] action tensor.
- """
- if global_step is not None:
- stddev *= tf.maximum( # Decay exploration during training.
- tf.train.exponential_decay(1.0, global_step, 1e6, 0.8), 0.5)
- def noisy_action_fn(state, context=None):
- """Noisy action fn."""
- action = action_fn(state, context)
- if debug:
- action = uvf_utils.tf_print(
- action, [action],
- message='[add_noise_fn] pre-noise action',
- first_n=100)
- noise_dist = tf.distributions.Normal(tf.zeros_like(action),
- tf.ones_like(action) * stddev)
- noise = noise_dist.sample()
- action += noise
- if debug:
- action = uvf_utils.tf_print(
- action, [action],
- message='[add_noise_fn] post-noise action',
- first_n=100)
- if clip:
- action = uvf_utils.clip_to_spec(action, self._action_spec)
- return action
- return noisy_action_fn
-
- def merged_state(self, state, context=None):
- """Returns the merged state from the environment state and contexts.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- context: A list of [num_context_dims] tensor representing a context.
- If None, use the internal context.
- Returns:
- A [num_merged_state_dims] tensor representing the merged state.
- """
- if context is None:
- context = list(self.context_vars)
- state = tf.concat([state,] + context, axis=-1)
- self._validate_states(self._batch_state(state))
- return state
-
- def merged_states(self, states, contexts=None):
- """Returns the batch merged state from the batch env state and contexts.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- contexts: A list of [batch_size, num_context_dims] tensor
- representing a batch of contexts. If None,
- use the internal context.
- Returns:
- A [batch_size, num_merged_state_dims] tensor representing the batch
- of merged states.
- """
- if contexts is None:
- contexts = [tf.tile(tf.expand_dims(context, axis=0),
- (tf.shape(states)[0], 1)) for
- context in self.context_vars]
- states = tf.concat([states,] + contexts, axis=-1)
- self._validate_states(states)
- return states
-
- def unmerged_states(self, merged_states):
- """Returns the batch state and contexts from the batch merged state.
-
- Args:
- merged_states: A [batch_size, num_merged_state_dims] tensor
- representing a batch of merged states.
- Returns:
- A [batch_size, num_state_dims] tensor and a list of
- [batch_size, num_context_dims] tensors representing the batch state
- and contexts respectively.
- """
- self._validate_states(merged_states)
- num_state_dims = self.env_observation_spec.shape.as_list()[0]
- num_context_dims_list = [c.shape.as_list()[0] for c in self.context_specs]
- states = merged_states[:, :num_state_dims]
- contexts = []
- i = num_state_dims
- for num_context_dims in num_context_dims_list:
- contexts.append(merged_states[:, i: i+num_context_dims])
- i += num_context_dims
- return states, contexts
-
- def sample_random_actions(self, batch_size=1):
- """Return random actions.
-
- Args:
- batch_size: Batch size.
- Returns:
- A [batch_size, num_action_dims] tensor representing the batch of actions.
- """
- actions = tf.concat(
- [
- tf.random_uniform(
- shape=(batch_size, 1),
- minval=self._action_spec.minimum[i],
- maxval=self._action_spec.maximum[i])
- for i in range(self._action_spec.shape[0].value)
- ],
- axis=1)
- return actions
-
- def clip_actions(self, actions):
- """Clip actions to spec.
-
- Args:
- actions: A [batch_size, num_action_dims] tensor representing
- the batch of actions.
- Returns:
- A [batch_size, num_action_dims] tensor representing the batch
- of clipped actions.
- """
- actions = tf.concat(
- [
- tf.clip_by_value(
- actions[:, i:i+1],
- self._action_spec.minimum[i],
- self._action_spec.maximum[i])
- for i in range(self._action_spec.shape[0].value)
- ],
- axis=1)
- return actions
-
- def mix_contexts(self, contexts, insert_contexts, indices):
- """Mix two contexts based on indices.
-
- Args:
- contexts: A list of [batch_size, num_context_dims] tensor representing
- the batch of contexts.
- insert_contexts: A list of [batch_size, num_context_dims] tensor
- representing the batch of contexts to be inserted.
- indices: A list of a list of integers denoting indices to replace.
- Returns:
- A list of resulting contexts.
- """
- if indices is None: indices = [[]] * len(contexts)
- assert len(contexts) == len(indices)
- assert all([spec.shape.ndims == 1 for spec in self.context_specs])
- mix_contexts = []
- for contexts_, insert_contexts_, indices_, spec in zip(
- contexts, insert_contexts, indices, self.context_specs):
- mix_contexts.append(
- tf.concat(
- [
- insert_contexts_[:, i:i + 1] if i in indices_ else
- contexts_[:, i:i + 1] for i in range(spec.shape.as_list()[0])
- ],
- axis=1))
- return mix_contexts
-
- def begin_episode_ops(self, mode, action_fn=None, state=None):
- """Returns ops that reset agent at beginning of episodes.
-
- Args:
- mode: a string representing the mode=[train, explore, eval].
- Returns:
- A list of ops.
- """
- all_ops = []
- for _, action_var in sorted(self._action_vars.items()):
- sample_action = self.sample_random_actions(1)[0]
- all_ops.append(tf.assign(action_var, sample_action))
- all_ops += self.tf_context.reset(mode=mode, agent=self._meta_agent,
- action_fn=action_fn, state=state)
- return all_ops
-
- def cond_begin_episode_op(self, cond, input_vars, mode, meta_action_fn):
- """Returns op that resets agent at beginning of episodes.
-
- A new episode is begun if the cond op evalues to `False`.
-
- Args:
- cond: a Boolean tensor variable.
- input_vars: A list of tensor variables.
- mode: a string representing the mode=[train, explore, eval].
- Returns:
- Conditional begin op.
- """
- (state, action, reward, next_state,
- state_repr, next_state_repr) = input_vars
- def continue_fn():
- """Continue op fn."""
- items = [state, action, reward, next_state,
- state_repr, next_state_repr] + list(self.context_vars)
- batch_items = [tf.expand_dims(item, 0) for item in items]
- (states, actions, rewards, next_states,
- state_reprs, next_state_reprs) = batch_items[:6]
- context_reward = self.compute_rewards(
- mode, state_reprs, actions, rewards, next_state_reprs,
- batch_items[6:])[0][0]
- context_reward = tf.cast(context_reward, dtype=reward.dtype)
- if self.meta_agent is not None:
- meta_action = tf.concat(self.context_vars, -1)
- items = [state, meta_action, reward, next_state,
- state_repr, next_state_repr] + list(self.meta_agent.context_vars)
- batch_items = [tf.expand_dims(item, 0) for item in items]
- (states, meta_actions, rewards, next_states,
- state_reprs, next_state_reprs) = batch_items[:6]
- meta_reward = self.meta_agent.compute_rewards(
- mode, states, meta_actions, rewards,
- next_states, batch_items[6:])[0][0]
- meta_reward = tf.cast(meta_reward, dtype=reward.dtype)
- else:
- meta_reward = tf.constant(0, dtype=reward.dtype)
-
- with tf.control_dependencies([context_reward, meta_reward]):
- step_ops = self.tf_context.step(mode=mode, agent=self._meta_agent,
- state=state,
- next_state=next_state,
- state_repr=state_repr,
- next_state_repr=next_state_repr,
- action_fn=meta_action_fn)
- with tf.control_dependencies(step_ops):
- context_reward, meta_reward = map(tf.identity, [context_reward, meta_reward])
- return context_reward, meta_reward
- def begin_episode_fn():
- """Begin op fn."""
- begin_ops = self.begin_episode_ops(mode=mode, action_fn=meta_action_fn, state=state)
- with tf.control_dependencies(begin_ops):
- return tf.zeros_like(reward), tf.zeros_like(reward)
- with tf.control_dependencies(input_vars):
- cond_begin_episode_op = tf.cond(cond, continue_fn, begin_episode_fn)
- return cond_begin_episode_op
-
- def get_env_base_wrapper(self, env_base, **begin_kwargs):
- """Create a wrapper around env_base, with agent-specific begin/end_episode.
-
- Args:
- env_base: A python environment base.
- **begin_kwargs: Keyword args for begin_episode_ops.
- Returns:
- An object with begin_episode() and end_episode().
- """
- begin_ops = self.begin_episode_ops(**begin_kwargs)
- return uvf_utils.get_contextual_env_base(env_base, begin_ops)
-
- def init_action_vars(self, name, i=None):
- """Create and return a tensorflow Variable holding an action.
-
- Args:
- name: Name of the variables.
- i: Integer id.
- Returns:
- A [num_action_dims] tensor.
- """
- if i is not None:
- name += '_%d' % i
- assert name not in self._action_vars, ('Conflict! %s is already '
- 'initialized.') % name
- self._action_vars[name] = tf.Variable(
- self.sample_random_actions(1)[0], name='%s_action' % (name))
- self._validate_actions(tf.expand_dims(self._action_vars[name], 0))
- return self._action_vars[name]
-
- @gin.configurable('uvf_critic_function')
- def critic_function(self, critic_vals, states, critic_fn=None):
- """Computes q values based on outputs from the critic net.
-
- Args:
- critic_vals: A tf.float32 [batch_size, ...] tensor representing outputs
- from the critic net.
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- critic_fn: A callable that process outputs from critic_net and
- outputs a [batch_size] tensor representing q values.
- Returns:
- A tf.float32 [batch_size] tensor representing q values.
- """
- if critic_fn is not None:
- env_states, contexts = self.unmerged_states(states)
- critic_vals = critic_fn(critic_vals, env_states, contexts)
- critic_vals.shape.assert_has_rank(1)
- return critic_vals
-
- def get_action_vars(self, key):
- return self._action_vars[key]
-
- def get_context_vars(self, key):
- return self.tf_context.context_vars[key]
-
- def step_cond_fn(self, *args):
- return self._step_cond_fn(self, *args)
-
- def reset_episode_cond_fn(self, *args):
- return self._reset_episode_cond_fn(self, *args)
-
- def reset_env_cond_fn(self, *args):
- return self._reset_env_cond_fn(self, *args)
-
- @property
- def context_vars(self):
- return self.tf_context.vars
-
-
-@gin.configurable
-class MetaAgentCore(UvfAgentCore):
- """Defines basic functions for UVF Meta-agent. Must be inherited with an RL agent.
-
- Used as higher-level agent.
- """
-
- def __init__(self,
- observation_spec,
- action_spec,
- tf_env,
- tf_context,
- sub_context,
- step_cond_fn=cond_fn.env_transition,
- reset_episode_cond_fn=cond_fn.env_restart,
- reset_env_cond_fn=cond_fn.false_fn,
- metrics=None,
- actions_reg=0.,
- k=2,
- **base_agent_kwargs):
- """Constructs a Meta agent.
-
- Args:
- observation_spec: A TensorSpec defining the observations.
- action_spec: A BoundedTensorSpec defining the actions.
- tf_env: A Tensorflow environment object.
- tf_context: A Context class.
- step_cond_fn: A function indicating whether to increment the num of steps.
- reset_episode_cond_fn: A function indicating whether to restart the
- episode, resampling the context.
- reset_env_cond_fn: A function indicating whether to perform a manual reset
- of the environment.
- metrics: A list of functions that evaluate metrics of the agent.
- **base_agent_kwargs: A dictionary of parameters for base RL Agent.
- Raises:
- ValueError: If 'dqda_clipping' is < 0.
- """
- self._step_cond_fn = step_cond_fn
- self._reset_episode_cond_fn = reset_episode_cond_fn
- self._reset_env_cond_fn = reset_env_cond_fn
- self.metrics = metrics
- self._actions_reg = actions_reg
- self._k = k
-
- # expose tf_context methods
- self.tf_context = tf_context(tf_env=tf_env)
- self.sub_context = sub_context(tf_env=tf_env)
- self.set_replay = self.tf_context.set_replay
- self.sample_contexts = self.tf_context.sample_contexts
- self.compute_rewards = self.tf_context.compute_rewards
- self.gamma_index = self.tf_context.gamma_index
- self.context_specs = self.tf_context.context_specs
- self.context_as_action_specs = self.tf_context.context_as_action_specs
- self.sub_context_as_action_specs = self.sub_context.context_as_action_specs
- self.init_context_vars = self.tf_context.create_vars
-
- self.env_observation_spec = observation_spec[0]
- merged_observation_spec = (uvf_utils.merge_specs(
- (self.env_observation_spec,) + self.context_specs),)
- self._context_vars = dict()
- self._action_vars = dict()
-
- assert len(self.context_as_action_specs) == 1
- self.BASE_AGENT_CLASS.__init__(
- self,
- observation_spec=merged_observation_spec,
- action_spec=self.sub_context_as_action_specs,
- **base_agent_kwargs
- )
-
- @gin.configurable('meta_add_noise_fn')
- def add_noise_fn(self, action_fn, stddev=1.0, debug=False,
- global_step=None):
- noisy_action_fn = super(MetaAgentCore, self).add_noise_fn(
- action_fn, stddev,
- clip=True, global_step=global_step)
- return noisy_action_fn
-
- def actor_loss(self, states, actions, rewards, discounts,
- next_states):
- """Returns the next action for the state.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- context: A list of [num_context_dims] tensor representing a context.
- Returns:
- A [num_action_dims] tensor representing the action.
- """
- actions = self.actor_net(states, stop_gradients=False)
- regularizer = self._actions_reg * tf.reduce_mean(
- tf.reduce_sum(tf.abs(actions[:, self._k:]), -1), 0)
- loss = self.BASE_AGENT_CLASS.actor_loss(self, states)
- return regularizer + loss
-
-
-@gin.configurable
-class UvfAgent(UvfAgentCore, ddpg_agent.TD3Agent):
- """A DDPG agent with UVF.
- """
- BASE_AGENT_CLASS = ddpg_agent.TD3Agent
- ACTION_TYPE = 'continuous'
-
- def __init__(self, *args, **kwargs):
- UvfAgentCore.__init__(self, *args, **kwargs)
-
-
-@gin.configurable
-class MetaAgent(MetaAgentCore, ddpg_agent.TD3Agent):
- """A DDPG meta-agent.
- """
- BASE_AGENT_CLASS = ddpg_agent.TD3Agent
- ACTION_TYPE = 'continuous'
-
- def __init__(self, *args, **kwargs):
- MetaAgentCore.__init__(self, *args, **kwargs)
-
-
-@gin.configurable()
-def state_preprocess_net(
- states,
- num_output_dims=2,
- states_hidden_layers=(100,),
- normalizer_fn=None,
- activation_fn=tf.nn.relu,
- zero_time=True,
- images=False):
- """Creates a simple feed forward net for embedding states.
- """
- with slim.arg_scope(
- [slim.fully_connected],
- activation_fn=activation_fn,
- normalizer_fn=normalizer_fn,
- weights_initializer=slim.variance_scaling_initializer(
- factor=1.0/3.0, mode='FAN_IN', uniform=True)):
-
- states_shape = tf.shape(states)
- states_dtype = states.dtype
- states = tf.to_float(states)
- if images: # Zero-out x-y
- states *= tf.constant([0.] * 2 + [1.] * (states.shape[-1] - 2), dtype=states.dtype)
- if zero_time:
- states *= tf.constant([1.] * (states.shape[-1] - 1) + [0.], dtype=states.dtype)
- orig_states = states
- embed = states
- if states_hidden_layers:
- embed = slim.stack(embed, slim.fully_connected, states_hidden_layers,
- scope='states')
-
- with slim.arg_scope([slim.fully_connected],
- weights_regularizer=None,
- weights_initializer=tf.random_uniform_initializer(
- minval=-0.003, maxval=0.003)):
- embed = slim.fully_connected(embed, num_output_dims,
- activation_fn=None,
- normalizer_fn=None,
- scope='value')
-
- output = embed
- output = tf.cast(output, states_dtype)
- return output
-
-
-@gin.configurable()
-def action_embed_net(
- actions,
- states=None,
- num_output_dims=2,
- hidden_layers=(400, 300),
- normalizer_fn=None,
- activation_fn=tf.nn.relu,
- zero_time=True,
- images=False):
- """Creates a simple feed forward net for embedding actions.
- """
- with slim.arg_scope(
- [slim.fully_connected],
- activation_fn=activation_fn,
- normalizer_fn=normalizer_fn,
- weights_initializer=slim.variance_scaling_initializer(
- factor=1.0/3.0, mode='FAN_IN', uniform=True)):
-
- actions = tf.to_float(actions)
- if states is not None:
- if images: # Zero-out x-y
- states *= tf.constant([0.] * 2 + [1.] * (states.shape[-1] - 2), dtype=states.dtype)
- if zero_time:
- states *= tf.constant([1.] * (states.shape[-1] - 1) + [0.], dtype=states.dtype)
- actions = tf.concat([actions, tf.to_float(states)], -1)
-
- embed = actions
- if hidden_layers:
- embed = slim.stack(embed, slim.fully_connected, hidden_layers,
- scope='hidden')
-
- with slim.arg_scope([slim.fully_connected],
- weights_regularizer=None,
- weights_initializer=tf.random_uniform_initializer(
- minval=-0.003, maxval=0.003)):
- embed = slim.fully_connected(embed, num_output_dims,
- activation_fn=None,
- normalizer_fn=None,
- scope='value')
- if num_output_dims == 1:
- return embed[:, 0, ...]
- else:
- return embed
-
-
-def huber(x, kappa=0.1):
- return (0.5 * tf.square(x) * tf.to_float(tf.abs(x) <= kappa) +
- kappa * (tf.abs(x) - 0.5 * kappa) * tf.to_float(tf.abs(x) > kappa)
- ) / kappa
-
-
-@gin.configurable()
-class StatePreprocess(object):
- STATE_PREPROCESS_NET_SCOPE = 'state_process_net'
- ACTION_EMBED_NET_SCOPE = 'action_embed_net'
-
- def __init__(self, trainable=False,
- state_preprocess_net=lambda states: states,
- action_embed_net=lambda actions, *args, **kwargs: actions,
- ndims=None):
- self.trainable = trainable
- self._scope = tf.get_variable_scope().name
- self._ndims = ndims
- self._state_preprocess_net = tf.make_template(
- self.STATE_PREPROCESS_NET_SCOPE, state_preprocess_net,
- create_scope_now_=True)
- self._action_embed_net = tf.make_template(
- self.ACTION_EMBED_NET_SCOPE, action_embed_net,
- create_scope_now_=True)
-
- def __call__(self, states):
- batched = states.get_shape().ndims != 1
- if not batched:
- states = tf.expand_dims(states, 0)
- embedded = self._state_preprocess_net(states)
- if self._ndims is not None:
- embedded = embedded[..., :self._ndims]
- if not batched:
- return embedded[0]
- return embedded
-
- def loss(self, states, next_states, low_actions, low_states):
- batch_size = tf.shape(states)[0]
- d = int(low_states.shape[1])
- # Sample indices into meta-transition to train on.
- probs = 0.99 ** tf.range(d, dtype=tf.float32)
- probs *= tf.constant([1.0] * (d - 1) + [1.0 / (1 - 0.99)],
- dtype=tf.float32)
- probs /= tf.reduce_sum(probs)
- index_dist = tf.distributions.Categorical(probs=probs, dtype=tf.int64)
- indices = index_dist.sample(batch_size)
- batch_size = tf.cast(batch_size, tf.int64)
- next_indices = tf.concat(
- [tf.range(batch_size, dtype=tf.int64)[:, None],
- (1 + indices[:, None]) % d], -1)
- new_next_states = tf.where(indices < d - 1,
- tf.gather_nd(low_states, next_indices),
- next_states)
- next_states = new_next_states
-
- embed1 = tf.to_float(self._state_preprocess_net(states))
- embed2 = tf.to_float(self._state_preprocess_net(next_states))
- action_embed = self._action_embed_net(
- tf.layers.flatten(low_actions), states=states)
-
- tau = 2.0
- fn = lambda z: tau * tf.reduce_sum(huber(z), -1)
- all_embed = tf.get_variable('all_embed', [1024, int(embed1.shape[-1])],
- initializer=tf.zeros_initializer())
- upd = all_embed.assign(tf.concat([all_embed[batch_size:], embed2], 0))
- with tf.control_dependencies([upd]):
- close = 1 * tf.reduce_mean(fn(embed1 + action_embed - embed2))
- prior_log_probs = tf.reduce_logsumexp(
- -fn((embed1 + action_embed)[:, None, :] - all_embed[None, :, :]),
- axis=-1) - tf.log(tf.to_float(all_embed.shape[0]))
- far = tf.reduce_mean(tf.exp(-fn((embed1 + action_embed)[1:] - embed2[:-1])
- - tf.stop_gradient(prior_log_probs[1:])))
- repr_log_probs = tf.stop_gradient(
- -fn(embed1 + action_embed - embed2) - prior_log_probs) / tau
- return close + far, repr_log_probs, indices
-
- def get_trainable_vars(self):
- return (
- slim.get_trainable_variables(
- uvf_utils.join_scope(self._scope, self.STATE_PREPROCESS_NET_SCOPE)) +
- slim.get_trainable_variables(
- uvf_utils.join_scope(self._scope, self.ACTION_EMBED_NET_SCOPE)))
-
-
-@gin.configurable()
-class InverseDynamics(object):
- INVERSE_DYNAMICS_NET_SCOPE = 'inverse_dynamics'
-
- def __init__(self, spec):
- self._spec = spec
-
- def sample(self, states, next_states, num_samples, orig_goals, sc=0.5):
- goal_dim = orig_goals.shape[-1]
- spec_range = (self._spec.maximum - self._spec.minimum) / 2 * tf.ones([goal_dim])
- loc = tf.cast(next_states - states, tf.float32)[:, :goal_dim]
- scale = sc * tf.tile(tf.reshape(spec_range, [1, goal_dim]),
- [tf.shape(states)[0], 1])
- dist = tf.distributions.Normal(loc, scale)
- if num_samples == 1:
- return dist.sample()
- samples = tf.concat([dist.sample(num_samples - 2),
- tf.expand_dims(loc, 0),
- tf.expand_dims(orig_goals, 0)], 0)
- return uvf_utils.clip_to_spec(samples, self._spec)
diff --git a/research/efficient-hrl/agents/__init__.py b/research/efficient-hrl/agents/__init__.py
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/agents/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/research/efficient-hrl/agents/circular_buffer.py b/research/efficient-hrl/agents/circular_buffer.py
deleted file mode 100644
index 72f90f0de89bf99956436e54a84bbcba903df6e7..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/agents/circular_buffer.py
+++ /dev/null
@@ -1,289 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A circular buffer where each element is a list of tensors.
-
-Each element of the buffer is a list of tensors. An example use case is a replay
-buffer in reinforcement learning, where each element is a list of tensors
-representing the state, action, reward etc.
-
-New elements are added sequentially, and once the buffer is full, we
-start overwriting them in a circular fashion. Reading does not remove any
-elements, only adding new elements does.
-"""
-
-import collections
-import numpy as np
-import tensorflow as tf
-
-import gin.tf
-
-
-@gin.configurable
-class CircularBuffer(object):
- """A circular buffer where each element is a list of tensors."""
-
- def __init__(self, buffer_size=1000, scope='replay_buffer'):
- """Circular buffer of list of tensors.
-
- Args:
- buffer_size: (integer) maximum number of tensor lists the buffer can hold.
- scope: (string) variable scope for creating the variables.
- """
- self._buffer_size = np.int64(buffer_size)
- self._scope = scope
- self._tensors = collections.OrderedDict()
- with tf.variable_scope(self._scope):
- self._num_adds = tf.Variable(0, dtype=tf.int64, name='num_adds')
- self._num_adds_cs = tf.CriticalSection(name='num_adds')
-
- @property
- def buffer_size(self):
- return self._buffer_size
-
- @property
- def scope(self):
- return self._scope
-
- @property
- def num_adds(self):
- return self._num_adds
-
- def _create_variables(self, tensors):
- with tf.variable_scope(self._scope):
- for name in tensors.keys():
- tensor = tensors[name]
- self._tensors[name] = tf.get_variable(
- name='BufferVariable_' + name,
- shape=[self._buffer_size] + tensor.get_shape().as_list(),
- dtype=tensor.dtype,
- trainable=False)
-
- def _validate(self, tensors):
- """Validate shapes of tensors."""
- if len(tensors) != len(self._tensors):
- raise ValueError('Expected tensors to have %d elements. Received %d '
- 'instead.' % (len(self._tensors), len(tensors)))
- if self._tensors.keys() != tensors.keys():
- raise ValueError('The keys of tensors should be the always the same.'
- 'Received %s instead %s.' %
- (tensors.keys(), self._tensors.keys()))
- for name, tensor in tensors.items():
- if tensor.get_shape().as_list() != self._tensors[
- name].get_shape().as_list()[1:]:
- raise ValueError('Tensor %s has incorrect shape.' % name)
- if not tensor.dtype.is_compatible_with(self._tensors[name].dtype):
- raise ValueError(
- 'Tensor %s has incorrect data type. Expected %s, received %s' %
- (name, self._tensors[name].read_value().dtype, tensor.dtype))
-
- def add(self, tensors):
- """Adds an element (list/tuple/dict of tensors) to the buffer.
-
- Args:
- tensors: (list/tuple/dict of tensors) to be added to the buffer.
- Returns:
- An add operation that adds the input `tensors` to the buffer. Similar to
- an enqueue_op.
- Raises:
- ValueError: If the shapes and data types of input `tensors' are not the
- same across calls to the add function.
- """
- return self.maybe_add(tensors, True)
-
- def maybe_add(self, tensors, condition):
- """Adds an element (tensors) to the buffer based on the condition..
-
- Args:
- tensors: (list/tuple of tensors) to be added to the buffer.
- condition: A boolean Tensor controlling whether the tensors would be added
- to the buffer or not.
- Returns:
- An add operation that adds the input `tensors` to the buffer. Similar to
- an maybe_enqueue_op.
- Raises:
- ValueError: If the shapes and data types of input `tensors' are not the
- same across calls to the add function.
- """
- if not isinstance(tensors, dict):
- names = [str(i) for i in range(len(tensors))]
- tensors = collections.OrderedDict(zip(names, tensors))
- if not isinstance(tensors, collections.OrderedDict):
- tensors = collections.OrderedDict(
- sorted(tensors.items(), key=lambda t: t[0]))
- if not self._tensors:
- self._create_variables(tensors)
- else:
- self._validate(tensors)
-
- #@tf.critical_section(self._position_mutex)
- def _increment_num_adds():
- # Adding 0 to the num_adds variable is a trick to read the value of the
- # variable and return a read-only tensor. Doing this in a critical
- # section allows us to capture a snapshot of the variable that will
- # not be affected by other threads updating num_adds.
- return self._num_adds.assign_add(1) + 0
- def _add():
- num_adds_inc = self._num_adds_cs.execute(_increment_num_adds)
- current_pos = tf.mod(num_adds_inc - 1, self._buffer_size)
- update_ops = []
- for name in self._tensors.keys():
- update_ops.append(
- tf.scatter_update(self._tensors[name], current_pos, tensors[name]))
- return tf.group(*update_ops)
-
- return tf.contrib.framework.smart_cond(condition, _add, tf.no_op)
-
- def get_random_batch(self, batch_size, keys=None, num_steps=1):
- """Samples a batch of tensors from the buffer with replacement.
-
- Args:
- batch_size: (integer) number of elements to sample.
- keys: List of keys of tensors to retrieve. If None retrieve all.
- num_steps: (integer) length of trajectories to return. If > 1 will return
- a list of lists, where each internal list represents a trajectory of
- length num_steps.
- Returns:
- A list of tensors, where each element in the list is a batch sampled from
- one of the tensors in the buffer.
- Raises:
- ValueError: If get_random_batch is called before calling the add function.
- tf.errors.InvalidArgumentError: If this operation is executed before any
- items are added to the buffer.
- """
- if not self._tensors:
- raise ValueError('The add function must be called before get_random_batch.')
- if keys is None:
- keys = self._tensors.keys()
-
- latest_start_index = self.get_num_adds() - num_steps + 1
- empty_buffer_assert = tf.Assert(
- tf.greater(latest_start_index, 0),
- ['Not enough elements have been added to the buffer.'])
- with tf.control_dependencies([empty_buffer_assert]):
- max_index = tf.minimum(self._buffer_size, latest_start_index)
- indices = tf.random_uniform(
- [batch_size],
- minval=0,
- maxval=max_index,
- dtype=tf.int64)
- if num_steps == 1:
- return self.gather(indices, keys)
- else:
- return self.gather_nstep(num_steps, indices, keys)
-
- def gather(self, indices, keys=None):
- """Returns elements at the specified indices from the buffer.
-
- Args:
- indices: (list of integers or rank 1 int Tensor) indices in the buffer to
- retrieve elements from.
- keys: List of keys of tensors to retrieve. If None retrieve all.
- Returns:
- A list of tensors, where each element in the list is obtained by indexing
- one of the tensors in the buffer.
- Raises:
- ValueError: If gather is called before calling the add function.
- tf.errors.InvalidArgumentError: If indices are bigger than the number of
- items in the buffer.
- """
- if not self._tensors:
- raise ValueError('The add function must be called before calling gather.')
- if keys is None:
- keys = self._tensors.keys()
- with tf.name_scope('Gather'):
- index_bound_assert = tf.Assert(
- tf.less(
- tf.to_int64(tf.reduce_max(indices)),
- tf.minimum(self.get_num_adds(), self._buffer_size)),
- ['Index out of bounds.'])
- with tf.control_dependencies([index_bound_assert]):
- indices = tf.convert_to_tensor(indices)
-
- batch = []
- for key in keys:
- batch.append(tf.gather(self._tensors[key], indices, name=key))
- return batch
-
- def gather_nstep(self, num_steps, indices, keys=None):
- """Returns elements at the specified indices from the buffer.
-
- Args:
- num_steps: (integer) length of trajectories to return.
- indices: (list of rank num_steps int Tensor) indices in the buffer to
- retrieve elements from for multiple trajectories. Each Tensor in the
- list represents the indices for a trajectory.
- keys: List of keys of tensors to retrieve. If None retrieve all.
- Returns:
- A list of list-of-tensors, where each element in the list is obtained by
- indexing one of the tensors in the buffer.
- Raises:
- ValueError: If gather is called before calling the add function.
- tf.errors.InvalidArgumentError: If indices are bigger than the number of
- items in the buffer.
- """
- if not self._tensors:
- raise ValueError('The add function must be called before calling gather.')
- if keys is None:
- keys = self._tensors.keys()
- with tf.name_scope('Gather'):
- index_bound_assert = tf.Assert(
- tf.less_equal(
- tf.to_int64(tf.reduce_max(indices) + num_steps),
- self.get_num_adds()),
- ['Trajectory indices go out of bounds.'])
- with tf.control_dependencies([index_bound_assert]):
- indices = tf.map_fn(
- lambda x: tf.mod(tf.range(x, x + num_steps), self._buffer_size),
- indices,
- dtype=tf.int64)
-
- batch = []
- for key in keys:
-
- def SampleTrajectories(trajectory_indices, key=key,
- num_steps=num_steps):
- trajectory_indices.set_shape([num_steps])
- return tf.gather(self._tensors[key], trajectory_indices, name=key)
-
- batch.append(tf.map_fn(SampleTrajectories, indices,
- dtype=self._tensors[key].dtype))
- return batch
-
- def get_position(self):
- """Returns the position at which the last element was added.
-
- Returns:
- An int tensor representing the index at which the last element was added
- to the buffer or -1 if no elements were added.
- """
- return tf.cond(self.get_num_adds() < 1,
- lambda: self.get_num_adds() - 1,
- lambda: tf.mod(self.get_num_adds() - 1, self._buffer_size))
-
- def get_num_adds(self):
- """Returns the number of additions to the buffer.
-
- Returns:
- An int tensor representing the number of elements that were added.
- """
- def num_adds():
- return self._num_adds.value()
-
- return self._num_adds_cs.execute(num_adds)
-
- def get_num_tensors(self):
- """Returns the number of tensors (slots) in the buffer."""
- return len(self._tensors)
diff --git a/research/efficient-hrl/agents/ddpg_agent.py b/research/efficient-hrl/agents/ddpg_agent.py
deleted file mode 100644
index 904eb6502717e30681d5a3d50437c31b2aa580b2..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/agents/ddpg_agent.py
+++ /dev/null
@@ -1,739 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A DDPG/NAF agent.
-
-Implements the Deep Deterministic Policy Gradient (DDPG) algorithm from
-"Continuous control with deep reinforcement learning" - Lilicrap et al.
-https://arxiv.org/abs/1509.02971, and the Normalized Advantage Functions (NAF)
-algorithm "Continuous Deep Q-Learning with Model-based Acceleration" - Gu et al.
-https://arxiv.org/pdf/1603.00748.
-"""
-
-import tensorflow as tf
-slim = tf.contrib.slim
-import gin.tf
-from utils import utils
-from agents import ddpg_networks as networks
-
-
-@gin.configurable
-class DdpgAgent(object):
- """An RL agent that learns using the DDPG algorithm.
-
- Example usage:
-
- def critic_net(states, actions):
- ...
- def actor_net(states, num_action_dims):
- ...
-
- Given a tensorflow environment tf_env,
- (of type learning.deepmind.rl.environments.tensorflow.python.tfpyenvironment)
-
- obs_spec = tf_env.observation_spec()
- action_spec = tf_env.action_spec()
-
- ddpg_agent = agent.DdpgAgent(obs_spec,
- action_spec,
- actor_net=actor_net,
- critic_net=critic_net)
-
- we can perform actions on the environment as follows:
-
- state = tf_env.observations()[0]
- action = ddpg_agent.actor_net(tf.expand_dims(state, 0))[0, :]
- transition_type, reward, discount = tf_env.step([action])
-
- Train:
-
- critic_loss = ddpg_agent.critic_loss(states, actions, rewards, discounts,
- next_states)
- actor_loss = ddpg_agent.actor_loss(states)
-
- critic_train_op = slim.learning.create_train_op(
- critic_loss,
- critic_optimizer,
- variables_to_train=ddpg_agent.get_trainable_critic_vars(),
- )
-
- actor_train_op = slim.learning.create_train_op(
- actor_loss,
- actor_optimizer,
- variables_to_train=ddpg_agent.get_trainable_actor_vars(),
- )
- """
-
- ACTOR_NET_SCOPE = 'actor_net'
- CRITIC_NET_SCOPE = 'critic_net'
- TARGET_ACTOR_NET_SCOPE = 'target_actor_net'
- TARGET_CRITIC_NET_SCOPE = 'target_critic_net'
-
- def __init__(self,
- observation_spec,
- action_spec,
- actor_net=networks.actor_net,
- critic_net=networks.critic_net,
- td_errors_loss=tf.losses.huber_loss,
- dqda_clipping=0.,
- actions_regularizer=0.,
- target_q_clipping=None,
- residual_phi=0.0,
- debug_summaries=False):
- """Constructs a DDPG agent.
-
- Args:
- observation_spec: A TensorSpec defining the observations.
- action_spec: A BoundedTensorSpec defining the actions.
- actor_net: A callable that creates the actor network. Must take the
- following arguments: states, num_actions. Please see networks.actor_net
- for an example.
- critic_net: A callable that creates the critic network. Must take the
- following arguments: states, actions. Please see networks.critic_net
- for an example.
- td_errors_loss: A callable defining the loss function for the critic
- td error.
- dqda_clipping: (float) clips the gradient dqda element-wise between
- [-dqda_clipping, dqda_clipping]. Does not perform clipping if
- dqda_clipping == 0.
- actions_regularizer: A scalar, when positive penalizes the norm of the
- actions. This can prevent saturation of actions for the actor_loss.
- target_q_clipping: (tuple of floats) clips target q values within
- (low, high) values when computing the critic loss.
- residual_phi: (float) [0.0, 1.0] Residual algorithm parameter that
- interpolates between Q-learning and residual gradient algorithm.
- http://www.leemon.com/papers/1995b.pdf
- debug_summaries: If True, add summaries to help debug behavior.
- Raises:
- ValueError: If 'dqda_clipping' is < 0.
- """
- self._observation_spec = observation_spec[0]
- self._action_spec = action_spec[0]
- self._state_shape = tf.TensorShape([None]).concatenate(
- self._observation_spec.shape)
- self._action_shape = tf.TensorShape([None]).concatenate(
- self._action_spec.shape)
- self._num_action_dims = self._action_spec.shape.num_elements()
-
- self._scope = tf.get_variable_scope().name
- self._actor_net = tf.make_template(
- self.ACTOR_NET_SCOPE, actor_net, create_scope_now_=True)
- self._critic_net = tf.make_template(
- self.CRITIC_NET_SCOPE, critic_net, create_scope_now_=True)
- self._target_actor_net = tf.make_template(
- self.TARGET_ACTOR_NET_SCOPE, actor_net, create_scope_now_=True)
- self._target_critic_net = tf.make_template(
- self.TARGET_CRITIC_NET_SCOPE, critic_net, create_scope_now_=True)
- self._td_errors_loss = td_errors_loss
- if dqda_clipping < 0:
- raise ValueError('dqda_clipping must be >= 0.')
- self._dqda_clipping = dqda_clipping
- self._actions_regularizer = actions_regularizer
- self._target_q_clipping = target_q_clipping
- self._residual_phi = residual_phi
- self._debug_summaries = debug_summaries
-
- def _batch_state(self, state):
- """Convert state to a batched state.
-
- Args:
- state: Either a list/tuple with an state tensor [num_state_dims].
- Returns:
- A tensor [1, num_state_dims]
- """
- if isinstance(state, (tuple, list)):
- state = state[0]
- if state.get_shape().ndims == 1:
- state = tf.expand_dims(state, 0)
- return state
-
- def action(self, state):
- """Returns the next action for the state.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- Returns:
- A [num_action_dims] tensor representing the action.
- """
- return self.actor_net(self._batch_state(state), stop_gradients=True)[0, :]
-
- @gin.configurable('ddpg_sample_action')
- def sample_action(self, state, stddev=1.0):
- """Returns the action for the state with additive noise.
-
- Args:
- state: A [num_state_dims] tensor representing a state.
- stddev: stddev for the Ornstein-Uhlenbeck noise.
- Returns:
- A [num_action_dims] action tensor.
- """
- agent_action = self.action(state)
- agent_action += tf.random_normal(tf.shape(agent_action)) * stddev
- return utils.clip_to_spec(agent_action, self._action_spec)
-
- def actor_net(self, states, stop_gradients=False):
- """Returns the output of the actor network.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- stop_gradients: (boolean) if true, gradients cannot be propogated through
- this operation.
- Returns:
- A [batch_size, num_action_dims] tensor of actions.
- Raises:
- ValueError: If `states` does not have the expected dimensions.
- """
- self._validate_states(states)
- actions = self._actor_net(states, self._action_spec)
- if stop_gradients:
- actions = tf.stop_gradient(actions)
- return actions
-
- def critic_net(self, states, actions, for_critic_loss=False):
- """Returns the output of the critic network.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] tensor representing a batch
- of actions.
- Returns:
- q values: A [batch_size] tensor of q values.
- Raises:
- ValueError: If `states` or `actions' do not have the expected dimensions.
- """
- self._validate_states(states)
- self._validate_actions(actions)
- return self._critic_net(states, actions,
- for_critic_loss=for_critic_loss)
-
- def target_actor_net(self, states):
- """Returns the output of the target actor network.
-
- The target network is used to compute stable targets for training.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- A [batch_size, num_action_dims] tensor of actions.
- Raises:
- ValueError: If `states` does not have the expected dimensions.
- """
- self._validate_states(states)
- actions = self._target_actor_net(states, self._action_spec)
- return tf.stop_gradient(actions)
-
- def target_critic_net(self, states, actions, for_critic_loss=False):
- """Returns the output of the target critic network.
-
- The target network is used to compute stable targets for training.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] tensor representing a batch
- of actions.
- Returns:
- q values: A [batch_size] tensor of q values.
- Raises:
- ValueError: If `states` or `actions' do not have the expected dimensions.
- """
- self._validate_states(states)
- self._validate_actions(actions)
- return tf.stop_gradient(
- self._target_critic_net(states, actions,
- for_critic_loss=for_critic_loss))
-
- def value_net(self, states, for_critic_loss=False):
- """Returns the output of the critic evaluated with the actor.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- q values: A [batch_size] tensor of q values.
- """
- actions = self.actor_net(states)
- return self.critic_net(states, actions,
- for_critic_loss=for_critic_loss)
-
- def target_value_net(self, states, for_critic_loss=False):
- """Returns the output of the target critic evaluated with the target actor.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- q values: A [batch_size] tensor of q values.
- """
- target_actions = self.target_actor_net(states)
- return self.target_critic_net(states, target_actions,
- for_critic_loss=for_critic_loss)
-
- def critic_loss(self, states, actions, rewards, discounts,
- next_states):
- """Computes a loss for training the critic network.
-
- The loss is the mean squared error between the Q value predictions of the
- critic and Q values estimated using TD-lambda.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] tensor representing a batch
- of actions.
- rewards: A [batch_size, ...] tensor representing a batch of rewards,
- broadcastable to the critic net output.
- discounts: A [batch_size, ...] tensor representing a batch of discounts,
- broadcastable to the critic net output.
- next_states: A [batch_size, num_state_dims] tensor representing a batch
- of next states.
- Returns:
- A rank-0 tensor representing the critic loss.
- Raises:
- ValueError: If any of the inputs do not have the expected dimensions, or
- if their batch_sizes do not match.
- """
- self._validate_states(states)
- self._validate_actions(actions)
- self._validate_states(next_states)
-
- target_q_values = self.target_value_net(next_states, for_critic_loss=True)
- td_targets = target_q_values * discounts + rewards
- if self._target_q_clipping is not None:
- td_targets = tf.clip_by_value(td_targets, self._target_q_clipping[0],
- self._target_q_clipping[1])
- q_values = self.critic_net(states, actions, for_critic_loss=True)
- td_errors = td_targets - q_values
- if self._debug_summaries:
- gen_debug_td_error_summaries(
- target_q_values, q_values, td_targets, td_errors)
-
- loss = self._td_errors_loss(td_targets, q_values)
-
- if self._residual_phi > 0.0: # compute residual gradient loss
- residual_q_values = self.value_net(next_states, for_critic_loss=True)
- residual_td_targets = residual_q_values * discounts + rewards
- if self._target_q_clipping is not None:
- residual_td_targets = tf.clip_by_value(residual_td_targets,
- self._target_q_clipping[0],
- self._target_q_clipping[1])
- residual_td_errors = residual_td_targets - q_values
- residual_loss = self._td_errors_loss(
- residual_td_targets, residual_q_values)
- loss = (loss * (1.0 - self._residual_phi) +
- residual_loss * self._residual_phi)
- return loss
-
- def actor_loss(self, states):
- """Computes a loss for training the actor network.
-
- Note that output does not represent an actual loss. It is called a loss only
- in the sense that its gradient w.r.t. the actor network weights is the
- correct gradient for training the actor network,
- i.e. dloss/dweights = (dq/da)*(da/dweights)
- which is the gradient used in Algorithm 1 of Lilicrap et al.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- A rank-0 tensor representing the actor loss.
- Raises:
- ValueError: If `states` does not have the expected dimensions.
- """
- self._validate_states(states)
- actions = self.actor_net(states, stop_gradients=False)
- critic_values = self.critic_net(states, actions)
- q_values = self.critic_function(critic_values, states)
- dqda = tf.gradients([q_values], [actions])[0]
- dqda_unclipped = dqda
- if self._dqda_clipping > 0:
- dqda = tf.clip_by_value(dqda, -self._dqda_clipping, self._dqda_clipping)
-
- actions_norm = tf.norm(actions)
- if self._debug_summaries:
- with tf.name_scope('dqda'):
- tf.summary.scalar('actions_norm', actions_norm)
- tf.summary.histogram('dqda', dqda)
- tf.summary.histogram('dqda_unclipped', dqda_unclipped)
- tf.summary.histogram('actions', actions)
- for a in range(self._num_action_dims):
- tf.summary.histogram('dqda_unclipped_%d' % a, dqda_unclipped[:, a])
- tf.summary.histogram('dqda_%d' % a, dqda[:, a])
-
- actions_norm *= self._actions_regularizer
- return slim.losses.mean_squared_error(tf.stop_gradient(dqda + actions),
- actions,
- scope='actor_loss') + actions_norm
-
- @gin.configurable('ddpg_critic_function')
- def critic_function(self, critic_values, states, weights=None):
- """Computes q values based on critic_net outputs, states, and weights.
-
- Args:
- critic_values: A tf.float32 [batch_size, ...] tensor representing outputs
- from the critic net.
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- weights: A list or Numpy array or tensor with a shape broadcastable to
- `critic_values`.
- Returns:
- A tf.float32 [batch_size] tensor representing q values.
- """
- del states # unused args
- if weights is not None:
- weights = tf.convert_to_tensor(weights, dtype=critic_values.dtype)
- critic_values *= weights
- if critic_values.shape.ndims > 1:
- critic_values = tf.reduce_sum(critic_values,
- range(1, critic_values.shape.ndims))
- critic_values.shape.assert_has_rank(1)
- return critic_values
-
- @gin.configurable('ddpg_update_targets')
- def update_targets(self, tau=1.0):
- """Performs a soft update of the target network parameters.
-
- For each weight w_s in the actor/critic networks, and its corresponding
- weight w_t in the target actor/critic networks, a soft update is:
- w_t = (1- tau) x w_t + tau x ws
-
- Args:
- tau: A float scalar in [0, 1]
- Returns:
- An operation that performs a soft update of the target network parameters.
- Raises:
- ValueError: If `tau` is not in [0, 1].
- """
- if tau < 0 or tau > 1:
- raise ValueError('Input `tau` should be in [0, 1].')
- update_actor = utils.soft_variables_update(
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)),
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.TARGET_ACTOR_NET_SCOPE)),
- tau)
- update_critic = utils.soft_variables_update(
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)),
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.TARGET_CRITIC_NET_SCOPE)),
- tau)
- return tf.group(update_actor, update_critic, name='update_targets')
-
- def get_trainable_critic_vars(self):
- """Returns a list of trainable variables in the critic network.
-
- Returns:
- A list of trainable variables in the critic network.
- """
- return slim.get_trainable_variables(
- utils.join_scope(self._scope, self.CRITIC_NET_SCOPE))
-
- def get_trainable_actor_vars(self):
- """Returns a list of trainable variables in the actor network.
-
- Returns:
- A list of trainable variables in the actor network.
- """
- return slim.get_trainable_variables(
- utils.join_scope(self._scope, self.ACTOR_NET_SCOPE))
-
- def get_critic_vars(self):
- """Returns a list of all variables in the critic network.
-
- Returns:
- A list of trainable variables in the critic network.
- """
- return slim.get_model_variables(
- utils.join_scope(self._scope, self.CRITIC_NET_SCOPE))
-
- def get_actor_vars(self):
- """Returns a list of all variables in the actor network.
-
- Returns:
- A list of trainable variables in the actor network.
- """
- return slim.get_model_variables(
- utils.join_scope(self._scope, self.ACTOR_NET_SCOPE))
-
- def _validate_states(self, states):
- """Raises a value error if `states` does not have the expected shape.
-
- Args:
- states: A tensor.
- Raises:
- ValueError: If states.shape or states.dtype are not compatible with
- observation_spec.
- """
- states.shape.assert_is_compatible_with(self._state_shape)
- if not states.dtype.is_compatible_with(self._observation_spec.dtype):
- raise ValueError('states.dtype={} is not compatible with'
- ' observation_spec.dtype={}'.format(
- states.dtype, self._observation_spec.dtype))
-
- def _validate_actions(self, actions):
- """Raises a value error if `actions` does not have the expected shape.
-
- Args:
- actions: A tensor.
- Raises:
- ValueError: If actions.shape or actions.dtype are not compatible with
- action_spec.
- """
- actions.shape.assert_is_compatible_with(self._action_shape)
- if not actions.dtype.is_compatible_with(self._action_spec.dtype):
- raise ValueError('actions.dtype={} is not compatible with'
- ' action_spec.dtype={}'.format(
- actions.dtype, self._action_spec.dtype))
-
-
-@gin.configurable
-class TD3Agent(DdpgAgent):
- """An RL agent that learns using the TD3 algorithm."""
-
- ACTOR_NET_SCOPE = 'actor_net'
- CRITIC_NET_SCOPE = 'critic_net'
- CRITIC_NET2_SCOPE = 'critic_net2'
- TARGET_ACTOR_NET_SCOPE = 'target_actor_net'
- TARGET_CRITIC_NET_SCOPE = 'target_critic_net'
- TARGET_CRITIC_NET2_SCOPE = 'target_critic_net2'
-
- def __init__(self,
- observation_spec,
- action_spec,
- actor_net=networks.actor_net,
- critic_net=networks.critic_net,
- td_errors_loss=tf.losses.huber_loss,
- dqda_clipping=0.,
- actions_regularizer=0.,
- target_q_clipping=None,
- residual_phi=0.0,
- debug_summaries=False):
- """Constructs a TD3 agent.
-
- Args:
- observation_spec: A TensorSpec defining the observations.
- action_spec: A BoundedTensorSpec defining the actions.
- actor_net: A callable that creates the actor network. Must take the
- following arguments: states, num_actions. Please see networks.actor_net
- for an example.
- critic_net: A callable that creates the critic network. Must take the
- following arguments: states, actions. Please see networks.critic_net
- for an example.
- td_errors_loss: A callable defining the loss function for the critic
- td error.
- dqda_clipping: (float) clips the gradient dqda element-wise between
- [-dqda_clipping, dqda_clipping]. Does not perform clipping if
- dqda_clipping == 0.
- actions_regularizer: A scalar, when positive penalizes the norm of the
- actions. This can prevent saturation of actions for the actor_loss.
- target_q_clipping: (tuple of floats) clips target q values within
- (low, high) values when computing the critic loss.
- residual_phi: (float) [0.0, 1.0] Residual algorithm parameter that
- interpolates between Q-learning and residual gradient algorithm.
- http://www.leemon.com/papers/1995b.pdf
- debug_summaries: If True, add summaries to help debug behavior.
- Raises:
- ValueError: If 'dqda_clipping' is < 0.
- """
- self._observation_spec = observation_spec[0]
- self._action_spec = action_spec[0]
- self._state_shape = tf.TensorShape([None]).concatenate(
- self._observation_spec.shape)
- self._action_shape = tf.TensorShape([None]).concatenate(
- self._action_spec.shape)
- self._num_action_dims = self._action_spec.shape.num_elements()
-
- self._scope = tf.get_variable_scope().name
- self._actor_net = tf.make_template(
- self.ACTOR_NET_SCOPE, actor_net, create_scope_now_=True)
- self._critic_net = tf.make_template(
- self.CRITIC_NET_SCOPE, critic_net, create_scope_now_=True)
- self._critic_net2 = tf.make_template(
- self.CRITIC_NET2_SCOPE, critic_net, create_scope_now_=True)
- self._target_actor_net = tf.make_template(
- self.TARGET_ACTOR_NET_SCOPE, actor_net, create_scope_now_=True)
- self._target_critic_net = tf.make_template(
- self.TARGET_CRITIC_NET_SCOPE, critic_net, create_scope_now_=True)
- self._target_critic_net2 = tf.make_template(
- self.TARGET_CRITIC_NET2_SCOPE, critic_net, create_scope_now_=True)
- self._td_errors_loss = td_errors_loss
- if dqda_clipping < 0:
- raise ValueError('dqda_clipping must be >= 0.')
- self._dqda_clipping = dqda_clipping
- self._actions_regularizer = actions_regularizer
- self._target_q_clipping = target_q_clipping
- self._residual_phi = residual_phi
- self._debug_summaries = debug_summaries
-
- def get_trainable_critic_vars(self):
- """Returns a list of trainable variables in the critic network.
- NOTE: This gets the vars of both critic networks.
-
- Returns:
- A list of trainable variables in the critic network.
- """
- return (
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)))
-
- def critic_net(self, states, actions, for_critic_loss=False):
- """Returns the output of the critic network.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] tensor representing a batch
- of actions.
- Returns:
- q values: A [batch_size] tensor of q values.
- Raises:
- ValueError: If `states` or `actions' do not have the expected dimensions.
- """
- values1 = self._critic_net(states, actions,
- for_critic_loss=for_critic_loss)
- values2 = self._critic_net2(states, actions,
- for_critic_loss=for_critic_loss)
- if for_critic_loss:
- return values1, values2
- return values1
-
- def target_critic_net(self, states, actions, for_critic_loss=False):
- """Returns the output of the target critic network.
-
- The target network is used to compute stable targets for training.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] tensor representing a batch
- of actions.
- Returns:
- q values: A [batch_size] tensor of q values.
- Raises:
- ValueError: If `states` or `actions' do not have the expected dimensions.
- """
- self._validate_states(states)
- self._validate_actions(actions)
- values1 = tf.stop_gradient(
- self._target_critic_net(states, actions,
- for_critic_loss=for_critic_loss))
- values2 = tf.stop_gradient(
- self._target_critic_net2(states, actions,
- for_critic_loss=for_critic_loss))
- if for_critic_loss:
- return values1, values2
- return values1
-
- def value_net(self, states, for_critic_loss=False):
- """Returns the output of the critic evaluated with the actor.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- q values: A [batch_size] tensor of q values.
- """
- actions = self.actor_net(states)
- return self.critic_net(states, actions,
- for_critic_loss=for_critic_loss)
-
- def target_value_net(self, states, for_critic_loss=False):
- """Returns the output of the target critic evaluated with the target actor.
-
- Args:
- states: A [batch_size, num_state_dims] tensor representing a batch
- of states.
- Returns:
- q values: A [batch_size] tensor of q values.
- """
- target_actions = self.target_actor_net(states)
- noise = tf.clip_by_value(
- tf.random_normal(tf.shape(target_actions), stddev=0.2), -0.5, 0.5)
- values1, values2 = self.target_critic_net(
- states, target_actions + noise,
- for_critic_loss=for_critic_loss)
- values = tf.minimum(values1, values2)
- return values, values
-
- @gin.configurable('td3_update_targets')
- def update_targets(self, tau=1.0):
- """Performs a soft update of the target network parameters.
-
- For each weight w_s in the actor/critic networks, and its corresponding
- weight w_t in the target actor/critic networks, a soft update is:
- w_t = (1- tau) x w_t + tau x ws
-
- Args:
- tau: A float scalar in [0, 1]
- Returns:
- An operation that performs a soft update of the target network parameters.
- Raises:
- ValueError: If `tau` is not in [0, 1].
- """
- if tau < 0 or tau > 1:
- raise ValueError('Input `tau` should be in [0, 1].')
- update_actor = utils.soft_variables_update(
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)),
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.TARGET_ACTOR_NET_SCOPE)),
- tau)
- # NOTE: This updates both critic networks.
- update_critic = utils.soft_variables_update(
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)),
- slim.get_trainable_variables(
- utils.join_scope(self._scope, self.TARGET_CRITIC_NET_SCOPE)),
- tau)
- return tf.group(update_actor, update_critic, name='update_targets')
-
-
-def gen_debug_td_error_summaries(
- target_q_values, q_values, td_targets, td_errors):
- """Generates debug summaries for critic given a set of batch samples.
-
- Args:
- target_q_values: set of predicted next stage values.
- q_values: current predicted value for the critic network.
- td_targets: discounted target_q_values with added next stage reward.
- td_errors: the different between td_targets and q_values.
- """
- with tf.name_scope('td_errors'):
- tf.summary.histogram('td_targets', td_targets)
- tf.summary.histogram('q_values', q_values)
- tf.summary.histogram('target_q_values', target_q_values)
- tf.summary.histogram('td_errors', td_errors)
- with tf.name_scope('td_targets'):
- tf.summary.scalar('mean', tf.reduce_mean(td_targets))
- tf.summary.scalar('max', tf.reduce_max(td_targets))
- tf.summary.scalar('min', tf.reduce_min(td_targets))
- with tf.name_scope('q_values'):
- tf.summary.scalar('mean', tf.reduce_mean(q_values))
- tf.summary.scalar('max', tf.reduce_max(q_values))
- tf.summary.scalar('min', tf.reduce_min(q_values))
- with tf.name_scope('target_q_values'):
- tf.summary.scalar('mean', tf.reduce_mean(target_q_values))
- tf.summary.scalar('max', tf.reduce_max(target_q_values))
- tf.summary.scalar('min', tf.reduce_min(target_q_values))
- with tf.name_scope('td_errors'):
- tf.summary.scalar('mean', tf.reduce_mean(td_errors))
- tf.summary.scalar('max', tf.reduce_max(td_errors))
- tf.summary.scalar('min', tf.reduce_min(td_errors))
- tf.summary.scalar('mean_abs', tf.reduce_mean(tf.abs(td_errors)))
diff --git a/research/efficient-hrl/agents/ddpg_networks.py b/research/efficient-hrl/agents/ddpg_networks.py
deleted file mode 100644
index 63074dfb91cf950b602212936ab2560db818c3a4..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/agents/ddpg_networks.py
+++ /dev/null
@@ -1,150 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Sample actor(policy) and critic(q) networks to use with DDPG/NAF agents.
-
-The DDPG networks are defined in "Section 7: Experiment Details" of
-"Continuous control with deep reinforcement learning" - Lilicrap et al.
-https://arxiv.org/abs/1509.02971
-
-The NAF critic network is based on "Section 4" of "Continuous deep Q-learning
-with model-based acceleration" - Gu et al. https://arxiv.org/pdf/1603.00748.
-"""
-
-import tensorflow as tf
-slim = tf.contrib.slim
-import gin.tf
-
-
-@gin.configurable('ddpg_critic_net')
-def critic_net(states, actions,
- for_critic_loss=False,
- num_reward_dims=1,
- states_hidden_layers=(400,),
- actions_hidden_layers=None,
- joint_hidden_layers=(300,),
- weight_decay=0.0001,
- normalizer_fn=None,
- activation_fn=tf.nn.relu,
- zero_obs=False,
- images=False):
- """Creates a critic that returns q values for the given states and actions.
-
- Args:
- states: (castable to tf.float32) a [batch_size, num_state_dims] tensor
- representing a batch of states.
- actions: (castable to tf.float32) a [batch_size, num_action_dims] tensor
- representing a batch of actions.
- num_reward_dims: Number of reward dimensions.
- states_hidden_layers: tuple of hidden layers units for states.
- actions_hidden_layers: tuple of hidden layers units for actions.
- joint_hidden_layers: tuple of hidden layers units after joining states
- and actions using tf.concat().
- weight_decay: Weight decay for l2 weights regularizer.
- normalizer_fn: Normalizer function, i.e. slim.layer_norm,
- activation_fn: Activation function, i.e. tf.nn.relu, slim.leaky_relu, ...
- Returns:
- A tf.float32 [batch_size] tensor of q values, or a tf.float32
- [batch_size, num_reward_dims] tensor of vector q values if
- num_reward_dims > 1.
- """
- with slim.arg_scope(
- [slim.fully_connected],
- activation_fn=activation_fn,
- normalizer_fn=normalizer_fn,
- weights_regularizer=slim.l2_regularizer(weight_decay),
- weights_initializer=slim.variance_scaling_initializer(
- factor=1.0/3.0, mode='FAN_IN', uniform=True)):
-
- orig_states = tf.to_float(states)
- #states = tf.to_float(states)
- states = tf.concat([tf.to_float(states), tf.to_float(actions)], -1) #TD3
- if images or zero_obs:
- states *= tf.constant([0.0] * 2 + [1.0] * (states.shape[1] - 2)) #LALA
- actions = tf.to_float(actions)
- if states_hidden_layers:
- states = slim.stack(states, slim.fully_connected, states_hidden_layers,
- scope='states')
- if actions_hidden_layers:
- actions = slim.stack(actions, slim.fully_connected, actions_hidden_layers,
- scope='actions')
- joint = tf.concat([states, actions], 1)
- if joint_hidden_layers:
- joint = slim.stack(joint, slim.fully_connected, joint_hidden_layers,
- scope='joint')
- with slim.arg_scope([slim.fully_connected],
- weights_regularizer=None,
- weights_initializer=tf.random_uniform_initializer(
- minval=-0.003, maxval=0.003)):
- value = slim.fully_connected(joint, num_reward_dims,
- activation_fn=None,
- normalizer_fn=None,
- scope='q_value')
- if num_reward_dims == 1:
- value = tf.reshape(value, [-1])
- if not for_critic_loss and num_reward_dims > 1:
- value = tf.reduce_sum(
- value * tf.abs(orig_states[:, -num_reward_dims:]), -1)
- return value
-
-
-@gin.configurable('ddpg_actor_net')
-def actor_net(states, action_spec,
- hidden_layers=(400, 300),
- normalizer_fn=None,
- activation_fn=tf.nn.relu,
- zero_obs=False,
- images=False):
- """Creates an actor that returns actions for the given states.
-
- Args:
- states: (castable to tf.float32) a [batch_size, num_state_dims] tensor
- representing a batch of states.
- action_spec: (BoundedTensorSpec) A tensor spec indicating the shape
- and range of actions.
- hidden_layers: tuple of hidden layers units.
- normalizer_fn: Normalizer function, i.e. slim.layer_norm,
- activation_fn: Activation function, i.e. tf.nn.relu, slim.leaky_relu, ...
- Returns:
- A tf.float32 [batch_size, num_action_dims] tensor of actions.
- """
-
- with slim.arg_scope(
- [slim.fully_connected],
- activation_fn=activation_fn,
- normalizer_fn=normalizer_fn,
- weights_initializer=slim.variance_scaling_initializer(
- factor=1.0/3.0, mode='FAN_IN', uniform=True)):
-
- states = tf.to_float(states)
- orig_states = states
- if images or zero_obs: # Zero-out x, y position. Hacky.
- states *= tf.constant([0.0] * 2 + [1.0] * (states.shape[1] - 2))
- if hidden_layers:
- states = slim.stack(states, slim.fully_connected, hidden_layers,
- scope='states')
- with slim.arg_scope([slim.fully_connected],
- weights_initializer=tf.random_uniform_initializer(
- minval=-0.003, maxval=0.003)):
- actions = slim.fully_connected(states,
- action_spec.shape.num_elements(),
- scope='actions',
- normalizer_fn=None,
- activation_fn=tf.nn.tanh)
- action_means = (action_spec.maximum + action_spec.minimum) / 2.0
- action_magnitudes = (action_spec.maximum - action_spec.minimum) / 2.0
- actions = action_means + action_magnitudes * actions
-
- return actions
diff --git a/research/efficient-hrl/cond_fn.py b/research/efficient-hrl/cond_fn.py
deleted file mode 100644
index cd1a276e136bf69fa453c3b90c5907eecb1bda1e..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/cond_fn.py
+++ /dev/null
@@ -1,244 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Defines many boolean functions indicating when to step and reset.
-"""
-
-import tensorflow as tf
-import gin.tf
-
-
-@gin.configurable
-def env_transition(agent, state, action, transition_type, environment_steps,
- num_episodes):
- """True if the transition_type is TRANSITION or FINAL_TRANSITION.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- Returns:
- cond: Returns an op that evaluates to true if the transition type is
- not RESTARTING
- """
- del agent, state, action, num_episodes, environment_steps
- cond = tf.logical_not(transition_type)
- return cond
-
-
-@gin.configurable
-def env_restart(agent, state, action, transition_type, environment_steps,
- num_episodes):
- """True if the transition_type is RESTARTING.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- Returns:
- cond: Returns an op that evaluates to true if the transition type equals
- RESTARTING.
- """
- del agent, state, action, num_episodes, environment_steps
- cond = tf.identity(transition_type)
- return cond
-
-
-@gin.configurable
-def every_n_steps(agent,
- state,
- action,
- transition_type,
- environment_steps,
- num_episodes,
- n=150):
- """True once every n steps.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- n: Return true once every n steps.
- Returns:
- cond: Returns an op that evaluates to true if environment_steps
- equals 0 mod n. We increment the step before checking this condition, so
- we do not need to add one to environment_steps.
- """
- del agent, state, action, transition_type, num_episodes
- cond = tf.equal(tf.mod(environment_steps, n), 0)
- return cond
-
-
-@gin.configurable
-def every_n_episodes(agent,
- state,
- action,
- transition_type,
- environment_steps,
- num_episodes,
- n=2,
- steps_per_episode=None):
- """True once every n episodes.
-
- Specifically, evaluates to True on the 0th step of every nth episode.
- Unlike environment_steps, num_episodes starts at 0, so we do want to add
- one to ensure it does not reset on the first call.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- n: Return true once every n episodes.
- steps_per_episode: How many steps per episode. Needed to determine when a
- new episode starts.
- Returns:
- cond: Returns an op that evaluates to true on the last step of the episode
- (i.e. if num_episodes equals 0 mod n).
- """
- assert steps_per_episode is not None
- del agent, action, transition_type
- ant_fell = tf.logical_or(state[2] < 0.2, state[2] > 1.0)
- cond = tf.logical_and(
- tf.logical_or(
- ant_fell,
- tf.equal(tf.mod(num_episodes + 1, n), 0)),
- tf.equal(tf.mod(environment_steps, steps_per_episode), 0))
- return cond
-
-
-@gin.configurable
-def failed_reset_after_n_episodes(agent,
- state,
- action,
- transition_type,
- environment_steps,
- num_episodes,
- steps_per_episode=None,
- reset_state=None,
- max_dist=1.0,
- epsilon=1e-10):
- """Every n episodes, returns True if the reset agent fails to return.
-
- Specifically, evaluates to True if the distance between the state and the
- reset state is greater than max_dist at the end of the episode.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- steps_per_episode: How many steps per episode. Needed to determine when a
- new episode starts.
- reset_state: State to which the reset controller should return.
- max_dist: Agent is considered to have successfully reset if its distance
- from the reset_state is less than max_dist.
- epsilon: small offset to ensure non-negative/zero distance.
- Returns:
- cond: Returns an op that evaluates to true if num_episodes+1 equals 0
- mod n. We add one to the num_episodes so the environment is not reset after
- the 0th step.
- """
- assert steps_per_episode is not None
- assert reset_state is not None
- del agent, state, action, transition_type, num_episodes
- dist = tf.sqrt(
- tf.reduce_sum(tf.squared_difference(state, reset_state)) + epsilon)
- cond = tf.logical_and(
- tf.greater(dist, tf.constant(max_dist)),
- tf.equal(tf.mod(environment_steps, steps_per_episode), 0))
- return cond
-
-
-@gin.configurable
-def q_too_small(agent,
- state,
- action,
- transition_type,
- environment_steps,
- num_episodes,
- q_min=0.5):
- """True of q is too small.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- q_min: Returns true if the qval is less than q_min
- Returns:
- cond: Returns an op that evaluates to true if qval is less than q_min.
- """
- del transition_type, environment_steps, num_episodes
- state_for_reset_agent = tf.stack(state[:-1], tf.constant([0], dtype=tf.float))
- qval = agent.BASE_AGENT_CLASS.critic_net(
- tf.expand_dims(state_for_reset_agent, 0), tf.expand_dims(action, 0))[0, :]
- cond = tf.greater(tf.constant(q_min), qval)
- return cond
-
-
-@gin.configurable
-def true_fn(agent, state, action, transition_type, environment_steps,
- num_episodes):
- """Returns an op that evaluates to true.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- Returns:
- cond: op that always evaluates to True.
- """
- del agent, state, action, transition_type, environment_steps, num_episodes
- cond = tf.constant(True, dtype=tf.bool)
- return cond
-
-
-@gin.configurable
-def false_fn(agent, state, action, transition_type, environment_steps,
- num_episodes):
- """Returns an op that evaluates to false.
-
- Args:
- agent: RL agent.
- state: A [num_state_dims] tensor representing a state.
- action: Action performed.
- transition_type: Type of transition after action
- environment_steps: Number of steps performed by environment.
- num_episodes: Number of episodes.
- Returns:
- cond: op that always evaluates to False.
- """
- del agent, state, action, transition_type, environment_steps, num_episodes
- cond = tf.constant(False, dtype=tf.bool)
- return cond
diff --git a/research/efficient-hrl/configs/base_uvf.gin b/research/efficient-hrl/configs/base_uvf.gin
deleted file mode 100644
index 2f3f47b67a3fb0a38ee35b7a4deaf54a2700a19a..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/configs/base_uvf.gin
+++ /dev/null
@@ -1,68 +0,0 @@
-#-*-Python-*-
-import gin.tf.external_configurables
-
-create_maze_env.top_down_view = %IMAGES
-## Create the agent
-AGENT_CLASS = @UvfAgent
-UvfAgent.tf_context = %CONTEXT
-UvfAgent.actor_net = @agent/ddpg_actor_net
-UvfAgent.critic_net = @agent/ddpg_critic_net
-UvfAgent.dqda_clipping = 0.0
-UvfAgent.td_errors_loss = @tf.losses.huber_loss
-UvfAgent.target_q_clipping = %TARGET_Q_CLIPPING
-
-# Create meta agent
-META_CLASS = @MetaAgent
-MetaAgent.tf_context = %META_CONTEXT
-MetaAgent.sub_context = %CONTEXT
-MetaAgent.actor_net = @meta/ddpg_actor_net
-MetaAgent.critic_net = @meta/ddpg_critic_net
-MetaAgent.dqda_clipping = 0.0
-MetaAgent.td_errors_loss = @tf.losses.huber_loss
-MetaAgent.target_q_clipping = %TARGET_Q_CLIPPING
-
-# Create state preprocess
-STATE_PREPROCESS_CLASS = @StatePreprocess
-StatePreprocess.ndims = %SUBGOAL_DIM
-state_preprocess_net.states_hidden_layers = (100, 100)
-state_preprocess_net.num_output_dims = %SUBGOAL_DIM
-state_preprocess_net.images = %IMAGES
-action_embed_net.num_output_dims = %SUBGOAL_DIM
-INVERSE_DYNAMICS_CLASS = @InverseDynamics
-
-# actor_net
-ACTOR_HIDDEN_SIZE_1 = 300
-ACTOR_HIDDEN_SIZE_2 = 300
-agent/ddpg_actor_net.hidden_layers = (%ACTOR_HIDDEN_SIZE_1, %ACTOR_HIDDEN_SIZE_2)
-agent/ddpg_actor_net.activation_fn = @tf.nn.relu
-agent/ddpg_actor_net.zero_obs = %ZERO_OBS
-agent/ddpg_actor_net.images = %IMAGES
-meta/ddpg_actor_net.hidden_layers = (%ACTOR_HIDDEN_SIZE_1, %ACTOR_HIDDEN_SIZE_2)
-meta/ddpg_actor_net.activation_fn = @tf.nn.relu
-meta/ddpg_actor_net.zero_obs = False
-meta/ddpg_actor_net.images = %IMAGES
-# critic_net
-CRITIC_HIDDEN_SIZE_1 = 300
-CRITIC_HIDDEN_SIZE_2 = 300
-agent/ddpg_critic_net.states_hidden_layers = (%CRITIC_HIDDEN_SIZE_1,)
-agent/ddpg_critic_net.actions_hidden_layers = None
-agent/ddpg_critic_net.joint_hidden_layers = (%CRITIC_HIDDEN_SIZE_2,)
-agent/ddpg_critic_net.weight_decay = 0.0
-agent/ddpg_critic_net.activation_fn = @tf.nn.relu
-agent/ddpg_critic_net.zero_obs = %ZERO_OBS
-agent/ddpg_critic_net.images = %IMAGES
-meta/ddpg_critic_net.states_hidden_layers = (%CRITIC_HIDDEN_SIZE_1,)
-meta/ddpg_critic_net.actions_hidden_layers = None
-meta/ddpg_critic_net.joint_hidden_layers = (%CRITIC_HIDDEN_SIZE_2,)
-meta/ddpg_critic_net.weight_decay = 0.0
-meta/ddpg_critic_net.activation_fn = @tf.nn.relu
-meta/ddpg_critic_net.zero_obs = False
-meta/ddpg_critic_net.images = %IMAGES
-
-tf.losses.huber_loss.delta = 1.0
-# Sample action
-uvf_add_noise_fn.stddev = 1.0
-meta_add_noise_fn.stddev = %META_EXPLORE_NOISE
-# Update targets
-ddpg_update_targets.tau = 0.001
-td3_update_targets.tau = 0.005
diff --git a/research/efficient-hrl/configs/eval_uvf.gin b/research/efficient-hrl/configs/eval_uvf.gin
deleted file mode 100644
index 7a58241e06aa4a6140faa8a74b262729f1f5e4c1..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/configs/eval_uvf.gin
+++ /dev/null
@@ -1,14 +0,0 @@
-#-*-Python-*-
-# Config eval
-evaluate.environment = @create_maze_env()
-evaluate.agent_class = %AGENT_CLASS
-evaluate.meta_agent_class = %META_CLASS
-evaluate.state_preprocess_class = %STATE_PREPROCESS_CLASS
-evaluate.num_episodes_eval = 50
-evaluate.num_episodes_videos = 1
-evaluate.gamma = 1.0
-evaluate.eval_interval_secs = 1
-evaluate.generate_videos = False
-evaluate.generate_summaries = True
-evaluate.eval_modes = %EVAL_MODES
-evaluate.max_steps_per_episode = %RESET_EPISODE_PERIOD
diff --git a/research/efficient-hrl/configs/train_uvf.gin b/research/efficient-hrl/configs/train_uvf.gin
deleted file mode 100644
index 8b02d7a6cb468f913ebaefe3fa8f519c3ad8fe4c..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/configs/train_uvf.gin
+++ /dev/null
@@ -1,52 +0,0 @@
-#-*-Python-*-
-# Create replay_buffer
-agent/CircularBuffer.buffer_size = 200000
-meta/CircularBuffer.buffer_size = 200000
-agent/CircularBuffer.scope = "agent"
-meta/CircularBuffer.scope = "meta"
-
-# Config train
-train_uvf.environment = @create_maze_env()
-train_uvf.agent_class = %AGENT_CLASS
-train_uvf.meta_agent_class = %META_CLASS
-train_uvf.state_preprocess_class = %STATE_PREPROCESS_CLASS
-train_uvf.inverse_dynamics_class = %INVERSE_DYNAMICS_CLASS
-train_uvf.replay_buffer = @agent/CircularBuffer()
-train_uvf.meta_replay_buffer = @meta/CircularBuffer()
-train_uvf.critic_optimizer = @critic/AdamOptimizer()
-train_uvf.actor_optimizer = @actor/AdamOptimizer()
-train_uvf.meta_critic_optimizer = @meta_critic/AdamOptimizer()
-train_uvf.meta_actor_optimizer = @meta_actor/AdamOptimizer()
-train_uvf.repr_optimizer = @repr/AdamOptimizer()
-train_uvf.num_episodes_train = 25000
-train_uvf.batch_size = 100
-train_uvf.initial_episodes = 5
-train_uvf.gamma = 0.99
-train_uvf.meta_gamma = 0.99
-train_uvf.reward_scale_factor = 1.0
-train_uvf.target_update_period = 2
-train_uvf.num_updates_per_observation = 1
-train_uvf.num_collect_per_update = 1
-train_uvf.num_collect_per_meta_update = 10
-train_uvf.debug_summaries = False
-train_uvf.log_every_n_steps = 1000
-train_uvf.save_policy_every_n_steps =100000
-
-# Config Optimizers
-critic/AdamOptimizer.learning_rate = 0.001
-critic/AdamOptimizer.beta1 = 0.9
-critic/AdamOptimizer.beta2 = 0.999
-actor/AdamOptimizer.learning_rate = 0.0001
-actor/AdamOptimizer.beta1 = 0.9
-actor/AdamOptimizer.beta2 = 0.999
-
-meta_critic/AdamOptimizer.learning_rate = 0.001
-meta_critic/AdamOptimizer.beta1 = 0.9
-meta_critic/AdamOptimizer.beta2 = 0.999
-meta_actor/AdamOptimizer.learning_rate = 0.0001
-meta_actor/AdamOptimizer.beta1 = 0.9
-meta_actor/AdamOptimizer.beta2 = 0.999
-
-repr/AdamOptimizer.learning_rate = 0.0001
-repr/AdamOptimizer.beta1 = 0.9
-repr/AdamOptimizer.beta2 = 0.999
diff --git a/research/efficient-hrl/context/__init__.py b/research/efficient-hrl/context/__init__.py
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/research/efficient-hrl/context/configs/ant_block.gin b/research/efficient-hrl/context/configs/ant_block.gin
deleted file mode 100644
index d5bd4f01e015611127bbc188b3ac9af3df6a288a..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_block.gin
+++ /dev/null
@@ -1,67 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntBlock"
-ZERO_OBS = False
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4), (20, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1", "eval2", "eval3"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
- "eval3": [@eval3/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [3, 4]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [16, 0]
-eval2/ConstantSampler.value = [16, 16]
-eval3/ConstantSampler.value = [0, 16]
diff --git a/research/efficient-hrl/context/configs/ant_block_maze.gin b/research/efficient-hrl/context/configs/ant_block_maze.gin
deleted file mode 100644
index cebf775be129b51588092699fbeb314fb4f985d0..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_block_maze.gin
+++ /dev/null
@@ -1,67 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntBlockMaze"
-ZERO_OBS = False
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4), (12, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1", "eval2", "eval3"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
- "eval3": [@eval3/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [3, 4]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [8, 0]
-eval2/ConstantSampler.value = [8, 16]
-eval3/ConstantSampler.value = [0, 16]
diff --git a/research/efficient-hrl/context/configs/ant_fall_multi.gin b/research/efficient-hrl/context/configs/ant_fall_multi.gin
deleted file mode 100644
index eb89ad0cb164ddb4c0c08ba9649d7f2e5d7a9944..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_fall_multi.gin
+++ /dev/null
@@ -1,62 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntFall"
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4, 0), (12, 28, 5))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [3]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1, 2]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [0, 27, 4.5]
diff --git a/research/efficient-hrl/context/configs/ant_fall_multi_img.gin b/research/efficient-hrl/context/configs/ant_fall_multi_img.gin
deleted file mode 100644
index b54fb7c91961ab38febe597325c0d816a872be20..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_fall_multi_img.gin
+++ /dev/null
@@ -1,68 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntFall"
-IMAGES = True
-
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4, 0), (12, 28, 5))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [3]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
-}
-meta/Context.context_transition_fn = @task/relative_context_transition_fn
-meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1, 2]
-task/negative_distance.relative_context = True
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-task/relative_context_transition_fn.k = 3
-task/relative_context_multi_transition_fn.k = 3
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [0, 27, 0]
diff --git a/research/efficient-hrl/context/configs/ant_fall_single.gin b/research/efficient-hrl/context/configs/ant_fall_single.gin
deleted file mode 100644
index 56bbc070072182cbcda7580c87cf65a593e8a743..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_fall_single.gin
+++ /dev/null
@@ -1,62 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntFall"
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4, 0), (12, 28, 5))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [3]
-meta/Context.samplers = {
- "train": [@eval1/ConstantSampler],
- "explore": [@eval1/ConstantSampler],
- "eval1": [@eval1/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1, 2]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [0, 27, 4.5]
diff --git a/research/efficient-hrl/context/configs/ant_maze.gin b/research/efficient-hrl/context/configs/ant_maze.gin
deleted file mode 100644
index 3a0b73e30d7054dc6d573669b7df728cff93226a..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_maze.gin
+++ /dev/null
@@ -1,66 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntMaze"
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4), (20, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1", "eval2", "eval3"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
- "eval3": [@eval3/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [16, 0]
-eval2/ConstantSampler.value = [16, 16]
-eval3/ConstantSampler.value = [0, 16]
diff --git a/research/efficient-hrl/context/configs/ant_maze_img.gin b/research/efficient-hrl/context/configs/ant_maze_img.gin
deleted file mode 100644
index ceed65a0884587d9cd64cdf162bf1b7e3495469d..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_maze_img.gin
+++ /dev/null
@@ -1,72 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntMaze"
-IMAGES = True
-
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-4, -4), (20, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1", "eval2", "eval3"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
- "eval3": [@eval3/ConstantSampler],
-}
-meta/Context.context_transition_fn = @task/relative_context_transition_fn
-meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = True
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-task/relative_context_transition_fn.k = 2
-task/relative_context_multi_transition_fn.k = 2
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [16, 0]
-eval2/ConstantSampler.value = [16, 16]
-eval3/ConstantSampler.value = [0, 16]
diff --git a/research/efficient-hrl/context/configs/ant_push_multi.gin b/research/efficient-hrl/context/configs/ant_push_multi.gin
deleted file mode 100644
index db9b4ed7bbe81fe38c9fbad10a43dde485a06802..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_push_multi.gin
+++ /dev/null
@@ -1,62 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntPush"
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-16, -4), (16, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval2"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval2": [@eval2/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval2/ConstantSampler.value = [0, 19]
diff --git a/research/efficient-hrl/context/configs/ant_push_multi_img.gin b/research/efficient-hrl/context/configs/ant_push_multi_img.gin
deleted file mode 100644
index abdc43402fca8a3e83438655bec26c06b8dfccbe..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_push_multi_img.gin
+++ /dev/null
@@ -1,68 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntPush"
-IMAGES = True
-
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-16, -4), (16, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval2"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval2": [@eval2/ConstantSampler],
-}
-meta/Context.context_transition_fn = @task/relative_context_transition_fn
-meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = True
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-task/relative_context_transition_fn.k = 2
-task/relative_context_multi_transition_fn.k = 2
-MetaAgent.k = %SUBGOAL_DIM
-
-eval2/ConstantSampler.value = [0, 19]
diff --git a/research/efficient-hrl/context/configs/ant_push_single.gin b/research/efficient-hrl/context/configs/ant_push_single.gin
deleted file mode 100644
index e85c5dfba4d04668cc5407c89aa42ca2044e12fd..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/ant_push_single.gin
+++ /dev/null
@@ -1,62 +0,0 @@
-#-*-Python-*-
-create_maze_env.env_name = "AntPush"
-context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX)
-meta_context_range = ((-16, -4), (16, 20))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval2"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@eval2/ConstantSampler],
- "explore": [@eval2/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval2/ConstantSampler.value = [0, 19]
diff --git a/research/efficient-hrl/context/configs/default.gin b/research/efficient-hrl/context/configs/default.gin
deleted file mode 100644
index 65f91e5292db86b62a9275fcc8929d46d779a677..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/default.gin
+++ /dev/null
@@ -1,12 +0,0 @@
-#-*-Python-*-
-ENV_CONTEXT = None
-EVAL_MODES = ["eval"]
-TARGET_Q_CLIPPING = None
-RESET_EPISODE_PERIOD = None
-ZERO_OBS = False
-CONTEXT_RANGE_MIN = -10
-CONTEXT_RANGE_MAX = 10
-SUBGOAL_DIM = 2
-
-uvf/negative_distance.summarize = False
-uvf/negative_distance.relative_context = True
diff --git a/research/efficient-hrl/context/configs/hiro_orig.gin b/research/efficient-hrl/context/configs/hiro_orig.gin
deleted file mode 100644
index e39ba96be7b7d323ecf1a849dcea89d1468e87c3..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/hiro_orig.gin
+++ /dev/null
@@ -1,14 +0,0 @@
-#-*-Python-*-
-ENV_CONTEXT = None
-EVAL_MODES = ["eval"]
-TARGET_Q_CLIPPING = None
-RESET_EPISODE_PERIOD = None
-ZERO_OBS = True
-IMAGES = False
-CONTEXT_RANGE_MIN = (-10, -10, -0.5, -1, -1, -1, -1, -0.5, -0.3, -0.5, -0.3, -0.5, -0.3, -0.5, -0.3)
-CONTEXT_RANGE_MAX = ( 10, 10, 0.5, 1, 1, 1, 1, 0.5, 0.3, 0.5, 0.3, 0.5, 0.3, 0.5, 0.3)
-SUBGOAL_DIM = 15
-META_EXPLORE_NOISE = 1.0
-
-uvf/negative_distance.summarize = False
-uvf/negative_distance.relative_context = True
diff --git a/research/efficient-hrl/context/configs/hiro_repr.gin b/research/efficient-hrl/context/configs/hiro_repr.gin
deleted file mode 100644
index a0a8057bd3cc834e5c1be33e73a9b7c6ae370a99..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/hiro_repr.gin
+++ /dev/null
@@ -1,18 +0,0 @@
-#-*-Python-*-
-ENV_CONTEXT = None
-EVAL_MODES = ["eval"]
-TARGET_Q_CLIPPING = None
-RESET_EPISODE_PERIOD = None
-ZERO_OBS = False
-IMAGES = False
-CONTEXT_RANGE_MIN = -10
-CONTEXT_RANGE_MAX = 10
-SUBGOAL_DIM = 2
-META_EXPLORE_NOISE = 5.0
-
-StatePreprocess.trainable = True
-StatePreprocess.state_preprocess_net = @state_preprocess_net
-StatePreprocess.action_embed_net = @action_embed_net
-
-uvf/negative_distance.summarize = False
-uvf/negative_distance.relative_context = True
diff --git a/research/efficient-hrl/context/configs/hiro_xy.gin b/research/efficient-hrl/context/configs/hiro_xy.gin
deleted file mode 100644
index f35026c9e24246a87e69e16031981a13e22c283d..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/hiro_xy.gin
+++ /dev/null
@@ -1,14 +0,0 @@
-#-*-Python-*-
-ENV_CONTEXT = None
-EVAL_MODES = ["eval"]
-TARGET_Q_CLIPPING = None
-RESET_EPISODE_PERIOD = None
-ZERO_OBS = False
-IMAGES = False
-CONTEXT_RANGE_MIN = -10
-CONTEXT_RANGE_MAX = 10
-SUBGOAL_DIM = 2
-META_EXPLORE_NOISE = 1.0
-
-uvf/negative_distance.summarize = False
-uvf/negative_distance.relative_context = True
diff --git a/research/efficient-hrl/context/configs/point_maze.gin b/research/efficient-hrl/context/configs/point_maze.gin
deleted file mode 100644
index 0ea67d2d5fffedfdbc7b9df443acc3adaf98ec99..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/configs/point_maze.gin
+++ /dev/null
@@ -1,73 +0,0 @@
-#-*-Python-*-
-# NOTE: For best training, low-level exploration (uvf_add_noise_fn.stddev)
-# should be reduced to around 0.1.
-create_maze_env.env_name = "PointMaze"
-context_range_min = -10
-context_range_max = 10
-context_range = (%context_range_min, %context_range_max)
-meta_context_range = ((-2, -2), (10, 10))
-
-RESET_EPISODE_PERIOD = 500
-RESET_ENV_PERIOD = 1
-# End episode every N steps
-UvfAgent.reset_episode_cond_fn = @every_n_steps
-every_n_steps.n = %RESET_EPISODE_PERIOD
-train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD
-# Do a manual reset every N episodes
-UvfAgent.reset_env_cond_fn = @every_n_episodes
-every_n_episodes.n = %RESET_ENV_PERIOD
-every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD
-
-## Config defaults
-EVAL_MODES = ["eval1", "eval2", "eval3"]
-
-## Config agent
-CONTEXT = @agent/Context
-META_CONTEXT = @meta/Context
-
-## Config agent context
-agent/Context.context_ranges = [%context_range]
-agent/Context.context_shapes = [%SUBGOAL_DIM]
-agent/Context.meta_action_every_n = 10
-agent/Context.samplers = {
- "train": [@train/DirectionSampler],
- "explore": [@train/DirectionSampler],
- "eval1": [@uvf_eval1/ConstantSampler],
- "eval2": [@uvf_eval2/ConstantSampler],
- "eval3": [@uvf_eval3/ConstantSampler],
-}
-
-agent/Context.context_transition_fn = @relative_context_transition_fn
-agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn
-
-agent/Context.reward_fn = @uvf/negative_distance
-
-## Config meta context
-meta/Context.context_ranges = [%meta_context_range]
-meta/Context.context_shapes = [2]
-meta/Context.samplers = {
- "train": [@train/RandomSampler],
- "explore": [@train/RandomSampler],
- "eval1": [@eval1/ConstantSampler],
- "eval2": [@eval2/ConstantSampler],
- "eval3": [@eval3/ConstantSampler],
-}
-meta/Context.reward_fn = @task/negative_distance
-
-## Config rewards
-task/negative_distance.state_indices = [0, 1]
-task/negative_distance.relative_context = False
-task/negative_distance.diff = False
-task/negative_distance.offset = 0.0
-
-## Config samplers
-train/RandomSampler.context_range = %meta_context_range
-train/DirectionSampler.context_range = %context_range
-train/DirectionSampler.k = %SUBGOAL_DIM
-relative_context_transition_fn.k = %SUBGOAL_DIM
-relative_context_multi_transition_fn.k = %SUBGOAL_DIM
-MetaAgent.k = %SUBGOAL_DIM
-
-eval1/ConstantSampler.value = [8, 0]
-eval2/ConstantSampler.value = [8, 8]
-eval3/ConstantSampler.value = [0, 8]
diff --git a/research/efficient-hrl/context/context.py b/research/efficient-hrl/context/context.py
deleted file mode 100644
index 76be00b4966539b869e714225fbba124b9602c3a..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/context.py
+++ /dev/null
@@ -1,467 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Context for Universal Value Function agents.
-
-A context specifies a list of contextual variables, each with
- own sampling and reward computation methods.
-
-Examples of contextual variables include
- goal states, reward combination vectors, etc.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import numpy as np
-import tensorflow as tf
-from tf_agents import specs
-import gin.tf
-from utils import utils as uvf_utils
-
-
-@gin.configurable
-class Context(object):
- """Base context."""
- VAR_NAME = 'action'
-
- def __init__(self,
- tf_env,
- context_ranges=None,
- context_shapes=None,
- state_indices=None,
- variable_indices=None,
- gamma_index=None,
- settable_context=False,
- timers=None,
- samplers=None,
- reward_weights=None,
- reward_fn=None,
- random_sampler_mode='random',
- normalizers=None,
- context_transition_fn=None,
- context_multi_transition_fn=None,
- meta_action_every_n=None):
- self._tf_env = tf_env
- self.variable_indices = variable_indices
- self.gamma_index = gamma_index
- self._settable_context = settable_context
- self.timers = timers
- self._context_transition_fn = context_transition_fn
- self._context_multi_transition_fn = context_multi_transition_fn
- self._random_sampler_mode = random_sampler_mode
-
- # assign specs
- self._obs_spec = self._tf_env.observation_spec()
- self._context_shapes = tuple([
- shape if shape is not None else self._obs_spec.shape
- for shape in context_shapes
- ])
- self.context_specs = tuple([
- specs.TensorSpec(dtype=self._obs_spec.dtype, shape=shape)
- for shape in self._context_shapes
- ])
- if context_ranges is not None:
- self.context_ranges = context_ranges
- else:
- self.context_ranges = [None] * len(self._context_shapes)
-
- self.context_as_action_specs = tuple([
- specs.BoundedTensorSpec(
- shape=shape,
- dtype=(tf.float32 if self._obs_spec.dtype in
- [tf.float32, tf.float64] else self._obs_spec.dtype),
- minimum=context_range[0],
- maximum=context_range[-1])
- for shape, context_range in zip(self._context_shapes, self.context_ranges)
- ])
-
- if state_indices is not None:
- self.state_indices = state_indices
- else:
- self.state_indices = [None] * len(self._context_shapes)
- if self.variable_indices is not None and self.n != len(
- self.variable_indices):
- raise ValueError(
- 'variable_indices (%s) must have the same length as contexts (%s).' %
- (self.variable_indices, self.context_specs))
- assert self.n == len(self.context_ranges)
- assert self.n == len(self.state_indices)
-
- # assign reward/sampler fns
- self._sampler_fns = dict()
- self._samplers = dict()
- self._reward_fns = dict()
-
- # assign reward fns
- self._add_custom_reward_fns()
- reward_weights = reward_weights or None
- self._reward_fn = self._make_reward_fn(reward_fn, reward_weights)
-
- # assign samplers
- self._add_custom_sampler_fns()
- for mode, sampler_fns in samplers.items():
- self._make_sampler_fn(sampler_fns, mode)
-
- # create normalizers
- if normalizers is None:
- self._normalizers = [None] * len(self.context_specs)
- else:
- self._normalizers = [
- normalizer(tf.zeros(shape=spec.shape, dtype=spec.dtype))
- if normalizer is not None else None
- for normalizer, spec in zip(normalizers, self.context_specs)
- ]
- assert self.n == len(self._normalizers)
-
- self.meta_action_every_n = meta_action_every_n
-
- # create vars
- self.context_vars = {}
- self.timer_vars = {}
- self.create_vars(self.VAR_NAME)
- self.t = tf.Variable(
- tf.zeros(shape=(), dtype=tf.int32), name='num_timer_steps')
-
- def _add_custom_reward_fns(self):
- pass
-
- def _add_custom_sampler_fns(self):
- pass
-
- def sample_random_contexts(self, batch_size):
- """Sample random batch contexts."""
- assert self._random_sampler_mode is not None
- return self.sample_contexts(self._random_sampler_mode, batch_size)[0]
-
- def sample_contexts(self, mode, batch_size, state=None, next_state=None,
- **kwargs):
- """Sample a batch of contexts.
-
- Args:
- mode: A string representing the mode [`train`, `explore`, `eval`].
- batch_size: Batch size.
- Returns:
- Two lists of [batch_size, num_context_dims] contexts.
- """
- contexts, next_contexts = self._sampler_fns[mode](
- batch_size, state=state, next_state=next_state,
- **kwargs)
- self._validate_contexts(contexts)
- self._validate_contexts(next_contexts)
- return contexts, next_contexts
-
- def compute_rewards(self, mode, states, actions, rewards, next_states,
- contexts):
- """Compute context-based rewards.
-
- Args:
- mode: A string representing the mode ['uvf', 'task'].
- states: A [batch_size, num_state_dims] tensor.
- actions: A [batch_size, num_action_dims] tensor.
- rewards: A [batch_size] tensor representing unmodified rewards.
- next_states: A [batch_size, num_state_dims] tensor.
- contexts: A list of [batch_size, num_context_dims] tensors.
- Returns:
- A [batch_size] tensor representing rewards.
- """
- return self._reward_fn(states, actions, rewards, next_states,
- contexts)
-
- def _make_reward_fn(self, reward_fns_list, reward_weights):
- """Returns a fn that computes rewards.
-
- Args:
- reward_fns_list: A fn or a list of reward fns.
- mode: A string representing the operating mode.
- reward_weights: A list of reward weights.
- """
- if not isinstance(reward_fns_list, (list, tuple)):
- reward_fns_list = [reward_fns_list]
- if reward_weights is None:
- reward_weights = [1.0] * len(reward_fns_list)
- assert len(reward_fns_list) == len(reward_weights)
-
- reward_fns_list = [
- self._custom_reward_fns[fn] if isinstance(fn, (str,)) else fn
- for fn in reward_fns_list
- ]
-
- def reward_fn(*args, **kwargs):
- """Returns rewards, discounts."""
- reward_tuples = [
- reward_fn(*args, **kwargs) for reward_fn in reward_fns_list
- ]
- rewards_list = [reward_tuple[0] for reward_tuple in reward_tuples]
- discounts_list = [reward_tuple[1] for reward_tuple in reward_tuples]
- ndims = max([r.shape.ndims for r in rewards_list])
- if ndims > 1: # expand reward shapes to allow broadcasting
- for i in range(len(rewards_list)):
- for _ in range(rewards_list[i].shape.ndims - ndims):
- rewards_list[i] = tf.expand_dims(rewards_list[i], axis=-1)
- for _ in range(discounts_list[i].shape.ndims - ndims):
- discounts_list[i] = tf.expand_dims(discounts_list[i], axis=-1)
- rewards = tf.add_n(
- [r * tf.to_float(w) for r, w in zip(rewards_list, reward_weights)])
- discounts = discounts_list[0]
- for d in discounts_list[1:]:
- discounts *= d
-
- return rewards, discounts
-
- return reward_fn
-
- def _make_sampler_fn(self, sampler_cls_list, mode):
- """Returns a fn that samples a list of context vars.
-
- Args:
- sampler_cls_list: A list of sampler classes.
- mode: A string representing the operating mode.
- """
- if not isinstance(sampler_cls_list, (list, tuple)):
- sampler_cls_list = [sampler_cls_list]
-
- self._samplers[mode] = []
- sampler_fns = []
- for spec, sampler in zip(self.context_specs, sampler_cls_list):
- if isinstance(sampler, (str,)):
- sampler_fn = self._custom_sampler_fns[sampler]
- else:
- sampler_fn = sampler(context_spec=spec)
- self._samplers[mode].append(sampler_fn)
- sampler_fns.append(sampler_fn)
-
- def batch_sampler_fn(batch_size, state=None, next_state=None, **kwargs):
- """Sampler fn."""
- contexts_tuples = [
- sampler(batch_size, state=state, next_state=next_state, **kwargs)
- for sampler in sampler_fns]
- contexts = [c[0] for c in contexts_tuples]
- next_contexts = [c[1] for c in contexts_tuples]
- contexts = [
- normalizer.update_apply(c) if normalizer is not None else c
- for normalizer, c in zip(self._normalizers, contexts)
- ]
- next_contexts = [
- normalizer.apply(c) if normalizer is not None else c
- for normalizer, c in zip(self._normalizers, next_contexts)
- ]
- return contexts, next_contexts
-
- self._sampler_fns[mode] = batch_sampler_fn
-
- def set_env_context_op(self, context, disable_unnormalizer=False):
- """Returns a TensorFlow op that sets the environment context.
-
- Args:
- context: A list of context Tensor variables.
- disable_unnormalizer: Disable unnormalization.
- Returns:
- A TensorFlow op that sets the environment context.
- """
- ret_val = np.array(1.0, dtype=np.float32)
- if not self._settable_context:
- return tf.identity(ret_val)
-
- if not disable_unnormalizer:
- context = [
- normalizer.unapply(tf.expand_dims(c, 0))[0]
- if normalizer is not None else c
- for normalizer, c in zip(self._normalizers, context)
- ]
-
- def set_context_func(*env_context_values):
- tf.logging.info('[set_env_context_op] Setting gym environment context.')
- # pylint: disable=protected-access
- self.gym_env.set_context(*env_context_values)
- return ret_val
- # pylint: enable=protected-access
-
- with tf.name_scope('set_env_context'):
- set_op = tf.py_func(set_context_func, context, tf.float32,
- name='set_env_context_py_func')
- set_op.set_shape([])
- return set_op
-
- def set_replay(self, replay):
- """Set replay buffer for samplers.
-
- Args:
- replay: A replay buffer.
- """
- for _, samplers in self._samplers.items():
- for sampler in samplers:
- sampler.set_replay(replay)
-
- def get_clip_fns(self):
- """Returns a list of clip fns for contexts.
-
- Returns:
- A list of fns that clip context tensors.
- """
- clip_fns = []
- for context_range in self.context_ranges:
- def clip_fn(var_, range_=context_range):
- """Clip a tensor."""
- if range_ is None:
- clipped_var = tf.identity(var_)
- elif isinstance(range_[0], (int, long, float, list, np.ndarray)):
- clipped_var = tf.clip_by_value(
- var_,
- range_[0],
- range_[1],)
- else: raise NotImplementedError(range_)
- return clipped_var
- clip_fns.append(clip_fn)
- return clip_fns
-
- def _validate_contexts(self, contexts):
- """Validate if contexts have right specs.
-
- Args:
- contexts: A list of [batch_size, num_context_dim] tensors.
- Raises:
- ValueError: If shape or dtype mismatches that of spec.
- """
- for i, (context, spec) in enumerate(zip(contexts, self.context_specs)):
- if context[0].shape != spec.shape:
- raise ValueError('contexts[%d] has invalid shape %s wrt spec shape %s' %
- (i, context[0].shape, spec.shape))
- if context.dtype != spec.dtype:
- raise ValueError('contexts[%d] has invalid dtype %s wrt spec dtype %s' %
- (i, context.dtype, spec.dtype))
-
- def context_multi_transition_fn(self, contexts, **kwargs):
- """Returns multiple future contexts starting from a batch."""
- assert self._context_multi_transition_fn
- return self._context_multi_transition_fn(contexts, None, None, **kwargs)
-
- def step(self, mode, agent=None, action_fn=None, **kwargs):
- """Returns [next_contexts..., next_timer] list of ops.
-
- Args:
- mode: a string representing the mode=[train, explore, eval].
- **kwargs: kwargs for context_transition_fn.
- Returns:
- a list of ops that set the context.
- """
- if agent is None:
- ops = []
- if self._context_transition_fn is not None:
- def sampler_fn():
- samples = self.sample_contexts(mode, 1)[0]
- return [s[0] for s in samples]
- values = self._context_transition_fn(self.vars, self.t, sampler_fn, **kwargs)
- ops += [tf.assign(var, value) for var, value in zip(self.vars, values)]
- ops.append(tf.assign_add(self.t, 1)) # increment timer
- return ops
- else:
- ops = agent.tf_context.step(mode, **kwargs)
- state = kwargs['state']
- next_state = kwargs['next_state']
- state_repr = kwargs['state_repr']
- next_state_repr = kwargs['next_state_repr']
- with tf.control_dependencies(ops): # Step high level context before computing low level one.
- # Get the context transition function output.
- values = self._context_transition_fn(self.vars, self.t, None,
- state=state_repr,
- next_state=next_state_repr)
- # Select a new goal every C steps, otherwise use context transition.
- low_level_context = [
- tf.cond(tf.equal(self.t % self.meta_action_every_n, 0),
- lambda: tf.cast(action_fn(next_state, context=None), tf.float32),
- lambda: values)]
- ops = [tf.assign(var, value)
- for var, value in zip(self.vars, low_level_context)]
- with tf.control_dependencies(ops):
- return [tf.assign_add(self.t, 1)] # increment timer
- return ops
-
- def reset(self, mode, agent=None, action_fn=None, state=None):
- """Returns ops that reset the context.
-
- Args:
- mode: a string representing the mode=[train, explore, eval].
- Returns:
- a list of ops that reset the context.
- """
- if agent is None:
- values = self.sample_contexts(mode=mode, batch_size=1)[0]
- if values is None:
- return []
- values = [value[0] for value in values]
- values[0] = uvf_utils.tf_print(
- values[0],
- values,
- message='context:reset, mode=%s' % mode,
- first_n=10,
- name='context:reset:%s' % mode)
- all_ops = []
- for _, context_vars in sorted(self.context_vars.items()):
- ops = [tf.assign(var, value) for var, value in zip(context_vars, values)]
- all_ops += ops
- all_ops.append(self.set_env_context_op(values))
- all_ops.append(tf.assign(self.t, 0)) # reset timer
- return all_ops
- else:
- ops = agent.tf_context.reset(mode)
- # NOTE: The code is currently written in such a way that the higher level
- # policy does not provide a low-level context until the second
- # observation. Insead, we just zero-out low-level contexts.
- for key, context_vars in sorted(self.context_vars.items()):
- ops += [tf.assign(var, tf.zeros_like(var)) for var, meta_var in
- zip(context_vars, agent.tf_context.context_vars[key])]
-
- ops.append(tf.assign(self.t, 0)) # reset timer
- return ops
-
- def create_vars(self, name, agent=None):
- """Create tf variables for contexts.
-
- Args:
- name: Name of the variables.
- Returns:
- A list of [num_context_dims] tensors.
- """
- if agent is not None:
- meta_vars = agent.create_vars(name)
- else:
- meta_vars = {}
- assert name not in self.context_vars, ('Conflict! %s is already '
- 'initialized.') % name
- self.context_vars[name] = tuple([
- tf.Variable(
- tf.zeros(shape=spec.shape, dtype=spec.dtype),
- name='%s_context_%d' % (name, i))
- for i, spec in enumerate(self.context_specs)
- ])
- return self.context_vars[name], meta_vars
-
- @property
- def n(self):
- return len(self.context_specs)
-
- @property
- def vars(self):
- return self.context_vars[self.VAR_NAME]
-
- # pylint: disable=protected-access
- @property
- def gym_env(self):
- return self._tf_env.pyenv._gym_env
-
- @property
- def tf_env(self):
- return self._tf_env
- # pylint: enable=protected-access
diff --git a/research/efficient-hrl/context/context_transition_functions.py b/research/efficient-hrl/context/context_transition_functions.py
deleted file mode 100644
index 70326debde4185ec9ee5300ebf06b94e8eb1f7ad..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/context_transition_functions.py
+++ /dev/null
@@ -1,123 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Context functions.
-
-Given the current contexts, timer and context sampler, returns new contexts
- after an environment step. This can be used to define a high-level policy
- that controls contexts as its actions.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-import gin.tf
-import utils as uvf_utils
-
-
-@gin.configurable
-def periodic_context_fn(contexts, timer, sampler_fn, period=1):
- """Periodically samples contexts.
-
- Args:
- contexts: a list of [num_context_dims] tensor variables representing
- current contexts.
- timer: a scalar integer tensor variable holding the current time step.
- sampler_fn: a sampler function that samples a list of [num_context_dims]
- tensors.
- period: (integer) period of update.
- Returns:
- a list of [num_context_dims] tensors.
- """
- contexts = list(contexts[:]) # create copy
- return tf.cond(tf.mod(timer, period) == 0, sampler_fn, lambda: contexts)
-
-
-@gin.configurable
-def timer_context_fn(contexts,
- timer,
- sampler_fn,
- period=1,
- timer_index=-1,
- debug=False):
- """Samples contexts based on timer in contexts.
-
- Args:
- contexts: a list of [num_context_dims] tensor variables representing
- current contexts.
- timer: a scalar integer tensor variable holding the current time step.
- sampler_fn: a sampler function that samples a list of [num_context_dims]
- tensors.
- period: (integer) period of update; actual period = `period` + 1.
- timer_index: (integer) Index of context list that present timer.
- debug: (boolean) Print debug messages.
- Returns:
- a list of [num_context_dims] tensors.
- """
- contexts = list(contexts[:]) # create copy
- cond = tf.equal(contexts[timer_index][0], 0)
- def reset():
- """Sample context and reset the timer."""
- new_contexts = sampler_fn()
- new_contexts[timer_index] = tf.zeros_like(
- contexts[timer_index]) + period
- return new_contexts
- def update():
- """Decrement the timer."""
- contexts[timer_index] -= 1
- return contexts
- values = tf.cond(cond, reset, update)
- if debug:
- values[0] = uvf_utils.tf_print(
- values[0],
- values + [timer],
- 'timer_context_fn',
- first_n=200,
- name='timer_context_fn:contexts')
- return values
-
-
-@gin.configurable
-def relative_context_transition_fn(
- contexts, timer, sampler_fn,
- k=2, state=None, next_state=None,
- **kwargs):
- """Contexts updated to be relative to next state.
- """
- contexts = list(contexts[:]) # create copy
- assert len(contexts) == 1
- new_contexts = [
- tf.concat(
- [contexts[0][:k] + state[:k] - next_state[:k],
- contexts[0][k:]], -1)]
- return new_contexts
-
-
-@gin.configurable
-def relative_context_multi_transition_fn(
- contexts, timer, sampler_fn,
- k=2, states=None,
- **kwargs):
- """Given contexts at first state and sequence of states, derives sequence of all contexts.
- """
- contexts = list(contexts[:]) # create copy
- assert len(contexts) == 1
- contexts = [
- tf.concat(
- [tf.expand_dims(contexts[0][:, :k] + states[:, 0, :k], 1) - states[:, :, :k],
- contexts[0][:, None, k:] * tf.ones_like(states[:, :, :1])], -1)]
- return contexts
diff --git a/research/efficient-hrl/context/gin_imports.py b/research/efficient-hrl/context/gin_imports.py
deleted file mode 100644
index 94512cef8479ac2e9c36a941f4b197b6939d0814..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/gin_imports.py
+++ /dev/null
@@ -1,25 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Import gin configurable modules.
-"""
-
-# pylint: disable=unused-import
-from context import context
-from context import context_transition_functions
-from context import gin_utils
-from context import rewards_functions
-from context import samplers
-# pylint: disable=unused-import
diff --git a/research/efficient-hrl/context/gin_utils.py b/research/efficient-hrl/context/gin_utils.py
deleted file mode 100644
index ab7c1b2d1dd1d7317071ad6e2c08d057d42ec2e1..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/gin_utils.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Gin configurable utility functions.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import gin.tf
-
-
-@gin.configurable
-def gin_sparse_array(size, values, indices, fill_value=0):
- arr = np.zeros(size)
- arr.fill(fill_value)
- arr[indices] = values
- return arr
-
-
-@gin.configurable
-def gin_sum(values):
- result = values[0]
- for value in values[1:]:
- result += value
- return result
-
-
-@gin.configurable
-def gin_range(n):
- return range(n)
diff --git a/research/efficient-hrl/context/rewards_functions.py b/research/efficient-hrl/context/rewards_functions.py
deleted file mode 100644
index ab560a7f4290dfa1269e001339e0e2cdb116e761..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/rewards_functions.py
+++ /dev/null
@@ -1,741 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Reward shaping functions used by Contexts.
-
- Each reward function should take the following inputs and return new rewards,
- and discounts.
-
- new_rewards, discounts = reward_fn(states, actions, rewards,
- next_states, contexts)
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-import gin.tf
-
-
-def summarize_stats(stats):
- """Summarize a dictionary of variables.
-
- Args:
- stats: a dictionary of {name: tensor} to compute stats over.
- """
- for name, stat in stats.items():
- mean = tf.reduce_mean(stat)
- tf.summary.scalar('mean_%s' % name, mean)
- tf.summary.scalar('max_%s' % name, tf.reduce_max(stat))
- tf.summary.scalar('min_%s' % name, tf.reduce_min(stat))
- std = tf.sqrt(tf.reduce_mean(tf.square(stat)) - tf.square(mean) + 1e-10)
- tf.summary.scalar('std_%s' % name, std)
- tf.summary.histogram(name, stat)
-
-
-def index_states(states, indices):
- """Return indexed states.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- indices: (a list of Numpy integer array) Indices of states dimensions
- to be mapped.
- Returns:
- A [batch_size, num_indices] Tensor representing the batch of indexed states.
- """
- if indices is None:
- return states
- indices = tf.constant(indices, dtype=tf.int32)
- return tf.gather(states, indices=indices, axis=1)
-
-
-def record_tensor(tensor, indices, stats, name='states'):
- """Record specified tensor dimensions into stats.
-
- Args:
- tensor: A [batch_size, num_dims] Tensor.
- indices: (a list of integers) Indices of dimensions to record.
- stats: A dictionary holding stats.
- name: (string) Name of tensor.
- """
- if indices is None:
- indices = range(tensor.shape.as_list()[1])
- for index in indices:
- stats['%s_%02d' % (name, index)] = tensor[:, index]
-
-
-@gin.configurable
-def potential_rewards(states,
- actions,
- rewards,
- next_states,
- contexts,
- gamma=1.0,
- reward_fn=None):
- """Return the potential-based rewards.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- gamma: Reward discount.
- reward_fn: A reward function.
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del actions # unused args
- gamma = tf.to_float(gamma)
- rewards_tp1, discounts = reward_fn(None, None, rewards, next_states, contexts)
- rewards, _ = reward_fn(None, None, rewards, states, contexts)
- return -rewards + gamma * rewards_tp1, discounts
-
-
-@gin.configurable
-def timed_rewards(states,
- actions,
- rewards,
- next_states,
- contexts,
- reward_fn=None,
- dense=False,
- timer_index=-1):
- """Return the timed rewards.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- reward_fn: A reward function.
- dense: (boolean) Provide dense rewards or sparse rewards at time = 0.
- timer_index: (integer) The context list index that specifies timer.
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- assert contexts[timer_index].get_shape().as_list()[1] == 1
- timers = contexts[timer_index][:, 0]
- rewards, discounts = reward_fn(states, actions, rewards, next_states,
- contexts)
- terminates = tf.to_float(timers <= 0) # if terminate set 1, else set 0
- for _ in range(rewards.shape.ndims - 1):
- terminates = tf.expand_dims(terminates, axis=-1)
- if not dense:
- rewards *= terminates # if terminate, return rewards, else return 0
- discounts *= (tf.to_float(1.0) - terminates)
- return rewards, discounts
-
-
-@gin.configurable
-def reset_rewards(states,
- actions,
- rewards,
- next_states,
- contexts,
- reset_index=0,
- reset_state=None,
- reset_reward_function=None,
- include_forward_rewards=True,
- include_reset_rewards=True):
- """Returns the rewards for a forward/reset agent.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- reset_index: (integer) The context list index that specifies reset.
- reset_state: Reset state.
- reset_reward_function: Reward function for reset step.
- include_forward_rewards: Include the rewards from the forward pass.
- include_reset_rewards: Include the rewards from the reset pass.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- reset_state = tf.constant(
- reset_state, dtype=next_states.dtype, shape=next_states.shape)
- reset_states = tf.expand_dims(reset_state, 0)
-
- def true_fn():
- if include_reset_rewards:
- return reset_reward_function(states, actions, rewards, next_states,
- [reset_states] + contexts[1:])
- else:
- return tf.zeros_like(rewards), tf.ones_like(rewards)
-
- def false_fn():
- if include_forward_rewards:
- return plain_rewards(states, actions, rewards, next_states, contexts)
- else:
- return tf.zeros_like(rewards), tf.ones_like(rewards)
-
- rewards, discounts = tf.cond(
- tf.cast(contexts[reset_index][0, 0], dtype=tf.bool), true_fn, false_fn)
- return rewards, discounts
-
-
-@gin.configurable
-def tanh_similarity(states,
- actions,
- rewards,
- next_states,
- contexts,
- mse_scale=1.0,
- state_scales=1.0,
- goal_scales=1.0,
- summarize=False):
- """Returns the similarity between next_states and contexts using tanh and mse.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- mse_scale: A float, to scale mse before tanh.
- state_scales: multiplicative scale for (next) states. A scalar or 1D tensor,
- must be broadcastable to number of state dimensions.
- goal_scales: multiplicative scale for contexts. A scalar or 1D tensor,
- must be broadcastable to number of goal dimensions.
- summarize: (boolean) enable summary ops.
-
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, actions, rewards # Unused
- mse = tf.reduce_mean(tf.squared_difference(next_states * state_scales,
- contexts[0] * goal_scales), -1)
- tanh = tf.tanh(mse_scale * mse)
- if summarize:
- with tf.name_scope('RewardFn/'):
- tf.summary.scalar('mean_mse', tf.reduce_mean(mse))
- tf.summary.histogram('mse', mse)
- tf.summary.scalar('mean_tanh', tf.reduce_mean(tanh))
- tf.summary.histogram('tanh', tanh)
- rewards = tf.to_float(1 - tanh)
- return rewards, tf.ones_like(rewards)
-
-
-@gin.configurable
-def negative_mse(states,
- actions,
- rewards,
- next_states,
- contexts,
- state_scales=1.0,
- goal_scales=1.0,
- summarize=False):
- """Returns the negative mean square error between next_states and contexts.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- state_scales: multiplicative scale for (next) states. A scalar or 1D tensor,
- must be broadcastable to number of state dimensions.
- goal_scales: multiplicative scale for contexts. A scalar or 1D tensor,
- must be broadcastable to number of goal dimensions.
- summarize: (boolean) enable summary ops.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, actions, rewards # Unused
- mse = tf.reduce_mean(tf.squared_difference(next_states * state_scales,
- contexts[0] * goal_scales), -1)
- if summarize:
- with tf.name_scope('RewardFn/'):
- tf.summary.scalar('mean_mse', tf.reduce_mean(mse))
- tf.summary.histogram('mse', mse)
- rewards = tf.to_float(-mse)
- return rewards, tf.ones_like(rewards)
-
-
-@gin.configurable
-def negative_distance(states,
- actions,
- rewards,
- next_states,
- contexts,
- state_scales=1.0,
- goal_scales=1.0,
- reward_scales=1.0,
- weight_index=None,
- weight_vector=None,
- summarize=False,
- termination_epsilon=1e-4,
- state_indices=None,
- goal_indices=None,
- vectorize=False,
- relative_context=False,
- diff=False,
- norm='L2',
- epsilon=1e-10,
- bonus_epsilon=0., #5.,
- offset=0.0):
- """Returns the negative euclidean distance between next_states and contexts.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- state_scales: multiplicative scale for (next) states. A scalar or 1D tensor,
- must be broadcastable to number of state dimensions.
- goal_scales: multiplicative scale for goals. A scalar or 1D tensor,
- must be broadcastable to number of goal dimensions.
- reward_scales: multiplicative scale for rewards. A scalar or 1D tensor,
- must be broadcastable to number of reward dimensions.
- weight_index: (integer) The context list index that specifies weight.
- weight_vector: (a number or a list or Numpy array) The weighting vector,
- broadcastable to `next_states`.
- summarize: (boolean) enable summary ops.
- termination_epsilon: terminate if dist is less than this quantity.
- state_indices: (a list of integers) list of state indices to select.
- goal_indices: (a list of integers) list of goal indices to select.
- vectorize: Return a vectorized form.
- norm: L1 or L2.
- epsilon: small offset to ensure non-negative/zero distance.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del actions, rewards # Unused
- stats = {}
- record_tensor(next_states, state_indices, stats, 'next_states')
- states = index_states(states, state_indices)
- next_states = index_states(next_states, state_indices)
- goals = index_states(contexts[0], goal_indices)
- if relative_context:
- goals = states + goals
- sq_dists = tf.squared_difference(next_states * state_scales,
- goals * goal_scales)
- old_sq_dists = tf.squared_difference(states * state_scales,
- goals * goal_scales)
- record_tensor(sq_dists, None, stats, 'sq_dists')
- if weight_vector is not None:
- sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype)
- old_sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype)
- if weight_index is not None:
- #sq_dists *= contexts[weight_index]
- weights = tf.abs(index_states(contexts[0], weight_index))
- #weights /= tf.reduce_sum(weights, -1, keepdims=True)
- sq_dists *= weights
- old_sq_dists *= weights
- if norm == 'L1':
- dist = tf.sqrt(sq_dists + epsilon)
- old_dist = tf.sqrt(old_sq_dists + epsilon)
- if not vectorize:
- dist = tf.reduce_sum(dist, -1)
- old_dist = tf.reduce_sum(old_dist, -1)
- elif norm == 'L2':
- if vectorize:
- dist = sq_dists
- old_dist = old_sq_dists
- else:
- dist = tf.reduce_sum(sq_dists, -1)
- old_dist = tf.reduce_sum(old_sq_dists, -1)
- dist = tf.sqrt(dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0)
- old_dist = tf.sqrt(old_dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0)
- else:
- raise NotImplementedError(norm)
- discounts = dist > termination_epsilon
- if summarize:
- with tf.name_scope('RewardFn/'):
- tf.summary.scalar('mean_dist', tf.reduce_mean(dist))
- tf.summary.histogram('dist', dist)
- summarize_stats(stats)
- bonus = tf.to_float(dist < bonus_epsilon)
- dist *= reward_scales
- old_dist *= reward_scales
- if diff:
- return bonus + offset + tf.to_float(old_dist - dist), tf.to_float(discounts)
- return bonus + offset + tf.to_float(-dist), tf.to_float(discounts)
-
-
-@gin.configurable
-def cosine_similarity(states,
- actions,
- rewards,
- next_states,
- contexts,
- state_scales=1.0,
- goal_scales=1.0,
- reward_scales=1.0,
- normalize_states=True,
- normalize_goals=True,
- weight_index=None,
- weight_vector=None,
- summarize=False,
- state_indices=None,
- goal_indices=None,
- offset=0.0):
- """Returns the cosine similarity between next_states - states and contexts.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- state_scales: multiplicative scale for (next) states. A scalar or 1D tensor,
- must be broadcastable to number of state dimensions.
- goal_scales: multiplicative scale for goals. A scalar or 1D tensor,
- must be broadcastable to number of goal dimensions.
- reward_scales: multiplicative scale for rewards. A scalar or 1D tensor,
- must be broadcastable to number of reward dimensions.
- weight_index: (integer) The context list index that specifies weight.
- weight_vector: (a number or a list or Numpy array) The weighting vector,
- broadcastable to `next_states`.
- summarize: (boolean) enable summary ops.
- termination_epsilon: terminate if dist is less than this quantity.
- state_indices: (a list of integers) list of state indices to select.
- goal_indices: (a list of integers) list of goal indices to select.
- vectorize: Return a vectorized form.
- norm: L1 or L2.
- epsilon: small offset to ensure non-negative/zero distance.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del actions, rewards # Unused
- stats = {}
- record_tensor(next_states, state_indices, stats, 'next_states')
- states = index_states(states, state_indices)
- next_states = index_states(next_states, state_indices)
- goals = index_states(contexts[0], goal_indices)
-
- if weight_vector is not None:
- goals *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype)
- if weight_index is not None:
- weights = tf.abs(index_states(contexts[0], weight_index))
- goals *= weights
-
- direction_vec = next_states - states
- if normalize_states:
- direction_vec = tf.nn.l2_normalize(direction_vec, -1)
- goal_vec = goals
- if normalize_goals:
- goal_vec = tf.nn.l2_normalize(goal_vec, -1)
-
- similarity = tf.reduce_sum(goal_vec * direction_vec, -1)
- discounts = tf.ones_like(similarity)
- return offset + tf.to_float(similarity), tf.to_float(discounts)
-
-
-@gin.configurable
-def diff_distance(states,
- actions,
- rewards,
- next_states,
- contexts,
- state_scales=1.0,
- goal_scales=1.0,
- reward_scales=1.0,
- weight_index=None,
- weight_vector=None,
- summarize=False,
- termination_epsilon=1e-4,
- state_indices=None,
- goal_indices=None,
- norm='L2',
- epsilon=1e-10):
- """Returns the difference in euclidean distance between states/next_states and contexts.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- state_scales: multiplicative scale for (next) states. A scalar or 1D tensor,
- must be broadcastable to number of state dimensions.
- goal_scales: multiplicative scale for goals. A scalar or 1D tensor,
- must be broadcastable to number of goal dimensions.
- reward_scales: multiplicative scale for rewards. A scalar or 1D tensor,
- must be broadcastable to number of reward dimensions.
- weight_index: (integer) The context list index that specifies weight.
- weight_vector: (a number or a list or Numpy array) The weighting vector,
- broadcastable to `next_states`.
- summarize: (boolean) enable summary ops.
- termination_epsilon: terminate if dist is less than this quantity.
- state_indices: (a list of integers) list of state indices to select.
- goal_indices: (a list of integers) list of goal indices to select.
- vectorize: Return a vectorized form.
- norm: L1 or L2.
- epsilon: small offset to ensure non-negative/zero distance.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del actions, rewards # Unused
- stats = {}
- record_tensor(next_states, state_indices, stats, 'next_states')
- next_states = index_states(next_states, state_indices)
- states = index_states(states, state_indices)
- goals = index_states(contexts[0], goal_indices)
- next_sq_dists = tf.squared_difference(next_states * state_scales,
- goals * goal_scales)
- sq_dists = tf.squared_difference(states * state_scales,
- goals * goal_scales)
- record_tensor(sq_dists, None, stats, 'sq_dists')
- if weight_vector is not None:
- next_sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype)
- sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype)
- if weight_index is not None:
- next_sq_dists *= contexts[weight_index]
- sq_dists *= contexts[weight_index]
- if norm == 'L1':
- next_dist = tf.sqrt(next_sq_dists + epsilon)
- dist = tf.sqrt(sq_dists + epsilon)
- next_dist = tf.reduce_sum(next_dist, -1)
- dist = tf.reduce_sum(dist, -1)
- elif norm == 'L2':
- next_dist = tf.reduce_sum(next_sq_dists, -1)
- next_dist = tf.sqrt(next_dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0)
- dist = tf.reduce_sum(sq_dists, -1)
- dist = tf.sqrt(dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0)
- else:
- raise NotImplementedError(norm)
- discounts = next_dist > termination_epsilon
- if summarize:
- with tf.name_scope('RewardFn/'):
- tf.summary.scalar('mean_dist', tf.reduce_mean(dist))
- tf.summary.histogram('dist', dist)
- summarize_stats(stats)
- diff = dist - next_dist
- diff *= reward_scales
- return tf.to_float(diff), tf.to_float(discounts)
-
-
-@gin.configurable
-def binary_indicator(states,
- actions,
- rewards,
- next_states,
- contexts,
- termination_epsilon=1e-4,
- offset=0,
- epsilon=1e-10,
- state_indices=None,
- summarize=False):
- """Returns 0/1 by checking if next_states and contexts overlap.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- termination_epsilon: terminate if dist is less than this quantity.
- offset: Offset the rewards.
- epsilon: small offset to ensure non-negative/zero distance.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, actions # unused args
- next_states = index_states(next_states, state_indices)
- dist = tf.reduce_sum(tf.squared_difference(next_states, contexts[0]), -1)
- dist = tf.sqrt(dist + epsilon)
- discounts = dist > termination_epsilon
- rewards = tf.logical_not(discounts)
- rewards = tf.to_float(rewards) + offset
- return tf.to_float(rewards), tf.ones_like(tf.to_float(discounts)) #tf.to_float(discounts)
-
-
-@gin.configurable
-def plain_rewards(states, actions, rewards, next_states, contexts):
- """Returns the given rewards.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, actions, next_states, contexts # Unused
- return rewards, tf.ones_like(rewards)
-
-
-@gin.configurable
-def ctrl_rewards(states,
- actions,
- rewards,
- next_states,
- contexts,
- reward_scales=1.0):
- """Returns the negative control cost.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- reward_scales: multiplicative scale for rewards. A scalar or 1D tensor,
- must be broadcastable to number of reward dimensions.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, rewards, contexts # Unused
- if actions is None:
- rewards = tf.to_float(tf.zeros(shape=next_states.shape[:1]))
- else:
- rewards = -tf.reduce_sum(tf.square(actions), axis=1)
- rewards *= reward_scales
- rewards = tf.to_float(rewards)
- return rewards, tf.ones_like(rewards)
-
-
-@gin.configurable
-def diff_rewards(
- states,
- actions,
- rewards,
- next_states,
- contexts,
- state_indices=None,
- goal_index=0,):
- """Returns (next_states - goals) as a batched vector reward."""
- del states, rewards, actions # Unused
- if state_indices is not None:
- next_states = index_states(next_states, state_indices)
- rewards = tf.to_float(next_states - contexts[goal_index])
- return rewards, tf.ones_like(rewards)
-
-
-@gin.configurable
-def state_rewards(states,
- actions,
- rewards,
- next_states,
- contexts,
- weight_index=None,
- state_indices=None,
- weight_vector=1.0,
- offset_vector=0.0,
- summarize=False):
- """Returns the rewards that are linear mapping of next_states.
-
- Args:
- states: A [batch_size, num_state_dims] Tensor representing a batch
- of states.
- actions: A [batch_size, num_action_dims] Tensor representing a batch
- of actions.
- rewards: A [batch_size] Tensor representing a batch of rewards.
- next_states: A [batch_size, num_state_dims] Tensor representing a batch
- of next states.
- contexts: A list of [batch_size, num_context_dims] Tensor representing
- a batch of contexts.
- weight_index: (integer) Index of contexts lists that specify weighting.
- state_indices: (a list of Numpy integer array) Indices of states dimensions
- to be mapped.
- weight_vector: (a number or a list or Numpy array) The weighting vector,
- broadcastable to `next_states`.
- offset_vector: (a number or a list of Numpy array) The off vector.
- summarize: (boolean) enable summary ops.
-
- Returns:
- A new tf.float32 [batch_size] rewards Tensor, and
- tf.float32 [batch_size] discounts tensor.
- """
- del states, actions, rewards # unused args
- stats = {}
- record_tensor(next_states, state_indices, stats)
- next_states = index_states(next_states, state_indices)
- weight = tf.constant(
- weight_vector, dtype=next_states.dtype, shape=next_states[0].shape)
- weights = tf.expand_dims(weight, 0)
- offset = tf.constant(
- offset_vector, dtype=next_states.dtype, shape=next_states[0].shape)
- offsets = tf.expand_dims(offset, 0)
- if weight_index is not None:
- weights *= contexts[weight_index]
- rewards = tf.to_float(tf.reduce_sum(weights * (next_states+offsets), axis=1))
- if summarize:
- with tf.name_scope('RewardFn/'):
- summarize_stats(stats)
- return rewards, tf.ones_like(rewards)
diff --git a/research/efficient-hrl/context/samplers.py b/research/efficient-hrl/context/samplers.py
deleted file mode 100644
index 15a22df5eb3bcbd419b5a01bc299b5d5ac71ad91..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/context/samplers.py
+++ /dev/null
@@ -1,445 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Samplers for Contexts.
-
- Each sampler class should define __call__(batch_size).
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-slim = tf.contrib.slim
-import gin.tf
-
-
-@gin.configurable
-class BaseSampler(object):
- """Base sampler."""
-
- def __init__(self, context_spec, context_range=None, k=2, scope='sampler'):
- """Construct a base sampler.
-
- Args:
- context_spec: A context spec.
- context_range: A tuple of (minval, max), where minval, maxval are floats
- or Numpy arrays with the same shape as the context.
- scope: A string denoting scope.
- """
- self._context_spec = context_spec
- self._context_range = context_range
- self._k = k
- self._scope = scope
-
- def __call__(self, batch_size, **kwargs):
- raise NotImplementedError
-
- def set_replay(self, replay=None):
- pass
-
- def _validate_contexts(self, contexts):
- """Validate if contexts have right spec.
-
- Args:
- contexts: A [batch_size, num_contexts_dim] tensor.
- Raises:
- ValueError: If shape or dtype mismatches that of spec.
- """
- if contexts[0].shape != self._context_spec.shape:
- raise ValueError('contexts has invalid shape %s wrt spec shape %s' %
- (contexts[0].shape, self._context_spec.shape))
- if contexts.dtype != self._context_spec.dtype:
- raise ValueError('contexts has invalid dtype %s wrt spec dtype %s' %
- (contexts.dtype, self._context_spec.dtype))
-
-
-@gin.configurable
-class ZeroSampler(BaseSampler):
- """Zero sampler."""
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- contexts = tf.zeros(
- dtype=self._context_spec.dtype,
- shape=[
- batch_size,
- ] + self._context_spec.shape.as_list())
- return contexts, contexts
-
-
-@gin.configurable
-class BinarySampler(BaseSampler):
- """Binary sampler."""
-
- def __init__(self, probs=0.5, *args, **kwargs):
- """Constructor."""
- super(BinarySampler, self).__init__(*args, **kwargs)
- self._probs = probs
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context."""
- spec = self._context_spec
- contexts = tf.random_uniform(
- shape=[
- batch_size,
- ] + spec.shape.as_list(), dtype=tf.float32)
- contexts = tf.cast(tf.greater(contexts, self._probs), dtype=spec.dtype)
- return contexts, contexts
-
-
-@gin.configurable
-class RandomSampler(BaseSampler):
- """Random sampler."""
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- spec = self._context_spec
- context_range = self._context_range
- if isinstance(context_range[0], (int, float)):
- contexts = tf.random_uniform(
- shape=[
- batch_size,
- ] + spec.shape.as_list(),
- minval=context_range[0],
- maxval=context_range[1],
- dtype=spec.dtype)
- elif isinstance(context_range[0], (list, tuple, np.ndarray)):
- assert len(spec.shape.as_list()) == 1
- assert spec.shape.as_list()[0] == len(context_range[0])
- assert spec.shape.as_list()[0] == len(context_range[1])
- contexts = tf.concat(
- [
- tf.random_uniform(
- shape=[
- batch_size, 1,
- ] + spec.shape.as_list()[1:],
- minval=context_range[0][i],
- maxval=context_range[1][i],
- dtype=spec.dtype) for i in range(spec.shape.as_list()[0])
- ],
- axis=1)
- else: raise NotImplementedError(context_range)
- self._validate_contexts(contexts)
- state, next_state = kwargs['state'], kwargs['next_state']
- if state is not None and next_state is not None:
- pass
- #contexts = tf.concat(
- # [tf.random_normal(tf.shape(state[:, :self._k]), dtype=tf.float64) +
- # tf.random_shuffle(state[:, :self._k]),
- # contexts[:, self._k:]], 1)
-
- return contexts, contexts
-
-
-@gin.configurable
-class ScheduledSampler(BaseSampler):
- """Scheduled sampler."""
-
- def __init__(self,
- scope='default',
- values=None,
- scheduler='cycle',
- scheduler_params=None,
- *args, **kwargs):
- """Construct sampler.
-
- Args:
- scope: Scope name.
- values: A list of numbers or [num_context_dim] Numpy arrays
- representing the values to cycle.
- scheduler: scheduler type.
- scheduler_params: scheduler parameters.
- *args: arguments.
- **kwargs: keyword arguments.
- """
- super(ScheduledSampler, self).__init__(*args, **kwargs)
- self._scope = scope
- self._values = values
- self._scheduler = scheduler
- self._scheduler_params = scheduler_params or {}
- assert self._values is not None and len(
- self._values), 'must provide non-empty values.'
- self._n = len(self._values)
- # TODO(shanegu): move variable creation outside. resolve tf.cond problem.
- self._count = 0
- self._i = tf.Variable(
- tf.zeros(shape=(), dtype=tf.int32),
- name='%s-scheduled_sampler_%d' % (self._scope, self._count))
- self._values = tf.constant(self._values, dtype=self._context_spec.dtype)
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- spec = self._context_spec
- next_op = self._next(self._i)
- with tf.control_dependencies([next_op]):
- value = self._values[self._i]
- if value.get_shape().as_list():
- values = tf.tile(
- tf.expand_dims(value, 0), (batch_size,) + (1,) * spec.shape.ndims)
- else:
- values = value + tf.zeros(
- shape=[
- batch_size,
- ] + spec.shape.as_list(), dtype=spec.dtype)
- self._validate_contexts(values)
- self._count += 1
- return values, values
-
- def _next(self, i):
- """Return op that increments pointer to next value.
-
- Args:
- i: A tensorflow integer variable.
- Returns:
- Op that increments pointer.
- """
- if self._scheduler == 'cycle':
- inc = ('inc' in self._scheduler_params and
- self._scheduler_params['inc']) or 1
- return tf.assign(i, tf.mod(i+inc, self._n))
- else:
- raise NotImplementedError(self._scheduler)
-
-
-@gin.configurable
-class ReplaySampler(BaseSampler):
- """Replay sampler."""
-
- def __init__(self,
- prefetch_queue_capacity=2,
- override_indices=None,
- state_indices=None,
- *args,
- **kwargs):
- """Construct sampler.
-
- Args:
- prefetch_queue_capacity: Capacity for prefetch queue.
- override_indices: Override indices.
- state_indices: Select certain indices from state dimension.
- *args: arguments.
- **kwargs: keyword arguments.
- """
- super(ReplaySampler, self).__init__(*args, **kwargs)
- self._prefetch_queue_capacity = prefetch_queue_capacity
- self._override_indices = override_indices
- self._state_indices = state_indices
-
- def set_replay(self, replay):
- """Set replay.
-
- Args:
- replay: A replay buffer.
- """
- self._replay = replay
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- batch = self._replay.GetRandomBatch(batch_size)
- next_states = batch[4]
- if self._prefetch_queue_capacity > 0:
- batch_queue = slim.prefetch_queue.prefetch_queue(
- [next_states],
- capacity=self._prefetch_queue_capacity,
- name='%s/batch_context_queue' % self._scope)
- next_states = batch_queue.dequeue()
- if self._override_indices is not None:
- assert self._context_range is not None and isinstance(
- self._context_range[0], (int, long, float))
- next_states = tf.concat(
- [
- tf.random_uniform(
- shape=next_states[:, :1].shape,
- minval=self._context_range[0],
- maxval=self._context_range[1],
- dtype=next_states.dtype)
- if i in self._override_indices else next_states[:, i:i + 1]
- for i in range(self._context_spec.shape.as_list()[0])
- ],
- axis=1)
- if self._state_indices is not None:
- next_states = tf.concat(
- [
- next_states[:, i:i + 1]
- for i in range(self._context_spec.shape.as_list()[0])
- ],
- axis=1)
- self._validate_contexts(next_states)
- return next_states, next_states
-
-
-@gin.configurable
-class TimeSampler(BaseSampler):
- """Time Sampler."""
-
- def __init__(self, minval=0, maxval=1, timestep=-1, *args, **kwargs):
- """Construct sampler.
-
- Args:
- minval: Min value integer.
- maxval: Max value integer.
- timestep: Time step between states and next_states.
- *args: arguments.
- **kwargs: keyword arguments.
- """
- super(TimeSampler, self).__init__(*args, **kwargs)
- assert self._context_spec.shape.as_list() == [1]
- self._minval = minval
- self._maxval = maxval
- self._timestep = timestep
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- if self._maxval == self._minval:
- contexts = tf.constant(
- self._maxval, shape=[batch_size, 1], dtype=tf.int32)
- else:
- contexts = tf.random_uniform(
- shape=[batch_size, 1],
- dtype=tf.int32,
- maxval=self._maxval,
- minval=self._minval)
- next_contexts = tf.maximum(contexts + self._timestep, 0)
-
- return tf.cast(
- contexts, dtype=self._context_spec.dtype), tf.cast(
- next_contexts, dtype=self._context_spec.dtype)
-
-
-@gin.configurable
-class ConstantSampler(BaseSampler):
- """Constant sampler."""
-
- def __init__(self, value=None, *args, **kwargs):
- """Construct sampler.
-
- Args:
- value: A list or Numpy array for values of the constant.
- *args: arguments.
- **kwargs: keyword arguments.
- """
- super(ConstantSampler, self).__init__(*args, **kwargs)
- self._value = value
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- spec = self._context_spec
- value_ = tf.constant(self._value, shape=spec.shape, dtype=spec.dtype)
- values = tf.tile(
- tf.expand_dims(value_, 0), (batch_size,) + (1,) * spec.shape.ndims)
- self._validate_contexts(values)
- return values, values
-
-
-@gin.configurable
-class DirectionSampler(RandomSampler):
- """Direction sampler."""
-
- def __call__(self, batch_size, **kwargs):
- """Sample a batch of context.
-
- Args:
- batch_size: Batch size.
- Returns:
- Two [batch_size, num_context_dims] tensors.
- """
- spec = self._context_spec
- context_range = self._context_range
- if isinstance(context_range[0], (int, float)):
- contexts = tf.random_uniform(
- shape=[
- batch_size,
- ] + spec.shape.as_list(),
- minval=context_range[0],
- maxval=context_range[1],
- dtype=spec.dtype)
- elif isinstance(context_range[0], (list, tuple, np.ndarray)):
- assert len(spec.shape.as_list()) == 1
- assert spec.shape.as_list()[0] == len(context_range[0])
- assert spec.shape.as_list()[0] == len(context_range[1])
- contexts = tf.concat(
- [
- tf.random_uniform(
- shape=[
- batch_size, 1,
- ] + spec.shape.as_list()[1:],
- minval=context_range[0][i],
- maxval=context_range[1][i],
- dtype=spec.dtype) for i in range(spec.shape.as_list()[0])
- ],
- axis=1)
- else: raise NotImplementedError(context_range)
- self._validate_contexts(contexts)
- if 'sampler_fn' in kwargs:
- other_contexts = kwargs['sampler_fn']()
- else:
- other_contexts = contexts
- state, next_state = kwargs['state'], kwargs['next_state']
- if state is not None and next_state is not None:
- my_context_range = (np.array(context_range[1]) - np.array(context_range[0])) / 2 * np.ones(spec.shape.as_list())
- contexts = tf.concat(
- [0.1 * my_context_range[:self._k] *
- tf.random_normal(tf.shape(state[:, :self._k]), dtype=state.dtype) +
- tf.random_shuffle(state[:, :self._k]) - state[:, :self._k],
- other_contexts[:, self._k:]], 1)
- #contexts = tf.Print(contexts,
- # [contexts, tf.reduce_max(contexts, 0),
- # tf.reduce_min(state, 0), tf.reduce_max(state, 0)], 'contexts', summarize=15)
- next_contexts = tf.concat( #LALA
- [state[:, :self._k] + contexts[:, :self._k] - next_state[:, :self._k],
- other_contexts[:, self._k:]], 1)
- next_contexts = contexts #LALA cosine
- else:
- next_contexts = contexts
- return tf.stop_gradient(contexts), tf.stop_gradient(next_contexts)
diff --git a/research/efficient-hrl/environments/__init__.py b/research/efficient-hrl/environments/__init__.py
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/research/efficient-hrl/environments/ant.py b/research/efficient-hrl/environments/ant.py
deleted file mode 100644
index feab1eef4c5fac51a2e0f683de00731b893751c4..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/ant.py
+++ /dev/null
@@ -1,141 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Wrapper for creating the ant environment in gym_mujoco."""
-
-import math
-import numpy as np
-import mujoco_py
-from gym import utils
-from gym.envs.mujoco import mujoco_env
-
-
-def q_inv(a):
- return [a[0], -a[1], -a[2], -a[3]]
-
-
-def q_mult(a, b): # multiply two quaternion
- w = a[0] * b[0] - a[1] * b[1] - a[2] * b[2] - a[3] * b[3]
- i = a[0] * b[1] + a[1] * b[0] + a[2] * b[3] - a[3] * b[2]
- j = a[0] * b[2] - a[1] * b[3] + a[2] * b[0] + a[3] * b[1]
- k = a[0] * b[3] + a[1] * b[2] - a[2] * b[1] + a[3] * b[0]
- return [w, i, j, k]
-
-
-class AntEnv(mujoco_env.MujocoEnv, utils.EzPickle):
- FILE = "ant.xml"
- ORI_IND = 3
-
- def __init__(self, file_path=None, expose_all_qpos=True,
- expose_body_coms=None, expose_body_comvels=None):
- self._expose_all_qpos = expose_all_qpos
- self._expose_body_coms = expose_body_coms
- self._expose_body_comvels = expose_body_comvels
- self._body_com_indices = {}
- self._body_comvel_indices = {}
-
- mujoco_env.MujocoEnv.__init__(self, file_path, 5)
- utils.EzPickle.__init__(self)
-
- @property
- def physics(self):
- # check mujoco version is greater than version 1.50 to call correct physics
- # model containing PyMjData object for getting and setting position/velocity
- # check https://github.com/openai/mujoco-py/issues/80 for updates to api
- if mujoco_py.get_version() >= '1.50':
- return self.sim
- else:
- return self.model
-
- def _step(self, a):
- return self.step(a)
-
- def step(self, a):
- xposbefore = self.get_body_com("torso")[0]
- self.do_simulation(a, self.frame_skip)
- xposafter = self.get_body_com("torso")[0]
- forward_reward = (xposafter - xposbefore) / self.dt
- ctrl_cost = .5 * np.square(a).sum()
- survive_reward = 1.0
- reward = forward_reward - ctrl_cost + survive_reward
- state = self.state_vector()
- done = False
- ob = self._get_obs()
- return ob, reward, done, dict(
- reward_forward=forward_reward,
- reward_ctrl=-ctrl_cost,
- reward_survive=survive_reward)
-
- def _get_obs(self):
- # No cfrc observation
- if self._expose_all_qpos:
- obs = np.concatenate([
- self.physics.data.qpos.flat[:15], # Ensures only ant obs.
- self.physics.data.qvel.flat[:14],
- ])
- else:
- obs = np.concatenate([
- self.physics.data.qpos.flat[2:15],
- self.physics.data.qvel.flat[:14],
- ])
-
- if self._expose_body_coms is not None:
- for name in self._expose_body_coms:
- com = self.get_body_com(name)
- if name not in self._body_com_indices:
- indices = range(len(obs), len(obs) + len(com))
- self._body_com_indices[name] = indices
- obs = np.concatenate([obs, com])
-
- if self._expose_body_comvels is not None:
- for name in self._expose_body_comvels:
- comvel = self.get_body_comvel(name)
- if name not in self._body_comvel_indices:
- indices = range(len(obs), len(obs) + len(comvel))
- self._body_comvel_indices[name] = indices
- obs = np.concatenate([obs, comvel])
- return obs
-
- def reset_model(self):
- qpos = self.init_qpos + self.np_random.uniform(
- size=self.model.nq, low=-.1, high=.1)
- qvel = self.init_qvel + self.np_random.randn(self.model.nv) * .1
-
- # Set everything other than ant to original position and 0 velocity.
- qpos[15:] = self.init_qpos[15:]
- qvel[14:] = 0.
- self.set_state(qpos, qvel)
- return self._get_obs()
-
- def viewer_setup(self):
- self.viewer.cam.distance = self.model.stat.extent * 0.5
-
- def get_ori(self):
- ori = [0, 1, 0, 0]
- rot = self.physics.data.qpos[self.__class__.ORI_IND:self.__class__.ORI_IND + 4] # take the quaternion
- ori = q_mult(q_mult(rot, ori), q_inv(rot))[1:3] # project onto x-y plane
- ori = math.atan2(ori[1], ori[0])
- return ori
-
- def set_xy(self, xy):
- qpos = np.copy(self.physics.data.qpos)
- qpos[0] = xy[0]
- qpos[1] = xy[1]
-
- qvel = self.physics.data.qvel
- self.set_state(qpos, qvel)
-
- def get_xy(self):
- return self.physics.data.qpos[:2]
diff --git a/research/efficient-hrl/environments/ant_maze_env.py b/research/efficient-hrl/environments/ant_maze_env.py
deleted file mode 100644
index 69a10663f4d02901d295f2781eca2dd3e601e292..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/ant_maze_env.py
+++ /dev/null
@@ -1,21 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-from environments.maze_env import MazeEnv
-from environments.ant import AntEnv
-
-
-class AntMazeEnv(MazeEnv):
- MODEL_CLASS = AntEnv
diff --git a/research/efficient-hrl/environments/assets/ant.xml b/research/efficient-hrl/environments/assets/ant.xml
deleted file mode 100755
index 5a49d7f52a0e577d64c47205ae32c00a9d23a2d9..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/assets/ant.xml
+++ /dev/null
@@ -1,81 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/research/efficient-hrl/environments/create_maze_env.py b/research/efficient-hrl/environments/create_maze_env.py
deleted file mode 100644
index f6dc4f42190b137364700d3dcd970c3ad8b1b9ad..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/create_maze_env.py
+++ /dev/null
@@ -1,97 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-from environments.ant_maze_env import AntMazeEnv
-from environments.point_maze_env import PointMazeEnv
-
-import tensorflow as tf
-import gin.tf
-from tf_agents.environments import gym_wrapper
-from tf_agents.environments import tf_py_environment
-
-
-@gin.configurable
-def create_maze_env(env_name=None, top_down_view=False):
- n_bins = 0
- manual_collision = False
- if env_name.startswith('Ego'):
- n_bins = 8
- env_name = env_name[3:]
- if env_name.startswith('Ant'):
- cls = AntMazeEnv
- env_name = env_name[3:]
- maze_size_scaling = 8
- elif env_name.startswith('Point'):
- cls = PointMazeEnv
- manual_collision = True
- env_name = env_name[5:]
- maze_size_scaling = 4
- else:
- assert False, 'unknown env %s' % env_name
-
- maze_id = None
- observe_blocks = False
- put_spin_near_agent = False
- if env_name == 'Maze':
- maze_id = 'Maze'
- elif env_name == 'Push':
- maze_id = 'Push'
- elif env_name == 'Fall':
- maze_id = 'Fall'
- elif env_name == 'Block':
- maze_id = 'Block'
- put_spin_near_agent = True
- observe_blocks = True
- elif env_name == 'BlockMaze':
- maze_id = 'BlockMaze'
- put_spin_near_agent = True
- observe_blocks = True
- else:
- raise ValueError('Unknown maze environment %s' % env_name)
-
- gym_mujoco_kwargs = {
- 'maze_id': maze_id,
- 'n_bins': n_bins,
- 'observe_blocks': observe_blocks,
- 'put_spin_near_agent': put_spin_near_agent,
- 'top_down_view': top_down_view,
- 'manual_collision': manual_collision,
- 'maze_size_scaling': maze_size_scaling
- }
- gym_env = cls(**gym_mujoco_kwargs)
- gym_env.reset()
- wrapped_env = gym_wrapper.GymWrapper(gym_env)
- return wrapped_env
-
-
-class TFPyEnvironment(tf_py_environment.TFPyEnvironment):
-
- def __init__(self, *args, **kwargs):
- super(TFPyEnvironment, self).__init__(*args, **kwargs)
-
- def start_collect(self):
- pass
-
- def current_obs(self):
- time_step = self.current_time_step()
- return time_step.observation[0] # For some reason, there is an extra dim.
-
- def step(self, actions):
- actions = tf.expand_dims(actions, 0)
- next_step = super(TFPyEnvironment, self).step(actions)
- return next_step.is_last()[0], next_step.reward[0], next_step.discount[0]
-
- def reset(self):
- return super(TFPyEnvironment, self).reset()
diff --git a/research/efficient-hrl/environments/maze_env.py b/research/efficient-hrl/environments/maze_env.py
deleted file mode 100644
index cf7d1f2dc0a0d5883a7953c623b3419a02282206..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/maze_env.py
+++ /dev/null
@@ -1,499 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Adapted from rllab maze_env.py."""
-
-import os
-import tempfile
-import xml.etree.ElementTree as ET
-import math
-import numpy as np
-import gym
-
-from environments import maze_env_utils
-
-# Directory that contains mujoco xml files.
-MODEL_DIR = 'environments/assets'
-
-
-class MazeEnv(gym.Env):
- MODEL_CLASS = None
-
- MAZE_HEIGHT = None
- MAZE_SIZE_SCALING = None
-
- def __init__(
- self,
- maze_id=None,
- maze_height=0.5,
- maze_size_scaling=8,
- n_bins=0,
- sensor_range=3.,
- sensor_span=2 * math.pi,
- observe_blocks=False,
- put_spin_near_agent=False,
- top_down_view=False,
- manual_collision=False,
- *args,
- **kwargs):
- self._maze_id = maze_id
-
- model_cls = self.__class__.MODEL_CLASS
- if model_cls is None:
- raise "MODEL_CLASS unspecified!"
- xml_path = os.path.join(MODEL_DIR, model_cls.FILE)
- tree = ET.parse(xml_path)
- worldbody = tree.find(".//worldbody")
-
- self.MAZE_HEIGHT = height = maze_height
- self.MAZE_SIZE_SCALING = size_scaling = maze_size_scaling
- self._n_bins = n_bins
- self._sensor_range = sensor_range * size_scaling
- self._sensor_span = sensor_span
- self._observe_blocks = observe_blocks
- self._put_spin_near_agent = put_spin_near_agent
- self._top_down_view = top_down_view
- self._manual_collision = manual_collision
-
- self.MAZE_STRUCTURE = structure = maze_env_utils.construct_maze(maze_id=self._maze_id)
- self.elevated = any(-1 in row for row in structure) # Elevate the maze to allow for falling.
- self.blocks = any(
- any(maze_env_utils.can_move(r) for r in row)
- for row in structure) # Are there any movable blocks?
-
- torso_x, torso_y = self._find_robot()
- self._init_torso_x = torso_x
- self._init_torso_y = torso_y
- self._init_positions = [
- (x - torso_x, y - torso_y)
- for x, y in self._find_all_robots()]
-
- self._xy_to_rowcol = lambda x, y: (2 + (y + size_scaling / 2) / size_scaling,
- 2 + (x + size_scaling / 2) / size_scaling)
- self._view = np.zeros([5, 5, 3]) # walls (immovable), chasms (fall), movable blocks
-
- height_offset = 0.
- if self.elevated:
- # Increase initial z-pos of ant.
- height_offset = height * size_scaling
- torso = tree.find(".//body[@name='torso']")
- torso.set('pos', '0 0 %.2f' % (0.75 + height_offset))
- if self.blocks:
- # If there are movable blocks, change simulation settings to perform
- # better contact detection.
- default = tree.find(".//default")
- default.find('.//geom').set('solimp', '.995 .995 .01')
-
- self.movable_blocks = []
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- struct = structure[i][j]
- if struct == 'r' and self._put_spin_near_agent:
- struct = maze_env_utils.Move.SpinXY
- if self.elevated and struct not in [-1]:
- # Create elevated platform.
- ET.SubElement(
- worldbody, "geom",
- name="elevated_%d_%d" % (i, j),
- pos="%f %f %f" % (j * size_scaling - torso_x,
- i * size_scaling - torso_y,
- height / 2 * size_scaling),
- size="%f %f %f" % (0.5 * size_scaling,
- 0.5 * size_scaling,
- height / 2 * size_scaling),
- type="box",
- material="",
- contype="1",
- conaffinity="1",
- rgba="0.9 0.9 0.9 1",
- )
- if struct == 1: # Unmovable block.
- # Offset all coordinates so that robot starts at the origin.
- ET.SubElement(
- worldbody, "geom",
- name="block_%d_%d" % (i, j),
- pos="%f %f %f" % (j * size_scaling - torso_x,
- i * size_scaling - torso_y,
- height_offset +
- height / 2 * size_scaling),
- size="%f %f %f" % (0.5 * size_scaling,
- 0.5 * size_scaling,
- height / 2 * size_scaling),
- type="box",
- material="",
- contype="1",
- conaffinity="1",
- rgba="0.4 0.4 0.4 1",
- )
- elif maze_env_utils.can_move(struct): # Movable block.
- # The "falling" blocks are shrunk slightly and increased in mass to
- # ensure that it can fall easily through a gap in the platform blocks.
- name = "movable_%d_%d" % (i, j)
- self.movable_blocks.append((name, struct))
- falling = maze_env_utils.can_move_z(struct)
- spinning = maze_env_utils.can_spin(struct)
- x_offset = 0.25 * size_scaling if spinning else 0.0
- y_offset = 0.0
- shrink = 0.1 if spinning else 0.99 if falling else 1.0
- height_shrink = 0.1 if spinning else 1.0
- movable_body = ET.SubElement(
- worldbody, "body",
- name=name,
- pos="%f %f %f" % (j * size_scaling - torso_x + x_offset,
- i * size_scaling - torso_y + y_offset,
- height_offset +
- height / 2 * size_scaling * height_shrink),
- )
- ET.SubElement(
- movable_body, "geom",
- name="block_%d_%d" % (i, j),
- pos="0 0 0",
- size="%f %f %f" % (0.5 * size_scaling * shrink,
- 0.5 * size_scaling * shrink,
- height / 2 * size_scaling * height_shrink),
- type="box",
- material="",
- mass="0.001" if falling else "0.0002",
- contype="1",
- conaffinity="1",
- rgba="0.9 0.1 0.1 1"
- )
- if maze_env_utils.can_move_x(struct):
- ET.SubElement(
- movable_body, "joint",
- armature="0",
- axis="1 0 0",
- damping="0.0",
- limited="true" if falling else "false",
- range="%f %f" % (-size_scaling, size_scaling),
- margin="0.01",
- name="movable_x_%d_%d" % (i, j),
- pos="0 0 0",
- type="slide"
- )
- if maze_env_utils.can_move_y(struct):
- ET.SubElement(
- movable_body, "joint",
- armature="0",
- axis="0 1 0",
- damping="0.0",
- limited="true" if falling else "false",
- range="%f %f" % (-size_scaling, size_scaling),
- margin="0.01",
- name="movable_y_%d_%d" % (i, j),
- pos="0 0 0",
- type="slide"
- )
- if maze_env_utils.can_move_z(struct):
- ET.SubElement(
- movable_body, "joint",
- armature="0",
- axis="0 0 1",
- damping="0.0",
- limited="true",
- range="%f 0" % (-height_offset),
- margin="0.01",
- name="movable_z_%d_%d" % (i, j),
- pos="0 0 0",
- type="slide"
- )
- if maze_env_utils.can_spin(struct):
- ET.SubElement(
- movable_body, "joint",
- armature="0",
- axis="0 0 1",
- damping="0.0",
- limited="false",
- name="spinable_%d_%d" % (i, j),
- pos="0 0 0",
- type="ball"
- )
-
- torso = tree.find(".//body[@name='torso']")
- geoms = torso.findall(".//geom")
- for geom in geoms:
- if 'name' not in geom.attrib:
- raise Exception("Every geom of the torso must have a name "
- "defined")
-
- _, file_path = tempfile.mkstemp(text=True, suffix='.xml')
- tree.write(file_path)
-
- self.wrapped_env = model_cls(*args, file_path=file_path, **kwargs)
-
- def get_ori(self):
- return self.wrapped_env.get_ori()
-
- def get_top_down_view(self):
- self._view = np.zeros_like(self._view)
-
- def valid(row, col):
- return self._view.shape[0] > row >= 0 and self._view.shape[1] > col >= 0
-
- def update_view(x, y, d, row=None, col=None):
- if row is None or col is None:
- x = x - self._robot_x
- y = y - self._robot_y
- th = self._robot_ori
-
- row, col = self._xy_to_rowcol(x, y)
- update_view(x, y, d, row=row, col=col)
- return
-
- row, row_frac, col, col_frac = int(row), row % 1, int(col), col % 1
- if row_frac < 0:
- row_frac += 1
- if col_frac < 0:
- col_frac += 1
-
- if valid(row, col):
- self._view[row, col, d] += (
- (min(1., row_frac + 0.5) - max(0., row_frac - 0.5)) *
- (min(1., col_frac + 0.5) - max(0., col_frac - 0.5)))
- if valid(row - 1, col):
- self._view[row - 1, col, d] += (
- (max(0., 0.5 - row_frac)) *
- (min(1., col_frac + 0.5) - max(0., col_frac - 0.5)))
- if valid(row + 1, col):
- self._view[row + 1, col, d] += (
- (max(0., row_frac - 0.5)) *
- (min(1., col_frac + 0.5) - max(0., col_frac - 0.5)))
- if valid(row, col - 1):
- self._view[row, col - 1, d] += (
- (min(1., row_frac + 0.5) - max(0., row_frac - 0.5)) *
- (max(0., 0.5 - col_frac)))
- if valid(row, col + 1):
- self._view[row, col + 1, d] += (
- (min(1., row_frac + 0.5) - max(0., row_frac - 0.5)) *
- (max(0., col_frac - 0.5)))
- if valid(row - 1, col - 1):
- self._view[row - 1, col - 1, d] += (
- (max(0., 0.5 - row_frac)) * max(0., 0.5 - col_frac))
- if valid(row - 1, col + 1):
- self._view[row - 1, col + 1, d] += (
- (max(0., 0.5 - row_frac)) * max(0., col_frac - 0.5))
- if valid(row + 1, col + 1):
- self._view[row + 1, col + 1, d] += (
- (max(0., row_frac - 0.5)) * max(0., col_frac - 0.5))
- if valid(row + 1, col - 1):
- self._view[row + 1, col - 1, d] += (
- (max(0., row_frac - 0.5)) * max(0., 0.5 - col_frac))
-
- # Draw ant.
- robot_x, robot_y = self.wrapped_env.get_body_com("torso")[:2]
- self._robot_x = robot_x
- self._robot_y = robot_y
- self._robot_ori = self.get_ori()
-
- structure = self.MAZE_STRUCTURE
- size_scaling = self.MAZE_SIZE_SCALING
- height = self.MAZE_HEIGHT
-
- # Draw immovable blocks and chasms.
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- if structure[i][j] == 1: # Wall.
- update_view(j * size_scaling - self._init_torso_x,
- i * size_scaling - self._init_torso_y,
- 0)
- if structure[i][j] == -1: # Chasm.
- update_view(j * size_scaling - self._init_torso_x,
- i * size_scaling - self._init_torso_y,
- 1)
-
- # Draw movable blocks.
- for block_name, block_type in self.movable_blocks:
- block_x, block_y = self.wrapped_env.get_body_com(block_name)[:2]
- update_view(block_x, block_y, 2)
-
- return self._view
-
- def get_range_sensor_obs(self):
- """Returns egocentric range sensor observations of maze."""
- robot_x, robot_y, robot_z = self.wrapped_env.get_body_com("torso")[:3]
- ori = self.get_ori()
-
- structure = self.MAZE_STRUCTURE
- size_scaling = self.MAZE_SIZE_SCALING
- height = self.MAZE_HEIGHT
-
- segments = []
- # Get line segments (corresponding to outer boundary) of each immovable
- # block or drop-off.
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- if structure[i][j] in [1, -1]: # There's a wall or drop-off.
- cx = j * size_scaling - self._init_torso_x
- cy = i * size_scaling - self._init_torso_y
- x1 = cx - 0.5 * size_scaling
- x2 = cx + 0.5 * size_scaling
- y1 = cy - 0.5 * size_scaling
- y2 = cy + 0.5 * size_scaling
- struct_segments = [
- ((x1, y1), (x2, y1)),
- ((x2, y1), (x2, y2)),
- ((x2, y2), (x1, y2)),
- ((x1, y2), (x1, y1)),
- ]
- for seg in struct_segments:
- segments.append(dict(
- segment=seg,
- type=structure[i][j],
- ))
- # Get line segments (corresponding to outer boundary) of each movable
- # block within the agent's z-view.
- for block_name, block_type in self.movable_blocks:
- block_x, block_y, block_z = self.wrapped_env.get_body_com(block_name)[:3]
- if (block_z + height * size_scaling / 2 >= robot_z and
- robot_z >= block_z - height * size_scaling / 2): # Block in view.
- x1 = block_x - 0.5 * size_scaling
- x2 = block_x + 0.5 * size_scaling
- y1 = block_y - 0.5 * size_scaling
- y2 = block_y + 0.5 * size_scaling
- struct_segments = [
- ((x1, y1), (x2, y1)),
- ((x2, y1), (x2, y2)),
- ((x2, y2), (x1, y2)),
- ((x1, y2), (x1, y1)),
- ]
- for seg in struct_segments:
- segments.append(dict(
- segment=seg,
- type=block_type,
- ))
-
- sensor_readings = np.zeros((self._n_bins, 3)) # 3 for wall, drop-off, block
- for ray_idx in range(self._n_bins):
- ray_ori = (ori - self._sensor_span * 0.5 +
- (2 * ray_idx + 1.0) / (2 * self._n_bins) * self._sensor_span)
- ray_segments = []
- # Get all segments that intersect with ray.
- for seg in segments:
- p = maze_env_utils.ray_segment_intersect(
- ray=((robot_x, robot_y), ray_ori),
- segment=seg["segment"])
- if p is not None:
- ray_segments.append(dict(
- segment=seg["segment"],
- type=seg["type"],
- ray_ori=ray_ori,
- distance=maze_env_utils.point_distance(p, (robot_x, robot_y)),
- ))
- if len(ray_segments) > 0:
- # Find out which segment is intersected first.
- first_seg = sorted(ray_segments, key=lambda x: x["distance"])[0]
- seg_type = first_seg["type"]
- idx = (0 if seg_type == 1 else # Wall.
- 1 if seg_type == -1 else # Drop-off.
- 2 if maze_env_utils.can_move(seg_type) else # Block.
- None)
- if first_seg["distance"] <= self._sensor_range:
- sensor_readings[ray_idx][idx] = (self._sensor_range - first_seg["distance"]) / self._sensor_range
-
- return sensor_readings
-
- def _get_obs(self):
- wrapped_obs = self.wrapped_env._get_obs()
- if self._top_down_view:
- view = [self.get_top_down_view().flat]
- else:
- view = []
-
- if self._observe_blocks:
- additional_obs = []
- for block_name, block_type in self.movable_blocks:
- additional_obs.append(self.wrapped_env.get_body_com(block_name))
- wrapped_obs = np.concatenate([wrapped_obs[:3]] + additional_obs +
- [wrapped_obs[3:]])
-
- range_sensor_obs = self.get_range_sensor_obs()
- return np.concatenate([wrapped_obs,
- range_sensor_obs.flat] +
- view + [[self.t * 0.001]])
-
- def reset(self):
- self.t = 0
- self.trajectory = []
- self.wrapped_env.reset()
- if len(self._init_positions) > 1:
- xy = random.choice(self._init_positions)
- self.wrapped_env.set_xy(xy)
- return self._get_obs()
-
- @property
- def viewer(self):
- return self.wrapped_env.viewer
-
- def render(self, *args, **kwargs):
- return self.wrapped_env.render(*args, **kwargs)
-
- @property
- def observation_space(self):
- shape = self._get_obs().shape
- high = np.inf * np.ones(shape)
- low = -high
- return gym.spaces.Box(low, high)
-
- @property
- def action_space(self):
- return self.wrapped_env.action_space
-
- def _find_robot(self):
- structure = self.MAZE_STRUCTURE
- size_scaling = self.MAZE_SIZE_SCALING
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- if structure[i][j] == 'r':
- return j * size_scaling, i * size_scaling
- assert False, 'No robot in maze specification.'
-
- def _find_all_robots(self):
- structure = self.MAZE_STRUCTURE
- size_scaling = self.MAZE_SIZE_SCALING
- coords = []
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- if structure[i][j] == 'r':
- coords.append((j * size_scaling, i * size_scaling))
- return coords
-
- def _is_in_collision(self, pos):
- x, y = pos
- structure = self.MAZE_STRUCTURE
- size_scaling = self.MAZE_SIZE_SCALING
- for i in range(len(structure)):
- for j in range(len(structure[0])):
- if structure[i][j] == 1:
- minx = j * size_scaling - size_scaling * 0.5 - self._init_torso_x
- maxx = j * size_scaling + size_scaling * 0.5 - self._init_torso_x
- miny = i * size_scaling - size_scaling * 0.5 - self._init_torso_y
- maxy = i * size_scaling + size_scaling * 0.5 - self._init_torso_y
- if minx <= x <= maxx and miny <= y <= maxy:
- return True
- return False
-
- def step(self, action):
- self.t += 1
- if self._manual_collision:
- old_pos = self.wrapped_env.get_xy()
- inner_next_obs, inner_reward, done, info = self.wrapped_env.step(action)
- new_pos = self.wrapped_env.get_xy()
- if self._is_in_collision(new_pos):
- self.wrapped_env.set_xy(old_pos)
- else:
- inner_next_obs, inner_reward, done, info = self.wrapped_env.step(action)
- next_obs = self._get_obs()
- done = False
- return next_obs, inner_reward, done, info
diff --git a/research/efficient-hrl/environments/maze_env_utils.py b/research/efficient-hrl/environments/maze_env_utils.py
deleted file mode 100644
index 4f52509b65a89b43c1baa8e7448e0692ceefaaab..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/maze_env_utils.py
+++ /dev/null
@@ -1,164 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Adapted from rllab maze_env_utils.py."""
-import numpy as np
-import math
-
-
-class Move(object):
- X = 11
- Y = 12
- Z = 13
- XY = 14
- XZ = 15
- YZ = 16
- XYZ = 17
- SpinXY = 18
-
-
-def can_move_x(movable):
- return movable in [Move.X, Move.XY, Move.XZ, Move.XYZ,
- Move.SpinXY]
-
-
-def can_move_y(movable):
- return movable in [Move.Y, Move.XY, Move.YZ, Move.XYZ,
- Move.SpinXY]
-
-
-def can_move_z(movable):
- return movable in [Move.Z, Move.XZ, Move.YZ, Move.XYZ]
-
-
-def can_spin(movable):
- return movable in [Move.SpinXY]
-
-
-def can_move(movable):
- return can_move_x(movable) or can_move_y(movable) or can_move_z(movable)
-
-
-def construct_maze(maze_id='Maze'):
- if maze_id == 'Maze':
- structure = [
- [1, 1, 1, 1, 1],
- [1, 'r', 0, 0, 1],
- [1, 1, 1, 0, 1],
- [1, 0, 0, 0, 1],
- [1, 1, 1, 1, 1],
- ]
- elif maze_id == 'Push':
- structure = [
- [1, 1, 1, 1, 1],
- [1, 0, 'r', 1, 1],
- [1, 0, Move.XY, 0, 1],
- [1, 1, 0, 1, 1],
- [1, 1, 1, 1, 1],
- ]
- elif maze_id == 'Fall':
- structure = [
- [1, 1, 1, 1],
- [1, 'r', 0, 1],
- [1, 0, Move.YZ, 1],
- [1, -1, -1, 1],
- [1, 0, 0, 1],
- [1, 1, 1, 1],
- ]
- elif maze_id == 'Block':
- O = 'r'
- structure = [
- [1, 1, 1, 1, 1],
- [1, O, 0, 0, 1],
- [1, 0, 0, 0, 1],
- [1, 0, 0, 0, 1],
- [1, 1, 1, 1, 1],
- ]
- elif maze_id == 'BlockMaze':
- O = 'r'
- structure = [
- [1, 1, 1, 1],
- [1, O, 0, 1],
- [1, 1, 0, 1],
- [1, 0, 0, 1],
- [1, 1, 1, 1],
- ]
- else:
- raise NotImplementedError('The provided MazeId %s is not recognized' % maze_id)
-
- return structure
-
-
-def line_intersect(pt1, pt2, ptA, ptB):
- """
- Taken from https://www.cs.hmc.edu/ACM/lectures/intersections.html
-
- this returns the intersection of Line(pt1,pt2) and Line(ptA,ptB)
- """
-
- DET_TOLERANCE = 0.00000001
-
- # the first line is pt1 + r*(pt2-pt1)
- # in component form:
- x1, y1 = pt1
- x2, y2 = pt2
- dx1 = x2 - x1
- dy1 = y2 - y1
-
- # the second line is ptA + s*(ptB-ptA)
- x, y = ptA
- xB, yB = ptB
- dx = xB - x
- dy = yB - y
-
- DET = (-dx1 * dy + dy1 * dx)
-
- if math.fabs(DET) < DET_TOLERANCE: return (0, 0, 0, 0, 0)
-
- # now, the determinant should be OK
- DETinv = 1.0 / DET
-
- # find the scalar amount along the "self" segment
- r = DETinv * (-dy * (x - x1) + dx * (y - y1))
-
- # find the scalar amount along the input line
- s = DETinv * (-dy1 * (x - x1) + dx1 * (y - y1))
-
- # return the average of the two descriptions
- xi = (x1 + r * dx1 + x + s * dx) / 2.0
- yi = (y1 + r * dy1 + y + s * dy) / 2.0
- return (xi, yi, 1, r, s)
-
-
-def ray_segment_intersect(ray, segment):
- """
- Check if the ray originated from (x, y) with direction theta intersects the line segment (x1, y1) -- (x2, y2),
- and return the intersection point if there is one
- """
- (x, y), theta = ray
- # (x1, y1), (x2, y2) = segment
- pt1 = (x, y)
- len = 1
- pt2 = (x + len * math.cos(theta), y + len * math.sin(theta))
- xo, yo, valid, r, s = line_intersect(pt1, pt2, *segment)
- if valid and r >= 0 and 0 <= s <= 1:
- return (xo, yo)
- return None
-
-
-def point_distance(p1, p2):
- x1, y1 = p1
- x2, y2 = p2
- return ((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5
diff --git a/research/efficient-hrl/environments/point.py b/research/efficient-hrl/environments/point.py
deleted file mode 100644
index 9c2fc80bc824dbc81e228a122b9aaea054f73b74..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/point.py
+++ /dev/null
@@ -1,97 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Wrapper for creating the ant environment in gym_mujoco."""
-
-import math
-import numpy as np
-import mujoco_py
-from gym import utils
-from gym.envs.mujoco import mujoco_env
-
-
-class PointEnv(mujoco_env.MujocoEnv, utils.EzPickle):
- FILE = "point.xml"
- ORI_IND = 2
-
- def __init__(self, file_path=None, expose_all_qpos=True):
- self._expose_all_qpos = expose_all_qpos
-
- mujoco_env.MujocoEnv.__init__(self, file_path, 1)
- utils.EzPickle.__init__(self)
-
- @property
- def physics(self):
- # check mujoco version is greater than version 1.50 to call correct physics
- # model containing PyMjData object for getting and setting position/velocity
- # check https://github.com/openai/mujoco-py/issues/80 for updates to api
- if mujoco_py.get_version() >= '1.50':
- return self.sim
- else:
- return self.model
-
- def _step(self, a):
- return self.step(a)
-
- def step(self, action):
- action[0] = 0.2 * action[0]
- qpos = np.copy(self.physics.data.qpos)
- qpos[2] += action[1]
- ori = qpos[2]
- # compute increment in each direction
- dx = math.cos(ori) * action[0]
- dy = math.sin(ori) * action[0]
- # ensure that the robot is within reasonable range
- qpos[0] = np.clip(qpos[0] + dx, -100, 100)
- qpos[1] = np.clip(qpos[1] + dy, -100, 100)
- qvel = self.physics.data.qvel
- self.set_state(qpos, qvel)
- for _ in range(0, self.frame_skip):
- self.physics.step()
- next_obs = self._get_obs()
- reward = 0
- done = False
- info = {}
- return next_obs, reward, done, info
-
- def _get_obs(self):
- if self._expose_all_qpos:
- return np.concatenate([
- self.physics.data.qpos.flat[:3], # Only point-relevant coords.
- self.physics.data.qvel.flat[:3]])
- return np.concatenate([
- self.physics.data.qpos.flat[2:3],
- self.physics.data.qvel.flat[:3]])
-
- def reset_model(self):
- qpos = self.init_qpos + self.np_random.uniform(
- size=self.physics.model.nq, low=-.1, high=.1)
- qvel = self.init_qvel + self.np_random.randn(self.physics.model.nv) * .1
-
- # Set everything other than point to original position and 0 velocity.
- qpos[3:] = self.init_qpos[3:]
- qvel[3:] = 0.
- self.set_state(qpos, qvel)
- return self._get_obs()
-
- def get_ori(self):
- return self.physics.data.qpos[self.__class__.ORI_IND]
-
- def set_xy(self, xy):
- qpos = np.copy(self.physics.data.qpos)
- qpos[0] = xy[0]
- qpos[1] = xy[1]
-
- qvel = self.physics.data.qvel
diff --git a/research/efficient-hrl/environments/point_maze_env.py b/research/efficient-hrl/environments/point_maze_env.py
deleted file mode 100644
index 8d6b819486370d609b87c232d92c4093aa906863..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/environments/point_maze_env.py
+++ /dev/null
@@ -1,21 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-from environments.maze_env import MazeEnv
-from environments.point import PointEnv
-
-
-class PointMazeEnv(MazeEnv):
- MODEL_CLASS = PointEnv
diff --git a/research/efficient-hrl/eval.py b/research/efficient-hrl/eval.py
deleted file mode 100644
index 4f5a4b20a53d920b4a9095c30de2c03698cd1b78..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/eval.py
+++ /dev/null
@@ -1,460 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Script for evaluating a UVF agent.
-
-To run locally: See run_eval.py
-
-To run on borg: See train_eval.borg
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import tensorflow as tf
-slim = tf.contrib.slim
-import gin.tf
-# pylint: disable=unused-import
-import agent
-import train
-from utils import utils as uvf_utils
-from utils import eval_utils
-from environments import create_maze_env
-# pylint: enable=unused-import
-
-flags = tf.app.flags
-
-flags.DEFINE_string('eval_dir', None,
- 'Directory for writing logs/summaries during eval.')
-flags.DEFINE_string('checkpoint_dir', None,
- 'Directory containing checkpoints to eval.')
-FLAGS = flags.FLAGS
-
-
-def get_evaluate_checkpoint_fn(master, output_dir, eval_step_fns,
- model_rollout_fn, gamma, max_steps_per_episode,
- num_episodes_eval, num_episodes_videos,
- tuner_hook, generate_videos,
- generate_summaries, video_settings):
- """Returns a function that evaluates a given checkpoint.
-
- Args:
- master: BNS name of the TensorFlow master
- output_dir: The output directory to which the metric summaries are written.
- eval_step_fns: A dictionary of a functions that return a list of
- [state, action, reward, discount, transition_type] tensors,
- indexed by summary tag name.
- model_rollout_fn: Model rollout fn.
- gamma: Discount factor for the reward.
- max_steps_per_episode: Maximum steps to run each episode for.
- num_episodes_eval: Number of episodes to evaluate and average reward over.
- num_episodes_videos: Number of episodes to record for video.
- tuner_hook: A callable(average reward, global step) that updates a Vizier
- tuner trial.
- generate_videos: Whether to generate videos of the agent in action.
- generate_summaries: Whether to generate summaries.
- video_settings: Settings for generating videos of the agent.
-
- Returns:
- A function that evaluates a checkpoint.
- """
- sess = tf.Session(master, graph=tf.get_default_graph())
- sess.run(tf.global_variables_initializer())
- sess.run(tf.local_variables_initializer())
- summary_writer = tf.summary.FileWriter(output_dir)
-
- def evaluate_checkpoint(checkpoint_path):
- """Performs a one-time evaluation of the given checkpoint.
-
- Args:
- checkpoint_path: Checkpoint to evaluate.
- Returns:
- True if the evaluation process should stop
- """
- restore_fn = tf.contrib.framework.assign_from_checkpoint_fn(
- checkpoint_path,
- uvf_utils.get_all_vars(),
- ignore_missing_vars=True,
- reshape_variables=False)
- assert restore_fn is not None, 'cannot restore %s' % checkpoint_path
- restore_fn(sess)
- global_step = sess.run(slim.get_global_step())
- should_stop = False
- max_reward = -1e10
- max_meta_reward = -1e10
-
- for eval_tag, (eval_step, env_base,) in sorted(eval_step_fns.items()):
- if hasattr(env_base, 'set_sess'):
- env_base.set_sess(sess) # set session
-
- if generate_summaries:
- tf.logging.info(
- '[%s] Computing average reward over %d episodes at global step %d.',
- eval_tag, num_episodes_eval, global_step)
- (average_reward, last_reward,
- average_meta_reward, last_meta_reward, average_success,
- states, actions) = eval_utils.compute_average_reward(
- sess, env_base, eval_step, gamma, max_steps_per_episode,
- num_episodes_eval)
- tf.logging.info('[%s] Average reward = %f', eval_tag, average_reward)
- tf.logging.info('[%s] Last reward = %f', eval_tag, last_reward)
- tf.logging.info('[%s] Average meta reward = %f', eval_tag, average_meta_reward)
- tf.logging.info('[%s] Last meta reward = %f', eval_tag, last_meta_reward)
- tf.logging.info('[%s] Average success = %f', eval_tag, average_success)
- if model_rollout_fn is not None:
- preds, model_losses = eval_utils.compute_model_loss(
- sess, model_rollout_fn, states, actions)
- for i, (pred, state, model_loss) in enumerate(
- zip(preds, states, model_losses)):
- tf.logging.info('[%s] Model rollout step %d: loss=%f', eval_tag, i,
- model_loss)
- tf.logging.info('[%s] Model rollout step %d: pred=%s', eval_tag, i,
- str(pred.tolist()))
- tf.logging.info('[%s] Model rollout step %d: state=%s', eval_tag, i,
- str(state.tolist()))
-
- # Report the eval stats to the tuner.
- if average_reward > max_reward:
- max_reward = average_reward
- if average_meta_reward > max_meta_reward:
- max_meta_reward = average_meta_reward
-
- for (tag, value) in [('Reward/average_%s_reward', average_reward),
- ('Reward/last_%s_reward', last_reward),
- ('Reward/average_%s_meta_reward', average_meta_reward),
- ('Reward/last_%s_meta_reward', last_meta_reward),
- ('Reward/average_%s_success', average_success)]:
- summary_str = tf.Summary(value=[
- tf.Summary.Value(
- tag=tag % eval_tag,
- simple_value=value)
- ])
- summary_writer.add_summary(summary_str, global_step)
- summary_writer.flush()
-
- if generate_videos or should_stop:
- # Do a manual reset before generating the video to see the initial
- # pose of the robot, towards which the reset controller is moving.
- if hasattr(env_base, '_gym_env'):
- tf.logging.info('Resetting before recording video')
- if hasattr(env_base._gym_env, 'reset_model'):
- env_base._gym_env.reset_model() # pylint: disable=protected-access
- else:
- env_base._gym_env.wrapped_env.reset_model()
- video_filename = os.path.join(output_dir, 'videos',
- '%s_step_%d.mp4' % (eval_tag,
- global_step))
- eval_utils.capture_video(sess, eval_step, env_base,
- max_steps_per_episode * num_episodes_videos,
- video_filename, video_settings,
- reset_every=max_steps_per_episode)
-
- should_stop = should_stop or (generate_summaries and tuner_hook and
- tuner_hook(max_reward, global_step))
- return bool(should_stop)
-
- return evaluate_checkpoint
-
-
-def get_model_rollout(uvf_agent, tf_env):
- """Model rollout function."""
- state_spec = tf_env.observation_spec()[0]
- action_spec = tf_env.action_spec()[0]
- state_ph = tf.placeholder(dtype=state_spec.dtype, shape=state_spec.shape)
- action_ph = tf.placeholder(dtype=action_spec.dtype, shape=action_spec.shape)
-
- merged_state = uvf_agent.merged_state(state_ph)
- diff_value = uvf_agent.critic_net(tf.expand_dims(merged_state, 0),
- tf.expand_dims(action_ph, 0))[0]
- diff_value = tf.cast(diff_value, dtype=state_ph.dtype)
- state_ph.shape.assert_is_compatible_with(diff_value.shape)
- next_state = state_ph + diff_value
-
- def model_rollout_fn(sess, state, action):
- return sess.run(next_state, feed_dict={state_ph: state, action_ph: action})
-
- return model_rollout_fn
-
-
-def get_eval_step(uvf_agent,
- state_preprocess,
- tf_env,
- action_fn,
- meta_action_fn,
- environment_steps,
- num_episodes,
- mode='eval'):
- """Get one-step policy/env stepping ops.
-
- Args:
- uvf_agent: A UVF agent.
- tf_env: A TFEnvironment.
- action_fn: A function to produce actions given current state.
- meta_action_fn: A function to produce meta actions given current state.
- environment_steps: A variable to count the number of steps in the tf_env.
- num_episodes: A variable to count the number of episodes.
- mode: a string representing the mode=[train, explore, eval].
-
- Returns:
- A collect_experience_op that excute an action and store into the
- replay_buffer
- """
-
- tf_env.start_collect()
- state = tf_env.current_obs()
- action = action_fn(state, context=None)
- state_repr = state_preprocess(state)
-
- action_spec = tf_env.action_spec()
- action_ph = tf.placeholder(dtype=action_spec.dtype, shape=action_spec.shape)
- with tf.control_dependencies([state]):
- transition_type, reward, discount = tf_env.step(action_ph)
-
- def increment_step():
- return environment_steps.assign_add(1)
-
- def increment_episode():
- return num_episodes.assign_add(1)
-
- def no_op_int():
- return tf.constant(0, dtype=tf.int64)
-
- step_cond = uvf_agent.step_cond_fn(state, action,
- transition_type,
- environment_steps, num_episodes)
- reset_episode_cond = uvf_agent.reset_episode_cond_fn(
- state, action,
- transition_type, environment_steps, num_episodes)
- reset_env_cond = uvf_agent.reset_env_cond_fn(state, action,
- transition_type,
- environment_steps, num_episodes)
-
- increment_step_op = tf.cond(step_cond, increment_step, no_op_int)
- with tf.control_dependencies([increment_step_op]):
- increment_episode_op = tf.cond(reset_episode_cond, increment_episode,
- no_op_int)
-
- with tf.control_dependencies([reward, discount]):
- next_state = tf_env.current_obs()
- next_state_repr = state_preprocess(next_state)
-
- with tf.control_dependencies([increment_episode_op]):
- post_reward, post_meta_reward = uvf_agent.cond_begin_episode_op(
- tf.logical_not(reset_episode_cond),
- [state, action_ph, reward, next_state,
- state_repr, next_state_repr],
- mode=mode, meta_action_fn=meta_action_fn)
-
- # Important: do manual reset after getting the final reward from the
- # unreset environment.
- with tf.control_dependencies([post_reward, post_meta_reward]):
- cond_reset_op = tf.cond(reset_env_cond,
- tf_env.reset,
- tf_env.current_time_step)
-
- # Add a dummy control dependency to force the reset_op to run
- with tf.control_dependencies(cond_reset_op):
- post_reward, post_meta_reward = map(tf.identity, [post_reward, post_meta_reward])
-
- eval_step = [next_state, action_ph, transition_type, post_reward, post_meta_reward, discount, uvf_agent.context_vars, state_repr]
-
- if callable(action):
- def step_fn(sess):
- action_value = action(sess)
- return sess.run(eval_step, feed_dict={action_ph: action_value})
- else:
- action = uvf_utils.clip_to_spec(action, action_spec)
- def step_fn(sess):
- action_value = sess.run(action)
- return sess.run(eval_step, feed_dict={action_ph: action_value})
-
- return step_fn
-
-
-@gin.configurable
-def evaluate(checkpoint_dir,
- eval_dir,
- environment=None,
- num_bin_actions=3,
- agent_class=None,
- meta_agent_class=None,
- state_preprocess_class=None,
- gamma=1.0,
- num_episodes_eval=10,
- eval_interval_secs=60,
- max_number_of_evaluations=None,
- checkpoint_timeout=None,
- timeout_fn=None,
- tuner_hook=None,
- generate_videos=False,
- generate_summaries=True,
- num_episodes_videos=5,
- video_settings=None,
- eval_modes=('eval',),
- eval_model_rollout=False,
- policy_save_dir='policy',
- checkpoint_range=None,
- checkpoint_path=None,
- max_steps_per_episode=None,
- evaluate_nohrl=False):
- """Loads and repeatedly evaluates a checkpointed model at a set interval.
-
- Args:
- checkpoint_dir: The directory where the checkpoints reside.
- eval_dir: Directory to save the evaluation summary results.
- environment: A BaseEnvironment to evaluate.
- num_bin_actions: Number of bins for discretizing continuous actions.
- agent_class: An RL agent class.
- meta_agent_class: A Meta agent class.
- gamma: Discount factor for the reward.
- num_episodes_eval: Number of episodes to evaluate and average reward over.
- eval_interval_secs: The number of seconds between each evaluation run.
- max_number_of_evaluations: The max number of evaluations. If None the
- evaluation continues indefinitely.
- checkpoint_timeout: The maximum amount of time to wait between checkpoints.
- If left as `None`, then the process will wait indefinitely.
- timeout_fn: Optional function to call after a timeout.
- tuner_hook: A callable that takes the average reward and global step and
- updates a Vizier tuner trial.
- generate_videos: Whether to generate videos of the agent in action.
- generate_summaries: Whether to generate summaries.
- num_episodes_videos: Number of episodes to evaluate for generating videos.
- video_settings: Settings for generating videos of the agent.
- optimal action based on the critic.
- eval_modes: A tuple of eval modes.
- eval_model_rollout: Evaluate model rollout.
- policy_save_dir: Optional sub-directory where the policies are
- saved.
- checkpoint_range: Optional. If provided, evaluate all checkpoints in
- the range.
- checkpoint_path: Optional sub-directory specifying which checkpoint to
- evaluate. If None, will evaluate the most recent checkpoint.
- """
- tf_env = create_maze_env.TFPyEnvironment(environment)
- observation_spec = [tf_env.observation_spec()]
- action_spec = [tf_env.action_spec()]
-
- assert max_steps_per_episode, 'max_steps_per_episode need to be set'
-
- if agent_class.ACTION_TYPE == 'discrete':
- assert False
- else:
- assert agent_class.ACTION_TYPE == 'continuous'
-
- if meta_agent_class is not None:
- assert agent_class.ACTION_TYPE == meta_agent_class.ACTION_TYPE
- with tf.variable_scope('meta_agent'):
- meta_agent = meta_agent_class(
- observation_spec,
- action_spec,
- tf_env,
- )
- else:
- meta_agent = None
-
- with tf.variable_scope('uvf_agent'):
- uvf_agent = agent_class(
- observation_spec,
- action_spec,
- tf_env,
- )
- uvf_agent.set_meta_agent(agent=meta_agent)
-
- with tf.variable_scope('state_preprocess'):
- state_preprocess = state_preprocess_class()
-
- # run both actor and critic once to ensure networks are initialized
- # and gin configs will be saved
- # pylint: disable=protected-access
- temp_states = tf.expand_dims(
- tf.zeros(
- dtype=uvf_agent._observation_spec.dtype,
- shape=uvf_agent._observation_spec.shape), 0)
- # pylint: enable=protected-access
- temp_actions = uvf_agent.actor_net(temp_states)
- uvf_agent.critic_net(temp_states, temp_actions)
-
- # create eval_step_fns for each action function
- eval_step_fns = dict()
- meta_agent = uvf_agent.meta_agent
- for meta in [True] + [False] * evaluate_nohrl:
- meta_tag = 'hrl' if meta else 'nohrl'
- uvf_agent.set_meta_agent(meta_agent if meta else None)
- for mode in eval_modes:
- # wrap environment
- wrapped_environment = uvf_agent.get_env_base_wrapper(
- environment, mode=mode)
- action_wrapper = lambda agent_: agent_.action
- action_fn = action_wrapper(uvf_agent)
- meta_action_fn = action_wrapper(meta_agent)
- eval_step_fns['%s_%s' % (mode, meta_tag)] = (get_eval_step(
- uvf_agent=uvf_agent,
- state_preprocess=state_preprocess,
- tf_env=tf_env,
- action_fn=action_fn,
- meta_action_fn=meta_action_fn,
- environment_steps=tf.Variable(
- 0, dtype=tf.int64, name='environment_steps'),
- num_episodes=tf.Variable(0, dtype=tf.int64, name='num_episodes'),
- mode=mode), wrapped_environment,)
-
- model_rollout_fn = None
- if eval_model_rollout:
- model_rollout_fn = get_model_rollout(uvf_agent, tf_env)
-
- tf.train.get_or_create_global_step()
-
- if policy_save_dir:
- checkpoint_dir = os.path.join(checkpoint_dir, policy_save_dir)
-
- tf.logging.info('Evaluating policies at %s', checkpoint_dir)
- tf.logging.info('Running episodes for max %d steps', max_steps_per_episode)
-
- evaluate_checkpoint_fn = get_evaluate_checkpoint_fn(
- '', eval_dir, eval_step_fns, model_rollout_fn, gamma,
- max_steps_per_episode, num_episodes_eval, num_episodes_videos, tuner_hook,
- generate_videos, generate_summaries, video_settings)
-
- if checkpoint_path is not None:
- checkpoint_path = os.path.join(checkpoint_dir, checkpoint_path)
- evaluate_checkpoint_fn(checkpoint_path)
- elif checkpoint_range is not None:
- model_files = tf.gfile.Glob(
- os.path.join(checkpoint_dir, 'model.ckpt-*.index'))
- tf.logging.info('Found %s policies at %s', len(model_files), checkpoint_dir)
- model_files = {
- int(f.split('model.ckpt-', 1)[1].split('.', 1)[0]):
- os.path.splitext(f)[0]
- for f in model_files
- }
- model_files = {
- k: v
- for k, v in model_files.items()
- if k >= checkpoint_range[0] and k <= checkpoint_range[1]
- }
- tf.logging.info('Evaluating %d policies at %s',
- len(model_files), checkpoint_dir)
- for _, checkpoint_path in sorted(model_files.items()):
- evaluate_checkpoint_fn(checkpoint_path)
- else:
- eval_utils.evaluate_checkpoint_repeatedly(
- checkpoint_dir,
- evaluate_checkpoint_fn,
- eval_interval_secs=eval_interval_secs,
- max_number_of_evaluations=max_number_of_evaluations,
- checkpoint_timeout=checkpoint_timeout,
- timeout_fn=timeout_fn)
diff --git a/research/efficient-hrl/run_env.py b/research/efficient-hrl/run_env.py
deleted file mode 100644
index 87fad542aea1dc0f9a39553b53d3da8978ca089f..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/run_env.py
+++ /dev/null
@@ -1,129 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Random policy on an environment."""
-
-import tensorflow as tf
-import numpy as np
-import random
-
-from environments import create_maze_env
-
-app = tf.app
-flags = tf.flags
-logging = tf.logging
-
-FLAGS = flags.FLAGS
-
-flags.DEFINE_string('env', 'AntMaze', 'environment name: AntMaze, AntPush, or AntFall')
-flags.DEFINE_integer('episode_length', 500, 'episode length')
-flags.DEFINE_integer('num_episodes', 50, 'number of episodes')
-
-
-def get_goal_sample_fn(env_name):
- if env_name == 'AntMaze':
- # NOTE: When evaluating (i.e. the metrics shown in the paper,
- # we use the commented out goal sampling function. The uncommented
- # one is only used for training.
- #return lambda: np.array([0., 16.])
- return lambda: np.random.uniform((-4, -4), (20, 20))
- elif env_name == 'AntPush':
- return lambda: np.array([0., 19.])
- elif env_name == 'AntFall':
- return lambda: np.array([0., 27., 4.5])
- else:
- assert False, 'Unknown env'
-
-
-def get_reward_fn(env_name):
- if env_name == 'AntMaze':
- return lambda obs, goal: -np.sum(np.square(obs[:2] - goal)) ** 0.5
- elif env_name == 'AntPush':
- return lambda obs, goal: -np.sum(np.square(obs[:2] - goal)) ** 0.5
- elif env_name == 'AntFall':
- return lambda obs, goal: -np.sum(np.square(obs[:3] - goal)) ** 0.5
- else:
- assert False, 'Unknown env'
-
-
-def success_fn(last_reward):
- return last_reward > -5.0
-
-
-class EnvWithGoal(object):
-
- def __init__(self, base_env, env_name):
- self.base_env = base_env
- self.goal_sample_fn = get_goal_sample_fn(env_name)
- self.reward_fn = get_reward_fn(env_name)
- self.goal = None
-
- def reset(self):
- obs = self.base_env.reset()
- self.goal = self.goal_sample_fn()
- return np.concatenate([obs, self.goal])
-
- def step(self, a):
- obs, _, done, info = self.base_env.step(a)
- reward = self.reward_fn(obs, self.goal)
- return np.concatenate([obs, self.goal]), reward, done, info
-
- @property
- def action_space(self):
- return self.base_env.action_space
-
-
-def run_environment(env_name, episode_length, num_episodes):
- env = EnvWithGoal(
- create_maze_env.create_maze_env(env_name).gym,
- env_name)
-
- def action_fn(obs):
- action_space = env.action_space
- action_space_mean = (action_space.low + action_space.high) / 2.0
- action_space_magn = (action_space.high - action_space.low) / 2.0
- random_action = (action_space_mean +
- action_space_magn *
- np.random.uniform(low=-1.0, high=1.0,
- size=action_space.shape))
- return random_action
-
- rewards = []
- successes = []
- for ep in range(num_episodes):
- rewards.append(0.0)
- successes.append(False)
- obs = env.reset()
- for _ in range(episode_length):
- obs, reward, done, _ = env.step(action_fn(obs))
- rewards[-1] += reward
- successes[-1] = success_fn(reward)
- if done:
- break
- logging.info('Episode %d reward: %.2f, Success: %d', ep + 1, rewards[-1], successes[-1])
-
- logging.info('Average Reward over %d episodes: %.2f',
- num_episodes, np.mean(rewards))
- logging.info('Average Success over %d episodes: %.2f',
- num_episodes, np.mean(successes))
-
-
-def main(unused_argv):
- logging.set_verbosity(logging.INFO)
- run_environment(FLAGS.env, FLAGS.episode_length, FLAGS.num_episodes)
-
-
-if __name__ == '__main__':
- app.run()
diff --git a/research/efficient-hrl/run_eval.py b/research/efficient-hrl/run_eval.py
deleted file mode 100644
index 12f12369c4c90762bdf3d7506b957588856bdd3f..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/run_eval.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Script for evaluating a UVF agent.
-
-To run locally: See scripts/local_eval.py
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-import gin.tf
-# pylint: disable=unused-import
-import eval as eval_
-# pylint: enable=unused-import
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-
-def main(_):
- tf.logging.set_verbosity(tf.logging.INFO)
- assert FLAGS.checkpoint_dir, "Flag 'checkpoint_dir' must be set."
- assert FLAGS.eval_dir, "Flag 'eval_dir' must be set."
-
- if FLAGS.config_file:
- for config_file in FLAGS.config_file:
- gin.parse_config_file(config_file)
- if FLAGS.params:
- gin.parse_config(FLAGS.params)
-
- eval_.evaluate(FLAGS.checkpoint_dir, FLAGS.eval_dir)
-
-
-if __name__ == "__main__":
- tf.app.run()
diff --git a/research/efficient-hrl/run_train.py b/research/efficient-hrl/run_train.py
deleted file mode 100644
index 1d459d60b7f870bdcd81a48edc896158a9c6e4eb..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/run_train.py
+++ /dev/null
@@ -1,49 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Script for training an RL agent using the UVF algorithm.
-
-To run locally: See scripts/local_train.py
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-import gin.tf
-# pylint: enable=unused-import
-import train
-# pylint: disable=unused-import
-
-flags = tf.app.flags
-FLAGS = flags.FLAGS
-
-
-def main(_):
- tf.logging.set_verbosity(tf.logging.INFO)
- if FLAGS.config_file:
- for config_file in FLAGS.config_file:
- gin.parse_config_file(config_file)
- if FLAGS.params:
- gin.parse_config(FLAGS.params)
-
- assert FLAGS.train_dir, "Flag 'train_dir' must be set."
- return train.train_uvf(FLAGS.train_dir)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/efficient-hrl/scripts/local_eval.py b/research/efficient-hrl/scripts/local_eval.py
deleted file mode 100644
index 89ef745a4086197b07cee5f98fabfcc29af6d145..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/scripts/local_eval.py
+++ /dev/null
@@ -1,76 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Script to run run_eval.py locally.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import os
-from subprocess import call
-import sys
-
-CONFIGS_PATH = 'configs'
-CONTEXT_CONFIGS_PATH = 'context/configs'
-
-def main():
- bb = './'
- base_num_args = 6
- if len(sys.argv) < base_num_args:
- print(
- "usage: python %s "
- " [params...]"
- % sys.argv[0])
- sys.exit(0)
- exp = sys.argv[1]
- context_setting = sys.argv[2]
- context = sys.argv[3]
- agent = sys.argv[4]
- assert sys.argv[5] in ["suite"], "args[5] must be `suite'"
- suite = ""
- binary = "python {bb}/run_eval{suite}.py ".format(bb=bb, suite=suite)
-
- h = os.environ["HOME"]
- ucp = CONFIGS_PATH
- ccp = CONTEXT_CONFIGS_PATH
- extra = ''
- command_str = ("{binary} "
- "--logtostderr "
- "--checkpoint_dir={h}/tmp/{context_setting}/{context}/{agent}/{exp}/train "
- "--eval_dir={h}/tmp/{context_setting}/{context}/{agent}/{exp}/eval "
- "--config_file={ucp}/{agent}.gin "
- "--config_file={ucp}/eval_{extra}uvf.gin "
- "--config_file={ccp}/{context_setting}.gin "
- "--config_file={ccp}/{context}.gin ").format(
- h=h,
- ucp=ucp,
- ccp=ccp,
- context_setting=context_setting,
- context=context,
- agent=agent,
- extra=extra,
- suite=suite,
- exp=exp,
- binary=binary)
- for extra_arg in sys.argv[base_num_args:]:
- command_str += "--params='%s' " % extra_arg
-
- print(command_str)
- call(command_str, shell=True)
-
-
-if __name__ == "__main__":
- main()
diff --git a/research/efficient-hrl/scripts/local_train.py b/research/efficient-hrl/scripts/local_train.py
deleted file mode 100644
index 718c88e8fedd381707ac944f5ee9243b636ac915..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/scripts/local_train.py
+++ /dev/null
@@ -1,76 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Script to run run_train.py locally.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import os
-import random
-from subprocess import call
-import sys
-
-CONFIGS_PATH = './configs'
-CONTEXT_CONFIGS_PATH = './context/configs'
-
-def main():
- bb = '.'
- base_num_args = 6
- if len(sys.argv) < base_num_args:
- print(
- "usage: python %s "
- " [params...]"
- % sys.argv[0])
- sys.exit(0)
- exp = sys.argv[1] # Name for experiment, e.g. 'test001'
- context_setting = sys.argv[2] # Context setting, e.g. 'hiro_orig'
- context = sys.argv[3] # Environment-specific context, e.g. 'ant_maze'
- agent = sys.argv[4] # Agent settings, e.g. 'base_uvf'
- assert sys.argv[5] in ["suite"], "args[5] must be `suite'"
- suite = ""
- binary = "python {bb}/run_train{suite}.py ".format(bb=bb, suite=suite)
-
- h = os.environ["HOME"]
- ucp = CONFIGS_PATH
- ccp = CONTEXT_CONFIGS_PATH
- extra = ''
- port = random.randint(2000, 8000)
- command_str = ("{binary} "
- "--train_dir={h}/tmp/{context_setting}/{context}/{agent}/{exp}/train "
- "--config_file={ucp}/{agent}.gin "
- "--config_file={ucp}/train_{extra}uvf.gin "
- "--config_file={ccp}/{context_setting}.gin "
- "--config_file={ccp}/{context}.gin "
- "--summarize_gradients=False "
- "--save_interval_secs=60 "
- "--save_summaries_secs=1 "
- "--master=local "
- "--alsologtostderr ").format(h=h, ucp=ucp,
- context_setting=context_setting,
- context=context, ccp=ccp,
- suite=suite, agent=agent, extra=extra,
- exp=exp, binary=binary,
- port=port)
- for extra_arg in sys.argv[base_num_args:]:
- command_str += "--params='%s' " % extra_arg
-
- print(command_str)
- call(command_str, shell=True)
-
-
-if __name__ == "__main__":
- main()
diff --git a/research/efficient-hrl/train.py b/research/efficient-hrl/train.py
deleted file mode 100644
index a40e81dbec6c103563192a373661cda8b5ae5fbb..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/train.py
+++ /dev/null
@@ -1,670 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r"""Script for training an RL agent using the UVF algorithm.
-
-To run locally: See run_train.py
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import time
-import tensorflow as tf
-slim = tf.contrib.slim
-
-import gin.tf
-# pylint: disable=unused-import
-import train_utils
-import agent as agent_
-from agents import circular_buffer
-from utils import utils as uvf_utils
-from environments import create_maze_env
-# pylint: enable=unused-import
-
-
-flags = tf.app.flags
-
-FLAGS = flags.FLAGS
-flags.DEFINE_string('goal_sample_strategy', 'sample',
- 'None, sample, FuN')
-
-LOAD_PATH = None
-
-
-def collect_experience(tf_env, agent, meta_agent, state_preprocess,
- replay_buffer, meta_replay_buffer,
- action_fn, meta_action_fn,
- environment_steps, num_episodes, num_resets,
- episode_rewards, episode_meta_rewards,
- store_context,
- disable_agent_reset):
- """Collect experience in a tf_env into a replay_buffer using action_fn.
-
- Args:
- tf_env: A TFEnvironment.
- agent: A UVF agent.
- meta_agent: A Meta Agent.
- replay_buffer: A Replay buffer to collect experience in.
- meta_replay_buffer: A Replay buffer to collect meta agent experience in.
- action_fn: A function to produce actions given current state.
- meta_action_fn: A function to produce meta actions given current state.
- environment_steps: A variable to count the number of steps in the tf_env.
- num_episodes: A variable to count the number of episodes.
- num_resets: A variable to count the number of resets.
- store_context: A boolean to check if store context in replay.
- disable_agent_reset: A boolean that disables agent from resetting.
-
- Returns:
- A collect_experience_op that excute an action and store into the
- replay_buffers
- """
- tf_env.start_collect()
- state = tf_env.current_obs()
- state_repr = state_preprocess(state)
- action = action_fn(state, context=None)
-
- with tf.control_dependencies([state]):
- transition_type, reward, discount = tf_env.step(action)
-
- def increment_step():
- return environment_steps.assign_add(1)
-
- def increment_episode():
- return num_episodes.assign_add(1)
-
- def increment_reset():
- return num_resets.assign_add(1)
-
- def update_episode_rewards(context_reward, meta_reward, reset):
- new_episode_rewards = tf.concat(
- [episode_rewards[:1] + context_reward, episode_rewards[1:]], 0)
- new_episode_meta_rewards = tf.concat(
- [episode_meta_rewards[:1] + meta_reward,
- episode_meta_rewards[1:]], 0)
- return tf.group(
- episode_rewards.assign(
- tf.cond(reset,
- lambda: tf.concat([[0.], episode_rewards[:-1]], 0),
- lambda: new_episode_rewards)),
- episode_meta_rewards.assign(
- tf.cond(reset,
- lambda: tf.concat([[0.], episode_meta_rewards[:-1]], 0),
- lambda: new_episode_meta_rewards)))
-
- def no_op_int():
- return tf.constant(0, dtype=tf.int64)
-
- step_cond = agent.step_cond_fn(state, action,
- transition_type,
- environment_steps, num_episodes)
- reset_episode_cond = agent.reset_episode_cond_fn(
- state, action,
- transition_type, environment_steps, num_episodes)
- reset_env_cond = agent.reset_env_cond_fn(state, action,
- transition_type,
- environment_steps, num_episodes)
-
- increment_step_op = tf.cond(step_cond, increment_step, no_op_int)
- increment_episode_op = tf.cond(reset_episode_cond, increment_episode,
- no_op_int)
- increment_reset_op = tf.cond(reset_env_cond, increment_reset, no_op_int)
- increment_op = tf.group(increment_step_op, increment_episode_op,
- increment_reset_op)
-
- with tf.control_dependencies([increment_op, reward, discount]):
- next_state = tf_env.current_obs()
- next_state_repr = state_preprocess(next_state)
- next_reset_episode_cond = tf.logical_or(
- agent.reset_episode_cond_fn(
- state, action,
- transition_type, environment_steps, num_episodes),
- tf.equal(discount, 0.0))
-
- if store_context:
- context = [tf.identity(var) + tf.zeros_like(var) for var in agent.context_vars]
- meta_context = [tf.identity(var) + tf.zeros_like(var) for var in meta_agent.context_vars]
- else:
- context = []
- meta_context = []
- with tf.control_dependencies([next_state] + context + meta_context):
- if disable_agent_reset:
- collect_experience_ops = [tf.no_op()] # don't reset agent
- else:
- collect_experience_ops = agent.cond_begin_episode_op(
- tf.logical_not(reset_episode_cond),
- [state, action, reward, next_state,
- state_repr, next_state_repr],
- mode='explore', meta_action_fn=meta_action_fn)
- context_reward, meta_reward = collect_experience_ops
- collect_experience_ops = list(collect_experience_ops)
- collect_experience_ops.append(
- update_episode_rewards(tf.reduce_sum(context_reward), meta_reward,
- reset_episode_cond))
-
- meta_action_every_n = agent.tf_context.meta_action_every_n
- with tf.control_dependencies(collect_experience_ops):
- transition = [state, action, reward, discount, next_state]
-
- meta_action = tf.to_float(
- tf.concat(context, -1)) # Meta agent action is low-level context
-
- meta_end = tf.logical_and( # End of meta-transition.
- tf.equal(agent.tf_context.t % meta_action_every_n, 1),
- agent.tf_context.t > 1)
- with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE):
- states_var = tf.get_variable('states_var',
- [meta_action_every_n, state.shape[-1]],
- state.dtype)
- actions_var = tf.get_variable('actions_var',
- [meta_action_every_n, action.shape[-1]],
- action.dtype)
- state_var = tf.get_variable('state_var', state.shape, state.dtype)
- reward_var = tf.get_variable('reward_var', reward.shape, reward.dtype)
- meta_action_var = tf.get_variable('meta_action_var',
- meta_action.shape, meta_action.dtype)
- meta_context_var = [
- tf.get_variable('meta_context_var%d' % idx,
- meta_context[idx].shape, meta_context[idx].dtype)
- for idx in range(len(meta_context))]
-
- actions_var_upd = tf.scatter_update(
- actions_var, (agent.tf_context.t - 2) % meta_action_every_n, action)
- with tf.control_dependencies([actions_var_upd]):
- actions = tf.identity(actions_var) + tf.zeros_like(actions_var)
- meta_reward = tf.identity(meta_reward) + tf.zeros_like(meta_reward)
- meta_reward = tf.reshape(meta_reward, reward.shape)
-
- reward = 0.1 * meta_reward
- meta_transition = [state_var, meta_action_var,
- reward_var + reward,
- discount * (1 - tf.to_float(next_reset_episode_cond)),
- next_state]
- meta_transition.extend([states_var, actions])
- if store_context: # store current and next context into replay
- transition += context + list(agent.context_vars)
- meta_transition += meta_context_var + list(meta_agent.context_vars)
-
- meta_step_cond = tf.squeeze(tf.logical_and(step_cond, tf.logical_or(next_reset_episode_cond, meta_end)))
-
- collect_experience_op = tf.group(
- replay_buffer.maybe_add(transition, step_cond),
- meta_replay_buffer.maybe_add(meta_transition, meta_step_cond),
- )
-
- with tf.control_dependencies([collect_experience_op]):
- collect_experience_op = tf.cond(reset_env_cond,
- tf_env.reset,
- tf_env.current_time_step)
-
- meta_period = tf.equal(agent.tf_context.t % meta_action_every_n, 1)
- states_var_upd = tf.scatter_update(
- states_var, (agent.tf_context.t - 1) % meta_action_every_n,
- next_state)
- state_var_upd = tf.assign(
- state_var,
- tf.cond(meta_period, lambda: next_state, lambda: state_var))
- reward_var_upd = tf.assign(
- reward_var,
- tf.cond(meta_period,
- lambda: tf.zeros_like(reward_var),
- lambda: reward_var + reward))
- meta_action = tf.to_float(tf.concat(agent.context_vars, -1))
- meta_action_var_upd = tf.assign(
- meta_action_var,
- tf.cond(meta_period, lambda: meta_action, lambda: meta_action_var))
- meta_context_var_upd = [
- tf.assign(
- meta_context_var[idx],
- tf.cond(meta_period,
- lambda: meta_agent.context_vars[idx],
- lambda: meta_context_var[idx]))
- for idx in range(len(meta_context))]
-
- return tf.group(
- collect_experience_op,
- states_var_upd,
- state_var_upd,
- reward_var_upd,
- meta_action_var_upd,
- *meta_context_var_upd)
-
-
-def sample_best_meta_actions(state_reprs, next_state_reprs, prev_meta_actions,
- low_states, low_actions, low_state_reprs,
- inverse_dynamics, uvf_agent, k=10):
- """Return meta-actions which approximately maximize low-level log-probs."""
- sampled_actions = inverse_dynamics.sample(state_reprs, next_state_reprs, k, prev_meta_actions)
- sampled_actions = tf.stop_gradient(sampled_actions)
- sampled_log_probs = tf.reshape(uvf_agent.log_probs(
- tf.tile(low_states, [k, 1, 1]),
- tf.tile(low_actions, [k, 1, 1]),
- tf.tile(low_state_reprs, [k, 1, 1]),
- [tf.reshape(sampled_actions, [-1, sampled_actions.shape[-1]])]),
- [k, low_states.shape[0],
- low_states.shape[1], -1])
- fitness = tf.reduce_sum(sampled_log_probs, [2, 3])
- best_actions = tf.argmax(fitness, 0)
- actions = tf.gather_nd(
- sampled_actions,
- tf.stack([best_actions,
- tf.range(prev_meta_actions.shape[0], dtype=tf.int64)], -1))
- return actions
-
-
-@gin.configurable
-def train_uvf(train_dir,
- environment=None,
- num_bin_actions=3,
- agent_class=None,
- meta_agent_class=None,
- state_preprocess_class=None,
- inverse_dynamics_class=None,
- exp_action_wrapper=None,
- replay_buffer=None,
- meta_replay_buffer=None,
- replay_num_steps=1,
- meta_replay_num_steps=1,
- critic_optimizer=None,
- actor_optimizer=None,
- meta_critic_optimizer=None,
- meta_actor_optimizer=None,
- repr_optimizer=None,
- relabel_contexts=False,
- meta_relabel_contexts=False,
- batch_size=64,
- repeat_size=0,
- num_episodes_train=2000,
- initial_episodes=2,
- initial_steps=None,
- num_updates_per_observation=1,
- num_collect_per_update=1,
- num_collect_per_meta_update=1,
- gamma=1.0,
- meta_gamma=1.0,
- reward_scale_factor=1.0,
- target_update_period=1,
- should_stop_early=None,
- clip_gradient_norm=0.0,
- summarize_gradients=False,
- debug_summaries=False,
- log_every_n_steps=100,
- prefetch_queue_capacity=2,
- policy_save_dir='policy',
- save_policy_every_n_steps=1000,
- save_policy_interval_secs=0,
- replay_context_ratio=0.0,
- next_state_as_context_ratio=0.0,
- state_index=0,
- zero_timer_ratio=0.0,
- timer_index=-1,
- debug=False,
- max_policies_to_save=None,
- max_steps_per_episode=None,
- load_path=LOAD_PATH):
- """Train an agent."""
- tf_env = create_maze_env.TFPyEnvironment(environment)
- observation_spec = [tf_env.observation_spec()]
- action_spec = [tf_env.action_spec()]
-
- max_steps_per_episode = max_steps_per_episode or tf_env.pyenv.max_episode_steps
-
- assert max_steps_per_episode, 'max_steps_per_episode need to be set'
-
- if initial_steps is None:
- initial_steps = initial_episodes * max_steps_per_episode
-
- if agent_class.ACTION_TYPE == 'discrete':
- assert False
- else:
- assert agent_class.ACTION_TYPE == 'continuous'
-
- assert agent_class.ACTION_TYPE == meta_agent_class.ACTION_TYPE
- with tf.variable_scope('meta_agent'):
- meta_agent = meta_agent_class(
- observation_spec,
- action_spec,
- tf_env,
- debug_summaries=debug_summaries)
- meta_agent.set_replay(replay=meta_replay_buffer)
-
- with tf.variable_scope('uvf_agent'):
- uvf_agent = agent_class(
- observation_spec,
- action_spec,
- tf_env,
- debug_summaries=debug_summaries)
- uvf_agent.set_meta_agent(agent=meta_agent)
- uvf_agent.set_replay(replay=replay_buffer)
-
- with tf.variable_scope('state_preprocess'):
- state_preprocess = state_preprocess_class()
-
- with tf.variable_scope('inverse_dynamics'):
- inverse_dynamics = inverse_dynamics_class(
- meta_agent.sub_context_as_action_specs[0])
-
- # Create counter variables
- global_step = tf.contrib.framework.get_or_create_global_step()
- num_episodes = tf.Variable(0, dtype=tf.int64, name='num_episodes')
- num_resets = tf.Variable(0, dtype=tf.int64, name='num_resets')
- num_updates = tf.Variable(0, dtype=tf.int64, name='num_updates')
- num_meta_updates = tf.Variable(0, dtype=tf.int64, name='num_meta_updates')
- episode_rewards = tf.Variable([0.] * 100, name='episode_rewards')
- episode_meta_rewards = tf.Variable([0.] * 100, name='episode_meta_rewards')
-
- # Create counter variables summaries
- train_utils.create_counter_summaries([
- ('environment_steps', global_step),
- ('num_episodes', num_episodes),
- ('num_resets', num_resets),
- ('num_updates', num_updates),
- ('num_meta_updates', num_meta_updates),
- ('replay_buffer_adds', replay_buffer.get_num_adds()),
- ('meta_replay_buffer_adds', meta_replay_buffer.get_num_adds()),
- ])
-
- tf.summary.scalar('avg_episode_rewards',
- tf.reduce_mean(episode_rewards[1:]))
- tf.summary.scalar('avg_episode_meta_rewards',
- tf.reduce_mean(episode_meta_rewards[1:]))
- tf.summary.histogram('episode_rewards', episode_rewards[1:])
- tf.summary.histogram('episode_meta_rewards', episode_meta_rewards[1:])
-
- # Create init ops
- action_fn = uvf_agent.action
- action_fn = uvf_agent.add_noise_fn(action_fn, global_step=None)
- meta_action_fn = meta_agent.action
- meta_action_fn = meta_agent.add_noise_fn(meta_action_fn, global_step=None)
- meta_actions_fn = meta_agent.actions
- meta_actions_fn = meta_agent.add_noise_fn(meta_actions_fn, global_step=None)
- init_collect_experience_op = collect_experience(
- tf_env,
- uvf_agent,
- meta_agent,
- state_preprocess,
- replay_buffer,
- meta_replay_buffer,
- action_fn,
- meta_action_fn,
- environment_steps=global_step,
- num_episodes=num_episodes,
- num_resets=num_resets,
- episode_rewards=episode_rewards,
- episode_meta_rewards=episode_meta_rewards,
- store_context=True,
- disable_agent_reset=False,
- )
-
- # Create train ops
- collect_experience_op = collect_experience(
- tf_env,
- uvf_agent,
- meta_agent,
- state_preprocess,
- replay_buffer,
- meta_replay_buffer,
- action_fn,
- meta_action_fn,
- environment_steps=global_step,
- num_episodes=num_episodes,
- num_resets=num_resets,
- episode_rewards=episode_rewards,
- episode_meta_rewards=episode_meta_rewards,
- store_context=True,
- disable_agent_reset=False,
- )
-
- train_op_list = []
- repr_train_op = tf.constant(0.0)
- for mode in ['meta', 'nometa']:
- if mode == 'meta':
- agent = meta_agent
- buff = meta_replay_buffer
- critic_opt = meta_critic_optimizer
- actor_opt = meta_actor_optimizer
- relabel = meta_relabel_contexts
- num_steps = meta_replay_num_steps
- my_gamma = meta_gamma,
- n_updates = num_meta_updates
- else:
- agent = uvf_agent
- buff = replay_buffer
- critic_opt = critic_optimizer
- actor_opt = actor_optimizer
- relabel = relabel_contexts
- num_steps = replay_num_steps
- my_gamma = gamma
- n_updates = num_updates
-
- with tf.name_scope(mode):
- batch = buff.get_random_batch(batch_size, num_steps=num_steps)
- states, actions, rewards, discounts, next_states = batch[:5]
- with tf.name_scope('Reward'):
- tf.summary.scalar('average_step_reward', tf.reduce_mean(rewards))
- rewards *= reward_scale_factor
- batch_queue = slim.prefetch_queue.prefetch_queue(
- [states, actions, rewards, discounts, next_states] + batch[5:],
- capacity=prefetch_queue_capacity,
- name='batch_queue')
-
- batch_dequeue = batch_queue.dequeue()
- if repeat_size > 0:
- batch_dequeue = [
- tf.tile(batch, (repeat_size+1,) + (1,) * (batch.shape.ndims - 1))
- for batch in batch_dequeue
- ]
- batch_size *= (repeat_size + 1)
- states, actions, rewards, discounts, next_states = batch_dequeue[:5]
- if mode == 'meta':
- low_states = batch_dequeue[5]
- low_actions = batch_dequeue[6]
- low_state_reprs = state_preprocess(low_states)
- state_reprs = state_preprocess(states)
- next_state_reprs = state_preprocess(next_states)
-
- if mode == 'meta': # Re-label meta-action
- prev_actions = actions
- if FLAGS.goal_sample_strategy == 'None':
- pass
- elif FLAGS.goal_sample_strategy == 'FuN':
- actions = inverse_dynamics.sample(state_reprs, next_state_reprs, 1, prev_actions, sc=0.1)
- actions = tf.stop_gradient(actions)
- elif FLAGS.goal_sample_strategy == 'sample':
- actions = sample_best_meta_actions(state_reprs, next_state_reprs, prev_actions,
- low_states, low_actions, low_state_reprs,
- inverse_dynamics, uvf_agent, k=10)
- else:
- assert False
-
- if state_preprocess.trainable and mode == 'meta':
- # Representation learning is based on meta-transitions, but is trained
- # along with low-level policy updates.
- repr_loss, _, _ = state_preprocess.loss(states, next_states, low_actions, low_states)
- repr_train_op = slim.learning.create_train_op(
- repr_loss,
- repr_optimizer,
- global_step=None,
- update_ops=None,
- summarize_gradients=summarize_gradients,
- clip_gradient_norm=clip_gradient_norm,
- variables_to_train=state_preprocess.get_trainable_vars(),)
-
- # Get contexts for training
- contexts, next_contexts = agent.sample_contexts(
- mode='train', batch_size=batch_size,
- state=states, next_state=next_states,
- )
- if not relabel: # Re-label context (in the style of TDM or HER).
- contexts, next_contexts = (
- batch_dequeue[-2*len(contexts):-1*len(contexts)],
- batch_dequeue[-1*len(contexts):])
-
- merged_states = agent.merged_states(states, contexts)
- merged_next_states = agent.merged_states(next_states, next_contexts)
- if mode == 'nometa':
- context_rewards, context_discounts = agent.compute_rewards(
- 'train', state_reprs, actions, rewards, next_state_reprs, contexts)
- elif mode == 'meta': # Meta-agent uses sum of rewards, not context-specific rewards.
- _, context_discounts = agent.compute_rewards(
- 'train', states, actions, rewards, next_states, contexts)
- context_rewards = rewards
-
- if agent.gamma_index is not None:
- context_discounts *= tf.cast(
- tf.reshape(contexts[agent.gamma_index], (-1,)),
- dtype=context_discounts.dtype)
- else: context_discounts *= my_gamma
-
- critic_loss = agent.critic_loss(merged_states, actions,
- context_rewards, context_discounts,
- merged_next_states)
-
- critic_loss = tf.reduce_mean(critic_loss)
-
- actor_loss = agent.actor_loss(merged_states, actions,
- context_rewards, context_discounts,
- merged_next_states)
- actor_loss *= tf.to_float( # Only update actor every N steps.
- tf.equal(n_updates % target_update_period, 0))
-
- critic_train_op = slim.learning.create_train_op(
- critic_loss,
- critic_opt,
- global_step=n_updates,
- update_ops=None,
- summarize_gradients=summarize_gradients,
- clip_gradient_norm=clip_gradient_norm,
- variables_to_train=agent.get_trainable_critic_vars(),)
- critic_train_op = uvf_utils.tf_print(
- critic_train_op, [critic_train_op],
- message='critic_loss',
- print_freq=1000,
- name='critic_loss')
- train_op_list.append(critic_train_op)
- if actor_loss is not None:
- actor_train_op = slim.learning.create_train_op(
- actor_loss,
- actor_opt,
- global_step=None,
- update_ops=None,
- summarize_gradients=summarize_gradients,
- clip_gradient_norm=clip_gradient_norm,
- variables_to_train=agent.get_trainable_actor_vars(),)
- actor_train_op = uvf_utils.tf_print(
- actor_train_op, [actor_train_op],
- message='actor_loss',
- print_freq=1000,
- name='actor_loss')
- train_op_list.append(actor_train_op)
-
- assert len(train_op_list) == 4
- # Update targets should happen after the networks have been updated.
- with tf.control_dependencies(train_op_list[2:]):
- update_targets_op = uvf_utils.periodically(
- uvf_agent.update_targets, target_update_period, 'update_targets')
- if meta_agent is not None:
- with tf.control_dependencies(train_op_list[:2]):
- update_meta_targets_op = uvf_utils.periodically(
- meta_agent.update_targets, target_update_period, 'update_targets')
-
- assert_op = tf.Assert( # Hack to get training to stop.
- tf.less_equal(global_step, 200 + num_episodes_train * max_steps_per_episode),
- [global_step])
- with tf.control_dependencies([update_targets_op, assert_op]):
- train_op = tf.add_n(train_op_list[2:], name='post_update_targets')
- # Representation training steps on every low-level policy training step.
- train_op += repr_train_op
- with tf.control_dependencies([update_meta_targets_op, assert_op]):
- meta_train_op = tf.add_n(train_op_list[:2],
- name='post_update_meta_targets')
-
- if debug_summaries:
- train_.gen_debug_batch_summaries(batch)
- slim.summaries.add_histogram_summaries(
- uvf_agent.get_trainable_critic_vars(), 'critic_vars')
- slim.summaries.add_histogram_summaries(
- uvf_agent.get_trainable_actor_vars(), 'actor_vars')
-
- train_ops = train_utils.TrainOps(train_op, meta_train_op,
- collect_experience_op)
-
- policy_save_path = os.path.join(train_dir, policy_save_dir, 'model.ckpt')
- policy_vars = uvf_agent.get_actor_vars() + meta_agent.get_actor_vars() + [
- global_step, num_episodes, num_resets
- ] + list(uvf_agent.context_vars) + list(meta_agent.context_vars) + state_preprocess.get_trainable_vars()
- # add critic vars, since some test evaluation depends on them
- policy_vars += uvf_agent.get_trainable_critic_vars() + meta_agent.get_trainable_critic_vars()
- policy_saver = tf.train.Saver(
- policy_vars, max_to_keep=max_policies_to_save, sharded=False)
-
- lowlevel_vars = (uvf_agent.get_actor_vars() +
- uvf_agent.get_trainable_critic_vars() +
- state_preprocess.get_trainable_vars())
- lowlevel_saver = tf.train.Saver(lowlevel_vars)
-
- def policy_save_fn(sess):
- policy_saver.save(
- sess, policy_save_path, global_step=global_step, write_meta_graph=False)
- if save_policy_interval_secs > 0:
- tf.logging.info(
- 'Wait %d secs after save policy.' % save_policy_interval_secs)
- time.sleep(save_policy_interval_secs)
-
- train_step_fn = train_utils.TrainStep(
- max_number_of_steps=num_episodes_train * max_steps_per_episode + 100,
- num_updates_per_observation=num_updates_per_observation,
- num_collect_per_update=num_collect_per_update,
- num_collect_per_meta_update=num_collect_per_meta_update,
- log_every_n_steps=log_every_n_steps,
- policy_save_fn=policy_save_fn,
- save_policy_every_n_steps=save_policy_every_n_steps,
- should_stop_early=should_stop_early).train_step
-
- local_init_op = tf.local_variables_initializer()
- init_targets_op = tf.group(uvf_agent.update_targets(1.0),
- meta_agent.update_targets(1.0))
-
- def initialize_training_fn(sess):
- """Initialize training function."""
- sess.run(local_init_op)
- sess.run(init_targets_op)
- if load_path:
- tf.logging.info('Restoring low-level from %s' % load_path)
- lowlevel_saver.restore(sess, load_path)
- global_step_value = sess.run(global_step)
- assert global_step_value == 0, 'Global step should be zero.'
- collect_experience_call = sess.make_callable(
- init_collect_experience_op)
-
- for _ in range(initial_steps):
- collect_experience_call()
-
- train_saver = tf.train.Saver(max_to_keep=2, sharded=True)
- tf.logging.info('train dir: %s', train_dir)
- return slim.learning.train(
- train_ops,
- train_dir,
- train_step_fn=train_step_fn,
- save_interval_secs=FLAGS.save_interval_secs,
- saver=train_saver,
- log_every_n_steps=0,
- global_step=global_step,
- master="",
- is_chief=(FLAGS.task == 0),
- save_summaries_secs=FLAGS.save_summaries_secs,
- init_fn=initialize_training_fn)
diff --git a/research/efficient-hrl/train_utils.py b/research/efficient-hrl/train_utils.py
deleted file mode 100644
index ae23ef9f095ed1755c74579223b017239ccf1009..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/train_utils.py
+++ /dev/null
@@ -1,175 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-r""""""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import namedtuple
-import os
-import time
-
-import tensorflow as tf
-
-import gin.tf
-
-flags = tf.app.flags
-
-
-flags.DEFINE_multi_string('config_file', None,
- 'List of paths to the config files.')
-flags.DEFINE_multi_string('params', None,
- 'Newline separated list of Gin parameter bindings.')
-
-flags.DEFINE_string('train_dir', None,
- 'Directory for writing logs/summaries during training.')
-flags.DEFINE_string('master', 'local',
- 'BNS name of the TensorFlow master to use.')
-flags.DEFINE_integer('task', 0, 'task id')
-flags.DEFINE_integer('save_interval_secs', 300, 'The frequency at which '
- 'checkpoints are saved, in seconds.')
-flags.DEFINE_integer('save_summaries_secs', 30, 'The frequency at which '
- 'summaries are saved, in seconds.')
-flags.DEFINE_boolean('summarize_gradients', False,
- 'Whether to generate gradient summaries.')
-
-FLAGS = flags.FLAGS
-
-TrainOps = namedtuple('TrainOps',
- ['train_op', 'meta_train_op', 'collect_experience_op'])
-
-
-class TrainStep(object):
- """Handles training step."""
-
- def __init__(self,
- max_number_of_steps=0,
- num_updates_per_observation=1,
- num_collect_per_update=1,
- num_collect_per_meta_update=1,
- log_every_n_steps=1,
- policy_save_fn=None,
- save_policy_every_n_steps=0,
- should_stop_early=None):
- """Returns a function that is executed at each step of slim training.
-
- Args:
- max_number_of_steps: Optional maximum number of train steps to take.
- num_updates_per_observation: Number of updates per observation.
- log_every_n_steps: The frequency, in terms of global steps, that the loss
- and global step and logged.
- policy_save_fn: A tf.Saver().save function to save the policy.
- save_policy_every_n_steps: How frequently to save the policy.
- should_stop_early: Optional hook to report whether training should stop.
- Raises:
- ValueError: If policy_save_fn is not provided when
- save_policy_every_n_steps > 0.
- """
- if save_policy_every_n_steps and policy_save_fn is None:
- raise ValueError(
- 'policy_save_fn is required when save_policy_every_n_steps > 0')
- self.max_number_of_steps = max_number_of_steps
- self.num_updates_per_observation = num_updates_per_observation
- self.num_collect_per_update = num_collect_per_update
- self.num_collect_per_meta_update = num_collect_per_meta_update
- self.log_every_n_steps = log_every_n_steps
- self.policy_save_fn = policy_save_fn
- self.save_policy_every_n_steps = save_policy_every_n_steps
- self.should_stop_early = should_stop_early
- self.last_global_step_val = 0
- self.train_op_fn = None
- self.collect_and_train_fn = None
- tf.logging.info('Training for %d max_number_of_steps',
- self.max_number_of_steps)
-
- def train_step(self, sess, train_ops, global_step, _):
- """This function will be called at each step of training.
-
- This represents one step of the DDPG algorithm and can include:
- 1. collect a transition
- 2. update the target network
- 3. train the actor
- 4. train the critic
-
- Args:
- sess: A Tensorflow session.
- train_ops: A DdpgTrainOps tuple of train ops to run.
- global_step: The global step.
-
- Returns:
- A scalar total loss.
- A boolean should stop.
- """
- start_time = time.time()
- if self.train_op_fn is None:
- self.train_op_fn = sess.make_callable([train_ops.train_op, global_step])
- self.meta_train_op_fn = sess.make_callable([train_ops.meta_train_op, global_step])
- self.collect_fn = sess.make_callable([train_ops.collect_experience_op, global_step])
- self.collect_and_train_fn = sess.make_callable(
- [train_ops.train_op, global_step, train_ops.collect_experience_op])
- self.collect_and_meta_train_fn = sess.make_callable(
- [train_ops.meta_train_op, global_step, train_ops.collect_experience_op])
- for _ in range(self.num_collect_per_update - 1):
- self.collect_fn()
- for _ in range(self.num_updates_per_observation - 1):
- self.train_op_fn()
-
- total_loss, global_step_val, _ = self.collect_and_train_fn()
- if (global_step_val // self.num_collect_per_meta_update !=
- self.last_global_step_val // self.num_collect_per_meta_update):
- self.meta_train_op_fn()
-
- time_elapsed = time.time() - start_time
- should_stop = False
- if self.max_number_of_steps:
- should_stop = global_step_val >= self.max_number_of_steps
- if global_step_val != self.last_global_step_val:
- if (self.save_policy_every_n_steps and
- global_step_val // self.save_policy_every_n_steps !=
- self.last_global_step_val // self.save_policy_every_n_steps):
- self.policy_save_fn(sess)
-
- if (self.log_every_n_steps and
- global_step_val % self.log_every_n_steps == 0):
- tf.logging.info(
- 'global step %d: loss = %.4f (%.3f sec/step) (%d steps/sec)',
- global_step_val, total_loss, time_elapsed, 1 / time_elapsed)
-
- self.last_global_step_val = global_step_val
- stop_early = bool(self.should_stop_early and self.should_stop_early())
- return total_loss, should_stop or stop_early
-
-
-def create_counter_summaries(counters):
- """Add named summaries to counters, a list of tuples (name, counter)."""
- if counters:
- with tf.name_scope('Counters/'):
- for name, counter in counters:
- tf.summary.scalar(name, counter)
-
-
-def gen_debug_batch_summaries(batch):
- """Generates summaries for the sampled replay batch."""
- states, actions, rewards, _, next_states = batch
- with tf.name_scope('batch'):
- for s in range(states.get_shape()[-1]):
- tf.summary.histogram('states_%d' % s, states[:, s])
- for s in range(states.get_shape()[-1]):
- tf.summary.histogram('next_states_%d' % s, next_states[:, s])
- for a in range(actions.get_shape()[-1]):
- tf.summary.histogram('actions_%d' % a, actions[:, a])
- tf.summary.histogram('rewards', rewards)
diff --git a/research/efficient-hrl/utils/__init__.py b/research/efficient-hrl/utils/__init__.py
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/utils/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/research/efficient-hrl/utils/eval_utils.py b/research/efficient-hrl/utils/eval_utils.py
deleted file mode 100644
index c88efc80fe1cc3399027cf71e310db85e3653df9..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/utils/eval_utils.py
+++ /dev/null
@@ -1,151 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Evaluation utility functions.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-import numpy as np
-import tensorflow as tf
-from collections import namedtuple
-logging = tf.logging
-import gin.tf
-
-
-@gin.configurable
-def evaluate_checkpoint_repeatedly(checkpoint_dir,
- evaluate_checkpoint_fn,
- eval_interval_secs=600,
- max_number_of_evaluations=None,
- checkpoint_timeout=None,
- timeout_fn=None):
- """Evaluates a checkpointed model at a set interval."""
- if max_number_of_evaluations is not None and max_number_of_evaluations <= 0:
- raise ValueError(
- '`max_number_of_evaluations` must be either None or a positive number.')
-
- number_of_evaluations = 0
- for checkpoint_path in tf.contrib.training.checkpoints_iterator(
- checkpoint_dir,
- min_interval_secs=eval_interval_secs,
- timeout=checkpoint_timeout,
- timeout_fn=timeout_fn):
- retries = 3
- for _ in range(retries):
- try:
- should_stop = evaluate_checkpoint_fn(checkpoint_path)
- break
- except tf.errors.DataLossError as e:
- logging.warn(
- 'Encountered a DataLossError while evaluating a checkpoint. This '
- 'can happen when reading a checkpoint before it is fully written. '
- 'Retrying...'
- )
- time.sleep(2.0)
-
-
-def compute_model_loss(sess, model_rollout_fn, states, actions):
- """Computes model loss."""
- preds, losses = [], []
- preds.append(states[0])
- losses.append(0)
- for state, action in zip(states[1:], actions[1:]):
- pred = model_rollout_fn(sess, preds[-1], action)
- loss = np.sqrt(np.sum((state - pred) ** 2))
- preds.append(pred)
- losses.append(loss)
- return preds, losses
-
-
-def compute_average_reward(sess, env_base, step_fn, gamma, num_steps,
- num_episodes):
- """Computes the discounted reward for a given number of steps.
-
- Args:
- sess: The tensorflow session.
- env_base: A python environment.
- step_fn: A function that takes in `sess` and returns a list of
- [state, action, reward, discount, transition_type] values.
- gamma: discounting factor to apply to the reward.
- num_steps: number of steps to compute the reward over.
- num_episodes: number of episodes to average the reward over.
- Returns:
- average_reward: a scalar of discounted reward.
- last_reward: last reward received.
- """
- average_reward = 0
- average_last_reward = 0
- average_meta_reward = 0
- average_last_meta_reward = 0
- average_success = 0.
- states, actions = None, None
- for i in range(num_episodes):
- env_base.end_episode()
- env_base.begin_episode()
- (reward, last_reward, meta_reward, last_meta_reward,
- states, actions) = compute_reward(
- sess, step_fn, gamma, num_steps)
- s_reward = last_meta_reward # Navigation
- success = (s_reward > -5.0) # When using diff=False
- logging.info('Episode = %d, reward = %s, meta_reward = %f, '
- 'last_reward = %s, last meta_reward = %f, success = %s',
- i, reward, meta_reward, last_reward, last_meta_reward,
- success)
- average_reward += reward
- average_last_reward += last_reward
- average_meta_reward += meta_reward
- average_last_meta_reward += last_meta_reward
- average_success += success
- average_reward /= num_episodes
- average_last_reward /= num_episodes
- average_meta_reward /= num_episodes
- average_last_meta_reward /= num_episodes
- average_success /= num_episodes
- return (average_reward, average_last_reward,
- average_meta_reward, average_last_meta_reward,
- average_success,
- states, actions)
-
-
-def compute_reward(sess, step_fn, gamma, num_steps):
- """Computes the discounted reward for a given number of steps.
-
- Args:
- sess: The tensorflow session.
- step_fn: A function that takes in `sess` and returns a list of
- [state, action, reward, discount, transition_type] values.
- gamma: discounting factor to apply to the reward.
- num_steps: number of steps to compute the reward over.
- Returns:
- reward: cumulative discounted reward.
- last_reward: reward received at final step.
- """
-
- total_reward = 0
- total_meta_reward = 0
- gamma_step = 1
- states = []
- actions = []
- for _ in range(num_steps):
- state, action, transition_type, reward, meta_reward, discount, _, _ = step_fn(sess)
- total_reward += reward * gamma_step * discount
- total_meta_reward += meta_reward * gamma_step * discount
- gamma_step *= gamma
- states.append(state)
- actions.append(action)
- return (total_reward, reward, total_meta_reward, meta_reward,
- states, actions)
diff --git a/research/efficient-hrl/utils/utils.py b/research/efficient-hrl/utils/utils.py
deleted file mode 100644
index e188316c33b006a34baaaf729a02cca2e13d92e8..0000000000000000000000000000000000000000
--- a/research/efficient-hrl/utils/utils.py
+++ /dev/null
@@ -1,318 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""TensorFlow utility functions.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from copy import deepcopy
-import tensorflow as tf
-from tf_agents import specs
-from tf_agents.utils import common
-
-_tf_print_counts = dict()
-_tf_print_running_sums = dict()
-_tf_print_running_counts = dict()
-_tf_print_ids = 0
-
-
-def get_contextual_env_base(env_base, begin_ops=None, end_ops=None):
- """Wrap env_base with additional tf ops."""
- # pylint: disable=protected-access
- def init(self_, env_base):
- self_._env_base = env_base
- attribute_list = ["_render_mode", "_gym_env"]
- for attribute in attribute_list:
- if hasattr(env_base, attribute):
- setattr(self_, attribute, getattr(env_base, attribute))
- if hasattr(env_base, "physics"):
- self_._physics = env_base.physics
- elif hasattr(env_base, "gym"):
- class Physics(object):
- def render(self, *args, **kwargs):
- return env_base.gym.render("rgb_array")
- physics = Physics()
- self_._physics = physics
- self_.physics = physics
- def set_sess(self_, sess):
- self_._sess = sess
- if hasattr(self_._env_base, "set_sess"):
- self_._env_base.set_sess(sess)
- def begin_episode(self_):
- self_._env_base.reset()
- if begin_ops is not None:
- self_._sess.run(begin_ops)
- def end_episode(self_):
- self_._env_base.reset()
- if end_ops is not None:
- self_._sess.run(end_ops)
- return type("ContextualEnvBase", (env_base.__class__,), dict(
- __init__=init,
- set_sess=set_sess,
- begin_episode=begin_episode,
- end_episode=end_episode,
- ))(env_base)
- # pylint: enable=protected-access
-
-
-def merge_specs(specs_):
- """Merge TensorSpecs.
-
- Args:
- specs_: List of TensorSpecs to be merged.
- Returns:
- a TensorSpec: a merged TensorSpec.
- """
- shape = specs_[0].shape
- dtype = specs_[0].dtype
- name = specs_[0].name
- for spec in specs_[1:]:
- assert shape[1:] == spec.shape[1:], "incompatible shapes: %s, %s" % (
- shape, spec.shape)
- assert dtype == spec.dtype, "incompatible dtypes: %s, %s" % (
- dtype, spec.dtype)
- shape = merge_shapes((shape, spec.shape), axis=0)
- return specs.TensorSpec(
- shape=shape,
- dtype=dtype,
- name=name,
- )
-
-
-def merge_shapes(shapes, axis=0):
- """Merge TensorShapes.
-
- Args:
- shapes: List of TensorShapes to be merged.
- axis: optional, the axis to merge shaped.
- Returns:
- a TensorShape: a merged TensorShape.
- """
- assert len(shapes) > 1
- dims = deepcopy(shapes[0].dims)
- for shape in shapes[1:]:
- assert shapes[0].ndims == shape.ndims
- dims[axis] += shape.dims[axis]
- return tf.TensorShape(dims=dims)
-
-
-def get_all_vars(ignore_scopes=None):
- """Get all tf variables in scope.
-
- Args:
- ignore_scopes: A list of scope names to ignore.
- Returns:
- A list of all tf variables in scope.
- """
- all_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
- all_vars = [var for var in all_vars if ignore_scopes is None or not
- any(var.name.startswith(scope) for scope in ignore_scopes)]
- return all_vars
-
-
-def clip(tensor, range_=None):
- """Return a tf op which clips tensor according to range_.
-
- Args:
- tensor: A Tensor to be clipped.
- range_: None, or a tuple representing (minval, maxval)
- Returns:
- A clipped Tensor.
- """
- if range_ is None:
- return tf.identity(tensor)
- elif isinstance(range_, (tuple, list)):
- assert len(range_) == 2
- return tf.clip_by_value(tensor, range_[0], range_[1])
- else: raise NotImplementedError("Unacceptable range input: %r" % range_)
-
-
-def clip_to_bounds(value, minimum, maximum):
- """Clips value to be between minimum and maximum.
-
- Args:
- value: (tensor) value to be clipped.
- minimum: (numpy float array) minimum value to clip to.
- maximum: (numpy float array) maximum value to clip to.
- Returns:
- clipped_value: (tensor) `value` clipped to between `minimum` and `maximum`.
- """
- value = tf.minimum(value, maximum)
- return tf.maximum(value, minimum)
-
-
-clip_to_spec = common.clip_to_spec
-def _clip_to_spec(value, spec):
- """Clips value to a given bounded tensor spec.
-
- Args:
- value: (tensor) value to be clipped.
- spec: (BoundedTensorSpec) spec containing min. and max. values for clipping.
- Returns:
- clipped_value: (tensor) `value` clipped to be compatible with `spec`.
- """
- return clip_to_bounds(value, spec.minimum, spec.maximum)
-
-
-join_scope = common.join_scope
-def _join_scope(parent_scope, child_scope):
- """Joins a parent and child scope using `/`, checking for empty/none.
-
- Args:
- parent_scope: (string) parent/prefix scope.
- child_scope: (string) child/suffix scope.
- Returns:
- joined scope: (string) parent and child scopes joined by /.
- """
- if not parent_scope:
- return child_scope
- if not child_scope:
- return parent_scope
- return '/'.join([parent_scope, child_scope])
-
-
-def assign_vars(vars_, values):
- """Returns the update ops for assigning a list of vars.
-
- Args:
- vars_: A list of variables.
- values: A list of tensors representing new values.
- Returns:
- A list of update ops for the variables.
- """
- return [var.assign(value) for var, value in zip(vars_, values)]
-
-
-def identity_vars(vars_):
- """Return the identity ops for a list of tensors.
-
- Args:
- vars_: A list of tensors.
- Returns:
- A list of identity ops.
- """
- return [tf.identity(var) for var in vars_]
-
-
-def tile(var, batch_size=1):
- """Return tiled tensor.
-
- Args:
- var: A tensor representing the state.
- batch_size: Batch size.
- Returns:
- A tensor with shape [batch_size,] + var.shape.
- """
- batch_var = tf.tile(
- tf.expand_dims(var, 0),
- (batch_size,) + (1,) * var.get_shape().ndims)
- return batch_var
-
-
-def batch_list(vars_list):
- """Batch a list of variables.
-
- Args:
- vars_list: A list of tensor variables.
- Returns:
- A list of tensor variables with additional first dimension.
- """
- return [tf.expand_dims(var, 0) for var in vars_list]
-
-
-def tf_print(op,
- tensors,
- message="",
- first_n=-1,
- name=None,
- sub_messages=None,
- print_freq=-1,
- include_count=True):
- """tf.Print, but to stdout."""
- # TODO(shanegu): `name` is deprecated. Remove from the rest of codes.
- global _tf_print_ids
- _tf_print_ids += 1
- name = _tf_print_ids
- _tf_print_counts[name] = 0
- if print_freq > 0:
- _tf_print_running_sums[name] = [0 for _ in tensors]
- _tf_print_running_counts[name] = 0
- def print_message(*xs):
- """print message fn."""
- _tf_print_counts[name] += 1
- if print_freq > 0:
- for i, x in enumerate(xs):
- _tf_print_running_sums[name][i] += x
- _tf_print_running_counts[name] += 1
- if (print_freq <= 0 or _tf_print_running_counts[name] >= print_freq) and (
- first_n < 0 or _tf_print_counts[name] <= first_n):
- for i, x in enumerate(xs):
- if print_freq > 0:
- del x
- x = _tf_print_running_sums[name][i]/_tf_print_running_counts[name]
- if sub_messages is None:
- sub_message = str(i)
- else:
- sub_message = sub_messages[i]
- log_message = "%s, %s" % (message, sub_message)
- if include_count:
- log_message += ", count=%d" % _tf_print_counts[name]
- tf.logging.info("[%s]: %s" % (log_message, x))
- if print_freq > 0:
- for i, x in enumerate(xs):
- _tf_print_running_sums[name][i] = 0
- _tf_print_running_counts[name] = 0
- return xs[0]
-
- print_op = tf.py_func(print_message, tensors, tensors[0].dtype)
- with tf.control_dependencies([print_op]):
- op = tf.identity(op)
- return op
-
-
-periodically = common.periodically
-def _periodically(body, period, name='periodically'):
- """Periodically performs a tensorflow op."""
- if period is None or period == 0:
- return tf.no_op()
-
- if period < 0:
- raise ValueError("period cannot be less than 0.")
-
- if period == 1:
- return body()
-
- with tf.variable_scope(None, default_name=name):
- counter = tf.get_variable(
- "counter",
- shape=[],
- dtype=tf.int64,
- trainable=False,
- initializer=tf.constant_initializer(period, dtype=tf.int64))
-
- def _wrapped_body():
- with tf.control_dependencies([body()]):
- return counter.assign(1)
-
- update = tf.cond(
- tf.equal(counter, period), _wrapped_body,
- lambda: counter.assign_add(1))
-
- return update
-
-soft_variables_update = common.soft_variables_update
diff --git a/research/feelvos/CONTRIBUTING.md b/research/feelvos/CONTRIBUTING.md
deleted file mode 100644
index 939e5341e74dc2371c8b47f0e27b50581bed5f63..0000000000000000000000000000000000000000
--- a/research/feelvos/CONTRIBUTING.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# How to Contribute
-
-We'd love to accept your patches and contributions to this project. There are
-just a few small guidelines you need to follow.
-
-## Contributor License Agreement
-
-Contributions to this project must be accompanied by a Contributor License
-Agreement. You (or your employer) retain the copyright to your contribution;
-this simply gives us permission to use and redistribute your contributions as
-part of the project. Head over to ).
- # The default value is larger than the expected actual vocab size to allow
- # for differences between tokenizer versions used in preprocessing. There is
- # no harm in using a value greater than the actual vocab size, but using a
- # value less than the actual vocab size will result in an error.
- self.vocab_size = 12000
-
- # Number of threads for image preprocessing. Should be a multiple of 2.
- self.num_preprocess_threads = 4
-
- # Batch size.
- self.batch_size = 32
-
- # File containing an Inception v3 checkpoint to initialize the variables
- # of the Inception model. Must be provided when starting training for the
- # first time.
- self.inception_checkpoint_file = None
-
- # Dimensions of Inception v3 input images.
- self.image_height = 299
- self.image_width = 299
-
- # Scale used to initialize model variables.
- self.initializer_scale = 0.08
-
- # LSTM input and output dimensionality, respectively.
- self.embedding_size = 512
- self.num_lstm_units = 512
-
- # If < 1.0, the dropout keep probability applied to LSTM variables.
- self.lstm_dropout_keep_prob = 0.7
-
-
-class TrainingConfig(object):
- """Wrapper class for training hyperparameters."""
-
- def __init__(self):
- """Sets the default training hyperparameters."""
- # Number of examples per epoch of training data.
- self.num_examples_per_epoch = 586363
-
- # Optimizer for training the model.
- self.optimizer = "SGD"
-
- # Learning rate for the initial phase of training.
- self.initial_learning_rate = 2.0
- self.learning_rate_decay_factor = 0.5
- self.num_epochs_per_decay = 8.0
-
- # Learning rate when fine tuning the Inception v3 parameters.
- self.train_inception_learning_rate = 0.0005
-
- # If not None, clip gradients to this value.
- self.clip_gradients = 5.0
-
- # How many model checkpoints to keep.
- self.max_checkpoints_to_keep = 5
diff --git a/research/im2txt/im2txt/data/build_mscoco_data.py b/research/im2txt/im2txt/data/build_mscoco_data.py
deleted file mode 100644
index 2c3e9d977669bf63d8e39128336319b48c0432dd..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/data/build_mscoco_data.py
+++ /dev/null
@@ -1,483 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Converts MSCOCO data to TFRecord file format with SequenceExample protos.
-
-The MSCOCO images are expected to reside in JPEG files located in the following
-directory structure:
-
- train_image_dir/COCO_train2014_000000000151.jpg
- train_image_dir/COCO_train2014_000000000260.jpg
- ...
-
-and
-
- val_image_dir/COCO_val2014_000000000042.jpg
- val_image_dir/COCO_val2014_000000000073.jpg
- ...
-
-The MSCOCO annotations JSON files are expected to reside in train_captions_file
-and val_captions_file respectively.
-
-This script converts the combined MSCOCO data into sharded data files consisting
-of 256, 4 and 8 TFRecord files, respectively:
-
- output_dir/train-00000-of-00256
- output_dir/train-00001-of-00256
- ...
- output_dir/train-00255-of-00256
-
-and
-
- output_dir/val-00000-of-00004
- ...
- output_dir/val-00003-of-00004
-
-and
-
- output_dir/test-00000-of-00008
- ...
- output_dir/test-00007-of-00008
-
-Each TFRecord file contains ~2300 records. Each record within the TFRecord file
-is a serialized SequenceExample proto consisting of precisely one image-caption
-pair. Note that each image has multiple captions (usually 5) and therefore each
-image is replicated multiple times in the TFRecord files.
-
-The SequenceExample proto contains the following fields:
-
- context:
- image/image_id: integer MSCOCO image identifier
- image/data: string containing JPEG encoded image in RGB colorspace
-
- feature_lists:
- image/caption: list of strings containing the (tokenized) caption words
- image/caption_ids: list of integer ids corresponding to the caption words
-
-The captions are tokenized using the NLTK (http://www.nltk.org/) word tokenizer.
-The vocabulary of word identifiers is constructed from the sorted list (by
-descending frequency) of word tokens in the training set. Only tokens appearing
-at least 4 times are considered; all other words get the "unknown" word id.
-
-NOTE: This script will consume around 100GB of disk space because each image
-in the MSCOCO dataset is replicated ~5 times (once per caption) in the output.
-This is done for two reasons:
- 1. In order to better shuffle the training data.
- 2. It makes it easier to perform asynchronous preprocessing of each image in
- TensorFlow.
-
-Running this script using 16 threads may take around 1 hour on a HP Z420.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import Counter
-from collections import namedtuple
-from datetime import datetime
-import json
-import os.path
-import random
-import sys
-import threading
-
-
-
-import nltk.tokenize
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-tf.flags.DEFINE_string("train_image_dir", "/tmp/train2014/",
- "Training image directory.")
-tf.flags.DEFINE_string("val_image_dir", "/tmp/val2014",
- "Validation image directory.")
-
-tf.flags.DEFINE_string("train_captions_file", "/tmp/captions_train2014.json",
- "Training captions JSON file.")
-tf.flags.DEFINE_string("val_captions_file", "/tmp/captions_val2014.json",
- "Validation captions JSON file.")
-
-tf.flags.DEFINE_string("output_dir", "/tmp/", "Output data directory.")
-
-tf.flags.DEFINE_integer("train_shards", 256,
- "Number of shards in training TFRecord files.")
-tf.flags.DEFINE_integer("val_shards", 4,
- "Number of shards in validation TFRecord files.")
-tf.flags.DEFINE_integer("test_shards", 8,
- "Number of shards in testing TFRecord files.")
-
-tf.flags.DEFINE_string("start_word", "",
- "Special word added to the beginning of each sentence.")
-tf.flags.DEFINE_string("end_word", "",
- "Special word added to the end of each sentence.")
-tf.flags.DEFINE_string("unknown_word", "",
- "Special word meaning 'unknown'.")
-tf.flags.DEFINE_integer("min_word_count", 4,
- "The minimum number of occurrences of each word in the "
- "training set for inclusion in the vocabulary.")
-tf.flags.DEFINE_string("word_counts_output_file", "/tmp/word_counts.txt",
- "Output vocabulary file of word counts.")
-
-tf.flags.DEFINE_integer("num_threads", 8,
- "Number of threads to preprocess the images.")
-
-FLAGS = tf.flags.FLAGS
-
-ImageMetadata = namedtuple("ImageMetadata",
- ["image_id", "filename", "captions"])
-
-
-class Vocabulary(object):
- """Simple vocabulary wrapper."""
-
- def __init__(self, vocab, unk_id):
- """Initializes the vocabulary.
-
- Args:
- vocab: A dictionary of word to word_id.
- unk_id: Id of the special 'unknown' word.
- """
- self._vocab = vocab
- self._unk_id = unk_id
-
- def word_to_id(self, word):
- """Returns the integer id of a word string."""
- if word in self._vocab:
- return self._vocab[word]
- else:
- return self._unk_id
-
-
-class ImageDecoder(object):
- """Helper class for decoding images in TensorFlow."""
-
- def __init__(self):
- # Create a single TensorFlow Session for all image decoding calls.
- self._sess = tf.Session()
-
- # TensorFlow ops for JPEG decoding.
- self._encoded_jpeg = tf.placeholder(dtype=tf.string)
- self._decode_jpeg = tf.image.decode_jpeg(self._encoded_jpeg, channels=3)
-
- def decode_jpeg(self, encoded_jpeg):
- image = self._sess.run(self._decode_jpeg,
- feed_dict={self._encoded_jpeg: encoded_jpeg})
- assert len(image.shape) == 3
- assert image.shape[2] == 3
- return image
-
-
-def _int64_feature(value):
- """Wrapper for inserting an int64 Feature into a SequenceExample proto."""
- return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
-
-
-def _bytes_feature(value):
- """Wrapper for inserting a bytes Feature into a SequenceExample proto."""
- return tf.train.Feature(bytes_list=tf.train.BytesList(value=[str(value)]))
-
-
-def _int64_feature_list(values):
- """Wrapper for inserting an int64 FeatureList into a SequenceExample proto."""
- return tf.train.FeatureList(feature=[_int64_feature(v) for v in values])
-
-
-def _bytes_feature_list(values):
- """Wrapper for inserting a bytes FeatureList into a SequenceExample proto."""
- return tf.train.FeatureList(feature=[_bytes_feature(v) for v in values])
-
-
-def _to_sequence_example(image, decoder, vocab):
- """Builds a SequenceExample proto for an image-caption pair.
-
- Args:
- image: An ImageMetadata object.
- decoder: An ImageDecoder object.
- vocab: A Vocabulary object.
-
- Returns:
- A SequenceExample proto.
- """
- with tf.gfile.FastGFile(image.filename, "r") as f:
- encoded_image = f.read()
-
- try:
- decoder.decode_jpeg(encoded_image)
- except (tf.errors.InvalidArgumentError, AssertionError):
- print("Skipping file with invalid JPEG data: %s" % image.filename)
- return
-
- context = tf.train.Features(feature={
- "image/image_id": _int64_feature(image.image_id),
- "image/data": _bytes_feature(encoded_image),
- })
-
- assert len(image.captions) == 1
- caption = image.captions[0]
- caption_ids = [vocab.word_to_id(word) for word in caption]
- feature_lists = tf.train.FeatureLists(feature_list={
- "image/caption": _bytes_feature_list(caption),
- "image/caption_ids": _int64_feature_list(caption_ids)
- })
- sequence_example = tf.train.SequenceExample(
- context=context, feature_lists=feature_lists)
-
- return sequence_example
-
-
-def _process_image_files(thread_index, ranges, name, images, decoder, vocab,
- num_shards):
- """Processes and saves a subset of images as TFRecord files in one thread.
-
- Args:
- thread_index: Integer thread identifier within [0, len(ranges)].
- ranges: A list of pairs of integers specifying the ranges of the dataset to
- process in parallel.
- name: Unique identifier specifying the dataset.
- images: List of ImageMetadata.
- decoder: An ImageDecoder object.
- vocab: A Vocabulary object.
- num_shards: Integer number of shards for the output files.
- """
- # Each thread produces N shards where N = num_shards / num_threads. For
- # instance, if num_shards = 128, and num_threads = 2, then the first thread
- # would produce shards [0, 64).
- num_threads = len(ranges)
- assert not num_shards % num_threads
- num_shards_per_batch = int(num_shards / num_threads)
-
- shard_ranges = np.linspace(ranges[thread_index][0], ranges[thread_index][1],
- num_shards_per_batch + 1).astype(int)
- num_images_in_thread = ranges[thread_index][1] - ranges[thread_index][0]
-
- counter = 0
- for s in xrange(num_shards_per_batch):
- # Generate a sharded version of the file name, e.g. 'train-00002-of-00010'
- shard = thread_index * num_shards_per_batch + s
- output_filename = "%s-%.5d-of-%.5d" % (name, shard, num_shards)
- output_file = os.path.join(FLAGS.output_dir, output_filename)
- writer = tf.python_io.TFRecordWriter(output_file)
-
- shard_counter = 0
- images_in_shard = np.arange(shard_ranges[s], shard_ranges[s + 1], dtype=int)
- for i in images_in_shard:
- image = images[i]
-
- sequence_example = _to_sequence_example(image, decoder, vocab)
- if sequence_example is not None:
- writer.write(sequence_example.SerializeToString())
- shard_counter += 1
- counter += 1
-
- if not counter % 1000:
- print("%s [thread %d]: Processed %d of %d items in thread batch." %
- (datetime.now(), thread_index, counter, num_images_in_thread))
- sys.stdout.flush()
-
- writer.close()
- print("%s [thread %d]: Wrote %d image-caption pairs to %s" %
- (datetime.now(), thread_index, shard_counter, output_file))
- sys.stdout.flush()
- shard_counter = 0
- print("%s [thread %d]: Wrote %d image-caption pairs to %d shards." %
- (datetime.now(), thread_index, counter, num_shards_per_batch))
- sys.stdout.flush()
-
-
-def _process_dataset(name, images, vocab, num_shards):
- """Processes a complete data set and saves it as a TFRecord.
-
- Args:
- name: Unique identifier specifying the dataset.
- images: List of ImageMetadata.
- vocab: A Vocabulary object.
- num_shards: Integer number of shards for the output files.
- """
- # Break up each image into a separate entity for each caption.
- images = [ImageMetadata(image.image_id, image.filename, [caption])
- for image in images for caption in image.captions]
-
- # Shuffle the ordering of images. Make the randomization repeatable.
- random.seed(12345)
- random.shuffle(images)
-
- # Break the images into num_threads batches. Batch i is defined as
- # images[ranges[i][0]:ranges[i][1]].
- num_threads = min(num_shards, FLAGS.num_threads)
- spacing = np.linspace(0, len(images), num_threads + 1).astype(np.int)
- ranges = []
- threads = []
- for i in xrange(len(spacing) - 1):
- ranges.append([spacing[i], spacing[i + 1]])
-
- # Create a mechanism for monitoring when all threads are finished.
- coord = tf.train.Coordinator()
-
- # Create a utility for decoding JPEG images to run sanity checks.
- decoder = ImageDecoder()
-
- # Launch a thread for each batch.
- print("Launching %d threads for spacings: %s" % (num_threads, ranges))
- for thread_index in xrange(len(ranges)):
- args = (thread_index, ranges, name, images, decoder, vocab, num_shards)
- t = threading.Thread(target=_process_image_files, args=args)
- t.start()
- threads.append(t)
-
- # Wait for all the threads to terminate.
- coord.join(threads)
- print("%s: Finished processing all %d image-caption pairs in data set '%s'." %
- (datetime.now(), len(images), name))
-
-
-def _create_vocab(captions):
- """Creates the vocabulary of word to word_id.
-
- The vocabulary is saved to disk in a text file of word counts. The id of each
- word in the file is its corresponding 0-based line number.
-
- Args:
- captions: A list of lists of strings.
-
- Returns:
- A Vocabulary object.
- """
- print("Creating vocabulary.")
- counter = Counter()
- for c in captions:
- counter.update(c)
- print("Total words:", len(counter))
-
- # Filter uncommon words and sort by descending count.
- word_counts = [x for x in counter.items() if x[1] >= FLAGS.min_word_count]
- word_counts.sort(key=lambda x: x[1], reverse=True)
- print("Words in vocabulary:", len(word_counts))
-
- # Write out the word counts file.
- with tf.gfile.FastGFile(FLAGS.word_counts_output_file, "w") as f:
- f.write("\n".join(["%s %d" % (w, c) for w, c in word_counts]))
- print("Wrote vocabulary file:", FLAGS.word_counts_output_file)
-
- # Create the vocabulary dictionary.
- reverse_vocab = [x[0] for x in word_counts]
- unk_id = len(reverse_vocab)
- vocab_dict = dict([(x, y) for (y, x) in enumerate(reverse_vocab)])
- vocab = Vocabulary(vocab_dict, unk_id)
-
- return vocab
-
-
-def _process_caption(caption):
- """Processes a caption string into a list of tonenized words.
-
- Args:
- caption: A string caption.
-
- Returns:
- A list of strings; the tokenized caption.
- """
- tokenized_caption = [FLAGS.start_word]
- tokenized_caption.extend(nltk.tokenize.word_tokenize(caption.lower()))
- tokenized_caption.append(FLAGS.end_word)
- return tokenized_caption
-
-
-def _load_and_process_metadata(captions_file, image_dir):
- """Loads image metadata from a JSON file and processes the captions.
-
- Args:
- captions_file: JSON file containing caption annotations.
- image_dir: Directory containing the image files.
-
- Returns:
- A list of ImageMetadata.
- """
- with tf.gfile.FastGFile(captions_file, "r") as f:
- caption_data = json.load(f)
-
- # Extract the filenames.
- id_to_filename = [(x["id"], x["file_name"]) for x in caption_data["images"]]
-
- # Extract the captions. Each image_id is associated with multiple captions.
- id_to_captions = {}
- for annotation in caption_data["annotations"]:
- image_id = annotation["image_id"]
- caption = annotation["caption"]
- id_to_captions.setdefault(image_id, [])
- id_to_captions[image_id].append(caption)
-
- assert len(id_to_filename) == len(id_to_captions)
- assert set([x[0] for x in id_to_filename]) == set(id_to_captions.keys())
- print("Loaded caption metadata for %d images from %s" %
- (len(id_to_filename), captions_file))
-
- # Process the captions and combine the data into a list of ImageMetadata.
- print("Processing captions.")
- image_metadata = []
- num_captions = 0
- for image_id, base_filename in id_to_filename:
- filename = os.path.join(image_dir, base_filename)
- captions = [_process_caption(c) for c in id_to_captions[image_id]]
- image_metadata.append(ImageMetadata(image_id, filename, captions))
- num_captions += len(captions)
- print("Finished processing %d captions for %d images in %s" %
- (num_captions, len(id_to_filename), captions_file))
-
- return image_metadata
-
-
-def main(unused_argv):
- def _is_valid_num_shards(num_shards):
- """Returns True if num_shards is compatible with FLAGS.num_threads."""
- return num_shards < FLAGS.num_threads or not num_shards % FLAGS.num_threads
-
- assert _is_valid_num_shards(FLAGS.train_shards), (
- "Please make the FLAGS.num_threads commensurate with FLAGS.train_shards")
- assert _is_valid_num_shards(FLAGS.val_shards), (
- "Please make the FLAGS.num_threads commensurate with FLAGS.val_shards")
- assert _is_valid_num_shards(FLAGS.test_shards), (
- "Please make the FLAGS.num_threads commensurate with FLAGS.test_shards")
-
- if not tf.gfile.IsDirectory(FLAGS.output_dir):
- tf.gfile.MakeDirs(FLAGS.output_dir)
-
- # Load image metadata from caption files.
- mscoco_train_dataset = _load_and_process_metadata(FLAGS.train_captions_file,
- FLAGS.train_image_dir)
- mscoco_val_dataset = _load_and_process_metadata(FLAGS.val_captions_file,
- FLAGS.val_image_dir)
-
- # Redistribute the MSCOCO data as follows:
- # train_dataset = 100% of mscoco_train_dataset + 85% of mscoco_val_dataset.
- # val_dataset = 5% of mscoco_val_dataset (for validation during training).
- # test_dataset = 10% of mscoco_val_dataset (for final evaluation).
- train_cutoff = int(0.85 * len(mscoco_val_dataset))
- val_cutoff = int(0.90 * len(mscoco_val_dataset))
- train_dataset = mscoco_train_dataset + mscoco_val_dataset[0:train_cutoff]
- val_dataset = mscoco_val_dataset[train_cutoff:val_cutoff]
- test_dataset = mscoco_val_dataset[val_cutoff:]
-
- # Create vocabulary from the training captions.
- train_captions = [c for image in train_dataset for c in image.captions]
- vocab = _create_vocab(train_captions)
-
- _process_dataset("train", train_dataset, vocab, FLAGS.train_shards)
- _process_dataset("val", val_dataset, vocab, FLAGS.val_shards)
- _process_dataset("test", test_dataset, vocab, FLAGS.test_shards)
-
-
-if __name__ == "__main__":
- tf.app.run()
diff --git a/research/im2txt/im2txt/data/download_and_preprocess_mscoco.sh b/research/im2txt/im2txt/data/download_and_preprocess_mscoco.sh
deleted file mode 100755
index ab3ff28d576adcbf1992de4c00dfa350dd93b1c3..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/data/download_and_preprocess_mscoco.sh
+++ /dev/null
@@ -1,90 +0,0 @@
-#!/bin/bash
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Script to download and preprocess the MSCOCO data set.
-#
-# The outputs of this script are sharded TFRecord files containing serialized
-# SequenceExample protocol buffers. See build_mscoco_data.py for details of how
-# the SequenceExample protocol buffers are constructed.
-#
-# usage:
-# ./download_and_preprocess_mscoco.sh
-set -e
-
-if [ -z "$1" ]; then
- echo "usage download_and_preproces_mscoco.sh [data dir]"
- exit
-fi
-
-if [ "$(uname)" == "Darwin" ]; then
- UNZIP="tar -xf"
-else
- UNZIP="unzip -nq"
-fi
-
-# Create the output directories.
-OUTPUT_DIR="${1%/}"
-SCRATCH_DIR="${OUTPUT_DIR}/raw-data"
-mkdir -p "${OUTPUT_DIR}"
-mkdir -p "${SCRATCH_DIR}"
-CURRENT_DIR=$(pwd)
-WORK_DIR="$0.runfiles/im2txt/im2txt"
-
-# Helper function to download and unpack a .zip file.
-function download_and_unzip() {
- local BASE_URL=${1}
- local FILENAME=${2}
-
- if [ ! -f ${FILENAME} ]; then
- echo "Downloading ${FILENAME} to $(pwd)"
- wget -nd -c "${BASE_URL}/${FILENAME}"
- else
- echo "Skipping download of ${FILENAME}"
- fi
- echo "Unzipping ${FILENAME}"
- ${UNZIP} ${FILENAME}
-}
-
-cd ${SCRATCH_DIR}
-
-# Download the images.
-BASE_IMAGE_URL="http://msvocds.blob.core.windows.net/coco2014"
-
-TRAIN_IMAGE_FILE="train2014.zip"
-download_and_unzip ${BASE_IMAGE_URL} ${TRAIN_IMAGE_FILE}
-TRAIN_IMAGE_DIR="${SCRATCH_DIR}/train2014"
-
-VAL_IMAGE_FILE="val2014.zip"
-download_and_unzip ${BASE_IMAGE_URL} ${VAL_IMAGE_FILE}
-VAL_IMAGE_DIR="${SCRATCH_DIR}/val2014"
-
-# Download the captions.
-BASE_CAPTIONS_URL="http://msvocds.blob.core.windows.net/annotations-1-0-3"
-CAPTIONS_FILE="captions_train-val2014.zip"
-download_and_unzip ${BASE_CAPTIONS_URL} ${CAPTIONS_FILE}
-TRAIN_CAPTIONS_FILE="${SCRATCH_DIR}/annotations/captions_train2014.json"
-VAL_CAPTIONS_FILE="${SCRATCH_DIR}/annotations/captions_val2014.json"
-
-# Build TFRecords of the image data.
-cd "${CURRENT_DIR}"
-BUILD_SCRIPT="${WORK_DIR}/build_mscoco_data"
-"${BUILD_SCRIPT}" \
- --train_image_dir="${TRAIN_IMAGE_DIR}" \
- --val_image_dir="${VAL_IMAGE_DIR}" \
- --train_captions_file="${TRAIN_CAPTIONS_FILE}" \
- --val_captions_file="${VAL_CAPTIONS_FILE}" \
- --output_dir="${OUTPUT_DIR}" \
- --word_counts_output_file="${OUTPUT_DIR}/word_counts.txt" \
diff --git a/research/im2txt/im2txt/evaluate.py b/research/im2txt/im2txt/evaluate.py
deleted file mode 100644
index 0c81a59dab56626cb2c6a19433544f4d239cbd9d..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/evaluate.py
+++ /dev/null
@@ -1,198 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Evaluate the model.
-
-This script should be run concurrently with training so that summaries show up
-in TensorBoard.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-import os.path
-import time
-
-
-import numpy as np
-import tensorflow as tf
-
-from im2txt import configuration
-from im2txt import show_and_tell_model
-
-FLAGS = tf.flags.FLAGS
-
-tf.flags.DEFINE_string("input_file_pattern", "",
- "File pattern of sharded TFRecord input files.")
-tf.flags.DEFINE_string("checkpoint_dir", "",
- "Directory containing model checkpoints.")
-tf.flags.DEFINE_string("eval_dir", "", "Directory to write event logs.")
-
-tf.flags.DEFINE_integer("eval_interval_secs", 600,
- "Interval between evaluation runs.")
-tf.flags.DEFINE_integer("num_eval_examples", 10132,
- "Number of examples for evaluation.")
-
-tf.flags.DEFINE_integer("min_global_step", 5000,
- "Minimum global step to run evaluation.")
-
-tf.logging.set_verbosity(tf.logging.INFO)
-
-
-def evaluate_model(sess, model, global_step, summary_writer, summary_op):
- """Computes perplexity-per-word over the evaluation dataset.
-
- Summaries and perplexity-per-word are written out to the eval directory.
-
- Args:
- sess: Session object.
- model: Instance of ShowAndTellModel; the model to evaluate.
- global_step: Integer; global step of the model checkpoint.
- summary_writer: Instance of FileWriter.
- summary_op: Op for generating model summaries.
- """
- # Log model summaries on a single batch.
- summary_str = sess.run(summary_op)
- summary_writer.add_summary(summary_str, global_step)
-
- # Compute perplexity over the entire dataset.
- num_eval_batches = int(
- math.ceil(FLAGS.num_eval_examples / model.config.batch_size))
-
- start_time = time.time()
- sum_losses = 0.
- sum_weights = 0.
- for i in range(num_eval_batches):
- cross_entropy_losses, weights = sess.run([
- model.target_cross_entropy_losses,
- model.target_cross_entropy_loss_weights
- ])
- sum_losses += np.sum(cross_entropy_losses * weights)
- sum_weights += np.sum(weights)
- if not i % 100:
- tf.logging.info("Computed losses for %d of %d batches.", i + 1,
- num_eval_batches)
- eval_time = time.time() - start_time
-
- perplexity = math.exp(sum_losses / sum_weights)
- tf.logging.info("Perplexity = %f (%.2g sec)", perplexity, eval_time)
-
- # Log perplexity to the FileWriter.
- summary = tf.Summary()
- value = summary.value.add()
- value.simple_value = perplexity
- value.tag = "Perplexity"
- summary_writer.add_summary(summary, global_step)
-
- # Write the Events file to the eval directory.
- summary_writer.flush()
- tf.logging.info("Finished processing evaluation at global step %d.",
- global_step)
-
-
-def run_once(model, saver, summary_writer, summary_op):
- """Evaluates the latest model checkpoint.
-
- Args:
- model: Instance of ShowAndTellModel; the model to evaluate.
- saver: Instance of tf.train.Saver for restoring model Variables.
- summary_writer: Instance of FileWriter.
- summary_op: Op for generating model summaries.
- """
- model_path = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
- if not model_path:
- tf.logging.info("Skipping evaluation. No checkpoint found in: %s",
- FLAGS.checkpoint_dir)
- return
-
- with tf.Session() as sess:
- # Load model from checkpoint.
- tf.logging.info("Loading model from checkpoint: %s", model_path)
- saver.restore(sess, model_path)
- global_step = tf.train.global_step(sess, model.global_step.name)
- tf.logging.info("Successfully loaded %s at global step = %d.",
- os.path.basename(model_path), global_step)
- if global_step < FLAGS.min_global_step:
- tf.logging.info("Skipping evaluation. Global step = %d < %d", global_step,
- FLAGS.min_global_step)
- return
-
- # Start the queue runners.
- coord = tf.train.Coordinator()
- threads = tf.train.start_queue_runners(coord=coord)
-
- # Run evaluation on the latest checkpoint.
- try:
- evaluate_model(
- sess=sess,
- model=model,
- global_step=global_step,
- summary_writer=summary_writer,
- summary_op=summary_op)
- except Exception as e: # pylint: disable=broad-except
- tf.logging.error("Evaluation failed.")
- coord.request_stop(e)
-
- coord.request_stop()
- coord.join(threads, stop_grace_period_secs=10)
-
-
-def run():
- """Runs evaluation in a loop, and logs summaries to TensorBoard."""
- # Create the evaluation directory if it doesn't exist.
- eval_dir = FLAGS.eval_dir
- if not tf.gfile.IsDirectory(eval_dir):
- tf.logging.info("Creating eval directory: %s", eval_dir)
- tf.gfile.MakeDirs(eval_dir)
-
- g = tf.Graph()
- with g.as_default():
- # Build the model for evaluation.
- model_config = configuration.ModelConfig()
- model_config.input_file_pattern = FLAGS.input_file_pattern
- model = show_and_tell_model.ShowAndTellModel(model_config, mode="eval")
- model.build()
-
- # Create the Saver to restore model Variables.
- saver = tf.train.Saver()
-
- # Create the summary operation and the summary writer.
- summary_op = tf.summary.merge_all()
- summary_writer = tf.summary.FileWriter(eval_dir)
-
- g.finalize()
-
- # Run a new evaluation run every eval_interval_secs.
- while True:
- start = time.time()
- tf.logging.info("Starting evaluation at " + time.strftime(
- "%Y-%m-%d-%H:%M:%S", time.localtime()))
- run_once(model, saver, summary_writer, summary_op)
- time_to_next_eval = start + FLAGS.eval_interval_secs - time.time()
- if time_to_next_eval > 0:
- time.sleep(time_to_next_eval)
-
-
-def main(unused_argv):
- assert FLAGS.input_file_pattern, "--input_file_pattern is required"
- assert FLAGS.checkpoint_dir, "--checkpoint_dir is required"
- assert FLAGS.eval_dir, "--eval_dir is required"
- run()
-
-
-if __name__ == "__main__":
- tf.app.run()
diff --git a/research/im2txt/im2txt/inference_utils/BUILD b/research/im2txt/im2txt/inference_utils/BUILD
deleted file mode 100644
index 82a15fd3ca487e542c41ab337404f8caa63b8c63..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_utils/BUILD
+++ /dev/null
@@ -1,31 +0,0 @@
-package(default_visibility = ["//im2txt:internal"])
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-py_library(
- name = "inference_wrapper_base",
- srcs = ["inference_wrapper_base.py"],
- srcs_version = "PY2AND3",
-)
-
-py_library(
- name = "vocabulary",
- srcs = ["vocabulary.py"],
- srcs_version = "PY2AND3",
-)
-
-py_library(
- name = "caption_generator",
- srcs = ["caption_generator.py"],
- srcs_version = "PY2AND3",
-)
-
-py_test(
- name = "caption_generator_test",
- srcs = ["caption_generator_test.py"],
- deps = [
- ":caption_generator",
- ],
-)
diff --git a/research/im2txt/im2txt/inference_utils/caption_generator.py b/research/im2txt/im2txt/inference_utils/caption_generator.py
deleted file mode 100644
index f158d3d2330e8f839efdad4cbc4d38811b58d826..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_utils/caption_generator.py
+++ /dev/null
@@ -1,213 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Class for generating captions from an image-to-text model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import heapq
-import math
-
-
-import numpy as np
-
-
-class Caption(object):
- """Represents a complete or partial caption."""
-
- def __init__(self, sentence, state, logprob, score, metadata=None):
- """Initializes the Caption.
-
- Args:
- sentence: List of word ids in the caption.
- state: Model state after generating the previous word.
- logprob: Log-probability of the caption.
- score: Score of the caption.
- metadata: Optional metadata associated with the partial sentence. If not
- None, a list of strings with the same length as 'sentence'.
- """
- self.sentence = sentence
- self.state = state
- self.logprob = logprob
- self.score = score
- self.metadata = metadata
-
- def __cmp__(self, other):
- """Compares Captions by score."""
- assert isinstance(other, Caption)
- if self.score == other.score:
- return 0
- elif self.score < other.score:
- return -1
- else:
- return 1
-
- # For Python 3 compatibility (__cmp__ is deprecated).
- def __lt__(self, other):
- assert isinstance(other, Caption)
- return self.score < other.score
-
- # Also for Python 3 compatibility.
- def __eq__(self, other):
- assert isinstance(other, Caption)
- return self.score == other.score
-
-
-class TopN(object):
- """Maintains the top n elements of an incrementally provided set."""
-
- def __init__(self, n):
- self._n = n
- self._data = []
-
- def size(self):
- assert self._data is not None
- return len(self._data)
-
- def push(self, x):
- """Pushes a new element."""
- assert self._data is not None
- if len(self._data) < self._n:
- heapq.heappush(self._data, x)
- else:
- heapq.heappushpop(self._data, x)
-
- def extract(self, sort=False):
- """Extracts all elements from the TopN. This is a destructive operation.
-
- The only method that can be called immediately after extract() is reset().
-
- Args:
- sort: Whether to return the elements in descending sorted order.
-
- Returns:
- A list of data; the top n elements provided to the set.
- """
- assert self._data is not None
- data = self._data
- self._data = None
- if sort:
- data.sort(reverse=True)
- return data
-
- def reset(self):
- """Returns the TopN to an empty state."""
- self._data = []
-
-
-class CaptionGenerator(object):
- """Class to generate captions from an image-to-text model."""
-
- def __init__(self,
- model,
- vocab,
- beam_size=3,
- max_caption_length=20,
- length_normalization_factor=0.0):
- """Initializes the generator.
-
- Args:
- model: Object encapsulating a trained image-to-text model. Must have
- methods feed_image() and inference_step(). For example, an instance of
- InferenceWrapperBase.
- vocab: A Vocabulary object.
- beam_size: Beam size to use when generating captions.
- max_caption_length: The maximum caption length before stopping the search.
- length_normalization_factor: If != 0, a number x such that captions are
- scored by logprob/length^x, rather than logprob. This changes the
- relative scores of captions depending on their lengths. For example, if
- x > 0 then longer captions will be favored.
- """
- self.vocab = vocab
- self.model = model
-
- self.beam_size = beam_size
- self.max_caption_length = max_caption_length
- self.length_normalization_factor = length_normalization_factor
-
- def beam_search(self, sess, encoded_image):
- """Runs beam search caption generation on a single image.
-
- Args:
- sess: TensorFlow Session object.
- encoded_image: An encoded image string.
-
- Returns:
- A list of Caption sorted by descending score.
- """
- # Feed in the image to get the initial state.
- initial_state = self.model.feed_image(sess, encoded_image)
-
- initial_beam = Caption(
- sentence=[self.vocab.start_id],
- state=initial_state[0],
- logprob=0.0,
- score=0.0,
- metadata=[""])
- partial_captions = TopN(self.beam_size)
- partial_captions.push(initial_beam)
- complete_captions = TopN(self.beam_size)
-
- # Run beam search.
- for _ in range(self.max_caption_length - 1):
- partial_captions_list = partial_captions.extract()
- partial_captions.reset()
- input_feed = np.array([c.sentence[-1] for c in partial_captions_list])
- state_feed = np.array([c.state for c in partial_captions_list])
-
- softmax, new_states, metadata = self.model.inference_step(sess,
- input_feed,
- state_feed)
-
- for i, partial_caption in enumerate(partial_captions_list):
- word_probabilities = softmax[i]
- state = new_states[i]
- # For this partial caption, get the beam_size most probable next words.
- # Sort the indexes with numpy, select the last self.beam_size
- # (3 by default) (ie, the most likely) and then reverse the sorted
- # indexes with [::-1] to sort them from higher to lower.
- most_likely_words = np.argsort(word_probabilities)[:-self.beam_size][::-1]
-
- for w in most_likely_words:
- p = word_probabilities[w]
- if p < 1e-12:
- continue # Avoid log(0).
- sentence = partial_caption.sentence + [w]
- logprob = partial_caption.logprob + math.log(p)
- score = logprob
- if metadata:
- metadata_list = partial_caption.metadata + [metadata[i]]
- else:
- metadata_list = None
- if w == self.vocab.end_id:
- if self.length_normalization_factor > 0:
- score /= len(sentence)**self.length_normalization_factor
- beam = Caption(sentence, state, logprob, score, metadata_list)
- complete_captions.push(beam)
- else:
- beam = Caption(sentence, state, logprob, score, metadata_list)
- partial_captions.push(beam)
- if partial_captions.size() == 0:
- # We have run out of partial candidates; happens when beam_size = 1.
- break
-
- # If we have no complete captions then fall back to the partial captions.
- # But never output a mixture of complete and partial captions because a
- # partial caption could have a higher score than all the complete captions.
- if not complete_captions.size():
- complete_captions = partial_captions
-
- return complete_captions.extract(sort=True)
diff --git a/research/im2txt/im2txt/inference_utils/caption_generator_test.py b/research/im2txt/im2txt/inference_utils/caption_generator_test.py
deleted file mode 100644
index bbd069313ac4ddb10a8463d166ab282b68b2e24d..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_utils/caption_generator_test.py
+++ /dev/null
@@ -1,178 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Unit tests for CaptionGenerator."""
-
-import math
-
-
-
-import numpy as np
-import tensorflow as tf
-
-from im2txt.inference_utils import caption_generator
-
-
-class FakeVocab(object):
- """Fake Vocabulary for testing purposes."""
-
- def __init__(self):
- self.start_id = 0 # Word id denoting sentence start.
- self.end_id = 1 # Word id denoting sentence end.
-
-
-class FakeModel(object):
- """Fake model for testing purposes."""
-
- def __init__(self):
- # Number of words in the vocab.
- self._vocab_size = 12
-
- # Dimensionality of the nominal model state.
- self._state_size = 1
-
- # Map of previous word to the probability distribution of the next word.
- self._probabilities = {
- 0: {1: 0.1,
- 2: 0.2,
- 3: 0.3,
- 4: 0.4},
- 2: {5: 0.1,
- 6: 0.9},
- 3: {1: 0.1,
- 7: 0.4,
- 8: 0.5},
- 4: {1: 0.3,
- 9: 0.3,
- 10: 0.4},
- 5: {1: 1.0},
- 6: {1: 1.0},
- 7: {1: 1.0},
- 8: {1: 1.0},
- 9: {1: 0.5,
- 11: 0.5},
- 10: {1: 1.0},
- 11: {1: 1.0},
- }
-
- # pylint: disable=unused-argument
-
- def feed_image(self, sess, encoded_image):
- # Return a nominal model state.
- return np.zeros([1, self._state_size])
-
- def inference_step(self, sess, input_feed, state_feed):
- # Compute the matrix of softmax distributions for the next batch of words.
- batch_size = input_feed.shape[0]
- softmax_output = np.zeros([batch_size, self._vocab_size])
- for batch_index, word_id in enumerate(input_feed):
- for next_word, probability in self._probabilities[word_id].items():
- softmax_output[batch_index, next_word] = probability
-
- # Nominal state and metadata.
- new_state = np.zeros([batch_size, self._state_size])
- metadata = None
-
- return softmax_output, new_state, metadata
-
- # pylint: enable=unused-argument
-
-
-class CaptionGeneratorTest(tf.test.TestCase):
-
- def _assertExpectedCaptions(self,
- expected_captions,
- beam_size=3,
- max_caption_length=20,
- length_normalization_factor=0):
- """Tests that beam search generates the expected captions.
-
- Args:
- expected_captions: A sequence of pairs (sentence, probability), where
- sentence is a list of integer ids and probability is a float in [0, 1].
- beam_size: Parameter passed to beam_search().
- max_caption_length: Parameter passed to beam_search().
- length_normalization_factor: Parameter passed to beam_search().
- """
- expected_sentences = [c[0] for c in expected_captions]
- expected_probabilities = [c[1] for c in expected_captions]
-
- # Generate captions.
- generator = caption_generator.CaptionGenerator(
- model=FakeModel(),
- vocab=FakeVocab(),
- beam_size=beam_size,
- max_caption_length=max_caption_length,
- length_normalization_factor=length_normalization_factor)
- actual_captions = generator.beam_search(sess=None, encoded_image=None)
-
- actual_sentences = [c.sentence for c in actual_captions]
- actual_probabilities = [math.exp(c.logprob) for c in actual_captions]
-
- self.assertEqual(expected_sentences, actual_sentences)
- self.assertAllClose(expected_probabilities, actual_probabilities)
-
- def testBeamSize(self):
- # Beam size = 1.
- expected = [([0, 4, 10, 1], 0.16)]
- self._assertExpectedCaptions(expected, beam_size=1)
-
- # Beam size = 2.
- expected = [([0, 4, 10, 1], 0.16), ([0, 3, 8, 1], 0.15)]
- self._assertExpectedCaptions(expected, beam_size=2)
-
- # Beam size = 3.
- expected = [
- ([0, 2, 6, 1], 0.18), ([0, 4, 10, 1], 0.16), ([0, 3, 8, 1], 0.15)
- ]
- self._assertExpectedCaptions(expected, beam_size=3)
-
- def testMaxLength(self):
- # Max length = 1.
- expected = [([0], 1.0)]
- self._assertExpectedCaptions(expected, max_caption_length=1)
-
- # Max length = 2.
- # There are no complete sentences, so partial sentences are returned.
- expected = [([0, 4], 0.4), ([0, 3], 0.3), ([0, 2], 0.2)]
- self._assertExpectedCaptions(expected, max_caption_length=2)
-
- # Max length = 3.
- # There is at least one complete sentence, so only complete sentences are
- # returned.
- expected = [([0, 4, 1], 0.12), ([0, 3, 1], 0.03)]
- self._assertExpectedCaptions(expected, max_caption_length=3)
-
- # Max length = 4.
- expected = [
- ([0, 2, 6, 1], 0.18), ([0, 4, 10, 1], 0.16), ([0, 3, 8, 1], 0.15)
- ]
- self._assertExpectedCaptions(expected, max_caption_length=4)
-
- def testLengthNormalization(self):
- # Length normalization factor = 3.
- # The longest caption is returned first, despite having low probability,
- # because it has the highest log(probability)/length**3.
- expected = [
- ([0, 4, 9, 11, 1], 0.06),
- ([0, 2, 6, 1], 0.18),
- ([0, 4, 10, 1], 0.16),
- ([0, 3, 8, 1], 0.15),
- ]
- self._assertExpectedCaptions(
- expected, beam_size=4, length_normalization_factor=3)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/im2txt/im2txt/inference_utils/inference_wrapper_base.py b/research/im2txt/im2txt/inference_utils/inference_wrapper_base.py
deleted file mode 100644
index e94cd6af474488e4b8175fc959e1dbe33cca18c9..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_utils/inference_wrapper_base.py
+++ /dev/null
@@ -1,181 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Base wrapper class for performing inference with an image-to-text model.
-
-Subclasses must implement the following methods:
-
- build_model():
- Builds the model for inference and returns the model object.
-
- feed_image():
- Takes an encoded image and returns the initial model state, where "state"
- is a numpy array whose specifics are defined by the subclass, e.g.
- concatenated LSTM state. It's assumed that feed_image() will be called
- precisely once at the start of inference for each image. Subclasses may
- compute and/or save per-image internal context in this method.
-
- inference_step():
- Takes a batch of inputs and states at a single time-step. Returns the
- softmax output corresponding to the inputs, and the new states of the batch.
- Optionally also returns metadata about the current inference step, e.g. a
- serialized numpy array containing activations from a particular model layer.
-
-Client usage:
- 1. Build the model inference graph via build_graph_from_config() or
- build_graph_from_proto().
- 2. Call the resulting restore_fn to load the model checkpoint.
- 3. For each image in a batch of images:
- a) Call feed_image() once to get the initial state.
- b) For each step of caption generation, call inference_step().
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os.path
-
-
-import tensorflow as tf
-
-# pylint: disable=unused-argument
-
-
-class InferenceWrapperBase(object):
- """Base wrapper class for performing inference with an image-to-text model."""
-
- def __init__(self):
- pass
-
- def build_model(self, model_config):
- """Builds the model for inference.
-
- Args:
- model_config: Object containing configuration for building the model.
-
- Returns:
- model: The model object.
- """
- tf.logging.fatal("Please implement build_model in subclass")
-
- def _create_restore_fn(self, checkpoint_path, saver):
- """Creates a function that restores a model from checkpoint.
-
- Args:
- checkpoint_path: Checkpoint file or a directory containing a checkpoint
- file.
- saver: Saver for restoring variables from the checkpoint file.
-
- Returns:
- restore_fn: A function such that restore_fn(sess) loads model variables
- from the checkpoint file.
-
- Raises:
- ValueError: If checkpoint_path does not refer to a checkpoint file or a
- directory containing a checkpoint file.
- """
- if tf.gfile.IsDirectory(checkpoint_path):
- checkpoint_path = tf.train.latest_checkpoint(checkpoint_path)
- if not checkpoint_path:
- raise ValueError("No checkpoint file found in: %s" % checkpoint_path)
-
- def _restore_fn(sess):
- tf.logging.info("Loading model from checkpoint: %s", checkpoint_path)
- saver.restore(sess, checkpoint_path)
- tf.logging.info("Successfully loaded checkpoint: %s",
- os.path.basename(checkpoint_path))
-
- return _restore_fn
-
- def build_graph_from_config(self, model_config, checkpoint_path):
- """Builds the inference graph from a configuration object.
-
- Args:
- model_config: Object containing configuration for building the model.
- checkpoint_path: Checkpoint file or a directory containing a checkpoint
- file.
-
- Returns:
- restore_fn: A function such that restore_fn(sess) loads model variables
- from the checkpoint file.
- """
- tf.logging.info("Building model.")
- self.build_model(model_config)
- saver = tf.train.Saver()
-
- return self._create_restore_fn(checkpoint_path, saver)
-
- def build_graph_from_proto(self, graph_def_file, saver_def_file,
- checkpoint_path):
- """Builds the inference graph from serialized GraphDef and SaverDef protos.
-
- Args:
- graph_def_file: File containing a serialized GraphDef proto.
- saver_def_file: File containing a serialized SaverDef proto.
- checkpoint_path: Checkpoint file or a directory containing a checkpoint
- file.
-
- Returns:
- restore_fn: A function such that restore_fn(sess) loads model variables
- from the checkpoint file.
- """
- # Load the Graph.
- tf.logging.info("Loading GraphDef from file: %s", graph_def_file)
- graph_def = tf.GraphDef()
- with tf.gfile.FastGFile(graph_def_file, "rb") as f:
- graph_def.ParseFromString(f.read())
- tf.import_graph_def(graph_def, name="")
-
- # Load the Saver.
- tf.logging.info("Loading SaverDef from file: %s", saver_def_file)
- saver_def = tf.train.SaverDef()
- with tf.gfile.FastGFile(saver_def_file, "rb") as f:
- saver_def.ParseFromString(f.read())
- saver = tf.train.Saver(saver_def=saver_def)
-
- return self._create_restore_fn(checkpoint_path, saver)
-
- def feed_image(self, sess, encoded_image):
- """Feeds an image and returns the initial model state.
-
- See comments at the top of file.
-
- Args:
- sess: TensorFlow Session object.
- encoded_image: An encoded image string.
-
- Returns:
- state: A numpy array of shape [1, state_size].
- """
- tf.logging.fatal("Please implement feed_image in subclass")
-
- def inference_step(self, sess, input_feed, state_feed):
- """Runs one step of inference.
-
- Args:
- sess: TensorFlow Session object.
- input_feed: A numpy array of shape [batch_size].
- state_feed: A numpy array of shape [batch_size, state_size].
-
- Returns:
- softmax_output: A numpy array of shape [batch_size, vocab_size].
- new_state: A numpy array of shape [batch_size, state_size].
- metadata: Optional. If not None, a string containing metadata about the
- current inference step (e.g. serialized numpy array containing
- activations from a particular model layer.).
- """
- tf.logging.fatal("Please implement inference_step in subclass")
-
-# pylint: enable=unused-argument
diff --git a/research/im2txt/im2txt/inference_utils/vocabulary.py b/research/im2txt/im2txt/inference_utils/vocabulary.py
deleted file mode 100644
index ecf0ada9c2242cb32c2ea9a300d16411f5e83fab..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_utils/vocabulary.py
+++ /dev/null
@@ -1,78 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Vocabulary class for an image-to-text model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-
-class Vocabulary(object):
- """Vocabulary class for an image-to-text model."""
-
- def __init__(self,
- vocab_file,
- start_word="",
- end_word="",
- unk_word=""):
- """Initializes the vocabulary.
-
- Args:
- vocab_file: File containing the vocabulary, where the words are the first
- whitespace-separated token on each line (other tokens are ignored) and
- the word ids are the corresponding line numbers.
- start_word: Special word denoting sentence start.
- end_word: Special word denoting sentence end.
- unk_word: Special word denoting unknown words.
- """
- if not tf.gfile.Exists(vocab_file):
- tf.logging.fatal("Vocab file %s not found.", vocab_file)
- tf.logging.info("Initializing vocabulary from file: %s", vocab_file)
-
- with tf.gfile.GFile(vocab_file, mode="r") as f:
- reverse_vocab = list(f.readlines())
- reverse_vocab = [line.split()[0] for line in reverse_vocab]
- assert start_word in reverse_vocab
- assert end_word in reverse_vocab
- if unk_word not in reverse_vocab:
- reverse_vocab.append(unk_word)
- vocab = dict([(x, y) for (y, x) in enumerate(reverse_vocab)])
-
- tf.logging.info("Created vocabulary with %d words" % len(vocab))
-
- self.vocab = vocab # vocab[word] = id
- self.reverse_vocab = reverse_vocab # reverse_vocab[id] = word
-
- # Save special word ids.
- self.start_id = vocab[start_word]
- self.end_id = vocab[end_word]
- self.unk_id = vocab[unk_word]
-
- def word_to_id(self, word):
- """Returns the integer word id of a word string."""
- if word in self.vocab:
- return self.vocab[word]
- else:
- return self.unk_id
-
- def id_to_word(self, word_id):
- """Returns the word string of an integer word id."""
- if word_id >= len(self.reverse_vocab):
- return self.reverse_vocab[self.unk_id]
- else:
- return self.reverse_vocab[word_id]
diff --git a/research/im2txt/im2txt/inference_wrapper.py b/research/im2txt/im2txt/inference_wrapper.py
deleted file mode 100644
index a047a9c8d084fd9e69c937915cea8553c2d51817..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/inference_wrapper.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Model wrapper class for performing inference with a ShowAndTellModel."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-from im2txt import show_and_tell_model
-from im2txt.inference_utils import inference_wrapper_base
-
-
-class InferenceWrapper(inference_wrapper_base.InferenceWrapperBase):
- """Model wrapper class for performing inference with a ShowAndTellModel."""
-
- def __init__(self):
- super(InferenceWrapper, self).__init__()
-
- def build_model(self, model_config):
- model = show_and_tell_model.ShowAndTellModel(model_config, mode="inference")
- model.build()
- return model
-
- def feed_image(self, sess, encoded_image):
- initial_state = sess.run(fetches="lstm/initial_state:0",
- feed_dict={"image_feed:0": encoded_image})
- return initial_state
-
- def inference_step(self, sess, input_feed, state_feed):
- softmax_output, state_output = sess.run(
- fetches=["softmax:0", "lstm/state:0"],
- feed_dict={
- "input_feed:0": input_feed,
- "lstm/state_feed:0": state_feed,
- })
- return softmax_output, state_output, None
diff --git a/research/im2txt/im2txt/ops/BUILD b/research/im2txt/im2txt/ops/BUILD
deleted file mode 100644
index 7d48bf3938c7ecfc94ac6498386e7ce214b8be92..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/ops/BUILD
+++ /dev/null
@@ -1,32 +0,0 @@
-package(default_visibility = ["//im2txt:internal"])
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-py_library(
- name = "image_processing",
- srcs = ["image_processing.py"],
- srcs_version = "PY2AND3",
-)
-
-py_library(
- name = "image_embedding",
- srcs = ["image_embedding.py"],
- srcs_version = "PY2AND3",
-)
-
-py_test(
- name = "image_embedding_test",
- size = "small",
- srcs = ["image_embedding_test.py"],
- deps = [
- ":image_embedding",
- ],
-)
-
-py_library(
- name = "inputs",
- srcs = ["inputs.py"],
- srcs_version = "PY2AND3",
-)
diff --git a/research/im2txt/im2txt/ops/image_embedding.py b/research/im2txt/im2txt/ops/image_embedding.py
deleted file mode 100644
index 58e3ddaa95fa799f245fe2a46f2e948be7d9ebf2..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/ops/image_embedding.py
+++ /dev/null
@@ -1,114 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Image embedding ops."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from tensorflow.contrib.slim.python.slim.nets.inception_v3 import inception_v3_base
-
-slim = tf.contrib.slim
-
-
-def inception_v3(images,
- trainable=True,
- is_training=True,
- weight_decay=0.00004,
- stddev=0.1,
- dropout_keep_prob=0.8,
- use_batch_norm=True,
- batch_norm_params=None,
- add_summaries=True,
- scope="InceptionV3"):
- """Builds an Inception V3 subgraph for image embeddings.
-
- Args:
- images: A float32 Tensor of shape [batch, height, width, channels].
- trainable: Whether the inception submodel should be trainable or not.
- is_training: Boolean indicating training mode or not.
- weight_decay: Coefficient for weight regularization.
- stddev: The standard deviation of the trunctated normal weight initializer.
- dropout_keep_prob: Dropout keep probability.
- use_batch_norm: Whether to use batch normalization.
- batch_norm_params: Parameters for batch normalization. See
- tf.contrib.layers.batch_norm for details.
- add_summaries: Whether to add activation summaries.
- scope: Optional Variable scope.
-
- Returns:
- end_points: A dictionary of activations from inception_v3 layers.
- """
- # Only consider the inception model to be in training mode if it's trainable.
- is_inception_model_training = trainable and is_training
-
- if use_batch_norm:
- # Default parameters for batch normalization.
- if not batch_norm_params:
- batch_norm_params = {
- "is_training": is_inception_model_training,
- "trainable": trainable,
- # Decay for the moving averages.
- "decay": 0.9997,
- # Epsilon to prevent 0s in variance.
- "epsilon": 0.001,
- # Collection containing the moving mean and moving variance.
- "variables_collections": {
- "beta": None,
- "gamma": None,
- "moving_mean": ["moving_vars"],
- "moving_variance": ["moving_vars"],
- }
- }
- else:
- batch_norm_params = None
-
- if trainable:
- weights_regularizer = tf.contrib.layers.l2_regularizer(weight_decay)
- else:
- weights_regularizer = None
-
- with tf.variable_scope(scope, "InceptionV3", [images]) as scope:
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- weights_regularizer=weights_regularizer,
- trainable=trainable):
- with slim.arg_scope(
- [slim.conv2d],
- weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
- activation_fn=tf.nn.relu,
- normalizer_fn=slim.batch_norm,
- normalizer_params=batch_norm_params):
- net, end_points = inception_v3_base(images, scope=scope)
- with tf.variable_scope("logits"):
- shape = net.get_shape()
- net = slim.avg_pool2d(net, shape[1:3], padding="VALID", scope="pool")
- net = slim.dropout(
- net,
- keep_prob=dropout_keep_prob,
- is_training=is_inception_model_training,
- scope="dropout")
- net = slim.flatten(net, scope="flatten")
-
- # Add summaries.
- if add_summaries:
- for v in end_points.values():
- tf.contrib.layers.summaries.summarize_activation(v)
-
- return net
diff --git a/research/im2txt/im2txt/ops/image_embedding_test.py b/research/im2txt/im2txt/ops/image_embedding_test.py
deleted file mode 100644
index 66324d68eee0ec9c450375c25229d80283fc909f..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/ops/image_embedding_test.py
+++ /dev/null
@@ -1,136 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for tensorflow_models.im2txt.ops.image_embedding."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from im2txt.ops import image_embedding
-
-
-class InceptionV3Test(tf.test.TestCase):
-
- def setUp(self):
- super(InceptionV3Test, self).setUp()
-
- batch_size = 4
- height = 299
- width = 299
- num_channels = 3
- self._images = tf.placeholder(tf.float32,
- [batch_size, height, width, num_channels])
- self._batch_size = batch_size
-
- def _countInceptionParameters(self):
- """Counts the number of parameters in the inception model at top scope."""
- counter = {}
- for v in tf.global_variables():
- name_tokens = v.op.name.split("/")
- if name_tokens[0] == "InceptionV3":
- name = "InceptionV3/" + name_tokens[1]
- num_params = v.get_shape().num_elements()
- assert num_params
- counter[name] = counter.get(name, 0) + num_params
- return counter
-
- def _verifyParameterCounts(self):
- """Verifies the number of parameters in the inception model."""
- param_counts = self._countInceptionParameters()
- expected_param_counts = {
- "InceptionV3/Conv2d_1a_3x3": 960,
- "InceptionV3/Conv2d_2a_3x3": 9312,
- "InceptionV3/Conv2d_2b_3x3": 18624,
- "InceptionV3/Conv2d_3b_1x1": 5360,
- "InceptionV3/Conv2d_4a_3x3": 138816,
- "InceptionV3/Mixed_5b": 256368,
- "InceptionV3/Mixed_5c": 277968,
- "InceptionV3/Mixed_5d": 285648,
- "InceptionV3/Mixed_6a": 1153920,
- "InceptionV3/Mixed_6b": 1298944,
- "InceptionV3/Mixed_6c": 1692736,
- "InceptionV3/Mixed_6d": 1692736,
- "InceptionV3/Mixed_6e": 2143872,
- "InceptionV3/Mixed_7a": 1699584,
- "InceptionV3/Mixed_7b": 5047872,
- "InceptionV3/Mixed_7c": 6080064,
- }
- self.assertDictEqual(expected_param_counts, param_counts)
-
- def _assertCollectionSize(self, expected_size, collection):
- actual_size = len(tf.get_collection(collection))
- if expected_size != actual_size:
- self.fail("Found %d items in collection %s (expected %d)." %
- (actual_size, collection, expected_size))
-
- def testTrainableTrueIsTrainingTrue(self):
- embeddings = image_embedding.inception_v3(
- self._images, trainable=True, is_training=True)
- self.assertEqual([self._batch_size, 2048], embeddings.get_shape().as_list())
-
- self._verifyParameterCounts()
- self._assertCollectionSize(376, tf.GraphKeys.GLOBAL_VARIABLES)
- self._assertCollectionSize(188, tf.GraphKeys.TRAINABLE_VARIABLES)
- self._assertCollectionSize(188, tf.GraphKeys.UPDATE_OPS)
- self._assertCollectionSize(94, tf.GraphKeys.REGULARIZATION_LOSSES)
- self._assertCollectionSize(0, tf.GraphKeys.LOSSES)
- self._assertCollectionSize(23, tf.GraphKeys.SUMMARIES)
-
- def testTrainableTrueIsTrainingFalse(self):
- embeddings = image_embedding.inception_v3(
- self._images, trainable=True, is_training=False)
- self.assertEqual([self._batch_size, 2048], embeddings.get_shape().as_list())
-
- self._verifyParameterCounts()
- self._assertCollectionSize(376, tf.GraphKeys.GLOBAL_VARIABLES)
- self._assertCollectionSize(188, tf.GraphKeys.TRAINABLE_VARIABLES)
- self._assertCollectionSize(0, tf.GraphKeys.UPDATE_OPS)
- self._assertCollectionSize(94, tf.GraphKeys.REGULARIZATION_LOSSES)
- self._assertCollectionSize(0, tf.GraphKeys.LOSSES)
- self._assertCollectionSize(23, tf.GraphKeys.SUMMARIES)
-
- def testTrainableFalseIsTrainingTrue(self):
- embeddings = image_embedding.inception_v3(
- self._images, trainable=False, is_training=True)
- self.assertEqual([self._batch_size, 2048], embeddings.get_shape().as_list())
-
- self._verifyParameterCounts()
- self._assertCollectionSize(376, tf.GraphKeys.GLOBAL_VARIABLES)
- self._assertCollectionSize(0, tf.GraphKeys.TRAINABLE_VARIABLES)
- self._assertCollectionSize(0, tf.GraphKeys.UPDATE_OPS)
- self._assertCollectionSize(0, tf.GraphKeys.REGULARIZATION_LOSSES)
- self._assertCollectionSize(0, tf.GraphKeys.LOSSES)
- self._assertCollectionSize(23, tf.GraphKeys.SUMMARIES)
-
- def testTrainableFalseIsTrainingFalse(self):
- embeddings = image_embedding.inception_v3(
- self._images, trainable=False, is_training=False)
- self.assertEqual([self._batch_size, 2048], embeddings.get_shape().as_list())
-
- self._verifyParameterCounts()
- self._assertCollectionSize(376, tf.GraphKeys.GLOBAL_VARIABLES)
- self._assertCollectionSize(0, tf.GraphKeys.TRAINABLE_VARIABLES)
- self._assertCollectionSize(0, tf.GraphKeys.UPDATE_OPS)
- self._assertCollectionSize(0, tf.GraphKeys.REGULARIZATION_LOSSES)
- self._assertCollectionSize(0, tf.GraphKeys.LOSSES)
- self._assertCollectionSize(23, tf.GraphKeys.SUMMARIES)
-
-
-if __name__ == "__main__":
- tf.test.main()
diff --git a/research/im2txt/im2txt/ops/image_processing.py b/research/im2txt/im2txt/ops/image_processing.py
deleted file mode 100644
index 6a7545547d5507febaabebf642ee81b6f94319f6..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/ops/image_processing.py
+++ /dev/null
@@ -1,133 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Helper functions for image preprocessing."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-
-def distort_image(image, thread_id):
- """Perform random distortions on an image.
-
- Args:
- image: A float32 Tensor of shape [height, width, 3] with values in [0, 1).
- thread_id: Preprocessing thread id used to select the ordering of color
- distortions. There should be a multiple of 2 preprocessing threads.
-
- Returns:
- distorted_image: A float32 Tensor of shape [height, width, 3] with values in
- [0, 1].
- """
- # Randomly flip horizontally.
- with tf.name_scope("flip_horizontal", values=[image]):
- image = tf.image.random_flip_left_right(image)
-
- # Randomly distort the colors based on thread id.
- color_ordering = thread_id % 2
- with tf.name_scope("distort_color", values=[image]):
- if color_ordering == 0:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.032)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- elif color_ordering == 1:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.032)
-
- # The random_* ops do not necessarily clamp.
- image = tf.clip_by_value(image, 0.0, 1.0)
-
- return image
-
-
-def process_image(encoded_image,
- is_training,
- height,
- width,
- resize_height=346,
- resize_width=346,
- thread_id=0,
- image_format="jpeg"):
- """Decode an image, resize and apply random distortions.
-
- In training, images are distorted slightly differently depending on thread_id.
-
- Args:
- encoded_image: String Tensor containing the image.
- is_training: Boolean; whether preprocessing for training or eval.
- height: Height of the output image.
- width: Width of the output image.
- resize_height: If > 0, resize height before crop to final dimensions.
- resize_width: If > 0, resize width before crop to final dimensions.
- thread_id: Preprocessing thread id used to select the ordering of color
- distortions. There should be a multiple of 2 preprocessing threads.
- image_format: "jpeg" or "png".
-
- Returns:
- A float32 Tensor of shape [height, width, 3] with values in [-1, 1].
-
- Raises:
- ValueError: If image_format is invalid.
- """
- # Helper function to log an image summary to the visualizer. Summaries are
- # only logged in thread 0.
- def image_summary(name, image):
- if not thread_id:
- tf.summary.image(name, tf.expand_dims(image, 0))
-
- # Decode image into a float32 Tensor of shape [?, ?, 3] with values in [0, 1).
- with tf.name_scope("decode", values=[encoded_image]):
- if image_format == "jpeg":
- image = tf.image.decode_jpeg(encoded_image, channels=3)
- elif image_format == "png":
- image = tf.image.decode_png(encoded_image, channels=3)
- else:
- raise ValueError("Invalid image format: %s" % image_format)
- image = tf.image.convert_image_dtype(image, dtype=tf.float32)
- image_summary("original_image", image)
-
- # Resize image.
- assert (resize_height > 0) == (resize_width > 0)
- if resize_height:
- image = tf.image.resize_images(image,
- size=[resize_height, resize_width],
- method=tf.image.ResizeMethod.BILINEAR)
-
- # Crop to final dimensions.
- if is_training:
- image = tf.random_crop(image, [height, width, 3])
- else:
- # Central crop, assuming resize_height > height, resize_width > width.
- image = tf.image.resize_image_with_crop_or_pad(image, height, width)
-
- image_summary("resized_image", image)
-
- # Randomly distort the image.
- if is_training:
- image = distort_image(image, thread_id)
-
- image_summary("final_image", image)
-
- # Rescale to [-1,1] instead of [0, 1]
- image = tf.subtract(image, 0.5)
- image = tf.multiply(image, 2.0)
- return image
diff --git a/research/im2txt/im2txt/ops/inputs.py b/research/im2txt/im2txt/ops/inputs.py
deleted file mode 100644
index 5dc90c0ce5dfd5c30fe0e0e543999bb15cc13a8c..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/ops/inputs.py
+++ /dev/null
@@ -1,204 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Input ops."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-
-def parse_sequence_example(serialized, image_feature, caption_feature):
- """Parses a tensorflow.SequenceExample into an image and caption.
-
- Args:
- serialized: A scalar string Tensor; a single serialized SequenceExample.
- image_feature: Name of SequenceExample context feature containing image
- data.
- caption_feature: Name of SequenceExample feature list containing integer
- captions.
-
- Returns:
- encoded_image: A scalar string Tensor containing a JPEG encoded image.
- caption: A 1-D uint64 Tensor with dynamically specified length.
- """
- context, sequence = tf.parse_single_sequence_example(
- serialized,
- context_features={
- image_feature: tf.FixedLenFeature([], dtype=tf.string)
- },
- sequence_features={
- caption_feature: tf.FixedLenSequenceFeature([], dtype=tf.int64),
- })
-
- encoded_image = context[image_feature]
- caption = sequence[caption_feature]
- return encoded_image, caption
-
-
-def prefetch_input_data(reader,
- file_pattern,
- is_training,
- batch_size,
- values_per_shard,
- input_queue_capacity_factor=16,
- num_reader_threads=1,
- shard_queue_name="filename_queue",
- value_queue_name="input_queue"):
- """Prefetches string values from disk into an input queue.
-
- In training the capacity of the queue is important because a larger queue
- means better mixing of training examples between shards. The minimum number of
- values kept in the queue is values_per_shard * input_queue_capacity_factor,
- where input_queue_memory factor should be chosen to trade-off better mixing
- with memory usage.
-
- Args:
- reader: Instance of tf.ReaderBase.
- file_pattern: Comma-separated list of file patterns (e.g.
- /tmp/train_data-?????-of-00100).
- is_training: Boolean; whether prefetching for training or eval.
- batch_size: Model batch size used to determine queue capacity.
- values_per_shard: Approximate number of values per shard.
- input_queue_capacity_factor: Minimum number of values to keep in the queue
- in multiples of values_per_shard. See comments above.
- num_reader_threads: Number of reader threads to fill the queue.
- shard_queue_name: Name for the shards filename queue.
- value_queue_name: Name for the values input queue.
-
- Returns:
- A Queue containing prefetched string values.
- """
- data_files = []
- for pattern in file_pattern.split(","):
- data_files.extend(tf.gfile.Glob(pattern))
- if not data_files:
- tf.logging.fatal("Found no input files matching %s", file_pattern)
- else:
- tf.logging.info("Prefetching values from %d files matching %s",
- len(data_files), file_pattern)
-
- if is_training:
- filename_queue = tf.train.string_input_producer(
- data_files, shuffle=True, capacity=16, name=shard_queue_name)
- min_queue_examples = values_per_shard * input_queue_capacity_factor
- capacity = min_queue_examples + 100 * batch_size
- values_queue = tf.RandomShuffleQueue(
- capacity=capacity,
- min_after_dequeue=min_queue_examples,
- dtypes=[tf.string],
- name="random_" + value_queue_name)
- else:
- filename_queue = tf.train.string_input_producer(
- data_files, shuffle=False, capacity=1, name=shard_queue_name)
- capacity = values_per_shard + 3 * batch_size
- values_queue = tf.FIFOQueue(
- capacity=capacity, dtypes=[tf.string], name="fifo_" + value_queue_name)
-
- enqueue_ops = []
- for _ in range(num_reader_threads):
- _, value = reader.read(filename_queue)
- enqueue_ops.append(values_queue.enqueue([value]))
- tf.train.queue_runner.add_queue_runner(tf.train.queue_runner.QueueRunner(
- values_queue, enqueue_ops))
- tf.summary.scalar(
- "queue/%s/fraction_of_%d_full" % (values_queue.name, capacity),
- tf.cast(values_queue.size(), tf.float32) * (1. / capacity))
-
- return values_queue
-
-
-def batch_with_dynamic_pad(images_and_captions,
- batch_size,
- queue_capacity,
- add_summaries=True):
- """Batches input images and captions.
-
- This function splits the caption into an input sequence and a target sequence,
- where the target sequence is the input sequence right-shifted by 1. Input and
- target sequences are batched and padded up to the maximum length of sequences
- in the batch. A mask is created to distinguish real words from padding words.
-
- Example:
- Actual captions in the batch ('-' denotes padded character):
- [
- [ 1 2 3 4 5 ],
- [ 1 2 3 4 - ],
- [ 1 2 3 - - ],
- ]
-
- input_seqs:
- [
- [ 1 2 3 4 ],
- [ 1 2 3 - ],
- [ 1 2 - - ],
- ]
-
- target_seqs:
- [
- [ 2 3 4 5 ],
- [ 2 3 4 - ],
- [ 2 3 - - ],
- ]
-
- mask:
- [
- [ 1 1 1 1 ],
- [ 1 1 1 0 ],
- [ 1 1 0 0 ],
- ]
-
- Args:
- images_and_captions: A list of pairs [image, caption], where image is a
- Tensor of shape [height, width, channels] and caption is a 1-D Tensor of
- any length. Each pair will be processed and added to the queue in a
- separate thread.
- batch_size: Batch size.
- queue_capacity: Queue capacity.
- add_summaries: If true, add caption length summaries.
-
- Returns:
- images: A Tensor of shape [batch_size, height, width, channels].
- input_seqs: An int32 Tensor of shape [batch_size, padded_length].
- target_seqs: An int32 Tensor of shape [batch_size, padded_length].
- mask: An int32 0/1 Tensor of shape [batch_size, padded_length].
- """
- enqueue_list = []
- for image, caption in images_and_captions:
- caption_length = tf.shape(caption)[0]
- input_length = tf.expand_dims(tf.subtract(caption_length, 1), 0)
-
- input_seq = tf.slice(caption, [0], input_length)
- target_seq = tf.slice(caption, [1], input_length)
- indicator = tf.ones(input_length, dtype=tf.int32)
- enqueue_list.append([image, input_seq, target_seq, indicator])
-
- images, input_seqs, target_seqs, mask = tf.train.batch_join(
- enqueue_list,
- batch_size=batch_size,
- capacity=queue_capacity,
- dynamic_pad=True,
- name="batch_and_pad")
-
- if add_summaries:
- lengths = tf.add(tf.reduce_sum(mask, 1), 1)
- tf.summary.scalar("caption_length/batch_min", tf.reduce_min(lengths))
- tf.summary.scalar("caption_length/batch_max", tf.reduce_max(lengths))
- tf.summary.scalar("caption_length/batch_mean", tf.reduce_mean(lengths))
-
- return images, input_seqs, target_seqs, mask
diff --git a/research/im2txt/im2txt/run_inference.py b/research/im2txt/im2txt/run_inference.py
deleted file mode 100644
index 9848522df162e52394ee8349dab1f5220aeb88f6..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/run_inference.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-r"""Generate captions for images using default beam search parameters."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-import os
-
-
-import tensorflow as tf
-
-from im2txt import configuration
-from im2txt import inference_wrapper
-from im2txt.inference_utils import caption_generator
-from im2txt.inference_utils import vocabulary
-
-FLAGS = tf.flags.FLAGS
-
-tf.flags.DEFINE_string("checkpoint_path", "",
- "Model checkpoint file or directory containing a "
- "model checkpoint file.")
-tf.flags.DEFINE_string("vocab_file", "", "Text file containing the vocabulary.")
-tf.flags.DEFINE_string("input_files", "",
- "File pattern or comma-separated list of file patterns "
- "of image files.")
-
-tf.logging.set_verbosity(tf.logging.INFO)
-
-
-def main(_):
- # Build the inference graph.
- g = tf.Graph()
- with g.as_default():
- model = inference_wrapper.InferenceWrapper()
- restore_fn = model.build_graph_from_config(configuration.ModelConfig(),
- FLAGS.checkpoint_path)
- g.finalize()
-
- # Create the vocabulary.
- vocab = vocabulary.Vocabulary(FLAGS.vocab_file)
-
- filenames = []
- for file_pattern in FLAGS.input_files.split(","):
- filenames.extend(tf.gfile.Glob(file_pattern))
- tf.logging.info("Running caption generation on %d files matching %s",
- len(filenames), FLAGS.input_files)
-
- with tf.Session(graph=g) as sess:
- # Load the model from checkpoint.
- restore_fn(sess)
-
- # Prepare the caption generator. Here we are implicitly using the default
- # beam search parameters. See caption_generator.py for a description of the
- # available beam search parameters.
- generator = caption_generator.CaptionGenerator(model, vocab)
-
- for filename in filenames:
- with tf.gfile.GFile(filename, "rb") as f:
- image = f.read()
- captions = generator.beam_search(sess, image)
- print("Captions for image %s:" % os.path.basename(filename))
- for i, caption in enumerate(captions):
- # Ignore begin and end words.
- sentence = [vocab.id_to_word(w) for w in caption.sentence[1:-1]]
- sentence = " ".join(sentence)
- print(" %d) %s (p=%f)" % (i, sentence, math.exp(caption.logprob)))
-
-
-if __name__ == "__main__":
- tf.app.run()
diff --git a/research/im2txt/im2txt/show_and_tell_model.py b/research/im2txt/im2txt/show_and_tell_model.py
deleted file mode 100644
index 0ac29e7fdb80fbefe3594eabc972648a3fb32312..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/show_and_tell_model.py
+++ /dev/null
@@ -1,358 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Image-to-text implementation based on http://arxiv.org/abs/1411.4555.
-
-"Show and Tell: A Neural Image Caption Generator"
-Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from im2txt.ops import image_embedding
-from im2txt.ops import image_processing
-from im2txt.ops import inputs as input_ops
-
-
-class ShowAndTellModel(object):
- """Image-to-text implementation based on http://arxiv.org/abs/1411.4555.
-
- "Show and Tell: A Neural Image Caption Generator"
- Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan
- """
-
- def __init__(self, config, mode, train_inception=False):
- """Basic setup.
-
- Args:
- config: Object containing configuration parameters.
- mode: "train", "eval" or "inference".
- train_inception: Whether the inception submodel variables are trainable.
- """
- assert mode in ["train", "eval", "inference"]
- self.config = config
- self.mode = mode
- self.train_inception = train_inception
-
- # Reader for the input data.
- self.reader = tf.TFRecordReader()
-
- # To match the "Show and Tell" paper we initialize all variables with a
- # random uniform initializer.
- self.initializer = tf.random_uniform_initializer(
- minval=-self.config.initializer_scale,
- maxval=self.config.initializer_scale)
-
- # A float32 Tensor with shape [batch_size, height, width, channels].
- self.images = None
-
- # An int32 Tensor with shape [batch_size, padded_length].
- self.input_seqs = None
-
- # An int32 Tensor with shape [batch_size, padded_length].
- self.target_seqs = None
-
- # An int32 0/1 Tensor with shape [batch_size, padded_length].
- self.input_mask = None
-
- # A float32 Tensor with shape [batch_size, embedding_size].
- self.image_embeddings = None
-
- # A float32 Tensor with shape [batch_size, padded_length, embedding_size].
- self.seq_embeddings = None
-
- # A float32 scalar Tensor; the total loss for the trainer to optimize.
- self.total_loss = None
-
- # A float32 Tensor with shape [batch_size * padded_length].
- self.target_cross_entropy_losses = None
-
- # A float32 Tensor with shape [batch_size * padded_length].
- self.target_cross_entropy_loss_weights = None
-
- # Collection of variables from the inception submodel.
- self.inception_variables = []
-
- # Function to restore the inception submodel from checkpoint.
- self.init_fn = None
-
- # Global step Tensor.
- self.global_step = None
-
- def is_training(self):
- """Returns true if the model is built for training mode."""
- return self.mode == "train"
-
- def process_image(self, encoded_image, thread_id=0):
- """Decodes and processes an image string.
-
- Args:
- encoded_image: A scalar string Tensor; the encoded image.
- thread_id: Preprocessing thread id used to select the ordering of color
- distortions.
-
- Returns:
- A float32 Tensor of shape [height, width, 3]; the processed image.
- """
- return image_processing.process_image(encoded_image,
- is_training=self.is_training(),
- height=self.config.image_height,
- width=self.config.image_width,
- thread_id=thread_id,
- image_format=self.config.image_format)
-
- def build_inputs(self):
- """Input prefetching, preprocessing and batching.
-
- Outputs:
- self.images
- self.input_seqs
- self.target_seqs (training and eval only)
- self.input_mask (training and eval only)
- """
- if self.mode == "inference":
- # In inference mode, images and inputs are fed via placeholders.
- image_feed = tf.placeholder(dtype=tf.string, shape=[], name="image_feed")
- input_feed = tf.placeholder(dtype=tf.int64,
- shape=[None], # batch_size
- name="input_feed")
-
- # Process image and insert batch dimensions.
- images = tf.expand_dims(self.process_image(image_feed), 0)
- input_seqs = tf.expand_dims(input_feed, 1)
-
- # No target sequences or input mask in inference mode.
- target_seqs = None
- input_mask = None
- else:
- # Prefetch serialized SequenceExample protos.
- input_queue = input_ops.prefetch_input_data(
- self.reader,
- self.config.input_file_pattern,
- is_training=self.is_training(),
- batch_size=self.config.batch_size,
- values_per_shard=self.config.values_per_input_shard,
- input_queue_capacity_factor=self.config.input_queue_capacity_factor,
- num_reader_threads=self.config.num_input_reader_threads)
-
- # Image processing and random distortion. Split across multiple threads
- # with each thread applying a slightly different distortion.
- assert self.config.num_preprocess_threads % 2 == 0
- images_and_captions = []
- for thread_id in range(self.config.num_preprocess_threads):
- serialized_sequence_example = input_queue.dequeue()
- encoded_image, caption = input_ops.parse_sequence_example(
- serialized_sequence_example,
- image_feature=self.config.image_feature_name,
- caption_feature=self.config.caption_feature_name)
- image = self.process_image(encoded_image, thread_id=thread_id)
- images_and_captions.append([image, caption])
-
- # Batch inputs.
- queue_capacity = (2 * self.config.num_preprocess_threads *
- self.config.batch_size)
- images, input_seqs, target_seqs, input_mask = (
- input_ops.batch_with_dynamic_pad(images_and_captions,
- batch_size=self.config.batch_size,
- queue_capacity=queue_capacity))
-
- self.images = images
- self.input_seqs = input_seqs
- self.target_seqs = target_seqs
- self.input_mask = input_mask
-
- def build_image_embeddings(self):
- """Builds the image model subgraph and generates image embeddings.
-
- Inputs:
- self.images
-
- Outputs:
- self.image_embeddings
- """
- inception_output = image_embedding.inception_v3(
- self.images,
- trainable=self.train_inception,
- is_training=self.is_training())
- self.inception_variables = tf.get_collection(
- tf.GraphKeys.GLOBAL_VARIABLES, scope="InceptionV3")
-
- # Map inception output into embedding space.
- with tf.variable_scope("image_embedding") as scope:
- image_embeddings = tf.contrib.layers.fully_connected(
- inputs=inception_output,
- num_outputs=self.config.embedding_size,
- activation_fn=None,
- weights_initializer=self.initializer,
- biases_initializer=None,
- scope=scope)
-
- # Save the embedding size in the graph.
- tf.constant(self.config.embedding_size, name="embedding_size")
-
- self.image_embeddings = image_embeddings
-
- def build_seq_embeddings(self):
- """Builds the input sequence embeddings.
-
- Inputs:
- self.input_seqs
-
- Outputs:
- self.seq_embeddings
- """
- with tf.variable_scope("seq_embedding"), tf.device("/cpu:0"):
- embedding_map = tf.get_variable(
- name="map",
- shape=[self.config.vocab_size, self.config.embedding_size],
- initializer=self.initializer)
- seq_embeddings = tf.nn.embedding_lookup(embedding_map, self.input_seqs)
-
- self.seq_embeddings = seq_embeddings
-
- def build_model(self):
- """Builds the model.
-
- Inputs:
- self.image_embeddings
- self.seq_embeddings
- self.target_seqs (training and eval only)
- self.input_mask (training and eval only)
-
- Outputs:
- self.total_loss (training and eval only)
- self.target_cross_entropy_losses (training and eval only)
- self.target_cross_entropy_loss_weights (training and eval only)
- """
- # This LSTM cell has biases and outputs tanh(new_c) * sigmoid(o), but the
- # modified LSTM in the "Show and Tell" paper has no biases and outputs
- # new_c * sigmoid(o).
- lstm_cell = tf.contrib.rnn.BasicLSTMCell(
- num_units=self.config.num_lstm_units, state_is_tuple=True)
- if self.mode == "train":
- lstm_cell = tf.contrib.rnn.DropoutWrapper(
- lstm_cell,
- input_keep_prob=self.config.lstm_dropout_keep_prob,
- output_keep_prob=self.config.lstm_dropout_keep_prob)
-
- with tf.variable_scope("lstm", initializer=self.initializer) as lstm_scope:
- # Feed the image embeddings to set the initial LSTM state.
- zero_state = lstm_cell.zero_state(
- batch_size=self.image_embeddings.get_shape()[0], dtype=tf.float32)
- _, initial_state = lstm_cell(self.image_embeddings, zero_state)
-
- # Allow the LSTM variables to be reused.
- lstm_scope.reuse_variables()
-
- if self.mode == "inference":
- # In inference mode, use concatenated states for convenient feeding and
- # fetching.
- tf.concat(axis=1, values=initial_state, name="initial_state")
-
- # Placeholder for feeding a batch of concatenated states.
- state_feed = tf.placeholder(dtype=tf.float32,
- shape=[None, sum(lstm_cell.state_size)],
- name="state_feed")
- state_tuple = tf.split(value=state_feed, num_or_size_splits=2, axis=1)
-
- # Run a single LSTM step.
- lstm_outputs, state_tuple = lstm_cell(
- inputs=tf.squeeze(self.seq_embeddings, axis=[1]),
- state=state_tuple)
-
- # Concatentate the resulting state.
- tf.concat(axis=1, values=state_tuple, name="state")
- else:
- # Run the batch of sequence embeddings through the LSTM.
- sequence_length = tf.reduce_sum(self.input_mask, 1)
- lstm_outputs, _ = tf.nn.dynamic_rnn(cell=lstm_cell,
- inputs=self.seq_embeddings,
- sequence_length=sequence_length,
- initial_state=initial_state,
- dtype=tf.float32,
- scope=lstm_scope)
-
- # Stack batches vertically.
- lstm_outputs = tf.reshape(lstm_outputs, [-1, lstm_cell.output_size])
-
- with tf.variable_scope("logits") as logits_scope:
- logits = tf.contrib.layers.fully_connected(
- inputs=lstm_outputs,
- num_outputs=self.config.vocab_size,
- activation_fn=None,
- weights_initializer=self.initializer,
- scope=logits_scope)
-
- if self.mode == "inference":
- tf.nn.softmax(logits, name="softmax")
- else:
- targets = tf.reshape(self.target_seqs, [-1])
- weights = tf.to_float(tf.reshape(self.input_mask, [-1]))
-
- # Compute losses.
- losses = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=targets,
- logits=logits)
- batch_loss = tf.div(tf.reduce_sum(tf.multiply(losses, weights)),
- tf.reduce_sum(weights),
- name="batch_loss")
- tf.losses.add_loss(batch_loss)
- total_loss = tf.losses.get_total_loss()
-
- # Add summaries.
- tf.summary.scalar("losses/batch_loss", batch_loss)
- tf.summary.scalar("losses/total_loss", total_loss)
- for var in tf.trainable_variables():
- tf.summary.histogram("parameters/" + var.op.name, var)
-
- self.total_loss = total_loss
- self.target_cross_entropy_losses = losses # Used in evaluation.
- self.target_cross_entropy_loss_weights = weights # Used in evaluation.
-
- def setup_inception_initializer(self):
- """Sets up the function to restore inception variables from checkpoint."""
- if self.mode != "inference":
- # Restore inception variables only.
- saver = tf.train.Saver(self.inception_variables)
-
- def restore_fn(sess):
- tf.logging.info("Restoring Inception variables from checkpoint file %s",
- self.config.inception_checkpoint_file)
- saver.restore(sess, self.config.inception_checkpoint_file)
-
- self.init_fn = restore_fn
-
- def setup_global_step(self):
- """Sets up the global step Tensor."""
- global_step = tf.Variable(
- initial_value=0,
- name="global_step",
- trainable=False,
- collections=[tf.GraphKeys.GLOBAL_STEP, tf.GraphKeys.GLOBAL_VARIABLES])
-
- self.global_step = global_step
-
- def build(self):
- """Creates all ops for training and evaluation."""
- self.build_inputs()
- self.build_image_embeddings()
- self.build_seq_embeddings()
- self.build_model()
- self.setup_inception_initializer()
- self.setup_global_step()
diff --git a/research/im2txt/im2txt/show_and_tell_model_test.py b/research/im2txt/im2txt/show_and_tell_model_test.py
deleted file mode 100644
index 0bdfb6e1a3ae3c15bd1c8daf005fe2542436ca8e..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/show_and_tell_model_test.py
+++ /dev/null
@@ -1,200 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for tensorflow_models.im2txt.show_and_tell_model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import numpy as np
-import tensorflow as tf
-
-from im2txt import configuration
-from im2txt import show_and_tell_model
-
-
-class ShowAndTellModel(show_and_tell_model.ShowAndTellModel):
- """Subclass of ShowAndTellModel without the disk I/O."""
-
- def build_inputs(self):
- if self.mode == "inference":
- # Inference mode doesn't read from disk, so defer to parent.
- return super(ShowAndTellModel, self).build_inputs()
- else:
- # Replace disk I/O with random Tensors.
- self.images = tf.random_uniform(
- shape=[self.config.batch_size, self.config.image_height,
- self.config.image_width, 3],
- minval=-1,
- maxval=1)
- self.input_seqs = tf.random_uniform(
- [self.config.batch_size, 15],
- minval=0,
- maxval=self.config.vocab_size,
- dtype=tf.int64)
- self.target_seqs = tf.random_uniform(
- [self.config.batch_size, 15],
- minval=0,
- maxval=self.config.vocab_size,
- dtype=tf.int64)
- self.input_mask = tf.ones_like(self.input_seqs)
-
-
-class ShowAndTellModelTest(tf.test.TestCase):
-
- def setUp(self):
- super(ShowAndTellModelTest, self).setUp()
- self._model_config = configuration.ModelConfig()
-
- def _countModelParameters(self):
- """Counts the number of parameters in the model at top level scope."""
- counter = {}
- for v in tf.global_variables():
- name = v.op.name.split("/")[0]
- num_params = v.get_shape().num_elements()
- assert num_params
- counter[name] = counter.get(name, 0) + num_params
- return counter
-
- def _checkModelParameters(self):
- """Verifies the number of parameters in the model."""
- param_counts = self._countModelParameters()
- expected_param_counts = {
- "InceptionV3": 21802784,
- # inception_output_size * embedding_size
- "image_embedding": 1048576,
- # vocab_size * embedding_size
- "seq_embedding": 6144000,
- # (embedding_size + num_lstm_units + 1) * 4 * num_lstm_units
- "lstm": 2099200,
- # (num_lstm_units + 1) * vocab_size
- "logits": 6156000,
- "global_step": 1,
- }
- self.assertDictEqual(expected_param_counts, param_counts)
-
- def _checkOutputs(self, expected_shapes, feed_dict=None):
- """Verifies that the model produces expected outputs.
-
- Args:
- expected_shapes: A dict mapping Tensor or Tensor name to expected output
- shape.
- feed_dict: Values of Tensors to feed into Session.run().
- """
- fetches = expected_shapes.keys()
-
- with self.test_session() as sess:
- sess.run(tf.global_variables_initializer())
- outputs = sess.run(fetches, feed_dict)
-
- for index, output in enumerate(outputs):
- tensor = fetches[index]
- expected = expected_shapes[tensor]
- actual = output.shape
- if expected != actual:
- self.fail("Tensor %s has shape %s (expected %s)." %
- (tensor, actual, expected))
-
- def testBuildForTraining(self):
- model = ShowAndTellModel(self._model_config, mode="train")
- model.build()
-
- self._checkModelParameters()
-
- expected_shapes = {
- # [batch_size, image_height, image_width, 3]
- model.images: (32, 299, 299, 3),
- # [batch_size, sequence_length]
- model.input_seqs: (32, 15),
- # [batch_size, sequence_length]
- model.target_seqs: (32, 15),
- # [batch_size, sequence_length]
- model.input_mask: (32, 15),
- # [batch_size, embedding_size]
- model.image_embeddings: (32, 512),
- # [batch_size, sequence_length, embedding_size]
- model.seq_embeddings: (32, 15, 512),
- # Scalar
- model.total_loss: (),
- # [batch_size * sequence_length]
- model.target_cross_entropy_losses: (480,),
- # [batch_size * sequence_length]
- model.target_cross_entropy_loss_weights: (480,),
- }
- self._checkOutputs(expected_shapes)
-
- def testBuildForEval(self):
- model = ShowAndTellModel(self._model_config, mode="eval")
- model.build()
-
- self._checkModelParameters()
-
- expected_shapes = {
- # [batch_size, image_height, image_width, 3]
- model.images: (32, 299, 299, 3),
- # [batch_size, sequence_length]
- model.input_seqs: (32, 15),
- # [batch_size, sequence_length]
- model.target_seqs: (32, 15),
- # [batch_size, sequence_length]
- model.input_mask: (32, 15),
- # [batch_size, embedding_size]
- model.image_embeddings: (32, 512),
- # [batch_size, sequence_length, embedding_size]
- model.seq_embeddings: (32, 15, 512),
- # Scalar
- model.total_loss: (),
- # [batch_size * sequence_length]
- model.target_cross_entropy_losses: (480,),
- # [batch_size * sequence_length]
- model.target_cross_entropy_loss_weights: (480,),
- }
- self._checkOutputs(expected_shapes)
-
- def testBuildForInference(self):
- model = ShowAndTellModel(self._model_config, mode="inference")
- model.build()
-
- self._checkModelParameters()
-
- # Test feeding an image to get the initial LSTM state.
- images_feed = np.random.rand(1, 299, 299, 3)
- feed_dict = {model.images: images_feed}
- expected_shapes = {
- # [batch_size, embedding_size]
- model.image_embeddings: (1, 512),
- # [batch_size, 2 * num_lstm_units]
- "lstm/initial_state:0": (1, 1024),
- }
- self._checkOutputs(expected_shapes, feed_dict)
-
- # Test feeding a batch of inputs and LSTM states to get softmax output and
- # LSTM states.
- input_feed = np.random.randint(0, 10, size=3)
- state_feed = np.random.rand(3, 1024)
- feed_dict = {"input_feed:0": input_feed, "lstm/state_feed:0": state_feed}
- expected_shapes = {
- # [batch_size, 2 * num_lstm_units]
- "lstm/state:0": (3, 1024),
- # [batch_size, vocab_size]
- "softmax:0": (3, 12000),
- }
- self._checkOutputs(expected_shapes, feed_dict)
-
-
-if __name__ == "__main__":
- tf.test.main()
diff --git a/research/im2txt/im2txt/train.py b/research/im2txt/im2txt/train.py
deleted file mode 100644
index db602735ba11e7f540a4e985333d8a457512c977..0000000000000000000000000000000000000000
--- a/research/im2txt/im2txt/train.py
+++ /dev/null
@@ -1,114 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Train the model."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from im2txt import configuration
-from im2txt import show_and_tell_model
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.flags.DEFINE_string("input_file_pattern", "",
- "File pattern of sharded TFRecord input files.")
-tf.flags.DEFINE_string("inception_checkpoint_file", "",
- "Path to a pretrained inception_v3 model.")
-tf.flags.DEFINE_string("train_dir", "",
- "Directory for saving and loading model checkpoints.")
-tf.flags.DEFINE_boolean("train_inception", False,
- "Whether to train inception submodel variables.")
-tf.flags.DEFINE_integer("number_of_steps", 1000000, "Number of training steps.")
-tf.flags.DEFINE_integer("log_every_n_steps", 1,
- "Frequency at which loss and global step are logged.")
-
-tf.logging.set_verbosity(tf.logging.INFO)
-
-
-def main(unused_argv):
- assert FLAGS.input_file_pattern, "--input_file_pattern is required"
- assert FLAGS.train_dir, "--train_dir is required"
-
- model_config = configuration.ModelConfig()
- model_config.input_file_pattern = FLAGS.input_file_pattern
- model_config.inception_checkpoint_file = FLAGS.inception_checkpoint_file
- training_config = configuration.TrainingConfig()
-
- # Create training directory.
- train_dir = FLAGS.train_dir
- if not tf.gfile.IsDirectory(train_dir):
- tf.logging.info("Creating training directory: %s", train_dir)
- tf.gfile.MakeDirs(train_dir)
-
- # Build the TensorFlow graph.
- g = tf.Graph()
- with g.as_default():
- # Build the model.
- model = show_and_tell_model.ShowAndTellModel(
- model_config, mode="train", train_inception=FLAGS.train_inception)
- model.build()
-
- # Set up the learning rate.
- learning_rate_decay_fn = None
- if FLAGS.train_inception:
- learning_rate = tf.constant(training_config.train_inception_learning_rate)
- else:
- learning_rate = tf.constant(training_config.initial_learning_rate)
- if training_config.learning_rate_decay_factor > 0:
- num_batches_per_epoch = (training_config.num_examples_per_epoch /
- model_config.batch_size)
- decay_steps = int(num_batches_per_epoch *
- training_config.num_epochs_per_decay)
-
- def _learning_rate_decay_fn(learning_rate, global_step):
- return tf.train.exponential_decay(
- learning_rate,
- global_step,
- decay_steps=decay_steps,
- decay_rate=training_config.learning_rate_decay_factor,
- staircase=True)
-
- learning_rate_decay_fn = _learning_rate_decay_fn
-
- # Set up the training ops.
- train_op = tf.contrib.layers.optimize_loss(
- loss=model.total_loss,
- global_step=model.global_step,
- learning_rate=learning_rate,
- optimizer=training_config.optimizer,
- clip_gradients=training_config.clip_gradients,
- learning_rate_decay_fn=learning_rate_decay_fn)
-
- # Set up the Saver for saving and restoring model checkpoints.
- saver = tf.train.Saver(max_to_keep=training_config.max_checkpoints_to_keep)
-
- # Run training.
- tf.contrib.slim.learning.train(
- train_op,
- train_dir,
- log_every_n_steps=FLAGS.log_every_n_steps,
- graph=g,
- global_step=model.global_step,
- number_of_steps=FLAGS.number_of_steps,
- init_fn=model.init_fn,
- saver=saver)
-
-
-if __name__ == "__main__":
- tf.app.run()
diff --git a/research/inception/.gitignore b/research/inception/.gitignore
deleted file mode 100644
index 58cbf2f4e0d5d39a0e3910d6993508546dad429f..0000000000000000000000000000000000000000
--- a/research/inception/.gitignore
+++ /dev/null
@@ -1,7 +0,0 @@
-/bazel-bin
-/bazel-ci_build-cache
-/bazel-genfiles
-/bazel-out
-/bazel-inception
-/bazel-testlogs
-/bazel-tf
diff --git a/research/inception/README.md b/research/inception/README.md
deleted file mode 100644
index beed66cf5cd83a6843ec39b28b5dbd88f1c0d3d0..0000000000000000000000000000000000000000
--- a/research/inception/README.md
+++ /dev/null
@@ -1,858 +0,0 @@
-
-
-
-
-**NOTE: For the most part, you will find a newer version of this code at [models/research/slim](https://github.com/tensorflow/models/tree/master/research/slim).** In particular:
-
-* `inception_train.py` and `imagenet_train.py` should no longer be used. The slim editions for running on multiple GPUs are the current best examples.
-* `inception_distributed_train.py` and `imagenet_distributed_train.py` are still valid examples of distributed training.
-
-For performance benchmarking, please see https://www.tensorflow.org/performance/benchmarks.
-
----
-
-# Inception in TensorFlow
-
-[ImageNet](http://www.image-net.org/) is a common academic data set in machine
-learning for training an image recognition system. Code in this directory
-demonstrates how to use TensorFlow to train and evaluate a type of convolutional
-neural network (CNN) on this academic data set. In particular, we demonstrate
-how to train the Inception v3 architecture as specified in:
-
-_Rethinking the Inception Architecture for Computer Vision_
-
-Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew
-Wojna
-
-http://arxiv.org/abs/1512.00567
-
-This network achieves 21.2% top-1 and 5.6% top-5 error for single frame
-evaluation with a computational cost of 5 billion multiply-adds per inference
-and with using less than 25 million parameters. Below is a visualization of the
-model architecture.
-
-
-
-## Description of Code
-
-The code base provides three core binaries for:
-
-* Training an Inception v3 network from scratch across multiple GPUs and/or
- multiple machines using the ImageNet 2012 Challenge training data set.
-* Evaluating an Inception v3 network using the ImageNet 2012 Challenge
- validation data set.
-* Retraining an Inception v3 network on a novel task and back-propagating the
- errors to fine tune the network weights.
-
-The training procedure employs synchronous stochastic gradient descent across
-multiple GPUs. The user may specify the number of GPUs they wish to harness. The
-synchronous training performs *batch-splitting* by dividing a given batch across
-multiple GPUs.
-
-The training set up is nearly identical to the section [Training a Model Using
-Multiple GPU Cards](https://www.tensorflow.org/tutorials/deep_cnn/index.html#launching_and_training_the_model_on_multiple_gpu_cards)
-where we have substituted the CIFAR-10 model architecture with Inception v3. The
-primary differences with that setup are:
-
-* Calculate and update the batch-norm statistics during training so that they
- may be substituted in during evaluation.
-* Specify the model architecture using a (still experimental) higher level
- language called TensorFlow-Slim.
-
-For more details about TensorFlow-Slim, please see the [Slim README](inception/slim/README.md). Please note that this higher-level language is still
-*experimental* and the API may change over time depending on usage and
-subsequent research.
-
-## Getting Started
-
-Before you run the training script for the first time, you will need to download
-and convert the ImageNet data to native TFRecord format. The TFRecord format
-consists of a set of sharded files where each entry is a serialized `tf.Example`
-proto. Each `tf.Example` proto contains the ImageNet image (JPEG encoded) as
-well as metadata such as label and bounding box information. See
-[`parse_example_proto`](inception/image_processing.py) for details.
-
-We provide a single [script](inception/data/download_and_preprocess_imagenet.sh) for
-downloading and converting ImageNet data to TFRecord format. Downloading and
-preprocessing the data may take several hours (up to half a day) depending on
-your network and computer speed. Please be patient.
-
-To begin, you will need to sign up for an account with [ImageNet](http://image-net.org) to gain access to the data. Look for the sign up page,
-create an account and request an access key to download the data.
-
-After you have `USERNAME` and `PASSWORD`, you are ready to run our script. Make
-sure that your hard disk has at least 500 GB of free space for downloading and
-storing the data. Here we select `DATA_DIR=$HOME/imagenet-data` as such a
-location but feel free to edit accordingly.
-
-When you run the below script, please enter *USERNAME* and *PASSWORD* when
-prompted. This will occur at the very beginning. Once these values are entered,
-you will not need to interact with the script again.
-
-```shell
-# location of where to place the ImageNet data
-DATA_DIR=$HOME/imagenet-data
-
-# build the preprocessing script.
-cd tensorflow-models/inception
-bazel build //inception:download_and_preprocess_imagenet
-
-# run it
-bazel-bin/inception/download_and_preprocess_imagenet "${DATA_DIR}"
-```
-
-The final line of the output script should read:
-
-```shell
-2016-02-17 14:30:17.287989: Finished writing all 1281167 images in data set.
-```
-
-When the script finishes, you will find 1024 training files and 128 validation
-files in the `DATA_DIR`. The files will match the patterns
-`train-?????-of-01024` and `validation-?????-of-00128`, respectively.
-
-[Congratulations!](https://www.youtube.com/watch?v=9bZkp7q19f0) You are now
-ready to train or evaluate with the ImageNet data set.
-
-## How to Train from Scratch
-
-**WARNING** Training an Inception v3 network from scratch is a computationally
-intensive task and depending on your compute setup may take several days or even
-weeks.
-
-*Before proceeding* please read the [Convolutional Neural Networks](https://www.tensorflow.org/tutorials/deep_cnn/index.html) tutorial; in
-particular, focus on [Training a Model Using Multiple GPU Cards](https://www.tensorflow.org/tutorials/deep_cnn/index.html#launching_and_training_the_model_on_multiple_gpu_cards). The model training method is nearly identical to that described in the
-CIFAR-10 multi-GPU model training. Briefly, the model training
-
-* Places an individual model replica on each GPU.
-* Splits the batch across the GPUs.
-* Updates model parameters synchronously by waiting for all GPUs to finish
- processing a batch of data.
-
-The training procedure is encapsulated by this diagram of how operations and
-variables are placed on CPU and GPUs respectively.
-
-
-
-...
-
-INFO:tensorflow:Created variable logits/logits/biases:0 with shape (1001,) and init
-INFO:tensorflow:SyncReplicas enabled: replicas_to_aggregate=2; total_num_replicas=2
-INFO:tensorflow:2016-04-13 01:56:26.405639 Supervisor
-INFO:tensorflow:Started 2 queues for processing input data.
-INFO:tensorflow:global_step/sec: 0
-INFO:tensorflow:Worker 0: 2016-04-13 01:58:40.342404: step 0, loss = 12.97(0.0 examples/sec; 65.428 sec/batch)
-INFO:tensorflow:global_step/sec: 0.0172907
-...
-```
-
-and a log in each `ps` job that looks like the following:
-
-```shell
-INFO:tensorflow:PS hosts are: ['ps0.example.com:2222', 'ps1.example.com:2222']
-INFO:tensorflow:Worker hosts are: ['worker0.example.com:2222', 'worker1.example.com:2222']
-I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job ps -> {localhost:2222, ps1.example.com:2222}
-I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job worker -> {worker0.example.com:2222, worker1.example.com:2222}
-I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:202] Started server with target: grpc://localhost:2222
-```
-
-If you compiled TensorFlow (from v1.1-rc3) with VERBS support and you have the
-required device and IB verbs SW stack, you can specify --protocol='grpc+verbs'
-In order to use Verbs RDMA for Tensor passing between workers and ps.
-Need to add the the --protocol flag in all tasks (ps and workers).
-The default protocol is the TensorFlow default protocol of grpc.
-
-
-[Congratulations!](https://www.youtube.com/watch?v=9bZkp7q19f0) You are now
-training Inception in a distributed manner.
-
-## How to Evaluate
-
-Evaluating an Inception v3 model on the ImageNet 2012 validation data set
-requires running a separate binary.
-
-The evaluation procedure is nearly identical to [Evaluating a Model](https://www.tensorflow.org/tutorials/deep_cnn/index.html#evaluating_a_model)
-described in the [Convolutional Neural Network](https://www.tensorflow.org/tutorials/deep_cnn/index.html) tutorial.
-
-**WARNING** Be careful not to run the evaluation and training binary on the same
-GPU or else you might run out of memory. Consider running the evaluation on a
-separate GPU if available or suspending the training binary while running the
-evaluation on the same GPU.
-
-Briefly, one can evaluate the model by running:
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:imagenet_eval
-
-# run it
-bazel-bin/inception/imagenet_eval --checkpoint_dir=/tmp/imagenet_train --eval_dir=/tmp/imagenet_eval
-```
-
-Note that we point `--checkpoint_dir` to the location of the checkpoints saved
-by `inception_train.py` above. Running the above command results in the
-following output:
-
-```shell
-2016-02-17 22:32:50.391206: precision @ 1 = 0.735
-...
-```
-
-The script calculates the precision @ 1 over the entire validation data
-periodically. The precision @ 1 measures the how often the highest scoring
-prediction from the model matched the ImageNet label -- in this case, 73.5%. If
-you wish to run the eval just once and not periodically, append the `--run_once`
-option.
-
-Much like the training script, `imagenet_eval.py` also exports summaries that
-may be visualized in TensorBoard. These summaries calculate additional
-statistics on the predictions (e.g. recall @ 5) as well as monitor the
-statistics of the model activations and weights during evaluation.
-
-## How to Fine-Tune a Pre-Trained Model on a New Task
-
-### Getting Started
-
-Much like training the ImageNet model we must first convert a new data set to
-the sharded TFRecord format which each entry is a serialized `tf.Example` proto.
-
-We have provided a script demonstrating how to do this for small data set of of
-a few thousand flower images spread across 5 labels:
-
-```shell
-daisy, dandelion, roses, sunflowers, tulips
-```
-
-There is a single automated script that downloads the data set and converts it
-to the TFRecord format. Much like the ImageNet data set, each record in the
-TFRecord format is a serialized `tf.Example` proto whose entries include a
-JPEG-encoded string and an integer label. Please see [`parse_example_proto`](inception/image_processing.py) for details.
-
-The script just takes a few minutes to run depending your network connection
-speed for downloading and processing the images. Your hard disk requires 200MB
-of free storage. Here we select `DATA_DIR=/tmp/flowers-data/` as such a location
-but feel free to edit accordingly.
-
-```shell
-# location of where to place the flowers data
-FLOWERS_DATA_DIR=/tmp/flowers-data/
-
-# build the preprocessing script.
-cd tensorflow-models/inception
-bazel build //inception:download_and_preprocess_flowers
-
-# run it
-bazel-bin/inception/download_and_preprocess_flowers "${FLOWERS_DATA_DIR}"
-```
-
-If the script runs successfully, the final line of the terminal output should
-look like:
-
-```shell
-2016-02-24 20:42:25.067551: Finished writing all 3170 images in data set.
-```
-
-When the script finishes you will find 2 shards for the training and validation
-files in the `DATA_DIR`. The files will match the patterns `train-?????-of-00002`
-and `validation-?????-of-00002`, respectively.
-
-**NOTE** If you wish to prepare a custom image data set for transfer learning,
-you will need to invoke [`build_image_data.py`](inception/data/build_image_data.py) on
-your custom data set. Please see the associated options and assumptions behind
-this script by reading the comments section of [`build_image_data.py`](inception/data/build_image_data.py). Also, if your custom data has a different
-number of examples or classes, you need to change the appropriate values in
-[`imagenet_data.py`](inception/imagenet_data.py).
-
-The second piece you will need is a trained Inception v3 image model. You have
-the option of either training one yourself (See [How to Train from Scratch](#how-to-train-from-scratch) for details) or you can download a pre-trained
-model like so:
-
-```shell
-# location of where to place the Inception v3 model
-INCEPTION_MODEL_DIR=$HOME/inception-v3-model
-mkdir -p ${INCEPTION_MODEL_DIR}
-cd ${INCEPTION_MODEL_DIR}
-
-# download the Inception v3 model
-curl -O http://download.tensorflow.org/models/image/imagenet/inception-v3-2016-03-01.tar.gz
-tar xzf inception-v3-2016-03-01.tar.gz
-
-# this will create a directory called inception-v3 which contains the following files.
-> ls inception-v3
-README.txt
-checkpoint
-model.ckpt-157585
-```
-
-[Congratulations!](https://www.youtube.com/watch?v=9bZkp7q19f0) You are now
-ready to fine-tune your pre-trained Inception v3 model with the flower data set.
-
-### How to Retrain a Trained Model on the Flowers Data
-
-We are now ready to fine-tune a pre-trained Inception-v3 model on the flowers
-data set. This requires two distinct changes to our training procedure:
-
-1. Build the exact same model as previously except we change the number of
- labels in the final classification layer.
-
-2. Restore all weights from the pre-trained Inception-v3 except for the final
- classification layer; this will get randomly initialized instead.
-
-We can perform these two operations by specifying two flags:
-`--pretrained_model_checkpoint_path` and `--fine_tune`. The first flag is a
-string that points to the path of a pre-trained Inception-v3 model. If this flag
-is specified, it will load the entire model from the checkpoint before the
-script begins training.
-
-The second flag `--fine_tune` is a boolean that indicates whether the last
-classification layer should be randomly initialized or restored. You may set
-this flag to false if you wish to continue training a pre-trained model from a
-checkpoint. If you set this flag to true, you can train a new classification
-layer from scratch.
-
-In order to understand how `--fine_tune` works, please see the discussion on
-`Variables` in the TensorFlow-Slim [`README.md`](inception/slim/README.md).
-
-Putting this all together you can retrain a pre-trained Inception-v3 model on
-the flowers data set with the following command.
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:flowers_train
-
-# Path to the downloaded Inception-v3 model.
-MODEL_PATH="${INCEPTION_MODEL_DIR}/inception-v3/model.ckpt-157585"
-
-# Directory where the flowers data resides.
-FLOWERS_DATA_DIR=/tmp/flowers-data/
-
-# Directory where to save the checkpoint and events files.
-TRAIN_DIR=/tmp/flowers_train/
-
-# Run the fine-tuning on the flowers data set starting from the pre-trained
-# Imagenet-v3 model.
-bazel-bin/inception/flowers_train \
- --train_dir="${TRAIN_DIR}" \
- --data_dir="${FLOWERS_DATA_DIR}" \
- --pretrained_model_checkpoint_path="${MODEL_PATH}" \
- --fine_tune=True \
- --initial_learning_rate=0.001 \
- --input_queue_memory_factor=1
-```
-
-We have added a few extra options to the training procedure.
-
-* Fine-tuning a model a separate data set requires significantly lowering the
- initial learning rate. We set the initial learning rate to 0.001.
-* The flowers data set is quite small so we shrink the size of the shuffling
- queue of examples. See [Adjusting Memory Demands](#adjusting-memory-demands)
- for more details.
-
-The training script will only reports the loss. To evaluate the quality of the
-fine-tuned model, you will need to run `flowers_eval`:
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:flowers_eval
-
-# Directory where we saved the fine-tuned checkpoint and events files.
-TRAIN_DIR=/tmp/flowers_train/
-
-# Directory where the flowers data resides.
-FLOWERS_DATA_DIR=/tmp/flowers-data/
-
-# Directory where to save the evaluation events files.
-EVAL_DIR=/tmp/flowers_eval/
-
-# Evaluate the fine-tuned model on a hold-out of the flower data set.
-bazel-bin/inception/flowers_eval \
- --eval_dir="${EVAL_DIR}" \
- --data_dir="${FLOWERS_DATA_DIR}" \
- --subset=validation \
- --num_examples=500 \
- --checkpoint_dir="${TRAIN_DIR}" \
- --input_queue_memory_factor=1 \
- --run_once
-```
-
-We find that the evaluation arrives at roughly 93.4% precision@1 after the model
-has been running for 2000 steps.
-
-```shell
-Successfully loaded model from /tmp/flowers/model.ckpt-1999 at step=1999.
-2016-03-01 16:52:51.761219: starting evaluation on (validation).
-2016-03-01 16:53:05.450419: [20 batches out of 20] (36.5 examples/sec; 0.684sec/batch)
-2016-03-01 16:53:05.450471: precision @ 1 = 0.9340 recall @ 5 = 0.9960 [500 examples]
-```
-
-## How to Construct a New Dataset for Retraining
-
-One can use the existing scripts supplied with this model to build a new dataset
-for training or fine-tuning. The main script to employ is
-[`build_image_data.py`](inception/data/build_image_data.py). Briefly, this script takes a
-structured directory of images and converts it to a sharded `TFRecord` that can
-be read by the Inception model.
-
-In particular, you will need to create a directory of training images that
-reside within `$TRAIN_DIR` and `$VALIDATION_DIR` arranged as such:
-
-```shell
- $TRAIN_DIR/dog/image0.jpeg
- $TRAIN_DIR/dog/image1.jpg
- $TRAIN_DIR/dog/image2.png
- ...
- $TRAIN_DIR/cat/weird-image.jpeg
- $TRAIN_DIR/cat/my-image.jpeg
- $TRAIN_DIR/cat/my-image.JPG
- ...
- $VALIDATION_DIR/dog/imageA.jpeg
- $VALIDATION_DIR/dog/imageB.jpg
- $VALIDATION_DIR/dog/imageC.png
- ...
- $VALIDATION_DIR/cat/weird-image.PNG
- $VALIDATION_DIR/cat/that-image.jpg
- $VALIDATION_DIR/cat/cat.JPG
- ...
-```
-**NOTE**: This script will append an extra background class indexed at 0, so
-your class labels will range from 0 to num_labels. Using the example above, the
-corresponding class labels generated from `build_image_data.py` will be as
-follows:
-```shell
-0
-1 dog
-2 cat
-```
-
-Each sub-directory in `$TRAIN_DIR` and `$VALIDATION_DIR` corresponds to a unique
-label for the images that reside within that sub-directory. The images may be
-JPEG or PNG images. We do not support other images types currently.
-
-Once the data is arranged in this directory structure, we can run
-`build_image_data.py` on the data to generate the sharded `TFRecord` dataset.
-Each entry of the `TFRecord` is a serialized `tf.Example` protocol buffer. A
-complete list of information contained in the `tf.Example` is described in the
-comments of `build_image_data.py`.
-
-To run `build_image_data.py`, you can run the following command line:
-
-```shell
-# location to where to save the TFRecord data.
-OUTPUT_DIRECTORY=$HOME/my-custom-data/
-
-# build the preprocessing script.
-cd tensorflow-models/inception
-bazel build //inception:build_image_data
-
-# convert the data.
-bazel-bin/inception/build_image_data \
- --train_directory="${TRAIN_DIR}" \
- --validation_directory="${VALIDATION_DIR}" \
- --output_directory="${OUTPUT_DIRECTORY}" \
- --labels_file="${LABELS_FILE}" \
- --train_shards=128 \
- --validation_shards=24 \
- --num_threads=8
-```
-
-where the `$OUTPUT_DIRECTORY` is the location of the sharded `TFRecords`. The
-`$LABELS_FILE` will be a text file that is read by the script that provides
-a list of all of the labels. For instance, in the case flowers data set, the
-`$LABELS_FILE` contained the following data:
-
-```shell
-daisy
-dandelion
-roses
-sunflowers
-tulips
-```
-
-Note that each row of each label corresponds with the entry in the final
-classifier in the model. That is, the `daisy` corresponds to the classifier for
-entry `1`; `dandelion` is entry `2`, etc. We skip label `0` as a background
-class.
-
-After running this script produces files that look like the following:
-
-```shell
- $TRAIN_DIR/train-00000-of-00128
- $TRAIN_DIR/train-00001-of-00128
- ...
- $TRAIN_DIR/train-00127-of-00128
-
-and
-
- $VALIDATION_DIR/validation-00000-of-00024
- $VALIDATION_DIR/validation-00001-of-00024
- ...
- $VALIDATION_DIR/validation-00023-of-00024
-```
-
-where 128 and 24 are the number of shards specified for each dataset,
-respectively. Generally speaking, we aim for selecting the number of shards such
-that roughly 1024 images reside in each shard. Once this data set is built, you
-are ready to train or fine-tune an Inception model on this data set.
-
-Note, if you are piggy backing on the flowers retraining scripts, be sure to
-update `num_classes()` and `num_examples_per_epoch()` in `flowers_data.py`
-to correspond with your data.
-
-## Practical Considerations for Training a Model
-
-The model architecture and training procedure is heavily dependent on the
-hardware used to train the model. If you wish to train or fine-tune this model
-on your machine **you will need to adjust and empirically determine a good set
-of training hyper-parameters for your setup**. What follows are some general
-considerations for novices.
-
-### Finding Good Hyperparameters
-
-Roughly 5-10 hyper-parameters govern the speed at which a network is trained. In
-addition to `--batch_size` and `--num_gpus`, there are several constants defined
-in [inception_train.py](inception/inception_train.py) which dictate the learning
-schedule.
-
-```shell
-RMSPROP_DECAY = 0.9 # Decay term for RMSProp.
-MOMENTUM = 0.9 # Momentum in RMSProp.
-RMSPROP_EPSILON = 1.0 # Epsilon term for RMSProp.
-INITIAL_LEARNING_RATE = 0.1 # Initial learning rate.
-NUM_EPOCHS_PER_DECAY = 30.0 # Epochs after which learning rate decays.
-LEARNING_RATE_DECAY_FACTOR = 0.16 # Learning rate decay factor.
-```
-
-There are many papers that discuss the various tricks and trade-offs associated
-with training a model with stochastic gradient descent. For those new to the
-field, some great references are:
-
-* Y Bengio, [Practical recommendations for gradient-based training of deep
- architectures](http://arxiv.org/abs/1206.5533)
-* I Goodfellow, Y Bengio and A Courville, [Deep Learning]
- (http://www.deeplearningbook.org/)
-
-What follows is a summary of some general advice for identifying appropriate
-model hyper-parameters in the context of this particular model training setup.
-Namely, this library provides *synchronous* updates to model parameters based on
-batch-splitting the model across multiple GPUs.
-
-* Higher learning rates leads to faster training. Too high of learning rate
- leads to instability and will cause model parameters to diverge to infinity
- or NaN.
-
-* Larger batch sizes lead to higher quality estimates of the gradient and
- permit training the model with higher learning rates.
-
-* Often the GPU memory is a bottleneck that prevents employing larger batch
- sizes. Employing more GPUs allows one to use larger batch sizes because
- this model splits the batch across the GPUs.
-
-**NOTE** If one wishes to train this model with *asynchronous* gradient updates,
-one will need to substantially alter this model and new considerations need to
-be factored into hyperparameter tuning. See [Large Scale Distributed Deep
-Networks](http://research.google.com/archive/large_deep_networks_nips2012.html)
-for a discussion in this domain.
-
-### Adjusting Memory Demands
-
-Training this model has large memory demands in terms of the CPU and GPU. Let's
-discuss each item in turn.
-
-GPU memory is relatively small compared to CPU memory. Two items dictate the
-amount of GPU memory employed -- model architecture and batch size. Assuming
-that you keep the model architecture fixed, the sole parameter governing the GPU
-demand is the batch size. A good rule of thumb is to try employ as large of
-batch size as will fit on the GPU.
-
-If you run out of GPU memory, either lower the `--batch_size` or employ more
-GPUs on your desktop. The model performs batch-splitting across GPUs, thus N
-GPUs can handle N times the batch size of 1 GPU.
-
-The model requires a large amount of CPU memory as well. We have tuned the model
-to employ about ~20GB of CPU memory. Thus, having access to about 40 GB of CPU
-memory would be ideal.
-
-If that is not possible, you can tune down the memory demands of the model via
-lowering `--input_queue_memory_factor`. Images are preprocessed asynchronously
-with respect to the main training across `--num_preprocess_threads` threads. The
-preprocessed images are stored in shuffling queue in which each GPU performs a
-dequeue operation in order to receive a `batch_size` worth of images.
-
-In order to guarantee good shuffling across the data, we maintain a large
-shuffling queue of 1024 x `input_queue_memory_factor` images. For the current
-model architecture, this corresponds to about 4GB of CPU memory. You may lower
-`input_queue_memory_factor` in order to decrease the memory footprint. Keep in
-mind though that lowering this value drastically may result in a model with
-slightly lower predictive accuracy when training from scratch. Please see
-comments in [`image_processing.py`](inception/image_processing.py) for more details.
-
-## Troubleshooting
-
-#### The model runs out of CPU memory.
-
-In lieu of buying more CPU memory, an easy fix is to decrease
-`--input_queue_memory_factor`. See [Adjusting Memory Demands](#adjusting-memory-demands).
-
-#### The model runs out of GPU memory.
-
-The data is not able to fit on the GPU card. The simplest solution is to
-decrease the batch size of the model. Otherwise, you will need to think about a
-more sophisticated method for specifying the training which cuts up the model
-across multiple `session.run()` calls or partitions the model across multiple
-GPUs. See [Using GPUs](https://www.tensorflow.org/how_tos/using_gpu/index.html)
-and [Adjusting Memory Demands](#adjusting-memory-demands) for more information.
-
-#### The model training results in NaN's.
-
-The learning rate of the model is too high. Turn down your learning rate.
-
-#### I wish to train a model with a different image size.
-
-The simplest solution is to artificially resize your images to `299x299` pixels.
-See [Images](https://www.tensorflow.org/api_docs/python/image.html) section for
-many resizing, cropping and padding methods. Note that the entire model
-architecture is predicated on a `299x299` image, thus if you wish to change the
-input image size, then you may need to redesign the entire model architecture.
-
-#### What hardware specification are these hyper-parameters targeted for?
-
-We targeted a desktop with 128GB of CPU ram connected to 8 NVIDIA Tesla K40 GPU
-cards but we have run this on desktops with 32GB of CPU ram and 1 NVIDIA Tesla
-K40. You can get a sense of the various training configurations we tested by
-reading the comments in [`inception_train.py`](inception/inception_train.py).
-
-#### How do I continue training from a checkpoint in distributed setting?
-
-You only need to make sure that the checkpoint is in a location that can be
-reached by all of the `ps` tasks. By specifying the checkpoint location with
-`--train_dir` , the `ps` servers will load the checkpoint before commencing
-training.
diff --git a/research/inception/WORKSPACE b/research/inception/WORKSPACE
deleted file mode 100644
index 2d7b4fb254a0fcebe695cb3fd3685af29a02e0b0..0000000000000000000000000000000000000000
--- a/research/inception/WORKSPACE
+++ /dev/null
@@ -1 +0,0 @@
-workspace(name = "inception")
diff --git a/research/inception/g3doc/inception_v3_architecture.png b/research/inception/g3doc/inception_v3_architecture.png
deleted file mode 100644
index 91fb734a104b2f63114ade7c8f9b2f95ce6334a6..0000000000000000000000000000000000000000
Binary files a/research/inception/g3doc/inception_v3_architecture.png and /dev/null differ
diff --git a/research/inception/inception/BUILD b/research/inception/inception/BUILD
deleted file mode 100644
index 21fc27aa57c14f6a72359cf15d446787c8ea6c2e..0000000000000000000000000000000000000000
--- a/research/inception/inception/BUILD
+++ /dev/null
@@ -1,198 +0,0 @@
-# Description:
-# Example TensorFlow models for ImageNet.
-
-package(default_visibility = [":internal"])
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-package_group(
- name = "internal",
- packages = ["//inception/..."],
-)
-
-py_library(
- name = "dataset",
- srcs = [
- "dataset.py",
- ],
-)
-
-py_library(
- name = "imagenet_data",
- srcs = [
- "imagenet_data.py",
- ],
- deps = [
- ":dataset",
- ],
-)
-
-py_library(
- name = "flowers_data",
- srcs = [
- "flowers_data.py",
- ],
- deps = [
- ":dataset",
- ],
-)
-
-py_library(
- name = "image_processing",
- srcs = [
- "image_processing.py",
- ],
-)
-
-py_library(
- name = "inception",
- srcs = [
- "inception_model.py",
- ],
- visibility = ["//visibility:public"],
- deps = [
- ":dataset",
- "//inception/slim",
- ],
-)
-
-py_binary(
- name = "imagenet_eval",
- srcs = [
- "imagenet_eval.py",
- ],
- deps = [
- ":imagenet_data",
- ":inception_eval",
- ],
-)
-
-py_binary(
- name = "flowers_eval",
- srcs = [
- "flowers_eval.py",
- ],
- deps = [
- ":flowers_data",
- ":inception_eval",
- ],
-)
-
-py_library(
- name = "inception_eval",
- srcs = [
- "inception_eval.py",
- ],
- deps = [
- ":image_processing",
- ":inception",
- ],
-)
-
-py_binary(
- name = "imagenet_train",
- srcs = [
- "imagenet_train.py",
- ],
- deps = [
- ":imagenet_data",
- ":inception_train",
- ],
-)
-
-py_binary(
- name = "imagenet_distributed_train",
- srcs = [
- "imagenet_distributed_train.py",
- ],
- deps = [
- ":imagenet_data",
- ":inception_distributed_train",
- ],
-)
-
-py_binary(
- name = "flowers_train",
- srcs = [
- "flowers_train.py",
- ],
- deps = [
- ":flowers_data",
- ":inception_train",
- ],
-)
-
-py_library(
- name = "inception_train",
- srcs = [
- "inception_train.py",
- ],
- deps = [
- ":image_processing",
- ":inception",
- ],
-)
-
-py_library(
- name = "inception_distributed_train",
- srcs = [
- "inception_distributed_train.py",
- ],
- deps = [
- ":image_processing",
- ":inception",
- ],
-)
-
-py_binary(
- name = "build_image_data",
- srcs = ["data/build_image_data.py"],
-)
-
-sh_binary(
- name = "download_and_preprocess_flowers",
- srcs = ["data/download_and_preprocess_flowers.sh"],
- data = [
- ":build_image_data",
- ],
-)
-
-sh_binary(
- name = "download_and_preprocess_imagenet",
- srcs = ["data/download_and_preprocess_imagenet.sh"],
- data = [
- "data/download_imagenet.sh",
- "data/imagenet_2012_validation_synset_labels.txt",
- "data/imagenet_lsvrc_2015_synsets.txt",
- "data/imagenet_metadata.txt",
- "data/preprocess_imagenet_validation_data.py",
- "data/process_bounding_boxes.py",
- ":build_imagenet_data",
- ],
-)
-
-py_binary(
- name = "build_imagenet_data",
- srcs = ["data/build_imagenet_data.py"],
-)
-
-filegroup(
- name = "srcs",
- srcs = glob(
- [
- "**/*.py",
- "BUILD",
- ],
- ),
-)
-
-filegroup(
- name = "imagenet_metadata",
- srcs = [
- "data/imagenet_lsvrc_2015_synsets.txt",
- "data/imagenet_metadata.txt",
- ],
- visibility = ["//visibility:public"],
-)
diff --git a/research/inception/inception/data/build_image_data.py b/research/inception/inception/data/build_image_data.py
deleted file mode 100755
index 894388b7f758a46746870f2f0d55d1df7d3fe29b..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/build_image_data.py
+++ /dev/null
@@ -1,436 +0,0 @@
-#!/usr/bin/python
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Converts image data to TFRecords file format with Example protos.
-
-The image data set is expected to reside in JPEG files located in the
-following directory structure.
-
- data_dir/label_0/image0.jpeg
- data_dir/label_0/image1.jpg
- ...
- data_dir/label_1/weird-image.jpeg
- data_dir/label_1/my-image.jpeg
- ...
-
-where the sub-directory is the unique label associated with these images.
-
-This TensorFlow script converts the training and evaluation data into
-a sharded data set consisting of TFRecord files
-
- train_directory/train-00000-of-01024
- train_directory/train-00001-of-01024
- ...
- train_directory/train-01023-of-01024
-
-and
-
- validation_directory/validation-00000-of-00128
- validation_directory/validation-00001-of-00128
- ...
- validation_directory/validation-00127-of-00128
-
-where we have selected 1024 and 128 shards for each data set. Each record
-within the TFRecord file is a serialized Example proto. The Example proto
-contains the following fields:
-
- image/encoded: string containing JPEG encoded image in RGB colorspace
- image/height: integer, image height in pixels
- image/width: integer, image width in pixels
- image/colorspace: string, specifying the colorspace, always 'RGB'
- image/channels: integer, specifying the number of channels, always 3
- image/format: string, specifying the format, always 'JPEG'
-
- image/filename: string containing the basename of the image file
- e.g. 'n01440764_10026.JPEG' or 'ILSVRC2012_val_00000293.JPEG'
- image/class/label: integer specifying the index in a classification layer.
- The label ranges from [0, num_labels] where 0 is unused and left as
- the background class.
- image/class/text: string specifying the human-readable version of the label
- e.g. 'dog'
-
-If your data set involves bounding boxes, please look at build_imagenet_data.py.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from datetime import datetime
-import os
-import random
-import sys
-import threading
-
-import numpy as np
-import tensorflow as tf
-
-tf.app.flags.DEFINE_string('train_directory', '/tmp/',
- 'Training data directory')
-tf.app.flags.DEFINE_string('validation_directory', '/tmp/',
- 'Validation data directory')
-tf.app.flags.DEFINE_string('output_directory', '/tmp/',
- 'Output data directory')
-
-tf.app.flags.DEFINE_integer('train_shards', 2,
- 'Number of shards in training TFRecord files.')
-tf.app.flags.DEFINE_integer('validation_shards', 2,
- 'Number of shards in validation TFRecord files.')
-
-tf.app.flags.DEFINE_integer('num_threads', 2,
- 'Number of threads to preprocess the images.')
-
-# The labels file contains a list of valid labels are held in this file.
-# Assumes that the file contains entries as such:
-# dog
-# cat
-# flower
-# where each line corresponds to a label. We map each label contained in
-# the file to an integer corresponding to the line number starting from 0.
-tf.app.flags.DEFINE_string('labels_file', '', 'Labels file')
-
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def _int64_feature(value):
- """Wrapper for inserting int64 features into Example proto."""
- if not isinstance(value, list):
- value = [value]
- return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
-
-
-def _bytes_feature(value):
- """Wrapper for inserting bytes features into Example proto."""
- return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
-
-
-def _convert_to_example(filename, image_buffer, label, text, height, width):
- """Build an Example proto for an example.
-
- Args:
- filename: string, path to an image file, e.g., '/path/to/example.JPG'
- image_buffer: string, JPEG encoding of RGB image
- label: integer, identifier for the ground truth for the network
- text: string, unique human-readable, e.g. 'dog'
- height: integer, image height in pixels
- width: integer, image width in pixels
- Returns:
- Example proto
- """
-
- colorspace = 'RGB'
- channels = 3
- image_format = 'JPEG'
-
- example = tf.train.Example(features=tf.train.Features(feature={
- 'image/height': _int64_feature(height),
- 'image/width': _int64_feature(width),
- 'image/colorspace': _bytes_feature(tf.compat.as_bytes(colorspace)),
- 'image/channels': _int64_feature(channels),
- 'image/class/label': _int64_feature(label),
- 'image/class/text': _bytes_feature(tf.compat.as_bytes(text)),
- 'image/format': _bytes_feature(tf.compat.as_bytes(image_format)),
- 'image/filename': _bytes_feature(tf.compat.as_bytes(os.path.basename(filename))),
- 'image/encoded': _bytes_feature(tf.compat.as_bytes(image_buffer))}))
- return example
-
-
-class ImageCoder(object):
- """Helper class that provides TensorFlow image coding utilities."""
-
- def __init__(self):
- # Create a single Session to run all image coding calls.
- self._sess = tf.Session()
-
- # Initializes function that converts PNG to JPEG data.
- self._png_data = tf.placeholder(dtype=tf.string)
- image = tf.image.decode_png(self._png_data, channels=3)
- self._png_to_jpeg = tf.image.encode_jpeg(image, format='rgb', quality=100)
-
- # Initializes function that decodes RGB JPEG data.
- self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
- self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
-
- def png_to_jpeg(self, image_data):
- return self._sess.run(self._png_to_jpeg,
- feed_dict={self._png_data: image_data})
-
- def decode_jpeg(self, image_data):
- image = self._sess.run(self._decode_jpeg,
- feed_dict={self._decode_jpeg_data: image_data})
- assert len(image.shape) == 3
- assert image.shape[2] == 3
- return image
-
-
-def _is_png(filename):
- """Determine if a file contains a PNG format image.
-
- Args:
- filename: string, path of the image file.
-
- Returns:
- boolean indicating if the image is a PNG.
- """
- return filename.endswith('.png')
-
-
-def _process_image(filename, coder):
- """Process a single image file.
-
- Args:
- filename: string, path to an image file e.g., '/path/to/example.JPG'.
- coder: instance of ImageCoder to provide TensorFlow image coding utils.
- Returns:
- image_buffer: string, JPEG encoding of RGB image.
- height: integer, image height in pixels.
- width: integer, image width in pixels.
- """
- # Read the image file.
- with tf.gfile.FastGFile(filename, 'rb') as f:
- image_data = f.read()
-
- # Convert any PNG to JPEG's for consistency.
- if _is_png(filename):
- print('Converting PNG to JPEG for %s' % filename)
- image_data = coder.png_to_jpeg(image_data)
-
- # Decode the RGB JPEG.
- image = coder.decode_jpeg(image_data)
-
- # Check that image converted to RGB
- assert len(image.shape) == 3
- height = image.shape[0]
- width = image.shape[1]
- assert image.shape[2] == 3
-
- return image_data, height, width
-
-
-def _process_image_files_batch(coder, thread_index, ranges, name, filenames,
- texts, labels, num_shards):
- """Processes and saves list of images as TFRecord in 1 thread.
-
- Args:
- coder: instance of ImageCoder to provide TensorFlow image coding utils.
- thread_index: integer, unique batch to run index is within [0, len(ranges)).
- ranges: list of pairs of integers specifying ranges of each batches to
- analyze in parallel.
- name: string, unique identifier specifying the data set
- filenames: list of strings; each string is a path to an image file
- texts: list of strings; each string is human readable, e.g. 'dog'
- labels: list of integer; each integer identifies the ground truth
- num_shards: integer number of shards for this data set.
- """
- # Each thread produces N shards where N = int(num_shards / num_threads).
- # For instance, if num_shards = 128, and the num_threads = 2, then the first
- # thread would produce shards [0, 64).
- num_threads = len(ranges)
- assert not num_shards % num_threads
- num_shards_per_batch = int(num_shards / num_threads)
-
- shard_ranges = np.linspace(ranges[thread_index][0],
- ranges[thread_index][1],
- num_shards_per_batch + 1).astype(int)
- num_files_in_thread = ranges[thread_index][1] - ranges[thread_index][0]
-
- counter = 0
- for s in range(num_shards_per_batch):
- # Generate a sharded version of the file name, e.g. 'train-00002-of-00010'
- shard = thread_index * num_shards_per_batch + s
- output_filename = '%s-%.5d-of-%.5d' % (name, shard, num_shards)
- output_file = os.path.join(FLAGS.output_directory, output_filename)
- writer = tf.python_io.TFRecordWriter(output_file)
-
- shard_counter = 0
- files_in_shard = np.arange(shard_ranges[s], shard_ranges[s + 1], dtype=int)
- for i in files_in_shard:
- filename = filenames[i]
- label = labels[i]
- text = texts[i]
-
- try:
- image_buffer, height, width = _process_image(filename, coder)
- except Exception as e:
- print(e)
- print('SKIPPED: Unexpected error while decoding %s.' % filename)
- continue
-
- example = _convert_to_example(filename, image_buffer, label,
- text, height, width)
- writer.write(example.SerializeToString())
- shard_counter += 1
- counter += 1
-
- if not counter % 1000:
- print('%s [thread %d]: Processed %d of %d images in thread batch.' %
- (datetime.now(), thread_index, counter, num_files_in_thread))
- sys.stdout.flush()
-
- writer.close()
- print('%s [thread %d]: Wrote %d images to %s' %
- (datetime.now(), thread_index, shard_counter, output_file))
- sys.stdout.flush()
- shard_counter = 0
- print('%s [thread %d]: Wrote %d images to %d shards.' %
- (datetime.now(), thread_index, counter, num_files_in_thread))
- sys.stdout.flush()
-
-
-def _process_image_files(name, filenames, texts, labels, num_shards):
- """Process and save list of images as TFRecord of Example protos.
-
- Args:
- name: string, unique identifier specifying the data set
- filenames: list of strings; each string is a path to an image file
- texts: list of strings; each string is human readable, e.g. 'dog'
- labels: list of integer; each integer identifies the ground truth
- num_shards: integer number of shards for this data set.
- """
- assert len(filenames) == len(texts)
- assert len(filenames) == len(labels)
-
- # Break all images into batches with a [ranges[i][0], ranges[i][1]].
- spacing = np.linspace(0, len(filenames), FLAGS.num_threads + 1).astype(np.int)
- ranges = []
- for i in range(len(spacing) - 1):
- ranges.append([spacing[i], spacing[i + 1]])
-
- # Launch a thread for each batch.
- print('Launching %d threads for spacings: %s' % (FLAGS.num_threads, ranges))
- sys.stdout.flush()
-
- # Create a mechanism for monitoring when all threads are finished.
- coord = tf.train.Coordinator()
-
- # Create a generic TensorFlow-based utility for converting all image codings.
- coder = ImageCoder()
-
- threads = []
- for thread_index in range(len(ranges)):
- args = (coder, thread_index, ranges, name, filenames,
- texts, labels, num_shards)
- t = threading.Thread(target=_process_image_files_batch, args=args)
- t.start()
- threads.append(t)
-
- # Wait for all the threads to terminate.
- coord.join(threads)
- print('%s: Finished writing all %d images in data set.' %
- (datetime.now(), len(filenames)))
- sys.stdout.flush()
-
-
-def _find_image_files(data_dir, labels_file):
- """Build a list of all images files and labels in the data set.
-
- Args:
- data_dir: string, path to the root directory of images.
-
- Assumes that the image data set resides in JPEG files located in
- the following directory structure.
-
- data_dir/dog/another-image.JPEG
- data_dir/dog/my-image.jpg
-
- where 'dog' is the label associated with these images.
-
- labels_file: string, path to the labels file.
-
- The list of valid labels are held in this file. Assumes that the file
- contains entries as such:
- dog
- cat
- flower
- where each line corresponds to a label. We map each label contained in
- the file to an integer starting with the integer 0 corresponding to the
- label contained in the first line.
-
- Returns:
- filenames: list of strings; each string is a path to an image file.
- texts: list of strings; each string is the class, e.g. 'dog'
- labels: list of integer; each integer identifies the ground truth.
- """
- print('Determining list of input files and labels from %s.' % data_dir)
- unique_labels = [l.strip() for l in tf.gfile.FastGFile(
- labels_file, 'r').readlines()]
-
- labels = []
- filenames = []
- texts = []
-
- # Leave label index 0 empty as a background class.
- label_index = 1
-
- # Construct the list of JPEG files and labels.
- for text in unique_labels:
- jpeg_file_path = '%s/%s/*' % (data_dir, text)
- matching_files = tf.gfile.Glob(jpeg_file_path)
-
- labels.extend([label_index] * len(matching_files))
- texts.extend([text] * len(matching_files))
- filenames.extend(matching_files)
-
- if not label_index % 100:
- print('Finished finding files in %d of %d classes.' % (
- label_index, len(labels)))
- label_index += 1
-
- # Shuffle the ordering of all image files in order to guarantee
- # random ordering of the images with respect to label in the
- # saved TFRecord files. Make the randomization repeatable.
- shuffled_index = list(range(len(filenames)))
- random.seed(12345)
- random.shuffle(shuffled_index)
-
- filenames = [filenames[i] for i in shuffled_index]
- texts = [texts[i] for i in shuffled_index]
- labels = [labels[i] for i in shuffled_index]
-
- print('Found %d JPEG files across %d labels inside %s.' %
- (len(filenames), len(unique_labels), data_dir))
- return filenames, texts, labels
-
-
-def _process_dataset(name, directory, num_shards, labels_file):
- """Process a complete data set and save it as a TFRecord.
-
- Args:
- name: string, unique identifier specifying the data set.
- directory: string, root path to the data set.
- num_shards: integer number of shards for this data set.
- labels_file: string, path to the labels file.
- """
- filenames, texts, labels = _find_image_files(directory, labels_file)
- _process_image_files(name, filenames, texts, labels, num_shards)
-
-
-def main(unused_argv):
- assert not FLAGS.train_shards % FLAGS.num_threads, (
- 'Please make the FLAGS.num_threads commensurate with FLAGS.train_shards')
- assert not FLAGS.validation_shards % FLAGS.num_threads, (
- 'Please make the FLAGS.num_threads commensurate with '
- 'FLAGS.validation_shards')
- print('Saving results to %s' % FLAGS.output_directory)
-
- # Run it!
- _process_dataset('validation', FLAGS.validation_directory,
- FLAGS.validation_shards, FLAGS.labels_file)
- _process_dataset('train', FLAGS.train_directory,
- FLAGS.train_shards, FLAGS.labels_file)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/data/build_imagenet_data.py b/research/inception/inception/data/build_imagenet_data.py
deleted file mode 100644
index c054735e782297f990451e29ff4383af24bbe802..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/build_imagenet_data.py
+++ /dev/null
@@ -1,707 +0,0 @@
-#!/usr/bin/python
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Converts ImageNet data to TFRecords file format with Example protos.
-
-The raw ImageNet data set is expected to reside in JPEG files located in the
-following directory structure.
-
- data_dir/n01440764/ILSVRC2012_val_00000293.JPEG
- data_dir/n01440764/ILSVRC2012_val_00000543.JPEG
- ...
-
-where 'n01440764' is the unique synset label associated with
-these images.
-
-The training data set consists of 1000 sub-directories (i.e. labels)
-each containing 1200 JPEG images for a total of 1.2M JPEG images.
-
-The evaluation data set consists of 1000 sub-directories (i.e. labels)
-each containing 50 JPEG images for a total of 50K JPEG images.
-
-This TensorFlow script converts the training and evaluation data into
-a sharded data set consisting of 1024 and 128 TFRecord files, respectively.
-
- train_directory/train-00000-of-01024
- train_directory/train-00001-of-01024
- ...
- train_directory/train-01023-of-01024
-
-and
-
- validation_directory/validation-00000-of-00128
- validation_directory/validation-00001-of-00128
- ...
- validation_directory/validation-00127-of-00128
-
-Each validation TFRecord file contains ~390 records. Each training TFREcord
-file contains ~1250 records. Each record within the TFRecord file is a
-serialized Example proto. The Example proto contains the following fields:
-
- image/encoded: string containing JPEG encoded image in RGB colorspace
- image/height: integer, image height in pixels
- image/width: integer, image width in pixels
- image/colorspace: string, specifying the colorspace, always 'RGB'
- image/channels: integer, specifying the number of channels, always 3
- image/format: string, specifying the format, always 'JPEG'
-
- image/filename: string containing the basename of the image file
- e.g. 'n01440764_10026.JPEG' or 'ILSVRC2012_val_00000293.JPEG'
- image/class/label: integer specifying the index in a classification layer.
- The label ranges from [1, 1000] where 0 is not used.
- image/class/synset: string specifying the unique ID of the label,
- e.g. 'n01440764'
- image/class/text: string specifying the human-readable version of the label
- e.g. 'red fox, Vulpes vulpes'
-
- image/object/bbox/xmin: list of integers specifying the 0+ human annotated
- bounding boxes
- image/object/bbox/xmax: list of integers specifying the 0+ human annotated
- bounding boxes
- image/object/bbox/ymin: list of integers specifying the 0+ human annotated
- bounding boxes
- image/object/bbox/ymax: list of integers specifying the 0+ human annotated
- bounding boxes
- image/object/bbox/label: integer specifying the index in a classification
- layer. The label ranges from [1, 1000] where 0 is not used. Note this is
- always identical to the image label.
-
-Note that the length of xmin is identical to the length of xmax, ymin and ymax
-for each example.
-
-Running this script using 16 threads may take around ~2.5 hours on an HP Z420.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from datetime import datetime
-import os
-import random
-import sys
-import threading
-
-import numpy as np
-import six
-import tensorflow as tf
-
-tf.app.flags.DEFINE_string('train_directory', '/tmp/',
- 'Training data directory')
-tf.app.flags.DEFINE_string('validation_directory', '/tmp/',
- 'Validation data directory')
-tf.app.flags.DEFINE_string('output_directory', '/tmp/',
- 'Output data directory')
-
-tf.app.flags.DEFINE_integer('train_shards', 1024,
- 'Number of shards in training TFRecord files.')
-tf.app.flags.DEFINE_integer('validation_shards', 128,
- 'Number of shards in validation TFRecord files.')
-
-tf.app.flags.DEFINE_integer('num_threads', 8,
- 'Number of threads to preprocess the images.')
-
-# The labels file contains a list of valid labels are held in this file.
-# Assumes that the file contains entries as such:
-# n01440764
-# n01443537
-# n01484850
-# where each line corresponds to a label expressed as a synset. We map
-# each synset contained in the file to an integer (based on the alphabetical
-# ordering). See below for details.
-tf.app.flags.DEFINE_string('labels_file',
- 'imagenet_lsvrc_2015_synsets.txt',
- 'Labels file')
-
-# This file containing mapping from synset to human-readable label.
-# Assumes each line of the file looks like:
-#
-# n02119247 black fox
-# n02119359 silver fox
-# n02119477 red fox, Vulpes fulva
-#
-# where each line corresponds to a unique mapping. Note that each line is
-# formatted as \t.
-tf.app.flags.DEFINE_string('imagenet_metadata_file',
- 'imagenet_metadata.txt',
- 'ImageNet metadata file')
-
-# This file is the output of process_bounding_box.py
-# Assumes each line of the file looks like:
-#
-# n00007846_64193.JPEG,0.0060,0.2620,0.7545,0.9940
-#
-# where each line corresponds to one bounding box annotation associated
-# with an image. Each line can be parsed as:
-#
-# , , , ,
-#
-# Note that there might exist mulitple bounding box annotations associated
-# with an image file.
-tf.app.flags.DEFINE_string('bounding_box_file',
- './imagenet_2012_bounding_boxes.csv',
- 'Bounding box file')
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def _int64_feature(value):
- """Wrapper for inserting int64 features into Example proto."""
- if not isinstance(value, list):
- value = [value]
- return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
-
-
-def _float_feature(value):
- """Wrapper for inserting float features into Example proto."""
- if not isinstance(value, list):
- value = [value]
- return tf.train.Feature(float_list=tf.train.FloatList(value=value))
-
-
-def _bytes_feature(value):
- """Wrapper for inserting bytes features into Example proto."""
- if six.PY3 and isinstance(value, six.text_type):
- value = six.binary_type(value, encoding='utf-8')
- return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
-
-
-def _convert_to_example(filename, image_buffer, label, synset, human, bbox,
- height, width):
- """Build an Example proto for an example.
-
- Args:
- filename: string, path to an image file, e.g., '/path/to/example.JPG'
- image_buffer: string, JPEG encoding of RGB image
- label: integer, identifier for the ground truth for the network
- synset: string, unique WordNet ID specifying the label, e.g., 'n02323233'
- human: string, human-readable label, e.g., 'red fox, Vulpes vulpes'
- bbox: list of bounding boxes; each box is a list of integers
- specifying [xmin, ymin, xmax, ymax]. All boxes are assumed to belong to
- the same label as the image label.
- height: integer, image height in pixels
- width: integer, image width in pixels
- Returns:
- Example proto
- """
- xmin = []
- ymin = []
- xmax = []
- ymax = []
- for b in bbox:
- assert len(b) == 4
- # pylint: disable=expression-not-assigned
- [l.append(point) for l, point in zip([xmin, ymin, xmax, ymax], b)]
- # pylint: enable=expression-not-assigned
-
- colorspace = 'RGB'
- channels = 3
- image_format = 'JPEG'
-
- example = tf.train.Example(features=tf.train.Features(feature={
- 'image/height': _int64_feature(height),
- 'image/width': _int64_feature(width),
- 'image/colorspace': _bytes_feature(colorspace),
- 'image/channels': _int64_feature(channels),
- 'image/class/label': _int64_feature(label),
- 'image/class/synset': _bytes_feature(synset),
- 'image/class/text': _bytes_feature(human),
- 'image/object/bbox/xmin': _float_feature(xmin),
- 'image/object/bbox/xmax': _float_feature(xmax),
- 'image/object/bbox/ymin': _float_feature(ymin),
- 'image/object/bbox/ymax': _float_feature(ymax),
- 'image/object/bbox/label': _int64_feature([label] * len(xmin)),
- 'image/format': _bytes_feature(image_format),
- 'image/filename': _bytes_feature(os.path.basename(filename)),
- 'image/encoded': _bytes_feature(image_buffer)}))
- return example
-
-
-class ImageCoder(object):
- """Helper class that provides TensorFlow image coding utilities."""
-
- def __init__(self):
- # Create a single Session to run all image coding calls.
- self._sess = tf.Session()
-
- # Initializes function that converts PNG to JPEG data.
- self._png_data = tf.placeholder(dtype=tf.string)
- image = tf.image.decode_png(self._png_data, channels=3)
- self._png_to_jpeg = tf.image.encode_jpeg(image, format='rgb', quality=100)
-
- # Initializes function that converts CMYK JPEG data to RGB JPEG data.
- self._cmyk_data = tf.placeholder(dtype=tf.string)
- image = tf.image.decode_jpeg(self._cmyk_data, channels=0)
- self._cmyk_to_rgb = tf.image.encode_jpeg(image, format='rgb', quality=100)
-
- # Initializes function that decodes RGB JPEG data.
- self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
- self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
-
- def png_to_jpeg(self, image_data):
- return self._sess.run(self._png_to_jpeg,
- feed_dict={self._png_data: image_data})
-
- def cmyk_to_rgb(self, image_data):
- return self._sess.run(self._cmyk_to_rgb,
- feed_dict={self._cmyk_data: image_data})
-
- def decode_jpeg(self, image_data):
- image = self._sess.run(self._decode_jpeg,
- feed_dict={self._decode_jpeg_data: image_data})
- assert len(image.shape) == 3
- assert image.shape[2] == 3
- return image
-
-
-def _is_png(filename):
- """Determine if a file contains a PNG format image.
-
- Args:
- filename: string, path of the image file.
-
- Returns:
- boolean indicating if the image is a PNG.
- """
- # File list from:
- # https://groups.google.com/forum/embed/?place=forum/torch7#!topic/torch7/fOSTXHIESSU
- return 'n02105855_2933.JPEG' in filename
-
-
-def _is_cmyk(filename):
- """Determine if file contains a CMYK JPEG format image.
-
- Args:
- filename: string, path of the image file.
-
- Returns:
- boolean indicating if the image is a JPEG encoded with CMYK color space.
- """
- # File list from:
- # https://github.com/cytsai/ilsvrc-cmyk-image-list
- blacklist = ['n01739381_1309.JPEG', 'n02077923_14822.JPEG',
- 'n02447366_23489.JPEG', 'n02492035_15739.JPEG',
- 'n02747177_10752.JPEG', 'n03018349_4028.JPEG',
- 'n03062245_4620.JPEG', 'n03347037_9675.JPEG',
- 'n03467068_12171.JPEG', 'n03529860_11437.JPEG',
- 'n03544143_17228.JPEG', 'n03633091_5218.JPEG',
- 'n03710637_5125.JPEG', 'n03961711_5286.JPEG',
- 'n04033995_2932.JPEG', 'n04258138_17003.JPEG',
- 'n04264628_27969.JPEG', 'n04336792_7448.JPEG',
- 'n04371774_5854.JPEG', 'n04596742_4225.JPEG',
- 'n07583066_647.JPEG', 'n13037406_4650.JPEG']
- return filename.split('/')[-1] in blacklist
-
-
-def _process_image(filename, coder):
- """Process a single image file.
-
- Args:
- filename: string, path to an image file e.g., '/path/to/example.JPG'.
- coder: instance of ImageCoder to provide TensorFlow image coding utils.
- Returns:
- image_buffer: string, JPEG encoding of RGB image.
- height: integer, image height in pixels.
- width: integer, image width in pixels.
- """
- # Read the image file.
- with tf.gfile.FastGFile(filename, 'rb') as f:
- image_data = f.read()
-
- # Clean the dirty data.
- if _is_png(filename):
- # 1 image is a PNG.
- print('Converting PNG to JPEG for %s' % filename)
- image_data = coder.png_to_jpeg(image_data)
- elif _is_cmyk(filename):
- # 22 JPEG images are in CMYK colorspace.
- print('Converting CMYK to RGB for %s' % filename)
- image_data = coder.cmyk_to_rgb(image_data)
-
- # Decode the RGB JPEG.
- image = coder.decode_jpeg(image_data)
-
- # Check that image converted to RGB
- assert len(image.shape) == 3
- height = image.shape[0]
- width = image.shape[1]
- assert image.shape[2] == 3
-
- return image_data, height, width
-
-
-def _process_image_files_batch(coder, thread_index, ranges, name, filenames,
- synsets, labels, humans, bboxes, num_shards):
- """Processes and saves list of images as TFRecord in 1 thread.
-
- Args:
- coder: instance of ImageCoder to provide TensorFlow image coding utils.
- thread_index: integer, unique batch to run index is within [0, len(ranges)).
- ranges: list of pairs of integers specifying ranges of each batches to
- analyze in parallel.
- name: string, unique identifier specifying the data set
- filenames: list of strings; each string is a path to an image file
- synsets: list of strings; each string is a unique WordNet ID
- labels: list of integer; each integer identifies the ground truth
- humans: list of strings; each string is a human-readable label
- bboxes: list of bounding boxes for each image. Note that each entry in this
- list might contain from 0+ entries corresponding to the number of bounding
- box annotations for the image.
- num_shards: integer number of shards for this data set.
- """
- # Each thread produces N shards where N = int(num_shards / num_threads).
- # For instance, if num_shards = 128, and the num_threads = 2, then the first
- # thread would produce shards [0, 64).
- num_threads = len(ranges)
- assert not num_shards % num_threads
- num_shards_per_batch = int(num_shards / num_threads)
-
- shard_ranges = np.linspace(ranges[thread_index][0],
- ranges[thread_index][1],
- num_shards_per_batch + 1).astype(int)
- num_files_in_thread = ranges[thread_index][1] - ranges[thread_index][0]
-
- counter = 0
- for s in range(num_shards_per_batch):
- # Generate a sharded version of the file name, e.g. 'train-00002-of-00010'
- shard = thread_index * num_shards_per_batch + s
- output_filename = '%s-%.5d-of-%.5d' % (name, shard, num_shards)
- output_file = os.path.join(FLAGS.output_directory, output_filename)
- writer = tf.python_io.TFRecordWriter(output_file)
-
- shard_counter = 0
- files_in_shard = np.arange(shard_ranges[s], shard_ranges[s + 1], dtype=int)
- for i in files_in_shard:
- filename = filenames[i]
- label = labels[i]
- synset = synsets[i]
- human = humans[i]
- bbox = bboxes[i]
-
- image_buffer, height, width = _process_image(filename, coder)
-
- example = _convert_to_example(filename, image_buffer, label,
- synset, human, bbox,
- height, width)
- writer.write(example.SerializeToString())
- shard_counter += 1
- counter += 1
-
- if not counter % 1000:
- print('%s [thread %d]: Processed %d of %d images in thread batch.' %
- (datetime.now(), thread_index, counter, num_files_in_thread))
- sys.stdout.flush()
-
- writer.close()
- print('%s [thread %d]: Wrote %d images to %s' %
- (datetime.now(), thread_index, shard_counter, output_file))
- sys.stdout.flush()
- shard_counter = 0
- print('%s [thread %d]: Wrote %d images to %d shards.' %
- (datetime.now(), thread_index, counter, num_files_in_thread))
- sys.stdout.flush()
-
-
-def _process_image_files(name, filenames, synsets, labels, humans,
- bboxes, num_shards):
- """Process and save list of images as TFRecord of Example protos.
-
- Args:
- name: string, unique identifier specifying the data set
- filenames: list of strings; each string is a path to an image file
- synsets: list of strings; each string is a unique WordNet ID
- labels: list of integer; each integer identifies the ground truth
- humans: list of strings; each string is a human-readable label
- bboxes: list of bounding boxes for each image. Note that each entry in this
- list might contain from 0+ entries corresponding to the number of bounding
- box annotations for the image.
- num_shards: integer number of shards for this data set.
- """
- assert len(filenames) == len(synsets)
- assert len(filenames) == len(labels)
- assert len(filenames) == len(humans)
- assert len(filenames) == len(bboxes)
-
- # Break all images into batches with a [ranges[i][0], ranges[i][1]].
- spacing = np.linspace(0, len(filenames), FLAGS.num_threads + 1).astype(np.int)
- ranges = []
- threads = []
- for i in range(len(spacing) - 1):
- ranges.append([spacing[i], spacing[i + 1]])
-
- # Launch a thread for each batch.
- print('Launching %d threads for spacings: %s' % (FLAGS.num_threads, ranges))
- sys.stdout.flush()
-
- # Create a mechanism for monitoring when all threads are finished.
- coord = tf.train.Coordinator()
-
- # Create a generic TensorFlow-based utility for converting all image codings.
- coder = ImageCoder()
-
- threads = []
- for thread_index in range(len(ranges)):
- args = (coder, thread_index, ranges, name, filenames,
- synsets, labels, humans, bboxes, num_shards)
- t = threading.Thread(target=_process_image_files_batch, args=args)
- t.start()
- threads.append(t)
-
- # Wait for all the threads to terminate.
- coord.join(threads)
- print('%s: Finished writing all %d images in data set.' %
- (datetime.now(), len(filenames)))
- sys.stdout.flush()
-
-
-def _find_image_files(data_dir, labels_file):
- """Build a list of all images files and labels in the data set.
-
- Args:
- data_dir: string, path to the root directory of images.
-
- Assumes that the ImageNet data set resides in JPEG files located in
- the following directory structure.
-
- data_dir/n01440764/ILSVRC2012_val_00000293.JPEG
- data_dir/n01440764/ILSVRC2012_val_00000543.JPEG
-
- where 'n01440764' is the unique synset label associated with these images.
-
- labels_file: string, path to the labels file.
-
- The list of valid labels are held in this file. Assumes that the file
- contains entries as such:
- n01440764
- n01443537
- n01484850
- where each line corresponds to a label expressed as a synset. We map
- each synset contained in the file to an integer (based on the alphabetical
- ordering) starting with the integer 1 corresponding to the synset
- contained in the first line.
-
- The reason we start the integer labels at 1 is to reserve label 0 as an
- unused background class.
-
- Returns:
- filenames: list of strings; each string is a path to an image file.
- synsets: list of strings; each string is a unique WordNet ID.
- labels: list of integer; each integer identifies the ground truth.
- """
- print('Determining list of input files and labels from %s.' % data_dir)
- challenge_synsets = [l.strip() for l in
- tf.gfile.FastGFile(labels_file, 'r').readlines()]
-
- labels = []
- filenames = []
- synsets = []
-
- # Leave label index 0 empty as a background class.
- label_index = 1
-
- # Construct the list of JPEG files and labels.
- for synset in challenge_synsets:
- jpeg_file_path = '%s/%s/*.JPEG' % (data_dir, synset)
- matching_files = tf.gfile.Glob(jpeg_file_path)
-
- labels.extend([label_index] * len(matching_files))
- synsets.extend([synset] * len(matching_files))
- filenames.extend(matching_files)
-
- if not label_index % 100:
- print('Finished finding files in %d of %d classes.' % (
- label_index, len(challenge_synsets)))
- label_index += 1
-
- # Shuffle the ordering of all image files in order to guarantee
- # random ordering of the images with respect to label in the
- # saved TFRecord files. Make the randomization repeatable.
- shuffled_index = list(range(len(filenames)))
- random.seed(12345)
- random.shuffle(shuffled_index)
-
- filenames = [filenames[i] for i in shuffled_index]
- synsets = [synsets[i] for i in shuffled_index]
- labels = [labels[i] for i in shuffled_index]
-
- print('Found %d JPEG files across %d labels inside %s.' %
- (len(filenames), len(challenge_synsets), data_dir))
- return filenames, synsets, labels
-
-
-def _find_human_readable_labels(synsets, synset_to_human):
- """Build a list of human-readable labels.
-
- Args:
- synsets: list of strings; each string is a unique WordNet ID.
- synset_to_human: dict of synset to human labels, e.g.,
- 'n02119022' --> 'red fox, Vulpes vulpes'
-
- Returns:
- List of human-readable strings corresponding to each synset.
- """
- humans = []
- for s in synsets:
- assert s in synset_to_human, ('Failed to find: %s' % s)
- humans.append(synset_to_human[s])
- return humans
-
-
-def _find_image_bounding_boxes(filenames, image_to_bboxes):
- """Find the bounding boxes for a given image file.
-
- Args:
- filenames: list of strings; each string is a path to an image file.
- image_to_bboxes: dictionary mapping image file names to a list of
- bounding boxes. This list contains 0+ bounding boxes.
- Returns:
- List of bounding boxes for each image. Note that each entry in this
- list might contain from 0+ entries corresponding to the number of bounding
- box annotations for the image.
- """
- num_image_bbox = 0
- bboxes = []
- for f in filenames:
- basename = os.path.basename(f)
- if basename in image_to_bboxes:
- bboxes.append(image_to_bboxes[basename])
- num_image_bbox += 1
- else:
- bboxes.append([])
- print('Found %d images with bboxes out of %d images' % (
- num_image_bbox, len(filenames)))
- return bboxes
-
-
-def _process_dataset(name, directory, num_shards, synset_to_human,
- image_to_bboxes):
- """Process a complete data set and save it as a TFRecord.
-
- Args:
- name: string, unique identifier specifying the data set.
- directory: string, root path to the data set.
- num_shards: integer number of shards for this data set.
- synset_to_human: dict of synset to human labels, e.g.,
- 'n02119022' --> 'red fox, Vulpes vulpes'
- image_to_bboxes: dictionary mapping image file names to a list of
- bounding boxes. This list contains 0+ bounding boxes.
- """
- filenames, synsets, labels = _find_image_files(directory, FLAGS.labels_file)
- humans = _find_human_readable_labels(synsets, synset_to_human)
- bboxes = _find_image_bounding_boxes(filenames, image_to_bboxes)
- _process_image_files(name, filenames, synsets, labels,
- humans, bboxes, num_shards)
-
-
-def _build_synset_lookup(imagenet_metadata_file):
- """Build lookup for synset to human-readable label.
-
- Args:
- imagenet_metadata_file: string, path to file containing mapping from
- synset to human-readable label.
-
- Assumes each line of the file looks like:
-
- n02119247 black fox
- n02119359 silver fox
- n02119477 red fox, Vulpes fulva
-
- where each line corresponds to a unique mapping. Note that each line is
- formatted as \t.
-
- Returns:
- Dictionary of synset to human labels, such as:
- 'n02119022' --> 'red fox, Vulpes vulpes'
- """
- lines = tf.gfile.FastGFile(imagenet_metadata_file, 'r').readlines()
- synset_to_human = {}
- for l in lines:
- if l:
- parts = l.strip().split('\t')
- assert len(parts) == 2
- synset = parts[0]
- human = parts[1]
- synset_to_human[synset] = human
- return synset_to_human
-
-
-def _build_bounding_box_lookup(bounding_box_file):
- """Build a lookup from image file to bounding boxes.
-
- Args:
- bounding_box_file: string, path to file with bounding boxes annotations.
-
- Assumes each line of the file looks like:
-
- n00007846_64193.JPEG,0.0060,0.2620,0.7545,0.9940
-
- where each line corresponds to one bounding box annotation associated
- with an image. Each line can be parsed as:
-
- , , , ,
-
- Note that there might exist mulitple bounding box annotations associated
- with an image file. This file is the output of process_bounding_boxes.py.
-
- Returns:
- Dictionary mapping image file names to a list of bounding boxes. This list
- contains 0+ bounding boxes.
- """
- lines = tf.gfile.FastGFile(bounding_box_file, 'r').readlines()
- images_to_bboxes = {}
- num_bbox = 0
- num_image = 0
- for l in lines:
- if l:
- parts = l.split(',')
- assert len(parts) == 5, ('Failed to parse: %s' % l)
- filename = parts[0]
- xmin = float(parts[1])
- ymin = float(parts[2])
- xmax = float(parts[3])
- ymax = float(parts[4])
- box = [xmin, ymin, xmax, ymax]
-
- if filename not in images_to_bboxes:
- images_to_bboxes[filename] = []
- num_image += 1
- images_to_bboxes[filename].append(box)
- num_bbox += 1
-
- print('Successfully read %d bounding boxes '
- 'across %d images.' % (num_bbox, num_image))
- return images_to_bboxes
-
-
-def main(unused_argv):
- assert not FLAGS.train_shards % FLAGS.num_threads, (
- 'Please make the FLAGS.num_threads commensurate with FLAGS.train_shards')
- assert not FLAGS.validation_shards % FLAGS.num_threads, (
- 'Please make the FLAGS.num_threads commensurate with '
- 'FLAGS.validation_shards')
- print('Saving results to %s' % FLAGS.output_directory)
-
- # Build a map from synset to human-readable label.
- synset_to_human = _build_synset_lookup(FLAGS.imagenet_metadata_file)
- image_to_bboxes = _build_bounding_box_lookup(FLAGS.bounding_box_file)
-
- # Run it!
- _process_dataset('validation', FLAGS.validation_directory,
- FLAGS.validation_shards, synset_to_human, image_to_bboxes)
- _process_dataset('train', FLAGS.train_directory, FLAGS.train_shards,
- synset_to_human, image_to_bboxes)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/data/download_and_preprocess_flowers.sh b/research/inception/inception/data/download_and_preprocess_flowers.sh
deleted file mode 100755
index ee045c164e803ab38be69fb1933134e7f37f1793..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/download_and_preprocess_flowers.sh
+++ /dev/null
@@ -1,96 +0,0 @@
-#!/bin/bash
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Script to download and preprocess the flowers data set. This data set
-# provides a demonstration for how to perform fine-tuning (i.e. tranfer
-# learning) from one model to a new data set.
-#
-# This script provides a demonstration for how to prepare an arbitrary
-# data set for training an Inception v3 model.
-#
-# We demonstrate this with the flowers data set which consists of images
-# of labeled flower images from 5 classes:
-#
-# daisy, dandelion, roses, sunflowers, tulips
-#
-# The final output of this script are sharded TFRecord files containing
-# serialized Example protocol buffers. See build_image_data.py for
-# details of how the Example protocol buffer contains image data.
-#
-# usage:
-# ./download_and_preprocess_flowers.sh [data-dir]
-set -e
-
-if [ -z "$1" ]; then
- echo "Usage: download_and_preprocess_flowers.sh [data dir]"
- exit
-fi
-
-# Create the output and temporary directories.
-DATA_DIR="${1%/}"
-SCRATCH_DIR="${DATA_DIR}/raw-data"
-WORK_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
-mkdir -p "${DATA_DIR}"
-mkdir -p "${SCRATCH_DIR}"
-
-# Download the flowers data.
-DATA_URL="http://download.tensorflow.org/example_images/flower_photos.tgz"
-CURRENT_DIR=$(pwd)
-cd "${DATA_DIR}"
-TARBALL="flower_photos.tgz"
-if [ ! -f ${TARBALL} ]; then
- echo "Downloading flower data set."
- curl -o ${TARBALL} "${DATA_URL}"
-else
- echo "Skipping download of flower data."
-fi
-
-# Note the locations of the train and validation data.
-TRAIN_DIRECTORY="${SCRATCH_DIR}/train"
-VALIDATION_DIRECTORY="${SCRATCH_DIR}/validation"
-
-# Expands the data into the flower_photos/ directory and rename it as the
-# train directory.
-tar xf flower_photos.tgz
-rm -rf "${TRAIN_DIRECTORY}" "${VALIDATION_DIRECTORY}"
-mv flower_photos "${TRAIN_DIRECTORY}"
-
-# Generate a list of 5 labels: daisy, dandelion, roses, sunflowers, tulips
-LABELS_FILE="${SCRATCH_DIR}/labels.txt"
-ls -1 "${TRAIN_DIRECTORY}" | grep -v 'LICENSE' | sed 's/\///' | sort > "${LABELS_FILE}"
-
-# Generate the validation data set.
-while read LABEL; do
- VALIDATION_DIR_FOR_LABEL="${VALIDATION_DIRECTORY}/${LABEL}"
- TRAIN_DIR_FOR_LABEL="${TRAIN_DIRECTORY}/${LABEL}"
-
- # Move the first randomly selected 100 images to the validation set.
- mkdir -p "${VALIDATION_DIR_FOR_LABEL}"
- VALIDATION_IMAGES=$(ls -1 "${TRAIN_DIR_FOR_LABEL}" | shuf | head -100)
- for IMAGE in ${VALIDATION_IMAGES}; do
- mv -f "${TRAIN_DIRECTORY}/${LABEL}/${IMAGE}" "${VALIDATION_DIR_FOR_LABEL}"
- done
-done < "${LABELS_FILE}"
-
-# Build the TFRecords version of the image data.
-cd "${CURRENT_DIR}"
-BUILD_SCRIPT="${WORK_DIR}/build_image_data.py"
-OUTPUT_DIRECTORY="${DATA_DIR}"
-"${BUILD_SCRIPT}" \
- --train_directory="${TRAIN_DIRECTORY}" \
- --validation_directory="${VALIDATION_DIRECTORY}" \
- --output_directory="${OUTPUT_DIRECTORY}" \
- --labels_file="${LABELS_FILE}"
diff --git a/research/inception/inception/data/download_and_preprocess_flowers_mac.sh b/research/inception/inception/data/download_and_preprocess_flowers_mac.sh
deleted file mode 100644
index 154905635b19aeaaea087a8e76afda9b8c624d59..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/download_and_preprocess_flowers_mac.sh
+++ /dev/null
@@ -1,96 +0,0 @@
-#!/bin/bash
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Script to download and preprocess the flowers data set. This data set
-# provides a demonstration for how to perform fine-tuning (i.e. tranfer
-# learning) from one model to a new data set.
-#
-# This script provides a demonstration for how to prepare an arbitrary
-# data set for training an Inception v3 model.
-#
-# We demonstrate this with the flowers data set which consists of images
-# of labeled flower images from 5 classes:
-#
-# daisy, dandelion, roses, sunflowers, tulips
-#
-# The final output of this script are sharded TFRecord files containing
-# serialized Example protocol buffers. See build_image_data.py for
-# details of how the Example protocol buffer contains image data.
-#
-# usage:
-# ./download_and_preprocess_flowers.sh [data-dir]
-set -e
-
-if [ -z "$1" ]; then
- echo "Usage: download_and_preprocess_flowers.sh [data dir]"
- exit
-fi
-
-# Create the output and temporary directories.
-DATA_DIR="${1%/}"
-SCRATCH_DIR="${DATA_DIR}/raw-data/"
-mkdir -p "${DATA_DIR}"
-mkdir -p "${SCRATCH_DIR}"
-WORK_DIR="$0.runfiles/inception/inception"
-
-# Download the flowers data.
-DATA_URL="http://download.tensorflow.org/example_images/flower_photos.tgz"
-CURRENT_DIR=$(pwd)
-cd "${DATA_DIR}"
-TARBALL="flower_photos.tgz"
-if [ ! -f ${TARBALL} ]; then
- echo "Downloading flower data set."
- curl -o ${TARBALL} "${DATA_URL}"
-else
- echo "Skipping download of flower data."
-fi
-
-# Note the locations of the train and validation data.
-TRAIN_DIRECTORY="${SCRATCH_DIR}train/"
-VALIDATION_DIRECTORY="${SCRATCH_DIR}validation/"
-
-# Expands the data into the flower_photos/ directory and rename it as the
-# train directory.
-tar xf flower_photos.tgz
-rm -rf "${TRAIN_DIRECTORY}" "${VALIDATION_DIRECTORY}"
-mv flower_photos "${TRAIN_DIRECTORY}"
-
-# Generate a list of 5 labels: daisy, dandelion, roses, sunflowers, tulips
-LABELS_FILE="${SCRATCH_DIR}/labels.txt"
-ls -1 "${TRAIN_DIRECTORY}" | grep -v 'LICENSE' | sed 's/\///' | sort > "${LABELS_FILE}"
-
-# Generate the validation data set.
-while read LABEL; do
- VALIDATION_DIR_FOR_LABEL="${VALIDATION_DIRECTORY}${LABEL}"
- TRAIN_DIR_FOR_LABEL="${TRAIN_DIRECTORY}${LABEL}"
-
- # Move the first randomly selected 100 images to the validation set.
- mkdir -p "${VALIDATION_DIR_FOR_LABEL}"
- VALIDATION_IMAGES=$(ls -1 "${TRAIN_DIR_FOR_LABEL}" | gshuf | head -100)
- for IMAGE in ${VALIDATION_IMAGES}; do
- mv -f "${TRAIN_DIRECTORY}${LABEL}/${IMAGE}" "${VALIDATION_DIR_FOR_LABEL}"
- done
-done < "${LABELS_FILE}"
-
-# Build the TFRecords version of the image data.
-cd "${CURRENT_DIR}"
-BUILD_SCRIPT="${WORK_DIR}/build_image_data"
-OUTPUT_DIRECTORY="${DATA_DIR}"
-"${BUILD_SCRIPT}" \
- --train_directory="${TRAIN_DIRECTORY}" \
- --validation_directory="${VALIDATION_DIRECTORY}" \
- --output_directory="${OUTPUT_DIRECTORY}" \
- --labels_file="${LABELS_FILE}"
diff --git a/research/inception/inception/data/download_and_preprocess_imagenet.sh b/research/inception/inception/data/download_and_preprocess_imagenet.sh
deleted file mode 100755
index 6faae831075d4f6bfdc8bf8797219f7a0e4c1797..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/download_and_preprocess_imagenet.sh
+++ /dev/null
@@ -1,101 +0,0 @@
-#!/bin/bash
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Script to download and preprocess ImageNet Challenge 2012
-# training and validation data set.
-#
-# The final output of this script are sharded TFRecord files containing
-# serialized Example protocol buffers. See build_imagenet_data.py for
-# details of how the Example protocol buffers contain the ImageNet data.
-#
-# The final output of this script appears as such:
-#
-# data_dir/train-00000-of-01024
-# data_dir/train-00001-of-01024
-# ...
-# data_dir/train-01023-of-01024
-#
-# and
-#
-# data_dir/validation-00000-of-00128
-# data_dir/validation-00001-of-00128
-# ...
-# data_dir/validation-00127-of-00128
-#
-# Note that this script may take several hours to run to completion. The
-# conversion of the ImageNet data to TFRecords alone takes 2-3 hours depending
-# on the speed of your machine. Please be patient.
-#
-# **IMPORTANT**
-# To download the raw images, the user must create an account with image-net.org
-# and generate a username and access_key. The latter two are required for
-# downloading the raw images.
-#
-# usage:
-# ./download_and_preprocess_imagenet.sh [data-dir]
-set -e
-
-if [ -z "$1" ]; then
- echo "Usage: download_and_preprocess_imagenet.sh [data dir]"
- exit
-fi
-
-# Create the output and temporary directories.
-DATA_DIR="${1%/}"
-SCRATCH_DIR="${DATA_DIR}/raw-data/"
-mkdir -p "${DATA_DIR}"
-mkdir -p "${SCRATCH_DIR}"
-WORK_DIR="$0.runfiles/inception/inception"
-
-# Download the ImageNet data.
-LABELS_FILE="${WORK_DIR}/data/imagenet_lsvrc_2015_synsets.txt"
-DOWNLOAD_SCRIPT="${WORK_DIR}/data/download_imagenet.sh"
-"${DOWNLOAD_SCRIPT}" "${SCRATCH_DIR}" "${LABELS_FILE}"
-
-# Note the locations of the train and validation data.
-TRAIN_DIRECTORY="${SCRATCH_DIR}train/"
-VALIDATION_DIRECTORY="${SCRATCH_DIR}validation/"
-
-# Preprocess the validation data by moving the images into the appropriate
-# sub-directory based on the label (synset) of the image.
-echo "Organizing the validation data into sub-directories."
-PREPROCESS_VAL_SCRIPT="${WORK_DIR}/data/preprocess_imagenet_validation_data.py"
-VAL_LABELS_FILE="${WORK_DIR}/data/imagenet_2012_validation_synset_labels.txt"
-
-"${PREPROCESS_VAL_SCRIPT}" "${VALIDATION_DIRECTORY}" "${VAL_LABELS_FILE}"
-
-# Convert the XML files for bounding box annotations into a single CSV.
-echo "Extracting bounding box information from XML."
-BOUNDING_BOX_SCRIPT="${WORK_DIR}/data/process_bounding_boxes.py"
-BOUNDING_BOX_FILE="${SCRATCH_DIR}/imagenet_2012_bounding_boxes.csv"
-BOUNDING_BOX_DIR="${SCRATCH_DIR}bounding_boxes/"
-
-"${BOUNDING_BOX_SCRIPT}" "${BOUNDING_BOX_DIR}" "${LABELS_FILE}" \
- | sort > "${BOUNDING_BOX_FILE}"
-echo "Finished downloading and preprocessing the ImageNet data."
-
-# Build the TFRecords version of the ImageNet data.
-BUILD_SCRIPT="${WORK_DIR}/build_imagenet_data"
-OUTPUT_DIRECTORY="${DATA_DIR}"
-IMAGENET_METADATA_FILE="${WORK_DIR}/data/imagenet_metadata.txt"
-
-"${BUILD_SCRIPT}" \
- --train_directory="${TRAIN_DIRECTORY}" \
- --validation_directory="${VALIDATION_DIRECTORY}" \
- --output_directory="${OUTPUT_DIRECTORY}" \
- --imagenet_metadata_file="${IMAGENET_METADATA_FILE}" \
- --labels_file="${LABELS_FILE}" \
- --bounding_box_file="${BOUNDING_BOX_FILE}"
diff --git a/research/inception/inception/data/download_imagenet.sh b/research/inception/inception/data/download_imagenet.sh
deleted file mode 100755
index f6c77781c0bcaad642ec7a38a7ba00693ef8ef83..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/download_imagenet.sh
+++ /dev/null
@@ -1,104 +0,0 @@
-#!/bin/bash
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Script to download ImageNet Challenge 2012 training and validation data set.
-#
-# Downloads and decompresses raw images and bounding boxes.
-#
-# **IMPORTANT**
-# To download the raw images, the user must create an account with image-net.org
-# and generate a username and access_key. The latter two are required for
-# downloading the raw images.
-#
-# usage:
-# ./download_imagenet.sh [dir name] [synsets file]
-set -e
-
-if [ "x$IMAGENET_ACCESS_KEY" == x -o "x$IMAGENET_USERNAME" == x ]; then
- cat < ')
- sys.exit(-1)
- data_dir = sys.argv[1]
- validation_labels_file = sys.argv[2]
-
- # Read in the 50000 synsets associated with the validation data set.
- labels = [l.strip() for l in open(validation_labels_file).readlines()]
- unique_labels = set(labels)
-
- # Make all sub-directories in the validation data dir.
- for label in unique_labels:
- labeled_data_dir = os.path.join(data_dir, label)
- # Catch error if sub-directory exists
- try:
- os.makedirs(labeled_data_dir)
- except OSError as e:
- # Raise all errors but 'EEXIST'
- if e.errno != errno.EEXIST:
- raise
-
- # Move all of the image to the appropriate sub-directory.
- for i in range(len(labels)):
- basename = 'ILSVRC2012_val_000%.5d.JPEG' % (i + 1)
- original_filename = os.path.join(data_dir, basename)
- if not os.path.exists(original_filename):
- print('Failed to find: %s' % original_filename)
- sys.exit(-1)
- new_filename = os.path.join(data_dir, labels[i], basename)
- os.rename(original_filename, new_filename)
diff --git a/research/inception/inception/data/process_bounding_boxes.py b/research/inception/inception/data/process_bounding_boxes.py
deleted file mode 100755
index 5e9fd786e40b6d95b89fcc9f9774aa7f132c1a6f..0000000000000000000000000000000000000000
--- a/research/inception/inception/data/process_bounding_boxes.py
+++ /dev/null
@@ -1,254 +0,0 @@
-#!/usr/bin/python
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Process the ImageNet Challenge bounding boxes for TensorFlow model training.
-
-This script is called as
-
-process_bounding_boxes.py [synsets-file]
-
-Where is a directory containing the downloaded and unpacked bounding box
-data. If [synsets-file] is supplied, then only the bounding boxes whose
-synstes are contained within this file are returned. Note that the
-[synsets-file] file contains synset ids, one per line.
-
-The script dumps out a CSV text file in which each line contains an entry.
- n00007846_64193.JPEG,0.0060,0.2620,0.7545,0.9940
-
-The entry can be read as:
- , , , ,
-
-The bounding box for contains two points (xmin, ymin) and
-(xmax, ymax) specifying the lower-left corner and upper-right corner of a
-bounding box in *relative* coordinates.
-
-The user supplies a directory where the XML files reside. The directory
-structure in the directory is assumed to look like this:
-
-/nXXXXXXXX/nXXXXXXXX_YYYY.xml
-
-Each XML file contains a bounding box annotation. The script:
-
- (1) Parses the XML file and extracts the filename, label and bounding box info.
-
- (2) The bounding box is specified in the XML files as integer (xmin, ymin) and
- (xmax, ymax) *relative* to image size displayed to the human annotator. The
- size of the image displayed to the human annotator is stored in the XML file
- as integer (height, width).
-
- Note that the displayed size will differ from the actual size of the image
- downloaded from image-net.org. To make the bounding box annotation useable,
- we convert bounding box to floating point numbers relative to displayed
- height and width of the image.
-
- Note that each XML file might contain N bounding box annotations.
-
- Note that the points are all clamped at a range of [0.0, 1.0] because some
- human annotations extend outside the range of the supplied image.
-
- See details here: http://image-net.org/download-bboxes
-
-(3) By default, the script outputs all valid bounding boxes. If a
- [synsets-file] is supplied, only the subset of bounding boxes associated
- with those synsets are outputted. Importantly, one can supply a list of
- synsets in the ImageNet Challenge and output the list of bounding boxes
- associated with the training images of the ILSVRC.
-
- We use these bounding boxes to inform the random distortion of images
- supplied to the network.
-
-If you run this script successfully, you will see the following output
-to stderr:
-> Finished processing 544546 XML files.
-> Skipped 0 XML files not in ImageNet Challenge.
-> Skipped 0 bounding boxes not in ImageNet Challenge.
-> Wrote 615299 bounding boxes from 544546 annotated images.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import glob
-import os.path
-import sys
-import xml.etree.ElementTree as ET
-
-
-class BoundingBox(object):
- pass
-
-
-def GetItem(name, root, index=0):
- count = 0
- for item in root.iter(name):
- if count == index:
- return item.text
- count += 1
- # Failed to find "index" occurrence of item.
- return -1
-
-
-def GetInt(name, root, index=0):
- # In some XML annotation files, the point values are not integers, but floats.
- # So we add a float function to avoid ValueError.
- return int(float(GetItem(name, root, index)))
-
-
-def FindNumberBoundingBoxes(root):
- index = 0
- while True:
- if GetInt('xmin', root, index) == -1:
- break
- index += 1
- return index
-
-
-def ProcessXMLAnnotation(xml_file):
- """Process a single XML file containing a bounding box."""
- # pylint: disable=broad-except
- try:
- tree = ET.parse(xml_file)
- except Exception:
- print('Failed to parse: ' + xml_file, file=sys.stderr)
- return None
- # pylint: enable=broad-except
- root = tree.getroot()
-
- num_boxes = FindNumberBoundingBoxes(root)
- boxes = []
-
- for index in range(num_boxes):
- box = BoundingBox()
- # Grab the 'index' annotation.
- box.xmin = GetInt('xmin', root, index)
- box.ymin = GetInt('ymin', root, index)
- box.xmax = GetInt('xmax', root, index)
- box.ymax = GetInt('ymax', root, index)
-
- box.width = GetInt('width', root)
- box.height = GetInt('height', root)
- box.filename = GetItem('filename', root) + '.JPEG'
- box.label = GetItem('name', root)
-
- xmin = float(box.xmin) / float(box.width)
- xmax = float(box.xmax) / float(box.width)
- ymin = float(box.ymin) / float(box.height)
- ymax = float(box.ymax) / float(box.height)
-
- # Some images contain bounding box annotations that
- # extend outside of the supplied image. See, e.g.
- # n03127925/n03127925_147.xml
- # Additionally, for some bounding boxes, the min > max
- # or the box is entirely outside of the image.
- min_x = min(xmin, xmax)
- max_x = max(xmin, xmax)
- box.xmin_scaled = min(max(min_x, 0.0), 1.0)
- box.xmax_scaled = min(max(max_x, 0.0), 1.0)
-
- min_y = min(ymin, ymax)
- max_y = max(ymin, ymax)
- box.ymin_scaled = min(max(min_y, 0.0), 1.0)
- box.ymax_scaled = min(max(max_y, 0.0), 1.0)
-
- boxes.append(box)
-
- return boxes
-
-if __name__ == '__main__':
- if len(sys.argv) < 2 or len(sys.argv) > 3:
- print('Invalid usage\n'
- 'usage: process_bounding_boxes.py [synsets-file]',
- file=sys.stderr)
- sys.exit(-1)
-
- xml_files = glob.glob(sys.argv[1] + '/*/*.xml')
- print('Identified %d XML files in %s' % (len(xml_files), sys.argv[1]),
- file=sys.stderr)
-
- if len(sys.argv) == 3:
- labels = set([l.strip() for l in open(sys.argv[2]).readlines()])
- print('Identified %d synset IDs in %s' % (len(labels), sys.argv[2]),
- file=sys.stderr)
- else:
- labels = None
-
- skipped_boxes = 0
- skipped_files = 0
- saved_boxes = 0
- saved_files = 0
- for file_index, one_file in enumerate(xml_files):
- # Example: <...>/n06470073/n00141669_6790.xml
- label = os.path.basename(os.path.dirname(one_file))
-
- # Determine if the annotation is from an ImageNet Challenge label.
- if labels is not None and label not in labels:
- skipped_files += 1
- continue
-
- bboxes = ProcessXMLAnnotation(one_file)
- assert bboxes is not None, 'No bounding boxes found in ' + one_file
-
- found_box = False
- for bbox in bboxes:
- if labels is not None:
- if bbox.label != label:
- # Note: There is a slight bug in the bounding box annotation data.
- # Many of the dog labels have the human label 'Scottish_deerhound'
- # instead of the synset ID 'n02092002' in the bbox.label field. As a
- # simple hack to overcome this issue, we only exclude bbox labels
- # *which are synset ID's* that do not match original synset label for
- # the XML file.
- if bbox.label in labels:
- skipped_boxes += 1
- continue
-
- # Guard against improperly specified boxes.
- if (bbox.xmin_scaled >= bbox.xmax_scaled or
- bbox.ymin_scaled >= bbox.ymax_scaled):
- skipped_boxes += 1
- continue
-
- # Note bbox.filename occasionally contains '%s' in the name. This is
- # data set noise that is fixed by just using the basename of the XML file.
- image_filename = os.path.splitext(os.path.basename(one_file))[0]
- print('%s.JPEG,%.4f,%.4f,%.4f,%.4f' %
- (image_filename,
- bbox.xmin_scaled, bbox.ymin_scaled,
- bbox.xmax_scaled, bbox.ymax_scaled))
-
- saved_boxes += 1
- found_box = True
- if found_box:
- saved_files += 1
- else:
- skipped_files += 1
-
- if not file_index % 5000:
- print('--> processed %d of %d XML files.' %
- (file_index + 1, len(xml_files)),
- file=sys.stderr)
- print('--> skipped %d boxes and %d XML files.' %
- (skipped_boxes, skipped_files), file=sys.stderr)
-
- print('Finished processing %d XML files.' % len(xml_files), file=sys.stderr)
- print('Skipped %d XML files not in ImageNet Challenge.' % skipped_files,
- file=sys.stderr)
- print('Skipped %d bounding boxes not in ImageNet Challenge.' % skipped_boxes,
- file=sys.stderr)
- print('Wrote %d bounding boxes from %d annotated images.' %
- (saved_boxes, saved_files),
- file=sys.stderr)
- print('Finished.', file=sys.stderr)
diff --git a/research/inception/inception/dataset.py b/research/inception/inception/dataset.py
deleted file mode 100644
index 752c97e03b0361975d64b72892cc94333e353dfb..0000000000000000000000000000000000000000
--- a/research/inception/inception/dataset.py
+++ /dev/null
@@ -1,103 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Small library that points to a data set.
-
-Methods of Data class:
- data_files: Returns a python list of all (sharded) data set files.
- num_examples_per_epoch: Returns the number of examples in the data set.
- num_classes: Returns the number of classes in the data set.
- reader: Return a reader for a single entry from the data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from abc import ABCMeta
-from abc import abstractmethod
-import os
-
-
-import tensorflow as tf
-
-FLAGS = tf.app.flags.FLAGS
-
-# Basic model parameters.
-tf.app.flags.DEFINE_string('data_dir', '/tmp/mydata',
- """Path to the processed data, i.e. """
- """TFRecord of Example protos.""")
-
-
-class Dataset(object):
- """A simple class for handling data sets."""
- __metaclass__ = ABCMeta
-
- def __init__(self, name, subset):
- """Initialize dataset using a subset and the path to the data."""
- assert subset in self.available_subsets(), self.available_subsets()
- self.name = name
- self.subset = subset
-
- @abstractmethod
- def num_classes(self):
- """Returns the number of classes in the data set."""
- pass
- # return 10
-
- @abstractmethod
- def num_examples_per_epoch(self):
- """Returns the number of examples in the data subset."""
- pass
- # if self.subset == 'train':
- # return 10000
- # if self.subset == 'validation':
- # return 1000
-
- @abstractmethod
- def download_message(self):
- """Prints a download message for the Dataset."""
- pass
-
- def available_subsets(self):
- """Returns the list of available subsets."""
- return ['train', 'validation']
-
- def data_files(self):
- """Returns a python list of all (sharded) data subset files.
-
- Returns:
- python list of all (sharded) data set files.
- Raises:
- ValueError: if there are not data_files matching the subset.
- """
- tf_record_pattern = os.path.join(FLAGS.data_dir, '%s-*' % self.subset)
- data_files = tf.gfile.Glob(tf_record_pattern)
- if not data_files:
- print('No files found for dataset %s/%s at %s' % (self.name,
- self.subset,
- FLAGS.data_dir))
-
- self.download_message()
- exit(-1)
- return data_files
-
- def reader(self):
- """Return a reader for a single entry from the data set.
-
- See io_ops.py for details of Reader class.
-
- Returns:
- Reader object that reads the data set.
- """
- return tf.TFRecordReader()
diff --git a/research/inception/inception/flowers_data.py b/research/inception/inception/flowers_data.py
deleted file mode 100644
index 022b5234deef035a6150a54ed74445b510f1b148..0000000000000000000000000000000000000000
--- a/research/inception/inception/flowers_data.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Small library that points to the flowers data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-from inception.dataset import Dataset
-
-
-class FlowersData(Dataset):
- """Flowers data set."""
-
- def __init__(self, subset):
- super(FlowersData, self).__init__('Flowers', subset)
-
- def num_classes(self):
- """Returns the number of classes in the data set."""
- return 5
-
- def num_examples_per_epoch(self):
- """Returns the number of examples in the data subset."""
- if self.subset == 'train':
- return 3170
- if self.subset == 'validation':
- return 500
-
- def download_message(self):
- """Instruction to download and extract the tarball from Flowers website."""
-
- print('Failed to find any Flowers %s files'% self.subset)
- print('')
- print('If you have already downloaded and processed the data, then make '
- 'sure to set --data_dir to point to the directory containing the '
- 'location of the sharded TFRecords.\n')
- print('Please see README.md for instructions on how to build '
- 'the flowers dataset using download_and_preprocess_flowers.\n')
diff --git a/research/inception/inception/flowers_eval.py b/research/inception/inception/flowers_eval.py
deleted file mode 100644
index ae3e9dc14c8dc83368aa83f523ade92e12113554..0000000000000000000000000000000000000000
--- a/research/inception/inception/flowers_eval.py
+++ /dev/null
@@ -1,40 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A binary to evaluate Inception on the flowers data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from inception import inception_eval
-from inception.flowers_data import FlowersData
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def main(unused_argv=None):
- dataset = FlowersData(subset=FLAGS.subset)
- assert dataset.data_files()
- if tf.gfile.Exists(FLAGS.eval_dir):
- tf.gfile.DeleteRecursively(FLAGS.eval_dir)
- tf.gfile.MakeDirs(FLAGS.eval_dir)
- inception_eval.evaluate(dataset)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/flowers_train.py b/research/inception/inception/flowers_train.py
deleted file mode 100644
index 1f044a539d48ef6ce011831210b4bc31eba278f3..0000000000000000000000000000000000000000
--- a/research/inception/inception/flowers_train.py
+++ /dev/null
@@ -1,41 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A binary to train Inception on the flowers data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-import tensorflow as tf
-
-from inception import inception_train
-from inception.flowers_data import FlowersData
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def main(_):
- dataset = FlowersData(subset=FLAGS.subset)
- assert dataset.data_files()
- if tf.gfile.Exists(FLAGS.train_dir):
- tf.gfile.DeleteRecursively(FLAGS.train_dir)
- tf.gfile.MakeDirs(FLAGS.train_dir)
- inception_train.train(dataset)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/image_processing.py b/research/inception/inception/image_processing.py
deleted file mode 100644
index fe74f1b3c9958060b15f52df80b11606c7ccf343..0000000000000000000000000000000000000000
--- a/research/inception/inception/image_processing.py
+++ /dev/null
@@ -1,513 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Read and preprocess image data.
-
- Image processing occurs on a single image at a time. Image are read and
- preprocessed in parallel across multiple threads. The resulting images
- are concatenated together to form a single batch for training or evaluation.
-
- -- Provide processed image data for a network:
- inputs: Construct batches of evaluation examples of images.
- distorted_inputs: Construct batches of training examples of images.
- batch_inputs: Construct batches of training or evaluation examples of images.
-
- -- Data processing:
- parse_example_proto: Parses an Example proto containing a training example
- of an image.
-
- -- Image decoding:
- decode_jpeg: Decode a JPEG encoded string into a 3-D float32 Tensor.
-
- -- Image preprocessing:
- image_preprocessing: Decode and preprocess one image for evaluation or training
- distort_image: Distort one image for training a network.
- eval_image: Prepare one image for evaluation.
- distort_color: Distort the color in one image for training.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_integer('batch_size', 32,
- """Number of images to process in a batch.""")
-tf.app.flags.DEFINE_integer('image_size', 299,
- """Provide square images of this size.""")
-tf.app.flags.DEFINE_integer('num_preprocess_threads', 4,
- """Number of preprocessing threads per tower. """
- """Please make this a multiple of 4.""")
-tf.app.flags.DEFINE_integer('num_readers', 4,
- """Number of parallel readers during train.""")
-
-# Images are preprocessed asynchronously using multiple threads specified by
-# --num_preprocss_threads and the resulting processed images are stored in a
-# random shuffling queue. The shuffling queue dequeues --batch_size images
-# for processing on a given Inception tower. A larger shuffling queue guarantees
-# better mixing across examples within a batch and results in slightly higher
-# predictive performance in a trained model. Empirically,
-# --input_queue_memory_factor=16 works well. A value of 16 implies a queue size
-# of 1024*16 images. Assuming RGB 299x299 images, this implies a queue size of
-# 16GB. If the machine is memory limited, then decrease this factor to
-# decrease the CPU memory footprint, accordingly.
-tf.app.flags.DEFINE_integer('input_queue_memory_factor', 16,
- """Size of the queue of preprocessed images. """
- """Default is ideal but try smaller values, e.g. """
- """4, 2 or 1, if host memory is constrained. See """
- """comments in code for more details.""")
-
-
-def inputs(dataset, batch_size=None, num_preprocess_threads=None):
- """Generate batches of ImageNet images for evaluation.
-
- Use this function as the inputs for evaluating a network.
-
- Note that some (minimal) image preprocessing occurs during evaluation
- including central cropping and resizing of the image to fit the network.
-
- Args:
- dataset: instance of Dataset class specifying the dataset.
- batch_size: integer, number of examples in batch
- num_preprocess_threads: integer, total number of preprocessing threads but
- None defaults to FLAGS.num_preprocess_threads.
-
- Returns:
- images: Images. 4D tensor of size [batch_size, FLAGS.image_size,
- image_size, 3].
- labels: 1-D integer Tensor of [FLAGS.batch_size].
- """
- if not batch_size:
- batch_size = FLAGS.batch_size
-
- # Force all input processing onto CPU in order to reserve the GPU for
- # the forward inference and back-propagation.
- with tf.device('/cpu:0'):
- images, labels = batch_inputs(
- dataset, batch_size, train=False,
- num_preprocess_threads=num_preprocess_threads,
- num_readers=1)
-
- return images, labels
-
-
-def distorted_inputs(dataset, batch_size=None, num_preprocess_threads=None):
- """Generate batches of distorted versions of ImageNet images.
-
- Use this function as the inputs for training a network.
-
- Distorting images provides a useful technique for augmenting the data
- set during training in order to make the network invariant to aspects
- of the image that do not effect the label.
-
- Args:
- dataset: instance of Dataset class specifying the dataset.
- batch_size: integer, number of examples in batch
- num_preprocess_threads: integer, total number of preprocessing threads but
- None defaults to FLAGS.num_preprocess_threads.
-
- Returns:
- images: Images. 4D tensor of size [batch_size, FLAGS.image_size,
- FLAGS.image_size, 3].
- labels: 1-D integer Tensor of [batch_size].
- """
- if not batch_size:
- batch_size = FLAGS.batch_size
-
- # Force all input processing onto CPU in order to reserve the GPU for
- # the forward inference and back-propagation.
- with tf.device('/cpu:0'):
- images, labels = batch_inputs(
- dataset, batch_size, train=True,
- num_preprocess_threads=num_preprocess_threads,
- num_readers=FLAGS.num_readers)
- return images, labels
-
-
-def decode_jpeg(image_buffer, scope=None):
- """Decode a JPEG string into one 3-D float image Tensor.
-
- Args:
- image_buffer: scalar string Tensor.
- scope: Optional scope for name_scope.
- Returns:
- 3-D float Tensor with values ranging from [0, 1).
- """
- with tf.name_scope(values=[image_buffer], name=scope,
- default_name='decode_jpeg'):
- # Decode the string as an RGB JPEG.
- # Note that the resulting image contains an unknown height and width
- # that is set dynamically by decode_jpeg. In other words, the height
- # and width of image is unknown at compile-time.
- image = tf.image.decode_jpeg(image_buffer, channels=3)
-
- # After this point, all image pixels reside in [0,1)
- # until the very end, when they're rescaled to (-1, 1). The various
- # adjust_* ops all require this range for dtype float.
- image = tf.image.convert_image_dtype(image, dtype=tf.float32)
- return image
-
-
-def distort_color(image, thread_id=0, scope=None):
- """Distort the color of the image.
-
- Each color distortion is non-commutative and thus ordering of the color ops
- matters. Ideally we would randomly permute the ordering of the color ops.
- Rather than adding that level of complication, we select a distinct ordering
- of color ops for each preprocessing thread.
-
- Args:
- image: Tensor containing single image.
- thread_id: preprocessing thread ID.
- scope: Optional scope for name_scope.
- Returns:
- color-distorted image
- """
- with tf.name_scope(values=[image], name=scope, default_name='distort_color'):
- color_ordering = thread_id % 2
-
- if color_ordering == 0:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.2)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- elif color_ordering == 1:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.2)
-
- # The random_* ops do not necessarily clamp.
- image = tf.clip_by_value(image, 0.0, 1.0)
- return image
-
-
-def distort_image(image, height, width, bbox, thread_id=0, scope=None):
- """Distort one image for training a network.
-
- Distorting images provides a useful technique for augmenting the data
- set during training in order to make the network invariant to aspects
- of the image that do not effect the label.
-
- Args:
- image: 3-D float Tensor of image
- height: integer
- width: integer
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged
- as [ymin, xmin, ymax, xmax].
- thread_id: integer indicating the preprocessing thread.
- scope: Optional scope for name_scope.
- Returns:
- 3-D float Tensor of distorted image used for training.
- """
- with tf.name_scope(values=[image, height, width, bbox], name=scope,
- default_name='distort_image'):
- # Each bounding box has shape [1, num_boxes, box coords] and
- # the coordinates are ordered [ymin, xmin, ymax, xmax].
-
- # Display the bounding box in the first thread only.
- if not thread_id:
- image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
- bbox)
- tf.summary.image('image_with_bounding_boxes', image_with_box)
-
- # A large fraction of image datasets contain a human-annotated bounding
- # box delineating the region of the image containing the object of interest.
- # We choose to create a new bounding box for the object which is a randomly
- # distorted version of the human-annotated bounding box that obeys an allowed
- # range of aspect ratios, sizes and overlap with the human-annotated
- # bounding box. If no box is supplied, then we assume the bounding box is
- # the entire image.
- sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
- tf.shape(image),
- bounding_boxes=bbox,
- min_object_covered=0.1,
- aspect_ratio_range=[0.75, 1.33],
- area_range=[0.05, 1.0],
- max_attempts=100,
- use_image_if_no_bounding_boxes=True)
- bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box
- if not thread_id:
- image_with_distorted_box = tf.image.draw_bounding_boxes(
- tf.expand_dims(image, 0), distort_bbox)
- tf.summary.image('images_with_distorted_bounding_box',
- image_with_distorted_box)
-
- # Crop the image to the specified bounding box.
- distorted_image = tf.slice(image, bbox_begin, bbox_size)
-
- # This resizing operation may distort the images because the aspect
- # ratio is not respected. We select a resize method in a round robin
- # fashion based on the thread number.
- # Note that ResizeMethod contains 4 enumerated resizing methods.
- resize_method = thread_id % 4
- distorted_image = tf.image.resize_images(distorted_image, [height, width],
- method=resize_method)
- # Restore the shape since the dynamic slice based upon the bbox_size loses
- # the third dimension.
- distorted_image.set_shape([height, width, 3])
- if not thread_id:
- tf.summary.image('cropped_resized_image',
- tf.expand_dims(distorted_image, 0))
-
- # Randomly flip the image horizontally.
- distorted_image = tf.image.random_flip_left_right(distorted_image)
-
- # Randomly distort the colors.
- distorted_image = distort_color(distorted_image, thread_id)
-
- if not thread_id:
- tf.summary.image('final_distorted_image',
- tf.expand_dims(distorted_image, 0))
- return distorted_image
-
-
-def eval_image(image, height, width, scope=None):
- """Prepare one image for evaluation.
-
- Args:
- image: 3-D float Tensor
- height: integer
- width: integer
- scope: Optional scope for name_scope.
- Returns:
- 3-D float Tensor of prepared image.
- """
- with tf.name_scope(values=[image, height, width], name=scope,
- default_name='eval_image'):
- # Crop the central region of the image with an area containing 87.5% of
- # the original image.
- image = tf.image.central_crop(image, central_fraction=0.875)
-
- # Resize the image to the original height and width.
- image = tf.expand_dims(image, 0)
- image = tf.image.resize_bilinear(image, [height, width],
- align_corners=False)
- image = tf.squeeze(image, [0])
- return image
-
-
-def image_preprocessing(image_buffer, bbox, train, thread_id=0):
- """Decode and preprocess one image for evaluation or training.
-
- Args:
- image_buffer: JPEG encoded string Tensor
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- train: boolean
- thread_id: integer indicating preprocessing thread
-
- Returns:
- 3-D float Tensor containing an appropriately scaled image
-
- Raises:
- ValueError: if user does not provide bounding box
- """
- if bbox is None:
- raise ValueError('Please supply a bounding box.')
-
- image = decode_jpeg(image_buffer)
- height = FLAGS.image_size
- width = FLAGS.image_size
-
- if train:
- image = distort_image(image, height, width, bbox, thread_id)
- else:
- image = eval_image(image, height, width)
-
- # Finally, rescale to [-1,1] instead of [0, 1)
- image = tf.subtract(image, 0.5)
- image = tf.multiply(image, 2.0)
- return image
-
-
-def parse_example_proto(example_serialized):
- """Parses an Example proto containing a training example of an image.
-
- The output of the build_image_data.py image preprocessing script is a dataset
- containing serialized Example protocol buffers. Each Example proto contains
- the following fields:
-
- image/height: 462
- image/width: 581
- image/colorspace: 'RGB'
- image/channels: 3
- image/class/label: 615
- image/class/synset: 'n03623198'
- image/class/text: 'knee pad'
- image/object/bbox/xmin: 0.1
- image/object/bbox/xmax: 0.9
- image/object/bbox/ymin: 0.2
- image/object/bbox/ymax: 0.6
- image/object/bbox/label: 615
- image/format: 'JPEG'
- image/filename: 'ILSVRC2012_val_00041207.JPEG'
- image/encoded:
-
- Args:
- example_serialized: scalar Tensor tf.string containing a serialized
- Example protocol buffer.
-
- Returns:
- image_buffer: Tensor tf.string containing the contents of a JPEG file.
- label: Tensor tf.int32 containing the label.
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- text: Tensor tf.string containing the human-readable label.
- """
- # Dense features in Example proto.
- feature_map = {
- 'image/encoded': tf.FixedLenFeature([], dtype=tf.string,
- default_value=''),
- 'image/class/label': tf.FixedLenFeature([1], dtype=tf.int64,
- default_value=-1),
- 'image/class/text': tf.FixedLenFeature([], dtype=tf.string,
- default_value=''),
- }
- sparse_float32 = tf.VarLenFeature(dtype=tf.float32)
- # Sparse features in Example proto.
- feature_map.update(
- {k: sparse_float32 for k in ['image/object/bbox/xmin',
- 'image/object/bbox/ymin',
- 'image/object/bbox/xmax',
- 'image/object/bbox/ymax']})
-
- features = tf.parse_single_example(example_serialized, feature_map)
- label = tf.cast(features['image/class/label'], dtype=tf.int32)
-
- xmin = tf.expand_dims(features['image/object/bbox/xmin'].values, 0)
- ymin = tf.expand_dims(features['image/object/bbox/ymin'].values, 0)
- xmax = tf.expand_dims(features['image/object/bbox/xmax'].values, 0)
- ymax = tf.expand_dims(features['image/object/bbox/ymax'].values, 0)
-
- # Note that we impose an ordering of (y, x) just to make life difficult.
- bbox = tf.concat(axis=0, values=[ymin, xmin, ymax, xmax])
-
- # Force the variable number of bounding boxes into the shape
- # [1, num_boxes, coords].
- bbox = tf.expand_dims(bbox, 0)
- bbox = tf.transpose(bbox, [0, 2, 1])
-
- return features['image/encoded'], label, bbox, features['image/class/text']
-
-
-def batch_inputs(dataset, batch_size, train, num_preprocess_threads=None,
- num_readers=1):
- """Contruct batches of training or evaluation examples from the image dataset.
-
- Args:
- dataset: instance of Dataset class specifying the dataset.
- See dataset.py for details.
- batch_size: integer
- train: boolean
- num_preprocess_threads: integer, total number of preprocessing threads
- num_readers: integer, number of parallel readers
-
- Returns:
- images: 4-D float Tensor of a batch of images
- labels: 1-D integer Tensor of [batch_size].
-
- Raises:
- ValueError: if data is not found
- """
- with tf.name_scope('batch_processing'):
- data_files = dataset.data_files()
- if data_files is None:
- raise ValueError('No data files found for this dataset')
-
- # Create filename_queue
- if train:
- filename_queue = tf.train.string_input_producer(data_files,
- shuffle=True,
- capacity=16)
- else:
- filename_queue = tf.train.string_input_producer(data_files,
- shuffle=False,
- capacity=1)
- if num_preprocess_threads is None:
- num_preprocess_threads = FLAGS.num_preprocess_threads
-
- if num_preprocess_threads % 4:
- raise ValueError('Please make num_preprocess_threads a multiple '
- 'of 4 (%d % 4 != 0).', num_preprocess_threads)
-
- if num_readers is None:
- num_readers = FLAGS.num_readers
-
- if num_readers < 1:
- raise ValueError('Please make num_readers at least 1')
-
- # Approximate number of examples per shard.
- examples_per_shard = 1024
- # Size the random shuffle queue to balance between good global
- # mixing (more examples) and memory use (fewer examples).
- # 1 image uses 299*299*3*4 bytes = 1MB
- # The default input_queue_memory_factor is 16 implying a shuffling queue
- # size: examples_per_shard * 16 * 1MB = 17.6GB
- min_queue_examples = examples_per_shard * FLAGS.input_queue_memory_factor
- if train:
- examples_queue = tf.RandomShuffleQueue(
- capacity=min_queue_examples + 3 * batch_size,
- min_after_dequeue=min_queue_examples,
- dtypes=[tf.string])
- else:
- examples_queue = tf.FIFOQueue(
- capacity=examples_per_shard + 3 * batch_size,
- dtypes=[tf.string])
-
- # Create multiple readers to populate the queue of examples.
- if num_readers > 1:
- enqueue_ops = []
- for _ in range(num_readers):
- reader = dataset.reader()
- _, value = reader.read(filename_queue)
- enqueue_ops.append(examples_queue.enqueue([value]))
-
- tf.train.queue_runner.add_queue_runner(
- tf.train.queue_runner.QueueRunner(examples_queue, enqueue_ops))
- example_serialized = examples_queue.dequeue()
- else:
- reader = dataset.reader()
- _, example_serialized = reader.read(filename_queue)
-
- images_and_labels = []
- for thread_id in range(num_preprocess_threads):
- # Parse a serialized Example proto to extract the image and metadata.
- image_buffer, label_index, bbox, _ = parse_example_proto(
- example_serialized)
- image = image_preprocessing(image_buffer, bbox, train, thread_id)
- images_and_labels.append([image, label_index])
-
- images, label_index_batch = tf.train.batch_join(
- images_and_labels,
- batch_size=batch_size,
- capacity=2 * num_preprocess_threads * batch_size)
-
- # Reshape images into these desired dimensions.
- height = FLAGS.image_size
- width = FLAGS.image_size
- depth = 3
-
- images = tf.cast(images, tf.float32)
- images = tf.reshape(images, shape=[batch_size, height, width, depth])
-
- # Display the training images in the visualizer.
- tf.summary.image('images', images)
-
- return images, tf.reshape(label_index_batch, [batch_size])
diff --git a/research/inception/inception/imagenet_data.py b/research/inception/inception/imagenet_data.py
deleted file mode 100644
index 0a6d22e1292632f0899355d5aa7183c3f5f33b2c..0000000000000000000000000000000000000000
--- a/research/inception/inception/imagenet_data.py
+++ /dev/null
@@ -1,59 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Small library that points to the ImageNet data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-from inception.dataset import Dataset
-
-
-class ImagenetData(Dataset):
- """ImageNet data set."""
-
- def __init__(self, subset):
- super(ImagenetData, self).__init__('ImageNet', subset)
-
- def num_classes(self):
- """Returns the number of classes in the data set."""
- return 1000
-
- def num_examples_per_epoch(self):
- """Returns the number of examples in the data set."""
- # Bounding box data consists of 615299 bounding boxes for 544546 images.
- if self.subset == 'train':
- return 1281167
- if self.subset == 'validation':
- return 50000
-
- def download_message(self):
- """Instruction to download and extract the tarball from Flowers website."""
-
- print('Failed to find any ImageNet %s files'% self.subset)
- print('')
- print('If you have already downloaded and processed the data, then make '
- 'sure to set --data_dir to point to the directory containing the '
- 'location of the sharded TFRecords.\n')
- print('If you have not downloaded and prepared the ImageNet data in the '
- 'TFRecord format, you will need to do this at least once. This '
- 'process could take several hours depending on the speed of your '
- 'computer and network connection\n')
- print('Please see README.md for instructions on how to build '
- 'the ImageNet dataset using download_and_preprocess_imagenet.\n')
- print('Note that the raw data size is 300 GB and the processed data size '
- 'is 150 GB. Please ensure you have at least 500GB disk space.')
diff --git a/research/inception/inception/imagenet_distributed_train.py b/research/inception/inception/imagenet_distributed_train.py
deleted file mode 100644
index f3615e012f042649b52e37aeaeeb2c3efc07f92c..0000000000000000000000000000000000000000
--- a/research/inception/inception/imagenet_distributed_train.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-# pylint: disable=line-too-long
-"""A binary to train Inception in a distributed manner using multiple systems.
-
-Please see accompanying README.md for details and instructions.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception import inception_distributed_train
-from inception.imagenet_data import ImagenetData
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def main(unused_args):
- assert FLAGS.job_name in ['ps', 'worker'], 'job_name must be ps or worker'
-
- # Extract all the hostnames for the ps and worker jobs to construct the
- # cluster spec.
- ps_hosts = FLAGS.ps_hosts.split(',')
- worker_hosts = FLAGS.worker_hosts.split(',')
- tf.logging.info('PS hosts are: %s' % ps_hosts)
- tf.logging.info('Worker hosts are: %s' % worker_hosts)
-
- cluster_spec = tf.train.ClusterSpec({'ps': ps_hosts,
- 'worker': worker_hosts})
- server = tf.train.Server(
- {'ps': ps_hosts,
- 'worker': worker_hosts},
- job_name=FLAGS.job_name,
- task_index=FLAGS.task_id,
- protocol=FLAGS.protocol)
-
- if FLAGS.job_name == 'ps':
- # `ps` jobs wait for incoming connections from the workers.
- server.join()
- else:
- # `worker` jobs will actually do the work.
- dataset = ImagenetData(subset=FLAGS.subset)
- assert dataset.data_files()
- # Only the chief checks for or creates train_dir.
- if FLAGS.task_id == 0:
- if not tf.gfile.Exists(FLAGS.train_dir):
- tf.gfile.MakeDirs(FLAGS.train_dir)
- inception_distributed_train.train(server.target, dataset, cluster_spec)
-
-if __name__ == '__main__':
- tf.logging.set_verbosity(tf.logging.INFO)
- tf.app.run()
diff --git a/research/inception/inception/imagenet_eval.py b/research/inception/inception/imagenet_eval.py
deleted file mode 100644
index e6f8bac2ee71021914715172296d63dd56b5a6f9..0000000000000000000000000000000000000000
--- a/research/inception/inception/imagenet_eval.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A binary to evaluate Inception on the ImageNet data set.
-
-Note that using the supplied pre-trained inception checkpoint, the eval should
-achieve:
- precision @ 1 = 0.7874 recall @ 5 = 0.9436 [50000 examples]
-
-See the README.md for more details.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from inception import inception_eval
-from inception.imagenet_data import ImagenetData
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def main(unused_argv=None):
- dataset = ImagenetData(subset=FLAGS.subset)
- assert dataset.data_files()
- if tf.gfile.Exists(FLAGS.eval_dir):
- tf.gfile.DeleteRecursively(FLAGS.eval_dir)
- tf.gfile.MakeDirs(FLAGS.eval_dir)
- inception_eval.evaluate(dataset)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/imagenet_train.py b/research/inception/inception/imagenet_train.py
deleted file mode 100644
index 3ffb55ee963e5b9f8e31915a78eef518324642aa..0000000000000000000000000000000000000000
--- a/research/inception/inception/imagenet_train.py
+++ /dev/null
@@ -1,41 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A binary to train Inception on the ImageNet data set.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-
-import tensorflow as tf
-
-from inception import inception_train
-from inception.imagenet_data import ImagenetData
-
-FLAGS = tf.app.flags.FLAGS
-
-
-def main(_):
- dataset = ImagenetData(subset=FLAGS.subset)
- assert dataset.data_files()
- if tf.gfile.Exists(FLAGS.train_dir):
- tf.gfile.DeleteRecursively(FLAGS.train_dir)
- tf.gfile.MakeDirs(FLAGS.train_dir)
- inception_train.train(dataset)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/inception/inception/inception_distributed_train.py b/research/inception/inception/inception_distributed_train.py
deleted file mode 100644
index c1a589acb5fe386fd648ae3fae926ee927c0ca79..0000000000000000000000000000000000000000
--- a/research/inception/inception/inception_distributed_train.py
+++ /dev/null
@@ -1,314 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A library to train Inception using multiple replicas with synchronous update.
-
-Please see accompanying README.md for details and instructions.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from datetime import datetime
-import os.path
-import time
-
-import numpy as np
-import tensorflow as tf
-
-from inception import image_processing
-from inception import inception_model as inception
-from inception.slim import slim
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_string('job_name', '', 'One of "ps", "worker"')
-tf.app.flags.DEFINE_string('ps_hosts', '',
- """Comma-separated list of hostname:port for the """
- """parameter server jobs. e.g. """
- """'machine1:2222,machine2:1111,machine2:2222'""")
-tf.app.flags.DEFINE_string('worker_hosts', '',
- """Comma-separated list of hostname:port for the """
- """worker jobs. e.g. """
- """'machine1:2222,machine2:1111,machine2:2222'""")
-tf.app.flags.DEFINE_string('protocol', 'grpc',
- """Communication protocol to use in distributed """
- """execution (default grpc) """)
-
-tf.app.flags.DEFINE_string('train_dir', '/tmp/imagenet_train',
- """Directory where to write event logs """
- """and checkpoint.""")
-tf.app.flags.DEFINE_integer('max_steps', 1000000, 'Number of batches to run.')
-tf.app.flags.DEFINE_string('subset', 'train', 'Either "train" or "validation".')
-tf.app.flags.DEFINE_boolean('log_device_placement', False,
- 'Whether to log device placement.')
-
-# Task ID is used to select the chief and also to access the local_step for
-# each replica to check staleness of the gradients in SyncReplicasOptimizer.
-tf.app.flags.DEFINE_integer(
- 'task_id', 0, 'Task ID of the worker/replica running the training.')
-
-# More details can be found in the SyncReplicasOptimizer class:
-# tensorflow/python/training/sync_replicas_optimizer.py
-tf.app.flags.DEFINE_integer('num_replicas_to_aggregate', -1,
- """Number of gradients to collect before """
- """updating the parameters.""")
-tf.app.flags.DEFINE_integer('save_interval_secs', 10 * 60,
- 'Save interval seconds.')
-tf.app.flags.DEFINE_integer('save_summaries_secs', 180,
- 'Save summaries interval seconds.')
-
-# **IMPORTANT**
-# Please note that this learning rate schedule is heavily dependent on the
-# hardware architecture, batch size and any changes to the model architecture
-# specification. Selecting a finely tuned learning rate schedule is an
-# empirical process that requires some experimentation. Please see README.md
-# more guidance and discussion.
-#
-# Learning rate decay factor selected from https://arxiv.org/abs/1604.00981
-tf.app.flags.DEFINE_float('initial_learning_rate', 0.045,
- 'Initial learning rate.')
-tf.app.flags.DEFINE_float('num_epochs_per_decay', 2.0,
- 'Epochs after which learning rate decays.')
-tf.app.flags.DEFINE_float('learning_rate_decay_factor', 0.94,
- 'Learning rate decay factor.')
-
-# Constants dictating the learning rate schedule.
-RMSPROP_DECAY = 0.9 # Decay term for RMSProp.
-RMSPROP_MOMENTUM = 0.9 # Momentum in RMSProp.
-RMSPROP_EPSILON = 1.0 # Epsilon term for RMSProp.
-
-
-def train(target, dataset, cluster_spec):
- """Train Inception on a dataset for a number of steps."""
- # Number of workers and parameter servers are inferred from the workers and ps
- # hosts string.
- num_workers = len(cluster_spec.as_dict()['worker'])
- num_parameter_servers = len(cluster_spec.as_dict()['ps'])
- # If no value is given, num_replicas_to_aggregate defaults to be the number of
- # workers.
- if FLAGS.num_replicas_to_aggregate == -1:
- num_replicas_to_aggregate = num_workers
- else:
- num_replicas_to_aggregate = FLAGS.num_replicas_to_aggregate
-
- # Both should be greater than 0 in a distributed training.
- assert num_workers > 0 and num_parameter_servers > 0, (' num_workers and '
- 'num_parameter_servers'
- ' must be > 0.')
-
- # Choose worker 0 as the chief. Note that any worker could be the chief
- # but there should be only one chief.
- is_chief = (FLAGS.task_id == 0)
-
- # Ops are assigned to worker by default.
- with tf.device('/job:worker/task:%d' % FLAGS.task_id):
- # Variables and its related init/assign ops are assigned to ps.
- with slim.scopes.arg_scope(
- [slim.variables.variable, slim.variables.global_step],
- device=slim.variables.VariableDeviceChooser(num_parameter_servers)):
- # Create a variable to count the number of train() calls. This equals the
- # number of updates applied to the variables.
- global_step = slim.variables.global_step()
-
- # Calculate the learning rate schedule.
- num_batches_per_epoch = (dataset.num_examples_per_epoch() /
- FLAGS.batch_size)
- # Decay steps need to be divided by the number of replicas to aggregate.
- decay_steps = int(num_batches_per_epoch * FLAGS.num_epochs_per_decay /
- num_replicas_to_aggregate)
-
- # Decay the learning rate exponentially based on the number of steps.
- lr = tf.train.exponential_decay(FLAGS.initial_learning_rate,
- global_step,
- decay_steps,
- FLAGS.learning_rate_decay_factor,
- staircase=True)
- # Add a summary to track the learning rate.
- tf.summary.scalar('learning_rate', lr)
-
- # Create an optimizer that performs gradient descent.
- opt = tf.train.RMSPropOptimizer(lr,
- RMSPROP_DECAY,
- momentum=RMSPROP_MOMENTUM,
- epsilon=RMSPROP_EPSILON)
-
- images, labels = image_processing.distorted_inputs(
- dataset,
- batch_size=FLAGS.batch_size,
- num_preprocess_threads=FLAGS.num_preprocess_threads)
-
- # Number of classes in the Dataset label set plus 1.
- # Label 0 is reserved for an (unused) background class.
- num_classes = dataset.num_classes() + 1
- logits = inception.inference(images, num_classes, for_training=True)
- # Add classification loss.
- inception.loss(logits, labels)
-
- # Gather all of the losses including regularization losses.
- losses = tf.get_collection(slim.losses.LOSSES_COLLECTION)
- losses += tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
-
- total_loss = tf.add_n(losses, name='total_loss')
-
- if is_chief:
- # Compute the moving average of all individual losses and the
- # total loss.
- loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
- loss_averages_op = loss_averages.apply(losses + [total_loss])
-
- # Attach a scalar summmary to all individual losses and the total loss;
- # do the same for the averaged version of the losses.
- for l in losses + [total_loss]:
- loss_name = l.op.name
- # Name each loss as '(raw)' and name the moving average version of the
- # loss as the original loss name.
- tf.summary.scalar(loss_name + ' (raw)', l)
- tf.summary.scalar(loss_name, loss_averages.average(l))
-
- # Add dependency to compute loss_averages.
- with tf.control_dependencies([loss_averages_op]):
- total_loss = tf.identity(total_loss)
-
- # Track the moving averages of all trainable variables.
- # Note that we maintain a 'double-average' of the BatchNormalization
- # global statistics.
- # This is not needed when the number of replicas are small but important
- # for synchronous distributed training with tens of workers/replicas.
- exp_moving_averager = tf.train.ExponentialMovingAverage(
- inception.MOVING_AVERAGE_DECAY, global_step)
-
- variables_to_average = (
- tf.trainable_variables() + tf.moving_average_variables())
-
- # Add histograms for model variables.
- for var in variables_to_average:
- tf.summary.histogram(var.op.name, var)
-
- # Create synchronous replica optimizer.
- opt = tf.train.SyncReplicasOptimizer(
- opt,
- replicas_to_aggregate=num_replicas_to_aggregate,
- total_num_replicas=num_workers,
- variable_averages=exp_moving_averager,
- variables_to_average=variables_to_average)
-
- batchnorm_updates = tf.get_collection(slim.ops.UPDATE_OPS_COLLECTION)
- assert batchnorm_updates, 'Batchnorm updates are missing'
- batchnorm_updates_op = tf.group(*batchnorm_updates)
- # Add dependency to compute batchnorm_updates.
- with tf.control_dependencies([batchnorm_updates_op]):
- total_loss = tf.identity(total_loss)
-
- # Compute gradients with respect to the loss.
- grads = opt.compute_gradients(total_loss)
-
- # Add histograms for gradients.
- for grad, var in grads:
- if grad is not None:
- tf.summary.histogram(var.op.name + '/gradients', grad)
-
- apply_gradients_op = opt.apply_gradients(grads, global_step=global_step)
-
- with tf.control_dependencies([apply_gradients_op]):
- train_op = tf.identity(total_loss, name='train_op')
-
- # Get chief queue_runners and init_tokens, which is used to synchronize
- # replicas. More details can be found in SyncReplicasOptimizer.
- chief_queue_runners = [opt.get_chief_queue_runner()]
- init_tokens_op = opt.get_init_tokens_op()
-
- # Create a saver.
- saver = tf.train.Saver()
-
- # Build the summary operation based on the TF collection of Summaries.
- summary_op = tf.summary.merge_all()
-
- # Build an initialization operation to run below.
- init_op = tf.global_variables_initializer()
-
- # We run the summaries in the same thread as the training operations by
- # passing in None for summary_op to avoid a summary_thread being started.
- # Running summaries and training operations in parallel could run out of
- # GPU memory.
- sv = tf.train.Supervisor(is_chief=is_chief,
- logdir=FLAGS.train_dir,
- init_op=init_op,
- summary_op=None,
- global_step=global_step,
- saver=saver,
- save_model_secs=FLAGS.save_interval_secs)
-
- tf.logging.info('%s Supervisor' % datetime.now())
-
- sess_config = tf.ConfigProto(
- allow_soft_placement=True,
- log_device_placement=FLAGS.log_device_placement)
-
- # Get a session.
- sess = sv.prepare_or_wait_for_session(target, config=sess_config)
-
- # Start the queue runners.
- queue_runners = tf.get_collection(tf.GraphKeys.QUEUE_RUNNERS)
- sv.start_queue_runners(sess, queue_runners)
- tf.logging.info('Started %d queues for processing input data.',
- len(queue_runners))
-
- if is_chief:
- sv.start_queue_runners(sess, chief_queue_runners)
- sess.run(init_tokens_op)
-
- # Train, checking for Nans. Concurrently run the summary operation at a
- # specified interval. Note that the summary_op and train_op never run
- # simultaneously in order to prevent running out of GPU memory.
- next_summary_time = time.time() + FLAGS.save_summaries_secs
- while not sv.should_stop():
- try:
- start_time = time.time()
- loss_value, step = sess.run([train_op, global_step])
- assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
- if step > FLAGS.max_steps:
- break
- duration = time.time() - start_time
-
- if step % 30 == 0:
- examples_per_sec = FLAGS.batch_size / float(duration)
- format_str = ('Worker %d: %s: step %d, loss = %.2f'
- '(%.1f examples/sec; %.3f sec/batch)')
- tf.logging.info(format_str %
- (FLAGS.task_id, datetime.now(), step, loss_value,
- examples_per_sec, duration))
-
- # Determine if the summary_op should be run on the chief worker.
- if is_chief and next_summary_time < time.time():
- tf.logging.info('Running Summary operation on the chief.')
- summary_str = sess.run(summary_op)
- sv.summary_computed(sess, summary_str)
- tf.logging.info('Finished running Summary operation.')
-
- # Determine the next time for running the summary.
- next_summary_time += FLAGS.save_summaries_secs
- except:
- if is_chief:
- tf.logging.info('Chief got exception while running!')
- raise
-
- # Stop the supervisor. This also waits for service threads to finish.
- sv.stop()
-
- # Save after the training ends.
- if is_chief:
- saver.save(sess,
- os.path.join(FLAGS.train_dir, 'model.ckpt'),
- global_step=global_step)
diff --git a/research/inception/inception/inception_eval.py b/research/inception/inception/inception_eval.py
deleted file mode 100644
index e7cfc3c399dd82a915b3a49c7ddd4a8565292f69..0000000000000000000000000000000000000000
--- a/research/inception/inception/inception_eval.py
+++ /dev/null
@@ -1,171 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A library to evaluate Inception on a single GPU.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from datetime import datetime
-import math
-import os.path
-import time
-
-
-import numpy as np
-import tensorflow as tf
-
-from inception import image_processing
-from inception import inception_model as inception
-
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_string('eval_dir', '/tmp/imagenet_eval',
- """Directory where to write event logs.""")
-tf.app.flags.DEFINE_string('checkpoint_dir', '/tmp/imagenet_train',
- """Directory where to read model checkpoints.""")
-
-# Flags governing the frequency of the eval.
-tf.app.flags.DEFINE_integer('eval_interval_secs', 60 * 5,
- """How often to run the eval.""")
-tf.app.flags.DEFINE_boolean('run_once', False,
- """Whether to run eval only once.""")
-
-# Flags governing the data used for the eval.
-tf.app.flags.DEFINE_integer('num_examples', 50000,
- """Number of examples to run. Note that the eval """
- """ImageNet dataset contains 50000 examples.""")
-tf.app.flags.DEFINE_string('subset', 'validation',
- """Either 'validation' or 'train'.""")
-
-
-def _eval_once(saver, summary_writer, top_1_op, top_5_op, summary_op):
- """Runs Eval once.
-
- Args:
- saver: Saver.
- summary_writer: Summary writer.
- top_1_op: Top 1 op.
- top_5_op: Top 5 op.
- summary_op: Summary op.
- """
- with tf.Session() as sess:
- ckpt = tf.train.get_checkpoint_state(FLAGS.checkpoint_dir)
- if ckpt and ckpt.model_checkpoint_path:
- if os.path.isabs(ckpt.model_checkpoint_path):
- # Restores from checkpoint with absolute path.
- saver.restore(sess, ckpt.model_checkpoint_path)
- else:
- # Restores from checkpoint with relative path.
- saver.restore(sess, os.path.join(FLAGS.checkpoint_dir,
- ckpt.model_checkpoint_path))
-
- # Assuming model_checkpoint_path looks something like:
- # /my-favorite-path/imagenet_train/model.ckpt-0,
- # extract global_step from it.
- global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
- print('Successfully loaded model from %s at step=%s.' %
- (ckpt.model_checkpoint_path, global_step))
- else:
- print('No checkpoint file found')
- return
-
- # Start the queue runners.
- coord = tf.train.Coordinator()
- try:
- threads = []
- for qr in tf.get_collection(tf.GraphKeys.QUEUE_RUNNERS):
- threads.extend(qr.create_threads(sess, coord=coord, daemon=True,
- start=True))
-
- num_iter = int(math.ceil(FLAGS.num_examples / FLAGS.batch_size))
- # Counts the number of correct predictions.
- count_top_1 = 0.0
- count_top_5 = 0.0
- total_sample_count = num_iter * FLAGS.batch_size
- step = 0
-
- print('%s: starting evaluation on (%s).' % (datetime.now(), FLAGS.subset))
- start_time = time.time()
- while step < num_iter and not coord.should_stop():
- top_1, top_5 = sess.run([top_1_op, top_5_op])
- count_top_1 += np.sum(top_1)
- count_top_5 += np.sum(top_5)
- step += 1
- if step % 20 == 0:
- duration = time.time() - start_time
- sec_per_batch = duration / 20.0
- examples_per_sec = FLAGS.batch_size / sec_per_batch
- print('%s: [%d batches out of %d] (%.1f examples/sec; %.3f'
- 'sec/batch)' % (datetime.now(), step, num_iter,
- examples_per_sec, sec_per_batch))
- start_time = time.time()
-
- # Compute precision @ 1.
- precision_at_1 = count_top_1 / total_sample_count
- recall_at_5 = count_top_5 / total_sample_count
- print('%s: precision @ 1 = %.4f recall @ 5 = %.4f [%d examples]' %
- (datetime.now(), precision_at_1, recall_at_5, total_sample_count))
-
- summary = tf.Summary()
- summary.ParseFromString(sess.run(summary_op))
- summary.value.add(tag='Precision @ 1', simple_value=precision_at_1)
- summary.value.add(tag='Recall @ 5', simple_value=recall_at_5)
- summary_writer.add_summary(summary, global_step)
-
- except Exception as e: # pylint: disable=broad-except
- coord.request_stop(e)
-
- coord.request_stop()
- coord.join(threads, stop_grace_period_secs=10)
-
-
-def evaluate(dataset):
- """Evaluate model on Dataset for a number of steps."""
- with tf.Graph().as_default():
- # Get images and labels from the dataset.
- images, labels = image_processing.inputs(dataset)
-
- # Number of classes in the Dataset label set plus 1.
- # Label 0 is reserved for an (unused) background class.
- num_classes = dataset.num_classes() + 1
-
- # Build a Graph that computes the logits predictions from the
- # inference model.
- logits, _ = inception.inference(images, num_classes)
-
- # Calculate predictions.
- top_1_op = tf.nn.in_top_k(logits, labels, 1)
- top_5_op = tf.nn.in_top_k(logits, labels, 5)
-
- # Restore the moving average version of the learned variables for eval.
- variable_averages = tf.train.ExponentialMovingAverage(
- inception.MOVING_AVERAGE_DECAY)
- variables_to_restore = variable_averages.variables_to_restore()
- saver = tf.train.Saver(variables_to_restore)
-
- # Build the summary operation based on the TF collection of Summaries.
- summary_op = tf.summary.merge_all()
-
- graph_def = tf.get_default_graph().as_graph_def()
- summary_writer = tf.summary.FileWriter(FLAGS.eval_dir,
- graph_def=graph_def)
-
- while True:
- _eval_once(saver, summary_writer, top_1_op, top_5_op, summary_op)
- if FLAGS.run_once:
- break
- time.sleep(FLAGS.eval_interval_secs)
diff --git a/research/inception/inception/inception_model.py b/research/inception/inception/inception_model.py
deleted file mode 100644
index fedae13ae712f09d23ff020b161d86e87ee46e95..0000000000000000000000000000000000000000
--- a/research/inception/inception/inception_model.py
+++ /dev/null
@@ -1,157 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Build the Inception v3 network on ImageNet data set.
-
-The Inception v3 architecture is described in http://arxiv.org/abs/1512.00567
-
-Summary of available functions:
- inference: Compute inference on the model inputs to make a prediction
- loss: Compute the loss of the prediction with respect to the labels
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import re
-
-import tensorflow as tf
-
-from inception.slim import slim
-
-FLAGS = tf.app.flags.FLAGS
-
-# If a model is trained using multiple GPUs, prefix all Op names with tower_name
-# to differentiate the operations. Note that this prefix is removed from the
-# names of the summaries when visualizing a model.
-TOWER_NAME = 'tower'
-
-# Batch normalization. Constant governing the exponential moving average of
-# the 'global' mean and variance for all activations.
-BATCHNORM_MOVING_AVERAGE_DECAY = 0.9997
-
-# The decay to use for the moving average.
-MOVING_AVERAGE_DECAY = 0.9999
-
-
-def inference(images, num_classes, for_training=False, restore_logits=True,
- scope=None):
- """Build Inception v3 model architecture.
-
- See here for reference: http://arxiv.org/abs/1512.00567
-
- Args:
- images: Images returned from inputs() or distorted_inputs().
- num_classes: number of classes
- for_training: If set to `True`, build the inference model for training.
- Kernels that operate differently for inference during training
- e.g. dropout, are appropriately configured.
- restore_logits: whether or not the logits layers should be restored.
- Useful for fine-tuning a model with different num_classes.
- scope: optional prefix string identifying the ImageNet tower.
-
- Returns:
- Logits. 2-D float Tensor.
- Auxiliary Logits. 2-D float Tensor of side-head. Used for training only.
- """
- # Parameters for BatchNorm.
- batch_norm_params = {
- # Decay for the moving averages.
- 'decay': BATCHNORM_MOVING_AVERAGE_DECAY,
- # epsilon to prevent 0s in variance.
- 'epsilon': 0.001,
- }
- # Set weight_decay for weights in Conv and FC layers.
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], weight_decay=0.00004):
- with slim.arg_scope([slim.ops.conv2d],
- stddev=0.1,
- activation=tf.nn.relu,
- batch_norm_params=batch_norm_params):
- logits, endpoints = slim.inception.inception_v3(
- images,
- dropout_keep_prob=0.8,
- num_classes=num_classes,
- is_training=for_training,
- restore_logits=restore_logits,
- scope=scope)
-
- # Add summaries for viewing model statistics on TensorBoard.
- _activation_summaries(endpoints)
-
- # Grab the logits associated with the side head. Employed during training.
- auxiliary_logits = endpoints['aux_logits']
-
- return logits, auxiliary_logits
-
-
-def loss(logits, labels, batch_size=None):
- """Adds all losses for the model.
-
- Note the final loss is not returned. Instead, the list of losses are collected
- by slim.losses. The losses are accumulated in tower_loss() and summed to
- calculate the total loss.
-
- Args:
- logits: List of logits from inference(). Each entry is a 2-D float Tensor.
- labels: Labels from distorted_inputs or inputs(). 1-D tensor
- of shape [batch_size]
- batch_size: integer
- """
- if not batch_size:
- batch_size = FLAGS.batch_size
-
- # Reshape the labels into a dense Tensor of
- # shape [FLAGS.batch_size, num_classes].
- sparse_labels = tf.reshape(labels, [batch_size, 1])
- indices = tf.reshape(tf.range(batch_size), [batch_size, 1])
- concated = tf.concat(axis=1, values=[indices, sparse_labels])
- num_classes = logits[0].get_shape()[-1].value
- dense_labels = tf.sparse_to_dense(concated,
- [batch_size, num_classes],
- 1.0, 0.0)
-
- # Cross entropy loss for the main softmax prediction.
- slim.losses.cross_entropy_loss(logits[0],
- dense_labels,
- label_smoothing=0.1,
- weight=1.0)
-
- # Cross entropy loss for the auxiliary softmax head.
- slim.losses.cross_entropy_loss(logits[1],
- dense_labels,
- label_smoothing=0.1,
- weight=0.4,
- scope='aux_loss')
-
-
-def _activation_summary(x):
- """Helper to create summaries for activations.
-
- Creates a summary that provides a histogram of activations.
- Creates a summary that measure the sparsity of activations.
-
- Args:
- x: Tensor
- """
- # Remove 'tower_[0-9]/' from the name in case this is a multi-GPU training
- # session. This helps the clarity of presentation on tensorboard.
- tensor_name = re.sub('%s_[0-9]*/' % TOWER_NAME, '', x.op.name)
- tf.summary.histogram(tensor_name + '/activations', x)
- tf.summary.scalar(tensor_name + '/sparsity', tf.nn.zero_fraction(x))
-
-
-def _activation_summaries(endpoints):
- with tf.name_scope('summaries'):
- for act in endpoints.values():
- _activation_summary(act)
diff --git a/research/inception/inception/inception_train.py b/research/inception/inception/inception_train.py
deleted file mode 100644
index e1c32713b2012aec8a18637ec5dd79a1cc84d90f..0000000000000000000000000000000000000000
--- a/research/inception/inception/inception_train.py
+++ /dev/null
@@ -1,357 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""A library to train Inception using multiple GPUs with synchronous updates.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import copy
-from datetime import datetime
-import os.path
-import re
-import time
-
-import numpy as np
-import tensorflow as tf
-
-from inception import image_processing
-from inception import inception_model as inception
-from inception.slim import slim
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_string('train_dir', '/tmp/imagenet_train',
- """Directory where to write event logs """
- """and checkpoint.""")
-tf.app.flags.DEFINE_integer('max_steps', 10000000,
- """Number of batches to run.""")
-tf.app.flags.DEFINE_string('subset', 'train',
- """Either 'train' or 'validation'.""")
-
-# Flags governing the hardware employed for running TensorFlow.
-tf.app.flags.DEFINE_integer('num_gpus', 1,
- """How many GPUs to use.""")
-tf.app.flags.DEFINE_boolean('log_device_placement', False,
- """Whether to log device placement.""")
-
-# Flags governing the type of training.
-tf.app.flags.DEFINE_boolean('fine_tune', False,
- """If set, randomly initialize the final layer """
- """of weights in order to train the network on a """
- """new task.""")
-tf.app.flags.DEFINE_string('pretrained_model_checkpoint_path', '',
- """If specified, restore this pretrained model """
- """before beginning any training.""")
-
-# **IMPORTANT**
-# Please note that this learning rate schedule is heavily dependent on the
-# hardware architecture, batch size and any changes to the model architecture
-# specification. Selecting a finely tuned learning rate schedule is an
-# empirical process that requires some experimentation. Please see README.md
-# more guidance and discussion.
-#
-# With 8 Tesla K40's and a batch size = 256, the following setup achieves
-# precision@1 = 73.5% after 100 hours and 100K steps (20 epochs).
-# Learning rate decay factor selected from http://arxiv.org/abs/1404.5997.
-tf.app.flags.DEFINE_float('initial_learning_rate', 0.1,
- """Initial learning rate.""")
-tf.app.flags.DEFINE_float('num_epochs_per_decay', 30.0,
- """Epochs after which learning rate decays.""")
-tf.app.flags.DEFINE_float('learning_rate_decay_factor', 0.16,
- """Learning rate decay factor.""")
-
-# Constants dictating the learning rate schedule.
-RMSPROP_DECAY = 0.9 # Decay term for RMSProp.
-RMSPROP_MOMENTUM = 0.9 # Momentum in RMSProp.
-RMSPROP_EPSILON = 1.0 # Epsilon term for RMSProp.
-
-
-def _tower_loss(images, labels, num_classes, scope, reuse_variables=None):
- """Calculate the total loss on a single tower running the ImageNet model.
-
- We perform 'batch splitting'. This means that we cut up a batch across
- multiple GPUs. For instance, if the batch size = 32 and num_gpus = 2,
- then each tower will operate on an batch of 16 images.
-
- Args:
- images: Images. 4D tensor of size [batch_size, FLAGS.image_size,
- FLAGS.image_size, 3].
- labels: 1-D integer Tensor of [batch_size].
- num_classes: number of classes
- scope: unique prefix string identifying the ImageNet tower, e.g.
- 'tower_0'.
-
- Returns:
- Tensor of shape [] containing the total loss for a batch of data
- """
- # When fine-tuning a model, we do not restore the logits but instead we
- # randomly initialize the logits. The number of classes in the output of the
- # logit is the number of classes in specified Dataset.
- restore_logits = not FLAGS.fine_tune
-
- # Build inference Graph.
- with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables):
- logits = inception.inference(images, num_classes, for_training=True,
- restore_logits=restore_logits,
- scope=scope)
-
- # Build the portion of the Graph calculating the losses. Note that we will
- # assemble the total_loss using a custom function below.
- split_batch_size = images.get_shape().as_list()[0]
- inception.loss(logits, labels, batch_size=split_batch_size)
-
- # Assemble all of the losses for the current tower only.
- losses = tf.get_collection(slim.losses.LOSSES_COLLECTION, scope)
-
- # Calculate the total loss for the current tower.
- regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
- total_loss = tf.add_n(losses + regularization_losses, name='total_loss')
-
- # Compute the moving average of all individual losses and the total loss.
- loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
- loss_averages_op = loss_averages.apply(losses + [total_loss])
-
- # Attach a scalar summmary to all individual losses and the total loss; do the
- # same for the averaged version of the losses.
- for l in losses + [total_loss]:
- # Remove 'tower_[0-9]/' from the name in case this is a multi-GPU training
- # session. This helps the clarity of presentation on TensorBoard.
- loss_name = re.sub('%s_[0-9]*/' % inception.TOWER_NAME, '', l.op.name)
- # Name each loss as '(raw)' and name the moving average version of the loss
- # as the original loss name.
- tf.summary.scalar(loss_name +' (raw)', l)
- tf.summary.scalar(loss_name, loss_averages.average(l))
-
- with tf.control_dependencies([loss_averages_op]):
- total_loss = tf.identity(total_loss)
- return total_loss
-
-
-def _average_gradients(tower_grads):
- """Calculate the average gradient for each shared variable across all towers.
-
- Note that this function provides a synchronization point across all towers.
-
- Args:
- tower_grads: List of lists of (gradient, variable) tuples. The outer list
- is over individual gradients. The inner list is over the gradient
- calculation for each tower.
- Returns:
- List of pairs of (gradient, variable) where the gradient has been averaged
- across all towers.
- """
- average_grads = []
- for grad_and_vars in zip(*tower_grads):
- # Note that each grad_and_vars looks like the following:
- # ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
- grads = []
- for g, _ in grad_and_vars:
- # Add 0 dimension to the gradients to represent the tower.
- expanded_g = tf.expand_dims(g, 0)
-
- # Append on a 'tower' dimension which we will average over below.
- grads.append(expanded_g)
-
- # Average over the 'tower' dimension.
- grad = tf.concat(axis=0, values=grads)
- grad = tf.reduce_mean(grad, 0)
-
- # Keep in mind that the Variables are redundant because they are shared
- # across towers. So .. we will just return the first tower's pointer to
- # the Variable.
- v = grad_and_vars[0][1]
- grad_and_var = (grad, v)
- average_grads.append(grad_and_var)
- return average_grads
-
-
-def train(dataset):
- """Train on dataset for a number of steps."""
- with tf.Graph().as_default(), tf.device('/cpu:0'):
- # Create a variable to count the number of train() calls. This equals the
- # number of batches processed * FLAGS.num_gpus.
- global_step = tf.get_variable(
- 'global_step', [],
- initializer=tf.constant_initializer(0), trainable=False)
-
- # Calculate the learning rate schedule.
- num_batches_per_epoch = (dataset.num_examples_per_epoch() /
- FLAGS.batch_size)
- decay_steps = int(num_batches_per_epoch * FLAGS.num_epochs_per_decay)
-
- # Decay the learning rate exponentially based on the number of steps.
- lr = tf.train.exponential_decay(FLAGS.initial_learning_rate,
- global_step,
- decay_steps,
- FLAGS.learning_rate_decay_factor,
- staircase=True)
-
- # Create an optimizer that performs gradient descent.
- opt = tf.train.RMSPropOptimizer(lr, RMSPROP_DECAY,
- momentum=RMSPROP_MOMENTUM,
- epsilon=RMSPROP_EPSILON)
-
- # Get images and labels for ImageNet and split the batch across GPUs.
- assert FLAGS.batch_size % FLAGS.num_gpus == 0, (
- 'Batch size must be divisible by number of GPUs')
- split_batch_size = int(FLAGS.batch_size / FLAGS.num_gpus)
-
- # Override the number of preprocessing threads to account for the increased
- # number of GPU towers.
- num_preprocess_threads = FLAGS.num_preprocess_threads * FLAGS.num_gpus
- images, labels = image_processing.distorted_inputs(
- dataset,
- num_preprocess_threads=num_preprocess_threads)
-
- input_summaries = copy.copy(tf.get_collection(tf.GraphKeys.SUMMARIES))
-
- # Number of classes in the Dataset label set plus 1.
- # Label 0 is reserved for an (unused) background class.
- num_classes = dataset.num_classes() + 1
-
- # Split the batch of images and labels for towers.
- images_splits = tf.split(axis=0, num_or_size_splits=FLAGS.num_gpus, value=images)
- labels_splits = tf.split(axis=0, num_or_size_splits=FLAGS.num_gpus, value=labels)
-
- # Calculate the gradients for each model tower.
- tower_grads = []
- reuse_variables = None
- for i in range(FLAGS.num_gpus):
- with tf.device('/gpu:%d' % i):
- with tf.name_scope('%s_%d' % (inception.TOWER_NAME, i)) as scope:
- # Force all Variables to reside on the CPU.
- with slim.arg_scope([slim.variables.variable], device='/cpu:0'):
- # Calculate the loss for one tower of the ImageNet model. This
- # function constructs the entire ImageNet model but shares the
- # variables across all towers.
- loss = _tower_loss(images_splits[i], labels_splits[i], num_classes,
- scope, reuse_variables)
-
- # Reuse variables for the next tower.
- reuse_variables = True
-
- # Retain the summaries from the final tower.
- summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
-
- # Retain the Batch Normalization updates operations only from the
- # final tower. Ideally, we should grab the updates from all towers
- # but these stats accumulate extremely fast so we can ignore the
- # other stats from the other towers without significant detriment.
- batchnorm_updates = tf.get_collection(slim.ops.UPDATE_OPS_COLLECTION,
- scope)
-
- # Calculate the gradients for the batch of data on this ImageNet
- # tower.
- grads = opt.compute_gradients(loss)
-
- # Keep track of the gradients across all towers.
- tower_grads.append(grads)
-
- # We must calculate the mean of each gradient. Note that this is the
- # synchronization point across all towers.
- grads = _average_gradients(tower_grads)
-
- # Add a summaries for the input processing and global_step.
- summaries.extend(input_summaries)
-
- # Add a summary to track the learning rate.
- summaries.append(tf.summary.scalar('learning_rate', lr))
-
- # Add histograms for gradients.
- for grad, var in grads:
- if grad is not None:
- summaries.append(
- tf.summary.histogram(var.op.name + '/gradients', grad))
-
- # Apply the gradients to adjust the shared variables.
- apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
-
- # Add histograms for trainable variables.
- for var in tf.trainable_variables():
- summaries.append(tf.summary.histogram(var.op.name, var))
-
- # Track the moving averages of all trainable variables.
- # Note that we maintain a "double-average" of the BatchNormalization
- # global statistics. This is more complicated then need be but we employ
- # this for backward-compatibility with our previous models.
- variable_averages = tf.train.ExponentialMovingAverage(
- inception.MOVING_AVERAGE_DECAY, global_step)
-
- # Another possibility is to use tf.slim.get_variables().
- variables_to_average = (tf.trainable_variables() +
- tf.moving_average_variables())
- variables_averages_op = variable_averages.apply(variables_to_average)
-
- # Group all updates to into a single train op.
- batchnorm_updates_op = tf.group(*batchnorm_updates)
- train_op = tf.group(apply_gradient_op, variables_averages_op,
- batchnorm_updates_op)
-
- # Create a saver.
- saver = tf.train.Saver(tf.global_variables())
-
- # Build the summary operation from the last tower summaries.
- summary_op = tf.summary.merge(summaries)
-
- # Build an initialization operation to run below.
- init = tf.global_variables_initializer()
-
- # Start running operations on the Graph. allow_soft_placement must be set to
- # True to build towers on GPU, as some of the ops do not have GPU
- # implementations.
- sess = tf.Session(config=tf.ConfigProto(
- allow_soft_placement=True,
- log_device_placement=FLAGS.log_device_placement))
- sess.run(init)
-
- if FLAGS.pretrained_model_checkpoint_path:
- assert tf.gfile.Exists(FLAGS.pretrained_model_checkpoint_path)
- variables_to_restore = tf.get_collection(
- slim.variables.VARIABLES_TO_RESTORE)
- restorer = tf.train.Saver(variables_to_restore)
- restorer.restore(sess, FLAGS.pretrained_model_checkpoint_path)
- print('%s: Pre-trained model restored from %s' %
- (datetime.now(), FLAGS.pretrained_model_checkpoint_path))
-
- # Start the queue runners.
- tf.train.start_queue_runners(sess=sess)
-
- summary_writer = tf.summary.FileWriter(
- FLAGS.train_dir,
- graph=sess.graph)
-
- for step in range(FLAGS.max_steps):
- start_time = time.time()
- _, loss_value = sess.run([train_op, loss])
- duration = time.time() - start_time
-
- assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
-
- if step % 10 == 0:
- examples_per_sec = FLAGS.batch_size / float(duration)
- format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
- 'sec/batch)')
- print(format_str % (datetime.now(), step, loss_value,
- examples_per_sec, duration))
-
- if step % 100 == 0:
- summary_str = sess.run(summary_op)
- summary_writer.add_summary(summary_str, step)
-
- # Save the model checkpoint periodically.
- if step % 5000 == 0 or (step + 1) == FLAGS.max_steps:
- checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt')
- saver.save(sess, checkpoint_path, global_step=step)
diff --git a/research/inception/inception/slim/BUILD b/research/inception/inception/slim/BUILD
deleted file mode 100644
index 174e77d5c2654380232174a2bb8b29c6b9affc5d..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/BUILD
+++ /dev/null
@@ -1,112 +0,0 @@
-# Description:
-# Contains the operations and nets for building TensorFlow-Slim models.
-
-package(default_visibility = ["//inception:internal"])
-
-licenses(["notice"]) # Apache 2.0
-
-exports_files(["LICENSE"])
-
-py_library(
- name = "scopes",
- srcs = ["scopes.py"],
-)
-
-py_test(
- name = "scopes_test",
- size = "small",
- srcs = ["scopes_test.py"],
- deps = [
- ":scopes",
- ],
-)
-
-py_library(
- name = "variables",
- srcs = ["variables.py"],
- deps = [
- ":scopes",
- ],
-)
-
-py_test(
- name = "variables_test",
- size = "small",
- srcs = ["variables_test.py"],
- deps = [
- ":variables",
- ],
-)
-
-py_library(
- name = "losses",
- srcs = ["losses.py"],
-)
-
-py_test(
- name = "losses_test",
- size = "small",
- srcs = ["losses_test.py"],
- deps = [
- ":losses",
- ],
-)
-
-py_library(
- name = "ops",
- srcs = ["ops.py"],
- deps = [
- ":losses",
- ":scopes",
- ":variables",
- ],
-)
-
-py_test(
- name = "ops_test",
- size = "small",
- srcs = ["ops_test.py"],
- deps = [
- ":ops",
- ":variables",
- ],
-)
-
-py_library(
- name = "inception",
- srcs = ["inception_model.py"],
- deps = [
- ":ops",
- ":scopes",
- ],
-)
-
-py_test(
- name = "inception_test",
- size = "medium",
- srcs = ["inception_test.py"],
- deps = [
- ":inception",
- ],
-)
-
-py_library(
- name = "slim",
- srcs = ["slim.py"],
- deps = [
- ":inception",
- ":losses",
- ":ops",
- ":scopes",
- ":variables",
- ],
-)
-
-py_test(
- name = "collections_test",
- size = "small",
- srcs = ["collections_test.py"],
- deps = [
- ":slim",
- ],
-)
diff --git a/research/inception/inception/slim/README.md b/research/inception/inception/slim/README.md
deleted file mode 100644
index 36d8b7eb19ae47d8810ed97abe203aa34be50a75..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/README.md
+++ /dev/null
@@ -1,621 +0,0 @@
-# TensorFlow-Slim
-
-TF-Slim is a lightweight library for defining, training and evaluating models in
-TensorFlow. It enables defining complex networks quickly and concisely while
-keeping a model's architecture transparent and its hyperparameters explicit.
-
-[TOC]
-
-## Teaser
-
-As a demonstration of the simplicity of using TF-Slim, compare the simplicity of
-the code necessary for defining the entire [VGG](http://www.robots.ox.ac.uk/~vgg/research/very_deep/) network using TF-Slim to
-the lengthy and verbose nature of defining just the first three layers (out of
-16) using native tensorflow:
-
-```python{.good}
-# VGG16 in TF-Slim.
-def vgg16(inputs):
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], stddev=0.01, weight_decay=0.0005):
- net = slim.ops.repeat_op(2, inputs, slim.ops.conv2d, 64, [3, 3], scope='conv1')
- net = slim.ops.max_pool(net, [2, 2], scope='pool1')
- net = slim.ops.repeat_op(2, net, slim.ops.conv2d, 128, [3, 3], scope='conv2')
- net = slim.ops.max_pool(net, [2, 2], scope='pool2')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 256, [3, 3], scope='conv3')
- net = slim.ops.max_pool(net, [2, 2], scope='pool3')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv4')
- net = slim.ops.max_pool(net, [2, 2], scope='pool4')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv5')
- net = slim.ops.max_pool(net, [2, 2], scope='pool5')
- net = slim.ops.flatten(net, scope='flatten5')
- net = slim.ops.fc(net, 4096, scope='fc6')
- net = slim.ops.dropout(net, 0.5, scope='dropout6')
- net = slim.ops.fc(net, 4096, scope='fc7')
- net = slim.ops.dropout(net, 0.5, scope='dropout7')
- net = slim.ops.fc(net, 1000, activation=None, scope='fc8')
- return net
-```
-
-```python{.bad}
-# Layers 1-3 (out of 16) of VGG16 in native tensorflow.
-def vgg16(inputs):
- with tf.name_scope('conv1_1') as scope:
- kernel = tf.Variable(tf.truncated_normal([3, 3, 3, 64], dtype=tf.float32, stddev=1e-1), name='weights')
- conv = tf.nn.conv2d(inputs, kernel, [1, 1, 1, 1], padding='SAME')
- biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases')
- bias = tf.nn.bias_add(conv, biases)
- conv1 = tf.nn.relu(bias, name=scope)
- with tf.name_scope('conv1_2') as scope:
- kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 64], dtype=tf.float32, stddev=1e-1), name='weights')
- conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
- biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases')
- bias = tf.nn.bias_add(conv, biases)
- conv1 = tf.nn.relu(bias, name=scope)
- with tf.name_scope('pool1')
- pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool1')
-```
-
-## Why TF-Slim?
-
-TF-Slim offers several advantages over just the built-in tensorflow libraries:
-
-* Allows one to define models much more compactly by eliminating boilerplate
- code. This is accomplished through the use of [argument scoping](./scopes.py)
- and numerous high level [operations](./ops.py). These tools increase
- readability and maintainability, reduce the likelihood of an error from
- copy-and-pasting hyperparameter values and simplifies hyperparameter tuning.
-* Makes developing models simple by providing commonly used [loss functions](./losses.py)
-* Provides a concise [definition](./inception_model.py) of [Inception v3](http://arxiv.org/abs/1512.00567) network architecture ready to be used
- out-of-the-box or subsumed into new models.
-
-Additionally TF-Slim was designed with several principles in mind:
-
-* The various modules of TF-Slim (scopes, variables, ops, losses) are
- independent. This flexibility allows users to pick and choose components of
- TF-Slim completely à la carte.
-* TF-Slim is written using a Functional Programming style. That means it's
- super-lightweight and can be used right alongside any of TensorFlow's native
- operations.
-* Makes re-using network architectures easy. This allows users to build new
- networks on top of existing ones as well as fine-tuning pre-trained models
- on new tasks.
-
-## What are the various components of TF-Slim?
-
-TF-Slim is composed of several parts which were designed to exist independently.
-These include:
-
-* [scopes.py](./scopes.py): provides a new scope named `arg_scope` that allows
- a user to define default arguments for specific operations within that
- scope.
-* [variables.py](./variables.py): provides convenience wrappers for variable
- creation and manipulation.
-* [ops.py](./ops.py): provides high level operations for building models using
- tensorflow.
-* [losses.py](./losses.py): contains commonly used loss functions.
-
-## Defining Models
-
-Models can be succinctly defined using TF-Slim by combining its variables,
-operations and scopes. Each of these elements are defined below.
-
-### Variables
-
-Creating [`Variables`](https://www.tensorflow.org/how_tos/variables/index.html)
-in native tensorflow requires either a predefined value or an initialization
-mechanism (random, normally distributed). Furthermore, if a variable needs to be
-created on a specific device, such as a GPU, the specification must be [made
-explicit](https://www.tensorflow.org/how_tos/using_gpu/index.html). To alleviate
-the code required for variable creation, TF-Slim provides a set of thin wrapper
-functions in [variables.py](./variables.py) which allow callers to easily define
-variables.
-
-For example, to create a `weight` variable, initialize it using a truncated
-normal distribution, regularize it with an `l2_loss` and place it on the `CPU`,
-one need only declare the following:
-
-```python
-weights = variables.variable('weights',
- shape=[10, 10, 3 , 3],
- initializer=tf.truncated_normal_initializer(stddev=0.1),
- regularizer=lambda t: losses.l2_loss(t, weight=0.05),
- device='/cpu:0')
-```
-
-In addition to the functionality provided by `tf.Variable`, `slim.variables`
-keeps track of the variables created by `slim.ops` to define a model, which
-allows one to distinguish variables that belong to the model versus other
-variables.
-
-```python
-# Get all the variables defined by the model.
-model_variables = slim.variables.get_variables()
-
-# Get all the variables with the same given name, i.e. 'weights', 'biases'.
-weights = slim.variables.get_variables_by_name('weights')
-biases = slim.variables.get_variables_by_name('biases')
-
-# Get all the variables in VARIABLES_TO_RESTORE collection.
-variables_to_restore = tf.get_collection(slim.variables.VARIABLES_TO_RESTORE)
-
-
-weights = variables.variable('weights',
- shape=[10, 10, 3 , 3],
- initializer=tf.truncated_normal_initializer(stddev=0.1),
- regularizer=lambda t: losses.l2_loss(t, weight=0.05),
- device='/cpu:0')
-```
-
-### Operations (Layers)
-
-While the set of TensorFlow operations is quite extensive, builders of neural
-networks typically think of models in terms of "layers". A layer, such as a
-Convolutional Layer, a Fully Connected Layer or a BatchNorm Layer are more
-abstract than a single TensorFlow operation and typically involve many such
-operations. For example, a Convolutional Layer in a neural network is built
-using several steps:
-
-1. Creating the weight variables
-2. Creating the bias variables
-3. Convolving the weights with the input from the previous layer
-4. Adding the biases to the result of the convolution.
-
-In python code this can be rather laborious:
-
-```python
-input = ...
-with tf.name_scope('conv1_1') as scope:
- kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32,
- stddev=1e-1), name='weights')
- conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1], padding='SAME')
- biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32),
- trainable=True, name='biases')
- bias = tf.nn.bias_add(conv, biases)
- conv1 = tf.nn.relu(bias, name=scope)
-```
-
-To alleviate the need to duplicate this code repeatedly, TF-Slim provides a
-number of convenient operations defined at the (more abstract) level of neural
-network layers. For example, compare the code above to an invocation of the
-TF-Slim code:
-
-```python
-input = ...
-net = slim.ops.conv2d(input, [3, 3], 128, scope='conv1_1')
-```
-
-TF-Slim provides numerous operations used in building neural networks which
-roughly correspond to such layers. These include:
-
-Layer | TF-Slim Op
---------------------- | ------------------------
-Convolutional Layer | [ops.conv2d](./ops.py)
-Fully Connected Layer | [ops.fc](./ops.py)
-BatchNorm layer | [ops.batch_norm](./ops.py)
-Max Pooling Layer | [ops.max_pool](./ops.py)
-Avg Pooling Layer | [ops.avg_pool](./ops.py)
-Dropout Layer | [ops.dropout](./ops.py)
-
-[ops.py](./ops.py) also includes operations that are not really "layers" per se,
-but are often used to manipulate hidden unit representations during inference:
-
-Operation | TF-Slim Op
---------- | ---------------------
-Flatten | [ops.flatten](./ops.py)
-
-TF-Slim also provides a meta-operation called `repeat_op` that allows one to
-repeatedly perform the same operation. Consider the following snippet from the
-[VGG](https://www.robots.ox.ac.uk/~vgg/research/very_deep/) network whose layers
-perform several convolutions in a row between pooling layers:
-
-```python
-net = ...
-net = slim.ops.conv2d(net, 256, [3, 3], scope='conv3_1')
-net = slim.ops.conv2d(net, 256, [3, 3], scope='conv3_2')
-net = slim.ops.conv2d(net, 256, [3, 3], scope='conv3_3')
-net = slim.ops.max_pool(net, [2, 2], scope='pool3')
-```
-
-This clear duplication of code can be removed via a standard loop:
-
-```python
-net = ...
-for i in range(3):
- net = slim.ops.conv2d(net, 256, [3, 3], scope='conv3_' % (i+1))
-net = slim.ops.max_pool(net, [2, 2], scope='pool3')
-```
-
-While this does reduce the amount of duplication, it can be made even cleaner by
-using the `RepeatOp`:
-
-```python
-net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 256, [3, 3], scope='conv3')
-net = slim.ops.max_pool(net, [2, 2], scope='pool2')
-```
-
-Notice that the RepeatOp not only applies the same argument in-line, it also is
-smart enough to unroll the scopes such that the scopes assigned to each
-subsequent call of `ops.conv2d` is appended with an underscore and iteration
-number. More concretely, the scopes in the example above would be 'conv3_1',
-'conv3_2' and 'conv3_3'.
-
-### Scopes
-
-In addition to the types of scope mechanisms in TensorFlow ([name_scope](https://www.tensorflow.org/api_docs/python/framework.html#name_scope),
-[variable_scope](https://www.tensorflow.org/api_docs/python/state_ops.html#variable_scope),
-TF-Slim adds a new scoping mechanism called "argument scope" or [arg_scope](./scopes.py). This new scope allows a user to specify one or more operations and
-a set of arguments which will be passed to each of the operations defined in the
-`arg_scope`. This functionality is best illustrated by example. Consider the
-following code snippet:
-
-```python
-net = slim.ops.conv2d(inputs, 64, [11, 11], 4, padding='SAME', stddev=0.01, weight_decay=0.0005, scope='conv1')
-net = slim.ops.conv2d(net, 128, [11, 11], padding='VALID', stddev=0.01, weight_decay=0.0005, scope='conv2')
-net = slim.ops.conv2d(net, 256, [11, 11], padding='SAME', stddev=0.01, weight_decay=0.0005, scope='conv3')
-```
-
-It should be clear that these three Convolution layers share many of the same
-hyperparameters. Two have the same padding, all three have the same weight_decay
-and standard deviation of its weights. Not only do the duplicated values make
-the code more difficult to read, it also adds the addition burder to the writer
-of needing to doublecheck that all of the values are identical in each step. One
-solution would be to specify default values using variables:
-
-```python
-padding='SAME'
-stddev=0.01
-weight_decay=0.0005
-net = slim.ops.conv2d(inputs, 64, [11, 11], 4, padding=padding, stddev=stddev, weight_decay=weight_decay, scope='conv1')
-net = slim.ops.conv2d(net, 128, [11, 11], padding='VALID', stddev=stddev, weight_decay=weight_decay, scope='conv2')
-net = slim.ops.conv2d(net, 256, [11, 11], padding=padding, stddev=stddev, weight_decay=weight_decay, scope='conv3')
-
-```
-
-This solution ensures that all three convolutions share the exact same variable
-values but doesn't reduce the code clutter. By using an `arg_scope`, we can both
-ensure that each layer uses the same values and simplify the code:
-
-```python
- with slim.arg_scope([slim.ops.conv2d], padding='SAME', stddev=0.01, weight_decay=0.0005):
- net = slim.ops.conv2d(inputs, 64, [11, 11], scope='conv1')
- net = slim.ops.conv2d(net, 128, [11, 11], padding='VALID', scope='conv2')
- net = slim.ops.conv2d(net, 256, [11, 11], scope='conv3')
-```
-
-As the example illustrates, the use of arg_scope makes the code cleaner, simpler
-and easier to maintain. Notice that while argument values are specifed in the
-arg_scope, they can be overwritten locally. In particular, while the padding
-argument has been set to 'SAME', the second convolution overrides it with the
-value of 'VALID'.
-
-One can also nest `arg_scope`s and use multiple operations in the same scope.
-For example:
-
-```python
-with arg_scope([slim.ops.conv2d, slim.ops.fc], stddev=0.01, weight_decay=0.0005):
- with arg_scope([slim.ops.conv2d], padding='SAME'), slim.arg_scope([slim.ops.fc], bias=1.0):
- net = slim.ops.conv2d(inputs, 64, [11, 11], 4, padding='VALID', scope='conv1')
- net = slim.ops.conv2d(net, 256, [5, 5], stddev=0.03, scope='conv2')
- net = slim.ops.flatten(net)
- net = slim.ops.fc(net, 1000, activation=None, scope='fc')
-```
-
-In this example, the first `arg_scope` applies the same `stddev` and
-`weight_decay` arguments to the `conv2d` and `fc` ops in its scope. In the
-second `arg_scope`, additional default arguments to `conv2d` only are specified.
-
-In addition to `arg_scope`, TF-Slim provides several decorators that wrap the
-use of tensorflow arg scopes. These include `@AddArgScope`, `@AddNameScope`,
-`@AddVariableScope`, `@AddOpScope` and `@AddVariableOpScope`. To illustrate
-their use, consider the following example.
-
-```python
-def MyNewOp(inputs):
- varA = ...
- varB = ...
- outputs = tf.multiply(varA, inputs) + varB
- return outputs
-
-```
-
-In this example, the user has created a new op which creates two variables. To
-ensure that these variables exist within a certain variable scope (to avoid
-collisions with variables with the same name), in standard TF, the op must be
-called within a variable scope:
-
-```python
-inputs = ...
-with tf.variable_scope('layer1'):
- outputs = MyNewOp(inputs)
-```
-
-As an alternative, one can use TF-Slim's decorators to decorate the function and
-simplify the call:
-
-```python
-@AddVariableScope
-def MyNewOp(inputs):
- ...
- return outputs
-
-
-inputs = ...
-outputs = MyNewOp('layer1')
-```
-
-The `@AddVariableScope` decorater simply applies the `tf.variable_scope` scoping
-to the called function taking "layer1" as its argument. This allows the code to
-be written more concisely.
-
-### Losses
-
-The loss function defines a quantity that we want to minimize. For
-classification problems, this is typically the cross entropy between the true
-(one-hot) distribution and the predicted probability distribution across
-classes. For regression problems, this is often the sum-of-squares differences
-between the predicted and true values.
-
-Certain models, such as multi-task learning models, require the use of multiple
-loss functions simultaneously. In other words, the loss function ultimatey being
-minimized is the sum of various other loss functions. For example, consider a
-model that predicts both the type of scene in an image as well as the depth from
-the camera of each pixel. This model's loss function would be the sum of the
-classification loss and depth prediction loss.
-
-TF-Slim provides an easy-to-use mechanism for defining and keeping track of loss
-functions via the [losses.py](./losses.py) module. Consider the simple case
-where we want to train the VGG network:
-
-```python
-# Load the images and labels.
-images, labels = ...
-
-# Create the model.
-predictions = ...
-
-# Define the loss functions and get the total loss.
-loss = losses.cross_entropy_loss(predictions, labels)
-```
-
-In this example, we start by creating the model (using TF-Slim's VGG
-implementation), and add the standard classification loss. Now, lets turn to the
-case where we have a multi-task model that produces multiple outputs:
-
-```python
-# Load the images and labels.
-images, scene_labels, depth_labels = ...
-
-# Create the model.
-scene_predictions, depth_predictions = CreateMultiTaskModel(images)
-
-# Define the loss functions and get the total loss.
-classification_loss = slim.losses.cross_entropy_loss(scene_predictions, scene_labels)
-sum_of_squares_loss = slim.losses.l2loss(depth_predictions - depth_labels)
-
-# The following two lines have the same effect:
-total_loss1 = classification_loss + sum_of_squares_loss
-total_loss2 = tf.get_collection(slim.losses.LOSSES_COLLECTION)
-```
-
-In this example, we have two losses which we add by calling
-`losses.cross_entropy_loss` and `losses.l2loss`. We can obtain the
-total loss by adding them together (`total_loss1`) or by calling
-`losses.GetTotalLoss()`. How did this work? When you create a loss function via
-TF-Slim, TF-Slim adds the loss to a special TensorFlow collection of loss
-functions. This enables you to either manage the total loss manually, or allow
-TF-Slim to manage them for you.
-
-What if you want to let TF-Slim manage the losses for you but have a custom loss
-function? [losses.py](./losses.py) also has a function that adds this loss to
-TF-Slims collection. For example:
-
-```python
-# Load the images and labels.
-images, scene_labels, depth_labels, pose_labels = ...
-
-# Create the model.
-scene_predictions, depth_predictions, pose_predictions = CreateMultiTaskModel(images)
-
-# Define the loss functions and get the total loss.
-classification_loss = slim.losses.cross_entropy_loss(scene_predictions, scene_labels)
-sum_of_squares_loss = slim.losses.l2loss(depth_predictions - depth_labels)
-pose_loss = MyCustomLossFunction(pose_predictions, pose_labels)
-tf.add_to_collection(slim.losses.LOSSES_COLLECTION, pose_loss) # Letting TF-Slim know about the additional loss.
-
-# The following two lines have the same effect:
-total_loss1 = classification_loss + sum_of_squares_loss + pose_loss
-total_loss2 = losses.GetTotalLoss()
-```
-
-In this example, we can again either produce the total loss function manually or
-let TF-Slim know about the additional loss and let TF-Slim handle the losses.
-
-## Putting the Pieces Together
-
-By combining TF-Slim Variables, Operations and scopes, we can write a normally
-very complex network with very few lines of code. For example, the entire [VGG](https://www.robots.ox.ac.uk/~vgg/research/very_deep/) architecture can be
-defined with just the following snippet:
-
-```python
-with arg_scope([slim.ops.conv2d, slim.ops.fc], stddev=0.01, weight_decay=0.0005):
- net = slim.ops.repeat_op(2, inputs, slim.ops.conv2d, 64, [3, 3], scope='conv1')
- net = slim.ops.max_pool(net, [2, 2], scope='pool1')
- net = slim.ops.repeat_op(2, net, slim.ops.conv2d, 128, [3, 3], scope='conv2')
- net = slim.ops.max_pool(net, [2, 2], scope='pool2')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 256, [3, 3], scope='conv3')
- net = slim.ops.max_pool(net, [2, 2], scope='pool3')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv4')
- net = slim.ops.max_pool(net, [2, 2], scope='pool4')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv5')
- net = slim.ops.max_pool(net, [2, 2], scope='pool5')
- net = slim.ops.flatten(net, scope='flatten5')
- net = slim.ops.fc(net, 4096, scope='fc6')
- net = slim.ops.dropout(net, 0.5, scope='dropout6')
- net = slim.ops.fc(net, 4096, scope='fc7')
- net = slim.ops.dropout(net, 0.5, scope='dropout7')
- net = slim.ops.fc(net, 1000, activation=None, scope='fc8')
-return net
-```
-
-## Re-using previously defined network architectures and pre-trained models.
-
-### Brief Recap on Restoring Variables from a Checkpoint
-
-After a model has been trained, it can be restored using `tf.train.Saver()`
-which restores `Variables` from a given checkpoint. For many cases,
-`tf.train.Saver()` provides a simple mechanism to restore all or just a few
-variables.
-
-```python
-# Create some variables.
-v1 = tf.Variable(..., name="v1")
-v2 = tf.Variable(..., name="v2")
-...
-# Add ops to restore all the variables.
-restorer = tf.train.Saver()
-
-# Add ops to restore some variables.
-restorer = tf.train.Saver([v1, v2])
-
-# Later, launch the model, use the saver to restore variables from disk, and
-# do some work with the model.
-with tf.Session() as sess:
- # Restore variables from disk.
- restorer.restore(sess, "/tmp/model.ckpt")
- print("Model restored.")
- # Do some work with the model
- ...
-```
-
-See [Restoring Variables](https://www.tensorflow.org/versions/r0.7/how_tos/variables/index.html#restoring-variables)
-and [Choosing which Variables to Save and Restore](https://www.tensorflow.org/versions/r0.7/how_tos/variables/index.html#choosing-which-variables-to-save-and-restore)
-sections of the [Variables](https://www.tensorflow.org/versions/r0.7/how_tos/variables/index.html) page for
-more details.
-
-### Using slim.variables to Track which Variables need to be Restored
-
-It is often desirable to fine-tune a pre-trained model on an entirely new
-dataset or even a new task. In these situations, one must specify which layers
-of the model should be reused (and consequently loaded from a checkpoint) and
-which layers are new. Indicating which variables or layers should be restored is
-a process that quickly becomes cumbersome when done manually.
-
-To help keep track of which variables to restore, `slim.variables` provides a
-`restore` argument when creating each Variable. By default, all variables are
-marked as `restore=True`, which results in all variables defined by the model
-being restored.
-
-```python
-# Create some variables.
-v1 = slim.variables.variable(name="v1", ..., restore=False)
-v2 = slim.variables.variable(name="v2", ...) # By default restore=True
-...
-# Get list of variables to restore (which contains only 'v2')
-variables_to_restore = tf.get_collection(slim.variables.VARIABLES_TO_RESTORE)
-restorer = tf.train.Saver(variables_to_restore)
-with tf.Session() as sess:
- # Restore variables from disk.
- restorer.restore(sess, "/tmp/model.ckpt")
- print("Model restored.")
- # Do some work with the model
- ...
-```
-
-Additionally, every layer in `slim.ops` that creates slim.variables (such as
-`slim.ops.conv2d`, `slim.ops.fc`, `slim.ops.batch_norm`) also has a `restore`
-argument which controls whether the variables created by that layer should be
-restored or not.
-
-```python
-# Create a small network.
-net = slim.ops.conv2d(images, 32, [7, 7], stride=2, scope='conv1')
-net = slim.ops.conv2d(net, 64, [3, 3], scope='conv2')
-net = slim.ops.conv2d(net, 128, [3, 3], scope='conv3')
-net = slim.ops.max_pool(net, [3, 3], stride=2, scope='pool3')
-net = slim.ops.flatten(net)
-net = slim.ops.fc(net, 10, scope='logits', restore=False)
-...
-
-# VARIABLES_TO_RESTORE would contain the 'weights' and 'bias' defined by 'conv1'
-# 'conv2' and 'conv3' but not the ones defined by 'logits'
-variables_to_restore = tf.get_collection(slim.variables.VARIABLES_TO_RESTORE)
-
-# Create a restorer that would restore only the needed variables.
-restorer = tf.train.Saver(variables_to_restore)
-
-# Create a saver that would save all the variables (including 'logits').
-saver = tf.train.Saver()
-with tf.Session() as sess:
- # Restore variables from disk.
- restorer.restore(sess, "/tmp/model.ckpt")
- print("Model restored.")
-
- # Do some work with the model
- ...
- saver.save(sess, "/tmp/new_model.ckpt")
-```
-
-Note: When restoring variables from a checkpoint, the `Saver` locates the
-variable names in a checkpoint file and maps them to variables in the current
-graph. Above, we created a saver by passing to it a list of variables. In this
-case, the names of the variables to locate in the checkpoint file were
-implicitly obtained from each provided variable's `var.op.name`.
-
-This works well when the variable names in the checkpoint file match those in
-the graph. However, sometimes, we want to restore a model from a checkpoint
-whose variables have different names those in the current graph. In this case,
-we must provide the `Saver` a dictionary that maps from each checkpoint variable
-name to each graph variable. Consider the following example where the checkpoint
-variables names are obtained via a simple function:
-
-```python
-# Assuming that 'conv1/weights' should be restored from 'vgg16/conv1/weights'
-def name_in_checkpoint(var):
- return 'vgg16/' + var.op.name
-
-# Assuming that 'conv1/weights' and 'conv1/bias' should be restored from 'conv1/params1' and 'conv1/params2'
-def name_in_checkpoint(var):
- if "weights" in var.op.name:
- return var.op.name.replace("weights", "params1")
- if "bias" in var.op.name:
- return var.op.name.replace("bias", "params2")
-
-variables_to_restore = tf.get_collection(slim.variables.VARIABLES_TO_RESTORE)
-variables_to_restore = {name_in_checkpoint(var):var for var in variables_to_restore}
-restorer = tf.train.Saver(variables_to_restore)
-with tf.Session() as sess:
- # Restore variables from disk.
- restorer.restore(sess, "/tmp/model.ckpt")
-```
-
-### Reusing the VGG16 network defined in TF-Slim on a different task, i.e. PASCAL-VOC.
-
-Assuming one have already a pre-trained VGG16 model, one just need to replace
-the last layer `fc8` with a new layer `fc8_pascal` and use `restore=False`.
-
-```python
-def vgg16_pascal(inputs):
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], stddev=0.01, weight_decay=0.0005):
- net = slim.ops.repeat_op(2, inputs, slim.ops.conv2d, 64, [3, 3], scope='conv1')
- net = slim.ops.max_pool(net, [2, 2], scope='pool1')
- net = slim.ops.repeat_op(2, net, slim.ops.conv2d, 128, [3, 3], scope='conv2')
- net = slim.ops.max_pool(net, [2, 2], scope='pool2')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 256, [3, 3], scope='conv3')
- net = slim.ops.max_pool(net, [2, 2], scope='pool3')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv4')
- net = slim.ops.max_pool(net, [2, 2], scope='pool4')
- net = slim.ops.repeat_op(3, net, slim.ops.conv2d, 512, [3, 3], scope='conv5')
- net = slim.ops.max_pool(net, [2, 2], scope='pool5')
- net = slim.ops.flatten(net, scope='flatten5')
- net = slim.ops.fc(net, 4096, scope='fc6')
- net = slim.ops.dropout(net, 0.5, scope='dropout6')
- net = slim.ops.fc(net, 4096, scope='fc7')
- net = slim.ops.dropout(net, 0.5, scope='dropout7')
- # To reuse vgg16 on PASCAL-VOC, just change the last layer.
- net = slim.ops.fc(net, 21, activation=None, scope='fc8_pascal', restore=False)
- return net
-```
-
-## Authors
-
-Sergio Guadarrama and Nathan Silberman
diff --git a/research/inception/inception/slim/collections_test.py b/research/inception/inception/slim/collections_test.py
deleted file mode 100644
index 2a1f170edaaedae337df8e0b552a03dd82b263d4..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/collections_test.py
+++ /dev/null
@@ -1,181 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for inception."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception.slim import slim
-
-
-def get_variables(scope=None):
- return slim.variables.get_variables(scope)
-
-
-def get_variables_by_name(name):
- return slim.variables.get_variables_by_name(name)
-
-
-class CollectionsTest(tf.test.TestCase):
-
- def testVariables(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d],
- batch_norm_params={'decay': 0.9997}):
- slim.inception.inception_v3(inputs)
- self.assertEqual(len(get_variables()), 388)
- self.assertEqual(len(get_variables_by_name('weights')), 98)
- self.assertEqual(len(get_variables_by_name('biases')), 2)
- self.assertEqual(len(get_variables_by_name('beta')), 96)
- self.assertEqual(len(get_variables_by_name('gamma')), 0)
- self.assertEqual(len(get_variables_by_name('moving_mean')), 96)
- self.assertEqual(len(get_variables_by_name('moving_variance')), 96)
-
- def testVariablesWithoutBatchNorm(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d],
- batch_norm_params=None):
- slim.inception.inception_v3(inputs)
- self.assertEqual(len(get_variables()), 196)
- self.assertEqual(len(get_variables_by_name('weights')), 98)
- self.assertEqual(len(get_variables_by_name('biases')), 98)
- self.assertEqual(len(get_variables_by_name('beta')), 0)
- self.assertEqual(len(get_variables_by_name('gamma')), 0)
- self.assertEqual(len(get_variables_by_name('moving_mean')), 0)
- self.assertEqual(len(get_variables_by_name('moving_variance')), 0)
-
- def testVariablesByLayer(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d],
- batch_norm_params={'decay': 0.9997}):
- slim.inception.inception_v3(inputs)
- self.assertEqual(len(get_variables()), 388)
- self.assertEqual(len(get_variables('conv0')), 4)
- self.assertEqual(len(get_variables('conv1')), 4)
- self.assertEqual(len(get_variables('conv2')), 4)
- self.assertEqual(len(get_variables('conv3')), 4)
- self.assertEqual(len(get_variables('conv4')), 4)
- self.assertEqual(len(get_variables('mixed_35x35x256a')), 28)
- self.assertEqual(len(get_variables('mixed_35x35x288a')), 28)
- self.assertEqual(len(get_variables('mixed_35x35x288b')), 28)
- self.assertEqual(len(get_variables('mixed_17x17x768a')), 16)
- self.assertEqual(len(get_variables('mixed_17x17x768b')), 40)
- self.assertEqual(len(get_variables('mixed_17x17x768c')), 40)
- self.assertEqual(len(get_variables('mixed_17x17x768d')), 40)
- self.assertEqual(len(get_variables('mixed_17x17x768e')), 40)
- self.assertEqual(len(get_variables('mixed_8x8x2048a')), 36)
- self.assertEqual(len(get_variables('mixed_8x8x2048b')), 36)
- self.assertEqual(len(get_variables('logits')), 2)
- self.assertEqual(len(get_variables('aux_logits')), 10)
-
- def testVariablesToRestore(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d],
- batch_norm_params={'decay': 0.9997}):
- slim.inception.inception_v3(inputs)
- variables_to_restore = tf.get_collection(
- slim.variables.VARIABLES_TO_RESTORE)
- self.assertEqual(len(variables_to_restore), 388)
- self.assertListEqual(variables_to_restore, get_variables())
-
- def testVariablesToRestoreWithoutLogits(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d],
- batch_norm_params={'decay': 0.9997}):
- slim.inception.inception_v3(inputs, restore_logits=False)
- variables_to_restore = tf.get_collection(
- slim.variables.VARIABLES_TO_RESTORE)
- self.assertEqual(len(variables_to_restore), 384)
-
- def testRegularizationLosses(self):
- batch_size = 5
- height, width = 299, 299
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], weight_decay=0.00004):
- slim.inception.inception_v3(inputs)
- losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
- self.assertEqual(len(losses), len(get_variables_by_name('weights')))
-
- def testTotalLossWithoutRegularization(self):
- batch_size = 5
- height, width = 299, 299
- num_classes = 1001
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- dense_labels = tf.random_uniform((batch_size, num_classes))
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], weight_decay=0):
- logits, end_points = slim.inception.inception_v3(
- inputs,
- num_classes=num_classes)
- # Cross entropy loss for the main softmax prediction.
- slim.losses.cross_entropy_loss(logits,
- dense_labels,
- label_smoothing=0.1,
- weight=1.0)
- # Cross entropy loss for the auxiliary softmax head.
- slim.losses.cross_entropy_loss(end_points['aux_logits'],
- dense_labels,
- label_smoothing=0.1,
- weight=0.4,
- scope='aux_loss')
- losses = tf.get_collection(slim.losses.LOSSES_COLLECTION)
- self.assertEqual(len(losses), 2)
-
- def testTotalLossWithRegularization(self):
- batch_size = 5
- height, width = 299, 299
- num_classes = 1000
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- dense_labels = tf.random_uniform((batch_size, num_classes))
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], weight_decay=0.00004):
- logits, end_points = slim.inception.inception_v3(inputs, num_classes)
- # Cross entropy loss for the main softmax prediction.
- slim.losses.cross_entropy_loss(logits,
- dense_labels,
- label_smoothing=0.1,
- weight=1.0)
- # Cross entropy loss for the auxiliary softmax head.
- slim.losses.cross_entropy_loss(end_points['aux_logits'],
- dense_labels,
- label_smoothing=0.1,
- weight=0.4,
- scope='aux_loss')
- losses = tf.get_collection(slim.losses.LOSSES_COLLECTION)
- self.assertEqual(len(losses), 2)
- reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
- self.assertEqual(len(reg_losses), 98)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/inception/inception/slim/inception_model.py b/research/inception/inception/slim/inception_model.py
deleted file mode 100644
index 6136ab1ba68716f4f135110a4d5c518b732b23df..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/inception_model.py
+++ /dev/null
@@ -1,356 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Inception-v3 expressed in TensorFlow-Slim.
-
- Usage:
-
- # Parameters for BatchNorm.
- batch_norm_params = {
- # Decay for the batch_norm moving averages.
- 'decay': BATCHNORM_MOVING_AVERAGE_DECAY,
- # epsilon to prevent 0s in variance.
- 'epsilon': 0.001,
- }
- # Set weight_decay for weights in Conv and FC layers.
- with slim.arg_scope([slim.ops.conv2d, slim.ops.fc], weight_decay=0.00004):
- with slim.arg_scope([slim.ops.conv2d],
- stddev=0.1,
- activation=tf.nn.relu,
- batch_norm_params=batch_norm_params):
- # Force all Variables to reside on the CPU.
- with slim.arg_scope([slim.variables.variable], device='/cpu:0'):
- logits, endpoints = slim.inception.inception_v3(
- images,
- dropout_keep_prob=0.8,
- num_classes=num_classes,
- is_training=for_training,
- restore_logits=restore_logits,
- scope=scope)
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception.slim import ops
-from inception.slim import scopes
-
-
-def inception_v3(inputs,
- dropout_keep_prob=0.8,
- num_classes=1000,
- is_training=True,
- restore_logits=True,
- scope=''):
- """Latest Inception from http://arxiv.org/abs/1512.00567.
-
- "Rethinking the Inception Architecture for Computer Vision"
-
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens,
- Zbigniew Wojna
-
- Args:
- inputs: a tensor of size [batch_size, height, width, channels].
- dropout_keep_prob: dropout keep_prob.
- num_classes: number of predicted classes.
- is_training: whether is training or not.
- restore_logits: whether or not the logits layers should be restored.
- Useful for fine-tuning a model with different num_classes.
- scope: Optional scope for name_scope.
-
- Returns:
- a list containing 'logits', 'aux_logits' Tensors.
- """
- # end_points will collect relevant activations for external use, for example
- # summaries or losses.
- end_points = {}
- with tf.name_scope(scope, 'inception_v3', [inputs]):
- with scopes.arg_scope([ops.conv2d, ops.fc, ops.batch_norm, ops.dropout],
- is_training=is_training):
- with scopes.arg_scope([ops.conv2d, ops.max_pool, ops.avg_pool],
- stride=1, padding='VALID'):
- # 299 x 299 x 3
- end_points['conv0'] = ops.conv2d(inputs, 32, [3, 3], stride=2,
- scope='conv0')
- # 149 x 149 x 32
- end_points['conv1'] = ops.conv2d(end_points['conv0'], 32, [3, 3],
- scope='conv1')
- # 147 x 147 x 32
- end_points['conv2'] = ops.conv2d(end_points['conv1'], 64, [3, 3],
- padding='SAME', scope='conv2')
- # 147 x 147 x 64
- end_points['pool1'] = ops.max_pool(end_points['conv2'], [3, 3],
- stride=2, scope='pool1')
- # 73 x 73 x 64
- end_points['conv3'] = ops.conv2d(end_points['pool1'], 80, [1, 1],
- scope='conv3')
- # 73 x 73 x 80.
- end_points['conv4'] = ops.conv2d(end_points['conv3'], 192, [3, 3],
- scope='conv4')
- # 71 x 71 x 192.
- end_points['pool2'] = ops.max_pool(end_points['conv4'], [3, 3],
- stride=2, scope='pool2')
- # 35 x 35 x 192.
- net = end_points['pool2']
- # Inception blocks
- with scopes.arg_scope([ops.conv2d, ops.max_pool, ops.avg_pool],
- stride=1, padding='SAME'):
- # mixed: 35 x 35 x 256.
- with tf.variable_scope('mixed_35x35x256a'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 64, [1, 1])
- with tf.variable_scope('branch5x5'):
- branch5x5 = ops.conv2d(net, 48, [1, 1])
- branch5x5 = ops.conv2d(branch5x5, 64, [5, 5])
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 64, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 32, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch5x5, branch3x3dbl, branch_pool])
- end_points['mixed_35x35x256a'] = net
- # mixed_1: 35 x 35 x 288.
- with tf.variable_scope('mixed_35x35x288a'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 64, [1, 1])
- with tf.variable_scope('branch5x5'):
- branch5x5 = ops.conv2d(net, 48, [1, 1])
- branch5x5 = ops.conv2d(branch5x5, 64, [5, 5])
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 64, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 64, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch5x5, branch3x3dbl, branch_pool])
- end_points['mixed_35x35x288a'] = net
- # mixed_2: 35 x 35 x 288.
- with tf.variable_scope('mixed_35x35x288b'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 64, [1, 1])
- with tf.variable_scope('branch5x5'):
- branch5x5 = ops.conv2d(net, 48, [1, 1])
- branch5x5 = ops.conv2d(branch5x5, 64, [5, 5])
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 64, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 64, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch5x5, branch3x3dbl, branch_pool])
- end_points['mixed_35x35x288b'] = net
- # mixed_3: 17 x 17 x 768.
- with tf.variable_scope('mixed_17x17x768a'):
- with tf.variable_scope('branch3x3'):
- branch3x3 = ops.conv2d(net, 384, [3, 3], stride=2, padding='VALID')
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 64, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 96, [3, 3],
- stride=2, padding='VALID')
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.max_pool(net, [3, 3], stride=2, padding='VALID')
- net = tf.concat(axis=3, values=[branch3x3, branch3x3dbl, branch_pool])
- end_points['mixed_17x17x768a'] = net
- # mixed4: 17 x 17 x 768.
- with tf.variable_scope('mixed_17x17x768b'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 192, [1, 1])
- with tf.variable_scope('branch7x7'):
- branch7x7 = ops.conv2d(net, 128, [1, 1])
- branch7x7 = ops.conv2d(branch7x7, 128, [1, 7])
- branch7x7 = ops.conv2d(branch7x7, 192, [7, 1])
- with tf.variable_scope('branch7x7dbl'):
- branch7x7dbl = ops.conv2d(net, 128, [1, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 128, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 128, [1, 7])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 128, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [1, 7])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch7x7, branch7x7dbl, branch_pool])
- end_points['mixed_17x17x768b'] = net
- # mixed_5: 17 x 17 x 768.
- with tf.variable_scope('mixed_17x17x768c'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 192, [1, 1])
- with tf.variable_scope('branch7x7'):
- branch7x7 = ops.conv2d(net, 160, [1, 1])
- branch7x7 = ops.conv2d(branch7x7, 160, [1, 7])
- branch7x7 = ops.conv2d(branch7x7, 192, [7, 1])
- with tf.variable_scope('branch7x7dbl'):
- branch7x7dbl = ops.conv2d(net, 160, [1, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [1, 7])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [1, 7])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch7x7, branch7x7dbl, branch_pool])
- end_points['mixed_17x17x768c'] = net
- # mixed_6: 17 x 17 x 768.
- with tf.variable_scope('mixed_17x17x768d'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 192, [1, 1])
- with tf.variable_scope('branch7x7'):
- branch7x7 = ops.conv2d(net, 160, [1, 1])
- branch7x7 = ops.conv2d(branch7x7, 160, [1, 7])
- branch7x7 = ops.conv2d(branch7x7, 192, [7, 1])
- with tf.variable_scope('branch7x7dbl'):
- branch7x7dbl = ops.conv2d(net, 160, [1, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [1, 7])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 160, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [1, 7])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch7x7, branch7x7dbl, branch_pool])
- end_points['mixed_17x17x768d'] = net
- # mixed_7: 17 x 17 x 768.
- with tf.variable_scope('mixed_17x17x768e'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 192, [1, 1])
- with tf.variable_scope('branch7x7'):
- branch7x7 = ops.conv2d(net, 192, [1, 1])
- branch7x7 = ops.conv2d(branch7x7, 192, [1, 7])
- branch7x7 = ops.conv2d(branch7x7, 192, [7, 1])
- with tf.variable_scope('branch7x7dbl'):
- branch7x7dbl = ops.conv2d(net, 192, [1, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [1, 7])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [7, 1])
- branch7x7dbl = ops.conv2d(branch7x7dbl, 192, [1, 7])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch7x7, branch7x7dbl, branch_pool])
- end_points['mixed_17x17x768e'] = net
- # Auxiliary Head logits
- aux_logits = tf.identity(end_points['mixed_17x17x768e'])
- with tf.variable_scope('aux_logits'):
- aux_logits = ops.avg_pool(aux_logits, [5, 5], stride=3,
- padding='VALID')
- aux_logits = ops.conv2d(aux_logits, 128, [1, 1], scope='proj')
- # Shape of feature map before the final layer.
- shape = aux_logits.get_shape()
- aux_logits = ops.conv2d(aux_logits, 768, shape[1:3], stddev=0.01,
- padding='VALID')
- aux_logits = ops.flatten(aux_logits)
- aux_logits = ops.fc(aux_logits, num_classes, activation=None,
- stddev=0.001, restore=restore_logits)
- end_points['aux_logits'] = aux_logits
- # mixed_8: 8 x 8 x 1280.
- # Note that the scope below is not changed to not void previous
- # checkpoints.
- # (TODO) Fix the scope when appropriate.
- with tf.variable_scope('mixed_17x17x1280a'):
- with tf.variable_scope('branch3x3'):
- branch3x3 = ops.conv2d(net, 192, [1, 1])
- branch3x3 = ops.conv2d(branch3x3, 320, [3, 3], stride=2,
- padding='VALID')
- with tf.variable_scope('branch7x7x3'):
- branch7x7x3 = ops.conv2d(net, 192, [1, 1])
- branch7x7x3 = ops.conv2d(branch7x7x3, 192, [1, 7])
- branch7x7x3 = ops.conv2d(branch7x7x3, 192, [7, 1])
- branch7x7x3 = ops.conv2d(branch7x7x3, 192, [3, 3],
- stride=2, padding='VALID')
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.max_pool(net, [3, 3], stride=2, padding='VALID')
- net = tf.concat(axis=3, values=[branch3x3, branch7x7x3, branch_pool])
- end_points['mixed_17x17x1280a'] = net
- # mixed_9: 8 x 8 x 2048.
- with tf.variable_scope('mixed_8x8x2048a'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 320, [1, 1])
- with tf.variable_scope('branch3x3'):
- branch3x3 = ops.conv2d(net, 384, [1, 1])
- branch3x3 = tf.concat(axis=3, values=[ops.conv2d(branch3x3, 384, [1, 3]),
- ops.conv2d(branch3x3, 384, [3, 1])])
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 448, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 384, [3, 3])
- branch3x3dbl = tf.concat(axis=3, values=[ops.conv2d(branch3x3dbl, 384, [1, 3]),
- ops.conv2d(branch3x3dbl, 384, [3, 1])])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch3x3, branch3x3dbl, branch_pool])
- end_points['mixed_8x8x2048a'] = net
- # mixed_10: 8 x 8 x 2048.
- with tf.variable_scope('mixed_8x8x2048b'):
- with tf.variable_scope('branch1x1'):
- branch1x1 = ops.conv2d(net, 320, [1, 1])
- with tf.variable_scope('branch3x3'):
- branch3x3 = ops.conv2d(net, 384, [1, 1])
- branch3x3 = tf.concat(axis=3, values=[ops.conv2d(branch3x3, 384, [1, 3]),
- ops.conv2d(branch3x3, 384, [3, 1])])
- with tf.variable_scope('branch3x3dbl'):
- branch3x3dbl = ops.conv2d(net, 448, [1, 1])
- branch3x3dbl = ops.conv2d(branch3x3dbl, 384, [3, 3])
- branch3x3dbl = tf.concat(axis=3, values=[ops.conv2d(branch3x3dbl, 384, [1, 3]),
- ops.conv2d(branch3x3dbl, 384, [3, 1])])
- with tf.variable_scope('branch_pool'):
- branch_pool = ops.avg_pool(net, [3, 3])
- branch_pool = ops.conv2d(branch_pool, 192, [1, 1])
- net = tf.concat(axis=3, values=[branch1x1, branch3x3, branch3x3dbl, branch_pool])
- end_points['mixed_8x8x2048b'] = net
- # Final pooling and prediction
- with tf.variable_scope('logits'):
- shape = net.get_shape()
- net = ops.avg_pool(net, shape[1:3], padding='VALID', scope='pool')
- # 1 x 1 x 2048
- net = ops.dropout(net, dropout_keep_prob, scope='dropout')
- net = ops.flatten(net, scope='flatten')
- # 2048
- logits = ops.fc(net, num_classes, activation=None, scope='logits',
- restore=restore_logits)
- # 1000
- end_points['logits'] = logits
- end_points['predictions'] = tf.nn.softmax(logits, name='predictions')
- return logits, end_points
-
-
-def inception_v3_parameters(weight_decay=0.00004, stddev=0.1,
- batch_norm_decay=0.9997, batch_norm_epsilon=0.001):
- """Yields the scope with the default parameters for inception_v3.
-
- Args:
- weight_decay: the weight decay for weights variables.
- stddev: standard deviation of the truncated guassian weight distribution.
- batch_norm_decay: decay for the moving average of batch_norm momentums.
- batch_norm_epsilon: small float added to variance to avoid dividing by zero.
-
- Yields:
- a arg_scope with the parameters needed for inception_v3.
- """
- # Set weight_decay for weights in Conv and FC layers.
- with scopes.arg_scope([ops.conv2d, ops.fc],
- weight_decay=weight_decay):
- # Set stddev, activation and parameters for batch_norm.
- with scopes.arg_scope([ops.conv2d],
- stddev=stddev,
- activation=tf.nn.relu,
- batch_norm_params={
- 'decay': batch_norm_decay,
- 'epsilon': batch_norm_epsilon}) as arg_scope:
- yield arg_scope
diff --git a/research/inception/inception/slim/inception_test.py b/research/inception/inception/slim/inception_test.py
deleted file mode 100644
index 231dea298f4b761aa90224df1c263873bc890ac5..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/inception_test.py
+++ /dev/null
@@ -1,134 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for slim.inception."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception.slim import inception_model as inception
-
-
-class InceptionTest(tf.test.TestCase):
-
- def testBuildLogits(self):
- batch_size = 5
- height, width = 299, 299
- num_classes = 1000
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- logits, _ = inception.inception_v3(inputs, num_classes)
- self.assertTrue(logits.op.name.startswith('logits'))
- self.assertListEqual(logits.get_shape().as_list(),
- [batch_size, num_classes])
-
- def testBuildEndPoints(self):
- batch_size = 5
- height, width = 299, 299
- num_classes = 1000
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- _, end_points = inception.inception_v3(inputs, num_classes)
- self.assertTrue('logits' in end_points)
- logits = end_points['logits']
- self.assertListEqual(logits.get_shape().as_list(),
- [batch_size, num_classes])
- self.assertTrue('aux_logits' in end_points)
- aux_logits = end_points['aux_logits']
- self.assertListEqual(aux_logits.get_shape().as_list(),
- [batch_size, num_classes])
- pre_pool = end_points['mixed_8x8x2048b']
- self.assertListEqual(pre_pool.get_shape().as_list(),
- [batch_size, 8, 8, 2048])
-
- def testVariablesSetDevice(self):
- batch_size = 5
- height, width = 299, 299
- num_classes = 1000
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- # Force all Variables to reside on the device.
- with tf.variable_scope('on_cpu'), tf.device('/cpu:0'):
- inception.inception_v3(inputs, num_classes)
- with tf.variable_scope('on_gpu'), tf.device('/gpu:0'):
- inception.inception_v3(inputs, num_classes)
- for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='on_cpu'):
- self.assertDeviceEqual(v.device, '/cpu:0')
- for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='on_gpu'):
- self.assertDeviceEqual(v.device, '/gpu:0')
-
- def testHalfSizeImages(self):
- batch_size = 5
- height, width = 150, 150
- num_classes = 1000
- with self.test_session():
- inputs = tf.random_uniform((batch_size, height, width, 3))
- logits, end_points = inception.inception_v3(inputs, num_classes)
- self.assertTrue(logits.op.name.startswith('logits'))
- self.assertListEqual(logits.get_shape().as_list(),
- [batch_size, num_classes])
- pre_pool = end_points['mixed_8x8x2048b']
- self.assertListEqual(pre_pool.get_shape().as_list(),
- [batch_size, 3, 3, 2048])
-
- def testUnknowBatchSize(self):
- batch_size = 1
- height, width = 299, 299
- num_classes = 1000
- with self.test_session() as sess:
- inputs = tf.placeholder(tf.float32, (None, height, width, 3))
- logits, _ = inception.inception_v3(inputs, num_classes)
- self.assertTrue(logits.op.name.startswith('logits'))
- self.assertListEqual(logits.get_shape().as_list(),
- [None, num_classes])
- images = tf.random_uniform((batch_size, height, width, 3))
- sess.run(tf.global_variables_initializer())
- output = sess.run(logits, {inputs: images.eval()})
- self.assertEquals(output.shape, (batch_size, num_classes))
-
- def testEvaluation(self):
- batch_size = 2
- height, width = 299, 299
- num_classes = 1000
- with self.test_session() as sess:
- eval_inputs = tf.random_uniform((batch_size, height, width, 3))
- logits, _ = inception.inception_v3(eval_inputs, num_classes,
- is_training=False)
- predictions = tf.argmax(logits, 1)
- sess.run(tf.global_variables_initializer())
- output = sess.run(predictions)
- self.assertEquals(output.shape, (batch_size,))
-
- def testTrainEvalWithReuse(self):
- train_batch_size = 5
- eval_batch_size = 2
- height, width = 150, 150
- num_classes = 1000
- with self.test_session() as sess:
- train_inputs = tf.random_uniform((train_batch_size, height, width, 3))
- inception.inception_v3(train_inputs, num_classes)
- tf.get_variable_scope().reuse_variables()
- eval_inputs = tf.random_uniform((eval_batch_size, height, width, 3))
- logits, _ = inception.inception_v3(eval_inputs, num_classes,
- is_training=False)
- predictions = tf.argmax(logits, 1)
- sess.run(tf.global_variables_initializer())
- output = sess.run(predictions)
- self.assertEquals(output.shape, (eval_batch_size,))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/inception/inception/slim/losses.py b/research/inception/inception/slim/losses.py
deleted file mode 100644
index 78298d092fab3afc264e427fb060602c27ea97b0..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/losses.py
+++ /dev/null
@@ -1,174 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains convenience wrappers for various Neural Network TensorFlow losses.
-
- All the losses defined here add themselves to the LOSSES_COLLECTION
- collection.
-
- l1_loss: Define a L1 Loss, useful for regularization, i.e. lasso.
- l2_loss: Define a L2 Loss, useful for regularization, i.e. weight decay.
- cross_entropy_loss: Define a cross entropy loss using
- softmax_cross_entropy_with_logits. Useful for classification.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-# In order to gather all losses in a network, the user should use this
-# key for get_collection, i.e:
-# losses = tf.get_collection(slim.losses.LOSSES_COLLECTION)
-LOSSES_COLLECTION = '_losses'
-
-
-def l1_regularizer(weight=1.0, scope=None):
- """Define a L1 regularizer.
-
- Args:
- weight: scale the loss by this factor.
- scope: Optional scope for name_scope.
-
- Returns:
- a regularizer function.
- """
- def regularizer(tensor):
- with tf.name_scope(scope, 'L1Regularizer', [tensor]):
- l1_weight = tf.convert_to_tensor(weight,
- dtype=tensor.dtype.base_dtype,
- name='weight')
- return tf.multiply(l1_weight, tf.reduce_sum(tf.abs(tensor)), name='value')
- return regularizer
-
-
-def l2_regularizer(weight=1.0, scope=None):
- """Define a L2 regularizer.
-
- Args:
- weight: scale the loss by this factor.
- scope: Optional scope for name_scope.
-
- Returns:
- a regularizer function.
- """
- def regularizer(tensor):
- with tf.name_scope(scope, 'L2Regularizer', [tensor]):
- l2_weight = tf.convert_to_tensor(weight,
- dtype=tensor.dtype.base_dtype,
- name='weight')
- return tf.multiply(l2_weight, tf.nn.l2_loss(tensor), name='value')
- return regularizer
-
-
-def l1_l2_regularizer(weight_l1=1.0, weight_l2=1.0, scope=None):
- """Define a L1L2 regularizer.
-
- Args:
- weight_l1: scale the L1 loss by this factor.
- weight_l2: scale the L2 loss by this factor.
- scope: Optional scope for name_scope.
-
- Returns:
- a regularizer function.
- """
- def regularizer(tensor):
- with tf.name_scope(scope, 'L1L2Regularizer', [tensor]):
- weight_l1_t = tf.convert_to_tensor(weight_l1,
- dtype=tensor.dtype.base_dtype,
- name='weight_l1')
- weight_l2_t = tf.convert_to_tensor(weight_l2,
- dtype=tensor.dtype.base_dtype,
- name='weight_l2')
- reg_l1 = tf.multiply(weight_l1_t, tf.reduce_sum(tf.abs(tensor)),
- name='value_l1')
- reg_l2 = tf.multiply(weight_l2_t, tf.nn.l2_loss(tensor),
- name='value_l2')
- return tf.add(reg_l1, reg_l2, name='value')
- return regularizer
-
-
-def l1_loss(tensor, weight=1.0, scope=None):
- """Define a L1Loss, useful for regularize, i.e. lasso.
-
- Args:
- tensor: tensor to regularize.
- weight: scale the loss by this factor.
- scope: Optional scope for name_scope.
-
- Returns:
- the L1 loss op.
- """
- with tf.name_scope(scope, 'L1Loss', [tensor]):
- weight = tf.convert_to_tensor(weight,
- dtype=tensor.dtype.base_dtype,
- name='loss_weight')
- loss = tf.multiply(weight, tf.reduce_sum(tf.abs(tensor)), name='value')
- tf.add_to_collection(LOSSES_COLLECTION, loss)
- return loss
-
-
-def l2_loss(tensor, weight=1.0, scope=None):
- """Define a L2Loss, useful for regularize, i.e. weight decay.
-
- Args:
- tensor: tensor to regularize.
- weight: an optional weight to modulate the loss.
- scope: Optional scope for name_scope.
-
- Returns:
- the L2 loss op.
- """
- with tf.name_scope(scope, 'L2Loss', [tensor]):
- weight = tf.convert_to_tensor(weight,
- dtype=tensor.dtype.base_dtype,
- name='loss_weight')
- loss = tf.multiply(weight, tf.nn.l2_loss(tensor), name='value')
- tf.add_to_collection(LOSSES_COLLECTION, loss)
- return loss
-
-
-def cross_entropy_loss(logits, one_hot_labels, label_smoothing=0,
- weight=1.0, scope=None):
- """Define a Cross Entropy loss using softmax_cross_entropy_with_logits.
-
- It can scale the loss by weight factor, and smooth the labels.
-
- Args:
- logits: [batch_size, num_classes] logits outputs of the network .
- one_hot_labels: [batch_size, num_classes] target one_hot_encoded labels.
- label_smoothing: if greater than 0 then smooth the labels.
- weight: scale the loss by this factor.
- scope: Optional scope for name_scope.
-
- Returns:
- A tensor with the softmax_cross_entropy loss.
- """
- logits.get_shape().assert_is_compatible_with(one_hot_labels.get_shape())
- with tf.name_scope(scope, 'CrossEntropyLoss', [logits, one_hot_labels]):
- num_classes = one_hot_labels.get_shape()[-1].value
- one_hot_labels = tf.cast(one_hot_labels, logits.dtype)
- if label_smoothing > 0:
- smooth_positives = 1.0 - label_smoothing
- smooth_negatives = label_smoothing / num_classes
- one_hot_labels = one_hot_labels * smooth_positives + smooth_negatives
- cross_entropy = tf.contrib.nn.deprecated_flipped_softmax_cross_entropy_with_logits(
- logits, one_hot_labels, name='xentropy')
-
- weight = tf.convert_to_tensor(weight,
- dtype=logits.dtype.base_dtype,
- name='loss_weight')
- loss = tf.multiply(weight, tf.reduce_mean(cross_entropy), name='value')
- tf.add_to_collection(LOSSES_COLLECTION, loss)
- return loss
diff --git a/research/inception/inception/slim/losses_test.py b/research/inception/inception/slim/losses_test.py
deleted file mode 100644
index e267f6520779f63be0becf41ceccc7de494e14f7..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/losses_test.py
+++ /dev/null
@@ -1,177 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for slim.losses."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from inception.slim import losses
-
-
-class LossesTest(tf.test.TestCase):
-
- def testL1Loss(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- weights = tf.constant(1.0, shape=shape)
- wd = 0.01
- loss = losses.l1_loss(weights, wd)
- self.assertEquals(loss.op.name, 'L1Loss/value')
- self.assertAlmostEqual(loss.eval(), num_elem * wd, 5)
-
- def testL2Loss(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- weights = tf.constant(1.0, shape=shape)
- wd = 0.01
- loss = losses.l2_loss(weights, wd)
- self.assertEquals(loss.op.name, 'L2Loss/value')
- self.assertAlmostEqual(loss.eval(), num_elem * wd / 2, 5)
-
-
-class RegularizersTest(tf.test.TestCase):
-
- def testL1Regularizer(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l1_regularizer()(tensor)
- self.assertEquals(loss.op.name, 'L1Regularizer/value')
- self.assertAlmostEqual(loss.eval(), num_elem, 5)
-
- def testL1RegularizerWithScope(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l1_regularizer(scope='L1')(tensor)
- self.assertEquals(loss.op.name, 'L1/value')
- self.assertAlmostEqual(loss.eval(), num_elem, 5)
-
- def testL1RegularizerWithWeight(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- weight = 0.01
- loss = losses.l1_regularizer(weight)(tensor)
- self.assertEquals(loss.op.name, 'L1Regularizer/value')
- self.assertAlmostEqual(loss.eval(), num_elem * weight, 5)
-
- def testL2Regularizer(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l2_regularizer()(tensor)
- self.assertEquals(loss.op.name, 'L2Regularizer/value')
- self.assertAlmostEqual(loss.eval(), num_elem / 2, 5)
-
- def testL2RegularizerWithScope(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l2_regularizer(scope='L2')(tensor)
- self.assertEquals(loss.op.name, 'L2/value')
- self.assertAlmostEqual(loss.eval(), num_elem / 2, 5)
-
- def testL2RegularizerWithWeight(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- weight = 0.01
- loss = losses.l2_regularizer(weight)(tensor)
- self.assertEquals(loss.op.name, 'L2Regularizer/value')
- self.assertAlmostEqual(loss.eval(), num_elem * weight / 2, 5)
-
- def testL1L2Regularizer(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l1_l2_regularizer()(tensor)
- self.assertEquals(loss.op.name, 'L1L2Regularizer/value')
- self.assertAlmostEqual(loss.eval(), num_elem + num_elem / 2, 5)
-
- def testL1L2RegularizerWithScope(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- loss = losses.l1_l2_regularizer(scope='L1L2')(tensor)
- self.assertEquals(loss.op.name, 'L1L2/value')
- self.assertAlmostEqual(loss.eval(), num_elem + num_elem / 2, 5)
-
- def testL1L2RegularizerWithWeights(self):
- with self.test_session():
- shape = [5, 5, 5]
- num_elem = 5 * 5 * 5
- tensor = tf.constant(1.0, shape=shape)
- weight_l1 = 0.01
- weight_l2 = 0.05
- loss = losses.l1_l2_regularizer(weight_l1, weight_l2)(tensor)
- self.assertEquals(loss.op.name, 'L1L2Regularizer/value')
- self.assertAlmostEqual(loss.eval(),
- num_elem * weight_l1 + num_elem * weight_l2 / 2, 5)
-
-
-class CrossEntropyLossTest(tf.test.TestCase):
-
- def testCrossEntropyLossAllCorrect(self):
- with self.test_session():
- logits = tf.constant([[10.0, 0.0, 0.0],
- [0.0, 10.0, 0.0],
- [0.0, 0.0, 10.0]])
- labels = tf.constant([[1, 0, 0],
- [0, 1, 0],
- [0, 0, 1]])
- loss = losses.cross_entropy_loss(logits, labels)
- self.assertEquals(loss.op.name, 'CrossEntropyLoss/value')
- self.assertAlmostEqual(loss.eval(), 0.0, 3)
-
- def testCrossEntropyLossAllWrong(self):
- with self.test_session():
- logits = tf.constant([[10.0, 0.0, 0.0],
- [0.0, 10.0, 0.0],
- [0.0, 0.0, 10.0]])
- labels = tf.constant([[0, 0, 1],
- [1, 0, 0],
- [0, 1, 0]])
- loss = losses.cross_entropy_loss(logits, labels)
- self.assertEquals(loss.op.name, 'CrossEntropyLoss/value')
- self.assertAlmostEqual(loss.eval(), 10.0, 3)
-
- def testCrossEntropyLossAllWrongWithWeight(self):
- with self.test_session():
- logits = tf.constant([[10.0, 0.0, 0.0],
- [0.0, 10.0, 0.0],
- [0.0, 0.0, 10.0]])
- labels = tf.constant([[0, 0, 1],
- [1, 0, 0],
- [0, 1, 0]])
- loss = losses.cross_entropy_loss(logits, labels, weight=0.5)
- self.assertEquals(loss.op.name, 'CrossEntropyLoss/value')
- self.assertAlmostEqual(loss.eval(), 5.0, 3)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/inception/inception/slim/ops.py b/research/inception/inception/slim/ops.py
deleted file mode 100644
index 54fda4eb81f3a138d9bb2748c21164b88570ede9..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/ops.py
+++ /dev/null
@@ -1,473 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains convenience wrappers for typical Neural Network TensorFlow layers.
-
- Additionally it maintains a collection with update_ops that need to be
- updated after the ops have been computed, for example to update moving means
- and moving variances of batch_norm.
-
- Ops that have different behavior during training or eval have an is_training
- parameter. Additionally Ops that contain variables.variable have a trainable
- parameter, which control if the ops variables are trainable or not.
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-
-from tensorflow.python.training import moving_averages
-
-from inception.slim import losses
-from inception.slim import scopes
-from inception.slim import variables
-
-# Used to keep the update ops done by batch_norm.
-UPDATE_OPS_COLLECTION = '_update_ops_'
-
-
-@scopes.add_arg_scope
-def batch_norm(inputs,
- decay=0.999,
- center=True,
- scale=False,
- epsilon=0.001,
- moving_vars='moving_vars',
- activation=None,
- is_training=True,
- trainable=True,
- restore=True,
- scope=None,
- reuse=None):
- """Adds a Batch Normalization layer.
-
- Args:
- inputs: a tensor of size [batch_size, height, width, channels]
- or [batch_size, channels].
- decay: decay for the moving average.
- center: If True, subtract beta. If False, beta is not created and ignored.
- scale: If True, multiply by gamma. If False, gamma is
- not used. When the next layer is linear (also e.g. ReLU), this can be
- disabled since the scaling can be done by the next layer.
- epsilon: small float added to variance to avoid dividing by zero.
- moving_vars: collection to store the moving_mean and moving_variance.
- activation: activation function.
- is_training: whether or not the model is in training mode.
- trainable: whether or not the variables should be trainable or not.
- restore: whether or not the variables should be marked for restore.
- scope: Optional scope for variable_scope.
- reuse: whether or not the layer and its variables should be reused. To be
- able to reuse the layer scope must be given.
-
- Returns:
- a tensor representing the output of the operation.
-
- """
- inputs_shape = inputs.get_shape()
- with tf.variable_scope(scope, 'BatchNorm', [inputs], reuse=reuse):
- axis = list(range(len(inputs_shape) - 1))
- params_shape = inputs_shape[-1:]
- # Allocate parameters for the beta and gamma of the normalization.
- beta, gamma = None, None
- if center:
- beta = variables.variable('beta',
- params_shape,
- initializer=tf.zeros_initializer(),
- trainable=trainable,
- restore=restore)
- if scale:
- gamma = variables.variable('gamma',
- params_shape,
- initializer=tf.ones_initializer(),
- trainable=trainable,
- restore=restore)
- # Create moving_mean and moving_variance add them to
- # GraphKeys.MOVING_AVERAGE_VARIABLES collections.
- moving_collections = [moving_vars, tf.GraphKeys.MOVING_AVERAGE_VARIABLES]
- moving_mean = variables.variable('moving_mean',
- params_shape,
- initializer=tf.zeros_initializer(),
- trainable=False,
- restore=restore,
- collections=moving_collections)
- moving_variance = variables.variable('moving_variance',
- params_shape,
- initializer=tf.ones_initializer(),
- trainable=False,
- restore=restore,
- collections=moving_collections)
- if is_training:
- # Calculate the moments based on the individual batch.
- mean, variance = tf.nn.moments(inputs, axis)
-
- update_moving_mean = moving_averages.assign_moving_average(
- moving_mean, mean, decay)
- tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_mean)
- update_moving_variance = moving_averages.assign_moving_average(
- moving_variance, variance, decay)
- tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_variance)
- else:
- # Just use the moving_mean and moving_variance.
- mean = moving_mean
- variance = moving_variance
- # Normalize the activations.
- outputs = tf.nn.batch_normalization(
- inputs, mean, variance, beta, gamma, epsilon)
- outputs.set_shape(inputs.get_shape())
- if activation:
- outputs = activation(outputs)
- return outputs
-
-
-def _two_element_tuple(int_or_tuple):
- """Converts `int_or_tuple` to height, width.
-
- Several of the functions that follow accept arguments as either
- a tuple of 2 integers or a single integer. A single integer
- indicates that the 2 values of the tuple are the same.
-
- This functions normalizes the input value by always returning a tuple.
-
- Args:
- int_or_tuple: A list of 2 ints, a single int or a tf.TensorShape.
-
- Returns:
- A tuple with 2 values.
-
- Raises:
- ValueError: If `int_or_tuple` it not well formed.
- """
- if isinstance(int_or_tuple, (list, tuple)):
- if len(int_or_tuple) != 2:
- raise ValueError('Must be a list with 2 elements: %s' % int_or_tuple)
- return int(int_or_tuple[0]), int(int_or_tuple[1])
- if isinstance(int_or_tuple, int):
- return int(int_or_tuple), int(int_or_tuple)
- if isinstance(int_or_tuple, tf.TensorShape):
- if len(int_or_tuple) == 2:
- return int_or_tuple[0], int_or_tuple[1]
- raise ValueError('Must be an int, a list with 2 elements or a TensorShape of '
- 'length 2')
-
-
-@scopes.add_arg_scope
-def conv2d(inputs,
- num_filters_out,
- kernel_size,
- stride=1,
- padding='SAME',
- activation=tf.nn.relu,
- stddev=0.01,
- bias=0.0,
- weight_decay=0,
- batch_norm_params=None,
- is_training=True,
- trainable=True,
- restore=True,
- scope=None,
- reuse=None):
- """Adds a 2D convolution followed by an optional batch_norm layer.
-
- conv2d creates a variable called 'weights', representing the convolutional
- kernel, that is convolved with the input. If `batch_norm_params` is None, a
- second variable called 'biases' is added to the result of the convolution
- operation.
-
- Args:
- inputs: a tensor of size [batch_size, height, width, channels].
- num_filters_out: the number of output filters.
- kernel_size: a list of length 2: [kernel_height, kernel_width] of
- of the filters. Can be an int if both values are the same.
- stride: a list of length 2: [stride_height, stride_width].
- Can be an int if both strides are the same. Note that presently
- both strides must have the same value.
- padding: one of 'VALID' or 'SAME'.
- activation: activation function.
- stddev: standard deviation of the truncated guassian weight distribution.
- bias: the initial value of the biases.
- weight_decay: the weight decay.
- batch_norm_params: parameters for the batch_norm. If is None don't use it.
- is_training: whether or not the model is in training mode.
- trainable: whether or not the variables should be trainable or not.
- restore: whether or not the variables should be marked for restore.
- scope: Optional scope for variable_scope.
- reuse: whether or not the layer and its variables should be reused. To be
- able to reuse the layer scope must be given.
- Returns:
- a tensor representing the output of the operation.
-
- """
- with tf.variable_scope(scope, 'Conv', [inputs], reuse=reuse):
- kernel_h, kernel_w = _two_element_tuple(kernel_size)
- stride_h, stride_w = _two_element_tuple(stride)
- num_filters_in = inputs.get_shape()[-1]
- weights_shape = [kernel_h, kernel_w,
- num_filters_in, num_filters_out]
- weights_initializer = tf.truncated_normal_initializer(stddev=stddev)
- l2_regularizer = None
- if weight_decay and weight_decay > 0:
- l2_regularizer = losses.l2_regularizer(weight_decay)
- weights = variables.variable('weights',
- shape=weights_shape,
- initializer=weights_initializer,
- regularizer=l2_regularizer,
- trainable=trainable,
- restore=restore)
- conv = tf.nn.conv2d(inputs, weights, [1, stride_h, stride_w, 1],
- padding=padding)
- if batch_norm_params is not None:
- with scopes.arg_scope([batch_norm], is_training=is_training,
- trainable=trainable, restore=restore):
- outputs = batch_norm(conv, **batch_norm_params)
- else:
- bias_shape = [num_filters_out,]
- bias_initializer = tf.constant_initializer(bias)
- biases = variables.variable('biases',
- shape=bias_shape,
- initializer=bias_initializer,
- trainable=trainable,
- restore=restore)
- outputs = tf.nn.bias_add(conv, biases)
- if activation:
- outputs = activation(outputs)
- return outputs
-
-
-@scopes.add_arg_scope
-def fc(inputs,
- num_units_out,
- activation=tf.nn.relu,
- stddev=0.01,
- bias=0.0,
- weight_decay=0,
- batch_norm_params=None,
- is_training=True,
- trainable=True,
- restore=True,
- scope=None,
- reuse=None):
- """Adds a fully connected layer followed by an optional batch_norm layer.
-
- FC creates a variable called 'weights', representing the fully connected
- weight matrix, that is multiplied by the input. If `batch_norm` is None, a
- second variable called 'biases' is added to the result of the initial
- vector-matrix multiplication.
-
- Args:
- inputs: a [B x N] tensor where B is the batch size and N is the number of
- input units in the layer.
- num_units_out: the number of output units in the layer.
- activation: activation function.
- stddev: the standard deviation for the weights.
- bias: the initial value of the biases.
- weight_decay: the weight decay.
- batch_norm_params: parameters for the batch_norm. If is None don't use it.
- is_training: whether or not the model is in training mode.
- trainable: whether or not the variables should be trainable or not.
- restore: whether or not the variables should be marked for restore.
- scope: Optional scope for variable_scope.
- reuse: whether or not the layer and its variables should be reused. To be
- able to reuse the layer scope must be given.
-
- Returns:
- the tensor variable representing the result of the series of operations.
- """
- with tf.variable_scope(scope, 'FC', [inputs], reuse=reuse):
- num_units_in = inputs.get_shape()[1]
- weights_shape = [num_units_in, num_units_out]
- weights_initializer = tf.truncated_normal_initializer(stddev=stddev)
- l2_regularizer = None
- if weight_decay and weight_decay > 0:
- l2_regularizer = losses.l2_regularizer(weight_decay)
- weights = variables.variable('weights',
- shape=weights_shape,
- initializer=weights_initializer,
- regularizer=l2_regularizer,
- trainable=trainable,
- restore=restore)
- if batch_norm_params is not None:
- outputs = tf.matmul(inputs, weights)
- with scopes.arg_scope([batch_norm], is_training=is_training,
- trainable=trainable, restore=restore):
- outputs = batch_norm(outputs, **batch_norm_params)
- else:
- bias_shape = [num_units_out,]
- bias_initializer = tf.constant_initializer(bias)
- biases = variables.variable('biases',
- shape=bias_shape,
- initializer=bias_initializer,
- trainable=trainable,
- restore=restore)
- outputs = tf.nn.xw_plus_b(inputs, weights, biases)
- if activation:
- outputs = activation(outputs)
- return outputs
-
-
-def one_hot_encoding(labels, num_classes, scope=None):
- """Transform numeric labels into onehot_labels.
-
- Args:
- labels: [batch_size] target labels.
- num_classes: total number of classes.
- scope: Optional scope for name_scope.
- Returns:
- one hot encoding of the labels.
- """
- with tf.name_scope(scope, 'OneHotEncoding', [labels]):
- batch_size = labels.get_shape()[0]
- indices = tf.expand_dims(tf.range(0, batch_size), 1)
- labels = tf.cast(tf.expand_dims(labels, 1), indices.dtype)
- concated = tf.concat(axis=1, values=[indices, labels])
- onehot_labels = tf.sparse_to_dense(
- concated, tf.stack([batch_size, num_classes]), 1.0, 0.0)
- onehot_labels.set_shape([batch_size, num_classes])
- return onehot_labels
-
-
-@scopes.add_arg_scope
-def max_pool(inputs, kernel_size, stride=2, padding='VALID', scope=None):
- """Adds a Max Pooling layer.
-
- It is assumed by the wrapper that the pooling is only done per image and not
- in depth or batch.
-
- Args:
- inputs: a tensor of size [batch_size, height, width, depth].
- kernel_size: a list of length 2: [kernel_height, kernel_width] of the
- pooling kernel over which the op is computed. Can be an int if both
- values are the same.
- stride: a list of length 2: [stride_height, stride_width].
- Can be an int if both strides are the same. Note that presently
- both strides must have the same value.
- padding: the padding method, either 'VALID' or 'SAME'.
- scope: Optional scope for name_scope.
-
- Returns:
- a tensor representing the results of the pooling operation.
- Raises:
- ValueError: if 'kernel_size' is not a 2-D list
- """
- with tf.name_scope(scope, 'MaxPool', [inputs]):
- kernel_h, kernel_w = _two_element_tuple(kernel_size)
- stride_h, stride_w = _two_element_tuple(stride)
- return tf.nn.max_pool(inputs,
- ksize=[1, kernel_h, kernel_w, 1],
- strides=[1, stride_h, stride_w, 1],
- padding=padding)
-
-
-@scopes.add_arg_scope
-def avg_pool(inputs, kernel_size, stride=2, padding='VALID', scope=None):
- """Adds a Avg Pooling layer.
-
- It is assumed by the wrapper that the pooling is only done per image and not
- in depth or batch.
-
- Args:
- inputs: a tensor of size [batch_size, height, width, depth].
- kernel_size: a list of length 2: [kernel_height, kernel_width] of the
- pooling kernel over which the op is computed. Can be an int if both
- values are the same.
- stride: a list of length 2: [stride_height, stride_width].
- Can be an int if both strides are the same. Note that presently
- both strides must have the same value.
- padding: the padding method, either 'VALID' or 'SAME'.
- scope: Optional scope for name_scope.
-
- Returns:
- a tensor representing the results of the pooling operation.
- """
- with tf.name_scope(scope, 'AvgPool', [inputs]):
- kernel_h, kernel_w = _two_element_tuple(kernel_size)
- stride_h, stride_w = _two_element_tuple(stride)
- return tf.nn.avg_pool(inputs,
- ksize=[1, kernel_h, kernel_w, 1],
- strides=[1, stride_h, stride_w, 1],
- padding=padding)
-
-
-@scopes.add_arg_scope
-def dropout(inputs, keep_prob=0.5, is_training=True, scope=None):
- """Returns a dropout layer applied to the input.
-
- Args:
- inputs: the tensor to pass to the Dropout layer.
- keep_prob: the probability of keeping each input unit.
- is_training: whether or not the model is in training mode. If so, dropout is
- applied and values scaled. Otherwise, inputs is returned.
- scope: Optional scope for name_scope.
-
- Returns:
- a tensor representing the output of the operation.
- """
- if is_training and keep_prob > 0:
- with tf.name_scope(scope, 'Dropout', [inputs]):
- return tf.nn.dropout(inputs, keep_prob)
- else:
- return inputs
-
-
-def flatten(inputs, scope=None):
- """Flattens the input while maintaining the batch_size.
-
- Assumes that the first dimension represents the batch.
-
- Args:
- inputs: a tensor of size [batch_size, ...].
- scope: Optional scope for name_scope.
-
- Returns:
- a flattened tensor with shape [batch_size, k].
- Raises:
- ValueError: if inputs.shape is wrong.
- """
- if len(inputs.get_shape()) < 2:
- raise ValueError('Inputs must be have a least 2 dimensions')
- dims = inputs.get_shape()[1:]
- k = dims.num_elements()
- with tf.name_scope(scope, 'Flatten', [inputs]):
- return tf.reshape(inputs, [-1, k])
-
-
-def repeat_op(repetitions, inputs, op, *args, **kwargs):
- """Build a sequential Tower starting from inputs by using an op repeatedly.
-
- It creates new scopes for each operation by increasing the counter.
- Example: given repeat_op(3, _, ops.conv2d, 64, [3, 3], scope='conv1')
- it will repeat the given op under the following variable_scopes:
- conv1/Conv
- conv1/Conv_1
- conv1/Conv_2
-
- Args:
- repetitions: number or repetitions.
- inputs: a tensor of size [batch_size, height, width, channels].
- op: an operation.
- *args: args for the op.
- **kwargs: kwargs for the op.
-
- Returns:
- a tensor result of applying the operation op, num times.
- Raises:
- ValueError: if the op is unknown or wrong.
- """
- scope = kwargs.pop('scope', None)
- with tf.variable_scope(scope, 'RepeatOp', [inputs]):
- tower = inputs
- for _ in range(repetitions):
- tower = op(tower, *args, **kwargs)
- return tower
diff --git a/research/inception/inception/slim/ops_test.py b/research/inception/inception/slim/ops_test.py
deleted file mode 100644
index 13dc5d9aacf6e283540a406d419a67d2d7215161..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/ops_test.py
+++ /dev/null
@@ -1,687 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for slim.ops."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import numpy as np
-import tensorflow as tf
-
-from inception.slim import ops
-from inception.slim import scopes
-from inception.slim import variables
-
-
-class ConvTest(tf.test.TestCase):
-
- def testCreateConv(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 3])
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32])
-
- def testCreateSquareConv(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, 3)
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32])
-
- def testCreateConvWithTensorShape(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, images.get_shape()[1:3])
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32])
-
- def testCreateFullyConv(self):
- height, width = 6, 6
- with self.test_session():
- images = tf.random_uniform((5, height, width, 32), seed=1)
- output = ops.conv2d(images, 64, images.get_shape()[1:3], padding='VALID')
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 64])
-
- def testCreateVerticalConv(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 1])
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(),
- [5, height, width, 32])
-
- def testCreateHorizontalConv(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [1, 3])
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(),
- [5, height, width, 32])
-
- def testCreateConvWithStride(self):
- height, width = 6, 6
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 3], stride=2)
- self.assertEquals(output.op.name, 'Conv/Relu')
- self.assertListEqual(output.get_shape().as_list(),
- [5, height/2, width/2, 32])
-
- def testCreateConvCreatesWeightsAndBiasesVars(self):
- height, width = 3, 3
- images = tf.random_uniform((5, height, width, 3), seed=1)
- with self.test_session():
- self.assertFalse(variables.get_variables('conv1/weights'))
- self.assertFalse(variables.get_variables('conv1/biases'))
- ops.conv2d(images, 32, [3, 3], scope='conv1')
- self.assertTrue(variables.get_variables('conv1/weights'))
- self.assertTrue(variables.get_variables('conv1/biases'))
-
- def testCreateConvWithScope(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 3], scope='conv1')
- self.assertEquals(output.op.name, 'conv1/Relu')
-
- def testCreateConvWithoutActivation(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 3], activation=None)
- self.assertEquals(output.op.name, 'Conv/BiasAdd')
-
- def testCreateConvValid(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.conv2d(images, 32, [3, 3], padding='VALID')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 32])
-
- def testCreateConvWithWD(self):
- height, width = 3, 3
- with self.test_session() as sess:
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.conv2d(images, 32, [3, 3], weight_decay=0.01)
- wd = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)[0]
- self.assertEquals(wd.op.name,
- 'Conv/weights/Regularizer/L2Regularizer/value')
- sess.run(tf.global_variables_initializer())
- self.assertTrue(sess.run(wd) <= 0.01)
-
- def testCreateConvWithoutWD(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.conv2d(images, 32, [3, 3], weight_decay=0)
- self.assertEquals(
- tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES), [])
-
- def testReuseVars(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.conv2d(images, 32, [3, 3], scope='conv1')
- self.assertEquals(len(variables.get_variables()), 2)
- ops.conv2d(images, 32, [3, 3], scope='conv1', reuse=True)
- self.assertEquals(len(variables.get_variables()), 2)
-
- def testNonReuseVars(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.conv2d(images, 32, [3, 3])
- self.assertEquals(len(variables.get_variables()), 2)
- ops.conv2d(images, 32, [3, 3])
- self.assertEquals(len(variables.get_variables()), 4)
-
- def testReuseConvWithWD(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.conv2d(images, 32, [3, 3], weight_decay=0.01, scope='conv1')
- self.assertEquals(len(variables.get_variables()), 2)
- self.assertEquals(
- len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1)
- ops.conv2d(images, 32, [3, 3], weight_decay=0.01, scope='conv1',
- reuse=True)
- self.assertEquals(len(variables.get_variables()), 2)
- self.assertEquals(
- len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1)
-
- def testConvWithBatchNorm(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 32), seed=1)
- with scopes.arg_scope([ops.conv2d], batch_norm_params={'decay': 0.9}):
- net = ops.conv2d(images, 32, [3, 3])
- net = ops.conv2d(net, 32, [3, 3])
- self.assertEquals(len(variables.get_variables()), 8)
- self.assertEquals(len(variables.get_variables('Conv/BatchNorm')), 3)
- self.assertEquals(len(variables.get_variables('Conv_1/BatchNorm')), 3)
-
- def testReuseConvWithBatchNorm(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 32), seed=1)
- with scopes.arg_scope([ops.conv2d], batch_norm_params={'decay': 0.9}):
- net = ops.conv2d(images, 32, [3, 3], scope='Conv')
- net = ops.conv2d(net, 32, [3, 3], scope='Conv', reuse=True)
- self.assertEquals(len(variables.get_variables()), 4)
- self.assertEquals(len(variables.get_variables('Conv/BatchNorm')), 3)
- self.assertEquals(len(variables.get_variables('Conv_1/BatchNorm')), 0)
-
-
-class FCTest(tf.test.TestCase):
-
- def testCreateFC(self):
- height, width = 3, 3
- with self.test_session():
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- output = ops.fc(inputs, 32)
- self.assertEquals(output.op.name, 'FC/Relu')
- self.assertListEqual(output.get_shape().as_list(), [5, 32])
-
- def testCreateFCWithScope(self):
- height, width = 3, 3
- with self.test_session():
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- output = ops.fc(inputs, 32, scope='fc1')
- self.assertEquals(output.op.name, 'fc1/Relu')
-
- def testCreateFcCreatesWeightsAndBiasesVars(self):
- height, width = 3, 3
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- with self.test_session():
- self.assertFalse(variables.get_variables('fc1/weights'))
- self.assertFalse(variables.get_variables('fc1/biases'))
- ops.fc(inputs, 32, scope='fc1')
- self.assertTrue(variables.get_variables('fc1/weights'))
- self.assertTrue(variables.get_variables('fc1/biases'))
-
- def testReuseVars(self):
- height, width = 3, 3
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- with self.test_session():
- ops.fc(inputs, 32, scope='fc1')
- self.assertEquals(len(variables.get_variables('fc1')), 2)
- ops.fc(inputs, 32, scope='fc1', reuse=True)
- self.assertEquals(len(variables.get_variables('fc1')), 2)
-
- def testNonReuseVars(self):
- height, width = 3, 3
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- with self.test_session():
- ops.fc(inputs, 32)
- self.assertEquals(len(variables.get_variables('FC')), 2)
- ops.fc(inputs, 32)
- self.assertEquals(len(variables.get_variables('FC')), 4)
-
- def testCreateFCWithoutActivation(self):
- height, width = 3, 3
- with self.test_session():
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- output = ops.fc(inputs, 32, activation=None)
- self.assertEquals(output.op.name, 'FC/xw_plus_b')
-
- def testCreateFCWithWD(self):
- height, width = 3, 3
- with self.test_session() as sess:
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- ops.fc(inputs, 32, weight_decay=0.01)
- wd = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)[0]
- self.assertEquals(wd.op.name,
- 'FC/weights/Regularizer/L2Regularizer/value')
- sess.run(tf.global_variables_initializer())
- self.assertTrue(sess.run(wd) <= 0.01)
-
- def testCreateFCWithoutWD(self):
- height, width = 3, 3
- with self.test_session():
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- ops.fc(inputs, 32, weight_decay=0)
- self.assertEquals(
- tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES), [])
-
- def testReuseFCWithWD(self):
- height, width = 3, 3
- with self.test_session():
- inputs = tf.random_uniform((5, height * width * 3), seed=1)
- ops.fc(inputs, 32, weight_decay=0.01, scope='fc')
- self.assertEquals(len(variables.get_variables()), 2)
- self.assertEquals(
- len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1)
- ops.fc(inputs, 32, weight_decay=0.01, scope='fc', reuse=True)
- self.assertEquals(len(variables.get_variables()), 2)
- self.assertEquals(
- len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1)
-
- def testFCWithBatchNorm(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height * width * 3), seed=1)
- with scopes.arg_scope([ops.fc], batch_norm_params={}):
- net = ops.fc(images, 27)
- net = ops.fc(net, 27)
- self.assertEquals(len(variables.get_variables()), 8)
- self.assertEquals(len(variables.get_variables('FC/BatchNorm')), 3)
- self.assertEquals(len(variables.get_variables('FC_1/BatchNorm')), 3)
-
- def testReuseFCWithBatchNorm(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height * width * 3), seed=1)
- with scopes.arg_scope([ops.fc], batch_norm_params={'decay': 0.9}):
- net = ops.fc(images, 27, scope='fc1')
- net = ops.fc(net, 27, scope='fc1', reuse=True)
- self.assertEquals(len(variables.get_variables()), 4)
- self.assertEquals(len(variables.get_variables('fc1/BatchNorm')), 3)
-
-
-class MaxPoolTest(tf.test.TestCase):
-
- def testCreateMaxPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, [3, 3])
- self.assertEquals(output.op.name, 'MaxPool/MaxPool')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
- def testCreateSquareMaxPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, 3)
- self.assertEquals(output.op.name, 'MaxPool/MaxPool')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
- def testCreateMaxPoolWithScope(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, [3, 3], scope='pool1')
- self.assertEquals(output.op.name, 'pool1/MaxPool')
-
- def testCreateMaxPoolSAME(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, [3, 3], padding='SAME')
- self.assertListEqual(output.get_shape().as_list(), [5, 2, 2, 3])
-
- def testCreateMaxPoolStrideSAME(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, [3, 3], stride=1, padding='SAME')
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 3])
-
- def testGlobalMaxPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.max_pool(images, images.get_shape()[1:3], stride=1)
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
-
-class AvgPoolTest(tf.test.TestCase):
-
- def testCreateAvgPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, [3, 3])
- self.assertEquals(output.op.name, 'AvgPool/AvgPool')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
- def testCreateSquareAvgPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, 3)
- self.assertEquals(output.op.name, 'AvgPool/AvgPool')
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
- def testCreateAvgPoolWithScope(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, [3, 3], scope='pool1')
- self.assertEquals(output.op.name, 'pool1/AvgPool')
-
- def testCreateAvgPoolSAME(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, [3, 3], padding='SAME')
- self.assertListEqual(output.get_shape().as_list(), [5, 2, 2, 3])
-
- def testCreateAvgPoolStrideSAME(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, [3, 3], stride=1, padding='SAME')
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 3])
-
- def testGlobalAvgPool(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.avg_pool(images, images.get_shape()[1:3], stride=1)
- self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 3])
-
-
-class OneHotEncodingTest(tf.test.TestCase):
-
- def testOneHotEncodingCreate(self):
- with self.test_session():
- labels = tf.constant([0, 1, 2])
- output = ops.one_hot_encoding(labels, num_classes=3)
- self.assertEquals(output.op.name, 'OneHotEncoding/SparseToDense')
- self.assertListEqual(output.get_shape().as_list(), [3, 3])
-
- def testOneHotEncoding(self):
- with self.test_session():
- labels = tf.constant([0, 1, 2])
- one_hot_labels = tf.constant([[1, 0, 0],
- [0, 1, 0],
- [0, 0, 1]])
- output = ops.one_hot_encoding(labels, num_classes=3)
- self.assertAllClose(output.eval(), one_hot_labels.eval())
-
-
-class DropoutTest(tf.test.TestCase):
-
- def testCreateDropout(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.dropout(images)
- self.assertEquals(output.op.name, 'Dropout/dropout/mul')
- output.get_shape().assert_is_compatible_with(images.get_shape())
-
- def testCreateDropoutNoTraining(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1, name='images')
- output = ops.dropout(images, is_training=False)
- self.assertEquals(output, images)
-
-
-class FlattenTest(tf.test.TestCase):
-
- def testFlatten4D(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1, name='images')
- output = ops.flatten(images)
- self.assertEquals(output.get_shape().num_elements(),
- images.get_shape().num_elements())
- self.assertEqual(output.get_shape()[0], images.get_shape()[0])
-
- def testFlatten3D(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width), seed=1, name='images')
- output = ops.flatten(images)
- self.assertEquals(output.get_shape().num_elements(),
- images.get_shape().num_elements())
- self.assertEqual(output.get_shape()[0], images.get_shape()[0])
-
- def testFlattenBatchSize(self):
- height, width = 3, 3
- with self.test_session() as sess:
- images = tf.random_uniform((5, height, width, 3), seed=1, name='images')
- inputs = tf.placeholder(tf.int32, (None, height, width, 3))
- output = ops.flatten(inputs)
- self.assertEquals(output.get_shape().as_list(),
- [None, height * width * 3])
- output = sess.run(output, {inputs: images.eval()})
- self.assertEquals(output.size,
- images.get_shape().num_elements())
- self.assertEqual(output.shape[0], images.get_shape()[0])
-
-
-class BatchNormTest(tf.test.TestCase):
-
- def testCreateOp(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- output = ops.batch_norm(images)
- self.assertTrue(output.op.name.startswith('BatchNorm/batchnorm'))
- self.assertListEqual(output.get_shape().as_list(), [5, height, width, 3])
-
- def testCreateVariables(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images)
- beta = variables.get_variables_by_name('beta')[0]
- self.assertEquals(beta.op.name, 'BatchNorm/beta')
- gamma = variables.get_variables_by_name('gamma')
- self.assertEquals(gamma, [])
- moving_mean = tf.moving_average_variables()[0]
- moving_variance = tf.moving_average_variables()[1]
- self.assertEquals(moving_mean.op.name, 'BatchNorm/moving_mean')
- self.assertEquals(moving_variance.op.name, 'BatchNorm/moving_variance')
-
- def testCreateVariablesWithScale(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, scale=True)
- beta = variables.get_variables_by_name('beta')[0]
- gamma = variables.get_variables_by_name('gamma')[0]
- self.assertEquals(beta.op.name, 'BatchNorm/beta')
- self.assertEquals(gamma.op.name, 'BatchNorm/gamma')
- moving_mean = tf.moving_average_variables()[0]
- moving_variance = tf.moving_average_variables()[1]
- self.assertEquals(moving_mean.op.name, 'BatchNorm/moving_mean')
- self.assertEquals(moving_variance.op.name, 'BatchNorm/moving_variance')
-
- def testCreateVariablesWithoutCenterWithScale(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, center=False, scale=True)
- beta = variables.get_variables_by_name('beta')
- self.assertEquals(beta, [])
- gamma = variables.get_variables_by_name('gamma')[0]
- self.assertEquals(gamma.op.name, 'BatchNorm/gamma')
- moving_mean = tf.moving_average_variables()[0]
- moving_variance = tf.moving_average_variables()[1]
- self.assertEquals(moving_mean.op.name, 'BatchNorm/moving_mean')
- self.assertEquals(moving_variance.op.name, 'BatchNorm/moving_variance')
-
- def testCreateVariablesWithoutCenterWithoutScale(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, center=False, scale=False)
- beta = variables.get_variables_by_name('beta')
- self.assertEquals(beta, [])
- gamma = variables.get_variables_by_name('gamma')
- self.assertEquals(gamma, [])
- moving_mean = tf.moving_average_variables()[0]
- moving_variance = tf.moving_average_variables()[1]
- self.assertEquals(moving_mean.op.name, 'BatchNorm/moving_mean')
- self.assertEquals(moving_variance.op.name, 'BatchNorm/moving_variance')
-
- def testMovingAverageVariables(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, scale=True)
- moving_mean = tf.moving_average_variables()[0]
- moving_variance = tf.moving_average_variables()[1]
- self.assertEquals(moving_mean.op.name, 'BatchNorm/moving_mean')
- self.assertEquals(moving_variance.op.name, 'BatchNorm/moving_variance')
-
- def testUpdateOps(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images)
- update_ops = tf.get_collection(ops.UPDATE_OPS_COLLECTION)
- update_moving_mean = update_ops[0]
- update_moving_variance = update_ops[1]
- self.assertEquals(update_moving_mean.op.name,
- 'BatchNorm/AssignMovingAvg')
- self.assertEquals(update_moving_variance.op.name,
- 'BatchNorm/AssignMovingAvg_1')
-
- def testReuseVariables(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, scale=True, scope='bn')
- ops.batch_norm(images, scale=True, scope='bn', reuse=True)
- beta = variables.get_variables_by_name('beta')
- gamma = variables.get_variables_by_name('gamma')
- self.assertEquals(len(beta), 1)
- self.assertEquals(len(gamma), 1)
- moving_vars = tf.get_collection('moving_vars')
- self.assertEquals(len(moving_vars), 2)
-
- def testReuseUpdateOps(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- ops.batch_norm(images, scope='bn')
- self.assertEquals(len(tf.get_collection(ops.UPDATE_OPS_COLLECTION)), 2)
- ops.batch_norm(images, scope='bn', reuse=True)
- self.assertEquals(len(tf.get_collection(ops.UPDATE_OPS_COLLECTION)), 4)
-
- def testCreateMovingVars(self):
- height, width = 3, 3
- with self.test_session():
- images = tf.random_uniform((5, height, width, 3), seed=1)
- _ = ops.batch_norm(images, moving_vars='moving_vars')
- moving_mean = tf.get_collection('moving_vars',
- 'BatchNorm/moving_mean')
- self.assertEquals(len(moving_mean), 1)
- self.assertEquals(moving_mean[0].op.name, 'BatchNorm/moving_mean')
- moving_variance = tf.get_collection('moving_vars',
- 'BatchNorm/moving_variance')
- self.assertEquals(len(moving_variance), 1)
- self.assertEquals(moving_variance[0].op.name, 'BatchNorm/moving_variance')
-
- def testComputeMovingVars(self):
- height, width = 3, 3
- with self.test_session() as sess:
- image_shape = (10, height, width, 3)
- image_values = np.random.rand(*image_shape)
- expected_mean = np.mean(image_values, axis=(0, 1, 2))
- expected_var = np.var(image_values, axis=(0, 1, 2))
- images = tf.constant(image_values, shape=image_shape, dtype=tf.float32)
- output = ops.batch_norm(images, decay=0.1)
- update_ops = tf.get_collection(ops.UPDATE_OPS_COLLECTION)
- with tf.control_dependencies(update_ops):
- output = tf.identity(output)
- # Initialize all variables
- sess.run(tf.global_variables_initializer())
- moving_mean = variables.get_variables('BatchNorm/moving_mean')[0]
- moving_variance = variables.get_variables('BatchNorm/moving_variance')[0]
- mean, variance = sess.run([moving_mean, moving_variance])
- # After initialization moving_mean == 0 and moving_variance == 1.
- self.assertAllClose(mean, [0] * 3)
- self.assertAllClose(variance, [1] * 3)
- for _ in range(10):
- sess.run([output])
- mean = moving_mean.eval()
- variance = moving_variance.eval()
- # After 10 updates with decay 0.1 moving_mean == expected_mean and
- # moving_variance == expected_var.
- self.assertAllClose(mean, expected_mean)
- self.assertAllClose(variance, expected_var)
-
- def testEvalMovingVars(self):
- height, width = 3, 3
- with self.test_session() as sess:
- image_shape = (10, height, width, 3)
- image_values = np.random.rand(*image_shape)
- expected_mean = np.mean(image_values, axis=(0, 1, 2))
- expected_var = np.var(image_values, axis=(0, 1, 2))
- images = tf.constant(image_values, shape=image_shape, dtype=tf.float32)
- output = ops.batch_norm(images, decay=0.1, is_training=False)
- update_ops = tf.get_collection(ops.UPDATE_OPS_COLLECTION)
- with tf.control_dependencies(update_ops):
- output = tf.identity(output)
- # Initialize all variables
- sess.run(tf.global_variables_initializer())
- moving_mean = variables.get_variables('BatchNorm/moving_mean')[0]
- moving_variance = variables.get_variables('BatchNorm/moving_variance')[0]
- mean, variance = sess.run([moving_mean, moving_variance])
- # After initialization moving_mean == 0 and moving_variance == 1.
- self.assertAllClose(mean, [0] * 3)
- self.assertAllClose(variance, [1] * 3)
- # Simulate assigment from saver restore.
- init_assigns = [tf.assign(moving_mean, expected_mean),
- tf.assign(moving_variance, expected_var)]
- sess.run(init_assigns)
- for _ in range(10):
- sess.run([output], {images: np.random.rand(*image_shape)})
- mean = moving_mean.eval()
- variance = moving_variance.eval()
- # Although we feed different images, the moving_mean and moving_variance
- # shouldn't change.
- self.assertAllClose(mean, expected_mean)
- self.assertAllClose(variance, expected_var)
-
- def testReuseVars(self):
- height, width = 3, 3
- with self.test_session() as sess:
- image_shape = (10, height, width, 3)
- image_values = np.random.rand(*image_shape)
- expected_mean = np.mean(image_values, axis=(0, 1, 2))
- expected_var = np.var(image_values, axis=(0, 1, 2))
- images = tf.constant(image_values, shape=image_shape, dtype=tf.float32)
- output = ops.batch_norm(images, decay=0.1, is_training=False)
- update_ops = tf.get_collection(ops.UPDATE_OPS_COLLECTION)
- with tf.control_dependencies(update_ops):
- output = tf.identity(output)
- # Initialize all variables
- sess.run(tf.global_variables_initializer())
- moving_mean = variables.get_variables('BatchNorm/moving_mean')[0]
- moving_variance = variables.get_variables('BatchNorm/moving_variance')[0]
- mean, variance = sess.run([moving_mean, moving_variance])
- # After initialization moving_mean == 0 and moving_variance == 1.
- self.assertAllClose(mean, [0] * 3)
- self.assertAllClose(variance, [1] * 3)
- # Simulate assigment from saver restore.
- init_assigns = [tf.assign(moving_mean, expected_mean),
- tf.assign(moving_variance, expected_var)]
- sess.run(init_assigns)
- for _ in range(10):
- sess.run([output], {images: np.random.rand(*image_shape)})
- mean = moving_mean.eval()
- variance = moving_variance.eval()
- # Although we feed different images, the moving_mean and moving_variance
- # shouldn't change.
- self.assertAllClose(mean, expected_mean)
- self.assertAllClose(variance, expected_var)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/inception/inception/slim/scopes.py b/research/inception/inception/slim/scopes.py
deleted file mode 100644
index 2c2fb0a2efa7d30eaddb36fc30265f30cbaeb9ef..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/scopes.py
+++ /dev/null
@@ -1,170 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains the new arg_scope used for TF-Slim ops.
-
- Allows one to define models much more compactly by eliminating boilerplate
- code. This is accomplished through the use of argument scoping (arg_scope).
-
- Example of how to use scopes.arg_scope:
-
- with scopes.arg_scope(ops.conv2d, padding='SAME',
- stddev=0.01, weight_decay=0.0005):
- net = ops.conv2d(inputs, 64, [11, 11], 4, padding='VALID', scope='conv1')
- net = ops.conv2d(net, 256, [5, 5], scope='conv2')
-
- The first call to conv2d will overwrite padding:
- ops.conv2d(inputs, 64, [11, 11], 4, padding='VALID',
- stddev=0.01, weight_decay=0.0005, scope='conv1')
-
- The second call to Conv will use predefined args:
- ops.conv2d(inputs, 256, [5, 5], padding='SAME',
- stddev=0.01, weight_decay=0.0005, scope='conv2')
-
- Example of how to reuse an arg_scope:
- with scopes.arg_scope(ops.conv2d, padding='SAME',
- stddev=0.01, weight_decay=0.0005) as conv2d_arg_scope:
- net = ops.conv2d(net, 256, [5, 5], scope='conv1')
- ....
-
- with scopes.arg_scope(conv2d_arg_scope):
- net = ops.conv2d(net, 256, [5, 5], scope='conv2')
-
- Example of how to use scopes.add_arg_scope:
-
- @scopes.add_arg_scope
- def conv2d(*args, **kwargs)
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import contextlib
-import functools
-
-from tensorflow.python.framework import ops
-
-_ARGSTACK_KEY = ("__arg_stack",)
-
-_DECORATED_OPS = set()
-
-
-def _get_arg_stack():
- stack = ops.get_collection(_ARGSTACK_KEY)
- if stack:
- return stack[0]
- else:
- stack = [{}]
- ops.add_to_collection(_ARGSTACK_KEY, stack)
- return stack
-
-
-def _current_arg_scope():
- stack = _get_arg_stack()
- return stack[-1]
-
-
-def _add_op(op):
- key_op = (op.__module__, op.__name__)
- if key_op not in _DECORATED_OPS:
- _DECORATED_OPS.add(key_op)
-
-
-@contextlib.contextmanager
-def arg_scope(list_ops_or_scope, **kwargs):
- """Stores the default arguments for the given set of list_ops.
-
- For usage, please see examples at top of the file.
-
- Args:
- list_ops_or_scope: List or tuple of operations to set argument scope for or
- a dictionary containg the current scope. When list_ops_or_scope is a dict,
- kwargs must be empty. When list_ops_or_scope is a list or tuple, then
- every op in it need to be decorated with @add_arg_scope to work.
- **kwargs: keyword=value that will define the defaults for each op in
- list_ops. All the ops need to accept the given set of arguments.
-
- Yields:
- the current_scope, which is a dictionary of {op: {arg: value}}
- Raises:
- TypeError: if list_ops is not a list or a tuple.
- ValueError: if any op in list_ops has not be decorated with @add_arg_scope.
- """
- if isinstance(list_ops_or_scope, dict):
- # Assumes that list_ops_or_scope is a scope that is being reused.
- if kwargs:
- raise ValueError("When attempting to re-use a scope by suppling a"
- "dictionary, kwargs must be empty.")
- current_scope = list_ops_or_scope.copy()
- try:
- _get_arg_stack().append(current_scope)
- yield current_scope
- finally:
- _get_arg_stack().pop()
- else:
- # Assumes that list_ops_or_scope is a list/tuple of ops with kwargs.
- if not isinstance(list_ops_or_scope, (list, tuple)):
- raise TypeError("list_ops_or_scope must either be a list/tuple or reused"
- "scope (i.e. dict)")
- try:
- current_scope = _current_arg_scope().copy()
- for op in list_ops_or_scope:
- key_op = (op.__module__, op.__name__)
- if not has_arg_scope(op):
- raise ValueError("%s is not decorated with @add_arg_scope", key_op)
- if key_op in current_scope:
- current_kwargs = current_scope[key_op].copy()
- current_kwargs.update(kwargs)
- current_scope[key_op] = current_kwargs
- else:
- current_scope[key_op] = kwargs.copy()
- _get_arg_stack().append(current_scope)
- yield current_scope
- finally:
- _get_arg_stack().pop()
-
-
-def add_arg_scope(func):
- """Decorates a function with args so it can be used within an arg_scope.
-
- Args:
- func: function to decorate.
-
- Returns:
- A tuple with the decorated function func_with_args().
- """
- @functools.wraps(func)
- def func_with_args(*args, **kwargs):
- current_scope = _current_arg_scope()
- current_args = kwargs
- key_func = (func.__module__, func.__name__)
- if key_func in current_scope:
- current_args = current_scope[key_func].copy()
- current_args.update(kwargs)
- return func(*args, **current_args)
- _add_op(func)
- return func_with_args
-
-
-def has_arg_scope(func):
- """Checks whether a func has been decorated with @add_arg_scope or not.
-
- Args:
- func: function to check.
-
- Returns:
- a boolean.
- """
- key_op = (func.__module__, func.__name__)
- return key_op in _DECORATED_OPS
diff --git a/research/inception/inception/slim/scopes_test.py b/research/inception/inception/slim/scopes_test.py
deleted file mode 100644
index cd349399ed7300dde38ac9bcb9818abc9d0680b4..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/scopes_test.py
+++ /dev/null
@@ -1,162 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests slim.scopes."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-
-import tensorflow as tf
-from inception.slim import scopes
-
-
-@scopes.add_arg_scope
-def func1(*args, **kwargs):
- return (args, kwargs)
-
-
-@scopes.add_arg_scope
-def func2(*args, **kwargs):
- return (args, kwargs)
-
-
-class ArgScopeTest(tf.test.TestCase):
-
- def testEmptyArgScope(self):
- with self.test_session():
- self.assertEqual(scopes._current_arg_scope(), {})
-
- def testCurrentArgScope(self):
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- key_op = (func1.__module__, func1.__name__)
- current_scope = {key_op: func1_kwargs.copy()}
- with self.test_session():
- with scopes.arg_scope([func1], a=1, b=None, c=[1]) as scope:
- self.assertDictEqual(scope, current_scope)
-
- def testCurrentArgScopeNested(self):
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- func2_kwargs = {'b': 2, 'd': [2]}
- key = lambda f: (f.__module__, f.__name__)
- current_scope = {key(func1): func1_kwargs.copy(),
- key(func2): func2_kwargs.copy()}
- with self.test_session():
- with scopes.arg_scope([func1], a=1, b=None, c=[1]):
- with scopes.arg_scope([func2], b=2, d=[2]) as scope:
- self.assertDictEqual(scope, current_scope)
-
- def testReuseArgScope(self):
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- key_op = (func1.__module__, func1.__name__)
- current_scope = {key_op: func1_kwargs.copy()}
- with self.test_session():
- with scopes.arg_scope([func1], a=1, b=None, c=[1]) as scope1:
- pass
- with scopes.arg_scope(scope1) as scope:
- self.assertDictEqual(scope, current_scope)
-
- def testReuseArgScopeNested(self):
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- func2_kwargs = {'b': 2, 'd': [2]}
- key = lambda f: (f.__module__, f.__name__)
- current_scope1 = {key(func1): func1_kwargs.copy()}
- current_scope2 = {key(func1): func1_kwargs.copy(),
- key(func2): func2_kwargs.copy()}
- with self.test_session():
- with scopes.arg_scope([func1], a=1, b=None, c=[1]) as scope1:
- with scopes.arg_scope([func2], b=2, d=[2]) as scope2:
- pass
- with scopes.arg_scope(scope1):
- self.assertDictEqual(scopes._current_arg_scope(), current_scope1)
- with scopes.arg_scope(scope2):
- self.assertDictEqual(scopes._current_arg_scope(), current_scope2)
-
- def testSimpleArgScope(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- with self.test_session():
- with scopes.arg_scope([func1], a=1, b=None, c=[1]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testSimpleArgScopeWithTuple(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- with self.test_session():
- with scopes.arg_scope((func1,), a=1, b=None, c=[1]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testOverwriteArgScope(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': 2, 'c': [1]}
- with scopes.arg_scope([func1], a=1, b=None, c=[1]):
- args, kwargs = func1(0, b=2)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testNestedArgScope(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- with scopes.arg_scope([func1], a=1, b=None, c=[1]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
- func1_kwargs['b'] = 2
- with scopes.arg_scope([func1], b=2):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testSharedArgScope(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- with scopes.arg_scope([func1, func2], a=1, b=None, c=[1]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
- args, kwargs = func2(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testSharedArgScopeTuple(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- with scopes.arg_scope((func1, func2), a=1, b=None, c=[1]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
- args, kwargs = func2(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
-
- def testPartiallySharedArgScope(self):
- func1_args = (0,)
- func1_kwargs = {'a': 1, 'b': None, 'c': [1]}
- func2_args = (1,)
- func2_kwargs = {'a': 1, 'b': None, 'd': [2]}
- with scopes.arg_scope([func1, func2], a=1, b=None):
- with scopes.arg_scope([func1], c=[1]), scopes.arg_scope([func2], d=[2]):
- args, kwargs = func1(0)
- self.assertTupleEqual(args, func1_args)
- self.assertDictEqual(kwargs, func1_kwargs)
- args, kwargs = func2(1)
- self.assertTupleEqual(args, func2_args)
- self.assertDictEqual(kwargs, func2_kwargs)
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/inception/inception/slim/slim.py b/research/inception/inception/slim/slim.py
deleted file mode 100644
index b7a5c0f8c52b66db899835480c331ffafdc386e2..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/slim.py
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""TF-Slim grouped API. Please see README.md for details and usage."""
-# pylint: disable=unused-import
-
-# Collapse tf-slim into a single namespace.
-from inception.slim import inception_model as inception
-from inception.slim import losses
-from inception.slim import ops
-from inception.slim import scopes
-from inception.slim import variables
-from inception.slim.scopes import arg_scope
diff --git a/research/inception/inception/slim/variables.py b/research/inception/inception/slim/variables.py
deleted file mode 100644
index 1d967b79e9563724b1114995a732cfd4dd486afd..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/variables.py
+++ /dev/null
@@ -1,289 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains convenience wrappers for creating variables in TF-Slim.
-
-The variables module is typically used for defining model variables from the
-ops routines (see slim.ops). Such variables are used for training, evaluation
-and inference of models.
-
-All the variables created through this module would be added to the
-MODEL_VARIABLES collection, if you create a model variable outside slim, it can
-be added with slim.variables.add_variable(external_variable, reuse).
-
-Usage:
- weights_initializer = tf.truncated_normal_initializer(stddev=0.01)
- l2_regularizer = lambda t: losses.l2_loss(t, weight=0.0005)
- weights = variables.variable('weights',
- shape=[100, 100],
- initializer=weights_initializer,
- regularizer=l2_regularizer,
- device='/cpu:0')
-
- biases = variables.variable('biases',
- shape=[100],
- initializer=tf.zeros_initializer(),
- device='/cpu:0')
-
- # More complex example.
-
- net = slim.ops.conv2d(input, 32, [3, 3], scope='conv1')
- net = slim.ops.conv2d(net, 64, [3, 3], scope='conv2')
- with slim.arg_scope([variables.variable], restore=False):
- net = slim.ops.conv2d(net, 64, [3, 3], scope='conv3')
-
- # Get all model variables from all the layers.
- model_variables = slim.variables.get_variables()
-
- # Get all model variables from a specific the layer, i.e 'conv1'.
- conv1_variables = slim.variables.get_variables('conv1')
-
- # Get all weights from all the layers.
- weights = slim.variables.get_variables_by_name('weights')
-
- # Get all bias from all the layers.
- biases = slim.variables.get_variables_by_name('biases')
-
- # Get all variables to restore.
- # (i.e. only those created by 'conv1' and 'conv2')
- variables_to_restore = slim.variables.get_variables_to_restore()
-
-************************************************
-* Initializing model variables from a checkpoint
-************************************************
-
-# Create some variables.
-v1 = slim.variables.variable(name="v1", ..., restore=False)
-v2 = slim.variables.variable(name="v2", ...) # By default restore=True
-...
-# The list of variables to restore should only contain 'v2'.
-variables_to_restore = slim.variables.get_variables_to_restore()
-restorer = tf.train.Saver(variables_to_restore)
-with tf.Session() as sess:
- # Restore variables from disk.
- restorer.restore(sess, "/tmp/model.ckpt")
- print("Model restored.")
- # Do some work with the model
- ...
-
-"""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception.slim import scopes
-
-# Collection containing all the variables created using slim.variables
-MODEL_VARIABLES = '_model_variables_'
-
-# Collection containing the slim.variables that are created with restore=True.
-VARIABLES_TO_RESTORE = '_variables_to_restore_'
-
-
-def add_variable(var, restore=True):
- """Adds a variable to the MODEL_VARIABLES collection.
-
- Optionally it will add the variable to the VARIABLES_TO_RESTORE collection.
- Args:
- var: a variable.
- restore: whether the variable should be added to the
- VARIABLES_TO_RESTORE collection.
-
- """
- collections = [MODEL_VARIABLES]
- if restore:
- collections.append(VARIABLES_TO_RESTORE)
- for collection in collections:
- if var not in tf.get_collection(collection):
- tf.add_to_collection(collection, var)
-
-
-def get_variables(scope=None, suffix=None):
- """Gets the list of variables, filtered by scope and/or suffix.
-
- Args:
- scope: an optional scope for filtering the variables to return.
- suffix: an optional suffix for filtering the variables to return.
-
- Returns:
- a copied list of variables with scope and suffix.
- """
- candidates = tf.get_collection(MODEL_VARIABLES, scope)[:]
- if suffix is not None:
- candidates = [var for var in candidates if var.op.name.endswith(suffix)]
- return candidates
-
-
-def get_variables_to_restore():
- """Gets the list of variables to restore.
-
- Returns:
- a copied list of variables.
- """
- return tf.get_collection(VARIABLES_TO_RESTORE)[:]
-
-
-def get_variables_by_name(given_name, scope=None):
- """Gets the list of variables that were given that name.
-
- Args:
- given_name: name given to the variable without scope.
- scope: an optional scope for filtering the variables to return.
-
- Returns:
- a copied list of variables with the given name and prefix.
- """
- return get_variables(scope=scope, suffix=given_name)
-
-
-def get_unique_variable(name):
- """Gets the variable uniquely identified by that name.
-
- Args:
- name: a name that uniquely identifies the variable.
-
- Returns:
- a tensorflow variable.
-
- Raises:
- ValueError: if no variable uniquely identified by the name exists.
- """
- candidates = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, name)
- if not candidates:
- raise ValueError('Couldnt find variable %s' % name)
-
- for candidate in candidates:
- if candidate.op.name == name:
- return candidate
- raise ValueError('Variable %s does not uniquely identify a variable', name)
-
-
-class VariableDeviceChooser(object):
- """Slim device chooser for variables.
-
- When using a parameter server it will assign them in a round-robin fashion.
- When not using a parameter server it allows GPU:0 placement otherwise CPU:0.
- """
-
- def __init__(self,
- num_parameter_servers=0,
- ps_device='/job:ps',
- placement='CPU:0'):
- """Initialize VariableDeviceChooser.
-
- Args:
- num_parameter_servers: number of parameter servers.
- ps_device: string representing the parameter server device.
- placement: string representing the placement of the variable either CPU:0
- or GPU:0. When using parameter servers forced to CPU:0.
- """
- self._num_ps = num_parameter_servers
- self._ps_device = ps_device
- self._placement = placement if num_parameter_servers == 0 else 'CPU:0'
- self._next_task_id = 0
-
- def __call__(self, op):
- device_string = ''
- if self._num_ps > 0:
- task_id = self._next_task_id
- self._next_task_id = (self._next_task_id + 1) % self._num_ps
- device_string = '%s/task:%d' % (self._ps_device, task_id)
- device_string += '/%s' % self._placement
- return device_string
-
-
-# TODO(sguada) Remove once get_variable is able to colocate op.devices.
-def variable_device(device, name):
- """Fix the variable device to colocate its ops."""
- if callable(device):
- var_name = tf.get_variable_scope().name + '/' + name
- var_def = tf.NodeDef(name=var_name, op='Variable')
- device = device(var_def)
- if device is None:
- device = ''
- return device
-
-
-@scopes.add_arg_scope
-def global_step(device=''):
- """Returns the global step variable.
-
- Args:
- device: Optional device to place the variable. It can be an string or a
- function that is called to get the device for the variable.
-
- Returns:
- the tensor representing the global step variable.
- """
- global_step_ref = tf.get_collection(tf.GraphKeys.GLOBAL_STEP)
- if global_step_ref:
- return global_step_ref[0]
- else:
- collections = [
- VARIABLES_TO_RESTORE,
- tf.GraphKeys.GLOBAL_VARIABLES,
- tf.GraphKeys.GLOBAL_STEP,
- ]
- # Get the device for the variable.
- with tf.device(variable_device(device, 'global_step')):
- return tf.get_variable('global_step', shape=[], dtype=tf.int64,
- initializer=tf.zeros_initializer(),
- trainable=False, collections=collections)
-
-
-@scopes.add_arg_scope
-def variable(name, shape=None, dtype=tf.float32, initializer=None,
- regularizer=None, trainable=True, collections=None, device='',
- restore=True):
- """Gets an existing variable with these parameters or creates a new one.
-
- It also add itself to a group with its name.
-
- Args:
- name: the name of the new or existing variable.
- shape: shape of the new or existing variable.
- dtype: type of the new or existing variable (defaults to `DT_FLOAT`).
- initializer: initializer for the variable if one is created.
- regularizer: a (Tensor -> Tensor or None) function; the result of
- applying it on a newly created variable will be added to the collection
- GraphKeys.REGULARIZATION_LOSSES and can be used for regularization.
- trainable: If `True` also add the variable to the graph collection
- `GraphKeys.TRAINABLE_VARIABLES` (see tf.Variable).
- collections: A list of collection names to which the Variable will be added.
- Note that the variable is always also added to the tf.GraphKeys.GLOBAL_VARIABLES
- and MODEL_VARIABLES collections.
- device: Optional device to place the variable. It can be an string or a
- function that is called to get the device for the variable.
- restore: whether the variable should be added to the
- VARIABLES_TO_RESTORE collection.
-
- Returns:
- The created or existing variable.
- """
- collections = list(collections or [])
-
- # Make sure variables are added to tf.GraphKeys.GLOBAL_VARIABLES and MODEL_VARIABLES
- collections += [tf.GraphKeys.GLOBAL_VARIABLES, MODEL_VARIABLES]
- # Add to VARIABLES_TO_RESTORE if necessary
- if restore:
- collections.append(VARIABLES_TO_RESTORE)
- # Remove duplicates
- collections = set(collections)
- # Get the device for the variable.
- with tf.device(variable_device(device, name)):
- return tf.get_variable(name, shape=shape, dtype=dtype,
- initializer=initializer, regularizer=regularizer,
- trainable=trainable, collections=collections)
diff --git a/research/inception/inception/slim/variables_test.py b/research/inception/inception/slim/variables_test.py
deleted file mode 100644
index b8c1944dfeb0fba7ad99f104b0c366c41d737c63..0000000000000000000000000000000000000000
--- a/research/inception/inception/slim/variables_test.py
+++ /dev/null
@@ -1,392 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for slim.variables."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from inception.slim import scopes
-from inception.slim import variables
-
-
-class VariablesTest(tf.test.TestCase):
-
- def testCreateVariable(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- self.assertEquals(a.op.name, 'A/a')
- self.assertListEqual(a.get_shape().as_list(), [5])
-
- def testGetVariables(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- with tf.variable_scope('B'):
- b = variables.variable('a', [5])
- self.assertEquals([a, b], variables.get_variables())
- self.assertEquals([a], variables.get_variables('A'))
- self.assertEquals([b], variables.get_variables('B'))
-
- def testGetVariablesSuffix(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- with tf.variable_scope('A'):
- b = variables.variable('b', [5])
- self.assertEquals([a], variables.get_variables(suffix='a'))
- self.assertEquals([b], variables.get_variables(suffix='b'))
-
- def testGetVariableWithSingleVar(self):
- with self.test_session():
- with tf.variable_scope('parent'):
- a = variables.variable('child', [5])
- self.assertEquals(a, variables.get_unique_variable('parent/child'))
-
- def testGetVariableWithDistractors(self):
- with self.test_session():
- with tf.variable_scope('parent'):
- a = variables.variable('child', [5])
- with tf.variable_scope('child'):
- variables.variable('grandchild1', [7])
- variables.variable('grandchild2', [9])
- self.assertEquals(a, variables.get_unique_variable('parent/child'))
-
- def testGetVariableThrowsExceptionWithNoMatch(self):
- var_name = 'cant_find_me'
- with self.test_session():
- with self.assertRaises(ValueError):
- variables.get_unique_variable(var_name)
-
- def testGetThrowsExceptionWithChildrenButNoMatch(self):
- var_name = 'parent/child'
- with self.test_session():
- with tf.variable_scope(var_name):
- variables.variable('grandchild1', [7])
- variables.variable('grandchild2', [9])
- with self.assertRaises(ValueError):
- variables.get_unique_variable(var_name)
-
- def testGetVariablesToRestore(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- with tf.variable_scope('B'):
- b = variables.variable('a', [5])
- self.assertEquals([a, b], variables.get_variables_to_restore())
-
- def testNoneGetVariablesToRestore(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5], restore=False)
- with tf.variable_scope('B'):
- b = variables.variable('a', [5], restore=False)
- self.assertEquals([], variables.get_variables_to_restore())
- self.assertEquals([a, b], variables.get_variables())
-
- def testGetMixedVariablesToRestore(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- b = variables.variable('b', [5], restore=False)
- with tf.variable_scope('B'):
- c = variables.variable('c', [5])
- d = variables.variable('d', [5], restore=False)
- self.assertEquals([a, b, c, d], variables.get_variables())
- self.assertEquals([a, c], variables.get_variables_to_restore())
-
- def testReuseVariable(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [])
- with tf.variable_scope('A', reuse=True):
- b = variables.variable('a', [])
- self.assertEquals(a, b)
- self.assertListEqual([a], variables.get_variables())
-
- def testVariableWithDevice(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [], device='cpu:0')
- b = variables.variable('b', [], device='cpu:1')
- self.assertDeviceEqual(a.device, 'cpu:0')
- self.assertDeviceEqual(b.device, 'cpu:1')
-
- def testVariableWithDeviceFromScope(self):
- with self.test_session():
- with tf.device('/cpu:0'):
- a = variables.variable('a', [])
- b = variables.variable('b', [], device='cpu:1')
- self.assertDeviceEqual(a.device, 'cpu:0')
- self.assertDeviceEqual(b.device, 'cpu:1')
-
- def testVariableWithDeviceFunction(self):
- class DevFn(object):
-
- def __init__(self):
- self.counter = -1
-
- def __call__(self, op):
- self.counter += 1
- return 'cpu:%d' % self.counter
-
- with self.test_session():
- with scopes.arg_scope([variables.variable], device=DevFn()):
- a = variables.variable('a', [])
- b = variables.variable('b', [])
- c = variables.variable('c', [], device='cpu:12')
- d = variables.variable('d', [])
- with tf.device('cpu:99'):
- e_init = tf.constant(12)
- e = variables.variable('e', initializer=e_init)
- self.assertDeviceEqual(a.device, 'cpu:0')
- self.assertDeviceEqual(a.initial_value.device, 'cpu:0')
- self.assertDeviceEqual(b.device, 'cpu:1')
- self.assertDeviceEqual(b.initial_value.device, 'cpu:1')
- self.assertDeviceEqual(c.device, 'cpu:12')
- self.assertDeviceEqual(c.initial_value.device, 'cpu:12')
- self.assertDeviceEqual(d.device, 'cpu:2')
- self.assertDeviceEqual(d.initial_value.device, 'cpu:2')
- self.assertDeviceEqual(e.device, 'cpu:3')
- self.assertDeviceEqual(e.initial_value.device, 'cpu:99')
-
- def testVariableWithReplicaDeviceSetter(self):
- with self.test_session():
- with tf.device(tf.train.replica_device_setter(ps_tasks=2)):
- a = variables.variable('a', [])
- b = variables.variable('b', [])
- c = variables.variable('c', [], device='cpu:12')
- d = variables.variable('d', [])
- with tf.device('cpu:99'):
- e_init = tf.constant(12)
- e = variables.variable('e', initializer=e_init)
- # The values below highlight how the replica_device_setter puts initial
- # values on the worker job, and how it merges explicit devices.
- self.assertDeviceEqual(a.device, '/job:ps/task:0/cpu:0')
- self.assertDeviceEqual(a.initial_value.device, '/job:worker/cpu:0')
- self.assertDeviceEqual(b.device, '/job:ps/task:1/cpu:0')
- self.assertDeviceEqual(b.initial_value.device, '/job:worker/cpu:0')
- self.assertDeviceEqual(c.device, '/job:ps/task:0/cpu:12')
- self.assertDeviceEqual(c.initial_value.device, '/job:worker/cpu:12')
- self.assertDeviceEqual(d.device, '/job:ps/task:1/cpu:0')
- self.assertDeviceEqual(d.initial_value.device, '/job:worker/cpu:0')
- self.assertDeviceEqual(e.device, '/job:ps/task:0/cpu:0')
- self.assertDeviceEqual(e.initial_value.device, '/job:worker/cpu:99')
-
- def testVariableWithVariableDeviceChooser(self):
-
- with tf.Graph().as_default():
- device_fn = variables.VariableDeviceChooser(num_parameter_servers=2)
- with scopes.arg_scope([variables.variable], device=device_fn):
- a = variables.variable('a', [])
- b = variables.variable('b', [])
- c = variables.variable('c', [], device='cpu:12')
- d = variables.variable('d', [])
- with tf.device('cpu:99'):
- e_init = tf.constant(12)
- e = variables.variable('e', initializer=e_init)
- # The values below highlight how the VariableDeviceChooser puts initial
- # values on the same device as the variable job.
- self.assertDeviceEqual(a.device, '/job:ps/task:0/cpu:0')
- self.assertDeviceEqual(a.initial_value.device, a.device)
- self.assertDeviceEqual(b.device, '/job:ps/task:1/cpu:0')
- self.assertDeviceEqual(b.initial_value.device, b.device)
- self.assertDeviceEqual(c.device, '/cpu:12')
- self.assertDeviceEqual(c.initial_value.device, c.device)
- self.assertDeviceEqual(d.device, '/job:ps/task:0/cpu:0')
- self.assertDeviceEqual(d.initial_value.device, d.device)
- self.assertDeviceEqual(e.device, '/job:ps/task:1/cpu:0')
- self.assertDeviceEqual(e.initial_value.device, '/cpu:99')
-
- def testVariableGPUPlacement(self):
-
- with tf.Graph().as_default():
- device_fn = variables.VariableDeviceChooser(placement='gpu:0')
- with scopes.arg_scope([variables.variable], device=device_fn):
- a = variables.variable('a', [])
- b = variables.variable('b', [])
- c = variables.variable('c', [], device='cpu:12')
- d = variables.variable('d', [])
- with tf.device('cpu:99'):
- e_init = tf.constant(12)
- e = variables.variable('e', initializer=e_init)
- # The values below highlight how the VariableDeviceChooser puts initial
- # values on the same device as the variable job.
- self.assertDeviceEqual(a.device, '/gpu:0')
- self.assertDeviceEqual(a.initial_value.device, a.device)
- self.assertDeviceEqual(b.device, '/gpu:0')
- self.assertDeviceEqual(b.initial_value.device, b.device)
- self.assertDeviceEqual(c.device, '/cpu:12')
- self.assertDeviceEqual(c.initial_value.device, c.device)
- self.assertDeviceEqual(d.device, '/gpu:0')
- self.assertDeviceEqual(d.initial_value.device, d.device)
- self.assertDeviceEqual(e.device, '/gpu:0')
- self.assertDeviceEqual(e.initial_value.device, '/cpu:99')
-
- def testVariableCollection(self):
- with self.test_session():
- a = variables.variable('a', [], collections='A')
- b = variables.variable('b', [], collections='B')
- self.assertEquals(a, tf.get_collection('A')[0])
- self.assertEquals(b, tf.get_collection('B')[0])
-
- def testVariableCollections(self):
- with self.test_session():
- a = variables.variable('a', [], collections=['A', 'C'])
- b = variables.variable('b', [], collections=['B', 'C'])
- self.assertEquals(a, tf.get_collection('A')[0])
- self.assertEquals(b, tf.get_collection('B')[0])
-
- def testVariableCollectionsWithArgScope(self):
- with self.test_session():
- with scopes.arg_scope([variables.variable], collections='A'):
- a = variables.variable('a', [])
- b = variables.variable('b', [])
- self.assertListEqual([a, b], tf.get_collection('A'))
-
- def testVariableCollectionsWithArgScopeNested(self):
- with self.test_session():
- with scopes.arg_scope([variables.variable], collections='A'):
- a = variables.variable('a', [])
- with scopes.arg_scope([variables.variable], collections='B'):
- b = variables.variable('b', [])
- self.assertEquals(a, tf.get_collection('A')[0])
- self.assertEquals(b, tf.get_collection('B')[0])
-
- def testVariableCollectionsWithArgScopeNonNested(self):
- with self.test_session():
- with scopes.arg_scope([variables.variable], collections='A'):
- a = variables.variable('a', [])
- with scopes.arg_scope([variables.variable], collections='B'):
- b = variables.variable('b', [])
- variables.variable('c', [])
- self.assertListEqual([a], tf.get_collection('A'))
- self.assertListEqual([b], tf.get_collection('B'))
-
- def testVariableRestoreWithArgScopeNested(self):
- with self.test_session():
- with scopes.arg_scope([variables.variable], restore=True):
- a = variables.variable('a', [])
- with scopes.arg_scope([variables.variable],
- trainable=False,
- collections=['A', 'B']):
- b = variables.variable('b', [])
- c = variables.variable('c', [])
- self.assertListEqual([a, b, c], variables.get_variables_to_restore())
- self.assertListEqual([a, c], tf.trainable_variables())
- self.assertListEqual([b], tf.get_collection('A'))
- self.assertListEqual([b], tf.get_collection('B'))
-
-
-class GetVariablesByNameTest(tf.test.TestCase):
-
- def testGetVariableGivenNameScoped(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- b = variables.variable('b', [5])
- self.assertEquals([a], variables.get_variables_by_name('a'))
- self.assertEquals([b], variables.get_variables_by_name('b'))
-
- def testGetVariablesByNameReturnsByValueWithScope(self):
- with self.test_session():
- with tf.variable_scope('A'):
- a = variables.variable('a', [5])
- matched_variables = variables.get_variables_by_name('a')
-
- # If variables.get_variables_by_name returns the list by reference, the
- # following append should persist, and be returned, in subsequent calls
- # to variables.get_variables_by_name('a').
- matched_variables.append(4)
-
- matched_variables = variables.get_variables_by_name('a')
- self.assertEquals([a], matched_variables)
-
- def testGetVariablesByNameReturnsByValueWithoutScope(self):
- with self.test_session():
- a = variables.variable('a', [5])
- matched_variables = variables.get_variables_by_name('a')
-
- # If variables.get_variables_by_name returns the list by reference, the
- # following append should persist, and be returned, in subsequent calls
- # to variables.get_variables_by_name('a').
- matched_variables.append(4)
-
- matched_variables = variables.get_variables_by_name('a')
- self.assertEquals([a], matched_variables)
-
-
-class GlobalStepTest(tf.test.TestCase):
-
- def testStable(self):
- with tf.Graph().as_default():
- gs = variables.global_step()
- gs2 = variables.global_step()
- self.assertTrue(gs is gs2)
-
- def testDevice(self):
- with tf.Graph().as_default():
- with scopes.arg_scope([variables.global_step], device='/gpu:0'):
- gs = variables.global_step()
- self.assertDeviceEqual(gs.device, '/gpu:0')
-
- def testDeviceFn(self):
- class DevFn(object):
-
- def __init__(self):
- self.counter = -1
-
- def __call__(self, op):
- self.counter += 1
- return '/cpu:%d' % self.counter
-
- with tf.Graph().as_default():
- with scopes.arg_scope([variables.global_step], device=DevFn()):
- gs = variables.global_step()
- gs2 = variables.global_step()
- self.assertDeviceEqual(gs.device, '/cpu:0')
- self.assertEquals(gs, gs2)
- self.assertDeviceEqual(gs2.device, '/cpu:0')
-
- def testReplicaDeviceSetter(self):
- device_fn = tf.train.replica_device_setter(2)
- with tf.Graph().as_default():
- with scopes.arg_scope([variables.global_step], device=device_fn):
- gs = variables.global_step()
- gs2 = variables.global_step()
- self.assertEquals(gs, gs2)
- self.assertDeviceEqual(gs.device, '/job:ps/task:0')
- self.assertDeviceEqual(gs.initial_value.device, '/job:ps/task:0')
- self.assertDeviceEqual(gs2.device, '/job:ps/task:0')
- self.assertDeviceEqual(gs2.initial_value.device, '/job:ps/task:0')
-
- def testVariableWithVariableDeviceChooser(self):
-
- with tf.Graph().as_default():
- device_fn = variables.VariableDeviceChooser()
- with scopes.arg_scope([variables.global_step], device=device_fn):
- gs = variables.global_step()
- gs2 = variables.global_step()
- self.assertEquals(gs, gs2)
- self.assertDeviceEqual(gs.device, 'cpu:0')
- self.assertDeviceEqual(gs.initial_value.device, gs.device)
- self.assertDeviceEqual(gs2.device, 'cpu:0')
- self.assertDeviceEqual(gs2.initial_value.device, gs2.device)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/keypointnet/CONTRIBUTING.md b/research/keypointnet/CONTRIBUTING.md
deleted file mode 100644
index 939e5341e74dc2371c8b47f0e27b50581bed5f63..0000000000000000000000000000000000000000
--- a/research/keypointnet/CONTRIBUTING.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# How to Contribute
-
-We'd love to accept your patches and contributions to this project. There are
-just a few small guidelines you need to follow.
-
-## Contributor License Agreement
-
-Contributions to this project must be accompanied by a Contributor License
-Agreement. You (or your employer) retain the copyright to your contribution;
-this simply gives us permission to use and redistribute your contributions as
-part of the project. Head over to from POBJ> olive`.
-2. The distributional information provided by the individual words; i.e., the
- word embeddings of the two consituents.
-3. The distributional signal provided by the compound itself; i.e., the
- embedding of the noun compound in context.
-
-The model includes several variants: *path-based model* uses (1) alone, the
-*distributional model* uses (2) alone, and the *integrated model* uses (1) and
-(2). The *distributional-nc model* and the *integrated-nc* model each add (3).
-
-Training a model requires the following:
-
-1. A collection of noun compounds that have been labeled using a *relation
- inventory*. The inventory describes the specific relationships that you'd
- like the model to differentiate (e.g. *part of* versus *composed of* versus
- *purpose*), and generally may consist of tens of classes. You can download
- the dataset used in the paper from
- [here](https://vered1986.github.io/papers/Tratz2011_Dataset.tar.gz).
-2. A collection of word embeddings: the path-based model uses the word
- embeddings as part of the path representation, and the distributional models
- use the word embeddings directly as prediction features.
-3. The path-based model requires a collection of syntactic dependency parses
- that connect the constituents for each noun compound. To generate these,
- you'll need a corpus from which to train this data; we used Wikipedia and the
- [LDC GigaWord5](https://catalog.ldc.upenn.edu/LDC2011T07) corpora.
-
-# Contents
-
-The following source code is included here:
-
-* `learn_path_embeddings.py` is a script that trains and evaluates a path-based
- model to predict a noun-compound relationship given labeled noun-compounds and
- dependency parse paths.
-* `learn_classifier.py` is a script that trains and evaluates a classifier based
- on any combination of paths, word embeddings, and noun-compound embeddings.
-* `get_indicative_paths.py` is a script that generates the most indicative
- syntactic dependency paths for a particular relationship.
-
-Also included are utilities for preparing data for training:
-
-* `text_embeddings_to_binary.py` converts a text file containing word embeddings
- into a binary file that is quicker to load.
-* `extract_paths.py` finds all the dependency paths that connect words in a
- corpus.
-* `sorted_paths_to_examples.py` processes the output of `extract_paths.py` to
- produce summarized training data.
-
-This code (in particular, the utilities used to prepare the data) differs from
-the code that was used to prepare data for the paper. Notably, we used a
-proprietary dependency parser instead of spaCy, which is used here.
-
-# Dependencies
-
-* [TensorFlow](http://www.tensorflow.org/): see detailed installation
- instructions at that site.
-* [SciKit Learn](http://scikit-learn.org/): you can probably just install this
- with `pip install sklearn`.
-* [SpaCy](https://spacy.io/): `pip install spacy` ought to do the trick, along
- with the English model.
-
-# Creating the Model
-
-This sections described the steps necessary to create and evaluate the model
-described in the paper.
-
-## Generate Path Data
-
-To begin, you need three text files:
-
-1. **Corpus**. This file should contain natural language sentences, written with
- one sentence per line. For purposes of exposition, we'll assume that you
- have English Wikipedia serialized this way in `${HOME}/data/wiki.txt`.
-2. **Labeled Noun Compound Pairs**. This file contain (modfier, head, label)
- tuples, tab-separated, with one per line. The *label* represented the
- relationship between the head and the modifier; e.g., if `purpose` is one
- your labels, you could possibly include `toothpastepurpose`.
-3. **Word Embeddings**. We used the
- [GloVe](https://nlp.stanford.edu/projects/glove/) word embeddings; in
- particular the 6B token, 300d variant. We'll assume you have this file as
- `${HOME}/data/glove.6B.300d.txt`.
-
-We first processed the embeddings from their text format into something that we
-can load a little bit more quickly:
-
- ./text_embeddings_to_binary.py \
- --input ${HOME}/data/glove.6B.300d.txt \
- --output_vocab ${HOME}/data/vocab.txt \
- --output_npy ${HOME}/data/glove.6B.300d.npy
-
-Next, we'll extract all the dependency parse paths connecting our labeled pairs
-from the corpus. This process takes a *looooong* time, but is trivially
-parallelized using map-reduce if you have access to that technology.
-
- ./extract_paths.py \
- --corpus ${HOME}/data/wiki.txt \
- --labeled_pairs ${HOME}/data/labeled-pairs.tsv \
- --output ${HOME}/data/paths.tsv
-
-The file it produces (`paths.tsv`) is a tab-separated file that contains the
-modifier, the head, the label, the encoded path, and the sentence from which the
-path was drawn. (This last is mostly for sanity checking.) A sample row might
-look something like this (where newlines would actually be tab characters):
-
- navy
- captain
- owner_emp_use
- /PROPN/dobj/>::enter/VERB/ROOT/^::follow/VERB/advcl/<::in/ADP/prep/<::footstep/NOUN/pobj/<::of/ADP/prep/<::father/NOUN/pobj/<::bover/PROPN/appos/<::/PROPN/compound/<
- He entered the Royal Navy following in the footsteps of his father Captain John Bover and two of his elder brothers as volunteer aboard HMS Perseus
-
-This file must be sorted as follows:
-
- sort -k1,3 -t$'\t' paths.tsv > sorted.paths.tsv
-
-In particular, rows with the same modifier, head, and label must appear
-contiguously.
-
-We next create a file that contains all the relation labels from our original
-labeled pairs:
-
- awk 'BEGIN {FS="\t"} {print $3}' < ${HOME}/data/labeled-pairs.tsv \
- | sort -u > ${HOME}/data/relations.txt
-
-With these in hand, we're ready to produce the train, validation, and test data:
-
- ./sorted_paths_to_examples.py \
- --input ${HOME}/data/sorted.paths.tsv \
- --vocab ${HOME}/data/vocab.txt \
- --relations ${HOME}/data/relations.txt \
- --splits ${HOME}/data/splits.txt \
- --output_dir ${HOME}/data
-
-Here, `splits.txt` is a file that indicates which "split" (train, test, or
-validation) you want the pair to appear in. It should be a tab-separate file
-which conatins the modifier, head, and the dataset ( `train`, `test`, or `val`)
-into which the pair should be placed; e.g.,:
-
- tooth paste train
- banana seat test
-
-The program will produce a separate file for each dataset split in the directory
-specified by `--output_dir`. Each file is contains `tf.train.Example` protocol
-buffers encoded using the `TFRecord` file format.
-
-## Create Path Embeddings
-
-Now we're ready to train the path embeddings using `learn_path_embeddings.py`:
-
- ./learn_path_embeddings.py \
- --train ${HOME}/data/train.tfrecs.gz \
- --val ${HOME}/data/val.tfrecs.gz \
- --text ${HOME}/data/test.tfrecs.gz \
- --embeddings ${HOME}/data/glove.6B.300d.npy
- --relations ${HOME}/data/relations.txt
- --output ${HOME}/data/path-embeddings \
- --logdir /tmp/learn_path_embeddings
-
-The path embeddings will be placed at the location specified by `--output`.
-
-## Train classifiers
-
-Train classifiers and evaluate on the validation and test data using
-`train_classifiers.py` script. This shell script fragment will iterate through
-each dataset, split, corpus, and model type to train and evaluate classifiers.
-
- LOGDIR=/tmp/learn_classifier
- for DATASET in tratz/fine_grained tratz/coarse_grained ; do
- for SPLIT in random lexical_head lexical_mod lexical_full ; do
- for CORPUS in wiki_gigiawords ; do
- for MODEL in dist dist-nc path integrated integrated-nc ; do
- # Filename for the log that will contain the classifier results.
- LOGFILE=$(echo "${DATASET}.${SPLIT}.${CORPUS}.${MODEL}.log" | sed -e "s,/,.,g")
- python learn_classifier.py \
- --dataset_dir ~/lexnet/datasets \
- --dataset "${DATASET}" \
- --corpus "${SPLIT}/${CORPUS}" \
- --embeddings_base_path ~/lexnet/embeddings \
- --logdir ${LOGDIR} \
- --input "${MODEL}" > "${LOGDIR}/${LOGFILE}"
- done
- done
- done
- done
-
-The log file will contain the final performance (precision, recall, F1) on the
-train, dev, and test sets, and will include a confusion matrix for each.
-
-# Contact
-
-If you have any questions, issues, or suggestions, feel free to contact either
-@vered1986 or @waterson.
-
-If you use this code for any published research, please include the following citation:
-
-Olive Oil Is Made of Olives, Baby Oil Is Made for Babies: Interpreting Noun Compounds Using Paraphrases in a Neural Model.
-Vered Shwartz and Chris Waterson. NAACL 2018. [link](https://arxiv.org/pdf/1803.08073.pdf).
diff --git a/research/lexnet_nc/extract_paths.py b/research/lexnet_nc/extract_paths.py
deleted file mode 100755
index 833eec2c1b8a176b487d4e663a737b9502b49eda..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/extract_paths.py
+++ /dev/null
@@ -1,119 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import itertools
-import sys
-
-import spacy
-import tensorflow as tf
-
-tf.flags.DEFINE_string('corpus', '', 'Filename of corpus')
-tf.flags.DEFINE_string('labeled_pairs', '', 'Filename of labeled pairs')
-tf.flags.DEFINE_string('output', '', 'Filename of output file')
-FLAGS = tf.flags.FLAGS
-
-
-def get_path(mod_token, head_token):
- """Returns the path between a modifier token and a head token."""
- # Compute the path from the root to each token.
- mod_ancestors = list(reversed(list(mod_token.ancestors)))
- head_ancestors = list(reversed(list(head_token.ancestors)))
-
- # If the paths don't start at the same place (odd!) then there is no path at
- # all.
- if (not mod_ancestors or not head_ancestors
- or mod_ancestors[0] != head_ancestors[0]):
- return None
-
- # Eject elements from the common path until we reach the first differing
- # ancestor.
- ix = 1
- while (ix < len(mod_ancestors) and ix < len(head_ancestors)
- and mod_ancestors[ix] == head_ancestors[ix]):
- ix += 1
-
- # Construct the path. TODO: add "satellites", possibly honor sentence
- # ordering between modifier and head rather than just always traversing from
- # the modifier to the head?
- path = ['/'.join(('', mod_token.pos_, mod_token.dep_, '>'))]
-
- path += ['/'.join((tok.lemma_, tok.pos_, tok.dep_, '>'))
- for tok in reversed(mod_ancestors[ix:])]
-
- root_token = mod_ancestors[ix - 1]
- path += ['/'.join((root_token.lemma_, root_token.pos_, root_token.dep_, '^'))]
-
- path += ['/'.join((tok.lemma_, tok.pos_, tok.dep_, '<'))
- for tok in head_ancestors[ix:]]
-
- path += ['/'.join(('', head_token.pos_, head_token.dep_, '<'))]
-
- return '::'.join(path)
-
-
-def main(_):
- nlp = spacy.load('en_core_web_sm')
-
- # Grab the set of labeled pairs for which we wish to collect paths.
- with tf.gfile.GFile(FLAGS.labeled_pairs) as fh:
- parts = (l.decode('utf-8').split('\t') for l in fh.read().splitlines())
- labeled_pairs = {(mod, head): rel for mod, head, rel in parts}
-
- # Create a mapping from each head to the modifiers that are used with it.
- mods_for_head = {
- head: set(hm[1] for hm in head_mods)
- for head, head_mods in itertools.groupby(
- sorted((head, mod) for (mod, head) in labeled_pairs.iterkeys()),
- lambda (head, mod): head)}
-
- # Collect all the heads that we know about.
- heads = set(mods_for_head.keys())
-
- # For each sentence that contains a (head, modifier) pair that's in our set,
- # emit the dependency path that connects the pair.
- out_fh = sys.stdout if not FLAGS.output else tf.gfile.GFile(FLAGS.output, 'w')
- in_fh = sys.stdin if not FLAGS.corpus else tf.gfile.GFile(FLAGS.corpus)
-
- num_paths = 0
- for line, sen in enumerate(in_fh, start=1):
- if line % 100 == 0:
- print('\rProcessing line %d: %d paths' % (line, num_paths),
- end='', file=sys.stderr)
-
- sen = sen.decode('utf-8').strip()
- doc = nlp(sen)
-
- for head_token in doc:
- head_text = head_token.text.lower()
- if head_text in heads:
- mods = mods_for_head[head_text]
- for mod_token in doc:
- mod_text = mod_token.text.lower()
- if mod_text in mods:
- path = get_path(mod_token, head_token)
- if path:
- label = labeled_pairs[(mod_text, head_text)]
- line = '\t'.join((mod_text, head_text, label, path, sen))
- print(line.encode('utf-8'), file=out_fh)
- num_paths += 1
-
- out_fh.close()
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lexnet_nc/get_indicative_paths.py b/research/lexnet_nc/get_indicative_paths.py
deleted file mode 100755
index f8b34cca221a07c0b633024b71f082b8f61b3a45..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/get_indicative_paths.py
+++ /dev/null
@@ -1,111 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Extracts paths that are indicative of each relation."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-import tensorflow as tf
-
-from . import path_model
-from . import lexnet_common
-
-tf.flags.DEFINE_string(
- 'dataset_dir', 'datasets',
- 'Dataset base directory')
-
-tf.flags.DEFINE_string(
- 'dataset',
- 'tratz/fine_grained',
- 'Subdirectory containing the corpus directories: '
- 'subdirectory of dataset_dir')
-
-tf.flags.DEFINE_string(
- 'corpus', 'random/wiki',
- 'Subdirectory containing the corpus and split: '
- 'subdirectory of dataset_dir/dataset')
-
-tf.flags.DEFINE_string(
- 'embeddings_base_path', 'embeddings',
- 'Embeddings base directory')
-
-tf.flags.DEFINE_string(
- 'logdir', 'logdir',
- 'Directory of model output files')
-
-tf.flags.DEFINE_integer(
- 'top_k', 20, 'Number of top paths to extract')
-
-tf.flags.DEFINE_float(
- 'threshold', 0.8, 'Threshold above which to consider paths as indicative')
-
-FLAGS = tf.flags.FLAGS
-
-
-def main(_):
- hparams = path_model.PathBasedModel.default_hparams()
-
- # First things first. Load the path data.
- path_embeddings_file = 'path_embeddings/{dataset}/{corpus}'.format(
- dataset=FLAGS.dataset,
- corpus=FLAGS.corpus)
-
- path_dim = (hparams.lemma_dim + hparams.pos_dim +
- hparams.dep_dim + hparams.dir_dim)
-
- path_embeddings, path_to_index = path_model.load_path_embeddings(
- os.path.join(FLAGS.embeddings_base_path, path_embeddings_file),
- path_dim)
-
- # Load and count the classes so we can correctly instantiate the model.
- classes_filename = os.path.join(
- FLAGS.dataset_dir, FLAGS.dataset, 'classes.txt')
-
- with open(classes_filename) as f_in:
- classes = f_in.read().splitlines()
-
- hparams.num_classes = len(classes)
-
- # We need the word embeddings to instantiate the model, too.
- print('Loading word embeddings...')
- lemma_embeddings = lexnet_common.load_word_embeddings(
- FLAGS.embeddings_base_path, hparams.lemma_embeddings_file)
-
- # Instantiate the model.
- with tf.Graph().as_default():
- with tf.variable_scope('lexnet'):
- instance = tf.placeholder(dtype=tf.string)
- model = path_model.PathBasedModel(
- hparams, lemma_embeddings, instance)
-
- with tf.Session() as session:
- model_dir = '{logdir}/results/{dataset}/path/{corpus}'.format(
- logdir=FLAGS.logdir,
- dataset=FLAGS.dataset,
- corpus=FLAGS.corpus)
-
- saver = tf.train.Saver()
- saver.restore(session, os.path.join(model_dir, 'best.ckpt'))
-
- path_model.get_indicative_paths(
- model, session, path_to_index, path_embeddings, classes,
- model_dir, FLAGS.top_k, FLAGS.threshold)
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lexnet_nc/learn_classifier.py b/research/lexnet_nc/learn_classifier.py
deleted file mode 100755
index ec284029535609ffd2cc0f2f5cddb9b87954aa81..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/learn_classifier.py
+++ /dev/null
@@ -1,223 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Trains the integrated LexNET classifier."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-import lexnet_common
-import lexnet_model
-import path_model
-from sklearn import metrics
-import tensorflow as tf
-
-tf.flags.DEFINE_string(
- 'dataset_dir', 'datasets',
- 'Dataset base directory')
-
-tf.flags.DEFINE_string(
- 'dataset', 'tratz/fine_grained',
- 'Subdirectory containing the corpus directories: '
- 'subdirectory of dataset_dir')
-
-tf.flags.DEFINE_string(
- 'corpus', 'wiki/random',
- 'Subdirectory containing the corpus and split: '
- 'subdirectory of dataset_dir/dataset')
-
-tf.flags.DEFINE_string(
- 'embeddings_base_path', 'embeddings',
- 'Embeddings base directory')
-
-tf.flags.DEFINE_string(
- 'logdir', 'logdir',
- 'Directory of model output files')
-
-tf.flags.DEFINE_string('hparams', '', 'Hyper-parameters')
-
-tf.flags.DEFINE_string(
- 'input', 'integrated',
- 'The model(dist/dist-nc/path/integrated/integrated-nc')
-
-FLAGS = tf.flags.FLAGS
-
-
-def main(_):
- # Pick up any one-off hyper-parameters.
- hparams = lexnet_model.LexNETModel.default_hparams()
- hparams.corpus = FLAGS.corpus
- hparams.input = FLAGS.input
- hparams.path_embeddings_file = 'path_embeddings/%s/%s' % (
- FLAGS.dataset, FLAGS.corpus)
-
- input_dir = hparams.input if hparams.input != 'path' else 'path_classifier'
-
- # Set the number of classes
- classes_filename = os.path.join(
- FLAGS.dataset_dir, FLAGS.dataset, 'classes.txt')
- with open(classes_filename) as f_in:
- classes = f_in.read().splitlines()
-
- hparams.num_classes = len(classes)
- print('Model will predict into %d classes' % hparams.num_classes)
-
- # Get the datasets
- train_set, val_set, test_set = (
- os.path.join(
- FLAGS.dataset_dir, FLAGS.dataset, FLAGS.corpus,
- filename + '.tfrecs.gz')
- for filename in ['train', 'val', 'test'])
-
- print('Running with hyper-parameters: {}'.format(hparams))
-
- # Load the instances
- print('Loading instances...')
- opts = tf.python_io.TFRecordOptions(
- compression_type=tf.python_io.TFRecordCompressionType.GZIP)
- train_instances = list(tf.python_io.tf_record_iterator(train_set, opts))
- val_instances = list(tf.python_io.tf_record_iterator(val_set, opts))
- test_instances = list(tf.python_io.tf_record_iterator(test_set, opts))
-
- # Load the word embeddings
- print('Loading word embeddings...')
- relata_embeddings, path_embeddings, nc_embeddings, path_to_index = (
- None, None, None, None)
- if hparams.input in ['dist', 'dist-nc', 'integrated', 'integrated-nc']:
- relata_embeddings = lexnet_common.load_word_embeddings(
- FLAGS.embeddings_base_path, hparams.relata_embeddings_file)
-
- if hparams.input in ['path', 'integrated', 'integrated-nc']:
- path_embeddings, path_to_index = path_model.load_path_embeddings(
- os.path.join(FLAGS.embeddings_base_path, hparams.path_embeddings_file),
- hparams.path_dim)
-
- if hparams.input in ['dist-nc', 'integrated-nc']:
- nc_embeddings = lexnet_common.load_word_embeddings(
- FLAGS.embeddings_base_path, hparams.nc_embeddings_file)
-
- # Define the graph and the model
- with tf.Graph().as_default():
- model = lexnet_model.LexNETModel(
- hparams, relata_embeddings, path_embeddings,
- nc_embeddings, path_to_index)
-
- # Initialize a session and start training
- session = tf.Session()
- session.run(tf.global_variables_initializer())
-
- # Initalize the path mapping
- if hparams.input in ['path', 'integrated', 'integrated-nc']:
- session.run(tf.tables_initializer())
- session.run(model.initialize_path_op, {
- model.path_initial_value_t: path_embeddings
- })
-
- # Initialize the NC embeddings
- if hparams.input in ['dist-nc', 'integrated-nc']:
- session.run(model.initialize_nc_op, {
- model.nc_initial_value_t: nc_embeddings
- })
-
- # Load the labels
- print('Loading labels...')
- train_labels = model.load_labels(session, train_instances)
- val_labels = model.load_labels(session, val_instances)
- test_labels = model.load_labels(session, test_instances)
-
- save_path = '{logdir}/results/{dataset}/{input}/{corpus}'.format(
- logdir=FLAGS.logdir, dataset=FLAGS.dataset,
- corpus=model.hparams.corpus, input=input_dir)
-
- if not os.path.exists(save_path):
- os.makedirs(save_path)
-
- # Train the model
- print('Training the model...')
- model.fit(session, train_instances, epoch_completed,
- val_instances, val_labels, save_path)
-
- # Print the best performance on the validation set
- print('Best performance on the validation set: F1=%.3f' %
- epoch_completed.best_f1)
-
- # Evaluate on the train and validation sets
- lexnet_common.full_evaluation(model, session, train_instances, train_labels,
- 'Train', classes)
- lexnet_common.full_evaluation(model, session, val_instances, val_labels,
- 'Validation', classes)
- test_predictions = lexnet_common.full_evaluation(
- model, session, test_instances, test_labels, 'Test', classes)
-
- # Write the test predictions to a file
- predictions_file = os.path.join(save_path, 'test_predictions.tsv')
- print('Saving test predictions to %s' % save_path)
- test_pairs = model.load_pairs(session, test_instances)
- lexnet_common.write_predictions(test_pairs, test_labels, test_predictions,
- classes, predictions_file)
-
-
-def epoch_completed(model, session, epoch, epoch_loss,
- val_instances, val_labels, save_path):
- """Runs every time an epoch completes.
-
- Print the performance on the validation set, and update the saved model if
- its performance is better on the previous ones. If the performance dropped,
- tell the training to stop.
-
- Args:
- model: The currently trained path-based model.
- session: The current TensorFlow session.
- epoch: The epoch number.
- epoch_loss: The current epoch loss.
- val_instances: The validation set instances (evaluation between epochs).
- val_labels: The validation set labels (for evaluation between epochs).
- save_path: Where to save the model.
-
- Returns:
- whether the training should stop.
- """
- stop_training = False
-
- # Evaluate on the validation set
- val_pred = model.predict(session, val_instances)
- precision, recall, f1, _ = metrics.precision_recall_fscore_support(
- val_labels, val_pred, average='weighted')
- print(
- 'Epoch: %d/%d, Loss: %f, validation set: P: %.3f, R: %.3f, F1: %.3f\n' % (
- epoch + 1, model.hparams.num_epochs, epoch_loss,
- precision, recall, f1))
-
- # If the F1 is much smaller than the previous one, stop training. Else, if
- # it's bigger, save the model.
- if f1 < epoch_completed.best_f1 - 0.08:
- stop_training = True
-
- if f1 > epoch_completed.best_f1:
- saver = tf.train.Saver()
- checkpoint_filename = os.path.join(save_path, 'best.ckpt')
- print('Saving model in: %s' % checkpoint_filename)
- saver.save(session, checkpoint_filename)
- print('Model saved in file: %s' % checkpoint_filename)
- epoch_completed.best_f1 = f1
-
- return stop_training
-
-epoch_completed.best_f1 = 0
-
-if __name__ == '__main__':
- tf.app.run(main)
diff --git a/research/lexnet_nc/learn_path_embeddings.py b/research/lexnet_nc/learn_path_embeddings.py
deleted file mode 100755
index 480378f4aa010ee27f0387685bac488cedbb2ab9..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/learn_path_embeddings.py
+++ /dev/null
@@ -1,186 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Trains the LexNET path-based model."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-
-import lexnet_common
-import path_model
-from sklearn import metrics
-import tensorflow as tf
-
-tf.flags.DEFINE_string('train', '', 'training dataset, tfrecs')
-tf.flags.DEFINE_string('val', '', 'validation dataset, tfrecs')
-tf.flags.DEFINE_string('test', '', 'test dataset, tfrecs')
-tf.flags.DEFINE_string('embeddings', '', 'embeddings, npy')
-tf.flags.DEFINE_string('relations', '', 'file containing relation labels')
-tf.flags.DEFINE_string('output_dir', '', 'output directory for path embeddings')
-tf.flags.DEFINE_string('logdir', '', 'directory for model training')
-FLAGS = tf.flags.FLAGS
-
-
-def main(_):
- # Pick up any one-off hyper-parameters.
- hparams = path_model.PathBasedModel.default_hparams()
-
- with open(FLAGS.relations) as fh:
- relations = fh.read().splitlines()
-
- hparams.num_classes = len(relations)
- print('Model will predict into %d classes' % hparams.num_classes)
-
- print('Running with hyper-parameters: {}'.format(hparams))
-
- # Load the instances
- print('Loading instances...')
- opts = tf.python_io.TFRecordOptions(
- compression_type=tf.python_io.TFRecordCompressionType.GZIP)
-
- train_instances = list(tf.python_io.tf_record_iterator(FLAGS.train, opts))
- val_instances = list(tf.python_io.tf_record_iterator(FLAGS.val, opts))
- test_instances = list(tf.python_io.tf_record_iterator(FLAGS.test, opts))
-
- # Load the word embeddings
- print('Loading word embeddings...')
- lemma_embeddings = lexnet_common.load_word_embeddings(FLAGS.embeddings)
-
- # Define the graph and the model
- with tf.Graph().as_default():
- with tf.variable_scope('lexnet'):
- options = tf.python_io.TFRecordOptions(
- compression_type=tf.python_io.TFRecordCompressionType.GZIP)
- reader = tf.TFRecordReader(options=options)
- _, train_instance = reader.read(
- tf.train.string_input_producer([FLAGS.train]))
- shuffled_train_instance = tf.train.shuffle_batch(
- [train_instance],
- batch_size=1,
- num_threads=1,
- capacity=len(train_instances),
- min_after_dequeue=100,
- )[0]
-
- train_model = path_model.PathBasedModel(
- hparams, lemma_embeddings, shuffled_train_instance)
-
- with tf.variable_scope('lexnet', reuse=True):
- val_instance = tf.placeholder(dtype=tf.string)
- val_model = path_model.PathBasedModel(
- hparams, lemma_embeddings, val_instance)
-
- # Initialize a session and start training
- best_model_saver = tf.train.Saver()
- f1_t = tf.placeholder(tf.float32)
- best_f1_t = tf.Variable(0.0, trainable=False, name='best_f1')
- assign_best_f1_op = tf.assign(best_f1_t, f1_t)
-
- supervisor = tf.train.Supervisor(
- logdir=FLAGS.logdir,
- global_step=train_model.global_step)
-
- with supervisor.managed_session() as session:
- # Load the labels
- print('Loading labels...')
- val_labels = train_model.load_labels(session, val_instances)
-
- # Train the model
- print('Training the model...')
-
- while True:
- step = session.run(train_model.global_step)
- epoch = (step + len(train_instances) - 1) // len(train_instances)
- if epoch > hparams.num_epochs:
- break
-
- print('Starting epoch %d (step %d)...' % (1 + epoch, step))
-
- epoch_loss = train_model.run_one_epoch(session, len(train_instances))
-
- best_f1 = session.run(best_f1_t)
- f1 = epoch_completed(val_model, session, epoch, epoch_loss,
- val_instances, val_labels, best_model_saver,
- FLAGS.logdir, best_f1)
-
- if f1 > best_f1:
- session.run(assign_best_f1_op, {f1_t: f1})
-
- if f1 < best_f1 - 0.08:
- tf.logging.info('Stopping training after %d epochs.\n' % epoch)
- break
-
- # Print the best performance on the validation set
- best_f1 = session.run(best_f1_t)
- print('Best performance on the validation set: F1=%.3f' % best_f1)
-
- # Save the path embeddings
- print('Computing the path embeddings...')
- instances = train_instances + val_instances + test_instances
- path_index, path_vectors = path_model.compute_path_embeddings(
- val_model, session, instances)
-
- if not os.path.exists(path_emb_dir):
- os.makedirs(path_emb_dir)
-
- path_model.save_path_embeddings(
- val_model, path_vectors, path_index, FLAGS.output_dir)
-
-
-def epoch_completed(model, session, epoch, epoch_loss,
- val_instances, val_labels, saver, save_path, best_f1):
- """Runs every time an epoch completes.
-
- Print the performance on the validation set, and update the saved model if
- its performance is better on the previous ones. If the performance dropped,
- tell the training to stop.
-
- Args:
- model: The currently trained path-based model.
- session: The current TensorFlow session.
- epoch: The epoch number.
- epoch_loss: The current epoch loss.
- val_instances: The validation set instances (evaluation between epochs).
- val_labels: The validation set labels (for evaluation between epochs).
- saver: tf.Saver object
- save_path: Where to save the model.
- best_f1: the best F1 achieved so far.
-
- Returns:
- The F1 achieved on the training set.
- """
- # Evaluate on the validation set
- val_pred = model.predict(session, val_instances)
- precision, recall, f1, _ = metrics.precision_recall_fscore_support(
- val_labels, val_pred, average='weighted')
- print(
- 'Epoch: %d/%d, Loss: %f, validation set: P: %.3f, R: %.3f, F1: %.3f\n' % (
- epoch + 1, model.hparams.num_epochs, epoch_loss,
- precision, recall, f1))
-
- if f1 > best_f1:
- save_filename = os.path.join(save_path, 'best.ckpt')
- print('Saving model in: %s' % save_filename)
- saver.save(session, save_filename)
- print('Model saved in file: %s' % save_filename)
-
- return f1
-
-
-if __name__ == '__main__':
- tf.app.run(main)
diff --git a/research/lexnet_nc/lexnet_common.py b/research/lexnet_nc/lexnet_common.py
deleted file mode 100644
index a2e8a104d00c1c2f90731f4045c3c8e69e370dbf..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/lexnet_common.py
+++ /dev/null
@@ -1,197 +0,0 @@
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Common stuff used with LexNET."""
-# pylint: disable=bad-whitespace
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import numpy as np
-from sklearn import metrics
-import tensorflow as tf
-
-# Part of speech tags used in the paths.
-POSTAGS = [
- 'PAD', 'VERB', 'CONJ', 'NOUN', 'PUNCT',
- 'ADP', 'ADJ', 'DET', 'ADV', 'PART',
- 'NUM', 'X', 'INTJ', 'SYM',
-]
-
-POSTAG_TO_ID = {tag: tid for tid, tag in enumerate(POSTAGS)}
-
-# Dependency labels used in the paths.
-DEPLABELS = [
- 'PAD', 'UNK', 'ROOT', 'abbrev', 'acomp', 'advcl',
- 'advmod', 'agent', 'amod', 'appos', 'attr', 'aux',
- 'auxpass', 'cc', 'ccomp', 'complm', 'conj', 'cop',
- 'csubj', 'csubjpass', 'dep', 'det', 'dobj', 'expl',
- 'infmod', 'iobj', 'mark', 'mwe', 'nc', 'neg',
- 'nn', 'npadvmod', 'nsubj', 'nsubjpass', 'num', 'number',
- 'p', 'parataxis', 'partmod', 'pcomp', 'pobj', 'poss',
- 'preconj', 'predet', 'prep', 'prepc', 'prt', 'ps',
- 'purpcl', 'quantmod', 'rcmod', 'ref', 'rel', 'suffix',
- 'title', 'tmod', 'xcomp', 'xsubj',
-]
-
-DEPLABEL_TO_ID = {label: lid for lid, label in enumerate(DEPLABELS)}
-
-# Direction codes used in the paths.
-DIRS = '_^V<>'
-DIR_TO_ID = {dir: did for did, dir in enumerate(DIRS)}
-
-
-def load_word_embeddings(embedding_filename):
- """Loads pretrained word embeddings from a binary file and returns the matrix.
-
- Adds the , , , and tokens to the beginning of the vocab.
-
- Args:
- embedding_filename: filename of the binary NPY data
-
- Returns:
- The word embeddings matrix
- """
- embeddings = np.load(embedding_filename)
- dim = embeddings.shape[1]
-
- # Four initially random vectors for the special tokens: , , ,
- special_embeddings = np.random.normal(0, 0.1, (4, dim))
- embeddings = np.vstack((special_embeddings, embeddings))
- embeddings = embeddings.astype(np.float32)
-
- return embeddings
-
-
-def full_evaluation(model, session, instances, labels, set_name, classes):
- """Prints a full evaluation on the current set.
-
- Performance (recall, precision and F1), classification report (per
- class performance), and confusion matrix).
-
- Args:
- model: The currently trained path-based model.
- session: The current TensorFlow session.
- instances: The current set instances.
- labels: The current set labels.
- set_name: The current set name (train/validation/test).
- classes: The class label names.
-
- Returns:
- The model's prediction for the given instances.
- """
-
- # Predict the labels
- pred = model.predict(session, instances)
-
- # Print the performance
- precision, recall, f1, _ = metrics.precision_recall_fscore_support(
- labels, pred, average='weighted')
-
- print('%s set: Precision: %.3f, Recall: %.3f, F1: %.3f' % (
- set_name, precision, recall, f1))
-
- # Print a classification report
- print('%s classification report:' % set_name)
- print(metrics.classification_report(labels, pred, target_names=classes))
-
- # Print the confusion matrix
- print('%s confusion matrix:' % set_name)
- cm = metrics.confusion_matrix(labels, pred, labels=range(len(classes)))
- cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] * 100
- print_cm(cm, labels=classes)
- return pred
-
-
-def print_cm(cm, labels):
- """Pretty print for confusion matrices.
-
- From: https://gist.github.com/zachguo/10296432.
-
- Args:
- cm: The confusion matrix.
- labels: The class names.
- """
- columnwidth = 10
- empty_cell = ' ' * columnwidth
- short_labels = [label[:12].rjust(10, ' ') for label in labels]
-
- # Print header
- header = empty_cell + ' '
- header += ''.join([' %{0}s '.format(columnwidth) % label
- for label in short_labels])
-
- print(header)
-
- # Print rows
- for i, label1 in enumerate(short_labels):
- row = '%{0}s '.format(columnwidth) % label1[:10]
- for j in range(len(short_labels)):
- value = int(cm[i, j]) if not np.isnan(cm[i, j]) else 0
- cell = ' %{0}d '.format(10) % value
- row += cell + ' '
- print(row)
-
-
-def load_all_labels(records):
- """Reads TensorFlow examples from a RecordReader and returns only the labels.
-
- Args:
- records: a record list with TensorFlow examples.
-
- Returns:
- The labels
- """
- curr_features = tf.parse_example(records, {
- 'rel_id': tf.FixedLenFeature([1], dtype=tf.int64),
- })
-
- labels = tf.squeeze(curr_features['rel_id'], [-1])
- return labels
-
-
-def load_all_pairs(records):
- """Reads TensorFlow examples from a RecordReader and returns the word pairs.
-
- Args:
- records: a record list with TensorFlow examples.
-
- Returns:
- The word pairs
- """
- curr_features = tf.parse_example(records, {
- 'pair': tf.FixedLenFeature([1], dtype=tf.string)
- })
-
- word_pairs = curr_features['pair']
- return word_pairs
-
-
-def write_predictions(pairs, labels, predictions, classes, predictions_file):
- """Write the predictions to a file.
-
- Args:
- pairs: the word pairs (list of tuple of two strings).
- labels: the gold-standard labels for these pairs (array of rel ID).
- predictions: the predicted labels for these pairs (array of rel ID).
- classes: a list of relation names.
- predictions_file: where to save the predictions.
- """
- with open(predictions_file, 'w') as f_out:
- for pair, label, pred in zip(pairs, labels, predictions):
- w1, w2 = pair
- f_out.write('\t'.join([w1, w2, classes[label], classes[pred]]) + '\n')
diff --git a/research/lexnet_nc/lexnet_model.py b/research/lexnet_nc/lexnet_model.py
deleted file mode 100644
index b0f16b030b3bb3fee68b91122bcd03226ffcfa4a..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/lexnet_model.py
+++ /dev/null
@@ -1,438 +0,0 @@
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""The integrated LexNET model."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import lexnet_common
-import numpy as np
-import tensorflow as tf
-from six.moves import xrange
-
-
-class LexNETModel(object):
- """The LexNET model for classifying relationships between noun compounds."""
-
- @classmethod
- def default_hparams(cls):
- """Returns the default hyper-parameters."""
- return tf.contrib.training.HParams(
- batch_size=10,
- num_classes=37,
- num_epochs=30,
- input_keep_prob=0.9,
- input='integrated', # dist/ dist-nc/ path/ integrated/ integrated-nc
- learn_relata=False,
- corpus='wiki_gigawords',
- random_seed=133, # zero means no random seed
- relata_embeddings_file='glove/glove.6B.300d.bin',
- nc_embeddings_file='nc_glove/vecs.6B.300d.bin',
- path_embeddings_file='path_embeddings/tratz/fine_grained/wiki',
- hidden_layers=1,
- path_dim=60)
-
- def __init__(self, hparams, relata_embeddings, path_embeddings, nc_embeddings,
- path_to_index):
- """Initialize the LexNET classifier.
-
- Args:
- hparams: the hyper-parameters.
- relata_embeddings: word embeddings for the distributional component.
- path_embeddings: embeddings for the paths.
- nc_embeddings: noun compound embeddings.
- path_to_index: a mapping from string path to an index in the path
- embeddings matrix.
- """
- self.hparams = hparams
-
- self.path_embeddings = path_embeddings
- self.relata_embeddings = relata_embeddings
- self.nc_embeddings = nc_embeddings
-
- self.vocab_size, self.relata_dim = 0, 0
- self.path_to_index = None
- self.path_dim = 0
-
- # Set the random seed
- if hparams.random_seed > 0:
- tf.set_random_seed(hparams.random_seed)
-
- # Get the vocabulary size and relata dim
- if self.hparams.input in ['dist', 'dist-nc', 'integrated', 'integrated-nc']:
- self.vocab_size, self.relata_dim = self.relata_embeddings.shape
-
- # Create the mapping from string path to an index in the embeddings matrix
- if self.hparams.input in ['path', 'integrated', 'integrated-nc']:
- self.path_to_index = tf.contrib.lookup.HashTable(
- tf.contrib.lookup.KeyValueTensorInitializer(
- tf.constant(path_to_index.keys()),
- tf.constant(path_to_index.values()),
- key_dtype=tf.string, value_dtype=tf.int32), 0)
-
- self.path_dim = self.path_embeddings.shape[1]
-
- # Create the network
- self.__create_computation_graph__()
-
- def __create_computation_graph__(self):
- """Initialize the model and define the graph."""
- network_input = 0
-
- # Define the network inputs
- # Distributional x and y
- if self.hparams.input in ['dist', 'dist-nc', 'integrated', 'integrated-nc']:
- network_input += 2 * self.relata_dim
- self.relata_lookup = tf.get_variable(
- 'relata_lookup',
- initializer=self.relata_embeddings,
- dtype=tf.float32,
- trainable=self.hparams.learn_relata)
-
- # Path-based
- if self.hparams.input in ['path', 'integrated', 'integrated-nc']:
- network_input += self.path_dim
-
- self.path_initial_value_t = tf.placeholder(tf.float32, None)
-
- self.path_lookup = tf.get_variable(
- name='path_lookup',
- dtype=tf.float32,
- trainable=False,
- shape=self.path_embeddings.shape)
-
- self.initialize_path_op = tf.assign(
- self.path_lookup, self.path_initial_value_t, validate_shape=False)
-
- # Distributional noun compound
- if self.hparams.input in ['dist-nc', 'integrated-nc']:
- network_input += self.relata_dim
-
- self.nc_initial_value_t = tf.placeholder(tf.float32, None)
-
- self.nc_lookup = tf.get_variable(
- name='nc_lookup',
- dtype=tf.float32,
- trainable=False,
- shape=self.nc_embeddings.shape)
-
- self.initialize_nc_op = tf.assign(
- self.nc_lookup, self.nc_initial_value_t, validate_shape=False)
-
- hidden_dim = network_input // 2
-
- # Define the MLP
- if self.hparams.hidden_layers == 0:
- self.weights1 = tf.get_variable(
- 'W1',
- shape=[network_input, self.hparams.num_classes],
- dtype=tf.float32)
- self.bias1 = tf.get_variable(
- 'b1',
- shape=[self.hparams.num_classes],
- dtype=tf.float32)
-
- elif self.hparams.hidden_layers == 1:
-
- self.weights1 = tf.get_variable(
- 'W1',
- shape=[network_input, hidden_dim],
- dtype=tf.float32)
- self.bias1 = tf.get_variable(
- 'b1',
- shape=[hidden_dim],
- dtype=tf.float32)
-
- self.weights2 = tf.get_variable(
- 'W2',
- shape=[hidden_dim, self.hparams.num_classes],
- dtype=tf.float32)
- self.bias2 = tf.get_variable(
- 'b2',
- shape=[self.hparams.num_classes],
- dtype=tf.float32)
-
- else:
- raise ValueError('Only 0 or 1 hidden layers are supported')
-
- # Define the variables
- self.instances = tf.placeholder(dtype=tf.string,
- shape=[self.hparams.batch_size])
-
- (self.x_embedding_id,
- self.y_embedding_id,
- self.nc_embedding_id,
- self.path_embedding_id,
- self.path_counts,
- self.labels) = parse_tensorflow_examples(
- self.instances, self.hparams.batch_size, self.path_to_index)
-
- # Create the MLP
- self.__mlp__()
-
- self.instances_to_load = tf.placeholder(dtype=tf.string, shape=[None])
- self.labels_to_load = lexnet_common.load_all_labels(self.instances_to_load)
- self.pairs_to_load = lexnet_common.load_all_pairs(self.instances_to_load)
-
- def load_labels(self, session, instances):
- """Loads the labels for these instances.
-
- Args:
- session: The current TensorFlow session,
- instances: The instances for which to load the labels.
-
- Returns:
- the labels of these instances.
- """
- return session.run(self.labels_to_load,
- feed_dict={self.instances_to_load: instances})
-
- def load_pairs(self, session, instances):
- """Loads the word pairs for these instances.
-
- Args:
- session: The current TensorFlow session,
- instances: The instances for which to load the labels.
-
- Returns:
- the word pairs of these instances.
- """
- word_pairs = session.run(self.pairs_to_load,
- feed_dict={self.instances_to_load: instances})
- return [pair[0].split('::') for pair in word_pairs]
-
- def __train_single_batch__(self, session, batch_instances):
- """Train a single batch.
-
- Args:
- session: The current TensorFlow session.
- batch_instances: TensorFlow examples containing the training intances
-
- Returns:
- The cost for the current batch.
- """
- cost, _ = session.run([self.cost, self.train_op],
- feed_dict={self.instances: batch_instances})
-
- return cost
-
- def fit(self, session, inputs, on_epoch_completed, val_instances, val_labels,
- save_path):
- """Train the model.
-
- Args:
- session: The current TensorFlow session.
- inputs:
- on_epoch_completed: A method to call after each epoch.
- val_instances: The validation set instances (evaluation between epochs).
- val_labels: The validation set labels (for evaluation between epochs).
- save_path: Where to save the model.
- """
- for epoch in range(self.hparams.num_epochs):
-
- losses = []
- epoch_indices = list(np.random.permutation(len(inputs)))
-
- # If the number of instances doesn't divide by batch_size, enlarge it
- # by duplicating training examples
- mod = len(epoch_indices) % self.hparams.batch_size
- if mod > 0:
- epoch_indices.extend([np.random.randint(0, high=len(inputs))] * mod)
-
- # Define the batches
- n_batches = len(epoch_indices) // self.hparams.batch_size
-
- for minibatch in range(n_batches):
-
- batch_indices = epoch_indices[minibatch * self.hparams.batch_size:(
- minibatch + 1) * self.hparams.batch_size]
- batch_instances = [inputs[i] for i in batch_indices]
-
- loss = self.__train_single_batch__(session, batch_instances)
- losses.append(loss)
-
- epoch_loss = np.nanmean(losses)
-
- if on_epoch_completed:
- should_stop = on_epoch_completed(self, session, epoch, epoch_loss,
- val_instances, val_labels, save_path)
- if should_stop:
- print('Stopping training after %d epochs.' % epoch)
- return
-
- def predict(self, session, inputs):
- """Predict the classification of the test set.
-
- Args:
- session: The current TensorFlow session.
- inputs: the train paths, x, y and/or nc vectors
-
- Returns:
- The test predictions.
- """
- predictions, _ = zip(*self.predict_with_score(session, inputs))
- return np.array(predictions)
-
- def predict_with_score(self, session, inputs):
- """Predict the classification of the test set.
-
- Args:
- session: The current TensorFlow session.
- inputs: the test paths, x, y and/or nc vectors
-
- Returns:
- The test predictions along with their scores.
- """
- test_pred = [0] * len(inputs)
-
- for chunk in xrange(0, len(test_pred), self.hparams.batch_size):
-
- # Initialize the variables with the current batch data
- batch_indices = list(
- range(chunk, min(chunk + self.hparams.batch_size, len(test_pred))))
-
- # If the batch is too small, add a few other examples
- if len(batch_indices) < self.hparams.batch_size:
- batch_indices += [0] * (self.hparams.batch_size-len(batch_indices))
-
- batch_instances = [inputs[i] for i in batch_indices]
-
- predictions, scores = session.run(
- [self.predictions, self.scores],
- feed_dict={self.instances: batch_instances})
-
- for index_in_batch, index_in_dataset in enumerate(batch_indices):
- prediction = predictions[index_in_batch]
- score = scores[index_in_batch][prediction]
- test_pred[index_in_dataset] = (prediction, score)
-
- return test_pred
-
- def __mlp__(self):
- """Performs the MLP operations.
-
- Returns: the prediction object to be computed in a Session
- """
- # Define the operations
-
- # Network input
- vec_inputs = []
-
- # Distributional component
- if self.hparams.input in ['dist', 'dist-nc', 'integrated', 'integrated-nc']:
- for emb_id in [self.x_embedding_id, self.y_embedding_id]:
- vec_inputs.append(tf.nn.embedding_lookup(self.relata_lookup, emb_id))
-
- # Noun compound component
- if self.hparams.input in ['dist-nc', 'integrated-nc']:
- vec = tf.nn.embedding_lookup(self.nc_lookup, self.nc_embedding_id)
- vec_inputs.append(vec)
-
- # Path-based component
- if self.hparams.input in ['path', 'integrated', 'integrated-nc']:
-
- # Get the current paths for each batch instance
- self.path_embeddings = tf.nn.embedding_lookup(self.path_lookup,
- self.path_embedding_id)
-
- # self.path_embeddings is of shape
- # [batch_size, max_path_per_instance, output_dim]
- # We need to multiply it by path counts
- # ([batch_size, max_path_per_instance]).
- # Start by duplicating path_counts along the output_dim axis.
- self.path_freq = tf.tile(tf.expand_dims(self.path_counts, -1),
- [1, 1, self.path_dim])
-
- # Compute the averaged path vector for each instance.
- # First, multiply the path embeddings and frequencies element-wise.
- self.weighted = tf.multiply(self.path_freq, self.path_embeddings)
-
- # Second, take the sum to get a tensor of shape [batch_size, output_dim].
- self.pair_path_embeddings = tf.reduce_sum(self.weighted, 1)
-
- # Finally, divide by the total number of paths.
- # The number of paths for each pair has a shape [batch_size, 1],
- # We duplicate it output_dim times along the second axis.
- self.num_paths = tf.clip_by_value(
- tf.reduce_sum(self.path_counts, 1), 1, np.inf)
- self.num_paths = tf.tile(tf.expand_dims(self.num_paths, -1),
- [1, self.path_dim])
-
- # And finally, divide pair_path_embeddings by num_paths element-wise.
- self.pair_path_embeddings = tf.div(
- self.pair_path_embeddings, self.num_paths)
- vec_inputs.append(self.pair_path_embeddings)
-
- # Concatenate the inputs and feed to the MLP
- self.input_vec = tf.nn.dropout(
- tf.concat(vec_inputs, 1),
- keep_prob=self.hparams.input_keep_prob)
-
- h = tf.matmul(self.input_vec, self.weights1)
- self.output = h
-
- if self.hparams.hidden_layers == 1:
- self.output = tf.matmul(tf.nn.tanh(h), self.weights2)
-
- self.scores = self.output
- self.predictions = tf.argmax(self.scores, axis=1)
-
- # Define the loss function and the optimization algorithm
- self.cross_entropies = tf.nn.sparse_softmax_cross_entropy_with_logits(
- logits=self.scores, labels=self.labels)
- self.cost = tf.reduce_sum(self.cross_entropies, name='cost')
- self.global_step = tf.Variable(0, name='global_step', trainable=False)
- self.optimizer = tf.train.AdamOptimizer()
- self.train_op = self.optimizer.minimize(
- self.cost, global_step=self.global_step)
-
-
-def parse_tensorflow_examples(record, batch_size, path_to_index):
- """Reads TensorFlow examples from a RecordReader.
-
- Args:
- record: a record with TensorFlow examples.
- batch_size: the number of instances in a minibatch
- path_to_index: mapping from string path to index in the embeddings matrix.
-
- Returns:
- The word embeddings IDs, paths and counts
- """
- features = tf.parse_example(
- record, {
- 'x_embedding_id': tf.FixedLenFeature([1], dtype=tf.int64),
- 'y_embedding_id': tf.FixedLenFeature([1], dtype=tf.int64),
- 'nc_embedding_id': tf.FixedLenFeature([1], dtype=tf.int64),
- 'reprs': tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.string, allow_missing=True),
- 'counts': tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'rel_id': tf.FixedLenFeature([1], dtype=tf.int64)
- })
-
- x_embedding_id = tf.squeeze(features['x_embedding_id'], [-1])
- y_embedding_id = tf.squeeze(features['y_embedding_id'], [-1])
- nc_embedding_id = tf.squeeze(features['nc_embedding_id'], [-1])
- labels = tf.squeeze(features['rel_id'], [-1])
- path_counts = tf.to_float(tf.reshape(features['counts'], [batch_size, -1]))
-
- path_embedding_id = None
- if path_to_index:
- path_embedding_id = path_to_index.lookup(features['reprs'])
-
- return (
- x_embedding_id, y_embedding_id, nc_embedding_id,
- path_embedding_id, path_counts, labels)
diff --git a/research/lexnet_nc/path_model.py b/research/lexnet_nc/path_model.py
deleted file mode 100644
index c283841775d673baa8a4bc8c438d65f288a2c555..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/path_model.py
+++ /dev/null
@@ -1,547 +0,0 @@
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""LexNET Path-based Model."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import itertools
-import os
-
-import lexnet_common
-import numpy as np
-import tensorflow as tf
-
-
-class PathBasedModel(object):
- """The LexNET path-based model for classifying semantic relations."""
-
- @classmethod
- def default_hparams(cls):
- """Returns the default hyper-parameters."""
- return tf.contrib.training.HParams(
- max_path_len=8,
- num_classes=37,
- num_epochs=30,
- input_keep_prob=0.9,
- learning_rate=0.001,
- learn_lemmas=False,
- random_seed=133, # zero means no random seed
- lemma_embeddings_file='glove/glove.6B.50d.bin',
- num_pos=len(lexnet_common.POSTAGS),
- num_dep=len(lexnet_common.DEPLABELS),
- num_directions=len(lexnet_common.DIRS),
- lemma_dim=50,
- pos_dim=4,
- dep_dim=5,
- dir_dim=1)
-
- def __init__(self, hparams, lemma_embeddings, instance):
- """Initialize the LexNET classifier.
-
- Args:
- hparams: the hyper-parameters.
- lemma_embeddings: word embeddings for the path-based component.
- instance: string tensor containing the input instance
- """
- self.hparams = hparams
- self.lemma_embeddings = lemma_embeddings
- self.instance = instance
- self.vocab_size, self.lemma_dim = self.lemma_embeddings.shape
-
- # Set the random seed
- if hparams.random_seed > 0:
- tf.set_random_seed(hparams.random_seed)
-
- # Create the network
- self.__create_computation_graph__()
-
- def __create_computation_graph__(self):
- """Initialize the model and define the graph."""
- self.lstm_input_dim = sum([self.hparams.lemma_dim, self.hparams.pos_dim,
- self.hparams.dep_dim, self.hparams.dir_dim])
- self.lstm_output_dim = self.lstm_input_dim
-
- network_input = self.lstm_output_dim
- self.lemma_lookup = tf.get_variable(
- 'lemma_lookup',
- initializer=self.lemma_embeddings,
- dtype=tf.float32,
- trainable=self.hparams.learn_lemmas)
- self.pos_lookup = tf.get_variable(
- 'pos_lookup',
- shape=[self.hparams.num_pos, self.hparams.pos_dim],
- dtype=tf.float32)
- self.dep_lookup = tf.get_variable(
- 'dep_lookup',
- shape=[self.hparams.num_dep, self.hparams.dep_dim],
- dtype=tf.float32)
- self.dir_lookup = tf.get_variable(
- 'dir_lookup',
- shape=[self.hparams.num_directions, self.hparams.dir_dim],
- dtype=tf.float32)
-
- self.weights1 = tf.get_variable(
- 'W1',
- shape=[network_input, self.hparams.num_classes],
- dtype=tf.float32)
- self.bias1 = tf.get_variable(
- 'b1',
- shape=[self.hparams.num_classes],
- dtype=tf.float32)
-
- # Define the variables
- (self.batch_paths,
- self.path_counts,
- self.seq_lengths,
- self.path_strings,
- self.batch_labels) = _parse_tensorflow_example(
- self.instance, self.hparams.max_path_len, self.hparams.input_keep_prob)
-
- # Create the LSTM
- self.__lstm__()
-
- # Create the MLP
- self.__mlp__()
-
- self.instances_to_load = tf.placeholder(dtype=tf.string, shape=[None])
- self.labels_to_load = lexnet_common.load_all_labels(self.instances_to_load)
-
- def load_labels(self, session, batch_instances):
- """Loads the labels of the current instances.
-
- Args:
- session: the current TensorFlow session.
- batch_instances: the dataset instances.
-
- Returns:
- the labels.
- """
- return session.run(self.labels_to_load,
- feed_dict={self.instances_to_load: batch_instances})
-
- def run_one_epoch(self, session, num_steps):
- """Train the model.
-
- Args:
- session: The current TensorFlow session.
- num_steps: The number of steps in each epoch.
-
- Returns:
- The mean loss for the epoch.
-
- Raises:
- ArithmeticError: if the loss becomes non-finite.
- """
- losses = []
-
- for step in range(num_steps):
- curr_loss, _ = session.run([self.cost, self.train_op])
- if not np.isfinite(curr_loss):
- raise ArithmeticError('nan loss at step %d' % step)
-
- losses.append(curr_loss)
-
- return np.mean(losses)
-
- def predict(self, session, inputs):
- """Predict the classification of the test set.
-
- Args:
- session: The current TensorFlow session.
- inputs: the train paths, x, y and/or nc vectors
-
- Returns:
- The test predictions.
- """
- predictions, _ = zip(*self.predict_with_score(session, inputs))
- return np.array(predictions)
-
- def predict_with_score(self, session, inputs):
- """Predict the classification of the test set.
-
- Args:
- session: The current TensorFlow session.
- inputs: the test paths, x, y and/or nc vectors
-
- Returns:
- The test predictions along with their scores.
- """
- test_pred = [0] * len(inputs)
-
- for index, instance in enumerate(inputs):
-
- prediction, scores = session.run(
- [self.predictions, self.scores],
- feed_dict={self.instance: instance})
-
- test_pred[index] = (prediction, scores[prediction])
-
- return test_pred
-
- def __mlp__(self):
- """Performs the MLP operations.
-
- Returns: the prediction object to be computed in a Session
- """
- # Feed the paths to the MLP: path_embeddings is
- # [num_batch_paths, output_dim], and when we multiply it by W
- # ([output_dim, num_classes]), we get a matrix of class distributions:
- # [num_batch_paths, num_classes].
- self.distributions = tf.matmul(self.path_embeddings, self.weights1)
-
- # Now, compute weighted average on the class distributions, using the path
- # frequency as weights.
-
- # First, reshape path_freq to the same shape of distributions
- self.path_freq = tf.tile(tf.expand_dims(self.path_counts, -1),
- [1, self.hparams.num_classes])
-
- # Second, multiply the distributions and frequencies element-wise.
- self.weighted = tf.multiply(self.path_freq, self.distributions)
-
- # Finally, take the average to get a tensor of shape [1, num_classes].
- self.weighted_sum = tf.reduce_sum(self.weighted, 0)
- self.num_paths = tf.clip_by_value(tf.reduce_sum(self.path_counts),
- 1, np.inf)
- self.num_paths = tf.tile(tf.expand_dims(self.num_paths, -1),
- [self.hparams.num_classes])
- self.scores = tf.div(self.weighted_sum, self.num_paths)
- self.predictions = tf.argmax(self.scores)
-
- # Define the loss function and the optimization algorithm
- self.cross_entropies = tf.nn.sparse_softmax_cross_entropy_with_logits(
- logits=self.scores, labels=tf.reduce_mean(self.batch_labels))
- self.cost = tf.reduce_sum(self.cross_entropies, name='cost')
- self.global_step = tf.Variable(0, name='global_step', trainable=False)
- self.optimizer = tf.train.AdamOptimizer()
- self.train_op = self.optimizer.minimize(self.cost,
- global_step=self.global_step)
-
- def __lstm__(self):
- """Defines the LSTM operations.
-
- Returns:
- A matrix of path embeddings.
- """
- lookup_tables = [self.lemma_lookup, self.pos_lookup,
- self.dep_lookup, self.dir_lookup]
-
- # Split the edges to components: list of 4 tensors
- # [num_batch_paths, max_path_len, 1]
- self.edge_components = tf.split(self.batch_paths, 4, axis=2)
-
- # Look up the components embeddings and concatenate them back together
- self.path_matrix = tf.concat([
- tf.squeeze(tf.nn.embedding_lookup(lookup_table, component), 2)
- for lookup_table, component in
- zip(lookup_tables, self.edge_components)
- ], axis=2)
-
- self.sequence_lengths = tf.reshape(self.seq_lengths, [-1])
-
- # Define the LSTM.
- # The input is [num_batch_paths, max_path_len, input_dim].
- lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.lstm_output_dim)
-
- # The output is [num_batch_paths, max_path_len, output_dim].
- self.lstm_outputs, _ = tf.nn.dynamic_rnn(
- lstm_cell, self.path_matrix, dtype=tf.float32,
- sequence_length=self.sequence_lengths)
-
- # Slice the last *relevant* output for each instance ->
- # [num_batch_paths, output_dim]
- self.path_embeddings = _extract_last_relevant(self.lstm_outputs,
- self.sequence_lengths)
-
-
-def _parse_tensorflow_example(record, max_path_len, input_keep_prob):
- """Reads TensorFlow examples from a RecordReader.
-
- Args:
- record: a record with TensorFlow example.
- max_path_len: the maximum path length.
- input_keep_prob: 1 - the word dropout probability
-
- Returns:
- The paths and counts
- """
- features = tf.parse_single_example(record, {
- 'lemmas':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'postags':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'deplabels':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'dirs':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'counts':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'pathlens':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.int64, allow_missing=True),
- 'reprs':
- tf.FixedLenSequenceFeature(
- shape=(), dtype=tf.string, allow_missing=True),
- 'rel_id':
- tf.FixedLenFeature([], dtype=tf.int64)
- })
-
- path_counts = tf.to_float(features['counts'])
- seq_lengths = features['pathlens']
-
- # Concatenate the edge components to create a path tensor:
- # [max_paths_per_ins, max_path_length, 4]
- lemmas = _word_dropout(
- tf.reshape(features['lemmas'], [-1, max_path_len]), input_keep_prob)
-
- paths = tf.stack(
- [lemmas] + [
- tf.reshape(features[f], [-1, max_path_len])
- for f in ('postags', 'deplabels', 'dirs')
- ],
- axis=-1)
-
- path_strings = features['reprs']
-
- # Add an empty path to pairs with no paths
- paths = tf.cond(
- tf.shape(paths)[0] > 0,
- lambda: paths,
- lambda: tf.zeros([1, max_path_len, 4], dtype=tf.int64))
-
- # Paths are left-padded. We reverse them to make them right-padded.
- #paths = tf.reverse(paths, axis=[1])
-
- path_counts = tf.cond(
- tf.shape(path_counts)[0] > 0,
- lambda: path_counts,
- lambda: tf.constant([1.0], dtype=tf.float32))
-
- seq_lengths = tf.cond(
- tf.shape(seq_lengths)[0] > 0,
- lambda: seq_lengths,
- lambda: tf.constant([1], dtype=tf.int64))
-
- # Duplicate the label for each path
- labels = tf.ones_like(path_counts, dtype=tf.int64) * features['rel_id']
-
- return paths, path_counts, seq_lengths, path_strings, labels
-
-
-def _extract_last_relevant(output, seq_lengths):
- """Get the last relevant LSTM output cell for each batch instance.
-
- Args:
- output: the LSTM outputs - a tensor with shape
- [num_paths, output_dim, max_path_len]
- seq_lengths: the sequences length per instance
-
- Returns:
- The last relevant LSTM output cell for each batch instance.
- """
- max_length = int(output.get_shape()[1])
- path_lengths = tf.clip_by_value(seq_lengths - 1, 0, max_length)
- relevant = tf.reduce_sum(tf.multiply(output, tf.expand_dims(
- tf.one_hot(path_lengths, max_length), -1)), 1)
- return relevant
-
-
-def _word_dropout(words, input_keep_prob):
- """Drops words with probability 1 - input_keep_prob.
-
- Args:
- words: a list of lemmas from the paths.
- input_keep_prob: the probability to keep the word.
-
- Returns:
- The revised list where some of the words are ed.
- """
- # Create the mask: (-1) to drop, 1 to keep
- prob = tf.random_uniform(tf.shape(words), 0, 1)
- condition = tf.less(prob, (1 - input_keep_prob))
- mask = tf.where(condition,
- tf.negative(tf.ones_like(words)), tf.ones_like(words))
-
- # We need to keep zeros (), and change other numbers to 1 ()
- # if their mask is -1. First, we multiply the mask and the words.
- # Zeros will stay zeros, and words to drop will become negative.
- # Then, we change negative values to 1.
- masked_words = tf.multiply(mask, words)
- condition = tf.less(masked_words, 0)
- dropped_words = tf.where(condition, tf.ones_like(words), words)
- return dropped_words
-
-
-def compute_path_embeddings(model, session, instances):
- """Compute the path embeddings for all the distinct paths.
-
- Args:
- model: The trained path-based model.
- session: The current TensorFlow session.
- instances: All the train, test and validation instances.
-
- Returns:
- The path to ID index and the path embeddings.
- """
- # Get an index for each distinct path
- path_index = collections.defaultdict(itertools.count(0).next)
- path_vectors = {}
-
- for instance in instances:
- curr_path_embeddings, curr_path_strings = session.run(
- [model.path_embeddings, model.path_strings],
- feed_dict={model.instance: instance})
-
- for i, path in enumerate(curr_path_strings):
- if not path:
- continue
-
- # Set a new/existing index for the path
- index = path_index[path]
-
- # Save its vector
- path_vectors[index] = curr_path_embeddings[i, :]
-
- print('Number of distinct paths: %d' % len(path_index))
- return path_index, path_vectors
-
-
-def save_path_embeddings(model, path_vectors, path_index, embeddings_base_path):
- """Saves the path embeddings.
-
- Args:
- model: The trained path-based model.
- path_vectors: The path embeddings.
- path_index: A map from path to ID.
- embeddings_base_path: The base directory where the embeddings are.
- """
- index_range = range(max(path_index.values()) + 1)
- path_matrix = [path_vectors[i] for i in index_range]
- path_matrix = np.vstack(path_matrix)
-
- # Save the path embeddings
- path_vector_filename = os.path.join(
- embeddings_base_path, '%d_path_vectors' % model.lstm_output_dim)
- with open(path_vector_filename, 'w') as f_out:
- np.save(f_out, path_matrix)
-
- index_to_path = {i: p for p, i in path_index.iteritems()}
- path_vocab = [index_to_path[i] for i in index_range]
-
- # Save the path vocabulary
- path_vocab_filename = os.path.join(
- embeddings_base_path, '%d_path_vocab' % model.lstm_output_dim)
- with open(path_vocab_filename, 'w') as f_out:
- f_out.write('\n'.join(path_vocab))
- f_out.write('\n')
-
- print('Saved path embeddings.')
-
-
-def load_path_embeddings(path_embeddings_dir, path_dim):
- """Loads pretrained path embeddings from a binary file and returns the matrix.
-
- Args:
- path_embeddings_dir: The directory for the path embeddings.
- path_dim: The dimension of the path embeddings, used as prefix to the
- path_vocab and path_vectors files.
-
- Returns:
- The path embeddings matrix and the path_to_index dictionary.
- """
- prefix = path_embeddings_dir + '/%d' % path_dim + '_'
- with open(prefix + 'path_vocab') as f_in:
- vocab = f_in.read().splitlines()
-
- vocab_size = len(vocab)
- embedding_file = prefix + 'path_vectors'
-
- print('Embedding file "%s" has %d paths' % (embedding_file, vocab_size))
-
- with open(embedding_file) as f_in:
- embeddings = np.load(f_in)
-
- path_to_index = {p: i for i, p in enumerate(vocab)}
- return embeddings, path_to_index
-
-
-def get_indicative_paths(model, session, path_index, path_vectors, classes,
- save_dir, k=20, threshold=0.8):
- """Gets the most indicative paths for each class.
-
- Args:
- model: The trained path-based model.
- session: The current TensorFlow session.
- path_index: A map from path to ID.
- path_vectors: The path embeddings.
- classes: The class label names.
- save_dir: Where to save the paths.
- k: The k for top-k paths.
- threshold: The threshold above which to consider paths as indicative.
- """
- # Define graph variables for this operation
- p_path_embedding = tf.placeholder(dtype=tf.float32,
- shape=[1, model.lstm_output_dim])
- p_distributions = tf.nn.softmax(tf.matmul(p_path_embedding, model.weights1))
-
- # Treat each path as a pair instance with a single path, and get the
- # relation distribution for it. Then, take the top paths for each relation.
-
- # This dictionary contains a relation as a key, and the value is a list of
- # tuples of path index and score. A relation r will contain (p, s) if the
- # path p is classified to r with a confidence of s.
- prediction_per_relation = collections.defaultdict(list)
-
- index_to_path = {i: p for p, i in path_index.iteritems()}
-
- # Predict all the paths
- for index in range(len(path_index)):
- curr_path_vector = path_vectors[index]
-
- distribution = session.run(p_distributions,
- feed_dict={
- p_path_embedding: np.reshape(
- curr_path_vector,
- [1, model.lstm_output_dim])})
-
- distribution = distribution[0, :]
- prediction = np.argmax(distribution)
- prediction_per_relation[prediction].append(
- (index, distribution[prediction]))
-
- if index % 10000 == 0:
- print('Classified %d/%d (%3.2f%%) of the paths' % (
- index, len(path_index), 100 * index / len(path_index)))
-
- # Retrieve k-best scoring paths for each relation
- for relation_index, relation in enumerate(classes):
- curr_paths = sorted(prediction_per_relation[relation_index],
- key=lambda item: item[1], reverse=True)
- above_t = [(p, s) for (p, s) in curr_paths if s >= threshold]
- top_k = curr_paths[k+1]
- relation_paths = above_t if len(above_t) > len(top_k) else top_k
-
- paths_filename = os.path.join(save_dir, '%s.paths' % relation)
- with open(paths_filename, 'w') as f_out:
- for index, score in relation_paths:
- print('\t'.join([index_to_path[index], str(score)]), file=f_out)
diff --git a/research/lexnet_nc/sorted_paths_to_examples.py b/research/lexnet_nc/sorted_paths_to_examples.py
deleted file mode 100755
index c21d25d710ae793f6eefd889b98414c923e4fbe6..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/sorted_paths_to_examples.py
+++ /dev/null
@@ -1,202 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Takes as input a sorted, tab-separated of paths to produce tf.Examples."""
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import collections
-import itertools
-import os
-import sys
-import tensorflow as tf
-
-import lexnet_common
-
-tf.flags.DEFINE_string('input', '', 'tab-separated input data')
-tf.flags.DEFINE_string('vocab', '', 'a text file containing lemma vocabulary')
-tf.flags.DEFINE_string('relations', '', 'a text file containing the relations')
-tf.flags.DEFINE_string('output_dir', '', 'output directory')
-tf.flags.DEFINE_string('splits', '', 'text file enumerating splits')
-tf.flags.DEFINE_string('default_split', '', 'default split for unlabeled pairs')
-tf.flags.DEFINE_string('compression', 'GZIP', 'compression for output records')
-tf.flags.DEFINE_integer('max_paths', 100, 'maximum number of paths per record')
-tf.flags.DEFINE_integer('max_pathlen', 8, 'maximum path length')
-FLAGS = tf.flags.FLAGS
-
-
-def _int64_features(value):
- return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
-
-
-def _bytes_features(value):
- value = [v.encode('utf-8') if isinstance(v, unicode) else v for v in value]
- return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
-
-
-class CreateExampleFn(object):
-
- def __init__(self):
- # Read the vocabulary. N.B. that 0 = PAD, 1 = UNK, 2 = , 3 = , hence
- # the enumeration starting at 4.
- with tf.gfile.GFile(FLAGS.vocab) as fh:
- self.vocab = {w: ix for ix, w in enumerate(fh.read().splitlines(), start=4)}
-
- self.vocab.update({'': 0, '': 1, '': 2, '': 3})
-
- # Read the relations.
- with tf.gfile.GFile(FLAGS.relations) as fh:
- self.relations = {r: ix for ix, r in enumerate(fh.read().splitlines())}
-
- # Some hackery to map from SpaCy postags to Google's.
- lexnet_common.POSTAG_TO_ID['PROPN'] = lexnet_common.POSTAG_TO_ID['NOUN']
- lexnet_common.POSTAG_TO_ID['PRON'] = lexnet_common.POSTAG_TO_ID['NOUN']
- lexnet_common.POSTAG_TO_ID['CCONJ'] = lexnet_common.POSTAG_TO_ID['CONJ']
- #lexnet_common.DEPLABEL_TO_ID['relcl'] = lexnet_common.DEPLABEL_TO_ID['rel']
- #lexnet_common.DEPLABEL_TO_ID['compound'] = lexnet_common.DEPLABEL_TO_ID['xcomp']
- #lexnet_common.DEPLABEL_TO_ID['oprd'] = lexnet_common.DEPLABEL_TO_ID['UNK']
-
- def __call__(self, mod, head, rel, raw_paths):
- # Drop any really long paths.
- paths = []
- counts = []
- for raw, count in raw_paths.most_common(FLAGS.max_paths):
- path = raw.split('::')
- if len(path) <= FLAGS.max_pathlen:
- paths.append(path)
- counts.append(count)
-
- if not paths:
- return None
-
- # Compute the true length.
- pathlens = [len(path) for path in paths]
-
- # Pad each path out to max_pathlen so the LSTM can eat it.
- paths = (
- itertools.islice(
- itertools.chain(path, itertools.repeat('/PAD/PAD/_')),
- FLAGS.max_pathlen)
- for path in paths)
-
- # Split the lemma, POS, dependency label, and direction each into a
- # separate feature.
- lemmas, postags, deplabels, dirs = zip(
- *(part.split('/') for part in itertools.chain(*paths)))
-
- lemmas = [self.vocab.get(lemma, 1) for lemma in lemmas]
- postags = [lexnet_common.POSTAG_TO_ID[pos] for pos in postags]
- deplabels = [lexnet_common.DEPLABEL_TO_ID.get(dep, 1) for dep in deplabels]
- dirs = [lexnet_common.DIR_TO_ID.get(d, 0) for d in dirs]
-
- return tf.train.Example(features=tf.train.Features(feature={
- 'pair': _bytes_features(['::'.join((mod, head))]),
- 'rel': _bytes_features([rel]),
- 'rel_id': _int64_features([self.relations[rel]]),
- 'reprs': _bytes_features(raw_paths),
- 'pathlens': _int64_features(pathlens),
- 'counts': _int64_features(counts),
- 'lemmas': _int64_features(lemmas),
- 'dirs': _int64_features(dirs),
- 'deplabels': _int64_features(deplabels),
- 'postags': _int64_features(postags),
- 'x_embedding_id': _int64_features([self.vocab[mod]]),
- 'y_embedding_id': _int64_features([self.vocab[head]]),
- }))
-
-
-def main(_):
- # Read the splits file, if there is one.
- assignments = {}
- if FLAGS.splits:
- with tf.gfile.GFile(FLAGS.splits) as fh:
- parts = (line.split('\t') for line in fh.read().splitlines())
- assignments = {(mod, head): split for mod, head, split in parts}
-
- splits = set(assignments.itervalues())
- if FLAGS.default_split:
- default_split = FLAGS.default_split
- splits.add(FLAGS.default_split)
- elif splits:
- default_split = iter(splits).next()
- else:
- print('Please specify --splits, --default_split, or both', file=sys.stderr)
- return 1
-
- last_mod, last_head, last_label = None, None, None
- raw_paths = collections.Counter()
-
- # Keep track of pairs we've seen to ensure that we don't get unsorted data.
- seen_labeled_pairs = set()
-
- # Set up output compression
- compression_type = getattr(
- tf.python_io.TFRecordCompressionType, FLAGS.compression)
- options = tf.python_io.TFRecordOptions(compression_type=compression_type)
-
- writers = {
- split: tf.python_io.TFRecordWriter(
- os.path.join(FLAGS.output_dir, '%s.tfrecs.gz' % split),
- options=options)
- for split in splits}
-
- create_example = CreateExampleFn()
-
- in_fh = sys.stdin if not FLAGS.input else tf.gfile.GFile(FLAGS.input)
- for lineno, line in enumerate(in_fh, start=1):
- if lineno % 100 == 0:
- print('\rProcessed %d lines...' % lineno, end='', file=sys.stderr)
-
- parts = line.decode('utf-8').strip().split('\t')
- if len(parts) != 5:
- print('Skipping line %d: %d columns (expected 5)' % (
- lineno, len(parts)), file=sys.stderr)
-
- continue
-
- mod, head, label, raw_path, source = parts
- if mod == last_mod and head == last_head and label == last_label:
- raw_paths.update([raw_path])
- continue
-
- if last_mod and last_head and last_label and raw_paths:
- if (last_mod, last_head, last_label) in seen_labeled_pairs:
- print('It looks like the input data is not sorted; ignoring extra '
- 'record for (%s::%s, %s) at line %d' % (
- last_mod, last_head, last_label, lineno))
- else:
- ex = create_example(last_mod, last_head, last_label, raw_paths)
- if ex:
- split = assignments.get((last_mod, last_head), default_split)
- writers[split].write(ex.SerializeToString())
-
- seen_labeled_pairs.add((last_mod, last_head, last_label))
-
- last_mod, last_head, last_label = mod, head, label
- raw_paths = collections.Counter()
-
- if last_mod and last_head and last_label and raw_paths:
- ex = create_example(last_mod, last_head, last_label, raw_paths)
- if ex:
- split = assignments.get((last_mod, last_head), default_split)
- writers[split].write(ex.SerializeToString())
-
- for writer in writers.itervalues():
- writer.close()
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lexnet_nc/text_embeddings_to_binary.py b/research/lexnet_nc/text_embeddings_to_binary.py
deleted file mode 100755
index 8226a7654e6da733ba1e8c46810a8ec8afd7a2c0..0000000000000000000000000000000000000000
--- a/research/lexnet_nc/text_embeddings_to_binary.py
+++ /dev/null
@@ -1,48 +0,0 @@
-#!/usr/bin/env python
-# Copyright 2017, 2018 Google, Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Converts a text embedding file into a binary format for quicker loading."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-import tensorflow as tf
-
-tf.flags.DEFINE_string('input', '', 'text file containing embeddings')
-tf.flags.DEFINE_string('output_vocab', '', 'output file for vocabulary')
-tf.flags.DEFINE_string('output_npy', '', 'output file for binary')
-FLAGS = tf.flags.FLAGS
-
-def main(_):
- vecs = []
- vocab = []
- with tf.gfile.GFile(FLAGS.input) as fh:
- for line in fh:
- parts = line.strip().split()
- vocab.append(parts[0])
- vecs.append([float(x) for x in parts[1:]])
-
- with tf.gfile.GFile(FLAGS.output_vocab, 'w') as fh:
- fh.write('\n'.join(vocab))
- fh.write('\n')
-
- vecs = np.array(vecs, dtype=np.float32)
- np.save(FLAGS.output_npy, vecs, allow_pickle=False)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lfads/README.md b/research/lfads/README.md
deleted file mode 100644
index c75b656e4746894c42251e29a530271bb6484e4f..0000000000000000000000000000000000000000
--- a/research/lfads/README.md
+++ /dev/null
@@ -1,224 +0,0 @@
-
-
-
-# LFADS - Latent Factor Analysis via Dynamical Systems
-
-This code implements the model from the paper "[LFADS - Latent Factor Analysis via Dynamical Systems](http://biorxiv.org/content/early/2017/06/20/152884)". It is a sequential variational auto-encoder designed specifically for investigating neuroscience data, but can be applied widely to any time series data. In an unsupervised setting, LFADS is able to decompose time series data into various factors, such as an initial condition, a generative dynamical system, control inputs to that generator, and a low dimensional description of the observed data, called the factors. Additionally, the observation model is a loss on a probability distribution, so when LFADS processes a dataset, a denoised version of the dataset is also created. For example, if the dataset is raw spike counts, then under the negative log-likelihood loss under a Poisson distribution, the denoised data would be the inferred Poisson rates.
-
-
-## Prerequisites
-
-The code is written in Python 2.7.6. You will also need:
-
-* **TensorFlow** version 1.5 ([install](https://www.tensorflow.org/install/)) -
-* **NumPy, SciPy, Matplotlib** ([install SciPy stack](https://www.scipy.org/install.html), contains all of them)
-* **h5py** ([install](https://pypi.python.org/pypi/h5py))
-
-
-## Getting started
-
-Before starting, run the following:
-
-':
- self._bos = idx
- elif word_name == '':
- self._eos = idx
- elif word_name == '':
- self._unk = idx
- if word_name == '!!!MAXTERMID':
- continue
-
- self._id_to_word.append(word_name)
- self._word_to_id[word_name] = idx
- idx += 1
-
- @property
- def bos(self):
- return self._bos
-
- @property
- def eos(self):
- return self._eos
-
- @property
- def unk(self):
- return self._unk
-
- @property
- def size(self):
- return len(self._id_to_word)
-
- def word_to_id(self, word):
- if word in self._word_to_id:
- return self._word_to_id[word]
- return self.unk
-
- def id_to_word(self, cur_id):
- if cur_id < self.size:
- return self._id_to_word[cur_id]
- return 'ERROR'
-
- def decode(self, cur_ids):
- """Convert a list of ids to a sentence, with space inserted."""
- return ' '.join([self.id_to_word(cur_id) for cur_id in cur_ids])
-
- def encode(self, sentence):
- """Convert a sentence to a list of ids, with special tokens added."""
- word_ids = [self.word_to_id(cur_word) for cur_word in sentence.split()]
- return np.array([self.bos] + word_ids + [self.eos], dtype=np.int32)
-
-
-class CharsVocabulary(Vocabulary):
- """Vocabulary containing character-level information."""
-
- def __init__(self, filename, max_word_length):
- super(CharsVocabulary, self).__init__(filename)
- self._max_word_length = max_word_length
- chars_set = set()
-
- for word in self._id_to_word:
- chars_set |= set(word)
-
- free_ids = []
- for i in range(256):
- if chr(i) in chars_set:
- continue
- free_ids.append(chr(i))
-
- if len(free_ids) < 5:
- raise ValueError('Not enough free char ids: %d' % len(free_ids))
-
- self.bos_char = free_ids[0] #
- self.eos_char = free_ids[1] #
- self.bow_char = free_ids[2] #
- self.eow_char = free_ids[3] #
- self.pad_char = free_ids[4] #
-
- chars_set |= {self.bos_char, self.eos_char, self.bow_char, self.eow_char,
- self.pad_char}
-
- self._char_set = chars_set
- num_words = len(self._id_to_word)
-
- self._word_char_ids = np.zeros([num_words, max_word_length], dtype=np.int32)
-
- self.bos_chars = self._convert_word_to_char_ids(self.bos_char)
- self.eos_chars = self._convert_word_to_char_ids(self.eos_char)
-
- for i, word in enumerate(self._id_to_word):
- self._word_char_ids[i] = self._convert_word_to_char_ids(word)
-
- @property
- def word_char_ids(self):
- return self._word_char_ids
-
- @property
- def max_word_length(self):
- return self._max_word_length
-
- def _convert_word_to_char_ids(self, word):
- code = np.zeros([self.max_word_length], dtype=np.int32)
- code[:] = ord(self.pad_char)
-
- if len(word) > self.max_word_length - 2:
- word = word[:self.max_word_length-2]
- cur_word = self.bow_char + word + self.eow_char
- for j in range(len(cur_word)):
- code[j] = ord(cur_word[j])
- return code
-
- def word_to_char_ids(self, word):
- if word in self._word_to_id:
- return self._word_char_ids[self._word_to_id[word]]
- else:
- return self._convert_word_to_char_ids(word)
-
- def encode_chars(self, sentence):
- chars_ids = [self.word_to_char_ids(cur_word)
- for cur_word in sentence.split()]
- return np.vstack([self.bos_chars] + chars_ids + [self.eos_chars])
-
-
-def get_batch(generator, batch_size, num_steps, max_word_length, pad=False):
- """Read batches of input."""
- cur_stream = [None] * batch_size
-
- inputs = np.zeros([batch_size, num_steps], np.int32)
- char_inputs = np.zeros([batch_size, num_steps, max_word_length], np.int32)
- global_word_ids = np.zeros([batch_size, num_steps], np.int32)
- targets = np.zeros([batch_size, num_steps], np.int32)
- weights = np.ones([batch_size, num_steps], np.float32)
-
- no_more_data = False
- while True:
- inputs[:] = 0
- char_inputs[:] = 0
- global_word_ids[:] = 0
- targets[:] = 0
- weights[:] = 0.0
-
- for i in range(batch_size):
- cur_pos = 0
-
- while cur_pos < num_steps:
- if cur_stream[i] is None or len(cur_stream[i][0]) <= 1:
- try:
- cur_stream[i] = list(generator.next())
- except StopIteration:
- # No more data, exhaust current streams and quit
- no_more_data = True
- break
-
- how_many = min(len(cur_stream[i][0]) - 1, num_steps - cur_pos)
- next_pos = cur_pos + how_many
-
- inputs[i, cur_pos:next_pos] = cur_stream[i][0][:how_many]
- char_inputs[i, cur_pos:next_pos] = cur_stream[i][1][:how_many]
- global_word_ids[i, cur_pos:next_pos] = cur_stream[i][2][:how_many]
- targets[i, cur_pos:next_pos] = cur_stream[i][0][1:how_many+1]
- weights[i, cur_pos:next_pos] = 1.0
-
- cur_pos = next_pos
- cur_stream[i][0] = cur_stream[i][0][how_many:]
- cur_stream[i][1] = cur_stream[i][1][how_many:]
- cur_stream[i][2] = cur_stream[i][2][how_many:]
-
- if pad:
- break
-
- if no_more_data and np.sum(weights) == 0:
- # There is no more data and this is an empty batch. Done!
- break
- yield inputs, char_inputs, global_word_ids, targets, weights
-
-
-class LM1BDataset(object):
- """Utility class for 1B word benchmark dataset.
-
- The current implementation reads the data from the tokenized text files.
- """
-
- def __init__(self, filepattern, vocab):
- """Initialize LM1BDataset reader.
-
- Args:
- filepattern: Dataset file pattern.
- vocab: Vocabulary.
- """
- self._vocab = vocab
- self._all_shards = tf.gfile.Glob(filepattern)
- tf.logging.info('Found %d shards at %s', len(self._all_shards), filepattern)
-
- def _load_random_shard(self):
- """Randomly select a file and read it."""
- return self._load_shard(random.choice(self._all_shards))
-
- def _load_shard(self, shard_name):
- """Read one file and convert to ids.
-
- Args:
- shard_name: file path.
-
- Returns:
- list of (id, char_id, global_word_id) tuples.
- """
- tf.logging.info('Loading data from: %s', shard_name)
- with tf.gfile.Open(shard_name) as f:
- sentences = f.readlines()
- chars_ids = [self.vocab.encode_chars(sentence) for sentence in sentences]
- ids = [self.vocab.encode(sentence) for sentence in sentences]
-
- global_word_ids = []
- current_idx = 0
- for word_ids in ids:
- current_size = len(word_ids) - 1 # without symbol
- cur_ids = np.arange(current_idx, current_idx + current_size)
- global_word_ids.append(cur_ids)
- current_idx += current_size
-
- tf.logging.info('Loaded %d words.', current_idx)
- tf.logging.info('Finished loading')
- return zip(ids, chars_ids, global_word_ids)
-
- def _get_sentence(self, forever=True):
- while True:
- ids = self._load_random_shard()
- for current_ids in ids:
- yield current_ids
- if not forever:
- break
-
- def get_batch(self, batch_size, num_steps, pad=False, forever=True):
- return get_batch(self._get_sentence(forever), batch_size, num_steps,
- self.vocab.max_word_length, pad=pad)
-
- @property
- def vocab(self):
- return self._vocab
diff --git a/research/lm_1b/lm_1b_eval.py b/research/lm_1b/lm_1b_eval.py
deleted file mode 100644
index ce8634757558c135ba137a9b9e09a733977adc3a..0000000000000000000000000000000000000000
--- a/research/lm_1b/lm_1b_eval.py
+++ /dev/null
@@ -1,308 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Eval pre-trained 1 billion word language model.
-"""
-import os
-import sys
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-from google.protobuf import text_format
-import data_utils
-
-FLAGS = tf.flags.FLAGS
-# General flags.
-tf.flags.DEFINE_string('mode', 'eval',
- 'One of [sample, eval, dump_emb, dump_lstm_emb]. '
- '"sample" mode samples future word predictions, using '
- 'FLAGS.prefix as prefix (prefix could be left empty). '
- '"eval" mode calculates perplexity of the '
- 'FLAGS.input_data. '
- '"dump_emb" mode dumps word and softmax embeddings to '
- 'FLAGS.save_dir. embeddings are dumped in the same '
- 'order as words in vocabulary. All words in vocabulary '
- 'are dumped.'
- 'dump_lstm_emb dumps lstm embeddings of FLAGS.sentence '
- 'to FLAGS.save_dir.')
-tf.flags.DEFINE_string('pbtxt', '',
- 'GraphDef proto text file used to construct model '
- 'structure.')
-tf.flags.DEFINE_string('ckpt', '',
- 'Checkpoint directory used to fill model values.')
-tf.flags.DEFINE_string('vocab_file', '', 'Vocabulary file.')
-tf.flags.DEFINE_string('save_dir', '',
- 'Used for "dump_emb" mode to save word embeddings.')
-# sample mode flags.
-tf.flags.DEFINE_string('prefix', '',
- 'Used for "sample" mode to predict next words.')
-tf.flags.DEFINE_integer('max_sample_words', 100,
- 'Sampling stops either when is met or this number '
- 'of steps has passed.')
-tf.flags.DEFINE_integer('num_samples', 3,
- 'Number of samples to generate for the prefix.')
-# dump_lstm_emb mode flags.
-tf.flags.DEFINE_string('sentence', '',
- 'Used as input for "dump_lstm_emb" mode.')
-# eval mode flags.
-tf.flags.DEFINE_string('input_data', '',
- 'Input data files for eval model.')
-tf.flags.DEFINE_integer('max_eval_steps', 1000000,
- 'Maximum mumber of steps to run "eval" mode.')
-
-
-# For saving demo resources, use batch size 1 and step 1.
-BATCH_SIZE = 1
-NUM_TIMESTEPS = 1
-MAX_WORD_LEN = 50
-
-
-def _LoadModel(gd_file, ckpt_file):
- """Load the model from GraphDef and Checkpoint.
-
- Args:
- gd_file: GraphDef proto text file.
- ckpt_file: TensorFlow Checkpoint file.
-
- Returns:
- TensorFlow session and tensors dict.
- """
- with tf.Graph().as_default():
- sys.stderr.write('Recovering graph.\n')
- with tf.gfile.FastGFile(gd_file, 'r') as f:
- s = f.read().decode()
- gd = tf.GraphDef()
- text_format.Merge(s, gd)
-
- tf.logging.info('Recovering Graph %s', gd_file)
- t = {}
- [t['states_init'], t['lstm/lstm_0/control_dependency'],
- t['lstm/lstm_1/control_dependency'], t['softmax_out'], t['class_ids_out'],
- t['class_weights_out'], t['log_perplexity_out'], t['inputs_in'],
- t['targets_in'], t['target_weights_in'], t['char_inputs_in'],
- t['all_embs'], t['softmax_weights'], t['global_step']
- ] = tf.import_graph_def(gd, {}, ['states_init',
- 'lstm/lstm_0/control_dependency:0',
- 'lstm/lstm_1/control_dependency:0',
- 'softmax_out:0',
- 'class_ids_out:0',
- 'class_weights_out:0',
- 'log_perplexity_out:0',
- 'inputs_in:0',
- 'targets_in:0',
- 'target_weights_in:0',
- 'char_inputs_in:0',
- 'all_embs_out:0',
- 'Reshape_3:0',
- 'global_step:0'], name='')
-
- sys.stderr.write('Recovering checkpoint %s\n' % ckpt_file)
- sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
- sess.run('save/restore_all', {'save/Const:0': ckpt_file})
- sess.run(t['states_init'])
-
- return sess, t
-
-
-def _EvalModel(dataset):
- """Evaluate model perplexity using provided dataset.
-
- Args:
- dataset: LM1BDataset object.
- """
- sess, t = _LoadModel(FLAGS.pbtxt, FLAGS.ckpt)
-
- current_step = t['global_step'].eval(session=sess)
- sys.stderr.write('Loaded step %d.\n' % current_step)
-
- data_gen = dataset.get_batch(BATCH_SIZE, NUM_TIMESTEPS, forever=False)
- sum_num = 0.0
- sum_den = 0.0
- perplexity = 0.0
- for i, (inputs, char_inputs, _, targets, weights) in enumerate(data_gen):
- input_dict = {t['inputs_in']: inputs,
- t['targets_in']: targets,
- t['target_weights_in']: weights}
- if 'char_inputs_in' in t:
- input_dict[t['char_inputs_in']] = char_inputs
- log_perp = sess.run(t['log_perplexity_out'], feed_dict=input_dict)
-
- if np.isnan(log_perp):
- sys.stderr.error('log_perplexity is Nan.\n')
- else:
- sum_num += log_perp * weights.mean()
- sum_den += weights.mean()
- if sum_den > 0:
- perplexity = np.exp(sum_num / sum_den)
-
- sys.stderr.write('Eval Step: %d, Average Perplexity: %f.\n' %
- (i, perplexity))
-
- if i > FLAGS.max_eval_steps:
- break
-
-
-def _SampleSoftmax(softmax):
- return min(np.sum(np.cumsum(softmax) < np.random.rand()), len(softmax) - 1)
-
-
-def _SampleModel(prefix_words, vocab):
- """Predict next words using the given prefix words.
-
- Args:
- prefix_words: Prefix words.
- vocab: Vocabulary. Contains max word chard id length and converts between
- words and ids.
- """
- targets = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- weights = np.ones([BATCH_SIZE, NUM_TIMESTEPS], np.float32)
-
- sess, t = _LoadModel(FLAGS.pbtxt, FLAGS.ckpt)
-
- if prefix_words.find('') != 0:
- prefix_words = ' ' + prefix_words
-
- prefix = [vocab.word_to_id(w) for w in prefix_words.split()]
- prefix_char_ids = [vocab.word_to_char_ids(w) for w in prefix_words.split()]
- for _ in xrange(FLAGS.num_samples):
- inputs = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- char_ids_inputs = np.zeros(
- [BATCH_SIZE, NUM_TIMESTEPS, vocab.max_word_length], np.int32)
- samples = prefix[:]
- char_ids_samples = prefix_char_ids[:]
- sent = ''
- while True:
- inputs[0, 0] = samples[0]
- char_ids_inputs[0, 0, :] = char_ids_samples[0]
- samples = samples[1:]
- char_ids_samples = char_ids_samples[1:]
-
- softmax = sess.run(t['softmax_out'],
- feed_dict={t['char_inputs_in']: char_ids_inputs,
- t['inputs_in']: inputs,
- t['targets_in']: targets,
- t['target_weights_in']: weights})
-
- sample = _SampleSoftmax(softmax[0])
- sample_char_ids = vocab.word_to_char_ids(vocab.id_to_word(sample))
-
- if not samples:
- samples = [sample]
- char_ids_samples = [sample_char_ids]
- sent += vocab.id_to_word(samples[0]) + ' '
- sys.stderr.write('%s\n' % sent)
-
- if (vocab.id_to_word(samples[0]) == '' or
- len(sent) > FLAGS.max_sample_words):
- break
-
-
-def _DumpEmb(vocab):
- """Dump the softmax weights and word embeddings to files.
-
- Args:
- vocab: Vocabulary. Contains vocabulary size and converts word to ids.
- """
- assert FLAGS.save_dir, 'Must specify FLAGS.save_dir for dump_emb.'
- inputs = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- targets = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- weights = np.ones([BATCH_SIZE, NUM_TIMESTEPS], np.float32)
-
- sess, t = _LoadModel(FLAGS.pbtxt, FLAGS.ckpt)
-
- softmax_weights = sess.run(t['softmax_weights'])
- fname = FLAGS.save_dir + '/embeddings_softmax.npy'
- with tf.gfile.Open(fname, mode='w') as f:
- np.save(f, softmax_weights)
- sys.stderr.write('Finished softmax weights\n')
-
- all_embs = np.zeros([vocab.size, 1024])
- for i in xrange(vocab.size):
- input_dict = {t['inputs_in']: inputs,
- t['targets_in']: targets,
- t['target_weights_in']: weights}
- if 'char_inputs_in' in t:
- input_dict[t['char_inputs_in']] = (
- vocab.word_char_ids[i].reshape([-1, 1, MAX_WORD_LEN]))
- embs = sess.run(t['all_embs'], input_dict)
- all_embs[i, :] = embs
- sys.stderr.write('Finished word embedding %d/%d\n' % (i, vocab.size))
-
- fname = FLAGS.save_dir + '/embeddings_char_cnn.npy'
- with tf.gfile.Open(fname, mode='w') as f:
- np.save(f, all_embs)
- sys.stderr.write('Embedding file saved\n')
-
-
-def _DumpSentenceEmbedding(sentence, vocab):
- """Predict next words using the given prefix words.
-
- Args:
- sentence: Sentence words.
- vocab: Vocabulary. Contains max word chard id length and converts between
- words and ids.
- """
- targets = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- weights = np.ones([BATCH_SIZE, NUM_TIMESTEPS], np.float32)
-
- sess, t = _LoadModel(FLAGS.pbtxt, FLAGS.ckpt)
-
- if sentence.find('') != 0:
- sentence = ' ' + sentence
-
- word_ids = [vocab.word_to_id(w) for w in sentence.split()]
- char_ids = [vocab.word_to_char_ids(w) for w in sentence.split()]
-
- inputs = np.zeros([BATCH_SIZE, NUM_TIMESTEPS], np.int32)
- char_ids_inputs = np.zeros(
- [BATCH_SIZE, NUM_TIMESTEPS, vocab.max_word_length], np.int32)
- for i in xrange(len(word_ids)):
- inputs[0, 0] = word_ids[i]
- char_ids_inputs[0, 0, :] = char_ids[i]
-
- # Add 'lstm/lstm_0/control_dependency' if you want to dump previous layer
- # LSTM.
- lstm_emb = sess.run(t['lstm/lstm_1/control_dependency'],
- feed_dict={t['char_inputs_in']: char_ids_inputs,
- t['inputs_in']: inputs,
- t['targets_in']: targets,
- t['target_weights_in']: weights})
-
- fname = os.path.join(FLAGS.save_dir, 'lstm_emb_step_%d.npy' % i)
- with tf.gfile.Open(fname, mode='w') as f:
- np.save(f, lstm_emb)
- sys.stderr.write('LSTM embedding step %d file saved\n' % i)
-
-
-def main(unused_argv):
- vocab = data_utils.CharsVocabulary(FLAGS.vocab_file, MAX_WORD_LEN)
-
- if FLAGS.mode == 'eval':
- dataset = data_utils.LM1BDataset(FLAGS.input_data, vocab)
- _EvalModel(dataset)
- elif FLAGS.mode == 'sample':
- _SampleModel(FLAGS.prefix, vocab)
- elif FLAGS.mode == 'dump_emb':
- _DumpEmb(vocab)
- elif FLAGS.mode == 'dump_lstm_emb':
- _DumpSentenceEmbedding(FLAGS.sentence, vocab)
- else:
- raise Exception('Mode not supported.')
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lm_commonsense/README.md b/research/lm_commonsense/README.md
deleted file mode 100644
index 78c8f53ca226f09c4b185490d6966f98bf584889..0000000000000000000000000000000000000000
--- a/research/lm_commonsense/README.md
+++ /dev/null
@@ -1,170 +0,0 @@
-
-
-
-
-# A Simple Method for Commonsense Reasoning
-
-This repository contains code to reproduce results from [*A Simple Method for Commonsense Reasoning*](https://arxiv.org/abs/1806.02847).
-
-Authors and contact:
-
-* Trieu H. Trinh (thtrieu@google.com, github: thtrieu)
-* Quoc V. Le (qvl@google.com)
-
-## TL;DR
-
-Commonsense reasoning is a long-standing challenge for deep learning. For example,
-it is difficult to use neural networks to tackle the Winograd Schema dataset - a difficult subset of Pronoun Disambiguation problems. In this work, we use language models to score substitued sentences to decide the correct reference of the ambiguous pronoun (see Figure below for an example).
-
-
-
-This simple unsupervised method achieves new state-of-the-art (*as of June 1st, 2018*) results on both benchmark PDP-60 and WSC-273 (See Table below), without using rule-based reasoning nor expensive annotated knowledge bases.
-
-| Commonsense-reasoning test | Previous best result | Ours |
-| ----------------------------|:----------------------:|:-----:|
-| Pronoun Disambiguation | 66.7% | 70% |
-| Winograd Schema Challenge | 52.8% | 63.7% |
-
-
-
-## Citation
-
-If you use our released models below in your publication, please cite the original paper:
-
-@article{TBD}
-
-
-## Requirements
-* Python >=2.6
-* Tensorflow >= v1.4
-* Numpy >= 1.12.1
-
-## Details of this release
-
-The open-sourced components include:
-
-* Test sets from Pronoun Disambiguation Problem (PDP-60) and Winograd Schema Challenges (WSC-273).
-* Tensorflow metagraph and checkpoints of 14 language models (See Appendix A in the paper).
-* A vocabulary file.
-* Code to reproduce results from the original paper.
-
-## How to run
-
-### 1. Download data files
-
-Download all files from the [Google Cloud Storage of this project](https://console.cloud.google.com/storage/browser/commonsense-reasoning/). The easiest way is to install and use `gsutil cp` command-line tool (See [install gsutil](https://cloud.google.com/storage/docs/gsutil_install)).
-
-
-```shell
-# Download everything from the project gs://commonsense-reasoning
-$ gsutil cp -R gs://commonsense-reasoning/* .
-Copying gs://commonsense-reasoning/reproduce/vocab.txt...
-Copying gs://commonsense-reasoning/reproduce/commonsense_test/pdp60.json...
-Copying gs://commonsense-reasoning/reproduce/commonsense_test/wsc273.json...
-
-...(omitted)
-```
-
-All downloaded content should be in `./reproduce/`. This includes two tests `pdp60.json` and `wsc273.json`, a vocabulary file `vocab.txt` and checkpoints for all 14 language models, each includes three files (`.data`, `.index` and `.meta`). All checkpoint names start with `ckpt-best` since they are saved at the best perplexity on a hold-out text corpus.
-
-```shell
-# Check for the content
-$ ls reproduce/*
-reproduce/vocab.txt
-
-reproduce/commonsense_test:
-pdp60.json wsc273.json
-
-reproduce/lm01:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm02:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm03:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm04:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm05:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm06:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm07:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm08:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm09:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm10:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm11:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm12:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm13:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-
-reproduce/lm14:
-ckpt-best.data-00000-of-00001 ckpt-best.index ckpt-best.meta
-```
-
-### 2. Run evaluation code
-
-To reproduce results from the paper, simply run `eval.py` script.
-
-```shell
-$ python eval.py --data_dir=reproduce
-
-Restored from ./reproduce/lm01
-Reset RNN states.
-Processing patch (1, 1) / (2, 4)
-Probs for
-[['Then' 'Dad' 'figured' ..., 'man' "'s" 'board-bill']
- ['Then' 'Dad' 'figured' ..., 'man' "'s" 'board-bill']
- ['Always' 'before' ',' ..., 'now' ',' 'for']
- ...,
- ['Mark' 'was' 'close' ..., 'promising' 'him' ',']
- ['Mark' 'was' 'close' ..., 'promising' 'him' ',']
- ['Mark' 'was' 'close' ..., 'promising' 'him' ',']]
-=
-[[ 1.64250596e-05 1.77780055e-06 4.14267970e-06 ..., 1.87315454e-03
- 1.57723188e-01 6.31845817e-02]
- [ 1.64250596e-05 1.77780055e-06 4.14267970e-06 ..., 1.87315454e-03
- 1.57723188e-01 6.31845817e-02]
- [ 1.28243030e-07 3.80435935e-03 1.12383246e-01 ..., 9.67682712e-03
- 2.17407525e-01 1.08243264e-01]
- ...,
- [ 1.15557734e-04 2.92792241e-03 3.46455898e-04 ..., 2.72328052e-05
- 3.37066874e-02 7.89367408e-02]
- [ 1.15557734e-04 2.92792241e-03 3.46455898e-04 ..., 2.72328052e-05
- 3.37066874e-02 7.89367408e-02]
- [ 1.15557734e-04 2.92792241e-03 3.46455898e-04 ..., 2.72328052e-05
- 3.37066874e-02 7.89367408e-02]]
-Processing patch (1, 2) / (2, 4)
-
-...(omitted)
-
-Accuracy of 1 LM(s) on pdp60 = 0.6
-
-...(omitted)
-
-Accuracy of 5 LM(s) on pdp60 = 0.7
-
-...(omitted)
-
-Accuracy of 10 LM(s) on wsc273 = 0.615
-
-...(omitted)
-
-Accuracy of 14 LM(s) on wsc273 = 0.637
-```
diff --git a/research/lm_commonsense/eval.py b/research/lm_commonsense/eval.py
deleted file mode 100644
index e5b7ff98b50a5af4e066d3d9f82c1acae81c3e93..0000000000000000000000000000000000000000
--- a/research/lm_commonsense/eval.py
+++ /dev/null
@@ -1,190 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import os
-import pickle as pkl
-import numpy as np
-import tensorflow as tf
-import utils
-
-tf.app.flags.DEFINE_string(
- 'data_dir', 'reproduce',
- 'Path to directory containing data and model checkpoints.')
-
-
-FLAGS = tf.app.flags.FLAGS
-
-
-class EnsembleLM(object):
- """Ensemble of language models."""
-
- def __init__(self, test_data_name='wsc273'):
- vocab_file = os.path.join(FLAGS.data_dir, 'vocab.txt')
- self.vocab = utils.CharsVocabulary(vocab_file, 50)
- assert test_data_name in ['pdp60', 'wsc273'], (
- 'Test data must be pdp60 or wsc273, got {}'.format(test_data_name))
- self.test_data_name = test_data_name
-
- test_data = utils.parse_commonsense_reasoning_test(test_data_name)
- self.question_ids, self.sentences, self.labels = test_data
- self.all_probs = [] # aggregate single-model prediction here.
-
- def add_single_model(self, model_name='lm1'):
- """Add a single model into the current ensemble."""
- # Create single LM
- single_lm = SingleRecurrentLanguageModel(self.vocab, model_name)
-
- # Add the single LM prediction.
- probs = single_lm.assign_probs(self.sentences, self.test_data_name)
- self.all_probs.append(probs)
- print('Done adding {}'.format(model_name))
-
- def evaluate(self):
- """Evaluate the current ensemble."""
- # Attach word probabilities and correctness label to each substitution
- ensembled_probs = sum(self.all_probs) / len(self.all_probs)
- scorings = []
- for i, sentence in enumerate(self.sentences):
- correctness = self.labels[i]
- word_probs = ensembled_probs[i, :len(sentence)]
- joint_prob = np.prod(word_probs, dtype=np.float64)
-
- scorings.append(dict(
- correctness=correctness,
- sentence=sentence,
- joint_prob=joint_prob,
- word_probs=word_probs))
- scoring_mode = 'full' if self.test_data_name == 'pdp60' else 'partial'
- return utils.compare_substitutions(
- self.question_ids, scorings, scoring_mode)
-
-
-class SingleRecurrentLanguageModel(object):
- """Single Recurrent Language Model."""
-
- def __init__(self, vocab, model_name='lm01'):
- self.vocab = vocab
- self.log_dir = os.path.join(FLAGS.data_dir, model_name)
-
- def reset(self):
- self.sess.run(self.tensors['states_init'])
-
- def _score(self, word_patch):
- """Score a matrix of shape (batch_size, num_timesteps+1) str tokens."""
- word_ids = np.array(
- [[self.vocab.word_to_id(word) for word in row]
- for row in word_patch])
- char_ids = np.array(
- [[self.vocab.word_to_char_ids(word) for word in row]
- for row in word_patch])
- print('Probs for \n{}\n='.format(np.array(word_patch)[:, 1:]))
-
- input_ids, target_ids = word_ids[:, :-1], word_ids[:, 1:]
- input_char_ids = char_ids[:, :-1, :]
-
- softmax = self.sess.run(self.tensors['softmax_out'], feed_dict={
- self.tensors['inputs_in']: input_ids,
- self.tensors['char_inputs_in']: input_char_ids
- })
-
- batch_size, num_timesteps = self.shape
- softmax = softmax.reshape((num_timesteps, batch_size, -1))
- softmax = np.transpose(softmax, [1, 0, 2])
- probs = np.array([[softmax[row, col, target_ids[row, col]]
- for col in range(num_timesteps)]
- for row in range(batch_size)])
- print(probs)
- return probs
-
- def _score_patches(self, word_patches):
- """Score a 2D matrix of word_patches and stitch results together."""
- batch_size, num_timesteps = self.shape
- nrow, ncol = len(word_patches), len(word_patches[0])
- max_len = num_timesteps * ncol
- probs = np.zeros([0, max_len]) # accumulate results into this.
-
- # Loop through the 2D matrix of word_patches and score each.
- for i, row in enumerate(word_patches):
- print('Reset RNN states.')
- self.reset() # reset states before processing each row.
- row_probs = np.zeros([batch_size, 0])
- for j, word_patch in enumerate(row):
- print('Processing patch '
- '({}, {}) / ({}, {})'.format(i+1, j+1, nrow, ncol))
- patch_probs = (self._score(word_patch) if word_patch else
- np.zeros([batch_size, num_timesteps]))
- row_probs = np.concatenate([row_probs, patch_probs], 1)
- probs = np.concatenate([probs, row_probs], 0)
- return probs
-
- def assign_probs(self, sentences, test_data_name='wsc273'):
- """Return prediction accuracy using this LM for a test."""
-
- probs_cache = os.path.join(self.log_dir, '{}.probs'.format(test_data_name))
- if os.path.exists(probs_cache):
- print('Reading cached result from {}'.format(probs_cache))
- with tf.gfile.Open(probs_cache, 'r') as f:
- probs = pkl.load(f)
- else:
- tf.reset_default_graph()
- self.sess = tf.Session()
- # Build the graph.
- saver = tf.train.import_meta_graph(
- os.path.join(self.log_dir, 'ckpt-best.meta'))
- saver.restore(self.sess, os.path.join(self.log_dir, 'ckpt-best'))
- print('Restored from {}'.format(self.log_dir))
- graph = tf.get_default_graph()
- self.tensors = dict(
- inputs_in=graph.get_tensor_by_name('test_inputs_in:0'),
- char_inputs_in=graph.get_tensor_by_name('test_char_inputs_in:0'),
- softmax_out=graph.get_tensor_by_name('SotaRNN_1/softmax_out:0'),
- states_init=graph.get_operation_by_name('SotaRNN_1/states_init'))
- self.shape = self.tensors['inputs_in'].shape.as_list()
-
- # Cut sentences into patches of shape processable by the LM.
- batch_size, num_timesteps = self.shape
- word_patches = utils.cut_to_patches(sentences, batch_size, num_timesteps)
- probs = self._score_patches(word_patches)
-
- # Cache the probs since they are expensive to evaluate
- with tf.gfile.Open(probs_cache, 'w') as f:
- pkl.dump(probs, f)
- return probs
-
-
-def evaluate_ensemble(test_data_name, number_of_lms):
- ensemble = EnsembleLM(test_data_name)
- model_list = ['lm{:02d}'.format(i+1) for i in range(number_of_lms)]
- for model_name in model_list:
- ensemble.add_single_model(model_name)
- accuracy = ensemble.evaluate()
- print('Accuracy of {} LM(s) on {} = {}'.format(
- number_of_lms, test_data_name, accuracy))
-
-
-def main(_):
- evaluate_ensemble('pdp60', 1) # 60%
- evaluate_ensemble('pdp60', 5) # 70%
- evaluate_ensemble('wsc273', 10) # 61.5%
- evaluate_ensemble('wsc273', 14) # 63.7%
-
-
-if __name__ == '__main__':
- tf.app.run(main)
diff --git a/research/lm_commonsense/method.jpg b/research/lm_commonsense/method.jpg
deleted file mode 100644
index ee8a5506fccca3cbb67f7bda0ccef78303cb228b..0000000000000000000000000000000000000000
Binary files a/research/lm_commonsense/method.jpg and /dev/null differ
diff --git a/research/lm_commonsense/utils.py b/research/lm_commonsense/utils.py
deleted file mode 100644
index d75f2b0fb72716860ea6d438e6b8ca2732d13c84..0000000000000000000000000000000000000000
--- a/research/lm_commonsense/utils.py
+++ /dev/null
@@ -1,368 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import json
-import os
-import numpy as np
-import tensorflow as tf
-
-FLAGS = tf.flags.FLAGS
-
-
-class Vocabulary(object):
- """Class that holds a vocabulary for the dataset."""
-
- def __init__(self, filename):
-
- self._id_to_word = []
- self._word_to_id = {}
- self._unk = -1
- self._bos = -1
- self._eos = -1
-
- with tf.gfile.Open(filename) as f:
- idx = 0
- for line in f:
- word_name = line.strip()
- if word_name == '':
- self._bos = idx
- elif word_name == '':
- self._eos = idx
- elif word_name == '':
- self._unk = idx
- if word_name == '!!!MAXTERMID':
- continue
-
- self._id_to_word.append(word_name)
- self._word_to_id[word_name] = idx
- idx += 1
-
- @property
- def bos(self):
- return self._bos
-
- @property
- def eos(self):
- return self._eos
-
- @property
- def unk(self):
- return self._unk
-
- @property
- def size(self):
- return len(self._id_to_word)
-
- def word_to_id(self, word):
- if word in self._word_to_id:
- return self._word_to_id[word]
- else:
- if word.lower() in self._word_to_id:
- return self._word_to_id[word.lower()]
- return self.unk
-
- def id_to_word(self, cur_id):
- if cur_id < self.size:
- return self._id_to_word[int(cur_id)]
- return ''
-
- def decode(self, cur_ids):
- return ' '.join([self.id_to_word(cur_id) for cur_id in cur_ids])
-
- def encode(self, sentence):
- word_ids = [self.word_to_id(cur_word) for cur_word in sentence.split()]
- return np.array([self.bos] + word_ids + [self.eos], dtype=np.int32)
-
-
-class CharsVocabulary(Vocabulary):
- """Vocabulary containing character-level information."""
-
- def __init__(self, filename, max_word_length):
- super(CharsVocabulary, self).__init__(filename)
-
- self._max_word_length = max_word_length
- chars_set = set()
-
- for word in self._id_to_word:
- chars_set |= set(word)
-
- free_ids = []
- for i in range(256):
- if chr(i) in chars_set:
- continue
- free_ids.append(chr(i))
-
- if len(free_ids) < 5:
- raise ValueError('Not enough free char ids: %d' % len(free_ids))
-
- self.bos_char = free_ids[0] #
- self.eos_char = free_ids[1] #
- self.bow_char = free_ids[2] #
- self.eow_char = free_ids[3] #
- self.pad_char = free_ids[4] #
-
- chars_set |= {self.bos_char, self.eos_char, self.bow_char, self.eow_char,
- self.pad_char}
-
- self._char_set = chars_set
- num_words = len(self._id_to_word)
-
- self._word_char_ids = np.zeros([num_words, max_word_length], dtype=np.int32)
-
- self.bos_chars = self._convert_word_to_char_ids(self.bos_char)
- self.eos_chars = self._convert_word_to_char_ids(self.eos_char)
-
- for i, word in enumerate(self._id_to_word):
- if i == self.bos:
- self._word_char_ids[i] = self.bos_chars
- elif i == self.eos:
- self._word_char_ids[i] = self.eos_chars
- else:
- self._word_char_ids[i] = self._convert_word_to_char_ids(word)
-
- @property
- def max_word_length(self):
- return self._max_word_length
-
- def _convert_word_to_char_ids(self, word):
- code = np.zeros([self.max_word_length], dtype=np.int32)
- code[:] = ord(self.pad_char)
-
- if len(word) > self.max_word_length - 2:
- word = word[:self.max_word_length-2]
- cur_word = self.bow_char + word + self.eow_char
- for j in range(len(cur_word)):
- code[j] = ord(cur_word[j])
- return code
-
- def word_to_char_ids(self, word):
- if word in self._word_to_id:
- return self._word_char_ids[self._word_to_id[word]]
- else:
- return self._convert_word_to_char_ids(word)
-
- def encode_chars(self, sentence):
- chars_ids = [self.word_to_char_ids(cur_word)
- for cur_word in sentence.split()]
- return np.vstack([self.bos_chars] + chars_ids + [self.eos_chars])
-
-
-_SPECIAL_CHAR_MAP = {
- '\xe2\x80\x98': '\'',
- '\xe2\x80\x99': '\'',
- '\xe2\x80\x9c': '"',
- '\xe2\x80\x9d': '"',
- '\xe2\x80\x93': '-',
- '\xe2\x80\x94': '-',
- '\xe2\x88\x92': '-',
- '\xce\x84': '\'',
- '\xc2\xb4': '\'',
- '`': '\''
-}
-
-_START_SPECIAL_CHARS = ['.', ',', '?', '!', ';', ':', '[', ']', '\'', '+', '/',
- '\xc2\xa3', '$', '~', '*', '%', '{', '}', '#', '&', '-',
- '"', '(', ')', '='] + list(_SPECIAL_CHAR_MAP.keys())
-_SPECIAL_CHARS = _START_SPECIAL_CHARS + [
- '\'s', '\'m', '\'t', '\'re', '\'d', '\'ve', '\'ll']
-
-
-def tokenize(sentence):
- """Tokenize a sentence."""
- sentence = str(sentence)
- words = sentence.strip().split()
- tokenized = [] # return this
-
- for word in words:
- if word.lower() in ['mr.', 'ms.']:
- tokenized.append(word)
- continue
-
- # Split special chars at the start of word
- will_split = True
- while will_split:
- will_split = False
- for char in _START_SPECIAL_CHARS:
- if word.startswith(char):
- tokenized.append(char)
- word = word[len(char):]
- will_split = True
-
- # Split special chars at the end of word
- special_end_tokens = []
- will_split = True
- while will_split:
- will_split = False
- for char in _SPECIAL_CHARS:
- if word.endswith(char):
- special_end_tokens = [char] + special_end_tokens
- word = word[:-len(char)]
- will_split = True
-
- if word:
- tokenized.append(word)
- tokenized += special_end_tokens
-
- # Add necessary end of sentence token.
- if tokenized[-1] not in ['.', '!', '?']:
- tokenized += ['.']
- return tokenized
-
-
-def parse_commonsense_reasoning_test(test_data_name):
- """Read JSON test data."""
- with tf.gfile.Open(os.path.join(
- FLAGS.data_dir, 'commonsense_test',
- '{}.json'.format(test_data_name)), 'r') as f:
- data = json.load(f)
-
- question_ids = [d['question_id'] for d in data]
- sentences = [tokenize(d['substitution']) for d in data]
- labels = [d['correctness'] for d in data]
-
- return question_ids, sentences, labels
-
-
-PAD = ''
-
-
-def cut_to_patches(sentences, batch_size, num_timesteps):
- """Cut sentences into patches of shape (batch_size, num_timesteps).
-
- Args:
- sentences: a list of sentences, each sentence is a list of str token.
- batch_size: batch size
- num_timesteps: number of backprop step
-
- Returns:
- patches: A 2D matrix,
- each entry is a matrix of shape (batch_size, num_timesteps).
- """
- preprocessed = [['']+sentence+[''] for sentence in sentences]
- max_len = max([len(sent) for sent in preprocessed])
-
- # Pad to shape [height, width]
- # where height is a multiple of batch_size
- # and width is a multiple of num_timesteps
- nrow = int(np.ceil(len(preprocessed) * 1.0 / batch_size))
- ncol = int(np.ceil(max_len * 1.0 / num_timesteps))
- height, width = nrow * batch_size, ncol * num_timesteps + 1
- preprocessed = [sent + [PAD] * (width - len(sent)) for sent in preprocessed]
- preprocessed += [[PAD] * width] * (height - len(preprocessed))
-
- # Cut preprocessed into patches of shape [batch_size, num_timesteps]
- patches = []
- for row in range(nrow):
- patches.append([])
- for col in range(ncol):
- patch = [sent[col * num_timesteps:
- (col+1) * num_timesteps + 1]
- for sent in preprocessed[row * batch_size:
- (row+1) * batch_size]]
- if np.all(np.array(patch)[:, 1:] == PAD):
- patch = None # no need to process this patch.
- patches[-1].append(patch)
- return patches
-
-
-def _substitution_mask(sent1, sent2):
- """Binary mask identifying substituted part in two sentences.
-
- Example sentence and their mask:
- First sentence = "I like the cat 's color"
- 0 0 0 1 0 0
- Second sentence = "I like the yellow dog 's color"
- 0 0 0 1 1 0 0
-
- Args:
- sent1: first sentence
- sent2: second sentence
-
- Returns:
- mask1: mask for first sentence
- mask2: mask for second sentence
- """
- mask1_start, mask2_start = [], []
- while sent1[0] == sent2[0]:
- sent1 = sent1[1:]
- sent2 = sent2[1:]
- mask1_start.append(0.)
- mask2_start.append(0.)
-
- mask1_end, mask2_end = [], []
- while sent1[-1] == sent2[-1]:
- if (len(sent1) == 1) or (len(sent2) == 1):
- break
- sent1 = sent1[:-1]
- sent2 = sent2[:-1]
- mask1_end = [0.] + mask1_end
- mask2_end = [0.] + mask2_end
-
- assert sent1 or sent2, 'Two sentences are identical.'
- return (mask1_start + [1.] * len(sent1) + mask1_end,
- mask2_start + [1.] * len(sent2) + mask2_end)
-
-
-def _convert_to_partial(scoring1, scoring2):
- """Convert full scoring into partial scoring."""
- mask1, mask2 = _substitution_mask(
- scoring1['sentence'], scoring2['sentence'])
-
- def _partial_score(scoring, mask):
- word_probs = [max(_) for _ in zip(scoring['word_probs'], mask)]
- scoring.update(word_probs=word_probs,
- joint_prob=np.prod(word_probs))
-
- _partial_score(scoring1, mask1)
- _partial_score(scoring2, mask2)
-
-
-def compare_substitutions(question_ids, scorings, mode='full'):
- """Return accuracy by comparing two consecutive scorings."""
- prediction_correctness = []
- # Compare two consecutive substitutions
- for i in range(len(scorings) // 2):
- scoring1, scoring2 = scorings[2*i: 2*i+2]
- if mode == 'partial': # fix joint prob into partial prob
- _convert_to_partial(scoring1, scoring2)
-
- prediction_correctness.append(
- (scoring2['joint_prob'] > scoring1['joint_prob']) ==
- scoring2['correctness'])
-
- # Two consecutive substitutions always belong to the same question
- question_ids = [qid for i, qid in enumerate(question_ids) if i % 2 == 0]
- assert len(question_ids) == len(prediction_correctness)
- num_questions = len(set(question_ids))
-
- # Question is correctly answered only if
- # all predictions of the same question_id is correct
- num_correct_answer = 0
- previous_qid = None
- correctly_answered = False
- for predict, qid in zip(prediction_correctness, question_ids):
- if qid != previous_qid:
- previous_qid = qid
- num_correct_answer += int(correctly_answered)
- correctly_answered = True
- correctly_answered = correctly_answered and predict
- num_correct_answer += int(correctly_answered)
-
- return num_correct_answer / num_questions
diff --git a/research/lstm_object_detection/README.md b/research/lstm_object_detection/README.md
deleted file mode 100644
index a696ba3df306768cfa28223ad957ef564667c7dd..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
-# Tensorflow Mobile Video Object Detection
-
-Tensorflow mobile video object detection implementation proposed in the
-following papers:
-
-/MobilenetV2_1/
-
- Args:
- preprocessed_inputs: preprocessed input images of shape:
- [batch, width, height, depth].
-
- Returns:
- net: the last feature map created from the base feature extractor.
- end_points: a dictionary of feature maps created.
- """
- scope_name = self._base_network_scope + '_1'
- with tf.variable_scope(scope_name, reuse=self._reuse_weights) as base_scope:
- net, end_points = mobilenet_v2.mobilenet_base(
- preprocessed_inputs,
- depth_multiplier=self._depth_multipliers[0],
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(
- is_quantized=self._is_quantized),
- use_explicit_padding=self._use_explicit_padding,
- scope=base_scope)
- return net, end_points
-
- def extract_base_features_small(self, preprocessed_inputs):
- """Extract the small base model features.
-
- Variables are created under the scope of /MobilenetV2_2/
-
- Args:
- preprocessed_inputs: preprocessed input images of shape:
- [batch, width, height, depth].
-
- Returns:
- net: the last feature map created from the base feature extractor.
- end_points: a dictionary of feature maps created.
- """
- scope_name = self._base_network_scope + '_2'
- with tf.variable_scope(scope_name, reuse=self._reuse_weights) as base_scope:
- if self._low_res:
- height_small = preprocessed_inputs.get_shape().as_list()[1] // 2
- width_small = preprocessed_inputs.get_shape().as_list()[2] // 2
- inputs_small = tf.image.resize_images(preprocessed_inputs,
- [height_small, width_small])
- # Create end point handle for tflite deployment.
- with tf.name_scope(None):
- inputs_small = tf.identity(
- inputs_small, name='normalized_input_image_tensor_small')
- else:
- inputs_small = preprocessed_inputs
- net, end_points = mobilenet_v2.mobilenet_base(
- inputs_small,
- depth_multiplier=self._depth_multipliers[1],
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(
- is_quantized=self._is_quantized, low_res=self._low_res),
- use_explicit_padding=self._use_explicit_padding,
- scope=base_scope)
- return net, end_points
-
- def create_lstm_cell(self, batch_size, output_size, state_saver, state_name,
- dtype=tf.float32):
- """Create the LSTM cell, and initialize state if necessary.
-
- Args:
- batch_size: input batch size.
- output_size: output size of the lstm cell, [width, height].
- state_saver: a state saver object with methods `state` and `save_state`.
- state_name: string, the name to use with the state_saver.
- dtype: dtype to initialize lstm state.
-
- Returns:
- lstm_cell: the lstm cell unit.
- init_state: initial state representations.
- step: the step
- """
- lstm_cell = lstm_cells.GroupedConvLSTMCell(
- filter_size=(3, 3),
- output_size=output_size,
- num_units=max(self._min_depth, self._lstm_state_depth),
- is_training=self._is_training,
- activation=tf.nn.relu6,
- flatten_state=self._flatten_state,
- scale_state=self._scale_state,
- clip_state=self._clip_state,
- output_bottleneck=True,
- pre_bottleneck=self._pre_bottleneck,
- is_quantized=self._is_quantized,
- visualize_gates=False)
-
- if state_saver is None:
- init_state = lstm_cell.init_state('lstm_state', batch_size, dtype)
- step = None
- else:
- step = state_saver.state(state_name + '_step')
- c = state_saver.state(state_name + '_c')
- h = state_saver.state(state_name + '_h')
- c.set_shape([batch_size] + c.get_shape().as_list()[1:])
- h.set_shape([batch_size] + h.get_shape().as_list()[1:])
- init_state = (c, h)
- return lstm_cell, init_state, step
-
- def extract_features(self, preprocessed_inputs, state_saver=None,
- state_name='lstm_state', unroll_length=10, scope=None):
- """Extract features from preprocessed inputs.
-
- The features include the base network features, lstm features and SSD
- features, organized in the following name scope:
-
- /MobilenetV2_1/...
- /MobilenetV2_2/...
- /LSTM/...
- /FeatureMap/...
-
- Args:
- preprocessed_inputs: a [batch, height, width, channels] float tensor
- representing a batch of consecutive frames from video clips.
- state_saver: A state saver object with methods `state` and `save_state`.
- state_name: Python string, the name to use with the state_saver.
- unroll_length: number of steps to unroll the lstm.
- scope: Scope for the base network of the feature extractor.
-
- Returns:
- feature_maps: a list of tensors where the ith tensor has shape
- [batch, height_i, width_i, depth_i]
- Raises:
- ValueError: if interleave_method not recognized or large and small base
- network output feature maps of different sizes.
- """
- preprocessed_inputs = shape_utils.check_min_image_dim(
- 33, preprocessed_inputs)
- preprocessed_inputs = ops.pad_to_multiple(
- preprocessed_inputs, self._pad_to_multiple)
- batch_size = preprocessed_inputs.shape[0].value // unroll_length
- batch_axis = 0
- nets = []
-
- # Batch processing of mobilenet features.
- with slim.arg_scope(mobilenet_v2.training_scope(
- is_training=self._is_training,
- bn_decay=0.9997)), \
- slim.arg_scope([mobilenet.depth_multiplier],
- min_depth=self._min_depth, divisible_by=8):
- # Big model.
- net, _ = self.extract_base_features_large(preprocessed_inputs)
- nets.append(net)
- large_base_feature_shape = net.shape
-
- # Small models
- net, _ = self.extract_base_features_small(preprocessed_inputs)
- nets.append(net)
- small_base_feature_shape = net.shape
- if not (large_base_feature_shape[1] == small_base_feature_shape[1] and
- large_base_feature_shape[2] == small_base_feature_shape[2]):
- raise ValueError('Large and Small base network feature map dimension '
- 'not equal!')
-
- with slim.arg_scope(self._conv_hyperparams_fn()):
- with tf.variable_scope('LSTM', reuse=self._reuse_weights):
- output_size = (large_base_feature_shape[1], large_base_feature_shape[2])
- lstm_cell, init_state, step = self.create_lstm_cell(
- batch_size, output_size, state_saver, state_name,
- dtype=preprocessed_inputs.dtype)
-
- nets_seq = [
- tf.split(net, unroll_length, axis=batch_axis) for net in nets
- ]
-
- net_seq, states_out = rnn_decoder.multi_input_rnn_decoder(
- nets_seq,
- init_state,
- lstm_cell,
- step,
- selection_strategy=self._interleave_method,
- is_training=self._is_training,
- is_quantized=self._is_quantized,
- pre_bottleneck=self._pre_bottleneck,
- flatten_state=self._flatten_state,
- scope=None)
- self._states_out = states_out
-
- image_features = {}
- if state_saver is not None:
- self._step = state_saver.state(state_name + '_step')
- batcher_ops = [
- state_saver.save_state(state_name + '_c', states_out[-1][0]),
- state_saver.save_state(state_name + '_h', states_out[-1][1]),
- state_saver.save_state(state_name + '_step', self._step + 1)]
- with tf_ops.control_dependencies(batcher_ops):
- image_features['layer_19'] = tf.concat(net_seq, 0)
- else:
- image_features['layer_19'] = tf.concat(net_seq, 0)
-
- # SSD layers.
- with tf.variable_scope('FeatureMap'):
- feature_maps = feature_map_generators.multi_resolution_feature_maps(
- feature_map_layout=self._feature_map_layout,
- depth_multiplier=self._depth_multiplier,
- min_depth=self._min_depth,
- insert_1x1_conv=True,
- image_features=image_features,
- pool_residual=True)
- return list(feature_maps.values())
diff --git a/research/lstm_object_detection/models/lstm_ssd_interleaved_mobilenet_v2_feature_extractor_test.py b/research/lstm_object_detection/models/lstm_ssd_interleaved_mobilenet_v2_feature_extractor_test.py
deleted file mode 100644
index b285f0e44417a309f54973327c16b55c1169260f..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/models/lstm_ssd_interleaved_mobilenet_v2_feature_extractor_test.py
+++ /dev/null
@@ -1,352 +0,0 @@
-# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for lstm_ssd_interleaved_mobilenet_v2_feature_extractor."""
-
-import numpy as np
-import tensorflow.compat.v1 as tf
-import tf_slim as slim
-from tensorflow.contrib import training as contrib_training
-
-from lstm_object_detection.models import lstm_ssd_interleaved_mobilenet_v2_feature_extractor
-from object_detection.models import ssd_feature_extractor_test
-
-
-class LSTMSSDInterleavedMobilenetV2FeatureExtractorTest(
- ssd_feature_extractor_test.SsdFeatureExtractorTestBase):
-
- def _create_feature_extractor(self,
- depth_multiplier,
- pad_to_multiple,
- is_quantized=False):
- """Constructs a new feature extractor.
-
- Args:
- depth_multiplier: float depth multiplier for feature extractor
- pad_to_multiple: the nearest multiple to zero pad the input height and
- width dimensions to.
- is_quantized: whether to quantize the graph.
- Returns:
- an ssd_meta_arch.SSDFeatureExtractor object.
- """
- min_depth = 32
- def conv_hyperparams_fn():
- with slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm), \
- slim.arg_scope([slim.batch_norm], is_training=False) as sc:
- return sc
- feature_extractor = (
- lstm_ssd_interleaved_mobilenet_v2_feature_extractor
- .LSTMSSDInterleavedMobilenetV2FeatureExtractor(False, depth_multiplier,
- min_depth,
- pad_to_multiple,
- conv_hyperparams_fn))
- feature_extractor.lstm_state_depth = int(320 * depth_multiplier)
- feature_extractor.depth_multipliers = [
- depth_multiplier, depth_multiplier / 4.0
- ]
- feature_extractor.is_quantized = is_quantized
- return feature_extractor
-
- def test_feature_extractor_construct_with_expected_params(self):
- def conv_hyperparams_fn():
- with (slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm) and
- slim.arg_scope([slim.batch_norm], decay=0.97, epsilon=1e-3)) as sc:
- return sc
-
- params = {
- 'is_training': True,
- 'depth_multiplier': .55,
- 'min_depth': 9,
- 'pad_to_multiple': 3,
- 'conv_hyperparams_fn': conv_hyperparams_fn,
- 'reuse_weights': False,
- 'use_explicit_padding': True,
- 'use_depthwise': False,
- 'override_base_feature_extractor_hyperparams': True}
-
- feature_extractor = (
- lstm_ssd_interleaved_mobilenet_v2_feature_extractor
- .LSTMSSDInterleavedMobilenetV2FeatureExtractor(**params))
-
- self.assertEqual(params['is_training'],
- feature_extractor._is_training)
- self.assertEqual(params['depth_multiplier'],
- feature_extractor._depth_multiplier)
- self.assertEqual(params['min_depth'],
- feature_extractor._min_depth)
- self.assertEqual(params['pad_to_multiple'],
- feature_extractor._pad_to_multiple)
- self.assertEqual(params['conv_hyperparams_fn'],
- feature_extractor._conv_hyperparams_fn)
- self.assertEqual(params['reuse_weights'],
- feature_extractor._reuse_weights)
- self.assertEqual(params['use_explicit_padding'],
- feature_extractor._use_explicit_padding)
- self.assertEqual(params['use_depthwise'],
- feature_extractor._use_depthwise)
- self.assertEqual(params['override_base_feature_extractor_hyperparams'],
- (feature_extractor.
- _override_base_feature_extractor_hyperparams))
-
- def test_extract_features_returns_correct_shapes_128(self):
- image_height = 128
- image_width = 128
- depth_multiplier = 1.0
- pad_to_multiple = 1
- expected_feature_map_shape = [(2, 4, 4, 640),
- (2, 2, 2, 256), (2, 1, 1, 256),
- (2, 1, 1, 256), (2, 1, 1, 256)]
- self.check_extract_features_returns_correct_shape(
- 2, image_height, image_width, depth_multiplier, pad_to_multiple,
- expected_feature_map_shape)
-
- def test_extract_features_returns_correct_shapes_unroll10(self):
- image_height = 128
- image_width = 128
- depth_multiplier = 1.0
- pad_to_multiple = 1
- expected_feature_map_shape = [(10, 4, 4, 640),
- (10, 2, 2, 256), (10, 1, 1, 256),
- (10, 1, 1, 256), (10, 1, 1, 256)]
- self.check_extract_features_returns_correct_shape(
- 10, image_height, image_width, depth_multiplier, pad_to_multiple,
- expected_feature_map_shape, unroll_length=10)
-
- def test_extract_features_returns_correct_shapes_320(self):
- image_height = 320
- image_width = 320
- depth_multiplier = 1.0
- pad_to_multiple = 1
- expected_feature_map_shape = [(2, 10, 10, 640),
- (2, 5, 5, 256), (2, 3, 3, 256),
- (2, 2, 2, 256), (2, 1, 1, 256)]
- self.check_extract_features_returns_correct_shape(
- 2, image_height, image_width, depth_multiplier, pad_to_multiple,
- expected_feature_map_shape)
-
- def test_extract_features_returns_correct_shapes_enforcing_min_depth(self):
- image_height = 320
- image_width = 320
- depth_multiplier = 0.5**12
- pad_to_multiple = 1
- expected_feature_map_shape = [(2, 10, 10, 64),
- (2, 5, 5, 32), (2, 3, 3, 32),
- (2, 2, 2, 32), (2, 1, 1, 32)]
- self.check_extract_features_returns_correct_shape(
- 2, image_height, image_width, depth_multiplier, pad_to_multiple,
- expected_feature_map_shape)
-
- def test_extract_features_returns_correct_shapes_with_pad_to_multiple(self):
- image_height = 299
- image_width = 299
- depth_multiplier = 1.0
- pad_to_multiple = 32
- expected_feature_map_shape = [(2, 10, 10, 640),
- (2, 5, 5, 256), (2, 3, 3, 256),
- (2, 2, 2, 256), (2, 1, 1, 256)]
- self.check_extract_features_returns_correct_shape(
- 2, image_height, image_width, depth_multiplier, pad_to_multiple,
- expected_feature_map_shape)
-
- def test_preprocess_returns_correct_value_range(self):
- image_height = 128
- image_width = 128
- depth_multiplier = 1
- pad_to_multiple = 1
- test_image = np.random.rand(4, image_height, image_width, 3)
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- preprocessed_image = feature_extractor.preprocess(test_image)
- self.assertTrue(np.all(np.less_equal(np.abs(preprocessed_image), 1.0)))
-
- def test_variables_only_created_in_scope(self):
- depth_multiplier = 1
- pad_to_multiple = 1
- scope_names = ['MobilenetV2', 'LSTM', 'FeatureMap']
- self.check_feature_extractor_variables_under_scopes(
- depth_multiplier, pad_to_multiple, scope_names)
-
- def test_has_fused_batchnorm(self):
- image_height = 40
- image_width = 40
- depth_multiplier = 1
- pad_to_multiple = 32
- image_placeholder = tf.placeholder(tf.float32,
- [1, image_height, image_width, 3])
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- preprocessed_image = feature_extractor.preprocess(image_placeholder)
- _ = feature_extractor.extract_features(preprocessed_image, unroll_length=1)
- self.assertTrue(any(op.type.startswith('FusedBatchNorm')
- for op in tf.get_default_graph().get_operations()))
-
- def test_variables_for_tflite(self):
- image_height = 40
- image_width = 40
- depth_multiplier = 1
- pad_to_multiple = 32
- image_placeholder = tf.placeholder(tf.float32,
- [1, image_height, image_width, 3])
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- preprocessed_image = feature_extractor.preprocess(image_placeholder)
- tflite_unsupported = ['SquaredDifference']
- _ = feature_extractor.extract_features(preprocessed_image, unroll_length=1)
- self.assertFalse(any(op.type in tflite_unsupported
- for op in tf.get_default_graph().get_operations()))
-
- def test_output_nodes_for_tflite(self):
- image_height = 64
- image_width = 64
- depth_multiplier = 1.0
- pad_to_multiple = 1
- image_placeholder = tf.placeholder(tf.float32,
- [1, image_height, image_width, 3])
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- preprocessed_image = feature_extractor.preprocess(image_placeholder)
- _ = feature_extractor.extract_features(preprocessed_image, unroll_length=1)
-
- tflite_nodes = [
- 'raw_inputs/init_lstm_c',
- 'raw_inputs/init_lstm_h',
- 'raw_inputs/base_endpoint',
- 'raw_outputs/lstm_c',
- 'raw_outputs/lstm_h',
- 'raw_outputs/base_endpoint_1',
- 'raw_outputs/base_endpoint_2'
- ]
- ops_names = [op.name for op in tf.get_default_graph().get_operations()]
- for node in tflite_nodes:
- self.assertTrue(any(node in s for s in ops_names))
-
- def test_fixed_concat_nodes(self):
- image_height = 64
- image_width = 64
- depth_multiplier = 1.0
- pad_to_multiple = 1
- image_placeholder = tf.placeholder(tf.float32,
- [1, image_height, image_width, 3])
- feature_extractor = self._create_feature_extractor(
- depth_multiplier, pad_to_multiple, is_quantized=True)
- preprocessed_image = feature_extractor.preprocess(image_placeholder)
- _ = feature_extractor.extract_features(preprocessed_image, unroll_length=1)
-
- concat_nodes = [
- 'MobilenetV2_1/expanded_conv_16/project/Relu6',
- 'MobilenetV2_2/expanded_conv_16/project/Relu6'
- ]
- ops_names = [op.name for op in tf.get_default_graph().get_operations()]
- for node in concat_nodes:
- self.assertTrue(any(node in s for s in ops_names))
-
- def test_lstm_states(self):
- image_height = 256
- image_width = 256
- depth_multiplier = 1
- pad_to_multiple = 1
- state_channel = 320
- init_state1 = {
- 'lstm_state_c': tf.zeros(
- [image_height // 32, image_width // 32, state_channel]),
- 'lstm_state_h': tf.zeros(
- [image_height // 32, image_width // 32, state_channel]),
- 'lstm_state_step': tf.zeros([1])
- }
- init_state2 = {
- 'lstm_state_c': tf.random_uniform(
- [image_height // 32, image_width // 32, state_channel]),
- 'lstm_state_h': tf.random_uniform(
- [image_height // 32, image_width // 32, state_channel]),
- 'lstm_state_step': tf.zeros([1])
- }
- seq = {'dummy': tf.random_uniform([2, 1, 1, 1])}
- stateful_reader1 = contrib_training.SequenceQueueingStateSaver(
- batch_size=1,
- num_unroll=1,
- input_length=2,
- input_key='',
- input_sequences=seq,
- input_context={},
- initial_states=init_state1,
- capacity=1)
- stateful_reader2 = contrib_training.SequenceQueueingStateSaver(
- batch_size=1,
- num_unroll=1,
- input_length=2,
- input_key='',
- input_sequences=seq,
- input_context={},
- initial_states=init_state2,
- capacity=1)
- image = tf.random_uniform([1, image_height, image_width, 3])
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- with tf.variable_scope('zero_state'):
- feature_maps1 = feature_extractor.extract_features(
- image, stateful_reader1.next_batch, unroll_length=1)
- with tf.variable_scope('random_state'):
- feature_maps2 = feature_extractor.extract_features(
- image, stateful_reader2.next_batch, unroll_length=1)
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- sess.run(tf.local_variables_initializer())
- sess.run(tf.get_collection(tf.GraphKeys.TABLE_INITIALIZERS))
- sess.run([stateful_reader1.prefetch_op, stateful_reader2.prefetch_op])
- maps1, maps2 = sess.run([feature_maps1, feature_maps2])
- state = sess.run(stateful_reader1.next_batch.state('lstm_state_c'))
- # feature maps should be different because states are different
- self.assertFalse(np.all(np.equal(maps1[0], maps2[0])))
- # state should no longer be zero after update
- self.assertTrue(state.any())
-
- def check_extract_features_returns_correct_shape(
- self, batch_size, image_height, image_width, depth_multiplier,
- pad_to_multiple, expected_feature_map_shapes, unroll_length=1):
- def graph_fn(image_tensor):
- feature_extractor = self._create_feature_extractor(depth_multiplier,
- pad_to_multiple)
- feature_maps = feature_extractor.extract_features(
- image_tensor, unroll_length=unroll_length)
- return feature_maps
-
- image_tensor = np.random.rand(batch_size, image_height, image_width,
- 3).astype(np.float32)
- feature_maps = self.execute(graph_fn, [image_tensor])
- for feature_map, expected_shape in zip(
- feature_maps, expected_feature_map_shapes):
- self.assertAllEqual(feature_map.shape, expected_shape)
-
- def check_feature_extractor_variables_under_scopes(
- self, depth_multiplier, pad_to_multiple, scope_names):
- g = tf.Graph()
- with g.as_default():
- feature_extractor = self._create_feature_extractor(
- depth_multiplier, pad_to_multiple)
- preprocessed_inputs = tf.placeholder(tf.float32, (4, 320, 320, 3))
- feature_extractor.extract_features(
- preprocessed_inputs, unroll_length=1)
- variables = g.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
- for variable in variables:
- self.assertTrue(
- any([
- variable.name.startswith(scope_name)
- for scope_name in scope_names
- ]), 'Variable name: ' + variable.name +
- ' is not under any provided scopes: ' + ','.join(scope_names))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor.py b/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor.py
deleted file mode 100644
index cccf740aadd337d29bec56a7fed93fc6937fc123..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor.py
+++ /dev/null
@@ -1,211 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""LSTMSSDFeatureExtractor for MobilenetV1 features."""
-
-import tensorflow.compat.v1 as tf
-import tf_slim as slim
-from tensorflow.python.framework import ops as tf_ops
-from lstm_object_detection.lstm import lstm_cells
-from lstm_object_detection.lstm import rnn_decoder
-from lstm_object_detection.meta_architectures import lstm_ssd_meta_arch
-from object_detection.models import feature_map_generators
-from object_detection.utils import context_manager
-from object_detection.utils import ops
-from object_detection.utils import shape_utils
-from nets import mobilenet_v1
-
-
-class LSTMSSDMobileNetV1FeatureExtractor(
- lstm_ssd_meta_arch.LSTMSSDFeatureExtractor):
- """LSTM Feature Extractor using MobilenetV1 features."""
-
- def __init__(self,
- is_training,
- depth_multiplier,
- min_depth,
- pad_to_multiple,
- conv_hyperparams_fn,
- reuse_weights=None,
- use_explicit_padding=False,
- use_depthwise=True,
- override_base_feature_extractor_hyperparams=False,
- lstm_state_depth=256):
- """Initializes instance of MobileNetV1 Feature Extractor for LSTMSSD Models.
-
- Args:
- is_training: A boolean whether the network is in training mode.
- depth_multiplier: A float depth multiplier for feature extractor.
- min_depth: A number representing minimum feature extractor depth.
- pad_to_multiple: The nearest multiple to zero pad the input height and
- width dimensions to.
- conv_hyperparams_fn: A function to construct tf slim arg_scope for conv2d
- and separable_conv2d ops in the layers that are added on top of the
- base feature extractor.
- reuse_weights: Whether to reuse variables. Default is None.
- use_explicit_padding: Whether to use explicit padding when extracting
- features. Default is False.
- use_depthwise: Whether to use depthwise convolutions. Default is True.
- override_base_feature_extractor_hyperparams: Whether to override
- hyperparameters of the base feature extractor with the one from
- `conv_hyperparams_fn`.
- lstm_state_depth: An integter of the depth of the lstm state.
- """
- super(LSTMSSDMobileNetV1FeatureExtractor, self).__init__(
- is_training=is_training,
- depth_multiplier=depth_multiplier,
- min_depth=min_depth,
- pad_to_multiple=pad_to_multiple,
- conv_hyperparams_fn=conv_hyperparams_fn,
- reuse_weights=reuse_weights,
- use_explicit_padding=use_explicit_padding,
- use_depthwise=use_depthwise,
- override_base_feature_extractor_hyperparams=
- override_base_feature_extractor_hyperparams)
- self._feature_map_layout = {
- 'from_layer': ['Conv2d_13_pointwise_lstm', '', '', '', ''],
- 'layer_depth': [-1, 512, 256, 256, 128],
- 'use_explicit_padding': self._use_explicit_padding,
- 'use_depthwise': self._use_depthwise,
- }
- self._base_network_scope = 'MobilenetV1'
- self._lstm_state_depth = lstm_state_depth
-
- def create_lstm_cell(self, batch_size, output_size, state_saver, state_name,
- dtype=tf.float32):
- """Create the LSTM cell, and initialize state if necessary.
-
- Args:
- batch_size: input batch size.
- output_size: output size of the lstm cell, [width, height].
- state_saver: a state saver object with methods `state` and `save_state`.
- state_name: string, the name to use with the state_saver.
- dtype: dtype to initialize lstm state.
-
- Returns:
- lstm_cell: the lstm cell unit.
- init_state: initial state representations.
- step: the step
- """
- lstm_cell = lstm_cells.BottleneckConvLSTMCell(
- filter_size=(3, 3),
- output_size=output_size,
- num_units=max(self._min_depth, self._lstm_state_depth),
- activation=tf.nn.relu6,
- visualize_gates=False)
-
- if state_saver is None:
- init_state = lstm_cell.init_state(state_name, batch_size, dtype)
- step = None
- else:
- step = state_saver.state(state_name + '_step')
- c = state_saver.state(state_name + '_c')
- h = state_saver.state(state_name + '_h')
- init_state = (c, h)
- return lstm_cell, init_state, step
-
- def extract_features(self,
- preprocessed_inputs,
- state_saver=None,
- state_name='lstm_state',
- unroll_length=5,
- scope=None):
- """Extracts features from preprocessed inputs.
-
- The features include the base network features, lstm features and SSD
- features, organized in the following name scope:
-
- /MobilenetV1/...
- /LSTM/...
- /FeatureMaps/...
-
- Args:
- preprocessed_inputs: A [batch, height, width, channels] float tensor
- representing a batch of consecutive frames from video clips.
- state_saver: A state saver object with methods `state` and `save_state`.
- state_name: A python string for the name to use with the state_saver.
- unroll_length: The number of steps to unroll the lstm.
- scope: The scope for the base network of the feature extractor.
-
- Returns:
- A list of tensors where the ith tensor has shape [batch, height_i,
- width_i, depth_i]
- """
- preprocessed_inputs = shape_utils.check_min_image_dim(
- 33, preprocessed_inputs)
- with slim.arg_scope(
- mobilenet_v1.mobilenet_v1_arg_scope(is_training=self._is_training)):
- with (slim.arg_scope(self._conv_hyperparams_fn())
- if self._override_base_feature_extractor_hyperparams else
- context_manager.IdentityContextManager()):
- with slim.arg_scope([slim.batch_norm], fused=False):
- # Base network.
- with tf.variable_scope(
- scope, self._base_network_scope,
- reuse=self._reuse_weights) as scope:
- net, image_features = mobilenet_v1.mobilenet_v1_base(
- ops.pad_to_multiple(preprocessed_inputs, self._pad_to_multiple),
- final_endpoint='Conv2d_13_pointwise',
- min_depth=self._min_depth,
- depth_multiplier=self._depth_multiplier,
- scope=scope)
-
- with slim.arg_scope(self._conv_hyperparams_fn()):
- with slim.arg_scope(
- [slim.batch_norm], fused=False, is_training=self._is_training):
- # ConvLSTM layers.
- batch_size = net.shape[0].value // unroll_length
- with tf.variable_scope('LSTM', reuse=self._reuse_weights) as lstm_scope:
- lstm_cell, init_state, _ = self.create_lstm_cell(
- batch_size,
- (net.shape[1].value, net.shape[2].value),
- state_saver,
- state_name,
- dtype=preprocessed_inputs.dtype)
- net_seq = list(tf.split(net, unroll_length))
-
- # Identities added for inputing state tensors externally.
- c_ident = tf.identity(init_state[0], name='lstm_state_in_c')
- h_ident = tf.identity(init_state[1], name='lstm_state_in_h')
- init_state = (c_ident, h_ident)
-
- net_seq, states_out = rnn_decoder.rnn_decoder(
- net_seq, init_state, lstm_cell, scope=lstm_scope)
- batcher_ops = None
- self._states_out = states_out
- if state_saver is not None:
- self._step = state_saver.state('%s_step' % state_name)
- batcher_ops = [
- state_saver.save_state('%s_c' % state_name, states_out[-1][0]),
- state_saver.save_state('%s_h' % state_name, states_out[-1][1]),
- state_saver.save_state('%s_step' % state_name, self._step + 1)
- ]
- with tf_ops.control_dependencies(batcher_ops):
- image_features['Conv2d_13_pointwise_lstm'] = tf.concat(net_seq, 0)
-
- # Identities added for reading output states, to be reused externally.
- tf.identity(states_out[-1][0], name='lstm_state_out_c')
- tf.identity(states_out[-1][1], name='lstm_state_out_h')
-
- # SSD layers.
- with tf.variable_scope('FeatureMaps', reuse=self._reuse_weights):
- feature_maps = feature_map_generators.multi_resolution_feature_maps(
- feature_map_layout=self._feature_map_layout,
- depth_multiplier=(self._depth_multiplier),
- min_depth=self._min_depth,
- insert_1x1_conv=True,
- image_features=image_features)
-
- return list(feature_maps.values())
diff --git a/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor_test.py b/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor_test.py
deleted file mode 100644
index 56ad2745dae558acdb806c8f236d25754799cf49..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/models/lstm_ssd_mobilenet_v1_feature_extractor_test.py
+++ /dev/null
@@ -1,179 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for models.lstm_ssd_mobilenet_v1_feature_extractor."""
-
-import numpy as np
-import tensorflow.compat.v1 as tf
-import tf_slim as slim
-from tensorflow.contrib import training as contrib_training
-
-from lstm_object_detection.models import lstm_ssd_mobilenet_v1_feature_extractor as feature_extractor
-from object_detection.models import ssd_feature_extractor_test
-
-
-class LstmSsdMobilenetV1FeatureExtractorTest(
- ssd_feature_extractor_test.SsdFeatureExtractorTestBase):
-
- def _create_feature_extractor(self,
- depth_multiplier=1.0,
- pad_to_multiple=1,
- is_training=True,
- use_explicit_padding=False):
- """Constructs a new feature extractor.
-
- Args:
- depth_multiplier: A float depth multiplier for feature extractor.
- pad_to_multiple: The nearest multiple to zero pad the input height and
- width dimensions to.
- is_training: A boolean whether the network is in training mode.
- use_explicit_padding: A boolean whether to use explicit padding.
-
- Returns:
- An lstm_ssd_meta_arch.LSTMSSDMobileNetV1FeatureExtractor object.
- """
- min_depth = 32
- extractor = (
- feature_extractor.LSTMSSDMobileNetV1FeatureExtractor(
- is_training,
- depth_multiplier,
- min_depth,
- pad_to_multiple,
- self.conv_hyperparams_fn,
- use_explicit_padding=use_explicit_padding))
- extractor.lstm_state_depth = int(256 * depth_multiplier)
- return extractor
-
- def test_feature_extractor_construct_with_expected_params(self):
- def conv_hyperparams_fn():
- with (slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm) and
- slim.arg_scope([slim.batch_norm], decay=0.97, epsilon=1e-3)) as sc:
- return sc
-
- params = {
- 'is_training': True,
- 'depth_multiplier': .55,
- 'min_depth': 9,
- 'pad_to_multiple': 3,
- 'conv_hyperparams_fn': conv_hyperparams_fn,
- 'reuse_weights': False,
- 'use_explicit_padding': True,
- 'use_depthwise': False,
- 'override_base_feature_extractor_hyperparams': True}
-
- extractor = (
- feature_extractor.LSTMSSDMobileNetV1FeatureExtractor(**params))
-
- self.assertEqual(params['is_training'],
- extractor._is_training)
- self.assertEqual(params['depth_multiplier'],
- extractor._depth_multiplier)
- self.assertEqual(params['min_depth'],
- extractor._min_depth)
- self.assertEqual(params['pad_to_multiple'],
- extractor._pad_to_multiple)
- self.assertEqual(params['conv_hyperparams_fn'],
- extractor._conv_hyperparams_fn)
- self.assertEqual(params['reuse_weights'],
- extractor._reuse_weights)
- self.assertEqual(params['use_explicit_padding'],
- extractor._use_explicit_padding)
- self.assertEqual(params['use_depthwise'],
- extractor._use_depthwise)
- self.assertEqual(params['override_base_feature_extractor_hyperparams'],
- (extractor.
- _override_base_feature_extractor_hyperparams))
-
- def test_extract_features_returns_correct_shapes_256(self):
- image_height = 256
- image_width = 256
- depth_multiplier = 1.0
- pad_to_multiple = 1
- batch_size = 5
- expected_feature_map_shape = [(batch_size, 8, 8, 256), (batch_size, 4, 4,
- 512),
- (batch_size, 2, 2, 256), (batch_size, 1, 1,
- 256)]
- self.check_extract_features_returns_correct_shape(
- batch_size,
- image_height,
- image_width,
- depth_multiplier,
- pad_to_multiple,
- expected_feature_map_shape,
- use_explicit_padding=False)
- self.check_extract_features_returns_correct_shape(
- batch_size,
- image_height,
- image_width,
- depth_multiplier,
- pad_to_multiple,
- expected_feature_map_shape,
- use_explicit_padding=True)
-
- def test_preprocess_returns_correct_value_range(self):
- test_image = np.random.rand(5, 128, 128, 3)
- extractor = self._create_feature_extractor()
- preprocessed_image = extractor.preprocess(test_image)
- self.assertTrue(np.all(np.less_equal(np.abs(preprocessed_image), 1.0)))
-
- def test_variables_only_created_in_scope(self):
- scope_name = 'MobilenetV1'
- g = tf.Graph()
- with g.as_default():
- preprocessed_inputs = tf.placeholder(tf.float32, (5, 256, 256, 3))
- extractor = self._create_feature_extractor()
- extractor.extract_features(preprocessed_inputs)
- variables = g.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
- find_scope = False
- for variable in variables:
- if scope_name in variable.name:
- find_scope = True
- break
- self.assertTrue(find_scope)
-
- def test_lstm_non_zero_state(self):
- init_state = {
- 'lstm_state_c': tf.zeros([8, 8, 256]),
- 'lstm_state_h': tf.zeros([8, 8, 256]),
- 'lstm_state_step': tf.zeros([1])
- }
- seq = {'test': tf.random_uniform([3, 1, 1, 1])}
- stateful_reader = contrib_training.SequenceQueueingStateSaver(
- batch_size=1,
- num_unroll=1,
- input_length=2,
- input_key='',
- input_sequences=seq,
- input_context={},
- initial_states=init_state,
- capacity=1)
- extractor = self._create_feature_extractor()
- image = tf.random_uniform([5, 256, 256, 3])
- with tf.variable_scope('zero_state'):
- feature_map = extractor.extract_features(
- image, stateful_reader.next_batch)
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- sess.run([stateful_reader.prefetch_op])
- _ = sess.run([feature_map])
- # Update states with the next batch.
- state = sess.run(stateful_reader.next_batch.state('lstm_state_c'))
- # State should no longer be zero after update.
- self.assertTrue(state.any())
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/lstm_object_detection/models/mobilenet_defs.py b/research/lstm_object_detection/models/mobilenet_defs.py
deleted file mode 100644
index 4f984240215b818c3e8c9b5481db3319b54ef8fd..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/models/mobilenet_defs.py
+++ /dev/null
@@ -1,142 +0,0 @@
-# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Definitions for modified MobileNet models used in LSTD."""
-
-import tensorflow.compat.v1 as tf
-import tf_slim as slim
-from nets import mobilenet_v1
-from nets.mobilenet import conv_blocks as mobilenet_convs
-from nets.mobilenet import mobilenet
-
-
-def mobilenet_v1_lite_def(depth_multiplier, low_res=False):
- """Conv definitions for a lite MobileNet v1 model.
-
- Args:
- depth_multiplier: float depth multiplier for MobileNet.
- low_res: An option of low-res conv input for interleave model.
-
- Returns:
- Array of convolutions.
-
- Raises:
- ValueError: On invalid channels with provided depth multiplier.
- """
- conv = mobilenet_v1.Conv
- sep_conv = mobilenet_v1.DepthSepConv
-
- def _find_target_depth(original, depth_multiplier):
- # Find the target depth such that:
- # int(target * depth_multiplier) == original
- pseudo_target = int(original / depth_multiplier)
- for target in range(pseudo_target - 1, pseudo_target + 2):
- if int(target * depth_multiplier) == original:
- return target
- raise ValueError('Cannot have %d channels with depth multiplier %0.2f' %
- (original, depth_multiplier))
-
- return [
- conv(kernel=[3, 3], stride=2, depth=32),
- sep_conv(kernel=[3, 3], stride=1, depth=64),
- sep_conv(kernel=[3, 3], stride=2, depth=128),
- sep_conv(kernel=[3, 3], stride=1, depth=128),
- sep_conv(kernel=[3, 3], stride=2, depth=256),
- sep_conv(kernel=[3, 3], stride=1, depth=256),
- sep_conv(kernel=[3, 3], stride=2, depth=512),
- sep_conv(kernel=[3, 3], stride=1, depth=512),
- sep_conv(kernel=[3, 3], stride=1, depth=512),
- sep_conv(kernel=[3, 3], stride=1, depth=512),
- sep_conv(kernel=[3, 3], stride=1, depth=512),
- sep_conv(kernel=[3, 3], stride=1, depth=512),
- sep_conv(kernel=[3, 3], stride=1 if low_res else 2, depth=1024),
- sep_conv(
- kernel=[3, 3],
- stride=1,
- depth=int(_find_target_depth(1024, depth_multiplier)))
- ]
-
-
-def mobilenet_v2_lite_def(reduced=False, is_quantized=False, low_res=False):
- """Conv definitions for a lite MobileNet v2 model.
-
- Args:
- reduced: Determines the scaling factor for expanded conv. If True, a factor
- of 6 is used. If False, a factor of 3 is used.
- is_quantized: Whether the model is trained in quantized mode.
- low_res: Whether the input to the model is of half resolution.
-
- Returns:
- Array of convolutions.
- """
- expanded_conv = mobilenet_convs.expanded_conv
- expand_input = mobilenet_convs.expand_input_by_factor
- op = mobilenet.op
- return dict(
- defaults={
- # Note: these parameters of batch norm affect the architecture
- # that's why they are here and not in training_scope.
- (slim.batch_norm,): {
- 'center': True,
- 'scale': True
- },
- (slim.conv2d, slim.fully_connected, slim.separable_conv2d): {
- 'normalizer_fn': slim.batch_norm,
- 'activation_fn': tf.nn.relu6
- },
- (expanded_conv,): {
- 'expansion_size': expand_input(6),
- 'split_expansion': 1,
- 'normalizer_fn': slim.batch_norm,
- 'residual': True
- },
- (slim.conv2d, slim.separable_conv2d): {
- 'padding': 'SAME'
- }
- },
- spec=[
- op(slim.conv2d, stride=2, num_outputs=32, kernel_size=[3, 3]),
- op(expanded_conv,
- expansion_size=expand_input(1, divisible_by=1),
- num_outputs=16),
- op(expanded_conv,
- expansion_size=(expand_input(3, divisible_by=1)
- if reduced else expand_input(6)),
- stride=2,
- num_outputs=24),
- op(expanded_conv,
- expansion_size=(expand_input(3, divisible_by=1)
- if reduced else expand_input(6)),
- stride=1,
- num_outputs=24),
- op(expanded_conv, stride=2, num_outputs=32),
- op(expanded_conv, stride=1, num_outputs=32),
- op(expanded_conv, stride=1, num_outputs=32),
- op(expanded_conv, stride=2, num_outputs=64),
- op(expanded_conv, stride=1, num_outputs=64),
- op(expanded_conv, stride=1, num_outputs=64),
- op(expanded_conv, stride=1, num_outputs=64),
- op(expanded_conv, stride=1, num_outputs=96),
- op(expanded_conv, stride=1, num_outputs=96),
- op(expanded_conv, stride=1, num_outputs=96),
- op(expanded_conv, stride=1 if low_res else 2, num_outputs=160),
- op(expanded_conv, stride=1, num_outputs=160),
- op(expanded_conv, stride=1, num_outputs=160),
- op(expanded_conv,
- stride=1,
- num_outputs=320,
- project_activation_fn=(tf.nn.relu6
- if is_quantized else tf.identity))
- ],
- )
diff --git a/research/lstm_object_detection/models/mobilenet_defs_test.py b/research/lstm_object_detection/models/mobilenet_defs_test.py
deleted file mode 100644
index f1b5bda504bb02ac89f55e3acd370862f513a3a3..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/models/mobilenet_defs_test.py
+++ /dev/null
@@ -1,136 +0,0 @@
-# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Tests for lstm_object_detection.models.mobilenet_defs."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow.compat.v1 as tf
-from lstm_object_detection.models import mobilenet_defs
-from nets import mobilenet_v1
-from nets.mobilenet import mobilenet_v2
-
-
-class MobilenetV1DefsTest(tf.test.TestCase):
-
- def test_mobilenet_v1_lite_def(self):
- net, _ = mobilenet_v1.mobilenet_v1_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- final_endpoint='Conv2d_13_pointwise',
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v1_lite_def(1.0),
- use_explicit_padding=True,
- scope='MobilenetV1')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 1024])
-
- def test_mobilenet_v1_lite_def_depthmultiplier_half(self):
- net, _ = mobilenet_v1.mobilenet_v1_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- final_endpoint='Conv2d_13_pointwise',
- min_depth=8,
- depth_multiplier=0.5,
- conv_defs=mobilenet_defs.mobilenet_v1_lite_def(0.5),
- use_explicit_padding=True,
- scope='MobilenetV1')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 1024])
-
- def test_mobilenet_v1_lite_def_depthmultiplier_2x(self):
- net, _ = mobilenet_v1.mobilenet_v1_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- final_endpoint='Conv2d_13_pointwise',
- min_depth=8,
- depth_multiplier=2.0,
- conv_defs=mobilenet_defs.mobilenet_v1_lite_def(2.0),
- use_explicit_padding=True,
- scope='MobilenetV1')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 1024])
-
- def test_mobilenet_v1_lite_def_low_res(self):
- net, _ = mobilenet_v1.mobilenet_v1_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- final_endpoint='Conv2d_13_pointwise',
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v1_lite_def(1.0, low_res=True),
- use_explicit_padding=True,
- scope='MobilenetV1')
- self.assertEqual(net.get_shape().as_list(), [10, 20, 20, 1024])
-
-
-class MobilenetV2DefsTest(tf.test.TestCase):
-
- def test_mobilenet_v2_lite_def(self):
- net, features = mobilenet_v2.mobilenet_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(),
- use_explicit_padding=True,
- scope='MobilenetV2')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 320])
- self._assert_contains_op('MobilenetV2/expanded_conv_16/project/Identity')
- self.assertEqual(
- features['layer_3/expansion_output'].get_shape().as_list(),
- [10, 160, 160, 96])
- self.assertEqual(
- features['layer_4/expansion_output'].get_shape().as_list(),
- [10, 80, 80, 144])
-
- def test_mobilenet_v2_lite_def_is_quantized(self):
- net, _ = mobilenet_v2.mobilenet_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(is_quantized=True),
- use_explicit_padding=True,
- scope='MobilenetV2')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 320])
- self._assert_contains_op('MobilenetV2/expanded_conv_16/project/Relu6')
-
- def test_mobilenet_v2_lite_def_low_res(self):
- net, _ = mobilenet_v2.mobilenet_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(low_res=True),
- use_explicit_padding=True,
- scope='MobilenetV2')
- self.assertEqual(net.get_shape().as_list(), [10, 20, 20, 320])
-
- def test_mobilenet_v2_lite_def_reduced(self):
- net, features = mobilenet_v2.mobilenet_base(
- tf.placeholder(tf.float32, (10, 320, 320, 3)),
- min_depth=8,
- depth_multiplier=1.0,
- conv_defs=mobilenet_defs.mobilenet_v2_lite_def(reduced=True),
- use_explicit_padding=True,
- scope='MobilenetV2')
- self.assertEqual(net.get_shape().as_list(), [10, 10, 10, 320])
- self.assertEqual(
- features['layer_3/expansion_output'].get_shape().as_list(),
- [10, 160, 160, 48])
- self.assertEqual(
- features['layer_4/expansion_output'].get_shape().as_list(),
- [10, 80, 80, 72])
-
- def _assert_contains_op(self, op_name):
- op_names = [op.name for op in tf.get_default_graph().get_operations()]
- self.assertIn(op_name, op_names)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/lstm_object_detection/protos/__init__.py b/research/lstm_object_detection/protos/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/lstm_object_detection/protos/input_reader_google.proto b/research/lstm_object_detection/protos/input_reader_google.proto
deleted file mode 100644
index 2c494a62e97321ee9206cebe28cd6601049f3293..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/protos/input_reader_google.proto
+++ /dev/null
@@ -1,32 +0,0 @@
-syntax = "proto2";
-
-package lstm_object_detection.protos;
-
-import "object_detection/protos/input_reader.proto";
-
-message GoogleInputReader {
- extend object_detection.protos.ExternalInputReader {
- optional GoogleInputReader google_input_reader = 444;
- }
-
- oneof input_reader {
- TFRecordVideoInputReader tf_record_video_input_reader = 1;
- }
-}
-
-message TFRecordVideoInputReader {
- // Path(s) to tfrecords of input data.
- repeated string input_path = 1;
-
- enum DataType {
- UNSPECIFIED = 0;
- TF_EXAMPLE = 1;
- TF_SEQUENCE_EXAMPLE = 2;
- }
- optional DataType data_type = 2 [default=TF_SEQUENCE_EXAMPLE];
-
- // Length of the video sequence. All the input video sequence should have the
- // same length in frames, e.g. 5 frames.
- optional int32 video_length = 3;
-}
-
diff --git a/research/lstm_object_detection/protos/pipeline.proto b/research/lstm_object_detection/protos/pipeline.proto
deleted file mode 100644
index 10dd652554ad38e933acdedf8ce1479f15eed9d7..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/protos/pipeline.proto
+++ /dev/null
@@ -1,69 +0,0 @@
-syntax = "proto2";
-
-package lstm_object_detection.protos;
-
-import "object_detection/protos/pipeline.proto";
-import "lstm_object_detection/protos/quant_overrides.proto";
-
-extend object_detection.protos.TrainEvalPipelineConfig {
- optional LstmModel lstm_model = 205743444;
- optional QuantOverrides quant_overrides = 246059837;
-}
-
-// Message for extra fields needed for configuring LSTM model.
-message LstmModel {
- // Unroll length for training LSTMs.
- optional int32 train_unroll_length = 1;
-
- // Unroll length for evaluating LSTMs.
- optional int32 eval_unroll_length = 2;
-
- // Depth of the lstm feature map.
- optional int32 lstm_state_depth = 3 [default = 256];
-
- // Depth multipliers for multiple feature extractors. Used for interleaved
- // or ensemble model.
- repeated float depth_multipliers = 4;
-
- // Specifies how models are interleaved when multiple feature extractors are
- // used during training. Must be in ['RANDOM', 'RANDOM_SKIP_SMALL'].
- optional string train_interleave_method = 5 [default = 'RANDOM'];
-
- // Specifies how models are interleaved when multiple feature extractors are
- // used during training. Must be in ['RANDOM', 'RANDOM_SKIP', 'SKIPK'].
- optional string eval_interleave_method = 6 [default = 'SKIP9'];
-
- // The stride of the lstm state.
- optional int32 lstm_state_stride = 7 [default = 32];
-
- // Whether to flattern LSTM state and output. Note that this is typically
- // intended only to be modified internally by export_tfmini_lstd_graph_lib
- // to support flatten state for tfmini/tflite. Do not set this field in
- // the pipeline config file unless necessary.
- optional bool flatten_state = 8 [default = false];
-
- // Whether to apply bottleneck layer before going into LSTM gates. This
- // allows multiple feature extractors to use separate bottleneck layers
- // instead of sharing the same one so that different base model output
- // feature dimensions are not forced to be the same.
- // For example:
- // Model 1 outputs feature map f_1 of depth d_1.
- // Model 2 outputs feature map f_2 of depth d_2.
- // Pre-bottlenecking allows lstm input to be either:
- // conv(concat([f_1, h])) or conv(concat([f_2, h])).
- optional bool pre_bottleneck = 9 [default = false];
-
- // Normalize LSTM state, default false.
- optional bool scale_state = 10 [default = false];
-
- // Clip LSTM state at [0, 6], default true.
- optional bool clip_state = 11 [default = true];
-
- // If the model is in quantized training. This field does NOT need to be set
- // manually. Instead, it will be overridden by configs in graph_rewriter.
- optional bool is_quantized = 12 [default = false];
-
- // Downsample input image when using the smaller network in interleaved
- // models, default false.
- optional bool low_res = 13 [default = false];
-}
diff --git a/research/lstm_object_detection/protos/quant_overrides.proto b/research/lstm_object_detection/protos/quant_overrides.proto
deleted file mode 100644
index 9dc0eaf86e5f507f87b87fe1571b4e3d82991df1..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/protos/quant_overrides.proto
+++ /dev/null
@@ -1,40 +0,0 @@
-syntax = "proto2";
-
-package lstm_object_detection.protos;
-
-// Message to override default quantization behavior.
-message QuantOverrides {
- repeated QuantConfig quant_configs = 1;
-}
-
-// Parameters to manually create fake quant ops outside of the generic
-// tensorflow/contrib/quantize/python/quantize.py script. This may be
-// used to override default behaviour or quantize ops not already supported.
-message QuantConfig {
- // The name of the op to add a fake quant op to.
- required string op_name = 1;
-
- // The name of the fake quant op.
- required string quant_op_name = 2;
-
- // Whether the fake quant op uses fixed ranges. Otherwise, learned moving
- // average ranges are used.
- required bool fixed_range = 3 [default = false];
-
- // The intitial minimum value of the range.
- optional float min = 4 [default = -6];
-
- // The initial maximum value of the range.
- optional float max = 5 [default = 6];
-
- // Number of steps to delay before quantization takes effect during training.
- optional int32 delay = 6 [default = 500000];
-
- // Number of bits to use for quantizing weights.
- // Only 8 bit is supported for now.
- optional int32 weight_bits = 7 [default = 8];
-
- // Number of bits to use for quantizing activations.
- // Only 8 bit is supported for now.
- optional int32 activation_bits = 8 [default = 8];
-}
diff --git a/research/lstm_object_detection/test_tflite_model.py b/research/lstm_object_detection/test_tflite_model.py
deleted file mode 100644
index a8b5e15e210ab6c191911d3c440cef33d936274c..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/test_tflite_model.py
+++ /dev/null
@@ -1,53 +0,0 @@
-# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Test a tflite model using random input data."""
-
-from __future__ import print_function
-from absl import flags
-import numpy as np
-import tensorflow.compat.v1 as tf
-
-flags.DEFINE_string('model_path', None, 'Path to model.')
-FLAGS = flags.FLAGS
-
-
-def main(_):
-
- flags.mark_flag_as_required('model_path')
-
- # Load TFLite model and allocate tensors.
- interpreter = tf.lite.Interpreter(model_path=FLAGS.model_path)
- interpreter.allocate_tensors()
-
- # Get input and output tensors.
- input_details = interpreter.get_input_details()
- print('input_details:', input_details)
- output_details = interpreter.get_output_details()
- print('output_details:', output_details)
-
- # Test model on random input data.
- input_shape = input_details[0]['shape']
- # change the following line to feed into your own data.
- input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32)
- interpreter.set_tensor(input_details[0]['index'], input_data)
-
- interpreter.invoke()
- output_data = interpreter.get_tensor(output_details[0]['index'])
- print(output_data)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/lstm_object_detection/tflite/BUILD b/research/lstm_object_detection/tflite/BUILD
deleted file mode 100644
index 66068925da4fde7eb99215d907d627e0ff1d3847..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/tflite/BUILD
+++ /dev/null
@@ -1,81 +0,0 @@
-package(
- default_visibility = ["//visibility:public"],
-)
-
-licenses(["notice"])
-
-cc_library(
- name = "mobile_ssd_client",
- srcs = ["mobile_ssd_client.cc"],
- hdrs = ["mobile_ssd_client.h"],
- deps = [
- "//protos:box_encodings_cc_proto",
- "//protos:detections_cc_proto",
- "//protos:labelmap_cc_proto",
- "//protos:mobile_ssd_client_options_cc_proto",
- "//utils:conversion_utils",
- "//utils:ssd_utils",
- "@com_google_absl//absl/base:core_headers",
- "@com_google_absl//absl/memory",
- "@com_google_absl//absl/types:span",
- "@com_google_glog//:glog",
- "@gemmlowp",
- ],
-)
-
-config_setting(
- name = "enable_edgetpu",
- define_values = {"enable_edgetpu": "true"},
- visibility = ["//visibility:public"],
-)
-
-cc_library(
- name = "mobile_ssd_tflite_client",
- srcs = ["mobile_ssd_tflite_client.cc"],
- hdrs = ["mobile_ssd_tflite_client.h"],
- defines = select({
- "//conditions:default": [],
- "enable_edgetpu": ["ENABLE_EDGETPU"],
- }),
- deps = [
- ":mobile_ssd_client",
- "@com_google_glog//:glog",
- "@com_google_absl//absl/memory",
- "@org_tensorflow//tensorflow/lite:arena_planner",
- "@org_tensorflow//tensorflow/lite:framework",
- "@org_tensorflow//tensorflow/lite/delegates/nnapi:nnapi_delegate",
- "@org_tensorflow//tensorflow/lite/kernels:builtin_ops",
- "//protos:anchor_generation_options_cc_proto",
- "//utils:file_utils",
- "//utils:ssd_utils",
- ] + select({
- "//conditions:default": [],
- "enable_edgetpu": [
- "@libedgetpu//libedgetpu:header",
- ],
- }),
- alwayslink = 1,
-)
-
-cc_library(
- name = "mobile_lstd_tflite_client",
- srcs = ["mobile_lstd_tflite_client.cc"],
- hdrs = ["mobile_lstd_tflite_client.h"],
- defines = select({
- "//conditions:default": [],
- "enable_edgetpu": ["ENABLE_EDGETPU"],
- }),
- deps = [
- ":mobile_ssd_client",
- ":mobile_ssd_tflite_client",
- "@com_google_glog//:glog",
- "@com_google_absl//absl/base:core_headers",
- "@org_tensorflow//tensorflow/lite/kernels:builtin_ops",
- ] + select({
- "//conditions:default": [],
- "enable_edgetpu": [
- "@libedgetpu//libedgetpu:header",
- ],
- }),
- alwayslink = 1,
-)
diff --git a/research/lstm_object_detection/tflite/WORKSPACE b/research/lstm_object_detection/tflite/WORKSPACE
deleted file mode 100644
index 3bce3814f365ec2bcc1122d7dfc8a5ba5f7d3dcb..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/tflite/WORKSPACE
+++ /dev/null
@@ -1,133 +0,0 @@
-workspace(name = "lstm_object_detection")
-
-load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
-load("@bazel_tools//tools/build_defs/repo:git.bzl", "git_repository")
-
-http_archive(
- name = "bazel_skylib",
- sha256 = "bbccf674aa441c266df9894182d80de104cabd19be98be002f6d478aaa31574d",
- strip_prefix = "bazel-skylib-2169ae1c374aab4a09aa90e65efe1a3aad4e279b",
- urls = ["https://github.com/bazelbuild/bazel-skylib/archive/2169ae1c374aab4a09aa90e65efe1a3aad4e279b.tar.gz"],
-)
-load("@bazel_skylib//lib:versions.bzl", "versions")
-versions.check(minimum_bazel_version = "0.23.0")
-
-# ABSL cpp library.
-http_archive(
- name = "com_google_absl",
- urls = [
- "https://github.com/abseil/abseil-cpp/archive/a02f62f456f2c4a7ecf2be3104fe0c6e16fbad9a.tar.gz",
- ],
- sha256 = "d437920d1434c766d22e85773b899c77c672b8b4865d5dc2cd61a29fdff3cf03",
- strip_prefix = "abseil-cpp-a02f62f456f2c4a7ecf2be3104fe0c6e16fbad9a",
-)
-
-http_archive(
- name = "rules_cc",
- strip_prefix = "rules_cc-master",
- urls = ["https://github.com/bazelbuild/rules_cc/archive/master.zip"],
-)
-
-# GoogleTest/GoogleMock framework. Used by most unit-tests.
-http_archive(
- name = "com_google_googletest",
- urls = ["https://github.com/google/googletest/archive/master.zip"],
- strip_prefix = "googletest-master",
-)
-
-# gflags needed by glog
-http_archive(
- name = "com_github_gflags_gflags",
- sha256 = "6e16c8bc91b1310a44f3965e616383dbda48f83e8c1eaa2370a215057b00cabe",
- strip_prefix = "gflags-77592648e3f3be87d6c7123eb81cbad75f9aef5a",
- urls = [
- "https://mirror.bazel.build/github.com/gflags/gflags/archive/77592648e3f3be87d6c7123eb81cbad75f9aef5a.tar.gz",
- "https://github.com/gflags/gflags/archive/77592648e3f3be87d6c7123eb81cbad75f9aef5a.tar.gz",
- ],
-)
-
-# glog
-http_archive(
- name = "com_google_glog",
- sha256 = "f28359aeba12f30d73d9e4711ef356dc842886968112162bc73002645139c39c",
- strip_prefix = "glog-0.4.0",
- urls = ["https://github.com/google/glog/archive/v0.4.0.tar.gz"],
-)
-
-http_archive(
- name = "zlib",
- build_file = "@com_google_protobuf//:third_party/zlib.BUILD",
- sha256 = "c3e5e9fdd5004dcb542feda5ee4f0ff0744628baf8ed2dd5d66f8ca1197cb1a1",
- strip_prefix = "zlib-1.2.11",
- urls = ["https://zlib.net/zlib-1.2.11.tar.gz"],
-)
-
-http_archive(
- name = "gemmlowp",
- sha256 = "6678b484d929f2d0d3229d8ac4e3b815a950c86bb9f17851471d143f6d4f7834",
- strip_prefix = "gemmlowp-12fed0cd7cfcd9e169bf1925bc3a7a58725fdcc3",
- urls = [
- "http://mirror.tensorflow.org/github.com/google/gemmlowp/archive/12fed0cd7cfcd9e169bf1925bc3a7a58725fdcc3.zip",
- "https://github.com/google/gemmlowp/archive/12fed0cd7cfcd9e169bf1925bc3a7a58725fdcc3.zip",
- ],
-)
-
-#-----------------------------------------------------------------------------
-# proto
-#-----------------------------------------------------------------------------
-# proto_library, cc_proto_library and java_proto_library rules implicitly depend
-# on @com_google_protobuf//:proto, @com_google_protobuf//:cc_toolchain and
-# @com_google_protobuf//:java_toolchain, respectively.
-# This statement defines the @com_google_protobuf repo.
-http_archive(
- name = "com_google_protobuf",
- strip_prefix = "protobuf-3.8.0",
- urls = ["https://github.com/google/protobuf/archive/v3.8.0.zip"],
- sha256 = "1e622ce4b84b88b6d2cdf1db38d1a634fe2392d74f0b7b74ff98f3a51838ee53",
-)
-
-# java_lite_proto_library rules implicitly depend on
-# @com_google_protobuf_javalite//:javalite_toolchain, which is the JavaLite proto
-# runtime (base classes and common utilities).
-http_archive(
- name = "com_google_protobuf_javalite",
- strip_prefix = "protobuf-384989534b2246d413dbcd750744faab2607b516",
- urls = ["https://github.com/google/protobuf/archive/384989534b2246d413dbcd750744faab2607b516.zip"],
- sha256 = "79d102c61e2a479a0b7e5fc167bcfaa4832a0c6aad4a75fa7da0480564931bcc",
-)
-
-#
-# http_archive(
-# name = "com_google_protobuf",
-# strip_prefix = "protobuf-master",
-# urls = ["https://github.com/protocolbuffers/protobuf/archive/master.zip"],
-# )
-
-# Needed by TensorFlow
-http_archive(
- name = "io_bazel_rules_closure",
- sha256 = "e0a111000aeed2051f29fcc7a3f83be3ad8c6c93c186e64beb1ad313f0c7f9f9",
- strip_prefix = "rules_closure-cf1e44edb908e9616030cc83d085989b8e6cd6df",
- urls = [
- "http://mirror.tensorflow.org/github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz",
- "https://github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz", # 2019-04-04
- ],
-)
-
-
-# TensorFlow r1.14-rc0
-http_archive(
- name = "org_tensorflow",
- strip_prefix = "tensorflow-1.14.0-rc0",
- sha256 = "76404a6157a45e8d7a07e4f5690275256260130145924c2a7c73f6eda2a3de10",
- urls = ["https://github.com/tensorflow/tensorflow/archive/v1.14.0-rc0.zip"],
-)
-
-load("@org_tensorflow//tensorflow:workspace.bzl", "tf_workspace")
-tf_workspace(tf_repo_name = "org_tensorflow")
-
-git_repository(
- name = "libedgetpu",
- remote = "sso://coral.googlesource.com/edgetpu-native",
- commit = "83e47d1bcf22686fae5150ebb99281f6134ef062",
-)
diff --git a/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.cc b/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.cc
deleted file mode 100644
index 05a7bbac1b5c8a58c4f10476a2be4fb3a097a463..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.cc
+++ /dev/null
@@ -1,261 +0,0 @@
-/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-#include "mobile_lstd_tflite_client.h"
-
-#include
-
-namespace lstm_object_detection {
-namespace tflite {
-
-std::unique_ptr MobileLSTDTfLiteClient::Create() {
- auto client = absl::make_unique();
- if (!client->InitializeClient(CreateDefaultOptions())) {
- LOG(ERROR) << "Failed to initialize client";
- return nullptr;
- }
- return client;
-}
-
-protos::ClientOptions MobileLSTDTfLiteClient::CreateDefaultOptions() {
- const int kMaxDetections = 100;
- const int kClassesPerDetection = 1;
- const double kScoreThreshold = -2.0;
- const double kIouThreshold = 0.5;
-
- protos::ClientOptions options;
- options.set_max_detections(kMaxDetections);
- options.set_max_categories(kClassesPerDetection);
- options.set_score_threshold(kScoreThreshold);
- options.set_iou_threshold(kIouThreshold);
- options.set_agnostic_mode(false);
- options.set_quantize(false);
- options.set_num_keypoints(0);
-
- return options;
-}
-
-std::unique_ptr MobileLSTDTfLiteClient::Create(
- const protos::ClientOptions& options) {
- auto client = absl::make_unique();
- if (!client->InitializeClient(options)) {
- LOG(ERROR) << "Failed to initialize client";
- return nullptr;
- }
- return client;
-}
-
-bool MobileLSTDTfLiteClient::InitializeInterpreter(
- const protos::ClientOptions& options) {
- if (options.prefer_nnapi_delegate()) {
- LOG(ERROR) << "NNAPI not supported.";
- return false;
- } else {
- interpreter_->UseNNAPI(false);
- }
-
-#ifdef ENABLE_EDGETPU
- interpreter_->SetExternalContext(kTfLiteEdgeTpuContext,
- edge_tpu_context_.get());
-#endif
-
- // Inputs are: normalized_input_image_tensor, raw_inputs/init_lstm_c,
- // raw_inputs/init_lstm_h
- if (interpreter_->inputs().size() != 3) {
- LOG(ERROR) << "Invalid number of interpreter inputs: " <<
- interpreter_->inputs().size();
- return false;
- }
-
- const std::vector input_tensor_indices = interpreter_->inputs();
- const TfLiteTensor& input_lstm_c =
- *interpreter_->tensor(input_tensor_indices[1]);
- if (input_lstm_c.dims->size != 4) {
- LOG(ERROR) << "Invalid input lstm_c dimensions: " <<
- input_lstm_c.dims->size;
- return false;
- }
- if (input_lstm_c.dims->data[0] != 1) {
- LOG(ERROR) << "Invalid input lstm_c batch size: " <<
- input_lstm_c.dims->data[0];
- return false;
- }
- lstm_state_width_ = input_lstm_c.dims->data[1];
- lstm_state_height_ = input_lstm_c.dims->data[2];
- lstm_state_depth_ = input_lstm_c.dims->data[3];
- lstm_state_size_ = lstm_state_width_ * lstm_state_height_ * lstm_state_depth_;
-
- const TfLiteTensor& input_lstm_h =
- *interpreter_->tensor(input_tensor_indices[2]);
- if (!ValidateStateTensor(input_lstm_h, "input lstm_h")) {
- return false;
- }
-
- // Outputs are:
- // TFLite_Detection_PostProcess,
- // TFLite_Detection_PostProcess:1,
- // TFLite_Detection_PostProcess:2,
- // TFLite_Detection_PostProcess:3,
- // raw_outputs/lstm_c, raw_outputs/lstm_h
- if (interpreter_->outputs().size() != 6) {
- LOG(ERROR) << "Invalid number of interpreter outputs: " <<
- interpreter_->outputs().size();
- return false;
- }
-
- const std::vector output_tensor_indices = interpreter_->outputs();
- const TfLiteTensor& output_lstm_c =
- *interpreter_->tensor(output_tensor_indices[4]);
- if (!ValidateStateTensor(output_lstm_c, "output lstm_c")) {
- return false;
- }
- const TfLiteTensor& output_lstm_h =
- *interpreter_->tensor(output_tensor_indices[5]);
- if (!ValidateStateTensor(output_lstm_h, "output lstm_h")) {
- return false;
- }
-
- // Initialize state with all zeroes.
- lstm_c_data_.resize(lstm_state_size_);
- lstm_h_data_.resize(lstm_state_size_);
- lstm_c_data_uint8_.resize(lstm_state_size_);
- lstm_h_data_uint8_.resize(lstm_state_size_);
-
- if (interpreter_->AllocateTensors() != kTfLiteOk) {
- LOG(ERROR) << "Failed to allocate tensors";
- return false;
- }
-
- return true;
-}
-
-bool MobileLSTDTfLiteClient::ValidateStateTensor(const TfLiteTensor& tensor,
- const std::string& name) {
- if (tensor.dims->size != 4) {
- LOG(ERROR) << "Invalid " << name << " dimensions: " << tensor.dims->size;
- return false;
- }
- if (tensor.dims->data[0] != 1) {
- LOG(ERROR) << "Invalid " << name << " batch size: " << tensor.dims->data[0];
- return false;
- }
- if (tensor.dims->data[1] != lstm_state_width_ ||
- tensor.dims->data[2] != lstm_state_height_ ||
- tensor.dims->data[3] != lstm_state_depth_) {
- LOG(ERROR) << "Invalid " << name << " dimensions: [" <<
- tensor.dims->data[0] << ", " << tensor.dims->data[1] << ", " <<
- tensor.dims->data[2] << ", " << tensor.dims->data[3] << "]";
- return false;
- }
- return true;
-}
-
-bool MobileLSTDTfLiteClient::ComputeOutputLayerCount() {
- // Outputs are: raw_outputs/box_encodings, raw_outputs/class_predictions,
- // raw_outputs/lstm_c, raw_outputs/lstm_h
- CHECK_EQ(interpreter_->outputs().size(), 4);
- num_output_layers_ = 1;
- return true;
-}
-
-bool MobileLSTDTfLiteClient::FloatInference(const uint8_t* input_data) {
- // Inputs are: normalized_input_image_tensor, raw_inputs/init_lstm_c,
- // raw_inputs/init_lstm_h
- CHECK(input_data) << "Input data cannot be null.";
- float* input = interpreter_->typed_input_tensor(0);
- CHECK(input) << "Input tensor cannot be null.";
- // Normalize the uint8 input image with mean_value_, std_value_.
- NormalizeInputImage(input_data, input);
-
- // Copy input LSTM state into TFLite's input tensors.
- float* lstm_c_input = interpreter_->typed_input_tensor(1);
- CHECK(lstm_c_input) << "Input lstm_c tensor cannot be null.";
- std::copy(lstm_c_data_.begin(), lstm_c_data_.end(), lstm_c_input);
-
- float* lstm_h_input = interpreter_->typed_input_tensor(2);
- CHECK(lstm_h_input) << "Input lstm_h tensor cannot be null.";
- std::copy(lstm_h_data_.begin(), lstm_h_data_.end(), lstm_h_input);
-
- // Run inference on inputs.
- CHECK_EQ(interpreter_->Invoke(), kTfLiteOk) << "Invoking interpreter failed.";
-
- // Copy LSTM state out of TFLite's output tensors.
- // Outputs are: raw_outputs/box_encodings, raw_outputs/class_predictions,
- // raw_outputs/lstm_c, raw_outputs/lstm_h
- float* lstm_c_output = interpreter_->typed_output_tensor(2);
- CHECK(lstm_c_output) << "Output lstm_c tensor cannot be null.";
- std::copy(lstm_c_output, lstm_c_output + lstm_state_size_,
- lstm_c_data_.begin());
-
- float* lstm_h_output = interpreter_->typed_output_tensor(3);
- CHECK(lstm_h_output) << "Output lstm_h tensor cannot be null.";
- std::copy(lstm_h_output, lstm_h_output + lstm_state_size_,
- lstm_h_data_.begin());
- return true;
-}
-
-bool MobileLSTDTfLiteClient::QuantizedInference(const uint8_t* input_data) {
- // Inputs are: normalized_input_image_tensor, raw_inputs/init_lstm_c,
- // raw_inputs/init_lstm_h
- CHECK(input_data) << "Input data cannot be null.";
- uint8_t* input = interpreter_->typed_input_tensor(0);
- CHECK(input) << "Input tensor cannot be null.";
- memcpy(input, input_data, input_size_);
-
- // Copy input LSTM state into TFLite's input tensors.
- uint8_t* lstm_c_input = interpreter_->typed_input_tensor(1);
- CHECK(lstm_c_input) << "Input lstm_c tensor cannot be null.";
- std::copy(lstm_c_data_uint8_.begin(), lstm_c_data_uint8_.end(), lstm_c_input);
-
- uint8_t* lstm_h_input = interpreter_->typed_input_tensor(2);
- CHECK(lstm_h_input) << "Input lstm_h tensor cannot be null.";
- std::copy(lstm_h_data_uint8_.begin(), lstm_h_data_uint8_.end(), lstm_h_input);
-
- // Run inference on inputs.
- CHECK_EQ(interpreter_->Invoke(), kTfLiteOk) << "Invoking interpreter failed.";
-
- // Copy LSTM state out of TFLite's output tensors.
- // Outputs are:
- // TFLite_Detection_PostProcess,
- // TFLite_Detection_PostProcess:1,
- // TFLite_Detection_PostProcess:2,
- // TFLite_Detection_PostProcess:3,
- // raw_outputs/lstm_c, raw_outputs/lstm_h
- uint8_t* lstm_c_output = interpreter_->typed_output_tensor(4);
- CHECK(lstm_c_output) << "Output lstm_c tensor cannot be null.";
- std::copy(lstm_c_output, lstm_c_output + lstm_state_size_,
- lstm_c_data_uint8_.begin());
-
- uint8_t* lstm_h_output = interpreter_->typed_output_tensor(5);
- CHECK(lstm_h_output) << "Output lstm_h tensor cannot be null.";
- std::copy(lstm_h_output, lstm_h_output + lstm_state_size_,
- lstm_h_data_uint8_.begin());
- return true;
-}
-
-bool MobileLSTDTfLiteClient::Inference(const uint8_t* input_data) {
- if (input_data == nullptr) {
- LOG(ERROR) << "input_data cannot be null for inference.";
- return false;
- }
- if (IsQuantizedModel())
- return QuantizedInference(input_data);
- else
- return FloatInference(input_data);
- return true;
-}
-
-} // namespace tflite
-} // namespace lstm_object_detection
diff --git a/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.h b/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.h
deleted file mode 100644
index e4f16bc945a6725025e285885967637629d0a5fc..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/tflite/mobile_lstd_tflite_client.h
+++ /dev/null
@@ -1,74 +0,0 @@
-/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-#ifndef TENSORFLOW_MODELS_LSTM_OBJECT_DETECTION_TFLITE_MOBILE_LSTD_TFLITE_CLIENT_H_
-#define TENSORFLOW_MODELS_LSTM_OBJECT_DETECTION_TFLITE_MOBILE_LSTD_TFLITE_CLIENT_H_
-
-#include
-#include
-
-#include
-#include "mobile_ssd_client.h"
-#include "mobile_ssd_tflite_client.h"
-
-namespace lstm_object_detection {
-namespace tflite {
-
-// Client for LSTD MobileNet TfLite model.
-class MobileLSTDTfLiteClient : public MobileSSDTfLiteClient {
- public:
- MobileLSTDTfLiteClient() = default;
- // Create with default options.
- static std::unique_ptr Create();
- static std::unique_ptr Create(
- const protos::ClientOptions& options);
- ~MobileLSTDTfLiteClient() override = default;
- static protos::ClientOptions CreateDefaultOptions();
-
- protected:
- bool InitializeInterpreter(const protos::ClientOptions& options) override;
- bool ComputeOutputLayerCount() override;
- bool Inference(const uint8_t* input_data) override;
-
- private:
- // MobileLSTDTfLiteClient is neither copyable nor movable.
- MobileLSTDTfLiteClient(const MobileLSTDTfLiteClient&) = delete;
- MobileLSTDTfLiteClient& operator=(const MobileLSTDTfLiteClient&) = delete;
-
- bool ValidateStateTensor(const TfLiteTensor& tensor, const std::string& name);
-
- // Helper functions used by Inference functions.
- bool FloatInference(const uint8_t* input_data);
- bool QuantizedInference(const uint8_t* input_data);
-
- // LSTM model parameters.
- int lstm_state_width_ = 0;
- int lstm_state_height_ = 0;
- int lstm_state_depth_ = 0;
- int lstm_state_size_ = 0;
-
- // LSTM state stored between float inference runs.
- std::vector lstm_c_data_;
- std::vector lstm_h_data_;
-
- // LSTM state stored between uint8 inference runs.
- std::vector lstm_c_data_uint8_;
- std::vector lstm_h_data_uint8_;
-};
-
-} // namespace tflite
-} // namespace lstm_object_detection
-
-#endif // TENSORFLOW_MODELS_LSTM_OBJECT_DETECTION_TFLITE_MOBILE_LSTD_TFLITE_CLIENT_H_
diff --git a/research/lstm_object_detection/tflite/mobile_ssd_client.cc b/research/lstm_object_detection/tflite/mobile_ssd_client.cc
deleted file mode 100644
index 27bf70109e46d2b9612480bb192f01aa3c9bfde1..0000000000000000000000000000000000000000
--- a/research/lstm_object_detection/tflite/mobile_ssd_client.cc
+++ /dev/null
@@ -1,209 +0,0 @@
-/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-#include "mobile_ssd_client.h"
-
-#include
-
-#include
-
-
-
-
-
-
-Paper: [https://arxiv.org/abs/1805.06066](https://arxiv.org/abs/1805.06066)
-
-
-## 1. Installation
-
-### Requirements
-
-#### Python Packages
-
-```shell
-networkx
-gin-config
-```
-
-### Download cognitive_planning
-
-```shell
-git clone --depth 1 https://github.com/tensorflow/models.git
-```
-
-## 2. Datasets
-
-### Download ActiveVision Dataset
-We used Active Vision Dataset (AVD) which can be downloaded from [here](http://cs.unc.edu/~ammirato/active_vision_dataset_website/). To make our code faster and reduce memory footprint, we created the AVD Minimal dataset. AVD Minimal consists of low resolution images from the original AVD dataset. In addition, we added annotations for target views, predicted object detections from pre-trained object detector on MS-COCO dataset, and predicted semantic segmentation from pre-trained model on NYU-v2 dataset. AVD minimal can be downloaded from [here](https://storage.googleapis.com/active-vision-dataset/AVD_Minimal.zip). Set `$AVD_DIR` as the path to the downloaded AVD Minimal.
-
-### TODO: SUNCG Dataset
-Current version of the code does not support SUNCG dataset. It can be added by
-implementing necessary functions of `envs/task_env.py` using the public
-released code of SUNCG environment such as
-[House3d](https://github.com/facebookresearch/House3D) and
-[MINOS](https://github.com/minosworld/minos).
-
-### ActiveVisionDataset Demo
-
-
-If you wish to navigate the environment, to see how the AVD looks like you can use the following command:
-```shell
-python viz_active_vision_dataset_main -- \
- --mode=human \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR'
-```
-
-## 3. Training
-Right now, the released version only supports training and inference using the real data from Active Vision Dataset.
-
-When RGB image modality is used, the Resnet embeddings are initialized. To start the training download pre-trained Resnet50 check point in the working directory ./resnet_v2_50_checkpoint/resnet_v2_50.ckpt
-
-```
-wget http://download.tensorflow.org/models/resnet_v2_50_2017_04_14.tar.gz
-```
-### Run training
-Use the following command for training:
-```shell
-# Train
-python train_supervised_active_vision.py \
- --mode='train' \
- --logdir=$CHECKPOINT_DIR \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR' \
- --logtostderr
-```
-
-The training can be run for different modalities and modality combinations, including semantic segmentation, object detectors, RGB images, depth images. Low resolution images and outputs of detectors pretrained on COCO dataset and semantic segmenation pre trained on NYU dataset are provided as a part of this distribution and can be found in Meta directory of AVD_Minimal.
-Additional details are described in the comments of the code and in the paper.
-
-### Run Evaluation
-Use the following command for unrolling the policy on the eval environments. The inference code periodically check the checkpoint folder for new checkpoints to use it for unrolling the policy on the eval environments. After each evaluation, it will create a folder in the $CHECKPOINT_DIR/evals/$ITER where $ITER is the iteration number at which the checkpoint is stored.
-```shell
-# Eval
-python train_supervised_active_vision.py \
- --mode='eval' \
- --logdir=$CHECKPOINT_DIR \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR' \
- --logtostderr
-```
-At any point, you can run the following command to compute statistics such as success rate over all the evaluations so far. It also generates gif images for unrolling of the best policy.
-```shell
-# Visualize and Compute Stats
-python viz_active_vision_dataset_main.py \
- --mode=eval \
- --eval_folder=$CHECKPOINT_DIR/evals/ \
- --output_folder=$OUTPUT_GIFS_FOLDER \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR'
-```
-## Contact
-
-To ask questions or report issues please open an issue on the tensorflow/models
-[issues tracker](https://github.com/tensorflow/models/issues).
-Please assign issues to @arsalan-mousavian.
-
-## Reference
-The details of the training and experiments can be found in the following paper. If you find our work useful in your research please consider citing our paper:
-
-```
-@inproceedings{MousavianECCVW18,
- author = {A. Mousavian and A. Toshev and M. Fiser and J. Kosecka and J. Davidson},
- title = {Visual Representations for Semantic Target Driven Navigation},
- booktitle = {ECCV Workshop on Visual Learning and Embodied Agents in Simulation Environments},
- year = {2018},
-}
-```
-
-
diff --git a/research/cognitive_planning/__init__.py b/research/cognitive_planning/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_planning/command b/research/cognitive_planning/command
deleted file mode 100644
index daf634b3c6e6eabba5df88e77b3c3bd81d163be1..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/command
+++ /dev/null
@@ -1,14 +0,0 @@
-python train_supervised_active_vision \
- --mode='train' \
- --logdir=/usr/local/google/home/kosecka/checkin_log_det/ \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=robotics/cognitive_planning/envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root="/usr/local/google/home/kosecka/AVD_minimal/"' \
- --logtostderr
diff --git a/research/cognitive_planning/embedders.py b/research/cognitive_planning/embedders.py
deleted file mode 100644
index 91ed9f45e2f7f0f9388041c1e624a6c0393ab5a1..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/embedders.py
+++ /dev/null
@@ -1,547 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Interface for different embedders for modalities."""
-
-import abc
-import numpy as np
-import tensorflow as tf
-import preprocessing
-from tensorflow.contrib.slim.nets import resnet_v2
-
-slim = tf.contrib.slim
-
-
-class Embedder(object):
- """Represents the embedder for different modalities.
-
- Modalities can be semantic segmentation, depth channel, object detection and
- so on, which require specific embedder for them.
- """
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def build(self, observation):
- """Builds the model to embed the observation modality.
-
- Args:
- observation: tensor that contains the raw observation from modality.
- Returns:
- Embedding tensor for the given observation tensor.
- """
- raise NotImplementedError(
- 'Needs to be implemented as part of Embedder Interface')
-
-
-class DetectionBoxEmbedder(Embedder):
- """Represents the model that encodes the detection boxes from images."""
-
- def __init__(self, rnn_state_size, scope=None):
- self._rnn_state_size = rnn_state_size
- self._scope = scope
-
- def build(self, observations):
- """Builds the model to embed object detection observations.
-
- Args:
- observations: a tuple of (dets, det_num).
- dets is a tensor of BxTxLxE that has the detection boxes in all the
- images of the batch. B is the batch size, T is the maximum length of
- episode, L is the maximum number of detections per image in the batch
- and E is the size of each detection embedding.
- det_num is a tensor of BxT that contains the number of detected boxes
- each image of each sequence in the batch.
- Returns:
- For each image in the batch, returns the accumulative embedding of all the
- detection boxes in that image.
- """
- with tf.variable_scope(self._scope, default_name=''):
- shape = observations[0].shape
- dets = tf.reshape(observations[0], [-1, shape[-2], shape[-1]])
- det_num = tf.reshape(observations[1], [-1])
- lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self._rnn_state_size)
- batch_size = tf.shape(dets)[0]
- lstm_outputs, _ = tf.nn.dynamic_rnn(
- cell=lstm_cell,
- inputs=dets,
- sequence_length=det_num,
- initial_state=lstm_cell.zero_state(batch_size, dtype=tf.float32),
- dtype=tf.float32)
- # Gathering the last state of each sequence in the batch.
- batch_range = tf.range(batch_size)
- indices = tf.stack([batch_range, det_num - 1], axis=1)
- last_lstm_outputs = tf.gather_nd(lstm_outputs, indices)
- last_lstm_outputs = tf.reshape(last_lstm_outputs,
- [-1, shape[1], self._rnn_state_size])
- return last_lstm_outputs
-
-
-class ResNet(Embedder):
- """Residual net embedder for image data."""
-
- def __init__(self, params, *args, **kwargs):
- super(ResNet, self).__init__(*args, **kwargs)
- self._params = params
- self._extra_train_ops = []
-
- def build(self, images):
- shape = images.get_shape().as_list()
- if len(shape) == 5:
- images = tf.reshape(images,
- [shape[0] * shape[1], shape[2], shape[3], shape[4]])
- embedding = self._build_model(images)
- if len(shape) == 5:
- embedding = tf.reshape(embedding, [shape[0], shape[1], -1])
-
- return embedding
-
- @property
- def extra_train_ops(self):
- return self._extra_train_ops
-
- def _build_model(self, images):
- """Builds the model."""
-
- # Convert images to floats and normalize them.
- images = tf.to_float(images)
- bs = images.get_shape().as_list()[0]
- images = [
- tf.image.per_image_standardization(tf.squeeze(i))
- for i in tf.split(images, bs)
- ]
- images = tf.concat([tf.expand_dims(i, axis=0) for i in images], axis=0)
-
- with tf.variable_scope('init'):
- x = self._conv('init_conv', images, 3, 3, 16, self._stride_arr(1))
-
- strides = [1, 2, 2]
- activate_before_residual = [True, False, False]
- if self._params.use_bottleneck:
- res_func = self._bottleneck_residual
- filters = [16, 64, 128, 256]
- else:
- res_func = self._residual
- filters = [16, 16, 32, 128]
-
- with tf.variable_scope('unit_1_0'):
- x = res_func(x, filters[0], filters[1], self._stride_arr(strides[0]),
- activate_before_residual[0])
- for i in xrange(1, self._params.num_residual_units):
- with tf.variable_scope('unit_1_%d' % i):
- x = res_func(x, filters[1], filters[1], self._stride_arr(1), False)
-
- with tf.variable_scope('unit_2_0'):
- x = res_func(x, filters[1], filters[2], self._stride_arr(strides[1]),
- activate_before_residual[1])
- for i in xrange(1, self._params.num_residual_units):
- with tf.variable_scope('unit_2_%d' % i):
- x = res_func(x, filters[2], filters[2], self._stride_arr(1), False)
-
- with tf.variable_scope('unit_3_0'):
- x = res_func(x, filters[2], filters[3], self._stride_arr(strides[2]),
- activate_before_residual[2])
- for i in xrange(1, self._params.num_residual_units):
- with tf.variable_scope('unit_3_%d' % i):
- x = res_func(x, filters[3], filters[3], self._stride_arr(1), False)
-
- with tf.variable_scope('unit_last'):
- x = self._batch_norm('final_bn', x)
- x = self._relu(x, self._params.relu_leakiness)
-
- with tf.variable_scope('pool_logit'):
- x = self._global_avg_pooling(x)
-
- return x
-
- def _stride_arr(self, stride):
- return [1, stride, stride, 1]
-
- def _batch_norm(self, name, x):
- """batch norm implementation."""
- with tf.variable_scope(name):
- params_shape = [x.shape[-1]]
-
- beta = tf.get_variable(
- 'beta',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(0.0, tf.float32))
- gamma = tf.get_variable(
- 'gamma',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(1.0, tf.float32))
-
- if self._params.is_train:
- mean, variance = tf.nn.moments(x, [0, 1, 2], name='moments')
-
- moving_mean = tf.get_variable(
- 'moving_mean',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(0.0, tf.float32),
- trainable=False)
- moving_variance = tf.get_variable(
- 'moving_variance',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(1.0, tf.float32),
- trainable=False)
-
- self._extra_train_ops.append(
- tf.assign_moving_average(moving_mean, mean, 0.9))
- self._extra_train_ops.append(
- tf.assign_moving_average(moving_variance, variance, 0.9))
- else:
- mean = tf.get_variable(
- 'moving_mean',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(0.0, tf.float32),
- trainable=False)
- variance = tf.get_variable(
- 'moving_variance',
- params_shape,
- tf.float32,
- initializer=tf.constant_initializer(1.0, tf.float32),
- trainable=False)
- tf.summary.histogram(mean.op.name, mean)
- tf.summary.histogram(variance.op.name, variance)
- # elipson used to be 1e-5. Maybe 0.001 solves NaN problem in deeper net.
- y = tf.nn.batch_normalization(x, mean, variance, beta, gamma, 0.001)
- y.set_shape(x.shape)
- return y
-
- def _residual(self,
- x,
- in_filter,
- out_filter,
- stride,
- activate_before_residual=False):
- """Residual unit with 2 sub layers."""
-
- if activate_before_residual:
- with tf.variable_scope('shared_activation'):
- x = self._batch_norm('init_bn', x)
- x = self._relu(x, self._params.relu_leakiness)
- orig_x = x
- else:
- with tf.variable_scope('residual_only_activation'):
- orig_x = x
- x = self._batch_norm('init_bn', x)
- x = self._relu(x, self._params.relu_leakiness)
-
- with tf.variable_scope('sub1'):
- x = self._conv('conv1', x, 3, in_filter, out_filter, stride)
-
- with tf.variable_scope('sub2'):
- x = self._batch_norm('bn2', x)
- x = self._relu(x, self._params.relu_leakiness)
- x = self._conv('conv2', x, 3, out_filter, out_filter, [1, 1, 1, 1])
-
- with tf.variable_scope('sub_add'):
- if in_filter != out_filter:
- orig_x = tf.nn.avg_pool(orig_x, stride, stride, 'VALID')
- orig_x = tf.pad(
- orig_x, [[0, 0], [0, 0], [0, 0], [(out_filter - in_filter) // 2,
- (out_filter - in_filter) // 2]])
- x += orig_x
-
- return x
-
- def _bottleneck_residual(self,
- x,
- in_filter,
- out_filter,
- stride,
- activate_before_residual=False):
- """A residual convolutional layer with a bottleneck.
-
- The layer is a composite of three convolutional layers with a ReLU non-
- linearity and batch normalization after each linear convolution. The depth
- if the second and third layer is out_filter / 4 (hence it is a bottleneck).
-
- Args:
- x: a float 4 rank Tensor representing the input to the layer.
- in_filter: a python integer representing depth of the input.
- out_filter: a python integer representing depth of the output.
- stride: a python integer denoting the stride of the layer applied before
- the first convolution.
- activate_before_residual: a python boolean. If True, then a ReLU is
- applied as a first operation on the input x before everything else.
- Returns:
- A 4 rank Tensor with batch_size = batch size of input, width and height =
- width / stride and height / stride of the input and depth = out_filter.
- """
- if activate_before_residual:
- with tf.variable_scope('common_bn_relu'):
- x = self._batch_norm('init_bn', x)
- x = self._relu(x, self._params.relu_leakiness)
- orig_x = x
- else:
- with tf.variable_scope('residual_bn_relu'):
- orig_x = x
- x = self._batch_norm('init_bn', x)
- x = self._relu(x, self._params.relu_leakiness)
-
- with tf.variable_scope('sub1'):
- x = self._conv('conv1', x, 1, in_filter, out_filter / 4, stride)
-
- with tf.variable_scope('sub2'):
- x = self._batch_norm('bn2', x)
- x = self._relu(x, self._params.relu_leakiness)
- x = self._conv('conv2', x, 3, out_filter / 4, out_filter / 4,
- [1, 1, 1, 1])
-
- with tf.variable_scope('sub3'):
- x = self._batch_norm('bn3', x)
- x = self._relu(x, self._params.relu_leakiness)
- x = self._conv('conv3', x, 1, out_filter / 4, out_filter, [1, 1, 1, 1])
-
- with tf.variable_scope('sub_add'):
- if in_filter != out_filter:
- orig_x = self._conv('project', orig_x, 1, in_filter, out_filter, stride)
- x += orig_x
-
- return x
-
- def _decay(self):
- costs = []
- for var in tf.trainable_variables():
- if var.op.name.find(r'DW') > 0:
- costs.append(tf.nn.l2_loss(var))
-
- return tf.mul(self._params.weight_decay_rate, tf.add_n(costs))
-
- def _conv(self, name, x, filter_size, in_filters, out_filters, strides):
- """Convolution."""
- with tf.variable_scope(name):
- n = filter_size * filter_size * out_filters
- kernel = tf.get_variable(
- 'DW', [filter_size, filter_size, in_filters, out_filters],
- tf.float32,
- initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0 / n)))
- return tf.nn.conv2d(x, kernel, strides, padding='SAME')
-
- def _relu(self, x, leakiness=0.0):
- return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
-
- def _fully_connected(self, x, out_dim):
- x = tf.reshape(x, [self._params.batch_size, -1])
- w = tf.get_variable(
- 'DW', [x.get_shape()[1], out_dim],
- initializer=tf.uniform_unit_scaling_initializer(factor=1.0))
- b = tf.get_variable(
- 'biases', [out_dim], initializer=tf.constant_initializer())
- return tf.nn.xw_plus_b(x, w, b)
-
- def _global_avg_pooling(self, x):
- assert x.get_shape().ndims == 4
- return tf.reduce_mean(x, [1, 2])
-
-
-class MLPEmbedder(Embedder):
- """Embedder of vectorial data.
-
- The net is a multi-layer perceptron, with ReLU nonlinearities in all layers
- except the last one.
- """
-
- def __init__(self, layers, *args, **kwargs):
- """Constructs MLPEmbedder.
-
- Args:
- layers: a list of python integers representing layer sizes.
- *args: arguments for super constructor.
- **kwargs: keyed arguments for super constructor.
- """
- super(MLPEmbedder, self).__init__(*args, **kwargs)
- self._layers = layers
-
- def build(self, features):
- shape = features.get_shape().as_list()
- if len(shape) == 3:
- features = tf.reshape(features, [shape[0] * shape[1], shape[2]])
- x = features
- for i, dim in enumerate(self._layers):
- with tf.variable_scope('layer_%i' % i):
- x = self._fully_connected(x, dim)
- if i < len(self._layers) - 1:
- x = self._relu(x)
-
- if len(shape) == 3:
- x = tf.reshape(x, shape[:-1] + [self._layers[-1]])
- return x
-
- def _fully_connected(self, x, out_dim):
- w = tf.get_variable(
- 'DW', [x.get_shape()[1], out_dim],
- initializer=tf.variance_scaling_initializer(distribution='uniform'))
- b = tf.get_variable(
- 'biases', [out_dim], initializer=tf.constant_initializer())
- return tf.nn.xw_plus_b(x, w, b)
-
- def _relu(self, x, leakiness=0.0):
- return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
-
-
-class SmallNetworkEmbedder(Embedder):
- """Embedder for image like observations.
-
- The network is comprised of multiple conv layers and a fully connected layer
- at the end. The number of conv layers and the parameters are configured from
- params.
- """
-
- def __init__(self, params, *args, **kwargs):
- """Constructs the small network.
-
- Args:
- params: params should be tf.hparams type. params need to have a list of
- conv_sizes, conv_strides, conv_channels. The length of these lists
- should be equal to each other and to the number of conv layers in the
- network. Plus, it also needs to have boolean variable named to_one_hot
- which indicates whether the input should be converted to one hot or not.
- The size of the fully connected layer is specified by
- params.embedding_size.
-
- *args: The rest of the parameters.
- **kwargs: the reset of the parameters.
-
- Raises:
- ValueError: If the length of params.conv_strides, params.conv_sizes, and
- params.conv_channels are not equal.
-
- """
-
- super(SmallNetworkEmbedder, self).__init__(*args, **kwargs)
- self._params = params
- if len(self._params.conv_sizes) != len(self._params.conv_strides):
- raise ValueError(
- 'Conv sizes and strides should have the same length: {} != {}'.format(
- len(self._params.conv_sizes), len(self._params.conv_strides)))
-
- if len(self._params.conv_sizes) != len(self._params.conv_channels):
- raise ValueError(
- 'Conv sizes and channels should have the same length: {} != {}'.
- format(len(self._params.conv_sizes), len(self._params.conv_channels)))
-
- def build(self, images):
- """Builds the embedder with the given speicifcation.
-
- Args:
- images: a tensor that contains the input images which has the shape of
- NxTxHxWxC where N is the batch size, T is the maximum length of the
- sequence, H and W are the height and width of the images and C is the
- number of channels.
-
- Returns:
- A tensor that is the embedding of the images.
- """
-
- shape = images.get_shape().as_list()
- images = tf.reshape(images,
- [shape[0] * shape[1], shape[2], shape[3], shape[4]])
-
- with slim.arg_scope(
- [slim.conv2d, slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_regularizer=slim.l2_regularizer(self._params.weight_decay_rate),
- biases_initializer=tf.zeros_initializer()):
- with slim.arg_scope([slim.conv2d], padding='SAME'):
- # convert the image to one hot if needed.
- if self._params.to_one_hot:
- net = tf.one_hot(
- tf.squeeze(tf.to_int32(images), axis=[-1]),
- self._params.one_hot_length)
- else:
- net = images
-
- p = self._params
- # Adding conv layers with the specified configurations.
- for conv_id, kernel_stride_channel in enumerate(
- zip(p.conv_sizes, p.conv_strides, p.conv_channels)):
- kernel_size, stride, channels = kernel_stride_channel
- net = slim.conv2d(
- net,
- channels, [kernel_size, kernel_size],
- stride,
- scope='conv_{}'.format(conv_id + 1))
-
- net = slim.flatten(net)
- net = slim.fully_connected(net, self._params.embedding_size, scope='fc')
-
- output = tf.reshape(net, [shape[0], shape[1], -1])
- return output
-
-
-class ResNet50Embedder(Embedder):
- """Uses ResNet50 to embed input images."""
-
- def build(self, images):
- """Builds a ResNet50 embedder for the input images.
-
- It assumes that the range of the pixel values in the images tensor is
- [0,255] and should be castable to tf.uint8.
-
- Args:
- images: a tensor that contains the input images which has the shape of
- NxTxHxWx3 where N is the batch size, T is the maximum length of the
- sequence, H and W are the height and width of the images and C is the
- number of channels.
- Returns:
- The embedding of the input image with the shape of NxTxL where L is the
- embedding size of the output.
-
- Raises:
- ValueError: if the shape of the input does not agree with the expected
- shape explained in the Args section.
- """
- shape = images.get_shape().as_list()
- if len(shape) != 5:
- raise ValueError(
- 'The tensor shape should have 5 elements, {} is provided'.format(
- len(shape)))
- if shape[4] != 3:
- raise ValueError('Three channels are expected for the input image')
-
- images = tf.cast(images, tf.uint8)
- images = tf.reshape(images,
- [shape[0] * shape[1], shape[2], shape[3], shape[4]])
- with slim.arg_scope(resnet_v2.resnet_arg_scope()):
-
- def preprocess_fn(x):
- x = tf.expand_dims(x, 0)
- x = tf.image.resize_bilinear(x, [299, 299],
- align_corners=False)
- return(tf.squeeze(x, [0]))
-
- images = tf.map_fn(preprocess_fn, images, dtype=tf.float32)
-
- net, _ = resnet_v2.resnet_v2_50(
- images, is_training=False, global_pool=True)
- output = tf.reshape(net, [shape[0], shape[1], -1])
- return output
-
-
-class IdentityEmbedder(Embedder):
- """This embedder just returns the input as the output.
-
- Used for modalitites that the embedding of the modality is the same as the
- modality itself. For example, it can be used for one_hot goal.
- """
-
- def build(self, images):
- return images
diff --git a/research/cognitive_planning/envs/__init__.py b/research/cognitive_planning/envs/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/cognitive_planning/envs/active_vision_dataset_env.py b/research/cognitive_planning/envs/active_vision_dataset_env.py
deleted file mode 100644
index 507cde76890369a0e407ceac074866c84fdfda5b..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/envs/active_vision_dataset_env.py
+++ /dev/null
@@ -1,1097 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Gym environment for the ActiveVision Dataset.
-
- The dataset is captured with a robot moving around and taking picture in
- multiple directions. The actions are moving in four directions, and rotate
- clockwise or counter clockwise. The observations are the output of vision
- pipelines such as object detectors. The goal is to find objects of interest
- in each environment. For more details, refer:
- http://cs.unc.edu/~ammirato/active_vision_dataset_website/.
-"""
-import tensorflow as tf
-import collections
-import copy
-import json
-import os
-from StringIO import StringIO
-import time
-import gym
-from gym.envs.registration import register
-import gym.spaces
-import networkx as nx
-import numpy as np
-import scipy.io as sio
-from absl import logging
-import gin
-import cv2
-import label_map_util
-import visualization_utils as vis_util
-from envs import task_env
-
-
-register(
- id='active-vision-env-v0',
- entry_point=
- 'cognitive_planning.envs.active_vision_dataset_env:ActiveVisionDatasetEnv', # pylint: disable=line-too-long
-)
-
-_MAX_DEPTH_VALUE = 12102
-
-SUPPORTED_ACTIONS = [
- 'right', 'rotate_cw', 'rotate_ccw', 'forward', 'left', 'backward', 'stop'
-]
-SUPPORTED_MODALITIES = [
- task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
- task_env.ModalityTypes.DEPTH,
- task_env.ModalityTypes.OBJECT_DETECTION,
- task_env.ModalityTypes.IMAGE,
- task_env.ModalityTypes.GOAL,
- task_env.ModalityTypes.PREV_ACTION,
- task_env.ModalityTypes.DISTANCE,
-]
-
-# Data structure for storing the information related to the graph of the world.
-_Graph = collections.namedtuple('_Graph', [
- 'graph', 'id_to_index', 'index_to_id', 'target_indexes', 'distance_to_goal'
-])
-
-
-def _init_category_index(label_map_path):
- """Creates category index from class indexes to name of the classes.
-
- Args:
- label_map_path: path to the mapping.
- Returns:
- A map for mapping int keys to string categories.
- """
-
- label_map = label_map_util.load_labelmap(label_map_path)
- num_classes = np.max(x.id for x in label_map.item)
- categories = label_map_util.convert_label_map_to_categories(
- label_map, max_num_classes=num_classes, use_display_name=True)
- category_index = label_map_util.create_category_index(categories)
- return category_index
-
-
-def _draw_detections(image_np, detections, category_index):
- """Draws detections on to the image.
-
- Args:
- image_np: Image in the form of uint8 numpy array.
- detections: a dictionary that contains the detection outputs.
- category_index: contains the mapping between indexes and the category names.
-
- Returns:
- Does not return anything but draws the boxes on the
- """
- vis_util.visualize_boxes_and_labels_on_image_array(
- image_np,
- detections['detection_boxes'],
- detections['detection_classes'],
- detections['detection_scores'],
- category_index,
- use_normalized_coordinates=True,
- max_boxes_to_draw=1000,
- min_score_thresh=.0,
- agnostic_mode=False)
-
-
-def generate_detection_image(detections,
- image_size,
- category_map,
- num_classes,
- is_binary=True):
- """Generates one_hot vector of the image using the detection boxes.
-
- Args:
- detections: 2D object detections from the image. It's a dictionary that
- contains detection_boxes, detection_classes, and detection_scores with
- dimensions of nx4, nx1, nx1 where n is the number of detections.
- image_size: The resolution of the output image.
- category_map: dictionary that maps label names to index.
- num_classes: Number of classes.
- is_binary: If true, it sets the corresponding channels to 0 and 1.
- Otherwise, sets the score in the corresponding channel.
- Returns:
- Returns image_size x image_size x num_classes image for the detection boxes.
- """
- res = np.zeros((image_size, image_size, num_classes), dtype=np.float32)
- boxes = detections['detection_boxes']
- labels = detections['detection_classes']
- scores = detections['detection_scores']
- for box, label, score in zip(boxes, labels, scores):
- transformed_boxes = [int(round(t)) for t in box * image_size]
- y1, x1, y2, x2 = transformed_boxes
- # Detector returns fixed number of detections. Boxes with area of zero
- # are equivalent of boxes that don't correspond to any detection box.
- # So, we need to skip the boxes with area 0.
- if (y2 - y1) * (x2 - x1) == 0:
- continue
- assert category_map[label] < num_classes, 'label = {}'.format(label)
- value = score
- if is_binary:
- value = 1
- res[y1:y2, x1:x2, category_map[label]] = value
- return res
-
-
-def _get_detection_path(root, detection_folder_name, world):
- return os.path.join(root, 'Meta', detection_folder_name, world + '.npy')
-
-
-def _get_image_folder(root, world):
- return os.path.join(root, world, 'jpg_rgb')
-
-
-def _get_json_path(root, world):
- return os.path.join(root, world, 'annotations.json')
-
-
-def _get_image_path(root, world, image_id):
- return os.path.join(_get_image_folder(root, world), image_id + '.jpg')
-
-
-def _get_image_list(path, worlds):
- """Builds a dictionary for all the worlds.
-
- Args:
- path: the path to the dataset on cns.
- worlds: list of the worlds.
-
- Returns:
- dictionary where the key is the world names and the values
- are the image_ids of that world.
- """
- world_id_dict = {}
- for loc in worlds:
- files = [t[:-4] for t in tf.gfile.ListDir(_get_image_folder(path, loc))]
- world_id_dict[loc] = files
- return world_id_dict
-
-
-def read_all_poses(dataset_root, world):
- """Reads all the poses for each world.
-
- Args:
- dataset_root: the path to the root of the dataset.
- world: string, name of the world.
-
- Returns:
- Dictionary of poses for all the images in each world. The key is the image
- id of each view and the values are tuple of (x, z, R, scale). Where x and z
- are the first and third coordinate of translation. R is the 3x3 rotation
- matrix and scale is a float scalar that indicates the scale that needs to
- be multipled to x and z in order to get the real world coordinates.
-
- Raises:
- ValueError: if the number of images do not match the number of poses read.
- """
- path = os.path.join(dataset_root, world, 'image_structs.mat')
- with tf.gfile.Open(path) as f:
- data = sio.loadmat(f)
- xyz = data['image_structs']['world_pos']
- image_names = data['image_structs']['image_name'][0]
- rot = data['image_structs']['R'][0]
- scale = data['scale'][0][0]
- n = xyz.shape[1]
- x = [xyz[0][i][0][0] for i in range(n)]
- z = [xyz[0][i][2][0] for i in range(n)]
- names = [name[0][:-4] for name in image_names]
- if len(names) != len(x):
- raise ValueError('number of image names are not equal to the number of '
- 'poses {} != {}'.format(len(names), len(x)))
- output = {}
- for i in range(n):
- if rot[i].shape[0] != 0:
- assert rot[i].shape[0] == 3
- assert rot[i].shape[1] == 3
- output[names[i]] = (x[i], z[i], rot[i], scale)
- else:
- output[names[i]] = (x[i], z[i], None, scale)
-
- return output
-
-
-def read_cached_data(should_load_images, dataset_root, segmentation_file_name,
- targets_file_name, output_size):
- """Reads all the necessary cached data.
-
- Args:
- should_load_images: whether to load the images or not.
- dataset_root: path to the root of the dataset.
- segmentation_file_name: The name of the file that contains semantic
- segmentation annotations.
- targets_file_name: The name of the file the contains targets annotated for
- each world.
- output_size: Size of the output images. This is used for pre-processing the
- loaded images.
- Returns:
- Dictionary of all the cached data.
- """
-
- load_start = time.time()
- result_data = {}
-
- annotated_target_path = os.path.join(dataset_root, 'Meta',
- targets_file_name + '.npy')
-
- logging.info('loading targets: %s', annotated_target_path)
- with tf.gfile.Open(annotated_target_path) as f:
- result_data['targets'] = np.load(f).item()
-
- depth_image_path = os.path.join(dataset_root, 'Meta/depth_imgs.npy')
- logging.info('loading depth: %s', depth_image_path)
- with tf.gfile.Open(depth_image_path) as f:
- depth_data = np.load(f).item()
-
- logging.info('processing depth')
- for home_id in depth_data:
- images = depth_data[home_id]
- for image_id in images:
- depth = images[image_id]
- depth = cv2.resize(
- depth / _MAX_DEPTH_VALUE, (output_size, output_size),
- interpolation=cv2.INTER_NEAREST)
- depth_mask = (depth > 0).astype(np.float32)
- depth = np.dstack((depth, depth_mask))
- images[image_id] = depth
- result_data[task_env.ModalityTypes.DEPTH] = depth_data
-
- sseg_path = os.path.join(dataset_root, 'Meta',
- segmentation_file_name + '.npy')
- logging.info('loading sseg: %s', sseg_path)
- with tf.gfile.Open(sseg_path) as f:
- sseg_data = np.load(f).item()
-
- logging.info('processing sseg')
- for home_id in sseg_data:
- images = sseg_data[home_id]
- for image_id in images:
- sseg = images[image_id]
- sseg = cv2.resize(
- sseg, (output_size, output_size), interpolation=cv2.INTER_NEAREST)
- images[image_id] = np.expand_dims(sseg, axis=-1).astype(np.float32)
- result_data[task_env.ModalityTypes.SEMANTIC_SEGMENTATION] = sseg_data
-
- if should_load_images:
- image_path = os.path.join(dataset_root, 'Meta/imgs.npy')
- logging.info('loading imgs: %s', image_path)
- with tf.gfile.Open(image_path) as f:
- image_data = np.load(f).item()
-
- result_data[task_env.ModalityTypes.IMAGE] = image_data
-
- with tf.gfile.Open(os.path.join(dataset_root, 'Meta/world_id_dict.npy')) as f:
- result_data['world_id_dict'] = np.load(f).item()
-
- logging.info('logging done in %f seconds', time.time() - load_start)
- return result_data
-
-
-@gin.configurable
-def get_spec_dtype_map():
- return {gym.spaces.Box: np.float32}
-
-
-@gin.configurable
-class ActiveVisionDatasetEnv(task_env.TaskEnv):
- """Simulates the environment from ActiveVisionDataset."""
- cached_data = None
-
- def __init__(
- self,
- episode_length,
- modality_types,
- confidence_threshold,
- output_size,
- worlds,
- targets,
- compute_distance,
- should_draw_detections,
- dataset_root,
- labelmap_path,
- reward_collision,
- reward_goal_range,
- num_detection_classes,
- segmentation_file_name,
- detection_folder_name,
- actions,
- targets_file_name,
- eval_init_points_file_name=None,
- shaped_reward=False,
- ):
- """Instantiates the environment for ActiveVision Dataset.
-
- Args:
- episode_length: the length of each episode.
- modality_types: a list of the strings where each entry indicates the name
- of the modalities to be loaded. Valid entries are "sseg", "det",
- "depth", "image", "distance", and "prev_action". "distance" should be
- used for computing metrics in tf agents.
- confidence_threshold: Consider detections more than confidence_threshold
- for potential targets.
- output_size: Resolution of the output image.
- worlds: List of the name of the worlds.
- targets: List of the target names. Each entry is a string label of the
- target category (e.g. 'fridge', 'microwave', so on).
- compute_distance: If True, outputs the distance of the view to the goal.
- should_draw_detections (bool): If True, the image returned for the
- observation will contains the bounding boxes.
- dataset_root: the path to the root folder of the dataset.
- labelmap_path: path to the dictionary that converts label strings to
- indexes.
- reward_collision: the reward the agents get after hitting an obstacle.
- It should be a non-positive number.
- reward_goal_range: the number of steps from goal, such that the agent is
- considered to have reached the goal. If the agent's distance is less
- than the specified goal range, the episode is also finishes by setting
- done = True.
- num_detection_classes: number of classes that detector outputs.
- segmentation_file_name: the name of the file that contains the semantic
- information. The file should be in the dataset_root/Meta/ folder.
- detection_folder_name: Name of the folder that contains the detections
- for each world. The folder should be under dataset_root/Meta/ folder.
- actions: The list of the action names. Valid entries are listed in
- SUPPORTED_ACTIONS.
- targets_file_name: the name of the file that contains the annotated
- targets. The file should be in the dataset_root/Meta/Folder
- eval_init_points_file_name: The name of the file that contains the initial
- points for evaluating the performance of the agent. If set to None,
- episodes start at random locations. Should be only set for evaluation.
- shaped_reward: Whether to add delta goal distance to the reward each step.
-
- Raises:
- ValueError: If one of the targets are not available in the annotated
- targets or the modality names are not from the domain specified above.
- ValueError: If one of the actions is not in SUPPORTED_ACTIONS.
- ValueError: If the reward_collision is a positive number.
- ValueError: If there is no action other than stop provided.
- """
- if reward_collision > 0:
- raise ValueError('"reward" for collision should be non positive')
-
- if reward_goal_range < 0:
- logging.warning('environment does not terminate the episode if the agent '
- 'is too close to the environment')
-
- if not modality_types:
- raise ValueError('modality names can not be empty')
-
- for name in modality_types:
- if name not in SUPPORTED_MODALITIES:
- raise ValueError('invalid modality type: {}'.format(name))
-
- actions_other_than_stop_found = False
- for a in actions:
- if a != 'stop':
- actions_other_than_stop_found = True
- if a not in SUPPORTED_ACTIONS:
- raise ValueError('invalid action %s', a)
-
- if not actions_other_than_stop_found:
- raise ValueError('environment needs to have actions other than stop.')
-
- super(ActiveVisionDatasetEnv, self).__init__()
-
- self._episode_length = episode_length
- self._modality_types = set(modality_types)
- self._confidence_threshold = confidence_threshold
- self._output_size = output_size
- self._dataset_root = dataset_root
- self._worlds = worlds
- self._targets = targets
- self._all_graph = {}
- for world in self._worlds:
- with tf.gfile.Open(_get_json_path(self._dataset_root, world), 'r') as f:
- file_content = f.read()
- file_content = file_content.replace('.jpg', '')
- io = StringIO(file_content)
- self._all_graph[world] = json.load(io)
-
- self._cur_world = ''
- self._cur_image_id = ''
- self._cur_graph = None # Loaded by _update_graph
- self._steps_taken = 0
- self._last_action_success = True
- self._category_index = _init_category_index(labelmap_path)
- self._category_map = dict(
- [(c, i) for i, c in enumerate(self._category_index)])
- self._detection_cache = {}
- if not ActiveVisionDatasetEnv.cached_data:
- ActiveVisionDatasetEnv.cached_data = read_cached_data(
- True, self._dataset_root, segmentation_file_name, targets_file_name,
- self._output_size)
- cached_data = ActiveVisionDatasetEnv.cached_data
-
- self._world_id_dict = cached_data['world_id_dict']
- self._depth_images = cached_data[task_env.ModalityTypes.DEPTH]
- self._semantic_segmentations = cached_data[
- task_env.ModalityTypes.SEMANTIC_SEGMENTATION]
- self._annotated_targets = cached_data['targets']
- self._cached_imgs = cached_data[task_env.ModalityTypes.IMAGE]
- self._graph_cache = {}
- self._compute_distance = compute_distance
- self._should_draw_detections = should_draw_detections
- self._reward_collision = reward_collision
- self._reward_goal_range = reward_goal_range
- self._num_detection_classes = num_detection_classes
- self._actions = actions
- self._detection_folder_name = detection_folder_name
- self._shaped_reward = shaped_reward
-
- self._eval_init_points = None
- if eval_init_points_file_name is not None:
- self._eval_init_index = 0
- init_points_path = os.path.join(self._dataset_root, 'Meta',
- eval_init_points_file_name + '.npy')
- with tf.gfile.Open(init_points_path) as points_file:
- data = np.load(points_file).item()
- self._eval_init_points = []
- for world in self._worlds:
- for goal in self._targets:
- if world in self._annotated_targets[goal]:
- for image_id in data[world]:
- self._eval_init_points.append((world, image_id[0], goal))
- logging.info('loaded %d eval init points', len(self._eval_init_points))
-
- self.action_space = gym.spaces.Discrete(len(self._actions))
-
- obs_shapes = {}
- if task_env.ModalityTypes.SEMANTIC_SEGMENTATION in self._modality_types:
- obs_shapes[task_env.ModalityTypes.SEMANTIC_SEGMENTATION] = gym.spaces.Box(
- low=0, high=255, shape=(self._output_size, self._output_size, 1))
- if task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types:
- obs_shapes[task_env.ModalityTypes.OBJECT_DETECTION] = gym.spaces.Box(
- low=0,
- high=255,
- shape=(self._output_size, self._output_size,
- self._num_detection_classes))
- if task_env.ModalityTypes.DEPTH in self._modality_types:
- obs_shapes[task_env.ModalityTypes.DEPTH] = gym.spaces.Box(
- low=0,
- high=_MAX_DEPTH_VALUE,
- shape=(self._output_size, self._output_size, 2))
- if task_env.ModalityTypes.IMAGE in self._modality_types:
- obs_shapes[task_env.ModalityTypes.IMAGE] = gym.spaces.Box(
- low=0, high=255, shape=(self._output_size, self._output_size, 3))
- if task_env.ModalityTypes.GOAL in self._modality_types:
- obs_shapes[task_env.ModalityTypes.GOAL] = gym.spaces.Box(
- low=0, high=1., shape=(len(self._targets),))
- if task_env.ModalityTypes.PREV_ACTION in self._modality_types:
- obs_shapes[task_env.ModalityTypes.PREV_ACTION] = gym.spaces.Box(
- low=0, high=1., shape=(len(self._actions) + 1,))
- if task_env.ModalityTypes.DISTANCE in self._modality_types:
- obs_shapes[task_env.ModalityTypes.DISTANCE] = gym.spaces.Box(
- low=0, high=255, shape=(1,))
- self.observation_space = gym.spaces.Dict(obs_shapes)
-
- self._prev_action = np.zeros((len(self._actions) + 1), dtype=np.float32)
-
- # Loading all the poses.
- all_poses = {}
- for world in self._worlds:
- all_poses[world] = read_all_poses(self._dataset_root, world)
- self._cached_poses = all_poses
- self._vertex_to_pose = {}
- self._pose_to_vertex = {}
-
- @property
- def actions(self):
- """Returns list of actions for the env."""
- return self._actions
-
- def _next_image(self, image_id, action):
- """Given the action, returns the name of the image that agent ends up in.
-
- Args:
- image_id: The image id of the current view.
- action: valid actions are ['right', 'rotate_cw', 'rotate_ccw',
- 'forward', 'left']. Each rotation is 30 degrees.
-
- Returns:
- The image name for the next location of the agent. If the action results
- in collision or it is not possible for the agent to execute that action,
- returns empty string.
- """
- assert action in self._actions, 'invalid action : {}'.format(action)
- assert self._cur_world in self._all_graph, 'invalid world {}'.format(
- self._cur_world)
- assert image_id in self._all_graph[
- self._cur_world], 'image_id {} is not in {}'.format(
- image_id, self._cur_world)
- return self._all_graph[self._cur_world][image_id][action]
-
- def _largest_detection_for_image(self, image_id, detections_dict):
- """Assigns area of the largest box for the view with given image id.
-
- Args:
- image_id: Image id of the view.
- detections_dict: Detections for the view.
- """
- for cls, box, score in zip(detections_dict['detection_classes'],
- detections_dict['detection_boxes'],
- detections_dict['detection_scores']):
- if cls not in self._targets:
- continue
- if score < self._confidence_threshold:
- continue
- ymin, xmin, ymax, xmax = box
- area = (ymax - ymin) * (xmax - xmin)
- if abs(area) < 1e-5:
- continue
- if image_id not in self._detection_area:
- self._detection_area[image_id] = area
- else:
- self._detection_area[image_id] = max(self._detection_area[image_id],
- area)
-
- def _compute_goal_indexes(self):
- """Computes the goal indexes for the environment.
-
- Returns:
- The indexes of the goals that are closest to target categories. A vertex
- is goal vertice if the desired objects are detected in the image and the
- target categories are not seen by moving forward from that vertice.
- """
- for image_id in self._world_id_dict[self._cur_world]:
- detections_dict = self._detection_table[image_id]
- self._largest_detection_for_image(image_id, detections_dict)
- goal_indexes = []
- for image_id in self._world_id_dict[self._cur_world]:
- if image_id not in self._detection_area:
- continue
- # Detection box is large enough.
- if self._detection_area[image_id] < 0.01:
- continue
- ok = True
- next_image_id = self._next_image(image_id, 'forward')
- if next_image_id:
- if next_image_id in self._detection_area:
- ok = False
- if ok:
- goal_indexes.append(self._cur_graph.id_to_index[image_id])
- return goal_indexes
-
- def to_image_id(self, vid):
- """Converts vertex id to the image id.
-
- Args:
- vid: vertex id of the view.
- Returns:
- image id of the input vertex id.
- """
- return self._cur_graph.index_to_id[vid]
-
- def to_vertex(self, image_id):
- return self._cur_graph.id_to_index[image_id]
-
- def observation(self, view_pose):
- """Returns the observation at the given the vertex.
-
- Args:
- view_pose: pose of the view of interest.
-
- Returns:
- Observation at the given view point.
-
- Raises:
- ValueError: if the given view pose is not similar to any of the poses in
- the current world.
- """
- vertex = self.pose_to_vertex(view_pose)
- if vertex is None:
- raise ValueError('The given found is not close enough to any of the poses'
- ' in the environment.')
- image_id = self._cur_graph.index_to_id[vertex]
- output = collections.OrderedDict()
-
- if task_env.ModalityTypes.SEMANTIC_SEGMENTATION in self._modality_types:
- output[task_env.ModalityTypes.
- SEMANTIC_SEGMENTATION] = self._semantic_segmentations[
- self._cur_world][image_id]
-
- detection = None
- need_det = (
- task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types or
- (task_env.ModalityTypes.IMAGE in self._modality_types and
- self._should_draw_detections))
- if need_det:
- detection = self._detection_table[image_id]
- detection_image = generate_detection_image(
- detection,
- self._output_size,
- self._category_map,
- num_classes=self._num_detection_classes)
-
- if task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types:
- output[task_env.ModalityTypes.OBJECT_DETECTION] = detection_image
-
- if task_env.ModalityTypes.DEPTH in self._modality_types:
- output[task_env.ModalityTypes.DEPTH] = self._depth_images[
- self._cur_world][image_id]
-
- if task_env.ModalityTypes.IMAGE in self._modality_types:
- output_img = self._cached_imgs[self._cur_world][image_id]
- if self._should_draw_detections:
- output_img = output_img.copy()
- _draw_detections(output_img, detection, self._category_index)
- output[task_env.ModalityTypes.IMAGE] = output_img
-
- if task_env.ModalityTypes.GOAL in self._modality_types:
- goal = np.zeros((len(self._targets),), dtype=np.float32)
- goal[self._targets.index(self._cur_goal)] = 1.
- output[task_env.ModalityTypes.GOAL] = goal
-
- if task_env.ModalityTypes.PREV_ACTION in self._modality_types:
- output[task_env.ModalityTypes.PREV_ACTION] = self._prev_action
-
- if task_env.ModalityTypes.DISTANCE in self._modality_types:
- output[task_env.ModalityTypes.DISTANCE] = np.asarray(
- [self.gt_value(self._cur_goal, vertex)], dtype=np.float32)
-
- return output
-
- def _step_no_reward(self, action):
- """Performs a step in the environment with given action.
-
- Args:
- action: Action that is used to step in the environment. Action can be
- string or integer. If the type is integer then it uses the ith element
- from self._actions list. Otherwise, uses the string value as the action.
-
- Returns:
- observation, done, info
- observation: dictonary that contains all the observations specified in
- modality_types.
- observation[task_env.ModalityTypes.OBJECT_DETECTION]: contains the
- detection of the current view.
- observation[task_env.ModalityTypes.IMAGE]: contains the
- image of the current view. Note that if using the images for training,
- should_load_images should be set to false.
- observation[task_env.ModalityTypes.SEMANTIC_SEGMENTATION]: contains the
- semantic segmentation of the current view.
- observation[task_env.ModalityTypes.DEPTH]: If selected, returns the
- depth map for the current view.
- observation[task_env.ModalityTypes.PREV_ACTION]: If selected, returns
- a numpy of (action_size + 1,). The first action_size elements indicate
- the action and the last element indicates whether the previous action
- was successful or not.
- done: True after episode_length steps have been taken, False otherwise.
- info: Empty dictionary.
-
- Raises:
- ValueError: for invalid actions.
- """
- # Primarily used for gym interface.
- if not isinstance(action, str):
- if not self.action_space.contains(action):
- raise ValueError('Not a valid actions: %d', action)
-
- action = self._actions[action]
-
- if action not in self._actions:
- raise ValueError('Not a valid action: %s', action)
-
- action_index = self._actions.index(action)
-
- if action == 'stop':
- next_image_id = self._cur_image_id
- done = True
- success = True
- else:
- next_image_id = self._next_image(self._cur_image_id, action)
- self._steps_taken += 1
- done = False
- success = True
- if not next_image_id:
- success = False
- else:
- self._cur_image_id = next_image_id
-
- if self._steps_taken >= self._episode_length:
- done = True
-
- cur_vertex = self._cur_graph.id_to_index[self._cur_image_id]
- observation = self.observation(self.vertex_to_pose(cur_vertex))
-
- # Concatenation of one-hot prev action + a binary number for success of
- # previous actions.
- self._prev_action = np.zeros((len(self._actions) + 1,), dtype=np.float32)
- self._prev_action[action_index] = 1.
- self._prev_action[-1] = float(success)
-
- distance_to_goal = self.gt_value(self._cur_goal, cur_vertex)
- if success:
- if distance_to_goal <= self._reward_goal_range:
- done = True
-
- return observation, done, {'success': success}
-
- @property
- def graph(self):
- return self._cur_graph.graph
-
- def state(self):
- return self.vertex_to_pose(self.to_vertex(self._cur_image_id))
-
- def gt_value(self, goal, v):
- """Computes the distance to the goal from vertex v.
-
- Args:
- goal: name of the goal.
- v: vertex id.
-
- Returns:
- Minimmum number of steps to the given goal.
- """
- assert goal in self._cur_graph.distance_to_goal, 'goal: {}'.format(goal)
- assert v in self._cur_graph.distance_to_goal[goal]
- res = self._cur_graph.distance_to_goal[goal][v]
- return res
-
- def _update_graph(self):
- """Creates the graph for each environment and updates the _cur_graph."""
- if self._cur_world not in self._graph_cache:
- graph = nx.DiGraph()
- id_to_index = {}
- index_to_id = {}
- image_list = self._world_id_dict[self._cur_world]
- for i, image_id in enumerate(image_list):
- id_to_index[image_id] = i
- index_to_id[i] = image_id
- graph.add_node(i)
-
- for image_id in image_list:
- for action in self._actions:
- if action == 'stop':
- continue
- next_image = self._all_graph[self._cur_world][image_id][action]
- if next_image:
- graph.add_edge(
- id_to_index[image_id], id_to_index[next_image], action=action)
- target_indexes = {}
- number_of_nodes_without_targets = graph.number_of_nodes()
- distance_to_goal = {}
- for goal in self._targets:
- if self._cur_world not in self._annotated_targets[goal]:
- continue
- goal_indexes = [
- id_to_index[i]
- for i in self._annotated_targets[goal][self._cur_world]
- if i
- ]
- super_source_index = graph.number_of_nodes()
- target_indexes[goal] = super_source_index
- graph.add_node(super_source_index)
- index_to_id[super_source_index] = goal
- id_to_index[goal] = super_source_index
- for v in goal_indexes:
- graph.add_edge(v, super_source_index, action='stop')
- graph.add_edge(super_source_index, v, action='stop')
- distance_to_goal[goal] = {}
- for v in range(number_of_nodes_without_targets):
- distance_to_goal[goal][v] = len(
- nx.shortest_path(graph, v, super_source_index)) - 2
-
- self._graph_cache[self._cur_world] = _Graph(
- graph, id_to_index, index_to_id, target_indexes, distance_to_goal)
- self._cur_graph = self._graph_cache[self._cur_world]
-
- def reset_for_eval(self, new_world, new_goal, new_image_id):
- """Resets to the given goal and image_id."""
- return self._reset_env(new_world=new_world, new_goal=new_goal, new_image_id=new_image_id)
-
- def get_init_config(self, path):
- """Exposes the initial state of the agent for the given path.
-
- Args:
- path: sequences of the vertexes that the agent moves.
-
- Returns:
- image_id of the first view, world, and the goal.
- """
- return self._cur_graph.index_to_id[path[0]], self._cur_world, self._cur_goal
-
- def _reset_env(
- self,
- new_world=None,
- new_goal=None,
- new_image_id=None,
- ):
- """Resets the agent in a random world and random id.
-
- Args:
- new_world: If not None, sets the new world to new_world.
- new_goal: If not None, sets the new goal to new_goal.
- new_image_id: If not None, sets the first image id to new_image_id.
-
- Returns:
- observation: dictionary of the observations. Content of the observation
- is similar to that of the step function.
- Raises:
- ValueError: if it can't find a world and annotated goal.
- """
- self._steps_taken = 0
- # The first prev_action is special all zero vector + success=1.
- self._prev_action = np.zeros((len(self._actions) + 1,), dtype=np.float32)
- self._prev_action[len(self._actions)] = 1.
- if self._eval_init_points is not None:
- if self._eval_init_index >= len(self._eval_init_points):
- self._eval_init_index = 0
- a = self._eval_init_points[self._eval_init_index]
- self._cur_world, self._cur_image_id, self._cur_goal = a
- self._eval_init_index += 1
- elif not new_world:
- attempts = 100
- found = False
- while attempts >= 0:
- attempts -= 1
- self._cur_goal = np.random.choice(self._targets)
- available_worlds = list(
- set(self._annotated_targets[self._cur_goal].keys()).intersection(
- set(self._worlds)))
- if available_worlds:
- found = True
- break
- if not found:
- raise ValueError('could not find a world that has a target annotated')
- self._cur_world = np.random.choice(available_worlds)
- else:
- self._cur_world = new_world
- self._cur_goal = new_goal
- if new_world not in self._annotated_targets[new_goal]:
- return None
-
- self._cur_goal_index = self._targets.index(self._cur_goal)
- if new_image_id:
- self._cur_image_id = new_image_id
- else:
- self._cur_image_id = np.random.choice(
- self._world_id_dict[self._cur_world])
- if self._cur_world not in self._detection_cache:
- with tf.gfile.Open(
- _get_detection_path(self._dataset_root, self._detection_folder_name,
- self._cur_world)) as f:
- # Each file contains a dictionary with image ids as keys and detection
- # dicts as values.
- self._detection_cache[self._cur_world] = np.load(f).item()
- self._detection_table = self._detection_cache[self._cur_world]
- self._detection_area = {}
- self._update_graph()
- if self._cur_world not in self._vertex_to_pose:
- # adding fake pose for the super nodes of each target categories.
- self._vertex_to_pose[self._cur_world] = {
- index: (-index,) for index in self._cur_graph.target_indexes.values()
- }
- # Calling vetex_to_pose for each vertex results in filling out the
- # dictionaries that contain pose related data.
- for image_id in self._world_id_dict[self._cur_world]:
- self.vertex_to_pose(self.to_vertex(image_id))
-
- # Filling out pose_to_vertex from vertex_to_pose.
- self._pose_to_vertex[self._cur_world] = {
- tuple(v): k
- for k, v in self._vertex_to_pose[self._cur_world].iteritems()
- }
-
- cur_vertex = self._cur_graph.id_to_index[self._cur_image_id]
- observation = self.observation(self.vertex_to_pose(cur_vertex))
- return observation
-
- def cur_vertex(self):
- return self._cur_graph.id_to_index[self._cur_image_id]
-
- def cur_image_id(self):
- return self._cur_image_id
-
- def path_to_goal(self, image_id=None):
- """Returns the path from image_id to the self._cur_goal.
-
- Args:
- image_id: If set to None, computes the path from the current view.
- Otherwise, sets the current view to the given image_id.
- Returns:
- The path to the goal.
- Raises:
- Exception if there's no path from the view to the goal.
- """
- if image_id is None:
- image_id = self._cur_image_id
- super_source = self._cur_graph.target_indexes[self._cur_goal]
- try:
- path = nx.shortest_path(self._cur_graph.graph,
- self._cur_graph.id_to_index[image_id],
- super_source)
- except:
- print 'path not found, image_id = ', self._cur_world, self._cur_image_id
- raise
- return path[:-1]
-
- def targets(self):
- return [self.vertex_to_pose(self._cur_graph.target_indexes[self._cur_goal])]
-
- def vertex_to_pose(self, v):
- """Returns pose of the view for a given vertex.
-
- Args:
- v: integer, vertex index.
-
- Returns:
- (x, z, dir_x, dir_z) where x and z are the tranlation and dir_x, dir_z are
- a vector giving direction of the view.
- """
- if v in self._vertex_to_pose[self._cur_world]:
- return np.copy(self._vertex_to_pose[self._cur_world][v])
-
- x, z, rot, scale = self._cached_poses[self._cur_world][self.to_image_id(
- v)]
- if rot is None: # if rotation is not provided for the given vertex.
- self._vertex_to_pose[self._cur_world][v] = np.asarray(
- [x * scale, z * scale, v])
- return np.copy(self._vertex_to_pose[self._cur_world][v])
- # Multiply rotation matrix by [0,0,1] to get a vector of length 1 in the
- # direction of the ray.
- direction = np.zeros((3, 1), dtype=np.float32)
- direction[2][0] = 1
- direction = np.matmul(np.transpose(rot), direction)
- direction = [direction[0][0], direction[2][0]]
- self._vertex_to_pose[self._cur_world][v] = np.asarray(
- [x * scale, z * scale, direction[0], direction[1]])
- return np.copy(self._vertex_to_pose[self._cur_world][v])
-
- def pose_to_vertex(self, pose):
- """Returns the vertex id for the given pose."""
- if tuple(pose) not in self._pose_to_vertex[self._cur_world]:
- raise ValueError(
- 'The given pose is not present in the dictionary: {}'.format(
- tuple(pose)))
-
- return self._pose_to_vertex[self._cur_world][tuple(pose)]
-
- def check_scene_graph(self, world, goal):
- """Checks the connectivity of the scene graph.
-
- Goes over all the views. computes the shortest path to the goal. If it
- crashes it means that it's not connected. Otherwise, the env graph is fine.
-
- Args:
- world: the string name of the world.
- goal: the string label for the goal.
- Returns:
- Nothing.
- """
- obs = self._reset_env(new_world=world, new_goal=goal)
- if not obs:
- print '{} is not availble in {}'.format(goal, world)
- return True
- for image_id in self._world_id_dict[self._cur_world]:
- print 'check image_id = {}'.format(image_id)
- self._cur_image_id = image_id
- path = self.path_to_goal()
- actions = []
- for i in range(len(path) - 2):
- actions.append(self.action(path[i], path[i + 1]))
- actions.append('stop')
-
- @property
- def goal_one_hot(self):
- res = np.zeros((len(self._targets),), dtype=np.float32)
- res[self._cur_goal_index] = 1.
- return res
-
- @property
- def goal_index(self):
- return self._cur_goal_index
-
- @property
- def goal_string(self):
- return self._cur_goal
-
- @property
- def worlds(self):
- return self._worlds
-
- @property
- def possible_targets(self):
- return self._targets
-
- def action(self, from_pose, to_pose):
- """Returns the action that takes source vertex to destination vertex.
-
- Args:
- from_pose: pose of the source.
- to_pose: pose of the destination.
- Returns:
- Returns the index of the action.
- Raises:
- ValueError: If it is not possible to go from the first vertice to second
- vertice with one action, it raises value error.
- """
- from_index = self.pose_to_vertex(from_pose)
- to_index = self.pose_to_vertex(to_pose)
- if to_index not in self.graph[from_index]:
- from_image_id = self.to_image_id(from_index)
- to_image_id = self.to_image_id(to_index)
- raise ValueError('{},{} is not connected to {},{}'.format(
- from_index, from_image_id, to_index, to_image_id))
- return self._actions.index(self.graph[from_index][to_index]['action'])
-
- def random_step_sequence(self, min_len=None, max_len=None):
- """Generates random step sequence that takes agent to the goal.
-
- Args:
- min_len: integer, minimum length of a step sequence. Not yet implemented.
- max_len: integer, should be set to an integer and it is the maximum number
- of observations and path length to be max_len.
- Returns:
- Tuple of (path, actions, states, step_outputs).
- path: a random path from a random starting point and random environment.
- actions: actions of the returned path.
- states: viewpoints of all the states in between.
- step_outputs: list of step() return tuples.
- Raises:
- ValueError: if first_n is not greater than zero; if min_len is different
- from None.
- """
- if max_len is None:
- raise ValueError('max_len can not be set as None')
- if max_len < 1:
- raise ValueError('first_n must be greater or equal to 1.')
- if min_len is not None:
- raise ValueError('min_len is not yet implemented.')
-
- path = []
- actions = []
- states = []
- step_outputs = []
- obs = self.reset()
- last_obs_tuple = [obs, 0, False, {}]
- for _ in xrange(max_len):
- action = np.random.choice(self._actions)
- # We don't want to sample stop action because stop does not add new
- # information.
- while action == 'stop':
- action = np.random.choice(self._actions)
- path.append(self.to_vertex(self._cur_image_id))
- onehot = np.zeros((len(self._actions),), dtype=np.float32)
- onehot[self._actions.index(action)] = 1.
- actions.append(onehot)
- states.append(self.vertex_to_pose(path[-1]))
- step_outputs.append(copy.deepcopy(last_obs_tuple))
- last_obs_tuple = self.step(action)
-
- return path, actions, states, step_outputs
diff --git a/research/cognitive_planning/envs/configs/active_vision_config.gin b/research/cognitive_planning/envs/configs/active_vision_config.gin
deleted file mode 100644
index edb10dc1f5339fc6fc2857ae8870d1df8f497263..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/envs/configs/active_vision_config.gin
+++ /dev/null
@@ -1,27 +0,0 @@
-#-*-Python-*-
-ActiveVisionDatasetEnv.episode_length = 200
-ActiveVisionDatasetEnv.actions = [
- 'right', 'rotate_cw', 'rotate_ccw', 'forward', 'left', 'backward', 'stop'
-]
-ActiveVisionDatasetEnv.confidence_threshold = 0.5
-ActiveVisionDatasetEnv.output_size = 64
-ActiveVisionDatasetEnv.worlds = [
- 'Home_001_1', 'Home_001_2', 'Home_002_1', 'Home_003_1', 'Home_003_2',
- 'Home_004_1', 'Home_004_2', 'Home_005_1', 'Home_005_2', 'Home_006_1',
- 'Home_007_1', 'Home_010_1', 'Home_011_1', 'Home_013_1', 'Home_014_1',
- 'Home_014_2', 'Home_015_1', 'Home_016_1'
-]
-ActiveVisionDatasetEnv.targets = [
- 'tv', 'dining_table', 'fridge', 'microwave', 'couch'
-]
-ActiveVisionDatasetEnv.compute_distance = False
-ActiveVisionDatasetEnv.should_draw_detections = False
-ActiveVisionDatasetEnv.dataset_root = '/usr/local/google/home/kosecka/AVD_Minimal/'
-ActiveVisionDatasetEnv.labelmap_path = 'label_map.txt'
-ActiveVisionDatasetEnv.reward_collision = 0
-ActiveVisionDatasetEnv.reward_goal_range = 2
-ActiveVisionDatasetEnv.num_detection_classes = 90
-ActiveVisionDatasetEnv.segmentation_file_name='sseg_crf'
-ActiveVisionDatasetEnv.detection_folder_name='Detections'
-ActiveVisionDatasetEnv.targets_file_name='annotated_targets'
-ActiveVisionDatasetEnv.shaped_reward=False
diff --git a/research/cognitive_planning/envs/task_env.py b/research/cognitive_planning/envs/task_env.py
deleted file mode 100644
index 84d527cd2e4e09b587fa47f2a98a6df1592915e9..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/envs/task_env.py
+++ /dev/null
@@ -1,218 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""An interface representing the topology of an environment.
-
-Allows for high level planning and high level instruction generation for
-navigation tasks.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import abc
-import enum
-import gym
-import gin
-
-
-@gin.config.constants_from_enum
-class ModalityTypes(enum.Enum):
- """Types of the modalities that can be used."""
- IMAGE = 0
- SEMANTIC_SEGMENTATION = 1
- OBJECT_DETECTION = 2
- DEPTH = 3
- GOAL = 4
- PREV_ACTION = 5
- PREV_SUCCESS = 6
- STATE = 7
- DISTANCE = 8
- CAN_STEP = 9
-
- def __lt__(self, other):
- if self.__class__ is other.__class__:
- return self.value < other.value
- return NotImplemented
-
-
-class TaskEnvInterface(object):
- """Interface for an environment topology.
-
- An environment can implement this interface if there is a topological graph
- underlying this environment. All paths below are defined as paths in this
- graph. Using path_to_actions function one can translate a topological path
- to a geometric path in the environment.
- """
-
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def random_step_sequence(self, min_len=None, max_len=None):
- """Generates a random sequence of actions and executes them.
-
- Args:
- min_len: integer, minimum length of a step sequence.
- max_len: integer, if it is set to non-None, the method returns only
- the first n steps of a random sequence. If the environment is
- computationally heavy this argument should be set to speed up the
- training and avoid unnecessary computations by the environment.
-
- Returns:
- A path, defined as a list of vertex indices, a list of actions, a list of
- states, and a list of step() return tuples.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractmethod
- def targets(self):
- """A list of targets in the environment.
-
- Returns:
- A list of target locations.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractproperty
- def state(self):
- """Returns the position for the current location of agent."""
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractproperty
- def graph(self):
- """Returns a graph representing the environment topology.
-
- Returns:
- nx.Graph object.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractmethod
- def vertex_to_pose(self, vertex_index):
- """Maps a vertex index to a pose in the environment.
-
- Pose of the camera can be represented by (x,y,theta) or (x,y,z,theta).
- Args:
- vertex_index: index of a vertex in the topology graph.
-
- Returns:
- A np.array of floats of size 3 or 4 representing the pose of the vertex.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractmethod
- def pose_to_vertex(self, pose):
- """Maps a coordinate in the maze to the closest vertex in topology graph.
-
- Args:
- pose: np.array of floats containing a the pose of the view.
-
- Returns:
- index of a vertex.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- @abc.abstractmethod
- def observation(self, state):
- """Returns observation at location xy and orientation theta.
-
- Args:
- state: a np.array of floats containing coordinates of a location and
- orientation.
-
- Returns:
- Dictionary of observations in the case of multiple observations.
- The keys are the modality names and the values are the np.array of float
- of observations for corresponding modality.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
- def action(self, init_state, final_state):
- """Computes the transition action from state1 to state2.
-
- If the environment is discrete and the views are not adjacent in the
- environment. i.e. it is not possible to move from the first view to the
- second view with one action it should return None. In the continuous case,
- it will be the continuous difference of first view and second view.
-
- Args:
- init_state: numpy array, the initial view of the agent.
- final_state: numpy array, the final view of the agent.
- """
- raise NotImplementedError(
- 'Needs implementation as part of EnvTopology interface.')
-
-
-@gin.configurable
-class TaskEnv(gym.Env, TaskEnvInterface):
- """An environment which uses a Task to compute reward.
-
- The environment implements a a gym interface, as well as EnvTopology. The
- former makes sure it can be used within an RL training, while the latter
- makes sure it can be used by a Task.
-
- This environment requires _step_no_reward to be implemented, which steps
- through it but does not return reward. Instead, the reward calculation is
- delegated to the Task object, which in return can access needed properties
- of the environment. These properties are exposed via the EnvTopology
- interface.
- """
-
- def __init__(self, task=None):
- self._task = task
-
- def set_task(self, task):
- self._task = task
-
- @abc.abstractmethod
- def _step_no_reward(self, action):
- """Same as _step without returning reward.
-
- Args:
- action: see _step.
-
- Returns:
- state, done, info as defined in _step.
- """
- raise NotImplementedError('Implement step.')
-
- @abc.abstractmethod
- def _reset_env(self):
- """Resets the environment. Returns initial observation."""
- raise NotImplementedError('Implement _reset. Must call super!')
-
- def step(self, action):
- obs, done, info = self._step_no_reward(action)
-
- reward = 0.0
- if self._task is not None:
- obs, reward, done, info = self._task.reward(obs, done, info)
-
- return obs, reward, done, info
-
- def reset(self):
- """Resets the environment. Gym API."""
- obs = self._reset_env()
- if self._task is not None:
- self._task.reset(obs)
- return obs
diff --git a/research/cognitive_planning/envs/util.py b/research/cognitive_planning/envs/util.py
deleted file mode 100644
index 32a384bc5fab8f75ed62e1c2fa3b1f8f832b228d..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/envs/util.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A module with utility functions.
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import numpy as np
-
-
-def trajectory_to_deltas(trajectory, state):
- """Computes a sequence of deltas of a state to traverse a trajectory in 2D.
-
- The initial state of the agent contains its pose -- location in 2D and
- orientation. When the computed deltas are incrementally added to it, it
- traverses the specified trajectory while keeping its orientation parallel to
- the trajectory.
-
- Args:
- trajectory: a np.array of floats of shape n x 2. The n-th row contains the
- n-th point.
- state: a 3 element np.array of floats containing agent's location and
- orientation in radians.
-
- Returns:
- A np.array of floats of size n x 3.
- """
- state = np.reshape(state, [-1])
- init_xy = state[0:2]
- init_theta = state[2]
-
- delta_xy = trajectory - np.concatenate(
- [np.reshape(init_xy, [1, 2]), trajectory[:-1, :]], axis=0)
-
- thetas = np.reshape(np.arctan2(delta_xy[:, 1], delta_xy[:, 0]), [-1, 1])
- thetas = np.concatenate([np.reshape(init_theta, [1, 1]), thetas], axis=0)
- delta_thetas = thetas[1:] - thetas[:-1]
-
- deltas = np.concatenate([delta_xy, delta_thetas], axis=1)
- return deltas
diff --git a/research/cognitive_planning/label_map.txt b/research/cognitive_planning/label_map.txt
deleted file mode 100644
index 1f4872bd0c7f53e70beecf88af005c07a5df9e08..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/label_map.txt
+++ /dev/null
@@ -1,400 +0,0 @@
-item {
- name: "/m/01g317"
- id: 1
- display_name: "person"
-}
-item {
- name: "/m/0199g"
- id: 2
- display_name: "bicycle"
-}
-item {
- name: "/m/0k4j"
- id: 3
- display_name: "car"
-}
-item {
- name: "/m/04_sv"
- id: 4
- display_name: "motorcycle"
-}
-item {
- name: "/m/05czz6l"
- id: 5
- display_name: "airplane"
-}
-item {
- name: "/m/01bjv"
- id: 6
- display_name: "bus"
-}
-item {
- name: "/m/07jdr"
- id: 7
- display_name: "train"
-}
-item {
- name: "/m/07r04"
- id: 8
- display_name: "truck"
-}
-item {
- name: "/m/019jd"
- id: 9
- display_name: "boat"
-}
-item {
- name: "/m/015qff"
- id: 10
- display_name: "traffic light"
-}
-item {
- name: "/m/01pns0"
- id: 11
- display_name: "fire hydrant"
-}
-item {
- name: "/m/02pv19"
- id: 13
- display_name: "stop sign"
-}
-item {
- name: "/m/015qbp"
- id: 14
- display_name: "parking meter"
-}
-item {
- name: "/m/0cvnqh"
- id: 15
- display_name: "bench"
-}
-item {
- name: "/m/015p6"
- id: 16
- display_name: "bird"
-}
-item {
- name: "/m/01yrx"
- id: 17
- display_name: "cat"
-}
-item {
- name: "/m/0bt9lr"
- id: 18
- display_name: "dog"
-}
-item {
- name: "/m/03k3r"
- id: 19
- display_name: "horse"
-}
-item {
- name: "/m/07bgp"
- id: 20
- display_name: "sheep"
-}
-item {
- name: "/m/01xq0k1"
- id: 21
- display_name: "cow"
-}
-item {
- name: "/m/0bwd_0j"
- id: 22
- display_name: "elephant"
-}
-item {
- name: "/m/01dws"
- id: 23
- display_name: "bear"
-}
-item {
- name: "/m/0898b"
- id: 24
- display_name: "zebra"
-}
-item {
- name: "/m/03bk1"
- id: 25
- display_name: "giraffe"
-}
-item {
- name: "/m/01940j"
- id: 27
- display_name: "backpack"
-}
-item {
- name: "/m/0hnnb"
- id: 28
- display_name: "umbrella"
-}
-item {
- name: "/m/080hkjn"
- id: 31
- display_name: "handbag"
-}
-item {
- name: "/m/01rkbr"
- id: 32
- display_name: "tie"
-}
-item {
- name: "/m/01s55n"
- id: 33
- display_name: "suitcase"
-}
-item {
- name: "/m/02wmf"
- id: 34
- display_name: "frisbee"
-}
-item {
- name: "/m/071p9"
- id: 35
- display_name: "skis"
-}
-item {
- name: "/m/06__v"
- id: 36
- display_name: "snowboard"
-}
-item {
- name: "/m/018xm"
- id: 37
- display_name: "sports ball"
-}
-item {
- name: "/m/02zt3"
- id: 38
- display_name: "kite"
-}
-item {
- name: "/m/03g8mr"
- id: 39
- display_name: "baseball bat"
-}
-item {
- name: "/m/03grzl"
- id: 40
- display_name: "baseball glove"
-}
-item {
- name: "/m/06_fw"
- id: 41
- display_name: "skateboard"
-}
-item {
- name: "/m/019w40"
- id: 42
- display_name: "surfboard"
-}
-item {
- name: "/m/0dv9c"
- id: 43
- display_name: "tennis racket"
-}
-item {
- name: "/m/04dr76w"
- id: 44
- display_name: "bottle"
-}
-item {
- name: "/m/09tvcd"
- id: 46
- display_name: "wine glass"
-}
-item {
- name: "/m/08gqpm"
- id: 47
- display_name: "cup"
-}
-item {
- name: "/m/0dt3t"
- id: 48
- display_name: "fork"
-}
-item {
- name: "/m/04ctx"
- id: 49
- display_name: "knife"
-}
-item {
- name: "/m/0cmx8"
- id: 50
- display_name: "spoon"
-}
-item {
- name: "/m/04kkgm"
- id: 51
- display_name: "bowl"
-}
-item {
- name: "/m/09qck"
- id: 52
- display_name: "banana"
-}
-item {
- name: "/m/014j1m"
- id: 53
- display_name: "apple"
-}
-item {
- name: "/m/0l515"
- id: 54
- display_name: "sandwich"
-}
-item {
- name: "/m/0cyhj_"
- id: 55
- display_name: "orange"
-}
-item {
- name: "/m/0hkxq"
- id: 56
- display_name: "broccoli"
-}
-item {
- name: "/m/0fj52s"
- id: 57
- display_name: "carrot"
-}
-item {
- name: "/m/01b9xk"
- id: 58
- display_name: "hot dog"
-}
-item {
- name: "/m/0663v"
- id: 59
- display_name: "pizza"
-}
-item {
- name: "/m/0jy4k"
- id: 60
- display_name: "donut"
-}
-item {
- name: "/m/0fszt"
- id: 61
- display_name: "cake"
-}
-item {
- name: "/m/01mzpv"
- id: 62
- display_name: "chair"
-}
-item {
- name: "/m/02crq1"
- id: 63
- display_name: "couch"
-}
-item {
- name: "/m/03fp41"
- id: 64
- display_name: "potted plant"
-}
-item {
- name: "/m/03ssj5"
- id: 65
- display_name: "bed"
-}
-item {
- name: "/m/04bcr3"
- id: 67
- display_name: "dining table"
-}
-item {
- name: "/m/09g1w"
- id: 70
- display_name: "toilet"
-}
-item {
- name: "/m/07c52"
- id: 72
- display_name: "tv"
-}
-item {
- name: "/m/01c648"
- id: 73
- display_name: "laptop"
-}
-item {
- name: "/m/020lf"
- id: 74
- display_name: "mouse"
-}
-item {
- name: "/m/0qjjc"
- id: 75
- display_name: "remote"
-}
-item {
- name: "/m/01m2v"
- id: 76
- display_name: "keyboard"
-}
-item {
- name: "/m/050k8"
- id: 77
- display_name: "cell phone"
-}
-item {
- name: "/m/0fx9l"
- id: 78
- display_name: "microwave"
-}
-item {
- name: "/m/029bxz"
- id: 79
- display_name: "oven"
-}
-item {
- name: "/m/01k6s3"
- id: 80
- display_name: "toaster"
-}
-item {
- name: "/m/0130jx"
- id: 81
- display_name: "sink"
-}
-item {
- name: "/m/040b_t"
- id: 82
- display_name: "refrigerator"
-}
-item {
- name: "/m/0bt_c3"
- id: 84
- display_name: "book"
-}
-item {
- name: "/m/01x3z"
- id: 85
- display_name: "clock"
-}
-item {
- name: "/m/02s195"
- id: 86
- display_name: "vase"
-}
-item {
- name: "/m/01lsmm"
- id: 87
- display_name: "scissors"
-}
-item {
- name: "/m/0kmg4"
- id: 88
- display_name: "teddy bear"
-}
-item {
- name: "/m/03wvsk"
- id: 89
- display_name: "hair drier"
-}
-item {
- name: "/m/012xff"
- id: 90
- display_name: "toothbrush"
-}
diff --git a/research/cognitive_planning/label_map_util.py b/research/cognitive_planning/label_map_util.py
deleted file mode 100644
index e258e3ab57fbe0de3aeb664e64f5df5a6dc5111d..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/label_map_util.py
+++ /dev/null
@@ -1,181 +0,0 @@
-# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Label map utility functions."""
-
-import logging
-
-import tensorflow as tf
-from google.protobuf import text_format
-import string_int_label_map_pb2
-
-
-def _validate_label_map(label_map):
- """Checks if a label map is valid.
-
- Args:
- label_map: StringIntLabelMap to validate.
-
- Raises:
- ValueError: if label map is invalid.
- """
- for item in label_map.item:
- if item.id < 0:
- raise ValueError('Label map ids should be >= 0.')
- if (item.id == 0 and item.name != 'background' and
- item.display_name != 'background'):
- raise ValueError('Label map id 0 is reserved for the background label')
-
-
-def create_category_index(categories):
- """Creates dictionary of COCO compatible categories keyed by category id.
-
- Args:
- categories: a list of dicts, each of which has the following keys:
- 'id': (required) an integer id uniquely identifying this category.
- 'name': (required) string representing category name
- e.g., 'cat', 'dog', 'pizza'.
-
- Returns:
- category_index: a dict containing the same entries as categories, but keyed
- by the 'id' field of each category.
- """
- category_index = {}
- for cat in categories:
- category_index[cat['id']] = cat
- return category_index
-
-
-def get_max_label_map_index(label_map):
- """Get maximum index in label map.
-
- Args:
- label_map: a StringIntLabelMapProto
-
- Returns:
- an integer
- """
- return max([item.id for item in label_map.item])
-
-
-def convert_label_map_to_categories(label_map,
- max_num_classes,
- use_display_name=True):
- """Loads label map proto and returns categories list compatible with eval.
-
- This function loads a label map and returns a list of dicts, each of which
- has the following keys:
- 'id': (required) an integer id uniquely identifying this category.
- 'name': (required) string representing category name
- e.g., 'cat', 'dog', 'pizza'.
- We only allow class into the list if its id-label_id_offset is
- between 0 (inclusive) and max_num_classes (exclusive).
- If there are several items mapping to the same id in the label map,
- we will only keep the first one in the categories list.
-
- Args:
- label_map: a StringIntLabelMapProto or None. If None, a default categories
- list is created with max_num_classes categories.
- max_num_classes: maximum number of (consecutive) label indices to include.
- use_display_name: (boolean) choose whether to load 'display_name' field
- as category name. If False or if the display_name field does not exist,
- uses 'name' field as category names instead.
- Returns:
- categories: a list of dictionaries representing all possible categories.
- """
- categories = []
- list_of_ids_already_added = []
- if not label_map:
- label_id_offset = 1
- for class_id in range(max_num_classes):
- categories.append({
- 'id': class_id + label_id_offset,
- 'name': 'category_{}'.format(class_id + label_id_offset)
- })
- return categories
- for item in label_map.item:
- if not 0 < item.id <= max_num_classes:
- logging.info('Ignore item %d since it falls outside of requested '
- 'label range.', item.id)
- continue
- if use_display_name and item.HasField('display_name'):
- name = item.display_name
- else:
- name = item.name
- if item.id not in list_of_ids_already_added:
- list_of_ids_already_added.append(item.id)
- categories.append({'id': item.id, 'name': name})
- return categories
-
-
-def load_labelmap(path):
- """Loads label map proto.
-
- Args:
- path: path to StringIntLabelMap proto text file.
- Returns:
- a StringIntLabelMapProto
- """
- with tf.gfile.GFile(path, 'r') as fid:
- label_map_string = fid.read()
- label_map = string_int_label_map_pb2.StringIntLabelMap()
- try:
- text_format.Merge(label_map_string, label_map)
- except text_format.ParseError:
- label_map.ParseFromString(label_map_string)
- _validate_label_map(label_map)
- return label_map
-
-
-def get_label_map_dict(label_map_path, use_display_name=False):
- """Reads a label map and returns a dictionary of label names to id.
-
- Args:
- label_map_path: path to label_map.
- use_display_name: whether to use the label map items' display names as keys.
-
- Returns:
- A dictionary mapping label names to id.
- """
- label_map = load_labelmap(label_map_path)
- label_map_dict = {}
- for item in label_map.item:
- if use_display_name:
- label_map_dict[item.display_name] = item.id
- else:
- label_map_dict[item.name] = item.id
- return label_map_dict
-
-
-def create_category_index_from_labelmap(label_map_path):
- """Reads a label map and returns a category index.
-
- Args:
- label_map_path: Path to `StringIntLabelMap` proto text file.
-
- Returns:
- A category index, which is a dictionary that maps integer ids to dicts
- containing categories, e.g.
- {1: {'id': 1, 'name': 'dog'}, 2: {'id': 2, 'name': 'cat'}, ...}
- """
- label_map = load_labelmap(label_map_path)
- max_num_classes = max(item.id for item in label_map.item)
- categories = convert_label_map_to_categories(label_map, max_num_classes)
- return create_category_index(categories)
-
-
-def create_class_agnostic_category_index():
- """Creates a category index with a single `object` class."""
- return {1: {'id': 1, 'name': 'object'}}
diff --git a/research/cognitive_planning/policies.py b/research/cognitive_planning/policies.py
deleted file mode 100644
index 5c7e2207db1302c3fd1d8bff3e30eaba022480fd..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/policies.py
+++ /dev/null
@@ -1,474 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Interface for the policy of the agents use for navigation."""
-
-import abc
-import tensorflow as tf
-from absl import logging
-import embedders
-from envs import task_env
-
-slim = tf.contrib.slim
-
-def _print_debug_ios(history, goal, output):
- """Prints sizes of history, goal and outputs."""
- if history is not None:
- shape = history.get_shape().as_list()
- # logging.info('history embedding shape ')
- # logging.info(shape)
- if len(shape) != 3:
- raise ValueError('history Tensor must have rank=3')
- if goal is not None:
- logging.info('goal embedding shape ')
- logging.info(goal.get_shape().as_list())
- if output is not None:
- logging.info('targets shape ')
- logging.info(output.get_shape().as_list())
-
-
-class Policy(object):
- """Represents the policy of the agent for navigation tasks.
-
- Instantiates a policy that takes embedders for each modality and builds a
- model to infer the actions.
- """
- __metaclass__ = abc.ABCMeta
-
- def __init__(self, embedders_dict, action_size):
- """Instantiates the policy.
-
- Args:
- embedders_dict: Dictionary of embedders for different modalities. Keys
- should be identical to keys of observation modality.
- action_size: Number of possible actions.
- """
- self._embedders = embedders_dict
- self._action_size = action_size
-
- @abc.abstractmethod
- def build(self, observations, prev_state):
- """Builds the model that represents the policy of the agent.
-
- Args:
- observations: Dictionary of observations from different modalities. Keys
- are the name of the modalities.
- prev_state: The tensor of the previous state of the model. Should be set
- to None if the policy is stateless
- Returns:
- Tuple of (action, state) where action is the action logits and state is
- the state of the model after taking new observation.
- """
- raise NotImplementedError(
- 'Needs implementation as part of Policy interface')
-
-
-class LSTMPolicy(Policy):
- """Represents the implementation of the LSTM based policy.
-
- The architecture of the model is as follows. It embeds all the observations
- using the embedders, concatenates the embeddings of all the modalities. Feed
- them through two fully connected layers. The lstm takes the features from
- fully connected layer and the previous action and success of previous action
- and feed them to LSTM. The value for each action is predicted afterwards.
- Although the class name has the word LSTM in it, it also supports a mode that
- builds the network without LSTM just for comparison purposes.
- """
-
- def __init__(self,
- modality_names,
- embedders_dict,
- action_size,
- params,
- max_episode_length,
- feedforward_mode=False):
- """Instantiates the LSTM policy.
-
- Args:
- modality_names: List of modality names. Makes sure the ordering in
- concatenation remains the same as modality_names list. Each modality
- needs to be in the embedders_dict.
- embedders_dict: Dictionary of embedders for different modalities. Keys
- should be identical to keys of observation modality. Values should be
- instance of Embedder class. All the observations except PREV_ACTION
- requires embedder.
- action_size: Number of possible actions.
- params: is instance of tf.hparams and contains the hyperparameters for the
- policy network.
- max_episode_length: integer, specifying the maximum length of each
- episode.
- feedforward_mode: If True, it does not add LSTM to the model. It should
- only be set True for comparison between LSTM and feedforward models.
- """
- super(LSTMPolicy, self).__init__(embedders_dict, action_size)
-
- self._modality_names = modality_names
-
- self._lstm_state_size = params.lstm_state_size
- self._fc_channels = params.fc_channels
- self._weight_decay = params.weight_decay
- self._target_embedding_size = params.target_embedding_size
- self._max_episode_length = max_episode_length
- self._feedforward_mode = feedforward_mode
-
- def _build_lstm(self, encoded_inputs, prev_state, episode_length,
- prev_action=None):
- """Builds an LSTM on top of the encoded inputs.
-
- If prev_action is not None then it concatenates them to the input of LSTM.
-
- Args:
- encoded_inputs: The embedding of the observations and goal.
- prev_state: previous state of LSTM.
- episode_length: The tensor that contains the length of the sequence for
- each element of the batch.
- prev_action: tensor to previous chosen action and additional bit for
- indicating whether the previous action was successful or not.
-
- Returns:
- a tuple of (lstm output, lstm state).
- """
-
- # Adding prev action and success in addition to the embeddings of the
- # modalities.
- if prev_action is not None:
- encoded_inputs = tf.concat([encoded_inputs, prev_action], axis=-1)
-
- with tf.variable_scope('LSTM'):
- lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self._lstm_state_size)
- if prev_state is None:
- # If prev state is set to None, a state of all zeros will be
- # passed as a previous value for the cell. Should be used for the
- # first step of each episode.
- tf_prev_state = lstm_cell.zero_state(
- encoded_inputs.get_shape().as_list()[0], dtype=tf.float32)
- else:
- tf_prev_state = tf.nn.rnn_cell.LSTMStateTuple(prev_state[0],
- prev_state[1])
-
- lstm_outputs, lstm_state = tf.nn.dynamic_rnn(
- cell=lstm_cell,
- inputs=encoded_inputs,
- sequence_length=episode_length,
- initial_state=tf_prev_state,
- dtype=tf.float32,
- )
- lstm_outputs = tf.reshape(lstm_outputs, [-1, lstm_cell.output_size])
- return lstm_outputs, lstm_state
-
- def build(
- self,
- observations,
- prev_state,
- ):
- """Builds the model that represents the policy of the agent.
-
- Args:
- observations: Dictionary of observations from different modalities. Keys
- are the name of the modalities. Observation should have the following
- key-values.
- observations['goal']: One-hot tensor that indicates the semantic
- category of the goal. The shape should be
- (batch_size x max_sequence_length x goals).
- observations[task_env.ModalityTypes.PREV_ACTION]: has action_size + 1
- elements where the first action_size numbers are the one hot vector
- of the previous action and the last element indicates whether the
- previous action was successful or not. If
- task_env.ModalityTypes.PREV_ACTION is not in the observation, it
- will not be used in the policy.
- prev_state: Previous state of the model. It should be a tuple of (c,h)
- where c and h are the previous cell value and hidden state of the lstm.
- Each element of tuple has shape of (batch_size x lstm_cell_size).
- If it is set to None, then it initializes the state of the lstm with all
- zeros.
-
- Returns:
- Tuple of (action, state) where action is the action logits and state is
- the state of the model after taking new observation.
- Raises:
- ValueError: If any of the modality names is not in observations or
- embedders_dict.
- ValueError: If 'goal' is not in the observations.
- """
-
- for modality_name in self._modality_names:
- if modality_name not in observations:
- raise ValueError('modality name does not exist in observations: {} not '
- 'in {}'.format(modality_name, observations.keys()))
- if modality_name not in self._embedders:
- if modality_name == task_env.ModalityTypes.PREV_ACTION:
- continue
- raise ValueError('modality name does not have corresponding embedder'
- ' {} not in {}'.format(modality_name,
- self._embedders.keys()))
-
- if task_env.ModalityTypes.GOAL not in observations:
- raise ValueError('goal should be provided in the observations')
-
- goal = observations[task_env.ModalityTypes.GOAL]
- prev_action = None
- if task_env.ModalityTypes.PREV_ACTION in observations:
- prev_action = observations[task_env.ModalityTypes.PREV_ACTION]
-
- with tf.variable_scope('policy'):
- with slim.arg_scope(
- [slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
- weights_regularizer=slim.l2_regularizer(self._weight_decay)):
- all_inputs = []
-
- # Concatenating the embedding of each modality by applying the embedders
- # to corresponding observations.
- def embed(name):
- with tf.variable_scope('embed_{}'.format(name)):
- # logging.info('Policy uses embedding %s', name)
- return self._embedders[name].build(observations[name])
-
- all_inputs = map(embed, [
- x for x in self._modality_names
- if x != task_env.ModalityTypes.PREV_ACTION
- ])
-
- # Computing goal embedding.
- shape = goal.get_shape().as_list()
- with tf.variable_scope('embed_goal'):
- encoded_goal = tf.reshape(goal, [shape[0] * shape[1], -1])
- encoded_goal = slim.fully_connected(encoded_goal,
- self._target_embedding_size)
- encoded_goal = tf.reshape(encoded_goal, [shape[0], shape[1], -1])
- all_inputs.append(encoded_goal)
-
- # Concatenating all the modalities and goal.
- all_inputs = tf.concat(all_inputs, axis=-1, name='concat_embeddings')
-
- shape = all_inputs.get_shape().as_list()
- all_inputs = tf.reshape(all_inputs, [shape[0] * shape[1], shape[2]])
-
- # Applying fully connected layers.
- encoded_inputs = slim.fully_connected(all_inputs, self._fc_channels)
- encoded_inputs = slim.fully_connected(encoded_inputs, self._fc_channels)
-
- if not self._feedforward_mode:
- encoded_inputs = tf.reshape(encoded_inputs,
- [shape[0], shape[1], self._fc_channels])
- lstm_outputs, lstm_state = self._build_lstm(
- encoded_inputs=encoded_inputs,
- prev_state=prev_state,
- episode_length=tf.ones((shape[0],), dtype=tf.float32) *
- self._max_episode_length,
- prev_action=prev_action,
- )
- else:
- # If feedforward_mode=True, directly compute bypass the whole LSTM
- # computations.
- lstm_outputs = encoded_inputs
-
- lstm_outputs = slim.fully_connected(lstm_outputs, self._fc_channels)
- action_values = slim.fully_connected(
- lstm_outputs, self._action_size, activation_fn=None)
- action_values = tf.reshape(action_values, [shape[0], shape[1], -1])
- if not self._feedforward_mode:
- return action_values, lstm_state
- else:
- return action_values, None
-
-
-class TaskPolicy(Policy):
- """A covenience abstract class providing functionality to deal with Tasks."""
-
- def __init__(self,
- task_config,
- model_hparams=None,
- embedder_hparams=None,
- train_hparams=None):
- """Constructs a policy which knows how to work with tasks (see tasks.py).
-
- It allows to read task history, goal and outputs in consistency with the
- task config.
-
- Args:
- task_config: an object of type tasks.TaskIOConfig (see tasks.py)
- model_hparams: a tf.HParams object containing parameter pertaining to
- model (these are implementation specific)
- embedder_hparams: a tf.HParams object containing parameter pertaining to
- history, goal embedders (these are implementation specific)
- train_hparams: a tf.HParams object containing parameter pertaining to
- trainin (these are implementation specific)`
- """
- super(TaskPolicy, self).__init__(None, None)
- self._model_hparams = model_hparams
- self._embedder_hparams = embedder_hparams
- self._train_hparams = train_hparams
- self._task_config = task_config
- self._extra_train_ops = []
-
- @property
- def extra_train_ops(self):
- """Training ops in addition to the loss, e.g. batch norm updates.
-
- Returns:
- A list of tf ops.
- """
- return self._extra_train_ops
-
- def _embed_task_ios(self, streams):
- """Embeds a list of heterogenous streams.
-
- These streams correspond to task history, goal and output. The number of
- streams is equal to the total number of history, plus one for the goal if
- present, plus one for the output. If the number of history is k, then the
- first k streams are the history.
-
- The used embedders depend on the input (or goal) types. If an input is an
- image, then a ResNet embedder is used, otherwise
- MLPEmbedder (see embedders.py).
-
- Args:
- streams: a list of Tensors.
- Returns:
- Three float Tensors history, goal, output. If there are no history, or no
- goal, then the corresponding returned values are None. The shape of the
- embedded history is batch_size x sequence_length x sum of all embedding
- dimensions for all history. The shape of the goal is embedding dimension.
- """
- # EMBED history.
- index = 0
- inps = []
- scopes = []
- for c in self._task_config.inputs:
- if c == task_env.ModalityTypes.IMAGE:
- scope_name = 'image_embedder/image'
- reuse = scope_name in scopes
- scopes.append(scope_name)
- with tf.variable_scope(scope_name, reuse=reuse):
- resnet_embedder = embedders.ResNet(self._embedder_hparams.image)
- image_embeddings = resnet_embedder.build(streams[index])
- # Uncover batch norm ops.
- if self._embedder_hparams.image.is_train:
- self._extra_train_ops += resnet_embedder.extra_train_ops
- inps.append(image_embeddings)
- index += 1
- else:
- scope_name = 'input_embedder/vector'
- reuse = scope_name in scopes
- scopes.append(scope_name)
- with tf.variable_scope(scope_name, reuse=reuse):
- input_vector_embedder = embedders.MLPEmbedder(
- layers=self._embedder_hparams.vector)
- vector_embedder = input_vector_embedder.build(streams[index])
- inps.append(vector_embedder)
- index += 1
- history = tf.concat(inps, axis=2) if inps else None
-
- # EMBED goal.
- goal = None
- if self._task_config.query is not None:
- scope_name = 'image_embedder/query'
- reuse = scope_name in scopes
- scopes.append(scope_name)
- with tf.variable_scope(scope_name, reuse=reuse):
- resnet_goal_embedder = embedders.ResNet(self._embedder_hparams.goal)
- goal = resnet_goal_embedder.build(streams[index])
- if self._embedder_hparams.goal.is_train:
- self._extra_train_ops += resnet_goal_embedder.extra_train_ops
- index += 1
-
- # Embed true targets if needed (tbd).
- true_target = streams[index]
-
- return history, goal, true_target
-
- @abc.abstractmethod
- def build(self, feeds, prev_state):
- pass
-
-
-class ReactivePolicy(TaskPolicy):
- """A policy which ignores history.
-
- It processes only the current observation (last element in history) and the
- goal to output a prediction.
- """
-
- def __init__(self, *args, **kwargs):
- super(ReactivePolicy, self).__init__(*args, **kwargs)
-
- # The current implementation ignores the prev_state as it is purely reactive.
- # It returns None for the current state.
- def build(self, feeds, prev_state):
- history, goal, _ = self._embed_task_ios(feeds)
- _print_debug_ios(history, goal, None)
-
- with tf.variable_scope('output_decoder'):
- # Concatenate the embeddings of the current observation and the goal.
- reactive_input = tf.concat([tf.squeeze(history[:, -1, :]), goal], axis=1)
- oconfig = self._task_config.output.shape
- assert len(oconfig) == 1
- decoder = embedders.MLPEmbedder(
- layers=self._embedder_hparams.predictions.layer_sizes + oconfig)
- predictions = decoder.build(reactive_input)
-
- return predictions, None
-
-
-class RNNPolicy(TaskPolicy):
- """A policy which takes into account the full history via RNN.
-
- The implementation might and will change.
- The history, together with the goal, is processed using a stacked LSTM. The
- output of the last LSTM step is used to produce a prediction. Currently, only
- a single step output is supported.
- """
-
- def __init__(self, lstm_hparams, *args, **kwargs):
- super(RNNPolicy, self).__init__(*args, **kwargs)
- self._lstm_hparams = lstm_hparams
-
- # The prev_state is ignored as for now the full history is specified as first
- # element of the feeds. It might turn out to be beneficial to keep the state
- # as part of the policy object.
- def build(self, feeds, state):
- history, goal, _ = self._embed_task_ios(feeds)
- _print_debug_ios(history, goal, None)
-
- params = self._lstm_hparams
- cell = lambda: tf.contrib.rnn.BasicLSTMCell(params.cell_size)
- stacked_lstm = tf.contrib.rnn.MultiRNNCell(
- [cell() for _ in range(params.num_layers)])
- # history is of shape batch_size x seq_len x embedding_dimension
- batch_size, seq_len, _ = tuple(history.get_shape().as_list())
-
- if state is None:
- state = stacked_lstm.zero_state(batch_size, tf.float32)
- for t in range(seq_len):
- if params.concat_goal_everywhere:
- lstm_input = tf.concat([tf.squeeze(history[:, t, :]), goal], axis=1)
- else:
- lstm_input = tf.squeeze(history[:, t, :])
- output, state = stacked_lstm(lstm_input, state)
-
- with tf.variable_scope('output_decoder'):
- oconfig = self._task_config.output.shape
- assert len(oconfig) == 1
- features = tf.concat([output, goal], axis=1)
- assert len(output.get_shape().as_list()) == 2
- assert len(goal.get_shape().as_list()) == 2
- decoder = embedders.MLPEmbedder(
- layers=self._embedder_hparams.predictions.layer_sizes + oconfig)
- # Prediction is done off the last step lstm output and the goal.
- predictions = decoder.build(features)
-
- return predictions, state
diff --git a/research/cognitive_planning/preprocessing/__init__.py b/research/cognitive_planning/preprocessing/__init__.py
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py b/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py
deleted file mode 100644
index 0b5a88fa4c31c13dca4cf92a5ee7614f08a935af..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py
+++ /dev/null
@@ -1,128 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Provides utilities to preprocess images in CIFAR-10.
-
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-_PADDING = 4
-
-slim = tf.contrib.slim
-
-
-def preprocess_for_train(image,
- output_height,
- output_width,
- padding=_PADDING,
- add_image_summaries=True):
- """Preprocesses the given image for training.
-
- Note that the actual resizing scale is sampled from
- [`resize_size_min`, `resize_size_max`].
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- padding: The amound of padding before and after each dimension of the image.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if add_image_summaries:
- tf.summary.image('image', tf.expand_dims(image, 0))
-
- # Transform the image to floats.
- image = tf.to_float(image)
- if padding > 0:
- image = tf.pad(image, [[padding, padding], [padding, padding], [0, 0]])
- # Randomly crop a [height, width] section of the image.
- distorted_image = tf.random_crop(image,
- [output_height, output_width, 3])
-
- # Randomly flip the image horizontally.
- distorted_image = tf.image.random_flip_left_right(distorted_image)
-
- if add_image_summaries:
- tf.summary.image('distorted_image', tf.expand_dims(distorted_image, 0))
-
- # Because these operations are not commutative, consider randomizing
- # the order their operation.
- distorted_image = tf.image.random_brightness(distorted_image,
- max_delta=63)
- distorted_image = tf.image.random_contrast(distorted_image,
- lower=0.2, upper=1.8)
- # Subtract off the mean and divide by the variance of the pixels.
- return tf.image.per_image_standardization(distorted_image)
-
-
-def preprocess_for_eval(image, output_height, output_width,
- add_image_summaries=True):
- """Preprocesses the given image for evaluation.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if add_image_summaries:
- tf.summary.image('image', tf.expand_dims(image, 0))
- # Transform the image to floats.
- image = tf.to_float(image)
-
- # Resize and crop if needed.
- resized_image = tf.image.resize_image_with_crop_or_pad(image,
- output_width,
- output_height)
- if add_image_summaries:
- tf.summary.image('resized_image', tf.expand_dims(resized_image, 0))
-
- # Subtract off the mean and divide by the variance of the pixels.
- return tf.image.per_image_standardization(resized_image)
-
-
-def preprocess_image(image, output_height, output_width, is_training=False,
- add_image_summaries=True):
- """Preprocesses the given image.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- is_training: `True` if we're preprocessing the image for training and
- `False` otherwise.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if is_training:
- return preprocess_for_train(
- image, output_height, output_width,
- add_image_summaries=add_image_summaries)
- else:
- return preprocess_for_eval(
- image, output_height, output_width,
- add_image_summaries=add_image_summaries)
diff --git a/research/cognitive_planning/preprocessing/inception_preprocessing.py b/research/cognitive_planning/preprocessing/inception_preprocessing.py
deleted file mode 100644
index 846b81b3cd30985f2aa55e6f7c471195ac6e046b..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/inception_preprocessing.py
+++ /dev/null
@@ -1,318 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Provides utilities to preprocess images for the Inception networks."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from tensorflow.python.ops import control_flow_ops
-
-
-def apply_with_random_selector(x, func, num_cases):
- """Computes func(x, sel), with sel sampled from [0...num_cases-1].
-
- Args:
- x: input Tensor.
- func: Python function to apply.
- num_cases: Python int32, number of cases to sample sel from.
-
- Returns:
- The result of func(x, sel), where func receives the value of the
- selector as a python integer, but sel is sampled dynamically.
- """
- sel = tf.random_uniform([], maxval=num_cases, dtype=tf.int32)
- # Pass the real x only to one of the func calls.
- return control_flow_ops.merge([
- func(control_flow_ops.switch(x, tf.equal(sel, case))[1], case)
- for case in range(num_cases)])[0]
-
-
-def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
- """Distort the color of a Tensor image.
-
- Each color distortion is non-commutative and thus ordering of the color ops
- matters. Ideally we would randomly permute the ordering of the color ops.
- Rather then adding that level of complication, we select a distinct ordering
- of color ops for each preprocessing thread.
-
- Args:
- image: 3-D Tensor containing single image in [0, 1].
- color_ordering: Python int, a type of distortion (valid values: 0-3).
- fast_mode: Avoids slower ops (random_hue and random_contrast)
- scope: Optional scope for name_scope.
- Returns:
- 3-D Tensor color-distorted image on range [0, 1]
- Raises:
- ValueError: if color_ordering not in [0, 3]
- """
- with tf.name_scope(scope, 'distort_color', [image]):
- if fast_mode:
- if color_ordering == 0:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- else:
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- else:
- if color_ordering == 0:
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.2)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- elif color_ordering == 1:
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.2)
- elif color_ordering == 2:
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.image.random_hue(image, max_delta=0.2)
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- elif color_ordering == 3:
- image = tf.image.random_hue(image, max_delta=0.2)
- image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
- image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
- image = tf.image.random_brightness(image, max_delta=32. / 255.)
- else:
- raise ValueError('color_ordering must be in [0, 3]')
-
- # The random_* ops do not necessarily clamp.
- return tf.clip_by_value(image, 0.0, 1.0)
-
-
-def distorted_bounding_box_crop(image,
- bbox,
- min_object_covered=0.1,
- aspect_ratio_range=(0.75, 1.33),
- area_range=(0.05, 1.0),
- max_attempts=100,
- scope=None):
- """Generates cropped_image using a one of the bboxes randomly distorted.
-
- See `tf.image.sample_distorted_bounding_box` for more documentation.
-
- Args:
- image: 3-D Tensor of image (it will be converted to floats in [0, 1]).
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged
- as [ymin, xmin, ymax, xmax]. If num_boxes is 0 then it would use the whole
- image.
- min_object_covered: An optional `float`. Defaults to `0.1`. The cropped
- area of the image must contain at least this fraction of any bounding box
- supplied.
- aspect_ratio_range: An optional list of `floats`. The cropped area of the
- image must have an aspect ratio = width / height within this range.
- area_range: An optional list of `floats`. The cropped area of the image
- must contain a fraction of the supplied image within in this range.
- max_attempts: An optional `int`. Number of attempts at generating a cropped
- region of the image of the specified constraints. After `max_attempts`
- failures, return the entire image.
- scope: Optional scope for name_scope.
- Returns:
- A tuple, a 3-D Tensor cropped_image and the distorted bbox
- """
- with tf.name_scope(scope, 'distorted_bounding_box_crop', [image, bbox]):
- # Each bounding box has shape [1, num_boxes, box coords] and
- # the coordinates are ordered [ymin, xmin, ymax, xmax].
-
- # A large fraction of image datasets contain a human-annotated bounding
- # box delineating the region of the image containing the object of interest.
- # We choose to create a new bounding box for the object which is a randomly
- # distorted version of the human-annotated bounding box that obeys an
- # allowed range of aspect ratios, sizes and overlap with the human-annotated
- # bounding box. If no box is supplied, then we assume the bounding box is
- # the entire image.
- sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
- tf.shape(image),
- bounding_boxes=bbox,
- min_object_covered=min_object_covered,
- aspect_ratio_range=aspect_ratio_range,
- area_range=area_range,
- max_attempts=max_attempts,
- use_image_if_no_bounding_boxes=True)
- bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box
-
- # Crop the image to the specified bounding box.
- cropped_image = tf.slice(image, bbox_begin, bbox_size)
- return cropped_image, distort_bbox
-
-
-def preprocess_for_train(image, height, width, bbox,
- fast_mode=True,
- scope=None,
- add_image_summaries=True):
- """Distort one image for training a network.
-
- Distorting images provides a useful technique for augmenting the data
- set during training in order to make the network invariant to aspects
- of the image that do not effect the label.
-
- Additionally it would create image_summaries to display the different
- transformations applied to the image.
-
- Args:
- image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
- [0, 1], otherwise it would converted to tf.float32 assuming that the range
- is [0, MAX], where MAX is largest positive representable number for
- int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
- height: integer
- width: integer
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged
- as [ymin, xmin, ymax, xmax].
- fast_mode: Optional boolean, if True avoids slower transformations (i.e.
- bi-cubic resizing, random_hue or random_contrast).
- scope: Optional scope for name_scope.
- add_image_summaries: Enable image summaries.
- Returns:
- 3-D float Tensor of distorted image used for training with range [-1, 1].
- """
- with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
- if bbox is None:
- bbox = tf.constant([0.0, 0.0, 1.0, 1.0],
- dtype=tf.float32,
- shape=[1, 1, 4])
- if image.dtype != tf.float32:
- image = tf.image.convert_image_dtype(image, dtype=tf.float32)
- # Each bounding box has shape [1, num_boxes, box coords] and
- # the coordinates are ordered [ymin, xmin, ymax, xmax].
- image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
- bbox)
- if add_image_summaries:
- tf.summary.image('image_with_bounding_boxes', image_with_box)
-
- distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
- # Restore the shape since the dynamic slice based upon the bbox_size loses
- # the third dimension.
- distorted_image.set_shape([None, None, 3])
- image_with_distorted_box = tf.image.draw_bounding_boxes(
- tf.expand_dims(image, 0), distorted_bbox)
- if add_image_summaries:
- tf.summary.image('images_with_distorted_bounding_box',
- image_with_distorted_box)
-
- # This resizing operation may distort the images because the aspect
- # ratio is not respected. We select a resize method in a round robin
- # fashion based on the thread number.
- # Note that ResizeMethod contains 4 enumerated resizing methods.
-
- # We select only 1 case for fast_mode bilinear.
- num_resize_cases = 1 if fast_mode else 4
- distorted_image = apply_with_random_selector(
- distorted_image,
- lambda x, method: tf.image.resize_images(x, [height, width], method),
- num_cases=num_resize_cases)
-
- if add_image_summaries:
- tf.summary.image('cropped_resized_image',
- tf.expand_dims(distorted_image, 0))
-
- # Randomly flip the image horizontally.
- distorted_image = tf.image.random_flip_left_right(distorted_image)
-
- # Randomly distort the colors. There are 1 or 4 ways to do it.
- num_distort_cases = 1 if fast_mode else 4
- distorted_image = apply_with_random_selector(
- distorted_image,
- lambda x, ordering: distort_color(x, ordering, fast_mode),
- num_cases=num_distort_cases)
-
- if add_image_summaries:
- tf.summary.image('final_distorted_image',
- tf.expand_dims(distorted_image, 0))
- distorted_image = tf.subtract(distorted_image, 0.5)
- distorted_image = tf.multiply(distorted_image, 2.0)
- return distorted_image
-
-
-def preprocess_for_eval(image, height, width,
- central_fraction=0.875, scope=None):
- """Prepare one image for evaluation.
-
- If height and width are specified it would output an image with that size by
- applying resize_bilinear.
-
- If central_fraction is specified it would crop the central fraction of the
- input image.
-
- Args:
- image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
- [0, 1], otherwise it would converted to tf.float32 assuming that the range
- is [0, MAX], where MAX is largest positive representable number for
- int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
- height: integer
- width: integer
- central_fraction: Optional Float, fraction of the image to crop.
- scope: Optional scope for name_scope.
- Returns:
- 3-D float Tensor of prepared image.
- """
- with tf.name_scope(scope, 'eval_image', [image, height, width]):
- if image.dtype != tf.float32:
- image = tf.image.convert_image_dtype(image, dtype=tf.float32)
- # Crop the central region of the image with an area containing 87.5% of
- # the original image.
- if central_fraction:
- image = tf.image.central_crop(image, central_fraction=central_fraction)
-
- if height and width:
- # Resize the image to the specified height and width.
- image = tf.expand_dims(image, 0)
- image = tf.image.resize_bilinear(image, [height, width],
- align_corners=False)
- image = tf.squeeze(image, [0])
- image = tf.subtract(image, 0.5)
- image = tf.multiply(image, 2.0)
- return image
-
-
-def preprocess_image(image, height, width,
- is_training=False,
- bbox=None,
- fast_mode=True,
- add_image_summaries=True):
- """Pre-process one image for training or evaluation.
-
- Args:
- image: 3-D Tensor [height, width, channels] with the image. If dtype is
- tf.float32 then the range should be [0, 1], otherwise it would converted
- to tf.float32 assuming that the range is [0, MAX], where MAX is largest
- positive representable number for int(8/16/32) data type (see
- `tf.image.convert_image_dtype` for details).
- height: integer, image expected height.
- width: integer, image expected width.
- is_training: Boolean. If true it would transform an image for train,
- otherwise it would transform it for evaluation.
- bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
- where each coordinate is [0, 1) and the coordinates are arranged as
- [ymin, xmin, ymax, xmax].
- fast_mode: Optional boolean, if True avoids slower transformations.
- add_image_summaries: Enable image summaries.
-
- Returns:
- 3-D float Tensor containing an appropriately scaled image
-
- Raises:
- ValueError: if user does not provide bounding box
- """
- if is_training:
- return preprocess_for_train(image, height, width, bbox, fast_mode,
- add_image_summaries=add_image_summaries)
- else:
- return preprocess_for_eval(image, height, width)
diff --git a/research/cognitive_planning/preprocessing/lenet_preprocessing.py b/research/cognitive_planning/preprocessing/lenet_preprocessing.py
deleted file mode 100644
index ac5e71af889866312a0896f35023d85b2c260b25..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/lenet_preprocessing.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Provides utilities for preprocessing."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-
-def preprocess_image(image, output_height, output_width, is_training):
- """Preprocesses the given image.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- is_training: `True` if we're preprocessing the image for training and
- `False` otherwise.
-
- Returns:
- A preprocessed image.
- """
- image = tf.to_float(image)
- image = tf.image.resize_image_with_crop_or_pad(
- image, output_width, output_height)
- image = tf.subtract(image, 128.0)
- image = tf.div(image, 128.0)
- return image
diff --git a/research/cognitive_planning/preprocessing/preprocessing_factory.py b/research/cognitive_planning/preprocessing/preprocessing_factory.py
deleted file mode 100644
index 1bd04c252a628fb016ef89bf65e7e5c498516f0c..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/preprocessing_factory.py
+++ /dev/null
@@ -1,81 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Contains a factory for building various models."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-from preprocessing import cifarnet_preprocessing
-from preprocessing import inception_preprocessing
-from preprocessing import lenet_preprocessing
-from preprocessing import vgg_preprocessing
-
-slim = tf.contrib.slim
-
-
-def get_preprocessing(name, is_training=False):
- """Returns preprocessing_fn(image, height, width, **kwargs).
-
- Args:
- name: The name of the preprocessing function.
- is_training: `True` if the model is being used for training and `False`
- otherwise.
-
- Returns:
- preprocessing_fn: A function that preprocessing a single image (pre-batch).
- It has the following signature:
- image = preprocessing_fn(image, output_height, output_width, ...).
-
- Raises:
- ValueError: If Preprocessing `name` is not recognized.
- """
- preprocessing_fn_map = {
- 'cifarnet': cifarnet_preprocessing,
- 'inception': inception_preprocessing,
- 'inception_v1': inception_preprocessing,
- 'inception_v2': inception_preprocessing,
- 'inception_v3': inception_preprocessing,
- 'inception_v4': inception_preprocessing,
- 'inception_resnet_v2': inception_preprocessing,
- 'lenet': lenet_preprocessing,
- 'mobilenet_v1': inception_preprocessing,
- 'nasnet_mobile': inception_preprocessing,
- 'nasnet_large': inception_preprocessing,
- 'pnasnet_large': inception_preprocessing,
- 'resnet_v1_50': vgg_preprocessing,
- 'resnet_v1_101': vgg_preprocessing,
- 'resnet_v1_152': vgg_preprocessing,
- 'resnet_v1_200': vgg_preprocessing,
- 'resnet_v2_50': vgg_preprocessing,
- 'resnet_v2_101': vgg_preprocessing,
- 'resnet_v2_152': vgg_preprocessing,
- 'resnet_v2_200': vgg_preprocessing,
- 'vgg': vgg_preprocessing,
- 'vgg_a': vgg_preprocessing,
- 'vgg_16': vgg_preprocessing,
- 'vgg_19': vgg_preprocessing,
- }
-
- if name not in preprocessing_fn_map:
- raise ValueError('Preprocessing name [%s] was not recognized' % name)
-
- def preprocessing_fn(image, output_height, output_width, **kwargs):
- return preprocessing_fn_map[name].preprocess_image(
- image, output_height, output_width, is_training=is_training, **kwargs)
-
- return preprocessing_fn
diff --git a/research/cognitive_planning/preprocessing/vgg_preprocessing.py b/research/cognitive_planning/preprocessing/vgg_preprocessing.py
deleted file mode 100644
index 3bd50598cde0e1ebf0bcaba38052300cedeb34e8..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/preprocessing/vgg_preprocessing.py
+++ /dev/null
@@ -1,365 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Provides utilities to preprocess images.
-
-The preprocessing steps for VGG were introduced in the following technical
-report:
-
- Very Deep Convolutional Networks For Large-Scale Image Recognition
- Karen Simonyan and Andrew Zisserman
- arXiv technical report, 2015
- PDF: http://arxiv.org/pdf/1409.1556.pdf
- ILSVRC 2014 Slides: http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
- CC-BY-4.0
-
-More information can be obtained from the VGG website:
-www.robots.ox.ac.uk/~vgg/research/very_deep/
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-slim = tf.contrib.slim
-
-_R_MEAN = 123.68
-_G_MEAN = 116.78
-_B_MEAN = 103.94
-
-_RESIZE_SIDE_MIN = 256
-_RESIZE_SIDE_MAX = 512
-
-
-def _crop(image, offset_height, offset_width, crop_height, crop_width):
- """Crops the given image using the provided offsets and sizes.
-
- Note that the method doesn't assume we know the input image size but it does
- assume we know the input image rank.
-
- Args:
- image: an image of shape [height, width, channels].
- offset_height: a scalar tensor indicating the height offset.
- offset_width: a scalar tensor indicating the width offset.
- crop_height: the height of the cropped image.
- crop_width: the width of the cropped image.
-
- Returns:
- the cropped (and resized) image.
-
- Raises:
- InvalidArgumentError: if the rank is not 3 or if the image dimensions are
- less than the crop size.
- """
- original_shape = tf.shape(image)
-
- rank_assertion = tf.Assert(
- tf.equal(tf.rank(image), 3),
- ['Rank of image must be equal to 3.'])
- with tf.control_dependencies([rank_assertion]):
- cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
-
- size_assertion = tf.Assert(
- tf.logical_and(
- tf.greater_equal(original_shape[0], crop_height),
- tf.greater_equal(original_shape[1], crop_width)),
- ['Crop size greater than the image size.'])
-
- offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0]))
-
- # Use tf.slice instead of crop_to_bounding box as it accepts tensors to
- # define the crop size.
- with tf.control_dependencies([size_assertion]):
- image = tf.slice(image, offsets, cropped_shape)
- return tf.reshape(image, cropped_shape)
-
-
-def _random_crop(image_list, crop_height, crop_width):
- """Crops the given list of images.
-
- The function applies the same crop to each image in the list. This can be
- effectively applied when there are multiple image inputs of the same
- dimension such as:
-
- image, depths, normals = _random_crop([image, depths, normals], 120, 150)
-
- Args:
- image_list: a list of image tensors of the same dimension but possibly
- varying channel.
- crop_height: the new height.
- crop_width: the new width.
-
- Returns:
- the image_list with cropped images.
-
- Raises:
- ValueError: if there are multiple image inputs provided with different size
- or the images are smaller than the crop dimensions.
- """
- if not image_list:
- raise ValueError('Empty image_list.')
-
- # Compute the rank assertions.
- rank_assertions = []
- for i in range(len(image_list)):
- image_rank = tf.rank(image_list[i])
- rank_assert = tf.Assert(
- tf.equal(image_rank, 3),
- ['Wrong rank for tensor %s [expected] [actual]',
- image_list[i].name, 3, image_rank])
- rank_assertions.append(rank_assert)
-
- with tf.control_dependencies([rank_assertions[0]]):
- image_shape = tf.shape(image_list[0])
- image_height = image_shape[0]
- image_width = image_shape[1]
- crop_size_assert = tf.Assert(
- tf.logical_and(
- tf.greater_equal(image_height, crop_height),
- tf.greater_equal(image_width, crop_width)),
- ['Crop size greater than the image size.'])
-
- asserts = [rank_assertions[0], crop_size_assert]
-
- for i in range(1, len(image_list)):
- image = image_list[i]
- asserts.append(rank_assertions[i])
- with tf.control_dependencies([rank_assertions[i]]):
- shape = tf.shape(image)
- height = shape[0]
- width = shape[1]
-
- height_assert = tf.Assert(
- tf.equal(height, image_height),
- ['Wrong height for tensor %s [expected][actual]',
- image.name, height, image_height])
- width_assert = tf.Assert(
- tf.equal(width, image_width),
- ['Wrong width for tensor %s [expected][actual]',
- image.name, width, image_width])
- asserts.extend([height_assert, width_assert])
-
- # Create a random bounding box.
- #
- # Use tf.random_uniform and not numpy.random.rand as doing the former would
- # generate random numbers at graph eval time, unlike the latter which
- # generates random numbers at graph definition time.
- with tf.control_dependencies(asserts):
- max_offset_height = tf.reshape(image_height - crop_height + 1, [])
- with tf.control_dependencies(asserts):
- max_offset_width = tf.reshape(image_width - crop_width + 1, [])
- offset_height = tf.random_uniform(
- [], maxval=max_offset_height, dtype=tf.int32)
- offset_width = tf.random_uniform(
- [], maxval=max_offset_width, dtype=tf.int32)
-
- return [_crop(image, offset_height, offset_width,
- crop_height, crop_width) for image in image_list]
-
-
-def _central_crop(image_list, crop_height, crop_width):
- """Performs central crops of the given image list.
-
- Args:
- image_list: a list of image tensors of the same dimension but possibly
- varying channel.
- crop_height: the height of the image following the crop.
- crop_width: the width of the image following the crop.
-
- Returns:
- the list of cropped images.
- """
- outputs = []
- for image in image_list:
- image_height = tf.shape(image)[0]
- image_width = tf.shape(image)[1]
-
- offset_height = (image_height - crop_height) / 2
- offset_width = (image_width - crop_width) / 2
-
- outputs.append(_crop(image, offset_height, offset_width,
- crop_height, crop_width))
- return outputs
-
-
-def _mean_image_subtraction(image, means):
- """Subtracts the given means from each image channel.
-
- For example:
- means = [123.68, 116.779, 103.939]
- image = _mean_image_subtraction(image, means)
-
- Note that the rank of `image` must be known.
-
- Args:
- image: a tensor of size [height, width, C].
- means: a C-vector of values to subtract from each channel.
-
- Returns:
- the centered image.
-
- Raises:
- ValueError: If the rank of `image` is unknown, if `image` has a rank other
- than three or if the number of channels in `image` doesn't match the
- number of values in `means`.
- """
- if image.get_shape().ndims != 3:
- raise ValueError('Input must be of size [height, width, C>0]')
- num_channels = image.get_shape().as_list()[-1]
- if len(means) != num_channels:
- raise ValueError('len(means) must match the number of channels')
-
- channels = tf.split(axis=2, num_or_size_splits=num_channels, value=image)
- for i in range(num_channels):
- channels[i] -= means[i]
- return tf.concat(axis=2, values=channels)
-
-
-def _smallest_size_at_least(height, width, smallest_side):
- """Computes new shape with the smallest side equal to `smallest_side`.
-
- Computes new shape with the smallest side equal to `smallest_side` while
- preserving the original aspect ratio.
-
- Args:
- height: an int32 scalar tensor indicating the current height.
- width: an int32 scalar tensor indicating the current width.
- smallest_side: A python integer or scalar `Tensor` indicating the size of
- the smallest side after resize.
-
- Returns:
- new_height: an int32 scalar tensor indicating the new height.
- new_width: and int32 scalar tensor indicating the new width.
- """
- smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
-
- height = tf.to_float(height)
- width = tf.to_float(width)
- smallest_side = tf.to_float(smallest_side)
-
- scale = tf.cond(tf.greater(height, width),
- lambda: smallest_side / width,
- lambda: smallest_side / height)
- new_height = tf.to_int32(tf.rint(height * scale))
- new_width = tf.to_int32(tf.rint(width * scale))
- return new_height, new_width
-
-
-def _aspect_preserving_resize(image, smallest_side):
- """Resize images preserving the original aspect ratio.
-
- Args:
- image: A 3-D image `Tensor`.
- smallest_side: A python integer or scalar `Tensor` indicating the size of
- the smallest side after resize.
-
- Returns:
- resized_image: A 3-D tensor containing the resized image.
- """
- smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
-
- shape = tf.shape(image)
- height = shape[0]
- width = shape[1]
- new_height, new_width = _smallest_size_at_least(height, width, smallest_side)
- image = tf.expand_dims(image, 0)
- resized_image = tf.image.resize_bilinear(image, [new_height, new_width],
- align_corners=False)
- resized_image = tf.squeeze(resized_image)
- resized_image.set_shape([None, None, 3])
- return resized_image
-
-
-def preprocess_for_train(image,
- output_height,
- output_width,
- resize_side_min=_RESIZE_SIDE_MIN,
- resize_side_max=_RESIZE_SIDE_MAX):
- """Preprocesses the given image for training.
-
- Note that the actual resizing scale is sampled from
- [`resize_size_min`, `resize_size_max`].
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- resize_side_min: The lower bound for the smallest side of the image for
- aspect-preserving resizing.
- resize_side_max: The upper bound for the smallest side of the image for
- aspect-preserving resizing.
-
- Returns:
- A preprocessed image.
- """
- resize_side = tf.random_uniform(
- [], minval=resize_side_min, maxval=resize_side_max+1, dtype=tf.int32)
-
- image = _aspect_preserving_resize(image, resize_side)
- image = _random_crop([image], output_height, output_width)[0]
- image.set_shape([output_height, output_width, 3])
- image = tf.to_float(image)
- image = tf.image.random_flip_left_right(image)
- return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
-
-
-def preprocess_for_eval(image, output_height, output_width, resize_side):
- """Preprocesses the given image for evaluation.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- resize_side: The smallest side of the image for aspect-preserving resizing.
-
- Returns:
- A preprocessed image.
- """
- image = _aspect_preserving_resize(image, resize_side)
- image = _central_crop([image], output_height, output_width)[0]
- image.set_shape([output_height, output_width, 3])
- image = tf.to_float(image)
- return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
-
-
-def preprocess_image(image, output_height, output_width, is_training=False,
- resize_side_min=_RESIZE_SIDE_MIN,
- resize_side_max=_RESIZE_SIDE_MAX):
- """Preprocesses the given image.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- is_training: `True` if we're preprocessing the image for training and
- `False` otherwise.
- resize_side_min: The lower bound for the smallest side of the image for
- aspect-preserving resizing. If `is_training` is `False`, then this value
- is used for rescaling.
- resize_side_max: The upper bound for the smallest side of the image for
- aspect-preserving resizing. If `is_training` is `False`, this value is
- ignored. Otherwise, the resize side is sampled from
- [resize_size_min, resize_size_max].
-
- Returns:
- A preprocessed image.
- """
- if is_training:
- return preprocess_for_train(image, output_height, output_width,
- resize_side_min, resize_side_max)
- else:
- return preprocess_for_eval(image, output_height, output_width,
- resize_side_min)
diff --git a/research/cognitive_planning/standard_fields.py b/research/cognitive_planning/standard_fields.py
deleted file mode 100644
index 99e04e66c56527e2c7be03aaf48836e077832c1f..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/standard_fields.py
+++ /dev/null
@@ -1,224 +0,0 @@
-# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Contains classes specifying naming conventions used for object detection.
-
-
-Specifies:
- InputDataFields: standard fields used by reader/preprocessor/batcher.
- DetectionResultFields: standard fields returned by object detector.
- BoxListFields: standard field used by BoxList
- TfExampleFields: standard fields for tf-example data format (go/tf-example).
-"""
-
-
-class InputDataFields(object):
- """Names for the input tensors.
-
- Holds the standard data field names to use for identifying input tensors. This
- should be used by the decoder to identify keys for the returned tensor_dict
- containing input tensors. And it should be used by the model to identify the
- tensors it needs.
-
- Attributes:
- image: image.
- image_additional_channels: additional channels.
- original_image: image in the original input size.
- key: unique key corresponding to image.
- source_id: source of the original image.
- filename: original filename of the dataset (without common path).
- groundtruth_image_classes: image-level class labels.
- groundtruth_boxes: coordinates of the ground truth boxes in the image.
- groundtruth_classes: box-level class labels.
- groundtruth_label_types: box-level label types (e.g. explicit negative).
- groundtruth_is_crowd: [DEPRECATED, use groundtruth_group_of instead]
- is the groundtruth a single object or a crowd.
- groundtruth_area: area of a groundtruth segment.
- groundtruth_difficult: is a `difficult` object
- groundtruth_group_of: is a `group_of` objects, e.g. multiple objects of the
- same class, forming a connected group, where instances are heavily
- occluding each other.
- proposal_boxes: coordinates of object proposal boxes.
- proposal_objectness: objectness score of each proposal.
- groundtruth_instance_masks: ground truth instance masks.
- groundtruth_instance_boundaries: ground truth instance boundaries.
- groundtruth_instance_classes: instance mask-level class labels.
- groundtruth_keypoints: ground truth keypoints.
- groundtruth_keypoint_visibilities: ground truth keypoint visibilities.
- groundtruth_label_scores: groundtruth label scores.
- groundtruth_weights: groundtruth weight factor for bounding boxes.
- num_groundtruth_boxes: number of groundtruth boxes.
- true_image_shapes: true shapes of images in the resized images, as resized
- images can be padded with zeros.
- multiclass_scores: the label score per class for each box.
- """
- image = 'image'
- image_additional_channels = 'image_additional_channels'
- original_image = 'original_image'
- key = 'key'
- source_id = 'source_id'
- filename = 'filename'
- groundtruth_image_classes = 'groundtruth_image_classes'
- groundtruth_boxes = 'groundtruth_boxes'
- groundtruth_classes = 'groundtruth_classes'
- groundtruth_label_types = 'groundtruth_label_types'
- groundtruth_is_crowd = 'groundtruth_is_crowd'
- groundtruth_area = 'groundtruth_area'
- groundtruth_difficult = 'groundtruth_difficult'
- groundtruth_group_of = 'groundtruth_group_of'
- proposal_boxes = 'proposal_boxes'
- proposal_objectness = 'proposal_objectness'
- groundtruth_instance_masks = 'groundtruth_instance_masks'
- groundtruth_instance_boundaries = 'groundtruth_instance_boundaries'
- groundtruth_instance_classes = 'groundtruth_instance_classes'
- groundtruth_keypoints = 'groundtruth_keypoints'
- groundtruth_keypoint_visibilities = 'groundtruth_keypoint_visibilities'
- groundtruth_label_scores = 'groundtruth_label_scores'
- groundtruth_weights = 'groundtruth_weights'
- num_groundtruth_boxes = 'num_groundtruth_boxes'
- true_image_shape = 'true_image_shape'
- multiclass_scores = 'multiclass_scores'
-
-
-class DetectionResultFields(object):
- """Naming conventions for storing the output of the detector.
-
- Attributes:
- source_id: source of the original image.
- key: unique key corresponding to image.
- detection_boxes: coordinates of the detection boxes in the image.
- detection_scores: detection scores for the detection boxes in the image.
- detection_classes: detection-level class labels.
- detection_masks: contains a segmentation mask for each detection box.
- detection_boundaries: contains an object boundary for each detection box.
- detection_keypoints: contains detection keypoints for each detection box.
- num_detections: number of detections in the batch.
- """
-
- source_id = 'source_id'
- key = 'key'
- detection_boxes = 'detection_boxes'
- detection_scores = 'detection_scores'
- detection_classes = 'detection_classes'
- detection_masks = 'detection_masks'
- detection_boundaries = 'detection_boundaries'
- detection_keypoints = 'detection_keypoints'
- num_detections = 'num_detections'
-
-
-class BoxListFields(object):
- """Naming conventions for BoxLists.
-
- Attributes:
- boxes: bounding box coordinates.
- classes: classes per bounding box.
- scores: scores per bounding box.
- weights: sample weights per bounding box.
- objectness: objectness score per bounding box.
- masks: masks per bounding box.
- boundaries: boundaries per bounding box.
- keypoints: keypoints per bounding box.
- keypoint_heatmaps: keypoint heatmaps per bounding box.
- is_crowd: is_crowd annotation per bounding box.
- """
- boxes = 'boxes'
- classes = 'classes'
- scores = 'scores'
- weights = 'weights'
- objectness = 'objectness'
- masks = 'masks'
- boundaries = 'boundaries'
- keypoints = 'keypoints'
- keypoint_heatmaps = 'keypoint_heatmaps'
- is_crowd = 'is_crowd'
-
-
-class TfExampleFields(object):
- """TF-example proto feature names for object detection.
-
- Holds the standard feature names to load from an Example proto for object
- detection.
-
- Attributes:
- image_encoded: JPEG encoded string
- image_format: image format, e.g. "JPEG"
- filename: filename
- channels: number of channels of image
- colorspace: colorspace, e.g. "RGB"
- height: height of image in pixels, e.g. 462
- width: width of image in pixels, e.g. 581
- source_id: original source of the image
- image_class_text: image-level label in text format
- image_class_label: image-level label in numerical format
- object_class_text: labels in text format, e.g. ["person", "cat"]
- object_class_label: labels in numbers, e.g. [16, 8]
- object_bbox_xmin: xmin coordinates of groundtruth box, e.g. 10, 30
- object_bbox_xmax: xmax coordinates of groundtruth box, e.g. 50, 40
- object_bbox_ymin: ymin coordinates of groundtruth box, e.g. 40, 50
- object_bbox_ymax: ymax coordinates of groundtruth box, e.g. 80, 70
- object_view: viewpoint of object, e.g. ["frontal", "left"]
- object_truncated: is object truncated, e.g. [true, false]
- object_occluded: is object occluded, e.g. [true, false]
- object_difficult: is object difficult, e.g. [true, false]
- object_group_of: is object a single object or a group of objects
- object_depiction: is object a depiction
- object_is_crowd: [DEPRECATED, use object_group_of instead]
- is the object a single object or a crowd
- object_segment_area: the area of the segment.
- object_weight: a weight factor for the object's bounding box.
- instance_masks: instance segmentation masks.
- instance_boundaries: instance boundaries.
- instance_classes: Classes for each instance segmentation mask.
- detection_class_label: class label in numbers.
- detection_bbox_ymin: ymin coordinates of a detection box.
- detection_bbox_xmin: xmin coordinates of a detection box.
- detection_bbox_ymax: ymax coordinates of a detection box.
- detection_bbox_xmax: xmax coordinates of a detection box.
- detection_score: detection score for the class label and box.
- """
- image_encoded = 'image/encoded'
- image_format = 'image/format' # format is reserved keyword
- filename = 'image/filename'
- channels = 'image/channels'
- colorspace = 'image/colorspace'
- height = 'image/height'
- width = 'image/width'
- source_id = 'image/source_id'
- image_class_text = 'image/class/text'
- image_class_label = 'image/class/label'
- object_class_text = 'image/object/class/text'
- object_class_label = 'image/object/class/label'
- object_bbox_ymin = 'image/object/bbox/ymin'
- object_bbox_xmin = 'image/object/bbox/xmin'
- object_bbox_ymax = 'image/object/bbox/ymax'
- object_bbox_xmax = 'image/object/bbox/xmax'
- object_view = 'image/object/view'
- object_truncated = 'image/object/truncated'
- object_occluded = 'image/object/occluded'
- object_difficult = 'image/object/difficult'
- object_group_of = 'image/object/group_of'
- object_depiction = 'image/object/depiction'
- object_is_crowd = 'image/object/is_crowd'
- object_segment_area = 'image/object/segment/area'
- object_weight = 'image/object/weight'
- instance_masks = 'image/segmentation/object'
- instance_boundaries = 'image/boundaries/object'
- instance_classes = 'image/segmentation/object/class'
- detection_class_label = 'image/detection/label'
- detection_bbox_ymin = 'image/detection/bbox/ymin'
- detection_bbox_xmin = 'image/detection/bbox/xmin'
- detection_bbox_ymax = 'image/detection/bbox/ymax'
- detection_bbox_xmax = 'image/detection/bbox/xmax'
- detection_score = 'image/detection/score'
diff --git a/research/cognitive_planning/string_int_label_map_pb2.py b/research/cognitive_planning/string_int_label_map_pb2.py
deleted file mode 100644
index 44a46d7abb400f580aec065f7d82a88c695a48da..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/string_int_label_map_pb2.py
+++ /dev/null
@@ -1,138 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# Generated by the protocol buffer compiler. DO NOT EDIT!
-# source: object_detection/protos/string_int_label_map.proto
-
-import sys
-_b=sys.version_info[0]<3 and (lambda x:x) or (lambda x:x.encode('latin1'))
-from google.protobuf import descriptor as _descriptor
-from google.protobuf import message as _message
-from google.protobuf import reflection as _reflection
-from google.protobuf import symbol_database as _symbol_database
-from google.protobuf import descriptor_pb2
-# @@protoc_insertion_point(imports)
-
-_sym_db = _symbol_database.Default()
-
-
-
-
-DESCRIPTOR = _descriptor.FileDescriptor(
- name='object_detection/protos/string_int_label_map.proto',
- package='object_detection.protos',
- syntax='proto2',
- serialized_pb=_b('\n2object_detection/protos/string_int_label_map.proto\x12\x17object_detection.protos\"G\n\x15StringIntLabelMapItem\x12\x0c\n\x04name\x18\x01 \x01(\t\x12\n\n\x02id\x18\x02 \x01(\x05\x12\x14\n\x0c\x64isplay_name\x18\x03 \x01(\t\"Q\n\x11StringIntLabelMap\x12<\n\x04item\x18\x01 \x03(\x0b\x32..object_detection.protos.StringIntLabelMapItem')
-)
-
-
-
-
-_STRINGINTLABELMAPITEM = _descriptor.Descriptor(
- name='StringIntLabelMapItem',
- full_name='object_detection.protos.StringIntLabelMapItem',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='name', full_name='object_detection.protos.StringIntLabelMapItem.name', index=0,
- number=1, type=9, cpp_type=9, label=1,
- has_default_value=False, default_value=_b("").decode('utf-8'),
- message_type=None, enum_type=None, containing_type=None,
- is_extension=False, extension_scope=None,
- options=None),
- _descriptor.FieldDescriptor(
- name='id', full_name='object_detection.protos.StringIntLabelMapItem.id', index=1,
- number=2, type=5, cpp_type=1, label=1,
- has_default_value=False, default_value=0,
- message_type=None, enum_type=None, containing_type=None,
- is_extension=False, extension_scope=None,
- options=None),
- _descriptor.FieldDescriptor(
- name='display_name', full_name='object_detection.protos.StringIntLabelMapItem.display_name', index=2,
- number=3, type=9, cpp_type=9, label=1,
- has_default_value=False, default_value=_b("").decode('utf-8'),
- message_type=None, enum_type=None, containing_type=None,
- is_extension=False, extension_scope=None,
- options=None),
- ],
- extensions=[
- ],
- nested_types=[],
- enum_types=[
- ],
- options=None,
- is_extendable=False,
- syntax='proto2',
- extension_ranges=[],
- oneofs=[
- ],
- serialized_start=79,
- serialized_end=150,
-)
-
-
-_STRINGINTLABELMAP = _descriptor.Descriptor(
- name='StringIntLabelMap',
- full_name='object_detection.protos.StringIntLabelMap',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='item', full_name='object_detection.protos.StringIntLabelMap.item', index=0,
- number=1, type=11, cpp_type=10, label=3,
- has_default_value=False, default_value=[],
- message_type=None, enum_type=None, containing_type=None,
- is_extension=False, extension_scope=None,
- options=None),
- ],
- extensions=[
- ],
- nested_types=[],
- enum_types=[
- ],
- options=None,
- is_extendable=False,
- syntax='proto2',
- extension_ranges=[],
- oneofs=[
- ],
- serialized_start=152,
- serialized_end=233,
-)
-
-_STRINGINTLABELMAP.fields_by_name['item'].message_type = _STRINGINTLABELMAPITEM
-DESCRIPTOR.message_types_by_name['StringIntLabelMapItem'] = _STRINGINTLABELMAPITEM
-DESCRIPTOR.message_types_by_name['StringIntLabelMap'] = _STRINGINTLABELMAP
-_sym_db.RegisterFileDescriptor(DESCRIPTOR)
-
-StringIntLabelMapItem = _reflection.GeneratedProtocolMessageType('StringIntLabelMapItem', (_message.Message,), dict(
- DESCRIPTOR = _STRINGINTLABELMAPITEM,
- __module__ = 'object_detection.protos.string_int_label_map_pb2'
- # @@protoc_insertion_point(class_scope:object_detection.protos.StringIntLabelMapItem)
- ))
-_sym_db.RegisterMessage(StringIntLabelMapItem)
-
-StringIntLabelMap = _reflection.GeneratedProtocolMessageType('StringIntLabelMap', (_message.Message,), dict(
- DESCRIPTOR = _STRINGINTLABELMAP,
- __module__ = 'object_detection.protos.string_int_label_map_pb2'
- # @@protoc_insertion_point(class_scope:object_detection.protos.StringIntLabelMap)
- ))
-_sym_db.RegisterMessage(StringIntLabelMap)
-
-
-# @@protoc_insertion_point(module_scope)
diff --git a/research/cognitive_planning/tasks.py b/research/cognitive_planning/tasks.py
deleted file mode 100644
index c3ef6ca328f7454ffe9aec61a704d1322d680d31..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/tasks.py
+++ /dev/null
@@ -1,1507 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A library of tasks.
-
-This interface is intended to implement a wide variety of navigation
-tasks. See go/navigation_tasks for a list.
-"""
-
-import abc
-import collections
-import math
-import threading
-import networkx as nx
-import numpy as np
-import tensorflow as tf
-#from pyglib import logging
-#import gin
-from envs import task_env
-from envs import util as envs_util
-
-
-# Utility functions.
-def _pad_or_clip_array(np_arr, arr_len, is_front_clip=True, output_mask=False):
- """Make np_arr array to have length arr_len.
-
- If the array is shorter than arr_len, then it is padded from the front with
- zeros. If it is longer, then it is clipped either from the back or from the
- front. Only the first dimension is modified.
-
- Args:
- np_arr: numpy array.
- arr_len: integer scalar.
- is_front_clip: a boolean. If true then clipping is done in the front,
- otherwise in the back.
- output_mask: If True, outputs a numpy array of rank 1 which represents
- a mask of which values have been added (0 - added, 1 - actual output).
-
- Returns:
- A numpy array and the size of padding (as a python int32). This size is
- negative is the array is clipped.
- """
- shape = list(np_arr.shape)
- pad_size = arr_len - shape[0]
- padded_or_clipped = None
- if pad_size < 0:
- if is_front_clip:
- padded_or_clipped = np_arr[-pad_size:, :]
- else:
- padded_or_clipped = np_arr[:arr_len, :]
- elif pad_size > 0:
- padding = np.zeros([pad_size] + shape[1:], dtype=np_arr.dtype)
- padded_or_clipped = np.concatenate([np_arr, padding], axis=0)
- else:
- padded_or_clipped = np_arr
-
- if output_mask:
- mask = np.ones((arr_len,), dtype=np.int)
- if pad_size > 0:
- mask[-pad_size:] = 0
- return padded_or_clipped, pad_size, mask
- else:
- return padded_or_clipped, pad_size
-
-
-def classification_loss(truth, predicted, weights=None, is_one_hot=True):
- """A cross entropy loss.
-
- Computes the mean of cross entropy losses for all pairs of true labels and
- predictions. It wraps around a tf implementation of the cross entropy loss
- with additional reformating of the inputs. If the truth and predicted are
- n-rank Tensors with n > 2, then these are reshaped to 2-rank Tensors. It
- allows for truth to be specified as one hot vector or class indices. Finally,
- a weight can be specified for each element in truth and predicted.
-
- Args:
- truth: an n-rank or (n-1)-rank Tensor containing labels. If is_one_hot is
- True, then n-rank Tensor is expected, otherwise (n-1) rank one.
- predicted: an n-rank float Tensor containing prediction probabilities.
- weights: an (n-1)-rank float Tensor of weights
- is_one_hot: a boolean.
-
- Returns:
- A TF float scalar.
- """
- num_labels = predicted.get_shape().as_list()[-1]
- if not is_one_hot:
- truth = tf.reshape(truth, [-1])
- truth = tf.one_hot(
- truth, depth=num_labels, on_value=1.0, off_value=0.0, axis=-1)
- else:
- truth = tf.reshape(truth, [-1, num_labels])
- predicted = tf.reshape(predicted, [-1, num_labels])
- losses = tf.nn.softmax_cross_entropy_with_logits(
- labels=truth, logits=predicted)
- if weights is not None:
- losses = tf.boolean_mask(losses,
- tf.cast(tf.reshape(weights, [-1]), dtype=tf.bool))
- return tf.reduce_mean(losses)
-
-
-class UnrolledTaskIOConfig(object):
- """Configuration of task inputs and outputs.
-
- A task can have multiple inputs, which define the context, and a task query
- which defines what is to be executed in this context. The desired execution
- is encoded in an output. The config defines the shapes of the inputs, the
- query and the outputs.
- """
-
- def __init__(self, inputs, output, query=None):
- """Constructs a Task input/output config.
-
- Args:
- inputs: a list of tuples. Each tuple represents the configuration of an
- input, with first element being the type (a string value) and the second
- element the shape.
- output: a tuple representing the configuration of the output.
- query: a tuple representing the configuration of the query. If no query,
- then None.
- """
- # A configuration of a single input, output or query. Consists of the type,
- # which can be one of the three specified above, and a shape. The shape must
- # be consistent with the type, e.g. if type == 'image', then shape is a 3
- # valued list.
- io_config = collections.namedtuple('IOConfig', ['type', 'shape'])
-
- def assert_config(config):
- if not isinstance(config, tuple):
- raise ValueError('config must be a tuple. Received {}'.format(
- type(config)))
- if len(config) != 2:
- raise ValueError('config must have 2 elements, has %d' % len(config))
- if not isinstance(config[0], tf.DType):
- raise ValueError('First element of config must be a tf.DType.')
- if not isinstance(config[1], list):
- raise ValueError('Second element of config must be a list.')
-
- assert isinstance(inputs, collections.OrderedDict)
- for modality_type in inputs:
- assert_config(inputs[modality_type])
- self._inputs = collections.OrderedDict(
- [(k, io_config(*value)) for k, value in inputs.iteritems()])
-
- if query is not None:
- assert_config(query)
- self._query = io_config(*query)
- else:
- self._query = None
-
- assert_config(output)
- self._output = io_config(*output)
-
- @property
- def inputs(self):
- return self._inputs
-
- @property
- def output(self):
- return self._output
-
- @property
- def query(self):
- return self._query
-
-
-class UnrolledTask(object):
- """An interface for a Task which can be unrolled during training.
-
- Each example is called episode and consists of inputs and target output, where
- the output can be considered as desired unrolled sequence of actions for the
- inputs. For the specified tasks, these action sequences are to be
- unambiguously definable.
- """
- __metaclass__ = abc.ABCMeta
-
- def __init__(self, config):
- assert isinstance(config, UnrolledTaskIOConfig)
- self._config = config
- # A dict of bookkeeping variables.
- self.info = {}
- # Tensorflow input is multithreaded and this lock is needed to prevent
- # race condition in the environment. Without the lock, non-thread safe
- # environments crash.
- self._lock = threading.Lock()
-
- @property
- def config(self):
- return self._config
-
- @abc.abstractmethod
- def episode(self):
- """Returns data needed to train and test a single episode.
-
- Each episode consists of inputs, which define the context of the task, a
- query which defines the task, and a target output, which defines a
- sequence of actions to be executed for this query. This sequence should not
- require feedback, i.e. can be predicted purely from input and query.]
-
- Returns:
- inputs, query, output, where inputs is a list of numpy arrays and query
- and output are numpy arrays. These arrays must be of shape and type as
- specified in the task configuration.
- """
- pass
-
- def reset(self, observation):
- """Called after the environment is reset."""
- pass
-
- def episode_batch(self, batch_size):
- """Returns a batch of episodes.
-
- Args:
- batch_size: size of batch.
-
- Returns:
- (inputs, query, output, masks) where inputs is list of numpy arrays and
- query, output, and mask are numpy arrays. These arrays must be of shape
- and type as specified in the task configuration with one additional
- preceding dimension corresponding to the batch.
-
- Raises:
- ValueError: if self.episode() returns illegal values.
- """
- batched_inputs = collections.OrderedDict(
- [[mtype, []] for mtype in self.config.inputs])
- batched_queries = []
- batched_outputs = []
- batched_masks = []
- for _ in range(int(batch_size)):
- with self._lock:
- # The episode function needs to be thread-safe. Since the current
- # implementation for the envs are not thread safe we need to have lock
- # the operations here.
- inputs, query, outputs = self.episode()
- if not isinstance(outputs, tuple):
- raise ValueError('Outputs return value must be tuple.')
- if len(outputs) != 2:
- raise ValueError('Output tuple must be of size 2.')
- if inputs is not None:
- for modality_type in batched_inputs:
- batched_inputs[modality_type].append(
- np.expand_dims(inputs[modality_type], axis=0))
-
- if query is not None:
- batched_queries.append(np.expand_dims(query, axis=0))
- batched_outputs.append(np.expand_dims(outputs[0], axis=0))
- if outputs[1] is not None:
- batched_masks.append(np.expand_dims(outputs[1], axis=0))
-
- batched_inputs = {
- k: np.concatenate(i, axis=0) for k, i in batched_inputs.iteritems()
- }
- if batched_queries:
- batched_queries = np.concatenate(batched_queries, axis=0)
- batched_outputs = np.concatenate(batched_outputs, axis=0)
- if batched_masks:
- batched_masks = np.concatenate(batched_masks, axis=0).astype(np.float32)
- else:
- # When the array is empty, the default np.dtype is float64 which causes
- # py_func to crash in the tests.
- batched_masks = np.array([], dtype=np.float32)
- batched_inputs = [batched_inputs[k] for k in self._config.inputs]
- return batched_inputs, batched_queries, batched_outputs, batched_masks
-
- def tf_episode_batch(self, batch_size):
- """A batch of episodes as TF Tensors.
-
- Same as episode_batch with the difference that the return values are TF
- Tensors.
-
- Args:
- batch_size: a python float for the batch size.
-
- Returns:
- inputs, query, output, mask where inputs is a dictionary of tf.Tensor
- where the keys are the modality types specified in the config.inputs.
- query, output, and mask are TF Tensors. These tensors must
- be of shape and type as specified in the task configuration with one
- additional preceding dimension corresponding to the batch. Both mask and
- output have the same shape as output.
- """
-
- # Define TF outputs.
- touts = []
- shapes = []
- for _, i in self._config.inputs.iteritems():
- touts.append(i.type)
- shapes.append(i.shape)
- if self._config.query is not None:
- touts.append(self._config.query.type)
- shapes.append(self._config.query.shape)
- # Shapes and types for batched_outputs.
- touts.append(self._config.output.type)
- shapes.append(self._config.output.shape)
- # Shapes and types for batched_masks.
- touts.append(self._config.output.type)
- shapes.append(self._config.output.shape[0:1])
-
- def episode_batch_func():
- if self.config.query is None:
- inp, _, output, masks = self.episode_batch(int(batch_size))
- return tuple(inp) + (output, masks)
- else:
- inp, query, output, masks = self.episode_batch(int(batch_size))
- return tuple(inp) + (query, output, masks)
-
- tf_episode_batch = tf.py_func(episode_batch_func, [], touts,
- stateful=True, name='taskdata')
- for episode, shape in zip(tf_episode_batch, shapes):
- episode.set_shape([batch_size] + shape)
-
- tf_episode_batch_dict = collections.OrderedDict([
- (mtype, episode)
- for mtype, episode in zip(self.config.inputs.keys(), tf_episode_batch)
- ])
- cur_index = len(self.config.inputs.keys())
- tf_query = None
- if self.config.query is not None:
- tf_query = tf_episode_batch[cur_index]
- cur_index += 1
- tf_outputs = tf_episode_batch[cur_index]
- tf_masks = tf_episode_batch[cur_index + 1]
-
- return tf_episode_batch_dict, tf_query, tf_outputs, tf_masks
-
- @abc.abstractmethod
- def target_loss(self, true_targets, targets, weights=None):
- """A loss for training a task model.
-
- This loss measures the discrepancy between the task outputs, the true and
- predicted ones.
-
- Args:
- true_targets: tf.Tensor of shape and type as defined in the task config
- containing the true outputs.
- targets: tf.Tensor of shape and type as defined in the task config
- containing the predicted outputs.
- weights: a bool tf.Tensor of shape as targets. Only true values are
- considered when formulating the loss.
- """
- pass
-
- def reward(self, obs, done, info):
- """Returns a reward.
-
- The tasks has to compute a reward based on the state of the environment. The
- reward computation, though, is task specific. The task is to use the
- environment interface, as defined in task_env.py, to compute the reward. If
- this interface does not expose enough information, it is to be updated.
-
- Args:
- obs: Observation from environment's step function.
- done: Done flag from environment's step function.
- info: Info dict from environment's step function.
-
- Returns:
- obs: Observation.
- reward: Floating point value.
- done: Done flag.
- info: Info dict.
- """
- # Default implementation does not do anything.
- return obs, 0.0, done, info
-
-
-class RandomExplorationBasedTask(UnrolledTask):
- """A Task which starts with a random exploration of the environment."""
-
- def __init__(self,
- env,
- seed,
- add_query_noise=False,
- query_noise_var=0.0,
- *args,
- **kwargs): # pylint: disable=keyword-arg-before-vararg
- """Initializes a Task using a random exploration runs.
-
- Args:
- env: an instance of type TaskEnv and gym.Env.
- seed: a random seed.
- add_query_noise: boolean, if True then whatever queries are generated,
- they are randomly perturbed. The semantics of the queries depends on the
- concrete task implementation.
- query_noise_var: float, the variance of Gaussian noise used for query
- perturbation. Used iff add_query_noise==True.
- *args: see super class.
- **kwargs: see super class.
- """
- super(RandomExplorationBasedTask, self).__init__(*args, **kwargs)
- assert isinstance(env, task_env.TaskEnv)
- self._env = env
- self._env.set_task(self)
- self._rng = np.random.RandomState(seed)
- self._add_query_noise = add_query_noise
- self._query_noise_var = query_noise_var
-
- # GoToStaticXTask can also take empty config but for the rest of the classes
- # the number of modality types is 1.
- if len(self.config.inputs.keys()) > 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type or less.')
-
- def _exploration(self):
- """Generates a random exploration run.
-
- The function uses the environment to generate a run.
-
- Returns:
- A tuple of numpy arrays. The i-th array contains observation of type and
- shape as specified in config.inputs[i].
- A list of states along the exploration path.
- A list of vertex indices corresponding to the path of the exploration.
- """
- in_seq_len = self._config.inputs.values()[0].shape[0]
- path, _, states, step_outputs = self._env.random_step_sequence(
- min_len=in_seq_len)
- obs = {modality_type: [] for modality_type in self._config.inputs}
- for o in step_outputs:
- step_obs, _, done, _ = o
- # It is expected that each value of step_obs is a dict of observations,
- # whose dimensions are consistent with the config.inputs sizes.
- for modality_type in self._config.inputs:
- assert modality_type in step_obs, '{}'.format(type(step_obs))
- o = step_obs[modality_type]
- i = self._config.inputs[modality_type]
- assert len(o.shape) == len(i.shape) - 1
- for dim_o, dim_i in zip(o.shape, i.shape[1:]):
- assert dim_o == dim_i, '{} != {}'.format(dim_o, dim_i)
- obs[modality_type].append(o)
- if done:
- break
-
- if not obs:
- return obs, states, path
-
- max_path_len = int(
- round(in_seq_len * float(len(path)) / float(len(obs.values()[0]))))
- path = path[-max_path_len:]
- states = states[-in_seq_len:]
-
- # The above obs is a list of tuples of np,array. Re-format them as tuple of
- # np.array, each array containing all observations from all steps.
- def regroup(obs, i):
- """Regroups observations.
-
- Args:
- obs: a list of tuples of same size. The k-th tuple contains all the
- observations from k-th step. Each observation is a numpy array.
- i: the index of the observation in each tuple to be grouped.
-
- Returns:
- A numpy array of shape config.inputs[i] which contains all i-th
- observations from all steps. These are concatenated along the first
- dimension. In addition, if the number of observations is different from
- the one specified in config.inputs[i].shape[0], then the array is either
- padded from front or clipped.
- """
- grouped_obs = np.concatenate(
- [np.expand_dims(o, axis=0) for o in obs[i]], axis=0)
- in_seq_len = self._config.inputs[i].shape[0]
- # pylint: disable=unbalanced-tuple-unpacking
- grouped_obs, _ = _pad_or_clip_array(
- grouped_obs, in_seq_len, is_front_clip=True)
- return grouped_obs
-
- all_obs = {i: regroup(obs, i) for i in self._config.inputs}
-
- return all_obs, states, path
-
- def _obs_to_state(self, path, states):
- """Computes mapping between path nodes and states."""
- # Generate a numpy array of locations corresponding to the path vertices.
- path_coordinates = map(self._env.vertex_to_pose, path)
- path_coordinates = np.concatenate(
- [np.reshape(p, [1, 2]) for p in path_coordinates])
-
- # The observations are taken along a smoothed trajectory following the path.
- # We compute a mapping between the obeservations and the map vertices.
- path_to_obs = collections.defaultdict(list)
- obs_to_state = []
- for i, s in enumerate(states):
- location = np.reshape(s[0:2], [1, 2])
- index = np.argmin(
- np.reshape(
- np.sum(np.power(path_coordinates - location, 2), axis=1), [-1]))
- index = path[index]
- path_to_obs[index].append(i)
- obs_to_state.append(index)
- return path_to_obs, obs_to_state
-
- def _perturb_state(self, state, noise_var):
- """Perturbes the state.
-
- The location are purturbed using a Gaussian noise with variance
- noise_var. The orientation is uniformly sampled.
-
- Args:
- state: a numpy array containing an env state (x, y locations).
- noise_var: float
- Returns:
- The perturbed state.
- """
-
- def normal(v, std):
- if std > 0:
- n = self._rng.normal(0.0, std)
- n = min(n, 2.0 * std)
- n = max(n, -2.0 * std)
- return v + n
- else:
- return v
-
- state = state.copy()
- state[0] = normal(state[0], noise_var)
- state[1] = normal(state[1], noise_var)
- if state.size > 2:
- state[2] = self._rng.uniform(-math.pi, math.pi)
- return state
-
- def _sample_obs(self,
- indices,
- observations,
- observation_states,
- path_to_obs,
- max_obs_index=None,
- use_exploration_obs=True):
- """Samples one observation which corresponds to vertex_index in path.
-
- In addition, the sampled observation must have index in observations less
- than max_obs_index. If these two conditions cannot be satisfied the
- function returns None.
-
- Args:
- indices: a list of integers.
- observations: a list of numpy arrays containing all the observations.
- observation_states: a list of numpy arrays, each array representing the
- state of the observation.
- path_to_obs: a dict of path indices to lists of observation indices.
- max_obs_index: an integer.
- use_exploration_obs: if True, then the observation is sampled among the
- specified observations, otherwise it is obtained from the environment.
- Returns:
- A tuple of:
- -- A numpy array of size width x height x 3 representing the sampled
- observation.
- -- The index of the sampld observation among the input observations.
- -- The state at which the observation is captured.
- Raises:
- ValueError: if the observation and observation_states lists are of
- different lengths.
- """
- if len(observations) != len(observation_states):
- raise ValueError('observation and observation_states lists must have '
- 'equal lengths')
- if not indices:
- return None, None, None
- vertex_index = self._rng.choice(indices)
- if use_exploration_obs:
- obs_indices = path_to_obs[vertex_index]
-
- if max_obs_index is not None:
- obs_indices = [i for i in obs_indices if i < max_obs_index]
-
- if obs_indices:
- index = self._rng.choice(obs_indices)
- if self._add_query_noise:
- xytheta = self._perturb_state(observation_states[index],
- self._query_noise_var)
- return self._env.observation(xytheta), index, xytheta
- else:
- return observations[index], index, observation_states[index]
- else:
- return None, None, None
- else:
- xy = self._env.vertex_to_pose(vertex_index)
- xytheta = np.array([xy[0], xy[1], 0.0])
- xytheta = self._perturb_state(xytheta, self._query_noise_var)
- return self._env.observation(xytheta), None, xytheta
-
-
-class AreNearbyTask(RandomExplorationBasedTask):
- """A task of identifying whether a query is nearby current location or not.
-
- The query is guaranteed to be in proximity of an already visited location,
- i.e. close to one of the observations. For each observation we have one
- query, which is either close or not to this observation.
- """
-
- def __init__(
- self,
- max_distance=0,
- *args,
- **kwargs): # pylint: disable=keyword-arg-before-vararg
- super(AreNearbyTask, self).__init__(*args, **kwargs)
- self._max_distance = max_distance
-
- if len(self.config.inputs.keys()) != 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type')
-
- def episode(self):
- """Episode data.
-
- Returns:
- observations: a tuple with one element. This element is a numpy array of
- size in_seq_len x observation_size x observation_size x 3 containing
- in_seq_len images.
- query: a numpy array of size
- in_seq_len x observation_size X observation_size x 3 containing a query
- image.
- A tuple of size two. First element is a in_seq_len x 2 numpy array of
- either 1.0 or 0.0. The i-th element denotes whether the i-th query
- image is neraby (value 1.0) or not (value 0.0) to the i-th observation.
- The second element in the tuple is a mask, a numpy array of size
- in_seq_len x 1 and values 1.0 or 0.0 denoting whether the query is
- valid or not (it can happen that the query is not valid, e.g. there are
- not enough observations to have a meaningful queries).
- """
- observations, states, path = self._exploration()
- assert len(observations.values()[0]) == len(states)
-
- # The observations are taken along a smoothed trajectory following the path.
- # We compute a mapping between the obeservations and the map vertices.
- path_to_obs, obs_to_path = self._obs_to_state(path, states)
-
- # Go over all observations, and sample a query. With probability 0.5 this
- # query is a nearby observation (defined as belonging to the same vertex
- # in path).
- g = self._env.graph
- queries = []
- labels = []
- validity_masks = []
- query_index_in_observations = []
- for i, curr_o in enumerate(observations.values()[0]):
- p = obs_to_path[i]
- low = max(0, i - self._max_distance)
-
- # A list of lists of vertex indices. Each list in this group corresponds
- # to one possible label.
- index_groups = [[], [], []]
- # Nearby visited indices, label 1.
- nearby_visited = [
- ii for ii in path[low:i + 1] + g[p].keys() if ii in obs_to_path[:i]
- ]
- nearby_visited = [ii for ii in index_groups[1] if ii in path_to_obs]
- # NOT Nearby visited indices, label 0.
- not_nearby_visited = [ii for ii in path[:low] if ii not in g[p].keys()]
- not_nearby_visited = [ii for ii in index_groups[0] if ii in path_to_obs]
- # NOT visited indices, label 2.
- not_visited = [
- ii for ii in range(g.number_of_nodes()) if ii not in path[:i + 1]
- ]
-
- index_groups = [not_nearby_visited, nearby_visited, not_visited]
-
- # Consider only labels for which there are indices.
- allowed_labels = [ii for ii, group in enumerate(index_groups) if group]
- label = self._rng.choice(allowed_labels)
-
- indices = list(set(index_groups[label]))
- max_obs_index = None if label == 2 else i
- use_exploration_obs = False if label == 2 else True
- o, obs_index, _ = self._sample_obs(
- indices=indices,
- observations=observations.values()[0],
- observation_states=states,
- path_to_obs=path_to_obs,
- max_obs_index=max_obs_index,
- use_exploration_obs=use_exploration_obs)
- query_index_in_observations.append(obs_index)
-
- # If we cannot sample a valid query, we mark it as not valid in mask.
- if o is None:
- label = 0.0
- o = curr_o
- validity_masks.append(0)
- else:
- validity_masks.append(1)
-
- queries.append(o.values()[0])
- labels.append(label)
-
- query = np.concatenate([np.expand_dims(q, axis=0) for q in queries], axis=0)
-
- def one_hot(label, num_labels=3):
- a = np.zeros((num_labels,), dtype=np.float)
- a[int(label)] = 1.0
- return a
-
- outputs = np.stack([one_hot(l) for l in labels], axis=0)
- validity_mask = np.reshape(
- np.array(validity_masks, dtype=np.int32), [-1, 1])
-
- self.info['query_index_in_observations'] = query_index_in_observations
- self.info['observation_states'] = states
-
- return observations, query, (outputs, validity_mask)
-
- def target_loss(self, truth, predicted, weights=None):
- pass
-
-
-class NeighboringQueriesTask(RandomExplorationBasedTask):
- """A task of identifying whether two queries are closeby or not.
-
- The proximity between queries is defined by the length of the shorest path
- between them.
- """
-
- def __init__(
- self,
- max_distance=1,
- *args,
- **kwargs): # pylint: disable=keyword-arg-before-vararg
- """Initializes a NeighboringQueriesTask.
-
- Args:
- max_distance: integer, the maximum distance in terms of number of vertices
- between the two queries, so that they are considered neighboring.
- *args: for super class.
- **kwargs: for super class.
- """
- super(NeighboringQueriesTask, self).__init__(*args, **kwargs)
- self._max_distance = max_distance
- if len(self.config.inputs.keys()) != 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type')
-
- def episode(self):
- """Episode data.
-
- Returns:
- observations: a tuple with one element. This element is a numpy array of
- size in_seq_len x observation_size x observation_size x 3 containing
- in_seq_len images.
- query: a numpy array of size
- 2 x observation_size X observation_size x 3 containing a pair of query
- images.
- A tuple of size two. First element is a numpy array of size 2 containing
- a one hot vector of whether the two observations are neighobring. Second
- element is a boolean numpy value denoting whether this is a valid
- episode.
- """
- observations, states, path = self._exploration()
- assert len(observations.values()[0]) == len(states)
- path_to_obs, _ = self._obs_to_state(path, states)
- # Restrict path to ones for which observations have been generated.
- path = [p for p in path if p in path_to_obs]
- # Sample first query.
- query1_index = self._rng.choice(path)
- # Sample label.
- label = self._rng.randint(2)
- # Sample second query.
- # If label == 1, then second query must be nearby, otherwise not.
- closest_indices = nx.single_source_shortest_path(
- self._env.graph, query1_index, self._max_distance).keys()
- if label == 0:
- # Closest indices on the path.
- indices = [p for p in path if p not in closest_indices]
- else:
- # Indices which are not closest on the path.
- indices = [p for p in closest_indices if p in path]
-
- query2_index = self._rng.choice(indices)
- # Generate an observation.
- query1, query1_index, _ = self._sample_obs(
- [query1_index],
- observations.values()[0],
- states,
- path_to_obs,
- max_obs_index=None,
- use_exploration_obs=True)
- query2, query2_index, _ = self._sample_obs(
- [query2_index],
- observations.values()[0],
- states,
- path_to_obs,
- max_obs_index=None,
- use_exploration_obs=True)
-
- queries = np.concatenate(
- [np.expand_dims(q, axis=0) for q in [query1, query2]])
- labels = np.array([0, 0])
- labels[label] = 1
- is_valid = np.array([1])
-
- self.info['observation_states'] = states
- self.info['query_indices_in_observations'] = [query1_index, query2_index]
-
- return observations, queries, (labels, is_valid)
-
- def target_loss(self, truth, predicted, weights=None):
- pass
-
-
-#@gin.configurable
-class GotoStaticXTask(RandomExplorationBasedTask):
- """Task go to a static X.
-
- If continuous reward is used only one goal is allowed so that the reward can
- be computed as a delta-distance to that goal..
- """
-
- def __init__(self,
- step_reward=0.0,
- goal_reward=1.0,
- hit_wall_reward=-1.0,
- done_at_target=False,
- use_continuous_reward=False,
- *args,
- **kwargs): # pylint: disable=keyword-arg-before-vararg
- super(GotoStaticXTask, self).__init__(*args, **kwargs)
- if len(self.config.inputs.keys()) > 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type or less.')
-
- self._step_reward = step_reward
- self._goal_reward = goal_reward
- self._hit_wall_reward = hit_wall_reward
- self._done_at_target = done_at_target
- self._use_continuous_reward = use_continuous_reward
-
- self._previous_path_length = None
-
- def episode(self):
- observations, _, path = self._exploration()
- if len(path) < 2:
- raise ValueError('The exploration path has only one node.')
-
- g = self._env.graph
- start = path[-1]
- while True:
- goal = self._rng.choice(path[:-1])
- if goal != start:
- break
- goal_path = nx.shortest_path(g, start, goal)
-
- init_orientation = self._rng.uniform(0, np.pi, (1,))
- trajectory = np.array(
- [list(self._env.vertex_to_pose(p)) for p in goal_path])
- init_xy = np.reshape(trajectory[0, :], [-1])
- init_state = np.concatenate([init_xy, init_orientation], 0)
-
- trajectory = trajectory[1:, :]
- deltas = envs_util.trajectory_to_deltas(trajectory, init_state)
- output_seq_len = self._config.output.shape[0]
- arr = _pad_or_clip_array(deltas, output_seq_len, output_mask=True)
- # pylint: disable=unbalanced-tuple-unpacking
- thetas, _, thetas_mask = arr
-
- query = self._env.observation(self._env.vertex_to_pose(goal)).values()[0]
-
- return observations, query, (thetas, thetas_mask)
-
- def reward(self, obs, done, info):
- if 'wall_collision' in info and info['wall_collision']:
- return obs, self._hit_wall_reward, done, info
-
- reward = 0.0
- current_vertex = self._env.pose_to_vertex(self._env.state)
-
- if current_vertex in self._env.targets():
- if self._done_at_target:
- done = True
- else:
- obs = self._env.reset()
- reward = self._goal_reward
- else:
- if self._use_continuous_reward:
- if len(self._env.targets()) != 1:
- raise ValueError(
- 'FindX task with continuous reward is assuming only one target.')
- goal_vertex = self._env.targets()[0]
- path_length = self._compute_path_length(goal_vertex)
- reward = self._previous_path_length - path_length
- self._previous_path_length = path_length
- else:
- reward = self._step_reward
-
- return obs, reward, done, info
-
- def _compute_path_length(self, goal_vertex):
- current_vertex = self._env.pose_to_vertex(self._env.state)
- path = nx.shortest_path(self._env.graph, current_vertex, goal_vertex)
- assert len(path) >= 2
- curr_xy = np.array(self._env.state[:2])
- next_xy = np.array(self._env.vertex_to_pose(path[1]))
- last_step_distance = np.linalg.norm(next_xy - curr_xy)
- return (len(path) - 2) * self._env.cell_size_px + last_step_distance
-
- def reset(self, observation):
- if self._use_continuous_reward:
- if len(self._env.targets()) != 1:
- raise ValueError(
- 'FindX task with continuous reward is assuming only one target.')
- goal_vertex = self._env.targets()[0]
- self._previous_path_length = self._compute_path_length(goal_vertex)
-
- def target_loss(self, truth, predicted, weights=None):
- """Action classification loss.
-
- Args:
- truth: a batch_size x sequence length x number of labels float
- Tensor containing a one hot vector for each label in each batch and
- time.
- predicted: a batch_size x sequence length x number of labels float
- Tensor containing a predicted distribution over all actions.
- weights: a batch_size x sequence_length float Tensor of bool
- denoting which actions are valid.
-
- Returns:
- An average cross entropy over all batches and elements in sequence.
- """
- return classification_loss(
- truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
-
-
-class RelativeLocationTask(RandomExplorationBasedTask):
- """A task of estimating the relative location of a query w.r.t current.
-
- It is to be used for debugging. It is designed such that the output is a
- single value, out of a discrete set of values, so that it can be phrased as
- a classification problem.
- """
-
- def __init__(self, num_labels, *args, **kwargs):
- """Initializes a relative location task.
-
- Args:
- num_labels: integer, number of orientations to bin the relative
- orientation into.
- *args: see super class.
- **kwargs: see super class.
- """
- super(RelativeLocationTask, self).__init__(*args, **kwargs)
- self._num_labels = num_labels
- if len(self.config.inputs.keys()) != 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type')
-
- def episode(self):
- observations, states, path = self._exploration()
-
- # Select a random element from history.
- path_to_obs, _ = self._obs_to_state(path, states)
- use_exploration_obs = not self._add_query_noise
- query, _, query_state = self._sample_obs(
- path[:-1],
- observations.values()[0],
- states,
- path_to_obs,
- max_obs_index=None,
- use_exploration_obs=use_exploration_obs)
-
- x, y, theta = tuple(states[-1])
- q_x, q_y, _ = tuple(query_state)
- t_x, t_y = q_x - x, q_y - y
- (rt_x, rt_y) = (np.sin(theta) * t_x - np.cos(theta) * t_y,
- np.cos(theta) * t_x + np.sin(theta) * t_y)
- # Bins are [a(i), a(i+1)] for a(i) = -pi + 0.5 * bin_size + i * bin_size.
- shift = np.pi * (1 - 1.0 / (2.0 * self._num_labels))
- orientation = np.arctan2(rt_y, rt_x) + shift
- if orientation < 0:
- orientation += 2 * np.pi
- label = int(np.floor(self._num_labels * orientation / (2 * np.pi)))
-
- out_shape = self._config.output.shape
- if len(out_shape) != 1:
- raise ValueError('Output shape should be of rank 1.')
- if out_shape[0] != self._num_labels:
- raise ValueError('Output shape must be of size %d' % self._num_labels)
- output = np.zeros(out_shape, dtype=np.float32)
- output[label] = 1
-
- return observations, query, (output, None)
-
- def target_loss(self, truth, predicted, weights=None):
- return classification_loss(
- truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
-
-
-class LocationClassificationTask(UnrolledTask):
- """A task of classifying a location as one of several classes.
-
- The task does not have an input, but just a query and an output. The query
- is an observation of the current location, e.g. an image taken from the
- current state. The output is a label classifying this location in one of
- predefined set of locations (or landmarks).
-
- The current implementation classifies locations as intersections based on the
- number and directions of biforcations. It is expected that a location can have
- at most 4 different directions, aligned with the axes. As each of these four
- directions might be present or not, the number of possible intersections are
- 2^4 = 16.
- """
-
- def __init__(self, env, seed, *args, **kwargs):
- super(LocationClassificationTask, self).__init__(*args, **kwargs)
- self._env = env
- self._rng = np.random.RandomState(seed)
- # A location property which can be set. If not set, a random one is
- # generated.
- self._location = None
- if len(self.config.inputs.keys()) > 1:
- raise NotImplementedError('current implementation supports input '
- 'with only one modality type or less.')
-
- @property
- def location(self):
- return self._location
-
- @location.setter
- def location(self, location):
- self._location = location
-
- def episode(self):
- # Get a location. If not set, sample on at a vertex with a random
- # orientation
- location = self._location
- if location is None:
- num_nodes = self._env.graph.number_of_nodes()
- vertex = int(math.floor(self._rng.uniform(0, num_nodes)))
- xy = self._env.vertex_to_pose(vertex)
- theta = self._rng.uniform(0, 2 * math.pi)
- location = np.concatenate(
- [np.reshape(xy, [-1]), np.array([theta])], axis=0)
- else:
- vertex = self._env.pose_to_vertex(location)
-
- theta = location[2]
- neighbors = self._env.graph.neighbors(vertex)
- xy_s = [self._env.vertex_to_pose(n) for n in neighbors]
-
- def rotate(xy, theta):
- """Rotates a vector around the origin by angle theta.
-
- Args:
- xy: a numpy darray of shape (2, ) of floats containing the x and y
- coordinates of a vector.
- theta: a python float containing the rotation angle in radians.
-
- Returns:
- A numpy darray of floats of shape (2,) containing the x and y
- coordinates rotated xy.
- """
- rotated_x = np.cos(theta) * xy[0] - np.sin(theta) * xy[1]
- rotated_y = np.sin(theta) * xy[0] + np.cos(theta) * xy[1]
- return np.array([rotated_x, rotated_y])
-
- # Rotate all intersection biforcation by the orientation of the agent as the
- # intersection label is defined in an agent centered fashion.
- xy_s = [
- rotate(xy - location[0:2], -location[2] - math.pi / 4) for xy in xy_s
- ]
- th_s = [np.arctan2(xy[1], xy[0]) for xy in xy_s]
-
- out_shape = self._config.output.shape
- if len(out_shape) != 1:
- raise ValueError('Output shape should be of rank 1.')
- num_labels = out_shape[0]
- if num_labels != 16:
- raise ValueError('Currently only 16 labels are supported '
- '(there are 16 different 4 way intersection types).')
-
- th_s = set([int(math.floor(4 * (th / (2 * np.pi) + 0.5))) for th in th_s])
- one_hot_label = np.zeros((num_labels,), dtype=np.float32)
- label = 0
- for th in th_s:
- label += pow(2, th)
- one_hot_label[int(label)] = 1.0
-
- query = self._env.observation(location).values()[0]
- return [], query, (one_hot_label, None)
-
- def reward(self, obs, done, info):
- raise ValueError('Do not call.')
-
- def target_loss(self, truth, predicted, weights=None):
- return classification_loss(
- truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
-
-
-class GotoStaticXNoExplorationTask(UnrolledTask):
- """An interface for findX tasks without exploration.
-
- The agent is initialized a random location in a random world and a random goal
- and the objective is for the agent to move toward the goal. This class
- generates episode for such task. Each generates a sequence of observations x
- and target outputs y. x is the observations and is an OrderedDict with keys
- provided from config.inputs.keys() and the shapes provided in the
- config.inputs. The output is a numpy arrays with the shape specified in the
- config.output. The shape of the array is (sequence_length x action_size) where
- action is the number of actions that can be done in the environment. Note that
- config.output.shape should be set according to the number of actions that can
- be done in the env.
- target outputs y are the groundtruth value of each action that is computed
- from the environment graph. The target output for each action is proportional
- to the progress that each action makes. Target value of 1 means that the
- action takes the agent one step closer, -1 means the action takes the agent
- one step farther. Value of -2 means that action should not take place at all.
- This can be because the action leads to collision or it wants to terminate the
- episode prematurely.
- """
-
- def __init__(self, env, *args, **kwargs):
- super(GotoStaticXNoExplorationTask, self).__init__(*args, **kwargs)
-
- if self._config.query is not None:
- raise ValueError('query should be None.')
- if len(self._config.output.shape) != 2:
- raise ValueError('output should only have two dimensions:'
- '(sequence_length x number_of_actions)')
- for input_config in self._config.inputs.values():
- if input_config.shape[0] != self._config.output.shape[0]:
- raise ValueError('the first dimension of the input and output should'
- 'be the same.')
- if len(self._config.output.shape) != 2:
- raise ValueError('output shape should be '
- '(sequence_length x number_of_actions)')
-
- self._env = env
-
- def _compute_shortest_path_length(self, vertex, target_vertices):
- """Computes length of the shortest path from vertex to any target vertexes.
-
- Args:
- vertex: integer, index of the vertex in the environment graph.
- target_vertices: list of the target vertexes
-
- Returns:
- integer, minimum distance from the vertex to any of the target_vertices.
-
- Raises:
- ValueError: if there is no path between the vertex and at least one of
- the target_vertices.
- """
- try:
- return np.min([
- len(nx.shortest_path(self._env.graph, vertex, t))
- for t in target_vertices
- ])
- except:
- #logging.error('there is no path between vertex %d and at least one of '
- # 'the targets %r', vertex, target_vertices)
- raise
-
- def _compute_gt_value(self, vertex, target_vertices):
- """Computes groundtruth value of all the actions at the vertex.
-
- The value of each action is the difference each action makes in the length
- of the shortest path to the goal. If an action takes the agent one step
- closer to the goal the value is 1. In case, it takes the agent one step away
- from the goal it would be -1. If it leads to collision or if the agent uses
- action stop before reaching to the goal it is -2. To avoid scale issues the
- gt_values are multipled by 0.5.
-
- Args:
- vertex: integer, the index of current vertex.
- target_vertices: list of the integer indexes of the target views.
-
- Returns:
- numpy array with shape (action_size,) and each element is the groundtruth
- value of each action based on the progress each action makes.
- """
- action_size = self._config.output.shape[1]
- output_value = np.ones((action_size), dtype=np.float32) * -2
- my_distance = self._compute_shortest_path_length(vertex, target_vertices)
- for adj in self._env.graph[vertex]:
- adj_distance = self._compute_shortest_path_length(adj, target_vertices)
- if adj_distance is None:
- continue
- action_index = self._env.action(
- self._env.vertex_to_pose(vertex), self._env.vertex_to_pose(adj))
- assert action_index is not None, ('{} is not adjacent to {}. There might '
- 'be a problem in environment graph '
- 'connectivity because there is no '
- 'direct edge between the given '
- 'vertices').format(
- self._env.vertex_to_pose(vertex),
- self._env.vertex_to_pose(adj))
- output_value[action_index] = my_distance - adj_distance
-
- return output_value * 0.5
-
- def episode(self):
- """Returns data needed to train and test a single episode.
-
- Returns:
- (inputs, None, output) where inputs is a dictionary of modality types to
- numpy arrays. The second element is query but we assume that the goal
- is also given as part of observation so it should be None for this task,
- and the outputs is the tuple of ground truth action values with the
- shape of (sequence_length x action_size) that is coming from
- config.output.shape and a numpy array with the shape of
- (sequence_length,) that is 1 if the corresponding element of the
- input and output should be used in the training optimization.
-
- Raises:
- ValueError: If the output values for env.random_step_sequence is not
- valid.
- ValueError: If the shape of observations coming from the env is not
- consistent with the config.
- ValueError: If there is a modality type specified in the config but the
- environment does not return that.
- """
- # Sequence length is the first dimension of any of the input tensors.
- sequence_length = self._config.inputs.values()[0].shape[0]
- modality_types = self._config.inputs.keys()
-
- path, _, _, step_outputs = self._env.random_step_sequence(
- max_len=sequence_length)
- target_vertices = [self._env.pose_to_vertex(x) for x in self._env.targets()]
-
- if len(path) != len(step_outputs):
- raise ValueError('path, and step_outputs should have equal length'
- ' {}!={}'.format(len(path), len(step_outputs)))
-
- # Building up observations. observations will be a OrderedDict of
- # modality types. The values are numpy arrays that follow the given shape
- # in the input config for each modality type.
- observations = collections.OrderedDict([k, []] for k in modality_types)
- for step_output in step_outputs:
- obs_dict = step_output[0]
- # Only going over the modality types that are specified in the input
- # config.
- for modality_type in modality_types:
- if modality_type not in obs_dict:
- raise ValueError('modality type is not returned from the environment.'
- '{} not in {}'.format(modality_type,
- obs_dict.keys()))
- obs = obs_dict[modality_type]
- if np.any(
- obs.shape != tuple(self._config.inputs[modality_type].shape[1:])):
- raise ValueError(
- 'The observations should have the same size as speicifed in'
- 'config for modality type {}. {} != {}'.format(
- modality_type, obs.shape,
- self._config.inputs[modality_type].shape[1:]))
- observations[modality_type].append(obs)
-
- gt_value = [self._compute_gt_value(v, target_vertices) for v in path]
-
- # pylint: disable=unbalanced-tuple-unpacking
- gt_value, _, value_mask = _pad_or_clip_array(
- np.array(gt_value),
- sequence_length,
- is_front_clip=False,
- output_mask=True,
- )
- for modality_type, obs in observations.iteritems():
- observations[modality_type], _, mask = _pad_or_clip_array(
- np.array(obs), sequence_length, is_front_clip=False, output_mask=True)
- assert np.all(mask == value_mask)
-
- return observations, None, (gt_value, value_mask)
-
- def reset(self, observation):
- """Called after the environment is reset."""
- pass
-
- def target_loss(self, true_targets, targets, weights=None):
- """A loss for training a task model.
-
- This loss measures the discrepancy between the task outputs, the true and
- predicted ones.
-
- Args:
- true_targets: tf.Tensor of tf.float32 with the shape of
- (batch_size x sequence_length x action_size).
- targets: tf.Tensor of tf.float32 with the shape of
- (batch_size x sequence_length x action_size).
- weights: tf.Tensor of tf.bool with the shape of
- (batch_size x sequence_length).
-
- Raises:
- ValueError: if the shapes of the input tensors are not consistent.
-
- Returns:
- L2 loss between the predicted action values and true action values.
- """
- targets_shape = targets.get_shape().as_list()
- true_targets_shape = true_targets.get_shape().as_list()
- if len(targets_shape) != 3 or len(true_targets_shape) != 3:
- raise ValueError('invalid shape for targets or true_targets_shape')
- if np.any(targets_shape != true_targets_shape):
- raise ValueError('the shape of targets and true_targets are not the same'
- '{} != {}'.format(targets_shape, true_targets_shape))
-
- if weights is not None:
- # Filtering targets and true_targets using weights.
- weights_shape = weights.get_shape().as_list()
- if np.any(weights_shape != targets_shape[0:2]):
- raise ValueError('The first two elements of weights shape should match'
- 'target. {} != {}'.format(weights_shape,
- targets_shape))
- true_targets = tf.boolean_mask(true_targets, weights)
- targets = tf.boolean_mask(targets, weights)
-
- return tf.losses.mean_squared_error(tf.reshape(targets, [-1]),
- tf.reshape(true_targets, [-1]))
-
- def reward(self, obs, done, info):
- raise NotImplementedError('reward is not implemented for this task')
-
-
-################################################################################
-class NewTask(UnrolledTask):
- def __init__(self, env, *args, **kwargs):
- super(NewTask, self).__init__(*args, **kwargs)
- self._env = env
-
- def _compute_shortest_path_length(self, vertex, target_vertices):
- """Computes length of the shortest path from vertex to any target vertexes.
-
- Args:
- vertex: integer, index of the vertex in the environment graph.
- target_vertices: list of the target vertexes
-
- Returns:
- integer, minimum distance from the vertex to any of the target_vertices.
-
- Raises:
- ValueError: if there is no path between the vertex and at least one of
- the target_vertices.
- """
- try:
- return np.min([
- len(nx.shortest_path(self._env.graph, vertex, t))
- for t in target_vertices
- ])
- except:
- logging.error('there is no path between vertex %d and at least one of '
- 'the targets %r', vertex, target_vertices)
- raise
-
- def _compute_gt_value(self, vertex, target_vertices):
- """Computes groundtruth value of all the actions at the vertex.
-
- The value of each action is the difference each action makes in the length
- of the shortest path to the goal. If an action takes the agent one step
- closer to the goal the value is 1. In case, it takes the agent one step away
- from the goal it would be -1. If it leads to collision or if the agent uses
- action stop before reaching to the goal it is -2. To avoid scale issues the
- gt_values are multipled by 0.5.
-
- Args:
- vertex: integer, the index of current vertex.
- target_vertices: list of the integer indexes of the target views.
-
- Returns:
- numpy array with shape (action_size,) and each element is the groundtruth
- value of each action based on the progress each action makes.
- """
- action_size = self._config.output.shape[1]
- output_value = np.ones((action_size), dtype=np.float32) * -2
- # own compute _compute_shortest_path_length - returnts float
- my_distance = self._compute_shortest_path_length(vertex, target_vertices)
- for adj in self._env.graph[vertex]:
- adj_distance = self._compute_shortest_path_length(adj, target_vertices)
- if adj_distance is None:
- continue
- action_index = self._env.action(
- self._env.vertex_to_pose(vertex), self._env.vertex_to_pose(adj))
- assert action_index is not None, ('{} is not adjacent to {}. There might '
- 'be a problem in environment graph '
- 'connectivity because there is no '
- 'direct edge between the given '
- 'vertices').format(
- self._env.vertex_to_pose(vertex),
- self._env.vertex_to_pose(adj))
- output_value[action_index] = my_distance - adj_distance
-
- return output_value * 0.5
-
- def episode(self):
- """Returns data needed to train and test a single episode.
-
- Returns:
- (inputs, None, output) where inputs is a dictionary of modality types to
- numpy arrays. The second element is query but we assume that the goal
- is also given as part of observation so it should be None for this task,
- and the outputs is the tuple of ground truth action values with the
- shape of (sequence_length x action_size) that is coming from
- config.output.shape and a numpy array with the shape of
- (sequence_length,) that is 1 if the corresponding element of the
- input and output should be used in the training optimization.
-
- Raises:
- ValueError: If the output values for env.random_step_sequence is not
- valid.
- ValueError: If the shape of observations coming from the env is not
- consistent with the config.
- ValueError: If there is a modality type specified in the config but the
- environment does not return that.
- """
- # Sequence length is the first dimension of any of the input tensors.
- sequence_length = self._config.inputs.values()[0].shape[0]
- modality_types = self._config.inputs.keys()
-
- path, _, _, step_outputs = self._env.random_step_sequence(
- max_len=sequence_length)
- target_vertices = [self._env.pose_to_vertex(x) for x in self._env.targets()]
-
- if len(path) != len(step_outputs):
- raise ValueError('path, and step_outputs should have equal length'
- ' {}!={}'.format(len(path), len(step_outputs)))
-
- # Building up observations. observations will be a OrderedDict of
- # modality types. The values are numpy arrays that follow the given shape
- # in the input config for each modality type.
- observations = collections.OrderedDict([k, []] for k in modality_types)
- for step_output in step_outputs:
- obs_dict = step_output[0]
- # Only going over the modality types that are specified in the input
- # config.
- for modality_type in modality_types:
- if modality_type not in obs_dict:
- raise ValueError('modality type is not returned from the environment.'
- '{} not in {}'.format(modality_type,
- obs_dict.keys()))
- obs = obs_dict[modality_type]
- if np.any(
- obs.shape != tuple(self._config.inputs[modality_type].shape[1:])):
- raise ValueError(
- 'The observations should have the same size as speicifed in'
- 'config for modality type {}. {} != {}'.format(
- modality_type, obs.shape,
- self._config.inputs[modality_type].shape[1:]))
- observations[modality_type].append(obs)
-
- gt_value = [self._compute_gt_value(v, target_vertices) for v in path]
-
- # pylint: disable=unbalanced-tuple-unpacking
- gt_value, _, value_mask = _pad_or_clip_array(
- np.array(gt_value),
- sequence_length,
- is_front_clip=False,
- output_mask=True,
- )
- for modality_type, obs in observations.iteritems():
- observations[modality_type], _, mask = _pad_or_clip_array(
- np.array(obs), sequence_length, is_front_clip=False, output_mask=True)
- assert np.all(mask == value_mask)
-
- return observations, None, (gt_value, value_mask)
-
- def reset(self, observation):
- """Called after the environment is reset."""
- pass
-
- def target_loss(self, true_targets, targets, weights=None):
- """A loss for training a task model.
-
- This loss measures the discrepancy between the task outputs, the true and
- predicted ones.
-
- Args:
- true_targets: tf.Tensor of tf.float32 with the shape of
- (batch_size x sequence_length x action_size).
- targets: tf.Tensor of tf.float32 with the shape of
- (batch_size x sequence_length x action_size).
- weights: tf.Tensor of tf.bool with the shape of
- (batch_size x sequence_length).
-
- Raises:
- ValueError: if the shapes of the input tensors are not consistent.
-
- Returns:
- L2 loss between the predicted action values and true action values.
- """
- targets_shape = targets.get_shape().as_list()
- true_targets_shape = true_targets.get_shape().as_list()
- if len(targets_shape) != 3 or len(true_targets_shape) != 3:
- raise ValueError('invalid shape for targets or true_targets_shape')
- if np.any(targets_shape != true_targets_shape):
- raise ValueError('the shape of targets and true_targets are not the same'
- '{} != {}'.format(targets_shape, true_targets_shape))
-
- if weights is not None:
- # Filtering targets and true_targets using weights.
- weights_shape = weights.get_shape().as_list()
- if np.any(weights_shape != targets_shape[0:2]):
- raise ValueError('The first two elements of weights shape should match'
- 'target. {} != {}'.format(weights_shape,
- targets_shape))
- true_targets = tf.boolean_mask(true_targets, weights)
- targets = tf.boolean_mask(targets, weights)
-
- return tf.losses.mean_squared_error(tf.reshape(targets, [-1]),
- tf.reshape(true_targets, [-1]))
-
- def reward(self, obs, done, info):
- raise NotImplementedError('reward is not implemented for this task')
diff --git a/research/cognitive_planning/train_supervised_active_vision.py b/research/cognitive_planning/train_supervised_active_vision.py
deleted file mode 100644
index 5931a24e15b2402e07e774c1e78b03374cddfdce..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/train_supervised_active_vision.py
+++ /dev/null
@@ -1,503 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# pylint: disable=line-too-long
-# pyformat: disable
-"""Train and eval for supervised navigation training.
-
-For training:
-python train_supervised_active_vision.py \
- --mode='train' \
- --logdir=$logdir/checkin_log_det/ \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root="$datadir"' \
- --logtostderr
-
-For testing:
-python train_supervised_active_vision.py
- --mode='eval' \
- --logdir=$logdir/checkin_log_det/ \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root="$datadir"' \
- --logtostderr
-"""
-
-import collections
-import os
-import time
-from absl import app
-from absl import flags
-from absl import logging
-import networkx as nx
-import numpy as np
-import tensorflow as tf
-import gin
-import embedders
-import policies
-import tasks
-from envs import active_vision_dataset_env
-from envs import task_env
-
-slim = tf.contrib.slim
-
-flags.DEFINE_string('logdir', '',
- 'Path to a directory to write summaries and checkpoints')
-# Parameters controlling the training setup. In general one would not need to
-# modify them.
-flags.DEFINE_string('master', 'local',
- 'BNS name of the TensorFlow master, or local.')
-flags.DEFINE_integer('task_id', 0,
- 'Task id of the replica running the training.')
-flags.DEFINE_integer('ps_tasks', 0,
- 'Number of tasks in the ps job. If 0 no ps job is used.')
-
-flags.DEFINE_integer('decay_steps', 1000,
- 'Number of steps for exponential decay.')
-flags.DEFINE_float('learning_rate', 0.0001, 'Learning rate.')
-flags.DEFINE_integer('batch_size', 8, 'Batch size.')
-flags.DEFINE_integer('sequence_length', 20, 'sequence length')
-flags.DEFINE_integer('train_iters', 200000, 'number of training iterations.')
-flags.DEFINE_integer('save_summaries_secs', 300,
- 'number of seconds between saving summaries')
-flags.DEFINE_integer('save_interval_secs', 300,
- 'numer of seconds between saving variables')
-flags.DEFINE_integer('log_every_n_steps', 20, 'number of steps between logging')
-flags.DEFINE_string('modality_types', '',
- 'modality names in _ separated format')
-flags.DEFINE_string('conv_window_sizes', '8_4_3',
- 'conv window size in separated by _')
-flags.DEFINE_string('conv_strides', '4_2_1', '')
-flags.DEFINE_string('conv_channels', '8_16_16', '')
-flags.DEFINE_integer('embedding_fc_size', 128,
- 'size of embedding for each modality')
-flags.DEFINE_integer('obs_resolution', 64,
- 'resolution of the input observations')
-flags.DEFINE_integer('lstm_cell_size', 2048, 'size of lstm cell size')
-flags.DEFINE_integer('policy_fc_size', 2048,
- 'size of fully connected layers for policy part')
-flags.DEFINE_float('weight_decay', 0.0002, 'weight decay')
-flags.DEFINE_integer('goal_category_count', 5, 'number of goal categories')
-flags.DEFINE_integer('action_size', 7, 'number of possible actions')
-flags.DEFINE_integer('max_eval_episode_length', 100,
- 'maximum sequence length for evaluation.')
-flags.DEFINE_enum('mode', 'train', ['train', 'eval'],
- 'indicates whether it is in training or evaluation')
-flags.DEFINE_integer('test_iters', 194,
- 'number of iterations that the eval needs to be run')
-flags.DEFINE_multi_string('gin_config', [],
- 'List of paths to a gin config files for the env.')
-flags.DEFINE_multi_string('gin_params', [],
- 'Newline separated list of Gin parameter bindings.')
-flags.DEFINE_string(
- 'resnet50_path', './resnet_v2_50_checkpoint/resnet_v2_50.ckpt', 'path to resnet50'
- 'checkpoint')
-flags.DEFINE_bool('freeze_resnet_weights', True, '')
-flags.DEFINE_string(
- 'eval_init_points_file_name', '',
- 'Name of the file that containts the initial locations and'
- 'worlds for each evalution point')
-
-FLAGS = flags.FLAGS
-TRAIN_WORLDS = [
- 'Home_001_1', 'Home_001_2', 'Home_002_1', 'Home_003_1', 'Home_003_2',
- 'Home_004_1', 'Home_004_2', 'Home_005_1', 'Home_005_2', 'Home_006_1',
- 'Home_010_1'
-]
-
-TEST_WORLDS = ['Home_011_1', 'Home_013_1', 'Home_016_1']
-
-
-def create_modality_types():
- """Parses the modality_types and returns a list of task_env.ModalityType."""
- if not FLAGS.modality_types:
- raise ValueError('there needs to be at least one modality type')
- modality_types = FLAGS.modality_types.split('_')
- for x in modality_types:
- if x not in ['image', 'sseg', 'det', 'depth']:
- raise ValueError('invalid modality type: {}'.format(x))
-
- conversion_dict = {
- 'image': task_env.ModalityTypes.IMAGE,
- 'sseg': task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
- 'depth': task_env.ModalityTypes.DEPTH,
- 'det': task_env.ModalityTypes.OBJECT_DETECTION,
- }
- return [conversion_dict[k] for k in modality_types]
-
-
-def create_task_io_config(
- modality_types,
- goal_category_count,
- action_size,
- sequence_length,
-):
- """Generates task io config."""
- shape_prefix = [sequence_length, FLAGS.obs_resolution, FLAGS.obs_resolution]
- shapes = {
- task_env.ModalityTypes.IMAGE: [sequence_length, 224, 224, 3],
- task_env.ModalityTypes.DEPTH: shape_prefix + [
- 2,
- ],
- task_env.ModalityTypes.SEMANTIC_SEGMENTATION: shape_prefix + [
- 1,
- ],
- task_env.ModalityTypes.OBJECT_DETECTION: shape_prefix + [
- 90,
- ]
- }
- types = {k: tf.float32 for k in shapes}
- types[task_env.ModalityTypes.IMAGE] = tf.uint8
- inputs = collections.OrderedDict(
- [[mtype, (types[mtype], shapes[mtype])] for mtype in modality_types])
- inputs[task_env.ModalityTypes.GOAL] = (tf.float32,
- [sequence_length, goal_category_count])
- inputs[task_env.ModalityTypes.PREV_ACTION] = (tf.float32, [
- sequence_length, action_size + 1
- ])
- print inputs
- return tasks.UnrolledTaskIOConfig(
- inputs=inputs,
- output=(tf.float32, [sequence_length, action_size]),
- query=None)
-
-
-def map_to_embedder(modality_type):
- """Maps modality_type to its corresponding embedder."""
- if modality_type == task_env.ModalityTypes.PREV_ACTION:
- return None
- if modality_type == task_env.ModalityTypes.GOAL:
- return embedders.IdentityEmbedder()
- if modality_type == task_env.ModalityTypes.IMAGE:
- return embedders.ResNet50Embedder()
- conv_window_sizes = [int(x) for x in FLAGS.conv_window_sizes.split('_')]
- conv_channels = [int(x) for x in FLAGS.conv_channels.split('_')]
- conv_strides = [int(x) for x in FLAGS.conv_strides.split('_')]
- params = tf.contrib.training.HParams(
- to_one_hot=modality_type == task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
- one_hot_length=10,
- conv_sizes=conv_window_sizes,
- conv_strides=conv_strides,
- conv_channels=conv_channels,
- embedding_size=FLAGS.embedding_fc_size,
- weight_decay_rate=FLAGS.weight_decay,
- )
- return embedders.SmallNetworkEmbedder(params)
-
-
-def create_train_and_init_ops(policy, task):
- """Creates training ops given the arguments.
-
- Args:
- policy: the policy for the task.
- task: the task instance.
-
- Returns:
- train_op: the op that needs to be runned at each step.
- summaries_op: the summary op that is executed.
- init_fn: the op that initializes the variables if there is no previous
- checkpoint. If Resnet50 is not used in the model it is None, otherwise
- it reads the weights from FLAGS.resnet50_path and sets the init_fn
- to the op that initializes the ResNet50 with the pre-trained weights.
- """
- assert isinstance(task, tasks.GotoStaticXNoExplorationTask)
- assert isinstance(policy, policies.Policy)
-
- inputs, _, gt_outputs, masks = task.tf_episode_batch(FLAGS.batch_size)
- outputs, _ = policy.build(inputs, None)
- loss = task.target_loss(gt_outputs, outputs, masks)
-
- init_fn = None
-
- # If resnet is added to the graph, init_fn should initialize resnet weights
- # if there is no previous checkpoint.
- variables_assign_dict = {}
- vars_list = []
- for v in slim.get_model_variables():
- if v.name.find('resnet') >= 0:
- if not FLAGS.freeze_resnet_weights:
- vars_list.append(v)
- variables_assign_dict[v.name[v.name.find('resnet'):-2]] = v
- else:
- vars_list.append(v)
-
- global_step = tf.train.get_or_create_global_step()
- learning_rate = tf.train.exponential_decay(
- FLAGS.learning_rate,
- global_step,
- decay_steps=FLAGS.decay_steps,
- decay_rate=0.98,
- staircase=True)
- optimizer = tf.train.AdamOptimizer(learning_rate)
- train_op = slim.learning.create_train_op(
- loss,
- optimizer,
- global_step=global_step,
- variables_to_train=vars_list,
- )
-
- if variables_assign_dict:
- init_fn = slim.assign_from_checkpoint_fn(
- FLAGS.resnet50_path,
- variables_assign_dict,
- ignore_missing_vars=False)
- scalar_summaries = {}
- scalar_summaries['LR'] = learning_rate
- scalar_summaries['loss'] = loss
-
- for name, summary in scalar_summaries.iteritems():
- tf.summary.scalar(name, summary)
-
- return train_op, init_fn
-
-
-def create_eval_ops(policy, config, possible_targets):
- """Creates the necessary ops for evaluation."""
- inputs_feed = collections.OrderedDict([[
- mtype,
- tf.placeholder(config.inputs[mtype].type,
- [1] + config.inputs[mtype].shape)
- ] for mtype in config.inputs])
- inputs_feed[task_env.ModalityTypes.PREV_ACTION] = tf.placeholder(
- tf.float32, [1, 1] + [
- config.output.shape[-1] + 1,
- ])
- prev_state_feed = [
- tf.placeholder(
- tf.float32, [1, FLAGS.lstm_cell_size], name='prev_state_{}'.format(i))
- for i in range(2)
- ]
- policy_outputs = policy.build(inputs_feed, prev_state_feed)
- summary_feed = {}
- for c in possible_targets + ['mean']:
- summary_feed[c] = tf.placeholder(
- tf.float32, [], name='eval_in_range_{}_input'.format(c))
- tf.summary.scalar('eval_in_range_{}'.format(c), summary_feed[c])
-
- return inputs_feed, prev_state_feed, policy_outputs, (tf.summary.merge_all(),
- summary_feed)
-
-
-def unroll_policy_for_eval(
- sess,
- env,
- inputs_feed,
- prev_state_feed,
- policy_outputs,
- number_of_steps,
- output_folder,
-):
- """unrolls the policy for testing.
-
- Args:
- sess: tf.Session
- env: The environment.
- inputs_feed: dictionary of placeholder for the input modalities.
- prev_state_feed: placeholder for the input to the prev_state of the model.
- policy_outputs: tensor that contains outputs of the policy.
- number_of_steps: maximum number of unrolling steps.
- output_folder: output_folder where the function writes a dictionary of
- detailed information about the path. The dictionary keys are 'states' and
- 'distance'. The value for 'states' is the list of states that the agent
- goes along the path. The value for 'distance' contains the length of
- shortest path to the goal at each step.
-
- Returns:
- states: list of states along the path.
- distance: list of distances along the path.
- """
- prev_state = [
- np.zeros((1, FLAGS.lstm_cell_size), dtype=np.float32) for _ in range(2)
- ]
- prev_action = np.zeros((1, 1, FLAGS.action_size + 1), dtype=np.float32)
- obs = env.reset()
- distances_to_goal = []
- states = []
- unique_id = '{}_{}'.format(env.cur_image_id(), env.goal_string)
- for _ in range(number_of_steps):
- distances_to_goal.append(
- np.min([
- len(
- nx.shortest_path(env.graph, env.pose_to_vertex(env.state()),
- env.pose_to_vertex(target_view)))
- for target_view in env.targets()
- ]))
- states.append(env.state())
- feed_dict = {inputs_feed[mtype]: [[obs[mtype]]] for mtype in inputs_feed}
- feed_dict[prev_state_feed[0]] = prev_state[0]
- feed_dict[prev_state_feed[1]] = prev_state[1]
- action_values, prev_state = sess.run(policy_outputs, feed_dict=feed_dict)
- chosen_action = np.argmax(action_values[0])
- obs, _, done, info = env.step(np.int32(chosen_action))
- prev_action[0][0][chosen_action] = 1.
- prev_action[0][0][-1] = float(info['success'])
- # If the agent chooses action stop or the number of steps exceeeded
- # env._episode_length.
- if done:
- break
-
- # logging.info('distance = %d, id = %s, #steps = %d', distances_to_goal[-1],
- output_path = os.path.join(output_folder, unique_id + '.npy')
- with tf.gfile.Open(output_path, 'w') as f:
- print 'saving path information to {}'.format(output_path)
- np.save(f, {'states': states, 'distance': distances_to_goal})
- return states, distances_to_goal
-
-
-def init(sequence_length, eval_init_points_file_name, worlds):
- """Initializes the common operations between train and test."""
- modality_types = create_modality_types()
- logging.info('modality types: %r', modality_types)
- # negative reward_goal_range prevents the env from terminating early when the
- # agent is close to the goal. The policy should keep the agent until the end
- # of the 100 steps either through chosing stop action or oscilating around
- # the target.
-
- env = active_vision_dataset_env.ActiveVisionDatasetEnv(
- modality_types=modality_types +
- [task_env.ModalityTypes.GOAL, task_env.ModalityTypes.PREV_ACTION],
- reward_goal_range=-1,
- eval_init_points_file_name=eval_init_points_file_name,
- worlds=worlds,
- output_size=FLAGS.obs_resolution,
- )
-
- config = create_task_io_config(
- modality_types=modality_types,
- goal_category_count=FLAGS.goal_category_count,
- action_size=FLAGS.action_size,
- sequence_length=sequence_length,
- )
- task = tasks.GotoStaticXNoExplorationTask(env=env, config=config)
- embedders_dict = {mtype: map_to_embedder(mtype) for mtype in config.inputs}
- policy_params = tf.contrib.training.HParams(
- lstm_state_size=FLAGS.lstm_cell_size,
- fc_channels=FLAGS.policy_fc_size,
- weight_decay=FLAGS.weight_decay,
- target_embedding_size=FLAGS.embedding_fc_size,
- )
- policy = policies.LSTMPolicy(
- modality_names=config.inputs.keys(),
- embedders_dict=embedders_dict,
- action_size=FLAGS.action_size,
- params=policy_params,
- max_episode_length=sequence_length)
- return env, config, task, policy
-
-
-def test():
- """Contains all the operations for testing policies."""
- env, config, _, policy = init(1, 'all_init_configs', TEST_WORLDS)
- inputs_feed, prev_state_feed, policy_outputs, summary_op = create_eval_ops(
- policy, config, env.possible_targets)
- sv = tf.train.Supervisor(logdir=FLAGS.logdir)
- prev_checkpoint = None
- with sv.managed_session(
- start_standard_services=False,
- config=tf.ConfigProto(allow_soft_placement=True)) as sess:
- while not sv.should_stop():
- while True:
- new_checkpoint = tf.train.latest_checkpoint(FLAGS.logdir)
- print 'new_checkpoint ', new_checkpoint
- if not new_checkpoint:
- time.sleep(1)
- continue
- if prev_checkpoint is None:
- prev_checkpoint = new_checkpoint
- break
- if prev_checkpoint != new_checkpoint:
- prev_checkpoint = new_checkpoint
- break
- else: # if prev_checkpoint == new_checkpoint, we have to wait more.
- time.sleep(1)
-
- checkpoint_step = int(new_checkpoint[new_checkpoint.rfind('-') + 1:])
- sv.saver.restore(sess, new_checkpoint)
- print '--------------------'
- print 'evaluating checkpoint {}'.format(new_checkpoint)
- folder_path = os.path.join(FLAGS.logdir, 'evals', str(checkpoint_step))
- if not tf.gfile.Exists(folder_path):
- tf.gfile.MakeDirs(folder_path)
- eval_stats = {c: [] for c in env.possible_targets}
- for test_iter in range(FLAGS.test_iters):
- print 'evaluating {} of {}'.format(test_iter, FLAGS.test_iters)
- _, distance_to_goal = unroll_policy_for_eval(
- sess,
- env,
- inputs_feed,
- prev_state_feed,
- policy_outputs,
- FLAGS.max_eval_episode_length,
- folder_path,
- )
- print 'goal = {}'.format(env.goal_string)
- eval_stats[env.goal_string].append(float(distance_to_goal[-1] <= 7))
- eval_stats = {k: np.mean(v) for k, v in eval_stats.iteritems()}
- eval_stats['mean'] = np.mean(eval_stats.values())
- print eval_stats
- feed_dict = {summary_op[1][c]: eval_stats[c] for c in eval_stats}
- summary_str = sess.run(summary_op[0], feed_dict=feed_dict)
- writer = sv.summary_writer
- writer.add_summary(summary_str, checkpoint_step)
- writer.flush()
-
-
-def train():
- _, _, task, policy = init(FLAGS.sequence_length, None, TRAIN_WORLDS)
- print(FLAGS.save_summaries_secs)
- print(FLAGS.save_interval_secs)
- print(FLAGS.logdir)
-
- with tf.device(
- tf.train.replica_device_setter(ps_tasks=FLAGS.ps_tasks, merge_devices=True)):
- train_op, init_fn = create_train_and_init_ops(policy=policy, task=task)
- print(FLAGS.logdir)
- slim.learning.train(
- train_op=train_op,
- init_fn=init_fn,
- logdir=FLAGS.logdir,
- is_chief=FLAGS.task_id == 0,
- number_of_steps=FLAGS.train_iters,
- save_summaries_secs=FLAGS.save_summaries_secs,
- save_interval_secs=FLAGS.save_interval_secs,
- session_config=tf.ConfigProto(allow_soft_placement=True),
- )
-
-
-def main(_):
- gin.parse_config_files_and_bindings(FLAGS.gin_config, FLAGS.gin_params)
- if FLAGS.mode == 'train':
- train()
- else:
- test()
-
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/cognitive_planning/train_supervised_active_vision.sh b/research/cognitive_planning/train_supervised_active_vision.sh
deleted file mode 100755
index f2ea22753443cce89bf1e78a3d8fae920e5e7266..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/train_supervised_active_vision.sh
+++ /dev/null
@@ -1,32 +0,0 @@
-#!/bin/bash
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-# blaze build -c opt train_supervised_active_vision
-# bazel build -c opt --config=cuda --copt=-mavx train_supervised_active_vision && \
-bazel-bin/research/cognitive_planning/train_supervised_active_vision \
- --mode='train' \
- --logdir=/usr/local/google/home/kosecka/local_avd_train/ \
- --modality_types='det' \
- --batch_size=8 \
- --train_iters=200000 \
- --lstm_cell_size=2048 \
- --policy_fc_size=2048 \
- --sequence_length=20 \
- --max_eval_episode_length=100 \
- --test_iters=194 \
- --gin_config=envs/configs/active_vision_config.gin \
- --gin_params='ActiveVisionDatasetEnv.dataset_root="/cns/jn-d/home/kosecka/AVD_Minimal/"' \
- --logtostderr
diff --git a/research/cognitive_planning/visualization_utils.py b/research/cognitive_planning/visualization_utils.py
deleted file mode 100644
index 7a7aeb50561dba9f8713d12a184ddd824c3c0e19..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/visualization_utils.py
+++ /dev/null
@@ -1,733 +0,0 @@
-# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""A set of functions that are used for visualization.
-
-These functions often receive an image, perform some visualization on the image.
-The functions do not return a value, instead they modify the image itself.
-
-"""
-import collections
-import functools
-# Set headless-friendly backend.
-import matplotlib; matplotlib.use('Agg') # pylint: disable=multiple-statements
-import matplotlib.pyplot as plt # pylint: disable=g-import-not-at-top
-import numpy as np
-import PIL.Image as Image
-import PIL.ImageColor as ImageColor
-import PIL.ImageDraw as ImageDraw
-import PIL.ImageFont as ImageFont
-import six
-import tensorflow as tf
-
-import standard_fields as fields
-
-
-_TITLE_LEFT_MARGIN = 10
-_TITLE_TOP_MARGIN = 10
-STANDARD_COLORS = [
- 'AliceBlue', 'Chartreuse', 'Aqua', 'Aquamarine', 'Azure', 'Beige', 'Bisque',
- 'BlanchedAlmond', 'BlueViolet', 'BurlyWood', 'CadetBlue', 'AntiqueWhite',
- 'Chocolate', 'Coral', 'CornflowerBlue', 'Cornsilk', 'Crimson', 'Cyan',
- 'DarkCyan', 'DarkGoldenRod', 'DarkGrey', 'DarkKhaki', 'DarkOrange',
- 'DarkOrchid', 'DarkSalmon', 'DarkSeaGreen', 'DarkTurquoise', 'DarkViolet',
- 'DeepPink', 'DeepSkyBlue', 'DodgerBlue', 'FireBrick', 'FloralWhite',
- 'ForestGreen', 'Fuchsia', 'Gainsboro', 'GhostWhite', 'Gold', 'GoldenRod',
- 'Salmon', 'Tan', 'HoneyDew', 'HotPink', 'IndianRed', 'Ivory', 'Khaki',
- 'Lavender', 'LavenderBlush', 'LawnGreen', 'LemonChiffon', 'LightBlue',
- 'LightCoral', 'LightCyan', 'LightGoldenRodYellow', 'LightGray', 'LightGrey',
- 'LightGreen', 'LightPink', 'LightSalmon', 'LightSeaGreen', 'LightSkyBlue',
- 'LightSlateGray', 'LightSlateGrey', 'LightSteelBlue', 'LightYellow', 'Lime',
- 'LimeGreen', 'Linen', 'Magenta', 'MediumAquaMarine', 'MediumOrchid',
- 'MediumPurple', 'MediumSeaGreen', 'MediumSlateBlue', 'MediumSpringGreen',
- 'MediumTurquoise', 'MediumVioletRed', 'MintCream', 'MistyRose', 'Moccasin',
- 'NavajoWhite', 'OldLace', 'Olive', 'OliveDrab', 'Orange', 'OrangeRed',
- 'Orchid', 'PaleGoldenRod', 'PaleGreen', 'PaleTurquoise', 'PaleVioletRed',
- 'PapayaWhip', 'PeachPuff', 'Peru', 'Pink', 'Plum', 'PowderBlue', 'Purple',
- 'Red', 'RosyBrown', 'RoyalBlue', 'SaddleBrown', 'Green', 'SandyBrown',
- 'SeaGreen', 'SeaShell', 'Sienna', 'Silver', 'SkyBlue', 'SlateBlue',
- 'SlateGray', 'SlateGrey', 'Snow', 'SpringGreen', 'SteelBlue', 'GreenYellow',
- 'Teal', 'Thistle', 'Tomato', 'Turquoise', 'Violet', 'Wheat', 'White',
- 'WhiteSmoke', 'Yellow', 'YellowGreen'
-]
-
-
-def save_image_array_as_png(image, output_path):
- """Saves an image (represented as a numpy array) to PNG.
-
- Args:
- image: a numpy array with shape [height, width, 3].
- output_path: path to which image should be written.
- """
- image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
- with tf.gfile.Open(output_path, 'w') as fid:
- image_pil.save(fid, 'PNG')
-
-
-def encode_image_array_as_png_str(image):
- """Encodes a numpy array into a PNG string.
-
- Args:
- image: a numpy array with shape [height, width, 3].
-
- Returns:
- PNG encoded image string.
- """
- image_pil = Image.fromarray(np.uint8(image))
- output = six.BytesIO()
- image_pil.save(output, format='PNG')
- png_string = output.getvalue()
- output.close()
- return png_string
-
-
-def draw_bounding_box_on_image_array(image,
- ymin,
- xmin,
- ymax,
- xmax,
- color='red',
- thickness=4,
- display_str_list=(),
- use_normalized_coordinates=True):
- """Adds a bounding box to an image (numpy array).
-
- Bounding box coordinates can be specified in either absolute (pixel) or
- normalized coordinates by setting the use_normalized_coordinates argument.
-
- Args:
- image: a numpy array with shape [height, width, 3].
- ymin: ymin of bounding box.
- xmin: xmin of bounding box.
- ymax: ymax of bounding box.
- xmax: xmax of bounding box.
- color: color to draw bounding box. Default is red.
- thickness: line thickness. Default value is 4.
- display_str_list: list of strings to display in box
- (each to be shown on its own line).
- use_normalized_coordinates: If True (default), treat coordinates
- ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
- coordinates as absolute.
- """
- image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
- draw_bounding_box_on_image(image_pil, ymin, xmin, ymax, xmax, color,
- thickness, display_str_list,
- use_normalized_coordinates)
- np.copyto(image, np.array(image_pil))
-
-
-def draw_bounding_box_on_image(image,
- ymin,
- xmin,
- ymax,
- xmax,
- color='red',
- thickness=4,
- display_str_list=(),
- use_normalized_coordinates=True):
- """Adds a bounding box to an image.
-
- Bounding box coordinates can be specified in either absolute (pixel) or
- normalized coordinates by setting the use_normalized_coordinates argument.
-
- Each string in display_str_list is displayed on a separate line above the
- bounding box in black text on a rectangle filled with the input 'color'.
- If the top of the bounding box extends to the edge of the image, the strings
- are displayed below the bounding box.
-
- Args:
- image: a PIL.Image object.
- ymin: ymin of bounding box.
- xmin: xmin of bounding box.
- ymax: ymax of bounding box.
- xmax: xmax of bounding box.
- color: color to draw bounding box. Default is red.
- thickness: line thickness. Default value is 4.
- display_str_list: list of strings to display in box
- (each to be shown on its own line).
- use_normalized_coordinates: If True (default), treat coordinates
- ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
- coordinates as absolute.
- """
- draw = ImageDraw.Draw(image)
- im_width, im_height = image.size
- if use_normalized_coordinates:
- (left, right, top, bottom) = (xmin * im_width, xmax * im_width,
- ymin * im_height, ymax * im_height)
- else:
- (left, right, top, bottom) = (xmin, xmax, ymin, ymax)
- draw.line([(left, top), (left, bottom), (right, bottom),
- (right, top), (left, top)], width=thickness, fill=color)
- try:
- font = ImageFont.truetype('arial.ttf', 24)
- except IOError:
- font = ImageFont.load_default()
-
- # If the total height of the display strings added to the top of the bounding
- # box exceeds the top of the image, stack the strings below the bounding box
- # instead of above.
- display_str_heights = [font.getsize(ds)[1] for ds in display_str_list]
- # Each display_str has a top and bottom margin of 0.05x.
- total_display_str_height = (1 + 2 * 0.05) * sum(display_str_heights)
-
- if top > total_display_str_height:
- text_bottom = top
- else:
- text_bottom = bottom + total_display_str_height
- # Reverse list and print from bottom to top.
- for display_str in display_str_list[::-1]:
- text_width, text_height = font.getsize(display_str)
- margin = np.ceil(0.05 * text_height)
- draw.rectangle(
- [(left, text_bottom - text_height - 2 * margin), (left + text_width,
- text_bottom)],
- fill=color)
- draw.text(
- (left + margin, text_bottom - text_height - margin),
- display_str,
- fill='black',
- font=font)
- text_bottom -= text_height - 2 * margin
-
-
-def draw_bounding_boxes_on_image_array(image,
- boxes,
- color='red',
- thickness=4,
- display_str_list_list=()):
- """Draws bounding boxes on image (numpy array).
-
- Args:
- image: a numpy array object.
- boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
- The coordinates are in normalized format between [0, 1].
- color: color to draw bounding box. Default is red.
- thickness: line thickness. Default value is 4.
- display_str_list_list: list of list of strings.
- a list of strings for each bounding box.
- The reason to pass a list of strings for a
- bounding box is that it might contain
- multiple labels.
-
- Raises:
- ValueError: if boxes is not a [N, 4] array
- """
- image_pil = Image.fromarray(image)
- draw_bounding_boxes_on_image(image_pil, boxes, color, thickness,
- display_str_list_list)
- np.copyto(image, np.array(image_pil))
-
-
-def draw_bounding_boxes_on_image(image,
- boxes,
- color='red',
- thickness=4,
- display_str_list_list=()):
- """Draws bounding boxes on image.
-
- Args:
- image: a PIL.Image object.
- boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
- The coordinates are in normalized format between [0, 1].
- color: color to draw bounding box. Default is red.
- thickness: line thickness. Default value is 4.
- display_str_list_list: list of list of strings.
- a list of strings for each bounding box.
- The reason to pass a list of strings for a
- bounding box is that it might contain
- multiple labels.
-
- Raises:
- ValueError: if boxes is not a [N, 4] array
- """
- boxes_shape = boxes.shape
- if not boxes_shape:
- return
- if len(boxes_shape) != 2 or boxes_shape[1] != 4:
- raise ValueError('Input must be of size [N, 4]')
- for i in range(boxes_shape[0]):
- display_str_list = ()
- if display_str_list_list:
- display_str_list = display_str_list_list[i]
- draw_bounding_box_on_image(image, boxes[i, 0], boxes[i, 1], boxes[i, 2],
- boxes[i, 3], color, thickness, display_str_list)
-
-
-def _visualize_boxes(image, boxes, classes, scores, category_index, **kwargs):
- return visualize_boxes_and_labels_on_image_array(
- image, boxes, classes, scores, category_index=category_index, **kwargs)
-
-
-def _visualize_boxes_and_masks(image, boxes, classes, scores, masks,
- category_index, **kwargs):
- return visualize_boxes_and_labels_on_image_array(
- image,
- boxes,
- classes,
- scores,
- category_index=category_index,
- instance_masks=masks,
- **kwargs)
-
-
-def _visualize_boxes_and_keypoints(image, boxes, classes, scores, keypoints,
- category_index, **kwargs):
- return visualize_boxes_and_labels_on_image_array(
- image,
- boxes,
- classes,
- scores,
- category_index=category_index,
- keypoints=keypoints,
- **kwargs)
-
-
-def _visualize_boxes_and_masks_and_keypoints(
- image, boxes, classes, scores, masks, keypoints, category_index, **kwargs):
- return visualize_boxes_and_labels_on_image_array(
- image,
- boxes,
- classes,
- scores,
- category_index=category_index,
- instance_masks=masks,
- keypoints=keypoints,
- **kwargs)
-
-
-def draw_bounding_boxes_on_image_tensors(images,
- boxes,
- classes,
- scores,
- category_index,
- instance_masks=None,
- keypoints=None,
- max_boxes_to_draw=20,
- min_score_thresh=0.2,
- use_normalized_coordinates=True):
- """Draws bounding boxes, masks, and keypoints on batch of image tensors.
-
- Args:
- images: A 4D uint8 image tensor of shape [N, H, W, C]. If C > 3, additional
- channels will be ignored.
- boxes: [N, max_detections, 4] float32 tensor of detection boxes.
- classes: [N, max_detections] int tensor of detection classes. Note that
- classes are 1-indexed.
- scores: [N, max_detections] float32 tensor of detection scores.
- category_index: a dict that maps integer ids to category dicts. e.g.
- {1: {1: 'dog'}, 2: {2: 'cat'}, ...}
- instance_masks: A 4D uint8 tensor of shape [N, max_detection, H, W] with
- instance masks.
- keypoints: A 4D float32 tensor of shape [N, max_detection, num_keypoints, 2]
- with keypoints.
- max_boxes_to_draw: Maximum number of boxes to draw on an image. Default 20.
- min_score_thresh: Minimum score threshold for visualization. Default 0.2.
- use_normalized_coordinates: Whether to assume boxes and kepoints are in
- normalized coordinates (as opposed to absolute coordiantes).
- Default is True.
-
- Returns:
- 4D image tensor of type uint8, with boxes drawn on top.
- """
- # Additional channels are being ignored.
- images = images[:, :, :, 0:3]
- visualization_keyword_args = {
- 'use_normalized_coordinates': use_normalized_coordinates,
- 'max_boxes_to_draw': max_boxes_to_draw,
- 'min_score_thresh': min_score_thresh,
- 'agnostic_mode': False,
- 'line_thickness': 4
- }
-
- if instance_masks is not None and keypoints is None:
- visualize_boxes_fn = functools.partial(
- _visualize_boxes_and_masks,
- category_index=category_index,
- **visualization_keyword_args)
- elems = [images, boxes, classes, scores, instance_masks]
- elif instance_masks is None and keypoints is not None:
- visualize_boxes_fn = functools.partial(
- _visualize_boxes_and_keypoints,
- category_index=category_index,
- **visualization_keyword_args)
- elems = [images, boxes, classes, scores, keypoints]
- elif instance_masks is not None and keypoints is not None:
- visualize_boxes_fn = functools.partial(
- _visualize_boxes_and_masks_and_keypoints,
- category_index=category_index,
- **visualization_keyword_args)
- elems = [images, boxes, classes, scores, instance_masks, keypoints]
- else:
- visualize_boxes_fn = functools.partial(
- _visualize_boxes,
- category_index=category_index,
- **visualization_keyword_args)
- elems = [images, boxes, classes, scores]
-
- def draw_boxes(image_and_detections):
- """Draws boxes on image."""
- image_with_boxes = tf.py_func(visualize_boxes_fn, image_and_detections,
- tf.uint8)
- return image_with_boxes
-
- images = tf.map_fn(draw_boxes, elems, dtype=tf.uint8, back_prop=False)
- return images
-
-
-def draw_side_by_side_evaluation_image(eval_dict,
- category_index,
- max_boxes_to_draw=20,
- min_score_thresh=0.2,
- use_normalized_coordinates=True):
- """Creates a side-by-side image with detections and groundtruth.
-
- Bounding boxes (and instance masks, if available) are visualized on both
- subimages.
-
- Args:
- eval_dict: The evaluation dictionary returned by
- eval_util.result_dict_for_single_example().
- category_index: A category index (dictionary) produced from a labelmap.
- max_boxes_to_draw: The maximum number of boxes to draw for detections.
- min_score_thresh: The minimum score threshold for showing detections.
- use_normalized_coordinates: Whether to assume boxes and kepoints are in
- normalized coordinates (as opposed to absolute coordiantes).
- Default is True.
-
- Returns:
- A [1, H, 2 * W, C] uint8 tensor. The subimage on the left corresponds to
- detections, while the subimage on the right corresponds to groundtruth.
- """
- detection_fields = fields.DetectionResultFields()
- input_data_fields = fields.InputDataFields()
- instance_masks = None
- if detection_fields.detection_masks in eval_dict:
- instance_masks = tf.cast(
- tf.expand_dims(eval_dict[detection_fields.detection_masks], axis=0),
- tf.uint8)
- keypoints = None
- if detection_fields.detection_keypoints in eval_dict:
- keypoints = tf.expand_dims(
- eval_dict[detection_fields.detection_keypoints], axis=0)
- groundtruth_instance_masks = None
- if input_data_fields.groundtruth_instance_masks in eval_dict:
- groundtruth_instance_masks = tf.cast(
- tf.expand_dims(
- eval_dict[input_data_fields.groundtruth_instance_masks], axis=0),
- tf.uint8)
- images_with_detections = draw_bounding_boxes_on_image_tensors(
- eval_dict[input_data_fields.original_image],
- tf.expand_dims(eval_dict[detection_fields.detection_boxes], axis=0),
- tf.expand_dims(eval_dict[detection_fields.detection_classes], axis=0),
- tf.expand_dims(eval_dict[detection_fields.detection_scores], axis=0),
- category_index,
- instance_masks=instance_masks,
- keypoints=keypoints,
- max_boxes_to_draw=max_boxes_to_draw,
- min_score_thresh=min_score_thresh,
- use_normalized_coordinates=use_normalized_coordinates)
- images_with_groundtruth = draw_bounding_boxes_on_image_tensors(
- eval_dict[input_data_fields.original_image],
- tf.expand_dims(eval_dict[input_data_fields.groundtruth_boxes], axis=0),
- tf.expand_dims(eval_dict[input_data_fields.groundtruth_classes], axis=0),
- tf.expand_dims(
- tf.ones_like(
- eval_dict[input_data_fields.groundtruth_classes],
- dtype=tf.float32),
- axis=0),
- category_index,
- instance_masks=groundtruth_instance_masks,
- keypoints=None,
- max_boxes_to_draw=None,
- min_score_thresh=0.0,
- use_normalized_coordinates=use_normalized_coordinates)
- return tf.concat([images_with_detections, images_with_groundtruth], axis=2)
-
-
-def draw_keypoints_on_image_array(image,
- keypoints,
- color='red',
- radius=2,
- use_normalized_coordinates=True):
- """Draws keypoints on an image (numpy array).
-
- Args:
- image: a numpy array with shape [height, width, 3].
- keypoints: a numpy array with shape [num_keypoints, 2].
- color: color to draw the keypoints with. Default is red.
- radius: keypoint radius. Default value is 2.
- use_normalized_coordinates: if True (default), treat keypoint values as
- relative to the image. Otherwise treat them as absolute.
- """
- image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
- draw_keypoints_on_image(image_pil, keypoints, color, radius,
- use_normalized_coordinates)
- np.copyto(image, np.array(image_pil))
-
-
-def draw_keypoints_on_image(image,
- keypoints,
- color='red',
- radius=2,
- use_normalized_coordinates=True):
- """Draws keypoints on an image.
-
- Args:
- image: a PIL.Image object.
- keypoints: a numpy array with shape [num_keypoints, 2].
- color: color to draw the keypoints with. Default is red.
- radius: keypoint radius. Default value is 2.
- use_normalized_coordinates: if True (default), treat keypoint values as
- relative to the image. Otherwise treat them as absolute.
- """
- draw = ImageDraw.Draw(image)
- im_width, im_height = image.size
- keypoints_x = [k[1] for k in keypoints]
- keypoints_y = [k[0] for k in keypoints]
- if use_normalized_coordinates:
- keypoints_x = tuple([im_width * x for x in keypoints_x])
- keypoints_y = tuple([im_height * y for y in keypoints_y])
- for keypoint_x, keypoint_y in zip(keypoints_x, keypoints_y):
- draw.ellipse([(keypoint_x - radius, keypoint_y - radius),
- (keypoint_x + radius, keypoint_y + radius)],
- outline=color, fill=color)
-
-
-def draw_mask_on_image_array(image, mask, color='red', alpha=0.4):
- """Draws mask on an image.
-
- Args:
- image: uint8 numpy array with shape (img_height, img_height, 3)
- mask: a uint8 numpy array of shape (img_height, img_height) with
- values between either 0 or 1.
- color: color to draw the keypoints with. Default is red.
- alpha: transparency value between 0 and 1. (default: 0.4)
-
- Raises:
- ValueError: On incorrect data type for image or masks.
- """
- if image.dtype != np.uint8:
- raise ValueError('`image` not of type np.uint8')
- if mask.dtype != np.uint8:
- raise ValueError('`mask` not of type np.uint8')
- if np.any(np.logical_and(mask != 1, mask != 0)):
- raise ValueError('`mask` elements should be in [0, 1]')
- if image.shape[:2] != mask.shape:
- raise ValueError('The image has spatial dimensions %s but the mask has '
- 'dimensions %s' % (image.shape[:2], mask.shape))
- rgb = ImageColor.getrgb(color)
- pil_image = Image.fromarray(image)
-
- solid_color = np.expand_dims(
- np.ones_like(mask), axis=2) * np.reshape(list(rgb), [1, 1, 3])
- pil_solid_color = Image.fromarray(np.uint8(solid_color)).convert('RGBA')
- pil_mask = Image.fromarray(np.uint8(255.0*alpha*mask)).convert('L')
- pil_image = Image.composite(pil_solid_color, pil_image, pil_mask)
- np.copyto(image, np.array(pil_image.convert('RGB')))
-
-
-def visualize_boxes_and_labels_on_image_array(
- image,
- boxes,
- classes,
- scores,
- category_index,
- instance_masks=None,
- instance_boundaries=None,
- keypoints=None,
- use_normalized_coordinates=False,
- max_boxes_to_draw=20,
- min_score_thresh=.5,
- agnostic_mode=False,
- line_thickness=4,
- groundtruth_box_visualization_color='black',
- skip_scores=False,
- skip_labels=False):
- """Overlay labeled boxes on an image with formatted scores and label names.
-
- This function groups boxes that correspond to the same location
- and creates a display string for each detection and overlays these
- on the image. Note that this function modifies the image in place, and returns
- that same image.
-
- Args:
- image: uint8 numpy array with shape (img_height, img_width, 3)
- boxes: a numpy array of shape [N, 4]
- classes: a numpy array of shape [N]. Note that class indices are 1-based,
- and match the keys in the label map.
- scores: a numpy array of shape [N] or None. If scores=None, then
- this function assumes that the boxes to be plotted are groundtruth
- boxes and plot all boxes as black with no classes or scores.
- category_index: a dict containing category dictionaries (each holding
- category index `id` and category name `name`) keyed by category indices.
- instance_masks: a numpy array of shape [N, image_height, image_width] with
- values ranging between 0 and 1, can be None.
- instance_boundaries: a numpy array of shape [N, image_height, image_width]
- with values ranging between 0 and 1, can be None.
- keypoints: a numpy array of shape [N, num_keypoints, 2], can
- be None
- use_normalized_coordinates: whether boxes is to be interpreted as
- normalized coordinates or not.
- max_boxes_to_draw: maximum number of boxes to visualize. If None, draw
- all boxes.
- min_score_thresh: minimum score threshold for a box to be visualized
- agnostic_mode: boolean (default: False) controlling whether to evaluate in
- class-agnostic mode or not. This mode will display scores but ignore
- classes.
- line_thickness: integer (default: 4) controlling line width of the boxes.
- groundtruth_box_visualization_color: box color for visualizing groundtruth
- boxes
- skip_scores: whether to skip score when drawing a single detection
- skip_labels: whether to skip label when drawing a single detection
-
- Returns:
- uint8 numpy array with shape (img_height, img_width, 3) with overlaid boxes.
- """
- # Create a display string (and color) for every box location, group any boxes
- # that correspond to the same location.
- box_to_display_str_map = collections.defaultdict(list)
- box_to_color_map = collections.defaultdict(str)
- box_to_instance_masks_map = {}
- box_to_instance_boundaries_map = {}
- box_to_keypoints_map = collections.defaultdict(list)
- if not max_boxes_to_draw:
- max_boxes_to_draw = boxes.shape[0]
- for i in range(min(max_boxes_to_draw, boxes.shape[0])):
- if scores is None or scores[i] > min_score_thresh:
- box = tuple(boxes[i].tolist())
- if instance_masks is not None:
- box_to_instance_masks_map[box] = instance_masks[i]
- if instance_boundaries is not None:
- box_to_instance_boundaries_map[box] = instance_boundaries[i]
- if keypoints is not None:
- box_to_keypoints_map[box].extend(keypoints[i])
- if scores is None:
- box_to_color_map[box] = groundtruth_box_visualization_color
- else:
- display_str = ''
- if not skip_labels:
- if not agnostic_mode:
- if classes[i] in category_index.keys():
- class_name = category_index[classes[i]]['name']
- else:
- class_name = 'N/A'
- display_str = str(class_name)
- if not skip_scores:
- if not display_str:
- display_str = '{}%'.format(int(100*scores[i]))
- else:
- display_str = '{}: {}%'.format(display_str, int(100*scores[i]))
- box_to_display_str_map[box].append(display_str)
- if agnostic_mode:
- box_to_color_map[box] = 'DarkOrange'
- else:
- box_to_color_map[box] = STANDARD_COLORS[
- classes[i] % len(STANDARD_COLORS)]
-
- # Draw all boxes onto image.
- for box, color in box_to_color_map.items():
- ymin, xmin, ymax, xmax = box
- if instance_masks is not None:
- draw_mask_on_image_array(
- image,
- box_to_instance_masks_map[box],
- color=color
- )
- if instance_boundaries is not None:
- draw_mask_on_image_array(
- image,
- box_to_instance_boundaries_map[box],
- color='red',
- alpha=1.0
- )
- draw_bounding_box_on_image_array(
- image,
- ymin,
- xmin,
- ymax,
- xmax,
- color=color,
- thickness=line_thickness,
- display_str_list=box_to_display_str_map[box],
- use_normalized_coordinates=use_normalized_coordinates)
- if keypoints is not None:
- draw_keypoints_on_image_array(
- image,
- box_to_keypoints_map[box],
- color=color,
- radius=line_thickness / 2,
- use_normalized_coordinates=use_normalized_coordinates)
-
- return image
-
-
-def add_cdf_image_summary(values, name):
- """Adds a tf.summary.image for a CDF plot of the values.
-
- Normalizes `values` such that they sum to 1, plots the cumulative distribution
- function and creates a tf image summary.
-
- Args:
- values: a 1-D float32 tensor containing the values.
- name: name for the image summary.
- """
- def cdf_plot(values):
- """Numpy function to plot CDF."""
- normalized_values = values / np.sum(values)
- sorted_values = np.sort(normalized_values)
- cumulative_values = np.cumsum(sorted_values)
- fraction_of_examples = (np.arange(cumulative_values.size, dtype=np.float32)
- / cumulative_values.size)
- fig = plt.figure(frameon=False)
- ax = fig.add_subplot('111')
- ax.plot(fraction_of_examples, cumulative_values)
- ax.set_ylabel('cumulative normalized values')
- ax.set_xlabel('fraction of examples')
- fig.canvas.draw()
- width, height = fig.get_size_inches() * fig.get_dpi()
- image = np.fromstring(fig.canvas.tostring_rgb(), dtype='uint8').reshape(
- 1, int(height), int(width), 3)
- return image
- cdf_plot = tf.py_func(cdf_plot, [values], tf.uint8)
- tf.summary.image(name, cdf_plot)
-
-
-def add_hist_image_summary(values, bins, name):
- """Adds a tf.summary.image for a histogram plot of the values.
-
- Plots the histogram of values and creates a tf image summary.
-
- Args:
- values: a 1-D float32 tensor containing the values.
- bins: bin edges which will be directly passed to np.histogram.
- name: name for the image summary.
- """
-
- def hist_plot(values, bins):
- """Numpy function to plot hist."""
- fig = plt.figure(frameon=False)
- ax = fig.add_subplot('111')
- y, x = np.histogram(values, bins=bins)
- ax.plot(x[:-1], y)
- ax.set_ylabel('count')
- ax.set_xlabel('value')
- fig.canvas.draw()
- width, height = fig.get_size_inches() * fig.get_dpi()
- image = np.fromstring(
- fig.canvas.tostring_rgb(), dtype='uint8').reshape(
- 1, int(height), int(width), 3)
- return image
- hist_plot = tf.py_func(hist_plot, [values, bins], tf.uint8)
- tf.summary.image(name, hist_plot)
diff --git a/research/cognitive_planning/viz_active_vision_dataset_main.py b/research/cognitive_planning/viz_active_vision_dataset_main.py
deleted file mode 100644
index e6b7deef63e4675fe0c1c05f0c0f4139af9c34de..0000000000000000000000000000000000000000
--- a/research/cognitive_planning/viz_active_vision_dataset_main.py
+++ /dev/null
@@ -1,379 +0,0 @@
-# Copyright 2018 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Initializes at random location and visualizes the optimal path.
-
-Different modes of execution:
-1) benchmark: It generates benchmark_iter sample trajectory to random goals
- and plots the histogram of path lengths. It can be also used to see how fast
- it runs.
-2) vis: It visualizes the generated paths by image, semantic segmentation, and
- so on.
-3) human: allows the user to navigate through environment from keyboard input.
-
-python viz_active_vision_dataset_main -- \
- --mode=benchmark --benchmark_iter=1000 --gin_config=envs/configs/active_vision_config.gin
-
-python viz_active_vision_dataset_main -- \
- --mode=vis \
- --gin_config=envs/configs/active_vision_config.gin
-
-python viz_active_vision_dataset_main -- \
- --mode=human \
- --gin_config=envs/configs/active_vision_config.gin
-
-python viz_active_vision_dataset_main.py --mode=eval --eval_folder=/usr/local/google/home/$USER/checkin_log_det/evals/ --output_folder=/usr/local/google/home/$USER/test_imgs/ --gin_config=envs/configs/active_vision_config.gin
-
-"""
-
-import matplotlib
-# pylint: disable=g-import-not-at-top
-# Need Tk for interactive plots.
-matplotlib.use('TkAgg')
-import tensorflow as tf
-from matplotlib import pyplot as plt
-import numpy as np
-import os
-from pyglib import app
-from pyglib import flags
-import gin
-import cv2
-from envs import active_vision_dataset_env
-from envs import task_env
-
-
-VIS_MODE = 'vis'
-HUMAN_MODE = 'human'
-BENCHMARK_MODE = 'benchmark'
-GRAPH_MODE = 'graph'
-EVAL_MODE = 'eval'
-
-flags.DEFINE_enum('mode', VIS_MODE,
- [VIS_MODE, HUMAN_MODE, BENCHMARK_MODE, GRAPH_MODE, EVAL_MODE],
- 'mode of the execution')
-flags.DEFINE_integer('benchmark_iter', 1000,
- 'number of iterations for benchmarking')
-flags.DEFINE_string('eval_folder', '', 'the path to the eval folder')
-flags.DEFINE_string('output_folder', '',
- 'the path to which the images and gifs are written')
-flags.DEFINE_multi_string('gin_config', [],
- 'List of paths to a gin config files for the env.')
-flags.DEFINE_multi_string('gin_params', [],
- 'Newline separated list of Gin parameter bindings.')
-
-mt = task_env.ModalityTypes
-FLAGS = flags.FLAGS
-
-def benchmark(env, targets):
- """Benchmarks the speed of sequence generation by env.
-
- Args:
- env: environment.
- targets: list of target classes.
- """
- episode_lengths = {}
- all_init_configs = {}
- all_actions = dict([(a, 0.) for a in env.actions])
- for i in range(FLAGS.benchmark_iter):
- path, actions, _, _ = env.random_step_sequence()
- selected_actions = np.argmax(actions, axis=-1)
- new_actions = dict([(a, 0.) for a in env.actions])
- for a in selected_actions:
- new_actions[env.actions[a]] += 1. / selected_actions.shape[0]
- for a in new_actions:
- all_actions[a] += new_actions[a] / FLAGS.benchmark_iter
- start_image_id, world, goal = env.get_init_config(path)
- print world
- if world not in all_init_configs:
- all_init_configs[world] = set()
- all_init_configs[world].add((start_image_id, goal, len(actions)))
- if env.goal_index not in episode_lengths:
- episode_lengths[env.goal_index] = []
- episode_lengths[env.goal_index].append(len(actions))
- for i, cls in enumerate(episode_lengths):
- plt.subplot(231 + i)
- plt.hist(episode_lengths[cls])
- plt.title(targets[cls])
- plt.show()
-
-
-def human(env, targets):
- """Lets user play around the env manually."""
- string_key_map = {
- 'a': 'left',
- 'd': 'right',
- 'w': 'forward',
- 's': 'backward',
- 'j': 'rotate_ccw',
- 'l': 'rotate_cw',
- 'n': 'stop'
- }
- integer_key_map = {
- 'a': env.actions.index('left'),
- 'd': env.actions.index('right'),
- 'w': env.actions.index('forward'),
- 's': env.actions.index('backward'),
- 'j': env.actions.index('rotate_ccw'),
- 'l': env.actions.index('rotate_cw'),
- 'n': env.actions.index('stop')
- }
- for k in integer_key_map:
- integer_key_map[k] = np.int32(integer_key_map[k])
- plt.ion()
- for _ in range(20):
- obs = env.reset()
- steps = -1
- action = None
- while True:
- print 'distance = ', obs[task_env.ModalityTypes.DISTANCE]
- steps += 1
- depth_value = obs[task_env.ModalityTypes.DEPTH][:, :, 0]
- depth_mask = obs[task_env.ModalityTypes.DEPTH][:, :, 1]
- seg_mask = np.squeeze(obs[task_env.ModalityTypes.SEMANTIC_SEGMENTATION])
- det_mask = np.argmax(
- obs[task_env.ModalityTypes.OBJECT_DETECTION], axis=-1)
- img = obs[task_env.ModalityTypes.IMAGE]
- plt.subplot(231)
- plt.title('steps = {}'.format(steps))
- plt.imshow(img.astype(np.uint8))
- plt.subplot(232)
- plt.imshow(depth_value)
- plt.title('depth value')
- plt.subplot(233)
- plt.imshow(depth_mask)
- plt.title('depth mask')
- plt.subplot(234)
- plt.imshow(seg_mask)
- plt.title('seg')
- plt.subplot(235)
- plt.imshow(det_mask)
- plt.title('det')
- plt.subplot(236)
- plt.title('goal={}'.format(targets[env.goal_index]))
- plt.draw()
- while True:
- s = raw_input('key = ')
- if np.random.rand() > 0.5:
- key_map = string_key_map
- else:
- key_map = integer_key_map
- if s in key_map:
- action = key_map[s]
- break
- else:
- print 'invalid action'
- print 'action = {}'.format(action)
- if action == 'stop':
- print 'dist to goal: {}'.format(len(env.path_to_goal()) - 2)
- break
- obs, reward, done, info = env.step(action)
- print 'reward = {}, done = {}, success = {}'.format(
- reward, done, info['success'])
-
-
-def visualize_random_step_sequence(env):
- """Visualizes random sequence of steps."""
- plt.ion()
- for _ in range(20):
- path, actions, _, step_outputs = env.random_step_sequence(max_len=30)
- print 'path = {}'.format(path)
- for action, step_output in zip(actions, step_outputs):
- obs, _, done, _ = step_output
- depth_value = obs[task_env.ModalityTypes.DEPTH][:, :, 0]
- depth_mask = obs[task_env.ModalityTypes.DEPTH][:, :, 1]
- seg_mask = np.squeeze(obs[task_env.ModalityTypes.SEMANTIC_SEGMENTATION])
- det_mask = np.argmax(
- obs[task_env.ModalityTypes.OBJECT_DETECTION], axis=-1)
- img = obs[task_env.ModalityTypes.IMAGE]
- plt.subplot(231)
- plt.imshow(img.astype(np.uint8))
- plt.subplot(232)
- plt.imshow(depth_value)
- plt.title('depth value')
- plt.subplot(233)
- plt.imshow(depth_mask)
- plt.title('depth mask')
- plt.subplot(234)
- plt.imshow(seg_mask)
- plt.title('seg')
- plt.subplot(235)
- plt.imshow(det_mask)
- plt.title('det')
- plt.subplot(236)
- print 'action = {}'.format(action)
- print 'done = {}'.format(done)
- plt.draw()
- if raw_input('press \'n\' to go to the next random sequence. Otherwise, '
- 'press any key to continue...') == 'n':
- break
-
-
-def visualize(env, input_folder, output_root_folder):
- """visualizes images for sequence of steps from the evals folder."""
- def which_env(file_name):
- img_name = file_name.split('_')[0][2:5]
- env_dict = {'161': 'Home_016_1', '131': 'Home_013_1', '111': 'Home_011_1'}
- if img_name in env_dict:
- return env_dict[img_name]
- else:
- raise ValueError('could not resolve env: {} {}'.format(
- img_name, file_name))
-
- def which_goal(file_name):
- return file_name[file_name.find('_')+1:]
-
- output_images_folder = os.path.join(output_root_folder, 'images')
- output_gifs_folder = os.path.join(output_root_folder, 'gifs')
- if not tf.gfile.IsDirectory(output_images_folder):
- tf.gfile.MakeDirs(output_images_folder)
- if not tf.gfile.IsDirectory(output_gifs_folder):
- tf.gfile.MakeDirs(output_gifs_folder)
- npy_files = [
- os.path.join(input_folder, name)
- for name in tf.gfile.ListDirectory(input_folder)
- if name.find('npy') >= 0
- ]
- for i, npy_file in enumerate(npy_files):
- print 'saving images {}/{}'.format(i, len(npy_files))
- pure_name = npy_file[npy_file.rfind('/') + 1:-4]
- output_folder = os.path.join(output_images_folder, pure_name)
- if not tf.gfile.IsDirectory(output_folder):
- tf.gfile.MakeDirs(output_folder)
- print '*******'
- print pure_name[0:pure_name.find('_')]
- env.reset_for_eval(which_env(pure_name),
- which_goal(pure_name),
- pure_name[0:pure_name.find('_')],
- )
- with tf.gfile.Open(npy_file) as h:
- states = np.load(h).item()['states']
- images = [
- env.observation(state)[mt.IMAGE] for state in states
- ]
- for j, img in enumerate(images):
- cv2.imwrite(os.path.join(output_folder, '{0:03d}'.format(j) + '.jpg'),
- img[:, :, ::-1])
- print 'converting to gif'
- os.system(
- 'convert -set delay 20 -colors 256 -dispose 1 {}/*.jpg {}.gif'.format(
- output_folder,
- os.path.join(output_gifs_folder, pure_name + '.gif')
- )
- )
-
-def evaluate_folder(env, folder_path):
- """Evaluates the performance from the evals folder."""
- targets = ['fridge', 'dining_table', 'microwave', 'tv', 'couch']
-
- def compute_acc(npy_file):
- with tf.gfile.Open(npy_file) as h:
- data = np.load(h).item()
- if npy_file.find('dining_table') >= 0:
- category = 'dining_table'
- else:
- category = npy_file[npy_file.rfind('_') + 1:-4]
- return category, data['distance'][-1] - 2
-
- def evaluate_iteration(folder):
- """Evaluates the data from the folder of certain eval iteration."""
- print folder
- npy_files = [
- os.path.join(folder, name)
- for name in tf.gfile.ListDirectory(folder)
- if name.find('npy') >= 0
- ]
- eval_stats = {c: [] for c in targets}
- for npy_file in npy_files:
- try:
- category, dist = compute_acc(npy_file)
- except: # pylint: disable=bare-except
- continue
- eval_stats[category].append(float(dist <= 5))
- for c in eval_stats:
- if not eval_stats[c]:
- print 'incomplete eval {}: empty class {}'.format(folder_path, c)
- return None
- eval_stats[c] = np.mean(eval_stats[c])
-
- eval_stats['mean'] = np.mean(eval_stats.values())
- return eval_stats
-
- checkpoint_folders = [
- folder_path + x
- for x in tf.gfile.ListDirectory(folder_path)
- if tf.gfile.IsDirectory(folder_path + x)
- ]
-
- print '{} folders found'.format(len(checkpoint_folders))
- print '------------------------'
- all_iters = []
- all_accs = []
- for i, folder in enumerate(checkpoint_folders):
- print 'processing {}/{}'.format(i, len(checkpoint_folders))
- eval_stats = evaluate_iteration(folder)
- if eval_stats is None:
- continue
- else:
- iter_no = int(folder[folder.rfind('/') + 1:])
- print 'result ', iter_no, eval_stats['mean']
- all_accs.append(eval_stats['mean'])
- all_iters.append(iter_no)
-
- all_accs = np.asarray(all_accs)
- all_iters = np.asarray(all_iters)
- idx = np.argmax(all_accs)
- print 'best result at iteration {} was {}'.format(all_iters[idx],
- all_accs[idx])
- order = np.argsort(all_iters)
- all_iters = all_iters[order]
- all_accs = all_accs[order]
- #plt.plot(all_iters, all_accs)
- #plt.show()
- #print 'done plotting'
-
- best_iteration_folder = os.path.join(folder_path, str(all_iters[idx]))
-
- print 'generating gifs and images for {}'.format(best_iteration_folder)
- visualize(env, best_iteration_folder, FLAGS.output_folder)
-
-
-def main(_):
- gin.parse_config_files_and_bindings(FLAGS.gin_config, FLAGS.gin_params)
- print('********')
- print(FLAGS.mode)
- print(FLAGS.gin_config)
- print(FLAGS.gin_params)
-
- env = active_vision_dataset_env.ActiveVisionDatasetEnv(modality_types=[
- task_env.ModalityTypes.IMAGE,
- task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
- task_env.ModalityTypes.OBJECT_DETECTION, task_env.ModalityTypes.DEPTH,
- task_env.ModalityTypes.DISTANCE
- ])
-
- if FLAGS.mode == BENCHMARK_MODE:
- benchmark(env, env.possible_targets)
- elif FLAGS.mode == GRAPH_MODE:
- for loc in env.worlds:
- env.check_scene_graph(loc, 'fridge')
- elif FLAGS.mode == HUMAN_MODE:
- human(env, env.possible_targets)
- elif FLAGS.mode == VIS_MODE:
- visualize_random_step_sequence(env)
- elif FLAGS.mode == EVAL_MODE:
- evaluate_folder(env, FLAGS.eval_folder)
-
-if __name__ == '__main__':
- app.run(main)
diff --git a/research/compression/README.md b/research/compression/README.md
deleted file mode 100644
index 7f431b5eac6805fbecc276783cef2bc6c62068e5..0000000000000000000000000000000000000000
--- a/research/compression/README.md
+++ /dev/null
@@ -1,19 +0,0 @@
-
-
-
-
-# Compression with Neural Networks
-
-This is a [TensorFlow](http://www.tensorflow.org/) model repo containing
-research on compression with neural networks. This repo currently contains
-code for the following papers:
-
-[Full Resolution Image Compression with Recurrent Neural Networks](https://arxiv.org/abs/1608.05148)
-
-## Organization
-[Image Encoder](image_encoder/): Encoding and decoding images into their binary representation.
-
-[Entropy Coder](entropy_coder/): Lossless compression of the binary representation.
-
-## Contact Info
-Model repository maintained by Nick Johnston ([nmjohn](https://github.com/nmjohn)).
diff --git a/research/compression/entropy_coder/README.md b/research/compression/entropy_coder/README.md
deleted file mode 100644
index 59e889990aab71e12ed13122c9b5a796a048402a..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/README.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# Neural net based entropy coding
-
-This is a [TensorFlow](http://www.tensorflow.org/) model for additional
-lossless compression of bitstreams generated by neural net based image
-encoders as described in
-[https://arxiv.org/abs/1703.10114](https://arxiv.org/abs/1703.10114).
-
-To be more specific, the entropy coder aims at compressing further binary
-codes which have a 3D tensor structure with:
-
-* the first two dimensions of the tensors corresponding to the height and
-the width of the binary codes,
-* the last dimension being the depth of the codes. The last dimension can be
-sliced into N groups of K, where each additional group is used by the image
-decoder to add more details to the reconstructed image.
-
-The code in this directory only contains the underlying code probability model
-but does not perform the actual compression using arithmetic coding.
-The code probability model is enough to compute the theoretical compression
-ratio.
-
-
-## Prerequisites
-The only software requirements for running the encoder and decoder is having
-Tensorflow installed.
-
-You will also need to add the top level source directory of the entropy coder
-to your `PYTHONPATH`, for example:
-
-`export PYTHONPATH=${PYTHONPATH}:/tmp/models/compression`
-
-
-## Training the entropy coder
-
-### Synthetic dataset
-If you do not have a training dataset, there is a simple code generative model
-that you can use to generate a dataset and play with the entropy coder.
-The generative model is located under dataset/gen\_synthetic\_dataset.py. Note
-that this simple generative model is not going to give good results on real
-images as it is not supposed to be close to the statistics of the binary
-representation of encoded images. Consider it as a toy dataset, no more, no
-less.
-
-To generate a synthetic dataset with 20000 samples:
-
-`mkdir -p /tmp/dataset`
-
-`python ./dataset/gen_synthetic_dataset.py --dataset_dir=/tmp/dataset/
---count=20000`
-
-Note that the generator has not been optimized at all, generating the synthetic
-dataset is currently pretty slow.
-
-### Training
-
-If you just want to play with the entropy coder trainer, here is the command
-line that can be used to train the entropy coder on the synthetic dataset:
-
-`mkdir -p /tmp/entropy_coder_train`
-
-`python ./core/entropy_coder_train.py --task=0
---train_dir=/tmp/entropy_coder_train/
---model=progressive
---model_config=./configs/synthetic/model_config.json
---train_config=./configs/synthetic/train_config.json
---input_config=./configs/synthetic/input_config.json
-`
-
-Training is configured using 3 files formatted using JSON:
-
-* One file is used to configure the underlying entropy coder model.
- Currently, only the *progressive* model is supported.
- This model takes 2 mandatory parameters and an optional one:
- * `layer_depth`: the number of bits per layer (a.k.a. iteration).
- Background: the image decoder takes each layer to add more detail
- to the image.
- * `layer_count`: the maximum number of layers that should be supported
- by the model. This should be equal or greater than the maximum number
- of layers in the input binary codes.
- * `coded_layer_count`: This can be used to consider only partial codes,
- keeping only the first `coded_layer_count` layers and ignoring the
- remaining layers. If left empty, the binary codes are left unchanged.
-* One file to configure the training, including the learning rate, ...
- The meaning of the parameters are pretty straightforward. Note that this
- file is only used during training and is not needed during inference.
-* One file to specify the input dataset to use during training.
- The dataset is formatted using tf.RecordIO.
-
-
-## Inference: file size after entropy coding.
-
-### Using a synthetic sample
-
-Here is the command line to generate a single synthetic sample formatted
-in the same way as what is provided by the image encoder:
-
-`python ./dataset/gen_synthetic_single.py
---sample_filename=/tmp/dataset/sample_0000.npz`
-
-To actually compute the additional compression ratio using the entropy coder
-trained in the previous step:
-
-`python ./core/entropy_coder_single.py
---model=progressive
---model_config=./configs/synthetic/model_config.json
---input_codes=/tmp/dataset/sample_0000.npz
---checkpoint=/tmp/entropy_coder_train/model.ckpt-209078`
-
-where the checkpoint number should be adjusted accordingly.
diff --git a/research/compression/entropy_coder/__init__.py b/research/compression/entropy_coder/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/compression/entropy_coder/all_models/__init__.py b/research/compression/entropy_coder/all_models/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/compression/entropy_coder/all_models/all_models.py b/research/compression/entropy_coder/all_models/all_models.py
deleted file mode 100644
index e376dac737667a348065eec622920b0a81ed1ac9..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/all_models/all_models.py
+++ /dev/null
@@ -1,19 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Import and register all the entropy coder models."""
-
-# pylint: disable=unused-import
-from entropy_coder.progressive import progressive
diff --git a/research/compression/entropy_coder/all_models/all_models_test.py b/research/compression/entropy_coder/all_models/all_models_test.py
deleted file mode 100644
index b8aff504a0a00d579d1b2768164b78b6c095b235..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/all_models/all_models_test.py
+++ /dev/null
@@ -1,68 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Basic test of all registered models."""
-
-import tensorflow as tf
-
-# pylint: disable=unused-import
-import all_models
-# pylint: enable=unused-import
-from entropy_coder.model import model_factory
-
-
-class AllModelsTest(tf.test.TestCase):
-
- def testBuildModelForTraining(self):
- factory = model_factory.GetModelRegistry()
- model_names = factory.GetAvailableModels()
-
- for m in model_names:
- tf.reset_default_graph()
-
- global_step = tf.Variable(tf.zeros([], dtype=tf.int64),
- trainable=False,
- name='global_step')
-
- optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
-
- batch_size = 3
- height = 40
- width = 20
- depth = 5
- binary_codes = tf.placeholder(dtype=tf.float32,
- shape=[batch_size, height, width, depth])
-
- # Create a model with the default configuration.
- print('Creating model: {}'.format(m))
- model = factory.CreateModel(m)
- model.Initialize(global_step,
- optimizer,
- model.GetConfigStringForUnitTest())
- self.assertTrue(model.loss is None, 'model: {}'.format(m))
- self.assertTrue(model.train_op is None, 'model: {}'.format(m))
- self.assertTrue(model.average_code_length is None, 'model: {}'.format(m))
-
- # Build the Tensorflow graph corresponding to the model.
- model.BuildGraph(binary_codes)
- self.assertTrue(model.loss is not None, 'model: {}'.format(m))
- self.assertTrue(model.average_code_length is not None,
- 'model: {}'.format(m))
- if model.train_op is None:
- print('Model {} is not trainable'.format(m))
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/configs/gru_prime3/model_config.json b/research/compression/entropy_coder/configs/gru_prime3/model_config.json
deleted file mode 100644
index cf63a4c454df5c47c732c5eaeea481b2aa714665..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/configs/gru_prime3/model_config.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "layer_count": 16,
- "layer_depth": 32
-}
diff --git a/research/compression/entropy_coder/configs/synthetic/input_config.json b/research/compression/entropy_coder/configs/synthetic/input_config.json
deleted file mode 100644
index 18455e65120cd45cb04106ed8b6b2d6641e1d49a..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/configs/synthetic/input_config.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "data": "/tmp/dataset/synthetic_dataset",
- "unique_code_size": true
-}
diff --git a/research/compression/entropy_coder/configs/synthetic/model_config.json b/research/compression/entropy_coder/configs/synthetic/model_config.json
deleted file mode 100644
index c6f1f3e11547a75c05019e24c59a7fc6d2a29e3b..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/configs/synthetic/model_config.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "layer_depth": 2,
- "layer_count": 8
-}
diff --git a/research/compression/entropy_coder/configs/synthetic/train_config.json b/research/compression/entropy_coder/configs/synthetic/train_config.json
deleted file mode 100644
index 79e4909fd3f93df983d79890e25b7b61ba14aa40..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/configs/synthetic/train_config.json
+++ /dev/null
@@ -1,6 +0,0 @@
-{
- "batch_size": 4,
- "learning_rate": 0.1,
- "decay_rate": 0.9,
- "samples_per_decay": 20000
-}
diff --git a/research/compression/entropy_coder/core/code_loader.py b/research/compression/entropy_coder/core/code_loader.py
deleted file mode 100644
index 603ab724afb0e6c4e94db9c121d7799eaf30fa02..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/core/code_loader.py
+++ /dev/null
@@ -1,73 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Load binary codes stored as tf.Example in a TFRecord table."""
-
-import tensorflow as tf
-
-
-def ReadFirstCode(dataset):
- """Read the first example from a binary code RecordIO table."""
- for record in tf.python_io.tf_record_iterator(dataset):
- tf_example = tf.train.Example()
- tf_example.ParseFromString(record)
- break
- return tf_example
-
-
-def LoadBinaryCode(input_config, batch_size):
- """Load a batch of binary codes from a tf.Example dataset.
-
- Args:
- input_config: An InputConfig proto containing the input configuration.
- batch_size: Output batch size of examples.
-
- Returns:
- A batched tensor of binary codes.
- """
- data = input_config.data
-
- # TODO: Possibly use multiple files (instead of just one).
- file_list = [data]
- filename_queue = tf.train.string_input_producer(file_list,
- capacity=4)
- reader = tf.TFRecordReader()
- _, values = reader.read(filename_queue)
-
- serialized_example = tf.reshape(values, shape=[1])
- serialized_features = {
- 'code_shape': tf.FixedLenFeature([3],
- dtype=tf.int64),
- 'code': tf.VarLenFeature(tf.float32),
- }
- example = tf.parse_example(serialized_example, serialized_features)
-
- # 3D shape: height x width x binary_code_depth
- z = example['code_shape']
- code_shape = tf.reshape(tf.cast(z, tf.int32), [3])
- # Un-flatten the binary codes.
- code = tf.reshape(tf.sparse_tensor_to_dense(example['code']), code_shape)
-
- queue_size = 10
- queue = tf.PaddingFIFOQueue(
- queue_size + 3 * batch_size,
- dtypes=[code.dtype],
- shapes=[[None, None, None]])
- enqueue_op = queue.enqueue([code])
- dequeue_code = queue.dequeue_many(batch_size)
- queue_runner = tf.train.queue_runner.QueueRunner(queue, [enqueue_op])
- tf.add_to_collection(tf.GraphKeys.QUEUE_RUNNERS, queue_runner)
-
- return dequeue_code
diff --git a/research/compression/entropy_coder/core/config_helper.py b/research/compression/entropy_coder/core/config_helper.py
deleted file mode 100644
index a7d949e329b93f33d330d1ba494f71ae1704fa3f..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/core/config_helper.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Helper functions used in both train and inference."""
-
-import json
-import os.path
-
-import tensorflow as tf
-
-
-def GetConfigString(config_file):
- config_string = ''
- if config_file is not None:
- config_string = open(config_file).read()
- return config_string
-
-
-class InputConfig(object):
-
- def __init__(self, config_string):
- config = json.loads(config_string)
- self.data = config["data"]
- self.unique_code_size = config["unique_code_size"]
-
-
-class TrainConfig(object):
-
- def __init__(self, config_string):
- config = json.loads(config_string)
- self.batch_size = config["batch_size"]
- self.learning_rate = config["learning_rate"]
- self.decay_rate = config["decay_rate"]
- self.samples_per_decay = config["samples_per_decay"]
-
-
-def SaveConfig(directory, filename, config_string):
- path = os.path.join(directory, filename)
- with tf.gfile.Open(path, mode='w') as f:
- f.write(config_string)
diff --git a/research/compression/entropy_coder/core/entropy_coder_single.py b/research/compression/entropy_coder/core/entropy_coder_single.py
deleted file mode 100644
index 8a61b488b6bdd11e1cff4a2da672129240eb7240..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/core/entropy_coder_single.py
+++ /dev/null
@@ -1,116 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Compute the additional compression ratio after entropy coding."""
-
-import io
-import os
-
-import numpy as np
-import tensorflow as tf
-
-import config_helper
-
-# pylint: disable=unused-import
-from entropy_coder.all_models import all_models
-# pylint: enable=unused-import
-from entropy_coder.model import model_factory
-
-
-# Checkpoint used to restore the model parameters.
-tf.app.flags.DEFINE_string('checkpoint', None,
- """Model checkpoint.""")
-
-# Model selection and configuration.
-tf.app.flags.DEFINE_string('model', None, """Underlying encoder model.""")
-tf.app.flags.DEFINE_string('model_config', None,
- """Model config protobuf given as text file.""")
-
-# File holding the binary codes.
-tf.flags.DEFINE_string('input_codes', None, 'Location of binary code file.')
-
-FLAGS = tf.flags.FLAGS
-
-
-def main(_):
- if (FLAGS.input_codes is None or FLAGS.model is None):
- print ('\nUsage: python entropy_coder_single.py --model=progressive '
- '--model_config=model_config.json'
- '--iteration=15\n\n')
- return
-
- #if FLAGS.iteration < -1 or FLAGS.iteration > 15:
- # print ('\n--iteration must be between 0 and 15 inclusive, or -1 to infer '
- # 'from file.\n')
- # return
- #iteration = FLAGS.iteration
-
- if not tf.gfile.Exists(FLAGS.input_codes):
- print('\nInput codes not found.\n')
- return
-
- with tf.gfile.FastGFile(FLAGS.input_codes, 'rb') as code_file:
- contents = code_file.read()
- loaded_codes = np.load(io.BytesIO(contents))
- assert ['codes', 'shape'] not in loaded_codes.files
- loaded_shape = loaded_codes['shape']
- loaded_array = loaded_codes['codes']
-
- # Unpack and recover code shapes.
- unpacked_codes = np.reshape(np.unpackbits(loaded_array)
- [:np.prod(loaded_shape)],
- loaded_shape)
-
- numpy_int_codes = unpacked_codes.transpose([1, 2, 3, 0, 4])
- numpy_int_codes = numpy_int_codes.reshape([numpy_int_codes.shape[0],
- numpy_int_codes.shape[1],
- numpy_int_codes.shape[2],
- -1])
- numpy_codes = numpy_int_codes.astype(np.float32) * 2.0 - 1.0
-
- with tf.Graph().as_default() as graph:
- # TF tensor to hold the binary codes to losslessly compress.
- batch_size = 1
- codes = tf.placeholder(tf.float32, shape=numpy_codes.shape)
-
- # Create the entropy coder model.
- global_step = None
- optimizer = None
- model = model_factory.GetModelRegistry().CreateModel(FLAGS.model)
- model_config_string = config_helper.GetConfigString(FLAGS.model_config)
- model.Initialize(global_step, optimizer, model_config_string)
- model.BuildGraph(codes)
-
- saver = tf.train.Saver(sharded=True, keep_checkpoint_every_n_hours=12.0)
-
- with tf.Session(graph=graph) as sess:
- # Initialize local variables.
- sess.run(tf.local_variables_initializer())
-
- # Restore model variables.
- saver.restore(sess, FLAGS.checkpoint)
-
- tf_tensors = {
- 'code_length': model.average_code_length
- }
- feed_dict = {codes: numpy_codes}
- np_tensors = sess.run(tf_tensors, feed_dict=feed_dict)
-
- print('Additional compression ratio: {}'.format(
- np_tensors['code_length']))
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/compression/entropy_coder/core/entropy_coder_train.py b/research/compression/entropy_coder/core/entropy_coder_train.py
deleted file mode 100644
index 27c489037d27095b578aed6ad10a5a190ec49b18..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/core/entropy_coder_train.py
+++ /dev/null
@@ -1,184 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Train an entropy coder model."""
-
-import time
-
-import tensorflow as tf
-
-import code_loader
-import config_helper
-
-# pylint: disable=unused-import
-from entropy_coder.all_models import all_models
-# pylint: enable=unused-import
-from entropy_coder.model import model_factory
-
-
-FLAGS = tf.app.flags.FLAGS
-
-# Hardware resources configuration.
-tf.app.flags.DEFINE_string('master', '',
- """Name of the TensorFlow master to use.""")
-tf.app.flags.DEFINE_string('train_dir', None,
- """Directory where to write event logs.""")
-tf.app.flags.DEFINE_integer('task', None,
- """Task id of the replica running the training.""")
-tf.app.flags.DEFINE_integer('ps_tasks', 0, """Number of tasks in the ps job.
- If 0 no ps job is used.""")
-
-# Model selection and configuration.
-tf.app.flags.DEFINE_string('model', None, """Underlying encoder model.""")
-tf.app.flags.DEFINE_string('model_config', None,
- """Model config protobuf given as text file.""")
-
-# Training data and parameters configuration.
-tf.app.flags.DEFINE_string('input_config', None,
- """Path to the training input config file.""")
-tf.app.flags.DEFINE_string('train_config', None,
- """Path to the training experiment config file.""")
-
-
-def train():
- if FLAGS.train_dir is None:
- raise ValueError('Parameter train_dir must be provided')
- if FLAGS.task is None:
- raise ValueError('Parameter task must be provided')
- if FLAGS.model is None:
- raise ValueError('Parameter model must be provided')
-
- input_config_string = config_helper.GetConfigString(FLAGS.input_config)
- input_config = config_helper.InputConfig(input_config_string)
-
- # Training parameters.
- train_config_string = config_helper.GetConfigString(FLAGS.train_config)
- train_config = config_helper.TrainConfig(train_config_string)
-
- batch_size = train_config.batch_size
- initial_learning_rate = train_config.learning_rate
- decay_rate = train_config.decay_rate
- samples_per_decay = train_config.samples_per_decay
-
- # Parameters for learning-rate decay.
- # The formula is decay_rate ** floor(steps / decay_steps).
- decay_steps = samples_per_decay / batch_size
- decay_steps = max(decay_steps, 1)
-
- first_code = code_loader.ReadFirstCode(input_config.data)
- first_code_height = (
- first_code.features.feature['code_shape'].int64_list.value[0])
- first_code_width = (
- first_code.features.feature['code_shape'].int64_list.value[1])
- max_bit_depth = (
- first_code.features.feature['code_shape'].int64_list.value[2])
- print('Maximum code depth: {}'.format(max_bit_depth))
-
- with tf.Graph().as_default():
- ps_ops = ["Variable", "VariableV2", "AutoReloadVariable", "VarHandleOp"]
- with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks,
- ps_ops=ps_ops)):
- codes = code_loader.LoadBinaryCode(
- input_config=input_config,
- batch_size=batch_size)
- if input_config.unique_code_size:
- print('Input code size: {} x {}'.format(first_code_height,
- first_code_width))
- codes.set_shape(
- [batch_size, first_code_height, first_code_width, max_bit_depth])
- else:
- codes.set_shape([batch_size, None, None, max_bit_depth])
- codes_effective_shape = tf.shape(codes)
-
- global_step = tf.contrib.framework.create_global_step()
-
- # Apply learning-rate decay.
- learning_rate = tf.train.exponential_decay(
- learning_rate=initial_learning_rate,
- global_step=global_step,
- decay_steps=decay_steps,
- decay_rate=decay_rate,
- staircase=True)
- tf.summary.scalar('Learning Rate', learning_rate)
- optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate,
- epsilon=1.0)
-
- # Create the entropy coder model.
- model = model_factory.GetModelRegistry().CreateModel(FLAGS.model)
- model_config_string = config_helper.GetConfigString(FLAGS.model_config)
- model.Initialize(global_step, optimizer, model_config_string)
- model.BuildGraph(codes)
-
- summary_op = tf.summary.merge_all()
-
- # Verify that the model can actually be trained.
- if model.train_op is None:
- raise ValueError('Input model {} is not trainable'.format(FLAGS.model))
-
- # We disable the summary thread run by Supervisor class by passing
- # summary_op=None. We still pass save_summaries_secs because it is used by
- # the global step counter thread.
- is_chief = (FLAGS.task == 0)
- sv = tf.train.Supervisor(logdir=FLAGS.train_dir,
- is_chief=is_chief,
- global_step=global_step,
- # saver=model.saver,
- summary_op=None,
- save_summaries_secs=120,
- save_model_secs=600,
- recovery_wait_secs=30)
-
- sess = sv.PrepareSession(FLAGS.master)
- sv.StartQueueRunners(sess)
-
- step = sess.run(global_step)
- print('Trainer initial step: {}.'.format(step))
-
- # Once everything has been setup properly, save the configs.
- if is_chief:
- config_helper.SaveConfig(FLAGS.train_dir, 'input_config.json',
- input_config_string)
- config_helper.SaveConfig(FLAGS.train_dir, 'model_config.json',
- model_config_string)
- config_helper.SaveConfig(FLAGS.train_dir, 'train_config.json',
- train_config_string)
-
- # Train the model.
- next_summary_time = time.time()
- while not sv.ShouldStop():
- feed_dict = None
-
- # Once in a while, update the summaries on the chief worker.
- if is_chief and next_summary_time < time.time():
- summary_str = sess.run(summary_op, feed_dict=feed_dict)
- sv.SummaryComputed(sess, summary_str)
- next_summary_time = time.time() + sv.save_summaries_secs
- else:
- tf_tensors = {
- 'train': model.train_op,
- 'code_length': model.average_code_length
- }
- np_tensors = sess.run(tf_tensors, feed_dict=feed_dict)
- print(np_tensors['code_length'])
-
- sv.Stop()
-
-
-def main(argv=None): # pylint: disable=unused-argument
- train()
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py b/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py
deleted file mode 100644
index de60aee324d4a6209d00a873ee681aa59aae0d8e..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py
+++ /dev/null
@@ -1,89 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Generate a synthetic dataset."""
-
-import os
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-import synthetic_model
-
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_string(
- 'dataset_dir', None,
- """Directory where to write the dataset and the configs.""")
-tf.app.flags.DEFINE_integer(
- 'count', 1000,
- """Number of samples to generate.""")
-
-
-def int64_feature(values):
- """Returns a TF-Feature of int64s.
-
- Args:
- values: A scalar or list of values.
-
- Returns:
- A TF-Feature.
- """
- if not isinstance(values, (tuple, list)):
- values = [values]
- return tf.train.Feature(int64_list=tf.train.Int64List(value=values))
-
-
-def float_feature(values):
- """Returns a TF-Feature of floats.
-
- Args:
- values: A scalar of list of values.
-
- Returns:
- A TF-Feature.
- """
- if not isinstance(values, (tuple, list)):
- values = [values]
- return tf.train.Feature(float_list=tf.train.FloatList(value=values))
-
-
-def AddToTFRecord(code, tfrecord_writer):
- example = tf.train.Example(features=tf.train.Features(feature={
- 'code_shape': int64_feature(code.shape),
- 'code': float_feature(code.flatten().tolist()),
- }))
- tfrecord_writer.write(example.SerializeToString())
-
-
-def GenerateDataset(filename, count, code_shape):
- with tf.python_io.TFRecordWriter(filename) as tfrecord_writer:
- for _ in xrange(count):
- code = synthetic_model.GenerateSingleCode(code_shape)
- # Convert {0,1} codes to {-1,+1} codes.
- code = 2.0 * code - 1.0
- AddToTFRecord(code, tfrecord_writer)
-
-
-def main(argv=None): # pylint: disable=unused-argument
- GenerateDataset(os.path.join(FLAGS.dataset_dir + '/synthetic_dataset'),
- FLAGS.count,
- [35, 48, 8])
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/compression/entropy_coder/dataset/gen_synthetic_single.py b/research/compression/entropy_coder/dataset/gen_synthetic_single.py
deleted file mode 100644
index b8c3821c38b6a0b95f01ad7ffb283cca4beb34b3..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/dataset/gen_synthetic_single.py
+++ /dev/null
@@ -1,72 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Generate a single synthetic sample."""
-
-import io
-import os
-
-import numpy as np
-import tensorflow as tf
-
-import synthetic_model
-
-
-FLAGS = tf.app.flags.FLAGS
-
-tf.app.flags.DEFINE_string(
- 'sample_filename', None,
- """Output file to store the generated binary code.""")
-
-
-def GenerateSample(filename, code_shape, layer_depth):
- # {0, +1} binary codes.
- # No conversion since the output file is expected to store
- # codes using {0, +1} codes (and not {-1, +1}).
- code = synthetic_model.GenerateSingleCode(code_shape)
- code = np.round(code)
-
- # Reformat the code so as to be compatible with what is generated
- # by the image encoder.
- # The image encoder generates a tensor of size:
- # iteration_count x batch_size x height x width x iteration_depth.
- # Here: batch_size = 1
- if code_shape[-1] % layer_depth != 0:
- raise ValueError('Number of layers is not an integer')
- height = code_shape[0]
- width = code_shape[1]
- code = code.reshape([1, height, width, -1, layer_depth])
- code = np.transpose(code, [3, 0, 1, 2, 4])
-
- int_codes = code.astype(np.int8)
- exported_codes = np.packbits(int_codes.reshape(-1))
-
- output = io.BytesIO()
- np.savez_compressed(output, shape=int_codes.shape, codes=exported_codes)
- with tf.gfile.FastGFile(filename, 'wb') as code_file:
- code_file.write(output.getvalue())
-
-
-def main(argv=None): # pylint: disable=unused-argument
- # Note: the height and the width is different from the training dataset.
- # The main purpose is to show that the entropy coder model is fully
- # convolutional and can be used on any image size.
- layer_depth = 2
- GenerateSample(FLAGS.sample_filename, [31, 36, 8], layer_depth)
-
-
-if __name__ == '__main__':
- tf.app.run()
-
diff --git a/research/compression/entropy_coder/dataset/synthetic_model.py b/research/compression/entropy_coder/dataset/synthetic_model.py
deleted file mode 100644
index 9cccb64a136aba5a623c95e7c2dede2191d2cd62..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/dataset/synthetic_model.py
+++ /dev/null
@@ -1,75 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Binary code sample generator."""
-
-import numpy as np
-from six.moves import xrange
-
-
-_CRC_LINE = [
- [0, 1, 0],
- [1, 1, 0],
- [1, 0, 0]
-]
-
-_CRC_DEPTH = [1, 1, 0, 1]
-
-
-def ComputeLineCrc(code, width, y, x, d):
- crc = 0
- for dy in xrange(len(_CRC_LINE)):
- i = y - 1 - dy
- if i < 0:
- continue
- for dx in xrange(len(_CRC_LINE[dy])):
- j = x - 2 + dx
- if j < 0 or j >= width:
- continue
- crc += 1 if (code[i, j, d] != _CRC_LINE[dy][dx]) else 0
- return crc
-
-
-def ComputeDepthCrc(code, y, x, d):
- crc = 0
- for delta in xrange(len(_CRC_DEPTH)):
- k = d - 1 - delta
- if k < 0:
- continue
- crc += 1 if (code[y, x, k] != _CRC_DEPTH[delta]) else 0
- return crc
-
-
-def GenerateSingleCode(code_shape):
- code = np.zeros(code_shape, dtype=np.int)
-
- keep_value_proba = 0.8
-
- height = code_shape[0]
- width = code_shape[1]
- depth = code_shape[2]
-
- for d in xrange(depth):
- for y in xrange(height):
- for x in xrange(width):
- v1 = ComputeLineCrc(code, width, y, x, d)
- v2 = ComputeDepthCrc(code, y, x, d)
- v = 1 if (v1 + v2 >= 6) else 0
- if np.random.rand() < keep_value_proba:
- code[y, x, d] = v
- else:
- code[y, x, d] = 1 - v
-
- return code
diff --git a/research/compression/entropy_coder/lib/__init__.py b/research/compression/entropy_coder/lib/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/compression/entropy_coder/lib/block_base.py b/research/compression/entropy_coder/lib/block_base.py
deleted file mode 100644
index 615dff82829dbbcab46c7217cd35f6259de01161..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/block_base.py
+++ /dev/null
@@ -1,258 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Base class for Tensorflow building blocks."""
-
-import collections
-import contextlib
-import itertools
-
-import tensorflow as tf
-
-_block_stacks = collections.defaultdict(lambda: [])
-
-
-class BlockBase(object):
- """Base class for transform wrappers of Tensorflow.
-
- To implement a Tensorflow transform block, inherit this class.
-
- 1. To create a variable, use NewVar() method. Do not overload this method!
- For example, use as follows.
- a_variable = self.NewVar(initial_value)
-
- 2. All Tensorflow-related code must be done inside 'with self._BlockScope().'
- Otherwise, name scoping and block hierarchy will not work. An exception
- is _Apply() method, which is already called inside the context manager
- by __call__() method.
-
- 3. Override and implement _Apply() method. This method is called by
- __call__() method.
-
- The users would use blocks like the following.
- nn1 = NN(128, bias=Bias(0), act=tf.nn.relu)
- y = nn1(x)
-
- Some things to consider.
-
- - Use lazy-initialization if possible. That is, initialize at first Apply()
- rather than at __init__().
-
- Note: if needed, the variables can be created on a specific parameter
- server by creating blocks in a scope like:
- with g.device(device):
- linear = Linear(...)
- """
-
- def __init__(self, name):
- self._variables = []
- self._subblocks = []
- self._called = False
-
- # Intentionally distinguishing empty string and None.
- # If name is an empty string, then do not use name scope.
- self.name = name if name is not None else self.__class__.__name__
- self._graph = tf.get_default_graph()
-
- if self.name:
- # Capture the scope string at the init time.
- with self._graph.name_scope(self.name) as scope:
- self._scope_str = scope
- else:
- self._scope_str = ''
-
- # Maintain hierarchy structure of blocks.
- self._stack = _block_stacks[self._graph]
- if self.__class__ is BlockBase:
- # This code is only executed to create the root, which starts in the
- # initialized state.
- assert not self._stack
- self._parent = None
- self._called = True # The root is initialized.
- return
-
- # Create a fake root if a root is not already present.
- if not self._stack:
- self._stack.append(BlockBase('NoOpRoot'))
-
- self._parent = self._stack[-1]
- self._parent._subblocks.append(self) # pylint: disable=protected-access
-
- def __repr__(self):
- return '"{}" ({})'.format(self._scope_str, self.__class__.__name__)
-
- @contextlib.contextmanager
- def _OptionalNameScope(self, scope_str):
- if scope_str:
- with self._graph.name_scope(scope_str):
- yield
- else:
- yield
-
- @contextlib.contextmanager
- def _BlockScope(self):
- """Context manager that handles graph, namescope, and nested blocks."""
- self._stack.append(self)
-
- try:
- with self._graph.as_default():
- with self._OptionalNameScope(self._scope_str):
- yield self
- finally: # Pop from the stack no matter exception is raised or not.
- # The following line is executed when leaving 'with self._BlockScope()'
- self._stack.pop()
-
- def __call__(self, *args, **kwargs):
- assert self._stack is _block_stacks[self._graph]
-
- with self._BlockScope():
- ret = self._Apply(*args, **kwargs)
-
- self._called = True
- return ret
-
- def _Apply(self, *args, **kwargs):
- """Implementation of __call__()."""
- raise NotImplementedError()
-
- # Redirect all variable creation to this single function, so that we can
- # switch to better variable creation scheme.
- def NewVar(self, value, **kwargs):
- """Creates a new variable.
-
- This function creates a variable, then returns a local copy created by
- Identity operation. To get the Variable class object, use LookupRef()
- method.
-
- Note that each time Variable class object is used as an input to an
- operation, Tensorflow will create a new Send/Recv pair. This hurts
- performance.
-
- If not for assign operations, use the local copy returned by this method.
-
- Args:
- value: Initialization value of the variable. The shape and the data type
- of the variable is determined by this initial value.
- **kwargs: Extra named arguments passed to Variable.__init__().
-
- Returns:
- A local copy of the new variable.
- """
- v = tf.Variable(value, **kwargs)
-
- self._variables.append(v)
- return v
-
- @property
- def initialized(self):
- """Returns bool if the block is initialized.
-
- By default, BlockBase assumes that a block is initialized when __call__()
- is executed for the first time. If this is an incorrect assumption for some
- subclasses, override this property in those subclasses.
-
- Returns:
- True if initialized, False otherwise.
- """
- return self._called
-
- def AssertInitialized(self):
- """Asserts initialized property."""
- if not self.initialized:
- raise RuntimeError('{} has not been initialized.'.format(self))
-
- def VariableList(self):
- """Returns the list of all tensorflow variables used inside this block."""
- variables = list(itertools.chain(
- itertools.chain.from_iterable(
- t.VariableList() for t in self._subblocks),
- self._VariableList()))
- return variables
-
- def _VariableList(self):
- """Returns the list of all tensorflow variables owned by this block."""
- self.AssertInitialized()
- return self._variables
-
- def CreateWeightLoss(self):
- """Returns L2 loss list of (almost) all variables used inside this block.
-
- When this method needs to be overridden, there are two choices.
-
- 1. Override CreateWeightLoss() to change the weight loss of all variables
- that belong to this block, both directly and indirectly.
- 2. Override _CreateWeightLoss() to change the weight loss of all
- variables that directly belong to this block but not to the sub-blocks.
-
- Returns:
- A Tensor object or None.
- """
- losses = list(itertools.chain(
- itertools.chain.from_iterable(
- t.CreateWeightLoss() for t in self._subblocks),
- self._CreateWeightLoss()))
- return losses
-
- def _CreateWeightLoss(self):
- """Returns weight loss list of variables that belong to this block."""
- self.AssertInitialized()
- with self._BlockScope():
- return [tf.nn.l2_loss(v) for v in self._variables]
-
- def CreateUpdateOps(self):
- """Creates update operations for this block and its sub-blocks."""
- ops = list(itertools.chain(
- itertools.chain.from_iterable(
- t.CreateUpdateOps() for t in self._subblocks),
- self._CreateUpdateOps()))
- return ops
-
- def _CreateUpdateOps(self):
- """Creates update operations for this block."""
- self.AssertInitialized()
- return []
-
- def MarkAsNonTrainable(self):
- """Mark all the variables of this block as non-trainable.
-
- All the variables owned directly or indirectly (through subblocks) are
- marked as non trainable.
-
- This function along with CheckpointInitOp can be used to load a pretrained
- model that consists in only one part of the whole graph.
- """
- assert self._called
-
- all_variables = self.VariableList()
- collection = tf.get_collection_ref(tf.GraphKeys.TRAINABLE_VARIABLES)
- for v in all_variables:
- if v in collection:
- collection.remove(v)
-
-
-def CreateWeightLoss():
- """Returns all weight losses from the blocks in the graph."""
- stack = _block_stacks[tf.get_default_graph()]
- if not stack:
- return []
- return stack[0].CreateWeightLoss()
-
-
-def CreateBlockUpdates():
- """Combines all updates from the blocks in the graph."""
- stack = _block_stacks[tf.get_default_graph()]
- if not stack:
- return []
- return stack[0].CreateUpdateOps()
diff --git a/research/compression/entropy_coder/lib/block_util.py b/research/compression/entropy_coder/lib/block_util.py
deleted file mode 100644
index 80479cc66df95338aa119ba1216cd213ecfbe08d..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/block_util.py
+++ /dev/null
@@ -1,101 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utility functions for blocks."""
-
-from __future__ import division
-from __future__ import unicode_literals
-
-import math
-
-import numpy as np
-import six
-import tensorflow as tf
-
-
-class RsqrtInitializer(object):
- """Gaussian initializer with standard deviation 1/sqrt(n).
-
- Note that tf.truncated_normal is used internally. Therefore any random sample
- outside two-sigma will be discarded and re-sampled.
- """
-
- def __init__(self, dims=(0,), **kwargs):
- """Creates an initializer.
-
- Args:
- dims: Dimension(s) index to compute standard deviation:
- 1.0 / sqrt(product(shape[dims]))
- **kwargs: Extra keyword arguments to pass to tf.truncated_normal.
- """
- if isinstance(dims, six.integer_types):
- self._dims = [dims]
- else:
- self._dims = dims
- self._kwargs = kwargs
-
- def __call__(self, shape, dtype):
- stddev = 1.0 / np.sqrt(np.prod([shape[x] for x in self._dims]))
- return tf.truncated_normal(
- shape=shape, dtype=dtype, stddev=stddev, **self._kwargs)
-
-
-class RectifierInitializer(object):
- """Gaussian initializer with standard deviation sqrt(2/fan_in).
-
- Note that tf.random_normal is used internally to ensure the expected weight
- distribution. This is intended to be used with ReLU activations, specially
- in ResNets.
-
- For details please refer to:
- Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet
- Classification
- """
-
- def __init__(self, dims=(0,), scale=2.0, **kwargs):
- """Creates an initializer.
-
- Args:
- dims: Dimension(s) index to compute standard deviation:
- sqrt(scale / product(shape[dims]))
- scale: A constant scaling for the initialization used as
- sqrt(scale / product(shape[dims])).
- **kwargs: Extra keyword arguments to pass to tf.truncated_normal.
- """
- if isinstance(dims, six.integer_types):
- self._dims = [dims]
- else:
- self._dims = dims
- self._kwargs = kwargs
- self._scale = scale
-
- def __call__(self, shape, dtype):
- stddev = np.sqrt(self._scale / np.prod([shape[x] for x in self._dims]))
- return tf.random_normal(
- shape=shape, dtype=dtype, stddev=stddev, **self._kwargs)
-
-
-class GaussianInitializer(object):
- """Gaussian initializer with a given standard deviation.
-
- Note that tf.truncated_normal is used internally. Therefore any random sample
- outside two-sigma will be discarded and re-sampled.
- """
-
- def __init__(self, stddev=1.0):
- self._stddev = stddev
-
- def __call__(self, shape, dtype):
- return tf.truncated_normal(shape=shape, dtype=dtype, stddev=self._stddev)
diff --git a/research/compression/entropy_coder/lib/blocks.py b/research/compression/entropy_coder/lib/blocks.py
deleted file mode 100644
index 002384eb07045f1cad963d217a205ade51ba03b6..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks.py
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-from block_base import *
-from block_util import *
-from blocks_binarizer import *
-from blocks_entropy_coding import *
-from blocks_lstm import *
-from blocks_masked_conv2d import *
-from blocks_masked_conv2d_lstm import *
-from blocks_operator import *
-from blocks_std import *
diff --git a/research/compression/entropy_coder/lib/blocks_binarizer.py b/research/compression/entropy_coder/lib/blocks_binarizer.py
deleted file mode 100644
index 8206731610613af2cf3ec15210fd5b9977f4a916..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_binarizer.py
+++ /dev/null
@@ -1,35 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Activation and weight binarizer implementations."""
-
-import math
-
-import numpy as np
-import tensorflow as tf
-
-
-def ConvertSignCodeToZeroOneCode(x):
- """Conversion from codes {-1, +1} to codes {0, 1}."""
- return 0.5 * (x + 1.0)
-
-
-def ConvertZeroOneCodeToSignCode(x):
- """Convert from codes {0, 1} to codes {-1, +1}."""
- return 2.0 * x - 1.0
-
-
-def CheckZeroOneCode(x):
- return tf.reduce_all(tf.equal(x * (x - 1.0), 0))
diff --git a/research/compression/entropy_coder/lib/blocks_entropy_coding.py b/research/compression/entropy_coder/lib/blocks_entropy_coding.py
deleted file mode 100644
index 6ee5d97926c1b50b12cb9853d16caa25ba31e8d7..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_entropy_coding.py
+++ /dev/null
@@ -1,49 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Set of blocks related to entropy coding."""
-
-import math
-
-import tensorflow as tf
-
-import block_base
-
-# pylint does not recognize block_base.BlockBase.__call__().
-# pylint: disable=not-callable
-
-
-class CodeLength(block_base.BlockBase):
- """Theoretical bound for a code length given a probability distribution.
- """
-
- def __init__(self, name=None):
- super(CodeLength, self).__init__(name)
-
- def _Apply(self, c, p):
- """Theoretical bound of the coded length given a probability distribution.
-
- Args:
- c: The binary codes. Belong to {0, 1}.
- p: The probability of: P(code==+1)
-
- Returns:
- The average code length.
- Note: the average code length can be greater than 1 bit (e.g. when
- encoding the least likely symbol).
- """
- entropy = ((1.0 - c) * tf.log(1.0 - p) + c * tf.log(p)) / (-math.log(2))
- entropy = tf.reduce_mean(entropy)
- return entropy
diff --git a/research/compression/entropy_coder/lib/blocks_entropy_coding_test.py b/research/compression/entropy_coder/lib/blocks_entropy_coding_test.py
deleted file mode 100644
index 5209865f5991598ee873ed24a4be572e3f9fc515..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_entropy_coding_test.py
+++ /dev/null
@@ -1,56 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for basic tensorflow blocks_entropy_coding."""
-
-from __future__ import division
-from __future__ import unicode_literals
-
-import math
-
-import numpy as np
-import tensorflow as tf
-
-import blocks_entropy_coding
-
-
-class BlocksEntropyCodingTest(tf.test.TestCase):
-
- def testCodeLength(self):
- shape = [2, 4]
- proba_feed = [[0.65, 0.25, 0.70, 0.10],
- [0.28, 0.20, 0.44, 0.54]]
- symbol_feed = [[1.0, 0.0, 1.0, 0.0],
- [0.0, 0.0, 0.0, 1.0]]
- mean_code_length = - (
- (math.log(0.65) + math.log(0.75) + math.log(0.70) + math.log(0.90) +
- math.log(0.72) + math.log(0.80) + math.log(0.56) + math.log(0.54)) /
- math.log(2.0)) / (shape[0] * shape[1])
-
- symbol = tf.placeholder(dtype=tf.float32, shape=shape)
- proba = tf.placeholder(dtype=tf.float32, shape=shape)
- code_length_calculator = blocks_entropy_coding.CodeLength()
- code_length = code_length_calculator(symbol, proba)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- code_length_eval = code_length.eval(
- feed_dict={symbol: symbol_feed, proba: proba_feed})
-
- self.assertAllClose(mean_code_length, code_length_eval)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/lib/blocks_lstm.py b/research/compression/entropy_coder/lib/blocks_lstm.py
deleted file mode 100644
index 6e474e3e3fcb6eeb3f18daf320e21a3acc88a2bf..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_lstm.py
+++ /dev/null
@@ -1,263 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Blocks of LSTM and its variants."""
-
-import numpy as np
-import tensorflow as tf
-
-import block_base
-import block_util
-import blocks_std
-
-# pylint does not recognize block_base.BlockBase.__call__().
-# pylint: disable=not-callable
-
-
-def LSTMBiasInit(shape, dtype):
- """Returns ones for forget-gate, and zeros for the others."""
- shape = np.array(shape)
-
- # Check internal consistencies.
- assert shape.shape == (1,), shape
- assert shape[0] % 4 == 0, shape
-
- n = shape[0] // 4
- ones = tf.fill([n], tf.constant(1, dtype=dtype))
- zeros = tf.fill([3 * n], tf.constant(0, dtype=dtype))
- return tf.concat([ones, zeros], 0)
-
-
-class LSTMBase(block_base.BlockBase):
- """Base class for LSTM implementations.
-
- These LSTM implementations use the pattern found in [1]. No peephole
- connection, i.e., cell content is not used in recurrence computation.
- Hidden units are also output units.
-
- [1] Zaremba, Sutskever, Vinyals. Recurrent Neural Network Regularization,
- 2015. arxiv:1409.2329.
- """
-
- def __init__(self, output_shape, name):
- """Initializes LSTMBase class object.
-
- Args:
- output_shape: List representing the LSTM output shape. This argument
- does not include batch dimension. For example, if the LSTM output has
- shape [batch, depth], then pass [depth].
- name: Name of this block.
- """
- super(LSTMBase, self).__init__(name)
-
- with self._BlockScope():
- self._output_shape = [None] + list(output_shape)
- self._hidden = None
- self._cell = None
-
- @property
- def hidden(self):
- """Returns the hidden units of this LSTM."""
- return self._hidden
-
- @hidden.setter
- def hidden(self, value):
- """Assigns to the hidden units of this LSTM.
-
- Args:
- value: The new value for the hidden units. If None, the hidden units are
- considered to be filled with zeros.
- """
- if value is not None:
- value.get_shape().assert_is_compatible_with(self._output_shape)
- self._hidden = value
-
- @property
- def cell(self):
- """Returns the cell units of this LSTM."""
- return self._cell
-
- @cell.setter
- def cell(self, value):
- """Assigns to the cell units of this LSTM.
-
- Args:
- value: The new value for the cell units. If None, the cell units are
- considered to be filled with zeros.
- """
- if value is not None:
- value.get_shape().assert_is_compatible_with(self._output_shape)
- self._cell = value
-
- # Consider moving bias terms to the base, and require this method to be
- # linear.
- def _TransformInputs(self, _):
- """Transforms the input units to (4 * depth) units.
-
- The forget-gate, input-gate, output-gate, and cell update is computed as
- f, i, j, o = T(h) + R(x)
- where h is hidden units, x is input units, and T, R are transforms of
- h, x, respectively.
-
- This method implements R. Note that T is strictly linear, so if LSTM is
- going to use bias, this method must include the bias to the transformation.
-
- Subclasses must implement this method. See _Apply() for more details.
- """
- raise NotImplementedError()
-
- def _TransformHidden(self, _):
- """Transforms the hidden units to (4 * depth) units.
-
- The forget-gate, input-gate, output-gate, and cell update is computed as
- f, i, j, o = T(h) + R(x)
- where h is hidden units, x is input units, and T, R are transforms of
- h, x, respectively.
-
- This method implements T in the equation. The method must implement a
- strictly linear transformation. For example, it may use MatMul or Conv2D,
- but must not add bias. This is because when hidden units are zeros, then
- the LSTM implementation will skip calling this method, instead of passing
- zeros to this function.
-
- Subclasses must implement this method. See _Apply() for more details.
- """
- raise NotImplementedError()
-
- def _Apply(self, *args):
- xtransform = self._TransformInputs(*args)
- depth_axis = len(self._output_shape) - 1
-
- if self.hidden is not None:
- htransform = self._TransformHidden(self.hidden)
- f, i, j, o = tf.split(
- value=htransform + xtransform, num_or_size_splits=4, axis=depth_axis)
- else:
- f, i, j, o = tf.split(
- value=xtransform, num_or_size_splits=4, axis=depth_axis)
-
- if self.cell is not None:
- self.cell = tf.sigmoid(f) * self.cell + tf.sigmoid(i) * tf.tanh(j)
- else:
- self.cell = tf.sigmoid(i) * tf.tanh(j)
-
- self.hidden = tf.sigmoid(o) * tf.tanh(self.cell)
- return self.hidden
-
-
-class LSTM(LSTMBase):
- """Efficient LSTM implementation used in [1].
-
- [1] Zaremba, Sutskever, Vinyals. Recurrent Neural Network Regularization,
- 2015. arxiv:1409.2329.
- """
-
- def __init__(self,
- depth,
- bias=LSTMBiasInit,
- initializer=block_util.RsqrtInitializer(),
- name=None):
- super(LSTM, self).__init__([depth], name)
-
- with self._BlockScope():
- self._depth = depth
- self._nn = blocks_std.NN(
- 4 * depth, bias=bias, act=None, initializer=initializer)
- self._hidden_linear = blocks_std.Linear(
- 4 * depth, initializer=initializer)
-
- def _TransformInputs(self, *args):
- return self._nn(*args)
-
- def _TransformHidden(self, h):
- return self._hidden_linear(h)
-
-
-class Conv2DLSTM(LSTMBase):
- """Convolutional LSTM implementation with optimizations inspired by [1].
-
- Note that when using the batch normalization feature, the bias initializer
- will not be used, since BN effectively cancels its effect out.
-
- [1] Zaremba, Sutskever, Vinyals. Recurrent Neural Network Regularization,
- 2015. arxiv:1409.2329.
- """
-
- def __init__(self,
- depth,
- filter_size,
- hidden_filter_size,
- strides,
- padding,
- bias=LSTMBiasInit,
- initializer=block_util.RsqrtInitializer(dims=(0, 1, 2)),
- use_moving_average=False,
- name=None):
- super(Conv2DLSTM, self).__init__([None, None, depth], name)
- self._iter = 0
-
- with self._BlockScope():
- self._input_conv = blocks_std.Conv2D(
- 4 * depth,
- filter_size,
- strides,
- padding,
- bias=None,
- act=None,
- initializer=initializer,
- name='input_conv2d')
-
- self._hidden_conv = blocks_std.Conv2D(
- 4 * depth,
- hidden_filter_size,
- [1, 1],
- 'SAME',
- bias=None,
- act=None,
- initializer=initializer,
- name='hidden_conv2d')
-
- if bias is not None:
- self._bias = blocks_std.BiasAdd(bias, name='biases')
- else:
- self._bias = blocks_std.PassThrough()
-
- def _TransformInputs(self, x):
- return self._bias(self._input_conv(x))
-
- def _TransformHidden(self, h):
- return self._hidden_conv(h)
-
- def _Apply(self, *args):
- xtransform = self._TransformInputs(*args)
- depth_axis = len(self._output_shape) - 1
-
- if self.hidden is not None:
- htransform = self._TransformHidden(self.hidden)
- f, i, j, o = tf.split(
- value=htransform + xtransform, num_or_size_splits=4, axis=depth_axis)
- else:
- f, i, j, o = tf.split(
- value=xtransform, num_or_size_splits=4, axis=depth_axis)
-
- if self.cell is not None:
- self.cell = tf.sigmoid(f) * self.cell + tf.sigmoid(i) * tf.tanh(j)
- else:
- self.cell = tf.sigmoid(i) * tf.tanh(j)
-
- self.hidden = tf.sigmoid(o) * tf.tanh(self.cell)
-
- self._iter += 1
- return self.hidden
diff --git a/research/compression/entropy_coder/lib/blocks_lstm_test.py b/research/compression/entropy_coder/lib/blocks_lstm_test.py
deleted file mode 100644
index 03c32dc136effda11163f2e35c5a48496f0187c0..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_lstm_test.py
+++ /dev/null
@@ -1,113 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for LSTM tensorflow blocks."""
-from __future__ import division
-
-import numpy as np
-import tensorflow as tf
-
-import block_base
-import blocks_std
-import blocks_lstm
-
-
-class BlocksLSTMTest(tf.test.TestCase):
-
- def CheckUnary(self, y, op_type):
- self.assertEqual(op_type, y.op.type)
- self.assertEqual(1, len(y.op.inputs))
- return y.op.inputs[0]
-
- def CheckBinary(self, y, op_type):
- self.assertEqual(op_type, y.op.type)
- self.assertEqual(2, len(y.op.inputs))
- return y.op.inputs
-
- def testLSTM(self):
- lstm = blocks_lstm.LSTM(10)
- lstm.hidden = tf.zeros(shape=[10, 10], dtype=tf.float32)
- lstm.cell = tf.zeros(shape=[10, 10], dtype=tf.float32)
- x = tf.placeholder(dtype=tf.float32, shape=[10, 11])
- y = lstm(x)
-
- o, tanhc = self.CheckBinary(y, 'Mul')
- self.assertEqual(self.CheckUnary(o, 'Sigmoid').name, 'LSTM/split:3')
-
- self.assertIs(lstm.cell, self.CheckUnary(tanhc, 'Tanh'))
- fc, ij = self.CheckBinary(lstm.cell, 'Add')
-
- f, _ = self.CheckBinary(fc, 'Mul')
- self.assertEqual(self.CheckUnary(f, 'Sigmoid').name, 'LSTM/split:0')
-
- i, j = self.CheckBinary(ij, 'Mul')
- self.assertEqual(self.CheckUnary(i, 'Sigmoid').name, 'LSTM/split:1')
- j = self.CheckUnary(j, 'Tanh')
- self.assertEqual(j.name, 'LSTM/split:2')
-
- def testLSTMBiasInit(self):
- lstm = blocks_lstm.LSTM(9)
- x = tf.placeholder(dtype=tf.float32, shape=[15, 7])
- lstm(x)
- b = lstm._nn._bias
-
- with self.test_session():
- tf.global_variables_initializer().run()
- bias_var = b._bias.eval()
-
- comp = ([1.0] * 9) + ([0.0] * 27)
- self.assertAllEqual(bias_var, comp)
-
- def testConv2DLSTM(self):
- lstm = blocks_lstm.Conv2DLSTM(depth=10,
- filter_size=[1, 1],
- hidden_filter_size=[1, 1],
- strides=[1, 1],
- padding='SAME')
- lstm.hidden = tf.zeros(shape=[10, 11, 11, 10], dtype=tf.float32)
- lstm.cell = tf.zeros(shape=[10, 11, 11, 10], dtype=tf.float32)
- x = tf.placeholder(dtype=tf.float32, shape=[10, 11, 11, 1])
- y = lstm(x)
-
- o, tanhc = self.CheckBinary(y, 'Mul')
- self.assertEqual(self.CheckUnary(o, 'Sigmoid').name, 'Conv2DLSTM/split:3')
-
- self.assertIs(lstm.cell, self.CheckUnary(tanhc, 'Tanh'))
- fc, ij = self.CheckBinary(lstm.cell, 'Add')
-
- f, _ = self.CheckBinary(fc, 'Mul')
- self.assertEqual(self.CheckUnary(f, 'Sigmoid').name, 'Conv2DLSTM/split:0')
-
- i, j = self.CheckBinary(ij, 'Mul')
- self.assertEqual(self.CheckUnary(i, 'Sigmoid').name, 'Conv2DLSTM/split:1')
- j = self.CheckUnary(j, 'Tanh')
- self.assertEqual(j.name, 'Conv2DLSTM/split:2')
-
- def testConv2DLSTMBiasInit(self):
- lstm = blocks_lstm.Conv2DLSTM(9, 1, 1, [1, 1], 'SAME')
- x = tf.placeholder(dtype=tf.float32, shape=[1, 7, 7, 7])
- lstm(x)
- b = lstm._bias
-
- with self.test_session():
- tf.global_variables_initializer().run()
- bias_var = b._bias.eval()
-
- comp = ([1.0] * 9) + ([0.0] * 27)
- self.assertAllEqual(bias_var, comp)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/lib/blocks_masked_conv2d.py b/research/compression/entropy_coder/lib/blocks_masked_conv2d.py
deleted file mode 100644
index 3f562384a681964554ead02477da24c13715d4d1..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_masked_conv2d.py
+++ /dev/null
@@ -1,226 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Define some typical masked 2D convolutions."""
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-import block_util
-import blocks_std
-
-# pylint does not recognize block_base.BlockBase.__call__().
-# pylint: disable=not-callable
-
-
-class RasterScanConv2D(blocks_std.Conv2DBase):
- """Conv2D with no dependency on future pixels (in raster scan order).
-
- For example, assuming a 5 x 5 kernel, the kernel is applied a spatial mask:
- T T T T T
- T T T T T
- T T x F F
- F F F F F
- F F F F F
- where 'T' are pixels which are available when computing the convolution
- for pixel 'x'. All the pixels marked with 'F' are not available.
- 'x' itself is not available if strict_order is True, otherwise, it is
- available.
- """
-
- def __init__(self, depth, filter_size, strides, padding,
- strict_order=True,
- bias=None, act=None, initializer=None, name=None):
- super(RasterScanConv2D, self).__init__(
- depth, filter_size, strides, padding, bias, act, name=name)
-
- if (filter_size[0] % 2) != 1 or (filter_size[1] % 2) != 1:
- raise ValueError('Kernel size should be odd.')
-
- with self._BlockScope():
- if initializer is None:
- initializer = block_util.RsqrtInitializer(dims=(0, 1, 2))
- self._initializer = initializer
- self._strict_order = strict_order
-
- def _CreateKernel(self, shape, dtype):
- init = self._initializer(shape, dtype)
- kernel = self.NewVar(init)
-
- mask = np.ones(shape[:2], dtype=dtype.as_numpy_dtype)
- center = shape[:2] // 2
- mask[center[0] + 1:, :] = 0
- if not self._strict_order:
- mask[center[0], center[1] + 1:] = 0
- else:
- mask[center[0], center[1]:] = 0
- mask = mask.reshape(mask.shape + (1, 1))
-
- return tf.convert_to_tensor(mask, dtype) * kernel
-
-
-class DepthOrderConv2D(blocks_std.Conv2DBase):
- """Conv2D with no dependency on higher depth dimensions.
-
- More precisely, the output depth #n has only dependencies on input depths #k
- for k < n (if strict_order is True) or for k <= n (if strict_order is False).
- """
-
- def __init__(self, depth, filter_size, strides, padding,
- strict_order=True,
- bias=None, act=None, initializer=None, name=None):
- super(DepthOrderConv2D, self).__init__(
- depth, filter_size, strides, padding, bias, act, name=name)
-
- with self._BlockScope():
- if initializer is None:
- initializer = block_util.RsqrtInitializer(dims=(0, 1, 2))
- self._initializer = initializer
- self._strict_order = strict_order
-
- def _CreateKernel(self, shape, dtype):
- init = self._initializer(shape, dtype)
- kernel = self.NewVar(init)
-
- mask = np.ones(shape[2:], dtype=dtype.as_numpy_dtype)
- depth_output = shape[3]
- for d in xrange(depth_output):
- if self._strict_order:
- mask[d:, d] = 0
- else:
- mask[d + 1:, d] = 0
- mask = mask.reshape((1, 1) + mask.shape)
-
- return tf.convert_to_tensor(mask, dtype) * kernel
-
-
-class GroupRasterScanConv2D(blocks_std.Conv2DBase):
- """Conv2D with no dependency on future pixels (in raster scan order).
-
- This version only introduces dependencies on previous pixels in raster scan
- order. It can also introduce some dependencies on previous depth positions
- of the current pixel (current pixel = center pixel of the kernel) in the
- following way:
- the depth dimension of the input is split into Ki groups of size
- |input_group_size|, the output dimension is split into Ko groups of size
- |output_group_size| (usually Ki == Ko). Each output group ko of the current
- pixel position can only depend on previous input groups ki
- (i.e. ki < ko if strict_order is True or ki <= ko if strict_order is False).
-
- Notes:
- - Block RasterScanConv2D is a special case of GroupRasterScanConv2D
- where Ki == Ko == 1 (i.e. input_group_size == input_depth and
- output_group_size == output_depth).
- - For 1x1 convolution, block DepthOrderConv2D is a special case of
- GroupRasterScanConv2D where input_group_size == 1 and
- output_group_size == 1.
- """
-
- def __init__(self, depth, filter_size, strides, padding,
- strict_order=True,
- input_group_size=1,
- output_group_size=1,
- bias=None, act=None, initializer=None, name=None):
- super(GroupRasterScanConv2D, self).__init__(
- depth, filter_size, strides, padding, bias, act, name=name)
-
- if (filter_size[0] % 2) != 1 or (filter_size[1] % 2) != 1:
- raise ValueError('Kernel size should be odd.')
-
- with self._BlockScope():
- if initializer is None:
- initializer = block_util.RsqrtInitializer(dims=(0, 1, 2))
- self._initializer = initializer
- self._input_group_size = input_group_size
- self._output_group_size = output_group_size
- self._strict_order = strict_order
-
- if depth % self._output_group_size != 0:
- raise ValueError(
- 'Invalid depth group size: {} for depth {}'.format(
- self._output_group_size, depth))
- self._output_group_count = depth // self._output_group_size
-
- def _CreateKernel(self, shape, dtype):
- init = self._initializer(shape, dtype)
- kernel = self.NewVar(init)
-
- depth_input = shape[2]
- if depth_input % self._input_group_size != 0:
- raise ValueError(
- 'Invalid depth group size: {} for depth {}'.format(
- self._input_group_size, depth_input))
- input_group_count = depth_input // self._input_group_size
- output_group_count = self._output_group_count
-
- # Set the mask to 0 for future pixels in raster scan order.
- center = shape[:2] // 2
- mask = np.ones([shape[0], shape[1],
- input_group_count, self._input_group_size,
- output_group_count, self._output_group_size],
- dtype=dtype.as_numpy_dtype)
- mask[center[0] + 1:, :, :, :, :, :] = 0
- mask[center[0], center[1] + 1:, :, :, :, :] = 0
-
- # Adjust the mask for the current position (the center position).
- depth_output = shape[3]
- for d in xrange(output_group_count):
- mask[center[0], center[1], d + 1:, :, d:d + 1, :] = 0
- if self._strict_order:
- mask[center[0], center[1], d, :, d:d + 1, :] = 0
-
- mask = mask.reshape([shape[0], shape[1], depth_input, depth_output])
- return tf.convert_to_tensor(mask, dtype) * kernel
-
-
-class InFillingConv2D(blocks_std.Conv2DBase):
- """Conv2D with kernel having no dependency on the current pixel.
-
- For example, assuming a 5 x 5 kernel, the kernel is applied a spatial mask:
- T T T T T
- T T T T T
- T T x T T
- T T T T T
- T T T T T
- where 'T' marks a pixel which is available when computing the convolution
- for pixel 'x'. 'x' itself is not available.
- """
-
- def __init__(self, depth, filter_size, strides, padding,
- bias=None, act=None, initializer=None, name=None):
- super(InFillingConv2D, self).__init__(
- depth, filter_size, strides, padding, bias, act, name=name)
-
- if (filter_size[0] % 2) != 1 or (filter_size[1] % 2) != 1:
- raise ValueError('Kernel size should be odd.')
- if filter_size[0] == 1 and filter_size[1] == 1:
- raise ValueError('Kernel size should be larger than 1x1.')
-
- with self._BlockScope():
- if initializer is None:
- initializer = block_util.RsqrtInitializer(dims=(0, 1, 2))
- self._initializer = initializer
-
- def _CreateKernel(self, shape, dtype):
- init = self._initializer(shape, dtype)
- kernel = self.NewVar(init)
-
- mask = np.ones(shape[:2], dtype=dtype.as_numpy_dtype)
- center = shape[:2] // 2
- mask[center[0], center[1]] = 0
- mask = mask.reshape(mask.shape + (1, 1))
-
- return tf.convert_to_tensor(mask, dtype) * kernel
diff --git a/research/compression/entropy_coder/lib/blocks_masked_conv2d_lstm.py b/research/compression/entropy_coder/lib/blocks_masked_conv2d_lstm.py
deleted file mode 100644
index 2d6dfeffcaff1289adf3bdec33cb0560db6b0416..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_masked_conv2d_lstm.py
+++ /dev/null
@@ -1,79 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Masked conv2d LSTM."""
-
-import block_base
-import block_util
-import blocks_masked_conv2d
-import blocks_lstm
-import blocks_std
-
-# pylint: disable=not-callable
-
-
-class RasterScanConv2DLSTM(blocks_lstm.LSTMBase):
- """Convolutional LSTM implementation with optimizations inspired by [1].
-
- Note that when using the batch normalization feature, the bias initializer
- will not be used, since BN effectively cancels its effect out.
-
- [1] Zaremba, Sutskever, Vinyals. Recurrent Neural Network Regularization,
- 2015. arxiv:1409.2329.
- """
-
- def __init__(self,
- depth,
- filter_size,
- hidden_filter_size,
- strides,
- padding,
- bias=blocks_lstm.LSTMBiasInit,
- initializer=block_util.RsqrtInitializer(dims=(0, 1, 2)),
- name=None):
- super(RasterScanConv2DLSTM, self).__init__([None, None, depth], name)
-
- with self._BlockScope():
- self._input_conv = blocks_masked_conv2d.RasterScanConv2D(
- 4 * depth,
- filter_size,
- strides,
- padding,
- strict_order=False,
- bias=None,
- act=None,
- initializer=initializer,
- name='input_conv2d')
-
- self._hidden_conv = blocks_std.Conv2D(
- 4 * depth,
- hidden_filter_size,
- [1, 1],
- 'SAME',
- bias=None,
- act=None,
- initializer=initializer,
- name='hidden_conv2d')
-
- if bias is not None:
- self._bias = blocks_std.BiasAdd(bias, name='biases')
- else:
- self._bias = blocks_std.PassThrough()
-
- def _TransformInputs(self, x):
- return self._bias(self._input_conv(x))
-
- def _TransformHidden(self, h):
- return self._hidden_conv(h)
diff --git a/research/compression/entropy_coder/lib/blocks_masked_conv2d_test.py b/research/compression/entropy_coder/lib/blocks_masked_conv2d_test.py
deleted file mode 100644
index 1d284ebffe5a24b91c96936c17d6c23febdf76d5..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_masked_conv2d_test.py
+++ /dev/null
@@ -1,207 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests of the 2D masked convolution blocks."""
-
-from __future__ import division
-from __future__ import unicode_literals
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-import blocks_masked_conv2d
-
-
-class MaskedConv2DTest(tf.test.TestCase):
-
- def testRasterScanKernel(self):
- kernel_size = 5
- input_depth = 1
- output_depth = 1
- kernel_shape = [kernel_size, kernel_size, input_depth, output_depth]
-
- # pylint: disable=bad-whitespace
- kernel_feed = [[ 1.0, 2.0, 3.0, 4.0, 5.0],
- [ 6.0, 7.0, 8.0, 9.0, 10.0],
- [11.0, 12.0, 13.0, 14.0, 15.0],
- [16.0, 17.0, 18.0, 19.0, 20.0],
- [21.0, 22.0, 23.0, 24.0, 25.0]]
- kernel_feed = np.reshape(kernel_feed, kernel_shape)
- kernel_expected = [[ 1.0, 2.0, 3.0, 4.0, 5.0],
- [ 6.0, 7.0, 8.0, 9.0, 10.0],
- [11.0, 12.0, 0.0, 0.0, 0.0],
- [ 0.0, 0.0, 0.0, 0.0, 0.0],
- [ 0.0, 0.0, 0.0, 0.0, 0.0]]
- kernel_expected = np.reshape(kernel_expected, kernel_shape)
- # pylint: enable=bad-whitespace
-
- init_kernel = lambda s, t: tf.constant(kernel_feed, dtype=t, shape=s)
- masked_conv2d = blocks_masked_conv2d.RasterScanConv2D(
- output_depth, [kernel_size] * 2, [1] * 2, 'SAME',
- initializer=init_kernel)
- x = tf.placeholder(dtype=tf.float32, shape=[10] * 3 + [input_depth])
- _ = masked_conv2d(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- kernel_value = masked_conv2d._kernel.eval()
-
- self.assertAllEqual(kernel_expected, kernel_value)
-
- def testDepthOrderKernel(self):
- kernel_size = 1
- input_depth = 7
- output_depth = input_depth
- kernel_shape = [kernel_size, kernel_size, input_depth, output_depth]
-
- kernel_feed = np.ones(kernel_shape)
- x_shape = [5] * 3 + [input_depth]
- x_feed = np.ones(x_shape)
- y_expected = np.zeros(x_shape[0:3] + [output_depth])
- y_expected[:, :, :] = np.arange(output_depth)
-
- init_kernel = lambda s, t: tf.constant(kernel_feed, dtype=t, shape=s)
- masked_conv2d = blocks_masked_conv2d.DepthOrderConv2D(
- output_depth, [kernel_size] * 2, [1] * 2, 'SAME',
- strict_order=True,
- initializer=init_kernel)
- x = tf.placeholder(dtype=tf.float32, shape=x_shape)
- y = masked_conv2d(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- y_value = y.eval(feed_dict={x: x_feed})
-
- self.assertAllEqual(y_expected, y_value)
-
- def testGroupRasterScanKernel(self):
- kernel_size = 3
- input_depth = 4
- input_group_size = 2
- output_depth = 2
- output_group_size = 1
- kernel_shape = [kernel_size, kernel_size, input_depth, output_depth]
- kernel_feed = np.ones(shape=kernel_shape)
-
- height = 5
- width = 5
- x_shape = [1, height, width, input_depth]
- x_feed = np.ones(shape=x_shape)
-
- # pylint: disable=bad-whitespace
- y_expected = [
- [[ 0, 2], [ 4, 6], [ 4, 6], [ 4, 6], [ 4, 6]],
- [[ 8, 10], [16, 18], [16, 18], [16, 18], [12, 14]],
- [[ 8, 10], [16, 18], [16, 18], [16, 18], [12, 14]],
- [[ 8, 10], [16, 18], [16, 18], [16, 18], [12, 14]],
- [[ 8, 10], [16, 18], [16, 18], [16, 18], [12, 14]],
- ]
- y_expected = np.reshape(y_expected, [1, height, width, output_depth])
- # pylint: enable=bad-whitespace
-
- init_kernel = lambda s, t: tf.constant(kernel_feed, dtype=t, shape=s)
- masked_conv2d = blocks_masked_conv2d.GroupRasterScanConv2D(
- output_depth, [kernel_size] * 2, [1] * 2, 'SAME',
- strict_order=True,
- input_group_size=input_group_size,
- output_group_size=output_group_size,
- initializer=init_kernel)
- x = tf.placeholder(dtype=tf.float32, shape=x_shape)
- y = masked_conv2d(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- y_value = y.eval(feed_dict={x: x_feed})
-
- self.assertAllEqual(y_expected, y_value)
-
- def testInFillingKernel(self):
- kernel_size = 5
- input_depth = 1
- output_depth = 1
- kernel_shape = [kernel_size, kernel_size, input_depth, output_depth]
-
- # pylint: disable=bad-whitespace
- kernel_feed = [[ 1.0, 2.0, 3.0, 4.0, 5.0],
- [ 6.0, 7.0, 8.0, 9.0, 10.0],
- [11.0, 12.0, 13.0, 14.0, 15.0],
- [16.0, 17.0, 18.0, 19.0, 20.0],
- [21.0, 22.0, 23.0, 24.0, 25.0]]
- kernel_feed = np.reshape(kernel_feed, kernel_shape)
- kernel_expected = [[ 1.0, 2.0, 3.0, 4.0, 5.0],
- [ 6.0, 7.0, 8.0, 9.0, 10.0],
- [11.0, 12.0, 0.0, 14.0, 15.0],
- [16.0, 17.0, 18.0, 19.0, 20.0],
- [21.0, 22.0, 23.0, 24.0, 25.0]]
- kernel_expected = np.reshape(kernel_expected, kernel_shape)
- # pylint: enable=bad-whitespace
-
- init_kernel = lambda s, t: tf.constant(kernel_feed, dtype=t, shape=s)
- masked_conv2d = blocks_masked_conv2d.InFillingConv2D(
- output_depth, [kernel_size] * 2, [1] * 2, 'SAME',
- initializer=init_kernel)
- x = tf.placeholder(dtype=tf.float32, shape=[10] * 3 + [input_depth])
- _ = masked_conv2d(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- kernel_value = masked_conv2d._kernel.eval()
-
- self.assertAllEqual(kernel_expected, kernel_value)
-
- def testConv2DMaskedNumerics(self):
- kernel_size = 5
- input_shape = [1, 10, 10, 1]
- filter_shape = [kernel_size, kernel_size, 1, 1]
- strides = [1, 1, 1, 1]
- output_shape = [1, 10, 10, 1]
-
- conv = blocks_masked_conv2d.RasterScanConv2D(
- depth=filter_shape[-1],
- filter_size=filter_shape[0:2],
- strides=strides[1:3],
- padding='SAME',
- initializer=tf.constant_initializer(value=1.0))
- x = tf.placeholder(dtype=tf.float32, shape=input_shape)
- y = conv(x)
-
- x_feed = - np.ones(input_shape, dtype=float)
- y_expected = np.ones(output_shape, dtype=float)
- for i in xrange(input_shape[1]):
- for j in xrange(input_shape[2]):
- x_feed[0, i, j, 0] = 10 * (j + 1) + i
- v = 0
- ki_start = max(i - kernel_size // 2, 0)
- kj_start = max(j - kernel_size // 2, 0)
- kj_end = min(j + kernel_size // 2, input_shape[2] - 1)
- for ki in range(ki_start, i + 1):
- for kj in range(kj_start, kj_end + 1):
- if ki > i:
- continue
- if ki == i and kj >= j:
- continue
- v += 10 * (kj + 1) + ki
- y_expected[0, i, j, 0] = v
-
- with self.test_session():
- tf.global_variables_initializer().run()
- y_value = y.eval(feed_dict={x: x_feed})
-
- self.assertAllEqual(y_expected, y_value)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/lib/blocks_operator.py b/research/compression/entropy_coder/lib/blocks_operator.py
deleted file mode 100644
index e35e37b27aa416ed48f91eda866d372601741cba..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_operator.py
+++ /dev/null
@@ -1,87 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Common blocks which work as operators on other blocks."""
-
-import tensorflow as tf
-
-import block_base
-
-# pylint: disable=not-callable
-
-
-class CompositionOperator(block_base.BlockBase):
- """Composition of several blocks."""
-
- def __init__(self, block_list, name=None):
- """Initialization of the composition operator.
-
- Args:
- block_list: List of blocks.BlockBase that are chained to create
- a new blocks.BlockBase.
- name: Name of this block.
- """
- super(CompositionOperator, self).__init__(name)
- self._blocks = block_list
-
- def _Apply(self, x):
- """Apply successively all the blocks on the given input tensor."""
- h = x
- for layer in self._blocks:
- h = layer(h)
- return h
-
-
-class LineOperator(block_base.BlockBase):
- """Repeat the same block over all the lines of an input tensor."""
-
- def __init__(self, block, name=None):
- super(LineOperator, self).__init__(name)
- self._block = block
-
- def _Apply(self, x):
- height = x.get_shape()[1].value
- if height is None:
- raise ValueError('Unknown tensor height')
- all_line_x = tf.split(value=x, num_or_size_splits=height, axis=1)
-
- y = []
- for line_x in all_line_x:
- y.append(self._block(line_x))
- y = tf.concat(values=y, axis=1)
-
- return y
-
-
-class TowerOperator(block_base.BlockBase):
- """Parallel execution with concatenation of several blocks."""
-
- def __init__(self, block_list, dim=3, name=None):
- """Initialization of the parallel exec + concat (Tower).
-
- Args:
- block_list: List of blocks.BlockBase that are chained to create
- a new blocks.BlockBase.
- dim: the dimension on which to concat.
- name: Name of this block.
- """
- super(TowerOperator, self).__init__(name)
- self._blocks = block_list
- self._concat_dim = dim
-
- def _Apply(self, x):
- """Apply successively all the blocks on the given input tensor."""
- outputs = [layer(x) for layer in self._blocks]
- return tf.concat(outputs, self._concat_dim)
diff --git a/research/compression/entropy_coder/lib/blocks_operator_test.py b/research/compression/entropy_coder/lib/blocks_operator_test.py
deleted file mode 100644
index 8b6d80da1d09102585e4725dd5c59f48d48eafcd..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_operator_test.py
+++ /dev/null
@@ -1,64 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests of the block operators."""
-
-import numpy as np
-import tensorflow as tf
-
-import block_base
-import blocks_operator
-
-
-class AddOneBlock(block_base.BlockBase):
-
- def __init__(self, name=None):
- super(AddOneBlock, self).__init__(name)
-
- def _Apply(self, x):
- return x + 1.0
-
-
-class SquareBlock(block_base.BlockBase):
-
- def __init__(self, name=None):
- super(SquareBlock, self).__init__(name)
-
- def _Apply(self, x):
- return x * x
-
-
-class BlocksOperatorTest(tf.test.TestCase):
-
- def testComposition(self):
- x_value = np.array([[1.0, 2.0, 3.0],
- [-1.0, -2.0, -3.0]])
- y_expected_value = np.array([[4.0, 9.0, 16.0],
- [0.0, 1.0, 4.0]])
-
- x = tf.placeholder(dtype=tf.float32, shape=[2, 3])
- complex_block = blocks_operator.CompositionOperator(
- [AddOneBlock(),
- SquareBlock()])
- y = complex_block(x)
-
- with self.test_session():
- y_value = y.eval(feed_dict={x: x_value})
-
- self.assertAllClose(y_expected_value, y_value)
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/lib/blocks_std.py b/research/compression/entropy_coder/lib/blocks_std.py
deleted file mode 100644
index 2c617485342452f500d4b1b0b18e33b07d51e487..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_std.py
+++ /dev/null
@@ -1,363 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Basic blocks for building tensorflow models."""
-
-import numpy as np
-import tensorflow as tf
-
-import block_base
-import block_util
-
-# pylint does not recognize block_base.BlockBase.__call__().
-# pylint: disable=not-callable
-
-
-def HandleConvPaddingModes(x, padding, kernel_shape, strides):
- """Returns an updated tensor and padding type for REFLECT and SYMMETRIC.
-
- Args:
- x: A 4D tensor with shape [batch_size, height, width, depth].
- padding: Padding mode (SAME, VALID, REFLECT, or SYMMETRIC).
- kernel_shape: Shape of convolution kernel that will be applied.
- strides: Convolution stride that will be used.
-
- Returns:
- x and padding after adjustments for REFLECT and SYMMETRIC.
- """
- # For 1x1 convolution, all padding modes are the same.
- if np.all(kernel_shape[:2] == 1):
- return x, 'VALID'
-
- if padding == 'REFLECT' or padding == 'SYMMETRIC':
- # We manually compute the number of paddings as if 'SAME'.
- # From Tensorflow kernel, the formulas are as follows.
- # output_shape = ceil(input_shape / strides)
- # paddings = (output_shape - 1) * strides + filter_size - input_shape
- # Let x, y, s be a shorthand notations for input_shape, output_shape, and
- # strides, respectively. Let (x - 1) = sn + r where 0 <= r < s. Note that
- # y - 1 = ceil(x / s) - 1 = floor((x - 1) / s) = n
- # provided that x > 0. Therefore
- # paddings = n * s + filter_size - (sn + r + 1)
- # = filter_size - r - 1.
- input_shape = x.get_shape() # shape at graph construction time
- img_shape = tf.shape(x)[1:3] # image shape (no batch) at run time
- remainder = tf.mod(img_shape - 1, strides[1:3])
- pad_sizes = kernel_shape[:2] - remainder - 1
-
- pad_rows = pad_sizes[0]
- pad_cols = pad_sizes[1]
- pad = tf.stack([[0, 0], tf.stack([pad_rows // 2, (pad_rows + 1) // 2]),
- tf.stack([pad_cols // 2, (pad_cols + 1) // 2]), [0, 0]])
-
- # Manually pad the input and switch the padding mode to 'VALID'.
- x = tf.pad(x, pad, mode=padding)
- x.set_shape([input_shape[0], x.get_shape()[1],
- x.get_shape()[2], input_shape[3]])
- padding = 'VALID'
-
- return x, padding
-
-
-class PassThrough(block_base.BlockBase):
- """A dummy transform block that does nothing."""
-
- def __init__(self):
- # Pass an empty string to disable name scoping.
- super(PassThrough, self).__init__(name='')
-
- def _Apply(self, inp):
- return inp
-
- @property
- def initialized(self):
- """Always returns True."""
- return True
-
-
-class Bias(object):
- """An initialization helper class for BiasAdd block below."""
-
- def __init__(self, value=0):
- self.value = value
-
-
-class BiasAdd(block_base.BlockBase):
- """A tf.nn.bias_add wrapper.
-
- This wrapper may act as a PassThrough block depending on the initializer
- provided, to make easier optional bias applications in NN blocks, etc.
- See __init__() for the details.
- """
-
- def __init__(self, initializer=Bias(0), name=None):
- """Initializes Bias block.
-
- |initializer| parameter have two special cases.
-
- 1. If initializer is None, then this block works as a PassThrough.
- 2. If initializer is a Bias class object, then tf.constant_initializer is
- used with the stored value.
-
- Args:
- initializer: An initializer for the bias variable.
- name: Name of this block.
- """
- super(BiasAdd, self).__init__(name)
-
- with self._BlockScope():
- if isinstance(initializer, Bias):
- self._initializer = tf.constant_initializer(value=initializer.value)
- else:
- self._initializer = initializer
-
- self._bias = None
-
- def _Apply(self, x):
- if not self._bias:
- init = self._initializer([int(x.get_shape()[-1])], x.dtype)
- self._bias = self.NewVar(init)
-
- return tf.nn.bias_add(x, self._bias)
-
- def CreateWeightLoss(self):
- return []
-
-
-class LinearBase(block_base.BlockBase):
- """A matmul wrapper.
-
- Returns input * W, where matrix W can be customized through derivation.
- """
-
- def __init__(self, depth, name=None):
- super(LinearBase, self).__init__(name)
-
- with self._BlockScope():
- self._depth = depth
- self._matrix = None
-
- def _CreateKernel(self, shape, dtype):
- raise NotImplementedError('This method must be sub-classed.')
-
- def _Apply(self, x):
- if not self._matrix:
- shape = [int(x.get_shape()[-1]), self._depth]
- self._matrix = self._CreateKernel(shape, x.dtype)
-
- return tf.matmul(x, self._matrix)
-
-
-class Linear(LinearBase):
- """A matmul wrapper.
-
- Returns input * W, where matrix W is learned.
- """
-
- def __init__(self,
- depth,
- initializer=block_util.RsqrtInitializer(),
- name=None):
- super(Linear, self).__init__(depth, name)
-
- with self._BlockScope():
- self._initializer = initializer
-
- def _CreateKernel(self, shape, dtype):
- init = self._initializer(shape, dtype)
- return self.NewVar(init)
-
-
-class NN(block_base.BlockBase):
- """A neural network layer wrapper.
-
- Returns act(input * W + b), where matrix W, bias b are learned, and act is an
- optional activation function (i.e., nonlinearity).
-
- This transform block can handle multiple inputs. If x_1, x_2, ..., x_m are
- the inputs, then returns act(x_1 * W_1 + ... + x_m * W_m + b).
-
- Attributes:
- nunits: The dimension of the output.
- """
-
- def __init__(self,
- depth,
- bias=Bias(0),
- act=None, # e.g., tf.nn.relu
- initializer=block_util.RsqrtInitializer(),
- linear_block_factory=(lambda d, i: Linear(d, initializer=i)),
- name=None):
- """Initializes NN block.
-
- Args:
- depth: The depth of the output.
- bias: An initializer for the bias, or a Bias class object. If None, there
- will be no bias term for this NN block. See BiasAdd block.
- act: Optional activation function. If None, no activation is applied.
- initializer: The initialization method for the matrix weights.
- linear_block_factory: A function used to create a linear block.
- name: The name of this block.
- """
- super(NN, self).__init__(name)
-
- with self._BlockScope():
- self._linear_block_factory = linear_block_factory
- self._depth = depth
- self._initializer = initializer
- self._matrices = None
-
- self._bias = BiasAdd(bias) if bias else PassThrough()
- self._act = act if act else PassThrough()
-
- def _Apply(self, *args):
- if not self._matrices:
- self._matrices = [
- self._linear_block_factory(self._depth, self._initializer)
- for _ in args]
-
- if len(self._matrices) != len(args):
- raise ValueError('{} expected {} inputs, but observed {} inputs'.format(
- self.name, len(self._matrices), len(args)))
-
- if len(args) > 1:
- y = tf.add_n([m(x) for m, x in zip(self._matrices, args)])
- else:
- y = self._matrices[0](args[0])
-
- return self._act(self._bias(y))
-
-
-class Conv2DBase(block_base.BlockBase):
- """A tf.nn.conv2d operator."""
-
- def __init__(self, depth, filter_size, strides, padding,
- bias=None, act=None, atrous_rate=None, conv=tf.nn.conv2d,
- name=None):
- """Initializes a Conv2DBase block.
-
- Arguments:
- depth: The output depth of the block (i.e. #filters); if negative, the
- output depth will be set to be the same as the input depth.
- filter_size: The size of the 2D filter. If it's specified as an integer,
- it's going to create a square filter. Otherwise, this is a tuple
- specifying the height x width of the filter.
- strides: A tuple specifying the y and x stride.
- padding: One of the valid padding modes allowed by tf.nn.conv2d, or
- 'REFLECT'/'SYMMETRIC' for mirror padding.
- bias: An initializer for the bias, or a Bias class object. If None, there
- will be no bias in this block. See BiasAdd block.
- act: Optional activation function applied to the output.
- atrous_rate: optional input rate for ATrous convolution. If not None, this
- will be used and the strides will be ignored.
- conv: The convolution function to use (e.g. tf.nn.conv2d).
- name: The name for this conv2d op.
- """
- super(Conv2DBase, self).__init__(name)
-
- with self._BlockScope():
- self._act = act if act else PassThrough()
- self._bias = BiasAdd(bias) if bias else PassThrough()
-
- self._kernel_shape = np.zeros((4,), dtype=np.int32)
- self._kernel_shape[:2] = filter_size
- self._kernel_shape[3] = depth
-
- self._strides = np.ones((4,), dtype=np.int32)
- self._strides[1:3] = strides
- self._strides = list(self._strides)
-
- self._padding = padding
-
- self._kernel = None
- self._conv = conv
-
- self._atrous_rate = atrous_rate
-
- def _CreateKernel(self, shape, dtype):
- raise NotImplementedError('This method must be sub-classed')
-
- def _Apply(self, x):
- """Apply the self._conv op.
-
- Arguments:
- x: input tensor. It needs to be a 4D tensor of the form
- [batch, height, width, channels].
- Returns:
- The output of the convolution of x with the current convolutional
- kernel.
- Raises:
- ValueError: if number of channels is not defined at graph construction.
- """
- input_shape = x.get_shape().with_rank(4)
- input_shape[3:].assert_is_fully_defined() # channels must be defined
- if self._kernel is None:
- assert self._kernel_shape[2] == 0, self._kernel_shape
- self._kernel_shape[2] = input_shape[3].value
- if self._kernel_shape[3] < 0:
- # Make output depth be the same as input depth.
- self._kernel_shape[3] = self._kernel_shape[2]
- self._kernel = self._CreateKernel(self._kernel_shape, x.dtype)
-
- x, padding = HandleConvPaddingModes(
- x, self._padding, self._kernel_shape, self._strides)
- if self._atrous_rate is None:
- x = self._conv(x, self._kernel, strides=self._strides, padding=padding)
- else:
- x = self._conv(x, self._kernel, rate=self._atrous_rate, padding=padding)
-
- if self._padding != 'VALID':
- # Manually update shape. Known shape information can be lost by tf.pad().
- height = (1 + (input_shape[1].value - 1) // self._strides[1]
- if input_shape[1].value else None)
- width = (1 + (input_shape[2].value - 1) // self._strides[2]
- if input_shape[2].value else None)
- shape = x.get_shape()
- x.set_shape([shape[0], height, width, shape[3]])
-
- return self._act(self._bias(x))
-
-
-class Conv2D(Conv2DBase):
- """A tf.nn.conv2d operator."""
-
- def __init__(self, depth, filter_size, strides, padding,
- bias=None, act=None, initializer=None, name=None):
- """Initializes a Conv2D block.
-
- Arguments:
- depth: The output depth of the block (i.e., #filters)
- filter_size: The size of the 2D filter. If it's specified as an integer,
- it's going to create a square filter. Otherwise, this is a tuple
- specifying the height x width of the filter.
- strides: A tuple specifying the y and x stride.
- padding: One of the valid padding modes allowed by tf.nn.conv2d, or
- 'REFLECT'/'SYMMETRIC' for mirror padding.
- bias: An initializer for the bias, or a Bias class object. If None, there
- will be no bias in this block. See BiasAdd block.
- act: Optional activation function applied to the output.
- initializer: Optional initializer for weights.
- name: The name for this conv2d op.
- """
- super(Conv2D, self).__init__(depth, filter_size, strides, padding, bias,
- act, conv=tf.nn.conv2d, name=name)
-
- with self._BlockScope():
- if initializer is None:
- initializer = block_util.RsqrtInitializer(dims=(0, 1, 2))
- self._initializer = initializer
-
- def _CreateKernel(self, shape, dtype):
- return self.NewVar(self._initializer(shape, dtype))
diff --git a/research/compression/entropy_coder/lib/blocks_std_test.py b/research/compression/entropy_coder/lib/blocks_std_test.py
deleted file mode 100644
index 328ebc9d2173436b2108b343b98650128a4613e3..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/lib/blocks_std_test.py
+++ /dev/null
@@ -1,340 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Tests for basic tensorflow blocks_std."""
-
-from __future__ import division
-from __future__ import unicode_literals
-
-import math
-import os
-
-import numpy as np
-from six.moves import xrange
-import tensorflow as tf
-
-import blocks_std
-
-
-def _NumpyConv2D(x, f, strides, padding, rate=1):
- assert strides[0] == 1 and strides[3] == 1, strides
-
- if rate > 1:
- f_shape = f.shape
- expand_f = np.zeros([f_shape[0], ((f_shape[1] - 1) * rate + 1),
- f_shape[2], f_shape[3]])
- expand_f[:, [y * rate for y in range(f_shape[1])], :, :] = f
- f = np.zeros([((f_shape[0] - 1) * rate + 1), expand_f.shape[1],
- f_shape[2], f_shape[3]])
- f[[y * rate for y in range(f_shape[0])], :, :, :] = expand_f
-
- if padding != 'VALID':
- assert x.shape[1] > 0 and x.shape[2] > 0, x.shape
- # Compute the number of padded rows and cols.
- # See Conv2D block comments for a math explanation.
- remainder = ((x.shape[1] - 1) % strides[1], (x.shape[2] - 1) % strides[2])
- pad_rows = f.shape[0] - remainder[0] - 1
- pad_cols = f.shape[1] - remainder[1] - 1
- pad = ((0, 0),
- (pad_rows // 2, (pad_rows + 1) // 2),
- (pad_cols // 2, (pad_cols + 1) // 2),
- (0, 0))
-
- # Pad the input using numpy.pad().
- mode = None
- if padding == 'SAME':
- mode = str('constant')
- if padding == 'REFLECT':
- mode = str('reflect')
- if padding == 'SYMMETRIC':
- mode = str('symmetric')
- x = np.pad(x, pad, mode=mode)
-
- # Since x is now properly padded, proceed as if padding mode is VALID.
- x_window = np.empty(
- (x.shape[0],
- int(math.ceil((x.shape[1] - f.shape[0] + 1) / strides[1])),
- int(math.ceil((x.shape[2] - f.shape[1] + 1) / strides[2])),
- np.prod(f.shape[:3])))
-
- # The output at pixel location (i, j) is the result of linear transformation
- # applied to the window whose top-left corner is at
- # (i * row_stride, j * col_stride).
- for i in xrange(x_window.shape[1]):
- k = i * strides[1]
- for j in xrange(x_window.shape[2]):
- l = j * strides[2]
- x_window[:, i, j, :] = x[:,
- k:(k + f.shape[0]),
- l:(l + f.shape[1]),
- :].reshape((x_window.shape[0], -1))
-
- y = np.tensordot(x_window, f.reshape((-1, f.shape[3])), axes=1)
- return y
-
-
-class BlocksStdTest(tf.test.TestCase):
-
- def CheckUnary(self, y, op_type):
- self.assertEqual(op_type, y.op.type)
- self.assertEqual(1, len(y.op.inputs))
- return y.op.inputs[0]
-
- def CheckBinary(self, y, op_type):
- self.assertEqual(op_type, y.op.type)
- self.assertEqual(2, len(y.op.inputs))
- return y.op.inputs
-
- def testPassThrough(self):
- p = blocks_std.PassThrough()
- x = tf.placeholder(dtype=tf.float32, shape=[1])
- self.assertIs(p(x), x)
-
- def CheckBiasAdd(self, y, b):
- x, u = self.CheckBinary(y, 'BiasAdd')
- self.assertIs(u, b._bias.value())
- self.assertEqual(x.dtype, u.dtype.base_dtype)
- return x
-
- def testBiasAdd(self):
- b = blocks_std.BiasAdd()
- x = tf.placeholder(dtype=tf.float32, shape=[4, 8])
- y = b(x)
- self.assertEqual(b._bias.get_shape(), x.get_shape()[-1:])
- self.assertIs(x, self.CheckBiasAdd(y, b))
-
- def testBiasRankTest(self):
- b = blocks_std.BiasAdd()
- x = tf.placeholder(dtype=tf.float32, shape=[10])
- with self.assertRaises(ValueError):
- b(x)
-
- def CheckLinear(self, y, m):
- x, w = self.CheckBinary(y, 'MatMul')
- self.assertIs(w, m._matrix.value())
- self.assertEqual(x.dtype, w.dtype.base_dtype)
- return x
-
- def testLinear(self):
- m = blocks_std.Linear(10)
- x = tf.placeholder(dtype=tf.float32, shape=[8, 9])
- y = m(x)
- self.assertEqual(m._matrix.get_shape(), [9, 10])
- self.assertIs(x, self.CheckLinear(y, m))
-
- def testLinearShared(self):
- # Create a linear map which is applied twice on different inputs
- # (i.e. the weights of the map are shared).
- linear_map = blocks_std.Linear(6)
- x1 = tf.random_normal(shape=[1, 5])
- x2 = tf.random_normal(shape=[1, 5])
- xs = x1 + x2
-
- # Apply the transform with the same weights.
- y1 = linear_map(x1)
- y2 = linear_map(x2)
- ys = linear_map(xs)
-
- with self.test_session() as sess:
- # Initialize all the variables of the graph.
- tf.global_variables_initializer().run()
-
- y1_res, y2_res, ys_res = sess.run([y1, y2, ys])
- self.assertAllClose(y1_res + y2_res, ys_res)
-
- def CheckNN(self, y, nn, act=None):
- if act:
- pre_act = self.CheckUnary(y, act)
- else:
- pre_act = y
-
- if not isinstance(nn._bias, blocks_std.PassThrough):
- pre_bias = self.CheckBiasAdd(pre_act, nn._bias)
- else:
- pre_bias = pre_act
-
- if len(nn._matrices) > 1:
- self.assertEqual('AddN', pre_bias.op.type)
- pre_bias = pre_bias.op.inputs
- else:
- pre_bias = [pre_bias]
-
- self.assertEqual(len(pre_bias), len(nn._matrices))
- return [self.CheckLinear(u, m) for u, m in zip(pre_bias, nn._matrices)]
-
- def testNNWithoutActWithoutBias(self):
- nn = blocks_std.NN(10, act=None, bias=None)
- x = tf.placeholder(dtype=tf.float32, shape=[5, 7])
- y = nn(x)
- self.assertIs(x, self.CheckNN(y, nn)[0])
-
- def testNNWithoutBiasWithAct(self):
- nn = blocks_std.NN(10, act=tf.nn.relu, bias=None)
- x = tf.placeholder(dtype=tf.float32, shape=[5, 7])
- y = nn(x)
- self.assertIs(x, self.CheckNN(y, nn, 'Relu')[0])
-
- def testNNWithBiasWithoutAct(self):
- nn = blocks_std.NN(10, bias=blocks_std.Bias(0), act=None)
- x = tf.placeholder(dtype=tf.float32, shape=[5, 7])
- y = nn(x)
- self.assertIs(x, self.CheckNN(y, nn)[0])
-
- def testNNWithBiasWithAct(self):
- nn = blocks_std.NN(10, bias=blocks_std.Bias(0), act=tf.square)
- x = tf.placeholder(dtype=tf.float32, shape=[5, 7])
- y = nn(x)
- self.assertIs(x, self.CheckNN(y, nn, 'Square')[0])
-
- def testNNMultipleInputs(self):
- nn = blocks_std.NN(10, bias=blocks_std.Bias(0), act=tf.tanh)
- x = [tf.placeholder(dtype=tf.float32, shape=[5, 7]),
- tf.placeholder(dtype=tf.float32, shape=[5, 3]),
- tf.placeholder(dtype=tf.float32, shape=[5, 5])]
- y = nn(*x)
- xs = self.CheckNN(y, nn, 'Tanh')
- self.assertEqual(len(x), len(xs))
- for u, v in zip(x, xs):
- self.assertIs(u, v)
-
- def testConv2DSAME(self):
- np.random.seed(142536)
-
- x_shape = [4, 16, 11, 5]
- f_shape = [4, 3, 5, 6]
- strides = [1, 2, 2, 1]
- padding = 'SAME'
-
- conv = blocks_std.Conv2D(depth=f_shape[-1],
- filter_size=f_shape[0:2],
- strides=strides[1:3],
- padding=padding,
- act=None,
- bias=None)
- x_value = np.random.normal(size=x_shape)
- x = tf.convert_to_tensor(x_value, dtype=tf.float32)
- y = conv(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- f_value = conv._kernel.eval()
- y_value = y.eval()
-
- y_expected = _NumpyConv2D(x_value, f_value,
- strides=strides, padding=padding)
- self.assertAllClose(y_expected, y_value)
-
- def testConv2DValid(self):
- np.random.seed(253647)
-
- x_shape = [4, 11, 12, 5]
- f_shape = [5, 2, 5, 5]
- strides = [1, 2, 2, 1]
- padding = 'VALID'
-
- conv = blocks_std.Conv2D(depth=f_shape[-1],
- filter_size=f_shape[0:2],
- strides=strides[1:3],
- padding=padding,
- act=None,
- bias=None)
- x_value = np.random.normal(size=x_shape)
- x = tf.convert_to_tensor(x_value, dtype=tf.float32)
- y = conv(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- f_value = conv._kernel.eval()
- y_value = y.eval()
-
- y_expected = _NumpyConv2D(x_value, f_value,
- strides=strides, padding=padding)
- self.assertAllClose(y_expected, y_value)
-
- def testConv2DSymmetric(self):
- np.random.seed(364758)
-
- x_shape = [4, 10, 12, 6]
- f_shape = [3, 4, 6, 5]
- strides = [1, 1, 1, 1]
- padding = 'SYMMETRIC'
-
- conv = blocks_std.Conv2D(depth=f_shape[-1],
- filter_size=f_shape[0:2],
- strides=strides[1:3],
- padding=padding,
- act=None,
- bias=None)
- x_value = np.random.normal(size=x_shape)
- x = tf.convert_to_tensor(x_value, dtype=tf.float32)
- y = conv(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- f_value = conv._kernel.eval()
- y_value = y.eval()
-
- y_expected = _NumpyConv2D(x_value, f_value,
- strides=strides, padding=padding)
- self.assertAllClose(y_expected, y_value)
-
- def testConv2DReflect(self):
- np.random.seed(768798)
-
- x_shape = [4, 10, 12, 6]
- f_shape = [3, 4, 6, 5]
- strides = [1, 2, 2, 1]
- padding = 'REFLECT'
-
- conv = blocks_std.Conv2D(depth=f_shape[-1],
- filter_size=f_shape[0:2],
- strides=strides[1:3],
- padding=padding,
- act=None,
- bias=None)
- x_value = np.random.normal(size=x_shape)
- x = tf.convert_to_tensor(x_value, dtype=tf.float32)
- y = conv(x)
-
- with self.test_session():
- tf.global_variables_initializer().run()
- f_value = conv._kernel.eval()
- y_value = y.eval()
-
- y_expected = _NumpyConv2D(x_value, f_value,
- strides=strides, padding=padding)
- self.assertAllClose(y_expected, y_value)
-
- def testConv2DBias(self):
- input_shape = [19, 14, 14, 64]
- filter_shape = [3, 7, 64, 128]
- strides = [1, 2, 2, 1]
- output_shape = [19, 6, 4, 128]
-
- conv = blocks_std.Conv2D(depth=filter_shape[-1],
- filter_size=filter_shape[0:2],
- strides=strides[1:3],
- padding='VALID',
- act=None,
- bias=blocks_std.Bias(1))
- x = tf.placeholder(dtype=tf.float32, shape=input_shape)
-
- y = conv(x)
- self.CheckBiasAdd(y, conv._bias)
- self.assertEqual(output_shape, y.get_shape().as_list())
-
-
-if __name__ == '__main__':
- tf.test.main()
diff --git a/research/compression/entropy_coder/model/__init__.py b/research/compression/entropy_coder/model/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/compression/entropy_coder/model/entropy_coder_model.py b/research/compression/entropy_coder/model/entropy_coder_model.py
deleted file mode 100644
index 67f7eb5bc05f3df7363529c19fa77d176caaabc1..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/model/entropy_coder_model.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Entropy coder model."""
-
-
-class EntropyCoderModel(object):
- """Entropy coder model."""
-
- def __init__(self):
- # Loss used for training the model.
- self.loss = None
-
- # Tensorflow op to run to train the model.
- self.train_op = None
-
- # Tensor corresponding to the average code length of the input bit field
- # tensor. The average code length is a number of output bits per input bit.
- # To get an effective compression, this number should be between 0.0
- # and 1.0 (1.0 corresponds to no compression).
- self.average_code_length = None
-
- def Initialize(self, global_step, optimizer, config_string):
- raise NotImplementedError()
-
- def BuildGraph(self, input_codes):
- """Build the Tensorflow graph corresponding to the entropy coder model.
-
- Args:
- input_codes: Tensor of size: batch_size x height x width x bit_depth
- corresponding to the codes to compress.
- The input codes are {-1, +1} codes.
- """
- # TODO:
- # - consider switching to {0, 1} codes.
- # - consider passing an extra tensor which gives for each (b, y, x)
- # what is the actual depth (which would allow to use more or less bits
- # for each (y, x) location.
- raise NotImplementedError()
-
- def GetConfigStringForUnitTest(self):
- """Returns a default model configuration to be used for unit tests."""
- return None
diff --git a/research/compression/entropy_coder/model/model_factory.py b/research/compression/entropy_coder/model/model_factory.py
deleted file mode 100644
index e6f9902f3bb720e76f228f2774a9eaf7774ef191..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/model/model_factory.py
+++ /dev/null
@@ -1,53 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Entropy coder model registrar."""
-
-
-class ModelFactory(object):
- """Factory of encoder/decoder models."""
-
- def __init__(self):
- self._model_dictionary = dict()
-
- def RegisterModel(self,
- entropy_coder_model_name,
- entropy_coder_model_factory):
- self._model_dictionary[entropy_coder_model_name] = (
- entropy_coder_model_factory)
-
- def CreateModel(self, model_name):
- current_model_factory = self._model_dictionary[model_name]
- return current_model_factory()
-
- def GetAvailableModels(self):
- return self._model_dictionary.keys()
-
-
-_model_registry = ModelFactory()
-
-
-def GetModelRegistry():
- return _model_registry
-
-
-class RegisterEntropyCoderModel(object):
-
- def __init__(self, model_name):
- self._model_name = model_name
-
- def __call__(self, f):
- _model_registry.RegisterModel(self._model_name, f)
- return f
diff --git a/research/compression/entropy_coder/progressive/__init__.py b/research/compression/entropy_coder/progressive/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/research/compression/entropy_coder/progressive/progressive.py b/research/compression/entropy_coder/progressive/progressive.py
deleted file mode 100644
index 7b03a07db055b62aa1c0f9cc89ddd2472899db3c..0000000000000000000000000000000000000000
--- a/research/compression/entropy_coder/progressive/progressive.py
+++ /dev/null
@@ -1,242 +0,0 @@
-# Copyright 2017 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Code probability model used for entropy coding."""
-
-import json
-
-from six.moves import xrange
-import tensorflow as tf
-
-from entropy_coder.lib import blocks
-from entropy_coder.model import entropy_coder_model
-from entropy_coder.model import model_factory
-
-# pylint: disable=not-callable
-
-
-class BrnnPredictor(blocks.BlockBase):
- """BRNN prediction applied on one layer."""
-
- def __init__(self, code_depth, name=None):
- super(BrnnPredictor, self).__init__(name)
-
- with self._BlockScope():
- hidden_depth = 2 * code_depth
-
- # What is coming from the previous layer/iteration
- # is going through a regular Conv2D layer as opposed to the binary codes
- # of the current layer/iteration which are going through a masked
- # convolution.
- self._adaptation0 = blocks.RasterScanConv2D(
- hidden_depth, [7, 7], [1, 1], 'SAME',
- strict_order=True,
- bias=blocks.Bias(0), act=tf.tanh)
- self._adaptation1 = blocks.Conv2D(
- hidden_depth, [3, 3], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh)
- self._predictor = blocks.CompositionOperator([
- blocks.LineOperator(
- blocks.RasterScanConv2DLSTM(
- depth=hidden_depth,
- filter_size=[1, 3],
- hidden_filter_size=[1, 3],
- strides=[1, 1],
- padding='SAME')),
- blocks.Conv2D(hidden_depth, [1, 1], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh),
- blocks.Conv2D(code_depth, [1, 1], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh)
- ])
-
- def _Apply(self, x, s):
- # Code estimation using both:
- # - the state from the previous iteration/layer,
- # - the binary codes that are before in raster scan order.
- h = tf.concat(values=[self._adaptation0(x), self._adaptation1(s)], axis=3)
-
- estimated_codes = self._predictor(h)
-
- return estimated_codes
-
-
-class LayerPrediction(blocks.BlockBase):
- """Binary code prediction for one layer."""
-
- def __init__(self, layer_count, code_depth, name=None):
- super(LayerPrediction, self).__init__(name)
-
- self._layer_count = layer_count
-
- # No previous layer.
- self._layer_state = None
- self._current_layer = 0
-
- with self._BlockScope():
- # Layers used to do the conditional code prediction.
- self._brnn_predictors = []
- for _ in xrange(layer_count):
- self._brnn_predictors.append(BrnnPredictor(code_depth))
-
- # Layers used to generate the input of the LSTM operating on the
- # iteration/depth domain.
- hidden_depth = 2 * code_depth
- self._state_blocks = []
- for _ in xrange(layer_count):
- self._state_blocks.append(blocks.CompositionOperator([
- blocks.Conv2D(
- hidden_depth, [3, 3], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh),
- blocks.Conv2D(
- code_depth, [3, 3], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh)
- ]))
-
- # Memory of the RNN is equivalent to the size of 2 layers of binary
- # codes.
- hidden_depth = 2 * code_depth
- self._layer_rnn = blocks.CompositionOperator([
- blocks.Conv2DLSTM(
- depth=hidden_depth,
- filter_size=[1, 1],
- hidden_filter_size=[1, 1],
- strides=[1, 1],
- padding='SAME'),
- blocks.Conv2D(hidden_depth, [1, 1], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh),
- blocks.Conv2D(code_depth, [1, 1], [1, 1], 'SAME',
- bias=blocks.Bias(0), act=tf.tanh)
- ])
-
- def _Apply(self, x):
- assert self._current_layer < self._layer_count
-
- # Layer state is set to 0 when there is no previous iteration.
- if self._layer_state is None:
- self._layer_state = tf.zeros_like(x, dtype=tf.float32)
-
- # Code estimation using both:
- # - the state from the previous iteration/layer,
- # - the binary codes that are before in raster scan order.
- estimated_codes = self._brnn_predictors[self._current_layer](
- x, self._layer_state)
-
- # Compute the updated layer state.
- h = self._state_blocks[self._current_layer](x)
- self._layer_state = self._layer_rnn(h)
- self._current_layer += 1
-
- return estimated_codes
-
-
-class ProgressiveModel(entropy_coder_model.EntropyCoderModel):
- """Progressive BRNN entropy coder model."""
-
- def __init__(self):
- super(ProgressiveModel, self).__init__()
-
- def Initialize(self, global_step, optimizer, config_string):
- if config_string is None:
- raise ValueError('The progressive model requires a configuration.')
- config = json.loads(config_string)
- if 'coded_layer_count' not in config:
- config['coded_layer_count'] = 0
-
- self._config = config
- self._optimizer = optimizer
- self._global_step = global_step
-
- def BuildGraph(self, input_codes):
- """Build the graph corresponding to the progressive BRNN model."""
- layer_depth = self._config['layer_depth']
- layer_count = self._config['layer_count']
-
- code_shape = input_codes.get_shape()
- code_depth = code_shape[-1].value
- if self._config['coded_layer_count'] > 0:
- prefix_depth = self._config['coded_layer_count'] * layer_depth
- if code_depth < prefix_depth:
- raise ValueError('Invalid prefix depth: {} VS {}'.format(
- prefix_depth, code_depth))
- input_codes = input_codes[:, :, :, :prefix_depth]
-
- code_shape = input_codes.get_shape()
- code_depth = code_shape[-1].value
- if code_depth % layer_depth != 0:
- raise ValueError(
- 'Code depth must be a multiple of the layer depth: {} vs {}'.format(
- code_depth, layer_depth))
- code_layer_count = code_depth // layer_depth
- if code_layer_count > layer_count:
- raise ValueError('Input codes have too many layers: {}, max={}'.format(
- code_layer_count, layer_count))
-
- # Block used to estimate binary codes.
- layer_prediction = LayerPrediction(layer_count, layer_depth)
-
- # Block used to compute code lengths.
- code_length_block = blocks.CodeLength()
-
- # Loop over all the layers.
- code_length = []
- code_layers = tf.split(
- value=input_codes, num_or_size_splits=code_layer_count, axis=3)
- for k in xrange(code_layer_count):
- x = code_layers[k]
- predicted_x = layer_prediction(x)
- # Saturate the prediction to avoid infinite code length.
- epsilon = 0.001
- predicted_x = tf.clip_by_value(
- predicted_x, -1 + epsilon, +1 - epsilon)
- code_length.append(code_length_block(
- blocks.ConvertSignCodeToZeroOneCode(x),
- blocks.ConvertSignCodeToZeroOneCode(predicted_x)))
- tf.summary.scalar('code_length_layer_{:02d}'.format(k), code_length[-1])
- code_length = tf.stack(code_length)
- self.loss = tf.reduce_mean(code_length)
- tf.summary.scalar('loss', self.loss)
-
- # Loop over all the remaining layers just to make sure they are
- # instantiated. Otherwise, loading model params could fail.
- dummy_x = tf.zeros_like(code_layers[0])
- for _ in xrange(layer_count - code_layer_count):
- dummy_predicted_x = layer_prediction(dummy_x)
-
- # Average bitrate over total_line_count.
- self.average_code_length = tf.reduce_mean(code_length)
-
- if self._optimizer:
- optim_op = self._optimizer.minimize(self.loss,
- global_step=self._global_step)
- block_updates = blocks.CreateBlockUpdates()
- if block_updates:
- with tf.get_default_graph().control_dependencies([optim_op]):
- self.train_op = tf.group(*block_updates)
- else:
- self.train_op = optim_op
- else:
- self.train_op = None
-
- def GetConfigStringForUnitTest(self):
- s = '{\n'
- s += '"layer_depth": 1,\n'
- s += '"layer_count": 8\n'
- s += '}\n'
- return s
-
-
-@model_factory.RegisterEntropyCoderModel('progressive')
-def CreateProgressiveModel():
- return ProgressiveModel()
diff --git a/research/compression/image_encoder/README.md b/research/compression/image_encoder/README.md
deleted file mode 100644
index a47da977aa4db4be26528c5ebfe030024f31291b..0000000000000000000000000000000000000000
--- a/research/compression/image_encoder/README.md
+++ /dev/null
@@ -1,105 +0,0 @@
-# Image Compression with Neural Networks
-
-This is a [TensorFlow](http://www.tensorflow.org/) model for compressing and
-decompressing images using an already trained Residual GRU model as descibed
-in [Full Resolution Image Compression with Recurrent Neural Networks](https://arxiv.org/abs/1608.05148). Please consult the paper for more details
-on the architecture and compression results.
-
-This code will allow you to perform the lossy compression on an model
-already trained on compression. This code doesn't not currently contain the
-Entropy Coding portions of our paper.
-
-
-## Prerequisites
-The only software requirements for running the encoder and decoder is having
-Tensorflow installed. You will also need to [download](http://download.tensorflow.org/models/compression_residual_gru-2016-08-23.tar.gz)
-and extract the model residual_gru.pb.
-
-If you want to generate the perceptual similarity under MS-SSIM, you will also
-need to [Install SciPy](https://www.scipy.org/install.html).
-
-## Encoding
-The Residual GRU network is fully convolutional, but requires the images
-height and width in pixels by a multiple of 32. There is an image in this folder
-called example.png that is 768x1024 if one is needed for testing. We also
-rely on TensorFlow's built in decoding ops, which support only PNG and JPEG at
-time of release.
-
-To encode an image, simply run the following command:
-
-`python encoder.py --input_image=/your/image/here.png
---output_codes=output_codes.npz --iteration=15
---model=/path/to/model/residual_gru.pb
-`
-
-The iteration parameter specifies the lossy-quality to target for compression.
-The quality can be [0-15], where 0 corresponds to a target of 1/8 (bits per
-pixel) bpp and every increment results in an additional 1/8 bpp.
-
-| Iteration | BPP | Compression Ratio |
-|---: |---: |---: |
-|0 | 0.125 | 192:1|
-|1 | 0.250 | 96:1|
-|2 | 0.375 | 64:1|
-|3 | 0.500 | 48:1|
-|4 | 0.625 | 38.4:1|
-|5 | 0.750 | 32:1|
-|6 | 0.875 | 27.4:1|
-|7 | 1.000 | 24:1|
-|8 | 1.125 | 21.3:1|
-|9 | 1.250 | 19.2:1|
-|10 | 1.375 | 17.4:1|
-|11 | 1.500 | 16:1|
-|12 | 1.625 | 14.7:1|
-|13 | 1.750 | 13.7:1|
-|14 | 1.875 | 12.8:1|
-|15 | 2.000 | 12:1|
-
-The output_codes file contains the numpy shape and a flattened, bit-packed
-array of the codes. These can be inspected in python by using numpy.load().
-
-
-## Decoding
-After generating codes for an image, the lossy reconstructions for that image
-can be done as follows:
-
-`python decoder.py --input_codes=codes.npz --output_directory=/tmp/decoded/
---model=residual_gru.pb`
-
-The output_directory will contain images decoded at each quality level.
-
-
-## Comparing Similarity
-One of our primary metrics for comparing how similar two images are
-is MS-SSIM.
-
-To generate these metrics on your images you can run:
-`python msssim.py --original_image=/path/to/your/image.png
---compared_image=/tmp/decoded/image_15.png`
-
-
-## Results
-CSV results containing the post-entropy bitrates and MS-SSIM over Kodak can
-are available for reference. Each row of the CSV represents each of the Kodak
-images in their dataset number (1-24). Each column of the CSV represents each
-iteration of the model (1-16).
-
-[Post Entropy Bitrates](https://storage.googleapis.com/compression-ml/residual_gru_results/bitrate.csv)
-
-[MS-SSIM](https://storage.googleapis.com/compression-ml/residual_gru_results/msssim.csv)
-
-
-## FAQ
-
-#### How do I train my own compression network?
-We currently don't provide the code to build and train a compression
-graph from scratch.
-
-#### I get an InvalidArgumentError: Incompatible shapes.
-This is usually due to the fact that our network only supports images that are
-both height and width divisible by 32 pixel. Try padding your images to 32
-pixel boundaries.
-
-
-## Contact Info
-Model repository maintained by Nick Johnston ([nmjohn](https://github.com/nmjohn)).
diff --git a/research/compression/image_encoder/decoder.py b/research/compression/image_encoder/decoder.py
deleted file mode 100644
index 75bc18cad0fdd4055df7b42d5440635365504774..0000000000000000000000000000000000000000
--- a/research/compression/image_encoder/decoder.py
+++ /dev/null
@@ -1,127 +0,0 @@
-#!/usr/bin/python
-#
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-r"""Neural Network Image Compression Decoder.
-
-Decompress an image from the numpy's npz format generated by the encoder.
-
-Example usage:
-python decoder.py --input_codes=output_codes.pkl --iteration=15 \
---output_directory=/tmp/compression_output/ --model=residual_gru.pb
-"""
-import io
-import os
-
-import numpy as np
-import tensorflow as tf
-
-tf.flags.DEFINE_string('input_codes', None, 'Location of binary code file.')
-tf.flags.DEFINE_integer('iteration', -1, 'The max quality level of '
- 'the images to output. Use -1 to infer from loaded '
- ' codes.')
-tf.flags.DEFINE_string('output_directory', None, 'Directory to save decoded '
- 'images.')
-tf.flags.DEFINE_string('model', None, 'Location of compression model.')
-
-FLAGS = tf.flags.FLAGS
-
-
-def get_input_tensor_names():
- name_list = ['GruBinarizer/SignBinarizer/Sign:0']
- for i in range(1, 16):
- name_list.append('GruBinarizer/SignBinarizer/Sign_{}:0'.format(i))
- return name_list
-
-
-def get_output_tensor_names():
- return ['loop_{0:02d}/add:0'.format(i) for i in range(0, 16)]
-
-
-def main(_):
- if (FLAGS.input_codes is None or FLAGS.output_directory is None or
- FLAGS.model is None):
- print('\nUsage: python decoder.py --input_codes=output_codes.pkl '
- '--iteration=15 --output_directory=/tmp/compression_output/ '
- '--model=residual_gru.pb\n\n')
- return
-
- if FLAGS.iteration < -1 or FLAGS.iteration > 15:
- print('\n--iteration must be between 0 and 15 inclusive, or -1 to infer '
- 'from file.\n')
- return
- iteration = FLAGS.iteration
-
- if not tf.gfile.Exists(FLAGS.output_directory):
- tf.gfile.MkDir(FLAGS.output_directory)
-
- if not tf.gfile.Exists(FLAGS.input_codes):
- print('\nInput codes not found.\n')
- return
-
- contents = ''
- with tf.gfile.FastGFile(FLAGS.input_codes, 'rb') as code_file:
- contents = code_file.read()
- loaded_codes = np.load(io.BytesIO(contents))
- assert ['codes', 'shape'] not in loaded_codes.files
- loaded_shape = loaded_codes['shape']
- loaded_array = loaded_codes['codes']
-
- # Unpack and recover code shapes.
- unpacked_codes = np.reshape(np.unpackbits(loaded_array)
- [:np.prod(loaded_shape)],
- loaded_shape)
-
- numpy_int_codes = np.split(unpacked_codes, len(unpacked_codes))
- if iteration == -1:
- iteration = len(unpacked_codes) - 1
- # Convert back to float and recover scale.
- numpy_codes = [np.squeeze(x.astype(np.float32), 0) * 2 - 1 for x in
- numpy_int_codes]
-
- with tf.Graph().as_default() as graph:
- # Load the inference model for decoding.
- with tf.gfile.FastGFile(FLAGS.model, 'rb') as model_file:
- graph_def = tf.GraphDef()
- graph_def.ParseFromString(model_file.read())
- _ = tf.import_graph_def(graph_def, name='')
-
- # For encoding the tensors into PNGs.
- input_image = tf.placeholder(tf.uint8)
- encoded_image = tf.image.encode_png(input_image)
-
- input_tensors = [graph.get_tensor_by_name(name) for name in
- get_input_tensor_names()][0:iteration+1]
- outputs = [graph.get_tensor_by_name(name) for name in
- get_output_tensor_names()][0:iteration+1]
-
- feed_dict = {key: value for (key, value) in zip(input_tensors,
- numpy_codes)}
-
- with tf.Session(graph=graph) as sess:
- results = sess.run(outputs, feed_dict=feed_dict)
-
- for index, result in enumerate(results):
- img = np.uint8(np.clip(result + 0.5, 0, 255))
- img = img.squeeze()
- png_img = sess.run(encoded_image, feed_dict={input_image: img})
-
- with tf.gfile.FastGFile(os.path.join(FLAGS.output_directory,
- 'image_{0:02d}.png'.format(index)),
- 'w') as output_image:
- output_image.write(png_img)
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/compression/image_encoder/encoder.py b/research/compression/image_encoder/encoder.py
deleted file mode 100644
index 27754bdaea19779cea653408d17ed2e6a051f0c5..0000000000000000000000000000000000000000
--- a/research/compression/image_encoder/encoder.py
+++ /dev/null
@@ -1,105 +0,0 @@
-#!/usr/bin/python
-#
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-r"""Neural Network Image Compression Encoder.
-
-Compresses an image to a binarized numpy array. The image must be padded to a
-multiple of 32 pixels in height and width.
-
-Example usage:
-python encoder.py --input_image=/your/image/here.png \
---output_codes=output_codes.pkl --iteration=15 --model=residual_gru.pb
-"""
-import io
-import os
-
-import numpy as np
-import tensorflow as tf
-
-tf.flags.DEFINE_string('input_image', None, 'Location of input image. We rely '
- 'on tf.image to decode the image, so only PNG and JPEG '
- 'formats are currently supported.')
-tf.flags.DEFINE_integer('iteration', 15, 'Quality level for encoding image. '
- 'Must be between 0 and 15 inclusive.')
-tf.flags.DEFINE_string('output_codes', None, 'File to save output encoding.')
-tf.flags.DEFINE_string('model', None, 'Location of compression model.')
-
-FLAGS = tf.flags.FLAGS
-
-
-def get_output_tensor_names():
- name_list = ['GruBinarizer/SignBinarizer/Sign:0']
- for i in range(1, 16):
- name_list.append('GruBinarizer/SignBinarizer/Sign_{}:0'.format(i))
- return name_list
-
-
-def main(_):
- if (FLAGS.input_image is None or FLAGS.output_codes is None or
- FLAGS.model is None):
- print('\nUsage: python encoder.py --input_image=/your/image/here.png '
- '--output_codes=output_codes.pkl --iteration=15 '
- '--model=residual_gru.pb\n\n')
- return
-
- if FLAGS.iteration < 0 or FLAGS.iteration > 15:
- print('\n--iteration must be between 0 and 15 inclusive.\n')
- return
-
- with tf.gfile.FastGFile(FLAGS.input_image, 'rb') as input_image:
- input_image_str = input_image.read()
-
- with tf.Graph().as_default() as graph:
- # Load the inference model for encoding.
- with tf.gfile.FastGFile(FLAGS.model, 'rb') as model_file:
- graph_def = tf.GraphDef()
- graph_def.ParseFromString(model_file.read())
- _ = tf.import_graph_def(graph_def, name='')
-
- input_tensor = graph.get_tensor_by_name('Placeholder:0')
- outputs = [graph.get_tensor_by_name(name) for name in
- get_output_tensor_names()]
-
- input_image = tf.placeholder(tf.string)
- _, ext = os.path.splitext(FLAGS.input_image)
- if ext == '.png':
- decoded_image = tf.image.decode_png(input_image, channels=3)
- elif ext == '.jpeg' or ext == '.jpg':
- decoded_image = tf.image.decode_jpeg(input_image, channels=3)
- else:
- assert False, 'Unsupported file format {}'.format(ext)
- decoded_image = tf.expand_dims(decoded_image, 0)
-
- with tf.Session(graph=graph) as sess:
- img_array = sess.run(decoded_image, feed_dict={input_image:
- input_image_str})
- results = sess.run(outputs, feed_dict={input_tensor: img_array})
-
- results = results[0:FLAGS.iteration + 1]
- int_codes = np.asarray([x.astype(np.int8) for x in results])
-
- # Convert int codes to binary.
- int_codes = (int_codes + 1)//2
- export = np.packbits(int_codes.reshape(-1))
-
- output = io.BytesIO()
- np.savez_compressed(output, shape=int_codes.shape, codes=export)
- with tf.gfile.FastGFile(FLAGS.output_codes, 'w') as code_file:
- code_file.write(output.getvalue())
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/compression/image_encoder/example.png b/research/compression/image_encoder/example.png
deleted file mode 100644
index d3409b01a557fe8c3058fad21ed969f8af28cb97..0000000000000000000000000000000000000000
Binary files a/research/compression/image_encoder/example.png and /dev/null differ
diff --git a/research/compression/image_encoder/msssim.py b/research/compression/image_encoder/msssim.py
deleted file mode 100644
index f07a3712785c62feb261feb90016e0f621a3ee1d..0000000000000000000000000000000000000000
--- a/research/compression/image_encoder/msssim.py
+++ /dev/null
@@ -1,217 +0,0 @@
-#!/usr/bin/python
-#
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Python implementation of MS-SSIM.
-
-Usage:
-
-python msssim.py --original_image=original.png --compared_image=distorted.png
-"""
-import numpy as np
-from scipy import signal
-from scipy.ndimage.filters import convolve
-import tensorflow as tf
-
-
-tf.flags.DEFINE_string('original_image', None, 'Path to PNG image.')
-tf.flags.DEFINE_string('compared_image', None, 'Path to PNG image.')
-FLAGS = tf.flags.FLAGS
-
-
-def _FSpecialGauss(size, sigma):
- """Function to mimic the 'fspecial' gaussian MATLAB function."""
- radius = size // 2
- offset = 0.0
- start, stop = -radius, radius + 1
- if size % 2 == 0:
- offset = 0.5
- stop -= 1
- x, y = np.mgrid[offset + start:stop, offset + start:stop]
- assert len(x) == size
- g = np.exp(-((x**2 + y**2)/(2.0 * sigma**2)))
- return g / g.sum()
-
-
-def _SSIMForMultiScale(img1, img2, max_val=255, filter_size=11,
- filter_sigma=1.5, k1=0.01, k2=0.03):
- """Return the Structural Similarity Map between `img1` and `img2`.
-
- This function attempts to match the functionality of ssim_index_new.m by
- Zhou Wang: http://www.cns.nyu.edu/~lcv/ssim/msssim.zip
-
- Arguments:
- img1: Numpy array holding the first RGB image batch.
- img2: Numpy array holding the second RGB image batch.
- max_val: the dynamic range of the images (i.e., the difference between the
- maximum the and minimum allowed values).
- filter_size: Size of blur kernel to use (will be reduced for small images).
- filter_sigma: Standard deviation for Gaussian blur kernel (will be reduced
- for small images).
- k1: Constant used to maintain stability in the SSIM calculation (0.01 in
- the original paper).
- k2: Constant used to maintain stability in the SSIM calculation (0.03 in
- the original paper).
-
- Returns:
- Pair containing the mean SSIM and contrast sensitivity between `img1` and
- `img2`.
-
- Raises:
- RuntimeError: If input images don't have the same shape or don't have four
- dimensions: [batch_size, height, width, depth].
- """
- if img1.shape != img2.shape:
- raise RuntimeError('Input images must have the same shape (%s vs. %s).',
- img1.shape, img2.shape)
- if img1.ndim != 4:
- raise RuntimeError('Input images must have four dimensions, not %d',
- img1.ndim)
-
- img1 = img1.astype(np.float64)
- img2 = img2.astype(np.float64)
- _, height, width, _ = img1.shape
-
- # Filter size can't be larger than height or width of images.
- size = min(filter_size, height, width)
-
- # Scale down sigma if a smaller filter size is used.
- sigma = size * filter_sigma / filter_size if filter_size else 0
-
- if filter_size:
- window = np.reshape(_FSpecialGauss(size, sigma), (1, size, size, 1))
- mu1 = signal.fftconvolve(img1, window, mode='valid')
- mu2 = signal.fftconvolve(img2, window, mode='valid')
- sigma11 = signal.fftconvolve(img1 * img1, window, mode='valid')
- sigma22 = signal.fftconvolve(img2 * img2, window, mode='valid')
- sigma12 = signal.fftconvolve(img1 * img2, window, mode='valid')
- else:
- # Empty blur kernel so no need to convolve.
- mu1, mu2 = img1, img2
- sigma11 = img1 * img1
- sigma22 = img2 * img2
- sigma12 = img1 * img2
-
- mu11 = mu1 * mu1
- mu22 = mu2 * mu2
- mu12 = mu1 * mu2
- sigma11 -= mu11
- sigma22 -= mu22
- sigma12 -= mu12
-
- # Calculate intermediate values used by both ssim and cs_map.
- c1 = (k1 * max_val) ** 2
- c2 = (k2 * max_val) ** 2
- v1 = 2.0 * sigma12 + c2
- v2 = sigma11 + sigma22 + c2
- ssim = np.mean((((2.0 * mu12 + c1) * v1) / ((mu11 + mu22 + c1) * v2)))
- cs = np.mean(v1 / v2)
- return ssim, cs
-
-
-def MultiScaleSSIM(img1, img2, max_val=255, filter_size=11, filter_sigma=1.5,
- k1=0.01, k2=0.03, weights=None):
- """Return the MS-SSIM score between `img1` and `img2`.
-
- This function implements Multi-Scale Structural Similarity (MS-SSIM) Image
- Quality Assessment according to Zhou Wang's paper, "Multi-scale structural
- similarity for image quality assessment" (2003).
- Link: https://ece.uwaterloo.ca/~z70wang/publications/msssim.pdf
-
- Author's MATLAB implementation:
- http://www.cns.nyu.edu/~lcv/ssim/msssim.zip
-
- Arguments:
- img1: Numpy array holding the first RGB image batch.
- img2: Numpy array holding the second RGB image batch.
- max_val: the dynamic range of the images (i.e., the difference between the
- maximum the and minimum allowed values).
- filter_size: Size of blur kernel to use (will be reduced for small images).
- filter_sigma: Standard deviation for Gaussian blur kernel (will be reduced
- for small images).
- k1: Constant used to maintain stability in the SSIM calculation (0.01 in
- the original paper).
- k2: Constant used to maintain stability in the SSIM calculation (0.03 in
- the original paper).
- weights: List of weights for each level; if none, use five levels and the
- weights from the original paper.
-
- Returns:
- MS-SSIM score between `img1` and `img2`.
-
- Raises:
- RuntimeError: If input images don't have the same shape or don't have four
- dimensions: [batch_size, height, width, depth].
- """
- if img1.shape != img2.shape:
- raise RuntimeError('Input images must have the same shape (%s vs. %s).',
- img1.shape, img2.shape)
- if img1.ndim != 4:
- raise RuntimeError('Input images must have four dimensions, not %d',
- img1.ndim)
-
- # Note: default weights don't sum to 1.0 but do match the paper / matlab code.
- weights = np.array(weights if weights else
- [0.0448, 0.2856, 0.3001, 0.2363, 0.1333])
- levels = weights.size
- downsample_filter = np.ones((1, 2, 2, 1)) / 4.0
- im1, im2 = [x.astype(np.float64) for x in [img1, img2]]
- mssim = np.array([])
- mcs = np.array([])
- for _ in range(levels):
- ssim, cs = _SSIMForMultiScale(
- im1, im2, max_val=max_val, filter_size=filter_size,
- filter_sigma=filter_sigma, k1=k1, k2=k2)
- mssim = np.append(mssim, ssim)
- mcs = np.append(mcs, cs)
- filtered = [convolve(im, downsample_filter, mode='reflect')
- for im in [im1, im2]]
- im1, im2 = [x[:, ::2, ::2, :] for x in filtered]
- return (np.prod(mcs[0:levels-1] ** weights[0:levels-1]) *
- (mssim[levels-1] ** weights[levels-1]))
-
-
-def main(_):
- if FLAGS.original_image is None or FLAGS.compared_image is None:
- print('\nUsage: python msssim.py --original_image=original.png '
- '--compared_image=distorted.png\n\n')
- return
-
- if not tf.gfile.Exists(FLAGS.original_image):
- print('\nCannot find --original_image.\n')
- return
-
- if not tf.gfile.Exists(FLAGS.compared_image):
- print('\nCannot find --compared_image.\n')
- return
-
- with tf.gfile.FastGFile(FLAGS.original_image) as image_file:
- img1_str = image_file.read('rb')
- with tf.gfile.FastGFile(FLAGS.compared_image) as image_file:
- img2_str = image_file.read('rb')
-
- input_img = tf.placeholder(tf.string)
- decoded_image = tf.expand_dims(tf.image.decode_png(input_img, channels=3), 0)
-
- with tf.Session() as sess:
- img1 = sess.run(decoded_image, feed_dict={input_img: img1_str})
- img2 = sess.run(decoded_image, feed_dict={input_img: img2_str})
-
- print((MultiScaleSSIM(img1, img2, max_val=255)))
-
-
-if __name__ == '__main__':
- tf.app.run()
diff --git a/research/cvt_text/README.md b/research/cvt_text/README.md
deleted file mode 100644
index 1c0a415b164192fe0175048575f875d055167d5d..0000000000000000000000000000000000000000
--- a/research/cvt_text/README.md
+++ /dev/null
@@ -1,38 +0,0 @@
-# Cross-View Training
-
-This repository contains code for *Semi-Supervised Sequence Modeling with Cross-View Training*. Currently sequence tagging and dependency parsing tasks are supported.
-
-## Requirements
-* [Tensorflow](https://www.tensorflow.org/)
-* [Numpy](http://www.numpy.org/)
-
-This code has been run with TensorFlow 1.10.1 and Numpy 1.14.5; other versions may work, but have not been tested.
-
-## Fetching and Preprocessing Data
-Run `fetch_data.sh` to download and extract pretrained [GloVe](https://nlp.stanford.edu/projects/glove/) vectors, the [1 Billion Word Language Model Benchmark](http://www.statmt.org/lm-benchmark/) corpus of unlabeled data, and the CoNLL-2000 [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/) dataset. Unfortunately the other datasets from our paper are not freely available and so can't be included in this repository.
-
-To apply CVT to other datasets, the data should be placed in `data/raw_data/ |
-  |
-
| Target: Fridge | -Target: Television | -
 |
-  |
-
| Target: Microwave | -Target: Couch | -
-  -
-  -
-  -
-
- -Running: - -* Installation.
-* Running DeepLab on PASCAL VOC 2012 semantic segmentation dataset.
-* Running DeepLab on Cityscapes semantic segmentation dataset.
-* Running DeepLab on ADE20K semantic segmentation dataset.
- -Models: - -* Checkpoints and frozen inference graphs.
- -Misc: - -* Please check FAQ if you have some questions before reporting the issues.
- -## Getting Help - -To get help with issues you may encounter while using the DeepLab Tensorflow -implementation, create a new question on -[StackOverflow](https://stackoverflow.com/) with the tag "tensorflow". - -Please report bugs (i.e., broken code, not usage questions) to the -tensorflow/models GitHub [issue -tracker](https://github.com/tensorflow/models/issues), prefixing the issue name -with "deeplab". - -## License - -All the codes in deeplab folder is covered by the [LICENSE](https://github.com/tensorflow/models/blob/master/LICENSE) -under tensorflow/models. Please refer to the LICENSE for details. - -## Change Logs - -### March 26, 2020 -* Supported EdgeTPU-DeepLab and EdgeTPU-DeepLab-slim on Cityscapes. -**Contributor**: Yun Long. - -### November 20, 2019 -* Supported MobileNetV3 large and small model variants on Cityscapes. -**Contributor**: Yukun Zhu. - - -### March 27, 2019 - -* Supported using different loss weights on different classes during training. -**Contributor**: Yuwei Yang. - - -### March 26, 2019 - -* Supported ResNet-v1-18. **Contributor**: Michalis Raptis. - - -### March 6, 2019 - -* Released the evaluation code (under the `evaluation` folder) for image -parsing, a.k.a. panoptic segmentation. In particular, the released code supports -evaluating the parsing results in terms of both the parsing covering and -panoptic quality metrics. **Contributors**: Maxwell Collins and Ting Liu. - - -### February 6, 2019 - -* Updated decoder module to exploit multiple low-level features with different -output_strides. - -### December 3, 2018 - -* Released the MobileNet-v2 checkpoint on ADE20K. - - -### November 19, 2018 - -* Supported NAS architecture for feature extraction. **Contributor**: Chenxi Liu. - -* Supported hard pixel mining during training. - - -### October 1, 2018 - -* Released MobileNet-v2 depth-multiplier = 0.5 COCO-pretrained checkpoints on -PASCAL VOC 2012, and Xception-65 COCO pretrained checkpoint (i.e., no PASCAL -pretrained). - - -### September 5, 2018 - -* Released Cityscapes pretrained checkpoints with found best dense prediction cell. - - -### May 26, 2018 - -* Updated ADE20K pretrained checkpoint. - - -### May 18, 2018 -* Added builders for ResNet-v1 and Xception model variants. -* Added ADE20K support, including colormap and pretrained Xception_65 checkpoint. -* Fixed a bug on using non-default depth_multiplier for MobileNet-v2. - - -### March 22, 2018 - -* Released checkpoints using MobileNet-V2 as network backbone and pretrained on -PASCAL VOC 2012 and Cityscapes. - - -### March 5, 2018 - -* First release of DeepLab in TensorFlow including deeper Xception network -backbone. Included chekcpoints that have been pretrained on PASCAL VOC 2012 -and Cityscapes. - -## References - -1. **Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs**
- Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (+ equal - contribution).
- [[link]](https://arxiv.org/abs/1412.7062). In ICLR, 2015. - -2. **DeepLab: Semantic Image Segmentation with Deep Convolutional Nets,** - **Atrous Convolution, and Fully Connected CRFs**
- Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille (+ equal - contribution).
- [[link]](http://arxiv.org/abs/1606.00915). TPAMI 2017. - -3. **Rethinking Atrous Convolution for Semantic Image Segmentation**
- Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam.
- [[link]](http://arxiv.org/abs/1706.05587). arXiv: 1706.05587, 2017. - -4. **Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation**
- Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam.
- [[link]](https://arxiv.org/abs/1802.02611). In ECCV, 2018. - -5. **ParseNet: Looking Wider to See Better**
- Wei Liu, Andrew Rabinovich, Alexander C Berg
- [[link]](https://arxiv.org/abs/1506.04579). arXiv:1506.04579, 2015. - -6. **Pyramid Scene Parsing Network**
- Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
- [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. - -7. **Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate shift**
- Sergey Ioffe, Christian Szegedy
- [[link]](https://arxiv.org/abs/1502.03167). In ICML, 2015. - -8. **MobileNetV2: Inverted Residuals and Linear Bottlenecks**
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
- [[link]](https://arxiv.org/abs/1801.04381). In CVPR, 2018. - -9. **Xception: Deep Learning with Depthwise Separable Convolutions**
- François Chollet
- [[link]](https://arxiv.org/abs/1610.02357). In CVPR, 2017. - -10. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
- Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
- [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge - Workshop, 2017. - -11. **Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems**
- M. Abadi, A. Agarwal, et al.
- [[link]](https://arxiv.org/abs/1603.04467). arXiv:1603.04467, 2016. - -12. **The Pascal Visual Object Classes Challenge – A Retrospective,**
- Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John - Winn, and Andrew Zisserma.
- [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. - -13. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
- [[link]](https://www.cityscapes-dataset.com/). In CVPR, 2016. - -14. **Deep Residual Learning for Image Recognition**
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
- [[link]](https://arxiv.org/abs/1512.03385). In CVPR, 2016. - -15. **Progressive Neural Architecture Search**
- Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy.
- [[link]](https://arxiv.org/abs/1712.00559). In ECCV, 2018. - -16. **Searching for MobileNetV3**
- Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam.
- [[link]](https://arxiv.org/abs/1905.02244). In ICCV, 2019. diff --git a/research/deeplab/__init__.py b/research/deeplab/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/common.py b/research/deeplab/common.py deleted file mode 100644 index 928f7176c377e69aa2c5b8bc676f092cf97819c9..0000000000000000000000000000000000000000 --- a/research/deeplab/common.py +++ /dev/null @@ -1,295 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Provides flags that are common to scripts. - -Common flags from train/eval/vis/export_model.py are collected in this script. -""" -import collections -import copy -import json -import tensorflow as tf - -flags = tf.app.flags - -# Flags for input preprocessing. - -flags.DEFINE_integer('min_resize_value', None, - 'Desired size of the smaller image side.') - -flags.DEFINE_integer('max_resize_value', None, - 'Maximum allowed size of the larger image side.') - -flags.DEFINE_integer('resize_factor', None, - 'Resized dimensions are multiple of factor plus one.') - -flags.DEFINE_boolean('keep_aspect_ratio', True, - 'Keep aspect ratio after resizing or not.') - -# Model dependent flags. - -flags.DEFINE_integer('logits_kernel_size', 1, - 'The kernel size for the convolutional kernel that ' - 'generates logits.') - -# When using 'mobilent_v2', we set atrous_rates = decoder_output_stride = None. -# When using 'xception_65' or 'resnet_v1' model variants, we set -# atrous_rates = [6, 12, 18] (output stride 16) and decoder_output_stride = 4. -# See core/feature_extractor.py for supported model variants. -flags.DEFINE_string('model_variant', 'mobilenet_v2', 'DeepLab model variant.') - -flags.DEFINE_multi_float('image_pyramid', None, - 'Input scales for multi-scale feature extraction.') - -flags.DEFINE_boolean('add_image_level_feature', True, - 'Add image level feature.') - -flags.DEFINE_list( - 'image_pooling_crop_size', None, - 'Image pooling crop size [height, width] used in the ASPP module. When ' - 'value is None, the model performs image pooling with "crop_size". This' - 'flag is useful when one likes to use different image pooling sizes.') - -flags.DEFINE_list( - 'image_pooling_stride', '1,1', - 'Image pooling stride [height, width] used in the ASPP image pooling. ') - -flags.DEFINE_boolean('aspp_with_batch_norm', True, - 'Use batch norm parameters for ASPP or not.') - -flags.DEFINE_boolean('aspp_with_separable_conv', True, - 'Use separable convolution for ASPP or not.') - -# Defaults to None. Set multi_grid = [1, 2, 4] when using provided -# 'resnet_v1_{50,101}_beta' checkpoints. -flags.DEFINE_multi_integer('multi_grid', None, - 'Employ a hierarchy of atrous rates for ResNet.') - -flags.DEFINE_float('depth_multiplier', 1.0, - 'Multiplier for the depth (number of channels) for all ' - 'convolution ops used in MobileNet.') - -flags.DEFINE_integer('divisible_by', None, - 'An integer that ensures the layer # channels are ' - 'divisible by this value. Used in MobileNet.') - -# For `xception_65`, use decoder_output_stride = 4. For `mobilenet_v2`, use -# decoder_output_stride = None. -flags.DEFINE_list('decoder_output_stride', None, - 'Comma-separated list of strings with the number specifying ' - 'output stride of low-level features at each network level.' - 'Current semantic segmentation implementation assumes at ' - 'most one output stride (i.e., either None or a list with ' - 'only one element.') - -flags.DEFINE_boolean('decoder_use_separable_conv', True, - 'Employ separable convolution for decoder or not.') - -flags.DEFINE_enum('merge_method', 'max', ['max', 'avg'], - 'Scheme to merge multi scale features.') - -flags.DEFINE_boolean( - 'prediction_with_upsampled_logits', True, - 'When performing prediction, there are two options: (1) bilinear ' - 'upsampling the logits followed by softmax, or (2) softmax followed by ' - 'bilinear upsampling.') - -flags.DEFINE_string( - 'dense_prediction_cell_json', - '', - 'A JSON file that specifies the dense prediction cell.') - -flags.DEFINE_integer( - 'nas_stem_output_num_conv_filters', 20, - 'Number of filters of the stem output tensor in NAS models.') - -flags.DEFINE_bool('nas_use_classification_head', False, - 'Use image classification head for NAS model variants.') - -flags.DEFINE_bool('nas_remove_os32_stride', False, - 'Remove the stride in the output stride 32 branch.') - -flags.DEFINE_bool('use_bounded_activation', False, - 'Whether or not to use bounded activations. Bounded ' - 'activations better lend themselves to quantized inference.') - -flags.DEFINE_boolean('aspp_with_concat_projection', True, - 'ASPP with concat projection.') - -flags.DEFINE_boolean('aspp_with_squeeze_and_excitation', False, - 'ASPP with squeeze and excitation.') - -flags.DEFINE_integer('aspp_convs_filters', 256, 'ASPP convolution filters.') - -flags.DEFINE_boolean('decoder_use_sum_merge', False, - 'Decoder uses simply sum merge.') - -flags.DEFINE_integer('decoder_filters', 256, 'Decoder filters.') - -flags.DEFINE_boolean('decoder_output_is_logits', False, - 'Use decoder output as logits or not.') - -flags.DEFINE_boolean('image_se_uses_qsigmoid', False, 'Use q-sigmoid.') - -flags.DEFINE_multi_float( - 'label_weights', None, - 'A list of label weights, each element represents the weight for the label ' - 'of its index, for example, label_weights = [0.1, 0.5] means the weight ' - 'for label 0 is 0.1 and the weight for label 1 is 0.5. If set as None, all ' - 'the labels have the same weight 1.0.') - -flags.DEFINE_float('batch_norm_decay', 0.9997, 'Batchnorm decay.') - -FLAGS = flags.FLAGS - -# Constants - -# Perform semantic segmentation predictions. -OUTPUT_TYPE = 'semantic' - -# Semantic segmentation item names. -LABELS_CLASS = 'labels_class' -IMAGE = 'image' -HEIGHT = 'height' -WIDTH = 'width' -IMAGE_NAME = 'image_name' -LABEL = 'label' -ORIGINAL_IMAGE = 'original_image' - -# Test set name. -TEST_SET = 'test' - - -class ModelOptions( - collections.namedtuple('ModelOptions', [ - 'outputs_to_num_classes', - 'crop_size', - 'atrous_rates', - 'output_stride', - 'preprocessed_images_dtype', - 'merge_method', - 'add_image_level_feature', - 'image_pooling_crop_size', - 'image_pooling_stride', - 'aspp_with_batch_norm', - 'aspp_with_separable_conv', - 'multi_grid', - 'decoder_output_stride', - 'decoder_use_separable_conv', - 'logits_kernel_size', - 'model_variant', - 'depth_multiplier', - 'divisible_by', - 'prediction_with_upsampled_logits', - 'dense_prediction_cell_config', - 'nas_architecture_options', - 'use_bounded_activation', - 'aspp_with_concat_projection', - 'aspp_with_squeeze_and_excitation', - 'aspp_convs_filters', - 'decoder_use_sum_merge', - 'decoder_filters', - 'decoder_output_is_logits', - 'image_se_uses_qsigmoid', - 'label_weights', - 'sync_batch_norm_method', - 'batch_norm_decay', - ])): - """Immutable class to hold model options.""" - - __slots__ = () - - def __new__(cls, - outputs_to_num_classes, - crop_size=None, - atrous_rates=None, - output_stride=8, - preprocessed_images_dtype=tf.float32): - """Constructor to set default values. - - Args: - outputs_to_num_classes: A dictionary from output type to the number of - classes. For example, for the task of semantic segmentation with 21 - semantic classes, we would have outputs_to_num_classes['semantic'] = 21. - crop_size: A tuple [crop_height, crop_width]. - atrous_rates: A list of atrous convolution rates for ASPP. - output_stride: The ratio of input to output spatial resolution. - preprocessed_images_dtype: The type after the preprocessing function. - - Returns: - A new ModelOptions instance. - """ - dense_prediction_cell_config = None - if FLAGS.dense_prediction_cell_json: - with tf.gfile.Open(FLAGS.dense_prediction_cell_json, 'r') as f: - dense_prediction_cell_config = json.load(f) - decoder_output_stride = None - if FLAGS.decoder_output_stride: - decoder_output_stride = [ - int(x) for x in FLAGS.decoder_output_stride] - if sorted(decoder_output_stride, reverse=True) != decoder_output_stride: - raise ValueError('Decoder output stride need to be sorted in the ' - 'descending order.') - image_pooling_crop_size = None - if FLAGS.image_pooling_crop_size: - image_pooling_crop_size = [int(x) for x in FLAGS.image_pooling_crop_size] - image_pooling_stride = [1, 1] - if FLAGS.image_pooling_stride: - image_pooling_stride = [int(x) for x in FLAGS.image_pooling_stride] - label_weights = FLAGS.label_weights - if label_weights is None: - label_weights = 1.0 - nas_architecture_options = { - 'nas_stem_output_num_conv_filters': ( - FLAGS.nas_stem_output_num_conv_filters), - 'nas_use_classification_head': FLAGS.nas_use_classification_head, - 'nas_remove_os32_stride': FLAGS.nas_remove_os32_stride, - } - return super(ModelOptions, cls).__new__( - cls, outputs_to_num_classes, crop_size, atrous_rates, output_stride, - preprocessed_images_dtype, - FLAGS.merge_method, - FLAGS.add_image_level_feature, - image_pooling_crop_size, - image_pooling_stride, - FLAGS.aspp_with_batch_norm, - FLAGS.aspp_with_separable_conv, - FLAGS.multi_grid, - decoder_output_stride, - FLAGS.decoder_use_separable_conv, - FLAGS.logits_kernel_size, - FLAGS.model_variant, - FLAGS.depth_multiplier, - FLAGS.divisible_by, - FLAGS.prediction_with_upsampled_logits, - dense_prediction_cell_config, - nas_architecture_options, - FLAGS.use_bounded_activation, - FLAGS.aspp_with_concat_projection, - FLAGS.aspp_with_squeeze_and_excitation, - FLAGS.aspp_convs_filters, - FLAGS.decoder_use_sum_merge, - FLAGS.decoder_filters, - FLAGS.decoder_output_is_logits, - FLAGS.image_se_uses_qsigmoid, - label_weights, - 'None', - FLAGS.batch_norm_decay) - - def __deepcopy__(self, memo): - return ModelOptions(copy.deepcopy(self.outputs_to_num_classes), - self.crop_size, - self.atrous_rates, - self.output_stride, - self.preprocessed_images_dtype) diff --git a/research/deeplab/common_test.py b/research/deeplab/common_test.py deleted file mode 100644 index 45b64e50e3bb0a574c0ec230075e6fddff3ae996..0000000000000000000000000000000000000000 --- a/research/deeplab/common_test.py +++ /dev/null @@ -1,52 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for common.py.""" -import copy - -import tensorflow as tf - -from deeplab import common - - -class CommonTest(tf.test.TestCase): - - def testOutputsToNumClasses(self): - num_classes = 21 - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) - self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], - num_classes) - - def testDeepcopy(self): - num_classes = 21 - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) - model_options_new = copy.deepcopy(model_options) - self.assertEqual((model_options_new. - outputs_to_num_classes[common.OUTPUT_TYPE]), - num_classes) - - num_classes_new = 22 - model_options_new.outputs_to_num_classes[common.OUTPUT_TYPE] = ( - num_classes_new) - self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], - num_classes) - self.assertEqual((model_options_new. - outputs_to_num_classes[common.OUTPUT_TYPE]), - num_classes_new) - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/__init__.py b/research/deeplab/core/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/core/conv2d_ws.py b/research/deeplab/core/conv2d_ws.py deleted file mode 100644 index 9aaaf33dd3c2e098d7d5e815b4918c436ee1796c..0000000000000000000000000000000000000000 --- a/research/deeplab/core/conv2d_ws.py +++ /dev/null @@ -1,369 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Augment slim.conv2d with optional Weight Standardization (WS). - -WS is a normalization method to accelerate micro-batch training. When used with -Group Normalization and trained with 1 image/GPU, WS is able to match or -outperform the performances of BN trained with large batch sizes. -[1] Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, Alan Yuille - Weight Standardization. arXiv:1903.10520 -[2] Lei Huang, Xianglong Liu, Yang Liu, Bo Lang, Dacheng Tao - Centered Weight Normalization in Accelerating Training of Deep Neural - Networks. ICCV 2017 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers - -from tensorflow.contrib.layers.python.layers import layers -from tensorflow.contrib.layers.python.layers import utils - - -class Conv2D(tf.keras.layers.Conv2D, tf.layers.Layer): - """2D convolution layer (e.g. spatial convolution over images). - - This layer creates a convolution kernel that is convolved - (actually cross-correlated) with the layer input to produce a tensor of - outputs. If `use_bias` is True (and a `bias_initializer` is provided), - a bias vector is created and added to the outputs. Finally, if - `activation` is not `None`, it is applied to the outputs as well. - """ - - def __init__(self, - filters, - kernel_size, - strides=(1, 1), - padding='valid', - data_format='channels_last', - dilation_rate=(1, 1), - activation=None, - use_bias=True, - kernel_initializer=None, - bias_initializer=tf.zeros_initializer(), - kernel_regularizer=None, - bias_regularizer=None, - use_weight_standardization=False, - activity_regularizer=None, - kernel_constraint=None, - bias_constraint=None, - trainable=True, - name=None, - **kwargs): - """Constructs the 2D convolution layer. - - Args: - filters: Integer, the dimensionality of the output space (i.e. the number - of filters in the convolution). - kernel_size: An integer or tuple/list of 2 integers, specifying the height - and width of the 2D convolution window. Can be a single integer to - specify the same value for all spatial dimensions. - strides: An integer or tuple/list of 2 integers, specifying the strides of - the convolution along the height and width. Can be a single integer to - specify the same value for all spatial dimensions. Specifying any stride - value != 1 is incompatible with specifying any `dilation_rate` value != - 1. - padding: One of `"valid"` or `"same"` (case-insensitive). - data_format: A string, one of `channels_last` (default) or - `channels_first`. The ordering of the dimensions in the inputs. - `channels_last` corresponds to inputs with shape `(batch, height, width, - channels)` while `channels_first` corresponds to inputs with shape - `(batch, channels, height, width)`. - dilation_rate: An integer or tuple/list of 2 integers, specifying the - dilation rate to use for dilated convolution. Can be a single integer to - specify the same value for all spatial dimensions. Currently, specifying - any `dilation_rate` value != 1 is incompatible with specifying any - stride value != 1. - activation: Activation function. Set it to None to maintain a linear - activation. - use_bias: Boolean, whether the layer uses a bias. - kernel_initializer: An initializer for the convolution kernel. - bias_initializer: An initializer for the bias vector. If None, the default - initializer will be used. - kernel_regularizer: Optional regularizer for the convolution kernel. - bias_regularizer: Optional regularizer for the bias vector. - use_weight_standardization: Boolean, whether the layer uses weight - standardization. - activity_regularizer: Optional regularizer function for the output. - kernel_constraint: Optional projection function to be applied to the - kernel after being updated by an `Optimizer` (e.g. used to implement - norm constraints or value constraints for layer weights). The function - must take as input the unprojected variable and must return the - projected variable (which must have the same shape). Constraints are not - safe to use when doing asynchronous distributed training. - bias_constraint: Optional projection function to be applied to the bias - after being updated by an `Optimizer`. - trainable: Boolean, if `True` also add variables to the graph collection - `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). - name: A string, the name of the layer. - **kwargs: Arbitrary keyword arguments passed to tf.keras.layers.Conv2D - """ - - super(Conv2D, self).__init__( - filters=filters, - kernel_size=kernel_size, - strides=strides, - padding=padding, - data_format=data_format, - dilation_rate=dilation_rate, - activation=activation, - use_bias=use_bias, - kernel_initializer=kernel_initializer, - bias_initializer=bias_initializer, - kernel_regularizer=kernel_regularizer, - bias_regularizer=bias_regularizer, - activity_regularizer=activity_regularizer, - kernel_constraint=kernel_constraint, - bias_constraint=bias_constraint, - trainable=trainable, - name=name, - **kwargs) - self.use_weight_standardization = use_weight_standardization - - def call(self, inputs): - if self.use_weight_standardization: - mean, var = tf.nn.moments(self.kernel, [0, 1, 2], keep_dims=True) - kernel = (self.kernel - mean) / tf.sqrt(var + 1e-5) - outputs = self._convolution_op(inputs, kernel) - else: - outputs = self._convolution_op(inputs, self.kernel) - - if self.use_bias: - if self.data_format == 'channels_first': - if self.rank == 1: - # tf.nn.bias_add does not accept a 1D input tensor. - bias = tf.reshape(self.bias, (1, self.filters, 1)) - outputs += bias - else: - outputs = tf.nn.bias_add(outputs, self.bias, data_format='NCHW') - else: - outputs = tf.nn.bias_add(outputs, self.bias, data_format='NHWC') - - if self.activation is not None: - return self.activation(outputs) - return outputs - - -@contrib_framework.add_arg_scope -def conv2d(inputs, - num_outputs, - kernel_size, - stride=1, - padding='SAME', - data_format=None, - rate=1, - activation_fn=tf.nn.relu, - normalizer_fn=None, - normalizer_params=None, - weights_initializer=contrib_layers.xavier_initializer(), - weights_regularizer=None, - biases_initializer=tf.zeros_initializer(), - biases_regularizer=None, - use_weight_standardization=False, - reuse=None, - variables_collections=None, - outputs_collections=None, - trainable=True, - scope=None): - """Adds a 2D convolution followed by an optional batch_norm layer. - - `convolution` creates a variable called `weights`, representing the - convolutional kernel, that is convolved (actually cross-correlated) with the - `inputs` to produce a `Tensor` of activations. If a `normalizer_fn` is - provided (such as `batch_norm`), it is then applied. Otherwise, if - `normalizer_fn` is None and a `biases_initializer` is provided then a `biases` - variable would be created and added the activations. Finally, if - `activation_fn` is not `None`, it is applied to the activations as well. - - Performs atrous convolution with input stride/dilation rate equal to `rate` - if a value > 1 for any dimension of `rate` is specified. In this case - `stride` values != 1 are not supported. - - Args: - inputs: A Tensor of rank N+2 of shape `[batch_size] + input_spatial_shape + - [in_channels]` if data_format does not start with "NC" (default), or - `[batch_size, in_channels] + input_spatial_shape` if data_format starts - with "NC". - num_outputs: Integer, the number of output filters. - kernel_size: A sequence of N positive integers specifying the spatial - dimensions of the filters. Can be a single integer to specify the same - value for all spatial dimensions. - stride: A sequence of N positive integers specifying the stride at which to - compute output. Can be a single integer to specify the same value for all - spatial dimensions. Specifying any `stride` value != 1 is incompatible - with specifying any `rate` value != 1. - padding: One of `"VALID"` or `"SAME"`. - data_format: A string or None. Specifies whether the channel dimension of - the `input` and output is the last dimension (default, or if `data_format` - does not start with "NC"), or the second dimension (if `data_format` - starts with "NC"). For N=1, the valid values are "NWC" (default) and - "NCW". For N=2, the valid values are "NHWC" (default) and "NCHW". For - N=3, the valid values are "NDHWC" (default) and "NCDHW". - rate: A sequence of N positive integers specifying the dilation rate to use - for atrous convolution. Can be a single integer to specify the same value - for all spatial dimensions. Specifying any `rate` value != 1 is - incompatible with specifying any `stride` value != 1. - activation_fn: Activation function. The default value is a ReLU function. - Explicitly set it to None to skip it and maintain a linear activation. - normalizer_fn: Normalization function to use instead of `biases`. If - `normalizer_fn` is provided then `biases_initializer` and - `biases_regularizer` are ignored and `biases` are not created nor added. - default set to None for no normalizer function - normalizer_params: Normalization function parameters. - weights_initializer: An initializer for the weights. - weights_regularizer: Optional regularizer for the weights. - biases_initializer: An initializer for the biases. If None skip biases. - biases_regularizer: Optional regularizer for the biases. - use_weight_standardization: Boolean, whether the layer uses weight - standardization. - reuse: Whether or not the layer and its variables should be reused. To be - able to reuse the layer scope must be given. - variables_collections: Optional list of collections for all the variables or - a dictionary containing a different list of collection per variable. - outputs_collections: Collection to add the outputs. - trainable: If `True` also add variables to the graph collection - `GraphKeys.TRAINABLE_VARIABLES` (see tf.Variable). - scope: Optional scope for `variable_scope`. - - Returns: - A tensor representing the output of the operation. - - Raises: - ValueError: If `data_format` is invalid. - ValueError: Both 'rate' and `stride` are not uniformly 1. - """ - if data_format not in [None, 'NWC', 'NCW', 'NHWC', 'NCHW', 'NDHWC', 'NCDHW']: - raise ValueError('Invalid data_format: %r' % (data_format,)) - - # pylint: disable=protected-access - layer_variable_getter = layers._build_variable_getter({ - 'bias': 'biases', - 'kernel': 'weights' - }) - # pylint: enable=protected-access - with tf.variable_scope( - scope, 'Conv', [inputs], reuse=reuse, - custom_getter=layer_variable_getter) as sc: - inputs = tf.convert_to_tensor(inputs) - input_rank = inputs.get_shape().ndims - - if input_rank != 4: - raise ValueError('Convolution expects input with rank %d, got %d' % - (4, input_rank)) - - data_format = ('channels_first' if data_format and - data_format.startswith('NC') else 'channels_last') - layer = Conv2D( - filters=num_outputs, - kernel_size=kernel_size, - strides=stride, - padding=padding, - data_format=data_format, - dilation_rate=rate, - activation=None, - use_bias=not normalizer_fn and biases_initializer, - kernel_initializer=weights_initializer, - bias_initializer=biases_initializer, - kernel_regularizer=weights_regularizer, - bias_regularizer=biases_regularizer, - use_weight_standardization=use_weight_standardization, - activity_regularizer=None, - trainable=trainable, - name=sc.name, - dtype=inputs.dtype.base_dtype, - _scope=sc, - _reuse=reuse) - outputs = layer.apply(inputs) - - # Add variables to collections. - # pylint: disable=protected-access - layers._add_variable_to_collections(layer.kernel, variables_collections, - 'weights') - if layer.use_bias: - layers._add_variable_to_collections(layer.bias, variables_collections, - 'biases') - # pylint: enable=protected-access - if normalizer_fn is not None: - normalizer_params = normalizer_params or {} - outputs = normalizer_fn(outputs, **normalizer_params) - - if activation_fn is not None: - outputs = activation_fn(outputs) - return utils.collect_named_outputs(outputs_collections, sc.name, outputs) - - -def conv2d_same(inputs, num_outputs, kernel_size, stride, rate=1, scope=None): - """Strided 2-D convolution with 'SAME' padding. - - When stride > 1, then we do explicit zero-padding, followed by conv2d with - 'VALID' padding. - - Note that - - net = conv2d_same(inputs, num_outputs, 3, stride=stride) - - is equivalent to - - net = conv2d(inputs, num_outputs, 3, stride=1, padding='SAME') - net = subsample(net, factor=stride) - - whereas - - net = conv2d(inputs, num_outputs, 3, stride=stride, padding='SAME') - - is different when the input's height or width is even, which is why we add the - current function. For more details, see ResnetUtilsTest.testConv2DSameEven(). - - Args: - inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. - num_outputs: An integer, the number of output filters. - kernel_size: An int with the kernel_size of the filters. - stride: An integer, the output stride. - rate: An integer, rate for atrous convolution. - scope: Scope. - - Returns: - output: A 4-D tensor of size [batch, height_out, width_out, channels] with - the convolution output. - """ - if stride == 1: - return conv2d( - inputs, - num_outputs, - kernel_size, - stride=1, - rate=rate, - padding='SAME', - scope=scope) - else: - kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) - pad_total = kernel_size_effective - 1 - pad_beg = pad_total // 2 - pad_end = pad_total - pad_beg - inputs = tf.pad(inputs, - [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]]) - return conv2d( - inputs, - num_outputs, - kernel_size, - stride=stride, - rate=rate, - padding='VALID', - scope=scope) diff --git a/research/deeplab/core/conv2d_ws_test.py b/research/deeplab/core/conv2d_ws_test.py deleted file mode 100644 index b6bea85ee034779ff5bf87b88cd912aa8dc863f2..0000000000000000000000000000000000000000 --- a/research/deeplab/core/conv2d_ws_test.py +++ /dev/null @@ -1,420 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for conv2d_ws.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers -from deeplab.core import conv2d_ws - - -class ConvolutionTest(tf.test.TestCase): - - def testInvalidShape(self): - with self.cached_session(): - images_3d = tf.random_uniform((5, 6, 7, 9, 3), seed=1) - with self.assertRaisesRegexp( - ValueError, 'Convolution expects input with rank 4, got 5'): - conv2d_ws.conv2d(images_3d, 32, 3) - - def testInvalidDataFormat(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.assertRaisesRegexp(ValueError, 'data_format'): - conv2d_ws.conv2d(images, 32, 3, data_format='CHWN') - - def testCreateConv(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, height, width, 4)).astype(np.float32) - output = conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateConvWithWS(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, height, width, 4)).astype(np.float32) - output = conv2d_ws.conv2d( - images, 32, [3, 3], use_weight_standardization=True) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateConvNCHW(self): - height, width = 7, 9 - with self.cached_session(): - images = np.random.uniform(size=(5, 4, height, width)).astype(np.float32) - output = conv2d_ws.conv2d(images, 32, [3, 3], data_format='NCHW') - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, 32, height, width]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 3, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateSquareConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, 3) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - - def testCreateConvWithTensorShape(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, images.get_shape()[1:3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - - def testCreateFullyConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - output = conv2d_ws.conv2d( - images, 64, images.get_shape()[1:3], padding='VALID') - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, 1, 1, 64]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [64]) - - def testFullyConvWithCustomGetter(self): - height, width = 7, 9 - with self.cached_session(): - called = [0] - - def custom_getter(getter, *args, **kwargs): - called[0] += 1 - return getter(*args, **kwargs) - - with tf.variable_scope('test', custom_getter=custom_getter): - images = tf.random_uniform((5, height, width, 32), seed=1) - conv2d_ws.conv2d(images, 64, images.get_shape()[1:3]) - self.assertEqual(called[0], 2) # Custom getter called twice. - - def testCreateVerticalConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 4), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 1]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [3, 1, 4, 32]) - biases = contrib_framework.get_variables_by_name('biases')[0] - self.assertListEqual(biases.get_shape().as_list(), [32]) - - def testCreateHorizontalConv(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 4), seed=1) - output = conv2d_ws.conv2d(images, 32, [1, 3]) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), [5, height, width, 32]) - weights = contrib_framework.get_variables_by_name('weights')[0] - self.assertListEqual(weights.get_shape().as_list(), [1, 3, 4, 32]) - - def testCreateConvWithStride(self): - height, width = 6, 8 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], stride=2) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), - [5, height / 2, width / 2, 32]) - - def testCreateConvCreatesWeightsAndBiasesVars(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.cached_session(): - self.assertFalse(contrib_framework.get_variables('conv1/weights')) - self.assertFalse(contrib_framework.get_variables('conv1/biases')) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertTrue(contrib_framework.get_variables('conv1/weights')) - self.assertTrue(contrib_framework.get_variables('conv1/biases')) - - def testCreateConvWithScope(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(output.op.name, 'conv1/Relu') - - def testCreateConvWithCollection(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with tf.name_scope('fe'): - conv = conv2d_ws.conv2d( - images, 32, [3, 3], outputs_collections='outputs', scope='Conv') - output_collected = tf.get_collection('outputs')[0] - self.assertEqual(output_collected.aliases, ['Conv']) - self.assertEqual(output_collected, conv) - - def testCreateConvWithoutActivation(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], activation_fn=None) - self.assertEqual(output.op.name, 'Conv/BiasAdd') - - def testCreateConvValid(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - output = conv2d_ws.conv2d(images, 32, [3, 3], padding='VALID') - self.assertListEqual(output.get_shape().as_list(), [5, 5, 7, 32]) - - def testCreateConvWithWD(self): - height, width = 7, 9 - weight_decay = 0.01 - with self.cached_session() as sess: - images = tf.random_uniform((5, height, width, 3), seed=1) - regularizer = contrib_layers.l2_regularizer(weight_decay) - conv2d_ws.conv2d(images, 32, [3, 3], weights_regularizer=regularizer) - l2_loss = tf.nn.l2_loss( - contrib_framework.get_variables_by_name('weights')[0]) - wd = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)[0] - self.assertEqual(wd.op.name, 'Conv/kernel/Regularizer/l2_regularizer') - sess.run(tf.global_variables_initializer()) - self.assertAlmostEqual(sess.run(wd), weight_decay * l2_loss.eval()) - - def testCreateConvNoRegularizers(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual( - tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES), []) - - def testReuseVars(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(len(contrib_framework.get_variables()), 2) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 2) - - def testNonReuseVars(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 2) - conv2d_ws.conv2d(images, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 4) - - def testReuseConvWithWD(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 3), seed=1) - weight_decay = contrib_layers.l2_regularizer(0.01) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - weights_regularizer=weight_decay): - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1') - self.assertEqual(len(contrib_framework.get_variables()), 2) - self.assertEqual( - len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1) - conv2d_ws.conv2d(images, 32, [3, 3], scope='conv1', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 2) - self.assertEqual( - len(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)), 1) - - def testConvWithBatchNorm(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - normalizer_fn=contrib_layers.batch_norm, - normalizer_params={'decay': 0.9}): - net = conv2d_ws.conv2d(images, 32, [3, 3]) - net = conv2d_ws.conv2d(net, 32, [3, 3]) - self.assertEqual(len(contrib_framework.get_variables()), 8) - self.assertEqual( - len(contrib_framework.get_variables('Conv/BatchNorm')), 3) - self.assertEqual( - len(contrib_framework.get_variables('Conv_1/BatchNorm')), 3) - - def testReuseConvWithBatchNorm(self): - height, width = 7, 9 - with self.cached_session(): - images = tf.random_uniform((5, height, width, 32), seed=1) - with contrib_framework.arg_scope([conv2d_ws.conv2d], - normalizer_fn=contrib_layers.batch_norm, - normalizer_params={'decay': 0.9}): - net = conv2d_ws.conv2d(images, 32, [3, 3], scope='Conv') - net = conv2d_ws.conv2d(net, 32, [3, 3], scope='Conv', reuse=True) - self.assertEqual(len(contrib_framework.get_variables()), 4) - self.assertEqual( - len(contrib_framework.get_variables('Conv/BatchNorm')), 3) - self.assertEqual( - len(contrib_framework.get_variables('Conv_1/BatchNorm')), 0) - - def testCreateConvCreatesWeightsAndBiasesVarsWithRateTwo(self): - height, width = 7, 9 - images = tf.random_uniform((5, height, width, 3), seed=1) - with self.cached_session(): - self.assertFalse(contrib_framework.get_variables('conv1/weights')) - self.assertFalse(contrib_framework.get_variables('conv1/biases')) - conv2d_ws.conv2d(images, 32, [3, 3], rate=2, scope='conv1') - self.assertTrue(contrib_framework.get_variables('conv1/weights')) - self.assertTrue(contrib_framework.get_variables('conv1/biases')) - - def testOutputSizeWithRateTwoSamePadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 10, 12, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='SAME') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testOutputSizeWithRateTwoValidPadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 6, 8, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testOutputSizeWithRateTwoThreeValidPadding(self): - num_filters = 32 - input_size = [5, 10, 12, 3] - expected_size = [5, 6, 6, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=[2, 3], padding='VALID') - self.assertListEqual(list(output.get_shape().as_list()), expected_size) - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testDynamicOutputSizeWithRateOneValidPadding(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [None, None, None, num_filters] - expected_size_dynamic = [5, 7, 9, num_filters] - - with self.cached_session(): - images = tf.placeholder(np.float32, [None, None, None, input_size[3]]) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=1, padding='VALID') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testDynamicOutputSizeWithRateOneValidPaddingNCHW(self): - if tf.test.is_gpu_available(cuda_only=True): - num_filters = 32 - input_size = [5, 3, 9, 11] - expected_size = [None, num_filters, None, None] - expected_size_dynamic = [5, num_filters, 7, 9] - - with self.session(use_gpu=True): - images = tf.placeholder(np.float32, [None, input_size[1], None, None]) - output = conv2d_ws.conv2d( - images, - num_filters, [3, 3], - rate=1, - padding='VALID', - data_format='NCHW') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testDynamicOutputSizeWithRateTwoValidPadding(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [None, None, None, num_filters] - expected_size_dynamic = [5, 5, 7, num_filters] - - with self.cached_session(): - images = tf.placeholder(np.float32, [None, None, None, input_size[3]]) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID') - tf.global_variables_initializer().run() - self.assertEqual(output.op.name, 'Conv/Relu') - self.assertListEqual(output.get_shape().as_list(), expected_size) - eval_output = output.eval({images: np.zeros(input_size, np.float32)}) - self.assertListEqual(list(eval_output.shape), expected_size_dynamic) - - def testWithScope(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [5, 5, 7, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, num_filters, [3, 3], rate=2, padding='VALID', scope='conv7') - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'conv7/Relu') - self.assertListEqual(list(output.eval().shape), expected_size) - - def testWithScopeWithoutActivation(self): - num_filters = 32 - input_size = [5, 9, 11, 3] - expected_size = [5, 5, 7, num_filters] - - images = tf.random_uniform(input_size, seed=1) - output = conv2d_ws.conv2d( - images, - num_filters, [3, 3], - rate=2, - padding='VALID', - activation_fn=None, - scope='conv7') - with self.cached_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertEqual(output.op.name, 'conv7/BiasAdd') - self.assertListEqual(list(output.eval().shape), expected_size) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/dense_prediction_cell.py b/research/deeplab/core/dense_prediction_cell.py deleted file mode 100644 index 8e32f8e227f0841d51df780618523a53c5eb4ae3..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell.py +++ /dev/null @@ -1,290 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Dense Prediction Cell class that can be evolved in semantic segmentation. - -DensePredictionCell is used as a `layer` in semantic segmentation whose -architecture is determined by the `config`, a dictionary specifying -the architecture. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import utils - -slim = contrib_slim - -# Local constants. -_META_ARCHITECTURE_SCOPE = 'meta_architecture' -_CONCAT_PROJECTION_SCOPE = 'concat_projection' -_OP = 'op' -_CONV = 'conv' -_PYRAMID_POOLING = 'pyramid_pooling' -_KERNEL = 'kernel' -_RATE = 'rate' -_GRID_SIZE = 'grid_size' -_TARGET_SIZE = 'target_size' -_INPUT = 'input' - - -def dense_prediction_cell_hparams(): - """DensePredictionCell HParams. - - Returns: - A dictionary of hyper-parameters used for dense prediction cell with keys: - - reduction_size: Integer, the number of output filters for each operation - inside the cell. - - dropout_on_concat_features: Boolean, apply dropout on the concatenated - features or not. - - dropout_on_projection_features: Boolean, apply dropout on the projection - features or not. - - dropout_keep_prob: Float, when `dropout_on_concat_features' or - `dropout_on_projection_features' is True, the `keep_prob` value used - in the dropout operation. - - concat_channels: Integer, the concatenated features will be - channel-reduced to `concat_channels` channels. - - conv_rate_multiplier: Integer, used to multiply the convolution rates. - This is useful in the case when the output_stride is changed from 16 - to 8, we need to double the convolution rates correspondingly. - """ - return { - 'reduction_size': 256, - 'dropout_on_concat_features': True, - 'dropout_on_projection_features': False, - 'dropout_keep_prob': 0.9, - 'concat_channels': 256, - 'conv_rate_multiplier': 1, - } - - -class DensePredictionCell(object): - """DensePredictionCell class used as a 'layer' in semantic segmentation.""" - - def __init__(self, config, hparams=None): - """Initializes the dense prediction cell. - - Args: - config: A dictionary storing the architecture of a dense prediction cell. - hparams: A dictionary of hyper-parameters, provided by users. This - dictionary will be used to update the default dictionary returned by - dense_prediction_cell_hparams(). - - Raises: - ValueError: If `conv_rate_multiplier` has value < 1. - """ - self.hparams = dense_prediction_cell_hparams() - if hparams is not None: - self.hparams.update(hparams) - self.config = config - - # Check values in hparams are valid or not. - if self.hparams['conv_rate_multiplier'] < 1: - raise ValueError('conv_rate_multiplier cannot have value < 1.') - - def _get_pyramid_pooling_arguments( - self, crop_size, output_stride, image_grid, image_pooling_crop_size=None): - """Gets arguments for pyramid pooling. - - Args: - crop_size: A list of two integers, [crop_height, crop_width] specifying - whole patch crop size. - output_stride: Integer, output stride value for extracted features. - image_grid: A list of two integers, [image_grid_height, image_grid_width], - specifying the grid size of how the pyramid pooling will be performed. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - - Returns: - A list of (resize_value, pooled_kernel) - """ - resize_height = utils.scale_dimension(crop_size[0], 1. / output_stride) - resize_width = utils.scale_dimension(crop_size[1], 1. / output_stride) - # If image_pooling_crop_size is not specified, use crop_size. - if image_pooling_crop_size is None: - image_pooling_crop_size = crop_size - pooled_height = utils.scale_dimension( - image_pooling_crop_size[0], 1. / (output_stride * image_grid[0])) - pooled_width = utils.scale_dimension( - image_pooling_crop_size[1], 1. / (output_stride * image_grid[1])) - return ([resize_height, resize_width], [pooled_height, pooled_width]) - - def _parse_operation(self, config, crop_size, output_stride, - image_pooling_crop_size=None): - """Parses one operation. - - When 'operation' is 'pyramid_pooling', we compute the required - hyper-parameters and save in config. - - Args: - config: A dictionary storing required hyper-parameters for one - operation. - crop_size: A list of two integers, [crop_height, crop_width] specifying - whole patch crop size. - output_stride: Integer, output stride value for extracted features. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - - Returns: - A dictionary stores the related information for the operation. - """ - if config[_OP] == _PYRAMID_POOLING: - (config[_TARGET_SIZE], - config[_KERNEL]) = self._get_pyramid_pooling_arguments( - crop_size=crop_size, - output_stride=output_stride, - image_grid=config[_GRID_SIZE], - image_pooling_crop_size=image_pooling_crop_size) - - return config - - def build_cell(self, - features, - output_stride=16, - crop_size=None, - image_pooling_crop_size=None, - weight_decay=0.00004, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - scope=None): - """Builds the dense prediction cell based on the config. - - Args: - features: Input feature map of size [batch, height, width, channels]. - output_stride: Int, output stride at which the features were extracted. - crop_size: A list [crop_height, crop_width], determining the input - features resolution. - image_pooling_crop_size: A list of two integers, [crop_height, crop_width] - specifying the crop size for image pooling operations. Note that we - decouple whole patch crop_size and image_pooling_crop_size as one could - perform the image_pooling with different crop sizes. - weight_decay: Float, the weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Boolean, is training or not. - fine_tune_batch_norm: Boolean, fine-tuning batch norm parameters or not. - scope: Optional string, specifying the variable scope. - - Returns: - Features after passing through the constructed dense prediction cell with - shape = [batch, height, width, channels] where channels are determined - by `reduction_size` returned by dense_prediction_cell_hparams(). - - Raises: - ValueError: Use Convolution with kernel size not equal to 1x1 or 3x3 or - the operation is not recognized. - """ - batch_norm_params = { - 'is_training': is_training and fine_tune_batch_norm, - 'decay': 0.9997, - 'epsilon': 1e-5, - 'scale': True, - } - hparams = self.hparams - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=tf.nn.relu, - normalizer_fn=slim.batch_norm, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([slim.batch_norm], **batch_norm_params): - with tf.variable_scope(scope, _META_ARCHITECTURE_SCOPE, [features]): - depth = hparams['reduction_size'] - branch_logits = [] - for i, current_config in enumerate(self.config): - scope = 'branch%d' % i - current_config = self._parse_operation( - config=current_config, - crop_size=crop_size, - output_stride=output_stride, - image_pooling_crop_size=image_pooling_crop_size) - tf.logging.info(current_config) - if current_config[_INPUT] < 0: - operation_input = features - else: - operation_input = branch_logits[current_config[_INPUT]] - if current_config[_OP] == _CONV: - if current_config[_KERNEL] == [1, 1] or current_config[ - _KERNEL] == 1: - branch_logits.append( - slim.conv2d(operation_input, depth, 1, scope=scope)) - else: - conv_rate = [r * hparams['conv_rate_multiplier'] - for r in current_config[_RATE]] - branch_logits.append( - utils.split_separable_conv2d( - operation_input, - filters=depth, - kernel_size=current_config[_KERNEL], - rate=conv_rate, - weight_decay=weight_decay, - scope=scope)) - elif current_config[_OP] == _PYRAMID_POOLING: - pooled_features = slim.avg_pool2d( - operation_input, - kernel_size=current_config[_KERNEL], - stride=[1, 1], - padding='VALID') - pooled_features = slim.conv2d( - pooled_features, - depth, - 1, - scope=scope) - pooled_features = tf.image.resize_bilinear( - pooled_features, - current_config[_TARGET_SIZE], - align_corners=True) - # Set shape for resize_height/resize_width if they are not Tensor. - resize_height = current_config[_TARGET_SIZE][0] - resize_width = current_config[_TARGET_SIZE][1] - if isinstance(resize_height, tf.Tensor): - resize_height = None - if isinstance(resize_width, tf.Tensor): - resize_width = None - pooled_features.set_shape( - [None, resize_height, resize_width, depth]) - branch_logits.append(pooled_features) - else: - raise ValueError('Unrecognized operation.') - # Merge branch logits. - concat_logits = tf.concat(branch_logits, 3) - if self.hparams['dropout_on_concat_features']: - concat_logits = slim.dropout( - concat_logits, - keep_prob=self.hparams['dropout_keep_prob'], - is_training=is_training, - scope=_CONCAT_PROJECTION_SCOPE + '_dropout') - concat_logits = slim.conv2d(concat_logits, - self.hparams['concat_channels'], - 1, - scope=_CONCAT_PROJECTION_SCOPE) - if self.hparams['dropout_on_projection_features']: - concat_logits = slim.dropout( - concat_logits, - keep_prob=self.hparams['dropout_keep_prob'], - is_training=is_training, - scope=_CONCAT_PROJECTION_SCOPE + '_dropout') - return concat_logits diff --git a/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json b/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json deleted file mode 100644 index 12b093d07d1a696258cae7eaf4d793978433a69f..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json +++ /dev/null @@ -1 +0,0 @@ -[{"kernel": 3, "rate": [1, 6], "op": "conv", "input": -1}, {"kernel": 3, "rate": [18, 15], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 3], "op": "conv", "input": 1}, {"kernel": 3, "rate": [1, 1], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 21], "op": "conv", "input": 0}] \ No newline at end of file diff --git a/research/deeplab/core/dense_prediction_cell_test.py b/research/deeplab/core/dense_prediction_cell_test.py deleted file mode 100644 index 1396a73626d90c5da1db3b187c5a927a0c9eeb11..0000000000000000000000000000000000000000 --- a/research/deeplab/core/dense_prediction_cell_test.py +++ /dev/null @@ -1,136 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for dense_prediction_cell.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import tensorflow as tf - -from deeplab.core import dense_prediction_cell - - -class DensePredictionCellTest(tf.test.TestCase): - - def setUp(self): - self.segmentation_layer = dense_prediction_cell.DensePredictionCell( - config=[ - { - dense_prediction_cell._INPUT: -1, - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: 1, - }, - { - dense_prediction_cell._INPUT: 0, - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: 3, - dense_prediction_cell._RATE: [1, 3], - }, - { - dense_prediction_cell._INPUT: 1, - dense_prediction_cell._OP: ( - dense_prediction_cell._PYRAMID_POOLING), - dense_prediction_cell._GRID_SIZE: [1, 2], - }, - ], - hparams={'conv_rate_multiplier': 2}) - - def testPyramidPoolingArguments(self): - features_size, pooled_kernel = ( - self.segmentation_layer._get_pyramid_pooling_arguments( - crop_size=[513, 513], - output_stride=16, - image_grid=[4, 4])) - self.assertListEqual(features_size, [33, 33]) - self.assertListEqual(pooled_kernel, [9, 9]) - - def testPyramidPoolingArgumentsWithImageGrid1x1(self): - features_size, pooled_kernel = ( - self.segmentation_layer._get_pyramid_pooling_arguments( - crop_size=[257, 257], - output_stride=16, - image_grid=[1, 1])) - self.assertListEqual(features_size, [17, 17]) - self.assertListEqual(pooled_kernel, [17, 17]) - - def testParseOperationStringWithConv1x1(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: [1, 1], - }, - crop_size=[513, 513], output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._CONV) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [1, 1]) - - def testParseOperationStringWithConv3x3(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._CONV, - dense_prediction_cell._KERNEL: [3, 3], - dense_prediction_cell._RATE: [9, 6], - }, - crop_size=[513, 513], output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._CONV) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [3, 3]) - self.assertEqual(operation[dense_prediction_cell._RATE], [9, 6]) - - def testParseOperationStringWithPyramidPooling2x2(self): - operation = self.segmentation_layer._parse_operation( - config={ - dense_prediction_cell._OP: dense_prediction_cell._PYRAMID_POOLING, - dense_prediction_cell._GRID_SIZE: [2, 2], - }, - crop_size=[513, 513], - output_stride=16) - self.assertEqual(operation[dense_prediction_cell._OP], - dense_prediction_cell._PYRAMID_POOLING) - # The feature maps of size [33, 33] should be covered by 2x2 kernels with - # size [17, 17]. - self.assertListEqual( - operation[dense_prediction_cell._TARGET_SIZE], [33, 33]) - self.assertListEqual(operation[dense_prediction_cell._KERNEL], [17, 17]) - - def testBuildCell(self): - with self.test_session(graph=tf.Graph()) as sess: - features = tf.random_normal([2, 33, 33, 5]) - concat_logits = self.segmentation_layer.build_cell( - features, - output_stride=8, - crop_size=[257, 257]) - sess.run(tf.global_variables_initializer()) - concat_logits = sess.run(concat_logits) - self.assertTrue(concat_logits.any()) - - def testBuildCellWithImagePoolingCropSize(self): - with self.test_session(graph=tf.Graph()) as sess: - features = tf.random_normal([2, 33, 33, 5]) - concat_logits = self.segmentation_layer.build_cell( - features, - output_stride=8, - crop_size=[257, 257], - image_pooling_crop_size=[129, 129]) - sess.run(tf.global_variables_initializer()) - concat_logits = sess.run(concat_logits) - self.assertTrue(concat_logits.any()) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/feature_extractor.py b/research/deeplab/core/feature_extractor.py deleted file mode 100644 index 553bd9b6a7393dd7f3e0ebce80302919215a9bfe..0000000000000000000000000000000000000000 --- a/research/deeplab/core/feature_extractor.py +++ /dev/null @@ -1,711 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Extracts features for different models.""" -import copy -import functools - -import tensorflow.compat.v1 as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import nas_network -from deeplab.core import resnet_v1_beta -from deeplab.core import xception -from nets.mobilenet import conv_blocks -from nets.mobilenet import mobilenet -from nets.mobilenet import mobilenet_v2 -from nets.mobilenet import mobilenet_v3 - -slim = contrib_slim - -# Default end point for MobileNetv2 (one-based indexing). -_MOBILENET_V2_FINAL_ENDPOINT = 'layer_18' -# Default end point for MobileNetv3. -_MOBILENET_V3_LARGE_FINAL_ENDPOINT = 'layer_17' -_MOBILENET_V3_SMALL_FINAL_ENDPOINT = 'layer_13' -# Default end point for EdgeTPU Mobilenet. -_MOBILENET_EDGETPU = 'layer_24' - - -def _mobilenet_v2(net, - depth_multiplier, - output_stride, - conv_defs=None, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Auxiliary function to add support for 'reuse' to mobilenet_v2. - - Args: - net: Input tensor of shape [batch_size, height, width, channels]. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops. The value must be greater than zero. Typical - usage will be to set this value in (0, 1) to reduce the number of - parameters or computation cost of the model. - output_stride: An integer that specifies the requested ratio of input to - output spatial resolution. If not None, then we invoke atrous convolution - if necessary to prevent the network from reducing the spatial resolution - of the activation maps. Allowed values are 8 (accurate fully convolutional - mode), 16 (fast fully convolutional mode), 32 (classification mode). - conv_defs: MobileNet con def. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - reuse: Reuse model variables. - scope: Optional variable scope. - final_endpoint: The endpoint to construct the network up to. - - Returns: - Features extracted by MobileNetv2. - """ - if divisible_by is None: - divisible_by = 8 if depth_multiplier == 1.0 else 1 - if conv_defs is None: - conv_defs = mobilenet_v2.V2_DEF - with tf.variable_scope( - scope, 'MobilenetV2', [net], reuse=reuse) as scope: - return mobilenet_v2.mobilenet_base( - net, - conv_defs=conv_defs, - depth_multiplier=depth_multiplier, - min_depth=8 if depth_multiplier == 1.0 else 1, - divisible_by=divisible_by, - final_endpoint=final_endpoint or _MOBILENET_V2_FINAL_ENDPOINT, - output_stride=output_stride, - scope=scope) - - -def _mobilenet_v3(net, - depth_multiplier, - output_stride, - conv_defs=None, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Auxiliary function to build mobilenet v3. - - Args: - net: Input tensor of shape [batch_size, height, width, channels]. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops. The value must be greater than zero. Typical - usage will be to set this value in (0, 1) to reduce the number of - parameters or computation cost of the model. - output_stride: An integer that specifies the requested ratio of input to - output spatial resolution. If not None, then we invoke atrous convolution - if necessary to prevent the network from reducing the spatial resolution - of the activation maps. Allowed values are 8 (accurate fully convolutional - mode), 16 (fast fully convolutional mode), 32 (classification mode). - conv_defs: A list of ConvDef namedtuples specifying the net architecture. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - reuse: Reuse model variables. - scope: Optional variable scope. - final_endpoint: The endpoint to construct the network up to. - - Returns: - net: The output tensor. - end_points: A set of activations for external use. - - Raises: - ValueError: If conv_defs or final_endpoint is not specified. - """ - del divisible_by - with tf.variable_scope( - scope, 'MobilenetV3', [net], reuse=reuse) as scope: - if conv_defs is None: - raise ValueError('conv_defs must be specified for mobilenet v3.') - if final_endpoint is None: - raise ValueError('Final endpoint must be specified for mobilenet v3.') - net, end_points = mobilenet_v3.mobilenet_base( - net, - depth_multiplier=depth_multiplier, - conv_defs=conv_defs, - output_stride=output_stride, - final_endpoint=final_endpoint, - scope=scope) - - return net, end_points - - -def mobilenet_v3_large_seg(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Final mobilenet v3 large model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_LARGE) - - # Reduce the filters by a factor of 2 in the last block. - for layer, expansion in [(13, 336), (14, 480), (15, 480), (16, None)]: - conv_defs['spec'][layer].params['num_outputs'] /= 2 - # Update expansion size - if expansion is not None: - factor = expansion / conv_defs['spec'][layer - 1].params['num_outputs'] - conv_defs['spec'][layer].params[ - 'expansion_size'] = mobilenet_v3.expand_input(factor) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, - final_endpoint=_MOBILENET_V3_LARGE_FINAL_ENDPOINT) - - -def mobilenet_edgetpu(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """EdgeTPU version of mobilenet model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_EDGETPU) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, # the scope is 'MobilenetEdgeTPU' - final_endpoint=_MOBILENET_EDGETPU) - - -def mobilenet_v3_small_seg(net, - depth_multiplier, - output_stride, - divisible_by=None, - reuse=None, - scope=None, - final_endpoint=None): - """Final mobilenet v3 small model for segmentation task.""" - del divisible_by - del final_endpoint - conv_defs = copy.deepcopy(mobilenet_v3.V3_SMALL) - - # Reduce the filters by a factor of 2 in the last block. - for layer, expansion in [(9, 144), (10, 288), (11, 288), (12, None)]: - conv_defs['spec'][layer].params['num_outputs'] /= 2 - # Update expansion size - if expansion is not None: - factor = expansion / conv_defs['spec'][layer - 1].params['num_outputs'] - conv_defs['spec'][layer].params[ - 'expansion_size'] = mobilenet_v3.expand_input(factor) - - return _mobilenet_v3( - net, - depth_multiplier=depth_multiplier, - output_stride=output_stride, - divisible_by=8, - conv_defs=conv_defs, - reuse=reuse, - scope=scope, - final_endpoint=_MOBILENET_V3_SMALL_FINAL_ENDPOINT) - - -# A map from network name to network function. -networks_map = { - 'mobilenet_v2': _mobilenet_v2, - 'mobilenet_edgetpu': mobilenet_edgetpu, - 'mobilenet_v3_large_seg': mobilenet_v3_large_seg, - 'mobilenet_v3_small_seg': mobilenet_v3_small_seg, - 'resnet_v1_18': resnet_v1_beta.resnet_v1_18, - 'resnet_v1_18_beta': resnet_v1_beta.resnet_v1_18_beta, - 'resnet_v1_50': resnet_v1_beta.resnet_v1_50, - 'resnet_v1_50_beta': resnet_v1_beta.resnet_v1_50_beta, - 'resnet_v1_101': resnet_v1_beta.resnet_v1_101, - 'resnet_v1_101_beta': resnet_v1_beta.resnet_v1_101_beta, - 'xception_41': xception.xception_41, - 'xception_65': xception.xception_65, - 'xception_71': xception.xception_71, - 'nas_pnasnet': nas_network.pnasnet, - 'nas_hnasnet': nas_network.hnasnet, -} - - -def mobilenet_v2_arg_scope(is_training=True, - weight_decay=0.00004, - stddev=0.09, - activation=tf.nn.relu6, - bn_decay=0.997, - bn_epsilon=None, - bn_renorm=None): - """Defines the default MobilenetV2 arg scope. - - Args: - is_training: Whether or not we're training the model. If this is set to None - is_training parameter in batch_norm is not set. Please note that this also - sets the is_training parameter in dropout to None. - weight_decay: The weight decay to use for regularizing the model. - stddev: Standard deviation for initialization, if negative uses xavier. - activation: If True, a modified activation is used (initialized ~ReLU6). - bn_decay: decay for the batch norm moving averages. - bn_epsilon: batch normalization epsilon. - bn_renorm: whether to use batchnorm renormalization - - Returns: - An `arg_scope` to use for the mobilenet v1 model. - """ - batch_norm_params = { - 'center': True, - 'scale': True, - 'decay': bn_decay, - } - if bn_epsilon is not None: - batch_norm_params['epsilon'] = bn_epsilon - if is_training is not None: - batch_norm_params['is_training'] = is_training - if bn_renorm is not None: - batch_norm_params['renorm'] = bn_renorm - dropout_params = {} - if is_training is not None: - dropout_params['is_training'] = is_training - - instance_norm_params = { - 'center': True, - 'scale': True, - 'epsilon': 0.001, - } - - if stddev < 0: - weight_intitializer = slim.initializers.xavier_initializer() - else: - weight_intitializer = tf.truncated_normal_initializer(stddev=stddev) - - # Set weight_decay for weights in Conv and FC layers. - with slim.arg_scope( - [slim.conv2d, slim.fully_connected, slim.separable_conv2d], - weights_initializer=weight_intitializer, - activation_fn=activation, - normalizer_fn=slim.batch_norm), \ - slim.arg_scope( - [conv_blocks.expanded_conv], normalizer_fn=slim.batch_norm), \ - slim.arg_scope([mobilenet.apply_activation], activation_fn=activation),\ - slim.arg_scope([slim.batch_norm], **batch_norm_params), \ - slim.arg_scope([mobilenet.mobilenet_base, mobilenet.mobilenet], - is_training=is_training),\ - slim.arg_scope([slim.dropout], **dropout_params), \ - slim.arg_scope([slim.instance_norm], **instance_norm_params), \ - slim.arg_scope([slim.conv2d], \ - weights_regularizer=slim.l2_regularizer(weight_decay)), \ - slim.arg_scope([slim.separable_conv2d], weights_regularizer=None), \ - slim.arg_scope([slim.conv2d, slim.separable_conv2d], padding='SAME') as s: - return s - - -# A map from network name to network arg scope. -arg_scopes_map = { - 'mobilenet_v2': mobilenet_v2.training_scope, - 'mobilenet_edgetpu': mobilenet_v2_arg_scope, - 'mobilenet_v3_large_seg': mobilenet_v2_arg_scope, - 'mobilenet_v3_small_seg': mobilenet_v2_arg_scope, - 'resnet_v1_18': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_18_beta': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_50': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_50_beta': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_101': resnet_v1_beta.resnet_arg_scope, - 'resnet_v1_101_beta': resnet_v1_beta.resnet_arg_scope, - 'xception_41': xception.xception_arg_scope, - 'xception_65': xception.xception_arg_scope, - 'xception_71': xception.xception_arg_scope, - 'nas_pnasnet': nas_network.nas_arg_scope, - 'nas_hnasnet': nas_network.nas_arg_scope, -} - -# Names for end point features. -DECODER_END_POINTS = 'decoder_end_points' - -# A dictionary from network name to a map of end point features. -networks_to_feature_maps = { - 'mobilenet_v2': { - DECODER_END_POINTS: { - 4: ['layer_4/depthwise_output'], - 8: ['layer_7/depthwise_output'], - 16: ['layer_14/depthwise_output'], - }, - }, - 'mobilenet_v3_large_seg': { - DECODER_END_POINTS: { - 4: ['layer_4/depthwise_output'], - 8: ['layer_7/depthwise_output'], - 16: ['layer_13/depthwise_output'], - }, - }, - 'mobilenet_v3_small_seg': { - DECODER_END_POINTS: { - 4: ['layer_2/depthwise_output'], - 8: ['layer_4/depthwise_output'], - 16: ['layer_9/depthwise_output'], - }, - }, - 'resnet_v1_18': { - DECODER_END_POINTS: { - 4: ['block1/unit_1/lite_bottleneck_v1/conv2'], - 8: ['block2/unit_1/lite_bottleneck_v1/conv2'], - 16: ['block3/unit_1/lite_bottleneck_v1/conv2'], - }, - }, - 'resnet_v1_18_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_1/lite_bottleneck_v1/conv2'], - 8: ['block2/unit_1/lite_bottleneck_v1/conv2'], - 16: ['block3/unit_1/lite_bottleneck_v1/conv2'], - }, - }, - 'resnet_v1_50': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_5/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_50_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_5/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_101': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_22/bottleneck_v1/conv3'], - }, - }, - 'resnet_v1_101_beta': { - DECODER_END_POINTS: { - 4: ['block1/unit_2/bottleneck_v1/conv3'], - 8: ['block2/unit_3/bottleneck_v1/conv3'], - 16: ['block3/unit_22/bottleneck_v1/conv3'], - }, - }, - 'xception_41': { - DECODER_END_POINTS: { - 4: ['entry_flow/block2/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'xception_65': { - DECODER_END_POINTS: { - 4: ['entry_flow/block2/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'xception_71': { - DECODER_END_POINTS: { - 4: ['entry_flow/block3/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 8: ['entry_flow/block5/unit_1/xception_module/' - 'separable_conv2_pointwise'], - 16: ['exit_flow/block1/unit_1/xception_module/' - 'separable_conv2_pointwise'], - }, - }, - 'nas_pnasnet': { - DECODER_END_POINTS: { - 4: ['Stem'], - 8: ['Cell_3'], - 16: ['Cell_7'], - }, - }, - 'nas_hnasnet': { - DECODER_END_POINTS: { - 4: ['Cell_2'], - 8: ['Cell_5'], - 16: ['Cell_7'], - }, - }, -} - -# A map from feature extractor name to the network name scope used in the -# ImageNet pretrained versions of these models. -name_scope = { - 'mobilenet_v2': 'MobilenetV2', - 'mobilenet_edgetpu': 'MobilenetEdgeTPU', - 'mobilenet_v3_large_seg': 'MobilenetV3', - 'mobilenet_v3_small_seg': 'MobilenetV3', - 'resnet_v1_18': 'resnet_v1_18', - 'resnet_v1_18_beta': 'resnet_v1_18', - 'resnet_v1_50': 'resnet_v1_50', - 'resnet_v1_50_beta': 'resnet_v1_50', - 'resnet_v1_101': 'resnet_v1_101', - 'resnet_v1_101_beta': 'resnet_v1_101', - 'xception_41': 'xception_41', - 'xception_65': 'xception_65', - 'xception_71': 'xception_71', - 'nas_pnasnet': 'pnasnet', - 'nas_hnasnet': 'hnasnet', -} - -# Mean pixel value. -_MEAN_RGB = [123.15, 115.90, 103.06] - - -def _preprocess_subtract_imagenet_mean(inputs, dtype=tf.float32): - """Subtract Imagenet mean RGB value.""" - mean_rgb = tf.reshape(_MEAN_RGB, [1, 1, 1, 3]) - num_channels = tf.shape(inputs)[-1] - # We set mean pixel as 0 for the non-RGB channels. - mean_rgb_extended = tf.concat( - [mean_rgb, tf.zeros([1, 1, 1, num_channels - 3])], axis=3) - return tf.cast(inputs - mean_rgb_extended, dtype=dtype) - - -def _preprocess_zero_mean_unit_range(inputs, dtype=tf.float32): - """Map image values from [0, 255] to [-1, 1].""" - preprocessed_inputs = (2.0 / 255.0) * tf.to_float(inputs) - 1.0 - return tf.cast(preprocessed_inputs, dtype=dtype) - - -_PREPROCESS_FN = { - 'mobilenet_v2': _preprocess_zero_mean_unit_range, - 'mobilenet_edgetpu': _preprocess_zero_mean_unit_range, - 'mobilenet_v3_large_seg': _preprocess_zero_mean_unit_range, - 'mobilenet_v3_small_seg': _preprocess_zero_mean_unit_range, - 'resnet_v1_18': _preprocess_subtract_imagenet_mean, - 'resnet_v1_18_beta': _preprocess_zero_mean_unit_range, - 'resnet_v1_50': _preprocess_subtract_imagenet_mean, - 'resnet_v1_50_beta': _preprocess_zero_mean_unit_range, - 'resnet_v1_101': _preprocess_subtract_imagenet_mean, - 'resnet_v1_101_beta': _preprocess_zero_mean_unit_range, - 'xception_41': _preprocess_zero_mean_unit_range, - 'xception_65': _preprocess_zero_mean_unit_range, - 'xception_71': _preprocess_zero_mean_unit_range, - 'nas_pnasnet': _preprocess_zero_mean_unit_range, - 'nas_hnasnet': _preprocess_zero_mean_unit_range, -} - - -def mean_pixel(model_variant=None): - """Gets mean pixel value. - - This function returns different mean pixel value, depending on the input - model_variant which adopts different preprocessing functions. We currently - handle the following preprocessing functions: - (1) _preprocess_subtract_imagenet_mean. We simply return mean pixel value. - (2) _preprocess_zero_mean_unit_range. We return [127.5, 127.5, 127.5]. - The return values are used in a way that the padded regions after - pre-processing will contain value 0. - - Args: - model_variant: Model variant (string) for feature extraction. For - backwards compatibility, model_variant=None returns _MEAN_RGB. - - Returns: - Mean pixel value. - """ - if model_variant in ['resnet_v1_50', - 'resnet_v1_101'] or model_variant is None: - return _MEAN_RGB - else: - return [127.5, 127.5, 127.5] - - -def extract_features(images, - output_stride=8, - multi_grid=None, - depth_multiplier=1.0, - divisible_by=None, - final_endpoint=None, - model_variant=None, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - regularize_depthwise=False, - preprocess_images=True, - preprocessed_images_dtype=tf.float32, - num_classes=None, - global_pool=False, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - use_bounded_activation=False): - """Extracts features by the particular model_variant. - - Args: - images: A tensor of size [batch, height, width, channels]. - output_stride: The ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - depth_multiplier: Float multiplier for the depth (number of channels) - for all convolution ops used in MobileNet. - divisible_by: None (use default setting) or an integer that ensures all - layers # channels will be divisible by this number. Used in MobileNet. - final_endpoint: The MobileNet endpoint to construct the network up to. - model_variant: Model variant for feature extraction. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - preprocess_images: Performs preprocessing on images or not. Defaults to - True. Set to False if preprocessing will be done by other functions. We - supprot two types of preprocessing: (1) Mean pixel substraction and (2) - Pixel values normalization to be [-1, 1]. - preprocessed_images_dtype: The type after the preprocessing function. - num_classes: Number of classes for image classification task. Defaults - to None for dense prediction tasks. - global_pool: Global pooling for image classification task. Defaults to - False, since dense prediction tasks do not use this. - nas_architecture_options: A dictionary storing NAS architecture options. - It is either None or its kerys are: - - `nas_stem_output_num_conv_filters`: Number of filters of the NAS stem - output tensor. - - `nas_use_classification_head`: Boolean, use image classification head. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. It is either None or its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. Currently, - bounded activation is only used in xception model. - - Returns: - features: A tensor of size [batch, feature_height, feature_width, - feature_channels], where feature_height/feature_width are determined - by the images height/width and output_stride. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: Unrecognized model variant. - """ - if 'resnet' in model_variant: - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.95, - batch_norm_epsilon=1e-5, - batch_norm_scale=True) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - multi_grid=multi_grid, - reuse=reuse, - scope=name_scope[model_variant]) - elif 'xception' in model_variant: - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.9997, - batch_norm_epsilon=1e-3, - batch_norm_scale=True, - regularize_depthwise=regularize_depthwise, - use_bounded_activation=use_bounded_activation) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=name_scope[model_variant]) - elif 'mobilenet' in model_variant or model_variant.startswith('mnas'): - arg_scope = arg_scopes_map[model_variant]( - is_training=(is_training and fine_tune_batch_norm), - weight_decay=weight_decay) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - depth_multiplier=depth_multiplier, - divisible_by=divisible_by, - output_stride=output_stride, - reuse=reuse, - scope=name_scope[model_variant], - final_endpoint=final_endpoint) - elif model_variant.startswith('nas'): - arg_scope = arg_scopes_map[model_variant]( - weight_decay=weight_decay, - batch_norm_decay=0.9997, - batch_norm_epsilon=1e-3) - features, end_points = get_network( - model_variant, preprocess_images, preprocessed_images_dtype, arg_scope)( - inputs=images, - num_classes=num_classes, - is_training=(is_training and fine_tune_batch_norm), - global_pool=global_pool, - output_stride=output_stride, - nas_architecture_options=nas_architecture_options, - nas_training_hyper_parameters=nas_training_hyper_parameters, - reuse=reuse, - scope=name_scope[model_variant]) - else: - raise ValueError('Unknown model variant %s.' % model_variant) - - return features, end_points - - -def get_network(network_name, preprocess_images, - preprocessed_images_dtype=tf.float32, arg_scope=None): - """Gets the network. - - Args: - network_name: Network name. - preprocess_images: Preprocesses the images or not. - preprocessed_images_dtype: The type after the preprocessing function. - arg_scope: Optional, arg_scope to build the network. If not provided the - default arg_scope of the network would be used. - - Returns: - A network function that is used to extract features. - - Raises: - ValueError: network is not supported. - """ - if network_name not in networks_map: - raise ValueError('Unsupported network %s.' % network_name) - arg_scope = arg_scope or arg_scopes_map[network_name]() - def _identity_function(inputs, dtype=preprocessed_images_dtype): - return tf.cast(inputs, dtype=dtype) - if preprocess_images: - preprocess_function = _PREPROCESS_FN[network_name] - else: - preprocess_function = _identity_function - func = networks_map[network_name] - @functools.wraps(func) - def network_fn(inputs, *args, **kwargs): - with slim.arg_scope(arg_scope): - return func(preprocess_function(inputs, preprocessed_images_dtype), - *args, **kwargs) - return network_fn diff --git a/research/deeplab/core/nas_cell.py b/research/deeplab/core/nas_cell.py deleted file mode 100644 index d179082dc72b6692e96289ef9ed6964165023c33..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_cell.py +++ /dev/null @@ -1,221 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Cell structure used by NAS.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools -from six.moves import range -from six.moves import zip -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import xception as xception_utils -from deeplab.core.utils import resize_bilinear -from deeplab.core.utils import scale_dimension -from tensorflow.contrib.slim.nets import resnet_utils - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim - -separable_conv2d_same = functools.partial(xception_utils.separable_conv2d_same, - regularize_depthwise=True) - - -class NASBaseCell(object): - """NASNet Cell class that is used as a 'layer' in image architectures.""" - - def __init__(self, num_conv_filters, operations, used_hiddenstates, - hiddenstate_indices, drop_path_keep_prob, total_num_cells, - total_training_steps, batch_norm_fn=slim.batch_norm): - """Init function. - - For more details about NAS cell, see - https://arxiv.org/abs/1707.07012 and https://arxiv.org/abs/1712.00559. - - Args: - num_conv_filters: The number of filters for each convolution operation. - operations: List of operations that are performed in the NASNet Cell in - order. - used_hiddenstates: Binary array that signals if the hiddenstate was used - within the cell. This is used to determine what outputs of the cell - should be concatenated together. - hiddenstate_indices: Determines what hiddenstates should be combined - together with the specified operations to create the NASNet cell. - drop_path_keep_prob: Float, drop path keep probability. - total_num_cells: Integer, total number of cells. - total_training_steps: Integer, total training steps. - batch_norm_fn: Function, batch norm function. Defaults to - slim.batch_norm. - """ - if len(hiddenstate_indices) != len(operations): - raise ValueError( - 'Number of hiddenstate_indices and operations should be the same.') - if len(operations) % 2: - raise ValueError('Number of operations should be even.') - self._num_conv_filters = num_conv_filters - self._operations = operations - self._used_hiddenstates = used_hiddenstates - self._hiddenstate_indices = hiddenstate_indices - self._drop_path_keep_prob = drop_path_keep_prob - self._total_num_cells = total_num_cells - self._total_training_steps = total_training_steps - self._batch_norm_fn = batch_norm_fn - - def __call__(self, net, scope, filter_scaling, stride, prev_layer, cell_num): - """Runs the conv cell.""" - self._cell_num = cell_num - self._filter_scaling = filter_scaling - self._filter_size = int(self._num_conv_filters * filter_scaling) - - with tf.variable_scope(scope): - net = self._cell_base(net, prev_layer) - for i in range(len(self._operations) // 2): - with tf.variable_scope('comb_iter_{}'.format(i)): - h1 = net[self._hiddenstate_indices[i * 2]] - h2 = net[self._hiddenstate_indices[i * 2 + 1]] - with tf.variable_scope('left'): - h1 = self._apply_conv_operation( - h1, self._operations[i * 2], stride, - self._hiddenstate_indices[i * 2] < 2) - with tf.variable_scope('right'): - h2 = self._apply_conv_operation( - h2, self._operations[i * 2 + 1], stride, - self._hiddenstate_indices[i * 2 + 1] < 2) - with tf.variable_scope('combine'): - h = h1 + h2 - net.append(h) - - with tf.variable_scope('cell_output'): - net = self._combine_unused_states(net) - - return net - - def _cell_base(self, net, prev_layer): - """Runs the beginning of the conv cell before the chosen ops are run.""" - filter_size = self._filter_size - - if prev_layer is None: - prev_layer = net - else: - if net.shape[2] != prev_layer.shape[2]: - prev_layer = resize_bilinear( - prev_layer, tf.shape(net)[1:3], prev_layer.dtype) - if filter_size != prev_layer.shape[3]: - prev_layer = tf.nn.relu(prev_layer) - prev_layer = slim.conv2d(prev_layer, filter_size, 1, scope='prev_1x1') - prev_layer = self._batch_norm_fn(prev_layer, scope='prev_bn') - - net = tf.nn.relu(net) - net = slim.conv2d(net, filter_size, 1, scope='1x1') - net = self._batch_norm_fn(net, scope='beginning_bn') - net = tf.split(axis=3, num_or_size_splits=1, value=net) - net.append(prev_layer) - return net - - def _apply_conv_operation(self, net, operation, stride, - is_from_original_input): - """Applies the predicted conv operation to net.""" - if stride > 1 and not is_from_original_input: - stride = 1 - input_filters = net.shape[3] - filter_size = self._filter_size - if 'separable' in operation: - num_layers = int(operation.split('_')[-1]) - kernel_size = int(operation.split('x')[0][-1]) - for layer_num in range(num_layers): - net = tf.nn.relu(net) - net = separable_conv2d_same( - net, - filter_size, - kernel_size, - depth_multiplier=1, - scope='separable_{0}x{0}_{1}'.format(kernel_size, layer_num + 1), - stride=stride) - net = self._batch_norm_fn( - net, scope='bn_sep_{0}x{0}_{1}'.format(kernel_size, layer_num + 1)) - stride = 1 - elif 'atrous' in operation: - kernel_size = int(operation.split('x')[0][-1]) - net = tf.nn.relu(net) - if stride == 2: - scaled_height = scale_dimension(tf.shape(net)[1], 0.5) - scaled_width = scale_dimension(tf.shape(net)[2], 0.5) - net = resize_bilinear(net, [scaled_height, scaled_width], net.dtype) - net = resnet_utils.conv2d_same( - net, filter_size, kernel_size, rate=1, stride=1, - scope='atrous_{0}x{0}'.format(kernel_size)) - else: - net = resnet_utils.conv2d_same( - net, filter_size, kernel_size, rate=2, stride=1, - scope='atrous_{0}x{0}'.format(kernel_size)) - net = self._batch_norm_fn(net, scope='bn_atr_{0}x{0}'.format(kernel_size)) - elif operation in ['none']: - if stride > 1 or (input_filters != filter_size): - net = tf.nn.relu(net) - net = slim.conv2d(net, filter_size, 1, stride=stride, scope='1x1') - net = self._batch_norm_fn(net, scope='bn_1') - elif 'pool' in operation: - pooling_type = operation.split('_')[0] - pooling_shape = int(operation.split('_')[-1].split('x')[0]) - if pooling_type == 'avg': - net = slim.avg_pool2d(net, pooling_shape, stride=stride, padding='SAME') - elif pooling_type == 'max': - net = slim.max_pool2d(net, pooling_shape, stride=stride, padding='SAME') - else: - raise ValueError('Unimplemented pooling type: ', pooling_type) - if input_filters != filter_size: - net = slim.conv2d(net, filter_size, 1, stride=1, scope='1x1') - net = self._batch_norm_fn(net, scope='bn_1') - else: - raise ValueError('Unimplemented operation', operation) - - if operation != 'none': - net = self._apply_drop_path(net) - return net - - def _combine_unused_states(self, net): - """Concatenates the unused hidden states of the cell.""" - used_hiddenstates = self._used_hiddenstates - states_to_combine = ([ - h for h, is_used in zip(net, used_hiddenstates) if not is_used]) - net = tf.concat(values=states_to_combine, axis=3) - return net - - @contrib_framework.add_arg_scope - def _apply_drop_path(self, net): - """Apply drop_path regularization.""" - drop_path_keep_prob = self._drop_path_keep_prob - if drop_path_keep_prob < 1.0: - # Scale keep prob by layer number. - assert self._cell_num != -1 - layer_ratio = (self._cell_num + 1) / float(self._total_num_cells) - drop_path_keep_prob = 1 - layer_ratio * (1 - drop_path_keep_prob) - # Decrease keep prob over time. - current_step = tf.cast(tf.train.get_or_create_global_step(), tf.float32) - current_ratio = tf.minimum(1.0, current_step / self._total_training_steps) - drop_path_keep_prob = (1 - current_ratio * (1 - drop_path_keep_prob)) - # Drop path. - noise_shape = [tf.shape(net)[0], 1, 1, 1] - random_tensor = drop_path_keep_prob - random_tensor += tf.random_uniform(noise_shape, dtype=tf.float32) - binary_tensor = tf.cast(tf.floor(random_tensor), net.dtype) - keep_prob_inv = tf.cast(1.0 / drop_path_keep_prob, net.dtype) - net = net * keep_prob_inv * binary_tensor - return net diff --git a/research/deeplab/core/nas_genotypes.py b/research/deeplab/core/nas_genotypes.py deleted file mode 100644 index a2e6dd55b450658e10acaa420a6cc31635817a8a..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_genotypes.py +++ /dev/null @@ -1,45 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Genotypes used by NAS.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import nas_cell - -slim = contrib_slim - - -class PNASCell(nas_cell.NASBaseCell): - """Configuration and construction of the PNASNet-5 Cell.""" - - def __init__(self, num_conv_filters, drop_path_keep_prob, total_num_cells, - total_training_steps, batch_norm_fn=slim.batch_norm): - # Name of operations: op_kernel-size_num-layers. - operations = [ - 'separable_5x5_2', 'max_pool_3x3', 'separable_7x7_2', 'max_pool_3x3', - 'separable_5x5_2', 'separable_3x3_2', 'separable_3x3_2', 'max_pool_3x3', - 'separable_3x3_2', 'none' - ] - used_hiddenstates = [1, 1, 0, 0, 0, 0, 0] - hiddenstate_indices = [1, 1, 0, 0, 0, 0, 4, 0, 1, 0] - - super(PNASCell, self).__init__( - num_conv_filters, operations, used_hiddenstates, hiddenstate_indices, - drop_path_keep_prob, total_num_cells, total_training_steps, - batch_norm_fn) diff --git a/research/deeplab/core/nas_network.py b/research/deeplab/core/nas_network.py deleted file mode 100644 index 1da2e04dbaa5cfcb7db6f21266daf846000481fd..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_network.py +++ /dev/null @@ -1,368 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Network structure used by NAS. - -Here we provide a few NAS backbones for semantic segmentation. -Currently, we have - -1. pnasnet -"Progressive Neural Architecture Search", Chenxi Liu, Barret Zoph, -Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, -Alan Yuille, Jonathan Huang, Kevin Murphy. In ECCV, 2018. - -2. hnasnet (also called Auto-DeepLab) -"Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic -Image Segmentation", Chenxi Liu, Liang-Chieh Chen, Florian Schroff, -Hartwig Adam, Wei Hua, Alan Yuille, Li Fei-Fei. In CVPR, 2019. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import layers as contrib_layers -from tensorflow.contrib import slim as contrib_slim -from tensorflow.contrib import training as contrib_training - -from deeplab.core import nas_genotypes -from deeplab.core import utils -from deeplab.core.nas_cell import NASBaseCell -from tensorflow.contrib.slim.nets import resnet_utils - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim -resize_bilinear = utils.resize_bilinear -scale_dimension = utils.scale_dimension - - -def config(num_conv_filters=20, - total_training_steps=500000, - drop_path_keep_prob=1.0): - return contrib_training.HParams( - # Multiplier when spatial size is reduced by 2. - filter_scaling_rate=2.0, - # Number of filters of the stem output tensor. - num_conv_filters=num_conv_filters, - # Probability to keep each path in the cell when training. - drop_path_keep_prob=drop_path_keep_prob, - # Total training steps to help drop path probability calculation. - total_training_steps=total_training_steps, - ) - - -def nas_arg_scope(weight_decay=4e-5, - batch_norm_decay=0.9997, - batch_norm_epsilon=0.001, - sync_batch_norm_method='None'): - """Default arg scope for the NAS models.""" - batch_norm_params = { - # Decay for the moving averages. - 'decay': batch_norm_decay, - # epsilon to prevent 0s in variance. - 'epsilon': batch_norm_epsilon, - 'scale': True, - } - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - weights_regularizer = contrib_layers.l2_regularizer(weight_decay) - weights_initializer = contrib_layers.variance_scaling_initializer( - factor=1 / 3.0, mode='FAN_IN', uniform=True) - with arg_scope([slim.fully_connected, slim.conv2d, slim.separable_conv2d], - weights_regularizer=weights_regularizer, - weights_initializer=weights_initializer): - with arg_scope([slim.fully_connected], - activation_fn=None, scope='FC'): - with arg_scope([slim.conv2d, slim.separable_conv2d], - activation_fn=None, biases_initializer=None): - with arg_scope([batch_norm], **batch_norm_params) as sc: - return sc - - -def _nas_stem(inputs, - batch_norm_fn=slim.batch_norm): - """Stem used for NAS models.""" - net = resnet_utils.conv2d_same(inputs, 64, 3, stride=2, scope='conv0') - net = batch_norm_fn(net, scope='conv0_bn') - net = tf.nn.relu(net) - net = resnet_utils.conv2d_same(net, 64, 3, stride=1, scope='conv1') - net = batch_norm_fn(net, scope='conv1_bn') - cell_outputs = [net] - net = tf.nn.relu(net) - net = resnet_utils.conv2d_same(net, 128, 3, stride=2, scope='conv2') - net = batch_norm_fn(net, scope='conv2_bn') - cell_outputs.append(net) - return net, cell_outputs - - -def _build_nas_base(images, - cell, - backbone, - num_classes, - hparams, - global_pool=False, - output_stride=16, - nas_use_classification_head=False, - reuse=None, - scope=None, - final_endpoint=None, - batch_norm_fn=slim.batch_norm, - nas_remove_os32_stride=False): - """Constructs a NAS model. - - Args: - images: A tensor of size [batch, height, width, channels]. - cell: Cell structure used in the network. - backbone: Backbone structure used in the network. A list of integers in - which value 0 means "output_stride=4", value 1 means "output_stride=8", - value 2 means "output_stride=16", and value 3 means "output_stride=32". - num_classes: Number of classes to predict. - hparams: Hyperparameters needed to construct the network. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: Interger, the stride of output feature maps. - nas_use_classification_head: Boolean, use image classification head. - reuse: Whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - final_endpoint: The endpoint to construct the network up to. - batch_norm_fn: Batch norm function. - nas_remove_os32_stride: Boolean, remove stride in output_stride 32 branch. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If output_stride is not a multiple of backbone output stride. - """ - with tf.variable_scope(scope, 'nas', [images], reuse=reuse): - end_points = {} - def add_and_check_endpoint(endpoint_name, net): - end_points[endpoint_name] = net - return final_endpoint and (endpoint_name == final_endpoint) - - net, cell_outputs = _nas_stem(images, - batch_norm_fn=batch_norm_fn) - if add_and_check_endpoint('Stem', net): - return net, end_points - - # Run the cells - filter_scaling = 1.0 - for cell_num in range(len(backbone)): - stride = 1 - if cell_num == 0: - if backbone[0] == 1: - stride = 2 - filter_scaling *= hparams.filter_scaling_rate - else: - if backbone[cell_num] == backbone[cell_num - 1] + 1: - stride = 2 - if backbone[cell_num] == 3 and nas_remove_os32_stride: - stride = 1 - filter_scaling *= hparams.filter_scaling_rate - elif backbone[cell_num] == backbone[cell_num - 1] - 1: - if backbone[cell_num - 1] == 3 and nas_remove_os32_stride: - # No need to rescale features. - pass - else: - # Scale features by a factor of 2. - scaled_height = scale_dimension(net.shape[1].value, 2) - scaled_width = scale_dimension(net.shape[2].value, 2) - net = resize_bilinear(net, [scaled_height, scaled_width], net.dtype) - filter_scaling /= hparams.filter_scaling_rate - net = cell( - net, - scope='cell_{}'.format(cell_num), - filter_scaling=filter_scaling, - stride=stride, - prev_layer=cell_outputs[-2], - cell_num=cell_num) - if add_and_check_endpoint('Cell_{}'.format(cell_num), net): - return net, end_points - cell_outputs.append(net) - net = tf.nn.relu(net) - - if nas_use_classification_head: - # Add image classification head. - # We will expand the filters for different output_strides. - output_stride_to_expanded_filters = {8: 256, 16: 512, 32: 1024} - current_output_scale = 2 + backbone[-1] - current_output_stride = 2 ** current_output_scale - if output_stride % current_output_stride != 0: - raise ValueError( - 'output_stride must be a multiple of backbone output stride.') - output_stride //= current_output_stride - rate = 1 - if current_output_stride != 32: - num_downsampling = 5 - current_output_scale - for i in range(num_downsampling): - # Gradually donwsample feature maps to output stride = 32. - target_output_stride = 2 ** (current_output_scale + 1 + i) - target_filters = output_stride_to_expanded_filters[ - target_output_stride] - scope = 'downsample_os{}'.format(target_output_stride) - if output_stride != 1: - stride = 2 - output_stride //= 2 - else: - stride = 1 - rate *= 2 - net = resnet_utils.conv2d_same( - net, target_filters, 3, stride=stride, rate=rate, - scope=scope + '_conv') - net = batch_norm_fn(net, scope=scope + '_bn') - add_and_check_endpoint(scope, net) - net = tf.nn.relu(net) - # Apply 1x1 convolution to expand dimension to 2048. - scope = 'classification_head' - net = slim.conv2d(net, 2048, 1, scope=scope + '_conv') - net = batch_norm_fn(net, scope=scope + '_bn') - add_and_check_endpoint(scope, net) - net = tf.nn.relu(net) - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='global_pool', keepdims=True) - if num_classes is not None: - net = slim.conv2d(net, num_classes, 1, activation_fn=None, - normalizer_fn=None, scope='logits') - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def pnasnet(images, - num_classes, - is_training=True, - global_pool=False, - output_stride=16, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - reuse=None, - scope='pnasnet', - final_endpoint=None, - sync_batch_norm_method='None'): - """Builds PNASNet model.""" - if nas_architecture_options is None: - raise ValueError( - 'Using NAS model variants. nas_architecture_options cannot be None.') - hparams = config(num_conv_filters=nas_architecture_options[ - 'nas_stem_output_num_conv_filters']) - if nas_training_hyper_parameters: - hparams.set_hparam('drop_path_keep_prob', - nas_training_hyper_parameters['drop_path_keep_prob']) - hparams.set_hparam('total_training_steps', - nas_training_hyper_parameters['total_training_steps']) - if not is_training: - tf.logging.info('During inference, setting drop_path_keep_prob = 1.0.') - hparams.set_hparam('drop_path_keep_prob', 1.0) - tf.logging.info(hparams) - if output_stride == 8: - backbone = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] - elif output_stride == 16: - backbone = [1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2] - elif output_stride == 32: - backbone = [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] - else: - raise ValueError('Unsupported output_stride ', output_stride) - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - cell = nas_genotypes.PNASCell(hparams.num_conv_filters, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps, - batch_norm_fn=batch_norm) - with arg_scope([slim.dropout, batch_norm], is_training=is_training): - return _build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - global_pool=global_pool, - output_stride=output_stride, - nas_use_classification_head=nas_architecture_options[ - 'nas_use_classification_head'], - reuse=reuse, - scope=scope, - final_endpoint=final_endpoint, - batch_norm_fn=batch_norm, - nas_remove_os32_stride=nas_architecture_options[ - 'nas_remove_os32_stride']) - - -# pylint: disable=unused-argument -def hnasnet(images, - num_classes, - is_training=True, - global_pool=False, - output_stride=8, - nas_architecture_options=None, - nas_training_hyper_parameters=None, - reuse=None, - scope='hnasnet', - final_endpoint=None, - sync_batch_norm_method='None'): - """Builds hierarchical model.""" - if nas_architecture_options is None: - raise ValueError( - 'Using NAS model variants. nas_architecture_options cannot be None.') - hparams = config(num_conv_filters=nas_architecture_options[ - 'nas_stem_output_num_conv_filters']) - if nas_training_hyper_parameters: - hparams.set_hparam('drop_path_keep_prob', - nas_training_hyper_parameters['drop_path_keep_prob']) - hparams.set_hparam('total_training_steps', - nas_training_hyper_parameters['total_training_steps']) - if not is_training: - tf.logging.info('During inference, setting drop_path_keep_prob = 1.0.') - hparams.set_hparam('drop_path_keep_prob', 1.0) - tf.logging.info(hparams) - operations = [ - 'atrous_5x5', 'separable_3x3_2', 'separable_3x3_2', 'atrous_3x3', - 'separable_3x3_2', 'separable_3x3_2', 'separable_5x5_2', - 'separable_5x5_2', 'separable_5x5_2', 'atrous_5x5' - ] - used_hiddenstates = [1, 1, 0, 0, 0, 0, 0] - hiddenstate_indices = [1, 0, 1, 0, 3, 1, 4, 2, 3, 5] - backbone = [0, 0, 0, 1, 2, 1, 2, 2, 3, 3, 2, 1] - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - cell = NASBaseCell(hparams.num_conv_filters, - operations, - used_hiddenstates, - hiddenstate_indices, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps, - batch_norm_fn=batch_norm) - with arg_scope([slim.dropout, batch_norm], is_training=is_training): - return _build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - global_pool=global_pool, - output_stride=output_stride, - nas_use_classification_head=nas_architecture_options[ - 'nas_use_classification_head'], - reuse=reuse, - scope=scope, - final_endpoint=final_endpoint, - batch_norm_fn=batch_norm, - nas_remove_os32_stride=nas_architecture_options[ - 'nas_remove_os32_stride']) diff --git a/research/deeplab/core/nas_network_test.py b/research/deeplab/core/nas_network_test.py deleted file mode 100644 index 18621b250ad7321f554b8d97449e19bde5ef4174..0000000000000000000000000000000000000000 --- a/research/deeplab/core/nas_network_test.py +++ /dev/null @@ -1,111 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for resnet_v1_beta module.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim -from tensorflow.contrib import training as contrib_training - -from deeplab.core import nas_genotypes -from deeplab.core import nas_network - -arg_scope = contrib_framework.arg_scope -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Creates test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.to_float( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels])) - - -class NASNetworkTest(tf.test.TestCase): - """Tests with complete small NAS networks.""" - - def _pnasnet(self, - images, - backbone, - num_classes, - is_training=True, - output_stride=16, - final_endpoint=None): - """Build PNASNet model backbone.""" - hparams = contrib_training.HParams( - filter_scaling_rate=2.0, - num_conv_filters=10, - drop_path_keep_prob=1.0, - total_training_steps=200000, - ) - if not is_training: - hparams.set_hparam('drop_path_keep_prob', 1.0) - - cell = nas_genotypes.PNASCell(hparams.num_conv_filters, - hparams.drop_path_keep_prob, - len(backbone), - hparams.total_training_steps) - with arg_scope([slim.dropout, slim.batch_norm], is_training=is_training): - return nas_network._build_nas_base( - images, - cell=cell, - backbone=backbone, - num_classes=num_classes, - hparams=hparams, - reuse=tf.AUTO_REUSE, - scope='pnasnet_small', - final_endpoint=final_endpoint) - - def testFullyConvolutionalEndpointShapes(self): - num_classes = 10 - backbone = [0, 0, 0, 1, 2, 1, 2, 2, 3, 3, 2, 1] - inputs = create_test_input(None, 321, 321, 3) - with slim.arg_scope(nas_network.nas_arg_scope()): - _, end_points = self._pnasnet(inputs, backbone, num_classes) - endpoint_to_shape = { - 'Stem': [None, 81, 81, 128], - 'Cell_0': [None, 81, 81, 50], - 'Cell_1': [None, 81, 81, 50], - 'Cell_2': [None, 81, 81, 50], - 'Cell_3': [None, 41, 41, 100], - 'Cell_4': [None, 21, 21, 200], - 'Cell_5': [None, 41, 41, 100], - 'Cell_6': [None, 21, 21, 200], - 'Cell_7': [None, 21, 21, 200], - 'Cell_8': [None, 11, 11, 400], - 'Cell_9': [None, 11, 11, 400], - 'Cell_10': [None, 21, 21, 200], - 'Cell_11': [None, 41, 41, 100] - } - for endpoint, shape in endpoint_to_shape.items(): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/preprocess_utils.py b/research/deeplab/core/preprocess_utils.py deleted file mode 100644 index 440717e414d1a6f67b0947eb78830ff84baa812d..0000000000000000000000000000000000000000 --- a/research/deeplab/core/preprocess_utils.py +++ /dev/null @@ -1,533 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Utility functions related to preprocessing inputs.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -from six.moves import range -from six.moves import zip -import tensorflow as tf - - -def flip_dim(tensor_list, prob=0.5, dim=1): - """Randomly flips a dimension of the given tensor. - - The decision to randomly flip the `Tensors` is made together. In other words, - all or none of the images pass in are flipped. - - Note that tf.random_flip_left_right and tf.random_flip_up_down isn't used so - that we can control for the probability as well as ensure the same decision - is applied across the images. - - Args: - tensor_list: A list of `Tensors` with the same number of dimensions. - prob: The probability of a left-right flip. - dim: The dimension to flip, 0, 1, .. - - Returns: - outputs: A list of the possibly flipped `Tensors` as well as an indicator - `Tensor` at the end whose value is `True` if the inputs were flipped and - `False` otherwise. - - Raises: - ValueError: If dim is negative or greater than the dimension of a `Tensor`. - """ - random_value = tf.random_uniform([]) - - def flip(): - flipped = [] - for tensor in tensor_list: - if dim < 0 or dim >= len(tensor.get_shape().as_list()): - raise ValueError('dim must represent a valid dimension.') - flipped.append(tf.reverse_v2(tensor, [dim])) - return flipped - - is_flipped = tf.less_equal(random_value, prob) - outputs = tf.cond(is_flipped, flip, lambda: tensor_list) - if not isinstance(outputs, (list, tuple)): - outputs = [outputs] - outputs.append(is_flipped) - - return outputs - - -def _image_dimensions(image, rank): - """Returns the dimensions of an image tensor. - - Args: - image: A rank-D Tensor. For 3-D of shape: `[height, width, channels]`. - rank: The expected rank of the image - - Returns: - A list of corresponding to the dimensions of the input image. Dimensions - that are statically known are python integers, otherwise they are integer - scalar tensors. - """ - if image.get_shape().is_fully_defined(): - return image.get_shape().as_list() - else: - static_shape = image.get_shape().with_rank(rank).as_list() - dynamic_shape = tf.unstack(tf.shape(image), rank) - return [ - s if s is not None else d for s, d in zip(static_shape, dynamic_shape) - ] - - -def get_label_resize_method(label): - """Returns the resize method of labels depending on label dtype. - - Args: - label: Groundtruth label tensor. - - Returns: - tf.image.ResizeMethod.BILINEAR, if label dtype is floating. - tf.image.ResizeMethod.NEAREST_NEIGHBOR, if label dtype is integer. - - Raises: - ValueError: If label is neither floating nor integer. - """ - if label.dtype.is_floating: - return tf.image.ResizeMethod.BILINEAR - elif label.dtype.is_integer: - return tf.image.ResizeMethod.NEAREST_NEIGHBOR - else: - raise ValueError('Label type must be either floating or integer.') - - -def pad_to_bounding_box(image, offset_height, offset_width, target_height, - target_width, pad_value): - """Pads the given image with the given pad_value. - - Works like tf.image.pad_to_bounding_box, except it can pad the image - with any given arbitrary pad value and also handle images whose sizes are not - known during graph construction. - - Args: - image: 3-D tensor with shape [height, width, channels] - offset_height: Number of rows of zeros to add on top. - offset_width: Number of columns of zeros to add on the left. - target_height: Height of output image. - target_width: Width of output image. - pad_value: Value to pad the image tensor with. - - Returns: - 3-D tensor of shape [target_height, target_width, channels]. - - Raises: - ValueError: If the shape of image is incompatible with the offset_* or - target_* arguments. - """ - with tf.name_scope(None, 'pad_to_bounding_box', [image]): - image = tf.convert_to_tensor(image, name='image') - original_dtype = image.dtype - if original_dtype != tf.float32 and original_dtype != tf.float64: - # If image dtype is not float, we convert it to int32 to avoid overflow. - image = tf.cast(image, tf.int32) - image_rank_assert = tf.Assert( - tf.logical_or( - tf.equal(tf.rank(image), 3), - tf.equal(tf.rank(image), 4)), - ['Wrong image tensor rank.']) - with tf.control_dependencies([image_rank_assert]): - image -= pad_value - image_shape = image.get_shape() - is_batch = True - if image_shape.ndims == 3: - is_batch = False - image = tf.expand_dims(image, 0) - elif image_shape.ndims is None: - is_batch = False - image = tf.expand_dims(image, 0) - image.set_shape([None] * 4) - elif image.get_shape().ndims != 4: - raise ValueError('Input image must have either 3 or 4 dimensions.') - _, height, width, _ = _image_dimensions(image, rank=4) - target_width_assert = tf.Assert( - tf.greater_equal( - target_width, width), - ['target_width must be >= width']) - target_height_assert = tf.Assert( - tf.greater_equal(target_height, height), - ['target_height must be >= height']) - with tf.control_dependencies([target_width_assert]): - after_padding_width = target_width - offset_width - width - with tf.control_dependencies([target_height_assert]): - after_padding_height = target_height - offset_height - height - offset_assert = tf.Assert( - tf.logical_and( - tf.greater_equal(after_padding_width, 0), - tf.greater_equal(after_padding_height, 0)), - ['target size not possible with the given target offsets']) - batch_params = tf.stack([0, 0]) - height_params = tf.stack([offset_height, after_padding_height]) - width_params = tf.stack([offset_width, after_padding_width]) - channel_params = tf.stack([0, 0]) - with tf.control_dependencies([offset_assert]): - paddings = tf.stack([batch_params, height_params, width_params, - channel_params]) - padded = tf.pad(image, paddings) - if not is_batch: - padded = tf.squeeze(padded, axis=[0]) - outputs = padded + pad_value - if outputs.dtype != original_dtype: - outputs = tf.cast(outputs, original_dtype) - return outputs - - -def _crop(image, offset_height, offset_width, crop_height, crop_width): - """Crops the given image using the provided offsets and sizes. - - Note that the method doesn't assume we know the input image size but it does - assume we know the input image rank. - - Args: - image: an image of shape [height, width, channels]. - offset_height: a scalar tensor indicating the height offset. - offset_width: a scalar tensor indicating the width offset. - crop_height: the height of the cropped image. - crop_width: the width of the cropped image. - - Returns: - The cropped (and resized) image. - - Raises: - ValueError: if `image` doesn't have rank of 3. - InvalidArgumentError: if the rank is not 3 or if the image dimensions are - less than the crop size. - """ - original_shape = tf.shape(image) - - if len(image.get_shape().as_list()) != 3: - raise ValueError('input must have rank of 3') - original_channels = image.get_shape().as_list()[2] - - rank_assertion = tf.Assert( - tf.equal(tf.rank(image), 3), - ['Rank of image must be equal to 3.']) - with tf.control_dependencies([rank_assertion]): - cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]]) - - size_assertion = tf.Assert( - tf.logical_and( - tf.greater_equal(original_shape[0], crop_height), - tf.greater_equal(original_shape[1], crop_width)), - ['Crop size greater than the image size.']) - - offsets = tf.cast(tf.stack([offset_height, offset_width, 0]), tf.int32) - - # Use tf.slice instead of crop_to_bounding box as it accepts tensors to - # define the crop size. - with tf.control_dependencies([size_assertion]): - image = tf.slice(image, offsets, cropped_shape) - image = tf.reshape(image, cropped_shape) - image.set_shape([crop_height, crop_width, original_channels]) - return image - - -def random_crop(image_list, crop_height, crop_width): - """Crops the given list of images. - - The function applies the same crop to each image in the list. This can be - effectively applied when there are multiple image inputs of the same - dimension such as: - - image, depths, normals = random_crop([image, depths, normals], 120, 150) - - Args: - image_list: a list of image tensors of the same dimension but possibly - varying channel. - crop_height: the new height. - crop_width: the new width. - - Returns: - the image_list with cropped images. - - Raises: - ValueError: if there are multiple image inputs provided with different size - or the images are smaller than the crop dimensions. - """ - if not image_list: - raise ValueError('Empty image_list.') - - # Compute the rank assertions. - rank_assertions = [] - for i in range(len(image_list)): - image_rank = tf.rank(image_list[i]) - rank_assert = tf.Assert( - tf.equal(image_rank, 3), - ['Wrong rank for tensor %s [expected] [actual]', - image_list[i].name, 3, image_rank]) - rank_assertions.append(rank_assert) - - with tf.control_dependencies([rank_assertions[0]]): - image_shape = tf.shape(image_list[0]) - image_height = image_shape[0] - image_width = image_shape[1] - crop_size_assert = tf.Assert( - tf.logical_and( - tf.greater_equal(image_height, crop_height), - tf.greater_equal(image_width, crop_width)), - ['Crop size greater than the image size.']) - - asserts = [rank_assertions[0], crop_size_assert] - - for i in range(1, len(image_list)): - image = image_list[i] - asserts.append(rank_assertions[i]) - with tf.control_dependencies([rank_assertions[i]]): - shape = tf.shape(image) - height = shape[0] - width = shape[1] - - height_assert = tf.Assert( - tf.equal(height, image_height), - ['Wrong height for tensor %s [expected][actual]', - image.name, height, image_height]) - width_assert = tf.Assert( - tf.equal(width, image_width), - ['Wrong width for tensor %s [expected][actual]', - image.name, width, image_width]) - asserts.extend([height_assert, width_assert]) - - # Create a random bounding box. - # - # Use tf.random_uniform and not numpy.random.rand as doing the former would - # generate random numbers at graph eval time, unlike the latter which - # generates random numbers at graph definition time. - with tf.control_dependencies(asserts): - max_offset_height = tf.reshape(image_height - crop_height + 1, []) - max_offset_width = tf.reshape(image_width - crop_width + 1, []) - offset_height = tf.random_uniform( - [], maxval=max_offset_height, dtype=tf.int32) - offset_width = tf.random_uniform( - [], maxval=max_offset_width, dtype=tf.int32) - - return [_crop(image, offset_height, offset_width, - crop_height, crop_width) for image in image_list] - - -def get_random_scale(min_scale_factor, max_scale_factor, step_size): - """Gets a random scale value. - - Args: - min_scale_factor: Minimum scale value. - max_scale_factor: Maximum scale value. - step_size: The step size from minimum to maximum value. - - Returns: - A random scale value selected between minimum and maximum value. - - Raises: - ValueError: min_scale_factor has unexpected value. - """ - if min_scale_factor < 0 or min_scale_factor > max_scale_factor: - raise ValueError('Unexpected value of min_scale_factor.') - - if min_scale_factor == max_scale_factor: - return tf.cast(min_scale_factor, tf.float32) - - # When step_size = 0, we sample the value uniformly from [min, max). - if step_size == 0: - return tf.random_uniform([1], - minval=min_scale_factor, - maxval=max_scale_factor) - - # When step_size != 0, we randomly select one discrete value from [min, max]. - num_steps = int((max_scale_factor - min_scale_factor) / step_size + 1) - scale_factors = tf.lin_space(min_scale_factor, max_scale_factor, num_steps) - shuffled_scale_factors = tf.random_shuffle(scale_factors) - return shuffled_scale_factors[0] - - -def randomly_scale_image_and_label(image, label=None, scale=1.0): - """Randomly scales image and label. - - Args: - image: Image with shape [height, width, 3]. - label: Label with shape [height, width, 1]. - scale: The value to scale image and label. - - Returns: - Scaled image and label. - """ - # No random scaling if scale == 1. - if scale == 1.0: - return image, label - image_shape = tf.shape(image) - new_dim = tf.cast( - tf.cast([image_shape[0], image_shape[1]], tf.float32) * scale, - tf.int32) - - # Need squeeze and expand_dims because image interpolation takes - # 4D tensors as input. - image = tf.squeeze(tf.image.resize_bilinear( - tf.expand_dims(image, 0), - new_dim, - align_corners=True), [0]) - if label is not None: - label = tf.image.resize( - label, - new_dim, - method=get_label_resize_method(label), - align_corners=True) - - return image, label - - -def resolve_shape(tensor, rank=None, scope=None): - """Fully resolves the shape of a Tensor. - - Use as much as possible the shape components already known during graph - creation and resolve the remaining ones during runtime. - - Args: - tensor: Input tensor whose shape we query. - rank: The rank of the tensor, provided that we know it. - scope: Optional name scope. - - Returns: - shape: The full shape of the tensor. - """ - with tf.name_scope(scope, 'resolve_shape', [tensor]): - if rank is not None: - shape = tensor.get_shape().with_rank(rank).as_list() - else: - shape = tensor.get_shape().as_list() - - if None in shape: - shape_dynamic = tf.shape(tensor) - for i in range(len(shape)): - if shape[i] is None: - shape[i] = shape_dynamic[i] - - return shape - - -def resize_to_range(image, - label=None, - min_size=None, - max_size=None, - factor=None, - keep_aspect_ratio=True, - align_corners=True, - label_layout_is_chw=False, - scope=None, - method=tf.image.ResizeMethod.BILINEAR): - """Resizes image or label so their sides are within the provided range. - - The output size can be described by two cases: - 1. If the image can be rescaled so its minimum size is equal to min_size - without the other side exceeding max_size, then do so. - 2. Otherwise, resize so the largest side is equal to max_size. - - An integer in `range(factor)` is added to the computed sides so that the - final dimensions are multiples of `factor` plus one. - - Args: - image: A 3D tensor of shape [height, width, channels]. - label: (optional) A 3D tensor of shape [height, width, channels] (default) - or [channels, height, width] when label_layout_is_chw = True. - min_size: (scalar) desired size of the smaller image side. - max_size: (scalar) maximum allowed size of the larger image side. Note - that the output dimension is no larger than max_size and may be slightly - smaller than max_size when factor is not None. - factor: Make output size multiple of factor plus one. - keep_aspect_ratio: Boolean, keep aspect ratio or not. If True, the input - will be resized while keeping the original aspect ratio. If False, the - input will be resized to [max_resize_value, max_resize_value] without - keeping the original aspect ratio. - align_corners: If True, exactly align all 4 corners of input and output. - label_layout_is_chw: If true, the label has shape [channel, height, width]. - We support this case because for some instance segmentation dataset, the - instance segmentation is saved as [num_instances, height, width]. - scope: Optional name scope. - method: Image resize method. Defaults to tf.image.ResizeMethod.BILINEAR. - - Returns: - A 3-D tensor of shape [new_height, new_width, channels], where the image - has been resized (with the specified method) so that - min(new_height, new_width) == ceil(min_size) or - max(new_height, new_width) == ceil(max_size). - - Raises: - ValueError: If the image is not a 3D tensor. - """ - with tf.name_scope(scope, 'resize_to_range', [image]): - new_tensor_list = [] - min_size = tf.cast(min_size, tf.float32) - if max_size is not None: - max_size = tf.cast(max_size, tf.float32) - # Modify the max_size to be a multiple of factor plus 1 and make sure the - # max dimension after resizing is no larger than max_size. - if factor is not None: - max_size = (max_size - (max_size - 1) % factor) - - [orig_height, orig_width, _] = resolve_shape(image, rank=3) - orig_height = tf.cast(orig_height, tf.float32) - orig_width = tf.cast(orig_width, tf.float32) - orig_min_size = tf.minimum(orig_height, orig_width) - - # Calculate the larger of the possible sizes - large_scale_factor = min_size / orig_min_size - large_height = tf.cast(tf.floor(orig_height * large_scale_factor), tf.int32) - large_width = tf.cast(tf.floor(orig_width * large_scale_factor), tf.int32) - large_size = tf.stack([large_height, large_width]) - - new_size = large_size - if max_size is not None: - # Calculate the smaller of the possible sizes, use that if the larger - # is too big. - orig_max_size = tf.maximum(orig_height, orig_width) - small_scale_factor = max_size / orig_max_size - small_height = tf.cast( - tf.floor(orig_height * small_scale_factor), tf.int32) - small_width = tf.cast(tf.floor(orig_width * small_scale_factor), tf.int32) - small_size = tf.stack([small_height, small_width]) - new_size = tf.cond( - tf.cast(tf.reduce_max(large_size), tf.float32) > max_size, - lambda: small_size, - lambda: large_size) - # Ensure that both output sides are multiples of factor plus one. - if factor is not None: - new_size += (factor - (new_size - 1) % factor) % factor - if not keep_aspect_ratio: - # If not keep the aspect ratio, we resize everything to max_size, allowing - # us to do pre-processing without extra padding. - new_size = [tf.reduce_max(new_size), tf.reduce_max(new_size)] - new_tensor_list.append(tf.image.resize( - image, new_size, method=method, align_corners=align_corners)) - if label is not None: - if label_layout_is_chw: - # Input label has shape [channel, height, width]. - resized_label = tf.expand_dims(label, 3) - resized_label = tf.image.resize( - resized_label, - new_size, - method=get_label_resize_method(label), - align_corners=align_corners) - resized_label = tf.squeeze(resized_label, 3) - else: - # Input label has shape [height, width, channel]. - resized_label = tf.image.resize( - label, - new_size, - method=get_label_resize_method(label), - align_corners=align_corners) - new_tensor_list.append(resized_label) - else: - new_tensor_list.append(None) - return new_tensor_list diff --git a/research/deeplab/core/preprocess_utils_test.py b/research/deeplab/core/preprocess_utils_test.py deleted file mode 100644 index 606fe46dd62787cf1a8adfaa27121affc4a02498..0000000000000000000000000000000000000000 --- a/research/deeplab/core/preprocess_utils_test.py +++ /dev/null @@ -1,515 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for preprocess_utils.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -from six.moves import range -import tensorflow as tf - -from deeplab.core import preprocess_utils - - -class PreprocessUtilsTest(tf.test.TestCase): - - def testNoFlipWhenProbIsZero(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - image = tf.convert_to_tensor(numpy_image) - - with self.test_session(): - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=0) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=1) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=2) - self.assertAllEqual(numpy_image, actual.eval()) - self.assertAllEqual(False, is_flipped.eval()) - - def testFlipWhenProbIsOne(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - dim0_flipped = np.dstack([[[9., 0.], - [5., 6.]], - [[3., 5.], - [4., 3.]]]) - dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - dim2_flipped = np.dstack([[[4., 3.], - [3., 5.]], - [[5., 6.], - [9., 0.]]]) - image = tf.convert_to_tensor(numpy_image) - - with self.test_session(): - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=0) - self.assertAllEqual(dim0_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=1) - self.assertAllEqual(dim1_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=2) - self.assertAllEqual(dim2_flipped, actual.eval()) - self.assertAllEqual(True, is_flipped.eval()) - - def testFlipMultipleImagesConsistentlyWhenProbIsOne(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - numpy_label = np.dstack([[[0., 1.], - [2., 3.]]]) - image_dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - label_dim1_flipped = np.dstack([[[1., 0.], - [3., 2.]]]) - image = tf.convert_to_tensor(numpy_image) - label = tf.convert_to_tensor(numpy_label) - - with self.test_session() as sess: - image, label, is_flipped = preprocess_utils.flip_dim( - [image, label], prob=1, dim=1) - actual_image, actual_label = sess.run([image, label]) - self.assertAllEqual(image_dim1_flipped, actual_image) - self.assertAllEqual(label_dim1_flipped, actual_label) - self.assertEqual(True, is_flipped.eval()) - - def testReturnRandomFlipsOnMultipleEvals(self): - numpy_image = np.dstack([[[5., 6.], - [9., 0.]], - [[4., 3.], - [3., 5.]]]) - dim1_flipped = np.dstack([[[6., 5.], - [0., 9.]], - [[3., 4.], - [5., 3.]]]) - image = tf.convert_to_tensor(numpy_image) - tf.compat.v1.set_random_seed(53) - - with self.test_session() as sess: - actual, is_flipped = preprocess_utils.flip_dim( - [image], prob=0.5, dim=1) - actual_image, actual_is_flipped = sess.run([actual, is_flipped]) - self.assertAllEqual(numpy_image, actual_image) - self.assertEqual(False, actual_is_flipped) - actual_image, actual_is_flipped = sess.run([actual, is_flipped]) - self.assertAllEqual(dim1_flipped, actual_image) - self.assertEqual(True, actual_is_flipped) - - def testReturnCorrectCropOfSingleImage(self): - np.random.seed(0) - - height, width = 10, 20 - image = np.random.randint(0, 256, size=(height, width, 3)) - - crop_height, crop_width = 2, 4 - - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop([image_placeholder], - crop_height, - crop_width) - - with self.test_session(): - cropped_image = cropped.eval(feed_dict={image_placeholder: image}) - - # Ensure we can find the cropped image in the original: - is_found = False - for x in range(0, width - crop_width + 1): - for y in range(0, height - crop_height + 1): - if np.isclose(image[y:y+crop_height, x:x+crop_width, :], - cropped_image).all(): - is_found = True - break - - self.assertTrue(is_found) - - def testRandomCropMaintainsNumberOfChannels(self): - np.random.seed(0) - - crop_height, crop_width = 10, 20 - image = np.random.randint(0, 256, size=(100, 200, 3)) - - tf.compat.v1.set_random_seed(37) - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop( - [image_placeholder], crop_height, crop_width) - - with self.test_session(): - cropped_image = cropped.eval(feed_dict={image_placeholder: image}) - self.assertTupleEqual(cropped_image.shape, (crop_height, crop_width, 3)) - - def testReturnDifferentCropAreasOnTwoEvals(self): - tf.compat.v1.set_random_seed(0) - - crop_height, crop_width = 2, 3 - image = np.random.randint(0, 256, size=(100, 200, 3)) - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - [cropped] = preprocess_utils.random_crop( - [image_placeholder], crop_height, crop_width) - - with self.test_session(): - crop0 = cropped.eval(feed_dict={image_placeholder: image}) - crop1 = cropped.eval(feed_dict={image_placeholder: image}) - self.assertFalse(np.isclose(crop0, crop1).all()) - - def testReturnConsistenCropsOfImagesInTheList(self): - tf.compat.v1.set_random_seed(0) - - height, width = 10, 20 - crop_height, crop_width = 2, 3 - labels = np.linspace(0, height * width-1, height * width) - labels = labels.reshape((height, width, 1)) - image = np.tile(labels, (1, 1, 3)) - - image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) - label_placeholder = tf.placeholder(tf.int32, shape=(None, None, 1)) - [cropped_image, cropped_label] = preprocess_utils.random_crop( - [image_placeholder, label_placeholder], crop_height, crop_width) - - with self.test_session() as sess: - cropped_image, cropped_labels = sess.run([cropped_image, cropped_label], - feed_dict={ - image_placeholder: image, - label_placeholder: labels}) - for i in range(3): - self.assertAllEqual(cropped_image[:, :, i], cropped_labels.squeeze()) - - def testDieOnRandomCropWhenImagesWithDifferentWidth(self): - crop_height, crop_width = 2, 3 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaises(tf.errors.InvalidArgumentError): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(4, 6, 1)}) - - def testDieOnRandomCropWhenImagesWithDifferentHeight(self): - crop_height, crop_width = 2, 3 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Wrong height for tensor'): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(3, 5, 1)}) - - def testDieOnRandomCropWhenCropSizeIsGreaterThanImage(self): - crop_height, crop_width = 5, 9 - image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) - image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) - cropped = preprocess_utils.random_crop( - [image1, image2], crop_height, crop_width) - - with self.test_session() as sess: - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Crop size greater than the image size.'): - sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), - image2: np.random.rand(4, 5, 1)}) - - def testReturnPaddedImageWithNonZeroPadValue(self): - for dtype in [np.int32, np.int64, np.float32, np.float64]: - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]).astype(dtype) - expected_image = np.dstack([[[255, 255, 255, 255, 255], - [255, 255, 255, 255, 255], - [255, 5, 6, 255, 255], - [255, 9, 0, 255, 255], - [255, 255, 255, 255, 255]], - [[255, 255, 255, 255, 255], - [255, 255, 255, 255, 255], - [255, 4, 3, 255, 255], - [255, 3, 5, 255, 255], - [255, 255, 255, 255, 255]]]).astype(dtype) - - with self.session() as sess: - padded_image = preprocess_utils.pad_to_bounding_box( - image, 2, 1, 5, 5, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, expected_image) - # Add batch size = 1 to image. - padded_image = preprocess_utils.pad_to_bounding_box( - np.expand_dims(image, 0), 2, 1, 5, 5, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, np.expand_dims(expected_image, 0)) - - def testReturnOriginalImageWhenTargetSizeIsEqualToImageSize(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.session() as sess: - padded_image = preprocess_utils.pad_to_bounding_box( - image, 0, 0, 2, 2, 255) - padded_image = sess.run(padded_image) - self.assertAllClose(padded_image, image) - - def testDieOnTargetSizeGreaterThanImageSize(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 2, 1, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target_width must be >= width'): - padded_image.eval(feed_dict={image_placeholder: image}) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 1, 2, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target_height must be >= height'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testDieIfTargetSizeNotPossibleWithGivenOffset(self): - image = np.dstack([[[5, 6], - [9, 0]], - [[4, 3], - [3, 5]]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 3, 0, 4, 4, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'target size not possible with the given target offsets'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testDieIfImageTensorRankIsTwo(self): - image = np.vstack([[5, 6], - [9, 0]]) - with self.test_session(): - image_placeholder = tf.placeholder(tf.float32) - padded_image = preprocess_utils.pad_to_bounding_box( - image_placeholder, 0, 0, 2, 2, 255) - with self.assertRaisesWithPredicateMatch( - tf.errors.InvalidArgumentError, - 'Wrong image tensor rank'): - padded_image.eval(feed_dict={image_placeholder: image}) - - def testResizeTensorsToRange(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 100 - factor = None - expected_shape_list = [(75, 50, 3), - (50, 100, 3), - (30, 100, 3)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=None, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - resized_image = session.run(new_tensor_list[0]) - self.assertEqual(resized_image.shape, expected_shape_list[i]) - - def testResizeTensorsToRangeWithFactor(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 98 - factor = 8 - expected_image_shape_list = [(81, 57, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(81, 57, 1), - (49, 97, 1), - (33, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithFactorAndLabelShapeCHW(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - min_size = 50 - max_size = 98 - factor = 8 - expected_image_shape_list = [(81, 57, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(5, 81, 57), - (5, 49, 97), - (5, 33, 97)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([5, test_shape[0], test_shape[1]]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True, - label_layout_is_chw=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithSimilarMinMaxSizes(self): - test_shapes = [[60, 40], - [15, 30], - [15, 50]] - # Values set so that one of the side = 97. - min_size = 96 - max_size = 98 - factor = 8 - expected_image_shape_list = [(97, 65, 3), - (49, 97, 3), - (33, 97, 3)] - expected_label_shape_list = [(97, 65, 1), - (49, 97, 1), - (33, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithEqualMaxSize(self): - test_shapes = [[97, 38], - [96, 97]] - # Make max_size equal to the larger value of test_shapes. - min_size = 97 - max_size = 97 - factor = 8 - expected_image_shape_list = [(97, 41, 3), - (97, 97, 3)] - expected_label_shape_list = [(97, 41, 1), - (97, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - def testResizeTensorsToRangeWithPotentialErrorInTFCeil(self): - test_shape = [3936, 5248] - # Make max_size equal to the larger value of test_shapes. - min_size = 1441 - max_size = 1441 - factor = 16 - expected_image_shape = (1089, 1441, 3) - expected_label_shape = (1089, 1441, 1) - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape) - - def testResizeTensorsToRangeWithEqualMaxSizeWithoutAspectRatio(self): - test_shapes = [[97, 38], - [96, 97]] - # Make max_size equal to the larger value of test_shapes. - min_size = 97 - max_size = 97 - factor = 8 - keep_aspect_ratio = False - expected_image_shape_list = [(97, 97, 3), - (97, 97, 3)] - expected_label_shape_list = [(97, 97, 1), - (97, 97, 1)] - for i, test_shape in enumerate(test_shapes): - image = tf.random.normal([test_shape[0], test_shape[1], 3]) - label = tf.random.normal([test_shape[0], test_shape[1], 1]) - new_tensor_list = preprocess_utils.resize_to_range( - image=image, - label=label, - min_size=min_size, - max_size=max_size, - factor=factor, - keep_aspect_ratio=keep_aspect_ratio, - align_corners=True) - with self.test_session() as session: - new_tensor_list = session.run(new_tensor_list) - self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) - self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/resnet_v1_beta.py b/research/deeplab/core/resnet_v1_beta.py deleted file mode 100644 index 0d5f1f19a234fb13cbac2d7397d0948b64d3011b..0000000000000000000000000000000000000000 --- a/research/deeplab/core/resnet_v1_beta.py +++ /dev/null @@ -1,827 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Resnet v1 model variants. - -Code branched out from slim/nets/resnet_v1.py, and please refer to it for -more details. - -The original version ResNets-v1 were proposed by: -[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition. arXiv:1512.03385 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import conv2d_ws -from deeplab.core import utils -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - -_DEFAULT_MULTI_GRID = [1, 1, 1] -_DEFAULT_MULTI_GRID_RESNET_18 = [1, 1] - - -@slim.add_arg_scope -def bottleneck(inputs, - depth, - depth_bottleneck, - stride, - unit_rate=1, - rate=1, - outputs_collections=None, - scope=None): - """Bottleneck residual unit variant with BN after convolutions. - - This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for - its definition. Note that we use here the bottleneck variant which has an - extra bottleneck layer. - - When putting together two consecutive ResNet blocks that use this unit, one - should use stride = 2 in the last unit of the first block. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth: The depth of the ResNet unit output. - depth_bottleneck: The depth of the bottleneck layers. - stride: The ResNet unit's stride. Determines the amount of downsampling of - the units output compared to its input. - unit_rate: An integer, unit rate for atrous convolution. - rate: An integer, rate for atrous convolution. - outputs_collections: Collection to add the ResNet unit output. - scope: Optional variable_scope. - - Returns: - The ResNet unit's output. - """ - with tf.variable_scope(scope, 'bottleneck_v1', [inputs]) as sc: - depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) - if depth == depth_in: - shortcut = resnet_utils.subsample(inputs, stride, 'shortcut') - else: - shortcut = conv2d_ws.conv2d( - inputs, - depth, - [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - - residual = conv2d_ws.conv2d(inputs, depth_bottleneck, [1, 1], stride=1, - scope='conv1') - residual = conv2d_ws.conv2d_same(residual, depth_bottleneck, 3, stride, - rate=rate*unit_rate, scope='conv2') - residual = conv2d_ws.conv2d(residual, depth, [1, 1], stride=1, - activation_fn=None, scope='conv3') - output = tf.nn.relu(shortcut + residual) - - return slim.utils.collect_named_outputs(outputs_collections, sc.name, - output) - - -@slim.add_arg_scope -def lite_bottleneck(inputs, - depth, - stride, - unit_rate=1, - rate=1, - outputs_collections=None, - scope=None): - """Bottleneck residual unit variant with BN after convolutions. - - This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for - its definition. Note that we use here the bottleneck variant which has an - extra bottleneck layer. - - When putting together two consecutive ResNet blocks that use this unit, one - should use stride = 2 in the last unit of the first block. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth: The depth of the ResNet unit output. - stride: The ResNet unit's stride. Determines the amount of downsampling of - the units output compared to its input. - unit_rate: An integer, unit rate for atrous convolution. - rate: An integer, rate for atrous convolution. - outputs_collections: Collection to add the ResNet unit output. - scope: Optional variable_scope. - - Returns: - The ResNet unit's output. - """ - with tf.variable_scope(scope, 'lite_bottleneck_v1', [inputs]) as sc: - depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) - if depth == depth_in: - shortcut = resnet_utils.subsample(inputs, stride, 'shortcut') - else: - shortcut = conv2d_ws.conv2d( - inputs, - depth, [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - - residual = conv2d_ws.conv2d_same( - inputs, depth, 3, 1, rate=rate * unit_rate, scope='conv1') - with slim.arg_scope([conv2d_ws.conv2d], activation_fn=None): - residual = conv2d_ws.conv2d_same( - residual, depth, 3, stride, rate=rate * unit_rate, scope='conv2') - output = tf.nn.relu(shortcut + residual) - - return slim.utils.collect_named_outputs(outputs_collections, sc.name, - output) - - -def root_block_fn_for_beta_variant(net, depth_multiplier=1.0): - """Gets root_block_fn for beta variant. - - ResNet-v1 beta variant modifies the first original 7x7 convolution to three - 3x3 convolutions. - - Args: - net: A tensor of size [batch, height, width, channels], input to the model. - depth_multiplier: Controls the number of convolution output channels for - each input channel. The total number of depthwise convolution output - channels will be equal to `num_filters_out * depth_multiplier`. - - Returns: - A tensor after three 3x3 convolutions. - """ - net = conv2d_ws.conv2d_same( - net, int(64 * depth_multiplier), 3, stride=2, scope='conv1_1') - net = conv2d_ws.conv2d_same( - net, int(64 * depth_multiplier), 3, stride=1, scope='conv1_2') - net = conv2d_ws.conv2d_same( - net, int(128 * depth_multiplier), 3, stride=1, scope='conv1_3') - - return net - - -def resnet_v1_beta(inputs, - blocks, - num_classes=None, - is_training=None, - global_pool=True, - output_stride=None, - root_block_fn=None, - reuse=None, - scope=None, - sync_batch_norm_method='None'): - """Generator for v1 ResNet models (beta variant). - - This function generates a family of modified ResNet v1 models. In particular, - the first original 7x7 convolution is replaced with three 3x3 convolutions. - See the resnet_v1_*() methods for specific model instantiations, obtained by - selecting different block instantiations that produce ResNets of various - depths. - - The code is modified from slim/nets/resnet_v1.py, and please refer to it for - more details. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - blocks: A list of length equal to the number of ResNet blocks. Each element - is a resnet_utils.Block object describing the units in the block. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - root_block_fn: The function consisting of convolution operations applied to - the root input. If root_block_fn is None, use the original setting of - RseNet-v1, which is simply one convolution with 7x7 kernel and stride=2. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If the target output_stride is not valid. - """ - if root_block_fn is None: - root_block_fn = functools.partial(conv2d_ws.conv2d_same, - num_outputs=64, - kernel_size=7, - stride=2, - scope='conv1') - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with tf.variable_scope(scope, 'resnet_v1', [inputs], reuse=reuse) as sc: - end_points_collection = sc.original_name_scope + '_end_points' - with slim.arg_scope([ - conv2d_ws.conv2d, bottleneck, lite_bottleneck, - resnet_utils.stack_blocks_dense - ], - outputs_collections=end_points_collection): - if is_training is not None: - arg_scope = slim.arg_scope([batch_norm], is_training=is_training) - else: - arg_scope = slim.arg_scope([]) - with arg_scope: - net = inputs - if output_stride is not None: - if output_stride % 4 != 0: - raise ValueError('The output_stride needs to be a multiple of 4.') - output_stride //= 4 - net = root_block_fn(net) - net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='pool1') - net = resnet_utils.stack_blocks_dense(net, blocks, output_stride) - - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='pool5', keepdims=True) - if num_classes is not None: - net = conv2d_ws.conv2d(net, num_classes, [1, 1], activation_fn=None, - normalizer_fn=None, scope='logits', - use_weight_standardization=False) - # Convert end_points_collection into a dictionary of end_points. - end_points = slim.utils.convert_collection_to_dict( - end_points_collection) - if num_classes is not None: - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def resnet_v1_beta_block(scope, base_depth, num_units, stride): - """Helper function for creating a resnet_v1 beta variant bottleneck block. - - Args: - scope: The scope of the block. - base_depth: The depth of the bottleneck layer for each unit. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - - Returns: - A resnet_v1 bottleneck block. - """ - return resnet_utils.Block(scope, bottleneck, [{ - 'depth': base_depth * 4, - 'depth_bottleneck': base_depth, - 'stride': 1, - 'unit_rate': 1 - }] * (num_units - 1) + [{ - 'depth': base_depth * 4, - 'depth_bottleneck': base_depth, - 'stride': stride, - 'unit_rate': 1 - }]) - - -def resnet_v1_small_beta_block(scope, base_depth, num_units, stride): - """Helper function for creating a resnet_18 beta variant bottleneck block. - - Args: - scope: The scope of the block. - base_depth: The depth of the bottleneck layer for each unit. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - - Returns: - A resnet_18 bottleneck block. - """ - block_args = [] - for _ in range(num_units - 1): - block_args.append({'depth': base_depth, 'stride': 1, 'unit_rate': 1}) - block_args.append({'depth': base_depth, 'stride': stride, 'unit_rate': 1}) - return resnet_utils.Block(scope, lite_bottleneck, block_args) - - -def resnet_v1_18(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_18', - sync_batch_norm_method='None'): - """Resnet v1 18. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID_RESNET_18 - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - - block4_args = [] - for rate in multi_grid: - block4_args.append({'depth': 512, 'stride': 1, 'unit_rate': rate}) - - blocks = [ - resnet_v1_small_beta_block( - 'block1', base_depth=64, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block2', base_depth=128, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block3', base_depth=256, num_units=2, stride=2), - resnet_utils.Block('block4', lite_bottleneck, block4_args), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_18_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - root_depth_multiplier=0.25, - reuse=None, - scope='resnet_v1_18', - sync_batch_norm_method='None'): - """Resnet v1 18 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-18. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - root_depth_multiplier: Float, depth multiplier used for the first three - convolution layers that replace the 7x7 convolution. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID_RESNET_18 - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - - block4_args = [] - for rate in multi_grid: - block4_args.append({'depth': 512, 'stride': 1, 'unit_rate': rate}) - - blocks = [ - resnet_v1_small_beta_block( - 'block1', base_depth=64, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block2', base_depth=128, num_units=2, stride=2), - resnet_v1_small_beta_block( - 'block3', base_depth=256, num_units=2, stride=2), - resnet_utils.Block('block4', lite_bottleneck, block4_args), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant, - depth_multiplier=root_depth_multiplier), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_50(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_50', - sync_batch_norm_method='None'): - """Resnet v1 50. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=6, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_50_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_50', - sync_batch_norm_method='None'): - """Resnet v1 50 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-50. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=6, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_101(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_101', - sync_batch_norm_method='None'): - """Resnet v1 101. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=23, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_v1_101_beta(inputs, - num_classes=None, - is_training=None, - global_pool=False, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_101', - sync_batch_norm_method='None'): - """Resnet v1 101 beta variant. - - This variant modifies the first convolution layer of ResNet-v1-101. In - particular, it changes the original one 7x7 convolution to three 3x3 - convolutions. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - num_classes: Number of predicted classes for classification tasks. If None - we return the features before the logit layer. - is_training: Enable/disable is_training for batch normalization. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - multi_grid: Employ a hierarchy of different atrous rates within network. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is None, then - net is the output of the last ResNet block, potentially after global - average pooling. If num_classes is not None, net contains the pre-softmax - activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: if multi_grid is not None and does not have length = 3. - """ - if multi_grid is None: - multi_grid = _DEFAULT_MULTI_GRID - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - blocks = [ - resnet_v1_beta_block( - 'block1', base_depth=64, num_units=3, stride=2), - resnet_v1_beta_block( - 'block2', base_depth=128, num_units=4, stride=2), - resnet_v1_beta_block( - 'block3', base_depth=256, num_units=23, stride=2), - resnet_utils.Block('block4', bottleneck, [ - {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid]), - ] - return resnet_v1_beta( - inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial(root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def resnet_arg_scope(weight_decay=0.0001, - batch_norm_decay=0.997, - batch_norm_epsilon=1e-5, - batch_norm_scale=True, - activation_fn=tf.nn.relu, - use_batch_norm=True, - sync_batch_norm_method='None', - normalization_method='unspecified', - use_weight_standardization=False): - """Defines the default ResNet arg scope. - - Args: - weight_decay: The weight decay to use for regularizing the model. - batch_norm_decay: The moving average decay when estimating layer activation - statistics in batch normalization. - batch_norm_epsilon: Small constant to prevent division by zero when - normalizing activations by their variance in batch normalization. - batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the - activations in the batch normalization layer. - activation_fn: The activation function which is used in ResNet. - use_batch_norm: Deprecated in favor of normalization_method. - sync_batch_norm_method: String, sync batchnorm method. - normalization_method: String, one of `batch`, `none`, or `group`, to use - batch normalization, no normalization, or group normalization. - use_weight_standardization: Boolean, whether to use weight standardization. - - Returns: - An `arg_scope` to use for the resnet models. - """ - batch_norm_params = { - 'decay': batch_norm_decay, - 'epsilon': batch_norm_epsilon, - 'scale': batch_norm_scale, - } - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - if normalization_method == 'batch': - normalizer_fn = batch_norm - elif normalization_method == 'none': - normalizer_fn = None - elif normalization_method == 'group': - normalizer_fn = slim.group_norm - elif normalization_method == 'unspecified': - normalizer_fn = batch_norm if use_batch_norm else None - else: - raise ValueError('Unrecognized normalization_method %s' % - normalization_method) - - with slim.arg_scope([conv2d_ws.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - weights_initializer=slim.variance_scaling_initializer(), - activation_fn=activation_fn, - normalizer_fn=normalizer_fn, - use_weight_standardization=use_weight_standardization): - with slim.arg_scope([batch_norm], **batch_norm_params): - # The following implies padding='SAME' for pool1, which makes feature - # alignment easier for dense prediction tasks. This is also used in - # https://github.com/facebook/fb.resnet.torch. However the accompanying - # code of 'Deep Residual Learning for Image Recognition' uses - # padding='VALID' for pool1. You can switch to that choice by setting - # slim.arg_scope([slim.max_pool2d], padding='VALID'). - with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc: - return arg_sc diff --git a/research/deeplab/core/resnet_v1_beta_test.py b/research/deeplab/core/resnet_v1_beta_test.py deleted file mode 100644 index 8b61edcce21803047ea047a0acb1bc9e7ae147da..0000000000000000000000000000000000000000 --- a/research/deeplab/core/resnet_v1_beta_test.py +++ /dev/null @@ -1,564 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for resnet_v1_beta module.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import functools - -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import resnet_v1_beta -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Create test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.to_float( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels])) - - -class ResnetCompleteNetworkTest(tf.test.TestCase): - """Tests with complete small ResNet v1 networks.""" - - def _resnet_small_lite_bottleneck(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_small'): - """A shallow and thin ResNet v1 with lite_bottleneck.""" - if multi_grid is None: - multi_grid = [1, 1] - else: - if len(multi_grid) != 2: - raise ValueError('Expect multi_grid to have length 2.') - block = resnet_v1_beta.resnet_v1_small_beta_block - blocks = [ - block('block1', base_depth=1, num_units=1, stride=2), - block('block2', base_depth=2, num_units=1, stride=2), - block('block3', base_depth=4, num_units=1, stride=2), - resnet_utils.Block('block4', resnet_v1_beta.lite_bottleneck, [ - {'depth': 8, - 'stride': 1, - 'unit_rate': rate} for rate in multi_grid])] - return resnet_v1_beta.resnet_v1_beta( - inputs, - blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial( - resnet_v1_beta.root_block_fn_for_beta_variant, - depth_multiplier=0.25), - reuse=reuse, - scope=scope) - - def _resnet_small(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - multi_grid=None, - reuse=None, - scope='resnet_v1_small'): - """A shallow and thin ResNet v1 for faster tests.""" - if multi_grid is None: - multi_grid = [1, 1, 1] - else: - if len(multi_grid) != 3: - raise ValueError('Expect multi_grid to have length 3.') - - block = resnet_v1_beta.resnet_v1_beta_block - blocks = [ - block('block1', base_depth=1, num_units=1, stride=2), - block('block2', base_depth=2, num_units=1, stride=2), - block('block3', base_depth=4, num_units=1, stride=2), - resnet_utils.Block('block4', resnet_v1_beta.bottleneck, [ - {'depth': 32, 'depth_bottleneck': 8, 'stride': 1, - 'unit_rate': rate} for rate in multi_grid])] - - return resnet_v1_beta.resnet_v1_beta( - inputs, - blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - root_block_fn=functools.partial( - resnet_v1_beta.root_block_fn_for_beta_variant), - reuse=reuse, - scope=scope) - - def testClassificationEndPointsWithLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithMultigridAndLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - multi_grid = [1, 2] - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - multi_grid=multi_grid, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationShapesWithLiteBottleneck(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 112, 112, 16], - 'resnet/conv1_2': [2, 112, 112, 16], - 'resnet/conv1_3': [2, 112, 112, 32], - 'resnet/block1': [2, 28, 28, 1], - 'resnet/block2': [2, 14, 14, 2], - 'resnet/block3': [2, 7, 7, 4], - 'resnet/block4': [2, 7, 7, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapesWithLiteBottleneck(self): - global_pool = False - num_classes = 10 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 16], - 'resnet/conv1_2': [2, 161, 161, 16], - 'resnet/conv1_3': [2, 161, 161, 32], - 'resnet/block1': [2, 41, 41, 1], - 'resnet/block2': [2, 21, 21, 2], - 'resnet/block3': [2, 11, 11, 4], - 'resnet/block4': [2, 11, 11, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapesWithLiteBottleneck(self): - global_pool = False - num_classes = 10 - output_stride = 8 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 16], - 'resnet/conv1_2': [2, 161, 161, 16], - 'resnet/conv1_3': [2, 161, 161, 32], - 'resnet/block1': [2, 41, 41, 1], - 'resnet/block2': [2, 41, 41, 2], - 'resnet/block3': [2, 41, 41, 4], - 'resnet/block4': [2, 41, 41, 8]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValuesWithLiteBottleneck(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 81, 81, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-4, rtol=1e-4) - - def testUnknownBatchSizeWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, _ = self._resnet_small_lite_bottleneck( - inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidthWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 8]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 3, 3, 8)) - - def testAtrousFullyConvolutionalUnknownHeightWidthWithLiteBottleneck(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small_lite_bottleneck( - inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 8]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 9, 9, 8)) - - def testClassificationEndPoints(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithWS(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(use_weight_standardization=True)): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithGN(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(normalization_method='group')): - with slim.arg_scope([slim.group_norm], groups=1): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testInvalidGroupsWithGN(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with self.assertRaisesRegexp(ValueError, 'Invalid groups'): - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope(normalization_method='group')): - with slim.arg_scope([slim.group_norm], groups=32): - _, _ = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - def testClassificationEndPointsWithGNWS(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope( - resnet_v1_beta.resnet_arg_scope( - normalization_method='group', use_weight_standardization=True)): - with slim.arg_scope([slim.group_norm], groups=1): - logits, end_points = self._resnet_small( - inputs, num_classes, global_pool=global_pool, scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationEndPointsWithMultigrid(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - multi_grid = [1, 2, 4] - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - multi_grid=multi_grid, - scope='resnet') - - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertIn('predictions', end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - - def testClassificationShapes(self): - global_pool = True - num_classes = 10 - inputs = create_test_input(2, 224, 224, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 112, 112, 64], - 'resnet/conv1_2': [2, 112, 112, 64], - 'resnet/conv1_3': [2, 112, 112, 128], - 'resnet/block1': [2, 28, 28, 4], - 'resnet/block2': [2, 14, 14, 8], - 'resnet/block3': [2, 7, 7, 16], - 'resnet/block4': [2, 7, 7, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 10 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 64], - 'resnet/conv1_2': [2, 161, 161, 64], - 'resnet/conv1_3': [2, 161, 161, 128], - 'resnet/block1': [2, 41, 41, 4], - 'resnet/block2': [2, 21, 21, 8], - 'resnet/block3': [2, 11, 11, 16], - 'resnet/block4': [2, 11, 11, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 10 - output_stride = 8 - inputs = create_test_input(2, 321, 321, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - _, end_points = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='resnet') - endpoint_to_shape = { - 'resnet/conv1_1': [2, 161, 161, 64], - 'resnet/conv1_2': [2, 161, 161, 64], - 'resnet/conv1_3': [2, 161, 161, 128], - 'resnet/block1': [2, 41, 41, 4], - 'resnet/block2': [2, 41, 41, 8], - 'resnet/block3': [2, 41, 41, 16], - 'resnet/block4': [2, 41, 41, 32]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValues(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 81, 81, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._resnet_small(inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._resnet_small(inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-4, rtol=1e-4) - - def testUnknownBatchSize(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - logits, _ = self._resnet_small(inputs, - num_classes, - global_pool=global_pool, - scope='resnet') - self.assertTrue(logits.op.name.startswith('resnet/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small(inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 32]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 3, 3, 32)) - - def testAtrousFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(resnet_utils.resnet_arg_scope()): - output, _ = self._resnet_small(inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 32]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEqual(output.shape, (batch, 9, 9, 32)) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/utils.py b/research/deeplab/core/utils.py deleted file mode 100644 index 4bf3d09ad4647c757da5f9ebb3c2f676e3ccc00c..0000000000000000000000000000000000000000 --- a/research/deeplab/core/utils.py +++ /dev/null @@ -1,214 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""This script contains utility functions.""" -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework -from tensorflow.contrib import slim as contrib_slim - -slim = contrib_slim - - -# Quantized version of sigmoid function. -q_sigmoid = lambda x: tf.nn.relu6(x + 3) * 0.16667 - - -def resize_bilinear(images, size, output_dtype=tf.float32): - """Returns resized images as output_type. - - Args: - images: A tensor of size [batch, height_in, width_in, channels]. - size: A 1-D int32 Tensor of 2 elements: new_height, new_width. The new size - for the images. - output_dtype: The destination type. - Returns: - A tensor of size [batch, height_out, width_out, channels] as a dtype of - output_dtype. - """ - images = tf.image.resize_bilinear(images, size, align_corners=True) - return tf.cast(images, dtype=output_dtype) - - -def scale_dimension(dim, scale): - """Scales the input dimension. - - Args: - dim: Input dimension (a scalar or a scalar Tensor). - scale: The amount of scaling applied to the input. - - Returns: - Scaled dimension. - """ - if isinstance(dim, tf.Tensor): - return tf.cast((tf.to_float(dim) - 1.0) * scale + 1.0, dtype=tf.int32) - else: - return int((float(dim) - 1.0) * scale + 1.0) - - -def split_separable_conv2d(inputs, - filters, - kernel_size=3, - rate=1, - weight_decay=0.00004, - depthwise_weights_initializer_stddev=0.33, - pointwise_weights_initializer_stddev=0.06, - scope=None): - """Splits a separable conv2d into depthwise and pointwise conv2d. - - This operation differs from `tf.layers.separable_conv2d` as this operation - applies activation function between depthwise and pointwise conv2d. - - Args: - inputs: Input tensor with shape [batch, height, width, channels]. - filters: Number of filters in the 1x1 pointwise convolution. - kernel_size: A list of length 2: [kernel_height, kernel_width] of - of the filters. Can be an int if both values are the same. - rate: Atrous convolution rate for the depthwise convolution. - weight_decay: The weight decay to use for regularizing the model. - depthwise_weights_initializer_stddev: The standard deviation of the - truncated normal weight initializer for depthwise convolution. - pointwise_weights_initializer_stddev: The standard deviation of the - truncated normal weight initializer for pointwise convolution. - scope: Optional scope for the operation. - - Returns: - Computed features after split separable conv2d. - """ - outputs = slim.separable_conv2d( - inputs, - None, - kernel_size=kernel_size, - depth_multiplier=1, - rate=rate, - weights_initializer=tf.truncated_normal_initializer( - stddev=depthwise_weights_initializer_stddev), - weights_regularizer=None, - scope=scope + '_depthwise') - return slim.conv2d( - outputs, - filters, - 1, - weights_initializer=tf.truncated_normal_initializer( - stddev=pointwise_weights_initializer_stddev), - weights_regularizer=slim.l2_regularizer(weight_decay), - scope=scope + '_pointwise') - - -def get_label_weight_mask(labels, ignore_label, num_classes, label_weights=1.0): - """Gets the label weight mask. - - Args: - labels: A Tensor of labels with the shape of [-1]. - ignore_label: Integer, label to ignore. - num_classes: Integer, the number of semantic classes. - label_weights: A float or a list of weights. If it is a float, it means all - the labels have the same weight. If it is a list of weights, then each - element in the list represents the weight for the label of its index, for - example, label_weights = [0.1, 0.5] means the weight for label 0 is 0.1 - and the weight for label 1 is 0.5. - - Returns: - A Tensor of label weights with the same shape of labels, each element is the - weight for the label with the same index in labels and the element is 0.0 - if the label is to ignore. - - Raises: - ValueError: If label_weights is neither a float nor a list, or if - label_weights is a list and its length is not equal to num_classes. - """ - if not isinstance(label_weights, (float, list)): - raise ValueError( - 'The type of label_weights is invalid, it must be a float or a list.') - - if isinstance(label_weights, list) and len(label_weights) != num_classes: - raise ValueError( - 'Length of label_weights must be equal to num_classes if it is a list, ' - 'label_weights: %s, num_classes: %d.' % (label_weights, num_classes)) - - not_ignore_mask = tf.not_equal(labels, ignore_label) - not_ignore_mask = tf.cast(not_ignore_mask, tf.float32) - if isinstance(label_weights, float): - return not_ignore_mask * label_weights - - label_weights = tf.constant(label_weights, tf.float32) - weight_mask = tf.einsum('...y,y->...', - tf.one_hot(labels, num_classes, dtype=tf.float32), - label_weights) - return tf.multiply(not_ignore_mask, weight_mask) - - -def get_batch_norm_fn(sync_batch_norm_method): - """Gets batch norm function. - - Currently we only support the following methods: - - `None` (no sync batch norm). We use slim.batch_norm in this case. - - Args: - sync_batch_norm_method: String, method used to sync batch norm. - - Returns: - Batchnorm function. - - Raises: - ValueError: If sync_batch_norm_method is not supported. - """ - if sync_batch_norm_method == 'None': - return slim.batch_norm - else: - raise ValueError('Unsupported sync_batch_norm_method.') - - -def get_batch_norm_params(decay=0.9997, - epsilon=1e-5, - center=True, - scale=True, - is_training=True, - sync_batch_norm_method='None', - initialize_gamma_as_zeros=False): - """Gets batch norm parameters. - - Args: - decay: Float, decay for the moving average. - epsilon: Float, value added to variance to avoid dividing by zero. - center: Boolean. If True, add offset of `beta` to normalized tensor. If - False,`beta` is ignored. - scale: Boolean. If True, multiply by `gamma`. If False, `gamma` is not used. - is_training: Boolean, whether or not the layer is in training mode. - sync_batch_norm_method: String, method used to sync batch norm. - initialize_gamma_as_zeros: Boolean, initializing `gamma` as zeros or not. - - Returns: - A dictionary for batchnorm parameters. - - Raises: - ValueError: If sync_batch_norm_method is not supported. - """ - batch_norm_params = { - 'is_training': is_training, - 'decay': decay, - 'epsilon': epsilon, - 'scale': scale, - 'center': center, - } - if initialize_gamma_as_zeros: - if sync_batch_norm_method == 'None': - # Slim-type gamma_initialier. - batch_norm_params['param_initializers'] = { - 'gamma': tf.zeros_initializer(), - } - else: - raise ValueError('Unsupported sync_batch_norm_method.') - return batch_norm_params diff --git a/research/deeplab/core/utils_test.py b/research/deeplab/core/utils_test.py deleted file mode 100644 index cfdb63ef2d3faaa8090867a5382876972b0cff3d..0000000000000000000000000000000000000000 --- a/research/deeplab/core/utils_test.py +++ /dev/null @@ -1,90 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for utils.py.""" - -import numpy as np -import tensorflow as tf - -from deeplab.core import utils - - -class UtilsTest(tf.test.TestCase): - - def testScaleDimensionOutput(self): - self.assertEqual(161, utils.scale_dimension(321, 0.5)) - self.assertEqual(193, utils.scale_dimension(321, 0.6)) - self.assertEqual(241, utils.scale_dimension(321, 0.75)) - - def testGetLabelWeightMask_withFloatLabelWeights(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = 0.5 - expected_label_weight_mask = np.array([0.5, 0.0, 0.5, 0.5, 0.5], - dtype=np.float32) - - with self.test_session() as sess: - label_weight_mask = utils.get_label_weight_mask( - labels, ignore_label, num_classes, label_weights=label_weights) - label_weight_mask = sess.run(label_weight_mask) - self.assertAllEqual(label_weight_mask, expected_label_weight_mask) - - def testGetLabelWeightMask_withListLabelWeights(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = [0.0, 0.1, 0.2, 0.3, 0.4] - expected_label_weight_mask = np.array([0.0, 0.0, 0.1, 0.3, 0.2], - dtype=np.float32) - - with self.test_session() as sess: - label_weight_mask = utils.get_label_weight_mask( - labels, ignore_label, num_classes, label_weights=label_weights) - label_weight_mask = sess.run(label_weight_mask) - self.assertAllEqual(label_weight_mask, expected_label_weight_mask) - - def testGetLabelWeightMask_withInvalidLabelWeightsType(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - - self.assertRaisesWithRegexpMatch( - ValueError, - '^The type of label_weights is invalid, it must be a float or a list', - utils.get_label_weight_mask, - labels=labels, - ignore_label=ignore_label, - num_classes=num_classes, - label_weights=None) - - def testGetLabelWeightMask_withInvalidLabelWeightsLength(self): - labels = tf.constant([0, 4, 1, 3, 2]) - ignore_label = 4 - num_classes = 5 - label_weights = [0.0, 0.1, 0.2] - - self.assertRaisesWithRegexpMatch( - ValueError, - '^Length of label_weights must be equal to num_classes if it is a list', - utils.get_label_weight_mask, - labels=labels, - ignore_label=ignore_label, - num_classes=num_classes, - label_weights=label_weights) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/core/xception.py b/research/deeplab/core/xception.py deleted file mode 100644 index f9925714716ea0346dd8df75b956a876e52bde69..0000000000000000000000000000000000000000 --- a/research/deeplab/core/xception.py +++ /dev/null @@ -1,945 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -r"""Xception model. - -"Xception: Deep Learning with Depthwise Separable Convolutions" -Fran{\c{c}}ois Chollet -https://arxiv.org/abs/1610.02357 - -We implement the modified version by Jifeng Dai et al. for their COCO 2017 -detection challenge submission, where the model is made deeper and has aligned -features for dense prediction tasks. See their slides for details: - -"Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge -2017 Entry" -Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei and Jifeng Dai -ICCV 2017 COCO Challenge workshop -http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf - -We made a few more changes on top of MSRA's modifications: -1. Fully convolutional: All the max-pooling layers are replaced with separable - conv2d with stride = 2. This allows us to use atrous convolution to extract - feature maps at any resolution. - -2. We support adding ReLU and BatchNorm after depthwise convolution, motivated - by the design of MobileNetv1. - -"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision -Applications" -Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, -Tobias Weyand, Marco Andreetto, Hartwig Adam -https://arxiv.org/abs/1704.04861 -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import collections -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import utils -from tensorflow.contrib.slim.nets import resnet_utils -from nets.mobilenet import conv_blocks as mobilenet_v3_ops - -slim = contrib_slim - - -_DEFAULT_MULTI_GRID = [1, 1, 1] -# The cap for tf.clip_by_value. -_CLIP_CAP = 6 - - -class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])): - """A named tuple describing an Xception block. - - Its parts are: - scope: The scope of the block. - unit_fn: The Xception unit function which takes as input a tensor and - returns another tensor with the output of the Xception unit. - args: A list of length equal to the number of units in the block. The list - contains one dictionary for each unit in the block to serve as argument to - unit_fn. - """ - - -def fixed_padding(inputs, kernel_size, rate=1): - """Pads the input along the spatial dimensions independently of input size. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. - kernel_size: The kernel to be used in the conv2d or max_pool2d operation. - Should be a positive integer. - rate: An integer, rate for atrous convolution. - - Returns: - output: A tensor of size [batch, height_out, width_out, channels] with the - input, either intact (if kernel_size == 1) or padded (if kernel_size > 1). - """ - kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) - pad_total = kernel_size_effective - 1 - pad_beg = pad_total // 2 - pad_end = pad_total - pad_beg - padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], - [pad_beg, pad_end], [0, 0]]) - return padded_inputs - - -@slim.add_arg_scope -def separable_conv2d_same(inputs, - num_outputs, - kernel_size, - depth_multiplier, - stride, - rate=1, - use_explicit_padding=True, - regularize_depthwise=False, - scope=None, - **kwargs): - """Strided 2-D separable convolution with 'SAME' padding. - - If stride > 1 and use_explicit_padding is True, then we do explicit zero- - padding, followed by conv2d with 'VALID' padding. - - Note that - - net = separable_conv2d_same(inputs, num_outputs, 3, - depth_multiplier=1, stride=stride) - - is equivalent to - - net = slim.separable_conv2d(inputs, num_outputs, 3, - depth_multiplier=1, stride=1, padding='SAME') - net = resnet_utils.subsample(net, factor=stride) - - whereas - - net = slim.separable_conv2d(inputs, num_outputs, 3, stride=stride, - depth_multiplier=1, padding='SAME') - - is different when the input's height or width is even, which is why we add the - current function. - - Consequently, if the input feature map has even height or width, setting - `use_explicit_padding=False` will result in feature misalignment by one pixel - along the corresponding dimension. - - Args: - inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. - num_outputs: An integer, the number of output filters. - kernel_size: An int with the kernel_size of the filters. - depth_multiplier: The number of depthwise convolution output channels for - each input channel. The total number of depthwise convolution output - channels will be equal to `num_filters_in * depth_multiplier`. - stride: An integer, the output stride. - rate: An integer, rate for atrous convolution. - use_explicit_padding: If True, use explicit padding to make the model fully - compatible with the open source version, otherwise use the native - Tensorflow 'SAME' padding. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - scope: Scope. - **kwargs: additional keyword arguments to pass to slim.conv2d - - Returns: - output: A 4-D tensor of size [batch, height_out, width_out, channels] with - the convolution output. - """ - def _separable_conv2d(padding): - """Wrapper for separable conv2d.""" - return slim.separable_conv2d(inputs, - num_outputs, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - padding=padding, - scope=scope, - **kwargs) - def _split_separable_conv2d(padding): - """Splits separable conv2d into depthwise and pointwise conv2d.""" - outputs = slim.separable_conv2d(inputs, - None, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - padding=padding, - scope=scope + '_depthwise', - **kwargs) - return slim.conv2d(outputs, - num_outputs, - 1, - scope=scope + '_pointwise', - **kwargs) - if stride == 1 or not use_explicit_padding: - if regularize_depthwise: - outputs = _separable_conv2d(padding='SAME') - else: - outputs = _split_separable_conv2d(padding='SAME') - else: - inputs = fixed_padding(inputs, kernel_size, rate) - if regularize_depthwise: - outputs = _separable_conv2d(padding='VALID') - else: - outputs = _split_separable_conv2d(padding='VALID') - return outputs - - -@slim.add_arg_scope -def xception_module(inputs, - depth_list, - skip_connection_type, - stride, - kernel_size=3, - unit_rate_list=None, - rate=1, - activation_fn_in_separable_conv=False, - regularize_depthwise=False, - outputs_collections=None, - scope=None, - use_bounded_activation=False, - use_explicit_padding=True, - use_squeeze_excite=False, - se_pool_size=None): - """An Xception module. - - The output of one Xception module is equal to the sum of `residual` and - `shortcut`, where `residual` is the feature computed by three separable - convolution. The `shortcut` is the feature computed by 1x1 convolution with - or without striding. In some cases, the `shortcut` path could be a simple - identity function or none (i.e, no shortcut). - - Note that we replace the max pooling operations in the Xception module with - another separable convolution with striding, since atrous rate is not properly - supported in current TensorFlow max pooling implementation. - - Args: - inputs: A tensor of size [batch, height, width, channels]. - depth_list: A list of three integers specifying the depth values of one - Xception module. - skip_connection_type: Skip connection type for the residual path. Only - supports 'conv', 'sum', or 'none'. - stride: The block unit's stride. Determines the amount of downsampling of - the units output compared to its input. - kernel_size: Integer, convolution kernel size. - unit_rate_list: A list of three integers, determining the unit rate for - each separable convolution in the xception module. - rate: An integer, rate for atrous convolution. - activation_fn_in_separable_conv: Includes activation function in the - separable convolution or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - outputs_collections: Collection to add the Xception unit output. - scope: Optional variable_scope. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - use_explicit_padding: If True, use explicit padding to make the model fully - compatible with the open source version, otherwise use the native - Tensorflow 'SAME' padding. - use_squeeze_excite: Boolean, use squeeze-and-excitation or not. - se_pool_size: None or integer specifying the pooling size used in SE module. - - Returns: - The Xception module's output. - - Raises: - ValueError: If depth_list and unit_rate_list do not contain three elements, - or if stride != 1 for the third separable convolution operation in the - residual path, or unsupported skip connection type. - """ - if len(depth_list) != 3: - raise ValueError('Expect three elements in depth_list.') - if unit_rate_list: - if len(unit_rate_list) != 3: - raise ValueError('Expect three elements in unit_rate_list.') - - with tf.variable_scope(scope, 'xception_module', [inputs]) as sc: - residual = inputs - - def _separable_conv(features, depth, kernel_size, depth_multiplier, - regularize_depthwise, rate, stride, scope): - """Separable conv block.""" - if activation_fn_in_separable_conv: - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - else: - if use_bounded_activation: - # When use_bounded_activation is True, we clip the feature values and - # apply relu6 for activation. - activation_fn = lambda x: tf.clip_by_value(x, -_CLIP_CAP, _CLIP_CAP) - features = tf.nn.relu6(features) - else: - # Original network design. - activation_fn = None - features = tf.nn.relu(features) - return separable_conv2d_same(features, - depth, - kernel_size, - depth_multiplier=depth_multiplier, - stride=stride, - rate=rate, - activation_fn=activation_fn, - use_explicit_padding=use_explicit_padding, - regularize_depthwise=regularize_depthwise, - scope=scope) - for i in range(3): - residual = _separable_conv(residual, - depth_list[i], - kernel_size=kernel_size, - depth_multiplier=1, - regularize_depthwise=regularize_depthwise, - rate=rate*unit_rate_list[i], - stride=stride if i == 2 else 1, - scope='separable_conv' + str(i+1)) - if use_squeeze_excite: - residual = mobilenet_v3_ops.squeeze_excite( - input_tensor=residual, - squeeze_factor=16, - inner_activation_fn=tf.nn.relu, - gating_fn=lambda x: tf.nn.relu6(x+3)*0.16667, - pool=se_pool_size) - - if skip_connection_type == 'conv': - shortcut = slim.conv2d(inputs, - depth_list[-1], - [1, 1], - stride=stride, - activation_fn=None, - scope='shortcut') - if use_bounded_activation: - residual = tf.clip_by_value(residual, -_CLIP_CAP, _CLIP_CAP) - shortcut = tf.clip_by_value(shortcut, -_CLIP_CAP, _CLIP_CAP) - outputs = residual + shortcut - if use_bounded_activation: - outputs = tf.nn.relu6(outputs) - elif skip_connection_type == 'sum': - if use_bounded_activation: - residual = tf.clip_by_value(residual, -_CLIP_CAP, _CLIP_CAP) - inputs = tf.clip_by_value(inputs, -_CLIP_CAP, _CLIP_CAP) - outputs = residual + inputs - if use_bounded_activation: - outputs = tf.nn.relu6(outputs) - elif skip_connection_type == 'none': - outputs = residual - else: - raise ValueError('Unsupported skip connection type.') - - return slim.utils.collect_named_outputs(outputs_collections, - sc.name, - outputs) - - -@slim.add_arg_scope -def stack_blocks_dense(net, - blocks, - output_stride=None, - outputs_collections=None): - """Stacks Xception blocks and controls output feature density. - - First, this function creates scopes for the Xception in the form of - 'block_name/unit_1', 'block_name/unit_2', etc. - - Second, this function allows the user to explicitly control the output - stride, which is the ratio of the input to output spatial resolution. This - is useful for dense prediction tasks such as semantic segmentation or - object detection. - - Control of the output feature density is implemented by atrous convolution. - - Args: - net: A tensor of size [batch, height, width, channels]. - blocks: A list of length equal to the number of Xception blocks. Each - element is an Xception Block object describing the units in the block. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution, which needs to be equal to - the product of unit strides from the start up to some level of Xception. - For example, if the Xception employs units with strides 1, 2, 1, 3, 4, 1, - then valid values for the output_stride are 1, 2, 6, 24 or None (which - is equivalent to output_stride=24). - outputs_collections: Collection to add the Xception block outputs. - - Returns: - net: Output tensor with stride equal to the specified output_stride. - - Raises: - ValueError: If the target output_stride is not valid. - """ - # The current_stride variable keeps track of the effective stride of the - # activations. This allows us to invoke atrous convolution whenever applying - # the next residual unit would result in the activations having stride larger - # than the target output_stride. - current_stride = 1 - - # The atrous convolution rate parameter. - rate = 1 - - for block in blocks: - with tf.variable_scope(block.scope, 'block', [net]) as sc: - for i, unit in enumerate(block.args): - if output_stride is not None and current_stride > output_stride: - raise ValueError('The target output_stride cannot be reached.') - with tf.variable_scope('unit_%d' % (i + 1), values=[net]): - # If we have reached the target output_stride, then we need to employ - # atrous convolution with stride=1 and multiply the atrous rate by the - # current unit's stride for use in subsequent layers. - if output_stride is not None and current_stride == output_stride: - net = block.unit_fn(net, rate=rate, **dict(unit, stride=1)) - rate *= unit.get('stride', 1) - else: - net = block.unit_fn(net, rate=1, **unit) - current_stride *= unit.get('stride', 1) - - # Collect activations at the block's end before performing subsampling. - net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net) - - if output_stride is not None and current_stride != output_stride: - raise ValueError('The target output_stride cannot be reached.') - - return net - - -def xception(inputs, - blocks, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - reuse=None, - scope=None, - sync_batch_norm_method='None'): - """Generator for Xception models. - - This function generates a family of Xception models. See the xception_*() - methods for specific model instantiations, obtained by selecting different - block instantiations that produce Xception of various depths. - - Args: - inputs: A tensor of size [batch, height_in, width_in, channels]. Must be - floating point. If a pretrained checkpoint is used, pixel values should be - the same as during training (see go/slim-classification-models for - specifics). - blocks: A list of length equal to the number of Xception blocks. Each - element is an Xception Block object describing the units in the block. - num_classes: Number of predicted classes for classification tasks. - If 0 or None, we return the features before the logit layer. - is_training: whether batch_norm layers are in training mode. - global_pool: If True, we perform global average pooling before computing the - logits. Set to True for image classification, False for dense prediction. - keep_prob: Keep probability used in the pre-logits dropout layer. - output_stride: If None, then the output will be computed at the nominal - network stride. If output_stride is not None, it specifies the requested - ratio of input to output spatial resolution. - reuse: whether or not the network and its variables should be reused. To be - able to reuse 'scope' must be given. - scope: Optional variable_scope. - sync_batch_norm_method: String, sync batchnorm method. Currently only - support `None`. - - Returns: - net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. - If global_pool is False, then height_out and width_out are reduced by a - factor of output_stride compared to the respective height_in and width_in, - else both height_out and width_out equal one. If num_classes is 0 or None, - then net is the output of the last Xception block, potentially after - global average pooling. If num_classes is a non-zero integer, net contains - the pre-softmax activations. - end_points: A dictionary from components of the network to the corresponding - activation. - - Raises: - ValueError: If the target output_stride is not valid. - """ - with tf.variable_scope( - scope, 'xception', [inputs], reuse=reuse) as sc: - end_points_collection = sc.original_name_scope + 'end_points' - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with slim.arg_scope([slim.conv2d, - slim.separable_conv2d, - xception_module, - stack_blocks_dense], - outputs_collections=end_points_collection): - with slim.arg_scope([batch_norm], is_training=is_training): - net = inputs - if output_stride is not None: - if output_stride % 2 != 0: - raise ValueError('The output_stride needs to be a multiple of 2.') - output_stride //= 2 - # Root block function operated on inputs. - net = resnet_utils.conv2d_same(net, 32, 3, stride=2, - scope='entry_flow/conv1_1') - net = resnet_utils.conv2d_same(net, 64, 3, stride=1, - scope='entry_flow/conv1_2') - - # Extract features for entry_flow, middle_flow, and exit_flow. - net = stack_blocks_dense(net, blocks, output_stride) - - # Convert end_points_collection into a dictionary of end_points. - end_points = slim.utils.convert_collection_to_dict( - end_points_collection, clear_collection=True) - - if global_pool: - # Global average pooling. - net = tf.reduce_mean(net, [1, 2], name='global_pool', keepdims=True) - end_points['global_pool'] = net - if num_classes: - net = slim.dropout(net, keep_prob=keep_prob, is_training=is_training, - scope='prelogits_dropout') - net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, - normalizer_fn=None, scope='logits') - end_points[sc.name + '/logits'] = net - end_points['predictions'] = slim.softmax(net, scope='predictions') - return net, end_points - - -def xception_block(scope, - depth_list, - skip_connection_type, - activation_fn_in_separable_conv, - regularize_depthwise, - num_units, - stride, - kernel_size=3, - unit_rate_list=None, - use_squeeze_excite=False, - se_pool_size=None): - """Helper function for creating a Xception block. - - Args: - scope: The scope of the block. - depth_list: The depth of the bottleneck layer for each unit. - skip_connection_type: Skip connection type for the residual path. Only - supports 'conv', 'sum', or 'none'. - activation_fn_in_separable_conv: Includes activation function in the - separable convolution or not. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - num_units: The number of units in the block. - stride: The stride of the block, implemented as a stride in the last unit. - All other units have stride=1. - kernel_size: Integer, convolution kernel size. - unit_rate_list: A list of three integers, determining the unit rate in the - corresponding xception block. - use_squeeze_excite: Boolean, use squeeze-and-excitation or not. - se_pool_size: None or integer specifying the pooling size used in SE module. - - Returns: - An Xception block. - """ - if unit_rate_list is None: - unit_rate_list = _DEFAULT_MULTI_GRID - return Block(scope, xception_module, [{ - 'depth_list': depth_list, - 'skip_connection_type': skip_connection_type, - 'activation_fn_in_separable_conv': activation_fn_in_separable_conv, - 'regularize_depthwise': regularize_depthwise, - 'stride': stride, - 'kernel_size': kernel_size, - 'unit_rate_list': unit_rate_list, - 'use_squeeze_excite': use_squeeze_excite, - 'se_pool_size': se_pool_size, - }] * num_units) - - -def xception_41(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_41', - sync_batch_norm_method='None'): - """Xception-41 model.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('entry_flow/block3', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=8, - stride=1), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - unit_rate_list=multi_grid), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_65_factory(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - kernel_size=3, - multi_grid=None, - reuse=None, - use_squeeze_excite=False, - se_pool_size=None, - scope='xception_65', - sync_batch_norm_method='None'): - """Xception-65 model factory.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block3', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=16, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - unit_rate_list=multi_grid, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_65(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_65', - sync_batch_norm_method='None'): - """Xception-65 model.""" - return xception_65_factory( - inputs=inputs, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=scope, - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_71_factory(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - kernel_size=3, - multi_grid=None, - reuse=None, - scope='xception_71', - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method='None'): - """Xception-71 model factory.""" - blocks = [ - xception_block('entry_flow/block1', - depth_list=[128, 128, 128], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block2', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block3', - depth_list=[256, 256, 256], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - xception_block('entry_flow/block4', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('entry_flow/block5', - depth_list=[728, 728, 728], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('middle_flow/block1', - depth_list=[728, 728, 728], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=16, - stride=1, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block1', - depth_list=[728, 1024, 1024], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2, - kernel_size=kernel_size, - use_squeeze_excite=use_squeeze_excite, - se_pool_size=se_pool_size), - xception_block('exit_flow/block2', - depth_list=[1536, 1536, 2048], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1, - kernel_size=kernel_size, - unit_rate_list=multi_grid, - use_squeeze_excite=False, - se_pool_size=se_pool_size), - ] - return xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - reuse=reuse, - scope=scope, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_71(inputs, - num_classes=None, - is_training=True, - global_pool=True, - keep_prob=0.5, - output_stride=None, - regularize_depthwise=False, - multi_grid=None, - reuse=None, - scope='xception_71', - sync_batch_norm_method='None'): - """Xception-71 model.""" - return xception_71_factory( - inputs=inputs, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - keep_prob=keep_prob, - output_stride=output_stride, - regularize_depthwise=regularize_depthwise, - multi_grid=multi_grid, - reuse=reuse, - scope=scope, - use_squeeze_excite=False, - se_pool_size=None, - sync_batch_norm_method=sync_batch_norm_method) - - -def xception_arg_scope(weight_decay=0.00004, - batch_norm_decay=0.9997, - batch_norm_epsilon=0.001, - batch_norm_scale=True, - weights_initializer_stddev=0.09, - regularize_depthwise=False, - use_batch_norm=True, - use_bounded_activation=False, - sync_batch_norm_method='None'): - """Defines the default Xception arg scope. - - Args: - weight_decay: The weight decay to use for regularizing the model. - batch_norm_decay: The moving average decay when estimating layer activation - statistics in batch normalization. - batch_norm_epsilon: Small constant to prevent division by zero when - normalizing activations by their variance in batch normalization. - batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the - activations in the batch normalization layer. - weights_initializer_stddev: The standard deviation of the trunctated normal - weight initializer. - regularize_depthwise: Whether or not apply L2-norm regularization on the - depthwise convolution weights. - use_batch_norm: Whether or not to use batch normalization. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - sync_batch_norm_method: String, sync batchnorm method. Currently only - support `None`. Also, it is only effective for Xception. - - Returns: - An `arg_scope` to use for the Xception models. - """ - batch_norm_params = { - 'decay': batch_norm_decay, - 'epsilon': batch_norm_epsilon, - 'scale': batch_norm_scale, - } - if regularize_depthwise: - depthwise_regularizer = slim.l2_regularizer(weight_decay) - else: - depthwise_regularizer = None - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_initializer=tf.truncated_normal_initializer( - stddev=weights_initializer_stddev), - activation_fn=activation_fn, - normalizer_fn=batch_norm if use_batch_norm else None): - with slim.arg_scope([batch_norm], **batch_norm_params): - with slim.arg_scope( - [slim.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay)): - with slim.arg_scope( - [slim.separable_conv2d], - weights_regularizer=depthwise_regularizer): - with slim.arg_scope( - [xception_module], - use_bounded_activation=use_bounded_activation, - use_explicit_padding=not use_bounded_activation) as arg_sc: - return arg_sc diff --git a/research/deeplab/core/xception_test.py b/research/deeplab/core/xception_test.py deleted file mode 100644 index fc338daa6e56d1290f5a9330a6728c1f8512881e..0000000000000000000000000000000000000000 --- a/research/deeplab/core/xception_test.py +++ /dev/null @@ -1,488 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for xception.py.""" -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -from deeplab.core import xception -from tensorflow.contrib.slim.nets import resnet_utils - -slim = contrib_slim - - -def create_test_input(batch, height, width, channels): - """Create test input tensor.""" - if None in [batch, height, width, channels]: - return tf.placeholder(tf.float32, (batch, height, width, channels)) - else: - return tf.cast( - np.tile( - np.reshape( - np.reshape(np.arange(height), [height, 1]) + - np.reshape(np.arange(width), [1, width]), - [1, height, width, 1]), - [batch, 1, 1, channels]), - tf.float32) - - -class UtilityFunctionTest(tf.test.TestCase): - - def testSeparableConv2DSameWithInputEvenSize(self): - n, n2 = 4, 2 - - # Input image. - x = create_test_input(1, n, n, 1) - - # Convolution kernel. - dw = create_test_input(1, 3, 3, 1) - dw = tf.reshape(dw, [3, 3, 1, 1]) - - tf.get_variable('Conv/depthwise_weights', initializer=dw) - tf.get_variable('Conv/pointwise_weights', - initializer=tf.ones([1, 1, 1, 1])) - tf.get_variable('Conv/biases', initializer=tf.zeros([1])) - tf.get_variable_scope().reuse_variables() - - y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=1, scope='Conv') - y1_expected = tf.cast([[14, 28, 43, 26], - [28, 48, 66, 37], - [43, 66, 84, 46], - [26, 37, 46, 22]], tf.float32) - y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) - - y2 = resnet_utils.subsample(y1, 2) - y2_expected = tf.cast([[14, 43], - [43, 84]], tf.float32) - y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) - - y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, - regularize_depthwise=True, - stride=2, scope='Conv') - y3_expected = y2_expected - - y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=2, scope='Conv') - y4_expected = tf.cast([[48, 37], - [37, 22]], tf.float32) - y4_expected = tf.reshape(y4_expected, [1, n2, n2, 1]) - - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertAllClose(y1.eval(), y1_expected.eval()) - self.assertAllClose(y2.eval(), y2_expected.eval()) - self.assertAllClose(y3.eval(), y3_expected.eval()) - self.assertAllClose(y4.eval(), y4_expected.eval()) - - def testSeparableConv2DSameWithInputOddSize(self): - n, n2 = 5, 3 - - # Input image. - x = create_test_input(1, n, n, 1) - - # Convolution kernel. - dw = create_test_input(1, 3, 3, 1) - dw = tf.reshape(dw, [3, 3, 1, 1]) - - tf.get_variable('Conv/depthwise_weights', initializer=dw) - tf.get_variable('Conv/pointwise_weights', - initializer=tf.ones([1, 1, 1, 1])) - tf.get_variable('Conv/biases', initializer=tf.zeros([1])) - tf.get_variable_scope().reuse_variables() - - y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=1, scope='Conv') - y1_expected = tf.cast([[14, 28, 43, 58, 34], - [28, 48, 66, 84, 46], - [43, 66, 84, 102, 55], - [58, 84, 102, 120, 64], - [34, 46, 55, 64, 30]], tf.float32) - y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) - - y2 = resnet_utils.subsample(y1, 2) - y2_expected = tf.cast([[14, 43, 34], - [43, 84, 55], - [34, 55, 30]], tf.float32) - y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) - - y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, - regularize_depthwise=True, - stride=2, scope='Conv') - y3_expected = y2_expected - - y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, - stride=2, scope='Conv') - y4_expected = y2_expected - - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - self.assertAllClose(y1.eval(), y1_expected.eval()) - self.assertAllClose(y2.eval(), y2_expected.eval()) - self.assertAllClose(y3.eval(), y3_expected.eval()) - self.assertAllClose(y4.eval(), y4_expected.eval()) - - -class XceptionNetworkTest(tf.test.TestCase): - """Tests with small Xception network.""" - - def _xception_small(self, - inputs, - num_classes=None, - is_training=True, - global_pool=True, - output_stride=None, - regularize_depthwise=True, - reuse=None, - scope='xception_small'): - """A shallow and thin Xception for faster tests.""" - block = xception.xception_block - blocks = [ - block('entry_flow/block1', - depth_list=[1, 1, 1], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('entry_flow/block2', - depth_list=[2, 2, 2], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('entry_flow/block3', - depth_list=[4, 4, 4], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1), - block('entry_flow/block4', - depth_list=[4, 4, 4], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('middle_flow/block1', - depth_list=[4, 4, 4], - skip_connection_type='sum', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=2, - stride=1), - block('exit_flow/block1', - depth_list=[8, 8, 8], - skip_connection_type='conv', - activation_fn_in_separable_conv=False, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=2), - block('exit_flow/block2', - depth_list=[16, 16, 16], - skip_connection_type='none', - activation_fn_in_separable_conv=True, - regularize_depthwise=regularize_depthwise, - num_units=1, - stride=1), - ] - return xception.xception(inputs, - blocks=blocks, - num_classes=num_classes, - is_training=is_training, - global_pool=global_pool, - output_stride=output_stride, - reuse=reuse, - scope=scope) - - def testClassificationEndPoints(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - logits, end_points = self._xception_small( - inputs, - num_classes=num_classes, - global_pool=global_pool, - scope='xception') - self.assertTrue( - logits.op.name.startswith('xception/logits')) - self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) - self.assertTrue('predictions' in end_points) - self.assertListEqual(end_points['predictions'].get_shape().as_list(), - [2, 1, 1, num_classes]) - self.assertTrue('global_pool' in end_points) - self.assertListEqual(end_points['global_pool'].get_shape().as_list(), - [2, 1, 1, 16]) - - def testEndpointNames(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes=num_classes, - global_pool=global_pool, - scope='xception') - expected = [ - 'xception/entry_flow/conv1_1', - 'xception/entry_flow/conv1_2', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block1/unit_1/xception_module/shortcut', - 'xception/entry_flow/block1/unit_1/xception_module', - 'xception/entry_flow/block1', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block2/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block2/unit_1/xception_module/shortcut', - 'xception/entry_flow/block2/unit_1/xception_module', - 'xception/entry_flow/block2', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block3/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block3/unit_1/xception_module/shortcut', - 'xception/entry_flow/block3/unit_1/xception_module', - 'xception/entry_flow/block3', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv1', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv2', - 'xception/entry_flow/block4/unit_1/xception_module/separable_conv3', - 'xception/entry_flow/block4/unit_1/xception_module/shortcut', - 'xception/entry_flow/block4/unit_1/xception_module', - 'xception/entry_flow/block4', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/middle_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/middle_flow/block1/unit_1/xception_module', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv1', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv2', - 'xception/middle_flow/block1/unit_2/xception_module/separable_conv3', - 'xception/middle_flow/block1/unit_2/xception_module', - 'xception/middle_flow/block1', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv1', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv2', - 'xception/exit_flow/block1/unit_1/xception_module/separable_conv3', - 'xception/exit_flow/block1/unit_1/xception_module/shortcut', - 'xception/exit_flow/block1/unit_1/xception_module', - 'xception/exit_flow/block1', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv1', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv2', - 'xception/exit_flow/block2/unit_1/xception_module/separable_conv3', - 'xception/exit_flow/block2/unit_1/xception_module', - 'xception/exit_flow/block2', - 'global_pool', - 'xception/logits', - 'predictions', - ] - self.assertItemsEqual(list(end_points.keys()), expected) - - def testClassificationShapes(self): - global_pool = True - num_classes = 3 - inputs = create_test_input(2, 64, 64, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/conv1_1': [2, 32, 32, 32], - 'xception/entry_flow/block1': [2, 16, 16, 1], - 'xception/entry_flow/block2': [2, 8, 8, 2], - 'xception/entry_flow/block4': [2, 4, 4, 4], - 'xception/middle_flow/block1': [2, 4, 4, 4], - 'xception/exit_flow/block1': [2, 2, 2, 8], - 'xception/exit_flow/block2': [2, 2, 2, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 3 - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/conv1_1': [2, 33, 33, 32], - 'xception/entry_flow/block1': [2, 17, 17, 1], - 'xception/entry_flow/block2': [2, 9, 9, 2], - 'xception/entry_flow/block4': [2, 5, 5, 4], - 'xception/middle_flow/block1': [2, 5, 5, 4], - 'xception/exit_flow/block1': [2, 3, 3, 8], - 'xception/exit_flow/block2': [2, 3, 3, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalEndpointShapes(self): - global_pool = False - num_classes = 3 - output_stride = 8 - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='xception') - endpoint_to_shape = { - 'xception/entry_flow/block1': [2, 17, 17, 1], - 'xception/entry_flow/block2': [2, 9, 9, 2], - 'xception/entry_flow/block4': [2, 9, 9, 4], - 'xception/middle_flow/block1': [2, 9, 9, 4], - 'xception/exit_flow/block1': [2, 9, 9, 8], - 'xception/exit_flow/block2': [2, 9, 9, 16]} - for endpoint, shape in six.iteritems(endpoint_to_shape): - self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) - - def testAtrousFullyConvolutionalValues(self): - """Verify dense feature extraction with atrous convolution.""" - nominal_stride = 32 - for output_stride in [4, 8, 16, 32, None]: - with slim.arg_scope(xception.xception_arg_scope()): - with tf.Graph().as_default(): - with self.test_session() as sess: - tf.set_random_seed(0) - inputs = create_test_input(2, 96, 97, 3) - # Dense feature extraction followed by subsampling. - output, _ = self._xception_small( - inputs, - None, - is_training=False, - global_pool=False, - output_stride=output_stride) - if output_stride is None: - factor = 1 - else: - factor = nominal_stride // output_stride - output = resnet_utils.subsample(output, factor) - # Make the two networks use the same weights. - tf.get_variable_scope().reuse_variables() - # Feature extraction at the nominal network rate. - expected, _ = self._xception_small( - inputs, - None, - is_training=False, - global_pool=False) - sess.run(tf.global_variables_initializer()) - self.assertAllClose(output.eval(), expected.eval(), - atol=1e-5, rtol=1e-5) - - def testUnknownBatchSize(self): - batch = 2 - height, width = 65, 65 - global_pool = True - num_classes = 10 - inputs = create_test_input(None, height, width, 3) - with slim.arg_scope(xception.xception_arg_scope()): - logits, _ = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - scope='xception') - self.assertTrue(logits.op.name.startswith('xception/logits')) - self.assertListEqual(logits.get_shape().as_list(), - [None, 1, 1, num_classes]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(logits, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 1, 1, num_classes)) - - def testFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(xception.xception_arg_scope()): - output, _ = self._xception_small( - inputs, - None, - global_pool=global_pool) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 16]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 3, 3, 16)) - - def testAtrousFullyConvolutionalUnknownHeightWidth(self): - batch = 2 - height, width = 65, 65 - global_pool = False - output_stride = 8 - inputs = create_test_input(batch, None, None, 3) - with slim.arg_scope(xception.xception_arg_scope()): - output, _ = self._xception_small( - inputs, - None, - global_pool=global_pool, - output_stride=output_stride) - self.assertListEqual(output.get_shape().as_list(), - [batch, None, None, 16]) - images = create_test_input(batch, height, width, 3) - with self.test_session() as sess: - sess.run(tf.global_variables_initializer()) - output = sess.run(output, {inputs: images.eval()}) - self.assertEquals(output.shape, (batch, 9, 9, 16)) - - def testEndpointsReuse(self): - inputs = create_test_input(2, 32, 32, 3) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points0 = xception.xception_65( - inputs, - num_classes=10, - reuse=False) - with slim.arg_scope(xception.xception_arg_scope()): - _, end_points1 = xception.xception_65( - inputs, - num_classes=10, - reuse=True) - self.assertItemsEqual(list(end_points0.keys()), list(end_points1.keys())) - - def testUseBoundedAcitvation(self): - global_pool = False - num_classes = 3 - output_stride = 16 - for use_bounded_activation in (True, False): - tf.reset_default_graph() - inputs = create_test_input(2, 65, 65, 3) - with slim.arg_scope(xception.xception_arg_scope( - use_bounded_activation=use_bounded_activation)): - _, _ = self._xception_small( - inputs, - num_classes, - global_pool=global_pool, - output_stride=output_stride, - scope='xception') - for node in tf.get_default_graph().as_graph_def().node: - if node.op.startswith('Relu'): - self.assertEqual(node.op == 'Relu6', use_bounded_activation) - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/datasets/__init__.py b/research/deeplab/datasets/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/datasets/build_ade20k_data.py b/research/deeplab/datasets/build_ade20k_data.py deleted file mode 100644 index fc04ed0db04c83af6deaad8b59087624e8bd40e8..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_ade20k_data.py +++ /dev/null @@ -1,123 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts ADE20K data to TFRecord file format with Example protos.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import math -import os -import random -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string( - 'train_image_folder', - './ADE20K/ADEChallengeData2016/images/training', - 'Folder containing trainng images') -tf.app.flags.DEFINE_string( - 'train_image_label_folder', - './ADE20K/ADEChallengeData2016/annotations/training', - 'Folder containing annotations for trainng images') - -tf.app.flags.DEFINE_string( - 'val_image_folder', - './ADE20K/ADEChallengeData2016/images/validation', - 'Folder containing validation images') - -tf.app.flags.DEFINE_string( - 'val_image_label_folder', - './ADE20K/ADEChallengeData2016/annotations/validation', - 'Folder containing annotations for validation') - -tf.app.flags.DEFINE_string( - 'output_dir', './ADE20K/tfrecord', - 'Path to save converted tfrecord of Tensorflow example') - -_NUM_SHARDS = 4 - - -def _convert_dataset(dataset_split, dataset_dir, dataset_label_dir): - """Converts the ADE20k dataset into into tfrecord format. - - Args: - dataset_split: Dataset split (e.g., train, val). - dataset_dir: Dir in which the dataset locates. - dataset_label_dir: Dir in which the annotations locates. - - Raises: - RuntimeError: If loaded image and label have different shape. - """ - - img_names = tf.gfile.Glob(os.path.join(dataset_dir, '*.jpg')) - random.shuffle(img_names) - seg_names = [] - for f in img_names: - # get the filename without the extension - basename = os.path.basename(f).split('.')[0] - # cover its corresponding *_seg.png - seg = os.path.join(dataset_label_dir, basename+'.png') - seg_names.append(seg) - - num_images = len(img_names) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('jpeg', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - output_filename = os.path.join( - FLAGS.output_dir, - '%s-%05d-of-%05d.tfrecord' % (dataset_split, shard_id, _NUM_SHARDS)) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, num_images, shard_id)) - sys.stdout.flush() - # Read the image. - image_filename = img_names[i] - image_data = tf.gfile.FastGFile(image_filename, 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_filename = seg_names[i] - seg_data = tf.gfile.FastGFile(seg_filename, 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - example = build_data.image_seg_to_tfexample( - image_data, img_names[i], height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - tf.gfile.MakeDirs(FLAGS.output_dir) - _convert_dataset( - 'train', FLAGS.train_image_folder, FLAGS.train_image_label_folder) - _convert_dataset('val', FLAGS.val_image_folder, FLAGS.val_image_label_folder) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/build_cityscapes_data.py b/research/deeplab/datasets/build_cityscapes_data.py deleted file mode 100644 index ce81baef20a460abaa634d3f1dcb6760a0858dec..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_cityscapes_data.py +++ /dev/null @@ -1,188 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts Cityscapes data to TFRecord file format with Example protos. - -The Cityscapes dataset is expected to have the following directory structure: - - + cityscapes - - build_cityscapes_data.py (current working directiory). - - build_data.py - + cityscapesscripts - + annotation - + evaluation - + helpers - + preparation - + viewer - + gtFine - + train - + val - + test - + leftImg8bit - + train - + val - + test - + tfrecord - -This script converts data into sharded data files and save at tfrecord folder. - -Note that before running this script, the users should (1) register the -Cityscapes dataset website at https://www.cityscapes-dataset.com to -download the dataset, and (2) run the script provided by Cityscapes -`preparation/createTrainIdLabelImgs.py` to generate the training groundtruth. - -Also note that the tensorflow model will be trained with `TrainId' instead -of `EvalId' used on the evaluation server. Thus, the users need to convert -the predicted labels to `EvalId` for evaluation on the server. See the -vis.py for more details. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import glob -import math -import os.path -import re -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string('cityscapes_root', - './cityscapes', - 'Cityscapes dataset root folder.') - -tf.app.flags.DEFINE_string( - 'output_dir', - './tfrecord', - 'Path to save converted SSTable of TensorFlow examples.') - - -_NUM_SHARDS = 10 - -# A map from data type to folder name that saves the data. -_FOLDERS_MAP = { - 'image': 'leftImg8bit', - 'label': 'gtFine', -} - -# A map from data type to filename postfix. -_POSTFIX_MAP = { - 'image': '_leftImg8bit', - 'label': '_gtFine_labelTrainIds', -} - -# A map from data type to data format. -_DATA_FORMAT_MAP = { - 'image': 'png', - 'label': 'png', -} - -# Image file pattern. -_IMAGE_FILENAME_RE = re.compile('(.+)' + _POSTFIX_MAP['image']) - - -def _get_files(data, dataset_split): - """Gets files for the specified data type and dataset split. - - Args: - data: String, desired data ('image' or 'label'). - dataset_split: String, dataset split ('train', 'val', 'test') - - Returns: - A list of sorted file names or None when getting label for - test set. - """ - if data == 'label' and dataset_split == 'test': - return None - pattern = '*%s.%s' % (_POSTFIX_MAP[data], _DATA_FORMAT_MAP[data]) - search_files = os.path.join( - FLAGS.cityscapes_root, _FOLDERS_MAP[data], dataset_split, '*', pattern) - filenames = glob.glob(search_files) - return sorted(filenames) - - -def _convert_dataset(dataset_split): - """Converts the specified dataset split to TFRecord format. - - Args: - dataset_split: The dataset split (e.g., train, val). - - Raises: - RuntimeError: If loaded image and label have different shape, or if the - image file with specified postfix could not be found. - """ - image_files = _get_files('image', dataset_split) - label_files = _get_files('label', dataset_split) - - num_images = len(image_files) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('png', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - shard_filename = '%s-%05d-of-%05d.tfrecord' % ( - dataset_split, shard_id, _NUM_SHARDS) - output_filename = os.path.join(FLAGS.output_dir, shard_filename) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, num_images, shard_id)) - sys.stdout.flush() - # Read the image. - image_data = tf.gfile.FastGFile(image_files[i], 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_data = tf.gfile.FastGFile(label_files[i], 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - re_match = _IMAGE_FILENAME_RE.search(image_files[i]) - if re_match is None: - raise RuntimeError('Invalid image filename: ' + image_files[i]) - filename = os.path.basename(re_match.group(1)) - example = build_data.image_seg_to_tfexample( - image_data, filename, height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - # Only support converting 'train' and 'val' sets for now. - for dataset_split in ['train', 'val']: - _convert_dataset(dataset_split) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/build_data.py b/research/deeplab/datasets/build_data.py deleted file mode 100644 index 45628674dbf3653ca0ca20014a968794bb8cd861..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_data.py +++ /dev/null @@ -1,161 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Contains common utility functions and classes for building dataset. - -This script contains utility functions and classes to converts dataset to -TFRecord file format with Example protos. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -import collections -import six -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_enum('image_format', 'png', ['jpg', 'jpeg', 'png'], - 'Image format.') - -tf.app.flags.DEFINE_enum('label_format', 'png', ['png'], - 'Segmentation label format.') - -# A map from image format to expected data format. -_IMAGE_FORMAT_MAP = { - 'jpg': 'jpeg', - 'jpeg': 'jpeg', - 'png': 'png', -} - - -class ImageReader(object): - """Helper class that provides TensorFlow image coding utilities.""" - - def __init__(self, image_format='jpeg', channels=3): - """Class constructor. - - Args: - image_format: Image format. Only 'jpeg', 'jpg', or 'png' are supported. - channels: Image channels. - """ - with tf.Graph().as_default(): - self._decode_data = tf.placeholder(dtype=tf.string) - self._image_format = image_format - self._session = tf.Session() - if self._image_format in ('jpeg', 'jpg'): - self._decode = tf.image.decode_jpeg(self._decode_data, - channels=channels) - elif self._image_format == 'png': - self._decode = tf.image.decode_png(self._decode_data, - channels=channels) - - def read_image_dims(self, image_data): - """Reads the image dimensions. - - Args: - image_data: string of image data. - - Returns: - image_height and image_width. - """ - image = self.decode_image(image_data) - return image.shape[:2] - - def decode_image(self, image_data): - """Decodes the image data string. - - Args: - image_data: string of image data. - - Returns: - Decoded image data. - - Raises: - ValueError: Value of image channels not supported. - """ - image = self._session.run(self._decode, - feed_dict={self._decode_data: image_data}) - if len(image.shape) != 3 or image.shape[2] not in (1, 3): - raise ValueError('The image channels not supported.') - - return image - - -def _int64_list_feature(values): - """Returns a TF-Feature of int64_list. - - Args: - values: A scalar or list of values. - - Returns: - A TF-Feature. - """ - if not isinstance(values, collections.Iterable): - values = [values] - - return tf.train.Feature(int64_list=tf.train.Int64List(value=values)) - - -def _bytes_list_feature(values): - """Returns a TF-Feature of bytes. - - Args: - values: A string. - - Returns: - A TF-Feature. - """ - def norm2bytes(value): - return value.encode() if isinstance(value, str) and six.PY3 else value - - return tf.train.Feature( - bytes_list=tf.train.BytesList(value=[norm2bytes(values)])) - - -def image_seg_to_tfexample(image_data, filename, height, width, seg_data): - """Converts one image/segmentation pair to tf example. - - Args: - image_data: string of image data. - filename: image filename. - height: image height. - width: image width. - seg_data: string of semantic segmentation data. - - Returns: - tf example of one image/segmentation pair. - """ - return tf.train.Example(features=tf.train.Features(feature={ - 'image/encoded': _bytes_list_feature(image_data), - 'image/filename': _bytes_list_feature(filename), - 'image/format': _bytes_list_feature( - _IMAGE_FORMAT_MAP[FLAGS.image_format]), - 'image/height': _int64_list_feature(height), - 'image/width': _int64_list_feature(width), - 'image/channels': _int64_list_feature(3), - 'image/segmentation/class/encoded': ( - _bytes_list_feature(seg_data)), - 'image/segmentation/class/format': _bytes_list_feature( - FLAGS.label_format), - })) diff --git a/research/deeplab/datasets/build_voc2012_data.py b/research/deeplab/datasets/build_voc2012_data.py deleted file mode 100644 index f0bdecb6a0f954d90164ac64b55966d0fe754557..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/build_voc2012_data.py +++ /dev/null @@ -1,146 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Converts PASCAL VOC 2012 data to TFRecord file format with Example protos. - -PASCAL VOC 2012 dataset is expected to have the following directory structure: - - + pascal_voc_seg - - build_data.py - - build_voc2012_data.py (current working directory). - + VOCdevkit - + VOC2012 - + JPEGImages - + SegmentationClass - + ImageSets - + Segmentation - + tfrecord - -Image folder: - ./VOCdevkit/VOC2012/JPEGImages - -Semantic segmentation annotations: - ./VOCdevkit/VOC2012/SegmentationClass - -list folder: - ./VOCdevkit/VOC2012/ImageSets/Segmentation - -This script converts data into sharded data files and save at tfrecord folder. - -The Example proto contains the following fields: - - image/encoded: encoded image content. - image/filename: image filename. - image/format: image file format. - image/height: image height. - image/width: image width. - image/channels: image channels. - image/segmentation/class/encoded: encoded semantic segmentation content. - image/segmentation/class/format: semantic segmentation file format. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import math -import os.path -import sys -import build_data -from six.moves import range -import tensorflow as tf - -FLAGS = tf.app.flags.FLAGS - -tf.app.flags.DEFINE_string('image_folder', - './VOCdevkit/VOC2012/JPEGImages', - 'Folder containing images.') - -tf.app.flags.DEFINE_string( - 'semantic_segmentation_folder', - './VOCdevkit/VOC2012/SegmentationClassRaw', - 'Folder containing semantic segmentation annotations.') - -tf.app.flags.DEFINE_string( - 'list_folder', - './VOCdevkit/VOC2012/ImageSets/Segmentation', - 'Folder containing lists for training and validation') - -tf.app.flags.DEFINE_string( - 'output_dir', - './tfrecord', - 'Path to save converted SSTable of TensorFlow examples.') - - -_NUM_SHARDS = 4 - - -def _convert_dataset(dataset_split): - """Converts the specified dataset split to TFRecord format. - - Args: - dataset_split: The dataset split (e.g., train, test). - - Raises: - RuntimeError: If loaded image and label have different shape. - """ - dataset = os.path.basename(dataset_split)[:-4] - sys.stdout.write('Processing ' + dataset) - filenames = [x.strip('\n') for x in open(dataset_split, 'r')] - num_images = len(filenames) - num_per_shard = int(math.ceil(num_images / _NUM_SHARDS)) - - image_reader = build_data.ImageReader('jpeg', channels=3) - label_reader = build_data.ImageReader('png', channels=1) - - for shard_id in range(_NUM_SHARDS): - output_filename = os.path.join( - FLAGS.output_dir, - '%s-%05d-of-%05d.tfrecord' % (dataset, shard_id, _NUM_SHARDS)) - with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: - start_idx = shard_id * num_per_shard - end_idx = min((shard_id + 1) * num_per_shard, num_images) - for i in range(start_idx, end_idx): - sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( - i + 1, len(filenames), shard_id)) - sys.stdout.flush() - # Read the image. - image_filename = os.path.join( - FLAGS.image_folder, filenames[i] + '.' + FLAGS.image_format) - image_data = tf.gfile.GFile(image_filename, 'rb').read() - height, width = image_reader.read_image_dims(image_data) - # Read the semantic segmentation annotation. - seg_filename = os.path.join( - FLAGS.semantic_segmentation_folder, - filenames[i] + '.' + FLAGS.label_format) - seg_data = tf.gfile.GFile(seg_filename, 'rb').read() - seg_height, seg_width = label_reader.read_image_dims(seg_data) - if height != seg_height or width != seg_width: - raise RuntimeError('Shape mismatched between image and label.') - # Convert to tf example. - example = build_data.image_seg_to_tfexample( - image_data, filenames[i], height, width, seg_data) - tfrecord_writer.write(example.SerializeToString()) - sys.stdout.write('\n') - sys.stdout.flush() - - -def main(unused_argv): - dataset_splits = tf.gfile.Glob(os.path.join(FLAGS.list_folder, '*.txt')) - for dataset_split in dataset_splits: - _convert_dataset(dataset_split) - - -if __name__ == '__main__': - tf.app.run() diff --git a/research/deeplab/datasets/convert_cityscapes.sh b/research/deeplab/datasets/convert_cityscapes.sh deleted file mode 100644 index a95b5d66aad79ae7cbd6ad2d3ee60550ab7f6239..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/convert_cityscapes.sh +++ /dev/null @@ -1,58 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to preprocess the Cityscapes dataset. Note (1) the users should -# register the Cityscapes dataset website at -# https://www.cityscapes-dataset.com/downloads/ to download the dataset, -# and (2) the users should download the utility scripts provided by -# Cityscapes at https://github.com/mcordts/cityscapesScripts. -# -# Usage: -# bash ./convert_cityscapes.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_cityscapes_data.py -# - convert_cityscapes.sh -# + cityscapes -# + cityscapesscripts (downloaded scripts) -# + gtFine -# + leftImg8bit -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="." - -# Root path for Cityscapes dataset. -CITYSCAPES_ROOT="${WORK_DIR}/cityscapes" - -# Create training labels. -python "${CITYSCAPES_ROOT}/cityscapesscripts/preparation/createTrainIdLabelImgs.py" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${CITYSCAPES_ROOT}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -BUILD_SCRIPT="${CURRENT_DIR}/build_cityscapes_data.py" - -echo "Converting Cityscapes dataset..." -python "${BUILD_SCRIPT}" \ - --cityscapes_root="${CITYSCAPES_ROOT}" \ - --output_dir="${OUTPUT_DIR}" \ diff --git a/research/deeplab/datasets/data_generator.py b/research/deeplab/datasets/data_generator.py deleted file mode 100644 index d84e66f9c48181d579a027daa08206491d995b65..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/data_generator.py +++ /dev/null @@ -1,350 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Wrapper for providing semantic segmentaion data. - -The SegmentationDataset class provides both images and annotations (semantic -segmentation and/or instance segmentation) for TensorFlow. Currently, we -support the following datasets: - -1. PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). - -PASCAL VOC 2012 semantic segmentation dataset annotates 20 foreground objects -(e.g., bike, person, and so on) and leaves all the other semantic classes as -one background class. The dataset contains 1464, 1449, and 1456 annotated -images for the training, validation and test respectively. - -2. Cityscapes dataset (https://www.cityscapes-dataset.com) - -The Cityscapes dataset contains 19 semantic labels (such as road, person, car, -and so on) for urban street scenes. - -3. ADE20K dataset (http://groups.csail.mit.edu/vision/datasets/ADE20K) - -The ADE20K dataset contains 150 semantic labels both urban street scenes and -indoor scenes. - -References: - M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, - and A. Zisserman, The pascal visual object classes challenge a retrospective. - IJCV, 2014. - - M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, - U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban - scene understanding," In Proc. of CVPR, 2016. - - B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, "Scene Parsing - through ADE20K dataset", In Proc. of CVPR, 2017. -""" - -import collections -import os -import tensorflow as tf -from deeplab import common -from deeplab import input_preprocess - -# Named tuple to describe the dataset properties. -DatasetDescriptor = collections.namedtuple( - 'DatasetDescriptor', - [ - 'splits_to_sizes', # Splits of the dataset into training, val and test. - 'num_classes', # Number of semantic classes, including the - # background class (if exists). For example, there - # are 20 foreground classes + 1 background class in - # the PASCAL VOC 2012 dataset. Thus, we set - # num_classes=21. - 'ignore_label', # Ignore label value. - ]) - -_CITYSCAPES_INFORMATION = DatasetDescriptor( - splits_to_sizes={'train_fine': 2975, - 'train_coarse': 22973, - 'trainval_fine': 3475, - 'trainval_coarse': 23473, - 'val_fine': 500, - 'test_fine': 1525}, - num_classes=19, - ignore_label=255, -) - -_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 1464, - 'train_aug': 10582, - 'trainval': 2913, - 'val': 1449, - }, - num_classes=21, - ignore_label=255, -) - -_ADE20K_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 20210, # num of samples in images/training - 'val': 2000, # num of samples in images/validation - }, - num_classes=151, - ignore_label=0, -) - -_DATASETS_INFORMATION = { - 'cityscapes': _CITYSCAPES_INFORMATION, - 'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION, - 'ade20k': _ADE20K_INFORMATION, -} - -# Default file pattern of TFRecord of TensorFlow Example. -_FILE_PATTERN = '%s-*' - - -def get_cityscapes_dataset_name(): - return 'cityscapes' - - -class Dataset(object): - """Represents input dataset for deeplab model.""" - - def __init__(self, - dataset_name, - split_name, - dataset_dir, - batch_size, - crop_size, - min_resize_value=None, - max_resize_value=None, - resize_factor=None, - min_scale_factor=1., - max_scale_factor=1., - scale_factor_step_size=0, - model_variant=None, - num_readers=1, - is_training=False, - should_shuffle=False, - should_repeat=False): - """Initializes the dataset. - - Args: - dataset_name: Dataset name. - split_name: A train/val Split name. - dataset_dir: The directory of the dataset sources. - batch_size: Batch size. - crop_size: The size used to crop the image and label. - min_resize_value: Desired size of the smaller image side. - max_resize_value: Maximum allowed size of the larger image side. - resize_factor: Resized dimensions are multiple of factor plus one. - min_scale_factor: Minimum scale factor value. - max_scale_factor: Maximum scale factor value. - scale_factor_step_size: The step size from min scale factor to max scale - factor. The input is randomly scaled based on the value of - (min_scale_factor, max_scale_factor, scale_factor_step_size). - model_variant: Model variant (string) for choosing how to mean-subtract - the images. See feature_extractor.network_map for supported model - variants. - num_readers: Number of readers for data provider. - is_training: Boolean, if dataset is for training or not. - should_shuffle: Boolean, if should shuffle the input data. - should_repeat: Boolean, if should repeat the input data. - - Raises: - ValueError: Dataset name and split name are not supported. - """ - if dataset_name not in _DATASETS_INFORMATION: - raise ValueError('The specified dataset is not supported yet.') - self.dataset_name = dataset_name - - splits_to_sizes = _DATASETS_INFORMATION[dataset_name].splits_to_sizes - - if split_name not in splits_to_sizes: - raise ValueError('data split name %s not recognized' % split_name) - - if model_variant is None: - tf.logging.warning('Please specify a model_variant. See ' - 'feature_extractor.network_map for supported model ' - 'variants.') - - self.split_name = split_name - self.dataset_dir = dataset_dir - self.batch_size = batch_size - self.crop_size = crop_size - self.min_resize_value = min_resize_value - self.max_resize_value = max_resize_value - self.resize_factor = resize_factor - self.min_scale_factor = min_scale_factor - self.max_scale_factor = max_scale_factor - self.scale_factor_step_size = scale_factor_step_size - self.model_variant = model_variant - self.num_readers = num_readers - self.is_training = is_training - self.should_shuffle = should_shuffle - self.should_repeat = should_repeat - - self.num_of_classes = _DATASETS_INFORMATION[self.dataset_name].num_classes - self.ignore_label = _DATASETS_INFORMATION[self.dataset_name].ignore_label - - def _parse_function(self, example_proto): - """Function to parse the example proto. - - Args: - example_proto: Proto in the format of tf.Example. - - Returns: - A dictionary with parsed image, label, height, width and image name. - - Raises: - ValueError: Label is of wrong shape. - """ - - # Currently only supports jpeg and png. - # Need to use this logic because the shape is not known for - # tf.image.decode_image and we rely on this info to - # extend label if necessary. - def _decode_image(content, channels): - return tf.cond( - tf.image.is_jpeg(content), - lambda: tf.image.decode_jpeg(content, channels), - lambda: tf.image.decode_png(content, channels)) - - features = { - 'image/encoded': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/filename': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/format': - tf.FixedLenFeature((), tf.string, default_value='jpeg'), - 'image/height': - tf.FixedLenFeature((), tf.int64, default_value=0), - 'image/width': - tf.FixedLenFeature((), tf.int64, default_value=0), - 'image/segmentation/class/encoded': - tf.FixedLenFeature((), tf.string, default_value=''), - 'image/segmentation/class/format': - tf.FixedLenFeature((), tf.string, default_value='png'), - } - - parsed_features = tf.parse_single_example(example_proto, features) - - image = _decode_image(parsed_features['image/encoded'], channels=3) - - label = None - if self.split_name != common.TEST_SET: - label = _decode_image( - parsed_features['image/segmentation/class/encoded'], channels=1) - - image_name = parsed_features['image/filename'] - if image_name is None: - image_name = tf.constant('') - - sample = { - common.IMAGE: image, - common.IMAGE_NAME: image_name, - common.HEIGHT: parsed_features['image/height'], - common.WIDTH: parsed_features['image/width'], - } - - if label is not None: - if label.get_shape().ndims == 2: - label = tf.expand_dims(label, 2) - elif label.get_shape().ndims == 3 and label.shape.dims[2] == 1: - pass - else: - raise ValueError('Input label shape must be [height, width], or ' - '[height, width, 1].') - - label.set_shape([None, None, 1]) - - sample[common.LABELS_CLASS] = label - - return sample - - def _preprocess_image(self, sample): - """Preprocesses the image and label. - - Args: - sample: A sample containing image and label. - - Returns: - sample: Sample with preprocessed image and label. - - Raises: - ValueError: Ground truth label not provided during training. - """ - image = sample[common.IMAGE] - label = sample[common.LABELS_CLASS] - - original_image, image, label = input_preprocess.preprocess_image_and_label( - image=image, - label=label, - crop_height=self.crop_size[0], - crop_width=self.crop_size[1], - min_resize_value=self.min_resize_value, - max_resize_value=self.max_resize_value, - resize_factor=self.resize_factor, - min_scale_factor=self.min_scale_factor, - max_scale_factor=self.max_scale_factor, - scale_factor_step_size=self.scale_factor_step_size, - ignore_label=self.ignore_label, - is_training=self.is_training, - model_variant=self.model_variant) - - sample[common.IMAGE] = image - - if not self.is_training: - # Original image is only used during visualization. - sample[common.ORIGINAL_IMAGE] = original_image - - if label is not None: - sample[common.LABEL] = label - - # Remove common.LABEL_CLASS key in the sample since it is only used to - # derive label and not used in training and evaluation. - sample.pop(common.LABELS_CLASS, None) - - return sample - - def get_one_shot_iterator(self): - """Gets an iterator that iterates across the dataset once. - - Returns: - An iterator of type tf.data.Iterator. - """ - - files = self._get_all_files() - - dataset = ( - tf.data.TFRecordDataset(files, num_parallel_reads=self.num_readers) - .map(self._parse_function, num_parallel_calls=self.num_readers) - .map(self._preprocess_image, num_parallel_calls=self.num_readers)) - - if self.should_shuffle: - dataset = dataset.shuffle(buffer_size=100) - - if self.should_repeat: - dataset = dataset.repeat() # Repeat forever for training. - else: - dataset = dataset.repeat(1) - - dataset = dataset.batch(self.batch_size).prefetch(self.batch_size) - return dataset.make_one_shot_iterator() - - def _get_all_files(self): - """Gets all the files to read data from. - - Returns: - A list of input files. - """ - file_pattern = _FILE_PATTERN - file_pattern = os.path.join(self.dataset_dir, - file_pattern % self.split_name) - return tf.gfile.Glob(file_pattern) diff --git a/research/deeplab/datasets/data_generator_test.py b/research/deeplab/datasets/data_generator_test.py deleted file mode 100644 index f4425d01da0c6f3bafaaff7c038498349a5c3f98..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/data_generator_test.py +++ /dev/null @@ -1,115 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for deeplab.datasets.data_generator.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import collections - -from six.moves import range -import tensorflow as tf - -from deeplab import common -from deeplab.datasets import data_generator - -ImageAttributes = collections.namedtuple( - 'ImageAttributes', ['image', 'label', 'height', 'width', 'image_name']) - - -class DatasetTest(tf.test.TestCase): - - # Note: training dataset cannot be tested since there is shuffle operation. - # When disabling the shuffle, training dataset is operated same as validation - # dataset. Therefore it is not tested again. - def testPascalVocSegTestData(self): - dataset = data_generator.Dataset( - dataset_name='pascal_voc_seg', - split_name='val', - dataset_dir= - 'deeplab/testing/pascal_voc_seg', - batch_size=1, - crop_size=[3, 3], # Use small size for testing. - min_resize_value=3, - max_resize_value=3, - resize_factor=None, - min_scale_factor=0.01, - max_scale_factor=2.0, - scale_factor_step_size=0.25, - is_training=False, - model_variant='mobilenet_v2') - - self.assertAllEqual(dataset.num_of_classes, 21) - self.assertAllEqual(dataset.ignore_label, 255) - - num_of_images = 3 - with self.test_session() as sess: - iterator = dataset.get_one_shot_iterator() - - for i in range(num_of_images): - batch = iterator.get_next() - batch, = sess.run([batch]) - image_attributes = _get_attributes_of_image(i) - self.assertEqual(batch[common.HEIGHT][0], image_attributes.height) - self.assertEqual(batch[common.WIDTH][0], image_attributes.width) - self.assertEqual(batch[common.IMAGE_NAME][0], - image_attributes.image_name.encode()) - - # All data have been read. - with self.assertRaisesRegexp(tf.errors.OutOfRangeError, ''): - sess.run([iterator.get_next()]) - - -def _get_attributes_of_image(index): - """Gets the attributes of the image. - - Args: - index: Index of image in all images. - - Returns: - Attributes of the image in the format of ImageAttributes. - - Raises: - ValueError: If index is of wrong value. - """ - if index == 0: - return ImageAttributes( - image=None, - label=None, - height=366, - width=500, - image_name='2007_000033') - elif index == 1: - return ImageAttributes( - image=None, - label=None, - height=335, - width=500, - image_name='2007_000042') - elif index == 2: - return ImageAttributes( - image=None, - label=None, - height=333, - width=500, - image_name='2007_000061') - else: - raise ValueError('Index can only be 0, 1 or 2.') - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/datasets/download_and_convert_ade20k.sh b/research/deeplab/datasets/download_and_convert_ade20k.sh deleted file mode 100644 index 3614ae42c16e4f727a725066be8948b666995241..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/download_and_convert_ade20k.sh +++ /dev/null @@ -1,80 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to download and preprocess the ADE20K dataset. -# -# Usage: -# bash ./download_and_convert_ade20k.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_data.py -# - build_ade20k_data.py -# - download_and_convert_ade20k.sh -# + ADE20K -# + tfrecord -# + ADEChallengeData2016 -# + annotations -# + training -# + validation -# + images -# + training -# + validation - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="./ADE20K" -mkdir -p "${WORK_DIR}" -cd "${WORK_DIR}" - -# Helper function to download and unpack ADE20K dataset. -download_and_uncompress() { - local BASE_URL=${1} - local FILENAME=${2} - - if [ ! -f "${FILENAME}" ]; then - echo "Downloading ${FILENAME} to ${WORK_DIR}" - wget -nd -c "${BASE_URL}/${FILENAME}" - fi - echo "Uncompressing ${FILENAME}" - unzip "${FILENAME}" -} - -# Download the images. -BASE_URL="http://data.csail.mit.edu/places/ADEchallenge" -FILENAME="ADEChallengeData2016.zip" - -download_and_uncompress "${BASE_URL}" "${FILENAME}" - -cd "${CURRENT_DIR}" - -# Root path for ADE20K dataset. -ADE20K_ROOT="${WORK_DIR}/ADEChallengeData2016" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${WORK_DIR}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -echo "Converting ADE20K dataset..." -python ./build_ade20k_data.py \ - --train_image_folder="${ADE20K_ROOT}/images/training/" \ - --train_image_label_folder="${ADE20K_ROOT}/annotations/training/" \ - --val_image_folder="${ADE20K_ROOT}/images/validation/" \ - --val_image_label_folder="${ADE20K_ROOT}/annotations/validation/" \ - --output_dir="${OUTPUT_DIR}" diff --git a/research/deeplab/datasets/download_and_convert_voc2012.sh b/research/deeplab/datasets/download_and_convert_voc2012.sh deleted file mode 100644 index c02235182d427dfb1d63154a8266ad37b0a1d53f..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/download_and_convert_voc2012.sh +++ /dev/null @@ -1,91 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# Script to download and preprocess the PASCAL VOC 2012 dataset. -# -# Usage: -# bash ./download_and_convert_voc2012.sh -# -# The folder structure is assumed to be: -# + datasets -# - build_data.py -# - build_voc2012_data.py -# - download_and_convert_voc2012.sh -# - remove_gt_colormap.py -# + pascal_voc_seg -# + VOCdevkit -# + VOC2012 -# + JPEGImages -# + SegmentationClass -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -CURRENT_DIR=$(pwd) -WORK_DIR="./pascal_voc_seg" -SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )" -mkdir -p "${WORK_DIR}" -cd "${WORK_DIR}" - -# Helper function to download and unpack VOC 2012 dataset. -download_and_uncompress() { - local BASE_URL=${1} - local FILENAME=${2} - - if [ ! -f "${FILENAME}" ]; then - echo "Downloading ${FILENAME} to ${WORK_DIR}" - wget -nd -c "${BASE_URL}/${FILENAME}" - fi - echo "Uncompressing ${FILENAME}" - tar -xf "${FILENAME}" -} - -# Download the images. -BASE_URL="http://host.robots.ox.ac.uk/pascal/VOC/voc2012/" -FILENAME="VOCtrainval_11-May-2012.tar" - -download_and_uncompress "${BASE_URL}" "${FILENAME}" - -cd "${CURRENT_DIR}" - -# Root path for PASCAL VOC 2012 dataset. -PASCAL_ROOT="${WORK_DIR}/VOCdevkit/VOC2012" - -# Remove the colormap in the ground truth annotations. -SEG_FOLDER="${PASCAL_ROOT}/SegmentationClass" -SEMANTIC_SEG_FOLDER="${PASCAL_ROOT}/SegmentationClassRaw" - -echo "Removing the color map in ground truth annotations..." -python3 "${SCRIPT_DIR}/remove_gt_colormap.py" \ - --original_gt_folder="${SEG_FOLDER}" \ - --output_dir="${SEMANTIC_SEG_FOLDER}" - -# Build TFRecords of the dataset. -# First, create output directory for storing TFRecords. -OUTPUT_DIR="${WORK_DIR}/tfrecord" -mkdir -p "${OUTPUT_DIR}" - -IMAGE_FOLDER="${PASCAL_ROOT}/JPEGImages" -LIST_FOLDER="${PASCAL_ROOT}/ImageSets/Segmentation" - -echo "Converting PASCAL VOC 2012 dataset..." -python3 "${SCRIPT_DIR}/build_voc2012_data.py" \ - --image_folder="${IMAGE_FOLDER}" \ - --semantic_segmentation_folder="${SEMANTIC_SEG_FOLDER}" \ - --list_folder="${LIST_FOLDER}" \ - --image_format="jpg" \ - --output_dir="${OUTPUT_DIR}" diff --git a/research/deeplab/datasets/remove_gt_colormap.py b/research/deeplab/datasets/remove_gt_colormap.py deleted file mode 100644 index 900570038ed0f1add9d670157494d4cab6bf5324..0000000000000000000000000000000000000000 --- a/research/deeplab/datasets/remove_gt_colormap.py +++ /dev/null @@ -1,83 +0,0 @@ -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Removes the color map from segmentation annotations. - -Removes the color map from the ground truth segmentation annotations and save -the results to output_dir. -""" -import glob -import os.path -import numpy as np - -from PIL import Image - -import tensorflow as tf - -FLAGS = tf.compat.v1.flags.FLAGS - -tf.compat.v1.flags.DEFINE_string('original_gt_folder', - './VOCdevkit/VOC2012/SegmentationClass', - 'Original ground truth annotations.') - -tf.compat.v1.flags.DEFINE_string('segmentation_format', 'png', 'Segmentation format.') - -tf.compat.v1.flags.DEFINE_string('output_dir', - './VOCdevkit/VOC2012/SegmentationClassRaw', - 'folder to save modified ground truth annotations.') - - -def _remove_colormap(filename): - """Removes the color map from the annotation. - - Args: - filename: Ground truth annotation filename. - - Returns: - Annotation without color map. - """ - return np.array(Image.open(filename)) - - -def _save_annotation(annotation, filename): - """Saves the annotation as png file. - - Args: - annotation: Segmentation annotation. - filename: Output filename. - """ - pil_image = Image.fromarray(annotation.astype(dtype=np.uint8)) - with tf.io.gfile.GFile(filename, mode='w') as f: - pil_image.save(f, 'PNG') - - -def main(unused_argv): - # Create the output directory if not exists. - if not tf.io.gfile.isdir(FLAGS.output_dir): - tf.io.gfile.makedirs(FLAGS.output_dir) - - annotations = glob.glob(os.path.join(FLAGS.original_gt_folder, - '*.' + FLAGS.segmentation_format)) - for annotation in annotations: - raw_annotation = _remove_colormap(annotation) - filename = os.path.basename(annotation)[:-4] - _save_annotation(raw_annotation, - os.path.join( - FLAGS.output_dir, - filename + '.' + FLAGS.segmentation_format)) - - -if __name__ == '__main__': - tf.compat.v1.app.run() diff --git a/research/deeplab/deeplab_demo.ipynb b/research/deeplab/deeplab_demo.ipynb deleted file mode 100644 index 81ccfde1b6484625ad1e0662d9a4cf12941d262c..0000000000000000000000000000000000000000 --- a/research/deeplab/deeplab_demo.ipynb +++ /dev/null @@ -1,369 +0,0 @@ -{ - "cells": [ - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "KFPcBuVFw61h" - }, - "source": [ - "# Overview\n", - "\n", - "This colab demonstrates the steps to use the DeepLab model to perform semantic segmentation on a sample input image. Expected outputs are semantic labels overlayed on the sample image.\n", - "\n", - "### About DeepLab\n", - "The models used in this colab perform semantic segmentation. Semantic segmentation models focus on assigning semantic labels, such as sky, person, or car, to multiple objects and stuff in a single image." - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "t3ozFsEEP-u_" - }, - "source": [ - "# Instructions\n", - "\u003ch3\u003e\u003ca href=\"https://cloud.google.com/tpu/\"\u003e\u003cimg valign=\"middle\" src=\"https://raw.githubusercontent.com/GoogleCloudPlatform/tensorflow-without-a-phd/master/tensorflow-rl-pong/images/tpu-hexagon.png\" width=\"50\"\u003e\u003c/a\u003e \u0026nbsp;\u0026nbsp;Use a free TPU device\u003c/h3\u003e\n", - "\n", - " 1. On the main menu, click Runtime and select **Change runtime type**. Set \"TPU\" as the hardware accelerator.\n", - " 1. Click Runtime again and select **Runtime \u003e Run All**. You can also run the cells manually with Shift-ENTER." - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "7cRiapZ1P3wy" - }, - "source": [ - "## Import Libraries" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "code", - "colab": {}, - "colab_type": "code", - "id": "kAbdmRmvq0Je" - }, - "outputs": [], - "source": [ - "import os\n", - "from io import BytesIO\n", - "import tarfile\n", - "import tempfile\n", - "from six.moves import urllib\n", - "\n", - "from matplotlib import gridspec\n", - "from matplotlib import pyplot as plt\n", - "import numpy as np\n", - "from PIL import Image\n", - "\n", - "%tensorflow_version 1.x\n", - "import tensorflow as tf" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "p47cYGGOQE1W" - }, - "source": [ - "## Import helper methods\n", - "These methods help us perform the following tasks:\n", - "* Load the latest version of the pretrained DeepLab model\n", - "* Load the colormap from the PASCAL VOC dataset\n", - "* Adds colors to various labels, such as \"pink\" for people, \"green\" for bicycle and more\n", - "* Visualize an image, and add an overlay of colors on various regions" - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "code", - "colab": {}, - "colab_type": "code", - "id": "vN0kU6NJ1Ye5" - }, - "outputs": [], - "source": [ - "class DeepLabModel(object):\n", - " \"\"\"Class to load deeplab model and run inference.\"\"\"\n", - "\n", - " INPUT_TENSOR_NAME = 'ImageTensor:0'\n", - " OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'\n", - " INPUT_SIZE = 513\n", - " FROZEN_GRAPH_NAME = 'frozen_inference_graph'\n", - "\n", - " def __init__(self, tarball_path):\n", - " \"\"\"Creates and loads pretrained deeplab model.\"\"\"\n", - " self.graph = tf.Graph()\n", - "\n", - " graph_def = None\n", - " # Extract frozen graph from tar archive.\n", - " tar_file = tarfile.open(tarball_path)\n", - " for tar_info in tar_file.getmembers():\n", - " if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):\n", - " file_handle = tar_file.extractfile(tar_info)\n", - " graph_def = tf.GraphDef.FromString(file_handle.read())\n", - " break\n", - "\n", - " tar_file.close()\n", - "\n", - " if graph_def is None:\n", - " raise RuntimeError('Cannot find inference graph in tar archive.')\n", - "\n", - " with self.graph.as_default():\n", - " tf.import_graph_def(graph_def, name='')\n", - "\n", - " self.sess = tf.Session(graph=self.graph)\n", - "\n", - " def run(self, image):\n", - " \"\"\"Runs inference on a single image.\n", - "\n", - " Args:\n", - " image: A PIL.Image object, raw input image.\n", - "\n", - " Returns:\n", - " resized_image: RGB image resized from original input image.\n", - " seg_map: Segmentation map of `resized_image`.\n", - " \"\"\"\n", - " width, height = image.size\n", - " resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)\n", - " target_size = (int(resize_ratio * width), int(resize_ratio * height))\n", - " resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS)\n", - " batch_seg_map = self.sess.run(\n", - " self.OUTPUT_TENSOR_NAME,\n", - " feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]})\n", - " seg_map = batch_seg_map[0]\n", - " return resized_image, seg_map\n", - "\n", - "\n", - "def create_pascal_label_colormap():\n", - " \"\"\"Creates a label colormap used in PASCAL VOC segmentation benchmark.\n", - "\n", - " Returns:\n", - " A Colormap for visualizing segmentation results.\n", - " \"\"\"\n", - " colormap = np.zeros((256, 3), dtype=int)\n", - " ind = np.arange(256, dtype=int)\n", - "\n", - " for shift in reversed(range(8)):\n", - " for channel in range(3):\n", - " colormap[:, channel] |= ((ind \u003e\u003e channel) \u0026 1) \u003c\u003c shift\n", - " ind \u003e\u003e= 3\n", - "\n", - " return colormap\n", - "\n", - "\n", - "def label_to_color_image(label):\n", - " \"\"\"Adds color defined by the dataset colormap to the label.\n", - "\n", - " Args:\n", - " label: A 2D array with integer type, storing the segmentation label.\n", - "\n", - " Returns:\n", - " result: A 2D array with floating type. The element of the array\n", - " is the color indexed by the corresponding element in the input label\n", - " to the PASCAL color map.\n", - "\n", - " Raises:\n", - " ValueError: If label is not of rank 2 or its value is larger than color\n", - " map maximum entry.\n", - " \"\"\"\n", - " if label.ndim != 2:\n", - " raise ValueError('Expect 2-D input label')\n", - "\n", - " colormap = create_pascal_label_colormap()\n", - "\n", - " if np.max(label) \u003e= len(colormap):\n", - " raise ValueError('label value too large.')\n", - "\n", - " return colormap[label]\n", - "\n", - "\n", - "def vis_segmentation(image, seg_map):\n", - " \"\"\"Visualizes input image, segmentation map and overlay view.\"\"\"\n", - " plt.figure(figsize=(15, 5))\n", - " grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1])\n", - "\n", - " plt.subplot(grid_spec[0])\n", - " plt.imshow(image)\n", - " plt.axis('off')\n", - " plt.title('input image')\n", - "\n", - " plt.subplot(grid_spec[1])\n", - " seg_image = label_to_color_image(seg_map).astype(np.uint8)\n", - " plt.imshow(seg_image)\n", - " plt.axis('off')\n", - " plt.title('segmentation map')\n", - "\n", - " plt.subplot(grid_spec[2])\n", - " plt.imshow(image)\n", - " plt.imshow(seg_image, alpha=0.7)\n", - " plt.axis('off')\n", - " plt.title('segmentation overlay')\n", - "\n", - " unique_labels = np.unique(seg_map)\n", - " ax = plt.subplot(grid_spec[3])\n", - " plt.imshow(\n", - " FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest')\n", - " ax.yaxis.tick_right()\n", - " plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels])\n", - " plt.xticks([], [])\n", - " ax.tick_params(width=0.0)\n", - " plt.grid('off')\n", - " plt.show()\n", - "\n", - "\n", - "LABEL_NAMES = np.asarray([\n", - " 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',\n", - " 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',\n", - " 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'\n", - "])\n", - "\n", - "FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1)\n", - "FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP)" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "nGcZzNkASG9A" - }, - "source": [ - "## Select a pretrained model\n", - "We have trained the DeepLab model using various backbone networks. Select one from the MODEL_NAME list." - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "colab": {}, - "colab_type": "code", - "id": "c4oXKmnjw6i_" - }, - "outputs": [], - "source": [ - "MODEL_NAME = 'mobilenetv2_coco_voctrainaug' # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval']\n", - "\n", - "_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'\n", - "_MODEL_URLS = {\n", - " 'mobilenetv2_coco_voctrainaug':\n", - " 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',\n", - " 'mobilenetv2_coco_voctrainval':\n", - " 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz',\n", - " 'xception_coco_voctrainaug':\n", - " 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz',\n", - " 'xception_coco_voctrainval':\n", - " 'deeplabv3_pascal_trainval_2018_01_04.tar.gz',\n", - "}\n", - "_TARBALL_NAME = 'deeplab_model.tar.gz'\n", - "\n", - "model_dir = tempfile.mkdtemp()\n", - "tf.gfile.MakeDirs(model_dir)\n", - "\n", - "download_path = os.path.join(model_dir, _TARBALL_NAME)\n", - "print('downloading model, this might take a while...')\n", - "urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME],\n", - " download_path)\n", - "print('download completed! loading DeepLab model...')\n", - "\n", - "MODEL = DeepLabModel(download_path)\n", - "print('model loaded successfully!')" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "SZst78N-4OKO" - }, - "source": [ - "## Run on sample images\n", - "\n", - "Select one of sample images (leave `IMAGE_URL` empty) or feed any internet image\n", - "url for inference.\n", - "\n", - "Note that this colab uses single scale inference for fast computation,\n", - "so the results may slightly differ from the visualizations in the\n", - "[README](https://github.com/tensorflow/models/blob/master/research/deeplab/README.md) file,\n", - "which uses multi-scale and left-right flipped inputs." - ] - }, - { - "cell_type": "code", - "execution_count": 0, - "metadata": { - "cellView": "form", - "colab": {}, - "colab_type": "code", - "id": "edGukUHXyymr" - }, - "outputs": [], - "source": [ - "\n", - "SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3']\n", - "IMAGE_URL = '' #@param {type:\"string\"}\n", - "\n", - "_SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/'\n", - " 'deeplab/g3doc/img/%s.jpg?raw=true')\n", - "\n", - "\n", - "def run_visualization(url):\n", - " \"\"\"Inferences DeepLab model and visualizes result.\"\"\"\n", - " try:\n", - " f = urllib.request.urlopen(url)\n", - " jpeg_str = f.read()\n", - " original_im = Image.open(BytesIO(jpeg_str))\n", - " except IOError:\n", - " print('Cannot retrieve image. Please check url: ' + url)\n", - " return\n", - "\n", - " print('running deeplab on image %s...' % url)\n", - " resized_im, seg_map = MODEL.run(original_im)\n", - "\n", - " vis_segmentation(resized_im, seg_map)\n", - "\n", - "\n", - "image_url = IMAGE_URL or _SAMPLE_URL % SAMPLE_IMAGE\n", - "run_visualization(image_url)" - ] - }, - { - "cell_type": "markdown", - "metadata": { - "colab_type": "text", - "id": "aUbVoHScTJYe" - }, - "source": [ - "## What's next\n", - "\n", - "* Learn about [Cloud TPUs](https://cloud.google.com/tpu/docs) that Google designed and optimized specifically to speed up and scale up ML workloads for training and inference and to enable ML engineers and researchers to iterate more quickly.\n", - "* Explore the range of [Cloud TPU tutorials and Colabs](https://cloud.google.com/tpu/docs/tutorials) to find other examples that can be used when implementing your ML project.\n", - "* For more information on running the DeepLab model on Cloud TPUs, see the [DeepLab tutorial](https://cloud.google.com/tpu/docs/tutorials/deeplab).\n" - ] - } - ], - "metadata": { - "colab": { - "collapsed_sections": [], - "name": "DeepLab Demo.ipynb", - "provenance": [], - "toc_visible": true, - "version": "0.3.2" - }, - "kernelspec": { - "display_name": "Python 3", - "name": "python3" - } - }, - "nbformat": 4, - "nbformat_minor": 0 -} diff --git a/research/deeplab/deprecated/__init__.py b/research/deeplab/deprecated/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/deprecated/segmentation_dataset.py b/research/deeplab/deprecated/segmentation_dataset.py deleted file mode 100644 index 2a5980b1d940878cd1aead4a5d301cca7b4a642b..0000000000000000000000000000000000000000 --- a/research/deeplab/deprecated/segmentation_dataset.py +++ /dev/null @@ -1,200 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Provides data from semantic segmentation datasets. - -The SegmentationDataset class provides both images and annotations (semantic -segmentation and/or instance segmentation) for TensorFlow. Currently, we -support the following datasets: - -1. PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). - -PASCAL VOC 2012 semantic segmentation dataset annotates 20 foreground objects -(e.g., bike, person, and so on) and leaves all the other semantic classes as -one background class. The dataset contains 1464, 1449, and 1456 annotated -images for the training, validation and test respectively. - -2. Cityscapes dataset (https://www.cityscapes-dataset.com) - -The Cityscapes dataset contains 19 semantic labels (such as road, person, car, -and so on) for urban street scenes. - -3. ADE20K dataset (http://groups.csail.mit.edu/vision/datasets/ADE20K) - -The ADE20K dataset contains 150 semantic labels both urban street scenes and -indoor scenes. - -References: - M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, - and A. Zisserman, The pascal visual object classes challenge a retrospective. - IJCV, 2014. - - M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, - U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban - scene understanding," In Proc. of CVPR, 2016. - - B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, "Scene Parsing - through ADE20K dataset", In Proc. of CVPR, 2017. -""" -import collections -import os.path -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim - -slim = contrib_slim - -dataset = slim.dataset - -tfexample_decoder = slim.tfexample_decoder - - -_ITEMS_TO_DESCRIPTIONS = { - 'image': 'A color image of varying height and width.', - 'labels_class': ('A semantic segmentation label whose size matches image.' - 'Its values range from 0 (background) to num_classes.'), -} - -# Named tuple to describe the dataset properties. -DatasetDescriptor = collections.namedtuple( - 'DatasetDescriptor', - ['splits_to_sizes', # Splits of the dataset into training, val, and test. - 'num_classes', # Number of semantic classes, including the background - # class (if exists). For example, there are 20 - # foreground classes + 1 background class in the PASCAL - # VOC 2012 dataset. Thus, we set num_classes=21. - 'ignore_label', # Ignore label value. - ] -) - -_CITYSCAPES_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 2975, - 'val': 500, - }, - num_classes=19, - ignore_label=255, -) - -_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 1464, - 'train_aug': 10582, - 'trainval': 2913, - 'val': 1449, - }, - num_classes=21, - ignore_label=255, -) - -# These number (i.e., 'train'/'test') seems to have to be hard coded -# You are required to figure it out for your training/testing example. -_ADE20K_INFORMATION = DatasetDescriptor( - splits_to_sizes={ - 'train': 20210, # num of samples in images/training - 'val': 2000, # num of samples in images/validation - }, - num_classes=151, - ignore_label=0, -) - - -_DATASETS_INFORMATION = { - 'cityscapes': _CITYSCAPES_INFORMATION, - 'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION, - 'ade20k': _ADE20K_INFORMATION, -} - -# Default file pattern of TFRecord of TensorFlow Example. -_FILE_PATTERN = '%s-*' - - -def get_cityscapes_dataset_name(): - return 'cityscapes' - - -def get_dataset(dataset_name, split_name, dataset_dir): - """Gets an instance of slim Dataset. - - Args: - dataset_name: Dataset name. - split_name: A train/val Split name. - dataset_dir: The directory of the dataset sources. - - Returns: - An instance of slim Dataset. - - Raises: - ValueError: if the dataset_name or split_name is not recognized. - """ - if dataset_name not in _DATASETS_INFORMATION: - raise ValueError('The specified dataset is not supported yet.') - - splits_to_sizes = _DATASETS_INFORMATION[dataset_name].splits_to_sizes - - if split_name not in splits_to_sizes: - raise ValueError('data split name %s not recognized' % split_name) - - # Prepare the variables for different datasets. - num_classes = _DATASETS_INFORMATION[dataset_name].num_classes - ignore_label = _DATASETS_INFORMATION[dataset_name].ignore_label - - file_pattern = _FILE_PATTERN - file_pattern = os.path.join(dataset_dir, file_pattern % split_name) - - # Specify how the TF-Examples are decoded. - keys_to_features = { - 'image/encoded': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/filename': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/format': tf.FixedLenFeature( - (), tf.string, default_value='jpeg'), - 'image/height': tf.FixedLenFeature( - (), tf.int64, default_value=0), - 'image/width': tf.FixedLenFeature( - (), tf.int64, default_value=0), - 'image/segmentation/class/encoded': tf.FixedLenFeature( - (), tf.string, default_value=''), - 'image/segmentation/class/format': tf.FixedLenFeature( - (), tf.string, default_value='png'), - } - items_to_handlers = { - 'image': tfexample_decoder.Image( - image_key='image/encoded', - format_key='image/format', - channels=3), - 'image_name': tfexample_decoder.Tensor('image/filename'), - 'height': tfexample_decoder.Tensor('image/height'), - 'width': tfexample_decoder.Tensor('image/width'), - 'labels_class': tfexample_decoder.Image( - image_key='image/segmentation/class/encoded', - format_key='image/segmentation/class/format', - channels=1), - } - - decoder = tfexample_decoder.TFExampleDecoder( - keys_to_features, items_to_handlers) - - return dataset.Dataset( - data_sources=file_pattern, - reader=tf.TFRecordReader, - decoder=decoder, - num_samples=splits_to_sizes[split_name], - items_to_descriptions=_ITEMS_TO_DESCRIPTIONS, - ignore_label=ignore_label, - num_classes=num_classes, - name=dataset_name, - multi_label=True) diff --git a/research/deeplab/eval.py b/research/deeplab/eval.py deleted file mode 100644 index 4f5fb8ba9c7493e45e567e9cd5ba9fe567dd9690..0000000000000000000000000000000000000000 --- a/research/deeplab/eval.py +++ /dev/null @@ -1,227 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Evaluation script for the DeepLab model. - -See model.py for more details and usage. -""" - -import numpy as np -import six -import tensorflow as tf -from tensorflow.contrib import metrics as contrib_metrics -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import tfprof as contrib_tfprof -from tensorflow.contrib import training as contrib_training -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator - -flags = tf.app.flags -FLAGS = flags.FLAGS - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -# Settings for log directories. - -flags.DEFINE_string('eval_logdir', None, 'Where to write the event logs.') - -flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') - -# Settings for evaluating the model. - -flags.DEFINE_integer('eval_batch_size', 1, - 'The number of images in each batch during evaluation.') - -flags.DEFINE_list('eval_crop_size', '513,513', - 'Image crop size [height, width] for evaluation.') - -flags.DEFINE_integer('eval_interval_secs', 60 * 5, - 'How often (in seconds) to run evaluation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. -flags.DEFINE_multi_float('eval_scales', [1.0], - 'The scales to resize images for evaluation.') - -# Change to True for adding flipped images during test. -flags.DEFINE_bool('add_flipped_images', False, - 'Add flipped images for evaluation or not.') - -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. - -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('eval_split', 'val', - 'Which split of the dataset used for evaluation') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - -flags.DEFINE_integer('max_number_of_evaluations', 0, - 'Maximum number of eval iterations. Will loop ' - 'indefinitely upon nonpositive values.') - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.eval_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=FLAGS.eval_batch_size, - crop_size=[int(sz) for sz in FLAGS.eval_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - model_variant=FLAGS.model_variant, - num_readers=2, - is_training=False, - should_shuffle=False, - should_repeat=False) - - tf.gfile.MakeDirs(FLAGS.eval_logdir) - tf.logging.info('Evaluating on %s set', FLAGS.eval_split) - - with tf.Graph().as_default(): - samples = dataset.get_one_shot_iterator().get_next() - - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_of_classes}, - crop_size=[int(sz) for sz in FLAGS.eval_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - # Set shape in order for tf.contrib.tfprof.model_analyzer to work properly. - samples[common.IMAGE].set_shape( - [FLAGS.eval_batch_size, - int(FLAGS.eval_crop_size[0]), - int(FLAGS.eval_crop_size[1]), - 3]) - if tuple(FLAGS.eval_scales) == (1.0,): - tf.logging.info('Performing single-scale test.') - predictions = model.predict_labels(samples[common.IMAGE], model_options, - image_pyramid=FLAGS.image_pyramid) - else: - tf.logging.info('Performing multi-scale test.') - if FLAGS.quantize_delay_step >= 0: - raise ValueError( - 'Quantize mode is not supported with multi-scale test.') - - predictions = model.predict_labels_multi_scale( - samples[common.IMAGE], - model_options=model_options, - eval_scales=FLAGS.eval_scales, - add_flipped_images=FLAGS.add_flipped_images) - predictions = predictions[common.OUTPUT_TYPE] - predictions = tf.reshape(predictions, shape=[-1]) - labels = tf.reshape(samples[common.LABEL], shape=[-1]) - weights = tf.to_float(tf.not_equal(labels, dataset.ignore_label)) - - # Set ignore_label regions to label 0, because metrics.mean_iou requires - # range of labels = [0, dataset.num_classes). Note the ignore_label regions - # are not evaluated since the corresponding regions contain weights = 0. - labels = tf.where( - tf.equal(labels, dataset.ignore_label), tf.zeros_like(labels), labels) - - predictions_tag = 'miou' - for eval_scale in FLAGS.eval_scales: - predictions_tag += '_' + str(eval_scale) - if FLAGS.add_flipped_images: - predictions_tag += '_flipped' - - # Define the evaluation metric. - metric_map = {} - num_classes = dataset.num_of_classes - metric_map['eval/%s_overall' % predictions_tag] = tf.metrics.mean_iou( - labels=labels, predictions=predictions, num_classes=num_classes, - weights=weights) - # IoU for each class. - one_hot_predictions = tf.one_hot(predictions, num_classes) - one_hot_predictions = tf.reshape(one_hot_predictions, [-1, num_classes]) - one_hot_labels = tf.one_hot(labels, num_classes) - one_hot_labels = tf.reshape(one_hot_labels, [-1, num_classes]) - for c in range(num_classes): - predictions_tag_c = '%s_class_%d' % (predictions_tag, c) - tp, tp_op = tf.metrics.true_positives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - fp, fp_op = tf.metrics.false_positives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - fn, fn_op = tf.metrics.false_negatives( - labels=one_hot_labels[:, c], predictions=one_hot_predictions[:, c], - weights=weights) - tp_fp_fn_op = tf.group(tp_op, fp_op, fn_op) - iou = tf.where(tf.greater(tp + fn, 0.0), - tp / (tp + fn + fp), - tf.constant(np.NaN)) - metric_map['eval/%s' % predictions_tag_c] = (iou, tp_fp_fn_op) - - (metrics_to_values, - metrics_to_updates) = contrib_metrics.aggregate_metric_map(metric_map) - - summary_ops = [] - for metric_name, metric_value in six.iteritems(metrics_to_values): - op = tf.summary.scalar(metric_name, metric_value) - op = tf.Print(op, [metric_value], metric_name) - summary_ops.append(op) - - summary_op = tf.summary.merge(summary_ops) - summary_hook = contrib_training.SummaryAtEndHook( - log_dir=FLAGS.eval_logdir, summary_op=summary_op) - hooks = [summary_hook] - - num_eval_iters = None - if FLAGS.max_number_of_evaluations > 0: - num_eval_iters = FLAGS.max_number_of_evaluations - - if FLAGS.quantize_delay_step >= 0: - contrib_quantize.create_eval_graph() - - contrib_tfprof.model_analyzer.print_model_analysis( - tf.get_default_graph(), - tfprof_options=contrib_tfprof.model_analyzer - .TRAINABLE_VARS_PARAMS_STAT_OPTIONS) - contrib_tfprof.model_analyzer.print_model_analysis( - tf.get_default_graph(), - tfprof_options=contrib_tfprof.model_analyzer.FLOAT_OPS_OPTIONS) - contrib_training.evaluate_repeatedly( - checkpoint_dir=FLAGS.checkpoint_dir, - master=FLAGS.master, - eval_ops=list(metrics_to_updates.values()), - max_number_of_evaluations=num_eval_iters, - hooks=hooks, - eval_interval_secs=FLAGS.eval_interval_secs) - - -if __name__ == '__main__': - flags.mark_flag_as_required('checkpoint_dir') - flags.mark_flag_as_required('eval_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/deeplab/evaluation/README.md b/research/deeplab/evaluation/README.md deleted file mode 100644 index 69255384e9a293e7acada74b40bd4288ba121edb..0000000000000000000000000000000000000000 --- a/research/deeplab/evaluation/README.md +++ /dev/null @@ -1,311 +0,0 @@ -# Evaluation Metrics for Whole Image Parsing - -Whole Image Parsing [1], also known as Panoptic Segmentation [2], generalizes -the tasks of semantic segmentation for "stuff" classes and instance -segmentation for "thing" classes, assigning both semantic and instance labels -to every pixel in an image. - -Previous works evaluate the parsing result with separate metrics (e.g., one for -semantic segmentation result and one for object detection result). Recently, -Kirillov et al. propose the unified instance-based Panoptic Quality (PQ) metric -[2] into several benchmarks [3, 4]. - -However, we notice that the instance-based PQ metric often places -disproportionate emphasis on small instance parsing, as well as on "thing" over -"stuff" classes. To remedy these effects, we propose an alternative -region-based Parsing Covering (PC) metric [5], which adapts the Covering -metric [6], previously used for class-agnostics segmentation quality -evaluation, to the task of image parsing. - -Here, we provide implementation of both PQ and PC for evaluating the parsing -results. We briefly explain both metrics below for reference. - -## Panoptic Quality (PQ) - -Given a groundtruth segmentation S and a predicted segmentation S', PQ is -defined as follows: - -
-  -
-
-  -
-
- Zhuowen Tu, Xiangrong Chen, Alan L. Yuille, and Song-Chun Zhu
- IJCV, 2005. - -2. **Panoptic Segmentation**
- Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother and Piotr - Dollár
- arXiv:1801.00868, 2018. - -3. **Microsoft COCO: Common Objects in Context**
- Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross - Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, - Piotr Dollar
- In the Proc. of ECCV, 2014. - -4. **The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes**
- Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulò, and Peter Kontschieder
- In the Proc. of ICCV, 2017. - -5. **DeeperLab: Single-Shot Image Parser**
- Tien-Ju Yang, Maxwell D. Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, - Xiao Zhang, Vivienne Sze, George Papandreou, Liang-Chieh Chen
- arXiv: 1902.05093, 2019. - -6. **Contour Detection and Hierarchical Image Segmentation**
- Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jitendra Malik
- PAMI, 2011 diff --git a/research/deeplab/evaluation/__init__.py b/research/deeplab/evaluation/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/evaluation/base_metric.py b/research/deeplab/evaluation/base_metric.py deleted file mode 100644 index ee7606ef44c1c2c027e593c494659f0dbcd455d3..0000000000000000000000000000000000000000 --- a/research/deeplab/evaluation/base_metric.py +++ /dev/null @@ -1,191 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Defines the top-level interface for evaluating segmentations.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import abc -import numpy as np -import six - - -_EPSILON = 1e-10 - - -def realdiv_maybe_zero(x, y): - """Element-wise x / y where y may contain zeros, for those returns 0 too.""" - return np.where( - np.less(np.abs(y), _EPSILON), np.zeros_like(x), np.divide(x, y)) - - -@six.add_metaclass(abc.ABCMeta) -class SegmentationMetric(object): - """Abstract base class for computers of segmentation metrics. - - Subclasses will implement both: - 1. Comparing the predicted segmentation for an image with the groundtruth. - 2. Computing the final metric over a set of images. - These are often done as separate steps, due to the need to accumulate - intermediate values other than the metric itself across images, computing the - actual metric value only on these accumulations after all the images have been - compared. - - A simple usage would be: - - metric = MetricImplementation(...) - for
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- [[link]](https://arxiv.org/abs/1512.03385), In CVPR, 2016. - -2. **Semantic Contours from Inverse Detectors**
- Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
- [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html), In ICCV, 2011. - -3. **Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials**
- Philipp Krähenbühl, Vladlen Koltun
- [[link]](http://graphics.stanford.edu/projects/densecrf/), In NIPS, 2011. diff --git a/research/deeplab/g3doc/img/image1.jpg b/research/deeplab/g3doc/img/image1.jpg deleted file mode 100644 index 939b6f9cef3da337e1279246090f20bd78920bc8..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image1.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image2.jpg b/research/deeplab/g3doc/img/image2.jpg deleted file mode 100644 index 5ec1b8ac278906921bd3b6efec8fbe2e9d8c429e..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image2.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image3.jpg b/research/deeplab/g3doc/img/image3.jpg deleted file mode 100644 index d788e3dc68d684ca6e282bdff66a32abc767214a..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/image3.jpg and /dev/null differ diff --git a/research/deeplab/g3doc/img/image_info.txt b/research/deeplab/g3doc/img/image_info.txt deleted file mode 100644 index 583d113e7ebb4d81ca1cdc51c3317243600809ee..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/img/image_info.txt +++ /dev/null @@ -1,13 +0,0 @@ -Image provenance: - -image1.jpg: Philippe Put, - https://www.flickr.com/photos/34547181@N00/14499172124 - -image2.jpg: Peretz Partensky - https://www.flickr.com/photos/ifl/3926001309 - -image3.jpg: Peter Harrison - https://www.flickr.com/photos/devcentre/392585679 - - -vis[1-3].png: Showing original image together with DeepLab segmentation map. diff --git a/research/deeplab/g3doc/img/vis1.png b/research/deeplab/g3doc/img/vis1.png deleted file mode 100644 index 41b8ecd89590dcf6b635e32c3af4d4b18fbafede..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis1.png and /dev/null differ diff --git a/research/deeplab/g3doc/img/vis2.png b/research/deeplab/g3doc/img/vis2.png deleted file mode 100644 index 7fa7a4cacc4807f2ab1a9c802757d76e932a41c1..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis2.png and /dev/null differ diff --git a/research/deeplab/g3doc/img/vis3.png b/research/deeplab/g3doc/img/vis3.png deleted file mode 100644 index 813b6340a61f63e3b838a91562bc0b914191ba47..0000000000000000000000000000000000000000 Binary files a/research/deeplab/g3doc/img/vis3.png and /dev/null differ diff --git a/research/deeplab/g3doc/installation.md b/research/deeplab/g3doc/installation.md deleted file mode 100644 index 8629aba42207fc6e35c907024485c0e7f29f5e10..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/installation.md +++ /dev/null @@ -1,73 +0,0 @@ -# Installation - -## Dependencies - -DeepLab depends on the following libraries: - -* Numpy -* Pillow 1.0 -* tf Slim (which is included in the "tensorflow/models/research/" checkout) -* Jupyter notebook -* Matplotlib -* Tensorflow - -For detailed steps to install Tensorflow, follow the [Tensorflow installation -instructions](https://www.tensorflow.org/install/). A typical user can install -Tensorflow using one of the following commands: - -```bash -# For CPU -pip install tensorflow -# For GPU -pip install tensorflow-gpu -``` - -The remaining libraries can be installed on Ubuntu 14.04 using via apt-get: - -```bash -sudo apt-get install python-pil python-numpy -pip install --user jupyter -pip install --user matplotlib -pip install --user PrettyTable -``` - -## Add Libraries to PYTHONPATH - -When running locally, the tensorflow/models/research/ directory should be -appended to PYTHONPATH. This can be done by running the following from -tensorflow/models/research/: - -```bash -# From tensorflow/models/research/ -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# [Optional] for panoptic evaluation, you might need panopticapi: -# https://github.com/cocodataset/panopticapi -# Please clone it to a local directory ${PANOPTICAPI_DIR} -touch ${PANOPTICAPI_DIR}/panopticapi/__init__.py -export PYTHONPATH=$PYTHONPATH:${PANOPTICAPI_DIR}/panopticapi -``` - -Note: This command needs to run from every new terminal you start. If you wish -to avoid running this manually, you can add it as a new line to the end of your -~/.bashrc file. - -# Testing the Installation - -You can test if you have successfully installed the Tensorflow DeepLab by -running the following commands: - -Quick test by running model_test.py: - -```bash -# From tensorflow/models/research/ -python deeplab/model_test.py -``` - -Quick running the whole code on the PASCAL VOC 2012 dataset: - -```bash -# From tensorflow/models/research/deeplab -sh local_test.sh -``` - diff --git a/research/deeplab/g3doc/model_zoo.md b/research/deeplab/g3doc/model_zoo.md deleted file mode 100644 index 76972dc796e77838004a6f36bef73ca5bb66aff5..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/model_zoo.md +++ /dev/null @@ -1,254 +0,0 @@ -# TensorFlow DeepLab Model Zoo - -We provide deeplab models pretrained several datasets, including (1) PASCAL VOC -2012, (2) Cityscapes, and (3) ADE20K for reproducing our results, as well as -some checkpoints that are only pretrained on ImageNet for training your own -models. - -## DeepLab models trained on PASCAL VOC 2012 - -Un-tar'ed directory includes: - -* a frozen inference graph (`frozen_inference_graph.pb`). All frozen inference - graphs by default use output stride of 8, a single eval scale of 1.0 and - no left-right flips, unless otherwise specified. MobileNet-v2 based models - do not include the decoder module. - -* a checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`) - -### Model details - -We provide several checkpoints that have been pretrained on VOC 2012 train_aug -set or train_aug + trainval set. In the former case, one could train their model -with smaller batch size and freeze batch normalization when limited GPU memory -is available, since we have already fine-tuned the batch normalization for you. -In the latter case, one could directly evaluate the checkpoints on VOC 2012 test -set or use this checkpoint for demo. Note *MobileNet-v2* based models do not -employ ASPP and decoder modules for fast computation. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder ---------------------------- | :--------------: | :-----------------: | :---: | :-----: -mobilenetv2_dm05_coco_voc_trainaug | MobileNet-v2
Depth-Multiplier = 0.5 | ImageNet
MS-COCO
VOC 2012 train_aug set| N/A | N/A -mobilenetv2_dm05_coco_voc_trainval | MobileNet-v2
Depth-Multiplier = 0.5 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A -mobilenetv2_coco_voc_trainaug | MobileNet-v2 | ImageNet
MS-COCO
VOC 2012 train_aug set| N/A | N/A -mobilenetv2_coco_voc_trainval | MobileNet-v2 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A -xception65_coco_voc_trainaug | Xception_65 | ImageNet
MS-COCO
VOC 2012 train_aug set| [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 -xception65_coco_voc_trainval | Xception_65 | ImageNet
MS-COCO
VOC 2012 train_aug + trainval sets | [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 - -In the table, **OS** denotes output stride. - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | PASCAL mIOU | File Size ------------------------------------------------------------------------------------------------------------------------- | :-------: | :------------------------: | :-------------: | :------------------: | :------------: | :----------------------------: | :-------: -[mobilenetv2_dm05_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz) | 16 | [1.0] | No | 0.88B | - | 70.19% (val) | 7.6MB -[mobilenetv2_dm05_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz) | 8 | [1.0] | No | 2.84B | - | 71.83% (test) | 7.6MB -[mobilenetv2_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 2.75B
152.59B | 0.1
26.9 | 75.32% (val)
77.33 (val) | 23MB -[mobilenetv2_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 152.59B | 26.9 | 80.25% (**test**) | 23MB -[xception65_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_pascal_train_aug_2018_01_04.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 54.17B
3055.35B | 0.7
223.2 | 82.20% (val)
83.58% (val) | 439MB -[xception65_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_pascal_trainval_2018_01_04.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 3055.35B | 223.2 | 87.80% (**test**) | 439MB - -In the table, we report both computation complexity (in terms of Multiply-Adds -and CPU Runtime) and segmentation performance (in terms of mIOU) on the PASCAL -VOC val or test set. The reported runtime is calculated by tfprof on a -workstation with CPU E5-1650 v3 @ 3.50GHz and 32GB memory. Note that applying -multi-scale inputs and left-right flips increases the segmentation performance -but also significantly increases the computation and thus may not be suitable -for real-time applications. - -## DeepLab models trained on Cityscapes - -### Model details - -We provide several checkpoints that have been pretrained on Cityscapes -train_fine set. Note *MobileNet-v2* based model has been pretrained on MS-COCO -dataset and does not employ ASPP and decoder modules for fast computation. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder -------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: -mobilenetv2_coco_cityscapes_trainfine | MobileNet-v2 | ImageNet
MS-COCO
Cityscapes train_fine set | N/A | N/A -mobilenetv3_large_cityscapes_trainfine | MobileNet-v3 Large | Cityscapes train_fine set
(No ImageNet) | N/A | OS = 8 -mobilenetv3_small_cityscapes_trainfine | MobileNet-v3 Small | Cityscapes train_fine set
(No ImageNet) | N/A | OS = 8 -xception65_cityscapes_trainfine | Xception_65 | ImageNet
Cityscapes train_fine set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 -xception71_dpc_cityscapes_trainfine | Xception_71 | ImageNet
MS-COCO
Cityscapes train_fine set | Dense Prediction Cell | OS = 4 -xception71_dpc_cityscapes_trainval | Xception_71 | ImageNet
MS-COCO
Cityscapes trainval_fine and coarse set | Dense Prediction Cell | OS = 4 - -In the table, **OS** denotes output stride. - -Note for mobilenet v3 models, we use additional commandline flags as follows: - -``` ---model_variant={ mobilenet_v3_large_seg | mobilenet_v3_small_seg } ---image_pooling_crop_size=769,769 ---image_pooling_stride=4,5 ---add_image_level_feature=1 ---aspp_convs_filters=128 ---aspp_with_concat_projection=0 ---aspp_with_squeeze_and_excitation=1 ---decoder_use_sum_merge=1 ---decoder_filters=19 ---decoder_output_is_logits=1 ---image_se_uses_qsigmoid=1 ---decoder_output_stride=8 ---output_stride=32 -``` - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | Cityscapes mIOU | File Size --------------------------------------------------------------------------------------------------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :------------: | :----------------------------: | :-------: -[mobilenetv2_coco_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_mnv2_cityscapes_train_2018_02_05.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 21.27B
433.24B | 0.8
51.12 | 70.71% (val)
73.57% (val) | 23MB -[mobilenetv3_large_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_mnv3_large_cityscapes_trainfine_2019_11_15.tar.gz) | 32 | [1.0] | No | 15.95B | 0.6 | 72.41% (val) | 17MB -[mobilenetv3_small_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_mnv3_small_cityscapes_trainfine_2019_11_15.tar.gz) | 32 | [1.0] | No | 4.63B | 0.4 | 68.99% (val) | 5MB -[xception65_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_cityscapes_train_2018_02_06.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 418.64B
8677.92B | 5.0
422.8 | 78.79% (val)
80.42% (val) | 439MB -[xception71_dpc_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainfine_2018_09_08.tar.gz) | 16 | [1.0] | No | 502.07B | - | 80.31% (val) | 445MB -[xception71_dpc_cityscapes_trainval](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainvalfine_2018_09_08.tar.gz) | 8 | [0.75:0.25:2] | Yes | - | - | 82.66% (**test**) | 446MB - -### EdgeTPU-DeepLab models on Cityscapes - -EdgeTPU is Google's machine learning accelerator architecture for edge devices -(exists in Coral devices and Pixel4's Neural Core). Leveraging nerual -architecture search (NAS, also named as Auto-ML) algorithms, -[EdgeTPU-Mobilenet](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) -has been released which yields higher hardware utilization, lower latency, as -well as better accuracy over Mobilenet-v2/v3. We use EdgeTPU-Mobilenet as the -backbone and provide checkpoints that have been pretrained on Cityscapes -train_fine set. We named them as EdgeTPU-DeepLab models. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder --------------------- | :----------------: | :----------------: | :--: | :-----: -EdgeTPU-DeepLab | EdgeMobilenet-1.0 | ImageNet | N/A | N/A -EdgeTPU-DeepLab-slim | EdgeMobilenet-0.75 | ImageNet | N/A | N/A - -For EdgeTPU-DeepLab-slim, the backbone feature extractor has depth multiplier = -0.75 and aspp_convs_filters = 128. We do not employ ASPP nor decoder modules to -further reduce the latency. We employ the same train/eval flags used for -MobileNet-v2 DeepLab model. Flags changed for EdgeTPU-DeepLab model are listed -here. - -``` ---decoder_output_stride='' ---aspp_convs_filters=256 ---model_variant=mobilenet_edgetpu -``` - -For EdgeTPU-DeepLab-slim, also include the following flags. - -``` ---depth_multiplier=0.75 ---aspp_convs_filters=128 -``` - -Checkpoint name | Eval OS | Eval scales | Cityscapes mIOU | Multiply-Adds | Simulator latency on Pixel 4 EdgeTPU ----------------------------------------------------------------------------------------------------- | :--------: | :---------: | :--------------------------: | :------------: | :----------------------------------: -[EdgeTPU-DeepLab](http://download.tensorflow.org/models/edgetpu-deeplab_2020_03_09.tar.gz) | 32
16 | [1.0] | 70.6% (val)
74.1% (val) | 5.6B
7.1B | 13.8 ms
17.5 ms -[EdgeTPU-DeepLab-slim](http://download.tensorflow.org/models/edgetpu-deeplab-slim_2020_03_09.tar.gz) | 32
16 | [1.0] | 70.0% (val)
73.2% (val) | 3.5B
4.3B | 9.9 ms
13.2 ms - -## DeepLab models trained on ADE20K - -### Model details - -We provide some checkpoints that have been pretrained on ADE20K training set. -Note that the model has only been pretrained on ImageNet, following the -dataset rule. - -Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder | Input size -------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: | :-----: -mobilenetv2_ade20k_train | MobileNet-v2 | ImageNet
ADE20K training set | N/A | OS = 4 | 257x257 -xception65_ade20k_train | Xception_65 | ImageNet
ADE20K training set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 | 513x513 - -The input dimensions of ADE20K have a huge amount of variation. We resize inputs so that the longest size is 257 for MobileNet-v2 (faster inference) and 513 for Xception_65 (better performation). Note that we also include the decoder module in the MobileNet-v2 checkpoint. - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | mIOU | Pixel-wise Accuracy | File Size -------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :-------------------: | :-------: -[mobilenetv2_ade20k_train](http://download.tensorflow.org/models/deeplabv3_mnv2_ade20k_train_2018_12_03.tar.gz) | 16 | [1.0] | No | 32.04% (val) | 75.41% (val) | 24.8MB -[xception65_ade20k_train](http://download.tensorflow.org/models/deeplabv3_xception_ade20k_train_2018_05_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 45.65% (val) | 82.52% (val) | 439MB - - -## Checkpoints pretrained on ImageNet - -Un-tar'ed directory includes: - -* model checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`). - -### Model details - -We also provide some checkpoints that are pretrained on ImageNet and/or COCO (as -post-fixed in the model name) so that one could use this for training your own -models. - -* mobilenet_v2: We refer the interested users to the TensorFlow open source - [MobileNet-V2](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) - for details. - -* xception_{41,65,71}: We adapt the original Xception model to the task of - semantic segmentation with the following changes: (1) more layers, (2) all - max pooling operations are replaced by strided (atrous) separable - convolutions, and (3) extra batch-norm and ReLU after each 3x3 depthwise - convolution are added. We provide three Xception model variants with - different network depths. - -* resnet_v1_{50,101}_beta: We modify the original ResNet-101 [10], similar to - PSPNet [11] by replacing the first 7x7 convolution with three 3x3 - convolutions. See resnet_v1_beta.py for more details. - -Model name | File Size --------------------------------------------------------------------------------------- | :-------: -[xception_41_imagenet](http://download.tensorflow.org/models/xception_41_2018_05_09.tar.gz ) | 288MB -[xception_65_imagenet](http://download.tensorflow.org/models/deeplabv3_xception_2018_01_04.tar.gz) | 447MB -[xception_65_imagenet_coco](http://download.tensorflow.org/models/xception_65_coco_pretrained_2018_10_02.tar.gz) | 292MB -[xception_71_imagenet](http://download.tensorflow.org/models/xception_71_2018_05_09.tar.gz ) | 474MB -[resnet_v1_50_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_50_2018_05_04.tar.gz) | 274MB -[resnet_v1_101_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_101_2018_05_04.tar.gz) | 477MB - -## References - -1. **Mobilenets: Efficient convolutional neural networks for mobile vision applications**
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
- [[link]](https://arxiv.org/abs/1704.04861). arXiv:1704.04861, 2017. - -2. **Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation**
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
- [[link]](https://arxiv.org/abs/1801.04381). arXiv:1801.04381, 2018. - -3. **Xception: Deep Learning with Depthwise Separable Convolutions**
- François Chollet
- [[link]](https://arxiv.org/abs/1610.02357). In the Proc. of CVPR, 2017. - -4. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
- Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
- [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge - Workshop, 2017. - -5. **The Pascal Visual Object Classes Challenge: A Retrospective**
- Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John M. Winn, Andrew Zisserman
- [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. - -6. **Semantic Contours from Inverse Detectors**
- Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
- [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html). In the Proc. of ICCV, 2011. - -7. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
- Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
- [[link]](https://www.cityscapes-dataset.com/). In the Proc. of CVPR, 2016. - -8. **Microsoft COCO: Common Objects in Context**
- Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollar
- [[link]](http://cocodataset.org/). In the Proc. of ECCV, 2014. - -9. **ImageNet Large Scale Visual Recognition Challenge**
- Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, Li Fei-Fei
- [[link]](http://www.image-net.org/). IJCV, 2015. - -10. **Deep Residual Learning for Image Recognition**
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- [[link]](https://arxiv.org/abs/1512.03385). CVPR, 2016. - -11. **Pyramid Scene Parsing Network**
- Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
- [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. - -12. **Scene Parsing through ADE20K Dataset**
- Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba
- [[link]](http://groups.csail.mit.edu/vision/datasets/ADE20K/). In CVPR, - 2017. - -13. **Searching for MobileNetV3**
- Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
- [[link]](https://arxiv.org/abs/1905.02244). In ICCV, 2019. diff --git a/research/deeplab/g3doc/pascal.md b/research/deeplab/g3doc/pascal.md deleted file mode 100644 index f4bc84eabb83e90ff192077749784fb2560057dd..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/pascal.md +++ /dev/null @@ -1,161 +0,0 @@ -# Running DeepLab on PASCAL VOC 2012 Semantic Segmentation Dataset - -This page walks through the steps required to run DeepLab on PASCAL VOC 2012 on -a local machine. - -## Download dataset and convert to TFRecord - -We have prepared the script (under the folder `datasets`) to download and -convert PASCAL VOC 2012 semantic segmentation dataset to TFRecord. - -```bash -# From the tensorflow/models/research/deeplab/datasets directory. -sh download_and_convert_voc2012.sh -``` - -The converted dataset will be saved at -./deeplab/datasets/pascal_voc_seg/tfrecord - -## Recommended Directory Structure for Training and Evaluation - -``` -+ datasets - + pascal_voc_seg - + VOCdevkit - + VOC2012 - + JPEGImages - + SegmentationClass - + tfrecord - + exp - + train_on_train_set - + train - + eval - + vis -``` - -where the folder `train_on_train_set` stores the train/eval/vis events and -results (when training DeepLab on the PASCAL VOC 2012 train set). - -## Running the train/eval/vis jobs - -A local training job using `xception_65` can be run with the following command: - -```bash -# From tensorflow/models/research/ -python deeplab/train.py \ - --logtostderr \ - --training_number_of_steps=30000 \ - --train_split="train" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --train_crop_size="513,513" \ - --train_batch_size=1 \ - --dataset="pascal_voc_seg" \ - --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \ - --train_logdir=${PATH_TO_TRAIN_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_INITIAL_CHECKPOINT} is the path to the initial checkpoint -(usually an ImageNet pretrained checkpoint), ${PATH_TO_TRAIN_DIR} is the -directory in which training checkpoints and events will be written to, and -${PATH_TO_DATASET} is the directory in which the PASCAL VOC 2012 dataset -resides. - -**Note that for {train,eval,vis}.py:** - -1. In order to reproduce our results, one needs to use large batch size (> 12), - and set fine_tune_batch_norm = True. Here, we simply use small batch size - during training for the purpose of demonstration. If the users have limited - GPU memory at hand, please fine-tune from our provided checkpoints whose - batch norm parameters have been trained, and use smaller learning rate with - fine_tune_batch_norm = False. - -2. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if - setting output_stride=8. - -3. The users could skip the flag, `decoder_output_stride`, if you do not want - to use the decoder structure. - -A local evaluation job using `xception_65` can be run with the following -command: - -```bash -# From tensorflow/models/research/ -python deeplab/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --eval_crop_size="513,513" \ - --dataset="pascal_voc_seg" \ - --checkpoint_dir=${PATH_TO_CHECKPOINT} \ - --eval_logdir=${PATH_TO_EVAL_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the -path to train_logdir), ${PATH_TO_EVAL_DIR} is the directory in which evaluation -events will be written to, and ${PATH_TO_DATASET} is the directory in which the -PASCAL VOC 2012 dataset resides. - -A local visualization job using `xception_65` can be run with the following -command: - -```bash -# From tensorflow/models/research/ -python deeplab/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --vis_crop_size="513,513" \ - --dataset="pascal_voc_seg" \ - --checkpoint_dir=${PATH_TO_CHECKPOINT} \ - --vis_logdir=${PATH_TO_VIS_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the -path to train_logdir), ${PATH_TO_VIS_DIR} is the directory in which evaluation -events will be written to, and ${PATH_TO_DATASET} is the directory in which the -PASCAL VOC 2012 dataset resides. Note that if the users would like to save the -segmentation results for evaluation server, set also_save_raw_predictions = -True. - -## Running Tensorboard - -Progress for training and evaluation jobs can be inspected using Tensorboard. If -using the recommended directory structure, Tensorboard can be run using the -following command: - -```bash -tensorboard --logdir=${PATH_TO_LOG_DIRECTORY} -``` - -where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the -train, eval, and vis directories (e.g., the folder `train_on_train_set` in the -above example). Please note it may take Tensorboard a couple minutes to populate -with data. - -## Example - -We provide a script to run the {train,eval,vis,export_model}.py on the PASCAL VOC -2012 dataset as an example. See the code in local_test.sh for details. - -```bash -# From tensorflow/models/research/deeplab -sh local_test.sh -``` diff --git a/research/deeplab/g3doc/quantize.md b/research/deeplab/g3doc/quantize.md deleted file mode 100644 index d88a2e9a8acbac4a0de6e3ea2bed65cb44535665..0000000000000000000000000000000000000000 --- a/research/deeplab/g3doc/quantize.md +++ /dev/null @@ -1,110 +0,0 @@ -# Quantize DeepLab model for faster on-device inference - -This page describes the steps required to quantize DeepLab model and convert it -to TFLite for on-device inference. The main steps include: - -1. Quantization-aware training -1. Exporting model -1. Converting to TFLite FlatBuffer - -We provide details for each step below. - -## Quantization-aware training - -DeepLab supports two approaches to quantize your model. - -1. **[Recommended]** Training a non-quantized model until convergence. Then - fine-tune the trained float model with quantization using a small learning - rate (on PASCAL we use the value of 3e-5) . This fine-tuning step usually - takes 2k to 5k steps to converge. - -1. Training a deeplab float model with delayed quantization. Usually we delay - quantization until the last a few thousand steps in training. - -In the current implementation, quantization is only supported with 1) -`num_clones=1` for training and 2) single scale inference for evaluation, -visualization and model export. To get the best performance for the quantized -model, we strongly recommend to train the float model with larger `num_clones` -and then fine-tune the model with a single clone. - -Here shows the commandline to quantize deeplab model trained on PASCAL VOC -dataset using fine-tuning: - -``` -# From tensorflow/models/research/ -python deeplab/train.py \ - --logtostderr \ - --training_number_of_steps=3000 \ - --train_split="train" \ - --model_variant="mobilenet_v2" \ - --output_stride=16 \ - --train_crop_size="513,513" \ - --train_batch_size=8 \ - --base_learning_rate=3e-5 \ - --dataset="pascal_voc_seg" \ - --initialize_last_layer \ - --quantize_delay_step=0 \ - --tf_initial_checkpoint=${PATH_TO_TRAINED_FLOAT_MODEL} \ - --train_logdir=${PATH_TO_TRAIN_DIR} \ - --dataset_dir=${PATH_TO_DATASET} -``` - -## Converting to TFLite FlatBuffer - -First use the following commandline to export your trained model. - -``` -# From tensorflow/models/research/ -python deeplab/export_model.py \ - --checkpoint_path=${CHECKPOINT_PATH} \ - --quantize_delay_step=0 \ - --export_path=${OUTPUT_DIR}/frozen_inference_graph.pb - -``` - -Commandline below shows how to convert exported graphdef to TFlite model. - -``` -tflite_convert \ - --graph_def_file=${OUTPUT_DIR}/frozen_inference_graph.pb \ - --output_file=${OUTPUT_DIR}/frozen_inference_graph.tflite \ - --output_format=TFLITE \ - --input_shape=1,513,513,3 \ - --input_arrays="MobilenetV2/MobilenetV2/input" \ - --inference_type=QUANTIZED_UINT8 \ - --inference_input_type=QUANTIZED_UINT8 \ - --std_dev_values=128 \ - --mean_values=128 \ - --change_concat_input_ranges=true \ - --output_arrays="ArgMax" -``` - -**[Important]** Note that converted model expects 513x513 RGB input and doesn't -include preprocessing (resize and pad input image) and post processing (crop -padded region and resize to original input size). These steps can be implemented -outside of TFlite model. - -## Quantized model on PASCAL VOC - -We provide float and quantized checkpoints that have been pretrained on VOC 2012 -train_aug set, using MobileNet-v2 backbone with different depth multipliers. -Quantized model usually have 1% decay in mIoU. - -For quantized (8bit) model, un-tar'ed directory includes: - -* a frozen inference graph (frozen_inference_graph.pb) - -* a checkpoint (model.ckpt.data*, model.ckpt.index) - -* a converted TFlite FlatBuffer file (frozen_inference_graph.tflite) - -Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Quantize | PASCAL mIOU | Folder Size | TFLite File Size --------------------------------------------------------------------------------------------------------------------------------------------- | :-----: | :---------: | :-------------: | :-----------: | :------: | :----------: | :-------: | :-------: -[mobilenetv2_dm05_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz) | 16 | [1.0] | No | 0.88B | No | 70.19% (val) | 7.6MB | N/A -[mobilenetv2_dm05_coco_voc_trainaug_8bit](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_train_aug_8bit_2019_04_26.tar.gz) | 16 | [1.0] | No | 0.88B | Yes | 69.65% (val) | 8.2MB | 751.1KB -[mobilenetv2_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz) | 16 | [1.0] | No | 2.75B | No | 75.32% (val) | 23MB | N/A -[mobilenetv2_coco_voc_trainaug_8bit](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_8bit_2019_04_26.tar.gz) | 16 | [1.0] | No | 2.75B | Yes | 74.26% (val) | 24MB | 2.2MB - -Note that you might need the nightly build of TensorFlow (see -[here](https://www.tensorflow.org/install) for install instructions) to convert -above quantized model to TFLite. diff --git a/research/deeplab/input_preprocess.py b/research/deeplab/input_preprocess.py deleted file mode 100644 index 9ca8bce4eb9104b22469419c4e6af4beaba9406a..0000000000000000000000000000000000000000 --- a/research/deeplab/input_preprocess.py +++ /dev/null @@ -1,139 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Prepares the data used for DeepLab training/evaluation.""" -import tensorflow as tf -from deeplab.core import feature_extractor -from deeplab.core import preprocess_utils - - -# The probability of flipping the images and labels -# left-right during training -_PROB_OF_FLIP = 0.5 - - -def preprocess_image_and_label(image, - label, - crop_height, - crop_width, - min_resize_value=None, - max_resize_value=None, - resize_factor=None, - min_scale_factor=1., - max_scale_factor=1., - scale_factor_step_size=0, - ignore_label=255, - is_training=True, - model_variant=None): - """Preprocesses the image and label. - - Args: - image: Input image. - label: Ground truth annotation label. - crop_height: The height value used to crop the image and label. - crop_width: The width value used to crop the image and label. - min_resize_value: Desired size of the smaller image side. - max_resize_value: Maximum allowed size of the larger image side. - resize_factor: Resized dimensions are multiple of factor plus one. - min_scale_factor: Minimum scale factor value. - max_scale_factor: Maximum scale factor value. - scale_factor_step_size: The step size from min scale factor to max scale - factor. The input is randomly scaled based on the value of - (min_scale_factor, max_scale_factor, scale_factor_step_size). - ignore_label: The label value which will be ignored for training and - evaluation. - is_training: If the preprocessing is used for training or not. - model_variant: Model variant (string) for choosing how to mean-subtract the - images. See feature_extractor.network_map for supported model variants. - - Returns: - original_image: Original image (could be resized). - processed_image: Preprocessed image. - label: Preprocessed ground truth segmentation label. - - Raises: - ValueError: Ground truth label not provided during training. - """ - if is_training and label is None: - raise ValueError('During training, label must be provided.') - if model_variant is None: - tf.logging.warning('Default mean-subtraction is performed. Please specify ' - 'a model_variant. See feature_extractor.network_map for ' - 'supported model variants.') - - # Keep reference to original image. - original_image = image - - processed_image = tf.cast(image, tf.float32) - - if label is not None: - label = tf.cast(label, tf.int32) - - # Resize image and label to the desired range. - if min_resize_value or max_resize_value: - [processed_image, label] = ( - preprocess_utils.resize_to_range( - image=processed_image, - label=label, - min_size=min_resize_value, - max_size=max_resize_value, - factor=resize_factor, - align_corners=True)) - # The `original_image` becomes the resized image. - original_image = tf.identity(processed_image) - - # Data augmentation by randomly scaling the inputs. - if is_training: - scale = preprocess_utils.get_random_scale( - min_scale_factor, max_scale_factor, scale_factor_step_size) - processed_image, label = preprocess_utils.randomly_scale_image_and_label( - processed_image, label, scale) - processed_image.set_shape([None, None, 3]) - - # Pad image and label to have dimensions >= [crop_height, crop_width] - image_shape = tf.shape(processed_image) - image_height = image_shape[0] - image_width = image_shape[1] - - target_height = image_height + tf.maximum(crop_height - image_height, 0) - target_width = image_width + tf.maximum(crop_width - image_width, 0) - - # Pad image with mean pixel value. - mean_pixel = tf.reshape( - feature_extractor.mean_pixel(model_variant), [1, 1, 3]) - processed_image = preprocess_utils.pad_to_bounding_box( - processed_image, 0, 0, target_height, target_width, mean_pixel) - - if label is not None: - label = preprocess_utils.pad_to_bounding_box( - label, 0, 0, target_height, target_width, ignore_label) - - # Randomly crop the image and label. - if is_training and label is not None: - processed_image, label = preprocess_utils.random_crop( - [processed_image, label], crop_height, crop_width) - - processed_image.set_shape([crop_height, crop_width, 3]) - - if label is not None: - label.set_shape([crop_height, crop_width, 1]) - - if is_training: - # Randomly left-right flip the image and label. - processed_image, label, _ = preprocess_utils.flip_dim( - [processed_image, label], _PROB_OF_FLIP, dim=1) - - return original_image, processed_image, label diff --git a/research/deeplab/local_test.sh b/research/deeplab/local_test.sh deleted file mode 100644 index d5e4a5f42bb4241d4b6dd1b9d8a2619c4ca9dc8b..0000000000000000000000000000000000000000 --- a/research/deeplab/local_test.sh +++ /dev/null @@ -1,147 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# This script is used to run local test on PASCAL VOC 2012. Users could also -# modify from this script for their use case. -# -# Usage: -# # From the tensorflow/models/research/deeplab directory. -# sh ./local_test.sh -# -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -# Move one-level up to tensorflow/models/research directory. -cd .. - -# Update PYTHONPATH. -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# Set up the working environment. -CURRENT_DIR=$(pwd) -WORK_DIR="${CURRENT_DIR}/deeplab" - -# Run model_test first to make sure the PYTHONPATH is correctly set. -python "${WORK_DIR}"/model_test.py - -# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. -DATASET_DIR="datasets" -cd "${WORK_DIR}/${DATASET_DIR}" -sh download_and_convert_voc2012.sh - -# Go back to original directory. -cd "${CURRENT_DIR}" - -# Set up the working directories. -PASCAL_FOLDER="pascal_voc_seg" -EXP_FOLDER="exp/train_on_trainval_set" -INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" -TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" -EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" -VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" -EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" -mkdir -p "${INIT_FOLDER}" -mkdir -p "${TRAIN_LOGDIR}" -mkdir -p "${EVAL_LOGDIR}" -mkdir -p "${VIS_LOGDIR}" -mkdir -p "${EXPORT_DIR}" - -# Copy locally the trained checkpoint as the initial checkpoint. -TF_INIT_ROOT="http://download.tensorflow.org/models" -TF_INIT_CKPT="deeplabv3_pascal_train_aug_2018_01_04.tar.gz" -cd "${INIT_FOLDER}" -wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" -tar -xf "${TF_INIT_CKPT}" -cd "${CURRENT_DIR}" - -PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" - -# Train 10 iterations. -NUM_ITERATIONS=10 -python "${WORK_DIR}"/train.py \ - --logtostderr \ - --train_split="trainval" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --train_crop_size="513,513" \ - --train_batch_size=4 \ - --training_number_of_steps="${NUM_ITERATIONS}" \ - --fine_tune_batch_norm=true \ - --tf_initial_checkpoint="${INIT_FOLDER}/deeplabv3_pascal_train_aug/model.ckpt" \ - --train_logdir="${TRAIN_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" - -# Run evaluation. This performs eval over the full val split (1449 images) and -# will take a while. -# Using the provided checkpoint, one should expect mIOU=82.20%. -python "${WORK_DIR}"/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --eval_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --eval_logdir="${EVAL_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_evaluations=1 - -# Visualize the results. -python "${WORK_DIR}"/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --vis_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --vis_logdir="${VIS_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_iterations=1 - -# Export the trained checkpoint. -CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" -EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" - -python "${WORK_DIR}"/export_model.py \ - --logtostderr \ - --checkpoint_path="${CKPT_PATH}" \ - --export_path="${EXPORT_PATH}" \ - --model_variant="xception_65" \ - --atrous_rates=6 \ - --atrous_rates=12 \ - --atrous_rates=18 \ - --output_stride=16 \ - --decoder_output_stride=4 \ - --num_classes=21 \ - --crop_size=513 \ - --crop_size=513 \ - --inference_scales=1.0 - -# Run inference with the exported checkpoint. -# Please refer to the provided deeplab_demo.ipynb for an example. diff --git a/research/deeplab/local_test_mobilenetv2.sh b/research/deeplab/local_test_mobilenetv2.sh deleted file mode 100644 index c38646fdf6caa3934b7c8db66e53ffbd4f9fd8c6..0000000000000000000000000000000000000000 --- a/research/deeplab/local_test_mobilenetv2.sh +++ /dev/null @@ -1,129 +0,0 @@ -#!/bin/bash -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -# -# This script is used to run local test on PASCAL VOC 2012 using MobileNet-v2. -# Users could also modify from this script for their use case. -# -# Usage: -# # From the tensorflow/models/research/deeplab directory. -# sh ./local_test_mobilenetv2.sh -# -# - -# Exit immediately if a command exits with a non-zero status. -set -e - -# Move one-level up to tensorflow/models/research directory. -cd .. - -# Update PYTHONPATH. -export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim - -# Set up the working environment. -CURRENT_DIR=$(pwd) -WORK_DIR="${CURRENT_DIR}/deeplab" - -# Run model_test first to make sure the PYTHONPATH is correctly set. -python "${WORK_DIR}"/model_test.py -v - -# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. -DATASET_DIR="datasets" -cd "${WORK_DIR}/${DATASET_DIR}" -sh download_and_convert_voc2012.sh - -# Go back to original directory. -cd "${CURRENT_DIR}" - -# Set up the working directories. -PASCAL_FOLDER="pascal_voc_seg" -EXP_FOLDER="exp/train_on_trainval_set_mobilenetv2" -INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" -TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" -EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" -VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" -EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" -mkdir -p "${INIT_FOLDER}" -mkdir -p "${TRAIN_LOGDIR}" -mkdir -p "${EVAL_LOGDIR}" -mkdir -p "${VIS_LOGDIR}" -mkdir -p "${EXPORT_DIR}" - -# Copy locally the trained checkpoint as the initial checkpoint. -TF_INIT_ROOT="http://download.tensorflow.org/models" -CKPT_NAME="deeplabv3_mnv2_pascal_train_aug" -TF_INIT_CKPT="${CKPT_NAME}_2018_01_29.tar.gz" -cd "${INIT_FOLDER}" -wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" -tar -xf "${TF_INIT_CKPT}" -cd "${CURRENT_DIR}" - -PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" - -# Train 10 iterations. -NUM_ITERATIONS=10 -python "${WORK_DIR}"/train.py \ - --logtostderr \ - --train_split="trainval" \ - --model_variant="mobilenet_v2" \ - --output_stride=16 \ - --train_crop_size="513,513" \ - --train_batch_size=4 \ - --training_number_of_steps="${NUM_ITERATIONS}" \ - --fine_tune_batch_norm=true \ - --tf_initial_checkpoint="${INIT_FOLDER}/${CKPT_NAME}/model.ckpt-30000" \ - --train_logdir="${TRAIN_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" - -# Run evaluation. This performs eval over the full val split (1449 images) and -# will take a while. -# Using the provided checkpoint, one should expect mIOU=75.34%. -python "${WORK_DIR}"/eval.py \ - --logtostderr \ - --eval_split="val" \ - --model_variant="mobilenet_v2" \ - --eval_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --eval_logdir="${EVAL_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_evaluations=1 - -# Visualize the results. -python "${WORK_DIR}"/vis.py \ - --logtostderr \ - --vis_split="val" \ - --model_variant="mobilenet_v2" \ - --vis_crop_size="513,513" \ - --checkpoint_dir="${TRAIN_LOGDIR}" \ - --vis_logdir="${VIS_LOGDIR}" \ - --dataset_dir="${PASCAL_DATASET}" \ - --max_number_of_iterations=1 - -# Export the trained checkpoint. -CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" -EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" - -python "${WORK_DIR}"/export_model.py \ - --logtostderr \ - --checkpoint_path="${CKPT_PATH}" \ - --export_path="${EXPORT_PATH}" \ - --model_variant="mobilenet_v2" \ - --num_classes=21 \ - --crop_size=513 \ - --crop_size=513 \ - --inference_scales=1.0 - -# Run inference with the exported checkpoint. -# Please refer to the provided deeplab_demo.ipynb for an example. diff --git a/research/deeplab/model.py b/research/deeplab/model.py deleted file mode 100644 index 311aaa1acb13cb445053ac12fa09e354423e56df..0000000000000000000000000000000000000000 --- a/research/deeplab/model.py +++ /dev/null @@ -1,911 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -r"""Provides DeepLab model definition and helper functions. - -DeepLab is a deep learning system for semantic image segmentation with -the following features: - -(1) Atrous convolution to explicitly control the resolution at which -feature responses are computed within Deep Convolutional Neural Networks. - -(2) Atrous spatial pyramid pooling (ASPP) to robustly segment objects at -multiple scales with filters at multiple sampling rates and effective -fields-of-views. - -(3) ASPP module augmented with image-level feature and batch normalization. - -(4) A simple yet effective decoder module to recover the object boundaries. - -See the following papers for more details: - -"Encoder-Decoder with Atrous Separable Convolution for Semantic Image -Segmentation" -Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam. -(https://arxiv.org/abs/1802.02611) - -"Rethinking Atrous Convolution for Semantic Image Segmentation," -Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam -(https://arxiv.org/abs/1706.05587) - -"DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, -Atrous Convolution, and Fully Connected CRFs", -Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, -Alan L Yuille (* equal contribution) -(https://arxiv.org/abs/1606.00915) - -"Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected -CRFs" -Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, -Alan L. Yuille (* equal contribution) -(https://arxiv.org/abs/1412.7062) -""" -import tensorflow as tf -from tensorflow.contrib import slim as contrib_slim -from deeplab.core import dense_prediction_cell -from deeplab.core import feature_extractor -from deeplab.core import utils - -slim = contrib_slim - -LOGITS_SCOPE_NAME = 'logits' -MERGED_LOGITS_SCOPE = 'merged_logits' -IMAGE_POOLING_SCOPE = 'image_pooling' -ASPP_SCOPE = 'aspp' -CONCAT_PROJECTION_SCOPE = 'concat_projection' -DECODER_SCOPE = 'decoder' -META_ARCHITECTURE_SCOPE = 'meta_architecture' - -PROB_SUFFIX = '_prob' - -_resize_bilinear = utils.resize_bilinear -scale_dimension = utils.scale_dimension -split_separable_conv2d = utils.split_separable_conv2d - - -def get_extra_layer_scopes(last_layers_contain_logits_only=False): - """Gets the scopes for extra layers. - - Args: - last_layers_contain_logits_only: Boolean, True if only consider logits as - the last layer (i.e., exclude ASPP module, decoder module and so on) - - Returns: - A list of scopes for extra layers. - """ - if last_layers_contain_logits_only: - return [LOGITS_SCOPE_NAME] - else: - return [ - LOGITS_SCOPE_NAME, - IMAGE_POOLING_SCOPE, - ASPP_SCOPE, - CONCAT_PROJECTION_SCOPE, - DECODER_SCOPE, - META_ARCHITECTURE_SCOPE, - ] - - -def predict_labels_multi_scale(images, - model_options, - eval_scales=(1.0,), - add_flipped_images=False): - """Predicts segmentation labels. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - eval_scales: The scales to resize images for evaluation. - add_flipped_images: Add flipped images for evaluation or not. - - Returns: - A dictionary with keys specifying the output_type (e.g., semantic - prediction) and values storing Tensors representing predictions (argmax - over channels). Each prediction has size [batch, height, width]. - """ - outputs_to_predictions = { - output: [] - for output in model_options.outputs_to_num_classes - } - - for i, image_scale in enumerate(eval_scales): - with tf.variable_scope(tf.get_variable_scope(), reuse=True if i else None): - outputs_to_scales_to_logits = multi_scale_logits( - images, - model_options=model_options, - image_pyramid=[image_scale], - is_training=False, - fine_tune_batch_norm=False) - - if add_flipped_images: - with tf.variable_scope(tf.get_variable_scope(), reuse=True): - outputs_to_scales_to_logits_reversed = multi_scale_logits( - tf.reverse_v2(images, [2]), - model_options=model_options, - image_pyramid=[image_scale], - is_training=False, - fine_tune_batch_norm=False) - - for output in sorted(outputs_to_scales_to_logits): - scales_to_logits = outputs_to_scales_to_logits[output] - logits = _resize_bilinear( - scales_to_logits[MERGED_LOGITS_SCOPE], - tf.shape(images)[1:3], - scales_to_logits[MERGED_LOGITS_SCOPE].dtype) - outputs_to_predictions[output].append( - tf.expand_dims(tf.nn.softmax(logits), 4)) - - if add_flipped_images: - scales_to_logits_reversed = ( - outputs_to_scales_to_logits_reversed[output]) - logits_reversed = _resize_bilinear( - tf.reverse_v2(scales_to_logits_reversed[MERGED_LOGITS_SCOPE], [2]), - tf.shape(images)[1:3], - scales_to_logits_reversed[MERGED_LOGITS_SCOPE].dtype) - outputs_to_predictions[output].append( - tf.expand_dims(tf.nn.softmax(logits_reversed), 4)) - - for output in sorted(outputs_to_predictions): - predictions = outputs_to_predictions[output] - # Compute average prediction across different scales and flipped images. - predictions = tf.reduce_mean(tf.concat(predictions, 4), axis=4) - outputs_to_predictions[output] = tf.argmax(predictions, 3) - outputs_to_predictions[output + PROB_SUFFIX] = tf.nn.softmax(predictions) - - return outputs_to_predictions - - -def predict_labels(images, model_options, image_pyramid=None): - """Predicts segmentation labels. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - image_pyramid: Input image scales for multi-scale feature extraction. - - Returns: - A dictionary with keys specifying the output_type (e.g., semantic - prediction) and values storing Tensors representing predictions (argmax - over channels). Each prediction has size [batch, height, width]. - """ - outputs_to_scales_to_logits = multi_scale_logits( - images, - model_options=model_options, - image_pyramid=image_pyramid, - is_training=False, - fine_tune_batch_norm=False) - - predictions = {} - for output in sorted(outputs_to_scales_to_logits): - scales_to_logits = outputs_to_scales_to_logits[output] - logits = scales_to_logits[MERGED_LOGITS_SCOPE] - # There are two ways to obtain the final prediction results: (1) bilinear - # upsampling the logits followed by argmax, or (2) argmax followed by - # nearest neighbor upsampling. The second option may introduce the "blocking - # effect" but is computationally efficient. - if model_options.prediction_with_upsampled_logits: - logits = _resize_bilinear(logits, - tf.shape(images)[1:3], - scales_to_logits[MERGED_LOGITS_SCOPE].dtype) - predictions[output] = tf.argmax(logits, 3) - predictions[output + PROB_SUFFIX] = tf.nn.softmax(logits) - else: - argmax_results = tf.argmax(logits, 3) - argmax_results = tf.image.resize_nearest_neighbor( - tf.expand_dims(argmax_results, 3), - tf.shape(images)[1:3], - align_corners=True, - name='resize_prediction') - predictions[output] = tf.squeeze(argmax_results, 3) - predictions[output + PROB_SUFFIX] = tf.image.resize_bilinear( - tf.nn.softmax(logits), - tf.shape(images)[1:3], - align_corners=True, - name='resize_prob') - return predictions - - -def multi_scale_logits(images, - model_options, - image_pyramid, - weight_decay=0.0001, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Gets the logits for multi-scale inputs. - - The returned logits are all downsampled (due to max-pooling layers) - for both training and evaluation. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - image_pyramid: Input image scales for multi-scale feature extraction. - weight_decay: The weight decay for model variables. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - outputs_to_scales_to_logits: A map of maps from output_type (e.g., - semantic prediction) to a dictionary of multi-scale logits names to - logits. For each output_type, the dictionary has keys which - correspond to the scales and values which correspond to the logits. - For example, if `scales` equals [1.0, 1.5], then the keys would - include 'merged_logits', 'logits_1.00' and 'logits_1.50'. - - Raises: - ValueError: If model_options doesn't specify crop_size and its - add_image_level_feature = True, since add_image_level_feature requires - crop_size information. - """ - # Setup default values. - if not image_pyramid: - image_pyramid = [1.0] - crop_height = ( - model_options.crop_size[0] - if model_options.crop_size else tf.shape(images)[1]) - crop_width = ( - model_options.crop_size[1] - if model_options.crop_size else tf.shape(images)[2]) - if model_options.image_pooling_crop_size: - image_pooling_crop_height = model_options.image_pooling_crop_size[0] - image_pooling_crop_width = model_options.image_pooling_crop_size[1] - - # Compute the height, width for the output logits. - if model_options.decoder_output_stride: - logits_output_stride = min(model_options.decoder_output_stride) - else: - logits_output_stride = model_options.output_stride - - logits_height = scale_dimension( - crop_height, - max(1.0, max(image_pyramid)) / logits_output_stride) - logits_width = scale_dimension( - crop_width, - max(1.0, max(image_pyramid)) / logits_output_stride) - - # Compute the logits for each scale in the image pyramid. - outputs_to_scales_to_logits = { - k: {} - for k in model_options.outputs_to_num_classes - } - - num_channels = images.get_shape().as_list()[-1] - - for image_scale in image_pyramid: - if image_scale != 1.0: - scaled_height = scale_dimension(crop_height, image_scale) - scaled_width = scale_dimension(crop_width, image_scale) - scaled_crop_size = [scaled_height, scaled_width] - scaled_images = _resize_bilinear(images, scaled_crop_size, images.dtype) - if model_options.crop_size: - scaled_images.set_shape( - [None, scaled_height, scaled_width, num_channels]) - # Adjust image_pooling_crop_size accordingly. - scaled_image_pooling_crop_size = None - if model_options.image_pooling_crop_size: - scaled_image_pooling_crop_size = [ - scale_dimension(image_pooling_crop_height, image_scale), - scale_dimension(image_pooling_crop_width, image_scale)] - else: - scaled_crop_size = model_options.crop_size - scaled_images = images - scaled_image_pooling_crop_size = model_options.image_pooling_crop_size - - updated_options = model_options._replace( - crop_size=scaled_crop_size, - image_pooling_crop_size=scaled_image_pooling_crop_size) - outputs_to_logits = _get_logits( - scaled_images, - updated_options, - weight_decay=weight_decay, - reuse=tf.AUTO_REUSE, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_training_hyper_parameters=nas_training_hyper_parameters) - - # Resize the logits to have the same dimension before merging. - for output in sorted(outputs_to_logits): - outputs_to_logits[output] = _resize_bilinear( - outputs_to_logits[output], [logits_height, logits_width], - outputs_to_logits[output].dtype) - - # Return when only one input scale. - if len(image_pyramid) == 1: - for output in sorted(model_options.outputs_to_num_classes): - outputs_to_scales_to_logits[output][ - MERGED_LOGITS_SCOPE] = outputs_to_logits[output] - return outputs_to_scales_to_logits - - # Save logits to the output map. - for output in sorted(model_options.outputs_to_num_classes): - outputs_to_scales_to_logits[output][ - 'logits_%.2f' % image_scale] = outputs_to_logits[output] - - # Merge the logits from all the multi-scale inputs. - for output in sorted(model_options.outputs_to_num_classes): - # Concatenate the multi-scale logits for each output type. - all_logits = [ - tf.expand_dims(logits, axis=4) - for logits in outputs_to_scales_to_logits[output].values() - ] - all_logits = tf.concat(all_logits, 4) - merge_fn = ( - tf.reduce_max - if model_options.merge_method == 'max' else tf.reduce_mean) - outputs_to_scales_to_logits[output][MERGED_LOGITS_SCOPE] = merge_fn( - all_logits, axis=4) - - return outputs_to_scales_to_logits - - -def extract_features(images, - model_options, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Extracts features by the particular model_variant. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - concat_logits: A tensor of size [batch, feature_height, feature_width, - feature_channels], where feature_height/feature_width are determined by - the images height/width and output_stride. - end_points: A dictionary from components of the network to the corresponding - activation. - """ - features, end_points = feature_extractor.extract_features( - images, - output_stride=model_options.output_stride, - multi_grid=model_options.multi_grid, - model_variant=model_options.model_variant, - depth_multiplier=model_options.depth_multiplier, - divisible_by=model_options.divisible_by, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - preprocessed_images_dtype=model_options.preprocessed_images_dtype, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_architecture_options=model_options.nas_architecture_options, - nas_training_hyper_parameters=nas_training_hyper_parameters, - use_bounded_activation=model_options.use_bounded_activation) - - if not model_options.aspp_with_batch_norm: - return features, end_points - else: - if model_options.dense_prediction_cell_config is not None: - tf.logging.info('Using dense prediction cell config.') - dense_prediction_layer = dense_prediction_cell.DensePredictionCell( - config=model_options.dense_prediction_cell_config, - hparams={ - 'conv_rate_multiplier': 16 // model_options.output_stride, - }) - concat_logits = dense_prediction_layer.build_cell( - features, - output_stride=model_options.output_stride, - crop_size=model_options.crop_size, - image_pooling_crop_size=model_options.image_pooling_crop_size, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm) - return concat_logits, end_points - else: - # The following codes employ the DeepLabv3 ASPP module. Note that we - # could express the ASPP module as one particular dense prediction - # cell architecture. We do not do so but leave the following codes - # for backward compatibility. - batch_norm_params = utils.get_batch_norm_params( - decay=0.9997, - epsilon=1e-5, - scale=True, - is_training=(is_training and fine_tune_batch_norm), - sync_batch_norm_method=model_options.sync_batch_norm_method) - batch_norm = utils.get_batch_norm_fn( - model_options.sync_batch_norm_method) - activation_fn = ( - tf.nn.relu6 if model_options.use_bounded_activation else tf.nn.relu) - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=activation_fn, - normalizer_fn=batch_norm, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([batch_norm], **batch_norm_params): - depth = model_options.aspp_convs_filters - branch_logits = [] - - if model_options.add_image_level_feature: - if model_options.crop_size is not None: - image_pooling_crop_size = model_options.image_pooling_crop_size - # If image_pooling_crop_size is not specified, use crop_size. - if image_pooling_crop_size is None: - image_pooling_crop_size = model_options.crop_size - pool_height = scale_dimension( - image_pooling_crop_size[0], - 1. / model_options.output_stride) - pool_width = scale_dimension( - image_pooling_crop_size[1], - 1. / model_options.output_stride) - image_feature = slim.avg_pool2d( - features, [pool_height, pool_width], - model_options.image_pooling_stride, padding='VALID') - resize_height = scale_dimension( - model_options.crop_size[0], - 1. / model_options.output_stride) - resize_width = scale_dimension( - model_options.crop_size[1], - 1. / model_options.output_stride) - else: - # If crop_size is None, we simply do global pooling. - pool_height = tf.shape(features)[1] - pool_width = tf.shape(features)[2] - image_feature = tf.reduce_mean( - features, axis=[1, 2], keepdims=True) - resize_height = pool_height - resize_width = pool_width - image_feature_activation_fn = tf.nn.relu - image_feature_normalizer_fn = batch_norm - if model_options.aspp_with_squeeze_and_excitation: - image_feature_activation_fn = tf.nn.sigmoid - if model_options.image_se_uses_qsigmoid: - image_feature_activation_fn = utils.q_sigmoid - image_feature_normalizer_fn = None - image_feature = slim.conv2d( - image_feature, depth, 1, - activation_fn=image_feature_activation_fn, - normalizer_fn=image_feature_normalizer_fn, - scope=IMAGE_POOLING_SCOPE) - image_feature = _resize_bilinear( - image_feature, - [resize_height, resize_width], - image_feature.dtype) - # Set shape for resize_height/resize_width if they are not Tensor. - if isinstance(resize_height, tf.Tensor): - resize_height = None - if isinstance(resize_width, tf.Tensor): - resize_width = None - image_feature.set_shape([None, resize_height, resize_width, depth]) - if not model_options.aspp_with_squeeze_and_excitation: - branch_logits.append(image_feature) - - # Employ a 1x1 convolution. - branch_logits.append(slim.conv2d(features, depth, 1, - scope=ASPP_SCOPE + str(0))) - - if model_options.atrous_rates: - # Employ 3x3 convolutions with different atrous rates. - for i, rate in enumerate(model_options.atrous_rates, 1): - scope = ASPP_SCOPE + str(i) - if model_options.aspp_with_separable_conv: - aspp_features = split_separable_conv2d( - features, - filters=depth, - rate=rate, - weight_decay=weight_decay, - scope=scope) - else: - aspp_features = slim.conv2d( - features, depth, 3, rate=rate, scope=scope) - branch_logits.append(aspp_features) - - # Merge branch logits. - concat_logits = tf.concat(branch_logits, 3) - if model_options.aspp_with_concat_projection: - concat_logits = slim.conv2d( - concat_logits, depth, 1, scope=CONCAT_PROJECTION_SCOPE) - concat_logits = slim.dropout( - concat_logits, - keep_prob=0.9, - is_training=is_training, - scope=CONCAT_PROJECTION_SCOPE + '_dropout') - if (model_options.add_image_level_feature and - model_options.aspp_with_squeeze_and_excitation): - concat_logits *= image_feature - - return concat_logits, end_points - - -def _get_logits(images, - model_options, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - nas_training_hyper_parameters=None): - """Gets the logits by atrous/image spatial pyramid pooling. - - Args: - images: A tensor of size [batch, height, width, channels]. - model_options: A ModelOptions instance to configure models. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - nas_training_hyper_parameters: A dictionary storing hyper-parameters for - training nas models. Its keys are: - - `drop_path_keep_prob`: Probability to keep each path in the cell when - training. - - `total_training_steps`: Total training steps to help drop path - probability calculation. - - Returns: - outputs_to_logits: A map from output_type to logits. - """ - features, end_points = extract_features( - images, - model_options, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - nas_training_hyper_parameters=nas_training_hyper_parameters) - - if model_options.decoder_output_stride: - crop_size = model_options.crop_size - if crop_size is None: - crop_size = [tf.shape(images)[1], tf.shape(images)[2]] - features = refine_by_decoder( - features, - end_points, - crop_size=crop_size, - decoder_output_stride=model_options.decoder_output_stride, - decoder_use_separable_conv=model_options.decoder_use_separable_conv, - decoder_use_sum_merge=model_options.decoder_use_sum_merge, - decoder_filters=model_options.decoder_filters, - decoder_output_is_logits=model_options.decoder_output_is_logits, - model_variant=model_options.model_variant, - weight_decay=weight_decay, - reuse=reuse, - is_training=is_training, - fine_tune_batch_norm=fine_tune_batch_norm, - use_bounded_activation=model_options.use_bounded_activation) - - outputs_to_logits = {} - for output in sorted(model_options.outputs_to_num_classes): - if model_options.decoder_output_is_logits: - outputs_to_logits[output] = tf.identity(features, - name=output) - else: - outputs_to_logits[output] = get_branch_logits( - features, - model_options.outputs_to_num_classes[output], - model_options.atrous_rates, - aspp_with_batch_norm=model_options.aspp_with_batch_norm, - kernel_size=model_options.logits_kernel_size, - weight_decay=weight_decay, - reuse=reuse, - scope_suffix=output) - - return outputs_to_logits - - -def refine_by_decoder(features, - end_points, - crop_size=None, - decoder_output_stride=None, - decoder_use_separable_conv=False, - decoder_use_sum_merge=False, - decoder_filters=256, - decoder_output_is_logits=False, - model_variant=None, - weight_decay=0.0001, - reuse=None, - is_training=False, - fine_tune_batch_norm=False, - use_bounded_activation=False, - sync_batch_norm_method='None'): - """Adds the decoder to obtain sharper segmentation results. - - Args: - features: A tensor of size [batch, features_height, features_width, - features_channels]. - end_points: A dictionary from components of the network to the corresponding - activation. - crop_size: A tuple [crop_height, crop_width] specifying whole patch crop - size. - decoder_output_stride: A list of integers specifying the output stride of - low-level features used in the decoder module. - decoder_use_separable_conv: Employ separable convolution for decoder or not. - decoder_use_sum_merge: Boolean, decoder uses simple sum merge or not. - decoder_filters: Integer, decoder filter size. - decoder_output_is_logits: Boolean, using decoder output as logits or not. - model_variant: Model variant for feature extraction. - weight_decay: The weight decay for model variables. - reuse: Reuse the model variables or not. - is_training: Is training or not. - fine_tune_batch_norm: Fine-tune the batch norm parameters or not. - use_bounded_activation: Whether or not to use bounded activations. Bounded - activations better lend themselves to quantized inference. - sync_batch_norm_method: String, method used to sync batch norm. Currently - only support `None` (no sync batch norm) and `tpu` (use tpu code to - sync batch norm). - - Returns: - Decoder output with size [batch, decoder_height, decoder_width, - decoder_channels]. - - Raises: - ValueError: If crop_size is None. - """ - if crop_size is None: - raise ValueError('crop_size must be provided when using decoder.') - batch_norm_params = utils.get_batch_norm_params( - decay=0.9997, - epsilon=1e-5, - scale=True, - is_training=(is_training and fine_tune_batch_norm), - sync_batch_norm_method=sync_batch_norm_method) - batch_norm = utils.get_batch_norm_fn(sync_batch_norm_method) - decoder_depth = decoder_filters - projected_filters = 48 - if decoder_use_sum_merge: - # When using sum merge, the projected filters must be equal to decoder - # filters. - projected_filters = decoder_filters - if decoder_output_is_logits: - # Overwrite the setting when decoder output is logits. - activation_fn = None - normalizer_fn = None - conv2d_kernel = 1 - # Use original conv instead of separable conv. - decoder_use_separable_conv = False - else: - # Default setting when decoder output is not logits. - activation_fn = tf.nn.relu6 if use_bounded_activation else tf.nn.relu - normalizer_fn = batch_norm - conv2d_kernel = 3 - with slim.arg_scope( - [slim.conv2d, slim.separable_conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - activation_fn=activation_fn, - normalizer_fn=normalizer_fn, - padding='SAME', - stride=1, - reuse=reuse): - with slim.arg_scope([batch_norm], **batch_norm_params): - with tf.variable_scope(DECODER_SCOPE, DECODER_SCOPE, [features]): - decoder_features = features - decoder_stage = 0 - scope_suffix = '' - for output_stride in decoder_output_stride: - feature_list = feature_extractor.networks_to_feature_maps[ - model_variant][ - feature_extractor.DECODER_END_POINTS][output_stride] - # If only one decoder stage, we do not change the scope name in - # order for backward compactibility. - if decoder_stage: - scope_suffix = '_{}'.format(decoder_stage) - for i, name in enumerate(feature_list): - decoder_features_list = [decoder_features] - # MobileNet and NAS variants use different naming convention. - if ('mobilenet' in model_variant or - model_variant.startswith('mnas') or - model_variant.startswith('nas')): - feature_name = name - else: - feature_name = '{}/{}'.format( - feature_extractor.name_scope[model_variant], name) - decoder_features_list.append( - slim.conv2d( - end_points[feature_name], - projected_filters, - 1, - scope='feature_projection' + str(i) + scope_suffix)) - # Determine the output size. - decoder_height = scale_dimension(crop_size[0], 1.0 / output_stride) - decoder_width = scale_dimension(crop_size[1], 1.0 / output_stride) - # Resize to decoder_height/decoder_width. - for j, feature in enumerate(decoder_features_list): - decoder_features_list[j] = _resize_bilinear( - feature, [decoder_height, decoder_width], feature.dtype) - h = (None if isinstance(decoder_height, tf.Tensor) - else decoder_height) - w = (None if isinstance(decoder_width, tf.Tensor) - else decoder_width) - decoder_features_list[j].set_shape([None, h, w, None]) - if decoder_use_sum_merge: - decoder_features = _decoder_with_sum_merge( - decoder_features_list, - decoder_depth, - conv2d_kernel=conv2d_kernel, - decoder_use_separable_conv=decoder_use_separable_conv, - weight_decay=weight_decay, - scope_suffix=scope_suffix) - else: - if not decoder_use_separable_conv: - scope_suffix = str(i) + scope_suffix - decoder_features = _decoder_with_concat_merge( - decoder_features_list, - decoder_depth, - decoder_use_separable_conv=decoder_use_separable_conv, - weight_decay=weight_decay, - scope_suffix=scope_suffix) - decoder_stage += 1 - return decoder_features - - -def _decoder_with_sum_merge(decoder_features_list, - decoder_depth, - conv2d_kernel=3, - decoder_use_separable_conv=True, - weight_decay=0.0001, - scope_suffix=''): - """Decoder with sum to merge features. - - Args: - decoder_features_list: A list of decoder features. - decoder_depth: Integer, the filters used in the convolution. - conv2d_kernel: Integer, the convolution kernel size. - decoder_use_separable_conv: Boolean, use separable conv or not. - weight_decay: Weight decay for the model variables. - scope_suffix: String, used in the scope suffix. - - Returns: - decoder features merged with sum. - - Raises: - RuntimeError: If decoder_features_list have length not equal to 2. - """ - if len(decoder_features_list) != 2: - raise RuntimeError('Expect decoder_features has length 2.') - # Only apply one convolution when decoder use sum merge. - if decoder_use_separable_conv: - decoder_features = split_separable_conv2d( - decoder_features_list[0], - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_split_sep_conv0'+scope_suffix) + decoder_features_list[1] - else: - decoder_features = slim.conv2d( - decoder_features_list[0], - decoder_depth, - conv2d_kernel, - scope='decoder_conv0'+scope_suffix) + decoder_features_list[1] - return decoder_features - - -def _decoder_with_concat_merge(decoder_features_list, - decoder_depth, - decoder_use_separable_conv=True, - weight_decay=0.0001, - scope_suffix=''): - """Decoder with concatenation to merge features. - - This decoder method applies two convolutions to smooth the features obtained - by concatenating the input decoder_features_list. - - This decoder module is proposed in the DeepLabv3+ paper. - - Args: - decoder_features_list: A list of decoder features. - decoder_depth: Integer, the filters used in the convolution. - decoder_use_separable_conv: Boolean, use separable conv or not. - weight_decay: Weight decay for the model variables. - scope_suffix: String, used in the scope suffix. - - Returns: - decoder features merged with concatenation. - """ - if decoder_use_separable_conv: - decoder_features = split_separable_conv2d( - tf.concat(decoder_features_list, 3), - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_conv0'+scope_suffix) - decoder_features = split_separable_conv2d( - decoder_features, - filters=decoder_depth, - rate=1, - weight_decay=weight_decay, - scope='decoder_conv1'+scope_suffix) - else: - num_convs = 2 - decoder_features = slim.repeat( - tf.concat(decoder_features_list, 3), - num_convs, - slim.conv2d, - decoder_depth, - 3, - scope='decoder_conv'+scope_suffix) - return decoder_features - - -def get_branch_logits(features, - num_classes, - atrous_rates=None, - aspp_with_batch_norm=False, - kernel_size=1, - weight_decay=0.0001, - reuse=None, - scope_suffix=''): - """Gets the logits from each model's branch. - - The underlying model is branched out in the last layer when atrous - spatial pyramid pooling is employed, and all branches are sum-merged - to form the final logits. - - Args: - features: A float tensor of shape [batch, height, width, channels]. - num_classes: Number of classes to predict. - atrous_rates: A list of atrous convolution rates for last layer. - aspp_with_batch_norm: Use batch normalization layers for ASPP. - kernel_size: Kernel size for convolution. - weight_decay: Weight decay for the model variables. - reuse: Reuse model variables or not. - scope_suffix: Scope suffix for the model variables. - - Returns: - Merged logits with shape [batch, height, width, num_classes]. - - Raises: - ValueError: Upon invalid input kernel_size value. - """ - # When using batch normalization with ASPP, ASPP has been applied before - # in extract_features, and thus we simply apply 1x1 convolution here. - if aspp_with_batch_norm or atrous_rates is None: - if kernel_size != 1: - raise ValueError('Kernel size must be 1 when atrous_rates is None or ' - 'using aspp_with_batch_norm. Gets %d.' % kernel_size) - atrous_rates = [1] - - with slim.arg_scope( - [slim.conv2d], - weights_regularizer=slim.l2_regularizer(weight_decay), - weights_initializer=tf.truncated_normal_initializer(stddev=0.01), - reuse=reuse): - with tf.variable_scope(LOGITS_SCOPE_NAME, LOGITS_SCOPE_NAME, [features]): - branch_logits = [] - for i, rate in enumerate(atrous_rates): - scope = scope_suffix - if i: - scope += '_%d' % i - - branch_logits.append( - slim.conv2d( - features, - num_classes, - kernel_size=kernel_size, - rate=rate, - activation_fn=None, - normalizer_fn=None, - scope=scope)) - - return tf.add_n(branch_logits) diff --git a/research/deeplab/model_test.py b/research/deeplab/model_test.py deleted file mode 100644 index d8413d7395d022adb4f43223eb06a4bdc1aa53db..0000000000000000000000000000000000000000 --- a/research/deeplab/model_test.py +++ /dev/null @@ -1,148 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for DeepLab model and some helper functions.""" - -import tensorflow as tf - -from deeplab import common -from deeplab import model - - -class DeeplabModelTest(tf.test.TestCase): - - def testWrongDeepLabVariant(self): - model_options = common.ModelOptions([])._replace( - model_variant='no_such_variant') - with self.assertRaises(ValueError): - model._get_logits(images=[], model_options=model_options) - - def testBuildDeepLabv2(self): - batch_size = 2 - crop_size = [41, 41] - - # Test with two image_pyramids. - image_pyramids = [[1], [0.5, 1]] - - # Test two model variants. - model_variants = ['xception_65', 'mobilenet_v2'] - - # Test with two output_types. - outputs_to_num_classes = {'semantic': 3, - 'direction': 2} - - expected_endpoints = [['merged_logits'], - ['merged_logits', - 'logits_0.50', - 'logits_1.00']] - expected_num_logits = [1, 3] - - for model_variant in model_variants: - model_options = common.ModelOptions(outputs_to_num_classes)._replace( - add_image_level_feature=False, - aspp_with_batch_norm=False, - aspp_with_separable_conv=False, - model_variant=model_variant) - - for i, image_pyramid in enumerate(image_pyramids): - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g): - inputs = tf.random_uniform( - (batch_size, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_logits = model.multi_scale_logits( - inputs, model_options, image_pyramid=image_pyramid) - - # Check computed results for each output type. - for output in outputs_to_num_classes: - scales_to_logits = outputs_to_scales_to_logits[output] - self.assertListEqual(sorted(scales_to_logits.keys()), - sorted(expected_endpoints[i])) - - # Expected number of logits = len(image_pyramid) + 1, since the - # last logits is merged from all the scales. - self.assertEqual(len(scales_to_logits), expected_num_logits[i]) - - def testForwardpassDeepLabv3plus(self): - crop_size = [33, 33] - outputs_to_num_classes = {'semantic': 3} - - model_options = common.ModelOptions( - outputs_to_num_classes, - crop_size, - output_stride=16 - )._replace( - add_image_level_feature=True, - aspp_with_batch_norm=True, - logits_kernel_size=1, - decoder_output_stride=[4], - model_variant='mobilenet_v2') # Employ MobileNetv2 for fast test. - - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g) as sess: - inputs = tf.random_uniform( - (1, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_logits = model.multi_scale_logits( - inputs, - model_options, - image_pyramid=[1.0]) - - sess.run(tf.global_variables_initializer()) - outputs_to_scales_to_logits = sess.run(outputs_to_scales_to_logits) - - # Check computed results for each output type. - for output in outputs_to_num_classes: - scales_to_logits = outputs_to_scales_to_logits[output] - # Expect only one output. - self.assertEqual(len(scales_to_logits), 1) - for logits in scales_to_logits.values(): - self.assertTrue(logits.any()) - - def testBuildDeepLabWithDensePredictionCell(self): - batch_size = 1 - crop_size = [33, 33] - outputs_to_num_classes = {'semantic': 2} - expected_endpoints = ['merged_logits'] - dense_prediction_cell_config = [ - {'kernel': 3, 'rate': [1, 6], 'op': 'conv', 'input': -1}, - {'kernel': 3, 'rate': [18, 15], 'op': 'conv', 'input': 0}, - ] - model_options = common.ModelOptions( - outputs_to_num_classes, - crop_size, - output_stride=16)._replace( - aspp_with_batch_norm=True, - model_variant='mobilenet_v2', - dense_prediction_cell_config=dense_prediction_cell_config) - g = tf.Graph() - with g.as_default(): - with self.test_session(graph=g): - inputs = tf.random_uniform( - (batch_size, crop_size[0], crop_size[1], 3)) - outputs_to_scales_to_model_results = model.multi_scale_logits( - inputs, - model_options, - image_pyramid=[1.0]) - for output in outputs_to_num_classes: - scales_to_model_results = outputs_to_scales_to_model_results[output] - self.assertListEqual( - list(scales_to_model_results), expected_endpoints) - self.assertEqual(len(scales_to_model_results), 1) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/testing/info.md b/research/deeplab/testing/info.md deleted file mode 100644 index b84d2adb1c5088ed2a6ec4799de7764d64f867b7..0000000000000000000000000000000000000000 --- a/research/deeplab/testing/info.md +++ /dev/null @@ -1,6 +0,0 @@ -This directory contains testing data. - -# pascal_voc_seg -This folder contains data specific to pascal_voc_seg dataset. val-00000-of-00001.tfrecord contains -three randomly generated images with format defined in -tensorflow/models/research/deeplab/datasets/build_voc2012_data.py. diff --git a/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord b/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord deleted file mode 100644 index e81455b2e1a1b5ac2f7c632512951a9ab26b7ef3..0000000000000000000000000000000000000000 Binary files a/research/deeplab/testing/pascal_voc_seg/val-00000-of-00001.tfrecord and /dev/null differ diff --git a/research/deeplab/train.py b/research/deeplab/train.py deleted file mode 100644 index fbe060dccd41793e3e843f4fcbe155576e42eb14..0000000000000000000000000000000000000000 --- a/research/deeplab/train.py +++ /dev/null @@ -1,464 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Training script for the DeepLab model. - -See model.py for more details and usage. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import six -import tensorflow as tf -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import tfprof as contrib_tfprof -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator -from deeplab.utils import train_utils -from deployment import model_deploy - -slim = tf.contrib.slim -flags = tf.app.flags -FLAGS = flags.FLAGS - -# Settings for multi-GPUs/multi-replicas training. - -flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy.') - -flags.DEFINE_boolean('clone_on_cpu', False, 'Use CPUs to deploy clones.') - -flags.DEFINE_integer('num_replicas', 1, 'Number of worker replicas.') - -flags.DEFINE_integer('startup_delay_steps', 15, - 'Number of training steps between replicas startup.') - -flags.DEFINE_integer( - 'num_ps_tasks', 0, - 'The number of parameter servers. If the value is 0, then ' - 'the parameters are handled locally by the worker.') - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -flags.DEFINE_integer('task', 0, 'The task ID.') - -# Settings for logging. - -flags.DEFINE_string('train_logdir', None, - 'Where the checkpoint and logs are stored.') - -flags.DEFINE_integer('log_steps', 10, - 'Display logging information at every log_steps.') - -flags.DEFINE_integer('save_interval_secs', 1200, - 'How often, in seconds, we save the model to disk.') - -flags.DEFINE_integer('save_summaries_secs', 600, - 'How often, in seconds, we compute the summaries.') - -flags.DEFINE_boolean( - 'save_summaries_images', False, - 'Save sample inputs, labels, and semantic predictions as ' - 'images to summary.') - -# Settings for profiling. - -flags.DEFINE_string('profile_logdir', None, - 'Where the profile files are stored.') - -# Settings for training strategy. - -flags.DEFINE_enum('optimizer', 'momentum', ['momentum', 'adam'], - 'Which optimizer to use.') - - -# Momentum optimizer flags - -flags.DEFINE_enum('learning_policy', 'poly', ['poly', 'step'], - 'Learning rate policy for training.') - -# Use 0.007 when training on PASCAL augmented training set, train_aug. When -# fine-tuning on PASCAL trainval set, use learning rate=0.0001. -flags.DEFINE_float('base_learning_rate', .0001, - 'The base learning rate for model training.') - -flags.DEFINE_float('decay_steps', 0.0, - 'Decay steps for polynomial learning rate schedule.') - -flags.DEFINE_float('end_learning_rate', 0.0, - 'End learning rate for polynomial learning rate schedule.') - -flags.DEFINE_float('learning_rate_decay_factor', 0.1, - 'The rate to decay the base learning rate.') - -flags.DEFINE_integer('learning_rate_decay_step', 2000, - 'Decay the base learning rate at a fixed step.') - -flags.DEFINE_float('learning_power', 0.9, - 'The power value used in the poly learning policy.') - -flags.DEFINE_integer('training_number_of_steps', 30000, - 'The number of steps used for training') - -flags.DEFINE_float('momentum', 0.9, 'The momentum value to use') - -# Adam optimizer flags -flags.DEFINE_float('adam_learning_rate', 0.001, - 'Learning rate for the adam optimizer.') -flags.DEFINE_float('adam_epsilon', 1e-08, 'Adam optimizer epsilon.') - -# When fine_tune_batch_norm=True, use at least batch size larger than 12 -# (batch size more than 16 is better). Otherwise, one could use smaller batch -# size and set fine_tune_batch_norm=False. -flags.DEFINE_integer('train_batch_size', 8, - 'The number of images in each batch during training.') - -# For weight_decay, use 0.00004 for MobileNet-V2 or Xcpetion model variants. -# Use 0.0001 for ResNet model variants. -flags.DEFINE_float('weight_decay', 0.00004, - 'The value of the weight decay for training.') - -flags.DEFINE_list('train_crop_size', '513,513', - 'Image crop size [height, width] during training.') - -flags.DEFINE_float( - 'last_layer_gradient_multiplier', 1.0, - 'The gradient multiplier for last layers, which is used to ' - 'boost the gradient of last layers if the value > 1.') - -flags.DEFINE_boolean('upsample_logits', True, - 'Upsample logits during training.') - -# Hyper-parameters for NAS training strategy. - -flags.DEFINE_float( - 'drop_path_keep_prob', 1.0, - 'Probability to keep each path in the NAS cell when training.') - -# Settings for fine-tuning the network. - -flags.DEFINE_string('tf_initial_checkpoint', None, - 'The initial checkpoint in tensorflow format.') - -# Set to False if one does not want to re-use the trained classifier weights. -flags.DEFINE_boolean('initialize_last_layer', True, - 'Initialize the last layer.') - -flags.DEFINE_boolean('last_layers_contain_logits_only', False, - 'Only consider logits as last layers or not.') - -flags.DEFINE_integer('slow_start_step', 0, - 'Training model with small learning rate for few steps.') - -flags.DEFINE_float('slow_start_learning_rate', 1e-4, - 'Learning rate employed during slow start.') - -# Set to True if one wants to fine-tune the batch norm parameters in DeepLabv3. -# Set to False and use small batch size to save GPU memory. -flags.DEFINE_boolean('fine_tune_batch_norm', True, - 'Fine tune the batch norm parameters or not.') - -flags.DEFINE_float('min_scale_factor', 0.5, - 'Mininum scale factor for data augmentation.') - -flags.DEFINE_float('max_scale_factor', 2., - 'Maximum scale factor for data augmentation.') - -flags.DEFINE_float('scale_factor_step_size', 0.25, - 'Scale factor step size for data augmentation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Hard example mining related flags. -flags.DEFINE_integer( - 'hard_example_mining_step', 0, - 'The training step in which exact hard example mining kicks off. Note we ' - 'gradually reduce the mining percent to the specified ' - 'top_k_percent_pixels. For example, if hard_example_mining_step=100K and ' - 'top_k_percent_pixels=0.25, then mining percent will gradually reduce from ' - '100% to 25% until 100K steps after which we only mine top 25% pixels.') - -flags.DEFINE_float( - 'top_k_percent_pixels', 1.0, - 'The top k percent pixels (in terms of the loss values) used to compute ' - 'loss during training. This is useful for hard pixel mining.') - -# Quantization setting. -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('train_split', 'train', - 'Which split of the dataset to be used for training') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - - -def _build_deeplab(iterator, outputs_to_num_classes, ignore_label): - """Builds a clone of DeepLab. - - Args: - iterator: An iterator of type tf.data.Iterator for images and labels. - outputs_to_num_classes: A map from output type to the number of classes. For - example, for the task of semantic segmentation with 21 semantic classes, - we would have outputs_to_num_classes['semantic'] = 21. - ignore_label: Ignore label. - """ - samples = iterator.get_next() - - # Add name to input and label nodes so we can add to summary. - samples[common.IMAGE] = tf.identity(samples[common.IMAGE], name=common.IMAGE) - samples[common.LABEL] = tf.identity(samples[common.LABEL], name=common.LABEL) - - model_options = common.ModelOptions( - outputs_to_num_classes=outputs_to_num_classes, - crop_size=[int(sz) for sz in FLAGS.train_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - outputs_to_scales_to_logits = model.multi_scale_logits( - samples[common.IMAGE], - model_options=model_options, - image_pyramid=FLAGS.image_pyramid, - weight_decay=FLAGS.weight_decay, - is_training=True, - fine_tune_batch_norm=FLAGS.fine_tune_batch_norm, - nas_training_hyper_parameters={ - 'drop_path_keep_prob': FLAGS.drop_path_keep_prob, - 'total_training_steps': FLAGS.training_number_of_steps, - }) - - # Add name to graph node so we can add to summary. - output_type_dict = outputs_to_scales_to_logits[common.OUTPUT_TYPE] - output_type_dict[model.MERGED_LOGITS_SCOPE] = tf.identity( - output_type_dict[model.MERGED_LOGITS_SCOPE], name=common.OUTPUT_TYPE) - - for output, num_classes in six.iteritems(outputs_to_num_classes): - train_utils.add_softmax_cross_entropy_loss_for_each_scale( - outputs_to_scales_to_logits[output], - samples[common.LABEL], - num_classes, - ignore_label, - loss_weight=model_options.label_weights, - upsample_logits=FLAGS.upsample_logits, - hard_example_mining_step=FLAGS.hard_example_mining_step, - top_k_percent_pixels=FLAGS.top_k_percent_pixels, - scope=output) - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - # Set up deployment (i.e., multi-GPUs and/or multi-replicas). - config = model_deploy.DeploymentConfig( - num_clones=FLAGS.num_clones, - clone_on_cpu=FLAGS.clone_on_cpu, - replica_id=FLAGS.task, - num_replicas=FLAGS.num_replicas, - num_ps_tasks=FLAGS.num_ps_tasks) - - # Split the batch across GPUs. - assert FLAGS.train_batch_size % config.num_clones == 0, ( - 'Training batch size not divisble by number of clones (GPUs).') - - clone_batch_size = FLAGS.train_batch_size // config.num_clones - - tf.gfile.MakeDirs(FLAGS.train_logdir) - tf.logging.info('Training on %s set', FLAGS.train_split) - - with tf.Graph().as_default() as graph: - with tf.device(config.inputs_device()): - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.train_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=clone_batch_size, - crop_size=[int(sz) for sz in FLAGS.train_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - min_scale_factor=FLAGS.min_scale_factor, - max_scale_factor=FLAGS.max_scale_factor, - scale_factor_step_size=FLAGS.scale_factor_step_size, - model_variant=FLAGS.model_variant, - num_readers=4, - is_training=True, - should_shuffle=True, - should_repeat=True) - - # Create the global step on the device storing the variables. - with tf.device(config.variables_device()): - global_step = tf.train.get_or_create_global_step() - - # Define the model and create clones. - model_fn = _build_deeplab - model_args = (dataset.get_one_shot_iterator(), { - common.OUTPUT_TYPE: dataset.num_of_classes - }, dataset.ignore_label) - clones = model_deploy.create_clones(config, model_fn, args=model_args) - - # Gather update_ops from the first clone. These contain, for example, - # the updates for the batch_norm variables created by model_fn. - first_clone_scope = config.clone_scope(0) - update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, first_clone_scope) - - # Gather initial summaries. - summaries = set(tf.get_collection(tf.GraphKeys.SUMMARIES)) - - # Add summaries for model variables. - for model_var in tf.model_variables(): - summaries.add(tf.summary.histogram(model_var.op.name, model_var)) - - # Add summaries for images, labels, semantic predictions - if FLAGS.save_summaries_images: - summary_image = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.IMAGE)).strip('/')) - summaries.add( - tf.summary.image('samples/%s' % common.IMAGE, summary_image)) - - first_clone_label = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.LABEL)).strip('/')) - # Scale up summary image pixel values for better visualization. - pixel_scaling = max(1, 255 // dataset.num_of_classes) - summary_label = tf.cast(first_clone_label * pixel_scaling, tf.uint8) - summaries.add( - tf.summary.image('samples/%s' % common.LABEL, summary_label)) - - first_clone_output = graph.get_tensor_by_name( - ('%s/%s:0' % (first_clone_scope, common.OUTPUT_TYPE)).strip('/')) - predictions = tf.expand_dims(tf.argmax(first_clone_output, 3), -1) - - summary_predictions = tf.cast(predictions * pixel_scaling, tf.uint8) - summaries.add( - tf.summary.image( - 'samples/%s' % common.OUTPUT_TYPE, summary_predictions)) - - # Add summaries for losses. - for loss in tf.get_collection(tf.GraphKeys.LOSSES, first_clone_scope): - summaries.add(tf.summary.scalar('losses/%s' % loss.op.name, loss)) - - # Build the optimizer based on the device specification. - with tf.device(config.optimizer_device()): - learning_rate = train_utils.get_model_learning_rate( - FLAGS.learning_policy, - FLAGS.base_learning_rate, - FLAGS.learning_rate_decay_step, - FLAGS.learning_rate_decay_factor, - FLAGS.training_number_of_steps, - FLAGS.learning_power, - FLAGS.slow_start_step, - FLAGS.slow_start_learning_rate, - decay_steps=FLAGS.decay_steps, - end_learning_rate=FLAGS.end_learning_rate) - - summaries.add(tf.summary.scalar('learning_rate', learning_rate)) - - if FLAGS.optimizer == 'momentum': - optimizer = tf.train.MomentumOptimizer(learning_rate, FLAGS.momentum) - elif FLAGS.optimizer == 'adam': - optimizer = tf.train.AdamOptimizer( - learning_rate=FLAGS.adam_learning_rate, epsilon=FLAGS.adam_epsilon) - else: - raise ValueError('Unknown optimizer') - - if FLAGS.quantize_delay_step >= 0: - if FLAGS.num_clones > 1: - raise ValueError('Quantization doesn\'t support multi-clone yet.') - contrib_quantize.create_training_graph( - quant_delay=FLAGS.quantize_delay_step) - - startup_delay_steps = FLAGS.task * FLAGS.startup_delay_steps - - with tf.device(config.variables_device()): - total_loss, grads_and_vars = model_deploy.optimize_clones( - clones, optimizer) - total_loss = tf.check_numerics(total_loss, 'Loss is inf or nan.') - summaries.add(tf.summary.scalar('total_loss', total_loss)) - - # Modify the gradients for biases and last layer variables. - last_layers = model.get_extra_layer_scopes( - FLAGS.last_layers_contain_logits_only) - grad_mult = train_utils.get_model_gradient_multipliers( - last_layers, FLAGS.last_layer_gradient_multiplier) - if grad_mult: - grads_and_vars = slim.learning.multiply_gradients( - grads_and_vars, grad_mult) - - # Create gradient update op. - grad_updates = optimizer.apply_gradients( - grads_and_vars, global_step=global_step) - update_ops.append(grad_updates) - update_op = tf.group(*update_ops) - with tf.control_dependencies([update_op]): - train_tensor = tf.identity(total_loss, name='train_op') - - # Add the summaries from the first clone. These contain the summaries - # created by model_fn and either optimize_clones() or _gather_clone_loss(). - summaries |= set( - tf.get_collection(tf.GraphKeys.SUMMARIES, first_clone_scope)) - - # Merge all summaries together. - summary_op = tf.summary.merge(list(summaries)) - - # Soft placement allows placing on CPU ops without GPU implementation. - session_config = tf.ConfigProto( - allow_soft_placement=True, log_device_placement=False) - - # Start the training. - profile_dir = FLAGS.profile_logdir - if profile_dir is not None: - tf.gfile.MakeDirs(profile_dir) - - with contrib_tfprof.ProfileContext( - enabled=profile_dir is not None, profile_dir=profile_dir): - init_fn = None - if FLAGS.tf_initial_checkpoint: - init_fn = train_utils.get_model_init_fn( - FLAGS.train_logdir, - FLAGS.tf_initial_checkpoint, - FLAGS.initialize_last_layer, - last_layers, - ignore_missing_vars=True) - - slim.learning.train( - train_tensor, - logdir=FLAGS.train_logdir, - log_every_n_steps=FLAGS.log_steps, - master=FLAGS.master, - number_of_steps=FLAGS.training_number_of_steps, - is_chief=(FLAGS.task == 0), - session_config=session_config, - startup_delay_steps=startup_delay_steps, - init_fn=init_fn, - summary_op=summary_op, - save_summaries_secs=FLAGS.save_summaries_secs, - save_interval_secs=FLAGS.save_interval_secs) - - -if __name__ == '__main__': - flags.mark_flag_as_required('train_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/deeplab/utils/__init__.py b/research/deeplab/utils/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/deeplab/utils/get_dataset_colormap.py b/research/deeplab/utils/get_dataset_colormap.py deleted file mode 100644 index c0502e3b3cdd4ee065701e5ee8d94d7f3701c576..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/get_dataset_colormap.py +++ /dev/null @@ -1,416 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Visualizes the segmentation results via specified color map. - -Visualizes the semantic segmentation results by the color map -defined by the different datasets. Supported colormaps are: - -* ADE20K (http://groups.csail.mit.edu/vision/datasets/ADE20K/). - -* Cityscapes dataset (https://www.cityscapes-dataset.com). - -* Mapillary Vistas (https://research.mapillary.com). - -* PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/). -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import numpy as np -from six.moves import range - -# Dataset names. -_ADE20K = 'ade20k' -_CITYSCAPES = 'cityscapes' -_MAPILLARY_VISTAS = 'mapillary_vistas' -_PASCAL = 'pascal' - -# Max number of entries in the colormap for each dataset. -_DATASET_MAX_ENTRIES = { - _ADE20K: 151, - _CITYSCAPES: 256, - _MAPILLARY_VISTAS: 66, - _PASCAL: 512, -} - - -def create_ade20k_label_colormap(): - """Creates a label colormap used in ADE20K segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - return np.asarray([ - [0, 0, 0], - [120, 120, 120], - [180, 120, 120], - [6, 230, 230], - [80, 50, 50], - [4, 200, 3], - [120, 120, 80], - [140, 140, 140], - [204, 5, 255], - [230, 230, 230], - [4, 250, 7], - [224, 5, 255], - [235, 255, 7], - [150, 5, 61], - [120, 120, 70], - [8, 255, 51], - [255, 6, 82], - [143, 255, 140], - [204, 255, 4], - [255, 51, 7], - [204, 70, 3], - [0, 102, 200], - [61, 230, 250], - [255, 6, 51], - [11, 102, 255], - [255, 7, 71], - [255, 9, 224], - [9, 7, 230], - [220, 220, 220], - [255, 9, 92], - [112, 9, 255], - [8, 255, 214], - [7, 255, 224], - [255, 184, 6], - [10, 255, 71], - [255, 41, 10], - [7, 255, 255], - [224, 255, 8], - [102, 8, 255], - [255, 61, 6], - [255, 194, 7], - [255, 122, 8], - [0, 255, 20], - [255, 8, 41], - [255, 5, 153], - [6, 51, 255], - [235, 12, 255], - [160, 150, 20], - [0, 163, 255], - [140, 140, 140], - [250, 10, 15], - [20, 255, 0], - [31, 255, 0], - [255, 31, 0], - [255, 224, 0], - [153, 255, 0], - [0, 0, 255], - [255, 71, 0], - [0, 235, 255], - [0, 173, 255], - [31, 0, 255], - [11, 200, 200], - [255, 82, 0], - [0, 255, 245], - [0, 61, 255], - [0, 255, 112], - [0, 255, 133], - [255, 0, 0], - [255, 163, 0], - [255, 102, 0], - [194, 255, 0], - [0, 143, 255], - [51, 255, 0], - [0, 82, 255], - [0, 255, 41], - [0, 255, 173], - [10, 0, 255], - [173, 255, 0], - [0, 255, 153], - [255, 92, 0], - [255, 0, 255], - [255, 0, 245], - [255, 0, 102], - [255, 173, 0], - [255, 0, 20], - [255, 184, 184], - [0, 31, 255], - [0, 255, 61], - [0, 71, 255], - [255, 0, 204], - [0, 255, 194], - [0, 255, 82], - [0, 10, 255], - [0, 112, 255], - [51, 0, 255], - [0, 194, 255], - [0, 122, 255], - [0, 255, 163], - [255, 153, 0], - [0, 255, 10], - [255, 112, 0], - [143, 255, 0], - [82, 0, 255], - [163, 255, 0], - [255, 235, 0], - [8, 184, 170], - [133, 0, 255], - [0, 255, 92], - [184, 0, 255], - [255, 0, 31], - [0, 184, 255], - [0, 214, 255], - [255, 0, 112], - [92, 255, 0], - [0, 224, 255], - [112, 224, 255], - [70, 184, 160], - [163, 0, 255], - [153, 0, 255], - [71, 255, 0], - [255, 0, 163], - [255, 204, 0], - [255, 0, 143], - [0, 255, 235], - [133, 255, 0], - [255, 0, 235], - [245, 0, 255], - [255, 0, 122], - [255, 245, 0], - [10, 190, 212], - [214, 255, 0], - [0, 204, 255], - [20, 0, 255], - [255, 255, 0], - [0, 153, 255], - [0, 41, 255], - [0, 255, 204], - [41, 0, 255], - [41, 255, 0], - [173, 0, 255], - [0, 245, 255], - [71, 0, 255], - [122, 0, 255], - [0, 255, 184], - [0, 92, 255], - [184, 255, 0], - [0, 133, 255], - [255, 214, 0], - [25, 194, 194], - [102, 255, 0], - [92, 0, 255], - ]) - - -def create_cityscapes_label_colormap(): - """Creates a label colormap used in CITYSCAPES segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - colormap = np.zeros((256, 3), dtype=np.uint8) - colormap[0] = [128, 64, 128] - colormap[1] = [244, 35, 232] - colormap[2] = [70, 70, 70] - colormap[3] = [102, 102, 156] - colormap[4] = [190, 153, 153] - colormap[5] = [153, 153, 153] - colormap[6] = [250, 170, 30] - colormap[7] = [220, 220, 0] - colormap[8] = [107, 142, 35] - colormap[9] = [152, 251, 152] - colormap[10] = [70, 130, 180] - colormap[11] = [220, 20, 60] - colormap[12] = [255, 0, 0] - colormap[13] = [0, 0, 142] - colormap[14] = [0, 0, 70] - colormap[15] = [0, 60, 100] - colormap[16] = [0, 80, 100] - colormap[17] = [0, 0, 230] - colormap[18] = [119, 11, 32] - return colormap - - -def create_mapillary_vistas_label_colormap(): - """Creates a label colormap used in Mapillary Vistas segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - return np.asarray([ - [165, 42, 42], - [0, 192, 0], - [196, 196, 196], - [190, 153, 153], - [180, 165, 180], - [102, 102, 156], - [102, 102, 156], - [128, 64, 255], - [140, 140, 200], - [170, 170, 170], - [250, 170, 160], - [96, 96, 96], - [230, 150, 140], - [128, 64, 128], - [110, 110, 110], - [244, 35, 232], - [150, 100, 100], - [70, 70, 70], - [150, 120, 90], - [220, 20, 60], - [255, 0, 0], - [255, 0, 0], - [255, 0, 0], - [200, 128, 128], - [255, 255, 255], - [64, 170, 64], - [128, 64, 64], - [70, 130, 180], - [255, 255, 255], - [152, 251, 152], - [107, 142, 35], - [0, 170, 30], - [255, 255, 128], - [250, 0, 30], - [0, 0, 0], - [220, 220, 220], - [170, 170, 170], - [222, 40, 40], - [100, 170, 30], - [40, 40, 40], - [33, 33, 33], - [170, 170, 170], - [0, 0, 142], - [170, 170, 170], - [210, 170, 100], - [153, 153, 153], - [128, 128, 128], - [0, 0, 142], - [250, 170, 30], - [192, 192, 192], - [220, 220, 0], - [180, 165, 180], - [119, 11, 32], - [0, 0, 142], - [0, 60, 100], - [0, 0, 142], - [0, 0, 90], - [0, 0, 230], - [0, 80, 100], - [128, 64, 64], - [0, 0, 110], - [0, 0, 70], - [0, 0, 192], - [32, 32, 32], - [0, 0, 0], - [0, 0, 0], - ]) - - -def create_pascal_label_colormap(): - """Creates a label colormap used in PASCAL VOC segmentation benchmark. - - Returns: - A colormap for visualizing segmentation results. - """ - colormap = np.zeros((_DATASET_MAX_ENTRIES[_PASCAL], 3), dtype=int) - ind = np.arange(_DATASET_MAX_ENTRIES[_PASCAL], dtype=int) - - for shift in reversed(list(range(8))): - for channel in range(3): - colormap[:, channel] |= bit_get(ind, channel) << shift - ind >>= 3 - - return colormap - - -def get_ade20k_name(): - return _ADE20K - - -def get_cityscapes_name(): - return _CITYSCAPES - - -def get_mapillary_vistas_name(): - return _MAPILLARY_VISTAS - - -def get_pascal_name(): - return _PASCAL - - -def bit_get(val, idx): - """Gets the bit value. - - Args: - val: Input value, int or numpy int array. - idx: Which bit of the input val. - - Returns: - The "idx"-th bit of input val. - """ - return (val >> idx) & 1 - - -def create_label_colormap(dataset=_PASCAL): - """Creates a label colormap for the specified dataset. - - Args: - dataset: The colormap used in the dataset. - - Returns: - A numpy array of the dataset colormap. - - Raises: - ValueError: If the dataset is not supported. - """ - if dataset == _ADE20K: - return create_ade20k_label_colormap() - elif dataset == _CITYSCAPES: - return create_cityscapes_label_colormap() - elif dataset == _MAPILLARY_VISTAS: - return create_mapillary_vistas_label_colormap() - elif dataset == _PASCAL: - return create_pascal_label_colormap() - else: - raise ValueError('Unsupported dataset.') - - -def label_to_color_image(label, dataset=_PASCAL): - """Adds color defined by the dataset colormap to the label. - - Args: - label: A 2D array with integer type, storing the segmentation label. - dataset: The colormap used in the dataset. - - Returns: - result: A 2D array with floating type. The element of the array - is the color indexed by the corresponding element in the input label - to the dataset color map. - - Raises: - ValueError: If label is not of rank 2 or its value is larger than color - map maximum entry. - """ - if label.ndim != 2: - raise ValueError('Expect 2-D input label. Got {}'.format(label.shape)) - - if np.max(label) >= _DATASET_MAX_ENTRIES[dataset]: - raise ValueError( - 'label value too large: {} >= {}.'.format( - np.max(label), _DATASET_MAX_ENTRIES[dataset])) - - colormap = create_label_colormap(dataset) - return colormap[label] - - -def get_dataset_colormap_max_entries(dataset): - return _DATASET_MAX_ENTRIES[dataset] diff --git a/research/deeplab/utils/get_dataset_colormap_test.py b/research/deeplab/utils/get_dataset_colormap_test.py deleted file mode 100644 index 89adb2c7391ce087100558fcf256acb1ca45638b..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/get_dataset_colormap_test.py +++ /dev/null @@ -1,97 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Tests for get_dataset_colormap.py.""" - -import numpy as np -import tensorflow as tf - -from deeplab.utils import get_dataset_colormap - - -class VisualizationUtilTest(tf.test.TestCase): - - def testBitGet(self): - """Test that if the returned bit value is correct.""" - self.assertEqual(1, get_dataset_colormap.bit_get(9, 0)) - self.assertEqual(0, get_dataset_colormap.bit_get(9, 1)) - self.assertEqual(0, get_dataset_colormap.bit_get(9, 2)) - self.assertEqual(1, get_dataset_colormap.bit_get(9, 3)) - - def testPASCALLabelColorMapValue(self): - """Test the getd color map value.""" - colormap = get_dataset_colormap.create_pascal_label_colormap() - - # Only test a few sampled entries in the color map. - self.assertTrue(np.array_equal([128., 0., 128.], colormap[5, :])) - self.assertTrue(np.array_equal([128., 192., 128.], colormap[23, :])) - self.assertTrue(np.array_equal([128., 0., 192.], colormap[37, :])) - self.assertTrue(np.array_equal([224., 192., 192.], colormap[127, :])) - self.assertTrue(np.array_equal([192., 160., 192.], colormap[175, :])) - - def testLabelToPASCALColorImage(self): - """Test the value of the converted label value.""" - label = np.array([[0, 16, 16], [52, 7, 52]]) - expected_result = np.array([ - [[0, 0, 0], [0, 64, 0], [0, 64, 0]], - [[0, 64, 192], [128, 128, 128], [0, 64, 192]] - ]) - colored_label = get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - self.assertTrue(np.array_equal(expected_result, colored_label)) - - def testUnExpectedLabelValueForLabelToPASCALColorImage(self): - """Raise ValueError when input value exceeds range.""" - label = np.array([[120], [600]]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - - def testUnExpectedLabelDimensionForLabelToPASCALColorImage(self): - """Raise ValueError if input dimension is not correct.""" - label = np.array([120]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_pascal_name()) - - def testGetColormapForUnsupportedDataset(self): - with self.assertRaises(ValueError): - get_dataset_colormap.create_label_colormap('unsupported_dataset') - - def testUnExpectedLabelDimensionForLabelToADE20KColorImage(self): - label = np.array([250]) - with self.assertRaises(ValueError): - get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_ade20k_name()) - - def testFirstColorInADE20KColorMap(self): - label = np.array([[1, 3], [10, 20]]) - expected_result = np.array([ - [[120, 120, 120], [6, 230, 230]], - [[4, 250, 7], [204, 70, 3]] - ]) - colored_label = get_dataset_colormap.label_to_color_image( - label, get_dataset_colormap.get_ade20k_name()) - self.assertTrue(np.array_equal(colored_label, expected_result)) - - def testMapillaryVistasColorMapValue(self): - colormap = get_dataset_colormap.create_mapillary_vistas_label_colormap() - self.assertTrue(np.array_equal([190, 153, 153], colormap[3, :])) - self.assertTrue(np.array_equal([102, 102, 156], colormap[6, :])) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/deeplab/utils/save_annotation.py b/research/deeplab/utils/save_annotation.py deleted file mode 100644 index 2444df79532d6ef999f470ab8eef5ab333491660..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/save_annotation.py +++ /dev/null @@ -1,66 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Saves an annotation as one png image. - -This script saves an annotation as one png image, and has the option to add -colormap to the png image for better visualization. -""" - -import numpy as np -import PIL.Image as img -import tensorflow as tf - -from deeplab.utils import get_dataset_colormap - - -def save_annotation(label, - save_dir, - filename, - add_colormap=True, - normalize_to_unit_values=False, - scale_values=False, - colormap_type=get_dataset_colormap.get_pascal_name()): - """Saves the given label to image on disk. - - Args: - label: The numpy array to be saved. The data will be converted - to uint8 and saved as png image. - save_dir: String, the directory to which the results will be saved. - filename: String, the image filename. - add_colormap: Boolean, add color map to the label or not. - normalize_to_unit_values: Boolean, normalize the input values to [0, 1]. - scale_values: Boolean, scale the input values to [0, 255] for visualization. - colormap_type: String, colormap type for visualization. - """ - # Add colormap for visualizing the prediction. - if add_colormap: - colored_label = get_dataset_colormap.label_to_color_image( - label, colormap_type) - else: - colored_label = label - if normalize_to_unit_values: - min_value = np.amin(colored_label) - max_value = np.amax(colored_label) - range_value = max_value - min_value - if range_value != 0: - colored_label = (colored_label - min_value) / range_value - - if scale_values: - colored_label = 255. * colored_label - - pil_image = img.fromarray(colored_label.astype(dtype=np.uint8)) - with tf.gfile.Open('%s/%s.png' % (save_dir, filename), mode='w') as f: - pil_image.save(f, 'PNG') diff --git a/research/deeplab/utils/train_utils.py b/research/deeplab/utils/train_utils.py deleted file mode 100644 index 14bbd6ee7e55533d94195fb4e7327e63e53a2800..0000000000000000000000000000000000000000 --- a/research/deeplab/utils/train_utils.py +++ /dev/null @@ -1,372 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utility functions for training.""" - -import six -import tensorflow as tf -from tensorflow.contrib import framework as contrib_framework - -from deeplab.core import preprocess_utils -from deeplab.core import utils - - -def _div_maybe_zero(total_loss, num_present): - """Normalizes the total loss with the number of present pixels.""" - return tf.to_float(num_present > 0) * tf.math.divide( - total_loss, - tf.maximum(1e-5, num_present)) - - -def add_softmax_cross_entropy_loss_for_each_scale(scales_to_logits, - labels, - num_classes, - ignore_label, - loss_weight=1.0, - upsample_logits=True, - hard_example_mining_step=0, - top_k_percent_pixels=1.0, - gt_is_matting_map=False, - scope=None): - """Adds softmax cross entropy loss for logits of each scale. - - Args: - scales_to_logits: A map from logits names for different scales to logits. - The logits have shape [batch, logits_height, logits_width, num_classes]. - labels: Groundtruth labels with shape [batch, image_height, image_width, 1]. - num_classes: Integer, number of target classes. - ignore_label: Integer, label to ignore. - loss_weight: A float or a list of loss weights. If it is a float, it means - all the labels have the same weight. If it is a list of weights, then each - element in the list represents the weight for the label of its index, for - example, loss_weight = [0.1, 0.5] means the weight for label 0 is 0.1 and - the weight for label 1 is 0.5. - upsample_logits: Boolean, upsample logits or not. - hard_example_mining_step: An integer, the training step in which the hard - exampling mining kicks off. Note that we gradually reduce the mining - percent to the top_k_percent_pixels. For example, if - hard_example_mining_step = 100K and top_k_percent_pixels = 0.25, then - mining percent will gradually reduce from 100% to 25% until 100K steps - after which we only mine top 25% pixels. - top_k_percent_pixels: A float, the value lies in [0.0, 1.0]. When its value - < 1.0, only compute the loss for the top k percent pixels (e.g., the top - 20% pixels). This is useful for hard pixel mining. - gt_is_matting_map: If true, the groundtruth is a matting map of confidence - score. If false, the groundtruth is an integer valued class mask. - scope: String, the scope for the loss. - - Raises: - ValueError: Label or logits is None, or groundtruth is matting map while - label is not floating value. - """ - if labels is None: - raise ValueError('No label for softmax cross entropy loss.') - - # If input groundtruth is a matting map of confidence, check if the input - # labels are floating point values. - if gt_is_matting_map and not labels.dtype.is_floating: - raise ValueError('Labels must be floats if groundtruth is a matting map.') - - for scale, logits in six.iteritems(scales_to_logits): - loss_scope = None - if scope: - loss_scope = '%s_%s' % (scope, scale) - - if upsample_logits: - # Label is not downsampled, and instead we upsample logits. - logits = tf.image.resize_bilinear( - logits, - preprocess_utils.resolve_shape(labels, 4)[1:3], - align_corners=True) - scaled_labels = labels - else: - # Label is downsampled to the same size as logits. - # When gt_is_matting_map = true, label downsampling with nearest neighbor - # method may introduce artifacts. However, to avoid ignore_label from - # being interpolated with other labels, we still perform nearest neighbor - # interpolation. - # TODO(huizhongc): Change to bilinear interpolation by processing padded - # and non-padded label separately. - if gt_is_matting_map: - tf.logging.warning( - 'Label downsampling with nearest neighbor may introduce artifacts.') - - scaled_labels = tf.image.resize_nearest_neighbor( - labels, - preprocess_utils.resolve_shape(logits, 4)[1:3], - align_corners=True) - - scaled_labels = tf.reshape(scaled_labels, shape=[-1]) - weights = utils.get_label_weight_mask( - scaled_labels, ignore_label, num_classes, label_weights=loss_weight) - # Dimension of keep_mask is equal to the total number of pixels. - keep_mask = tf.cast( - tf.not_equal(scaled_labels, ignore_label), dtype=tf.float32) - - train_labels = None - logits = tf.reshape(logits, shape=[-1, num_classes]) - - if gt_is_matting_map: - # When the groundtruth is integer label mask, we can assign class - # dependent label weights to the loss. When the groundtruth is image - # matting confidence, we do not apply class-dependent label weight (i.e., - # label_weight = 1.0). - if loss_weight != 1.0: - raise ValueError( - 'loss_weight must equal to 1 if groundtruth is matting map.') - - # Assign label value 0 to ignore pixels. The exact label value of ignore - # pixel does not matter, because those ignore_value pixel losses will be - # multiplied to 0 weight. - train_labels = scaled_labels * keep_mask - - train_labels = tf.expand_dims(train_labels, 1) - train_labels = tf.concat([1 - train_labels, train_labels], axis=1) - else: - train_labels = tf.one_hot( - scaled_labels, num_classes, on_value=1.0, off_value=0.0) - - default_loss_scope = ('softmax_all_pixel_loss' - if top_k_percent_pixels == 1.0 else - 'softmax_hard_example_mining') - with tf.name_scope(loss_scope, default_loss_scope, - [logits, train_labels, weights]): - # Compute the loss for all pixels. - pixel_losses = tf.nn.softmax_cross_entropy_with_logits_v2( - labels=tf.stop_gradient( - train_labels, name='train_labels_stop_gradient'), - logits=logits, - name='pixel_losses') - weighted_pixel_losses = tf.multiply(pixel_losses, weights) - - if top_k_percent_pixels == 1.0: - total_loss = tf.reduce_sum(weighted_pixel_losses) - num_present = tf.reduce_sum(keep_mask) - loss = _div_maybe_zero(total_loss, num_present) - tf.losses.add_loss(loss) - else: - num_pixels = tf.to_float(tf.shape(logits)[0]) - # Compute the top_k_percent pixels based on current training step. - if hard_example_mining_step == 0: - # Directly focus on the top_k pixels. - top_k_pixels = tf.to_int32(top_k_percent_pixels * num_pixels) - else: - # Gradually reduce the mining percent to top_k_percent_pixels. - global_step = tf.to_float(tf.train.get_or_create_global_step()) - ratio = tf.minimum(1.0, global_step / hard_example_mining_step) - top_k_pixels = tf.to_int32( - (ratio * top_k_percent_pixels + (1.0 - ratio)) * num_pixels) - top_k_losses, _ = tf.nn.top_k(weighted_pixel_losses, - k=top_k_pixels, - sorted=True, - name='top_k_percent_pixels') - total_loss = tf.reduce_sum(top_k_losses) - num_present = tf.reduce_sum( - tf.to_float(tf.not_equal(top_k_losses, 0.0))) - loss = _div_maybe_zero(total_loss, num_present) - tf.losses.add_loss(loss) - - -def get_model_init_fn(train_logdir, - tf_initial_checkpoint, - initialize_last_layer, - last_layers, - ignore_missing_vars=False): - """Gets the function initializing model variables from a checkpoint. - - Args: - train_logdir: Log directory for training. - tf_initial_checkpoint: TensorFlow checkpoint for initialization. - initialize_last_layer: Initialize last layer or not. - last_layers: Last layers of the model. - ignore_missing_vars: Ignore missing variables in the checkpoint. - - Returns: - Initialization function. - """ - if tf_initial_checkpoint is None: - tf.logging.info('Not initializing the model from a checkpoint.') - return None - - if tf.train.latest_checkpoint(train_logdir): - tf.logging.info('Ignoring initialization; other checkpoint exists') - return None - - tf.logging.info('Initializing model from path: %s', tf_initial_checkpoint) - - # Variables that will not be restored. - exclude_list = ['global_step'] - if not initialize_last_layer: - exclude_list.extend(last_layers) - - variables_to_restore = contrib_framework.get_variables_to_restore( - exclude=exclude_list) - - if variables_to_restore: - init_op, init_feed_dict = contrib_framework.assign_from_checkpoint( - tf_initial_checkpoint, - variables_to_restore, - ignore_missing_vars=ignore_missing_vars) - global_step = tf.train.get_or_create_global_step() - - def restore_fn(sess): - sess.run(init_op, init_feed_dict) - sess.run([global_step]) - - return restore_fn - - return None - - -def get_model_gradient_multipliers(last_layers, last_layer_gradient_multiplier): - """Gets the gradient multipliers. - - The gradient multipliers will adjust the learning rates for model - variables. For the task of semantic segmentation, the models are - usually fine-tuned from the models trained on the task of image - classification. To fine-tune the models, we usually set larger (e.g., - 10 times larger) learning rate for the parameters of last layer. - - Args: - last_layers: Scopes of last layers. - last_layer_gradient_multiplier: The gradient multiplier for last layers. - - Returns: - The gradient multiplier map with variables as key, and multipliers as value. - """ - gradient_multipliers = {} - - for var in tf.model_variables(): - # Double the learning rate for biases. - if 'biases' in var.op.name: - gradient_multipliers[var.op.name] = 2. - - # Use larger learning rate for last layer variables. - for layer in last_layers: - if layer in var.op.name and 'biases' in var.op.name: - gradient_multipliers[var.op.name] = 2 * last_layer_gradient_multiplier - break - elif layer in var.op.name: - gradient_multipliers[var.op.name] = last_layer_gradient_multiplier - break - - return gradient_multipliers - - -def get_model_learning_rate(learning_policy, - base_learning_rate, - learning_rate_decay_step, - learning_rate_decay_factor, - training_number_of_steps, - learning_power, - slow_start_step, - slow_start_learning_rate, - slow_start_burnin_type='none', - decay_steps=0.0, - end_learning_rate=0.0, - boundaries=None, - boundary_learning_rates=None): - """Gets model's learning rate. - - Computes the model's learning rate for different learning policy. - Right now, only "step" and "poly" are supported. - (1) The learning policy for "step" is computed as follows: - current_learning_rate = base_learning_rate * - learning_rate_decay_factor ^ (global_step / learning_rate_decay_step) - See tf.train.exponential_decay for details. - (2) The learning policy for "poly" is computed as follows: - current_learning_rate = base_learning_rate * - (1 - global_step / training_number_of_steps) ^ learning_power - - Args: - learning_policy: Learning rate policy for training. - base_learning_rate: The base learning rate for model training. - learning_rate_decay_step: Decay the base learning rate at a fixed step. - learning_rate_decay_factor: The rate to decay the base learning rate. - training_number_of_steps: Number of steps for training. - learning_power: Power used for 'poly' learning policy. - slow_start_step: Training model with small learning rate for the first - few steps. - slow_start_learning_rate: The learning rate employed during slow start. - slow_start_burnin_type: The burnin type for the slow start stage. Can be - `none` which means no burnin or `linear` which means the learning rate - increases linearly from slow_start_learning_rate and reaches - base_learning_rate after slow_start_steps. - decay_steps: Float, `decay_steps` for polynomial learning rate. - end_learning_rate: Float, `end_learning_rate` for polynomial learning rate. - boundaries: A list of `Tensor`s or `int`s or `float`s with strictly - increasing entries. - boundary_learning_rates: A list of `Tensor`s or `float`s or `int`s that - specifies the values for the intervals defined by `boundaries`. It should - have one more element than `boundaries`, and all elements should have the - same type. - - Returns: - Learning rate for the specified learning policy. - - Raises: - ValueError: If learning policy or slow start burnin type is not recognized. - ValueError: If `boundaries` and `boundary_learning_rates` are not set for - multi_steps learning rate decay. - """ - global_step = tf.train.get_or_create_global_step() - adjusted_global_step = tf.maximum(global_step - slow_start_step, 0) - if decay_steps == 0.0: - tf.logging.info('Setting decay_steps to total training steps.') - decay_steps = training_number_of_steps - slow_start_step - if learning_policy == 'step': - learning_rate = tf.train.exponential_decay( - base_learning_rate, - adjusted_global_step, - learning_rate_decay_step, - learning_rate_decay_factor, - staircase=True) - elif learning_policy == 'poly': - learning_rate = tf.train.polynomial_decay( - base_learning_rate, - adjusted_global_step, - decay_steps=decay_steps, - end_learning_rate=end_learning_rate, - power=learning_power) - elif learning_policy == 'cosine': - learning_rate = tf.train.cosine_decay( - base_learning_rate, - adjusted_global_step, - training_number_of_steps - slow_start_step) - elif learning_policy == 'multi_steps': - if boundaries is None or boundary_learning_rates is None: - raise ValueError('Must set `boundaries` and `boundary_learning_rates` ' - 'for multi_steps learning rate decay.') - learning_rate = tf.train.piecewise_constant_decay( - adjusted_global_step, - boundaries, - boundary_learning_rates) - else: - raise ValueError('Unknown learning policy.') - - adjusted_slow_start_learning_rate = slow_start_learning_rate - if slow_start_burnin_type == 'linear': - # Do linear burnin. Increase linearly from slow_start_learning_rate and - # reach base_learning_rate after (global_step >= slow_start_steps). - adjusted_slow_start_learning_rate = ( - slow_start_learning_rate + - (base_learning_rate - slow_start_learning_rate) * - tf.to_float(global_step) / slow_start_step) - elif slow_start_burnin_type != 'none': - raise ValueError('Unknown burnin type.') - - # Employ small learning rate at the first few steps for warm start. - return tf.where(global_step < slow_start_step, - adjusted_slow_start_learning_rate, learning_rate) diff --git a/research/deeplab/vis.py b/research/deeplab/vis.py deleted file mode 100644 index 20808d37bf2f45f196a04391548c6745fcc6603b..0000000000000000000000000000000000000000 --- a/research/deeplab/vis.py +++ /dev/null @@ -1,327 +0,0 @@ -# Lint as: python2, python3 -# Copyright 2018 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""Segmentation results visualization on a given set of images. - -See model.py for more details and usage. -""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function -import os.path -import time -import numpy as np -from six.moves import range -import tensorflow as tf -from tensorflow.contrib import quantize as contrib_quantize -from tensorflow.contrib import training as contrib_training -from deeplab import common -from deeplab import model -from deeplab.datasets import data_generator -from deeplab.utils import save_annotation - -flags = tf.app.flags - -FLAGS = flags.FLAGS - -flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') - -# Settings for log directories. - -flags.DEFINE_string('vis_logdir', None, 'Where to write the event logs.') - -flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') - -# Settings for visualizing the model. - -flags.DEFINE_integer('vis_batch_size', 1, - 'The number of images in each batch during evaluation.') - -flags.DEFINE_list('vis_crop_size', '513,513', - 'Crop size [height, width] for visualization.') - -flags.DEFINE_integer('eval_interval_secs', 60 * 5, - 'How often (in seconds) to run evaluation.') - -# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or -# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note -# one could use different atrous_rates/output_stride during training/evaluation. -flags.DEFINE_multi_integer('atrous_rates', None, - 'Atrous rates for atrous spatial pyramid pooling.') - -flags.DEFINE_integer('output_stride', 16, - 'The ratio of input to output spatial resolution.') - -# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. -flags.DEFINE_multi_float('eval_scales', [1.0], - 'The scales to resize images for evaluation.') - -# Change to True for adding flipped images during test. -flags.DEFINE_bool('add_flipped_images', False, - 'Add flipped images for evaluation or not.') - -flags.DEFINE_integer( - 'quantize_delay_step', -1, - 'Steps to start quantized training. If < 0, will not quantize model.') - -# Dataset settings. - -flags.DEFINE_string('dataset', 'pascal_voc_seg', - 'Name of the segmentation dataset.') - -flags.DEFINE_string('vis_split', 'val', - 'Which split of the dataset used for visualizing results') - -flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') - -flags.DEFINE_enum('colormap_type', 'pascal', ['pascal', 'cityscapes', 'ade20k'], - 'Visualization colormap type.') - -flags.DEFINE_boolean('also_save_raw_predictions', False, - 'Also save raw predictions.') - -flags.DEFINE_integer('max_number_of_iterations', 0, - 'Maximum number of visualization iterations. Will loop ' - 'indefinitely upon nonpositive values.') - -# The folder where semantic segmentation predictions are saved. -_SEMANTIC_PREDICTION_SAVE_FOLDER = 'segmentation_results' - -# The folder where raw semantic segmentation predictions are saved. -_RAW_SEMANTIC_PREDICTION_SAVE_FOLDER = 'raw_segmentation_results' - -# The format to save image. -_IMAGE_FORMAT = '%06d_image' - -# The format to save prediction -_PREDICTION_FORMAT = '%06d_prediction' - -# To evaluate Cityscapes results on the evaluation server, the labels used -# during training should be mapped to the labels for evaluation. -_CITYSCAPES_TRAIN_ID_TO_EVAL_ID = [7, 8, 11, 12, 13, 17, 19, 20, 21, 22, - 23, 24, 25, 26, 27, 28, 31, 32, 33] - - -def _convert_train_id_to_eval_id(prediction, train_id_to_eval_id): - """Converts the predicted label for evaluation. - - There are cases where the training labels are not equal to the evaluation - labels. This function is used to perform the conversion so that we could - evaluate the results on the evaluation server. - - Args: - prediction: Semantic segmentation prediction. - train_id_to_eval_id: A list mapping from train id to evaluation id. - - Returns: - Semantic segmentation prediction whose labels have been changed. - """ - converted_prediction = prediction.copy() - for train_id, eval_id in enumerate(train_id_to_eval_id): - converted_prediction[prediction == train_id] = eval_id - - return converted_prediction - - -def _process_batch(sess, original_images, semantic_predictions, image_names, - image_heights, image_widths, image_id_offset, save_dir, - raw_save_dir, train_id_to_eval_id=None): - """Evaluates one single batch qualitatively. - - Args: - sess: TensorFlow session. - original_images: One batch of original images. - semantic_predictions: One batch of semantic segmentation predictions. - image_names: Image names. - image_heights: Image heights. - image_widths: Image widths. - image_id_offset: Image id offset for indexing images. - save_dir: The directory where the predictions will be saved. - raw_save_dir: The directory where the raw predictions will be saved. - train_id_to_eval_id: A list mapping from train id to eval id. - """ - (original_images, - semantic_predictions, - image_names, - image_heights, - image_widths) = sess.run([original_images, semantic_predictions, - image_names, image_heights, image_widths]) - - num_image = semantic_predictions.shape[0] - for i in range(num_image): - image_height = np.squeeze(image_heights[i]) - image_width = np.squeeze(image_widths[i]) - original_image = np.squeeze(original_images[i]) - semantic_prediction = np.squeeze(semantic_predictions[i]) - crop_semantic_prediction = semantic_prediction[:image_height, :image_width] - - # Save image. - save_annotation.save_annotation( - original_image, save_dir, _IMAGE_FORMAT % (image_id_offset + i), - add_colormap=False) - - # Save prediction. - save_annotation.save_annotation( - crop_semantic_prediction, save_dir, - _PREDICTION_FORMAT % (image_id_offset + i), add_colormap=True, - colormap_type=FLAGS.colormap_type) - - if FLAGS.also_save_raw_predictions: - image_filename = os.path.basename(image_names[i]) - - if train_id_to_eval_id is not None: - crop_semantic_prediction = _convert_train_id_to_eval_id( - crop_semantic_prediction, - train_id_to_eval_id) - save_annotation.save_annotation( - crop_semantic_prediction, raw_save_dir, image_filename, - add_colormap=False) - - -def main(unused_argv): - tf.logging.set_verbosity(tf.logging.INFO) - - # Get dataset-dependent information. - dataset = data_generator.Dataset( - dataset_name=FLAGS.dataset, - split_name=FLAGS.vis_split, - dataset_dir=FLAGS.dataset_dir, - batch_size=FLAGS.vis_batch_size, - crop_size=[int(sz) for sz in FLAGS.vis_crop_size], - min_resize_value=FLAGS.min_resize_value, - max_resize_value=FLAGS.max_resize_value, - resize_factor=FLAGS.resize_factor, - model_variant=FLAGS.model_variant, - is_training=False, - should_shuffle=False, - should_repeat=False) - - train_id_to_eval_id = None - if dataset.dataset_name == data_generator.get_cityscapes_dataset_name(): - tf.logging.info('Cityscapes requires converting train_id to eval_id.') - train_id_to_eval_id = _CITYSCAPES_TRAIN_ID_TO_EVAL_ID - - # Prepare for visualization. - tf.gfile.MakeDirs(FLAGS.vis_logdir) - save_dir = os.path.join(FLAGS.vis_logdir, _SEMANTIC_PREDICTION_SAVE_FOLDER) - tf.gfile.MakeDirs(save_dir) - raw_save_dir = os.path.join( - FLAGS.vis_logdir, _RAW_SEMANTIC_PREDICTION_SAVE_FOLDER) - tf.gfile.MakeDirs(raw_save_dir) - - tf.logging.info('Visualizing on %s set', FLAGS.vis_split) - - with tf.Graph().as_default(): - samples = dataset.get_one_shot_iterator().get_next() - - model_options = common.ModelOptions( - outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_of_classes}, - crop_size=[int(sz) for sz in FLAGS.vis_crop_size], - atrous_rates=FLAGS.atrous_rates, - output_stride=FLAGS.output_stride) - - if tuple(FLAGS.eval_scales) == (1.0,): - tf.logging.info('Performing single-scale test.') - predictions = model.predict_labels( - samples[common.IMAGE], - model_options=model_options, - image_pyramid=FLAGS.image_pyramid) - else: - tf.logging.info('Performing multi-scale test.') - if FLAGS.quantize_delay_step >= 0: - raise ValueError( - 'Quantize mode is not supported with multi-scale test.') - predictions = model.predict_labels_multi_scale( - samples[common.IMAGE], - model_options=model_options, - eval_scales=FLAGS.eval_scales, - add_flipped_images=FLAGS.add_flipped_images) - predictions = predictions[common.OUTPUT_TYPE] - - if FLAGS.min_resize_value and FLAGS.max_resize_value: - # Only support batch_size = 1, since we assume the dimensions of original - # image after tf.squeeze is [height, width, 3]. - assert FLAGS.vis_batch_size == 1 - - # Reverse the resizing and padding operations performed in preprocessing. - # First, we slice the valid regions (i.e., remove padded region) and then - # we resize the predictions back. - original_image = tf.squeeze(samples[common.ORIGINAL_IMAGE]) - original_image_shape = tf.shape(original_image) - predictions = tf.slice( - predictions, - [0, 0, 0], - [1, original_image_shape[0], original_image_shape[1]]) - resized_shape = tf.to_int32([tf.squeeze(samples[common.HEIGHT]), - tf.squeeze(samples[common.WIDTH])]) - predictions = tf.squeeze( - tf.image.resize_images(tf.expand_dims(predictions, 3), - resized_shape, - method=tf.image.ResizeMethod.NEAREST_NEIGHBOR, - align_corners=True), 3) - - tf.train.get_or_create_global_step() - if FLAGS.quantize_delay_step >= 0: - contrib_quantize.create_eval_graph() - - num_iteration = 0 - max_num_iteration = FLAGS.max_number_of_iterations - - checkpoints_iterator = contrib_training.checkpoints_iterator( - FLAGS.checkpoint_dir, min_interval_secs=FLAGS.eval_interval_secs) - for checkpoint_path in checkpoints_iterator: - num_iteration += 1 - tf.logging.info( - 'Starting visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', - time.gmtime())) - tf.logging.info('Visualizing with model %s', checkpoint_path) - - scaffold = tf.train.Scaffold(init_op=tf.global_variables_initializer()) - session_creator = tf.train.ChiefSessionCreator( - scaffold=scaffold, - master=FLAGS.master, - checkpoint_filename_with_path=checkpoint_path) - with tf.train.MonitoredSession( - session_creator=session_creator, hooks=None) as sess: - batch = 0 - image_id_offset = 0 - - while not sess.should_stop(): - tf.logging.info('Visualizing batch %d', batch + 1) - _process_batch(sess=sess, - original_images=samples[common.ORIGINAL_IMAGE], - semantic_predictions=predictions, - image_names=samples[common.IMAGE_NAME], - image_heights=samples[common.HEIGHT], - image_widths=samples[common.WIDTH], - image_id_offset=image_id_offset, - save_dir=save_dir, - raw_save_dir=raw_save_dir, - train_id_to_eval_id=train_id_to_eval_id) - image_id_offset += FLAGS.vis_batch_size - batch += 1 - - tf.logging.info( - 'Finished visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', - time.gmtime())) - if max_num_iteration > 0 and num_iteration >= max_num_iteration: - break - -if __name__ == '__main__': - flags.mark_flag_as_required('checkpoint_dir') - flags.mark_flag_as_required('vis_logdir') - flags.mark_flag_as_required('dataset_dir') - tf.app.run() diff --git a/research/delf/.gitignore b/research/delf/.gitignore deleted file mode 100644 index b61ddd100012ab30e0bf438f3a5ab01ea3f44281..0000000000000000000000000000000000000000 --- a/research/delf/.gitignore +++ /dev/null @@ -1,4 +0,0 @@ -*pyc -*~ -*pb2.py -*pb2.pyc diff --git a/research/delf/DETECTION.md b/research/delf/DETECTION.md deleted file mode 100644 index 7fa7570f74dc58622151bee37f9a2a5697b896de..0000000000000000000000000000000000000000 --- a/research/delf/DETECTION.md +++ /dev/null @@ -1,69 +0,0 @@ -## Quick start: landmark detection - -[](https://arxiv.org/abs/1812.01584) - -### Install DELF library - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -### Download Oxford buildings dataset - -To illustrate detector usage, please download the Oxford buildings dataset, by -following the instructions -[here](EXTRACTION_MATCHING.md#download-oxford-buildings-dataset). Then, create -the file `list_images_detector.txt` as follows: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -echo data/oxford5k_images/all_souls_000002.jpg >> list_images_detector.txt -echo data/oxford5k_images/all_souls_000035.jpg >> list_images_detector.txt -``` - -### Download detector model - -Also, you will need to download the pre-trained detector model: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir parameters && cd parameters -wget http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz -tar -xvzf d2r_frcnn_20190411.tar.gz -``` - -**Note**: this is the Faster-RCNN based model. We also release a MobileNet-SSD -model, see the [README](README.md#pre-trained-models) for download link. The -instructions should work seamlessly for both models. - -### Detecting landmarks - -Now that you have everything in place, running this command should detect boxes -for the images `all_souls_000002.jpg` and `all_souls_000035.jpg`, with a -threshold of 0.8, and produce visualizations. - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -python3 extract_boxes.py \ - --detector_path parameters/d2r_frcnn_20190411 \ - --detector_thresh 0.8 \ - --list_images_path list_images_detector.txt \ - --output_dir data/oxford5k_boxes \ - --output_viz_dir data/oxford5k_boxes_viz -``` - -Two images are generated in the `data/oxford5k_boxes_viz` directory, they should -look similar to these ones: - - - - -### Troubleshooting - -#### `matplotlib` - -`matplotlib` may complain with a message such as `no display name and no -$DISPLAY environment variable`. To fix this, one option is add the line -`backend : Agg` to the file `.config/matplotlib/matplotlibrc`. On this problem, -see the discussion -[here](https://stackoverflow.com/questions/37604289/tkinter-tclerror-no-display-name-and-no-display-environment-variable). diff --git a/research/delf/EXTRACTION_MATCHING.md b/research/delf/EXTRACTION_MATCHING.md deleted file mode 100644 index 53159638587282658129aa13ac165fbd7d3803ea..0000000000000000000000000000000000000000 --- a/research/delf/EXTRACTION_MATCHING.md +++ /dev/null @@ -1,87 +0,0 @@ -## Quick start: DELF extraction and matching - -[](https://arxiv.org/abs/1612.06321) - -### Install DELF library - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -### Download Oxford buildings dataset - -To illustrate DELF usage, please download the Oxford buildings dataset. To -follow these instructions closely, please download the dataset to the -`tensorflow/models/research/delf/delf/python/examples` directory, as in the -following commands: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir data && cd data -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images oxford5k_features -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ -cd ../ -echo data/oxford5k_images/hertford_000056.jpg >> list_images.txt -echo data/oxford5k_images/oxford_000317.jpg >> list_images.txt -``` - -### Download pre-trained DELF model - -Also, you will need to download the trained DELF model: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -mkdir parameters && cd parameters -wget http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz -tar -xvzf delf_gld_20190411.tar.gz -``` - -### DELF feature extraction - -Now that you have everything in place, running this command should extract DELF -features for the images `hertford_000056.jpg` and `oxford_000317.jpg`: - -```bash -# From tensorflow/models/research/delf/delf/python/examples/ -python3 extract_features.py \ - --config_path delf_config_example.pbtxt \ - --list_images_path list_images.txt \ - --output_dir data/oxford5k_features -``` - -### Image matching using DELF features - -After feature extraction, run this command to perform feature matching between -the images `hertford_000056.jpg` and `oxford_000317.jpg`: - -```bash -python3 match_images.py \ - --image_1_path data/oxford5k_images/hertford_000056.jpg \ - --image_2_path data/oxford5k_images/oxford_000317.jpg \ - --features_1_path data/oxford5k_features/hertford_000056.delf \ - --features_2_path data/oxford5k_features/oxford_000317.delf \ - --output_image matched_images.png -``` - -The image `matched_images.png` is generated and should look similar to this one: - - - -### Troubleshooting - -#### `matplotlib` - -`matplotlib` may complain with a message such as `no display name and no -$DISPLAY environment variable`. To fix this, one option is add the line -`backend : Agg` to the file `.config/matplotlib/matplotlibrc`. On this problem, -see the discussion -[here](https://stackoverflow.com/questions/37604289/tkinter-tclerror-no-display-name-and-no-display-environment-variable). - -#### 'skimage' - -By default, skimage 0.13.XX or 0.14.1 is installed if you followed the -instructions. According to -[https://github.com/scikit-image/scikit-image/issues/3649#issuecomment-455273659] -If you have scikit-image related issues, upgrading to a version above 0.14.1 -with `pip3 install -U scikit-image` should fix the issue diff --git a/research/delf/INSTALL_INSTRUCTIONS.md b/research/delf/INSTALL_INSTRUCTIONS.md deleted file mode 100644 index 4f66e9389fdd126dd769a8282a69482b989c9c9e..0000000000000000000000000000000000000000 --- a/research/delf/INSTALL_INSTRUCTIONS.md +++ /dev/null @@ -1,122 +0,0 @@ -## DELF installation - -### Tensorflow - -[](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0) -[](https://www.python.org/downloads/release/python-360/) - -For detailed steps to install Tensorflow, follow the -[Tensorflow installation instructions](https://www.tensorflow.org/install/). A -typical user can install Tensorflow using one of the following commands: - -```bash -# For CPU: -pip3 install 'tensorflow' -# For GPU: -pip3 install 'tensorflow-gpu' -``` - -### TF-Slim - -Note: currently, we need to install the latest version from source, to avoid -using previous versions which relied on tf.contrib (which is now deprecated). - -```bash -git clone git@github.com:google-research/tf-slim.git -cd tf-slim -pip3 install . -``` - -Note that these commands assume you are cloning using SSH. If you are using -HTTPS instead, use `git clone https://github.com/google-research/tf-slim.git` -instead. See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. - -### Protobuf - -The DELF library uses [protobuf](https://github.com/google/protobuf) (the python -version) to configure feature extraction and its format. You will need the -`protoc` compiler, version >= 3.3. The easiest way to get it is to download -directly. For Linux, this can be done as (see -[here](https://github.com/google/protobuf/releases) for other platforms): - -```bash -wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip -unzip protoc-3.3.0-linux-x86_64.zip -PATH_TO_PROTOC=`pwd` -``` - -### Python dependencies - -Install python library dependencies: - -```bash -pip3 install matplotlib numpy scikit-image scipy -sudo apt-get install python3-tk -``` - -### `tensorflow/models` - -Now, clone `tensorflow/models`, and install required libraries: (note that the -`object_detection` library requires you to add `tensorflow/models/research/` to -your `PYTHONPATH`, as instructed -[here](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md)) - -```bash -git clone git@github.com:tensorflow/models.git - -# Setup the object_detection module by editing PYTHONPATH. -cd .. -# From tensorflow/models/research/ -export PYTHONPATH=$PYTHONPATH:`pwd` -``` - -Note that these commands assume you are cloning using SSH. If you are using -HTTPS instead, use `git clone https://github.com/tensorflow/models.git` instead. -See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. - -Then, compile DELF's protobufs. Use `PATH_TO_PROTOC` as the directory where you -downloaded the `protoc` compiler. - -```bash -# From tensorflow/models/research/delf/ -${PATH_TO_PROTOC?}/bin/protoc delf/protos/*.proto --python_out=. -``` - -Finally, install the DELF package. This may also install some other dependencies -under the hood. - -```bash -# From tensorflow/models/research/delf/ -pip3 install -e . # Install "delf" package. -``` - -At this point, running - -```bash -python3 -c 'import delf' -``` - -should just return without complaints. This indicates that the DELF package is -loaded successfully. - -### Troubleshooting - -#### `pip3 install` - -Issues might be observed if using `pip3 install` with `-e` option (editable -mode). You may try out to simply remove the `-e` from the commands above. Also, -depending on your machine setup, you might need to run the `sudo pip3 install` -command, that is with a `sudo` at the beginning. - -#### Cloning github repositories - -The default commands above assume you are cloning using SSH. If you are using -HTTPS instead, use for example `git clone -https://github.com/tensorflow/models.git` instead of `git clone -git@github.com:tensorflow/models.git`. See -[this link](https://help.github.com/en/github/using-git/which-remote-url-should-i-use) -for more information. diff --git a/research/delf/README.md b/research/delf/README.md deleted file mode 100644 index f10852759c3455ae2990475ea917a4e45ee96264..0000000000000000000000000000000000000000 --- a/research/delf/README.md +++ /dev/null @@ -1,324 +0,0 @@ -# Deep Local and Global Image Features - -[](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0) -[](https://www.python.org/downloads/release/python-360/) - -This project presents code for deep local and global image feature methods, -which are particularly useful for the computer vision tasks of instance-level -recognition and retrieval. These were introduced in the -[DELF](https://arxiv.org/abs/1612.06321), -[Detect-to-Retrieve](https://arxiv.org/abs/1812.01584), -[DELG](https://arxiv.org/abs/2001.05027) and -[Google Landmarks Dataset v2](https://arxiv.org/abs/2004.01804) papers. - -We provide Tensorflow code for building and training models, and python code for -image retrieval and local feature matching. Pre-trained models for the landmark -recognition domain are also provided. - -If you make use of this codebase, please consider citing the following papers: - -DELF: -[](https://arxiv.org/abs/1612.06321) - -``` -"Large-Scale Image Retrieval with Attentive Deep Local Features", -H. Noh, A. Araujo, J. Sim, T. Weyand and B. Han, -Proc. ICCV'17 -``` - -Detect-to-Retrieve: -[](https://arxiv.org/abs/1812.01584) - -``` -"Detect-to-Retrieve: Efficient Regional Aggregation for Image Search", -M. Teichmann*, A. Araujo*, M. Zhu and J. Sim, -Proc. CVPR'19 -``` - -DELG: -[](https://arxiv.org/abs/2001.05027) - -``` -"Unifying Deep Local and Global Features for Image Search", -B. Cao*, A. Araujo* and J. Sim, -arxiv:2001.05027 -``` - -GLDv2: -[](https://arxiv.org/abs/2004.01804) - -``` -"Google Landmarks Dataset v2 - A Large-Scale Benchmark for Instance-Level Recognition and Retrieval", -T. Weyand*, A. Araujo*, B. Cao and J. Sim, -Proc. CVPR'20 -``` - -## News - -- [Apr'20] Check out our CVPR'20 paper: ["Google Landmarks Dataset v2 - A - Large-Scale Benchmark for Instance-Level Recognition and - Retrieval"](https://arxiv.org/abs/2004.01804) -- [Jan'20] Check out our new paper: - ["Unifying Deep Local and Global Features for Image Search"](https://arxiv.org/abs/2001.05027) -- [Jun'19] DELF achieved 2nd place in - [CVPR Visual Localization challenge (Local Features track)](https://sites.google.com/corp/view/ltvl2019). - See our slides - [here](https://docs.google.com/presentation/d/e/2PACX-1vTswzoXelqFqI_pCEIVl2uazeyGr7aKNklWHQCX-CbQ7MB17gaycqIaDTguuUCRm6_lXHwCdrkP7n1x/pub?start=false&loop=false&delayms=3000). -- [Apr'19] Check out our CVPR'19 paper: - ["Detect-to-Retrieve: Efficient Regional Aggregation for Image Search"](https://arxiv.org/abs/1812.01584) -- [Jun'18] DELF achieved state-of-the-art results in a CVPR'18 image retrieval - paper: [Radenovic et al., "Revisiting Oxford and Paris: Large-Scale Image - Retrieval Benchmarking"](https://arxiv.org/abs/1803.11285). -- [Apr'18] DELF was featured in - [ModelDepot](https://modeldepot.io/mikeshi/delf/overview) -- [Mar'18] DELF is now available in - [TF-Hub](https://www.tensorflow.org/hub/modules/google/delf/1) - -## Datasets - -We have two Google-Landmarks dataset versions: - -- Initial version (v1) can be found - [here](https://www.kaggle.com/google/google-landmarks-dataset). In includes - the Google Landmark Boxes which were described in the Detect-to-Retrieve - paper. -- Second version (v2) has been released as part of two Kaggle challenges: - [Landmark Recognition](https://www.kaggle.com/c/landmark-recognition-2019) - and [Landmark Retrieval](https://www.kaggle.com/c/landmark-retrieval-2019). - It can be downloaded from CVDF - [here](https://github.com/cvdfoundation/google-landmark). See also - [the CVPR'20 paper](https://arxiv.org/abs/2004.01804) on this new dataset - version. - -If you make use of these datasets in your research, please consider citing the -papers mentioned above. - -## Installation - -To be able to use this code, please follow -[these instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF -library. - -## Quick start - -### Pre-trained models - -We release several pre-trained models. See instructions in the following -sections for examples on how to use the models. - -**DELF pre-trained on the Google-Landmarks dataset v1** -([link](http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz)). Presented -in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). Boosts -performance by ~4% mAP compared to ICCV'17 DELF model. - -**DELG pre-trained on the Google-Landmarks dataset v1** -([link](http://storage.googleapis.com/delf/delg_gld_20200520.tar.gz)). Presented -in the [DELG paper](https://arxiv.org/abs/2001.05027). - -**RN101-ArcFace pre-trained on the Google-Landmarks dataset v2 (train-clean)** -([link](https://storage.googleapis.com/delf/rn101_af_gldv2clean_20200521.tar.gz)). -Presented in the [GLDv2 paper](https://arxiv.org/abs/2004.01804). - -**DELF pre-trained on Landmarks-Clean/Landmarks-Full dataset** -([link](http://storage.googleapis.com/delf/delf_v1_20171026.tar.gz)). Presented -in the [DELF paper](https://arxiv.org/abs/1612.06321), model was trained on the -dataset released by the [DIR paper](https://arxiv.org/abs/1604.01325). - -**Faster-RCNN detector pre-trained on Google Landmark Boxes** -([link](http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz)). -Presented in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). - -**MobileNet-SSD detector pre-trained on Google Landmark Boxes** -([link](http://storage.googleapis.com/delf/d2r_mnetssd_20190411.tar.gz)). -Presented in the [Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584). - -Besides these, we also release pre-trained codebooks for local feature -aggregation. See the -[Detect-to-Retrieve instructions](delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md) -for details. - -### DELF extraction and matching - -Please follow [these instructions](EXTRACTION_MATCHING.md). At the end, you -should obtain a nice figure showing local feature matches, as: - - - -### DELF training - -Please follow [these instructions](delf/python/training/README.md). - -### DELG - -Please follow [these instructions](delf/python/delg/DELG_INSTRUCTIONS.md). At -the end, you should obtain image retrieval results on the Revisited Oxford/Paris -datasets. - -### GLDv2 baseline - -Please follow -[these instructions](delf/python/google_landmarks_dataset/README.md). At the -end, you should obtain image retrieval results on the Revisited Oxford/Paris -datasets. - -### Landmark detection - -Please follow [these instructions](DETECTION.md). At the end, you should obtain -a nice figure showing a detection, as: - - - -### Detect-to-Retrieve - -Please follow -[these instructions](delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md). -At the end, you should obtain image retrieval results on the Revisited -Oxford/Paris datasets. - -## Code overview - -DELF/D2R/DELG/GLD code is located under the `delf` directory. There are two -directories therein, `protos` and `python`. - -### `delf/protos` - -This directory contains protobufs: - -- `aggregation_config.proto`: protobuf for configuring local feature - aggregation. -- `box.proto`: protobuf for serializing detected boxes. -- `datum.proto`: general-purpose protobuf for serializing float tensors. -- `delf_config.proto`: protobuf for configuring DELF/DELG extraction. -- `feature.proto`: protobuf for serializing DELF features. - -### `delf/python` - -This directory contains files for several different purposes: - -- `box_io.py`, `datum_io.py`, `feature_io.py` are helper files for reading and - writing tensors and features. -- `delf_v1.py` contains code to create DELF models. -- `feature_aggregation_extractor.py` contains a module to perform local - feature aggregation. -- `feature_aggregation_similarity.py` contains a module to perform similarity - computation for aggregated local features. -- `feature_extractor.py` contains the code to extract features using DELF. - This is particularly useful for extracting features over multiple scales, - with keypoint selection based on attention scores, and PCA/whitening - post-processing. - -The subdirectory `delf/python/examples` contains sample scripts to run DELF -feature extraction/matching, and object detection: - -- `delf_config_example.pbtxt` shows an example instantiation of the DelfConfig - proto, used for DELF feature extraction. -- `detector.py` is a module to construct an object detector function. -- `extract_boxes.py` enables object detection from a list of images. -- `extract_features.py` enables DELF extraction from a list of images. -- `extractor.py` is a module to construct a DELF/DELG local feature extraction - function. -- `match_images.py` supports image matching using DELF features extracted - using `extract_features.py`. - -The subdirectory `delf/python/delg` contains sample scripts/configs related to -the DELG paper: - -- `delg_gld_config.pbtxt` gives the DelfConfig used in DELG paper. -- `extract_features.py` for local+global feature extraction on Revisited - datasets. -- `perform_retrieval.py` for performing retrieval/evaluating methods on - Revisited datasets. - -The subdirectory `delf/python/detect_to_retrieve` contains sample -scripts/configs related to the Detect-to-Retrieve paper: - -- `aggregation_extraction.py` is a library to extract/save feature - aggregation. -- `boxes_and_features_extraction.py` is a library to extract/save boxes and - DELF features. -- `cluster_delf_features.py` for local feature clustering. -- `dataset.py` for parsing/evaluating results on Revisited Oxford/Paris - datasets. -- `delf_gld_config.pbtxt` gives the DelfConfig used in Detect-to-Retrieve - paper. -- `extract_aggregation.py` for aggregated local feature extraction. -- `extract_index_boxes_and_features.py` for index image local feature - extraction / bounding box detection on Revisited datasets. -- `extract_query_features.py` for query image local feature extraction on - Revisited datasets. -- `image_reranking.py` is a module to re-rank images with geometric - verification. -- `perform_retrieval.py` for performing retrieval/evaluating methods using - aggregated local features on Revisited datasets. -- `index_aggregation_config.pbtxt`, `query_aggregation_config.pbtxt` give - AggregationConfig's for Detect-to-Retrieve experiments. - -The subdirectory `delf/python/google_landmarks_dataset` contains sample -scripts/modules for computing GLD metrics / reproducing results from the GLDv2 -paper: - -- `compute_recognition_metrics.py` performs recognition metric computation - given input predictions and solution files. -- `compute_retrieval_metrics.py` performs retrieval metric computation given - input predictions and solution files. -- `dataset_file_io.py` is a module for dataset-related file IO. -- `metrics.py` is a module for GLD metric computation. -- `rn101_af_gldv2clean_config.pbtxt` gives the DelfConfig used in the - ResNet101-ArcFace (trained on GLDv2-train-clean) baseline used in the GLDv2 - paper. - -The subdirectory `delf/python/training` contains sample scripts/modules for -performing DELF training: - -- `datasets/googlelandmarks.py` is the dataset module used for training. -- `model/delf_model.py` is the model module used for training. -- `model/export_model.py` is a script for exporting trained models in the - format used by the inference code. -- `model/export_model_utils.py` is a module with utilities for model - exporting. -- `model/resnet50.py` is a module with a backbone RN50 implementation. -- `build_image_dataset.py` converts downloaded dataset into TFRecords format - for training. -- `train.py` is the main training script. - -Besides these, other files in the different subdirectories contain tests for the -various modules. - -## Maintainers - -André Araujo (@andrefaraujo) - -## Release history - -### May, 2020 - -- Codebase is now Python3-first -- DELG model/code released -- GLDv2 baseline model released - -**Thanks to contributors**: Barbara Fusinska and André Araujo. - -### April, 2020 (version 2.0) - -- Initial DELF training code released. -- Codebase is now fully compatible with TF 2.1. - -**Thanks to contributors**: Arun Mukundan, Yuewei Na and André Araujo. - -### April, 2019 - -Detect-to-Retrieve code released. - -Includes pre-trained models to detect landmark boxes, and DELF model pre-trained -on Google Landmarks v1 dataset. - -**Thanks to contributors**: André Araujo, Marvin Teichmann, Menglong Zhu, -Jack Sim. - -### October, 2017 - -Initial release containing DELF-v1 code, including feature extraction and -matching examples. Pre-trained DELF model from ICCV'17 paper is released. - -**Thanks to contributors**: André Araujo, Hyeonwoo Noh, Youlong Cheng, -Jack Sim. diff --git a/research/delf/delf/__init__.py b/research/delf/delf/__init__.py deleted file mode 100644 index a52df3c4546414e61f479357d06b65d4c132c753..0000000000000000000000000000000000000000 --- a/research/delf/delf/__init__.py +++ /dev/null @@ -1,39 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Module to extract deep local features.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import -from delf.protos import aggregation_config_pb2 -from delf.protos import box_pb2 -from delf.protos import datum_pb2 -from delf.protos import delf_config_pb2 -from delf.protos import feature_pb2 -from delf.python import box_io -from delf.python import datum_io -from delf.python import feature_aggregation_extractor -from delf.python import feature_aggregation_similarity -from delf.python import feature_extractor -from delf.python import feature_io -from delf.python import utils -from delf.python.examples import detector -from delf.python.examples import extractor -from delf.python import detect_to_retrieve -from delf.python import training -from delf.python.training import model -from delf.python.training import datasets -# pylint: enable=unused-import diff --git a/research/delf/delf/protos/__init__.py b/research/delf/delf/protos/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/delf/delf/protos/aggregation_config.proto b/research/delf/delf/protos/aggregation_config.proto deleted file mode 100644 index b1d5953d43ffc84f435c57be7145c7c17ae01186..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/aggregation_config.proto +++ /dev/null @@ -1,63 +0,0 @@ -// Protocol buffer for feature aggregation configuration. -// -// Used for both extraction and comparison of aggregated representations. Note -// that some options are only relevant for the former or the latter. -// -// For more details, please refer to the paper: -// "Detect-to-Retrieve: Efficient Regional Aggregation for Image Search", -// Proc. CVPR'19 (https://arxiv.org/abs/1812.01584). - -syntax = "proto2"; - -package delf.protos; - -message AggregationConfig { - // Number of codewords (ie, visual words) in the codebook. - optional int32 codebook_size = 1 [default = 65536]; - - // Dimensionality of local features (eg, 128 for DELF used in - // Detect-to-Retrieve paper). - optional int32 feature_dimensionality = 2 [default = 128]; - - // Type of aggregation to use. - // For example, to use R-ASMK*, `aggregation_type` should be set to ASMK_STAR - // and `use_regional_aggregation` should be set to true. - enum AggregationType { - INVALID = 0; - VLAD = 1; - ASMK = 2; - ASMK_STAR = 3; - } - optional AggregationType aggregation_type = 3 [default = ASMK_STAR]; - - // L2 normalization option. - // - For vanilla aggregated kernels (eg, VLAD/ASMK/ASMK*), this should be - // set to true. - // - For regional aggregated kernels (ie, if `use_regional_aggregation` is - // true, leading to R-VLAD/R-ASMK/R-ASMK*), this should be set to false. - // Note that it is used differently depending on the `aggregation_type`: - // - For VLAD, this option is only used for extraction. - // - For ASMK/ASMK*, this option is only used for comparisons. - optional bool use_l2_normalization = 4 [default = true]; - - // Additional options used only for extraction. - // - Path to codebook checkpoint for aggregation. - optional string codebook_path = 5; - // - Number of visual words to assign each feature. - optional int32 num_assignments = 6 [default = 1]; - // - Whether to use regional aggregation. - optional bool use_regional_aggregation = 7 [default = false]; - // - Batch size to use for local features when computing aggregated - // representations. Particularly useful if `codebook_size` and - // `feature_dimensionality` are large, to avoid OOM. A value of zero or - // lower indicates that no batching is used. - optional int32 feature_batch_size = 10 [default = 100]; - - // Additional options used only for comparison. - // Only relevant if `aggregation_type` is ASMK or ASMK_STAR. - // - Power-law exponent for similarity of visual word descriptors. - optional float alpha = 8 [default = 3.0]; - // - Threshold above which similarity of visual word descriptors are - // considered; below this, similarity is set to zero. - optional float tau = 9 [default = 0.0]; -} diff --git a/research/delf/delf/protos/box.proto b/research/delf/delf/protos/box.proto deleted file mode 100644 index 28da7fb71410262f9be98e206e756c82ba3beb38..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/box.proto +++ /dev/null @@ -1,24 +0,0 @@ -// Protocol buffer for serializing detected bounding boxes. - -syntax = "proto2"; - -package delf.protos; - -message Box { - // Coordinates: [ymin, xmin, ymax, xmax] corresponds to - // [top, left, bottom, right]. - optional float ymin = 1; - optional float xmin = 2; - optional float ymax = 3; - optional float xmax = 4; - - // Detection score. Usually, the higher the more confident. - optional float score = 5; - - // Indicates which class the box corresponds to. - optional int32 class_index = 6; -} - -message Boxes { - repeated Box box = 1; -} diff --git a/research/delf/delf/protos/datum.proto b/research/delf/delf/protos/datum.proto deleted file mode 100644 index 6806e56b25e912bfb6a87280432c8566dba0c41a..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/datum.proto +++ /dev/null @@ -1,66 +0,0 @@ -// Protocol buffer for serializing arbitrary float tensors. -// Note: Currently only floating point feature is supported. - -syntax = "proto2"; - -package delf.protos; - -// A DatumProto is a data structure used to serialize tensor with arbitrary -// shape. DatumProto contains an array of floating point values and its shape -// is represented as a sequence of integer values. Values are contained in -// row major order. -// -// Example: -// 3 x 2 array -// -// [1.1, 2.2] -// [3.3, 4.4] -// [5.5, 6.6] -// -// can be represented with the following DatumProto: -// -// DatumProto { -// shape { -// dim: 3 -// dim: 2 -// } -// float_list { -// value: 1.1 -// value: 2.2 -// value: 3.3 -// value: 4.4 -// value: 5.5 -// value: 6.6 -// } -// } - -// DatumShape is array of dimension of the tensor. -message DatumShape { - repeated int64 dim = 1 [packed = true]; -} - -// FloatList is a container of tensor values, which are saved as a list of -// floating point values. -message FloatList { - repeated float value = 1 [packed = true]; -} - -// Uint32List is a container of tensor values, which are saved as a list of -// uint32 values. -message Uint32List { - repeated uint32 value = 1 [packed = true]; -} - -message DatumProto { - optional DatumShape shape = 1; - oneof kind_oneof { - FloatList float_list = 2; - Uint32List uint32_list = 3; - } -} - -// Groups two DatumProto's. -message DatumPairProto { - optional DatumProto first = 1; - optional DatumProto second = 2; -} diff --git a/research/delf/delf/protos/delf_config.proto b/research/delf/delf/protos/delf_config.proto deleted file mode 100644 index 10ae0a614cbdd483f08f1f9f806a9d3adbe6b46d..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/delf_config.proto +++ /dev/null @@ -1,121 +0,0 @@ -// Protocol buffer for configuring DELF feature extraction. - -syntax = "proto2"; - -package delf.protos; - -message DelfPcaParameters { - // Path to PCA mean file. - optional string mean_path = 1; // Required. - - // Path to PCA matrix file. - optional string projection_matrix_path = 2; // Required. - - // Dimensionality of feature after PCA. - optional int32 pca_dim = 3; // Required. - - // If whitening is to be used, this must be set to true. - optional bool use_whitening = 4 [default = false]; - - // Path to PCA variances file, used for whitening. This is used only if - // use_whitening is set to true. - optional string pca_variances_path = 5; -} - -message DelfLocalFeatureConfig { - // If PCA is to be used, this must be set to true. - optional bool use_pca = 1 [default = true]; - - // Target layer name for DELF model. This is used to obtain receptive field - // parameters used for localizing features with respect to the input image. - optional string layer_name = 2 [default = ""]; - - // Intersection over union threshold for the non-max suppression (NMS) - // operation. If two features overlap by at most this amount, both are kept. - // Otherwise, the one with largest attention score is kept. This should be a - // number between 0.0 (no region is selected) and 1.0 (all regions are - // selected and NMS is not performed). - optional float iou_threshold = 3 [default = 1.0]; - - // Maximum number of features that will be selected. The features with largest - // scores (eg, largest attention score if score_type is "Att") are the - // selected ones. - optional int32 max_feature_num = 4 [default = 1000]; - - // Threshold to be used for feature selection: no feature with score lower - // than this number will be selected). - optional float score_threshold = 5 [default = 100.0]; - - // PCA parameters for DELF local feature. This is used only if use_pca is - // true. - optional DelfPcaParameters pca_parameters = 6; -} - -message DelfGlobalFeatureConfig { - // If PCA is to be used, this must be set to true. - optional bool use_pca = 1 [default = true]; - - // PCA parameters for DELF global feature. This is used only if use_pca is - // true. - optional DelfPcaParameters pca_parameters = 2; - - // Denotes indices of DelfConfig's scales that will be used for global - // descriptor extraction. For example, if DelfConfig's image_scales are - // [0.25, 0.5, 1.0] and image_scales_ind is [0, 2], global descriptor - // extraction will use solely scales [0.25, 1.0]. Note that local feature - // extraction will still use [0.25, 0.5, 1.0] in this case. If empty (default) - // , all scales are used. - repeated int32 image_scales_ind = 3; -} - -message DelfConfig { - // Whether to extract local features when using the model. - // At least one of {use_local_features, use_global_features} must be true. - optional bool use_local_features = 7 [default = true]; - // Configuration used for local features. Note: this is used only if - // use_local_features is true. - optional DelfLocalFeatureConfig delf_local_config = 3; - - // Whether to extract global features when using the model. - // At least one of {use_local_features, use_global_features} must be true. - optional bool use_global_features = 8 [default = false]; - // Configuration used for global features. Note: this is used only if - // use_global_features is true. - optional DelfGlobalFeatureConfig delf_global_config = 9; - - // Path to DELF model. - optional string model_path = 1; // Required. - - // Image scales to be used. - repeated float image_scales = 2; - - // Image resizing options. - // - The maximum/minimum image size (in terms of height or width) to be used - // when extracting DELF features. If set to -1 (default), no upper/lower - // bound for image size. If use_square_images option is false (default): - // * If the height *OR* width is larger than max_image_size, it will be - // resized to max_image_size, and the other dimension will be resized by - // preserving the aspect ratio. - // * If both height *AND* width are smaller than min_image_size, the larger - // side is set to min_image_size. - // - If use_square_images option is true, it needs to be resized to square - // resolution. To be more specific: - // * If the height *OR* width is larger than max_image_size, it is resized - // to square resolution of max_image_size. - // * If both height *AND* width are smaller than min_image_size, it is - // resized to square resolution of min_image_size. - // * Else, if the input image's resolution is not square, it is resized to - // square resolution of the larger side. - // Image resizing is useful when we want to ensure that the input to the image - // pyramid has a reasonable number of pixels, which could have large impact in - // terms of image matching performance. - // When using local features, note that the feature locations and scales will - // be consistent with the original image input size. - // Note that when both max_image_size and min_image_size are specified - // (which is a valid and legit use case), as long as max_image_size >= - // min_image_size, there's no conflicting scenario (i.e. never triggers both - // enlarging / shrinking). Bilinear interpolation is used. - optional int32 max_image_size = 4 [default = -1]; - optional int32 min_image_size = 5 [default = -1]; - optional bool use_square_images = 6 [default = false]; -} diff --git a/research/delf/delf/protos/feature.proto b/research/delf/delf/protos/feature.proto deleted file mode 100644 index 64c342fe2c36b9170de10628b8ddc83ee3cfb2c6..0000000000000000000000000000000000000000 --- a/research/delf/delf/protos/feature.proto +++ /dev/null @@ -1,22 +0,0 @@ -// Protocol buffer for serializing the DELF feature information. - -syntax = "proto2"; - -package delf.protos; - -import "delf/protos/datum.proto"; - -// FloatList is the container of tensor values. The tensor values are saved as -// a list of floating point values. -message DelfFeature { - optional DatumProto descriptor = 1; - optional float x = 2; - optional float y = 3; - optional float scale = 4; - optional float orientation = 5; - optional float strength = 6; -} - -message DelfFeatures { - repeated DelfFeature feature = 1; -} diff --git a/research/delf/delf/python/__init__.py b/research/delf/delf/python/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/research/delf/delf/python/box_io.py b/research/delf/delf/python/box_io.py deleted file mode 100644 index 8b0f0d2c973d5b83f9110f651f5c5541fad049b7..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/box_io.py +++ /dev/null @@ -1,151 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Python interface for Boxes proto. - -Support read and write of Boxes from/to numpy arrays and file. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from delf import box_pb2 - - -def ArraysToBoxes(boxes, scores, class_indices): - """Converts `boxes` to Boxes proto. - - Args: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - - Returns: - boxes_proto: Boxes object. - """ - num_boxes = len(scores) - assert num_boxes == boxes.shape[0] - assert num_boxes == len(class_indices) - - boxes_proto = box_pb2.Boxes() - for i in range(num_boxes): - boxes_proto.box.add( - ymin=boxes[i, 0], - xmin=boxes[i, 1], - ymax=boxes[i, 2], - xmax=boxes[i, 3], - score=scores[i], - class_index=class_indices[i]) - - return boxes_proto - - -def BoxesToArrays(boxes_proto): - """Converts data saved in Boxes proto to numpy arrays. - - If there are no boxes, the function returns three empty arrays. - - Args: - boxes_proto: Boxes proto object. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - num_boxes = len(boxes_proto.box) - if num_boxes == 0: - return np.array([]), np.array([]), np.array([]) - - boxes = np.zeros([num_boxes, 4]) - scores = np.zeros([num_boxes]) - class_indices = np.zeros([num_boxes]) - - for i in range(num_boxes): - box_proto = boxes_proto.box[i] - boxes[i] = [box_proto.ymin, box_proto.xmin, box_proto.ymax, box_proto.xmax] - scores[i] = box_proto.score - class_indices[i] = box_proto.class_index - - return boxes, scores, class_indices - - -def SerializeToString(boxes, scores, class_indices): - """Converts numpy arrays to serialized Boxes. - - Args: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - - Returns: - Serialized Boxes string. - """ - boxes_proto = ArraysToBoxes(boxes, scores, class_indices) - return boxes_proto.SerializeToString() - - -def ParseFromString(string): - """Converts serialized Boxes proto string to numpy arrays. - - Args: - string: Serialized Boxes string. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - boxes_proto = box_pb2.Boxes() - boxes_proto.ParseFromString(string) - return BoxesToArrays(boxes_proto) - - -def ReadFromFile(file_path): - """Helper function to load data from a Boxes proto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParseFromString(f.read()) - - -def WriteToFile(file_path, boxes, scores, class_indices): - """Helper function to write data to a file in Boxes proto format. - - Args: - file_path: Path to file that will be written. - boxes: [N, 4] float array denoting bounding box coordinates, in format [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - serialized_data = SerializeToString(boxes, scores, class_indices) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) diff --git a/research/delf/delf/python/box_io_test.py b/research/delf/delf/python/box_io_test.py deleted file mode 100644 index c659185daeec7efc9097ff72637d0d8f7c38664b..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/box_io_test.py +++ /dev/null @@ -1,82 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for box_io, the python interface of Boxes proto.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os - -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import box_io - -FLAGS = flags.FLAGS - - -class BoxesIoTest(tf.test.TestCase): - - def _create_data(self): - """Creates data to be used in tests. - - Returns: - boxes: [N, 4] float array denoting bounding box coordinates, in format - [top, - left, bottom, right]. - scores: [N] float array with detection scores. - class_indices: [N] int array with class indices. - """ - boxes = np.arange(24, dtype=np.float32).reshape(6, 4) - scores = np.arange(6, dtype=np.float32) - class_indices = np.arange(6, dtype=np.int32) - - return boxes, scores, class_indices - - def testConversionAndBack(self): - boxes, scores, class_indices = self._create_data() - - serialized = box_io.SerializeToString(boxes, scores, class_indices) - parsed_data = box_io.ParseFromString(serialized) - - self.assertAllEqual(boxes, parsed_data[0]) - self.assertAllEqual(scores, parsed_data[1]) - self.assertAllEqual(class_indices, parsed_data[2]) - - def testWriteAndReadToFile(self): - boxes, scores, class_indices = self._create_data() - - filename = os.path.join(FLAGS.test_tmpdir, 'test.boxes') - box_io.WriteToFile(filename, boxes, scores, class_indices) - data_read = box_io.ReadFromFile(filename) - - self.assertAllEqual(boxes, data_read[0]) - self.assertAllEqual(scores, data_read[1]) - self.assertAllEqual(class_indices, data_read[2]) - - def testWriteAndReadToFileEmptyFile(self): - filename = os.path.join(FLAGS.test_tmpdir, 'test.box') - box_io.WriteToFile(filename, np.array([]), np.array([]), np.array([])) - data_read = box_io.ReadFromFile(filename) - - self.assertAllEqual(np.array([]), data_read[0]) - self.assertAllEqual(np.array([]), data_read[1]) - self.assertAllEqual(np.array([]), data_read[2]) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/delf/delf/python/datum_io.py b/research/delf/delf/python/datum_io.py deleted file mode 100644 index f0d4cbfd11a140c6805c1fa017b7328cf3d04e38..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/datum_io.py +++ /dev/null @@ -1,221 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Python interface for DatumProto. - -DatumProto is protocol buffer used to serialize tensor with arbitrary shape. -Please refer to datum.proto for details. - -Support read and write of DatumProto from/to NumPy array and file. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import numpy as np -import tensorflow as tf - -from delf import datum_pb2 - - -def ArrayToDatum(arr): - """Converts NumPy array to DatumProto. - - Supports arrays of types: - - float16 (it is converted into a float32 in DatumProto) - - float32 - - float64 (it is converted into a float32 in DatumProto) - - uint8 (it is converted into a uint32 in DatumProto) - - uint16 (it is converted into a uint32 in DatumProto) - - uint32 - - uint64 (it is converted into a uint32 in DatumProto) - - Args: - arr: NumPy array of arbitrary shape. - - Returns: - datum: DatumProto object. - - Raises: - ValueError: If array type is unsupported. - """ - datum = datum_pb2.DatumProto() - if arr.dtype in ('float16', 'float32', 'float64'): - datum.float_list.value.extend(arr.astype('float32').flat) - elif arr.dtype in ('uint8', 'uint16', 'uint32', 'uint64'): - datum.uint32_list.value.extend(arr.astype('uint32').flat) - else: - raise ValueError('Unsupported array type: %s' % arr.dtype) - - datum.shape.dim.extend(arr.shape) - return datum - - -def ArraysToDatumPair(arr_1, arr_2): - """Converts numpy arrays to DatumPairProto. - - Supports same formats as `ArrayToDatum`, see documentation therein. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - - Returns: - datum_pair: DatumPairProto object. - """ - datum_pair = datum_pb2.DatumPairProto() - datum_pair.first.CopyFrom(ArrayToDatum(arr_1)) - datum_pair.second.CopyFrom(ArrayToDatum(arr_2)) - - return datum_pair - - -def DatumToArray(datum): - """Converts data saved in DatumProto to NumPy array. - - Args: - datum: DatumProto object. - - Returns: - NumPy array of arbitrary shape. - """ - if datum.HasField('float_list'): - return np.array(datum.float_list.value).astype('float32').reshape( - datum.shape.dim) - elif datum.HasField('uint32_list'): - return np.array(datum.uint32_list.value).astype('uint32').reshape( - datum.shape.dim) - else: - raise ValueError('Input DatumProto does not have float_list or uint32_list') - - -def DatumPairToArrays(datum_pair): - """Converts data saved in DatumPairProto to NumPy arrays. - - Args: - datum_pair: DatumPairProto object. - - Returns: - Two NumPy arrays of arbitrary shape. - """ - first_datum = DatumToArray(datum_pair.first) - second_datum = DatumToArray(datum_pair.second) - return first_datum, second_datum - - -def SerializeToString(arr): - """Converts NumPy array to serialized DatumProto. - - Args: - arr: NumPy array of arbitrary shape. - - Returns: - Serialized DatumProto string. - """ - datum = ArrayToDatum(arr) - return datum.SerializeToString() - - -def SerializePairToString(arr_1, arr_2): - """Converts pair of NumPy arrays to serialized DatumPairProto. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - - Returns: - Serialized DatumPairProto string. - """ - datum_pair = ArraysToDatumPair(arr_1, arr_2) - return datum_pair.SerializeToString() - - -def ParseFromString(string): - """Converts serialized DatumProto string to NumPy array. - - Args: - string: Serialized DatumProto string. - - Returns: - NumPy array. - """ - datum = datum_pb2.DatumProto() - datum.ParseFromString(string) - return DatumToArray(datum) - - -def ParsePairFromString(string): - """Converts serialized DatumPairProto string to NumPy arrays. - - Args: - string: Serialized DatumProto string. - - Returns: - Two NumPy arrays. - """ - datum_pair = datum_pb2.DatumPairProto() - datum_pair.ParseFromString(string) - return DatumPairToArrays(datum_pair) - - -def ReadFromFile(file_path): - """Helper function to load data from a DatumProto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - data: NumPy array. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParseFromString(f.read()) - - -def ReadPairFromFile(file_path): - """Helper function to load data from a DatumPairProto format in a file. - - Args: - file_path: Path to file containing data. - - Returns: - Two NumPy arrays. - """ - with tf.io.gfile.GFile(file_path, 'rb') as f: - return ParsePairFromString(f.read()) - - -def WriteToFile(data, file_path): - """Helper function to write data to a file in DatumProto format. - - Args: - data: NumPy array. - file_path: Path to file that will be written. - """ - serialized_data = SerializeToString(data) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) - - -def WritePairToFile(arr_1, arr_2, file_path): - """Helper function to write pair of arrays to a file in DatumPairProto format. - - Args: - arr_1: NumPy array of arbitrary shape. - arr_2: NumPy array of arbitrary shape. - file_path: Path to file that will be written. - """ - serialized_data = SerializePairToString(arr_1, arr_2) - with tf.io.gfile.GFile(file_path, 'w') as f: - f.write(serialized_data) diff --git a/research/delf/delf/python/datum_io_test.py b/research/delf/delf/python/datum_io_test.py deleted file mode 100644 index f3587a10017f93af49715a9becc1ed72da8ebe69..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/datum_io_test.py +++ /dev/null @@ -1,97 +0,0 @@ -# Copyright 2017 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for datum_io, the python interface of DatumProto.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os - -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import datum_io - -FLAGS = flags.FLAGS - - -class DatumIoTest(tf.test.TestCase): - - def Conversion2dTestWithType(self, dtype): - original_data = np.arange(9).reshape(3, 3).astype(dtype) - serialized = datum_io.SerializeToString(original_data) - retrieved_data = datum_io.ParseFromString(serialized) - self.assertTrue(np.array_equal(original_data, retrieved_data)) - - def Conversion3dTestWithType(self, dtype): - original_data = np.arange(24).reshape(2, 3, 4).astype(dtype) - serialized = datum_io.SerializeToString(original_data) - retrieved_data = datum_io.ParseFromString(serialized) - self.assertTrue(np.array_equal(original_data, retrieved_data)) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # ParseFromString, DatumToArray. - def testConversion2dWithType(self): - self.Conversion2dTestWithType(np.uint16) - self.Conversion2dTestWithType(np.uint32) - self.Conversion2dTestWithType(np.uint64) - self.Conversion2dTestWithType(np.float16) - self.Conversion2dTestWithType(np.float32) - self.Conversion2dTestWithType(np.float64) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # ParseFromString, DatumToArray. - def testConversion3dWithType(self): - self.Conversion3dTestWithType(np.uint16) - self.Conversion3dTestWithType(np.uint32) - self.Conversion3dTestWithType(np.uint64) - self.Conversion3dTestWithType(np.float16) - self.Conversion3dTestWithType(np.float32) - self.Conversion3dTestWithType(np.float64) - - def testConversionWithUnsupportedType(self): - with self.assertRaisesRegex(ValueError, 'Unsupported array type'): - self.Conversion3dTestWithType(int) - - # This test covers the following functions: ArrayToDatum, SerializeToString, - # WriteToFile, ReadFromFile, ParseFromString, DatumToArray. - def testWriteAndReadToFile(self): - data = np.array([[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], - [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]) - filename = os.path.join(FLAGS.test_tmpdir, 'test.datum') - datum_io.WriteToFile(data, filename) - data_read = datum_io.ReadFromFile(filename) - self.assertAllEqual(data_read, data) - - # This test covers the following functions: ArraysToDatumPair, - # SerializePairToString, WritePairToFile, ReadPairFromFile, - # ParsePairFromString, DatumPairToArrays. - def testWriteAndReadPairToFile(self): - data_1 = np.array([[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], - [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]) - data_2 = np.array( - [[[255, 0, 5], [10, 300, 0]], [[20, 1, 100], [255, 360, 420]]], - dtype='uint32') - filename = os.path.join(FLAGS.test_tmpdir, 'test.datum_pair') - datum_io.WritePairToFile(data_1, data_2, filename) - data_read_1, data_read_2 = datum_io.ReadPairFromFile(filename) - self.assertAllEqual(data_read_1, data_1) - self.assertAllEqual(data_read_2, data_2) - - -if __name__ == '__main__': - tf.test.main() diff --git a/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md b/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md deleted file mode 100644 index 2b62ac29003e3d4b13a3ccc8fad5b43e236f96da..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/DELG_INSTRUCTIONS.md +++ /dev/null @@ -1,159 +0,0 @@ -## DELG instructions - -[](https://arxiv.org/abs/2001.05027) - -These instructions can be used to reproduce the results from the -[DELG paper](https://arxiv.org/abs/2001.05027) for the Revisited Oxford/Paris -datasets. - -### Install DELF library - -To be able to use this code, please follow -[these instructions](../../../INSTALL_INSTRUCTIONS.md) to properly install the -DELF library. - -### Download datasets - -```bash -mkdir -p ~/delg/data && cd ~/delg/data - -# Oxford dataset. -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ - -# Paris dataset. Download and move all images to same directory. -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_1.tgz -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_2.tgz -mkdir paris6k_images_tmp -tar -xvzf paris_1.tgz -C paris6k_images_tmp/ -tar -xvzf paris_2.tgz -C paris6k_images_tmp/ -mkdir paris6k_images -mv paris6k_images_tmp/paris/*/*.jpg paris6k_images/ - -# Revisited annotations. -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/roxford5k/gnd_roxford5k.mat -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/rparis6k/gnd_rparis6k.mat -``` - -### Download model - -This is necessary to reproduce the main paper results: - -```bash -# From models/research/delf/delf/python/delg -mkdir parameters && cd parameters - -# DELG-GLD model. -wget http://storage.googleapis.com/delf/delg_gld_20200520.tar.gz -tar -xvzf delg_gld_20200520.tar.gz -``` - -### Feature extraction - -We present here commands for extraction on `roxford5k`. To extract on `rparis6k` -instead, please edit the arguments accordingly (especially the -`dataset_file_path` argument). - -#### Query feature extraction - -For query feature extraction, the cropped query image should be used to extract -features, according to the Revisited Oxford/Paris experimental protocol. Note -that this is done in the `extract_features` script, when setting -`image_set=query`. - -Query feature extraction can be run as follows: - -```bash -# From models/research/delf/delf/python/delg -python3 extract_features.py \ - --delf_config_path delg_gld_config.pbtxt \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --images_dir ~/delg/data/oxford5k_images \ - --image_set query \ - --output_features_dir ~/delg/data/oxford5k_features/query -``` - -#### Index feature extraction - -Run index feature extraction as follows: - -```bash -# From models/research/delf/delf/python/delg -python3 extract_features.py \ - --delf_config_path delg_gld_config.pbtxt \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --images_dir ~/delg/data/oxford5k_images \ - --image_set index \ - --output_features_dir ~/delg/data/oxford5k_features/index -``` - -### Perform retrieval - -To run retrieval on `roxford5k`, the following command can be used: - -```bash -# From models/research/delf/delf/python/delg -python3 perform_retrieval.py \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --query_features_dir ~/delg/data/oxford5k_features/query \ - --index_features_dir ~/delg/data/oxford5k_features/index \ - --output_dir ~/delg/results/oxford5k -``` - -A file with named `metrics.txt` will be written to the path given in -`output_dir`, with retrieval metrics for an experiment where geometric -verification is not used. The contents should look approximately like: - -``` -hard - mAP=45.11 - mP@k[ 1 5 10] [85.71 72.29 60.14] - mR@k[ 1 5 10] [19.15 29.72 36.32] -medium - mAP=69.71 - mP@k[ 1 5 10] [95.71 92. 86.86] - mR@k[ 1 5 10] [10.17 25.94 33.83] -``` - -which are the results presented in Table 3 of the paper. - -If you want to run retrieval with geometric verification, set -`use_geometric_verification` to `True`. It's much slower since (1) in this code -example the re-ranking is loading DELF local features from disk, and (2) -re-ranking needs to be performed separately for each dataset protocol, since the -junk images from each protocol should be removed when re-ranking. Here is an -example command: - -```bash -# From models/research/delf/delf/python/delg -python3 perform_retrieval.py \ - --dataset_file_path ~/delg/data/gnd_roxford5k.mat \ - --query_features_dir ~/delg/data/oxford5k_features/query \ - --index_features_dir ~/delg/data/oxford5k_features/index \ - --use_geometric_verification \ - --output_dir ~/delg/results/oxford5k_with_gv -``` - -The `metrics.txt` should now show: - -``` -hard - mAP=45.11 - mP@k[ 1 5 10] [85.71 72.29 60.14] - mR@k[ 1 5 10] [19.15 29.72 36.32] -hard_after_gv - mAP=53.72 - mP@k[ 1 5 10] [91.43 83.81 74.38] - mR@k[ 1 5 10] [19.45 34.45 44.64] -medium - mAP=69.71 - mP@k[ 1 5 10] [95.71 92. 86.86] - mR@k[ 1 5 10] [10.17 25.94 33.83] -medium_after_gv - mAP=75.42 - mP@k[ 1 5 10] [97.14 95.24 93.81] - mR@k[ 1 5 10] [10.21 27.21 37.72] -``` - -which, again, are the results presented in Table 3 of the paper. diff --git a/research/delf/delf/python/delg/delg_gld_config.pbtxt b/research/delf/delf/python/delg/delg_gld_config.pbtxt deleted file mode 100644 index a659a0a3ee502c31f7d4b71fd634803f94d425b7..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/delg_gld_config.pbtxt +++ /dev/null @@ -1,22 +0,0 @@ -use_local_features: true -use_global_features: true -model_path: "parameters/delg_gld_20200520" -image_scales: 0.25 -image_scales: 0.35355338 -image_scales: 0.5 -image_scales: 0.70710677 -image_scales: 1.0 -image_scales: 1.4142135 -image_scales: 2.0 -delf_local_config { - use_pca: false - max_feature_num: 1000 - score_threshold: 175.0 -} -delf_global_config { - use_pca: false - image_scales_ind: 3 - image_scales_ind: 4 - image_scales_ind: 5 -} -max_image_size: 1024 diff --git a/research/delf/delf/python/delg/extract_features.py b/research/delf/delf/python/delg/extract_features.py deleted file mode 100644 index ad65d66e69ddaa032d1201b34a2f10a04fe61eb5..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/extract_features.py +++ /dev/null @@ -1,162 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Extracts DELG features for images from Revisited Oxford/Paris datasets. - -Note that query images are cropped before feature extraction, as required by the -evaluation protocols of these datasets. - -The types of extracted features (local and/or global) depend on the input -DelfConfig. - -The program checks if features already exist, and skips computation for those. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os -import time - -from absl import app -from absl import flags -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import datum_io -from delf import feature_io -from delf import utils -from delf.python.detect_to_retrieve import dataset -from delf import extractor - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'delf_config_path', '/tmp/delf_config_example.pbtxt', - 'Path to DelfConfig proto text file with configuration to be used for DELG ' - 'extraction. Local features are extracted if use_local_features is True; ' - 'global features are extracted if use_global_features is True.') -flags.DEFINE_string( - 'dataset_file_path', '/tmp/gnd_roxford5k.mat', - 'Dataset file for Revisited Oxford or Paris dataset, in .mat format.') -flags.DEFINE_string( - 'images_dir', '/tmp/images', - 'Directory where dataset images are located, all in .jpg format.') -flags.DEFINE_enum('image_set', 'query', ['query', 'index'], - 'Whether to extract features from query or index images.') -flags.DEFINE_string( - 'output_features_dir', '/tmp/features', - "Directory where DELG features will be written to. Each image's features " - 'will be written to files with same name but different extension: the ' - 'global feature is written to a file with extension .delg_global and the ' - 'local features are written to a file with extension .delg_local.') - -# Extensions. -_DELG_GLOBAL_EXTENSION = '.delg_global' -_DELG_LOCAL_EXTENSION = '.delg_local' -_IMAGE_EXTENSION = '.jpg' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 50 - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Read list of images from dataset file. - print('Reading list of images from dataset file...') - query_list, index_list, ground_truth = dataset.ReadDatasetFile( - FLAGS.dataset_file_path) - if FLAGS.image_set == 'query': - image_list = query_list - else: - image_list = index_list - num_images = len(image_list) - print('done! Found %d images' % num_images) - - # Parse DelfConfig proto. - config = delf_config_pb2.DelfConfig() - with tf.io.gfile.GFile(FLAGS.delf_config_path, 'r') as f: - text_format.Parse(f.read(), config) - - # Create output directory if necessary. - if not tf.io.gfile.exists(FLAGS.output_features_dir): - tf.io.gfile.makedirs(FLAGS.output_features_dir) - - extractor_fn = extractor.MakeExtractor(config) - - start = time.time() - for i in range(num_images): - if i == 0: - print('Starting to extract features...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Processing image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed)) - start = time.time() - - image_name = image_list[i] - input_image_filename = os.path.join(FLAGS.images_dir, - image_name + _IMAGE_EXTENSION) - - # Compose output file name and decide if image should be skipped. - should_skip_global = True - should_skip_local = True - if config.use_global_features: - output_global_feature_filename = os.path.join( - FLAGS.output_features_dir, image_name + _DELG_GLOBAL_EXTENSION) - if not tf.io.gfile.exists(output_global_feature_filename): - should_skip_global = False - if config.use_local_features: - output_local_feature_filename = os.path.join( - FLAGS.output_features_dir, image_name + _DELG_LOCAL_EXTENSION) - if not tf.io.gfile.exists(output_local_feature_filename): - should_skip_local = False - if should_skip_global and should_skip_local: - print('Skipping %s' % image_name) - continue - - pil_im = utils.RgbLoader(input_image_filename) - resize_factor = 1.0 - if FLAGS.image_set == 'query': - # Crop query image according to bounding box. - original_image_size = max(pil_im.size) - bbox = [int(round(b)) for b in ground_truth[i]['bbx']] - pil_im = pil_im.crop(bbox) - cropped_image_size = max(pil_im.size) - resize_factor = cropped_image_size / original_image_size - - im = np.array(pil_im) - - # Extract and save features. - extracted_features = extractor_fn(im, resize_factor) - if config.use_global_features: - global_descriptor = extracted_features['global_descriptor'] - datum_io.WriteToFile(global_descriptor, output_global_feature_filename) - if config.use_local_features: - locations = extracted_features['local_features']['locations'] - descriptors = extracted_features['local_features']['descriptors'] - feature_scales = extracted_features['local_features']['scales'] - attention = extracted_features['local_features']['attention'] - feature_io.WriteToFile(output_local_feature_filename, locations, - feature_scales, descriptors, attention) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/delg/measure_latency.py b/research/delf/delf/python/delg/measure_latency.py deleted file mode 100644 index 21ffbda4179a191139ae35244c8ae34693594fd9..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/measure_latency.py +++ /dev/null @@ -1,108 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Times DELF/G extraction.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import time - -from absl import app -from absl import flags -import numpy as np -from six.moves import range -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import utils -from delf import extractor - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'delf_config_path', '/tmp/delf_config_example.pbtxt', - 'Path to DelfConfig proto text file with configuration to be used for DELG ' - 'extraction. Local features are extracted if use_local_features is True; ' - 'global features are extracted if use_global_features is True.') -flags.DEFINE_string('list_images_path', '/tmp/list_images.txt', - 'Path to list of images whose features will be extracted.') -flags.DEFINE_integer('repeat_per_image', 10, - 'Number of times to repeat extraction per image.') - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 100 - - -def _ReadImageList(list_path): - """Helper function to read image paths. - - Args: - list_path: Path to list of images, one image path per line. - - Returns: - image_paths: List of image paths. - """ - with tf.io.gfile.GFile(list_path, 'r') as f: - image_paths = f.readlines() - image_paths = [entry.rstrip() for entry in image_paths] - return image_paths - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Read list of images. - print('Reading list of images...') - image_paths = _ReadImageList(FLAGS.list_images_path) - num_images = len(image_paths) - print(f'done! Found {num_images} images') - - # Load images in memory. - print('Loading images, %d times per image...' % FLAGS.repeat_per_image) - im_array = [] - for filename in image_paths: - im = np.array(utils.RgbLoader(filename)) - for _ in range(FLAGS.repeat_per_image): - im_array.append(im) - np.random.shuffle(im_array) - print('done!') - - # Parse DelfConfig proto. - config = delf_config_pb2.DelfConfig() - with tf.io.gfile.GFile(FLAGS.delf_config_path, 'r') as f: - text_format.Parse(f.read(), config) - - extractor_fn = extractor.MakeExtractor(config) - - start = time.time() - for i, im in enumerate(im_array): - if i == 0: - print('Starting to extract DELF features from images...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print(f'Processing image {i} out of {len(im_array)}, last ' - f'{_STATUS_CHECK_ITERATIONS} images took {elapsed} seconds,' - f'ie {elapsed/_STATUS_CHECK_ITERATIONS} secs/image.') - start = time.time() - - # Extract and save features. - extracted_features = extractor_fn(im) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/delg/perform_retrieval.py b/research/delf/delf/python/delg/perform_retrieval.py deleted file mode 100644 index fb53abb1a9e15a5d5a040be42213f325ab345163..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/delg/perform_retrieval.py +++ /dev/null @@ -1,215 +0,0 @@ -# Copyright 2020 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Performs DELG-based image retrieval on Revisited Oxford/Paris datasets.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import os -import time - -from absl import app -from absl import flags -import numpy as np -import tensorflow as tf - -from delf import datum_io -from delf.python.detect_to_retrieve import dataset -from delf.python.detect_to_retrieve import image_reranking - -FLAGS = flags.FLAGS - -flags.DEFINE_string( - 'dataset_file_path', '/tmp/gnd_roxford5k.mat', - 'Dataset file for Revisited Oxford or Paris dataset, in .mat format.') -flags.DEFINE_string('query_features_dir', '/tmp/features/query', - 'Directory where query DELG features are located.') -flags.DEFINE_string('index_features_dir', '/tmp/features/index', - 'Directory where index DELG features are located.') -flags.DEFINE_boolean( - 'use_geometric_verification', False, - 'If True, performs re-ranking using local feature-based geometric ' - 'verification.') -flags.DEFINE_float( - 'local_feature_distance_threshold', 1.0, - 'Optional, only used if `use_geometric_verification` is True. ' - 'Distance threshold below which a pair of local descriptors is considered ' - 'a potential match, and will be fed into RANSAC.') -flags.DEFINE_float( - 'ransac_residual_threshold', 20.0, - 'Optional, only used if `use_geometric_verification` is True. ' - 'Residual error threshold for considering matches as inliers, used in ' - 'RANSAC algorithm.') -flags.DEFINE_string( - 'output_dir', '/tmp/retrieval', - 'Directory where retrieval output will be written to. A file containing ' - "metrics for this run is saved therein, with file name 'metrics.txt'.") - -# Extensions. -_DELG_GLOBAL_EXTENSION = '.delg_global' -_DELG_LOCAL_EXTENSION = '.delg_local' - -# Precision-recall ranks to use in metric computation. -_PR_RANKS = (1, 5, 10) - -# Pace to log. -_STATUS_CHECK_LOAD_ITERATIONS = 50 - -# Output file names. -_METRICS_FILENAME = 'metrics.txt' - - -def _ReadDelgGlobalDescriptors(input_dir, image_list): - """Reads DELG global features. - - Args: - input_dir: Directory where features are located. - image_list: List of image names for which to load features. - - Returns: - global_descriptors: NumPy array of shape (len(image_list), D), where D - corresponds to the global descriptor dimensionality. - """ - num_images = len(image_list) - global_descriptors = [] - print('Starting to collect global descriptors for %d images...' % num_images) - start = time.time() - for i in range(num_images): - if i > 0 and i % _STATUS_CHECK_LOAD_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Reading global descriptors for image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_LOAD_ITERATIONS, elapsed)) - start = time.time() - - descriptor_filename = image_list[i] + _DELG_GLOBAL_EXTENSION - descriptor_fullpath = os.path.join(input_dir, descriptor_filename) - global_descriptors.append(datum_io.ReadFromFile(descriptor_fullpath)) - - return np.array(global_descriptors) - - -def main(argv): - if len(argv) > 1: - raise RuntimeError('Too many command-line arguments.') - - # Parse dataset to obtain query/index images, and ground-truth. - print('Parsing dataset...') - query_list, index_list, ground_truth = dataset.ReadDatasetFile( - FLAGS.dataset_file_path) - num_query_images = len(query_list) - num_index_images = len(index_list) - (_, medium_ground_truth, - hard_ground_truth) = dataset.ParseEasyMediumHardGroundTruth(ground_truth) - print('done! Found %d queries and %d index images' % - (num_query_images, num_index_images)) - - # Read global features. - query_global_features = _ReadDelgGlobalDescriptors(FLAGS.query_features_dir, - query_list) - index_global_features = _ReadDelgGlobalDescriptors(FLAGS.index_features_dir, - index_list) - - # Compute similarity between query and index images, potentially re-ranking - # with geometric verification. - ranks_before_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - if FLAGS.use_geometric_verification: - medium_ranks_after_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - hard_ranks_after_gv = np.zeros([num_query_images, num_index_images], - dtype='int32') - for i in range(num_query_images): - print('Performing retrieval with query %d (%s)...' % (i, query_list[i])) - start = time.time() - - # Compute similarity between global descriptors. - similarities = np.dot(index_global_features, query_global_features[i]) - ranks_before_gv[i] = np.argsort(-similarities) - - # Re-rank using geometric verification. - if FLAGS.use_geometric_verification: - medium_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification( - input_ranks=ranks_before_gv[i], - initial_scores=similarities, - query_name=query_list[i], - index_names=index_list, - query_features_dir=FLAGS.query_features_dir, - index_features_dir=FLAGS.index_features_dir, - junk_ids=set(medium_ground_truth[i]['junk']), - local_feature_extension=_DELG_LOCAL_EXTENSION, - ransac_seed=0, - feature_distance_threshold=FLAGS.local_feature_distance_threshold, - ransac_residual_threshold=FLAGS.ransac_residual_threshold) - hard_ranks_after_gv[i] = image_reranking.RerankByGeometricVerification( - input_ranks=ranks_before_gv[i], - initial_scores=similarities, - query_name=query_list[i], - index_names=index_list, - query_features_dir=FLAGS.query_features_dir, - index_features_dir=FLAGS.index_features_dir, - junk_ids=set(hard_ground_truth[i]['junk']), - local_feature_extension=_DELG_LOCAL_EXTENSION, - ransac_seed=0, - feature_distance_threshold=FLAGS.local_feature_distance_threshold, - ransac_residual_threshold=FLAGS.ransac_residual_threshold) - - elapsed = (time.time() - start) - print('done! Retrieval for query %d took %f seconds' % (i, elapsed)) - - # Create output directory if necessary. - if not tf.io.gfile.exists(FLAGS.output_dir): - tf.io.gfile.makedirs(FLAGS.output_dir) - - # Compute metrics. - medium_metrics = dataset.ComputeMetrics(ranks_before_gv, medium_ground_truth, - _PR_RANKS) - hard_metrics = dataset.ComputeMetrics(ranks_before_gv, hard_ground_truth, - _PR_RANKS) - if FLAGS.use_geometric_verification: - medium_metrics_after_gv = dataset.ComputeMetrics(medium_ranks_after_gv, - medium_ground_truth, - _PR_RANKS) - hard_metrics_after_gv = dataset.ComputeMetrics(hard_ranks_after_gv, - hard_ground_truth, _PR_RANKS) - - # Write metrics to file. - mean_average_precision_dict = { - 'medium': medium_metrics[0], - 'hard': hard_metrics[0] - } - mean_precisions_dict = {'medium': medium_metrics[1], 'hard': hard_metrics[1]} - mean_recalls_dict = {'medium': medium_metrics[2], 'hard': hard_metrics[2]} - if FLAGS.use_geometric_verification: - mean_average_precision_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[0], - 'hard_after_gv': hard_metrics_after_gv[0] - }) - mean_precisions_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[1], - 'hard_after_gv': hard_metrics_after_gv[1] - }) - mean_recalls_dict.update({ - 'medium_after_gv': medium_metrics_after_gv[2], - 'hard_after_gv': hard_metrics_after_gv[2] - }) - dataset.SaveMetricsFile(mean_average_precision_dict, mean_precisions_dict, - mean_recalls_dict, _PR_RANKS, - os.path.join(FLAGS.output_dir, _METRICS_FILENAME)) - - -if __name__ == '__main__': - app.run(main) diff --git a/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md b/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md deleted file mode 100644 index 2d18a328997ace5ee01f60a4b2c95714a18eb7d9..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/DETECT_TO_RETRIEVE_INSTRUCTIONS.md +++ /dev/null @@ -1,231 +0,0 @@ -## Detect-to-Retrieve instructions - -[](https://arxiv.org/abs/1812.01584) - -These instructions can be used to reproduce the results from the -[Detect-to-Retrieve paper](https://arxiv.org/abs/1812.01584) for the Revisited -Oxford/Paris datasets. - -### Install DELF library - -To be able to use this code, please follow -[these instructions](../../../INSTALL_INSTRUCTIONS.md) to properly install the -DELF library. - -### Download datasets - -```bash -mkdir -p ~/detect_to_retrieve/data && cd ~/detect_to_retrieve/data - -# Oxford dataset. -wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz -mkdir oxford5k_images -tar -xvzf oxbuild_images.tgz -C oxford5k_images/ - -# Paris dataset. Download and move all images to same directory. -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_1.tgz -wget http://www.robots.ox.ac.uk/~vgg/data/parisbuildings/paris_2.tgz -mkdir paris6k_images_tmp -tar -xvzf paris_1.tgz -C paris6k_images_tmp/ -tar -xvzf paris_2.tgz -C paris6k_images_tmp/ -mkdir paris6k_images -mv paris6k_images_tmp/paris/*/*.jpg paris6k_images/ - -# Revisited annotations. -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/roxford5k/gnd_roxford5k.mat -wget http://cmp.felk.cvut.cz/revisitop/data/datasets/rparis6k/gnd_rparis6k.mat -``` - -### Download models - -These are necessary to reproduce the main paper results: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -mkdir parameters && cd parameters - -# DELF-GLD model. -wget http://storage.googleapis.com/delf/delf_gld_20190411.tar.gz -tar -xvzf delf_gld_20190411.tar.gz - -# Faster-RCNN detector model. -wget http://storage.googleapis.com/delf/d2r_frcnn_20190411.tar.gz -tar -xvzf d2r_frcnn_20190411.tar.gz - -# Codebooks. -# Note: you should use codebook trained on rparis6k for roxford5k retrieval -# experiments, and vice-versa. -wget http://storage.googleapis.com/delf/rparis6k_codebook_65536.tar.gz -mkdir rparis6k_codebook_65536 -tar -xvzf rparis6k_codebook_65536.tar.gz -C rparis6k_codebook_65536/ -wget http://storage.googleapis.com/delf/roxford5k_codebook_65536.tar.gz -mkdir roxford5k_codebook_65536 -tar -xvzf roxford5k_codebook_65536.tar.gz -C roxford5k_codebook_65536/ -``` - -We also make available other models/parameters that can be used to reproduce -more results from the paper: - -- [MobileNet-SSD trained detector](http://storage.googleapis.com/delf/d2r_mnetssd_20190411.tar.gz). -- Codebooks with 1024 centroids: - [rparis6k](http://storage.googleapis.com/delf/rparis6k_codebook_1024.tar.gz), - [roxford5k](http://storage.googleapis.com/delf/roxford5k_codebook_1024.tar.gz). - -### Feature extraction - -We present here commands for extraction on `roxford5k`. To extract on `rparis6k` -instead, please edit the arguments accordingly (especially the -`dataset_file_path` argument). - -#### Query feature extraction - -For query feature extraction, the cropped query image should be used to extract -features, according to the Revisited Oxford/Paris experimental protocol. Note -that this is done in the `extract_query_features` script. - -Query feature extraction can be run as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_query_features.py \ - --delf_config_path delf_gld_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --images_dir ~/detect_to_retrieve/data/oxford5k_images \ - --output_features_dir ~/detect_to_retrieve/data/oxford5k_features/query -``` - -#### Index feature extraction and box detection - -Index feature extraction / box detection can be run as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_index_boxes_and_features.py \ - --delf_config_path delf_gld_config.pbtxt \ - --detector_model_dir parameters/d2r_frcnn_20190411 \ - --detector_thresh 0.1 \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --images_dir ~/detect_to_retrieve/data/oxford5k_images \ - --output_boxes_dir ~/detect_to_retrieve/data/oxford5k_boxes/index \ - --output_features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --output_index_mapping ~/detect_to_retrieve/data/oxford5k_features/index_mapping_0.1.csv -``` - -### R-ASMK* aggregation extraction - -We present here commands for aggregation extraction on `roxford5k`. To extract -on `rparis6k` instead, please edit the arguments accordingly. In particular, -note that feature aggregation on `roxford5k` should use a codebook trained on -`rparis6k`, and vice-versa (this can be edited in the -`query_aggregation_config.pbtxt` and `index_aggregation_config.pbtxt` files. - -#### Query - -Run query feature aggregation as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_aggregation.py \ - --use_query_images True \ - --aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --features_dir ~/detect_to_retrieve/data/oxford5k_features/query \ - --output_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query -``` - -#### Index - -Run index feature aggregation as follows: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 extract_aggregation.py \ - --aggregation_config_path index_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --index_mapping_path ~/detect_to_retrieve/data/oxford5k_features/index_mapping_0.1.csv \ - --output_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 -``` - -### Perform retrieval - -Currently, we support retrieval via brute-force comparison of aggregated -features. - -To run retrieval on `roxford5k`, the following command can be used: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 perform_retrieval.py \ - --index_aggregation_config_path index_aggregation_config.pbtxt \ - --query_aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --index_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 \ - --query_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query \ - --output_dir ~/detect_to_retrieve/results/oxford5k -``` - -A file with named `metrics.txt` will be written to the path given in -`output_dir`, with retrieval metrics for an experiment where geometric -verification is not used. The contents should look approximately like: - -``` -hard -mAP=47.61 -mP@k[ 1 5 10] [84.29 73.71 64.43] -mR@k[ 1 5 10] [18.84 29.44 36.82] -medium -mAP=73.3 -mP@k[ 1 5 10] [97.14 94.57 90.14] -mR@k[ 1 5 10] [10.14 26.2 34.75] -``` - -which are the results presented in Table 2 of the paper (with small numerical -precision differences). - -If you want to run retrieval with geometric verification, set -`use_geometric_verification` to `True` and the arguments -`index_features_dir`/`query_features_dir`. It's much slower since (1) in this -code example the re-ranking is loading DELF local features from disk, and (2) -re-ranking needs to be performed separately for each dataset protocol, since the -junk images from each protocol should be removed when re-ranking. Here is an -example command: - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 perform_retrieval.py \ - --index_aggregation_config_path index_aggregation_config.pbtxt \ - --query_aggregation_config_path query_aggregation_config.pbtxt \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_roxford5k.mat \ - --index_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/index_0.1 \ - --query_aggregation_dir ~/detect_to_retrieve/data/oxford5k_aggregation/query \ - --use_geometric_verification True \ - --index_features_dir ~/detect_to_retrieve/data/oxford5k_features/index_0.1 \ - --query_features_dir ~/detect_to_retrieve/data/oxford5k_features/query \ - --output_dir ~/detect_to_retrieve/results/oxford5k_with_gv -``` - -### Clustering - -In the code example above, we used a pre-trained DELF codebook. We also provide -code for re-training the codebook if desired. - -Note that for the time being this can only run on CPU, since the main ops in -K-means are not registered for GPU usage in Tensorflow. - -```bash -# From models/research/delf/delf/python/detect_to_retrieve -python3 cluster_delf_features.py \ - --dataset_file_path ~/detect_to_retrieve/data/gnd_rparis6k.mat \ - --features_dir ~/detect_to_retrieve/data/paris6k_features/index_0.1 \ - --num_clusters 1024 \ - --num_iterations 50 \ - --output_cluster_dir ~/detect_to_retrieve/data/paris6k_clusters_1024 -``` - -### Next steps - -To make retrieval more scalable and handle larger datasets more smoothly, we are -considering to provide code for inverted index building and retrieval. Please -reach out if you would like to help doing that -- feel free submit a pull -request. diff --git a/research/delf/delf/python/detect_to_retrieve/__init__.py b/research/delf/delf/python/detect_to_retrieve/__init__.py deleted file mode 100644 index 06972a7d06738da1dc50e832c4e8443b0e6fb5b6..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/__init__.py +++ /dev/null @@ -1,24 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Module for Detect-to-Retrieve technique.""" -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -# pylint: disable=unused-import -from delf.python.detect_to_retrieve import aggregation_extraction -from delf.python.detect_to_retrieve import boxes_and_features_extraction -from delf.python.detect_to_retrieve import dataset -# pylint: enable=unused-import diff --git a/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py b/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py deleted file mode 100644 index 4ddab944b8a3365209b8e92af38241d297974122..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/aggregation_extraction.py +++ /dev/null @@ -1,193 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Library to extract/save feature aggregation.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import csv -import os -import time - -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import aggregation_config_pb2 -from delf import datum_io -from delf import feature_aggregation_extractor -from delf import feature_io - -# Aliases for aggregation types. -_VLAD = aggregation_config_pb2.AggregationConfig.VLAD -_ASMK = aggregation_config_pb2.AggregationConfig.ASMK -_ASMK_STAR = aggregation_config_pb2.AggregationConfig.ASMK_STAR - -# Extensions. -_DELF_EXTENSION = '.delf' -_VLAD_EXTENSION_SUFFIX = 'vlad' -_ASMK_EXTENSION_SUFFIX = 'asmk' -_ASMK_STAR_EXTENSION_SUFFIX = 'asmk_star' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 50 - - -def _ReadMappingBasenameToBoxNames(input_path, index_image_names): - """Reads mapping from image name to DELF file names for each box. - - Args: - input_path: Path to CSV file containing mapping. - index_image_names: List containing index image names, in order, for the - dataset under consideration. - - Returns: - images_to_box_feature_files: Dict. key=string (image name); value=list of - strings (file names containing DELF features for boxes). - """ - images_to_box_feature_files = {} - with tf.io.gfile.GFile(input_path, 'r') as f: - reader = csv.DictReader(f) - for row in reader: - index_image_name = index_image_names[int(row['index_image_id'])] - if index_image_name not in images_to_box_feature_files: - images_to_box_feature_files[index_image_name] = [] - - images_to_box_feature_files[index_image_name].append(row['name']) - - return images_to_box_feature_files - - -def ExtractAggregatedRepresentationsToFiles(image_names, features_dir, - aggregation_config_path, - mapping_path, - output_aggregation_dir): - """Extracts aggregated feature representations, saving them to files. - - It checks if the aggregated representation for an image already exists, - and skips computation for those. - - Args: - image_names: List of image names. These are used to compose input file names - for the feature files, and the output file names for aggregated - representations. - features_dir: Directory where DELF features are located. - aggregation_config_path: Path to AggregationConfig proto text file with - configuration to be used for extraction. - mapping_path: Optional CSV file which maps each .delf file name to the index - image ID and detected box ID. If regional aggregation is performed, this - should be set. Otherwise, this is ignored. - output_aggregation_dir: Directory where aggregation output will be written - to. - - Raises: - ValueError: If AggregationConfig is malformed, or `mapping_path` is - missing. - """ - num_images = len(image_names) - - # Parse AggregationConfig proto, and select output extension. - config = aggregation_config_pb2.AggregationConfig() - with tf.io.gfile.GFile(aggregation_config_path, 'r') as f: - text_format.Merge(f.read(), config) - output_extension = '.' - if config.use_regional_aggregation: - output_extension += 'r' - if config.aggregation_type == _VLAD: - output_extension += _VLAD_EXTENSION_SUFFIX - elif config.aggregation_type == _ASMK: - output_extension += _ASMK_EXTENSION_SUFFIX - elif config.aggregation_type == _ASMK_STAR: - output_extension += _ASMK_STAR_EXTENSION_SUFFIX - else: - raise ValueError('Invalid aggregation type: %d' % config.aggregation_type) - - # Read index mapping path, if provided. - if mapping_path: - images_to_box_feature_files = _ReadMappingBasenameToBoxNames( - mapping_path, image_names) - - # Create output directory if necessary. - if not tf.io.gfile.exists(output_aggregation_dir): - tf.io.gfile.makedirs(output_aggregation_dir) - - extractor = feature_aggregation_extractor.ExtractAggregatedRepresentation( - config) - - start = time.time() - for i in range(num_images): - if i == 0: - print('Starting to extract aggregation from images...') - elif i % _STATUS_CHECK_ITERATIONS == 0: - elapsed = (time.time() - start) - print('Processing image %d out of %d, last %d ' - 'images took %f seconds' % - (i, num_images, _STATUS_CHECK_ITERATIONS, elapsed)) - start = time.time() - - image_name = image_names[i] - - # Compose output file name, skip extraction for this image if it already - # exists. - output_aggregation_filename = os.path.join(output_aggregation_dir, - image_name + output_extension) - if tf.io.gfile.exists(output_aggregation_filename): - print('Skipping %s' % image_name) - continue - - # Load DELF features. - if config.use_regional_aggregation: - if not mapping_path: - raise ValueError( - 'Requested regional aggregation, but mapping_path was not ' - 'provided') - descriptors_list = [] - num_features_per_box = [] - for box_feature_file in images_to_box_feature_files[image_name]: - delf_filename = os.path.join(features_dir, - box_feature_file + _DELF_EXTENSION) - _, _, box_descriptors, _, _ = feature_io.ReadFromFile(delf_filename) - # If `box_descriptors` is empty, reshape it such that it can be - # concatenated with other descriptors. - if not box_descriptors.shape[0]: - box_descriptors = np.reshape(box_descriptors, - [0, config.feature_dimensionality]) - descriptors_list.append(box_descriptors) - num_features_per_box.append(box_descriptors.shape[0]) - - descriptors = np.concatenate(descriptors_list) - else: - input_delf_filename = os.path.join(features_dir, - image_name + _DELF_EXTENSION) - _, _, descriptors, _, _ = feature_io.ReadFromFile(input_delf_filename) - # If `descriptors` is empty, reshape it to avoid extraction failure. - if not descriptors.shape[0]: - descriptors = np.reshape(descriptors, - [0, config.feature_dimensionality]) - num_features_per_box = None - - # Extract and save aggregation. If using VLAD, only - # `aggregated_descriptors` needs to be saved. - (aggregated_descriptors, - feature_visual_words) = extractor.Extract(descriptors, - num_features_per_box) - if config.aggregation_type == _VLAD: - datum_io.WriteToFile(aggregated_descriptors, - output_aggregation_filename) - else: - datum_io.WritePairToFile(aggregated_descriptors, - feature_visual_words.astype('uint32'), - output_aggregation_filename) diff --git a/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py b/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py deleted file mode 100644 index 1faef983b2e0413e2f2746c5d56b5e62045e5a39..0000000000000000000000000000000000000000 --- a/research/delf/delf/python/detect_to_retrieve/boxes_and_features_extraction.py +++ /dev/null @@ -1,202 +0,0 @@ -# Copyright 2019 The TensorFlow Authors All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Library to extract/save boxes and DELF features.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import csv -import math -import os -import time - -import numpy as np -import tensorflow as tf - -from google.protobuf import text_format -from delf import delf_config_pb2 -from delf import box_io -from delf import feature_io -from delf import utils -from delf import detector -from delf import extractor - -# Extension of feature files. -_BOX_EXTENSION = '.boxes' -_DELF_EXTENSION = '.delf' - -# Pace to report extraction log. -_STATUS_CHECK_ITERATIONS = 100 - - -def _WriteMappingBasenameToIds(index_names_ids_and_boxes, output_path): - """Helper function to write CSV mapping from DELF file name to IDs. - - Args: - index_names_ids_and_boxes: List containing 3-element lists with name, image - ID and box ID. - output_path: Output CSV path. - """ - with tf.io.gfile.GFile(output_path, 'w') as f: - csv_writer = csv.DictWriter( - f, fieldnames=['name', 'index_image_id', 'box_id']) - csv_writer.writeheader() - for name_imid_boxid in index_names_ids_and_boxes: - csv_writer.writerow({ - 'name': name_imid_boxid[0], - 'index_image_id': name_imid_boxid[1], - 'box_id': name_imid_boxid[2], - }) - - -def ExtractBoxesAndFeaturesToFiles(image_names, image_paths, delf_config_path, - detector_model_dir, detector_thresh, - output_features_dir, output_boxes_dir, - output_mapping): - """Extracts boxes and features, saving them to files. - - Boxes are saved to
- 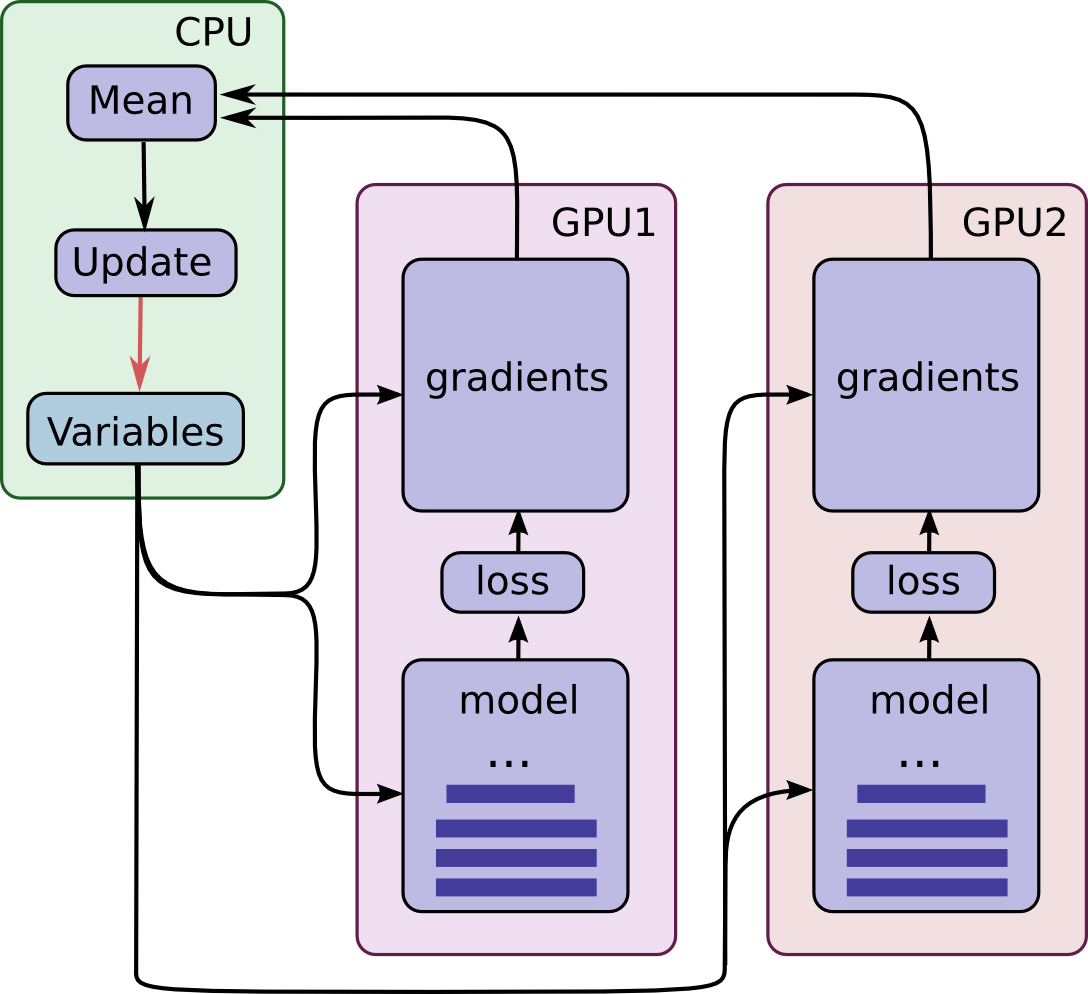 -
-
-
-Each tower computes the gradients for a portion of the batch and the gradients
-are combined and averaged across the multiple towers in order to provide a
-single update of the Variables stored on the CPU.
-
-A crucial aspect of training a network of this size is *training speed* in terms
-of wall-clock time. The training speed is dictated by many factors -- most
-importantly the batch size and the learning rate schedule. Both of these
-parameters are heavily coupled to the hardware set up.
-
-Generally speaking, a batch size is a difficult parameter to tune as it requires
-balancing memory demands of the model, memory available on the GPU and speed of
-computation. Generally speaking, employing larger batch sizes leads to more
-efficient computation and potentially more efficient training steps.
-
-We have tested several hardware setups for training this model from scratch but
-we emphasize that depending your hardware set up, you may need to adapt the
-batch size and learning rate schedule.
-
-Please see the comments in `inception_train.py` for a few selected learning rate
-plans based on some selected hardware setups.
-
-To train this model, you simply need to specify the following:
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:imagenet_train
-
-# run it
-bazel-bin/inception/imagenet_train --num_gpus=1 --batch_size=32 --train_dir=/tmp/imagenet_train --data_dir=/tmp/imagenet_data
-```
-
-The model reads in the ImageNet training data from `--data_dir`. If you followed
-the instructions in [Getting Started](#getting-started), then set
-`--data_dir="${DATA_DIR}"`. The script assumes that there exists a set of
-sharded TFRecord files containing the ImageNet data. If you have not created
-TFRecord files, please refer to [Getting Started](#getting-started)
-
-Here is the output of the above command line when running on a Tesla K40c:
-
-```shell
-2016-03-07 12:24:59.922898: step 0, loss = 13.11 (5.3 examples/sec; 6.064 sec/batch)
-2016-03-07 12:25:55.206783: step 10, loss = 13.71 (9.4 examples/sec; 3.394 sec/batch)
-2016-03-07 12:26:28.905231: step 20, loss = 14.81 (9.5 examples/sec; 3.380 sec/batch)
-2016-03-07 12:27:02.699719: step 30, loss = 14.45 (9.5 examples/sec; 3.378 sec/batch)
-2016-03-07 12:27:36.515699: step 40, loss = 13.98 (9.5 examples/sec; 3.376 sec/batch)
-2016-03-07 12:28:10.220956: step 50, loss = 13.92 (9.6 examples/sec; 3.327 sec/batch)
-2016-03-07 12:28:43.658223: step 60, loss = 13.28 (9.6 examples/sec; 3.350 sec/batch)
-...
-```
-
-In this example, a log entry is printed every 10 step and the line includes the
-total loss (starts around 13.0-14.0) and the speed of processing in terms of
-throughput (examples / sec) and batch speed (sec/batch).
-
-The number of GPU devices is specified by `--num_gpus` (which defaults to 1).
-Specifying `--num_gpus` greater then 1 splits the batch evenly split across the
-GPU cards.
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:imagenet_train
-
-# run it
-bazel-bin/inception/imagenet_train --num_gpus=2 --batch_size=64 --train_dir=/tmp/imagenet_train
-```
-
-This model splits the batch of 64 images across 2 GPUs and calculates the
-average gradient by waiting for both GPUs to finish calculating the gradients
-from their respective data (See diagram above). Generally speaking, using larger
-numbers of GPUs leads to higher throughput as well as the opportunity to use
-larger batch sizes. In turn, larger batch sizes imply better estimates of the
-gradient enabling the usage of higher learning rates. In summary, using more
-GPUs results in simply faster training speed.
-
-Note that selecting a batch size is a difficult parameter to tune as it requires
-balancing memory demands of the model, memory available on the GPU and speed of
-computation. Generally speaking, employing larger batch sizes leads to more
-efficient computation and potentially more efficient training steps.
-
-Note that there is considerable noise in the loss function on individual steps
-in the previous log. Because of this noise, it is difficult to discern how well
-a model is learning. The solution to the last problem is to launch TensorBoard
-pointing to the directory containing the events log.
-
-```shell
-tensorboard --logdir=/tmp/imagenet_train
-```
-
-TensorBoard has access to the many Summaries produced by the model that describe
-multitudes of statistics tracking the model behavior and the quality of the
-learned model. In particular, TensorBoard tracks a exponentially smoothed
-version of the loss. In practice, it is far easier to judge how well a model
-learns by monitoring the smoothed version of the loss.
-
-## How to Train from Scratch in a Distributed Setting
-
-**NOTE** Distributed TensorFlow requires version 0.8 or later.
-
-Distributed TensorFlow lets us use multiple machines to train a model faster.
-This is quite different from the training with multiple GPU towers on a single
-machine where all parameters and gradients computation are in the same place. We
-coordinate the computation across multiple machines by employing a centralized
-repository for parameters that maintains a unified, single copy of model
-parameters. Each individual machine sends gradient updates to the centralized
-parameter repository which coordinates these updates and sends back updated
-parameters to the individual machines running the model training.
-
-We term each machine that runs a copy of the training a `worker` or `replica`.
-We term each machine that maintains model parameters a `ps`, short for
-`parameter server`. Note that we might have more than one machine acting as a
-`ps` as the model parameters may be sharded across multiple machines.
-
-Variables may be updated with synchronous or asynchronous gradient updates. One
-may construct a an [`Optimizer`](https://www.tensorflow.org/api_docs/python/train.html#optimizers) in TensorFlow
-that constructs the necessary graph for either case diagrammed below from the
-TensorFlow [Whitepaper](http://download.tensorflow.org/paper/whitepaper2015.pdf):
-
-
-
- 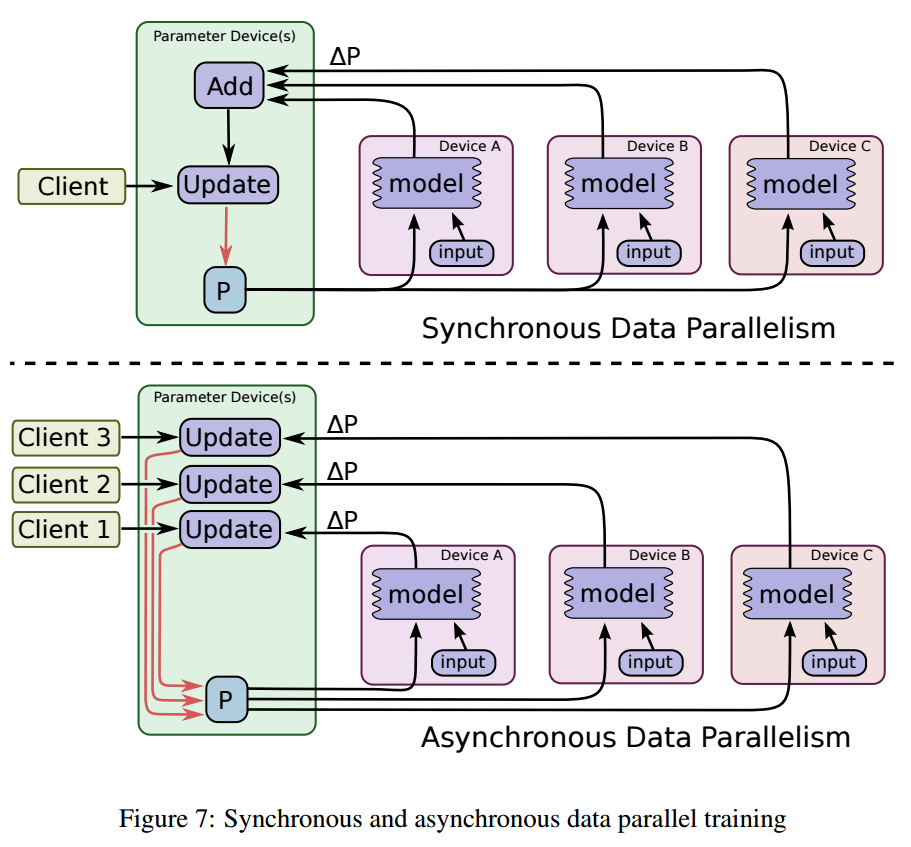 -
-
-
-In [a recent paper](https://arxiv.org/abs/1604.00981), synchronous gradient
-updates have demonstrated to reach higher accuracy in a shorter amount of time.
-In this distributed Inception example we employ synchronous gradient updates.
-
-Note that in this example each replica has a single tower that uses one GPU.
-
-The command-line flags `worker_hosts` and `ps_hosts` specify available servers.
-The same binary will be used for both the `worker` jobs and the `ps` jobs.
-Command line flag `job_name` will be used to specify what role a task will be
-playing and `task_id` will be used to identify which one of the jobs it is
-running. Several things to note here:
-
-* The numbers of `ps` and `worker` tasks are inferred from the lists of hosts
- specified in the flags. The `task_id` should be within the range `[0,
- num_ps_tasks)` for `ps` tasks and `[0, num_worker_tasks)` for `worker`
- tasks.
-* `ps` and `worker` tasks can run on the same machine, as long as that machine
- has sufficient resources to handle both tasks. Note that the `ps` task does
- not benefit from a GPU, so it should not attempt to use one (see below).
-* Multiple `worker` tasks can run on the same machine with multiple GPUs so
- machine_A with 2 GPUs may have 2 workers while machine_B with 1 GPU just has
- 1 worker.
-* The default learning rate schedule works well for a wide range of number of
- replicas [25, 50, 100] but feel free to tune it for even better results.
-* The command line of both `ps` and `worker` tasks should include the complete
- list of `ps_hosts` and `worker_hosts`.
-* There is a chief `worker` among all workers which defaults to `worker` 0.
- The chief will be in charge of initializing all the parameters, writing out
- the summaries and the checkpoint. The checkpoint and summary will be in the
- `train_dir` of the host for `worker` 0.
-* Each worker processes a batch_size number of examples but each gradient
- update is computed from all replicas. Hence, the effective batch size of
- this model is batch_size * num_workers.
-
-```shell
-# Build the model. Note that we need to make sure the TensorFlow is ready to
-# use before this as this command will not build TensorFlow.
-cd tensorflow-models/inception
-bazel build //inception:imagenet_distributed_train
-
-# To start worker 0, go to the worker0 host and run the following (Note that
-# task_id should be in the range [0, num_worker_tasks):
-bazel-bin/inception/imagenet_distributed_train \
---batch_size=32 \
---data_dir=$HOME/imagenet-data \
---job_name='worker' \
---task_id=0 \
---ps_hosts='ps0.example.com:2222' \
---worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
-
-# To start worker 1, go to the worker1 host and run the following (Note that
-# task_id should be in the range [0, num_worker_tasks):
-bazel-bin/inception/imagenet_distributed_train \
---batch_size=32 \
---data_dir=$HOME/imagenet-data \
---job_name='worker' \
---task_id=1 \
---ps_hosts='ps0.example.com:2222' \
---worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
-
-# To start the parameter server (ps), go to the ps host and run the following (Note
-# that task_id should be in the range [0, num_ps_tasks):
-bazel-bin/inception/imagenet_distributed_train \
---job_name='ps' \
---task_id=0 \
---ps_hosts='ps0.example.com:2222' \
---worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
-```
-
-If you have installed a GPU-compatible version of TensorFlow, the `ps` will also
-try to allocate GPU memory although it is not helpful. This could potentially
-crash the worker on the same machine as it has little to no GPU memory to
-allocate. To avoid this, you can prepend the previous command to start `ps`
-with: `CUDA_VISIBLE_DEVICES=''`
-
-```shell
-CUDA_VISIBLE_DEVICES='' bazel-bin/inception/imagenet_distributed_train \
---job_name='ps' \
---task_id=0 \
---ps_hosts='ps0.example.com:2222' \
---worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
-```
-
-If you have run everything correctly, you should see a log in each `worker` job
-that looks like the following. Note the training speed varies depending on your
-hardware and the first several steps could take much longer.
-
-```shell
-INFO:tensorflow:PS hosts are: ['ps0.example.com:2222', 'ps1.example.com:2222']
-INFO:tensorflow:Worker hosts are: ['worker0.example.com:2222', 'worker1.example.com:2222']
-I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job ps -> {ps0.example.com:2222, ps1.example.com:2222}
-I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job worker -> {localhost:2222, worker1.example.com:2222}
-I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:202] Started server with target: grpc://localhost:2222
-INFO:tensorflow:Created variable global_step:0 with shape () and init
--$ export PYTHONPATH=$PYTHONPATH:/path/to/your/directory/lfads/ -- -where "path/to/your/directory" is replaced with the path to the LFADS repository (you can get this path by using the `pwd` command). This allows the nested directories to access modules from their parent directory. - -## Generate synthetic data - -In order to generate the synthetic datasets first, from the top-level lfads directory, run: - -```sh -$ cd synth_data -$ ./run_generate_synth_data.sh -$ cd .. -``` - -These synthetic datasets are provided 1. to gain insight into how the LFADS algorithm operates, and 2. to give reasonable starting points for analyses you might be interested for your own data. - -## Train an LFADS model - -Now that we have our example datasets, we can train some models! To spin up an LFADS model on the synthetic data, run any of the following commands. For the examples that are in the paper, the important hyperparameters are roughly replicated. Most hyperparameters are insensitive to small changes or won't ever be changed unless you want a very fine level of control. In the first example, all hyperparameter flags are enumerated for easy copy-pasting, but for the rest of the examples only the most important flags (~the first 9) are specified for brevity. For a full list of flags, their descriptions, and their default values, refer to the top of `run_lfads.py`. Please see Table 1 in the Online Methods of the associated paper for definitions of the most important hyperparameters. - -```sh -# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with spiking noise -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_no_inputs \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_no_inputs \ ---co_dim=0 \ ---factors_dim=20 \ ---ext_input_dim=0 \ ---controller_input_lag=1 \ ---output_dist=poisson \ ---do_causal_controller=false \ ---batch_size=128 \ ---learning_rate_init=0.01 \ ---learning_rate_stop=1e-05 \ ---learning_rate_decay_factor=0.95 \ ---learning_rate_n_to_compare=6 \ ---do_reset_learning_rate=false \ ---keep_prob=0.95 \ ---con_dim=128 \ ---gen_dim=200 \ ---ci_enc_dim=128 \ ---ic_dim=64 \ ---ic_enc_dim=128 \ ---ic_prior_var_min=0.1 \ ---gen_cell_input_weight_scale=1.0 \ ---cell_weight_scale=1.0 \ ---do_feed_factors_to_controller=true \ ---kl_start_step=0 \ ---kl_increase_steps=2000 \ ---kl_ic_weight=1.0 \ ---l2_con_scale=0.0 \ ---l2_gen_scale=2000.0 \ ---l2_start_step=0 \ ---l2_increase_steps=2000 \ ---ic_prior_var_scale=0.1 \ ---ic_post_var_min=0.0001 \ ---kl_co_weight=1.0 \ ---prior_ar_nvar=0.1 \ ---cell_clip_value=5.0 \ ---max_ckpt_to_keep_lve=5 \ ---do_train_prior_ar_atau=true \ ---co_prior_var_scale=0.1 \ ---csv_log=fitlog \ ---feedback_factors_or_rates=factors \ ---do_train_prior_ar_nvar=true \ ---max_grad_norm=200.0 \ ---device=gpu:0 \ ---num_steps_for_gen_ic=100000000 \ ---ps_nexamples_to_process=100000000 \ ---checkpoint_name=lfads_vae \ ---temporal_spike_jitter_width=0 \ ---checkpoint_pb_load_name=checkpoint \ ---inject_ext_input_to_gen=false \ ---co_mean_corr_scale=0.0 \ ---gen_cell_rec_weight_scale=1.0 \ ---max_ckpt_to_keep=5 \ ---output_filename_stem="" \ ---ic_prior_var_max=0.1 \ ---prior_ar_atau=10.0 \ ---do_train_io_only=false \ ---do_train_encoder_only=false - -# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with Gaussian noise -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=gaussian_chaotic_rnn_no_inputs \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ ---co_dim=1 \ ---factors_dim=20 \ ---output_dist=gaussian - - -# Run LFADS on chaotic rnn data with input pulses (g = 2.5) -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_inputs_g2p5 \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ ---co_dim=1 \ ---factors_dim=20 \ ---output_dist=poisson - -# Run LFADS on multi-session RNN data -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_multisession \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_multisession \ ---factors_dim=10 \ ---output_dist=poisson - -# Run LFADS on integration to bound model data -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=itb_rnn \ ---lfads_save_dir=/tmp/lfads_itb_rnn \ ---co_dim=1 \ ---factors_dim=20 \ ---controller_input_lag=0 \ ---output_dist=poisson - -# Run LFADS on chaotic RNN data with labels -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnns_labeled \ ---lfads_save_dir=/tmp/lfads_chaotic_rnns_labeled \ ---co_dim=0 \ ---factors_dim=20 \ ---controller_input_lag=0 \ ---ext_input_dim=1 \ ---output_dist=poisson - -# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with Gaussian noise -$ python run_lfads.py --kind=train \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_no_inputs \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_no_inputs \ ---co_dim=0 \ ---factors_dim=20 \ ---ext_input_dim=0 \ ---controller_input_lag=1 \ ---output_dist=gaussian \ - - -``` - -**Tip**: If you are running LFADS on GPU and would like to run more than one model concurrently, set the `--allow_gpu_growth=True` flag on each job, otherwise one model will take up the entire GPU for performance purposes. Also, one needs to install the TensorFlow libraries with GPU support. - - -## Visualize a training model - -To visualize training curves and various other metrics while training and LFADS model, run the following command on your model directory. To launch a tensorboard on the chaotic RNN data with input pulses, for example: - -```sh -tensorboard --logdir=/tmp/lfads_chaotic_rnn_inputs_g2p5 -``` - -## Evaluate a trained model - -Once your model is finished training, there are multiple ways you can evaluate -it. Below are some sample commands to evaluate an LFADS model trained on the -chaotic rnn data with input pulses (g = 2.5). The key differences here are -setting the `--kind` flag to the appropriate mode, as well as the -`--checkpoint_pb_load_name` flag to `checkpoint_lve` and the `--batch_size` flag -(if you'd like to make it larger or smaller). All other flags should be the -same as used in training, so that the same model architecture is built. - -```sh -# Take samples from posterior then average (denoising operation) -$ python run_lfads.py --kind=posterior_sample_and_average \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_inputs_g2p5 \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ ---co_dim=1 \ ---factors_dim=20 \ ---batch_size=1024 \ ---checkpoint_pb_load_name=checkpoint_lve - -# Sample from prior (generation of completely new samples) -$ python run_lfads.py --kind=prior_sample \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_inputs_g2p5 \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ ---co_dim=1 \ ---factors_dim=20 \ ---batch_size=50 \ ---checkpoint_pb_load_name=checkpoint_lve - -# Write down model parameters -$ python run_lfads.py --kind=write_model_params \ ---data_dir=/tmp/rnn_synth_data_v1.0/ \ ---data_filename_stem=chaotic_rnn_inputs_g2p5 \ ---lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ ---co_dim=1 \ ---factors_dim=20 \ ---checkpoint_pb_load_name=checkpoint_lve -``` - -## Contact - -File any issues with the [issue tracker](https://github.com/tensorflow/models/issues). For any questions or problems, this code is maintained by [@sussillo](https://github.com/sussillo) and [@jazcollins](https://github.com/jazcollins). - diff --git a/research/lfads/distributions.py b/research/lfads/distributions.py deleted file mode 100644 index 351d019af2b16117eb329b6ef1812aa006834b62..0000000000000000000000000000000000000000 --- a/research/lfads/distributions.py +++ /dev/null @@ -1,493 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -import numpy as np -import tensorflow as tf -from utils import linear, log_sum_exp - -class Poisson(object): - """Poisson distributon - - Computes the log probability under the model. - - """ - def __init__(self, log_rates): - """ Create Poisson distributions with log_rates parameters. - - Args: - log_rates: a tensor-like list of log rates underlying the Poisson dist. - """ - self.logr = log_rates - - def logp(self, bin_counts): - """Compute the log probability for the counts in the bin, under the model. - - Args: - bin_counts: array-like integer counts - - Returns: - The log-probability under the Poisson models for each element of - bin_counts. - """ - k = tf.to_float(bin_counts) - # log poisson(k, r) = log(r^k * e^(-r) / k!) = k log(r) - r - log k! - # log poisson(k, r=exp(x)) = k * x - exp(x) - lgamma(k + 1) - return k * self.logr - tf.exp(self.logr) - tf.lgamma(k + 1) - - -def diag_gaussian_log_likelihood(z, mu=0.0, logvar=0.0): - """Log-likelihood under a Gaussian distribution with diagonal covariance. - Returns the log-likelihood for each dimension. One should sum the - results for the log-likelihood under the full multidimensional model. - - Args: - z: The value to compute the log-likelihood. - mu: The mean of the Gaussian - logvar: The log variance of the Gaussian. - - Returns: - The log-likelihood under the Gaussian model. - """ - - return -0.5 * (logvar + np.log(2*np.pi) + \ - tf.square((z-mu)/tf.exp(0.5*logvar))) - - -def gaussian_pos_log_likelihood(unused_mean, logvar, noise): - """Gaussian log-likelihood function for a posterior in VAE - - Note: This function is specialized for a posterior distribution, that has the - form of z = mean + sigma * noise. - - Args: - unused_mean: ignore - logvar: The log variance of the distribution - noise: The noise used in the sampling of the posterior. - - Returns: - The log-likelihood under the Gaussian model. - """ - # ln N(z; mean, sigma) = - ln(sigma) - 0.5 ln 2pi - noise^2 / 2 - return - 0.5 * (logvar + np.log(2 * np.pi) + tf.square(noise)) - - -class Gaussian(object): - """Base class for Gaussian distribution classes.""" - pass - - -class DiagonalGaussian(Gaussian): - """Diagonal Gaussian with different constant mean and variances in each - dimension. - """ - - def __init__(self, batch_size, z_size, mean, logvar): - """Create a diagonal gaussian distribution. - - Args: - batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. - z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. - mean: The N-D mean of the distribution. - logvar: The N-D log variance of the diagonal distribution. - """ - size__xz = [None, z_size] - self.mean = mean # bxn already - self.logvar = logvar # bxn already - self.noise = noise = tf.random_normal(tf.shape(logvar)) - self.sample = mean + tf.exp(0.5 * logvar) * noise - mean.set_shape(size__xz) - logvar.set_shape(size__xz) - self.sample.set_shape(size__xz) - - def logp(self, z=None): - """Compute the log-likelihood under the distribution. - - Args: - z (optional): value to compute likelihood for, if None, use sample. - - Returns: - The likelihood of z under the model. - """ - if z is None: - z = self.sample - - # This is needed to make sure that the gradients are simple. - # The value of the function shouldn't change. - if z == self.sample: - return gaussian_pos_log_likelihood(self.mean, self.logvar, self.noise) - - return diag_gaussian_log_likelihood(z, self.mean, self.logvar) - - -class LearnableDiagonalGaussian(Gaussian): - """Diagonal Gaussian whose mean and variance are learned parameters.""" - - def __init__(self, batch_size, z_size, name, mean_init=0.0, - var_init=1.0, var_min=0.0, var_max=1000000.0): - """Create a learnable diagonal gaussian distribution. - - Args: - batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. - z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. - name: prefix name for the mean and log TF variables. - mean_init (optional): The N-D mean initialization of the distribution. - var_init (optional): The N-D variance initialization of the diagonal - distribution. - var_min (optional): The minimum value the learned variance can take in any - dimension. - var_max (optional): The maximum value the learned variance can take in any - dimension. - """ - - size_1xn = [1, z_size] - size__xn = [None, z_size] - size_bx1 = tf.stack([batch_size, 1]) - assert var_init > 0.0, "Problems" - assert var_max >= var_min, "Problems" - assert var_init >= var_min, "Problems" - assert var_max >= var_init, "Problems" - - - z_mean_1xn = tf.get_variable(name=name+"/mean", shape=size_1xn, - initializer=tf.constant_initializer(mean_init)) - self.mean_bxn = mean_bxn = tf.tile(z_mean_1xn, size_bx1) - mean_bxn.set_shape(size__xn) # tile loses shape - - log_var_init = np.log(var_init) - if var_max > var_min: - var_is_trainable = True - else: - var_is_trainable = False - - z_logvar_1xn = \ - tf.get_variable(name=(name+"/logvar"), shape=size_1xn, - initializer=tf.constant_initializer(log_var_init), - trainable=var_is_trainable) - - if var_is_trainable: - z_logit_var_1xn = tf.exp(z_logvar_1xn) - z_var_1xn = tf.nn.sigmoid(z_logit_var_1xn)*(var_max-var_min) + var_min - z_logvar_1xn = tf.log(z_var_1xn) - - logvar_bxn = tf.tile(z_logvar_1xn, size_bx1) - self.logvar_bxn = logvar_bxn - self.noise_bxn = noise_bxn = tf.random_normal(tf.shape(logvar_bxn)) - self.sample_bxn = mean_bxn + tf.exp(0.5 * logvar_bxn) * noise_bxn - - def logp(self, z=None): - """Compute the log-likelihood under the distribution. - - Args: - z (optional): value to compute likelihood for, if None, use sample. - - Returns: - The likelihood of z under the model. - """ - if z is None: - z = self.sample - - # This is needed to make sure that the gradients are simple. - # The value of the function shouldn't change. - if z == self.sample_bxn: - return gaussian_pos_log_likelihood(self.mean_bxn, self.logvar_bxn, - self.noise_bxn) - - return diag_gaussian_log_likelihood(z, self.mean_bxn, self.logvar_bxn) - - @property - def mean(self): - return self.mean_bxn - - @property - def logvar(self): - return self.logvar_bxn - - @property - def sample(self): - return self.sample_bxn - - -class DiagonalGaussianFromInput(Gaussian): - """Diagonal Gaussian whose mean and variance are conditioned on other - variables. - - Note: the parameters to convert from input to the learned mean and log - variance are held in this class. - """ - - def __init__(self, x_bxu, z_size, name, var_min=0.0): - """Create an input dependent diagonal Gaussian distribution. - - Args: - x: The input tensor from which the mean and variance are computed, - via a linear transformation of x. I.e. - mu = Wx + b, log(var) = Mx + c - z_size: The size of the distribution. - name: The name to prefix to learned variables. - var_min (optional): Minimal variance allowed. This is an additional - way to control the amount of information getting through the stochastic - layer. - """ - size_bxn = tf.stack([tf.shape(x_bxu)[0], z_size]) - self.mean_bxn = mean_bxn = linear(x_bxu, z_size, name=(name+"/mean")) - logvar_bxn = linear(x_bxu, z_size, name=(name+"/logvar")) - if var_min > 0.0: - logvar_bxn = tf.log(tf.exp(logvar_bxn) + var_min) - self.logvar_bxn = logvar_bxn - - self.noise_bxn = noise_bxn = tf.random_normal(size_bxn) - self.noise_bxn.set_shape([None, z_size]) - self.sample_bxn = mean_bxn + tf.exp(0.5 * logvar_bxn) * noise_bxn - - def logp(self, z=None): - """Compute the log-likelihood under the distribution. - - Args: - z (optional): value to compute likelihood for, if None, use sample. - - Returns: - The likelihood of z under the model. - """ - - if z is None: - z = self.sample - - # This is needed to make sure that the gradients are simple. - # The value of the function shouldn't change. - if z == self.sample_bxn: - return gaussian_pos_log_likelihood(self.mean_bxn, - self.logvar_bxn, self.noise_bxn) - - return diag_gaussian_log_likelihood(z, self.mean_bxn, self.logvar_bxn) - - @property - def mean(self): - return self.mean_bxn - - @property - def logvar(self): - return self.logvar_bxn - - @property - def sample(self): - return self.sample_bxn - - -class GaussianProcess: - """Base class for Gaussian processes.""" - pass - - -class LearnableAutoRegressive1Prior(GaussianProcess): - """AR(1) model where autocorrelation and process variance are learned - parameters. Assumed zero mean. - - """ - - def __init__(self, batch_size, z_size, - autocorrelation_taus, noise_variances, - do_train_prior_ar_atau, do_train_prior_ar_nvar, - num_steps, name): - """Create a learnable autoregressive (1) process. - - Args: - batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. - z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. - autocorrelation_taus: The auto correlation time constant of the AR(1) - process. - A value of 0 is uncorrelated gaussian noise. - noise_variances: The variance of the additive noise, *not* the process - variance. - do_train_prior_ar_atau: Train or leave as constant, the autocorrelation? - do_train_prior_ar_nvar: Train or leave as constant, the noise variance? - num_steps: Number of steps to run the process. - name: The name to prefix to learned TF variables. - """ - - # Note the use of the plural in all of these quantities. This is intended - # to mark that even though a sample z_t from the posterior is thought of a - # single sample of a multidimensional gaussian, the prior is actually - # thought of as U AR(1) processes, where U is the dimension of the inferred - # input. - size_bx1 = tf.stack([batch_size, 1]) - size__xu = [None, z_size] - # process variance, the variance at time t over all instantiations of AR(1) - # with these parameters. - log_evar_inits_1xu = tf.expand_dims(tf.log(noise_variances), 0) - self.logevars_1xu = logevars_1xu = \ - tf.Variable(log_evar_inits_1xu, name=name+"/logevars", dtype=tf.float32, - trainable=do_train_prior_ar_nvar) - self.logevars_bxu = logevars_bxu = tf.tile(logevars_1xu, size_bx1) - logevars_bxu.set_shape(size__xu) # tile loses shape - - # \tau, which is the autocorrelation time constant of the AR(1) process - log_atau_inits_1xu = tf.expand_dims(tf.log(autocorrelation_taus), 0) - self.logataus_1xu = logataus_1xu = \ - tf.Variable(log_atau_inits_1xu, name=name+"/logatau", dtype=tf.float32, - trainable=do_train_prior_ar_atau) - - # phi in x_t = \mu + phi x_tm1 + \eps - # phi = exp(-1/tau) - # phi = exp(-1/exp(logtau)) - # phi = exp(-exp(-logtau)) - phis_1xu = tf.exp(-tf.exp(-logataus_1xu)) - self.phis_bxu = phis_bxu = tf.tile(phis_1xu, size_bx1) - phis_bxu.set_shape(size__xu) - - # process noise - # pvar = evar / (1- phi^2) - # logpvar = log ( exp(logevar) / (1 - phi^2) ) - # logpvar = logevar - log(1-phi^2) - # logpvar = logevar - (log(1-phi) + log(1+phi)) - self.logpvars_1xu = \ - logevars_1xu - tf.log(1.0-phis_1xu) - tf.log(1.0+phis_1xu) - self.logpvars_bxu = logpvars_bxu = tf.tile(self.logpvars_1xu, size_bx1) - logpvars_bxu.set_shape(size__xu) - - # process mean (zero but included in for completeness) - self.pmeans_bxu = pmeans_bxu = tf.zeros_like(phis_bxu) - - # For sampling from the prior during de-novo generation. - self.means_t = means_t = [None] * num_steps - self.logvars_t = logvars_t = [None] * num_steps - self.samples_t = samples_t = [None] * num_steps - self.gaussians_t = gaussians_t = [None] * num_steps - sample_bxu = tf.zeros_like(phis_bxu) - for t in range(num_steps): - # process variance used here to make process completely stationary - if t == 0: - logvar_pt_bxu = self.logpvars_bxu - else: - logvar_pt_bxu = self.logevars_bxu - - z_mean_pt_bxu = pmeans_bxu + phis_bxu * sample_bxu - gaussians_t[t] = DiagonalGaussian(batch_size, z_size, - mean=z_mean_pt_bxu, - logvar=logvar_pt_bxu) - sample_bxu = gaussians_t[t].sample - samples_t[t] = sample_bxu - logvars_t[t] = logvar_pt_bxu - means_t[t] = z_mean_pt_bxu - - def logp_t(self, z_t_bxu, z_tm1_bxu=None): - """Compute the log-likelihood under the distribution for a given time t, - not the whole sequence. - - Args: - z_t_bxu: sample to compute likelihood for at time t. - z_tm1_bxu (optional): sample condition probability of z_t upon. - - Returns: - The likelihood of p_t under the model at time t. i.e. - p(z_t|z_tm1_bxu) = N(z_tm1_bxu * phis, eps^2) - - """ - if z_tm1_bxu is None: - return diag_gaussian_log_likelihood(z_t_bxu, self.pmeans_bxu, - self.logpvars_bxu) - else: - means_t_bxu = self.pmeans_bxu + self.phis_bxu * z_tm1_bxu - logp_tgtm1_bxu = diag_gaussian_log_likelihood(z_t_bxu, - means_t_bxu, - self.logevars_bxu) - return logp_tgtm1_bxu - - -class KLCost_GaussianGaussian(object): - """log p(x|z) + KL(q||p) terms for Gaussian posterior and Gaussian prior. See - eqn 10 and Appendix B in VAE for latter term, - http://arxiv.org/abs/1312.6114 - - The log p(x|z) term is the reconstruction error under the model. - The KL term represents the penalty for passing information from the encoder - to the decoder. - To sample KL(q||p), we simply sample - ln q - ln p - by drawing samples from q and averaging. - """ - - def __init__(self, zs, prior_zs): - """Create a lower bound in three parts, normalized reconstruction - cost, normalized KL divergence cost, and their sum. - - E_q[ln p(z_i | z_{i+1}) / q(z_i | x) - \int q(z) ln p(z) dz = - 0.5 ln(2pi) - 0.5 \sum (ln(sigma_p^2) + \ - sigma_q^2 / sigma_p^2 + (mean_p - mean_q)^2 / sigma_p^2) - - \int q(z) ln q(z) dz = - 0.5 ln(2pi) - 0.5 \sum (ln(sigma_q^2) + 1) - - Args: - zs: posterior z ~ q(z|x) - prior_zs: prior zs - """ - # L = -KL + log p(x|z), to maximize bound on likelihood - # -L = KL - log p(x|z), to minimize bound on NLL - # so 'KL cost' is postive KL divergence - kl_b = 0.0 - for z, prior_z in zip(zs, prior_zs): - assert isinstance(z, Gaussian) - assert isinstance(prior_z, Gaussian) - # ln(2pi) terms cancel - kl_b += 0.5 * tf.reduce_sum( - prior_z.logvar - z.logvar - + tf.exp(z.logvar - prior_z.logvar) - + tf.square((z.mean - prior_z.mean) / tf.exp(0.5 * prior_z.logvar)) - - 1.0, [1]) - - self.kl_cost_b = kl_b - self.kl_cost = tf.reduce_mean(kl_b) - - -class KLCost_GaussianGaussianProcessSampled(object): - """ log p(x|z) + KL(q||p) terms for Gaussian posterior and Gaussian process - prior via sampling. - - The log p(x|z) term is the reconstruction error under the model. - The KL term represents the penalty for passing information from the encoder - to the decoder. - To sample KL(q||p), we simply sample - ln q - ln p - by drawing samples from q and averaging. - """ - - def __init__(self, post_zs, prior_z_process): - """Create a lower bound in three parts, normalized reconstruction - cost, normalized KL divergence cost, and their sum. - - Args: - post_zs: posterior z ~ q(z|x) - prior_z_process: prior AR(1) process - """ - assert len(post_zs) > 1, "GP is for time, need more than 1 time step." - assert isinstance(prior_z_process, GaussianProcess), "Must use GP." - - # L = -KL + log p(x|z), to maximize bound on likelihood - # -L = KL - log p(x|z), to minimize bound on NLL - # so 'KL cost' is postive KL divergence - z0_bxu = post_zs[0].sample - logq_bxu = post_zs[0].logp(z0_bxu) - logp_bxu = prior_z_process.logp_t(z0_bxu) - z_tm1_bxu = z0_bxu - for z_t in post_zs[1:]: - # posterior is independent in time, prior is not - z_t_bxu = z_t.sample - logq_bxu += z_t.logp(z_t_bxu) - logp_bxu += prior_z_process.logp_t(z_t_bxu, z_tm1_bxu) - z_tm1_bxu = z_t_bxu - - kl_bxu = logq_bxu - logp_bxu - kl_b = tf.reduce_sum(kl_bxu, [1]) - self.kl_cost_b = kl_b - self.kl_cost = tf.reduce_mean(kl_b) diff --git a/research/lfads/lfads.py b/research/lfads/lfads.py deleted file mode 100644 index 308ebabe90fbbb90701ac0585e7c1eaeaf6e3649..0000000000000000000000000000000000000000 --- a/research/lfads/lfads.py +++ /dev/null @@ -1,2170 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -""" -LFADS - Latent Factor Analysis via Dynamical Systems. - -LFADS is an unsupervised method to decompose time series data into -various factors, such as an initial condition, a generative -dynamical system, control inputs to that generator, and a low -dimensional description of the observed data, called the factors. -Additionally, the observations have a noise model (in this case -Poisson), so a denoised version of the observations is also created -(e.g. underlying rates of a Poisson distribution given the observed -event counts). - -The main data structure being passed around is a dataset. This is a dictionary -of data dictionaries. - -DATASET: The top level dictionary is simply name (string -> dictionary). -The nested dictionary is the DATA DICTIONARY, which has the following keys: - 'train_data' and 'valid_data', whose values are the corresponding training - and validation data with shape - ExTxD, E - # examples, T - # time steps, D - # dimensions in data. - The data dictionary also has a few more keys: - 'train_ext_input' and 'valid_ext_input', if there are know external inputs - to the system being modeled, these take on dimensions: - ExTxI, E - # examples, T - # time steps, I = # dimensions in input. - 'alignment_matrix_cxf' - If you are using multiple days data, it's possible - that one can align the channels (see manuscript). If so each dataset will - contain this matrix, which will be used for both the input adapter and the - output adapter for each dataset. These matrices, if provided, must be of - size [data_dim x factors] where data_dim is the number of neurons recorded - on that day, and factors is chosen and set through the '--factors' flag. - 'alignment_bias_c' - See alignment_matrix_cxf. This bias will used to - the offset for the alignment transformation. It will *subtract* off the - bias from the data, so pca style inits can align factors across sessions. - - - If one runs LFADS on data where the true rates are known for some trials, - (say simulated, testing data, as in the example shipped with the paper), then - one can add three more fields for plotting purposes. These are 'train_truth' - and 'valid_truth', and 'conversion_factor'. These have the same dimensions as - 'train_data', and 'valid_data' but represent the underlying rates of the - observations. Finally, if one needs to convert scale for plotting the true - underlying firing rates, there is the 'conversion_factor' key. -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - - -import numpy as np -import os -import tensorflow as tf -from distributions import LearnableDiagonalGaussian, DiagonalGaussianFromInput -from distributions import diag_gaussian_log_likelihood -from distributions import KLCost_GaussianGaussian, Poisson -from distributions import LearnableAutoRegressive1Prior -from distributions import KLCost_GaussianGaussianProcessSampled - -from utils import init_linear, linear, list_t_bxn_to_tensor_bxtxn, write_data -from utils import log_sum_exp, flatten -from plot_lfads import plot_lfads - - -class GRU(object): - """Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078). - - """ - def __init__(self, num_units, forget_bias=1.0, weight_scale=1.0, - clip_value=np.inf, collections=None): - """Create a GRU object. - - Args: - num_units: Number of units in the GRU - forget_bias (optional): Hack to help learning. - weight_scale (optional): weights are scaled by ws/sqrt(#inputs), with - ws being the weight scale. - clip_value (optional): if the recurrent values grow above this value, - clip them. - collections (optional): List of additonal collections variables should - belong to. - """ - self._num_units = num_units - self._forget_bias = forget_bias - self._weight_scale = weight_scale - self._clip_value = clip_value - self._collections = collections - - @property - def state_size(self): - return self._num_units - - @property - def output_size(self): - return self._num_units - - @property - def state_multiplier(self): - return 1 - - def output_from_state(self, state): - """Return the output portion of the state.""" - return state - - def __call__(self, inputs, state, scope=None): - """Gated recurrent unit (GRU) function. - - Args: - inputs: A 2D batch x input_dim tensor of inputs. - state: The previous state from the last time step. - scope (optional): TF variable scope for defined GRU variables. - - Returns: - A tuple (state, state), where state is the newly computed state at time t. - It is returned twice to respect an interface that works for LSTMs. - """ - - x = inputs - h = state - if inputs is not None: - xh = tf.concat(axis=1, values=[x, h]) - else: - xh = h - - with tf.variable_scope(scope or type(self).__name__): # "GRU" - with tf.variable_scope("Gates"): # Reset gate and update gate. - # We start with bias of 1.0 to not reset and not update. - r, u = tf.split(axis=1, num_or_size_splits=2, value=linear(xh, - 2 * self._num_units, - alpha=self._weight_scale, - name="xh_2_ru", - collections=self._collections)) - r, u = tf.sigmoid(r), tf.sigmoid(u + self._forget_bias) - with tf.variable_scope("Candidate"): - xrh = tf.concat(axis=1, values=[x, r * h]) - c = tf.tanh(linear(xrh, self._num_units, name="xrh_2_c", - collections=self._collections)) - new_h = u * h + (1 - u) * c - new_h = tf.clip_by_value(new_h, -self._clip_value, self._clip_value) - - return new_h, new_h - - -class GenGRU(object): - """Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078). - - This version is specialized for the generator, but isn't as fast, so - we have two. Note this allows for l2 regularization on the recurrent - weights, but also implicitly rescales the inputs via the 1/sqrt(input) - scaling in the linear helper routine to be large magnitude, if there are - fewer inputs than recurrent state. - - """ - def __init__(self, num_units, forget_bias=1.0, - input_weight_scale=1.0, rec_weight_scale=1.0, clip_value=np.inf, - input_collections=None, recurrent_collections=None): - """Create a GRU object. - - Args: - num_units: Number of units in the GRU - forget_bias (optional): Hack to help learning. - input_weight_scale (optional): weights are scaled ws/sqrt(#inputs), with - ws being the weight scale. - rec_weight_scale (optional): weights are scaled ws/sqrt(#inputs), - with ws being the weight scale. - clip_value (optional): if the recurrent values grow above this value, - clip them. - input_collections (optional): List of additonal collections variables - that input->rec weights should belong to. - recurrent_collections (optional): List of additonal collections variables - that rec->rec weights should belong to. - """ - self._num_units = num_units - self._forget_bias = forget_bias - self._input_weight_scale = input_weight_scale - self._rec_weight_scale = rec_weight_scale - self._clip_value = clip_value - self._input_collections = input_collections - self._rec_collections = recurrent_collections - - @property - def state_size(self): - return self._num_units - - @property - def output_size(self): - return self._num_units - - @property - def state_multiplier(self): - return 1 - - def output_from_state(self, state): - """Return the output portion of the state.""" - return state - - def __call__(self, inputs, state, scope=None): - """Gated recurrent unit (GRU) function. - - Args: - inputs: A 2D batch x input_dim tensor of inputs. - state: The previous state from the last time step. - scope (optional): TF variable scope for defined GRU variables. - - Returns: - A tuple (state, state), where state is the newly computed state at time t. - It is returned twice to respect an interface that works for LSTMs. - """ - - x = inputs - h = state - with tf.variable_scope(scope or type(self).__name__): # "GRU" - with tf.variable_scope("Gates"): # Reset gate and update gate. - # We start with bias of 1.0 to not reset and not update. - r_x = u_x = 0.0 - if x is not None: - r_x, u_x = tf.split(axis=1, num_or_size_splits=2, value=linear(x, - 2 * self._num_units, - alpha=self._input_weight_scale, - do_bias=False, - name="x_2_ru", - normalized=False, - collections=self._input_collections)) - - r_h, u_h = tf.split(axis=1, num_or_size_splits=2, value=linear(h, - 2 * self._num_units, - do_bias=True, - alpha=self._rec_weight_scale, - name="h_2_ru", - collections=self._rec_collections)) - r = r_x + r_h - u = u_x + u_h - r, u = tf.sigmoid(r), tf.sigmoid(u + self._forget_bias) - - with tf.variable_scope("Candidate"): - c_x = 0.0 - if x is not None: - c_x = linear(x, self._num_units, name="x_2_c", do_bias=False, - alpha=self._input_weight_scale, - normalized=False, - collections=self._input_collections) - c_rh = linear(r*h, self._num_units, name="rh_2_c", do_bias=True, - alpha=self._rec_weight_scale, - collections=self._rec_collections) - c = tf.tanh(c_x + c_rh) - - new_h = u * h + (1 - u) * c - new_h = tf.clip_by_value(new_h, -self._clip_value, self._clip_value) - - return new_h, new_h - - -class LFADS(object): - """LFADS - Latent Factor Analysis via Dynamical Systems. - - LFADS is an unsupervised method to decompose time series data into - various factors, such as an initial condition, a generative - dynamical system, inferred inputs to that generator, and a low - dimensional description of the observed data, called the factors. - Additoinally, the observations have a noise model (in this case - Poisson), so a denoised version of the observations is also created - (e.g. underlying rates of a Poisson distribution given the observed - event counts). - """ - - def __init__(self, hps, kind="train", datasets=None): - """Create an LFADS model. - - train - a model for training, sampling of posteriors is used - posterior_sample_and_average - sample from the posterior, this is used - for evaluating the expected value of the outputs of LFADS, given a - specific input, by averaging over multiple samples from the approx - posterior. Also used for the lower bound on the negative - log-likelihood using IWAE error (Importance Weighed Auto-encoder). - This is the denoising operation. - prior_sample - a model for generation - sampling from priors is used - - Args: - hps: The dictionary of hyper parameters. - kind: the type of model to build (see above). - datasets: a dictionary of named data_dictionaries, see top of lfads.py - """ - print("Building graph...") - all_kinds = ['train', 'posterior_sample_and_average', 'posterior_push_mean', - 'prior_sample'] - assert kind in all_kinds, 'Wrong kind' - if hps.feedback_factors_or_rates == "rates": - assert len(hps.dataset_names) == 1, \ - "Multiple datasets not supported for rate feedback." - num_steps = hps.num_steps - ic_dim = hps.ic_dim - co_dim = hps.co_dim - ext_input_dim = hps.ext_input_dim - cell_class = GRU - gen_cell_class = GenGRU - - def makelambda(v): # Used with tf.case - return lambda: v - - # Define the data placeholder, and deal with all parts of the graph - # that are dataset dependent. - self.dataName = tf.placeholder(tf.string, shape=()) - # The batch_size to be inferred from data, as normal. - # Additionally, the data_dim will be inferred as well, allowing for a - # single placeholder for all datasets, regardless of data dimension. - if hps.output_dist == 'poisson': - # Enforce correct dtype - assert np.issubdtype( - datasets[hps.dataset_names[0]]['train_data'].dtype, int), \ - "Data dtype must be int for poisson output distribution" - data_dtype = tf.int32 - elif hps.output_dist == 'gaussian': - assert np.issubdtype( - datasets[hps.dataset_names[0]]['train_data'].dtype, float), \ - "Data dtype must be float for gaussian output dsitribution" - data_dtype = tf.float32 - else: - assert False, "NIY" - self.dataset_ph = dataset_ph = tf.placeholder(data_dtype, - [None, num_steps, None], - name="data") - self.train_step = tf.get_variable("global_step", [], tf.int64, - tf.zeros_initializer(), - trainable=False) - self.hps = hps - ndatasets = hps.ndatasets - factors_dim = hps.factors_dim - self.preds = preds = [None] * ndatasets - self.fns_in_fac_Ws = fns_in_fac_Ws = [None] * ndatasets - self.fns_in_fatcor_bs = fns_in_fac_bs = [None] * ndatasets - self.fns_out_fac_Ws = fns_out_fac_Ws = [None] * ndatasets - self.fns_out_fac_bs = fns_out_fac_bs = [None] * ndatasets - self.datasetNames = dataset_names = hps.dataset_names - self.ext_inputs = ext_inputs = None - - if len(dataset_names) == 1: # single session - if 'alignment_matrix_cxf' in datasets[dataset_names[0]].keys(): - used_in_factors_dim = factors_dim - in_identity_if_poss = False - else: - used_in_factors_dim = hps.dataset_dims[dataset_names[0]] - in_identity_if_poss = True - else: # multisession - used_in_factors_dim = factors_dim - in_identity_if_poss = False - - for d, name in enumerate(dataset_names): - data_dim = hps.dataset_dims[name] - in_mat_cxf = None - in_bias_1xf = None - align_bias_1xc = None - - if datasets and 'alignment_matrix_cxf' in datasets[name].keys(): - dataset = datasets[name] - if hps.do_train_readin: - print("Initializing trainable readin matrix with alignment matrix" \ - " provided for dataset:", name) - else: - print("Setting non-trainable readin matrix to alignment matrix" \ - " provided for dataset:", name) - in_mat_cxf = dataset['alignment_matrix_cxf'].astype(np.float32) - if in_mat_cxf.shape != (data_dim, factors_dim): - raise ValueError("""Alignment matrix must have dimensions %d x %d - (data_dim x factors_dim), but currently has %d x %d."""% - (data_dim, factors_dim, in_mat_cxf.shape[0], - in_mat_cxf.shape[1])) - if datasets and 'alignment_bias_c' in datasets[name].keys(): - dataset = datasets[name] - if hps.do_train_readin: - print("Initializing trainable readin bias with alignment bias " \ - "provided for dataset:", name) - else: - print("Setting non-trainable readin bias to alignment bias " \ - "provided for dataset:", name) - align_bias_c = dataset['alignment_bias_c'].astype(np.float32) - align_bias_1xc = np.expand_dims(align_bias_c, axis=0) - if align_bias_1xc.shape[1] != data_dim: - raise ValueError("""Alignment bias must have dimensions %d - (data_dim), but currently has %d."""% - (data_dim, in_mat_cxf.shape[0])) - if in_mat_cxf is not None and align_bias_1xc is not None: - # (data - alignment_bias) * W_in - # data * W_in - alignment_bias * W_in - # So b = -alignment_bias * W_in to accommodate PCA style offset. - in_bias_1xf = -np.dot(align_bias_1xc, in_mat_cxf) - - if hps.do_train_readin: - # only add to IO transformations collection only if we want it to be - # learnable, because IO_transformations collection will be trained - # when do_train_io_only - collections_readin=['IO_transformations'] - else: - collections_readin=None - - in_fac_lin = init_linear(data_dim, used_in_factors_dim, - do_bias=True, - mat_init_value=in_mat_cxf, - bias_init_value=in_bias_1xf, - identity_if_possible=in_identity_if_poss, - normalized=False, name="x_2_infac_"+name, - collections=collections_readin, - trainable=hps.do_train_readin) - in_fac_W, in_fac_b = in_fac_lin - fns_in_fac_Ws[d] = makelambda(in_fac_W) - fns_in_fac_bs[d] = makelambda(in_fac_b) - - with tf.variable_scope("glm"): - out_identity_if_poss = False - if len(dataset_names) == 1 and \ - factors_dim == hps.dataset_dims[dataset_names[0]]: - out_identity_if_poss = True - for d, name in enumerate(dataset_names): - data_dim = hps.dataset_dims[name] - in_mat_cxf = None - if datasets and 'alignment_matrix_cxf' in datasets[name].keys(): - dataset = datasets[name] - in_mat_cxf = dataset['alignment_matrix_cxf'].astype(np.float32) - - if datasets and 'alignment_bias_c' in datasets[name].keys(): - dataset = datasets[name] - align_bias_c = dataset['alignment_bias_c'].astype(np.float32) - align_bias_1xc = np.expand_dims(align_bias_c, axis=0) - - out_mat_fxc = None - out_bias_1xc = None - if in_mat_cxf is not None: - out_mat_fxc = in_mat_cxf.T - if align_bias_1xc is not None: - out_bias_1xc = align_bias_1xc - - if hps.output_dist == 'poisson': - out_fac_lin = init_linear(factors_dim, data_dim, do_bias=True, - mat_init_value=out_mat_fxc, - bias_init_value=out_bias_1xc, - identity_if_possible=out_identity_if_poss, - normalized=False, - name="fac_2_logrates_"+name, - collections=['IO_transformations']) - out_fac_W, out_fac_b = out_fac_lin - - elif hps.output_dist == 'gaussian': - out_fac_lin_mean = \ - init_linear(factors_dim, data_dim, do_bias=True, - mat_init_value=out_mat_fxc, - bias_init_value=out_bias_1xc, - normalized=False, - name="fac_2_means_"+name, - collections=['IO_transformations']) - out_fac_W_mean, out_fac_b_mean = out_fac_lin_mean - - mat_init_value = np.zeros([factors_dim, data_dim]).astype(np.float32) - bias_init_value = np.ones([1, data_dim]).astype(np.float32) - out_fac_lin_logvar = \ - init_linear(factors_dim, data_dim, do_bias=True, - mat_init_value=mat_init_value, - bias_init_value=bias_init_value, - normalized=False, - name="fac_2_logvars_"+name, - collections=['IO_transformations']) - out_fac_W_mean, out_fac_b_mean = out_fac_lin_mean - out_fac_W_logvar, out_fac_b_logvar = out_fac_lin_logvar - out_fac_W = tf.concat( - axis=1, values=[out_fac_W_mean, out_fac_W_logvar]) - out_fac_b = tf.concat( - axis=1, values=[out_fac_b_mean, out_fac_b_logvar]) - else: - assert False, "NIY" - - preds[d] = tf.equal(tf.constant(name), self.dataName) - data_dim = hps.dataset_dims[name] - fns_out_fac_Ws[d] = makelambda(out_fac_W) - fns_out_fac_bs[d] = makelambda(out_fac_b) - - pf_pairs_in_fac_Ws = zip(preds, fns_in_fac_Ws) - pf_pairs_in_fac_bs = zip(preds, fns_in_fac_bs) - pf_pairs_out_fac_Ws = zip(preds, fns_out_fac_Ws) - pf_pairs_out_fac_bs = zip(preds, fns_out_fac_bs) - - this_in_fac_W = tf.case(pf_pairs_in_fac_Ws, exclusive=True) - this_in_fac_b = tf.case(pf_pairs_in_fac_bs, exclusive=True) - this_out_fac_W = tf.case(pf_pairs_out_fac_Ws, exclusive=True) - this_out_fac_b = tf.case(pf_pairs_out_fac_bs, exclusive=True) - - # External inputs (not changing by dataset, by definition). - if hps.ext_input_dim > 0: - self.ext_input = tf.placeholder(tf.float32, - [None, num_steps, ext_input_dim], - name="ext_input") - else: - self.ext_input = None - ext_input_bxtxi = self.ext_input - - self.keep_prob = keep_prob = tf.placeholder(tf.float32, [], "keep_prob") - self.batch_size = batch_size = int(hps.batch_size) - self.learning_rate = tf.Variable(float(hps.learning_rate_init), - trainable=False, name="learning_rate") - self.learning_rate_decay_op = self.learning_rate.assign( - self.learning_rate * hps.learning_rate_decay_factor) - - # Dropout the data. - dataset_do_bxtxd = tf.nn.dropout(tf.to_float(dataset_ph), keep_prob) - if hps.ext_input_dim > 0: - ext_input_do_bxtxi = tf.nn.dropout(ext_input_bxtxi, keep_prob) - else: - ext_input_do_bxtxi = None - - # ENCODERS - def encode_data(dataset_bxtxd, enc_cell, name, forward_or_reverse, - num_steps_to_encode): - """Encode data for LFADS - Args: - dataset_bxtxd - the data to encode, as a 3 tensor, with dims - time x batch x data dims. - enc_cell: encoder cell - name: name of encoder - forward_or_reverse: string, encode in forward or reverse direction - num_steps_to_encode: number of steps to encode, 0:num_steps_to_encode - Returns: - encoded data as a list with num_steps_to_encode items, in order - """ - if forward_or_reverse == "forward": - dstr = "_fwd" - time_fwd_or_rev = range(num_steps_to_encode) - else: - dstr = "_rev" - time_fwd_or_rev = reversed(range(num_steps_to_encode)) - - with tf.variable_scope(name+"_enc"+dstr, reuse=False): - enc_state = tf.tile( - tf.Variable(tf.zeros([1, enc_cell.state_size]), - name=name+"_enc_t0"+dstr), tf.stack([batch_size, 1])) - enc_state.set_shape([None, enc_cell.state_size]) # tile loses shape - - enc_outs = [None] * num_steps_to_encode - for i, t in enumerate(time_fwd_or_rev): - with tf.variable_scope(name+"_enc"+dstr, reuse=True if i > 0 else None): - dataset_t_bxd = dataset_bxtxd[:,t,:] - in_fac_t_bxf = tf.matmul(dataset_t_bxd, this_in_fac_W) + this_in_fac_b - in_fac_t_bxf.set_shape([None, used_in_factors_dim]) - if ext_input_dim > 0 and not hps.inject_ext_input_to_gen: - ext_input_t_bxi = ext_input_do_bxtxi[:,t,:] - enc_input_t_bxfpe = tf.concat( - axis=1, values=[in_fac_t_bxf, ext_input_t_bxi]) - else: - enc_input_t_bxfpe = in_fac_t_bxf - enc_out, enc_state = enc_cell(enc_input_t_bxfpe, enc_state) - enc_outs[t] = enc_out - - return enc_outs - - # Encode initial condition means and variances - # ([x_T, x_T-1, ... x_0] and [x_0, x_1, ... x_T] -> g0/c0) - self.ic_enc_fwd = [None] * num_steps - self.ic_enc_rev = [None] * num_steps - if ic_dim > 0: - enc_ic_cell = cell_class(hps.ic_enc_dim, - weight_scale=hps.cell_weight_scale, - clip_value=hps.cell_clip_value) - ic_enc_fwd = encode_data(dataset_do_bxtxd, enc_ic_cell, - "ic", "forward", - hps.num_steps_for_gen_ic) - ic_enc_rev = encode_data(dataset_do_bxtxd, enc_ic_cell, - "ic", "reverse", - hps.num_steps_for_gen_ic) - self.ic_enc_fwd = ic_enc_fwd - self.ic_enc_rev = ic_enc_rev - - # Encoder control input means and variances, bi-directional encoding so: - # ([x_T, x_T-1, ..., x_0] and [x_0, x_1 ... x_T] -> u_t) - self.ci_enc_fwd = [None] * num_steps - self.ci_enc_rev = [None] * num_steps - if co_dim > 0: - enc_ci_cell = cell_class(hps.ci_enc_dim, - weight_scale=hps.cell_weight_scale, - clip_value=hps.cell_clip_value) - ci_enc_fwd = encode_data(dataset_do_bxtxd, enc_ci_cell, - "ci", "forward", - hps.num_steps) - if hps.do_causal_controller: - ci_enc_rev = None - else: - ci_enc_rev = encode_data(dataset_do_bxtxd, enc_ci_cell, - "ci", "reverse", - hps.num_steps) - self.ci_enc_fwd = ci_enc_fwd - self.ci_enc_rev = ci_enc_rev - - # STOCHASTIC LATENT VARIABLES, priors and posteriors - # (initial conditions g0, and control inputs, u_t) - # Note that zs represent all the stochastic latent variables. - with tf.variable_scope("z", reuse=False): - self.prior_zs_g0 = None - self.posterior_zs_g0 = None - self.g0s_val = None - if ic_dim > 0: - self.prior_zs_g0 = \ - LearnableDiagonalGaussian(batch_size, ic_dim, name="prior_g0", - mean_init=0.0, - var_min=hps.ic_prior_var_min, - var_init=hps.ic_prior_var_scale, - var_max=hps.ic_prior_var_max) - ic_enc = tf.concat(axis=1, values=[ic_enc_fwd[-1], ic_enc_rev[0]]) - ic_enc = tf.nn.dropout(ic_enc, keep_prob) - self.posterior_zs_g0 = \ - DiagonalGaussianFromInput(ic_enc, ic_dim, "ic_enc_2_post_g0", - var_min=hps.ic_post_var_min) - if kind in ["train", "posterior_sample_and_average", - "posterior_push_mean"]: - zs_g0 = self.posterior_zs_g0 - else: - zs_g0 = self.prior_zs_g0 - if kind in ["train", "posterior_sample_and_average", "prior_sample"]: - self.g0s_val = zs_g0.sample - else: - self.g0s_val = zs_g0.mean - - # Priors for controller, 'co' for controller output - self.prior_zs_co = prior_zs_co = [None] * num_steps - self.posterior_zs_co = posterior_zs_co = [None] * num_steps - self.zs_co = zs_co = [None] * num_steps - self.prior_zs_ar_con = None - if co_dim > 0: - # Controller outputs - autocorrelation_taus = [hps.prior_ar_atau for x in range(hps.co_dim)] - noise_variances = [hps.prior_ar_nvar for x in range(hps.co_dim)] - self.prior_zs_ar_con = prior_zs_ar_con = \ - LearnableAutoRegressive1Prior(batch_size, hps.co_dim, - autocorrelation_taus, - noise_variances, - hps.do_train_prior_ar_atau, - hps.do_train_prior_ar_nvar, - num_steps, "u_prior_ar1") - - # CONTROLLER -> GENERATOR -> RATES - # (u(t) -> gen(t) -> factors(t) -> rates(t) -> p(x_t|z_t) ) - self.controller_outputs = u_t = [None] * num_steps - self.con_ics = con_state = None - self.con_states = con_states = [None] * num_steps - self.con_outs = con_outs = [None] * num_steps - self.gen_inputs = gen_inputs = [None] * num_steps - if co_dim > 0: - # gen_cell_class here for l2 penalty recurrent weights - # didn't split the cell_weight scale here, because I doubt it matters - con_cell = gen_cell_class(hps.con_dim, - input_weight_scale=hps.cell_weight_scale, - rec_weight_scale=hps.cell_weight_scale, - clip_value=hps.cell_clip_value, - recurrent_collections=['l2_con_reg']) - with tf.variable_scope("con", reuse=False): - self.con_ics = tf.tile( - tf.Variable(tf.zeros([1, hps.con_dim*con_cell.state_multiplier]), - name="c0"), - tf.stack([batch_size, 1])) - self.con_ics.set_shape([None, con_cell.state_size]) # tile loses shape - con_states[-1] = self.con_ics - - gen_cell = gen_cell_class(hps.gen_dim, - input_weight_scale=hps.gen_cell_input_weight_scale, - rec_weight_scale=hps.gen_cell_rec_weight_scale, - clip_value=hps.cell_clip_value, - recurrent_collections=['l2_gen_reg']) - with tf.variable_scope("gen", reuse=False): - if ic_dim == 0: - self.gen_ics = tf.tile( - tf.Variable(tf.zeros([1, gen_cell.state_size]), name="g0"), - tf.stack([batch_size, 1])) - else: - self.gen_ics = linear(self.g0s_val, gen_cell.state_size, - identity_if_possible=True, - name="g0_2_gen_ic") - - self.gen_states = gen_states = [None] * num_steps - self.gen_outs = gen_outs = [None] * num_steps - gen_states[-1] = self.gen_ics - gen_outs[-1] = gen_cell.output_from_state(gen_states[-1]) - self.factors = factors = [None] * num_steps - factors[-1] = linear(gen_outs[-1], factors_dim, do_bias=False, - normalized=True, name="gen_2_fac") - - self.rates = rates = [None] * num_steps - # rates[-1] is collected to potentially feed back to controller - with tf.variable_scope("glm", reuse=False): - if hps.output_dist == 'poisson': - log_rates_t0 = tf.matmul(factors[-1], this_out_fac_W) + this_out_fac_b - log_rates_t0.set_shape([None, None]) - rates[-1] = tf.exp(log_rates_t0) # rate - rates[-1].set_shape([None, hps.dataset_dims[hps.dataset_names[0]]]) - elif hps.output_dist == 'gaussian': - mean_n_logvars = tf.matmul(factors[-1],this_out_fac_W) + this_out_fac_b - mean_n_logvars.set_shape([None, None]) - means_t_bxd, logvars_t_bxd = tf.split(axis=1, num_or_size_splits=2, - value=mean_n_logvars) - rates[-1] = means_t_bxd - else: - assert False, "NIY" - - # We support multiple output distributions, for example Poisson, and also - # Gaussian. In these two cases respectively, there are one and two - # parameters (rates vs. mean and variance). So the output_dist_params - # tensor will variable sizes via tf.concat and tf.split, along the 1st - # dimension. So in the case of gaussian, for example, it'll be - # batch x (D+D), where each D dims is the mean, and then variances, - # respectively. For a distribution with 3 parameters, it would be - # batch x (D+D+D). - self.output_dist_params = dist_params = [None] * num_steps - self.log_p_xgz_b = log_p_xgz_b = 0.0 # log P(x|z) - for t in range(num_steps): - # Controller - if co_dim > 0: - # Build inputs for controller - tlag = t - hps.controller_input_lag - if tlag < 0: - con_in_f_t = tf.zeros_like(ci_enc_fwd[0]) - else: - con_in_f_t = ci_enc_fwd[tlag] - if hps.do_causal_controller: - # If controller is causal (wrt to data generation process), then it - # cannot see future data. Thus, excluding ci_enc_rev[t] is obvious. - # Less obvious is the need to exclude factors[t-1]. This arises - # because information flows from g0 through factors to the controller - # input. The g0 encoding is backwards, so we must necessarily exclude - # the factors in order to keep the controller input purely from a - # forward encoding (however unlikely it is that - # g0->factors->controller channel might actually be used in this way). - con_in_list_t = [con_in_f_t] - else: - tlag_rev = t + hps.controller_input_lag - if tlag_rev >= num_steps: - # better than zeros - con_in_r_t = tf.zeros_like(ci_enc_rev[0]) - else: - con_in_r_t = ci_enc_rev[tlag_rev] - con_in_list_t = [con_in_f_t, con_in_r_t] - - if hps.do_feed_factors_to_controller: - if hps.feedback_factors_or_rates == "factors": - con_in_list_t.append(factors[t-1]) - elif hps.feedback_factors_or_rates == "rates": - con_in_list_t.append(rates[t-1]) - else: - assert False, "NIY" - - con_in_t = tf.concat(axis=1, values=con_in_list_t) - con_in_t = tf.nn.dropout(con_in_t, keep_prob) - with tf.variable_scope("con", reuse=True if t > 0 else None): - con_outs[t], con_states[t] = con_cell(con_in_t, con_states[t-1]) - posterior_zs_co[t] = \ - DiagonalGaussianFromInput(con_outs[t], co_dim, - name="con_to_post_co") - if kind == "train": - u_t[t] = posterior_zs_co[t].sample - elif kind == "posterior_sample_and_average": - u_t[t] = posterior_zs_co[t].sample - elif kind == "posterior_push_mean": - u_t[t] = posterior_zs_co[t].mean - else: - u_t[t] = prior_zs_ar_con.samples_t[t] - - # Inputs to the generator (controller output + external input) - if ext_input_dim > 0 and hps.inject_ext_input_to_gen: - ext_input_t_bxi = ext_input_do_bxtxi[:,t,:] - if co_dim > 0: - gen_inputs[t] = tf.concat(axis=1, values=[u_t[t], ext_input_t_bxi]) - else: - gen_inputs[t] = ext_input_t_bxi - else: - gen_inputs[t] = u_t[t] - - # Generator - data_t_bxd = dataset_ph[:,t,:] - with tf.variable_scope("gen", reuse=True if t > 0 else None): - gen_outs[t], gen_states[t] = gen_cell(gen_inputs[t], gen_states[t-1]) - gen_outs[t] = tf.nn.dropout(gen_outs[t], keep_prob) - with tf.variable_scope("gen", reuse=True): # ic defined it above - factors[t] = linear(gen_outs[t], factors_dim, do_bias=False, - normalized=True, name="gen_2_fac") - with tf.variable_scope("glm", reuse=True if t > 0 else None): - if hps.output_dist == 'poisson': - log_rates_t = tf.matmul(factors[t], this_out_fac_W) + this_out_fac_b - log_rates_t.set_shape([None, None]) - rates[t] = dist_params[t] = tf.exp(tf.clip_by_value(log_rates_t, -hps._clip_value, hps._clip_value)) # rates feed back - rates[t].set_shape([None, hps.dataset_dims[hps.dataset_names[0]]]) - loglikelihood_t = Poisson(log_rates_t).logp(data_t_bxd) - - elif hps.output_dist == 'gaussian': - mean_n_logvars = tf.matmul(factors[t],this_out_fac_W) + this_out_fac_b - mean_n_logvars.set_shape([None, None]) - means_t_bxd, logvars_t_bxd = tf.split(axis=1, num_or_size_splits=2, - value=mean_n_logvars) - rates[t] = means_t_bxd # rates feed back to controller - dist_params[t] = tf.concat( - axis=1, values=[means_t_bxd, tf.exp(tf.clip_by_value(logvars_t_bxd, -hps._clip_value, hps._clip_value))]) - loglikelihood_t = \ - diag_gaussian_log_likelihood(data_t_bxd, - means_t_bxd, logvars_t_bxd) - else: - assert False, "NIY" - - log_p_xgz_b += tf.reduce_sum(loglikelihood_t, [1]) - - # Correlation of inferred inputs cost. - self.corr_cost = tf.constant(0.0) - if hps.co_mean_corr_scale > 0.0: - all_sum_corr = [] - for i in range(hps.co_dim): - for j in range(i+1, hps.co_dim): - sum_corr_ij = tf.constant(0.0) - for t in range(num_steps): - u_mean_t = posterior_zs_co[t].mean - sum_corr_ij += u_mean_t[:,i]*u_mean_t[:,j] - all_sum_corr.append(0.5 * tf.square(sum_corr_ij)) - self.corr_cost = tf.reduce_mean(all_sum_corr) # div by batch and by n*(n-1)/2 pairs - - # Variational Lower Bound on posterior, p(z|x), plus reconstruction cost. - # KL and reconstruction costs are normalized only by batch size, not by - # dimension, or by time steps. - kl_cost_g0_b = tf.zeros_like(batch_size, dtype=tf.float32) - kl_cost_co_b = tf.zeros_like(batch_size, dtype=tf.float32) - self.kl_cost = tf.constant(0.0) # VAE KL cost - self.recon_cost = tf.constant(0.0) # VAE reconstruction cost - self.nll_bound_vae = tf.constant(0.0) - self.nll_bound_iwae = tf.constant(0.0) # for eval with IWAE cost. - if kind in ["train", "posterior_sample_and_average", "posterior_push_mean"]: - kl_cost_g0_b = 0.0 - kl_cost_co_b = 0.0 - if ic_dim > 0: - g0_priors = [self.prior_zs_g0] - g0_posts = [self.posterior_zs_g0] - kl_cost_g0_b = KLCost_GaussianGaussian(g0_posts, g0_priors).kl_cost_b - kl_cost_g0_b = hps.kl_ic_weight * kl_cost_g0_b - if co_dim > 0: - kl_cost_co_b = \ - KLCost_GaussianGaussianProcessSampled( - posterior_zs_co, prior_zs_ar_con).kl_cost_b - kl_cost_co_b = hps.kl_co_weight * kl_cost_co_b - - # L = -KL + log p(x|z), to maximize bound on likelihood - # -L = KL - log p(x|z), to minimize bound on NLL - # so 'reconstruction cost' is negative log likelihood - self.recon_cost = - tf.reduce_mean(log_p_xgz_b) - self.kl_cost = tf.reduce_mean(kl_cost_g0_b + kl_cost_co_b) - - lb_on_ll_b = log_p_xgz_b - kl_cost_g0_b - kl_cost_co_b - - # VAE error averages outside the log - self.nll_bound_vae = -tf.reduce_mean(lb_on_ll_b) - - # IWAE error averages inside the log - k = tf.cast(tf.shape(log_p_xgz_b)[0], tf.float32) - iwae_lb_on_ll = -tf.log(k) + log_sum_exp(lb_on_ll_b) - self.nll_bound_iwae = -iwae_lb_on_ll - - # L2 regularization on the generator, normalized by number of parameters. - self.l2_cost = tf.constant(0.0) - if self.hps.l2_gen_scale > 0.0 or self.hps.l2_con_scale > 0.0: - l2_costs = [] - l2_numels = [] - l2_reg_var_lists = [tf.get_collection('l2_gen_reg'), - tf.get_collection('l2_con_reg')] - l2_reg_scales = [self.hps.l2_gen_scale, self.hps.l2_con_scale] - for l2_reg_vars, l2_scale in zip(l2_reg_var_lists, l2_reg_scales): - for v in l2_reg_vars: - numel = tf.reduce_prod(tf.concat(axis=0, values=tf.shape(v))) - numel_f = tf.cast(numel, tf.float32) - l2_numels.append(numel_f) - v_l2 = tf.reduce_sum(v*v) - l2_costs.append(0.5 * l2_scale * v_l2) - self.l2_cost = tf.add_n(l2_costs) / tf.add_n(l2_numels) - - # Compute the cost for training, part of the graph regardless. - # The KL cost can be problematic at the beginning of optimization, - # so we allow an exponential increase in weighting the KL from 0 - # to 1. - self.kl_decay_step = tf.maximum(self.train_step - hps.kl_start_step, 0) - self.l2_decay_step = tf.maximum(self.train_step - hps.l2_start_step, 0) - kl_decay_step_f = tf.cast(self.kl_decay_step, tf.float32) - l2_decay_step_f = tf.cast(self.l2_decay_step, tf.float32) - kl_increase_steps_f = tf.cast(hps.kl_increase_steps, tf.float32) - l2_increase_steps_f = tf.cast(hps.l2_increase_steps, tf.float32) - self.kl_weight = kl_weight = \ - tf.minimum(kl_decay_step_f / kl_increase_steps_f, 1.0) - self.l2_weight = l2_weight = \ - tf.minimum(l2_decay_step_f / l2_increase_steps_f, 1.0) - - self.timed_kl_cost = kl_weight * self.kl_cost - self.timed_l2_cost = l2_weight * self.l2_cost - self.weight_corr_cost = hps.co_mean_corr_scale * self.corr_cost - self.cost = self.recon_cost + self.timed_kl_cost + \ - self.timed_l2_cost + self.weight_corr_cost - - if kind != "train": - # save every so often - self.seso_saver = tf.train.Saver(tf.global_variables(), - max_to_keep=hps.max_ckpt_to_keep) - # lowest validation error - self.lve_saver = tf.train.Saver(tf.global_variables(), - max_to_keep=hps.max_ckpt_to_keep_lve) - - return - - # OPTIMIZATION - # train the io matrices only - if self.hps.do_train_io_only: - self.train_vars = tvars = \ - tf.get_collection('IO_transformations', - scope=tf.get_variable_scope().name) - # train the encoder only - elif self.hps.do_train_encoder_only: - tvars1 = \ - tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, - scope='LFADS/ic_enc_*') - tvars2 = \ - tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, - scope='LFADS/z/ic_enc_*') - - self.train_vars = tvars = tvars1 + tvars2 - # train all variables - else: - self.train_vars = tvars = \ - tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, - scope=tf.get_variable_scope().name) - print("done.") - print("Model Variables (to be optimized): ") - total_params = 0 - for i in range(len(tvars)): - shape = tvars[i].get_shape().as_list() - print(" ", i, tvars[i].name, shape) - total_params += np.prod(shape) - print("Total model parameters: ", total_params) - - grads = tf.gradients(self.cost, tvars) - grads, grad_global_norm = tf.clip_by_global_norm(grads, hps.max_grad_norm) - opt = tf.train.AdamOptimizer(self.learning_rate, beta1=0.9, beta2=0.999, - epsilon=1e-01) - self.grads = grads - self.grad_global_norm = grad_global_norm - self.train_op = opt.apply_gradients( - zip(grads, tvars), global_step=self.train_step) - - self.seso_saver = tf.train.Saver(tf.global_variables(), - max_to_keep=hps.max_ckpt_to_keep) - - # lowest validation error - self.lve_saver = tf.train.Saver(tf.global_variables(), - max_to_keep=hps.max_ckpt_to_keep) - - # SUMMARIES, used only during training. - # example summary - self.example_image = tf.placeholder(tf.float32, shape=[1,None,None,3], - name='image_tensor') - self.example_summ = tf.summary.image("LFADS example", self.example_image, - collections=["example_summaries"]) - - # general training summaries - self.lr_summ = tf.summary.scalar("Learning rate", self.learning_rate) - self.kl_weight_summ = tf.summary.scalar("KL weight", self.kl_weight) - self.l2_weight_summ = tf.summary.scalar("L2 weight", self.l2_weight) - self.corr_cost_summ = tf.summary.scalar("Corr cost", self.weight_corr_cost) - self.grad_global_norm_summ = tf.summary.scalar("Gradient global norm", - self.grad_global_norm) - if hps.co_dim > 0: - self.atau_summ = [None] * hps.co_dim - self.pvar_summ = [None] * hps.co_dim - for c in range(hps.co_dim): - self.atau_summ[c] = \ - tf.summary.scalar("AR Autocorrelation taus " + str(c), - tf.exp(self.prior_zs_ar_con.logataus_1xu[0,c])) - self.pvar_summ[c] = \ - tf.summary.scalar("AR Variances " + str(c), - tf.exp(self.prior_zs_ar_con.logpvars_1xu[0,c])) - - # cost summaries, separated into different collections for - # training vs validation. We make placeholders for these, because - # even though the graph computes these costs on a per-batch basis, - # we want to report the more reliable metric of per-epoch cost. - kl_cost_ph = tf.placeholder(tf.float32, shape=[], name='kl_cost_ph') - self.kl_t_cost_summ = tf.summary.scalar("KL cost (train)", kl_cost_ph, - collections=["train_summaries"]) - self.kl_v_cost_summ = tf.summary.scalar("KL cost (valid)", kl_cost_ph, - collections=["valid_summaries"]) - l2_cost_ph = tf.placeholder(tf.float32, shape=[], name='l2_cost_ph') - self.l2_cost_summ = tf.summary.scalar("L2 cost", l2_cost_ph, - collections=["train_summaries"]) - - recon_cost_ph = tf.placeholder(tf.float32, shape=[], name='recon_cost_ph') - self.recon_t_cost_summ = tf.summary.scalar("Reconstruction cost (train)", - recon_cost_ph, - collections=["train_summaries"]) - self.recon_v_cost_summ = tf.summary.scalar("Reconstruction cost (valid)", - recon_cost_ph, - collections=["valid_summaries"]) - - total_cost_ph = tf.placeholder(tf.float32, shape=[], name='total_cost_ph') - self.cost_t_summ = tf.summary.scalar("Total cost (train)", total_cost_ph, - collections=["train_summaries"]) - self.cost_v_summ = tf.summary.scalar("Total cost (valid)", total_cost_ph, - collections=["valid_summaries"]) - - self.kl_cost_ph = kl_cost_ph - self.l2_cost_ph = l2_cost_ph - self.recon_cost_ph = recon_cost_ph - self.total_cost_ph = total_cost_ph - - # Merged summaries, for easy coding later. - self.merged_examples = tf.summary.merge_all(key="example_summaries") - self.merged_generic = tf.summary.merge_all() # default key is 'summaries' - self.merged_train = tf.summary.merge_all(key="train_summaries") - self.merged_valid = tf.summary.merge_all(key="valid_summaries") - - session = tf.get_default_session() - self.logfile = os.path.join(hps.lfads_save_dir, "lfads_log") - self.writer = tf.summary.FileWriter(self.logfile) - - def build_feed_dict(self, train_name, data_bxtxd, ext_input_bxtxi=None, - keep_prob=None): - """Build the feed dictionary, handles cases where there is no value defined. - - Args: - train_name: The key into the datasets, to set the tf.case statement for - the proper readin / readout matrices. - data_bxtxd: The data tensor - ext_input_bxtxi (optional): The external input tensor - keep_prob: The drop out keep probability. - - Returns: - The feed dictionary with TF tensors as keys and data as values, for use - with tf.Session.run() - - """ - feed_dict = {} - B, T, _ = data_bxtxd.shape - feed_dict[self.dataName] = train_name - feed_dict[self.dataset_ph] = data_bxtxd - - if self.ext_input is not None and ext_input_bxtxi is not None: - feed_dict[self.ext_input] = ext_input_bxtxi - - if keep_prob is None: - feed_dict[self.keep_prob] = self.hps.keep_prob - else: - feed_dict[self.keep_prob] = keep_prob - - return feed_dict - - @staticmethod - def get_batch(data_extxd, ext_input_extxi=None, batch_size=None, - example_idxs=None): - """Get a batch of data, either randomly chosen, or specified directly. - - Args: - data_extxd: The data to model, numpy tensors with shape: - # examples x # time steps x # dimensions - ext_input_extxi (optional): The external inputs, numpy tensor with shape: - # examples x # time steps x # external input dimensions - batch_size: The size of the batch to return - example_idxs (optional): The example indices used to select examples. - - Returns: - A tuple with two parts: - 1. Batched data numpy tensor with shape: - batch_size x # time steps x # dimensions - 2. Batched external input numpy tensor with shape: - batch_size x # time steps x # external input dims - """ - assert batch_size is not None or example_idxs is not None, "Problems" - E, T, D = data_extxd.shape - if example_idxs is None: - example_idxs = np.random.choice(E, batch_size) - - ext_input_bxtxi = None - if ext_input_extxi is not None: - ext_input_bxtxi = ext_input_extxi[example_idxs,:,:] - - return data_extxd[example_idxs,:,:], ext_input_bxtxi - - @staticmethod - def example_idxs_mod_batch_size(nexamples, batch_size): - """Given a number of examples, E, and a batch_size, B, generate indices - [0, 1, 2, ... B-1; - [B, B+1, ... 2*B-1; - ... - ] - returning those indices as a 2-dim tensor shaped like E/B x B. Note that - shape is only correct if E % B == 0. If not, then an extra row is generated - so that the remainder of examples is included. The extra examples are - explicitly to to the zero index (see randomize_example_idxs_mod_batch_size) - for randomized behavior. - - Args: - nexamples: The number of examples to batch up. - batch_size: The size of the batch. - Returns: - 2-dim tensor as described above. - """ - bmrem = batch_size - (nexamples % batch_size) - bmrem_examples = [] - if bmrem < batch_size: - #bmrem_examples = np.zeros(bmrem, dtype=np.int32) - ridxs = np.random.permutation(nexamples)[0:bmrem].astype(np.int32) - bmrem_examples = np.sort(ridxs) - example_idxs = range(nexamples) + list(bmrem_examples) - example_idxs_e_x_edivb = np.reshape(example_idxs, [-1, batch_size]) - return example_idxs_e_x_edivb, bmrem - - @staticmethod - def randomize_example_idxs_mod_batch_size(nexamples, batch_size): - """Indices 1:nexamples, randomized, in 2D form of - shape = (nexamples / batch_size) x batch_size. The remainder - is managed by drawing randomly from 1:nexamples. - - Args: - nexamples: number of examples to randomize - batch_size: number of elements in batch - - Returns: - The randomized, properly shaped indicies. - """ - assert nexamples > batch_size, "Problems" - bmrem = batch_size - nexamples % batch_size - bmrem_examples = [] - if bmrem < batch_size: - bmrem_examples = np.random.choice(range(nexamples), - size=bmrem, replace=False) - example_idxs = range(nexamples) + list(bmrem_examples) - mixed_example_idxs = np.random.permutation(example_idxs) - example_idxs_e_x_edivb = np.reshape(mixed_example_idxs, [-1, batch_size]) - return example_idxs_e_x_edivb, bmrem - - def shuffle_spikes_in_time(self, data_bxtxd): - """Shuffle the spikes in the temporal dimension. This is useful to - help the LFADS system avoid overfitting to individual spikes or fast - oscillations found in the data that are irrelevant to behavior. A - pure 'tabula rasa' approach would avoid this, but LFADS is sensitive - enough to pick up dynamics that you may not want. - - Args: - data_bxtxd: numpy array of spike count data to be shuffled. - Returns: - S_bxtxd, a numpy array with the same dimensions and contents as - data_bxtxd, but shuffled appropriately. - - """ - - B, T, N = data_bxtxd.shape - w = self.hps.temporal_spike_jitter_width - - if w == 0: - return data_bxtxd - - max_counts = np.max(data_bxtxd) - S_bxtxd = np.zeros([B,T,N]) - - # Intuitively, shuffle spike occurances, 0 or 1, but since we have counts, - # Do it over and over again up to the max count. - for mc in range(1,max_counts+1): - idxs = np.nonzero(data_bxtxd >= mc) - - data_ones = np.zeros_like(data_bxtxd) - data_ones[data_bxtxd >= mc] = 1 - - nfound = len(idxs[0]) - shuffles_incrs_in_time = np.random.randint(-w, w, size=nfound) - - shuffle_tidxs = idxs[1].copy() - shuffle_tidxs += shuffles_incrs_in_time - - # Reflect on the boundaries to not lose mass. - shuffle_tidxs[shuffle_tidxs < 0] = -shuffle_tidxs[shuffle_tidxs < 0] - shuffle_tidxs[shuffle_tidxs > T-1] = \ - (T-1)-(shuffle_tidxs[shuffle_tidxs > T-1] -(T-1)) - - for iii in zip(idxs[0], shuffle_tidxs, idxs[2]): - S_bxtxd[iii] += 1 - - return S_bxtxd - - def shuffle_and_flatten_datasets(self, datasets, kind='train'): - """Since LFADS supports multiple datasets in the same dynamical model, - we have to be careful to use all the data in a single training epoch. But - since the datasets my have different data dimensionality, we cannot batch - examples from data dictionaries together. Instead, we generate random - batches within each data dictionary, and then randomize these batches - while holding onto the dataname, so that when it's time to feed - the graph, the correct in/out matrices can be selected, per batch. - - Args: - datasets: A dict of data dicts. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - kind: 'train' or 'valid' - - Returns: - A flat list, in which each element is a pair ('name', indices). - """ - batch_size = self.hps.batch_size - ndatasets = len(datasets) - random_example_idxs = {} - epoch_idxs = {} - all_name_example_idx_pairs = [] - kind_data = kind + '_data' - for name, data_dict in datasets.items(): - nexamples, ntime, data_dim = data_dict[kind_data].shape - epoch_idxs[name] = 0 - random_example_idxs, _ = \ - self.randomize_example_idxs_mod_batch_size(nexamples, batch_size) - - epoch_size = random_example_idxs.shape[0] - names = [name] * epoch_size - all_name_example_idx_pairs += zip(names, random_example_idxs) - - np.random.shuffle(all_name_example_idx_pairs) # shuffle in place - - return all_name_example_idx_pairs - - def train_epoch(self, datasets, batch_size=None, do_save_ckpt=True): - """Train the model through the entire dataset once. - - Args: - datasets: A dict of data dicts. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - batch_size (optional): The batch_size to use - do_save_ckpt (optional): Should the routine save a checkpoint on this - training epoch? - - Returns: - A tuple with 6 float values: - (total cost of the epoch, epoch reconstruction cost, - epoch kl cost, KL weight used this training epoch, - total l2 cost on generator, and the corresponding weight). - """ - ops_to_eval = [self.cost, self.recon_cost, - self.kl_cost, self.kl_weight, - self.l2_cost, self.l2_weight, - self.train_op] - collected_op_values = self.run_epoch(datasets, ops_to_eval, kind="train") - - total_cost = total_recon_cost = total_kl_cost = 0.0 - # normalizing by batch done in distributions.py - epoch_size = len(collected_op_values) - for op_values in collected_op_values: - total_cost += op_values[0] - total_recon_cost += op_values[1] - total_kl_cost += op_values[2] - - kl_weight = collected_op_values[-1][3] - l2_cost = collected_op_values[-1][4] - l2_weight = collected_op_values[-1][5] - - epoch_total_cost = total_cost / epoch_size - epoch_recon_cost = total_recon_cost / epoch_size - epoch_kl_cost = total_kl_cost / epoch_size - - if do_save_ckpt: - session = tf.get_default_session() - checkpoint_path = os.path.join(self.hps.lfads_save_dir, - self.hps.checkpoint_name + '.ckpt') - self.seso_saver.save(session, checkpoint_path, - global_step=self.train_step) - - return epoch_total_cost, epoch_recon_cost, epoch_kl_cost, \ - kl_weight, l2_cost, l2_weight - - - def run_epoch(self, datasets, ops_to_eval, kind="train", batch_size=None, - do_collect=True, keep_prob=None): - """Run the model through the entire dataset once. - - Args: - datasets: A dict of data dicts. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - ops_to_eval: A list of tensorflow operations that will be evaluated in - the tf.session.run() call. - batch_size (optional): The batch_size to use - do_collect (optional): Should the routine collect all session.run - output as a list, and return it? - keep_prob (optional): The dropout keep probability. - - Returns: - A list of lists, the internal list is the return for the ops for each - session.run() call. The outer list collects over the epoch. - """ - hps = self.hps - all_name_example_idx_pairs = \ - self.shuffle_and_flatten_datasets(datasets, kind) - - kind_data = kind + '_data' - kind_ext_input = kind + '_ext_input' - - total_cost = total_recon_cost = total_kl_cost = 0.0 - session = tf.get_default_session() - epoch_size = len(all_name_example_idx_pairs) - evaled_ops_list = [] - for name, example_idxs in all_name_example_idx_pairs: - data_dict = datasets[name] - data_extxd = data_dict[kind_data] - if hps.output_dist == 'poisson' and hps.temporal_spike_jitter_width > 0: - data_extxd = self.shuffle_spikes_in_time(data_extxd) - - ext_input_extxi = data_dict[kind_ext_input] - data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, ext_input_extxi, - example_idxs=example_idxs) - - feed_dict = self.build_feed_dict(name, data_bxtxd, ext_input_bxtxi, - keep_prob=keep_prob) - evaled_ops_np = session.run(ops_to_eval, feed_dict=feed_dict) - if do_collect: - evaled_ops_list.append(evaled_ops_np) - - return evaled_ops_list - - def summarize_all(self, datasets, summary_values): - """Plot and summarize stuff in tensorboard. - - Note that everything done in the current function is otherwise done on - a single, randomly selected dataset (except for summary_values, which are - passed in.) - - Args: - datasets, the dictionary of datasets used in the study. - summary_values: These summary values are created from the training loop, - and so summarize the entire set of datasets. - """ - hps = self.hps - tr_kl_cost = summary_values['tr_kl_cost'] - tr_recon_cost = summary_values['tr_recon_cost'] - tr_total_cost = summary_values['tr_total_cost'] - kl_weight = summary_values['kl_weight'] - l2_weight = summary_values['l2_weight'] - l2_cost = summary_values['l2_cost'] - has_any_valid_set = summary_values['has_any_valid_set'] - i = summary_values['nepochs'] - - session = tf.get_default_session() - train_summ, train_step = session.run([self.merged_train, - self.train_step], - feed_dict={self.l2_cost_ph:l2_cost, - self.kl_cost_ph:tr_kl_cost, - self.recon_cost_ph:tr_recon_cost, - self.total_cost_ph:tr_total_cost}) - self.writer.add_summary(train_summ, train_step) - if has_any_valid_set: - ev_kl_cost = summary_values['ev_kl_cost'] - ev_recon_cost = summary_values['ev_recon_cost'] - ev_total_cost = summary_values['ev_total_cost'] - eval_summ = session.run(self.merged_valid, - feed_dict={self.kl_cost_ph:ev_kl_cost, - self.recon_cost_ph:ev_recon_cost, - self.total_cost_ph:ev_total_cost}) - self.writer.add_summary(eval_summ, train_step) - print("Epoch:%d, step:%d (TRAIN, VALID): total: %.2f, %.2f\ - recon: %.2f, %.2f, kl: %.2f, %.2f, l2: %.5f,\ - kl weight: %.2f, l2 weight: %.2f" % \ - (i, train_step, tr_total_cost, ev_total_cost, - tr_recon_cost, ev_recon_cost, tr_kl_cost, ev_kl_cost, - l2_cost, kl_weight, l2_weight)) - - csv_outstr = "epoch,%d, step,%d, total,%.2f,%.2f, \ - recon,%.2f,%.2f, kl,%.2f,%.2f, l2,%.5f, \ - klweight,%.2f, l2weight,%.2f\n"% \ - (i, train_step, tr_total_cost, ev_total_cost, - tr_recon_cost, ev_recon_cost, tr_kl_cost, ev_kl_cost, - l2_cost, kl_weight, l2_weight) - - else: - print("Epoch:%d, step:%d TRAIN: total: %.2f recon: %.2f, kl: %.2f,\ - l2: %.5f, kl weight: %.2f, l2 weight: %.2f" % \ - (i, train_step, tr_total_cost, tr_recon_cost, tr_kl_cost, - l2_cost, kl_weight, l2_weight)) - csv_outstr = "epoch,%d, step,%d, total,%.2f, recon,%.2f, kl,%.2f, \ - l2,%.5f, klweight,%.2f, l2weight,%.2f\n"% \ - (i, train_step, tr_total_cost, tr_recon_cost, - tr_kl_cost, l2_cost, kl_weight, l2_weight) - - if self.hps.csv_log: - csv_file = os.path.join(self.hps.lfads_save_dir, self.hps.csv_log+'.csv') - with open(csv_file, "a") as myfile: - myfile.write(csv_outstr) - - - def plot_single_example(self, datasets): - """Plot an image relating to a randomly chosen, specific example. We use - posterior sample and average by taking one example, and filling a whole - batch with that example, sample from the posterior, and then average the - quantities. - - """ - hps = self.hps - all_data_names = datasets.keys() - data_name = np.random.permutation(all_data_names)[0] - data_dict = datasets[data_name] - has_valid_set = True if data_dict['valid_data'] is not None else False - cf = 1.0 # plotting concern - - # posterior sample and average here - E, _, _ = data_dict['train_data'].shape - eidx = np.random.choice(E) - example_idxs = eidx * np.ones(hps.batch_size, dtype=np.int32) - - train_data_bxtxd, train_ext_input_bxtxi = \ - self.get_batch(data_dict['train_data'], data_dict['train_ext_input'], - example_idxs=example_idxs) - - truth_train_data_bxtxd = None - if 'train_truth' in data_dict and data_dict['train_truth'] is not None: - truth_train_data_bxtxd, _ = self.get_batch(data_dict['train_truth'], - example_idxs=example_idxs) - cf = data_dict['conversion_factor'] - - # plotter does averaging - train_model_values = self.eval_model_runs_batch(data_name, - train_data_bxtxd, - train_ext_input_bxtxi, - do_average_batch=False) - - train_step = train_model_values['train_steps'] - feed_dict = self.build_feed_dict(data_name, train_data_bxtxd, - train_ext_input_bxtxi, keep_prob=1.0) - - session = tf.get_default_session() - generic_summ = session.run(self.merged_generic, feed_dict=feed_dict) - self.writer.add_summary(generic_summ, train_step) - - valid_data_bxtxd = valid_model_values = valid_ext_input_bxtxi = None - truth_valid_data_bxtxd = None - if has_valid_set: - E, _, _ = data_dict['valid_data'].shape - eidx = np.random.choice(E) - example_idxs = eidx * np.ones(hps.batch_size, dtype=np.int32) - valid_data_bxtxd, valid_ext_input_bxtxi = \ - self.get_batch(data_dict['valid_data'], - data_dict['valid_ext_input'], - example_idxs=example_idxs) - if 'valid_truth' in data_dict and data_dict['valid_truth'] is not None: - truth_valid_data_bxtxd, _ = self.get_batch(data_dict['valid_truth'], - example_idxs=example_idxs) - else: - truth_valid_data_bxtxd = None - - # plotter does averaging - valid_model_values = self.eval_model_runs_batch(data_name, - valid_data_bxtxd, - valid_ext_input_bxtxi, - do_average_batch=False) - - example_image = plot_lfads(train_bxtxd=train_data_bxtxd, - train_model_vals=train_model_values, - train_ext_input_bxtxi=train_ext_input_bxtxi, - train_truth_bxtxd=truth_train_data_bxtxd, - valid_bxtxd=valid_data_bxtxd, - valid_model_vals=valid_model_values, - valid_ext_input_bxtxi=valid_ext_input_bxtxi, - valid_truth_bxtxd=truth_valid_data_bxtxd, - bidx=None, cf=cf, output_dist=hps.output_dist) - example_image = np.expand_dims(example_image, axis=0) - example_summ = session.run(self.merged_examples, - feed_dict={self.example_image : example_image}) - self.writer.add_summary(example_summ) - - def train_model(self, datasets): - """Train the model, print per-epoch information, and save checkpoints. - - Loop over training epochs. The function that actually does the - training is train_epoch. This function iterates over the training - data, one epoch at a time. The learning rate schedule is such - that it will stay the same until the cost goes up in comparison to - the last few values, then it will drop. - - Args: - datasets: A dict of data dicts. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - """ - hps = self.hps - has_any_valid_set = False - for data_dict in datasets.values(): - if data_dict['valid_data'] is not None: - has_any_valid_set = True - break - - session = tf.get_default_session() - lr = session.run(self.learning_rate) - lr_stop = hps.learning_rate_stop - i = -1 - train_costs = [] - valid_costs = [] - ev_total_cost = ev_recon_cost = ev_kl_cost = 0.0 - lowest_ev_cost = np.Inf - while True: - i += 1 - do_save_ckpt = True if i % 10 ==0 else False - tr_total_cost, tr_recon_cost, tr_kl_cost, kl_weight, l2_cost, l2_weight = \ - self.train_epoch(datasets, do_save_ckpt=do_save_ckpt) - - # Evaluate the validation cost, and potentially save. Note that this - # routine will not save a validation checkpoint until the kl weight and - # l2 weights are equal to 1.0. - if has_any_valid_set: - ev_total_cost, ev_recon_cost, ev_kl_cost = \ - self.eval_cost_epoch(datasets, kind='valid') - valid_costs.append(ev_total_cost) - - # > 1 may give more consistent results, but not the actual lowest vae. - # == 1 gives the lowest vae seen so far. - n_lve = 1 - run_avg_lve = np.mean(valid_costs[-n_lve:]) - - # conditions for saving checkpoints: - # KL weight must have finished stepping (>=1.0), AND - # L2 weight must have finished stepping OR L2 is not being used, AND - # the current run has a lower LVE than previous runs AND - # len(valid_costs > n_lve) (not sure what that does) - if kl_weight >= 1.0 and \ - (l2_weight >= 1.0 or \ - (self.hps.l2_gen_scale == 0.0 and self.hps.l2_con_scale == 0.0)) \ - and (len(valid_costs) > n_lve and run_avg_lve < lowest_ev_cost): - - lowest_ev_cost = run_avg_lve - checkpoint_path = os.path.join(self.hps.lfads_save_dir, - self.hps.checkpoint_name + '_lve.ckpt') - self.lve_saver.save(session, checkpoint_path, - global_step=self.train_step, - latest_filename='checkpoint_lve') - - # Plot and summarize. - values = {'nepochs':i, 'has_any_valid_set': has_any_valid_set, - 'tr_total_cost':tr_total_cost, 'ev_total_cost':ev_total_cost, - 'tr_recon_cost':tr_recon_cost, 'ev_recon_cost':ev_recon_cost, - 'tr_kl_cost':tr_kl_cost, 'ev_kl_cost':ev_kl_cost, - 'l2_weight':l2_weight, 'kl_weight':kl_weight, - 'l2_cost':l2_cost} - self.summarize_all(datasets, values) - self.plot_single_example(datasets) - - # Manage learning rate. - train_res = tr_total_cost - n_lr = hps.learning_rate_n_to_compare - if len(train_costs) > n_lr and train_res > np.max(train_costs[-n_lr:]): - _ = session.run(self.learning_rate_decay_op) - lr = session.run(self.learning_rate) - print(" Decreasing learning rate to %f." % lr) - # Force the system to run n_lr times while at this lr. - train_costs.append(np.inf) - else: - train_costs.append(train_res) - - if lr < lr_stop: - print("Stopping optimization based on learning rate criteria.") - break - - def eval_cost_epoch(self, datasets, kind='train', ext_input_extxi=None, - batch_size=None): - """Evaluate the cost of the epoch. - - Args: - data_dict: The dictionary of data (training and validation) used for - training and evaluation of the model, respectively. - - Returns: - a 3 tuple of costs: - (epoch total cost, epoch reconstruction cost, epoch KL cost) - """ - ops_to_eval = [self.cost, self.recon_cost, self.kl_cost] - collected_op_values = self.run_epoch(datasets, ops_to_eval, kind=kind, - keep_prob=1.0) - - total_cost = total_recon_cost = total_kl_cost = 0.0 - # normalizing by batch done in distributions.py - epoch_size = len(collected_op_values) - for op_values in collected_op_values: - total_cost += op_values[0] - total_recon_cost += op_values[1] - total_kl_cost += op_values[2] - - epoch_total_cost = total_cost / epoch_size - epoch_recon_cost = total_recon_cost / epoch_size - epoch_kl_cost = total_kl_cost / epoch_size - - return epoch_total_cost, epoch_recon_cost, epoch_kl_cost - - def eval_model_runs_batch(self, data_name, data_bxtxd, ext_input_bxtxi=None, - do_eval_cost=False, do_average_batch=False): - """Returns all the goodies for the entire model, per batch. - - If data_bxtxd and ext_input_bxtxi can have fewer than batch_size along dim 1 - in which case this handles the padding and truncating automatically - - Args: - data_name: The name of the data dict, to select which in/out matrices - to use. - data_bxtxd: Numpy array training data with shape: - batch_size x # time steps x # dimensions - ext_input_bxtxi: Numpy array training external input with shape: - batch_size x # time steps x # external input dims - do_eval_cost (optional): If true, the IWAE (Importance Weighted - Autoencoder) log likeihood bound, instead of the VAE version. - do_average_batch (optional): average over the batch, useful for getting - good IWAE costs, and model outputs for a single data point. - - Returns: - A dictionary with the outputs of the model decoder, namely: - prior g0 mean, prior g0 variance, approx. posterior mean, approx - posterior mean, the generator initial conditions, the control inputs (if - enabled), the state of the generator, the factors, and the rates. - """ - session = tf.get_default_session() - - # if fewer than batch_size provided, pad to batch_size - hps = self.hps - batch_size = hps.batch_size - E, _, _ = data_bxtxd.shape - if E < hps.batch_size: - data_bxtxd = np.pad(data_bxtxd, ((0, hps.batch_size-E), (0, 0), (0, 0)), - mode='constant', constant_values=0) - if ext_input_bxtxi is not None: - ext_input_bxtxi = np.pad(ext_input_bxtxi, - ((0, hps.batch_size-E), (0, 0), (0, 0)), - mode='constant', constant_values=0) - - feed_dict = self.build_feed_dict(data_name, data_bxtxd, - ext_input_bxtxi, keep_prob=1.0) - - # Non-temporal signals will be batch x dim. - # Temporal signals are list length T with elements batch x dim. - tf_vals = [self.gen_ics, self.gen_states, self.factors, - self.output_dist_params] - tf_vals.append(self.cost) - tf_vals.append(self.nll_bound_vae) - tf_vals.append(self.nll_bound_iwae) - tf_vals.append(self.train_step) # not train_op! - if self.hps.ic_dim > 0: - tf_vals += [self.prior_zs_g0.mean, self.prior_zs_g0.logvar, - self.posterior_zs_g0.mean, self.posterior_zs_g0.logvar] - if self.hps.co_dim > 0: - tf_vals.append(self.controller_outputs) - tf_vals_flat, fidxs = flatten(tf_vals) - - np_vals_flat = session.run(tf_vals_flat, feed_dict=feed_dict) - - ff = 0 - gen_ics = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - gen_states = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - factors = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - out_dist_params = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - costs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - nll_bound_vaes = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - nll_bound_iwaes = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 - train_steps = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 - if self.hps.ic_dim > 0: - prior_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 - prior_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - post_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - post_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - if self.hps.co_dim > 0: - controller_outputs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - - # [0] are to take out the non-temporal items from lists - gen_ics = gen_ics[0] - costs = costs[0] - nll_bound_vaes = nll_bound_vaes[0] - nll_bound_iwaes = nll_bound_iwaes[0] - train_steps = train_steps[0] - - # Convert to full tensors, not lists of tensors in time dim. - gen_states = list_t_bxn_to_tensor_bxtxn(gen_states) - factors = list_t_bxn_to_tensor_bxtxn(factors) - out_dist_params = list_t_bxn_to_tensor_bxtxn(out_dist_params) - if self.hps.ic_dim > 0: - # select first time point - prior_g0_mean = prior_g0_mean[0] - prior_g0_logvar = prior_g0_logvar[0] - post_g0_mean = post_g0_mean[0] - post_g0_logvar = post_g0_logvar[0] - if self.hps.co_dim > 0: - controller_outputs = list_t_bxn_to_tensor_bxtxn(controller_outputs) - - # slice out the trials in case < batch_size provided - if E < hps.batch_size: - idx = np.arange(E) - gen_ics = gen_ics[idx, :] - gen_states = gen_states[idx, :] - factors = factors[idx, :, :] - out_dist_params = out_dist_params[idx, :, :] - if self.hps.ic_dim > 0: - prior_g0_mean = prior_g0_mean[idx, :] - prior_g0_logvar = prior_g0_logvar[idx, :] - post_g0_mean = post_g0_mean[idx, :] - post_g0_logvar = post_g0_logvar[idx, :] - if self.hps.co_dim > 0: - controller_outputs = controller_outputs[idx, :, :] - - if do_average_batch: - gen_ics = np.mean(gen_ics, axis=0) - gen_states = np.mean(gen_states, axis=0) - factors = np.mean(factors, axis=0) - out_dist_params = np.mean(out_dist_params, axis=0) - if self.hps.ic_dim > 0: - prior_g0_mean = np.mean(prior_g0_mean, axis=0) - prior_g0_logvar = np.mean(prior_g0_logvar, axis=0) - post_g0_mean = np.mean(post_g0_mean, axis=0) - post_g0_logvar = np.mean(post_g0_logvar, axis=0) - if self.hps.co_dim > 0: - controller_outputs = np.mean(controller_outputs, axis=0) - - model_vals = {} - model_vals['gen_ics'] = gen_ics - model_vals['gen_states'] = gen_states - model_vals['factors'] = factors - model_vals['output_dist_params'] = out_dist_params - model_vals['costs'] = costs - model_vals['nll_bound_vaes'] = nll_bound_vaes - model_vals['nll_bound_iwaes'] = nll_bound_iwaes - model_vals['train_steps'] = train_steps - if self.hps.ic_dim > 0: - model_vals['prior_g0_mean'] = prior_g0_mean - model_vals['prior_g0_logvar'] = prior_g0_logvar - model_vals['post_g0_mean'] = post_g0_mean - model_vals['post_g0_logvar'] = post_g0_logvar - if self.hps.co_dim > 0: - model_vals['controller_outputs'] = controller_outputs - - return model_vals - - def eval_model_runs_avg_epoch(self, data_name, data_extxd, - ext_input_extxi=None): - """Returns all the expected value for goodies for the entire model. - - The expected value is taken over hidden (z) variables, namely the initial - conditions and the control inputs. The expected value is approximate, and - accomplished via sampling (batch_size) samples for every examples. - - Args: - data_name: The name of the data dict, to select which in/out matrices - to use. - data_extxd: Numpy array training data with shape: - # examples x # time steps x # dimensions - ext_input_extxi (optional): Numpy array training external input with - shape: # examples x # time steps x # external input dims - - Returns: - A dictionary with the averaged outputs of the model decoder, namely: - prior g0 mean, prior g0 variance, approx. posterior mean, approx - posterior mean, the generator initial conditions, the control inputs (if - enabled), the state of the generator, the factors, and the output - distribution parameters, e.g. (rates or mean and variances). - """ - hps = self.hps - batch_size = hps.batch_size - E, T, D = data_extxd.shape - E_to_process = hps.ps_nexamples_to_process - if E_to_process > E: - E_to_process = E - - if hps.ic_dim > 0: - prior_g0_mean = np.zeros([E_to_process, hps.ic_dim]) - prior_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) - post_g0_mean = np.zeros([E_to_process, hps.ic_dim]) - post_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) - - if hps.co_dim > 0: - controller_outputs = np.zeros([E_to_process, T, hps.co_dim]) - gen_ics = np.zeros([E_to_process, hps.gen_dim]) - gen_states = np.zeros([E_to_process, T, hps.gen_dim]) - factors = np.zeros([E_to_process, T, hps.factors_dim]) - - if hps.output_dist == 'poisson': - out_dist_params = np.zeros([E_to_process, T, D]) - elif hps.output_dist == 'gaussian': - out_dist_params = np.zeros([E_to_process, T, D+D]) - else: - assert False, "NIY" - - costs = np.zeros(E_to_process) - nll_bound_vaes = np.zeros(E_to_process) - nll_bound_iwaes = np.zeros(E_to_process) - train_steps = np.zeros(E_to_process) - for es_idx in range(E_to_process): - print("Running %d of %d." % (es_idx+1, E_to_process)) - example_idxs = es_idx * np.ones(batch_size, dtype=np.int32) - data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, - ext_input_extxi, - batch_size=batch_size, - example_idxs=example_idxs) - model_values = self.eval_model_runs_batch(data_name, data_bxtxd, - ext_input_bxtxi, - do_eval_cost=True, - do_average_batch=True) - - if self.hps.ic_dim > 0: - prior_g0_mean[es_idx,:] = model_values['prior_g0_mean'] - prior_g0_logvar[es_idx,:] = model_values['prior_g0_logvar'] - post_g0_mean[es_idx,:] = model_values['post_g0_mean'] - post_g0_logvar[es_idx,:] = model_values['post_g0_logvar'] - gen_ics[es_idx,:] = model_values['gen_ics'] - - if self.hps.co_dim > 0: - controller_outputs[es_idx,:,:] = model_values['controller_outputs'] - gen_states[es_idx,:,:] = model_values['gen_states'] - factors[es_idx,:,:] = model_values['factors'] - out_dist_params[es_idx,:,:] = model_values['output_dist_params'] - costs[es_idx] = model_values['costs'] - nll_bound_vaes[es_idx] = model_values['nll_bound_vaes'] - nll_bound_iwaes[es_idx] = model_values['nll_bound_iwaes'] - train_steps[es_idx] = model_values['train_steps'] - print('bound nll(vae): %.3f, bound nll(iwae): %.3f' \ - % (nll_bound_vaes[es_idx], nll_bound_iwaes[es_idx])) - - model_runs = {} - if self.hps.ic_dim > 0: - model_runs['prior_g0_mean'] = prior_g0_mean - model_runs['prior_g0_logvar'] = prior_g0_logvar - model_runs['post_g0_mean'] = post_g0_mean - model_runs['post_g0_logvar'] = post_g0_logvar - model_runs['gen_ics'] = gen_ics - - if self.hps.co_dim > 0: - model_runs['controller_outputs'] = controller_outputs - model_runs['gen_states'] = gen_states - model_runs['factors'] = factors - model_runs['output_dist_params'] = out_dist_params - model_runs['costs'] = costs - model_runs['nll_bound_vaes'] = nll_bound_vaes - model_runs['nll_bound_iwaes'] = nll_bound_iwaes - model_runs['train_steps'] = train_steps - return model_runs - - def eval_model_runs_push_mean(self, data_name, data_extxd, - ext_input_extxi=None): - """Returns values of interest for the model by pushing the means through - - The mean values for both initial conditions and the control inputs are - pushed through the model instead of sampling (as is done in - eval_model_runs_avg_epoch). - This is a quick and approximate version of estimating these values instead - of sampling from the posterior many times and then averaging those values of - interest. - - Internally, a total of batch_size trials are run through the model at once. - - Args: - data_name: The name of the data dict, to select which in/out matrices - to use. - data_extxd: Numpy array training data with shape: - # examples x # time steps x # dimensions - ext_input_extxi (optional): Numpy array training external input with - shape: # examples x # time steps x # external input dims - - Returns: - A dictionary with the estimated outputs of the model decoder, namely: - prior g0 mean, prior g0 variance, approx. posterior mean, approx - posterior mean, the generator initial conditions, the control inputs (if - enabled), the state of the generator, the factors, and the output - distribution parameters, e.g. (rates or mean and variances). - """ - hps = self.hps - batch_size = hps.batch_size - E, T, D = data_extxd.shape - E_to_process = hps.ps_nexamples_to_process - if E_to_process > E: - print("Setting number of posterior samples to process to : ", E) - E_to_process = E - - if hps.ic_dim > 0: - prior_g0_mean = np.zeros([E_to_process, hps.ic_dim]) - prior_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) - post_g0_mean = np.zeros([E_to_process, hps.ic_dim]) - post_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) - - if hps.co_dim > 0: - controller_outputs = np.zeros([E_to_process, T, hps.co_dim]) - gen_ics = np.zeros([E_to_process, hps.gen_dim]) - gen_states = np.zeros([E_to_process, T, hps.gen_dim]) - factors = np.zeros([E_to_process, T, hps.factors_dim]) - - if hps.output_dist == 'poisson': - out_dist_params = np.zeros([E_to_process, T, D]) - elif hps.output_dist == 'gaussian': - out_dist_params = np.zeros([E_to_process, T, D+D]) - else: - assert False, "NIY" - - costs = np.zeros(E_to_process) - nll_bound_vaes = np.zeros(E_to_process) - nll_bound_iwaes = np.zeros(E_to_process) - train_steps = np.zeros(E_to_process) - - # generator that will yield 0:N in groups of per items, e.g. - # (0:per-1), (per:2*per-1), ..., with the last group containing <= per items - # this will be used to feed per=batch_size trials into the model at a time - def trial_batches(N, per): - for i in range(0, N, per): - yield np.arange(i, min(i+per, N), dtype=np.int32) - - for batch_idx, es_idx in enumerate(trial_batches(E_to_process, - hps.batch_size)): - print("Running trial batch %d with %d trials" % (batch_idx+1, - len(es_idx))) - data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, - ext_input_extxi, - batch_size=batch_size, - example_idxs=es_idx) - model_values = self.eval_model_runs_batch(data_name, data_bxtxd, - ext_input_bxtxi, - do_eval_cost=True, - do_average_batch=False) - - if self.hps.ic_dim > 0: - prior_g0_mean[es_idx,:] = model_values['prior_g0_mean'] - prior_g0_logvar[es_idx,:] = model_values['prior_g0_logvar'] - post_g0_mean[es_idx,:] = model_values['post_g0_mean'] - post_g0_logvar[es_idx,:] = model_values['post_g0_logvar'] - gen_ics[es_idx,:] = model_values['gen_ics'] - - if self.hps.co_dim > 0: - controller_outputs[es_idx,:,:] = model_values['controller_outputs'] - gen_states[es_idx,:,:] = model_values['gen_states'] - factors[es_idx,:,:] = model_values['factors'] - out_dist_params[es_idx,:,:] = model_values['output_dist_params'] - - # TODO - # model_values['costs'] and other costs come out as scalars, summed over - # all the trials in the batch. what we want is the per-trial costs - costs[es_idx] = model_values['costs'] - nll_bound_vaes[es_idx] = model_values['nll_bound_vaes'] - nll_bound_iwaes[es_idx] = model_values['nll_bound_iwaes'] - - train_steps[es_idx] = model_values['train_steps'] - - model_runs = {} - if self.hps.ic_dim > 0: - model_runs['prior_g0_mean'] = prior_g0_mean - model_runs['prior_g0_logvar'] = prior_g0_logvar - model_runs['post_g0_mean'] = post_g0_mean - model_runs['post_g0_logvar'] = post_g0_logvar - model_runs['gen_ics'] = gen_ics - - if self.hps.co_dim > 0: - model_runs['controller_outputs'] = controller_outputs - model_runs['gen_states'] = gen_states - model_runs['factors'] = factors - model_runs['output_dist_params'] = out_dist_params - - # You probably do not want the LL associated values when pushing the mean - # instead of sampling. - model_runs['costs'] = costs - model_runs['nll_bound_vaes'] = nll_bound_vaes - model_runs['nll_bound_iwaes'] = nll_bound_iwaes - model_runs['train_steps'] = train_steps - return model_runs - - def write_model_runs(self, datasets, output_fname=None, push_mean=False): - """Run the model on the data in data_dict, and save the computed values. - - LFADS generates a number of outputs for each examples, and these are all - saved. They are: - The mean and variance of the prior of g0. - The mean and variance of approximate posterior of g0. - The control inputs (if enabled) - The initial conditions, g0, for all examples. - The generator states for all time. - The factors for all time. - The output distribution parameters (e.g. rates) for all time. - - Args: - datasets: a dictionary of named data_dictionaries, see top of lfads.py - output_fname: a file name stem for the output files. - push_mean: if False (default), generates batch_size samples for each trial - and averages the results. if True, runs each trial once without noise, - pushing the posterior mean initial conditions and control inputs through - the trained model. False is used for posterior_sample_and_average, True - is used for posterior_push_mean. - """ - hps = self.hps - kind = hps.kind - - for data_name, data_dict in datasets.items(): - data_tuple = [('train', data_dict['train_data'], - data_dict['train_ext_input']), - ('valid', data_dict['valid_data'], - data_dict['valid_ext_input'])] - for data_kind, data_extxd, ext_input_extxi in data_tuple: - if not output_fname: - fname = "model_runs_" + data_name + '_' + data_kind + '_' + kind - else: - fname = output_fname + data_name + '_' + data_kind + '_' + kind - - print("Writing data for %s data and kind %s." % (data_name, data_kind)) - if push_mean: - model_runs = self.eval_model_runs_push_mean(data_name, data_extxd, - ext_input_extxi) - else: - model_runs = self.eval_model_runs_avg_epoch(data_name, data_extxd, - ext_input_extxi) - full_fname = os.path.join(hps.lfads_save_dir, fname) - write_data(full_fname, model_runs, compression='gzip') - print("Done.") - - def write_model_samples(self, dataset_name, output_fname=None): - """Use the prior distribution to generate batch_size number of samples - from the model. - - LFADS generates a number of outputs for each sample, and these are all - saved. They are: - The mean and variance of the prior of g0. - The control inputs (if enabled) - The initial conditions, g0, for all examples. - The generator states for all time. - The factors for all time. - The output distribution parameters (e.g. rates) for all time. - - Args: - dataset_name: The name of the dataset to grab the factors -> rates - alignment matrices from. - output_fname: The name of the file in which to save the generated - samples. - """ - hps = self.hps - batch_size = hps.batch_size - - print("Generating %d samples" % (batch_size)) - tf_vals = [self.factors, self.gen_states, self.gen_ics, - self.cost, self.output_dist_params] - if hps.ic_dim > 0: - tf_vals += [self.prior_zs_g0.mean, self.prior_zs_g0.logvar] - if hps.co_dim > 0: - tf_vals += [self.prior_zs_ar_con.samples_t] - tf_vals_flat, fidxs = flatten(tf_vals) - - session = tf.get_default_session() - feed_dict = {} - feed_dict[self.dataName] = dataset_name - feed_dict[self.keep_prob] = 1.0 - - np_vals_flat = session.run(tf_vals_flat, feed_dict=feed_dict) - - ff = 0 - factors = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - gen_states = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - gen_ics = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - costs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - output_dist_params = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - if hps.ic_dim > 0: - prior_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - prior_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - if hps.co_dim > 0: - prior_zs_ar_con = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 - - # [0] are to take out the non-temporal items from lists - gen_ics = gen_ics[0] - costs = costs[0] - - # Convert to full tensors, not lists of tensors in time dim. - gen_states = list_t_bxn_to_tensor_bxtxn(gen_states) - factors = list_t_bxn_to_tensor_bxtxn(factors) - output_dist_params = list_t_bxn_to_tensor_bxtxn(output_dist_params) - if hps.ic_dim > 0: - prior_g0_mean = prior_g0_mean[0] - prior_g0_logvar = prior_g0_logvar[0] - if hps.co_dim > 0: - prior_zs_ar_con = list_t_bxn_to_tensor_bxtxn(prior_zs_ar_con) - - model_vals = {} - model_vals['gen_ics'] = gen_ics - model_vals['gen_states'] = gen_states - model_vals['factors'] = factors - model_vals['output_dist_params'] = output_dist_params - model_vals['costs'] = costs.reshape(1) - if hps.ic_dim > 0: - model_vals['prior_g0_mean'] = prior_g0_mean - model_vals['prior_g0_logvar'] = prior_g0_logvar - if hps.co_dim > 0: - model_vals['prior_zs_ar_con'] = prior_zs_ar_con - - full_fname = os.path.join(hps.lfads_save_dir, output_fname) - write_data(full_fname, model_vals, compression='gzip') - print("Done.") - - @staticmethod - def eval_model_parameters(use_nested=True, include_strs=None): - """Evaluate and return all of the TF variables in the model. - - Args: - use_nested (optional): For returning values, use a nested dictoinary, based - on variable scoping, or return all variables in a flat dictionary. - include_strs (optional): A list of strings to use as a filter, to reduce the - number of variables returned. A variable name must contain at least one - string in include_strs as a sub-string in order to be returned. - - Returns: - The parameters of the model. This can be in a flat - dictionary, or a nested dictionary, where the nesting is by variable - scope. - """ - all_tf_vars = tf.global_variables() - session = tf.get_default_session() - all_tf_vars_eval = session.run(all_tf_vars) - vars_dict = {} - strs = ["LFADS"] - if include_strs: - strs += include_strs - - for i, (var, var_eval) in enumerate(zip(all_tf_vars, all_tf_vars_eval)): - if any(s in include_strs for s in var.name): - if not isinstance(var_eval, np.ndarray): # for H5PY - print(var.name, """ is not numpy array, saving as numpy array - with value: """, var_eval, type(var_eval)) - e = np.array(var_eval) - print(e, type(e)) - else: - e = var_eval - vars_dict[var.name] = e - - if not use_nested: - return vars_dict - - var_names = vars_dict.keys() - nested_vars_dict = {} - current_dict = nested_vars_dict - for v, var_name in enumerate(var_names): - var_split_name_list = var_name.split('/') - split_name_list_len = len(var_split_name_list) - current_dict = nested_vars_dict - for p, part in enumerate(var_split_name_list): - if p < split_name_list_len - 1: - if part in current_dict: - current_dict = current_dict[part] - else: - current_dict[part] = {} - current_dict = current_dict[part] - else: - current_dict[part] = vars_dict[var_name] - - return nested_vars_dict - - @staticmethod - def spikify_rates(rates_bxtxd): - """Randomly spikify underlying rates according a Poisson distribution - - Args: - rates_bxtxd: a numpy tensor with shape: - - Returns: - A numpy array with the same shape as rates_bxtxd, but with the event - counts. - """ - - B,T,N = rates_bxtxd.shape - assert all([B > 0, N > 0]), "problems" - - # Because the rates are changing, there is nesting - spikes_bxtxd = np.zeros([B,T,N], dtype=np.int32) - for b in range(B): - for t in range(T): - for n in range(N): - rate = rates_bxtxd[b,t,n] - count = np.random.poisson(rate) - spikes_bxtxd[b,t,n] = count - - return spikes_bxtxd diff --git a/research/lfads/plot_lfads.py b/research/lfads/plot_lfads.py deleted file mode 100644 index c4e1a0332ef2affeae147edda4779cc4a7e9a0ef..0000000000000000000000000000000000000000 --- a/research/lfads/plot_lfads.py +++ /dev/null @@ -1,181 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import matplotlib -matplotlib.use('Agg') -from matplotlib import pyplot as plt -import numpy as np -import tensorflow as tf - -def _plot_item(W, name, full_name, nspaces): - plt.figure() - if W.shape == (): - print(name, ": ", W) - elif W.shape[0] == 1: - plt.stem(W.T) - plt.title(full_name) - elif W.shape[1] == 1: - plt.stem(W) - plt.title(full_name) - else: - plt.imshow(np.abs(W), interpolation='nearest', cmap='jet'); - plt.colorbar() - plt.title(full_name) - - -def all_plot(d, full_name="", exclude="", nspaces=0): - """Recursively plot all the LFADS model parameters in the nested - dictionary.""" - for k, v in d.iteritems(): - this_name = full_name+"/"+k - if isinstance(v, dict): - all_plot(v, full_name=this_name, exclude=exclude, nspaces=nspaces+4) - else: - if exclude == "" or exclude not in this_name: - _plot_item(v, name=k, full_name=full_name+"/"+k, nspaces=nspaces+4) - - - -def plot_time_series(vals_bxtxn, bidx=None, n_to_plot=np.inf, scale=1.0, - color='r', title=None): - - if bidx is None: - vals_txn = np.mean(vals_bxtxn, axis=0) - else: - vals_txn = vals_bxtxn[bidx,:,:] - - T, N = vals_txn.shape - if n_to_plot > N: - n_to_plot = N - - plt.plot(vals_txn[:,0:n_to_plot] + scale*np.array(range(n_to_plot)), - color=color, lw=1.0) - plt.axis('tight') - if title: - plt.title(title) - - -def plot_lfads_timeseries(data_bxtxn, model_vals, ext_input_bxtxi=None, - truth_bxtxn=None, bidx=None, output_dist="poisson", - conversion_factor=1.0, subplot_cidx=0, - col_title=None): - - n_to_plot = 10 - scale = 1.0 - nrows = 7 - plt.subplot(nrows,2,1+subplot_cidx) - - if output_dist == 'poisson': - rates = means = conversion_factor * model_vals['output_dist_params'] - plot_time_series(rates, bidx, n_to_plot=n_to_plot, scale=scale, - title=col_title + " rates (LFADS - red, Truth - black)") - elif output_dist == 'gaussian': - means_vars = model_vals['output_dist_params'] - means, vars = np.split(means_vars,2, axis=2) # bxtxn - stds = np.sqrt(vars) - plot_time_series(means, bidx, n_to_plot=n_to_plot, scale=scale, - title=col_title + " means (LFADS - red, Truth - black)") - plot_time_series(means+stds, bidx, n_to_plot=n_to_plot, scale=scale, - color='c') - plot_time_series(means-stds, bidx, n_to_plot=n_to_plot, scale=scale, - color='c') - else: - assert 'NIY' - - - if truth_bxtxn is not None: - plot_time_series(truth_bxtxn, bidx, n_to_plot=n_to_plot, color='k', - scale=scale) - - input_title = "" - if "controller_outputs" in model_vals.keys(): - input_title += " Controller Output" - plt.subplot(nrows,2,3+subplot_cidx) - u_t = model_vals['controller_outputs'][0:-1] - plot_time_series(u_t, bidx, n_to_plot=n_to_plot, color='c', scale=1.0, - title=col_title + input_title) - - if ext_input_bxtxi is not None: - input_title += " External Input" - plot_time_series(ext_input_bxtxi, n_to_plot=n_to_plot, color='b', - scale=scale, title=col_title + input_title) - - plt.subplot(nrows,2,5+subplot_cidx) - plot_time_series(means, bidx, - n_to_plot=n_to_plot, scale=1.0, - title=col_title + " Spikes (LFADS - red, Spikes - black)") - plot_time_series(data_bxtxn, bidx, n_to_plot=n_to_plot, color='k', scale=1.0) - - plt.subplot(nrows,2,7+subplot_cidx) - plot_time_series(model_vals['factors'], bidx, n_to_plot=n_to_plot, color='b', - scale=2.0, title=col_title + " Factors") - - plt.subplot(nrows,2,9+subplot_cidx) - plot_time_series(model_vals['gen_states'], bidx, n_to_plot=n_to_plot, - color='g', scale=1.0, title=col_title + " Generator State") - - if bidx is not None: - data_nxt = data_bxtxn[bidx,:,:].T - params_nxt = model_vals['output_dist_params'][bidx,:,:].T - else: - data_nxt = np.mean(data_bxtxn, axis=0).T - params_nxt = np.mean(model_vals['output_dist_params'], axis=0).T - if output_dist == 'poisson': - means_nxt = params_nxt - elif output_dist == 'gaussian': # (means+vars) x time - means_nxt = np.vsplit(params_nxt,2)[0] # get means - else: - assert "NIY" - - plt.subplot(nrows,2,11+subplot_cidx) - plt.imshow(data_nxt, aspect='auto', interpolation='nearest') - plt.title(col_title + ' Data') - - plt.subplot(nrows,2,13+subplot_cidx) - plt.imshow(means_nxt, aspect='auto', interpolation='nearest') - plt.title(col_title + ' Means') - - -def plot_lfads(train_bxtxd, train_model_vals, - train_ext_input_bxtxi=None, train_truth_bxtxd=None, - valid_bxtxd=None, valid_model_vals=None, - valid_ext_input_bxtxi=None, valid_truth_bxtxd=None, - bidx=None, cf=1.0, output_dist='poisson'): - - # Plotting - f = plt.figure(figsize=(18,20), tight_layout=True) - plot_lfads_timeseries(train_bxtxd, train_model_vals, - train_ext_input_bxtxi, - truth_bxtxn=train_truth_bxtxd, - conversion_factor=cf, bidx=bidx, - output_dist=output_dist, col_title='Train') - plot_lfads_timeseries(valid_bxtxd, valid_model_vals, - valid_ext_input_bxtxi, - truth_bxtxn=valid_truth_bxtxd, - conversion_factor=cf, bidx=bidx, - output_dist=output_dist, - subplot_cidx=1, col_title='Valid') - - # Convert from figure to an numpy array width x height x 3 (last for RGB) - f.canvas.draw() - data = np.fromstring(f.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data_wxhx3 = data.reshape(f.canvas.get_width_height()[::-1] + (3,)) - plt.close() - - return data_wxhx3 diff --git a/research/lfads/run_lfads.py b/research/lfads/run_lfads.py deleted file mode 100755 index bd1c0d5e4deab50481cd32efdd044c61707204cc..0000000000000000000000000000000000000000 --- a/research/lfads/run_lfads.py +++ /dev/null @@ -1,815 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -from lfads import LFADS -import numpy as np -import os -import tensorflow as tf -import re -import utils -import sys -MAX_INT = sys.maxsize - -# Lots of hyperparameters, but most are pretty insensitive. The -# explanation of these hyperparameters is found below, in the flags -# session. - -CHECKPOINT_PB_LOAD_NAME = "checkpoint" -CHECKPOINT_NAME = "lfads_vae" -CSV_LOG = "fitlog" -OUTPUT_FILENAME_STEM = "" -DEVICE = "gpu:0" # "cpu:0", or other gpus, e.g. "gpu:1" -MAX_CKPT_TO_KEEP = 5 -MAX_CKPT_TO_KEEP_LVE = 5 -PS_NEXAMPLES_TO_PROCESS = MAX_INT # if larger than number of examples, process all -EXT_INPUT_DIM = 0 -IC_DIM = 64 -FACTORS_DIM = 50 -IC_ENC_DIM = 128 -GEN_DIM = 200 -GEN_CELL_INPUT_WEIGHT_SCALE = 1.0 -GEN_CELL_REC_WEIGHT_SCALE = 1.0 -CELL_WEIGHT_SCALE = 1.0 -BATCH_SIZE = 128 -LEARNING_RATE_INIT = 0.01 -LEARNING_RATE_DECAY_FACTOR = 0.95 -LEARNING_RATE_STOP = 0.00001 -LEARNING_RATE_N_TO_COMPARE = 6 -INJECT_EXT_INPUT_TO_GEN = False -DO_TRAIN_IO_ONLY = False -DO_TRAIN_ENCODER_ONLY = False -DO_RESET_LEARNING_RATE = False -FEEDBACK_FACTORS_OR_RATES = "factors" -DO_TRAIN_READIN = True - -# Calibrated just above the average value for the rnn synthetic data. -MAX_GRAD_NORM = 200.0 -CELL_CLIP_VALUE = 5.0 -KEEP_PROB = 0.95 -TEMPORAL_SPIKE_JITTER_WIDTH = 0 -OUTPUT_DISTRIBUTION = 'poisson' # 'poisson' or 'gaussian' -NUM_STEPS_FOR_GEN_IC = MAX_INT # set to num_steps if greater than num_steps - -DATA_DIR = "/tmp/rnn_synth_data_v1.0/" -DATA_FILENAME_STEM = "chaotic_rnn_inputs_g1p5" -LFADS_SAVE_DIR = "/tmp/lfads_chaotic_rnn_inputs_g1p5/" -CO_DIM = 1 -DO_CAUSAL_CONTROLLER = False -DO_FEED_FACTORS_TO_CONTROLLER = True -CONTROLLER_INPUT_LAG = 1 -PRIOR_AR_AUTOCORRELATION = 10.0 -PRIOR_AR_PROCESS_VAR = 0.1 -DO_TRAIN_PRIOR_AR_ATAU = True -DO_TRAIN_PRIOR_AR_NVAR = True -CI_ENC_DIM = 128 -CON_DIM = 128 -CO_PRIOR_VAR_SCALE = 0.1 -KL_INCREASE_STEPS = 2000 -L2_INCREASE_STEPS = 2000 -L2_GEN_SCALE = 2000.0 -L2_CON_SCALE = 0.0 -# scale of regularizer on time correlation of inferred inputs -CO_MEAN_CORR_SCALE = 0.0 -KL_IC_WEIGHT = 1.0 -KL_CO_WEIGHT = 1.0 -KL_START_STEP = 0 -L2_START_STEP = 0 -IC_PRIOR_VAR_MIN = 0.1 -IC_PRIOR_VAR_SCALE = 0.1 -IC_PRIOR_VAR_MAX = 0.1 -IC_POST_VAR_MIN = 0.0001 # protection from KL blowing up - -flags = tf.app.flags -flags.DEFINE_string("kind", "train", - "Type of model to build {train, \ - posterior_sample_and_average, \ - posterior_push_mean, \ - prior_sample, write_model_params") -flags.DEFINE_string("output_dist", OUTPUT_DISTRIBUTION, - "Type of output distribution, 'poisson' or 'gaussian'") -flags.DEFINE_boolean("allow_gpu_growth", False, - "If true, only allocate amount of memory needed for \ - Session. Otherwise, use full GPU memory.") - -# DATA -flags.DEFINE_string("data_dir", DATA_DIR, "Data for training") -flags.DEFINE_string("data_filename_stem", DATA_FILENAME_STEM, - "Filename stem for data dictionaries.") -flags.DEFINE_string("lfads_save_dir", LFADS_SAVE_DIR, "model save dir") -flags.DEFINE_string("checkpoint_pb_load_name", CHECKPOINT_PB_LOAD_NAME, - "Name of checkpoint files, use 'checkpoint_lve' for best \ - error") -flags.DEFINE_string("checkpoint_name", CHECKPOINT_NAME, - "Name of checkpoint files (.ckpt appended)") -flags.DEFINE_string("output_filename_stem", OUTPUT_FILENAME_STEM, - "Name of output file (postfix will be added)") -flags.DEFINE_string("device", DEVICE, - "Which device to use (default: \"gpu:0\", can also be \ - \"cpu:0\", \"gpu:1\", etc)") -flags.DEFINE_string("csv_log", CSV_LOG, - "Name of file to keep running log of fit likelihoods, \ - etc (.csv appended)") -flags.DEFINE_integer("max_ckpt_to_keep", MAX_CKPT_TO_KEEP, - "Max # of checkpoints to keep (rolling)") -flags.DEFINE_integer("ps_nexamples_to_process", PS_NEXAMPLES_TO_PROCESS, - "Number of examples to process for posterior sample and \ - average (not number of samples to average over).") -flags.DEFINE_integer("max_ckpt_to_keep_lve", MAX_CKPT_TO_KEEP_LVE, - "Max # of checkpoints to keep for lowest validation error \ - models (rolling)") -flags.DEFINE_integer("ext_input_dim", EXT_INPUT_DIM, "Dimension of external \ -inputs") -flags.DEFINE_integer("num_steps_for_gen_ic", NUM_STEPS_FOR_GEN_IC, - "Number of steps to train the generator initial conditon.") - - -# If there are observed inputs, there are two ways to add that observed -# input to the model. The first is by treating as something to be -# inferred, and thus encoding the observed input via the encoders, and then -# input to the generator via the "inferred inputs" channel. Second, one -# can input the input directly into the generator. This has the downside -# of making the generation process strictly dependent on knowing the -# observed input for any generated trial. -flags.DEFINE_boolean("inject_ext_input_to_gen", - INJECT_EXT_INPUT_TO_GEN, - "Should observed inputs be input to model via encoders, \ - or injected directly into generator?") - -# CELL - -# The combined recurrent and input weights of the encoder and -# controller cells are by default set to scale at ws/sqrt(#inputs), -# with ws=1.0. You can change this scaling with this parameter. -flags.DEFINE_float("cell_weight_scale", CELL_WEIGHT_SCALE, - "Input scaling for input weights in generator.") - - -# GENERATION - -# Note that the dimension of the initial conditions is separated from the -# dimensions of the generator initial conditions (and a linear matrix will -# adapt the shapes if necessary). This is just another way to control -# complexity. In all likelihood, setting the ic dims to the size of the -# generator hidden state is just fine. -flags.DEFINE_integer("ic_dim", IC_DIM, "Dimension of h0") -# Setting the dimensions of the factors to something smaller than the data -# dimension is a way to get a reduced dimensionality representation of your -# data. -flags.DEFINE_integer("factors_dim", FACTORS_DIM, - "Number of factors from generator") -flags.DEFINE_integer("ic_enc_dim", IC_ENC_DIM, - "Cell hidden size, encoder of h0") - -# Controlling the size of the generator is one way to control complexity of -# the dynamics (there is also l2, which will squeeze out unnecessary -# dynamics also). The modern deep learning approach is to make these cells -# as large as tolerable (from a waiting perspective), and then regularize -# them to death with drop out or whatever. I don't know if this is correct -# for the LFADS application or not. -flags.DEFINE_integer("gen_dim", GEN_DIM, - "Cell hidden size, generator.") -# The weights of the generator cell by default set to scale at -# ws/sqrt(#inputs), with ws=1.0. You can change ws for -# the input weights or the recurrent weights with these hyperparameters. -flags.DEFINE_float("gen_cell_input_weight_scale", GEN_CELL_INPUT_WEIGHT_SCALE, - "Input scaling for input weights in generator.") -flags.DEFINE_float("gen_cell_rec_weight_scale", GEN_CELL_REC_WEIGHT_SCALE, - "Input scaling for rec weights in generator.") - -# KL DISTRIBUTIONS -# If you don't know what you are donig here, please leave alone, the -# defaults should be fine for most cases, irregardless of other parameters. -# -# If you don't want the prior variance to be learned, set the -# following values to the same thing: ic_prior_var_min, -# ic_prior_var_scale, ic_prior_var_max. The prior mean will be -# learned regardless. -flags.DEFINE_float("ic_prior_var_min", IC_PRIOR_VAR_MIN, - "Minimum variance in posterior h0 codes.") -flags.DEFINE_float("ic_prior_var_scale", IC_PRIOR_VAR_SCALE, - "Variance of ic prior distribution") -flags.DEFINE_float("ic_prior_var_max", IC_PRIOR_VAR_MAX, - "Maximum variance of IC prior distribution.") -# If you really want to limit the information from encoder to decoder, -# Increase ic_post_var_min above 0.0. -flags.DEFINE_float("ic_post_var_min", IC_POST_VAR_MIN, - "Minimum variance of IC posterior distribution.") -flags.DEFINE_float("co_prior_var_scale", CO_PRIOR_VAR_SCALE, - "Variance of control input prior distribution.") - - -flags.DEFINE_float("prior_ar_atau", PRIOR_AR_AUTOCORRELATION, - "Initial autocorrelation of AR(1) priors.") -flags.DEFINE_float("prior_ar_nvar", PRIOR_AR_PROCESS_VAR, - "Initial noise variance for AR(1) priors.") -flags.DEFINE_boolean("do_train_prior_ar_atau", DO_TRAIN_PRIOR_AR_ATAU, - "Is the value for atau an init, or the constant value?") -flags.DEFINE_boolean("do_train_prior_ar_nvar", DO_TRAIN_PRIOR_AR_NVAR, - "Is the value for noise variance an init, or the constant \ - value?") - -# CONTROLLER -# This parameter critically controls whether or not there is a controller -# (along with controller encoders placed into the LFADS graph. If CO_DIM > -# 1, that means there is a 1 dimensional controller outputs, if equal to 0, -# then no controller. -flags.DEFINE_integer("co_dim", CO_DIM, - "Number of control net outputs (>0 builds that graph).") - -# The controller will be more powerful if it can see the encoding of the entire -# trial. However, this allows the controller to create inferred inputs that are -# acausal with respect to the actual data generation process. E.g. the data -# generator could have an input at time t, but the controller, after seeing the -# entirety of the trial could infer that the input is coming a little before -# time t, because there are no restrictions on the data the controller sees. -# One can force the controller to be causal (with respect to perturbations in -# the data generator) so that it only sees forward encodings of the data at time -# t that originate at times before or at time t. One can also control the data -# the controller sees by using an input lag (forward encoding at time [t-tlag] -# for controller input at time t. The same can be done in the reverse direction -# (controller input at time t from reverse encoding at time [t+tlag], in the -# case of an acausal controller). Setting this lag > 0 (even lag=1) can be a -# powerful way of avoiding very spiky decodes. Finally, one can manually control -# whether the factors at time t-1 are fed to the controller at time t. -# -# If you don't care about any of this, and just want to smooth your data, set -# do_causal_controller = False -# do_feed_factors_to_controller = True -# causal_input_lag = 0 -flags.DEFINE_boolean("do_causal_controller", - DO_CAUSAL_CONTROLLER, - "Restrict the controller create only causal inferred \ - inputs?") -# Strictly speaking, feeding either the factors or the rates to the controller -# violates causality, since the g0 gets to see all the data. This may or may not -# be only a theoretical concern. -flags.DEFINE_boolean("do_feed_factors_to_controller", - DO_FEED_FACTORS_TO_CONTROLLER, - "Should factors[t-1] be input to controller at time t?") -flags.DEFINE_string("feedback_factors_or_rates", FEEDBACK_FACTORS_OR_RATES, - "Feedback the factors or the rates to the controller? \ - Acceptable values: 'factors' or 'rates'.") -flags.DEFINE_integer("controller_input_lag", CONTROLLER_INPUT_LAG, - "Time lag on the encoding to controller t-lag for \ - forward, t+lag for reverse.") - -flags.DEFINE_integer("ci_enc_dim", CI_ENC_DIM, - "Cell hidden size, encoder of control inputs") -flags.DEFINE_integer("con_dim", CON_DIM, - "Cell hidden size, controller") - - -# OPTIMIZATION -flags.DEFINE_integer("batch_size", BATCH_SIZE, - "Batch size to use during training.") -flags.DEFINE_float("learning_rate_init", LEARNING_RATE_INIT, - "Learning rate initial value") -flags.DEFINE_float("learning_rate_decay_factor", LEARNING_RATE_DECAY_FACTOR, - "Learning rate decay, decay by this fraction every so \ - often.") -flags.DEFINE_float("learning_rate_stop", LEARNING_RATE_STOP, - "The lr is adaptively reduced, stop training at this value.") -# Rather put the learning rate on an exponentially decreasiong schedule, -# the current algorithm pays attention to the learning rate, and if it -# isn't regularly decreasing, it will decrease the learning rate. So far, -# it works fine, though it is not perfect. -flags.DEFINE_integer("learning_rate_n_to_compare", LEARNING_RATE_N_TO_COMPARE, - "Number of previous costs current cost has to be worse \ - than, to lower learning rate.") - -# This sets a value, above which, the gradients will be clipped. This hp -# is extremely useful to avoid an infrequent, but highly pathological -# problem whereby the gradient is so large that it destroys the -# optimziation by setting parameters too large, leading to a vicious cycle -# that ends in NaNs. If it's too large, it's useless, if it's too small, -# it essentially becomes the learning rate. It's pretty insensitive, though. -flags.DEFINE_float("max_grad_norm", MAX_GRAD_NORM, - "Max norm of gradient before clipping.") - -# If your optimizations start "NaN-ing out", reduce this value so that -# the values of the network don't grow out of control. Typically, once -# this parameter is set to a reasonable value, one stops having numerical -# problems. -flags.DEFINE_float("cell_clip_value", CELL_CLIP_VALUE, - "Max value recurrent cell can take before being clipped.") - -# This flag is used for an experiment where one sees if training a model with -# many days data can be used to learn the dynamics from a held-out days data. -# If you don't care about that particular experiment, this flag should always be -# false. -flags.DEFINE_boolean("do_train_io_only", DO_TRAIN_IO_ONLY, - "Train only the input (readin) and output (readout) \ - affine functions.") - -# This flag is used for an experiment where one wants to know if the dynamics -# learned by the generator generalize across conditions. In that case, you might -# train up a model on one set of data, and then only further train the encoder -# on another set of data (the conditions to be tested) so that the model is -# forced to use the same dynamics to describe that data. If you don't care about -# that particular experiment, this flag should always be false. -flags.DEFINE_boolean("do_train_encoder_only", DO_TRAIN_ENCODER_ONLY, - "Train only the encoder weights.") - -flags.DEFINE_boolean("do_reset_learning_rate", DO_RESET_LEARNING_RATE, - "Reset the learning rate to initial value.") - - -# for multi-session "stitching" models, the per-session readin matrices map from -# neurons to input factors which are fed into the shared encoder. These are -# initialized by alignment_matrix_cxf and alignment_bias_c in the input .h5 -# files. They can be fixed or made trainable. -flags.DEFINE_boolean("do_train_readin", DO_TRAIN_READIN, "Whether to train the \ - readin matrices and bias vectors. False leaves them fixed \ - at their initial values specified by the alignment \ - matrices and vectors.") - - -# OVERFITTING -# Dropout is done on the input data, on controller inputs (from -# encoder), on outputs from generator to factors. -flags.DEFINE_float("keep_prob", KEEP_PROB, "Dropout keep probability.") -# It appears that the system will happily fit spikes (blessing or -# curse, depending). You may not want this. Jittering the spikes a -# bit will help (-/+ bin size, as specified here). -flags.DEFINE_integer("temporal_spike_jitter_width", - TEMPORAL_SPIKE_JITTER_WIDTH, - "Shuffle spikes around this window.") - -# General note about helping ascribe controller inputs vs dynamics: -# -# If controller is heavily penalized, then it won't have any output. -# If dynamics are heavily penalized, then generator won't make -# dynamics. Note this l2 penalty is only on the recurrent portion of -# the RNNs, as dropout is also available, penalizing the feed-forward -# connections. -flags.DEFINE_float("l2_gen_scale", L2_GEN_SCALE, - "L2 regularization cost for the generator only.") -flags.DEFINE_float("l2_con_scale", L2_CON_SCALE, - "L2 regularization cost for the controller only.") -flags.DEFINE_float("co_mean_corr_scale", CO_MEAN_CORR_SCALE, - "Cost of correlation (thru time)in the means of \ - controller output.") - -# UNDERFITTING -# If the primary task of LFADS is "filtering" of data and not -# generation, then it is possible that the KL penalty is too strong. -# Empirically, we have found this to be the case. So we add a -# hyperparameter in front of the the two KL terms (one for the initial -# conditions to the generator, the other for the controller outputs). -# You should always think of the the default values as 1.0, and that -# leads to a standard VAE formulation whereby the numbers that are -# optimized are a lower-bound on the log-likelihood of the data. When -# these 2 HPs deviate from 1.0, one cannot make any statement about -# what those LL lower bounds mean anymore, and they cannot be compared -# (AFAIK). -flags.DEFINE_float("kl_ic_weight", KL_IC_WEIGHT, - "Strength of KL weight on initial conditions KL penatly.") -flags.DEFINE_float("kl_co_weight", KL_CO_WEIGHT, - "Strength of KL weight on controller output KL penalty.") - -# Sometimes the task can be sufficiently hard to learn that the -# optimizer takes the 'easy route', and simply minimizes the KL -# divergence, setting it to near zero, and the optimization gets -# stuck. These two parameters will help avoid that by by getting the -# optimization to 'latch' on to the main optimization, and only -# turning in the regularizers later. -flags.DEFINE_integer("kl_start_step", KL_START_STEP, - "Start increasing weight after this many steps.") -# training passes, not epochs, increase by 0.5 every kl_increase_steps -flags.DEFINE_integer("kl_increase_steps", KL_INCREASE_STEPS, - "Increase weight of kl cost to avoid local minimum.") -# Same story for l2 regularizer. One wants a simple generator, for scientific -# reasons, but not at the expense of hosing the optimization. -flags.DEFINE_integer("l2_start_step", L2_START_STEP, - "Start increasing l2 weight after this many steps.") -flags.DEFINE_integer("l2_increase_steps", L2_INCREASE_STEPS, - "Increase weight of l2 cost to avoid local minimum.") - -FLAGS = flags.FLAGS - - -def build_model(hps, kind="train", datasets=None): - """Builds a model from either random initialization, or saved parameters. - - Args: - hps: The hyper parameters for the model. - kind: (optional) The kind of model to build. Training vs inference require - different graphs. - datasets: The datasets structure (see top of lfads.py). - - Returns: - an LFADS model. - """ - - build_kind = kind - if build_kind == "write_model_params": - build_kind = "train" - with tf.variable_scope("LFADS", reuse=None): - model = LFADS(hps, kind=build_kind, datasets=datasets) - - if not os.path.exists(hps.lfads_save_dir): - print("Save directory %s does not exist, creating it." % hps.lfads_save_dir) - os.makedirs(hps.lfads_save_dir) - - cp_pb_ln = hps.checkpoint_pb_load_name - cp_pb_ln = 'checkpoint' if cp_pb_ln == "" else cp_pb_ln - if cp_pb_ln == 'checkpoint': - print("Loading latest training checkpoint in: ", hps.lfads_save_dir) - saver = model.seso_saver - elif cp_pb_ln == 'checkpoint_lve': - print("Loading lowest validation checkpoint in: ", hps.lfads_save_dir) - saver = model.lve_saver - else: - print("Loading checkpoint: ", cp_pb_ln, ", in: ", hps.lfads_save_dir) - saver = model.seso_saver - - ckpt = tf.train.get_checkpoint_state(hps.lfads_save_dir, - latest_filename=cp_pb_ln) - - session = tf.get_default_session() - print("ckpt: ", ckpt) - if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path): - print("Reading model parameters from %s" % ckpt.model_checkpoint_path) - saver.restore(session, ckpt.model_checkpoint_path) - else: - print("Created model with fresh parameters.") - if kind in ["posterior_sample_and_average", "posterior_push_mean", - "prior_sample", "write_model_params"]: - print("Possible error!!! You are running ", kind, " on a newly \ - initialized model!") - # cannot print ckpt.model_check_point path if no ckpt - print("Are you sure you sure a checkpoint in ", hps.lfads_save_dir, - " exists?") - - tf.global_variables_initializer().run() - - if ckpt: - train_step_str = re.search('-[0-9]+$', ckpt.model_checkpoint_path).group() - else: - train_step_str = '-0' - - fname = 'hyperparameters' + train_step_str + '.txt' - hp_fname = os.path.join(hps.lfads_save_dir, fname) - hps_for_saving = jsonify_dict(hps) - utils.write_data(hp_fname, hps_for_saving, use_json=True) - - return model - - -def jsonify_dict(d): - """Turns python booleans into strings so hps dict can be written in json. - Creates a shallow-copied dictionary first, then accomplishes string - conversion. - - Args: - d: hyperparameter dictionary - - Returns: hyperparameter dictionary with bool's as strings - """ - - d2 = d.copy() # shallow copy is fine by assumption of d being shallow - def jsonify_bool(boolean_value): - if boolean_value: - return "true" - else: - return "false" - - for key in d2.keys(): - if isinstance(d2[key], bool): - d2[key] = jsonify_bool(d2[key]) - return d2 - - -def build_hyperparameter_dict(flags): - """Simple script for saving hyper parameters. Under the hood the - flags structure isn't a dictionary, so it has to be simplified since we - want to be able to view file as text. - - Args: - flags: From tf.app.flags - - Returns: - dictionary of hyper parameters (ignoring other flag types). - """ - d = {} - # Data - d['output_dist'] = flags.output_dist - d['data_dir'] = flags.data_dir - d['lfads_save_dir'] = flags.lfads_save_dir - d['checkpoint_pb_load_name'] = flags.checkpoint_pb_load_name - d['checkpoint_name'] = flags.checkpoint_name - d['output_filename_stem'] = flags.output_filename_stem - d['max_ckpt_to_keep'] = flags.max_ckpt_to_keep - d['max_ckpt_to_keep_lve'] = flags.max_ckpt_to_keep_lve - d['ps_nexamples_to_process'] = flags.ps_nexamples_to_process - d['ext_input_dim'] = flags.ext_input_dim - d['data_filename_stem'] = flags.data_filename_stem - d['device'] = flags.device - d['csv_log'] = flags.csv_log - d['num_steps_for_gen_ic'] = flags.num_steps_for_gen_ic - d['inject_ext_input_to_gen'] = flags.inject_ext_input_to_gen - # Cell - d['cell_weight_scale'] = flags.cell_weight_scale - # Generation - d['ic_dim'] = flags.ic_dim - d['factors_dim'] = flags.factors_dim - d['ic_enc_dim'] = flags.ic_enc_dim - d['gen_dim'] = flags.gen_dim - d['gen_cell_input_weight_scale'] = flags.gen_cell_input_weight_scale - d['gen_cell_rec_weight_scale'] = flags.gen_cell_rec_weight_scale - # KL distributions - d['ic_prior_var_min'] = flags.ic_prior_var_min - d['ic_prior_var_scale'] = flags.ic_prior_var_scale - d['ic_prior_var_max'] = flags.ic_prior_var_max - d['ic_post_var_min'] = flags.ic_post_var_min - d['co_prior_var_scale'] = flags.co_prior_var_scale - d['prior_ar_atau'] = flags.prior_ar_atau - d['prior_ar_nvar'] = flags.prior_ar_nvar - d['do_train_prior_ar_atau'] = flags.do_train_prior_ar_atau - d['do_train_prior_ar_nvar'] = flags.do_train_prior_ar_nvar - # Controller - d['do_causal_controller'] = flags.do_causal_controller - d['controller_input_lag'] = flags.controller_input_lag - d['do_feed_factors_to_controller'] = flags.do_feed_factors_to_controller - d['feedback_factors_or_rates'] = flags.feedback_factors_or_rates - d['co_dim'] = flags.co_dim - d['ci_enc_dim'] = flags.ci_enc_dim - d['con_dim'] = flags.con_dim - d['co_mean_corr_scale'] = flags.co_mean_corr_scale - # Optimization - d['batch_size'] = flags.batch_size - d['learning_rate_init'] = flags.learning_rate_init - d['learning_rate_decay_factor'] = flags.learning_rate_decay_factor - d['learning_rate_stop'] = flags.learning_rate_stop - d['learning_rate_n_to_compare'] = flags.learning_rate_n_to_compare - d['max_grad_norm'] = flags.max_grad_norm - d['cell_clip_value'] = flags.cell_clip_value - d['do_train_io_only'] = flags.do_train_io_only - d['do_train_encoder_only'] = flags.do_train_encoder_only - d['do_reset_learning_rate'] = flags.do_reset_learning_rate - d['do_train_readin'] = flags.do_train_readin - - # Overfitting - d['keep_prob'] = flags.keep_prob - d['temporal_spike_jitter_width'] = flags.temporal_spike_jitter_width - d['l2_gen_scale'] = flags.l2_gen_scale - d['l2_con_scale'] = flags.l2_con_scale - # Underfitting - d['kl_ic_weight'] = flags.kl_ic_weight - d['kl_co_weight'] = flags.kl_co_weight - d['kl_start_step'] = flags.kl_start_step - d['kl_increase_steps'] = flags.kl_increase_steps - d['l2_start_step'] = flags.l2_start_step - d['l2_increase_steps'] = flags.l2_increase_steps - d['_clip_value'] = 80 # bounds the tf.exp to avoid INF - - return d - - -class hps_dict_to_obj(dict): - """Helper class allowing us to access hps dictionary more easily.""" - - def __getattr__(self, key): - if key in self: - return self[key] - else: - assert False, ("%s does not exist." % key) - def __setattr__(self, key, value): - self[key] = value - - -def train(hps, datasets): - """Train the LFADS model. - - Args: - hps: The dictionary of hyperparameters. - datasets: A dictionary of data dictionaries. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - """ - model = build_model(hps, kind="train", datasets=datasets) - if hps.do_reset_learning_rate: - sess = tf.get_default_session() - sess.run(model.learning_rate.initializer) - - model.train_model(datasets) - - -def write_model_runs(hps, datasets, output_fname=None, push_mean=False): - """Run the model on the data in data_dict, and save the computed values. - - LFADS generates a number of outputs for each examples, and these are all - saved. They are: - The mean and variance of the prior of g0. - The mean and variance of approximate posterior of g0. - The control inputs (if enabled) - The initial conditions, g0, for all examples. - The generator states for all time. - The factors for all time. - The rates for all time. - - Args: - hps: The dictionary of hyperparameters. - datasets: A dictionary of data dictionaries. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - output_fname (optional): output filename stem to write the model runs. - push_mean: if False (default), generates batch_size samples for each trial - and averages the results. if True, runs each trial once without noise, - pushing the posterior mean initial conditions and control inputs through - the trained model. False is used for posterior_sample_and_average, True - is used for posterior_push_mean. - """ - model = build_model(hps, kind=hps.kind, datasets=datasets) - model.write_model_runs(datasets, output_fname, push_mean) - - -def write_model_samples(hps, datasets, dataset_name=None, output_fname=None): - """Use the prior distribution to generate samples from the model. - Generates batch_size number of samples (set through FLAGS). - - LFADS generates a number of outputs for each examples, and these are all - saved. They are: - The mean and variance of the prior of g0. - The control inputs (if enabled) - The initial conditions, g0, for all examples. - The generator states for all time. - The factors for all time. - The output distribution parameters (e.g. rates) for all time. - - Args: - hps: The dictionary of hyperparameters. - datasets: A dictionary of data dictionaries. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - dataset_name: The name of the dataset to grab the factors -> rates - alignment matrices from. Only a concern with models trained on - multi-session data. By default, uses the first dataset in the data dict. - output_fname: The name prefix of the file in which to save the generated - samples. - """ - if not output_fname: - output_fname = "model_runs_" + hps.kind - else: - output_fname = output_fname + "model_runs_" + hps.kind - if not dataset_name: - dataset_name = datasets.keys()[0] - else: - if dataset_name not in datasets.keys(): - raise ValueError("Invalid dataset name '%s'."%(dataset_name)) - model = build_model(hps, kind=hps.kind, datasets=datasets) - model.write_model_samples(dataset_name, output_fname) - - -def write_model_parameters(hps, output_fname=None, datasets=None): - """Save all the model parameters - - Save all the parameters to hps.lfads_save_dir. - - Args: - hps: The dictionary of hyperparameters. - output_fname: The prefix of the file in which to save the generated - samples. - datasets: A dictionary of data dictionaries. The dataset dict is simply a - name(string)-> data dictionary mapping (See top of lfads.py). - """ - if not output_fname: - output_fname = "model_params" - else: - output_fname = output_fname + "_model_params" - fname = os.path.join(hps.lfads_save_dir, output_fname) - print("Writing model parameters to: ", fname) - # save the optimizer params as well - model = build_model(hps, kind="write_model_params", datasets=datasets) - model_params = model.eval_model_parameters(use_nested=False, - include_strs="LFADS") - utils.write_data(fname, model_params, compression=None) - print("Done.") - - -def clean_data_dict(data_dict): - """Add some key/value pairs to the data dict, if they are missing. - Args: - data_dict - dictionary containing data for LFADS - Returns: - data_dict with some keys filled in, if they are absent. - """ - - keys = ['train_truth', 'train_ext_input', 'valid_data', - 'valid_truth', 'valid_ext_input', 'valid_train'] - for k in keys: - if k not in data_dict: - data_dict[k] = None - - return data_dict - - -def load_datasets(data_dir, data_filename_stem): - """Load the datasets from a specified directory. - - Example files look like - >data_dir/my_dataset_first_day - >data_dir/my_dataset_second_day - - If my_dataset (filename) stem is in the directory, the read routine will try - and load it. The datasets dictionary will then look like - dataset['first_day'] -> (first day data dictionary) - dataset['second_day'] -> (first day data dictionary) - - Args: - data_dir: The directory from which to load the datasets. - data_filename_stem: The stem of the filename for the datasets. - - Returns: - datasets: a dataset dictionary, with one name->data dictionary pair for - each dataset file. - """ - print("Reading data from ", data_dir) - datasets = utils.read_datasets(data_dir, data_filename_stem) - for k, data_dict in datasets.items(): - datasets[k] = clean_data_dict(data_dict) - - train_total_size = len(data_dict['train_data']) - if train_total_size == 0: - print("Did not load training set.") - else: - print("Found training set with number examples: ", train_total_size) - - valid_total_size = len(data_dict['valid_data']) - if valid_total_size == 0: - print("Did not load validation set.") - else: - print("Found validation set with number examples: ", valid_total_size) - - return datasets - - -def main(_): - """Get this whole shindig off the ground.""" - d = build_hyperparameter_dict(FLAGS) - hps = hps_dict_to_obj(d) # hyper parameters - kind = FLAGS.kind - - # Read the data, if necessary. - train_set = valid_set = None - if kind in ["train", "posterior_sample_and_average", "posterior_push_mean", - "prior_sample", "write_model_params"]: - datasets = load_datasets(hps.data_dir, hps.data_filename_stem) - else: - raise ValueError('Kind {} is not supported.'.format(kind)) - - # infer the dataset names and dataset dimensions from the loaded files - hps.kind = kind # needs to be added here, cuz not saved as hyperparam - hps.dataset_names = [] - hps.dataset_dims = {} - for key in datasets: - hps.dataset_names.append(key) - hps.dataset_dims[key] = datasets[key]['data_dim'] - - # also store down the dimensionality of the data - # - just pull from one set, required to be same for all sets - hps.num_steps = datasets.values()[0]['num_steps'] - hps.ndatasets = len(hps.dataset_names) - - if hps.num_steps_for_gen_ic > hps.num_steps: - hps.num_steps_for_gen_ic = hps.num_steps - - # Build and run the model, for varying purposes. - config = tf.ConfigProto(allow_soft_placement=True, - log_device_placement=False) - if FLAGS.allow_gpu_growth: - config.gpu_options.allow_growth = True - sess = tf.Session(config=config) - with sess.as_default(): - with tf.device(hps.device): - if kind == "train": - train(hps, datasets) - elif kind == "posterior_sample_and_average": - write_model_runs(hps, datasets, hps.output_filename_stem, - push_mean=False) - elif kind == "posterior_push_mean": - write_model_runs(hps, datasets, hps.output_filename_stem, - push_mean=True) - elif kind == "prior_sample": - write_model_samples(hps, datasets, hps.output_filename_stem) - elif kind == "write_model_params": - write_model_parameters(hps, hps.output_filename_stem, datasets) - else: - assert False, ("Kind %s is not implemented. " % kind) - - -if __name__ == "__main__": - tf.app.run() diff --git a/research/lfads/synth_data/generate_chaotic_rnn_data.py b/research/lfads/synth_data/generate_chaotic_rnn_data.py deleted file mode 100644 index 3de72e58b2208eacf508e6048d3fb6d66bf2e167..0000000000000000000000000000000000000000 --- a/research/lfads/synth_data/generate_chaotic_rnn_data.py +++ /dev/null @@ -1,200 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import print_function - -import h5py -import numpy as np -import os -import tensorflow as tf # used for flags here - -from utils import write_datasets -from synthetic_data_utils import add_alignment_projections, generate_data -from synthetic_data_utils import generate_rnn, get_train_n_valid_inds -from synthetic_data_utils import nparray_and_transpose -from synthetic_data_utils import spikify_data, gaussify_data, split_list_by_inds -import matplotlib -import matplotlib.pyplot as plt -import scipy.signal - -matplotlib.rcParams['image.interpolation'] = 'nearest' -DATA_DIR = "rnn_synth_data_v1.0" - -flags = tf.app.flags -flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", - "Directory for saving data.") -flags.DEFINE_string("datafile_name", "thits_data", - "Name of data file for input case.") -flags.DEFINE_string("noise_type", "poisson", "Noise type for data.") -flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") -flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") -flags.DEFINE_integer("C", 100, "Number of conditions") -flags.DEFINE_integer("N", 50, "Number of units for the RNN") -flags.DEFINE_integer("S", 50, "Number of sampled units from RNN") -flags.DEFINE_integer("npcs", 10, "Number of PCS for multi-session case.") -flags.DEFINE_float("train_percentage", 4.0/5.0, - "Percentage of train vs validation trials") -flags.DEFINE_integer("nreplications", 40, - "Number of noise replications of the same underlying rates.") -flags.DEFINE_float("g", 1.5, "Complexity of dynamics") -flags.DEFINE_float("x0_std", 1.0, - "Volume from which to pull initial conditions (affects diversity of dynamics.") -flags.DEFINE_float("tau", 0.025, "Time constant of RNN") -flags.DEFINE_float("dt", 0.010, "Time bin") -flags.DEFINE_float("input_magnitude", 20.0, - "For the input case, what is the value of the input?") -flags.DEFINE_float("max_firing_rate", 30.0, "Map 1.0 of RNN to a spikes per second") -FLAGS = flags.FLAGS - - -# Note that with N small, (as it is 25 above), the finite size effects -# will have pretty dramatic effects on the dynamics of the random RNN. -# If you want more complex dynamics, you'll have to run the script a -# lot, or increase N (or g). - -# Getting hard vs. easy data can be a little stochastic, so we set the seed. - -# Pull out some commonly used parameters. -# These are user parameters (configuration) -rng = np.random.RandomState(seed=FLAGS.synth_data_seed) -T = FLAGS.T -C = FLAGS.C -N = FLAGS.N -S = FLAGS.S -input_magnitude = FLAGS.input_magnitude -nreplications = FLAGS.nreplications -E = nreplications * C # total number of trials -# S is the number of measurements in each datasets, w/ each -# dataset having a different set of observations. -ndatasets = N/S # ok if rounded down -train_percentage = FLAGS.train_percentage -ntime_steps = int(T / FLAGS.dt) -# End of user parameters - -rnn = generate_rnn(rng, N, FLAGS.g, FLAGS.tau, FLAGS.dt, FLAGS.max_firing_rate) - -# Check to make sure the RNN is the one we used in the paper. -if N == 50: - assert abs(rnn['W'][0,0] - 0.06239899) < 1e-8, 'Error in random seed?' - rem_check = nreplications * train_percentage - assert abs(rem_check - int(rem_check)) < 1e-8, \ - 'Train percentage * nreplications should be integral number.' - - -# Initial condition generation, and condition label generation. This -# happens outside of the dataset loop, so that all datasets have the -# same conditions, which is similar to a neurophys setup. -condition_number = 0 -x0s = [] -condition_labels = [] -for c in range(C): - x0 = FLAGS.x0_std * rng.randn(N, 1) - x0s.append(np.tile(x0, nreplications)) # replicate x0 nreplications times - # replicate the condition label nreplications times - for ns in range(nreplications): - condition_labels.append(condition_number) - condition_number += 1 -x0s = np.concatenate(x0s, axis=1) - -# Containers for storing data across data. -datasets = {} -for n in range(ndatasets): - print(n+1, " of ", ndatasets) - - # First generate all firing rates. in the next loop, generate all - # replications this allows the random state for rate generation to be - # independent of n_replications. - dataset_name = 'dataset_N' + str(N) + '_S' + str(S) - if S < N: - dataset_name += '_n' + str(n+1) - - # Sample neuron subsets. The assumption is the PC axes of the RNN - # are not unit aligned, so sampling units is adequate to sample all - # the high-variance PCs. - P_sxn = np.eye(S,N) - for m in range(n): - P_sxn = np.roll(P_sxn, S, axis=1) - - if input_magnitude > 0.0: - # time of "hits" randomly chosen between [1/4 and 3/4] of total time - input_times = rng.choice(int(ntime_steps/2), size=[E]) + int(ntime_steps/4) - else: - input_times = None - - rates, x0s, inputs = \ - generate_data(rnn, T=T, E=E, x0s=x0s, P_sxn=P_sxn, - input_magnitude=input_magnitude, - input_times=input_times) - - if FLAGS.noise_type == "poisson": - noisy_data = spikify_data(rates, rng, rnn['dt'], rnn['max_firing_rate']) - elif FLAGS.noise_type == "gaussian": - noisy_data = gaussify_data(rates, rng, rnn['dt'], rnn['max_firing_rate']) - else: - raise ValueError("Only noise types supported are poisson or gaussian") - - # split into train and validation sets - train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, - nreplications) - - # Split the data, inputs, labels and times into train vs. validation. - rates_train, rates_valid = \ - split_list_by_inds(rates, train_inds, valid_inds) - noisy_data_train, noisy_data_valid = \ - split_list_by_inds(noisy_data, train_inds, valid_inds) - input_train, inputs_valid = \ - split_list_by_inds(inputs, train_inds, valid_inds) - condition_labels_train, condition_labels_valid = \ - split_list_by_inds(condition_labels, train_inds, valid_inds) - input_times_train, input_times_valid = \ - split_list_by_inds(input_times, train_inds, valid_inds) - - # Turn rates, noisy_data, and input into numpy arrays. - rates_train = nparray_and_transpose(rates_train) - rates_valid = nparray_and_transpose(rates_valid) - noisy_data_train = nparray_and_transpose(noisy_data_train) - noisy_data_valid = nparray_and_transpose(noisy_data_valid) - input_train = nparray_and_transpose(input_train) - inputs_valid = nparray_and_transpose(inputs_valid) - - # Note that we put these 'truth' rates and input into this - # structure, the only data that is used in LFADS are the noisy - # data e.g. spike trains. The rest is either for printing or posterity. - data = {'train_truth': rates_train, - 'valid_truth': rates_valid, - 'input_train_truth' : input_train, - 'input_valid_truth' : inputs_valid, - 'train_data' : noisy_data_train, - 'valid_data' : noisy_data_valid, - 'train_percentage' : train_percentage, - 'nreplications' : nreplications, - 'dt' : rnn['dt'], - 'input_magnitude' : input_magnitude, - 'input_times_train' : input_times_train, - 'input_times_valid' : input_times_valid, - 'P_sxn' : P_sxn, - 'condition_labels_train' : condition_labels_train, - 'condition_labels_valid' : condition_labels_valid, - 'conversion_factor': 1.0 / rnn['conversion_factor']} - datasets[dataset_name] = data - -if S < N: - # Note that this isn't necessary for this synthetic example, but - # it's useful to see how the input factor matrices were initialized - # for actual neurophysiology data. - datasets = add_alignment_projections(datasets, npcs=FLAGS.npcs) - -# Write out the datasets. -write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) diff --git a/research/lfads/synth_data/generate_itb_data.py b/research/lfads/synth_data/generate_itb_data.py deleted file mode 100644 index 66bc45d02e962915eb4be09d41da3162763ad40c..0000000000000000000000000000000000000000 --- a/research/lfads/synth_data/generate_itb_data.py +++ /dev/null @@ -1,209 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import print_function - -import h5py -import numpy as np -import os -from six.moves import xrange -import tensorflow as tf - -from utils import write_datasets -from synthetic_data_utils import normalize_rates -from synthetic_data_utils import get_train_n_valid_inds, nparray_and_transpose -from synthetic_data_utils import spikify_data, split_list_by_inds - -DATA_DIR = "rnn_synth_data_v1.0" - -flags = tf.app.flags -flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", - "Directory for saving data.") -flags.DEFINE_string("datafile_name", "itb_rnn", - "Name of data file for input case.") -flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") -flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") -flags.DEFINE_integer("C", 800, "Number of conditions") -flags.DEFINE_integer("N", 50, "Number of units for the RNN") -flags.DEFINE_float("train_percentage", 4.0/5.0, - "Percentage of train vs validation trials") -flags.DEFINE_integer("nreplications", 5, - "Number of spikifications of the same underlying rates.") -flags.DEFINE_float("tau", 0.025, "Time constant of RNN") -flags.DEFINE_float("dt", 0.010, "Time bin") -flags.DEFINE_float("max_firing_rate", 30.0, - "Map 1.0 of RNN to a spikes per second") -flags.DEFINE_float("u_std", 0.25, - "Std dev of input to integration to bound model") -flags.DEFINE_string("checkpoint_path", "SAMPLE_CHECKPOINT", - """Path to directory with checkpoints of model - trained on integration to bound task. Currently this - is a placeholder which tells the code to grab the - checkpoint that is provided with the code - (in /trained_itb/..). If you have your own checkpoint - you would like to restore, you would point it to - that path.""") -FLAGS = flags.FLAGS - - -class IntegrationToBoundModel: - def __init__(self, N): - scale = 0.8 / float(N**0.5) - self.N = N - self.Wh_nxn = tf.Variable(tf.random_normal([N, N], stddev=scale)) - self.b_1xn = tf.Variable(tf.zeros([1, N])) - self.Bu_1xn = tf.Variable(tf.zeros([1, N])) - self.Wro_nxo = tf.Variable(tf.random_normal([N, 1], stddev=scale)) - self.bro_o = tf.Variable(tf.zeros([1])) - - def call(self, h_tm1_bxn, u_bx1): - act_t_bxn = tf.matmul(h_tm1_bxn, self.Wh_nxn) + self.b_1xn + u_bx1 * self.Bu_1xn - h_t_bxn = tf.nn.tanh(act_t_bxn) - z_t = tf.nn.xw_plus_b(h_t_bxn, self.Wro_nxo, self.bro_o) - return z_t, h_t_bxn - -def get_data_batch(batch_size, T, rng, u_std): - u_bxt = rng.randn(batch_size, T) * u_std - running_sum_b = np.zeros([batch_size]) - labels_bxt = np.zeros([batch_size, T]) - for t in xrange(T): - running_sum_b += u_bxt[:, t] - labels_bxt[:, t] += running_sum_b - labels_bxt = np.clip(labels_bxt, -1, 1) - return u_bxt, labels_bxt - - -rng = np.random.RandomState(seed=FLAGS.synth_data_seed) -u_rng = np.random.RandomState(seed=FLAGS.synth_data_seed+1) -T = FLAGS.T -C = FLAGS.C -N = FLAGS.N # must be same N as in trained model (provided example is N = 50) -nreplications = FLAGS.nreplications -E = nreplications * C # total number of trials -train_percentage = FLAGS.train_percentage -ntimesteps = int(T / FLAGS.dt) -batch_size = 1 # gives one example per ntrial - -model = IntegrationToBoundModel(N) -inputs_ph_t = [tf.placeholder(tf.float32, - shape=[None, 1]) for _ in range(ntimesteps)] -state = tf.zeros([batch_size, N]) -saver = tf.train.Saver() - -P_nxn = rng.randn(N,N) / np.sqrt(N) # random projections - -# unroll RNN for T timesteps -outputs_t = [] -states_t = [] - -for inp in inputs_ph_t: - output, state = model.call(state, inp) - outputs_t.append(output) - states_t.append(state) - -with tf.Session() as sess: - # restore the latest model ckpt - if FLAGS.checkpoint_path == "SAMPLE_CHECKPOINT": - dir_path = os.path.dirname(os.path.realpath(__file__)) - model_checkpoint_path = os.path.join(dir_path, "trained_itb/model-65000") - else: - model_checkpoint_path = FLAGS.checkpoint_path - try: - saver.restore(sess, model_checkpoint_path) - print ('Model restored from', model_checkpoint_path) - except: - assert False, ("No checkpoints to restore from, is the path %s correct?" - %model_checkpoint_path) - - # generate data for trials - data_e = [] - u_e = [] - outs_e = [] - for c in range(C): - u_1xt, outs_1xt = get_data_batch(batch_size, ntimesteps, u_rng, FLAGS.u_std) - - feed_dict = {} - for t in xrange(ntimesteps): - feed_dict[inputs_ph_t[t]] = np.reshape(u_1xt[:,t], (batch_size,-1)) - - states_t_bxn, outputs_t_bxn = sess.run([states_t, outputs_t], - feed_dict=feed_dict) - states_nxt = np.transpose(np.squeeze(np.asarray(states_t_bxn))) - outputs_t_bxn = np.squeeze(np.asarray(outputs_t_bxn)) - r_sxt = np.dot(P_nxn, states_nxt) - - for s in xrange(nreplications): - data_e.append(r_sxt) - u_e.append(u_1xt) - outs_e.append(outputs_t_bxn) - - truth_data_e = normalize_rates(data_e, E, N) - -spiking_data_e = spikify_data(truth_data_e, rng, dt=FLAGS.dt, - max_firing_rate=FLAGS.max_firing_rate) -train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, - nreplications) - -data_train_truth, data_valid_truth = split_list_by_inds(truth_data_e, - train_inds, - valid_inds) -data_train_spiking, data_valid_spiking = split_list_by_inds(spiking_data_e, - train_inds, - valid_inds) - -data_train_truth = nparray_and_transpose(data_train_truth) -data_valid_truth = nparray_and_transpose(data_valid_truth) -data_train_spiking = nparray_and_transpose(data_train_spiking) -data_valid_spiking = nparray_and_transpose(data_valid_spiking) - -# save down the inputs used to generate this data -train_inputs_u, valid_inputs_u = split_list_by_inds(u_e, - train_inds, - valid_inds) -train_inputs_u = nparray_and_transpose(train_inputs_u) -valid_inputs_u = nparray_and_transpose(valid_inputs_u) - -# save down the network outputs (may be useful later) -train_outputs_u, valid_outputs_u = split_list_by_inds(outs_e, - train_inds, - valid_inds) -train_outputs_u = np.array(train_outputs_u) -valid_outputs_u = np.array(valid_outputs_u) - - -data = { 'train_truth': data_train_truth, - 'valid_truth': data_valid_truth, - 'train_data' : data_train_spiking, - 'valid_data' : data_valid_spiking, - 'train_percentage' : train_percentage, - 'nreplications' : nreplications, - 'dt' : FLAGS.dt, - 'u_std' : FLAGS.u_std, - 'max_firing_rate': FLAGS.max_firing_rate, - 'train_inputs_u': train_inputs_u, - 'valid_inputs_u': valid_inputs_u, - 'train_outputs_u': train_outputs_u, - 'valid_outputs_u': valid_outputs_u, - 'conversion_factor' : FLAGS.max_firing_rate/(1.0/FLAGS.dt) } - -# just one dataset here -datasets = {} -dataset_name = 'dataset_N' + str(N) -datasets[dataset_name] = data - -# write out the dataset -write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) -print ('Saved to ', os.path.join(FLAGS.save_dir, - FLAGS.datafile_name + '_' + dataset_name)) diff --git a/research/lfads/synth_data/generate_labeled_rnn_data.py b/research/lfads/synth_data/generate_labeled_rnn_data.py deleted file mode 100644 index 0695585486534428c77e328e7ee1de755292d6c0..0000000000000000000000000000000000000000 --- a/research/lfads/synth_data/generate_labeled_rnn_data.py +++ /dev/null @@ -1,147 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import print_function - -import os -import h5py -import numpy as np -from six.moves import xrange - -from synthetic_data_utils import generate_data, generate_rnn -from synthetic_data_utils import get_train_n_valid_inds -from synthetic_data_utils import nparray_and_transpose -from synthetic_data_utils import spikify_data, split_list_by_inds -import tensorflow as tf -from utils import write_datasets - -DATA_DIR = "rnn_synth_data_v1.0" - -flags = tf.app.flags -flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", - "Directory for saving data.") -flags.DEFINE_string("datafile_name", "conditioned_rnn_data", - "Name of data file for input case.") -flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") -flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") -flags.DEFINE_integer("C", 400, "Number of conditions") -flags.DEFINE_integer("N", 50, "Number of units for the RNN") -flags.DEFINE_float("train_percentage", 4.0/5.0, - "Percentage of train vs validation trials") -flags.DEFINE_integer("nreplications", 10, - "Number of spikifications of the same underlying rates.") -flags.DEFINE_float("g", 1.5, "Complexity of dynamics") -flags.DEFINE_float("x0_std", 1.0, - "Volume from which to pull initial conditions (affects diversity of dynamics.") -flags.DEFINE_float("tau", 0.025, "Time constant of RNN") -flags.DEFINE_float("dt", 0.010, "Time bin") -flags.DEFINE_float("max_firing_rate", 30.0, "Map 1.0 of RNN to a spikes per second") -FLAGS = flags.FLAGS - -rng = np.random.RandomState(seed=FLAGS.synth_data_seed) -rnn_rngs = [np.random.RandomState(seed=FLAGS.synth_data_seed+1), - np.random.RandomState(seed=FLAGS.synth_data_seed+2)] -T = FLAGS.T -C = FLAGS.C -N = FLAGS.N -nreplications = FLAGS.nreplications -E = nreplications * C -train_percentage = FLAGS.train_percentage -ntimesteps = int(T / FLAGS.dt) - -rnn_a = generate_rnn(rnn_rngs[0], N, FLAGS.g, FLAGS.tau, FLAGS.dt, - FLAGS.max_firing_rate) -rnn_b = generate_rnn(rnn_rngs[1], N, FLAGS.g, FLAGS.tau, FLAGS.dt, - FLAGS.max_firing_rate) -rnns = [rnn_a, rnn_b] - -# pick which RNN is used on each trial -rnn_to_use = rng.randint(2, size=E) -ext_input = np.repeat(np.expand_dims(rnn_to_use, axis=1), ntimesteps, axis=1) -ext_input = np.expand_dims(ext_input, axis=2) # these are "a's" in the paper - -x0s = [] -condition_labels = [] -condition_number = 0 -for c in range(C): - x0 = FLAGS.x0_std * rng.randn(N, 1) - x0s.append(np.tile(x0, nreplications)) - for ns in range(nreplications): - condition_labels.append(condition_number) - condition_number += 1 -x0s = np.concatenate(x0s, axis=1) - -P_nxn = rng.randn(N, N) / np.sqrt(N) - -# generate trials for both RNNs -rates_a, x0s_a, _ = generate_data(rnn_a, T=T, E=E, x0s=x0s, P_sxn=P_nxn, - input_magnitude=0.0, input_times=None) -spikes_a = spikify_data(rates_a, rng, rnn_a['dt'], rnn_a['max_firing_rate']) - -rates_b, x0s_b, _ = generate_data(rnn_b, T=T, E=E, x0s=x0s, P_sxn=P_nxn, - input_magnitude=0.0, input_times=None) -spikes_b = spikify_data(rates_b, rng, rnn_b['dt'], rnn_b['max_firing_rate']) - -# not the best way to do this but E is small enough -rates = [] -spikes = [] -for trial in xrange(E): - if rnn_to_use[trial] == 0: - rates.append(rates_a[trial]) - spikes.append(spikes_a[trial]) - else: - rates.append(rates_b[trial]) - spikes.append(spikes_b[trial]) - -# split into train and validation sets -train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, - nreplications) - -rates_train, rates_valid = split_list_by_inds(rates, train_inds, valid_inds) -spikes_train, spikes_valid = split_list_by_inds(spikes, train_inds, valid_inds) -condition_labels_train, condition_labels_valid = split_list_by_inds( - condition_labels, train_inds, valid_inds) -ext_input_train, ext_input_valid = split_list_by_inds( - ext_input, train_inds, valid_inds) - -rates_train = nparray_and_transpose(rates_train) -rates_valid = nparray_and_transpose(rates_valid) -spikes_train = nparray_and_transpose(spikes_train) -spikes_valid = nparray_and_transpose(spikes_valid) - -# add train_ext_input and valid_ext input -data = {'train_truth': rates_train, - 'valid_truth': rates_valid, - 'train_data' : spikes_train, - 'valid_data' : spikes_valid, - 'train_ext_input' : np.array(ext_input_train), - 'valid_ext_input': np.array(ext_input_valid), - 'train_percentage' : train_percentage, - 'nreplications' : nreplications, - 'dt' : FLAGS.dt, - 'P_sxn' : P_nxn, - 'condition_labels_train' : condition_labels_train, - 'condition_labels_valid' : condition_labels_valid, - 'conversion_factor': 1.0 / rnn_a['conversion_factor']} - -# just one dataset here -datasets = {} -dataset_name = 'dataset_N' + str(N) -datasets[dataset_name] = data - -# write out the dataset -write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) -print ('Saved to ', os.path.join(FLAGS.save_dir, - FLAGS.datafile_name + '_' + dataset_name)) diff --git a/research/lfads/synth_data/run_generate_synth_data.sh b/research/lfads/synth_data/run_generate_synth_data.sh deleted file mode 100755 index 9ebc8ce2e5eec1e21fd839db18f247b38ebfde38..0000000000000000000000000000000000000000 --- a/research/lfads/synth_data/run_generate_synth_data.sh +++ /dev/null @@ -1,40 +0,0 @@ -#!/bin/bash - -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== - -SYNTH_PATH=/tmp/rnn_synth_data_v1.0/ - - echo "Generating chaotic rnn data with no input pulses (g=1.5) with spiking noise" - python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_no_inputs --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='poisson' - -echo "Generating chaotic rnn data with no input pulses (g=1.5) with Gaussian noise" -python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=gaussian_chaotic_rnn_no_inputs --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='gaussian' - - echo "Generating chaotic rnn data with input pulses (g=1.5)" - python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_inputs_g1p5 --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=20.0 --max_firing_rate=30.0 --noise_type='poisson' - - echo "Generating chaotic rnn data with input pulses (g=2.5)" - python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_inputs_g2p5 --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=2.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=20.0 --max_firing_rate=30.0 --noise_type='poisson' - - echo "Generate the multi-session RNN data (no multi-session synth example in paper)" - python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_multisession --synth_data_seed=5 --T=1.0 --C=150 --N=100 --S=20 --npcs=10 --train_percentage=0.8 --nreplications=40 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='poisson' - - echo "Generating Integration-to-bound RNN data" - python generate_itb_data.py --save_dir=$SYNTH_PATH --datafile_name=itb_rnn --u_std=0.25 --checkpoint_path=SAMPLE_CHECKPOINT --synth_data_seed=5 --T=1.0 --C=800 --N=50 --train_percentage=0.8 --nreplications=5 --tau=0.025 --dt=0.01 --max_firing_rate=30.0 - - echo "Generating chaotic rnn data with external input labels (no external input labels example in paper)" - python generate_labeled_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnns_labeled --synth_data_seed=5 --T=1.0 --C=400 --N=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --max_firing_rate=30.0 diff --git a/research/lfads/synth_data/synthetic_data_utils.py b/research/lfads/synth_data/synthetic_data_utils.py deleted file mode 100644 index cc264ee49fdc7fbb53f17d52ca4ced64addefb27..0000000000000000000000000000000000000000 --- a/research/lfads/synth_data/synthetic_data_utils.py +++ /dev/null @@ -1,348 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import print_function - -import h5py -import numpy as np -import os - -from utils import write_datasets -import matplotlib -import matplotlib.pyplot as plt -import scipy.signal - - -def generate_rnn(rng, N, g, tau, dt, max_firing_rate): - """Create a (vanilla) RNN with a bunch of hyper parameters for generating -chaotic data. - Args: - rng: numpy random number generator - N: number of hidden units - g: scaling of recurrent weight matrix in g W, with W ~ N(0,1/N) - tau: time scale of individual unit dynamics - dt: time step for equation updates - max_firing_rate: how to resecale the -1,1 firing rates - Returns: - the dictionary of these parameters, plus some others. -""" - rnn = {} - rnn['N'] = N - rnn['W'] = rng.randn(N,N)/np.sqrt(N) - rnn['Bin'] = rng.randn(N)/np.sqrt(1.0) - rnn['Bin2'] = rng.randn(N)/np.sqrt(1.0) - rnn['b'] = np.zeros(N) - rnn['g'] = g - rnn['tau'] = tau - rnn['dt'] = dt - rnn['max_firing_rate'] = max_firing_rate - mfr = rnn['max_firing_rate'] # spikes / sec - nbins_per_sec = 1.0/rnn['dt'] # bins / sec - # Used for plotting in LFADS - rnn['conversion_factor'] = mfr / nbins_per_sec # spikes / bin - return rnn - - -def generate_data(rnn, T, E, x0s=None, P_sxn=None, input_magnitude=0.0, - input_times=None): - """ Generates data from an randomly initialized RNN. - Args: - rnn: the rnn - T: Time in seconds to run (divided by rnn['dt'] to get steps, rounded down. - E: total number of examples - S: number of samples (subsampling N) - Returns: - A list of length E of NxT tensors of the network being run. - """ - N = rnn['N'] - def run_rnn(rnn, x0, ntime_steps, input_time=None): - rs = np.zeros([N,ntime_steps]) - x_tm1 = x0 - r_tm1 = np.tanh(x0) - tau = rnn['tau'] - dt = rnn['dt'] - alpha = (1.0-dt/tau) - W = dt/tau*rnn['W']*rnn['g'] - Bin = dt/tau*rnn['Bin'] - Bin2 = dt/tau*rnn['Bin2'] - b = dt/tau*rnn['b'] - - us = np.zeros([1, ntime_steps]) - for t in range(ntime_steps): - x_t = alpha*x_tm1 + np.dot(W,r_tm1) + b - if input_time is not None and t == input_time: - us[0,t] = input_magnitude - x_t += Bin * us[0,t] # DCS is this what was used? - r_t = np.tanh(x_t) - x_tm1 = x_t - r_tm1 = r_t - rs[:,t] = r_t - return rs, us - - if P_sxn is None: - P_sxn = np.eye(N) - ntime_steps = int(T / rnn['dt']) - data_e = [] - inputs_e = [] - for e in range(E): - input_time = input_times[e] if input_times is not None else None - r_nxt, u_uxt = run_rnn(rnn, x0s[:,e], ntime_steps, input_time) - r_sxt = np.dot(P_sxn, r_nxt) - inputs_e.append(u_uxt) - data_e.append(r_sxt) - - S = P_sxn.shape[0] - data_e = normalize_rates(data_e, E, S) - - return data_e, x0s, inputs_e - - -def normalize_rates(data_e, E, S): - # Normalization, made more complex because of the P matrices. - # Normalize by min and max in each channel. This normalization will - # cause offset differences between identical rnn runs, but different - # t hits. - for e in range(E): - r_sxt = data_e[e] - for i in range(S): - rmin = np.min(r_sxt[i,:]) - rmax = np.max(r_sxt[i,:]) - assert rmax - rmin != 0, 'Something wrong' - r_sxt[i,:] = (r_sxt[i,:] - rmin)/(rmax-rmin) - data_e[e] = r_sxt - return data_e - - -def spikify_data(data_e, rng, dt=1.0, max_firing_rate=100): - """ Apply spikes to a continuous dataset whose values are between 0.0 and 1.0 - Args: - data_e: nexamples length list of NxT trials - dt: how often the data are sampled - max_firing_rate: the firing rate that is associated with a value of 1.0 - Returns: - spikified_e: a list of length b of the data represented as spikes, - sampled from the underlying poisson process. - """ - - E = len(data_e) - spikes_e = [] - for e in range(E): - data = data_e[e] - N,T = data.shape - data_s = np.zeros([N,T]).astype(np.int) - for n in range(N): - f = data[n,:] - s = rng.poisson(f*max_firing_rate*dt, size=T) - data_s[n,:] = s - spikes_e.append(data_s) - - return spikes_e - - -def gaussify_data(data_e, rng, dt=1.0, max_firing_rate=100): - """ Apply gaussian noise to a continuous dataset whose values are between - 0.0 and 1.0 - - Args: - data_e: nexamples length list of NxT trials - dt: how often the data are sampled - max_firing_rate: the firing rate that is associated with a value of 1.0 - Returns: - gauss_e: a list of length b of the data with noise. - """ - - E = len(data_e) - mfr = max_firing_rate - gauss_e = [] - for e in range(E): - data = data_e[e] - N,T = data.shape - noisy_data = data * mfr + np.random.randn(N,T) * (5.0*mfr) * np.sqrt(dt) - gauss_e.append(noisy_data) - - return gauss_e - - - -def get_train_n_valid_inds(num_trials, train_fraction, nreplications): - """Split the numbers between 0 and num_trials-1 into two portions for - training and validation, based on the train fraction. - Args: - num_trials: the number of trials - train_fraction: (e.g. .80) - nreplications: the number of spiking trials per initial condition - Returns: - a 2-tuple of two lists: the training indices and validation indices - """ - train_inds = [] - valid_inds = [] - for i in range(num_trials): - # This line divides up the trials so that within one initial condition, - # the randomness of spikifying the condition is shared among both - # training and validation data splits. - if (i % nreplications)+1 > train_fraction * nreplications: - valid_inds.append(i) - else: - train_inds.append(i) - - return train_inds, valid_inds - - -def split_list_by_inds(data, inds1, inds2): - """Take the data, a list, and split it up based on the indices in inds1 and - inds2. - Args: - data: the list of data to split - inds1, the first list of indices - inds2, the second list of indices - Returns: a 2-tuple of two lists. - """ - if data is None or len(data) == 0: - return [], [] - else: - dout1 = [data[i] for i in inds1] - dout2 = [data[i] for i in inds2] - return dout1, dout2 - - -def nparray_and_transpose(data_a_b_c): - """Convert the list of items in data to a numpy array, and transpose it - Args: - data: data_asbsc: a nested, nested list of length a, with sublist length - b, with sublist length c. - Returns: - a numpy 3-tensor with dimensions a x c x b -""" - data_axbxc = np.array([datum_b_c for datum_b_c in data_a_b_c]) - data_axcxb = np.transpose(data_axbxc, axes=[0,2,1]) - return data_axcxb - - -def add_alignment_projections(datasets, npcs, ntime=None, nsamples=None): - """Create a matrix that aligns the datasets a bit, under - the assumption that each dataset is observing the same underlying dynamical - system. - - Args: - datasets: The dictionary of dataset structures. - npcs: The number of pcs for each, basically like lfads factors. - nsamples (optional): Number of samples to take for each dataset. - ntime (optional): Number of time steps to take in each sample. - - Returns: - The dataset structures, with the field alignment_matrix_cxf added. - This is # channels x npcs dimension -""" - nchannels_all = 0 - channel_idxs = {} - conditions_all = {} - nconditions_all = 0 - for name, dataset in datasets.items(): - cidxs = np.where(dataset['P_sxn'])[1] # non-zero entries in columns - channel_idxs[name] = [cidxs[0], cidxs[-1]+1] - nchannels_all += cidxs[-1]+1 - cidxs[0] - conditions_all[name] = np.unique(dataset['condition_labels_train']) - - all_conditions_list = \ - np.unique(np.ndarray.flatten(np.array(conditions_all.values()))) - nconditions_all = all_conditions_list.shape[0] - - if ntime is None: - ntime = dataset['train_data'].shape[1] - if nsamples is None: - nsamples = dataset['train_data'].shape[0] - - # In the data workup in the paper, Chethan did intra condition - # averaging, so let's do that here. - avg_data_all = {} - for name, conditions in conditions_all.items(): - dataset = datasets[name] - avg_data_all[name] = {} - for cname in conditions: - td_idxs = np.argwhere(np.array(dataset['condition_labels_train'])==cname) - data = np.squeeze(dataset['train_data'][td_idxs,:,:], axis=1) - avg_data = np.mean(data, axis=0) - avg_data_all[name][cname] = avg_data - - # Visualize this in the morning. - all_data_nxtc = np.zeros([nchannels_all, ntime * nconditions_all]) - for name, dataset in datasets.items(): - cidx_s = channel_idxs[name][0] - cidx_f = channel_idxs[name][1] - for cname in conditions_all[name]: - cidxs = np.argwhere(all_conditions_list == cname) - if cidxs.shape[0] > 0: - cidx = cidxs[0][0] - all_tidxs = np.arange(0, ntime+1) + cidx*ntime - all_data_nxtc[cidx_s:cidx_f, all_tidxs[0]:all_tidxs[-1]] = \ - avg_data_all[name][cname].T - - # A bit of filtering. We don't care about spectral properties, or - # filtering artifacts, simply correlate time steps a bit. - filt_len = 6 - bc_filt = np.ones([filt_len])/float(filt_len) - for c in range(nchannels_all): - all_data_nxtc[c,:] = scipy.signal.filtfilt(bc_filt, [1.0], all_data_nxtc[c,:]) - - # Compute the PCs. - all_data_mean_nx1 = np.mean(all_data_nxtc, axis=1, keepdims=True) - all_data_zm_nxtc = all_data_nxtc - all_data_mean_nx1 - corr_mat_nxn = np.dot(all_data_zm_nxtc, all_data_zm_nxtc.T) - evals_n, evecs_nxn = np.linalg.eigh(corr_mat_nxn) - sidxs = np.flipud(np.argsort(evals_n)) # sort such that 0th is highest - evals_n = evals_n[sidxs] - evecs_nxn = evecs_nxn[:,sidxs] - - # Project all the channels data onto the low-D PCA basis, where - # low-d is the npcs parameter. - all_data_pca_pxtc = np.dot(evecs_nxn[:, 0:npcs].T, all_data_zm_nxtc) - - # Now for each dataset, we regress the channel data onto the top - # pcs, and this will be our alignment matrix for that dataset. - # |B - A*W|^2 - for name, dataset in datasets.items(): - cidx_s = channel_idxs[name][0] - cidx_f = channel_idxs[name][1] - all_data_zm_chxtc = all_data_zm_nxtc[cidx_s:cidx_f,:] # ch for channel - W_chxp, _, _, _ = \ - np.linalg.lstsq(all_data_zm_chxtc.T, all_data_pca_pxtc.T) - dataset['alignment_matrix_cxf'] = W_chxp - alignment_bias_cx1 = all_data_mean_nx1[cidx_s:cidx_f] - dataset['alignment_bias_c'] = np.squeeze(alignment_bias_cx1, axis=1) - - do_debug_plot = False - if do_debug_plot: - pc_vecs = evecs_nxn[:,0:npcs] - ntoplot = 400 - - plt.figure() - plt.plot(np.log10(evals_n), '-x') - plt.figure() - plt.subplot(311) - plt.imshow(all_data_pca_pxtc) - plt.colorbar() - - plt.subplot(312) - plt.imshow(np.dot(W_chxp.T, all_data_zm_chxtc)) - plt.colorbar() - - plt.subplot(313) - plt.imshow(np.dot(all_data_zm_chxtc.T, W_chxp).T - all_data_pca_pxtc) - plt.colorbar() - - import pdb - pdb.set_trace() - - return datasets diff --git a/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001 b/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001 deleted file mode 100644 index 9459a2a1b72f56dc16b3eca210911f14081e7fd5..0000000000000000000000000000000000000000 Binary files a/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001 and /dev/null differ diff --git a/research/lfads/synth_data/trained_itb/model-65000.index b/research/lfads/synth_data/trained_itb/model-65000.index deleted file mode 100644 index dd9c793acf8dc79e07833d1c0edc8a2fa86d806a..0000000000000000000000000000000000000000 Binary files a/research/lfads/synth_data/trained_itb/model-65000.index and /dev/null differ diff --git a/research/lfads/synth_data/trained_itb/model-65000.meta b/research/lfads/synth_data/trained_itb/model-65000.meta deleted file mode 100644 index 07bd2b9688eda16e329e7b08492151a65a88fb8a..0000000000000000000000000000000000000000 Binary files a/research/lfads/synth_data/trained_itb/model-65000.meta and /dev/null differ diff --git a/research/lfads/utils.py b/research/lfads/utils.py deleted file mode 100644 index e64825ffc1d423de1d9fe85bc1c00a19e5f4ad7e..0000000000000000000000000000000000000000 --- a/research/lfads/utils.py +++ /dev/null @@ -1,367 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# ============================================================================== -from __future__ import print_function - -import os -import h5py -import json - -import numpy as np -import tensorflow as tf - - -def log_sum_exp(x_k): - """Computes log \sum exp in a numerically stable way. - log ( sum_i exp(x_i) ) - log ( sum_i exp(x_i - m + m) ), with m = max(x_i) - log ( sum_i exp(x_i - m)*exp(m) ) - log ( sum_i exp(x_i - m) + m - - Args: - x_k - k -dimensional list of arguments to log_sum_exp. - - Returns: - log_sum_exp of the arguments. - """ - m = tf.reduce_max(x_k) - x1_k = x_k - m - u_k = tf.exp(x1_k) - z = tf.reduce_sum(u_k) - return tf.log(z) + m - - -def linear(x, out_size, do_bias=True, alpha=1.0, identity_if_possible=False, - normalized=False, name=None, collections=None): - """Linear (affine) transformation, y = x W + b, for a variety of - configurations. - - Args: - x: input The tensor to tranformation. - out_size: The integer size of non-batch output dimension. - do_bias (optional): Add a learnable bias vector to the operation. - alpha (optional): A multiplicative scaling for the weight initialization - of the matrix, in the form \alpha * 1/\sqrt{x.shape[1]}. - identity_if_possible (optional): just return identity, - if x.shape[1] == out_size. - normalized (optional): Option to divide out by the norms of the rows of W. - name (optional): The name prefix to add to variables. - collections (optional): List of additional collections. (Placed in - tf.GraphKeys.GLOBAL_VARIABLES already, so no need for that.) - - Returns: - In the equation, y = x W + b, returns the tensorflow op that yields y. - """ - in_size = int(x.get_shape()[1]) # from Dimension(10) -> 10 - stddev = alpha/np.sqrt(float(in_size)) - mat_init = tf.random_normal_initializer(0.0, stddev) - wname = (name + "/W") if name else "/W" - - if identity_if_possible and in_size == out_size: - # Sometimes linear layers are nothing more than size adapters. - return tf.identity(x, name=(wname+'_ident')) - - W,b = init_linear(in_size, out_size, do_bias=do_bias, alpha=alpha, - normalized=normalized, name=name, collections=collections) - - if do_bias: - return tf.matmul(x, W) + b - else: - return tf.matmul(x, W) - - -def init_linear(in_size, out_size, do_bias=True, mat_init_value=None, - bias_init_value=None, alpha=1.0, identity_if_possible=False, - normalized=False, name=None, collections=None, trainable=True): - """Linear (affine) transformation, y = x W + b, for a variety of - configurations. - - Args: - in_size: The integer size of the non-batc input dimension. [(x),y] - out_size: The integer size of non-batch output dimension. [x,(y)] - do_bias (optional): Add a (learnable) bias vector to the operation, - if false, b will be None - mat_init_value (optional): numpy constant for matrix initialization, if None - , do random, with additional parameters. - alpha (optional): A multiplicative scaling for the weight initialization - of the matrix, in the form \alpha * 1/\sqrt{x.shape[1]}. - identity_if_possible (optional): just return identity, - if x.shape[1] == out_size. - normalized (optional): Option to divide out by the norms of the rows of W. - name (optional): The name prefix to add to variables. - collections (optional): List of additional collections. (Placed in - tf.GraphKeys.GLOBAL_VARIABLES already, so no need for that.) - - Returns: - In the equation, y = x W + b, returns the pair (W, b). - """ - - if mat_init_value is not None and mat_init_value.shape != (in_size, out_size): - raise ValueError( - 'Provided mat_init_value must have shape [%d, %d].'%(in_size, out_size)) - if bias_init_value is not None and bias_init_value.shape != (1,out_size): - raise ValueError( - 'Provided bias_init_value must have shape [1,%d].'%(out_size,)) - - if mat_init_value is None: - stddev = alpha/np.sqrt(float(in_size)) - mat_init = tf.random_normal_initializer(0.0, stddev) - - wname = (name + "/W") if name else "/W" - - if identity_if_possible and in_size == out_size: - return (tf.constant(np.eye(in_size).astype(np.float32)), - tf.zeros(in_size)) - - # Note the use of get_variable vs. tf.Variable. this is because get_variable - # does not allow the initialization of the variable with a value. - if normalized: - w_collections = [tf.GraphKeys.GLOBAL_VARIABLES, "norm-variables"] - if collections: - w_collections += collections - if mat_init_value is not None: - w = tf.Variable(mat_init_value, name=wname, collections=w_collections, - trainable=trainable) - else: - w = tf.get_variable(wname, [in_size, out_size], initializer=mat_init, - collections=w_collections, trainable=trainable) - w = tf.nn.l2_normalize(w, dim=0) # x W, so xW_j = \sum_i x_bi W_ij - else: - w_collections = [tf.GraphKeys.GLOBAL_VARIABLES] - if collections: - w_collections += collections - if mat_init_value is not None: - w = tf.Variable(mat_init_value, name=wname, collections=w_collections, - trainable=trainable) - else: - w = tf.get_variable(wname, [in_size, out_size], initializer=mat_init, - collections=w_collections, trainable=trainable) - b = None - if do_bias: - b_collections = [tf.GraphKeys.GLOBAL_VARIABLES] - if collections: - b_collections += collections - bname = (name + "/b") if name else "/b" - if bias_init_value is None: - b = tf.get_variable(bname, [1, out_size], - initializer=tf.zeros_initializer(), - collections=b_collections, - trainable=trainable) - else: - b = tf.Variable(bias_init_value, name=bname, - collections=b_collections, - trainable=trainable) - - return (w, b) - - -def write_data(data_fname, data_dict, use_json=False, compression=None): - """Write data in HD5F format. - - Args: - data_fname: The filename of teh file in which to write the data. - data_dict: The dictionary of data to write. The keys are strings - and the values are numpy arrays. - use_json (optional): human readable format for simple items - compression (optional): The compression to use for h5py (disabled by - default because the library borks on scalars, otherwise try 'gzip'). - """ - - dir_name = os.path.dirname(data_fname) - if not os.path.exists(dir_name): - os.makedirs(dir_name) - - if use_json: - the_file = open(data_fname,'wb') - json.dump(data_dict, the_file) - the_file.close() - else: - try: - with h5py.File(data_fname, 'w') as hf: - for k, v in data_dict.items(): - clean_k = k.replace('/', '_') - if clean_k is not k: - print('Warning: saving variable with name: ', k, ' as ', clean_k) - else: - print('Saving variable with name: ', clean_k) - hf.create_dataset(clean_k, data=v, compression=compression) - except IOError: - print("Cannot open %s for writing.", data_fname) - raise - - -def read_data(data_fname): - """ Read saved data in HDF5 format. - - Args: - data_fname: The filename of the file from which to read the data. - Returns: - A dictionary whose keys will vary depending on dataset (but should - always contain the keys 'train_data' and 'valid_data') and whose - values are numpy arrays. - """ - - try: - with h5py.File(data_fname, 'r') as hf: - data_dict = {k: np.array(v) for k, v in hf.items()} - return data_dict - except IOError: - print("Cannot open %s for reading." % data_fname) - raise - - -def write_datasets(data_path, data_fname_stem, dataset_dict, compression=None): - """Write datasets in HD5F format. - - This function assumes the dataset_dict is a mapping ( string -> - to data_dict ). It calls write_data for each data dictionary, - post-fixing the data filename with the key of the dataset. - - Args: - data_path: The path to the save directory. - data_fname_stem: The filename stem of the file in which to write the data. - dataset_dict: The dictionary of datasets. The keys are strings - and the values data dictionaries (str -> numpy arrays) associations. - compression (optional): The compression to use for h5py (disabled by - default because the library borks on scalars, otherwise try 'gzip'). - """ - - full_name_stem = os.path.join(data_path, data_fname_stem) - for s, data_dict in dataset_dict.items(): - write_data(full_name_stem + "_" + s, data_dict, compression=compression) - - -def read_datasets(data_path, data_fname_stem): - """Read dataset sin HD5F format. - - This function assumes the dataset_dict is a mapping ( string -> - to data_dict ). It calls write_data for each data dictionary, - post-fixing the data filename with the key of the dataset. - - Args: - data_path: The path to the save directory. - data_fname_stem: The filename stem of the file in which to write the data. - """ - - dataset_dict = {} - fnames = os.listdir(data_path) - - print ('loading data from ' + data_path + ' with stem ' + data_fname_stem) - for fname in fnames: - if fname.startswith(data_fname_stem): - data_dict = read_data(os.path.join(data_path,fname)) - idx = len(data_fname_stem) + 1 - key = fname[idx:] - data_dict['data_dim'] = data_dict['train_data'].shape[2] - data_dict['num_steps'] = data_dict['train_data'].shape[1] - dataset_dict[key] = data_dict - - if len(dataset_dict) == 0: - raise ValueError("Failed to load any datasets, are you sure that the " - "'--data_dir' and '--data_filename_stem' flag values " - "are correct?") - - print (str(len(dataset_dict)) + ' datasets loaded') - return dataset_dict - - -# NUMPY utility functions -def list_t_bxn_to_list_b_txn(values_t_bxn): - """Convert a length T list of BxN numpy tensors of length B list of TxN numpy - tensors. - - Args: - values_t_bxn: The length T list of BxN numpy tensors. - - Returns: - The length B list of TxN numpy tensors. - """ - T = len(values_t_bxn) - B, N = values_t_bxn[0].shape - values_b_txn = [] - for b in range(B): - values_pb_txn = np.zeros([T,N]) - for t in range(T): - values_pb_txn[t,:] = values_t_bxn[t][b,:] - values_b_txn.append(values_pb_txn) - - return values_b_txn - - -def list_t_bxn_to_tensor_bxtxn(values_t_bxn): - """Convert a length T list of BxN numpy tensors to single numpy tensor with - shape BxTxN. - - Args: - values_t_bxn: The length T list of BxN numpy tensors. - - Returns: - values_bxtxn: The BxTxN numpy tensor. - """ - - T = len(values_t_bxn) - B, N = values_t_bxn[0].shape - values_bxtxn = np.zeros([B,T,N]) - for t in range(T): - values_bxtxn[:,t,:] = values_t_bxn[t] - - return values_bxtxn - - -def tensor_bxtxn_to_list_t_bxn(tensor_bxtxn): - """Convert a numpy tensor with shape BxTxN to a length T list of numpy tensors - with shape BxT. - - Args: - tensor_bxtxn: The BxTxN numpy tensor. - - Returns: - A length T list of numpy tensors with shape BxT. - """ - - values_t_bxn = [] - B, T, N = tensor_bxtxn.shape - for t in range(T): - values_t_bxn.append(np.squeeze(tensor_bxtxn[:,t,:])) - - return values_t_bxn - - -def flatten(list_of_lists): - """Takes a list of lists and returns a list of the elements. - - Args: - list_of_lists: List of lists. - - Returns: - flat_list: Flattened list. - flat_list_idxs: Flattened list indices. - """ - flat_list = [] - flat_list_idxs = [] - start_idx = 0 - for item in list_of_lists: - if isinstance(item, list): - flat_list += item - l = len(item) - idxs = range(start_idx, start_idx+l) - start_idx = start_idx+l - else: # a value - flat_list.append(item) - idxs = [start_idx] - start_idx += 1 - flat_list_idxs.append(idxs) - - return flat_list, flat_list_idxs diff --git a/research/lm_1b/BUILD b/research/lm_1b/BUILD deleted file mode 100644 index ca5bc1f6ce4347a3b5f18d1bb59284aa9d07a567..0000000000000000000000000000000000000000 --- a/research/lm_1b/BUILD +++ /dev/null @@ -1,27 +0,0 @@ -package(default_visibility = [":internal"]) - -licenses(["notice"]) # Apache 2.0 - -exports_files(["LICENSE"]) - -package_group( - name = "internal", - packages = [ - "//lm_1b/...", - ], -) - -py_library( - name = "data_utils", - srcs = ["data_utils.py"], -) - -py_binary( - name = "lm_1b_eval", - srcs = [ - "lm_1b_eval.py", - ], - deps = [ - ":data_utils", - ], -) diff --git a/research/lm_1b/README.md b/research/lm_1b/README.md deleted file mode 100644 index f48afbfe23aff6681e641296e73b2c6b0e5a9b48..0000000000000000000000000000000000000000 --- a/research/lm_1b/README.md +++ /dev/null @@ -1,198 +0,0 @@ - - - - -Language Model on One Billion Word Benchmark - -Authors: - -Oriol Vinyals (vinyals@google.com, github: OriolVinyals), -Xin Pan - -Paper Authors: - -Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, Yonghui Wu - -TL;DR - -This is a pretrained model on One Billion Word Benchmark. -If you use this model in your publication, please cite the original paper: - -@article{jozefowicz2016exploring, - title={Exploring the Limits of Language Modeling}, - author={Jozefowicz, Rafal and Vinyals, Oriol and Schuster, Mike - and Shazeer, Noam and Wu, Yonghui}, - journal={arXiv preprint arXiv:1602.02410}, - year={2016} -} - -Introduction - -In this release, we open source a model trained on the One Billion Word -Benchmark (http://arxiv.org/abs/1312.3005), a large language corpus in English -which was released in 2013. This dataset contains about one billion words, and -has a vocabulary size of about 800K words. It contains mostly news data. Since -sentences in the training set are shuffled, models can ignore the context and -focus on sentence level language modeling. - -In the original release and subsequent work, people have used the same test set -to train models on this dataset as a standard benchmark for language modeling. -Recently, we wrote an article (http://arxiv.org/abs/1602.02410) describing a -model hybrid between character CNN, a large and deep LSTM, and a specific -Softmax architecture which allowed us to train the best model on this dataset -thus far, almost halving the best perplexity previously obtained by others. - -Code Release - -The open-sourced components include: - -* TensorFlow GraphDef proto buffer text file. -* TensorFlow pre-trained checkpoint shards. -* Code used to evaluate the pre-trained model. -* Vocabulary file. -* Test set from LM-1B evaluation. - -The code supports 4 evaluation modes: - -* Given provided dataset, calculate the model's perplexity. -* Given a prefix sentence, predict the next words. -* Dump the softmax embedding, character-level CNN word embeddings. -* Give a sentence, dump the embedding from the LSTM state. - -Results - -Model | Test Perplexity | Number of Params [billions] -------|-----------------|---------------------------- -Sigmoid-RNN-2048 [Blackout] | 68.3 | 4.1 -Interpolated KN 5-gram, 1.1B n-grams [chelba2013one] | 67.6 | 1.76 -Sparse Non-Negative Matrix LM [shazeer2015sparse] | 52.9 | 33 -RNN-1024 + MaxEnt 9-gram features [chelba2013one] | 51.3 | 20 -LSTM-512-512 | 54.1 | 0.82 -LSTM-1024-512 | 48.2 | 0.82 -LSTM-2048-512 | 43.7 | 0.83 -LSTM-8192-2048 (No Dropout) | 37.9 | 3.3 -LSTM-8192-2048 (50\% Dropout) | 32.2 | 3.3 -2-Layer LSTM-8192-1024 (BIG LSTM) | 30.6 | 1.8 -(THIS RELEASE) BIG LSTM+CNN Inputs | 30.0 | 1.04 - -How To Run - -Prerequisites: - -* Install TensorFlow. -* Install Bazel. -* Download the data files: - * Model GraphDef file: - [link](http://download.tensorflow.org/models/LM_LSTM_CNN/graph-2016-09-10.pbtxt) - * Model Checkpoint sharded file: - [1](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-base) - [2](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-char-embedding) - [3](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-lstm) - [4](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax0) - [5](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax1) - [6](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax2) - [7](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax3) - [8](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax4) - [9](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax5) - [10](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax6) - [11](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax7) - [12](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax8) - * Vocabulary file: - [link](http://download.tensorflow.org/models/LM_LSTM_CNN/vocab-2016-09-10.txt) - * test dataset: link - [link](http://download.tensorflow.org/models/LM_LSTM_CNN/test/news.en.heldout-00000-of-00050) -* It is recommended to run on a modern desktop instead of a laptop. - -```shell -# 1. Clone the code to your workspace. -# 2. Download the data to your workspace. -# 3. Create an empty WORKSPACE file in your workspace. -# 4. Create an empty output directory in your workspace. -# Example directory structure below: -$ ls -R -.: -data lm_1b output WORKSPACE - -./data: -ckpt-base ckpt-lstm ckpt-softmax1 ckpt-softmax3 ckpt-softmax5 -ckpt-softmax7 graph-2016-09-10.pbtxt vocab-2016-09-10.txt -ckpt-char-embedding ckpt-softmax0 ckpt-softmax2 ckpt-softmax4 ckpt-softmax6 -ckpt-softmax8 news.en.heldout-00000-of-00050 - -./lm_1b: -BUILD data_utils.py lm_1b_eval.py README.md - -./output: - -# Build the codes. -$ bazel build -c opt lm_1b/... -# Run sample mode: -$ bazel-bin/lm_1b/lm_1b_eval --mode sample \ - --prefix "I love that I" \ - --pbtxt data/graph-2016-09-10.pbtxt \ - --vocab_file data/vocab-2016-09-10.txt \ - --ckpt 'data/ckpt-*' -...(omitted some TensorFlow output) -I love -I love that -I love that I -I love that I find -I love that I find that -I love that I find that amazing -...(omitted) - -# Run eval mode: -$ bazel-bin/lm_1b/lm_1b_eval --mode eval \ - --pbtxt data/graph-2016-09-10.pbtxt \ - --vocab_file data/vocab-2016-09-10.txt \ - --input_data data/news.en.heldout-00000-of-00050 \ - --ckpt 'data/ckpt-*' -...(omitted some TensorFlow output) -Loaded step 14108582. -# perplexity is high initially because words without context are harder to -# predict. -Eval Step: 0, Average Perplexity: 2045.512297. -Eval Step: 1, Average Perplexity: 229.478699. -Eval Step: 2, Average Perplexity: 208.116787. -Eval Step: 3, Average Perplexity: 338.870601. -Eval Step: 4, Average Perplexity: 228.950107. -Eval Step: 5, Average Perplexity: 197.685857. -Eval Step: 6, Average Perplexity: 156.287063. -Eval Step: 7, Average Perplexity: 124.866189. -Eval Step: 8, Average Perplexity: 147.204975. -Eval Step: 9, Average Perplexity: 90.124864. -Eval Step: 10, Average Perplexity: 59.897914. -Eval Step: 11, Average Perplexity: 42.591137. -...(omitted) -Eval Step: 4529, Average Perplexity: 29.243668. -Eval Step: 4530, Average Perplexity: 29.302362. -Eval Step: 4531, Average Perplexity: 29.285674. -...(omitted. At convergence, it should be around 30.) - -# Run dump_emb mode: -$ bazel-bin/lm_1b/lm_1b_eval --mode dump_emb \ - --pbtxt data/graph-2016-09-10.pbtxt \ - --vocab_file data/vocab-2016-09-10.txt \ - --ckpt 'data/ckpt-*' \ - --save_dir output -...(omitted some TensorFlow output) -Finished softmax weights -Finished word embedding 0/793471 -Finished word embedding 1/793471 -Finished word embedding 2/793471 -...(omitted) -$ ls output/ -embeddings_softmax.npy ... - -# Run dump_lstm_emb mode: -$ bazel-bin/lm_1b/lm_1b_eval --mode dump_lstm_emb \ - --pbtxt data/graph-2016-09-10.pbtxt \ - --vocab_file data/vocab-2016-09-10.txt \ - --ckpt 'data/ckpt-*' \ - --sentence "I love who I am ." \ - --save_dir output -$ ls output/ -lstm_emb_step_0.npy lstm_emb_step_2.npy lstm_emb_step_4.npy -lstm_emb_step_6.npy lstm_emb_step_1.npy lstm_emb_step_3.npy -lstm_emb_step_5.npy -``` diff --git a/research/lm_1b/data_utils.py b/research/lm_1b/data_utils.py deleted file mode 100644 index ad8d3391ef6db07c1d6c234450a6d23a8e19a178..0000000000000000000000000000000000000000 --- a/research/lm_1b/data_utils.py +++ /dev/null @@ -1,279 +0,0 @@ -# Copyright 2016 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== - -"""A library for loading 1B word benchmark dataset.""" - -import random - -import numpy as np -import tensorflow as tf - - -class Vocabulary(object): - """Class that holds a vocabulary for the dataset.""" - - def __init__(self, filename): - """Initialize vocabulary. - - Args: - filename: Vocabulary file name. - """ - - self._id_to_word = [] - self._word_to_id = {} - self._unk = -1 - self._bos = -1 - self._eos = -1 - - with tf.gfile.Open(filename) as f: - idx = 0 - for line in f: - word_name = line.strip() - if word_name == '
-  -
-
-  -
-