
Merge branch 'master' of github.com:tensorflow/models
Showing
Too many changes to show.
To preserve performance only 302 of 302+ files are displayed.
object_detection/exporter.py
0 → 100644
{kind=link}

364 KB
{kind=link}

377 KB
{kind=link}

270 KB
{kind=link}
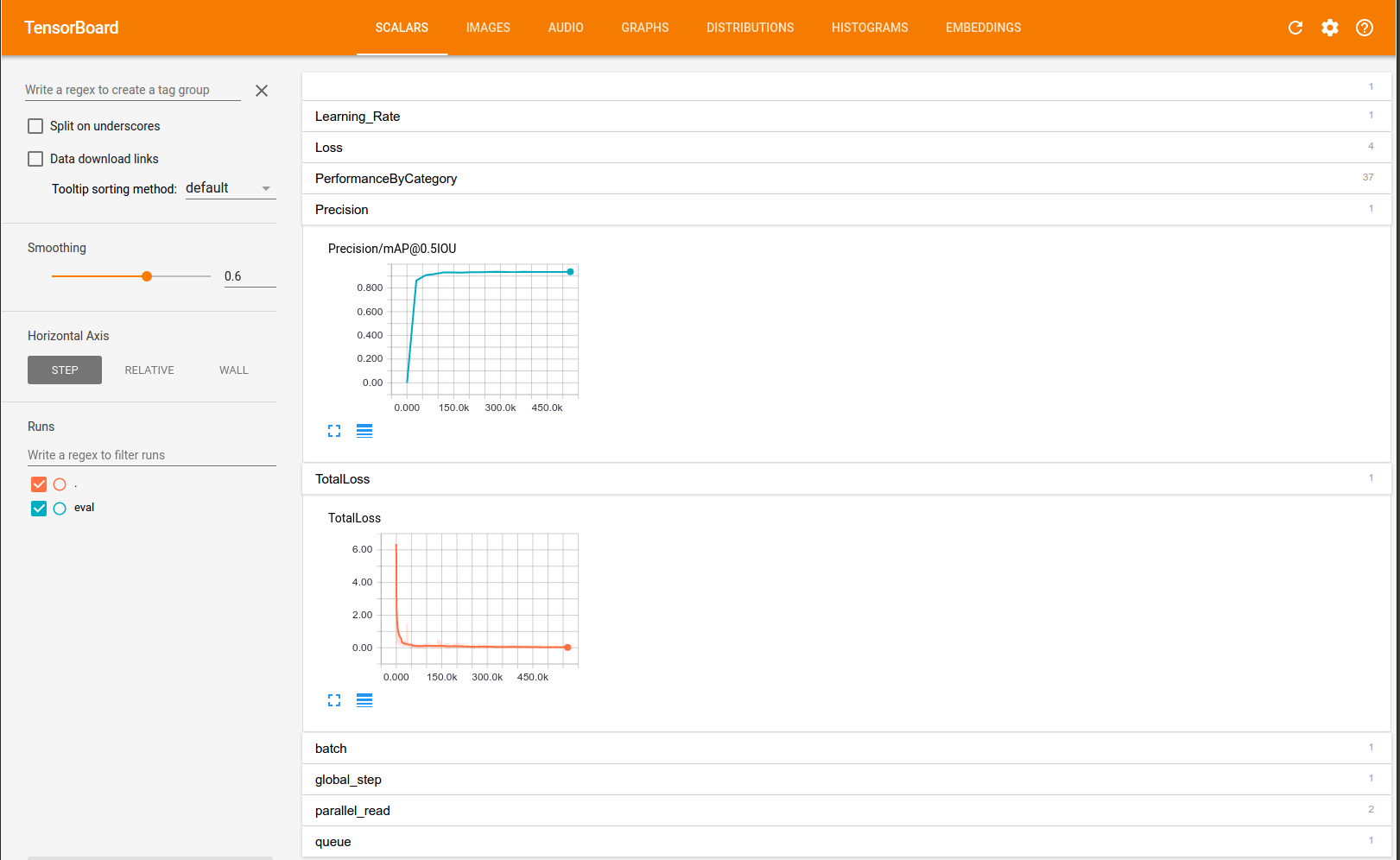
77.5 KB
{kind=link}
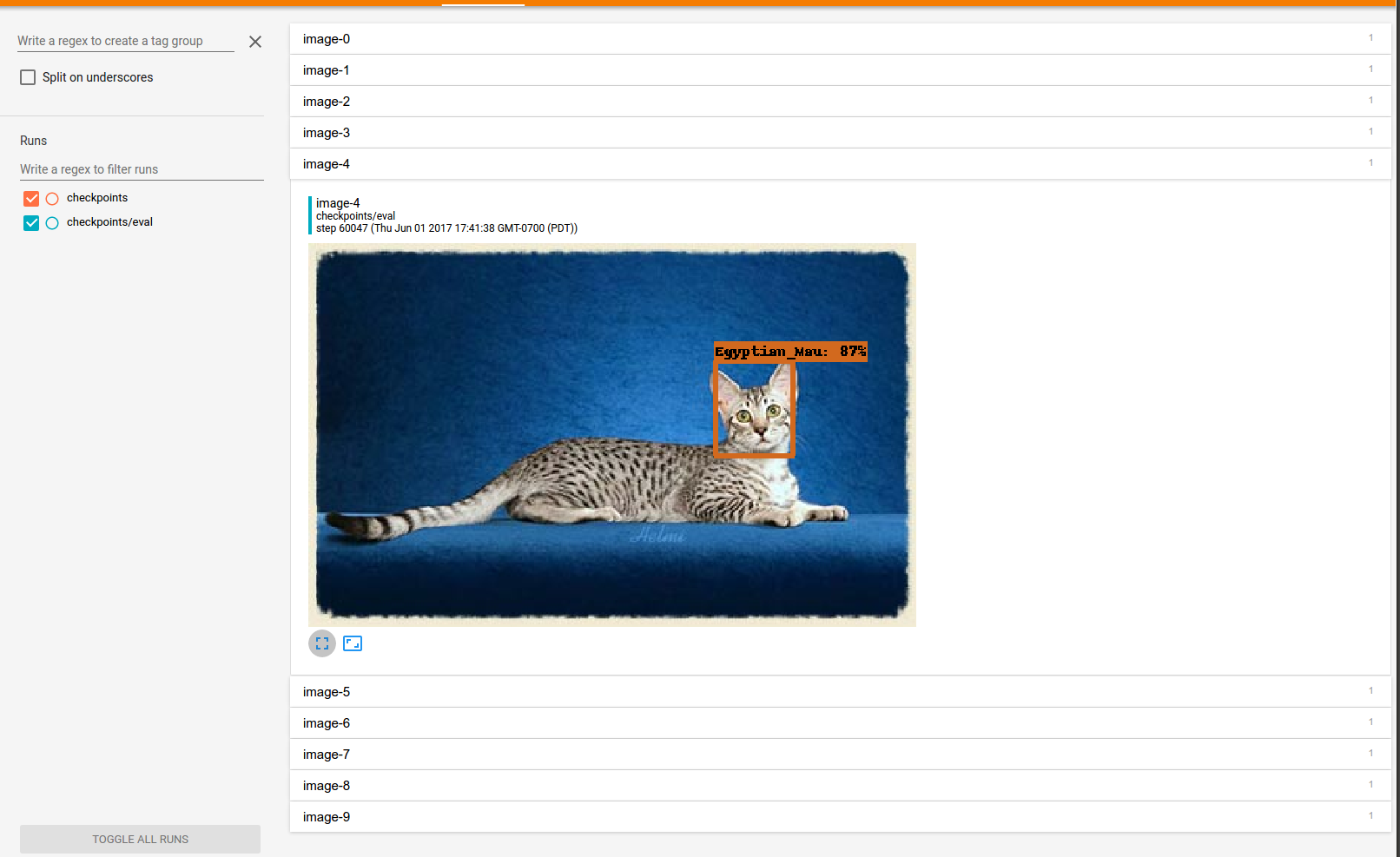
231 KB