
Adding TCN.
Showing
research/tcn/eval.py
0 → 100644
{kind=link}
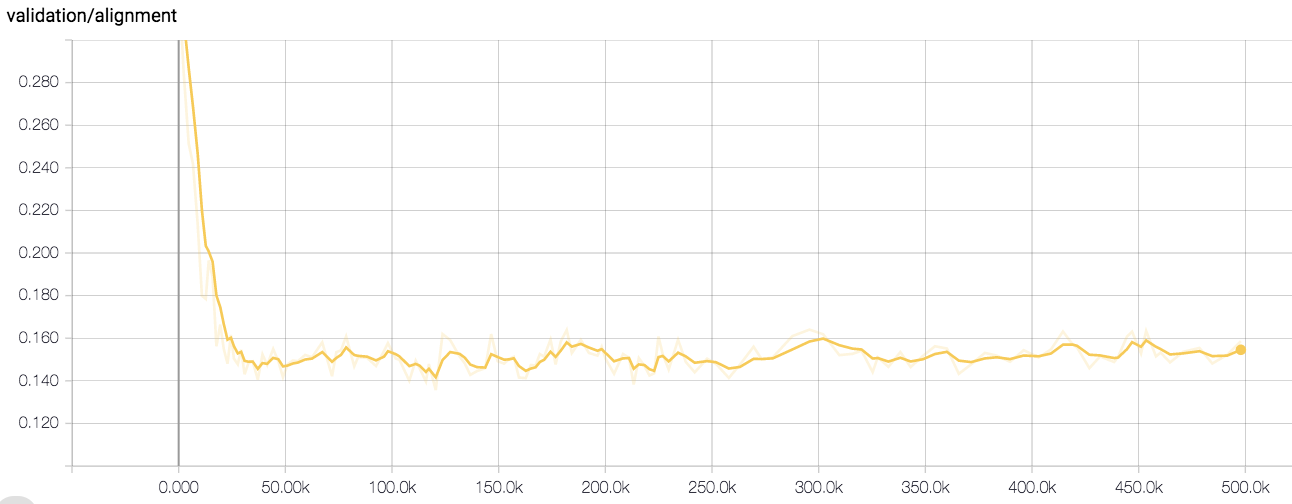
82.3 KB
{kind=link}
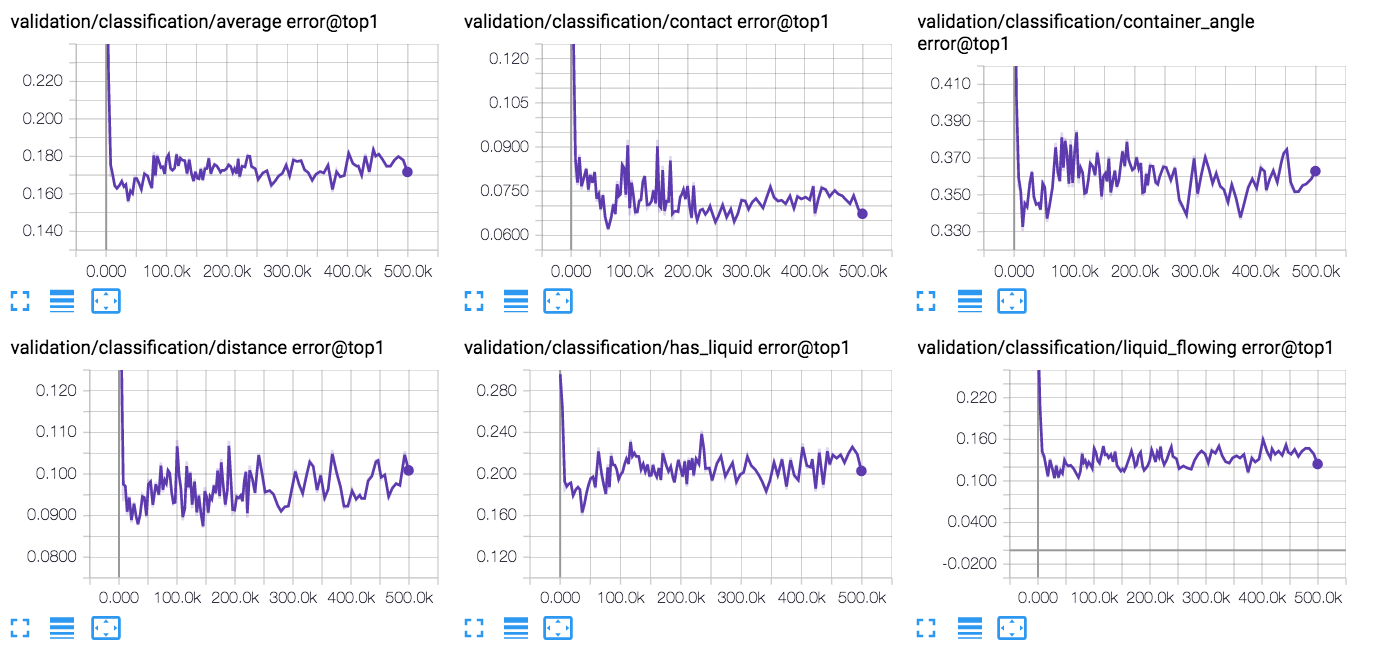
204 KB
{kind=link}
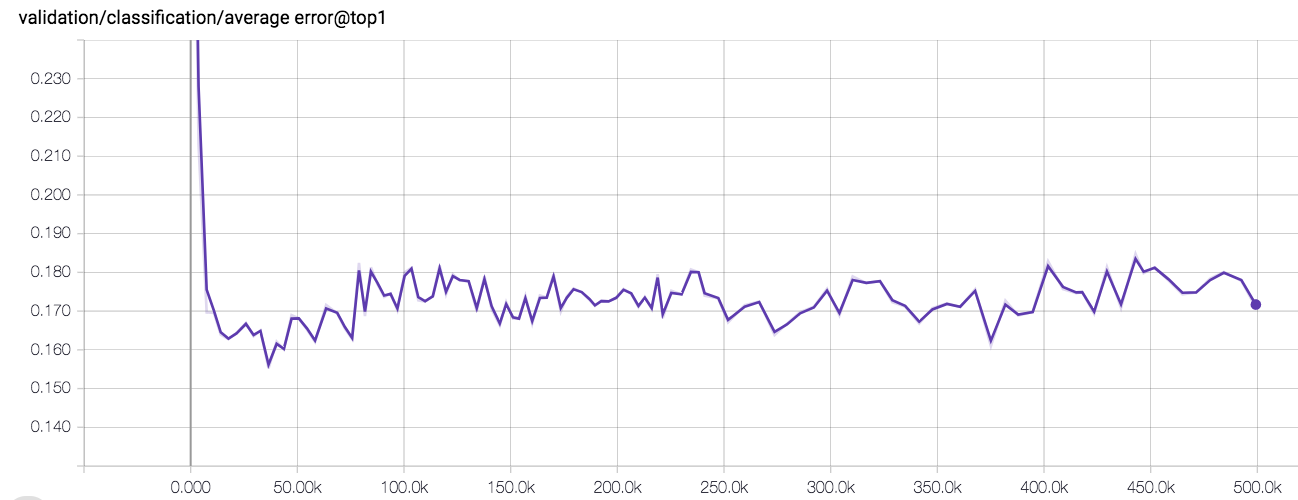
96.3 KB
research/tcn/g3doc/im.gif
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
research/tcn/g3doc/loss.png
0 → 100644
{kind=link}
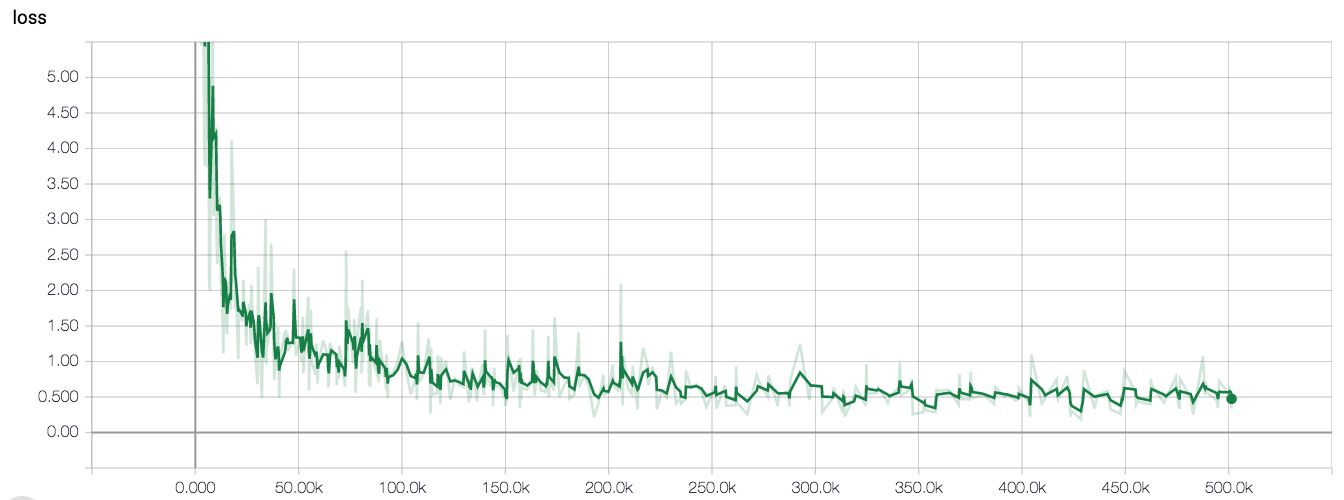
103 KB
research/tcn/g3doc/pca.png
0 → 100644
{kind=link}

924 KB
{kind=link}
109 KB
research/tcn/labeled_eval.py
0 → 100644
research/tcn/model.py
0 → 100644
research/tcn/train.py
0 → 100644
research/tcn/utils/util.py
0 → 100644