Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
ResNet50_tensorflow
Commits
44fa1d37
Commit
44fa1d37
authored
Jun 29, 2017
by
Alex Lee
Browse files
Merge remote-tracking branch 'upstream/master'
parents
d3628a74
6e367f67
Changes
293
Hide whitespace changes
Inline
Side-by-side
Showing
13 changed files
with
891 additions
and
0 deletions
+891
-0
object_detection/g3doc/img/kites_detections_output.jpg
object_detection/g3doc/img/kites_detections_output.jpg
+0
-0
object_detection/g3doc/img/oxford_pet.png
object_detection/g3doc/img/oxford_pet.png
+0
-0
object_detection/g3doc/img/tensorboard.png
object_detection/g3doc/img/tensorboard.png
+0
-0
object_detection/g3doc/img/tensorboard2.png
object_detection/g3doc/img/tensorboard2.png
+0
-0
object_detection/g3doc/installation.md
object_detection/g3doc/installation.md
+79
-0
object_detection/g3doc/preparing_inputs.md
object_detection/g3doc/preparing_inputs.md
+45
-0
object_detection/g3doc/running_locally.md
object_detection/g3doc/running_locally.md
+81
-0
object_detection/g3doc/running_notebook.md
object_detection/g3doc/running_notebook.md
+15
-0
object_detection/g3doc/running_on_cloud.md
object_detection/g3doc/running_on_cloud.md
+128
-0
object_detection/g3doc/running_pets.md
object_detection/g3doc/running_pets.md
+303
-0
object_detection/matchers/BUILD
object_detection/matchers/BUILD
+51
-0
object_detection/matchers/__init__.py
object_detection/matchers/__init__.py
+0
-0
object_detection/matchers/argmax_matcher.py
object_detection/matchers/argmax_matcher.py
+189
-0
No files found.
Too many changes to show.
To preserve performance only
293 of 293+
files are displayed.
Plain diff
Email patch
object_detection/g3doc/img/kites_detections_output.jpg
0 → 100644
View file @
44fa1d37
377 KB
object_detection/g3doc/img/oxford_pet.png
0 → 100644
View file @
44fa1d37
270 KB
object_detection/g3doc/img/tensorboard.png
0 → 100644
View file @
44fa1d37
77.5 KB
object_detection/g3doc/img/tensorboard2.png
0 → 100644
View file @
44fa1d37
231 KB
object_detection/g3doc/installation.md
0 → 100644
View file @
44fa1d37
# Installation
## Dependencies
Tensorflow Object Detection API depends on the following libraries:
*
Protobuf 2.6
*
Pillow 1.0
*
lxml
*
tf Slim (which is included in the "tensorflow/models" checkout)
*
Jupyter notebook
*
Matplotlib
*
Tensorflow
For detailed steps to install Tensorflow, follow the
[
Tensorflow installation instructions
](
https://www.tensorflow.org/install/
)
.
A typically user can install Tensorflow using one of the following commands:
```
bash
# For CPU
pip
install
tensorflow
# For GPU
pip
install
tensorflow-gpu
```
The remaining libraries can be installed on Ubuntu 16.04 using via apt-get:
```
bash
sudo
apt-get
install
protobuf-compiler python-pil python-lxml
sudo
pip
install
jupyter
sudo
pip
install
matplotlib
```
Alternatively, users can install dependencies using pip:
```
bash
sudo
pip
install
pillow
sudo
pip
install
lxml
sudo
pip
install
jupyter
sudo
pip
install
matplotlib
```
## Protobuf Compilation
The Tensorflow Object Detection API uses Protobufs to configure model and
training parameters. Before the framework can be used, the Protobuf libraries
must be compiled. This should be done by running the following command from
the tensorflow/models directory:
```
bash
# From tensorflow/models/
protoc object_detection/protos/
*
.proto
--python_out
=
.
```
## Add Libraries to PYTHONPATH
When running locally, the tensorflow/models/ and slim directories should be
appended to PYTHONPATH. This can be done by running the following from
tensorflow/models/:
```
bash
# From tensorflow/models/
export
PYTHONPATH
=
$PYTHONPATH
:
`
pwd
`
:
`
pwd
`
/slim
```
Note: This command needs to run from every new terminal you start. If you wish
to avoid running this manually, you can add it as a new line to the end of your
~/.bashrc file.
# Testing the Installation
You can test that you have correctly installed the Tensorflow Object Detection
\
API by running the following command:
```
bash
python object_detection/builders/model_builder_test.py
```
object_detection/g3doc/preparing_inputs.md
0 → 100644
View file @
44fa1d37
# Preparing Inputs
Tensorflow Object Detection API reads data using the TFRecord file format. Two
sample scripts (
`create_pascal_tf_record.py`
and
`create_pet_tf_record.py`
) are
provided to convert from the PASCAL VOC dataset and Oxford-IIIT Pet dataset to
TFRecords.
## Generating the PASCAL VOC TFRecord files.
The raw 2012 PASCAL VOC data set can be downloaded
[
here
](
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
)
.
Extract the tar file and run the
`create_pascal_tf_record`
script:
```
bash
# From tensorflow/models/object_detection
tar
-xvf
VOCtrainval_11-May-2012.tar
python create_pascal_tf_record.py
--data_dir
=
VOCdevkit
\
--year
=
VOC2012
--set
=
train
--output_path
=
pascal_train.record
python create_pascal_tf_record.py
--data_dir
=
VOCdevkit
\
--year
=
VOC2012
--set
=
val
--output_path
=
pascal_val.record
```
You should end up with two TFRecord files named
`pascal_train.record`
and
`pascal_val.record`
in the
`tensorflow/models/object_detection`
directory.
The label map for the PASCAL VOC data set can be found at
`data/pascal_label_map.pbtxt`
.
## Generation the Oxford-IIIT Pet TFRecord files.
The Oxford-IIIT Pet data set can be downloaded from
[
their website
](
http://www.robots.ox.ac.uk/~vgg/data/pets/
)
. Extract the tar
file and run the
`create_pet_tf_record`
script to generate TFRecords.
```
bash
# From tensorflow/models/object_detection
tar
-xvf
annotations.tar.gz
tar
-xvf
images.tar.gz
python create_pet_tf_record.py
--data_dir
=
`
pwd
`
--output_dir
=
`
pwd
`
```
You should end up with two TFRecord files named
`pet_train.record`
and
`pet_val.record`
in the
`tensorflow/models/object_detection`
directory.
The label map for the Pet dataset can be found at
`data/pet_label_map.pbtxt`
.
object_detection/g3doc/running_locally.md
0 → 100644
View file @
44fa1d37
# Running Locally
This page walks through the steps required to train an object detection model
on a local machine. It assumes the reader has completed the
following prerequisites:
1.
The Tensorflow Object Detection API has been installed as documented in the
[
installation instructions
](
installation.md
)
. This includes installing library
dependencies, compiling the configuration protobufs and setting up the Python
environment.
2.
A valid data set has been created. See
[
this page
](
preparing_inputs.md
)
for
instructions on how to generate a dataset for the PASCAL VOC challenge or the
Oxford-IIIT Pet dataset.
3.
A Object Detection pipeline configuration has been written. See
[
this page
](
configuring_jobs.md
)
for details on how to write a pipeline configuration.
## Recommended Directory Structure for Training and Evaluation
```
+data
-label_map file
-train TFRecord file
-eval TFRecord file
+models
+ model
-pipeline config file
+train
+eval
```
## Running the Training Job
A local training job can be run with the following command:
```
bash
# From the tensorflow/models/ directory
python object_detection/train.py
\
--logtostderr
\
--pipeline_config_path
=
${
PATH_TO_YOUR_PIPELINE_CONFIG
}
\
--train_dir
=
${
PATH_TO_TRAIN_DIR
}
```
where
`${PATH_TO_YOUR_PIPELINE_CONFIG}`
points to the pipeline config and
`${PATH_TO_TRAIN_DIR}`
points to the directory in which training checkpoints
and events will be written to. By default, the training job will
run indefinitely until the user kills it.
## Running the Evaluation Job
Evaluation is run as a separate job. The eval job will periodically poll the
train directory for new checkpoints and evaluate them on a test dataset. The
job can be run using the following command:
```
bash
# From the tensorflow/models/ directory
python object_detection/eval.py
\
--logtostderr
\
--pipeline_config_path
=
${
PATH_TO_YOUR_PIPELINE_CONFIG
}
\
--checkpoint_dir
=
${
PATH_TO_TRAIN_DIR
}
\
--eval_dir
=
${
PATH_TO_EVAL_DIR
}
```
where
`${PATH_TO_YOUR_PIPELINE_CONFIG}`
points to the pipeline config,
`${PATH_TO_TRAIN_DIR}`
points to the directory in which training checkpoints
were saved (same as the training job) and
`${PATH_TO_EVAL_DIR}`
points to the
directory in which evaluation events will be saved. As with the training job,
the eval job run until terminated by default.
## Running Tensorboard
Progress for training and eval jobs can be inspected using Tensorboard. If
using the recommended directory structure, Tensorboard can be run using the
following command:
```
bash
tensorboard
--logdir
=
${
PATH_TO_MODEL_DIRECTORY
}
```
where
`${PATH_TO_MODEL_DIRECTORY}`
points to the directory that contains the
train and eval directories. Please note it make take Tensorboard a couple
minutes to populate with data.
object_detection/g3doc/running_notebook.md
0 → 100644
View file @
44fa1d37
# Quick Start: Jupyter notebook for off-the-shelf inference
If you'd like to hit the ground running and run detection on a few example
images right out of the box, we recommend trying out the Jupyter notebook demo.
To run the Jupyter notebook, run the following command from
`tensorflow/models/object_detection`
:
```
# From tensorflow/models/object_detection
jupyter notebook
```
The notebook should open in your favorite web browser. Click the
[
`object_detection_tutorial.ipynb`
](
../object_detection_tutorial.ipynb
)
link
to open the demo.
object_detection/g3doc/running_on_cloud.md
0 → 100644
View file @
44fa1d37
# Running on Google Cloud Platform
The Tensorflow Object Detection API supports distributed training on Google
Cloud ML Engine. This section documents instructions on how to train and
evaluate your model using Cloud ML. The reader should complete the following
prerequistes:
1.
The reader has created and configured a project on Google Cloud Platform.
See
[
the Cloud ML quick start guide
](
https://cloud.google.com/ml-engine/docs/quickstarts/command-line
)
.
2.
The reader has installed the Tensorflow Object Detection API as documented
in the
[
installation instructions
](
installation.md
)
.
3.
The reader has a valid data set and stored it in a Google Cloud Storage
bucket. See
[
this page
](
preparing_inputs.md
)
for instructions on how to generate
a dataset for the PASCAL VOC challenge or the Oxford-IIIT Pet dataset.
4.
The reader has configured a valid Object Detection pipeline, and stored it
in a Google Cloud Storage bucket. See
[
this page
](
configuring_jobs.md
)
for
details on how to write a pipeline configuration.
Additionally, it is recommended users test their job by running training and
evaluation jobs for a few iterations
[
locally on their own machines
](
running_locally.md
)
.
## Packaging
In order to run the Tensorflow Object Detection API on Cloud ML, it must be
packaged (along with it's TF-Slim dependency). The required packages can be
created with the following command
```
bash
# From tensorflow/models/
python setup.py sdist
(
cd
slim
&&
python setup.py sdist
)
```
This will create python packages in dist/object_detection-0.1.tar.gz and
slim/dist/slim-0.1.tar.gz.
## Running a Multiworker Training Job
Google Cloud ML requires a YAML configuration file for a multiworker training
job using GPUs. A sample YAML file is given below:
```
trainingInput:
runtimeVersion: "1.0"
scaleTier: CUSTOM
masterType: standard_gpu
workerCount: 9
workerType: standard_gpu
parameterServerCount: 3
parameterServerType: standard
```
Please keep the following guidelines in mind when writing the YAML
configuration:
*
A job with n workers will have n + 1 training machines (n workers + 1 master).
*
The number of parameters servers used should be an odd number to prevent
a parameter server from storing only weight variables or only bias variables
(due to round robin parameter scheduling).
*
The learning rate in the training config should be decreased when using a
larger number of workers. Some experimentation is required to find the
optimal learning rate.
The YAML file should be saved on the local machine (not on GCP). Once it has
been written, a user can start a training job on Cloud ML Engine using the
following command:
```
bash
# From tensorflow/models/
gcloud ml-engine
jobs
submit training object_detection_
`
date
+%s
`
\
--job-dir
=
gs://
${
TRAIN_DIR
}
\
--packages
dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
\
--module-name
object_detection.train
\
--region
us-central1
\
--config
${
PATH_TO_LOCAL_YAML_FILE
}
\
--
\
--train_dir
=
gs://
${
TRAIN_DIR
}
\
--pipeline_config_path
=
gs://
${
PIPELINE_CONFIG_PATH
}
```
Where
`${PATH_TO_LOCAL_YAML_FILE}`
is the local path to the YAML configuration,
`gs://${TRAIN_DIR}`
specifies the directory on Google Cloud Storage where the
training checkpoints and events will be written to and
`gs://${PIPELINE_CONFIG_PATH}`
points to the pipeline configuration stored on
Google Cloud Storage.
Users can monitor the progress of their training job on the
[
ML Engine
Dashboard
](
https://pantheon.corp.google.com/mlengine/jobs
)
.
## Running an Evaluation Job on Cloud
Evaluation jobs run on a single machine, so it is not necessary to write a YAML
configuration for evaluation. Run the following command to start the evaluation
job:
```
bash
gcloud ml-engine
jobs
submit training object_detection_eval_
`
date
+%s
`
\
--job-dir
=
gs://
${
TRAIN_DIR
}
\
--packages
dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
\
--module-name
object_detection.eval
\
--region
us-central1
\
--scale-tier
BASIC_GPU
\
--
\
--checkpoint_dir
=
gs://
${
TRAIN_DIR
}
\
--eval_dir
=
gs://
${
EVAL_DIR
}
\
--pipeline_config_path
=
gs://
${
PIPELINE_CONFIG_PATH
}
```
Where
`gs://${TRAIN_DIR}`
points to the directory on Google Cloud Storage where
training checkpoints are saved (same as the training job),
`gs://${EVAL_DIR}`
points to where evaluation events will be saved on Google Cloud Storage and
`gs://${PIPELINE_CONFIG_PATH}`
points to where the pipeline configuration is
stored on Google Cloud Storage.
## Running Tensorboard
You can run Tensorboard locally on your own machine to view progress of your
training and eval jobs on Google Cloud ML. Run the following command to start
Tensorboard:
```
bash
tensorboard
--logdir
=
gs://
${
YOUR_CLOUD_BUCKET
}
```
Note it may Tensorboard a few minutes to populate with results.
object_detection/g3doc/running_pets.md
0 → 100644
View file @
44fa1d37
# Quick Start: Distributed Training on the Oxford-IIIT Pets Dataset on Google Cloud
This page is a walkthrough for training an object detector using the Tensorflow
Object Detection API. In this tutorial, we'll be training on the Oxford-IIIT Pets
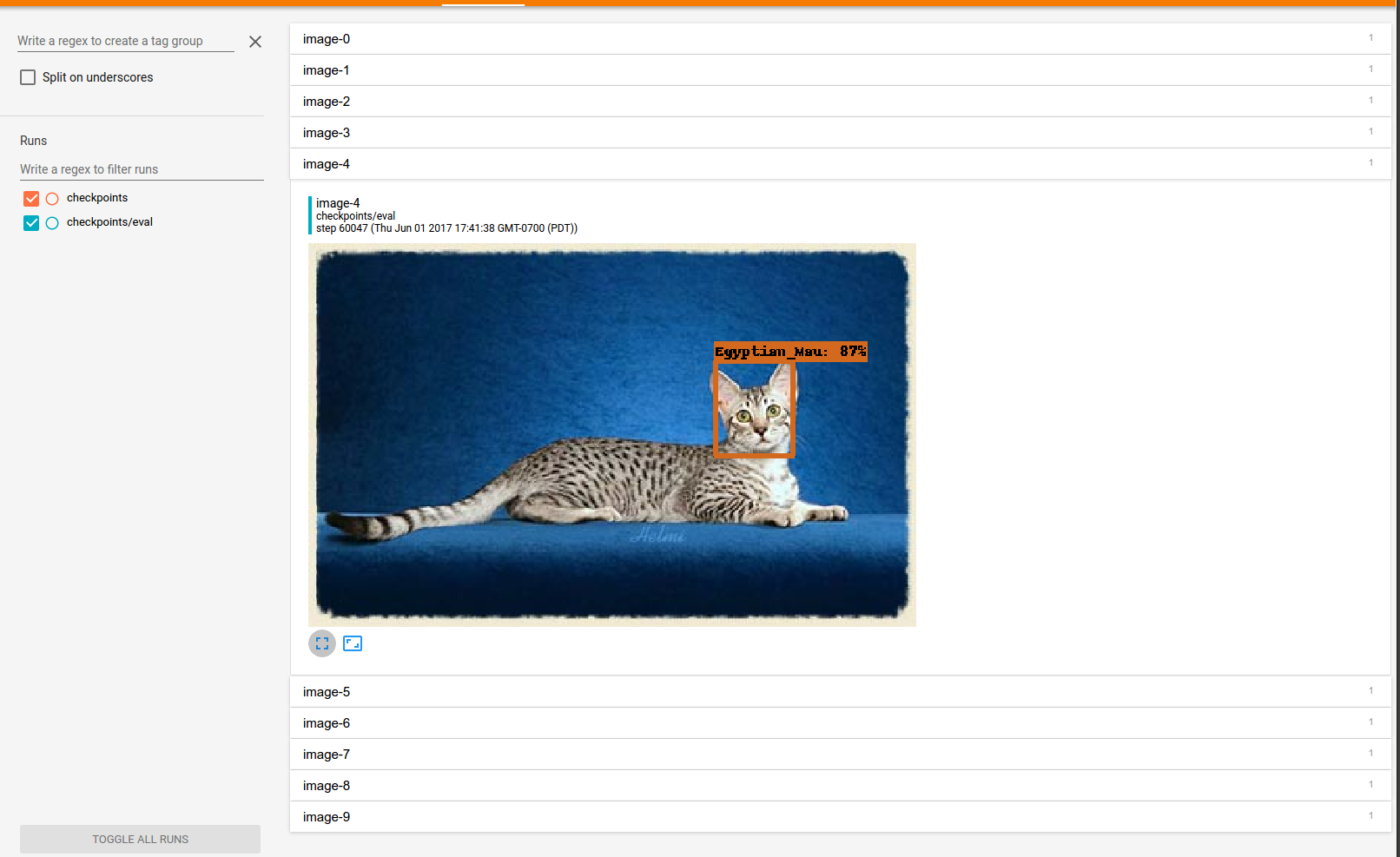
dataset to build a system to detect various breeds of cats and dogs. The output
of the detector will look like the following:

## Setting up a Project on Google Cloud
To accelerate the process, we'll run training and evaluation on
[
Google Cloud
ML Engine
](
https://cloud.google.com/ml-engine/
)
to leverage multiple GPUs. To
begin, you will have to set up Google Cloud via the following steps (if you have
already done this, feel free to skip to the next section):
1.
[
Create a GCP project
](
https://cloud.google.com/resource-manager/docs/creating-managing-projects
)
.
2.
[
Install the Google Cloud SDK
](
https://cloud.google.com/sdk/downloads
)
on
your workstation or laptop.
This will provide the tools you need to upload files to Google Cloud Storage and
start ML training jobs.
3.
[
Enable the ML Engine
APIs
](
https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component&_ga=1.73374291.1570145678.1496689256
)
.
By default, a new GCP project does not enable APIs to start ML Engine training
jobs. Use the above link to explicitly enable them.
4.
[
Set up a Google Cloud Storage (GCS)
bucket
](
https://cloud.google.com/storage/docs/creating-buckets
)
. ML Engine
training jobs can only access files on a Google Cloud Storage bucket. In this
tutorial, we'll be required to upload our dataset and configuration to GCS.
Please remember the name of your GCS bucket, as we will reference it multiple
times in this document. Substitute
`${YOUR_GCS_BUCKET}`
with the name of
your bucket in this document. For your convenience, you should define the
environment variable below:
```
bash
export
YOUR_GCS_BUCKET
=
${
YOUR_GCS_BUCKET
}
```
## Installing Tensorflow and the Tensorflow Object Detection API
Please run through the
[
installation instructions
](
installation.md
)
to install
Tensorflow and all it dependencies. Ensure the Protobuf libraries are
compiled and the library directories are added to
`PYTHONPATH`
.
## Getting the Oxford-IIIT Pets Dataset and Uploading it to Google Cloud Storage
In order to train a detector, we require a dataset of images, bounding boxes and
classifications. For this demo, we'll use the Oxford-IIIT Pets dataset. The raw
dataset for Oxford-IIIT Pets lives
[
here
](
http://www.robots.ox.ac.uk/~vgg/data/pets/
)
. You will need to download
both the image dataset
[
`images.tar.gz`
](
http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
)
and the groundtruth data
[
`annotations.tar.gz`
](
http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
)
to the
`tensorflow/models`
directory. This may take some time. After downloading
the tarballs, your
`object_detection`
directory should appear as follows:
```
lang-none
+ object_detection/
+ data/
- images.tar.gz
- annotations.tar.gz
- create_pet_tf_record.py
... other files and directories
```
The Tensorflow Object Detection API expects data to be in the TFRecord format,
so we'll now run the
`create_pet_tf_record`
script to convert from the raw
Oxford-IIIT Pet dataset into TFRecords. Run the following commands from the
`object_detection`
directory:
```
bash
# From tensorflow/models/
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
tar
-xvf
annotations.tar.gz
tar
-xvf
images.tar.gz
python object_detection/create_pet_tf_record.py
\
--label_map_path
=
object_detection/data/pet_label_map.pbtxt
\
--data_dir
=
`
pwd
`
\
--output_dir
=
`
pwd
`
```
Note: It is normal to see some warnings when running this script. You may ignore
them.
Two TFRecord files named
`pet_train.record`
and
`pet_val.record`
should be generated
in the
`object_detection`
directory.
Now that the data has been generated, we'll need to upload it to Google Cloud
Storage so the data can be accessed by ML Engine. Run the following command to
copy the files into your GCS bucket (substituting
`${YOUR_GCS_BUCKET}`
):
```
bash
# From tensorflow/models/
gsutil
cp
pet_train.record gs://
${
YOUR_GCS_BUCKET
}
/data/pet_train.record
gsutil
cp
pet_val.record gs://
${
YOUR_GCS_BUCKET
}
/data/pet_val.record
gsutil
cp
object_detection/data/pet_label_map.pbtxt gs://
${
YOUR_GCS_BUCKET
}
/data/pet_label_map.pbtxt
```
Please remember the path where you upload the data to, as we will need this
information when configuring the pipeline in a following step.
## Downloading a COCO-pretrained Model for Transfer Learning
Training a state of the art object detector from scratch can take days, even
when using multiple GPUs! In order to speed up training, we'll take an object
detector trained on a different dataset (COCO), and reuse some of it's
parameters to initialize our new model.
Download our
[
COCO-pretrained Faster R-CNN with Resnet-101
model
](
http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
)
.
Unzip the contents of the folder and copy the
`model.ckpt*`
files into your GCS
Bucket.
```
bash
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
tar
-xvf
faster_rcnn_resnet101_coco_11_06_2017.tar.gz
gsutil
cp
faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.
*
gs://
${
YOUR_GCS_BUCKET
}
/data/
```
Remember the path where you uploaded the model checkpoint to, as we will need it
in the following step.
## Configuring the Object Detection Pipeline
In the Tensorflow Object Detection API, the model parameters, training
parameters and eval parameters are all defined by a config file. More details
can be found
[
here
](
configuring_jobs.md
)
. For this tutorial, we will use some
predefined templates provided with the source code. In the
`object_detection/samples/configs`
folder, there are skeleton object_detection
configuration files. We will use
`faster_rcnn_resnet101_pets.config`
as a
starting point for configuring the pipeline. Open the file with your favourite
text editor.
We'll need to configure some paths in order for the template to work. Search the
file for instances of
`PATH_TO_BE_CONFIGURED`
and replace them with the
appropriate value (typically
`gs://${YOUR_GCS_BUCKET}/data/`
). Afterwards
upload your edited file onto GCS, making note of the path it was uploaded to
(we'll need it when starting the training/eval jobs).
```
bash
# From tensorflow/models/
# Edit the faster_rcnn_resnet101_pets.config template. Please note that there
# are multiple places where PATH_TO_BE_CONFIGURED needs to be set.
sed
-i
"s|PATH_TO_BE_CONFIGURED|"
gs://
${
YOUR_GCS_BUCKET
}
"/data|g"
\
object_detection/samples/configs/faster_rcnn_resnet101_pets.config
# Copy edited template to cloud.
gsutil
cp
object_detection/samples/configs/faster_rcnn_resnet101_pets.config
\
gs://
${
YOUR_GCS_BUCKET
}
/data/faster_rcnn_resnet101_pets.config
```
## Checking Your Google Cloud Storage Bucket
At this point in the tutorial, you should have uploaded the training/validation
datasets (including label map), our COCO trained FasterRCNN finetune checkpoint and your job
configuration to your Google Cloud Storage Bucket. Your bucket should look like
the following:
```
lang-none
+ ${YOUR_GCS_BUCKET}/
+ data/
- faster_rcnn_resnet101_pets.config
- model.ckpt.index
- model.ckpt.meta
- model.ckpt.data-00000-of-00001
- pet_label_map.pbtxt
- pet_train.record
- pet_val.record
```
You can inspect your bucket using the
[
Google Cloud Storage
browser
](
https://console.cloud.google.com/storage/browser
)
.
## Starting Training and Evaluation Jobs on Google Cloud ML Engine
Before we can start a job on Google Cloud ML Engine, we must:
1.
Package the Tensorflow Object Detection code.
2.
Write a cluster configuration for our Google Cloud ML job.
To package the Tensorflow Object Detection code, run the following commands from
the
`tensorflow/models/`
directory:
```
bash
# From tensorflow/models/
python setup.py sdist
(
cd
slim
&&
python setup.py sdist
)
```
You should see two tar.gz files created at
`dist/object_detection-0.1.tar.gz`
and
`slim/dist/slim-0.1.tar.gz`
.
For running the training Cloud ML job, we'll configure the cluster to use 10
training jobs (1 master + 9 workers) and three parameters servers. The
configuration file can be found at
`object_detection/samples/cloud/cloud.yml`
.
To start training, execute the following command from the
`tensorflow/models/`
directory:
```
bash
# From tensorflow/models/
gcloud ml-engine
jobs
submit training
`
whoami
`
_object_detection_
`
date
+%s
`
\
--job-dir
=
gs://
${
YOUR_GCS_BUCKET
}
/train
\
--packages
dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
\
--module-name
object_detection.train
\
--region
us-central1
\
--config
object_detection/samples/cloud/cloud.yml
\
--
\
--train_dir
=
gs://
${
YOUR_GCS_BUCKET
}
/train
\
--pipeline_config_path
=
gs://
${
YOUR_GCS_BUCKET
}
/data/faster_rcnn_resnet101_pets.config
```
Once training has started, we can run an evaluation concurrently:
```
bash
# From tensorflow/models/
gcloud ml-engine
jobs
submit training
`
whoami
`
_object_detection_eval_
`
date
+%s
`
\
--job-dir
=
gs://
${
YOUR_GCS_BUCKET
}
/train
\
--packages
dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz
\
--module-name
object_detection.eval
\
--region
us-central1
\
--scale-tier
BASIC_GPU
\
--
\
--checkpoint_dir
=
gs://
${
YOUR_GCS_BUCKET
}
/train
\
--eval_dir
=
gs://
${
YOUR_GCS_BUCKET
}
/eval
\
--pipeline_config_path
=
gs://
${
YOUR_GCS_BUCKET
}
/data/faster_rcnn_resnet101_pets.config
```
Note: Even though we're running an evaluation job, the
`gcloud ml-engine jobs
submit training`
command is correct. ML Engine does not distinguish between
training and evaluation jobs.
Users can monitor and stop training and evaluation jobs on the
[
ML Engine
Dashboard
](
https://console.cloud.google.com/mlengine/jobs
)
.
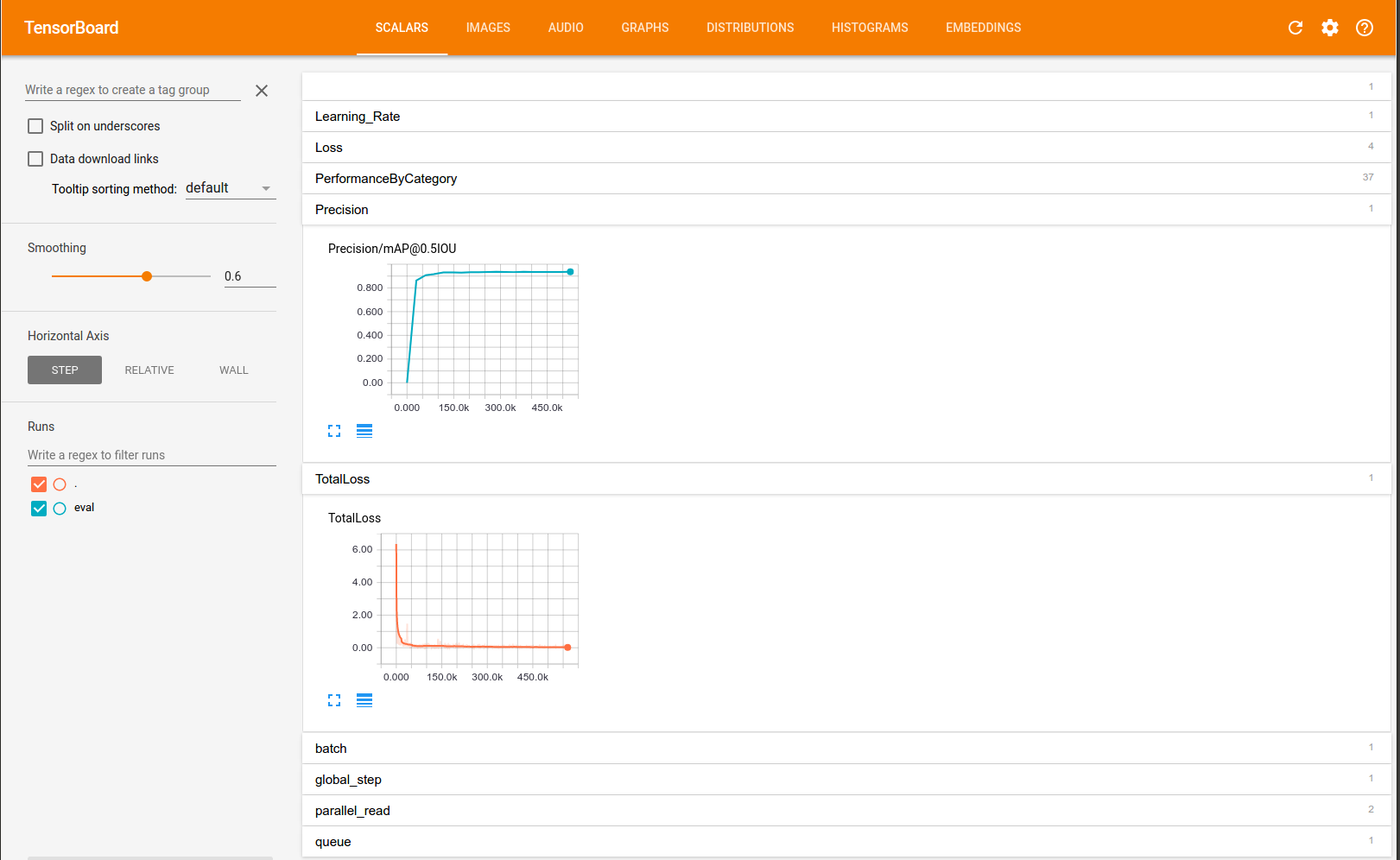
## Monitoring Progress with Tensorboard
You can monitor progress of the training and eval jobs by running Tensorboard on
your local machine:
```
bash
# This command needs to be run once to allow your local machine to access your
# GCS bucket.
gcloud auth application-default login
tensorboard
--logdir
=
gs://
${
YOUR_GCS_BUCKET
}
```
Once Tensorboard is running, navigate to
`localhost:6006`
from your favourite
web browser. You should something similar see the following:

You will also want to click on the images tab to see example detections made by
the model while it trains. After about an hour and a half of training, you can
expect to see something like this:

Note: It takes roughly 10 minutes for a job to get started on ML Engine, and
roughly an hour for the system to evaluate the validation dataset. It may take
some time to populate the dashboards. If you do not see any entries after half
an hour, check the logs from the
[
ML Engine
Dashboard
](
https://console.cloud.google.com/mlengine/jobs
)
.
## Exporting the Tensorflow Graph
After your model has been trained, you should export it to a Tensorflow
graph proto. First, you need to identify a candidate checkpoint to export. You
can search your bucket using the
[
Google Cloud Storage
Browser
](
https://console.cloud.google.com/storage/browser
)
. The file should be
stored under
`${YOUR_GCS_BUCKET}/train`
. The checkpoint will typically consist of
three files:
*
`model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001`
*
`model.ckpt-${CHECKPOINT_NUMBER}.index`
*
`model.ckpt-${CHECKPOINT_NUMBER}.meta`
After you've identified a candidate checkpoint to export, run the following
command from
`tensorflow/models/object_detection`
:
```
bash
# From tensorflow/models
gsutil
cp
gs://
${
YOUR_GCS_BUCKET
}
/train/model.ckpt-
${
CHECKPOINT_NUMBER
}
.
*
.
python object_detection/export_inference_graph.py
\
--input_type
image_tensor
\
--pipeline_config_path
object_detection/samples/configs/faster_rcnn_resnet101_pets.config
\
--checkpoint_path
model.ckpt-
${
CHECKPOINT_NUMBER
}
\
--inference_graph_path
output_inference_graph.pb
```
Afterwards, you should see a graph named
`output_inference_graph.pb`
.
## What's Next
Congratulations, you have now trained an object detector for various cats and
dogs! There different things you can do now:
1.
[
Test your exported model using the provided Jupyter notebook.
](
running_notebook.md
)
2.
[
Experiment with different model configurations.
](
configuring_jobs.md
)
3.
Train an object detector using your own data.
object_detection/matchers/BUILD
0 → 100644
View file @
44fa1d37
# Tensorflow Object Detection API: Matcher implementations.
package
(
default_visibility
=
[
"//visibility:public"
],
)
licenses
([
"notice"
])
# Apache 2.0
py_library
(
name
=
"argmax_matcher"
,
srcs
=
[
"argmax_matcher.py"
,
],
deps
=
[
"//tensorflow"
,
"//tensorflow_models/object_detection/core:matcher"
,
],
)
py_test
(
name
=
"argmax_matcher_test"
,
srcs
=
[
"argmax_matcher_test.py"
],
deps
=
[
":argmax_matcher"
,
"//tensorflow"
,
],
)
py_library
(
name
=
"bipartite_matcher"
,
srcs
=
[
"bipartite_matcher.py"
,
],
deps
=
[
"//tensorflow"
,
"//tensorflow/contrib/image:image_py"
,
"//tensorflow_models/object_detection/core:matcher"
,
],
)
py_test
(
name
=
"bipartite_matcher_test"
,
srcs
=
[
"bipartite_matcher_test.py"
,
],
deps
=
[
":bipartite_matcher"
,
"//tensorflow"
,
],
)
object_detection/matchers/__init__.py
0 → 100644
View file @
44fa1d37
object_detection/matchers/argmax_matcher.py
0 → 100644
View file @
44fa1d37
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Argmax matcher implementation.
This class takes a similarity matrix and matches columns to rows based on the
maximum value per column. One can specify matched_thresholds and
to prevent columns from matching to rows (generally resulting in a negative
training example) and unmatched_theshold to ignore the match (generally
resulting in neither a positive or negative training example).
This matcher is used in Fast(er)-RCNN.
Note: matchers are used in TargetAssigners. There is a create_target_assigner
factory function for popular implementations.
"""
import
tensorflow
as
tf
from
object_detection.core
import
matcher
class
ArgMaxMatcher
(
matcher
.
Matcher
):
"""Matcher based on highest value.
This class computes matches from a similarity matrix. Each column is matched
to a single row.
To support object detection target assignment this class enables setting both
matched_threshold (upper threshold) and unmatched_threshold (lower thresholds)
defining three categories of similarity which define whether examples are
positive, negative, or ignored:
(1) similarity >= matched_threshold: Highest similarity. Matched/Positive!
(2) matched_threshold > similarity >= unmatched_threshold: Medium similarity.
Depending on negatives_lower_than_unmatched, this is either
Unmatched/Negative OR Ignore.
(3) unmatched_threshold > similarity: Lowest similarity. Depending on flag
negatives_lower_than_unmatched, either Unmatched/Negative OR Ignore.
For ignored matches this class sets the values in the Match object to -2.
"""
def
__init__
(
self
,
matched_threshold
,
unmatched_threshold
=
None
,
negatives_lower_than_unmatched
=
True
,
force_match_for_each_row
=
False
):
"""Construct ArgMaxMatcher.
Args:
matched_threshold: Threshold for positive matches. Positive if
sim >= matched_threshold, where sim is the maximum value of the
similarity matrix for a given column. Set to None for no threshold.
unmatched_threshold: Threshold for negative matches. Negative if
sim < unmatched_threshold. Defaults to matched_threshold
when set to None.
negatives_lower_than_unmatched: Boolean which defaults to True. If True
then negative matches are the ones below the unmatched_threshold,
whereas ignored matches are in between the matched and umatched
threshold. If False, then negative matches are in between the matched
and unmatched threshold, and everything lower than unmatched is ignored.
force_match_for_each_row: If True, ensures that each row is matched to
at least one column (which is not guaranteed otherwise if the
matched_threshold is high). Defaults to False. See
argmax_matcher_test.testMatcherForceMatch() for an example.
Raises:
ValueError: if unmatched_threshold is set but matched_threshold is not set
or if unmatched_threshold > matched_threshold.
"""
if
(
matched_threshold
is
None
)
and
(
unmatched_threshold
is
not
None
):
raise
ValueError
(
'Need to also define matched_threshold when'
'unmatched_threshold is defined'
)
self
.
_matched_threshold
=
matched_threshold
if
unmatched_threshold
is
None
:
self
.
_unmatched_threshold
=
matched_threshold
else
:
if
unmatched_threshold
>
matched_threshold
:
raise
ValueError
(
'unmatched_threshold needs to be smaller or equal'
'to matched_threshold'
)
self
.
_unmatched_threshold
=
unmatched_threshold
if
not
negatives_lower_than_unmatched
:
if
self
.
_unmatched_threshold
==
self
.
_matched_threshold
:
raise
ValueError
(
'When negatives are in between matched and '
'unmatched thresholds, these cannot be of equal '
'value. matched: %s, unmatched: %s'
,
self
.
_matched_threshold
,
self
.
_unmatched_threshold
)
self
.
_force_match_for_each_row
=
force_match_for_each_row
self
.
_negatives_lower_than_unmatched
=
negatives_lower_than_unmatched
def
_match
(
self
,
similarity_matrix
):
"""Tries to match each column of the similarity matrix to a row.
Args:
similarity_matrix: tensor of shape [N, M] representing any similarity
metric.
Returns:
Match object with corresponding matches for each of M columns.
"""
def
_match_when_rows_are_empty
():
"""Performs matching when the rows of similarity matrix are empty.
When the rows are empty, all detections are false positives. So we return
a tensor of -1's to indicate that the columns do not match to any rows.
Returns:
matches: int32 tensor indicating the row each column matches to.
"""
return
-
1
*
tf
.
ones
([
tf
.
shape
(
similarity_matrix
)[
1
]],
dtype
=
tf
.
int32
)
def
_match_when_rows_are_non_empty
():
"""Performs matching when the rows of similarity matrix are non empty.
Returns:
matches: int32 tensor indicating the row each column matches to.
"""
# Matches for each column
matches
=
tf
.
argmax
(
similarity_matrix
,
0
)
# Deal with matched and unmatched threshold
if
self
.
_matched_threshold
is
not
None
:
# Get logical indices of ignored and unmatched columns as tf.int64
matched_vals
=
tf
.
reduce_max
(
similarity_matrix
,
0
)
below_unmatched_threshold
=
tf
.
greater
(
self
.
_unmatched_threshold
,
matched_vals
)
between_thresholds
=
tf
.
logical_and
(
tf
.
greater_equal
(
matched_vals
,
self
.
_unmatched_threshold
),
tf
.
greater
(
self
.
_matched_threshold
,
matched_vals
))
if
self
.
_negatives_lower_than_unmatched
:
matches
=
self
.
_set_values_using_indicator
(
matches
,
below_unmatched_threshold
,
-
1
)
matches
=
self
.
_set_values_using_indicator
(
matches
,
between_thresholds
,
-
2
)
else
:
matches
=
self
.
_set_values_using_indicator
(
matches
,
below_unmatched_threshold
,
-
2
)
matches
=
self
.
_set_values_using_indicator
(
matches
,
between_thresholds
,
-
1
)
if
self
.
_force_match_for_each_row
:
forced_matches_ids
=
tf
.
cast
(
tf
.
argmax
(
similarity_matrix
,
1
),
tf
.
int32
)
# Set matches[forced_matches_ids] = [0, ..., R], R is number of rows.
row_range
=
tf
.
range
(
tf
.
shape
(
similarity_matrix
)[
0
])
col_range
=
tf
.
range
(
tf
.
shape
(
similarity_matrix
)[
1
])
forced_matches_values
=
tf
.
cast
(
row_range
,
matches
.
dtype
)
keep_matches_ids
,
_
=
tf
.
setdiff1d
(
col_range
,
forced_matches_ids
)
keep_matches_values
=
tf
.
gather
(
matches
,
keep_matches_ids
)
matches
=
tf
.
dynamic_stitch
(
[
forced_matches_ids
,
keep_matches_ids
],
[
forced_matches_values
,
keep_matches_values
])
return
tf
.
cast
(
matches
,
tf
.
int32
)
return
tf
.
cond
(
tf
.
greater
(
tf
.
shape
(
similarity_matrix
)[
0
],
0
),
_match_when_rows_are_non_empty
,
_match_when_rows_are_empty
)
def
_set_values_using_indicator
(
self
,
x
,
indicator
,
val
):
"""Set the indicated fields of x to val.
Args:
x: tensor.
indicator: boolean with same shape as x.
val: scalar with value to set.
Returns:
modified tensor.
"""
indicator
=
tf
.
cast
(
indicator
,
x
.
dtype
)
return
tf
.
add
(
tf
.
multiply
(
x
,
1
-
indicator
),
val
*
indicator
)
Prev
1
…
11
12
13
14
15
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}

{kind=link}
{kind=link}