Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
ResNet50_tensorflow
Commits
7adc6ec1
Commit
7adc6ec1
authored
May 11, 2021
by
Dan Kondratyuk
Committed by
A. Unique TensorFlower
May 11, 2021
Browse files
Internal change
PiperOrigin-RevId: 373155894
parent
6d6cd4ac
Changes
28
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
3441 additions
and
0 deletions
+3441
-0
official/vision/beta/projects/movinet/README.google.md
official/vision/beta/projects/movinet/README.google.md
+13
-0
official/vision/beta/projects/movinet/README.md
official/vision/beta/projects/movinet/README.md
+163
-0
official/vision/beta/projects/movinet/configs/movinet.py
official/vision/beta/projects/movinet/configs/movinet.py
+138
-0
official/vision/beta/projects/movinet/configs/movinet_test.py
...cial/vision/beta/projects/movinet/configs/movinet_test.py
+42
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_cpu_local.yaml
...jects/movinet/configs/yaml/movinet_a0_k600_cpu_local.yaml
+58
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_stream_k600_8x8.yaml
...ects/movinet/configs/yaml/movinet_a0_stream_k600_8x8.yaml
+74
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a1_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a1_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a1_stream_k600_8x8.yaml
...ects/movinet/configs/yaml/movinet_a1_stream_k600_8x8.yaml
+74
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a2_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a2_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a2_stream_k600_8x8.yaml
...ects/movinet/configs/yaml/movinet_a2_stream_k600_8x8.yaml
+74
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a3_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a3_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a3_stream_k600_8x8.yaml
...ects/movinet/configs/yaml/movinet_a3_stream_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a4_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a4_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_a5_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_a5_k600_8x8.yaml
+73
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_t0_k600_8x8.yaml
...ta/projects/movinet/configs/yaml/movinet_t0_k600_8x8.yaml
+72
-0
official/vision/beta/projects/movinet/configs/yaml/movinet_t0_stream_k600_8x8.yaml
...ects/movinet/configs/yaml/movinet_t0_stream_k600_8x8.yaml
+72
-0
official/vision/beta/projects/movinet/export_saved_model.py
official/vision/beta/projects/movinet/export_saved_model.py
+151
-0
official/vision/beta/projects/movinet/modeling/movinet.py
official/vision/beta/projects/movinet/modeling/movinet.py
+529
-0
official/vision/beta/projects/movinet/modeling/movinet_layers.py
...l/vision/beta/projects/movinet/modeling/movinet_layers.py
+1470
-0
No files found.
official/vision/beta/projects/movinet/README.google.md
0 → 100644
View file @
7adc6ec1
# Mobile Video Networks (MoViNets)
Design doc: go/movinet
## Getting Started
```
shell
bash third_party/tensorflow_models/official/vision/beta/projects/movinet/google/run_train.sh
```
## Results
Results are tracked at go/movinet-experiments.
official/vision/beta/projects/movinet/README.md
0 → 100644
View file @
7adc6ec1
# Mobile Video Networks (MoViNets)
[

](https://colab.research.google.com/github/tensorflow/models/tree/master/official/vision/beta/projects/movinet/movinet_tutorial.ipynb)
[

](https://tfhub.dev/google/collections/movinet)
[

](https://arxiv.org/abs/2103.11511)
This repository is the official implementation of
[
MoViNets: Mobile Video Networks for Efficient Video
Recognition
](
https://arxiv.org/abs/2103.11511
)
.
## Description
Mobile Video Networks (MoViNets) are efficient video classification models
runnable on mobile devices. MoViNets demonstrate state-of-the-art accuracy and
efficiency on several large-scale video action recognition datasets.
There is a large gap between video model performance of accurate models and
efficient models for video action recognition. On the one hand, 2D MobileNet
CNNs are fast and can operate on streaming video in real time, but are prone to
be noisy and are inaccurate. On the other hand, 3D CNNs are accurate, but are
memory and computation intensive and cannot operate on streaming video.
MoViNets bridge this gap, producing:
-
State-of-the art efficiency and accuracy across the model family (MoViNet-A0
to A6).
-
Streaming models with 3D causal convolutions substantially reducing memory
usage.
-
Temporal ensembles of models to boost efficiency even higher.
Small MoViNets demonstrate higher efficiency and accuracy than MobileNetV3 for
video action recognition (Kinetics 600).
MoViNets also improve efficiency by outputting high-quality predictions with a
single frame, as opposed to the traditional multi-clip evaluation approach.
[

](https://arxiv.org/pdf/2103.11511.pdf)
[
](https://arxiv.org/pdf/2103.11511.pdf)
## History
-
Initial Commit.
## Authors and Maintainers
*
Dan Kondratyuk (
[
@hyperparticle
](
https://github.com/hyperparticle
)
)
*
Liangzhe Yuan (
[
@yuanliangzhe
](
https://github.com/yuanliangzhe
)
)
*
Yeqing Li (
[
@yeqingli
](
https://github.com/yeqingli
)
)
## Table of Contents
-
[
Requirements
](
#requirements
)
-
[
Results and Pretrained Weights
](
#results-and-pretrained-weights
)
-
[
Kinetics 600
](
#kinetics-600
)
-
[
Training and Evaluation
](
#training-and-evaluation
)
-
[
References
](
#references
)
-
[
License
](
#license
)
-
[
Citation
](
#citation
)
## Requirements
[

](https://github.com/tensorflow/tensorflow/releases/tag/v2.1.0)
[

](https://www.python.org/downloads/release/python-360/)
To install requirements:
```
shell
pip
install
-r
requirements.txt
```
## Results and Pretrained Weights
[

](https://tfhub.dev/google/collections/movinet)
[

](https://tensorboard.dev/experiment/Q07RQUlVRWOY4yDw3SnSkA/)
### Kinetics 600
[

](https://arxiv.org/pdf/2103.11511.pdf)
[
tensorboard.dev summary
](
https://tensorboard.dev/experiment/Q07RQUlVRWOY4yDw3SnSkA/
)
of training runs across all models.
The table below summarizes the performance of each model and provides links to
download pretrained models. All models are evaluated on single clips with the
same resolution as training.
Streaming MoViNets will be added in the future.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | GFLOPs
\*
| Checkpoint | TF Hub SavedModel |
|------------|----------------|----------------|----------|------------|-------------------|
| MoViNet-A0-Base | 71.41 | 90.91 | 2.7 |
[
checkpoint (12 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a0/base/kinetics-600/classification/
)
|
| MoViNet-A1-Base | 76.01 | 93.28 | 6.0 |
[
checkpoint (18 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a1_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a1/base/kinetics-600/classification/
)
|
| MoViNet-A2-Base | 78.03 | 93.99 | 10 |
[
checkpoint (20 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a2_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a2/base/kinetics-600/classification/
)
|
| MoViNet-A3-Base | 81.22 | 95.35 | 57 |
[
checkpoint (29 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a3_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a3/base/kinetics-600/classification/
)
|
| MoViNet-A4-Base | 82.96 | 95.98 | 110 |
[
checkpoint (44 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a4_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a4/base/kinetics-600/classification/
)
|
| MoViNet-A5-Base | 84.22 | 96.36 | 280 |
[
checkpoint (72 MiB)
](
https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a5_base.tar.gz
)
|
[
tfhub
](
https://tfhub.dev/tensorflow/movinet/a5/base/kinetics-600/classification/
)
|
\*
GFLOPs per video on Kinetics 600.
## Training and Evaluation
Please check out our
[
Colab Notebook
](
https://colab.research.google.com/github/tensorflow/models/tree/master/official/vision/beta/projects/movinet/movinet_tutorial.ipynb
)
to get started with MoViNets.
Run this command line for continuous training and evaluation.
```
shell
MODE
=
train_and_eval
# Can also be 'train'
CONFIG_FILE
=
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
python3 official/vision/beta/projects/movinet/train.py
\
--experiment
=
movinet_kinetics600
\
--mode
=
${
MODE
}
\
--model_dir
=
/tmp/movinet/
\
--config_file
=
${
CONFIG_FILE
}
\
--params_override
=
""
\
--gin_file
=
""
\
--gin_params
=
""
\
--tpu
=
""
\
--tf_data_service
=
""
```
Run this command line for evaluation.
```
shell
MODE
=
eval
# Can also be 'eval_continuous' for use during training
CONFIG_FILE
=
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
python3 official/vision/beta/projects/movinet/train.py
\
--experiment
=
movinet_kinetics600
\
--mode
=
${
MODE
}
\
--model_dir
=
/tmp/movinet/
\
--config_file
=
${
CONFIG_FILE
}
\
--params_override
=
""
\
--gin_file
=
""
\
--gin_params
=
""
\
--tpu
=
""
\
--tf_data_service
=
""
```
## References
-
[
Kinetics Datasets
](
https://deepmind.com/research/open-source/kinetics
)
-
[
MoViNets (Mobile Video Networks)
](
https://arxiv.org/abs/2103.11511
)
## License
[

](https://opensource.org/licenses/Apache-2.0)
This project is licensed under the terms of the
**Apache License 2.0**
.
## Citation
If you want to cite this code in your research paper, please use the following
information.
```
@article{kondratyuk2021movinets,
title={MoViNets: Mobile Video Networks for Efficient Video Recognition},
author={Dan Kondratyuk, Liangzhe Yuan, Yandong Li, Li Zhang, Matthew Brown, and Boqing Gong},
journal={arXiv preprint arXiv:2103.11511},
year={2021}
}
```
official/vision/beta/projects/movinet/configs/movinet.py
0 → 100644
View file @
7adc6ec1
# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Definitions for MoViNet structures.
Reference: "MoViNets: Mobile Video Networks for Efficient Video Recognition"
https://arxiv.org/pdf/2103.11511.pdf
MoViNets are efficient video classification networks that are part of a model
family, ranging from the smallest model, MoViNet-A0, to the largest model,
MoViNet-A6. Each model has various width, depth, input resolution, and input
frame-rate associated with them. See the main paper for more details.
"""
import
dataclasses
from
official.core
import
config_definitions
as
cfg
from
official.core
import
exp_factory
from
official.modeling
import
hyperparams
from
official.vision.beta.configs
import
backbones_3d
from
official.vision.beta.configs
import
common
from
official.vision.beta.configs.google
import
video_classification
@
dataclasses
.
dataclass
class
Movinet
(
hyperparams
.
Config
):
"""Backbone config for Base MoViNet."""
model_id
:
str
=
'a0'
causal
:
bool
=
False
use_positional_encoding
:
bool
=
False
# Choose from ['3d', '2plus1d', '3d_2plus1d']
# 3d: default 3D convolution
# 2plus1d: (2+1)D convolution with Conv2D (2D reshaping)
# 3d_2plus1d: (2+1)D convolution with Conv3D (no 2D reshaping)
conv_type
:
str
=
'3d'
stochastic_depth_drop_rate
:
float
=
0.2
@
dataclasses
.
dataclass
class
MovinetA0
(
Movinet
):
"""Backbone config for MoViNet-A0.
Represents the smallest base MoViNet searched by NAS.
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
model_id
:
str
=
'a0'
@
dataclasses
.
dataclass
class
MovinetA1
(
Movinet
):
"""Backbone config for MoViNet-A1."""
model_id
:
str
=
'a1'
@
dataclasses
.
dataclass
class
MovinetA2
(
Movinet
):
"""Backbone config for MoViNet-A2."""
model_id
:
str
=
'a2'
@
dataclasses
.
dataclass
class
MovinetA3
(
Movinet
):
"""Backbone config for MoViNet-A3."""
model_id
:
str
=
'a3'
@
dataclasses
.
dataclass
class
MovinetA4
(
Movinet
):
"""Backbone config for MoViNet-A4."""
model_id
:
str
=
'a4'
@
dataclasses
.
dataclass
class
MovinetA5
(
Movinet
):
"""Backbone config for MoViNet-A5.
Represents the largest base MoViNet searched by NAS.
"""
model_id
:
str
=
'a5'
@
dataclasses
.
dataclass
class
MovinetT0
(
Movinet
):
"""Backbone config for MoViNet-T0.
MoViNet-T0 is a smaller version of MoViNet-A0 for even faster processing.
"""
model_id
:
str
=
't0'
@
dataclasses
.
dataclass
class
Backbone3D
(
backbones_3d
.
Backbone3D
):
"""Configuration for backbones.
Attributes:
type: 'str', type of backbone be used, on the of fields below.
movinet: movinet backbone config.
"""
type
:
str
=
'movinet'
movinet
:
Movinet
=
Movinet
()
@
dataclasses
.
dataclass
class
MovinetModel
(
video_classification
.
VideoClassificationModel
):
"""The MoViNet model config."""
model_type
:
str
=
'movinet'
backbone
:
Backbone3D
=
Backbone3D
()
norm_activation
:
common
.
NormActivation
=
common
.
NormActivation
(
activation
=
'swish'
,
norm_momentum
=
0.99
,
norm_epsilon
=
1e-3
,
use_sync_bn
=
True
)
output_states
:
bool
=
False
@
exp_factory
.
register_config_factory
(
'movinet_kinetics600'
)
def
movinet_kinetics600
()
->
cfg
.
ExperimentConfig
:
"""Video classification on Videonet with MoViNet backbone."""
exp
=
video_classification
.
video_classification_kinetics600
()
exp
.
task
.
train_data
.
dtype
=
'bfloat16'
exp
.
task
.
validation_data
.
dtype
=
'bfloat16'
model
=
MovinetModel
()
exp
.
task
.
model
=
model
return
exp
official/vision/beta/projects/movinet/configs/movinet_test.py
0 → 100644
View file @
7adc6ec1
# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tests for movinet video classification."""
from
absl.testing
import
parameterized
import
tensorflow
as
tf
from
official.core
import
config_definitions
as
cfg
from
official.core
import
exp_factory
from
official.vision.beta.configs
import
video_classification
as
exp_cfg
from
official.vision.beta.projects.movinet.configs
import
movinet
class
MovinetConfigTest
(
tf
.
test
.
TestCase
,
parameterized
.
TestCase
):
@
parameterized
.
parameters
(
(
'movinet_kinetics600'
,),)
def
test_video_classification_configs
(
self
,
config_name
):
config
=
exp_factory
.
get_exp_config
(
config_name
)
self
.
assertIsInstance
(
config
,
cfg
.
ExperimentConfig
)
self
.
assertIsInstance
(
config
.
task
,
exp_cfg
.
VideoClassificationTask
)
self
.
assertIsInstance
(
config
.
task
.
model
,
movinet
.
MovinetModel
)
self
.
assertIsInstance
(
config
.
task
.
train_data
,
exp_cfg
.
DataConfig
)
config
.
task
.
train_data
.
is_training
=
None
with
self
.
assertRaises
(
KeyError
):
config
.
validate
()
if
__name__
==
'__main__'
:
tf
.
test
.
main
()
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A0 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 71.65% Top-1 accuracy.
# http://mldash/experiments/4591693621833944103
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a0'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
192
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
192
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_k600_cpu_local.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A0 backbone.
# --experiment_type=movinet_kinetics600
runtime
:
distribution_strategy
:
'
mirrored'
mixed_precision_dtype
:
'
float32'
task
:
model
:
backbone
:
movinet
:
model_id
:
'
a0'
norm_activation
:
use_sync_bn
:
false
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
4
-
172
-
172
-
3
temporal_stride
:
5
random_stride_range
:
0
global_batch_size
:
2
dtype
:
'
float32'
shuffle_buffer_size
:
32
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
4
-
172
-
172
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
2
dtype
:
'
float32'
drop_remainder
:
true
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
0.8
decay_steps
:
42104
warmup
:
linear
:
warmup_steps
:
1053
train_steps
:
10
validation_steps
:
10
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a0_stream_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A0-Stream backbone.
# --experiment_type=movinet_kinetics600
# Achieves 69.56% Top-1 accuracy.
# http://mldash/experiments/6696393165423234453
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a0'
causal
:
true
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
192
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
192
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a1_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A1 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 76.63% Top-1 accuracy.
# http://mldash/experiments/6004897086445740406
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a1'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
192
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
192
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a1_stream_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A1-Stream backbone.
# --experiment_type=movinet_kinetics600
# Achieves x% Top-1 accuracy.
# http://mldash/experiments/
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a1'
causal
:
true
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
stochastic_depth_rate
:
0.2
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
192
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
172
-
172
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
192
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a2_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A2 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 78.62% Top-1 accuracy.
# http://mldash/experiments/7122292520723231204
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a2'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
224
-
224
-
3
temporal_stride
:
5
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
256
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
224
-
224
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
256
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a2_stream_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A2-Stream backbone.
# --experiment_type=movinet_kinetics600
# Achieves 78.40% Top-1 accuracy.
# http://mldash/experiments/3089118812758230318
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a2'
causal
:
true
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
stochastic_depth_rate
:
0.2
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
50
-
224
-
224
-
3
temporal_stride
:
5
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
256
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
50
-
224
-
224
-
3
temporal_stride
:
5
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
256
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a3_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A3 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 81.79% Top-1 accuracy.
# http://mldash/experiments/1893120685388985498
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a3'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
64
-
256
-
256
-
3
temporal_stride
:
2
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
288
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
120
-
256
-
256
-
3
temporal_stride
:
2
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
288
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a3_stream_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A3-Stream backbone.
# --experiment_type=movinet_kinetics600
# Achieves x% Top-1 accuracy.
# http://mldash/experiments/
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a3'
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
stochastic_depth_rate
:
0.2
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
64
-
256
-
256
-
3
temporal_stride
:
2
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
288
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
120
-
256
-
256
-
3
temporal_stride
:
2
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
288
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a4_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A4 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 83.48% Top-1 accuracy.
# http://mldash/experiments/8781090241570014456
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a4'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
32
-
290
-
290
-
3
temporal_stride
:
3
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
320
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
autoaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
80
-
290
-
290
-
3
temporal_stride
:
3
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
320
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_a5_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-A5 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 84.00% Top-1 accuracy.
# http://mldash/experiments/2864919645986275853
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
a5'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
32
-
320
-
320
-
3
temporal_stride
:
2
random_stride_range
:
1
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
368
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
aug_type
:
'
randaug'
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
120
-
320
-
320
-
3
temporal_stride
:
2
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
32
min_image_size
:
368
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_t0_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-T0 backbone.
# --experiment_type=movinet_kinetics600
# Achieves 68.40% Top-1 accuracy.
# http://mldash/experiments/3958407113491615048
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
t0'
stochastic_depth_drop_rate
:
0.2
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
25
-
160
-
160
-
3
temporal_stride
:
10
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
176
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
25
-
160
-
160
-
3
temporal_stride
:
10
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
176
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/configs/yaml/movinet_t0_stream_k600_8x8.yaml
0 → 100644
View file @
7adc6ec1
# Video classification on Kinetics-600 using MoViNet-T0-Stream backbone.
# --experiment_type=movinet_kinetics600
# Achieves x% Top-1 accuracy.
# http://mldash/experiments/
runtime
:
distribution_strategy
:
'
tpu'
mixed_precision_dtype
:
'
bfloat16'
task
:
losses
:
l2_weight_decay
:
0.00003
label_smoothing
:
0.1
model
:
backbone
:
movinet
:
model_id
:
'
t0'
norm_activation
:
use_sync_bn
:
true
dropout_rate
:
0.5
stochastic_depth_rate
:
0.2
train_data
:
name
:
kinetics600
variant_name
:
rgb
feature_shape
:
!!python/tuple
-
25
-
160
-
160
-
3
temporal_stride
:
10
random_stride_range
:
0
global_batch_size
:
1024
dtype
:
'
bfloat16'
shuffle_buffer_size
:
1024
min_image_size
:
176
aug_max_area_ratio
:
1.0
aug_max_aspect_ratio
:
2.0
aug_min_area_ratio
:
0.08
aug_min_aspect_ratio
:
0.5
validation_data
:
name
:
kinetics600
feature_shape
:
!!python/tuple
-
25
-
160
-
160
-
3
temporal_stride
:
10
num_test_clips
:
1
num_test_crops
:
1
global_batch_size
:
64
min_image_size
:
176
dtype
:
'
bfloat16'
drop_remainder
:
false
trainer
:
optimizer_config
:
learning_rate
:
cosine
:
initial_learning_rate
:
1.8
decay_steps
:
85785
warmup
:
linear
:
warmup_steps
:
2145
optimizer
:
type
:
'
rmsprop'
rmsprop
:
rho
:
0.9
momentum
:
0.9
epsilon
:
1.0
clipnorm
:
1.0
train_steps
:
85785
steps_per_loop
:
500
summary_interval
:
500
validation_interval
:
500
official/vision/beta/projects/movinet/export_saved_model.py
0 → 100644
View file @
7adc6ec1
# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
r
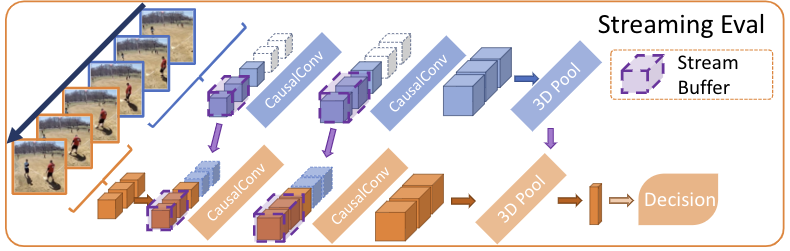
"""Exports models to tf.saved_model.
Export example:
```shell
python3 export_saved_model.py \
--output_path=/tmp/movinet/ \
--model_id=a0 \
--causal=True \
--use_2plus1d=False \
--num_classes=600 \
--checkpoint_path=""
```
To use an exported saved_model in various applications:
```python
import tensorflow as tf
import tensorflow_hub as hub
saved_model_path = ...
inputs = tf.keras.layers.Input(
shape=[None, None, None, 3],
dtype=tf.float32)
encoder = hub.KerasLayer(saved_model_path, trainable=True)
outputs = encoder(inputs)
model = tf.keras.Model(inputs, outputs)
example_input = tf.ones([1, 8, 172, 172, 3])
outputs = model(example_input, states)
```
"""
from
typing
import
Sequence
from
absl
import
app
from
absl
import
flags
import
tensorflow
as
tf
from
official.vision.beta.projects.movinet.modeling
import
movinet
from
official.vision.beta.projects.movinet.modeling
import
movinet_model
flags
.
DEFINE_string
(
'output_path'
,
'/tmp/movinet/'
,
'Path to saved exported saved_model file.'
)
flags
.
DEFINE_string
(
'model_id'
,
'a0'
,
'MoViNet model name.'
)
flags
.
DEFINE_bool
(
'causal'
,
False
,
'Run the model in causal mode.'
)
flags
.
DEFINE_bool
(
'use_2plus1d'
,
False
,
'Use (2+1)D features instead of 3D.'
)
flags
.
DEFINE_integer
(
'num_classes'
,
600
,
'The number of classes for prediction.'
)
flags
.
DEFINE_string
(
'checkpoint_path'
,
''
,
'Checkpoint path to load. Leave blank for default initialization.'
)
FLAGS
=
flags
.
FLAGS
def
main
(
argv
:
Sequence
[
str
])
->
None
:
if
len
(
argv
)
>
1
:
raise
app
.
UsageError
(
'Too many command-line arguments.'
)
# Use dimensions of 1 except the channels to export faster,
# since we only really need the last dimension to build and get the output
# states. These dimensions will be set to `None` once the model is built.
input_shape
=
[
1
,
1
,
1
,
1
,
3
]
backbone
=
movinet
.
Movinet
(
FLAGS
.
model_id
,
causal
=
FLAGS
.
causal
,
use_2plus1d
=
FLAGS
.
use_2plus1d
)
model
=
movinet_model
.
MovinetClassifier
(
backbone
,
num_classes
=
FLAGS
.
num_classes
,
output_states
=
FLAGS
.
causal
)
model
.
build
(
input_shape
)
if
FLAGS
.
checkpoint_path
:
model
.
load_weights
(
FLAGS
.
checkpoint_path
)
if
FLAGS
.
causal
:
# Call the model once to get the output states. Call again with `states`
# input to ensure that the inputs with the `states` argument is built
_
,
states
=
model
(
dict
(
image
=
tf
.
ones
(
input_shape
),
states
=
{}))
_
,
states
=
model
(
dict
(
image
=
tf
.
ones
(
input_shape
),
states
=
states
))
input_spec
=
tf
.
TensorSpec
(
shape
=
[
None
,
None
,
None
,
None
,
3
],
dtype
=
tf
.
float32
,
name
=
'inputs'
)
state_specs
=
{}
for
name
,
state
in
states
.
items
():
shape
=
state
.
shape
if
len
(
state
.
shape
)
==
5
:
shape
=
[
None
,
state
.
shape
[
1
],
None
,
None
,
state
.
shape
[
-
1
]]
new_spec
=
tf
.
TensorSpec
(
shape
=
shape
,
dtype
=
state
.
dtype
,
name
=
name
)
state_specs
[
name
]
=
new_spec
specs
=
(
input_spec
,
state_specs
)
# Define a tf.keras.Model with custom signatures to allow it to accept
# a state dict as an argument. We define it inline here because
# we first need to determine the shape of the state tensors before
# applying the `input_signature` argument to `tf.function`.
class
ExportStateModule
(
tf
.
Module
):
"""Module with state for exporting to saved_model."""
def
__init__
(
self
,
model
):
self
.
model
=
model
@
tf
.
function
(
input_signature
=
[
input_spec
])
def
__call__
(
self
,
inputs
):
return
self
.
model
(
dict
(
image
=
inputs
,
states
=
{}))
@
tf
.
function
(
input_signature
=
[
input_spec
])
def
base
(
self
,
inputs
):
return
self
.
model
(
dict
(
image
=
inputs
,
states
=
{}))
@
tf
.
function
(
input_signature
=
specs
)
def
stream
(
self
,
inputs
,
states
):
return
self
.
model
(
dict
(
image
=
inputs
,
states
=
states
))
module
=
ExportStateModule
(
model
)
tf
.
saved_model
.
save
(
module
,
FLAGS
.
output_path
)
else
:
_
=
model
(
tf
.
ones
(
input_shape
))
tf
.
keras
.
models
.
save_model
(
model
,
FLAGS
.
output_path
)
print
(
' ----- Done. Saved Model is saved at {}'
.
format
(
FLAGS
.
output_path
))
if
__name__
==
'__main__'
:
app
.
run
(
main
)
official/vision/beta/projects/movinet/modeling/movinet.py
0 → 100644
View file @
7adc6ec1
# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Contains definitions of Mobile Video Networks.
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
from
typing
import
Optional
,
Sequence
,
Tuple
import
dataclasses
import
tensorflow
as
tf
from
official.modeling
import
hyperparams
from
official.vision.beta.modeling.backbones
import
factory
from
official.vision.beta.projects.movinet.modeling
import
movinet_layers
# Defines a set of kernel sizes and stride sizes to simplify and shorten
# architecture definitions for configs below.
KernelSize
=
Tuple
[
int
,
int
,
int
]
# K(ab) represents a 3D kernel of size (a, b, b)
K13
:
KernelSize
=
(
1
,
3
,
3
)
K15
:
KernelSize
=
(
1
,
5
,
5
)
K33
:
KernelSize
=
(
3
,
3
,
3
)
K53
:
KernelSize
=
(
5
,
3
,
3
)
# S(ab) represents a 3D stride of size (a, b, b)
S11
:
KernelSize
=
(
1
,
1
,
1
)
S12
:
KernelSize
=
(
1
,
2
,
2
)
S22
:
KernelSize
=
(
2
,
2
,
2
)
S21
:
KernelSize
=
(
2
,
1
,
1
)
@
dataclasses
.
dataclass
class
BlockSpec
:
"""Configuration of a block."""
pass
@
dataclasses
.
dataclass
class
StemSpec
(
BlockSpec
):
"""Configuration of a Movinet block."""
filters
:
int
=
0
kernel_size
:
KernelSize
=
(
0
,
0
,
0
)
strides
:
KernelSize
=
(
0
,
0
,
0
)
@
dataclasses
.
dataclass
class
MovinetBlockSpec
(
BlockSpec
):
"""Configuration of a Movinet block."""
base_filters
:
int
=
0
expand_filters
:
Sequence
[
int
]
=
()
kernel_sizes
:
Sequence
[
KernelSize
]
=
()
strides
:
Sequence
[
KernelSize
]
=
()
@
dataclasses
.
dataclass
class
HeadSpec
(
BlockSpec
):
"""Configuration of a Movinet block."""
project_filters
:
int
=
0
head_filters
:
int
=
0
output_per_frame
:
bool
=
False
max_pool_predictions
:
bool
=
False
# Block specs specify the architecture of each model
BLOCK_SPECS
=
{
'a0'
:
(
StemSpec
(
filters
=
8
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
8
,
expand_filters
=
(
24
,),
kernel_sizes
=
(
K15
,),
strides
=
(
S12
,)),
MovinetBlockSpec
(
base_filters
=
32
,
expand_filters
=
(
80
,
80
,
80
),
kernel_sizes
=
(
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
56
,
expand_filters
=
(
184
,
112
,
184
),
kernel_sizes
=
(
K53
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
56
,
expand_filters
=
(
184
,
184
,
184
,
184
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
104
,
expand_filters
=
(
384
,
280
,
280
,
344
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K15
),
strides
=
(
S12
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
480
,
head_filters
=
2048
),
),
'a1'
:
(
StemSpec
(
filters
=
16
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
16
,
expand_filters
=
(
40
,
40
),
kernel_sizes
=
(
K15
,
K33
),
strides
=
(
S12
,
S11
)),
MovinetBlockSpec
(
base_filters
=
40
,
expand_filters
=
(
96
,
120
,
96
,
96
),
kernel_sizes
=
(
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
64
,
expand_filters
=
(
216
,
128
,
216
,
168
,
216
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
64
,
expand_filters
=
(
216
,
216
,
216
,
128
,
128
,
216
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K15
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
136
,
expand_filters
=
(
456
,
360
,
360
,
360
,
456
,
456
,
544
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K15
,
K15
,
K33
,
K13
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
600
,
head_filters
=
2048
),
),
'a2'
:
(
StemSpec
(
filters
=
16
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
16
,
expand_filters
=
(
40
,
40
,
64
),
kernel_sizes
=
(
K15
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
40
,
expand_filters
=
(
96
,
120
,
96
,
96
,
120
),
kernel_sizes
=
(
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
72
,
expand_filters
=
(
240
,
160
,
240
,
192
,
240
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
72
,
expand_filters
=
(
240
,
240
,
240
,
240
,
144
,
240
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K15
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
144
,
expand_filters
=
(
480
,
384
,
384
,
480
,
480
,
480
,
576
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K15
,
K15
,
K33
,
K13
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
640
,
head_filters
=
2048
),
),
'a3'
:
(
StemSpec
(
filters
=
16
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
16
,
expand_filters
=
(
40
,
40
,
64
,
40
),
kernel_sizes
=
(
K15
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
48
,
expand_filters
=
(
112
,
144
,
112
,
112
,
144
,
144
),
kernel_sizes
=
(
K33
,
K33
,
K33
,
K15
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
80
,
expand_filters
=
(
240
,
152
,
240
,
192
,
240
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
88
,
expand_filters
=
(
264
,
264
,
264
,
264
,
160
,
264
,
264
,
264
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K15
,
K33
,
K33
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
168
,
expand_filters
=
(
560
,
448
,
448
,
560
,
560
,
560
,
448
,
448
,
560
,
672
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K15
,
K15
,
K33
,
K15
,
K15
,
K33
,
K13
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
744
,
head_filters
=
2048
),
),
'a4'
:
(
StemSpec
(
filters
=
24
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
24
,
expand_filters
=
(
64
,
64
,
96
,
64
,
96
,
64
),
kernel_sizes
=
(
K15
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
56
,
expand_filters
=
(
168
,
168
,
136
,
136
,
168
,
168
,
168
,
136
,
136
),
kernel_sizes
=
(
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K15
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
96
,
expand_filters
=
(
320
,
160
,
320
,
192
,
320
,
160
,
320
,
256
,
320
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
96
,
expand_filters
=
(
320
,
320
,
320
,
320
,
192
,
320
,
320
,
192
,
320
,
320
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K15
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
192
,
expand_filters
=
(
640
,
512
,
512
,
640
,
640
,
640
,
512
,
512
,
640
,
768
,
640
,
640
,
768
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K15
,
K15
,
K33
,
K15
,
K15
,
K15
,
K15
,
K15
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
856
,
head_filters
=
2048
),
),
'a5'
:
(
StemSpec
(
filters
=
24
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
24
,
expand_filters
=
(
64
,
64
,
96
,
64
,
96
,
64
),
kernel_sizes
=
(
K15
,
K15
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
64
,
expand_filters
=
(
192
,
152
,
152
,
152
,
192
,
192
,
192
,
152
,
152
,
192
,
192
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
112
,
expand_filters
=
(
376
,
224
,
376
,
376
,
296
,
376
,
224
,
376
,
376
,
296
,
376
,
376
,
376
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
120
,
expand_filters
=
(
376
,
376
,
376
,
376
,
224
,
376
,
376
,
224
,
376
,
376
,
376
),
kernel_sizes
=
(
K53
,
K33
,
K33
,
K33
,
K15
,
K33
,
K33
,
K33
,
K33
,
K33
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
224
,
expand_filters
=
(
744
,
744
,
600
,
600
,
744
,
744
,
744
,
896
,
600
,
600
,
896
,
744
,
744
,
896
,
600
,
600
,
744
,
744
),
kernel_sizes
=
(
K53
,
K33
,
K15
,
K15
,
K15
,
K15
,
K33
,
K15
,
K15
,
K15
,
K15
,
K15
,
K33
,
K15
,
K15
,
K15
,
K15
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
992
,
head_filters
=
2048
),
),
't0'
:
(
StemSpec
(
filters
=
8
,
kernel_size
=
K13
,
strides
=
S12
),
MovinetBlockSpec
(
base_filters
=
8
,
expand_filters
=
(
16
,),
kernel_sizes
=
(
K15
,),
strides
=
(
S12
,)),
MovinetBlockSpec
(
base_filters
=
32
,
expand_filters
=
(
72
,
72
),
kernel_sizes
=
(
K33
,
K15
),
strides
=
(
S12
,
S11
)),
MovinetBlockSpec
(
base_filters
=
56
,
expand_filters
=
(
112
,
112
,
112
),
kernel_sizes
=
(
K53
,
K15
,
K33
),
strides
=
(
S12
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
56
,
expand_filters
=
(
184
,
184
,
184
,
184
),
kernel_sizes
=
(
K53
,
K15
,
K33
,
K33
),
strides
=
(
S11
,
S11
,
S11
,
S11
)),
MovinetBlockSpec
(
base_filters
=
104
,
expand_filters
=
(
344
,
344
,
344
,
344
),
kernel_sizes
=
(
K53
,
K15
,
K15
,
K33
),
strides
=
(
S12
,
S11
,
S11
,
S11
)),
HeadSpec
(
project_filters
=
240
,
head_filters
=
1024
),
),
}
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
Movinet
(
tf
.
keras
.
Model
):
"""Class to build Movinet family model.
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
def
__init__
(
self
,
model_id
:
str
=
'a0'
,
causal
:
bool
=
False
,
use_positional_encoding
:
bool
=
False
,
conv_type
:
str
=
'3d'
,
input_specs
:
Optional
[
tf
.
keras
.
layers
.
InputSpec
]
=
None
,
activation
:
str
=
'swish'
,
use_sync_bn
:
bool
=
True
,
norm_momentum
:
float
=
0.99
,
norm_epsilon
:
float
=
0.001
,
kernel_initializer
:
str
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
str
]
=
None
,
bias_regularizer
:
Optional
[
str
]
=
None
,
stochastic_depth_drop_rate
:
float
=
0.
,
**
kwargs
):
"""MoViNet initialization function.
Args:
model_id: name of MoViNet backbone model.
causal: use causal mode, with CausalConv and CausalSE operations.
use_positional_encoding: if True, adds a positional encoding before
temporal convolutions and the cumulative global average pooling
layers.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' configures the network
to use the default 3D convolution. '2plus1d' uses (2+1)D convolution
with Conv2D operations and 2D reshaping (e.g., a 5x3x3 kernel becomes
3x3 followed by 5x1 conv). '3d_2plus1d' uses (2+1)D convolution with
Conv3D and no 2D reshaping (e.g., a 5x3x3 kernel becomes 1x3x3 followed
by 5x1x1 conv).
input_specs: the model input spec to use.
activation: name of the activation function.
use_sync_bn: if True, use synchronized batch normalization.
norm_momentum: normalization momentum for the moving average.
norm_epsilon: small float added to variance to avoid dividing by
zero.
kernel_initializer: kernel_initializer for convolutional layers.
kernel_regularizer: tf.keras.regularizers.Regularizer object for Conv2D.
Defaults to None.
bias_regularizer: tf.keras.regularizers.Regularizer object for Conv2d.
Defaults to None.
stochastic_depth_drop_rate: the base rate for stochastic depth.
**kwargs: keyword arguments to be passed.
"""
block_specs
=
BLOCK_SPECS
[
model_id
]
if
input_specs
is
None
:
input_specs
=
tf
.
keras
.
layers
.
InputSpec
(
shape
=
[
None
,
None
,
None
,
None
,
3
])
if
conv_type
not
in
(
'3d'
,
'2plus1d'
,
'3d_2plus1d'
):
raise
ValueError
(
'Unknown conv type: {}'
.
format
(
conv_type
))
self
.
_model_id
=
model_id
self
.
_block_specs
=
block_specs
self
.
_causal
=
causal
self
.
_use_positional_encoding
=
use_positional_encoding
self
.
_conv_type
=
conv_type
self
.
_input_specs
=
input_specs
self
.
_use_sync_bn
=
use_sync_bn
self
.
_activation
=
activation
self
.
_norm_momentum
=
norm_momentum
self
.
_norm_epsilon
=
norm_epsilon
if
use_sync_bn
:
self
.
_norm
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
else
:
self
.
_norm
=
tf
.
keras
.
layers
.
BatchNormalization
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_bias_regularizer
=
bias_regularizer
self
.
_stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
if
not
isinstance
(
block_specs
[
0
],
StemSpec
):
raise
ValueError
(
'Expected first spec to be StemSpec, got {}'
.
format
(
block_specs
[
0
]))
if
not
isinstance
(
block_specs
[
-
1
],
HeadSpec
):
raise
ValueError
(
'Expected final spec to be HeadSpec, got {}'
.
format
(
block_specs
[
-
1
]))
self
.
_head_filters
=
block_specs
[
-
1
].
head_filters
if
tf
.
keras
.
backend
.
image_data_format
()
==
'channels_last'
:
bn_axis
=
-
1
else
:
bn_axis
=
1
# Build MoViNet backbone.
inputs
=
tf
.
keras
.
Input
(
shape
=
input_specs
.
shape
[
1
:],
name
=
'inputs'
)
x
=
inputs
states
=
{}
endpoints
=
{}
num_layers
=
sum
(
len
(
block
.
expand_filters
)
for
block
in
block_specs
if
isinstance
(
block
,
MovinetBlockSpec
))
stochastic_depth_idx
=
1
for
block_idx
,
block
in
enumerate
(
block_specs
):
if
isinstance
(
block
,
StemSpec
):
x
,
states
=
movinet_layers
.
Stem
(
block
.
filters
,
block
.
kernel_size
,
block
.
strides
,
conv_type
=
self
.
_conv_type
,
causal
=
self
.
_causal
,
activation
=
self
.
_activation
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
,
name
=
'stem'
)(
x
,
states
=
states
)
endpoints
[
'stem'
]
=
x
elif
isinstance
(
block
,
MovinetBlockSpec
):
if
not
(
len
(
block
.
expand_filters
)
==
len
(
block
.
kernel_sizes
)
==
len
(
block
.
strides
)):
raise
ValueError
(
'Lenths of block parameters differ: {}, {}, {}'
.
format
(
len
(
block
.
expand_filters
),
len
(
block
.
kernel_sizes
),
len
(
block
.
strides
)))
params
=
list
(
zip
(
block
.
expand_filters
,
block
.
kernel_sizes
,
block
.
strides
))
for
layer_idx
,
layer
in
enumerate
(
params
):
stochastic_depth_drop_rate
=
(
self
.
_stochastic_depth_drop_rate
*
stochastic_depth_idx
/
num_layers
)
expand_filters
,
kernel_size
,
strides
=
layer
name
=
f
'b
{
block_idx
-
1
}
/l
{
layer_idx
}
'
x
,
states
=
movinet_layers
.
MovinetBlock
(
block
.
base_filters
,
expand_filters
,
kernel_size
=
kernel_size
,
strides
=
strides
,
causal
=
self
.
_causal
,
activation
=
self
.
_activation
,
stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
,
conv_type
=
self
.
_conv_type
,
use_positional_encoding
=
self
.
_use_positional_encoding
and
self
.
_causal
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
,
name
=
name
)(
x
,
states
=
states
)
endpoints
[
name
]
=
x
stochastic_depth_idx
+=
1
elif
isinstance
(
block
,
HeadSpec
):
x
,
states
=
movinet_layers
.
Head
(
project_filters
=
block
.
project_filters
,
conv_type
=
self
.
_conv_type
,
activation
=
self
.
_activation
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
batch_norm_layer
=
self
.
_norm
,
batch_norm_momentum
=
self
.
_norm_momentum
,
batch_norm_epsilon
=
self
.
_norm_epsilon
)(
x
,
states
=
states
)
endpoints
[
'head'
]
=
x
else
:
raise
ValueError
(
'Unknown block type {}'
.
format
(
block
))
self
.
_output_specs
=
{
l
:
endpoints
[
l
].
get_shape
()
for
l
in
endpoints
}
inputs
=
{
'image'
:
inputs
,
'states'
:
{
name
:
tf
.
keras
.
Input
(
shape
=
state
.
shape
[
1
:],
name
=
f
'states/
{
name
}
'
)
for
name
,
state
in
states
.
items
()
},
}
outputs
=
(
endpoints
,
states
)
super
(
Movinet
,
self
).
__init__
(
inputs
=
inputs
,
outputs
=
outputs
,
**
kwargs
)
def
get_config
(
self
):
config_dict
=
{
'model_id'
:
self
.
_model_id
,
'causal'
:
self
.
_causal
,
'use_positional_encoding'
:
self
.
_use_positional_encoding
,
'conv_type'
:
self
.
_conv_type
,
'activation'
:
self
.
_activation
,
'use_sync_bn'
:
self
.
_use_sync_bn
,
'norm_momentum'
:
self
.
_norm_momentum
,
'norm_epsilon'
:
self
.
_norm_epsilon
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'bias_regularizer'
:
self
.
_bias_regularizer
,
'stochastic_depth_drop_rate'
:
self
.
_stochastic_depth_drop_rate
,
}
return
config_dict
@
classmethod
def
from_config
(
cls
,
config
,
custom_objects
=
None
):
return
cls
(
**
config
)
@
property
def
output_specs
(
self
):
"""A dict of {level: TensorShape} pairs for the model output."""
return
self
.
_output_specs
@
factory
.
register_backbone_builder
(
'movinet'
)
def
build_movinet
(
input_specs
:
tf
.
keras
.
layers
.
InputSpec
,
backbone_config
:
hyperparams
.
Config
,
norm_activation_config
:
hyperparams
.
Config
,
l2_regularizer
:
tf
.
keras
.
regularizers
.
Regularizer
=
None
)
->
tf
.
keras
.
Model
:
"""Builds MoViNet backbone from a config."""
l2_regularizer
=
l2_regularizer
or
tf
.
keras
.
regularizers
.
L2
(
1.5e-5
)
backbone_type
=
backbone_config
.
type
backbone_cfg
=
backbone_config
.
get
()
assert
backbone_type
==
'movinet'
,
(
'Inconsistent backbone type '
f
'
{
backbone_type
}
'
)
return
Movinet
(
model_id
=
backbone_cfg
.
model_id
,
causal
=
backbone_cfg
.
causal
,
use_positional_encoding
=
backbone_cfg
.
use_positional_encoding
,
conv_type
=
backbone_cfg
.
conv_type
,
input_specs
=
input_specs
,
activation
=
norm_activation_config
.
activation
,
use_sync_bn
=
norm_activation_config
.
use_sync_bn
,
norm_momentum
=
norm_activation_config
.
norm_momentum
,
norm_epsilon
=
norm_activation_config
.
norm_epsilon
,
kernel_regularizer
=
l2_regularizer
,
stochastic_depth_drop_rate
=
backbone_cfg
.
stochastic_depth_drop_rate
)
official/vision/beta/projects/movinet/modeling/movinet_layers.py
0 → 100644
View file @
7adc6ec1
# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Contains common building blocks for MoViNets.
Reference: https://arxiv.org/pdf/2103.11511.pdf
"""
from
typing
import
Any
,
Optional
,
Sequence
,
Tuple
,
Union
,
Dict
import
tensorflow
as
tf
from
official.vision.beta.modeling.layers
import
nn_layers
# Default kernel weight decay that may be overridden
KERNEL_WEIGHT_DECAY
=
1.5e-5
def
normalize_tuple
(
value
:
Union
[
int
,
Tuple
[
int
,
...]],
size
:
int
,
name
:
str
):
"""Transforms a single integer or iterable of integers into an integer tuple.
Arguments:
value: The value to validate and convert. Could an int, or any iterable of
ints.
size: The size of the tuple to be returned.
name: The name of the argument being validated, e.g. "strides" or
"kernel_size". This is only used to format error messages.
Returns:
A tuple of `size` integers.
Raises:
ValueError: If something else than an int/long or iterable thereof was
passed.
"""
if
isinstance
(
value
,
int
):
return
(
value
,)
*
size
else
:
try
:
value_tuple
=
tuple
(
value
)
except
TypeError
:
raise
ValueError
(
'The `'
+
name
+
'` argument must be a tuple of '
+
str
(
size
)
+
' integers. Received: '
+
str
(
value
))
if
len
(
value_tuple
)
!=
size
:
raise
ValueError
(
'The `'
+
name
+
'` argument must be a tuple of '
+
str
(
size
)
+
' integers. Received: '
+
str
(
value
))
for
single_value
in
value_tuple
:
try
:
int
(
single_value
)
except
(
ValueError
,
TypeError
):
raise
ValueError
(
'The `'
+
name
+
'` argument must be a tuple of '
+
str
(
size
)
+
' integers. Received: '
+
str
(
value
)
+
' '
'including element '
+
str
(
single_value
)
+
' of type'
+
' '
+
str
(
type
(
single_value
)))
return
value_tuple
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
Squeeze3D
(
tf
.
keras
.
layers
.
Layer
):
"""Squeeze3D layer to remove singular dimensions."""
def
call
(
self
,
inputs
):
"""Calls the layer with the given inputs."""
return
tf
.
squeeze
(
inputs
,
axis
=
(
1
,
2
,
3
))
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
MobileConv2D
(
tf
.
keras
.
layers
.
Layer
):
"""Conv2D layer with extra options to support mobile devices.
Reshapes 5D video tensor inputs to 4D, allowing Conv2D to run across
dimensions (2, 3) or (3, 4). Reshapes tensors back to 5D when returning the
output.
"""
def
__init__
(
self
,
filters
:
int
,
kernel_size
:
Union
[
int
,
Sequence
[
int
]],
strides
:
Union
[
int
,
Sequence
[
int
]]
=
(
1
,
1
),
padding
:
str
=
'valid'
,
data_format
:
Optional
[
str
]
=
None
,
dilation_rate
:
Union
[
int
,
Sequence
[
int
]]
=
(
1
,
1
),
groups
:
int
=
1
,
activation
:
Optional
[
nn_layers
.
Activation
]
=
None
,
use_bias
:
bool
=
True
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'glorot_uniform'
,
bias_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'zeros'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
None
,
bias_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
None
,
activity_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
None
,
kernel_constraint
:
Optional
[
tf
.
keras
.
constraints
.
Constraint
]
=
None
,
bias_constraint
:
Optional
[
tf
.
keras
.
constraints
.
Constraint
]
=
None
,
use_depthwise
:
bool
=
False
,
use_temporal
:
bool
=
False
,
use_buffered_input
:
bool
=
False
,
**
kwargs
):
# pylint: disable=g-doc-args
"""Initializes mobile conv2d.
For the majority of arguments, see tf.keras.layers.Conv2D.
Args:
use_depthwise: if True, use DepthwiseConv2D instead of Conv2D
use_temporal: if True, apply Conv2D starting from the temporal dimension
instead of the spatial dimensions.
use_buffered_input: if True, the input is expected to be padded
beforehand. In effect, calling this layer will use 'valid' padding on
the temporal dimension to simulate 'causal' padding.
**kwargs: keyword arguments to be passed to this layer.
Returns:
A output tensor of the MobileConv2D operation.
"""
super
(
MobileConv2D
,
self
).
__init__
(
**
kwargs
)
self
.
_filters
=
filters
self
.
_kernel_size
=
kernel_size
self
.
_strides
=
strides
self
.
_padding
=
padding
self
.
_data_format
=
data_format
self
.
_dilation_rate
=
dilation_rate
self
.
_groups
=
groups
self
.
_activation
=
activation
self
.
_use_bias
=
use_bias
self
.
_kernel_initializer
=
kernel_initializer
self
.
_bias_initializer
=
bias_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_bias_regularizer
=
bias_regularizer
self
.
_activity_regularizer
=
activity_regularizer
self
.
_kernel_constraint
=
kernel_constraint
self
.
_bias_constraint
=
bias_constraint
self
.
_use_depthwise
=
use_depthwise
self
.
_use_temporal
=
use_temporal
self
.
_use_buffered_input
=
use_buffered_input
kernel_size
=
normalize_tuple
(
kernel_size
,
2
,
'kernel_size'
)
if
self
.
_use_temporal
and
kernel_size
[
1
]
>
1
:
raise
ValueError
(
'Temporal conv with spatial kernel is not supported.'
)
if
use_depthwise
:
self
.
_conv
=
nn_layers
.
DepthwiseConv2D
(
kernel_size
=
kernel_size
,
strides
=
strides
,
padding
=
padding
,
depth_multiplier
=
1
,
data_format
=
data_format
,
dilation_rate
=
dilation_rate
,
activation
=
activation
,
use_bias
=
use_bias
,
depthwise_initializer
=
kernel_initializer
,
bias_initializer
=
bias_initializer
,
depthwise_regularizer
=
kernel_regularizer
,
bias_regularizer
=
bias_regularizer
,
activity_regularizer
=
activity_regularizer
,
depthwise_constraint
=
kernel_constraint
,
bias_constraint
=
bias_constraint
,
use_buffered_input
=
use_buffered_input
)
else
:
self
.
_conv
=
nn_layers
.
Conv2D
(
filters
=
filters
,
kernel_size
=
kernel_size
,
strides
=
strides
,
padding
=
padding
,
data_format
=
data_format
,
dilation_rate
=
dilation_rate
,
groups
=
groups
,
activation
=
activation
,
use_bias
=
use_bias
,
kernel_initializer
=
kernel_initializer
,
bias_initializer
=
bias_initializer
,
kernel_regularizer
=
kernel_regularizer
,
bias_regularizer
=
bias_regularizer
,
activity_regularizer
=
activity_regularizer
,
kernel_constraint
=
kernel_constraint
,
bias_constraint
=
bias_constraint
,
use_buffered_input
=
use_buffered_input
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'filters'
:
self
.
_filters
,
'kernel_size'
:
self
.
_kernel_size
,
'strides'
:
self
.
_strides
,
'padding'
:
self
.
_padding
,
'data_format'
:
self
.
_data_format
,
'dilation_rate'
:
self
.
_dilation_rate
,
'groups'
:
self
.
_groups
,
'activation'
:
self
.
_activation
,
'use_bias'
:
self
.
_use_bias
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'bias_initializer'
:
self
.
_bias_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'bias_regularizer'
:
self
.
_bias_regularizer
,
'activity_regularizer'
:
self
.
_activity_regularizer
,
'kernel_constraint'
:
self
.
_kernel_constraint
,
'bias_constraint'
:
self
.
_bias_constraint
,
'use_depthwise'
:
self
.
_use_depthwise
,
'use_temporal'
:
self
.
_use_temporal
,
'use_buffered_input'
:
self
.
_use_buffered_input
,
}
base_config
=
super
(
MobileConv2D
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
):
"""Calls the layer with the given inputs."""
if
self
.
_use_temporal
:
input_shape
=
[
tf
.
shape
(
inputs
)[
0
],
tf
.
shape
(
inputs
)[
1
],
tf
.
shape
(
inputs
)[
2
]
*
tf
.
shape
(
inputs
)[
3
],
inputs
.
shape
[
4
]]
else
:
input_shape
=
[
tf
.
shape
(
inputs
)[
0
]
*
tf
.
shape
(
inputs
)[
1
],
tf
.
shape
(
inputs
)[
2
],
tf
.
shape
(
inputs
)[
3
],
inputs
.
shape
[
4
]]
x
=
tf
.
reshape
(
inputs
,
input_shape
)
x
=
self
.
_conv
(
x
)
if
self
.
_use_temporal
:
output_shape
=
[
tf
.
shape
(
x
)[
0
],
tf
.
shape
(
x
)[
1
],
tf
.
shape
(
inputs
)[
2
],
tf
.
shape
(
inputs
)[
3
],
x
.
shape
[
3
]]
else
:
output_shape
=
[
tf
.
shape
(
inputs
)[
0
],
tf
.
shape
(
inputs
)[
1
],
tf
.
shape
(
x
)[
1
],
tf
.
shape
(
x
)[
2
],
x
.
shape
[
3
]]
x
=
tf
.
reshape
(
x
,
output_shape
)
return
x
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
ConvBlock
(
tf
.
keras
.
layers
.
Layer
):
"""A Conv followed by optional BatchNorm and Activation."""
def
__init__
(
self
,
filters
:
int
,
kernel_size
:
Union
[
int
,
Sequence
[
int
]],
strides
:
Union
[
int
,
Sequence
[
int
]]
=
1
,
depthwise
:
bool
=
False
,
causal
:
bool
=
False
,
use_bias
:
bool
=
False
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
use_batch_norm
:
bool
=
True
,
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
activation
:
Optional
[
Any
]
=
None
,
conv_type
:
str
=
'3d'
,
use_positional_encoding
:
bool
=
False
,
use_buffered_input
:
bool
=
False
,
**
kwargs
):
"""Initializes a conv block.
Args:
filters: filters for the conv operation.
kernel_size: kernel size for the conv operation.
strides: strides for the conv operation.
depthwise: if True, use DepthwiseConv2D instead of Conv2D
causal: if True, use causal mode for the conv operation.
use_bias: use bias for the conv operation.
kernel_initializer: kernel initializer for the conv operation.
kernel_regularizer: kernel regularizer for the conv operation.
use_batch_norm: if True, apply batch norm after the conv operation.
batch_norm_layer: class to use for batch norm, if applied.
batch_norm_momentum: momentum of the batch norm operation, if applied.
batch_norm_epsilon: epsilon of the batch norm operation, if applied.
activation: activation after the conv and batch norm operations.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
use_positional_encoding: add a positional encoding before the temporal
convolution. Assumes `use_2plus1d=True` and `kernel_size[0] > 1`.
Otherwise, this argument is ignored.
use_buffered_input: if True, the input is expected to be padded
beforehand. In effect, calling this layer will use 'valid' padding on
the temporal dimension to simulate 'causal' padding.
**kwargs: keyword arguments to be passed to this layer.
Returns:
A output tensor of the ConvBlock operation.
"""
super
(
ConvBlock
,
self
).
__init__
(
**
kwargs
)
kernel_size
=
normalize_tuple
(
kernel_size
,
3
,
'kernel_size'
)
strides
=
normalize_tuple
(
strides
,
3
,
'strides'
)
self
.
_filters
=
filters
self
.
_kernel_size
=
kernel_size
self
.
_strides
=
strides
self
.
_depthwise
=
depthwise
self
.
_causal
=
causal
self
.
_use_bias
=
use_bias
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_use_batch_norm
=
use_batch_norm
self
.
_batch_norm_layer
=
batch_norm_layer
self
.
_batch_norm_momentum
=
batch_norm_momentum
self
.
_batch_norm_epsilon
=
batch_norm_epsilon
self
.
_activation
=
activation
self
.
_conv_type
=
conv_type
self
.
_use_positional_encoding
=
use_positional_encoding
self
.
_use_buffered_input
=
use_buffered_input
if
activation
is
not
None
:
self
.
_activation_layer
=
tf
.
keras
.
layers
.
Activation
(
activation
)
else
:
self
.
_activation_layer
=
None
self
.
_groups
=
None
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'filters'
:
self
.
_filters
,
'kernel_size'
:
self
.
_kernel_size
,
'strides'
:
self
.
_strides
,
'depthwise'
:
self
.
_depthwise
,
'causal'
:
self
.
_causal
,
'use_bias'
:
self
.
_use_bias
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'use_batch_norm'
:
self
.
_use_batch_norm
,
'batch_norm_momentum'
:
self
.
_batch_norm_momentum
,
'batch_norm_epsilon'
:
self
.
_batch_norm_epsilon
,
'activation'
:
self
.
_activation
,
'conv_type'
:
self
.
_conv_type
,
'use_positional_encoding'
:
self
.
_use_positional_encoding
,
'use_buffered_input'
:
self
.
_use_buffered_input
,
}
base_config
=
super
(
ConvBlock
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
build
(
self
,
input_shape
):
"""Builds the layer with the given input shape."""
padding
=
'causal'
if
self
.
_causal
else
'same'
self
.
_groups
=
input_shape
[
-
1
]
if
self
.
_depthwise
else
1
self
.
_conv_temporal
=
None
if
self
.
_conv_type
==
'3d_2plus1d'
and
self
.
_kernel_size
[
0
]
>
1
:
self
.
_conv
=
nn_layers
.
Conv3D
(
self
.
_filters
,
(
1
,
self
.
_kernel_size
[
1
],
self
.
_kernel_size
[
2
]),
strides
=
(
1
,
self
.
_strides
[
1
],
self
.
_strides
[
2
]),
padding
=
'same'
,
groups
=
self
.
_groups
,
use_bias
=
self
.
_use_bias
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_buffered_input
=
False
,
name
=
'conv3d'
)
self
.
_conv_temporal
=
nn_layers
.
Conv3D
(
self
.
_filters
,
(
self
.
_kernel_size
[
0
],
1
,
1
),
strides
=
(
self
.
_strides
[
0
],
1
,
1
),
padding
=
padding
,
groups
=
self
.
_groups
,
use_bias
=
self
.
_use_bias
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_buffered_input
=
self
.
_use_buffered_input
,
name
=
'conv3d_temporal'
)
elif
self
.
_conv_type
==
'2plus1d'
:
self
.
_conv
=
MobileConv2D
(
self
.
_filters
,
(
self
.
_kernel_size
[
1
],
self
.
_kernel_size
[
2
]),
strides
=
(
self
.
_strides
[
1
],
self
.
_strides
[
2
]),
padding
=
'same'
,
use_depthwise
=
self
.
_depthwise
,
groups
=
self
.
_groups
,
use_bias
=
self
.
_use_bias
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_buffered_input
=
False
,
name
=
'conv2d'
)
if
self
.
_kernel_size
[
0
]
>
1
:
self
.
_conv_temporal
=
MobileConv2D
(
self
.
_filters
,
(
self
.
_kernel_size
[
0
],
1
),
strides
=
(
self
.
_strides
[
0
],
1
),
padding
=
padding
,
use_temporal
=
True
,
use_depthwise
=
self
.
_depthwise
,
groups
=
self
.
_groups
,
use_bias
=
self
.
_use_bias
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_buffered_input
=
self
.
_use_buffered_input
,
name
=
'conv2d_temporal'
)
else
:
self
.
_conv
=
nn_layers
.
Conv3D
(
self
.
_filters
,
self
.
_kernel_size
,
strides
=
self
.
_strides
,
padding
=
padding
,
groups
=
self
.
_groups
,
use_bias
=
self
.
_use_bias
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_buffered_input
=
self
.
_use_buffered_input
,
name
=
'conv3d'
)
if
self
.
_use_positional_encoding
and
self
.
_conv_temporal
is
not
None
:
self
.
_pos_encoding
=
nn_layers
.
PositionalEncoding
()
else
:
self
.
_pos_encoding
=
None
self
.
_batch_norm
=
None
self
.
_batch_norm_temporal
=
None
if
self
.
_use_batch_norm
:
self
.
_batch_norm
=
self
.
_batch_norm_layer
(
momentum
=
self
.
_batch_norm_momentum
,
epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'bn'
)
if
self
.
_conv_type
!=
'3d'
and
self
.
_conv_temporal
is
not
None
:
self
.
_batch_norm_temporal
=
self
.
_batch_norm_layer
(
momentum
=
self
.
_batch_norm_momentum
,
epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'bn_temporal'
)
super
(
ConvBlock
,
self
).
build
(
input_shape
)
def
call
(
self
,
inputs
):
"""Calls the layer with the given inputs."""
x
=
inputs
if
self
.
_pos_encoding
is
not
None
:
x
=
self
.
_pos_encoding
(
x
)
x
=
self
.
_conv
(
x
)
if
self
.
_batch_norm
is
not
None
:
x
=
self
.
_batch_norm
(
x
)
if
self
.
_activation_layer
is
not
None
:
x
=
self
.
_activation_layer
(
x
)
if
self
.
_conv_temporal
is
not
None
:
if
self
.
_pos_encoding
is
not
None
:
x
=
self
.
_pos_encoding
(
x
)
x
=
self
.
_conv_temporal
(
x
)
if
self
.
_batch_norm_temporal
is
not
None
:
x
=
self
.
_batch_norm_temporal
(
x
)
if
self
.
_activation_layer
is
not
None
:
x
=
self
.
_activation_layer
(
x
)
return
x
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
StreamBuffer
(
tf
.
keras
.
layers
.
Layer
):
"""Stream buffer wrapper which caches activations of previous frames."""
def
__init__
(
self
,
buffer_size
:
int
,
**
kwargs
):
"""Initializes a stream buffer.
Args:
buffer_size: the number of input frames to cache.
**kwargs: keyword arguments to be passed to this layer.
Returns:
A output tensor of the StreamBuffer operation.
"""
super
(
StreamBuffer
,
self
).
__init__
(
**
kwargs
)
self
.
_buffer_size
=
buffer_size
def
build
(
self
,
input_shape
):
"""Builds the layer with the given input shape."""
# Here we define strings that will uniquely reference the buffer states
# in the TF graph. These will be used for passing in a mapping of states
# for streaming mode. To do this, we can use a name scope.
with
tf
.
name_scope
(
'buffer'
)
as
state_name
:
self
.
_state_name
=
state_name
super
(
StreamBuffer
,
self
).
build
(
input_shape
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'buffer_size'
:
self
.
_buffer_size
,
}
base_config
=
super
(
StreamBuffer
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
Any
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
buffer
=
states
.
get
(
self
.
_state_name
,
None
)
# `tf.pad` has limited support for tf lite, so use tf.concat instead
if
buffer
is
None
:
shape
=
tf
.
shape
(
inputs
)
buffer
=
tf
.
zeros
(
[
shape
[
0
],
self
.
_buffer_size
,
shape
[
2
],
shape
[
3
],
shape
[
4
]],
dtype
=
inputs
.
dtype
)
full_inputs
=
tf
.
concat
([
buffer
,
inputs
],
axis
=
1
)
# Cache the last b frames of the input where b is the buffer size and f
# is the number of input frames. If b > f, then we will cache the last b - f
# frames from the previous buffer concatenated with the current f input
# frames.
new_buffer
=
full_inputs
[:,
-
self
.
_buffer_size
:]
states
[
self
.
_state_name
]
=
new_buffer
return
full_inputs
,
states
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
StreamConvBlock
(
ConvBlock
):
"""ConvBlock with StreamBuffer."""
def
__init__
(
self
,
filters
:
int
,
kernel_size
:
Union
[
int
,
Sequence
[
int
]],
strides
:
Union
[
int
,
Sequence
[
int
]]
=
1
,
depthwise
:
bool
=
False
,
causal
:
bool
=
False
,
use_bias
:
bool
=
False
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
use_batch_norm
:
bool
=
True
,
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
activation
:
Optional
[
Any
]
=
None
,
conv_type
:
str
=
'3d'
,
use_positional_encoding
:
bool
=
False
,
**
kwargs
):
"""Initializes a stream conv block.
Args:
filters: filters for the conv operation.
kernel_size: kernel size for the conv operation.
strides: strides for the conv operation.
depthwise: if True, use DepthwiseConv2D instead of Conv2D
causal: if True, use causal mode for the conv operation.
use_bias: use bias for the conv operation.
kernel_initializer: kernel initializer for the conv operation.
kernel_regularizer: kernel regularizer for the conv operation.
use_batch_norm: if True, apply batch norm after the conv operation.
batch_norm_layer: class to use for batch norm, if applied.
batch_norm_momentum: momentum of the batch norm operation, if applied.
batch_norm_epsilon: epsilon of the batch norm operation, if applied.
activation: activation after the conv and batch norm operations.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
use_positional_encoding: add a positional encoding before the convolution.
**kwargs: keyword arguments to be passed to this layer.
Returns:
A output tensor of the StreamConvBlock operation.
"""
kernel_size
=
normalize_tuple
(
kernel_size
,
3
,
'kernel_size'
)
buffer_size
=
kernel_size
[
0
]
-
1
use_buffer
=
buffer_size
>
0
and
causal
super
(
StreamConvBlock
,
self
).
__init__
(
filters
,
kernel_size
,
strides
=
strides
,
depthwise
=
depthwise
,
causal
=
causal
,
use_bias
=
use_bias
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
use_batch_norm
,
batch_norm_layer
=
batch_norm_layer
,
batch_norm_momentum
=
batch_norm_momentum
,
batch_norm_epsilon
=
batch_norm_epsilon
,
activation
=
activation
,
conv_type
=
conv_type
,
use_positional_encoding
=
use_positional_encoding
,
use_buffered_input
=
use_buffer
,
**
kwargs
)
self
.
_stream_buffer
=
None
if
use_buffer
:
self
.
_stream_buffer
=
StreamBuffer
(
buffer_size
=
buffer_size
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{}
base_config
=
super
(
StreamConvBlock
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
x
=
inputs
if
self
.
_stream_buffer
is
not
None
:
x
,
states
=
self
.
_stream_buffer
(
x
,
states
=
states
)
x
=
super
(
StreamConvBlock
,
self
).
call
(
x
)
return
x
,
states
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
StreamSqueezeExcitation
(
tf
.
keras
.
layers
.
Layer
):
"""Squeeze and excitation layer with causal mode.
Reference: https://arxiv.org/pdf/1709.01507.pdf
"""
def
__init__
(
self
,
hidden_filters
:
int
,
activation
:
nn_layers
.
Activation
=
'swish'
,
gating_activation
:
nn_layers
.
Activation
=
'sigmoid'
,
causal
:
bool
=
False
,
conv_type
:
str
=
'3d'
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
use_positional_encoding
:
bool
=
False
,
**
kwargs
):
"""Implementation for squeeze and excitation.
Args:
hidden_filters: The hidden filters of squeeze excite.
activation: name of the activation function.
gating_activation: name of the activation function for gating.
causal: if True, use causal mode in the global average pool.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv operation.
use_positional_encoding: add a positional encoding after the (cumulative)
global average pooling layer.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
StreamSqueezeExcitation
,
self
).
__init__
(
**
kwargs
)
self
.
_hidden_filters
=
hidden_filters
self
.
_activation
=
activation
self
.
_gating_activation
=
gating_activation
self
.
_causal
=
causal
self
.
_conv_type
=
conv_type
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_use_positional_encoding
=
use_positional_encoding
self
.
_pool
=
nn_layers
.
GlobalAveragePool3D
(
keepdims
=
True
,
causal
=
causal
)
if
use_positional_encoding
:
self
.
_pos_encoding
=
nn_layers
.
PositionalEncoding
()
else
:
self
.
_pos_encoding
=
None
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'hidden_filters'
:
self
.
_hidden_filters
,
'activation'
:
self
.
_activation
,
'gating_activation'
:
self
.
_gating_activation
,
'causal'
:
self
.
_causal
,
'conv_type'
:
self
.
_conv_type
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'use_positional_encoding'
:
self
.
_use_positional_encoding
,
}
base_config
=
super
(
StreamSqueezeExcitation
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
build
(
self
,
input_shape
):
"""Builds the layer with the given input shape."""
self
.
_se_reduce
=
ConvBlock
(
filters
=
self
.
_hidden_filters
,
kernel_size
=
1
,
causal
=
self
.
_causal
,
use_bias
=
True
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_batch_norm
=
False
,
activation
=
self
.
_activation
,
conv_type
=
self
.
_conv_type
,
name
=
'se_reduce'
)
self
.
_se_expand
=
ConvBlock
(
filters
=
input_shape
[
-
1
],
kernel_size
=
1
,
causal
=
self
.
_causal
,
use_bias
=
True
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
use_batch_norm
=
False
,
activation
=
self
.
_gating_activation
,
conv_type
=
self
.
_conv_type
,
name
=
'se_expand'
)
super
(
StreamSqueezeExcitation
,
self
).
build
(
input_shape
)
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
x
,
states
=
self
.
_pool
(
inputs
,
states
=
states
)
if
self
.
_pos_encoding
is
not
None
:
x
=
self
.
_pos_encoding
(
x
)
x
=
self
.
_se_reduce
(
x
)
x
=
self
.
_se_expand
(
x
)
return
x
*
inputs
,
states
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
MobileBottleneck
(
tf
.
keras
.
layers
.
Layer
):
"""A depthwise inverted bottleneck block.
Uses dependency injection to allow flexible definition of different layers
within this block.
"""
def
__init__
(
self
,
expansion_layer
:
tf
.
keras
.
layers
.
Layer
,
feature_layer
:
tf
.
keras
.
layers
.
Layer
,
projection_layer
:
tf
.
keras
.
layers
.
Layer
,
attention_layer
:
Optional
[
tf
.
keras
.
layers
.
Layer
]
=
None
,
skip_layer
:
Optional
[
tf
.
keras
.
layers
.
Layer
]
=
None
,
stochastic_depth_drop_rate
:
Optional
[
float
]
=
None
,
**
kwargs
):
"""Implementation for mobile bottleneck.
Args:
expansion_layer: initial layer used for pointwise expansion.
feature_layer: main layer used for computing 3D features.
projection_layer: layer used for pointwise projection.
attention_layer: optional layer used for attention-like operations (e.g.,
squeeze excite).
skip_layer: optional skip layer used to project the input before summing
with the output for the residual connection.
stochastic_depth_drop_rate: optional drop rate for stochastic depth.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
MobileBottleneck
,
self
).
__init__
(
**
kwargs
)
self
.
_projection_layer
=
projection_layer
self
.
_attention_layer
=
attention_layer
self
.
_skip_layer
=
skip_layer
self
.
_stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
self
.
_identity
=
tf
.
keras
.
layers
.
Activation
(
tf
.
identity
)
self
.
_rezero
=
nn_layers
.
Scale
(
initializer
=
'zeros'
,
name
=
'rezero'
)
if
stochastic_depth_drop_rate
:
self
.
_stochastic_depth
=
nn_layers
.
StochasticDepth
(
stochastic_depth_drop_rate
,
name
=
'stochastic_depth'
)
else
:
self
.
_stochastic_depth
=
None
self
.
_feature_layer
=
feature_layer
self
.
_expansion_layer
=
expansion_layer
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'stochastic_depth_drop_rate'
:
self
.
_stochastic_depth_drop_rate
,
}
base_config
=
super
(
MobileBottleneck
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
x
=
self
.
_expansion_layer
(
inputs
)
x
,
states
=
self
.
_feature_layer
(
x
,
states
=
states
)
x
,
states
=
self
.
_attention_layer
(
x
,
states
=
states
)
x
=
self
.
_projection_layer
(
x
)
# Add identity so that the ops are ordered as written. This is useful for,
# e.g., quantization.
x
=
self
.
_identity
(
x
)
x
=
self
.
_rezero
(
x
)
if
self
.
_stochastic_depth
is
not
None
:
x
=
self
.
_stochastic_depth
(
x
)
if
self
.
_skip_layer
is
not
None
:
skip
=
self
.
_skip_layer
(
inputs
)
else
:
skip
=
inputs
return
x
+
skip
,
states
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
SkipBlock
(
tf
.
keras
.
layers
.
Layer
):
"""Skip block for bottleneck blocks."""
def
__init__
(
self
,
out_filters
:
int
,
downsample
:
bool
=
False
,
conv_type
:
str
=
'3d'
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
**
kwargs
):
"""Implementation for skip block.
Args:
out_filters: the number of projected output filters.
downsample: if True, downsamples the input by a factor of 2 by applying
average pooling with a 3x3 kernel size on the spatial dimensions.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv projection.
batch_norm_layer: class to use for batch norm.
batch_norm_momentum: momentum of the batch norm operation.
batch_norm_epsilon: epsilon of the batch norm operation.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
SkipBlock
,
self
).
__init__
(
**
kwargs
)
self
.
_out_filters
=
out_filters
self
.
_downsample
=
downsample
self
.
_conv_type
=
conv_type
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_batch_norm_layer
=
batch_norm_layer
self
.
_batch_norm_momentum
=
batch_norm_momentum
self
.
_batch_norm_epsilon
=
batch_norm_epsilon
self
.
_projection
=
ConvBlock
(
filters
=
self
.
_out_filters
,
kernel_size
=
1
,
conv_type
=
conv_type
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'skip_project'
)
if
downsample
:
if
self
.
_conv_type
==
'2plus1d'
:
self
.
_pool
=
tf
.
keras
.
layers
.
AveragePooling2D
(
pool_size
=
(
3
,
3
),
strides
=
(
2
,
2
),
padding
=
'same'
,
name
=
'skip_pool'
)
else
:
self
.
_pool
=
tf
.
keras
.
layers
.
AveragePooling3D
(
pool_size
=
(
1
,
3
,
3
),
strides
=
(
1
,
2
,
2
),
padding
=
'same'
,
name
=
'skip_pool'
)
else
:
self
.
_pool
=
None
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'out_filters'
:
self
.
_out_filters
,
'downsample'
:
self
.
_downsample
,
'conv_type'
:
self
.
_conv_type
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'batch_norm_momentum'
:
self
.
_batch_norm_momentum
,
'batch_norm_epsilon'
:
self
.
_batch_norm_epsilon
,
}
base_config
=
super
(
SkipBlock
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
):
"""Calls the layer with the given inputs."""
x
=
inputs
if
self
.
_pool
is
not
None
:
if
self
.
_conv_type
==
'2plus1d'
:
x
=
tf
.
reshape
(
x
,
[
-
1
,
tf
.
shape
(
x
)[
2
],
tf
.
shape
(
x
)[
3
],
x
.
shape
[
4
]])
x
=
self
.
_pool
(
x
)
if
self
.
_conv_type
==
'2plus1d'
:
x
=
tf
.
reshape
(
x
,
[
tf
.
shape
(
inputs
)[
0
],
-
1
,
tf
.
shape
(
x
)[
1
],
tf
.
shape
(
x
)[
2
],
x
.
shape
[
3
]])
return
self
.
_projection
(
x
)
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
MovinetBlock
(
tf
.
keras
.
layers
.
Layer
):
"""A basic block for MoViNets.
Applies a mobile inverted bottleneck with pointwise expansion, 3D depthwise
convolution, 3D squeeze excite, pointwise projection, and residual connection.
"""
def
__init__
(
self
,
out_filters
:
int
,
expand_filters
:
int
,
kernel_size
:
Union
[
int
,
Sequence
[
int
]]
=
(
3
,
3
,
3
),
strides
:
Union
[
int
,
Sequence
[
int
]]
=
(
1
,
1
,
1
),
causal
:
bool
=
False
,
activation
:
nn_layers
.
Activation
=
'swish'
,
se_ratio
:
float
=
0.25
,
stochastic_depth_drop_rate
:
float
=
0.
,
conv_type
:
str
=
'3d'
,
use_positional_encoding
:
bool
=
False
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
**
kwargs
):
"""Implementation for MoViNet block.
Args:
out_filters: number of output filters for the final projection.
expand_filters: number of expansion filters after the input.
kernel_size: kernel size of the main depthwise convolution.
strides: strides of the main depthwise convolution.
causal: if True, run the temporal convolutions in causal mode.
activation: activation to use across all conv operations.
se_ratio: squeeze excite filters ratio.
stochastic_depth_drop_rate: optional drop rate for stochastic depth.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
use_positional_encoding: add a positional encoding after the (cumulative)
global average pooling layer in the squeeze excite layer.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv operations.
batch_norm_layer: class to use for batch norm.
batch_norm_momentum: momentum of the batch norm operation.
batch_norm_epsilon: epsilon of the batch norm operation.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
MovinetBlock
,
self
).
__init__
(
**
kwargs
)
self
.
_kernel_size
=
normalize_tuple
(
kernel_size
,
3
,
'kernel_size'
)
self
.
_strides
=
normalize_tuple
(
strides
,
3
,
'strides'
)
se_hidden_filters
=
nn_layers
.
make_divisible
(
se_ratio
*
expand_filters
,
divisor
=
8
)
self
.
_out_filters
=
out_filters
self
.
_expand_filters
=
expand_filters
self
.
_kernel_size
=
kernel_size
self
.
_causal
=
causal
self
.
_activation
=
activation
self
.
_se_ratio
=
se_ratio
self
.
_downsample
=
any
(
s
>
1
for
s
in
self
.
_strides
)
self
.
_stochastic_depth_drop_rate
=
stochastic_depth_drop_rate
self
.
_conv_type
=
conv_type
self
.
_use_positional_encoding
=
use_positional_encoding
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_batch_norm_layer
=
batch_norm_layer
self
.
_batch_norm_momentum
=
batch_norm_momentum
self
.
_batch_norm_epsilon
=
batch_norm_epsilon
self
.
_expansion
=
ConvBlock
(
expand_filters
,
(
1
,
1
,
1
),
activation
=
activation
,
conv_type
=
conv_type
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'expansion'
)
self
.
_feature
=
StreamConvBlock
(
expand_filters
,
self
.
_kernel_size
,
strides
=
self
.
_strides
,
depthwise
=
True
,
causal
=
self
.
_causal
,
activation
=
activation
,
conv_type
=
conv_type
,
use_positional_encoding
=
use_positional_encoding
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'feature'
)
self
.
_projection
=
ConvBlock
(
out_filters
,
(
1
,
1
,
1
),
activation
=
None
,
conv_type
=
conv_type
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'projection'
)
self
.
_attention
=
StreamSqueezeExcitation
(
se_hidden_filters
,
activation
=
activation
,
causal
=
self
.
_causal
,
conv_type
=
conv_type
,
use_positional_encoding
=
use_positional_encoding
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
name
=
'se'
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'out_filters'
:
self
.
_out_filters
,
'expand_filters'
:
self
.
_expand_filters
,
'kernel_size'
:
self
.
_kernel_size
,
'strides'
:
self
.
_strides
,
'causal'
:
self
.
_causal
,
'activation'
:
self
.
_activation
,
'se_ratio'
:
self
.
_se_ratio
,
'stochastic_depth_drop_rate'
:
self
.
_stochastic_depth_drop_rate
,
'conv_type'
:
self
.
_conv_type
,
'use_positional_encoding'
:
self
.
_use_positional_encoding
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'batch_norm_momentum'
:
self
.
_batch_norm_momentum
,
'batch_norm_epsilon'
:
self
.
_batch_norm_epsilon
,
}
base_config
=
super
(
MovinetBlock
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
build
(
self
,
input_shape
):
"""Builds the layer with the given input shape."""
if
input_shape
[
-
1
]
==
self
.
_out_filters
and
not
self
.
_downsample
:
self
.
_skip
=
None
else
:
self
.
_skip
=
SkipBlock
(
self
.
_out_filters
,
downsample
=
self
.
_downsample
,
conv_type
=
self
.
_conv_type
,
kernel_initializer
=
self
.
_kernel_initializer
,
kernel_regularizer
=
self
.
_kernel_regularizer
,
name
=
'skip'
)
self
.
_mobile_bottleneck
=
MobileBottleneck
(
self
.
_expansion
,
self
.
_feature
,
self
.
_projection
,
attention_layer
=
self
.
_attention
,
skip_layer
=
self
.
_skip
,
stochastic_depth_drop_rate
=
self
.
_stochastic_depth_drop_rate
,
name
=
'bneck'
)
super
(
MovinetBlock
,
self
).
build
(
input_shape
)
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
return
self
.
_mobile_bottleneck
(
inputs
,
states
=
states
)
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
Stem
(
tf
.
keras
.
layers
.
Layer
):
"""Stem layer for video networks.
Applies an initial convolution block operation.
"""
def
__init__
(
self
,
out_filters
:
int
,
kernel_size
:
Union
[
int
,
Sequence
[
int
]],
strides
:
Union
[
int
,
Sequence
[
int
]]
=
(
1
,
1
,
1
),
causal
:
bool
=
False
,
conv_type
:
str
=
'3d'
,
activation
:
nn_layers
.
Activation
=
'swish'
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
**
kwargs
):
"""Implementation for video model stem.
Args:
out_filters: number of output filters.
kernel_size: kernel size of the convolution.
strides: strides of the convolution.
causal: if True, run the temporal convolutions in causal mode.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
activation: the input activation name.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv operations.
batch_norm_layer: class to use for batch norm.
batch_norm_momentum: momentum of the batch norm operation.
batch_norm_epsilon: epsilon of the batch norm operation.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
Stem
,
self
).
__init__
(
**
kwargs
)
self
.
_kernel_size
=
normalize_tuple
(
kernel_size
,
3
,
'kernel_size'
)
self
.
_strides
=
normalize_tuple
(
strides
,
3
,
'strides'
)
self
.
_out_filters
=
out_filters
self
.
_conv_type
=
conv_type
self
.
_causal
=
causal
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_batch_norm_layer
=
batch_norm_layer
self
.
_batch_norm_momentum
=
batch_norm_momentum
self
.
_batch_norm_epsilon
=
batch_norm_epsilon
self
.
_stem
=
StreamConvBlock
(
filters
=
self
.
_out_filters
,
kernel_size
=
self
.
_kernel_size
,
strides
=
self
.
_strides
,
causal
=
self
.
_causal
,
activation
=
activation
,
conv_type
=
self
.
_conv_type
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'stem'
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'out_filters'
:
self
.
_out_filters
,
'kernel_size'
:
self
.
_kernel_size
,
'strides'
:
self
.
_strides
,
'causal'
:
self
.
_causal
,
'conv_type'
:
self
.
_conv_type
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'batch_norm_momentum'
:
self
.
_batch_norm_momentum
,
'batch_norm_epsilon'
:
self
.
_batch_norm_epsilon
,
}
base_config
=
super
(
Stem
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
tf
.
Tensor
,
states
:
Optional
[
nn_layers
.
States
]
=
None
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
return
self
.
_stem
(
inputs
,
states
=
states
)
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
Head
(
tf
.
keras
.
layers
.
Layer
):
"""Head layer for video networks.
Applies pointwise projection and global pooling.
"""
def
__init__
(
self
,
project_filters
:
int
,
conv_type
:
str
=
'3d'
,
activation
:
nn_layers
.
Activation
=
'swish'
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
batch_norm_layer
:
tf
.
keras
.
layers
.
Layer
=
tf
.
keras
.
layers
.
experimental
.
SyncBatchNormalization
,
batch_norm_momentum
:
float
=
0.99
,
batch_norm_epsilon
:
float
=
1e-3
,
**
kwargs
):
"""Implementation for video model head.
Args:
project_filters: number of pointwise projection filters.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
activation: the input activation name.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv operations.
batch_norm_layer: class to use for batch norm.
batch_norm_momentum: momentum of the batch norm operation.
batch_norm_epsilon: epsilon of the batch norm operation.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
Head
,
self
).
__init__
(
**
kwargs
)
self
.
_project_filters
=
project_filters
self
.
_conv_type
=
conv_type
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_batch_norm_layer
=
batch_norm_layer
self
.
_batch_norm_momentum
=
batch_norm_momentum
self
.
_batch_norm_epsilon
=
batch_norm_epsilon
self
.
_project
=
ConvBlock
(
filters
=
project_filters
,
kernel_size
=
1
,
activation
=
activation
,
conv_type
=
conv_type
,
kernel_regularizer
=
kernel_regularizer
,
use_batch_norm
=
True
,
batch_norm_layer
=
self
.
_batch_norm_layer
,
batch_norm_momentum
=
self
.
_batch_norm_momentum
,
batch_norm_epsilon
=
self
.
_batch_norm_epsilon
,
name
=
'project'
)
self
.
_pool
=
nn_layers
.
GlobalAveragePool3D
(
keepdims
=
True
,
causal
=
False
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'project_filters'
:
self
.
_project_filters
,
'conv_type'
:
self
.
_conv_type
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
'batch_norm_momentum'
:
self
.
_batch_norm_momentum
,
'batch_norm_epsilon'
:
self
.
_batch_norm_epsilon
,
}
base_config
=
super
(
Head
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
Union
[
tf
.
Tensor
,
Dict
[
str
,
tf
.
Tensor
]],
states
:
Optional
[
nn_layers
.
States
]
=
None
,
)
->
Tuple
[
tf
.
Tensor
,
nn_layers
.
States
]:
"""Calls the layer with the given inputs.
Args:
inputs: the input tensor or dict of endpoints.
states: a dict of states such that, if any of the keys match for this
layer, will overwrite the contents of the buffer(s).
Returns:
the output tensor and states
"""
states
=
dict
(
states
)
if
states
is
not
None
else
{}
x
=
self
.
_project
(
inputs
)
return
self
.
_pool
(
x
,
states
=
states
)
@
tf
.
keras
.
utils
.
register_keras_serializable
(
package
=
'Vision'
)
class
ClassifierHead
(
tf
.
keras
.
layers
.
Layer
):
"""Head layer for video networks.
Applies dense projection, dropout, and classifier projection. Expects input
to be pooled vector with shape [batch_size, 1, 1, 1, num_channels]
"""
def
__init__
(
self
,
head_filters
:
int
,
num_classes
:
int
,
dropout_rate
:
float
=
0.
,
conv_type
:
str
=
'3d'
,
activation
:
nn_layers
.
Activation
=
'swish'
,
output_activation
:
Optional
[
nn_layers
.
Activation
]
=
None
,
max_pool_predictions
:
bool
=
False
,
kernel_initializer
:
tf
.
keras
.
initializers
.
Initializer
=
'HeNormal'
,
kernel_regularizer
:
Optional
[
tf
.
keras
.
regularizers
.
Regularizer
]
=
tf
.
keras
.
regularizers
.
L2
(
KERNEL_WEIGHT_DECAY
),
**
kwargs
):
"""Implementation for video model classifier head.
Args:
head_filters: number of dense head projection filters.
num_classes: number of output classes for the final logits.
dropout_rate: the dropout rate applied to the head projection.
conv_type: '3d', '2plus1d', or '3d_2plus1d'. '3d' uses the default 3D
ops. '2plus1d' split any 3D ops into two sequential 2D ops with their
own batch norm and activation. '3d_2plus1d' is like '2plus1d', but
uses two sequential 3D ops instead.
activation: the input activation name.
output_activation: optional final activation (e.g., 'softmax').
max_pool_predictions: apply temporal softmax pooling to predictions.
Intended for multi-label prediction, where multiple labels are
distributed across the video. Currently only supports single clips.
kernel_initializer: kernel initializer for the conv operations.
kernel_regularizer: kernel regularizer for the conv operations.
**kwargs: keyword arguments to be passed to this layer.
"""
super
(
ClassifierHead
,
self
).
__init__
(
**
kwargs
)
self
.
_head_filters
=
head_filters
self
.
_num_classes
=
num_classes
self
.
_dropout_rate
=
dropout_rate
self
.
_conv_type
=
conv_type
self
.
_output_activation
=
output_activation
self
.
_max_pool_predictions
=
max_pool_predictions
self
.
_kernel_initializer
=
kernel_initializer
self
.
_kernel_regularizer
=
kernel_regularizer
self
.
_dropout
=
tf
.
keras
.
layers
.
Dropout
(
dropout_rate
)
self
.
_head
=
ConvBlock
(
filters
=
head_filters
,
kernel_size
=
1
,
activation
=
activation
,
use_bias
=
True
,
use_batch_norm
=
False
,
conv_type
=
conv_type
,
kernel_initializer
=
kernel_initializer
,
kernel_regularizer
=
kernel_regularizer
,
name
=
'head'
)
self
.
_classifier
=
ConvBlock
(
filters
=
num_classes
,
kernel_size
=
1
,
kernel_initializer
=
tf
.
keras
.
initializers
.
random_normal
(
stddev
=
0.01
),
kernel_regularizer
=
None
,
use_bias
=
True
,
use_batch_norm
=
False
,
conv_type
=
conv_type
,
name
=
'classifier'
)
self
.
_max_pool
=
nn_layers
.
TemporalSoftmaxPool
()
self
.
_squeeze
=
Squeeze3D
()
output_activation
=
output_activation
if
output_activation
else
'linear'
self
.
_cast
=
tf
.
keras
.
layers
.
Activation
(
output_activation
,
dtype
=
'float32'
,
name
=
'cast'
)
def
get_config
(
self
):
"""Returns a dictionary containing the config used for initialization."""
config
=
{
'head_filters'
:
self
.
_head_filters
,
'num_classes'
:
self
.
_num_classes
,
'dropout_rate'
:
self
.
_dropout_rate
,
'conv_type'
:
self
.
_conv_type
,
'output_activation'
:
self
.
_output_activation
,
'max_pool_predictions'
:
self
.
_max_pool_predictions
,
'kernel_initializer'
:
self
.
_kernel_initializer
,
'kernel_regularizer'
:
self
.
_kernel_regularizer
,
}
base_config
=
super
(
ClassifierHead
,
self
).
get_config
()
return
dict
(
list
(
base_config
.
items
())
+
list
(
config
.
items
()))
def
call
(
self
,
inputs
:
tf
.
Tensor
)
->
tf
.
Tensor
:
"""Calls the layer with the given inputs."""
# Input Shape: [batch_size, 1, 1, 1, input_channels]
x
=
inputs
x
=
self
.
_head
(
x
)
if
self
.
_dropout_rate
and
self
.
_dropout_rate
>
0
:
x
=
self
.
_dropout
(
x
)
x
=
self
.
_classifier
(
x
)
if
self
.
_max_pool_predictions
:
x
=
self
.
_max_pool
(
x
)
x
=
self
.
_squeeze
(
x
)
x
=
self
.
_cast
(
x
)
return
x
Prev
1
2
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment
