Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
ResNet50_tensorflow
Commits
e9f041c0
Commit
e9f041c0
authored
Jun 04, 2021
by
Dan Kondratyuk
Committed by
A. Unique TensorFlower
Jun 04, 2021
Browse files
Improve MoViNet stream interface, fix state propagation.
PiperOrigin-RevId: 377562613
parent
4bf492a8
Changes
10
Expand all
Show whitespace changes
Inline
Side-by-side
Showing
10 changed files
with
727 additions
and
237 deletions
+727
-237
official/vision/beta/modeling/layers/nn_layers.py
official/vision/beta/modeling/layers/nn_layers.py
+81
-31
official/vision/beta/modeling/layers/nn_layers_test.py
official/vision/beta/modeling/layers/nn_layers_test.py
+28
-3
official/vision/beta/projects/movinet/README.md
official/vision/beta/projects/movinet/README.md
+159
-28
official/vision/beta/projects/movinet/configs/movinet.py
official/vision/beta/projects/movinet/configs/movinet.py
+1
-0
official/vision/beta/projects/movinet/modeling/movinet.py
official/vision/beta/projects/movinet/modeling/movinet.py
+205
-42
official/vision/beta/projects/movinet/modeling/movinet_layers.py
...l/vision/beta/projects/movinet/modeling/movinet_layers.py
+86
-75
official/vision/beta/projects/movinet/modeling/movinet_layers_test.py
...ion/beta/projects/movinet/modeling/movinet_layers_test.py
+0
-4
official/vision/beta/projects/movinet/modeling/movinet_model.py
...al/vision/beta/projects/movinet/modeling/movinet_model.py
+75
-28
official/vision/beta/projects/movinet/modeling/movinet_model_test.py
...sion/beta/projects/movinet/modeling/movinet_model_test.py
+67
-10
official/vision/beta/projects/movinet/modeling/movinet_test.py
...ial/vision/beta/projects/movinet/modeling/movinet_test.py
+25
-16
No files found.
official/vision/beta/modeling/layers/nn_layers.py
View file @
e9f041c0
...
...
@@ -281,9 +281,6 @@ class Scale(tf.keras.layers.Layer):
This is useful for applying ReZero to layers, which improves convergence
speed. This implements the paper:
Thomas Bachlechner, Bodhisattwa Prasad Majumder, Huanru Henry Mao,
Garrison W. Cottrell, Julian McAuley.
ReZero is All You Need: Fast Convergence at Large Depth.
(https://arxiv.org/pdf/2003.04887.pdf).
"""
...
...
@@ -371,6 +368,7 @@ class PositionalEncoding(tf.keras.layers.Layer):
def
__init__
(
self
,
initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'zeros'
,
cache_encoding
:
bool
=
False
,
state_prefix
:
Optional
[
str
]
=
None
,
**
kwargs
):
"""Initializes positional encoding.
...
...
@@ -380,6 +378,7 @@ class PositionalEncoding(tf.keras.layers.Layer):
after calling build. Otherwise, rebuild the tensor for every call.
Setting this to False can be useful when we want to input a variable
number of frames, so the positional encoding tensor can change shape.
state_prefix: a prefix string to identify states.
**kwargs: Additional keyword arguments to be passed to this layer.
Returns:
...
...
@@ -390,33 +389,43 @@ class PositionalEncoding(tf.keras.layers.Layer):
self
.
_cache_encoding
=
cache_encoding
self
.
_pos_encoding
=
None
self
.
_rezero
=
Scale
(
initializer
=
initializer
,
name
=
'rezero'
)
state_prefix
=
state_prefix
if
state_prefix
is
not
None
else
''
self
.
_state_prefix
=
state_prefix
self
.
_frame_count_name
=
f
'
{
state_prefix
}
/pos_enc_frame_count'
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'initializer'
:
self
.
_initializer
,
'cache_encoding'
:
self
.
_cache_encoding
,
'state_prefix'
:
self
.
_state_prefix
,
}
base_config
=
super
(
PositionalEncoding
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
_positional_encoding
(
self
,
num_positions
:
int
,
hidden_size
:
int
,
dtype
:
tf
.
DType
=
tf
.
float32
):
num_positions
:
Union
[
int
,
tf
.
Tensor
],
hidden_size
:
Union
[
int
,
tf
.
Tensor
],
start_position
:
Union
[
int
,
tf
.
Tensor
]
=
0
,
dtype
:
str
=
'float32'
)
->
tf
.
Tensor
:
"""Creates a sequence of sinusoidal positional encoding vectors.
Args:
num_positions: An `int` of number of positions (frames).
hidden_size: An `int` of number of channels used for the hidden vectors.
dtype: The dtype of the output tensor.
num_positions: the total number of positions (frames).
hidden_size: the number of channels used for the hidden vectors.
start_position: the start position.
dtype: the dtype of the output tensor.
Returns:
The positional encoding tensor with shape [num_positions, hidden_size].
"""
if
isinstance
(
start_position
,
tf
.
Tensor
)
and
start_position
.
shape
.
rank
==
1
:
start_position
=
start_position
[
0
]
# Calling `tf.range` with `dtype=tf.bfloat16` results in an error,
# so we cast afterward.
positions
=
tf
.
cast
(
tf
.
range
(
num_positions
)[:,
tf
.
newaxis
],
dtype
)
positions
=
tf
.
range
(
start_position
,
start_position
+
num_positions
)
positions
=
tf
.
cast
(
positions
,
dtype
)[:,
tf
.
newaxis
]
idx
=
tf
.
range
(
hidden_size
)[
tf
.
newaxis
,
:]
power
=
tf
.
cast
(
2
*
(
idx
//
2
),
dtype
)
...
...
@@ -430,11 +439,24 @@ class PositionalEncoding(tf.keras.layers.Layer):
return
pos_encoding
def
_get_pos_encoding
(
self
,
input_shape
):
"""Calculates the positional encoding from the input shape."""
def
_get_pos_encoding
(
self
,
input_shape
:
tf
.
Tensor
,
frame_count
:
int
=
0
)
->
tf
.
Tensor
:
"""Calculates the positional encoding from the input shape.
Args:
input_shape: the shape of the input.
frame_count: a count of frames that indicates the index of the first
frame.
Returns:
The positional encoding tensor with shape [num_positions, hidden_size].
"""
frames
=
input_shape
[
1
]
channels
=
input_shape
[
-
1
]
pos_encoding
=
self
.
_positional_encoding
(
frames
,
channels
,
dtype
=
self
.
dtype
)
pos_encoding
=
self
.
_positional_encoding
(
frames
,
channels
,
start_position
=
frame_count
,
dtype
=
self
.
dtype
)
pos_encoding
=
tf
.
reshape
(
pos_encoding
,
[
1
,
frames
,
1
,
1
,
channels
])
return
pos_encoding
...
...
@@ -455,16 +477,46 @@ class PositionalEncoding(tf.keras.layers.Layer):
super
(
PositionalEncoding
,
self
).
build
(
input_shape
)
def
call
(
self
,
inputs
):
"""Calls the layer with the given inputs."""
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
States
]
=
None
,
output_states
:
bool
=
True
,
)
->
Union
[
tf
.
Tensor
,
Tuple
[
tf
.
Tensor
,
States
]]:
"""Calls the layer with the given inputs.
Args:
inputs: An input `tf.Tensor`.
states: A `dict` of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s). Expected keys
include `state_prefix + '/pos_enc_frame_count'`.
output_states: A `bool`. If True, returns the output tensor and output
states. Returns just the output tensor otherwise.
Returns:
An output `tf.Tensor` (and optionally the states if `output_states=True`).
Raises:
ValueError: If using 'channels_first' data format.
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
# Keep a count of frames encountered across input iterations in
# num_frames to be able to accurately update the positional encoding.
num_frames
=
tf
.
shape
(
inputs
)[
1
]
frame_count
=
tf
.
cast
(
states
.
get
(
self
.
_frame_count_name
,
[
0
]),
tf
.
int32
)
states
[
self
.
_frame_count_name
]
=
frame_count
+
num_frames
if
self
.
_cache_encoding
:
pos_encoding
=
self
.
_pos_encoding
else
:
pos_encoding
=
self
.
_get_pos_encoding
(
tf
.
shape
(
inputs
))
pos_encoding
=
self
.
_get_pos_encoding
(
tf
.
shape
(
inputs
),
frame_count
=
frame_count
)
pos_encoding
=
tf
.
cast
(
pos_encoding
,
inputs
.
dtype
)
pos_encoding
=
tf
.
stop_gradient
(
pos_encoding
)
pos_encoding
=
self
.
_rezero
(
pos_encoding
)
return
inputs
+
pos_encoding
outputs
=
inputs
+
pos_encoding
return
(
outputs
,
states
)
if
output_states
else
outputs
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
...
...
@@ -480,6 +532,7 @@ class GlobalAveragePool3D(tf.keras.layers.Layer):
def
__init__
(
self
,
keepdims
:
bool
=
False
,
causal
:
bool
=
False
,
state_prefix
:
Optional
[
str
]
=
None
,
**
kwargs
):
"""Initializes a global average pool layer.
...
...
@@ -487,6 +540,7 @@ class GlobalAveragePool3D(tf.keras.layers.Layer):
keepdims: A `bool`. If True, keep the averaged dimensions.
causal: A `bool` of whether to run in causal mode with a cumulative sum
across frames.
state_prefix: a prefix string to identify states.
**kwargs: Additional keyword arguments to be passed to this layer.
Returns:
...
...
@@ -496,29 +550,22 @@ class GlobalAveragePool3D(tf.keras.layers.Layer):
self
.
_keepdims
=
keepdims
self
.
_causal
=
causal
state_prefix
=
state_prefix
if
state_prefix
is
not
None
else
''
self
.
_state_prefix
=
state_prefix
self
.
_frame_count
=
None
self
.
_state_name
=
f
'
{
state_prefix
}
/pool_buffer'
self
.
_frame_count_name
=
f
'
{
state_prefix
}
/pool_frame_count'
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'keepdims'
:
self
.
_keepdims
,
'causal'
:
self
.
_causal
,
'state_prefix'
:
self
.
_state_prefix
,
}
base_config
=
super
(
GlobalAveragePool3D
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
build
(
self
,
input_shape
):
"""Builds the layer with the given input shape."""
# Here we define strings that will uniquely reference the buffer states
# in the TF graph. These will be used for passing in a mapping of states
# for streaming mode. To do this, we can use a name scope.
with
tf
.
name_scope
(
'buffer'
)
as
state_name
:
self
.
_state_name
=
state_name
self
.
_frame_count_name
=
state_name
+
'_frame_count'
super
(
GlobalAveragePool3D
,
self
).
build
(
input_shape
)
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
States
]
=
None
,
...
...
@@ -530,6 +577,8 @@ class GlobalAveragePool3D(tf.keras.layers.Layer):
inputs: An input `tf.Tensor`.
states: A `dict` of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Expected keys include `state_prefix + '/pool_buffer'` and
`state_prefix + '/pool_frame_count'`.
output_states: A `bool`. If True, returns the output tensor and output
states. Returns just the output tensor otherwise.
...
...
@@ -561,7 +610,8 @@ class GlobalAveragePool3D(tf.keras.layers.Layer):
# num_frames to be able to accurately take a cumulative average across
# all frames when running in streaming mode
num_frames
=
tf
.
shape
(
inputs
)[
1
]
frame_count
=
states
.
get
(
self
.
_frame_count_name
,
0
)
frame_count
=
states
.
get
(
self
.
_frame_count_name
,
tf
.
constant
([
0
]))
frame_count
=
tf
.
cast
(
frame_count
,
tf
.
int32
)
states
[
self
.
_frame_count_name
]
=
frame_count
+
num_frames
if
self
.
_causal
:
...
...
official/vision/beta/modeling/layers/nn_layers_test.py
View file @
e9f041c0
...
...
@@ -48,8 +48,8 @@ class NNLayersTest(parameterized.TestCase, tf.test.TestCase):
initializer
=
'ones'
,
cache_encoding
=
True
)
inputs
=
tf
.
ones
([
1
,
4
,
1
,
1
,
3
])
outputs
=
pos_encoding
(
inputs
)
outputs_cached
=
pos_encoding_cached
(
inputs
)
outputs
,
_
=
pos_encoding
(
inputs
)
outputs_cached
,
_
=
pos_encoding_cached
(
inputs
)
expected
=
tf
.
constant
(
[[[[[
1.0000000
,
1.0000000
,
2.0000000
]]],
...
...
@@ -70,7 +70,7 @@ class NNLayersTest(parameterized.TestCase, tf.test.TestCase):
pos_encoding
=
nn_layers
.
PositionalEncoding
(
initializer
=
'ones'
)
inputs
=
tf
.
ones
([
1
,
4
,
1
,
1
,
3
],
dtype
=
tf
.
bfloat16
)
outputs
=
pos_encoding
(
inputs
)
outputs
,
_
=
pos_encoding
(
inputs
)
expected
=
tf
.
constant
(
[[[[[
1.0000000
,
1.0000000
,
2.0000000
]]],
...
...
@@ -92,6 +92,31 @@ class NNLayersTest(parameterized.TestCase, tf.test.TestCase):
self
.
assertEqual
(
outputs
.
shape
,
expected
.
shape
)
self
.
assertAllEqual
(
outputs
,
expected
)
def
test_positional_encoding_stream
(
self
):
pos_encoding
=
nn_layers
.
PositionalEncoding
(
initializer
=
'ones'
,
cache_encoding
=
False
)
inputs
=
tf
.
range
(
4
,
dtype
=
tf
.
float32
)
+
1.
inputs
=
tf
.
reshape
(
inputs
,
[
1
,
4
,
1
,
1
,
1
])
inputs
=
tf
.
tile
(
inputs
,
[
1
,
1
,
1
,
1
,
3
])
expected
,
_
=
pos_encoding
(
inputs
)
for
num_splits
in
[
1
,
2
,
4
]:
frames
=
tf
.
split
(
inputs
,
num_splits
,
axis
=
1
)
states
=
{}
predicted
=
[]
for
frame
in
frames
:
output
,
states
=
pos_encoding
(
frame
,
states
=
states
)
predicted
.
append
(
output
)
predicted
=
tf
.
concat
(
predicted
,
axis
=
1
)
self
.
assertEqual
(
predicted
.
shape
,
expected
.
shape
)
self
.
assertAllClose
(
predicted
,
expected
)
self
.
assertAllClose
(
predicted
,
[[[[[
1.0000000
,
1.0000000
,
2.0000000
]]],
[[[
2.8414710
,
2.0021544
,
2.5403023
]]],
[[[
3.9092975
,
3.0043090
,
2.5838532
]]],
[[[
4.1411200
,
4.0064630
,
3.0100074
]]]]])
def
test_global_average_pool_keras
(
self
):
pool
=
nn_layers
.
GlobalAveragePool3D
(
keepdims
=
False
)
keras_pool
=
tf
.
keras
.
layers
.
GlobalAveragePooling3D
()
...
...
official/vision/beta/projects/movinet/README.md
View file @
e9f041c0
...
...
@@ -8,16 +8,27 @@ This repository is the official implementation of
[
MoViNets: Mobile Video Networks for Efficient Video
Recognition
](
https://arxiv.org/abs/2103.11511
)
.
<p
align=
"center"
>
<img
src=
"https://storage.googleapis.com/tf_model_garden/vision/movinet/artifacts/hoverboard_stream.gif"
height=
500
>
</p>
## Description
Mobile Video Networks (MoViNets) are efficient video classification models
runnable on mobile devices. MoViNets demonstrate state-of-the-art accuracy and
efficiency on several large-scale video action recognition datasets.
On
[
Kinetics 600
](
https://deepmind.com/research/open-source/kinetics
)
,
MoViNet-A6 achieves 84.8% top-1 accuracy, outperforming recent
Vision Transformer models like
[
ViViT
](
https://arxiv.org/abs/2103.15691
)
(
83.0%
)
and
[
VATT
](
https://arxiv.org/abs/2104.11178
)
(
83.6%
)
without any additional
training data, while using 10x fewer FLOPs. And streaming MoViNet-A0 achieves
72% accuracy while using 3x fewer FLOPs than MobileNetV3-large (68%).
There is a large gap between video model performance of accurate models and
efficient models for video action recognition. On the one hand, 2D MobileNet
CNNs are fast and can operate on streaming video in real time, but are prone to
be noisy and
are
inaccurate. On the other hand, 3D CNNs are accurate, but are
be noisy and inaccurate. On the other hand, 3D CNNs are accurate, but are
memory and computation intensive and cannot operate on streaming video.
MoViNets bridge this gap, producing:
...
...
@@ -28,19 +39,22 @@ to A6).
usage.
-
Temporal ensembles of models to boost efficiency even higher.
Small MoViNets demonstrate higher efficiency and accuracy than MobileNetV3 for
video action recognition (Kinetics 600).
MoViNets also improve computational efficiency by outputting high-quality
predictions frame by frame, as opposed to the traditional multi-clip evaluation
approach that performs redundant computation and limits temporal scope.
MoViNets also improve efficiency by outputting high-quality predictions with a
single frame, as opposed to the traditional multi-clip evaluation approach.
<p
align=
"center"
>
<img
src=
"https://storage.googleapis.com/tf_model_garden/vision/movinet/artifacts/movinet_multi_clip_eval.png"
height=
200
>
</p>
[

](https://arxiv.org/pdf/2103.11511.pdf)
[
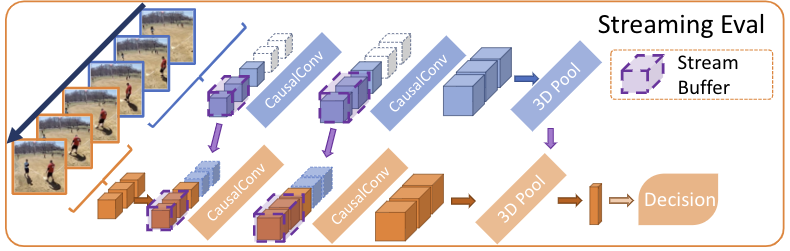
](https://arxiv.org/pdf/2103.11511.pdf)
<p
align=
"center"
>
<img
src=
"https://storage.googleapis.com/tf_model_garden/vision/movinet/artifacts/movinet_stream_eval.png"
height=
200
>
</p>
## History
-
Initial Commit.
-
**2021-05-30**
Add streaming MoViNet checkpoints and examples.
-
**2021-05-11**
Initial Commit.
## Authors and Maintainers
...
...
@@ -53,6 +67,7 @@ single frame, as opposed to the traditional multi-clip evaluation approach.
-
[
Requirements
](
#requirements
)
-
[
Results and Pretrained Weights
](
#results-and-pretrained-weights
)
-
[
Kinetics 600
](
#kinetics-600
)
-
[
Prediction Examples
](
#prediction-examples
)
-
[
Training and Evaluation
](
#training-and-evaluation
)
-
[
References
](
#references
)
-
[
License
](
#license
)
...
...
@@ -76,33 +91,154 @@ pip install -r requirements.txt
### Kinetics 600
[

](https://arxiv.org/pdf/2103.11511.pdf)
<p
align=
"center"
>
<img
src=
"https://storage.googleapis.com/tf_model_garden/vision/movinet/artifacts/movinet_comparison.png"
height=
500
>
</p>
[
tensorboard.dev summary
](
https://tensorboard.dev/experiment/Q07RQUlVRWOY4yDw3SnSkA/
)
of training runs across all models.
The table below summarizes the performance of each model and provides links to
download pretrained models. All models are evaluated on single clips with the
same resolution as training.
The table below summarizes the performance of each model on
[
Kinetics 600
](
https://deepmind.com/research/open-source/kinetics
)
and provides links to download pretrained models. All models are evaluated on
single clips with the same resolution as training.
Note: MoViNet-A6 can be constructed as an ensemble of MoViNet-A4 and
MoViNet-A5.
Streaming MoViNets will be added in the future.
#### Base Models
| Model Name | Top-1 Accuracy | Top-5 Accuracy | GFLOPs
\*
| Checkpoint | TF Hub SavedModel |
|------------|----------------|----------------|----------|------------|-------------------|
| MoViNet-A0-Base | 71.41 | 90.91 | 2.7 |
[
checkpoint (12 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a0/base/kinetics-600/classification/
)
|
| MoViNet-A1-Base | 76.01 | 93.28 | 6.0 |
[
checkpoint (18 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a1/base/kinetics-600/classification/
)
|
| MoViNet-A2-Base | 78.03 | 93.99 | 10 |
[
checkpoint (20 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a2/base/kinetics-600/classification/
)
|
| MoViNet-A3-Base | 81.22 | 95.35 | 57 |
[
checkpoint (29 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a3/base/kinetics-600/classification/
)
|
| MoViNet-A4-Base | 82.96 | 95.98 | 110 |
[
checkpoint (44 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a4/base/kinetics-600/classification/
)
|
| MoViNet-A5-Base | 84.22 | 96.36 | 280 |
[
checkpoint (72 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a5/base/kinetics-600/classification/
)
|
Base models implement standard 3D convolutions without stream buffers.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | Input Shape | GFLOPs
\*
| Chekpoint | TF Hub SavedModel |
|------------|----------------|----------------|-------------|----------|-----------|-------------------|
| MoViNet-A0-Base | 72.28 | 90.92 | 50 x 172 x 172 | 2.7 |
[
checkpoint (12 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a0/base/kinetics-600/classification/
)
|
| MoViNet-A1-Base | 76.69 | 93.40 | 50 x 172 x 172 | 6.0 |
[
checkpoint (18 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a1/base/kinetics-600/classification/
)
|
| MoViNet-A2-Base | 78.62 | 94.17 | 50 x 224 x 224 | 10 |
[
checkpoint (20 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a2/base/kinetics-600/classification/
)
|
| MoViNet-A3-Base | 81.79 | 95.67 | 120 x 256 x 256 | 57 |
[
checkpoint (29 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a3/base/kinetics-600/classification/
)
|
| MoViNet-A4-Base | 83.48 | 96.16 | 80 x 290 x 290 | 110 |
[
checkpoint (44 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a4/base/kinetics-600/classification/
)
|
| MoViNet-A5-Base | 84.27 | 96.39 | 120 x 320 x 320 | 280 |
[
checkpoint (72 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a5/base/kinetics-600/classification/
)
|
\*
GFLOPs per video on Kinetics 600.
## Training and Evaluation
#### Streaming Models
Streaming models implement causal 3D convolutions with stream buffers.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | Input Shape
\*
| GFLOPs
\*\*
| Chekpoint | TF Hub SavedModel |
|------------|----------------|----------------|---------------|------------|-----------|-------------------|
| MoViNet-A0-Stream | 72.05 | 90.63 | 50 x 172 x 172 | 2.7 |
[
checkpoint (12 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a0/stream/kinetics-600/classification/
)
|
| MoViNet-A1-Stream | 76.45 | 93.25 | 50 x 172 x 172 | 6.0 |
[
checkpoint (18 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a1/stream/kinetics-600/classification/
)
|
| MoViNet-A2-Stream | 78.40 | 94.05 | 50 x 224 x 224 | 10 |
[
checkpoint (20 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a2/stream/kinetics-600/classification/
)
|
| MoViNet-A3-Stream | 80.09 | 94.84 | 120 x 256 x 256 | 57 |
[
checkpoint (29 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a3/stream/kinetics-600/classification/
)
|
| MoViNet-A4-Stream | 81.49 | 95.66 | 80 x 290 x 290 | 110 |
[
checkpoint (44 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a4/stream/kinetics-600/classification/
)
|
| MoViNet-A5-Stream | 82.37 | 95.79 | 120 x 320 x 320 | 280 |
[
checkpoint (72 MB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_stream.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a5/stream/kinetics-600/classification/
)
|
\*
In streaming mode, the number of frames correspond to the total accumulated
duration of the 10-second clip.
\*\*
GFLOPs per video on Kinetics 600.
## Prediction Examples
Please check out our
[
Colab Notebook
](
https://colab.research.google.com/github/tensorflow/models/tree/master/official/vision/beta/projects/movinet/movinet_tutorial.ipynb
)
to get started with MoViNets.
This section provides examples on how to run prediction.
For base models, run the following:
```
python
import
tensorflow
as
tf
from
official.vision.beta.projects.movinet.modeling
import
movinet
from
official.vision.beta.projects.movinet.modeling
import
movinet_model
# Create backbone and model.
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
)
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
600
,
output_states
=
True
)
# Create your example input here.
# Refer to the paper for recommended input shapes.
inputs
=
tf
.
ones
([
1
,
8
,
172
,
172
,
3
])
# [Optional] Build the model and load a pretrained checkpoint
model
.
build
(
inputs
.
shape
)
checkpoint_dir
=
'/path/to/checkpoint'
checkpoint_path
=
tf
.
train
.
latest_checkpoint
(
checkpoint_dir
)
checkpoint
=
tf
.
train
.
Checkpoint
(
model
=
model
)
status
=
checkpoint
.
restore
(
checkpoint_path
)
status
.
assert_existing_objects_matched
()
# Run the model prediction.
output
=
model
(
inputs
)
prediction
=
tf
.
argmax
(
output
,
-
1
)
```
For streaming models, run the following:
```
python
import
tensorflow
as
tf
from
official.vision.beta.projects.movinet.modeling
import
movinet
from
official.vision.beta.projects.movinet.modeling
import
movinet_model
# Create backbone and model.
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
)
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
600
,
output_states
=
True
)
# Create your example input here.
# Refer to the paper for recommended input shapes.
inputs
=
tf
.
ones
([
1
,
8
,
172
,
172
,
3
])
# [Optional] Build the model and load a pretrained checkpoint
model
.
build
(
inputs
.
shape
)
checkpoint_dir
=
'/path/to/checkpoint'
checkpoint_path
=
tf
.
train
.
latest_checkpoint
(
checkpoint_dir
)
checkpoint
=
tf
.
train
.
Checkpoint
(
model
=
model
)
status
=
checkpoint
.
restore
(
checkpoint_path
)
status
.
assert_existing_objects_matched
()
# Split the video into individual frames.
# Note: we can also split into larger clips as well (e.g., 8-frame clips).
# Running on larger clips will slightly reduce latency overhead, but
# will consume more memory.
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
# Initialize the dict of states. All state tensors are initially zeros.
init_states
=
model
.
init_states
(
tf
.
shape
(
inputs
))
# Run the model prediction by looping over each frame.
states
=
init_states
predictions
=
[]
for
frame
in
frames
:
output
,
states
=
model
({
**
states
,
'image'
:
frame
})
predictions
.
append
(
output
)
# The video classification will simply be the last output of the model.
final_prediction
=
tf
.
argmax
(
predictions
[
-
1
],
-
1
)
# Alternatively, we can run the network on the entire input video.
# The output should be effectively the same
# (but it may differ a small amount due to floating point errors).
non_streaming_output
,
_
=
model
({
**
init_states
,
'image'
:
inputs
})
non_streaming_prediction
=
tf
.
argmax
(
non_streaming_output
,
-
1
)
```
## Training and Evaluation
Run this command line for continuous training and evaluation.
```
shell
...
...
@@ -137,11 +273,6 @@ python3 official/vision/beta/projects/movinet/train.py \
--tf_data_service
=
""
```
## References
-
[
Kinetics Datasets
](
https://deepmind.com/research/open-source/kinetics
)
-
[
MoViNets (Mobile Video Networks)
](
https://arxiv.org/abs/2103.11511
)
## License
[

](https://opensource.org/licenses/Apache-2.0)
...
...
official/vision/beta/projects/movinet/configs/movinet.py
View file @
e9f041c0
...
...
@@ -45,6 +45,7 @@ class Movinet(hyperparams.Config):
# 3d_2plus1d: (2+1)D convolution with Conv3D (no 2D reshaping)
conv_type
:
str
=
'3d'
stochastic_depth_drop_rate
:
float
=
0.2
use_external_states
:
bool
=
False
@
dataclasses
.
dataclass
...
...
official/vision/beta/projects/movinet/modeling/movinet.py
View file @
e9f041c0
...
...
@@ -17,7 +17,8 @@
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
from
typing
import
Optional
,
Sequence
,
Tuple
import
math
from
typing
import
Dict
,
Mapping
,
Optional
,
Sequence
,
Tuple
,
Union
import
dataclasses
import
tensorflow
as
tf
...
...
@@ -71,8 +72,6 @@ class HeadSpec(BlockSpec):
"""Configuration of a Movinet block."""
project_filters
:
int
=
0
head_filters
:
int
=
0
output_per_frame
:
bool
=
False
max_pool_predictions
:
bool
=
False
# Block specs specify the architecture of each model
...
...
@@ -317,6 +316,7 @@ class Movinet(tf.keras.Model):
kernel_regularizer
:
Optional
[
str
]
=
None
,
bias_regularizer
:
Optional
[
str
]
=
None
,
stochastic_depth_drop_rate
:
float
=
0.
,
use_external_states
:
bool
=
False
,
**
kwargs
):
"""MoViNet initialization function.
...
...
@@ -344,6 +344,8 @@ class Movinet(tf.keras.Model):
bias_regularizer: tf.keras.regularizers.Regularizer object for Conv2d.
Defaults to None.
stochastic_depth_drop_rate: the base rate for stochastic depth.
use_external_states: if True, expects states to be passed as additional
input.
**kwargs: keyword arguments to be passed.
"""
block_specs
=
BLOCK_SPECS
[
model_id
]
...
...
@@ -371,7 +373,10 @@ class Movinet(tf.keras.Model):
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_bias_regularizer
=
bias_regularizer
self
.
_stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
self
.
_use_external_states
=
use_external_states
if
self
.
_use_external_states
and
not
self
.
_causal
:
raise
ValueError
(
'External states should be used with causal mode.'
)
if
not
isinstance
(
block_specs
[
0
],
StemSpec
):
raise
ValueError
(
'Expected first spec to be StemSpec, got {}'
.
format
(
block_specs
[
0
]))
...
...
@@ -380,22 +385,55 @@ class Movinet(tf.keras.Model):
'Expected final spec to be HeadSpec, got {}'
.
format
(
block_specs
[
-
1
]))
self
.
_head_filters
=
block_specs
[
-
1
].
head_filters
if
tf
.
keras
.
backend
.
image_data_format
()
==
'channels_last'
:
bn_axis
=
-
1
else
:
bn_axis
=
1
state_specs
=
None
if
use_external_states
:
self
.
_set_dtype_policy
(
input_specs
.
dtype
)
state_specs
=
self
.
initial_state_specs
(
input_specs
.
shape
)
# Build MoViNet backbone.
inputs
=
tf
.
keras
.
Input
(
shape
=
input_specs
.
shape
[
1
:],
name
=
'inputs'
)
inputs
,
outputs
=
self
.
_build_network
(
input_specs
,
state_specs
=
state_specs
)
x
=
inputs
states
=
{}
super
(
Movinet
,
self
).
__init__
(
inputs
=
inputs
,
outputs
=
outputs
,
**
kwargs
)
self
.
_state_specs
=
state_specs
def
_build_network
(
self
,
input_specs
:
tf
.
keras
.
layers
.
InputSpec
,
state_specs
:
Optional
[
Mapping
[
str
,
tf
.
keras
.
layers
.
InputSpec
]]
=
None
,
)
->
Tuple
[
Mapping
[
str
,
tf
.
keras
.
Input
],
Tuple
[
Mapping
[
str
,
tf
.
Tensor
],
Mapping
[
str
,
tf
.
Tensor
]]]:
"""Builds the model network.
Args:
input_specs: the model input spec to use.
state_specs: a dict mapping a state name to the corresponding state spec.
State names should match with the `state` input/output dict.
Returns:
Inputs and outputs as a tuple. Inputs are expected to be a dict with
base input and states. Outputs are expected to be a dict of endpoints
and output states.
"""
state_specs
=
state_specs
if
state_specs
is
not
None
else
{}
image_input
=
tf
.
keras
.
Input
(
shape
=
input_specs
.
shape
[
1
:],
name
=
'inputs'
)
states
=
{
name
:
tf
.
keras
.
Input
(
shape
=
spec
.
shape
[
1
:],
dtype
=
spec
.
dtype
,
name
=
name
)
for
name
,
spec
in
state_specs
.
items
()
}
inputs
=
{
**
states
,
'image'
:
image_input
}
endpoints
=
{}
num_layers
=
sum
(
len
(
block
.
expand_filters
)
for
block
in
block_specs
x
=
image_input
num_layers
=
sum
(
len
(
block
.
expand_filters
)
for
block
in
self
.
_block_specs
if
isinstance
(
block
,
MovinetBlockSpec
))
stochastic_depth_idx
=
1
for
block_idx
,
block
in
enumerate
(
block_specs
):
for
block_idx
,
block
in
enumerate
(
self
.
_
block_specs
):
if
isinstance
(
block
,
StemSpec
):
x
,
states
=
movinet_layers
.
Stem
(
block
.
filters
,
...
...
@@ -404,12 +442,14 @@ class Movinet(tf.keras.Model):
conv_type
=
self
.
_conv_type
,
causal
=
self
.
_causal
,
activation
=
self
.
_activation
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
kernel_initializer
=
self
.
_
kernel_initializer
,
kernel_regularizer
=
self
.
_
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
,
name
=
'stem'
)(
x
,
states
=
states
)
state_prefix
=
'state/stem'
,
name
=
'stem'
)(
x
,
states
=
states
)
endpoints
[
'stem'
]
=
x
elif
isinstance
(
block
,
MovinetBlockSpec
):
if
not
(
len
(
block
.
expand_filters
)
==
len
(
block
.
kernel_sizes
)
==
...
...
@@ -437,14 +477,16 @@ class Movinet(tf.keras.Model):
activation
=
self
.
_activation
,
stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
,
conv_type
=
self
.
_conv_type
,
use_positional_encoding
=
self
.
_use_positional_encoding
and
self
.
_causal
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_positional_encoding
=
self
.
_use_positional_encoding
and
self
.
_causal
,
kernel_initializer
=
self
.
_
kernel_initializer
,
kernel_regularizer
=
self
.
_
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
,
name
=
name
)(
x
,
states
=
states
)
state_prefix
=
f
'state/
{
name
}
'
,
name
=
name
)(
x
,
states
=
states
)
endpoints
[
name
]
=
x
stochastic_depth_idx
+=
1
elif
isinstance
(
block
,
HeadSpec
):
...
...
@@ -452,27 +494,154 @@ class Movinet(tf.keras.Model):
project_filters
=
block
.
project_filters
,
conv_type
=
self
.
_conv_type
,
activation
=
self
.
_activation
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
kernel_initializer
=
self
.
_
kernel_initializer
,
kernel_regularizer
=
self
.
_
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
)(
x
,
states
=
states
)
batch_norm_epsilon
=
self
.
_norm_epsilon
,
state_prefix
=
'state/head'
,
name
=
'head'
)(
x
,
states
=
states
)
endpoints
[
'head'
]
=
x
else
:
raise
ValueError
(
'Unknown block type {}'
.
format
(
block
))
self
.
_output_specs
=
{
l
:
endpoints
[
l
].
get_shape
()
for
l
in
endpoints
}
outputs
=
(
endpoints
,
states
)
return
inputs
,
outputs
def
_get_initial_state_shapes
(
self
,
block_specs
:
Sequence
[
BlockSpec
],
input_shape
:
Union
[
Sequence
[
int
],
tf
.
Tensor
],
use_positional_encoding
:
bool
=
False
)
->
Dict
[
str
,
Sequence
[
int
]]:
"""Generates names and shapes for all input states.
Args:
block_specs: sequence of specs used for creating a model.
input_shape: the expected 5D shape of the image input.
use_positional_encoding: whether the model will use positional encoding.
Returns:
A dict mapping state names to state shapes.
"""
def
divide_resolution
(
shape
,
num_downsamples
):
"""Downsamples the dimension to calculate strided convolution shape."""
if
shape
is
None
:
return
None
if
isinstance
(
shape
,
tf
.
Tensor
):
# Avoid using div and ceil to support tf lite
shape
=
tf
.
cast
(
shape
,
tf
.
float32
)
resolution_divisor
=
2
**
num_downsamples
resolution_multiplier
=
0.5
**
num_downsamples
shape
=
((
shape
+
resolution_divisor
-
1
)
*
resolution_multiplier
)
return
tf
.
cast
(
shape
,
tf
.
int32
)
else
:
resolution_divisor
=
2
**
num_downsamples
return
math
.
ceil
(
shape
/
resolution_divisor
)
inputs
=
{
'image'
:
inputs
,
'states'
:
{
name
:
tf
.
keras
.
Input
(
shape
=
state
.
shape
[
1
:],
name
=
f
'states/
{
name
}
'
)
for
name
,
state
in
states
.
items
()
},
states
=
{}
num_downsamples
=
0
for
block_idx
,
block
in
enumerate
(
block_specs
):
if
isinstance
(
block
,
StemSpec
):
if
block
.
kernel_size
[
0
]
>
1
:
states
[
'state/stem/stream_buffer'
]
=
(
input_shape
[
0
],
input_shape
[
1
],
divide_resolution
(
input_shape
[
2
],
num_downsamples
),
divide_resolution
(
input_shape
[
3
],
num_downsamples
),
block
.
filters
,
)
num_downsamples
+=
1
elif
isinstance
(
block
,
MovinetBlockSpec
):
block_idx
-=
1
params
=
list
(
zip
(
block
.
expand_filters
,
block
.
kernel_sizes
,
block
.
strides
))
for
layer_idx
,
layer
in
enumerate
(
params
):
expand_filters
,
kernel_size
,
strides
=
layer
if
kernel_size
[
0
]
>
1
:
states
[
f
'state/b
{
block_idx
}
/l
{
layer_idx
}
/stream_buffer'
]
=
(
input_shape
[
0
],
kernel_size
[
0
]
-
1
,
divide_resolution
(
input_shape
[
2
],
num_downsamples
),
divide_resolution
(
input_shape
[
3
],
num_downsamples
),
expand_filters
,
)
states
[
f
'state/b
{
block_idx
}
/l
{
layer_idx
}
/pool_buffer'
]
=
(
input_shape
[
0
],
1
,
1
,
1
,
expand_filters
,
)
states
[
f
'state/b
{
block_idx
}
/l
{
layer_idx
}
/pool_frame_count'
]
=
(
1
,)
if
use_positional_encoding
:
name
=
f
'state/b
{
block_idx
}
/l
{
layer_idx
}
/pos_enc_frame_count'
states
[
name
]
=
(
1
,)
if
strides
[
1
]
!=
strides
[
2
]:
raise
ValueError
(
'Strides must match in the spatial dimensions, '
'got {}'
.
format
(
strides
))
if
strides
[
1
]
!=
1
or
strides
[
2
]
!=
1
:
num_downsamples
+=
1
elif
isinstance
(
block
,
HeadSpec
):
states
[
'state/head/pool_buffer'
]
=
(
input_shape
[
0
],
1
,
1
,
1
,
block
.
project_filters
,
)
states
[
'state/head/pool_frame_count'
]
=
(
1
,)
return
states
def
_get_state_dtype
(
self
,
name
:
str
)
->
str
:
"""Returns the dtype associated with a state."""
if
'frame_count'
in
name
:
return
'int32'
return
self
.
dtype
def
initial_state_specs
(
self
,
input_shape
:
Sequence
[
int
])
->
Dict
[
str
,
tf
.
keras
.
layers
.
InputSpec
]:
"""Creates a mapping of state name to InputSpec from the input shape."""
state_shapes
=
self
.
_get_initial_state_shapes
(
self
.
_block_specs
,
input_shape
,
use_positional_encoding
=
self
.
_use_positional_encoding
)
return
{
name
:
tf
.
keras
.
layers
.
InputSpec
(
shape
=
shape
,
dtype
=
self
.
_get_state_dtype
(
name
))
for
name
,
shape
in
state_shapes
.
items
()
}
outputs
=
(
endpoints
,
states
)
super
(
Movinet
,
self
).
__init__
(
inputs
=
inputs
,
outputs
=
outputs
,
**
kwargs
)
def
init_states
(
self
,
input_shape
:
Sequence
[
int
])
->
Dict
[
str
,
tf
.
Tensor
]:
"""Returns initial states for the first call in steaming mode."""
state_shapes
=
self
.
_get_initial_state_shapes
(
self
.
_block_specs
,
input_shape
,
use_positional_encoding
=
self
.
_use_positional_encoding
)
states
=
{
name
:
tf
.
zeros
(
shape
,
dtype
=
self
.
_get_state_dtype
(
name
))
for
name
,
shape
in
state_shapes
.
items
()
}
return
states
@
property
def
use_external_states
(
self
)
->
bool
:
"""Whether this model is expecting input states as additional input."""
return
self
.
_use_external_states
@
property
def
head_filters
(
self
):
"""The number of filters expected to be in the head classifer layer."""
return
self
.
_head_filters
@
property
def
conv_type
(
self
):
"""The expected convolution type (see __init__ for more details)."""
return
self
.
_conv_type
def
get_config
(
self
):
config_dict
=
{
...
...
@@ -495,11 +664,6 @@ class Movinet(tf.keras.Model):
def
from_config
(
cls
,
config
,
custom_objects
=
None
):
return
cls
(
**
config
)
@
property
def
output_specs
(
self
):
"""A dict of {level: TensorShape} pairs for the model output."""
return
self
.
_output_specs
@
factory
.
register_backbone_builder
(
'movinet'
)
def
build_movinet
(
...
...
@@ -508,8 +672,6 @@ def build_movinet(
norm_activation_config
:
hyperparams
.
Config
,
l2_regularizer
:
tf
.
keras
.
regularizers
.
Regularizer
=
None
)
->
tf
.
keras
.
Model
:
"""Builds MoViNet backbone from a config."""
l2_regularizer
=
l2_regularizer
or
tf
.
keras
.
regularizers
.
L2
(
1.5e-5
)
backbone_type
=
backbone_config
.
type
backbone_cfg
=
backbone_config
.
get
()
assert
backbone_type
==
'movinet'
,
(
'Inconsistent backbone type '
...
...
@@ -526,4 +688,5 @@ def build_movinet(
norm_momentum
=
norm_activation_config
.
norm_momentum
,
norm_epsilon
=
norm_activation_config
.
norm_epsilon
,
kernel_regularizer
=
l2_regularizer
,
stochastic_depth_drop_rate
=
backbone_cfg
.
stochastic_depth_drop_rate
)
stochastic_depth_drop_rate
=
backbone_cfg
.
stochastic_depth_drop_rate
,
use_external_states
=
backbone_cfg
.
use_external_states
)
official/vision/beta/projects/movinet/modeling/movinet_layers.py
View file @
e9f041c0
This diff is collapsed.
Click to expand it.
official/vision/beta/projects/movinet/modeling/movinet_layers_test.py
View file @
e9f041c0
...
...
@@ -146,7 +146,6 @@ class MovinetLayersTest(parameterized.TestCase, tf.test.TestCase):
use_bias
=
False
,
activation
=
'relu'
,
conv_type
=
'2plus1d'
,
use_positional_encoding
=
True
,
)
stream_conv_block
=
movinet_layers
.
StreamConvBlock
(
...
...
@@ -158,7 +157,6 @@ class MovinetLayersTest(parameterized.TestCase, tf.test.TestCase):
use_bias
=
False
,
activation
=
'relu'
,
conv_type
=
'2plus1d'
,
use_positional_encoding
=
True
,
)
inputs
=
tf
.
ones
([
1
,
4
,
2
,
2
,
3
])
...
...
@@ -197,7 +195,6 @@ class MovinetLayersTest(parameterized.TestCase, tf.test.TestCase):
use_bias
=
False
,
activation
=
'relu'
,
conv_type
=
'3d_2plus1d'
,
use_positional_encoding
=
True
,
)
stream_conv_block
=
movinet_layers
.
StreamConvBlock
(
...
...
@@ -209,7 +206,6 @@ class MovinetLayersTest(parameterized.TestCase, tf.test.TestCase):
use_bias
=
False
,
activation
=
'relu'
,
conv_type
=
'3d_2plus1d'
,
use_positional_encoding
=
True
,
)
inputs
=
tf
.
ones
([
1
,
4
,
2
,
2
,
3
])
...
...
official/vision/beta/projects/movinet/modeling/movinet_model.py
View file @
e9f041c0
...
...
@@ -16,7 +16,7 @@
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
from
typing
import
Mapping
,
Optional
from
typing
import
Any
,
Dict
,
Mapping
,
Optional
,
Sequence
,
Tuple
,
Union
from
absl
import
logging
import
tensorflow
as
tf
...
...
@@ -71,47 +71,94 @@ class MovinetClassifier(tf.keras.Model):
self
.
_bias_regularizer
=
bias_regularizer
self
.
_output_states
=
output_states
# Keras model variable that excludes @property.setters from tracking
self
.
_self_setattr_tracking
=
False
state_specs
=
None
if
backbone
.
use_external_states
:
state_specs
=
backbone
.
initial_state_specs
(
input_shape
=
input_specs
[
'image'
].
shape
)
inputs
=
{
name
:
tf
.
keras
.
Input
(
shape
=
state
.
shape
[
1
:],
name
=
f
'states/
{
name
}
'
)
for
name
,
state
in
input_specs
.
items
()
inputs
,
outputs
=
self
.
_build_network
(
backbone
,
input_specs
,
state_specs
=
state_specs
)
super
(
MovinetClassifier
,
self
).
__init__
(
inputs
=
inputs
,
outputs
=
outputs
,
**
kwargs
)
# Move backbone after super() call so Keras is happy
self
.
_backbone
=
backbone
def
_build_network
(
self
,
backbone
:
tf
.
keras
.
Model
,
input_specs
:
Mapping
[
str
,
tf
.
keras
.
layers
.
InputSpec
],
state_specs
:
Optional
[
Mapping
[
str
,
tf
.
keras
.
layers
.
InputSpec
]]
=
None
,
)
->
Tuple
[
Mapping
[
str
,
tf
.
keras
.
Input
],
Union
[
Tuple
[
Mapping
[
str
,
tf
.
Tensor
],
Mapping
[
str
,
tf
.
Tensor
]],
Mapping
[
str
,
tf
.
Tensor
]]]:
"""Builds the model network.
Args:
backbone: the model backbone.
input_specs: the model input spec to use.
state_specs: a dict of states such that, if any of the keys match for a
layer, will overwrite the contents of the buffer(s).
Returns:
Inputs and outputs as a tuple. Inputs are expected to be a dict with
base input and states. Outputs are expected to be a dict of endpoints
and (optionally) output states.
"""
state_specs
=
state_specs
if
state_specs
is
not
None
else
{}
states
=
{
name
:
tf
.
keras
.
Input
(
shape
=
spec
.
shape
[
1
:],
dtype
=
spec
.
dtype
,
name
=
name
)
for
name
,
spec
in
state_specs
.
items
()
}
states
=
inputs
.
get
(
'states'
,
{})
image
=
tf
.
keras
.
Input
(
shape
=
input_specs
[
'image'
].
shape
[
1
:],
name
=
'image'
)
inputs
=
{
**
states
,
'image'
:
image
}
if
backbone
.
use_external_states
:
before_states
=
set
(
states
)
endpoints
,
states
=
backbone
(
inputs
)
after_states
=
set
(
states
)
new_states
=
after_states
-
before_states
if
new_states
:
raise
AttributeError
(
'Expected input and output states to be the same. '
'Got extra states {}, expected {}'
.
format
(
new_states
,
before_states
))
else
:
endpoints
,
states
=
backbone
(
inputs
)
endpoints
,
states
=
backbone
(
dict
(
image
=
inputs
[
'image'
],
states
=
states
))
x
=
endpoints
[
'head'
]
x
=
movinet_layers
.
ClassifierHead
(
head_filters
=
backbone
.
_head_filters
,
num_classes
=
num_classes
,
dropout_rate
=
dropout_rate
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
conv_type
=
backbone
.
_conv_type
)(
x
)
if
output_states
:
inputs
[
'states'
]
=
{
k
:
tf
.
keras
.
Input
(
shape
=
v
.
shape
[
1
:],
name
=
k
)
for
k
,
v
in
states
.
items
()
}
head_filters
=
backbone
.
head_filters
,
num_classes
=
self
.
_num_classes
,
dropout_rate
=
self
.
_dropout_rate
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
conv_type
=
backbone
.
conv_type
)(
x
)
outputs
=
(
x
,
states
)
if
output_states
else
x
outputs
=
(
x
,
states
)
if
self
.
_
output_states
else
x
super
(
MovinetClassifier
,
self
).
__init__
(
inputs
=
inputs
,
outputs
=
outputs
,
**
kwargs
)
return
inputs
,
outputs
# Move backbone after super() call so Keras is happy
self
.
_backbone
=
backbone
def
initial_state_specs
(
self
,
input_shape
:
Sequence
[
int
])
->
Dict
[
str
,
tf
.
keras
.
layers
.
InputSpec
]:
return
self
.
_backbone
.
initial_state_specs
(
input_shape
=
input_shape
)
@
tf
.
function
def
init_states
(
self
,
input_shape
:
Sequence
[
int
])
->
Dict
[
str
,
tf
.
Tensor
]:
"""Returns initial states for the first call in steaming mode."""
return
self
.
_backbone
.
init_states
(
input_shape
)
@
property
def
checkpoint_items
(
self
):
def
checkpoint_items
(
self
)
->
Dict
[
str
,
Any
]
:
"""Returns a dictionary of items to be additionally checkpointed."""
return
dict
(
backbone
=
self
.
backbone
)
@
property
def
backbone
(
self
):
def
backbone
(
self
)
->
tf
.
keras
.
Model
:
"""Returns the backbone of the model."""
return
self
.
_backbone
def
get_config
(
self
):
...
...
@@ -142,7 +189,7 @@ class MovinetClassifier(tf.keras.Model):
@
model_factory
.
register_model_builder
(
'movinet'
)
def
build_movinet_model
(
input_specs
:
tf
.
keras
.
layers
.
InputSpec
,
input_specs
:
Mapping
[
str
,
tf
.
keras
.
layers
.
InputSpec
]
,
model_config
:
cfg
.
MovinetModel
,
num_classes
:
int
,
l2_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
None
):
...
...
official/vision/beta/projects/movinet/modeling/movinet_model_test.py
View file @
e9f041c0
...
...
@@ -48,28 +48,85 @@ class MovinetModelTest(parameterized.TestCase, tf.test.TestCase):
self
.
assertAllEqual
([
2
,
num_classes
],
logits
.
shape
)
def
test_movinet_classifier_stream
(
self
):
"""Test if the classifier can be run in streaming mode."""
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
model
=
movinet
.
Movinet
(
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
)
inputs
=
tf
.
ones
([
1
,
5
,
128
,
128
,
3
])
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
600
,
output_states
=
True
)
inputs
=
tf
.
ones
([
1
,
8
,
172
,
172
,
3
])
init_states
=
model
.
init_states
(
tf
.
shape
(
inputs
))
expected
,
_
=
model
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
({
**
states
,
'image'
:
frame
})
predicted
=
output
self
.
assertEqual
(
predicted
.
shape
,
expected
.
shape
)
self
.
assertAllClose
(
predicted
,
expected
,
1e-5
,
1e-5
)
def
test_movinet_classifier_stream_pos_enc
(
self
):
"""Test if the classifier can be run in streaming mode with pos encoding."""
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
use_positional_encoding
=
True
,
)
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
600
,
output_states
=
True
)
inputs
=
tf
.
ones
([
1
,
8
,
172
,
172
,
3
])
expected_endpoints
,
_
=
model
(
dict
(
image
=
inputs
,
states
=
{}))
init_states
=
model
.
init_states
(
tf
.
shape
(
inputs
))
expected
,
_
=
model
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
output
,
states
=
None
,
{}
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
(
dict
(
image
=
frame
,
states
=
states
))
predicted_endpoints
=
output
output
,
states
=
model
({
**
states
,
'image'
:
frame
})
predicted
=
output
self
.
assertEqual
(
predicted
.
shape
,
expected
.
shape
)
self
.
assertAllClose
(
predicted
,
expected
,
1e-5
,
1e-5
)
def
test_movinet_classifier_stream_pos_enc_2plus1d
(
self
):
"""Test if the model can run in streaming mode with pos encoding, (2+1)D."""
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
use_positional_encoding
=
True
,
conv_type
=
'2plus1d'
,
)
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
600
,
output_states
=
True
)
predicted
=
predicted_endpoints
[
'head'
]
inputs
=
tf
.
ones
([
1
,
8
,
172
,
172
,
3
])
# The expected final output is simply the mean across frames
expected
=
expected_endpoints
[
'head'
]
expected
=
tf
.
reduce_mean
(
expected
,
1
,
keepdims
=
True
)
init_states
=
model
.
init_states
(
tf
.
shape
(
inputs
))
expected
,
_
=
model
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
({
**
states
,
'image'
:
frame
})
predicted
=
output
self
.
assertEqual
(
predicted
.
shape
,
expected
.
shape
)
self
.
assertAllClose
(
predicted
,
expected
,
1e-5
,
1e-5
)
...
...
official/vision/beta/projects/movinet/modeling/movinet_test.py
View file @
e9f041c0
...
...
@@ -48,14 +48,15 @@ class MoViNetTest(parameterized.TestCase, tf.test.TestCase):
"""Test creation of MoViNet family models with states."""
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
network
=
movinet
.
Movinet
(
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
)
inputs
=
tf
.
ones
([
1
,
8
,
128
,
128
,
3
])
_
,
states
=
network
(
inputs
)
endpoints
,
new_states
=
network
(
dict
(
image
=
inputs
,
states
=
states
)
)
init_
states
=
backbone
.
init_states
(
tf
.
shape
(
inputs
)
)
endpoints
,
new_states
=
backbone
({
**
init_states
,
'
image
'
:
inputs
}
)
self
.
assertAllEqual
(
endpoints
[
'stem'
].
shape
,
[
1
,
8
,
64
,
64
,
8
])
self
.
assertAllEqual
(
endpoints
[
'b0/l0'
].
shape
,
[
1
,
8
,
32
,
32
,
8
])
...
...
@@ -65,25 +66,28 @@ class MoViNetTest(parameterized.TestCase, tf.test.TestCase):
self
.
assertAllEqual
(
endpoints
[
'b4/l0'
].
shape
,
[
1
,
8
,
4
,
4
,
104
])
self
.
assertAllEqual
(
endpoints
[
'head'
].
shape
,
[
1
,
1
,
1
,
1
,
480
])
self
.
assertNotEmpty
(
states
)
self
.
assertNotEmpty
(
init_
states
)
self
.
assertNotEmpty
(
new_states
)
def
test_movinet_stream
(
self
):
"""Test if the backbone can be run in streaming mode."""
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
model
=
movinet
.
Movinet
(
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
use_external_states
=
True
,
)
inputs
=
tf
.
ones
([
1
,
5
,
128
,
128
,
3
])
expected_endpoints
,
_
=
model
(
dict
(
image
=
inputs
,
states
=
{}))
init_states
=
backbone
.
init_states
(
tf
.
shape
(
inputs
))
expected_endpoints
,
_
=
backbone
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
output
,
states
=
None
,
{}
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
(
dict
(
image
=
frame
,
states
=
states
)
)
output
,
states
=
backbone
({
**
states
,
'
image
'
:
frame
}
)
predicted_endpoints
=
output
predicted
=
predicted_endpoints
[
'head'
]
...
...
@@ -98,20 +102,22 @@ class MoViNetTest(parameterized.TestCase, tf.test.TestCase):
def
test_movinet_2plus1d_stream
(
self
):
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
model
=
movinet
.
Movinet
(
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
conv_type
=
'2plus1d'
,
use_external_states
=
True
,
)
inputs
=
tf
.
ones
([
1
,
5
,
128
,
128
,
3
])
expected_endpoints
,
_
=
model
(
dict
(
image
=
inputs
,
states
=
{}))
init_states
=
backbone
.
init_states
(
tf
.
shape
(
inputs
))
expected_endpoints
,
_
=
backbone
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
output
,
states
=
None
,
{}
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
(
dict
(
image
=
frame
,
states
=
states
)
)
output
,
states
=
backbone
({
**
states
,
'
image
'
:
frame
}
)
predicted_endpoints
=
output
predicted
=
predicted_endpoints
[
'head'
]
...
...
@@ -126,20 +132,22 @@ class MoViNetTest(parameterized.TestCase, tf.test.TestCase):
def
test_movinet_3d_2plus1d_stream
(
self
):
tf
.
keras
.
backend
.
set_image_data_format
(
'channels_last'
)
model
=
movinet
.
Movinet
(
backbone
=
movinet
.
Movinet
(
model_id
=
'a0'
,
causal
=
True
,
conv_type
=
'3d_2plus1d'
,
use_external_states
=
True
,
)
inputs
=
tf
.
ones
([
1
,
5
,
128
,
128
,
3
])
expected_endpoints
,
_
=
model
(
dict
(
image
=
inputs
,
states
=
{}))
init_states
=
backbone
.
init_states
(
tf
.
shape
(
inputs
))
expected_endpoints
,
_
=
backbone
({
**
init_states
,
'image'
:
inputs
})
frames
=
tf
.
split
(
inputs
,
inputs
.
shape
[
1
],
axis
=
1
)
output
,
states
=
None
,
{}
states
=
init_states
for
frame
in
frames
:
output
,
states
=
model
(
dict
(
image
=
frame
,
states
=
states
)
)
output
,
states
=
backbone
({
**
states
,
'
image
'
:
frame
}
)
predicted_endpoints
=
output
predicted
=
predicted_endpoints
[
'head'
]
...
...
@@ -157,6 +165,7 @@ class MoViNetTest(parameterized.TestCase, tf.test.TestCase):
model_id
=
'a0'
,
causal
=
True
,
use_positional_encoding
=
True
,
use_external_states
=
True
,
)
network
=
movinet
.
Movinet
(
**
kwargs
)
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment
