
Add Tensorflow Object Detection API. (#1561)
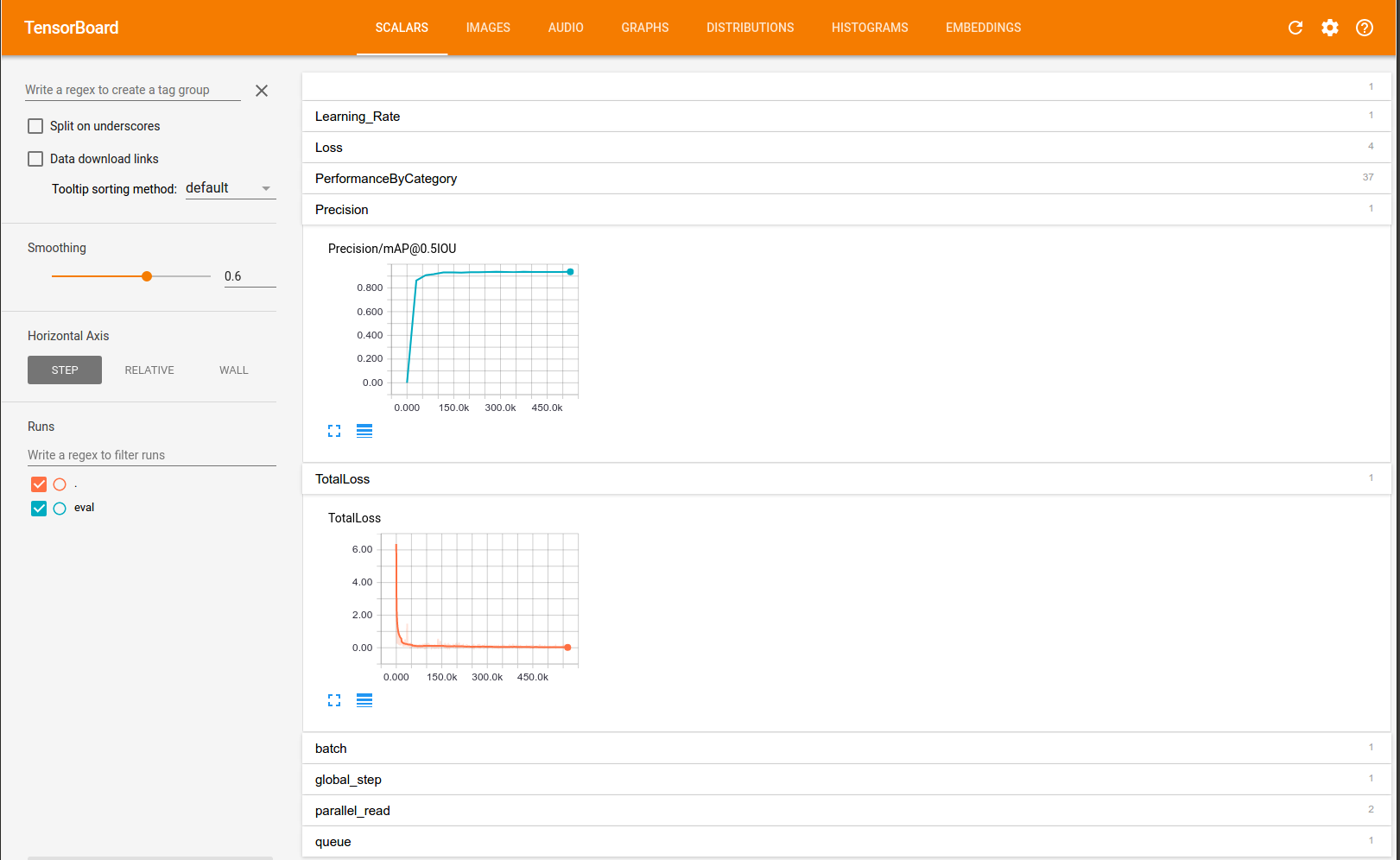
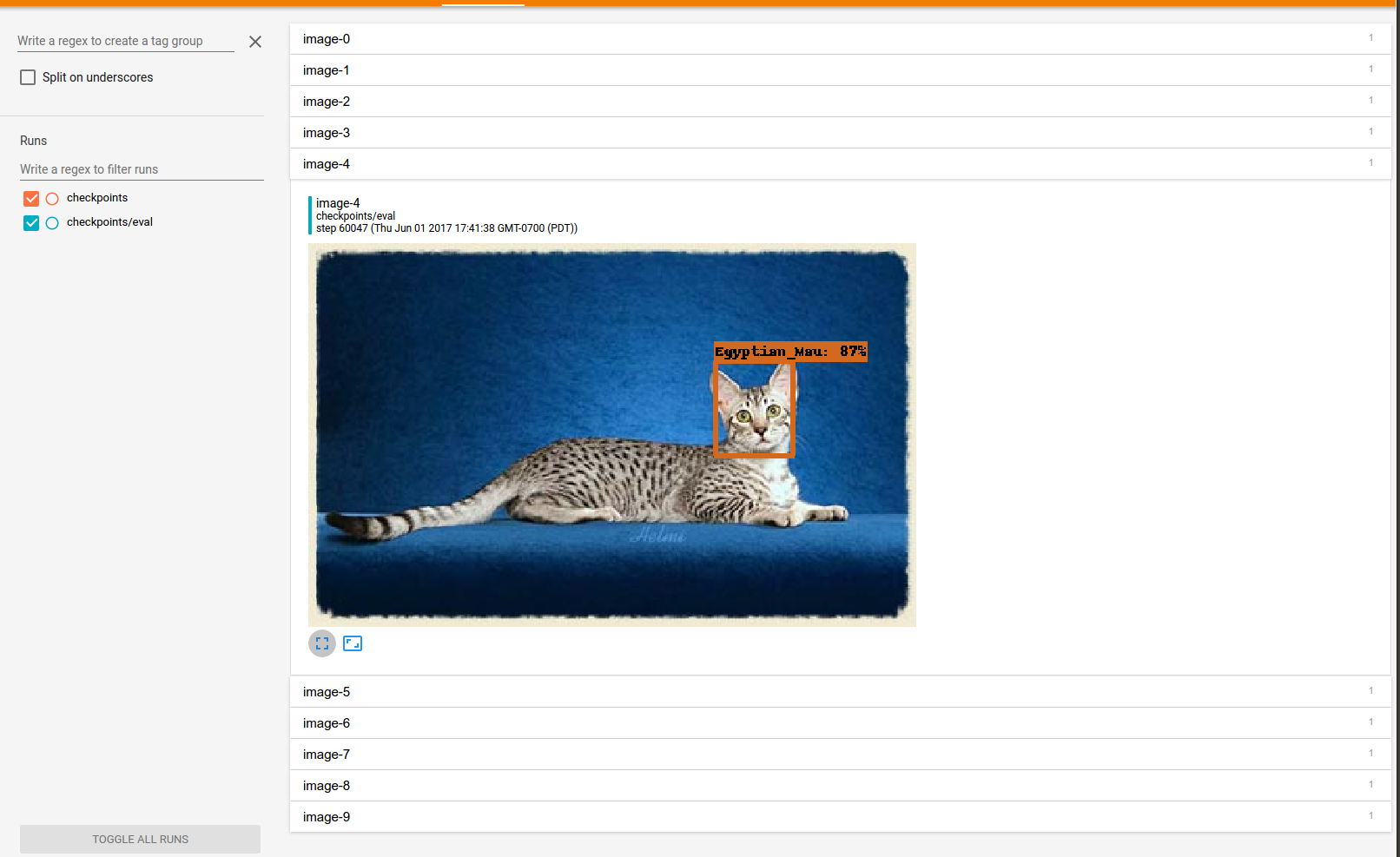
For details see our paper: "Speed/accuracy trade-offs for modern convolutional object detectors." Huang J, Rathod V, Sun C, Zhu M, Korattikara A, Fathi A, Fischer I, Wojna Z, Song Y, Guadarrama S, Murphy K, CVPR 2017 https://arxiv.org/abs/1611.10012
Showing
{kind=link}

364 KB
{kind=link}

377 KB
{kind=link}

270 KB
{kind=link}
77.5 KB
{kind=link}
231 KB